Generation Is Compression: Zero-Shot Video Coding via Stochastic Rectified Flow
Existing generative video compression methods use generative models only as post-hoc reconstruction modules atop conventional codecs. We propose \emph{Generative Video Codec} (GVC), a zero-shot framework that turns a pretrained video generative model…
Authors: Ziyue Zeng, Xun Su, Haoyuan Liu
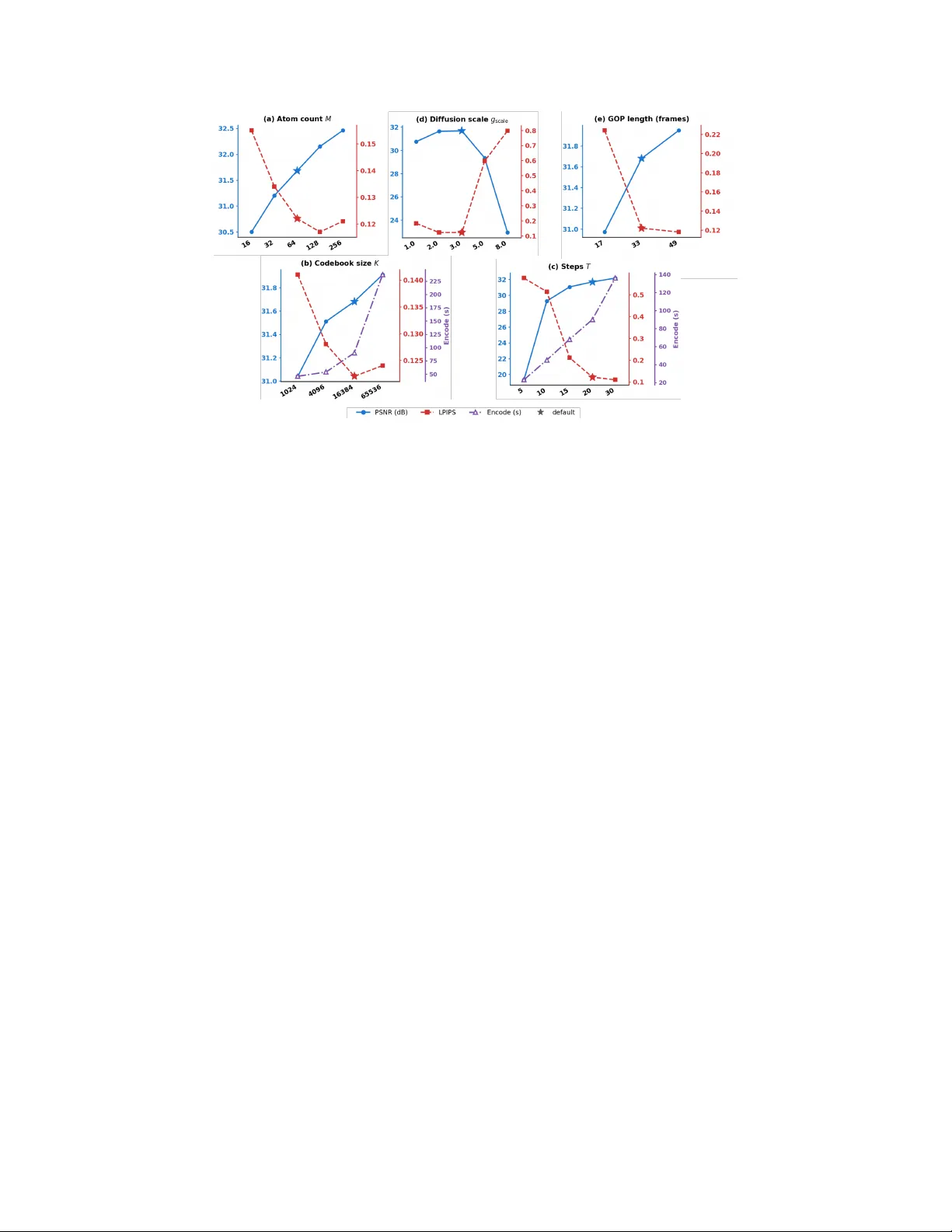
Generation Is Compr ession: Zer o-Shot V ideo Coding via Stochastic Rectified Flow Ziyue Zeng ∗ Xun Su ∗ Haoyuan Liu Bingyu Lu Y ui T atsumi Hiroshi W atanabe Graduate School of Fundamental Science and Engineering, W aseda University T okyo, Japan zengziyue@fuji.waseda.jp, suxun_opt@asagi.waseda.jp Abstract Existing generativ e video compression methods use generative models only as post-hoc reconstruction modules atop con ventional codecs. W e propose Gener- ative V ideo Codec (GVC), a zero-shot framework that turns a pretrained video generativ e model into the codec itself: the transmitted bitstream directly specifies the generati ve decoding trajectory , with no retraining required. T o enable this, we con vert the deterministic rectified-flow ODE of modern video foundation models into an equi valent SDE at inference time, unlocking per -step stochastic injection points for codebook-dri ven compression. Building on this unified backbone, we instantiate three complementary conditioning strategies— Ima ge-to-V ideo (I2V) with adapti ve tail-frame atom allocation, T ext-to-V ideo (T2V) operating at near -zero side information as a pure generati ve prior , and F irst-Last-F rame-to-V ideo (FLF2V) with boundary-sharing GOP chaining for dual-anchor temporal control. T ogether , these v ariants span a principled trade-off space between spatial fidelity , temporal coherence, and compression ef ficiency . Experiments on standard benchmarks sho w that GVC achie ves high-quality reconstruction belo w 0.002 bpp while supporting flexible bitrate control through a single hyperparameter . 1 Introduction V ideo compression at extremely low bitrates remains a fundamental challenge. As the bitrate decreases, both con ventional h ybrid codecs and learned neural codecs suffer from se vere detail loss and ov ersmoothing. Although generative modeling has opened a promising direction for perceptual reconstruction, most existing generati ve video compression methods do not make generation itself the core of compression. Instead, they follo w a hybrid design: a con ventional codec first produces a compressed representation, and a generati ve model is introduced afterward as a refinement module. In such systems, the generative model improv es the output appearance but does not define the compressed symbols or the decoding trajectory . In the image domain, generativ e compression has progressed from GAN-based learned decoders to diffusion-based approaches with superior sample quality . Among them, zero-shot codebook methods such as DDCM and T urbo-DDCM show that a pretrained dif fusion model can be directly repurposed as a codec by replacing re verse-step noise with reproducible codebook atoms and transmitting only compact indices—without any retraining. Extending this idea to video, recent works such as GNVC- VD replace image-based priors with a pretrained video diffusion model for sequence-le vel latent refinement, substantially reducing temporal flickering. Howe ver , these methods still follo w the hybrid paradigm: a dedicated latent codec produces the compressed representation, and the video generativ e model serves only as a post-hoc restorer rather than defining the codec itself. ∗ Equal contribution. Preprint. Figure 1: GVC produces perceptually superior reconstruction at ultra-low bitrates. Left: diagonal split comparison between DCVC-R T (0.0017 bpp) and our GVC-T2V (0.0016 bpp) on the UVG J ocke y sequence. GVC recovers sharp te xtures and coherent details while DCVC-R T exhibits se vere oversmoothing. Middle: zoomed-in crops comparing DCVC-R T , GNVC-VD, and GVC. Right: LPIPS comparison shows GVC achie ves a 70.3% reduction ov er DCVC-R T at comparable bitrate; a user study confirms that GVC is preferred o ver DCVC-R T in 97% and over GNVC-VD in 88% of pairwise comparisons. In this work, we pursue a different goal: we ask whether a pretrained video generative model can itself serve as the codec. This leads to a truly generative formulation of video compression, in which the transmitted bitstream directly controls the generation process at the decoder . Decoding becomes the reproducible replay of a constrained video generation trajectory rather than deterministic reconstruction follo wed by generati ve enhancement. W e refer to this frame work as Generative V ideo Codec (GVC) . A natural starting point is to e xtend codebook-driv en image dif fusion compression to video by compressing each frame independently . Ho wever , our early exploration rev eals that such a per- frame strategy leads to se vere flickering, unstable te xtures, and appearance drift, since the per-frame generation trajectories are not temporally coordinated. This confirms that a successful generative video codec must model temporal coherence at the sequence lev el, moti v ating the adoption of video foundation models as the compression backbone. Moving to video foundation models introduces a technical obstacle: state-of-the-art video generators such as W an 2.1 are built on rectified flow (RF), which follo ws a deterministic ODE trajectory with no per-step noise injection. W e address this by con verting the RF ODE into an equi v alent SDE at inference time via Score-SDE theory , re-introducing controllable stochastic injection points that can be encoded with multi-atom codebook selections. This con version is purely mathematical and requires no retraining of the backbone model. Building on this unified SDE-codebook backbone, we instantiate three complementary conditioning strategies, each occup ying a dif ferent point in the trade-of f space between spatial fidelity , temporal coherence, and compression efficienc y . I2V (Image-to-Video) adopts an autore gressiv e GOP chain: the first GOP uses the ground-truth first frame as a free reference, and each subsequent GOP reuses the decoded last frame of its predecessor at zero additional cost. T o prev ent error accumulation along the chain, we propose adaptive tail-frame atom allocation , which assigns more codebook atoms to temporally distant frames, and tail latent r esidual correction , which transmits a lightweight quantized residual for the last latent frame before it propagates as the next GOP’ s reference. T2V (T ext-to- V ideo) transmits no reference frame at all—the entire bitrate consists of codebook indices—operating as a pure generativ e prior that tests the fundamental limit of codebook-steered reconstruction. FLF2V (First-Last-Frame-to-V ideo) compresses both the first and last frames of each GOP as dual temporal anchors, constraining the generati ve trajectory from both ends; we introduce a boundary-sharing GOP chaining scheme in which the last frame of one GOP is reused as the first frame of the next, reducing boundary frame ov erhead by approximately 50% while ensuring seamless continuity at splice points. T ogether, these three variants span a conditioning spectrum—from zero side information (T2V), through single-anchor (I2V), to dual-anchor (FLF2V)—re vealing ho w conditioning strength shapes spatial fidelity , temporal stability , and bitrate composition in codebook-driven generativ e compression, it rev eals how different conditioning regimes af fect spatial fidelity , temporal stability , and bitrate composition in codebook-driv en generative compression. 2 Our contributions are summarized as follo ws: • W e propose GVC, a truly generati ve video compression frame work where a pretrained video model directly defines the decoding process via codebook-driven stochastic trajectory replay , without any retraining. • W e instantiate three conditioning strategies—I2V , T2V , and FLF2V —with dedicated innov a- tions including adapti ve atom allocation and boundary-sharing GOP chaining, spanning a systematic trade-off between fidelity , coherence, and bitrate. • W e demonstrate that GVC achiev es high-quality video reconstruction belo w 0.002 bpp on standard benchmarks, with flexible bitrate control through a single hyperparameter . 2 Related W ork Generative Compr ession. In the image domain, generati ve compression has e volved from GAN- based learned decoders that restore perceptual details from quantized latents, to diffusion-based methods that lev erage stronger generati ve priors for reconstruction at lo w bitrates. For video, recent perceptual codecs introduce generativ e models into the decoding pipeline to combat ov ersmoothing under extreme compression. GNVC-VD is a representati ve work that replaces image-based priors with a pretrained video diffusion model for s equence-lev el latent refinement, substantially reducing temporal flickering. Howe ver , these methods still follow a hybrid paradigm in which a dedicated latent codec produces the compressed representation and the generative model acts as a post-hoc restorer . In contrast, GVC makes the pretrained video model the codec itself: the transmitted bitstream directly gov erns the generativ e decoding trajectory . Zero-Shot Codebook-Dri ven Compression. DDCM introduces a zero-shot image compression scheme that replaces the Gaussian noise at each DDPM reverse step with atoms from a reproducible codebook; transmitting only the selected indices suf fices to replay the same generative trajectory without retraining the backbone. Turbo-DDCM improv es this framew ork with a multi-atom thresh- olding strategy and an ef ficient combinatorial bitstream protocol, dramatically reducing runtime and enabling finer bitrate control through a single parameter M . Howe ver , both methods are designed for DDPM-based image models whose rev erse process explicitly injects stochastic noise at e very step. Modern video foundation models such as W an 2.1 are built on rectified flo w , which follo ws a deterministic ODE with no per-step noise injection, making existing codebook-dri ven compression inapplicable out of the box. Stochastic Sampling in Flow Models. Score-SDE theory establishes that any probability-flow ODE can be con verted into a family of SDEs sharing the same marginal distributions, parameterized by a free diffusion coefficient g t . SiT extends this result to the stochastic interpolant framework used by flow-matching models, pro viding the score-from-velocity formula that makes the con version practical. More recently , this ODE-to-SDE con version has been exploited for inference-time scaling in flo w models: by introducing stochasticity into the otherwise deterministic sampling process, particle-based search methods can explore a broader sample space to find high-re ward outputs. Our work repurposes this con version for a fundamentally dif ferent goal—not to improv e generation quality , but to create per-step noise injection points that enable codebook-driv en compression on pretrained rectified-flow video models. 3 Method GVC compresses each Group of Pictures (GOP) through a unified pipeline: a pretrained rectified- flow video model is con verted into a stochastic process at inference time, and the per -step noise is replaced by reproducible codebook selections whose indices form the transmitted bitstream. All three conditioning variants—I2V , T2V , and FLF2V —share the same SDE-codebook backbone and differ only in how the generative model is conditioned. W e first describe the shared compression backbone (Sec. 3.1–3.3), then detail the three conditioning strategies and their respectiv e innov ations (Sec. 3.5 – 3.6). 3 3.1 ODE-to-SDE Con version Rectified flow models learn a v elocity field u t : R d → R d under the linear interpolation x t = (1 − t ) x 0 + t ϵ , t ∈ [0 , 1] , ϵ ∼ N ( 0 , I ) , (1) where α t = 1 − t and σ t = t denote the signal and noise coefficients, respecti vely . Standard sampling solves the probability-flo w ODE backward in time: d x t = u t ( x t ) d t. (2) This process is purely deterministic: giv en an initial noise x 1 , the entire trajectory is uniquely determined, leaving no per -step degree of freedom for information embedding. By the Score-SDE equi v alence theorem, for any probability-flo w ODE generating marginals { p t } , there exists a family of rev erse-time SDEs that share the same marginals for any dif fusion coefficient g t ≥ 0 : d x t = u t ( x t ) − g 2 t 2 ∇ log p t ( x t ) | {z } f t ( x t ) d t + g t d ¯ w , (3) where ¯ w denotes the standard W iener process in rev erse time. Setting g t = 0 recov ers the original ODE (2) ; setting g t > 0 introduces per-step stochasticity—precisely the noise injection mechanism that codebook compression requires. W e adopt a quadratic diffusion schedule g t = g scale · t 2 , (4) which ensures g 0 = 0 (no noise injection near clean data) and concentrates stochasticity in the high-noise regime where the codebook can deli ver the most correcti ve information. The scalar g scale serves as the primary knob for the rate–quality trade-of f. 3.2 Score Function fr om the V elocity Field The SDE drift in Eq. (3) requires the score function ∇ log p t ( x t ) , which the rectified-flo w model does not directly output. Following the stochastic interpolant analysis of SiT , the score can be derived analytically from the velocity field. For the general interpolant x t = α t x 0 + σ t ϵ with learned velocity u t : ∇ log p t ( x t ) = 1 σ t · α t u t ( x t ) − ˙ α t x t ˙ α t σ t − α t ˙ σ t . (5) Substituting the linear schedule α t = 1 − t , σ t = t (hence ˙ α t = − 1 , ˙ σ t = 1 ) yields: ∇ log p t ( x t ) = − (1 − t ) u t ( x t ) + x t t . (6) This can be verified by noting that (1 − t ) u t + x t ≈ ϵ under the interpolation (1) , recovering the classical identity ∇ log p t = − ϵ /σ t . Crucially , Eq. (6) is computed entirely from the pretrained velocity network and requires no additional training. Substituting Eqs. (4) and (6) into the drift term of Eq. (3), the complete SDE drift becomes: f t ( x t ) = u t ( x t ) + g 2 t 2 · (1 − t ) u t ( x t ) + x t t . (7) When g t = 0 , the drift reduces to the original velocity u t , confirming that the SDE is a strict generalization of the ODE. 3.3 Codebook-Driven SDE Sampling W e adopt the codebook-driven compression mechanism introduced by DDCM and its multi-atom extension T urbo-DDCM, adapting it from the DDPM setting to the SDE formulation derived abo ve. Discretizing Eq. (3) via the Euler–Maruyama scheme with step size ∆ t giv es: x t − ∆ t = x t − f t ( x t ) ∆ t + g t √ ∆ t z , z ∼ N ( 0 , I ) . (8) 4 The noise z is the per-step stochastic v ariable that carries compressed information. Follo wing T urbo-DDCM’ s thresholding-based strategy , we replace it with a codebook-selected vector z ∗ as follows. At each SDE step, the encoder first estimates the clean signal as ˆ x 0 | t = x t − t · u t ( x t ) and computes the denoising residual r = x 0 − ˆ x 0 | t , where x 0 is the ground-truth latent a v ailable only at the encoder . A reproducible codebook C = { z (1) , . . . , z ( K ) } is then generated from a deterministic seed shared by both sides. The M atoms with the lar gest absolute inner product with r are selected, along with their signs: { j 1 , . . . , j M } = top - M i ⟨ z ( i ) , r ⟩ , s k = sign ⟨ z ( j k ) , r ⟩ . (9) The selected atoms are combined and normalized to unit variance to match the theoretical noise magnitude of the SDE: z ∗ = P M k =1 s k z ( j k ) std P M k =1 s k z ( j k ) . (10) The codebook noise z ∗ then replaces z in Eq. (8): x t − ∆ t = x t − f t ( x t ) ∆ t + g t √ ∆ t z ∗ . (11) Since both encoder and decoder share the same seed, model weights, and codebook construction rule, transmitting only the M indices and signs per step suffices for the decoder to reproduce the identical trajectory . For the last N steps, we set g t = 0 and revert to the deterministic ODE x t − ∆ t = x t − u t ( x t ) ∆ t , which requires zero transmitted bits since both sides produce identical outputs from the synchronized preceding state. 3.4 T2V : Pure Generative Prior Compr ession The T2V variant represents the most extreme point in GVC’ s design space: no reference frame is transmitted at all. The model recei ves only an empty text prompt, and the entire bitrate consists of codebook indices. This design isolates the contribution of the pretrained video model as a learned spatio-temporal prior—the codebook steers an otherwise unconditioned generation trajectory toward the target video. Because no spatial anchor is provided, the bitrate per GOP reduces to pure codebook cost: BPP T2V = ( T − 1 − N ) · F · B step F px × H px × W px × 3 , (12) which is the lowest achie v able bitrate among the three variants. T2V thus serves as a lower bound on the rate–quality trade-off, re vealing how much reconstruction quality the generati ve prior alone can deliv er under pure codebook control. A known limitation of T2V is the absence of spatial anchoring: without a reference frame, the model may produce subtle positional drift or content de viation across GOPs. T o mitigate discontinuities at GOP boundaries, an optional ov erlap-blending mechanism can be applied, where adjacent GOPs share a small number of ov erlapping frames and a linear cross-fade smooths the transition. 3.5 I2V : A utoregr essive Compression with T ail Correction The I2V v ariant conditions each GOP on a single reference frame through CLIP visual embedding and V AE latent encoding, providing the strongest spatial anchor among the three strategies. T o minimize side-information cost, we adopt an autoregressi ve GOP structure: the first GOP recei ves the ground-truth first frame as free side information (standard I-frame assumption), and each subsequent GOP reuses the decoded last frame of its predecessor as the reference, requiring zero additional transmitted bytes: GOP 0 : ref = I GT 0 , GOP n> 0 : ref = ˜ I last n − 1 . (13) A critical challenge in this autore gressi ve chain is error accumulation: the last frame of each GOP is farthest from the conditioning anchor and thus has the highest reconstruction error , yet it directly determines the quality of the next GOP’ s reference. W e address this with two complementary mechanisms. 5 First, adaptive tail-frame atom allocation increases the codebook atom count from M to M tail for the last F tail latent frames, concentrating more bits where the generativ e prior is weakest. Second, tail latent residual correction transmits a lightweight residual for the last latent frame. After SDE encoding, the encoder computes the difference between the ground-truth latent and the decoded latent for the final temporal position, quantizes it to 8 bits per channel with min/max normalization, and applies lossless compression (zlib). At the decoder , this residual is added to the reconstructed latent before V AE decoding, substantially improving the quality of the frame that will propagate as the next GOP’ s reference. The overhead of this residual is included in the bitrate computation. The total bitrate per GOP is: BPP I2V = ( T − 1 − N ) · F · B step + B tail _ residual F px × H px × W px × 3 , (14) where B tail _ residual denotes the compressed residual bytes (zero for the T2V and FLF2V v ariants). Note that B ref =0 for all GOPs: the first frame is free and subsequent references are decoded outputs. 3.6 FLF2V : Dual-Anchor Compression with Boundary Sharing The FLF2V v ariant conditions each GOP on both the first and last frames, providing dual temporal anchors that constrain the generati ve trajectory from both ends. Compared with single-anchor I2V , this design substantially reduces temporal drift within each GOP , as the model must simultaneously satisfy boundary conditions at both the beginning and the end of the sequence. Both boundary frames are compressed via a learned image codec, and the conditioning is constructed by encoding both frames through CLIP and placing them at the temporal endpoints of the V AE latent volume with a binary mask indicating which positions are conditioned. The generative model thus “interpolates” between two kno wn endpoints, which is inherently more constrained and temporally stable than extrapolating from a single anchor . The key engineering innov ation of FLF2V is a boundary-sharing GOP chaining scheme that amortizes reference frame cost across consecuti ve GOPs. The last frame of GOP n is reused as the first frame of GOP n +1 : GOP n : first = ˜ I n , last = ˜ I n +1 , GOP n +1 : first = ˜ I n +1 , last = ˜ I n +2 . (15) Under this scheme, GOP 0 transmits two boundary frames while each subsequent GOP transmits only one new frame, reducing boundary frame ov erhead by approximately 50% over a long sequence. The bitrate is: BPP FLF2V = ( T − 1 − N ) · F · B step + B boundary F px × H px × W px × 3 , (16) where B boundary equals B first + B last for the initial GOP and B last only for all subsequent GOPs. Beyond bitrate sa vings, boundary sharing also ensures seamless temporal continuity at splice points: both adjacent GOPs observe exactly the same decoded reference frame, eliminating mismatch artif acts at the junction. 4 Experiments 4.1 Experimental Setup Datasets and protocol. Ablation studies and cross-variant comparisons are conducted on UVG at 720p ( 1280 × 720 , 3 GOPs per sequence). For state-of-the-art comparisons, we ev aluate on the full UVG dataset at nativ e 1080p ( 1920 × 1080 , all available frames per sequence). Each video is segmented into non-o verlapping GOPs of 33 frames. W e additionally test on self-captured videos to rule out training-data ov erlap in the pretrained backbone. Models and configuration. All three GVC v ariants use the W an 2.1 14B model family . I2V uses the ground-truth first frame as free side information and chains subsequent GOPs autore gressi vely; FLF2V compresses boundary frames via CompressAI (cheng2020-attn, quality 4); T2V transmits codebook indices only . Experiments run on a single NVIDIA R TX 6000 Ada (48 GB). 6 Figure 2: Hyperparameter sweeps on UV G Beauty (T2V -1.3B, 720p). Blue: PSNR (left axis, ↑ ). Red: LPIPS (right axis, ↓ ). Purple: encoding time (where sho wn). Stars: selected defaults. (a) M . (b) K . (c) T . (d) g scale . (e) GOP length. Metrics. Distortion: PSNR, MS-SSIM. Perceptual quality: LPIPS (AlexNet). Compression ef fi- ciency: BPP and kbps. Per-frame PSNR curves are reported for temporal analysis. Encoding and decoding times are recorded for computational cost. 4.2 Default Parameter Selection W e sweep each hyperparameter individually on the UVG Beauty sequence using T2V -1.3B at 720p, with results sho wn in Fig. 2. The atom count M controls bitrate almost linearly: M =16 → 64 yields a 1.2 dB gain at only 0.0016 BPP , but beyond M =128 returns diminish and LPIPS slightly de grades (Fig. 2a). The codebook size K =16384 captures most of the quality gain ov er K =1024 (+0.64 dB) at reasonable encoding cost, while doubling to 65536 adds only 0.23 dB at 2 . 6 × the time (Fig. 2b). Sampling steps T has the most dramatic effect— T =5 causes catastrophic failure (19.3 dB) and gains plateau beyond T =20 (Fig. 2c). A notable finding is the narrow sweet spot of the diffusion scale g scale : 2 . 0 – 3 . 0 performs well but quality collapses at g scale ≥ 5 . 0 as injected noise overwhelms the codebook’ s correctiv e capacity (Fig. 2d). GOP length of 33 frames outperforms 17 (LPIPS: 0 . 12 vs. 0 . 22 ) and matches 49 at lo wer cost (Fig. 2e). Based on these sweeps, we adopt M =64 , K =16384 , T =20 , g scale =3 . 0 , and GOP =33 as defaults for all subsequent e xperiments. The complete parameter table with 720p/1080p configurations is provided in Appendix A. 4.3 Cross-V ariant Comparison W e compare the three GVC variants across all sev en UVG sequences. Since W an 2.1 is designed and optimized for 720p generation, we conduct this comparison at 1280 × 720 resolution (3 GOPs per sequence, 33 frames/GOP). F or reference, we also e valuate DCVC-R T on the same resized sequences to provide an anchor from a state-of-the-art learned codec under identical conditions. Results are reported in T able 1. The three variants exhibit distinct and complementary trade-of f profiles. I2V achie ves the highest fidelity across all sequences (+2.96 dB over T2V on av erage), but its bitrate is dominated by the 8-bit tail latent residual correction ( ∼ 91% of total bytes), which is the cost of maintaining autoregressi ve chain stability . T2V operates at the lowest bitrate (71.2 kbps, pure codebook) and deli vers surprisingly consistent perceptual quality (LPIPS 0.052–0.239), though PSNR varies substantially with scene complexity . The most striking finding is FLF2V’ s rate–distortion efficienc y: it recovers 81% of I2V’ s PSNR gain ov er T2V at only 15% of I2V’ s additional bitrate cost, yielding a marginal ef ficiency of ∼ 1000 dB/BPP versus I2V’ s ∼ 181 dB/BPP . This confirms that dual-anchor boundary interpolation 7 T able 1: Cross-variant comparison on UV G 720p (3 GOPs per sequence, 33 frames/GOP). Red : best per sequence. Blue : second best. DCVC-R T at its lowest quality point (avg. 0.0017 bpp) is included as a perceptual reference. GVC-T2V GVC-I2V GVC-FLF2V DCVC-R T (71 kbps) (802 kbps) (193 kbps) (0.0017 bpp) Seq. PSNR ↑ LPIPS ↓ BPP PSNR ↑ LPIPS ↓ BPP PSNR ↑ LPIPS ↓ BPP LPIPS ↓ Beau. 31.79 0.154 0.0016 32.90 0.109 0.0189 32.26 0.158 0.0025 0.512 Bosp. 30.32 0.098 0.0016 33.63 0.055 0.0182 32.72 0.086 0.0036 0.391 Honey . 30.78 0.052 0.0016 36.21 0.020 0.0181 34.73 0.033 0.0047 0.240 Jock. 31.28 0.090 0.0016 33.27 0.070 0.0178 33.09 0.080 0.0035 0.360 RSG 26.74 0.086 0.0016 29.48 0.053 0.0172 29.44 0.063 0.0056 0.324 SnD 25.55 0.239 0.0016 30.11 0.136 0.0183 29.52 0.166 0.0059 0.554 Y acht. 26.60 0.103 0.0016 28.21 0.075 0.0183 28.02 0.089 0.0047 0.410 A vg. 29.01 0.117 0.0016 31.97 0.074 0.0181 31.40 0.096 0.0044 0.399 Codebook 18.4 KB (100%) 18.4 KB ( ∼ 9%) 18.4 KB ( ∼ 40%) — Ref frames 0 0 (free GT + AR) ∼ 28 KB ( ∼ 60%) — T ail residual N/A ∼ 189 KB ( ∼ 91%) N/A — Spatial anchor None Single (first) Dual (first + last) Learned GOP structure Independent AR chain Boundary sharing P-frame Strength Lowest bitrate Highest fidelity Best marginal ef f. Best PSNR provides a highly cost-ef fectiv e alternati ve to autoregressi ve chaining, especially when bitrate budget is constrained. 4.4 Comparison with State-of-the-Art W e compare GVC against representative codecs on the full UVG dataset at native 1920 × 1080 . Since the three GVC variants operate at distinct bitrate regimes—T2V at ∼ 0 . 002 bpp, FLF2V at ∼ 0 . 005 bpp, and I2V at ∼ 0 . 018 bpp—we e valuate all baselines at the quality point closest to each regime, enabling f air per-tier comparison. For baselines that support adjustable quality , we linearly interpolate from their published rate–distortion curves or our o wn measurements at the BPP nearest to each tier . DCVC-R T values are interpolated from our reproduction; other baseline values are estimated from published RD curves in GNVC-VD under identical conditions (UV G 1080p, RGB, 96 frames). References References follo w the acknowledgments in the camera-ready paper . Use unnumbered first-lev el heading for the references. Any choice of citation style is acceptable as long as you are consistent. It is permissible to reduce the font size to small (9 point) when listing the references. Note that the Reference section does not count tow ards the page limit. [1] Alexander , J.A. & Mozer, M.C. (1995) T emplate-based algorithms for connectionist rule extraction. In G. T esauro, D.S. T ouretzky and T .K. Leen (eds.), Advances in Neural Information Pr ocessing Systems 7 , pp. 609–616. Cambridge, MA: MIT Press. [2] Bower , J.M. & Beeman, D. (1995) The Book of GENESIS: Exploring Realistic Neural Models with the GEneral NEural SImulation System. New Y ork: TELOS/Springer–V erlag. [3] Hasselmo, M.E., Schnell, E. & Barkai, E. (1995) Dynamics of learning and recall at excitatory recurrent synapses and cholinergic modulation in rat hippocampal region CA3. Journal of Neur oscience 15 (7):5249-5262. 8 T able 2: State-of-the-art comparison on UV G 1080p at three bitrate tiers corresponding to the three GVC v ariants. Baseline results are interpolated to matched BPP from published RD curv es or our measurements. Bold : best LPIPS per tier . Underline: second best. T ier 1: ∼ 0.002 bpp T ier 2: ∼ 0.005 bpp T ier 3: ∼ 0.018 bpp Method PSNR ↑ LPIPS ↓ BPP PSNR ↑ LPIPS ↓ BPP PSNR ↑ LPIPS ↓ BPP T raditional HEVC 26.0 0.400 0.002 28.0 0.380 0.005 32.0 0.320 0.018 VVC 27.0 0.380 0.002 29.5 0.350 0.005 34.0 0.280 0.018 Learned DCVC-FM 28.0 0.350 0.002 31.0 0.280 0.005 35.5 0.180 0.018 DCVC-R T 34.5 0.376 0.002 37.4 0.295 0.005 40.5 0.228 0.018 Generative (trained) GLC-V ideo 28.5 0.280 0.002 30.0 0.240 0.005 32.5 0.200 0.018 GNVC-VD 28.0 0.200 0.002 30.5 0.160 0.005 34.0 0.100 0.018 Ours (zero-shot) GVC-T2V 29.69 0.133 0.0009 GVC-FLF2V 31.9 0.105 0.003 GVC-I2V 32.5 0.082 0.017 A Default Hyperparameter Configuration T able 3 lists the full set of hyperparameters used across all three GVC v ariants at 720p and 1080p resolutions. T able 3: Default hyperparameters for GVC (720p / 1080p). Parameter 720p 1080p Role M 64 80 Atoms per step (bitrate knob) M tail (I2V) 128 128 Atoms for AR tail frames K 16384 16384 Codebook size T 20 20 T otal sampling steps N (DDIM tail) 3 3 Bit-free ODE tail steps g scale 3.0 3.0 SDE diffusion coef ficient GOP length 33 33 Frames per GOP ( 4 k +1 ) Ref quality (FLF2V) 4 4 CompressAI quality lev el T ail residual (I2V) 8-bit 8-bit Quantization for AR correction Seed 42 42 Shared encoder/decoder seed 9
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment