Towards Emotion Recognition with 3D Pointclouds Obtained from Facial Expression Images
Facial Emotion Recognition is a critical research area within Affective Computing due to its wide-ranging applications in Human Computer Interaction, mental health assessment and fatigue monitoring. Current FER methods predominantly rely on Deep Lear…
Authors: Laura Rayón Ropero, Jasper De Laet, Filip Lemic
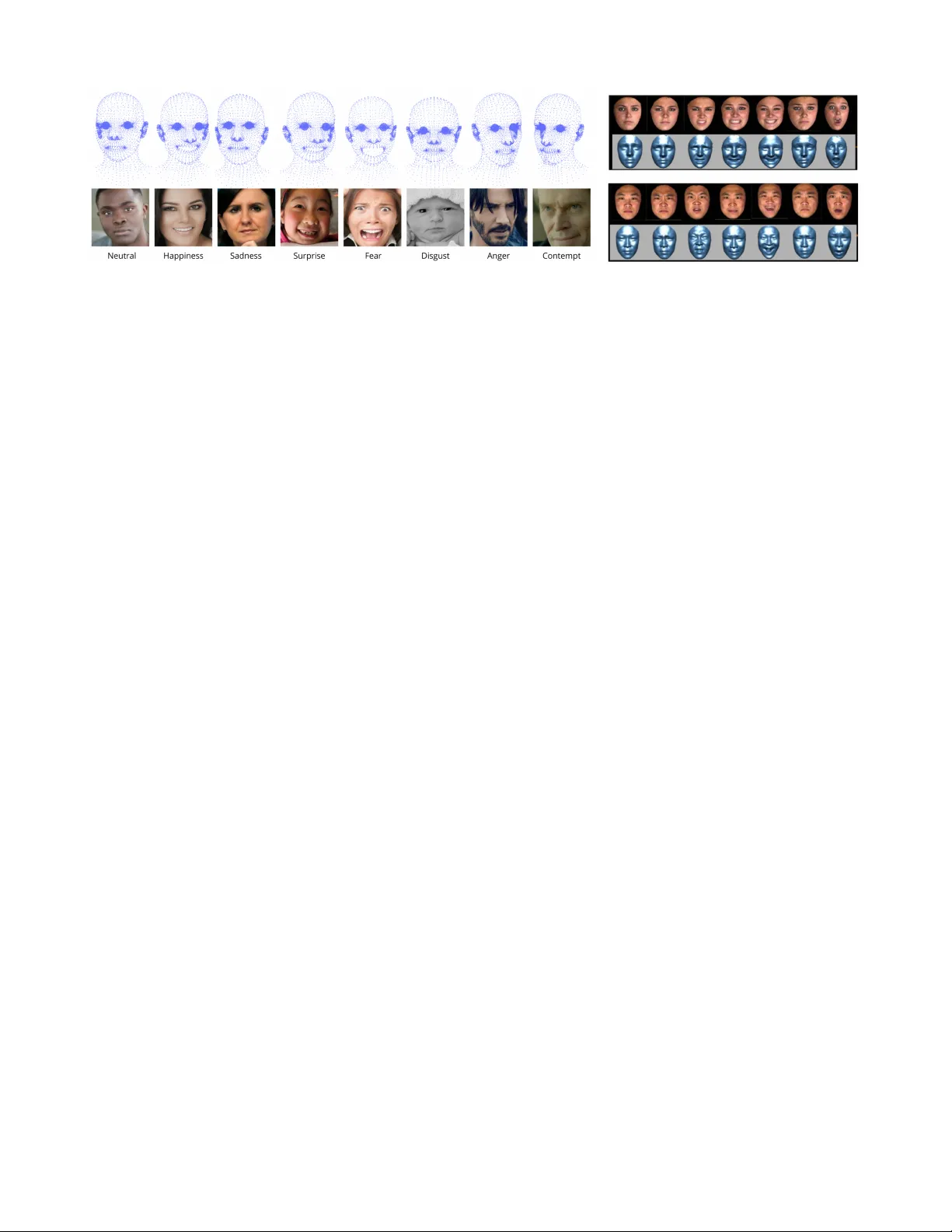
This article has been accepted for publication in IEEE T ransactions on Affecti ve Computing. This is the author’ s version which has not been fully edited and content may change prior to final publication. Citation information: DOI 10.1109/T AFFC.2026.3679039. T o wards Emotion Recognition with 3D Pointclouds Obtained from F acial Expression Images Laura Ray ´ on Ropero ∗ , Jasper De Laet ∗ , Filip Lemic † , Pau Sabater N ´ acher , Nabeel Nisar Bhat, Sergi Abadal, Jeroen Famae y , Eduard Alarc ´ on, Xavier Costa-P ´ erez Abstract —Facial expression-based Emotion Recognition (FER) is a critical resear ch area within Affecti ve Computing (A C) due to its wide-ranging applications in Human Computer Interaction (HCI), as well as its potential use in mental health assessment and fatigue monitoring. Howe ver , current FER methods pr e- dominantly rely on Deep Learning (DL) techniques trained on 2-Dimensional (2D) image data, which pose significant privacy concerns and ar e unsuitable for continuous, r eal-time monitoring. As an alternativ e, we propose High-Frequency Wir eless Sens- ing (HFWS) as an enabler of continuous, privacy-awar e FER, through the generation of detailed 3-Dimensional (3D) facial pointclouds via on-person sensors embedded in wearables. W e present ar guments supporting the pri vacy adv antages of HFWS over traditional 2D imaging approaches, particularly under in- creasingly stringent data protection regulations. A major barrier to adopting HFWS for FER is the scarcity of labeled 3D FER datasets. T owards addressing this issue, we introduce a method based on the Faces Lear ned with an Articulated Model and Expressions (FLAME) model to generate 3D facial pointclouds from existing public 2D datasets. Using this approach, we create AffectNet3D, a 3D version of the AffectNet database. T o evaluate the quality and usability of the generated data, we design a pointcloud refinement pipeline f ocused on isolating the facial region, and train the popular PointNet++ model on the refined pointclouds. Fine-tuning the model on a small subset of the unseen 3D FER dataset BU-3DFE yields a classification accu- racy exceeding 70%, comparable to oracle-lev el performance. T o further in vestigate the potential of HFWS-based FER for continuous monitoring, we simulate wearable sensing conditions by masking portions of the generated pointclouds. Experimental results show that models trained on AffectNet3D and fine-tuned with just 25% of BU-3DFE significantly outperform those trained solely on BU-3DFE. These findings highlight the viability of our data generation pipeline and support the feasibility of continuous, privacy-awar e FER via wearable HFWS systems. Index T erms —Human-centered computing, Facial emotion recognition, Point-based models, P ointNet++, BU-3DFE; ∗ Equal contribution. † Corresponding author . L. Ray ´ on, E. Alarc ´ on, and S. Abadal are affiliated with the Univ ersitat Polit ` ecnica de Catalunya, Spain, email: { name.surname } @upc.edu. J. De Laet, N. N. Bhat, and J. Famaey are affiliated with the University of Antwerp, Belgium, email: { name.surname } @uantwerpen.be. N. N. Bhat and J. Famaey are additionally affiliated with imec, Belgium. F . Lemic, P . Sabater, and X. Costa-P ´ erez are affiliated with i2CA T Foun- dation, Spain, email: { name.surname } @i2cat.net. F . Lemic is also with the Faculty of Electrical Engineering and Computing, Uni versity of Zagreb, Croatia. X. Costa-P ´ erez is also affiliated with the NEC Labs Europe GmbH, Germany and ICREA, Spain. This work has been supported by the Smart Networks and Services Joint Undertaking (SNS JU) under the European Union’ s Horizon Europe research and innovation programme (grants nº 101139161 - INSTINCT and nº 101192521 - MultiX projects). The work of Nabeel Nisar Bhat was supported by the Fund for Scientific Research Flanders (FWO), grant nº 1SH5X24N. I . I N T R O D U C T I O N The exploration of computational models for recognizing and interpreting human emotions has been an activ e research area for ov er three decades [1]. This interest stems from humanity’ s curiosity about its psyche and the ambition to im- prov e quality of life through emotional well-being. Emotion- aware computational models fall under the umbrella of Affec- tiv e Computing (A C) [2], which le verages computer science, psychology , and cogniti ve science, to create systems that can recognize human emotions, thus enhancing Human Computer Interaction (HCI). Facial expressions, generated by facial mus- cle movements, are ke y non-verbal communication cues [3]. W ithin A C, the concept of continuous emotional monitoring has emerged as a promising yet undere xplored direction, particularly in domains such as healthcare and education. Research in these fields highlights the importance of long-term affecti ve observation, with studies such as [4], [5], [6] linking mental diseases and neurodi ver gence to traceable emotional patterns, detectable only through day-to-day tracking. The 2-Dimensional (2D) Facial expression-based Emotion Recognition (FER), also referred to as the image-based FER, was one of the first FER methodologies explored within A C. The early models were based on handcrafted features and geometric facial models [7] [8]. A significant limitation of these methods was that they needed to be tailored for specific datasets or targets, resulting in low re-usability [9]. The proliferation of large FER-labeled databases such as Real- world Affecti ve Faces Database (RAF-DB) [10] (containing around 30K facial images), and AffectNet [11] (containing around 400K facial images), enabled a transition to DL archi- tectures. These models require a high amounts of training data to pre vent overfitting, but have also demonstrated improv ed abstraction and generalization abilities [12]. While image-based FER methods hav e achieved impressiv e results, they face significant challenges: 1) The acquisition of 2D images introduces priv acy concerns under global regulations such as the EU Artificial Intel- ligence (AI) Act and General Data Protection Regulation (GDPR) [13], [14]. 2) In scenarios requiring continuous facial monitoring, tradi- tional image acquisition systems (e.g., cameras) are often impractical, intrusi ve, and uncomfortable for long-term use. These limitations hav e motiv ated research into alternative modalities such as the 3D pointcloud-based FER, which enhances priv acy by removing high-resolution facial te xtures while preserving essential geometric features. Howe ver , 3D FER introduces its own set of challenges, particularly for IEEE DRAFT 2 Fig. 1: Pri v acy-aw are 3D FER through High- Frequency Wireless Sensing (HFWS) Fig. 2: Comparison between 2D and 3D FER databases training Deep Learning (DL) models. The acquisition of 3D facial data is inherently complex and costly , often requiring so- phisticated equipment such as multi-camera 3D scanners [15]. As a result, existing 3D FER datasets (such as Binghamton Univ ersity 3D Facial Expression (BU-3DFE) [15] and Bospho- rus [16]) are significantly smaller than their 2D counterparts. This scarcity increases the risk of overfitting and limits the generalization of DL-based models to real-world conditions. Furthermore, most av ailable 3D datasets contain posed ex- pressions captured in controlled environments, whereas 2D datasets such as Af fectNet [11] and RAF-DB [10] include large-scale, di verse, and in-the-wild samples. The absence of an equiv alent in-the-wild 3D FER dataset remains a critical bottleneck, largely due to the difficulty of acquiring 3D data outside studio conditions. A promising avenue to ov ercome these limitations lies in lev eraging High-Frequency W ireless Sensing (HFWS) (cf., Figure 1) for facial imaging [17]. HFWS repurposes communi- cation signals for sensing, eliminating the need for dedicated sensors, thereby reducing hardware comple xity , energy con- sumption, and priv ac y risks. W earables equipped with HFWS, such as smart glasses, can continuously generate 3D facial maps, enabling non-intrusive and priv ac y-aware continuous FER [18], [19], [20]. In this paper , we use the term privacy- awar e to denote a representation-level reduction of directly identifiable visual cues, achieved by relying on texture-free 3D geometry rather than high-resolution 2D imagery . W e do not claim formal pri vac y guarantees against re-identification, in- version, or reconstruction attacks. In remote intelligent health systems, this capability supports affect-a ware and priv acy- compliant monitoring, aligning with applications such as tele- consultations and fatigue tracking. By combining HFWS 3D FER with physiological data, such as heart rate or respira- tion [21], comprehensive user profiles can be obtained without increasing the intrusi veness of the sensing infrastructure. For HFWS-enabled systems to perform emotion recognition effecti vely , the y require robust DL models trained on div erse 3D data accurately reflecting real-world conditions. Since data captured by HFWS will inherently be in-the-wild , the lack of large-scale 3D FER datasets presents a fundamental challenge (cf., Figure 2). T o address this, we explore the feasibility of generating extensi ve labeled 3D FER datasets from existing labeled 2D databases using statistical face re- construction techniques. By con verting 2D images into 3D pointclouds, our approach leverages the wealth of a vailable 2D FER data to train models capable of generalizing to real- world 3D FER scenarios, including those enabled by HFWS- based sensing. By relying on 3D pointclouds without high- resolution textures, the framew ork presented in this study mitigates identity disclosure risks (a major barrier to adopting FER in healthcare en vironments), while ensuring compatibility with HFWS enabled wearables for continuous, regulation- compliant, and pri vacy-a ware emotion recognition. A. Contributions This work makes the follo wing contributions: • W e in vestig ate the feasibility of using 2D image-generated pointclouds as a training dataset for 3D FER, le veraging publicly av ailable in-the-wild 2D FER datasets to ov ercome the scarcity of labeled 3D FER data. This approach sig- nificantly reduces data collection burdens while improving model generalization. Using a contemporary Faces Learned with an Articulated Model and Expressions (FLAME)-based 3D reconstruction techniques [22], we con vert Af fectNet 2D images into 3D pointclouds and train a 3D DL model. • W e explore the use of 3D facial imaging for real-world inference, showing that publicly a v ailable 2D FER datasets can be repurposed for priv acy-a ware 3D FER. T o enhance robustness, we develop a data refining pipeline that isolates facial regions in 3D pointclouds, ensuring models trained on HFWS-like data maintain high classification accuracy . T o assess the feasibility of HFWS-based FER for continuous monitoring, we simulate wearable sensing by selectively masking portions of the generated pointclouds, replicating occlusion constraints. • W e fine-tune our trained 3D FER model on a small subset of the unseen 3D FER dataset (BU-3DFE) and ev aluate its generalization performance. Our results show that this approach achiev es classification accuracy comparable to an oracle solution trained on the entire 3D dataset, significantly outperforming baselines trained solely on small 3D datasets. IEEE DRAFT 3 B. P aper Structur e This paper is structured as follows. Section II provides the necessary background on FER and the role of 3D pointclouds in emotion recognition. Section III revie ws prior works in DL architectures for face reconstruction from images, providing a rationale for selecting a FLAME-based method for Af fectNet 3D generation, as well as for the utilizing PointNet++ for 3D FER. In addition, the section outlines literature efforts outlin- ing advances in THz-based 3D reconstruction, paving the way tow ard short-range and small-scale HFWS systems for FER. Sections V and VI present our experimental methodology and ev aluation results for the proposed 3D FER model, respec- tiv ely . Finally , Section VII discusses the broader implications of our findings and potential future research directions, while Section VIII concludes the paper . I I . B AC K G RO U N D A. Theor etical F oundations of FER Theoretical foundations of FER technology hav e their roots in the Charles Darwin’ s Expression of the Emotions in Man and Animals [23]. Darwin treated emotions as separate discrete entities and, presumably driv en by his global travels aboard the HMS Beagle, stated that facial expressions of emotion are univ ersal. These foundational ideas led subsequent emotion theorists to the development of several models about af fectiv e facial behaviors, i.e., how emotions are represented and rec- ognized through facial expressions. The most utilized among these models include the Categorical, Dimensional, and Facial Action Coding System (F A CS) models [11]. The Categorical model links facial expressions to a discrete set of basic and univ ersal emotion categories (e.g., happiness, surprise, anger) [24]. The compound version emer ged as a way to handle samples displaying a mixture of two emotions, by defining a set of compound emotion categories that are deriv ed from the Categorical model (i.e., happily surprised, sadly fearful) [25]. The Dimensional model appeared as an alternativ e to the Categorical model, proposing a continuous rather than discrete representation of emotions. A notable implementation of this model is the V alence-Arousal scale, where V alence assesses the positi vity or negati vity of an emotion, and Arousal measures its le vel of excitement or calmness [26]. Differently from these models, the F A CS takes an anatomical approach, focusing not on inferring af fecti ve states directly , but on identifying changes in facial muscles. This model codes the actions of individual or groups of muscles present in facial e xpressions [27]. B. T echnological F oundations of FER The Categorical model is the most pre valent in the Com- puter V ision community . Consequently , it serves as the basis for labeling most FER databases. This model, proposed by discrete emotion theorist Paul Ekman et al. [24], initially categorized facial expressions into six basic emotions: anger , disgust, fear , happiness, sadness, and surprise. Subsequent research added contempt [28] and neutral emotions to the list. Both databases employed within this work, the 3D version of AffectNet and the BU-3DFE database, are labelled according to Ekman’ s 6-emotion categorical model. They each include the “neutral” category , while AffectNet additionally incorpo- rates the “contempt” category . FER typically inv olv es 3 steps: i) pre-processing consisting of applying transformations to the data samples for facilitating feature extraction; ii) feature extraction that aims to extract from the data samples the facial features that con ve y emotion; and iii) classification according to an emotion model. FER studies can be broadly categorized based on the nature of the data they use as static and dynamic FER [7], [29]. Static FER relies on static facial features. In contrast, dynamic FER, also kno wn as video-based FER, uses spatio- temporal features to capture the dynamics in facial expression sequences. T ypically , dynamic FER delivers higher accurac y rates than static FER due to its incorporation of temporal data. Howe ver , dynamic FER faces significant challenges; dynamic features can vary significantly in their duration and charac- teristics based on the individual. Furthermore, the process of temporal normalization, which aims to standardize expression sequences to a consistent frame count, often results in the loss of essential temporal details that are critical for accurate emotion recognition. Due to these complexities, and the fact that static FER databases are more numerous, research in static FER has been more prev alent and it is in the focus of this study . Howe ver , considering the anticipated energy- efficient characteristics of the devices de veloped within the HFWS paradigm, high sampling frequencies could enable the exploration of dynamic FER. C. 2D vs. 3D FER FER databases can be categorized by the dimension of their data samples as 2D or 3D. 2D samples consist of labeled images that capture facial expressions in a flat plane. 3D samples encompass models that represent facial expressions in a volumetric space. This work bridges the 2D and 3D worlds by exploring whether 3D pointclouds inferred from 2D images can be used for DL model training for 3D-FER tasks. 2D FER was among the earliest e xplored FER methodolo- gies, with the early models primarily based on handcrafted features and geometric facial priors [7], [8], some of which continue to be used today , sometimes in conjunction with DL architectures [30]. This continued usage is attributed to their ability for solving typical FER challenges such as variations in illumination, pose, and occlusion. Nonetheless, a significant limitation of these methods is that they need to be tailored for specific datasets or targets, resulting in low reusability [9]. A major contribution of DL to 2D FER has been the in- troduction of Con volutional Neural Networks (CNNs), which automate the process of feature extraction and hav e become the foundational components of modern FER architectures. CNNs, together with ensemble methods that combine mul- tiple network outputs to enhance robustness and predictiv e power [30], have improved the reliability of 2D FER systems. Current benchmarks on widely used 2D FER datasets, such as RAF-DB and AffectNet, rev eal that leading architectures typically rely on either CNN layers [9], [30], [31], [32] or T ransformer blocks [33], [34] as their primary building units. IEEE DRAFT 4 The main difficulty in FER lies in the phenomenon of small inter-class dif ferences coupled with large intra-class v ariabil- ity . Emotion categories often exhibit subtle distinctions from one another (inter-class similarity), while expressions of the same emotion can v ary widely across indi viduals (intra-class variability). T o address this, recent models hav e incorporated attention mechanisms and multi-scale learning strate gies as core design principles. Attention mechanisms enable networks to focus on key facial re gions (such as the eyes, eyebro ws, nose, and mouth) thereby improving sensitivity to emotionally relev ant features while suppressing redundant or irrelev ant information. Multi-scale learning, in turn, allows models to integrate both fine-grained and global facial features, improv- ing generalization and robustness. CNN-based methods often implement attention mechanisms through U-Net-style segmentation [9], [30] or masking strate- gies [30], and employ residual connections to facilitate multi- scale feature learning [9], [30], [31]. Other variants intro- duce dual attention heads [31] or transformer -inspired dot- product self-attention modules [32] to better capture spatial dependencies. T ransformer based methods include the use of V isual Transformers (V iT) [34], cross-fusion transformer encoders [33], and windo w-based cross-attention [33], [34]. Multi-scale learning in transformer-based methods is tackled through pyramidal [33] or multi-le vel [34] architectures. These ke y architectural characteristics are not e xclusiv e to 2D-based FER; they are widely shared with emerging 3D- based FER approaches. This con ver gence underscores a funda- mental principle: the essence of facial expressions transcends the dimensionality of the data. 3D-based FER is a relatively nov el field in Affecti ve Com- puting. Whereas 2D-based FER was already well-established by the early 2000s, 3D FER began gaining attention later as a means to overcome challenges presented by 2D images, such as variations in pose and illumination [7]. In image-based settings, lighting conditions and changes in the subject’ s pose can drastically affect the visibility and appearance of facial features, complicating the process of emotion recognition. W ith the emer gence of the HFWS paradigm, the exploration of 3D-based FER has become ev en more critical. Nonetheless, 3D FER introduces its o wn challenges, partic- ularly in the training of DL models. While 2D FER already benefits from large, readily av ailable databases compiled from internet-sourced data [10], [11], [35], producing equiv alent 3D databases is more challenging. 3D data capture still requires controlled studio settings and in v olves more expensi v e and sophisticated equipment, such as 3D scanners composed of sev eral cameras [15], [36]. This results in a limited av ailability of 3D facial expression data. In addition, occlusions such as hair , glasses, or other objects that partially cover the face present a significant challenge in FER in general. Models based on 2D FER can be more ef fecti vely trained to handle these challenges because there are av ailable data samples that include occlusions. 3D-based FER databases typically lack such samples, with only the Bosphorus database [16] including data with such occlusions. In this work, we bridge the gap between 2D and 3D FER by proposing a method to generate high-quality 3D pointclouds from existing 2D FER datasets, enabling pri v acy-a ware and robust emotion recognition with- out relying on costly 3D scanning setups. D. Privacy Enhancements of 3D FER The use of 2D facial images for FER raises significant pri- vac y concerns due to the risk of identity disclosure, unautho- rized surveillance, and the misuse of high-resolution biometric data. Global regulations, including the EU AI Act, GDPR, and UNESCO AI ethics recommendations, classify facial images as sensitiv e personal data, mandating strict compliance for their storage, processing, and transmission [13], [14]. Recent studies hav e shown that 2D facial landmarks can be extracted from images and used for FER without storing full facial images [37], [38]. Howe ver , while on-device extraction of 2D f acial landmarks can reduce priv acy risks compared to full-image FER, these reduced representations still encode bio- metric characteristics that enable re-identification [38], [39], thereby remaining subject to the same priv acy vulnerabilities and legal constraints as other biometric identifiers. As an alternative, 3D pointclouds inherently offer priv acy- aware advantages at the representation lev el.Their lack of texture and color information reduces the exposure of directly identifiable visual cues and makes them less susceptible to direct identity disclosure. Unlike 2D images, which contain fine details such as skin tone, hair color and other identifi- able features, pointclouds primarily encode spatial geometry . Research confirms that the remov al of texture data can compli- cate identity reconstruction, aligning with modern priv acy-by- design principles [40]. Despite the advantages, 3D data is not immune to pri vac y risks. Prior work on 3D Structure-from- Motion (SfM) has shown that even sparse pointclouds can be in v erted to recover recognizable scenes [41]. This indicates that 3D representations can still carry latent identity cues that may be e xploited under adversarial conditions. Sev eral methods can further complicate de-anonymization attempts while maintaining task-rele v ant information. In the context of HFWS embedded in wearables, on-device identity- standardizing affine transformations (such as normalizing inter-ocular distance, nose length, or facial depth) can preserve affecti ve cues while removing individual biometric markers. Prior work has shown that automatic detection of e yes and nose followed by geometric alignment can normalize 3D facial data [42] and that pose-normalization via geometry-analysis is feasible for 3D head models [43]. These landmark- and PCA- driv en normalization techniques could similarly be adapted to normalize 3D pointclouds to a standard template, thereby re- ducing identifiable variations while retaining the structural and affecti ve information necessary for emotion recognition. These transformations can be combined with spatial downsampling or partial anonymization techniques, which hav e been shown to make reconstruction and re-identification substantially more difficult [40]. Such practices align with privac y-by-design principles and pro vide resilience against data breaches. T o place this contribution in context, T able I summa- rizes representative priv acy-preserving FER paradigms (e.g., landmark/A U-based inputs, federated learning, differential pri- vac y) and contrasts their priv ac y mechanism, deployment IEEE DRAFT 5 T ABLE I: Priv acy–utility positioning of representativ e FER paradigms. This table provides a high-level design-space positioning rather than a performance leaderboard; reported utility trends depend on dataset, protocol, and (for DP) priv ac y budget. Paradigm / approach family Primary privacy mechanism Data repr esentation (stored/pr ocessed) Formal pri vacy guarantee? T ypical deployment burden Compatibility with our pipeline Standard 2D FER (RGB) None (full texture expo- sure) Raw RGB facial images No Moderate (standard training/inference) Not applicable (different priv acy objectiv e) Landmark- based FER Representation minimization (sparse geometry cues) 2D landmarks / keypoints No (biometric leakage possible) Low Compatible (alternativ e or auxiliary input) A U-based FER Representation minimization (semantic/physiological coding) Action Unit vectors / in- tensities No (depends on pipeline) Low–Moderate (A U extraction + training) Compatible (can be fused or used as auxiliary) Federated learning FER Distributed training (data stays local) Local training + model updates (gradients/weights) No (unless combined with DP/secure aggregation) High (protocol, comms, orchestration) Orthogonal; can be com- bined with ours Differential priv acy (DP) FER Noise injection during training Noisy gradients/updates; priv acy budget ε Y es (under DP assumptions) High (pri v acy budget selection, tuning, util- ity trade-off) Orthogonal; can be com- bined with ours Geometry- only 3D FER (this work) Representation minimization (no texture) T exture-free 3D pointcloud / mesh geometry No Moderate (3D pro- cessing + FER model) Core approach (repre- sentation layer) requirements, and complementarity with our representation- lev el approach. Approaches such as federated learning and differential pri v acy target pri v acy at the training and update lev els (distrib uted optimization and noise injection), whereas our contrib ution targets priv acy at the representation le vel by reducing the e xposure of raw texture-bearing imagery . These paradigms are therefore orthogonal and can be composed: for example, a model trained on geometry-only inputs can addi- tionally be trained with dif ferential priv acy or via federated learning if the deployment scenario requires it. Threat model and non-goals: W e consider scenarios where FER must be performed under stringent priv acy and regulatory constraints, in which raw RGB facial images are undesir- able to store, transmit, or centrally process. Our approach reduces e xposure by design by operating on texture-free 3D geometry . Ho we ver , geometry-only representations may still carry biometric signals and can, in principle, support partial identity inference. By le veraging 3D pointclouds obtained from HFWS-enabled sensing, our approach reduces texture exposure by design while maintaining accurate FER, sup- porting regulation-compliant deployments where storing or transmitting raw facial imagery is undesirable. I I I . R E L AT E D W O R K S A. F ace Reconstruction fr om Images Reconstructing 3D models from 2D images is a k ey research direction for overcoming the inherent limitations of flat im- agery . By inferring 3D geometry , systems g ain a more robust and viewpoint-independent understanding of facial structure and expression. This capability enables applications in realistic av atar creation, animation and AR/VR applications, while also supporting medical, biometric, and forensic use cases. The reconstruction of 3D facial structures from 2D images is another piv otal element in FER systems, traditionally achiev ed through statistical models like 3D Morphable Face Models (3DMM), which use Principal Component Analysis (PCA) to fit face shapes and expressions. K ey methods include BFM, which separates shape and expression parameters using PCA [44]; FLAME [22], which enhances reconstruction detail by incorporating real-expression deformation variables [22]; and D AD-3dHeads, which further refines this process by re- gressing FLAME parameters from a wild dataset for improv ed accuracy in div erse conditions [45]. Recent state-of-the-art methods are able to achie v e 3D facial reconstruction from in-the-wild 2D images. RingNet [46] tackles this problem without requiring paired 2D-to-3D su- pervision by learning a mapping from 2D images to 3D face representations using identity-labeled images and a consis- tency loss. During training, the network le verages multiple images of the same person to enforce similarity in their latent embeddings while keeping embeddings of different individuals distinct. These embeddings are then decoded into a full 3D face model using FLAME [22]. Building on a similar principle, DECA [47] extends this approach to capture details such as expression-dependent wrinkles. Using a consistency loss, DECA jointly learns a geometric detail model and a regressor that predicts both image-specific and subject-specific parameters. The detail model is then used to refine FLAME’ s geometry . EMOCA [48] focuses on the geometric changes critical for emotion perception. It builds on DECA by adding a trainable branch for facial expression prediction while keeping the rest of the architecture fixed. Based on [49], we le verage a FLAME-based method [22] for 3D face reconstruction from RGB images. This choice is motiv ated by its in-house av ailability and due to the fact that our goal is not to strictly optimize 3D model generation itself, but to ev aluate the end-to-end pipeline, from 2D in-the- wild images to 3D pointcloud reconstruction and subsequent FER inference on HFWS-lik e data. Also, FLAME’ s parametric representation enables integration with models that capture fine-grained details and expression-dependent deformations, as demonstrated by DECA and EMOCA. The transition from 2D RGB images to 3D pointclouds IEEE DRAFT 6 in the lev eraged method requires the use of precise depth estimation. Se veral state-of-the-art estimators hav e been con- sidered for this purpose. MiDaS [50] integrates diverse train- ing datasets and loss functions to optimize depth estimation accuracy , while AdaBins [51] introduces adaptive binning for improved performance in complex scenes. ZoeDepth [52] unifies metric and relative depth estimation to deliv er practical metrical values. Boost Y our Own Depth [53] merges high- resolution estimates to enhance the detail and consistency of depth maps. Follo wing the findings of [49], this study adopts a combination of ZoeDepth and Boost Y our Own Depth for depth estimation. Although this approach entails higher memory consumption [52], [53], it offers optimal accuracy in depth map detail and metrical values [49]. B. 3D FER benc hmarks DL models serving as benchmarks for 3D FER have sev eral common characteristics. The main ones are the incorporation of attention [54], [55], [56], [57] as well as feature fusion mechanisms [54], [56], [57]. The D A-CNN [55] model in- troduces an attention module to CNN models. The AFNet- M [57] model includes mask attention modules targeting salient facial re gions. The FE2DNet and FE3DNet [54] models employ an orthogonal loss-guided feature fusion approach to ensure that features are orthogonalized before fusion to av oid redundancies. CMANET [56] incorporates a homo- modal curvature-a ware attention module that uses a soft mask to guide attention to important facial areas, coupled with a multi-modal (2D+3D) attention fusion module that allows for pixel-le v el feature interaction and feature interaction over a larger field of view . The DrFER approach [58], rather than employing attention mechanisms, uses the concept of disentanglement to address the challenge of intra-class variability in FER. In this context, disentanglement refers to the separation of identity-specific information from affecti ve information. The DrFER model accomplishes this through two main components: a disentan- gling component and a fusion component. The disentangling component employs a dual-branch architecture to separately learn features associated with facial expressions and identity , thereby creating de-identified and de-expressed versions of the faces. Subsequently , the fusion component recombines these features in a crossov er f ashion, reconstructing the original face. Throughout this process, various losses are employed to guide the learning of the network effecti vely . The AFNet-M [57] and D A-CNN [55] models are examples of how transfer learning is applied using pre-trained 2D archi- tectures to handle 3D data. Both of these models begin with architectures that were originally trained on 2D images, specif- ically in conte xts that are unrelated to FER. The AFNet-M [57] model is an adaptive fusion network (2D + 3D) that employs dual-branch ResNet18s [59], which are initialized with pre- trained parameters from ImageNet [60]; to enable treating 3D depth images as if the y were standard 2D images, the y are preprocessed and resized to dimensions of 3 × 224 × 224. The DA-CNN model [55] uses five pre-trained CNN models, specifically VGG16-BN [61] (meaning VGG16 with Batch Normalization (BN) after each con v olutional layer), to process the fiv e types of shape attribute maps that represent the 3D facial scan. The VGG-16 models are equipped with bottom- up top-down feedforward attention modules. In summary , attention mechanisms, feature fusion mecha- nisms, and the incorporation of pre-trained 2D-based archi- tectures are key factors contributing to the success of these models in 3D FER tasks. In this work, PointNet++ [62] was se- lected as the backbone model for 3D FER (cf., Section IV -E). Unlike the aforementioned architectures, PointNet++ does not utilize explicit attention mechanisms, feature fusion, pre- trained 2D networks, or disentanglement. The rationale for its selection is not to achieve state-of-the-art performance, but rather to test whether the 3D data we generated is suitable for FER. PointNet++ is an established benchmark in pointcloud processing, capable of learning hierarchical local and global features directly from raw 3D data. Its relati vely simple and modular architecture makes it computationally efficient and practical for deployment on edge devices, such as smart glasses, without the overhead associated with multi-branch attention networks or 2D pre-trained models. As such, it provides a reliable, replaceable baseline for ev aluating our generated 3D facial scans within a feasibility-first, end-to- end e valuation scope, while remaining flexible for future experimentation with alternativ e architectures. Importantly , our contribution is not a ne w 3D FER backbone; rather, it is the dataset generation and end-to-end pipeline that enables 3D FER learning from in-the-wild 2D data. C. THz-based HFWS for 3D Reconstruction Usage of high-frequency Electromagnetic (EM) wa v es in the T erahertz (THz) regime has a potential of simultaneously enabling both 3D imaging of the human face and the high- throughput communication from the users’ devices to the more powerful edge and cloud processing infrastructure. 3D imaging using high-frequency wireless wa ves is an established tech- nology [63], which finds its utility in medical imaging [64], tomography [65], and cancer diagnosis [66]. Primarily due to the a v ailability of large bandwidth at THz frequencies, 3D THz imaging systems are known to feature sub-millimeter imaging reconstruction accuracy , making them suitable for facial imaging considered in this work [63], [67]. Promising THz 3D imaging system designs and implemen- tations are based on Synthetic Aperture Radars (SARs) [67]. The basic concept of radar techniques is to measure the time delay between the transmitted and recei ved EM signals, which can then be con verted to distance based on the known propagation velocity of the EM wa ves. In SAR systems, a 3D image can be obtained by synthesizing a 2D aperture and azimuth distinguishing by array signal processing approaches, mostly a digital beamformer [68]. SAR systems can be cate- gorized based on the pulse generation method as pulse and Continuous W ave (CW) radars. Pulse-based radars feature easier implementation at high frequencies and support large bandwidths at the considered small imaging distances of a few centimeters [69]. They can be implemented in an energy- efficient manner through graphene-based transceiver imple- IEEE DRAFT 7 mentation [70]. As such, we consider pulse-based SAR radars as the prime candidate for 3D imaging for FER purposes. Communication using THz frequencies is expected as a key component of the 6G communication systems [71], [72]. THz communication at shorter ranges is expected to be enabled through the utilization of pulse-based Modulation and Coding Scheme (MCS) schemes due to the ease of their implementa- tion in small physical form factor suitable for wearable de vices such as glasses [73]. The reuse of pulse-based schemes in array-based THz transcei ver implementations in the glasses for both 3D imaging of the human face and the high-throughput communication of the sensed data for cloud processing can be considered as an example of a HFWS system [17]. From the ener gy consumption perspective, the re-utilization of the same technology for both communication and sensing in the HFWS systems represents a unique design adv antage over the utilization of different technologies for sensing and communi- cation [17]. In addition to hardware and energy benefits, such HFWS-based 3D imaging supports priv acy-aware deployments by avoiding the acquisition and transmission of raw texture- bearing facial imagery . As such, we consider the small- scale THz-based HFWS system as the prime candidate for meeting the communication and 3D imaging requirements of the considered system. I V . S Y S T E M O V E R V I E W A. System Design Requir ements a) Privacy-awar e FER: The system should incorporate priv acy-aware, representation-lev el mechanisms by utilizing on-person sensors that employ the HFWS paradigm for captur- ing high-frequency electromagnetic wa ves to generate detailed 3D facial images. This design choice aligns with the global regulatory initiativ es for ethical usage of AI, with emphasis on protecting fundamental rights, particularly users priv acy [13], [14]. T aking European Union (EU) legislation as an example, the EU AI Act outlined in T itle II, Chapter 2, Article 9 [74] mandates that AI systems must respect fundamental rights and av oid creating risks to priv acy and data protection. By ensuring that the system does not rely on traditional 2D image data, which could pose significant pri v acy risks due to potential misuse or unauthorized access, it complies with the Act’ s requirements to minimize the risk of data misuse ( T itle III, Chapter 1, Article 10 [74]). W e use the term privacy-awar e to denote reduced exposure of directly identifiable visual cues by av oiding texture-bearing imagery; we do not claim formal guarantees against re-identification, inv ersion, or reconstruc- tion attacks. While we consider high-frequency HFWS to be the most promising potential enabler for obtaining 3D facial images, it is just one of several potential methods. Other technologies, such as structured light or time-of-flight sensors, may also be considered depending on the specific application requirements and pri v acy constraints, ensuring flexibility while adhering to the Act’ s standards. b) Cost-Effective T raining: T o comply with the EU AI Act’ s requirement for high-quality , reliable, and bias-free training data, as emphasized in T itle III, Chapter 1, Article 10 [74], the system should av oid relying on expensi ve and complex training processes based solely on 3D pointcloud data. Instead, the system should be designed to leverage 2D images, which are more readily av ailable from public databases, by transforming these 2D images into correspond- ing 3D pointclouds for training purposes. This innovati ve ap- proach allows the system to utilize widely accessible 2D FER datasets, transforming them into 3D data that can ef fecti vely train deep learning models like PointNet++. By refining the generated 3D pointclouds to focus on the facial region, the system can achieve high accuracy while maintaining a cost- effecti ve training process. This approach meets the EU AI Act’ s requirements for using high-quality data and ensuring the system’ s economic viability in high-risk AI applications like FER ( T itle III, Chapter 2, Article 13 [74]). B. System Design This study hypothesizes that using publicly a v ailable 2D image data can be lev eraged to train a 3D pointcloud DL model to obtain similar FER accuracy as State-of-the-Art (SotA) models that use 2D images as input. Figure 3 illustrates the ov erall system design flow for assessing the validity of the hypothesis. The tar get datasets are the 3D v ersion of the AffectNet database, generated through a data preprocessing method proposed in this work and the BU-3DFE dataset. Our methodology follows a three-step approach typical in FER studies, starting with custom data preprocessing, and subsequently performing feature extraction and classification. First, a method for transforming 2D Red, Green, Blue (RGB) FER images into 3D pointclouds is leveraged to allow the creation of accurate 3D facial representations from 2D data. The generated 3D AffectNet pointclouds consist of entire head models with varying e xpressions. Ho we ver , popular 3D FER datasets such as BU-3DFE and Bosphorus focus solely on facial structures. This discrepanc y led us to question whether the inclusion of non-facial areas could negati vely impact the network’ s learning. Second, to improve the network’ s capacity to learn from the data, a secondary processing branch was incorporated into the system. This branch refines the pointclouds by isolating the facial region and removing the head and neck, ensuring that only information pertinent to the emotion recognition task is provided to the network. Feature extraction and classification are then performed through a single end-to-end training pro- cedure using the selected classifier . Additionally , we inv estigate fine-tuning the trained model on a small subset of the BU-3DFE database, a well-established 3D benchmark, to ev aluate the ef fectiv eness of leveraging FLAME-generated 3D data for training models in 3D-based emotion recognition. C. Generation of Raw AffectNet3D The FLAME method for transforming 2D RGB images into 3D pointclouds starts by regressing 2D landmarks from the images, which include labeled facial expressions. These 2D landmarks are back-projected to create corresponding 3D landmarks, aligning them with the FLAME template model. IEEE DRAFT 8 Fig. 3: System design of the envisioned privac y-aw are 3D FER system trained on in-the-wild 2D images The parameters of the FLAME model, including identity , expression, and pose, are then optimized to fit the facial data. T o enhance the accuracy of the 3D pointcloud generation, we utilized ZoeDepth combined with Boost Y our Own Depth. This approach integrates high-resolution depth estimation and adaptiv e binning techniques, improving the detail and preci- sion of the depth maps. The combined method generates high- resolution 3D pointclouds by sampling the surface of the 3D facial mesh, which captures fine details of facial geometry and expressions. The resulting 3D pointclouds are subsequently refined through grouping, filtering, and subsampling to prepare them for deep learning models. These processed pointclouds are then used for feature extraction and classification in facial emotion recognition tasks. D. Raw AffectNet3D Refining Due to the fact that the generated pointclouds contain entire head models, the model recei ves substantial amounts of non- essential information as input. Only the facial regions of a pointcloud contain expressions, the remaining portions pro vide no useful data for the FER task. This work hypothesizes that as a result this could ultimately hinder the model’ s ability to recognize facial expressions. Moreover , the presence of a significant amount of irrelev ant points could lead to unnecessary computational overhead and prolonged processing times. W ith the aim of impro ving the network’ s learning ability from the data, a data refining module is en visioned in our system design, as illustrated in Figure 3. The module is en visaged to refine the pointclouds by isolating the facial re gion, excluding the head and neck. This is done using the model’ s eye orbits as a reliable anatomical landmark for establishing a cropping boundary . All Affect- Net3D pointclouds are b uilt with the (0,0,0) coordinate point consistently positioned at the center of the head. Nev ertheless, the orientation of the heads v aries significantly: they display different degrees of rotation and tilt. The method we developed takes into account the angular orientation of the head when defining the cropping plane to isolate the facial region. Our pipeline is designed to detect the center of the eye orbits, establish a cropping plane at a calculated distance of 2.3 times the orbit radius, and execute a vertical crop of the pointcloud. Empirical e v aluations of this technique ha ve prov en its ef ficacy in consistently isolating the facial region. The o verall data refining pipeline proposed in this work is depicted in Figure 4. This pipeline is di vided in two major parts: i) A 2D processing segment aimed at identifying the centers of the eyes and determining the radius of the eyeballs, and ii) a 3D processing segment focused on defining the cropping plane and filtering the pointcloud accordingly . 1) 2D Pr ocessing Se gment: The initial step in this segment in v olves projecting the pointcloud onto a 2D plane using the three coordinate axes. Subsequently , the projections undergo a series of transformations that result in the identification of the three-dimensional coordinates of the eye centers, as well as their radii. The transformations consist of: 1) Con v erting the 2D projections into binary image format enables the application of image processing methods. Based on empirical evidence, only the x-y and z-x projec- tions are used, as they hav e pro v en to be more effecti ve in simplifying the identification of eye positions. 2) Applying mathematical morphology [75] for easier eye region identification. Specifically , the dilation transfor- mation is used to ’open’ the structures within the image. In a binary image where dense, black regions represent potential areas of interest (eye orbits in this case), dilation helps to eliminate smaller, irrele v ant black regions. The structuring elements (kernels) used are empirically set to 1x2 for the x-z projection and 2x5 for the x-y projection. 3) Using Canny Edge Detection [76] to reduce noise by identifying the edges of features in the image, clarifying regions before applying more complex transformations. 4) Applying the Hough Circle T ransform to detect circles within the image that correspond to potential eye orbits. The range of possible radii for the circles is empirically determined. The Hough Circle Transform returns a list of circle centers and their radii. 5) Filtering the results from the Hough T ransform [77] by retaining only the circles that most likely represent the eyes. This filtering process considers factors such as the Hough transform confidence and the geometric plausibility of intercircle distances, i.e., the expected distance between tw o eyes. 6) Matching the coordinates of e ye centers between pro- jections. Once the eye centers are identified in both the x-y and x-z projections, their coordinates are matched. This in volv es aligning the z-coordinates from the x-z projection with the x and y coordinates from the x-y projection. The correct pairs are identified by ensuring the closest match in the x-coordinates between the two projections. The final step of the 2D processing in volv es back-projecting the e ye coordinates from 2D to 3D. 2) 3D Processing Se gment: The objective of the 3D pro- cessing segment is to isolate the facial area from the rest of the pointcloud. This is achiev ed by constructing a plane (based on reference points near the e ye centers) and using this plane to determine which points to keep or discard. The steps in v olved are as follows (cf., Figure 5): 1. Generating Lines from Eye Centers: Lines are drawn from each eye center to the origin IEEE DRAFT 9 Fig. 4: Pipeline for refining AffectNet-3D pointcloud, divided into 2D (purple) and 3D (yellow) processing segments Fig. 5: Transformations applied to pointcloud projections for eye center localization of coordinates (0,0,0) which, as already stated, is consistently located at the center of the head. 2) Defining Reference Points for the Plane: T wo points, prigth and pleft, are chosen along these lines, positioned at an empirically determined distance of 2.3 times the radius of each eye as detected by the Hough Circle T ransform. 3) Plane Construction: The plane is defined by creating two vectors: one connecting pright to pleft and another aligned with the positive Y -axis (which points towards the neck). This configuration ensures that the plane’ s normal vector points towards the facial region of the pointcloud. 4) Filtering Points Relati ve to the Plane: The pointcloud points are filtered based on their position relativ e to the plane using the inequality Ax + B y + C z + D > 0 , where (x, y , z) are the coordinates of a point in the pointcloud, while (A,B,C) are the components of the plane’ s normal vector , with D being the perpendicular distance of the plane from the origin. Points that satisfy this condition lie on the ’positi ve’ side of the plane, which has been oriented to coincide with the facial region of the pointcloud. Before feeding the refined pointclouds into the network, they undergo Farthest Point Sampling (FPS) to standardize the number of points across all samples. The number of points is adjusted to match the smallest pointcloud in both the test and training sets, which contained 1,496 points. In this work, we ha v e considered reducing the pointclouds to 512 centroids, with each centroid having 16 neighbors, due to the f act this number of centroids empirically yielded optimal performance in terms of the trade-of f between classification accuracy and training time. Regardless, the optimization for the number of centroids is considered as out of scope. E. Utilized P ointNet++ Model T o process the generated 3D pointclouds, PointNet++ [62] was selected due to its proven performance in the SotA literature and the av ailability of mature open-source imple- mentations. Specifically , the PointNet++ is inspired from [78], in which reasonable accuracies were achiev ed on two different facial pointcloud databases (Bosphorus [16] 69.01% and SIA T - 3DFE [79] 78.80%) using the PointNet++ network architec- ture. PointNet++ constitutes a foundational design component of our hypothesis ev aluation pipeline. The primary goal is to establish a baseline for point-based DL on 3D FER. This decision does not limit the framework to this specific architecture, and more adv anced DL models such as vox el- based approaches can be inte grated in future work. The PointNet++ netw ork architecture is giv en in Figure 6. PointNet++ [62] is a geometric deep learning model that can be seen as an extension of the pre vious PointNet [80] archi- tecture with incorporated hierarchical structure. The original PointNet architecture is capable of doing feature extraction using a function that maps a set of points to a feature vector in- variant to the input order . In this function, multi-layer percep- tron networks are used to learn features independently for each point and global features are extracted using a max-pooling layer . Ho wev er , the independent learning per point causes the PointNet not being able to capture local conte xt between points in local regions. PointNet++ adresses this problem by adding sampling and grouping layers. A PointNet++ based model, designed for classification of pointclouds, consists of a number of set abstraction levels for feature extraction which are then follo wed by a classifier consisting of fully connected layers. A single set abstraction lev el contains three key layers: a sampling layer , a grouping layer and a PointNet layer . The sampling layer samples a number of points from a set of input points, which determines the centroids for local regions in the pointcloud. The grouping layer determines local region sets by finding neighbouring points for each centroid. Then, the PointNet layer encodes these local regions into feature vectors. As visible in Figure 6, the PointNet++ model is composed of two set abstraction levels which form the feature extraction component of the model. This is follo wed by the classifier which consists of a single PointNet layer that conv erts the sets of points into a single feature vector such that it can be giv en as input to the follo wing fully connected layers. V . P E R F O R M A N C E E V A L UA T I O N M E T H O D O L O G Y The performance ev aluation of the proposed approach is designed to assess the ef fecti veness of the entire processing pipeline rather than analyzing individual components in isola- tion. The absence of corresponding ground-truth pointclouds IEEE DRAFT 10 Fig. 6: High-level design of the PointNet++ network, extracted from [78] makes validating the 3D reconstruction of AffectNet images (cf., Figure 7) inherently challenging. Without reference data, it is impossible to directly quantify reconstruction accuracy or compute con ventional error metrics, such as point-to-point distances. This limitation underscores the importance of ev alu- ating the reconstructed 3D data within the context of a practi- cal downstream FER task, where performance can be assessed through classification metrics rather than reconstruction errors. Accordingly , we qualify the data by its ability to support FER using a standard DL model (PointNet++). This model serves purely as a validation tool and could be replaced by a better performing alternative. The focus is on demonstrating that the FLAME-based reconstruction method, adapted here for 3D FER to ensure pipeline compatibility while preserving high-fidelity facial geometry , enables accurate and priv acy- aware 3D FER. In this work, privacy-awar e refers to reducing exposure of directly identifiable cues by relying on texture- free geometry rather than raw facial imagery; we do not claim formal priv acy guarantees against re-identification, in version, or reconstruction attacks. Consequently , an ablation study aimed at optimizing individual components is beyond this work’ s scope. A. Evaluation Setup The experimental evaluation incorporates the BU-3DFE dataset (cf., Figure 8), which provides high-quality 3D f acial pointclouds without the noise typically present in practical HFWS-based imaging. The BU-3DFE database has been cho- sen due to it being one of the most frequent databases for val- idation in 3D FER studies [81]. The purpose of this ev aluation is not to demonstrate dataset generalizability , but to validate the reliability of the proposed FLAME-based reconstruction method. Specifically , BU-3DFE serves as a high-quality ref- erence to determine whether the reconstructed 3D pointclouds from AffectNet (cf., Figure 7) possess sufficient geometric and expressi v e fidelity to enable effecti ve emotion classification. In this sense, the comparison is used to assess data quality and task relev ance rather than cross-dataset generalization. Furthermore, to assess whether using FLAME-generated 3D data for DL training of fers advantages for HFWS-based FER in continuous monitoring scenarios, beyond relying solely on the readily av ailable 3D FER datasets, we ev aluate the trained network on pointclouds where specific facial regions hav e been masked to simulate realistic wearable sensing conditions. W e emphasize that this masking analysis e valuates utility under reduced observ ability and does not constitute a formal priv acy-robustness ev aluation (e.g., against re-identification or in v ersion attacks). The training datasets used in the following experiments are a modified version of the original 3D AffectNet and the BU-3DFE dataset. The training subset of the 3D Af fectNet database was reduced from 287,651 samples to 30,000 sam- ples, selecting 3,750 samples for each of the eight emotion categories. The filtering process consisted of dataset shuffling to mitigate order bias, that could hinder the model’ s gener - alization capabilities, along with sample selection. Regarding BU-3DFE, the dataset was used without any filtering for all experiments. Our e xperiments present results for both the preprocessed and unprocessed versions of the 3D AffectNet database. In the follo wing sections, we will refer to the IEEE DRAFT 11 Fig. 7: Examples of original 2D Af fectNet images alongside their corresponding 3D generated pointclouds Fig. 8: Examples of BU-3DFE 3D point- clouds preprocessed dataset as Af fectNet3D and the unprocessed dataset as Ra w AffectNet3D. Model training sessions were executed using an NVIDIA A100 80GB PCie Graphics Processing Unit (GPU) with Compute Unified Device Architecture (CUD A) v . 12.0, within a Miniconda en vironment running Python 3.7. In addition to this, the system operated using 4 Central Processing Unit (CPU) with 16GB of Random Access Memory (RAM). B. Evaluation Scenarios Our e v aluation scenarios include two sets of experiments. First, we do a set of baseline experiments (E1 - E3). These experiments are meant to be compared to our proposed method and to also serve as sanity checks. Then, we do a set of experiments that ev aluate our proposed strate gy (E4 - E6). 1) Experiment 1 (E1.a/b): First, we aim to establish an “oracle” solution by training the PointNet++ model on the complete training portion of the BU-3DFE database (i.e., 80%). The model is first trained using the full size of the pointclouds (E1.a). In addition to this, we also train the model on pointclouds that contain 512 points (E1.b) which were obtained through FPS. 512 points have been selected empirically for optimally balancing the trade-off between classification accuracy and training time. As BU-3DFE is a commonly used FER database, finding this baseline gi ves us an understanding on the performance of the PointNet++ regarding capturing meaningful pointcloud semantics for FER tasks with regard to the existing literature. Both training procedures were done for 100 epochs. 2) Experiment 2 (E2.a/b): This experiment includes train- ing the PointNet++ model using only 25% percent of the BU-3DFE database and performing inference using the re- maining unseen 75% percent. Again, we repeat two times, once using the full size of the pointclouds (E2.a) and once using pointclouds downsampled to 512 points (E2.b). This experiment serves as a baseline for comparison with the fine- tuning experiments of the proposed solution (i.e., E6.a and E6.b). The training was carried out for 15 epochs, same as the fine-tuning in E6.a/b . 3) Experiment 3 (E3.a/b): The PointNet++ model is trained on an even smaller portion of BU-3DFE. Specifically , we use only 10% and perform inference using the remaining unseen 90% of the database, repeated for full size pointclouds (E3.a) and for pointclouds having 512 points (E3.b). This experiment serves as a baseline for experiment E6.c. Training for both solutions was done for 15 epochs. These experiments were defined to showcase the effects of reducing the amount of fine-tuning data on the classification accuracy . 4) Experiment 4 (E4.a/b): This experiment includes train- ing the PointNet++ model on the raw AffectNet3D dataset. As before, E4.a stands for using the full sized pointclouds and E4.b for using pointclouds downsampled to 512 points. 5) Experiment 5 (E5.a/b): Similar to Experiment 2, the PointNet++ model is trained on AffectNet3D. Ho we ver , in this experiment, AffectNet3D has been preprocessed before training using the procedure described in Section IV -D. 6) Experiment 6 (E6.a/b/c): This e xperiment is a successive experiment to experiments E4.b and E5.b using the resulting models after training on the downsampled Af fectNet3D and downsampled raw Af fectNet3D. The trained PointNet++ mod- els are fine-tuned for 15 epochs using only 25% of the BU- 3DFE dataset (E6.a/b). Then, the fine-tuned models are tested using the other -ne ver seen-part (75%) of the BU-3DFE dataset. In addition to this, this is again repeated for the model trained on the preprocessed downsampled AffectNet3D but now only using 10% of the BU-3DFE database where the other 90% is used for inference (E6.c). V I . E V A L UA T I O N R E S U LT S T able II displays the classification accuracy and training times observed in all experiments. First, we analyse the results of the baseline experiments (i.e., E1-E3) after which we ex- amine the results of our proposed strategies (i.e., E4-E6) with reference to the baseline results. Experiment E1 sho ws that PointNet++ is capable of learning features present in the facial pointclouds, resulting in meaningful emotion classification. In addition to this, it shows that having less points per pointcloud logically results in a lower training time, but also increases the inference accuracy . Regarding experiments E2 and E3, we see that if PointNet++ is trained on a small portion of BU-3DFE (25% and 10%, respectively), it can still achie v e inference accuracy considerably better than random. Experiment E4 demonstrates that direct training on the raw AffectNet3D is possible as it results in training/validation accuracy better than random. Ho wever , the features e xtracted by such training do not transfer to another FER database as is sho wn by the inference accuracy on BU-3DFE. This is the case for both E4.a and E4.b, yielding low inference IEEE DRAFT 12 T ABLE II: Summarized classification performance observed in different experiments Experiment/Metric Used part of BU-3DFE [%] T raining accuracy [%] V alidation accuracy [%] Inference accuracy [%] T raining time [min] BASELINE: T raining and Inference on BU-3DFE E1.a: Raw BU-3DFE (full) 80 96.50 - 74.02 198 E1.b: Raw BU-3DFE (512) 80 98.25 - 78.90 162 E2.a: Raw BU-3DFE (full) 25 67.34 50.12 45.57 10 E2.b: Raw BU-3DFE (512) 25 66.13 62.98 49.12 8 E3.a: Raw BU-3DFE (full) 10 84.38 50.00 37.34 4.5 E3.b: Raw BU-3DFE (512) 10 72.92 45.31 42.83 4 PROPOSED: T raining on AffectNet3D, Fine-tuning and Inference on BU-3DFE E4.a: Raw AffectNet3D (full) 0 42.99 43.37 15.57 2040 E4.b: Raw AffectNet3D (512) 0 58.40 41.54 16.76 1764 E5.a: AffectNet3D (full) 0 51.52 42.41 16.12 447 E5.b: AffectNet3D (512) 0 48.84 42.07 14.21 396 E6.a: Raw AffectNet3D + Fine-tuning 25 78.42 69.41 69.76 2040 + 8 E6.b: AffectNet3D + Fine-tuning 25 89.31 70.25 70.64 1764 + 8 E6.c: AffectNet3D + Fine-tuning 10 88.54 67.19 58.52 1764 + 3.5 accuracies on BU-3DFE with no fine-tuning of 15.57% and 16.76%, respectiv ely . This lo w inference accuracy is due to the cross-dataset transfer from FLAME-generated, full-head AffectNet3D pointclouds to the studio-scanned, face-only BU- 3DFE with no fine-tuning, the pretrained PointNet++ yields low direct inference (16.76%), whereas a brief fine-tuning on 25% of BU-3DFE raises accurac y to 70.64% (E6.b), indicating the features become effecti ve once the domain gap is bridged. Regarding experiment E5, we train on refined AffectNet3D with the aim to improve accuracy and/or training time. W e see that this does not increase the inference accuracy , yet it substantially lowers the training time by four times. For all sub-cases of experiment E6, we observe that fine-tuning results in a competiti ve inference accuracy on BU-3DFE. When comparing to the baseline, the accuracies from E6.a, E6.b and E6.c are higher than the ones of the corresponding baselines where only a small portion of BU-3DFE is used for training (i.e., E2.b and E3.b). When considering both inference accuracy and training time, experiment E6.b yields the best results (70.64% on BU-3DFE). W e note that it is only 8.26% lower than the ones yielded by the oracle solution in experiment E1.b . Figure 9 displays the confusion matrix for the results of experiment E6.b . The model shows notable confusion between ”Happiness” and ”Fear” with 41 instances of ”Happiness” being misclassified as ”Fear . ” Additionally , there is significant confusion between ”Sadness” and ”Anger”. ” Further tuning of features or improving the dataset balance may help reduce these pronounced errors. The main trade-off of the proposed solution is the increased training time compared to the baseline, primarily due to the fact that AffectNet3D is a much lar ger database than BU- 3DFE. For example, training on AffectNet3D in E6.a takes 2040 minutes plus 8 minutes for fine-tuning, whereas training on BU-3DFE in E1.a takes only 198 minutes. Howe ver , giv en that the training only needs to be performed once, we do not consider this increase in time as a significant drawback. One could en vision a generic training of the proposed FER system on Af fectNet3D, follo wed by collecting a small sample of user-specific 3D FER pointclouds for fine-tuning to individual users. In this scenario, user data collection requirements would be substantially reduced, and the system could be made oper- ational within the fine-tuning latenc y of just a fe w minutes. Fig. 9: Confusion matrix for experiment E6.b While the current frame work is designed for full-facial pointclouds (e.g., full-head helmets), devices with more lim- ited coverage, such as smart glasses, are more practical for continuous emotion monitoring. Although 3D pointclouds inherently capture less identifiable information (e.g., color , texture, or lighting) than traditional 2D images, prior studies show that geometry-only data may still allo w partial identity reconstruction [82], [83], [84]. Applying geometric transfor- mations or restricting visible facial regions can substantially reduce re-identification risks [82], [84], [85], suggesting that wearables with limited facial coverage could further enhance priv acy awareness by reducing the amount of potentially identifying geometry captured. T o ev aluate the system’ s adaptability to different wearable configurations, we simulate varying degrees of facial cov erage representativ e of HFWS-enabled de vices by applying region- based masks to the reconstructed pointclouds, constraining the visible areas to approximate wearable sensing conditions. This analysis focuses on utility under reduced coverage and should not be interpreted as an empirical validation of priv acy robustness against adv ersarial attacks. As sho wn in Figure 10, tw o masking strategies were ev al- uated, reflecting the expected coverage of devices such as smart glasses and Head Mounted Devices (HMDs) for Ex- tended Reality (xR) applications [86]. The results indicate that classification accurac y can be to a certain extent maintained IEEE DRAFT 13 Fig. 10: Classification accuracy under reduced facial coverage for example masking strategies (utility under constrained observability) under reduced coverage conditions. Specifically , our proposal that combines Af fectNet3D with 25% fine-tuning on BU- 3DFE maintains the highest ratio of the classification accuracy compared to the considered oracle (i.e., using 80% of BU- 3DFE for training) and baseline (using 25% of BU-3DFE for training). These findings establish a promising insight to ward expanding the system’ s applicability to wearables with more constrained facial coverage. V I I . D I S C U S S I O N A N D F U T U R E W O R K A. Accuracy Enhancements T o enhance accuracy , multiple consecutiv ely captured point- clouds could be mer ged to represent a single emotion. Emo- tions typically last around 90 seconds, which provides ample time to collect sev eral pointclouds and aggregate them to im- prov e classification accuracy . This compounding approach can potentially refine emotion detection by lev eraging temporal data. Additionally , HFWS used for 3D structural imaging of the face can be adapted to estimate the temperature of different facial regions, which is a feature that has been demonstrated to aid FER [87]. Integrating thermal information with 3D facial data could enhance the robustness of emotion classification, offering a more nuanced understanding of facial expressions. While this work focuses on ev aluating the use of Af fect- Net3D as a pre-training dataset with BU-3DFE, incorporating additional databases would help assess and improve the gener- alizability of the proposed pipeline. Evaluating the inference performance on other datasets could be part of the process tow ards enhancing the direct transfer accuracy of the pre- trained model without fine-tuning. Moreov er , PointNet++ was used as a baseline model for 3D FER due to its well-established performance in pointcloud- based classification tasks. Future research could explore more advanced DL models. For instance, Graph Con volutional Networks (GCNs) such as Dynamic Graph CNN (DGCNN) could better capture spatial relationships between f acial land- marks, while voxel-based models like Minko wskiNet could lev erage sparse conv olutions to enhance feature extraction. Additionally , transformer-based architectures, such as Point T ransformers (PTs), may provide improved global feature learning and robustness to occlusions. Exploring these models could lead to further impro vements in classification accuracy , especially when dealing with incomplete or noisy pointclouds expected in real-world THz imaging systems. Similarly , replacing our in-house FLAME-based reconstruc- tion with the EMOCA model could produce higher-quality 3D point clouds and potentially improve FER performance. Howe ver , it remains an open question whether the quality of the High-Frequency Wireless Sensing (HFWS)-generated data is comparable to that produced by EMOCA, or if it exhibits considerably higher le vels of noise. This distinction is critical, as optimizing FER performance in practical scenarios requires training on data that closely reflects the characteristics that the input model will encounter in deployment. B. 3D Imaging Using HFWS Our system aims to lev erage short-range HFWS, a novel approach that presents unique challenges and opportunities. Designing transceiv ers for such a system will in v olve address- ing the spatial constraints of wearable devices like glasses. Optimizing the placement of transcei v ers is crucial for maxi- mizing 3D imaging cov erage while maintaining the system’ s compactness and practicality . As a motiv ating example illustrating a foundational ap- proach for future development, we explored the potential of using phased arrays in the THz band for 3D facial surface recognition. W e began by modeling the complex topography of the human face [88], [89], phased array geometry [90], [91], and short-range THz wav e propagation [92], [93]. Our phased arrays allowed for precise control over the direction of emitted EM waves by adjusting the phase at each element. The opera- tional range for the considered beamforming and beamsteering model is controlled within the elev ation and azimuth ranges of [-50º,50º] (Figure 11.b). Utilizing the unique properties of THz radiation, primarily its high spatial resolution, we aimed to achiev e detailed f acial surface mapping. The f ace was modeled as a 3D surface with v arying topography , captured using a Gaussian map triangulation method (cf., Figure 11.a). This setup allowed the THz wa vefront to interact with the facial surface, reflecting back with varying phase delays, which were then captured by a set of single-antenna receivers distributed in a grid-like fashion throughout the frame of the glasses. W e emphasize that this section provides an illustrative feasibility- oriented sensing design sketch and does not constitute an implemented end-to-end THz imaging prototype. W e parameterized the model by focusing on aspects such as the number of array elements, element spacing, and beamwidth. W e used an N × N planar configuration of elements of transmitter arrays with element spacing set to λ/ 2 to achieve optimal interferometry and minimal grating lobes and feasible form-factors for wearables such as glasses. As shown in Figure 11.b, a 32x32 array provided a precise 3D radiation pattern, with the array size optimized to maintain coherence ev en in mid- and far-field approximations. This configuration allowed us to cover the facial surface within the desired elev ation and azimuth angles effecti vely . W e employed a uniform beam distribution strategy to ensure broad facial surface co verage, with strate gic placement of transmitters and omnidirectional receiv ers to maximize detection e ven in complex topography . Figure 11.b also illustrates the use of a diamond distribution to achie v e near-uniform co verage in all critical areas of the face. Our initial configuration included a setup of 10 arrays of 32x32 transmitting elements, with their central orientation for IEEE DRAFT 14 (a) Face and glasses model (b) THz beamforming and beamsteering (c) Positioning of transmitting arrays (d) 3D imaging coverage Fig. 11: Illustrative example of THz array configurations and beam coverage for facial surface 3D imaging the phased-array radiation emission as depicted in Figure 11.c. This setup yielded a comprehensiv e view of the face, as shown in Figure 11.d. As visible in the figure, not only locations near glasses were imaged by the considered system, but also for example points on the forehead and near mouth. This is due to the phased arrays’ high spatial resolution, enabling the imaging signals to be reflected back to the receiv ers even from small aberrations. Regardless of the encouraging co verage, a more thorough ev aluation with an enhanced le v el for realism is required. Based on this, an optimization on the number of transmitters and recei vers should be performed to further enhance the co verage of HFWS imaging. The utilized PointNet++ model shows promise for deplo y- ment on edge devices like smart glasses. When quantized to INT8, the model footprint reduces to a quarter , enabling real- time inference within ∼ 10 ms on embedded Neural Processing Units (NPUs) ( ∼ 1 TOPS) and within ∼ 20 ms on FP16-capable mobile GPUs, well within real-time performance bounds [94], [95]. THz-based sensing used to capture the 3D facial input features is expected to exhibit sub-millisecond latency , not constituting a bottleneck. CPU-only ex ecution remains feasible ( ∼ 100 ms) for prototyping but is less suited for continuous wearable use. Future w ork will explore additional optimization strate gies to further reduce compute overhead while maintaining accu- racy . For example, we will consider structured channel prun- ing (20–40%) and hardware-aware neural architecture search, which are expected to lower the number of Floating-Point Operations per Seconds (FLOPs) and improv e efficienc y on resource-constrained Systems on a Chip (SoCs). Furthermore, we will consider adopting faster spatial indexing methods for pre-processing stages or learned approximations [96], [97]. C. System-Level Considerations T o optimize the system, targeting specific regions of the face that carry the most relev ant information for FER could be beneficial. Pre vious studies have sho wn that focusing on a limited number of characteristic points can maintain high classification accuracy for 2D RGB images [98]. Applying a similar approach to 3D facial pointclouds could enhance system efficienc y . A focused analysis of critical facial regions might reduce the amount of data processed, leading to en- ergy savings and faster classification rates. In v estigating this approach for 3D FER could fill a gap in the literature and provide valuable insights into improving system performance and energy efficienc y . Additionally , determining the lo west bandwidth that main- tains FER accuracy requires in vestig ating the impact of point- cloud do wnsampling and noise introduction. By analyzing the correlation between noise le vels and 3D imaging resolution, we can identify the minimum bandwidth necessary to ensure effecti ve emotion recognition. As a simplified example, we assume the average human face has dimensions of 16 × 24 cm, resulting in a surface area of 0.0384 m 2 . For facial recognition using 3D pointclouds, we vary the point density as shown in Figure 12, assuming homogeneous co verage over the face. The spacing between points, calculated as Surf ace Area / N 1 / 2 , defines the required resolution for accurate recognition. The radar system’ s bandwidth B is deriv ed using X r = c 2 B , where X r is the required resolution. As the number of points increases, the required bandwidth rises. As visible from the figure around 256 points, we find a “sweet spot” where bandwidth minimization is achie ved without significant loss in FER performance. This bandwidth is av ailable at THz frequencies and as- suming short-range 3D imaging, offering windows e xceed- ing 10 GHz of bandwidth [69]. Howe ver , implementing transceiv ers that operate at these high frequencies presents significant challenges. One of the primary challenges is the dev elopment of compact, high-performance antennas and cir - cuits. At such frequencies, e ven small v ariations in the physical dimensions of components can lead to substantial performance degradation due to the shorter w av elengths in volv ed. Design- ing antennas that are small enough to be integrated into mobile devices or other compact form factors while maintaining efficienc y and signal strength is a major hurdle. Another issue is the po wer consumption of transceiv ers operating at THz frequencies. The power requirements in- crease significantly as frequency increases, which can lead to heat dissipation problems and limit the practical use of such systems in battery-powered or portable devices. De veloping efficient power amplifiers and low-po wer circuitry that can operate at such frequencies without excessi v e energy demands is an ongoing challenge. Overcoming these challenges will be critical for enabling the widespread use of HFWS systems, especially in compact and mobile applications. IEEE DRAFT 15 Fig. 12: Classification accuracy for different number of downsampled points and corresponding bandwidths required for 3D imaging D. Implementational Challenges While our work en visions embedding THz arrays in smart glasses for priv acy-a ware 3D FER, sev eral engineering chal- lenges are foreseen. Miniaturizing THz transcei vers within a wearable form factor introduces constraints in power con- sumption, thermal dissipation, and antenna array design. De- veloping compact, low-po wer THz transceivers with efficient cooling mechanisms is a crucial aspect of making this ap- proach practical. Additionally , the glass-mounted arrays must be optimized to balance field of view and depth accuracy while maintaining user comfort and aesthetics. Future work should explore hardware design strategies, such as inte grat- ing advanced beamforming techniques, using energy-ef ficient graphene-based THz transceiv ers, and optimizing antenna ar- ray geometry for improved coverage. Another open question is the quality of 3D pointclouds generated from a glasses-mounted THz system. Unlike full- head imaging setups, glasses provide a limited viewpoint, potentially leading to occlusions and incomplete reconstruc- tions. A thorough study on pointcloud usability is needed, including ho w missing regions impact FER accurac y and whether computational techniques, such as inpainting or fusing multi-view captures, can mitigate limitations. Future research should include simulation-based e v aluations of THz imaging cov erage from a wearable form factor , alongside practical experiments using scaled-down THz imaging prototypes. Despite its potential priv acy advantages, 3D FER is not completely free of risks. High-resolution scans may still al- low shape-based f acial re-identification, and adv ersarial tech- niques could potentially reconstruct identifiable facial features from 3D pointclouds. Accordingly , while we motiv ate priv acy awareness through texture-free geometry and limited co verage, we do not claim formal pri vacy guarantees in this work. T o mitigate these risks, further work is needed to explore differential pri v acy techniques, noise injection methods, and adaptiv e downsampling strategies to balance priv acy and accu- racy in 3D FER models. Additionally , hybrid FER approaches that combine 3D pointclouds with thermal imaging may offer complementary protection by reducing reliance on identity- rev ealing geometric cues while retaining emotionally relev ant physiological signals. V I I I . C O N C L U S I O N This work addresses the critical need for priv acy-aware data generation in FER, particularly in light of the limitations posed by current EU regulations on 2D image-based methods. By le veraging the HFWS paradigm, we offer an alternativ e through detailed 3D facial imaging via wearable sensors. T o support the inte gration of HFWS into the DL-based FER re- search community , we introduced a FLAME-flavoured method for generating 3D FER databases from existing 2D datasets. Our creation of a 3D version of the AffectNet database and subsequent training of the PointNet++ 3D FER DL model, demonstrated promising results, with significant improvements in classification accuracy following the application of a face- isolating data refining pipeline. Additionally , we sho wed that further fine-tuning the PointNet++ model on a limited portion of the unseen 3D FER database BU3DFE results in effecti ve performance across the entire database. T o ev aluate the system’ s applicability to wearable de vices with limited facial cov erage, such as smart glasses, we per- formed masking experiments on the reconstructed pointclouds, simulating the partial visibility conditions of HFWS-enabled wearables. These e xperiments provide a practical utility indi- cator under constrained observability and hint at the fact that emotion classification accuracy could be maintained ev en un- der reduced coverage, highlighting the feasibility of deploying the approach in practical continuous-monitoring scenarios. Although our exploration of THz-based imaging for 3D FER remains theoretical, our proposed and implemented pipeline for generating and processing 3D facial pointclouds serves as a strong foundation for future practical dev elopments. By demonstrating that 3D FER models can be effecti vely trained using synthetic 3D datasets deri ved from 2D images, this work provides a crucial stepping stone to wards real- world applications of pri vacy-a ware emotion recognition. W e emphasize that, while texture-free geometry and reduced facial cov erage can mitigate identity disclosure risk, this w ork does not pro vide a formal pri v ac y guarantee or an empirical priv ac y- attack ev aluation. The proposed framework not only validates the feasibility of 3D FER b ut also highlights the potential of integrating HFWS-enabled sensing into wearable devices. Future ef forts in THz-based imaging can build upon our findings, refining the hardw are and imaging pipeline to achie ve high-quality 3D reconstructions suitable for real-time emotion recognition. R E F E R E N C E S [1] S. Ojha, J. V itale, and M.-A. W illiams, “Computational emotion models: A thematic revie w , ” International Journal of Social Robotics , vol. 13, no. 6, pp. 1253–1279, 2021. [2] J. Zhang, Z. Y in, et al., “Emotion recognition using multi-modal data and machine learning techniques: A tutorial and review, ” Information Fusion , vol. 59, pp. 103–126, 2020. [3] J. Hall, T . Hogan, and N. Murphy, Non verbal communication annual r evie w of psychology , 2022. [4] K. A. Loveland, B. T unali–K otoski, Y . R. Chen, J. Ortegon, D. A. Pearson, K. A. Brelsford, and M. C. Gibbs, “Emotion recognition in autism: V erbal and non verbal information, ” Development and psychopathology , vol. 9, no. 3, pp. 579–593, 1997. [5] N. Y irmiya, C. Kasari, M. Sigman, and P . Mundy, “Facial expressions of affect in autistic, mentally retarded and normal children, ” Journal of Child Psychology & Psychiatry , vol. 30, no. 5, pp. 725–735, 1989. IEEE DRAFT 16 [6] G. Esposito, P . V enuti, and M. H. Bornstein, “ Assessment of distress in young children: A comparison of autistic disorder , developmental delay , and typical development, ” Researc h in Autism Spectrum Dis- or ders , vol. 5, no. 4, pp. 1510–1516, 2011. [7] B. C. K o, “A brief revie w of facial emotion recognition based on visual information, ” sensors , vol. 18, no. 2, p. 401, 2018. [8] F . V . Massoli, D. Cafarelli, C. Gennaro, G. Amato, and F . Falchi, “Mafer: A multi-resolution approach to facial e xpression recognition, ” arXiv Pr eprint:2105.02481 , 2021. [9] S. V ignesh, M. Savithade vi, M. Sridevi, and R. Sridhar, “A novel facial emotion recognition model using segmentation vgg-19 archi- tecture, ” International Journal of Information T echnology , v ol. 15, no. 4, pp. 1777–1787, 2023. [10] L. Shan and W . Deng, “Reliable crowdsourcing and deep locality- preserving learning for unconstrained facial expression recognition, ” IEEE T ransactions on Image Processing , vol. 28, no. 1, pp. 356–370, 2018. [11] A. Mollahosseini, B. Hasani, and M. H. Mahoor , “ Affectnet: A database for facial expression, v alence, and arousal computing in the wild, ” IEEE T ransactions on Affective Computing , vol. 10, no. 1, pp. 18–31, 2017. [12] F . Z. Canal, T . R. M ¨ uller, J. C. Matias, G. G. Scotton, A. R. de Sa Junior, E. Pozzebon, and A. C. Sobieranski, “A survey on facial emotion recognition techniques: A state-of-the-art literature revie w, ” Information Sciences , vol. 582, pp. 593–617, 2022. [13] J. Butt, “Analytical study of the world’ s first eu artificial intelligence (ai) act, ” International Journal of Researc h and Publications , vol. 5, no. 3, 2024. [14] F . Morandin-Ahuerma, “T en unesco recommendations on the ethics of artificial intelligence, ” 2023. [15] L. Y in, X. W ei, Y . Sun, J. W ang, and M. J. Rosato, “A 3d f acial expression database for facial behavior research, ” in 7th international confer ence on automatic face and gestur e reco gnition (FGR06) , IEEE, 2006, pp. 211–216. [16] A. Savran, N. Aly ¨ uz, H. Dibeklio ˘ glu, O. C ¸ eliktutan, B. G ¨ okberk, B. Sankur, and L. Akarun, “Bosphorus database for 3d face analysis, ” in Biometrics and Identity Management: F irst European W orkshop, BIOID 2008, Roskilde , Denmark, May 7-9, 2008. Revised Selected P apers 1 , Springer, 2008, pp. 47–56. [17] Y . W u, F . Lemic, C. Han, and Z. Chen, “Sensing integrated dft- spread ofdm w av eform and deep learning-powered recei ver design for terahertz integrated sensing and communication systems, ” IEEE T ransactions on Communications , vol. 71, no. 1, pp. 595–610, 2022. [18] Y . Hong and J. Choi, “60 ghz patch antenna array with parasitic elements for smart glasses, ” IEEE Antennas and W ir eless Pr opagation Letters , vol. 17, no. 7, pp. 1252–1256, 2018. [19] M. Zubair, A. Jabbar, F . A. T ahir, et al., “A high-performance sub- thz planar antenna array for thz sensing and imaging applications, ” Scientific Reports , vol. 14, no. 1, p. 17 030, 2024. [20] A. Singh, M. Andrello, N. Thawdar , and J. M. Jornet, “Design and operation of a graphene-based plasmonic nano-antenna array for communication in the terahertz band, ” IEEE Journal on Selected Ar eas in Communications , vol. 38, no. 9, pp. 2104–2117, 2020. [21] D. T . Petkie, E. Bryan, C. Benton, C. Phelps, J. Y oakum, M. Rogers, and A. Reed, “Remote respiration and heart rate monitoring with millimeter-wa ve/terahertz radars, ” in Millimetre W ave and T erahertz Sensors and T echnology , SPIE, vol. 7117, 2008, pp. 129–134. [22] T . Li, T . Bolkart, M. J. Black, H. Li, and J. Romero, “Learning a model of facial shape and expression from 4d scans., ” ACM T rans. Graph. , vol. 36, no. 6, pp. 194–1, 2017. [23] C. Newmark, “Charles darwin: The expression of the emotions in man and animals, ” in Schl ¨ usselwerke der Emotionssoziologie , Springer, 2022, pp. 111–115. [24] P . Ekman and W . V . Friesen, “Constants across cultures in the face and emotion., ” Journal of personality and social psychology , vol. 17, no. 2, p. 124, 1971. [25] S. Du, Y . T ao, and A. M. Martinez, “Compound facial expressions of emotion, ” National Academy of Sciences , vol. 111, no. 15, E1454– E1462, 2014. [26] J. A. Russell, “A circumplex model of affect., ” Journal of personality and social psychology , vol. 39, no. 6, p. 1161, 1980. [27] P . Ekman and W . V . Friesen, “Facial action coding system, ” Envir on- mental Psychology & Non verbal Behavior , 1978. [28] H.-X. Xie, L. Lo, H.-H. Shuai, and W .-H. Cheng, “An overview of facial micro-expression analysis: Data, methodology and challenge, ” IEEE T ransactions on Affective Computing , vol. 14, no. 3, pp. 1857– 1875, 2022. [29] M. J. A. Dujaili, “Surv ey on facial e xpressions recognition: Databases, features and classification schemes, ” Multimedia T ools and Applica- tions , vol. 83, no. 3, pp. 7457–7478, 2024. [30] L. Pham, T . H. V u, and T . A. Tran, “Facial expression recognition us- ing residual masking network, ” in 2020 25Th international conference on pattern r ecognition (ICPR) , IEEE, 2021, pp. 4513–4519. [31] S. Zhang, Y . Zhang, et al., “A dual-direction attention mix ed fea- ture network for facial expression recognition, ” Electronics , vol. 12, no. 17, p. 3595, 2023. [32] J. Le Ngwe and K. o. Lim, “Patt-lite: Lightweight patch and atten- tion mobilenet for challenging facial expression recognition, ” IEEE Access , 2024. [33] J. Mao, R. Xu, X. Y in, Y . Chang, B. Nie, A. Huang, and Y . W ang, “Poster++: A simpler and stronger facial expression recognition network, ” P attern Recognition , vol. 157, p. 110 951, 2025. [34] A. T . W asi, K. ˇ Serbetar, R. Islam, T . H. Rafi, and D.-K. Chae, Arbex: Attentive feature extraction with reliability balancing for rob ust facial expr ession learning , 2023. arXiv: 2305.01486. [35] I. J. Goodfellow , D. Erhan, et al., “Challenges in representation learning: A report on three machine learning contests, ” in Neu- ral Information Processing: 20th International Confer ence, ICONIP 2013, Daegu, Kor ea, November 3-7, 2013. Pr oceedings, P art III 20 , Springer, 2013, pp. 117–124. [36] X. Zhang, L. Y in, J. F . Cohn, S. Canav an, M. Reale, A. Horowitz, and P . Liu, “A high-resolution spontaneous 3d dynamic facial expression database, ” in 2013 10th IEEE international confer ence and workshops on automatic face and gesture r ecognition (FG) , IEEE, 2013, pp. 1–6. [37] Y . Qiu and Y . W an, “Facial expression recognition based on land- marks, ” in IEEE Advanced Information T echnology , Electr onic and Automation Contr ol Confer ence , IEEE, 2019, pp. 1356–1360. [38] M. A. Haghpanah, E. Saeedizade, M. T . Masouleh, and A. Kalhor, “Real-time facial expression recognition using facial landmarks and neural networks, ” in International Conference on Machine V ision and Image Pr ocessing (MVIP) , IEEE, 2022, pp. 1–7. [39] M. Pantic and L. J. Rothkrantz, “Facial action recognition for facial expression analysis from static face images, ” IEEE T ransactions on Systems, Man, and Cybernetics , vol. 34, no. 3, pp. 1449–1461, 2004. [40] Y . W u, V . Kakaraparthi, Z. Li, T . Pham, J. Liu, and P . Nguyen, “Bioface-3d: Continuous 3d facial reconstruction through lightweight single-ear biosensors, ” in International Conference on Mobile Com- puting and Networking , 2021, pp. 350–363. [41] F . Pittaluga, S. J. K oppal, S. B. Kang, and S. N. Sinha, “Rev eal- ing scenes by inverting structure from motion reconstructions, ” in IEEE/CVF Conference on Computer V ision and P attern Recognition , 2019, pp. 145–154. [42] J. Wu, R. Tse, and L. G. Shapiro, “Automated face extraction and normalization of 3d mesh data, ” in 2014 36th Annual International Confer ence of the IEEE Engineering in Medicine and Biology Society , IEEE, 2014, pp. 750–753. [43] V . Be vilacqua, F . Andriani, and G. Mastronardi, “3d head pose normalization with face geometry analysis, genetic algorithms and pca, ” Journal of Circuits, Systems, and Computers , vol. 18, no. 08, pp. 1425–1439, 2009. [44] P . Paysan, R. Knothe, B. Amberg, S. Romdhani, and T . V etter, “A 3d face model for pose and illumination inv ariant face recognition, ” in IEEE international conference on advanced video and signal based surveillance , Ieee, 2009, pp. 296–301. [45] T . Martyniuk, O. Kupyn, Y . Kurlyak, I. Krashenyi, J. Matas, and V . Sharmanska, “Dad-3dheads: A large-scale dense, accurate and div erse dataset for 3d head alignment from a single image, ” in IEEE/CVF Conference on computer vision and pattern recognition , 2022, pp. 20 942–20 952. [46] S. Sanyal, T . Bolkart, H. Feng, and M. Black, “Learning to regress 3d face shape and expression from an image without 3d supervision, ” in IEEE Conference on Computer V ision and P attern Recognition (CVPR) , 2019. [47] Y . Feng, H. Feng, M. J. Black, and T . Bolkart, “Learning an animatable detailed 3d face model from in-the-wild images, ” ACM T ransactions on Graphics (T oG) , vol. 40, no. 4, 88:1–88:13, 2021. [48] R. Dane ˇ cek, M. J. Black, and T . Bolkart, “EMOCA: Emotion driven monocular face capture and animation, ” in 2022 IEEE/CVF Confer- ence on Computer V ision and P attern Recognition (CVPR) , 2022, pp. 20 279–20 290. [49] M. V ilalta i Soler, “Ai-based construction of 3d human face rep- resentations from 2d images for emotion recognition, ” M.S. thesis, Univ ersitat Polit ` ecnica de Catalunya, 2024. IEEE DRAFT 17 [50] R. Ranftl, K. Lasinger, D. Hafner, K. Schindler, and V . Koltun, “T o- wards robust monocular depth estimation: Mixing datasets for zero- shot cross-dataset transfer , ” IEEE tr ansactions on pattern analysis and machine intelligence , vol. 44, no. 3, pp. 1623–1637, 2020. [51] S. F . Bhat, I. Alhashim, and P . W onka, “Adabins: Depth estimation using adapti ve bins, ” in IEEE/CVF conference on computer vision and pattern r ecognition , 2021, pp. 4009–4018. [52] S. F . Bhat, R. Birkl, D. W ofk, P . W onka, and M. M ¨ uller, “Zoedepth: Zero-shot transfer by combining relati ve and metric depth, ” arXiv Pr eprint:2302.12288 , 2023. [53] S. M. H. Miangoleh, S. Dille, L. Mai, S. Paris, and Y . Aksoy , “Boosting monocular depth estimation models to high-resolution via content-adaptiv e multi-resolution merging, ” in IEEE/CVF Conference on Computer V ision and P attern Recognition , 2021, pp. 9685–9694. [54] S. Lin, M. Bai, F . Liu, L. Shen, and Y . Zhou, “Orthogonalization- guided feature fusion network for multimodal 2d+3d facial expression recognition, ” IEEE T ransactions on Multimedia , vol. PP, pp. 1–1, 2020. [55] K. Zhu, Z. Du, W . Li, D. Huang, and L. Chen, “Discriminative attention-based con volutional neural network for 3d facial expression recognition, ” in 2019 14th IEEE International Conference on Auto- matic F ace & Gesture Recognition (FG 2019) , IEEE, 2019, pp. 1–8. [56] Z. Zhu, M. Sui, H. Li, and F . Zhao, “Cmanet: Curvature-aware soft mask guided attention fusion network for 2d+3d facial expression recognition, ” in 2022 IEEE International Confer ence on Multimedia and Expo (ICME) , IEEE, 2022, pp. 1–6. [57] M. Sui, H. Li, Z. Zhu, and F . Zhao, “Afnet-m: Adaptive fusion network with masks for 2d+ 3d facial expression recognition, ” in 2023 IEEE International Conference on Image Pr ocessing (ICIP) , IEEE, 2023, pp. 116–120. [58] H. Li, H. Y ang, and D. Huang, “Drfer: Learning disentangled repre- sentations for 3d facial expression recognition, ” in 2024 IEEE 18th International Conference on Automatic F ace and Gestur e Recognition (FG) , IEEE, 2024, pp. 1–8. [59] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition, ” in 2016 IEEE Conference on Computer V ision and P attern Recognition (CVPR) , IEEE, 2016, pp. 770–778. [60] J. Deng, W . Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database, ” in 2009 IEEE Confer ence on Computer V ision and P attern Recognition (CVPR) , IEEE, 2009, pp. 248–255. [61] K. Simonyan and A. Zisserman, “V ery deep conv olutional networks for large-scale image recognition, ” arXiv preprint , 2014. [62] C. R. Qi, L. Y i, H. Su, and L. J. Guibas, “Pointnet++: Deep hierarchical feature learning on point sets in a metric space, ” Advances in neural information processing systems , vol. 30, 2017. [63] L. Y i, Y . Li, and T . Nagatsuma, “Photonic radar for 3d imaging: From millimeter to terahertz waves, ” IEEE Journal of Selected T opics in Quantum Electr onics , 2023. [64] D. D. Arnone, C. M. Ciesla, A. Corchia, S. Egusa, M. Pepper, J. M. Chamberlain, C. Bezant, E. H. Linfield, R. Clothier, and N. Khammo, “Applications of terahertz (thz) technology to medical imaging, ” in THz Spectr oscopy and Applications , SPIE, vol. 3828, 1999, pp. 209– 219. [65] X.-C. Zhang, “Three-dimensional terahertz wave imaging, ” Philo- sophical T ransactions of the Royal Society of London. Series A: Mathematical, Physical and Engineering Sciences , vol. 362, no. 1815, pp. 283–299, 2004. [66] A. Rahman, A. K. Rahman, and B. Rao, “Early detection of skin cancer via terahertz spectral profiling and 3d imaging, ” Biosensor s and Bioelectr onics , vol. 82, pp. 64–70, 2016. [67] J. Ding, M. Kahl, O. Loffeld, and P . H. Boliv ar , “Thz 3-d image for- mation using sar techniques: Simulation, processing and experimental results, ” IEEE T ransactions on T erahertz Science and T echnology , vol. 3, no. 5, pp. 606–616, 2013. [68] I. G. Cumming and F . H. W ong, “Digital processing of synthetic aperture radar data, ” Artech house , vol. 1, no. 3, pp. 108–110, 2005. [69] S. Abadal, J. Sol ´ e-Pareta, E. Alarc ´ on, and A. Cabellos-Aparicio, “Me- dia access control for nanoscale communications and networking, ” in Nanoscale Networking and Communications Handbook , CRC Press, 2019, pp. 185–200. [70] S. Abadal, I. Llatser, A. Mestres, H. Lee, E. Alarc ´ on, and A. Cabellos- Aparicio, “Time-domain analysis of graphene-based miniaturized antennas for ultra-short-range impulse radio communications, ” IEEE T ransactions on communications , vol. 63, no. 4, pp. 1470–1482, 2015. [71] W . Jiang, Q. Zhou, J. He, M. A. Habibi, S. Meln yk, M. El-Absi, B. Han, M. Di Renzo, H. D. Schotten, F .-L. Luo, et al., “T erahertz communications and sensing for 6g and beyond: A comprehensiv e revie w, ” IEEE Communications Surveys & T utorials , 2024. [72] S. Tripathi, N. V . Sabu, A. K. Gupta, and H. S. Dhillon, “Millimeter- wav e and terahertz spectrum for 6g wireless, ” in 6G Mobile W ir eless Networks , Springer, 2021, pp. 83–121. [73] F . Lemic, S. Abadal, W . T avernier , P . Stroobant, D. Colle, E. Alarc ´ on, J. Marquez-Barja, and J. Famaey, “Survey on terahertz nanocommu- nication and networking: A top-down perspectiv e, ” IEEE Journal on Selected Areas in Communications , vol. 39, no. 6, pp. 1506–1543, 2021. [74] European Commission, Pr oposal for a re gulation of the eur opean parliament and of the council laying down harmonised rules on artificial intelligence (artificial intelligence act) and amending certain union le gislative acts , COM/2021/206 final, 2021. [75] J. Serra, Image analysis and mathematical morphology . Academic Press, Inc., 1983. [76] J. Canny, “A computational approach to edge detection, ” IEEE T ransactions on pattern analysis and machine intelligence , no. 6, pp. 679–698, 1986. [77] A. S. Hassanein, S. Mohammad, M. Sameer, and M. E. Ragab, “A survey on hough transform, theory , techniques and applications, ” International Journal of Computer Science Issues (IJCSI) , v ol. 12, no. 1, p. 139, 2015. [78] D.-P . Nguyen, M.-C. Ho Ba Tho, et al., “Enhanced facial expression recognition using 3d point sets and geometric deep learning, ” Medical & Biological Engineering & Computing , vol. 59, May 2021. [79] Y . Y e, Z. Song, J. Guo, and Y . Qiao, “Siat-3dfe: A high-resolution 3d facial expression dataset, ” IEEE Access , vol. 8, pp. 205–211, 2020. [80] C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation, ” in IEEE conference on computer vision and pattern r ecognition , 2017, pp. 652–660. [81] G. R. Alexandre, J. M. Soares, and G. A. Pereira Th ´ e, “Systematic revie w of 3d facial expression recognition methods, ” P attern Recog- nition , vol. 100, p. 107 108, 2020. [82] K. Chelani, F . Kahl, and T . Sattler, “How priv acy-preserving are line clouds? reco vering scene details from 3d lines, ” IEEE/CVF Confer ence on Computer V ision and P attern Recognition (CVPR) , 2021. [83] C.-W . W ang and C.-C. Peng, “3d face point cloud reconstruction and recognition using depth sensor, ” Sensors , 2021. [84] X. Y ang, R. Li, and X. Y ang, “Coordinate-wise monotonic transfor- mations enable priv acy-preserving age estimation with 3d face point cloud., ” Sci. China Life Sci. , 2024. [85] Y . Y ang, J. L yu, and R. W ang, “A digital mask to safeguard patient priv acy ., ” Nat Med , 2022. [86] J. Struye, S. V an Damme, N. N. Bhat, A. Troch, B. V an Liempd, H. Assasa, F . Lemic, J. Famaey, and M. T . V ega, “T o ward interactiv e multi-user extended reality using millimeter-wav e networking, ” IEEE Communications Magazine , vol. 62, no. 8, pp. 54–60, 2024. [87] E. E. Berlovskaya, S. A. Isaychev , A. M. Chernorizov , I. A. Ozhere- dov , et al., “Diagnosing human psychoemotional states by combining psychological and psychophysiological methods with measurements of infrared and thz radiation from face areas, ” Psychology in Russia: State of the Art.–2020.–13 , no. 2, pp. 64–83, 2020. [88] G. Barbarino, M. Jabareen, J. Trze wik, A. Nkengne, G. Stamatas, and E. Mazza, “Development and validation of a three-dimensional finite element model of the face, ” J ournal of biomechanical engineering , vol. 131, no. 4, p. 041 006, 2009. [89] L. Munn and C. N. Stephan, “Changes in face topography from supine-to-upright position—and soft tissue correction values for craniofacial identification, ” F or ensic science international , vol. 289, pp. 40–50, 2018. [90] H. G. Hoang, H. D. T uan, and B.-N. V o, “Low-dimensional sdp formulation for large antenna array synthesis, ” IEEE transactions on antennas and pr opagation , vol. 55, no. 6, pp. 1716–1725, 2007. [91] Y . T ousi and E. Afshari, “14.6 a scalable thz 2d phased array with+ 17dbm of eirp at 338ghz in 65nm bulk cmos, ” in IEEE International Solid-State Cir cuits Conference Digest of T echnical P apers (ISSCC) , IEEE, 2014, pp. 258–259. [92] R. Piesiewicz, T . Kleine-Ostmann, N. Krumbholz, D. Mittleman, M. Koch, J. Schoebel, and T . Kurner, “Short-range ultra-broadband terahertz communications: Concepts and perspectiv es, ” IEEE Anten- nas and Pr opagation Magazine , vol. 49, no. 6, pp. 24–39, 2007. IEEE DRAFT 18 [93] T . Nagatsuma, K. Oogimoto, Y . Inubushi, and J. Hirokawa, “Practical considerations of terahertz communications for short distance appli- cations, ” Nano Communication Networks , vol. 10, pp. 1–12, 2016. [94] M. Paolieri, J. Garcia, M. Bernaschi, and V . Prasanna, “A benchmark for ml inference latency on mobile devices, ” in International W ork- shop on Edge Systems, Analytics and Networking (EdgeSys) , 2024. [95] J. Moosmann, P . Bonazzi, Y . Li, S. Bian, P . Mayer, L. Benini, and M. Magno, “Ultra-efficient on-device object detection on ai-integrated smart glasses with tinyissimoyolo, ” in European Conference on Com- puter V ision , Springer, 2024, pp. 262–280. [96] Y . Hu, R. Gong, Q. Sun, and Y . W ang, “Low latency point cloud ren- dering with learned splatting, ” in IEEE/CVF Confer ence on Computer V ision and P attern Recognition , 2024, pp. 5752–5761. [97] H. Zhao, Y . W eng, and L. Fuxin, “Pointnetv3: A f aster and more accurate pointnet++, ” OpenReview (preprint) , 2025. [98] Y . W ang, M. Cao, Z. Fan, and S. Peng, “Learning to detect 3d facial landmarks via heatmap regression with graph conv olutional network, ” in AAAI Confer ence on Artificial Intelligence , vol. 36, 2022, pp. 2595– 2603. B I O G R A P H I E S Laura Ray on is a T elecommunications engineer with MSc in Audiovisual Signal Processing and AI from UPC BarcelonaT ech. Founding member of the RIT A team mission, the winning project of the IEEE GRSS 2nd Student Grand Challenge, her research has included mission design and path planning algorithms for satellite networks, and a collaboration with i2CA T on Affecti ve Computing. After working on the integration of an ethernet- based data acquisition protocol for CERN’ s Quench Protection System, she is currently a Rust developer . Jasper De Laet recei ved his MSc in Artificial Intelligence and Data Science from the Uni versity of Antwerp, Belgium. He conducted research on the interpretability and explainability of spiking neural networks in collaboration with sqIRL/IDLab–imec and the University of Antwerp. His research inter- ests include affectiv e computing, explainable artifi- cial intelligence, human–AI interaction, and spiking neural networks. He is currently working on the dev elopment of AI-driv en applications with a focus on software and cloud-based systems. Filip Lemic is a senior researcher and a research lead at the i2Cat Foundation, and a visiting re- searcher at the Univ ersity of Zagreb . He held posi- tions at the University of Antwerp, imec, Universitat Polit ` ecnica de Catalunya, Univ ersity of California at Berkeley , Shanghai Jiao T ong University , FIW ARE Foundation, and T echnische Uni versit ¨ at Berlin. He receiv ed his M.Sc. and Ph.D. from the Univ ersity of Zagreb and T echnische Universit ¨ at Berlin, respec- tiv ely . Pau Sabater is a junior researcher at the Ul- trabroadband Nanonetworking Laboratory , Boston, MA, within a visiting student program at Department of Electrical and Computer Engineering, Northeast- ern University , where his work focuses on THz- based wav efront engineering for long-range wireless communications. He is an undergraduate student in Mathematics (B.Sc.) and Physics (B.E.) at UPC BarcelonaT ech, Spain, under the CFIS excellence program. He has conducted research at i2CA T Foun- dation, the Institute of Robotics and Industrial Infor- matics under a CSIC-UPC Research Grant, and Esperanto T echnologies. He also serves as a Data Scientist at REVER (YC-S22). Nabeel Nisar Bhat is a Ph.D. researcher in the field of Joint Communication and Sensing at the IDLab research group (University of Antwerp) and imec research institute, Belgium. He obtained his M.Sc. (2021) in Communications and Computer Networks Engineering at Politecnico di T orino. His current re- search focuses on lev eraging mmW ave communica- tion signals for pose estimation in Extended Reality applications. He has experience in signal processing, wireless communications, and deep learning. Sergi Abadal is an associate professor at the Uni- versitat Polit ` ecnica de Catalunya (UPC) and the recipient of a Starting Grant from the European Re- search Council (ERC). He holds editorial positions in journals such as the IEEE TMC, IEEE TCAD, or IEEE JETCAS. He has served as a TPC member of more than 40 conferences and has published over 150 articles in top-tier journals and conferences. His current research interests are in the areas of wireless communications in extreme en vironments and its applications. Jer oen Famaey is an associate professor at the Uni- versity of Antwerp, Belgium, and a senior researcher at IMEC, Belgium. He leads the Perceptive Radio Systems lab at the IDLab research group, performing research on wireless communications and sensing. His current research interests include low-po wer distributed machine learning and wireless commu- nications for Ambient IoT , as well as data-driv en integrated sensing and communications. He has co- authored over 200 articles, published in international peer-re vie wed journals and conference proceedings. Eduard Alarc ´ on received the M.Sc. and Ph.D. degrees in EE from UPC BarcelonaT ech, Spain, in 1995 and 2000, respectively . He is a Full Professor with the School of T elecommunications, UPC. He was a V isiting Professor with the Univ ersity of Colorado at Boulder, USA, and the Royal Institute of T echnology (KTH), Stockholm. He has been in volv ed in dif ferent European (H2020 FET -Open and FlagERA) and U.S. (DARP A and NSF) research and development projects within his research inter- ests including the areas of on chip energy manage- ment, wireless networks-on-chip, machine learning accelerator architectures, nanotechnology-enabled wireless communications and quantum compute ar- chitectures. He has recei ved major research awards and fellowships, along with a national master’s study award, and has held senior IEEE Circuits and Systems leadership roles. He has also led and organized multiple flagship conferences and special sessions. Xavier Costa-P ´ erez is an ICREA Research Pro- fessor and Scientific Director at the i2cat Research Center , concurrently leading 5G/6G R&D at NEC Laboratories Europe. His team consistently delivers impactful research, e videnced by publications in top-tier scientific venues and numerous awards for successful technology transfers. Notably , his innov a- tions have been integrated into commercial mobile phones, base stations, and network management sys- tems, and have spurred the creation of multiple start- ups. He has also serv ed on organizing committees for prominent conferences (e.g., ACM MOBICOM, IEEE INFOCOM) and as an Editor for leading journals like IEEE Transactions on Mobile Computing (TMC), IEEE Transactions on Communications (TCOM), as well as Elsevier Computer Communications (COMCOM). Dr . Costa-P ´ erez holds M.Sc. and Ph.D. degrees in T elecommunications from the Polytechnic Univ ersity of Catalonia (UPC), receiving a national aw ard for his doctoral thesis. He is the in ventor of approximately 100 granted patents.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment