AgentSwing: Adaptive Parallel Context Management Routing for Long-Horizon Web Agents
As large language models (LLMs) evolve into autonomous agents for long-horizon information-seeking, managing finite context capacity has become a critical bottleneck. Existing context management methods typically commit to a single fixed strategy thr…
Authors: Zhaopeng Feng, Liangcai Su, Zhen Zhang
2026-03-31 A G E N T S W I N G : Adaptive Parallel Context Management Routing for Long-Horizon W eb Agents Zhaopeng Feng † ( ) , Liangcai Su † , Zhen Zhang † , Xinyu W ang ( ) , Xiaotian Zhang Xiaobin W ang, Runnan Fang, Qi Zhang, Baixuan Li, Shihao Cai, Rui Y e, Hui Chen, Jiang Y ong Joey T ianyi Zhou, Chenxiong Qian, Pengjun Xie, Bryan Hooi, Zuozhu Liu, Jingren Zhou T ongyi Lab , Alibaba Group https://tongyi- agent.github.io/blog https://github.com/Alibaba- NLP/DeepResearch Abstract As large language models (LLMs) evolve into autonomous agents for long- horizon information-seeking, managing finite context capacity has become a critical bottleneck. Existing context management methods typically commit to a single fixed strategy throughout the entire trajectory . Such static designs may work well in some states, but they cannot adapt as the usefulness and r eliability of the accumulated context evolve during long-horizon search. T o formalize this challenge, we introduce a probabilistic framework that characterizes long- horizon success through two complementary dimensions: sear ch ef ficiency and terminal precision . Building on this perspective, we pr opose AgentSwing , a state-aware adaptive parallel context management r outing framework. At each trigger point, AgentSwing expands multiple context-managed branches in parallel and uses lookahead routing to select the most promising contin- uation. Experiments acr oss diverse benchmarks and agent backbones show that AgentSwing consistently outperforms str ong static context management methods, often matching or exceeding their performance with up to 3 × fewer interaction turns while also improving the ultimate performance ceiling of long-horizon web agents. Beyond the empirical gains, the pr oposed probabilis- tic framework provides a principled lens for analyzing and designing future context management strategies for long-horizon agents. 1 Intro duction As large language models (LLMs) evolve fr om single-turn question answering assistants into autonomous agents capable of web browsing and sequential tool use, long-horizon information-seeking has emer ged as a critical testbed of their r eal-world capabilities ( W u et al. , 2025b ; a ; T eam , 2025a ; Fang et al. , 2025 ; Li et al. , 2025c ; T ao et al. , 2025 ; Li et al. , 2025b ). In such tasks, solving a problem often requir es tens or even hundreds of steps of sear ching, visiting, verifying, and backtracking before the agent can locate the key evidence and produce a final answer . A central bottleneck in deep information-seeking is the tension between finite context capacity and the need for long-horizon exploration ( W ei et al. , 2025 ; Phan et al. , 2025 ; W ong et al. , 2025 ). Under a fixed context budget, an agent may exhaust its workspace before completing a sufficiently informative sear ch † Equal contribution. Correspondence to: { zhaopengfeng424 , wangxinyu.nlp}@gmail.com . 1 trajectory . As a result, context management has become a key mechanism shaping the performance ceiling of long-horizon agents ( Anthropic , 2025b ; Liu et al. , 2025a ). Recent frontier systems have shown that aggressive context management, such as Discard-All , can substantially improve long-horizon performance by enabling agents to discard accumulated context to sustain more interaction turns ( Liu et al. , 2025a ; T eam et al. , 2026 ; Zeng et al. , 2026a ). Most existing context management approaches rely on a single fixed strategy that is r epeatedly applied throughout the entire trajectory . This design is inherently limited in long-horizon search, where the quality of the accumulated context evolves over time. Some trajectory states contain useful intermediate str uctures that should be retained, while others ar e dominated by noise, drift, or unproductive sear ch history and therefore call for mor e aggressive intervention. T o make this limitation explicit, we introduce the first probabilistic perspective for deep information- seeking agents that characterizes success through two complementary dimensions: search efficiency and terminal precision . Search ef ficiency measures whether an agent can r each a stopping point before exhausting available resour ces, while terminal precision measures whether the final answer is corr ect conditioned on reaching such a stopping point. This view reveals that commonly reported metrics such as Pass@1 or accuracy are not monolithic indicators in long-horizon settings. Instead, end-to-end success depends jointly on whether the agent can arrive at a terminal state with the final answer and whether it can answer correctly once ther e. Building on this perspective, we propose AgentSwing , an adaptive parallel context management routing framework for long-horizon web agents. Instead of committing to a single context management operation at every trigger point, AgentSwing expands multiple context-managed branches from the current trajec- tory state and uses a lookahead routing mechanism to select the most pr omising continuation. In this way , AgentSwing leverages the complementary strengths of heter ogeneous context management strategies and moves beyond the efficiency-pr ecision trade-off of static context management methods. Experiments on 200 400 600 800 Max T urns 40 45 50 55 60 65 P ass@1 (%) Saves 3x T urns Higher Upper Bound T ongyi-DR w/o CM GPT -OS S-120B w/o CM BrowseComp GPT - OSS-120B (Discar d- All) T ongyi-DR (Discar d- All) GPT - OSS-120B (AgentSwing) T ongyi-DR (AgentSwing) Figure 1: Performance on BrowseComp under differ ent interaction budgets. Dashed lines de- note the baselines without context management. several challenging long-horizon benchmarks with diverse open-source backbones, including GPT -OSS- 120B ( OpenAI , 2025b ), DeepSeek-v3.2 ( Liu et al. , 2025a ), and T ongyi-DR-30B-A3B ( T eam , 2025b ), show that AgentSwing consistently outperforms str ong static methods. Under constrained interaction bud- gets, it reaches or exceeds the performance of static strategies that requir e up to 3 × more interaction turns, while also achieving a higher ultimate performance ceiling (see Figure 1 ). It pushes DeepSeek-v3.2 to 71.3 on BrowseComp-ZH and 44.4 on HLE, surpassing sev- eral proprietary foundation models, and establishes leading performance for T ongyi-DR-30B-A3B among information-seeking agents of comparable scale. Our core contributions ar e as follows: • W e introduce the first pr obabilistic framework for long-horizon web agents that characterizes context management through two complementary dimensions, search ef ficiency η and terminal precision ρ , providing a unified lens for understanding the behavior of dif ferent strategies. • W e propose AgentSwing, a state-awar e adaptive context management framework that dynami- cally switches among candidate strategies according to the quality of the current trajectory and continuations, thereby balancing sear ch efficiency and terminal r eliability and improving overall long-horizon agent performance. • Extensive experiments across multiple long-horizon benchmarks and model backbones demon- strate the effectiveness and generalization of AgentSwing, and provide a fine-grained analysis of how differ ent context management strategies behave and why adaptive routing works. 2 2 A Complementa ry Probabilistic View of Long-Ho rizon W eb Agents W e begin with a probabilistic charact erization of long-horizon web agents under resource-constrained execution. In deep information-seeking, end-to-end success cannot be understood solely by final answer accuracy . Before pr oducing a correct answer , the agent must first navigate a long interaction trajectory , accumulate sufficient evidence, and reach a stopping point before exhausting its available resour ces, such as context budget and maximum interaction turns. Accordingly , failures arise from two distinct sources: the agent may fail to reach a stopping point within the allowed resources, or it may terminate but produce an incorr ect answer . 2.1 T w o P ersp ectives on Success: Sea rch Efficiency and T erminal Precision W e assume tasks τ are independently sampled from an underlying task distribution T . For a task τ , consider an agent executed under a test-time strategy π , where π specifies the execution protocol, including context management, stopping rules, and resource constraints. Let S π denote the event that the agent reaches a stopping point and emits a final answer under strategy π , and let C π denote the event that this answer is correct. W e define two task-level quantities: η π τ : = P ( S π | τ ) , ρ π τ : = P ( C π | S π , τ ) . (1) Here, η π τ is the agent’s search efficiency , i.e., the pr obability of reaching a stopping point befor e the protocol terminates, and ρ π τ is its terminal precision , i.e., the probability that the answer is correct conditioned on reaching such a stopping point. T ask-level success then follows from the chain rule: P ( Success π | τ ) = P ( S π ∩ C π | τ ) = η π τ ρ π τ . (2) Thus, success requir es both reaching a terminal state and answering corr ectly once there. At the popula- tion level, we define η π : = P ( S π ) = E τ ∼T [ η π τ ] , (3) ρ π : = P ( C π | S π ) = P ( C π ∩ S π ) P ( S π ) = E τ ∼T [ η π τ ρ π τ ] E τ ∼T [ η π τ ] . (4) Accordingly , the population-level success pr obability can be written as Pass@1 π = P ( Success π ) = P ( S π ∩ C π ) = η π ρ π . (5) This decomposition shows that commonly used end-to-end metrics such as Pass@1 or accuracy should not be treated as monolithic indicators in long-horizon settings. Instead, they jointly reflect search ef ficiency and terminal precision. In practice, suppose a benchmark contains M tasks. For a fixed strategy π , let N π finish denote the number of tasks on which the agent reaches a stopping point and emits a final answer , and let N π correct denote the number of tasks on which the final answer is corr ect. Following T eam et al. ( 2026 ); Zeng et al. ( 2026a ), tasks that exhaust the allowed resour ces before producing a final answer ar e directly counted as failed. W e estimate η π ≈ N π finish M , ρ π ≈ N π correct N π finish , (6) 3 with the corresponding empirical end-to-end success rate Pass@1 π = η π ρ π ≈ N π correct M . (7) Since different strategies may finish on different task subsets, we additionally report aligned terminal precision for cross-strategy comparison. Let N aligned - finish be the number of tasks that finish under all compared strategies or settings, and let N π aligned - correct be the number of these tasks answered correctly by strategy π . W e compute ρ π align ≈ N π aligned - correct N aligned - finish . (8) By reporting terminal precision on the shared finished subset, this metric enables a fairer comparison across strategies or settings. 2.2 Disca rd-All vs. Baseline W e use Discard-All as a concrete case study to instantiate the framework above and explain why context management can outperform the standard w/o context management baseline. Let π = std denote the baseline without context management. Under this protocol, the agent continuously appends its interaction history and follows a single uninterrupted search trajectory . It therefore either reaches a stopping point and produces a final answer , or exhausts the maximum context length and is counted as failed. In contrast, Discard-All ( π = DA ) introduces a context-management trigger . Once the accumulated context exceeds a pr edefined thr eshold, the agent discar ds the full trajectory history and continues from the original user prompt only . As a result, the same task execution under Discard-All may contain multiple reset-based attempts. If the maximum turn budget is exhausted before a final answer is produced, the task is counted as failed. 25.6k 51.2k 76.8k 102.4k Context Budget 20 30 40 50 60 70 80 90 P ass@1 (%) T ongyi-DR w/o CM GPT -OS S-120B w/o CM GPT - OSS-120B: P ass@1 T ongyi-DR : P ass@1 GPT - OSS-120B: Aligned P r ecision T ongyi-DR : Aligned P r ecision 20 30 40 50 60 70 80 90 A l i g n e d T e r m i n a l P r e c i s i o n A l i g n - F i n i s h ( % ) Context Rot Phenomenon in Discard-all Figure 2: Performance on BrowseComp under Discard- All with differ ent context budgets. W e next study how the trigger threshold af- fects the performance of Discard-All , while also using it to understand the differ ence between Discard-All and the baseline. W e vary the trig- ger ratio while fixing the maximum interac- tion turns to 400, so that the primary chang- ing factor is the effective context budget per attempt. Figure 2 shows that, for both T ongyi- DR-30B-A3B and GPT -OSS-120B, aligned ter- minal precision consistently decreases as the context budget increases. This indicates that larger working contexts lead to more severe context rot at termination ( Hsieh et al. , 2024 ; Modarressi et al. , 2025 ; Hong et al. , 2025 ; Fang et al. , 2026 ). Since the baseline corresponds to the largest context regime, it is also the least favorable for terminal precision. At the same time, an appropriate context budget allows Discard-All to outperform the baseline in overall performance. This phenomenon can be further interpr eted through our ef ficiency-precision framework. In Figure 3 b, the standard baseline typically has the lowest terminal precision, consistent with the tr end in Figur e 2 , but also the highest sear ch efficiency . In other words, it r eaches stopping points on more tasks, yet the resulting terminal states ar e less reliable. By contrast, Discard-All usually has lower sear ch efficiency η , because each reset-based attempt operates under a smaller effective context budget and is less likely 4 to finish on its own. However , this efficiency loss can be alleviated by increasing the number of reset opportunities N . For a task τ , let S i denote the event that the agent reaches a stopping point during the i -th reset-based attempt, and suppose at most N such attempts are allowed. Then η DA τ = P N [ i = 1 S i τ , (9) which, under a conditional independence approximation acr oss reset-based segments, becomes η DA τ = 1 − N ∏ i = 1 1 − η DA τ , i ≈ 1 − 1 − η DA τ ,single N . (10) Although each individual attempt is less likely to finish than the baseline, increasing N provides mor e chances to reach a stopping point. Combined with the higher precision of smaller contexts, this allows Discard-All to outperform the baseline. 2.3 Static Context Management Strategies in the Efficiency-Precision Plane The same perspective extends naturally beyond Discard-All to other context management strategies. Figure 3 compares Summary , Discard-All , Keep-Last-N , and AgentSwing under maximum interaction budget of 400 turns. As shown in Figure 3 a, all context management strategies outperform the baseline in Pass@1, but through dif ferent efficiency-pr ecision trade-offs. w/o CM Summary K eep- Last-N Discar d- All AgentSwing 30 35 40 45 50 55 60 65 Accuracy (%) (a) P ass@1 Comparison GPT - OSS-120B T ongyi-DR 60 65 70 75 80 85 90 95 100 S e a r c h E f f i c i e n c y / ( % ) 40 50 60 70 80 T e r m i n a l P r e c i s i o n / ( % ) 40% 50% 60% ( b ) E f f i c i e n c y ( ) v s P r e c i s i o n ( ) w/o CM Summary K eep-Last-N Discar d- All AgentSwing w/o CM Summary K eep- Last-N Discar d- All AgentSwing 55 60 65 70 75 80 85 90 Precision (%) ( c ) A l i g n e d T e r m i n a l P r e c i s i o n ( A l i g n - F i n i s h ) Figure 3: Comparison of context management strategies through the efficiency-pr ecision lens. (a) Pass@1 on BrowseComp. (b) Search ef ficiency η vs. terminal precision ρ . (c) Aligned terminal precision, wher e Align-Finish refers to the common finished cases shar ed by different strategies within the same model. Figure 3 b shows that static strategies occupy dif ferent operating points in the ef ficiency-precision plane, forming an empirical trade-off fr ontier . As discussed above, the standard baseline is high-efficiency but low-precision, whereas Discard-All lies near the opposite end. Summary and Keep-Last-N fall between these extremes, impr oving search ef ficiency over Discard-All but not matching its terminal precision; see also Figure 3 c. In contrast, AgentSwing moves to a more favorable region of the plane by adaptively routing multiple strategies, leading to the str ongest overall performance. 3 AgentSwing AgentSwing consists of two components: (1) Parallel Context Management and (2) Lookahead Routing , as illustrated in Figure 4 . W e consider the standard deep information-seeking setting, where an agent starts from a user prompt q and interacts with the envir onment through repeated (, , ) turns. When the current context length exceeds a predefined fraction r of the model’s maximum context length, the framework activates context management over the accumulated trajectory . (1) Parallel Context Management. At each trigger point, AgentSwing applies multiple candidate context management strategies to the same raw context in parallel, producing a set of alternative managed contexts. In this work, we consider three r epresentative strategies: 5 Think Tool Call Tool Response Think Tool Call Tool Response ... Think Tool Call Tool Response Max Context Length User Prompt ≥ r% x MaxContext Length Linear Information-Seeking Process Summary Keep-Last-N Discard-All ... ... ... ... ... Last N Turns Only User Prompt Context Summarization New K Turns New K Turns New K Turns ... Continue Information-Seeking Process 1) Parallel Context Management AgentSwing 2) Lookahead Routing Mechanism Raw Context Figure 4: Overview of AgentSwing. AgentSwing triggers context management once the accumulated context exceeds a predefined thr eshold, executes multiple candidate strategies in parallel, extends each branch for K new turns, and dynamically routes to the most promising continuation. • Keep-Last-N: Preserves only the latest N interaction turns, i.e., the last N (, , ) tuples, and discards earlier history ( Liu et al. , 2025a ; Zeng et al. , 2026a ). • Summary: Compresses the accumulated trajectory into a summarized text and keeps the context in the form of the original user pr ompt together with the summary , i.e., ( q , Sum ) ( Liu et al. , 2025a ; Anthropic , 2025b ). • Discard-All: Discards the entire accumulated interaction history and keeps only the original user prompt q ( Liu et al. , 2025a ; T eam et al. , 2026 ; Zeng et al. , 2026a ). Applying these strategies in parallel can further yield multiple candidate continuations fr om the same trajectory state, each corresponding to a dif ferent way of managing the accumulated context. (2) Lookahead Routing Mechanism. After parallel context management, AgentSwing does not immedi- ately select a branch. Instead, it performs short-horizon lookahead for each managed context. Concretely , each branch continues interacting with the environment for K additional turns. After the lookahead phase, AgentSwing presents the candidate continuations together with the original raw context to the agent model, which then selects the most reasonable branch for subsequent exploration. The remaining branches are discarded, and the selected continuation becomes the new main trajectory . This design allows branch selection to depend not only on the managed context itself, but also on its short-term downstream behavior under real environment feedback. In this way , AgentSwing differs from static strategies, which repeatedly apply a single fixed strategy thr oughout the entire search pr ocess. 4 Exp eriments 4.1 Setup Benchmarks. W e evaluate AgentSwing on three challenging deep information-seeking benchmarks: BrowseComp ( W ei et al. , 2025 ), BrowseComp-ZH ( Zhou et al. , 2025 ), and Humanity’s Last Exam (HLE) ( Phan et al. , 2025 ). These benchmarks jointly assess deep search and reasoning ability . For efficient evaluation, we use sampled subsets for the lar ger benchmarks: 200 randomly selected tasks from BrowseComp and 500 text-only tasks from HLE, following prior work ( Li et al. , 2025d ; Nguyen et al. , 2025 ). For BrowseComp-ZH, we use the full set of 289 tasks. T ools. W e adopt the standard tool configuration used by deep information-seeking agents ( W u et al. , 2025a ; Li et al. , 2025b ), with Search and V isit as the cor e tools. For HLE, following Chen et al. ( 2026 ), we 6 further include Google Scholar and a Python Interpreter . Details are as follows: • Search: Performs batched Google queries and returns the top-10 ranked r esults for each query . • V isit: Fetches webpages from URLs and extracts information r elevant to the specified goal. • Google Scholar: Returns top-10 academic search r esults with snippets, citations, and scholarly metadata. • Python Interpreter: Executes arbitrary Python code in a secure sandbox for computational tasks and data analysis. W e use Code Sandbox 1 to ensure secur e and isolated execution. Agent Models. W e use three open-source models with diverse parameter scales and strong tool-use capability for deep information-seeking tasks: GPT -OSS-120B ( OpenAI , 2025b ), DeepSeek-v3.2 ( Liu et al. , 2025a ), and T ongyi-DeepResearch-30B-A3B (T ongyi-DR-30B-A3B) ( T eam , 2025b ). All models are invoked under their official function-calling pr otocol. Unless otherwise specified, we use the same agent model for both stages in AgentSwing. T able 1: Overall performance on long-horizon agentic benchmarks. Scores marked with ‡ repr esent full-benchmark results, wher eas unmarked scores correspond to our benchmark settings. Model / Framework Context Management BrowseComp BrowseComp-ZH HLE Foundation Models with T ools Claude-4.5-Opus ( Anthropic , 2025a ) w/o CM 37.0 ‡ 62.4 43.4 ‡ Gemini-3.0-Pro ( DeepMind , 2025 ) w/o CM 37.8 ‡ 66.8 45.8 ‡ GPT -5.1 High ( OpenAI , 2025a ) w/o CM 50.8 ‡ – 42.7 ‡ OpenAI-o3 ( OpenAI , 2025c ) w/o CM 49.7 ‡ 58.1 – Deep Information-Seeking Agents OpenAI DeepResearch ( OpenAI , 2025d ) - 51.5 ‡ 42.9 26.6 ‡ ASearcher -W eb-32B ( Gao et al. , 2025 ) - 5.2 ‡ 15.6 12.5 ‡ DeepMiner-32B-RL ( T ang et al. , 2025 ) - 33.5 ‡ 40.1 – IterResearch-30B-A3B ( Chen et al. , 2026 ) - 37.3 ‡ 45.2 28.8 ‡ AgentFold-30B-A3B ( Y e et al. , 2026 ) - 36.2 ‡ 47.3 – AgentFounder-30B-A3B ( Su et al. , 2026 ) - 39.9 ‡ 43.3 31.5 ‡ MiroThinker -v1.5-30B-A3B ( T eam , 2026 ) - 56.1 ‡ 66.8 31.0 ‡ Open-Source Models with Context Management GPT -OSS-120B Baseline (w/o CM) 39.5 28.4 33.2 Discard-All 50.5 31.5 34.2 Keep-Last-N 52.5 33.6 34.1 Summary 48.0 30.8 34.4 AgentSwing (Ours) 60.0 38.0 35.1 DeepSeek-v3.2 Baseline (w/o CM) 51.4 ‡ / 43.5 65.0 ‡ / 61.6 40.8 ‡ / 40.2 Discard-All 58.0 70.2 42.0 Keep-Last-N 52.0 69.9 39.6 Summary 48.5 69.2 43.5 AgentSwing (Ours) 62.5 71.3 44.4 T ongyi-DR-30B-A3B Baseline (w/o CM) 43.4 ‡ / 48.0 46.7 ‡ / 47.1 32.9 ‡ / 31.7 Discard-All 58.0 53.9 32.7 Keep-Last-N 53.0 50.1 32.2 Summary 55.0 49.1 32.0 AgentSwing (Ours) 60.5 56.7 33.1 Baselines. In addition to the standard baseline without context management ( w/o CM ), we compare AgentSwing with several r epresentative static context management strategies intr oduced in Section 3 , including Discard-All , Keep-Last-N ( N = 5), and Summary . For Summary , the summarization step is always performed by GPT -OSS-120B. 1 https://github.com/bytedance/SandboxFusion 7 Evaluation Metrics and Hyper -parameters. All evaluations are conducted under the LLM-as-a-Judge protocol ( Gu et al. , 2024 ), using the official evaluation prompts and judging models released by each benchmark. For all agent models, we set the maximum context length to 128k tokens. Unless otherwise specified, we set the maximum interaction budget to 400 turns for all context management strategies. T o ensure fair comparison and reproducibility , model-specific hyper-parameters follow the officially recommended or empirically optimal settings of each agent backbone. For all experiments involving context management, we set the context budget as a fixed ratio r of the 128k maximum context length. Specifically , we use r = 0.2 for GPT -OSS-120B and r = 0.4 for both T ongyi-DR-30B-A3B and DeepSeek- v3.2. The rationale behind these settings is discussed in Section 2.2 . 4.2 Overall P erfo rmance T able 1 shows that AgentSwing consistently achieves advanced performance across all benchmarks and agent backbones, outperforming both the standard baseline and repr esentative context management strategies. Notably , AgentSwing pushes DeepSeek-v3.2 to 71.3 on BrowseComp-ZH and 44.4 on HLE, surpassing several proprietary foundation models. It also establishes leading performance for T ongyi-DR- 30B-A3B among deep information-seeking agents of comparable scale. These results show that adaptive context management is a strong and general test-time scaling mechanism for long-horizon web agents. 4.3 Analysis and Ablation W e next provide a fine-grained analysis of AgentSwing. W e examine how different context management strategies scale with interaction budget, compare their behavior on aligned har der cases, ablate the lookahead routing mechanism, and pr esent case studies. Further analyses of strategy combinations and strategy transitions are deferr ed to Appendices A and B . Analysis of Context Management Strategies. Figure 5 shows how differ ent context management strategies scale with the maximum interaction budget on BrowseComp. Under small turn budgets, context management provides only limited gains over the baseline, and some static strategies may even 100 200 300 400 Max T urns 35 40 45 50 55 60 65 BrowseComp P ass@1 (%) GPT -OS S-120B 100 200 300 400 Max T urns DeepSeek-v3.2 100 200 300 400 Max T urns T ongyi-DR Baseline Summary K eep-Last-N Discar d- All AgentSwing Figure 5: Performance of different context management strategies on BrowseComp over maximum interaction turns. underperform it, since the baseline benefits fr om its large single-attempt context and ther efore retains relatively str ong search efficiency . Once the budget becomes sufficiently lar ge, all context management strategies consistently surpass the baseline, indicating that the precision advantage of managed contexts becomes dominant as more interaction turns ar e allowed. This trend matches the analysis in Section 2.3 . AgentSwing stands out by outperforming the baseline even under limited budgets and maintaining a consistent advantage over static strategies across the full scaling curve. T o further isolate strategy behavior on harder cases, T able 2 r eports results on the subset of tasks where context management is triggered under all compared strategies within the same model. W e can observe 8 T able 2: Performance comparison of different context management methods on aligned cases that trigger context management under all evaluated strategies ( ρ Align-CM ). Model Strategy N align N finish N correct η (%) ρ (%) Pass@1 (%) N turn GPT -OSS-120B Discard-All 122 51 35 41.8 68.6 28.7 297.2 Summary 68 35 55.7 51.5 28.7 248.0 Keep-Last-N 91 43 74.6 47.3 35.2 205.4 AgentSwing 90 51 73.8 56.7 41.8 190.3 DeepSeek-v3.2 Discard-All 73 40 24 54.8 60.0 32.9 268.3 Summary 72 22 98.6 30.6 30.1 132.2 Keep-Last-N 53 23 72.6 43.4 31.5 183.5 AgentSwing 68 26 93.2 38.2 35.6 151.9 T ongyi-DR-30B-A3B Discard-All 45 11 9 24.4 81.8 20.0 340.8 Summary 35 9 77.8 25.7 20.0 215.7 Keep-Last-N 42 9 93.3 21.4 20.0 153.0 AgentSwing 34 14 75.6 41.2 31.1 203.6 that Keep-Last-N and Summary usually achieve str onger sear ch ef ficiency η , while Discard-All achieves the strongest terminal pr ecision ρ . AgentSwing combines the strengths of both r egimes, with efficiency close to the former and precision close to the latter , leading to the highest overall Pass@1 across all three models on this aligned subset. Moreover , AgentSwing also achieves average turn counts close to the more ef ficiency-oriented strategies, while being substantially more efficient than Discard-All . This shows that its gains do not come from simply paying a larger interaction cost, but from adaptively selecting the most suitable context management decision according to the curr ent trajectory state. Ablation of the Lookahead Routing Mechanism. T o validate the ef fectiveness of the routing mechanism, T able 3: Ablation on lookahead strategy . Routing Mechanism GPT -OSS-120B T ongyi-DR-30B-A3B random 51.0 56.5 w/o Lookahead 50.0 57.0 Lookahead ( k = 1) 52.5 58.0 Lookahead ( k = 3) 60.0 60.5 Lookahead ( k = 5) 55.0 59.0 we report ablations in T able 3 . W e compare AgentSwing with two variants: random , which selects a context management branch uniformly at random after triggering, and w/o Lookahead , which performs parallel context management but re- moves rollout and ther efore selects solely based on the managed contexts themselves. Both variants consistently underperform AgentSwing, showing that the gains do not come merely from maintaining multiple candidate strategies, but from using short-horizon lookahead to evaluate their downstream consequences befor e routing. W e further vary the lookahead depth k , i.e., the number of newly generated turns per branch before routing. The results show that moderate lookahead is most effective. In particular , k = 3 generally provides the strongest performance acr oss models. Compared with k = 1, it exposes richer future trajectory information, while larger lookahead such as k = 5 does not always improve performance further , since it may risk exceeding maximum length constraints of agent models. Comparison of T oken Efficiency . Figure 6 compares token efficiency on the aligned cases used in T able 2 . Each point denotes one finished task, plotted by its total interaction turns and cumulative token count at termination. Although AgentSwing introduces additional token usage due to lookahead r outing, the overhead remains modest in practice. One reason is that efficiency-oriented strategies such as Keep-Last-N often incur higher cumulative token usage at similar turn counts, since they retain mor e trajectory history in the context. By contrast, Discard-All tends to accumulate fewer tokens, but usually requir es more turns to finish. T aken together , these results show that AgentSwing does not achieve its gains by paying a substantially larger overall cost. 9 0 100 200 300 400 T otal T urns 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 T otal T ok ens Count 1e7 GPT -OS S-120B 0 50 100 150 200 250 300 350 T otal T urns DeepSeek-v3.2 0 50 100 150 200 250 300 350 T otal T urns T ongyi-DR Baseline Summary K eep-Last-N Discar d- All AgentSwing Figure 6: T oken efficiency on the aligned cases used in T able 2 . Each point corresponds to one finished task and is plotted by its total interaction turns and cumulative token count at termination. 4.4 Case Study Figure 7 shows a case from DeepSeek-v3.2. When context management is trigger ed at T urn 23, the curr ent history contains both substantial distractions arising from incorr ect hypotheses (“Nipsey Hussle”, “Lil Durk”, and “Hit-Boy”) and a newly surfaced local clue (“$tupid Y oung”). This mixed state makes static context management brittle. Question :There’s an American rapper and songwriter who was born in the 1990s and in October. He joined a gang when he was 14. He has a “Libra” zodiac sign. Between the years 2015-2020 (inclusive), he released a viral hit song, which was from one of his album's that was released between the years 2015-2019 (inclusive) and that song featured another American rapper whose father spent 15 years in the penitentiary, as of January 21, 2016. Can you tell me the name of that viral song? Full Trajectory: [Turn 1-5]: Broadly searched for an " October-born", "Libra", "gang-at- 14" rapper and checked Nipsey Hussleand Lil Durkon Wikipedia.Nipsey Hussle was eliminated by birth month, while Lil Durk became the leading but still unverified candidate. [Turn 6-10]: Tested theLil Durkhypothesis by searching " Lil Durk joined gang at 14" , " viral hit 2015--2020" , and " featured rapper whose father served 15 years" , then checkedHit-Boy.The search shifted from main- artist identification to the featured-artist clue, withHit-Boyemerging as the strongest father-side match. [Turn 11-15] :Expanded theLil Durkpath through Lil Durk discography , " collaborations in 2015--2018" , " a Billboard article on Hit-Boy's father" , and alternative featured artists such as Polo G, Lil Baby, and King Von.Hit- Boy's father clue was confirmed, but theLil Durk hypothesis weakened because the key collaboration found, Loyal To A Fault , was outside the required time range. [Turn 16-20]: Reopened the search with " October-born rapper who joined a gang at 14" , " Hit-Boy father 15-year sentence" , " songs featuring Hit-Boy in 2015--2018" , and checked Racks in the Middle . This phase failed to produce a consistent match, asHit-Boy-related songs kept leading back to candidates that violated the original identity clues. [Turn 21-23]: Reframed the search around explicit queries such as " I joined a gang at 14" , "joined the Crips at 14" , and " joined the Bloods at 14" , while also probing October-born Crips/Bloods members and the January 21, 2016 date clue.This reformulation surfaced the critical$tupid Young . Discard-All: [Lookahead Turn 1]: Broadly searched "American rapper born in October in the 1990s"; "Libra zodiac sign"; "joined a gang at 14"; "father served 15 years in prison". [Lookahead Turn 2]: Searched "Rapper whose father served15 years in prison", foundHit-Boy. [Lookahead Turn 3]: Searched "January 21, 2016 and fatherserved 15 years in prison". Summary: [Lookahead Turn 1]: Continued from a compressed summarycentered onLil DurkandHit-Boy.Searched "Lil Durk joined gang at 14" ;"Lil Durk–Hit-Boy collabora-tions in 2015–2020". [Lookahead Turn 2]: Visited Lil Durk discography and Wikipedia again. [Lookahead Turn 3]: Began searching "October-born Libra rapperwho joined a gang at 14"for alternatives. Keep-Last-N: [Lookahead Turn 1] :Attempted to visit $tupid Young (Wikipediapage). [Lookahead Turn 2] : Searched "$tupid Young birthday" . [Lookahead Turn 3] :Searched "$tupid Young viral song", "$tupid Young featuring" and identified “Mando” as a strong candidate due to popularity and its feature with Mozzy. Router Reasoning: Branch 1 (keep_last_n) shows the most promise for solving the question because it has made a critical breakthrough by identifying the correct main rapper: $tupid Young (Alex Pham). This branch discovered that $tupid Young was born October 3, 1992 (Libra zodiac sign), joined the Cambodian Crips at age 14, and is an American rapper/songwriter—perfectly matching all the initial clues . The branch then began searching for $tupid Young's viral songs between 2015-2020, which is the correct next step to identify the specific song mentioned in the question. In contrast, Branch 0 (discard_all) restarted from scratch and got stuck on generic searches without identifying a specific rapper, while Branch 3 (summary) remained fixated on Lil Durk despite evidence that he joined a gang at age 17 (not 14) and had no relevant collaborations with Hit-Boy within the required timeframe . Branch 1's focused investigation on $tupid Young's discography and features positions it to efficiently find the viral song that features another rapper whose father served 15 years in prison, making it the most promising path to the correct answer. Continuation after AgentSwing: [Turn 24-26]: Refer to Lookahead Turns in Keep-Last-N. [Turn 27-31]: Verified Mando through release date, album information, and the official YouTube video .These checks confirmed that Mando was a 2017 viral song from the 2018 album One of One, allowing the agent to finalize the answer. AgentSwing - Parallel Context Management Context Management triggered by context length Figure 7: Case Study . The three candidate branches produce clearly differ ent continuations. Discard-All resets the search and falls back to broad exploration. Summary preserves the dominant but incorrect “Lil Durk” hypothesis. In contrast, Keep-Last-N preserves the recent clue chain around “$tupid Y oung”, enabling the agent to verify the rapper ’s identity and identify “Mando” within lookahead turns. Based on these continuations, the router corr ectly selects Keep-Last-N , after which the agent verifies the remaining constraints and reaches the final answer shortly afterward. This example illustrates the central advantage of AgentSwing. It treats context management as a state-dependent routing problem over futur e continuations rather than as a fixed compression heuristic. Appendix C provides a detailed turn-by-turn summary of this example, together with a complementary GPT -OSS-120B case in which Discard-All is selected. 10 5 Related W ork Long-horizon web agents. LLM-based web agents have rapidly evolved from single-turn assistants into autonomous systems capable of web br owsing, tool use, and long-horizon information seeking ( W u et al. , 2025b ; a ; Li et al. , 2025c ; Fang et al. , 2025 ; Liu et al. , 2025b ). Recent ef forts from both academia and industry have demonstrated strong potential on deep information-seeking tasks, while also highlighting the importance of test-time scaling and long-horizon interaction design ( Chai et al. , 2025 ; Huang et al. , 2025 ; Li et al. , 2025a ; Zeng et al. , 2026b ). However , most existing agents still r ely on ReAct-style trajectories ( Y ao et al. , 2023 ), making them increasingly vulnerable to context saturation, drift, and err or accumulation as the search horizon gr ows ( Fang et al. , 2026 ). Context management for LLM agents. Context management, or context engineering, aims to provide LLM-based agents with a mor e effective working context ( Anthr opic , 2025b ; Qiao et al. , 2025 ). W ithin long-horizon agents, prior methods mainly rely on static intra-task context curation, including reset-based policies such as Discard-All , recent-turn r etention such as Keep-Last-N ( Liu et al. , 2025a ; T eam et al. , 2026 ; Zeng et al. , 2026a ), and context compaction strategies closely related to Summary ( Y u et al. , 2025 ; Y e et al. , 2026 ; Anthropic , 2025b ; Liu et al. , 2025a ). These methods improve context efficiency , but once a strategy is selected, the same operation is repeatedly applied throughout the entire trajectory . In contrast, AgentSwing treats context management as a state-dependent routing problem and dynamically selects among heterogeneous strategies. 6 Conclusion In this work, we introduce the first pr obabilistic framework that decomposes the end-to-end success of deep information-seeking agents into two complementary dimensions, search efficiency and terminal pre- cision, providing a unified view of how context management strategies af fect long-horizon performance. Building on this perspective, we propose AgentSwing, an adaptive framework that moves beyond a single static context management strategy by expanding multiple parallel context management branches and dynamically selecting among them thr ough a lookahead routing mechanism. Experiments across multiple benchmarks and backbones demonstrate that AgentSwing is both ef fective and generalizable, consistently improving long-horizon agent performance over static context management baselines. 7 Limitations and F uture W ork Our work focuses on test-time context management as an external control mechanism for long-horizon agents. The proposed perspective helps clarify the efficiency-pr ecision trade-off and leads to strong em- pirical gains. A more fundamental direction is to translate these principles into model-level competence, for example, by training agents that are intrinsically more efficient under smaller context budgets or more r eliable under long-horizon noisy trajectories. In addition, the current r outing mechanism is still performed by the agent model itself. Although this design is simple and effective, it may not be optimal. A stronger dedicated router , verifier , or trajectory evaluator with better for esight may further improve branch selection quality and therefor e unlock additional gains for adaptive context management. 11 References Anthropic. Introducing claude opus 4.5, 2025a. URL https://www.anth r o pic.com/news/claude- opu s- 4- 5 . Anthropic. Effective context engineering for ai agents, 2025b. URL https://www.anthropic.com/engi neering/effective- context- engineering- for- ai- agents . Jingyi Chai, Shuo T ang, Rui Y e, Y uwen Du, Xinyu Zhu, Mengcheng Zhou, Y anfeng W ang, Y uzhi Zhang, Linfeng Zhang, Siheng Chen, et al. Scimaster: T owar ds general-purpose scientific ai agents, part i. x-master as foundation: Can we lead on humanity’s last exam? arXiv pr eprint arXiv:2507.05241 , 2025. Guoxin Chen, Zile Qiao, Xuanzhong Chen, Donglei Y u, Haotian Xu, Xin Zhao, Ruihua Song, W enbiao Y in, Huifeng Y in, Liwen Zhang, Kuan Li, Minpeng Liao, Y ong Jiang, Pengjun Xie, Fei Huang, and Jingren Zhou. Iterr esearch: Rethinking long-horizon agents via markovian state reconstr uction. In The Fourteenth International Conference on Learning Repr esentations , 2026. URL https://openreview.net/f orum?id=qQ5MZ5Mx7p . Google DeepMind. A new era of intelligence with gemini 3, 2025. URL https://blog.google/produc ts- and- platforms/products/gemini/gemini- 3 . Runnan Fang, Shihao Cai, Baixuan Li, Jialong W u, Guangyu Li, W enbiao Y in, Xinyu W ang, Xiaobin W ang, Liangcai Su, Zhen Zhang, et al. T owards general agentic intelligence via envir onment scaling. arXiv preprint arXiv:2509.13311 , 2025. Shicheng Fang, Y uxin W ang, XiaoRan Liu, Jiahao Lu, Chuanyuan T an, Xinchi Chen, Y ining Zheng Huang, Xipeng Qiu, et al. Agentlongbench: A controllable long benchmark for long-contexts agents via environment r ollouts. arXiv preprint , 2026. Jiaxuan Gao, W ei Fu, Minyang Xie, Shusheng Xu, Chuyi He, Zhiyu Mei, Banghua Zhu, and Y i W u. Beyond ten turns: Unlocking long-horizon agentic search with large-scale asynchronous rl. arXiv preprint arXiv:2508.07976 , 2025. Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang T an, Xuehao Zhai, Chengjin Xu, W ei Li, Y inghan Shen, Shengjie Ma, Honghao Liu, et al. A survey on llm-as-a-judge. arXiv pr eprint arXiv:2411.15594 , 2024. Kelly Hong, Anton T r oynikov , and Jeff Huber . Context rot: How increasing input tokens impacts llm performance. T echnical report, Chroma, July 2025. URL https://research.trychroma.com/context - rot . Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, and Boris Ginsburg. RULER: What’s the real context size of your long-context language models? In First Conference on Language Modeling , 2024. URL https://openreview.net/forum?id=kIoBbc76Sy . Y uchen Huang, Sijia Li, Minghao Liu, W ei Liu, Shijue Huang, Zhiyuan Fan, Hou Pong Chan, and Y i R Fung. Envir onment scaling for interactive agentic experience collection: A survey . arXiv preprint arXiv:2511.09586 , 2025. Baixuan Li, Dingchu Zhang, Jialong W u, W enbiao Y in, Zhengwei T ao, Y ida Zhao, Liwen Zhang, Haiyang Shen, Runnan Fang, Pengjun Xie, et al. Parallelmuse: Agentic parallel thinking for deep information seeking. arXiv preprint , 2025a. Kuan Li, Zhongwang Zhang, Huifeng Y in, Rui Y e, Y ida Zhao, Liwen Zhang, Litu Ou, Dingchu Zhang, Xixi W u, Jialong W u, Xinyu W ang, Zile Qiao, Zhen Zhang, Y ong Jiang, Pengjun Xie, Fei Huang, and Jingren Zhou. W ebsailor-v2: Bridging the chasm to proprietary agents via synthetic data and scalable reinfor cement learning, 2025b. URL . 12 Kuan Li, Zhongwang Zhang, Huifeng Y in, Liwen Zhang, Litu Ou, Jialong W u, W enbiao Y in, Baixuan Li, Zhengwei T ao, Xinyu W ang, W eizhou Shen, Junkai Zhang, Dingchu Zhang, Xixi W u, Y ong Jiang, Ming Y an, Pengjun Xie, Fei Huang, and Jingr en Zhou. W ebsailor: Navigating super-human r easoning for web agent, 2025c. URL . Xiaoxi Li, Jiajie Jin, Guanting Dong, Hongjin Qian, Y utao Zhu, Y ongkang W u, Ji-Rong W en, and Zhicheng Dou. W ebthinker: Empowering large r easoning models with deep research capability . CoRR , abs/2504.21776, 2025d. doi: 10.48550/ARXIV.2504.21776. URL https://doi.org/10.48550/a rXiv.2504.21776 . Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan W ang, Bingzheng Xu, Bochao W u, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3.2: Pushing the frontier of open large language models. arXiv preprint arXiv:2512.02556 , 2025a. Junteng Liu, Y unji Li, Chi Zhang, Jingyang Li, Aili Chen, Ke Ji, W eiyu Cheng, Zijia W u, Chengyu Du, Qidi Xu, et al. W ebexplor er: Explore and evolve for training long-horizon web agents. arXiv preprint arXiv:2509.06501 , 2025b. Ali Modarressi, Hanieh Deilamsalehy , Franck Dernoncourt, T rung Bui, Ryan A. Rossi, Seunghyun Y oon, and Hinrich Schuetze. Nolima: Long-context evaluation beyond literal matching. In Forty-second International Conference on Machine Learning , 2025. URL https://openreview.net/forum?id=0OshX1 hiSa . Xuan-Phi Nguyen, Shrey Pandit, Revanth Gangi Reddy , Austin Xu, Silvio Savarese, Caiming Xiong, and Shafiq Joty . Sfr-deepresear ch: T owards effective r einforcement learning for autonomously reasoning single agents. arXiv preprint , 2025. OpenAI. Gpt - 5.1: A smarter , more conversational chatgpt, 2025a. URL https://openai.com/index/gpt - 5- 1 . OpenAI. gpt-oss-120b & gpt-oss-20b model card, 2025b. URL . OpenAI. Introducing openai o3 and o4-mini, 2025c. URL https://openai.com/index/introducing- o 3- and- o4- mini/ . OpenAI. Deep resear ch system card, 2025d. URL https://cdn.openai.com/deep- research- system- c ard.pdf . Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, Josephina Hu, Hugh Zhang, Chen Bo Calvin Zhang, Mohamed Shaaban, John Ling, Sean Shi, et al. Humanity’s last exam. arXiv preprint , 2025. Zile Qiao, Shen Huang, Jialong W u, Kuan Li, W enbiao Y in, Xinyu W ang, Liwen Zhang, Baixuan Li, Zhengwei T ao, W eizhou Shen, Xixi W u, Y ong Jiang, Pengjun Xie, Fei Huang, Jun Zhang, and Jingren Zhou. W ebResearcher: Unleashing unbounded reasoning capability in long-horizon agents, 2025. Liangcai Su, Zhen Zhang, Guangyu Li, Zhuo Chen, Chenxi W ang, Maojia Song, Xinyu W ang, Kuan Li, Jialong W u, Xuanzhong Chen, Zile Qiao, Zhongwang Zhang, Huifeng Y in, Shihao Cai, Runnan Fang, Zhengwei T ao, W enbiao Y in, Rui Y e, Y ong Jiang, Ningyu Zhang, Pengjun Xie, Fei Huang, Kai Y e, Kewei T u, Chenxiong Qian, and Jingren Zhou. Scaling agents via continual pre-training. In The Fourteenth International Conference on Learning Representations , 2026. URL https://openreview.net/forum?id=Dr u5mm9anE . Qiaoyu T ang, Hao Xiang, Le Y u, Bowen Y u, Y aojie Lu, Xianpei Han, Le Sun, W enJuan Zhang, Pengbo W ang, Shixuan Liu, et al. Beyond turn limits: T raining deep search agents with dynamic context window . arXiv preprint , 2025. 13 Zhengwei T ao, Jialong W u, W enbiao Y in, Junkai Zhang, Baixuan Li, Haiyang Shen, Kuan Li, Liwen Zhang, Xinyu W ang, Y ong Jiang, Pengjun Xie, Fei Huang, and Jingr en Zhou. W ebShaper: Agentically data synthesizing via information-seeking formalization, 2025. Kimi T eam. Kimi resear cher tech report, 2025a. URL https://moonshotai.github.io/Kimi- Researche r/ . Kimi T eam, T ongtong Bai, Y ifan Bai, Y iping Bao, SH Cai, Y uan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: V isual agentic intelligence. arXiv preprint , 2026. MiroMind T eam. Introducing mirothinker 1.5: 30b parameters that outperform 1t models, 2026. URL https://www.miro m ind.ai/blog/introducin g- mirothinker - 1.5- 30b- parameter s- that- outperf orm- 1t- models . T ongyi DeepResearch T eam. T ongyi deepresearch: A new era of open-source ai resear chers. ht t ps : //github.com/Alibaba- NLP/DeepResearch , 2025b. Jason W ei, Zhiqing Sun, Spencer Papay , Scott McKinney , Jef frey Han, Isa Fulford, Hyung W on Chung, Alex T achar d Passos, W illiam Fedus, and Amelia Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents. arXiv preprint , 2025. R yan W ong, Jiawei W ang, Junjie Zhao, Li Chen, Y an Gao, Long Zhang, Xuan Zhou, Zuo W ang, Kai Xiang, Ge Zhang, et al. W idesearch: Benchmarking agentic broad info-seeking. arXiv preprint , 2025. Jialong W u, Baixuan Li, Runnan Fang, W enbiao Y in, Liwen Zhang, Zhengwei T ao, Dingchu Zhang, Zekun Xi, Gang Fu, Y ong Jiang, Pengjun Xie, Fei Huang, and Jingren Zhou. W ebdancer: T owar ds autonomous information seeking agency , 2025a. URL . Jialong W u, W enbiao Y in, Y ong Jiang, Zhenglin W ang, Zekun Xi, Runnan Fang, Linhai Zhang, Y ulan He, Deyu Zhou, Pengjun Xie, and Fei Huang. W ebwalker: Benchmarking llms in web traversal, 2025b. URL . Shunyu Y ao, Jeffrey Zhao, Dian Y u, Nan Du, Izhak Shafran, Karthik Narasimhan, and Y uan Cao. Re- act: Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR) , 2023. Rui Y e, Zhongwang Zhang, Kuan Li, Huifeng Y in, Zhengwei T ao, Y ida Zhao, Liangcai Su, Liwen Zhang, Zile Qiao, Xinyu W ang, Y ong Jiang, Pengjun Xie, Fei Huang, Siheng Chen, and Jingren Zhou. Agentfold: Long-horizon web agents with proactive context folding. In The Fourteenth International Conference on Learning Representations , 2026. URL https://openreview.net/forum?id=IuZoTgsUws . Hongli Y u, T inghong Chen, Jiangtao Feng, Jiangjie Chen, W einan Dai, Qiying Y u, Y a-Qin Zhang, W ei-Y ing Ma, Jingjing Liu, Mingxuan W ang, et al. Memagent: Reshaping long-context llm with multi-conv rl-based memory agent. arXiv preprint , 2025. Aohan Zeng, Xin Lv , Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Y in, Chendi Ge, Chengx- ing Xie, Cunxiang W ang, et al. Glm-5: from vibe coding to agentic engineering. arXiv preprint arXiv:2602.15763 , 2026a. W eihao Zeng, Keqing He, Chuqiao Kuang, Xiaoguang Li, and Junxian He. Pushing test-time scaling limits of deep sear ch with asymmetric verification. In The Fourteenth International Conference on Learning Representations , 2026b. URL https://openreview.net/forum?id=hxL4Uf9tR3 . Peilin Zhou, Bruce Leon, Xiang Y ing, Can Zhang, Y ifan Shao, Qichen Y e, Dading Chong, Zhiling Jin, Chenxuan Xie, Meng Cao, et al. Browsecomp-zh: Benchmarking web browsing ability of large language models in chinese. arXiv preprint , 2025. 14 A Gains from P a rallel Context Management Combinations Figure 8 compares different candidate context management combinations within AgentSwing. Baseline D A KLN SUM KLN-SUM D A -KLN D A -SUM D A -D A -D A D A -KLN-SUM Strategy 46 48 50 52 54 56 58 60 62 Performance (%) 48.0 58.0 53.0 55.0 55.5 56.5 60.0 59.0 60.5 Context Management Combination Ablation Figure 8: Performance of T ongyi-DR-30B-A3B on BrowseComp under AgentSwing with differ ent con- text management combinations. Although some single strategies, especially Discard-All , already perform strongly , combining multiple candidate strategies generally yields fur- ther gains. This is particularly clear for combina- tions such as Discard-All + Summary , which outper- form either constituent strategy used alone. These results suggest that dif ferent context management operations provide complementary advantages, and that AgentSwing benefits from routing over a richer set of candidate continuations than any single static policy can offer . Mor e broadly , they indicate that AgentSwing’s effectiveness depends not only on the routing mechanism itself, but also on the diversity and complementarity of the can- didate strategy set. This also suggests that exploring richer or more specialized candidate strategies is a promising dir ection for further improving performance. B Analysis of Strategy T ransitions under AgentSwing Figure 9 shows the empirical strategy-transition probabilities under AgentSwing. The transition matrices are clearly non-uniform, indicating that routing behavior is not random. Instead, the pr eferred transitions depend on the underlying backbone. DeepSeek-v3.2 and T ongyi-DR tend to favor Summary , whereas GPT -OSS-120B more often transitions to Discard-All . Summary K eep-Last-N Discar d- All Next Strategy Summary K eep-Last-N Discar d- All Current Strategy 0.31 0.20 0.49 0.24 0.26 0.50 0.25 0.26 0.49 GPT -OS S-120B Summary K eep-Last-N Discar d- All Next Strategy 0.55 0.26 0.19 0.52 0.28 0.20 0.55 0.27 0.18 DeepSeek-v3.2 Summary K eep-Last-N Discar d- All Next Strategy 0.58 0.21 0.20 0.57 0.19 0.25 0.55 0.14 0.31 T ongyi-DR 0.0 0.2 0.4 0.6 0.8 1.0 Figure 9: Statistical analysis of strategy transitions under AgentSwing. Each entry gives the probability of routing to the next strategy conditioned on the curr ent one. C Case Study T ables 4 and 5 provide a mor e detailed turn-by-turn summary of the main trajectory in the "Mando" case from Figur e 7 , while T able 6 r eports the corr esponding lookahead continuations under differ ent context management strategies. In addition, T ables 7 , 8 , and 9 present a complementary case from GPT -OSS-120B in which Discard-All is selected as the context management strategy . This case demonstrates that long-horizon web agents may become trapped in trajectories dominated by substantial noise, repetition, and failed local exploration. In such situations, aggressively resetting the accumulated context thr ough Discard-All allows the agent to recover a cleaner sear ch state, refocus on the most r elevant clues, and ultimately impr ove the chance of reaching the corr ect answer . 15 T urn ID T ool Call Content Key State T urn 1 search American rapper born in Octo- ber in the 1990s; Libra zodiac sign; joined a gang at 14. Started with broad candidate retrieval based on birth month, zodiac sign, and gang involvement; surfaced candidates such as Lil Durk. T urn 2 search Rapper joined gang at age 14; American rapper gang member at 14. Narrowed the sear ch to rappers who explicitly joined a gang at age 14; exposed promising clues including $tupid Y oung and Nipsey Hussle. T urn 3 visit Nipsey Hussle (W ikipedia) V erified that Nipsey Hussle was born in August and therefor e did not satisfy the October/Libra clue. T urn 4 search October-born rapper who joined a gang at 14; Libra rapper with gang affiliation. Searched again for October -born gang-affiliated rappers; Lil Durk became a stronger candidate. T urn 5 visit Lil Durk (W ikipedia) Confirmed that Lil Durk was born on October 19, 1992 (Libra), but his gang-entry age remained unsupported and appeared inconsistent with the clue. T urn 6 search Lil Durk joined gang at 14; Durk Banks gang age. T ried to verify whether Lil Durk joined a gang at age 14; no direct evidence supported this claim. T urn 7 search Lil Durk viral hit (2015–2020); featured rapper whose father served 15 years. Shifted from identity matching to song matching; at- tempted to find a Lil Durk viral song and a featured rapper with the father-in-prison clue, but results wer e inconclusive. T urn 8 search Rapper whose father served 15 years in prison. Focused on the featured-artist clue; Hit-Boy emer ged as the strongest match. T urn 9 visit Hit-Boy (W ikipedia) Checked Hit-Boy’s profile; found ambiguity because one source suggested 9 years, creating tension with the 15- year clue. T urn 10 search Lil Durk collaborations in 2015– 2018. Collected candidate Lil Durk collaborations and featur ed artists for downstream filtering. T urn 11 visit Lil Durk discography (W ikipedia) Examined Lil Durk’s discography in detail to match songs, years, and featured artists. T urn 12 search Rapper whose father was in prison for 15 years. Revisited the father clue; Hit-Boy r emained the dominant candidate. T urn 13 visit Hit-Boy’s father article (Bill- board) Confirmed through Billboar d that Hit-Boy’s father had indeed served 15 years, r esolving the earlier inconsis- tency . T urn 14 search Lil Durk and Hit-Boy collabora- tion. Looked for Lil Durk–Hit-Boy collaborations; found “Loyal T o A Fault,” but it was released in 2021 and thus fell outside the requir ed window . T urn 15 search Polo G father prison; Lil Baby father prison; King V on father prison. Explored alternative featured rappers connected to Lil Durk’s songs, but none fit the father clue clearly . T urn 16 search October-born rapper who joined a gang at 14. Reopened the identity search because the Lil Durk hy- pothesis was weakening; results r emained noisy . T able 4: Main-branch trajectory for the "Mando" case (Part I). 16 T urn ID T ool Call Content Key State T urn 17 search Hit-Boy father 15-year sentence; Big Hit prison timeline. Further validated the 15-year imprisonment timeline around Hit-Boy’s father , strengthening the father-side clue. T urn 18 search Songs featuring Hit-Boy in 2015– 2018. Looked for songs where Hit-Boy was explicitly cr edited as a featured artist; r esults were still fragmented. T urn 19 visit Racks in the Middle (W ikipedia) Checked “Racks in the Middle” and confirmed that al- though Hit-Boy was involved, Nipsey Hussle did not fit the October/1990s clue. T urn 20 search V iral songs featuring Hit-Boy in 2017–2019. Continued searching for a viral song featuring Hit-Boy; no decisive match was found yet. T urn 21 search October-born Crips/Bloods member in the 1990s. Explored W est Coast gang-affiliated rappers born in Oc- tober; results wer e mostly generic gang refer ences. T urn 22 search January 21, 2016 and father served 15 years in prison. Investigated the date anchor around January 21, 2016, but this direction pr oduced little value. T urn 23 search I joined a gang at 14; joined the Crips/Bloods at 14. Reframed the search ar ound explicit self-reports of join- ing a gang at 14; this surfaced the critical $tupid Y oung clue. CM – Context management triggered. The r outer selected the Keep-Last-N branch so that it can continue with $tupid Y oung clue. T urn 24 visit $tupid Y oung (W ikipedia page lookup) Attempted to open a W ikipedia page for $tupid Y oung , but the page was unavailable. T urn 25 search $tupid Y oung birthday; Stupid Y oung birth date. V erified the rapper ’s identity: $tupid Y oung was born on October 3, 1992, matching both the 1990s and Libra clues. T urn 26 search $tupid Y oung viral song; $tupid Y oung hit song; $tupid Y oung featuring. Searched his discography and identified “Mando” as a strong candidate due to popularity and its feature with Mozzy . T urn 27 search Mozzy father prison 15 years; Mozzy dad penitentiary . V erified the featured-artist clue; found a V ice article stat- ing that Mozzy’s father had spent 15 years in prison. T urn 28 visit Mando (W ikipedia page lookup) Attempted to visit a dedicated page for “Mando,” but no useful W ikipedia entry was available. T urn 29 search Mando by $tupid Y oung and Mozzy; release date; album in- formation. Confirmed that “Mando” was released on November 17, 2017 and linked to the 2018 album One of One . T urn 30 visit Mando official Y ouT ube video Used the Y ouT ube page to confirm the song’s viral status via its massive view count (68M+). T urn 31 answer – Integrated all evidence and finalized the answer: “Mando” . T able 5: Main-branch trajectory for the "Mando" case (Part II). 17 Branch T urn ID T ool Call Content Key State LA T urn 1 search American rapper born in October in the 1990s; Li- bra zodiac sign; joined a gang at 14; father served 15 years in prison. Restarted from scratch with broad re- trieval. It surfaced generic October - born candidates such as Lil Durk, but made no decisive progress on the real target. Discard-All LA T urn 2 search Rapper whose father served 15 years in prison. Focused on the father clue and rediscov- ered Hit-Boy , but still lacked a correct main-rapper hypothesis. LA T urn 3 search January 21, 2016 and fa- ther served 15 years in prison. Pursued the date-anchored clue with- out traction. This branch remained broad and under -focused. LA T urn 1 visit $tupid Y oung (W ikipedia page lookup) Attempted to open a W ikipedia page for $tupid Y oung, but the page was un- available. Keep-Last-N LA T urn 2 sear ch $tupid Y oung birthday; Stupid Y oung birth date. V erified the rapper ’s identity: $tupid Y oung was born on October 3, 1992, matching both the 1990s and Libra clues. LA T urn 3 search $tupid Y oung viral song; $tupid Y oung hit song; $tupid Y oung featuring. Searched his discography and identi- fied “Mando” as a str ong candidate due to popularity and its feature with Mozzy . LA T urn 1 search Lil Durk joined gang at 14; Lil Durk–Hit-Boy collabo- rations in 2015–2020. Continued from a compressed sum- mary centered on Lil Durk and Hit-Boy . This preserved structur e but also inher- ited a misleading focus. Summary LA T urn 2 visit Lil Durk (W ikipedia); Lil Durk discography (W ikipedia). V erified that Lil Durk joined the Black Disciples at age 17 rather than 14, and found no Lil Durk–Hit-Boy collabora- tion within 2015–2020. LA T urn 3 search October-born Libra rapper who joined a gang at 14. Only after falsifying the Lil Durk path did this branch begin searching for al- ternative rappers; within the lookahead horizon, it did not r each the $tupid Y oung breakthrough. T able 6: Lookahead branches triggered by context management in the "Mando" case. 18 T urn ID T ool Call Content Key State T urn 1 search Performer who stapled paper to his forehead; sideshow stapling act. Started with direct retrieval on the stapling clue, but results were dominated by noisy modern pages, social media posts, and irrelevant literal uses of “stapled pa- per .” T urn 2 search Paper-to-for ehead sideshow per- former who ate something live. T ried to combine the stapling clue with the “ate live crea- tures” clue; surfaced sideshow-related entities such as Jim Rose Circus, but no stable performer identity . T urn 3 search Strongwoman associated with “beef, game, and plenty of vegetables.” Shifted to a secondary clue in the question, but the re- trieved r esults were largely noisy and did not yet identify the relevant str ongwoman. T urn 4 search Bethel, Connecticut; Manhattan mu- seum; Feejee Mermaid. Used the Bethel / museum / Feejee Mermaid clue to infer the publication domain; this pointed toward P . T . Barnum and the historical oddities / sideshow space. T urn 5 search Bethel, Connecticut; sideshow; Man- hattan museum; Feejee Mermaid. Repeated the supporting-entity search, but the results were still not suf ficiently specific to identify the source publication. T urn 6 search Strongwoman who threw a heckler across a tent. Switched to another distinctive supporting clue in order to identify the common sour ce through a secondary fig- ure. T urn 7 search Strongwoman thr ew a heckler . A simplified version of the query surfaced refer ences to Minerva, helping move the search toward historical strongwoman material. T urn 8 visit V ictorian strongwomen article (iN- ews). V isited the article and confirmed that the strongwoman was Josephine Schauer Blatt (Minerva), establishing that the question belongs to the historical sideshow / fr eak- show domain. T urn 9 search Circus performer who staples paper to his forehead. Returned to the stapling clue after confirming the do- main; the results now included mor e circus / sideshow- related pages, but still no exact match. T urn 10 visit Jelly Boy the Clown article (East Bay T imes). Found a modern performer who allowed money to be stapled to his face, but this did not match the clue about eating live creatur es. T urn 11 search Stapling performer who also eats live creatur es. T ried to jointly resolve the two key attributes, but the results still lacked a decisive sour ce text. T urn 12 search Paper on forehead; eating live crea- tures. Continued direct clue sear ch, but the retrieval r emained noisy and failed to identify the exact publication or per - former . T urn 13 search Exact phrase: “stapled paper to his forehead.” Achieved the first major breakthrough: sear ch results surfaced the PDF The V ictorian Sideshow , with a snip- pet containing the critical phrase “has willingly stapled paper to his forehead ... eaten a mouthful ...” T urn 14 visit The V ictorian Sideshow PDF (direct access attempt). T ried to open the PDF dir ectly , but the tool returned no extractable content. This established the central bottle- neck of the case. T urn 15 search The V ictorian Sideshow PDF . Searched for alternative paths to the same PDF , but the results still pointed back to the same inaccessible source. T urn 16 visit The V ictorian Sideshow PDF (sec- ond access attempt). Repeated the PDF visit attempt, but the extraction failure persisted. T urn 17 search Paper to his forehead; sideshow . Looked for alternative source surfaces after the failed PDF access; results still pointed mainly to the same PDF and its mirrors. T urn 18 visit Scribd mirror of Sideshow . Attempted to recover the content thr ough Scribd, but the page was effectively inaccessible. T able 7: Main-branch trajectory for the "live-crickets" case (Part I). 19 T urn ID T ool Call Content Key State T urn 19 search Stapled paper; forehead; sideshow; eaten. Combined the snippet clues again, but the results still revolved ar ound the unresolved PDF sour ce. T urn 20 search Full snippet phrase including “eaten a mouthful.” Queried the visible snippet directly; this helped con- firm the source phrase, but still did not reveal the missing object after “eaten a mouthful of ...” T urn 21 search Performer name from the stapling clue. T ried to infer the performer identity directly from the snippet description, but the retrieval remained inconclusive. T urn 22 search Exact phrase: “has willingly stapled pa- per to his forehead.” Repeated exact-phrase retrieval to localize the pas- sage more pr ecisely , but still without extractable full text. T urn 23 search The V ictorian Sideshow PDF . Re-confirmed that The V ictorian Sideshow was the likely shared sour ce behind the unusual individuals in the question. T urn 24 visit The V ictorian Sideshow PDF (targeted extraction attempt). Made a more targeted attempt to extract the para- graph about the stapling performer and the live- creatur e clue, but the visit tool still failed. CM – Context management triggered. Context management was triggered because the tra- jectory had become long, noisy , and partially r epet- itive. The router evaluated three branches and se- lected Discard-All . T urn 25 search Stapled paper to forehead performer . After the reset, r estarted with a cleaner search plan; quickly re-enter ed the correct search space without carrying over the accumulated local noise. T urn 26 search Feejee Mermaid; Minerva; Jo-Jo; support- ing clue bundle. Used multiple supporting entities together to verify that the publication family was corr ect and that the search was gr ounded in the historical sideshow do- main. T urn 27 visit Jo-Jo the Dog-Faced Boy article. Confirmed another supporting figure from the same source family , incr easing confidence that the publica- tion hypothesis was correct. T urn 28 search Exact stapling-performer phrasing. Returned to the core unresolved clue after re- confirming the correct publication The V ictorian Sideshow . T urn 29 visit The V ictorian Sideshow PDF . Direct extraction still failed, confirming that the bot- tleneck was tool-access related rather than search- related. T urn 30 visit Alternative text-extraction endpoint for the PDF . Achieved the decisive breakthr ough by using an al- ternative access path that successfully r eturned the source text, r evealing that the performer had “eaten a mouthful of live crickets.” T urn 31 answer – Integrated all evidence and produced the final an- swer: the person who stapled paper to his forehead ate a mouthful of live crickets . T able 8: Main-branch trajectory for the "live-crickets" case (Part II). 20 Branch T urn ID T ool Call Content Key State LA T urn 1 search Stapled paper to forehead performer . Restarted from scratch and quickly re- entered the corr ect search space around the stapling-performer clue, without in- heriting the noisy local loop around failed PDF extraction. Discard-All LA T urn 2 search Feejee Mermaid; Minerva; Jo-Jo; supporting clue bun- dle. Used multiple supporting entities to- gether to verify that the publication fam- ily was correct and that the search was grounded in the historical sideshow do- main. LA T urn 3 visit Jo-Jo the Dog-Faced Boy ar- ticle. Also revisited supporting clues fr om the question, indicating that the branch was reconstructing the sour ce-publication hy- pothesis through multiple entities rather than overfitting to one failed access path. LA T urn 1 visit Scribd mirror of Sideshow . Preserved the most recent local context, which was already dominated by failed source-extraction attempts; immediately re-enter ed the same bottleneck. Keep-Last-N LA T urn 2 search The V ictorian Sideshow PDF . Continued searching for alternative ac- cess points to the same PDF , but re- mained trapped in the same unr esolved extraction problem. LA T urn 3 visit The V ictorian Sideshow PDF . Attempted direct PDF access again and failed, showing that preserving the most recent context mainly preserved the local dead end rather than useful progr ess. LA T urn 1 search Exact stapling phrase; sideshow; live-creature clue. Used the summary-preserved hypothesis that The V ictorian Sideshow was likely the correct source, and re-center ed search on the key unresolved phrase. Summary LA T urn 2 search Repeated phrase-centered retrieval. Continued operating at the correct ab- straction level, but still remained depen- dent on search-r esult snippets and inac- cessible source pages. LA T urn 3 search Repeated snippet-oriented search behavior . Maintained a cleaner high-level focus than Keep-Last-N, but did not produce a concrete r ecovery step that would break the extraction bottleneck. T able 9: Lookahead branches triggered by context management in the "live-crickets" case. 21
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
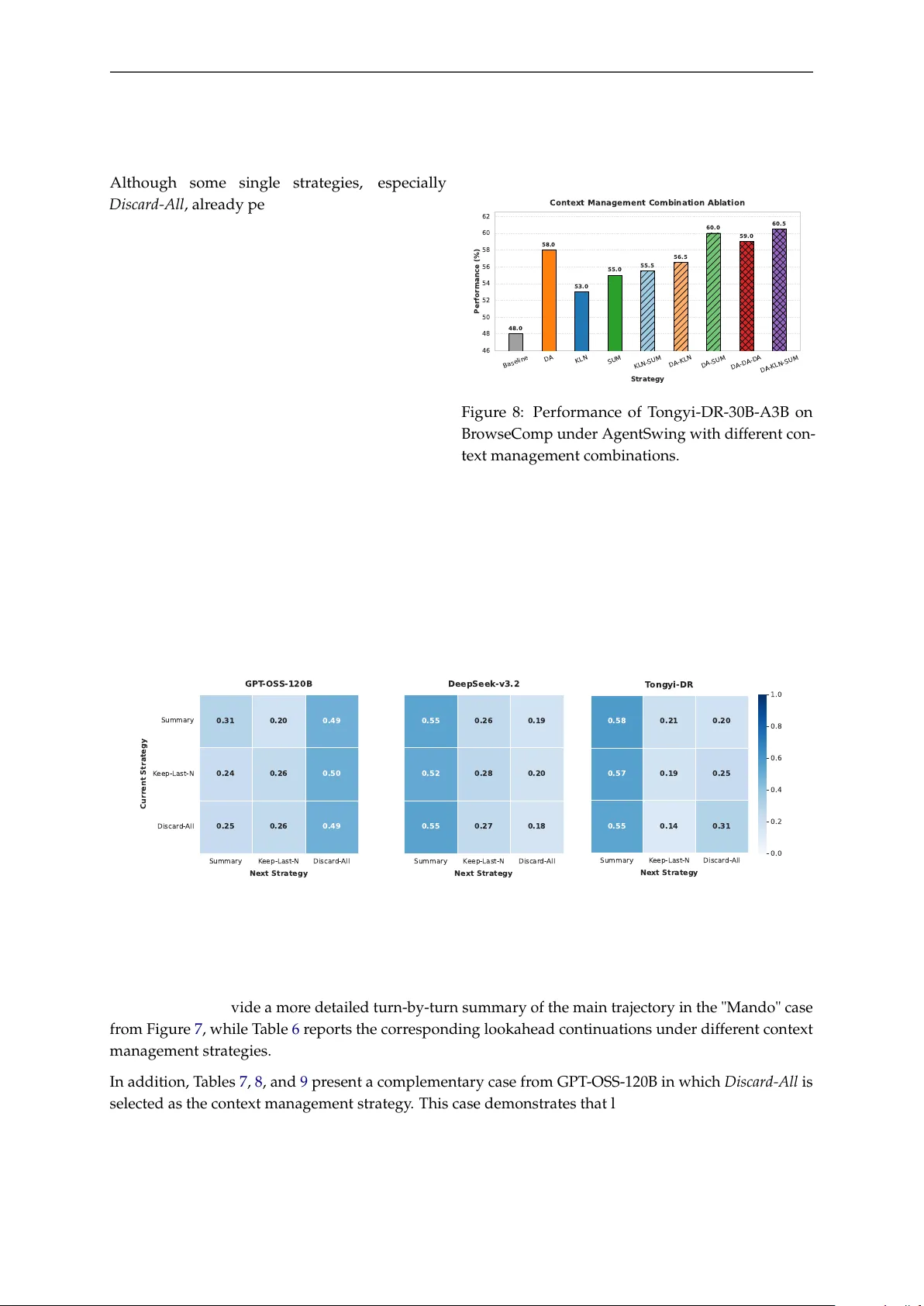
Leave a Comment