WiMamba: Linear-Scale Wireless Foundation Model
Foundation models learn transferable representations, motivating growing interest in their application to wireless systems. Existing wireless foundation models are predominantly based on transformer architectures, whose quadratic computational and me…
Authors: Tomer Raviv, Nir Shlezinger
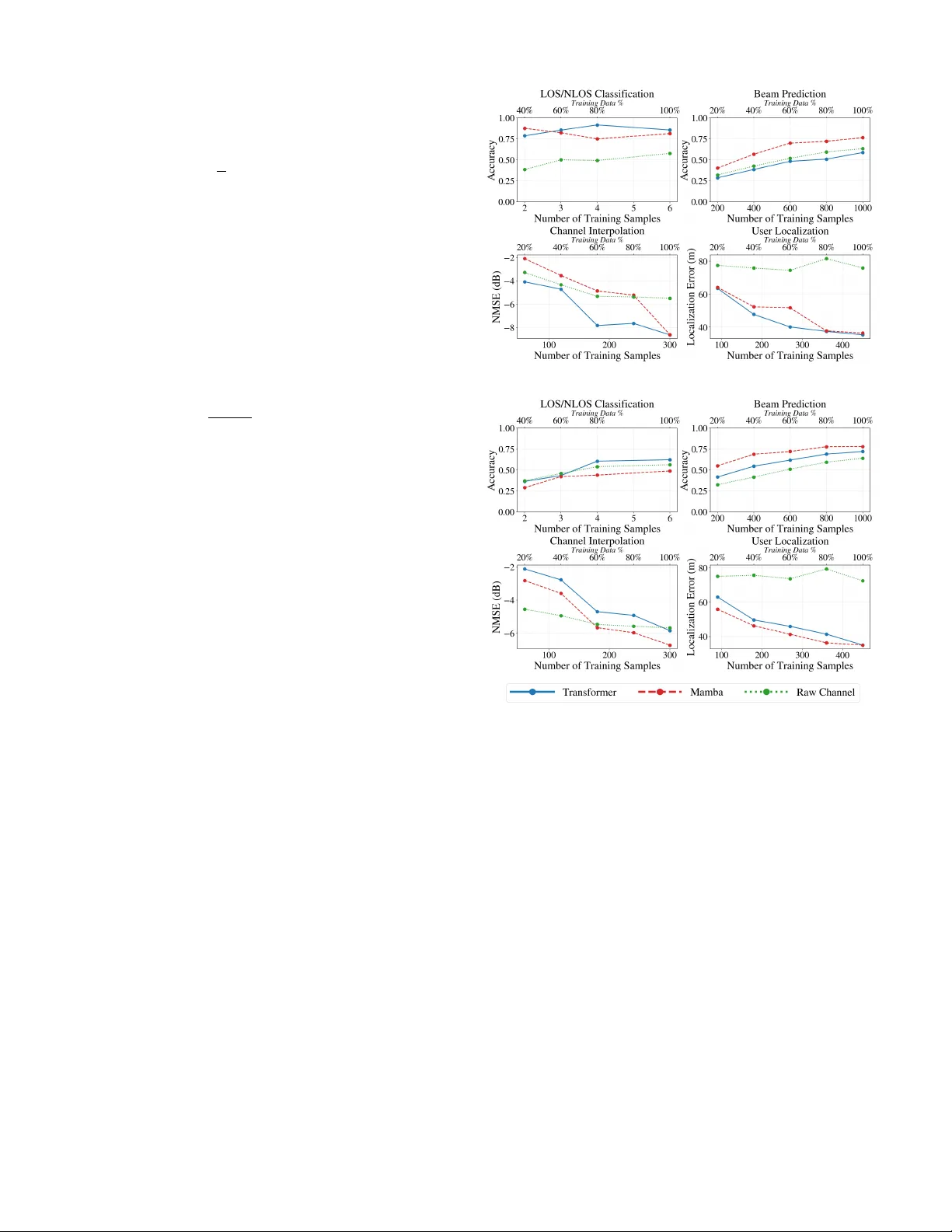
W iMamba: Linear -Scale W ireless F oundation Model T omer Ravi v and Nir Shlezinger Abstract —Foundation models learn transferable representations, motivating gr owing interest in their application to wireless systems. Existing wireless foundation models are pr edominantly based on transformer architectures, whose quadratic computational and memory complexity can hinder practical deployment f or large-scale channels. In this work, we introduce WiMamba, a wireless founda- tion model b uilt upon the recently proposed Mamba architectur e, which replaces attention mechanisms with selective state-space models and enables linear-time sequence modeling. Leveraging this architectural advantage combined with adaptive preprocessing, WiMamba achieves scalable and low-latency inference while maintaining strong r epresentational expressi vity . W e further de velop a dedicated task-agnostic, self-supervised pre-training framework tailored to wireless channels, resulting in a genuine foundation model that learns transferable channel repr esentations. Evaluations across f our downstream tasks demonstrate that WiMamba matches or outperforms transf ormer-based wir eless f oundation models, while offering dramatic latency and memory reductions. Index T erms —Channel foudation models, Mamba. I . I N T RO D U C T I O N Foundation models have emerged as a po werful machine learn- ing ( ML ) paradigm, centered around large-scale task-agnostic models that learn informativ e representations transferable across multiple downstream tasks [ 1 ]. Their remarkable success in natural language processing and computer vision has enabled rapid adaptation and improved generalization in data-limited regimes [ 2 ]. These advances lead to a growing interest in dev elop- ing foundation models for communications [ 3 ], and particularly for wireless channels [ 4 ], where a learned channel state informa- tion ( CSI ) representation can be reused for diverse tasks such as beam prediction, localization, and channel classification [ 5 ]. Existing wireless foundation models can be broadly categorized into two classes. The first uses large pre-trained language and vision models, such as the GPT [ 6 ]–[ 8 ], LLaMA [ 9 ] and DINO [ 10 ] families, and de vises pre- and post-processing pipelines that map wireless data into formats compatible with these architectures, possiblely with limited fine-tuning [ 11 ]. While this approach lev erages the expressi ve po wer and maturity of general-purpose foundation models, it relies on large models designed and trained for dif ferent modalities. This leads to high computational complexity , significant memory requirements, and when combined with the need for elaborate pre- and post-processing, also introduces notable ov erhead and latency . The second class develops dedicated foundation models tailored to wireless channels. This can be achiev ed by training a model to process wireless data and alter its parameters for each task via hypernetworks [ 12 ] or fine-tuning [ 13 ]. Alternativ ely , recent works [ 14 ]–[ 20 ] have demonstrated that self-supervised pre-training on large-scale CSI datasets can The authors are with the School of ECE, Ben-Gurion University of the Nege v , Beer-She va, Israel (e-mail: tomerravi v95@gmail.com; nirshl@bgu.ac.il). The w ork was supported by the European Research Council (ERC) under the ERC starting grant nr . 101163973 (FLAIR). yield meaningful and transferable channel representations that benefit a wide range of do wnstream tasks [ 3 ]. Ho wev er, existing dedicated wireless foundation models rely almost exclusi vely on transformers, which incur substantial inference latency and memory consumption, particularly when processing large channel inputs. This limitation stems from the quadratic scaling of attention mechanisms with respect to the number of input tokens and the maintenance of key–v alue caches during inference [ 21 ]. Moti vated by these observations, this work introduces a founda- tion model for wireless channels whose complexity and inference latency scale sub-quadratically with the channel dimensions. Our model, termed W iMamba , le verages the recently proposed Mamba architecture [ 22 ], which has been shown to achieve expressi ve sequence modeling comparable to transformers while being substantially more efficient in both computation and memory [ 23 ]. Mamba relies on selective state-space models ( SSM s) rather than self-attention mechanisms, resulting in linear complexity with respect to the input sequence length and eliminating the need for ke y–value caches in inference. While a few recent works have explored Mamba for specific wireless tasks [ 24 ], [ 25 ], to the best of our knowledge, this is the first work to demonstrate its effecti veness as enabling efficient wireless foundation models. W e design WiMamba as a wireless foundation model built upon a Mamba bidirectional Mamba backbone, accounting by the fact that the antenna–subcarrier ordering has no inherent temporal direction. T o support varying CSI dimensionaltiy , we introduce an adapti ve granularity mechanism that enables seamless operation across multiple resolutions without retraining or architectural modification. A dedicated task-agnostic, self- supervised pre-training framework allows W iMamba to learn transferable channel embeddings without task-specific labels. W iMamba is ev aluated on four distinct downstream tasks using DeepMIMO [ 26 ], covering both classification and regression objectiv es. Our results demonstrate that W iMamba achiev es performance comparable to, and in se veral cases exceeding, transformer-based wireless foundation models, while yielding dra- matic reductions in inference latency and memory consumption. The paper is structured as follows. Section II presents the system model. W e introduce and evaluate W iMamba in Sec- tions III - IV , respecti vely . Section V provides concluding remarks. I I . S Y S T E M M O D E L A. Pr oblem F ormulation F oundation Models : W e consider channel foundation models as task-agnostic models that map CSI realizations into informa- ti ve latent representations suitable for a wide range of do wnstream inference tasks. W e focus on multicarrier multiple-input multiple- output ( MIMO ) channels with N antennas and M subcarriers, represented by a complex-v alued matrix H ∈ C N × M . A channel foundation model is defined as a mapping x = f θ ( H ) , (1) 1 where f θ ( · ) is a function with trainable parameters θ that extracts a latent representation x ∈ R D from the input CSI . The foundation model learns θ from a large set of channel realizations, assumed to capture div erse channel conditions, denoted D pre = H ( i ) |D pre | i =1 . (2) Inference Pipeline : The ef fectiveness of a foundation model is assessed through its ability to support downstream tasks . In particular , for a downstream task indexed by p , the inference pipeline is provided with: ( i ) a relati vely small labeled dataset D p task = H ( j ) , s ( j ) p |D p task | j =1 , (3) where s ( j ) p denotes the task- p label associated with the channel realization H ( j ) ; and ( ii ) a task-specific loss function ℓ p ( · , · ) . The downstream task is addressed by learning a task-specific mapping from the latent representation x = f θ ( H ) to the desired output s p , using the limited data ( 3 ) . The utility of the foundation model for task p is quantified by the accuracy with which such a mapping can be learned, as measured by ℓ p . Requirements : In this work, we focus on channel foundation models designed to satisfy the following key requirements: R1 T ask agnosticism : f θ ( · ) must support multiple do wnstream tasks that are not known during its design or pre-training. R2 Scalability : the foundation model should operate on CSI of varying dimensions without architectural modifications. R3 Latency : The model should enable low-latency inference with a limited memory footprint for all channel dimensions. B. Mamba and Selective State-Space Models Mamba : A key ingredient in our design is the recent Mamba architecture [ 22 ], whose core innov ation lies in the use of selective SSM s for efficient sequence modeling [ 27 ]. At a high lev el, a Mamba layer processes an input sequence through a stack of a linear projection layer, followed by a lightweight con volutional operation, and a selecti ve SSM module. The output of the SSM is then gated, projected back to the feature dimension, and combined with a skip connection, as illustrated in Fig. 1 . Selective SSM s : SSM s-type ML modules parameterize the mapping from an input sequence { y t } into an output sequence { z t } through a latent state sequence { h t } [ 28 ]. SSM s can be viewed as a form of recurrent neural networks ( RNN s) which operate via e volution and readout equations gi ven by h t = W y y t + W h h t − 1 , z t = W z h t , (4) where W y , W h , and W z are learnable parameters, and the latent state h t serves as a compact memory that aggregates information from past inputs. In selective SSM s [ 27 ], W y , W h , and W z are generated through learned functions of the input y t , effecti vely resulting in a time-varying and nonlinear SSM . Specifically , the state e volution in ( 4 ) is parameterized as W h = exp ∆ · ¯ W h , (5a) W y = ∆ · ¯ W h − 1 W h − I ∆ · ¯ W y , (5b) where ¯ W h and ¯ W y represent continuous-time state transition and input matrices, respectiv ely . Selective SSM s use a dedicated neural layer to map y t into the discretization step ∆ , the Fig. 1: Mamba layer and selectiv e SSM illustration. The activ ation σ ( · ) is typically a sigmoid linear unit. continuous-time input matrix ¯ W y , and the output mapping W z . These quantities are then substituted into ( 5 ) together with the learned ¯ W h , yielding an input-adaptiv e state ev olution. Gains : Unlike transformers, which rely on attention mecha- nisms that correlate all inputs with one another , Mamba utilizes SSM representations that enable linear-time processing with respect to the sequence length, while retaining strong expressi ve power . This property makes Mamba particularly appealing for large-scale wireless channel representations, where both latency and memory ef ficiency are critical ( R3 ), as proposed next. I I I . W I M A M B A C H A N N E L F O U N D A T I O N M O D E L A. Ar chitectur e W iMamba maps an input CSI realization H into a latent representation f θ ( H ) that is reusable across v arious do wnstream inference tasks. Unlike natural language or temporal data, wireless channel matrices lack an inherent causal ordering, while also requiring low-latency processing under strict memory constraints. W iMamba is therefore designed to accommodate these characteristics by combining two key aspects: ( i ) an adaptive-r esolution tokenization and embedding mechanism that enables flexible control ov er the sequence length and computational cost; and ( ii ) a bidirectional Mamba backbone tailored to the non-causal structure of wireless channel matrices. W e next describe how an input channel is conv erted into a token sequence and subsequently processed by the proposed backbone. 1) Data Pr epr ocessing and Adaptive T okenization: W iMamba adopts a tokenization procedure that conv erts the input CSI matrix into a sequence of fixed-dimensional real-valued tokens. The procedure is inspired by preprocessing pipelines used in existing channel foundation models, e.g., [ 15 ], while explicitly enabling adaptive control over the token resolution. Specifically , we support a set of E possible token embedding dimension { L e } E e =1 , that determine the granularity at which the channel is represented (with the granularity level e treated as additional input). Given an input channel H ∈ C N × M , we separate its real and imaginary components and vectorize them. The total number of real-valued channel coefficients is thus 2 N M , and the resulting number of tokens for granularity e is T e = 2 N M L e . The token sequence { t 1 , . . . , t T e } , with t i ∈ R L e , is obtained by stacking the vectorized real and imaginary parts of H , with zero-padding applied if needed to complete the 2 Fig. 2: WiMamba with Q = 1 forward Mamba (Fwd. MMB) and backward Mamba (Bwd. MMB) layers, and three task heads final token. Following [ 29 ], a learnable class token t e cls ∈ R L e is prepended to the token sequence to facilitate aggregating global channel information. The architecture is designed to support dif ferent choices of L e , which balances the resolution-complexity tradeof f of the representation: smaller values of L e yield longer token sequences that capture finer-grained spatial-frequency structure, whereas larger values reduce the sequence length and processing latency at the expense of representational detail. 2) Bidirectional Mamba Bac kbone: Before being processed, each token is projected into the D -dimension embedding space. Specifically , all tokens, including the class token, are mapped from R L e to R D using a shared learnable af fine embedding, y i = W e emb t i + b e emb , i ∈ { cls , 1 , . . . , T e } , (6) where W e emb ∈ R D × L e and b e emb ∈ R D . Since the token sequence corresponds to antenna-subcarrier groupings rather than a temporal e volution, imposing a causal ordering as in standard Mamba may introduce an undesirable inductive bias. Accordingly , the embedded token sequence is then processed by a backbone composed of Q bidir ectional Mamba layers, drawing inspiration from vision foundation models [ 30 ]. Specifically , each layer employs a forward-directional Mamba and a backward-directional one, each operating with embedding dimension D / 2 . Specifically , by di viding each embedding vector into two subvectors via y i = [ y F i || y B i ] with y F i , y B i ∈ R D/ 2 , the forward Mamba (with trainable parameters θ F ) processes y F cls , y F 1 , . . . , y F T e , while the backward Mamba (with trainable parameters θ B ) processes the rev erse sequence y B T e , y B T e − 1 , . . . , y B 1 , y B cls . The outputs of the two streams are concatenated to form the final representation { x cls , x 1 , . . . , x T e } , x i ∈ R D . (7) B. Pr etraining W e pretrain W iMamba in a task-agnostic and self-supervised manner using the unlabeled CSI realizations ( 2 ) . Pretraining tunes the trainable parameters θ = { θ F , θ B , { W e emb , b e emb , t e cls } E e =1 } to ha ve W iMamba produce contextualized channel representations that capture the underlying structure of wireless channels and can be transferred to diverse downstream tasks with limited labeled data. W e follow the masked language modelling practice [ 29 ], along with a dedicated sampling mechanism designed to learn resolution-adaptiv e representations. Giv en a realization H drawn from the unlabeled dataset ( 2 ), we first set a granularity le vel e uniformly drawn from { 1 , . . . , E } , and apply the preprocessing procedure to obtain a sequence of tokens { t 1 , . . . , t T e } . A subset of token indices M ⊂ { 1 , . . . , T e } is then randomly selected for masking. T o gurantee that subsequent masking applied to both the real and its corresponding imaginary components, we set M such that if i ∈ M , and i ≤ T e / 2 (representing an index of a token taken from Re { H } ), then also i + T e / 2 ∈ M (the corresponding imaginary part). The token t i for each i ∈ M is modified according to a predefined masking policy: Inspired by the masked approach of [ 31 ], among the tokens in M , 80% are replaced with a ones vector , 10% are replaced with sampled Gaussian vectors, and the remaining 10% are left unchanged. Pretraining is formulated as a reconstruction problem using an auxiliary linear reconstruction model used only for training, whose goal is to recov er the masked tokens. Specifically , the masked token sequence is processed by the backbone to produce { x cls , x 1 , . . . , x T e } , and these embeddings are mapped into the token dimension using a linear decoder with trainable parameters W e dec ∈ R L e × D , yielding ˆ t i = W e dec x i . The pretraining loss computed for a token sequence { t i } is the mean squared error between the reconstructed and original tokens [ 31 ], L pre ( { t i } ; θ , W e dec ) = 1 |M| X i ∈M ˆ t i − t i 2 2 . (8) The self-supervised objective in ( 8 ) encourages W iMamba to learn rich and transferable representations of wireless channels. C. Infer ence Pipeline A foundation model is assessed through its ability to support a div erse set of downstr eam tasks . The inference pipeline is thus comprised of two stages: ( i ) the formulation of the new task through a (relativ ely small) dataset D p task ( 3 ) and a loss measure ℓ p (with p being the task index); and ( ii ) actual task inference ap- plied to a new CSI . The granularity level e is assumed to be fixed in inference, based on predefined latency and compute constraints. Therefore, in the following we omit the index e for brevity . 1) Infering T ask p : Given a ne w task with a channel realization H , we apply WiMamba as described in Subsection III-A to obtain the contextualized embeddings in ( 7 ). The translation of the embeddings { x cls , x 1 , . . . , x T } of channel H into its estimate for the p th task, denoted ˆ s p , is done by mapping the embeddings into a feature vector x , and processing it using a dedicated ML model trained for task p (referred to as p th head). The feature vector x is a task-dependent latent representation of H that serves as input to downstream inference heads. It accomodates three types of representations, each capturing a different level of abstraction: ( i ) Class embedding , giv en by the class token x cls , which aggregates information from the entire channel realization into a compact and informativ e 3 vector; ( ii ) Flattened patch embeddings , obtained as x flatten = vec( x 1 , . . . x T ) (zero-padded to length 2 N M ), which preserves localized spatial–frequency information across the channel matrix; and ( iii ) Mean-pooled patch embeddings , computed as x mean = 1 T P T i =1 x i , capturing the overall channel structure while remaining agnostic to the number of patches. The representation x ∈ { x class , x flatten , x mean } is processed by a downstream neural network with parameters θ p , denoted g p θ p ( · ) . The resulting estimate is giv en by ˆ s p = g p θ p ( x ) . The ov erall pipeline is illustrated in Fig. 2 , highlighting ho w dif ferent representations are deri ved from the pretrained backbone. 2) Learning T ask p : The inference pipeline uses the pretrained W iMamba to map a channel H to its representation x . The only task-specific component is the neural network g p θ p ( · ) . Accordingly , the dataset ( 3 ) is required for training solely θ p , which is based on the empirical risk L D p task ( θ p ) = 1 |D p task | |D p task | X j =1 ℓ p g p θ p ( x ( j ) ) , s ( j ) p , (9) with x ( j ) is obtained by pretrained W iMamba applied to H ( j ) . 3) Complexity: A key consideration in our design of W iMamba is its inference complexity how it scales with the channel dimensions. For a given granularity lev el e , the token sequence length is T e = ⌈ 2 N M /L e ⌉ . The bidirectional Mamba backbone consists of two parallel Mamba models of Q stacked layers, each operating with linear complexity in the sequence length due to the selectiv e SSM formulation. As a result, the overall backbone complexity scales as O ( QT e D ) = O ( QD ⌈ 2 N M /L e ⌉ ) , which is linear in both N and M . Importantly , the granularity parameter e (through L e ), enables balancing computational cost, memory usage, and representation fidelity . Unlike transformer-based models, whose complexity grows quadratically with T e [ 32 ], WiMamba maintains linear scaling even for high-resolution channel representations. I V . N U M E R I C A L E V A L UA T I O N S A. Experimental Setup Data: W e numerically e valuate W iMamba 1 using the Deep- MIMO dataset [ 26 ]. W e construct the pretraining dataset D pre using channel realizations with dimensions 16 × 16 , 32 × 32 , 64 × 64 , 128 × 128 , and 256 × 256 , and employ adaptiv e tokenization with sizes L e ∈ { 16 , 64 } , respecti vely corresponding to CSI patch sizes of 4 × 4 and 8 × 8 . W e focus on four downstream tasks accomodated by DeepMIMO: line-of-sight (LOS) vs. non-LOS (NLOS) classification, beam prediction, channel interpolation, and user localization. The loss measures are cross entropy for classification tasks ( LOS / NLOS and beam prediction) or ℓ 2 loss for channel interpolation and localization. Each downstream task is handled by a dedicated multilayer perceptron ( MLP )-based head operating on the patch embeddings, which are: • LOS/NLOS classification uses a shallo w MLP with an 8-unit hidden layer to output binary logits. • Beam pr ediction employs an MLP with 256- and 128-unit hidden layers to produce logits over 64 beams. 1 The source code used in our empirical study , along with the hyperparameters is available at https://github .com/tomerravi v95/mamba- lwm- project (a) 4 × 4 Patch Size (b) 8 × 8 Patch Size Fig. 3: T ask performance vs. |D p task | • Channel interpolation maps each patch embedding through a linear layer to a P × P × 2 spatial patch, followed by deterministic patch reassembly to recov er the full channel. • User localization applies a three-layer MLP with hidden dimensions 64 and 32 to output 2-D coordinates. Algorithms: W e implement WiMamba using Q = 12 bidirectional Mamba layers, with an ov erall embedding size of D = 128 (with each directional Mamba processing D / 2 = 64 features). The Mamba cells use an 8 × 1 state ( h t in ( 4 )) with local con volution kernel size of 4 to capture short-range interactions. Our main benchmark is the transformer -based large wireless model (L WM) 1.1 model of [ 15 ], comprised of 12 transformer encoder layers with embedding size of D = 128 . Both foundation models have 2 . 5 · 10 6 paramteres, and are pre-trained for 100 epochs using a batch size of 32 for both training and validation. T raining hyperparameters are selected via empirical trials, and are based on those used in [ 15 ]. B. Experimental Results T ask P erformance: W e first ev aluate performance on the considered tasks. Here we examine whether replacing trans- 4 T ABLE I: Inference latency and peak GPU memory . Patch T ransformer Mamba Lat. (ms) Mem. (MB) Lat. (ms) Mem. (MB) 4 × 4 363.59 4836.63 23.70 114.40 6 × 6 79.15 1002.19 16.17 75.38 8 × 8 29.42 355.67 16.21 62.41 fomers with SSM -based Mamba impacts task-level performance. Accordingly , we compare the performance achieved for each task when training the dedicated task head based on the outputs of the foundation models, as well as when training using the raw channels in D p task without any learned representation. Fig. 3 presents the do wnstream task performance for the Transformer -based L WM, W iMamba, and a raw-channel baseline. For each resolution, we vary the number of task-specific training samples and report accuracy for classification tasks and normalized mean squared error ( NMSE ) or mean absolute error for regression tasks. W e first observe a consistent improvement in performance as the number of labeled training samples increases, across all tasks and patch sizes. This trend confirms that the representations extracted by both foundation models are effecti vely le veraged by the lightweight do wnstream heads. Comparing architectures, W iMamba achiev es performance that is consistently competitive with the T ransformer baseline. For the smallest patches (4 × 4), where the sequence length is longest, the two models exhibit closely matched performance. Minor differences appear across individual tasks and data regimes, but no consistent performance gap emer ges in fav or of the T ransformer . These results support our key conclusion, that properly designed SSM -based models can lead to comparable representations as that of transformer-based foundation models. Latency and Memory Evaluation: W e next ev aluate the efficienc y of W iMamba under varying token granularity , in comparison with the transformer-based L WM . Since the patch size controls the token sequence length T e , smaller patches induce longer sequences and higher computational b urden. T able I reports both the inference latency and the peak GPU memory consumption of the two architectures as a function of the patch size, ev aluated on the same NVIDIA R TX 3060. L WM exhibits a sharp increase in latency and memory usage as the patch size decreases from 8 × 8 to 4 × 4 , the latter leading to sub- stantially higher inference time and nearly an order -of-magnitude increase in peak memory due the quadratic cost of self-attention with the sequence length. In contrast, W iMamba maintains consis- tently low latenc y and memory consumption across all patch sizes. This stable behavior highlights its linear -scaling and the flexibility provied through our adaptive tokenization mechanism. Overall, these results confirm the key complexity adv antage of WiMamba. V . C O N C L U S I O N W e introduced W iMamba, a wireless foundation model built on a selecti ve SSM s tailored to the structural properties of CSI . Through task-agnostic self-supervised pretraining and an adapti ve granularity mechanism, W iMamba learns transferable channel representations that operate seamlessly across multiple patch resolutions without retraining. W iMamba is shown to match transformer-based baselines in downstream performance, while of fering notably improved computational scalability and latenc y . R E F E R E N C E S [1] Y . Y uan, “On the power of foundation models, ” in International Conference on Machine Learning . PMLR, 2023, pp. 40 519–40 530. [2] M. A wais et al. , “Foundation models defining a ne w era in vision: a survey and outlook, ” IEEE Tr ans. P attern Anal. Mach. Intell. , vol. 47, no. 4, pp. 2245–2264, 2025. [3] Y . Gao et al. , “AI-driven channel state information e xtrapolation for 6G: Current situations, challenges and future research, ” , 2026. [4] J. Jiang et al. , “T o wards channel foundation models (CFMs): Motiv ations, methodologies and opportunities, ” , 2025. [5] J. Guo, Y . Cui, S. Jin, and J. Zhang, “Large AI models for wireless physical layer, ” , 2025. [6] C. Zheng et al. , “M2BeamLLM: Multimodal sensing-empowered mmWav e beam prediction with lar ge language models, ” , 2025. [7] B. Liu et al. , “LLM4CP: Adapting large language models for channel prediction, ” J. Commn. Net’ , vol. 9, no. 2, pp. 113–125, 2024. [8] Y . Sheng et al. , “Beam prediction based on large language models, ” IEEE W ir eless Commun. Lett. , vol. 14, no. 5, pp. 1406–1410, 2025. [9] T . Zheng and L. Dai, “Large language model enabled multi-task physical layer network, ” IEEE T rans. Commun. , vol. 74, pp. 307–321, 2025. [10] J. Guo et al. , “L VM4CSI: Enabling direct application of pre-trained large vision models for wireless channel tasks, ” , 2025. [11] S. Chen et al. , “RadioLLM: Introducing large language model into cognitive radio via hybrid prompt and token reprogrammings, ” arXiv:2501.17888 , 2025. [12] T . Zheng et al. , “MUSE-FM: Multi-task en vironment-aware foundation model for wireless communications, ” , 2025. [13] O. Mashaal and H. Abou-Zeid, “IQFM: A wireless foundational model for I/Q streams in AI-nativ e 6G, ” , 2025. [14] T . Y ang et al. , “WirelessGPT : A generative pre-trained multi-task learning framew ork for wireless communication, ” IEEE Netw . , 2025. [15] S. Alikhani, G. Charan, and A. Alkhateeb, “Large wireless model (L WM): A foundation model for wireless channels, ” , 2024. [16] M. Cheraghinia et al. , “Foundation model for wireless technology recognition using IQ timeseries, ” , 2025. [17] F . Zhou et al. , “SpectrumFM: A foundation model for intelligent spectrum management, ” , 2025. [18] F . O. Catak, M. Kuzlu, and U. Cali, “BER T4MIMO: A foundation model using bert architecture for massive MIMO channel state information prediction, ” , 2025. [19] B. Guler , G. Geraci, and H. Jafarkhani, “ A multi-task foundation model for wireless channel representation using contrastiv e and masked autoencoder learning, ” , 2025. [20] A. Aboulfotouh, E. Mohammed, and H. Abou-Zeid, “6G W av esFM: A foundation model for sensing, communication, and localization, ” arXiv:2504.14100 , 2025. [21] G. Xiao et al. , “Efficient streaming language models with attention sinks, ” in International Confer ence on Learning Repr esentations , 2024. [22] A. Gu and T . Dao, “Mamba: Linear-time sequence modeling with selective state spaces, ” in Fir st confer ence on language modeling , 2024. [23] H. Qu et al. , “ A survey of Mamba, ” , 2024. [24] S. Luo, J. Xie, Y . Che, J. Y ao, J. Tian, D. Feng, and K. Wu, “CPMamba: Selectiv e state space models for MIMO channel prediction in high-mobility en vironments, ” , 2025. [25] Z. Li, C. Zheng, J. Xiao, J. W ang, G. W ang, M. Zeng, and O. A. Dobre, “Deep learning based joint channel estimation and positioning for sparse XL-MIMO OFDM systems, ” , 2025. [26] A. Alkhateeb, “DeepMIMO: A generic deep learning dataset for millimeter wav e and massive MIMO applications, ” , 2019. [27] A. Gu, K. Goel, and C. R ´ e, “Ef ficiently modeling long sequences with structured state spaces, ” International Conference on Learning Repr esentations , 2022. [28] A. Gu et al. , “Combining recurrent, conv olutional, and continuous-time models with linear state space layers, ” Advances in Neural Information Pr ocessing Systems , 2021. [29] J. Devlin, M.-W . Chang, K. Lee, and K. T outano va, “BER T: Pre-training of deep bidirectional transformers for language understanding, ” in Conference of the North American Chapter of the Association for Computational Linguistics: Human Language T ec hnologies , 2019, pp. 4171–4186. [30] L. Zhu et al. , “V ision Mamba: Efficient visual representation learning with bidirectional state space model, ” , 2024. [31] Y . Liu et al. , “RoBER T a: A robustly optimized bert pretraining approach, ” arXiv:1907.11692 , 2019. [32] F . D. K eles, P . M. W ijewardena, and C. Hegde, “On the computational complexity of self-attention, ” in International Confer ence on Algorithmic Learning Theory . PMLR, 2023, pp. 597–619. 5
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment