Improving Attributed Long-form Question Answering with Intent Awareness
Large language models (LLMs) are increasingly being used to generate comprehensive, knowledge-intensive reports. However, while these models are trained on diverse academic papers and reports, they are not exposed to the reasoning processes and inten…
Authors: Xinran Zhao, Aakanksha Naik, Jay DeYoung
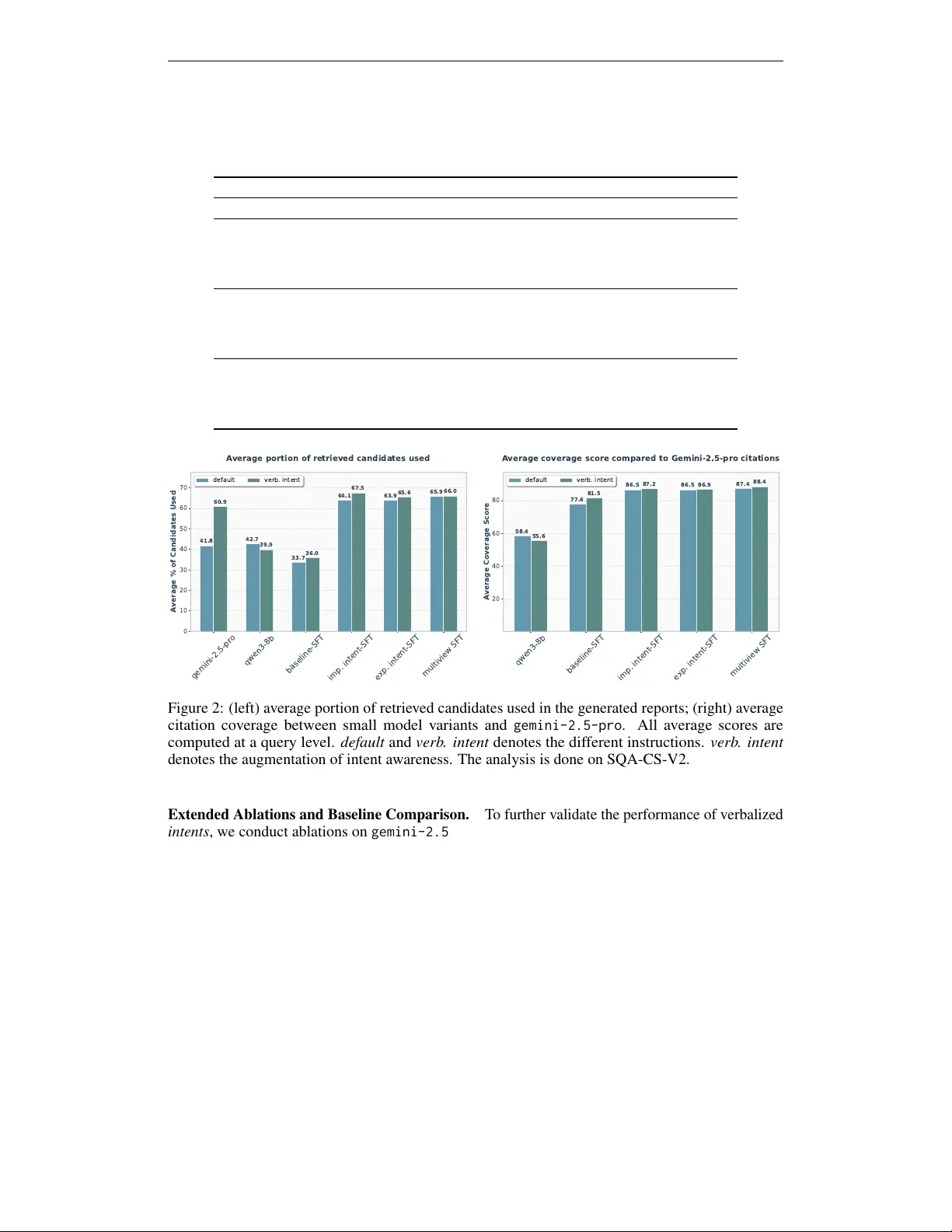
Published as a conference paper at ICLR 2026 I M P R OV I N G A T T R I B U T E D L O N G - F O R M Q U E S T I O N A N S W E R I N G W I T H I N T E N T A W A R E N E S S Xinran Zhao 1 , 2 ∗ , Aakanksha Naik 1 , Jay DeY oung 1 , Joseph Chee Chang 1 , Jena D . Hwang 1 , T ongshuang W u 2 , V arsha Kishore 1 , 3 1 Allen Institute for AI, 2 Carnegie Mellon Uni versity , 3 Univ ersity of W ashington A B S T R AC T Large language models (LLMs) are increasingly being used to generate compre- hensiv e, knowledge-intensi ve reports. Howe ver , while these models are trained on div erse academic papers and reports, they are not exposed to the reasoning pro- cesses and intents that guide authors in crafting these documents. W e hypothesize that enhancing a model’ s intent awareness can significantly improv e the quality of generated long-form reports. W e dev elop and employ a structured tag-based schema to elicit underlying intents more ef fectiv ely for writing. W e demonstrate that these extracted intents enhance both zero-shot generation capabilities in LLMs and enable the creation of high-quality synthetic data for fine-tuning smaller mod- els. Across various challenging scientific report generation tasks, our e xperiments show a verage improv ements of +2.9 and +12.3 absolute points for large and small models over baselines, respectiv ely . Furthermore, our analysis illuminates how intent awareness enhances model citation usage and substantially impro ves report readability . 1 I N T RO D U C T I O N Recent adv ances in LLMs ha ve fueled gro wing interest in building deep research systems that analyze information from v arious sources and produce a detailed report (DeepMind, 2025; OpenAI, 2025; Skarlinski et al., 2024; Y ang et al., 2024; Singh et al., 2025). Unlike older question answering systems, which focus on retrieving a fe w relev ant documents to produce concise answers to specific questions, deep research systems aim to gather dozens or e ven hundreds of sources and organize them into a coherent report. These often lengthy reports demand more than simply aggregating retrie ved content; they require careful or ganization of information, structured argumentation to wea ve e vidence into a coherent narrativ e, and proper attribution of sources. In this work, we argue that deep research systems can benefit from strategies humans use during the process of sensemaking (Pirolli & Card, 2005) and writing (Flower & Hayes, 1981). Humans write with intent —every paragraph and sentence serves a particular purpose (Lauscher et al., 2022). Much of this intent remains invisible in the final text, though its role is measurable through observation: a recent study recorded scholars writing on Overleaf (W ang et al., 2025) showed nearly 10% of keystrok es were dev oted to outlining, planning, and or ganization. These high-level intents, though essential for guiding the writing process, are not preserved in the final written texts and thus remain absent from data used to train language models. Therefore, models learn to mimic human writing style but don’ t explicitly model the thought process that goes into writing. T o model the thought process, we explore whether incorporating intent awareness helps language models generate better quality text, especially for scientific deep research tasks. Specifically , we propose an intent-aw are writing frame work that consists of intents at two le vels–paragraphs and citations. These intents are represented in a tag-based format inspired by ST aR (Zelikman et al., 2022) and T oW (Xu et al., 2025), where we include a dedicated intent type and a natural language rationale (see Figure 1 for an example). For citation intents, we identify fine-grained intent types from ∗ Correspondance to xinranz3@andrew .cmu.edu. Our code and data is at: https://github.com/ colinzhaoust/intent- aware- deep- research . 1 Published as a conference paper at ICLR 2026 What empirical studies examine causes of pivots or major idea changes during a scientific research pr oject? […] Beyond obstacles, r esearch pivots often emer ge from rese archers' career tr ajectories and professional incentives. Scientists rarely confine themselves to a single r esearch problem thr oughout their careers, instead advancing knowledge across differ ent topics with varying frequencies [1]. T hese transitions can range from minor thema tic adjustments to significant disciplinary shifts [2]. […] Does not concern shifts in resear ch It is about career pivots […] Beyond obstacles, r esearch pivots often emer ge from resear chers' encounters with unexpected findings that challenge their initial assumptions and open new avenues of inquiry [1][2] . When data reveals pat terns or outcomes that contradict the original hypothesis, r esearchers must decide whether to refine their approach [3] or completely r edirect their focus toward these surprising discoveries […] With Intent T agging Citation Intents: (why use these citation?) [1] [2] : [CIT -Motivation] Unexpected findings [3] : [CIT -Background] Hypothesis reformulation P aragraph Intent: [PIT -Cause-Effect] This paragr aph outlines how unforeseen results in an ongoing study can lead to significant changes in research dir ection. Deep-research agent default answer Intent-Aware Attributive Long-F orm Answering Figure 1: Current long-form question answering systems don’t consider intents when generating responses. The figure abov e shows ho w ha ving explicit citation intents and paragraph intents helps reason about the text and generate better responses. literature on citation intent classification (T eufel et al., 2006; Jurgens et al., 2018; Cohan et al., 2019; Lauscher et al., 2022). Specifically , we adopt the six-category framew ork from A CL-ARC (Jurgens et al., 2018) in our pipeline, which includes categories such as Backgr ound , Motivation , and Uses . For paragraph intents, we choose fine-grained types from well-established discourse modes that capture the functional purpose of writing (Smith, 2003; Song et al., 2017), with categories such as Exposition , Definition , Compar e and Contrast , Pr oblem-solution , etc. W e explore the effecti veness of our intent-aware writing frame work in improving the performance of scientific deep research systems (Singh et al., 2025) when incorporated during inference as well as training. At inference time, intent a wareness is incorporated by prompting a model to produce reports with embedded intents (Tian et al., 2023). For intent-aware training, we first prompt a teacher model to produce reports with embedded intents; then this data, containing intent information, is used as high-quality training data for smaller models. W e conduct experiments on three recent long-form report generation benchmarks (Bragg et al., 2025; Patel et al., 2025; Y ifei et al., 2025). Our results show that the intent a wareness we induced consistently improv es model performance across model backbones and tasks. W ith a macro-av erage across metrics, we observe an average improv ement of +2.9 absolute points for large commercial language models, despite their already strong base model performance. For small models, we observe a +12.3 absolute point impro vement after intent-a ware SFT , where the best variants reach the lev el of performance of larger models such as gemini-2.5-pro . The performance improv ements in automatic e valuations are dri ven by substantial gains in citation metrics which e valuate attrib ution quality . W ith intent awareness, we see +3.7 and +18.7 absolute point gains (av eraged across models), for large commercial language models and small models, respecti vely . Finally , we perform a detailed analysis of how the model’ s citation behavior changes with intent awareness, e.g., small models will make use of more retrie ved information. W e also conduct a user study showi ng that intents produced by our system aid in transparency and impro ved readability of long-form answers. For instance, they help guide the reader’ s attention, especially when the material is unfamiliar to them. Our approach leverages intent a wareness to produce attributed responses that are more focused, reliable, and useful, particularly in scientific reporting. 2 R E L A T E D W O R K Attributed long-form generation. Associating claims with evidence from identifiable sources plays a key role in measuring the f aithfulness of model-generated text (Bohnet et al., 2023; Rashkin et al., 2023). Researchers hav e studied citation quality in scientific text generation (Funkquist et al., 2022), generati ve search engines (Liu et al., 2023), and W ikipedia-style document generation (Gao et al., 2023b). Prior work has predominantly used retriev al-augmented generation framew orks (RA G, 2 Published as a conference paper at ICLR 2026 Lewis et al., 2020), wherein LLMs are trained to incorporate external or parametric knowledge sources and supporting documents while generating citations (Nakano et al., 2022; Menick et al., 2022; Gao et al., 2023a). More recently , the introduction of deep resear ch systems (DeepMind, 2025; OpenAI, 2025) has led to improved performance on knowledge based reasoning-intensive short-form question-answering tasks (Mialon et al., 2023; Phan et al., 2025; W ei et al., 2025; Coelho et al., 2025) through active and strategic usage of retrie val. Such success motiv ates the community to further assess broader capabilities of these systems in answering long-form open-ended questions from real-world applications, such as advanced search engine use (Du et al., 2025), scientific QA systems (Bragg et al., 2025), and literature synthesis and comparison (Patel et al., 2025; Y ifei et al., 2025). In our work, we explore ho w introducing intent awareness during writing and citation selection can improv e performance on attributed long-form report generation tasks. Our work focuses on changes through decoding time strategies and distillation, leaving existing RAG-style architectures intact, enabling potential plug-and-play generalization. Intents in writing. Understanding ho w people determine what to write has interested researchers for decades. Prior work has examined intents underlying both citations (Goodwin, 1980; T eufel et al., 2006) and discourse structures (Bain, 1890; Smith, 2003; Song et al., 2017), often treating intent understanding as a classification or parsing task, e.g., citation intent classification (Cohan et al., 2019) and discourse parsing (Marcu, 2000; Feng & Hirst, 2012; Li et al., 2014). Advances in LLMs hav e opened up new opportunities to assist and automate writing (Lee et al., 2024; Shen et al., 2023), motiv ating researchers to incorporate intent understanding into generation (Padmakumar et al., 2025; W ang et al., 2025). Recently , W u et al. (2025) discussed the LLM sensitivity of human intentions and incenti ves. In our work, we propose methods to add intent awareness during both training and inference, resulting in improv ed LLM text generation capabilities. Learning with rationales. Besides drawing inspiration from human writing processes, our method connects to prior work on eliciting additional context or rationales to augment and improv e model generation, including chain-of-thought (CoT) style inference (W ei et al., 2022a; Kojima et al., 2022), rationale bootstrapping training (Zelikman et al., 2022), te xt metadata conditioning (Gao et al., 2025), word-le vel reasoning (Xu et al., 2025), and confidence verbalization to improve calibration (T ian et al., 2023). From this perspectiv e, our intent-aware method can be vie wed as a form of generative planning, where models explicitly reason about the organization of their outputs to improve both quality and transparency . 3 T A S K F O R M U L A T I O N A N D M E T H O D O L O G Y W e first briefly describe the formulation of the attributed long-form question-answering task. Then, we introduce our intent-aw are writing frame work, describing: (i) how intents are represented while writing, and (ii) the types of intent that can be produced. Finally , we discuss how we incorporate intent awareness into LLMs for attributed long-form question answering, during both inference and training stages. 3 . 1 T A S K F O R M U L A T I O N W e focus on the task of attrib uted long-form scientific question answering, which is formalized as follows: giv en a user query q , a system is required to generate a multi-section report R , where each section consists of multiple paragraphs { p 1 , p 2 , ... } . Each paragraph p i contains sentences s i 1 , s i 2 , ... with supporting citations c 1 , c 2 , ... ∈ C added wherever e xternal references are required. The list of potential texts to cite ( C ) can either come from the model’ s parametric knowledge or from retrie ved documents. 3 . 2 I N T E N T - A W A R E W R I T I N G F R A M E W O R K W e propose an intent-aware writing framew ork that incorporates two broad categories of intents, often used in prior work: (i) paragraph-le vel writing intents ( paragraph intents , hereafter), and (ii) sentence-lev el citation intents . Paragraph intents specify the purpose of ev ery paragraph p i within 3 Published as a conference paper at ICLR 2026 T able 1: The types and descriptions for our intent a wareness schemes. W e adopt the citation intent types from A CL-ARC (Jurgens et al., 2018) and extend the paragraph intent types from the discourse modes studied in (Song et al., 2017). Intent Category & T ype Description Citation Intent Background The citation pro vides rele vant information for this domain Motiv ation The citation illustrates the need for data, goals, methods, etc. Uses The sentence uses data, methods, etc. from the citation Extension The sentence e xtends the referenced work’ s data, methods, etc. of the citation Comparison or Contrast The sentence e xpresses similarity/dif ferences to the referenced work Future The citation identifies the reference as a potential a venue for future work Paragraph Intent Exposition Explains, clarifies, or pro vides background information on a topic Definition Defines a k ey term, concept, or theory with necessary boundaries Argumentation Presents a claim supported by evidence, logic, or reasoning Compare-contrast Highlights similarities and/or differences between subjects or findings Cause-effect Explains causal relationships between e vents or phenomena Problem-solution Identifies a problem and proposes a solution or response Evaluation Assesses strengths, weaknesses, or significance according to criteria Narration Recounts a sequence of events or chronological processes the ov erall narrative of the report (e.g., this para graph pr ovides backgr ound conte xt or this paragr aph compar es two state-of-the-art methods ). Citation intents, which are more granular , are designed to capture why a certain citation c j is used to support a particular sentence s ix (e.g., this sentence uses the method pr oposed in the citation or this sentence expr esses similarities to or differ ences fr om the cited work ). By first generating such intents, we provide the model with cues helpful for the writing process. W e prime the model to consider intents during text generation. Intent Representation. T o distinguish the intent te xt from report text, we use an inline tag-based schema with rationales to represent intents. More specifically , intents are represented using the follo wing template: < be gin intent > [ intent type ] rationale < end intent >. For begin and end intent tags, we use and for citation and paragraph intents, respecti vely . Rationales for paragraph intents are brief textual explanations of why the paragraph fits the chosen type, based on its planned content and function within the report. For citation intents, rationales typically explain the connection between the sentence containing the citation and a brief summary of supporting evidence from the cited reference. Intent T ypes. W ithin both paragraph and citation intents, we utilize a more fine-grained set of intent types; these are listed in T able 1. For citation intents, we use the categories defined in A CL- ARC (Jurgens et al., 2018), and for paragraph intents we use the types defined in the discourse modes from (Song et al., 2017) 1 . 3 . 3 I N T E N T A W A R E N E S S D U R I N G I N F E R E N C E First, we explore the ef fectiveness of incorporating our intent-a ware writing frame work at inference time for attributed long-form report generation. Models are prompted to directly output reports with paragraph and citation intent tags embedded within them. For paragraph intents, the intent tags are placed before the text of each paragraph. For citation intents, intent tags are placed between the citing sentence and the inline citation. This intent-aw are prompting strate gy , which we will refer to as verbalized intents , can be considered a variant of test-time scaling. It focused on eliciting a specific category of thoughts (i.e., intents) alongside the reports. 3 . 4 I N T E N T A W A R E N E S S D U R I N G T R A I N I N G Besides inference-time augmentation, we e xplore strategies to incorporate intent aw areness during training. This is especially useful for smaller models, which already lag behind larger ones (Asta Bench, Bragg et al., 2025) because they struggle more with the added complexity introduced by explicit intent elicitation during report generation. 1 W e focus on the non-psycho-lingual functional intents and remove the emotion e xpr essing mode. 4 Published as a conference paper at ICLR 2026 For intent-aw are training, we first apply our intent-aware prompting strate gy to a large teacher model to produce training data with embedded intent tags and rationales. W e then conduct supervised fine-tuning (SFT) on this data, in the following settings: • intent-implicit SFT : W e remov e the embedded intent tags and rationales before training the smaller models. While the SFT training data is generated in an intent-aware manner, the intent information is not explicitly present during training: the large teacher model generates intents when producing the training data, but the small student models learn only the direct report generation task, not intent generation. • intent-explicit SFT : This variant retains the embedded intent tags and rationales. These explicit tags can potentially help smaller models understand ho w to better structure paragraphs and use citations. This setting is motiv ated by previous work that augments training data with explanations (Murty et al., 2020) and thoughts (Xu et al., 2025). • intent-multiview SFT : Previous variants require small models to learn how to use both ci- tation and paragraph intents simultaneously . T o further reduce the instruction complexity of each data point during training, we decompose intent-a ware generation into multiple sub-tasks, corresponding to overall intent categories. Following Liang et al. (2023), for each data point, we produce four instruction-report pairs: (1) an intent-explicit version (intent tags/rationales retained); (2) a paragraph-intent version with only paragraph intents retained in prompts/reports; (3) a citation-intent version with only citation intents retained in prompts/reports; (4) a no-intent version with tags/rationales remo ved and the prompt scrubbed of intent-related instructions. W e train a model on all of the instruction-report pairs (4x the instances of teacher-generated reports). W e consider two baselines: (1) directly prompting models without additional training or intent- awareness, (2) fine-tuning models on reports generated for the same query subset from the same teacher model, but without intent a wareness (baseline SFT ). 4 E X P E R I M E N T S A N D A N A L Y S I S 4 . 1 E X P E R I M E N TA L S E T T I N G W e conduct experiments on sev eral recent datasets for attributed long-form text generation. These tasks expect long report-style answers to open-ended questions. W e run experiments with the following three datasets: SQA-CS-V2 (Bragg et al., 2025): AstaBench provides a suite of tasks to allo w a holistic measure of agents for scientific research, including literature understanding, data analysis, paper search, coding, etc 2 . W e ev aluate on their report generation benchmark AstaBench-ScholarQA-CS2 . For this benchmark, the task is to generate reports for complex scientific questions. Our main results are on the 100-sample test set, and our ablations are on the 100-sample v alidation set. Each generated report is ev aluated based on four metrics: rubric-based ev aluation (whether key points identified by human-verified rubrics are contained in the answer), answer precision (whether each paragraph of the answer is on-topic and addresses the question), citation precision (whether the cited source text supports the claim), and citation recall (whether each claim in the answer is well-supported by citations, if necessary). These metrics were scored using an LLM-judge pipeline with answer decomposition and atomic ev aluation. DeepScholar Bench (P atel et al., 2025) is a benchmark for generating related-work sections for recent ar χ iv papers. The task in volv es retrieving, synthesizing, and citing prior research. Generated reports are judged for nugget cov erage (are essential facts found in the report; akin to Rubric measures), organization (structure and coherence of system answer), citation precision (paralleling SQA-CS-V2 citation precision), and claim cov erage (assesses fraction of claims that are fully supported by cited sources). W e elide the retriev al quality metrics as we use a fixed retriev al set for all experiments. W e use the 63 papers from the official GitHub Repository as our dataset. The original task in volv es writing a related work section for a gi ven paper title and abstract. Since this task is under-specified, we slightly modify the task setting and generate the related work section using the title and the sub-section headers in the ground truth related work section. 2 https://asta.allen.ai/chat 5 Published as a conference paper at ICLR 2026 T able 2: Performance comparison across various models on SQA-CS-V2. Overall denotes the macro- av erage of other sub-metics. Bold indicates the best-performing row for overall metrics. +intent denotes the use of our intent-aware-writing frame work with both paragraph and citaiton intents. Method SQA-CS-V2 Overall Rubrics Ans. P Citation P Citation R o3 85.1 91.4 96.5 89.4 63.4 + intent 86.0 90.7 96.6 89.9 66.9 gemini-2.5-pro 88.1 82.6 94.1 93.2 82.4 + intent 89.7 82.6 94.5 95.7 86.1 Claude opus-4 85.4 84.3 87.9 89.6 79.6 + intent 89.0 85.5 89.3 95.1 86.0 T able 3: Performance comparison on DeepScholar Bench and ReseachQA. RQA denotes ResearchQA. Overall denotes the macro-a verage of other sub-metics. Bold indicates the best-performing ro w for ov erall metrics. Method DeepScholar Bench (DSB) RQA Overall Nug. Cov . Org. Cite-P Claim Cov Rubrics o3 46.8 47.0 61.1 39.1 40.2 76.3 + intent 43.2 49.1 64.1 27.2 34.3 79.3 gemini-2.5-pro 54.8 49.0 63.1 53.0 54.2 71.9 + intent 57.8 49.0 58.0 61.1 63.3 74.0 Claude opus-4 58.1 54.0 64.1 56.6 57.6 74.3 + intent 59.9 53.3 65.3 60.1 61.1 75.7 ResearchQA (Y ifei et al., 2025) is a dataset of twenty thousand queries (3.7k test), answers, and rubrics deri ved from surv ey articles written by humans. Every ResearchQA question is paired with rubrics generated from the same survey article as the one used for generating the question. W e use the ResearchQA questions with the subdomain: Artificial Intelligence (50 test questions). Follo wing the official benchmark guidelines, we report the av eraged rubric scores (RQA) to ev aluate responses to ResearchQA questions. Since the original paper shows better results in a parametric setting without retriev al, we follow this setting and only use paragraph intents for this task. For all tasks, we use the of ficial implementations for ev aluation. For retrie val, we use the publicly av ailable Semantic Scholar keyword search API (Kinne y et al., 2023) and Semantic Scholar snippet search API (Singh et al., 2025). The retrieved snippets are often ov erly lengthy , so we use an LLM to extract only the salient parts. W e fix the retrieved information set for each query in order to control for retriev al quality , only measuring writing performance differences in our e xperimental settings. W e test the effecti veness of intent-aw are inference with commercial lar ge language models, including o3 from OpenAI (OpenAI, 2025), gemini-2.5-pro (Comanici et al., 2025), and claude-4.1-opus (Anthropic, 2025). For intent-aware training, we utilize 1,000 random-sampled queries from OpenScholar (Asai et al., 2024) and generate synthetic data with gemini-2.5-pro . W e use qwen3-4B/8B (Y ang et al., 2025) and llama3.1-8B (Grattafiori et al., 2024) as the base models for SFT training. W e open-source both our training data and model checkpoints to support future research in this area. W e compare all the variants in Section 4.2 with a control on the training steps, i.e., e ven if we can reformat 4x multivie w data points from a certain number of data points generated from the large models, we use 1/4 steps to allow fair comparison in terms of compute. W e include further details of the inference, training, and ev aluation setup in Appendix A.1. 4 . 2 E X P E R I M E N TA L R E S U LT S Eliciting intents at test time impr oves model perf ormance. W e test the effecti veness of the intents by eliciting intents directly during inference (see appendix A.6 for the prompt). T able 2 and T able 3 show that using intents leads to improv ed overall performance for all model backbones, despite 6 Published as a conference paper at ICLR 2026 default generation from these models being a strong baseline. From the specific metric scores, we observe that intents help models to perform better attrib ution compared to default report generation: both citation metrics impro ve: citation precision and citation recall increase by 5-7 absolute points for Claude. The rubric score and the answer precision score, which do not consider citation quality , remain the same because state-of-the-art LLMs are already highly capable of e xtracting key facts from retriev ed information and ensuring that the presented information is topically rele vant to the query . T o further validate the performance of rows with small mar gins, we conduct a paired t-test to test the hypothesis that +intent is better than default inference for the Overall scores. For gemini-2.5-pro , the p-v alue is 0.013; For o3 , the p-value is 0.072. The low p-value shows that our results are statistically significant if we set alpha =0.1. Interestingly , during our experiments, we observed that o3 has much worse citation behavior than other frontier LLMs, especially on citation recall. From a qualitative analysis of 20 claims from o3 - generated answers, we observe that for nearly 60% cas es, the claims contain additional information about a paper added from o3’ s own memory , going beyond the specific snippets pro vided from that paper in context. Adding citation intents seems to have mix ed eff ects on this behavior , improving citation quality on AstaBench-SQA-CSV2 while dropping citation quality on DeepScholar Bench. Giv en the atypical citation behavior , we report the o3 performance of our intent-aware inference with paragraph intent only in Appendix A.7. It achiev es achiev es 49.3 points overall, achie ving a 2.5 absolute point gain ov er the default inference. Intent-aware generations help smaller models. W e further explore the effecti veness of intent- aware training with SQA-CS-V2. T able 4 presents the performance of different language models trained with the SFT v ariants described in Section 3.4. W e test all the intent-a ware method v ariants by prompting the resulting models to generate intents during inference. W e ablate training with intents, by using the default inference prompt without explicitly asking for intents (Appendix; T able 7). As sho wn in T able 4, across v arious LLMs, intent-aw are SFT v ariants show improv ed performance when compared to no training or baseline SFT , with +7.9, 22.8, 6.1 absolute points of improv ement compared to the base models, for qwen3-8b , llama3.1-8b , and qwen3-4b , respecti vely . For 8B mod- els, intent-multi view SFT consistently leads to the best performance, surpassing gemini-2.5-pro , sho wing benefit from SFT with data points decomposed into multiple subtasks. For qwen3-4b , intent- explicit SFT and intent-multi view SFT perform much better than intent-implicit SFT ; validating our hypothesis that the retained intent tags and rationales can potentially serve as extra explanations and help small models to better understand how to structure paragraphs and citations. As with the larger models, our performance gains primarily come from improved attribution (citation precision and citation recall). T o further validate the generalizability of our SFT variants, we further report the performance on DeepScholar Bench of the qwen3-8b variants in Appendix A.7. The best performing intent-implicit variant achie ves 60.3 overall, which is better than the best performance large models, i.e., Claude opus-4 , T able 3. Intent awareness influences model citation usage. In addition to the performance improvements on the metrics listed abov e, we conduct an analysis on gemini-2.5-pro and qwen3-8b to understand how intent awareness during inference and training shapes the model behavior . Figure 2 presents the change of (1) average portion of retrie ved candidates used in the report and (2) average cov erage score between citations of qwen3-8b variants and gemini-2.5-pro . Adding intents at inference time significantly increases the portion of retrieved candidates (e.g., relev ant papers) used in the report generation, without precision loss, as sho wn previously in T able 2. The increased retrie ved candidate usage without precision loss indicates that the model can appropriately use a larger set of snippets to support the various claims in the answer . Similarly , intent-aware training leads to much higher retriev ed candidates usage compared to the base model or baseline SFT , which sheds light on the model behavior change be yond averaged performance. W e also examine the ov erlap between citations used in the small models and citations used in gemini-2.5-pro . W e find that this coverage analysis sho ws a similar trend: after intent-aware SFT , small models use citations like large models and the o verlap in citations between the small and large models is much larger . Again we see that inference-time verbalized intents also consistently offer extra gain on the SFT -ed models. 7 Published as a conference paper at ICLR 2026 T able 4: SQA-CS-V2 Performance Across dif ferent base models and method v ariants. For each of the intent-aware method v ariants, the inference prompt explicitly asks the model to use intents. Base Model V ariant Ov erall Rubrics Answer P Citation P Citation R gemini-2.5-pro(ref) - 88.1 82.6 94.1 93.2 82.4 qwen3-8b no training 80.7 82.1 90.4 83.2 66.9 baseline SFT 83.2 78.7 94.3 85.8 73.9 intent-explicit SFT 88.0 80.5 93.0 93.6 85.0 intent-implicit SFT 87.1 78.9 94.0 92.5 82.9 intent-multivie w SFT 88.6 81.4 94.7 93.7 84.7 llama3.1-8B no training 66.4 64.6 77.5 67.2 56.1 baseline SFT 84.4 78.1 92.3 89.8 77.4 intent-explicit SFT 85.8 77.6 93.1 90.5 82.2 intent-implicit SFT 87.8 77.9 93.3 94.0 85.9 intent-multivie w SFT 89.2 79.5 95.1 95.4 86.7 qwen3-4b no training 80.9 78.0 94.6 82.8 68.1 baseline SFT 83.4 80.1 92.4 86.2 74.8 intent-explicit SFT 87.5 80.1 97.0 91.5 81.3 intent-implicit SFT 85.2 78.4 93.5 90.1 78.7 intent-multivie w SFT 87.0 80.2 92.2 93.3 82.5 gemini-2.5-pr o qwen3-8b baseline-SF T imp. intent-SF T e xp. intent-SF T multiview SF T 0 10 20 30 40 50 60 70 A verage % of Candidates Used 41.8 42.7 33.7 64.1 63.9 65.9 60.9 39.9 36.0 67.5 65.6 66.0 A verage portion of retrieved candidates used default verb. intent qwen3-8b baseline-SF T imp. intent-SF T e xp. intent-SF T multiview SF T 20 40 60 80 A verage Coverage Score 58.4 77.6 86.5 86.5 87.4 55.6 81.5 87.2 86.9 88.4 A verage coverage score compared to Gemini-2.5-pro citations default verb. intent Figure 2: (left) average portion of retrie ved candidates used in the generated reports; (right) average citation coverage between small model variants and gemini-2.5-pro . All average scores are computed at a query level. default and verb. intent denotes the different instructions. verb . intent denotes the augmentation of intent awareness. The analysis is done on SQA-CS-V2. Extended Ablations and Baseline Comparison. T o further validate the performance of v erbalized intents , we conduct ablations on gemini-2.5-pro with dif ferent intent categories. T able 5 presents the complementary benefits of both intent cate gories. On the development set of SQA-CS-V2, citation intents and paragraph intents work orthogonally to result in the best performance. W e also compare our inference methods with zero-shot CoT (W ei et al., 2022b; Kojima et al., 2023) prompting and ReAct (Y ao et al., 2023). Results show that our intent-aware inference shows better performance when compared to these methods for long-form report generation tasks. 4 . 3 E FF E C T I V E N E S S O F I N T E N T S I N U N D E R S TA N D I N G M O D E L B E H A V I O R Intent types re veal the model differ ences in beha vior . W e study the distribution of the tag types for citation and paragraph intents in T able 6 , by comparing the model generations with human annotations in the original A CL-ARC (Jurgens et al., 2018) dataset. Overall, the trends align with human annotations, where Backgr ound and Uses emerge as dominant citation intent categories. This suggests that models hav e learned to capture core citation usage patterns in scholarly writing. There are also a hew notable differences; we see that models significantly underuse Comparison or Contrast (around 5%), a category more pre valent in human writing (17%). This gap highlights a limitation in current systems: a tendency to inform or describe rather than synthesize or compare—skills essential for composing useful long-form reports. 8 Published as a conference paper at ICLR 2026 T able 5: SQA-CS-V2-dev Performance results with verbalized intents and gemini-2.5-pro . W e bold the best row for the Ov erall metric. Method V ariant Ov erall Rubrics Answer P Citation P Citation R verbalized intent (gemini) no 88.1 82.6 94.1 93.2 82.4 all 89.7 82.6 94.5 95.7 86.1 citation-only 88.6 81.5 91.7 95.3 86.2 paragraph-only 89.1 82.7 92.9 95.2 85.6 other inference methods CoT 81.3 71.5 94.5 83.3 76.1 ReAct 77.6 67.4 94.6 76.5 72.0 T able 6: Distribution of the intent types: (left) citation intents and (right) paragraph intents. See T able 1 for the full intent type reference. others denotes that the model does not output these pre-defined categories, e.g., just comparison for citation intents. W e report the human reference from Jur gens et al. (2018) on their A CL-ARC dataset labels, as a reference to general human writing distributions. Citation (%) o3 gemini opus-4.1 Human r ef Background 28.2 29.6 21.1 51.9 Motiv ation 10.6 7.1 6.8 5.0 Uses 40.4 55.9 47.4 18.5 Extension 6.9 0.7 12.8 3.7 Comparison 4.7 4.8 3.8 17.5 Future 4.2 0.9 2.8 3.5 (error) 5.0 0.9 5.3 0.0 Paragraph (%) o3 gemini opus-4.1 Expos. 41.5 51.5 39.9 Def. 7.0 7.1 7.3 Argu. 11.6 8.6 5.1 Comp.-Contr . 6.4 6.1 9.7 Cause-Eff. 6.1 2.6 5.4 Prob .-Sol. 14.5 13.4 22.8 Narr . 2.7 5.2 1.3 Eval. 9.6 5.4 8.5 (error) 0.0 0.0 0.0 W e also observe model-specific differences. gemini-2.5-pro achiev es the best performance but leans heavily on Uses (55.9%). It also rarely produces Extension or Future W ork intents, indicating a narrower functional di versity . In contrast, o3 distributes its citations more e venly , with higher use of Motivation and Futur e categories. These differences suggest that intent tagging can help diagnose model tendencies and may guide fine-tuning or ev aluation strategies. Case Study: Intents help navigate r eaders in model-generated long-form r eports. T o explore the impact of intent-awareness beyond performance on automatic metrics, we conduct a user study to in vestigate ho w the presence of intents can shape the users’ report-reading experience. Our user study takes a between-subject approach, where some participants read multiple gemini-2.5-pro -generated reports from a baseline system, and others read reports generated from our system with intents. T o reduce confounds related to the users’ prior kno wledge and personal interest, participants read reports generated on their own questions. They are instructed to pose/select questions that they (1) genuinely want answered and (2) do not already kno w the answer to. Details of the system design, interfaces (with screen shots), and the participant pool are introduced in Appendix A.9. The participants are asked to decide if (1) the displayed information helps them understand whether they want to read this section without opening up the paragraphs; (2) they feel confident that they know what the y will learn if they follow the citation and read the cited paper , for each paragraph and highlighted citation, respectiv ely . For each paragraph/highlighted citation, the participants provide a Likert rating on a scale of 1-5 (from Strongly Disagree to Strongly Agree). In total, we collected labels from 20 participants and 71 reports, with labels for 349 unique paragraphs and 416 unique citations. On average, the participants who read with our systems report 4 . 47 ± 0 . 83 and 4 . 46 ± 0 . 87 for paragraph and citation questions, respecti vely , which suggests that participants generally agree that the intents help them decide whether to read a paragraph in detail or di ve into a citation. In contrast, the participants who read with the baseline system report 3 . 84 ± 1 . 05 and 3 . 62 ± 1 . 18 , which suggests the insuf fi ciency of section titles, first sentences, and supporting snippets alone. W e also qualitativ ely analyzed participants’ optional free-form reflections after they completed the task, which further confirmed that our intent-aware annotations were useful: participants in the experiment condition found the annotations helpful for guiding their reading and their attention span. For e xample, one participant noted, “Intents are particularly useful when the report includes man y hard concepts. Intents help guide the understanding of the relations among the entities”. Another 9 Published as a conference paper at ICLR 2026 annotator reported that “intent labels ( backgr ound, uses, motivation , etc.)” can “let me quickly judge whether the citation was central to the argument or just providing broader context. ”, highlighting the usefulness of the schema design. In contrast, participants in the baseline condition found the information ov erwhelming b ut still insuf ficient: “the citation snippet is hard to read and understand the relev ance when they are long”. These findings highlight the promise of incorporating intent annotations into reading interfaces to support targeted comprehension (Russell et al., 1993; Chang et al., 2023; Lo et al., 2023). 5 D I S C U S S I O N The Complexity and Hierarchy of Intent. Our results show that paragraph- and citation-lev el intents already offer complementary perspectives on the structure of scientific writing. Ho wev er, we believe these two levels likely only scratch the surface. Human authors often operate with multi-layered, hierarchical intents—where paragraphs build upon one another and citations serve nuanced rhetorical roles (Samraj, 2013; Bhatnagar et al., 2022). For instance, writers may structure paragraphs to contrast ideas or build a multi-step argument, and use citations to critique, anticipate, or contextualize claims. Our schema, though effecti ve, was purely synthetic. W e hypothesize that grounding intent schemas in human annotation or behavioral data (e.g., writing process logs, document plans, or outlining strategies) could lead to more sophisticated, accurate modeling of intent hierarchies. Future work could explore tree-structured or graph-based representations of intent to reflect how one paragraph supports, contrasts, or contextualizes another , allowing models to generate globally coherent narrativ es rather than well-formed but some what isolated paragraphs. Intent as a Diagnostic and Analysis Lay er . Besides enabling the generation of higher-quality reports, we see that intent aw areness provides a ne w lens for model ev aluation and analysis. While existing benchmarks emphasize factuality and citat ion correctness, they often miss why and ho w content is organized. In contrast, our intent-centric analysis already helps highlight the distributional dif ferences between human- and model-written texts in Sec. 4.3 (e.g., human writing include significantly more comparisons). This suggests that intents can help inform the design of new benchmarks or scoring rubrics that reward desirable patterns of argumentation, such as balanced comparisons, causality chains, or synthesis of conflicting evidence, so as to distinguish models that have strong capability to synthesize complex information beyond f actual lists. Intent scaf folding may also support self-critique or refinement loops, where models justify and revise their o wn structure. Generalization Across Domains. Our study focused on scientific domains, where writing tends to follow con ventional structures. Howe ver , in other disciplines such as policy , law , or the humanities, the nature of intent types may v ary considerably (Harrington et al., 2019; Lafia et al., 2023). Citations might serve rhetorical, historical, or ethical functions that our current schema does not capture. T o generalize, future work is needed for understanding how intent distributions v ary by domain, whether schemas need to be domain-adaptiv e, and how models might learn new intent categories from domain-specific corpora. 6 C O N C L U S I O N Drawing inspiration from the human writing process, we de velop an intent-a ware writing frame work that helps language models produce better quality reports for scientific deep research tasks. Our strategies of incorporating intent awareness, during both inference and training, lead to improved model performance across several challenging benchmarks. W e further showed that training data generated with intent awareness can be used for distillation, enabling the smaller base models to match state-of-the-art larger model performance. W e demonstrate potential utility beyond automatic metrics: a case study with researchers suggests that our intents can potentially aid reading compre- hension and efficienc y . More broadly , our results provide preliminary yet encouraging evidence that incorporating elements of human writing processes—especially those missing from data used to train language models—can enhance their text generation capabilities. W e open-source our code and model checkpoints to encourage further research in this area. 10 Published as a conference paper at ICLR 2026 A C K N O W L E D G M E N T S The authors thank Hongming Zhang, Sihao Chen, T ong Chen, Runlong Zhou, Ryan Liu, Shannon Shen, Boyuan Zheng, Ken Liu, Xiang Li, Y iming Zhang, as well as other AI2 interns (including but not limited to Y ue Y ang, Hita Kambhamettu, Y apei Chang, Federica Bologna, Amanda Bertsch, Michael Noukhovitch, Nishant Balepur , Peiling Jiang, Alexiss Ross, Ruochen Li, and Anej Sv ete) and UW students (including but not limited to Scott Geng, Rui Xin, Rulin Shao, Zhiyuan Zhang, Hamish Ivison, and Oscar Y in), for their insights into design and ev aluation choices. The authors sincerely appreciate the constructiv e discussions with colleagues from CMU WInE Lab. The authors also thank the anonymous re vie wers and area chair for helpful discussions and comments. At CMU, Xinran Zhao is supported by the ONR A ward N000142312840 and the Amazon AI PhD Fellowship. R E F E R E N C E S Anthropic. Introducing claude 4, May 2025. URL https://www.anthropic.com/news/claude- 4 . Anthropic News Release. Akari Asai, Jacqueline He, Rulin Shao, W eijia Shi, Amanpreet Singh, Joseph Chee Chang, Kyle Lo, Luca Soldaini, Serge y Feldman, Mike D’arcy , et al. Openscholar: Synthesizing scientific literature with retriev al-augmented lms. arXiv pr eprint arXiv:2411.14199 , 2024. A. Bain. English Composition and Rhetoric . Number 1 in English Composition and Rhetoric. Long- mans, Green & Company , 1890. URL https://books.google.com/books?id=ycMCAAAAYAAJ . V asudha Bhatnagar, Swagata Duari, and SK Gupta. Quantitati ve discourse cohesion analysis of scientific scholarly texts using multilayer networks. IEEE Access , 10:88538–88557, 2022. Bernd Bohnet, V inh Q. Tran, Pat V er ga, Roee Aharoni, Daniel Andor , Livio Baldini Soares, Massimiliano Ciaramita, Jacob Eisenstein, Kuzman Ganchev , Jonathan Herzig, Kai Hui, T om Kwiatko wski, Ji Ma, Jianmo Ni, Lierni Sestorain Saralegui, T al Schuster, W illiam W . Cohen, Michael Collins, Dipanjan Das, Donald Metzler , Slav Petrov , and Kellie W ebster . Attributed question answering: Ev aluation and modeling for attrib uted large language models, 2023. URL https://arxiv.org/abs/2212.08037 . Jonathan Bragg, Mike D’Arcy , Nishant Balepur, Dan Bareket, Bhavana Dalvi, Sergey Feldman, Dany Haddad, Jena D. Hwang, Peter Jansen, V arsha Kishore, Bodhisattwa Prasad Majumder , Aakanksha Naik, Sigal Rahamimo v , Kyle Richardson, Amanpreet Singh, Harshit Surana, Aryeh T iktinsky , Rosni V asu, Guy W iener, et al. Astabench: Rigorous benchmarking of ai agents with a holistic scientific research suite. arXiv preprint , 2025. URL https://www.datocms- assets. com/64837/1756213171- astabench- 16.pdf . Joseph Chee Chang, Amy X. Zhang, Jonathan Bragg, Andre w Head, Kyle Lo, Doug Downe y , and Daniel S. W eld. Citesee: Augmenting citations in scientific papers with persistent and personalized historical context. In Pr oceedings of the 2023 CHI Conference on Human F actors in Computing Systems , CHI ’23, New Y ork, NY , USA, 2023. Association for Computing Machinery . ISBN 9781450394215. doi: 10.1145/3544548.3580847. URL https://doi.org/10.1145/3544548. 3580847 . João Coelho, Jingjie Ning, Jingyuan He, Kangrui Mao, Abhijay Paladugu, Pranav Setlur, Jiahe Jin, Jamie Callan, João Magalhães, Bruno Martins, and Chenyan Xiong. Deepresearchgym: A free, transparent, and reproducible ev aluation sandbox for deep research, 2025. URL https: //arxiv.org/abs/2505.19253 . Arman Cohan, W aleed Ammar , Madeleine van Zuylen, and Field Cady . Structural scaffolds for citation intent classification in scientific publications. In Jill Burstein, Christy Doran, and Thamar Solorio (eds.), Proceedings of the 2019 Confer ence of the North American Chapter of the As- sociation for Computational Linguistics: Human Language T echnolo gies, V olume 1 (Long and Short P apers) , pp. 3586–3596, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19- 1361. URL https://aclanthology.org/N19- 1361/ . 11 Published as a conference paper at ICLR 2026 Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Nov een Sachde va, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, Luke Marris, Sam Petulla, Colin Gaffne y , Asaf Aharoni, Nathan Lintz, T iago Cardal Pais, Henrik Jacobsson, Idan Szpektor , Nan- Jiang Jiang, Krishna Haridasan, Ahmed Omran, Nikunj Saunshi, Dara Bahri, Gaurav Mishra, Eric Chu, T oby Boyd, Brad Hekman, Aaron Parisi, Chao yi Zhang, K ornraphop Kawintiranon, T ania Bedrax-W eiss, Oli ver W ang, Y a Xu, Ollie Purkiss, Uri Mendlovic, Ilaï Deutel, Nam Nguyen, Adam Langley , Flip K orn, Lucia Rossazza, Alexandre Ramé, Sagar W aghmare, Helen Miller , Nathan Byrd, Ashrith Sheshan, Raia Hadsell Sangnie Bhardwaj, Pawel Janus, T ero Rissa, Dan Horgan, Sharon Silver , A yzaan W ahid, Sergey Brin, Yves Raimond, Klemen Kloboves, Cindy W ang, Nitesh Bharadw aj Gunda varapu, Ilia Shumailov , Bo W ang, Mantas P ajarskas, Joe Heyward, Martin Nikoltche v , Maciej Kula, Hao Zhou, Zachary Garrett, Sushant Kafle, Sercan Arik, Ankita Goel, Mingyao Y ang, Jiho Park, Koji K ojima, Parsa Mahmoudieh, Koray Kavukcuoglu, Grace Chen, Doug Fritz, Anton Bulyenov , Sudeshna Roy , Dimitris Paparas, Hadar Shemtov , Bo-Juen Chen, Robin Strudel, David Reitter , Aurk o Roy , Andrey Vlasov , Changwan Ryu, Chas Leichner , Haichuan Y ang, Zelda Mariet, Denis Vnuko v , Tim Sohn, Amy Stuart, W ei Liang, Minmin Chen, Praynaa Rawlani, Christy K oh, JD Co-Re yes, Guangda Lai, Praseem Banzal, Dimitrios Vytiniotis, Jieru Mei, Mu Cai, Mohammed Badawi, Corey Fry , Ale Hartman, Daniel Zheng, Eric Jia, James Keeling, Annie Louis, Y ing Chen, Efren Robles, W ei-Chih Hung, Howard Zhou, Nikita Saxena, Sonam Goenka, Olivia Ma, Zach Fisher , Mor Hazan T aege, Emily Grav es, David Steiner , Y ujia Li, Sarah Nguyen, Rahul Sukthankar , Joe Stanton, Ali Eslami, Gloria Shen, Berkin Akin, Alex ey Guse ynov , Y iqian Zhou, Jean-Baptiste Alayrac, Armand Joulin, Efrat Farkash, Ashish Thapliyal, Stephen Roller , Noam Shazeer , T odor Davche v , T erry Koo, Hannah Forbes-Pollard, Kartik Audhkhasi, Greg Farquhar , Adi Mayra v Gilady , Maggie Song, John Aslanides, Piermaria Mendolicchio, Alicia Parrish, John Blitzer, Pramod Gupta, Xiaoen Ju, Xiaochen Y ang, Puranjay Datta, Andrea T acchetti, Sanket V aibha v Mehta, Gre gory Dibb, Shubham Gupta, Federico Piccinini, Raia Hadsell, Sujee Rajayogam, Jiepu Jiang, Patrick Griffin, Patrik Sundberg, Jamie Hayes, Alexe y Frolov , T ian Xie, Adam Zhang, Kingshuk Dasgupta, Uday Kalra, Lior Shani, Klaus Macherey , Tzu- Kuo Huang, Liam MacDermed, Karthik Duddu, Paulo Zacchello, Zi Y ang, Jessica Lo, Kai Hui, Matej Kastelic, Derek Gasaway , Qijun T an, Summer Y ue, Pablo Barrio, John W ieting, W eel Y ang, Andrew Nystrom, Solomon Demmessie, Anselm Levskaya, Fabio V iola, Chetan T ekur , Greg Billock, Geor ge Necula, Mandar Joshi, Rylan Schaeffer , Swachhand Lokhande, Christina Sorokin, Pradeep Shenoy , Mia Chen, Mark Collier, Hongji Li, T aylor Bos, Nev an W ichers, Sun Jae Lee, Angéline Pouget, Santhosh Thangaraj, K yriakos Axiotis, Phil Crone, Rachel Sterneck, Nikolai Chinaev , V ictoria Krakovna, Oleksandr Ferludin, Ian Gemp, Stephanie Winkler , Dan Goldberg, Iv an Korotk ov , Kef an Xiao, Malika Mehrotra, Sandeep Mariserla, V ihari Piratla, T erry Thurk, Khiem Pham, Hongxu Ma, Alexandre Senges, Ra vi Kumar , Clemens Meyer , Ellie T alius, Nuo W ang Pierse, Ballie Sandhu, Horia T oma, Kuo Lin, Swaroop Nath, T om Stone, Dorsa Sadigh, Nikita Gupta, Arthur Guez, A vi Singh, Matt Thomas, T om Duerig, Y uan Gong, Richard T anburn, L ydia Lihui Zhang, Phuong Dao, Mohamed Hammad, Sirui Xie, Shruti Rijhw ani, Ben Murdoch, Duhyeon Kim, W ill Thompson, Heng-Tze Cheng, Daniel Sohn, Pablo Sprechmann, Qiantong Xu, Sriniv as T adepalli, Peter Y oung, Y e Zhang, Hansa Sriniv asan, Miranda Aperghis, Aditya A yyar , Hen Fitoussi, Ryan Burnell, Da vid Madras, Mike Dusenberry , Xi Xiong, T ayo Oguntebi, Ben Albrecht, Jörg Bornschein, Jov ana Mitrovi ´ c, Mason Dimarco, Bhar gav Kanag al Shamanna, Premal Shah, Eren Sezener , Shyam Upadhyay , Dav e Lacey , Craig Schiff, Sebastien Baur , Sanjay Ganapathy , Ev a Schnider , Mateo W irth, Connor Schenck, Andrey Simanovsky , Y i-Xuan T an, Philipp Fränken, Dennis Duan, Bharath Mankalale, Nikhil Dhawan, Ke vin Sequeira, Zichuan W ei, Shiv anker Goel, Caglar Unlu, Y ukun Zhu, Haitian Sun, Ananth Balashankar , Kurt Shuster , Megh Umekar , Mahmoud Alnahla wi, Aäron v an den Oord, Kelly Chen, Y uexiang Zhai, Zihang Dai, Kuang-Huei Lee, Eric Doi, Lukas Zilka, Rohith V allu, Disha Shriv astav a, Jason Lee, Hisham Husain, Honglei Zhuang, V incent Cohen-Addad, Jarred Barber, James Atw ood, Adam Sadovsk y , Quentin W ellens, Stev en Hand, Arunkumar Rajendran, A ybuke T urker , CJ Carey , Y uanzhong Xu, Hagen Soltau, Zefei Li, Xinying Song, Conglong Li, Iurii Kemae v , Sasha Brown, Andrea Burns, V iorica Patraucean, Piotr Stanczyk, Renga Ara vamudhan, Mathieu Blondel, Hila Noga, Lorenzo Blanco, W ill Song, Michael Isard, Mandar Sharma, Reid Hayes, Dalia El Bada wy , A very Lamp, Itay Laish, Olga K ozlov a, Kelvin Chan, Sahil Singla, Sriniv as Sunkara, Mayank Upadhyay , Chang Liu, Aijun Bai, Jarek W ilkie wicz, Martin Zlocha, Jeremiah Liu, Zhuowan Li, Haiguang Li, Omer Barak, Ganna Raboshchuk, Jiho Choi, Fangyu Liu, Erik Jue, Mohit Sharma, Andreea Marzoca, Robert Busa-Fekete, Anna K orsun, Andre Elisseef f, Zhe Shen, Sara Mc Carthy , Kay Lamerigts, Anahita Hosseini, Hanzhao Lin, Charlie Chen, Fan Y ang, Kushal Chauhan, Mark Omernick, 12 Published as a conference paper at ICLR 2026 Dawei Jia, Karina Zainullina, Demis Hassabis, Danny V ainstein, Ehsan Amid, Xiang Zhou, Ronny V otel, Eszter Vértes, Xinjian Li, Zongwei Zhou, Angeliki Lazaridou, Brendan McMahan, Arjun Narayanan, Hubert Soyer , Sujoy Basu, Kayi Lee, Bryan Perozzi, Qin Cao, Leonard Berrada, Rahul Arya, Ke Chen, Katrina, Xu, Matthias Lochbrunner , Alex Hofer , Sahand Sharifzadeh, Renjie W u, Sally Goldman, Pranjal A wasthi, Xuezhi W ang, Y an W u, Claire Sha, Biao Zhang, Maciej Mikuła, Filippo Graziano, Siobhan Mcloughlin, Irene Giannoumis, Y ouhei Namiki, Chase Malik, Carey Radebaugh, Jamie Hall, Ramiro Leal-Cav azos, Jianmin Chen, V ikas Sindhwani, David Kao, David Greene, Jordan Griffith, Chris W elty , Ceslee Montgomery , T oshihiro Y oshino, Liangzhe Y uan, Noah Goodman, Assaf Hurwitz Michaely , Ke vin Lee, KP Sawhney , W ei Chen, Zheng Zheng, Megan Shum, Nikolay Sa vinov , Etienne Pot, Ale x Pak, Morteza Zadimoghaddam, Sijal Bhatnagar , Y oad Le wenberg, Blair K utzman, Ji Liu, Lesley Katzen, Jeremy Selier , Josip Djolonga, Dmitry Lepikhin, Kelvin Xu, Jacky Liang, Jiewen T an, Benoit Schillings, Muge Ersoy , Pete Blois, Bernd Bandemer , Abhimanyu Singh, Sergei Lebede v , Pankaj Joshi, Adam R. Bro wn, Ev an Palmer , Shreya Pathak, Komal Jalan, Fedir Zubach, Shuba Lall, Randall Parker , Alok Gunjan, Serge y Rogulenko, Sumit Sanghai, Zhaoqi Leng, Zoltan Egyed, Shixin Li, Maria Ivanov a, Kostas Andriopoulos, Jin Xie, Elan Rosenfeld, Auriel Wright, Ankur Sharma, Xinyang Geng, Y icheng W ang, Sam Kwei, Renke Pan, Y ujing Zhang, Gabby W ang, Xi Liu, Chak Y eung, Elizabeth Cole, A viv Rosenberg, Zhen Y ang, Phil Chen, George Polovets, Pranav Nair , Rohun Saxena, Josh Smith, Shuo yiin Chang, Aroma Mahendru, Svetlana Grant, Anand Iyer, Irene Cai, Jed McGif fin, Jiaming Shen, Alanna W alton, Antonious Girgis, Oli ver W oodman, Rosemary K e, Mike Kwong, Louis Rouillard, Jinmeng Rao, Zhihao Li, Y untao Xu, Flavien Prost, Chi Zou, Ziwei Ji, Alberto Magni, T yler Liechty , Dan A. Calian, Deepak Ramachandran, Igor Kri vok on, Hui Huang, T erry Chen, Anja Hauth, Anastasija Ili ´ c, W eijuan Xi, Hyeontaek Lim, Vlad-Doru Ion, Pooya Moradi, Metin T oksoz-Exley , Kalesha Bullard, Miltos Allamanis, Xiaomeng Y ang, Sophie W ang, Zhi Hong, Anita Gergely , Cheng Li, Bhavish ya Mittal, V italy K ovale v , V ictor Ungureanu, Jane Labanowski, Jan W assenberg, Nicolas Lacasse, Geof frey Cideron, Petar De vi ´ c, Annie Marsden, L ynn Nguyen, Michael Fink, Y in Zhong, T atsuya Kiyono, Desi Ivano v , Sally Ma, Max Bain, Kiran Y alasangi, Jennifer She, Anastasia Petrushkina, Mayank Lunayach, Carla Bromberg, Sarah Hodkinson, V ilobh Meshram, Daniel Vlasic, Austin Kyk er , Stev e Xu, Jeff Stanway , Zuguang Y ang, Kai Zhao, Matthew T ung, Seth Odoom, Y asuhisa Fujii, Justin Gilmer , Eun young Kim, Felix Halim, Quoc Le, Bernd Bohnet, Seliem El-Sayed, Behnam Neyshab ur, Malcolm Reynolds, Dean Reich, Y ang Xu, Erica Moreira, Anuj Sharma, Zeyu Liu, Mohammad Jav ad Hosseini, Naina Raisinghani, Y i Su, Ni Lao, Daniel Formoso, Marco Gelmi, Almog Gueta, T apomay Dey , Elena Gribovskaya, Domagoj ´ Cevid, Sidharth Mudgal, Garrett Bingham, Jianling W ang, Anurag Kumar , Alex Cullum, Feng Han, Konstantinos Bousmalis, Diego Cedillo, Grace Chu, Vladimir Magay , Paul Michel, Ester Hlavno v a, Daniele Calandriello, Setareh Ariafar , Kaisheng Y ao, V ikash Sehwag, Arpi V ezer, Agustin Dal Lago, Zhenkai Zhu, Paul Kishan Rubenstein, Allen Porter , Anirudh Baddepudi, Oriana Riv a, Mihai Dorin Istin, Chih-Kuan Y eh, Zhi Li, Andre w How ard, Nilpa Jha, Jeremy Chen, Raoul de Liedekerke, Zafarali Ahmed, Mikel Rodriguez, T anuj Bhatia, Bangju W ang, Ali Elqursh, David Klinghoffer , Peter Chen, Pushmeet K ohli, T e I, W eiyang Zhang, Zack Nado, Jilin Chen, Maxwell Chen, Geor ge Zhang, Aayush Singh, Adam Hillier, Federico Lebron, Y iqing T ao, T ing Liu, Gabriel Dulac-Arnold, Jingwei Zhang, Shashi Narayan, Buhuang Liu, Orhan Firat, Abhishek Bhowmick, Bingyuan Liu, Hao Zhang, Zizhao Zhang, Georges Rotiv al, Nathan Howard, Anu Sinha, Ale xander Grushetsky , Benjamin Beyret, K eerthana Gopalakrishnan, James Zhao, Kyle He, Szabolcs P ayrits, Zaid Nabulsi, Zhaoyi Zhang, W eijie Chen, Edward Lee, Nov a Fallen, Sreeniv as Gollapudi, Aurick Zhou, Filip Pav eti ´ c, Thomas Köppe, Shiyu Huang, Rama Pasumarthi, Nick Fernando, Felix Fischer , Daria ´ Curko, Y ang Gao, James Svensson, Austin Stone, Haroon Qureshi, Abhishek Sinha, Apoorv Kulshreshtha, Martin Matysiak, Jieming Mao, Carl Saroufim, Aleksandra Faust, Qingnan Duan, Gil Fidel, Kaan Katircioglu, Raphaël Lopez Kaufman, Dhruv Shah, W eize Kong, Abhishek Bapna, Gellért W eisz, Emma Dunlea vy , Praneet Dutta, T ianqi Liu, Rahma Chaabouni, Carolina Parada, Marcus W u, Alexandra Belias, Alessandro Bissacco, Stanislav Fort, Li Xiao, Fantine Huot, Chris Knutsen, Y ochai Blau, Gang Li, Jennifer Prendki, Juliette Love, Y inlam Cho w , Pichi Charoenpanit, Hidetoshi Shimokaw a, V incent Coriou, Karol Gregor , T omas Izo, Arjun Akula, Mario Pinto, Chris Hahn, Dominik Paulus, Jiaxian Guo, Neha Sharma, Cho-Jui Hsieh, Adaeze Chukwuka, Kazuma Hashimoto, Nathalie Rauschmayr , Ling W u, Christof Angermueller , Y ulong W ang, Sebastian Gerlach, Michael Pliskin, Daniil Mirylenka, Min Ma, Lexi Baugher, Bryan Gale, Shaan Bijwadia, Nemanja Raki ´ cevi ´ c, David W ood, Jane Park, Chung-Ching Chang, Babi Seal, Chris T ar , Kacper Krasowiak, Y iwen Song, Georgi Stephano v , Gary W ang, Marcello Maggioni, Stein Xudong Lin, Felix W u, Shachi Paul, Zixuan Jiang, Shubham Agrawal, Bilal Piot, 13 Published as a conference paper at ICLR 2026 Alex Feng, Cheolmin Kim, T ulsee Doshi, Jonathan Lai, Chuqiao, Xu, Sharad V ikram, Ciprian Chelba, Sebastian Krause, V incent Zhuang, Jack Rae, Timo Denk, Adrian Collister , Lotte W eerts, Xianghong Luo, Y ifeng Lu, Håvard Garnes, Nitish Gupta, T erry Spitz, A vinatan Hassidim, Lihao Liang, Izhak Shafran, Peter Humphreys, K enny V assigh, Phil W allis, V irat Shejwalkar , Nicolas Perez-Niev es, Rachel Hornung, Melissa T an, Beka W estberg, Andy L y , Richard Zhang, Brian Farris, Jongbin Park, Alec Kosik, Zeynep Cankara, Andrii Maksai, Y unhan Xu, Albin Cassirer, Sergi Caelles, Abbas Abdolmaleki, Mencher Chiang, Alex Fabrikant, Shravya Shetty , Luheng He, Mai Giménez, Hadi Hashemi, Sheena Panthaplack el, Y ana Kulizhskaya, Salil Deshmukh, Daniele Pighin, Robin Alazard, Disha Jindal, Seb Noury , Pradeep Kumar S, Siyang Qin, Xerx es Dotiwalla, Stephen Spencer , Mohammad Babaeizadeh, Blake JianHang Chen, V aibhav Mehta, Jennie Lees, Andrew Leach, Penporn K oanantakool, Ilia Akolzin, Ramona Comanescu, Junwhan Ahn, Alexe y Svyatkovskiy , Basil Mustafa, David D’Ambrosio, Shi va Mohan Reddy Garlapati, Pascal Lamblin, Alekh Agarwal, Shuang Song, Pier Giuseppe Sessa, Pauline Coquinot, John Maggs, Hussain Masoom, Divya Pitta, Y aqing W ang, Patrick Morris-Suzuki, Billy Porter , Johnson Jia, Jeffrey Dudek, Raghav ender R, Cosmin Paduraru, Alan Ansell, T olga Bolukbasi, T ony Lu, Ramya Ganeshan, Zi W ang, Henry Grif fiths, Rodrigo Benenson, Y ifan He, James Swirhun, George Papamakarios, Aditya Chawla, K untal Sengupta, Y an W ang, V edrana Milutinovic, Igor Mordatch, Zhipeng Jia, Jamie Smith, W ill Ng, Shitij Nigam, Matt Y oung, Eugen V ušak, Blake Hechtman, Sheela Goenka, A vital Zipori, Kareem A youb, Ashok Popat, T rilok Acharya, Luo Y u, Dawn Bloxwich, Hugo Song, Paul Roit, Haiqiong Li, A viel Boag, Nigamaa Nayakanti, Bilv a Chandra, T ianli Ding, Aahil Mehta, Cath Hope, Jiageng Zhang, Idan Heimlich Shtacher , Kartikeya Badola, Ryo Nakashima, Andrei Sozanschi, Iulia Com ¸ sa, Ante Žužul, Emily Cav eness, Julian Odell, Matthew W atson, Dario de Cesare, Phillip Lippe, Derek Lockhart, Siddharth V erma, Huizhong Chen, Sean Sun, Lin Zhuo, Aditya Shah, Prakhar Gupta, Alex Muzio, Ning Niu, Amir Zait, Abhinav Singh, Meenu Gaba, F an Y e, Prajit Ramachandran, Mohammad Saleh, Raluca Ada Popa, A yush Dubey , Frederick Liu, Sara Jav anmardi, Mark Epstein, Ross Hemsley , Richard Green, Nishant Ranka, Eden Cohen, Chuyuan Kelly Fu, Sanjay Ghemaw at, Jed Borovik, James Martens, Anthony Chen, Prana v Shyam, André Susano Pinto, Ming-Hsuan Y ang, Alexandru ¸ T ifrea, David Du, Boqing Gong, A yushi Agarwal, Seungyeon Kim, Christian Frank, Saloni Shah, Xiaodan Song, Zhiwei Deng, Ales Mikhalap, Kleopatra Chatziprimou, Timothy Chung, T oni Creswell, Susan Zhang, Y ennie Jun, Carl Lebsack, W ill Truong, Sla vica Anda ˇ ci ´ c, Itay Y ona, Marco Fornoni, Rong Rong, Serge T oropov , Afzal Shama Soudagar , Andrew Audibert, Salah Zaiem, Zaheer Abbas, Andrei Rusu, Sahitya Potluri, Shitao W eng, Anastasios K ementsietsidis, Anton Tsitsulin, Daiyi Peng, Natalie Ha, Sanil Jain, T ejasi Latkar , Simeon Ivano v , Cory McLean, Anirudh GP , Rajesh V enkataraman, Canoee Liu, Dilip Krishnan, Joel D’ sa, Roey Y ogev , Paul Collins, Benjamin Lee, Lewis Ho, Carl Doersch, Gal Y ona, Shawn Gao, Felipe T iengo Ferreira, Adnan Ozturel, Hannah Muckenhirn, Ce Zheng, Gargi Balasubramaniam, Mudit Bansal, Geor ge van den Driessche, Si van Eiger , Salem Haykal, V edant Misra, Abhimanyu Goyal, Danilo Martins, Gary Leung, Jonas V alfridsson, Four Flynn, W ill Bishop, Chenxi Pang, Y oni Halpern, Honglin Y u, Lawrence Moore, Y uvein, Zhu, Sridhar Thiagarajan, Y oel Drori, Zhisheng Xiao, Lucio Dery , Rolf Jagerman, Jing Lu, Eric Ge, V aibha v Aggarwal, Arjun Khare, V inh T ran, Oded Elyada, Ferran Alet, James Rubin, Ian Chou, David T ian, Libin Bai, Lawrence Chan, Lukasz Lew , Karolis Misiunas, T aylan Bilal, Aniket Ray , Sindhu Raghuram, Alex Castro-Ros, V iral Carpenter , CJ Zheng, Michael Kilgore, Josef Broder , Emily Xue, Praveen Kallakuri, Dheeru Dua, Nancy Y uen, Stev e Chien, John Schultz, Saurabh Agra wal, Reut Tsarf aty , Jingcao Hu, Ajay Kannan, Dror Marcus, Nisarg K othari, Baochen Sun, Ben Horn, Matko Bošnjak, Ferjad Naeem, Dean Hirsch, Lewis Chiang, Bo ya Fang, Jie Han, Qifei W ang, Ben Hora, Antoine He, Mario Lu ˇ ci ´ c, Beer Changpinyo, Anshuman Tripathi, John Y oussef, Chester Kwak, Philippe Schlattner , Cat Graves, Rémi Leblond, W enjun Zeng, Anders Andreassen, Gabriel Rasskin, Y ue Song, Eddie Cao, Junhyuk Oh, Matt Hoffman, W ojtek Skut, Y ichi Zhang, Jon Stritar , Xingyu Cai, Saarthak Khanna, Kathie W ang, Shriya Sharma, Christian Reisswig, Y ounghoon Jun, Aman Prasad, T atiana Sholokhova, Preeti Singh, Adi Gerzi Rosenthal, Anian Ruoss, Françoise Beaufays, Sean Kirmani, Dongkai Chen, Johan Schalkwyk, Jonathan Herzig, Been Kim, Josh Jacob, Damien V incent, Adrian N Reyes, Iv ana Balazevic, Léonard Hussenot, Jon Schneider, Parker Barnes, Luis Castro, Spandana Raj Babbula, Simon Green, Serkan Cabi, Nico Duduta, Dann y Driess, Rich Galt, Noam V elan, Junjie W ang, Hongyang Jiao, Matthew Mauger , Du Phan, Miteyan Patel, Vlado Gali ´ c, Jerry Chang, Eyal Marcus, Matt Harve y , Julian Salazar , Elahe Dabir, Suraj Satishkumar Sheth, Amol Mandhane, Hanie Sedghi, Jeremiah W illcock, Amir Zandieh, Shruthi Prabhakara, Aida Amini, Antoine Miech, V ictor Stone, Massimo Nicosia, Paul Niemczyk, Y ing Xiao, Lucy Kim, Sławek Kwasiborski, V ikas V erma, Ada Maksutaj 14 Published as a conference paper at ICLR 2026 Oflazer , Christoph Hirnschall, Peter Sung, Lu Liu, Richard Everett, Michiel Bakker , Ágoston W eisz, Y ufei W ang, V iv ek Sampathkumar, Uri Shaham, Bibo Xu, Y asemin Altun, Mingqiu W ang, T akaaki Saeki, Guanjie Chen, Emanuel T aropa, Shanthal V asanth, Sophia Austin, Lu Huang, Goran Petrovic, Qingyun Dou, Daniel Golo vin, Grigory Rozhdestv enskiy , Allie Culp, W ill W u, Motoki Sano, Divya Jain, Julia Proskurnia, Sébastien Cev ey , Alejandro Cruzado Ruiz, Piyush Patil, Mahdi Mirzazadeh, Eric Ni, Ja vier Snaider , Lijie Fan, Alexandre Fréchette, AJ Pierigiov anni, Shariq Iqbal, K enton Lee, Claudio Fantacci, Jinwei Xing, Lisa W ang, Ale x Irpan, David Raposo, Y i Luan, Zhuoyuan Chen, Harish Ganapath y , Ke vin Hui, Jiazhong Nie, Isabelle Guyon, Heming Ge, Roopali V ij, Hui Zheng, Dayeong Lee, Alfonso Castaño, Khuslen Baatarsukh, Gabriel Ibagon, Alexandra Chronopoulou, Nicholas FitzGerald, Shashank V iswanadha, Safeen Huda, Rivka Moroshko, Geor gi Stoyano v , Prateek Kolhar , Alain V aucher , Ishaan W atts, Adhi Kuncoro, Henryk Michalewski, Satish Kambala, Bat-Or gil Batsaikhan, Alek Andreev , Irina Jurenka, Maigo Le, Qihang Chen, W ael Al Jishi, Sarah Chakera, Zhe Chen, Aditya Kini, V ikas Y adav , Aditya Siddhant, Ilia Labzovsk y , Balaji Lakshminarayanan, Carrie Grimes Bostock, Pankil Botadra, Ankesh Anand, Colton Bishop, Sam Conw ay-Rahman, Mohit Agarwal, Y ani Donchev , Achintya Singhal, Félix de Chaumont Quitry , Natalia Ponomare va, Nishant Agrawal, Bin Ni, Kalpesh Krishna, Masha Samsikov a, John Karro, Y ilun Du, T amara von Glehn, Caden Lu, Christopher A. Choquette-Choo, Zhen Qin, T ingnan Zhang, Sicheng Li, Divya T yam, Swaroop Mishra, Wing Lowe, Colin Ji, W eiyi W ang, Manaal Faruqui, Ambrose Slone, V alentin Dalibard, Arunachalam Narayanaswamy , John Lambert, Pierre-Antoine Manzagol, Dan Karliner , Andrew Bolt, Ivan Lobov , Aditya Kusupati, Chang Y e, Xuan Y ang, Heiga Zen, Nelson George, Mukul Bhutani, Olivier Lacombe, Robert Riachi, Gagan Bansal, Rachel Soh, Y ue Gao, Y ang Y u, Adams Y u, Emily Nottage, T ania Rojas-Esponda, James Noraky , Manish Gupta, Ragha Kotikalapudi, Jichuan Chang, Sanja Deur , Dan Graur , Alex Mossin, Erin Farnese, Ricardo Figueira, Alexandre Moufarek, Austin Huang, Patrik Zochbauer , Ben Ingram, T ongzhou Chen, Zelin W u, Adrià Puigdomènech, Leland Rechis, Da Y u, Sri Gayatri Sundara Padmanabhan, Rui Zhu, Chu ling K o, Andrea Banino, Samira Daruki, Aarush Selvan, Dhruva Bhaswar , Daniel Hernandez Diaz, Chen Su, Salvatore Scellato, Jennifer Brennan, W oohyun Han, Grace Chung, Priyanka Agrawal, Urv ashi Khandelwal, Khe Chai Sim, Morgane Lustman, Sam Ritter , Kelvin Guu, Jiawei Xia, Prateek Jain, Emma W ang, T yrone Hill, Mirko Rossini, Marija Kostelac, T autvydas Misiunas, Amit Sabne, Kyuyeun Kim, Ahmet Iscen, Congchao W ang, José Leal, Ashwin Sreev atsa, Utku Evci, Manfred W armuth, Saket Joshi, Daniel Suo, James Lottes, Garrett Honke, Brendan Jou, Stef ani Karp, Jieru Hu, Himanshu Sahni, Adrien Ali T aïga, W illiam K ong, Samrat Ghosh, Renshen W ang, Jay Pav agadhi, Natalie Axelsson, Nikolai Grigore v , Patrick Siegler , Rebecca Lin, Guohui W ang, Emilio Parisotto, Sharath Maddineni, Krishan Subudhi, Eyal Ben-David, Elena Pochernina, Orgad K eller, Thi A vrahami, Zhe Y uan, Pulkit Mehta, Jialu Liu, Sherry Y ang, W endy Kan, Katherine Lee, T om Funkhouser , Derek Cheng, Hongzhi Shi, Archit Sharma, Joe Kelle y , Matan Eyal, Y ury Malkov , Corentin T allec, Y uval Bahat, Shen Y an, Xintian, W u, David Lindner , Chengda W u, A vi Caciularu, Xiyang Luo, Rodolphe Jenatton, T im Zaman, Y ingying Bi, Ilya Kornako v , Ganesh Mallya, Daisuke Ikeda, Itay Karo, Anima Singh, Colin Evans, Praneeth Netrapalli, V incent Nallatamby , Isaac T ian, Y annis Assael, V ikas Raunak, V ictor Carbune, Ioana Bica, Lior Madmoni, Dee Cattle, Snchit Grover , Krishna Somandepalli, Sid Lall, Amelio Vázquez-Reina, Riccardo Patana, Jiaqi Mu, Pranav T alluri, Maggie T ran, Rajeev Aggarwal, RJ Skerry-Ryan, Jun Xu, Mik e Burro ws, Xiaoyue Pan, Edouard Yvinec, Di Lu, Zhiying Zhang, Duc Dung Nguyen, Hairong Mu, Gabriel Barcik, Helen Ran, Lauren Beltrone, Krzysztof Choromanski, Dia Kharrat, Samuel Albanie, Sean Purser-hask ell, David Bieber , Carrie Zhang, Jing W ang, T om Hudson, Zhiyuan Zhang, Han Fu, Johannes Mauerer , Mohammad Hossein Bateni, AJ Maschinot, Bing W ang, Muye Zhu, Arjun Pillai, T obias W eyand, Shuang Liu, Oscar Akerlund, Fred Bertsch, V ittal Premachandran, Alicia Jin, V incent Roulet, Peter de Boursac, Shubham Mittal, Ndaba Ndebele, Georgi Karadzhov , Sahra Ghalebikesabi, Ricky Liang, Allen W u, Y ale Cong, Nimesh Ghelani, Sumeet Singh, Bahar Fatemi, W arren, Chen, Charles Kwong, Ale xe y K olganov , Steve Li, Richard Song, Chenkai K uang, Sobhan Miryoosefi, Dale W ebster, James W endt, Arkadiusz Socala, Guolong Su, Artur Mendonça, Abhinav Gupta, Xiaowei Li, T omy Tsai, Qiong, Hu, Kai Kang, Angie Chen, Sertan Girgin, Y ongqin Xian, Andrew Lee, Nolan Ramsden, Leslie Bak er , Madeleine Clare Elish, V arvara Krayv anov a, Rishabh Joshi, Jiri Simsa, Y ao-Y uan Y ang, Piotr Ambroszczyk, Dipankar Ghosh, Arjun Kar , Y uan Shangguan, Y umeya Y amamori, Y aroslav Akulov , Andy Brock, Haotian T ang, Siddharth V ashishtha, Rich Munoz, Andreas Steiner , Kalyan Andra, Daniel Eppens, Qixuan Feng, Hayato K obayashi, Sasha Goldshtein, Mona El Mahdy , Xin W ang, Jilei, W ang, Richard Killam, T om Kwiatko wski, Kavya K opparapu, Serena Zhan, Chao Jia, Alexei Bendebury , Sheryl Luo, Adrià Recasens, Timoth y 15 Published as a conference paper at ICLR 2026 Knight, Jing Chen, Mohak Patel, Y aGuang Li, Ben Withbroe, Dean W eesner , Kush Bhatia, Jie Ren, Danielle Eisenb ud, Ebrahim Songhori, Y anhua Sun, T ravis Choma, T asos K ementsietsidis, Lucas Manning, Brian Roark, W ael Farhan, Jie Feng, Susheel T atineni, James Cobon-Kerr , Y unjie Li, Lisa Anne Hendricks, Isaac Noble, Chris Breaux, Nate K ushman, Liqian Peng, Fuzhao Xue, T aylor T obin, Jamie Rogers, Josh Lipschultz, Chris Alberti, Alex ey Vlaskin, M ostafa Dehghani, Roshan Sharma, Tris W arkentin, Chen-Y u Lee, Benigno Uria, Da-Cheng Juan, Angad Chandorkar , Hila Sheftel, Ruibo Liu, Elnaz Dav oodi, Borja De Balle Pigem, K edar Dhamdhere, Da vid Ross, Jonathan Hoech, Mahdis Mahdieh, Li Liu, Qiujia Li, Liam McCafferty , Chenxi Liu, Markus Mircea, Y unting Song, Omkar Savant, Alaa Saade, Colin Cherry , V incent Hellendoorn, Siddharth Goyal, Paul Pucciarelli, Da vid V ilar T orres, Zohar Y aha v , Hyo Lee, Lars Lowe Sjoesund, Christo Kirov , Bo Chang, Deepanway Ghoshal, Lu Li, Gilles Baechler , Sébastien Pereira, T ara Sainath, Anudhyan Boral, Dominik Grewe, Afief Halumi, Nguyet Minh Phu, T ianxiao Shen, Marco T ulio Ribeiro, Dhriti V arma, Alex Kaskasoli, Vlad Feinberg, Navneet Potti, Jarrod Kahn, Matheus W isniewski, Shakir Mohamed, Arnar Mar Hrafnkelsson, Bobak Shahriari, Jean-Baptiste Lespiau, Lisa Patel, Legg Y eung, T om Paine, Lantao Mei, Alex Ramirez, Rakesh Shiv anna, Li Zhong, Josh W oodward, Guilherme T ubone, Samira Khan, Heng Chen, Elizabeth Nielsen, Catalin Ionescu, Utsav Prabhu, Mingcen Gao, Qingze W ang, Sean Augenstein, Neesha Subramaniam, Jason Chang, Fotis Iliopoulos, Jiaming Luo, Myriam Khan, W eicheng Kuo, Denis T eplyashin, Florence Perot, Logan Kilpatrick, Amir Globerson, Hongkun Y u, Anfal Siddiqui, Nick Sukhanov , Arun Kandoor , Umang Gupta, Marco Andreetto, Moran Ambar , Donnie Kim, Paweł W esołowski, Sarah Perrin, Ben Limonchik, W ei Fan, Jim Stephan, Ian Ste wart-Binks, Ryan Kappedal, T ong He, Sarah Cogan, Romina Datta, T ong Zhou, Jiayu Y e, Leandro Kieliger , Ana Ramalho, Kyle Kastner , Fabian Mentzer , W ei-Jen K o, Arun Suggala, Tianhao Zhou, Shiraz Butt, Hana Strej ˇ cek, Lior Belenki, Subhashini V enugopalan, Mingyang Ling, Evgenii Eltyshev , Y unxiao Deng, Geza K ov acs, Mukund Raghav achari, Hanjun Dai, T al Schuster, Stev en Schwarcz, Richard Nguyen, Arthur Nguyen, Ga vin Buttimore, Shrestha Basu Mallick, Sudeep Gandhe, Seth Benjamin, Michal Jastrzebski, Le Y an, Sugato Basu, Chris Apps, Isabel Edkins, James Allingham, Immanuel Odisho, T omas Kocisk y , Jewel Zhao, Linting Xue, Apoorv Reddy , Chrysov alantis Anastasiou, A viel Atias, Sam Redmond, Kieran Milan, Nicolas Heess, Herman Schmit, Allan Dafoe, Daniel Andor , T ynan Gangwani, Anca Dragan, Sheng Zhang, Ashyana Kachra, Gang W u, Siyang Xue, Ke vin A ydin, Siqi Liu, Y uxiang Zhou, Mahan Malihi, Austin W u, Siddharth Gopal, Candice Schumann, Peter Stys, Alek W ang, Mirek Olšák, Dangyi Liu, Christian Schallhart, Y iran Mao, Demetra Brady , Hao Xu, T omas Mery , Chawin Sitawarin, Si va V elusamy , T om Cobley , Alex Zhai, Christian W alder , Nitzan Katz, Ganesh Jawahar , Chinmay Kulkarni, Antoine Y ang, Adam Paszke, Y inan W ang, Bogdan Damoc, Zalán Borsos, Ray Smith, Jinning Li, Mansi Gupta, Andrei Kapishnikov , Sushant Prakash, Florian Luisier, Rishabh Agarwal, W ill Grathwohl, Kuangyuan Chen, K ehang Han, Nikhil Mehta, Andrew Ov er , Shekoofeh Azizi, Lei Meng, Niccolò Dal Santo, Kelvin Zheng, Jane Shapiro, Igor Petrovski, Jef frey Hui, Amin Ghafouri, Jasper Snoek, James Qin, Mandy Jordan, Caitlin Sikora, Jonathan Malmaud, Y uheng Kuang, Ag a ´ Swietlik, Ruoxin Sang, Chongyang Shi, Leon Li, Andre w Rosenberg, Shubin Zhao, Andy Crawford, Jan-Thorsten Peter , Y un Lei, Xavier Garcia, Long Le, T odd W ang, Julien Amelot, Dav e Orr, Praneeth Kacham, Dana Alon, Gladys T yen, Abhinav Arora, James L yon, Alex Kurakin, Mimi L y , Theo Guidroz, Zhipeng Y an, Rina Panigrahy , Pingmei Xu, Thais Kagohara, Y ong Cheng, Eric Noland, Jinhyuk Lee, Jonathan Lee, Cathy Y ip, Maria W ang, Efrat Nehoran, Alexander Bykovsk y , Zhihao Shan, Ankit Bhagatwala, Chaochao Y an, Jie T an, Guillermo Garrido, Dan Ethier , Nate Hurley , Grace V esom, Xu Chen, Siyuan Qiao, Abhishek Nayyar , Julian W alker , Paramjit Sandhu, Mihaela Rosca, Dann y Swisher , Mikhail Dektiarev , Josh Dillon, George-Cristian Muraru, Manuel T ragut, Artiom Myaskovsk y , David Reid, Mark o V elic, Owen Xiao, Jasmine George, Mark Brand, Jing Li, W enhao Y u, Shane Gu, Xiang Deng, François-Xavier Aubet, Soheil Hassas Y eganeh, Fred Alcober, Celine Smith, T revor Cohn, Kay McKinne y , Michael Tschannen, Ramesh Sampath, Gow oon Cheon, Liangchen Luo, Luyang Liu, Jordi Orbay , Hui Peng, Gabriela Botea, Xiaofan Zhang, Charles Y oon, Cesar Magalhaes, Pa weł Stradomski, Ian Mackinnon, Stev en Hemingray , Kumaran V enkatesan, Rhys May , Jaeyoun Kim, Alex Druinsk y , Jingchen Y e, Zheng Xu, T erry Huang, Jad Al Abdallah, Adil Dostmohamed, Rachana Fellinger , Tsendsuren Munkhdalai, Akanksha Maurya, Peter Garst, Y in Zhang, Maxim Krikun, Simon Bucher , Aditya Srikanth V eerubhotla, Y axin Liu, Sheng Li, Nishesh Gupta, Jakub Adamek, Hanwen Chen, Bernett Orlando, Aleksandr Zaks, Joost v an Amersfoort, Josh Camp, Hui W an, HyunJeong Choe, Zhichun W u, Kate Olszewska, W eiren Y u, Archita V adali, Martin Scholz, Daniel De Freitas, Jason Lin, Amy Hua, Xin Liu, Frank Ding, Y ichao Zhou, Boone Sev erson, Katerina Tsihlas, Samuel Y ang, T ammo Spalink, V arun Y erram, Helena P anko v , Rory 16 Published as a conference paper at ICLR 2026 Blevins, Ben V arg as, Sarthak Jauhari, Matt Miecnikowski, Ming Zhang, Sandeep Kumar , Clement Farabet, Charline Le Lan, Sebastian Flennerhag, Y onatan Bitton, Ada Ma, Arthur Bražinskas, Eli Collins, Niharika Ahuja, Sneha Kudugunta, Anna Bortsova, Minh Giang, W anzheng Zhu, Ed Chi, Scott Lundberg, Alexey Stern, Subha Puttagunta, Jing Xiong, Xiao W u, Y ash Pande, Amit Jhindal, Daniel Murphy , Jon Clark, Marc Brockschmidt, Maxine Deines, Ke vin R. McKee, Dan Bahir, Jiajun Shen, Minh Truong, Daniel McDuff, Andrea Gesmundo, Edouard Rosseel, Bowen Liang, Ken Caluwaerts, Jessica Hamrick, Joseph Kready , Mary Cassin, Rishikesh Ingale, Li Lao, Scott Pollom, Y ifan Ding, W ei He, Lizzetth Bellot, Joana Iljazi, Ramya Sree Boppana, Shan Han, T ara Thompson, Amr Khalifa, Anna Bulanova, Blagoj Mitrevski, Bo Pang, Emma Cooney , T ian Shi, Rey Coaguila, T amar Y akar , Marc’aurelio Ranzato, Nikola Momchev , Chris Rawles, Zachary Charles, Y oung Maeng, Y uan Zhang, Rishabh Bansal, Xiaokai Zhao, Brian Albert, Y uan Y uan, Sudheendra V ijayanarasimhan, Roy Hirsch, V inay Ramasesh, Kiran V odrahalli, Xingyu W ang, Arushi Gupta, DJ Strouse, Jianmo Ni, Roma Patel, Gabe T aubman, Zhouyuan Huo, Dero Gharibian, Marianne Monteiro, Hoi Lam, Shobha V asude v an, Aditi Chaudhary , Isabela Albuquerque, Kilol Gupta, Sebastian Riedel, Chaitra Hegde, A vraham Ruderman, András György , Marcus W ainwright, Ashwin Chaugule, Burcu Karagol A yan, T omer Levinboim, Sam Shleifer , Y ogesh Kalley , V ahab Mirrokni, Abhishek Rao, Prabakar Radhakrishnan, Jay Hartford, Jialin W u, Zhenhai Zhu, Francesco Bertolini, Hao Xiong, Nicolas Serrano, Hamish T omlinson, Myle Ott, Y ifan Chang, Mark Graham, Jian Li, Marco Liang, Xiangzhu Long, Sebastian Borgeaud, Y anif Ahmad, Alex Grills, Diana Mincu, Martin Izzard, Y uan Liu, Jinyu Xie, Louis O’Bryan, Sameera Ponda, Simon T ong, Michelle Liu, Dan Malkin, Khalid Salama, Y uankai Chen, Rohan Anil, Anand Rao, Rigel Swavely , Misha Bilenko, Nina Anderson, T at T an, Jing Xie, Xing W u, Lijun Y u, Oriol V inyals, Andrey Ryabtsev , Rumen Dangovski, Kate Baumli, Daniel Keysers, Christian Wright, Zoe Ashwood, Betty Chan, Artem Shtefan, Y aohui Guo, Ankur Bapna, Radu Soricut, Stev en Pecht, Sabela Ramos, Rui W ang, Jiahao Cai, T rieu T rinh, Paul Barham, Linda Friso, Eli Stickgold, Xiangzhuo Ding, Siamak Shakeri, Diego Ardila, Eleftheria Briakou, Phil Culliton, Adam Ra veret, Jingyu Cui, David Saxton, Subhrajit Roy , Jav ad Azizi, Pengcheng Y in, Lucia Loher , Andrew Bunner , Min Choi, Faruk Ahmed, Eric Li, Y in Li, Shengyang Dai, Michael Elabd, Sriram Ganapathy , Shi vani Agra wal, Y iqing Hua, Paige K unkle, Sujee van Rajayogam, Arun Ahuja, Arthur Conmy , Alex V asiloff, P arker Beak, Christopher Y ew , Jayaram Mudigonda, Bartek W ydrowski, Jon Blanton, Zhengdong W ang, Y ann Dauphin, Zhuo Xu, Martin Polacek, Xi Chen, Hexiang Hu, Pauline Sho, Markus Kunesch, Mehdi Hafezi Manshadi, Eliza Rutherford, Bo Li, Sissie Hsiao, Iain Barr , Alex Tudor , Matija Kecman, Arsha Nagrani, Vladimir Pchelin, Martin Sundermeyer , Aishwarya P S, Abhijit Karmarkar , Y i Gao, Grishma Chole, Olivier Bachem, Isabel Gao, Arturo BC, Matt Dibb, Mauro V erzetti, Felix Hernandez-Campos, Y ana Lunts, Matthew Johnson, Julia Di Trapani, Raphael K oster , Idan Brusilovsk y , Binbin Xiong, Megha Mohabey , Han Ke, Joe Zou, T ea Saboli ´ c, Víctor Campos, John P alo witch, Alex Morris, Linhai Qiu, Prana varaj Ponnuramu, Fangtao Li, V iv ek Sharma, Kiranbir Sodhia, Kaan T ekelioglu, Aleksandr Chuklin, Madhavi Y enugula, Erika Gemzer , Theofilos Strinopoulos, Sam El-Husseini, Huiyu W ang, Y an Zhong, Edouard Leurent, Paul Natse v , W eijun W ang, Dre Mahaarachchi, T ao Zhu, Songyou Peng, Sami Alabed, Cheng-Chun Lee, Anthony Brohan, Arthur Szlam, GS Oh, Anton Ko vsharov , Jenny Lee, Renee W ong, Megan Barnes, Gregory Thornton, Felix Gimeno, Omer Levy , Martin Sev enich, Melvin Johnson, Jonathan Mallinson, Robert Dadashi, Ziyue W ang, Qingchun Ren, Preethi Lahoti, Arka Dhar , Josh Feldman, Dan Zheng, Thatcher Ulrich, Li viu Panait, Michiel Blokzijl, Cip Baetu, Josip Matak, Jitendra Harlalka, Maulik Shah, T al Marian, Daniel v on Dincklage, Cosmo Du, Ruy Ley-W ild, Bethanie Brownfield, Max Schumacher , Y ury Stuken, Shadi Noghabi, Sonal Gupta, Xiaoqi Ren, Eric Malmi, Felix W eissenberger , Blanca Huergo, Maria Bauza, Thomas Lampe, Arthur Douillard, Mojtaba Seyedhosseini, Roy Frostig, Zoubin Ghahramani, Kelvin Nguyen, Kashyap Krishnakumar , Chengxi Y e, Rahul Gupta, Alireza Nazari, Robert Geirhos, Pete Shaw , Ahmed Eleryan, Dima Damen, Jennimaria Palomaki, T ed Xiao, Qiyin Wu, Quan Y uan, Phoenix Meadowlark, Matthew Bilotti, Raymond Lin, Mukund Sridhar, Y annick Schroecker , Da-W oon Chung, Jincheng Luo, T rev or Strohman, T ianlin Liu, Anne Zheng, Jesse Emond, W ei W ang, Andrew Lampinen, T oshiyuki Fukuzawa, Fola wiyo Campbell-Ajala, Monica Roy , James Lee-Thorp, Lily W ang, Iftekhar Naim, T ony , Nguy ên, Guy Bensky , Aditya Gupta, Dominika Rogozi ´ nska, Justin Fu, Thanumalayan Sankaranarayana Pillai, Petar V eli ˇ ckovi ´ c, Shahar Drath, Philipp Neubeck, V aibhav Tulsyan, Arseniy Klimovskiy , Don Metzler , Sage Stevens, Angel Y eh, Junwei Y uan, T ianhe Y u, Kelvin Zhang, Alec Go, V incent Tsang, Y ing Xu, Andy W an, Isaac Galatzer-Le vy , Sam Sobell, Abodunrinwa T oki, Elizabeth Salesky , W enlei Zhou, Diego Antognini, Sholto Douglas, Shimu W u, Adam Lelkes, Frank Kim, Paul Ca vallaro, Ana Salazar , 17 Published as a conference paper at ICLR 2026 Y uchi Liu, James Besley , T iziana Refice, Y iling Jia, Zhang Li, Michal Sokolik, Arvind Kannan, Jon Simon, Jo Chick, A via Aharon, Meet Gandhi, Mayank Daswani, Ke yvan Amiri, V ighnesh Birodkar , Abe Ittycheriah, Peter Grabowski, Oscar Chang, Charles Sutton, Zhixin, Lai, Umesh T elang, Susie Sargsyan, T ao Jiang, Raphael Hoffmann, Nicole Brichtov a, Matteo Hessel, Jonathan Halcrow , Sammy Jerome, Geoff Brown, Alex T omala, Elena Buchatskaya, Dian Y u, Sachit Menon, Pol Moreno, Y uguo Liao, V icky Zayats, Luming T ang, SQ Mah, Ashish Shenoy , Alex Siegman, Majid Hadian, Okw an Kwon, T ao T u, Nima Khajehnouri, Ryan Fole y , Parisa Haghani, Zhongru W u, V aishakh Kesha va, Khyatti Gupta, T ony Bruguier , Rui Y ao, Danny Karmon, Luisa Zintgraf, Zhicheng W ang, Enrique Piqueras, Junehyuk Jung, Jenny Brennan, Diego Machado, Marissa Giustina, MH T essler , Kamyu Lee, Qiao Zhang, Joss Moore, Kaspar Daug aard, Alexander Frömmgen, Jennifer Beattie, Fred Zhang, Daniel Kasenberg, T y Geri, Danfeng Qin, Gaurav Singh T omar , T om Ouyang, Tianli Y u, Luowei Zhou, Rajiv Mathews, Andy Davis, Y aoyiran Li, Jai Gupta, Damion Y ates, Linda Deng, Elizabeth Kemp, Ga-Y oung Joung, Sergei V assilvitskii, Mandy Guo, Palla vi L V , Da ve Dopson, Sami Lachgar , Lara McConnaughey , Himadri Choudhury , Dragos Dena, Aaron Cohen, Joshua Ainslie, Serge y Le vi, Parthasarathy Gopa varapu, Polina Zablotskaia, Hugo V allet, Sanaz Bahargam, Xiaodan T ang, Nenad T omasev , Ethan Dyer, Daniel Balle, Hongrae Lee, W illiam Bono, Jorge Gonzalez Mendez, V adim Zubov , Shentao Y ang, Ivor Rendulic, Y anyan Zheng, Andrew Hogue, Golan Pundak, Ralph Leith, A vishkar Bhoopchand, Michael Han, Mislav Žani ´ c, T om Schaul, Manolis Delakis, T ejas Iyer , Guanyu W ang, Harman Singh, Abdelrahman Abdelhamed, T ara Thomas, Siddhartha Brahma, Hilal Dib, Naveen K umar , W enxuan Zhou, Liang Bai, Pushkar Mishra, Jiao Sun, V alentin Anklin, Roykrong Sukkerd, Lauren Agubuzu, Anton Briukhov , Anmol Gulati, Maximilian Sieb, Fabio P ardo, Sara Nasso, Junquan Chen, K exin Zhu, T iberiu Sosea, Alex Goldin, Keith Rush, Spurthi Amba Hombaiah, Andreas Noe ver , Allan Zhou, Sam Hav es, Mary Phuong, Jake Ades, Y i ting Chen, Lin Y ang, Joseph Pagadora, Stan Bileschi, V ictor Cotruta, Rachel Saputro, Arijit Pramanik, Sean Ammirati, Dan Garrette, Ke vin V illela, T im Blyth, Canfer Akbulut, Neha Jha, Alban Rrustemi, Arissa W ongpanich, Chirag Nagpal, Y onghui W u, Morgane Ri vière, Serge y Kishchenko, Pranesh Sriniv asan, Alice Chen, Animesh Sinha, T rang Pham, Bill Jia, T om Hennigan, Anton Bakalov , Nithya Attaluri, Drew Garmon, Daniel Rodriguez, Dawid W egner , W enhao Jia, Evan Senter , Noah Fiedel, Denis Petek, Y uchuan Liu, Cassidy Hardin, Harshal T ushar Lehri, Joao Carreira, Sara Smoot, Marcel Prasetya, Nami Akazawa, Anca Stef anoiu, Chia-Hua Ho, Anelia Angelov a, Kate Lin, Min Kim, Charles Chen, Marcin Sieniek, Alice Li, T ongfei Guo, Sorin Baltateanu, Pouya T afti, Michael W under , Nada v Olmert, Di vyansh Shukla, Jingwei Shen, Neel K ovelamudi, Balaji V enkatraman, Seth Neel, Romal Thoppilan, Jerome Connor, Frederik Benzing, Axel Stjerngren, Golnaz Ghiasi, Ale x Polozov , Joshua Ho wland, Theophane W eber , Justin Chiu, Ganesh Poomal Girirajan, Andreas T erzis, Pidong W ang, Fangda Li, Y oav Ben Shalom, Dinesh T ewari, Matthe w Denton, Roee Aharoni, Norbert Kalb, Heri Zhao, Junlin Zhang, Angelos Filos, Matthew Rahtz, Lalit Jain, Connie Fan, V itor Rodrigues, Ruth W ang, Richard Shin, Jacob Austin, Roman Ring, Mariella Sanchez-V argas, Mehadi Hassen, Ido Kessler , Uri Alon, Gufeng Zhang, W enhu Chen, Y enai Ma, Xiance Si, Le Hou, Azalia Mirhoseini, Marc W ilson, Geoff Bacon, Becca Roelofs, Lei Shu, Gautam V asudev an, Jonas Adler , Artur Dwornik, T ayfun T erzi, Matt Lawlor , Harry Askham, Mike Bernico, Xuanyi Dong, Chris Hidey , Ke vin Kilgour , Gaël Liu, Surya Bhupatiraju, Luke Leonhard, Siqi Zuo, Partha T alukdar , Qing W ei, Aliaksei Se veryn, Vít Listík, Jong Lee, Aditya Tripathi, SK P ark, Y ossi Matias, Hao Liu, Alex Ruiz, Rajesh Jayaram, Jackson T olins, Pierre Marcenac, Y iming W ang, Bryan Seybold, Henry Prior , Deepak Sharma, Jack W eber , Mikhail Sirotenko, Y unhsuan Sung, Dayou Du, Ellie Pa vlick, Stefan Zinke, Markus Freitag, Max Dylla, Montse Gonzalez Arenas, Natan Potikha, Omer Goldman, Connie T ao, Rachita Chhaparia, Maria V oitovich, Paw an Dogra, Andrija Ražnatovi ´ c, Zak Tsai, Chong Y ou, Oleaser Johnson, George T ucker , Chenjie Gu, Jae Y oo, Maryam Majzoubi, V alentin Gabeur , Bahram Raad, Rocky Rhodes, Kashyap Kolipaka, Heidi Howard, Geta Sampemane, Benny Li, Chulayuth Asaw aroengchai, Duy Nguyen, Chiyuan Zhang, T imothee Cour, Xinxin Y u, Zhao Fu, Joe Jiang, Po-Sen Huang, Gabriela Surita, Iñaki Iturrate, Y ael Karov , Michael Collins, Martin Baeuml, Fabian Fuchs, Shilpa Shetty , Swaroop Ramaswamy , Sayna Ebrahimi, Qiuchen Guo, Jeremy Shar, Gabe Barth-Maron, Srav anti Addepalli, Bryan Richter , Chin-Y i Cheng, Eugénie Riv es, Fei Zheng, Johannes Griesser, Nishanth Dikkala, Y oel Zeldes, Ilkin Safarli, Dipanjan Das, Himanshu Sri vasta v a, Sadh MNM Khan, Xin Li, Aditya Pande y , Larisa Markee va, Dan Belov , Qiqi Y an, Mik ołaj Rybi ´ nski, T ao Chen, Me gha Nawhal, Michael Quinn, V ineetha Govindaraj, Sarah Y ork, Reed Roberts, Roopal Garg, Namrata Godbole, Jake Abernethy , Anil Das, Lam Nguyen Thiet, Jonathan T ompson, John Nham, Neera V ats, Ben Caine, W esley Helmholz, Francesco Pongetti, Y eongil Ko, James An, Clara Huiyi Hu, Y u-Cheng Ling, Julia Pawar , Robert Leland, 18 Published as a conference paper at ICLR 2026 Keisuk e Kinoshita, W aleed Khaw aja, Marco Selvi, Eugene Ie, Danila Sinopalniko v , Lev Prolee v , Nilesh Tripuraneni, Michele Bevilacqua, Seungji Lee, Clayton Sanford, Dan Suh, Dustin Tran, Jeff Dean, Simon Baumgartner , Jens Heitkaemper, Sagar Gubbi, Kristina T outano va, Y ichong Xu, Chandu Thekkath, Keran Rong, Palak Jain, Annie Xie, Y an V irin, Y ang Li, Lubo Litchev , Richard Powell, T arun Bharti, Adam Kraft, Nan Hua, Marissa Ikonomidis, A yal Hitron, Sanjiv Kumar , Loic Matthey , Sophie Bridgers, Lauren Lax, Ishaan Malhi, Ondrej Skopek, Ashish Gupta, Jia wei Cao, Mitchelle Rasquinha, Siim Põder , W ojciech Stokowiec, Nicholas Roth, Guo wang Li, Michaël Sander , Joshua K essinger , V ihan Jain, Edward Loper , W onpyo Park, Michal Y arom, Liqun Cheng, Guru Guruganesh, Kanishka Rao, Y an Li, Catarina Barros, Mikhail Sushko v , Chun-Sung Ferng, Rohin Shah, Ophir Aharoni, Ravin Kumar , Tim McConnell, Peiran Li, Chen W ang, Fernando Pereira, Craig Swanson, Fayaz Jamil, Y an Xiong, Anitha V ijayakumar, Prakash Shroff, K edar Soparkar , Jindong Gu, Livio Baldini Soares, Eric W ang, Kushal Majmundar, Aurora W ei, Kai Bailey , Nora Kassner, Chizu Kawamoto, Goran Žuži ´ c, V ictor Gomes, Abhirut Gupta, Michael Guzman, Ishita Dasgupta, Xinyi Bai, Zhufeng Pan, Francesco Piccinno, Hadas Natalie V ogel, Octavio Ponce, Adrian Hutter , Paul Chang, Pan-P an Jiang, Ionel Gog, Vlad Ionescu, James Manyika, Fabian Pedregosa, Harry Rag an, Zach Behrman, Ryan Mullins, Coline De vin, Aroonalok Pyne, Swapnil Gawde, Martin Chadwick, Y iming Gu, Sasan T av akkol, Andy T wigg, Naman Goyal, Ndidi Elue, Anna Goldie, Srini vasan V enkatachary , Hongliang Fei, Ziqiang Feng, Marvin Ritter , Isabel Leal, Sudeep Dasari, Pei Sun, Alif Raditya Rochman, Brendan O’Donoghue, Y uchen Liu, Jim Sproch, Kai Chen, Natalie Clay , Slav Petrov , Sailesh Sidhwani, Ioana Mihailescu, Ale x Panagopoulos, AJ Piergio v anni, Y unfei Bai, George Po well, Deep Karkhanis, T revor Y acovone, Petr Mitriche v , Joe Ko vac, Da ve Uthus, Amir Y azdanbakhsh, David Amos, Ste ven Zheng, Bing Zhang, Jin Miao, Bhuv ana Ramabhadran, Soroush Radpour , Shantanu Thakoor , Josh Ne wlan, Oran Lang, Orion Jankowski, Shikhar Bharadw aj, Jean-Michel Sarr, Shereen Ashraf, Sneha Mondal, Jun Y an, Ankit Singh Ra wat, Sarmishta V elury , Greg K ochanski, T om Eccles, Franz Och, Abhanshu Sharma, Ethan Mahintorabi, Alex Gurney , Carrie Muir, V ered Cohen, Saksham Thakur , Adam Bloniarz, Asier Mujika, Alexander Pritzel, Paul Caron, Altaf Rahman, Fiona Lang, Y asumasa Onoe, Petar Sirko vic, Jay Hoov er , Y ing Jian, Pablo Duque, Arun Narayanan, David Soer gel, Alex Haig, Loren Maggiore, Shyamal Buch, Josef Dean, Ilya Figotin, Igor Karpov , Shaleen Gupta, Denny Zhou, Muhuan Huang, Ashwin V aswani, Christopher Semturs, Kaushik Shi vakumar , Y u W atanabe, V inodh Kumar Rajendran, Ev a Lu, Y anhan Hou, W enting Y e, Shikhar V ashishth, Nana Nti, Vytenis Sakenas, Darren Ni, Doug DeCarlo, Michael Bendersky , Sumit Bagri, Nacho Cano, Elijah Peake, Simon T okumine, V arun Godbole, Carlos Guía, T anya Lando, V ittorio Selo, Seher Ellis, Danny T arlow , Daniel Gillick, Alessandro Epasto, Siddhartha Reddy Jonnalagadda, Meng W ei, Meiyan Xie, Ankur T aly , Michela Paganini, Mukund Sundararajan, Daniel T oyama, Ting Y u, Dessie Petrov a, Aneesh Pappu, Rohan Agrawal, Senaka Buthpitiya, Justin Frye, Thomas Buschmann, Remi Crocker , Marco T agliasacchi, Mengchao W ang, Da Huang, Sagi Perel, Brian W ieder , Hideto Kazawa, W eiyue W ang, Jeremy Cole, Himanshu Gupta, Ben Golan, Seojin Bang, Nitish Kulkarni, K en Franko, Casper Liu, Doug Reid, Sid Dalmia, Jay Whang, K evin Cen, Prasha Sundaram, Johan Ferret, Beriv an Isik, Lucian Ionita, Guan Sun, Anna Shekhawat, Muqthar Mohammad, Philip Pham, Ronny Huang, Karthik Raman, Xingyi Zhou, Ross Mcilroy , Austin Myers, Sheng Peng, Jacob Scott, Paul Covington, Sofia Erell, Pratik Joshi, João Gabriel Oliv eira, Natasha Noy , T ajwar Nasir , Jake W alker , V era Ax elrod, T im Dozat, Pu Han, Chun-T e Chu, Eugene W einstein, Anand Shukla, Shreyas Chandrakaladharan, Petra Poklukar , Bonnie Li, Y e Jin, Prem Eruvbetine, Stev en Hansen, A vigail Dabush, Alon Jacovi, Samrat Phatale, Chen Zhu, Steven Baker , Mo Shomrat, Y ang Xiao, Jean Pouget-Abadie, Mingyang Zhang, Fann y W ei, Y ang Song, Helen King, Y iling Huang, Y un Zhu, Ruoxi Sun, Juliana V icente Franco, Chu-Cheng Lin, Sho Arora, Hui, Li, V ivian Xia, Luke V ilnis, Mariano Schain, Kaiz Alarakyia, Laurel Prince, Aaron Phillips, Caleb Habte gebriel, Luyao Xu, Huan Gui, Santiago Ontanon, Lora Aroyo, Karan Gill, Peggy Lu, Y ash Katariya, Dhruv Madeka, Shankar Krishnan, Shubha Sriniv as Raghvendra, James Freedman, Y i T ay , Gaurav Menghani, Peter Choy , Nishita Shetty , Dan Abolafia, Doron Kukliansky , Edward Chou, Jared Lichtarge, K en Burke, Ben Coleman, Dee Guo, Larry Jin, Indro Bhattacharya, V ictoria Langston, Y iming Li, Suyog Kotecha, Ale x Y akubovich, Xin yun Chen, Petre Petrov , T olly Powell, Y anzhang He, Corbin Quick, Kanav Gar g, Dawsen Hwang, Y ang Lu, Srinadh Bhojanapalli, Kristian Kjems, Ramin Mehran, Aaron Archer , Hado v an Hasselt, Ashwin Balakrishna, JK Kearns, Meiqi Guo, Jason Riesa, Mikita Sazanovich, Xu Gao, Chris Sauer , Chengrun Y ang, XiangHai Sheng, Thomas Jimma, W outer V an Gansbeke, V italy Nikolaev , W ei W ei, Katie Millican, Ruizhe Zhao, Justin Snyder , Lev ent Bolelli, Maura O’Brien, Shawn Xu, Fei Xia, W entao Y uan, Arvind Neelakantan, David Bark er , Sachin Y ada v , Hannah Kirkwood, Farooq Ahmad, Joel W ee, Jordan Grimstad, Bo yu 19 Published as a conference paper at ICLR 2026 W ang, Matthew W iethoff, Shane Settle, Miaosen W ang, Charles Blundell, Jingjing Chen, Chris Duvarne y , Grace Hu, Olaf Ronneberger , Alex Lee, Y uanzhen Li, Abhishek Chakladar , Alena Butryna, Georgios Evangelopoulos, Guillaume Desjardins, Jonni Kanerva, Henry W ang, A veri No wak, Nick Li, Alyssa Loo, Art Khurshudov , Laurent El Shafe y , Nagabhushan Baddi, Karel Lenc, Y asaman Razeghi, T om Lieber , Amer Sinha, Xiao Ma, Y ao Su, James Huang, Asahi Ushio, Hanna Klimczak-Pluci ´ nska, Kareem Mohamed, JD Chen, Simon Osindero, Stav Ginzburg, Lampros Lamprou, V asilisa Bashlovkina, Duc-Hieu T ran, Ali Khodaei, Ankit Anand, Y ixian Di, Ramy Eskander , Manish Reddy V uyyuru, Jasmine Liu, Aishwarya Kamath, Roman Goldenberg, Mathias Bellaiche, Juliette Pluto, Bill Rosgen, Hassan Mansoor , William W ong, Suhas Ganesh, Eric Bailey , Scott Baird, Dan Deutsch, Jinoo Baek, Xuhui Jia, Chansoo Lee, Abe Friesen, Nathaniel Braun, Kate Lee, Amayika Panda, Ste ven M. Hernandez, Duncan W illiams, Jianqiao Liu, Ethan Liang, Arnaud Autef, Emily Pitler , Deepali Jain, Phoebe Kirk, Oskar Bunyan, Jaume Sanchez Elias, T ongxin Y in, Machel Reid, Aedan Pope, Nikita Putikhin, Bidisha Samanta, Sergio Guadarrama, Dahun Kim, Simon Rowe, Marcella V alentine, Geng Y an, Alex Salcianu, Da vid Silver , Gan Song, Richa Singh, Shuai Y e, Hannah DeBalsi, Majd Al Merey , Eran Ofek, Albert W ebson, Shibl Mourad, Ashwin Kakarla, Silvio Lattanzi, Nick Roy , Evgeny Sluzhaev , Christina Butterfield, Alessio T onioni, Nathan W aters, Sudhindra K opalle, Jason Chase, James Cohan, Girish Ramchandra Rao, Robert Berry , Michael V oznesensk y , Shuguang Hu, Kristen Chiafullo, Sharat Chikkerur , George Scri vener , Ivy Zheng, Jeremy W iesner , W olfgang Macherey , T imothy Lillicrap, Fei Liu, Brian W alker , David W elling, Elinor Davies, Y angsibo Huang, Lijie Ren, Nir Shabat, Alessandro Agostini, Mariko Iinuma, Dustin Zelle, Rohit Sathyanarayana, Andrea D’olimpio, Morgan Redshaw , Matt Ginsberg, Ashwin Murthy , Mark Geller, T atiana Matejovicov a, A yan Chakrabarti, Ryan Julian, Christine Chan, Qiong Hu, Daniel Jarrett, Manu Agarw al, Jeshwanth Challagundla, T ao Li, Sandeep T ata, W en Ding, Maya Meng, Zhuyun Dai, Giulia V ezzani, Shefali Gar g, Jannis Bulian, Mary Jasarevic, Honglong Cai, Harish Rajamani, Adam Santoro, Florian Hartmann, Chen Liang, Bartek Perz, Apoorv Jindal, Fan Bu, Sungyong Seo, Ryan Poplin, Adrian Goedeckemeyer , Badih Ghazi, Nikhil Khadke, Leon Liu, Ke vin Mather , Mingda Zhang, Ali Shah, Alex Chen, Jinliang W ei, Kesha v Shiv am, Y uan Cao, Donghyun Cho, Angelo Scorza Scarpati, Michael Moffitt, Clara Barbu, Iv an Jurin, Ming-W ei Chang, Hongbin Liu, Hao Zheng, Shachi Dave, Christine Kaeser -Chen, Xiaobin Y u, Alvin Abdagic, Lucas Gonzalez, Y anping Huang, Peilin Zhong, Cordelia Schmid, Bryce Petrini, Alex W ertheim, Jifan Zhu, Hoang Nguyen, Kaiyang Ji, Y anqi Zhou, T ao Zhou, F angxiaoyu Feng, Regev Cohen, David Rim, Shubham Milind Phal, Petko Georgiev , Ariel Brand, Y ue Ma, W ei Li, Somit Gupta, Chao W ang, Pav el Dubov , Jean T arbouriech, Kingshuk Majumder , Huijian Li, Norman Rink, Apurv Suman, Y ang Guo, Y inghao Sun, Arun Nair , Xiaowei Xu, Mohamed Elhawaty , Rodrigo Cabrera, Guangxing Han, Julian Eisenschlos, Junwen Bai, Y uqi Li, Y amini Bansal, Thibault Sellam, Mina Khan, Hung Nguyen, Justin Mao-Jones, Nikos Parotsidis, Jake Marcus, Cindy Fan, Roland Zimmermann, Y on y K ochinski, Laura Graesser , Feryal Behbahani, Alvaro Caceres, Michael Rile y , Patrick Kane, Sandra Lefdal, Rob W illoughby , Paul V icol, Lun W ang, Shujian Zhang, Ashleah Gill, Y u Liang, Gautam Prasad, Soroosh Mariooryad, Mehran Kazemi, Zifeng W ang, Kritika Muralidharan, Paul V oigtlaender , Jeffre y Zhao, Huanjie Zhou, Nina D’Souza, Aditi Mav alankar , Séb Arnold, Nick Y oung, Obaid Sarvana, Chace Lee, Milad Nasr , Tingting Zou, Seokhwan Kim, Lukas Haas, Kaushal Patel, Neslihan Bulut, David Parkinson, Courtney Biles, Dmitry Kalashnikov , Chi Ming T o, A viral Kumar , Jessica Austin, Alex Grev e, Lei Zhang, Megha Goel, Y eqing Li, Serge y Y aroshenko, Max Chang, Abhishek Jindal, Geoff Clark, Hagai T aitelbaum, Dale Johnson, Ofir Rov al, Jeongwoo K o, Anhad Mohananey , Christian Schuler , Shenil Dodhia, Ruichao Li, Kazuki Osawa, Claire Cui, Peng Xu, Rushin Shah, T ao Huang, Ela Gruzewska, Nathan Clement, Mudit V erma, Olcan Sercinoglu, Hai Qian, V iral Shah, Masa Y amaguchi, Abhinit Modi, T akahiro Kosakai, Thomas Strohmann, Junhao Zeng, Beliz Gunel, Jun Qian, Austin T arango, Krzysztof Jastrz ˛ ebski, Robert David, Jyn Shan, Park er Schuh, Kunal Lad, W illi Gierke, Mukundan Madhav an, Xinyi Chen, Mark Kurzeja, Rebeca Santamaria-Fernandez, Dawn Chen, Ale xandra Cordell, Y uri Chervonyi, Frankie Garcia, Nithish Kannen, V incent Perot, Nan Ding, Shlomi Cohen-Ganor , V ictor Lavrenk o, Junru W u, Georgie Ev ans, Cicero Nogueira dos Santos, Madhavi Se wak, Ashley Bro wn, Andrew Hard, Joan Puigcerver , Zeyu Zheng, Y izhong Liang, Evgeny Gladchenk o, Ree ve Ingle, Uri First, Pierre Sermanet, Charlotte Magister , Mihajlo V elimirovi ´ c, Sashank Reddi, Susanna Ricco, Eirikur Agustsson, Hartwig Adam, Nir Levine, Da vid Gaddy , Dan Holtmann-Rice, Xuanhui W ang, Ashutosh Sathe, Abhijit Guha Ro y , Blaž Bratani ˇ c, Alen Carin, Harsh Mehta, Silvano Bonacina, Nicola De Cao, Mara Finkelstein, V erena Rieser , Xinyi W u, Florent Altché, Dylan Scandinaro, Li Li, Nino V ieillard, Nikhil Sethi, Garrett T anzer , Zhi Xing, Shibo W ang, Parul Bhatia, Gui Citovsk y , Thomas Anthony , Sharon Lin, Tianze Shi, 20 Published as a conference paper at ICLR 2026 Shoshana Jakobovits, Gena Gibson, Raj Apte, Lisa Lee, Mingqing Chen, Arunkumar Byrav an, Petros Maniatis, Kellie W ebster, Andrew Dai, Pu-Chin Chen, Jiaqi Pan, Asya Fadeev a, Zach Gleicher , Thang Luong, and Niket Kumar Bhumihar . Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality , long context, and next generation agentic capabilities, 2025. URL . Google DeepMind. Gemini Deep Research, 2025. URL https://gemini.google/overview/ deep- research/?hl=en . Mingxuan Du, Benfeng Xu, Chiwei Zhu, Xiaorui W ang, and Zhendong Mao. Deepresearch bench: A comprehensiv e benchmark for deep research agents. arXiv preprint , 2025. V anessa W ei Feng and Graeme Hirst. T ext-le vel discourse parsing with rich linguistic features. In Haizhou Li, Chin-Y e w Lin, Miles Osborne, Gary Geunbae Lee, and Jong C. Park (eds.), Pr oceed- ings of the 50th Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pp. 60–68, Jeju Island, K orea, July 2012. Association for Computational Linguistics. URL https://aclanthology.org/P12- 1007/ . Linda Flower and John R. Hayes. A cogniti ve process theory of writing. Colle ge Composition & Com- munication , 32(4):365–387, 1981. ISSN 1939-9006. doi: https://doi.org/10.58680/ccc198115885. URL https://publicationsncte.org/content/journals/10.58680/ccc198115885 . Martin Funkquist, Ilia K uznetsov , Y ufang Hou, and Iryna Gure vych. Citebench: A benchmark for scientific citation text generation. arXiv preprint , 2022. Luyu Gao, Zhuyun Dai, Panupong Pasupat, Anthony Chen, Arun T ejasvi Chaganty , Y icheng Fan, V incent Zhao, Ni Lao, Hongrae Lee, Da-Cheng Juan, and Kelvin Guu. RARR: Researching and revising what language models say , using language models. In Anna Rogers, Jordan Boyd- Graber , and Naoaki Okazaki (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pp. 16477–16508, T oronto, Canada, July 2023a. Association for Computational Linguistics. doi: 10.18653/v1/2023.acl- long.910. URL https://aclanthology.org/2023.acl- long.910/ . T ianyu Gao, Howard Y en, Jiatong Y u, and Danqi Chen. Enabling large language models to generate text with citations. In Empirical Methods in Natural Language Pr ocessing (EMNLP) , 2023b. T ianyu Gao, Alexander W ettig, Luxi He, Y ihe Dong, Sadhika Malladi, and Danqi Chen. Metadata conditioning accelerates language model pre-training. In ICML , 2025. Jack Goodwin. Citation indexing—its theory and application in science, technology , and humanities by eugene garfield. T echnology and Cultur e , 21(4):714–715, 1980. Aaron Grattafiori, Abhimanyu Dube y , Abhinav Jauhri, Abhinav P andey , Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur , Alan Schelten, Alex V aughan, Amy Y ang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Y ang, Archi Mitra, Archie Sra vankumar , Artem Korene v , Arthur Hinsv ark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gre gerson, A va Spataru, Baptiste Roziere, Bethany Biron, Binh T ang, Bobbie Chern, Charlotte Caucheteux, Chaya Nayak, Chloe Bi, Chris Marra, Chris McConnell, Christian Keller , Christophe T ouret, Chunyang W u, Corinne W ong, Cristian Canton Ferrer , Cyrus Nikolaidis, Damien Allonsius, Daniel Song, Danielle Pintz, Danny Livshits, Danny W yatt, David Esiobu, Dhruv Choudhary , Dhruv Mahajan, Diego Garcia-Olano, Diego Perino, Dieuwke Hupkes, Egor Lakomkin, Ehab AlBadawy , Elina Lobanov a, Emily Dinan, Eric Michael Smith, Filip Radenovic, Francisco Guzmán, Frank Zhang, Gabriel Synnae ve, Gabrielle Lee, Georgia Le wis Anderson, Go vind Thattai, Graeme Nail, Gregoire Mialon, Guan Pang, Guillem Cucurell, Hailey Nguyen, Hannah Kore vaar , Hu Xu, Hugo T ouvron, Iliyan Zarov , Imanol Arrieta Ibarra, Isabel Kloumann, Ishan Misra, Iv an Evtimov , Jack Zhang, Jade Copet, Jaew on Lee, Jan Geffert, Jana Vranes, Jason Park, Jay Mahadeokar , Jeet Shah, Jelmer van der Linde, Jennifer Billock, Jenny Hong, Jenya Lee, Jeremy Fu, Jianfeng Chi, Jian yu Huang, Jiawen Liu, Jie W ang, Jiecao Y u, Joanna Bitton, Joe Spisak, Jongsoo Park, Joseph Rocca, Joshua Johnstun, Joshua Saxe, Junteng Jia, Kalyan V asuden Alwala, Karthik Prasad, Kartikeya Upasani, Kate Plawiak, Ke Li, Kenneth Heafield, K evin Stone, Khalid El-Arini, Krithika Iyer , Kshitiz Malik, Kuenley Chiu, Kunal Bhalla, K ushal Lakhotia, Lauren Rantala-Y eary , Laurens van der Maaten, Lawrence Chen, Liang T an, Liz Jenkins, Louis Martin, Lovish Madaan, Lubo Malo, Lukas Blecher , Lukas 21 Published as a conference paper at ICLR 2026 Landzaat, Luke de Oli veira, Madeline Muzzi, Mahesh Pasupuleti, Mannat Singh, Manohar P aluri, Marcin Kardas, Maria Tsimpoukelli, Mathew Oldham, Mathieu Rita, Maya Pa vlov a, Melanie Kambadur , Mike Lewis, Min Si, Mitesh Kumar Singh, Mona Hassan, Naman Goyal, Narjes T orabi, Nikolay Bashlykov , Nikolay Bogoyche v , Niladri Chatterji, Ning Zhang, Olivier Duchenne, Onur Çelebi, Patrick Alrassy , Pengchuan Zhang, Pengwei Li, Petar V asic, Peter W eng, Prajjwal Bharga va, Pratik Dubal, Praveen Krishnan, Punit Singh K oura, Puxin Xu, Qing He, Qingxiao Dong, Ragav an Sriniv asan, Raj Ganapathy , Ramon Calderer , Ricardo Silveira Cabral, Robert Stojnic, Roberta Raileanu, Rohan Maheswari, Rohit Girdhar , Rohit Patel, Romain Sauvestre, Ronnie Polidoro, Roshan Sumbaly , Ross T aylor , Ruan Silv a, Rui Hou, Rui W ang, Saghar Hosseini, Sahana Chennabasappa, Sanjay Singh, Sean Bell, Seohyun Sonia Kim, Sergey Edunov , Shaoliang Nie, Sharan Narang, Sharath Raparthy , Sheng Shen, Shengye W an, Shruti Bhosale, Shun Zhang, Simon V andenhende, Soumya Batra, Spencer Whitman, Sten Sootla, Stephane Collot, Suchin Gururang an, Sydney Borodinsky , T amar Herman, T ara Fo wler , T arek Sheasha, Thomas Georgiou, Thomas Scialom, T obias Speckbacher , T odor Mihaylov , T ong Xiao, Ujjwal Karn, V edanuj Goswami, V ibhor Gupta, V ignesh Ramanathan, V iktor Kerkez, V incent Gonguet, V irginie Do, V ish V ogeti, Vítor Albiero, Vladan Petrovic, W eiwei Chu, W enhan Xiong, W enyin Fu, Whitney Meers, Xa vier Martinet, Xiaodong W ang, Xiaofang W ang, Xiaoqing Ellen T an, Xide Xia, Xinfeng Xie, Xuchao Jia, Xuewei W ang, Y aelle Goldschlag, Y ashesh Gaur , Y asmine Babaei, Y i W en, Y iwen Song, Y uchen Zhang, Y ue Li, Y uning Mao, Zacharie Delpierre Coudert, Zheng Y an, Zhengxing Chen, Zoe Papakipos, Aaditya Singh, Aayushi Sriv astav a, Abha Jain, Adam K elsey , Adam Shajnfeld, Adith ya Gangidi, Adolfo V ictoria, Ahuva Goldstand, Ajay Menon, Ajay Sharma, Alex Boesenberg, Alex ei Baevski, Allie Feinstein, Amanda Kallet, Amit Sangani, Amos T eo, Anam Y unus, Andrei Lupu, Andres Alv arado, Andrew Caples, Andrew Gu, Andrew Ho, Andre w Poulton, Andre w Ryan, Ankit Ramchandani, Annie Dong, Annie Franco, Anuj Goyal, Aparajita Saraf, Arkabandhu Chowdhury , Ashley Gabriel, Ashwin Bharambe, Assaf Eisenman, Azadeh Y azdan, Beau James, Ben Maurer , Benjamin Leonhardi, Bernie Huang, Beth Loyd, Beto De Paola, Bharga vi Paranjape, Bing Liu, Bo W u, Boyu Ni, Braden Hancock, Bram W asti, Brandon Spence, Brani Stojkovic, Brian Gamido, Britt Montalv o, Carl Park er, Carly Burton, Catalina Mejia, Ce Liu, Changhan W ang, Changkyu Kim, Chao Zhou, Chester Hu, Ching-Hsiang Chu, Chris Cai, Chris Tindal, Christoph Feichtenhofer , Cynthia Gao, Damon Civin, Dana Beaty , Daniel Kreymer , Daniel Li, David Adkins, David Xu, Davide T estuggine, Delia Da vid, De vi Parikh, Diana Lisko vich, Didem F oss, Dingkang W ang, Duc Le, Dustin Holland, Edward Do wling, Eissa Jamil, Elaine Montgomery , Eleonora Presani, Emily Hahn, Emily W ood, Eric-T uan Le, Erik Brinkman, Esteban Arcaute, Evan Dunbar , Evan Smothers, Fei Sun, Felix Kreuk, Feng T ian, Filippos K okkinos, Firat Ozgenel, Francesco Caggioni, Frank Kanayet, Frank Seide, Gabriela Medina Florez, Gabriella Schwarz, Gada Badeer , Georgia Swee, Gil Halpern, Grant Herman, Grigory Sizov , Guangyi, Zhang, Guna Lakshminarayanan, Hakan Inan, Hamid Shojanazeri, Han Zou, Hannah W ang, Hanwen Zha, Haroun Habeeb, Harrison Rudolph, Helen Suk, Henry Aspegren, Hunter Goldman, Hongyuan Zhan, Ibrahim Damlaj, Igor Molybog, Igor T ufanov , Ilias Leontiadis, Irina-Elena V eliche, Itai Gat, Jake W eissman, James Geboski, James K ohli, Janice Lam, Japhet Asher , Jean-Baptiste Gaya, Jeff Marcus, Jef f T ang, Jennifer Chan, Jenny Zhen, Jeremy Reizenstein, Jeremy T eboul, Jessica Zhong, Jian Jin, Jingyi Y ang, Joe Cummings, Jon Carvill, Jon Shepard, Jonathan McPhie, Jonathan T orres, Josh Ginsbur g, Junjie W ang, Kai W u, Kam Hou U, Karan Saxena, Kartikay Khandelwal, Katayoun Zand, Kathy Matosich, Kaushik V eeraraghav an, K elly Michelena, K eqian Li, Kiran Jagadeesh, Kun Huang, K unal Chawla, Kyle Huang, Lailin Chen, Lakshya Gar g, Lav ender A, Leandro Silva, Lee Bell, Lei Zhang, Liangpeng Guo, Licheng Y u, Liron Moshkovich, Luca W ehrstedt, Madian Khabsa, Manav A valani, Manish Bhatt, Martynas Mankus, Matan Hasson, Matthe w Lennie, Matthias Reso, Maxim Groshe v , Maxim Naumov , Maya Lathi, Meghan K eneally , Miao Liu, Michael L. Seltzer , Michal V alko, Michelle Restrepo, Mihir Patel, Mik Vyatsko v , Mikayel Samvelyan, Mike Clark, Mike Mace y , Mike W ang, Miquel Jubert Hermoso, Mo Metanat, Mohammad Rasteg ari, Munish Bansal, Nandhini Santhanam, Natascha Parks, Natasha White, Navyata Bawa, Nayan Singhal, Nick Egebo, Nicolas Usunier , Nikhil Mehta, Nikolay Pavlo vich Laptev , Ning Dong, Norman Cheng, Oleg Chernoguz, Olivia Hart, Omkar Salpekar , Ozlem Kalinli, Parkin K ent, Parth P arekh, Paul Saab, P avan Balaji, Pedro Rittner , Philip Bontrager, Pierre Roux, Piotr Dollar, Polina Zvyagina, Prashant Ratanchandani, Pritish Y uvraj, Qian Liang, Rachad Alao, Rachel Rodriguez, Rafi A yub, Raghotham Murthy , Raghu Nayani, Rahul Mitra, Rangaprabhu P arthasarathy , Raymond Li, Rebekkah Hogan, Robin Battey , Rocky W ang, Russ Howes, Ruty Rinott, Sachin Mehta, Sachin Siby , Sai Jayesh Bondu, Samyak Datta, Sara Chugh, Sara Hunt, Sargun Dhillon, Sasha Sidorov , Satadru Pan, Saurabh Mahajan, Saurabh V erma, Seiji Y amamoto, Sharadh Ramaswamy , Shaun Lindsay , Shaun Lindsay , 22 Published as a conference paper at ICLR 2026 Sheng Feng, Shenghao Lin, Shengxin Cindy Zha, Shishir P atil, Shiv a Shankar , Shuqiang Zhang, Shuqiang Zhang, Sinong W ang, Sneha Agarwal, Soji Sajuyigbe, Soumith Chintala, Stephanie Max, Stephen Chen, Steve Kehoe, Steve Satterfield, Sudarshan Govindaprasad, Sumit Gupta, Summer Deng, Sungmin Cho, Sunny V irk, Suraj Subramanian, Sy Choudhury , Sydney Goldman, T al Remez, T amar Glaser , T amara Best, Thilo K oehler , Thomas Robinson, Tianhe Li, T ianjun Zhang, T im Matthews, T imothy Chou, Tzook Shaked, V arun V ontimitta, V ictoria Ajayi, V ictoria Montanez, V ijai Mohan, V inay Satish Kumar , V ishal Mangla, Vlad Ionescu, Vlad Poenaru, Vlad T iberiu Mihailescu, Vladimir Ivano v , W ei Li, W enchen W ang, W enwen Jiang, W es Bouaziz, W ill Constable, Xiaocheng T ang, Xiaojian W u, Xiaolan W ang, Xilun W u, Xinbo Gao, Y ani v Kleinman, Y anjun Chen, Y e Hu, Y e Jia, Y e Qi, Y enda Li, Y ilin Zhang, Y ing Zhang, Y ossi Adi, Y oungjin Nam, Y u, W ang, Y u Zhao, Y uchen Hao, Y undi Qian, Y unlu Li, Y uzi He, Zach Rait, Zachary DeV ito, Zef Rosnbrick, Zhaoduo W en, Zhenyu Y ang, Zhiwei Zhao, and Zhiyu Ma. The llama 3 herd of models, 2024. URL . John Harrington, Lucy Series, and Alexander Ruck-K eene. Law and rhetoric: critical possibilities. Journal of law and Society , 46(2):302–327, 2019. David Jurgens, Srijan Kumar , Raine Hoover , Dan McFarland, and Dan Jurafsky . Measuring the ev olution of a scientific field through citation frames. T ransactions of the Association for Compu- tational Linguistics , 6:391–406, 07 2018. ISSN 2307-387X. doi: 10.1162/tacl_a_00028. URL https://doi.org/10.1162/tacl_a_00028 . Rodney Kinney , Chloe Anastasiades, Russell Authur , Iz Beltagy , Jonathan Bragg, Alexandra Bu- raczynski, Isabel Cachola, Stefan Candra, Y oganand Chandrasekhar, Arman Cohan, et al. The semantic scholar open data platform. arXiv pr eprint arXiv:2301.10140 , 2023. T akeshi K ojima, Shixiang Shane Gu, Machel Reid, Y utaka Matsuo, and Y usuke Iwasawa. Large language models are zero-shot reasoners. Advances in neural information pr ocessing systems , 35: 22199–22213, 2022. T akeshi K ojima, Shixiang Shane Gu, Machel Reid, Y utaka Matsuo, and Y usuke Iwasawa. Large language models are zero-shot reasoners, 2023. URL . Sara Lafia, Andrea Thomer , Elizabeth Moss, David Bleckle y , and Libby Hemphill. Ho w and why do researchers reference data? a study of rhetorical features and functions of data references in academic articles. arXiv pr eprint arXiv:2302.08477 , 2023. Anne Lauscher , Brandon K o, Bailey Kuehl, Sophie Johnson, Arman Cohan, David Jur gens, and Kyle Lo. MultiCite: Modeling realistic citations requires moving beyond the single-sentence single- label setting. In Marine Carpuat, Marie-Catherine de Marneffe, and Ivan Vladimir Meza Ruiz (eds.), Pr oceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Languag e T echnologies , pp. 1875–1889, Seattle, United States, July 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.naacl- main.137. URL https://aclanthology.org/2022.naacl- main.137/ . Mina Lee, Katy Ilonka Gero, John Joon Y oung Chung, Simon Buckingham Shum, V ipul Raheja, Hua Shen, Subhashini V enugopalan, Thiemo W ambsganss, David Zhou, Emad A Alghamdi, et al. A design space for intelligent and interacti ve writing assistants. In Proceedings of the 2024 CHI Confer ence on Human F actors in Computing Systems , pp. 1–35, 2024. Patrick Le wis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler , Mike Le wis, W en-tau Y ih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retriev al-augmented generation for knowledge-intensi ve nlp tasks. In Pr oceedings of the 34th International Confer ence on Neural Information Pr ocessing Systems , NIPS ’20, Red Hook, NY , USA, 2020. Curran Associates Inc. ISBN 9781713829546. Jiwei Li, Rumeng Li, and Eduard Hovy . Recursiv e deep models for discourse parsing. In Pr oceedings of the 2014 confer ence on empirical methods in natural language pr ocessing (EMNLP) , pp. 2061–2069, 2014. Zhenwen Liang, Dian Y u, Xiaoman Pan, W enlin Y ao, Qingkai Zeng, Xiangliang Zhang, and Dong Y u. Mint: Boosting generalization in mathematical reasoning via multi-view fine-tuning. arXiv pr eprint arXiv:2307.07951 , 2023. 23 Published as a conference paper at ICLR 2026 Nelson F Liu, T ianyi Zhang, and Percy Liang. Evaluating verifiability in generati ve search engines. arXiv pr eprint arXiv:2304.09848 , 2023. Kyle Lo, Joseph Chee Chang, Andrew Head, Jonathan Bragg, Amy X Zhang, Cassidy T rier, Chloe Anastasiades, T al August, Russell Authur , Danielle Bragg, et al. The semantic reader project: Augmenting scholarly documents through ai-po wered interacti ve reading interfaces. arXiv pr eprint arXiv:2303.14334 , 2023. Daniel Marcu. The theory and practice of discour se parsing and summarization . MIT press, 2000. Jacob Menick, Maja T rebacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chadwick, Mia Glaese, Susannah Y oung, Lucy Campbell-Gillingham, Geoff rey Irving, et al. T eaching language models to support answers with verified quotes. arXiv preprint , 2022. Grégoire Mialon, Clémentine Fourrier , Craig Swift, Thomas W olf, Y ann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants, 2023. URL . Shikhar Murty , Pang W ei K oh, and Percy Liang. ExpBER T: Representation engineering with natural language explanations. In Dan Jurafsky , Joyce Chai, Natalie Schluter , and Joel T etreault (eds.), Pr oceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pp. 2106–2113, Online, July 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020. acl- main.190. URL https://aclanthology.org/2020.acl- main.190/ . Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jef f W u, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, V ineet K osaraju, W illiam Saunders, Xu Jiang, Karl Cobbe, T yna Eloundou, Gretchen Krueger , Ke vin Button, Matthew Knight, Benjamin Chess, and John Schulman. W ebgpt: Browser -assisted question-answering with human feedback, 2022. URL abs/2112.09332 . OpenAI. Openai o3 and o4-mini system card. System card, OpenAI, April 2025. URL https://cdn.openai.com/pdf/2221c875- 02dc- 4789- 800b- e7758f3722c1/ o3- and- o4- mini- system- card.pdf . OpenAI. Introducing deep research, 2025. URL https://openai.com/index/ introducing- deep- research/ . V ishakh Padmakumar , Katy Gero, Thiemo W ambsganss, Sarah Sterman, T ing-Hao Huang, Da vid Zhou, and John Chung (eds.). Proceedings of the F ourth W orkshop on Intelligent and Interactive Writing Assistants (In2Writing 2025) , Albuquerque, New Mexico, US, May 2025. Association for Computational Linguistics. ISBN 979-8-89176-239-8. doi: 10.18653/v1/2025.in2writing- 1.0. URL https://aclanthology.org/2025.in2writing- 1.0/ . Liana Patel, Ne gar Arabzadeh, Harshit Gupta, Ankita Sundar , Ion Stoica, Matei Zaharia, and Carlos Guestrin. Deepscholar-bench: A live benchmark and automated e valuation for generati ve research synthesis. 2025. URL . Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, Josephina Hu, Hugh Zhang, Chen Bo Calvin Zhang, Mohamed Shaaban, John Ling, Sean Shi, Michael Choi, Anish Agraw al, Arna v Chopra, Adam Khoja, Ryan Kim, Richard Ren, Jason Hausenloy , Oliv er Zhang, Mantas Mazeika, Dmitry Dodonov , T ung Nguyen, Jaeho Lee, Daron Anderson, Mikhail Doroshenko, Alun Cennyth Stokes, Mobeen Mahmood, Oleksandr Pokutnyi, Oleg Iskra, Jessica P . W ang, John-Clark Levin, Mstysla v Kazakov , Fiona Feng, Steven Y . Feng, Haoran Zhao, Michael Y u, V arun Gangal, Chelsea Zou, Zihan W ang, Serguei Popov , Robert Gerbicz, Geoff Galgon, Johannes Schmitt, W ill Y eadon, Y ongki Lee, Scott Sauers, Alvaro Sanchez, Fabian Giska, Marc Roth, Søren Riis, Saiteja Utpala, Noah Burns, Gashaw M. Goshu, Mohinder Maheshbhai Naiya, Chidozie Agu, Zachary Gibone y , Antrell Cheatom, Francesco Fournier-F acio, Sarah-Jane Crowson, Lennart Finke, Zerui Cheng, Jennifer Zampese, Ryan G. Hoerr , Mark Nandor , Hyunwoo P ark, T im Gehrunger, Jiaqi Cai, Ben McCarty , Alexis C Garretson, Edwin T aylor , Damien Sileo, Qiuyu Ren, Usman Qazi, Lianghui Li, Jungbae Nam, John B. W ydallis, Pa vel Arkhipov , Jack W ei Lun Shi, Aras Bacho, Chris G. W illcocks, Hangrui Cao, Sumeet Motwani, Emily de Oliveira Santos, Johannes V eith, Edward V endrow , Doru Cojoc, Kengo Zenitani, Joshua Robinson, Longke T ang, Y uqi Li, Joshua V endro w , Natanael W ildner Fraga, Vladyslav K uchkin, Andrey Pupasov Maksimo v , Pierre Marion, Denis 24 Published as a conference paper at ICLR 2026 Efremov , Jayson L ynch, Kaiqu Liang, Aleksandar Mikov , Andrew Gritsevskiy , Julien Guillod, Gözdenur Demir , Dakotah Martinez, Ben Pageler , K evin Zhou, Saeed Soori, Ori Press, Henry T ang, Paolo Rissone, Sean R. Green, Lina Brüssel, Moon T wayana, A ymeric Dieule veut, Joseph Marvin Imperial, Ameya Prabhu, Jinzhou Y ang, Nick Crispino, Arun Rao, Dimitri Zvonkine, Gabriel Loiseau, Mikhail Kalinin, Marco Lukas, Ciprian Manolescu, Nate Stambaugh, Subrata Mishra, T ad Hogg, Carlo Bosio, Brian P Coppola, Julian Salazar , Jaehyeok Jin, Rafael Sayous, Stefan Ivano v , Philippe Schwaller , Shaipranesh Senthilkuma, Andres M Bran, Andres Algaba, K elsey V an den Houte, L ynn V an Der Sypt, Brecht V erbeken, Da vid Noev er , Alexei K opylov , Benjamin Myklebust, Bikun Li, Lisa Schut, Evgenii Zheltonozhskii, Qiaochu Y uan, Derek Lim, Richard Stanley , T ong Y ang, John Maar , Julian W yko wski, Martí Oller , Anmol Sahu, Cesare Giulio Ardito, Y uzheng Hu, Ariel Ghislain Kemogne Kamdoum, Alvin Jin, T obias Garcia V ilchis, Y uexuan Zu, Martin Lackner , James K oppel, Gongbo Sun, Daniil S. Antonenko, Stef fi Chern, Bingchen Zhao, Pierrot Arsene, Joseph M Cav anagh, Daofeng Li, Jiawei Shen, Donato Crisostomi, W enjin Zhang, Ali Dehghan, Serge y Iv anov , David Perrella, Nurdin Kaparov , Allen Zang, Ilia Sucholutsky , Arina Kharlamov a, Daniil Orel, Vladislav Poritski, Shalev Ben-David, Zachary Berger , Parker Whitfill, Michael Foster , Daniel Munro, Linh Ho, Shankar Siv arajan, Dan Bar Hav a, Aleksey Kuchkin, David Holmes, Alexandra Rodriguez-Romero, Frank Sommerhage, Anji Zhang, Richard Moat, K eith Schneider , Zakayo Kazibwe, Don Clarke, Dae Hyun Kim, Felipe Meneguitti Dias, Sara Fish, V eit Elser , T obias Kreiman, V ictor Efren Guadarrama V ilchis, Immo Klose, Ujjwala Anantheswaran, Adam Zweiger , Kaiv alya Raw al, Jeffery Li, Jeremy Nguyen, Nicolas Daans, Haline Heidinger , Maksim Radionov , Václav Rozho ˇ n, V incent Ginis, Christian Stump, Niv Cohen, Rafał Po ´ swiata, Josef Tkadlec, Alan Goldfarb, Chenguang W ang, Piotr Padle wski, Stanislaw Barzowski, Kyle Mont- gomery , Ryan Stendall, Jamie T ucker -Foltz, Jack Stade, T . Ryan Rogers, T om Goertzen, Declan Grabb, Abhishek Shukla, Alan Givré, John Arnold Ambay , Archan Sen, Muhammad Fayez Aziz, Mark H Inlo w , Hao He, Ling Zhang, Y ounesse Kaddar , Iv ar Ängquist, Y anxu Chen, Harrison K W ang, Kalyan Ramakrishnan, Elliott Thornle y , Antonio T erpin, Hailey Schoelk opf, Eric Zheng, A vishy Carmi, Ethan D. L. Brown, K elin Zhu, Max Bartolo, Richard Wheeler , Martin Stehberger , Peter Bradshaw , JP Heimonen, Kaustubh Sridhar , Ido Akov , Jennifer Sandlin, Y ury Makarychev , Joanna T am, Hieu Hoang, David M. Cunningham, Vladimir Goryachev , Demosthenes Patramanis, Michael Krause, Andrew Redenti, David Aldous, Jesyin Lai, Shannon Coleman, Jiangnan Xu, Sangwon Lee, Ilias Magoulas, Sandy Zhao, Ning T ang, Michael K. Cohen, Orr Paradise, Jan Hen- drik Kirchner , Maksym Ovchynnikov , Jason O. Matos, Adithya Shenoy , Michael W ang, Y uzhou Nie, Anna Sztyber-Betle y , Paolo Faraboschi, Robin Riblet, Jonathan Crozier , Shiv Halasyamani, Shreyas V erma, Prashant Joshi, Eli Meril, Ziqiao Ma, Jérémy Andréoletti, Raghav Singhal, Jacob Platnick, V olodymyr Ne virkov ets, Luke Basler , Alexander Iv anov , Seri Khoury , Nils Gustafsson, Marco Piccardo, Hamid Mostaghimi, Qijia Chen, V irendra Singh, Tran Quoc Khánh, P aul Rosu, Hannah Szlyk, Zachary Bro wn, Himanshu Narayan, Aline Menezes, Jonathan Roberts, W illiam Alley , Kun yang Sun, Arkil Patel, Max Lamparth, Anka Reuel, Linwei Xin, Hanmeng Xu, Jacob Loader , Freddie Martin, Zixuan W ang, Andrea Achilleos, Thomas Preu, T omek Korbak, Ida Bosio, Fereshteh Kazemi, Ziye Chen, Biró Bálint, Ev e J. Y . Lo, Jiaqi W ang, Maria Inês S. Nunes, Jeremiah Milbauer , M Saiful Bari, Zihao W ang, Behzad Ansarinejad, Y ewen Sun, Stephane Durand, Hossam Elgnainy , Guillaume Douville, Daniel T ordera, George Balabanian, He w W olff, L ynna Kvistad, Hsiaoyun Milliron, Ahmad Sakor , Murat Eron, Andrew Fa vre D. O., Shailesh Shah, Xiaoxiang Zhou, Firuz Kamalov , Sherwin Abdoli, Tim Santens, Shaul Barkan, Allison T ee, Robin Zhang, Alessandro T omasiello, G. Bruno De Luca, Shi-Zhuo Looi, V inh-Kha Le, Noam K olt, Jiayi Pan, Emma Rodman, Jacob Drori, Carl J Fossum, Niklas Muennighoff, Milind Jagota, Ronak Pradeep, Honglu Fan, Jonathan Eicher , Michael Chen, Kushal Thaman, W illiam Merrill, Moritz Firsching, Carter Harris, Stefan Ciobâc ˘ a, Jason Gross, Rohan Pande y , Ilya Gusev , Adam Jones, Shashank Agnihotri, Pa vel Zhelnov , Mohammadreza Mofayezi, Ale xander Piperski, David K. Zhang, K os- tiantyn Dobarskyi, Roman Le ventov , Ignat Soroko, Joshua Duersch, V age T aamazyan, Andrew Ho, W enjie Ma, W illiam Held, Ruicheng Xian, Armel Randy Zebaze, Mohanad Mohamed, Julian Noah Leser , Michelle X Y uan, Laila Y acar , Johannes Lengler , Katarzyna Olszewska, Claudio Di Fratta, Edson Oliv eira, Joseph W . Jackson, Andy Zou, Muthu Chidambaram, Timothy Manik, Hector Haffenden, Dashiell Stander, Ali Dasouqi, Alexander Shen, Bita Golshani, David Stap, Egor Kretov , Mikalai Uzhou, Alina Borisovna Zhidkovskaya, Nick W inter, Miguel Orbe gozo Rodriguez, Robert Lauf f, Dustin W ehr , Colin T ang, Zaki Hossain, Shaun Phillips, Fortuna Samuele, Fredrik Ekström, Angela Hammon, Oam Patel, Faraz Farhidi, George Medle y , Forough Mohammadzadeh, Madellene Peñaflor , Haile Kassahun, Alena Friedrich, Rayner Hernandez Perez, Daniel Pyda, T aom Sakal, Omkar Dhamane, Ali Khajegili Mirabadi, Eric Hallman, K enchi Okutsu, Mike 25 Published as a conference paper at ICLR 2026 Battaglia, Mohammad Maghsoudimehrabani, Alon Amit, Dav e Hulbert, Roberto Pereira, Simon W eber , Handoko, Anton Peristyy , Stephen Malina, Mustafa Mehkary , Rami Aly , Frank Reidegeld, Anna-Katharina Dick, Cary Friday , Mukhwinder Singh, Hassan Shapourian, W anyoung Kim, Mar- iana Costa, Hubeyb Gurdogan, Harsh K umar , Chiara Ceconello, Chao Zhuang, Haon Park, Micah Carroll, Andrew R. T awfeek, Stef an Steinerberger , Daattavya Aggarwal, Michael Kirchhof, Linjie Dai, Evan Kim, Johan Ferret, Jainam Shah, Y uzhou W ang, Minghao Y an, Krzysztof Burdzy , Lixin Zhang, Antonio Franca, Diana T . Pham, Kang Y ong Loh, Joshua Robinson, Abram Jackson, Paolo Giordano, Philipp Petersen, Adrian Cosma, Jesus Colino, Colin White, Jacob V otav a, Vladimir V innikov , Ethan Delane y , Petr Spelda, V it Stritecky , Syed M. Shahid, Jean-Christophe Mourrat, Lavr V etoshkin, Koen Sponselee, Renas Bacho, Zheng-Xin Y ong, Florencia de la Rosa, Nathan Cho, Xiuyu Li, Guillaume Malod, Orion W eller , Guglielmo Albani, Leon Lang, Julien Laurendeau, Dmitry Kazak ov , Fatimah Adesanya, Julien Portier , Lawrence Hollom, V ictor Souza, Y uchen Anna Zhou, Julien Degorre, Y i ˘ git Y alın, Gbenga Daniel Obikoya, Rai, Filippo Bigi, M. C. Boscá, Oleg Shumar , Kaniuar Bacho, Gabriel Recchia, Mara Popescu, Nikita Shulga, Ngefor Mildred T anwie, Thomas C. H. Lux, Ben Rank, Colin Ni, Matthew Brooks, Alesia Y akimchyk, Huanxu, Liu, Stefano Cav alleri, Olle Häggström, Emil V erkama, Joshua Newbould, Hans Gundlach, Leonor Brito-Santana, Brian Amaro, V ivek V ajipey , Rynaa Grov er, T ing W ang, Y osi Kratish, W en-Ding Li, Siv akanth Gopi, Andrea Caciolai, Christian Schroeder de Witt, Pablo Hernández-Cámara, Emanuele Rodolà, Jules Robins, Dominic W illiamson, V incent Cheng, Brad Raynor , Hao Qi, Ben Sege v , Jingxuan Fan, Sarah Martinson, Erik Y . W ang, Kaylie Hausknecht, Michael P . Brenner, Mao Mao, Christoph Demian, Peyman Kassani, Xinyu Zhang, David A vagian, Eshawn Jessica Scipio, Alon Ragoler, Justin T an, Blake Sims, Rebeka Plecnik, Aaron Kirtland, Omer Faruk Bodur , D. P . Shinde, Y an Carlos Leyva Labrador , Zahra Adoul, Mohamed Zekry , Ali Karakoc, T ania C. B. Santos, Samir Shamseldeen, Loukmane Karim, Anna Liakho vitskaia, Nate Resman, Nicholas Farina, Juan Carlos Gonzalez, Gabe Maayan, Earth Anderson, Rodrigo De Oliv eira Pena, Elizabeth Kelle y , Hodjat Mariji, Rasoul Pouriamanesh, W entao W u, Ross Finocchio, Ismail Alarab, Joshua Cole, Danyelle Ferreira, Bryan Johnson, Mohammad Safdari, Liangti Dai, Siriphan Arthornthurasuk, Isaac C. McAlister, Alejandro José Moyano, Alexey Pronin, Jing Fan, Angel Ramirez-T rinidad, Y ana Malyshev a, Daphiny Pottmaier , Omid T aheri, Stanley Stepanic, Samuel Perry , Luke Aske w , Raúl Adrián Huerta Rodríguez, Ali M. R. Minissi, Ricardo Lorena, Krishna- murthy Iyer , Arshad Anil Fasiludeen, Ronald Clark, Josh Duce y , Matheus Piza, Maja Somrak, Eric V ergo, Juehang Qin, Benjámin Borbás, Eric Chu, Jack Lindse y , Antoine Jallon, I. M. J. McInnis, Evan Chen, A vi Semler, Luk Gloor, T ej Shah, Marc Carauleanu, Pascal Lauer, Tran Ðuc Huy , Hossein Shahrtash, Emilien Duc, Lukas Lew ark, Assaf Brown, Samuel Albanie, Brian W eber , W arren S. V az, Pierre Clavier , Y iyang Fan, Gabriel Poesia Reis e Silva, Long, Lian, Marcus Abramovitch, Xi Jiang, Sandra Mendoza, Murat Islam, Juan Gonzalez, V asilios Mavroudis, Justin Xu, Pa wan K umar, Laxman Prasad Goswami, Daniel Bugas, Nasser Heydari, Ferenc Jeanplong, Thorben Jansen, Antonella Pinto, Archimedes Apronti, Abdallah Galal, Ng Ze-An, Ankit Singh, T ong Jiang, Joan of Arc Xavier , Kanu Priya Agarwal, Mohammed Berkani, Gang Zhang, Zhehang Du, Benedito Alves de Oli veira Junior , Dmitry Malishev , Nicolas Remy , T aylor D. Hartman, Tim T arver , Stephen Mensah, Gautier Abou Loume, W iktor Morak, Farzad Habibi, Sarah Hoback, W ill Cai, Javier Gimenez, Roselynn Grace Montecillo, Jakub Łucki, Russell Campbell, Asankhaya Sharma, Khalida Meer , Shreen Gul, Daniel Espinosa Gonzalez, Xavier Alapont, Alex Hoover , Gun- jan Chhablani, Freddie V ar gus, Arunim Agarwal, Y ibo Jiang, Deepakkumar Patil, David Oute vsky , Ke vin Joseph Scaria, Rajat Maheshwari, Abdelkader Dendane, Priti Shukla, Ashley Cartwright, Sergei Bogdano v , Niels Mündler , Sören Möller , Luca Arnaboldi, Kun var Thaman, Muhammad Re- han Siddiqi, Prajvi Saxena, Himanshu Gupta, T ony Fruhauff, Glen Sherman, Mátyás V incze, Siranut Usaw asutsakorn, Dylan Ler , Anil Radhakrishnan, Innocent En yekwe, Sk Md Salauddin, Jiang Muzhen, Aleksandr Maksapetyan, V ivien Rossbach, Chris Harjadi, Mohsen Bahaloohoreh, Claire Sparro w , Jasdeep Sidhu, Sam Ali, Song Bian, John Lai, Eric Singer, Justine Leon Uro, Greg Bateman, Mohamed Sayed, Ahmed Menshawy , Darling Duclosel, Dario Bezzi, Y ashaswini Jain, Ashley Aaron, Murat T iryakioglu, Sheeshram Siddh, Keith Krenek, Imad Ali Shah, Jun Jin, Scott Creighton, Denis Peskof f, Zienab EL-W asif, Raga vendran P V , Michael Richmond, Joseph McGow an, T ejal Patwardhan, Hao-Y u Sun, Ting Sun, Nikola Zubi ´ c, Samuele Sala, Stephen Ebert, Jean Kaddour , Manuel Schottdorf, Dianzhuo W ang, Gerol Petruzella, Alex Meiburg, Tilen Medved, Ali ElSheikh, S Ashwin Hebbar , Lorenzo V aquero, Xianjun Y ang, Jason Poulos, V ilém Zouhar , Serge y Bogdanik, Mingfang Zhang, Jor ge Sanz-Ros, David Anugraha, Y inwei Dai, Anh N. Nhu, Xue W ang, Ali Anil Demircali, Zhibai Jia, Y uyin Zhou, Juncheng W u, Mike He, Nitin Chandok, Aarush Sinha, Gaoxiang Luo, Long Le, Mickaël Noyé, Michał Perełkiewicz, Ioannis Pantidis, 26 Published as a conference paper at ICLR 2026 T ianbo Qi, Soham Sachin Purohit, Letitia Parcalabescu, Thai-Hoa Nguyen, Genta Indra W inata, Edoardo M. Ponti, Hanchen Li, Kaustubh Dhole, Jongee P ark, Dario Abbondanza, Y uanli W ang, Anupam Nayak, Diogo M. Caetano, Antonio A. W . L. W ong, Maria del Rio-Chanona, Dániel K ondor, Pieter Francois, Ed Chalstrey , Jakob Zsambok, Dan Hoyer , Jenny Reddish, Jakob Hauser , Francisco-Javier Rodrigo-Ginés, Suchandra Datta, Maxwell Shepherd, Thom Kamphuis, Qizheng Zhang, Hyunjun Kim, Ruiji Sun, Jianzhu Y ao, Franck Dernoncourt, Satyapriya Krishna, Sina Rismanchian, Bonan Pu, Francesco Pinto, Y ingheng W ang, Kumar Shridhar , Kalon J. Overholt, Glib Briia, Hieu Nguyen, David, Soler Bartomeu, T ony CY Pang, Adam W ecker , Y ifan Xiong, Fanfei Li, Lukas S. Huber , Joshua Jaeger , Romano De Maddalena, Xing Han Lù, Y uhui Zhang, Claas Beger , Patrick Tser Jern K on, Sean Li, V iv ek Sanker , Ming Y in, Y ihao Liang, Xinlu Zhang, Ankit Agrawal, Li S. Y ifei, Zechen Zhang, Mu Cai, Y asin Sonmez, Costin Cozianu, Changhao Li, Alex Slen, Shoubin Y u, Hyun K yu Park, Gabriele Sarti, Marcin Bria ´ nski, Alessandro Stolfo, T ruong An Nguyen, Mike Zhang, Y otam Perlitz, Jose Hernandez-Orallo, Runjia Li, Amin Sha- bani, Felix Juefei-Xu, Shikhar Dhingra, Orr Zohar, My Chiffon Nguyen, Alexander Pondaven, Abdurrahim Y ilmaz, Xuandong Zhao, Chuanyang Jin, Muyan Jiang, Stefan T odoran, Xinyao Han, Jules Kreuer , Brian Rabern, Anna Plassart, Martino Maggetti, Luther Y ap, Robert Geirhos, Jonathon Kean, Dingsu W ang, Sina Mollaei, Chenkai Sun, Y ifan Y in, Shiqi W ang, Rui Li, Y aowen Chang, Anjiang W ei, Alice Bizeul, Xiaohan W ang, Alexandre Oli veira Arrais, K ushin Mukherjee, Jorge Chamorro-Padial, Jiachen Liu, Xingyu Qu, Junyi Guan, Adam Bouyamourn, Shuyu W u, Martyna Plomecka, Junda Chen, Mengze T ang, Jiaqi Deng, Shreyas Subramanian, Haocheng Xi, Haoxuan Chen, W eizhi Zhang, Y inuo Ren, Haoqin T u, Sejong Kim, Y ushun Chen, Sara V era Marjanovi ´ c, Junwoo Ha, Grzegorz Luczyna, Jeff J. Ma, Zewen Shen, Dawn Song, Cedegao E. Zhang, Zhun W ang, Gaël Gendron, Y unze Xiao, Leo Smucker , Erica W eng, Kwok Hao Lee, Zhe Y e, Stefano Ermon, Ignacio D. Lopez-Miguel, Theo Knights, Anthon y Gitter , Namkyu Park, Boyi W ei, Hongzheng Chen, K unal Pai, Ahmed Elkhanany , Han Lin, Philipp D. Siedler , Jichao Fang, Ritwik Mishra, Károly Zsolnai-Fehér , Xilin Jiang, Shadab Khan, Jun Y uan, Rishab Kumar Jain, Xi Lin, Mike Peterson, Zhe W ang, Aditya Malusare, Maosen T ang, Isha Gupta, Iv an Fosin, T imothy Kang, Barbara Dworako wska, Kazuki Matsumoto, Guangyao Zheng, Gerben Sewuster , Jorge Pretel V illanuev a, Ivan Ranne v , Igor Chernyavsk y , Jiale Chen, Deepayan Banik, Ben Racz, W enchao Dong, Jianxin W ang, Laila Bashmal, Duarte V . Gonçalves, W ei Hu, Kaushik Bar , Ondrej Bohdal, Atharv Singh Patlan, Shehzaad Dhuliaw ala, Caroline Geirhos, Julien W ist, Y uval Kansal, Bingsen Chen, Kutay T ire, Atak T alay Yücel, Brandon Christof, V eerupaksh Singla, Zijian Song, Sanxing Chen, Jiaxin Ge, Kaustubh Ponkshe, Isaac Park, T ianneng Shi, Martin Q. Ma, Joshua Mak, Sherwin Lai, Antoine Moulin, Zhuo Cheng, Zhanda Zhu, Ziyi Zhang, V aidehi Patil, K etan Jha, Qiutong Men, Jiaxuan W u, Tianchi Zhang, Bruno Hebling V ieira, Alham Fikri Aji, Jae-W on Chung, Mohammed Mahfoud, Ha Thi Hoang, Marc Sperzel, W ei Hao, Kristof Meding, Sihan Xu, V assilis Kostak os, Davide Manini, Y ueying Liu, Christopher T oukmaji, Jay Paek, Eunmi Y u, Arif Engin Demircali, Zhiyi Sun, Ivan De werpe, Hongsen Qin, Roman Pflugfelder, James Baile y , Johnathan Morris, V ille Heilala, Sybille Rosset, Zishun Y u, Peter E. Chen, W oongyeong Y eo, Eeshaan Jain, Ryan Y ang, Sreekar Chigurupati, Julia Chernya vsky , Sai Prajwal Reddy , Subhashini V enugopalan, Hunar Batra, Core Francisco Park, Hieu T ran, Guilherme Maximiano, Genghan Zhang, Y izhuo Liang, Hu Shiyu, Rongwu Xu, Rui Pan, Siddharth Suresh, Ziqi Liu, Samaksh Gu- lati, Songyang Zhang, Peter T urchin, Christopher W . Bartlett, Christopher R. Scotese, Phuong M. Cao, Aakaash Nattanmai, Gordon McK ellips, Anish Cheraku, Asim Suhail, Ethan Luo, Marvin Deng, Jason Luo, Ashley Zhang, Ka vin Jindel, Jay Paek, Kasper Hale vy , Allen Baranov , Michael Liu, Advaith A vadhanam, David Zhang, V incent Cheng, Brad Ma, Evan Fu, Liam Do, Joshua Lass, Hubert Y ang, Surya Sunkari, V ishruth Bharath, V iolet Ai, James Leung, Rishit Agrawal, Alan Zhou, Ke vin Chen, T ejas Kalpathi, Ziqi Xu, Gavin W ang, T yler Xiao, Erik Maung, Sam Lee, Ryan Y ang, Roy Y ue, Ben Zhao, Julia Y oon, Sunny Sun, Aryan Singh, Ethan Luo, Clark Peng, T yler Osbey , T aozhi W ang, Daryl Echeazu, Hubert Y ang, T imothy W u, Spandan Patel, V idhi Kulkarni, V ijaykaarti Sundarapandiyan, Ashley Zhang, Andre w Le, Zafir Nasim, Srikar Y alam, Ritesh Kasamsetty , Soham Samal, Hubert Y ang, David Sun, Nihar Shah, Abhijeet Saha, Alex Zhang, Leon Nguyen, Laasya Nagumalli, Kaixin W ang, Alan Zhou, Aidan W u, Jason Luo, Anwith T elluri, Summer Y ue, Alexandr W ang, and Dan Hendrycks. Humanity’ s last exam, 2025. URL https://arxiv.org/abs/2501.14249 . Peter Pirolli and Stuart Card. The sensemaking process and lev erage points for analyst technology as identified through cogniti ve task analysis. In Pr oceedings of international conference on intelligence analysis , v olume 5, pp. 2–4. McLean, V A, USA, 2005. 27 Published as a conference paper at ICLR 2026 Hannah Rashkin, V italy Nikolaev , Matthew Lamm, Lora Aroyo, Michael Collins, Dipanjan Das, Slav Petro v , Gaurav Singh T omar , Iulia T urc, and David Reitter . Measuring attribution in natural language generation models. Computational Linguistics , 49(4):777–840, 2023. Daniel M. Russell, Mark J. Stefik, Peter Pirolli, and Stuart K. Card. The cost structure of sensemaking. In Pr oceedings of the INTERACT ’93 and CHI ’93 Confer ence on Human F actors in Computing Systems , CHI ’93, pp. 269–276, New Y ork, NY , USA, 1993. Association for Computing Machinery . ISBN 0897915755. doi: 10.1145/169059.169209. URL https://doi.org/10.1145/169059. 169209 . Betty Samraj. Form and function of citations in discussion sections of master’ s theses and research articles. J ournal of English for Academic Purposes , 12(4):299–310, 2013. Zejiang Shen, T al August, Pao Siangliulue, Kyle Lo, Jonathan Bragg, Jeff Hammerbacher, Doug Do wney , Joseph Chee Chang, and David Sontag. Beyond summarization: Designing ai support for real-world expository writing tasks. arXiv pr eprint arXiv:2304.02623 , 2023. Amanpreet Singh, Joseph Chee Chang, Chloe Anastasiades, Dany Haddad, Aakanksha Naik, Amber T anaka, Angele Zamarron, Cecile Nguyen, Jena D Hwang, Jason Dunkleberger , et al. Ai2 scholar qa: Organized literature synthesis with attribution. arXiv preprint , 2025. doi: 10.48550/arXiv . 2504.10861. Michael D Skarlinski, Sam Cox, Jon M Laurent, James D Braza, Michaela Hinks, Michael J Hammerling, Man vitha Ponnapati, Samuel G Rodriques, and Andrew D White. Language agents achiev e superhuman synthesis of scientific knowledge. arXiv pr eprint , 2024. doi: 10.48550/arXiv . 2409.13740. Carlota S Smith. Modes of discour se: The local structur e of texts , volume 103. Cambridge Univ ersity Press, 2003. W ei Song, Dong W ang, Ruiji Fu, Lizhen Liu, T ing Liu, and Guoping Hu. Discourse mode identifica- tion in essays. In Re gina Barzilay and Min-Y en Kan (eds.), Pr oceedings of the 55th Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pp. 112–122, V ancou- ver , Canada, July 2017. Association for Computational Linguistics. doi: 10.18653/v1/P17- 1011. URL https://aclanthology.org/P17- 1011/ . Simone T eufel, Adv aith Siddharthan, and Dan T idhar . Automatic classification of citation function. In Dan Jurafsky and Eric Gaussier (eds.), Pr oceedings of the 2006 Confer ence on Empirical Methods in Natural Language Pr ocessing , pp. 103–110, Sydney , Australia, July 2006. Association for Computational Linguistics. URL https://aclanthology.org/W06- 1613/ . Katherine T ian, Eric Mitchell, Allan Zhou, Archit Sharma, Raf ael Rafailov , Huaxiu Y ao, Chelsea Finn, and Christopher Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), Pr oceedings of the 2023 Conference on Empirical Methods in Natural Language Pr ocessing , pp. 5433–5442, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp- main.330. URL https://aclanthology.org/2023. emnlp- main.330/ . Linghe W ang, Minhwa Lee, Ross V olkov , Luan T uyen Chau, and Dongyeop Kang. Scholawrite: A dataset of end-to-end scholarly writing process, 2025. URL 02904 . Jason W ei, Xuezhi W ang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information pr ocessing systems , 35:24824–24837, 2022a. Jason W ei, Xuezhi W ang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed H Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in lar ge language models. In Advances in Neural Information Pr ocessing Systems , 2022b. Jason W ei, Zhiqing Sun, Spencer Papay , Scott McKinney , Jeffre y Han, Isa Fulford, Hyung W on Chung, Alex T achard Passos, W illiam Fedus, and Amelia Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents, 2025. URL . 28 Published as a conference paper at ICLR 2026 Addison J. W u, Ryan Liu, Kerem Oktar, Theodore R. Sumers, and Thomas L. Griffiths. Are large language models sensiti ve to the motiv es behind communication?, 2025. URL https: //arxiv.org/abs/2510.19687 . Zhikun Xu, Ming Shen, Jacob Dineen, Zhaonan Li, Xiao Y e, Shijie Lu, Aswin Rrv , Chitta Baral, and Ben Zhou. ToW: Thoughts of words improve reasoning in large language models. In Luis Chiruzzo, Alan Ritter, and Lu W ang (eds.), Pr oceedings of the 2025 Confer ence of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language T echnolo gies (V olume 1: Long P apers) , pp. 3057–3075, Alb uquerque, Ne w Mexico, April 2025. Association for Computational Linguistics. ISBN 979-8-89176-189-6. doi: 10.18653/v1/2025. naacl- long.157. URL https://aclanthology.org/2025.naacl- long.157/ . An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chang Gao, Chengen Huang, Chenxu Lv , et al. Qwen3 technical report. arXiv pr eprint , 2025. doi: 10.48550/arXiv .2505.09388. Zonglin Y ang, Xin ya Du, Junxian Li, Jie Zheng, Soujanya Poria, and Erik Cambria. Large language models for automated open-domain scientific hypotheses discovery . In Lun-W ei Ku, Andre Martins, and V ivek Srikumar (eds.), Association for Computational Linguistics (A CL) , August 2024. doi: 10.18653/v1/2024.findings- acl.804. Shunyu Y ao, Jeffre y Zhao, Dian Y u, Nan Du, Izhak Shafran, Karthik Narasimhan, and Y uan Cao. ReAct: Synergizing reasoning and acting in language models. In International Conference on Learning Repr esentations (ICLR) , 2023. Li S. Y ifei, Allen Chang, Chaitanya Malaviya, and Mark Y atskar . ResearchQA: Ev aluating scholarly question answering at scale across 75 fields with surve y-mined questions and rubrics. arXiv pr eprint , 2025. Eric Zelikman, Y uhuai W u, Jesse Mu, and Noah Goodman. STar: Bootstrapping reasoning with reasoning. In Alice H. Oh, Alekh Agarw al, Danielle Belgrav e, and K yunghyun Cho (eds.), Advances in Neural Information Pr ocessing Systems , 2022. URL https://openreview.net/ forum?id=_3ELRdg2sgI . Lianmin Zheng, Liangsheng Y in, Zhiqiang Xie, Chuyue Livia Sun, Jef f Huang, Cody Hao Y u, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model programs. Advances in neural information pr ocessing systems , 37: 62557–62583, 2024. 29 Published as a conference paper at ICLR 2026 A A P P E N D I X A . 1 I M P L E M E N TA T I O N D E TA I L S . For Gemini, Claude, and GPT models, we use the official API service. For other open-sourced models, we use our locally served model on nodes with 8 Nvidia H100 (80G) GPUs with CUD A 12 installed, with an inference structure built upon SGLang (Zheng et al., 2024). If applicable, we set the max output token to be 22,000, the temperature to be 1.0. If not further specified, we use the original hyperparameters and settings when ev aluating the tasks. Following the original LLM-as-a-judge choice. W e use gemini-2.5-flash for AstaBench-SQA-CS-V2; gpt-4o for DeepScholar Bench, and gpt-4.1-mini for ResearchQA. For fine-tuning, we use 5 e − 6 learning rate, 80 training epochs, and 4 gradient accumulation steps for all base models and v ariants, unless further specified. W e generated training data from Gemini- 2.5-pro with our inference pipeline; this model was within 2 points of the best-performing model (Claude-4-Opus) on all datasets when we generated answers while eliciting intents at inference time, while being an order of magnitude cheaper . W e use the inference prompt in Appendix A.6 to collect the training data. A . 2 T H E U S E O F L A R G E L A N G UA G E M O D E L S ( L L M S ) . In this work, LLMs are used for correcting grammatical errors in writing and coding. W e do not use LLMs to write papers or construct the logic of the whole code base. A . 3 F U L L P E R F O R M A N C E F O R S F T V A R I A N T S In the main paper , we mainly discuss the performance with intent-a ware prompts. Here we further compare the performance difference across different fine-tuned small models in T able 7. W e can observe consistent findings in the main content: in most cases, augmenting the models with intent awareness at test time helps impro ve model performance, especially for fine-tuned models. A . 4 P R E - P L A N N I N G W I T H I N T E N T S In our proposed method, the intents are generated in-line with the rest of the text. W e also tested a variant where we do pre-planning by generating potential citation intents and a relev ance score for each retriev ed paper before generating the answer . The retriev ed papers are reordered according to the generated citation scores and the answer is generated conditioned on the reordered retrieved documents and their corresponding intents. The results from this setting are shown in T able 8. A . 5 E T H I C A L S TA T E M E N T S W e foresee no ethical concerns or potential risks in our work. All datasets are open-sourced, as shown in Section 4.1. The LLMs we applied in the experiments are also publicly av ailable. Giv en our context (long-form report generation with queries verified by humans), the outputs of LLMs are unlikely to contain harmful and dangerous information. The experiments in our paper are mainly on English. 30 Published as a conference paper at ICLR 2026 T able 7: SQA-CS-V2 Performance Results Across Base Models and V ariants Base Model V ariant Ov erall Rubrics Answer P Citation P Citation R gemini-2.5-pro(ref) - 88.1 82.6 94.1 93.2 82.4 qwen3-8b no training 80.7 82.1 90.4 83.2 66.9 -verb . intent 80.9 80.2 92.6 81.3 69.8 SFT 83.2 78.7 94.3 85.8 73.9 -verb . intent 84.6 79.0 94.6 87.6 76.9 intent-explicit SFT 86.7 79.4 91.7 92.3 83.6 -verb . intent 88.0 80.5 93.0 93.6 85.0 intent-implicit SFT 86.7 77.9 91.1 93.7 83.9 -verb . intent 87.1 78.9 94.0 92.5 82.9 intent-multivie w SFT 87.9 79.2 93.6 94.1 84.7 -verb . intent 88.6 81.4 94.7 93.7 84.7 llama-3.1-8B no training 66.4 64.6 77.5 67.2 56.1 -verb . intent 64.7 59.5 86.1 63.2 49.8 SFT 84.4 78.1 92.3 89.8 77.4 -verb . intent 85.5 78.4 93.8 89.9 79.9 intent-explicit SFT 87.8 80.1 93.1 93.4 84.8 -verb . intent 85.8 77.6 93.1 90.5 82.2 intent-implicit SFT 87.2 79.0 92.3 93.2 84.3 -verb . intent 87.8 77.9 93.3 94.0 85.9 intent-multivie w SFT 87.5 77.3 93.9 93.8 85.0 -verb . intent 89.2 79.5 95.1 95.4 86.7 qwen3-4b no training 80.9 78.0 94.6 82.8 68.1 -verb . intent 80.2 78.6 94.7 80.7 67.0 SFT 83.4 80.1 92.4 86.2 74.8 -verb . intent 86.7 77.3 93.2 92.5 83.6 intent-explicit SFT 86.3 80.4 91.3 92.2 81.5 -verb . intent 87.5 80.1 97.0 91.5 81.3 intent-implicit SFT 83.7 77.0 92.8 88.0 77.0 -verb . intent 85.2 78.4 93.5 90.1 78.7 intent-multivie w SFT 87.9 79.0 93.7 93.7 85.2 -verb . intent 87.0 80.2 92.2 93.3 82.5 T able 8: SQA-CS-V2 Performance Results with Pre-planning Base Model V ariant Ov erall Rubrics Answer P Citation P Citation R o3 default 85.1 91.4 96.5 89.4 63.4 + pre-planning 86.5 90.5 95.1 91.7 68.8 + intents 86.2 89.6 95.1 90.5 69.8 gemini-2.5-pro default 88.1 82.6 94.1 93.2 82.4 + pre-planning 88.4 81.3 93.7 93.4 85.3 + intents 90.7 80.6 94.0 97.2 90.9 claude-opus-4.1 Default 85.4 84.3 87.9 89.6 79.6 + pre-planning 89.4 85.3 93.9 93.8 84.7 + intents 90.0 85.2 93.1 95.7 86.2 31 Published as a conference paper at ICLR 2026 A . 6 P R O M P T S U S E D W e present the example prompt we used for verbalized intents below . During inference, retrieved information will be provided to the model by replacing {section_references}. Each snippet in {section_references} will be in the format of “[Citation X] Snippet”, and the model is instructed to cite the relev ant references. A user issued a query and a set of research papers were pro vided with salient content. The user query was: query I will provide you with a list of chosen quotes from these papers that may be rele vant to the user query . It’ s important to note that the quotes may *not* be rele v ant. Carefully consider this before adding them to the answer . Y our job is to help me write a multi-section answer to the query and cite the provided relev ant quoted references. Cite all of the *relev ant* quoted references. Exclude all of the irrelev ant quoted references from your answer . Here are the relev ant reference quotes to cite: section_references {section_references} Citation Instructions: - Each reference quote (section) is a k ey v alue pair , where the ke y is in the form "[Citation ‘int‘]". Y ou should cite ‘int‘ when referring to any of these sections as evidence. - Please write the answer , making sure to cite the relev ant references inline using the corresponding reference ke y in the format: [CitationNumber]. Y ou may use more than one reference key in a ro w if it’ s appropriate but no more than five references in a row . In general, use all of the references that support your written text, b ut cite no more than five references in a row . Having more than fiv e references or citations at a time overwhelms the user , so only include up to the fiv e most relev ant. - For each reference you cited in the section content, be sure to carefully consider the intent of the citation. Y our citation intent must be expressed in the format of: your description [citation intent T ype]: your rationale [Citation ‘int‘]... The T ype ([citation intent T ype]) should be a single, capitalized word from the list below , and the rationale should be a brief explanation of why the citation is used in this context giv en the type. Only use one type per citation and add your own type if none of the types fit. Here is a list of the potential citation intent types: (1) CIT -B ACKGR OUND: the citation provides relev ant information for this domain; (2) CIT -MO TIV A TION: the citation illustrates need for data, goals, methods, etc.; (3) CIT -USES: the sentence uses data, methods, etc. from the citation; (4) CIT -EXTENSION: the sentence extends the referenced work’ s data, methods, etc. of the citation; (5) CIT -COMP ARISON OR CONTRAST : the sentence expresses similarity/dif ferences to the referenced work of the citation; (6) CIT -FUTURE: the citation identifies the referenced work as a potential a venue for future work. - The rationale wrapped in should be a brief and contextual e xplanation of what text in the quote triggers the citation. 32 Published as a conference paper at ICLR 2026 - **Do not** repeat the information and text that is already in the citing sentence. - Y our rationale should use or summarize the rele vant part of the reference quote you are citing and connect it to the citing sentence. - Y ou should write **different** citation intents for each citations e ven if they are in the same sentence or hav e the same type. - Y our citation intent should potentially help the reader understand why you are citing the reference quote and what they could potentially learn from further reading the cited paper . - Along with the quote, if any of its accompan ying inline citations are rele vant to or mentioned in the claim you are writing, you should cite the reference of the section (i.e. the integer in [Citation ‘int‘]) - if you are using multiple citations, you should write separate citation intents for each of the citations, although you can hav e the same type for multiple citations. - Y ou can add something from your own knowledge. This should only be done if you are sure about its truth and if there is not enough information in the references to answer the user’ s question. Cite the text from your kno wledge as [LLM MEMOR Y | 2025]. The citation should follow AFTER the te xt. Don’t cite LLM Memory with another evidence source. - Note that all citations that support what you write must come after the text you write. That’ s how humans read in-line cited te xt. First text, then the citation intent tag, then the citation. Writing instructions: Guidance for organizing content: - Write a well-organized narrative that flows logically , with clear structure and coherence between ideas. - The answer should be written in sections that break down the user query for a scientific audience. - Each section should discuss a **dimension or theme** that is related to the query . - Most sections will correspond to a cluster of related quotes that comprise of **similar claims, shared concepts, or o verlapping e vidence**. If multiple quotes from different cita- tions support the same idea or theme, the y should be grouped and cited together in one section. - Be sure to carefully consider your intents to write each paragraph in the section. Each section should hav e the following characteristics: - Before the section write a 2 sentence "TLDR;" of the section. No citations here. Precede with the text "TLDR;" - The first section should almost always be "Background" or "Introduction" to provide the user the key basics needed to understand the rest of the answer . - Every section can contain multiple paragraphs and should correspond to a theme or dimension. - Use multiple paragraph to organize the content within each section. - Each paragraph should focus on a central high-le vel idea and should correspond to a cluster of similar citations. 33 Published as a conference paper at ICLR 2026 - Be sure to carefully consider your intents to write each paragraph. Before each paragraph within the text field, you must insert a paragraph intent tag in the format: [paragraph intent T ype]: Rationale... . The [paragraph intent T ype] should be a single, capitalized word from the list provided belo w extracted from research about discourse mode. The Rationale should be a brief explanation of why the paragraph fits the chosen type, based on its content and function within the report. Here is a list of potential paragraph intent [paragraph intent T ype]s and their descriptions: (1) PIT -Exposition: This paragraph’ s main function is to explain, clarify , or provide background information on a topic (e.g., introducing a concept, summarizing prior work). (2) PIT -Definition: This paragraph’ s primary purpose is to define a key term, concept, or theory , often providing necessary boundaries for its use in the report. (3) PIT -Argumentation: This paragraph presents a specific claim or thesis and supports it with evidence, logic, or reasoning to persuade the reader . (4) PIT -Compare-Contrast: This paragraph’ s structure is org anized around highlighting the similarities and/or differences between tw o or more subjects, theories, or findings. (5) PIT -Cause-Ef fect: This paragraph focuses on explaining the causal relationship between ev ents or phenomena, detailing why something happened or what its results were. (6) PIT -Problem-Solution: This paragraph identifies a specific problem, gap, or challenge and then proposes or describes a potential solution or response. (7) PIT -Ev aluation: This paragraph assesses the strengths, weaknesses, v alidity , or significance of a study , theory , or piece of evidence according to a set of criteria. (8) PIT -Narration: This paragraph recounts a sequence of ev ents, such as the historical dev elopment of a field, the chronology of a case study , or the steps in a process. For e xample, you can write: [PIT -Exposition] This paragraph provides background context by introducing Con volutional Neural Networks (CNNs) and stating their established success in image classification, setting the stage for the subsequent discussion. Con volutional neural netw orks (CNNs) have achieved state-of-the-art results in image classification [CIT -B ACKGR OUND]: these citations provides foundational conte xt linking CNN to major image classification tasks [1] [2]. They ha ve become a foundational tool... - Use direct and simple language e verywhere, like "use" and "can". A void using more complex w ords if simple ones will do. Use the citation count to decide what is "notable" or "important". If the citation count is 100 or more, you are allowed to use value judgments like "notable." - Some references are older . Something that claims to be "state of the art" b ut is from 2020 may not be any more. Please avoid making such claims that may no longer be true. - The answer should directly respond to the user query . Every paragraph should be directly relev ant to the user query . If the user asked about "V isual RAG", don’t write a paragraph about just RA G unless it’ s in the one background section. 34 Published as a conference paper at ICLR 2026 Format Instructions When references present conflicting findings or contradictory claims: - Explicitly acknowledge the disagreement rather than ignoring it. Use phrases like "While X et al. found..., Y et al. reported contrasting results..." - Present both/all perspectiv es with their respective citations - If possible, identify potential reasons for the discrepancy (e.g., different methodologies, sample sizes, time periods, or contexts) - Use citation counts as one indicator of relativ e weight, but do not dismiss lo wer-cited work solely on this basis - If one claim has substantially more supporting e vidence across multiple papers, you may note this: "The majority of studies support..." while still acknowledging the minority view - A void taking sides unless the e vidence ov erwhelmingly supports one position - If the conflict is central to answering the user’ s query , consider dedicating a section to "Conflicting Findings" or "Ongoing Debates" Start the section with a ’SECTION;’ marker followed by its section name and then a newline and then the text "TLDR;", the actual TLDR, and then write the summary . Write the section content using markdown format. Rules for section formatting: - For each section, decide if it should be a b ullet-point list or a synthesis paragraph. - Bullet-point lists are right when the user wants a list or table of items. - Synthesis paragraphs are right when the user wants a coherent explanation or comparison or analysis or singular answer . - Use section names to judge what section format would be best. Lists and syntheses paragraphs are the only allowed formats. - Remember to include both citation intents ( and ) and paragraph intents ( and ) in your answer . 35 Published as a conference paper at ICLR 2026 T able 9: Extended performance comparison on Deepscholar Bench. Bold indicates the best- performing row for o verall metrics. Method DeepScholar Bench (DSB) Overall Nug. Cov . Org. Cite-P Claim Cov o3 46.8 47.0 61.1 39.1 40.2 + intent 43.2 49.1 64.1 27.2 34.3 + intent (paragraph-only) 49.3 48.0 66.0 39.1 44.3 qwen3-8b 56.0 46.0 59.0 57.0 62.0 intent-explicit 59.5 48.2 68.0 61.2 63.1 intent-implicit 60.3 45.1 68.0 63.1 65.0 intent-multi view 57.5 45.1 60.0 62.3 63.1 T able 10: SQA-CS-V2-dev Performance results with verbalized intents and gemini-2.5-pro . W e compare variants of intent schema design. free denotes the use of model improvised types. current denotes the use of our schema. mix denotes the use of most frequent types in our schema and let the model has freedom on adding their own. W e bold the best row for the Overall metric. Method V ariant Overall Rubrics Answer P Citation P Citation R verbalized intent (gemini) free 89.3 82.4 92.0 96.1 86.7 current 89.7 82.6 94.5 95.7 86.1 mix 91.6 83.1 95.0 97.3 91.0 A . 7 E X T E N D E D D E E P S C H O L A R B E N C H R E S U LT S In the main paper, we found that, while o3 has much worse citation behavior than other frontier models on DeepScholar Bench, our intent-a ware inference will degrade the citation quality . T o further validate the performance of our method, we report the performance on DeepScholar Bench with our paragraph-intent-only inference and SFT v ariants in T able 9. The variants are with the same setting as in T able 4 and T able 5 in the main paper , without further training. Results show that our models generalize to DeepScholar Bench: the best performing v ariant (intent- implicit) achie ves better performance than the best performing lar ge model (opus-4) in our T able 3. On the citation metrics, our SFT variants generally sho w better overall scores compared to o3 as well. A . 8 F U RT H E R A B L A T I O N O N I N T E N T S C H E M A D E S I G N W e further design a variant of our intent-aware inference with a more dynamic schema: we only keep the top-3 most used types for citation and paragraph intents from T able 6, respecti vely , in the instruction, and ask the model to impro vise if necessary . W e denote this variant as intent (mix) and compare with the current version, i.e., intent (current), and an ablated variant, intent (free), where the model outputs their own types. W e observe that k eeping the most frequent types in our schema + extra freedom (i.e., intent (mix)) would lead to the best performance. W e will update these e xperiments in the appendix as an alternati ve design. On the other hand, giv en that most of our design is kept the same (type + rationale), inference without a pre-set type leads to similar performance as with model-improvised types. Ho wev er, beyond the performance, the types used will be inconsistent across questions for intent (mix) and intent (free type) as a trade-of f of the freedom, e.g., [Example] vs. [Exemplify] vs. [Instance]. The intent (current) variant, where we extract a unified schema for all questions extracted from literature, has its value in pro viding consistent types for analysis and readability . 36 Published as a conference paper at ICLR 2026 Figure 3: A screenshot of the instructions to the users. Besides the tasks shown in the figure, the users will also be pro vided with a step-by-step guide on the annotation tasks and the k ey points to remember . The instructions can be revisited during the annotation task by the users by clicking a “Click to Expand Instruction” button. A . 9 U S E R S T U D Y D E TA I L S The participants are first introduced to the instructions, background of the report generation tasks, and the schemes for our intents. Then, they will start an interacti ve session with random intent text and the corresponding context to answer questions one by one. They are also allowed to provide optional qualitativ e feedback. Baseline systems present (in GUI): (1) for paragraphs, the section titles and first sentences, with the full content folded; (2) for citations, relev ant snippets from the papers cited are inline in tooltips that appear when hov ering over the citation. Our system presents automatically generated PITs (before each paragraph) and CITs (before the snippet) in our experimental condition. The participants are asked to decide if (1) the displayed information helps them understand whether they want to read this section without opening up the paragraphs; (2) they feel confident that they know what they will learn if they div e into the citation, for each paragraph and highlighted citation, respectively . For each paragraph/highlighted citation, the participants provide a Likert rating on a scale of 1-5 (from Strongly Disagree to Strongly Agree). The screenshots of the systems are shown in Figure 3 (general instructions), Figure 4 (PIT questions for the baseline system), Figure 5 (CIT questions for the baseline system), Figure 6 (PIT questions for our intent-aware system), and Figure 7 (CIT questions for our intent-aware system)). Participant pool. W e are recruiting participants with a master’ s or PhD in computer science to obtain more di verse and representati ve expertise. In this round, we recruited from two sources: (1) Personal advertising: we recruited 8 participants from 7 af filiations; (2) Prolific 3 : we recruited 12 participants. Each annotator receiv es compensation of 30 USD per hour . All participants are new to the task. W e rule out annotators whose av erage score is outside 2 standard deviations of the mean of all other annotators or who spent significantly less time than others, e.g., less than 2 minutes. User -centered task design. T o reduce confounds related to the users’ prior knowledge and personal interest, participants read reports generated on their own questions. They are instructed to pose/select questions that they (1) genuinely want answered and (2) do not already kno w the answer to. Besides the results reported in main paper , there is also high consistency in the findings with participants hired from dif ferent sources: (1) From personal advertising, 8 participants reading with our system report 4.26 and 4.19 for paragraph and citation questions, while the scores are 3.77 and 3.29 for the baseline system; (2) From Prolific, 12 participants report 4.55 and 4.60 for paragraph and citation questions reading reports with our system, while 3.94 and 4.06 reading with the baseline system. Consistent annotation results from different demographics strengthen the claim in our original case study that the intent annotations in reading interfaces help support tar geted comprehension. 3 https://www.prolific.com/ 37 Published as a conference paper at ICLR 2026 Figure 4: A screenshot of the PIT questions for the baseline system. Users are sho wn with the section titles and paragraph first sentences to answer the questions. Figure 5: A screenshot of the CIT question for the baseline system. Users are shown with a specific paragraph with one highlighted citation to answer the question. The snippet will sho w as the users mov e their mouse ov er it. Figure 6: A screenshot of the PIT questions for our intent-aware reading system. Users are sho wn with the section titles, the paragraph-lev el intents, and paragraph first sentences to answer the questions. 38 Published as a conference paper at ICLR 2026 Figure 7: A screenshot of the CIT question for the intent-aware reading system. Users are shown with a specific paragraph with one highlighted citation to answer the question. The potential citation intent and the snippet will show as the users mo ve their mouse ov er it. 39
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment