Retromorphic Testing with Hierarchical Verification for Hallucination Detection in RAG
Large language models (LLMs) continue to hallucinate in retrieval-augmented generation (RAG), producing claims that are unsupported by or conflict with the retrieved context. Detecting such errors remains challenging when faithfulness is evaluated so…
Authors: Boxi Yu, Yuzhong Zhang, Liting Lin
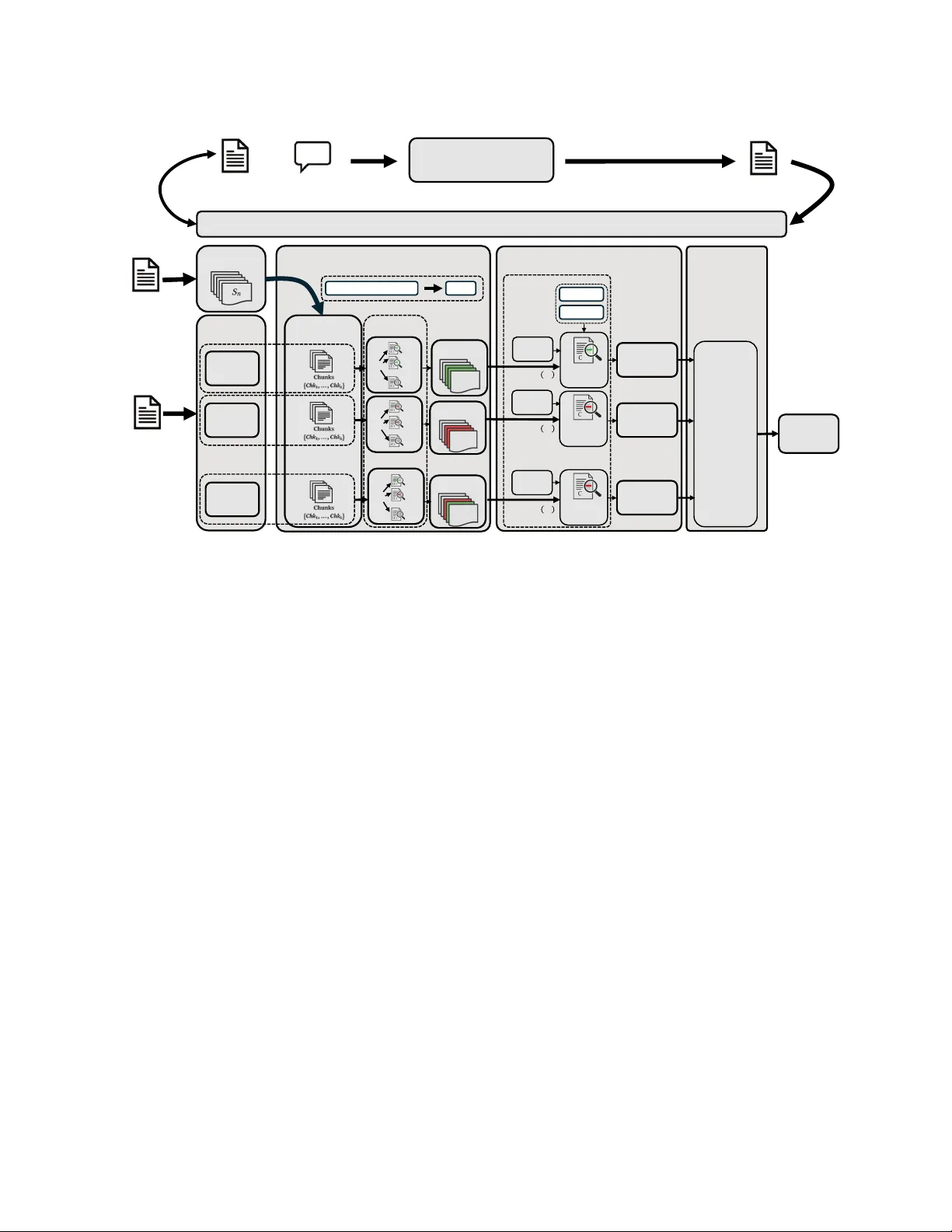
Retromorphic T esting with Hierarchical V erification for Hallucination Dete ction in RA G Boxi Y u Lero, the Resear ch Ireland Centre for Software, Univ ersity of Limerick Ireland boxi.yu@lero.ie Y uzhong Zhang The Chinese University of Hong Kong, Shenzhen China 123090848@link.cuhk.edu.cn Liting Lin Lero, the Resear ch Ireland Centre for Software, Univ ersity of Limerick Ireland Liting.Lin@ul.ie Lionel Briand Lero, the Resear ch Ireland Centre for Software, Univ ersity of Limerick Ireland University of Ottawa Canada lbriand@uottawa.ca Emir Muñoz Genesys Ireland emir .munoz@gmail.com Abstract Large language models can still hallucinate in retrieval-augmented generation (RAG), producing claims that are unsupp orted by or conict with the retrieved context. Detecting such errors r emains challenging when faithfulness is judged solely against the retrieved context: many existing detectors r eturn holistic answer-level scores, while others target open-domain factuality or fail to provide evidence- grounded diagnostics. W e present RT4CHART , a retromorphic testing framework for context-faithfulness assessment that decom- poses an answer into independently veriable claims, performs hierarchical local-to-global verication against the retrieved con- text, and assigns each claim one of three labels—entailed, contra- dicted, or baseless. RT4CHART further maps these claim-level de- cisions back to specic answer spans and returns explicit conte xt- side evidence, enabling ne-grained auditing rather than opaque scoring. W e evaluate RT4CHART on RAGT ruth++ (408 samples) and our r e-annotated RA GTruth-Enhance (2,675 samples), where it achieves the best answ er-level hallucination-detection F1 com- pared to baselines; on RAGT ruth++, it reaches 0.776, improving over the strongest baseline by 83%, and it attains 47.5% span-level F1 score on RAGT ruth-Enhance. Ablations show that the hierar- chical verication design is the main driv er of performance. Last, our re-annotation uncovers 1.68 × more hallucination cases than the original lab els, suggesting that commonly used benchmarks substantially understate the prevalence of hallucination. 1 Introduction Retrieval-augmented generation (RAG) [ 10 ] grounds large language models (LLMs) in retrieved documents, reducing their reliance on parametric memory . Y et LLMs may still hallucinate , producing claims that are unsupported by or directly conict with the re- trieved context [ 7 ], even when the r elevant evidence is present in the prompt. In this work, we dene faithfulness strictly with respect to the retrieved context, not external knowledge or the model’s parametric memor y . This restriction is particularly imp ortant in operational settings where the retrieved documents serve as the au- thoritative record. For example, if a user asks whether a subscription plan includes priority email support, the relevant evidence should come from the r etrieved policy or product documentation rather than from what the model may have memorized or inferred from elsewhere, since such details may vary across plans and change over time. Note that such situations are very common in practice for many agents. This deliberate restriction ensures that every claim can be veried solely by inspecting the retrieved documents, a pre- requisite for auditable deployment. A single unsupp orted claim in a deployed system can erode user trust and lead to awed decisions. Detecting such unfaithful outputs before they reach end users is therefore essential. For auditing purposes, however , it is not enough to ag an LLM answer as problematic. A useful detector must also identify which part of the answer is unsupported and ground that judgment in ex- plicit context evidence. In practice, existing hallucination detectors fall short of this requirement. Hallucination detection can op er- ate at multiple levels: answer-le vel methods return a single verdict for the entire response, whereas span-level methods localize po- tentially unfaithful fragments. Commercial answer-level detectors such as V ectara [ 11 , 21 ] produce only a scalar score, while span- level dete ctors such as LettuceDete ct [ 26 ] highlight problematic fragments but do not return the corresponding evidence in the context. Other lines of work, including self-consistency and claim- decomposition approaches [ 12 , 14 , 22 , 23 ], likewise do not provide evidence-grounded diagnostics under a strict retrieved-context set- ting. Consequently , existing hallucination dete ctors can either score an entire answer or highlight suspicious spans, but they do not provide evidence-gr ounded diagnostics that link agged content to explicit supporting or contradicting sentences in the retriev ed context. Figure 1 illustrates this contrast: answer-level detectors return a single verdict for the whole response, span-level detectors localize suspicious answer fragments, and RT4CHART further links those fragments to explicit context evidence . W e view context-faithfulness detection in RA G as a traceability problem : each generated claim should admit a consistent alignment back to the retrieved context. W e instantiate this idea through retromorphic testing [ 24 ], which inverts the generative mapping and checks whether generated claims can be traced back to their Y u et al. Context C (excerpt): • s ₀: “Only the free - trial plan is eligible for the promotional extension; paid plans are not.” • s ₁: “Only new users are eligible, and identity veri fication is required before activation.” • s ₂: “The free trial lasts 14 days.” • s ₃ : “V erified new users may request one promotional extension of seven days.” Question Q: What are the rules for the free trial? Answer - level d etection (e.g., Ve c t a r a ) Span - level localization + Evidence (e.g., RT4CHAR T ) • Answer A: "The policy applies to all users, verification is not required, the free trial lasts 14 days, verified new users can receive a one - time 7 - day extension of the free trial, and the trial includes priority email support. " Span - level localization (e.g., Lettuce) • Answer A: “ The policy appli es to all users , verification is not requir ed , the free trial lasts 14 days, verified new users can receive a one - time 7 - day extension of the free trial, and the trial includes priority email support ." • Answer A: “ The poli cy applies to all users , verification is not required , the free trial lasts 14 days , verified new users can receive a one - time 7 - day extension of the free trial , and the trial includes priority email support . " • Context: • s₀: Only the free - trial plan is eligible for the promotional extension; paid plans are not. • s₁: Only new users are eligible, and identity verification is required before activation. • s₂: The free trial lasts 14 days. • s ₃ : V erified new users may request one promotional extension of seven days. ∅ (No Evidence) CONTRADICTED ENT AILED BASELESS Score : 0.32 → Hallucinated Figure 1: Dete ction granularity on a motivating example. RT4CHART adds explicit context evidence to lo calized an- swer spans. Red denotes Contradicted , green Ent ailed , and yellow Baseless . originating inputs. This traceability perspective is particularly im- portant in realistic RAG settings, where retrieved contexts often span dozens of sentences. If the system uses an LLM to v erify the full context in a single pass, the model can b e overwhelmed and miss subtle contradictions, whereas purely local checking may overlook globally relevant evidence . T o address this challenge, we propose RT4CHART ( R etromorphic T esting for C ontext-grounded H allucination A ssessment in R etrieval- A ugmented T ext), a hierarchical verication pipeline for evidence- grounded hallucination detection. RT4CHART rst decomposes the generated answer into self-contained claims. It then performs local verication by screening each claim against overlapping context chunks, followed by global verication that re-evaluates each claim against the full context using the local result as guidance. Finally , the claim-level labels are aggregated into an answ er-level verdict. For each claim, RT4CHART returns one of three labels— Ent ailed , Con- tradicted , or Baseless —and localizes the corresponding answer spans together with explicit supporting or contradicting context evidence. Reliable evaluation of ne-grained hallucination detection also requires reliable ground truth. RA GTruth [ 15 ] is widely adopted, yet its annotations contain substantial false negatives: many hallu- cinated spans are unlabeled, so a detector that correctly ags them is penalized as producing false p ositives. RA GTruth++ [ 3 , 8 ] par- tially addresses this issue by re-annotating a 408-sample subset via independent dual-annotator review , increasing the hallucination span from 86 to 865. Its coverage, however , remains limited. W e therefore construct RA GTruth-Enhance , a broader two-author re-annotation of the RAGT ruth evaluation split (Se ction 4.2), to improve benchmark reliability for ne-grained auditing. On these improved benchmarks, RT4CHART achiev es the best answer-level detection performance among the compared baselines. On RA GTruth++, it impr oves answer-lev el F1 from 0.424 to 0.776 ( + 83% relative improv ement over the best baseline). On RAGTruth- Enhance, it raises F1 from 0.724 to 0.845 ( + 17% ). Contributions. • A retromorphic framework for context-faithfulness detection. W e formulate hallucination detection in RAG as a traceability problem and instantiate this view in RT4CHART , a detector that produces claim-level v erdicts, localized an- swer spans, and context-side evidence rather than only an answer-level scor e. • A hierarchical verication pip eline. RT4CHART com- bines local verication with global verication, enabling ne-grained detection under long retrieved contexts while preserving global consistency . • An enhanced benchmark for ne-grained auditing. W e construct RA GTruth-Enhance , a broader re-annotation of the RA GTruth evaluation split, to reduce annotation noise and b etter assess ne-grained hallucination detec- tion. • Strong empirical results on improved benchmarks. RT4CHART achieves the best answer-level dete ction perfor- mance among the compared baselines on RA GTruth++ and RA GTruth-Enhance while providing ner-grained, evidence- grounded outputs suitable for auditing. 2 Preliminaries Problem setting. W e study context-faithfulness detection in a retrieval- augmented generation (RAG) setting. Giv en a retrieved context 𝐶 , a user query 𝑄 , and an answer 𝐴 produced by a RAG pipeline, the goal is to determine, for each claim in 𝐴 , whether it is entailed by , contradicted by , or not supported by the retrieved context 𝐶 . Under the strict context-only assumption, the retrieved context 𝐶 is treated as the sole authoritative source of evidence. A statement may be factually correct in the world yet still be considered unfaithful if it is unsupported by 𝐶 . Input format. Let 𝐶 denote the retrieved context, 𝑄 the user query , and 𝐴 the generated answer . For tasks such as summarization, 𝑄 may be empty . W e segment 𝐶 into an ordered sentence sequence S = ( 𝑠 0 , 𝑠 1 , . . . , 𝑠 𝑚 − 1 ) . Sentences are the atomic unit for context-side evidence attribution: every nal evidence span returned by the verier is aligned to one or more source sentences 𝑠 𝑗 . Context chunking. For local verication, S is partitione d with a sliding window of 𝑊 consecutive sentences and an overlap of 𝑂 Retromorphic T esting with Hierarchical V erification for Hallucination Detection in RAG Forward Progr am P (RAG Pipeline) Context C Question Q (Optional) Answer A Backward Progr am B (C, Q, A) Answer A Local V erific ation Claim Decomposition Claim 1 𝐶 𝑙𝑚 ! Claim 2 𝐶 𝑙𝑚 " Claim 𝑛 𝐶 𝑙𝑚 # … … Sentence Split Context C Window Overlap Chunking Global V er ification Answer- Level Aggregation Claim 1 𝐶 𝑙𝑚 ! Claim 2 𝐶 𝑙𝑚 " Claim n 𝐶 𝑙𝑚 # Full-context verifier Answer-level AND Join 𝑂 $%& Final Claim Label 𝒚 𝟏 ∗ Final Claim Label 𝒚 𝟐 ∗ Final Claim Label 𝒚 𝒏 ∗ … … … Final Answer Label 𝑦 $#% & 𝑉 ! 𝑉 " 𝑉 # 𝐶𝑙𝑚 ! 𝑣 !'! 𝑣 !'" 𝑣 !'( 𝑣 "'! 𝑣 "'" 𝑣 "'( 𝑣 #'! 𝑣 #'" 𝑣 #'( Local V erifier … Full-context verifier Full-context verifier S = [S ) , S )*!'+' S ,-! ] 𝐶ℎ𝑘 . Context Questi on 𝐶𝑙𝑚 " 𝐶𝑙𝑚 # 𝑦 - " = 𝒪 /0 𝑉 " 𝑦 - ! = 𝒪 /0 𝑉 ! 𝑦 - # = 𝒪 /0 𝑉 # Chunk - specific Assessment Chunk - specific Assessment Chunk - specific Assessment Figure 2: Overview of RT4CHART . The system decomposes 𝐴 into claims, veries them locally and globally against 𝐶 , and returns claim-level and answer-level outputs. sentences, yielding 𝐾 overlapping chunks Chk 0 , Chk 1 , . . . , Chk 𝐾 − 1 . Each chunk Chk 𝑘 serves as a local evidence window during local verication. The overlap mitigates boundary ee cts when support- ing evidence is distributed across adjacent sentences. Claims. The generated answ er 𝐴 is decomposed into an ordered list of self-contained claims ( Clm 1 , Clm 2 , . . . , Clm 𝑛 ) , where each claim expr esses a single proposition that can be veried against the context 𝐶 . Each claim retains a pointer to its originating answer sentence. This association allo ws claim-level decisions to be mapped back to answer-side spans, enabling localization of hallucinated content in 𝐴 . Label semantics. W e use the label set Y = { Ent , Con , Nic } , where Ent denotes entailed , Con denotes contradicted , and Nic denotes not in context ( baseless). At the nal claim level, each claim Clm 𝑖 receives a label 𝑦 ∗ 𝑖 ∈ Y . Any nal label other than Ent constitutes a faithfulness violation. Evidence attribution. Each nal claim label is paired with a set of context-side evidence spans 𝐸 ∗ 𝑖 , where ev ery span is anchored to one or more sentences in S . For entailed claims, the verier returns supporting evidence spans. For contradicted claims, it returns con- tradicting evidence spans. For baseless claims, no context evidence should be returned. Formally , we enforce 𝑦 ∗ 𝑖 = Nic = ⇒ 𝐸 ∗ 𝑖 = ∅ . (1) Answer-level aggregation. Final claim labels induce answer- level signals: contradiction ( 𝐴, 𝐶 ) ≜ ∃ Clm 𝑖 : 𝑦 ∗ 𝑖 = Con , baseless ( 𝐴, 𝐶 ) ≜ ∃ Clm 𝑖 : 𝑦 ∗ 𝑖 = Nic . W e then dene the overall hallucination indicator as hallucinated ( 𝐴, 𝐶 ) ≜ contradiction ( 𝐴, 𝐶 ) ∨ baseless ( 𝐴, 𝐶 ) . 3 Approach 3.1 Theoretical Foundation: Retromorphic T esting W e cast context-faithfulness detection as an instance of retromorphic testing [ 24 ], a black-box testing approach designed to addr ess the test oracle problem . In many generative settings, including retrie val- augmented generation (RAG), there is no single gold answer for a given input: multiple r esponses may be acceptable for the same context–question pair ( 𝐶, 𝑄 ) . The relevant criterion is therefore not an exact match to a r eference answer , but whether the generated answer is supported by the retrieved context. Intuitively , retromorphic testing veries an output by mapping it back to the input domain and checking whether the former is consistent with the original inputs. It couples a forward program 𝑃 with an auxiliary backward program 𝐵 . The forward program produces the system output, while the backward program analyzes Y u et al. that output and generates a verication trace that can be checked against the inputs. In our setting, 𝑃 represents the RA G generator that maps the context and question ( 𝐶, 𝑄 ) to an answer 𝐴 , whereas 𝐵 acts as a verier that consumes ( 𝐶, 𝑄 , 𝐴 ) and produces a verication trace 𝑇 : 𝐴 = 𝑃 ( 𝐶 , 𝑄 ) , 𝑇 = 𝐵 ( 𝐶 , 𝑄 , 𝐴 ) , check RR ( ( 𝐶 , 𝑄 ) , 𝑇 ) . (2) The retromorphic relation RR acts as the test oracle : it determines whether every element of the trace 𝑇 is traceable to and supporte d by the original inputs ( 𝐶, 𝑄 ) . The backward program, therefore, produces a structured representation that can be checke d directly against the source context. In RT4CHART , this representation is dened as 𝑇 = { ( Clm 𝑖 , 𝑦 ∗ 𝑖 , 𝐸 ∗ 𝑖 ) } 𝑛 𝑖 = 1 , where each tuple contains a claim Clm 𝑖 , its nal claim label 𝑦 ∗ 𝑖 , and its nal evidence spans 𝐸 ∗ 𝑖 in the context 𝐶 . The relation RR ( ( 𝐶 , 𝑄 ) , 𝑇 ) holds when, for every claim, the extracted evidence 𝐸 ∗ 𝑖 is grounded in 𝐶 and justies the nal claim lab el 𝑦 ∗ 𝑖 . For entailed claims, 𝐸 ∗ 𝑖 contains supporting evidence spans. For contradicted claims, it contains contradicting evidence spans. For baseless claims, 𝐸 ∗ 𝑖 = ∅ (Eq. (1)). 3.2 Pipeline Overview RT4CHART implements the backward program 𝐵 in four stages (Figure 2): (1) Claim decomposition (Section 3.3). The answer 𝐴 is de- composed into self-contained claims that can be veried independently against the retrieved context. (2) Local verication (Se ction 3.4). The context is divide d into overlapping chunks. For each claim, the verier scans these chunks for supporting or conicting evidence. The resulting chunk-specic assessments are consolidated into a single local claim label via an OR-join . (3) Global verication (Section 3.5). Each claim is then re- veried against the full context 𝐶 , using the local claim label and an optional focus chunk only as search hints. (4) Answer-level aggregation (Section 3.6). Final claim labels are aggregated via an AND-join : a single unfaithful claim suces to ag the entire answer . W e re visit the running example from Figur e 1 throughout this section. 3.3 Claim De composition A claim is an atomic, self-contained proposition obtaine d by de- composing the answer 𝐴 that can be veried independently against evidence. Here , self-contained means that the claim preserves the minimal semantic content needed for verication, without relying on unresolv ed pronouns, omitted predicates, or cross-sentence con- text. Following the decompose-then-verify paradigm [ 14 ], we adopt a sentence-based decomposition strategy: we rst segment 𝐴 into sentences and then use an LLM to decompose each sentence into claims independently . The decomposition step preser ves qualiers, including negation, quantities, temporal markers, and mo dality , since dropping them may change the claim’s meaning or veria- bility . The decomposition mo del only sees the answer 𝐴 without context 𝐶 , so that claim formation remains faithful to the answer itself rather than being inuenced by the retrieved context. In the running example (Figure 1), this step yields ve claims: • Clm 1 : “the policy applies to all users”; • Clm 2 : “verication is not required”; • Clm 3 : “the free trial lasts 14 days”; • Clm 4 : “veried new users can receive a one-time 7-day extension of the free trial”; • Clm 5 : “the trial includes priority email support” . In this example, Clm 4 requires combining evidence from multiple context chunks, whereas Clm 5 has no supp ort anywhere in the context. T able 1 shows how these claims are assessed across local context chunks. 3.4 Local V erication RA G contexts often contain many retrieved passages. A verier that reads all passages at once may miss subtle contradictions or overlook evidence distribute d across the context. Local verica- tion, therefore, scans each claim over overlapping chunks of the context to identify supporting or conicting signals before global verication. Given a claim Clm 𝑖 and a context chunk Chk 𝑘 , an LLM judge produces a chunk-specic assessment 𝑣 𝑖 ,𝑘 ∈ Y , optionally together with provisional evidence spans restricted to that chunk. When available, we also provide the user question 𝑄 as additional task context. Chunking. Given the sentence sequence S dened in Section 2, we apply a sliding window with size 𝑊 and overlap 𝑂 to gener- ate 𝐾 overlapping chunks of consecutive sentences. The overlap reduces boundary artifacts: without it, two consecutive sentences that jointly support a claim may fall into dierent chunks, leaving neither chunk with sucient evidence on its own. OR-join ( O 𝑜𝑟 ). For each claim Clm 𝑖 , the chunk-specic assess- ments collected across local chunks are merged into a single local claim label ˆ 𝑦 𝑖 . RT4CHART uses a deterministic priority rule over Y = { Ent , Nic , Con } . The OR-join returns: • Con if any label in 𝑉 𝑖 is Con (contradiction dominates) ; • Ent else if any label in 𝑉 𝑖 is Ent (one supp orting chunk suces) ; • Nic otherwise (no local chunk provides decisive evidence) . A local Nic label means only that no individual chunk, when ex- amined in isolation, contains sucient evidence during local veri- cation; it does not imply that the claim is unsupported in the full context. Chunk-wise local assessment. For each claim Clm 𝑖 , the judge is applied to every chunk Chk 𝑘 , yielding a chunk-spe cic assessment 𝑣 𝑖 ,𝑘 ∈ Y . W e collect these assessments into the set: 𝑉 𝑖 = { 𝑣 𝑖 , 0 , 𝑣 𝑖 , 1 , . . . , 𝑣 𝑖 ,𝐾 − 1 } . The local claim label ˆ 𝑦 𝑖 is then obtained by applying the OR-join to this set: ˆ 𝑦 𝑖 = O 𝑜𝑟 ( 𝑉 𝑖 ) . (3) Continuing the running example in Figure 1, T able 1 summarizes local assessment under 𝑊 = 2 and 𝑂 = 1 , yielding three overlapping Retromorphic T esting with Hierarchical V erification for Hallucination Detection in RAG T able 1: Local assessment matrix for the running example with 𝑊 = 2 and 𝑂 = 1 . The rst three columns show chunk-level assessments, followed by the OR-joined local lab el ˆ 𝑦 𝑖 and the nal label 𝑦 ∗ 𝑖 . Local verication OR-join Final Claim Chk 0 Chk 1 Chk 2 ˆ 𝑦 𝑖 𝑦 ∗ 𝑖 { 𝑠 0 , 𝑠 1 } { 𝑠 1 , 𝑠 2 } { 𝑠 2 , 𝑠 3 } Clm 1 Con Con Nic Con Con Clm 2 Con Con Nic Con Con Clm 3 Nic Ent Ent Ent Ent Clm 4 Nic Nic Nic Nic Ent Clm 5 Nic Nic Nic Nic Nic A nswer-level (AND-join): Con chunks. The rst three columns list chunk-level judgments, fol- lowed by the OR-joined local label ˆ 𝑦 𝑖 and the nal label 𝑦 ∗ 𝑖 after global verication: Chk 0 = { 𝑠 0 , 𝑠 1 } , Chk 1 = { 𝑠 1 , 𝑠 2 } , and Chk 2 = { 𝑠 2 , 𝑠 3 } . For Clm 3 , at least one local chunk contains sucient support, so the claim is labeled Ent . By contrast, Clm 4 remains locally Nic be- cause no individual chunk contains the full proposition, but global verication revises it to Ent once the full context is considered. Clm 5 remains Nic in every chunk because the context contains no supporting evidence for it. 3.5 Global V erication Local verication examines individual chunks in isolation. However , this fragmented view can lead to errors: evidence may be distributed across multiple chunks, or an apparent lo cal contradiction may be resolved by surrounding te xt elsewhere in the conte xt. Global verication addresses these blind spots by re-evaluating each claim against the entire context 𝐶 . Global verication uses local verication outputs only as search hints. That is, local verication may suggest which chunk is worth inspecting, but it does not provide evidence that can be directly reused as the nal justication. Instead, the global judge must read the full context 𝐶 and re-extract the nal evidence spans from 𝐶 itself before assigning the nal claim label 𝑦 ∗ 𝑖 . Adaptive prompting strategy . Be cause dierent local claim labels ( Nic , Con , Ent ) suggest dierent likely failure modes during local verication, we adapt the prompt for global verication accordingly (summarized in T able 2): • Handling locally Nic -labeled claims: The claim may still be true, but its evidence may be distributed across chunk boundaries. T o catch this case, the judge receives the full context and searches from scratch, with no location hint. • Handling locally entailed ( Ent ) or contradicted ( Con ) claims: Lo cal verication found a strong signal in a specic chunk. W e pass that chunk to the global judge as a “location hint. ” The judge then examines this hint in its full context to determine whether the local decision still holds or whether the surrounding text alters its interpretation. For instance, returning to our running example (Figure 1), Clm 4 is locally Nic because its support is distributed across non-lo cal T able 2: Global verication strategy conditioned on the lo cal claim label. Local label Prompt input Likely local failure mode V erication goal Nic Full 𝐶 + claim No single chunk con- tains enough evidence Conrm baseless or revise to en- tailed Con Full 𝐶 + focus chunk + claim Local contradiction, globally resolved Conrm contradiction or revise Ent Full 𝐶 + focus chunk + claim Locally entailed, glob- ally overridden Conrm entailment or revise sentences rather than contained in a single chunk. Under global verication, the judge reads the full context 𝐶 , combines the relevant evidence, and corr ectly revises the nal claim label 𝑦 ∗ 4 to entailed ( Ent ). By contrast, Clm 5 (“priority email supp ort”) remains Nic even after global verication, conrming that it is genuinely baseless. 3.6 Answer-Lev el Aggregation AND-join ( O 𝑎𝑛𝑑 ). After global verication assigns a nal claim label 𝑦 ∗ 𝑖 to each claim, these labels are aggregated into an answer- level ver dict. RT4CHART uses a deterministic AND-join. Given a set of labels 𝑍 ⊆ Y , the AND-join returns: • Con if any label in 𝑍 is Con (contradiction dominates) ; • Nic else if any lab el in 𝑍 is Nic (missing evidence blocks full entailment) ; • Ent otherwise (all claims are satised) . This aggregation is intentionally strict: a single unfaithful claim is sucient to ag the entire answer . Formally , the answer-lev el label is 𝑦 ∗ ans = O 𝑎𝑛𝑑 ( { 𝑦 ∗ 1 , . . . , 𝑦 ∗ 𝑛 }) . (4) This design ensures that a partially hallucinated answer is still agged rather than masked by faithful claims. 4 Experiments This section evaluates RT4CHART as a context-faithfulness detec- tor , operating under the strict assumption that only the pro vided context serves as evidence. The experiments are structured around four research questions (RQs). 4.1 Research Questions RQ1. Overall eectiveness: Under the same ( 𝐶, 𝑄 , 𝐴 ) protocol, how eective is RT4CHART on answ er-level hallucination detec- tion and span-level localization? RQ2. Contribution of hierarchical verication: How do local verication and global verication each contribute to answer-level detection and span-level localization? RQ3. Design sensitivity: How sensitiv e is RT4CHART to claim decomposition granularity and chunking hyperparameters? RQ4. Robustness and cost: How robust is RT4CHART across judge models and repeated runs, and what cost does it incur? 4.2 Experimental Setup Datasets. W e evaluate on two benchmarks. RA GTruth++ is a re-annotation of a 408-example Q A/summarization subset of the Y u et al. RA GTruth test set [ 15 ], with substantially more complete hallucination- span annotations than the original subset annotations. RA GTruth- Enhance is our broader re-annotation of the RA GTruth evalu- ation split. Unlike RAGT ruth++, RA GTruth-Enhance covers the full RA GTruth evaluation split, including Q A, summarization, and data-to-text tasks. A nnotation completeness and the need for RA GTruth-Enhance . RA GTruth [ 15 ] is a popular benchmark for RAG hallucination de- tection, but its original span annotations can contain substantial false negatives. On the 408-example QA/summarization subset later released as RA GTruth++ , re-annotation incr eased the number of annotated hallucination spans fr om 86 to 865, indicating substantial under-annotation in the original annotations for that subset [ 3 , 8 ]. This motivates a br oader r e-annotation of the RAGT ruth evaluation split, which we release as RA GTruth-Enhance . Construction of RA GTruth-Enhance. RA GTruth-Enhance is built with a disagreement-driven two-stage protocol: (1) W e rst use an LLM-based auditor to ag samples whose judgments dier from the original annotation, while leaving matched cases unchanged. As a sanity che ck, we randomly inspect 70 matched cases and observe an accuracy above 98%, which supports treating them as low-priority for fur- ther review . (2) For the agged subset (1,546 cases, approximately 58% of the data), two authors independently review each case and r e- solve disagreements through discussion. Residual disputes are rare ( < 0 . 5% of the reviewed cases). Analogous to the answer-side hallucination spans, RAGT ruth-Enhance also includes refuting context evidence for contradiction labels, which enables the context-evidence grounding evaluation reported later . Compared dete ctors. W e compare RT4CHART against a diverse set of strong baselines chosen to cover both span-level and answer- level hallucination detection, as well as b oth open-source and closed- source systems. Specically , we include Lettuce [ 26 ] as a strong open-source span-level dete ctor , MetaQA [ 23 ] and Self Check- GPT [ 12 ] as representative open-source LLM-driven answer-level baselines, and V ectara as a strong closed-source commercial factual- consistency system. RT4CHART and Lettuce produce localized span outputs, whereas MetaQ A, Self CheckGPT , and V ectara are answer- level baselines. Lettuce is a supervised token-level span tagger base d on ModernBERT , while V ectara is a commercial factual-consistency API. Unied evaluation contract. All methods are evaluated under the same ( 𝐶, 𝑄 , 𝐴 ) contract, where the retrieved context 𝐶 , user query 𝑄 , and model answer 𝐴 are provided as input. Their outputs are mapped to the common lab el space { Ent , Con , Nic } dened in Section 2. For methods that do not return span-level predictions, span-level evaluation is not applicable and is ther efore omitted. Context-only adaptation of non-native baselines. MetaQA, Self- CheckGPT , and V ectara were not originally designed for our strict retrieved-context setting, in which 𝐶 is the only admissible evidence source. W e therefore adapt them with minimal changes. Spe cically , we (1) use 𝐶 as the sole evidence source , (2) retain each baseline ’s original inference workow and decision procedure as much as possible, and (3) map outputs into the common label space. This design keeps the comparison as faithful as possible to the original methods while enforcing the same context-only evaluation setting for all detectors. Baseline-specic implementations. • MetaQ A (conte xt-adapted). W e adapt MetaQ A to the retrieved-context setting by reusing its mutation-generation prompts on the ( 𝑄 , 𝐴 ) pair and replacing open-world v er- ication with verication against the provided context 𝐶 . W e aggregate mutation-based v erication signals into an answer-level pr ediction rather than producing span-level outputs. • SelfChe ckGPT (context-adapted). W e follow the up- stream LLM-prompt baseline: sample 𝑛 = 10 alternative an- swers for the same ( 𝐶, 𝑄 ) , query whether 𝐴 is supported by each sampled passage, map the r esulting Y es/No/N/A votes to 0 . 0 / 1 . 0 / 0 . 5 , and average them into a scalar inconsistency score. Using a thr eshold sweep on our validation runs, we found 0 . 5 to be a more stable threshold in our setting, and therefore use it to map the continuous score to Ent versus Nic . 1 • V ectara. W e use V ectara’s HHEM [ 11 , 21 ], which returns an answer-level factual-consistency score for a generated answer given sour ce passages. W e pass the full answ er as the hyp othesis and the full provided context 𝐶 in a sin- gle API call. Following V e ctara’s recommended threshold, we use a threshold of 0 . 5 : scores b elow the threshold are mapped to Con , and Nic is not predicted. Implementation details. Unless other wise specie d, RT4CHART employs judge model GPT -4o mini, claim decomposition setting Sentence-based, chunking window/overlap ( 𝑊 , 𝑂 ) = ( 25 , 10 ) , and global verication (Section 3.5). W e set the random seed to 42 ; claim decomposition, local verication, and global verication all use temperature 0 . 0 . Metrics. W e evaluate all methods on: Answer-level hallucination detection. W e report precision, recall, and F1 on the hallucination indicator hallucinated ( 𝐴, 𝐶 ) de- ned in Section 2, where an answer is positive if any claim is labeled Con or Nic . W e use F1 as the primary summar y metric for overall comparison. Answer-side span localization. W e follow the o verlap-based protocol of RA GTruth [ 15 ] and evaluate the o verlap between the predicted and gold hallucinated text spans in the original answer . For each sample 𝑠 , let 𝐺 𝑠 and 𝑃 𝑠 denote the union of gold and predicted hallucinated character osets in the answer . W e compute TP = 𝑠 | 𝐺 𝑠 ∩ 𝑃 𝑠 | , FP = 𝑠 | 𝑃 𝑠 \ 𝐺 𝑠 | , FN = 𝑠 | 𝐺 𝑠 \ 𝑃 𝑠 | , and report micro precision, recall, and F1. Context-side evidence grounding. For contradiction cases with mappable gold refuting evidence, we additionally evaluate 1 Although the prompt asks ab out supp ort, the upstream prompt baseline encodes Yes → 0 , No → 1 , so lower scores indicate stronger supp ort and higher scores indi- cate greater unsupportedness / hallucination risk. The baseline does not explicitly distinguish contradiction from missing support. Retromorphic T esting with Hierarchical V erification for Hallucination Detection in RAG T able 3: Main answer-level hallucination dete ction results on RA GTruth++ and RAGT ruth-Enhance (Precision/Recall/F1). Methods marke d with “*” are adapted to the context-only setting. Detector Precision Recall F1 RA GTruth++ RT4CHART 0.845 0.718 0.776 Lettuce 0.921 0.233 0.371 MetaQA * 0.941 0.216 0.352 SelfCheckGPT* 0.843 0.143 0.244 V ectara* 1.000 0.269 0.424 RA GTruth-Enhance RT4CHART 0.781 0.920 0.845 Lettuce 0.907 0.545 0.681 MetaQA * 0.853 0.102 0.182 SelfCheckGPT* 1.000 0.167 0.286 V ectara* 0.894 0.608 0.724 T able 4: Answer-side span lo calization results on RA GTruth- Enhance and RA GTruth++ (Precision/Re call/F1). Dataset Detector Precision Recall F1 RA GTruth-Enhance RT4CHART 39.9% 58.6% 47.5% RA GTruth-Enhance Lettuce 72.7% 29.4% 41.9% RA GTruth++ RT4CHART 50.8% 33.6% 40.4% RA GTruth++ Lettuce 91.2% 13.5% 23.5% context-side evidence grounding using the same overlap-based scoring. Because this analysis is only available for RT4CHART on the contradiction subset of RAGT ruth-Enhance, we treat it as a complementary diagnostic. 4.3 Overall Eectiveness RQ1 investigates whether RT4CHART improves both answer- level hallucination detection and span-level localization un- der the same ( 𝐶, 𝑄 , 𝐴 ) evaluation contract. W e answ er this ques- tion using the answer-level results in T able 3 and the span-level localization results in T able 4. Main results. Across both benchmarks, RT4CHART achieves the highest answer-level F1 among all compared methods (T able 3). Its advantage stems primarily from str onger recall, especially on the larger and more diverse RA GTruth-Enhance benchmark, suggesting that local verication helps detect partially hallucinated answ ers that holistic answer scorers often miss. This recall-oriented behav- ior is particularly desirable in practical auditing settings, where missing a hallucination can be substantially more costly than ag- ging an additional suspicious case, since undete cted hallucinations may be expose d directly to end users. Among the baselines, V ec- tara is the strongest answer-level competitor . On RAGT ruth++ and RA GTruth-Enhance, RT4CHART improves ov er the best baseline by Δ F1 = + 0 . 352 and + 0 . 121 , respectively . Span-level localization. Under this span-level evaluation rule, RT4CHART achieves the highest localization F1 on both datasets T able 5: Conict-case detection and refuting-evidence grounding on RA GTruth-Enhance (Precision/Recall/F1). T ask Method Precision Recall F1 Conict-case detection RT4CHART 62.9% 40.9% 49.6% GPT -4o mini (direct) 42.0% 27.5% 33.2% Refuting-evidence grounding RT4CHART 51.1% 59.1% 54.8% GPT -4o mini (direct) 36.5% 34.9% 35.7% (T able 4). Compared with Lettuce, RT4CHART attains substantially higher recall, while Lettuce achieves higher precision. A likely reason is that RT4CHART localizes hallucinations at a coarser , often sentence-level granularity , which tends to include additional non-hallucinated te xt and therefore lowers precision under overlap- based scoring. Context-evidence diagnostic on conict cases. T able 4 evaluates whether the system can localize unsupported text in the answer . Be- yond answer-side span localization, we further ask whether correct conict predictions are also grounded in the right refuting context evidence . For this diagnostic only , w e additionally include a GPT -4o mini (direct) baseline that uses a single dir ect prompt o ver the full context and answ er to output an answer-level judgment in the com- mon label space together with answer-span and refuting-evidence spans. RA GTruth-Enhance includes r efuting context evidence for contradiction labels, enabling this analysis on the conict subset. W e map each gold evidence string back to sentence-local osets in the source context. Conict-case detection is evaluated at the answer-level, while r efuting-evidence grounding is evaluated using overlap-based Precision/Recall/F1 on correctly detected conict cases with alignable gold evidence . Refuting-evidence grounding is reported as a conditional diagnostic on each system’s corr ectly detected conict cases. As shown in T able 5, RT4CHART outperforms the dir ect GPT -4o mini baseline on both conict-case detection (49.6% vs. 33.2%) and refuting-context localization (54.8% vs. 35.7%). Even for RT4CHART , the evidence-level score remains below the case-level score, sug- gesting that precisely grounding contradicted claims in the source context remains harder than detecting the conict case itself. Answer to RQ1: RT4CHART performs b est overall: it achieves the highest answ er-level F1 and span-level local- ization F1 on both RA GTruth++ and RA GTruth-Enhance. Its gains come primarily from higher recall. For contradic- tion cases, it also provides useful refuting evidence ground- ing. 4.4 Why Both Lo cal and Global V erication Are Needed RQ2 asks how hierarchical verication contributes to per- formance. W e e xamine this question from two sides: by ablating global verication, and by testing a direct variant that bypasses local verication. Y u et al. T able 6: Ee ct of global verication on answer-level halluci- nation detection (Precision/Recall/F1). Dataset Setting Precision Recall F1 RA GTruth++ w/ global verif. 0.845 0.718 0.776 w/o global verif. 0.851 0.655 0.740 RA GTruth-Enhance w/ global verif. 0.781 0.920 0.845 w/o global verif. 0.811 0.881 0.845 T able 7: RT4CHART versus the direct span-prediction variant on RA GTruth++ (answer-level Precision/Recall/F1 and span F1). V ariant Precision Recall F1 Span F1 RT4CHART (full pipeline) 0.845 0.718 0.776 0.404 GPT -4o mini (direct spans) 0.861 0.630 0.727 0.081 Eect of global verication. T able 6 reports the comparison. On RA GTruth++, global verication improves performance ( Δ F1 = +0.036) by mitigating false positives caused by context fragmentation. On RA GTruth-Enhance, ho wever , global verication does not improve overall answer-level performance ( Δ F1 = 0.000): it yields a large gain on baseless detection ( Δ F1 = +0.205) but no corresponding overall impro vement. This pattern suggests that local verication is the primary driver of RT4CHART’s gains, while global verica- tion is complementary rather than uniformly benecial. Its clear- est overall benet appears on the more challenging RA GTruth++ benchmark, where supporting evidence may be distributed across multiple chunks and cannot be recovered solely fr om chunk-local verication. Necessity of local verication. W e next examine the rev erse set- ting: a variant that bypasses claim de composition and local veri- cation entirely , and instead predicts hallucination spans directly from ( 𝐶, 𝑄 , 𝐴 ) with a single prompt. T able 7 reports the resulting performance on RAGT ruth++. Its span-level lo calization perfor- mance is substantially worse than that of the full pipeline, trail- ing RT4CHART by 32.3 points in span F1, conrming that local verication is the primary source of gain rather than an optional renement. Answer to RQ2: Local verication is the primary source of RT4CHART’s gains. By de composing the answer into veriable units and aligning them with localized evidence, it enables ne-grained hallucination localization that the direct variant cannot match. Global verication is comple- mentary: it is most useful when supp orting evidence is distributed across multiple chunks, but its benet is sele c- tive rather than uniform across datasets. 4.5 Design Sensitivity RQ3 examines how sensitive RT4CHART is to key design choices. W e fo cus on two factors that shape the verication process: the granularity of claim decomposition and the hyperparameters T able 8: Decomposition ablation on RAGT ruth-Enhance. Sentence-based and Holistic yield similar overall F1, with a precision–recall trade-o by task type. T ask Mode Precision Recall F1 QA Sent. 0.735 0.892 0.806 Hol. 0.755 0.830 0.791 Summary Sent. 0.668 0.829 0.740 Hol. 0.716 0.770 0.742 Data2T ext Sent. 0.877 0.983 0.927 Hol. 0.902 0.943 0.922 Overall Sent. – – 0.844 Hol. – – 0.839 used for localized evidence screening. Unless otherwise noted, all analyses in this section are conducted on RA GTruth-Enhance. Sensitivity to claim decomposition granularity . T able 8 compares two de composition strategies: Sentence-based , which extracts claims sentence by sentence, and Holistic , which reads the full answer once and then produces a claim set for verication. The two strategies achieve similar overall answer-level F1 (0.844 vs. 0.839), but exhibit a consistent precision–recall trade-o across task types. Sentence-based decomposition yields higher recall (e.g., 0.892 on QA ), whereas Holistic decomp osition tends to achieve higher precision (e.g., 0.755 on QA ). The same pattern holds for Summary and Data2T ext. These results suggest that RT4CHART is robust to decomposition style, although granularity aects error preference: Sentence-based decomposition is mor e likely to surface localized or partial hallucinations, while Holistic decomposition is more conservative. The two strategies also dier in span-level localizability . Sentence- based decomposition extracts claims from each sentence individ- ually , so every claim retains a direct link to its source sentence; when a claim is judged unfaithful, the verdict traces back to a pre- cise character span in the answer (Table 4). Holistic decomposition extracts claims from the full answer at once and does not track which sentence each claim originates from, so it cannot produce span-level output. This structural advantage is the main reason RT4CHART adopts Sentence-based decomposition. Sensitivity to chunking hyperparameters. W e next vary the chunk window and overlap parameters ( 𝑊 , 𝑂 ) over a small grid and re- port the resulting answer-lev el performance in T able 9. The main pattern is stability rather than sharp sensitivity . Once the window is large enough to preserve local evidence dependencies ( 𝑊 ≥ 25 ), performance remains strong across nearby settings. The best con- guration is ( 25 , 10 ) with F1 = 0 . 840 , and among the high-coverage settings, the spread is at most 0.010. This suggests that RT4CHART does not rely on narrowly tuned chunk boundaries, as long as the local window is wide enough to r etain the evidence ne eded for local verication. Retromorphic T esting with Hierarchical V erification for Hallucination Detection in RAG T able 9: Chunking sensitivity on RAGT ruth-Enhance under dierent ( 𝑊 , 𝑂 ) settings (answer-lev el P/R/F1). ( 𝑊 , 𝑂 ) P/R/F1 (15,5) 0.679/0.907/0.777 (15,10) 0.636/0.895/0.743 (25,5) 0.768/0.904/0.830 (25,10) 0.772/0.921/0.840 (35,5) 0.778/0.909/0.838 (35,10) 0.771/0.902/0.831 T able 10: Cross-model robustness when swapping the de com- position model and judge model (answer-level Precision/Re- call/F1). Dataset Model Precision Recall F1 RA GTruth++ GPT -4o mini 0.845 0.718 0.776 RA GTruth++ GLM-4.7 0.808 0.983 0.887 RA GTruth-Enhance GPT -4o mini 0.781 0.920 0.845 RA GTruth-Enhance GLM-4.7 0.663 0.992 0.795 Answer to RQ3: RT4CHART is congurable without being brittle. Sentence-based decomposition is the b etter default because it preserves comparable F1, improv es recall, and uniquely enables span-level localization, while chunking remains stable once the lo cal window is large enough to retain the evidence needed for verication. 4.6 Robustness, Reproducibility , and Cost RQ4 asks whether RT4CHART is reliable under model varia- tion and repeated runs, and what cost it incurs in practice. W e examine this question from three perspectives: robustness to the choice of decomp osition model and judge model, run-to-run reproducibility , and API cost under realistic evaluation w orkloads. Robustness to judge-model choice. As a stronger , more expensive alternative to the default judge, we replace GPT -4o mini with GLM- 4.7 , an op en-weight, MI T -licensed alternative. This substitution tests whether RT4CHART’s verication behavior transfers across LLM backends rather than depending on a single low-cost judge. W e rerun the full RT4CHART pipeline—claim decomposition, lo cal verication, and global verication—under the same conte xt-only protocol and hyperparameter settings. T able 10 reports the results. Across both b enchmarks, performance remains broadly stable under this model swap, suggesting that RT4CHART do es not rely on a specic judge model to function ee ctively . Run-to-run reproducibility . W e next examine whether the pipeline remains stable across repeated executions. Because LLM serving APIs do not guarantee strict determinism, identical inputs can still produce slightly dierent outputs across calls. T o quantify this in- herent variance, w e execute RT4CHART 3 times on RA GTruth++ under the same conguration (temp erature 0 . 0 and all other hyp er- parameters unchanged) and measure the spread of the resulting metrics. Across runs, RT4CHART achieves a mean answer-level F1 of 0 . 779 ± 0 . 014 and a span-level localization F1 of 0 . 407 ± 0 . 009 . These small standar d de viations indicate that the reported gains are not artifacts of stochastic instability , but remain consistent across repeated executions. Deployment cost under the default judge model. W e nally analyze the computational cost of RT4CHART to assess whether its v erica- tion procedure is practical for routine context-faithfulness auditing. Using GPT -4o mini on RAGT ruth-Enhance ( 𝑁 = 2 , 675 ), this corre- sponds to a total API cost of $27.93 USD, or approximately $0.0104 per sample . Despite performing claim-level decomposition, local- ized evidence matching, and structured verication, RT4CHART remains inexpensive enough to run repeatedly in practice. This makes it suitable for post-up date audits of context-faithfulness, where teams rerun the same e valuation after prompt changes, re- triever updates, or model replacements to check whether outputs have become less well grounded in the retrieved context. Answer to RQ4: RT4CHART is robust acr oss judge mod- els and reproducible across repeated runs. Swapping from GPT -4o mini to GLM-4.7 preser ves strong performance on both b enchmarks, and repeate d executions exhibit only marginal variance. Under the default judge model, the cost is approximately $0.0104 p er sample , making routine post-update context-faithfulness auditing practical. 4.7 Case Study: Uncovering Overlooked Hallucinations W e inspe ct the 1,546 cases where RA GTruth-Enhance disagrees with the original RA GTruth annotations. In 676 of these cases, the original annotations contain no hallucination span, whereas the rened annotations identify at least one. Across all changed cases, we categorize the 3,540 newly added hallucination spans into four recurring patterns, which together account for 89.66% of the newly added spans: • Unsupported Generalization (1,367, 38.62%); • Numeric/Logic Inconsistency (900, 25.42%); • Inference Stated as Fact (621, 17.54%); • Prior Knowledge Interference (286, 8.08%); • Others (366, 10.34%). Below , we present one repr esentative example for each pattern. • Numeric/Logic Inconsistency (Sample #879). The con- text states that an illness aected “ 100 people ” (95 passen- gers and 5 crew ). The model rewrites this as “ 100 passen- gers and 5 crew . ” Although the numbers appear similar , the semantic categories conict: the source gives 100 total pe o- ple, not 100 passengers. This is a minor arithmetic/logical inconsistency that the original annotations failed to mark. • Prior Knowledge Interference (Sample #587). The con- text explicitly names the plainti as “ Joe Doe, ” but the model outputs “ John Doe. ” This error is likely driven by parametric prior knowledge of the common placeholder name rather than by the retrieved evidence . • Unsupported Generalization (Sample #25). The rened annotation adds a baseless span claiming that a country Y u et al. is a “ common route ” to another destination for joining an organization, while the context states only that it is the easiest place to enter the destination. The model thus gener- alizes beyond the retriev ed evidence, and Lettuce predicts no hallucination span for this case. 2 • Inference Stated as Fact (Sample #57). The source presents conditional legal reasoning about whether people asso ci- ated with the University of Virginia and Phi Kappa Psi could sue Rolling Stone for defamation. The model, ho wever , rewrites this tentative analysis as a settled fact. For example, it claims that Phi Kappa Psi’s ability to sue is “ limited due to the fact that it is not a public gure , ” reversing the source ’s logic, and further states that the fraternity “ cannot demonstrate actual nancial harm , ” although the source only says that damages would need to be established. The error is therefore not a topic mismatch, but the conversion of tentative reasoning into denite factual claims. These cases reveal a recurring source of benchmark noise: micr o- hallucinations that remain supercially plausible while violating exact entities, quantities, or evidential limits. They further motivate span-level, evidence-anchor ed evaluation for context-faithfulness auditing. 5 Limitations and Threats to V alidity 5.1 Limitations Scope: context-only faithfulness. RT4CHART evaluates faithful- ness strictly with respect to the pro vided context 𝐶 (Section 2). If 𝐶 is incomplete, noisy , or itself incorrect, RT4CHART may ag factually correct statements as baseless, or fail to detect errors that are consistently supported by incorrect context passages. This is an intentional design choice for auditing RAG pipelines, but it lim- its applicability to settings where the desired notion of truth is grounded in 𝐶 . Current failure mo des. RT4CHART can still make errors in two recurring situations. First, it may miss shifts in certainty , treating hedged evidence and stronger factual restatements as equivalent when their topical content overlaps. Second, it may over-ag faith- ful answers when the retrieved context is redundant, internally conicting, or contains minor surface-form inconsistencies. Rep- resentative examples ar e included in our artifact [ 1 ], highlighting current limitations in handling epistemic nuance and contextual inconsistency . Residual performance gap. Although RT4CHART consistently outperforms the compared baselines, its F1 scores remain far from perfect, especially for ne-grained localization and evidence ground- ing. This indicates that context-faithfulness auditing is still an un- solved problem rather than a solved one. Accordingly , RT4CHART should be viewed as an auditing aid for prioritizing suspicious outputs and surfacing evidence-grounded diagnostics, not as a sub- stitute for exhaustive human re view in high-stakes settings. 2 RAGT ruth: no spans (sample id 25). RAGTruth-Enhance adds “had pur chased a visa to Turke y , a common route to Syria for joining the terrorist group. ” (265–353). Lettuce predicts zero spans. 5.2 Threats to V alidity Model and implementation dependence. RT4CHART dep ends on the LLMs used for claim decomposition and verication, and its out- puts may vary with decoding behavior and implementation choices. W e mitigate this risk by using deterministic decoding where pos- sible, evaluating cr oss-model robustness (T able 10), and releasing prompts and code. In addition, some baselines require adaptation to the ( 𝐶, 𝑄 , 𝐴 ) contract, which may not fully preserve their original operating assumptions. Generality . Our evaluation is base d on RAGT ruth-derived datasets spanning English-language Q A, summarization, and data-to-text tasks. While this provides diversity in evidence structur e and gen- eration style, it remains a bounde d evaluation setting. Accordingly , transferability to non-English corpora, highly sp ecialized domains, or substantially dierent RA G pipeline designs remains to be estab- lished. 6 Related W ork W e position RT4CHART along three dimensions: hallucination detection, claim decomposition and fact verication, and test-oracle techniques. Hallucination detection in LLM outputs. Existing detectors [ 7 ] span several paradigms: zero-resour ce self-consistency methods [ 12 , 23 ], model-based classiers [ 16 , 20 , 26 ], and NLI-based scorers [ 4 , 9 , 25 ]. These approaches typically return holistic scores or labels and do not provide claim-level, context-side evidence under a strict retrieved-context assumption. RT4CHART diers by requir- ing no task-spe cic training data or response sampling, and pro- ducing claim-level v erdicts together with localized answer spans and context-side evidence. Claim decomposition and fact verication. The decompose-then- verify paradigm—breaking generated text into atomic claims before verication—was established by F ActScore [ 14 ] and extended by SAFE [ 22 ], V eriScore [ 19 ], and ALCE [ 6 ] with search-augmented or citation-based verication. These approaches share the decom- position structure with RT4CHART but mostly rely on external retrieval or op en-world knowledge rather than a xed retrieved context. RT4CHART veries claims strictly against 𝐶 and does so hierarchically , combining local chunk-level screening with global full-context re-verication (Section 3.4). T est-oracle techniques in software engineering. RT4CHART ad- dresses the test oracle problem [ 2 ]: determining correctness when no direct gold output is available . Classical strategies such as dif- ferential [ 13 ], metamorphic [ 5 , 18 ], and intramorphic testing [ 17 ] are either impractical for RAG pipelines (requiring multiple im- plementations or white-box access) or do not map output claims back to input-side evidence. Retr omorphic testing [ 24 ] composes a forward pr ogram with a backward program and che cks consistency in the input modality (Se ction 3.1). T o our knowledge, RT4CHART is the rst instantiation of retromorphic testing for RA G faithful- ness detection: the RAG pipeline ser ves as the forward program, and the backward program decomposes the answer into claims, veries them against the retrieved context, and checks whether the resulting evidence-grounded trace is consistent with 𝐶 . Retromorphic T esting with Hierarchical V erification for Hallucination Detection in RAG 7 Conclusion W e presented RT4CHART , a retromorphic testing frame work for context-faithfulness detection in RAG. By decomposing answers into independently veriable claims and enforcing a strict context- only evidence requirement, RT4CHART moves hallucination detec- tion b eyond holistic answer-level scoring toward evidence-grounded, ne-grained diagnosis. It produces claim-level verdicts, localized an- swer spans, and context-side evidence , enabling more transparent auditing of grounded generation. Evaluation on RA GTruth++ and the newly constructed RAGT ruth-Enhance shows that RT4CHART consistently outperforms the baselines on answer-level detection and achieves the best span-lev el answer localization performance. Our re-annotation results further suggest that standard bench- marks may substantially underestimate hallucination prevalence: RA GTruth-Enhance uncov ers 1.68 × more hallucination cases and 3.1 × more hallucination spans than the original labels. Data A vailability The code, prompts, and data used in this paper are available at here [1]. References [1] Anonymous. 2026. A to olkit for RT4CHART . https://anonymous.4open.science/ r/rt4hallucination- 374D [2] Earl T . Barr , Mark Harman, P hil McMinn, Muzammil Shahbaz, and Shin Y oo. 2015. The Oracle Problem in Software T esting: A Survey . IEEE Transactions on Software Engineering 41, 5 (2015), 507–525. doi:10.1109/TSE.2014.2372785 [3] Blue Guardrails. 2025. ragtruth-plus-plus. https://huggingface.co/datasets/blue- guardrails/ragtruth- plus- plus Dataset on the Hugging Face Hub. [4] Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D. Man- ning. 2015. A large annotate d corpus for learning natural language inference. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP) . 632–642. doi:10.18653/v1/D15- 1075 [5] T . Y. Chen, F.-C. Kuo, H. Liu, P.-L. Po on, D. T owey , T. H. T se, and Z. Q. Zhou. 2018. Metamorphic T esting: A Re view of Challenges and Opportunities. Comput. Surveys 51, 1 (2018), 4:1–4:27. doi:10.1145/3143561 [6] Tianyu Gao, Howard Y en, Jiatong Yu, and Danqi Chen. 2023. Enabling Large Language Models to Generate T ext with Citations. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) . 6465– 6488. doi:10.18653/v1/2023.emnlp- main.398 [7] Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Y an Xu, Etsuko Ishii, Y e Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Sur vey of Hallucination in Natural Language Generation. Comput. Surveys 55, 12 (2023), 248:1–248:38. doi:10.1145/3571730 [8] Miriam Kümmel. 2025. RAGTruth++: Enhanced Hallucination Detection Bench- mark. Blue Guardrails blog. https://ww w .blueguardrails.com/en/blog/ragtruth- plus- plus- enhanced- hallucination- detection- b enchmark Accessed: 2026-02-13. [9] Philippe Laban, T obias Schnab el, Paul N. Bennett, and Marti A. Hearst. 2022. SummaC: Re- Visiting NLI-based Models for Inconsistency Detection in Summa- rization. Transactions of the Association for Computational Linguistics 10 (2022), 163–177. doi:10.1162/tacl_a_00453 [10] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler , Mike Lewis, W en tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-A ugmented Generation for Knowledge-Intensive NLP Tasks. arXiv:2005.11401 [cs.CL] https://arxiv .org/abs/2005.11401 [11] Miaoran Li, Rogger Luo, and Ofer Mendelevitch. 2024. HHEM-2.1-Open. doi:10. 57967/hf/3240 [12] Potsawee Manakul, Adian Liusie, and Mark JF Gales. 2023. Self CheckGPT: Zero- Resource Black-Box Hallucination Dete ction for Generative Large Language Models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) . [13] William M. McK eeman. 1998. Dierential T esting for Software. Digital T echnical Journal 10, 1 (1998), 100–107. [14] Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, W en-tau Yih, Pang W ei Koh, Mohit Iyyer , Luke Zettlemoyer , and Hannaneh Hajishirzi. 2023. FA ctScore: Fine- grained Atomic Evaluation of Factual Precision in Long Form T ext Generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) . 12076–12100. [15] Cheng Niu, Y uanhao Wu, Juno Zhu, Siliang Xu, KaShun Shum, Randy Zhong, Juntong Song, and T ong Zhang. 2024. RAGT ruth: A Hallucination Corpus for Developing Trustw orthy Retrieval-A ugmented Language Models. In Procee dings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers) . 10862–10878. doi:10.18653/v1/2024.acl- long.585 [16] Selvan Sunitha Ravi, Bartosz Mielczarek, Anand Kannappan, Douwe Kiela, and Rebecca Qian. 2024. Lynx: An Open Source Hallucination Evaluation Model. arXiv:2407.08488 [cs.CL] [17] Manuel Rigger and Zhendong Su. 2022. Intramorphic T esting: A New Approach to the T est Oracle Problem. In Proceedings of the 2022 ACM SIGPLAN International Symposium on New Ideas, New Paradigms, and Reections on Programming and Software (Onward!) . doi:10.1145/3563835.3567662 [18] Sergio Segura, Gordon Fraser , Ana B. Sánchez, and Antonio Ruiz-Cortés. 2016. A Survey on Metamorphic T esting. IEEE Transactions on Software Engineering 42, 9 (2016), 805–824. doi:10.1109/TSE.2016.2532875 [19] Yixiao Song, Y ekyung Kim, and Mohit Iy yer . 2024. V eriScore: Evaluating the Factuality of V eriable Claims in Long-Form T ext Generation. In Findings of the Association for Computational Linguistics: EMNLP 2024 . 9447–9474. doi:10.18653/ v1/2024.ndings- emnlp.552 [20] Liyan T ang, Philippe Laban, and Greg Durrett. 2024. MiniChe ck: Ecient Fact- Checking of LLMs on Grounding Documents. In Proceedings of the 2024 Confer- ence on Empirical Methods in Natural Language Processing (EMNLP) . 8818–8847. doi:10.18653/v1/2024.emnlp- main.499 [21] V ectara. 2026. Hallucination evaluation. V ectara Docs. https://docs.vectara.com/ docs/hallucination- and- evaluation/hallucination- evaluation Accessed: 2026-02- 13. [22] Jerry W ei, Chengrun Y ang, Xinying Song, Yifeng Lu, Nathan Hu, Dustin Tran, Daiyi Peng, Ruibo Liu, Da Huang, Cosmo Du, and Quo c V . Le. 2024. Long- form Factuality in Large Language Models. In Advances in Neural Information Processing Systems (NeurIPS) . [23] Borui Y ang, Md Af Al Mamun, Jie M. Zhang, and Gias Uddin. 2025. Hallucination Detection in Large Language Models with Metamorphic Relations. Proceedings of the ACM on Software Engineering 2, FSE (July 2025). doi:10.1145/3715735 [24] Boxi Yu, Qiuyang Mang, Qingshuo Guo, and Pinjia He. 2023. Retromorphic T esting: A New Approach to the T est Oracle Problem. arXiv:2310.06433 [cs.SE] [25] Y uheng Zha, Yichi Yang, Ruichen Li, and Zhiting Hu. 2023. AlignScore: Evaluating Factual Consistency with A Unied Alignment Function. In Proceedings of the 61st Annual Me eting of the Association for Computational Linguistics (V olume 1: Long Papers) . 11328–11348. doi:10.18653/v1/2023.acl- long.634 [26] Ádám K ovács and Gábor Recski. 2025. LettuceDetect: A Hallucination Detection Framework for RA G Applications. arXiv:2502.17125 [cs.CL] abs/2502.17125
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment