Shapley meets Rawls: an integrated framework for measuring and explaining unfairness
Explainability and fairness have mainly been considered separately, with recent exceptions trying the explain the sources of unfairness. This paper shows that the Shapley value can be used to both define and explain unfairness, under standard group f…
Authors: Fadoua Amri-Jouidel, Emmanuel Kemel, Stéphane Mussard
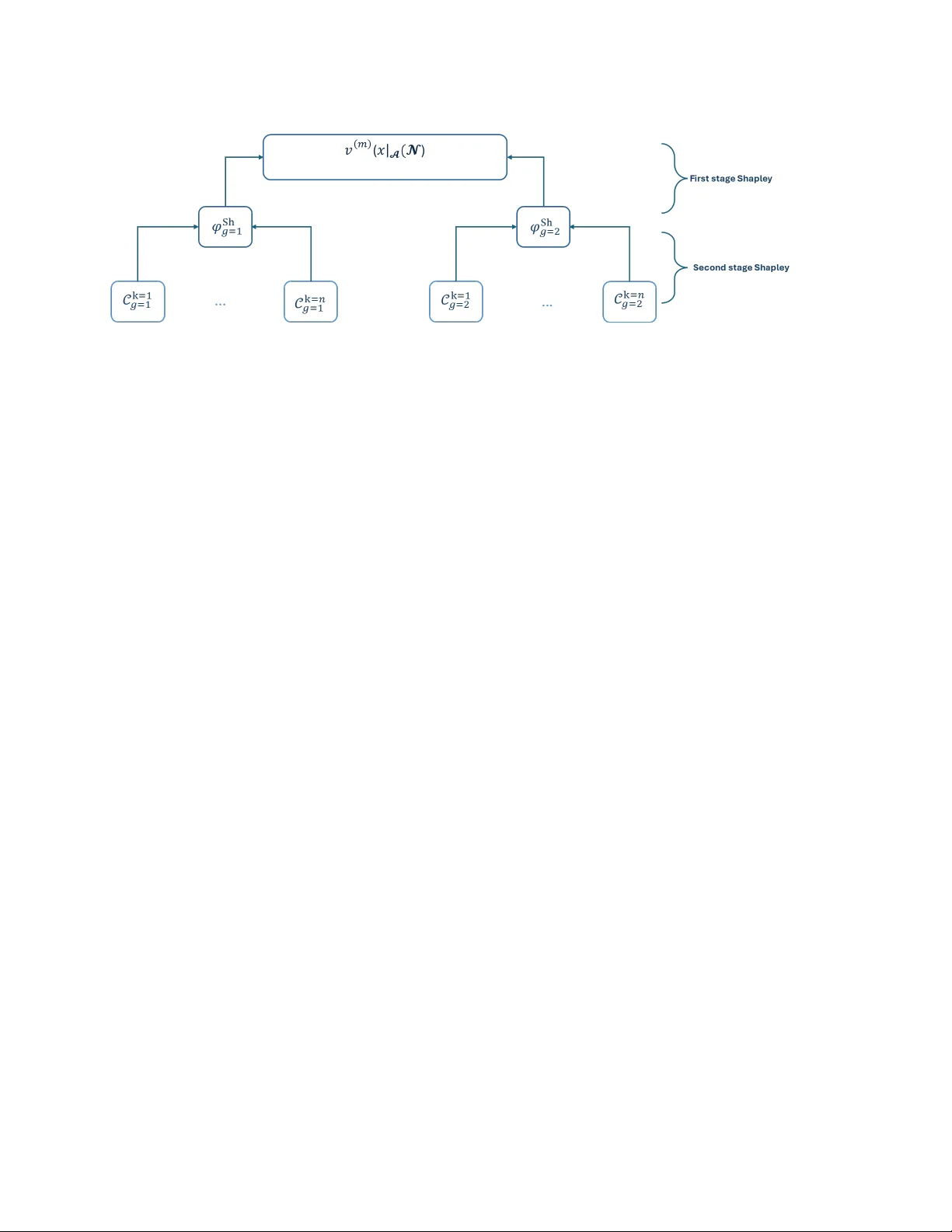
Shapley meets Ra wls: an in tegrated framew ork for measuring and explaining unfairness F adoua Amri-Jouidel ∗ UM6P Airess Emman uel Kemel † GREGHEC, CNRS HEC P aris St ´ ephane Mussard ‡ EndAName Univ. N ˆ ımes Chr ome Um6p, Airess Abstract Explainabilit y and fairness ha ve mainly b een c onsidered separately , with recent exceptions trying the explain the sources of unfairness. This paper shows that the Shapley v alue can b e used to b oth define and explain unfairness, under standard group fairness criteria. This offers an integrated framew ork to estimate and derive inference on unfairness as-w ell-as the features that contribute to it. Our framew ork can also b e extended from Shapley v alues to the family of Efficien t-Symmetric-Linear (ESL) v alues, some of whic h offer more robust definitions of fairness, and shorter computation times. An illustration is run on the Census Income dataset from the UCI Mac hine Learning Rep ository . Our approac h sho ws that “Age”, “Num b er of hours” and “Marital status” generate gender unfairness, using shorter computation time than traditional Bo otstrap tests. Keyw ords: Asymptotic test; ESL v alues ; Explainability ; F air learning ; Shapley V alue ; XAIOR. Sub ject classification: Computers/computer science (artificial intelligence) ; Games / group decisions (co op erativ e). Area of review: Machine Learning and Data Science. ∗ Univ ersit y Mohammed VI Polytec hnic, Rabat, Sal´ e. Corresp onding author: F adoua.JOUIDEL- AMRI@um6p.ma † Cnrs , HEC P aris ‡ Univ. N ˆ ımes Chrome , Rue du Dr Georges Salan, 30000 N ˆ ımes ; Email: stephane.mussard@unimes.fr ; Researc h fellow Liser Luxem b ourg and Univ ersity Mohammed VI Polytec hnic. 1 1 In tro duction Artificial Intelligence (AI) is increasingly b eing in tegrated to assist or automate decision making across v arious domains such as healthcare (Ob ermeyer et al., 2019 ), hiring (K¨ oc hling and W ehner, 2020 ), credit (M. S. A. Lee and Floridi, 2021 ), justice (Za vr ˇ snik, 2021 ) and public p olicy (Penc hev a et al., 2020 ). While these automated decisions are cost effective and more systematic than human decisions, they also raise ethical concerns. Notorious examples include the COMP AS algorithm (Flores et al., 2016 ), accused of pro ducing more false negatives among ethnic minorities, and the Amazon recruitmen t algorithm rep orted to generate low er acceptance rates for women (Dastin, 2022 ). These examples illustrate the need for to ols to monitor unfairness across groups. Moni- toring unfair decisions also requires explainabilit y . At the individual level, those who receiv e a negativ e outcome deserv e an explanation ab out the reasons for this outcome. A t the aggre- gate level, it is imp ortant to quan tify how features ( i.e. , v ariables) contribute to the outcome of an algorithm in order to assess p ossible trade-offs betw een fairness and p erformance. In line with m uch of the literature, w e fo cus on algorithms that produce categorical outcomes, whic h w e hereafter refer to as classifiers. W e study the fairness and explainability of classifiers, tw o notions that, although complementary , ha v e essen tially b een considered separately . Gr oup fairness ev aluates whether a classifier yields different outcome distributions across groups defined by sensitiv e features ( e.g. , gender, ethnicity). F or instance, (Klare et al., 2012 ) ev aluate the outcomes of multiple face-recognition classifiers and rep ort disparities b et w een white and non-white women. The algorithmic fairness literature prop oses criteria to either audit predictions (Baro cas et al., 2023 ; Charp entier, 2024a ; Hurlin et al., 2026 ) and detect unfairness, or to imp ose ”fair learning”, i.e., to incorp orate fairness constraints during classifier training (Hardt et al., 2016 ), consequen tly allo wing for a trade-off b etw een efficiency of classifiers and fairness as is done in op er ational r ese ar ch (De Bo ck et al., 2024 ). In both cases, the criteria consist of a group level equality condition on certain metrics. Sp ecifically , a given statistical metric related to the outcome distribution should b e equal across groups. Three main fairness criteria are generally considered in the literature (see Section 2.1 for details). Indep endence ( IND ), also kno wn as statistical parity (Dw ork et al., 2012 ), requires that the exp ected outcome b e equal across groups. In this case, the metric is the group exp ected outcome, and the fairness criterion is the equalit y of the metric b etw een groups. This criterion can result in groups with differen t level of merit receiving the same exp ected outcome, whic h may b e p erceiv ed as unfair. Separabilit y ( SEP ), also known as equalized o dds (Hardt et al., 2016 ), requires that error distributions b e equal across groups. In other w ords, it ensures that, when predicting a giv en outcome, the classifier yields equal true and false p ositiv e rates across groups. Sufficiency ( SUF ), also called conditional use accuracy (Berk et al., 2021 ), equalizes reliabilit y across groups. It ensures that for b oth p ositiv e and 2 negativ e predicted outcomes, the reliability is equal across groups. Imp ossibility results sho w that one cannot generally satisfy these three criteria sim ultaneously (Kleinberg et al., 2016 ; Chouldec hov a, 2017 ). Cho osing one of them is a matter of ethical v alues. AI fairness th us places regulators and users in a Ra wlsian situation where a commonly agreed rule of fairness m ust b e adopted (Rawls, 1971 ) and then implemen ted b y institutions. Explainable AI (XAI) is another field in AI ethics that enhances the transparency of algorithms, making their decision-making pro cesses more in terpretable and understandable. A particular atten tion is dedicated to the measuremen t of the importance of each feature to the decision making outcomes. A p opular approac h for measuring features contribution is the partial dep enden t plot (PDP) (Molnar 2020 ). Suc h plot shows how a mo del’s pre- dicted outcome changes as one feature v aries across its range, a veraging o v er the observed v alues of all the other features. Another approach builds on the Shapley v alue (Shapley , 1953 ), whic h attributes a score of imp ortance to each feature. It is an agnostic attribution metho d , meaning that it is indep enden t of the type of algorithm used for classification tasks (classification of images, texts, etc., see Castro et al. 2009 ; Yi Sun and Sundarara jan 2011 ; Ancona et al. 2019 ; Arenas et al. 2021 ; Condev aux et al. 2022 for applications). Although more computationally demanding, Shapley v alues offer t wo k ey adv antages ov er PDP . First, b y considering all possible com binations of v ariables, they accoun t for the exhaustive list of p ossible in teractions. Second, they allo w for a linear decomp osition of the feature contri- butions, whic h facilitates interpretation. T o o vercome the exp onen tial computational cost, Condev aux et al. ( 2022 ) prop osed alternativ e attribution metho ds such as F air-Efficient- Symmetric-P erturbation (FESP) and the Equal Surplus v alue (Driessen and F unaki, 1991 ) whic h are c haracterized b y linear complexit y , making them con v enien t alternativ es to the Shapley v alue. Gr oup fairness and explainability hav e been considered separately in the literature till recen tly Begley et al. ( 2020 ) and Pelegrina, Sira j, et al. ( 2024 ) prop ose to explain unfairness using Shapley v alues. The metho d prop osed b y Pelegrina, Sira j, et al. ( 2024 ) applies to differen t fairness criteria. F or example, it could b e applied to equality of opp ortunit y ( SEP ) b et w een genders. The difference in true p ositiv e rates (TPR) betw een men and w omen can b e computed, then the con tribution of eac h feature to the gender gap can b e measured in the form of Shapley v alue. The presen t pap er pushes the connection b et ween fairness criteria and Shapley explain- abilit y y et further. W e show that the fairness citerion itself can be measured as a difference b et w een Shapley v alues (Theorem 3.1 ). Sp ecifically , w e introduce the notion of “group- Shapley” that measures the con tribution of the observ ations corresp onding to a given group ( e.g. , “men”) of a sensitiv e feature ( e.g. , gender) to the ov erall v alue of an outcome metric (e.g. accuracy , acceptance rate, or false p ositiv e rate...). Thanks to this result, an y unfair- ness criterion whic h is defined as group-differences in outcome metrics can also b e defined as 3 differences of group-Shapley v alues. Besides the conceptual elegance of connecting formally Shapley v alues and fairness criteria, this approach allo ws to build on the recursive nature of Shapley decomp ositions. Concretely , our metho d pro ceeds in tw o-stages: (i) in the first stage Shapley , w e measure unfairness as differences in group-Shapley v alues across groups; (ii) in the second stage Shap- ley , w e recursiv ely decomp ose eac h group-Shapley v alue o ver the features. This approac h first breaks inequality b et w een groups, then breaks inequalit y within eac h group ov er all the features. It corresp onds to a standard approach emplo y ed in the income inequality literature ( e.g. , Chan treuil and T rannoy , 2011 ). This can b e particularly useful when the sensitive fea- ture contains more than tw o lev els. Combined with linearity , recursivity provides conv enien t prop erties for explaining the contributions of features to unfairness. In our framew ork, the con tribution of each feature to the differences of group-Shapley v alues is measured as differ- ences of Shapley contributions to each group. Indeed our Theorem 3.1 sho ws that a fairness criterion is satisfied if the Shapley con tribution of eac h feature con tributions to eac h group is equal. This approach of fairness has tw o noticeable adv an tages. The first relates to interpreta- tion, the second relates to inference. In terms of in terpretation, for eac h feature and each group, the Shapley con tribution informs ab out the impact of the feature on the outcome of the group. Supp ose that the outcome is measured b y the acceptance rate, and that feature ”income” contributes p ositiv ely to it for b oth genders, but to a larger extent for men. Mit- igating the role of income will reduce the gap by deteriorating the acceptance rate for b oth men and women: an inequality reducing, but Pareto deteriorating solution. Supp ose instead that another v ariable, e.g. , marital status, has a p ositiv e impact for men and a negative impact for w omen. Here, mitigating the role of this v ariable reduces the gap b y decreasing the acceptance rate of men and increasing the acceptance rate of women. A so cial planner who is unfairness a v erse but does not wan t to deteriorate the outcome of the disadv antaged group ma y prefer the second solution. Another adv an tage of our approac h is that the Shapley con tribution of a feature to the gap is defined as a difference of group-Shapley v alues. This difference can b e p ositive or negative. In con trast, partial dep endence plots, pro duce only non-negativ e weigh ts. The second adv antage regards with inference. Once the asymptotic prop erties of the fairness criteria ha v e b een defined, they can b e applied to the second-stage Shapley . In particular, when the first-stage Shapley v alue is computed, a second-stage Shap- ley v alue is made along features to explain their imp ortance to each group-Shapley , in the same vein as Pelegrina, Sira j, et al. ( 2024 ). How ev er, in our framew ork, the Shapley v alue is also used for a second statistical test, i.e. , to test whether the contribution of a partic- ular feature is the same along groups ( e.g. , contribution of education for men vs . w omen). Consequen tly , the tw o-stage Shapley pro vides a test to assess whether a feature contributes significan tly to the difference in group-Shapley v alues and is precisely sho wn to b e asymp- 4 totically normal. Additional results generalize our approach and allow for fast and robust implementation. The main limitation of the Shapley v alue is its exp onential time complexity . Also, it can b e found to p ossibly attribute to o m uc h imp ortance to irrelev an t v ariables (Marques-Silv a and Huang, 2024 ). F aster and more robust attribution pro cedures can b e needed. W e extend our Theorem 3.1 to the more general Efficient-Linear-Symmetric (ESL) family of v alues, whic h con tains the Shapley v alue and the Equal Surplus v alue, among others. The Equal Surplus v alue has a linear time complexit y , whereas most of the other members of the ESL family exhibit exponential time complexit y . Considering all ESL v alues enables a more robust attribution pro cedure based on ma jorit y voting 1 . T aking fiv e mem b ers of the ESL v alue, w e compute feature con tributions under each member separately , and classify a feature as unfair (or fair) when a ma jority of members indicate unfairness (of fairness). W e illustrate our framework on the Census Income dataset from the UCI Machine Learn- ing Rep ository (Koha vi, 1996 ), where “men” and “w omen” constitute the t w o groups of the sensitive feature. W e sho w that all mem b ers of the ESL family agree with group un- fairness (first-stage ESL). In terms of explainabilit y , most of ESL v alues sho w that women are p enalized b y age, and Marital status is the most significant feature that leads to un- fairness (t wo-stage ESL). These results suggest that remo ving Marital status w ould lead to an increase in the unfairness gap. Regarding computation time, the empirical application illustrates the tractability of our framew ork. Inference derived from our asymptotic formula pro vides results that are consistent with b o otstrapping, but with shorter computation time. The paper is organized as follo ws. Group fairness and Shapley explainability are pre- sen ted in Section 2 , which can b e skipp ed by readers familiar with this literature. Section 3 describ es the equiv alence b etw een group fairness and explainabilit y with the prop osed tw o- stage Shapley . Section 4 presen ts the generalization to all ESL v alues. In Section 5 , an application is p erformed on Census Income data. Section 6 concludes the pap er. 2 Group fairness and explainabilit y: separate litera- ture streams W e briefly summarize tw o seemingly indep endent literature streams. The first fo cuses on group fairness criteria for classifiers with resp ect to sensitiv e features ( e.g. , gender , ethnicit y). The second examines attribution metho ds used for explainabilit y . These metho ds assign to each feature a con tribution to a sp ecific metric ( e.g. , con tribution to the classification probabilit y or to the go o dness of fit of the classifier). 1 Ma jorit y v oting is w ell established in so cial c hoice theory (Y oung, 1988 ), and w as latter adopted in mac hine learning to combine multiple classifier decisions (Battiti and Colla, 1994 ; Lam and Suen, 1997 ; Mien y e and Y anxia Sun, 2022 ). 5 2.1 Group fairness criteria Group fairness criteria fall into three categories, namely indep endence (Dwork et al., 2012 ), separation (Hardt et al., 2016 ) and sufficiency (Berk et al., 2021 ). 2 Eac h criterion addresses a particular asp ect of the classifier outcome to ensure equal treatment across groups defined b y the sensitive feature. W e introduce these criteria for a binary classifier. Let ( X , A, Y ) b e a random tuple with distribution P , where Y ∈ { 0 . 1 } is the actual observed outcome used for fairness assessmen t, X ∈ X ⊆ R N is a collection of features, and A = { 0 . 1 } is a binary sensitiv e feature. W e consider a binary classification function f t that maps X × { 0 . 1 } to { 0 . 1 } , based on a given threshold t ∈ (0 . 1): ˆ Y = f t ( X , A ) = ( 1 if P [ Y = 1 | X , A ] ≥ t 0 if P [ Y = 1 | X , A ] < t In what follows, ⊥ ⊥ denotes indep endence or conditional indep endence betw een random v ariables. The three following definitions are given b y (Baro cas et al., 2023 ). Definition 2.1. Indep endence: F or a binary classifier f t , indep endenc e c orr esp onds to ˆ Y ⊥ ⊥ A , or e quivalently, P [ ˆ Y = 1 | A = 0] = P [ ˆ Y = 1 | A = 1] (IND) wher e P [ ˆ Y = 1 | A = g ] c orr esp ond to the sele ction r ate (SR) for gr oup g. The independence criterion, also called statistical parit y (Dwork et al., 2012 ) or demo- graphic parity (Kusner et al., 2017 ), requires that the probability of receiving a fav orable outcome ( e.g., loan approv al, being hired) b e equal across groups. How ev er, enforcing in- dep endence can yield situations in which groups with different lev els of “merit” ( e.g., qual- ifications) receive the same expected outcome. T o address this issue, Corb ett-Da vies et al. ( 2017 ) prop ose conditional statistical parit y as a relaxation of demographic parity . Definition 2.2. Separation: F or a binary classifier f t , sep ar ation c orr esp onds to ˆ Y ⊥ ⊥ A | Y , or e quivalently, P [ ˆ Y = 1 | Y = 1 , A = 0] = P [ ˆ Y = 1 | Y = 1 , A = 1] P [ ˆ Y = 1 | Y = 0 .A = 0] = P [ ˆ Y = 1 | Y = 0 .A = 1] (SEP) wher e P ( ˆ Y = 1 | Y = 1 , A = g ) and P ( ˆ Y = 1 | Y = 0 .A = g ) c orr esp ond to the true p ositive r ate (TPR) and false p ositive r ate (FPR) for gr oup g , r esp e ctively. The separation criterion, also referred to as equalized odds (Hardt et al., 2016 ), fo cuses on balancing error rates across groups. In other w ords, it ensures that the classifier is inv ariant to the sensitive feature when predicting a giv en class, with resp ect to b oth true positive and false 2 See Charp entier ( 2024b ) for a comprehensive literature review. 6 p ositiv e rates. The fair learning literature also refers to the equality of opp ortunity criterion (Hardt et al., 2016 ), a relaxation of separation that requires equalit y of true p ositiv e rates across groups. This criterion formalizes that, conditionally on the true lab el ( i.e., among those who qualify), individuals should hav e equal chances of a p ositive prediction. It aligns with rewarding merit and effort by ev aluating parity among those who are truly qualified for a p ositiv e outcome. Definition 2.3. Sufficiency: F or a binary classifier f t , sufficiency c orr esp onds to Y ⊥ ⊥ A | ˆ Y , or e quivalently, P [ Y = 1 | ˆ Y = 1 , A = 0] = P [ Y = 1 | ˆ Y = 1 , A = 1] P [ Y = 1 | ˆ Y = 0 .A = 0] = P [ Y = 1 | ˆ Y = 0 .A = 1] (SUF) wher e P [ Y = 1 | ˆ Y = 1 , A = g ] and P [ Y = 1 | ˆ Y = 0 .A = g ] c orr esp ond to the p ositive pr e dictive value (PPV) and ne gative pr e dictive value (NPV) for gr oup g , r esp e ctively. Sufficiency , also kno wn as conditional use accuracy (Berk et al., 2021 ), balances the precision of prediction across groups. It requires that b oth positive predictive v alues and negativ e predictive v alues b e equal across groups. A relaxation of this criterion is predictiv e parit y (Chouldecho v a, 2017 ), whic h requires equality of p ositive predictive v alues across groups. 2.2 Explainabilit y with the Shapley v alue The co op erative game theory literature has pa ved the w ay for measuring disparities in out- comes across groups, with a sp ecial fo cus on income inequality decomp osition, and inequality- reducing p olicies Chan treuil and T rannoy ( 2011 ), Chan treuil and T ranno y ( 2013 ), Chantreuil, Courtin, et al. ( 2019 ), Tido T akeng et al. ( 2023 ), and F ourrey ( 2023 ). Within this literature, the Shapley v alue (Shapley , 1953 ), a concept from coop erative game theory , serv es as a classic to ol to quan tify ho w differen t factors ( e.g., education, gender) contribute to o verall income inequalit y . The computer science literature has also adopted the Shapley v alue as a standard to ol for XAI. In particular, it is used to explain mo del predictions b y attributing to each feature its con tribution to the outcome. These attribution metho ds 3 quan tify feature imp ortance, i.e, ho w they driv e the predictions (Lundberg and S.-I. Lee, 2017 ; Ancona et al., 2019 ; Linardatos et al., 2021 ). Within this framew ork, P elegrina and Sira j ( 2024 ) use the Shapley v alue to attribute eac h feature’s contribution to predictiv e p erformance, such as the true p ositive rate (TPR), the false p ositive rate (FPR)... In what follows, w e use Shapley and ESL v alues more 3 A ttribution metho ds pro vide either global or lo cal explanations: global explainability fo cuses on un- derstanding the mo del b eha vior o ver the entire dataset, whereas lo cal explainabilit y aims to understand individual predictions. 7 generally for explainability (ESL v alues will be in tro duced later in Section 4 to generalize our approach). In co op erative game theory , the Shapley v alue is defined as an attribution metho d (or allo cation rule) that allo cates to eac h pla yer a unique share of the total pay off, based on their marginal contributions across all p ossible coalitions. A game is c haracterized by the pair ( N , v ), where N = { 1 , . . . , N } is the set of N play ers and v : 2 N → R is the c haracteristic function assigning a w orth to eac h coalition S N ⊆ N . In our context, each feature X k of the the random input vector X := [ X 1 , . . . , X N ] ∈ R N is a “pla yer”, where the total n um b er of features is N = |N | . A coalition refers to a subset of features. F or any subset S N ⊆ N , the v ector X ( S N ) = ( X i , . . . , X s ) contains only the features in S N , while features in N \ S N are dropp ed. The total pa y off v ( N ) is the metric to b e explained using the full set of features. The goal is to allo cate v ( N ) across features based on their con tributions. In coop erative game theory , a common conv en tion is to set v ( ∅ ) = 0, when the coalition is empty . Ho w ever, in explainabilit y settings, having an empt y feature set do es not directly translate to zero pa yoffs. Instead v ( ∅ ) is set to a baseline. F or binary classification, a natural baseline is the prior class probabilit y v ( ∅ ) = P ( Y = 1) (P elegrina and Sira j, 2024 ), ensuring that the baseline used in the Shapley v alue reflects the class distribution. T o ev aluate the marginal contribution of feature X k to a subset S N , we consider the aug- men ted subset S N ∪{ k } and the corresp onding feature v ector X ( S N ∪{ k } ) = ( X i , . . . , X s , X k ). In order to quan tify the marginal impact of feature x k , the marginal contribution of x k to a subset S N is expressed as v ( X ( S N ∪ { k } )) − v ( X ( S N )). An attribution metho d is said to b e mar ginalist if it assigns to each feature a pay off that dep ends on its a v erage marginal con tributions referred as feature con tribution. All feature contributions are group ed into the pa yoff vector φ ( X , v ): φ ( X , v ) = [ φ 1 ( X , v ) , . . . , φ N ( X , v )] ∈ R N The Shapley v alue for feature k ∈ N is defined by , φ S h k ( X , v ) := X S N ⊆N \{ k } P ( S N ) v ( X ( S N ∪ { k } )) − v ( X ( S N )) (2.1) where P ( S N ) := ( N − S − 1)! S ! /N !, with S := |S N | . Eac h φ S h k represen ts feature X k con tribution for the metric b eing explained. Note that φ S h k ( X , v ) can b e either p ositiv e or negativ e, dep ending on the c hoice of the characteristic function v . The Shapley v alue satisfies four axioms 4 (Shapley, 1953 ) a nd ha v e been widely in vok ed to justify the use of Shapley v alues in explainability (Strum b elj and Kononenk o, 2010 ). 4 The standard Shapley axioms are: efficiency , if P k ∈ N φ S h k ( X , v ) = v ( X ( N )) − v ( X ( ∅ )) ; symmetry , if φ S h π ( k ) ( X , π v ) = φ S h k ( X , v ) for every p ermutation π on N (for all k ∈ N ) ; additivity , if φ S h k ( X , v + w ) = φ S h k ( X , v ) + φ S h k ( X , w ) for all games ( N , v ) (for all k ∈ N ) ; dummy player pr op erty , if φ S h k ( X , v ) = v ( X ( ∅ )), suc h that the play er i is a dummy in the game ( N , v ), i.e. , v ( X ( S N ∪ { i } )) − v ( X ( S N )) = v ( X ( ∅ )) for all S N ⊆ N \ { i } . 8 3 Shapley for F airness and Explainabilit y In this section, we in tro duce a Shapley based framework that connects group fairness and explainabilit y . W e first present our main theorem on group-Shapley which establishes a link b et w een fairness criteria and the Shapley v alue. W e then extend this result by in tro ducing a decomp osition that b oth tests whether a given fairness criterion holds and attributes any detected disparities to sp ecific features. This yields a direct equiv alence b etw een group fairness criteria and explainability , thereb y unifying tw o concepts that are often studied in isolation. 3.1 Group lev el explainabilit y Let A b e a sensitive feature ( e.g. , gender), with t wo lev els, called groups 5 . Denote the set of groups b y A = { 1 , 2 } , where eac h group g ∈ A corresp onds to the subset of observ ations asso ciated with sensitiv e feature lev el ( e.g. , men, w omen). Let S A ∈ {{∅} , { 1 } , { 2 } , { 1 , 2 }} denote a coalition of groups. With sligh t language abuse, w e call coalition b oth the sets of lev els of the sensitive feature, and the subset of data asso ciated to these levels. F or a feature set N and a coalition S A , the feature v ector restricted to S A , is denoted X | S A ( N ). An empt y coalition ∅ represen ts the situation in whic h no group (hence, no data) is included. This is similar to explainability , where the empty coalition corresp onds to the absence of an y feature. Let m denote a classification m etric suc h as selection rate (SR), true positive rate (TPR), false p ositve rate (FPR), p ositive predictiv e v alue (PPV) and negativ e predictive v alue (NPV). Let v ( m ) : 2 A → [0 . 1] b e the c haracteristic function asso ciated with p . Since the ob jectiv e is to explain the con tribution of each group to v ( m ) ev aluated on the full dataset X | A ( N ), w e define v ( m ) ( X | A ( N )) as the relativ e deviation of the classification metric from the baseline defined b y a random classifier. The the following indicator function is in tro duced: 1 |S A | = ( 1 if |S A | = 0 0 otherwise . This ensures that v ( m ) ( X | {∅} ( N )) = 0 remains nul l as in standard co op erative games. 6 Consisten t with the case of feature explainability , the baseline v alue of a random binary classifier P ( ˆ Y = 1 | A ∈ ∅ ) is set as follows: if the outcome distribution is uniform, the baseline is set to 0.5. Otherwise, it is set to the ov erall prop ortion of the p ositive class P ( Y = 1). F ormally , the classifier trained on the combined dataset (for b oth men and w omen) is ev aluated using the characteristic function v ( S R ) defined as the relativ e selection 5 The setup can b e adapted to a sensitiv e feature with more than t wo levels. 6 Since the empty coalition corresp onds to the baseline case of no information, setting its v alue to zero insures that the contribution sums to the total pa yoff, i.e. , the efficiency axiom holds. 9 rate of the classifier v ( S R ) ( X | S A ( N )) = P ( ˆ Y = 1 | A ∈ S A ) P ( ˆ Y = 1 | A ∈ ∅ ) (1 − 1 |S A | ) Hence, v ( S R ) ( X | S A ( N )) measures the allo cation of p ositiv e outcome when including S A rel- ativ e to the baseline. A higher selection rate is view ed as either a fav orable ( e.g. , loan appro v al) or undesirable outcome ( e.g. , recidivism) dep ending on the context. Notice that ha ving v ( S R ) ( X | S A ( N )) > 1, indicates that the classifier assigns more p ositive predictions than the baseline. Conv ersely , v ( S R ) ( X | S A ( N )) < 1 suggests that it assigns few er p ositive predictions. Similarly , let v ( T P R ) , v ( F P R ) , v ( P P V ) and v ( N P V ) b e the relative p erformance rate of the classifier: v ( T P R ( X | S A ( N )) = P ( ˆ Y = 1 | Y = 1 , A ∈ S A ) P ( ˆ Y = 1 | Y = 1 , A ∈ ∅ ) (1 − 1 |S A | ) v ( F P R ) ( X | S A ( N )) = P ( ˆ Y = 1 | Y = 0 .A ∈ S A ) P ( ˆ Y = 1 | Y = 0 .A ∈ ∅ ) (1 − 1 |S A | ) v ( P P V ) ( X | S A ( N )) = P ( Y = 1 | ˆ Y = 1 , A ∈ S A ) P ( Y = 1 | ˆ Y = 1 , A ∈ ∅ ) (1 − 1 |S A | ) v ( N P V ) ( X | S A ( N )) = P ( Y = 1 | ˆ Y = 0 .A ∈ S A ) P ( Y = 1 | ˆ Y = 0 .A ∈ ∅ ) (1 − 1 |S A | ) In this case, v ( T P R ) ( X | S A ( N )) measures the abilit y of the classifier to detect true p ositives, while v ( F P R ) ( X | S A ( N )) captures false p ositiv es predictions. When v ( T P R ) ( X | S A ( N )) > 1, the classifier ability to capture true p ositives improv es when including S A relativ e to the baseline, while v ( T P R ) | S A ( N )) < 1 reflects ho w the classifier is missing true positives under the same group. Conv ersely , v ( F P R ) > 1 indicates an ov er prediction of false p ositives when including S A relativ e to the baseline, whic h is undesirable and can be costly ( e.g. , in the con text of judicial or medical decisions), while v ( N P V ) ( X | S A ( N )) < 1 is often desirable. On the other hand, v ( P P V ) ( X | S A ( N )) and v ( N P V ) ( X | S A ( N )) captures the change in PPV and NPV, respectively . As suc h, when v ( P P V ) ( X | S A ( N )) > 1, precision is high when including S A relativ e to the baseline, while it is lo w when v ( P P V ) ( X | S A ( N )) < 1. How ever, ha ving v ( N P V ) ( X | S A ( N )) > 1 reflects how the classifier under-p erforms in predicting true negatives when including S A relativ e to the baseline, while it is doing b etter in predicting them when v ( N P V ) ( X | S A ( N )) < 1. Finally , ha ving v ( m ) ( X | S A ( N )) = 1 refers to the situation where the classifier do es not differ from a random classifier. F ollowing the literature on income inequality decomp osition (Chan treuil and T rannoy, 2013 ; Chan treuil, Courtin, et al., 2019 ), the Shapley v alue is used to decomp ose the ov erall ratio v p ( X | A ( N )) in order to quantify each group’s a v erage marginal con tribution to it. 10 According to the c hosen definition of v ( m ) , the Shapley v alue asso ciated with group g ∈ A , i.e. , the group-Shapley , is defined as: φ S h g ( X , v ( m ) ) := X g ∈A\S A P ( S A ) v ( m ) ( X | S A ∪{ g } ( N )) − v ( m ) ( X | S A ( N )) (3.1) where P ( S A ) := ( a − s − 1)! s ! /a !, with a := |A| = 2 and s := |S A | . In what follows, we refer to φ S h g as the group-Shapley . As in the case of feature explain- abilit y Eq.( 2.1 ), φ S h g satisfies the efficiency axiom, i.e., P a g =1 φ S h g ( X , v ( m ) ) = v ( m ) ( X | A ( N )). In the sequel, Shapley explainability is shown to b e equiv alen t to group fairness criteria. 3.2 Equiv alences: First-stage Shapley W e first explain how eac h group impacts the b eha vior of the classifier relativ e to the baseline. In the binary case, let us take A := { 1 , 2 } , where { 1 } corresp onds to the subset of data asso ciated with men and { 2 } to the subset asso ciated with women. This leads to a situation with four cases (lik e in standard 2-play er games), where each case is obtained b y filtering ro ws according to the sensitive feature: X | S A = ∅ ( N ): All the groups ( i.e. , all the observ ations) are excluded. Since there is no pattern to learn from the data, the output of a random classifier is used. X | S A = { 1 } ( N ): The classifier is ev aluated on the men group ( i.e., the subset of data asso ciated to men). X | S A = { 2 } ( N ): The classifier is ev aluated on the w omen group ( i.e., the subset of data asso ciated to women). X | A ( N ): The classifier is ev aluated on the union of b oth groups. Then, the Shapley v alue is used to understand ho w each group drives the classification metric with resp ect to the baseline. In the follo wing theorem, group explainabilit y via the Shapley v alue is shown to b e equiv alen t to group fairness. Theorem 3.1 (Group F airness ⇔ Shapley) . L et f t b e a binary classifier and φ S h the Shapley value. Equivalenc es: (i) f t r esp e cts ( IND ) ⇔ φ S h g =1 ( X , v ( S R ) ) = φ S h g =2 ( X , v ( S R ) ) (ii) f t r esp e cts ( SEP ) ⇔ ( φ S h g =1 ( X , v ( T P R ) ) = φ S h g =2 ( X , v ( T P R ) ) φ S h g =1 ( X , v ( F P R ) ) = φ S h g =2 ( X , v ( F P R ) ) (iii) f t r esp e cts ( SUF ) ⇔ ( φ S h g =1 ( X , v ( P P V ) ) = φ S h g =2 ( X , v ( P P V ) ) φ S h g =1 ( X , v ( N P V ) ) = φ S h g =2 ( X , v ( N P V ) ) . Pr o of. See the App endix A . Theorem 3.1 states tha t group fairness can be achiev ed b y ensuring similar group-Shapley across levels. In this sense, the Shapley v alue resp ects some principles of “equalit y”. Con- sequen tly , the Shapley v alue can offer a direct statistical test (see Section 5 ) to chec k group 11 fairness in terms of ( IND ), ( SEP ) or ( SUF ), dep ending on the application at hand. When the h yp othesis of group fairness is rejected, the difference in group-Shapley across groups, ∆ φ S h g ( X , v ( m ) ) := φ S h g =1 ( X , v ( m ) ) − φ S h g =2 ( X , v ( m ) ), reveals how v ( m ) ( X | A ( N )) is impacted b y a sp ecific group. Analogously to the literature where Shapley-based decomp ositions b y subgroups are used to iden tify the driv ers of ov erall inequality ( e.g. , Chan treuil and T rannoy 2013 ), the group- Shapley indicates that the disparity arises b ecause the men’s group receiv es larger v alues of v ( m ) than w omen’s group. In other w ords, the classifier’s outcome fa vors men’s group and thereb y reinforces existing disparities. Theorem 3.1 shows that group-Shapley can b e used as a to ol for testing group fairness, hence, establishing an equiv alence b etw een group fairness and group explainability . 3.3 Equiv alences: Tw o-stage Shapley Theorem 3.1 is restricted to group fairness. W e no w build on the explainability literature on feature c ontributions . In particular, we extend our group-Shapley with a tw o-stage Shap- ley decomp osition, which allo ws us to ev aluate the con tribution of eac h feature to group unfairness. The tw o-stage Shapley v alue (also called nested Shapley v alue) w as in tro duced by Chan treuil and T ranno y ( 1999 ) and Chan treuil and T rannoy ( 2013 ) to decomp ose income inequality indices. W e adapt this nested decomp osition to our setting in order to decomp ose eac h group-Shapley in to feature contributions. Sp ecifically , we denote C k g ( v ( m ) ) the contribution of feature X k to the group-Shapley of g in A . F or all S N ⊆ N , let X | S A ( S N ) b e the vector of features in S N restricted to S A . F ormally , the tw o-stage Shapley is obtained as follo ws: • In the first stage, group-Shapley φ S h g ( X , v ( m ) ) is derived (Eq.( 3.1 )). • In the second stage, the characteristic function is φ S h g ( X ( S N ) , v ( m ) ), with φ S h g ( ∅ , v ( m ) ) = 0. F or eac h group g in A , the Shapley v alue is applied to eac h group-Shapley φ S h g ( X , v ( m ) ) to capture the explainabilit y of each feature k i.e., C k g ( v ( m ) ) = φ S h k ◦ φ S h g ( X , v ( m ) ) (Eq. 2.1 ). By efficiency of the Shapley v alue, these contributions add up to the group- Shapley: φ S h g ( X , v ( m ) ) = P k C k g ( v ( m ) ). 12 Prop osition 3.1 (Two-stage Shapley) . L et f t b e a binary classifier. F or al l g ∈ A and for al l k ∈ N , the two-stage Shapley value φ Sh k ◦ φ Sh g ( X , v ( m ) ) yields the fol lowing e quivalenc es: (i) f t r esp e cts ( IND ) ⇐ ⇒ C k g ( v ( S R ) ) = 1 2 φ S h k ( X , v ( S R ) ) , (ii) f t r esp e cts ( SEP ) ⇐ ⇒ C k g ( v ( T P R ) ) = 1 2 φ S h k ( X , v ( T P R ) ) , C k g ( v ( F P R ) ) = 1 2 φ S h k ( X , v ( F P R ) ) , (iii) f t r esp e cts ( SUF ) ⇐ ⇒ C k g ( v ( P P V ) ) = 1 2 φ S h k ( X , v ( P P V ) ) , C k g ( v ( N P V ) ) = 1 2 φ S h k ( X , v ( N P V ) ) . Pr o of. See the App endix A . Prop osition 3.1 shows that group fairness criteria imp ose a strong structure. Sp ecifi- cally , for a classifier to satisfy group fairness, eac h feature’s con tribution must b e equal- ized across groups. Con v ersely , when the group-Shapley differs across groups, breaking do wn each group-Shapley in to feature con tributions allows us to identify which features driv e the disparities b et ween groups. Concretely , in the second-stage Shapley , the differ- ence across groups is explained by eac h feature’s contribution, i.e., each feature explains ∆ φ S h g ( X , v ( m ) ) := φ S h g =1 ( X , v ( m ) ) − φ S h g =2 ( X , v ( m ) ). Remark 3.1. By the additivity of the Shapley value, de c omp osing e ach φ S h g ( X , v ( m ) ) by fe a- tur es is the same as de c omp osing the differ enc e ∆ φ S h g ( X , v ( m ) ) : φ S h k ◦ ∆ φ S h g ( X , v ( m ) ) = φ S h k ◦ φ S h g =1 ( X , v ( m ) ) − φ S h k ◦ φ S h g =2 ( X , v ( m ) ) Conse quently, the discr ep ancy in gr oup-Shapley c an b e explaine d thr ough the differ enc e in fe atur e c ontributions acr oss gr oups: φ S h g =1 ( X , v ( m ) ) − φ S h g =2 ( X , v ( m ) ) = ( C 1 1 ( v ( m ) ) − C 1 2 ( v ( m ) )) + · · · + ( C N 1 ( v ( m ) ) − C N 2 ( v ( m ) )) Figure 1 illustrates the pro cess of the tw o-stage Shapley . In the first stage, the chosen p erformance metric ev aluated on the full dataset is decomposed by group, yielding group- Shapley . In the second stage, each group-Shapley is further decomp osed ov er features, yield- ing feature contributions within eac h group. Comparing these feature contributions across groups reveals which features driv e the group unfairness. 13 Figure 1: Tw o-stage Shapley attribution metho d T o chec k the robustness of the prop osed tw o-stage Shapley , ma jorit y voting of group fairness along different ESL v alues is prop osed in the next section. 4 Additional results: robustness, inference and imple- men tabilit y W e now prop ose tw o directions to impro ve the robustness and practical implementabilit y of our framework. First, we extend our results to a broader family of allo cation rules, the ESL v alues, whic h also share axiomatic foundations (efficiency , symmetry , and linearit y) but differ in their allocation pro cedures. This extension enables faster computation and more robust conclusions through ma jorit y v oting across ESL allo cation rules. Second, we dev elop statisti- cal inference procedures for group unfairness. W e derive asymptotically normal estimators for b oth group-ESL and second-stage feature contributions, enabling formal h yp othesis testing of fairness criteria and of the drivers of unfairness. 4.1 F airness explanation under ESL In the literature on co op erative game theory , a v alue satisfying efficiency , symmetry and linearit y axioms is called Efficien t-Symmetric-Linear v alue ( i.e., ESL v alue). The family of ESL v alues includes allo cation rules such as, the Shapley v alue (Shapley, 1953 ), the Solidarit y v alue (Now ak and Radzik, 1994 ), the Consensus v alue (Ju et al., 2007 ), the Equal surplus v alue (Driessen and F unaki, 199 1 ) and the Least Square Pren ucleolus v alue (Ruiz et al., 1996 ). ESL v alues ha ve b een extensiv ely c haracterized in the literature (Hernandez-Lamoneda et al., 2008 ; Nembua, 2012 ; Radzik and Driessen, 2013 ; Nem bua and W endji, 2016 ) and generalize the Shapley v alue as shown in Prop osition 4.1 recalled b elo w. Prop osition 4.1. (Radzik and Driessen, 2013 ): A value φ E S L g ( X , v ( m ) ) is an ESL value if and only if ther e exists a unique se quenc e of a − 1 r e al numb ers { b s } a − 1 s =1 such that for e ach 14 g ∈ A with b 0 = 0 and b a = 1 : φ E S L g ( X , v ( m ) ) = X S A ⊆A\{ g } ( a − s − 1)! s ! a ! × b s +1 v ( m ) ( X | S A ∪{ g } ( N )) − b s v ( m ) ( X | S A ( N )) Eac h ESL v alue is describ ed b y a sp ecific collection of real constan ts { b s } a − 1 s =1 leading to differen t in terpretations. The Solidarit y v alue φ S o is defined by taking b s = 1 s +1 , for s = 1 , . . . , a − 1, such that lev els within the same coalition receive similar share of the marginal con tribution of that coalition. The Least Squares Prenucleolus φ LS P is defined with b a = 1 and b s = a − 1 s s 2 a − 2 for s = 1 , . . . , a − 1, and it fo cuses on minimizing the v ariance of the v alue v ( m ) ( X | A ( N )) − P k φ LS P k ( X , v ( m ) ). the Equal Surplus v alue φ E S is defined with b 1 = a − 1 , and b s = 0 for s = 2 , . . . , a − 1. It quan tifies the con tribution of group g under the assumption that the total co op eration surplus is equally distributed among all groups. The Shapley v alue is defined suc h that b s = 1 for s = 1 , . . . , a − 1. Finally , The Consensus v alue φ C o is defined with b 1 = a 2 , and b s = 1 2 for s = 2 , . . . , a − 1, and refers to the arithmetic means of the Shapley v alue and the Equal surplus v alue. In the sequel, Theorem 3.1 is generalized to all ESL v alues, where φ E S L g denotes ESL group contribution. Theorem 4.1 (Group F airness ⇔ ESL v alue) . L et f t b e a binary classifier and φ E S L any given ESL value. Equivalenc es: (i) f t r esp e cts ( IND ) ⇔ φ E S L g =1 ( X , v ( S R ) ) = φ E S L g =2 ( X , v ( S R ) ) (ii) f t r esp e cts ( SEP ) ⇔ ( φ E S L g =1 ( X , v ( T P R ) ) = φ E S L g =2 ( X , v ( T P R ) ) φ E S L g =1 ( X , v ( F P R ) ) = φ E S L g =2 ( X , v ( F P R ) ) (iii) f t r esp e cts ( SUF ) ⇔ ( φ E S L g =1 ( X , v ( P P V ) ) = φ E S L g =2 ( X , v ( P P V ) ) φ E S L g =1 ( X , v ( N P V ) ) = φ E S L g =2 ( X , v ( N P V ) ) . Pr o of. See the App endix A . As in the case of the Shapley v alue, Theorem 4.1 establishes a generalization to all ESL v alues and sho ws that group fairness can b e assessed b y requiring comparable group-ESL φ E S L g across groups. Hence, a new statistical test for group fairness assessmen t is prop osed in terms of ( IND ), ( SEP ) or ( SUF ). The following test will b e used in the empirical application: H 0 : φ E S L g =1 ( X , v ( m ) ) = φ E S L g =2 ( X , v ( m ) ) H 1 : φ E S L g =1 ( X , v ( m ) ) = φ E S L g =2 ( X , v ( m ) ) Theorem 4.2. F or a fixe d classific ation metric m ( e.g., S R , T P R , F P R , P V , N P V ) , c onsider the nul l hyp othesis: H 0 : φ E S L g =1 ( X , v ( m ) ) = φ E S L g =2 ( X , v ( m ) ) Under H 0 , the fol lowing test statistic Z is asymptotic al ly normal: Z = b φ E S L 1 − b φ E S L 2 r 4 b 2 1 ˆ p A (1 − ˆ p A ) 1 n + 1 + 1 n + 2 ∼ N (0 . 1) 15 wher e ˆ p A denotes the p o ole d empiric al estimate of metric m on the ful l sample, n + g is the denominator of metric m within gr oup g ∈ { 1 , 2 } and b 1 is determine d by Pr op osition 4.1 . Theorem 4.2 provides an asymptotic test statistic. In particular, the denominator n p g dep ends on the metric m : for TPR it is the num b er of actual positives in group g ; for FPR the n umber of actual negativ es; for SR the group size; for PPV the num b er of predicted positives; and for NPV the n um b er of predicted negativ es. In App endix B (see Prop osition B.1 ), we deriv e the asymptotic v ariance and the resulting test statistic explicitly for m = T P R . The same steps can b e repro duced for other classification metrics ( e.g. , F P R , S R , P V , N P V ), yielding analogous test statistics. It is notew orth y that the literature p oints out that the Equal Surplus (ES) v alue is a relev an t ESL v alue for text and image classifications (Condev aux et al., 2022 ). Contrary to the Shapley v alue and other ESL v alues that are characterized by an exp onential time complexity , the ES v alue has a linear time complexity . Accordingly , testing the n ull hypothesis ( H 0 ) regarding a sp ecific group fairness criterion can b e p erformed using a single mem b er of the ESL family (see Section 5 ). This computational adv an tage enhances the implementabilit y of h yp othesis testing through the ES. Let us now prop ose the tw o-stage ESL. Prop osition 3.1 (tw o-stage Shapley) provides the generalization to all ESL v alues. Corollary 4.1 (Tw o-stage ESL) . L et f t b e a binary classifier. The two-stage ESL φ E S L k ◦ φ E S L g ( X , v ( m ) ) for al l g ∈ A and for al l k ∈ N yields the fol lowing e quivalenc es: (i) f t r esp e cts ( IND ) ⇐ ⇒ C k g ( v ( S R ) ) = 1 2 φ ESL k ( X , v ( S R ) ) , (ii) f t r esp e cts ( SEP ) ⇐ ⇒ C k g ( v ( T P R ) ) = 1 2 φ ESL k ( X , v ( T P R ) ) , C k g ( v ( F P R ) ) = 1 2 φ ESL k ( X , v ( F P R ) ) , (iii) f t r esp e cts ( SUF ) ⇐ ⇒ C k g ( v ( P P V ) ) = 1 2 φ ESL k ( X , v ( P P V ) ) , C k g ( v ( N P V ) ) = 1 2 φ ESL k ( X , v ( N P V ) ) . Pr o of. F ollo ws directly from Prop osition 3.1 F rom Corollary 4.1 another statistical test can b e emplo yed to assess the significance of the group unfairness, ov er each feature k ∈ N . A ma jorit y v oting scheme can b e introduced to extend the robustness of explainability . F ormally , for eac h ESL v alue, the follo wing null h yp othesis H 0 is tested to look for the con tribution of feature k to group fairness. If at least 3 out of 5 ESL v alues reject the null h yp othesis H 0 , ma jority v oting ensures that H 0 is rejected 16 at a given risk level. F or a giv en k ∈ N , the test is the follo wing: H 0 : C k g =1 ( v ( m ) ) = C k g =2 ( v ( m ) ) H 1 : C k g =1 ( v ( m ) ) = C k g =2 ( v ( m ) ) Theorem 4.3. F or a fixe d classific ation metric m ( e.g., S R , T P R , F P R , P V , N P V ) , c onsider the nul l hyp othesis: H 0 : C k g =1 ( v ( m ) ) = C k g =2 ( v ( m ) ) Under H 0 , the fol lowing test statistic Z k is asymptotic al ly normal: Z k = ˆ C k 1 ( v ( m ) ) − ˆ C k 2 ( v ( m ) ) q V ar ( ˆ C k 1 ( v ( m ) )) + V ar ( ˆ C k 2 ( v ( m ) )) − 2 Cov ( ˆ C k 1 ( v ( m ) ) , ˆ C k 2 ( v ( m ) )) ∼ N (0 . 1) F or each feature X k , Theorem 4.3 provides a test of whether the feature con tribution differs significantly across groups. Rejecting H 0 indicates that feature con tributes differently to the metric m across groups and therefore identifies a p otential driver of group unfairness. As b efore, in App endix B (see Prop osition B.2 ), w e deriv e the asymptotic v ariance and the resulting test statistic for m = T P R . These tests can b e extended to multiple sensitive features. In some situations, applying group fairness indep endently to eac h sensitiv e feature can result in fairness at the marginal lev el, whereas taking groups defined by intersectional sensitive feature ( e.g. , gender, ethnicity) ma y detect unfairness. This is called “fairness gerrymandering” (Kearns et al., 2018 ). In this regard, we prop ose a multi-stage ESL pro cedure that accounts for multiple sensitive features with binary levels. The result is presented in App endix A (Theorem A.1 ). 5 Application on Census Data W e illustrate the practical implications of our theorems on the Census Income dataset from the UCI Mac hine Learning Rep ository (Kohavi, 1996 ). 7 This dataset con tains 48,842 in- stances with 15 demographic features, including tw o binary sensitive features: ethnicity and gender. The task is to predict whether an individual’s y early income exceeds $ 50.000 USD. T o ac hiev e this, we adopt a soft voting classifier 8 that combines fiv e classifiers, namely , De- cision T rees, X GBo ost, Linear Support V ector Mac hine, Logistic Regression and Random F orest 9 . The dataset is c haracterized by gender im balance, with a men to women ratio of 7 All co de is accessible at the following github rep ository . 8 The soft voting mo del is an ensemble learning metho d where different base mo dels are used to predict the probabilit y of each class. It then takes the a verage of the probabilities of each class. The class with the highest weigh ted probability is declared as the winning prediction. 9 Our c hoice of classifiers is primarily motiv ated b y their ability to include penalty terms that address class im balance in the data. 17 32 , 650 16 , 192 = 2 . 016. Additionally , only 25% of the individuals earn o v er $ 50.000 USD. A 70/30 train-test split is used, where a few features are used to train the classifier for illustra- tion purp oses, namely age, educational-num (years of education), work ed hours-p er-week (w eekly hours w ork ed), marital-status (married, nev er married or other), while gender (men or women) is treated as the sensitive attribute. 5.1 Application of the main theorems W e examine group fairness in terms of e qual opp ortunity b y fo cusing on differences in ESL group con tributions. Recall that equal opp ortunity is a relaxation of ( SEP ) and is equiv alen t to the following: φ E S L g =1 ( X , v ( T P R ) ) = φ E S L g =2 ( X , v ( T P R ) ) (SHAP-EOD) According to Theorem 4.1 , the criterion ( SHAP-EOD ) can b e assessed using ESL v alues. T o address class imbalance, sampling weigh ts are adjusted for each classification mo del so that b oth classes con tribute equally during training, with higher weigh ts assigned to the underrepresen ted class. Consequen tly , it is appropriate to take a TPR of 0.5 as the outcome of a random classifier. T o ev aluate group fairness with resp ect to ( SHAP-EOD ), the group- ESL φ E S L g ( X , v ( T P R ) ) for each group are computed and rep orted in T able 1 . ESL v alue v ( T P R ) ( X | A ( N )) φ E S L g ( X , v ( T P R ) ) (men) (w omen) ES, Shapley , Consensus, LSP 1.61 1,047 (64.95%) 0.565 (35.05%) Solidarit y 0.926 (57,48%) 0.685 (42,52%) T able 1: Summary of ESL v alues for men and w omen group F rom T able 1 , the total relative deviation of TPR from the baseline, v ( T P R ) ( X | A ( N )) = 1 . 61 > 1, indicates that including the set X | A ( N ) increases the TPR b y 61%. Y et, what mat- ters for assess ing group unfairness is the difference in group-ESL. According to ES, Shapley , Consensus and LSP , 64,95% of the improv emen t is attributed to men, while women account for only 35.05%. According to the Solidarit y v alue, the corresponding p ercen tages are 57.48% and 42.52%, resp ectiv ely . This difference b et w een groups indicates that the impro vemen t in TPR is unequally supp orted across groups, with men receiving higher contributions than w omen. This imbalance highlights group unfairness, as the classifier’s predictive gains are not shared equally . T o assess the statistical significance of group unfairness b etw een men and w omen, the difference in group-ESL is tested using: 18 ( H 0 : φ E S L g =1 ( X , v ( T P R ) ) − φ E S L g =2 ( X , v ( T P R ) ) = 0 H 1 : φ E S L g =1 ( X , v ( T P R ) ) − φ E S L g =2 ( X , v ( T P R ) ) = 0 When dealing with binary groups, all ESL v alues share the same co efficients ( b 1 = 1 and b 2 = 1), except for Solidary v alue (which uses b 1 = 0 . 5 and b 2 = 1). Since the Z -statistic (see Theorem B.1 in App endix A ) dep ends on b 1 , it is sufficien t to test one ESL v alue out of fiv e. The Equal Surplus w as selected b ecause it has linear time complexity . The h yp othesis test rejects the null h yp othesis of fairness at the 5% significance level, indicating a significant difference in ESL group contribution of 0.482 (with 95% CI: [0 . 407 , 0 . 557]). T o illustrate Prop osition 3.1 and Corollary 4.1 , w e apply the t wo-stage ESL to decom- p ose the differences in ESL group. T able 2 rep orts the con tribution of each feature (to the con tribution of eac h group-ESL). In other w ords, we aim to assess group fairness in terms of equal opp ortunit y , according to the following definition: C k g =1 ( v ( T P R ) ) = C k g =2 ( v ( T P R ) ) , (F-SHAP-EOD) and test for differences in ESL feature contributions across groups, ( H 0 : C k g =1 ( v ( T P R ) ) − C k g =2 ( v ( T P R ) ) = 0 H 1 : C k g =1 ( v ( T P R ) ) − C k g =2 ( v ( T P R ) ) = 0 T able 2 rev eals systematic differences in feature contributions across groups. F or instance, using the ES v alue, “Age” contributes 0.681 to the men’s group con tribution and -0.137 to the women’s group contribution, with a significant difference across groups (95% CI: [0 . 707 , 0 . 928]]). Con v ersely , “Marital status” contributes 0.231 to the men’s group con tri- bution and 0.633 to the women’s group con tribution, also sho wing a significant difference (95% CI : [ − 0 . 598 , − 0 . 205]). This pattern is consisten t across other ESL v alues as w ell. Applying the ma jorit y v oting rule, since at least 3 out of 5 ESL v alues reject H 0 , for each of these features, the null hypothesis of equal feature con tributions is rejected. These results indicate that the differences in feature con tributions are not unique to any one ESL v alue but are observ ed consisten tly across m ultiple v alues. Hence ( F-SHAP-EOD ) is violated, since “Age”, “Hours/W eek”, and “Marital status” exhibit marked differences in their con tributions across groups. These features therefore explain a large part of this gap. While P elegrina, Sira j, et al. ( 2024 ), iden tify proxy features for gender, such as “Marital status”, as the main source of group unfairness, our results further indicate that “Age” and “Hours/W eek” also con tribute significantly . This finding illustrates the necessit y of the t w o-stage ESL for a more gran ular group fairness assessment and motiv ates the developmen t of asymptotically normal estimators for the tw o-stage ESL to statistically test for the significant con tributions at b oth stages. 19 Metho d F eature C k g =1 ( v ( T P R ) ) CI ( g = 1 ) C k g =2 ( v ( T P R ) ) CI ( g = 2 ) ES Age 0 . 681 ∗∗∗ [0 . 615 , 0 . 747] − 0 . 137 ∗∗∗ [ − 0 . 201 , − 0 . 072] Educ Num 0.009 [ − 0 . 09 , 0 . 109] 0 . 161 ∗∗ [0 . 061 , 0 . 261] Hours/W eek 0 . 126 ∗∗∗ [0 . 056 , 0 . 196] − 0 . 092 ∗∗ [ − 0 . 161 , − 0 . 023] Marital status 0 . 231 ∗∗∗ [0 . 128 , 0 . 334] 0 . 633 ∗∗∗ [0 . 527 , 0 . 738] Shapley Age 0 . 424 ∗∗∗ [0 . 380 . 0 . 468] − 0 . 006 [ − 0 . 036 , 0 . 024] Educ Num 0 . 181 ∗∗∗ [0 . 123 , 0 . 238] 0 . 114 ∗∗∗ [0 . 058 , 0 . 169] Hours/W eek 0 . 257 ∗∗∗ [0 . 219 , 0 . 296] − 0 . 023 [ − 0 . 056 , 0 . 009] Marital status 0 . 185 ∗∗∗ [0 . 110 , 0 . 260] 0 . 481 ∗∗∗ [0 . 398 , 0 . 564] Solidarit y Age 0 . 275 ∗∗∗ [0 . 257 , 0 . 292] 0 . 143 ∗∗∗ [0 . 128 , 0 . 158] Educ Num 0 . 198 ∗∗∗ [0 . 178 , 0 . 218] 0 . 156 ∗∗∗ [0 . 137 , 0 . 175] Hours/W eek 0 . 207 ∗∗∗ [0 . 190 , 0 . 224] 0 . 120 ∗∗∗ [0 . 105 , 0 . 135] Marital status 0 . 247 ∗∗∗ [0 . 225 , 0 . 269] 0 . 266 ∗∗∗ [0 . 241 , 0 . 291] Consensus Age 0 . 552 ∗∗∗ [0 . 505 , 0 . 599] − 0 . 071 ∗∗∗ [ − 0 . 113 , − 0 . 030] Educ Num 0 . 095 ∗ [0 . 021 , 0 . 168] 0 . 137 ∗∗∗ [0 . 064 , 0 . 210] Hours/W eek 0 . 192 ∗∗∗ [0 . 144 , 0 . 240] − 0 . 058 ∗ [ − 0 . 103 , − 0 . 013] Marital status 0 . 208 ∗∗∗ [0 . 125 , 0 . 291] 0 . 557 ∗∗∗ [0 . 468 , 0 . 646] LSP Age 0 . 410 ∗∗∗ [0 . 368 , 0 . 453] 0 . 001 [ − 0 . 032 , 0 . 034] Educ Num 0 . 188 ∗∗∗ [0 . 131 , 0 . 244] 0 . 111 ∗∗∗ [0 . 057 , 0 . 166] Hours/W eek 0 . 269 ∗∗∗ [0 . 229 , 0 . 310] − 0 . 019 [ − 0 . 054 , 0 . 016] Marital status 0 . 179 ∗∗∗ [0 . 105 , 0 . 253] 0 . 472 ∗∗∗ [0 . 390 , 0 . 553] * p < 0 . 05, ** p < 0 . 01, *** p < 0 . 001 T able 2: F eature contributions to group-ESL 5.2 Computation times The implementabilit y of our test is assessed b y ev aluating its computational cost. All com- putation times were obtained using the T oubk al sup ercomputer (Kissami et al., 2025 ), using a single no de with 56 CPU cores and no GPU resources. Computation is parallelized using m ulti-core CPU pro cessing to accelerate the computation of LES v alues and their asso ciated v ariance estimates. The runtime of tw o approac hes is compared: (i) our prop osed tw o-stage ESL test based on a single plug-in v ariance estimator, and (ii) a nonparametric stratified b o otstrap test for the tw o-stage ESL on the test set. Sp ecifically , observ ations are resampled with replacemen t within eac h stratum defined b y group and outcome label. F or the b o ot- strap baseline, B = 1 , 000 indep endent b o otstrap replications are p erformed and parallelized across CPU cores. The first-stage group-ESL and the second-stage feature contributions are recomputed, and confidence in terv als are constructed from the empirical distribution of the b o otstrap replicates. In contrast to the plug-in approac h ( i.e., single v ariance estimate across ESL v alues), the b o otstrap pro cedure requires separate recomputation for each ESL v alue, whic h increases the total runtime. 20 T able 3 rep orts feature contribution estimates with b oth asymptotic confidence in terv als deriv ed from the plug-in v ariance estimator and bo otstrap confidence interv als. Across all ESL v alues and features, the tw o types of in terv als are closely aligned with the same con- clusions regarding the statistical significance of feature con tributions. 10 This supp orts the v alidit y of the asymptotic normal appro ximation for t wo-stage ESL. T able 4 rep orts the resulting computation times. Our tw o-stage ESL test runs in ap- pro ximately 8 min utes, since the v ariance estimation is calculated only once across all ESL. In contrast, the b o otstrap approac h requires approximately more than 1h20 min utes for the second stage, as b o otstrap resampling m ust b e p erformed separately for each ESL v alue. These results highlight the time efficiency of the tw o-stage ESL test for fairness ev aluation compared to the computationally intensiv e b o otstrap alternative. Metho d F eature ∆ C k g 95%CI µ bootstrap (∆ C k g ) 95% Bo otstrap CI ES Age 0 . 817 ∗∗∗ [0 . 707 , 0 . 928] 0.818 [0 . 784 , 0 . 851] Educ Num − 0 . 152 [ − 0 . 337 , 0 . 033] -0.152 [ − 0 . 218 , − 0 . 086] Hours/W eek 0 . 218 ∗∗∗ [0 . 100 , 0 . 337] 0.218 [0 . 181 , 0 . 255] Marital status − 0 . 402 ∗∗∗ [ − 0 . 598 , − 0 . 205] -0.400 [ − 0 . 476 , − 0 . 314] Shapley Age 0 . 430 ∗∗∗ [0 . 366 , 0 . 493] 0.430 [0 . 399 , 0 . 459] Educ Num 0 . 067 [ − 0 . 035 , 0 . 169] 0.067 [0 . 012 , 0 . 125] Hours/W eek 0 . 281 ∗∗∗ [0 . 217 , 0 . 344] 0.281 [0 . 251 , 0 . 312] Marital status − 0 . 296 ∗∗∗ [ − 0 . 439 , − 0 . 152] -0.294 [ − 0 . 377 , − 0 . 210] Solidarit y Age 0 . 131 ∗∗∗ [0 . 105 , 0 . 157] 0.131 [0 . 121 , 0 . 141] Educ Num 0 . 042 ∗∗ [0 . 010 , 0 . 074] 0.042 [0 . 028 , 0 . 056] Hours/W eek 0 . 087 ∗∗∗ [0 . 061 , 0 . 113] 0.087 [0 . 077 , 0 . 097] Marital status − 0 . 019 [ − 0 . 059 , 0 . 021] -0.019 [ − 0 . 039 , 0 . 003] Consensus Age 0 . 624 ∗∗∗ [0 . 549 , 0 . 698] 0.624 [0 . 596 , 0 . 652] Educ Num − 0 . 043 [ − 0 . 176 , 0 . 091] -0.043 [ − 0 . 103 , 0 . 016] Hours/W eek 0 . 250 ∗∗∗ [0 . 170 , 0 . 329] 0.250 [0 . 220 , 0 . 281] Marital status − 0 . 349 ∗∗∗ [ − 0 . 508 , − 0 . 190] -0.347 [ − 0 . 429 , − 0 . 262] LSP Age 0 . 409 ∗∗∗ [0 . 340 , 0 . 479] 0.410 [0 . 379 , 0 . 439] Educ Num 0 . 076 [ − 0 . 025 , 0 . 178] 0.076 [0 . 020 , 0 . 133] Hours/W eek 0 . 288 ∗∗∗ [0 . 219 , 0 . 357] 0.288 [0 . 259 , 0 . 319] Marital status − 0 . 292 ∗∗∗ [ − 0 . 434 , − 0 . 151] -0.291 [ − 0 . 373 , − 0 . 206] T able 3: Asymptotic confidence interv als and b o otstrap confidence interv als 10 The discrepancy b etw een the confidence interv als for ”Educ Num” under the Equal Surplus and Con- sensus settings is mainly due to class imbalance: there are 501 p ositive for women compared with 2,862 for men. As a result, the v ariance of the estimated TPR for w omen is 5.7 time higher than the v ariance for men. 21 Time complexity Tw o-stage ESL Bo otstrap (t w o stage) ES 8 min 1 h 37 min Shapley 1 h 34 min Solidarit y 1 h 18 min Consensus 1 h 36 min LSP 1 h 39 min T able 4: Summary of time complexity for different metho ds 5.3 F airness mitigation The application to the Census Income dataset shows that our approach b oth assesses and explains unfairness present in the data. As a robustness c heck, w e also verify that the metho d recognizes the absence of unfairness once a mitigation pro cedure is applied. Unfairness is corrected using Equalized Odds p ostpro cessing algorithm 11 from the AI F airness 360 (AIF360) toolkit. The analyses presen ted in Section 5.1 are then replicated after fairness correction. T able 5 rep orts the ESL group con tributions following mitigation. ESL v alue v ( T P R ) ( X | A ( N )) φ E S L g ( X , v ( T P R ) ) (men) (w omen) ES, Shapley , Consensus, LSP 1.365 0.706 (51.72%) 0.659 (48.28%) Solidarit y 0.694 (50.84%) 0.671 (49.16%) T able 5: ESL group contributions (after fairness mitigation). The difference in ESL group con tributions b etw een women and men is close to zero across all ESL v alues. F or Shapley , Consensus, and LSP , the difference is 0.047 (95% CI: [ − 0 . 028 , 0 . 122]), indicating no statistically significant gender-based disparit y . Then, a second- stage decomposition is applied to understand the consequence of fairness mitigation. T able 6 summarizes the contributions of each feature to the ESL group contributions. F or all ESL v alues, the difference in feature contributions are reduced. This decrease is reflected in more balanced con tributions across groups, where the remaining differences in con tributions are not statistically significant at %5 level. 11 The algorithm directly implements the approac h describ ed in Hardt et al. ( 2016 ). 22 Metho d F eature C k g =1 ( v ( T P R ) ) C k g =2 ( v ( T P R ) ) ∆ C k 95% CI ES Age -0.099 -0.097 -0.002 [ − 0 . 100 , 0 . 096] Educ Num 0.192 0.168 0.024 [ − 0 . 164 , 0 . 212] Hours/W eek -0.099 -0.098 -0.001 [ − 0 . 096 , 0 . 094] Marital status 0.712 0.685 0.027 [ − 0 . 150 , 0 . 204] Shapley Age 0.027 0.009 0.018 [ − 0 . 062 , 0 . 098] Educ Num 0.132 0.131 0.001 [ − 0 . 103 , 0 . 105] Hours/W eek 0.008 -0.000 0.008 [ − 0 . 068 , 0 . 084] Marital status 0.539 0.520 0.019 [ − 0 . 099 , 0 . 137] Solidarit y Age 0.109 0.103 0.006 [ − 0 . 023 , 0 . 035] Educ Num 0.163 0.158 0.005 [ − 0 . 028 , 0 . 038] Hours/W eek 0.105 0.100 0.005 [ − 0 . 024 , 0 . 034] Marital status 0.317 0.309 0.008 [ − 0 . 027 , 0 . 043] Consensus Age -0.036 -0.044 0.008 [ − 0 . 061 , 0 . 077] Educ Num 0.162 0.149 0.013 [ − 0 . 121 , 0 . 147] Hours/W eek -0.045 -0.049 0.004 [ − 0 . 062 , 0 . 070] Marital status 0.625 0.602 0.023 [ − 0 . 110 , 0 . 156] LSP Age 0.031 0.014 0.017 [ − 0 . 064 , 0 . 098] Educ Num 0.132 0.131 0.001 [ − 0 . 100 , 0 . 102] Hours/W eek 0.015 0.004 0.011 [ − 0 . 070 , 0 . 092] Marital status 0.528 0.509 0.019 [ − 0 . 094 , 0 . 132] T able 6: Con tributions of features to group-ESL after fairness correction. 6 Conclusion W e hav e prop osed a unified attribution based framework for assessing and testing group fair- ness in binary classification mo dels. By formulating standard group fairness criteria, namely indep endence, separation, and sufficiency in terms of ESL v alues computed o ver classifica- tion metrics, w e ha ve provided a bridge betw een axiomatic attribution theory and formal statistical notions of group fairness. Building on this, w e hav e introduced a tw o-stage ESL decomp osition: first b etw een groups, then in a second stage w e ha ve decomp osed eac h group’s con tribution across features. This decomp osition enables a more granular and interpretable diagnosis of the sources of unfairness while remaining consistent with the axiomatic founda- tions of explainability , namely efficiency , symmetry , and linearity em b o died by Shapley v alue in particular and ESL v alues more generally . F rom a practical p ersp ectiv e, the proposed approac h offers computational tractabilit y and robustness, achiev ed through the Equal Surplus v alue as a linear time alternative to classical 23 Shapley computations. This makes large scale fairness analysis feasible for complex and realistic problems. The application to the Census Income dataset shows that our metho dology (i) detect violations of group fairness through first-stage ESL v alue and allows for formal statistical testing; (ii) emplo ys the t wo-stage ESL to identify the sp ecific features that drive discrepancies in group contributions, thereby not only reco vering kno wn sources of gender based disparity suc h as “Marital status”, but also highlighting additional drivers suc h as “Age”, and “hours-p er-w eek” Hence, a voiding the conclusion that unfairness arises only from purely pro xy features for gender and finally provides a statistical test that is more time efficient than b o otstrap test. W e ha ve extended the t wo-stage ESL framew ork b ey ond the case of a single binary sen- sitiv e feature. Because ESL v alues are defined indep endently of the num b er of groups, this approac h can b e extended to accoun t for m ultiple sensitiv e features and their in tersections, thereb y supp orting a systematic fairness gerrymandering analysis within the same axiomatic and computational framework. Co de and Data Co de and data are av ailable on our anonymous gith ub: link References Ancona, M., C. ¨ Oztireli, and M. Gross (2019). “Explaining deep neural netw orks with a p olynomial time algorithm for shapley v alue approximation”. International Confer enc e on Machine L e arning . PMLR, pp. 272–281. Arenas, Marcelo, Pablo Barcel´ o, Leop oldo E. Bertossi, and Mik a ¨ el Monet (2021). “The T ractability of SHAP-Score-Based Explanations for Classification ov er Deterministic and Decomp osable Bo olean Circuits”. Thirty-Fifth AAAI Confer enc e on Artificial Intel li- genc e . AAAI Press, pp. 6670–6678. Baro cas, S olon, Moritz Hardt, and Arvind Nara yanan (2023). F airness and machine le arning: Limitations and opp ortunities . MIT press. Battiti, Rob erto and Anna Maria Colla (1994). “Demo cracy in neural nets: V oting sc hemes for classification”. Neur al Networks 7.4, pp. 691–707. Begley , T om, T obias Sc hw edes, Christopher F rye, and Ily a F eige (2020). “Explainability for fair machine learning”. arXiv pr eprint arXiv:2010.07389 . Berk, Richard, Ho da Heidari, Shahin Jabbari, Michael Kearns, and Aaron Roth (2021). “F airness in criminal justice risk assessmen ts: The state of the art”. So ciolo gic al Metho ds & R ese ar ch 50.1, pp. 3–44. Castro, J., D. G´ omez, and J. T ejada (2009). “P olynomial calculation of the Shapley v alue based on sampling”. Computers & Op er ations R ese ar ch 36.5, pp. 1726–1730. Chan treuil, F, S Courtin, K F ourrey, and I Leb on (2019). “A note on the decomp osability of inequalit y measures”. So cial Choic e and Welfar e 53, pp. 283–298. 24 Chan treuil, F and A T rannoy (1999). “Inequalit y Decomp osition V alues: The T rade-off Be- t ween Marginality and Consistency”. W orking pap er DP 9924 THEMA. — (2011). “Inequality decomp osition v alues”. Annals of Ec onomics and Statistics 101.102, pp. 6–29. — (2013). “Inequality Decomp osition V alues: The T rade-off Bet w een Marginalit y and Effi- ciency”. The Journal of Ec onomic Ine quality 11.1, pp. 83–98. Charp en tier, Arthur (2024a). Insur anc e, biases, discrimination and fairness . Springer. — (2024b). Insur anc e, biases, discrimination and fairness . Springer. Chouldec hov a, Alexandra (2017). “F air prediction with disparate impact: A study of bias in recidivism prediction instruments”. Big data 5.2, pp. 153–163. Condev aux, C., S. Harisp e, and S. Mussard (Sept. 2022). “F air and Efficien t Alternativ es to Shapley-based Attribution Metho ds”. ECMLPKDD 2022 - The Eur op e an Confer enc e on Machine L e arning and Principles and Pr actic e of Know le dge Disc overy in Datab ases . Grenoble, F rance. Corb ett-Da vies, Sam, Emma Pierson, Avi F eller, Sharad Go el, and Aziz Huq (2017). “Al- gorithmic decision making and the cost of fairness”. Pr o c e e dings of the 23r d acm sigkdd international c onfer enc e on know le dge disc overy and data mining , pp. 797–806. Dastin, Jeffrey (2022). “Amazon scraps secret AI recruiting to ol that sho wed bias against w omen”. Ethics of data and analytics . Auerbach Publications, pp. 296–299. De Bo ck, Ko en W., Kristof Coussement, Arno De Caigny, Roman S lo wi ´ nski, Bart Baesens, Rob ert N. Boute, Tsan-Ming Choi, Dursun Delen, Mathias Kraus, Stefan Lessmann, Se- basti´ an Maldonado, David Martens, Mar ´ ıa ´ Osk arsd´ ottir, Carla V airetti, W outer V erb eke, and Ric hard W eb er (2024). “Explainable AI for Op erational Research: A defining frame- w ork, methods, applications, and a researc h agenda”. Eur op e an Journal of Op er ational R ese ar ch 317.2, pp. 249–272. issn : 0377-2217. Driessen, Theo and Y. F unaki (1991). “Coincidence of and collinearity b et w een game theoretic solutions”. Op er ations-R ese ar ch-Sp ektrum 13(1), pp. 15–30. Dw ork, Cynthia, Moritz Hardt, T oniann Pitassi, Omer Reingold, and Richard Zemel (2012). “F airness through a w areness”. Pr o c e e dings of the 3r d innovations in the or etic al c omputer scienc e c onfer enc e , pp. 214–226. Flores, An thon y W, Kristin Bec h tel, and Christopher T Lo w enk amp (2016). “F alse p osi- tiv es, false negativ es, and false analyses: A rejoinder to machine bias: There’s soft ware used across the country to predict future criminals. and it’s biased against blac ks”. F e d. Pr ob ation 80, p. 38. F ourrey , K ´ evin (2023). “A regression-based Shapley decomp osition for inequality measures”. A nnals of Ec onomics and Statistics 149, pp. 39–62. Hardt, M., E. Price, and N. Srebro (2016). “Equalit y of Opportunity in Sup ervised Learning”. 30th Confer enc e on Neur al Information Pr o c essing Systems . Hernandez-Lamoneda, Luis, Rub en Juarez, and F rancisco Sanchez-Sanc hez (2008). “Solu- tions without dummy axiom for TU co op erative games”. Ec onomics Bul letin 3.1, pp. 1– 9. Hurlin, Christophe, Ch ristophe P´ erignon, and S ´ ebastien Saurin (2026). “The fairness of credit scoring mo dels”. Management Scienc e 72.1, pp. 406–425. Ju, Y uan, P eter Borm, and Pieter Ruys (2007) . “The consensus v alue: a new solution concept for co operative games”. So cial Choic e and Welfar e 28, pp. 685–703. 25 Kearns, Michael, Seth Neel, Aaron Roth, and Zhiwei Stev en W u (2018). “Preven ting fairness gerrymandering: Auditing and learning for subgroup fairness”. International c onfer enc e on machine le arning . PMLR, pp. 2564–2572. Kissami, Imad, Rob ert Basmadjian, Othmane Chakir, and M Riduan Abid (2025). “TOUBKAL: a high-p erformance sup ercomputer pow ering scientific research in Africa”. The Journal of Sup er c omputing 81.15, pp. 1–45. Klare, Brendan F, Mark J Burge, Joshua C Klon tz, Ric hard W V order Bruegge, and Anil K Jain (2012). “F ace recognition p erformance: Role of demographic information”. IEEE T r ansactions on information for ensics and se curity 7.6, pp. 1789–1801. Klein b erg, Jon, Sendhil Mullainathan, and Manish Raghav an (2016). “Inherent trade-offs in the fair determination of risk scores”. arXiv pr eprint arXiv:1609.05807 . K¨ ochling, Alina and Marius Claus W ehner (2020). “Discriminated by an algorithm: a system- atic review of discrimination and fairness by algorithmic decision-making in the con text of HR recruitment and HR developmen t”. Business R ese ar ch 13.3, pp. 795–848. Koha vi, Ron (1996). Census Inc ome . UCI Mac hine Learning Rep ository. Kusner, Matt J, Josh ua Loftus, Chris Russell, and Ricardo Silv a (2017). “Coun terfactual fairnessAdv ances in Neural Inform”. Pr o c ess. Syst . Lam, Louisa and SY Suen (1997). “Application of ma jorit y voting to pattern recognition: an analysis of its b ehavior and p erformance”. IEEE T r ansactions on Systems, Man, and Cyb ernetics-Part A: Systems and Humans 27.5, pp. 553–568. Lee, Mic helle Seng Ah and Luciano Floridi (2021). “Algorithmic fairness in mortgage lending: from absolute conditions to relational trade-offs”. Minds and Machines 31.1, pp. 165–191. Linardatos, Pan telis, V asilis Papastefanopoulos, and Sotiris Kotsiantis (2021). “Explainable AI: A Review of Machine Learning Interpretabilit y Metho ds”. Entr opy 23.1, p. 18. Lundb erg, Scott M and Su-In Lee (2017). “A Unified Approac h to Interpreting Mo del Pre- dictions”. A dvanc es in Neur al Information Pr o c essing Systems 30 . Ed. by I. Guy on, U. V. Luxburg, S. Bengio, H. W allach, R. F ergus, S. Vish wanathan, and R. Garnett. Curran Asso ciates, Inc., pp. 4765–4774. Marques-Silv a, Joao and Xuanxiang Huang (2024). “Explainability is not a game”. Commu- nic ations of the A CM 67.7, pp. 66–75. Mien ye, Ib omoiye Domor and Y anxia Sun (2022). “A survey of ensemble learning: Concepts, algorithms, applications, and prosp ects”. Ie e e A c c ess 10, pp. 99129–99149. Molnar, Christoph (2020). Interpr etable machine le arning . Lulu. com. Nem bua, C Chameni (2012). “Linear efficien t and symmetric v alues for TU-games: sharing the joint gain of co op eration”. Games and Ec onomic Behavior 74.1, pp. 431–433. Nem bua, C Chameni and C Miamo W endji (2016). “Ordinal equiv alence of v alues, Pigou– Dalton transfers and inequality in TU-games”. Games and Ec onomic Behavior 99, pp. 117– 133. No wak, Andrzej and T adeusz Radzik (1994). “A Solidarity V alue for n-P erson T ransferable Utilit y Games.” International Journal of Game The ory 23 (1), pp. 43–48. Ob ermey er, Ziad, Brian P o wers, Christine V ogeli, and Sendhil Mullainathan (2019). “Dis- secting racial bias in an algorithm used to manage the health of p opulations”. Scienc e 366.6464, pp. 447–453. 26 P elegrina, Guilherme Dean and Sa jid Sira j (2024). “Shapley v alue-based approac hes to ex- plain the qualit y of predictions b y classifiers”. IEEE T r ansactions on Artificial Intel li- genc e . P elegrina, Guilherme Dean, Sa jid Sira j, Leonardo T omazeli Duarte, and Michel Grabisc h (2024). “Explaining contributions of features tow ards unfairness in classifiers: A nov el threshold-dep enden t Shapley v alue-based approach”. Engine ering Applic ations of A rtifi- cial Intel ligenc e 138, p. 109427. P enchev a, Irina, Marc Esteve, and Slav a Jankin Mikhaylo v (2020). “Big Data and AI–A transformational shift for gov ernmen t: So, what next for research?” Public Policy and A dministr ation 35.1, pp. 24–44. Radzik, T adeusz and Theo Driessen (2013). “On a family of v alues for TU-games generalizing the Shapley v alue”. Mathematic al So cial Scienc es 65.2, pp. 105–111. Ra wls, John (1971). A The ory of Justic e: Original Edition . Harv ard Universit y Press. Ruiz, Luis M, F ederico V alenciano, and Jose M Zarzuelo (1996). “The least square pren ucleo- lus and the least square nucleolus. Two v alues for TU games based on the excess vector”. International Journal of Game The ory 25, pp. 113–134. Shapley , L. (1953). “A v alue for n-p erson games”. Contributions to the The ory of Games 2.28, pp. 307–317. Strum b elj, Erik and Igor Kononenk o (2010). “An efficient explanation of individual classifi- cations using game theory”. The Journal of Machine L e arning R ese ar ch 11, pp. 1–18. Sun, Yi and Mukund Sundarara jan (2011). “Axiomatic attribution for multilinear functions”. Pr o c e e dings of the 12th ACM c onfer enc e on Ele ctr onic c ommer c e , pp. 177–178. Tido T ak eng, R., A.C. Soh V outsa, and K. F ourrey (2023). “Decompositions of inequalit y measures from the p ersp ectiv e of the Shapley–Ow en v alue”. The ory and De cision 94.2, pp. 299–331. Y oung, HP (1988). “Condorcet’s Theory of V oting, 82 Am”. Pol. Sci. R ev 1231. Za vr ˇ snik, Ale ˇ s (2021). “Algorithmic justice: Algorithms and big data in criminal justice settings”. Eur op e an Journal of criminolo gy 18.5, pp. 623–642. A App endix A: ESL decomp ositions In this app endix, we provide the pro ofs of the theoretical results stated in Sections 3 and 4 . A.1 Theorems on first stage and t w o-stage decomp ositions Pro of of Theorem 3.1 The Shapley v alue applied to the c haracteristic function v ( m ) ( X | S A ( N )) such that S A ⊆ A is defined as: φ S h g ( X , v ( m ) ) := X S A ⊆A\{ g } P ( S A ) v ( m ) ( X | S A ∪{ g } ( N )) − v ( m ) ( X | S A ( N )) The Shapley v alue yields, for the sensitiv e feature lev el asso ciated to men: φ S h g =1 ( X , v ( m ) ) = 1 2 v ( m ) ( X | ∅∪{ 1 } ( N )) − v ( m ) ( X | ∅ ( N )) + 1 2 v ( m ) ( X | { 2 }∪{ 1 } ( N )) − v ( m ) ( X | { 2 } ( N )) 27 Similarly , the contribution of the w omen group is: φ S h g =2 ( X , v ( m ) ) = 1 2 v ( m ) ( X | ∅∪{ 2 } ( N )) − v ( m ) ( X | ∅ ( N )) + 1 2 v ( m ) ( X | { 1 }∪{ 2 } ( N )) − v ( m ) ( X | { 1 } ( N )) 1. Let us assume that f t resp ects ( IND ). W e ha ve by definition: v ( S R ) ( X | { 1 } ( N )) = P ( ˆ Y = 1 | A = 0) P ( ˆ Y = 1 | A ∈ ∅ ) (1 − 1 |{ 1 }| ) = P ( ˆ Y = 1 | A = 0) P ( ˆ Y = 1 | A ∈ ∅ ) v ( S R ) ( X | { 2 } ( N )) = P ( ˆ Y = 1 | A = 1) P ( ˆ Y = 1 | A ∈ ∅ ) (1 − 1 |{ 2 }| ) = P ( ˆ Y = 1 | A = 1) P ( ˆ Y = 1 | A ∈ ∅ ) Therefore, by ( IND ) it comes, v ( S R ) ( X | { 1 } ( N )) − v ( S R ) ( X | { 2 } ( N )) = P ( ˆ Y = 1 | A = 0) P ( ˆ Y = 1 | A ∈ ∅ ) − P ( ˆ Y = 1 | A = 1) P ( ˆ Y = 1 | A ∈ ∅ ) = 0 Then, φ S h g =1 ( X , v ( S R ) ) − φ S h g =2 ( X , v ( S R ) ) = 0 Con versely , if φ S h g =1 ( X , v ( S R ) ) = φ S h g =2 ( X , v ( S R ) ), it is easy to sho w that ( IND ) holds directly since v ( S R ) ( X | { 1 } ( N )) − v ( S R ) ( X | { 2 } ( N )) = 0. 2. Let us assume that f t resp ects ( SEP ). W e ha ve by definition, v ( T P R ) ( X | { 1 } ( N )) = P ( ˆ Y = 1 | Y = 1 , A = 0) P ( ˆ Y = 1 | Y = 1 , A ∈ ∅ ) (1 − 1 |{ 1 }| ) = P ( ˆ Y = 1 | Y = 1 , A = 0) P ( ˆ Y = 1 | Y = 1 , A ∈ ∅ ) v ( T P R ) ( X | { 2 } ( N )) = P ( ˆ Y = 1 | Y = 1 , A = 1) P ( ˆ Y = 1 | Y = 1 , A ∈ ∅ ) (1 − 1 |{ 2 }| ) = P ( ˆ Y = 1 | Y = 1 , A = 1) P ( ˆ Y = 1 | Y = 1 , A ∈ ∅ ) Then, by ( SEP ) it comes, v ( T P R ) ( X | { 1 } ( N )) − v ( T P R ) ( X | { 2 } ( N )) = P ( ˆ Y = 1 | Y = 1 , A = 0) P ( ˆ Y = 1 | Y = 1 , A ∈ ∅ ) − P ( ˆ Y = 1 | Y = 1 , A = 1) P ( ˆ Y = 1 | Y = 1 , A ∈ ∅ ) = 0 Then, φ S h g =1 ( X , v ( T P R ) ) − φ S h g =2 ( X , v ( T P R ) ) = 0 The same logic holds when using v ( F P R ) . Conv ersely , if φ S h g =1 ( X , v ( T P R ) ) = φ S h g =2 ( X , v ( T P R ) ), and φ S h g =1 ( X , v ( F P R ) ) = φ S h g =2 ( X , v ( F P R ) ) it is easy to show that ( SEP ) holds. 28 3. Let assume that f t resp ects ( SUF ). W e hav e b y definition, v ( P P V ) ( X | { 1 } ( N )) = P ( Y = 1 | ˆ Y = 1 , A = 0) P ( Y = 1 | ˆ Y = 1 , A ∈ ∅ ) (1 − 1 |{ 1 }| ) = P ( Y = 1 | ˆ Y = 1 , A = 0) P ( Y = 1 | ˆ Y = 1 , A ∈ ∅ ) v ( P P V ) ( X | { 2 } ( N )) = P ( Y = 1 | ˆ Y = 1 , A = 1) P ( Y = 1 | ˆ Y = 1 , A ∈ ∅ ) (1 − 1 |{ 2 }| ) = P ( Y = 1 | ˆ Y = 1 , A = 1) P ( Y = 1 | ˆ Y = 1 , A ∈ ∅ ) Then, by ( SUF ) w e ha ve, v ( P P V ) ( X | { 1 } ( N )) − v ( P P V ) ( X | { 2 } ( N )) = P ( Y = 1 | ˆ Y = 1 , A = 0) P ( Y = 1 | ˆ Y = 1 , A ∈ ∅ ) − P ( Y = 1 | ˆ Y = 1 , A = 1) P ( Y = 1 | ˆ Y = 1 , A ∈ ∅ ) = 0 Therefore, φ S h g =1 ( X , v ( P P V ) ) − φ S h g =2 ( X , v ( P P V ) ) = 0 The same logic holds when using v ( N P V ) . Conv ersely , if φ S h g =1 ( X , v ( P P V ) ) = φ S h g =2 ( X , v ( P P V ) ), and φ S h g =1 ( X , v ( N P V ) ) = φ S h g =2 ( X , v ( N P V ) ), it is easy to show that ( SUF ) holds. Pro of of Prop osition 3.1 F rom Theorem 3.1 , the contribution of lev el g is giv en b y φ S h g ( X , v ( m ) ) = 1 2 v ( m ) ( X | {A} ( N )) , for all g ∈ A . Applying the Shapley v alue to the c haracteristic function 1 2 v ( m ) ( X | {A} ( N )), whic h is indepen- den t of g , yields, by additivity of the Shapley v alue, 1 2 φ S h k ( X , v ( m ) ) . The conv erse implication ( ⇐ ) follows directly , which completes the pro of. Pro of of Theorem 4.1 W e work with the case of binary sensitiv e feature with v ( . ) ( X | {∅} ( N )) = 0, then φ E S L g =1 ( X , v ( m ) ) = 1 2 b 2 v ( m ) ( X | A ( N )) − b 1 v ( m ) ( X | { 2 } ( N )) + 1 2 b 1 v ( m ) ( X | { 1 } ( N )) φ E S L g =2 ( X , v ( m ) ) = 1 2 b 2 v ( m ) ( X | A ( N )) − b 1 v ( m ) ( X | { 1 } ( N )) + 1 2 b 1 v ( m ) ( X | { 2 } ( N )) Th us, φ E S L g =1 ( X , v ( m ) ) − φ E S L g =2 ( X , v ( m ) ) = 1 2 ( b 1 ( v ( m ) ( X | { 1 } ( N )) − v ( m ) ( X | { 2 } ( N ))) + b 1 ( v ( m ) ( X | { 1 } ( N )) − v ( m ) ( X | { 2 } ( N )))) 29 F or the five ESL v alues, we hav e b 2 = 1 and b 1 > 0. Therefore, φ E S L g =1 ( X , v ( m ) ) − φ E S L g =2 ( X , v ( m ) ) = b 1 ( v ( m ) ( X | { 1 } ( N )) − v ( m ) ( X | { 2 } ( N ))) Assume that either ( IND ), ( SEP ), or ( SUF ) holds. Then, v ( m ) ( X | { 1 } ( N )) = v ( m ) ( X | { 2 } ( N )) = v ( m ) ( X | A ( N )) . Therefore, φ E S L g =1 ( X , v ( m ) ) = φ E S L g =2 ( X , v ( m ) ) , and, in particular, φ E S L g =1 ( X , v ( m ) ) = b 2 2 v ( m ) ( X | A ( N )) . Con versely , assume that φ E S L g =1 ( X , v ( m ) ) = φ E S L g =2 ( X , v ( m ) ) . Then, we hav e either v ( m ) ( X | { 1 } ( N )) − v ( m ) ( X | { 2 } ( N )) = 0 or b 1 = 0 . Since b 1 > 0, it follows that v ( m ) ( X | { 1 } ( N )) = v ( m ) ( X | { 2 } ( N ) . Therefore, ( IND ), ( SEP ), or ( SUF ) holds. A.2 Generalization: Pro of of the m ulti-stage ESL decomp osition Theorem A.1. (Multi-stage ESL) L et f t b e a binary classifier and A j a binary set of sensitive fe atur e levels. The multi-stage ESL value φ S h k ◦ ... ◦ φ E S L a i 1 1 ,...,a i s s ( X , v ( m ) ) for al l k ∈ 1 , · · · , N and for al l a i 1 1 ∈ A 1 , ..., a i s s ∈ A s yields the fol lowing e quivalenc es: (i) f t r esp e cts ( IND ) ⇐ ⇒ C k a i 1 1 ,...,a i s s ( v ( S R ) ) = ( b 2 2 ) s φ E S L k ( X , v ( S R ) ) ∀ k ∈ N (ii) f t r esp e cts ( SEP ) ⇐ ⇒ C k a i 1 1 ,...,a i s s ( v ( T P R ) ) = ( b 2 2 ) s φ E S L k ( X , v ( T P R ) ) ∀ k ∈ N , C k a i 1 1 ,...,a i s s ( v ( F P R ) ) = ( b 2 2 ) s φ E S L k ( X , v ( F P R ) ) ∀ k ∈ N , (iii) f t r esp e cts ( SUF ) ⇐ ⇒ C k a i 1 1 ,...,a i s s ( v ( P P V ) ) = ( b 2 2 ) s φ E S L k ( x , v ( P P V ) ) ∀ k ∈ N , C k a i 1 1 ,...,a i s s ( v ( N P V ) ) = ( b 2 2 ) s φ E S L k ( x , v ( N P V ) ) ∀ k ∈ N . 30 Pr o of. Let assume that we ha ve tw o sensitive features with binary levels, gender (men, w omen) and ethnicit y (ma jorit y , minorit y). F or the ease of exp osition, let G = { 1 , 2 } b e the set of gender lev els where g ∈ G . Similarly , let R ∈ { 1 , 2 } b e the set of ethnicit y levels where r ∈ R . In the first stage, ESL v alue is applied to determine the con tribution of gender lev els. F ollowing Theorem 4.1 we ha v e: φ E S L g =1 ( X , v ( m ) ) = 1 2 b 2 v ( m ) ( X | G ( N )) − b 1 v ( m ) ( X | { 2 } ( N )) + 1 2 b 1 v ( m ) ( X | { 1 } ( N )) φ E S L g =2 ( X , v ( m ) ) = 1 2 b 2 v ( m ) ( X | G ( N )) − b 1 v ( m ) ( X | { 1 } ( N )) + 1 2 b 1 v ( m ) ( X | { 2 } ( N )) Then in a second stage, ESL v alue is applied on ethnicit y lev els to determine their contri- bution to φ E S L g =1 ( X , v ( m ) ). Let S ⊆ N , define the subset of features without ethnicit y . F or simplicit y , let take z g ≡ X | G , z 1 ≡ X | { 1 } and z 2 ≡ X | { 2 } as the features defined on each test data defined with resp ect to gender levels g ∈ G . Thus, φ E S L g =1 ,r =1 ( z , v ( m ) ) = 1 4 b 2 b 2 v ( m ) ( z g | R ( S )) − b 1 v ( m ) ( z g | { 2 } ( S )) + b 1 v ( m ) ( z g | { 1 } ( S )) − 1 4 b 1 b 2 v ( m ) ( z 2 | R ( S )) − b 1 v ( m ) ( z 2 | { 2 } ( S )) + b 1 v ( m ) ( z 2 | { 1 } ( S )) + 1 4 b 1 b 2 v ( m ) ( z 1 | R ( S )) − b 1 v ( m ) ( z 1 | { 2 } ( S )) + b 1 v ( m ) ( z 1 | { 1 } ( S )) Similarit y , we find: φ E S L g =1 ,r =2 ( z , v ( m ) ) = 1 4 b 2 b 2 v ( m ) ( z g | R ( S )) − b 1 v ( m ) ( z g | { 1 } ( S )) + b 1 v ( m ) ( z g | { 2 } ( S )) − 1 4 b 1 b 2 v ( m ) ( z 2 | R ( S )) − b 1 v ( m ) ( z 2 | { 1 } ( S )) + b 1 v ( m ) ( z 2 | { 2 } ( S )) + 1 4 b 1 b 2 v ( m ) ( z 1 | R ( S )) − b 1 v ( m ) ( z 1 | { 1 } ( S )) + b 1 v ( m ) ( z 1 | { 2 } ( S )) This yields the following difference: φ E S L g =1 ,r =1 ( z , v ( m ) ) − φ E S L g =1 ,r =2 ( z , v ( m ) ) = b 1 b 2 2 v ( m ) z g | { 1 } − v ( m ) z g | { 2 } + b 2 1 2 h v ( m ) z 1 | { 1 } − v ( m ) z 1 | { 2 } − v ( m ) z 2 | { 1 } − v ( m ) z 2 | { 2 } i . Let assume that either ( IND ), ( SEP ), or ( SUF ) holds at the ethnicity lev el. Hence, v ( m ) ( z ( . ) | { 1 } ( S ) = v ( m ) ( z ( . ) | { 2 } ( S )) = v ( m ) ( z ( . ) | R ) . Therefore, φ E S L g =1 ,r =1 ( z , v ( m ) ) = φ E S L g =1 ,r =2 ( z , v ( m ) ) , 31 suc h that φ E S L g =1 ,r =1 ( z , v ( m ) ) = 1 4 b 2 2 v ( m ) ( z g | R ( S ) − b 1 b 2 v ( m ) ( z 2 | R ( S ) + b 1 b 2 v ( m ) ( z 1 | R ( S ) If we assume that group fairness under ( IND ), ( SEP ) or ( SUF ) holds at gender level, the con tribution is reduced to: φ E S L g =1 ,r =1 ( z , v ( m ) ) = 1 4 b 2 2 v ( m ) ( z g | R ( S )) The same pro cedure is applied to determine φ E S L g =2 ,r =1 ( z , v ( m ) ). Note that, under group fairness, φ E S L g =1 ( X , v ( m ) ) = φ E S L g =2 ( X , v ( m ) ). By the axiom of efficiency , φ E S L g =1 ,r =1 ( z , v ( m ) ) + φ E S L g =1 ,r =2 ( z , v ( m ) ) = φ E S L g =2 ,r =1 ( z , v ( m ) ) + φ E S L g =2 ,r =2 ( z , v ( . ) ) Since φ E S L g =1 ,r =1 ( z , v ( m ) ) = φ E S L g =1 ,r =2 ( z , v ( m ) ), then φ E S L g =1 ,r =1 ( z , v ( m ) ) = φ E S L g =2 ,r =1 ( z , v ( m ) ) and, φ E S L g =1 ,r =2 ( z , v ( m ) ) = φ E S L g =2 ,r =2 ( z , v ( m ) ) Then, group fairness is ensured for all nested groups. Similarly to Theorem 3.1 , since the con tribution of the ethnicity lev el j ∈ R is φ E S L g =1 ,r =1 ( z , v ( m ) ) = φ E S L g =1 ,r =2 ( z , v ( m ) ) = 1 4 b 2 2 v ( m ) ( z g | R ( S )) = 1 4 b 2 2 v ( m ) ( X | G ∪R ( S ))). Then, applying the ESL v alue to the characteristic function φ E S L g =1 ,r ( z , v ( . ) ), which is indep enden t of ethnicit y and gender lev els, yields b y the additivit y of the ESL, C k g =1 ,r ( v ( . ) ) = 1 4 b 2 2 φ E S L k ( X , v ( m ) ). Similarly we find C k g =2 ,r ( v ( . ) ) = 1 4 b 2 2 φ E S L k ( X , v ( m ) ). When ha ving m ultiple sensitiv e features with binary levels, b y recurrence, the contribution of the s th sensitiv e feature with level j is expressed as, φ E S L a i 1 1 ,...,a i s s ( X , v ( . ) ) = b 2 2 s v ( m ) ( X | A 1 ∪ ... ∪A s ( S ))) Therefore, C k a i 1 1 ,...,a i s s ( v ( . ) ) = ( b 2 2 ) s φ E S L k ( X , v ( m ) ). The other direction ( ⇐ ) holds directly , and this ends the pro of. B App endix B: T esting equalit y of opp ortunit y W e provide a statistical fairness test with resp ect to equalit y of opp ortunit y using the ESL v alues prop osed in Theorem 4.1 and Corollary 4.1 . Recall that equalit y of opp ortunit y ( EOD ) is a relaxation of ( SEP ): P ( ˆ Y = 1 | Y = 1 , A = 1) = P ( ˆ Y = 1 | Y = 1 , A = 2) (EOD) Imp ortan tly , the framew ork can b e adapted to test other group fairness criteria, namely ( IND ), ( SEP ) and ( SUF ) by mo difying the characteristic function v ( m ) . 32 B.1 First stage ESL statistical test T o assess whether group fairness holds with resp ect to equalit y of opportunity ( EOD ), the follo wing null hypothesis derived from Theorem 4.1 is introduced: H 0 : φ E S L g =1 ( X , T P R ) = φ E S L g =2 ( X , T P R ) ⇐ ⇒ ( EOD ) H 1 : φ E S L g =1 ( X , T P R ) = φ E S L g =2 ( X , T P R ) ⇐ ⇒ ¬ ( EOD ) In other words, testing φ E S L g =1 ( X , T P R ) = φ E S L g =2 ( X , T P R ) assesses whether ( EOD ) holds. The rejection of H 0 implies the violation of ( EOD ). F or simplicit y , let b φ E S L g := b φ E S L g ( X , T P R ). W e establish the asymptotic distribution of the difference b φ E S L 1 − b φ E S L 2 . Prop osition B.1. Under the nul l hyp othesis that ( EOD ) holds, the fol lowing test statistic Z is asymptotic al ly normal: Z = b φ E S L 1 − b φ E S L 2 r 4 b 2 1 ˆ p A (1 − ˆ p A ) 1 n + 1 + 1 n + 2 ∼ N (0 . 1) , wher e n + 1 and n + 2 denote the numb er of actual p ositive in data asso ciate d with men and women, r esp e ctively, ˆ p A is the estimator of the true p ositive r ate for the c ombine d p opulation and b 1 is determine d by Pr op osition 4.1 . Pr o of. Let X | g ( N ) = ( X 1 , . . . , X N ) | g and X | A ( N ) = ( X 1 , . . . , X N ) | A denote the random feature vector asso ciated to lev el g ∈ { 1 , 2 } , and com bined lev el A = { 1 , 2 } , resp ectiv ely . These features are used to ev aluate a binary classifier f t on a sp ecific dataset ( e.g. , combined data, level data). Let us denote the indicator of true p ositive when b oth the ground truth lab el Y i and the predicted lab el ˆ Y i are p ositiv e as: I i, N = 1 { ˆ Y i =1 ,Y i =1 } Similarly , the indicator of an actual p ositive is defined as: J i = 1 { Y i =1 } Let n g and n A denote the total num b er of observ ations in data b elonging to group g and all groups, resp ectiv ely , where 0 < n g < ∞ and 0 < n A < ∞ . Assume that I i, N and J i are i.i.d Bernoulli random v ariables. F or the ease of exp osition, w e define α g , N := P ( ˆ Y = 1 , Y = 1 | A = g ), α N := P ( ˆ Y = 1 , Y = 1), γ g := P ( Y = 1 | A = g ) and γ := P ( Y = 1). By the Law of Large Num b ers (LLN), w e ha ve the following P n g i =1 I i, N n g p − → E ( I i, N | A i = g ) = α g , N and P n A i =1 I i, N n A p − → E ( I i, N ) = α N P n g i =1 J i n g p − → E ( J i | A i = g ) = γ g and P n A i =1 J i n A p − → E ( J i ) = γ 33 Denote p g := P ( ˆ Y = 1 | Y = 1 , A = g ) and let ˆ p g b e the plug in estimator of the true p ositive rate of group g . In particular, ˆ p g := [ T P R ( X | { g } ( N )) = P n g i =1 I i, N n g P n g i =1 J i n g ≡ f ( U n g ) , where U n g := P n g i =1 J i n g , P n g i =1 I i, N n g is the t w o-dimensional sample mean with p opulation mean θ g := ( γ g , α g , N ). By the Con tin uous Mapping Theorem and assuming that γ g > 0, we hav e: [ T P R ( X | { g } ( N )) = f ( U n g ) p − → f ( θ g ) = α g , N γ g = p g Hence, [ T P R ( X | { g } ( N )) is a consisten t estimator of P ( ˆ Y = 1 | Y = 1 , A = g ). Moreo v er, by the Multiv ariate Central Limit Theorem, √ n g U n g − θ g d − → N (0 . Σ g ) where, Σ g = γ g (1 − γ g ) α g , N − γ g α g , N α g , N − γ g α g , N α g , N (1 − α g , N ) Therefore, since f is differentiable at θ g , then by Rao’s Delta metho d we ha v e, √ n g f ( U n g ) − f ( θ g ) d − → N 0 . ∇ f ( θ g ) ⊤ Σ g ∇ f ( θ g ) where ∇ f ( γ g , α l, N ) = − α l, N γ 2 g 1 γ g and ∇ f ( θ g ) ⊤ Σ g ∇ f ( θ g ) = p g ( 1 − p g ) γ g . Hence, √ n g [ T P R ( X | { g } ( N )) − p g d − → N 0 . p g (1 − p g ) γ g That is, for sufficiently large n g , [ T P R ( X | { g } ( N )) ∼ N p g , p g (1 − p g ) n + g where n + g ≈ n g γ g is the exp ected num b er of p ositives in lev el g suc h that 0 < n + g < ∞ . F ollowing the same steps, w e can find that [ T P R ( X | A ( N )) is a consisten t estimator of p A := P ( ˆ Y = 1 | Y = 1) and by assuming that γ > 0 and n + A ≈ nγ , with 0 < n + A < ∞ , [ T P R ( X | A ( N )) ∼ N p A , p A (1 − p A ) n + A 34 Recall that φ E S L g ( X , T P R ) assigns to each data belonging to level g ∈ { 1 , 2 } the follo wing group contribution 12 : φ E S L g =1 X , T P R 2 = 1 2 h 2 b 2 T P R ( X | A ( N )) − 2 b 1 T P R ( X | { 2 } ( N )) + 2 b 1 T P R ( X | { 1 } ( N )) i φ E S L g =2 X , T P R 2 = 1 2 h 2 b 2 T P R ( X | A ( N )) − 2 b 1 T P R ( X | { 1 } ( N )) + 2 b 1 T P R ( X | { 2 } ( N )) i Since φ E S L g is a contin uous function of T P R g and T P R A , the plug-in estimator of φ E S L g ( X , T P R 2 ) is c φ g E S L := φ E S L g ( X , [ T P R ). By the Contin uous Mapping Theorem, w e hav e c φ 1 E S L p − → b 2 p A + b 1 ( p 1 − p 2 ) c φ 2 E S L p − → b 2 p A − b 1 ( p 1 − p 2 ) F or ease of exp osition, w e define [ T P R g ( N ) := [ T P R ( X | { g } ( N )). Since [ T P R g ( N ) is computed on group observ ations and the group are disjoint in test sample, and since w e treat the trained classifier as fixed during ev aluation, we assume that [ T P R g ( N ) as indep endent across groups. [ T P R g ( N ) and [ T P R A ( N ) are asymptotically normal, it follo ws that c φ g E S L (a linear com bination of those later) is also asymptotically normally distributed: b φ E S L g =1 ∼ N b 2 p A + b 1 ( p 1 − p 2 ) , h b 2 2 p A (1 − p A ) n + A + b 2 1 p 1 (1 − p 1 ) n + 1 + p 2 (1 − p 2 ) n + 2 i + 2 b 1 b 2 ( c 1 − c 2 ) , where c j := Cov( [ T P R A ( N ) , [ T P R j ( N )) and Cov( [ T P R 1 ( N ) , [ T P R 2 ( N )) = 0. Similarly , b φ E S L j =2 is normally distributed as follows: b φ E S L g =2 ∼ N b 2 p A − b 1 ( p 1 − p 2 ) , h b 2 2 p A (1 − p A ) n + A + b 2 1 p 1 (1 − p 1 ) n + 1 + p 2 (1 − p 2 ) n + 2 i − 2 b 1 b 2 ( c 1 − c 2 ) F urther, let us define D := b φ E S L j =1 − b φ E S L j =2 . Therefore, w e ha v e the following: D ∼ N 2 b 1 ( p 1 − p 2 ) , 4 b 2 1 p 1 (1 − p 1 ) n + 1 + p 2 (1 − p 2 ) n + 2 Note that when ( EOD ) is satisfied, w e ha ve p 1 = p 2 = p A . Therefore, under the null h yp othesis, the asymptotic distribution of the standardized test statistic is: Z := D r 4 b 2 1 ˆ p A (1 − ˆ p A ) 1 n + 1 + 1 n + 2 H 0 ∼ N (0 . 1) Consequen tly , the null h yp othesis is rejected at lev el α when | Z | > z α/ 2 , where z α 2 is the (1 − α 2 ) quantile of the standardized normal distribution N (0 . 1). 12 The baseline of a random classifier 1 2 w as used in the definition of v m . Hence, the use of 2 in the equations for φ E S L g =1 ( X , T P R ) and φ E S L g =2 ( X , T P R ). 35 B.2 Second stage ESL statistical test Con trary to the first stage, the second stage fo cuses on testing the equalit y in feature con- tributions across lev els. By Corollary 4.1 , equalit y of opp ortunity ( EOD ) can b e tested for an y given k ∈ N : H 0 : C k 1 ( v ( T P R ) ) = C k 2 ( v ( T P R ) ) H 1 : C k 1 ( v ( T P R ) ) = C k 2 ( v ( T P R ) ) Prop osition B.2. Under the nul l hyp othesis that ( EOD ) holds, the test statistic Z k is asymp- totic al ly normal: Z k = ˆ C k 1 ( v ( T P R ) ) − ˆ C k 2 ( v ( T P R ) ) q V ar ( ˆ C k 1 ( v ( T P R ) )) + V ar ( ˆ C k 2 ( v ( T P R ) )) − 2Co v( ˆ C k 1 ( v ( T P R ) ) , ˆ C k 2 ( v ( T P R ) )) ∼ N (0 . 1) Pr o of. Let ˆ Y i, S b e the predicted lab el using features X | g ( S ) = ( X s , . . . , X S ) | g . F ollowing the first stage statistical test, the estimated true p ositive rate on test data b elonging to g based on feature vector X | { g } ( S ) is given b y: [ T P R ( X | { g } ( S )) = P n g i =1 I i, S n g P n g i =1 J i n g where I i, S = 1 { ˆ Y i, S =1 ,Y i =1 } and J i = 1 { Y i =1 } . Again, substituting the feature vector X | g ( N ) = ( x 1 , . . . , x N ) | g b y X | g ( S ) = ( X s , . . . , X S ) | g , b y the Central Limit Theorem, the asymptotic distribution of [ T P R g ( S ) for n g sufficien tly large is: [ T P R g ( S ) ∼ N p g ( S ) , p g ( S )(1 − p g ( S )) n + g where p g ( S ) := P ( ˆ Y S = 1 | Y = 1 , A = g ) ∈ (0 . 1), γ g > 0 and n + g ≈ n g γ g with 0 < n + l < ∞ . Similarly , when n A is large, [ T P R A ( S ) ∼ N p A ( S ) , p A ( S ) (1 − p A ( S )) n + A where p A ( S ) := P ( ˆ Y S = 1 | Y = 1) ∈ (0 . 1), γ A > 0 and n + A ≈ n A γ A with 0 < n + A < ∞ . In the second stage, the aim is to allo cate ˆ φ E S L g ( X , T P R ) across all features. F or simplic- it y , we define ˆ w g ( S ) := ˆ φ E S L g ( X ( S ) , T P R ). F or every coalition S , since the mapping from [ T P R g ( S ) to ˆ w g ( S ) is contin uous, then ˆ w 1 ( S ) p − → b 2 p A ( S ) + b 1 ( p 1 ( S ) − p 2 ( S )) ˆ w 2 ( S ) p − → b 2 p A ( S ) − b 1 ( p 1 ( S ) − p 2 ( S )) 36 F or large n g and n A , since ˆ w g ( S ) is a linear combination of normally distributed random v ariables, ˆ w g ( S ) follows a normal distribution: ˆ w g ( S ) ∼ N µ g ( S ) , σ 2 g ( S ) where, for g ∈ { 1 , 2 } , µ 1 ( S ) = b 2 p A ( S ) + b 1 ( p 1 ( S ) − p 2 ( S )) µ 2 ( S ) = b 2 p A ( S ) − b 1 ( p 1 ( S ) − p 2 ( S )) σ 2 1 ( S ) = b 2 2 p A ( S )(1 − p A ( S )) n + A + b 2 1 ( p 1 ( S )(1 − p 1 ( S )) n + 1 + p 2 ( S )(1 − p 2 ( S )) n + 2 ) + 2 b 1 b 2 ( c 1 ( S ) − c 2 ( S )) σ 2 2 ( S ) = b 2 2 p A ( S )(1 − p A ( S )) n + A + b 2 1 ( p 1 ( S )(1 − p 1 ( S )) n + 1 + p 2 ( S )(1 − p 2 ( S )) n + 2 ) − 2 b 1 b 2 ( c 1 ( S ) − c 2 ( S )) with c g = Co v( [ T P R A ( S ) , [ T P R g ( S )). The estimator of C k g ( v ( T P R ) ) is given by: ˆ C k g ( v ( T P R ) ) = X S ⊆N \{ k } P ( S ) ˆ W g ( S ) := X S ⊆N \{ k } P ( S ) b s +1 ˆ w g ( S ∪ { k } ) − b s ˆ w g ( S ) Since the mapping from ˆ w g ( S ) to ˆ C k g is also con tinuous, applying the Con tinuous Mapping Theorem a second time leads to, ˆ C k g ( v ( T P R ) ) p − → C k g ( v ( T P R ) ) = X S ⊆N \{ k } P ( S ) b s +1 µ g ( S ∪ { k } ) − b s µ g ( S ) ˆ w g ( S ) is asymptotically normally distributed, by linearity , ˆ C k g ( v ( T P R ) ) is also asymptotically normal. Thus, ˆ C k g ( v ( T P R ) ) − C k g ( v ( T P R ) ) d − → N 0 .σ 2 g ,k Next, we establish the asymptotic v ariance: V ar ( ˆ C k g ( v ( T P R ) )) = V ar X S ⊆N \{ k } P ( S ) ˆ W g ( S ) = X S ⊆N \{ k } X T ⊆N \{ k } P ( S ) P ( T )Cov ˆ W g ( S )) , ˆ W g ( T ) = X S ⊆N \{ k } P ( S ) 2 V ar ˆ W g ( S ) + 2 X S,T ⊆P P ( S ) P ( T )Cov ˆ W g ( S ) , ˆ W g ( T ) where, V ar ˆ W 1 ( S ) = b 2 s +1 σ 2 1 ( S ∪ { k } ) + b 2 s σ 2 1 ( S ) − 2 b s +1 b s Co v ˆ w 1 ( S ∪ { k } ) , ˆ w 1 ( S ) 37 Let us formally derive Cov( ˆ w 1 ( S ∪ { k } ) , ˆ w 1 ( S )), we ha v e: Co v( ˆ w 1 ( S ∪ { k } ) , ˆ w 1 ( S )) = b 2 2 Co v [ T P R A ( S ∪ { k } ) , [ T P R A ( S ) + b 2 b 1 ( Co v [ T P R A ( S ∪ { k } ) , [ T P R 1 ( S ) − [ T P R 2 ( S ) + Co v [ T P R 1 ( S ∪ { k } ) − [ T P R 2 ( S ∪ { k } ) , [ T P R A ( S ) ) + b 2 1 h Co v [ T P R 1 ( S ∪ { k } ) , [ T P R 1 ( S ) + Co v [ T P R 2 ( S ∪ { k } ) , [ T P R 2 ( S ) i Similarly , we hav e Co v ˆ w 2 ( S ∪ { k } ) , ˆ w 2 ( S ) = b 2 2 Co v [ T P R A ( S ∪ { k } ) , [ T P R A ( S ) − b 2 b 1 ( Co v [ T P R A ( S ∪ { k } ) , [ T P R 1 ( S ) − [ T P R 2 ( S ) + Co v [ T P R 1 ( S ∪ { k } ) − [ T P R 2 ( S ∪ { k } ) , [ T P R A ( S ) ) + b 2 1 h Co v [ T P R 1 ( S ∪ { k } ) , [ T P R 1 ( S ) + Co v [ T P R 2 ( S ∪ { k } ) , [ T P R 2 ( S ) i Note that since \ T P R g = T P g n + g := P n g i =1 I i, S P n g i =1 J i , then Co v [ T P R g ( S ∪ { k } ) , [ T P R g ( S ) = 1 ( n + g ) 2 Co v T P g ( S ∪ { k } ) , T P g ( S ) where Cov( T P g ( S ∪ { k } ) , T P g ( S )) is given b y the following: Co v T P g ( S ∪ { k } ) , T P g ( S ) = E ( T P g ( S ∪ { k } ) · T P g ( S )) − E ( T P g ( S ∪ { k } )) E ( T P g ( S )) = E n + g X i =1 I i,g , S ∪{ k } n + g X i =1 I i,g , S − E n + g X i =1 I i,g , S ∪{ k } E n + g X i =1 I i,g , S = n + g X i =1 E I i,g , S ∪{ k } I i,g , S + n + g X i,j =1 i = j E I i,g , S ∪{ k } I j,g , S − E n + g X i =1 I i,g S ∪{ k } E n + g X i =1 I i,g , S 38 = n + g X i =1 P ( I i,g , S ∪{ k } = 1 , I i,g , S = 1) + n + g X i =1 n + g − 1 X j =1 E I i,l, S ∪{ k } E I j,g , S − n + g X i =1 E I i,g , S ∪{ k } n + g X i =1 E ( I i,g , S ) = n + g P ( I g , S ∪{ k } = 1 , I g , S = 1) − n + g P ( I g , S ∪{ k } = 1) P ( I g , S = 1) = n + g P ( I g , S ∪{ k } = 1 , I g , S = 1) − n + g p g ( S ∪ { k } ) p g ( S )) Let us set T P A := T P 1 + T P 2 , where T P g represen ts the true p ositiv es asso ciated with g . It follows that Co v T P A ( S ) n + A , T P 1 ( S ) n + 1 − T P 2 ( S ) n + 2 = 1 n + A n + 1 Co v( T P A ( S ) , T P 1 ( S )) − 1 n + A n + 2 Co v( T P A ( S ) , T P 2 ( S )) . Moreo ver, we ha v e: Co v T P A ( S ∪ { k } ) , T P 1 ( S ) = n + 1 P ( I 1 , S ∪{ k } = 1 , I 1 , S = 1) − n + 1 P ( I 1 , S ∪{ k } = 1) P ( I 1 , S = 1) Co v T P A ( S ∪ { k } ) , T P 2 ( S ) = n + 2 P ( I 2 , S ∪{ k } = 1 , I 2 , S = 1) − n + 2 P ( I 2 , S ∪{ k } = 1) P ( I 2 , S = 1) . Similarly , Co v( ˆ W g ( S ) , ˆ W g ( T )) = Cov b s +1 ˆ w g ( S ∪ { k } ) − b s ˆ w g ( S ) , b t +1 ˆ w g ( T ∪ { k } ) − b t ˆ w g ( T ) = b s +1 b t +1 Co v ˆ w g ( S ∪ { k } ) , ˆ w g ( T ∪ { k } ) − b s +1 b t Co v ˆ w g ( S ∪ { k } ) , ˆ w g ( T ) − b t +1 b s Co v ˆ w g ( T ∪ { k } ) , ˆ w g ( S ) + b s b t Co v ˆ w g ( S ) , ˆ w g ( T ) . Under the n ull hypothesis that C k 1 ( v ( T P R ) ) = C k 2 ( v ( T P R ) ), the asymptotic distribution of the standardized test statistic is: Z k = ˆ C k 1 − ˆ C k 2 q V ar ( ˆ C k 1 ) + V ar ( ˆ C k 2 ) − 2Co v( ˆ C k 1 ( v ( T P R ) ) , ˆ C k 2 ( v ( T P R ) )) ∼ N (0 . 1) 39 No w, it remains to compute Cov( ˆ C k 1 ( v ( T P R ) ) , ˆ C k 2 ( v ( T P R ) )). W e ha ve: Co v( ˆ C k 1 ( v ( T P R ) ) , ˆ C k 2 ( v ( T P R ) )) = X S P ( S ) 2 Co v ˆ W 1 ( S ) , ˆ W 2 ( S ) + X S X T P ( S ) P ( T )Cov ˆ W 1 ( S ) , ˆ W 2 ( T ) where X S P ( S ) 2 Co v ˆ W 1 ( S ) , ˆ W 2 ( S ) = X S P ( S ) 2 h Co v( b s +1 ˆ w 1 ( S ∪ { k } ) − b s ˆ w 1 ( S ) , b s +1 ˆ w 2 ( S ∪ { k } ) − b s ˆ w 2 ( S )) i = X S P ( S ) 2 h b s +1 b s +1 Co v( ˆ w 1 ( S ∪ { k } ) , ˆ w 2 ( S ∪ { k } )) − b s +1 b s Co v( ˆ w 1 ( S ∪ { k } ) , ˆ w 2 ( S )) − b s +1 b s Co v( ˆ w 2 ( S ∪ { k } ) , ˆ w 1 ( S )) + b s b s Co v( ˆ w 2 ( S ) , ˆ w 1 ( S )) i = X S P ( S ) 2 b 2 s +1 h b 2 2 V ar ( [ T P R A ( S ∪ { k } )) − b 2 1 ( V ar ( [ T P R 1 ( S ∪ { k } )) − b 2 1 V ar ( [ T P R 2 ( S ∪ { k } )) i − b s +1 b s h b 2 2 Co v( [ T P R A ( S ∪ { k } ) , [ T P R A ( S )) − b 2 1 Co v( [ T P R 1 ( S ∪ { k } ) , [ T P R 1 ( S )) − b 2 1 Co v( [ T P R 2 ( S ∪ { k } ) , [ T P R 2 ( S )) i − b 1 b 2 Co v( [ T P R A ( S ∪ { k } ) , [ T P R 1 ( S )) + b 1 b 2 Co v( [ T P R A ( S ∪ { k } ) , [ T P R 2 ( S )) + b 1 b 2 Co v( [ T P R 1 ( S ∪ { k } ) , [ T P R A ( S )) − b 1 b 2 Co v( [ T P R 2 ( S ∪ { k } ) , [ T P R A ( S )) i − b s +1 b s h b 2 2 Co v( [ T P R A ( S ∪ { k } ) , [ T P R A ( S )) − b 2 1 Co v( [ T P R 1 ( S ∪ { k } ) , [ T P R 1 ( S )) − b 2 1 Co v( [ T P R 2 ( S ∪ { k } ) , [ T P R 2 ( S )) i − b 1 b 2 Co v( [ T P R A ( S ) , [ T P R 1 ( S ∪ { k } )) + b 1 b 2 Co v( [ T P R A ( S ) , [ T P R 2 ( S ∪ { k } )) + b 1 b 2 Co v( [ T P R 1 ( S ) , [ T P R A ( S ∪ { k } )) − b 1 b 2 Co v( [ T P R 2 ( S ) , [ T P R A ( S ∪ { k } )) i + b 2 s h b 2 2 V ar ( [ T P R A ( S )) − b 2 1 V ar ( [ T P R 1 ( S )) − b 2 1 V ar ( [ T P R 2 ( S )) i = X S P ( S ) 2 b 2 s +1 h b 2 2 V ar ( [ T P R A ( S ∪ { k } )) − b 2 1 V ar ( [ T P R 1 ( S ∪ { k } )) − b 2 1 V ar ( [ T P R 2 ( S ∪ { k } ) i − b s +1 b s h 2 b 2 2 Co v( [ T P R A ( S ∪ { k } ) , [ T P R A ( S )) − 2 b 2 1 Co v( [ T P R 1 ( S ∪ { k } ) , [ T P R 1 ( S )) − 2 b 2 1 Co v( [ T P R 2 ( S ∪ { k } ) , [ T P R 2 ( S )) i + b 2 s h b 2 2 V ar ( [ T P R A ( S )) − b 2 1 V ar ( [ T P R 1 ( S )) − b 2 1 V ar ( [ T P R 2 ( S )) i The same kind of computation is used for P S P T P ( S ) P ( T )Cov( ˆ W 1 ( S ) , ˆ W 2 ( T )). Conse- quen tly , the null h yp othesis is rejected at lev el α when | Z k | > z α/ 2 . 40
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment