Trace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills
Equipping Large Language Model (LLM) agents with domain-specific skills is critical for tackling complex tasks. Yet, manual authoring creates a severe scalability bottleneck. Conversely, automated skill generation often yields fragile or fragmented r…
Authors: Jingwei Ni, Yihao Liu, Xinpeng Liu
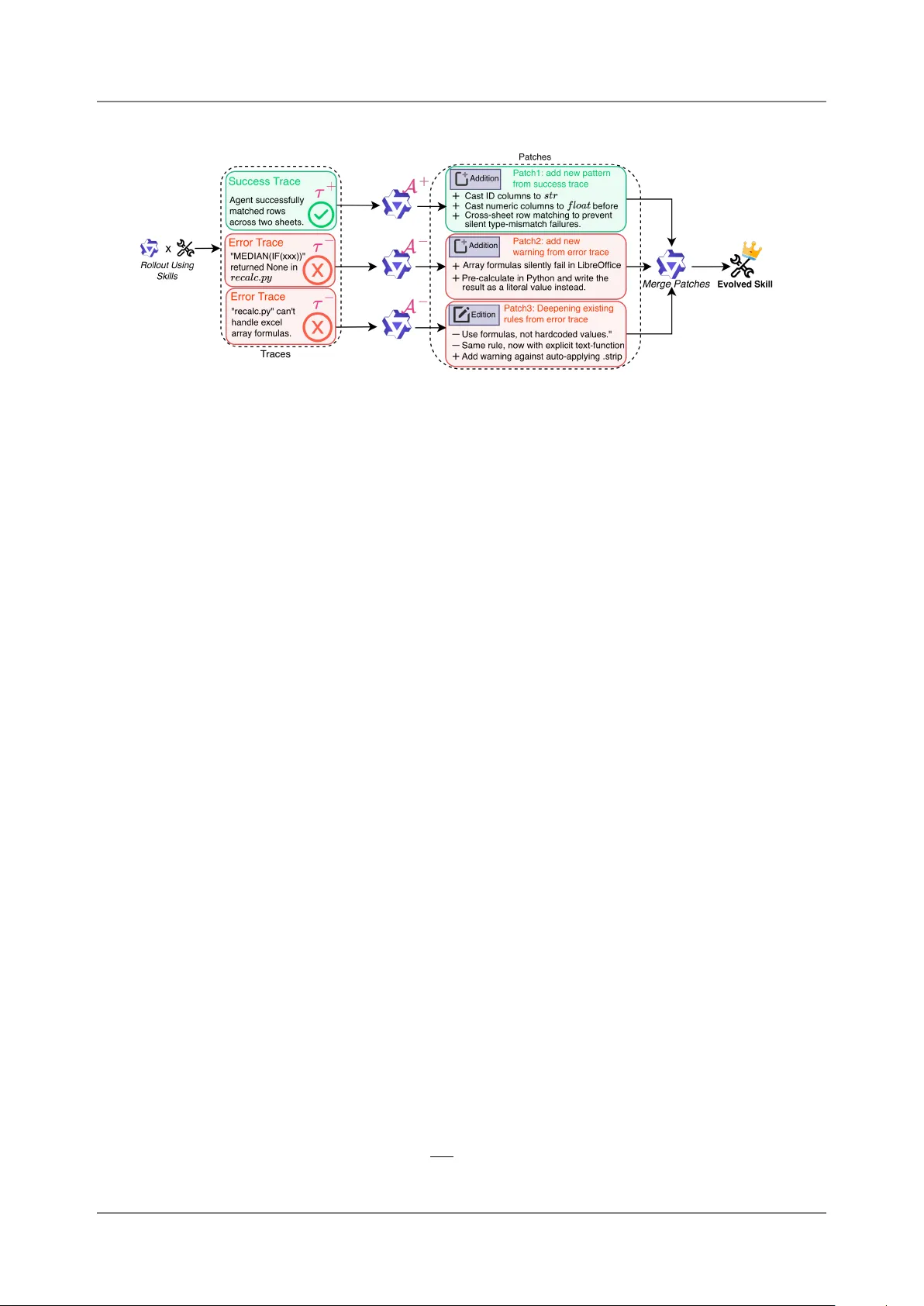
Trace2S kill: Distill Trajectory-L oca l L essons into Transf era b l e Agent S kills Jingwei Ni § ,* 2,3 , Yihao Liu § ,* 4 , Xinpeng Liu § ,* 4 , Yutao Sun § ,* 5 , Mengyu Z hou † 1 , Pengyu Cheng 1 , Dexin W ang 1 , Erchao Zhao 1 , Xi aoxi Jiang 1 and Gu anjun Jiang 1 1 Qwen Large Model Application T eam, Alibaba, 2 ETH Zürich, 3 Uni versit y of Zurich, 4 Peking Uni versit y , 5 Zhejiang Uni versity * W ork done during an internship at Alibaba. † Corresponding author . § Core Contrib utors. Equipping Large Language Model (LLM) a gents with domain-specific skills is critica l for t ackling complex tasks. Y et, man ual authoring creates a severe scalabilit y bottleneck. Con versely , automated skill genera- tio n often yields fragile or fragmented results because it either relies on shall ow parametric kno wledge or sequentially ov erfits to non-genera lizabl e trajectory-loca l lessons. T o ov ercome this, we introdu ce T race2Skill, a framew ork that mirrors how human experts author skills: by holistically analyzing broad executio n experience bef ore distilling it into a single, comprehensiv e guide. Instead o f reacting sequen- tially to individ ual trajectories, Trace2S kill dispatches a parallel fleet of sub-agents to analyze a diverse pool of executions. It extracts trajectory-specific lessons and hierarchically consolidates them into a unified, confli ct-free skill directory via inducti ve reaso ning. T race2Skill supports both deepening existing human-written skills and creating new ones from scratch. Experiments in cha llenging domains, such as spreadsheet, Visio nQ A and math reaso ning, sho w that Trace2S kill significantly impro ves upon strong baselin es, including Anthropic’s officia l xlsx skills. Cru cially , this trajectory-grounded evoluti on does not merely memorize t as k inst ances or model-specifi c quirks: evolv ed skills transfer across LLM scales and generalize to OO D settings. F or example, skills evolv ed by Qwen3.5-35B on its own trajectories impro ved a Qwen3.5-122B agent by up to 57.65 absolute percent a ge points on WikiT ab leQuesti ons. Further analysis confirms that our holistic, parallel consolidation outperforms both online sequentia l editing and retriev al-ba sed experien ce banks. Ultimately , our results demo nstrate that complex agent experien ce can be packaged into highly transfera bl e, decl arativ e skills—requiring no parameter updates, no extern al retrieval mod ules, and utilizing open-source models as small as 35B parameters. a a W ork in progress. 1. Introd ucti on Trace1 Skill Bank v1 Trace1 ... ... ... Traces Pool Distilled Skill : Skill Patch : Patch Merge Trace2 Trace3 TraceN Trace2 Skill Bank v2 Trace3 Skill Bank v3 TraceN Skill Bank vN Sequential Updates of a Skill Bank Parallel Distillation of All Lessons into a Skill Traces Seq Figure 1 | Left: Concurrent work’s online setting where lessons from in-coming traces ev olve a skill bank se- quentially . Right: T race2Skill’s an alyze a pool of traces in parallel, and hierarchica lly consolidating lessons to ind uce genera liz ab le SO Ps. LLM-based agents are increa singly rely on skills — structured, reusab le documents that encode t ask- solving procedures, domain kno wledge, and opera- tio nal guidelines — to navigate complex environ- ments ( Anthropic , 2026b ). As these a gents are deployed across increa singly broad and nuanced domain-specifi c use cases, demand for highly spe- cialized skills grows accordingly , creating a scalabil- it y bottleneck for manual skill creatio n and mainte- nance ( Han et al. , 2026 ; Li et al. , 2026a ; Anthropic , 2026a ; Liang et al. , 2026 ). Ev en when a human- written skill exists, it is not guaranteed to improv e performan ce for a giv en agent, model, or t as k dis- trib ution ( e.g., T a b le 1 sho ws that a human-expert- written skill that lifts a 122B agent by + 20 pp on Spreads heetBench- V erified ( Ma et al. , 2024 ) actively Corres ponding author( s): zhoumengyu.zmy@aliba ba-inc.com T race2Skill: Distill T rajectory-Local L essons into T ransfera ble Agent Skills harms a 35B a gent). These pressures m otivate automati c creation and adaptation of skills for specific use ca ses ( Han et al. , 2026 ). Ho w ever , synthesizing skills relying solely on an LLM’s parametric kno wledge yields limited benefits, even with leading proprietary models, primarily because parametric kno wledge l acks informati on about the specifics and comm on pitf a lls of the t arget domain ( Li et al. , 2026b ; Jiang et al. , 2026 ). T o address this, con current work proposes impro ving skills using agent executio n experience in an online setting, where an a gent continu ously interacts with the enviro nment and ev olves its skill collectio n based on inco ming trajectories ( Y ang et al. , 2026 ; Xia et al. , 2026a ; Alzubi et al. , 2026 ; Zhou et al. , 2026 ; Jiang et al. , 2026 ). While this continu ous, online paradigm has sho wn promise, we approach the prob lem of s kill ev olution from a different angle—on e that more closely mirrors how human experts author s kills. Specifica lly , we observ e that existing onlin e paradigms o ften diverge from human methodology in t w o key ways: • Skill Fragmentation vs. Consolidatio n: Existing works o ften create new , narrowly t ailored skills to host trajectory-loca l lessons, resulting in massiv e skill collectio ns that can lead to retriev al difficulti es ( Li , 2026 ). In contra st, human experts t ypically craft a single, comprehensiv e skill per domain, complete with broad proced ural guidance and error preventi on checklists. • Sequential vs. Holistic Updates: In an online setting, skills are updated sequentially using lessons from isolated inco ming trajectories ( Ji ang et al. , 2026 ; Xia et al. , 2026a ). This mimics a scenario where an author contin uo usly edits a skill while sequentia lly learning about a domain, reacting prematurely before acquiring adequate domain-specific kn o wledge. Human experts, conv ersely , b uild a comprehensiv e, high-level understanding o f the domain before instanti ating it into a skill. Figure 1 illustrates these compariso ns. Motivated by these observatio ns, we introd uce T race2Skill, a framew ork designed to simulate this human, holistic approach. Rather than reacting to trajectories sequentially , Trace2S kill analyzes a wide range of trajectory-loca l lessons in parallel, and distills common patterns into a single, comprehensiv e a gent skill. T race2Skill operates in three stages: (1) Trajectory Generation: An agent runs in parallel on an evolving set of tasks, prod ucing a pool of execution trajectories. (2) P ara llel Multi-Agent P atch Proposal: A fleet of success and error-analyst sub-agents independently processes batches o f trajectories, proposing t argeted patches to the skill. (3) Confli ct-Free Consolidatio n: Sub-a gent-proposed patches are hierarchi cally merged into a coherent update to the skill directory , utilizing programmatic conflict detectio n and format validati on at each step. W e process all patches simultaneous ly during consolidati on for t w o reasons. First, this acts as an indu ctiv e reaso ning process ( Xiong et al. , 2025 ; Li et al. , 2025 ; Lin et al. , 2025 ) that mines generalizab le patterns from experien ce-specific patches, building a high-lev el underst anding of the domain analogous to a human expert’s prior knowl edge. S econd, analyzing a massiv e number o f trajectories in parall el brings subst antial effici ency benefits and ensures a holistic view o f the domain. This reflects the core design wisdom of agent swarms ( Kimi T eam , 2026 ), which process multiple informatio n sources efficiently using parallelized sub-agents. The framew ork supports t w o m odes: deepening an existing human-written skill, and creating an effective skill from scratch starting from an ineff ective LLM-generated draft. The mo st surprising finding of this work is not just that trajectory an a lysis improv es skill qu ality , but that it does so without sacrificing generalizabilit y . Despite the deep analysis ov er a specific t as k distributi on and trajectories of a specific LLM, evolv ed skills transfer across model scales ( e.g., a skill evolv ed by Qwen3.5- 35B ( T eam , 2026 ) improv es Qwen3.5-122B) and generalize to out-of -distributi on t ask domains ( e.g. fro m spreadsheet editing to Wikipedia tab le Q A). Analyses attribute this transfera bilit y to the successf ul mining of preva lent, highly useful patterns ind uced from broad trajectories. This cha llenges the comm on assumptio n that experience is inherently m odel- and t ask-s pecific and mu st be mana ged through the retrieval of episodic mem ories ( Ouyang et al. , 2026 ; W ang et al. , 2024 ; Q ian et al. , 2024 ; Nottingham et al. , 2024 ; Liu et al. , 2025 ). Instead, we show that experien ce can be distilled into transferab le, declarative skills. W e further confirm the effectiv eness of T race2Skill on creating usef ul skills for math and vision reasoning. Further analysis sho ws that T race2Skill outperforms other popular paradigms o f experience-l earning: (1) R easo ning Bank ( Ouyang et al. , 2026 ) that first sav es genera liz ab le lessons from each trajectory , and retriev e useful experiences at inference time based on task simil arit y . (2) An online setting where new trajectories sequentially come in, and the skill ev olves based on new lessons learned. Crucially , because the skills created or deepened by Trace2S kill operate entirely without an extern a l retrieval m odul e, they are seamlessly portab le across the broader agent-skill ecosystem. 2 T race2Skill: Distill T rajectory-Local L essons into T ransfera ble Agent Skills Figure 2 | Ov erview of Trace2S kill’s three-st a ge pipeline. St age 1: a frozen a gent 𝜋 𝜃 rolls out on the evolving set using an initial skill S 0 ( human-written or LLM-drafted), produ cing labeled trajectories T − ( failures) and T + (successes). St age 2: parallel error and su ccess an aly sts independently processes individ ual traces and proposes skill patches. Stage 3: all patches are merged into a single consolidated update via indu ctive reaso ning with programmatic confli ct preventi on, produ cing an evolv ed skill S ∗ with improv ed performance and generalizatio n. • T race2Skill, a framew ork for automati c skill creation and adaptation that supports both deepening existing human-written skills and creating new on es from scratch. By utili zing f ully parallelized patch proposal and confli ct-free consolidation, Trace2S kill mirrors human skill writing: building broad prior kno wledge through extensiv e trajectory an a lysis before drafting comprehensiv e skills (§ 2 ). • Empirica l evidence that trajectory-grounded evoluti on yields high-qualit y , generalizab le skills that transfer effectiv ely across LLM scal es and out-o f -distributi on task domains (§ 3 ). • A demo nstration that open-source, small-scal e LLMs ( e.g., 35B) are sufficient for robust skill ev olution, rem oving the dependency on proprietary m odels seen in con current work (§ 3 ). • Further analysis showing that parallelized outperforms sequential onlin e skill updates; single comprehensiv e skill outperf orms retrieva l-based reaso ning banks; and a gentic error analysis outperf orms pl ain LLM-based analysis (§ 4 ). 2. Trace2Skill Figure 2 visualizes the three-st age pipeline o f T race2S kill. W e first forma liz e the skill structure and the evoluti on objectiv e (§ 2.1 ). Stage 1, St a ge 2, and Stage 3 are det ailed in § 2.2 , § 2.3 , and § 2.4 accordingly . 2.1. Skill and Problem F orma lization A skill S is a structured, human-readab le knowl edge directory consisting of a root markdown document 𝑀 ( SKILL.md ) and a set o f auxiliary resources R = { 𝑟 1 , . . . , 𝑟 𝐾 } : S = ( 𝑀 , R ) , R = { scripts , references , assets } . (1) 𝑀 encodes proced ural kno wledge in n atura l l anguage: when to apply a techniqu e, step-by-step strategies, and kno wn failure m odes. A uxiliary resources provide executabl e scripts f or deterministic subt as ks and context- or domain-specifi c references. Skill E voluti on Prob lem F orma lization. L et 𝜋 𝜃 denote an LLM-based a gent with fixed parameters 𝜃 , equipped at inference time with a prepended skill S . L et D evolv e and D test be disjoint task sets drawn from potentially different distributio ns. W e define success rate a s P ( S ; 𝜋 𝜃 , D ) = 1 | D | 𝑡 ∈ D 1 [ 𝜋 𝜃 ( 𝑡 ; S ) = 𝑦 ∗ 𝑡 ] , (2) 3 T race2Skill: Distill T rajectory-Local L essons into T ransfera ble Agent Skills where 𝑦 ∗ 𝑡 is the ground-truth answer for task 𝑡 . The objectiv e of s kill evoluti on is to construct an improv ed skill from trajectories on D evolv e , without updating 𝜃 , such that: S ∗ = E ( S 0 , D evolv e ; 𝜋 𝜃 ) , P ( S ∗ ; 𝜋 𝜃 , D test ) > P ( S 0 ; 𝜋 𝜃 , D test ) . (3) W e study t w o initializations for S 0 : a human-expert-written skill (deepening mode) and an LLM-generated draft from parametric kno wledge alon e ( creation mode), reflecting the t wo primary real-world use cases of T race2Skill. 2.2. Stage 1: Trajectory Generati on W e adopt ReAct ( Y ao et a l. , 2023 ) as the a gent harness. Given S 0 , we run 𝜋 𝜃 on each task 𝑡 𝑖 ∈ D evolv e with query 𝑞 𝑖 , yielding a trajectory: 𝜏 𝑖 = 𝜋 𝜃 ( 𝑞 𝑖 ; S 0 ) = 𝑞 𝑖 , ( 𝑟 ( 𝑖 ) 1 , 𝑎 ( 𝑖 ) 1 , 𝑜 ( 𝑖 ) 1 ) , . . . , ( 𝑟 ( 𝑖 ) 𝑇 𝑖 , 𝑎 ( 𝑖 ) 𝑇 𝑖 , 𝑜 ( 𝑖 ) 𝑇 𝑖 ) , 𝑦 𝑖 , (4) where 𝑟 ( 𝑖 ) 𝑘 is the 𝑘 -th reaso ning trace, 𝑎 ( 𝑖 ) 𝑘 the tool call, 𝑜 ( 𝑖 ) 𝑘 the observati on, and 𝑦 𝑖 ∈ { 0 , 1 } the correctness outcome. The corpus T = { 𝜏 1 , . . . , 𝜏 𝑁 } is partitio ned into: T − = { 𝜏 𝑖 ∈ T : 𝑦 𝑖 = 0 } , T + = { 𝜏 𝑖 ∈ T : 𝑦 𝑖 = 1 } . (5) T rajectory generation is f ully para llelizabl e; in practice, 200 trajectories with 50+ turns using a 122B -parameter LLM require less than 2 GP U-hours. The a gent system prompt template is reprod uced in Appendix B.1 . 2.3. Stage 2: P arallel Multi-Agent P atch Proposa l A fleet o f specialized an a lyst sub-agents, each assigned to a single trajectory 𝜏 𝑖 , independently proposes edits to the skill. Each analyst t akes a frozen copy of S 0 and one trajectory , and outputs a skill patch : 𝑝 𝑖 = ( A − ( S 0 , 𝜏 𝑖 ) , 𝜏 𝑖 ∈ T − A + ( S 0 , 𝜏 𝑖 ) , 𝜏 𝑖 ∈ T + (6) All analysts are dispatched concurrently to a thread pool, yielding the patch pool P = { 𝑝 𝑖 } with no sequential dependency bet w een agents. Both roles are instructed to propose patches that generalize beyo nd the single observ ed trajectory , and strictly f ollo w Anthropic’s recommendati on f or skill writing st yle ( Anthropic , 2026a ) on con ciseness, actiona bilit y , and hierarchi cal disclosure. Since w e assume no stronger teacher model is availab le, errors are subst antially harder to diagn ose than successes, moti vating asymmetri c an a lyst designs. Success Analyst ( A + ). A + foll ow s a fixed single-pass workfl ow: it cleans the trajectory , identifies generalizab le behavi or patterns that contributed to the correct answer , and proposes skill patches. The single-call design is both sufficient and effici ent since successful trajectories require no interactive di a gno sis. Error An a lyst ( A − ). A − is implemented as a ReAct-st yle multi-turn agenti c loop. Giv en 𝜏 𝑖 ∈ T − , it can inspect the f ull trace, read input/output files, and compare the agent’s answer a gainst ground truth — iteratively narrowing down the root cause before proposing a patch. The loop termin ates when A − either (1) successf ully fixes and causa lly expl ains the f ailure, or (2) exhausts its turn b udget. If neither condition yields a va lid causa l analysis, 𝜏 𝑖 is excluded from the patch pool. This qu a lit y gate ensures ev ery patch in P − is grounded in a v erified f ailure cause, in contrast to prior work deriving insights vi a a single non-interactiv e LLM call ( Ouyang et al. , 2026 ). An ablatio n comparing agenti c and LLM-only error an aly sis is presented in § 4.3 . Independence of Patch Proposa l. All analysts operate on a frozen copy of S 0 with no visibilit y into other a gents’ patches. This independence prevents premature conv ergence, preserving the f ull diversity of per- trajectory observati ons in P . An a lyst prompt templates and represent ativ e example patches are provided in Appendix B.2 . 2.4. Stage 3: Conflict-Free P atch Consolidati on Let P = P − ∪ P + be the f ull patch pool from St a ge 2. St a ge 3 consolidates P into a single coherent skill update 𝑝 ∗ and applies it to S 0 , jointly serving t wo purposes: conflict elimin ati on and indu ctiv e generalization. 4 T race2Skill: Distill T rajectory-Local L essons into T ransfera ble Agent Skills Hierarchi cal merging with programmatic conflict prev ention. The patches are merged in a hierarchy of 𝐿 = ⌈ log 𝐵 merge | P | ⌉ lev els ( 𝐿 ≤ 𝐿 max ). At each lev el ℓ , groups of up to 𝐵 merge patches are synthesiz ed into a single consolidated patch: 𝑝 ( ℓ + 1 ) = M 𝜋 𝜃 , S 0 , { 𝑝 ( ℓ ) 1 , . . . , 𝑝 ( ℓ ) 𝐵 merge } , (7) where M ( 𝜋 𝜃 , S 0 , ·) ded uplicates, resolves confli cts, and preserves uniqu e insights. Crucia lly , M reuses the same 𝜋 𝜃 that generated trajectories and proposed patches — making the entire pipeline self-co nt ained : a single LLM collects experien ce, analyzes it, and distills it into an impro v ed skill with no external teacher . The fin al 𝑝 ∗ is translated into diff-st yle edit operati ons and appli ed programmatically . Three deterministic guardrails enforce correctness: (1) patches referencing no n-existent files are rejected; (2) edits t argeting the same line range within the same file are fl a gged a s confli cts and withheld; (3) the updated S is validated by a skill format checker . P atch consolidatio n as ind uctiv e reasoning. Bey ond conflict elimin atio n, the hierarchical applicati on o f M performs indu ctive reasoning ov er the patch pool. Because each 𝑝 𝑖 deriv es from a single trajectory , P as a whole encodes the distributi on of behavi ors 𝜋 𝜃 exhibits across the evolving set. M is explicitly instructed to identif y preva lent patterns — edits appearing consistently across independent patches — on the grounds that recurring observati ons across div erse trajectories are more likely to reflect systemati c t as k properties and generalize to unseen t as ks and different agent models. Conv ersely , edits a ppearing in only on e or few patches are treated as potentially idio syncrati c and discarded. This prevalen ce-weighted consolidatio n is the mechanism by which deep per-trajectory analysis produ ces a generalizab le skill. The evolv ed skill S ∗ = ( 𝑀 ∗ , R ∗ ) replaces S 0 and is used directly at inference without any retrieva l index. The merge operator prompt templ ate and an example consolidated patch 𝑝 ∗ are given in Appendix B.3 . 2.5. T w o Ev oluti on Modes Skill deepening. S 0 is initialized with a human-expert-written skill. The pipeline refines S 0 by adding failure-specific guidance from T − and reinforcing effecti ve strategies from T + . Skill creation from scratch. S 0 is initialized with a skill drafted by 𝜋 𝜃 from parametric kno wledge alo ne, with no access to t as k trajectories. As we sho w in § 3 , this draft provides no subst antial improv ement ov er no skill — P ( S 0 ; 𝜋 𝜃 , D test ) ≈ P ( ∅ ; 𝜋 𝜃 , D test ) — so ev olution from this point constitutes genuin e skill creation: the pipeline prod uces a usef ul skill from a performan ce-neutral initializ ati on, driv en entirely by trajectory evidence. 3. Experiments 3.1. Experimental S etup Datasets and Skills. Our main experiments focus on the spreadsheet domain, which challenges a gents to interact with a file system and manipulate xlsx files whose contents are hard to inspect without structured tooling. W e use SpreadsheetBen ch- V erified ( Ma et al. , 2024 ), splitting its 400 samples into 200 for the ev olving set and 200 held-out for testing; no test samples are seen during evoluti on. W e additio nally report Soft (sub-probl em pass rate) and Hard ( a ll sub-prob lems m ust pass) scores on the f ull SpreadsheetBen ch. F or out-o f-distrib utio n ( O OD) generalization, we eva luate on WikiT ab leQuesti ons ( Pa supat & Liang , 2015 ) (WikiTQ), which differs in dat a source (Wikipedia) and task t ype ( compositi onal semantic parsing); inputs and expected outputs are con v erted to spreadsheet format so the xlsx skill appli es without modifi cation. All results are av eraged ov er three random seeds (41, 42, 43) using each benchmark’s offi cial evaluati on criteria. Tw o baseline skills are compared: (1) the Anthropic offi cial xlsx skill ( Human- W ritten ), a high-qu ality human-expert-written skill; and (2) an xlsx-basic skill generated by prompting Qwen3.5-122B-A10B from parametric kno wledge alo ne ( P arametric ), containing only commo n-sense-lev el t as k descriptio ns with no trajectory grounding (details in Appendix B.1 ). Skill Settings. W e eva luate six conditio ns: No Skill (no skill document), Human- W ritten ( xlsx ), P arametric ( xlsx-basic ), +Error (Trace2S kill with error an aly sts only), +Success (T race2Skill with success analysts only), and +Combined (T race2Skill with both analyst t ypes). Skill Deepening initializes from Human- W ritten; Skill Creation initializes from P arametric. 5 T race2Skill: Distill T rajectory-Local L essons into T ransfera ble Agent Skills T ab le 1 | Main results sho wn as delt as (%). Skill A uthor = model that evolv ed the skill (row groups); Skill U ser = m odel at inferen ce ( column groups). R eferen ce rows remain absolute scores for context. Ev olved ro ws sho w signed deltas with per-column color intensit y; green = impro vement, red = decline. Delt a s: Deepening is measured against the Human- W ritten baseline; Creatio n against the Parametri c baselin e. A vg : equally w eights in-distributi on SpreadsheetBen ch (V rf/Soft/Hard, both model scal es) and OOD WikiTQ ( both model scal es), expressed a s delt a from the corresponding baselin e. Skill User: Qwen3.5-122B-A10B Skill User: Qw en3.5-35B -A3B Spreads heetBen ch O OD Spreads heetBen ch OO D Conditio n V rf ↑ Soft ↑ Hard ↑ W ikiTQ ↑ V rf ↑ Soft ↑ Hard ↑ WikiTQ ↑ A vg ↑ R eferen ce ( absolute scores) No Skill 27.67 28.90 17.57 21.50 19.00 18.00 4.60 13.33 18.35 Human- W ritten 48.33 36.30 17.03 74.68 9.67 13.03 3.37 9.02 31.57 P arametric 26.17 36.60 17.50 23.73 20.17 13.70 3.87 20.14 20.80 Skill Author: Qwen3.5-122B-A10B Deepening ( init: Human- W ritten) +Error +17.50 +10.30 +10.40 +1.62 +27.00 +9.44 +2.86 +9.26 +9.18 +Success -21.83 -8.57 +0.04 -10.35 +9.16 +3.57 +1.56 +12.09 -0.90 +Combined +21.50 +10.87 +12.50 +4.56 +21.16 +8.84 +1.80 +6.64 +9.19 Creatio n (init: P arametri c) +Error +22.83 +3.77 +5.87 +7.89 +8.66 +9.53 +4.00 +2.06 +7.04 +Success +15.33 -0.93 +4.33 +23.70 +12.83 +11.57 +6.13 +30.36 +17.62 +Combined +0.16 -9.23 -1.40 +32.32 -1.17 +3.73 +1.36 +29.70 +14.96 Skill Author: Qwen3.5-35B-A3B Deepening ( init: Human- W ritten) +Error +16.67 +8.50 +8.14 -6.36 +17.33 +9.17 +4.83 +2.71 +4.47 +Success -22.00 -8.83 -0.50 +1.46 +11.00 +3.64 +0.83 +43.23 +9.85 +Combined +6.67 +3.87 +4.17 +2.65 +20.00 +5.77 +2.36 +42.20 +14.78 Creatio n (init: P arametri c) +Error +1.00 -7.70 +1.03 +57.65 +3.83 +7.30 +2.66 +12.66 +18.26 +Success +5.33 -4.57 +2.43 +9.09 +5.66 +5.80 +2.63 +3.31 +4.54 +Combined -0.84 -9.17 -1.63 +30.82 -0.17 +4.40 +1.26 +18.00 +11.69 Implementation Details. T race2S kill condu cts end-to-end self-ev olutio n: the same LLM serves as trajectory generator , patch proposer , and skill editor . W e experiment with t w o Qwen3.5 MoE m odels: Qwen3.5-122B - A10B and Qw en3.5-35B -A3B. Both are instruct/think hybrid models; we use instruct mode f or m ulti-turn R eAct-st yle agenti c t as ks and thinking mode for single-call tasks (hierarchical merging, success analysis, patch con versi on). Models are served with vLLM ( Kw on et al. , 2023 ) using the recommended Qwen3.5 generatio n configurati on 1 . St age 1 generates 1 trajectory per prob lem. At Stage 2, 128 sub-a gents run in parallel, and w e use a merge batch size of 32. For all R eAct-st yle agents, we set the interaction turn budget to 100. 3.2. Main Results T ab le 1 presents results across all skill conditions, model scales, and transfer directions. W e report the performan ce of evolv ed skills as delt as against their respective baselines: comparing skill deepening against existing human-written skills, and skill creatio n against the model’s base parametric performan ce. W e use A vg as the primary summary metric: a skill that genuin ely benefits an agent should transfer across model scales and t as k domains, so A vg equally weights in-distrib ution SpreadsheetBench perf ormance (V rf/Soft/Hard, both m odel scales) and WikiTQ transfer performance ( both model scales), rewarding generalization rather than in-distrib ution specialization. 1 See https://huggingface.co/Qwen/Qwen3.5- 35B- A3B and https://huggingface.co/Qwen/Qwen3.5- 122B- A10B . 6 T race2Skill: Distill T rajectory-Local L essons into T ransfera ble Agent Skills Human-written is a strong handcrafted prior , b ut not a port ab le one; parametric is wea k. The Human- W ritten baselin e is strong for the 122B agent, reaching 48.33% on SprBench- V rf and 74.68% on WikiTQ , but it does not transfer cleanly across model sca le: for the 35B a gent it underperforms No Skill by − 9.3 pp on SprBen ch- V rf and − 4.3 pp on WikiTQ . By contrast, the Parametri c baseline remains close to No Skill o vera ll (26.17% vs. 27.67% SprBench- Vrf for the 122B agent), confirming that parametric knowl edge alo ne does not yield useful skill content ( H an et al. , 2026 ). These t wo referen ces motiv ate both Deepening and Creation: the former asks whether a strong manual prior can be refined, while the latter asks whether trajectory-grounded distillation can b uild a usef ul skill st arting from an inadequ ate on e. Deepening reliably strengthens the human-written s kill on in-distributi on spreads heet tas ks. Starting from Human- W ritten, 122B -authored Deepening gains + 17.5 pp on SprBench- V rf with +E rror and + 21.5 pp with +Combined, while also improving S o ft and Hard scores. These gains are not confined to the authoring m odel: the 35B -authored Deepening +Error skill gains + 16.7 pp on SprBench- Vrf when used by the 122B agent, and the 122B -authored counterpart gains + 27.0 pp for the 35B agent. The same refined skills also transfer bey ond the training distributio n, with 122B -authored Deepening improving WikiTQ by + 1.6 pp (+E rror) and + 4.6 pp (+Combined). Creatio n subst antially outperf orms the w eak parametric baselin e and can match or exceed human-written qualit y . Because P arametric is a poor st arting point, the relevant comparison is whether distilled skills recov er meaningf ul capa bilit y from scratch. The answ er is yes: 122B -authored Creation +Error gains + 22.8 pp on SprBen ch- V rf , bringing performance close to Human- W ritten despite starting from a weak prior . In some settings Creatio n even outperforms Human- W ritten: the 35B -authored Creation +E rror skill, when used by the 122B agent, gains + 57.7 pp on WikiTQ ov er P arametric ( best in tab le , reaching 81.38%) and surpasses Human- W ritten by + 6.7 pp. The Avg column identifies the settings that are rob ust across in-distributi on, OO D, and cross-m odel use. Vi ewed through Avg, the strongest configuratio ns are those that improv e multiple slices of the t ab le at once rather than spiking on only one benchmark or skill user model. The best A vg scores come from Creation, with 35B -authored Creatio n +Error reaching + 18.3 pp and 122B -authored Creation +Success reaching + 17.6 pp, sho wing that from-scratch skill synthesis can remain strong after av eraging ov er both dat asets and both user m odels. At the same time, Deepening remains broad ly competitiv e, and +Combined is notew orthy because it stays consistently high across all four A uthor–Mode combinations rather than depending on a single especially fav orab le setting. Across analyst t ypes, +Combined is the mo st consistently strong signal, +Error the most reliab le, and +Success the mo st volatile. Measured by A vg improv ement ov er the corresponding referen ce baseline, +Combined is the steadiest high performer , while +Error remains reliab ly positiv e in every setting and serves as the safest default sign al. +Success , by contrast, has the highest variance: it produces the largest single-setting A vg gain ( + 17.6 pp for 122B -authored Creation) b ut is a lso the only conditi on that drops belo w baselin e ( − 0.9 pp for 122B -authored Deepening). This pattern suggests that success-deriv ed patches can be highly valua bl e, but only when the hierarchica l merge filters them effectiv ely; otherwise they are less st ab le than error-driven updates, motivating a m ore selectiv e success analyst design (see § 6 ). 3.3. Math Rea soning T ab le 2 | Math reasoning results sho wn as deltas from the No Skill baselin e. D - T est : DAPO -Math- T est-100 pass rate (%); AIME : AIME 2026 avg@8 o ver 30 problems (%). R eference ro w remains absolute; evolv ed rows use green / red delt a intensit y . Skill U ser: 122B Skill User: 35B Conditio n D-T est ↑ AIME ↑ D-T est ↑ AIME ↑ No Skill 92.0 90.4 89.0 83.3 122B -A uthored +Error +3.0 +2.9 +5.0 +5.0 35B -A uthored +Error +2.0 +1.3 +4.0 +0.5 T o assess whether T race2Skill genera lizes be- y ond spreadsheets, we apply it to mathematical reaso ning using DAPO -Math- Train-400 as the ev olving set. W e eva luate on DAPO -Math- T est-100 (in- distrib ution; pass rate %) and AIME 2026 ( out-o f-distributi on competition mathematics; avg@8 o ver 30 problems). F ollowing the cross- m odel protocol o f Section 3.2 , we create skills from scratch using error analysts. R esults are sho wn in T abl e 2 . 7 T race2Skill: Distill T rajectory-Local L essons into T ransfera ble Agent Skills Distilled math skills yield consistent gains across m odels and benchmarks (T ab le 2 ). The 122B -authored skill gains + 3.0 pp on DAPO-Math-T est-100 and + 2.9 pp on AIME 2026 (same-model), and transfers positiv ely cross-model: + 5.0 pp on DAPO -Math- T est-100 and + 5.0 pp on AIME 2026 for the 35B agent. The 35B -authored skill is compara b ly effective: + 4.0 pp same-model and + 2.0 pp cross-model on DAPO-Math- T est-100, confirming that trajectory-grounded distillation is domain-agn ostic and scales to competiti on-lev el eva luation. 3.4. Visual Questi on Answering T o evaluate whether Trace2S kill generalizes to multim odal visual reasoning, we apply it to Visua l Questi on Answering ( VQ A) using DocVQ A Mathew et al. ( 2020 ) as the t arget benchmark. DocVQ A requires jointly understanding document ima ges—forms, tab les, inv oices, letters, reports—and answering n atural-langua ge questi ons by extracting, locating, and reaso ning ov er visual and textual elements. W e use the o fficial validatio n split (5,349 question–ima ge pairs), reserving the first 2,700 inst ances as the evolving set and the remaining 2,649 as the held-out evaluati on set . W e report ANL S ( Av erage Norma liz ed Levenshtein Similarit y , the officia l metric) and Accuracy ( ANL S ≥ 0 . 5 , %). Similar to Section 3.2 , we create skills from scratch using error analysts. R esults are shown in T ab le 3 . T ab le 3 | DocVQ A results shown as delt a s from the No Skill baselin e ( evaluati on set: 2,649 inst ances). ANLS : A vera ge Norma lized L ev enshtein Simil arit y; Acc : ANLS ≥ 0 . 5 (%). R eference ro w remains absolute; ev olved rows use green / red delt a intensit y . Skill U ser: 122B Skill User: 35B Conditio n ANL S ↑ Acc ↑ ANL S ↑ Acc ↑ No Skill 0.6424 71.2 0.6843 75.2 122B -A uthored +Error +0.1639 +15.3 +0.1554 +13.6 35B -A uthored +Error +0.0093 +0.9 -0.0620 -6.2 T ab le 3 presents a nuanced picture. The No Skill ro w revea ls an unexpected reversa l: the 35B a gent (0.6843 ANL S) outperforms the 122B agent (0.6424 ANL S) on DocVQ A without any skill. Despite this task performance advanta ge, the 35B model f alls behind as a skill author . The 35B -authored skill yields negligibl e gains for the 122B model ( + 0.009 ANL S) and ac- tiv ely degrades same-model 35B performan ce ( − 0.062 ANL S , − 6.2 pp accuracy). By con- trast, the 122B -authored skill gains + 0.1639 ANL S and + 15.3 pp accuracy (same-model), and transfers just as strongly to the 35B model ( + 0.1554 ANL S , + 13.6 pp accuracy). This dissociatio n suggests that inductiv e reaso ning for skill authoring — identif ying recurring f ailure patterns across trajectories and distilling them into actio nab le rules — is a distinct capa bilit y from t as k execution. A model that performs well on DocVQ A does not necessarily possess the reflectiv e ca pacit y to analyze why it fails and generalize those observati ons into a transferab le skill. 4. Analysis 4.1. P arallel Consolidatio n vs. Sequential Editing In the online skill evoluti on paradigm, the skill is updated sequentially as new trajectory batches arrive. W e isolate the contrib ution o f parallel, many-to-on e consolidation by comparing against t wo sequential baselin es: Seq- 𝐵 = 1 , where the skill is updated after every single trajectory , and Seq- 𝐵 = 4 , where the skill is updated after ev ery batch of four trajectories. All three conditions use error analysts only and initialize from the Human- W ritten skill; results are sho wn in T ab le 4 . On the 122B model, parallel consolidation outperforms both sequential settings across all SpreadsheetBen ch metrics ( + 4.0 pp V rf o ver Seq- 𝐵 = 1 , + 6.8 pp ov er Seq- 𝐵 = 4 ). On the 35B model, parallel wins on V rf but Seq- 𝐵 = 1 scores modestly higher on Soft and Hard, suggesting the smaller model may benefit from m ore incremental updates in some conditi ons. How ever , this marginal qualit y variatio n comes at 20 × the computational cost, and the efficiency gap widens linearly with the number of trajectories an a lyzed. Latency . With 𝑊 = 128 workers and 𝑁 ≈ 70 error lesso ns, all an aly sts execute in a single parallel round; the hierarchi cal merge adds ⌈ log 2 𝑁 ⌉ ≈ 7 f urther sequential rounds ( one per merge layer), yielding ≈ 8 sequential 8 T race2Skill: Distill T rajectory-Local L essons into T ransfera ble Agent Skills T ab le 4 | P arallel consolidati on vs. sequential editing on SpreadsheetBen ch (same-model Deepening, +Error only , %). Seq- 𝐵 : skill updated after ev ery batch of 𝐵 trajectories. Bold = best per column. Skill U ser: 122B Skill U ser: 35B Conditio n V rf ↑ Soft ↑ H ard ↑ V rf ↑ Soft ↑ Hard ↑ Time ↓ Seq- 𝐵 = 4 59.00 40.63 20.63 26.17 22.37 7.47 ∼ 15 min Seq- 𝐵 = 1 61.83 44.40 25.40 26.00 23.83 10.57 ∼ 60 min P arallel ( ours) 65.83 46.60 27.43 27.00 22.20 8.20 ∼ 3 min LLM-call rounds in tot a l. The sequential baselines require 𝑁 and ⌈ 𝑁 / 𝐵 ⌉ rounds respectiv ely , since each skill edit depends on the preceding one. In practice this translates to 3 min (parallel) vs. 60 min (Seq- 𝐵 = 1 , 20 × ) and 15 min (S eq- 𝐵 = 4 , 5 × ), with the gap scaling linearly in 𝑁 . All times are in node hours of an 8-GPU A800 node. Bey ond effici ency , parallel consolidati on has a structura l advantage: all patch proposals are deriv ed from the same frozen initial skill S 0 , preventing the sequentia l drift inherent to the online setting, where each skill update alters the context in which subsequent trajectories are an alyzed. The hierarchica l merge then performs ind uctiv e reaso ning ov er the f ull popul ati on of trajectory-local observati ons sim ult aneo usly , selecting patterns that recur across diverse trajectories rather than patterns that recur in the m ost recent updates. 4.2. Trace2Skill vs. Retri eva l-Memory Baselin e R easoningBank ( Ouyang et al. , 2026 ) stores generalizab le lessons derived from each trajectory and retriev es the mo st relevant memori es at inference time using task-qu ery simil arit y . Since it draws on both success and failure trajectories, we compare it a gainst +Combined , which uses the same trajectory pool but distills it into a portab le skill document rather than maintaining a retrieva l index. W e implement a Rea soningBank-st yle retrieva l baselin e with their o fficial prompt and recommended retrieval setting (top 1) with Qwen3-Embedding-8B a s the retriev er . R esults on same-model Deepening are sho wn in T ab le 5 . T ab le 5 | T race2Skill (Human W ritten+Combined) vs. Rea soningBank on SpreadsheetBen ch (same-model Deepening, %). R easoningBank retrieves success and failure mem ories at inference via Qwen3-Embedding-8B; +Combined distills the same trajectory pool into a single port ab le skill with n o retrieval mod ule. Bold = best per column. Skill U ser: 122B Skill U ser: 35B Conditio n V rf ↑ Soft ↑ H ard ↑ V rf ↑ Soft ↑ Hard ↑ R easo ningBank ( O uyang et al. , 2026 ) 56.00 40.10 21.30 20.50 17.30 4.97 Human- Written+Co mbined ( ours) 69.83 47.17 29.53 29.67 18.80 5.73 +Combined outperforms Rea soningBank by large margins: + 13.8 pp V rf , + 7.1 pp Soft, + 8.2 pp Hard for the 122B model; + 9.2 pp Vrf , + 1.5 pp S o ft, + 0.8 pp H ard for 35B. R easoningBank on the 35B model (20.50% V rf ) barely exceeds No Skill (19.00%), indicating the retriev er fails to surface relevant guidance when the 35B m odel’s query represent atio ns do not align w ell with the stored memory embeddings. W e attrib ute the performance gap to three f actors. First, retrieval qualit y is sensitive to surf ace-lev el similarit y bet w een the test query and stored memory keys: when the test distributi on differs in phrasing or structure from the evolving set, retrieva l degrades, while the distilled skill transfers without modifi catio n. Second, retriev ed snippets compete with the t a sk context for model attention, whereas a skill pre-loaded into the system prompt is already integrated before any task-s pecific content is seen. Third, T race2Skill’s hierarchi cal merge actively dedupli cates and a bstracts trajectory-local observati ons into genera l principles; raw trajectory summaries in a retrieva l bank are not filtered for redundan cy or genera liz a bilit y . T aken together , these results support the premise that distillation into a compact, model-a gno stic skill document is a more effectiv e use of trajectory evidence than episodic retrieva l. 9 T race2Skill: Distill T rajectory-Local L essons into T ransfera ble Agent Skills 4.3. Agentic Error Analysis vs. Single-LLM-Call Baselines Many prior w orks derive transferab le lessons or skills from error trajectories via a single no n-interactiv e LLM call ( O uyang et al. , 2026 ; Xia et al. , 2026a ; Y ang et al. , 2026 ; Jiang et al. , 2026 ). The +E rror LLM conditi on ab l ates our agenti c loop design: a single LLM call receives each error trajectory and proposes a patch directly , without the abilit y to inspect files, query ground truth, or iterativ ely narrow the root cause. T ab le 6 compares +Error ( agenti c, ours) against +Error LLM across all four Author–Mode combinations. T ab le 6 | Agentic error analysis (+E rror) vs. single-LLM-call error analysis (+Error LLM) across all A uthor–Mode combinatio ns (%). Same-model cells are shaded; plain cells are cross-m odel transfer . Bold = better o f the t wo conditi ons per cell. Skill U ser: Qw en3.5-122B -A10B Skill U ser: Qw en3.5-35B -A3B Spreads heetBench O OD Spreads heetBench OO D Conditio n V rf Soft Hard WikiTQ V rf Soft Hard WikiTQ Avg Skill A uthor: Qwen3.5-122B-A10B Deepening +Error ( ours) 65.83 46.60 27.43 76.30 36.67 22.47 6.23 18.28 40.75 +Error LLM 67.00 43.93 25.23 39.81 25.00 22.43 6.23 11.24 28.58 Creatio n +Error ( ours) 49.00 40.37 23.37 31.62 28.83 23.23 7.87 22.20 27.84 +Error LLM 27.17 27.73 16.20 47.26 19.83 17.60 4.70 23.30 27.08 Skill A uthor: Qwen3.5-35B-A3B Deepening +Error ( ours) 65.00 44.80 25.17 68.32 27.00 22.20 8.20 11.73 36.04 +Error LLM 37.83 22.93 12.83 77.05 30.50 20.17 8.73 9.95 32.83 Creatio n +Error ( ours) 27.17 28.90 18.53 81.38 24.00 21.00 6.53 32.80 39.06 +Error LLM 22.00 27.67 16.60 54.61 23.50 16.87 4.93 11.24 25.76 Agentic analysis wins in Avg across all settings. Agentic +Error outperf orms +E rror LLM in weighted A vg in all four settings, with gaps of + 12.2 pp (122B Deepening), + 0.8 pp (122B Creatio n), + 3.2 pp (35B Deepening), and + 13.3 pp (35B Creation). The 122B Creation setting is the only near-ti e: both conditio ns score around 27 pp, masking a striking intern a l divergen ce (see belo w). Agentic error analysis produ ces more transfera bl e patches. The A vg advantage holds across both in- distrib ution SpreadsheetBench and OOD WikiTQ columns: +E rror LLM patches that achiev e comparab le ID scores frequently degrade on WikiTQ and cross-m odel cells, while agenti c patches remain positiv e across both axes. Why the agentic loop prod uces more transfera bl e patches. A qualitative study o f 33 shared error cases confirms the structural advantage built into A − (§ 2 ): the t w o pipelines reach strong agreement on only 4 cases (12.1%), with clear disagreement in 18 (54.5%). The LLM-only analyzer , limited to the executio n log, o ver-attrib utes parse failures as the primary root cause in 57% of cases where parse-error messages appear (vs. 14% for a gentic), and in at lea st on e case hallu cinated three distinct failure causes for a trajectory where artifact evaluatio n confirmed the output wa s already correct. Artif act access and fix validati on let A − reject such f alse positives and anchor each patch to a v erified f ailure mechanism — producing the domain-general guardrails that transfer across model scal es and OOD settings. 4.4. Genera liz ab le S oP s L earned W e inspect the 323 map patches produ ced by the 122B Deepening +Combined run to characteri ze which standard operating procedures (SoPs) the pipeline distills. The four m ost preval ent themes together account for 546/323 patch cit atio ns ( patches can cite multipl e themes) and are encoded directly in the main SKILL.md ; less comm on patterns are detailed in Appendix A . 10 T race2Skill: Distill T rajectory-Local L essons into T ransfera ble Agent Skills F ormula reca lculation and write-back verifi catio n (178/323 patches). R un recalc.py after every form ula write and reopen with data_only=True to confirm evaluati on; skipping this step lea v es cells stale and is the single m ost comm on error mode in the run. T ool selecti on: openpyxl o ver pandas.to_excel() (177/323 patches). U se pandas for read/transform logic and openpyxl for write-back; copy the input file to the output path first to preserve all stru ctural anchors. pandas.to_excel() silently destroys form ul a relationships and n amed ranges. Explicit read-back v erificatio n (138/323 patches). After writing, reopen the output file and confirm every target cell holds the expected valu e before submitting; error trajectori es that f ail characteristica lly omit this check. Structura l-edit safety (53/323 patches). Delete rows in descending order to prev ent index-shift corruption; copy the input w orkbook before editing to preserv e formatting and f ormula s. Error trajectories document both failure m odes; success trajectories confirm the protectiv e w orkflo w . Ni che quirks are routed to references/ . L o w-support observatio ns are n ot discarded b ut routed into 13 supplementary referen ce files rather than the main SKILL.md . F or example, cell color extractio n, FI FO vs LI FO mismatch under a special busin ess logic etc. This mirrors est ab lished skill-design practice: procedura l guidance flo ws from general to ca se-specific, with the main document encoding universa l workfl ow rules and references/ serving as an on-demand look-up layer for infrequent edge cases. Trace2S kill recov ers this hierarchy auto matica lly from trajectory evidence rather than requiring manual curation. 5. R el ated W ork Agent Skills. Anthropic’s skill framework formalizes skills as light weight, expert-authored documents that encode st andard operating procedures (SO Ps) for focused task domains. These are designed for dynamic loading, progressiv e disclosure, and compatibilit y with diverse agent harnesses ( Anthropic , 2026b ). SkillsBen ch ( Li et al. , 2026b ) pro vides the first systematic benchmark of skill qualit y , rev ealing that while curated, human- written skills genera lly improv e performan ce, self -generated skills relying purely on parametric kno wledge rarely help. Furthermore, they find that a small set of focu sed skills consistently outperforms a single, b loated document. Simil arly , Li ( 2026 ) dem onstrate that single agents augmented with in-depth skills can match the performance of multi-a gent frameworks, though skill retriev al remains a bottlen eck. S WE-Skills-Ben ch ( Han et al. , 2026 ) evaluates skill injection in real soft ware-engineering t as ks, reporting an av erage + 1.2% gain when skills are well-matched to the t as k context, b ut a notabl e performan ce drop during context mismatch. AgentSkillOS and SkillNet extend this ecosystem to encompa ss skill selecti on and gov ern ance ( Li et a l. , 2026a ; Liang et al. , 2026 ). Our positio n: W e build upon the est ab lished consensus that high-qualit y , focu sed skills are critica l. How ever , we address a narro wer , underexplored question: giv en a single skill o f bounded scope, ho w much can systemati c trajectory analysis improv e it? The vulnera bilit y to context mismatch highlighted by SWE-Skills-Bench directly moti vates our design choice to indu ctively distill genera liz a bl e patterns rather than o verfit to specifi c queries. Experien ce Mem ory for Agent Self-Ev olution. Early work demonstrated that iterativ e feed back on execution trajectories can significantly improv e a gent behavi or . F or instance, V oyager ( W ang et al. , 2023 ) accumulates reusab le skills through open-ended interactio n, while Refl exion ( Shinn et al. , 2023 ) refines decisio ns vi a verba l self-refl ection on past successes and failures. Building on these foundati ons, subsequent research ha s focused on storing trajectory-derived insights in retrieva l banks, which are then queried to augment f uture t a sks ( Ouyang et al. , 2026 ; F ang et al. , 2026 ; W ang et al. , 2024 ; Qian et al. , 2024 ; Nottingham et al. , 2024 ; Liu et al. , 2025 ). O ur positio n: While these systems rely on test-time retriev al from episodic mem ory banks, we explore a f undamentally different approach: distilling experience into declarativ e skills as st ati c, shareab le artifacts. This distincti on is moti vated by t wo properties. First, indu ctive compressi on across many trajectories smooths out the quirks of any single episode, yielding robust principl es rather than loca liz ed anecdotes. Second, a distilled declarative skill is architecture-agno stic and seamlessly shareab le across agents and model scales, whereas retrieva l banks are t ypically tightly coupl ed to the specifi c harness that generated them. 11 T race2Skill: Distill T rajectory-Local L essons into T ransfera ble Agent Skills A utomatic S kill Self-Ev olution. The closest neighbors to our work automatica lly evolv e skills from agent trajec- tories. SkillW eav er ( Zheng et al. , 2025 ) generates w eb API skills through structured exploratio n. A utoSkill ( Y ang et al. , 2026 ) creates and updates skills online from user chat trajectories vi a an extraction–maintenance–reuse lifecycle. XSkill ( Jiang et al. , 2026 ) maint ains dua l stores: skills encoding t as k-lev el SOP s, and experiences encoding context-sensitive, action-lev el guidance. EvoS kill ( Alzubi et al. , 2026 ) iterativ ely diagn oses failures and validates skill updates, making it the closest single-system neighbor . Memento-Skills ( Z hou et a l. , 2026 ) employs st atef ul markdo wn skills updated incrementally through a read–write loop. Beyo nd f ully automated ev olution, Anthropic’s skill-creator system ( Anthropic , 2026a ) represents the st ate-o f-the-art in human-guided refinement, where practition ers qualitatively revise skills based on agent outputs from a small test set. O ur positi on: While prior w ork has activ ely explored trajectory-based skill evolutio n, T race2Skill introd uces three critica l differentiators. (1) Many-to-one consolidatio n: W e merge all trajectory-loca l patches sim ultaneously rather than editing the skill sequentially per trajectory , a vo iding order dependence and o verfitting to early observati ons. (2) Comprehensive declarative artif acts: W e t arget unified, Anthropic-st yle skill directories rather than n arro w API objects, d ual stores, or retrieva l-augmented hybrids. (3) No test-time retrieval: The ev olved skill is consumed directly , making it natively compatibl e with any a gent harness. Furthermore, while con current automated systems rely on propriet ary LLMs ( e.g., Claude), our f ull pipeline achiev es robust evolu- tio n using open-source m odels as small as 35B parameters. Fin a lly , T race2Skill serves as a scalab le complement to manual ov ersight ( like Anthropic’s skill-creator), distilling lessons across hundreds of trajectories where human review w ould bottleneck. Skill and Poli cy Co-ev olution. SkillRL ( Xia et al. , 2026a ) co-ev olves skills and model polici es vi a reinforcement learning, treating skills as localized experience triggers (“when X, do Y”) rather than comprehensive S OPs. Similarly , ARISE and Met aClaw ( Xia et al. , 2026b ; Li et al. , 2026c ) explore d ual-timescal e online adapt ati on with contin ual poli cy updates. O ur position: In contrast to co-evoluti on methods that require parameter updates, w e strictly study frozen-model, training-free, artif act-lev el adaptation, ensuring our distilled skills remain entirely model-a gnostic. 6. Conclu sio n W e introd uced T race2Skill, a framework f or automatic skill creatio n and adaptatio n that sim ulates ho w human experts author skills: accumulating broad domain kno wledge through extensive experience before instanti ating it into a con cise, decl arativ e artifact. Rather than updating a skill sequentially as individ ual trajectories arriv e, T race2Skill dispatches a parallel fleet of analyst sub-agents to propose targeted editing patches from disjoint trajectory batches. It then consolidates all proposals simultaneous ly into a single, coherent skill directory vi a ind uctiv e reasoning and programmatic conflict prev ention. Our findings show that skills distilled from one m odel’s trajectories genera lize remarkab ly well across model scal es and to out-of -distributio n t a sks. Furthermore, an a lyses demo nstrate that consolidating a broad set of trajectory-loca l lessons sim ult aneo usly impro ves both computational efficien cy and do wnstream performance, and a single portab le skill f older outperforms retrieval-ba sed per-case experience. By structuring the output as a hierarchica l directory ( e.g., broad principles in a primary ‘SKI LL.md‘ file and case-specific heuristics in a ‘referen ces/‘ subdirectory), T race2Skill successfully encodes both generalizab le patterns and nuanced, case-s pecific pitfalls. Limitation and Future W ork. As a work in progress, the current paper is limited in these aspects, which we plan to address in the near f uture: (1) Causal effect quantificatio n of editing patches: Currently , patches are consolidated holistica lly , making it difficult to isol ate the margin al contributi on or potential interference of any single proposed change. W e aim to develop methods to rigorously quantif y the causal impact of individ ual trajectory-deriv ed patches on the final skill. (2) Tracing the utilit y o f s pecific s kill sections: W e hav e not yet implemented a mechanism to dynamically trace how heavily the a gent relies on specific sections of the generated skill directory during inference. Future work will focus on fine-grained attributi on tracking to determine the exact utilit y of different compon ents ( e.g., specific checklist items vs. referen ce files), which will enab le automated pruning of ineffecti ve or distracting skill sectio ns. 12 T race2Skill: Distill T rajectory-Local L essons into T ransfera ble Agent Skills R eferen ces Salaheddin Alzubi, Noah Pro venzano, Jaydo n Bingham, W eiyuan Chen, and Tu Vu. Ev oskill: A utomated skill disco very for multi-a gent systems, 2026. URL . Anthropic. Ho w to create a s kill with claude through conv ersation. Claude Tutorials, 2026a. URL https://claude.com/resources/tutorials/ how- to- create- a- skill- with- claude- through- conversation . Anthropic. What are skills? Cl aude Help Center , 2026b. URL https://support.claude.com/en/ articles/12512176- what- are- skills . Access Date: 2026-03-22. R unnan F ang, Y uan Liang, Xiaobin W ang, Jialong Wu, Shu o fei Qiao, Peng jun Xie, Fei Huang, Huajun Chen, and Ningyu Zhang. Memp: Exploring agent proced ural mem ory , 2026. URL 2508.06433 . T ingxu Han, Yi Zhang, W ei Song, Chunrong F ang, Z henyu Chen, Y oucheng Sun, and Lijie Hu. Swe-skills-ben ch: Do agent skills actually help in real-w orld so ft ware engineering?, 2026. URL 2603.15401 . Guanyu Jiang, Zhaochen Su, Xiaoye Qu, and Yi R. Fung. Xskill: Continua l learning from experience and skills in multim odal agents, 2026. URL . Kimi T eam. Kimi introdu ces agent swarm: L et 100 ai a gents work for y ou. Kimi Blog, 2026. URL https: //www.kimi.com/blog/agent- swarm . W oosuk Kw on, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Y u, Joseph E. Gonzal ez, Hao Zhang, and Ion Stoica. Efficient memory man a gement for large langu a ge m odel serving with pa gedattention, 2023. URL . Hao Li, Chunjiang Mu, Jianhao Chen, Siyue R en, Zhiyao Cui, Y iqun Zhang, L ei Bai, and Shuyu e Hu. Organi zing, orchestrating, and benchmarking agent skills at ecosystem scale, 2026a. URL 2603.02176 . Jiachun Li, P engfei Cao, Z hu oran Jin, Y ubo Chen, Kang Liu, and Jun Z hao. Mira ge: Eva lu ating and expl aining ind uctiv e reasoning process in language m odels, 2025. URL . Xiangyi Li, W enbo Chen, Y imin Liu, S henghan Zheng, Xiaokun Chen, Y ifeng He, Y ubo Li, Bingran Y ou, Haotian Shen, Jiankai Sun, Shuyi W ang, Binxu Li, Qunhong Zeng, Di W ang, Xuandong Zhao, Yuanli W ang, R oey Ben Chaim, Zonglin Di, Yipeng Gao, Junw ei He, Y izhuo He, Liqiang Jing, Luyang Kong, Xin Lan, Jiachen Li, S onglin Li, Yijiang Li, Y ueqian Lin, Xinyi Liu, Xuanqing Liu, Haoran Lyu, Ze Ma, Bow ei W ang, R unhui W ang, T ianyu W ang, W engao Y e, Yu e Z hang, Hanw en Xing, Y iqi Xue, Steven Dillmann, and Han chung L ee. Skillsbench: Benchmarking how well agent skills work across div erse tasks, 2026b. URL https://arxiv.org/abs/2602.12670 . Xiaoxiao Li. When single-agent with skills replace multi-a gent systems and when they fail, 2026. URL https://arxiv.org/abs/2601.04748 . Y u Li, Rui Miao, Z hengling Qi, and Tian Lan. Arise: Agent reasoning with intrinsic skill evoluti on in hierarchica l reinforcement learning, 2026c. URL . Y u an Liang, Ru obin Z hong, H aoming Xu, Chen Jiang, Y i Zhong, Runnan F ang, Jia-Chen Gu, Shumin Deng, Y unzhi Y ao, Mengru W ang, Shu of ei Qiao, Xin Xu, T ongtong W u, Kun W ang, Y ang Liu, Zhen Bi, Jungang Lou, Y uchen Eleanor Jiang, Hangcheng Zhu, Gang Y u, H aiw en Hong, Longtao Hu ang, Hui Xue, Chenxi W ang, Yijun W ang, Zifei Shan, Xi Chen, Z haopeng Tu, F eiyu Xiong, Xin Xie, P eng Z hang, Zhengke Gui, Lei Liang, Jun Z hou, Chiyu Wu, Jin Shang, Y u Gong, Junyu Lin, Changliang Xu, Hong jie Deng, W en Zhang, Keyan Ding, Qiang Z hang, Fei Huang, Ningyu Zhang, Jeff Z. P an, Guilin Qi, Haofen W ang, and Huajun Chen. Skilln et: Create, eva luate, and conn ect ai skills, 2026. URL . Brian S . Lin, Jiaxin Y uan, Z ihan Zhou, Shouli W ang, S huo W ang, Cunliang Kong, Qi Shi, Y uxu an Li, Liner Y ang, Zhiyuan Liu, and Maosong Sun. O n llm-based scientific ind uctiv e reaso ning beyo nd equations, 2025. URL https://arxiv.org/abs/2509.16226 . 13 T race2Skill: Distill T rajectory-Local L essons into T ransfera ble Agent Skills Y it ao Liu, Chenglei Si, Karthik Nara simhan, and Shunyu Y ao. Contextual experience replay for self-impro vement o f l anguage agents, 2025. URL . Zeyao Ma, Bohan Zhang, Jing Z hang, Jif an Y u, Xiaokang Zhang, Xiaohan Z hang, Sijia Luo, Xi W ang, and Jie T ang. Spreads heetbench: T ow ards challenging real world spreadsheet manipulation, 2024. URL https://arxiv.org/abs/2406.14991 . Minesh Mathew , Dimosthenis Karatz a s, R Manmatha, and CV Ja wahar . Docvqa: A dataset for vqa on document ima ges. corr a bs/2007.00398 (2020). arXiv preprint , 2020. Kolby Nottingham, Bod hisatt wa Pra sad Majumder , Bhav ana Dalvi Mishra, Sameer Singh, Peter Clark, and R oy Fox. S kill set optimization: R einforcing langu a ge m odel behavi or via transfera b le skills, 2024. URL https://arxiv.org/abs/2402.03244 . Siru Ouyang, Jun Y an, I-Hung Hsu, Y anfei Chen, Ke Jiang, Zifeng W ang, Rujun Han, L ong T . L e, Samira Daruki, Xiangru T ang, Vishy Tiruma lashett y , George L ee, Mahsan R o fou ei, H angfei Lin, Jiaw ei Han, Chen- Y u Lee, and T omas Pfister . R easo ningbank: S ca ling agent self-ev olving with rea soning mem ory , 2026. URL https://arxiv.org/abs/2509.25140 . P anupong P asupat and Percy Li ang. Compositio nal semantic parsing on semi-structured t a bles, 2015. URL https://arxiv.org/abs/1508.00305 . Cheng Qian, Shihao Liang, Yujia Q in, Y ining Y e, Xin Cong, Y ankai Lin, Y esai Wu, Z hiyuan Liu, and Maosong Sun. Inv estigate-consolidate-explo it: A general strategy for inter-t ask a gent self-ev olution, 2024. URL https://arxiv.org/abs/2401.13996 . Noa h Shinn, Federi co Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Y ao. R eflexion: Language a gents with verbal reinforcement learning, 2023. URL 2303.11366 . Qwen T eam. Qw en3.5: Accelerating produ ctivit y with n ativ e m ultimoda l a gents, F ebruary 2026. URL https://qwen.ai/blog?id=qwen3.5 . Guanzhi W ang, Yu qi Xie, Y unf an Ji ang, Ajay Mand lekar , Chaow ei Xiao, Y uke Zhu, Linxi F an, and Anima Anand kumar . V oyager: An open-ended embodied agent with large language m odels, 2023. URL https: //arxiv.org/abs/2305.16291 . Zora Zhiruo W ang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent w orkflo w memory , 2024. URL https://arxiv.org/abs/2409.07429 . Peng Xia, Jianwen Chen, H anyang W ang, Jiaqi Liu, Kaide Zeng, Yu W ang, Siw ei Han, Y iyang Zhou, Xujiang Zhao, H aif eng Chen, Zeyu Z heng, Cihang Xie, and Huaxiu Y ao. Skillrl: Ev olving agents vi a recursive skill-augmented reinforcement learning, 2026a. URL . Peng Xia, Ji an wen Chen, Xinyu Y ang, Haoqin Tu, Ji aqi Liu, Kaiw en Xiong, Siwei Han, Shi Qiu, Haonian Ji, Y uyin Zhou, Zeyu Z heng, Cihang Xie, and Huaxiu Y ao. Met aclaw: Just t alk – an agent that met a-learns and ev olves in the wild, 2026b. URL . Chenfei Xiong, Jingwei Ni, Yu F an, Vilém Zouhar , Donya R ooein, L orena Calv o-Bartolomé, Alexander Hoyle, Zhijing Jin, Mrinma ya Sachan, Markus L eippold, Dirk Ho vy , Mennat allah El-Assady , and Elliott Ash. Co- D ET ECT: Collaborativ e disco very of edge cases in text cl assifi catio n. In Ivan Habernal, Peter Schul am, and Jörg T iedemann ( eds.), Proceedings o f the 2025 Conf erence on Empirica l Methods in Natura l Lan- guage Processing: System Demonstrati ons , pp. 354–364, Suzhou, China, No vember 2025. Association for Computational Linguistics. ISBN 979-8-89176-334-0. doi: 10.18653/v1/2025.emnlp- demos.25. URL https://aclanthology.org/2025.emnlp- demos.25/ . Y ut ao Y ang, Junsong Li, Qianjun Pan, Bihao Zhan, Y uxuan Cai, Lin Du, Jie Zhou, Kai Chen, Qin Chen, Xin Li, Bo Zhang, and Liang He. Auto skill: Experience-driv en lifelong learning vi a skill self-evoluti on, 2026. URL https://arxiv.org/abs/2603.01145 . 14 T race2Skill: Distill T rajectory-Local L essons into T ransfera ble Agent Skills Shunyu Y ao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. R eact: Syn ergizing reasoning and acting in l angua ge models, 2023. URL 03629 . Boyuan Z heng, Michael Y . F atemi, Xi aolo ng Jin, Zora Zhiruo W ang, Apurva Gand hi, Y ueqi Song, Y u Gu, J ayanth Sriniv asa, Gao wen Liu, Graham Neubig, and Yu Su. Skillw eav er: W eb agents can self-impro ve by disco vering and honing skills, 2025. URL . Huichi Zhou, Siyuan Guo, Anjie Liu, Z hongw ei Y u, Z i qin Gong, Bow en Zhao, Zhixun Chen, Menglo ng Z hang, Y ihang Chen, Jinsong Li, R unyu Y ang, Qi angbin Liu, Xinlei Yu, Jianmin Zhou, Na W ang, Chunyang Sun, and Jun W ang. Memento-skills: Let a gents design agents, 2026. URL 18743 . 15 T race2Skill: Distill T rajectory-Local L essons into T ransfera ble Agent Skills A. Secondary SoPs from Qualitative Analysis The f ollo wing SoPs appear in the 122B Deepening +Combined run with moderate support (10–15/323 patches) and are encoded in the ev olv ed skill but not discussed in the main text. T arget-range and answer-po sition validati on (15/323 patches). Before writing, verif y the exact t arget sheet n ame, cell range, and answer_position field from the t a sk metadat a. Misreading these fields — writing to the wrong sheet or an o ff-by-on e range — causes silent f ailures that produ ce no error message b ut score zero. Datat ype and datetime preservatio n (15/323 patches). Write dates and numeri c valu es as native Python t ypes, not strings. Both pandas date parsing and openpyxl cell assignment can silently stringif y datetime va lues; inspect each column’s dt ype before writing and use openpyxl ’s native datetime assignment. W orkbook structure explorati on before editing ( success-dominant, ∼ 13/323 patches). List all sheets, inspect ro w/column lay out, and verif y header positio ns before any write. This pre-edit exploration prevents wrong-sheet and wrong-range failures and accounts for a subst antial share o f the 151 success-leaning patches in the run. B. Prompt T empl ates and Intermediate Outputs This appendix reprodu ces the key prompt templ ates used in each pipeline st age and illustrates representative intermediate outputs to make the pipeline f ully transparent and reprodu cibl e. B.1. Stage 1: Agent S ystem Prompt T emplate The a gent 𝜋 𝜃 operates under the foll owing system prompt d uring trajectory collecti on. The skill S 0 is prepended to the user context at inference time. Note that this differs from standard loading process of skills, where initially the a gent only ha s access to skill descriptions. W e simplif y this by preload the SKI LL.md content to system prompt because Trace2S kill focus on improving a fixed t arget skill which is kno wn relative to the t as k. Therefore, there is no need for skill selectio n as the standard skill loading. Import antly , the T race2Skill skill using agent still need to procedura lly discov er resources pointed by the preloaded SKI LL.md ( e.g., resources and scripts), which are not preloaded. Stage 1 — Agent System Prompt ( ab breviated) R ole: Y ou are an expert role ( e.g., spreadsheet analysis) agent. Skill context: [Contents of S 0 inserted here] T as k: Describing t a sks and input files. T ools av ailabl e: Describing tools and environment. E.g., bash (shell execution) f or ReAct with file system access. F ormat: R eAct-st yle interaction — alternate bet ween reasoning traces and tool calls until the t a sk is complete. B.2. Stage 2: Analyst Prompt T empl ates and Example P atches In Stage 2, the patch proposing a gents first draw error and success memory items similar to ( Ouyang et a l. , 2026 ), which are genera liz ab le trajectory-level kno wledge that might be helpful for future task executions. Next, the a gents read the origin a l skill directory and then propose a patch to encode the memory items into the skill. 16 T race2Skill: Distill T rajectory-Local L essons into T ransfera ble Agent Skills B.2.1. Error Analyst Prompt ( A − ) Error Analyst System Prompt ( abbreviated) R ole: Y ou are an expert f ailure-analysis a gent for X X X t asks. Missio n: Giv en an agent’s executio n artifacts (logs + produ ced files) and the ground-truth solution, diagn ose why the agent f ailed , identif y causal failure reasons , and validate yo ur diagno sis by implementing a minimal fix that makes the agent output match the ground truth. Y our analysis must be systematic , evidence-driv en , and reprodu cible . Do not guess when you can verify . R equired W orkflow (MANDA TO R Y): 1. Understand the t a sk and f ailure surf ace — identif y exactly what is wrong in the output. 2. Trace the f ailure to agent beha vior — locate the decisio n or code step that produ ced the mismatch. 3. V alidate the root cause with a minimal fix — write fixed output and re-evaluate against the ground truth. 4. Re-eva lu ate — if still failing, return to steps 1–3 and revise yo ur di a gnosis. Output: Produce (1) F ailure Cause Items — systematic, causal reaso ns grounded in observab le agent behavi or; (2) F ailure Mem ory Items ( ≤ 3) — genera liz a ble insights the agent should remember to av oid similar failures. B.2.2. Success Analyst Prompt ( A + ) Success Analyst System Prompt ( ab breviated) R ole: Y ou are an expert in success pattern analysis for AI agent systems. Missio n: Giv en a successful agent trajectory , identif y generalizab le behavi or patterns that contributed to the correct answer . R equirements: Broad C o verage — every effecti ve behavi or in the trajectory must be captured by a pattern. Frequency A wareness — patterns cov ering more instances should be listed first; rare behavi ors should be absorbed into the nearest broader pattern. Genera liz atio n — each pattern must describe a genera l mechanism, not a single t a sk-specific detail. Output: A compact set o f Success Memory Items with title, descriptio n, and concrete examples o f the effective behaviors observed. B.2.3. Example T rajectory-L evel P atch (Error Analyst Output) Each analyst produ ces a structured patch f or a single trajectory . The f ollo wing example is from an error analyst ( A − ) processing one f ailure trajectory where the agent deleted row s outside the specified range. The patch proposes adding a new SKILL.md sectio n on row-manipulatio n safet y; this patch, alo ng with 52 others citing related structural-edit failures, is later consolidated into the “Structural-edit safet y” SoP (§ 4.4 ). Example St age 2 Trajectory-L ev el P atch ( error analyst, one trajectory) Analyst reaso ning: Single error record rev eals a clear failure pattern: the agent deletes ro ws outside the specified range and f ails to distinguish partially-empt y dat a rows from completely empt y padding rows. The skill lacks any guidance on ro w/column manipul atio n or range boundary enforcement. --- a/SKILL.md +++ b/SKILL.md @@ -55,0 +55,26 @@ ## Formula Verification Checklist +## Row and Column Operations + +### Range Boundary Enforcement +- When a task specifies a cell range (e.g., F14:M83), operations + MUST stay within those exact boundaries +- Parse range format: start_col + start_row : end_col + end_row +- Never apply operations to rows/columns outside the range 17 T race2Skill: Distill T rajectory-Local L essons into T ransfera ble Agent Skills + +### Row Deletion Logic +Before deleting any row, verify BOTH conditions: +1. Target columns are empty (as specified by task) +2. Row falls within the explicit deletion range + + ** Do NOT delete ** completely empty rows across ALL columns unless +explicitly instructed -- these often serve as structural padding. + +### Post-Operation Validation +After row/column operations: +- [ ] Count remaining rows matches expected count +- [ ] No header/footer/padding rows outside range were affected +- [ ] Data integrity is maintained in adjacent columns +- [ ] Range boundaries were respected (no off-by-one errors) B.3. Stage 3: Merge Operator Prompt and Example C onsolidated P atch B.3.1. Merge Operator Prompt ( M ) Merge Operator System Prompt ( f ull) Y ou are a skill edit coordinator . Y ou receive multipl e independently-proposed patches that each suggest changes to a skill folder . Y our job is to merge them into on e coherent, non-red undant patch. Guidelines: 1. Deduplicate : When multipl e patches propose the same or very similar edits, keep the best versio n (m ost specific, best worded). 2. R esolve conflicts : If patches propose contradictory edits to the same section, choose the one with stronger justificati on or synthesi ze both into a better edit. 3. Preserve unique insights : Different patches address different f ailures — include all unique, no n-redundant edits. 4. Maintain concisen ess : The merged patch should ha ve ≤ the sum o f unique edits across all input patches. R emo ve redundan cy . 5. Ensure independence : Edits in the merged patch MUST be line-lev el independent — no t wo edits ma y t arget o verlapping lines or the same passa ge of text, even across different operati ons. 6. Atomic create/link pa airs : A create operatio n for references/ * .md and the SKILL.md edit that inserts a link to it are an inseparabl e pair — keep both or drop both. Preval ent pattern bias: When multiple patches independently propose simil ar edits addressing the same class of failure or success pattern, treat this recurrence as evidence o f a systemati c propert y of the task. Preserve such preval ent edits with higher priorit y and express them as genera l principles rather than instance-specific fixes. B.3.2. Example Final Consolidated P atch 𝑝 ∗ ( A fter Full Merge Hierarchy) The foll owing excerpt sho ws the reaso ning and represent ativ e edits from the fin a l consolidated patch 𝑝 ∗ prod uced after four lev els of hierarchica l merging ov er 323 individua l trajectory patches on SpreadsheetBen ch- V erified. Example St age 3 Final P atch Output ( excerpt) { "reasoning": "Merged 3 patches addressing mixed failure/success evidence. Key consolidation decisions: (1) Synthesized recalc.py workflow from all patches using the most prominent CRITICAL WARNING placement, CSV fallback validation, and a verification loop; (2) Consolidated library selection guidance into a comprehensive decision tree; (3) Combined row deletion guidance emphasizing bottom-up/right-to-left deletion order from all patches; (4) Merged formula validation checklists without redundancy.", "edits": [ 18 T race2Skill: Distill T rajectory-Local L essons into T ransfera ble Agent Skills { "file": "SKILL.md", "op": "insert_after", "target_section": "# Requirements for Outputs", "content": "## Important Automation Guidelines\n\n ** Prefer Python over VBA for Automation ** : When tasks request VBA macros or spreadsheet automation, implement the logic in Python using openpyxl/pandas instead. This provides better error handling, easier debugging, cross-platform compatibility, and avoids macro security issues." }, { "file": "SKILL.md", "op": "insert_after", "target_section": "## Important Requirements", "content": "### When to Compute Directly in Python\n If LibreOffice/recalc.py cannot evaluate certain formula patterns (complex array formulas, advanced INDEX/MATCH combinations), compute the logic directly in Python and write results as values. Use this fallback when formula returns errors after recalculation despite correct syntax." } ], "changelog_entries": [ "Added automation guidelines preferring Python over VBA", "Consolidated recalc.py warnings into a single CRITICAL WARNING" ] } B.3.3. Example T rans lated Diff: Fin a l Consolidated P atch 𝑝 ∗ The JSO N patch 𝑝 ∗ prod uced by St a ge 3 is translated programmatically into a unified diff and a pplied directly to the skill directory . The follo wing excerpt show s t wo hunks from the fin al applied diff on Spreads heetBench- V erified, corresponding to the t wo mo st prevalent S oP s: form ul a recal cul ati on enforcement (178/323 patches) and tool-selectio n guidance (177/323 patches). Example St age 3 Applied Diff ( excerpt from final 𝑝 ∗ ) --- a/SKILL.md +++ b/SKILL.md @@ -126,3 +261,18 @@ ## Common Workflow ## Common Workflow +### CRITICAL WARNING: Formula Recalculation Is Mandatory + + ** If you write ANY formulas to an Excel file using openpyxl, +you MUST run recalc.py before considering the task complete. ** + +Formulas written via openpyxl exist only as text strings until +recalculated. Without running recalc.py: +- Cells return None/empty when read with data_only=True +- Evaluation fails even if formulas are syntactically correct +- The output file is incomplete + +This is non-negotiable. Do not proceed to verification or +delivery until recalc.py confirms success. + @@ -138,3 +285,9 @@ ### Working with openpyxl 19 T race2Skill: Distill T rajectory-Local L essons into T ransfera ble Agent Skills +### Tool Selection Warning + + ** CRITICAL ** : When modifying spreadsheets that contain existing +formulas you need to preserve: +- Use openpyxl (load_workbook() then save()) -- formulas remain + as strings +- Avoid pandas (to_excel()) -- silently converts formulas to + static values permanently 20
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment