Safer Builders, Risky Maintainers: A Comparative Study of Breaking Changes in Human vs Agentic PRs
AI coding agents are increasingly integrated into modern software engineering workflows, actively collaborating with human developers to create pull requests (PRs) in open-source repositories. Although coding agents improve developer productivity, th…
Authors: K M Ferdous, Dipayan Banik, Kowshik Chowdhury
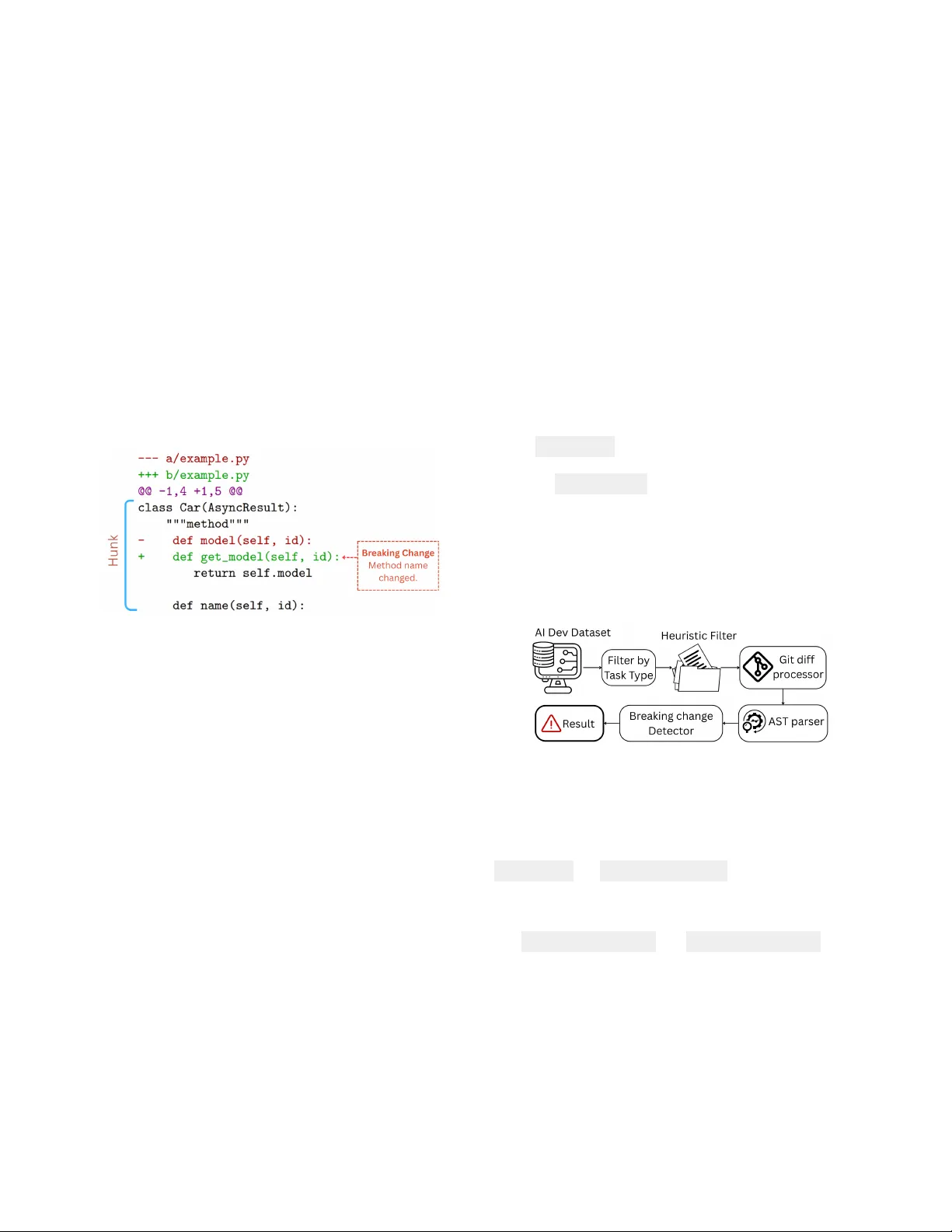
Safer Builders, Risky Maintainers: A Comparative Study of Breaking Changes in Human vs A gentic PRs K M Ferdous kferdous@students.kennesaw .edu Kennesaw State Univ ersity Marietta, Georgia, USA Dipayan Banik dipayan5175@gmail.com Quanta T echnology Raleigh, North Carolina, USA Ko wshik Chowdhury kchowdh1@students.kennesaw .edu Kennesaw State Univ ersity Marietta, Georgia, USA Shazibul Islam Shamim mshamim@kennesaw .edu Kennesaw State Univ ersity Marietta, Georgia, USA Abstract AI coding agents are increasingly integrated into mo dern software engineering workows, actively collaborating with human devel- opers to create pull requests (PRs) in open-source repositories. Al- though coding agents improve de veloper productivity , they often generate code with more bugs and security issues than human- authored code. While human-authored PRs often break backward compatibility , leading to breaking changes, the potential for agentic PRs to introduce breaking changes remains underexplored. The goal of this paper is to help developers and researchers evaluate the reliability of AI-generated PRs by examining the frequency and task contexts in which AI agents introduce breaking changes. W e conduct a comparative analysis of 7,191 agent-generated PRs with 1402 human-authored PRs from Python repositories in the AIDev dataset. W e develop a tool that analyzes code changes in commits corresponding to the agentic PRs and leverages an ab- stract syntax tree (AST) based analysis to detect p otential breaking changes. Our ndings sho w that AI agents introduce fewer breaking changes overall than humans (3.45% vs. 7.40%) in code generation tasks. Howev er , agents exhibit substantially higher risk during maintenance tasks, with r efactoring and chore changes introducing breaking changes at rates of 6.72% and 9.35%, respe ctively . W e also identify a “Condence T rap” where highly condent agentic PRs still introduce breaking changes, indicating the nee d for stricter review during maintenance oriented changes regardless of reported condence score. CCS Concepts • Software and its engineering → Software development tech- niques ; Collaboration in software development ; Software cre- ation and management ; A rticial intelligence . Ke ywords Breaking Changes, AI Agents, Coding Agents, Software Mainte- nance, Software Security , Secure Software Engineering This work is licensed under a Creativ e Commons Attribution 4.0 International License. MSR ’26, Rio de Janeiro, Brazil © 2026 Copyright held by the owner/author(s). ACM ISBN 979-8-4007-2474-9/2026/04 https://doi.org/10.1145/3793302.3793610 A CM Reference Format: K M Ferdous, Dipayan Banik, Kowshik Chowdhury, and Shazibul Islam Shamim. 2026. Safer Builders, Risky Maintainers: A Comparative Study of Breaking Changes in Human vs Agentic PRs. In 23r d International Conference on Mining Software Rep ositories (MSR ’26), A pril 13–14, 2026, Rio de Janeiro, Brazil . ACM, Ne w Y ork, N Y , USA, 5 pages. https://doi.org/10.1145/3793302. 3793610 1 Introduction The AI coding agents, such as Devin, Claude Code, and GitHub Copilot, have brought about a paradigm shift in modern software development worko ws [ 27 ] [ 11 ]. These AI agents enhance devel- oper productivity by performing co ding tasks, generating test cases, and handling complex end-to-end dev elopment tasks, such as issue resolution and pull request (PR) cr eation [ 10 ] [ 28 ] [ 14 ] [ 4 ]. These agents have become active participants alongside human develop- ers in creating pull r equests in open-source repositories [ 11 ] [ 12 ]. For instance, OpenAI Codex has created more than 400,000 PRs in open-source GitHub repositories within the rst two months of its release [ 19 ]. Agentic PRs are increasingly common in real repositories, and datasets such as AIDev capture thousands of these contributions across diverse projects [19]. Despite improvements in developer productivity and active in- volvement in modern software engineering pr ocesses, AI-generated code remains susceptible to signicant quality issues. The AI gen- erated code often contains more bugs and security vulnerabilities than human-authored code [ 3 ] [ 16 ] [ 22 ] [ 25 ]. According to a re- cent study by Co deRabbit of 470 open-source pull requests on GitHub, AI-generated co de contains 1.7 times more issues than human-authored code [ 20 ]. Researchers also reported that devel- opers using AI assistance experienced higher rates of broken tests and integration failures during refactoring tasks [23]. While prior work has primarily fo cused on AI agent performance and bug analysis, comparatively little attention has been given to their impact on backwar d compatibility . AI agents may unintention- ally introduce breaking changes when generating patches and pull requests [ 30 ] [ 29 ], y et this risk remains underexplored compared to human-authored changes. In this research, we investigate whether AI agents can introduce breaking changes. T o address this gap, we evaluate the reliability of agent-generate d pull requests by analyzing the frequency of breaking changes and the development contexts in which they o ccur . W e also include MSR ’26, April 13–14, 2026, Rio de Janeiro, Brazil K M Ferdous, Dipayan Banik, Kowshik Cho wdhury, and Shazibul Islam Shamim our replication package to replicate our ndings [ 7 ]. Our study addresses the following resear ch questions: • RQ1: How often do AI agents introduce breaking changes compared to human developers? • RQ2: How does the breaking change rate of AI-generated pull requests dier between generative tasks and maintenance tasks? • RQ3: T o what extent are AI agent condence scores associated with the occurrence of breaking changes? 2 Background A breaking change is a co de modication that violates backward compatibility and disrupts existing usage [ 21 ]. Such changes often result from structural alterations to a program’s public interface, such as renaming functions or classes, modifying parameters or re- turn types, changing class hierarchies, or removing public memb ers [ 2 ] [ 6 ] [ 29 ]. These changes can br eak dependent code , as illustrate d in Figure 1. Figure 1: Git hunk and Breaking change In Git-base d version control systems, code changes are repre- sented as dis that capture line-level dierences between le revi- sions [ 26 ]. A di is composed of one or more hunks, each repre- senting a contiguous block of adde d, removed, or modied lines [8]. Figure 1 illustrates a hunk within a Git di. 3 Related works Breaking changes are a well established concern in software evolu- tion. Xavier et al. [ 29 ] studied the frequency of breaking changes, while Zhang et al. [ 30 ] found that over 40% of API changes in Python packages are breaking. Du et al. [ 6 ] proposed AexPy , a Python specic tool for detecting breaking changes. However , prior work focuses on human-authored code, leaving AI-generated con- tributions largely unexplored. Prior studies on AI programming tools report improvements in productivity [ 10 ] and demonstrate the ability to generate complete pull requests [ 13 ] [ 19 ], but also reveal limitations in correctness and contextual understanding [ 28 ]. Li et al. [ 19 ], examining the transition to “Software Engineering 3.0” through the AIDev dataset, highlight a gap between benchmark performance and real-w orld eectiveness. They nd that AI agents increase contribution volume but achieve lower acceptance rates than human developers. Pearce et al. [ 22 ] found that up to 40% of AI-generated code may contain security vulnerabilities, while Chen et al. [ 4 ] reported that only 28–48% of AI-generated solutions pass all tests, indicating frequent failures. Additionally , Horikawa et al. [13] observed that over 53% of agentic refactoring occurs implicitly within commits fo cused on other tasks. Although prior research benchmarks AI performance, there is limited research on detecting breaking changes in AI-generate d contributions. Our work addresses this gap by comparing task-wise breaking change rates b etween AI agent-generated and human- authored pull requests and evaluating whether agent condence scores predict breaking changes. 4 Methodology T o address our research questions, we use the AIDev dataset [ 18 ], which provides a comprehensive collection of both AI-agent and human-authored contributions. Our analysis fo cuses on the patches (Git dis) include d in the dataset. W e restrict our study to pull requests from Python-based repositories, as Python is heavily rep- resented in LLM training corpora [ 4 , 17 ], ensuring that our results accurately reect the capabilities of AI coding agents. The repository table lists 2,807 GitHub repositories with at least 100 stars, including 530 Python projects. From these reposi- tories, the pull_request table contains 7,191 AI-generated pull requests and 1,402 human-authored pull requests. Since state of the art A exPy [ 6 ] and other tools like pidi [ 24 ], Py- Compat [ 30 ] analyze dierences between full source code versions rather than directly parsing Git dis, making these tools unsuit- able for our study . Therefore, we develop a tool to detect potential breaking changes from Git dis. Figure 2 illustrates the worko w of our breaking change detection process. Figure 2: W orkow of potential Breaking change dete ction In the rst stage, we lter pull requests by selecting ve task categories: feat, x, p erf, refactor , and chore, which directly im- pact program structure according to the commit convention [ 1 , 5 ]. This step results in 4,798 AI-generated pull requests. Using tables pr_commits and pr_commit_details , w e extract commit-level metadata, yielding 75,467 le-level patches. Applying the same criteria to human-authored pull requests, we identify 1,026 relevant PRs. Although the dataset includes ta- bles human_pull_request and human_pr_task_type , it does not provide commit-level data and le patches. T o address this lim- itation, we used a GitHub API–based mining script to retrieve the missing commit data, collecting 5,788 commits and 93,044 le-level patches for analysis. W e then applied a heuristic path-based lter to keep only cor e Python source les and exclude non-essential directories (e.g. tests, examples, etc). This process results in 23,333 agentic and 36,991 human-authored patches (60,324 total) and removing approximately 66% of the original patches. Safer Builders, Risky Maintainers: A Comparative Study of Breaking Changes in Human vs Agentic PRs MSR ’26, April 13–14, 2026, Rio de Janeiro, Brazil Since AST parser cannot process a patch (git di ) directly , in this step, we r econstruct the pre-commit and post-commit versions of code for each di hunk using the git di processor . These recon- structed codes contain valid syntax suitable for AST parsing. Finally , we parse the pre-commit and post-commit co de of all 60,324 patches using Python’s AST parser , categorizing changes by scope like class-level, function-le vel, etc. The breaking change detector then applies 17 patterns from Du et al. [ 6 ] to identify po- tential breaking changes, organized into thr ee categories: Remo vals, Modications, and Additions. W e measure the Potential Breaking Change Rate, dene d as the percentage of commit les (patches) that contain at least one detected breaking change. Potential Breaking Change (PBC) Rate = Number of patches contain Potential Breaking Change T otal Number of patches (1) W e ran our potential br eaking change detector on 60,324 patches and detected 3,538 potential breaking changes. T o validate the re- liability of our to ol, we randomly sele cted 94 patches from 3,538 detected potential breaking changes using a 95% condence level and a 10% margin of error . T wo authors indep endently reviewed the sample , conrming 90/94 (95.7%) and 88/94 (93.6%) true positive matches, respectively . This yielded substantial inter-rater agree- ment ( Cohen’s K appa = 0.79), and any disagreements were resolved through discussion. 5 Analysis and Findings 5.1 Frequency of Potential Breaking Changes ( AI vs. Humans) Our analysis shows that AI agents introduced potential breaking changes in 805 of 23,333 patches (3.45%), aecting 11.3% of agent- generated pull requests. In comparison, human developers intro- duced potential br eaking changes in 2,733 of 36,991 patches (7.40%), impacting 21.18% of human-authored pull requests. Figure 3 sum- marizes these results, indicating that AI-generated commits exhibit a lower rate of potential breaking changes than human-author ed commits. Figure 3: Breaking Change Rates (%) in AI Agents vs Humans Figure 4 demonstrates the distribution of potential breaking changes across AI agents. Claude Code exhibits 74 breaking changes across 1,450 patches (ratio 5.10), while Copilot, Cursor , Devin, and OpenAI Codex have ratios of 3.04, 4.20, 4.09, and 2.62, respectively . These results indicate that although all agents introduce some po- tential breaking changes, their frequency remains low er than that observed in human-authored patches. Figure 4: Agent wise potential breaking change rate (%) Answer of RQ1 Our analysis shows that AI agents intr oduce potential breaking changes at a lower rate (3.45%) compare to human developers (7.40%). While all agents produce some potential breaking changes, their frequency remains lower than that of human-authored com- mits. 5.2 T ask-Spe cic Breaking Change (Generative vs. Maintenance) T o address RQ2, we categorize tasks into generative activities (feat, x, perf ) and maintenance activities (refactor , chore). Figure 5 shows that AI agents exhibit relatively low breaking change rates in gen- erative tasks: 2.89% for featur e additions, 2.69% for bug xes, and 4.12% for performance improvements. In contrast, maintenance tasks carr y higher risks, with refactoring at 6.72% and chore-related tasks at 9.35%. Figure 5: T ask-Specic breaking change rate comparison. For human-authored patches, we notice the opposite trend. Gen- erative tasks have higher breaking change rates, with feat at 7.74%, x at 5.32%, and perf at 0.90%, whereas maintenance tasks show relatively low er rates, with refactor at 4.36% and chore at 4.95%. Overall, AI agents demonstrate more reliability for code gener- ation but are more risky in maintenance tasks, whereas humans show the opposite trend. This comparison suggests that AI agents MSR ’26, April 13–14, 2026, Rio de Janeiro, Brazil K M Ferdous, Dipayan Banik, Kowshik Cho wdhury, and Shazibul Islam Shamim need more understanding for maintenance related patches and the changes should undergo careful revie w . Answer of RQ2 AI agents are more prone to breaking changes in maintenance tasks (chore: 9.35%, refactor: 6.72%) than in generative tasks (feat: 2.89%, x: 2.69%), indicating that AI agents require deeper under- standing for structural modications. 5.3 The Condence Trap W e notice that the condence scores are strongly right-skewed, with 99.9% of AI-generated pull requests between 8 and 10. Therefore, we focus on condence scores 8, 9, and 10 to assess the relationship between condence and breaking changes. Figure 6: The relationship b etween AI agent condence scores and potential breaking changes. In Figur e 6, our ndings highlight that br eaking change rates are relatively similar for levels 8 and 9, at 3.94% (33 of 837 patches) and 3.96% (311 of 7,854 patches), respectively . Interestingly , condence level 10 also e xhibits potential breaking changes, but at a slightly lower rate of 3.16% (458 breaks out of 14,509 commits). These results indicate that high condence does not reliably guarantee safe code generation. Therefore, condence scores alone are insucient for prioritizing revie w or deployment, and should be supplemente d with additional verication mechanisms when using agent-generated code in production. Answer of RQ3 Breaking changes occur across all high-condence levels (8–10), ranging from 3.16% to 3.96%, indicating that AI agents’ condence scores alone do not guarantee safe code. 6 Discussion 6.1 Interpretation of Findings 6.1.1 Maintenance Task Risk : Our results indicate that AI agents introduce substantially higher rates of potential breaking changes in maintenance oriented tasks, such as refactoring (6.72%) and chore (9.35%) related updates (gure 5). This highlights the need for further research to improve AI agent p erformance and reliability specically in maintenance tasks. 6.1.2 Unreliable Confidence Score : Figure 6 highlights that AI- generated PRs introduce potential breaking changes even at high condence levels (8–10), indicating that condence scores do not reliably reect breaking change risk. This suggests the need to align condence with structural risk. 6.2 Implications for Practitioners 6.2.1 T ask-Specific Review Policy : In gure 5, we observe that agent-generated maintenance tasks introduce more potential break- ing changes than generative tasks. So , we recommend practition- ers apply enhanced, task-specic review policies regardless of the agent’s reported condence. 6.3 Implications for Researchers 6.3.1 Assessing Breaking Changes in Benchmarks : Current AI cod- ing benchmarks ( e.g., HumanEval, SWE-b ench) focus on functional correctness, but agents can introduce breaking changes (Figure 4). So future research should incorporate breaking-change analysis into these benchmarks. 7 Threats to V alidity 7.1 Internal V alidity Our analysis focuses on ve task categories and their PRs that di- rectly aect program structure. This selection may have overlooked “tangled commits” , combining code and do cumentation but labeled as document type tasks. Additionally , our static analysis may over- estimate breaking changes due to challenges in handling nested functions, which are not publicly accessible and dicult to identify from patches [9]. 7.2 External V alidity For task-based pull request ltering, w e relied exclusively on the classication schema provided by the AIDev dataset. Any misclassi- cations in the dataset’s tagging logic could aect the transferability of our task-specic ndings. 7.3 Construct V alidity W e measure ’Potential Breaking Changes’ based on syntactic-level modications, even though some changes may aect functions with no downstream users. However , in API evolution, any syntactic- level change is considered a breaking change, irrespe ctive of its usage. [ 15 ]. Additionally , our ndings are limited to the Python ecosystem, and statically typed languages need further investiga- tion. 8 Conclusion AI coding agents are increasingly use d in software development but may introduce breaking changes through unintended structural modications. In this study , we conduct a comparative analysis of agent-generated and human-authored Python pull requests and nd that although agents introduce few er breaking changes ov erall, they ar e signicantly more prone to breaking changes during main- tenance tasks, espe cially refactoring and chore-related changes. W e also show that agent condence scores p oorly predict breaking change risk. These ndings highlight the need for task-aware review processes and new benchmarks that explicitly evaluate breaking change risks in AI-generated code. Safer Builders, Risky Maintainers: A Comparative Study of Breaking Changes in Human vs Agentic PRs MSR ’26, April 13–14, 2026, Rio de Janeiro, Brazil References [1] Angular T eam. 2025. Angular Commit Message Guidelines (from CON TRIBU T - ING.md). GitHub repositor y documentation. https://github.com/angular/ angular/blob/22b96b9/CON TRIBUTING.md#- commit- message- guidelines [Ac- cessed: Dec. 02, 2025]. [2] A. Brito, L. Xavier , A. Hora, and M. T . Valente . 2018. Why and how Java developers break APIs. In 2018 IEEE 25th International Conference on Software Analysis, Evolution and Reengineering (SANER) . 255–265. doi:10.1109/SANER.2018.8330214 [3] T uan-Dung Bui, Thanh Trong Vu, Thu-T rang Nguyen, Son Nguyen, and Hieu Dinh V o. 2025. Correctness Assessment of Code Generated by Large Language Mo dels Using Internal Representations. arXiv:2501.12934 [cs.SE] https://arxiv .org/abs/2501.12934 [4] Mark Chen, Jerry T worek, Heewoo Jun, Qiming Y uan, Jared Kaplan, et al . 2021. Evaluating Large Language Models Trained on Code. arXiv:2107.03374 [cs.LG] https://arxiv .org/abs/2107.03374 [5] Conventional Commits. 2023. Conventional Commits Specication. Online. https://www.conv entionalcommits.org/ [A ccessed: Dec. 02, 2025]. [6] Xingliang Du and Jun Ma. 2022. AexPy: Detecting API Breaking Changes in Python Packages. In 2022 IEEE 33rd International Symposium on Software Relia- bility Engineering (ISSRE) . 470–481. doi:10.1109/ISSRE55969.2022.00052 [7] K M Ferdous, D . Banik, K. Chowdhury , and S.I. Shamim. 2026. AIDev Breaking Change Analysis. gshare. doi:10.6084/m9.gshare.30978262.v1 [8] Free Software Foundation. 2025. Hunks — GNU diutils Manual. Online. https: //www.gnu.org/softwar e/diutils/manual/html_node/Hunks.html [Accessed: Dec. 02, 2025]. [9] GeeksforGeeks. 2025. Python Inner Functions. Online. https://www. geeksforgeeks.org/python/python- inner- functions/ [Accessed: Dec. 2, 2025]. [10] GitHub. 2022. Do es GitHub Copilot Improve Code Quality? Here’s What the Data Says. GitHub Blog (2022). Accessed: 2025. [11] Ahmed E. Hassan, Hao Li, Dayi Lin, Bram Adams, Tse-Hsun Chen, Yutaro Kashiwa, and Dong Qiu. 2025. Agentic Software Engine ering: Foundational Pillars and a Research Roadmap. arXiv:2509.06216 [cs.SE] 2509.06216 [12] Ahmed E. Hassan, Gustavo A. Oliva, Dayi Lin, Bo yuan Chen, Zhen Ming, and Jiang. 2024. T owards AI-Native Software Engineering (SE 3.0): A Vision and a Challenge Roadmap. arXiv:2410.06107 [cs.SE] https://arxiv .org/abs/2410.06107 [13] Kosei Horikawa, Hao Li, Yutar o Kashiwa, Bram Adams, Hajimu Iida, and Ahmed E. Hassan. 2025. Agentic Refactoring: An Empirical Study of AI Coding Agents. arXiv preprint (2025). V ol. 1, No. 1. [14] Carlos E. Jimenez, John Y ang, Alexander W ettig, Shunyu Y ao, Kexin Pei, Or Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real- W orld GitHub Issues? arXiv:2310.06770 [cs.CL] https://ar xiv .org/abs/2310.06770 [15] M. Keshani, S. V os, and S. Proksch. 2023. On the relation of method popularity to breaking changes in the Maven ecosystem. Journal of Systems and Software 203 (2023), 111738. doi:10.1016/j.jss.2023.111738 [16] Raphaël Khoury , Anderson R. A vila, Jacob Brunelle, and Baba Mamadou Camara. 2023. How Secure is Code Generate d by ChatGPT ? arXiv:2304.09655 [cs.CR] https://arxiv .org/abs/2304.09655 [17] Denis Kocetkov , Raymond Li, Loubna Ben Allal, Jia Li, Chenghao Mou, Car- los Muñoz Ferrandis, Y acine Jernite, Margaret Mitchell, Sean Hughes, Thomas W olf, Dzmitry Bahdanau, Leandro von W erra, and Harm de Vries. 2022. The Stack: 3 TB of p ermissively licensed source co de. arXiv:2211.15533 [cs.CL] https://arxiv .org/abs/2211.15533 [18] Hao Li and Contributors. 2024. AIDev: Dataset for AI Development Analytics. Hugging Face Dataset. https://huggingface.co/datasets/hao- li/AIDev [Online; accessed: Dec. 02, 2025]. [19] Hao Li, Hao xiang Zhang, and Ahmed E. Hassan. 2025. The Rise of AI T eammates in Software Engineering (SE) 3.0: How Autonomous Coding Agents Are Reshap- ing Software Engineering. arXiv:2507.15003 [cs.SE] https://arxiv .org/abs/2507. 15003 [20] David Loker . 2025. State of AI vs Human Code Generation Report. CodeRabbit Blog. https://www .coderabbit.ai/blog/state- of- ai- vs- human- code- generation- report [Accessed: Dec. 02, 2025]. [21] L. Ochoa, T . Degueule, J.-R. Falleri, and J. Vinju. 2022. Breaking bad? Semantic versioning and impact of breaking changes in Mav en Central: An external and dierentiated replication study . In Empirical Software Engineering , V ol. 27. 61. [22] Hammond Pearce, Baleegh Ahmad, Benjamin T an, Brendan Dolan-Gavitt, and Ramesh Karri. 2021. Asleep at the Keyboard? A ssessing the Security of GitHub Copilot’s Code Contributions. arXiv:2108.09293 [cs.CR] 2108.09293 [23] Neil Perry , Megha Srivastava, Deepak Kumar , and Dan Boneh. 2023. Do Users W rite More Insecure Code with AI Assistants? . In Procee dings of the 2023 ACM SIGSAC Conference on Computer and Communications Security (CCS ’23) . ACM, 2785–2799. doi:10.1145/3576915.3623157 [24] R. Rohan. [n. d.]. pidi: The Python interface di tool. GitHub. https://github . com/rohanpm/pidi [Accessed: Sep. 7, 2025]. [25] Gustavo Sandoval, Hammond Pearce, T eo Nys, Ramesh Karri, Siddharth Garg, and Brendan Dolan-Gavitt. 2023. Lost at C: A User Study on the Security Implications of Large Language Model Co de Assistants. arXiv:2208.09727 [cs.CR] https: //arxiv .org/abs/2208.09727 [26] Software Freedom Conservancy. 2025. git - di Documentation. Online. https: //git- scm.com/docs/git- di [Accessed: Dec. 2, 2025]. [27] Christoph Treude and Margaret- Anne Storey . 2025. Generative AI and Empirical Software Engineering: A Paradigm Shift. arXiv:2502.08108 [cs.SE] https://ar xiv . org/abs/2502.08108 [28] Priyan V aithilingam, Tianyi Zhang, and Elena L. Glassman. 2022. Expectation vs. Experience: Evaluating the Usability of Code Generation T ools Powered by Large Language Models (CHI EA ’22) . Association for Computing Machinery, New Y ork, N Y , USA, Article 332, 7 pages. doi:10.1145/3491101.3519665 [29] L. Xavier , A. Brito, A. Hora, and M. T . Valente . 2017. Historical and impact analysis of API breaking changes: A large-scale study. In 2017 IEEE 24th International Conference on Software A nalysis, Evolution and Reengineering (SANER) . 138–147. doi:10.1109/SANER.2017.7884616 [30] Z. Zhang, H. Zhu, M. W en, Y . Tao , Y. Liu, and Y . Xiong. 2020. How do Python framework APIs ev olve? An exploratory study . In 2020 IEEE 27th International Conference on Software Analysis, Evolution and Reengine ering (SANER) . 81–92. doi:10.1109/SANER48275.2020.9054800
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment