Bayesian analysis of the causal reference-based model for missing data in clinical trials, accommodating partially observed post-intercurrent event data
When treatment policy estimands are of interest, clinical trials often attempt to collect patient data after intercurrent events (ICEs), although such data are often limited. Retrieved dropout imputation methods, which use pre-ICE and available post-…
Authors: Brendah Nansereko, Marcel Wolbers, James R. Carpenter
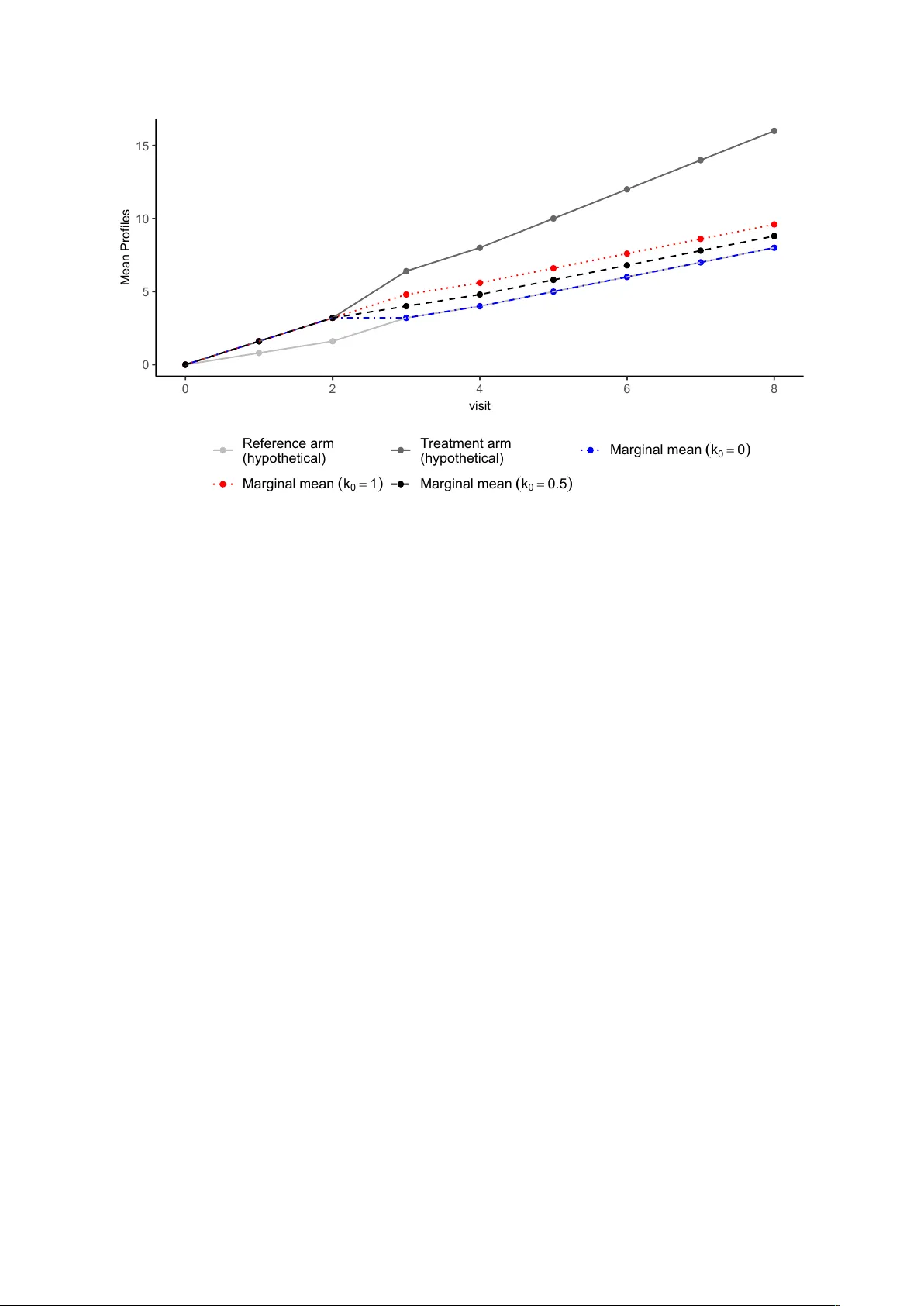
Ba y esian analysis of the causal reference-based mo del for missing data in clinical trials accommo dating partially observ ed p ost-in tercurren t ev en t data Brendah Nanserek o Departmen t of Medical Statistics, London Sc ho ol of Hygiene and T ropical Medicine Marcel W olb ers Data and Statistical Sciences, Pharma Dev elopmen t, Ro c he, Basel, Switzerland James R. Carp en ter Departmen t of Medical Statistics, London Sc ho ol of Hygiene and T ropical Medicine Jonathan W. Bartlett Departmen t of Medical Statistics, London Sc ho ol of Hygiene and T ropical Medicine Marc h 31, 2026 Abstract When treatmen t p olicy estimands are of interest, clinical trials often attempt to collect patien t data after intercurren t even ts (ICEs), although such data are often 1 limited. Retriev ed drop out imputation metho ds, which use pre-ICE and av ailable p ost-ICE data to impute missing p ost-ICE outcomes, are commonly applied but often yield treatment effect estimates with large standard errors (SEs) and may en- coun ter con vergence issues when p ost-ICE data are sparse. Reference-based impu- tation metho ds are also used, but they rely on strong assumptions ab out p ost-ICE outcomes, whic h can lead to biased estimates if these assumptions are incorrect. T o address these limitations, w e previously prop osed the reference-based Bay esian causal mo del (BCM), which incorp orates a prior on the main tained effect parame- ter to reflect uncertain ty in reference-based assumptions for missing post-ICE data. Our earlier work assumed no p ost-ICE data were observ ed. Here, we extend the BCM to incorp orate a v ailable p ost-ICE outcomes, providing an approach that mit- igates limitations of b oth retrieved-dropout and standard reference-based metho ds. W e prop ose both a fully Bay esian model and an imputation-based approac h. A sim ulation study w as conducted to ev aluate the frequen tist properties of the prop osed methods in settings with partially observ ed post-ICE data and to compare p erformance with existing approaches. Retriev ed-drop out metho ds produced higher estimated SEs than the BCM, particularly when p ost-ICE data were sparse. Under the BCM, treatmen t effect SEs increased as post-ICE data b ecame more limited for b oth mo delling approaches. Imp ortan tly , this increase can b e controlled through the prior v ariance of the maintained effect parameter, with more informative priors stabilising estimation when p ost-ICE data are scarce. Keywor ds: Reference-based imputation, Retrieved-dropout, Ba y esian causal mo del 2 1 In tro duction The ICH E9(R1) addendum provided a framew ork for the construction of estimands, whic h aids in the precise description of treatment effects in randomised con trolled trials (R CTs). It comprises five key comp onents , whic h in tegrate both clinical considera- tions and so-called intercurren t ev ents (ICEs) [1]. These comp onents are the treatmen t conditions of interest, the patient target p opulation, the end p oint, the p opulation-lev el summary measure, and ho w ICEs are to b e handled. The ICH E9(R1) guideline pro- vides a n um b er of strategies for in tegrating ICEs into the estimand definition. These include the treatmen t p olicy strategy , the hypothetical strategy , and other approaches that ensure a structured and consistent framew ork for estimand sp ecification in clinical trials. F ollowing the ICH E9 guidelines, it is typical for clinical trials to attempt to collect patien t outcome data after the o ccurrence of intercurren t ev ents (ICE). Aligned with the in ten t-to-treat (ITT) principle, the treatmen t p olicy strategy seeks to assess the treatment effect including the effects of ICEs on subsequen t outcomes. Data after the o ccurrence of the ICE are used directly in the estimation of the treatmen t effect under the treatment p olicy strategy . F ollo wing an ICE, t w o scenarios may arise. The patien t can contin ue to b e observ ed, allowing the collection of p ost-ICE data; these are sometimes referred to as retriev ed drop out data (RD). Alternatively , the patient ma y b ecome lost to follow-up im- mediately or at a later stage, resulting in missing data. In many studies, despite the b est efforts of trial in v estigators, some p ost-ICE data ma y b e missing, p osing challenges for estimation and analysis. F or example, discon tinuation of randomised treatmen t can sub- stan tially increase the risk of missing subsequen t clinic visits ev en when trial in vestigators attempt to contin ue visits for such patien ts. Sev eral metho ds ha v e b een prop osed to handle missing data in the presence of ICEs. Metho ds suc h as the Mixed Model for Rep eated Measures (MMRM) and standard multi- ple imputation (MI) under a missing at random (MAR) assumption ignore the o ccurrence of the ICEs and the missing data is (implicitly or explicitly) imputed under MAR. F or missing p ost-ICE data, standard MAR-based metho ds (effectively) assume the condi- 3 tional distribution of missing (p ost-ICE) data is the same as the corresp onding condi- tional distribution in those who did not hav e the ICE if there is no or little p ost-ICE data observ ed data in the trial. This assumption is often unrealistic in RCTs, giv en that the o ccurrence of an ICE t ypically implies some change in the patien t’s treatment or condition. Giv en that ICH E9(R1) mandates alignmen t b etw een the statistical metho ds used for handling missing data and the predefined strategy for addressing ICEs within the estimand framew ork, standard MAR-based approaches are t ypically not appropriate in the context of estimating treatment policy effects [2]. The reference-based imputation (RBI) metho ds proposed b y Carpenter et al. assume that the distribution of missing (p ost-ICE) data for patien ts who exp erience an ICE in a giv en treatment arm is based (in a sp ecified w a y) on the corresp onding outcome distribution of the reference arm [2]. RBI metho ds are primarily relev ant to treatmen t discon tin uation follo wing ICEs in placeb o-con trolled trials, but ma y also b e useful for other types of ICEs. The original prop osal for RBI was made in the con text of a trial where outcome data are not a v ailable post-ICE. When some p ost-ICE data are observ ed, in some softw are implemen tations (e.g. the R pac k age rbmi [3]), observ ed p ost-ICE data are not used in the imputation mo del fitting pro cess, but when calculating the imputation distribution, the rbmi pack age conditions on all observ ed data, including an y observ ed p ost-ICE v alues [3]. Consequently , the imputed missing p ost-ICE v alues are impacted b y observ ed p ost-ICE data, if present. A limitation of curren t reference-based metho ds is their reliance on strong assumptions ab out p ost-ICE outcomes, whic h, if incorrect, will generally lead to biased estimates of the treatmen t effect. In addition, the imputation mo del fit do es not utilise an y observed post-ICE data to learn ab out the effect of the ICE on outcomes. An alternativ e set of approaches, often termed ‘RD metho ds’, impute missing data based on pre-ICE data and a v ailable p ost-ICE data [4]. A range of MI implementations ha v e b een proposed and in v estigated that adjust in some wa y for the ICE o ccurrence in- formation, and that rely on a different MAR assumption to the MMRM and ‘standard MI’ men tioned earlier. W ang and Hu prop osed a retriev ed-drop out metho d, which imputes 4 the missing p ost-ICE data at the final time p oin t using information from the individuals who experience the ICE [5]. MMRM metho ds hav e also been expanded to accommo date the p ost-ICE data through the inclusion of the ICE v ariable [6]. How ever, these metho ds often lead to treatment effect estimates with large standard errors, esp ecially when the amoun t of retriev ed data after the ICE is limited [7]. F urthermore, the retrieved drop out mo dels are prone to conv ergence failure, again due to the limited amount of av ailable p ost-ICE data [8]. Cro et al. recen tly prop osed a retrieved drop out reference-based metho d for imputing missing p ost-ICE data [9]. This metho d imputes the missing data b y com bining b oth the parameters obtained from a core reference-based mo del and the retrieved drop out mo del parameters. Under this metho d, the traditional reference-based mo del is extended to include offset parameters ( γ ∗ akj ) whic h capture departures from the reference-based assumption and whose v alues are informed b y observed p ost-ICE outcomes. The γ ∗ akj parameters are estimated using a Ba y esian mo del fitted to the retriev ed drop out data, with priors sp ecified. A p oten tial drawbac k of this approach is that it requires the sp ec- ification of a m ultiv ariate prior for the γ ∗ akj parameters at different visits, whic h can b e c hallenging due to the large num b er of parameters inv olved, particularly when there are many follow-up visits. F urthermore, estimation of these parameters ma y b e difficult when no p ost-ICE data are observ ed for some ICE patterns defined by the timing of the ICE, esp ecially when non-informative priors are used. Giv en the ab o ve limitations with the av ailable approac hes, there is a need for metho ds that can utilise the p ost-ICE data when a v ailable, can handle the common situation when suc h p ost-ICE data is limited, and appropriately ackno wledge uncertain t y ab out the missing data assumptions. White et al proposed the causal reference-based imputation mo del, whic h uses p o- ten tial outcomes and explicitly defines assumptions ab out ho w the o ccurrence of an ICE affects subsequen t outcomes [10]. In our previous w ork, we used this causal mo del and prop osed the Reference-Based Bay esian Causal Mo del (BCM), which introduces a prior on the magnitude of the treatment effect that is maintained after the ICE occurs [11]. In our previous w ork, we considered the setting where no post-ICE data w ere a v ailable and 5 dev elop ed a Bay esian inference metho d. In practice, it is increasingly common for some p ost-ICE data to b e observed in clinical trials. These observ ations should b e utilised, b oth to impro v e the precision of the estimated treatmen t effect and b ecause they pro- vide v aluable information ab out the distribution of the missing data. As such, in this pap er, w e prop ose an extension of the BCM approach to incorp orate p ost-ICE obser- v ations. W e also develop imputation-based approaches based on the BCM, which rely on the reference-based causal mo del only insofar as it is needed to handle imputation of missing data. F or concreteness of exp osition, until the discussion, w e fo cus on a setting with a single type of ICE—treatmen t discontin uation, although the prop osed metho ds could p oten tially b e applied to other types of ICEs. In Section 2, w e describ e the original BCM and its extension that incorp orates p ost- ICE observ ations. This section also includes the description of imputation approaches based on the BCM. Section 3 describ es a simulation study conducted to ev aluate the p erformance of the prop osed metho d alongside existing approac hes. In Section 4, w e apply the BCM metho ds to an an tidepressant dataset with some post-ICE data a v ailable, and in Section 5, w e conclude with a discussion. 2 Reference-based Ba y esian causal mo del White et al. in tro duced a reference-based causal imputation mo del for handling missing p ost-ICE data within the p otential outcomes framew ork, whic h we now describ e [10]. Their setup is motiv ated for a setting with discon tinuation of randomised treatment as the ICE. Let Y j ( s ) denote the p oten tial outcome at visit j for a given patient if, p ossibly con trary to fact, they receive the active treatment for the first s visits, follo wed b y the con trol or reference treatmen t for the remaining time. Define D as the last visit b efore the o ccurrence of an ICE for an individual patient. Define Y ( s ) as the vector of suc h potential outcomes across all j max follo w-up visits under this treatmen t scenario. The sub-vectors Y ≤ j ( s ) and Y >j ( s ) refer to the potential outcomes at and before visit j , and strictly after visit j , resp ectiv ely . The expected v alues of these vectors are denoted b y: µ ( s ) = E [ Y ( s )], 6 µ ≤ j ( s ) = E [ Y ≤ j ( s )], µ >j ( s ) = E [ Y >j ( s )]. The v ariance-co v ariance matrix of Y ( s ) is given b y Σ( s ) = V ar( Y ( s )). The corresp onding submatrices are: Σ ≤ j ≤ j ( s ) = V ar( Y ≤ j ( s )), Σ >j ≤ j ( s ) = Cov( Y >j ( s ) , Y ≤ j ( s )), Σ ≤ j >j ( s ) = Σ >j ≤ j ( s ) ⊤ , Σ >j >j ( s ) = V ar( Y >j ( s )). The regression co efficien ts linking past to future outcomes are defined as: β j ( s ) = Σ >j ≤ j ( s ) Σ ≤ j ≤ j ( s ) − 1 . F or example, β j ( j ) represen ts the m ultiv ariate regression co efficien ts for predicting future p oten tial outcomes Y >j ( j ) from prior outcomes Y ≤ j ( j ), assuming the patien t receiv ed activ e treatment up to visit j . Actual (as opp osed to counterfactual) missing outcomes in the con trol arm are as- sumed to b e MAR. W e assume an MMRM for the full-data mo del of the h yp othetical un treated/con trol outcomes across all visits Y ( j max ). Y j (0) = µ j (0) + X ⊤ i α j + ϵ ij , ε i = ( ε i 1 , . . . , ε ij max ) ⊤ ∼ N (0 , Σ(0)) , where X i is a vector of baseline co v ariates, α j is the vector of regression co efficien ts for baseline cov ariate effects on outcome at visit j . W e also assume an MMRM for the full-data model of the h yp othetical fully treated outcomes across all visits Y ( j max ). This mo del is sp ecified as: Y j ( j max ) = µ j ( j max ) + X ⊤ i α j + ϵ ij , ε i = ( ε i 1 , . . . , ε ij max ) ⊤ ∼ N (0 , Σ( j max )) , The central assumption of the reference-based causal mo del is that mean outcomes at the p ost-ICE visits can b e expressed as a function of the difference in mean outcomes b et ween treatmen t arms (i.e. the treatmen t effects) at the pre-ICE visits through a matrix v alued main tained effect parameter K j . In the p oten tial outcome notation defined earlier, 7 this is that E [ Y >j ( j ) − Y >j (0)] = K j E [ Y ≤ j ( j ) − Y ≤ j (0)] where K j is a ( j max − j ) × ( j + 1) matrix of parameters for the main tained treatmen t effect. White et al. prop osed a simpler single-parameter mo del for the difference in mean outcomes at visit u after discontin uation at visit j : E [ Y u ( j ) − Y u (0)] = k 0 E [ Y j ( j ) − Y j (0)] (1) Under this single-parameter mo del, k 0 is a real-v alued maintained effect parameter that reflects the user’s assumptions ab out ho w the treatmen t effect is main tained or deca ys after discontin uation of active treatmen t, as illustrated in Figure 1. Under this sp ecification, the maintained treatment effect is assumed to remain constant across all p ost-ICE visits. Under White’s single-parameter causal mo del, the p ost-ICE outcomes conditional on the pre-ICE outcomes are multiv ariate normal, with the conditional mean of the p ost-ICE outcomes Y >t giv en by: E ( Y >j | Y ≤ j , T = a, D = j ) = β j ( j ) Y ≤ j − β j ( j ) µ ≤ j ( j ) + k 0 ( µ j ( j ) − µ j (0)) + µ >j (0) , (2) The residual cov ariance matrix for p ost-ICE outcomes Y >j giv en the pre-ICE outcomes Y ≤ j is given b y Ω j ( j ) where Ω j ( s ) = Σ >j,j,j | Y ≤ j , D = j is included, with mean as given in Equation 2. As in the initial BCM with no p ost-ICE data, the treatment effect at the final time p oint is estimated using Equation 3, as deriv ed by White et al . In our earlier w ork, where no post-ICE data w ere assumed to b e observ ed, the poste- rior for the k 0 parameter remained unc hanged from the prior, since there w ere no data to inform its estimation. How ever, with some p ost-ICE data observ ed, the data are infor- mativ e ab out the v alue of k 0 , and so the mo del can learn ab out its v alue from the data as w ell as the prior. When no p ost-ICE data are av ailable, the v alue of k 0 m ust b e fixed (assumed kno wn) or an informativ e prior used. When some p ost-ICE data are observed, w e can p oten tially use a w eak er or even essen tially flat prior for k 0 . W e discuss prior c hoice further in Section 2.3. 10 2.2 Imputation approac h for the Ba yesian causal mo del In this subsection, w e prop ose t wo imputation-based approac hes whic h utilise the Ba yesian causal mo del. Our motiv ation for using imputation rather than direct Bay es as describ ed in the previous subsection is the idea that w e may only w ant to use the Bay esian causal mo del so far as it is needed to handle the missing data. Sp ecifically , if w e do ha v e com- plete or almost complete p ost-ICE data, we w ould wan t our inference to b e essen tially the same as the complete data analysis inference (e.g. based on a simple ANCOV A of the final time p oin t outcome). Generally , if we use the direct/full Bay es approac h, this will not b e the case, whereas it is if w e use imputation. An imputation approach ma y moreo v er b e particularly adv an tageous in settings with multiple ICEs, where different assumptions ma y apply to different ev en ts. Unlik e the initial BCM approach, which in- tegrates imputation and analysis within a Bay esian framew ork, an imputation approach separates the tw o, offering greater flexibility . W e prop ose t w o approac hes for imputing p ost-ICE data under the causal mo del: a conditional mean imputation method and a m ultiple imputation–based metho d. The m ultiple imputation approach is com bined with the b ootstrap. W e use the b o otstrap v ariance rather than Rubin’s rules-based v ariances b ecause the imputation and analysis mo dels are uncongenial under Rubin’s rules, leading to an upw ard bias in the Rubin’s MI v ariance estimate relative to the rep eated–sampling v ariance. F or eac h b o otstrap sample, the parameters of the causal mo del are estimated b y the maxim um a p osteriori v alues (MAP) using the Stan pac k age’s built-in optimisation routines (sp ecifically , the optimising() function), whic h a voids the need for MCMC sampling. These parameter estimates are then used to construct the m ultiv ariate normal distribution from which p ost- ICE outcomes are imputed, generating M complete datasets. Each dataset is analysed separately using a regression of the final time p oin t outcome on baseline c haracteristics and treatmen t arm. Within eac h b o otstrap sample, M imputations are created. The treatmen t effect parameter within each b o otstrap sample is calculated as the av erage of the M estimates obtained from the imputed datasets, and the ov erall treatment effect is obtained using the original dataset using the same pro cedure. The standard errors are 11 estimated from the empirical v ariability of the b o otstrap-sample mean estimates (i.e. the sampling distribution of the mean treatment effect across b o otstrap samples). In the conditional mean approac h, the missing p ost-ICE v alues are imputed using the conditional exp ectations deriv ed from the causal mo del [12]. The parameters of the causal mo del are estimated via MAP optimisation using the Stan pac k age and substituted in to Equation 2 to obtain the conditional means for p ost-ICE outcomes in the active treatmen t arm. The missing data in the reference arm are also imputed using the MAP estimates under the MAR assumption. W olbers et al. show ed that conditional mean imputation, a deterministic metho d, yields similar estimates to the Ba y esian MI for the standard reference-based imputation approac h [12]. W olb ers et al. also sho wed that the deterministic conditional mean imputation approac h is equiv alen t to the MI approac h describ ed ab o ve, with an infinite n umber of random imputations, pro vided that the analysis mo del is a linear mo del suc h as ANCOV A. Standard errors under the BCM conditional mean imputation approach can be estimated using the jackknife or the b ootstrap metho d. The jackknife has the adv antage of av oiding resampling v ariabilit y , in contrast to the b o otstrap, and thus yields a deterministic pro cedure when used with conditional mean imputation. 2.3 Choice of priors The BCM requires sp ecification of prior distributions for the parameters in Equation 2, including the h yp othetical mean parameters µ j , the proportions of patien ts experiencing an in tercurren t even t (ICE) at each visit in the active treatment arm π j , and the main- tained treatmen t-effect parameter k 0 . Non-informativ e normal priors may b e specified for the µ j parameters, while a Diric hlet prior is a natural choice for the vector of prop ortions π j . The parameter k 0 captures the extent to whic h the treatmen t effect is main tained or deca ys following the ICE, and its prior sp ecification should reflect the analyst’s assump- tions ab out the post-ICE outcome distribution. k 0 > 0 means that if there was a benefit of activ e treatmen t b efore the ICE, there is still some benefit afterw ards, whereas k 0 < 0 12 means that a b enefit of the active treatment b efore the ICE leads to a w orse outcome (compared to control) p ost-ICE. A normal prior ma y b e sp ecified for k 0 ∼ N ( µ k 0 , σ 2 k 0 ), allowing for either a main- tained b eneficial effect ( k 0 > 0) or a switc h from b enefit to harmful effect ( k 0 < 0). Alternativ ely , priors that constrain k 0 to b e strictly p ositiv e may b e used when there is strong substan tiv e prior b elief-for example, a strictly p ositiv e prior can b e sp ecified if it can b e assumed that a b enefit of active treatment while it is tak en could not translate in to w orse outcomes (on a verage) after discontin uation. V alues of k 0 outside the in terv al [0 , 1] could b e deemed implausible in settings where the ICE corresp onds to treatment discon tin uation; hence, priors such as a Beta distribution may b e appropriate. When a substantial amount of p ost-ICE data is observed, weakly informativ e or flat priors ma y b e sp ecified for k 0 , and inference under the fully Bay esian approac h will b e driven primarily b y the observed data rather than the prior. In this setting, the MAP estimates obtained under the BCM imputation approach will b e close to maxim um lik eliho o d estimates. Ho wev er, when p ost-ICE data are sparse, whic h is often the case in practice, more informativ e priors are required. In such settings, the resulting estimates and inferences will b e influenced by the prior sp ecification under b oth the fully Ba yesian approac h and the BCM multiple imputation approac h. 3 Sim ulation Study W e conducted a sim ulation study to in vestigate the frequentist prop erties of the prop osed BCM and imputation approac hes when applied to settings with some a v ailable p ost-ICE data. In addition, w e compared the p erformance of the BCM-based metho ds with that of a retriev ed drop out metho d and traditional RBI. The ob jectiv es of the sim ulation study were therefore tw ofold: (i) to assess bias, precision, and frequenti st co v erage of credible/confidence interv als of the prop osed causal mo del approac hes under differen t scenarios of ICE rates and missingness; and (ii) to ev aluate ho w the p erformance of the new metho ds compares to traditional RBI and retriev ed drop out metho ds. 13 0 5 10 15 0 2 4 6 8 visit Mean Profiles Reference arm (hypothetical) Treatment arm (hypothetical) Marginal mean ( k 0 = 0 ) Marginal mean ( k 0 = 1 ) Marginal mean ( k 0 = 0.5 ) Figure 1: Implied mean tra jectories under the causal mo del. The blue, red and black lines show the implied mean tra jectories for someone who discontin ues active treatmen t after visit 2 for k 0 = 0, k 0 = 0 . 5, and k 0 = 1, resp ectively . 3.1 Sim ulation Scenarios The design of our simulation study was adapted from Bell et al. [8], which in turn was mo delled to reflect the structure of the PIONEER 1 trial [13]. This trial ev aluated the efficacy of oral semaglutide monotherap y versus placeb o in patients with type 2 diabetes. In PIONEER 1, HbA1c levels were measured at weeks 0, 4, 8, 14, 20, and 26 for b oth treatmen t and placeb o arms. T o mirror this setting, we sim ulated h yp othetical on-treatment outcomes separately for the treatmen t and placeb o groups, generating outcomes for 500 patien ts p er arm from a multiv ariate normal distribution: Y iT ∼ M V N ( µ T , Σ) where T = a and T = r corresp ond to the active treatment and control arms, resp ec- tiv ely . The parameters used for the sim ulation are summarized in T able 1. 14 T able 1: Simulation parameters for HbA1c outcomes at each visit ( t j ) ov er 26 w eeks Visit ( t j ) Mean ( µ a ) Mean ( µ p ) V ariance* (Σ) 0 7.92 7.92 0.48 4 7.55 7.82 0.80 8 7.20 7.80 1.10 14 7.10 7.80 1.40 20 7.05 7.78 1.23 26 7.05 7.78 1.48 * The v alues represent the diagonal elements of the co v ariance matrix. The cov ari- ance matrix w as constructed using a first-order spatial p ow er structure: cor( t i , t j ) = ρ | t i − t j | / 4 , with ρ = 0 . 8. T reatment discontin uation w as modeled under t wo intercurren t ev en t (ICE) scenarios: lo w (25% in the control arm and 15% in the active treatmen t arm) and high (60% in the control arm and 50% in the active treatment arm) discontin uation rates. At eac h p ost-baseline visit j , the probabilit y of discon tinuation was sim ulated under a logistic regression, incorp orating baseline v alues, prior outcomes, and treatmen t assignment: logit( P ( D i = j | D i ≥ j, Y i 0 , Y ij − 1 , T )) = β m 0 + β T base × Y i 0 + β T prev × Y ij − 1 Here, β T base and β T prev are treatmen t-sp ecific regression co efficien ts (with T = a, p for activ e and placeb o), selected based on Bell et al. [8]. The in tercept β m 0 ( m = l ow , hig h ) w as calibrated to achiev e the target ov erall discontin uation rates in b oth treatment arms. Off-treatmen t outcomes for patients in the activ e group who discontin ued were simu- lated using the causal imputation mo del (Equation 2). W e considered tw o data-generating scenarios, with true v alues k 0 = 0 and k 0 = 1 corresp onding to J2R and CIR, resp ec- tiv ely . F or patien ts in the control group who discontin ued treatment, the distribution of off-treatmen t outcomes was assumed to remain unc hanged after the ICE. Missing p ost-ICE data were generated under a missing completely at random (MCAR) mec hanism among those who had the ICE. F or eac h individual who exp erienced an ICE, w e randomly determined whether they had complete p ost-ICE outcomes or whether all p ost-ICE outcomes were missing. W e considered four scenarios defined b y tw o scenarios of treatmen t discon tin uation (lo w and high) crossed with tw o probabilities of missingness. The resulting missing data scenarios follo wing treatment discon tin uation are summarised 15 in T able 3. T able 2: Logistic regression parameters for discon tin uation probability W eek β A base β A prev β P base β P prev β low 0 β hig h 0 8 0.30 1.14 0.30 1.14 -15 -13 14 0.10 1.47 0.10 1.33 -15 -13 20 0.05 1.48 0.05 1.51 -15 -13 26 0.00 1.40 0.00 1.46 -15 -13 T able 3: T reatmen t discon tin uation and missingness scenarios Scenarios (%) LD–LM LD– HM HD– LM HD– HM Activ e treatmen t Ov erall probability of discon tinuation 15 15 50 50 Probabilit y of missingness among those with ICE 20 90 20 90 Con trol treatmen t Ov erall probability of discon tinuation 25 25 60 60 Probabilit y of missingness among those with ICE 20 90 20 90 LD = low discon tinuation; HD = high discontin uation; LM = lo w missingness; HM = high missingness 3.2 Estimators F or each of 5,000 simulated datasets, we applied the following estimators of treatmen t effect at the final visit: • Complete-data analysis: W e conducted a complete-data analysis b y sim ulating a fully observed dataset in which p ost-ICE outcomes were generated under the causal mo del using the true parameter v alues. An ANCOV A mo del was then used to estimate the treatment effect at the final time p oin t, assuming that all post-ICE data were av ailable. Because, in practice, it is often not feasible to collect complete p ost-ICE data, this complete-data scenario serves as a b enchmark against which w e compare the metho ds describ ed in this section for handling missing p ost-ICE outcomes. 16 W e also analyzed the fully observ ed dataset with a Ba y esian BCM with a prior of k 0 ∼ N (0 , 100). This analysis w as p erformed to compare the resulting estimates with those obtained from the complete-data ANCO V A mo del. • Retrieved-dropout imputation: This metho d uses parameters estimated from the a v ailable p ost-ICE data to impute missing outcomes. The imputation mo del incorp orates observ ed data from previous visits together with a parameter that cap- tures eac h patient’s discon tinuation pattern b y that visit. This approach is similar to the Pattern In tercepts Common Slop es (PICS) mo del describ ed by Drury [4], whic h includes separate in tercept terms for eac h treatmen t discon tin uation pattern up to the ICE timepoint D = j . Retrieved-dropout imputation was p erformed using sequen tial imputation in the mice pack age in R. Both patients who exp erienced an ICE and those who did not contributed to the estimation of the imputation mo del, whic h was sp ecified as a normal linear regression model, separate for each time p oin t. At each time p oin t j , the imputation model included a co v ariate represen ting the discontin uation pattern at that visit, defined as the time since discontin uation and co ded as 0 for patients who had not y et discon tin ued b y visit j , and treated as a numeric v ariable thereafter. The mo del additionally included the baseline and previously observ ed outcomes Y
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment