Grounding Social Perception in Intuitive Physics
People infer rich social information from others' actions. These inferences are often constrained by the physical world: what agents can do, what obstacles permit, and how the physical actions of agents causally change an environment and other agents…
Authors: Lance Ying, Aydan Y. Huang, Aviv Netanyahu
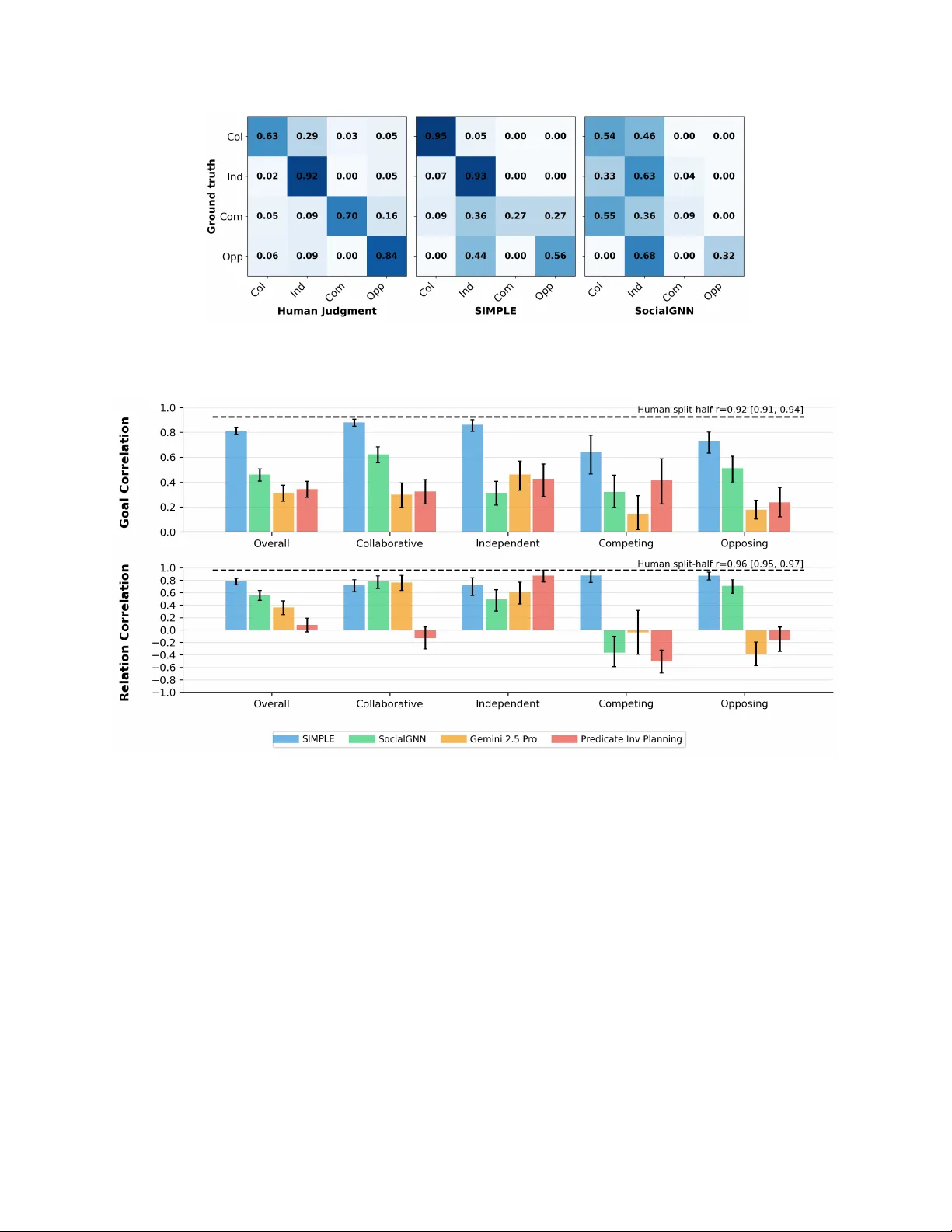
Grounding So cial P erception in In tuitiv e Ph ysics Lance Ying 1,2,* , Aydan Y. Huang 3,* , Aviv Netan yah u 1,* , Andrei Barbu 4 , Boris Katz 1 Josh ua B. T enen baum 1 , Tianmin Sh u 3, † 1 Massachusetts Institute of T e chnolo gy 2 Harvar d University 3 Johns Hopkins University 4 A mazon Abstract P eople infer ric h social information from others’ actions. These inferences are often con- strained b y the ph ysical w orld: what agen ts can do, what obstacles permit, and ho w the ph ysical actions of agen ts causally change an en vironment and other agents’ men tal states and behavior. W e prop ose that suc h ric h so cial p erception is more than visual pattern matching, but rather a reasoning pro cess grounded in an in tegration of intuitiv e psychology with intuitiv e physics. T o test this h yp othesis, w e introduced PHASE (PHysically grounded Abstract So cial Even ts), a large dataset of pro cedurally generated animations, depicting ph ysically sim ulated t wo-agen t in teractions on a 2D surface. Each animation follo ws the style of the Heider and Simmel movie, with systematic v ariation in en vironment geometry , ob ject dynamics, agent capacities, goals, and relationships (friendly/adv ersarial/neutral). W e then present a computational model, SIM- PLE, a ph ysics-grounded Bay esian in verse planning model that integrates planning, probabilis- tic planning, and physics sim ulation to infer agents’ goals and relations from their tra jectories. Our experimental results sho wed that SIMPLE ac hiev ed high accuracy and agreemen t with h u- man judgments across div erse scenarios, while feedforw ard baseline mo dels—including strong vision-language mo dels—and physics-agnostic inv erse planning failed to ac hieve human-lev el p erformance and did not align with h uman judgments. These results suggest that our mo del pro vides a computational accoun t for ho w p eople understand physically grounded so cial scenes b y in verting a generative model of ph ysics and agents. Keyw ords: so cial p erception | in tuitive ph ysics | intuitiv e psychology | in verse planning 1 In tro duction Human so cial p erception is richly grounded in our understanding of physics. As illustrated in Figure 1 A , when w e infer that one agen t is c hasing, blo c king, or helping another, we rely not only on intuitiv e psyc hology (e.g., agen ts act purp osefully) but also on intuitiv e ph ysics (e.g., b odies mo ve con tinuously , forces ha ve effects, and obstacles constrain what is p ossible). Classic demonstrations suc h as the Heider and Simmel movie [Heider and Simmel, 1944] sho w that ev en mov emen ts of simple geometric shap es can elicit ric h so cial narratives (as depicted in Figure 1 B ). Critically , those an throp omorphic narrativ es of so cial behavior rely on viewers’ interpretation of the physical in teractions (e.g., contact, collision, and imp eded motion). This raises a core cognitive science question: ho w do people infer rich so cial information from physically grounded observ ations? ∗ These authors contributed equally to this w ork. † Corresp onding author. E-mail: tianmin.shu@jh u.edu 1 Figure 1: ( A ) Examples of real-life so cial in teractions in physical en vironmen ts: a basketball pla yer trying to blo c k an opp onent from sho oting a ball; t w o p eople carrying a couch together. ( B ) The classic Heider-Simmel animation abstracts such real-life interactions in animated displays of simple geometric shap es. ( C ) PHASE mo dels so cial interactions as physically grounded abstract ev ents, where animated agen ts with limited fields of view mov e in a ph ysics-based environmen t with ob jects, landmarks, and obstacles, enabling behaviors such as helping, hindering, or collab orating to ward goals. There hav e b een many computational accoun ts of so cial p erception that capture asp ects of rational action understanding. One prominen t type of computational approac hes is in verse planning [Bak er et al., 2009, 2017, Jara-Ettinger et al., 2020, Ying et al., 2025], which p osits that p eople assume others are rational planners that select the most optimal action to ac hieve their goal, minimizing costs and maximizing utilities. The observer can then in vert this generative model to compute the most likely men tal states that can b est explain the observed action. How ev er, existing mo dels of inv erse planning [Baker et al., 2009, 2017, Jara-Ettinger et al., 2016, Ullman et al., 2009, Zhi-Xuan et al., 2020] often abstract aw ay physical dynamics, treating actions as symbolic state transitions. Conv ersely , recent end-to-end neural mo dels hav e emerged as p o w erful approaches to mo del so cial p erception by training on large corpora of div erse social scenes [Rabinowitz et al., 2018, Ho v aidi-Ardestani et al., 2018, Malik and Isik, 2023]. Although these mo dels can learn predictive represen tations from large corp ora, they t ypically rely on visual features and also do not explicitly sho w sophisticated ph ysical reasoning pro cesses. In this pap er, we study ho w p eople flexibly interpret so cial scenes in ph ysically grounded en- vironmen ts. W e h yp othesize that p eople can utilize an analysis-by-syn thesis approach [Y uille and Kersten, 2006] on these tasks: w e p ossess a joint ph ysical and so cial generativ e mo del of agents planning in our minds and inv ert this generative process to infer the most likely goal, relations, and ph ysical parameters that b est explain the observ ation. This view builds on prior work on infan ts’ judgmen t of agen ts’ goal-directed actions in ph ysical en vironments [Liu et al., 2017, 2022, Saxe et al., 2005]. As prior work has demonstrated, p eople, starting from as early as 10 months old, can estimate the costs of actions for pursuing goals under v arious ph ysical constrain ts, and reason ab out cost-utilit y trade-offs to in terpret their behavior. Recent studies in neuroscience and computational cognitiv e science hav e also provided evidence that p eople’s in tuitive theory of psychology builds on their intuitiv e theory of physics [Liu et al., 2025]. In this work, w e extend the prior work and op erationalize this view with a dataset and a computational mo del. Our main con tributions are tw ofold. First, w e in troduce PHASE (PHysically grounded Abstract So cial Even ts), a dataset of physically simulated tw o-agen t interactions with controlled v ariation 2 to : move to : go to to to : chase : move : go to : move : move : avoid Agent Goals Representative Frames Collaborative Independent Competing Opposing Scenario T ypes A B C D Figure 2: Example PHASE animations for differen t scenario types. A). In this collab orative sce- nario, agen ts collab orate to mo ve the pink circle to the y ellow landmark. The green agent is to o large to mov e past the barrier. Therefore, the red agent first mo ves the circle to the left of the barrier and then carries it together with the green agent to the yello w landmark. B). Two agents mo ve tow ards differen t landmarks with no interaction. C). In this comp eting scenario, the agents w ant to mo v e the blue circle to different landmarks, but there is only one blue circle. They therefore pull the circle in differen t directions. D). In this opp osing scenario, the red agent tries to chase the green agen t, while the green agent tries to get aw a y from the red agent. The videos for these examples can b e found at https://osf.io/fkp5m/. in scene geometry , physical dynamics, agen t capacities, and so cial structure (goals and relation- ships), as illustrated Figure 1 C . Second, we prop ose SIMPLE (SIMulation, Planning, and Lo cal Estimation), a ph ysics-grounded Ba yesian inv erse planning model that combines a forw ard ph ysics engine with probabilistic planning and inference o ver goals and relations. W e sho w that incorp orat- ing ph ysical dynamics improv es goal and relationship inference relative to ph ysics-agnostic inv erse planning and end-to-end video baselines, and that the resulting inferences b etter align with human judgmen ts. 2 A P aradigm for Ph ysically Grounded So cial P erception Inspired by the seminal work by Heider and Simmel [Heider and Simmel, 1944], w e curated the PHASE dataset to study human so cial p erception in abstract physically grounded scenes. The videos of the PHASE dataset feature tw o agents in the shap e of trap ezoids. The agents can v ary in their sizes and strengths. They ha ve limited fields of view. There are four landmarks in the scene, eac h of which is a square at one of the four corners. There are ob jects in the scene, represen ted as circles, which agents ma y or may not b e able to mov e dep ending on their strengths. The agen t’s ob jectiv e is to mo ve to a landmark, mov e an ob ject to a landmark, mo ve close to 3 Scenario Type Description Relation Collab orativ e Tw o agen ts collab orate on a shared goal. F riendly Indep enden t The tw o agents ha ve differen t, non-conflicting goals. Neutral Comp eting The tw o agents ha ve conflicting goals ab out the same ob ject. Adv ersarial Opp osing The agents ha ve opposite goals, where one agen t’s goal is to inten tionally prev ent the other agent from reaching its goal. Adv ersarial T able 1: T yp es of agent goal scenarios, their descriptions, and the corresp onding relations. Figure 3: Consistent human resp onses showing how many videos (p ercen tages) w ere assigned with an interaction category b y at least 50% of the participants who ha ve w atc hed the videos. the other agent, or hinder a particular goal (e.g., keep an agen t or an ob ject a w ay from a landmark). By p erm uting the ob jects and landmarks, we generate 36 p ossible goals in total for the goal space. As each video con tains t wo agen ts who ma y hav e the same or different goals, we classify the pair of agen t goals in each video in to 4 scenario goal types : collab orativ e, indep endent, comp eting, and opp osing as defined in T able 1. Figure 2 shows an example for each type. These scenario goal t yp es map onto three relation lab els: friendly , neutral, and adv ersarial. PHASE contains 500 videos of abstract social ev ents. Eac h goal category has 47–129 examples. Relationship lab els are distributed as 200 friendly , 192 adv ersarial, and 108 neutral videos. W e split the dataset into 320 training, 80 v alidation, and 100 test videos. Our h uman exp erimen t v alidated that p eople would consisten tly lab el the 100 test videos with 23 differen t types of so cial in teractions, as sho wn in Figure 3. The PHASE dataset co v ers div erse so cial interaction scenarios. W e compiled a list of 23 in terac- tion labels from prior w ork [Gao and Sc holl, 2011, Gordon and Roemmele, 2014] and from free-form descriptions collected in a pilot study (see App endix 1A). W e then recruited 130 participants to annotate 100 PHASE videos. Our analysis shows that the 23 lab els w ere used to describ e at least one video; moreov er, under a ma jority-v ote criterion, PHASE videos co vered 18 distinct interaction categories (Figure 3). In another human exp erimen t, we found that the test videos in PHASE were indistinguishable from human-generated animations in the same en vironment through a con troller 4 A C B Initial State Proposed Hypotheses Simulated T rajectories Hypothesis h1 go to move to Hypothesis h2 move to move to Observed T rajectories How much does the simulation deviate from the observation? strength: 60 strength: 60 strength: 60 strength: 120 relation: neutral relation: friendly Joint Physical-Social Simulation Update hypotheses Location Estimation … … Figure 4: ( A ) Pseudo co de for the SIMPLE mo del. ( B ) Illustration of the key mo del comp onents of SIMPLE. ( C ) Illustration of the joint physical and so cial sim ulator in SIMPLE. (see App endix 1B). 3 The SIMPLE Mo del W e prop ose that h uman so cial understanding relies on the flexible integration of intuitiv e physics and in tuitive psychology . W e h yp othesize that observ ers form ulate a generativ e mo del of agent in- teraction and in vert this model to infer ric h social information from ph ysically grounded scenes. W e instan tiate this approach with a computational mo del named SIMPLE (SIMulation, Planning, and Lo cal Estimation). While standard in v erse planning assumes agen ts are rational planners and infers men tal states b y inv erting a planning mo del, it often abstracts a wa y the physical environmen t. W e h yp othesize that p eople inv ert a joint ph ysical and so cial generativ e mo del. This allows for the sim ultaneous inference of latent v ariables, including agen t goals, social relationships, and physical capacities (e.g., strengths). Therefore, SIMPLE extends the framework of Bay esian inv erse plan- ning b y coupling computational theory of mind [Baker et al., 2017] with simulation-based physical reasoning [Battaglia et al., 2013]. W e formalize the observer’s reasoning as inference ov er a set of h yp otheses ab out laten t v ariables. Let h = ⟨ g i , g j , α ij , α j i , f i , f j ⟩ denote a sp ecific hypothesis, where g represen ts agen t goals, α denotes so cial relationship parameters, and f indicates ph ysical strengths (i.e., the maximum amoun t of force an agent can exert). Let s 1: T b e the observ ed state sequence (specifically , the tra jectories of all entities) and ˆ s 1: T = G ( h ) b e the sim ulated tra jectory given the hypothesis. The generative function G ( · ) is a closed-lo op pro cess that couples a hierarchical planner—representing intuitiv e psyc hology—with a forward physics engine—represen ting intuitiv e physics—that resolv es con tact dynamics and ob ject motion. T o infer the goals and relations, w e p erform Bay esian inv erse planning. W e define the posterior 5 probabilit y distribution as: P ( h = ⟨ g i , g j , α ij , α j i , f i , f j ⟩| s 1: T ) ∝ P ( s 1: T | h ) P ( g i ) P ( g j ) P ( α ij , α j i ) P ( f i ) P ( f j ) , (1) where P ( s 1: T | Y ) = e − β P T t =1 || s t − ˆ s t || 2 is the lik eliho o d of the observed tra jectory conditioned on the h yp othesis, and β > 0 is a constan t co efficien t. Because this inference m ust accoun t for complex en vironment geometry , unobserv able agent capacities, and diverse so cial interactions (e.g., helping, hindering, or neutral co-presence), the h yp othesis space is high-dimensional and contin uous. W e therefore approximate the posterior using sampling-based probabilistic inference, outlined b elo w. 3.0.1 Join t Ph ysical and So cial Sim ulation W e employ a joint physical and so cial sim ulator as our generativ e mo del. Unlik e approac hes that rely solely on symbolic planners, SIMPLE in tegrates a ph ysical simulation engine with a hierarc hical planner (details are provided in App endix 3). Giv en a scene configuration (the initial state) and a hypothesis h , the simulation pro ceeds in steps: (1) the hierarchical planner samples actions for all agents based on their goals and b eliefs; (2) these actions are fed into the ph ysics engine to resolve dynamics; and (3) the engine renders the next frame of the tra jectory . This generates a fully physically grounded prediction ˆ s 1: T that accoun ts for interactions such as collisions or join t ob ject manipulation. Additional information and implementation details can b e found in the App endix 4. 3.0.2 Inference via Metrop olis-Hastings with Lo cal Estimation Due to the combinatorially large space of h yp otheses that makes exact inference intractable, we use an efficient algorithm to appro ximate the p osterior distribution. W e first use a b ottom-up approac h to propose lik ely hypotheses (See Appendix 4B). T o explore the hypothesis space and infer the p osterior distribution, we utilize Marko v Chain Monte Carlo (MCMC). Sp ecifically , we emplo y the Metropolis-Hastings algorithm. W e run multiple iterations to up date the prop osals. Giv en the M proposals at iteration l , we simulate the tra jectories, i.e., ˆ s 1: T l,m , ∀ m = 1 , · · · , M , and compare them with the observed tra jectories, s 1: T . F or eac h prop osal, we sample a time interv al with a fixed length, ∆ T , based on the errors betw een the sim ulation and the observ ations, i.e., t l,m ∝ e η P t l,m +∆ T τ = t l,m || ˆ s τ l,m − s τ || 2 , where η is the scaling factor. The intuition b ehind this is that lo cal deviation is often more informativ e in terms of how the prop osal should b e updated compared to the o verall deviation. After selecting a lo cal time interv al, w e use the same b ottom-up mec hanism to again prop ose a new hypothesis for each particle, h ′ m , based only on S ′ = s t l,m : t l,m +∆ T . W e then use the Metrop olis–Hastings algorithm to decide whether to accept this new prop osal for the particle, where the acceptance rate is α = min { 1 , Q ( h ′ | S ′ ) P ( s 1: T | h ′ ) Q ( h l,m | S ′ ) P ( s 1: T | h l,m ) } , where Q ( · ) is the prop osal distribution. This pro cess allows the c hain to con verge to the stationary distribution corresponding to the true p osterior P ( h | s 1: T ). 3.0.3 Marginalization Finally , given the appro ximated join t p osterior distribution, w e marginalize ov er the h yp otheses to extract the probability distributions for individual latent v ariables of interest, suc h as the probabil- it y of a specific social relation α ij or goal g i . F or instance, w e can compute the p osterior distribution of g i as 6 P ( g i | s 1: T ) = X g j ,α ij ,α j i ,f i ,f j P ( g i , g j , α ij , α j i , f i , f j | s 1: T ) . (2) 3.1 Alternativ e Mo dels W e compared SIMPLE against a range of alternative mo dels. First, we ev aluated end-to-end neural baselines, which ha ve been p opular in mo deling and understanding visual scenes, including so cial p erception. W e included So cialGNN [Malik and Isik, 2023] and Gemini 2.5 Pro [Comanici et al., 2025] as our neural baselines. So cialGNN is a graph neural net work (GNN) that learns to predict so cial lab els from visual scenes. Because the original So cialGNN only predicts relations, we extended the mo del by training it on the 500 training videos in PHASE to join tly predict the goal and relation lab els. G emini 2.5 Pro is a state-of-the-art VLM trained on large corp ora of visual and language datasets. Second, we included a predicate in verse planning mo del, a ph ysics-agnostic v ariant of SIMPLE. This model extracts high-level predicates from states and p erforms in verse planning to infer goals and relations. Compared to SIMPLE, this ablated mo del does not enco de the ph ysical dynamics necessary to reason ab out the fine-grained motions of agen ts and ob jects in the scenes. See App endix 4 for implementation details. Figure 5: Accuracy results for goal classification task across all 100 scenarios and group ed by 4 distinct scenario goal types. The num b er of goal judgmen ts is sho wn in the brac ket. Humans and mo dels are ev aluated on 100 test videos, each with tw o goal classification tasks and one relation classification task. Error bars show 95% confidence interv al from 1000 b o otstrapp ed samples. 7 Figure 6: Confusion matrix of SIMPLE and So cialGNN on goal classification tasks. (Col = Col- lab orativ e, Ind = Indep endent, Com = Comp eting, Opp = Opp osite) Figure 7: Correlation b et ween model and h uman judgments tasks. 4 Results W e compared human participants, SIMPLE, and alternativ e computational mo dels on the same 100 test videos and compared their judgments with h uman judgmen ts. Among all mo dels, SIMPLE not only achiev ed the highest accuracy in goal and relation accuracy , but also b est captures human judgmen ts. W e summarize the k ey results b elow. 4.1 Human results W e recruited 200 participants (Mean age = 39.95, 89 F emale, Male 105, 6 Non-binary) to judge the agents’ goals and relations for the 100 test videos (eac h video is rated b y 20 people). W e found that participants were highly consistent in their judgments. T o quantify this consistency , w e computed the split-half correlation among the human participan ts (the av erage correlation b et w een the a verage resp onses of 1000 random splits). The agreemen t was high for both tasks 8 Figure 8: Scatterplots comparing h uman judgmen t against SIMPLE model judgmen t on goals (left) and relations (right). The colors indicate the scenario types. ( r = 0 . 92 , CI = [0 . 91 , 0 . 94] for goals; r = 0 . 96 , CI = [0 . 95 , 0 . 97] for relations), indicating that participan ts largely shared the same interpretations of the PHASE animations. W e then computed classification accuracy against ground truth. As shown in Figure 5, participan ts achiev ed high classification accuracy on a verage, with an accuracy of 0.89 on relation classification and 0.78 on goal classification. W e provide more details of correlation analysis in Appendix 5C. 4.2 Comparing mo del and human accuracy on classification tasks The mo del classification accuracy is illustrated in Figure 5. Among all mo dels, SIMPLE achiev es the highest ov erall accuracy in b oth goal and relation classification tasks. W e then break do wn the classification accuracy b y scenario types. Ov erall, the SIMPLE model ac hieved high classification accuracy in goals and relations across scenario types. Notably , there w as no statistical significance b et w een human accuracy and SIMPLE accuracy in three of the four scenario types for goal classification and all scenario t yp es for relation classification. On the other hand, alternative mo dels scored muc h low er on goal classification tasks compared to relation classification. Among the goal classification tasks, comp eting scenarios app ear to b e the most difficult for SIMPLE (mean accuracy = 0.59, 95% CI = [0.41, 0.77]), whereas the human a verage is 0.76, 95% CI = [0.74,0.78]. W e show the confusion matrix for humans, SIMPLE, and So cialGNN in Figure 6, whic h indicates that while humans accurately recognized goals in comp eting scenarios most of the time, SIMPLE often classified goals in comp eting scenarios as opp osing or indep endent. On the other hand, SocialGNN frequently confused competing goals as collaborative instead. This explains wh y SIMPLE still achiev ed relativ ely high relation classification accuracy (mean = 0.91, 95% CI = [0.72, 1.0]) while So cialGNN had a relation classification accuracy of 0. Qualitativ e analysis indicates that comp etitiv e scenarios often exhibit a “tug-of-w ar” dynamic, in whic h t wo agents remain attac hed to the same ob ject while exerting opp osing forces. This pattern is illustrated in the diagnostic example shown in Figure 9 A . F or mo dels that primarily rely on motion cues, suc h as So cialGNN, the correlated mov emen t of tw o agents alongside a shared ob ject can resemble co operative b eha vior—e.g., agents join tly pushing an ob ject tow ard a common 9 Representative Stimuli Human and Model Judgment A B C Figure 9: Qualitativ e examples showing human and mo del judgments on PHASE animations. Ex- amples A and B sho w a comp eting and collab orativ e scenario, resp ectiv ely . Across both scenarios, SIMPLE aligns with h uman distribution on goal and relation classifications, whereas So cialGNN fits less well. Example C sho ws a comp etitiv e scenario where SIMPLE misaligns with humans. In this example, the tw o agents wan t to push the blue circle to different landmarks. The green agen t ev entually steals the blue circle from the red agent. SIMPLE was able to correctly recognize the goal of the red agent, but misclassified the green agent’s goal as hindering the red agent (mov e the blue circle a wa y from the yello w landmark) and other indep endent goals (e.g., mo ving to the red landmark). landmark. As a result, the in teraction ma y be misclassified as friendly . In contrast, SIMPLE emplo ys an analysis-by-syn thesis approach, enabling it to detect that the irregular and conflicting motion patterns are inconsistent with a shared goal of transp orting the ob ject to ward the same destination. Although SIMPLE may still struggle to fully in terpret the scene or assign the correct in teraction lab el, it more effectively captures the underlying comp etitiv e dynamics. This limitation is further illustrated in Figure 9 C , where the mo del incorrectly attributed opp osing goals within a comp eting scenario. The Predicate In verse Planning mo del p erformed w ell at classifying neutral relations in Inde- p enden t scenarios. This suggests that observ ers ma y not alw ays require detailed ph ysical sim ulation to in terpret social relations in relatively simple contexts. F or example, if Agen t A mo ves tow ard a red circle while Agent B mov es tow ard a blue one, symbolic predicates alone may be sufficien t to infer that their relationship is neutral. Ho wev er, the same mo del struggled with goal classification in these scenarios, achieving a mean accuracy of 0.35 (95% CI = [0.22, 0.48]). This disso ciation indicates that while broad relational categories can sometimes b e deriv ed from sym b olic cues, in- ferring sp ecific ph ysical goals—suc h as whether Agent A is capable of pushing the circle to ward a landmark given its strength—demands a more fine-grained understanding of the underlying ph ys- ical constrain ts. Such inferences are better captured b y a physically grounded in verse planning 10 framew ork like SIMPLE. 4.3 Explaining h uman graded judgmen ts Human so cial p erception and judgment are rarely unanimous, and it in volv es graded degrees of b elief and uncertain ty within and across p eople. T o ev aluate whether mo dels capture this nuance, w e compared the mo dels’ posterior probability distributions against the empirical distribution of h uman resp onses on b oth goal and relation classification tasks. Figure 7 shows the Pearson correlation b et w een mo del predictions and human judgments on b oth goal and relation classification tasks. SIMPLE ac hieves a strong correlation against h uman distribution ( r = 0 . 82, 95% CI = [0.78, 0.85] for goals; r = 0 . 78, 95% CI = [0.71, 0.82] for relations). In contrast, baseline correlations are significantly low er ( r < 0 . 6). Figure 8 presents scatterplots of mo del judgments against h uman judgmen ts, revealing shared patterns of uncertaint y across the t wo. A comparison of the plots shows that b oth human partic- ipan ts and SIMPLE exhibited greater uncertaint y in goal judgments than in relation judgments, as reflected b y the concentration of data p oin ts in the 0.6–0.8 range. This is b ecause the goal space is substan tially larger and more complex than the relation space. As a result, iden tifying an agen t’s sp ecific goal from limited observ ational data is inherently more challenging than assigning a broader relational lab el. 5 Discussion W e presented the PHASE dataset, consisting of syn thetic animations in the style of Heider and Simmel movie, to study ho w p eople p erceive so cial scenes in physically grounded scenarios. W e also prop osed a computational mo del, SIMPLE, which in tegrates a forward physics engine into a Ba yesian inv erse planning framew ork. By doing so, it ac hieved high accuracy and correlation with h uman judgmen ts across div erse social in teraction scenarios and explained h uman judgmen ts better than baselines, including mo del-free, feedforward models—such as graph neural netw orks and large vision-language mo dels—and a purely symbolic-predicate based in verse planning model. The comparison b et w een feedforw ard baselines and our SIMPLE mo del highlights the need for an analysis-by-syn thesis type of so cial inference for reverse engineering h uman-like, ph ysically grounded so cial p erception. F eedforward recognition mo dels either learn predictive visual repre- sen tations from provided training videos of agen t social in teractions in PHASE environmen ts (e.g., So cialGNN) or visual reasoning capacities emerged from internet-scale pretraining (e.g., Gemini 2.5 Pro). These mo dels treat so cial p erception as a strictly feedforward pro cess, mapping visual patterns to social judgmen ts. Prior work has demonstrated that discriminativ e visual patterns can b e predictiv e of basic asp ects of agent b ehavior, suc h as animacy [Ho v aidi-Ardestani et al., 2018, Sh u et al., 2021a], inten tionalit y [Epstein et al., 2020], interactivit y [Sh u et al., 2018], shared at- ten tion [F an et al., 2018], and relationships [Hov aidi-Ardestani et al., 2018, Malik and Isik, 2023]. Ho wev er, unlike p eople or SIMPLE, these feedforw ard mo dels require a large amoun t of training data; struggle with generalization to unseen so cial interactions or trivial alterations (such as dif- feren t physical en vironments); and cannot robustly make inferences of agen ts’ mental states, suc h as goals as demonstrated in our exp erimen t, b eliefs [Ullman, 2023, Shapira et al., 2023, Jin et al., 2024], and desires [Shu et al., 2021b]. They also do not p ossess the sophisticated physical reasoning abilities required to understand the so cial b eha vior grounded in complex physical environmen ts. This is particularly evident in the low recognition accuracy of So cialGNN and Gemini 2.5 Pro in comp eting scenarios where agen ts engage in muc h more complex and diverse physical in teractions 11 with one another and the ob jects compared to other scenarios. In particular, similar to our exp er- imen t, prior work has also observed a similar lack of ph ysical common sense in VLMs [Gao et al., 2025], which could partially explain Gemini 2.5 Pro’s p oor understanding of PHASE videos. By in verting the generativ e pro cess of ho w agen ts plan to act under the physical dynamics of a giv en en vironment, SIMPLE pro duced muc h more human-aligned so cial judgment without the need for mo del training. SIMPLE’s core ability to simulate physically grounded so cial b eha vior matched with prior findings on how p eople rely on ph ysical concepts—such as efficient actions [Liu et al., 2017, Jara-Ettinger et al., 2020, Sh u et al., 2021b] and danger [Liu et al., 2022]—and extended the prior work from single-agen t b eha vior to m ulti-agent interactions. SIMPLE also differs from prior w ork on inv erse planning, whic h largely relies on sym b olic represen tations of agent b eha vior and environmen ts and fo cuses on in verting only the action plan- ning pro cess. In particular, SIMPLE pro vides a computational account of the in tegration of in tu- itiv e physics and intuitiv e psychology . First, as agents’ actions are constrained by ph ysics. Their planning pro cesses naturally consider their own physical capacities and constrain ts (such as their strengths and sizes). They also plan their actions to actively alter the dynamics of the physical in teractions, including agent-en vironmen t, agent-ob ject, and agent-agen t in teractions. Second, the sim ulation of the physical consequences of the agen ts’ actions giv es rise to a more fine-grained estimation of behavior likelihoo d given h yp otheses of the so cial in terpretations of the observed motion tra jectories. While feedforward mo dels may learn predictive visual cues from large-scale training, analysis-b y-synthesis style inference instantiated in SIMPLE provides a more principled and generalizable w a y to in terpret the social meanings b ehind complex motion tra jectories. Indeed, p eople can flexibly understand agent b eha vior in different kinds of visual stimuli, even abstract an- imations such as the Heider and Simmel movie or the PHASE videos, without the need for any training data. SIMPLE, by in verting a joint physical and so cial generative model as an approx- imated human mental sim ulation, can capture the strong generalizability of ph ysically grounded h uman so cial p erception. The join t ph ysical and social sim ulation in the SIMPLE model ec hoes the core kno wledge system in human cognition [Sp elke and Kinzler, 2007]. The physical simulation, b y enco ding ph ysical dynamics (such as how en tities mo ve and resp ond to forces) and constrain ts (such as the sizes of the en tities and the gaps b etw een walls), represents concepts of ob jects and geometry . Coupled with concepts of agen ts’ rational b ehavior, the join t physical and so cial sim ulation endows our SIMPLE mo del with crucial foundations for commonsense physical and social scene understanding. 5.1 Limitations Our approac h has several limitations. First, as noted in qualitative analyses, physical ambiguit y can arise during sustained con tact. In hindering in teractions, once agen ts mak e con tact, the specific target goal often b ecomes am biguous in the lik eliho od function (e.g., when being block ed b y another agen t, it is often unclear whic h landmark the agent is trying to reac h). While the tra jectory segmen t prior to contact often re v eals the inten tion, a purely instantaneous frame-b y-frame likelihoo d can struggle without longer temp oral integration. Second, the computational cost of SIMPLE is high. Bay esian inv erse planning requires many sim ulations p er inference iteration for m ultiple iterations. While this captures human so cial rea- soning, it lik ely do es not reflect the mechanisms of rapid, real-time so cial p erception that p eople often p erform effortlessly . F uture w ork can improv e the efficiency of the SIMPLE mo del through p erformance engineering, like recent approaches in Sequen tial Mon te Carlo metho ds for rapid online so cial inference [Zhi-Xuan et al., 2020]. Third, human so cial p erception can b e resource rational. The brain likely employs a noisy 12 ph ysics engine to p erform coarse ph ysical sim ulation [Battaglia et al., 2013, Ullman et al., 2017, Sc hw ettmann et al., 2018, Pramo d et al., 2020]. In man y cases, p eople may resort to simple heuristics that do not w arrant physical simulations at all. Such fast recognition mechanisms could b e accounted for b y amortized inference [Gershman and Go odman, 2014, Jha et al., 2024, 2025], in whic h a feedforw ard mo del can b e trained to matc h its predictions with p osterior distributions pro duced from explicit probabilistic inference. W e intend to in vestigate ho w to amortize the join t ph ysical and so cial inference in SIMPLE via neural mo del training in future work. W e also plan to prob e when and what kind of ph ysical simulation is needed. Lastly , our domain is limited to 2D geometric shap es. While this follows the ric h tradition of the Heider and Simmel mo vie, real-w orld so cial p erception inv olv es articulated 3D b o dies, gaze, and fine-grained motor control. The physics of 2D discs is a simplified pro xy for the complex biomec hanics of h uman mov emen t. There hav e b een recent works that lev erage pretrained LLMs and VLMs to achiev e op en-ended inv erse planning [Ying et al., 2023, Zhi-Xuan et al., 2024, Shi et al., 2025, Kim et al., 2025, Zhang et al., 2025, Ying et al., 2024, Jha et al., 2025]. While these mo dels can conduct b oth efficient and robust men tal state inferences giv en complex, real-world stim uli, they rely on symbolic representations of states and actions. It remains unclear whether and how these t yp es of h ybrid mo dels can generalize to understanding the so cial and ph ysical dynamics of contin uous motions. 6 Materials and Metho ds The PHASE dataset, all the qualitative examples featured in this pap er, as well as the code for the SIMPLE mo del, can b e accessed via https://osf.io/fkp5m/. All human exp erimen ts are conducted through a customized online interface (h ttps://phase- in terface.web.app/). All participants provided informed consen t, and the study was appro ved by the MIT Institutional Review Board. References F ritz Heider and Marianne Simmel. An exp erimen tal study of apparen t behavior. The A meric an journal of psycholo gy , 57(2):243–259, 1944. Chris L Bak er, Reb ecca Saxe, and Josh ua B T enen baum. Action understanding as in v erse planning. Co gnition , 113(3):329–349, 2009. Chris L Bak er, Julian Jara-Ettinger, Reb ecca Saxe, and Joshua B T enenbaum. Rational quan tita- tiv e attribution of b eliefs, desires and p ercepts in human men talizing. Natur e Human Behaviour , 1(4):0064, 2017. Julian Jara-Ettinger, Laura E Sch ulz, and Joshua B T enenbaum. The naive utility calculus as a unified, quantitativ e framew ork for action understanding. Co gnitive Psycholo gy , 123:101334, 2020. Lance Ying, Ry an T ruong, Katherine M Collins, Cedegao E Zhang, Megan W ei, T yler Bro ok e- Wilson, T an Zhi-Xuan, Lionel W ong, and Joshua B T enen baum. Language-informed syn the- sis of rational agen t models for grounded theory-of-mind reasoning on-the-fly . arXiv pr eprint arXiv:2506.16755 , 2025. 13 Julian Jara-Ettinger, Hyo w on Gweon, Laura E Sc hulz, and Josh ua B T enen baum. The na ¨ ıv e utility calculus: Computational principles underlying commonsense psyc hology . T r ends in c o gnitive scienc es , 20(8):589–604, 2016. T omer Ullman, Chris Baker, Owen Macindoe, Ow ain Ev ans, Noah Go o dman, and Josh ua T enen- baum. Help or hinder: Bay esian mo dels of so cial goal inference. A dvanc es in neur al information pr o c essing systems , 22, 2009. T an Zhi-Xuan, Jordyn Mann, T om Silver, Josh T enenbaum, and Vik ash Mansinghk a. Online Ba yesian goal inference for b oundedly rational planning agen ts. A dvanc es in neur al information pr o c essing systems , 33:19238–19250, 2020. Neil Rabinowitz, F rank Perbet, F rancis Song, Chiyuan Zhang, SM Ali Eslami, and Matthew Botvinic k. Mac hine theory of mind. In International c onfer enc e on machine le arning , pages 4218–4227. PMLR, 2018. Mohammad Hov aidi-Ardestani, Nitin Saini, Aleix M Martinez, and Martin A Giese. Neural mo del for the visual recognition of animacy and so cial in teraction. In International c onfer enc e on artificial neur al networks , pages 168–177. Springer, 2018. Manasi Malik and Leyla Isik. Relational visual representations underlie h uman so cial in teraction recognition. Natur e Communic ations , 14(1):7317, 2023. Alan Y uille and Daniel Kersten. Vision as bay esian inference: analysis b y syn thesis? T r ends in c o gnitive scienc es , 10(7):301–308, 2006. Shari Liu, T omer D Ullman, Josh ua B T enenbaum, and Elizab eth S Sp elke. T en-mon th-old infan ts infer the v alue of goals from the costs of actions. Scienc e , 358(6366):1038–1041, 2017. Shari Liu, Bill P ep e, Manasa Ganesh Kumar, T omer D Ullman, Joshua B T enenbaum, and Eliz- ab eth S Sp elk e. Dangerous ground: One-y ear-old infants are sensitive to p eril in other agents’ action plans. Op en Mind , 6:211–231, 2022. Reb ecca Saxe, Josh ua Brett T enenbaum, and Susan Carey . Secret agents: Inferences about hidden causes by 10-and 12-mon th-old infants. Psycholo gic al scienc e , 16(12):995–1001, 2005. Shari Liu, Seda Karak ose-Akbiyik, Joseph Outa, and Minjae J Kim. How physical information is used to make sense of the psychological world. Natur e R eviews Psycholo gy , pages 1–15, 2025. T ao G ao and Brian J Sc holl. Chasing vs. stalking: interrupting the p erception of animacy . Journal of exp erimental psycholo gy: Human p er c eption and p erformanc e , 37(3):669, 2011. Andrew S Gordon and Melissa Roemmele. An authoring to ol for movies in the style of heider and simmel. In International Confer enc e on Inter active Digital Storytel ling , pages 49–60. Springer, 2014. P eter W Battaglia, Jessica B Hamrick, and Joshua B T enenbaum. Sim ulation as an engine of ph ysical scene understanding. Pr o c e e dings of the National A c ademy of Scienc es , 110(45):18327– 18332, 2013. Gheorghe Comanici, Eric Bieb er, Mik e Sc haekermann, Ice P asupat, Nov een Sac hdev a, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Ev an Rosen, et al. Gemini 2.5: Pushing the fron tier with adv anced reasoning, m ultimo dalit y , long context, and next generation agentic ca- pabilities. arXiv pr eprint arXiv:2507.06261 , 2025. 14 Tianmin Shu, Y ujia Peng, Song-Ch un Zh u, and Hong jing Lu. A unified psychological space for h uman p erception of physical and so cial ev ents. Co gnitive Psycholo gy , 128:101398, 2021a. Da ve Epstein, Boyuan Chen, and Carl V ondrick. Oops! predicting unin tentional action in video. In Pr o c e e dings of the IEEE/CVF c onfer enc e on c omputer vision and p attern r e c o gnition , pages 919–929, 2020. Tianmin Shu, Y ujia Peng, Lifeng F an, Hong jing Lu, and Song-Chun Zhu. Perception of h uman in teraction based on motion tra jectories: F rom aerial videos to decon textualized animations. T opics in c o gnitive scienc e , 10(1):225–241, 2018. Lifeng F an, Yixin Chen, Ping W ei, W enguan W ang, and Song-Ch un Zh u. Inferring shared atten tion in so cial scene videos. In Pr o c e e dings of the IEEE c onfer enc e on c omputer vision and p attern r e c o gnition , pages 6460–6468, 2018. T omer Ullman. Large language mo dels fail on trivial alterations to theory-of-mind tasks. arXiv pr eprint arXiv:2302.08399 , 2023. Natalie Shapira, Mosh Levy , Sey ed Hossein Ala vi, Xuh ui Zhou, Y ejin Choi, Y oav Goldb erg, Maarten Sap, and V ered Sh wartz. Clever hans or neural theory of mind? stress testing so cial reasoning in large language mo dels. arXiv pr eprint arXiv:2305.14763 , 2023. Ch uany ang Jin, Y utong W u, Jing Cao, Jiannan Xiang, Y en-Ling Kuo, Zhiting Hu, T omer Ullman, An tonio T orralba, Joshua T enenbaum, and Tianmin Sh u. Mm tom-qa: Multimo dal theory of mind question answering. pages 16077–16102, 2024. Tianmin Shu, Abhishek Bhandw aldar, Ch uang Gan, Kevin Smith, Shari Liu, Dan Gutfreund, Eliza- b eth Spelke, Josh ua T enenbaum, and T omer Ullman. Agen t: A b enc hmark for core psyc hological reasoning. In International Confer enc e on Machine L e arning , pages 9614–9625. PMLR, 2021b. Qiyue Gao, Xin yu Pi, Kevin Liu, Junrong Chen, Ruolan Y ang, Xinqi Huang, Xin yu F ang, Lu Sun, Gautham Kishore, Bo Ai, et al. Do vision-language mo dels hav e internal world mo dels? tow ards an atomic ev aluation. In Findings of the Asso ciation for Computational Linguistics: ACL 2025 , pages 26170–26195, 2025. Elizab eth S Sp elk e and Katherine D Kinzler. Core kno wledge. Developmental scienc e , 10(1):89–96, 2007. T omer D Ullman, Elizabeth Spelke, Peter Battaglia, and Josh ua B T enenbaum. Mind games: Game engines as an arc hitecture for in tuitive ph ysics. T r ends in c o gnitive scienc es , 21(9):649–665, 2017. Sarah Sc hw ettmann, Jason Fischer, Josh T enen baum, and Nancy Kanwisher. Evidence for an in tuitive ph ysics engine in the h uman brain. In Co gSci , 2018. R T Pramod, Mic hael Cohen, Kirsten Lydic, Josh T enenbaum, and Nancy Kan wisher. Evidence that the brain’s physics engine runs forward simulations of what will happ en next. Journal of Vision , 20(11):1521–1521, 2020. Sam uel Gershman and Noah Go odman. Amortized inference in probabilistic reasoning. In Pr o- c e e dings of the annual me eting of the c o gnitive scienc e so ciety , v olume 36, 2014. Kunal Jha, T uan Anh Le, Chuan y ang Jin, Y en-Ling Kuo, Joshua B T enenbaum, and Tianmin Sh u. Neural amortized inference for nested m ulti-agent reasoning. In Pr o c e e dings of the AAAI Confer enc e on Artificial Intel ligenc e , v olume 38, pages 530–537, 2024. 15 Kunal Jha, Aydan Y uenan Huang, Eric Y e, Natasha Jaques, and Max Kleiman-W einer. Mo deling others’ minds as co de. arXiv pr eprint arXiv:2510.01272 , 2025. Lance Ying, Katherine M Collins, Megan W ei, Cedegao E Zhang, and T an et al Zhi-Xuan. The neuro-sym b olic inv erse planning engine (nip e): Mo deling probabilistic so cial inferences from linguistic inputs. arXiv pr eprint arXiv:2306.14325 , 2023. T an Zhi-Xuan, Lance Ying, Vik ash Mansinghk a, and Joshua B T enenbaum. Pragmatic instruction follo wing and goal assistance via co op erativ e language-guided inv erse planning. In Pr o c e e dings of the 23r d International Confer enc e on Autonomous A gents and Multiagent Systems , pages 2094– 2103, 2024. Hao jun Shi, Suyu Y e, Xinyu F ang, Ch uany ang Jin, Leyla Isik, Y en-Ling Kuo, and Tianmin Shu. Muma-tom: Multi-mo dal m ulti-agent theory of mind. v olume 39, pages 1510–1519, 2025. Hyun woo Kim, Melanie Sclar, T an Zhi-Xuan, Lance Ying, Sydney Levine, Y ang Liu, Josh ua B. T enenbaum, and Y ejin Choi. Hyp othesis-driv en theory-of-mind reasoning for large language mo dels. 2025. Zhining Zhang, Ch uany ang Jin, Mung Y ao Jia, Shunc hi Zhang, and Tianmin Shu. Autotom: Scaling mo del-based men tal inference via automated agent mo deling. 2025. Lance Ying, Xinyi Li, Shiv am Aarya, Yizirui F ang, Yifan Yin, Jason Xinyu Liu, Stefanie T ellex, Josh ua B T enenbaum, and Tianmin Shu. Pragmatic em b o died sp oken instruction following in h uman-rob ot collab oration with theory of mind. arXiv pr eprint arXiv:2409.10849 , 2024. Da vid Silver and Jo el V eness. Monte-carlo planning in large pomdps. In A dvanc es in neur al information pr o c essing systems , pages 2164–2172, 2010. Da vid Silver, Thomas Hub ert, Julian Schritt wieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graep el, Timothy Lillicrap, Karen Simon yan, and Demis Hassabis. A general reinforcemen t learning algorithm that masters c hess, shogi, and go through self-play . Scienc e , 362(6419):1140–1144, 2018. 16 App endix A Human Ev aluation of the PHASE Dataset A.1 Human video lab el tagging for PHASE videos The 23 lab els used in this exp erimen t are: not interacting, interacting unin tentionally , chasing, running aw a y , stalking, approaching, a voiding, meeting, gathering together, guiding, following the lead (of another agent), playing a game of tag, blo cking, figh ting, comp eting, stealing, protecting an ob ject, attac king, hindering, bullying, pla ying tug of w ar, helping, collab orating. A.2 Comparing PHASE and h uman-generated videos W e recruited 3 human participants to create videos in the same 2D environmen t as PHASE. The h uman video generation pro cedure is similar to the setup in PHASE, except that actions are obtained from human user input. In eac h game, there are t wo pla yers, one for controlling each agen t. The play ers each view the environmen t and con trol their agen t from separate screens. Pla yers can use the following actions b y pressing keys on their keyboards: 4 directions (forward, bac kward, righ t, left), turning righ t or left, and grabbing or letting go of an ob ject. W e reset the v elo cit y of each agen t to 0 after each step to make it easier for play ers to control the agents. Before eac h session, the pla yers were shown a tutorial on ho w the agen ts w ork (partial observ abilit y and the con trols). They w ere given an opp ortunit y to play freely in the game en vironment to get familiar with the controls. A t the b eginning of a session, they w ere told the goals assigned to b oth pla yers (so they knew eac h other’s goals) and asked to start pla ying the game to achiev e the assigned goals. Eac h session ended either when the goals of both pla yers were achiev ed or when the time limit was reac hed. W e then recruited 186 participan ts on Mec hanical T urk and randomly divided them into tw o groups. One group w atched the h uman-controlled videos, and the other watc hed matc hing videos from PHASE. F or each video, participants were ask ed to judge the goals and relations of the agen ts, and rate how lik ely humans w ere to b eha v e similarly to these agents under the same goals and relations (on a scale of 1 to 5). W e compare the mo de h uman resp onse against the ground truth. In b oth groups, the mo de of participan ts’ resp onses pro duces a high accuracy for goal and relation recognition (0 . 965 and 0 . 92 for goal and relation recognition on the h uman-controlled videos, and 0 . 97 and 0 . 99 for goal and relation recognition on the PHASE videos). The a veraged h uman-likelihoo d rating for the human-con trolled videos is 4 . 06 ( σ = 0 . 36); and for PHASE, it is 3 . 98 ( σ = 0 . 42). This suggests that to the participants, (i) the PHASE videos and the human- con trolled videos exhibit similar so cial even ts in terms of goals and relationships, ev en though they ha ve differen t motion tra jectories, and (ii) the agent b eha viors in these tw o types of videos all hav e similar degrees of human-lik eliho od. App endix B Main Exp eriment on Collecting Human Goal and Relation Judgmen ts on Videos Human goal and relation judgmen ts w ere collected using a custom w eb-based annotation interface applied to videos from the PHASE dataset (Fig. B1). Each participant completed 10 trials. On eac h trial, participan ts view ed a PHASE in teraction video and selected the most likely goal for eac h agen t from a predefined set of candidate goals. P articipants also indicated the p erceiv ed so cial relationship b etw een the agen ts (adversarial, neutral, or friendly). The interface display ed the video on the left and the resp onse panel on the righ t, allowing participan ts to insp ect the in teraction while making selections. A progress indicator provided feedbac k on task completion. 17 Figure B1: Interface used to collect human judgmen ts of agent goals and so cial relations from PHASE videos. P articipants selected the most lik ely goal for each agent and indicated the agen ts’ relationship after viewing each video. Prior to the main task, participan ts completed a brief tutorial and a comprehension quiz designed to ensure understanding of the agents’ dynamics and the resp onse pro cedure. Selections and resp onse timestamps w ere recorded automatically under anonymized participant iden tifiers and stored in a cloud-hosted database for analysis. App endix C Details of Join t Ph ysical-So cial Sim ulation Our join t ph ysical-so cial simulation is described in Algorithm C1, whic h includes a physical sim ulation T , and a hierarchical planner whic h consists of a high-level planner (HP) and a low- lev el planner (LP). Giv en the scene configuration, the simulation up dates the b elief particles based on new observ ations, uses the hierarchical planner to sample actions for all agents based on the up dated particles, feeds the actions to the physics engine to sim ulate one step, and renders 5 frames of video based on the simulated ph ysical states. The final video has a frame rate of 20 FPS. W e discuss more implementation details as follo ws. C.1 Predicates, Sym b olic States, Goals, and Subgoals In our simulation, w e define a set of predicates as summarized in T able C1. These predicates and their negations are used to (i) con vert a ph ysical state into a sym b olic state, and also (ii) b ecome a subgoal space that our hierarc hical planner considers for the high-level plans. F urthermore, the final goal states for physical goals and so cial goals of agents are also represen ted b y a subset of these predicates, i.e., On ( agent/obje ct , landmark ), Touch ( agent , agent) , and their negations. 18 Algorithm C1 Join t Physical-Social Simulation 1: Input: g 1 , g 2 , α 12 , α 21 , f 1 , f 2 , and initial state s 1 2: Output: Abstract so cial even t s 1: T 3: for agen t i = 1 , . . . , 2 do 4: Initialize b elief particles { b 0 i,k } K k =1 5: end for 6: for time steps t = 1 , . . . , T do 7: for agen t i = 1 , . . . , 2 do 8: Up date observ ation o t i 9: Up date belief particles { b t i,k } K k =1 based on o t i 10: Set the other agent j ← { 1 , 2 } \ { i } 11: for each particle k = 1 , . . . , K do 12: Get subgoal h t i,k ← HP( g i , g j , α ij , b t i,k ) 13: end for 14: for subgoal h ∈ H do 15: Estimate v alue: 16: V ( B t i , h, g i , g j , α ij ) = 1 K P K k =1 1 ( h = h t i,k ) − λ P K k =1 1 ( h = h t i,k ) P K k =1 1 ( h = h t i,k ) ˆ C ( b t i,k , s g ) 17: end for 18: Select subgoal h t i, ∗ = argmax h V ( B t i , h, g i , g j , α ij ) 19: Get b elief particles ˜ B t i that corresp ond to h t i, ∗ 20: Get action a t i ← LP( ˜ B t i , h t i, ∗ ) 21: end for 22: Up date state s t +1 ← T ( s t , { a t i } 2 i =1 , { f i } 2 i =1 ) 23: end for Predicate Definition On ( agent/obje ct , landmark ) An entit y is on a landmark Touch ( agent , agent/obje ct) An agent touc hes another en tity A tt a ch ( agent , obje ct ) An ob ject is attached to an agen t’s b o dy Close ( agent/obje ct , agent/obje ct/landmark ) An entit y is within a certain distance a wa y from another entit y o r a landmark T able C1: Predicates and their definitions. Note that we also consider their negations, whic h are not shown in the table for brevity . C.2 Hierarc hical Planner F or the high-level planner, w e use A ∗ to search for a plan of subgoals for N = 2 agents based on K = 50 b elief particles. T o ensure a subgoal selection for sim ulating natural agent b eha vior without exp ensiv e compu- tation, we design a heuristics-based v alue estimation V ( B t i , h, g i , g j , α ij ) for each subgoal as shown in Algorithm C1. This v alue function fav ors subgoals that are more likely to b e the best subgoal in the true state (i.e., high frequency subgoals generated by all b elief particles) and hav e low er cost (i.e., ˆ C estimated by the distance from the current state to the final goal state according to a given b elief particle). By changing the weigh t λ , w e are able to alter the agent’s b eha vior. Figure C1 demonstrates an example of how λ affects the agent’s b eha vior. In practice, w e find λ = 0 . 05 offers a go od balance and can consistently generate natural b eha viors. F or the low-lev el action planner, w e use POMCP [Silver and V eness, 2010] with 1000 simula- 19 A B 1 2 3 4 5 6 7 8 9 10 11 12 13 14 1 2 3 4 5 6 7 Figure C1: Illustration of the effect of the estimated v alue function for the high-level planner. The n umbers indicate the temp oral order of the frames. In b oth sequences, the green agen t’s goal is to mov e the blue ob ject to the red landmark in the b ottom-righ t corner. Since it do es not see the blue ob ject initially , it needs to first find the ob ject. ( A ) The sequence when λ = 0. Since there is more unseen space in the left part of the environmen t, it is more likely that the blue ob ject is in the left part. So the green agen t first searches the left part when not considering the cost of doing so. ( B ) The sequence when λ = 0 . 05. When considering the cost, it is worth while for the green agen t to searc h the nearby region first. The chance of finding the blue ob ject there is slightly low er than in the left region, but the resulting cost is considerably low er. In particular, it first lo oks around (frame #2) and then pro ceeds to search the upp er-righ t part (frame #3 and #4). This comparison demonstrates that an appropriate λ could give us more natural agent behaviors under partial observ abilit y . tions and 10 rollout steps. F or exploration in POMCP , w e adopt a v arian t of the PUCT algorithm in tro duced in Silver et al. [Silv er et al., 2018], where we use c init = 1 . 25 and c base = 1000. C.3 Belief Represen tation and Up date Eac h agent’s b elief is represented by K = 50 particles in the simulation. Eac h particle represents a p ossible world state that is consistent with the observ ations. The state in a particle includes the environmen t la yout, and ph ysical prop erties of each en tity — shape, size, center p osition, orien tation of the b ody , linear and angular velocity , and attached entities. Eac h particle is up dated with the ground truth prop erties of observe d entities: the agen t itself, other entities in its field of view (approximated b y 1 × 1 grid cells on the map) or entities in contact with the agen t. Entities that are in con tact with observed entities are also defined as observ ed. 1 Con tact o ccurs when entities are attac hed or collide, and is signaled b y agents’ touc h sensory . Unobserv ed entit y prop erties differ betw een particles. W e start by randomly sampling p ossible initial p ositions from the 2D environmen t and setting other prop erties (orien tation and velocity) to 0. T o up date a belief particle from t to t + 1, w e first apply the physics engine to simulate one step, where w e assume constan t motion for entities. Then w e chec k the consistency b et w een 1 This is to ensure that the agent knows (i) whether there is any other agent grabbing the same ob ject it is curren tly grabbing, and (ii) whether an observ ed agen t is grabbing any ob ject. 20 Figure C2: Illustration of ho w the red agen t up dates its b elief using K = 10 particles. ( A ) T rue states s t (top) and s t +1 (b ottom). The brigh t pixels indicate the red agent’s field of view. ( B ) { b t red ,k } K k =1 (top) and { b t +1 red ,k } K k =1 (b ottom). The states in all the particles are visualized together. A t step t + 1 the red agent observ es the blue ob ject via its field of view. All particles are then up dated accordingly with the ground truth prop erties of the blue ob ject, and the inconsisten t b elief states are also resampled. ( C ) The state in one of the b elief particles, b t red ,k (top) and b t +1 red ,k (b ottom). The particle is up dated with ground truth prop erties blue ob ject at step t + 1. The prop erties of the pink ob ject are resampled at step t + 1 since its b eliev ed p osition in step t conflicts with the observ ation at step t + 1. the sim ulated state at t + 1 and the actual observ ation at t + 1. F or entities that contradict the observ ation, we resample their p ositions and orien tations. W e then rep eat the consistency chec k and resampling until there is no conflict. Figure C2 depicts an example of how an agen t updates its b elief from step t to step t + 1 based on its observ ation at step t + 1. App endix D Mo del Implemen tation Details D.1 So cialGNN The original So cialGNN model [Malik and Isik, 2023] w as designed to classify the so cial relationship b et w een t w o agen ts (friendly , neutral, or adv ersarial) from visuospatial input. The model represen ts eac h video frame as a graph with no des for agents and ob jects connected by bidirectional edges when en tities are in physical con tact. Landmark and w all co ordinates w ere previously app ended as global context features to each edge rather than represen ted as graph nodes. A single linear classification head op erating on the final LSTM state pro duced a 3-class relation prediction. In the presen t w ork, we extended this architecture to join tly infer each agent’s goal alongside the so cial relation, requiring mo difications to b oth the graph representation and the output structure. T o represent goal-relev ant dynamics, w e extended the input graph by adding the landmarks in the scene as explicit graph no des. In the original mo del, landmarks pro vided no direct relational signal b et w een agents and landmarks. Because the goals in the PHASE dataset inv olv e directed na vigation tow ard or a wa y from a landmark, or to ward the other agent, making landmarks graph no des allows the mo del to learn relational representations that are directly diagnostic of goal pursuit. Eac h landmark no de follo ws the same feature vector structure as entit y no des, with v elo cit y and angle set to zero as they are stationary . Corresp ondingly , we added a new class of bidirectional edges connecting eac h entit y to an y landmark it is in pro ximit y to, analogous to the existing con tact- based en tity–en tit y edges. This structural expansion allows the mo del to capture the relativ e spatial 21 dynamics necessary for goal recognition. The PHASE dataset enco des each agent’s goal as one of several discrete types, which can b e categorized in to three functional groups: (1) moving an ob ject to a sp ecific landmark, (2) navigating the agen t itself tow ard or a wa y from a landmark, and (3) pursuing a so cial in teraction goal directed to ward the other agen t with a sp ecific v alence. The ground-truth lab el for eac h video is represented as a concatenated v ector enco ding the goal for eac h agent. At inference time, softmax is applied separately o ver eac h agent’s goal partition to pro duce indep enden t probability distributions ov er the p ossible in tents. W e extended the S ocial GN N E arc hitecture with a second output head to enable join t prediction of goals and relations. The shared backbone remains identical to the original. The final LSTM state is passed in parallel to t w o linear classifiers: a relation head (3-class softmax) and a goal head that predicts the in tents for b oth agents. The mo del is trained end-to-end by minimizing a com bined loss L = L relation + L goal + λ ∥ θ ∥ 2 , where b oth L relation and L goal are cross-en tropy losses. Class w eights are applied to the relation loss to up weigh t the underrepresen ted neutral class. This join t training ob jective encourages the shared represen tation to simultaneously capture features diagnostic of b oth so cial relations and individual agent goals. D.2 SIMPLE D.2.1 Mo del parameters F or SIMPLE mo del, w e use the follo wing parameters: • n um b er of iterations: L = 6 • n um b er of particles/hypotheses: M = 15 • scaling factor: η = 0 . 1 • lik eliho od parameter β = 0 . 05 • time in terv al for lo cation estimation: ∆ T = 10 D.2.2 Bottom-up prop osal for hypotheses W e devise a b ottom-up prop osal based on heuristics extracted from observ ed tra jectories within a time interv al S t 1 : t 2 , i.e., h ∼ Q ( h | S t 1 : t 2 ). In this work, the prop osal distribution is decomp osed into separate terms for prop osing goals ( g i , g j ), so cial utility weigh ts ( α ij , α j i ), and strengths ( f i , f j ), resp ectiv ely , i.e., Q ( h | S t 1 : t 2 ) = Q ( g i | S t 1 : t 2 ) Q ( g j | S t 1 : t 2 ) · Q ( α ij , α j i | S t 1 : t 2 ) · Q ( f i | S t 1 : t 2 ) Q ( f j | S t 1 : t 2 ) . (D1) W e define the goal prop osal distribution for an agen t by Q ( g | S t 1 : t 2 ) ∝ e γ || s t 2 i − s g || 2 e γ ( || s t 2 i − s g || 2 −| s t 1 i − s g || 2 ) ∝ e γ (2 || s t 2 i − s g || 2 −| s t 1 i − s g || 2 ) , (D2) where γ = 10 is a constant w eight. In tuitively , if the tra jectories hav e demonstrated either achiev e- men t at the end of the p eriod ( t 2 ) or progress tow ards a goal during the p eriod (from t 1 to t 2 ), then that goal is likely to b e the true goal. F or the so cial utilit y w eights, we first randomly select 22 u ∈ {− 1 , 0 , 1 } . If u = 0, we set both α ij and α j i to be zero; if u ∈ {− 1 , 1 } , w e randomly select either α ij or α j i , and set it to b e u while setting the other one to be zero. This is essentially assuming that there will b e at most one agen t pursuing a so cial goal in a so cial even t. F or the strengths, w e train a 2-lay er MLP (64-dim for each la yer) using training data in PHASE to estimate the maximum forces that agents can exert. D.3 Gemini 2.5 Pro F or Gemini 2.5 Pro, we use the default mo del configuration (default mo del temp erature and thinking budget). The following prompt is used for the mo del. 23 Agen t Interaction Prompt Y ou are watc hing an animation of t wo agen ts acting in a 2D environmen t. Each animated video has the following: * En tities: creatures (trap ezoids) or ob jects (circles). En tities can b e of differen t colors and sizes. Bigger entities are hea vier. * Landmarks: colored squares that creatures ma y try to get to or mov e ob jects to. * W alls: blac k lines, creatures and ob jects can’t mov e through w alls. The agen t’s ob jective is to mo ve to a landmark, mo ve an ob ject to a landmark, mo ve close to the other agent, or hinder a particular goal (e.g., k eep an agen t or an ob ject aw ay from a landmark). By p erm uting the ob jects and landmarks, w e hav e 36 p ossible goals in total for the goal space. The agen t’s relation can b e friendly (collab orating on a goal), neutral (pursuing indep enden t goals) or adversarial (e.g. hindering or comp eting with other agent). Y our task is to classify eac h agen t’s goal and relations. Y ou will b e given the full goal space and p ossible relation lab els and you will output a probability distribution of top 10 goals for eac h agent, and a probability distribution of p ossible agen t relations. 1. red agent goals: exactly 10 goals for the red agen t. Dictionary mapping goal string -¿ probabilit y . Cho ose only from this goal space: { goals str } 2. green agen t goals: exactly 10 goals for the green agen t. Same format, same goal space. 3. relation: distribution o ver the relationship. Dictionary with exactly three k eys ”Adv er- sarial”, ”F riendly”, ”Neutral”; v alues sum to 1.0. Y our resp onse must b e ONL Y v alid JSON—one ob ject with exactly these 3 k eys, no other text: { "red_agent_goals": { "": 0.12, "": 0.11, ...exactly 10 entries, values sum to 1.0 }, "green_agent_goals": { "": 0.15, ...exactly 10 entries, values sum to 1.0 }, "relation": { "Adversarial": 0.1, "Friendly": 0.7, "Neutral": 0.2 } } D.4 Predicate In v erse Planning The predicate inv erse planning mo del infers agents’ goals and their so cial relations from ob- serv ed tra jectories b y (1) abstracting con tin uous states into symbolic predicates, and (2) inv erting a forw ard planning pro cess ov er those symbolic states. It do es not use physical dynamics; it op erates only on a discrete, predicate-based represen tation of the scene ov er time. 24 Let the contin uous state at time t b e s t ∈ S (e.g., p ositions and v elocities of agen ts and ob jects). The model first maps s t to a set of Bo olean predicates ev aluated at thresholds, yielding a sym bolic state ϕ t . So at each t , w e hav e a vector (or set) of predicate truth v alues: ϕ t = ON( e, ℓ ) , TOUCH( e 1 , e 2 ) , A TT ACH( a, o ) , CLOSE( · , · ) , . . . . The observed tra jectory is then represented as a symbolic tra jectory τ ϕ = ( ϕ 0 , ϕ 1 , . . . , ϕ T ). Assume a (sym b olic) forward mo del: giv en the goal g i , the agen t is assumed to pro duce a sequence of actions that, under a simplified sym b olic dynamics, leads to predicate tra jectories that satisfy or progress tow ard the goal. Let P ( τ ϕ | g i ) denote the probability of the observ ed sym b olic tra jectory τ ϕ giv en that agent i has goal g i (and optionally giv en the other agen t’s goal or a relation prior). This is typically implemen ted by forward-sim ulating or scoring candidate goals against τ ϕ (e.g., b y c hec king whic h goal b est “explains” the observed ON/TOUCH/A TT ACH/CLOSE pattern o ver time). In verse planning inv erts this forward mo del under a prior o ver goals P ( g i ) (often uniform o ver G ): P ( g i | τ ϕ ) ∝ P ( τ ϕ | g i ) P ( g i ) . (D3) Unlik e physics-based mo dels (e.g., SIMPLE), this mo del do es not use forces, masses, or contin- uous dynamics. It only sees which predicates hold at each time. As a result it can do w ell when relations are discernible from coarse symbolic structure (e.g., Independent when eac h agent mo v es to ward different ob jects/landmarks), but it struggles when fine-grained physics is required (e.g., whether an agen t can actually push an ob ject to a landmark, or whether tw o agents are opp osing vs. co operating on the same ob ject), leading to lo wer goal accuracy than ph ysically grounded in verse planning. App endix E Additional Exp erimen t Details E.1 Goals in PHASE There are 36 p ossible goals in PHASE, whic h are listed b elo w: "Get blue item to blue lm", "Get blue item to green lm", "Get blue item to red lm", "Get blue item to yellow lm", "Get blue item away from blue lm", "Get blue item away from green lm", "Get blue item away from red lm", "Get blue item away from yellow lm", "Get green agent to blue lm", "Get green agent to green lm", "Get green agent to red lm", "Get green agent to yellow lm", "Get green agent away from blue lm", "Get green agent away from green lm", "Get green agent away from red lm", "Get green agent away from yellow lm", "Get pink item to blue lm", 25 "Get pink item to green lm", "Get pink item to red lm", "Get pink item to yellow lm", "Get pink item away from blue lm", "Get pink item away from green lm", "Get pink item away from red lm", "Get pink item away from yellow lm", "Get red agent to blue lm", "Get red agent to green lm", "Get red agent to red lm", "Get red agent to yellow lm", "Get red agent away from blue lm", "Get red agent away from green lm", "Get red agent away from red lm", "Get red agent away from yellow lm", "get away from green agent", "get away from red agent", "get to green agent", "get to red agent" E.2 Accuracy F or h uman accuracy , w e compute the p er participan t accuracy on goal/relation classification and a verage across all participants. Supp ose N participants attempt the exp erimen t. The accuracy is computed by Goal Accuracy = 1 N X i Num b er of correct goal classifications b y participant i T otal n umber of goal classifications by participant i (E1) The accuracy of mo dels are computed by taking the option with the highest assigned probabilit y and comparing against the ground-truth lab el. E.3 Correlation T o compute mo del/human or human split-half correlations, w e first normalize the human ratings. Eac h video has 2 goals and 1 relation. F or each goal, w e get a distribution o ver 36 goal labels. F or video v , the probability of agen t i ha ving goal g is defined as P (agen t i has goal g in video v ) = total num ber of p eople c hose g for agen t i in video v total num ber of p eople who rated the goal of agen t i in video v (E2) Since we hav e 100 videos, 2 goal tasks p er video with 36 p ossible goals p er task, 1 relation task p er video with 3 p ossible relation lab els p er video, this pro duces 7200 probability measures for goals and 300 probability measures for relations. W e flatten these into one goal v ector of dimension 7200 and one relation vector of dimension 300, and then compute the correlation b et w een human subgroups or humans and mo dels, where the same dimension vector can be extracted from mo del distribution ov er goals and relation lab els. 26
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment