Dual-branch Graph Domain Adaptation for Cross-scenario Multi-modal Emotion Recognition
Multimodal Emotion Recognition in Conversations (MERC) aims to predict speakers' emotional states in multi-turn dialogues through text, audio, and visual cues. In real-world settings, conversation scenarios differ significantly in speakers, topics, s…
Authors: Yuntao Shou, Jun Zhou, Tao Meng
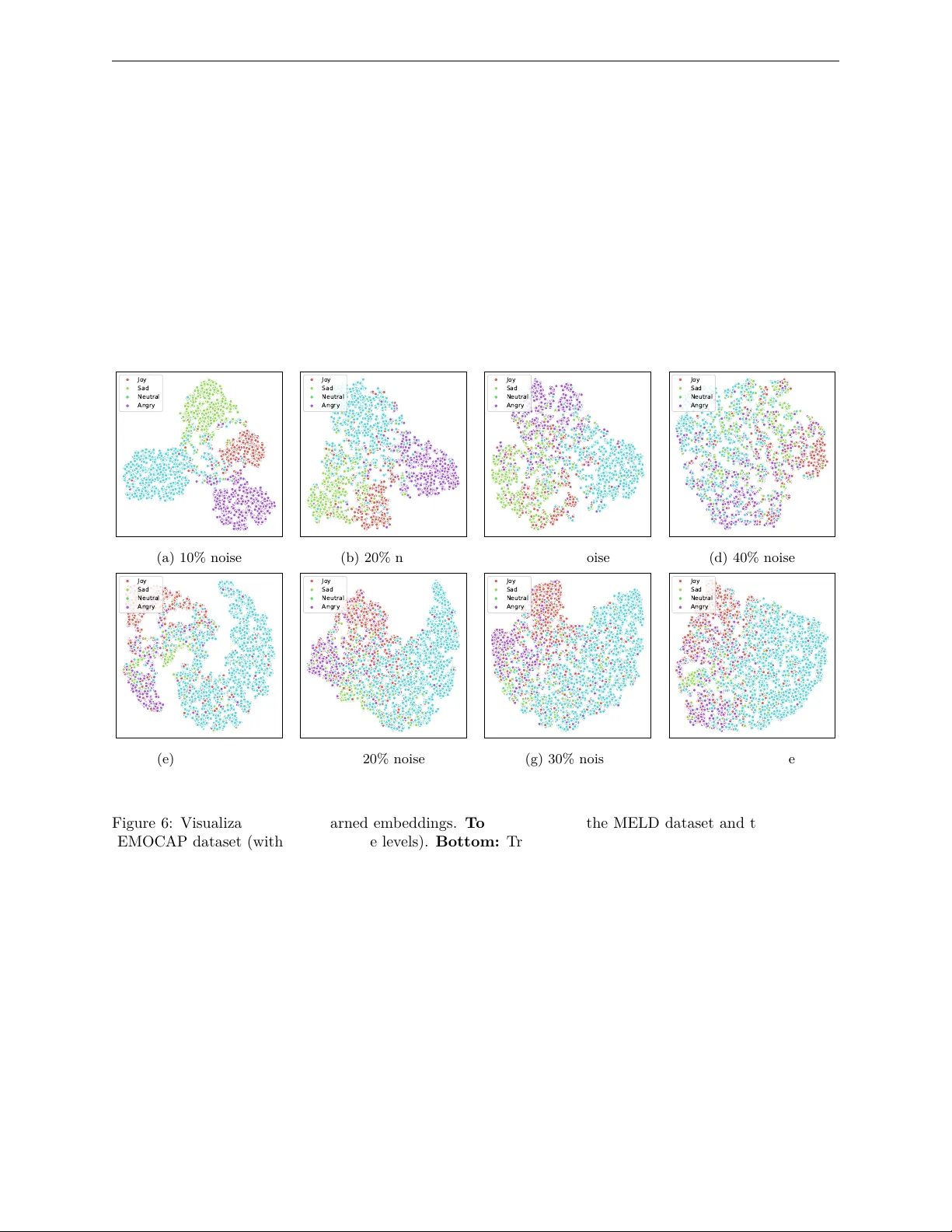
Dual-b ranch Graph Domain A daptation fo r Cross-scena rio Multi-mo dal Emotion Recognition Y un tao Shou shouyuntao@stu.xjtu.e du.cn Col le ge of Computer and Mathematics Centr al South University of F or estry and T echnolo gy Jun Zhou zhoujun@csuft.e du.cn Col le ge of Computer and Mathematics Centr al South University of F or estry and T echnolo gy T ao Meng mengtao@hnu.e du.cn Col le ge of Computer and Mathematics Centr al South University of F or estry and T echnolo gy W ei Ai aiwei@hnu.e du.cn Col le ge of Computer and Mathematics Centr al South University of F or estry and T echnolo gy Keqin Li lik@newp altz.e du Dep artment of Computer Scienc e State University of New Y ork Abstract Multimo dal Emotion Recognition in Con versations (MER C) aims to predict speakers’ emo- tional states in m ulti-turn dialogues through text, audio, and visual cues. In real-w orld settings, con versation scenarios differ significantly in sp eak ers, topics, styles, and noise lev- els. Existing MER C methods generally neglect these cross-scenario v ariations, limiting their abilit y to transfer mo dels trained on a source domain to unseen target domains. T o ad- dress this issue, w e propose a Dual-branch Graph Domain Adaptation framework (DGDA) for multimodal emotion recognition under cross-scenario conditions. W e first construct an emotion interaction graph to c haracterize complex emotional dep endencies among utter- ances. A dual-branc h encoder, consisting of a hypergraph neural netw ork (HGNN) and a path neural net work (P athNN), is then designed to explicitly mo del multiv ariate relation- ships and implicitly capture global dep endencies. T o enable out-of-domain generalization, a domain adv ersarial discriminator is introduced to learn inv arian t representations across domains. F urthermore, a regularization loss is incorporated to suppress the negativ e influ- ence of noisy labels. T o the best of our kno wledge, DGD A is the first MER C framework that jointly addresses domain shift and lab el noise. Theoretical analysis pro vides tigh ter generalization bounds, and extensiv e exp erimen ts on IEMOCAP and MELD demonstrate that DGD A consisten tly outp erforms strong baselines and b etter adapts to cross-scenario con v ersations. Our co de is a v ailable at https://gith ub.com/Xudmm1239439/DGDA-Net. 1 1 Intro duction Multimo dal emotion recognition in conv ersations (MER C) Shou et al. (2026b; 2022); Ai et al. (2025); Shou et al. (2024c;b); Meng et al. (2024b); Shou et al. (2025a) aims to predict the emotional state of participan ts in a multi-round conv ersation through m ultimo dal information (e.g., text, audio, and video) and has broad application prospects in dialogue generation Ghosh et al. (2017); T u et al. (2024); Zhang et al. (2024a); T ellamekala et al. (2023); W en et al. (2024); Meng et al. (2024a); Shou et al. (2026a; 2024a), so cial media analysis Khare & Ba ja j (2020); P eng et al. (2024); Xu et al. (2025); Huang et al. (2020), in telligent systems lik e smart homes and c hatb ots Y oung et al. (2018); Lu et al. (2025); Kang & Cho (2025); Li et al. (2025); Shou et al. (2025b); Ai et al. (2026). N o t rai n i n g re q u i r ed fo r the t arg et d o mai n V id eo A u d io T ex t V id eo A u d io T ex t O h w ha t, yo u w a n t both of them? Oh! I thought you guys got . . . L ab e l e d S ou r c e D om ain Unl ab e l e d T ar ge t D om ain Enc oder Em otion Classifier … … T ra i ning Free ze d u ri n g i n fe ren ce (a ) Co m mo n M E RC method s V id eo A u d io T ex t V id eo A u d io T ex t O h w ha t, yo u w a n t both of them? Oh! I thought you guys got . . . L ab e l e d S ou r c e D om ain Unl ab e l e d T ar ge t D om ain Dua l B ra nc h En c ode r T ra i ning (b) Ou r P ropos ed DG DA Em otion Classifier … … D oma in A dve r sa r i a l Alignm e nt R e gula riz a ti on Co nstra int L oss S ourc e domain Ta r ge t doma in Figure 1: (a) Common MERC metho ds. A w ell-crafted encoder architecture is used to ac hiev e m ultimo dal emotion recognition without considering out-of-domain distribution differences. (b) Our Prop osed Dual- branc h Graph Domain A daptation (DGDA) method. DGD A exploits a dual-branc h enco der to explicitly and implicitly extract m ultimo dal features, and constructs a domain adv ersarial alignment strategy and regularization loss to ac hieve out-of-domain distribution data generalization and resistance to noise label in terference. In the MER C task, researchers mainly focus on learning the emotional feature represen tation of in-domain data. As shown in Fig. 1 (a), a well-crafted enco der-classifier architecture is used to achiev e multimodal emotion recognition without considering out-of-domain distribution differences. The mainstream MERC metho d mainly uses T ransformers Hazmoune & Bougamouza (2024); Lian et al. (2021); Ma et al. (2023); Shou et al. (2025d;g) and graph neural net works (GNN) Y ang et al. (2024); Chen et al. (2023); Shou et al. (2025e;i; 2023; 2025c) as the enco der to mo del con textual dep endency information and sp eaker dep endency . Although existing metho ds hav e ac hiev ed relatively go o d emotion recognition results, they ignore the impact of cross-domain distribution differences on emotion recognition p erformance. In other w ords, there ma y b e significan t differences in language st yles, emotional expressions, and contextual environmen ts in different domains, and these differences ma y lead to the limited generalization capabilities of the mo del. F urthermore, if some samples in the dataset are incorrectly lab eled, e.g., the emotion of anger is incorrectly lab eled as neutral, then the mo del may learn these wrong patterns during training. As a result, the model may misclassify the angry emotion as neutral in practical applications, thus affecting the accuracy and reliability of emotion recognition Lian et al. (2023); W agner et al. (2023); Shou et al. (2025f). T o address the ab ov e problems, we prop ose a Dual-branch Graph Domain Adaptation (DGD A) for multi- mo dal emotion recognition in cross-scenario conv ersations, as shown in Fig. 1 (b). Sp ecifically , to capture the discriminative features of emotion in multimodal utterances, we first construct an emotion interaction graph to model the complex emotional dep endencies b etw een utterances. Then, we design a h yp ergraph aggregation and path aggregation dual-branc h graph enco der to explicitly and implicitly capture the dynamic c hanges in emotion betw een utterances and explore m ultiv ariate relationships, resp ectiv ely . T o address the problem of out-of-domain distribution differences, we in tro duce a domain adversarial classifier to improv e the represen tation abilit y of in v ariant features in the source domain. In addition, we construct a regularization loss to prev ent the model from memorizing noise and improv e the mo del’s ability to resist in terference from noisy labels in source domains. Extensiv e experiments and ev aluations demonstrate DGDA’s sup eriority . The main contributions of this pap er are summarized as follows: 2 • T o the b est of our knowledge, we make the first attempt to simultaneously mitigate domain shift and noisy lab el interference problems in MERC scenarios, thereby enhancing usability in real-world scenarios. • W e impro v e the expressiveness of domain-inv arian t features of the original graph by in tro ducing a domain adv ersarial classifier and solving the problem of out-of-domain distribution differences. • W e added a regularization constraint loss on the basis of the cross-entrop y loss term to effectively suppress the mo del’s ov er-learning of noisy lab els and encourage the mo del to pay more attention to the real signals in the data. • W e provide theoretical pro of to ensure that the designed DGDA is more precisely tailored for cross- scenario conv ersations. Extensive exp eriments conducted on the IEMOCAP and MELD datasets sho w ed that DGD A is significantly b etter than existing baseline metho ds. 2 Related w ork 2.1 Multimo dal Emotion Recognition in Conversations Multimo dal emotion recognition in conv ersations (MERC) has emerged as a key research area in artificial in telligence, esp ecially at the in tersection of natural language pro cessing (NLP), computer vision (CV), and sp eec h pro cessing Li et al. (2024b); Liu et al. (2024a); T ao et al. (2025); Qin et al. (2025); Shou et al. (2025c;h). Its ob jective is to infer human emotional states b y jointly analyzing textual conten t, acoustic cues, and visual expressions Sun et al. (2024); Chen et al. (2024); Guo et al. (2025); T ang et al. (2025). RNN-based MERC metho ds primarily fo cus on extracting contextual semantic information by mo deling sequential dep endencies within multimodal inputs through recurrent memory units Ma jumder et al. (2019); Huddar et al. (2021); Ho et al. (2020). T ransformer-based metho ds leverage self-attention and multi-head attention mec hanisms, often com bined with pretrained language mo dels, to capture long-range dep endencies in conv ersations and achiev e more effectiv e multimodal fusion Zhao et al. (2023); Ma et al. (2023). Meanwhile, GCN-based approaches uti- lize the structural flexibility of graph conv olutional net w orks to mo del in ter-utterance relations, multimodal asso ciations, and laten t in teraction patterns within dialogues Ren et al. (2021); Y uan et al. (2023); Ai et al. (2024). Despite their effe ctiveness within individual datasets, these metho ds gener al ly overlo ok the chal lenges of cr oss-sc enario multimo dal emotion r e c o gnition and exhibit limite d gener alization when applie d to out-of- domain c onversational distributions. Existing mo dels often rely heavily on dataset-sp ecific characteristics and struggle to maintain stable p erformance when domain shifts arise, such as v ariations in conv ersation st yles, recording conditions, sp eaker demographics, or mo dality quality . This vulnerability leads to degraded robustness and restricts the deploymen t of MERC systems in real-world, heterogeneous environmen ts. In c ontr ast, as il lustr ate d in Fig. 2, our pr op ose d DGDA fr amework explicitly addr esses this limitation by in- tr o ducing a domain adversarial classifier. This c omp onent enc our ages the mo del to le arn domain-invariant fe atur e r epr esentations thr ough an adversarial optimization pr o c ess, ther eby mitigating domain discr ep ancies b etwe en the sour c e and tar get distributions. By enhancing the extr action of shar e d, stable, and tr ansfer able multimo dal fe atur es, DGDA signific antly impr oves the mo del’s c ap ability to gener alize to out-of-domain c on- versational datasets and ensur es mor e r obust emotional understanding acr oss diverse r e al-world sc enarios. 2.2 Graph Domain Adaption Graph domain adaptation is a core issue in graph transfer learning Qiu et al. (2020); Sun et al. (2022); Liu et al. (2024b); Zhang et al. (2025); Shou et al. (2024d) and has received increasing attention in recent years, particularly in fields such as so cial netw orks and molecular biology Y ou et al. (2023); Chen et al. (2025); Zhang et al. (2024c). Early studies mainly fo cused on transferring knowledge from a well-labeled source graph to an unlab eled target graph, aiming to learn discriminative representations for target graph no des through lab el sup ervision from the source domain W u et al. (2020); Jin et al. (2024); Dan et al. (2024). These metho ds generally rely on propagating information along graph top ology so that the target graph can inherit seman tic cues and structural priors from the source graph. More recent researc h has further extended this paradigm to the graph-level setting, where multiple lab eled source graphs must guide an unlab eled target 3 graph Y ang et al. (2020); Hu et al. (2024). In this scenario, the challenges go b ey ond simple no de-level transfer; mo dels must also handle semantic alignment, structural corresp ondence, and cross-graph knowledge in tegration at a holistic level Yin et al. (2022). A c hieving suc h adaptation requires capturing similarities and discrepancies across heterogeneous graph distributions, reconciling differen t structural patterns, and transferring high-level semantic information. How ever, current graph-based domain adaptation metho ds face sev eral fundamental limitations. Most mo dels rely heavily on message-passing mechanisms that aggregate information from lo cal neigh b orho o ds. Although effective for learning lo calized patterns, such approac hes struggle to capture high-order semantic dependencies, long-range relational structures, and global graph top ology . As a result, they ma y fail to mo del complex structural v ariations b etw een the source and target graphs, leading to insufficient domain alignmen t. In addition, existing metho ds typically assume that lab els in the source domain are clean and reliable. In real-world scenarios, how ever, labeled graphs often contain noisy , am biguous, or ev en contradictory annotations. Suc h label noise can propagate through the message-passing pro cess, amplifying errors and degrading representation quality . The lack of explicit mechanisms to suppress noisy-lab el in terference further limits the robustness and generalization p erformance of current approac hes. Ther efor e, mor e advanc e d gr aph domain adaptation metho ds ar e ne e de d to simultane ously c aptur e glob al semantic structur es and pr ovide r obustness against lab el noise, enabling mor e ac cur ate and r eliable cr oss- gr aph know le dge tr ansfer. 3 METHODOLOGY 3.1 T ask Definition In the task of Cross-Scenario Multimo dal Emotion Recognition, we aim to build robust emotion recognition mo dels that can generalize across diverse domains or scenarios, suc h as differen t datasets, environmen ts, recording conditions, or sp eak er groups. F ormally , we assume a set of sp eakers S = { s 1 , s 2 , . . . , s M } partici- pating in emotionally rich con versations. Each con versation is composed of a sequence of utterances in chrono- logical order, denoted as U = { u 1 , u 2 , . . . , u N } , where N is the total n um b er of utterances. Each utterance u i is asso ciated with a sp eaker s p i , defined through a sp eaker mapping function p ( · ) : { 1 , . . . , N } → { 1 , . . . , M } . F urthermore, each utterance u p i con tains multimodal information, including textual modality u t p i , visual mo dalit y u v p i , and acoustic mo dalit y u a p i . Unlike traditional emotion recognition tasks that assume training and testing data come from the same distribution, cross-scenario multimodal emotion recognition explicitly considers the domain shift b etw een source and target scenarios. These shifts may arise due to v ariations in background, lighting, language usage, sp eaker identit y , or even cultural differences. The ob jective is to predict the discrete emotion lab els for each utterance in the target scenario, leveraging the m ultimo dal in- formation while ensuring robust generalization from the source to the target domain. This problem setting p oses unique c hallenges, suc h as mo dalit y-sp ecific noise, seman tic gaps b et ween scenarios, and inconsisten t emotion distributions. Therefore, effective cross-scenario multimodal emotion recognition mo dels must learn domain-in v arian t y et emotion-discriminativ e represen tations across mo dalities and scenarios. 3.2 Multimo dal Feature Extraction W e extract unimo dal features at the utterance level as follows. F ollowing our previous work Ma et al. (2023), w e introduce the RoBER T a Large mo del Kim & V ossen (2021) for text feature extraction. The dimension of the final text feature representati on is 1024. W e use op enSMILE Eyb en et al. (2010) to extract acoustic features. After feature extraction using op enSMILE, we p erform dimensionalit y reduction on the acoustic features through fully connected (FC) lay ers, reducing the feature dimension to 1582 for the IEMOCAP dataset and 300 for the MELD dataset. W e use the DenseNet mo del Huang et al. (2017) pre-trained on the F acial Expression Recognition Plus dataset for visual feature extraction. In the pro cess of visual feature extraction, w e use the output dimension of DenseNet as 342. 3.3 Mo dal Feature Enco ding F or the MERC, the original dimensionality spaces of text, visual, and acoustic mo dalities are usually sig- nifican tly differen t, which makes them not directly usable for graph construction or fusion. T o address this 4 Lab el e d Source D omain Unlabeled Target D omain Fea t u re E x t rac t i o n A d a p t i v e Pe rt u rb at i o n fo r G rap h D o m ai n A l i g n me n t Co n t ex t u al F eat u re s E x t ra ct i o n FC FC FC FC Bi - GRU Bi - GRU A d d δ t o Node F e a ture s D u a l Bra n ch G rap h E n c o d er F(· ) D u a l Bra n ch G rap h E n c o d er F(· ) Sha r e d P a r a met er s Per tur ba ti on δ Use pe rtur b to pe r for m attac k D o m ai n A d v ers ari al A l i g n m en t E mo t i o n Cl as s i fi er E mo t i o n Cl as s i fi er D o m ai n D i s cr i mi n at o r … … Rel i ab l e P s eu d o L ab el s So u r ce Cl as s i fi c at i o n L o s s D o m ai n D i s cr i mi n at i o n Lo s s T arg et C l as s i fi cat i o n L o s s D eco u p l i n g D u al B ran ch es fo r C at eg o r y A l i g n ment So u r ce c at eg o r y d i s t r i b u t i o n T arg et c at eg o r y d i s t r i b u t i o n Ps eu d o - l ab e l s So u r ce la b e l s Features Extra ct i ng Features Extra ct i ng FC FC FC FC Bi - GR U Bi - GR U V id eo A u d io Te x t Oh wh at, y o u wan t b o th o f th em ? Oh ! I th o u g h t y o u g u y s g o t ... Te x t V id eo A u d io So u r ce D o mai n U t t era n ce s I n t er act i o n G rap h T arg et D o mai n U t t era n ce s I n t er act i o n G rap h R eg u l ar i za t i o n Co n s t rai n t L o s s Tex t A udi o V i s ua l N o t a ti o ns : In ter - m o d a l agg reg a t i o n I ntra - m o d a l agg reg a t i o n Figure 2: An o verview of the proposed DGD A framework. The model operates on a lab eled source domain and an unlab eled target domain. In b oth domains, audio, visual, and text features are first extracted and used to construct utterance-level in teraction graphs. A dual-branc h graph enco der encodes these graphs. F or domain alignment, the source domain is adaptively perturb ed b y a learned noise δ , while a domain discriminator promotes feature in v ariance across domains. Mean while, category-level alignmen t is enforced b y coupling the dual-branch outputs. The final emotion classifier is trained using source labels and pseudo- lab eled target samples. problem, w e design a shallo w feature extractor that con tains three indep endent encoders to map them into the same dimensional space. F or text modality , w e use a bidirectional gated recurren t unit (Bi-GRU) Poria et al. (2017) to capture the bidirectional dep endencies of context. How ever, through empirical observ ation Chen et al. (2023), w e find that using recurrent neural net work mo dules to enco de visual and acoustic mo dalities do es not bring p erformance improv ements. Therefore, we use a simple and efficient linear lay er to conv ert them to the same dimensional space as the text mo dalit y . After feature extraction, we then input it in to the subsequent emotion reasoning netw ork. 3.4 Dual Branch Enco der Hyp ergraph neural netw ork (HGNN) branch. T raditional graph neural netw orks (GNNs) usually represen t graph structures through no des and edges, while hypergraph neural netw orks (HGNNs) further extend this framework by allowing a h yp eredge to connect m ultiple nodes, thereby effectively mo deling complex relationships and high-order dep endencies. Sp ecifically , given a sequence of utterances containing N dialogue turns, w e construct a h yp ergraph H = ( V , E , H ) , where V is a set of nodes, E is a set of h yp eredges, and H is an incidence matrix. Each no de v ∈ V corresp onds to a unimo dal utterance. Each h yp eredge e ∈ E enco des high-order dep endencies betw een multimodal data and is assigned a w eight w ( e ) . Eac h hyperedge e ∈ E and each no de v ∈ V asso ciated with e is also assigned a w eigh t w e ( v ) . Incidence matrix H ∈ R | V |×| E | represen ts the relationship b etw een no des and hyperedges. If no de v is asso ciated with h yp eredge e , then H v e = 1 , otherwise H v e = 0 . F ollo wing the paradigm of previous work Chen et al. (2023), w e adopted the no de-hyperedge information interaction mechanism to achiev e iterative up date and fusion of features by alternately performing node con volution and h yp eredge con volution. Mathematically , H ( l +1) = σ D − 1 HW e B − 1 ˆ H ⊤ H ( l ) , (1) 5 where H ( l ) = { v x i, ( l ) | i ∈ [ 1 , N ] , x ∈ { t, a, v }} ∈ R | H |× D is the input at lay er l , v t i , v a i , v v i is the textual mo dality , acoustic mo dality and visual mo dality , resp ectively , W e = diag ( w ( e 1 ) , ..., w ( e | E | )) is the hyperedge weigh t matrix, B and D are the hyperedge degree and no de degree matrix, respectively . P ath neural net works (P athNN) branch . T o effectiv ely capture the global dep endencies b etw een no des, w e introduced PathNN Michel et al. (2023) into the mo del to make up for the lack of mo deling capabilities of long-distance node relationships based on neigh b or aggregation metho ds when dealing with complex graph structures. W e first extract the feature represen tations of each no de in the path based on the predefined paths in the graph, and then fuse the information of the no des in the path into path representations through path aggregation operations. Finally , these path representations will b e reversely injected into the start and end no des asso ciated with the path to achiev e feedback of path information and enhancemen t of no de represen tation. Supp ose there is a set of paths P , each path is represented as p = ( v 1 , v 2 , ..., v l ) , where v i is the i -th no de in the path and l is the path length. T o further improv e the expressiv eness of node feature aggregation within a path and dynamically capture the imp ortance of different no des in path representation, w e introduced an aggregation metho d based on the attention mechanism. W e first calculate the atten tion score α v i for eac h node in the path, defined as follo ws: α v i = exp LeakyReLU a ⊤ [ Wh v i ∥ c p ] P l j =1 exp LeakyReLU a ⊤ [ Wh v j ∥ c p ] , (2) where W is a learnable matrix, c p is the path global context vector, a is a learnable attention weigh t vector, and [ · || · ] represents a v ector concatenation op eration. Next, the path represen tation h p is obtained b y w eigh ted summing of the node features in the path according to the atten tion w eights: h p = l X i =1 α v i · Wh v i . (3) Finally , the path information is passed bac k to the path-related no des and up dated as follo ws: h ( new ) v i = h ( old ) v i + X p ∈P ( v i ) 1 |P ( v i ) | h p , (4) where P ( v i ) is the set of paths asso ciated with no de v i . 3.5 A dversarial Alignment for Domain Adaptation T o alleviate the distribution difference b etw een the source domain and the target domain in the multimodal graph semantic space and promote the consistency of the feature space, w e in tro duced the adaptiv e p ertur- bation and adv ersarial alignmen t mec hanisms in b oth the HGNN branch and the PathNN branc h. The core idea is to enhance the robustness of the model to domain changes by introducing learnable p erturbations in the feature space, and dynamically optimizing the distribution of source domain and target domain features with the help of adv ersarial training to align them in the feature space. Specifically , for the original no de feature H extracted by the HGNN branch and the PathNN branc h, we first generate a p erturbation vec- tor for it through the adaptive p erturbation generator and inject it into the original feature to obtain the p erturb ed feature representation: e H H GN N = H H GN N + δ H GN N · M ( H H GN N ) , e H P athN N = H P athN N + δ P athN N · M ( H P athN N ) , (5) where δ is the p erturbation intensit y co efficient and M ( · ) is the p erturbation generation netw ork, usually MLP . Next, we designed a domain discriminator to distinguish whether the features come from the source domain H src or the target domain H tg t as follo ws: L D = − E e H src [log D ( e H src )] − E e H tgt [log(1 − D ( e H tg t ))] . (6) 6 The feature extractor (i.e., HGNN and PathNN branch) optimization objectives are as follo ws: L adv = − E e H tgt [log D ( e H tg t )] . (7) During the training process, the domain discriminator and feature extractor are optimized alternately . The former attempts to correctly distinguish the source/target domain features, while the latter is con tinuously optimized b y introducing p erturbations and adv ersarial training so that the distributions of the t w o gradually con v erge. 3.6 Branch Coupling for High-confidence Pseudo-lab el Generation In the cross-session m ultimo dal emotion recognition task, the source domain data has re liable emotion lab els, while the target domain has the problem of missing labels. Directly assigning pseudo lab els to target samples for training often introduces noise due to lo w-confidence lab els, affecting mo del p erformance. T o this end, we prop ose branc h coupling to generate high-confidence pseudo lab els, aiming to make full use of the complementary features of the HGNN p θ and the PathNN q ϕ branc h in graph seman tic mo deling and jointly optimize the quality of pseudo lab els. W e maximize the evidence low er b ound (ELBO) of the log-lik eliho o d with the source and target lab els y s and y t : log p θ ( y s | G s , G t ) = log Z p θ ( y s , y t | G s , G t ) dy t = log Z p θ ( y s , y t | G s , G t ) q ϕ ( y t | G t ) q ϕ ( y t | G t ) dy t ≥ Z q ϕ ( y t | G t ) log p θ ( y s , y t | G s , G t ) q ϕ ( y t | G t ) dy t ≥ E q ϕ ( y t | G t ) log p θ ( y s , y t | G s , G t ) − log q ϕ ( y t | G t ) . (8) The traditional ELBO optimization strategy is mainly used to learn the approximate distribution q of the target distribution p . How ever, the HGNN branch and the PathNN branch can mo del the p otential lab el distribution of the samples resp ectively , one of which acts as the target distribution p , providing a relativ ely stable teac her signal, and the other as the appro ximate distribution q , which is as close to the target distribution as p ossible by maximizing the ELBO. T o b e sp ecific, the ELBO in Eq. 8 can b e equiv alently written as: E q ϕ ( y t | G t ) log p θ ( y t | G s , G t , y s ) p θ ( y s | G s ) − log q ϕ ( y t | G t ) = E q ϕ ( y t | G t ) log p θ ( y t | G s , G t , y s ) q ϕ ( y t | G t ) + E q ϕ ( y t | G t ) [ p θ ( y s | G s )] = − K L ( q ϕ ( y t | G t ) ∥ p θ ( y t | G s , G t , y s )) + E q ϕ ( y t | G t ) [ p θ ( y s | G s )] . (9) When optimizing the HGNN branch, we use the distribution q ϕ of the P athNN branch output as the target and calculate the loss of the HGNN branch to appro ximate this distribution. Con versely , when optimizing the PathNN branch, we fix the distribution p θ of the HGNN branch and use it as the optimization target of the P athNN branc h. Based on the abov e ideas, we define the optimization loss functions of the HGNN and P athNN branc hes when they are up dated alternately as follo ws: L 1 = E p θ ( ˆ y t i | G t ) >ζ log q ϕ y s i , ˆ y t i | G s i , G t i − log q ϕ ˆ y t i | G t i − E q ϕ ( y s ,G s ) log p θ ( y s i | G s i ) , L 2 = E p ϕ ( ˆ y t i | G t ) >ζ log q θ y s i , ˆ y t i | G s i , G t i − log q θ ˆ y t i | G t i − E q θ ( y s ,G s ) log p ϕ ( y s i | G s i ) , (10) where ˆ y t i is the target pseudo-lab el filtered by the HGNN or PathNN branch. It should b e noted that we in tro duced a confidence threshold ζ to ensure that only those samples with higher confidence and more reliable prediction results can participate in the subsequen t optimization process. Theorem 1. F or a deviation measure based on the lab el function max G 1 ,G 2 | ˆ h D ( G 1 ) − ˆ h D ( G 2 ) | η ( G 1 ,G 2 ) = C h ≤ C f C g ( D ∈ { S, T } ) , let H := { h : G → Y } denote a set of b ounded real-v alued functions that map from feature space 7 G to label space Y , the samples closest to the source domain distribution are selected in the target domain, the empirical risk ˆ ϵ T in the target domain can be significan tly reduced: ϵτ ( h, ˆ h T ) ≤ N ′ T N S + N ′ T ˆ ϵ T ( h, ˆ h T ) + N S N S + N ′ T ˆ ϵ S ( h, ˆ h S ) + r 4 d N S log( eN S d ) + 1 N S log( 1 δ ) + N S N S + N ′ T 2 C f C g W 1 ( P S ( G ) , P T ( G )) + ω ≤ ˆ ϵ S ( h, ˆ h ) + r 4 d N S log( eN S d ) + 1 N S log( 1 δ ) + 2 C f C g W 1 ( P S ( G ) , P T ( G )) + ω ′ , (11) where ω = min ∥ g ∥ Lip ≤ C g , ∥ f ∥ Lip ≤ C f { ϵ S ( h, ˆ h S ) + ϵ T ( h, ˆ h S ) } and ω ′ = min ( | ϵ S ( h, ˆ h S ) − ϵ S ( h, ˆ h T ) , ϵ T ( h, ˆ h S ) − ϵ T ( h − ˆ h T ) . 3.7 Mo del T raining In cross-scenario emotion recognition, although the source domain data has lab els, a certain prop ortion of lab eling errors are inevitable in the real-w orld lab eling pro cess Liu et al. (2020). Meanwhile, in the pro cess of generating pseudo-labels in the target domain, inaccurate pseudo-lab els are also inevitable. If noisy lab els are used directly for mo del training, it is easy to cause the mo del to ov erfit the noise samples in the tw o branc hes of HGNN and PathNN. T o alleviate this problem, w e prop ose to introduce a regularization term in the cross- en trop y loss. By introducing historical prediction results, the mo del can suppress the high-confidence fitting of labels in the later stage of training. Mathematically: L CLS = − 1 N N X i =1 y i log p θ ( y | x i ) + λ · 1 N N X i =1 log (1 − ⟨ p θ ( y | x i ) , ˆ p i ⟩ ) ! , (12) where λ is the w eight coefficient and ˆ p i is the exponential mo ving av erage (EMA) of the model’s predicted probabilit y for sample x i in the early training stage. Theorem 2. Assume the input space is X ⊆ R d and the lab el space is Y = { 1 , 2 , ..., K } . The real data distribution is D , and the observ ation distribution with noisy lab els is ˜ D , where the upp er limit of the noise ratio is η ≤ 0 . 5 . In the early stage of training (the first T 0 steps), the mo del’s prediction of clean samples satisfies p i θ i ( x ) ≈ y i , where t ≤ T 0 , and ( x, y ) comes from the clean data subset D clean ⊂ ˜ D 2 , w e then hav e: p θ ( y i | x i ) ≈ ˜ y i ˜ y i + λy i (1 − p θ ( y i | x i )) . (13) Theorem 3. Assume that the mo del complexity is characterized by Rademacher complexity R n ( F ) Yin et al. (2019). F or an y δ > 0 , the generalization error upp er b ound of L CLS satisfies with probability 1 − δ : GenError L CLS ≤ GenError L CE ≤ 2 R n ( F ) √ λ + r log(1 /δ ) 2 n + O η + ϵ µ . (14) 4 DET AILED PROOFS 4.1 Pro of of Theo rem 1 In tuitiv ely , by com bining training samples from the target and source domains, the class distributions betw een the t w o domains can b e effectively aligned. Here, w e pro vide a theoretical analysis to supp ort this intuition. Sp ecifically , we prov e that after in tro ducing the class distribution alignment mo dule, the empirical risk low er b ound in the target domain can b e significan tly reduced compared to mo dels without this mo dule. Before presen ting our results, we first introduce a lemma Redko et al. (2017); Shen et al. (2018); W ang et al. (2024b), whic h is used in our proof: 8 Lemma 1. L et the le arne d discriminator g b e C g -Lipschitz c ontinuous, wher e the Lipschitz norm is define d as || g || Lip = max Z 1 ,Z 2 | g ( Z 1 ) − g ( Z 2 ) | ρ ( Z 1 ,Z 2 ) , ρ is a Euclide an distanc e function, and H := { g : Z → Y } denote a set of b ounde d r e al-value d functions define d on the input sp ac e Z and mapp e d to the output sp ac e Y . A ssume that the pseudo-dimension of this set of functions is d, i.e., P dim ( H ) = d . A b ound on the r elationship b etwe en empiric al risk and true risk holds for the discriminator g ∈ H with pr ob ability at le ast 1 − δ : ϵ T ( h, ˆ h ) ≤ ˆ ϵ S ( h, ˆ h ) + r 4 d N S log( eN S d ) + 1 N S log( 1 δ ) + 2 C f C g W 1 ( P S ( G ) , P T ( G )) + ω T ( G ) , (15) wher e ω = min || g || Lip ≤ C g { ϵ S ( g , ˆ g ) + ϵ T ( g , ˆ g ) } denotes the mo del discriminative ability, and the W asserstein distanc e is define d as Vil lani et al. (2009): W 1 ( P , Q ) = sup || g || Lip ≤ 1 E P S ( Z ) g ( Z ) − E P T ( Z ) g ( Z ) . (16) No w, w e presen t our theoretical results in the follo wing theorem, as w ell as its pro of. Theorem 1. F or a deviation measure based on the lab el function max G 1 ,G 2 | ˆ h D ( G 1 ) − ˆ h D ( G 2 ) | η ( G 1 ,G 2 ) = C h ≤ C f C g ( D ∈ { S, T } ) , let H := { h : G → Y } denote a set of b ounded real-v alued functions that map from feature space G to lab el space Y , under the assumptions of Lemma 1 and the following assumptions: And w e ha ve 1. Assume a small n umber of pseudo-lab eled indep endent and identically distributed samples { ( G n , Y n ) } N ′ T n =1 , where N ′ T ≪ N S (the num b er of target domain samples is muc h smaller than source domain samples). 2. Assume the source domain and the target domain hav e differen t lab el functions, satisfying ˆ h S = ˆ h T . 3. Assuming the samples closest to the source domain distribution are selected in the target domain, the empirical risk ˆ ϵ T in the target domain can be significan tly reduced. ˆ ϵ T ≤ ϵ T ≤ ˆ ϵ S ( h, ˆ h ) + r 4 d N S log( eN S d ) + 1 N S log( 1 δ ) + 2 C f C g W 1 ( P S ( G ) , P T ( G )) + ω ′ , (17) where ω ′ = min || g ||| Lip ≤ C g , || f || Lip ≤ C f { ϵ S ( h, ˆ h ) + ϵ T ( h, ˆ h ) } , ˆ ϵ T is the empirical risk on the high confi- dence samples, ϵ S is the empirical risk on the target domain. 4. Assume the pseudo-dimension of this set of functions is P dim ( H ) = d . F or any function h ∈ H , with probabilit y of at least 1 − δ , the following inequality holds: ϵ T ( h, ˆ h T ) ≤ ˆ ϵ S ( h, ˆ h S ) + r 4 d N S log( eN S d ) + 1 N S log( 1 δ ) + 2 C f C g W 1 ( P S ( G ) , P T ( G )) + ω , (18) where ω = min || g ||| Lip ≤ C g , || f || Lip ≤ C f { ϵ S ( h, ˆ h S ) + ϵ T ( h, ˆ h S ) } . Pr o of. W e first introduce the follo wing inequalit y to b e used: | ϵ S ( h, ˆ h S ) − ϵ T ( h, ˆ h T ) | = | ϵ S ( h, ˆ h S ) − ϵ S ( h, ˆ h T ) + ϵ S ( h, ˆ h T ) − ϵ T ( h, ˆ h T ) | ≤ | ϵ S ( h, ˆ h S ) − ϵ S ( h, ˆ h T ) | + | ϵ S ( h, ˆ h T ) − ϵ T ( h, ˆ h T ) | ( a ) ≤ ϵ S ( h, ˆ h S ) − ϵ S ( h, ˆ h T ) + 2 C f C g W 1 ( P S ( G ) , P T ( G )) , (19) where (a) results from Shen et al. (2018) Lemma 1 with the assumption max ( || h || Lip , max G 1 ,G 2 | ˆ h D ( G 1 ) − ˆ h D ( G 2 ) | η ( G 1 ,G 2 ) ) ≤ C f C g , D ∈ { S, T } . Similarly , w e obtain: 9 | ϵ S ( h, ˆ h S ) − ϵ T ( h, ˆ h T ) | ≤ | ϵ T ( h, ˆ h S ) − ϵ T ( h, ˆ h T ) | + 2 C f C g W 1 ( P S ( G ) , P T ( G )) . (20) Com bining Eqs 19 and 20, w e can obtain: | ϵ S ( h, ˆ h S ) − ϵ T ( h, ˆ h T ) | ≤ 2 C f C g W 1 ( P S ( G ) , P T ( G )) + min | ϵ S ( h, ˆ h S ) − ϵ S ( h, ˆ h T ) | , | ϵ T ( h, ˆ h S ) − ϵ T ( h, ˆ h T ) | . (21) Therefore, w e can derive the generalization error bound on the target domain ϵ T ( h, ˆ h T ) : ϵ T ( h, ˆ h T ) ≤ ϵ S ( h, ˆ h S ) + 2 C f C g W 1 ( P S ( G ) , P T ( G )) + min | ϵ S ( h, ˆ h S ) − ϵ S ( h, ˆ h T ) | , | ϵ T ( h, ˆ h S ) − ϵ T ( h, ˆ h T ) | . (22) W e next link the b ound with the empirical risk and lab eled sample size by sho wing, with probability at least 1 − δ that: ϵ T ( h, ˆ h T ) ≤ ϵ S ( h, ˆ h S ) + 2 C f C g W 1 ( P S ( G ) , P T ( G )) + min | ϵ S ( h, ˆ h S ) − ϵ S ( h, ˆ h T ) | , | ϵ T ( h, ˆ h S ) − ϵ T ( h, ˆ h T ) | ≤ ˆ ϵ S ( h, ˆ h S ) + 2 C f C g W 1 ( P S ( G ) , P T ( G )) + min | ϵ S ( h, ˆ h S ) − ϵ S ( h, ˆ h T ) | , | ϵ T ( h, ˆ h S ) − ϵ T ( h, ˆ h T ) | + r 2 d N S log( eN S d ) + r 1 2 N S log( 1 δ ) , (23) and according to previous work Mohri (2018), the upp er b ound of the target domain generalization error ϵ T ( h, ˆ h T ) is defined as follows: ϵ T ( h, ˆ h T ) ≤ ˆ ϵ T ( h, ˆ h T ) + s 2 d N ′ T log( eN ′ T d ) + s 1 2 N ′ T log( 1 δ ) , (24) 10 Com bining Eq. 23 and 24, w e can derive: ϵ T ( h, ˆ h T ) ( a ) ≤ N ′ T N S + N ′ T ˆ ϵ T ( h, ˆ h T ) + r 2 d N ′ T log( eN ′ T d ) + r 1 2 N ′ T log( 1 δ ) + N S N S + N ′ T ˆ ϵ S ( h, ˆ h S ) + r 2 d N S log( eN S d ) + r 1 2 N S log( 1 δ ) + N S N S + N ′ T 2 C f C g W 1 ( P S ( G ) , P T ( G )) + min | ϵ S ( h, ˆ h S ) − ϵ S ( h, ˆ h T ) | , | ϵ T ( h, ˆ h S ) − ϵ T ( h, ˆ h T ) | ( b ) ≤ N ′ T N S + N ′ T ˆ ϵ T ( h, ˆ h T ) + r 4 d N ′ T log( eN ′ T d ) + 1 N ′ T log( 1 δ ) + N S N S + N ′ T ˆ ϵ S ( h, ˆ h S ) + r 4 d N S log( eN S d ) + 1 N S log( 1 δ ) + N S N S + N ′ T 2 C f C g W 1 ( P S ( G ) , P T ( G )) + min | ϵ S ( h, ˆ h S ) − ϵ S ( h, ˆ h T ) | , | ϵ T ( h, ˆ h S ) − ϵ T ( h, ˆ h T ) | ( c ) ≤ N ′ T N S + N ′ T ˆ ϵ T ( h, ˆ h T ) + N S N S + N ′ T ˆ ϵ S ( h, ˆ h S ) + N S N S + N ′ T 2 C f C g W 1 ( P S ( G ) , P T ( G )) + min | ϵ S h, ˆ h S ) − ϵ S ( h, ˆ h T ) | , | ϵ T ( h, ˆ h S ) − ϵ T ( h, ˆ h T ) | + N ′ T N S + N ′ T r 4 d N ′ T log( eN ′ T d ) + 1 N ′ T log( 1 δ ) + N S N S + N ′ T r 4 d N S log( eN S d ) + 1 N S log( 1 δ ) = N ′ T N S + N ′ T ˆ ϵ T ( h, ˆ h T ) + N S N S + N ′ T ˆ ϵ S ( h, ˆ h S ) + N S N S + N ′ T r 4 d N S log( eN S d ) + 1 N S log( 1 δ ) + N S N S + N ′ T 2 C f C g W 1 ( P S ( G ) , P T ( G )) + min | ϵ S ( h, ˆ h S ) − ϵ S ( h, ˆ h T ) | , | ϵ T ( h, ˆ h S ) − ϵ T ( h, ˆ h T ) | = N ′ T N S + N ′ T ˆ ϵ T ( h, ˆ h T ) + N S N S + N ′ T ˆ ϵ S ( h, ˆ h S ) + r 4 d N S log( eN S d ) + 1 N S log( 1 δ ) + N S N S + N ′ T 2 C f C g W 1 ( P S ( G ) , P T ( G )) + min | ϵ S ( h, ˆ h S ) − ϵ S ( h, ˆ h T ) | , | ϵ T ( h, ˆ h S ) − ϵ T ( h, ˆ h T ) | , (25) where (a) is the outcome of applying the union b ound Blitzer et al. (2007) with co efficient N ′ T N S + N ′ T , N S N S + N ′ T resp ectiv ely; (b) and (c) result from the Cauch y-Sch wartz inequality Yin et al. (2024b) and (c) additionally adopt the assumption N ′ T ≪ N S follo wing the sleight-of-hand Li et al. (2021). Due to the samples are selected with high confidence, th us, w e ha ve the follo wing assumption: ˆ ϵ T ≤ ϵ T ≤ ˆ ϵ S ( h, ˆ h ) + r 4 d N S log( eN S d ) + 1 N S log( 1 δ ) + 2 C f C g W 1 ( P S ( G ) , P T ( G )) + ω ′ , (26) where ω ′ = min || g ||| Lip ≤ C g , || f || Lip ≤ C f { ϵ S ( h, ˆ h ) + ϵ T ( h, ˆ h ) } , ˆ ϵ T is the empirical risk on the high confidence samples, ϵ S is the empirical risk on the target domain. Besides, we hav e: min( | ϵ S ( h, ˆ h S ) − ϵ S ( h, ˆ h T ) | , | ϵ T ( h, ˆ h S ) − ϵ T ( h, ˆ h T ) | ) ≤ min ( ϵ S ( h, ˆ h S ) + ϵ T ( h, ˆ h S )) . (27) Therefore, w e can derive the upper bound of the target domain generalization error ϵτ ( h, ˆ h T ) as follows: ϵτ ( h, ˆ h T ) ≤ N ′ T N S + N ′ T ˆ ϵ T ( h, ˆ h T ) + N S N S + N ′ T ˆ ϵ S ( h, ˆ h S ) + r 4 d N S log( eN S d ) + 1 N S log( 1 δ ) + N S N S + N ′ T 2 C f C g W 1 ( P S ( G ) , P T ( G )) + ω ≤ ˆ ϵ S ( h, ˆ h ) + r 4 d N S log( eN S d ) + 1 N S log( 1 δ ) + 2 C f C g W 1 ( P S ( G ) , P T ( G )) + ω ′ . (28) 11 4.2 Pro of of Theo rem 2 Pro of of Theorem 2. Assume the input space is X ⊆ R d and the lab el space is Y = { 1 , 2 , ..., K } . The real data distribution is D , and the observ ation distribution with noisy lab els is ˜ D , where the upp er limit of the noise ratio is η ≤ 0 . 5 . In the early stage of training (the first T 0 steps), the model’s prediction of clean samples satisfies p i θ i ( x ) ≈ y i , where t ≤ T 0 , and ( x, y ) comes from the clean data subset D clean ⊂ ˜ D 2 , we then ha ve: p θ ( y i | x i ) ≈ ˜ y i ˜ y i + λy i (1 − p θ ( y i | x i )) . (29) Pr o of. F or clean samples ( x i , y i ) , the early EMA prediction satisfies p i → y i when the training step n umber t → ∞ . Decomp ose the loss into the con tribution of clean samples and noise samples: L CLS = L clean CE + L noisy CE + λ L clean Reg + L noisy Reg . (30) F or clean samples ( x i , y i ) , since p i ≈ y i , the regularization term is appro ximately: L clean Reg ≈ 1 N clean X i ∈ clean log (1 − ⟨ p θ ( y | x i ) , y i ⟩ ) . (31) Due to ⟨ p θ ( y | x i ) , y i ⟩ = p θ ( y i | x i ) , when p θ ( y i | x i ) → 1 , log(1 − p θ ( y i | x i )) → −∞ , but in actual optimization, through gradient descent, the model will adjust p θ ( y i | x i ) to balance the cross entrop y and regularization terms. F or clean samples, the gradien t of the regularization term is: ∇ θ L clean Reg ∝ − ˆ p i 1 − ⟨ p θ , ˆ p i ⟩ · ∇ θ p θ . (32) Since p i ≈ y i , the gradient direction encourages p θ ( y i | x i ) to b e close to y i , consistent with the cross-entrop y ob jectiv e. F or the noise sample ( x i , ˜ y i = y i ) , assuming that p i do es not conv erge to any fixed distribution (it may be close to a uniform distribution or the wrong category): L noisy Reg = 1 N noisy X i ∈ noisy log (1 − ⟨ p θ ( y | x i ) , ˆ p i ⟩ ) . (33) If ˆ p i is close to uniform distribution, then ⟨ p θ , ˆ p i ⟩ ≈ 1 K , and the regularization term has little effect on the gradien t; if hatp i is biased tow ards the wrong label, the regularization term preven ts p θ from o verfitting ˆ y i . The cross entrop y gradien t ∇ θ L noisy CE of the noise sample p oints in the wrong direction, while the regularization gradien t ∇ θ L noisy Reg p oin ts in the opposite direction, thereb y partially offsetting the effect of the noise. Under the assumption that ˆ p i → y i , the total loss of CLS is appro ximately: L CLS ≈ L clean CE + λ L clean Reg + η . (34) Since the noise interference term is suppressed by the regularization term, the optimization pro cess is mainly driv en by clean samples. Assuming that the parameter θ is updated using gradient descent with a step size of β , the parameter update is: θ t +1 = θ t − β ∇ θ L CLS . (35) When clean samples dominate, the gradient direction tends to minimize the true cross en tropy L clean CE . Since p i ≈ y i , the gradient of the regularization term is appro ximately: ∇ θ L Reg ≈ − 1 N clean X i ∈ clean y i 1 − p θ ( y i | x i ) ∇ θ p θ ( y i | x i ) . (36) Com bined with the cross entrop y gradien t ∇ θ L CE = − 1 N P N i =1 ˜ y i p θ ( y i | x i ) ∇ θ p θ ( y i | x i ) : p θ ( y i | x i ) ≈ ˜ y i ˜ y i + λy i (1 − p θ ( y i | x i )) , (37) When λ is moderate, the mo del predicts p θ ( y i | x i ) close to 1, consistent with the real label. 12 4.3 Pro of of Theo rem 3 Theorem 3. Assume that the mo del complexity is characterized by Rademacher complexity R n ( F ) Yin et al. (2019). F or an y δ > 0 , the generalization error upp er b ound of L CLS satisfies with probability 1 − δ : GenError L CLS ≤ GenError L CE ≤ 2 R n ( F ) √ λ + r log(1 /δ ) 2 n + O η + ϵ µ . (38) Pr o of. F or a function class G , its Rademacher complexity is defined as: R N ( G ) = E x i ,σ i " sup g ∈G 1 N N X i =1 σ i g ( x i ) # . (39) where σ i is an indep endent uniformly distributed Rademac her random v ariable. According to statistical learning theory , for the loss function ℓ , the upper bound of the generalization error can be expressed as: GenError ≤ 2 R N ( ℓ ◦ F ) + O r log(1 /δ ) N ! . (40) where ℓ ◦ F = { ( x, y ) 7→ ℓ ( f θ ( x ) , y ) | f θ ∈ F } . In cross en trop y loss G CE = { ( x, y ) 7→ ℓ CE ( f θ ( x ) , y ) } and L CLS loss G ELR = { ( x, y ) 7→ ℓ CE ( f θ ( x ) , y ) + λ L Reg ( f θ ) } , since L Reg in tro duces constrain ts on prediction consistency , the hypothesis space F CLS is more restricted than F CE , that is: F CLS ⊂ F CE . (41) Due to the inclusion relationship of the function class, its Rademac her complexit y satisfies: R N ( G CLS ) ≤ R N ( G CE ) . (42) Assuming ℓ CE is L -Lipschitz con tin uous and L Reg is L ’-Lipschitz con tin uous, then we hav e: R N ( G CLS ) ≤ R N ( G CE ) + λ · R N ( L Reg ◦ F ) . (43) Ho w ever, since the design goal of L Reg is to constrain the consistency of mo del predictions (i.e., reduce v ariance), in practice R N ( G CE gro ws slow er than the complexit y reduction of the cross entrop y loss, resulting in lo wer ov erall complexit y . In the presence of noisy lab els, the relationship b etw een the true risk R ( f ) and the empirical risk ˆ R N ( f ) needs to b e modified to: R ( f ) ≤ ˆ R N ( f ) + 2 R N ( G ) + 3 r log(2 /δ ) 2 N + η · C , (44) where C is a constant related to lab el noise. Combined with the complexit y difference R N ( G CLS ) ≤ R N ( G CE ) , and Error CLS ≤ 2 R N ( G CLS ) + O r log(1 /δ ) N ! + η · C CLS , Error CE ≤ 2 R N ( G CE ) + O r log(1 /δ ) N ! + η · C CE . (45) Therefore, w e can infer that the generalization error upp er bound of L CLS is lo wer. 13 T able 1: The performance of different metho ds is shown under differen t noisy rates on the IEMOCAP and MELD datasets. The arrow → means from source to target domains. Underlines indicate sub optimal p erformance. Bold results indicate the b est performance. W e set the noise rate to 10%. Metho ds IEMOCAP → MELD MELD → IEMOCAP Jo y Sadness Neutral Anger WF1 Jo y Sadness Neutral Anger WF1 T r adition T extCNN 38.79 14.47 54.07 29.98 44.12 39.13 60.65 35.52 54.21 46.73 LSTM 11.17 6.86 57.27 33.37 39.98 51.27 60.89 46.76 46.74 50.68 DialogueRNN 24.02 12.95 63.69 35.23 47.08 37.75 56.47 14.91 59.92 39.46 MMGCN 24.87 0.00 46.98 28.73 35.77 50.95 0.00 54.90 64.13 43.94 M3NET 45.15 4.69 38.16 29.25 35.48 46.91 71.08 35.31 71.76 54.72 CFN-ESA 9.90 3.23 69.36 3.16 42.08 19.26 9.38 44.62 16.50 25.57 SDT 8.74 6.78 67.10 40.06 45.96 50.18 61.20 50.25 64.86 56.58 EmotionIC 0.21 24.16 45.68 18.52 30.58 30.55 37.11 37.64 33.74 35.51 DEDNet 25.99 1.77 57.86 27.31 42.13 40.40 0.00 29.68 33.61 25.28 Denoising OMG 34.73 4.56 58.19 31.23 44.92 47.55 67.21 41.23 54.22 51.54 SPOR T 29.57 9.04 60.74 32.38 45.84 49.11 61.23 39.18 66.89 52.89 A daption A2GNN 41.24 3.91 66.73 27.15 50.50 53.11 55.43 50.18 60.38 54.46 Amanda 36.29 10.15 62.18 29.03 47.69 55.68 45.81 54.28 56.76 53.14 Bo omda 45.69 6.87 65.19 31.42 51.40 60.19 44.19 51.01 69.77 55.57 DGD A 56.21 9.81 76.68 36.00 60.99 61.04 66.10 57.19 82.91 66.47 5 Exp eriments 5.1 Exp erimental Setup Datasets. IEMOCAP Busso et al. (2008) and MELD Poria et al. (2018) are commonly used multimodal databases in MERC. The IEMOCAP dataset includes 10 actors (5 men and 5 w omen). Eac h pair of actors sim ulates a real dialogue scene and conducts 5 conv ersations of ab out 1 hour, totaling ab out 12 hours. All conv ersations are man ually annotated by emotion category . The MELD dataset is an extension of the EmotionLines dataset, and is designed for MERC. The dataset con tains ab out 13,000 con v ersations, including more than 1,400 m ulti-turn con versations and ab out 13,000 single-turn conv ersations with emotion lab els. All conv ersations are p erformed by actors and the scenes are set in the plot of the TV series. These datasets come from differen t scenarios and therefore represent a v ariety of differen t application areas. F ollowing previous studies Zhang et al. (2024b), we selected samples of four common emotions: neutral, joy , sadness, and anger. Baselines. T o v erify the sup erior performance of our prop osed metho d DGD A, we compared it with other comparison metho ds, including traditional metho ds, i.e., T extCNN Kim (2014), LSTM P oria et al. (2017), DialogueRNN Ma jumder et al. (2019), MMGCN Hu et al. (2021), M3NET Chen et al. (2023), CFN-ESA Li et al. (2024a), SDT Ma et al. (2024), EmotionIC Liu et al. (2023), and DEDNet W ang et al. (2024a), denoising metho ds, i.e., OMG Yin et al. (2023), and SPOR T Yin et al. (2024a), and domain adaption (DA) metho ds, i.e., A2GNN Liu et al. (2024b), Amanda Zhang et al. (2024b), and Bo omda Sun et al. (2026). Implemen tation details. All exp eriments are conducted in Python 3.9, using the PyT orc h 2.1 framework, and computed on a NVIDIA A100 40GB GPU. W e chose the Adam optimizer to train the model, and the i nitial learning rate is set to 0.0005. The loss function consisted of the cross entrop y loss and the regularization loss we prop osed, which preven ted the mo del from memorizing noisy lab els during training and thus improv ed the generalization ability of the mo del. The batch size is set to 32. In all exp eriments, the rep orted results are the av erage of 10 independent runs. The w eight initialization of eac h run w as random. 14 T able 2: The performance of different metho ds is shown under differen t noisy rates on the IEMOCAP and MELD datasets. The arrow → means from source to target domains. Bold results indicate the b est p erformance. Underlines indicate sub optimal performance. W e set the noise rate to 20%. Metho ds IEMOCAP → MELD MELD → IEMOCAP Jo y Sadness Neutral Anger WF1 Jo y Sadness Neutral Anger WF1 T r adition T extCNN 38.56 13.11 51.71 29.19 42.51 36.46 54.51 32.58 52.26 43.33 LSTM 10.76 5.70 54.03 32.34 37.82 45.85 55.67 43.47 43.85 46.74 DialogueRNN 22.82 11.40 60.06 34.34 44.52 35.04 51.49 14.60 55.60 36.68 MMGCN 22.62 0.00 45.54 27.99 34.38 46.66 0.00 53.57 59.24 41.59 M3NET 41.50 5.45 33.53 26.18 31.74 42.24 64.74 32.60 65.40 49.94 CFN-ESA 9.13 7.14 69.07 3.40 42.13 14.39 19.65 41.20 29.47 29.38 SDT 8.75 5.22 62.88 37.65 43.10 44.10 53.77 48.23 60.01 52.00 EmotionIC 1.80 21.76 39.57 14.98 26.75 33.12 34.81 17.77 44.26 30.76 DEDNet 25.21 1.40 54.80 26.52 40.09 42.24 0.00 39.37 12.19 30.76 Denoising OMG 27.65 5.51 53.23 26.22 40.02 42.74 61.89 35.66 53.51 47.39 SPOR T 23.58 13.55 55.73 27.87 41.52 44.17 56.38 33.47 70.69 49.95 A daption A2GNN 36.23 7.11 61.24 32.65 47.38 46.28 48.59 51.93 54.88 51.13 Amanda 30.83 5.14 57.67 24.83 42.97 51.33 40.53 47.31 52.27 47.58 Bo omda 49.27 12.38 60.77 26.42 49.37 54.63 38.91 45.73 74.49 52.84 DGD A 54.97 25.61 66.11 48.76 57.87 59.60 40.74 64.28 77.48 61.56 T able 3: The performance of different metho ds is shown under differen t noisy rates on the IEMOCAP and MELD datasets. The arrow → means from source to target domains. Bold results indicate the b est p erformance. Underlines indicate sub optimal performance. W e set the noise rate to 30%. Metho ds IEMOCAP → MELD MELD → IEMOCAP Jo y Sadness Neutral Anger WF1 Jo y Sadness Neutral Anger WF1 T r adition T extCNN 34.59 9.87 47.79 26.69 38.83 35.46 52.43 30.87 47.59 40.87 LSTM 9.74 4.57 49.49 29.03 34.48 43.19 51.54 40.71 38.57 43.03 DialogueRNN 20.81 8.62 54.72 31.3 40.41 34.10 49.35 13.84 49.94 34.31 MMGCN 21.64 0.00 41.58 25.73 31.62 42.27 0.00 50.85 53.90 38.59 M3NET 40.43 7.58 31.80 23.16 30.30 39.68 60.41 31.84 59.79 46.84 CFN-ESA 18.25 3.38 67.01 0.61 42.15 14.53 20.45 45.78 15.42 27.63 SDT 7.61 4.24 56.37 31.16 38.20 40.84 48.39 44.76 55.03 47.72 EmotionIC 4.85 17.87 19.14 8.34 14.56 26.60 39.60 22.16 31.23 29.20 DEDNet 23.87 1.09 49.70 22.6 36.35 39.05 0.00 37.85 13.57 22.90 Denoising OMG 22.44 3.14 48.47 22.87 35.57 40.15 57.61 32.78 50.06 44.08 SPOR T 18.37 8.59 53.16 22.83 37.85 42.39 52.18 30.17 51.19 42.46 A daption A2GNN 34.47 2.82 54.31 29.48 42.27 42.17 43.12 45.69 49.37 45.55 Amanda 26.88 3.83 57.96 20.01 41.54 47.33 34.49 46.14 50.15 44.63 Bo omda 46.13 7.18 54.48 21.36 44.06 51.13 39.17 42.23 70.85 50.18 DGD A 57.16 24.22 65.99 21.36 54.36 49.82 62.96 47.06 68.79 56.79 15 T able 4: The performance of different metho ds is shown under differen t noisy rates on the IEMOCAP and MELD datasets. The arrow → means from source to target domains. Bold results indicate the b est p erformance. Underlines indicate sub optimal performance. W e set the noise rate to 40%. Metho ds IEMOCAP → MELD MELD → IEMOCAP Jo y Sadness Neutral Anger WF1 Jo y Sadness Neutral Anger WF1 T r adition T extCNN 33.92 9.04 44.59 24.53 36.51 34.33 48.97 26.65 43.49 37.29 LSTM 9.67 4.61 44.72 26.50 31.41 41.46 48.47 36.83 37.65 40.40 DialogueRNN 20.60 8.08 49.99 28.84 37.30 33.55 47.75 12.01 44.78 31.85 MMGCN 21.46 0.00 38.70 23.59 29.66 40.82 0.00 46.71 51.12 36.14 M3NET 39.99 6.48 28.77 20.79 28.07 38.09 55.89 27.35 54.40 42.52 CFN-ESA 10.47 5.00 68.76 4.20 42.16 10.19 20.05 46.56 25.02 29.71 SDT 7.34 36.10 50.78 29.34 37.49 38.01 44.88 40.09 49.54 43.36 EmotionIC 37.53 11.72 2.11 9.43 11.34 24.74 33.33 15.07 30.98 24.80 DEDNet 23.14 0.92 44.84 20.68 33.17 37.64 0.00 36.42 11.59 21.67 Denoising OMG 20.58 6.14 45.23 19.97 33.21 38.83 53.31 29.91 47.42 41.15 SPOR T 15.52 4.17 46.31 18.47 32.39 38.74 50.15 27.14 46.68 39.19 A daption A2GNN 31.25 4.63 52.29 26.14 40.15 41.43 40.05 42.22 46.38 42.68 Amanda 41.28 9.16 50.06 16.77 40.08 41.39 36.62 36.12 42.34 38.59 Bo omda 41.29 3.33 50.02 15.53 39.38 36.07 34.28 41.27 44.51 39.75 DGD A 37.85 13.51 64.74 28.91 49.74 35.58 56.90 35.51 57.51 46.21 T able 5: The ablation studies are shown under differen t noisy rates on the IEMOCAP and MELD datasets. The arrow → means from source to target domains. Bold results indicate the b est p erformance. W e set the noise rate to 10%. Metho ds IEMOCAP → MELD MELD → IEMOCAP Jo y Sadness Neutral Anger WF1 Jo y Sadness Neutral Anger WF1 DGD A-HGNN 40.17 11.41 69.41 32.58 53.19 56.46 54.99 42.79 77.15 56.45 DGD A- P athNN 43.59 9.87 62.43 31.68 49.69 52.47 48.31 50.07 67.43 54.49 DGD A/ σ H GN N 44.39 7.78 74.95 20.48 55.23 58.44 57.03 45.67 73.41 57.29 DGD A/ σ P athN N 48.37 7.65 75.27 18.93 56.01 56.55 62.39 51.65 74.83 60.85 DGD A/AP 28.96 4.25 66.79 25.27 47.74 34.97 42.53 54.78 58.09 50.01 DGD A/BC 19.69 13.74 60.03 30.02 43.46 30.05 54.17 46.28 47.89 46.26 DGD A/R T 51.33 6.77 71.29 37.18 56.82 56.88 65.76 52.19 77.97 62.69 DGD A 56.21 9.81 76.68 36.00 60.99 61.04 66.10 57.19 82.91 66.47 T o further ev aluate the statistical significance of the exp erimen tal results, paired t -tests are p erformed on the results of the 10 runs. All t -test results show p v alues less than 0.05, indicating that the differences in mo del performance in multiple exp eriments were statistically significan t. Ev aluation metrics. F or the multi-emotional dialogue datasets IEMOCAP and MELD, we adopt the W eigh ted F1-score (WF1) as the primary ev aluation metric. Due to the inherent class imbalance in these datasets, WF1 pro vides a more reliable assessment than Macro-F1 by weigh ting eac h category according to its sample prop ortion. 16 First, for each emotion class i , the F1-score is computed as the harmonic mean of precision and recall: F i = 2 · ( Precision i · Recall i ) Precision i + Recall i , (46) where Precision i measures the correctness of predictions for class i , and Recall i measures how many true samples of class i are correctly identified. The o verall WF1 is then obtained by weigh ting eac h class-specific F i using its sample coun t n i : WF1 = N X i =1 n i P N j =1 n j · F i ! , (47) where N denotes the total n um b er of emotion categories. Compared with unw eighted metrics, WF1 more faithfully reflects model performance under im balanced distributions, preven ts b oth minority and ma jority classes from dominating the ov erall score, and offers a stable and comprehensive ev aluation b y join tly considering precision and recall. 5.2 Compa rison with the State-of-the-arts T ables 1, 2, 3, and 4 show the p erformance comparison results of our proposed DGD A metho d and v arious baseline metho ds on the IEMOCAP and MELD datasets under differen t noise conditions. The following imp ortan t findings can b e observed through comparative analysis. First, D A metho ds, including A2GNN, Amanda, Bo omda, and DGDA, are generally b etter than traditional metho ds and show more robust emotion recognition p erformance regardless of the noise interference conditions. This shows that the traditional metho ds are difficult to effectively mo del the distribution difference b etw een the source domain and the target domain. Second, compared with v arious recen tly prop osed DA metho ds (A2GNN, Amanda, Bo omda) and typical denoising metho ds (OMG, SPOR T), DGDA has achiev ed better p erformance. The p erformance impro v ement may b e attributed to the synergy of the following key design factors: (i) First, DGDA adopts a dual-branc h graph semantic extraction mechanism to mo del and integrate graph structure information based on message passing and shortest path aggregation strategies, resp ectively . This design effectively lev erages the complementary adv antages of the tw o mo dels in lo cal relationship mo deling and global structure capture. (ii) Secondly , DGD A in tro duces a branch coupling module and an adaptive p erturbation mec hanism to dynamically adjust the interaction b etw een the tw o branc hes, which not only promotes the efficient transfer of cross-domain knowledge but also effectiv ely alleviates the negative impact of category distribution differences. (iii) Finally , we fully consider the tw o key factors of domain inv ariance and noise lab el interference. Through a joint optimization strategy , while ensuring feature domain alignmen t, w e effectiv ely suppress the negativ e impact of noisy labels on the model learning process. 5.3 Ablation Study T o comprehensiv ely analyze the actual contribution of each module of DGDA to the ov erall mo del p erfor- mance, we designed and conducted multiple sets of ablation exp eriments as shown in T ables 5, 6, 7, and 8. Sp ecifically , we constructed the follo wing seven v ariant configurations: (1) DGDA-HGNN: HGNN is used in b oth branches for graph semantic feature extraction; (2) DGDA-P athNN: PathNN is used in b oth branc hes. (3) DGDA/ σ H GN N : The p erturbation module is remov ed from the HGNN branch of DGD A. (4) DGD A/ σ P athN N : The p erturbation mo dule is remov ed from the PathNN branch. (5) DGDA/AP: The p er- turbation mo dule is remo ved from b oth branc hes. (6) DGDA/BC: The branch coupling mo dule is remo ved. (7) DGDA/R T: The regularization term is remov ed from b oth branches. DGD A significantly outp erforms DGD A-HGNN and DGD A-PathNN in o verall performance, indicating that a single graph seman tic mo del- ing metho d is not sufficien t to extract and fuse graph semantic features from different p ersp ectiv es. DGD A sho ws significant p erformance adv antages in comparison with the three v ersions of the p erturbation remov al mo dule (DGDA/ σ H GN N , DGDA/ σ P athN N , and DGDA/AP). By in tro ducing p erturbations in the feature space, the mo del can effectively prev ent ov erfitting of the source domain features. Due to the lack of coupling and category alignmen t mechanism betw een branches, DGDA/BC has a significantly insufficien t ability to 17 T able 6: The ablation studies are shown under differen t noisy rates on the IEMOCAP and MELD datasets. The arrow → means from source to target domains. Bold results indicate the b est p erformance. W e set the noise rate to 20%. Metho ds IEMOCAP → MELD MELD → IEMOCAP Jo y Sadness Neutral Anger WF1 Jo y Sadness Neutral Anger WF1 DGD A-HGNN 36.07 7.77 66.00 29.34 49.64 53.21 51.47 40.09 73.97 53.36 DGD A- P athNN 39.77 6.26 57.87 28.38 45.54 49.27 45.05 47.46 63.93 51.42 DGD A/ σ H GN N 39.71 4.72 70.37 15.73 50.73 55.98 53.49 41.75 70.72 53.99 DGD A/ σ P athN N 44.56 4.30 71.80 15.75 52.52 53.54 59.50 47.97 72.54 57.80 DGD A/AP 25.02 7.33 63.48 22.15 44.88 32.35 38.62 52.36 54.77 46.98 DGD A/BC 18.73 8.96 55.04 25.68 39.41 27.63 50.51 43.11 44.89 43.13 DGD A/R T 46.83 3.24 67.01 32.97 52.57 54.54 62.48 50.13 73.99 59.81 DGD A 54.97 25.61 66.11 48.76 57.87 59.60 40.74 64.28 77.48 61.56 T able 7: The ablation studies are shown under differen t noisy rates on the IEMOCAP and MELD datasets. The arrow → means from source to target domains. Bold results indicate the b est p erformance. W e set the noise rate to 30%. Metho ds IEMOCAP → MELD MELD → IEMOCAP Jo y Sadness Neutral Anger WF1 Jo y Sadness Neutral Anger WF1 DGD A-HGNN 33.28 3.21 62.38 25.83 46.13 50.47 48.93 38.01 69.02 50.34 DGD A- P athNN 35.99 2.61 53.52 23.48 41.30 47.06 42.46 42.80 61.26 48.10 DGD A/ σ H GN N 35.73 2.74 67.35 10.94 47.36 53.77 51.10 39.30 66.06 51.01 DGD A/ σ P athN N 39.61 1.70 69.56 13.14 49.63 50.95 56.79 43.36 69.06 54.21 DGD A/AP 20.93 5.06 60.07 19.45 41.52 28.86 35.47 49.80 52.39 44.20 DGD A/BC 16.50 5.39 52.21 22.03 36.53 25.51 48.00 40.81 41.26 40.46 DGD A/R T 42.96 5.89 64.37 30.05 50.09 50.93 60.22 46.30 60.06 53.76 DGD A 57.16 24.22 65.99 21.36 54.36 49.82 62.96 47.06 68.79 56.79 distinguish categories in the target domain. F urthermore, without the in tro duction of regularization loss, the o verall p erformance of the model shows a certain degree of degradation when facing training data with noisy labels. 5.4 Effect of Different Mo dalities T o further explore the contribution of different mo dalities in emotion recognition, we designed a mo dality ablation experiment under the exp erimental condition of 10% noise rate. By gradually removing one or t w o mo dalities, we observ ed the p erformance differences of the mo del under v arious combinations. T able 3 shows the results of different mo dal combinations. First, for the single-mo dal exp erimental results, the p erformance of the text mo dality is far better than that of the audio mo dality and the visual mo dality . This phenomenon shows that although multimodal information has a synergistic effect, text features are still the most critical basis for emotion discrimination. Secondly , in the dual-mo dal com bination exp erimen t, the performance of all combinations is b etter than the corresp onding single-mo dal results, whic h v erifies that there is a complementary relationship b etw een different mo dalities and joint mo deling helps to improv e the emotion recognition effect. Finally , when the three mo dalities are simultaneously in v olv ed in feature mo deling, the model achiev es the b est recognition effect, significantly b etter than all single-modal and bimo dal configurations. 18 T V T +A A T +V T +A+V MELD IEMOCAP IE MOCA P MELD 37 42 47 52 57 62 67 66.47 60.99 58.74 64.56 55.73 61.98 50.04 42.09 54.31 46.75 51.24 51.65 W - F 1( %) Figure 3: V erify the effectiv eness of multimodal features. (a) MELD → IEMOCAP (b) IEMOCAP → MELD (c) MELD → IEMOCAP (d) IEMOCAP → MELD Figure 4: Hyp erparameter sensitivit y of threshold ζ and regularization weigh t λ . 19 T able 8: The performance of different metho ds is shown under differen t noisy rates on the IEMOCAP and MELD datasets. The arrow → means from source to target domains. Bold results indicate the b est p erformance. W e set the noise rate to 40%. Metho ds IEMOCAP → MELD MELD → IEMOCAP Jo y Sadness Neutral Anger WF1 Jo y Sadness Neutral Anger WF1 DGD A-HGNN 29.05 2.17 60.09 22.28 43.37 37.82 44.14 35.26 44.37 40.05 DGD A- P athNN 33.60 4.32 51.39 19.75 39.23 33.53 36.77 38.02 48.31 39.77 DGD A/ σ H GN N 33.23 6.86 64.70 6.45 45.07 31.58 39.01 34.45 61.35 42.08 DGD A/ σ P athN N 35.08 3.19 60.37 8.89 43.02 38.82 31.96 40.72 46.25 39.85 DGD A/AP 17.75 1.72 56.67 16.23 38.20 26.81 31.16 47.53 48.98 41.19 DGD A/BC 11.91 2.98 47.58 17.50 32.12 23.35 43.63 36.36 38.76 36.85 DGD A/R T 38.22 3.21 59.93 25.67 45.75 26.23 37.51 32.33 47.81 36.70 DGD A 37.85 13.51 64.74 28.91 49.74 35.58 56.90 35.51 57.51 46.21 Joy Sadness Neutral Anger Joy Sadness Neutral Anger (a) 10% noise Joy Sadness Neutral Anger Joy Sadness Neutral Anger (b) 20% noise Joy Sadness Neutral Anger Joy Sadness Neutral Anger (c) 30% noise Joy Sadness Neutral Anger Joy Sadness Neutral Anger (d) 40% noise Joy Sadness Neutral Anger Joy Sadness Neutral Anger (e) 10% noise Joy Sadness Neutral Anger Joy Sadness Neutral Anger (f ) 20% noise Joy Sadness Neutral Anger Joy Sadness Neutral Anger (g) 30% noise Joy Sadness Neutral Anger Joy Sadness Neutral Anger (h) 40% noise Figure 5: Confusion matrices for multimodal emotion recognition datasets. The matrices provide insights in to the model’s classification accuracy , highlighting the challenges and successes in distinguishing betw een differen t emotional categories. T op: Results with v arying noise levels on the first dataset setting. Bottom: Results with v arying noise levels on the second dataset setting. 5.5 Sensitivit y Analysis Figs. 4 (a) and (b) sho w the effect of the pseudo-lab el selection threshold ζ on mo del p erformance under differen t noise rates. When the noise rate is 0.1, as the threshold increases, the p erformance of the mo del increases significan tly , and reac hes the optimal v alue at 0.3, and then decreases sligh tly when the threshold is to o high. This shows that under low-noise conditions, appropriately improving the pseudo-lab el selection 20 criteria can help screen out more reliable pseudo-lab els. How ever, when the threshold is further increased, the n um b er of optional pseudo-lab el samples decreases significan tly , resulting in insufficien t sup ervision signals. Under high noise rates, the impact of threshold changes on mo del p erformance is relatively gen tle. This is mainly b ecause in a high-noise en vironment, the qualit y of the candidate pseudo-labels themselves is po or, and it is difficult to completely solv e the pseudo-lab el noise problem b y simply increasing the threshold. Figs. 4 (c) and (d) further analyze the impact of the regularization weigh t λ on mo del p erformance. The o v erall trend shows that at lo wer λ , the mo del p erformance is p o or, esp ecially at high noise rates, and the WFI p erformance is low. As λ gradually increases, the effect of the mo del at each noise rate is generally impro v ed, and the best state is reached when λ is ab out 0.7 ∼ 0.8. This shows that appropriately increasing the weigh t of the regularization term can b etter suppress the ov erfitting of the mo del to the noisy pseudo- lab els, esp ecially in a high-noise environmen t. Ho w ev er, it is worth noting that when λ contin ues to increase to 0.9, the model performance under some noise rates decreases sligh tly . Joy Sad Neutral Angry (a) 10% noise Joy Sad Neutral Angry (b) 20% noise Joy Sad Neutral Angry (c) 30% noise Joy Sad Neutral Angry (d) 40% noise Joy Sad Neutral Angry (e) 10% noise Joy Sad Neutral Angry (f ) 20% noise Joy Sad Neutral Angry (g) 30% noise Joy Sad Neutral Angry (h) 40% noise Figure 6: Visualization of the learned embeddings. T op: T rained on the MELD dataset and tested on the IEMOCAP dataset (with v arying noise lev els). Bottom: T rained on the IEMOCAP dataset and tested on the MELD dataset (with v arying noise levels). 5.6 Confusion Matrices Fig. 5 shows the confusion matrix of the mo del prediction results on the IEMOCAP and MELD datasets, whic h pro vides an imp ortant basis for an in-depth understanding of the mo del’s classification ability and p erformance differences in differen t emotion categories. It can b e observed that the mo del has a relatively ideal recognition effect on the t wo categories of “Jo y" and “Neutral". Most of the samples b elonging to these tw o categories are accurately classified, and the misclassification ratio b etw een the tw o is low. This phenomenon shows that the mo del has successfully learned the discriminative features that are highly related to these tw o categories of emotions and can effectively distinguish them, reflecting its go o d mo deling abilit y for common emotion categories. How ever, the confusion matrix also reveals the classification difficulties in low-frequency emotion categories such as “Sadness" and “Anger". Compared with common emotions suc h as “Joy" and “Neutral", these categories already ha v e the problem of insufficient sample num b er in m ultimo dal emotion recognition datasets, and the category im balance phenomenon is more significan t. Due 21 to the small num b er of “Sadness" and “Anger" samples av ailable for learning during the training pro cess, the model has certain difficulties in capturing the key patterns and features related to these t wo categories of emotions, resulting in its insufficient generalization ability on these tw o categories of samples. Therefore, the model’s recognition effect on these t wo types of emotions is significantly inferior, and a high proportion of misclassification o ccurs. Sp ecifically , the confusion matrix shows that a considerable num b er of samples in the “Sadness" and “Anger" categories are mistakenly classified into other categories such as “Happy" or “Neutral". This result reflects that the mo del has a certain degree of discrimination ambiguit y b et w een these emotions; that is, when distinguishing low-frequency emotion categories from common emotion categories, it ma y rely on o verlapping or fuzzy features in emotional expressions, whic h leads to confusion. 5.7 Visualization Fig. 6 sho ws the distribution of emotional features learned by the mo del on the IEMOCAP and MELD datasets under differen t noise ratios (10%, 20%, 30%, and 40%), which in tuitively reveals the impact of noise level changes on the model’s discriminativ e abilit y and the effectiveness of the proposed method in com bating noise interference. F rom the visualization results, on the IEMOCAP dataset (upp er row in the figure), as the noise ratio gradually increases, the b oundaries b etw een different emotional categories b egin to b ecome blurred, the sample distribution within the category tends to b e lo ose, and the feature ov erlap b et w een categories b ecomes more obvious. Esp ecially when the noise ratio reac hes 30% and 40%, the degree of confusion b et w een emotional categories increases significan tly , and samples of categories suc h as Sad and Neutral, Joy and Angry appear to b e distributed in a large area, resulting in a sharp decline in the mo del’s ability to distinguish these emotional categories, and the reliability of the discrimination results is greatly affected. This phenomenon reflects that in a medium-to-high noise environmen t, the p oten tial feature commonalit y b et ween emotional categories and the perturbation effect of noise increase the learning difficulty of the mo del, making it difficult to main tain the effectiv e extraction of discriminative features. In con trast, the MELD dataset (low er line in the figure) sho ws stronger robustness and category separability under the same noise level. Although the noise ratio also increased from 10% to 40%, the feature distribution b etw een emotion categories still maintained a go o d clustering structure and relatively clear category b oundaries. Ev en under the most stringen t 40% noise condition, the samples of each category still show ed a relatively stable distribution pattern, and the distinction b etw een categories was preserv ed to a certain extent. This result fully demonstrates that the prop osed metho d exhibits sup erior noise resistance on the MELD dataset, and can effectively suppress the erosion of the mo del feature space by erroneous lab els in an en vironmen t with significant noise interference, ensuring that the mo del maintains go o d discrimination ability for emotion categories. It is w orth noting that the MELD dataset itself is more challenging in terms of mo dal com bination, con text diversit y , and sp eaker complexity . Therefore, the mo del can still sho w strong noise resistance on this dataset, which further prov es the robustness and generalization ability of the prop osed metho d in the face of complex multimodal data and label uncertain ty . 6 Conclusions In this pap er, we prop ose a Dual-branch Graph Domain Adaptation (DGDA) for multi-modal emotion recog- nition in cross-scenario con versations. Sp ecifically , w e first construct an emotion in teraction graph to mo del the complex emotional dependencies b etw een utterances. Then, w e design a neighborho o d aggregation and path aggregation dual-branch graph enco der to explicitly and implicitly capture the dynamic changes in emotion betw een utterances and explore m ultiv ariate relationships, respectively . T o address the problem of out-of-domain distribution differences, w e introduce a domain adv ersarial classifier to improv e the represen- tation abilit y of inv arian t features in the source domain. F urthermore, we construct a regularization loss to prev en t the mo del from memorizing noise and improv e the mo del’s ability to resist in terference from noisy lab els. References W ei Ai, Y untao Shou, T ao Meng, and Keqin Li. Der-gcn: Dialog and even t relation-aw are graph conv olutional neural netw ork for multimodal dialog emotion recognition. IEEE T r ansactions on Neur al Networks and 22 L e arning Systems , 2024. W ei Ai, F uchen Zhang, Y untao Shou, T ao Meng, Hao w en Chen, and Keqin Li. Revisiting m ultimo dal emotion recognition in conv ersation from the persp ective of graph sp ectrum. In Pr o c e e dings of the AAAI Confer enc e on A rtificial Intel ligenc e , v olume 39, pp. 11418–11426, 2025. W ei Ai, Yilong T an, Y un tao Shou, T ao Meng, Haow en Chen, Zhixiong He, and Keqin Li. The paradigm shift: A comprehensive surv ey on large vision language mo dels for m ultimo dal fake news detection. Computer Scienc e R eview , 60:100893, 2026. John Blitzer, Kob y Crammer, Alex Kulesza, F ernando Pereira, and Jennifer W ortman. Learning b ounds for domain adaptation. A dvanc es in neur al information pr o c essing systems , 20, 2007. Carlos Busso, Murtaza Bulut, Chi-Chun Lee, Ab e Kazemzadeh, Emily Mow er, Samuel Kim, Jeannette N Chang, Sungb ok Lee, and Shrikan th S Naray anan. Iemo cap: In teractive emotional dyadic motion capture database. L anguage r esour c es and evaluation , 42:335–359, 2008. Ch uangquan Chen, Zhenc heng Li, Kit Ian K ou, Jie Du, Chen Li, Hongtao W ang, and Chi-Man V ong. Comprehensiv e multisource learning net w ork for cross-subject m ultimo dal emotion recognition. IEEE T r ansactions on Emer ging T opics in Computational Intel ligenc e , 2024. F eiyu Chen, Jie Shao, Shuyuan Zhu, and Heng T ao Shen. Multiv ariate, multi-frequency and multimodal: Re- thinking graph neural netw orks for emotion recognition in conv ersation. In Pr o c e e dings of the IEEE/CVF Confer enc e on Computer Vision and Pattern R e c o gnition , pp. 10761–10770, 2023. W ei Chen, Guo Y e, Y akun W ang, Zhao Zhang, Libang Zhang, Daixin W ang, Zhiqiang Zhang, and F uzhen Zh uang. Smo othness really matters: A simple yet effective approach for unsupervised graph domain adaptation. In Pr o c e e dings of the AAAI Confer enc e on A rtificial Intel ligenc e , volume 39, pp. 15875– 15883, 2025. Jun Dan, W eiming Liu, Xie Xie, Hua Y u, Sh unjie Dong, and Y anchao T an. Tfgda: Exploring top ology and feature alignment in semi-supervised graph domain adaptation through robust clustering. A dvanc es in Neur al Information Pr o c essing Systems , 37:50230–50255, 2024. Florian Eyb en, Martin Wöllmer, and Björn Sc huller. Op ensmile: the m unich versatile and fast op en-source audio feature extractor. In Pr o c e e dings of the 18th A CM international c onfer enc e on Multime dia , pp. 1459–1462, 2010. Sa y an Ghosh, Mathieu Chollet, Eugene Laksana, Louis-Philipp e Morency , and Stefan Scherer. Affect-lm: A neural language model for customizable affective text generation. arXiv pr eprint arXiv:1704.06851 , 2017. Zirun Guo, T ao Jin, W enlong Xu, W ang Lin, and Y angy ang W u. Bridging the gap for test-time multimodal sen timen t analysis. In Pr o c e e dings of the AAAI Confer enc e on A rtificial Intel ligenc e , volume 39, pp. 16987–16995, 2025. Samira Hazmoune and F ateh Bougamouza. Using transformers for multimodal emotion recognition: T ax- onomies and state of the art review. Engine ering Applic ations of A rtificial Intel ligenc e , 133:108339, 2024. Ngo c-Huynh Ho, Hyung-Jeong Y ang, So o-Hyung Kim, and Gueesang Lee. Multimo dal approach of speech emotion recognition using multi-lev el multi-head fusion attention-based recurrent neural netw ork. IEEE A c c ess , 8:61672–61686, 2020. Jingw en Hu, Y uc hen Liu, Jinming Zhao, and Qin Jin. Mmgcn: Multimo dal fusion via deep graph conv olution net w ork for emotion recognition in con v ersation. In Pr o c e e dings of the 59th A nnual Me eting of the A sso- ciation for Computational Linguistics and the 11th International Joint Confer enc e on Natur al L anguage Pr o c essing (V olume 1: L ong Pap ers) , pp. 5666–5675, 2021. Y uchen Hu, Chen Chen, Chao-Han Y ang, Chengwei Qin, Pin-Y u Chen, Eng-Siong Chng, and Chao Zhang. Self-taugh t recognizer: T o ward unsupervised adaptation for sp eech foundation mo dels. A dvanc es in Neur al Information Pr o c essing Systems , 37:29566–29594, 2024. 23 Gao Huang, Zh uang Liu, Laurens V an Der Maaten, and Kilian Q W ein b erger. Densely connected con volu- tional netw orks. In Pr o c e e dings of the IEEE c onfer enc e on c omputer vision and p attern r e c o gnition , pp. 4700–4708, 2017. Minlie Huang, Xiaoy an Zhu, and Jianfeng Gao. Challenges in building intelligen t op en-domain dialog sys- tems. A CM T r ansactions on Information Systems (TOIS) , 38(3):1–32, 2020. Mahesh G Huddar, Sanjeev S Sannakki, and Vijay S Ra jpurohit. Atten tion-based m ulti-mo dal sentimen t analysis and emotion detection in con versation using rnn. 2021. Y ufei Jin, Heng Lian, Yi He, and Xingquan Zhu. Hgdl: Heterogeneous graph lab el distribution learning. A dvanc es in Neur al Information Pr o c essing Systems , 37:40792–40830, 2024. Y ujin Kang and Y o on-Sik Cho. Bey ond single emotion: Multi-lab el approach to conv ersational emotion recognition. In Pr o c e e dings of the AAAI Confer enc e on A rtificial Intel ligenc e , v olume 39, pp. 24321– 24329, 2025. Smith K Khare and V arun Ba ja j. Time–frequency represen tation and con v olutional neural net w ork-based emotion recognition. IEEE tr ansactions on neur al networks and le arning systems , 32(7):2901–2909, 2020. T aewoon Kim and Piek V ossen. Emoberta: Speaker-a ware emotion recognition in conv ersation with rob erta. arXiv pr eprint arXiv:2108.12009 , 2021. Y o on Kim. Conv olutional neural netw orks for sentence classification. In Pr o c e e dings of the 2014 Confer enc e on Empiric al Metho ds in Natur al L anguage Pr o c essing (EMNLP) , pp. 1746–1751. A CL, Octob er 2014. Bob o Li, Hao F ei, F ei Li, Shengqiong W u, Lizi Liao, Yin wei W ei, T at-Seng Chua, and Donghong Ji. Revisiting con v ersation discourse for dialogue disentanglemen t. A CM T r ansactions on Information Systems , 43(1): 1–34, 2025. Jiang Li, Xiaoping W ang, Ying jian Liu, and Zhigang Zeng. CFN-ESA: A cross-mo dal fusion netw ork with emotion-shift aw areness for dialogue emotion recognition. IEEE T r ansactions on Affe ctive Computing , 15 (4):1919–1933, 2024a. doi: 10.1109/T AFF C.2024.3389453. Jiang Li, Xiaoping W ang, Ying jian Liu, and Zhigang Zeng. Cfn-esa: A cross-mo dal fusion netw ork with emotion-shift aw areness for dialogue emotion recognition. IEEE T r ansactions on Affe ctive Computing , 2024b. Junnan Li, Caiming Xiong, and Stev en CH Hoi. Learning from noisy data with robust represen tation learning. In Pr o c e e dings of the IEEE/CVF International Confer enc e on Computer Vision , pp. 9485–9494, 2021. Zheng Lian, Bin Liu, and Jianhua T ao. Ctnet: Con versational transformer netw ork for emotion recognition. IEEE/A CM T r ansactions on A udio, Sp e e ch, and L anguage Pr o c essing , 29:985–1000, 2021. Zheng Lian, Lan Chen, Licai Sun, Bin Liu, and Jianh ua T ao. Gcnet: Graph completion net work for incom- plete multimodal learning in conv ersation. IEEE T r ansactions on p attern analysis and machine intel li- genc e , 45(7):8419–8432, 2023. Huan Liu, Tianyu Lou, Y uzhe Zhang, Yixiao W u, Y ang Xiao, Christian S Jensen, and Dalin Zhang. Eeg-based m ultimo dal emotion recognition: a mac hine learning persp ective. IEEE T r ansactions on Instrumentation and Me asur ement , 2024a. Meihan Liu, Zeyu F ang, Zhen Zhang, Ming Gu, Sheng Zhou, Xin W ang, and Jia jun Bu. Rethinking prop- agation for unsupervised graph domain adaptation. In Pr o c e e dings of the AAAI Confer enc e on A rtificial Intel ligenc e , v olume 38, pp. 13963–13971, 2024b. Sheng Liu, Jonathan Niles-W eed, Narges Razavian, and Carlos F ernandez-Granda. Early-learning regular- ization prev ents memorization of noisy lab els. A dvanc es in neur al information pr o c essing systems , 33: 20331–20342, 2020. 24 Ying jian Liu, Jiang Li, Xiaoping W ang, and Zhigang Zeng. Emotionic: Emotional inertia and contagion- driv en dep endency modeling for emotion recognition in con versation. SCIENCE CHINA Information Scienc es , 67(8):182103:1–182103:17, 2023. doi: 10.1007/s11432- 023- 3908- 6. Haifeng Lu, Jiuyi Chen, F eng Liang, Mingkui T an, Runhao Zeng, and Xiping Hu. Understanding emo- tional b o dy expressions via large language mo dels. In Pr o c e e dings of the AAAI Confer enc e on A rtificial Intel ligenc e , v olume 39, pp. 1447–1455, 2025. Hui Ma, Jian W ang, Hongfei Lin, Bo Zhang, Yijia Zhang, and Bo Xu. A transformer-based mo del with self-distillation for multimodal emotion recognition in conv ersations. IEEE T r ansactions on Multime dia , 2023. Hui Ma, Jian W ang, Hongfei Lin, Bo Zhang, Yijia Zhang, and Bo Xu. A transformer-based mo del with self-distillation for multimodal emotion recognition in conv ersations. IEEE T r ansactions on Multime dia , 26:776–788, 2024. Na v onil Majumder, Soujany a Poria, Dev amanyu Hazarika, Rada Mihalcea, Alexander Gelbukh, and Erik Cam bria. Dialoguernn: An attentiv e rnn for emotion detection in conv ersations. In Pr o c e e dings of the AAAI c onfer enc e on artificial intel ligenc e , v olume 33, pp. 6818–6825, 2019. T ao Meng, Y un tao Shou, W ei Ai, Jiayi Du, Haiyan Liu, and Keqin Li. A m ulti-message passing framework based on heterogeneous graphs in conv ersational emotion recognition. Neur o c omputing , 569:127109, 2024a. T ao Meng, Y untao Shou, W ei Ai, Nan Yin, and Keqin Li. Deep imbalanced learning for multimodal emotion recognition in conv ersations. IEEE T r ansactions on A rtificial Intel ligenc e , 5(12):6472–6487, 2024b. Gaspard Michel, Giannis Nikolen tzos, Johannes F Lutzeyer, and Mic halis V azirgiannis. Path neural net works: Expressiv e and accurate graph neural netw orks. In International Confer enc e on Machine L e arning , pp. 24737–24755. PMLR, 2023. Mehry ar Mohri. F oundations of mac hine learning, 2018. Cheng Peng, Ke Chen, Lidan Shou, and Gang Chen. Carat: con trastive feature reconstruction and aggrega- tion for multi-modal m ulti-lab el emotion recognition. In Pr o c e e dings of the AAAI Confer enc e on A rtificial Intel ligenc e , v olume 38, pp. 14581–14589, 2024. Soujan y a P oria, Erik Cambria, Dev aman yu Hazarika, Nav onil Ma jumder, Amir Zadeh, and Louis-Philipp e Morency . Con text-dep enden t sen timent analysis in user-generated videos. In Pr o c e e dings of the 55th annual me eting of the asso ciation for c omputational linguistics (volume 1: L ong p ap ers) , pp. 873–883, 2017. Soujan y a Poria, Dev aman yu Hazarika, Nav onil Ma jumder, Gautam Naik, Erik Cambria, and Rada Mihal- cea. Meld: A multimodal m ulti-part y dataset for emotion recognition in conv ersations. arXiv pr eprint arXiv:1810.02508 , 2018. Jingh ui Qin, Changsong Liu, Tianchi T ang, Dah uang Liu, Minghao W ang, Qianying Huang, and R umin Zhang. Men tal-p erceiver: Audio-textual multi-modal learning for estimating mental disorders. In Pr o- c e e dings of the AAAI Confer enc e on A rtificial Intel ligenc e , v olume 39, pp. 25029–25037, 2025. Jiezhong Qiu, Qibin Chen, Y uxiao Dong, Jing Zhang, Hongxia Y ang, Ming Ding, Kuansan W ang, and Jie T ang. Gcc: Graph contrastiv e co ding for graph neural netw ork pre-training. In Pr o c e e dings of the 26th A CM SIGKDD international c onfer enc e on know le dge disc overy & data mining , pp. 1150–1160, 2020. Ievgen Redko, Amaury Habrard, and Marc Sebban. Theoretical analysis of domain adaptation with optimal transp ort. In Machine L e arning and K now le dge Disc overy in Datab ases: Eur op e an Confer enc e, ECML PKDD 2017, Skopje, Mac e donia, Septemb er 18–22, 2017, Pr o c e e dings, Part II 10 , pp. 737–753. Springer, 2017. 25 Minjie Ren, Xiangdong Huang, W enhui Li, Dan Song, and W eizhi Nie. Lr-gcn: Latent relation-aw are graph con v olutional net work for con versational emotion recognition. IEEE T r ansactions on Multime dia , 24: 4422–4432, 2021. Jian Shen, Y anru Qu, W einan Zhang, and Y ong Y u. W asserstein distance guided representation learning for domain adaptation. In Pr o c e e dings of the AAAI c onfer enc e on artificial intel ligenc e , v olume 32, 2018. Y untao Shou, T ao Meng, W ei Ai, Sihan Y ang, and Keqin Li. Con versational emotion recognition studies based on graph conv olutional neural net w orks and a dep endent syn tactic analysis. Neur o c omputing , 501: 629–639, 2022. Y unT ao Shou, W ei Ai, T ao Meng, F uChen Zhang, and KeQin Li. Graphunet: Graph make strong enco ders for remote sensing segmentation. In 2023 IEEE 29th International Confer enc e on Par al lel and Distribute d Systems (ICP ADS) , pp. 2734–2737. IEEE, 2023. Y untao Shou, W ei Ai, Jia yi Du, T ao Meng, Haiy an Liu, and Nan Yin. Efficien t long-distance laten t relation-a w are graph neural netw ork for multi-modal emotion recognition in conv ersations. arXiv pr eprint arXiv:2407.00119 , 2024a. Y untao Shou, Huan Liu, Xiangy ong Cao, Deyu Meng, and Bo Dong. A low-rank matching atten tion based cross-mo dal feature fusion metho d for conv ersational emotion recognition. IEEE T r ansactions on Affe ctive Computing , 16(2):1177–1189, 2024b. Y untao Shou, T ao Meng, W ei Ai, F uc hen Zhang, Nan Yin, and Keqin Li. Adv ersarial alignmen t and graph fusion via information bottleneck for multimodal emotion recognition in conv ersations. Information F usion , 112:102590, 2024c. Y untao Shou, Peiqiang Y an, Xing jian Y uan, Xiangyong Cao, Qian Zhao, and Deyu Meng. Graph domain adaptation with dual-branch enco der and tw o-level alignment for whole slide image-based surviv al predic- tion. arXiv pr eprint arXiv:2411.14001 , 2024d. Y untao Shou, Xiangy ong Cao, Huan Liu, and Deyu Meng. Masked contrastiv e graph representation learning for age estimation. Pattern R e c o gnition , 158:110974, 2025a. Y untao Shou, Xiangyong Cao, and Deyu Meng. Sp egcl: Self-sup ervised graph sp ectrum contrastiv e learning without positive samples. IEEE T r ansactions on Neur al Networks and L e arning Systems , 2025b. Y untao Shou, Xiangy ong Cao, Peiqiang Y an, Qiao Hui, Qian Zhao, and Deyu Meng. Graph domain adap- tation with dual-branch enco der and t wo-lev el alignmen t for whole slide image-based surviv al prediction. In Pr o c e e dings of the IEEE/CVF International Confer enc e on Computer Vision , pp. 19925–19935, 2025c. Y untao Shou, Haozhi Lan, and Xiangyong Cao. Contrastiv e graph represen tation learning with adversarial cross-view reconstruction and information b ottleneck. Neur al Networks , 184:107094, 2025d. Y untao Shou, T ao Meng, W ei Ai, and Keqin Li. Dynamic graph neural ode netw ork for multi-modal emotion recognition in con versation. In Pr o c e e dings of the 31st International Confer enc e on Computational Linguistics , pp. 256–268, 2025e. Y untao Shou, T ao Meng, W ei Ai, and Keqin Li. Multimo dal large language mo dels meet multimodal emotion recognition and reasoning: A surv ey . arXiv pr eprint arXiv:2509.24322 , 2025f. Y untao Shou, T ao Meng, W ei Ai, and Keqin Li. Revisiting m ulti-mo dal emotion learning with broad state space mo dels and probability-guidance fusion. In Joint Eur op e an Confer enc e on Machine L e arning and K now le dge Disc overy in Datab ases , pp. 509–525. Springer, 2025g. Y untao Shou, T ao Meng, W ei Ai, Nan Yin, and Keqin Li. Cilf-ciae: Clip-driv en image–language fusion for correcting in verse age estimation. Neur al Networks , pp. 108518, 2025h. 26 Y untao Shou, Jun Y ao, T ao Meng, W ei Ai, Cen Chen, and Keqin Li. Gsdnet: Revisiting incomplete m ultimo dalit y-diffusion emotion recognition from the p ersp ective of graph spectrum. In Pr o c e e dings of the Thirty-F ourth International Joint Confer enc e on A rtificial Intel ligenc e, IJCAI-25. International Joint Confer enc es on A rtificial Intel ligenc e Or ganization , pp. 6182–6190, 2025i. Y untao Shou, W ei Ai, T ao Meng, and Keqin Li. Graph diffusion mo dels: A comprehensiv e survey of metho ds and applications. Computer Scienc e R eview , 59:100854, 2026a. Y untao Shou, T ao Meng, W ei Ai, F angze F u, Nan Yin, and Keqin Li. A comprehensive survey on m ulti-mo dal con v ersational emotion recognition with deep learning. A CM T r ansactions on Information Systems , 44 (2):1–48, 2026b. Jun Sun, Xinxin Zhang, Simin Hong, Jian Zh u, and Xiang Gao. Bo omda: Balanced m ulti-ob jectiv e optimiza- tion for multimodal domain adaptation. In Pr o c e e dings of the AAAI Confer enc e on A rtificial Intel ligenc e , v olume 40, pp. 25700–25708, 2026. Mingc hen Sun, Kaixiong Zhou, Xin He, Ying W ang, and Xin W ang. Gppt: Graph pre-training and prompt tuning to generalize graph neural net works. In Pr o c e e dings of the 28th A CM SIGKDD Confer enc e on K now le dge Disc overy and Data Mining , pp. 1717–1727, 2022. T eng Sun, Yinw ei W ei, Juntong Ni, Zixin Liu, Xuemeng Song, Y ao wei W ang, and Liqiang Nie. Muti-mo dal emotion recognition via hierarc hical kno wledge distillation. IEEE T r ansactions on Multime dia , 2024. Bin T ang, Ke-Qi P an, Miao Zheng, Ning Zhou, Jia-Lu Sui, Dandan Zhu, Cheng-Long Deng, and Shu- Guang Kuai. Pose as a mo dalit y: A psyc hology-inspired netw ork for p ersonality recognition with a new m ultimo dal dataset. In Pr o c e e dings of the AAAI Confer enc e on A rtificial Intel ligenc e , volume 39, pp. 1538–1546, 2025. Ch uanqi T ao, Jiaming Li, Tianzi Zang, and P eng Gao. A m ulti-fo cus-driven multi-branc h net work for robust multimodal sentimen t analysis. In Pr o c e e dings of the AAAI Confer enc e on A rtificial Intel ligenc e , v olume 39, pp. 1547–1555, 2025. Mani Kumar T ellamekala, Shahin Amiriparian, Björn W Sch uller, Elisab eth André, Timo Giesbrec h t, and Mic hel V alstar. Cold fusion: Calibrated and ordinal laten t distribution fusion for uncertain ty-a ware mul- timo dal emotion recognition. IEEE T r ansactions on Pattern A nalysis and Machine Intel ligenc e , 46(2): 805–822, 2023. Geng T u, Tian Xie, Bin Liang, Hongpeng W ang, and Ruifeng Xu. A daptive graph learning for m ultimo dal con v ersational emotion detection. In Pr o c e e dings of the AAAI Confer enc e on A rtificial Intel ligenc e , vol- ume 38, pp. 19089–19097, 2024. Cédric Villani et al. Optimal tr ansp ort: old and new , v olume 338. Springer, 2009. Johannes W agner, Andreas T rian tafyllop oulos, Hagen Wierstorf, Maximilian Sc hmitt, F elix Burkhardt, Flo- rian Eyb en, and Björn W Sch uller. Dawn of the transformer era in sp eech emotion recognition: closing the v alence gap. IEEE T r ansactions on Pattern A nalysis and Machine Int el ligenc e , 45(9):10745–10759, 2023. Y e W ang, W ei Zhang, Ke Liu, W ei W u, F eng Hu, Hong Y u, and Guoyin W ang. Dynamic emotion-dep endent net w ork with relational subgraph in teraction for m ultimo dal emotion recognition. IEEE T r ansactions on Affe ctive Computing , pp. 1–14, 2024a. doi: 10.1109/T AFFC.2024.3461148. Yingxu W ang, Mengzhu W ang, Siw ei Liu, and Nan Yin. Degree distribution based spiking graph net works for domain adaptation. arXiv pr eprint arXiv:2410.06883 , 2024b. Zhiyuan W en, Jiannong Cao, Jiaxing Shen, Ruosong Y ang, Sh uaiqi Liu, and Maosong Sun. Personalit y- affected emotion generation in dialog systems. A CM T r ansactions on Information Systems , 42(5):1–27, 2024. 27 Man W u, Shirui Pan, Ch uan Zhou, Xiao jun Chang, and Xingquan Zh u. Unsupervised domain adaptiv e graph con volutional netw orks. In Pr o c e e dings of the W eb Confer enc e 2020 , pp. 1457–1467, 2020. Qinfu Xu, Shaozu Y uan, Yiw ei W ei, Jie W u, Leiquan W ang, and Chunlei W u. Multiple feature refining net w ork for visual emotion distribution learning. In Pr o c e e dings of the AAAI Confer enc e on A rtificial Intel ligenc e , v olume 39, pp. 8924–8932, 2025. Xu Y ang, Cheng Deng, T ongliang Liu, and Dacheng T ao. Heterogeneous graph attention netw ork for un- sup ervised m ultiple-target domain adaptation. IEEE T r ansactions on Pattern A nalysis and Machine Intel ligenc e , 44(4):1992–2003, 2020. Zhen yu Y ang, Xiaoy ang Li, Y uh u Cheng, T ong Zhang, and Xuesong W ang. Emotion recognition in con ver- sation based on a dynamic complemen tary graph conv olutional netw ork. IEEE T r ansactions on Affe ctive Computing , 2024. Dong Yin, Ramchandran Kannan, and P eter Bartlett. Rademacher complexity for adv ersarially robust generalization. In International c onfer enc e on machine le arning , pp. 7085–7094. PMLR, 2019. Nan Yin, Li Shen, Baopu Li, Mengzh u W ang, Xiao Luo, Chong Chen, Zhigang Luo, and Xian-Sheng Hua. Deal: An unsup ervised domain adaptiv e framework for graph-lev el classification. In Pr o c e e dings of the 30th A CM International Confer enc e on Multime dia , pp. 3470–3479, 2022. Nan Yin, Li Shen, Mengzh u W ang, Xiao Luo, Zhigang Luo, and Dacheng T ao. Omg: T o wards effective graph classification against lab el noise. IEEE T r ansactions on K now le dge and Data Engine ering , 35(12): 12873–12886, 2023. Nan Yin, Li Shen, Chong Chen, Xian-Sheng Hua, and Xiao Luo. Sp ort: A subgraph p ersp ective on graph classification with lab el noise. 18(9), 2024a. ISSN 1556-4681. URL https://doi.org/10.1145/3687468 . W enzhe Yin, Shujian Y u, Yicong Lin, Jie Liu, Jan-Jakob Sonke, and Stratis Gavv es. Domain adaptation with cauch y-sch warz divergence. In The 40th Confer enc e on Unc ertainty in A rtificial Intel ligenc e , 2024b. Y uning Y ou, Tianlong Chen, Zhangy ang W ang, and Y ang Shen. Graph domain adaptation via theory- grounded sp ectral regularization. In The Eleventh International Confer enc e on L e arning R epr esentations , 2023. T om Y oung, Erik Cambria, Iti Chaturvedi, Hao Zhou, Subham Biswas, and Minlie Huang. A ugmenting end-to-end dialogue systems with commonsense knowledge. In Pr o c e e dings of the AAAI c onfer enc e on artificial intel ligenc e , volume 32, 2018. Lin Y uan, Guoheng Huang, F engh uan Li, Xiao chen Y uan, Chi-Man Pun, and Guo Zhong. Rba-gcn: Rela- tional bilevel aggregation graph conv olutional netw ork for emotion recognition. IEEE/A CM T r ansactions on A udio, Sp e e ch, and L anguage Pr o c essing , 31:2325–2337, 2023. Bo w en Zhang, Zhichao Huang, Guangning Xu, Xiaomao F an, Mingyan Xiao, Genan Dai, and Hu Huang. Core kno wledge learning framework for graph. In Pr o c e e dings of the AAAI Confer enc e on A rtificial Intel ligenc e , v olume 39, pp. 13179–13187, 2025. Linhao Zhang, Li Jin, Guangluan Xu, Xiao yu Li, Cai Xu, Kaiwen W ei, Nayu Liu, and Haonan Liu. Camel: capturing metaphorical alignment with con text disentan gling for multimodal emotion recognition. In Pr o c e e dings of the AAAI Confer enc e on A rtificial Intel ligenc e , v olume 38, pp. 9341–9349, 2024a. Xinxin Zhang, Jun Sun, Simin Hong, and T aihao Li. Amanda: A daptiv ely mo dality-balanced domain adap- tation for m ultimo dal emotion recognition. In Findings of the A sso ciation for Computational Linguistics A CL 2024 , pp. 14448–14458, 2024b. Zhen Zhang, Meihan Liu, Anhui W ang, Hongyang Chen, Zhao Li, Jia jun Bu, and Bingsheng He. Collaborate to adapt: Source-free graph domain adaptation via bi-directional adaptation. In Pr o c e e dings of the A CM W eb Confer enc e 2024 , pp. 664–675, 2024c. 28 Zhengdao Zhao, Y uhua W ang, Guang Shen, Y uezh u Xu, and Jiayuan Zhang. T dfnet: T ransformer-based deep-scale fusion netw ork for multimodal emotion recognition. IEEE/A CM T r ansactions on A udio, Sp e e ch, and L anguage Pr o c essing , 31:3771–3782, 2023. 29
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment