The Geometric Cost of Normalization: Affine Bounds on the Bayesian Complexity of Neural Networks
LayerNorm and RMSNorm impose fundamentally different geometric constraints on their outputs - and this difference has a precise, quantifiable consequence for model complexity. We prove that LayerNorm's mean-centering step, by confining data to a line…
Authors: Sungbae Chun
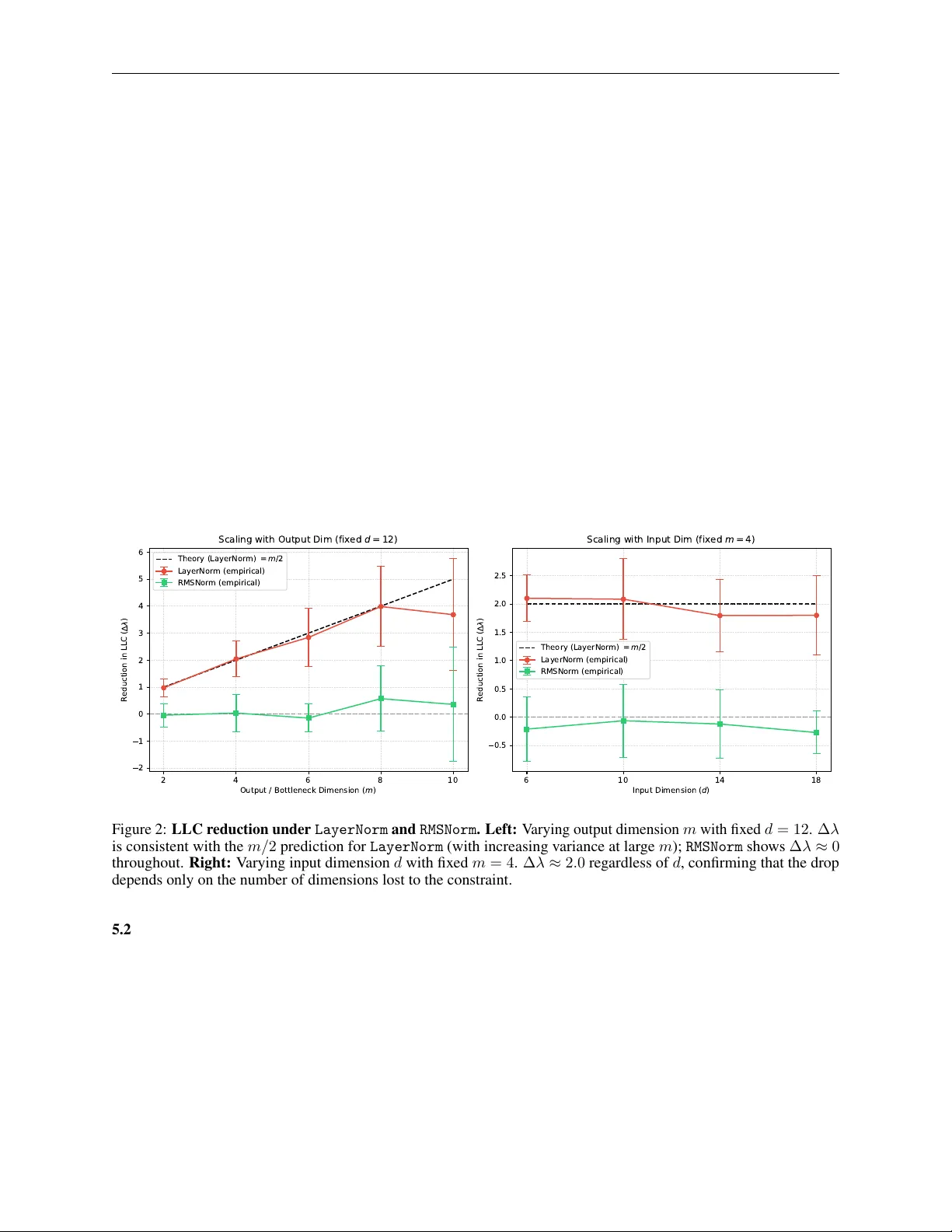
T H E G E O M E T R I C C O S T O F N O R M A L I Z A T I O N : A FFI N E B O U N D S O N T H E B A Y E S I A N C O M P L E X I T Y O F N E U R A L N E T W O R K S A P R E P R I N T Sungbae Chun Department of Mathematics Univ ersität Bonn sungbae.chun@uni-bonn.de March 31, 2026 A B S T R AC T LayerNorm and RMSNorm impose fundamentally dif ferent geometric constraints on their outputs — and this dif ference has a precise, quantifiable consequence for model comple xity . W e prove that LayerNorm ’ s mean-centering step, by confining data to a linear hyperplane (through the origin), reduces the Local Learning Coef ficient (LLC) of the subsequent weight matrix by e xactly m/ 2 (where m is its output dimension); RMSNorm ’ s projection onto a sphere preserv es the LLC entirely . This reduction is structurally guaranteed before any training be gins, determined by data manifold geometry alone. The underlying condition is a geometric threshold: for the codimension-one manifolds we study , the LLC drop is binary — any non-zero curv ature, re gardless of sign or magnitude, is suf ficient to preserve the LLC, while only af finely flat manifolds cause the drop. At finite sample sizes this threshold acquires a smooth crosso ver whose width depends on ho w much of the data distrib ution actually experiences the curv ature, not merely on whether curvature exists some where. W e verify both predictions experimentally with controlled single-layer scaling experiments using the wrLLC framework [ 1 ]. W e further sho w that Softmax simplex data introduces a “smuggled bias” that activ ates the same m/ 2 LLC drop when paired with an explicit downstream bias, pro ved via the affine symmetry e xtension of the main theorem and confirmed empirically . Keyw ords Deep Learning · Singular Learning Theory · Normalization · Bayesian Complexity 1 Introduction LayerNorm and RMSNorm are widely treated as interchangeable design choices, but the y differ in a structural way that has not previously been quantified: LayerNorm reduces the effecti ve parameter count of any subsequent weight matrix, while RMSNorm does not. W e prove this using the Local Learning Coef ficient (LLC) [ 2 , 3 ], a Bayesian measure of a model’ s effecti ve complexity: LayerNorm ’ s mean-centering step reduces LLC by exactly m/ 2 per normalized layer , a reduction that is structurally guaranteed before training begins. RMSNorm incurs no such cost. The mechanism is geometric. Normalization layers [ 4 – 6 ] constrain data to a submanifold of R d , and directions of the weight matrix orthogonal to that manifold become invisible to the loss — genuine symmetries that reduce the LLC. What pr operty of the manifold determines whether this dr op occurs? Our answer is a geometric one: whether the manifold is af finely flat. W e prov e this for single linear layers with squared loss and find experimentally that the threshold is binary — any non-zero curv ature, regardless of sign or magnitude, is suf ficient to preserve the LLC. Our contributions are: • A geometric thr eshold f or LLC reduction. W e pro ve that a weight matrix W ∈ R m × d loses exactly m/ 2 from its LLC whenev er the input data lies on a linear hyperplane (through the origin; linear span d s = d − 1 ) The Geometric Cost of Normalization A P R E P R I N T (Section 2.5). Experimentally , we find that for codimension-one manifolds, an y non-zero curvature is suf ficient to prev ent this drop (Section 3). • A finite-sample phase transition. Experimentally , we find that the observed binary threshold acquires a smooth crossov er at finite sample sizes. The width and location of the transition depend on ho w much of the data distribution actually experiences the curv ature, not merely on whether curvature exists some where on the manifold (Section 3). • Exact LLC pr edictions for LayerNorm and RMSNorm . LayerNorm confines data to a linear hyperplane (mean-centering sets 1 ⊤ x = 0 ), reducing LLC by m/ 2 . RMSNorm projects onto a sphere, which has full linear span, leaving LLC unchanged. W e v alidate both predictions with controlled scaling experiments (Section 4). • Simplex-Bias Duality (Proposition 1). Softmax simplex data carries a hidden implicit bias ( b smuggled ) that is inert in strictly linear layers ( ∆ λ = 0 ) but acti vates an m -dimensional symmetry and drops LLC by m/ 2 whenev er the layer includes an explicit bias (proved theoretically; measured ∆ λ = 2 . 26 ≈ m/ 2 = 2 . 0 , robust across seeds). The Post- LayerNorm case is an open problem: the theoretical mechanism is plausible b ut current SGLD estimation is unreliable for this configuration (Section 2.5). 2 Background 2.1 Singular Learning Theory and the LLC Singular Learning Theory (SL T), dev eloped by W atanabe [ 2 ] and applied to deep learning by W ei et al. [7] , measures a model’ s Bayesian complexity via the Local Learning Coefficient (LLC) — the ef fective number of parameters as seen by the Bayesian posterior . When the loss has continuous symmetries (directions in parameter space that leave the loss unchanged), the LLC is strictly less than the nominal parameter count. W e show that normalization layers introduce such symmetries structurally , before any training occurs. 2.2 Related W ork The geometry of the loss landscape and continuous symmetries in o verparameterized networks has been studied from sev eral angles. ¸ Sim ¸ sek et al. [8] characterize ho w permutation symmetries of the network architecture give rise to connected manifolds of equi valent optima, reducing LLC in a manner structurally analogous to our symmetry space S M . Our contribution is orthogonal: we identify a separate, data-manifold-induced source of degeneracy that is independent of the weight-space symmetries of the architecture itself. Gupta et al. [9] study the geometric structure of LayerNorm and RMSNorm at inference time; our work dif fers in connecting normalization geometry to the LLC and deriving e xact algebraic predictions. The LLC has been applied to study training dynamics and phase transitions in T ransformers [ 10 ] and to characterize degenerac y in singular models [ 3 ]. Our work complements these by pinpointing a structural—rather than emer gent— source of degenerac y arising from normalization operations. Attention sinks. Xiao et al. [11] empirically identified sink tokens in autoregressi ve language models; Ran-Milo [12] prov ed their existence is necessary in softmax T ransformers; Ruscio et al. [13] offer a complementary geometric analysis of the sink phenomenon. Our frame work suggests a structural interpretation: LayerNorm ’ s mean-centering reduces LLC( W V ) by m/ 2 , which may structurally bias W V tow ard low-rank solutions associated with sink behavior . W e were unable to validate this prediction experimentally (see Conclusion); the connection between LLC reduction and sink formation remains an open question. 2.3 Holonomic Constraints from Normalization Each normalization operation acts as a holonomic constraint on the data manifold, confining its output to a specific geometric surface. This surface determines the linear span av ailable to the next weight matrix, which in turn determines whether an LLC drop occurs. • LayerNorm [ 5 ] enforces zero mean and unit variance. The mean-centering step projects data onto the hyperplane { 1 ⊤ x = 0 } , a linear subspace of dimension d − 1 . The variance normalization further confines data to a sphere within this h yperplane, but the linear span of that sphere equals the span of the full hyperplane, so d s = d − 1 reg ardless. • RMSNorm [ 6 ] enforces unit RMS without mean-centering. Outputs lie on a sphere {∥ x ∥ = √ d } , which contains ± √ d e i for each standard basis direction e i , so span( S d − 1 ) = R d . Linear span: d s = d . 2 The Geometric Cost of Normalization A P R E P R I N T The span reduction in LayerNorm is the precise condition for an LLC drop; RMSNorm av oids it. W e observe in Section 3 and Appendix A that for the manifolds we test, non-zero curv ature is sufficient to achie ve full linear span, while af finely flat manifolds do not span the full ambient space. Remark 1 (Lagrangian Mechanics Analogy) . The term holonomic is borrowed deliberately fr om Lagr angian mec hanics. In that setting, holonomic constraints r estrict a system’ s trajectory to an allowed configuration manifold, r educing the effective de gr ees of freedom of the dynamics. Normalization oper ations play an analogous r ole here: the y confine the input data to a submanifold of R d , constraining whic h dir ections of W ar e observable by the loss. This should be distinguished fr om the symmetries of the Lagrangian—in variances such as the GL ( r ) scaling symmetry in adjacent matrix factorizations, which leave the loss unchang ed r egar dless of the data geometry . In the La grangian analogy , these corr espond to Noether symmetries: each continuous in variance pr oduces a conserved (flat) direction in the loss landscape. The holonomic constr aint cost and the Lagr angian symmetry cost are structur ally independent sour ces of deg eneracy . The wrLLC [ 1 ] methodology is pr ecisely designed to isolate the former from the latter , fr eezing all components that carry Lagrangian symmetries so that the measured LLC dr op reflects only the geometric cost of the constraint. 2.4 The Simplex, the Smuggled Bias, and Affine Symmetries Beyond v ariance-based normalizations, routing mechanisms like Softmax impose holonomic constraints of a different kind. Softmax projects arbitrary real vectors onto the standard simple x: Σ d − 1 = ( x ∈ R d d X i =1 x i = 1 , x i > 0 ) Remark 2 (Semi-algebraic nature of the Softmax constraint) . Strictly speaking, the Softmax simplex is defined by one equality ( P x i = 1 ) together with d strict inequality constraints ( x i > 0 ), making it a semi-algebraic set rather than a holonomic constraint in the classical mechanics sense . The open simple x is nevertheless a smooth manifold, and the term holonomic is used loosely thr oughout this work to mean any constraint that confines data to a smooth submanifold. F or all results in this section, only span( M ) matters, and the inequality constraints contrib ute nothing to this span: span(Σ d − 1 ) = R d (since e 1 , . . . , e d ∈ cl(Σ d − 1 ) ). All results ther efor e apply to the Softmax case without modification. Because the outputs are strictly constrained by 1 T x = 1 , the data lies on a ( d − 1) -dimensional hyperplane. T o rigorously analyze the degenerac y of a subsequent linear layer W ∈ R m × d , we can apply an affine shift to center this hyperplane at the origin. Let x ′ = x − 1 d 1 . By construction, 1 T x ′ = 0 , meaning x ′ resides strictly in a ( d − 1) -dimensional linear span. Applying the linear layer W to the original data yields: W x = W x ′ + 1 d 1 = W x ′ + 1 d W 1 Let b smug g led = 1 d W 1 (the ro w-wise mean of W ). Thus, W x = W x ′ + b smug g led . This geometric decomposition formalizes three architectural scenarios with distinct degenerac y consequences: Proposition 1 (Simple x-Bias Duality) . Let f ( x ) = W x with W ∈ R m × d , and let the input lie on the standard simple x Σ d − 1 , so 1 ⊤ x = 1 . Decompose x = x ′ + 1 d 1 wher e 1 ⊤ x ′ = 0 ; then f ( x ) = W x ′ + b smuggled wher e b smuggled = 1 d W 1 . The LLC dr op ∆ λ r elative to a full-rank Gaussian baseline is: (i) Strictly linear ( y = W x , MSE loss): span(Σ d − 1 ) = R d , so no symmetry space exists and ∆ λ = 0 . (ii) Affine layer ( y = W x + b , MSE loss): F or any c ∈ R m , the substitution ( W , b ) → ( W + c 1 ⊤ , b − c ) leaves y unchanged on Σ d − 1 , since b smuggled and b ar e indistinguishable to the loss. This yields an m -dimensional symmetry space and, by Cor ollary 3, ∆ λ = m/ 2 . Conjecture 1 (Post-LayerNorm Smuggled-Bias De generacy) . Under the same setting , with y = LN( W x ) and MSE loss on the LayerNorm output: ∆ λ = m/ 2 . The mechanism is that LayerNorm ’ s translation-in variance renders b smuggled an ef fective blind spot, but the pr ecise symmetry gr oup of the P ost- LN loss landscape has not been c haracterized. Curr ent SGLD-based LLC estimation is unreliable in this configur ation: multi-seed testing gives ∆ λ = − 0 . 92 ± 0 . 86 (5 seeds), indicating that the Gaussian baseline LLC is poorly calibrated for the non-affine LN loss landscape. V alidating this conjectur e requir es either a dir ect pr oof or an estimator better calibrated to P ost- LN models. The common thread is that Softmax ’ s affine geometry primes the network for degenerac y , with the precise mechanism determined by downstream operations. 3 The Geometric Cost of Normalization A P R E P R I N T 2.5 Main Result: Data-Manifold Induced RLCT Reduction When a weight matrix W ∈ R m × d operates on data confined to a manifold M , those directions of W orthogonal to span( M ) are in visible to the loss. This “blind spot” is the precise algebraic manifestation of the data-manifold induced singularity in the parameter space. Notation (Symmetry Space) . Let M ⊂ R d and let d s = dim(span( M )) . The symmetry space of M is S M := { U ∈ R m × d | U x = 0 ∀ x ∈ M} . Since S M is the kernel of the e valuation map W 7→ ( W x ) x ∈M , which has r ank d s , we have dim( S M ) = m ( d − d s ) by rank-nullity . This setting admits a closed-form RLCT via W atanabe’ s formula: the loss is a quadratic polynomial, the zero-loss manifold W 0 is smooth and explicitly characterizable, and the Morse-Bott condition holds for any non-de generate input distribution. The result is an e xact algebraic prediction of normalization’ s Bayesian cost: for any normalization that acts as a span restriction, the LLC drop is ∆ λ = m ( d − d s ) / 2 , determined entirely by the data geometry before any training occurs. W e conjecture that the same reduction holds per-layer in deep networks under the wrLLC isolation protocol. Theorem 1 (Symmetry-Induced RLCT Reduction) . Let f ( x ) = W x be a single linear layer with W ∈ R m × d , let L be the squar ed loss with a r ealizable teacher W ∗ , and let the input data lie on M with d s = dim(span( M )) . Let λ 0 = md/ 2 denote the RLCT of the same model with full-rank input data. (i) F ree action. The symmetry space S M acts fr eely on W 0 by translation: for any U ∈ S M and W ∈ W 0 , ( W + U ) x = W x ∀ x ∈ M , so W + U ∈ W 0 . (ii) Zero-loss manifold. W 0 = W ∗ + S M , so dim( W 0 ) = m ( d − d s ) and codim( W 0 ) = m · d s . (iii) RLCT . The expected loss is L ( W ) = ∥ ( W − W ∗ )Σ 1 / 2 ∥ 2 F , a polynomial with smooth zer o set W 0 and non- de generate normal Hessian Σ | span( M ) ⊗ I m (the FIM restricted to span( M ) ), which is non-de generate for any non-de generate input distrib ution. By [2], the RLCT equals λ = co dim( W 0 ) 2 = m · d s 2 . Consequently , the RLCT r eduction r elative to the full-rank baseline is ∆ λ := λ 0 − λ = md 2 − m · d s 2 = m ( d − d s ) 2 . Corollary 1 (LLC Drop for Normalization Layers) . Let W ∈ R m × d be a single linear layer with squared loss and non-de generate input distribution. If a preceding normalization r estricts the input to M with dim(span( M )) = d s , then ∆ λ = m ( d − d s ) 2 . In particular: LayerNorm gives d s = d − 1 and ∆ λ = m/ 2 ; RMSNorm gives d s = d and ∆ λ = 0 . Remark 3 (Extension to deep networks) . Theor em 1 is pr oved for single linear layers with squar ed loss. W e conjectur e that the same RLCT r eduction holds for each normalized weight matrix W l in a deep network, with the wrLLC methodology [ 1 ] pr oviding the isolation mec hanism: freezing all parameter s except W l r educes the multi-layer pr oblem to the single-layer case of Theor em 1 locally . The experiments in Section 4 confirm the single-layer theor em; they do not test this conjectur e, as all ar chitectur es used are single linear layers in a teacher -student setup. Empirical validation in actual multi-layer models, and a formal pr oof r equiring verification of the Morse-Bott condition for the composed map g ◦ norm ◦ W l , ar e left to future work. Corollary 2 (Layer -wise Additivity under wrLLC (conditional)) . Assume the conjecture in the Remark above holds. Let f be a multi-layer network in which layer l has weight matrix W l ∈ R m l × d l pr eceded by a normalization restricting its input to M l with d s,l = dim(span( M l )) . Under the wrLLC pr otocol—which fr eezes all parameter s e xcept W l —the model locally r educes to the single-layer case of Corollary 1. Hence the LLC dr op at layer l is ∆ λ l = m l ( d l − d s,l ) 2 , independently of all other layers. 4 The Geometric Cost of Normalization A P R E P R I N T Remark 4. The motivation for the wrLLC pr otocol in Cor ollary 2 differs fr om its original use in multi-layer networks [ 1 ]. In the single-layer experiments of Section 4, ther e are no adjacent matrix factors and hence no GL ( r ) scaling symmetry to eliminate; wrLLC simply identifies the tar get weight matrix W . In a multi-layer setting, fr eezing all other weights additionally r emoves the GL ( r ) in variances inher ent in adjacent factorizations, making the two isolation benefits structurally independent. Remark 5 (wrLLC as a lower bound on degeneracy) . The wrLLC measur ement pr ovides a lower bound on the de generacy that W l contributes to the full network. The ar gument is direct: any U ∈ S M l satisfies U x = 0 for all x ∈ M l , so ( W l + U ) x = W l x on all training data. Every downstr eam operation—nonlinearities, subsequent layers, the loss—sees the identical input and produces the identical output, so U is a genuine symmetry of the full network loss, not only of the isolated layer . Joint ef fects such as GL ( r ) scaling symmetries between adjacent layers can only add further symmetries on top. Hence the full network has at least m l ( d l − d s,l ) de generate dir ections attributable to W l alone. If p total denotes the total parameter count, the global RLCT satisfies λ global ≤ p total − m l ( d l − d s,l ) 2 , meaning the m l d l de grees of fr eedom of W l contribute at most wrLLC( W l ) = m l d s,l / 2 to the global RLCT , rather than the naive m l d l / 2 . 2.6 Supporting Geometric Results The following results are mathematically straightforward, b ut we include proof sketches as these e xact statements do not appear verbatim in the literature. Theorem 2 (Rank Manifold Codimension [ 14 , Ch. 1, §4, Exercise 13]) . The set R r := { A ∈ R m × d | rk( A ) = r } is a smooth submanifold of R m × d of codimension ( m − r )( d − r ) . Pr oof sketch. The result is posed as an ex ercise in [ 14 ] with the hint to consider the Schur complement map Φ( A ) := E − D B − 1 C ∈ R ( m − r ) × ( d − r ) , where B , C , D , E are the blocks of A after permuting so that the top-left r × r block is in vertible. Since ∂ Φ /∂ E = Id , the differential d Φ is surjecti ve, and the result follows by the regular value theorem. Combining the symmetry space dimension (Notation above) and Theorem 2, we establish the dimension of the constrained weight manifold: Theorem 3 (Constrained W eight Manifold Dimension) . Let M ⊂ R d with d s = dim(span( M )) , and let W M ,r := { W ∈ R m × d | rk( W ) = r, W x = 0 ∀ x ∈ M} . Then dim( W M ,r ) = r ( d − d s + m − r ) . Pr oof sketch. Choose a basis for R d aligning span( M ) with the first d s coordinate directions. The constraint W x = 0 for all x ∈ M then reduces to W 1 = 0 (the first d s columns v anish), so W M ,r ∼ = R r ( m × ( d − d s )) . The dimension r ( d − d s + m − r ) follo ws directly from Theorem 2. Remark 6. Theor em 3 is not used in the pr oof of Theorem 1 or its cor ollaries. It is a standalone g eometric r esult char acterizing the dimension of the rank- r constrained weight manifold when data lies on a lower -dimensional subspace . Its r elevance to LoRA [ 15 ] settings — wher e W is explicitly constr ained to rank r — is a structural observation; we do not experimentally validate this connection her e. 2.7 Generalization to Affine T ransformations The results established above apply to strictly linear weight matrices. Howe ver , as demonstrated in Section 2.3, neural network layers often include e xplicit bias terms or operate on affine manifolds (e.g., f ( x ) = W x + b ). The extension to the affine case is immediate via homogeneous coordinates: Remark 7 (Affine symmetry space) . Let M ⊂ R d have affine span d a . Augmenting x 7→ ˜ x = [ x ⊤ , 1] ⊤ ∈ R d +1 con verts the affine condition U x + c = 0 into the linear condition ˜ U ˜ x = 0 for ˜ U = [ U, c ] . The augmented manifold ˜ M has linear span d a + 1 , so the rank-nullity ar gument of the Notation gives dim( S affine M ) = m ( d + 1) − ( d a + 1) = m ( d − d a ) . 5 The Geometric Cost of Normalization A P R E P R I N T Corollary 3 (Af fine LLC Drop) . Under the same conditions as Theorem 1 (single linear layer with bias, squar ed loss, r ealizable teacher , non-deg enerate input distrib ution), applied in homogeneous coor dinates: let f ( x ) = W x + b with W ∈ R m × d , b ∈ R m , and let the input data lie on a manifold M ⊂ R d with affine span d a . Then the parameter pair ( W , b ) admits a continuous symmetry space of dimension m ( d − d a ) , and ∆ λ = m ( d − d a ) 2 . In particular , Softmax maps its input to the standard simplex, which has af fine span d a = d − 1 , yielding ∆ λ = m/ 2 whenev er the layer includes an explicit bias. A strictly linear layer ( b = 0 ) is unaf fected, as the simple x’ s linear span remains d . Remark 8 (Symmetry-type matching principle) . Corollaries 1 and 3 together expr ess a single principle: for data confined to a hyperplane { n ⊤ x = c } ⊂ R d , an LLC drop of m/ 2 occurs if and only if the tr ansformation type has at least as muc h affinity as the constraint. A strictly linear layer W x is symmetry-coupled only when c = 0 (the hyperplane passes thr ough the origin); an affine layer W x + b is symmetry-coupled for any c , including c = 0 . When c = 0 , a strictly linear tr ansformation admits no symmetry because the offset cannot be cancelled without a free bias term. Data not confined to any hyperplane (e .g. a sphere) has full affine span and yields ∆ λ = 0 under either transformation type . 3 The Geometric Threshold: Curvatur e vs. Flatness The main theorem proves that af fine flatness is sufficient for an LLC drop: a holonomic constraint that eliminates a full dimension of linear span costs exactly m/ 2 from the LLC. This suggests a binary threshold — any non-zero curvature, regardless of sign or magnitude, should be suf ficient to preserve the LLC entirely . W e test this con verse direction by training on manifolds with systematically varied geometry . 3.1 Setup All experiments use a single linear layer W ∈ R m × d , MSE loss with a teacher-student setup, Gaussian inputs mapped onto the target manifold, N = 2000 samples, 5 seeds (median reported). Full experimental details are gi ven in Section 4. W e use d = 5 , m = 4 throughout, gi ving a theoretical ∆ λ = m/ 2 = 2 . 0 for flat manifolds. LLC is estimated via SGLD with the de vinterp library [ 16 ] (3 chains, 4000 b urn-in + 4000 recorded draws, localization γ = 2 /p , lr = 5 × 10 − 4 ). W e compare the LLC against an unconstrained Gaussian baseline ( λ Gaussian = 12 . 045 ± 0 . 283 ). 3.2 Block A: The Binary Curvatur e Threshold W e test three qualitativ ely dif ferent curvature re gimes, each a ( d − 1) -dimensional manifold embedded in R d : • P ositive cur vatur e: Paraboloid ( x d = ∥ x 0 . This characterizes a limitation of SGLD-based LLC estimation: the sampler is blind to geometric structure belo w its thermal noise floor . The measured LLC is not just a function of whether curv ature exists, but of how much of the data distribution e xperiences it . Belo w a critical amplitude that depends on the data–curvature ov erlap, the sampler cannot distinguish the manifold from flat. The true RLCT remains binary (as the algebraic theory predicts); the smooth crossov er is a property of the estimator , not the geometry . T able 2: LLC vs. Gaussian bump amplitude. Flat baseline = 9 . 939 . δ = LLC − LLC flat . Wide ( α = 0 . 1 ) Narro w ( α = 10 . 0 ) A LLC δ LLC δ 0.01 9.941 +0 . 002 9.939 +0 . 000 0.10 9.982 +0 . 043 9.940 +0 . 001 0.20 10.073 +0 . 133 9.944 +0 . 004 0.50 10.540 +0 . 601 9.965 +0 . 026 1.00 11.261 +1 . 322 10.041 +0 . 102 2.00 11.710 +1 . 771 10.267 +0 . 328 Gaussian P araboloid Hyperboloid Saddle Flat hyperplane 0 2 4 6 8 10 12 LLC (median over seeds) Block A : LLC by Manifold Curvatur e Class Gaussian baseline Flat theory (baseline 2) 1 0 2 1 0 1 1 0 0 B u m p a m p l i t u d e A 10.0 10.5 11.0 11.5 12.0 LLC (median over seeds) B l o c k B : P h a s e T r a n s i t i o n i n A m p l i t u d e A Flat baseline (LLC 9.94) = 0 . 1 ( w i d e b u m p ) = 1 0 . 0 ( n a r r o w b u m p ) Figure 1: Curvatur e geometry and effective LLC. Left: Median LLC per manifold class ( d = 5 , m = 4 , 5 seeds). All curv ed surf aces match the Gaussian baseline ( ≈ 12 . 0 ); only the flat hyperplane drops to ≈ 9 . 9 ≈ 12 . 0 − m/ 2 . Curvature sign is irrele v ant: the threshold is between flat and non-flat. Right: LLC vs. b ump amplitude A for wide ( α = 0 . 1 ) and narrow ( α = 10 . 0 ) bumps. The wide bump reco vers near A ∗ ≈ 0 . 1 ; the narrow b ump stays near the flat bound until A ≥ 1 . 0 , showing that the effecti ve RLCT depends on data–curv ature overlap, not just the existence of curvature. 7 The Geometric Cost of Normalization A P R E P R I N T 4 A pplication to Normalization Layers T o empirically verify the bounds established in Theorem 1 and Corollary 1, we must isolate the geometric cost of normalization from the inherent degeneracies of neural networks. The key challenge is that a multi-layer network exposes unbounded continuous symmetries — such as the GL ( r ) scaling in variances inherent in adjacent matrix factorizations — which flood the SGLD sampler and make clean LLC estimation intractable. W e eliminate this problem by restricting to a minimal single-layer architecture where the only source of de generacy is the holonomic constraint imposed by the normalization under study . 4.1 Minimal Single-Layer Ar chitecture Our model consists of a single linear layer W ∈ R m × d (no bias) optionally preceded by a normalization operation: f ( x ) = W · ϕ ( x ) where ϕ is one of three conditions: (1) Baseline ( ϕ = identity ), (2) LayerNorm (zero-mean, unit-v ariance, no learned affine parameters), or (3) RMSNorm (unit-RMS, no learned af fine parameters). Because there is only a single weight matrix and no downstream frozen components, W is the sole source of any structural de generacy . Any LLC drop measured relativ e to the Baseline is therefore uniquely attributable to the data manifold’ s geometric constraint. 4.2 T eacher -Student Setup W e construct a T eacher-Student setup to guarantee a perfectly realizable tar get, ensuring the student can reach a true global minimum ( L ≈ 0 ). For each condition, a T eacher model with the same architecture is randomly initialized (weights drawn from N (0 , 1) ) and frozen. Inputs X ∈ R N × d ( N = 2000 ) are drawn from N (0 , I d ) and targets are set to Y = teacher ( X ) . The Student is then trained on ( X, Y ) via MSE loss until con vergence, ensuring it finds the same zero-loss manifold as the T eacher . 4.3 T raining and Conv ergence The Student model is optimized using Adam [ 17 ] with cosine annealing [ 18 ] (initial lr = 10 − 2 , minimum lr = 10 − 5 , 1000 epochs, batch size 256). After training, we v erify con vergence by checking that the final MSE loss is below 10 − 4 . Seeds that fail this criterion are flagged as poorly conv erged; no such failures were observed in the experiments reported here. 4.4 SGLD λ Estimation After training, we estimate the LLC using SGLD [ 19 ] via the devinterp library [ 16 ]. T o keep the per-parameter spring energy constant re gardless of model size, we use an adaptiv e localization γ = 2 . 0 / ( m · d ) , calibrated to the reference value of γ = 0 . 1 that works well for p = 20 parameters (since 2 / 20 = 0 . 1 ). W e run 3 chains of 4000 burn-in steps followed by 4000 recorded dra ws, with SGLD learning rate 5 × 10 − 4 . T o suppress the occasional di vergent chain, we repeat each configuration o ver 5 independent seeds and report the median ∆ λ = λ Baseline − λ norm across seeds, together with the standard deviation as a measure of per -seed variance. 4.5 Scaling Experiments W e conduct two systematic sweeps to verify the scaling predictions of Corollary 1: • Experiment 1 (vary m ): Output dimension m ∈ { 2 , 4 , 6 , 8 , 10 } with input dimension fixed at d = 12 . Theory predicts ∆ λ = m/ 2 . • Experiment 2 (vary d ): Input dimension d ∈ { 6 , 10 , 14 , 18 } with output dimension fixed at m = 4 . Theory predicts ∆ λ = 2 . 0 reg ardless of d . 4.6 Softmax Degeneracy Experiment T o empirically validate Corollary 3, we e valuate a separate configuration where the input data X is dra wn from the af fine hyperplane { x ∈ R d | 1 ⊤ x = 1 } rather than a Gaussian. Concretely , each sample is generated as x = z − ¯ z 1 + 1 d 1 where z ∼ N (0 , I ) , ensuring 1 ⊤ x = 1 while preserving the spread of a standard Gaussian. This captures the essential affine geometry of Softmax outputs (which satisfy the same constraint) while keeping the data v ariance high enough 8 The Geometric Cost of Normalization A P R E P R I N T for reliable LLC estimation. W e use the same single-layer architecture ( d = 5 , m = 4 ) and compare three downstream configurations: (1) strictly linear ( b = 0 ), (2) explicit bias ( y = W x + b ), and (3) LayerNorm post-projection. This isolates whether the simple x geometry triggers the “smuggled bias” degeneracy predicted by the affine symmetry analysis. 5 Empirical Results 5.1 LayerNorm Reduces LLC by m/ 2 The LLC drop induced by LayerNorm is consistent with the m/ 2 prediction across all tested output dimensions (Figure 2, Left), in agreement with Corollary 1. Because LayerNorm mean-centers the data, it projects x onto the hyperplane { v ∈ R d | 1 ⊤ v = 0 } , restricting the linear span to d s = d − 1 and introducing an m -dimensional symmetry space in W . Each lost dimension costs exactly 1 / 2 from the LLC. At m = 10 the estimator breaks do wn: seeds cluster near 3 and 7 – 8 separately , yielding a median ∆ λ = 3 . 68 ± 2 . 07 against a theoretical prediction of 5 . 0 . The bimodal distribution indicates the SGLD sampler is not conv erging to a single stable estimate but settling into two distinct modes in the loss landscape. The theory predicts ∆ λ = 5 . 0 ; neither observed mode matches this. This is an estimator failure at lar ger parameter counts, not a confirmation of the theory; controlled single-layer experiments at this scale would require more chains, longer burn-in, or better -calibrated localization. Figure 2 (Right) confirms that the drop is independent of input dimension d : fixing m = 4 giv es ∆ λ ≈ 2 . 0 for d ∈ { 6 , 10 , 14 , 18 } . The LLC reduction depends only on the number of dimensions lost to the constraint, not on the ambient size of the manifold. 2 4 6 8 10 O u t p u t / B o t t l e n e c k D i m e n s i o n ( m ) 2 1 0 1 2 3 4 5 6 R e d u c t i o n i n L L C ( ) S c a l i n g w i t h O u t p u t D i m ( f i x e d d = 1 2 ) T h e o r y ( L a y e r N o r m ) = m / 2 LayerNor m (empirical) RMSNor m (empirical) 6 10 14 18 I n p u t D i m e n s i o n ( d ) 0.5 0.0 0.5 1.0 1.5 2.0 2.5 R e d u c t i o n i n L L C ( ) S c a l i n g w i t h I n p u t D i m ( f i x e d m = 4 ) T h e o r y ( L a y e r N o r m ) = m / 2 LayerNor m (empirical) RMSNor m (empirical) Figure 2: LLC reduction under LayerNorm and RMSNorm . Left: V arying output dimension m with fixed d = 12 . ∆ λ is consistent with the m/ 2 prediction for LayerNorm (with increasing v ariance at large m ); RMSNorm shows ∆ λ ≈ 0 throughout. Right: V arying input dimension d with fixed m = 4 . ∆ λ ≈ 2 . 0 regardless of d , confirming that the drop depends only on the number of dimensions lost to the constraint. 5.2 RMSNorm Preser ves LLC RMSNorm shows ∆ λ ≈ 0 across all tested v alues of m and d (Figure 2). W ithout mean-centering, its outputs lie on a hypersphere with d s = d : W has no data-induced null space and no continuous symmetry is introduced. This gi ves a theoretical account of why RMSNorm provides normalization’ s training-stability benefits without reducing the effecti ve parameter count of the subsequent weight matrix. 5.3 Softmax and the Smuggled Bias Results are summarized in T able 3. W ith a strictly linear layer ( b = 0 ), the simplex data yields ∆ λ ≈ 0 : because the simplex does not pass through the origin, its linear span is d and no symmetry space e xists. The LLC drop is conditional, not automatic. 9 The Geometric Cost of Normalization A P R E P R I N T Adding an explicit bias activ ates the degeneracy . W ith y = W x + b , the measured ∆ λ = 2 . 26 ≈ m/ 2 = 2 . 0 : the smuggled bias b smuggled = 1 d W 1 and the explicit bias b are indistinguishable to the loss, collapsing m parameters in accordance with Corollary 3. This result is robust across seeds (std < 0 . 5 ). The post-projection LayerNorm case (Conjecture 1) is not experimentally resolved: multi-seed estimation gives ∆ λ = − 0 . 92 ± 0 . 86 , indicating that the SGLD-based Gaussian baseline is poorly calibrated for the non-affine LN loss landscape. W e omit that row from the table and lea ve v alidation to future work. T able 3: LLC under Softmax simplex geometry . d = 5 , m = 4 . ∆ λ measured relativ e to Gaussian-input baseline (5-seed median). The simplex alone causes no drop; degeneracy requires a downstream operation sensiti ve to the affine offset. The Post- LayerNorm case is omitted: SGLD estimation is unreliable for the non-af fine LN loss landscape (see Conjecture 1). Configuration Baseline ( λ ) Simplex ( λ ) ∆ λ Expected Strictly Linear ( b = 0 ) 10.38 10.62 − 0 . 24 0 . 0 Explicit Bias ( + b ) 12.40 10.14 2 . 26 m/ 2 = 2 . 0 6 Conclusion The central finding is a geometric threshold: whether a normalization operation reduces the LLC of the subsequent weight matrix depends entirely on whether the data manifold is affinely flat, not on an y continuous geometric quantity like curvature. LayerNorm confines data to a linear hyperplane ( 1 ⊤ x = 0 , d s = d − 1 ), producing an LLC drop of m/ 2 (prov ed for single linear layers with squared loss); RMSNorm projects onto a sphere, which has full linear span, producing no drop. For the codimension-one manifolds we study , any non-zero curv ature is sufficient to preserve the LLC — the distinction appears binary , not graded. This binary threshold has a smooth finite-sample counterpart. The effecti ve RLCT measured by SGLD depends not just on whether curvature e xists, but on how much of the data distrib ution actually experiences it. Wide, distrib uted curvature restores the LLC at amplitudes an order of magnitude smaller than narro w , concentrated curvature — e ven when both are theoretically non-flat. This is an intrinsic feature of SGLD-based LLC estimation, not a failure of the algebraic theory; the true RLCT remains binary . The wrLLC methodology mak es the geometric cost of normalization precise and measurable in a single-layer experiment. Under the conditions of Theorem 1 (single linear layer , squared loss), LayerNorm reduces ∆ λ = m/ 2 for any non- degenerate input distribution; RMSNorm preserves LLC by projecting onto a full-rank sphere; Softmax induces the same m/ 2 drop when paired with an explicit bias (prov ed, experimentally confirmed); the Post- LayerNorm case is a theoretical open problem. A natural open question is whether the LLC drop in W V under Pre- LayerNorm manifests as stronger attention sinks in practice. Our preliminary experiments on a small attention-only transformer found no significant dif f erence between LayerNorm and RMSNorm conditions, suggesting this connection, if it exists, may require larger models or tasks that more directly e xpose the lo w-rank structure of W V . A further direction concerns gr okking dynamics : by removing degrees of freedom associated with memorization, LayerNorm ’ s LLC reduction may make the lo w-LLC generalizing circuit more accessible during training, potentially accelerating the grokking transition relativ e to RMSNorm or unnormalized baselines. References [1] George W ang, Jesse Hoogland, Stan v an W ingerden, Zach Furman, and Daniel Murfet. Differentiation and specialization of attention heads via the refined local learning coefficient. arXiv preprint , 2024. [2] Sumio W atanabe. Algebr aic Geometry and Statistical Learning Theory . Cambridge Monographs on Applied and Computational Mathematics. Cambridge Univ ersity Press, 2009. [3] Edmund Lau, Zach Furman, George W ang, Daniel Murfet, and Susan W ei. The local learning coefficient: A singularity-aware comple xity measure. arXiv pr eprint arXiv:2308.12108 , 2024. [4] Serge y Iof fe and Christian Szegedy . Batch normalization: Accelerating deep netw ork training by reducing internal cov ariate shift. In Pr oceedings of the 32nd International Conference on Machine Learning (ICML) , pages 448–456, 2015. [5] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffre y E. Hinton. Layer normalization. arXiv pr eprint arXiv:1607.06450 , 2016. 10 The Geometric Cost of Normalization A P R E P R I N T [6] Biao Zhang and Rico Sennrich. Root mean square layer normalization. In Advances in Neur al Information Pr ocessing Systems , volume 32, 2019. [7] Susan W ei, Daniel Murfet, Mingming Gong, Hui Li, Jesse Gell-Redman, and Thomas Quella. Deep learning is singular , and that’ s good. IEEE T ransactions on Neural Networks and Learning Systems , 34(12):10473–10486, 2022. doi:10.1109/TNNLS.2022.3167409. [8] Berfin ¸ Sim ¸ sek, François Ged, Arthur Jacot, Francesco Spadaro, Clément Hongler, W ulfram Gerstner, and Johanni Brea. Geometry of the loss landscape in o verparameterized neural networks: Symmetries and inv ariances. In Pr oceedings of the 38th International Conference on Mac hine Learning (ICML) , pages 9722–9732. PMLR, 2021. [9] Akshat Gupta, Atahan Ozdemir , and Gopala Anumanchipalli. Geometric interpretation of layer normalization and a comparativ e analysis with RMSNorm, 2025. URL . [10] Jesse Hoogland, Geor ge W ang, Matthew Farrugia-Roberts, Liam Carroll, Susan W ei, and Daniel Murfet. Loss landscape degenerac y and stagewise de velopment in transformers. arXiv pr eprint arXiv:2402.02364 , 2024. [11] Guangxuan Xiao, Y uandong Tian, Beidi Chen, Song Han, and Mike Le wis. Efficient streaming language models with attention sinks. In International Conference on Learning Repr esentations (ICLR) , 2024. [12] Y uval Ran-Milo. Attention sinks are prov ably necessary in softmax transformers: Evidence from trigger- conditional tasks. arXiv preprint , 2026. [13] V aleria Ruscio, Umberto Nanni, and Fabrizio Silvestri. What are you sinking? a geometric approach on attention sink. In Advances in Neural Information Pr ocessing Systems (NeurIPS) , 2025. [14] V ictor Guillemin and Alan Pollack. Differ ential T opology . Prentice-Hall, Englew ood Clif fs, NJ, 1974. [15] Edward J. Hu, Y elong Shen, Phillip W allis, Zeyuan Allen-Zhu, Y uanzhi Li, Shean W ang, Lu W ang, and W eizhu Chen. LoRA: Low-rank adaptation of lar ge language models. arXiv preprint , 2021. [16] Stan van Wingerden, Jesse Hoogland, George W ang, and W illiam Zhou. Devinterp. https://github.com/ timaeus- research/devinterp , 2024. [17] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv pr eprint arXiv:1412.6980 , 2014. [18] Ilya Loshchilov and Frank Hutter . Sgdr: Stochastic gradient descent with warm restarts. arXiv pr eprint arXiv:1608.03983 , 2016. [19] Max W elling and Y ee Whye T eh. Bayesian learning via stochastic gradient langevin dynamics. In Proceedings of the 28th International Confer ence on International Confer ence on Machine Learning , ICML ’11, page 681–688, Madison, WI, USA, 2011. Omnipress. ISBN 9781450306195. [20] Allen Hatcher . Algebraic T opology . Cambridge University Press, 2002. ISBN 978-0-521-79540-1. A Homology vs. Curvatur e: Guaranteeing Affine Span In Section 3 we observed empirically that LLC drops for affinely flat manifolds and is preserved for the curved manifolds we tested. Here we give the algebraic-topological explanation for why global topology (non-tri vial homology) provides a particularly r obust guarantee of full linear span, and wh y this robustness is qualitativ ely stronger than the finite-sample guarantee provided by local curv ature alone. RMSNorm projects data onto a hypersphere S d − 1 , which possesses a non-trivial top-homology group ( H d − 1 ( S d − 1 ) = 0 ; see [ 20 ]). The linear span of S d − 1 is full directly: for each standard basis vector e i , both e i and − e i lie on S d − 1 , so span( S d − 1 ) = R d . Consequently d s = d , and by Corollary 1 no LLC is lost. Con versely , the standard simplex generated by Softmax is contractible and strictly flat. Its af fine span is d − 1 because it lies entirely in the h yperplane { P i x i = 1 } ; unlike the sphere, no point and its antipode both belong to it, so there is no topological mechanism forcing full linear span. (The simplex does ha ve full linear span R d through its vertices e 1 , . . . , e d ; the point is that this span is not guaranteed by any robust global property of the manifold, as it is for the sphere.) What the simplex lacks is not full linear span per se, but an affine structure that av oids the origin: its constraint 1 ⊤ x = 1 ( c = 0 ) is what creates the “smuggled bias” phenomenon discussed in Section 2.5. Local Curvatur e vs. Global Homology Section 3 sho ws empirically that local curvature is suf ficient to preserve the LLC: all curved manifolds tested (paraboloid, hyperboloid, saddle) matched the Gaussian baseline, while the flat hyperplane dropped by ∆ λ ≈ m/ 2 = 2 . 0 (T able 1). Among the manifolds tested, curvature sign is irrele vant; only flatness matters. 11 The Geometric Cost of Normalization A P R E P R I N T Howe ver , the Block B experiment (T able 2) shows that local curvature and global homology differ sharply in their r obustness at finite sample sizes . When curv ature is small or concentrated, the SGLD sampler cannot distinguish a weakly curved manifold from a flat one: the effecti ve RLCT collapses to the flat bound even when the manifold is theoretically non-flat. This is a finite-sample phase transition in the estimated RLCT , not a failure of the algebraic theory . Global non-tri vial homology (as in S d − 1 ) is immune to this ef fect. A closed orientable hypersurface with non-tri vial top-homology separates R d into two components and cannot be embedded in any proper hyperplane — unlik e a curved b ut non-closed patch, which could in principle be continuously flattened. Furthermore, because normalization operations fix the macroscopic scale of the data (standardizing to unit RMS), the topological volume is locked well abov e the thermal noise floor of the SGLD sampler . W e conjecture that non-trivial top-homology therefore provides an unconditional, scale-independent guarantee of LLC preservation, while local curv ature provides only a conditional guarantee that breaks down at finite amplitude. W e lea ve a formal proof of this conjecture to future work. 12
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment