ParaQAOA: Efficient Parallel Divide-and-Conquer QAOA for Large-Scale Max-Cut Problems Beyond 10,000 Vertices
Quantum Approximate Optimization Algorithm (QAOA) has emerged as a promising solution for combinatorial optimization problems using a hybrid quantum-classical framework. Among combinatorial optimization problems, the Maximum Cut (Max-Cut) problem is …
Authors: Po-Hsuan Huang, Xie-Ru Li, Chi Chuang
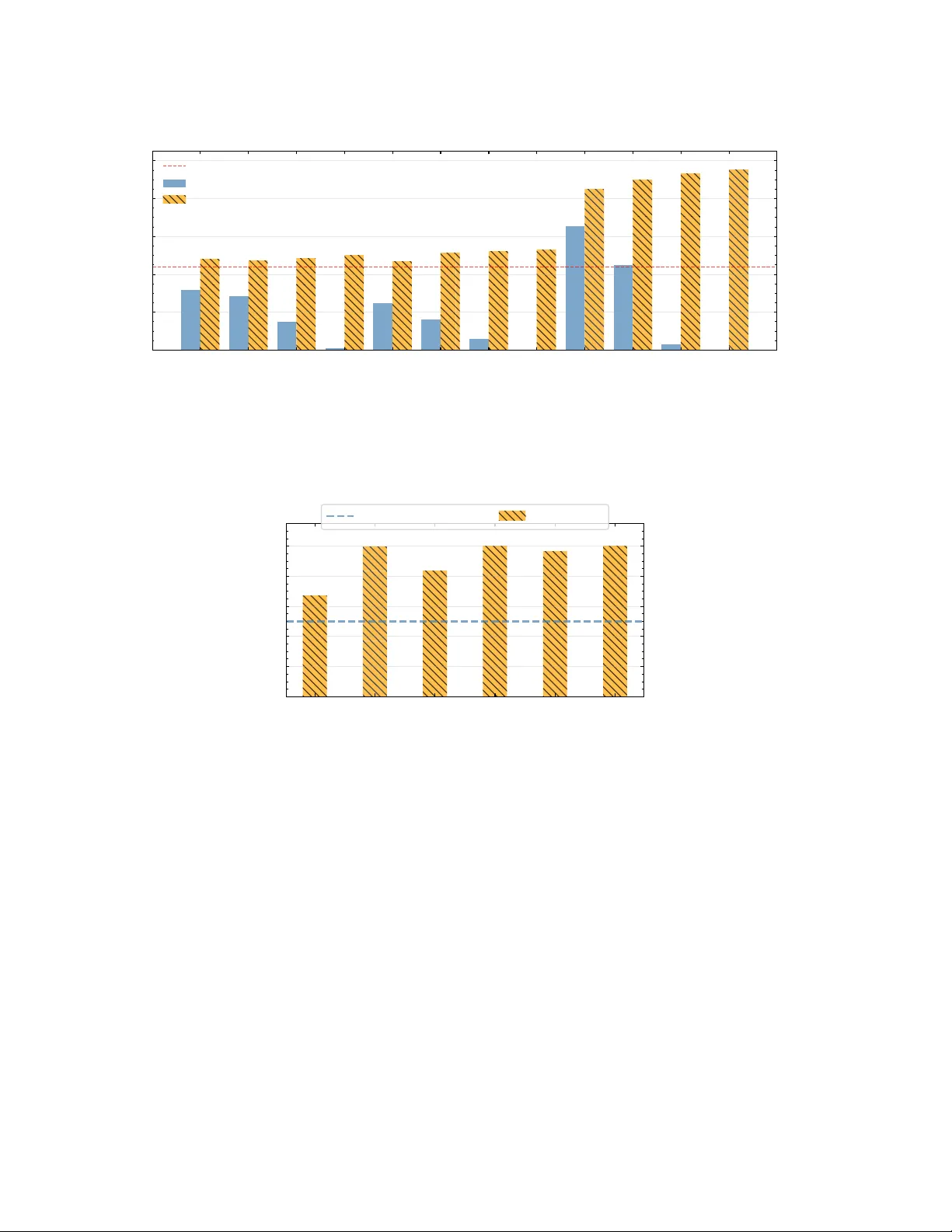
ParaQ A O A: Eicient Parallel Divide-and-Conquer Q A O A for Large-Scale Max-Cut Problems Bey ond 10,000 V ertices PO-HSU AN H U ANG , National T aiwan University, T aiwan XIE-RU LI , National Cheng Kung University, T aiwan CHI CH U ANG , National Cheng Kung University, T aiwan CHIA -HENG T U ∗ , National Cheng Kung University, T aiwan SHIH-HA O HUNG , National T aiwan University, T aiwan Quantum Appro ximate Optimization Algorithm (Q A O A) has emerged as a promising solution for combinatorial optimization problems using a hybrid quantum-classical framework. Among combinatorial optimization problems, the Maximum Cut (Max-Cut) problem is particularly important due to its broad applicability in various domains. While Q A OA -based Max-Cut solvers have been developed, they primarily favor solution accuracy over execution eciency , which signicantly limits their practicality for large-scale problems. T o address the limitation, w e propose ParaQA O A, a parallel divide-and-conquer QA O A framework that leverages parallel computing hardware to eciently solve large Max-Cut problems. ParaQ AO A signicantly reduces runtime by partitioning large pr oblems into subproblems and solving them in parallel while pr eserving solution quality . This design not only scales to graphs with tens of thousands of vertices but also provides tunable control over accuracy-eciency trade-os, making ParaQA O A adaptable to diverse performance requirements. Experimental results demonstrate that ParaQA O A achieves up to 1,600x speedup over state-of-the-art methods on Max-Cut problems with 400 vertices while maintaining solution accuracy within 2% of the best-known solutions. Furthermore, ParaQA O A solves a 16,000-verte x instance in 19 minutes, compared to over 13.6 days required by the best-known appr oach. These ndings establish ParaQ AO A as a practical and scalable framew ork for large-scale Max-Cut problems under stringent time constraints. CCS Concepts: • Computing methodologies → Massively parallel and high-performance simulations ; • Mathematics of computing → Approximation algorithms ; • Computer systems organization → Quantum computing . Additional Key W ords and Phrases: Quantum Computing, Quantum Circuit Simulation, Quantum Approximation Optimization Algorithm, Parallel Computing, Performance Eciency Index, Max-Cut Problem 1 Introduction Quantum computing is an emerging computational paradigm that extends beyond the scalability limits of classical computers. By harnessing quantum mechanical phenomena, such as superposition, entanglement, and interference [ 14 , 34 ], quantum computers can achieve exponential sp eedups [ 3 , 28 , 36 , 37 ] for specic computational tasks, which makes them well-suited for a range of computationally intensive problems in elds, such as cryptography , machine learning, and combinatorial optimization. Driven by rapid advances in both theoretical algorithms and hardwar e development, ∗ Corresponding author Authors’ Contact Information: Po-Hsuan Huang , aben20807@gmail.com, Department of Computer Science and Information Engineering, National T aiwan University, T aipei, T aiwan; Xie-Ru Li , p76134587@gs.ncku.edu.tw, Department of Computer Science and Information Engineering, National Cheng Kung University, T ainan, T aiwan; Chi Chuang , ab321013@gmail.com, Department of Computer Science and Information Engineering, National Cheng Kung University, T ainan, T aiwan; Chia-Heng T u , chiaheng@ncku.edu.tw, Department of Computer Science and Information Engineering, National Cheng Kung University, T ainan, T aiwan; Shih-Hao Hung , hungsh@csie.ntu.edu.tw, Department of Computer Science and Information Engineering, National T aiwan University, T aipei, T aiwan. 1 2 P.-H. Huang et al. quantum computing has attracted signicant global attention and is incr easingly recognized as a key technology for next-generation computational solutions [ 2 , 42 ]. Hybrid quantum-classical algorithms, among various quantum computing paradigms, have demonstrated r emarkable suitability for deployment on current quantum hardware platforms by leveraging the complementary strengths of quantum and classical computational resources. These hybrid approaches exploit practical quantum advantage while mitigating the inherent limitations of contemporar y quantum hardware. The Quantum Approximate Optimization Algorithm [ 13 ] is a notable example , which provides a r obust theoretical foundation and has demonstrated practical performance for solving Quadratic Unconstrained Binary Optimization (QUBO) [ 23 ] problems across various applica- tion domains. In particular , Q AO A ’s quantum-classical optimization framework has pro ven particularly eective for addressing combinatorial optimization problems faced in real-world applications. The Maximum Cut problem is a classic application domain for Q AO A -based optimization, as it serves both as a fundamental benchmark in computational complexity and as a practical optimization problem with real-world impact. The Max-Cut problem seeks a partition of a graph’s vertices into two disjoint sets that maximizes the number of edges crossing between the sets. As a representative NP-hard combinatorial problem, Max-Cut has direct applications in various domains, such as VLSI circuit design optimization [ 4 ], social network community detection [ 1 , 24 ], and wireless network frequency assignment [ 43 ]. The problem’s broad applicability and inher ent computational diculty call for ecient, scalable algorithms that can handle large-scale instances while preserving solution quality . Many Q AO A -based solutions have been developed for Max-Cut problems. T raditional Q A OA implementations ar e resource-intensive as pr oblem size scales, where circuit depth and gate complexity grow polynomially with the number of qubits. These resource demands r ender QA O A implementations infeasible on current quantum and classical har dware, thereby limiting their practical deployment for real-world applications. T o address this, recent divide-and-conquer approaches [ 29 , 31 , 46 ] apply problem decomposition techniques, such as graph clustering, hierar chical partitioning, and recursive subdivision, couple d with quantum circuit simulations on classical computers. Unfortunately , while these methods reduce the computational load of subproblems and prioritize preserving solution quality (measured by approximation ratio as introduce d in Section 2.1 ), the y typically increase overall execution time , which constrains their applicability to large problems. For instance, in our experiments in Section 4.3 , Coupling QA OA [ 31 ] attains approximately 99% of the approximation ratio on a 30-vertex graph but requires about eight hours to produce the Max-Cut result. This evidence sho ws that balancing computational eciency and solution quality remains a central challenge for scaling Q AO A to practical problem sizes. In this work, we propose ParaQ A O A , a parallel divide-and-conquer QA O A framework that le verages modern parallel computing hardware to eciently tackle large-scale Max-Cut problems. The ParaQ AO A framew ork incorporates four key components. First, the framework employs a linear-time graph partitioning algorithm that reduces decomposition complexity and enables ecient handling of large graphs. Second, a parallelized execution pipeline is used to handle subproblem solving and solution reconstruction by leveraging modern parallel architectures to reduce overall runtime. Third, the framework provides a systematic parameterize d design to better control parallel execution and manage the trade-o between execution eciency and solution quality . Fourth, ParaQA OA introduces a unie d metric that jointly evaluates solution quality and execution eciency , and the metric enables consistent comparisons and informed trade-os across dierent Max-Cut solutions. The ke y features of the framework ar e further detailed in Section 2.5 . The contributions of this work are as follows. ParaQ AO A for Handling Large-Scale Max-Cut Problems 3 (1) A parallel divide-and-conquer Q AO A framew ork, ParaQA O A, is proposed to eciently solve large-scale Max- Cut problems with parallel computing architectures on classical computers. T o the b est of our knowledge, ParaQ AO A is the pioneering work that demonstrates an ecient solution for solving Max-Cut problems with over 10,000 vertices on classical computers and enables control over the trade-o between solution quality and execution eciency , which is important when users aim to nd a solution quickly even if it requires a sacrice in solution quality . (2) An important consideration, the trade-o between solution quality and execution eciency , is intr oduced as a critical design aspe ct of a Max-Cut solver . This is a critical consideration when evaluating dierent Max- Cut solutions, especially for large-scale problems. T o this end, we propose the Performance Eciency Index (PEI), a novel evaluation metric that integrates approximation quality and runtime eciency . Furthermor e, the parameterized design of ParaQA O A enables control ov er the trade-o. (3) A series of experiments has been conducted to demonstrate the ee ctiv eness of ParaQA O A. The experiments show that ParaQA O A eectively manages the trade-o b etw een solution quality and execution eciency . For instance, ParaQ AO A achieves up to 1,600 × speedup over state-of-the-art methods while maintaining approximation ratios within 2% of the best-known solutions on 400-v ertex instances ( as medium-size problems). Additionally , the best-known prior approach would r equire 13.6 days to obtain a r esult for a 16,000-vertex graph, while ParaQ A OA generates the result within 19 minutes. These results sho wcase the applicability of ParaQ A O A to large-scale Max-Cut problems, particularly in scenarios with stringent time constraints. The remainder of this article is organized as follows. Section 2 provides the background on QA O A for Max-Cut, introduces the existing Q A OA -based solutions to Max-Cut problems, analyzes their limitations, and elab orates the motivation for our proposed framework. Section 3 details the o verall system design and the key components of the ParaQ AO A framework. Experimental evaluation and analysis are presented in Section 4 to demonstrate the ee ctiv eness of our approach. Finally , Section 5 concludes this work and discusses potential directions for future work. 2 Background and Motivation This section establishes the theoretical foundations and motivation for the proposed ParaQA OA framew ork, with a focus on the Max-Cut problem and its r elevance in quantum optimization studies in the literature . In Section 2.1 , we introduce the formal denition of the Max-Cut problem. Section 2.2 outlines how Q AO A can b e applied to solve Max-Cut instances, and Section 2.3 discusses the quantum circuit simulation for Q AO A. W e then review e xisting QA OA -based approaches in Section 2.4 for solving the Max-Cut problem. W e also summarize their strategies and limitations. Finally , in Se ction 2.5 , we present our observations that motivated the development of ParaQA OA. These observations are based on the limitations of existing approaches, as discussed in Section 2.4 . Moreover , we highlight the features of our framework for handling large-scale Max-Cut problems. 2.1 Maximum Cut Problem The Max-Cut problem [ 16 , 22 ] has emerged as a fundamental benchmark for quantum optimization algorithms due to its dual signicance in computational complexity theor y and practical applications [ 1 , 4 , 11 , 24 , 43 ]. Max-Cut belongs to the class of NP-hard combinatorial optimization problems, making it computationally intractable for classical algorithms to solve optimally on large instances, ev en when seeking approximate solutions within polynomial time bounds. Formally , the Max-Cut problem is dene d on an undirected graph 𝐺 = ( 𝑉 , 𝐸 ) , where 𝑉 represents the set of vertices with | 𝑉 | 4 P.-H. Huang et al. nodes, and 𝐸 denotes the set of edges with | 𝐸 | connections. Each edge ( 𝑖 , 𝑗 ) ∈ 𝐸 may be associate d with a non-negative weight 𝑤 𝑖 𝑗 , though the unweighted case where 𝑤 𝑖 𝑗 = 1 for all edges is commonly studied. A cut 𝐶 = ( 𝑆 , ¯ 𝑆 ) represents a bipartition of the vertex set 𝑉 into two disjoint subsets 𝑆 and ¯ 𝑆 = 𝑉 \ 𝑆 . The objective function to maximize is the cut value, dened as CutV al ( 𝐶 ) = Í ( 𝑖 , 𝑗 ) ∈ 𝐸 : 𝑖 ∈ 𝑆 , 𝑗 ∈ ¯ 𝑆 𝑤 𝑖 𝑗 , which quanties the total weight of edges crossing the partition boundary . The Max-Cut problem seeks to identify the partition ( 𝑆 ∗ , ¯ 𝑆 ∗ ) that maximizes this objective function over all possible bipartitions of the vertex set. Algorithms are typically evaluated using the approximation ratio metric, due to the computational complexity inherent in nding exact solutions to Max-Cut instances at scale. This metric quanties solution quality relative to the optimal value. Specically , for a given Max-Cut instance with optimal cut value CutV al OPT and an algorithm that produces a cut value CutV al ALG , the approximation ratio is dened as AR = CutV al ALG /CutV al OPT , where AR ∈ [ 0 , 1 ] with higher values indicating better performance. For example, consider a graph where the optimal Max-Cut value is 10, and an optimization algorithm identies a cut value 9; the corresponding approximation ratio would be AR = 9 / 10 = 0 . 9 (or 90 %). This metric enables meaningful comparison of algorithm performance across dierent problem instances and scales, particularly when exact optimal solutions are computationally infeasible to determine. A famous classical algorithm for Max-Cut is the Goemans- Williamson (GW) algorithm [ 16 ], which achieves a guaranteed approximation ratio of at least 0.878 using semidenite programming techniques. Moreover , as an unconstrained discrete optimization problem, Max-Cut admits a natural enco ding as a QUBO formulation or equivalently as an Ising model. This property makes the Max-Cut problem well-suited for quantum optimization frameworks, such as the Quantum Appro ximate Optimization Algorithm. 2.2 antum Approximate Optimization Algorithm The Quantum Approximate Optimization Algorithm [ 13 ] represents the most prominent quantum heuristic for ad- dressing combinatorial optimization problems on near-term quantum devices, particularly those formulated as QUBO problems. QA OA belongs to the broader class of V ariational Quantum Algorithms [ 7 , 40 ], which leverage hybrid quantum-classical computation paradigms to exploit the complementar y strengths of quantum superp osition and classical optimization techniques. The algorithm operates through an iterative framework in which a classical optimizer systematically adjusts parameters of a parameterized quantum circuit to maximize the expected value of a problem- specic cost function. This variational approach makes Q AO A particularly well-suited for implementation on Noisy Intermediate-Scale Quantum (NISQ) devices, where these quantum processors are characterized by limited number of qubits and susceptibility to noise (that aects gate delities). QA OA can tolerate such hardware limitations and still potentially achieve a quantum advantage, thanks to the hybrid quantum-classical computation framework [ 32 , 39 , 45 ]. The mathematical foundation of QA OA rests on the quantum adiabatic theorem and the approximation of adi- abatic quantum computation using discrete quantum gates. For a given combinatorial optimization problem en- coded as an 𝑛 -qubit cost Hamiltonian 𝐻 𝐶 , QA O A constructs an ansatz quantum state | 𝜓 ( 𝛾 , 𝛽 ) ⟩ through alternating applications of two parameterized unitary operators: the cost op erator 𝑈 𝐶 ( 𝛾 ) = 𝑒 − 𝑖𝛾 𝐻 𝐶 and the mixing op erator 𝑈 𝑀 ( 𝛽 ) = 𝑒 − 𝑖 𝛽 𝐻 𝑀 , where 𝐻 𝑀 is typically chosen as the transverse eld Hamiltonian. The ansatz state for 𝑝 layers is given by | 𝜓 ( 𝛾 , 𝛽 ) ⟩ = 𝑈 𝑀 ( 𝛽 𝑝 ) 𝑈 𝐶 ( 𝛾 𝑝 ) · · · 𝑈 𝑀 ( 𝛽 1 ) 𝑈 𝐶 ( 𝛾 1 ) | +⟩ ⊗ 𝑛 , where | +⟩ ⊗ 𝑛 is the uniform sup erposition initial state. The optimization objective is to maximize the expectation value ⟨ 𝜓 ( 𝛾 , 𝛽 ) | 𝐻 𝐶 | 𝜓 ( 𝛾 , 𝛽 ) ⟩ , which requires iterative parameter optimization using classical algorithms, such as gradient descent or evolutionary strategies. The practical implementation of QA OA involves sev eral key factors that inuence its performance and scalability [ 6 , 17 ]. The ansatz circuit depth, set by the number of Q AO A layers 𝑝 , introduces a trade-o between solution quality and ParaQ AO A for Handling Large-Scale Max-Cut Problems 5 quantum resource demands: deeper circuits often yield better approximation ratios but require longer coherence times and higher gate delity . Parameter initialization strategies also signicantly aect solution quality and the number of optimization iterations required [ 35 , 45 ]. 2.3 Classical Simulation of Q AO A Quantum circuit simulation [ 44 ] on classical computers is an essential tool for quantum algorithm development, given current hardware limitations in qubit count, gate delity , and accessibility . Hybrid quantum-classical algorithms, such as QA OA, are often evaluated on classical systems to enable prototyping, the oretical validation, and performance benchmarking on problem instances beyond the reach of existing quantum devices. The computational cost of simulating general quantum circuits gro ws exponentially with the number of qubits, imposing a fundamental size limitation. State- vector simulation [ 5 , 21 , 38 ] maintains the complete quantum state and applies gates via matrix-vector multiplications, yielding exact results but requiring 𝑂 ( 2 𝑛 ) memory and computation for 𝑛 qubits (e .g., 64 GiB for 𝑛 = 32 in double precision), limiting feasibility to relatively small systems. T ensor network approaches [ 33 , 41 ], such as Matrix Product States and related de compositions, exploit limited entanglement to reduce complexity . This allows the simulation of larger quantum systems when entanglement is bounde d, but it can come at the cost of accuracy . Density matrix simulation [ 27 ] extends state-vector methods to incorporate quantum noise and decoherence, providing mor e realistic modeling of NISQ devices with additional computational overhead. Some existing works have explored the simulation of Q AO A circuits, specically focusing on optimizing the simulation process for the unique structure of QA OA circuits. For instance, the work by Lin et al. [ 30 ] pr esents optimizations on the cost layer and uses multiple GP Us to accelerate the simulation of Q AO A circuits. FOR-Q AO A [ 8 ] is a framework that optimizes the mixer layer of Q A OA cir cuits and allows multi-node parallelization to spee d up the simulation process. These works demonstrate that while QA OA circuits can be simulated eciently on classical hardware, the exponential scaling of quantum state representation remains a fundamental challenge , particularly for larger problem instances. 2.4 Divide-and-Conquer Q AO A for Solving Max-Cut Problems The divide-and-conquer paradigm in quantum computing can be trace d to Dunjko et al. [ 10 ], who introduced the idea of decomposing large quantum optimization problems into smaller subproblems that can b e solved independently . This concept is later extended by Ge et al. [ 15 ]. In the context of the Quantum Approximate Optimization Algorithm, divide- and-conquer methodologies address the scalability limitations of implementations for large-scale Max-Cut problems. In particular , the divide-and-conquer paradigm partitions the original instance into smaller , manageable subproblems, solves them independently or with limited interdependence, and then combines the solutions to reconstruct the result for the original problem. This strategy mitigates the exponential scaling bottleneck of quantum optimization algorithms, and it enables the solution of Max-Cut instances with hundreds or thousands of vertices on current quantum hardware or classical simulators. Its eectiveness depends on the decomposition scheme, the subpr oblem-solving method, and the integration procedure used to preserve solution quality . A Divide-and-Conquer QA OA Example. An example of the divide-and-conquer QA OA approach for solving Max-Cut problems is illustrated in Fig. 1 . The approach consists of four phases. (1) Graph Partition . The original Max-Cut graph is divide d into smaller subgraphs. Some vertices are shared b etween subgraphs, which are later used in the solution reconstruction phase. 6 P.-H. Huang et al. (2) Q AO A Execution . QA OA is applied independently to each subgraph to obtain approximate solutions. Each subgraph is represented by a bitstring that encodes its partition scheme, with the mapping illustrated in Fig. 2 . For example, subgraph 1 yields the bitstring 110 , indicating vertices 𝑣 1 and 𝑣 2 belong to set 𝑆 and 𝑣 3 belongs to ¯ 𝑆 . (3) Merging . Subgraph solutions are combine d by concatenating their bitstrings. This step requires consistent assignments for shared vertices. For instance , in Fig. 1 , the two subgraphs can only be merged if both assign 𝑣 3 to the same set. As the vertex 𝑣 3 in the bitstrings for subgraphs 1 and 2 is 0 , and the two subgraphs can be merged to form the bitstring 11010 . (4) Result Evaluation . The merged bitstring is evaluated against the original Max-Cut objective to maximize the number of edges between 𝑆 and ¯ 𝑆 . As illustrated in the top-right of Fig. 1 , the resulting solution may not be optimal (with the cut value of 3). Therefore , the approximation ratio is used to assess solution quality , and it is dened as the ratio of the cut value fr om the merged bitstring to the optimal cut value of the original graph (e.g., 3/4 in the e xample). Subgraph 1 Input graph Subgraph 2 QAOA Solver Subgraph 1's Distribution Subgraph 2's Distribution 2 1 3 3 4 5 (1) Graph Partition (2) QAOA Execution (3) Merging (4) Result Evaluation 2 1 3 4 5 2 1 3 Bitstring: 1 10 3 4 5 Bitstring: 010 2 1 3 3 4 5 Bitstring: 1 1010 2 1 3 4 5 Cut V alue: 3 QAOA Solver 2 1 3 4 5 Maximum Cut V alue: 4 Fig. 1. A divide-and-conquer QA OA e xample for solving the Max-Cut problem. Existing Graph Partitioning Strategies. Graph partitioning is a key preprocessing step in divide-and-conquer ap- proaches to combinatorial optimization, including Max-Cut. Its objective is to de compose a graph into smaller subgraphs while minimizing inter-partition edges. Minimizing these edges reduces subproblem complexity , enables parallel execu- tion, and preserves structural properties that support high-quality solutions. Traditional partitioning algorithms often have high computational complexity , scaling quadratically or worse with the number of vertices. For large instances, this can create signicant preprocessing bottlenecks, particularly in frameworks that r ely on sophisticated partitioning to achieve str ong approximation ratios. In quantum optimization, especially within divide-and-conquer based frameworks, partitioning enables large-scale Max-Cut instances to t within hardware limits, such as qubit capacity . While dividing the graph into smaller subgraphs reduces computational demands, r emoving inter-partition edges can degrade AR. This creates a trade-o between computational eciency and solution quality . Existing strategies vary in their trade-os. ParaQ AO A for Handling Large-Scale Max-Cut Problems 7 2 1 3 2 1 3 2 1 3 2 1 3 2 1 3 2 1 3 2 1 3 2 1 3 Bitstring: 000 Bitstring: 001 Bitstring: 010 Bitstring: 01 1 Bitstring: 100 Bitstring: 101 Bitstring: 110 Bitstring: 11 1 Fig. 2. Graphs and their corresponding bitstring representations under dierent partitions. DC-Q AO A [ 29 ] uses a Large Graph Partitioning (LGP) algorithm to achieve strong AR by balancing subgraphs, but its high runtime and connectivity constraints limit scalability . QA OA 2 [ 46 ] employs randomized partitioning for faster execution. It osets potential AR loss through advance d merging strategies, though this introduces additional merging overhead. Coupling Q AO A [ 31 ] adopts a binary decomposition that preser ves connectivity via coupling terms in the Hamiltonian, but it is restricted to binary partitions and does not scale ee ctively to larger graphs. Limitations of Existing Divide-and-Conquer QA OA A pproaches. Existing divide-and-conquer Q A OA variants, such as DC-Q AO A [ 29 ], Q AO A 2 [ 46 ], and Coupling Q A OA [ 31 ], primarily focus on solution quality but face signicant limitations that reduce their practical utility and scalability . These limitations can be grouped into three main categories. First, execution time b ottlenecks arise from computationally expensive prepr ocessing, particularly graph partitioning algorithms with quadratic or higher time complexity in the number of vertices. For example, DC-Q AO A relies on sophisticated partitioning with 𝑂 ( | 𝑉 | 2 ) or higher complexity , which can dominate total runtime for large instances and oset potential quantum sp eedups. Since DC-QA O A ’s implementation is not publicly available, our evaluation is based on a reimplementation from their description. QA OA 2 and Coupling QA OA incur additional overhead from e xhaustive searches over subpr oblem combinations, leading to exponential scaling in both runtime and memory usage. Second, parameter optimization is often ad hoc or absent, resulting in convergence issues and inconsistent solution quality . Without systematic parameter initialization and tuning, performance varies signicantly across problem instances, limiting reliability for practical deplo yment. Third, scalability constraints limit the extent of problem de composition and the maximum problem size addressable. Coupling QA OA ’s binary-only de composition restricts problem size reduction. DC-Q AO A suers performance degradation on dense graphs, where partitioning is dicult. QA O A 2 lacks ecient parallelization for subproblem execution, reducing scalability gains. Chuang et al. [ 9 ] also identied these challenges and emphasized the nee d for a more comprehensive, systematically designed approach. How ever , their evaluation was limited to small-scale Max-Cut instances (up to 26 vertices), insucient to assess the scalability of divide-and-conquer Q AO A methods. 2.5 Motivation As elaborate d in Section 2.4 , current divide-and-conquer Q AO A methods favor solution quality over e xecution eciency . This design choice limits their ee ctiveness for large or complex problem instances. For problems exceeding 100 vertices, evaluation becomes challenging due to substantial variation in execution time. From our experiments, QA OA 2 requires approximately 4.7 hours to compute a solution for a medium-scale, high-density graph with 400 vertices, 8 P.-H. Huang et al. and is estimate d to take about 13.6 days for a large-scale, high-density graph with 16,000 vertices. Further results are presented in Section 4 . The key obser vation is that prior work develops novel graph partitioning algorithms to lower the computation load for the subgraphs ( e.g., LGP in DC-Q A OA and binary decomposition in Coupling QA OA ) and employs intricate merging strategies to mitigate approximation ratio degradation, but these come at the cost of increased execution time. Unfortunately , these approaches do not fully leverage the presence of high p erformance computing hardware, such as multi-core processors and multiple GP Us, which can b e leveraged to parallelize the execution of subproblems and solution r econstruction. As a result, their scalability and eciency for large Max-Cut problems remain limited. By recognizing their limitations and considering the presence of high-p erformance computing har dware, w e propose ParaQ AO A , a framework that incorp orates an ecient graph partitioning algorithm, a parallelized execution ow , a systematic parameterize d design, and a performance evaluation metric for Max-Cut problems. The features of these innovations are highlighted as follows. First, a linear-time graph partitioning algorithm is dev eloped. It reduces decomposition complexity from quadratic or higher to linear in the number of vertices by exploiting structural properties. This improvement eliminates preprocessing bottlene cks and enables ecient partitioning of large graphs. Second, a fully parallelized execution ow is introduced. This parallel execution pipeline encompasses both subproblem solving and solution reconstruction and enables eective use of modern parallel architectures to reduce overall runtime . Third, a systematic parameterized design is proposed. This design incorporates hardware platform specications for parameter conguration and leaves tunable parameters for users to manage the trade-o between execution eciency and solution quality . These parameters are introduced during the framework’s introduction in the following section, and a concrete example of how to set up these parameters is introduced in Section 4.2 . Fourth, a unied evaluation metric is introduced. This metric jointly considers solution quality and execution eciency , enabling consistent comparisons and informed trade-o decisions acr oss dierent algorithms and congurations. This is particularly important for large-scale pr oblems, where signicant variations in execution time can complicate the evaluation of algorithm ee ctiveness. T ogether , these innovations enable ParaQ A OA to achiev e superior scalability and computational eciency for addressing large-scale Max-Cut problems. 3 ParaQ AO A In this section, we present our methodology for solving large-scale Max-Cut problems. The overview of the proposed ParaQ AO A framwork is presented in Section 3.1 . After that, three key components of the ParaQ AO A framework are described in detail: the graph partitioning strategy in Section 3.2 , the parallelized QA OA e xecution in Section 3.3 , and the level-aware parallel merge process in Section 3.4 . Finally , the proposed Performance Eciency Index is introduced in Section 3.5 to systematically evaluate the performance trade-os for methodologies used to handle large-scale Max-Cut problems. 3.1 Framework Overview The proposed ParaQA OA framew ork employs a hierarchical and highly parallel architecture to eciently solv e large- scale Max-Cut problems by leveraging quantum computing capabilities. The architecture addresses the computational complexity of large graphs through decomposition into manageable subgraphs, parallel processing, and structured result aggregation. The framework incorporates several key optimizations to enhance computational eciency and improve solution quality in solving the Max-Cut problem. As illustrated in Fig. 3 , these optimizations ar e organized into three sequential stages to progress from the input graph to the nal output solution. A dditionally , a performance ParaQ AO A for Handling Large-Scale Max-Cut Problems 9 evaluation stage is included to generate the proposed Performance Eciency Index, providing a quantitative measure for assessing the eciency of the obtained Max-Cut solutions. The key components of the framework are described as follows. 's results Graph Partition Input graph, 's results 's results Depth-First T raversal Subgraphs Bitstrings 's results 's results 's results QAOA Solver QAOA Solver QAOA Solver -qubit QAOA Solvers with Multiple GPUs Level-A ware Parallel Merge Partition Performance Evaluation Parallelized QAOA Execution Max-Cut Result AR EF End-to-end Latency Performance Efficiency Index Fig. 3. ParaQA OA frame work overview . 1 The Graph Partition stage decomposes the input graph 𝐺 into multiple smaller subgraphs { 𝐺 [ 𝑉 𝑖 ] } 𝑀 𝑖 = 1 , where each pair of adjacent subgraphs shares at most one node. This partitioning ensures that problem sizes remain manageable for the Q AO A solvers, which typically have constraints on the number of qubits they can handle. While various partitioning strategies are available, in this framework, we employ a Connectivity-Preserving Par- titioning Algorithm that eciently divides the graph into a predened number of subgraphs with approximately equal sizes while preser ving essential connectivity information. This approach enables eective load balancing across the available quantum resources, ther eby facilitating scalable parallel processing of large graphs. 2 The Parallelized QA OA Exe cution stage assigns each subgraph to a Q AO A solver operating concurrently across multiple computational units, such as GP Us, to eciently explore the solution space of each subgraph. The subgraphs { 𝐺 [ 𝑉 𝑖 ] } 𝑀 𝑖 = 1 will be batched into multiple QA OA Solv ers. For each subgraph, the Q A OA solv er outputs a set of top- 𝐾 bitstrings { 𝑏 𝑖 } 𝐾 𝑖 = 1 , where 𝑏 𝑖 ∈ { 0 , 1 } | 𝑉 𝑖 | sorted by their corresponding probability 𝜋 𝑖 ; that is, each 𝑏 𝑖 is a binary string of length | 𝑉 𝑖 | representing a bipartition of the vertex set 𝑉 𝑖 . Moreover , we proposed a Selective Distribution Exploration Strategy that provides exibility in adjusting the number of bitstrings 𝐾 to balance computational resources and solution quality . This stage leverages parallel execution for eciently exploring the solution space of each subgraph, and fexibility in adjusting the number of bitstrings to balance computational resources and solution quality . 3 The Level- A ware Parallel Merge stage reconstructs the bitstring results from all subgraphs using depth-rst traversal of the Cartesian product space fr om the bitstring set { 𝑏 𝑖 } 𝐾 𝑖 = 1 to enumerate possible global solutions. For each reconstructed global bitstring, the potential Max-Cut value is calculated again by considering all edges of the original input graph 𝐺 . The algorithm then selects the bitstring yielding the maximum cut value as the nal output. Moreover , this methodology provides dynamic exibility by adjusting the candidate pool size to make balance between computational eciency and solution quality . 4 The Performance Evaluation stage systematically evaluates the eectiveness of the large-scale Max-Cut solv- ing for balancing execution time and approximation ratio. W e introduce a new performance index, Performance Eciency Index , a composite metric designed to quantify the fundamental trade-o between solution quality and computational eciency for benchmarking dierent Max-Cut problem-solving approaches. 10 P.-H. Huang et al. The following subsections detail our implementation of each component within the ParaQA OA framew ork. 3.2 Graph Partition The graph partitioning phase is a critical component of DC-QA OA -like frameworks and enables ecient parallel processing of large-scale Max-Cut problems by decomposing the input graph into smaller subgraphs. W e improv e upon the DC-QA OA [ 29 ] and QA OA 2 [ 46 ] algorithms by proposing the Connectivity-Preserving Partitioning algorithm, which divides the input graph 𝐺 into 𝑀 subgraphs { 𝐺 [ 𝑉 1 ] , 𝐺 [ 𝑉 2 ] , . . . , 𝐺 [ 𝑉 𝑀 ] } . The numb er of subgraphs 𝑀 is determined based on the capacity of the available Q A OA solv ers and the underlying hardware r esources. Most importantly , each subgraph preserves essential connectivity information, as illustrated in Fig. 4 , while r educing the problem size to t within the constraints of an 𝑁 -qubit QA OA solver . 13 8 9 7 1 2 3 4 6 5 12 1 1 14 15 10 1 2 3 4 6 5 8 9 7 6 1 1 10 13 12 1 1 14 15 1 2 3 4 5 8 9 7 6 10 13 12 1 1 14 15 Randomized graph partitioning Connectivity- preserving partitioning Fig. 4. Comparing random partitioning and proposed conne ctivity-preserving partitioning algorithms. 3.2.1 Partitioning Constraints. Given an input graph 𝐺 = ( 𝑉 , 𝐸 ) with | 𝑉 | vertices, we seek to partition 𝐺 into 𝑀 subgraphs while maintaining computational feasibility for subsequent QA OA processing. The partitioning function 𝑃 : 𝐺 → { 𝐺 [ 𝑉 𝑖 ] } 𝑀 𝑖 = 1 satises the following constraints. (1) Adjacent subgraph connectivity: | 𝑉 𝑖 ∩ 𝑉 𝑖 + 1 | = 1 for all 𝑖 ∈ { 1 , 2 , . . . , 𝑀 − 1 } , meaning that subgraph 𝑖 and subgraph 𝑖 + 1 share exactly one node. This property creates a sequential chain of conne cted subgraphs to preserve connectivity information. (2) Q AO A compatibility: | 𝑉 𝑖 | ≤ 𝑁 for each subgraph 𝐺 [ 𝑉 𝑖 ] , where 𝑁 denotes the numb er of qubits available in the QA OA solver . This property ensures that each subgraph can be processed by the QA OA solver without exceeding the solver’s qubit capacity . ParaQ AO A for Handling Large-Scale Max-Cut Problems 11 (3) Size balancing: | 𝑉 𝑖 | ≤ ⌈ | 𝑉 | / 𝑀 ⌉ for each subgraph 𝐺 [ 𝑉 𝑖 ] , ensuring a balanced distribution of vertices across partitions. A simpler approach is to set | 𝑉 𝑖 | = ⌊ | 𝑉 | / 𝑀 ⌋ for each subgraph, which satises the constraint. Partitioning the graph into subgraphs of similar size ensures balanced computational loads. 3.2.2 Partitioning Algorithm. W e leverage an ecient Connectivity-Preserving Partitioning approach to achieving a computational complexity of 𝑂 ( | 𝑉 | + | 𝐸 | ) while maintaining acceptable solution quality . The algorithm takes as input the graph 𝐺 = ( 𝑉 , 𝐸 ) and the desired numb er of subgraphs 𝑀 , and outputs 𝑀 subgraphs ( 𝐺 [ 𝑉 1 ] , 𝐺 [ 𝑉 2 ] , . . . , 𝐺 [ 𝑉 𝑀 ] ) . The core method divides the vertices of 𝐺 into 𝑀 approximately equal-sized groups and then generates an induced subgraph for each group, preserving all original connections between vertices within the same group. Algorithm 1 details the implementation of our ecient graph partitioning approach. First, the base partition size is calculated as 𝑠 = ⌊ | 𝑉 | / 𝑀 ⌋ − 1 to guarantee a balanced distribution of v ertices among partitions. The subtraction of 1 accounts for the shared node to be added later . The algorithm then iterates from 1 to 𝑀 , performing graph partitioning while tracking vertex assignments to each of the 𝑀 partitions and employing a node-sharing technique to preserve connectivity information across subgraphs. The last partition accommodates any r emaining vertices to handle cases where | 𝑉 | is not perfe ctly divisible by 𝑀 . For each partition, the subgraph 𝐺 [ 𝑉 𝑖 ] is generate d using GetSubgraph , which collects all edges ( 𝑢, 𝑣 ) ∈ 𝐸 where both endpoints b elong to the same vertex set 𝑉 𝑖 . Finally , the list of partitioned subgraphs, { 𝐺 [ 𝑉 𝑖 ] } 𝑀 𝑖 = 1 , is returned. Algorithm 1: Connectivity-Preserving Partitioning: a ecient graph partitioning that preser ves connectivity information of adjacent subgraphs through shared nodes. Input: 𝐺 , input graph, 𝑀 , numb er of subgraphs Output: { 𝐺 [ 𝑉 1 ] , 𝐺 [ 𝑉 2 ] , . . . , 𝐺 [ 𝑉 𝑀 ] } , partitioned subgraphs 1 𝑉 ← 𝑉 ( 𝐺 ) ; ⊲ set of vertices in 𝐺 , indexed from 0 to | 𝑉 | − 1 2 𝑠 ← ⌊ | 𝑉 | / 𝑀 ⌋ − 1 ; ⊲ load-balance partition size; ‘ − 1 ’ is for node sharing later 3 subgraphs ← ∅ ; 4 for 𝑖 ← 1 to 𝑀 do 5 start_index ← ( 𝑖 − 1 ) × 𝑠 ; 6 if 𝑖 = 𝑀 then 7 end_index ← | 𝑉 | ; 8 else 9 end_index ← start_index + 𝑠 + 1 ; ⊲ ‘ + 1 ’ is for node sharing 10 𝑉 𝑖 ← { 𝑣 ∈ 𝑉 | start_index ≤ index ( 𝑣 ) < end_index } ; 11 𝐺 [ 𝑉 𝑖 ] ← GetSubgraph( 𝐺 , 𝑉 𝑖 ) ; 12 subgraphs ← subgraphs ∪ { 𝐺 [ 𝑉 𝑖 ] } ; 13 r eturn subgraphs ; 14 Function GetSubgraph( 𝐺 , 𝑉 𝑖 ) : 15 Initialize 𝐺 [ 𝑉 𝑖 ] = ( 𝑉 𝑖 , 𝐸 𝑖 ) where 𝐸 𝑖 = ∅ ; 16 foreach ( 𝑢, 𝑣 ) ∈ 𝐸 do 17 if 𝑢 ∈ 𝑉 𝑖 and 𝑣 ∈ 𝑉 𝑖 then 18 𝐸 𝑖 ← 𝐸 𝑖 ∪ { ( 𝑢, 𝑣 ) } ; 19 return 𝐺 [ 𝑉 𝑖 ] ; 12 P.-H. Huang et al. While this approach may appear simplistic compar ed to sophisticated partitioning schemes, experimental results demonstrate its eectiveness in maintaining solution quality while enabling rapid processing of large-scale instances. The method is particularly w ell-suited for dense graphs where edge distribution is approximately uniform. The primary advantages of this methodology are: 1) linear-time prepr ocessing suitable for large-scale instances, 2) deterministic execution time independent of graph structure, 3) minimal memory usage, and 4) excellent scalability properties. These characteristics make our partitioning approach particularly suitable for solving large-scale Max-Cut problems within the ParaQ AO A framework, where computational eciency is paramount. 3.3 Parallelized QA OA Execution The parallelized QA OA execution phase is the main computational stage of our framework, in which simultaneous quantum computation is p erformed across all partitioned subgraphs. As shown in Fig. 5 , this phase takes the 𝑀 subgraphs generate d by the Graph Partition phase and executes QA O A on each subgraph independently . For each subgraph 𝐺 [ 𝑉 𝑖 ] , the execution produces a set of top- 𝐾 bitstrings { 𝑏 1 , 𝑏 2 , . . . , 𝑏 𝐾 } , where each bitstring encodes a vertex assignment (0 or 1) and is sele cted base d on its high probability in the Q AO A output distribution. These lter ed bitstrings serve as candidate solutions for the subsequent merge phase. Our framework employs an 𝑁 -qubit QA OA Solver Pool, where 𝑁 is determined based on the available quantum processing units (QP Us) or classical computing resources. W e utilize a Multi-GP U Computing A rchitecture to execute Q AO A in parallel, with each subgraph assigne d to one of the QA OA solvers. Each solver performs quantum circuit execution to calculate the solution distribution for its assigned subgraph. A dditionally , w e provide a Selective Distribution Exploration Strategy by making the parameter 𝐾 be congurable by the user and can b e adjusted to p otentially increase the approximation ratio ( with a larger 𝐾 value). That is, the exibility in balancing computational resources against solution quality is controlled by the parameter 𝐾 . QAOA Solver 's round # , Number of QAOA solving rounds , Number of QAOA solvers -qubit QAOA Solvers with Multi-GPU 's results 's results 's results 's results QAOA Solver 's round # QAOA Solver 's round # 's Distribution Probability QAOA GPU Kernel Select T op-K Bitstrings QAOA Solver 's round # QAOA Solver 's round # QAOA Solver 's round # QAOA Solver 's round # QAOA Solver 's round # QAOA Solver 's round # 's results Fig. 5. The proposed parallelize d QA OA execution workflow integrated with a multi-GP U system. ParaQ AO A for Handling Large-Scale Max-Cut Problems 13 3.3.1 Multi-GP U Computing A rchitecture. Simulating quantum circuits for multiple subgraphs requires an eective distributed computing approach. Our multi-GP U architecture addresses this challenge through dynamic resource allocation and parallel execution. As shown in the middle of Fig. 5 , the system uses a load balancing strategy to distribute subgraphs across GP Us based on subgraph size and current GP U utilization, ensuring optimal resource use and minimizing idle time. This parallel execution framew ork processes multiple quantum circuits at the same time, with each subgraph computed independently . This design achieves near-linear speedup as the number of GP Us increases, which is important for large problem instances where sequential processing would be too slow . Synchronized result aggregation ensures that all Q AO A executions nish b efore proceeding to the next phase. In the current prototype implementation, we utilize the QA OA GP U kernel from Lu et al. [ 31 ], which employs the numba [ 25 ] package to accelerate QA OA execution on N VIDIA GP Us. This kernel computes the full quantum state distribution for each subgraph, where each bitstring corresponds to a potential solution. It eciently applies quantum gates based on the subgraph’s Hamiltonian and outputs the r esulting bitstring probabilities by lev eraging GP U parallelism. As illustrated in Fig. 5 , given 𝑁 𝑠 available QA OA solvers and 𝑀 subgraphs, execution proceeds in 𝑇 = ⌈ 𝑀 / 𝑁 𝑠 ⌉ rounds. In each round, a Q A OA GP U kernel processes a subgraph and outputs a probability distribution { 𝜋 1 , 𝜋 2 , . . . , 𝜋 2 𝑁 } over 2 𝑁 bitstrings, where 𝑁 is the number of qubits in the subgraph. For example, the subgraph 𝐺 [ 𝑉 1 ] is processed in the rst round, producing a distribution { 𝜋 ( 1 ) 1 , 𝜋 ( 1 ) 2 , . . . , 𝜋 ( 1 ) 8 } . This process is repeated for all subgraphs, with each QA OA solver outputting candidate solutions to the Max-Cut problem in the form of bitstrings and their associated probabilities. 3.3.2 Selective Distribution Exploration Strategy . A QA OA solver generates 2 𝑁 bitstrings per subgraph, where 𝑁 is the number of qubits corresponding to the subgraph size. T o reduce computational complexity and focus on high-quality candidates, we employ a Selective Distribution Exploration Strategy that lters bitstrings based on their measured probabilities. As a result, each Q AO A execution yields a set of 𝐾 bitstrings { 𝑏 ( 𝑖 ) 1 , 𝑏 ( 𝑖 ) 2 , . . . , 𝑏 ( 𝑖 ) 𝐾 } for the 𝑖 -th subgraph, representing the most promising solutions identied by quantum optimization. Each bitstring 𝑏 ( 𝑖 ) 𝑗 ∈ { 0 , 1 } | 𝑉 𝑖 | encodes a binar y partitioning of subgraph 𝐺 [ 𝑉 𝑖 ] , where | 𝑉 𝑖 | is the numb er of vertices and 1 ≤ 𝑗 ≤ 𝐾 . The value 𝑏 ( 𝑖 ) 𝑗 [ 𝑣 ] = 0 assigns vertex 𝑣 to one partition, and 𝑏 ( 𝑖 ) 𝑗 [ 𝑣 ] = 1 to the other . While high-probability bitstrings typically correspond to better cuts, the strategy also preserves diversity by allowing lower-pr obability candidates, so as to acknowledge that globally optimal solutions may reside in less probable regions of the state space. The parameter 𝐾 controls the number of candidate solutions retained for each subgraph after QA OA execution. A larger 𝐾 increases the diversity of solutions considered in the subsequent merge phase, potentially improving the approximation ratio but incurring higher computational overhead. Conversely , a smaller 𝐾 limits the selection to top-performing bitstrings, reducing complexity while fo cusing on the most probable solutions. As the simplied example illustrated in Fig. 5 , when 𝐾 = 3 , the ParaQ AO A framework selects the top-3 bitstrings with the highest probabilities, e.g., { 𝑏 ( 1 ) 1 , 𝑏 ( 1 ) 2 , 𝑏 ( 1 ) 3 } = { 100 , 101 , 110 } for subgraph 𝐺 [ 𝑉 1 ] . These bitstrings are then stored as candidate results for use in the merge phase. This tunable parameter enables a trade-o b etween computational eciency and solution quality , allowing users to tailor the framework to dierent application constraints. Although the theoretical solution space for each subgraph consists of 2 | 𝑉 𝑖 | congurations, QA OA naturally concentrates probability mass on a small subset of high-quality solutions, eciently identifying promising candidates through quantum superposition. 14 P.-H. Huang et al. 3.4 Level- A ware Parallel Merge The level-aware parallel merge phase is responsible for reconstructing global solutions from the parallel QA OA execution results. While this phase does not impact the appr oximation ratio, it constitutes the most computationally intensive post-processing step to calculate and nd the Max-Cut from plenty of p otential solutions. Substantial hardware resources are required for optimal performance. The merge process reconstructs pr oblem solutions by merging (concatenating) subgraph results to identify congurations that maximize the global cut value for the original graph. The concatenation process employs Parallel Depth-First Traversal Merging of the Cartesian product space formed by subgraph results, where each level corr esponds to one subgraph’s solution set and branches represent potential solution paths through the combinatorial space. Moreover , to fully leverage parallel pr ocessing capabilities, the merge phase is designed to operate in a Level- A ware Scheme , enabling the use of additional hardware resources to eciently perform the merging process and identify the maximum cut result. 3.4.1 Parallel Depth-First Traversal Merging. The merge phase workow is illustrated in Fig. 6 , where the results from multiple subgraphs are presented in a level-wise manner and combined to form global candidate solutions. Each le vel corresponds to a subgraph, and each branch represents a potential solution path through the combinatorial space. This process uses a parallel depth-rst traversal of the solution space forme d by the subgraph solution sets, with each worker process assigned to explore a specic branch starting from the bitstrings of 𝐺 [ 𝑉 1 ] . When the traversal reaches the nal level, corresponding to the total number of subgraphs (as shown in the b ottom of Fig. 6 ), the CutV al ( · ) function is invoked to calculate the cut value for the concatenated bitstring. The algorithm then updates the current maximum cut value if a better solution is found. The total candidate solution space for the merging stage is dened as the Cartesian product of the candidate bitstring sets from each subgraph. Let 𝐵 𝑖 = { 𝑏 ( 𝑖 ) 1 , 𝑏 ( 𝑖 ) 1 , 𝑏 ( 𝑖 ) 2 , 𝑏 ( 𝑖 ) 2 , . . . , 𝑏 ( 𝑖 ) 𝑗 , 𝑏 ( 𝑖 ) 𝑗 , . . . , 𝑏 ( 𝑖 ) 𝐾 , 𝑏 ( 𝑖 ) 𝐾 } denote the set of candidate bitstrings for subgraph 𝑖 , where 𝑏 represents the bitwise inverse of 𝑏 , capturing both possible group assignments for each solution. The Cartesian product space is then dened as: 𝐵 1 × 𝐵 2 × · · · × 𝐵 𝑀 = ( 𝑏 ( 1 ) , 𝑏 ( 2 ) , . . . , 𝑏 ( 𝑀 ) ) | 𝑏 ( 𝑖 ) ∈ 𝐵 𝑖 for each 𝑖 = 1 , 2 , . . . , 𝑀 . This Cartesian product space repr esents the total set of candidate global solutions formed by selecting one bitstring from each subgraph for e valuation in the merging stage . Although each 𝐵 𝑖 contains 2 𝐾 bitstrings to account for b oth original and inverted representations, only half can b e selected at each level due to the connectivity constraints preserved during partitioning. Specically , for any bitstring 𝑏 ( 𝑖 ) 𝑗 from subgraph 𝑖 , the possible concatenation at the next lev el is either 𝑏 ( 𝑖 + 1 ) 𝑗 ′ or its inverse 𝑏 ( 𝑖 + 1 ) 𝑗 ′ . Therefore, the total number of candidate solutions is 2 𝐾 𝑀 , where 𝐾 is the number of top bitstrings retained by the Q AO A solvers and 𝑀 is the number of subgraphs. Finally , the algorithm updates the maximum cut value by identifying the optimal global conguration, 𝐵 ∗ . Formally , given 𝑀 subgraphs { 𝐺 [ 𝑉 1 ] , 𝐺 [ 𝑉 2 ] , . . . , 𝐺 [ 𝑉 𝑀 ] } with corresponding QA OA solution sets { 𝐵 1 , 𝐵 2 , . . . , 𝐵 𝑀 } , the merge phase seeks: 𝐵 ∗ = 𝑏 ( 1 ) ∥ 𝑏 ( 2 ) ∥ · · · ∥ 𝑏 ( 𝑀 ) , where 𝑏 ( 𝑖 ) ∈ 𝐵 𝑖 for each 𝑖 = 1 , 2 , . . . , 𝑀 , to maximize the global cut value: Cut ( 𝐵 ∗ ) = 𝑀 𝑖 = 1 Cut ( 𝑏 ( 𝑖 ) ) + ( 𝑢, 𝑣 ) ∈ 𝐸 inter I 𝐵 ∗ [ 𝑢 ] ≠ 𝐵 ∗ [ 𝑣 ] , ParaQ AO A for Handling Large-Scale Max-Cut Problems 15 's results 's results 's results 's results 's results worker processes level level level level level level-by-level merging of bitstrings calculating cut values when reaching the last level Fig. 6. Parallel depth-first traversal merging workf low . Multiple worker processes explore the solution space by starting from dierent bitstring results of 𝐺 [ 𝑉 1 ] and traversing the Cartesian product space formed by the subgraph solutions. where 𝐸 inter denotes the set of inter-partition edges discarded during partitioning, and I [ ·] is the indicator function. The indicator function I [ ·] is a mathematical function that returns 1 if the condidition inside the brackets is true , and 0 otherwise. In this context, it evalutes each inter-partition edge ( 𝑢, 𝑣 ) by checking whether the vertices 𝑢 and 𝑣 are assigned to dierent partitions ( 0 or 1 ). in the reconstructed global solution 𝐵 ∗ . If 𝐵 ∗ [ 𝑢 ] ≠ 𝐵 ∗ [ 𝑣 ] , the edge contributes to the cut and the function r eturns 1 ; otherwise, it returns 0 . This mechanism eectively ensures that the totla cut value accounts for both the intra-subgraph cuts calculated by individual QA OA solv ers and the inter-partition edges that were discarded during the partitioning phasembut must be considerd in the nal global solution. 3.4.2 Level-A war e Scheme. T o eciently explore the solution space formed by the Cartesian product of subgraph results, we emplo y a Level- A ware merging strategy . This approach allows users to set the starting level of the merge phase, enabling ner-grained parallelism in searching the solution space. Fig. 7 illustrates the level-aware merging process starting at level 2 , which increases parallelism compared to Fig. 6 , where the merge begins at the rst level. This design enhances hardware utilization by expanding the number of worker processes from 2 𝐾 to 2 𝐾 2 , thereby improving scalability when additional computational resources ar e available. In general, the number of worker processes is 2 𝐾 L , where L is the starting lev el of the merge phase. This allows for exible parallel processing based on available hardware resources and user-dened parameters. Algorithm 2 details the proposed Lev el- A ware Parallel Merge methodology . It recursively constructs valid global congurations by traversing the solution space level by level, maintaining a current path that r epresents the partially constructed global solution. The algorithm employs parallel and level-awar e merge techniques mentioned above, and nally returns the maximum cut value and the corresponding global conguration. The algorithm operates through 16 P.-H. Huang et al. level level level results worker processes 's results 's results 's results 's results level , level level Fig. 7. Level-aware parallel depth-first traversal merging. Starting at level 2 increases parallelism compared to starting at level 1 (Fig. 6 ) by merging the results of 𝐺 [ 𝑉 1 ] and 𝐺 [ 𝑉 2 ] first. The right-hand side is dimmed to indicate that the subsequent process is identical to that shown in Fig. 6 . several distinct phases.First, it initializes the maximum cut value and the corresponding conguration which track the best solution found during the traversal. The algorithm then generates starting points by merging the bitstring results of the rst 𝐿 subgraphs, where 𝐿 is the user-dened starting level for the merge phase. This step creates a set of initial paths that will be expanded in parallel. Second, the algorithm spawns parallel processes to continue DepthFirstTrav ersal from each starting path at lev el 𝐿 + 1 iteratively until it reaches the nal level 𝑀 . Each process explores the solution space by appending compatible bitstrings from the current subgraph’s result set to the curr ent path. When the travelsal reaches the nal le vel 𝑀 , the algorithm computes the cut and updates the maximum cut value if a b etter solution is found. Then, the algorithm waits for all processes to complete. Finally , the maximum cut value 𝐶 𝑚𝑎𝑥 and the associated global conguration 𝑉 𝑚𝑎𝑥 are returned. 3.5 Performance Evaluation Metric T o systematically evaluate the overall performance delivered by dierent approaches to the Max-Cut problem, the Performance Eciency Index is proposed as a unied metric to quantify the p erformance trade-o between solution quality and computational eciency . Inspired by the Energy Delay Product [ 26 ], originally proposed by Horowitz [ 19 ] for evaluating trade-os in digital circuit designs, PEI is tailored to the domain of quantum optimization, where gains in solution quality often come at the cost of increased execution time. Formally , the PEI is dened as follows. PEI = AR × EF × 100 This index integrates two key components: the A pproximation Ratio (AR) , which measures the quality of the Max-Cut solution relative to optimal or benchmark values, and the Eciency Factor (EF) , which quanties computational eciency with respect to baseline runtimes. By combining these dimensions, PEI oers a standardized and interpretable metric ParaQ AO A for Handling Large-Scale Max-Cut Problems 17 Algorithm 2: Level- A ware Parallel Merge Input: { 𝐵 1 , 𝐵 2 , . . . , 𝐵 𝑀 } , list of subgraph results, 𝐿 , starting level of the merge phase for level-awar e merging Output: ( 𝑉 𝑚𝑎𝑥 , 𝐶 𝑚𝑎𝑥 ) , the maximum cut value and its asso ciated cut conguration 1 Initialize 𝑉 𝑚𝑎𝑥 ← 0 , 𝐶 𝑚𝑎𝑥 ← null; 2 starting_paths ← merge 𝐵 1 , . . . , 𝐵 𝐿 ; ⊲ Use L to merge bitstrings and create starting p oints /* Parallel depth-rst traversal from level L */ 3 foreach path in starting_paths do 4 Spawn Process: DepthFirstTraversal( L+1, path ) ; 5 Function DepthFirstTra versal( level, current_path ) : 6 if level = 𝑀 then 7 𝑉 𝑐𝑢 𝑡 ← CutV al ( current_path ) ; 8 if 𝑉 𝑐𝑢 𝑡 > 𝑉 𝑚𝑎𝑥 then 9 𝑉 𝑚𝑎𝑥 ← 𝑉 𝑐𝑢 𝑡 ; 𝐶 𝑚𝑎𝑥 ← current_path; 10 return ; 11 foreach compatible bitstring 𝑏 in 𝐵 𝑙 𝑒 𝑣 𝑒𝑙 do 12 DepthFirstTra versal( level + 1 , current_path ∥ 𝑏 ) ; ⊲ Bitstring concatenation 13 W ait for all processes to complete ; 14 return ( 𝑉 𝑚𝑎𝑥 , 𝐶 𝑚𝑎𝑥 ) ; for assessing algorithm performance across various parameter settings and baseline methods, enabling multi-obje ctive evaluation in a single score. Approximation Ratio: AR = CutV al ALG CutV al OPT , where CutV al ALG denotes the cut value obtained by the evaluated algorithm, and CutV al OPT represents the optimal cut value of the original graph or the best-known value from existing methods. The approximation ratio quanties how close the obtained solution is to the optimal, with values ranging from 0 to 1, where AR = 1 indicates an optimal solution. In this work, for problems with 100 to 400 vertices, the best cut value is obtained from the GW method [ 16 ], which guarante es an approximation ratio of at least 0.878 in polynomial time. For larger instances, best-known solutions from state-of-the-art classical algorithms are used as reference baselines for e valuating solution quality . Eciency Factor: EF = 1 1 + 𝑒 𝛼 · ( 𝑇 ALG − 𝑇 Base ) , where 𝑇 ALG is the execution time of the evaluated method, 𝑇 Base is the baseline execution time, and 𝛼 is a scaling parameter that controls the sensitivity of the eciency ratio 𝑒 to timing dierences. The eciency ratio employs a sigmoid function that provides smooth transitions between performance regimes and bounded output values. As the illustration of Fig. 8 , when 𝑇 ALG = 𝑇 Base , the eciency ratio equals 0.5, representing performance parity . V alues approaching 1.0 indicate signicant computational acceleration (when 𝑇 ALG ≪ 𝑇 Base ), while values approaching 0.0 represent substantial performance degradation (when 𝑇 ALG ≫ 𝑇 Base ). The sigmoid formulation oers several advantages over linear or logarithmic normalization: it naturally handles extreme timing variations without numerical instability , provides intuitive interpretation thr ough its bounded range, 18 P.-H. Huang et al. T ime EF baseline: slower than the baseline faster than the baseline Fig. 8. Visualization of the eiciency factor’s value range. and ensures balanced contribution to the overall PEI scor e regardless of the magnitude of timing dierences. In this work, we set the scaling parameter to a small value, e .g., 𝛼 = 0 . 001 , to ensure smooth transitions and prevent e xtreme timing variations from dominating the eciency component. 4 Evaluation This se ction presents the experimental evaluation of the proposed ParaQA OA framework. The experimental setup and computational infrastructure ar e described in Section 4.1 . W e show that our frame work is capable of managing the trade-o between solution quality and computational eciency by conguring the framework’s parameters in Section 4.2 . Section 4.3 compares the performance of ParaQ AO A with state-of-the-art QA OA -based Max-Cut solvers on small- and medium-scale graphs (fewer than 400 vertices), focusing on approximation ratio and execution time. Scalability r esults on large-scale instances ( over 1,000 vertices) ar e presented in Section 4.4 . Finally , Section 4.5 evaluates performance eciency using the proposed Performance Eciency Index, which captures the trade-o between solution quality and computational cost. 4.1 Experimental Setup All experiments are conducted on a lo cal high-performance computing system, with sp ecications provided in T able 1 . It is imp ortant to note that although the motherboard supports PCIe 5.0, the NVIDIA RTX 4090 GP Us operate at PCIe 4.0 spe eds due to hardware limitations of the GP Us. Moreover , for a fair comparison, the classical Goemans- Williamson approximation algorithm (GW) [ 16 ] (implemented by [ 31 ]), Coupling QA OA (CQ) [ 31 ] 1 and QA OA -in-QA OA (Q A OA 2 ) [ 46 ] 2 are downloaded and evaluated on the same hardware platform. W e evaluate performance across various Erdős-Rényi random graph [ 12 ] congurations, covering small-scale (20–26 vertices), medium-scale (100–400 vertices), and large-scale (1,000–16,000 vertices) instances, with edge probabilities set to 0.1, 0.3, 0.5, and 0.8. T en test graphs are generated using the gen_erdos_renyi_graph function from the NetworkX library [ 18 ], each with a dierent random see d 3 to ensure consistent and reproducible randomization across all experiments. For me dium- and large-scale instances, a single xed seed is used to manage the overall runtime of the experiments. Due to inherent limitations, not all frameworks are applicable to all graph sizes. In the small-scale evaluation, we report results for GW , CQ, and Q AO A 2 . For medium-scale graphs (up to 400 vertices), only QA O A 2 and ParaQ AO A are evaluated by using GW as the baseline. CQ is excluded. In the large-scale setting (up to 16,000 vertices), 1 https://github.com/LucidaLu/Q AO A- with- fewer- qubits/tree/30a6a3fe24fe664281e17a3723573d1abf0b06df . 2 https://github.com/ZeddTheGoat/Q AO A_in_QAQ A/tree/7704cfd2c2cbfac58a11f bf4f8b eebb1ef b9c04c . 3 Integer seeds from 0 to 9 are used for all graph generation congurations. ParaQ AO A for Handling Large-Scale Max-Cut Problems 19 T able 1. Experimental computing infrastructure specifications. Component Specication CP U AMD Ryzen Threadripper 7960X (24-core) GP U 2 × NVIDIA RTX 4090s each with 24 GB GDDR6X VRAM System Memory 256 GB (8 × 32 GB DDR5 4800 MHz) Motherboard TRX50 AERO D with two PCIe 5.0 x16 slots Operating System Ubuntu 20.04 LTS Software CUD A 12.5, Python 3.12 Python Packages NetworkX 3.4.2, Numpy 2.0.2, Numba 0.60.0 we compare Q AO A 2 and ParaQ AO A; however , QA OA 2 requires over 9 hours to solve graphs with 4,000 vertices, so its results for larger instances are extrapolated. 4.2 Parameter Configurations for Managing the ality-Eiciency Trade-o Our framew ork involves several key parameters: the number of QA OA solv ers ( 𝑁 𝑠 ), the numb er of qubits per solver ( 𝑁 ), the number of partitioned subgraphs ( 𝑀 ), the number of Q AO A solving rounds ( 𝑇 ), the candidate solution preser vation parameter ( 𝐾 ), and the starting level ( 𝐿 ) in the merging process. These parameters jointly inuence the trade-o between solution quality and computational eciency . This se ction evaluates their impact on solution quality and execution time. W e categorize the parameters into three types: hardware-dependent, input-dependent, and tunable. W e describe the conguration of these parameters and present the experimental r esults showing how the tunable parameter inuences the performance of solving the Max-Cut problem. T o assess the eectiveness of tunable parameters, we analyze their impact on the obtained cut value and execution time for graphs with 200 and 600 vertices across various edge probabilities. Hardware-Dependent Parameters. The hardware-dependent parameters include 𝑁 𝑠 and 𝑁 , which are determined by the available computational resources. Based on the hardwar e specications (T able 1 ), we deploy up to 12 concurrent Q AO A solver instances per GP U, yielding 𝑁 𝑠 = 24 solvers in total. This conguration maximizes physical CP U core utilization without overloading the system. Each solv er is allocated up to 𝑁 = 26 qubits, allowing it to process subgraphs with up to 26 vertices, while consuming less than 1 GB of GP U memory . The remaining memor y is reser ved for intermediate data during execution. Input-Dependent Parameters. The input-dependent parameters include the number of partitione d subgraphs ( 𝑀 ) and the number of QA OA solving rounds ( 𝑇 ). The value of 𝑀 is determined by the input graph size | 𝑉 | and the number of qubits 𝑁 allocated per solver . Specically , 𝑀 is set to | 𝑉 | / ( 𝑁 − 1 ) , where the subtraction accounts for one shared node between adjacent subgraphs. The numb er of solving rounds 𝑇 is set to 𝑀 / 𝑁 𝑠 , ensuring that each QA OA solver handles a balanced workload and that all solvers are fully utilized throughout the execution. T unable Parameters. The tunable parameters, 𝐾 and 𝐿 , allow further control over the trade-o b etween solution quality and computational eciency . Parameter 𝐾 species the numb er of top- 𝐾 high-probability bitstrings preserved during the parallel Q AO A execution stage, inuencing the diversity of candidate solutions. Parameter 𝐿 denes the starting level in the merging process, aecting how early subgraph solutions begin to combine. These parameters can be adjusted to align the framework’s behavior with application-specic requirements and hardware capabilities. 20 P .-H. Huang et al. Parameter 𝐾 serves as a tunable trade-o control in our framework. It allows users to balance solution quality and computational eciency according to application-specic needs. T o evaluate this trade-o, we analyze the impact of 𝐾 on the cut value and execution time. Fig. 9 pr esents the results for varying 𝐾 values, which determine the number of top- 𝐾 high-probability bitstrings retained during the parallel Q AO A execution. The x-axis represents 𝐾 , while the left y-axis shows execution time and the right y-axis indicates the achieved cut values by ParaQA OA. The results indicate that increasing 𝐾 improves solution quality but incurs higher execution time, reecting a trade-o between accuracy and eciency . In most cases, ParaQA OA achieves cut values comparable to Q AO A 2 with 𝐾 = 1 or 𝐾 = 2 , while maintaining substantially lower execution times, demonstrating its ability to balance quality and eciency through parameter tuning. 1 2 4 8 K 10 0 10 1 10 2 10 3 Time (s) Edge Probability = 0.1 Time by ParaQA OA Cut V alue by ParaQAO A Cut V alue by QAOA 2 1 2 4 8 K 10 0 10 1 10 2 10 3 Edge Probability = 0.3 1 2 4 8 K 10 0 10 1 10 2 10 3 Time (s) Edge Probability = 0.5 1 2 4 8 K 10 0 10 1 10 2 10 3 Edge Probability = 0.8 1025 1050 1075 1100 1125 1150 1175 3100 3200 3300 3400 Cut V alue 5000 5200 5400 5600 5800 6000 6200 7800 8000 8200 8400 8600 Cut V alue Fig. 9. Cut values and execution times of ParaQ AO A for varying filtering parameter 𝐾 on Erdős-Rényi graphs with 200 vertices across dierent edge probabilities. The parameter 𝐿 controls the starting level in the merging process and directly aects parallelism during post- processing. An appropriate choice of 𝐿 improves computational eciency by aligning the parallel merge operations with available CP U cores. A recommended conguration is to set 2 𝐾 𝐿 close to the number of physical CP U cores, which ensures ecient use of hardware without incurring system overhead. Fig. 10 illustrates the performance of ParaQA OA with 𝐿 ranging from 1 to 3. The parameter 𝐿 determines the number of processes executed in parallel. For example, ParaQ AO A for Handling Large-Scale Max-Cut Problems 21 when 𝐿 = 1 , four processes are spawned; when 𝐿 = 2 , eight processes; and when 𝐿 = 3 , sixteen processes. The results show that doubling the numb er of processes reduces the runtime by approximately half. This highlights the impact of 𝐿 on execution eciency and underscores the framew ork’s scalability potential on modern multi-core and many-core systems [ 20 ]. 1 2 3 L 0 100 200 300 400 500 Time (s) 513.6 261.1 138.8 518.0 261.6 141.7 519.0 269.6 143.6 530.2 274.1 144.9 Edge Probabilit y 0.1 0.3 0.5 0.8 Fig. 10. Execution time of ParaQA OA with varying starting point 𝐿 on Erdős-Rényi graphs with 600 v ertices across dierent edge probabilities with 𝐾 = 2 . 4.3 Performance Evaluation on Small- and Medium-scale Graphs W e begin our evaluation with small-scale Max-Cut instances, specically Erdős-Rényi random graphs with 20 to 30 vertices. The results are summarized in T able 2 , which compares the approximation ratios and execution times of ParaQ AO A against CQ, and QA OA 2 . The results show that ParaQA OA achieves competitive approximation ratios while signicantly outperforming the other methods in terms of execution time. For instance , on a 20-vertex graph with edge probability 0.1, ParaQA OA achieves an approximation ratio of 82.5% in just 0.85 seconds, while QA OA 2 takes 2.46 seconds and CQ takes 106.87 se conds to achieve similar results. As the graph size and edge probability increases, ParaQ A OA continues to demonstrate superior performance, maintaining high appr oximation ratios while keeping execution times low . The results demonstrate that ParaQA OA achieves competitive appro ximation ratios while signicantly outperforming the other methods in terms of execution time. For medium-scale problems, we compare the performance of our ParaQA OA framework with Q AO A 2 , a state-of-the- art Q AO A-based Max-Cut solv er . CQ is excluded from this evaluation due to its long runtime (exceeding 8 hours for a 30-vertex graph), its restriction to bipartite graphs, and its inability to handle larger instances. The GW algorithm serves as the baseline, as brute-for ce methods ar e infeasible at this scale. T able 3 and Fig. 11 summarize the p erformance results delivered by ParaQ AO A and QA O A 2 . T able 3 reports execution time results and demonstrates the computational eciency of ParaQA OA. Our framework consistently outperforms QA OA 2 across all congurations, with speedups increasing with graph edge probability . For example, on a 100-verte x graph with edge probability 0.1, ParaQA O A achieves a 112 . 1 × speedup, which scales to 1652 . 2 × 22 P .-H. Huang et al. T able 2. Comparison of execution runtime and approximation ratio on small-scale Max-Cut instances with varying graph sizes ( | 𝑉 | ) and edge probabilities ( 𝑃 ). AR values are calculated by dividing the obtained cut value by the optimal cut value, determined by a brute-force method. 𝑃 | 𝑉 | Runtime (s) AR (%) Q AO A 2 CQ ParaQA OA QA OA 2 CQ ParaQ AO A 0.1 20 2.46 106.87 0.85 84.6 94.8 82.5 22 2.56 181.51 0.86 87.0 95.6 85.9 24 2.93 280.82 0.87 83.7 96.1 90.7 26 2.92 1044.23 0.89 84.7 96.8 81.4 0.3 20 8.18 151.88 0.85 93.8 97.7 89.4 22 8.89 246.90 0.85 92.1 97.9 89.5 24 8.71 488.65 0.87 91.5 98.4 90.9 26 9.55 1531.19 0.91 90.9 98.4 86.9 0.5 20 16.18 179.31 0.86 95.6 98.4 92.0 22 17.16 290.58 0.88 95.1 98.6 93.3 24 18.92 501.91 0.90 94.5 98.7 93.9 26 19.38 1590.81 0.91 94.1 98.8 93.0 0.8 20 33.29 219.46 0.87 96.9 98.5 94.6 22 35.39 367.41 0.89 95.5 99.1 96.1 24 34.23 586.28 0.90 96.4 99.1 97.2 26 37.49 1592.60 0.91 95.4 99.1 95.6 on a 400-vertex graph with edge probability 0.8. This performance trend underscores key algorithmic dierences. Q AO A 2 exhibits exponential growth in computation time with increasing graph edge probability due to its exhaustive sub-solution enumeration. In contrast, ParaQA OA ’s runtime is dominated by the performance of individual QA OA solvers, making it signicantly less sensitive to graph complexity . T able 3. Execution time comparison of QA OA 2 and ParaQA OA on medium-scale Max-Cut instances with varying graph sizes ( | 𝑉 | ) and edge probabilities ( 𝑃 ). 𝑃 | 𝑉 | Q AO A 2 Runtime (s) ParaQ AO A Runtime (s) Speedup 0.1 100 668.0 6.0 112.1 × 200 1128.6 7.3 155.2 × 400 2158.8 8.7 247.0 × 0.3 100 888.8 6.4 138.0 × 200 1754.1 7.7 227.2 × 400 3320.7 9.9 334.4 × 0.5 100 1753.5 6.5 268.1 × 200 2937.7 7.9 372.8 × 400 6943.8 10.2 679.4 × 0.8 100 4659.4 6.6 706.0 × 200 8591.3 8.2 1051.6 × 400 17001.0 10.3 1652.2 × ParaQ AO A for Handling Large-Scale Max-Cut Problems 23 Fig. 11 presents the approximation ratio comparison between ParaQ A OA and QA OA 2 . T wo key observations are drawn from the results. First, both methods yield lower ARs on graphs with low edge probability due to the increased inuence of individual e dges on the cut value. Since both frameworks employ random partitioning and disregard inter-subgraph edges, sparse graphs are more susceptible to approximation degradation. In contrast, on denser graphs, where individual edges contribute less signicantly , both methods achieve ARs approaching that of the GW algorithm. Second, the worst-case AR degradation of our framework relativ e to QA OA 2 is within 2%, while the typical dierence remains around 1%. In sev eral congurations, ParaQA OA ev en surpasses QA OA 2 in solution quality . 100 200 400 Graph Size 0.8 0.5 0.3 0.1 Edge Probability 98.4 97.7 98.1 96.1 95.9 96.5 93.5 94.5 95.5 89.9 88.1 89.2 QA OA 2 100 200 400 Graph Size 97.8 97.6 97.3 94.8 95.9 95.9 92.2 94.5 93.5 94.0 87.2 88.5 P araQAO A 80 82 85 88 90 92 95 98 100 Approximation Ratio (%) Fig. 11. Approximation ratio, computed using cut values from GW , shown as a heatmap comparing QA OA 2 and ParaQA OA. 4.4 Scalability Results on Large-scale Graphs T o e valuate scalability , we extended our experiments to large-scale graph instances ranging from 1,000 to 16,000 vertices. At this scale, only QA OA 2 and our ParaQA OA framew ork are capable of solving the problems. Fig. 12 shows execution time trends for repr esentative low (0.1) and high (0.8) edge probability congurations; intermediate edge probability cases exhibit similar scaling patterns. Due to the high computational cost of Q AO A 2 at large scales, its execution time was measured only for graphs with up to 4,000 vertices. For larger instances, we applied linear regr ession to extrapolate execution time (denoted by “Projecttion”) based on the obser ved relationship between the numb er of vertices and Q AO A 2 ’s runtime. Our analysis yields two key observations. First, as problem size increases, the performance of QA OA 2 is signicantly aected by edge density . Specically , increasing the edge probability from 0.1 to 0.8 results in approximately a 10-fold increase in execution time for graphs with the same number of vertices. In contrast, our framework demonstrates much greater robustness to edge density , with execution time increasing by at most 1.5 × across the same range of edge probabilities for graphs with 1,000 to 4,000 vertices. Second, our framework consistently outperforms QA OA 2 in terms of computational eciency and achieves speedups ranging from 300 × to 2,000 × as problem complexity increases. In addition to relative performance, w e present absolute execution times to emphasize the practical applicability of our 24 P .-H. Huang et al. framework. For graphs with 16,000 vertices, our method completes in minutes, whereas Q AO A 2 requires several days, rendering it impractical for real-world use at this scale . 1,000 2,000 4,000 8,000 16,000 Graph Size 10 0 10 1 10 2 10 3 10 4 10 5 10 6 10 7 Execution Time (s) 383 × 1.6 days 5.4 minutes QAO A 2 QAO A 2 (Pro jection) ParaQAO A (a) Edge Probability = 0.1 1,000 2,000 4,000 8,000 16,000 Graph Size 10 0 10 1 10 2 10 3 10 4 10 5 10 6 10 7 Execution Time (s) 2269 × 13.6 days 18.7 minutes QAO A 2 QAO A 2 (Pro jection) ParaQAO A (b) Edge Probability = 0.8 Fig. 12. Scalability analysis comparing execution times between QA OA 2 and ParaQA OA for large-scale Max-Cut problems. 4.5 Performance Eiciency Index Evaluation As presented in Section 3.5 , PEI is a novel metric that combines appr oximation ratio and execution time into a single index to evaluate the performance of dierent solutions to the Max-Cut problem. Fig. 13 plots PEI values across various medium-scale graph congurations, co vering vertex counts of 100, 200, and 400, and edge pr obabilities ranging from 0.1 to 0.8. The GW algorithm serves as the baseline for computing AR and EF in the proposed PEI metric, with 𝛼 = 0 . 001 used to ensure smooth scaling of runtime data. Our proposed framework consistently outperforms QA OA 2 in all tested congurations. Notably , the advantage b ecomes more pronounced as graph complexity increases, either through larger vertex counts or higher edge densities. In addition, our metho d surpasses the approximation performance guarantee of the GW algorithm (represented by the horizontal red dashed line), highlighting its ability to achieve a better trade-o between solution quality and computational eciency . Additionally , we extend the PEI evaluation to large-scale Max-Cut instances, as sho wn in Fig. 14 . Due to the size of these graphs and the limitation of the e xisting implementation, the GW algorithm is no longer applicable. Instead, we use Q A OA 2 as the baseline, treating its best cut values as reference . In addition, the parameter 𝛼 is set to 0 . 0001 to ensure smooth scaling of runtime data and to reect the runtime gap observed at this problem scale. The results show that ParaQ AO A continues to deliver strong performance eciency across all tested large-scale graphs. 5 Conclusion This paper presents the ParaQA OA framework, a novel hybrid quantum-classical approach that successfully addresses the fundamental trade-o between solution quality and computational eciency in large-scale combinatorial optimization. Through systematic algorithmic innovations and comprehensive experimental validation, we demonstrate that practical ParaQ AO A for Handling Large-Scale Max-Cut Problems 25 100-0.1 100-0.3 100-0.5 100-0.8 200-0.1 200-0.3 200-0.5 200-0.8 400-0.1 400-0.3 400-0.5 400-0.8 Graph (Size-Edge Probability) 0 20 40 60 80 100 Performance Efficiency Index (PEI) 31.5 48.1 28.3 47.2 14.8 48.5 1.0 50.0 24.6 46.7 16.1 51.2 5.7 51.9 0.0220 52.7 65.5 84.9 44.7 89.8 3.0 93.1 0.0002 95.3 GW guarantee (AR=0.878) QAO A 2 ParaQA OA Fig. 13. Comparison of the Performance Eiciency Index between QA OA 2 and ParaQA OA across dierent graph sizes and edge probabilities, using the GW algorithm as the baseline for cut values and runtimes. 1000-0.1 1000-0.8 2000-0.1 2000-0.8 4000-0.1 4000-0.8 Graph (Size-Edge Probability) 0 20 40 60 80 100 Performance Efficiency Index (PEI) 67.2 99.7 83.4 99.9 96.3 99.9 QAO A 2 (Baseline) ParaQA OA Fig. 14. Performance Eiciency Index of ParaQA OA across dierent graph sizes and edge probabilities, using QA OA 2 as the baseline for cut values and runtimes. quantum-inspired optimization can achieve both scalability and performance suitable for real-world deployment. The introduction of the Performance Eciency Index oers a generalizable frame work for evaluating trade-os between solution quality and computational eciency across optimization algorithms. Despite these strengths, several limitations suggest directions for future r esearch. Current randomized partitioning may underperform on structured graphs, motivating exploration of adaptive partitioning techniques. While the method is evaluated on Max-Cut, extending it to other QUBO problems ( e.g., TSP , graph coloring) could demonstrate broader applicability . Hardware-specic optimization and noise-aware circuit designs are also promising dir ections. 26 P .-H. Huang et al. Acknowledgments This work was supported in part by National Science and T e chnology Council, T aiwan, under Grants 113-2119-M-002 -024 and 114-2221-E-006 -165 -MY3. W e thank to National Center for High performance Computing (NCHC), High Performance and Scientic Computing Center at National T aiwan University , and Inv entec for providing computational and storage resources. W e thank the nancial supports from the Featured Area Research Center Program within the framework of the Higher Education Sprout Pr oject by the Ministr y of Education (114L900903). References [1] Rakesh Agrawal, Sridhar Rajagopalan, Ramakrishnan Srikant, and Yirong Xu. 2003. Mining Newsgroups Using Networks Arising from Social Behavior . In Procee dings of the 12th International Conference on W orld Wide W eb (WW W) . 529–535. doi:10.1145/775152.775227 [2] Frank Arute, Kunal Arya, Ryan Babbush, Dave Bacon, Joseph C. Bardin, Rami Bar ends, Rupak Biswas, Sergio Boixo, Fernando G. S. L. Brandao, David A. Buell, Brian Burkett, Y u Chen, Zijun Chen, Ben Chiaro, Roberto Collins, William Courtney , Andrew Dunsworth, Edward Farhi, Brooks Foxen, A ustin Fowler , Craig Gidney , Marissa Giustina, Rob Gra, Keith Guerin, Steve Habegger , Matthew P. Harrigan, Michael J. Hartmann, Alan Ho, Markus Homann, Trent Huang, Travis S. Humble, Sergei V . Isakov , Evan Jerey , Zhang Jiang, Dvir Kafri, Kostyantyn Kechedzhi, Julian Kelly , Paul V . Klimov , Sergey Knysh, Alexander Korotkov , Fedor Kostritsa, David Landhuis, Mike Lindmark, Erik Lucero, Dmitry Lyakh, Salvatore Mandrà, Jarrod R. McClean, Matthew McEwen, Anthony Megrant, Xiao Mi, Kristel Michielsen, Masoud Mohseni, Josh Mutus, Ofer Naaman, Matthew Neeley , Charles Neill, Murphy Yuezhen Niu, Eric Ostby , Andre Petukhov , John C. Platt, Chris Quintana, Eleanor G. Rieel, Pe dram Roushan, Nicholas C. Rubin, Daniel Sank, Kevin J. Satzinger , V adim Smelyanskiy , Ke vin J. Sung, Matthew D . Trevithick, Amit V ainsencher , Benjamin Villalonga, Theodore White, Z. Jamie Y ao, Ping Y eh, Adam Zalcman, Hartmut Neven, and John M. Martinis. 2019. Quantum supremacy using a programmable superconducting processor . Nature 574, 7779 (2019), 505–510. doi:10.1038/s41586- 019- 1666- 5 [3] Ryan Babbush, Dominic W . Berr y , Robin Kothari, Rolando D. Somma, and Nathan Wieb e. 2023. Exp onential Quantum Sp eedup in Simulating Coupled Classical Oscillators. Physical Review X 13 (2023), 041041. Issue 4. doi:10.1103/P hysRevX.13.041041 [4] Francisco Barahona, Martin Grötschel, Michael Jünger , and Gerhard Reinelt. 1988. An Application of Combinatorial Optimization to Statistical Physics and Circuit Layout Design. Op erations Research 36, 3 (1988), 493–513. https://dl.acm.org/doi/10.5555/2804709.2804720 [5] Harun Bayraktar , Ali Charara, David Clark, Saul Cohen, Timothy Costa, Y ao-Lung L. Fang, Y ang Gao, Jack Guan, John Gunnels, Azzam Haidar , Andreas Hehn, Markus Hohnerbach, Matthew Jones, T om Lubowe, Dmitry Lyakh, Shinya Morino, Paul Springer , Sam Stanwyck, Igor T erentyev , Satya V aradhan, Jonathan W ong, and Takuma Y amaguchi. 2023. cuQuantum SDK: A High-Performance Librar y for Accelerating Quantum Science. In Proceedings of the IEEE International Conference on Quantum Computing and Engineering (QCE) . 1050–1061. doi:10.1109/QCE57702.2023.00119 [6] Kostas Blekos, Dean Brand, Andrea Ceschini, Chiao-Hui Chou, Rui-Hao Li, K omal Pandya, and Alessandro Summer . 2024. A review on Quantum Approximate Optimization Algorithm and its variants. Physics Reports 1068 (2024), 1–66. doi:10.1016/j.physrep.2024.03.002 [7] M. Cerezo, Andrew Arrasmith, Ryan Babbush, Simon C. Benjamin, Suguru Endo, K eisuke Fujii, Jarrod R. McClean, Kosuke Mitarai, Xiao Yuan, Lukasz Cincio, and Patrick J. Coles. 2021. Variational quantum algorithms. Nature Reviews P hysics 3, 9 (2021), 625–644. doi:10.1038/s42254- 021- 00348- 9 [8] Shin- W ei Chiu, Chuo-Min Y ang, Shan-Jung Hou, Po-Hsuan Huang, Chuan-Chi W ang, Chia-Heng Tu, and Shih-Hao Hung. 2025. FOR-QAO A: Fully Optimized Resource-Ecient QA OA Circuit Simulation for Solving the Max-Cut Problems. In Proceedings of Practice and Exp erience in Advanced Research Computing 2025: The Power of Collaboration (PEARC) . Article 2, 11 pages. doi:10.1145/3708035.3736006 [9] Chi Chuang, Po-Hsuan Huang, Chia-Heng T u, and Shih-Hao Hung. 2024. Maximizing Q AO A Potential: Ecient Max-Cut Solutions through Classical Parallel Searching for Time-Sensitive Applications. In Proceedings of the International Conference on Consumer Electronics - Taiwan (ICCE- T aiwan) . 157–158. doi:10.1109/ICCE- Taiwan62264.2024.10674517 [10] V edran Dunjko, Yimin Ge, and J. Ignacio Cirac. 2018. Computational Spee dups Using Small Quantum Devices. P hysical Review Letters 121 (2018), 250501. Issue 25. doi:10.1103/PhysRevLett.121.250501 [11] Maxime Dupont, Bhuvanesh Sundar , Bram Evert, David E. Bernal Neira, Zedong Peng, Stephen Jerey , and Mark J. Hodson. 2025. Benchmarking quantum optimization for the maximum-cut problem on a superconducting quantum computer . Physical Review Applied 23 (2025), 014045. Issue 1. doi:10.1103/PhysRev Applied.23.014045 [12] Paul Erdös and Alfréd Rényi. 1959. On Random Graphs I. Publicationes Mathematicae Debrecen 6, 290–297 (1959), 18. https://snap.stanford.edu/ class/cs224w- readings/erdos59random.pdf [13] Edward Farhi, Jerey Goldstone , and Sam Gutmann. 2014. A Quantum Approximate Optimization Algorithm. arXiv: 1411.4028 [quant-ph] [14] Richard P. Feynman. 1982. Simulating physics with computers. International Journal of Theoretical P hysics 21, 6 (1982), 467–488. doi:10.1007/ BF02650179 [15] Yimin Ge and V edran Dunjko. 2020. A hybrid algorithm framework for small quantum computers with application to nding Hamiltonian cycles. J. Math. Phys. 61, 1 (2020), 012201. doi:10.1063/1.5119235 [16] Michel X. Go emans and David P. Williamson. 1995. Improved approximation algorithms for maximum cut and satisability problems using semidenite programming. J. ACM 42, 6 (1995), 1115–1145. doi:10.1145/227683.227684 ParaQ AO A for Handling Large-Scale Max-Cut Problems 27 [17] Gian Giacomo Guerreschi and Anne Y . Matsuura. 2019. QA OA for max-cut requires hundreds of qubits for quantum speed-up. Scientic Rep orts 9, 1 (2019), 6903. [18] Aric A. Hagberg, Daniel A. Schult, and Pieter J. Swart. 2008. Exploring Network Structure, Dynamics, and Function using NetworkX. In Procee dings of the 7th Python in Science Conference (SciPy) . 11–15. doi:10.25080/TCW V9851 [19] Mark Horowitz, Thomas Indermaur , and Ricardo Gonzalez. 1994. Low-power digital design. In Proceedings of the IEEE Symposium on Low Power Electronics (LPE) . 8–11. doi:10.1109/LPE.1994.573184 [20] Jim Jeers, James Reinders, and A vinash Sodani. 2016. Chapter 1 - Introduction. In Intel Xeon P hi Processor High Performance Programming (Second Edition) . Morgan Kaufmann, 3–13. doi:10.1016/B978- 0- 12- 809194- 4.00001- 6 [21] T yson Jones, Anna Brown, Ian Bush, and Simon C. Benjamin. 2019. QuEST and High Performance Simulation of Quantum Computers. Scientic Reports 9, 1 (2019), 10736. doi:10.1038/s41598- 019- 47174- 9 [22] Richard M. Karp . 1972. Reducibility among Combinatorial Problems . Springer US, 85–103. doi:10.1007/978- 1- 4684- 2001- 2_9 [23] Gary Kochenberger , Jin-Kao Hao, Fred Glover , Mark Lewis, Zhipeng Lü, Haib o W ang, and Y ang Wang. 2014. The unconstrained binary quadratic programming problem: a survey . Journal of Combinatorial Optimization 28, 1 (2014), 58–81. doi:10.1007/s10878- 014- 9734- 0 [24] Naimisha Kolli and Balakrishnan Narayanaswamy . 2019. Inuence Maximization From Cascade Information Traces in Comple x Networks in the Absence of Network Structure. IEEE Transactions on Computational Social Systems 6 (2019), 1147–1155. doi:10.1109/TCSS.2019.2939841 [25] Siu K wan Lam, Antoine Pitrou, and Stanley Seibert. 2015. Numba: a LLVM-based Python JI T compiler. In Pr oceedings of the 2nd W orkshop on the LLVM Compiler Infrastructure in HPC (LLVM) . Article 7, 6 pages. doi:10.1145/2833157.2833162 [26] James H. Laros III, Ke vin Pedretti, Suzanne M. Kelly , W ei Shu, Kurt Ferreira, John V andyke, and Courtenay V aughan. 2013. Energy Delay Product . Springer London, 51–55. doi:10.1007/978- 1- 4471- 4492- 2_8 [27] Ang Li, Omer Subasi, Xiu Yang, and Sriram Krishnamoorthy . 2020. Density Matrix Quantum Circuit Simulation via the BSP Machine on Modern GP U Clusters. In Procee dings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC) . 1–15. doi:10.1109/SC41405.2020.00017 [28] Jianqiang Li. 2025. Exponential speedup of quantum algorithms for the pathnding problem. Quantum Information Processing 24, 3 (2025), 67. doi:10.1007/s11128- 025- 04689- 7 [29] Junde Li, Mahabubul Alam, and Swaroop Ghosh. 2023. Large-Scale Quantum Approximate Optimization via Divide-and-Conquer . IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 42 (2023), 1852–1860. doi:10.1109/TCAD.2022.3212196 [30] Y u-Cheng Lin, Chuan-Chi W ang, Chia-Heng Tu, and Shih-Hao Hung. 2024. Towar ds Optimizations of Quantum Circuit Simulation for Solving Max-Cut Problems with QA OA. In Proceedings of the 39th ACM/SIGAPP Symposium on A pplied Computing (SA C) (A vila, Spain). 1487–1494. doi:10.1145/3605098.3635897 [31] Yiren Lu, Guojing Tian, and Xiaoming Sun. 2023. QAO A with fewer qubits: a coupling framework to solve larger-scale Max-Cut problem. arXiv: 2307.15260 [quant-ph] [32] Jhon Alejandro Montañez-Barrera and Kristel Michielsen. 2025. T oward a linear-ramp QA OA protocol: evidence of a scaling advantage in solving some combinatorial optimization problems. npj Quantum Information 11, 1 (2025), 131. doi:10.1038/s41534- 025- 01082- 1 [33] Roger Penrose et al . 1971. Applications of negative dimensional tensors. Combinatorial mathematics and its applications 1, 221-244 (1971), 3. https://homepages.math.uic.edu/~kauman/Penrose.pdf [34] John Preskill. 2018. Quantum Computing in the NISQ era and beyond. Quantum 2 (2018), 79. doi:10.22331/q- 2018- 08- 06- 79 [35] Stefan H. Sack and Maksym Serbyn. 2021. Quantum annealing initialization of the quantum approximate optimization algorithm. Quantum 5 (2021), 491. doi:10.22331/q- 2021- 07- 01- 491 [36] Peter W . Shor . 1994. Algorithms for quantum computation: discrete logarithms and factoring. In Proceedings of the 35th A nnual Symposium on Foundations of Computer Science (SFCS) . 124–134. doi:10.1109/SFCS.1994.365700 [37] Daniel R. Simon. 1994. On the p ower of quantum computation. In Proceedings of the 35th Annual Symposium on Foundations of Computer Science (SFCS) . 116–123. doi:10.1109/SFCS.1994.365701 [38] Damian S. Steiger , Thomas Häner, and Matthias T royer . 2018. ProjectQ: an open source software framework for quantum computing. Quantum 2 (2018), 49. doi:10.22331/q- 2018- 01- 31- 49 [39] Michael Streif, Martin Leib, Filip Wudarski, Eleanor Rieel, and Zhihui W ang. 2021. Quantum algorithms with local particle-number conservation: Noise eects and error correction. Physical Review A 103 (2021), 042412. Issue 4. doi:10.1103/P hysRev A.103.042412 [40] Jules Tilly , Hong xiang Chen, Shuxiang Cao, Dario Picozzi, Kanav Setia, Ying Li, Edward Grant, Leonard W ossnig, Ivan Rungger, George H. Booth, and Jonathan T ennyson. 2022. The V ariational Quantum Eigensolver: A review of methods and best practices. Physics Rep orts 986 (2022), 1–128. doi:10.1016/j.physrep.2022.08.003 [41] Steven R. White. 1993. Density-matrix algorithms for quantum renormalization groups. Physical Review B 48 (1993), 10345–10356. Issue 14. doi:10.1103/PhysRevB.48.10345 [42] Y u- T sung Wu, Po-Hsuan Huang, Kai-Chieh Chang, Chia-Heng T u, and Shih-Hao Hung. 2025. QOPS: a compiler framework for quantum circuit simulation acceleration with prole-guided optimizations. The Journal of Supercomputing 81 (2025). doi:10.1007/s11227- 025- 07157- 2 [43] Ming Y ang, Bo Liu, W ei W ang, Junzhou Luo, and Xiaojun Shen. 2014. Maximum Capacity Overlapping Channel Assignment Based on Max-Cut in 802.11 Wireless Mesh Networks. Journal of Universal Computer Science 20, 13 (2014), 1855–1874. doi:10.3217/jucs- 020- 13- 1855 28 P .-H. Huang et al. [44] Kieran Y oung, Marcus Scese , and Ali Ebnenasir . 2023. Simulating Quantum Computations on Classical Machines: A Survey . arXiv: 2311.16505 [ quant- ph] [45] Leo Zhou, Sheng- Tao W ang, Soonwon Choi, Hannes Pichler , and Mikhail D. Lukin. 2020. Quantum Approximate Optimization Algorithm: Performance, Mechanism, and Implementation on Near- T erm Devices. Physical Review X 10 (2020), 021067. Issue 2. doi:10.1103/PhysRevX.10.021067 [46] Zeqiao Zhou, Yuxuan Du, Xinmei Tian, and Dacheng T ao. 2023. QAO A-in-QA OA: Solving Large-Scale MaxCut Problems on Small Quantum Machines. Physical Review Applied 19 (2023), 024027. Issue 2. doi:10.1103/PhysRevApplied.19.024027
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment