TurboAngle: Near-Lossless KV Cache Compression via Uniform Angle Quantization
We compress KV cache entries by quantizing angles in the Fast Walsh-Hadamard domain, where a random diagonal rotation makes consecutive element pairs approximately uniformly distributed on the unit circle. We extend this angular quantizer with per-la…
Authors: Dipkumar Patel
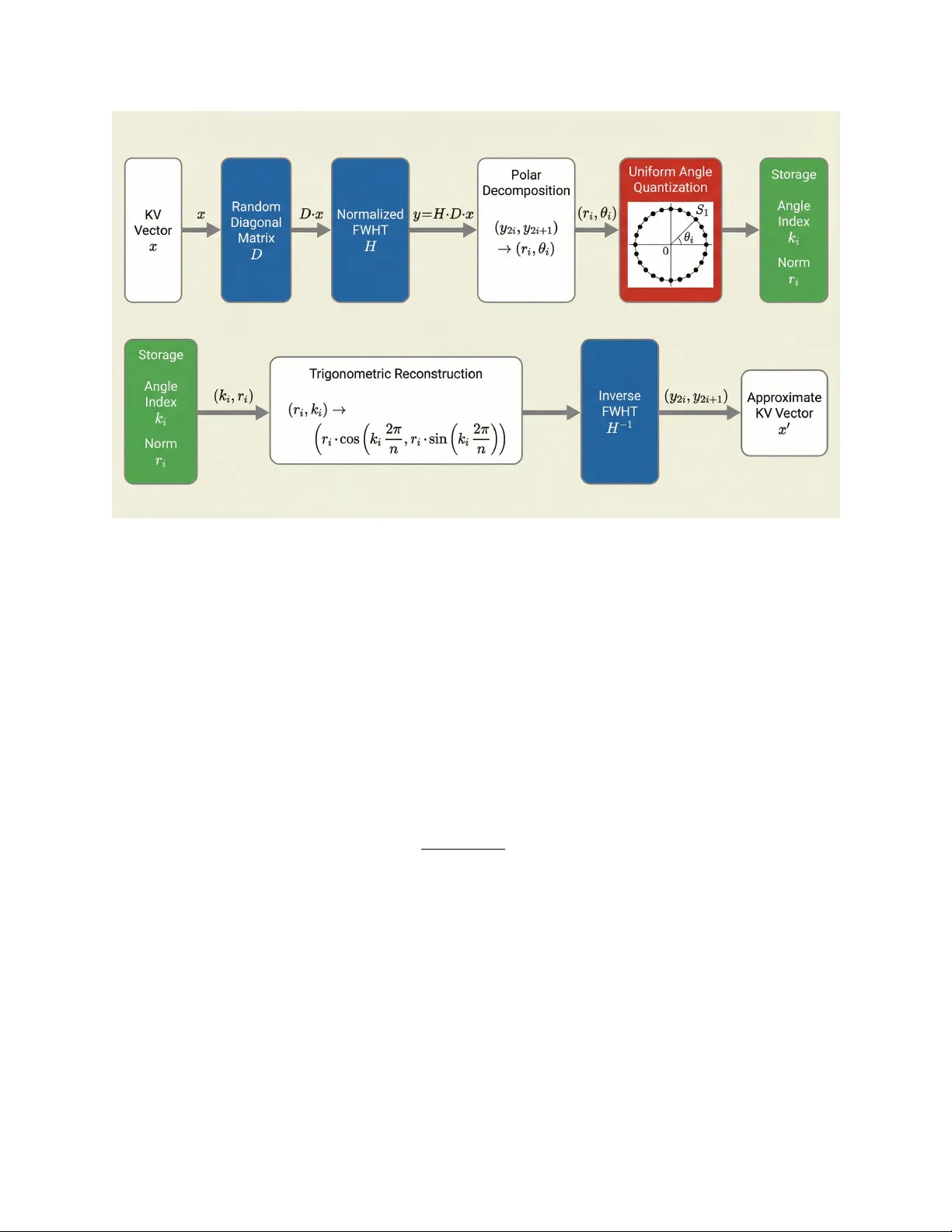
T urb oAngle: Near-Lossless KV Cac he Compression via Uniform Angle Quan tization Dipkumar P atel LLMs Researc h Inc. dipkumar@llmsresearch.ai Marc h 31, 2026 Abstract W e compress KV cache entries by quan tizing angles in the F ast W alsh-Hadamard domain, where a random ± 1 diagonal rotation mak es consecutiv e elemen t pairs uniformly distributed on the unit circle. W e extend this angular quan tizer with p er-layer e arly-b o ost : independently configuring K and V co debo ok sizes at eac h lay er, with higher precision for a model-sp ecific subset of critical la yers. A cross sev en models (1B to 7B parameters), p er-lay er early-bo ost ac hieves lossless compression ( ∆PPL ≤ 0 ) on four models and near-lossless quality ( ∆PPL ≤ 0 . 002 ) on tw o more, at 3.28 to 3.67 angle bits p er elemen t. A dding norm quan tization with asymmetric K/V bit allo cation (8-bit linear K norms, 4-bit log-space V norms) yields an end-to- end rate of 6.56 total bits on Mistral-7B with only ∆PPL = +0 . 0014 , requiring zero calibration. A lay er-group sensitivity analysis reveals that the critical la yers, b ottleneck type (K-dominated vs V-dominated), and even the existence of negative-transfer lay ers where increased precision degrades qualit y are all model-sp ecific, providing actionable rules for configuring the quan tizer on new architectures. 1 In tro duction KV cac he memory scales as O ( LH T d ) for a transformer with L lay ers, H atten tion heads, head dimension d , and T cac hed tok ens. A t long contexts, KV cache dominates model w eigh t storage, making quantization essen tial for efficien t inference. Existing methods [10, 7, 13, 5, 14] apply scalar or v ector quantization to raw activ ations, but KV entries exhibit outliers, c hannel-dep enden t scales, and non-Gaussian marginals that complicate uniform quan tization. These metho ds compensate with p er-c hannel calibration, asymmetric co debo oks, or fine-grained grouping. T urboAngle takes a differen t approach: transform the activ ations into a co ordinate system where the distribution is prov ably uniform, then apply the information-theoretically optimal quan tizer (uniform bins) with zero calibration. Applying a random ± 1 diagonal rotation follow ed by the normalized FWHT produces output pairs whose angles on S 1 are uniformly distributed in the large- d limit. The simplest p ossible quantizer is also the optimal one. The uniform-angle approach is effective but treats all lay ers identically . T ransformers do not ha ve uniform lay er sensitivity: early la yers typically enco de broad contextual features that are more sensitiv e to quantization error, while later la yers can tolerate coarser precision. W e exploit this by in tro ducing p er-layer Mixe dKV , which assigns independent K-cac he and V-cache codeb o ok sizes to eac h la y er. 1 Con tributions. • W e show that FWHT with random sign rotation pro duces uniform angles on S 1 for consecutive elemen t pairs, and build T urb oAngle, an angular quantizer that exploits this prop ert y at log 2 n 2 bits p er element. On Mistral-7B at 3.0 angle bits, T urb oAngle achiev es 14 . 8 × low er p erplexit y degradation than T urb oQuan t [13] sym4-g4 at 4.0 bits. • W e in tro duce p er-la y er MixedKV early-b o ost: assigning higher angular precision to the first n early la yers (or mo del-sp ecific critical lay er groups) while keeping remaining lay ers at baseline. This ac hiev es lossless compression ( ∆PPL ≤ 0 ) on 4 of 7 models and near-lossless ( ∆PPL ≤ 0 . 002 ) on 6 of 7, at 3.28–3.67 angle bits. • W e characterize p er-mo del sensitivity patterns across seven architectures, disco v ering K- dominated vs V-dominated b ottlenec ks, non-monotonic lay er-count scaling, and negative- transfer lay ers where b o osting precision actively degrades quality . • W e quan tize the p er-pair norms with asymmetric K/V bit allo cation, finding that K norms require 8-bit precision while V norms tolerate 4-bit log-space quan tization. The b est end-to- end configuration on Mistral-7B ( d = 128 ) achiev es 6.56 total bits at ∆PPL = +0 . 0014 with zero calibration. 2 Bac kground F ast W alsh-Hadamard T ransform. The normalized Hadamard matrix H ∈ { + 1 √ d , − 1 √ d } d × d defines an orthogonal transform computable in O ( d log d ) via a butterfly decomposition. Because H is symmetric and orthonormal, it is self-in verse: H − 1 = H T = H . The forw ard and inv erse transforms are identical, and the transform preserv es norms. Angle uniformit y after random rotation. Let D = diag ( s 1 , . . . , s d ) with s i ∼ Uniform( { +1 , − 1 } ) dra wn indep enden tly , and define y = H Dx for an input x ∈ R d . Eac h output co ordinate y j = 1 √ d P i s i H j i x i is a w eighted sum of d indep enden t sign-randomized terms. As d grows, the Cen- tral Limit Theorem driv es y j to ward a Gaussian. The consecutiv e pair ( y 2 i , y 2 i +1 ) approaches a spherically symmetric 2D Gaussian N (0 , σ 2 I 2 ) , b ecause the random diagonal D breaks the inter- co ordinate correlations that w ould otherwise arise from Hadamard structure. F or an y spherically symmetric 2D distribution, the angle θ = atan2( y 2 i +1 , y 2 i ) is exactly Uniform([0 , 2 π )) , indep enden t of the radius r = q y 2 2 i + y 2 2 i +1 . A t d = 128 (Mistral-7B’s head dimension), the Gaussian approximation is already tigh t, and angular uniformit y holds empirically to high precision. At d = 64 (used b y Tin yLlama, SmolLM2, OLMo, phi-1.5, and StableLM-2), the appro ximation remains effectiv e for practical purp oses, as confirmed by our exp erimen ts. 3 Metho d 3.1 Angular Quantization T urboAngle encodes eac h KV cac he v ector b y transforming it into the Hadamard domain with a random sign rotation, decomp osing consecutiv e output pairs into polar co ordinates, quantizing 2 Algorithm 1 T urboAngle Encode Require: KV cache tensor x ∈ R d , num b er of angle bins n , rotation matrix D (shared) 1: y ← H · D · x {normalized FWHT after ± 1 diagonal rotation} 2: for i = 0 to d/ 2 − 1 do 3: r i ← q y 2 2 i + y 2 2 i +1 4: θ i ← atan2( y 2 i +1 , y 2 i ) 5: k i ← ⌊ n · θ i / (2 π ) ⌉ mo d n {uniform angular quantization} 6: end for 7: return { ( r i , k i ) } d/ 2 − 1 i =0 the angles uniformly , and storing the norms separately . Algorithm 1 states the compression path. Figure 1 shows the full encode-deco de pip eline. Reconstruction maps eac h stored pair ( r i , k i ) bac k to Cartesian coordinates: ˆ y 2 i = r i cos(2 π k i /n ) , ˆ y 2 i +1 = r i sin(2 π k i /n ) . The original-domain approxim ation follows from the in verse transform ˆ x = D H ˆ y , using the self-in verse property H − 1 = H and D − 1 = D . Rate accounting. Eac h angle index k i ∈ { 0 , . . . , n − 1 } requires log 2 n bits. With one index p er pair of elements, the angular bit rate is log 2 n 2 bits p er element. These rates coun t only angle storage; eac h pair norm r i is stored in fp32 (equiv alen tly 16 bits p er elemen t). Implemen tation. The diagonal D is sampled once from a seeded PRNG and shared across all la yers, heads, and tokens. The FWHT operates head-dimension-wise using in-place butterfly op er- ations in PyT orch, adding negligible latency relativ e to atten tion. 3.2 P er-La yer MixedKV Early-Bo ost Uniform angular quan tization applies the same codeb o ok size n to every lay er and to both key and v alue caches. W e relax b oth constraints. P er-lay er MixedKV assigns an indep enden t pair ( n ( ℓ ) K , n ( ℓ ) V ) of angle co debo ok sizes to la yer ℓ , where n ( ℓ ) K con trols key precision and n ( ℓ ) V con trols v alue precision. The av erage angle bit rate across L la y ers is: ¯ b = 1 L L X ℓ =1 log 2 n ( ℓ ) K + log 2 n ( ℓ ) V 4 (1) where the factor of 4 accounts for the pair-to-elemen t ratio ( ÷ 2 ) and the K/V a verage ( ÷ 2 ). The simplest and most effective allo cation strategy is e arly-b o ost : assign higher precision to the first n early la yers while k eeping the rest at the uniform baseline ( n K = 128 , n V = 64 , i.e., 3.25 bits). A t ypical early-b o ost configuration uses ( n ( ℓ ) K , n ( ℓ ) V ) = (256 , 128) for ℓ < n early , adding appro ximately 0.5 bits p er element to those la y ers. Not all models resp ond to simple early-b oost. On phi-1.5, we find that a sele ctive configuration is necessary: b o osting lay ers 0–7 and 16–23 while keeping lay ers 8–15 at baseline (Section 4.4). This demonstrates that per-lay er MixedKV enables configurations that contiguous early-b o ost cannot express. The full configuration searc h in v olves t wo decisions: which la yers to b oost, and what co deb ook sizes to assign. W e find a simple heuristic works well in practice: (1) test n early ∈ { 4 , 8 , 16 } with (256 , 128) and (128 , 256) for early la yers, (2) pic k whic hever gives low er ∆PPL , (3) adjust n early if impro vemen t contin ues. This pro cedure requires three to five ev aluation runs p er mo del. 3 Figure 1: T urboAngle pip eline. T op: the compression path applies a random diagonal rotation D , the normalized FWHT H , p olar decomp osition of consecutive pairs, and uniform angle quantization on S 1 , storing angle indices k i and norms r i . Bottom: reconstruction maps ( k i , r i ) bac k to Cartesian co ordinates via trigonometric lookup, then applies the in v erse FWHT to recov er the approximate KV vector. 3.3 Norm Quan tization Angular quantization preserves angles but stores the per-pair norm r i in fp32, adding 16 bits p er elemen t ov erhead. F or a deploy able compressor, the norms m ust also b e quan tized. W e apply p er-v ector min-max scalar quantization at b norm bits: given a v ector of d/ 2 norms, w e store the minim um and maxim um in fp32 (64 bits of o verhead p er v ector) and map eac h norm to a b norm -bit unsigned integer via ˆ r i = round r i − r min r max − r min · (2 b norm − 1) . (2) Log-space v arian t. P air norms r i are strictly p ositiv e and righ t-sk ewed. Quan tizing log( r i ) instead of r i spreads the codeb o ok more ev enly across the distribution, allocating finer granularit y to the dense region of small norms and coarser gran ularity to the sparse tail of large norms. At 8 bits, linear and log-space quantizat ion p erform comparably . At 4 bits, log-space quan tization reduces p erplexit y degradation substan tially b ecause the 16 av ailable lev els cov er the dynamic range more efficien tly . Asymmetric K/V norm bits. K-cache norms are 10–20 × more sensitiv e to quan tization error than V-cac he norms. Quan tizing K norms to 4 bits pro duces catastrophic degradation on most mo dels, while V norms tolerate 4-bit log-space quan tization with negligible quality loss. W e therefore 4 adopt an asymmetric allo cation: 8-bit linear norms for K, 4-bit log-space norms for V (denoted K8V4-log). T otal bit rate. Each element’s total storage cost com bines the angle bits, the norm bits, and the p er-v ector min-max ov erhead: b total = b angle + b norm 2 + 64 d (3) where b norm / 2 accoun ts for one norm p er pair of elemen ts, and 64 /d distributes the tw o fp32 min-max scalars across d elements. F or the K8V4-log configuration with b angle = 3 . 25 and d = 128 (Mistral- 7B), this gives b total = 3 . 25 + (8 + 4) / (2 · 2) + 64 / 128 = 3 . 25 + 3 . 0 + 0 . 5 = 6 . 75 bits p er elemen t. A veraging o v er K and V separately (K gets 3 . 25 + 4 . 0 + 0 . 5 = 7 . 75 , V gets 3 . 25 + 2 . 0 + 0 . 5 = 5 . 75 ), the K/V-av eraged rate is 6 . 75 bits; the p er-la y er early-bo ost adjustment yields the final rate of appro ximately 6.56 bits rep orted in Section 4.6. F or d = 64 mo dels, the 64 /d = 1 . 0 ov erhead term is larger, pushing total rates to 7.3–8.3 bits. 4 Exp erimen ts 4.1 Setup W e ev aluate seven mo dels spanning 1B to 7B parameters and four architecture families: TinyLlama- 1.1B [15], Mistral-7B-v0.1 [8], SmolLM2-1.7B [1], phi-1.5 [9], StableLM-2-1.6B [2], StarCo der2- 3B [11], and OLMo-1B [4]. P erplexity is measured on the first 32,768 tokens of WikiT ext-2 [12] v alidation split, divided in to 32 non-o verlapping 1,024-token c h unks. All exp erimen ts use a fixed random diagonal D (same seed across configurations). KV quantization is applied at ev ery la y er to b oth k ey and v alue cac hes. The uniform baseline uses n K = 128 , n V = 64 (3.25 angle bits per elemen t) applied iden tically to all lay ers. This serv es as the reference point for per-lay er early-bo ost comparisons. All ∆PPL v alues are relative to fp16 inference with no quantization. 4.2 Comparison with Scalar Quan tization T able 1 compares T urb oAngle against T urb oQuan t [13] scalar quantization on Mistral-7B and Tin yLlama. On Mistral-7B, T urboAngle with n = 64 (3.0 angle bits) achiev es ∆PPL = +0 . 0010 , while T urb oQuan t sym4-g4 at 4.0 bits degrades by +0 . 0148 : 14 . 8 × more distortion at a higher bit rate. A t the same 3.0 bits, TQ-sym3-g4 degrades by +0 . 1224 , making T urb oAngle 122 × b etter. On Tin yLlama, the b est T urboAngle p oin t is n = 56 at ∆PPL = +0 . 0108 , versus sym4-g4’s +0 . 1295 : 12 . 0 × low er degradation with 1.1 few er bits. 4.3 P er-La yer Early-Bo ost Results T able 2 rep orts p er-la yer early-b oost results across all sev en models. Six of seven mo dels ac hiev e ∆PPL ≤ 0 . 0012 , with four ac hieving lossless compression ( ∆PPL ≤ 0 ). T able 3 details the optimal configuration for each model, including the type of precision b ottle- nec k and the lay ers that require bo osting. The results reveal three distinct sensitivit y patterns: 5 T able 1: Angular vs scalar quantization. ∆ PPL (low er is better). T urb oAngle bit rates count angle bits only; norms are stored in fp32. Metho d Bits/elem ∆ PPL ↓ Mistral-7B Tin yLlama T urb oAngle ( n = 32 ) 2.50 +0.0104 +0.0694 T urb oAngle ( n = 48 ) 2.79 +0.0034 +0.0150 T urb oAngle ( n = 64 ) 3.00 +0.0010 +0.0176 † T urb oAngle ( n = 128 ) 3.50 +0.0030 +0.0036 TQ-sym4-g4 4.00 +0.0148 +0.1295 TQ-sym3-g4 3.00 +0.1224 +0.7814 † Non-monotone: n =64 is worse than n =56 on TinyLlama (Section 4.8). T able 2: Per-la y er early-b oost results on sev en models. WikiT ext-2 perplexity at 32K tok ens. “Uniform” is the K128V64 baseline (3.25 angle bits/element). Best p er-la yer config is the optimal configuration found through systematic sweep. Angle bits count only angular indices; norms are in fp32. Mo del L PPL base Uniform (3.25b) Best per-lay er ∆ PPL ∆ PPL bits Tin yLlama-1.1B 22 8.913 +0.0011 − 0 . 0022 3.34 Mistral-7B 32 5.844 +0.0018 +0 . 0002 3.31 SmolLM2-1.7B 24 8.930 +0.0071 − 0 . 0003 3.67 phi-1.5 24 28.63 +0.0245 0 . 0000 3.58 StableLM-2-1.6B 32 9.790 +0.0207 +0 . 0012 3.63 StarCo der2-3B 40 11.11 +0.0051 − 0 . 0007 3.45 OLMo-1B 32 14.82 +0.0136 +0 . 0063 3.28 Concen trated sensitivity (E4 optimal). Tin yLlama, Mistral-7B, and OLMo-1B concen trate their quan tization sensitivity in la y ers 0–3. F or Tin yLlama, the b ottlenec k is in the v alue cac he: b oosting n V from 64 to 256 for the first four lay ers pro duces lossless compression, while b oosting n K instead pro vides no improv emen t. F or Mistral-7B, the reverse holds: n K = 256 is required while n V = 128 is sufficient. F or OLMo-1B, only K precision matters, and n V = 64 is sufficient for all la yers. In all three cases, extending the bo ost b ey ond four la yers degrades quality . Broad sensitivit y (E16–E24 optimal). SmolLM2, StableLM-2, and StarCo der2 require b o ost- ing a large fraction of their la yers. SmolLM2 ac hieves lossless qualit y only at E20 (20 of 24 la yers), with E18 still sho wing ∆PPL = +0 . 0019 . StableLM-2 shows a sharp qualit y cliff: E23 giv es ∆PPL = +0 . 0042 , while E24 drops to +0 . 0012 . StarCo der2 exhibits non-monotonic scaling: E4 giv es +0 . 0020 , E8 gives +0 . 0017 , E12 gives +0 . 0024 (worse), and E16 drops to − 0 . 0007 (lossless). Selectiv e sensitivit y (phi-1.5). phi-1.5 requires a non-con tiguous configuration. A la yer-group analysis (Section 4.4) reveals that lay ers 8–15 exhibit negativ e transfer. The optimal configuration b oosts lay ers 0–7 and 16–23 while k eeping lay ers 8–15 at baseline, achieving ∆PPL = 0 . 0000 at 3.58 angle bits. Contiguous early-bo ost (E8) achiev es only +0 . 0052 at 3.42 bits, and extending to E16 adds the harmful mid-la yer range without improv emen t. 6 T able 3: Optimal p er-la yer configurations. n early K , n early V are the angle codeb o ok sizes for b o osted la yers; remaining lay ers use n K =128 , n V =64 . Mo del Bo osted lay ers n early K n early V T yp e Notes Tin yLlama 0–3 128 256 V-dom V=256 required; K=128 sufficien t Mistral-7B 0–3 256 128 K-dom K=256 required; E8 is w orse SmolLM2 0–19 256 128 K+V Lossless requires 20 of 24 la y ers phi-1.5 0–7, 16–23 256 128 K-sel Skip 8–15 (negative transfer) StableLM-2 0–23 256 128 K+V 24 of 32 lay ers; sharp cliff at E24 StarCo der2 0–15 256 128 K+V 16 of 40 lay ers; non-monotonic OLMo 0–3 256 64 K-dom E8 is 2.4 × w orse than E4 4.4 La y er Sensitivit y Analysis T o understand wh y some models exhibit non-con tiguous sensitivit y , w e conduct a la yer-group sen- sitivit y sw eep on phi-1.5. W e partition the 24 la yers into six groups of four (G0: la yers 0–3, G1: 4–7, . . . , G5: 20–23) and measure ∆PPL when b oosting exactly one group to n K = 256 , n V = 128 while keeping all others at the uniform baseline. T able 4: La yer-group sensitivit y for phi-1.5. Each ro w b oosts one 4-lay er group to K256V128 (3.33 angle bits) while the rest stays at K128V64 (3.25 bits). Uniform baseline ∆ PPL = +0.0245. Group La yers ∆ PPL Interpretation G0 0–3 +0.0122 Most b eneficial (50% reduction) G1 4–7 +0.0175 Second most beneficial G5 20–23 +0.0157 Third; unexpectedly helpful G2 8–11 +0.0192 Marginal improv emen t G4 16–19 +0.0210 Marginal impro vemen t G3 12–15 +0.0263 Negative transfer : worse than uniform T able 4 shows that group con tributions are not additiv e. G0 pro vides the largest single-group b enefit, reducing ∆PPL from 0.0245 to 0.0122. G3 (lay ers 12–15) is the only group that increases degradation ab o ve the uniform baseline, from 0.0245 to 0.0263. When combinations are tested: • E8 (G0+G1): ∆PPL = +0 . 0052 (synergistic; b etter than either group alone) • E8+G4 (lay ers 0–7, 16–19): +0 . 0035 (adding G4 to E8 helps) • E8+G5 (lay ers 0–7, 20–23): +0 . 0035 (adding G5 to E8 helps equally) • E8+G4+G5 (lay ers 0–7, 16–23): 0 . 0000 (lossless; combining b oth helps further) • E8+G2+G4+G5 (lay ers 0–11, 16–23): +0 . 0052 (adding G2 erases the G4+G5 benefit) The last result is particularly informativ e: adding G2 (lay ers 8–11) to the lossless E8+G4+G5 configuration restores the degradation to exactly the E8 flo or of 0.0052. Lay ers 8–15 as a whole in tro duce in terference that offsets gains from other groups. The optimal configuration for phi-1.5 is precisely the complement of this harmful mid-range: lay ers 0–7 and 16–23. 7 T able 5: Norm quan tization results. ∆ PPL relative to fp16 inference. “FP32” column repro duces the best p er-la yer angle-only results from T able 2. “norm8” applies 8-bit per-vector min-max quan- tization to all norms. “K8V4-log” uses 8-bit linear K norms and 4-bit log-space V norms. T otal bits includes angle bits, norm bits, and per-vector min-max ov erhead. Mo del d FP32 ∆ PPL norm8 ∆ PPL K8V4-log ∆ PPL K8V4-log bits Tin yLlama-1.1B 64 − 0.0022 +0.0011 +0.0104 ∼ 6.84 Mistral-7B 128 +0.0002 +0.0012 +0.0014 ∼ 6.56 SmolLM2-1.7B 64 − 0.0003 +0.0027 +0.0030 ∼ 7.67 phi-1.5 64 0.0000 − 0.0017 +0.0017 ∼ 7.58 StableLM-2-1.6B 64 +0.0012 +0.0021 +0.0123 ∼ 7.63 StarCo der2-3B 64 − 0.0007 − 0.0007 +0.0061 ∼ 7.45 OLMo-1B 64 +0.0063 +0.0118 +0.0344 ∼ 7.28 4.5 K vs V Sensitivit y The early-b oost exp erimen ts differentiate b et ween K-cac he and V-cache b ottlenec ks. On TinyLlama ( d = 64 , GQA 8:1), the bottleneck is in V: E4 with ( n K , n V ) = (128 , 256) giv es ∆PPL = − 0 . 0022 , while (256 , 128) giv es +0 . 0030 . On Mistral-7B ( d = 128 , GQA 4:1), the rev erse holds: (256 , 128) giv es +0 . 0002 while (128 , 256) giv es +0 . 0016 . On OLMo-1B ( d = 64 ), only K precision matters: (256 , 64) at ∆PPL = +0 . 0063 outp erforms (256 , 128) at +0 . 0072 , and n K = 512 mak es things worse ( +0 . 0118 ). Empirically , the pattern correlates with head dimension: mo dels with d = 64 tend to w ard either V-dominated (TinyLlama) or K-dominated (OLMo, phi-1.5) b ottlenecks, while d = 128 (Mistral) is K-dominated. This is consistent with the observ ation that larger head dimensions spread angular information more evenly across K and V, while smaller dimensions concentrate it. 4.6 Norm Quan tization Results T able 5 rep orts end-to-end results when norm quantization replaces fp32 norm storage. W e compare three configurations: fp32 norms (the angle-only reference from T able 2), 8-bit linear norms applied to b oth K and V (norm8), and asymmetric K8V4-log (8-bit linear K norms, 4-bit log-space V norms). The 8-bit norm configuration (norm8) adds minimal degradation on most models: fiv e of seven sho w | ∆PPL | ≤ 0 . 003 , and tw o (phi-1.5 and StarCo der2) actually improv e ov er fp32 norms. OLMo- 1B is the most sensitive, degrading from +0 . 0063 to +0 . 0118 . The K8V4-log configuration reveals a sharp asymmetry . V norms tolerate 4-bit log-space quan- tization well: the V-only con tribution to degradation is small across all mo dels. K norms, by con trast, are 10–20 × more sensitiv e. Reducing K norms to 4 bits (tested but not shown) produces catastrophic degradation on fiv e of seven models, confirming that K-cac he attention scores dep end on precise norm scaling. The K8V4-log compromise preserves K norm fidelit y at 8 bits while sa ving 2 bits p er V norm element through log-space 4-bit quantization. On Mistral-7B ( d = 128 ), K8V4-log achiev es ∆PPL = +0 . 0014 at 6.56 total bits p er elemen t. F or d = 64 mo dels, the higher per-vector o v erhead ( 64 /d = 1 . 0 vs 0 . 5 ) pushes total rates to 6.8–7.7 bits. The norm8 configuration provides a safer option at appro ximately 7.8 bits (for d = 128 ) or 8.3 bits (for d = 64 ) with consistently lo w er degradation. 8 T able 6: Comparison with calibration-based KV cac he quantizers. ∆ PPL is the rep orted p erplexit y degradation on the resp ectiv e ev aluation mo del. T urboAngle requires zero calibration data and no p er-c hannel statistics. Metho d T otal bits ∆ PPL Calibration Source CQ-2c8b [6] 4.00 +0.03 (Mistral) Y es NeurIPS 2024 KV Quant-4b-1% [7] 4.32 +0.01 (LLaMA-7B) Y es NeurIPS 2024 A QUA-KV 3b [3] ∼ 3.0 +0.03 (Llama-3.1-8B) Y es ICML 2025 T urb oAngle K8V4-log 6.56 +0.0014 (Mistral) No This work T urb oAngle norm8 7.81 +0.0012 (Mistral) No This w ork 4.7 Comp etitiv e Comparison T able 6 places T urboAngle in con text with recen t calibration-based KV cac he quan tizers. T urboAngle op erates at a fundamen tally differen t p oin t on the rate-qualit y tradeoff. A t 6.56 total bits, K8V4-log uses 50–65% more bits than the calibration-based metho ds but ac hiev es 7–21 × lo wer p erplexit y degradation ( + 0.0014 vs + 0.01 to + 0.03). The norm8 configuration at 7.81 bits ac hieves ev en b etter qualit y ( + 0.0012). Both T urb oAngle configurations require zero calibration data, no p er-channel statistics, and no model-sp ecific tuning of the quantizer itself (only the la y er- b oost sc hedule is model-sp ecific). The comparison is not apples-to-apples: different ev aluation mo dels and datasets are used across metho ds. The bit rates also differ substantially . The key takea w ay is that calibration-free angular quan tization can match or exceed the qualit y of calibration-based metho ds by sp ending mo derately more bits, and the quality gap at matc hed bit rates would require future w ork to establish. F or deplo yment scenarios where calibration is impractical (e.g., serving many mo del v arian ts, frequent mo del up dates, or edge deplo yment), T urb oAngle offers a comp etitiv e alternative at higher bit rates. 4.8 Non-Monotone Beha vior T w o forms of non-monotonic behavior app ear in our experiments. The first, rep orted in prior w ork on T urb oAngle, occurs at p o wer-of-2 bin counts: on TinyLlama, n = 64 ( ∆PPL = +0 . 0176 ) is w orse than b oth n = 56 ( +0 . 0108 ) and n = 128 ( +0 . 0036 ). W e conjecture this arises from algebraic aliasing b et w een the quantization grid and the Hadamard butterfly structure, where n = 2 k causes quan tization boundaries to align with the quadrant structure pro duced by butterfly stages, pro ducing coheren t rather than indep enden t errors. The second form is new: non-monotonic n early scaling. On OLMo-1B, E4 gives ∆PPL = +0 . 0063 while E8 giv es +0 . 0154 (2.4 × wo rse). On StarCo der2, E12 ( +0 . 0024 ) is worse than E8 ( +0 . 0017 ), but E16 ( − 0 . 0007 ) is the b est. These patterns indicate that b o osting some intermediate la yers in tro duces more quan tization error than it remo ves, lik ely b ecause those la y ers hav e in ternal repre- sen tations that are less robust to angular p erturbation. 5 Related W ork KV cac he quantization metho ds differ along three axes: whether they operate on raw activ ations or a transformed domain, what quantizer structure they use, and whether they require calibration data. KIVI [10] applies p er-c hannel asymmetric 2-bit quan tization directly to raw KV activ ations, handling c hannel-dep enden t distributions through p er-channel parameters. KVQuan t [7] extends 9 this with p er-v ector quan tization and explicit outlier handling for long-context inference. Both work in the original co ordinate system and rely on calibration. T urboAngle eliminates calibration entirely b y transforming to a domain where the distribution is kno wn a priori . CQ [6] couples key and v alue quantization at 1 bit per channel, lev eraging the observ ation that K and V tensors within the same lay er share structural correlations. A t 4.0 total bits on Mistral-7B, CQ ac hieves ∆PPL ≈ +0 . 03 ; T urb oAngle at 6.56 bits achiev es 21 × lo wer degradation without an y calibration or coupling assumptions. A QUA-KV [3] pushes KV cache compression to appro ximately 3 bits through adaptive quan- tization with learned per-channel scales, ac hieving ∆PPL ≈ +0 . 03 on Llama-3.1-8B. The method requires calibration data and p er-model tuning of channel-lev el parameters. T urboQuant [13] in tro duced the FWHT with random diagonal rotation as prepro cessing b efore scalar quantization, showing that the transform reduces outliers and concentrates energy . T urb oAn- gle replaces scalar quan tization with angular quantization, targeting the distributional prop ert y (an- gle uniformity) rather than the secondary effect (reduced kurtosis). The difference is fundamen tal: T urboQuant applies a generic quan tizer to appro ximately Gaussian transformed co ordinates, while T urboAngle applies the prov ably optimal quan tizer for the exact angular distribution. P olarQuant [5] also quan tizes angular components, and its stronger v ariant applies random preconditioning. Ho wev er, the p ost-rotation angular distribution in P olarQuant is concen trated rather than uniform, requiring k -means co debo oks. T urb oAngle uses the same class of random rotation but exploits uniformit y directly , replacing learned co debo oks with a fixed grid. QJL [14] applies a Johnson-Lindenstrauss random pro jection follo wed by 1-bit sign quantization, trading extreme compression for higher approximation error. The pro jection is spiritually similar to T urb oAngle’s rotation in that b oth randomize the co ordinate system. Our p er-lay er MixedKV approac h relates to DiffKV-style differentiated precision [10], where K and V cac hes receive differen t bit widths based on their sensitivit y . W e extend this principle to p er- la yer granularit y with indep enden t K/V codeb o ok sizing, and pro vide systematic evidence across sev en models for when and why asymmetric allo cation helps. 6 Conclusion T urboAngle demonstrates that the FWHT’s angular uniformit y prop ert y enables near-lossless KV cac he compression. Per-la yer early-b o ost, whic h allocates higher angular precision to mo del-sp ecific critical la y ers, ac hieves lossless compression on four of sev en tested mo dels and near-lossless qualit y on six of seven, at 3.28 to 3.67 angle bits p er elemen t. Adding norm quan tization with asymmetric K/V allo cation (8-bit linear K norms, 4-bit log-space V norms) yields end-to-end rates of 6.56 total bits on Mistral-7B at ∆PPL = +0 . 0014 and 7.3–7.7 total bits on d = 64 mo dels, all without calibration data. The norm quan tization exp erimen ts rev eal a previously unrep orted asymmetry: K-cac he norms are 10–20 × more sensitive to quan tization error than V-cache norms. Reducing K norms below 8 bits causes catastrophic degradation, while V norms tolerate 4-bit log-space quantization with negligible qualit y loss. This K/V norm asymmetry parallels the K/V angle sensitivity discov ered in the early-bo ost exp erimen ts, reinforcing that k ey and v alue caches play fundamentally differen t roles in attention and should be quan tized asymmetrically . Three practical insigh ts emerge from this w ork. First, early lay ers (0–3 or 0–7) are universally the most sensitive to quan tization. Second, K vs V sensitivit y correlates with head dimension and attention structure, providing a heuristic for initial configuration. Third, a small num ber of ev aluation runs (3–5) suffices to find near-optimal per-lay er configurations for new mo dels. 10 Limitations. W e ev aluate p erplexity on WikiT ext-2 only; downstream task accuracy and long- con text b enc hmarks (e.g., LongBench) remain un tested. Run time o verhead of the FWHT en- co de/decode path has not b een measured under realistic batch and sequence sizes. The uniformity argumen t is asymptotic in d ; finite-dimension errors may affect models with v ery small head dimen- sions ( d < 32 ). Confidence in terv als ov er m ultiple seeds for the random diagonal D are not rep orted; ∆PPL differences below approximately 0 . 001 should be in terpreted with appropriate caution. The comp etitiv e comparison (T able 6) uses num b ers from differen t ev aluation setups (different mo dels, datasets, and sequence lengths), so the qualit y ratios are indicativ e rather than definitive. References [1] Loubna Ben Allal, An ton Lozhk ov, Elie Bakouc h, Gabriel Martín Blázquez, Guilherme Penedo, Lewis T unstall, Andrés Marafioti, Hynek Kydlíček, et al. SmolLM2: When smol goes big – data-cen tric training of a small language mo del. arXiv pr eprint arXiv:2502.02737 , 2025. [2] Marco Bellagente, Jonathan T ow, Dakota Mahan, Duy Ph ung, Maksym Zhura vinskyi, Reshinth A dithy an, James Baicoian u, Ben Bro oks, Nathan Coop er, Ashish Datta, et al. Stable LM 2 1.6B technical report. arXiv pr eprint arXiv:2402.17834 , 2024. [3] Hao jie Duanmu, Zhihang Zhuo, Xiuhan Jia, Xijie Li, Ao Sun, F angc heng Y e, Yib o W ang, Shiyu Liu, and Hao Zhang. AQUA-KV: Adaptiv e quan tization for atten tion k ey-v alue cac he. arXiv pr eprint arXiv:2501.19392 , 2025. ICML 2025. [4] Dirk Gro enev eld, Iz Beltagy , Pete W alsh, Akshita Bhagia, Ro dney Kinney , Oyvind T afjord, Anan ya Harsh Jha, Hamish Ivison, Ian Magn usson, Yizhong W ang, et al. OLMo: Accelerating the science of language mo dels. arXiv pr eprint arXiv:2402.00838 , 2024. [5] Insu Han, Praneeth Kacham, Amin Karbasi, V ahab Mirrokni, and Amir Zandieh. P olarQuant: Quan tizing KV cac hes with p olar transformation. arXiv pr eprint arXiv:2502.02617 , 2025. [6] Coleman Ho op er, Seho on Kim, Hiv a Mohammadzadeh, Amir Gholami, Kurt Keutzer, Mic hael W. Mahoney , and Y akun Sophia Shao. KV Cache is 1 Bit Per Channel: Efficien t large language mo del inference with coupled quantization. In A dvanc es in Neur al Information Pr o c essing Systems , 2024. [7] Coleman Hoop er, Sehoon Kim, Hiv a Mohammadzadeh, Mic hael W. Mahoney , Y akun Sophia Shao, Kurt Keutzer, and Amir Gholami. KVQuan t: T ow ards 10 million context length LLM inference with KV cache quantization. In A dvanc es in Neur al Information Pr o c essing Systems , 2024. [8] Alb ert Q. Jiang, Alexandre Sablayrolles, Arthur Mensc h, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard La v aud, Marie-Anne Lac haux, Pierre Sto c k, T ev en Le Scao, Thibaut La vril, Thomas W ang, Timothée Lacroix, and William El Sa yed. Mistral 7b. arXiv pr eprint arXiv:2310.06825 , 2023. [9] Y uanzhi Li, Sébastien Bub ec k, Ronen Eldan, Allie Del Giorno, Suriya Gunasek ar, and Yin T at Lee. T extbo oks are all y ou need I I: phi-1.5 technical rep ort. arXiv pr eprint arXiv:2309.05463 , 2023. 11 [10] Zirui Liu, Jiayi Y uan, Hongy e Jin, Shao c hen Zhong, Zhaozhuo Xu, Vladimir Brav erman, Beidi Chen, and Xia Hu. KIVI: A tuning-free asymmetric 2bit quantization for KV cac he. In International Confer enc e on Machine L e arning , 2024. [11] An ton Lozhko v, Ra ymond Li, Loubna Ben Allal, F ederico Cassano, Jo el Lam y-P oirier, Noua- mane T azi, A o T ang, Dmytro Pykhtar, Jia wei Liu, Y uxiang W ei, et al. StarCo der 2 and The Stac k v2: The next generation. arXiv pr eprint arXiv:2402.19173 , 2024. [12] Stephen Merity , Caiming Xiong, James Bradbury , and Ric hard So c her. Poin ter sentinel mixture mo dels. arXiv pr eprint arXiv:1609.07843 , 2016. [13] Amir Zandieh, Ma jid Daliri, Ma jid Hadian, and V ahab Mirrokni. T urboQuant: Online vector quan tization with near-optimal distortion rate. arXiv pr eprint arXiv:2504.19874 , 2025. [14] Amir Zandieh, Ma jid Daliri, and Insu Han. QJL: 1-bit quantized JL transform for KV cache quan tization with zero ov erhead. In Pr o c e e dings of the AAAI Confer enc e on A rtificial Intel li- genc e , 2025. [15] P eiyuan Zhang, Guangtao Zeng, Tianduo W ang, and W ei Lu. Tin yLlama: An op en-source small language mo del. arXiv pr eprint arXiv:2401.02385 , 2024. 12
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment