FlowRL: A Taxonomy and Modular Framework for Reinforcement Learning with Diffusion Policies
Thanks to their remarkable flexibility, diffusion models and flow models have emerged as promising candidates for policy representation. However, efficient reinforcement learning (RL) upon these policies remains a challenge due to the lack of explici…
Authors: Chenxiao Gao, Edward Chen, Tianyi Chen
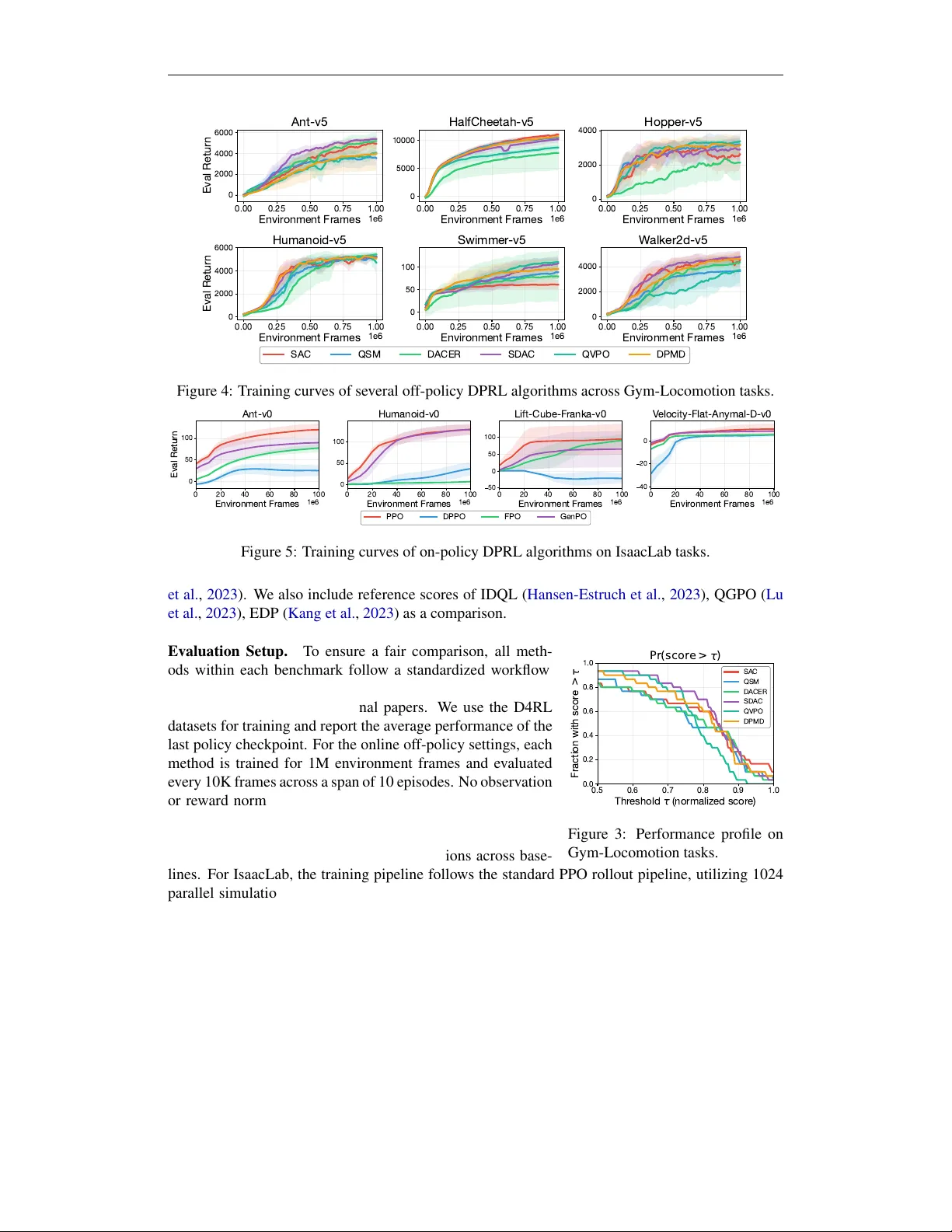
F L OW R L : A T axonomy and Modular Framework f or Reinf orcement Lear ning with Diffusion Policies Chenxiao Gao 1 , Edward Chen 1 , Tianyi Chen 1 , Bo Dai 1 {cgao,echen324,tchen667,bodai@gatech.edu} 1 Georgia Institute of T echnology Abstract Thanks to their remarkable flexibility , diffusion models and flo w models hav e emerged as promising candidates for policy representation. Howe ver , efficient reinforcement learning (RL) upon these policies remains a challenge due to the lack of explicit log - probabilities for vanilla policy gradient estimators. While numerous attempts have been proposed to address this, the field lacks a unified perspecti ve to reconcile these seemingly disparate methods, thus hampering ongoing dev elopment. In this paper , we bridge this gap by introducing a comprehensiv e taxonomy for RL algorithms with diffusion/flo w policies. T o support reproducibility and agile prototyping, we intro- duce a modular, J AX-based open-source codebase that le verages JIT -compilation for high-throughput training. Finally , we provide systematic and standardized benchmarks across Gym-Locomotion, DeepMind Control Suite, and IsaacLab, of fering a rigorous side-by-side comparison of diffusion-based methods and guidance for practitioners to choose proper algorithms based on the application. Our work establishes a clear foun- dation for understanding and algorithm design, a high-efficiency toolkit for future re- search in the field, and an algorithmic guideline for practitioners in generative models and robotics. Our code is av ailable at https://github.com/typo verflow/flo w-rl . 1 Introduction Deep Reinforcement Learning (RL) has traditionally relied on simple distributions ( Haarnoja et al. , 2018 ; Fujimoto et al. , 2018 ; Christodoulou , 2019 ), such as the diagonal Gaussian distribution or Dirac delta distribution for policy parameterization. The appeal of such simple distributions lies in their mathematical con venience: they permit easy log -probability computation, rapid sampling, and tractable reparameterization, making them compatible with various optimization paradigms. Despite these computational benefits, simple distributions often fail to capture complex and multi-modal action distributions encountered in high-dimensional control ( W ang et al. , 2022 ; Hansen-Estruch et al. , 2023 ; Chen et al. , 2022 ). This limitation becomes increasingly evident in recent work, when more ef forts are dedicated to training generalist policies that are capable of capturing di verse human behaviors ( Black et al. , 2024 ; Kim et al. , 2024 ). Recently , diffusion models (DMs) ( Ho et al. , 2020 ; Song et al. , 2020 ) and flow models (FMs) ( Al- bergo et al. , 2025 ; Lipman et al. , 2022 ) hav e emerged as powerful alternati ves for policy represen- tation ( W ang et al. , 2022 ; Chen et al. , 2022 ). The y both employ an iterativ e sampling process and therefore offer greater flexibility in distribution modeling. Howe ver , integrating DMs and FMs into the RL optimization loop is non-trivial. T raditional RL workflows rely on policy gradient ( Schulman et al. , 2017 ; 2015 ) or the reparameterization trick ( Fujimoto et al. , 2018 ), both of which are noto- riously difficult for DMs and FMs ( Song et al. , 2020 ). While in RL, the target action distribution is typically defined implicitly through the utilities measured by value functions or return functions 1 ( Haarnoja et al. , 2017 ; Peng et al. , 2019 ), from which direct samples are not av ailable ( Pan et al. , 2024 ), making vanilla dif fusion/flow model training losses intractable. T o address these challenges, recent literature has proposed various solutions for diffusion policy- based Reinforcement Learning (DPRL). Existing methods span disparate scenarios, including of- fline ( W ang et al. , 2022 ; Fang et al. , 2024 ; Gao et al. , 2025 ), online ( Psenka et al. , 2024 ; W ang et al. , 2024 ; Ma et al. , 2025 ), and offline-to-online RL ( Huang et al. , 2025 ). Besides, the y often in volve confounding factors such as differences in noise schedules ( Chen , 2023 ), network architec- tures ( Hansen-Estruch et al. , 2023 ; Celik et al. , 2025 ; Nauman et al. , 2024 ; Lee et al. , 2024 ), and ev aluation protocols. These discrepancies make it difficult to isolate the true driv ers of the algorith- mic performance. Therefore, in this paper , we aim to systematize the landscape of DPRL, providing a unified perspec- tiv e to study these methods. Specifically , our contributions are threefold: 1) W e summarize and categorize modern DPRL algorithms based on their guidance mechanism and choice of reference policy . This taxonomy allows us to study these methods from first principles and expose the underlying mathematical relationships between them. 2) Le veraging JIT -compilation provided by J AX ( Bradbury et al. , 2018 ) and its ecosystem ( Deep- Mind et al. , 2020 ; Heek et al. , 2024 ), we provide a modular , open-source codebase for representati ve DPRL algorithms with high-throughput training and inference. Furthermore, the library’ s modular design allows researchers to swap en vironments and algorithmic components with minimal effort, significantly reducing the migration cost and barrier for RL research. 3) Based on our systematic taxonomy and high-performance algorithm library , we conduct a large- scale comparativ e study of DPRL algorithms across three di verse continuous control suites: Gym- Locomotion, DeepMind Control (DMC), and IsaacLab . Our results establish rigorous baselines and provide practitioners with actionable insights tailored to specific application requirements. Comparison to existing surveys. Sev eral surveys examine dif fusion models in RL from different angles. Zhu et al. ( 2023 ) and Xu et al. ( 2025 ) provide broad taxonomies of dif fusion roles (planners, synthesizers, policies) but lack a deep div e into the underlying policy optimization process. W olf et al. ( 2025 ) and Li et al. ( 2025 ) shift the focus on specific applications like robotics and broader decision-making tasks. The closest work to ours is Choi et al. ( 2026 ), which revie ws online dif fusion policy algorithms. Howe ver , their cate gorization focuses only on guidance mechanisms, whereas we additionally in vestigate DPRL methods with different regularization objectives, thereby providing a more comprehensiv e overvie w of DPRL across different settings. 2 Background Reinfor cement Learning is based on the frame work of Markov Decision Process (MDP) ⟨S , A , T , R, γ , d 0 ⟩ ( Sutton et al. , 1998 ), where S is the state space, A is the action space, T ( s ′ | s, a ) denotes the transition function, R ( s, a ) is a bounded reward function, γ is the discount factor and d 0 ( s 0 ) denotes the initial state distribution. The agent aims to learn a policy π : S → ∆( A ) to maximize the expected discounted return E π [ P ∞ t =0 γ t R ( s t , a t )] . In online RL, the agent can in- teract with the en vironment to gather experiences for policy optimization, while in offline RL, the agent is provided with an offline dataset D = { ( s t , a t , s t +1 , r t ) } , where s t +1 ∼ T ( ·| s t , a t ) and r t = R ( s t , a t ) ∈ R . W e define the value functions as the expected reward of executing a certain policy π : Q π ( s, a ) = E π [ P ∞ t =0 γ t r t | s 0 = s, a 0 = a ] , V π ( s ) = E π [ P ∞ t =0 γ t r t | s 0 = s ] , (1) which satisfy the Bellman equation Q π ( s, a ) = R ( s, a ) + γ E s ′ ∼ T [ V ( s ′ )] . (2) 2 W ith v alue functions defined, we can define the policy optimization objective ( W u et al. , 2019 ; Geist et al. , 2019 ): max π ∈ Π E π [ Q π ( s, a )] − λD KL ( π ∥ ν ) , (3) where D KL ( π ∥ ν ) is introduced to shape the beha vior of the final polic y . The optimal solution to ( 3 ) can be obtained by the KKT conditions, i.e. , π ∗ ( a | s ) ∝ ν ( a | s ) exp( Q ( s, a ) /λ ) . (4) Existing RL algorithms can be roughly categorized based on how the gradient is com- puted: 1), P olicy Gradient methods ( Sutton et al. , 1999 ; Schulman et al. , 2015 ; 2017 ), which uses the r einfor ce trick to derive the gradient of ( 3 ) as ∇ θ ( E π θ [ Q ( s, a )] − λD ( π θ ∥ ν )) = E π θ [ Q ( s, a ) ∇ θ log π θ ( a | s )] − λ ∇ θ D ( π θ ∥ ν ) , and 2) Reparameterization-based methods ( Fujimoto et al. , 2018 ; Haarnoja et al. , 2018 ), which keeps the gradients through sampling and computes the gradients as E π θ [ ∇ a θ Q ( s, a θ ) ∇ θ a θ ] − λ ∇ θ D ( π θ ∥ ν ) . Diffusion Models (DMs) and Flow Models (FMs) approximate data distributions by gradually perturbing clean data x 0 ∼ q 0 = p data with isotropic Gaussian noise according to a forward process ( Song et al. , 2020 ; Albergo et al. , 2025 ): x ( t ) = α t x (0) + σ t ϵ, ϵ ∼ N (0 , I ) , (5) which emits the condition distribution q t | 0 ( x ( t ) | x (0) ) = N ( x ( t ) ; α t x (0) , σ 2 t ) . It then learns the score function s θ ( x ( t ) , t ) or velocity function v θ ( x ( t ) , t ) to reverse this process to sample from the target distribution p data . Since DMs and FMs mainly differ in the noise schedules ( α t , σ t ) and their network predictions s t and v t can be reparameterized interchangeably ( Li & He , 2025 ; Lu & Song , 2024 ), we will discuss with DMs for simplicity , but we emphasize the proposed taxonomy can also be applicable to FMs. The target for the score function is to match the mar ginal score field, s t ( x ( t ) ) = E x (0) ∼ p 0 | t ( ·| x ( t ) ) h s t | 0 x ( t ) | x (0) i , (6) where p 0 | t is the posterior distribution defined via Bayes’ theorem as p 0 | t ( x (0) | x ( t ) ) = q t | 0 ( x ( t ) | x (0) ) q 0 ( x (0) ) /q t ( x ( t ) ) , and s t | 0 ( x ( t ) | x (0) ) = ∇ x ( t ) log p t | 0 ( x ( t ) | x (0) ) = − ( x ( t ) − α t x (0) ) /σ 2 t . (7) Howe ver , the posterior is not accessible. In practice, we employ conditional scor e matching , which also yields the same target score: L ( θ ) = E x (0) ,x ( t ) h ∥ s θ ( x ( t ) , t ) − s t | 0 ( x ( t ) , x (0) ) ∥ 2 i . (8) After training, sampling is done by solving a stochastic or ordinary differential equation (SDE/ODE). For e xample, d x ( t ) = ˙ α t α t x ( t ) − σ 2 t ˙ σ t σ t − ˙ α t α t s θ ( x ( t ) , t ) − η s θ ( x ( t ) , t ) d t + p 2 η d ¯ w , (9) where η ⩾ 0 controls the stochasticity and ¯ w is the Bro wnian motion in reverse time ( Albergo et al. , 2025 ; Albergo & V anden-Eijnden , 2022 ). Diffusion Policies ( Chi et al. , 2025 ; W ang et al. , 2022 ; Kang et al. , 2023 ; Ren et al. , 2025 ) have been dev eloped by exploiting conditional diffusion models for generating action a conditioned on a giv en state s . In this paper , we use π t to denote the distrib ution of intermediate samples at dif fusion time t and k to denote the environment time. Under this terminology , a ( t ) k denotes the intermediate action sample at s k and diffusion step t . 3 3 T axonomy of RL with Diffusion Policies At its core, RL optimizes the regularized objectiv e iterativ ely defined in ( 3 ), whose optimal policy takes the form π ( a | s ) ∝ ν ( a | s ) exp( Q ( s, a )) , where ν is a reference policy and Q ( s, a ) is the v alue function from policy ev aluation. The choice of ν ( a | s ) determines the algorithm’ s behavior across different learning paradigms: • Maximum Entropy RL : When ν = Unif ( A ) , the KL div ergence reduces to the policy entropy up to some constant, which is a standard approach in online RL to encourage exploration; • P olicy Mirr or Descent : When ν = π k − 1 (the policy checkpoint from the last iteration), this ensures safe exploitation by constraining updates to the proximity of the current polic y; • Behavior Regularized RL : When ν = π D (the dataset’ s behavior policy), this restricts the policy to the support of the offline data D , ensuring stable optimization in offline settings. Consequently , implementing RL for diffusion policies requires addressing two concurrent chal- lenges: 1. How to effectively guide diffusion policy optimization using the value function Q ( s, a ) , and 2. How to enforce pr oximity to the chosen refer ence policy ν . Therefore, we examine e xisting literature through the lens of guidance method and r efer ence policy , respectiv ely . T able 1 provides a cate gorization of existing DPRL methods based on our taxonomy . T able 1: Summarization of existing DPRL algorithms, based on their guidance mechanism and reference policy . Guidance Method Reference P olicy Algorithm Name BoN Sampling π D IDQL ( Hansen-Estruch et al. , 2023 ), SfBC ( Chen et al. , 2022 ) Q-value Guidance Unif ( A ) QSM ( Psenka et al. , 2024 ), iDEM ( Akhound-Sadegh et al. , 2024 ), DPS ( Jain et al. , 2024 ) π D D AC ( F ang et al. , 2024 ), QGPO ( Lu et al. , 2023 ), Diffusion-DICE ( Mao et al. , 2024 ) W eighted Matching Unif ( A ) SD AC ( Ma et al. , 2025 ), MaxEntDP ( Dong et al. , 2025 ), QVPO ( Ding et al. , 2024 ) π k − 1 DPMD ( Ma et al. , 2025 ), FPMD ( Chen et al. , 2025 ) π D QIPO ( Zhang et al. , 2024 ) Reparameterization Unif ( A ) D ACER ( W ang et al. , 2024 ), DA CERv2 ( W ang et al. , 2025 ), DIME ( Celik et al. , 2025 ) π D D-QL ( W ang et al. , 2022 ), BDPO ( Gao et al. , 2025 ), EDP ( Kang et al. , 2023 ), FQL ( Park et al. , 2025 ) Policy Gradient π k − 1 FPO ( McAllister et al. , 2025 ), GenPO ( Ding et al. , 2025 ), DPPO ( Ren et al. , 2025 ) 3.1 Best-of-N (BoN) Sampling The simplest approach is pretraining a dif fusion polic y to approximate the reference distribution ν ( a | s ) and refining it at inference time via Best-of-N sampling: a ∗ = argmax a i ∈{ a 1 ,...,a N } Q ( s, a i ) , where a i ∼ ν ( ·| s ) . (10) This approach was first proposed in offline settings by Chen et al. ( 2022 ) and Hansen-Estruch et al. ( 2023 ), where a diffusion model is trained to represent the offline data distribution and actions are subsequently refined using a learned critic Q ( s, a ) . T oday , BoN sampling is increasingly used in the ev aluation of modern DPRL methods. Because dif fusion policies exhibit superior coverage across the action space, applying BoN sampling at inference enables the agent to select the highest- valued actions within the distribution, effecti vely trading additional inference-time computation for improv ed performance. 4 3.2 Q -v alue Guidance Drawing inspiration from classifier guidance ( Dhariwal & Nichol , 2021 ), sampling from a Q - weighted distribution π ∗ ( a | s ) ∝ ν ( a | s ) exp( Q ( s, a ) /λ ) can be achiev ed by injecting action gradi- ents ∇ a Q ( s, a ) into the sampling process. This is due to the following score function relationship: ∇ a log π ∗ ( a | s ) = ∇ a log ν ( a | s ) + ∇ a Q ( s, a ) /λ. (11) Some algorithms utilize an explicit policy optimization step to internalize this guidance, while others inject the action gradient directly during sampling. For example, in the offline RL setting, D A C ( Fang et al. , 2024 ) performs dif fusion matching ov er offline dataset samples combined with the action gradient; in online RL, where ν = Unif ( A ) , QSM ( Psenka et al. , 2024 ) directly regresses the score network to wards the action gradients. Unfortunately , directly using the action gradient is biased due to imprecise score mixing at interme- diate diffusion steps. The precise score of diffusion step t is giv en by ∇ a ( t ) log π ∗ t ( a ( t ) | s ) = ∇ a ( t ) log ν t ( a | s ) + ∇ a ( t ) η log E a (0) ∼ p 0 | t [exp( Q ( s, a (0) ) /η )] | {z } Q t ( s,a ( t ) ) . (12) QGPO ( Lu et al. , 2023 ) first formalizes this mismatch in offline scenarios where ν = π D , and introduces a contrasti ve learning objecti ve to construct the intermediate Q t -functions. Similarly , Diffusion-DICE ( Mao et al. , 2024 ) leverages Gumbel regression to estimate the intermediate Q t - functions. In online scenarios where π ∗ ( a | s ) ∝ exp( Q ( s, a )) , rather than learning the Q t -function explicitly , iDEM ( Akhound-Sadegh et al. , 2024 ) and DPS ( Jain et al. , 2024 ) propose an importance- sampling approach to estimate the intermediate scores: ∇ a ( t ) log π ∗ t ( a ( t ) | s ) = E ˆ a (0) ∼ p t | 0 [exp( Q ( s, ˆ a (0) )) ∇ a ( t ) Q ( s, ˆ a (0) )] E ˆ a (0) ∼ p t | 0 [exp( Q ( s, ˆ a (0) ))] (13) where the RHS can be approximated by Monte-Carlo samples and reweighting. The resulting smoothing of the action gradients helps alleviate the slo w mixing issue in Langevin-style sampling. 3.3 Reparameterization Similar to reparameterization-based methods like SA C ( Haarnoja et al. , 2018 ) and TD3 ( Fujimoto et al. , 2018 ), recent work explores reparameterizing the dif fusion sampling process, and optimizing the network by maximizing Q -values of the generated samples. A common approach is Backprop- agation Through T ime (BPTT) ( W ang et al. , 2022 ; 2024 ; 2025 ; Celik et al. , 2025 ), which computes and backpropagates the gradients across the entire sampling chain: max θ E a (0: T ) ∼ π θ [ Q ( s, a (0) θ )] . (14) Howe ver , BPTT incurs significant memory and computational ov erhead due to the need to preserve the computational graph across all diffusion timesteps. T o mitigate this, several methods aim to amortize or bypass the sampling cost. For example, BDPO ( Gao et al. , 2025 ) constructs step-lev el value functions Q ( s, a, t ) for each diffusion step t , and optimizes only for single-step transitions max θ E a ( t ) ∼ π t | t +1 ,θ [ Q ( s, a ( t ) θ , t )] . EDP ( Kang et al. , 2023 ) lev erages the posterior mean estimate ˆ a (0) via the identity ˆ a (0) = E a (0) ∼ p 0 | t [ a (0) ] ≈ ( a ( t ) + σ 2 t ϵ θ ) /α t and turns to optimize an efficient yet biased objectiv e: max θ E a ( t ) , ˆ a (0) θ =( a ( t ) + σ 2 t ϵ θ ) /α t [ Q ( s, ˆ a (0) θ )] . (15) Another line of research, exemplified by FQL ( Park et al. , 2025 ), employs distillation to compress multi-step diffusion into single-step models, enabling ef ficient reparameterization in a single pass. 5 Nev ertheless, a fundamental challenge for this guidance style is how to ensure the policy respects the regularization. Since the log -probability of actions is difficult to compute, these methods typi- cally require additional loss terms for regularization. One approach is to sample from the reference distribution and apply a standard dif fusion loss on these samples to anchor the policy . For example, D-QL ( W ang et al. , 2022 ) applies a score matching objectiv e on samples from the offline dataset D to prev ent the dif fusion policy from deviating. Alternatively , BDPO formulates the KL constraint across the entire diffusion path and enforces the constraint at every denoising step by decomposing the pathwise KL. Similarly , DIME ( Celik et al. , 2025 ) derives a tractable lower bound for action entropy , which enables optimizing the dif fusion policy with the maximum entropy frame work. 3.4 W eighted Matching W eighted matching methods optimize diffusion policies by reframing policy improvement as a weighted supervised learning task. These methods reweight the diffusion training objectiv e using functions deri ved from the Q -function or advantage function to bias the learned polic y toward high- value actions. Zhang et al. ( 2024 ) and Ma et al. ( 2025 ) demonstrate that the weighted score/flow matching objectiv e yields an optimal policy that exactly matches the closed-form expression in ( 4 ), providing formal guarantees for polic y improv ement. In its general form, the weighted matching objectiv e is defined as: min θ E a (0) ,a ( t ) ∼ ˜ p 0 ,t exp Q ( s, a (0) ) λ s θ a ( t ) ; s, t − s t | 0 a ( t ) | a (0) 2 , (16) where ˜ p 0 ,t represents a proposal distribution for the coupling ( a (0) , a ( t ) ) , and the choice of this distribution varies by setting. In of fline RL where ν = π D , QIPO ( Zhang et al. , 2024 ) proves that sampling a (0) ∼ D , a ( t ) ∼ q t | 0 recov ers the optimal policy ( 4 ). For mirror descent where ν = π k − 1 , methods such as DPMD ( Ma et al. , 2025 ) and FPMD ( Chen et al. , 2025 ) sample a (0) ∼ π k − 1 and a ( t ) ∼ q t | 0 , which also recovers the optimal policy in ( 4 ). In online RL, QVPO ( Ding et al. , 2024 ) samples a (0) from a mixture of the uniform distribution and the last policy checkpoint; while SD AC ( Ma et al. , 2025 ) and MaxEntDP ( Dong et al. , 2025 ) concurrently propose re verse sampling , where a (0) is drawn by re versing the forward perturbation kernel q t | 0 giv en a ( t ) . 3.5 P olicy Gradient Policy gradient methods optimize the policy by estimating the gradients of the objectiv e in ( 3 ) via the policy gradient theorem. A prominent example is Proximal Policy Optimization (PPO) ( Schulman et al. , 2017 ), which stabilizes training by applying proximal regularization relative to the previous iteration’ s policy , π k − 1 . The training objecti ve is max θ E a ∼ π k − 1 h min r ( θ ) ˆ A, clip r ( θ ) , 1 − ϵ clip , 1 + ϵ clip ˆ A i , (17) where ϵ clip is a clipping threshold to av oid large updates and r ( θ ) = π θ ( a | s ) π k − 1 ( a | s ) is the policy ratio. The primary obstacle in applying policy gradient methods to diffusion policies is that computing the ratio r ( θ ) requires the exact log-likelihood log π ( a | s ) , which is intractable due to the iterative generation process. By discretizing the generative SDE, DPPO ( Ren et al. , 2025 ) treats the denoising process as a Markov Decision Process (MDP) where each transition step is tractable. This allows extending PPO directly to the denoising steps. GenPO ( Ding et al. , 2025 ) constructs an inv ertible diffusion model by introducing dummy actions and uses the change-of-variables theorem to compute the action likelihood. Howe ver , this is computationally expensi ve. Finally , FPO ( McAllister et al. , 2025 ) employs the conditional flow matching (CFM) loss as an approximation of the evidence lower bound (ELBO), and estimates the policy ratio as: ˆ r FPO ( θ ) = exp ˆ L CFM ,θ k − 1 ( a ) − ˆ L CFM ,θ ( a ) , (18) 6 (1) Network Architectures (2) Mo dels MLP SimBa BroNet Diffusion/Flow ·DDPM ·EDM ·CNF ·ALD … Actor Critic ·DMs/FMs ·Scalar ·Gaussian ·Dist. (3) Algorithms On - Policy Off - Policy Offline ·DPPO ·FPO … ·SDAC ·DACER … ·DAC ·D - QL … (4) Workflow Hydra - based Config Multi - backend Logging Benchmarks Checkpointing Figure 1: The ov erview of F L O W R L . where the CFM loss is estimated via Monte Carlo samples: ˆ L CFM ,θ ( a ) = 1 N N X i =1 s θ a ( t ) , t − s t | 0 a ( t ) , a (0) 2 . (19) 4 Design of F L OW R L 4.1 Design Principles T o support the large-scale comparati ve study and facilitate future research, our codebase, F L O W R L, is designed according to the following principles: Modularity and Composability . The library decouples RL algorithms into orthogonal, reusable components, such as neural network architectures, actor/critic variants, generative models (flow and diffusion), and training infrastructure. Each component adheres to a shared interface, allo wing researchers to combine them flexibly . Computational Efficiency . F L OW R L is built around J AX and its ecosystem. Since diffusion mod- els require multiple iterations to sample a single action, J AX’ s Just-In-Time compilation provides a significant speedup in training and inference ov er PyT orch-based alternati ves. Additionally , J AX’ s functional paradigm enables the native use of transformations like vmap (used, e.g., for critic en- sembles) and lax.scan (for the iterativ e denoising loop in diffusion). 4.2 Ar chitecture Overview Figure 1 provides a semantic overvie w of F L O W R L. The system is organized into four layers, de- scribed below from bottom to top. (1) Network Architecture Layer . While traditional RL often relies on simple backbones like Multi-Layer Perceptrons (MLPs) with ReLU activations, recent evidence suggests that RL perfor- mance scales significantly with more sophisticated architectures and increased parameter counts. Accordingly , we support a di verse suite of backbones, including standard MLP , as well as modern alternativ es such as SimBa ( Lee et al. , 2024 ) and BroNet ( Nauman et al. , 2024 ). (2) Model Layer . W e implement DMs, FMs, and standard RL components with a common in- terface. For DMs, we support both discrete and continuous-time DDPM; for FMs, we support Continuous Normalizing Flo ws (CNFs). W e also include annealed Langevin dynamics (ALD) due to its connection to DMs and FMs. The actor-critic framew ork supports actors parameterized by any of the aforementioned generati ve models or by standard deterministic and probabilistic distri- butions. For critics, both scalar and distributional critics are supported. All these models can utilize any architecture from the pre vious layer as their backbones. 7 MuJoCo (Gymnasium) DMC IsaacLab In vertedPendulum Reacher Cheetah-run Hopper-Stand Ant Humanoid Swimmer W alker2d W alker-walk Humanoid-W alk Lift-Cube-Franka V elocity-Flat-Anymal-D Figure 2: Representativ e tasks across three continuous-control suites. Left: MuJoCo Gymnasium. Middle: DeepMind Control Suite. Right: IsaacLab. (3) Algorithm Layer . Algorithms are implemented as subclasses of a BaseAgent . T o imple- ment a new algorithm, the user only needs to define three components: 1) the initialization logic, which assembles tools and models from pre vious layers; 2) the update logic, which is JIT -compiled to maximize computational throughput; and 3) sampling logic, which is greatly simplified, as the underlying DMs and FMs already provide samplers that work out-of-the-box. (4) W orkflow Layer . The workflo w layer orchestrates all components through a main script. Specifically , a Hydra-based configuration system merges algorithm-specific Y AMLs with shared set- tings, providing hierarchical hyperparameter management and command-line overrides. The main script also instantiates the en vironment, data buf fer, and agent, then enters a loop alternating among en vironment interaction, dataset sampling, and compiled agent updates. The logging system sup- ports simultaneous writes to multiple backends, including T ensorBoard, W eights & Biases, and CSV files, while Orbax handles checkpointing. Finally , we support a div erse range of tasks, spanning 2D visualization datasets, classic locomotion benchmarks such as Gym-MuJoCo and the DeepMind Control Suite, high-dimensional control tasks like HumanoidBench, and IsaacLab, which enables large-scale, hardw are-accelerated simulation across multiple embodiments. 5 Benchmarking RL with Diffusion Policies 5.1 Experiment Setup Benchmarks. W e select three complementary continuous control benchmarks that collectively span a wide range of task complexities and action dimensionalities. Gym-Locomotion ( T owers et al. , 2025 ) and DeepMind Control Suite (DMC) ( T assa et al. , 2018 ) are both powered by the Mu- JoCo physics engine ( T odorov et al. , 2012 ) and provide standard locomotion and balancing tasks widely used in the RL literature. IsaacLab ( NVIDIA et al. , 2025 ) provides GPU-accelerated robotic en vironments that support massiv ely parallel simulation across div erse embodiments, including lo- comotion and manipulation tasks. W e use Gym-Locomotion and DMC for off-polic y and offline settings, and IsaacLab for on-policy settings. The full list of tasks is provided in the Appendix A.1 . Algorithms. W e ev aluate representativ e DPRL methods from each guidance category in our tax- onomy against strong Gaussian baselines. F or online of f-policy RL, we compare QSM ( Psenka et al. , 2024 ), D A CER ( W ang et al. , 2024 ), DPMD ( Ma et al. , 2025 ), SD A C ( Ma et al. , 2025 ), and QVPO ( Ding et al. , 2024 ) against SAC ( Haarnoja et al. , 2018 ). For online on-policy RL, we compare DPPO ( Ren et al. , 2025 ), GenPO ( Ding et al. , 2025 ), and FPO ( McAllister et al. , 2025 ) against PPO ( Schulman et al. , 2017 ). For offline RL, we compare Diffusion-QL ( W ang et al. , 2022 ), FQL ( Park et al. , 2025 ), DA C ( Fang et al. , 2024 ), and BDPO ( Gao et al. , 2025 ) against IQL ( Hansen-Estruch 8 0.00 0.25 0.50 0.75 1.00 Envir onment Frames 1e6 0 2000 4000 6000 Eval Retur n Ant-v5 0.00 0.25 0.50 0.75 1.00 Envir onment Frames 1e6 0 5000 10000 HalfCheetah-v5 0.00 0.25 0.50 0.75 1.00 Envir onment Frames 1e6 0 2000 4000 Hopper -v5 0.00 0.25 0.50 0.75 1.00 Envir onment Frames 1e6 0 2000 4000 6000 Eval Retur n Humanoid-v5 0.00 0.25 0.50 0.75 1.00 Envir onment Frames 1e6 0 50 100 Swimmer -v5 0.00 0.25 0.50 0.75 1.00 Envir onment Frames 1e6 0 2000 4000 W alker2d-v5 SAC QSM DACER SDAC QVPO DPMD Figure 4: T raining curves of se veral off-polic y DPRL algorithms across Gym-Locomotion tasks. 0 20 40 60 80 100 Envir onment Frames 1e6 0 50 100 Eval Retur n Ant-v0 0 20 40 60 80 100 Envir onment Frames 1e6 0 50 100 Humanoid-v0 0 20 40 60 80 100 Envir onment Frames 1e6 50 0 50 100 Lift-Cube-Franka-v0 0 20 40 60 80 100 Envir onment Frames 1e6 40 20 0 V elocity-Flat-Anymal-D-v0 PPO DPPO FPO GenPO Figure 5: T raining curves of on-polic y DPRL algorithms on IsaacLab tasks. et al. , 2023 ). W e also include reference scores of IDQL ( Hansen-Estruch et al. , 2023 ), QGPO ( Lu et al. , 2023 ), EDP ( Kang et al. , 2023 ) as a comparison. 0.5 0.6 0.7 0.8 0.9 1.0 T h r e s h o l d ( n o r m a l i z e d s c o r e ) 0.0 0.2 0.4 0.6 0.8 1.0 F r a c t i o n w i t h s c o r e > P r ( s c o r e > ) SAC QSM DACER SDAC QVPO DPMD Figure 3: Performance profile on Gym-Locomotion tasks. Evaluation Setup. T o ensure a fair comparison, all meth- ods within each benchmark follow a standardized workflow . For of fline settings, we keep the hyperparameters and network designs identical to their original papers. W e use the D4RL datasets for training and report the a verage performance of the last policy checkpoint. For the online off-policy settings, each method is trained for 1M environment frames and e valuated ev ery 10K frames across a span of 10 episodes. No observation or rew ard normalization is applied in this setting. Unless an algorithm explicitly designates a specific architectural choice as a core contribution, we align all hyperparameters, network structures, and diffusion model implementations across base- lines. For IsaacLab, the training pipeline follows the standard PPO rollout pipeline, utilizing 1024 parallel simulations for a total of 100M frames. For all en vironments, we report the undiscounted episodic return, visualized using the mean (solid line) and one standard deviation (shaded region). Detailed per-algorithm hyperparameters are pro vided in the Appendix A . 5.2 General P erformance Gym-Locomotion. Learning curves for the Gym-Locomotion en vironments are shown in Fig- ure 4 . In Figure 3 , we further present the performance profiles of each algorithm by normalizing the e valuation returns and computing the fraction of runs that achiev e performance abov e different thresholds τ . Comparing the area under the curve in Figure 3 , SD AC, D ACER, and DPMD deliv er the strongest overall results and outperform the Gaussian baseline SA C. That said, no single DPRL algorithm dominates across all en vironments, and SA C remains competitive on the majority of tasks. QSM and QVPO underperform and show noticeable instability during training. 9 T able 2: Normalized returns of the final policy checkpoint for offline DPRL methods. Methods marked with † denote results reported in the original paper . Results are averaged ov er fiv e indepen- dent runs of 10 ev aluation episodes each. Numbers within 95% of the highest scores are bolded. Dataset IQL IDQL † QGPO † QIPO † Diffusion-QL D A C BDPO halfcheetah-m 47.4 51.0 54.1 54.2 ± 1 . 3 50.7 ± 0 . 7 59.1 ± 0 . 6 71.2 ± 0 . 9 hopper-m 66.3 65.4 98.0 94.0 ± 13 . 3 80.4 ± 15 . 7 103.5 ± 0 . 3 100.6 ± 0 . 7 walker2d-m 78.3 82.5 86.0 87.6 ± 1 . 5 86.7 ± 1 . 6 97.9 ± 0 . 9 93.4 ± 0 . 5 halfcheetah-m-r 44.2 45.9 47.6 48.0 ± 0 . 8 47.4 ± 0 . 6 55.4 ± 0 . 5 58.9 ± 0 . 9 hopper-m-r 94.7 92.1 96.9 101.3 ± 2 . 2 101.0 ± 0 . 3 103.1 ± 0 . 1 101.4 ± 0 . 5 walker2d-m-r 73.9 85.1 84.4 75.6 ± 25 . 1 95.7 ± 1 . 4 98.4 ± 0 . 5 95.5 ± 1 . 6 halfcheetah-m-e 86.7 95.9 93.5 94.5 ± 0 . 5 96.0 ± 0 . 7 100.1 ± 0 . 7 108.7 ± 0 . 9 hopper-m-e 91.5 108.6 108.0 108.0 ± 5 . 2 106.9 ± 11 . 7 112.3 ± 1 . 0 111.3 ± 0 . 2 walker2d-m-e 109.6 112.7 110.7 110.9 ± 1 . 0 108.7 ± 0 . 2 115.3 ± 7 . 5 115.6 ± 0 . 4 IsaacLab . In Figure 5 , we plot the return curves of three on-policy DPRL methods together with the baseline method, PPO. Overall, PPO deliv ers the best and most stable performance across the four tasks. Among the DPRL methods, GenPO achiev es the strongest performance. Howe ver , its training cost is significantly higher due to Jacobian computation. W e also observ e that FPO occasionally collapses during training. After careful inspection, we find that this instability arises because, for samples with negati ve adv antage, optimizing ( 17 ) with ( 18 ) effecti vely leads to an unbounded optimization problem. D4RL. In T able 2 , we find that DPRL methods, especially those lev eraging RL to train the dif- fusion policy , significantly outperform traditional offline RL algorithms such as IQL and inference- time refinement methods such as IDQL. These results demonstrate the efficacy of diffusion models not only as expressiv e priors for capturing complex, multi-modal offline distributions, but also as promising policy representations for of fline RL. 5.3 Empirical Analysis 1 cartpole-balance 4 hopper -stand 6 cheetah-run 12 quadruped-run 21 humanoid-walk Action Dimensionality 0.00 0.25 0.50 0.75 1.00 1.25 1.50 Relative to SAC QSM DACER SDAC SAC Figure 6: Effect of Action Dimensionality . Per- formance is normalized by SAC across tasks of increasing action dimension. Effect of Action Dimensionality . A key dis- tinction among different guidance methods is how each utilizes the Q -function: both Q -value guidance and reparameterization methods ex- ploit first-order gradients ∇ a Q for optimiza- tion, while weighted matching methods rely on function e valuations Q ( s, a ) to reweight sam- pled actions, which is less efficient and prone to higher variance in high-dimensional action spaces. In Figure 6 , we select three represen- tativ e methods, QSM (from Sec 3.2 ), DA CER (from Sec 3.3 ), and SD A C (from Sec 3.4 ), and compare their performance relative to SAC with tasks of increasing action dimensionality . W e find that while QSM and D A CER remain competitiv e, the performance of SDA C degrades sig- nificantly as dimensionality grows. This suggests that for weighted matching methods to remain effecti ve, the proposal distribution must be meticulously designed to ensure high-v alued actions can be sampled and reinforced during training. Effect of Diffusion Steps. Since diffusion models refine samples through an iterative denoising process, a natural question is how the number of diffusion steps affects each algorithm. W e again select QSM, D A CER and SD A C and vary the number of diffusion steps in Figure 7 . W e discov er 10 0.0 0.2 0.4 0.6 0.8 1.0 Envir onment Frames 1e6 0.0 0.2 0.4 0.6 0.8 Normalized Retur n QSM 0.0 0.2 0.4 0.6 0.8 1.0 Envir onment Frames 1e6 0.0 0.2 0.4 0.6 0.8 SDAC 0.0 0.2 0.4 0.6 0.8 1.0 Envir onment Frames 1e6 0.0 0.2 0.4 0.6 0.8 DACER 2 5 10 50 Figure 7: Effect of diffusion steps on performance. Performance of QSM, SD A C, and D ACER when varying the number of diffusion steps (2, 5, 10, and 50). Returns are normalized by task- specific maximum scores and av eraged across Ant, HalfCheetah, Humanoid, and W alker2d. 0.00 0.25 0.50 0.75 1.00 Envir onment Frames 1e6 0 250 500 750 1000 Eval Retur n quadruped-run 0.00 0.25 0.50 0.75 1.00 Envir onment Frames 1e6 0 50 100 150 200 humanoid-run 0.00 0.25 0.50 0.75 1.00 Envir onment Frames 1e6 0 250 500 750 1000 humanoid-stand 0.00 0.25 0.50 0.75 1.00 Envir onment Frames 1e6 0 200 400 600 dog-run QSM (MLP) QSM (SimBa) DACER (MLP) DACER (SimBa) Figure 8: Effect of network architectur e. Comparison between MLP and SimBa backbones for QSM (blue) and D A CER (green) on DMControl hard tasks. Solid lines denote MLP policies and dashed lines denote Simba policies. that both QSM and SD A C improve monotonically with more diffusion steps, while SD A C works significantly better e ven with fe wer diffusion steps. In contrast, D A CER exhibits the opposite trend, with its performance degrading when the number of steps exceeds fi ve. W e attrib ute this behavior to the nature of reparameterization-based methods, which rely on techniques such as BPTT to optimize the dif fusion polic y . Increasing the number of diffusion steps complicates the optimization problem, making the training process more indirect and susceptible. Effect of Netw ork Backbone. Recent studies ( Lee et al. , 2024 ; Nauman et al. , 2024 ) hav e demon- strated that network architecture is a significant confounding factor in online Reinforcement Learn- ing performance, yet their effects are often left unexamined in the existing literature. The modular design of F L O W R L enables users to seamlessly swap between neural network backbones. In Figure 8 , we select the most difficult tasks from DMC and change the network architecture from MLP to SimBa. W e find that all ev aluated algorithms achie ve significant performance gains on tasks previ- ously considered challenging. These results highlight the importance of controlling for architecture when ev aluating algorithmic improvements. Effect of Noise Schedule. Prior work on DMs has shown that the choice of noise schedules can affect sample quality ( Ho et al. , 2020 ; Song et al. , 2022 ). W e in vestigate whether these design choices carry ov er to the RL setting by replacing the default cosine schedule with a linear schedule. As shown in Figure 9 , switching to a linear noise schedule has minimal impact on performance across all three methods. 6 Closing Remarks In this paper, we presented a systematic study of diffusion policy-based Reinforcement Learning. W e first proposed a unified taxonomy that categorizes existing DPRL algorithms along two axes: diffusion policy optimization guidance and regularization objectiv e. Building upon this taxonomy , we de veloped a modular , J AX-based library that enables high-throughput training and fair compari- son of DPRL algorithms. Our standardized benchmark results across Gym-Locomotion, DeepMind Control Suite, and IsaacLab provide rigorous performance references and practical guidelines for 11 0.0 0.2 0.4 0.6 0.8 1.0 Envir onment Frames 1e6 0.0 0.2 0.4 0.6 0.8 Normalized Retur n SDAC 0.0 0.2 0.4 0.6 0.8 1.0 Envir onment Frames 1e6 0.0 0.2 0.4 0.6 0.8 QSM 0.0 0.2 0.4 0.6 0.8 1.0 Envir onment Frames 1e6 0.0 0.2 0.4 0.6 0.8 DACER Cosine Noise Schedule Linear Noise Schedule Figure 9: Effect of noise schedule. Performance of SD AC, QSM, and DA CER with a cosine (black) or linear noise schedule. selecting algorithm configurations. Important open questions remain in the field of DPRL, includ- ing designing algorithms robust to diverse en vironment characteristics, scaling to long-horizon and sparse-rew ard tasks, and developing a thorough understanding of the diffusion policy optimization landscape. W e believ e our proposed taxonomy and library provide a solid foundation for future research and practical applications in this direction. References T ara Akhound-Sadegh, Jarrid Rector-Brooks, A vishek Joey Bose, Sarthak Mittal, Pablo Lemos, Cheng-Hao Liu, Marcin Sendera, Siamak Ravanbakhsh, Gauthier Gidel, Y oshua Bengio, et al. Iterated denoising energy matching for sampling from boltzmann densities. arXiv pr eprint arXiv:2402.06121 , 2024. Michael Albergo, Nicholas M Bof fi, and Eric V anden-Eijnden. Stochastic interpolants: A unifying framew ork for flo ws and diffusions. J ournal of Machine Learning Researc h , 26(209):1–80, 2025. Michael S Alber go and Eric V anden-Eijnden. Building normalizing flows with stochastic inter- polants. arXiv preprint , 2022. Ke vin Black, Noah Bro wn, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter , et al. π 0 : A vision-language-action flow model for general robot control. arXiv preprint , 2024. James Bradbury , Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary , Dougal Maclaurin, George Necula, Adam P aszke, Jake V anderPlas, Skye W anderman-Milne, and Qiao Zhang. J AX: composable transformations of Python+NumPy programs, 2018. URL http://github .com/jax-ml/jax . Onur Celik, Zechu Li, Denis Blessing, Ge Li, Daniel Palenicek, Jan Peters, Georgia Chalvatzaki, and Gerhard Neumann. Dime: Diffusion-based maximum entrop y reinforcement learning. In International Confer ence on Machine Learning , pp. 6958–6977. PMLR, 2025. Huayu Chen, Cheng Lu, Chengyang Y ing, Hang Su, and Jun Zhu. Of fline reinforcement learning via high-fidelity generativ e behavior modeling. arXiv preprint , 2022. T ianyi Chen, Haitong Ma, Na Li, Kai W ang, and Bo Dai. One-step flow policy mirror descent. arXiv pr eprint arXiv:2507.23675 , 2025. T ing Chen. On the importance of noise scheduling for diffusion models. arXiv pr eprint arXiv:2301.10972 , 2023. Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Y ilun Du, Benjamin Burchfiel, Russ T edrake, and Shuran Song. Dif fusion policy: V isuomotor policy learning via action diffusion. The Inter- national Journal of Robotics Resear ch , 44(10-11):1684–1704, 2025. 12 W onhyeok Choi, Shutong Ding, Minw oo Choi, Jungwan W oo, K yumin Hwang, Jaeyeul Kim, Y e Shi, and Sunghoon Im. A revie w of online dif fusion policy rl algorithms for scalable robotic control. arXiv preprint , 2026. Petros Christodoulou. Soft actor-critic for discrete action settings. arXiv preprint , 2019. DeepMind, Igor Babuschkin, Kate Baumli, Alison Bell, Surya Bhupatiraju, Jake Bruce, Peter Buchlovsk y , David Budden, Tre vor Cai, Aidan Clark, Ivo Danihelka, Antoine Dedieu, Clau- dio Fantacci, Jonathan Godwin, Chris Jones, Ross Hemsley , T om Hennigan, Matteo Hes- sel, Shaobo Hou, Steven Kapturo wski, Thomas Keck, Iurii Kemae v , Michael King, Markus Kunesch, Lena Martens, Hamza Merzic, Vladimir Mikulik, T amara Norman, George P apamakar- ios, John Quan, Roman Ring, Francisco Ruiz, Alv aro Sanchez, Laurent Sartran, Rosalia Schnei- der , Eren Sezener , Stephen Spencer , Sri vatsan Sriniv asan, Miloš Stanojevi ´ c, W ojciech Stok owiec, Luyu W ang, Guangyao Zhou, and Fabio V iola. The DeepMind J AX Ecosystem, 2020. URL http://github .com/google-deepmind . Prafulla Dhariw al and Alexander Nichol. Diffusion models beat gans on image synthesis. Advances in neural information pr ocessing systems , 34:8780–8794, 2021. Shutong Ding, Ke Hu, Zhenhao Zhang, Kan Ren, W einan Zhang, Jingyi Y u, Jingya W ang, and Y e Shi. Dif fusion-based reinforcement learning via q-weighted variational policy optimization. Advances in Neural Information Pr ocessing Systems , 37:53945–53968, 2024. Shutong Ding, K e Hu, Shan Zhong, Haoyang Luo, W einan Zhang, Jingya W ang, Jun W ang, and Y e Shi. Genpo: Generativ e diffusion models meet on-policy reinforcement learning. arXiv pr eprint arXiv:2505.18763 , 2025. Xiaoyi Dong, Jian Cheng, and Xi Sheryl Zhang. Maximum entropy reinforcement learning with diffusion polic y . arXiv pr eprint arXiv:2502.11612 , 2025. Linjiajie Fang, Ruoxue Liu, Jing Zhang, W enjia W ang, and Bingyi Jing. Diffusion actor-critic: Formulating constrained policy iteration as diffusion noise regression for offline reinforcement learning. In The Thirteenth International Conference on Learning Representations , 2024. Scott Fujimoto, Herke Hoof, and David Meger . Addressing function approximation error in actor- critic methods. In International conference on machine learning , pp. 1587–1596. PMLR, 2018. Chen-Xiao Gao, Chenyang W u, Mingjun Cao, Chenjun Xiao, Y ang Y u, and Zongzhang Zhang. Behavior -regularized diffusion policy optimization for offline reinforcement learning. In F orty- second International Confer ence on Machine Learning , 2025. Matthieu Geist, Bruno Scherrer , and Olivier Pietquin. A theory of regularized marko v decision processes. In International conference on machine learning , pp. 2160–2169. PMLR, 2019. T uomas Haarnoja, Haoran T ang, Pieter Abbeel, and Sergey Le vine. Reinforcement learning with deep energy-based policies. In International confer ence on machine learning , pp. 1352–1361. PMLR, 2017. T uomas Haarnoja, Aurick Zhou, Kristian Hartikainen, George T ucker , Sehoon Ha, Jie T an, V ikash Kumar , Henry Zhu, Abhishek Gupta, Pieter Abbeel, et al. Soft actor-critic algorithms and appli- cations. arXiv preprint , 2018. Philippe Hansen-Estruch, Ilya K ostrikov , Michael Janner , Jakub Grudzien Kuba, and Sergey Le vine. Idql: Implicit q-learning as an actor-critic method with diffusion policies. arXiv pr eprint arXiv:2304.10573 , 2023. Jonathan Heek, Anselm Levskaya, A vital Oliver , Marvin Ritter, Bertrand Rondepierre, Andreas Steiner , and Marc van Zee. Flax: A neural network library and ecosystem for J AX, 2024. URL http://github .com/google/flax . 13 Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif fusion probabilistic models. Advances in neural information pr ocessing systems , 33:6840–6851, 2020. Xiao Huang, Xu Liu, Enze Zhang, T ong Y u, and Shuai Li. Offline-to-online reinforcement learning with classifier-free dif fusion generation. arXiv preprint , 2025. V ineet Jain, T ara Akhound-Sadegh, and Siamak Ra vanbakhsh. Sampling from energy-based policies using diffusion. arXiv preprint , 2024. Bingyi Kang, Xiao Ma, Chao Du, T ianyu Pang, and Shuicheng Y an. Efficient dif fusion policies for offline reinforcement learning. Advances in Neural Information Pr ocessing Systems , 36:67195– 67212, 2023. Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, T ed Xiao, Ashwin Balakrishna, Suraj Nair , Rafael Rafailov , Ethan Foster , Grace Lam, Pannag Sanketi, et al. Open vla: An open-source vision-language-action model. arXiv preprint , 2024. Hojoon Lee, Dongyoon Hwang, Donghu Kim, Hyunseung Kim, Jun Jet T ai, Kaushik Subramanian, Peter R W urman, Jae gul Choo, Peter Stone, and T akuma Seno. Simba: Simplicity bias for scaling up parameters in deep reinforcement learning. arXiv preprint , 2024. T ianhong Li and Kaiming He. Back to basics: Let denoising generati ve models denoise. arXiv pr eprint arXiv:2511.13720 , 2025. Y inchuan Li, Xinyu Shao, Jianping Zhang, Haozhi W ang, Leo Maxime Brunswic, Kaiwen Zhou, Jiqian Dong, Kaiyang Guo, Xiu Li, Zhitang Chen, et al. Generati ve models in decision making: A surve y . arXiv preprint , 2025. Y aron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generativ e modeling. arXiv pr eprint arXiv:2210.02747 , 2022. Cheng Lu and Y ang Song. Simplifying, stabilizing and scaling continuous-time consistency models. arXiv pr eprint arXiv:2410.11081 , 2024. Cheng Lu, Huayu Chen, Jianfei Chen, Hang Su, Chongxuan Li, and Jun Zhu. Contrasti ve energy prediction for exact ener gy-guided diffusion sampling in of fline reinforcement learning. In Inter- national Confer ence on Machine Learning , pp. 22825–22855. PMLR, 2023. Haitong Ma, T ianyi Chen, Kai W ang, Na Li, and Bo Dai. Efficient online reinforcement learning for diffusion polic y . In F orty-second International Conference on Machine Learning , 2025. Liyuan Mao, Haoran Xu, Xianyuan Zhan, W einan Zhang, and Amy Zhang. Diffusion-dice: In- sample dif fusion guidance for offline reinforcement learning. Advances in Neural Information Pr ocessing Systems , 37:98806–98834, 2024. David McAllister , Songwei Ge, Brent Y i, Chung Min Kim, Ethan W eber , Hongsuk Choi, Haiwen Feng, and Angjoo Kanazawa. Flow matching policy gradients. arXiv pr eprint arXiv:2507.21053 , 2025. Michal Nauman, Mateusz Ostaszewski, Krzysztof Jankowski, Piotr Miło ´ s, and Marek Cygan. Big- ger , regularized, optimistic: scaling for compute and sample efficient continuous control. Ad- vances in neural information pr ocessing systems , 37:113038–113071, 2024. NVIDIA, :, Mayank Mittal, Pascal Roth, James T igue, Antoine Richard, Octi Zhang, Peter Du, Antonio Serrano-Muñoz, Xinjie Y ao, René Zurbrügg, Nikita Rudin, Lukasz W awrzyniak, Mi- lad Rakhsha, Alain Denzler , Eric Heiden, Ales Borovicka, Ossama Ahmed, Iretiayo Akinola, Abrar Anwar, Mark T . Carlson, Ji Y uan Feng, Animesh Gar g, Renato Gasoto, Lionel Gulich, Y ijie Guo, M. Gussert, Alex Hansen, Mihir Kulkarni, Chenran Li, W ei Liu, V iktor Mako viy- chuk, Grzegorz Malczyk, Hammad Mazhar , Masoud Moghani, Adithyav airav an Murali, Michael 14 Nosew orthy , Alexander Poddubny , Nathan Ratliff, W elf Rehberg, Clemens Schwarke, Ritvik Singh, James Latham Smith, Bingjie T ang, Ruchik Thaker , Matthe w Trepte, Karl V an W yk, Fangzhou Y u, Alex Millane, V ikram Ramasamy , Remo Steiner , Sangeeta Subramanian, Clemens V olk, CY Chen, Neel Jawale, Ashwin V arghese K uruttukulam, Michael A. Lin, Ajay Mandlekar , Karsten Patzwaldt, John W elsh, Huihua Zhao, F atima Anes, Jean-Francois Lafleche, Nicolas Moënne-Loccoz, Soo wan Park, Rob Stepinski, Dirk V an Gelder , Chris Amev or , Jan Carius, Jumyung Chang, Anka He Chen, Pablo de Heras Ciechomski, Gilles Daviet, Mohammad Mo- hajerani, Julia von Muralt, V iktor Reutskyy , Michael Sauter , Simon Schirm, Eric L. Shi, Pierre T erdiman, K enny V ilella, T obias Widmer , Gordon Y eoman, T if fany Chen, Sergey Grizan, Cathy Li, Lotus Li, Connor Smith, Raf ael W iltz, Kostas Alexis, Y an Chang, Da vid Chu, Linxi "Jim" F an, Farbod Farshidian, Ankur Handa, Spencer Huang, Marco Hutter, Y ashraj Narang, Soha Pouya, Shiwei Sheng, Y uke Zhu, Miles Macklin, Adam Moravanszk y , Philipp Reist, Y unrong Guo, David Hoeller , and Gavriel State. Isaac lab: A gpu-accelerated simulation framework for multi-modal robot learning, 2025. URL https://arxiv .org/abs/2511.04831 . Chaoyi Pan, Zeji Y i, Guanya Shi, and Guannan Qu. Model-based diffusion for trajectory optimiza- tion. Advances in Neural Information Pr ocessing Systems , 37:57914–57943, 2024. Seohong Park, Qiyang Li, and Sergey Levine. Flow q-learning, 2025. URL https://arxiv .org/abs/2502.02538 . Xue Bin Peng, A viral Kumar , Grace Zhang, and Serge y Levine. Advantage-weighted regression: Simple and scalable off-polic y reinforcement learning. arXiv pr eprint arXiv:1910.00177 , 2019. Michael Psenka, Alejandro Escontrela, Pieter Abbeel, and Y i Ma. Learning a diffusion model policy from rew ards via q-score matching. In International Conference on Machine Learning , pp. 41163–41182. PMLR, 2024. Allen Z Ren, Justin Lidard, Lars L Ankile, Anthony Simeonov , Pulkit Agraw al, Anirudha Majum- dar , Benjamin Burchfiel, Hongkai Dai, and Max Simchowitz. Dif fusion policy policy optimiza- tion. In 13th International Confer ence on Learning Representations, ICLR 2025 , pp. 58018– 58059. International Conference on Learning Representations, ICLR, 2025. John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. In International conference on machine learning , pp. 1889–1897. PMLR, 2015. John Schulman, Filip W olski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov . Proximal policy optimization algorithms. arXiv preprint , 2017. Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models, 2022. URL https://arxiv .org/abs/2010.02502 . Y ang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar , Stefano Ermon, and Ben Poole. Score-based generativ e modeling through stochastic dif ferential equations. arXiv preprint arXiv:2011.13456 , 2020. Richard S Sutton, Andre w G Barto, et al. Reinfor cement learning: An introduction , v olume 1. MIT press Cambridge, 1998. Richard S Sutton, David McAllester , Satinder Singh, and Y ishay Mansour . Policy gradient meth- ods for reinforcement learning with function approximation. Advances in neural information pr ocessing systems , 12, 1999. Y uval T assa, Y otam Doron, Alistair Muldal, T om Erez, Y azhe Li, Diego de Las Casas, David Bud- den, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, Timothy Lillicrap, and Martin Ried- miller . Deepmind control suite, 2018. URL https://arxiv .org/abs/1801.00690 . 15 Emanuel T odorov , T om Erez, and Y uval T assa. Mujoco: A physics engine for model-based con- trol. 2012 IEEE/RSJ International Confer ence on Intelligent Robots and Systems , pp. 5026–5033, 2012. URL https://api.semanticscholar .org/Cor pusID:5230692 . Mark T owers, Ariel Kwiatko wski, Jordan T erry , John U. Balis, Gianluca De Cola, T ristan Deleu, Manuel Goulão, Andreas Kallinteris, Markus Krimmel, Arjun KG, Rodrigo Perez- V icente, Andrea Pierré, Sander Schulhof f, Jun Jet T ai, Hannah T an, and Omar G. Y ou- nis. Gymnasium: A standard interface for reinforcement learning en vironments, 2025. URL https://arxiv .org/abs/2407.17032 . Y inuo W ang, Likun W ang, Y uxuan Jiang, W enjun Zou, T ong Liu, Xujie Song, W enxuan W ang, Liming Xiao, Jiang W u, Jingliang Duan, et al. Dif fusion actor-critic with entropy regulator . Advances in Neural Information Pr ocessing Systems , 37:54183–54204, 2024. Y inuo W ang, Likun W ang, Mining T an, W enjun Zou, Xujie Song, W enxuan W ang, T ong Liu, Guo- jian Zhan, Tianze Zhu, Shiqi Liu, et al. Enhanced dacer algorithm with high diffusion efficienc y . arXiv pr eprint arXiv:2505.23426 , 2025. Zhendong W ang, Jonathan J Hunt, and Mingyuan Zhou. Diffusion policies as an expressi ve policy class for offline reinforcement learning. arXiv preprint , 2022. Rosa W olf, Y itian Shi, Sheng Liu, and Rania Rayyes. Diffusion models for robotic manipulation: A surve y . F r ontiers in Robotics and AI , 12:1606247, 2025. Y ifan W u, George T ucker , and Ofir Nachum. Behavior regularized offline reinforcement learning. arXiv pr eprint arXiv:1911.11361 , 2019. Changfu Xu, Jianxiong Guo, Y uzhu Liang, Haiyang Huang, Haodong Zou, Xi Zheng, Shui Y u, Xi- aowen Chu, Jiannong Cao, and Tian W ang. Diffusion models for reinforcement learning: Foun- dations, taxonomy , and de velopment. arXiv preprint , 2025. Shiyuan Zhang, W eitong Zhang, and Quanquan Gu. Energy-weighted flow matching for offline reinforcement learning. In The Thirteenth International Conference on Learning Repr esentations , 2024. Zhengbang Zhu, Hanye Zhao, Haoran He, Y ichao Zhong, Shenyu Zhang, Haoquan Guo, T ingting Chen, and W einan Zhang. Diffusion models for reinforcement learning: A surv ey . arXiv preprint arXiv:2311.01223 , 2023. 16 A Experimental Details A.1 Benchmark T asks W e ev aluate on the following continuous control tasks across three benchmarks. Gym-Locomotion (6 tasks). Ant-v5, HalfCheetah-v5, Hopper-v5, Humanoid-v5, Swimmer-v5, W alker2d-v5. DeepMind Control Suite (8 tasks). Cartpole-Balance, Hopper -Stand, Cheetah-Run, Quadruped- Run, Humanoid-W alk, Humanoid-Run, Humanoid-Stand, Dog-Run. IsaacLab (4 tasks). Isaac-Ant-v0, Isaac-Humanoid-v0, Isaac-Lift-Cube-Franka-v0, Isaac- V elocity-Flat-Anymal-D-v0. A.2 Shar ed T raining Settings T able 3: Shared training settings per benchmark. Setting Gym-Locomotion DMC IsaacLab T raining frames 1M 1M 100M Batch size 256 512 6144 Replay buf fer size 10 6 10 6 — Discount γ 0.99 0.99 0.99 W armup frames 5K 10K — Random frames 5K 10K — Eval frequenc y (frames) 10K 10K 5M Eval episodes 10 10 10 Observation norm. No No Y es Rew ard norm. No No No Parallel en vs 1 1 1024 Frame skip 1 2 — A.3 Algorithm-Specific Hyper parameters Shared off-policy defaults. Unless we state otherwise, all off-policy methods follow a standard setup. For the critic, we use a 2-layer MLP (256 units, ReLU) for Gym-Locomotion tasks and a deeper 3-layer MLP (512 units, ELU) for DMC, both utilizing an ensemble size of 2 and an EMA of 0 . 005 .The diffusion actor uses a 3-layer MLP—sized at 256 for Gym or 512 for DMC—with Mish activ ation and a 64-dimensional Fourier time embedding. W e run this for 20 DDPM steps using a cosine noise schedule and clip actions between -1 and 1. Finally , our SA C implementation relies on a standard Gaussian actor with tanh squashing and automatic entropy tuning. Off-policy algorithm-specific h yperparameters. All of f-policy diffusion methods use actor lr 3e-4 and critic lr 3e-4, except D A CER (1e-4 for both) and DPMD (actor lr 1e-4, critic lr 3e-4). QVPO and SAC use a 2-layer (256, 256) actor; all other dif fusion methods use a 3-layer (256, 256, 256) actor . QSM samples num_samples =10 actions per state for the score matching update, with temperature λ = 0 . 1 . D A CER updates the actor ev ery 2 critic steps. It uses entropy_num_samples =200 for Monte Carlo entropy estimation, noise_scaler =0.1 (0.15 for HalfCheetah/Humanoid) for exploration, reward_scale =0.2 (1.0 on DMC), and updates α ev ery 10K steps with alpha_lr =0.03. 17 DPMD constrains policy updates via target_kl =2.5 and refreshes the reference policy e very 1000 steps. It uses num_particles =64 for policy ev aluation, additive_noise =0.2 (0.1 for Ant), and linear advantage re weighting. SD A C draws num_reverse_samples =500 Monte Carlo samples during re verse diffusion for gradient estimation, with temperature λ =0.05 (0.01 on DMC). QVPO trains with num_train_samples =64, advantage-based reweighting, entropy_coef =0.01, and num_behavior_samples =2 (4 for HalfCheetah, 1 for Hop- per). Shared on-policy defaults. Unless otherwise specified, all on-policy methods utilize a standard- ized configuration. Both the actor and critic networks are implemented as 3-layer MLPs with hid- den dimensions of (256 , 256 , 256) ; the critic uses a learning rate of 10 − 3 , while the actor uses 10 − 4 . For PPO-specific hyperparameters, we employ Generalized Advantage Estimation (GAE) with λ = 0 . 95 , a clipping parameter ϵ = 0 . 2 , and a gradient clipping norm of 1 . 0 . Training is conducted o ver 4 epochs per update using 4 minibatches with adv antage normalization and a rollout length of 24 . The infrastructure leverages 1024 parallel environments, resulting in a total batch size of 6144 . T able 4: On-policy algorithm-specific hyperparameters on IsaacLab . Only parameters that differ from the shared defaults are listed. DPPO FPO GenPO PPO Actor activ ation Mish SiLU ELU ELU Critic activ ation Mish ELU ELU ELU Denoising steps 10 10 5 — T ime embed dim 32 16 32 — Clip ϵ 0.2 0.05 0.2 0.2 Entropy coef — — 0.002 1e-4 Compression coef — — 0.01 — num_mc_samples — 8 — — T able 5: Maximum return values used for normalization in performance profiles (Figures 3 and 7 ). En vironment Max Return Ant-v5 6000 HalfCheetah-v5 11000 Hopper-v5 4000 Humanoid-v5 6000 Swimmer-v5 150 W alker2d-v5 6000 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment