SmaAT-QMix-UNet: A Parameter-Efficient Vector-Quantized UNet for Precipitation Nowcasting
Weather forecasting supports critical socioeconomic activities and complements environmental protection, yet operational Numerical Weather Prediction (NWP) systems remain computationally intensive, thus being inefficient for certain applications. Mea…
Authors: Nikolas Stavrou, Siamak Mehrkanoon
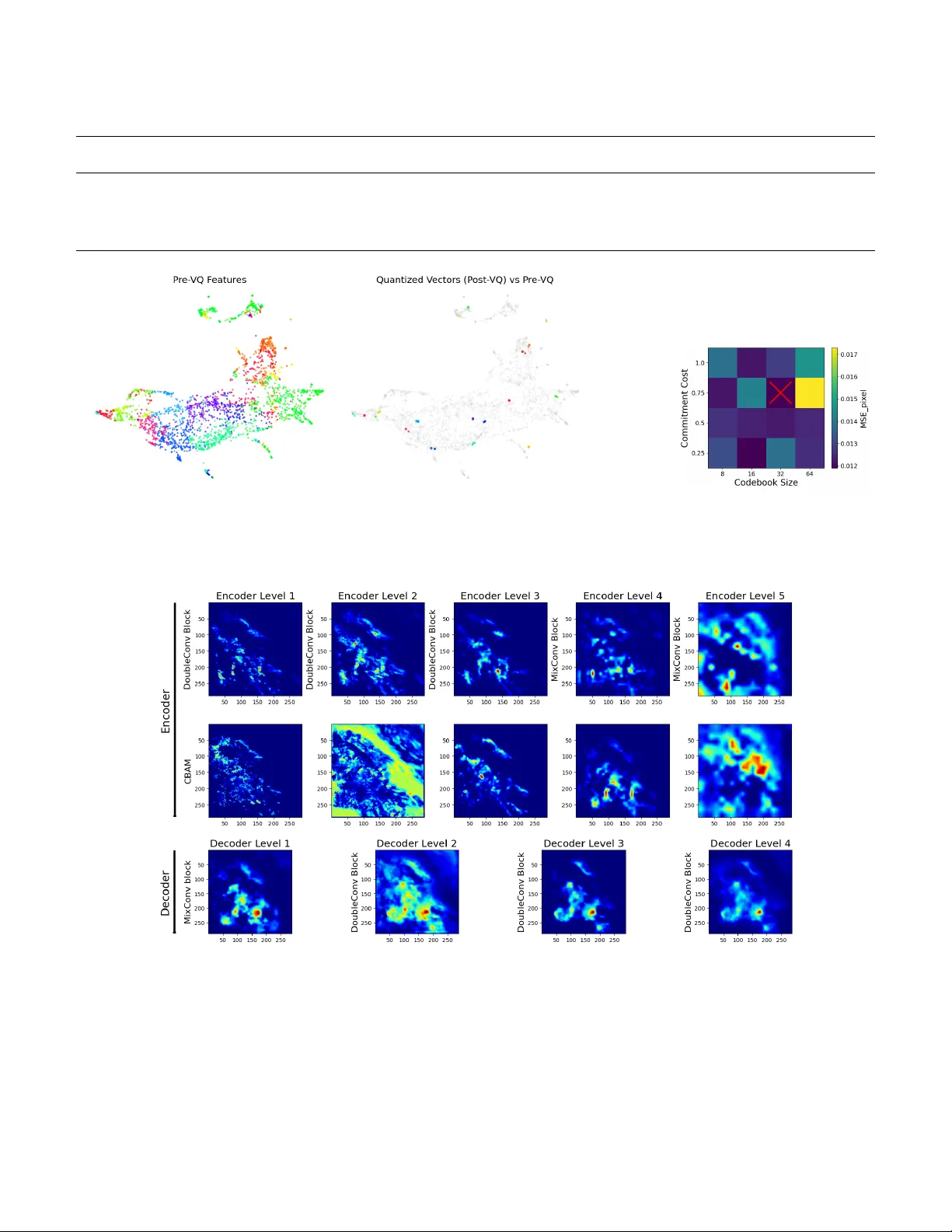
SmaA T -QMix-UNet: A P arameter -Ef ficient V ector -Quantized UNet for Precipitation No wcasting Nikolas Stavrou, Siamak Mehrkanoon ∗ Department of Information and Computing Sciences, Utr echt University , Utr echt, Netherlands n.stavrou@students.uu.nl, s.mehrkanoon@uu.nl Abstract —W eather f or ecasting supports critical socioeconomic activities and complements en vironmental protection, yet oper - ational Numerical W eather Prediction (NWP) systems remain computationally intensive, thus being inefficient f or certain applications. Meanwhile, recent advances in deep data-driven models hav e demonstrated promising results in nowcasting tasks. This paper pr esents SmaA T -QMix-UNet, an enhanced variant of SmaA T -UNet that introduces two key innovations: a vector quantization (VQ) bottleneck at the encoder–decoder bridge, and mixed kernel depth-wise con volutions (MixCon v) replacing selected encoder and decoder blocks. These enhancements both reduce the model’ s size and impro ve its nowcasting performance. W e train and evaluate SmaA T -QMix-UNet on a Dutch radar precipitation dataset (2016–2019), predicting precipitation 30 minutes ahead. Three configurations are benchmarked: using only VQ, only MixConv , and the full SmaA T -QMix-UNet. Grad- CAM saliency maps highlight the regions influencing each nowcast, while a UMAP embedding of the codewords illustrates how the VQ layer clusters encoder outputs. The source code for SmaA T -QMix-UNet is publicly a vailable on GitHub 1 . Index T erms —UNet, Precipitation Nowcasting, Deep Learning, V ector Quantization, Mixed Kernel I . I N T RO D U C T I O N Numerical W eather Prediction (NWP) models are com- putationally expensiv e, requiring large-scale simulations that are impractical for edge deployment or rapid ensemble fore- casting. As a result, many researchers have turned to data- driv en approaches, with deep learning models increasingly explored and adopted for weather forecasting ov er the past decade [1]–[6]. Early data-driven nowcasting mainly relied on recurrent sequence models such as RNNs, LSTMs, and GR Us to model temporal dynamics, but these approaches largely ne glected the spatial structure of radar and satellite imagery . ConvLSTM mitigates this by embedding con volu- tions within LSTM gates, enabling joint learning of motion and morphology and outperforming optical-flo w baselines for short-range forecasts [7], while the PredRNN family extends this with spatio-temporal memory to better preserve storm structure at longer lead times [3]. More recent approaches adopt attention-based architectures. SmaA T -UNet integrates attention and depthwise-separable con volutions within a U- Net backbone to capture multi-scale features efficiently [8]. It achiev es competitive no wcasting performance while only using a quarter of the parameters of a standard U-Net variant. Other related models such as WF-UNet and STC-V iT further *Corresponding author. 1 https://github .com/nstavr04/MasterThesisSnellius demonstrating the effecti veness of lightweight attention and transformer-style mechanisms for nowcasting [9], [10]. Interpretability is essential for deploying deep models. Explainable-AI methods like Grad-CAM [11] and UMAP [12] provide human-readable insights into both individual predictions and overall model beha vior . Recent XAI surveys in meteorology argue that combining such local and global views is essential for building practitioner trust and for debugging models before operational rollout [13]. This paper introduces SmaA T -QMix-UNet, a compact e vo- lution of SmaA T -UNet that achieves marginally improv ed accuracy and precision while reducing trainable parameters by 37.5%. The improvement comes from two modifications: a discrete vector-quantization (VQ) bottleneck and MixCon v blocks. A VQ module is inserted at the encoder–decoder bridge, replacing the latent feature map with nearest codew ord indices to produce a compressed, noise-robust representation that also supports cluster-lev el interpretation. In addition, selected depthwise-separable con volutions in the encoder and decoder are replaced with MixConv layers that blend multiple receptiv e field sizes within a single block [14], preserv- ing multi-scale sensitivity while reducing redundanc y . Inter- pretability is provided through Grad-CAM salienc y maps and UMAP projections of the learned VQ codew ords. T ogether, these changes improv e ef ficiency , accuracy , and interpretability while remaining suitable for edge deployment. I I . R E L A T E D W O R K Sev eral studies hav e built upon the classic UNet architecture [15] to tackle precipitation no wcasting. For instance, AA- T ransUNet [16] uses a transformer and a UNet with attention modules and depthwise-separable con volutions, demonstrating improv ed performance on precipitation nowcasting. Similarly , Broad-UNet [17] refines the UNet backbone with multi-scale feature extraction via asymmetric parallel conv olutions and Atrous Spatial Pyramid Pooling (ASPP) module, yielding more accurate predictions with fewer parameters. V ariants extending the SmaAt-UNet [8] approach include GA-SmaAt- GNet [18], which le verages a generati ve adv ersarial frame work and integrates precipitation masks to boost performance in extreme events, and SAR-UNet [19], which introduces resid- ual connections alongside depthwise-separable conv olutions to enhance both accuracy and interpretability through visual explanations. Lastly , WF-UNet [9] took a different approach by fusing additional meteorological inputs via a 3D-UNet architecture. Other deep learning approaches hav e also been proposed for precipitation no wcasting beyond the UNet f amily . Early work using ConvLSTM has e volv ed into models like T rajGR U [20], which learn location-v ariant recurrent con- nections to better capture natural motion. Moreover , models like MetNet [21] and Nowcasting-Nets [22] combine self- attention and recurrent structures to extend forecast horizons and deliv er probabilistic predictions that capture uncertainty . The authors in [23] formulated precipitation nowcasting as a spatiotemporal graph sequence problem. V arious studies ha ve demonstrated the ef fecti veness of VQ techniques across a range of applications, highlighting their potential to enhance model robustness, efficiency , and rep- resentational power . In the medical imaging domain, work has been done which sho ws that integrating a quantization block into a UNet architecture leads to improved segmentation accuracy and rob ustness against noise, domain shifts, and other perturbations by learning a discrete, lo w-dimensional represen- tation [24]. Similarly , VQ-UNet [25] applies a multi-scale hier - archical VQ approach to defend deep neural networks against adversarial attacks, ef fectiv ely reducing unwanted noise and reconstructing data with high fidelity . The widely known VQ- V AE paper, further establishes that replacing continuous latent codes with a learned discrete codebook can av oid issues like posterior collapse, ultimately enabling high-quality generation in images, videos, and speech [26]. Finally , the aforementioned GPTCast model [27], which adapts the VQ-GAN frame work [28], illustrates that vector quantization can be effecti vely employed in precipitation nowcasting, in their case with a variational autoencoder , to generate accurate, high-resolution forecasts. Beyond the depthwise-separable con volutions emplo yed in SmaA T -UNet, ef ficient con v olutions continue to diversify . MixCon v partitions channels and applies sev eral kernel sizes within one depth-wise layer , improving the accurac y-to-FLOPs ratio on mobile-scale models [14], while GhostCon v (from GhostNet) generates “ghost” feature maps through ine xpensiv e linear operations, slashing parameter count without sacrificing representational power [29]. I I I . M E T H O D A. Pr oposed SmaA T -QMix-UNet model 1) Ar chitectur e: Fig. 1 sketches the proposed SmaA T - QMix-UNet, which follows the encoder–bottleneck–decoder template of SmaA T -UNet [8] but introduces two ke y modifi- cations. The encoder comprises fiv e hierarchical le vels (blue and c yan arro ws). In each le vel, two 3 × 3 depth-wise separable con volutions, BatchNorm and ReLU are follo wed by a CBAM attention module. The CB AM output is forwarded via a skip connection (gre y arro ws) to the matching decoder stage, while a 2×2 max pool (red arro w) halves the spatial resolution and feeds the next lev el. Lev els 1–3 use the original depthwise- separable con volutions while Lev els 4 and 5 use a MixCon v block (cyan arrows) that processes channel groups with 3×3 and 5×5 kernels in parallel [14]. At the bottleneck between encoder and decoder , the last encoder tensor is routed through a VQ module (purple arrow). Each latent vector is replaced by its nearest codeword entry in a learned codebook and then passed to the decoder . The decoder mirrors the encoder with four stages. Each begins with bilinear up-sampling (green arrows) that doubles spatial dimensions and concatenates the result with the corresponding skip connection. The first decoder stage reuses the MixCon v block, while the remaining stages revert to depth-wise separable con v olutions. A final 1×1 conv olution (purple arro w) produces the single-channel precipitation nowcast at 30 mins lead time. 2) V ector-Quantization (VQ) Module: On the bottleneck of our model architecture, we use a VQ module following the lines of VQ-V AE, [26]. The continuous encoder output z e ∈ R B × H × W × C is mapped to a discrete latent space defined by a learnable codebook E = { e k } K k =1 , with code word e k ∈ R D . W e choose the codew ord dimensionality D to match the number of channels C , i.e., D = C . Therefore, in the rest of the paper , we use D to also indicate the number of channels. As in [30], the codebook E is a set of learnable parameters, optimized jointly with the rest of the model. Next we flatten z e to a matrix z e ∈ R N × D , where N = B × H × W . W e denote ev ery row of this matrix as v n ∈ R D . For each vector v n , we compute the squared ℓ 2 distance to ev ery codew ord and select the index of the nearest codew ord as follows: k n = arg min k ∈{ 1 ,...,K } v n − e k 2 2 , for n = 1 , . . . , N . (1) Next, each v n is replaced with its corresponding codeword e k n , and the result is reshaped to match the original layout, producing the quantized tensor as follows: z q = reshape { e k n } N n =1 , z q ∈ R B × H × W × D . (2) Incorporating the VQ module introduces two additional loss terms, commitment loss and codebook loss which are com- puted during training. Commitment loss penalizes encoder vectors for drifting away from their selected code embeddings and thus encourages them to “commit” stably to a discrete code and codebook loss, which pulls each codeword in E tow ard its detached encoder output to keep the dictionary representativ e. Training uses the straight-through estimator together with the two-term loss: L VQ = 1 N N X n =1 sg[ v n ] − e k n 2 2 | {z } codebook + β N N X n =1 v n − sg[ e k n ] 2 2 | {z } commitment , (3) where sg[ · ] is the stop-gradient operator and β is the commitment cost controlling how strongly the encoder is encouraged to commit to its selected codes. All terms are computed as the mean squared error ov er all latent elements, making the loss magnitude insensitive to batch size or spatial resolution. At inference time the module is deterministic, mapping each encoder activ ation to the nearest code word entry in E . 3) Mixed Con volution Block: In the original SmaA T -UNet, each DoubleDSC unit stacks two depth-wise separable con- volutions with fixed 3×3 kernels. Since the deepest encoder Fig. 1. (a) SmaA T -QMix-UNet architectur e: Rectangles represent feature maps, with height indicating spatial resolution and width the channel dimension. MixCon v blocks are used in the last two encoder lev els and the first decoder stage, while a VQ layer discretizes the B × 18 × 18 × 512 bottleneck tensor . (b) V ector-quantization module: Latent features are flattened, each 512-D vector is assigned to its nearest codebook entry ( K = 32 ), and reshaped into a quantized feature map. T raining optimizes the combined codebook and β -weighted commitment losses. layers have the widest channel dimensions and require the largest receptiv e fields, we modify only these layers and the first decoder stage after the VQ bottleneck. Specifically , we replace the DoubleDSC units in the two deepest encoder levels and the first decoder stage with a double MixConv block. Each MixCon v splits the feature map into two equal channel groups, applies 3×3 and 5×5 depth-wise con volutions, concatenates the results, and projects them through a shared 1×1 point- wise conv olution with BN and ReLU (Fig. 2). This sequence is repeated twice to mirror the original DoubleDSC structure. The resulting design captures both local and broader spatial context while reducing parameter count, and is applied only at these three locations to preserve the baseline behaviour elsewhere. Fig. 2. Mixed depthwise con volution (MixConv). The input tensor is split in two disjoint groups. First group is processed by a 3x3 depthwise con volution and the second group by a 5x5 depthwise conv olution. The two outputs are then concatenated along the channel dimension. 4) Model V ariation: T o showcase the ef fects of VQ and MixCon v we ev aluate four progressiv ely modified networks. The starting point is the unaltered SmaA T -UNet, which acts as the reference baseline. Adding MixCon v alone, restricted to the last two encoder le vels and the first decoder stage, yields SmaA T -Mix-UNet, a purely con volutional variant that probes the impact of kernel div ersity on accuracy and size. Additionally , we train SmaA T -Q-UNet, which inserts the VQ bottleneck but leaves all depth-wise separable con volution layers unchanged, isolating the contrib ution of discretized latents. Finally , we combine both modifications in SmaA T - QMix-UNet. This model includes the VQ layer and the same three MixCon v replacements used in SmaA T -Mix-UNet, providing the configuration that jointly targets compactness and accuracy . All four networks share identical training and optimizer settings, and early-stopping criteria, ensuring that any performance dif ferences can be attributed to the architec- tural changes alone. B. T raining For our training, we follow the same steps as [8]. Our model ingests twelve consecuti ve radar maps per step and is trained for at most 100 epochs on a single NVIDIA H100 GPU with the Adam optimiser and an initial learning rate of 0.001 and a learning rate patience of 4 which reduces learning rate if no improvement on validation loss is shown for 4 consecutiv e epochs. If the validation loss shows no improvement for 15 straight epochs, training stops early . Through hyperparameter tuning, we set a codebook length of 32 and a commitment cost of 0.75 that giv e the best model performance. C. Evaluation Primary performance is reported as mean-squared error (MSE) ov er the test split. T o assess ev ent detection quality , each output is thresholded into rain/no-rain masks, counts of true positi ves, f alse positi ves, true negati ves and false negati ves then yield precision, recall, accuracy and F1-score. Results for ev ery SmaA T -QMix-UNet variant are benchmarked against the unaltered SmaA T -UNet and a Persistence baseline that simply repeats the last input frame. D. Explainability W e pair a local and a global tool to scrutinise model behavior . Gradient-weighted Class Activ ation Mapping (Grad- CAM) is applied to ev ery encoder and decoder lev el to highlight the pixels that most influence each nowcast hori- zon. Complementing these salienc y maps, Uniform Manifold Approximation and Projection (UMAP) embeds the full set of vector -quantized code indices into two dimensions, rev ealing how discrete codes cluster into recurring weather regimes and allowing their associated Grad-CAM maps to be inspected side by side. T ogether , Grad-CAM and UMAP provide a coherent view of ho w the network combines spatial cues and latent code patterns to produce its predictions. I V . E X P E R I M E N T S W e use the KNMI precipitation dataset from [8], comprising approximately 420 000 radar composites recorded e very fiv e minutes between 2016 and 2019 by the Dutch C-band radars at De Bilt and Den Helder . Images are normalised, cropped to the common radar coverage, and centre-cropped to 288 × 288 pixels. Following [8], only samples with at least 50% rainy pixels in the target frame are retained, forming the NL- 50 subset used for all experiments. Each sample consists of twelve consecutiv e rain maps (60 min history), with the model predicting precipitation 30 min ahead using mean squared error as the loss. T raining follo ws the baseline setup with Adam, batch size 8, and identical learning-rate scheduling and early stopping. The only additional hyperparameters are the VQ codebook size K and commitment cost β , tuned on the validation set; the best configuration uses K = 32 and β = 0 . 75 . The model with the lowest validation loss is ev aluated on the NL-50 test set. V . R E S U LT S A N D D I S C U S S I O N A. Pr ecipitation nowcasting 1) T uning: W e tune the two VQ-specific hyperparame- ters, the codebook size K and the commitment cost β , using a coarse grid search with K ∈ { 8 , 16 , 32 , 64 } and β ∈ { 0 . 25 , 0 . 50 , 0 . 75 , 1 . 00 } on the NL-50 validation set. Fig. 4(b) shows the resulting pixel-wise MSE heatmap. The best performance is obtained at K = 32 and β = 0 . 75 , with K = 16 , β = 0 . 25 yielding comparable results. Overall, moderate codebook capacity combined with a relativ ely high Fig. 3. Comparison of predictions generated by different models. The SmaA T - QMix-UNet model shows better alignment with the ground truth. commitment cost provides the best balance between repre- sentation diversity and quantization stability . W e therefore fix K = 32 and β = 0 . 75 for all subsequent SMiQ-UNet experiments. 2) Evaluation: The experimental results on the Dutch precipitation dataset demonstrate the adv antages of SmaA T - QMix-UNet in both predictive performance and model com- pactness. T able I reports 30-minute lead-time results on the NL-50 test set, including accurac y metrics, model size, and runtime. In terms of MSE, SmaA T -Q-UNet and SmaA T -QMix- UNet slightly outperform the SmaA T -UNet baseline (0.0119 and 0.0120 vs. 0.0122), whereas SmaA T -Mix-UNet alone underperforms (0.0129), indicating that MixCon v without discretization is insuf ficient. All learned models outperform the persistence baseline by a large mar gin. Across secondary metrics, SmaA T -QMix-UNet matches or exceeds the baseline on all scores except recall (0.812 vs. 0.850), likely due to VQ regularization suppressing weak precipitation cells. This is offset by higher precision (+0.033) and improv ed overall accuracy . Crucially , SmaA T -QMix-UNet achie ves these results with only 2.5M parameters, 37.5% fewer than the baseline, and reduces inference time by approximately 6 ms per batch. Overall, the results confirm that selecti ve MixConv dri ves parameter efficiency , while the VQ bottleneck preserves or improv es skill, yielding a compact and ef ficient nowcasting model. Figure 3 provides a qualitativ e comparison of 30- minute forecasts, showing that SmaA T -QMix-UNet produces predictions closest to the ground truth, particularly in regions of higher precipitation intensity . B. UMAP visualization Fig. 4(a) uses Uniform Manifold Approximation and Pro- jection (UMAP) to visualize the effect of vector quantization on the encoder latent space. The left panel shows a two- dimensional embedding of the 512-D encoder features, colored by their assigned code word. After quantization (right), features collapse onto a small set of discrete code words, with colored points indicating codeword locations and grey points showing T ABLE I P E RF O R M AN C E C O M P A R IS O N AT 3 0- M I N L E A D T IM E O N T H E N L- 5 0 T E S T S E T , I N C L UD I N G P E RS I S T EN C E , S M A A T - U N ET , A N D P RO P O S ED M O DE L S , W I TH M O DE L S IZ E A ND I N FE R E N CE T I ME R E PO RT E D . B E S T V A L UE S A R E I N B O L D Model Parameters Inference Time (ms) MSE (px) Precision Recall Accuracy F1 Score Persistence – – 0.0248 0.678 0.643 0.756 0.660 SmaA T -UNet 4 M 45 0.0122 0.730 0.850 0.829 0.786 SmaA T -Q-UNet 4 M 41 0.0119 0.748 0.820 0.832 0.782 SmaA T -Mix-UNet 2.5 M 42 0.0129 0.670 0.866 0.794 0.756 SmaA T -QMix-UNet 2.5 M 39 0.0120 0.763 0.812 0.838 0.787 (a) (b) Fig. 4. (a) UMAP visualization of encoder feature vectors before and after vector quantization in SmaA T -QMix-UNet, where grey points denote pre-VQ representations and colored points indicate their assigned code words. (b) Hyperparameter tuning results for the VQ module, showing validation performance across 16 combinations of codebook size and commitment cost, with K = 32 and β = 0 . 75 achieving the best performance. Fig. 5. Heatmaps generated with Grad-CAM for SmaA T -QMix-UNet, showing acti vation regions across the five encoder and four decoder le vels, including responses from the con volutional blocks (DoubleDSC or MixCon v) and the CB AM modules in the encoder . the original feature positions. The tight clustering demonstrates that the codebook efficiently compresses similar patterns while preserving the ov erall latent-space structure. C. Grad-CAM visualization Fig. 5 presents Grad-CAM salienc y maps for all encoder and decoder le vels of SmaA T -QMix-UNet, showing heatmaps for the con volutional blocks and the corresponding CBAM units. In the shallow encoder (Levels 1–3), DoubleDSC blocks already outline the main precipitation regions, while CB AM distributes attention more broadly . By Lev el 3, both modules con ver ge on the central rain areas. In deeper encoder layers (Lev els 4–5), MixCon v maintains focus on precipitation struc- tures, with CBAM highlighting complementary regions as rep- resentations become more abstract. During decoding, saliency initially remains concentrated on high-intensity precipitation, then e xpands through up-sampling and skip connections before progressiv ely refocusing on the heaviest rainfall. Overall, the saliency maps indicate a hierarchical representation in which SmaA T -QMix-UNet captures global rainfall geometry in early layers, emphasizes intense precipitation in deeper layers, and refines this information during decoding, while MixConv preserves spatial localization despite lar ger recepti ve fields. V I . C O N C L U S I O N In this work, we introduced SmaA T -QMix-UNet, which combines a vector-quantization bottleneck with MixCon v to preserve the multi-scale design of SmaA T -UNet while sub- stantially reducing model size. By discretizing the latent space and replacing the deepest con volutional blocks with MixCon v , the model achieves mar ginal improvements in nowcasting skill with significantly fe wer parameters, making it well suited for resource-constrained and edge deployments. Interpretability is enhanced through a two-le vel analysis: Grad-CAM highlights spatial regions driving the 30-minute forecast, while UMAP projections of the VQ code words reveal coherent latent- space clusters. T ogether , these properties reduce inference and training costs and support ef ficient, interpretable precipitation nowcasting. R E F E R E N C E S [1] S. Mehrkanoon, “Deep shared representation learning for weather ele- ments forecasting, ” Knowledge-Based Systems , vol. 179, pp. 120–128, 2019. [2] I. A. Abdellaoui and S. Mehrkanoon, “Symbolic regression for scientific discovery: an application to wind speed forecasting, ” in IEEE symposium series on computational intelligence (SSCI) . IEEE, 2021, pp. 01–08. [3] Y . W ang, Z. Gao, M. Long, J. W ang, and P . S. Y u, “Predrnn++: T owards a resolution of the deep-in-time dilemma in spatiotemporal predicti ve learning, ” in International confer ence on machine learning . PMLR, 2018, pp. 5123–5132. [4] K. Trebing and S. Mehrkanoon, “W ind speed prediction using multidi- mensional conv olutional neural networks, ” in IEEE Symposium Series on Computational Intelligence (SSCI) , 2020, pp. 713–720. [5] T . Sta ´ nczyk and S. Mehrkanoon, “Deep graph con volutional networks for wind speed prediction, ” in proceedings of Eur opean Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN) , 2021, pp. 147–152. [6] D. A ykas and S. Mehrkanoon, “Multistream graph attention networks for wind speed forecasting, ” in IEEE Symposium Series on Computational Intelligence (SSCI) . IEEE, 2021, pp. 1–8. [7] X. Shi, Z. Chen, H. W ang, D.-Y . Y eung, W .-K. W ong, and W .-c. W oo, “Con volutional lstm network: A machine learning approach for precipitation nowcasting, ” Advances in neural information pr ocessing systems , vol. 28, 2015. [8] K. T rebing, T . Sta ´ nczyk, and S. Mehrkanoon, “SmaAt-UNet: Precip- itation nowcasting using a small attention-unet architecture, ” P attern Recognition Letters , v ol. 145, pp. 178–186, 2021. [9] C. Kaparakis and S. Mehrkanoon, “WF-UNet: W eather data fusion using 3d-unet for precipitation no wcasting, ” Pr ocedia Computer Science , vol. 222, pp. 223–232, 2023. [10] H. Saleem, F . Salim, and C. Purcell, “Stc-vit: Spatio temporal con- tinuous vision transformer for weather forecasting, ” arXiv pr eprint arXiv:2402.17966 , 2024. [11] R. R. Selvaraju, M. Cogswell, A. Das, R. V edantam, D. Parikh, and D. Batra, “Grad-cam: V isual explanations from deep networks via gradient-based localization, ” in Proceedings of the IEEE international confer ence on computer vision , 2017, pp. 618–626. [12] L. McInnes, J. Healy , and J. Melville, “Umap: Uniform manifold approximation and projection for dimension reduction, ” arXiv preprint arXiv:1802.03426 , 2018. [13] A. Mamalakis, I. Ebert-Uphoff, and E. A. Barnes, “Explainable artificial intelligence in meteorology and climate science: Model fine-tuning, calibrating trust and learning new science, ” in International W orkshop on Extending Explainable AI Beyond Deep Models and Classifiers . Springer , 2020, pp. 315–339. [14] M. T an and Q. V . Le, “Mixcon v: Mixed depthwise con volutional kernels, ” arXiv preprint , 2019. [15] O. Ronneberger , P . Fischer, and T . Brox, “U-net: Con volutional netw orks for biomedical image segmentation, ” in Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international con- fer ence, Munich, Germany, October 5-9, 2015, proceedings, part III 18 . Springer , 2015, pp. 234–241. [16] Y . Y ang and S. Mehrkanoon, “AA-Transunet: Attention augmented transunet for nowcasting tasks, ” in IEEE international joint confer ence on neural networks (IJCNN) , 2022, pp. 01–08. [17] J. G. Fern ´ andez and S. Mehrkanoon, “Broad-UNet: Multi-scale feature learning for nowcasting tasks, ” Neural Networks , vol. 144, pp. 419–427, 2021. [18] E. Reulen, J. Shi, and S. Mehrkanoon, “GA-SmaAt-GNet: Generative adversarial small attention gnet for e xtreme precipitation nowcasting, ” Knowledge-Based Systems , vol. 305, p. 112612, 2024. [19] M. Renault and S. Mehrkanoon, “SAR-UNet: Small attention residual unet for explainable nowcasting tasks, ” in IEEE International Joint Confer ence on Neural Networks (IJCNN) , 2023, pp. 1–8. [20] X. Shi, Z. Gao, L. Lausen, H. W ang, D.-Y . Y eung, W .-k. W ong, and W .-c. W oo, “Deep learning for precipitation nowcasting: A benchmark and a ne w model, ” Advances in neural information pr ocessing systems , vol. 30, 2017. [21] C. K. Sønderby , L. Espeholt, J. Heek, M. Dehghani, A. Oliver , T . Salimans, S. Agrawal, J. Hickey , and N. Kalchbrenner, “Metnet: A neural weather model for precipitation forecasting, ” arXiv pr eprint arXiv:2003.12140 , 2020. [22] M. R. Ehsani, A. Zarei, H. V . Gupta, K. Barnard, and A. Behrangi, “Nowcasting-nets: Deep neural network structures for precipitation nowcasting using imer g, ” arXiv pr eprint arXiv:2108.06868 , 2021. [23] L. V atam ´ any and S. Mehrkanoon, “Graph dual-stream conv olutional attention fusion for precipitation nowcasting, ” Engineering Applications of Artificial Intelligence , vol. 141, p. 109788, 2025. [24] A. Santhirasekaram, A. Kori, M. W inkler , A. Rockall, and B. Glocker , “V ector quantisation for rob ust segmentation, ” in International Confer- ence on Medical Image Computing and Computer-Assisted Intervention . Springer , 2022, pp. 663–672. [25] Z. He and M. Singhal, “Vqunet: V ector quantization u-net for defending adversarial attacks by regularizing unwanted noise, ” in Pr oceedings of the 2024 7th International Confer ence on Machine V ision and Applications , 2024, pp. 69–76. [26] W . Y an, Y . Zhang, P . Abbeel, and A. Srinivas, “Videogpt: V ideo gener- ation using vq-vae and transformers, ” arXiv pr eprint arXiv:2104.10157 , 2021. [27] G. Franch, E. T omasi, R. W anjari, V . Poli, C. Cardinali, P . P . Alberoni, and M. Cristoforetti, “Gptcast: a weather language model for precipita- tion nowcasting, ” arXiv pr eprint arXiv:2407.02089 , 2024. [28] P . Esser , R. Rombach, and B. Ommer , “T aming transformers for high- resolution image synthesis, ” in Pr oceedings of the IEEE/CVF confer ence on computer vision and pattern r ecognition , 2021, pp. 12 873–12 883. [29] K. Han, Y . W ang, Q. Tian, J. Guo, C. Xu, and C. Xu, “Ghostnet: More features from cheap operations, ” in Pr oceedings of the IEEE/CVF confer ence on computer vision and pattern recognition , 2020, pp. 1580– 1589. [30] A. V an Den Oord, O. V inyals et al. , “Neural discrete representation learning, ” Advances in neural information pr ocessing systems , vol. 30, 2017.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment