Towards single-shot coherent imaging via overlap-free ptychography
Ptychographic imaging at synchrotron and XFEL sources requires dense overlapping scans, limiting throughput and increasing dose. Extending coherent diffractive imaging to overlap-free operation on extended samples remains an open problem. Here, we ex…
Authors: Oliver Hoidn, Aashwin Mishra, Steven Henke
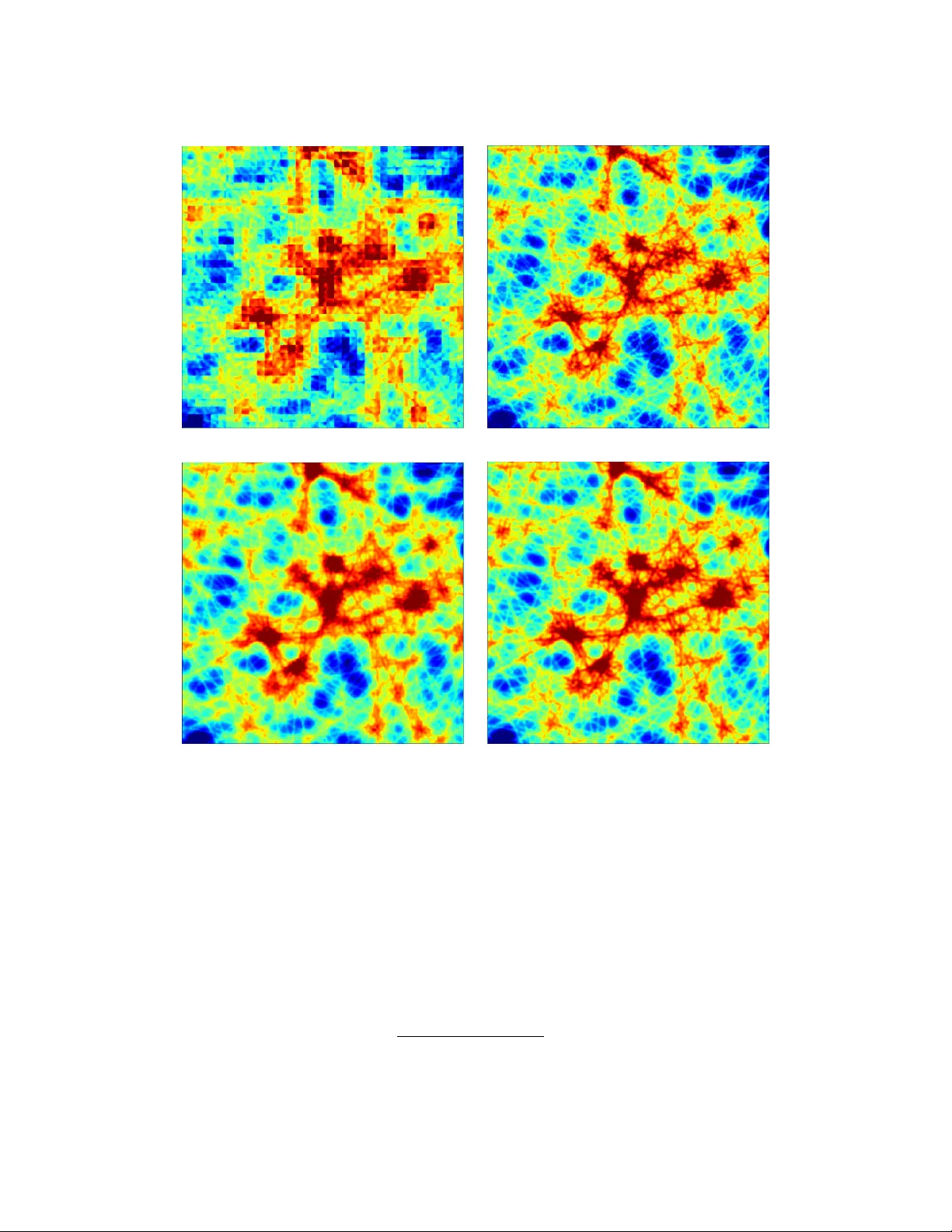
T ow a rds s in g l e - s h o t co h e r e n t im a g in g v i a ove r l a p - f r e e pt y ch o g r a p hy O . H O I D N , 1 , * A . M I S H R A , 1 S . H E N K E , 2 A . V O N G , 2 A N D M . S E A B E R G 1 1 SL A C National A cceler ator Labor atory, Menlo P ark, California 94025, USA 2 Argonne N ational Labor atory, Lemont, Illinois 60439, USA * ohoidn@slac.stanf ord.edu Abstract: Pty chographic imaging at synchrotron and XFEL sources requires dense o ver lapping scans, limiting throughput and increasing dose. Extending coherent diffractiv e imaging to ov erlap- free operation on e xtended samples remains an open problem. Here, we e xtend Ptyc hoPINN (O. Hoidn et al. , Scientific Reports 13 , 22789, 2023) to deliv er ov erlap-fr ee, sing le-shot reconstructions in a Fresnel coherent diffraction imaging (CDI) geometry while also accelerating con v entional multi-shot pty chograph y . The frame w ork couples a differentiable f or ward model of coherent scattering with a Poisson photon-counting likelihood; real-space o v erlap enters as a tunable parameter via coordinate-based grouping rather than a hard requirement. On synthetic benc hmarks, recons tructions remain accurate at lo w counts ( ∼ 10 4 photons/frame), and o v er lap-free single-shot reconstruction with an e xperimental probe reaches amplitude structural similarity (SSIM) 0.904, compared with 0.968 f or o ver lap-constrained reconstruction. Ag ainst a data-saturated supervised model with the same backbone (16,384 training images), Ptyc hoPINN achie v es higher SSIM with only 1,024 imag es and g eneralizes to unseen illumination profiles. Per -graphics processing unit (GPU) throughput is approximatel y 40 × that of least-sq uares maximum-likelihood (LSQ-ML) recons tr uction at matched 128 × 128 resolution. These results, validated on e xper imental data from the A dvanced Photon Source and the Linac Coherent Light Source, unify single-e xposure Fresnel CDI and ov erlapped ptyc hography within one framew ork, supporting dose-efficient, high-throughput imaging at moder n light sources. 1. Introduction Modern light sources, suc h as f our th-generation synchrotrons and X -ray Free-Electron Lasers (XFELs), generate coherent diffraction data f ar fas ter than imag es can be reconstructed [1]. This g ro wing g ap between acquisition and analy sis precludes real-time f eedback and on-the-fly e xperimental steering, both essential f or maximizing the scientific output of these facilities. Pty chographic coherent diffraction imaging (CDI) is a cornerstone x-ra y nanoscale imaging technique [2], but the computational reconstruction of real-space imag es from diffraction f aces some limitations and tradeoffs. Firs t, classical iterative algor ithms lik e the Ptyc hographic Iterativ e Engine (PIE) require ∼ 60–70% scan o v er lap f or robus t con ver gence and process onl y ∼ 0.1–1 diffraction patterns per second on standard hardw are [3, 4]; e ven graphics processing unit (GPU)-accelerated solv ers struggle to k eep pace with high-repetition-rate sources [5, 6]. Supervised machine lear ning (ML) approac hes ha ve been introduced to accelerate reconstruc- tion by mo ving from iterativ e optimization-based procedures to single-shot inf erence using trained models. These approac hes can accelerate inf erence but are often limited by poor g eneralization and the need f or large labeled training sets generated by iterative solv ers. [6, 7] Moreo v er , single- frame supervised methods cannot e xploit ov erlap redundancy , failing outr ight when o v er lap constraints are required. In short, neither conv entional methods nor direct supervised in v ersion unifies speed, resolution, and flexible handling of real-space cons traints. Be y ond super vised direct in v ersion techniques, recent dev elopments in machine learning-based phase retriev al f or ptyc hography include h ybrid ph y sics-learning approaches (e.g., deep-prior regularization and learned accelerators within iterativ e solv ers) [8, 9], implicit neural representa- tions including sinusoidal representation netw orks (SIREN)-sty le parameter izations [10], learned probe-position cor rection f or larg e scan errors [11], and unrolled transf or mer -based pty chograph y netw orks [12]. R elated unsupervised ph ysics-a ware in version has also been demonstrated f or 3D Bragg CDI (A utoPhaseNN) [13]. Within ptyc hograph y and extended-sample CDI, no single prior approach has jointl y demonstrated reusable pre-trained inference, label-free training, and operation without strict o ver lap constraints. In this conte xt, w e address se veral limitations of pr ior approaches with a phy sics-constrained, self-supervised framew ork: a trainable inv erse-mapping netw ork is composed with a differentiable f orward simulator of coherent scatter ing, and the full system is optimized end-to-end as an autoencoder using diffraction-domain losses (Poisson photon-counting lik elihood [14, 15]). A ke y proper ty of this f or mulation is that real-space redundancy is treated as a configurable parameter rather than a hard requirement. Specifically , the number of simultaneousl y recons tructed coherent scattering shots can be dialed to match the acquisition regime, including the ov erlap-free setting. In practice, when a curv ed or def ocused probe pro vides sufficient phase div ersity , the diffraction-domain lik elihood alone can anc hor reconstruction and spatial redundancy can be reduced to zero. This is the pr inciple underl ying Fresnel CDI [16, 17]. W e use “single-shot” throughout in the limited sense of a single diffraction measurement with a str uctured probe (without lateral scanning, beam multiplexing [18, 19], or downs tream modulators [20, 21]). Our previous w ork [22] demonstrated this phy sics-constrained approac h on synthetic data; here, we extend it to realistic probes, arbitrar y scan geometries, and single-shot recons truction. W e ev aluate the model under both typical and non-ideal conditions, including lo w photon dose and large position jitter , and demonstrate good perf or mance on e xperimental data from the A dvanced Photon Source (APS) and the Linac Coherent Light Source (LCLS). Specificall y , this w ork demonstrates: 1. self-supervised recons tr uction of e xper imental data (APS, LCLS) at ∼ 6 . 1 × 10 3 diffraction patterns/s; 2. o v er lap-free, single-shot reconstruction in Fresnel CDI g eometr y; 3. dose-efficient imaging via P oisson likelihood at ∼ 10 4 photons/frame; 4. an order -of-magnitude impro vement in data efficiency ov er a super vised baseline with the same network architecture. In this study all reconstructions are performed in o v erlap-free single-shot mode, e x cept in e xplicitl y labeled o v erlap ablations. 2. Methods and Arc hitecture 2.1. F or mulation and F orward Model W e lear n an inv erse map 𝐺 : 𝑋 → 𝑌 from diffraction space to real space and optimize it b y composing with a differentiable f or ward model 𝐹 : 𝑌 → 𝑋 . The o verall autoencoder is 𝐹 ◦ 𝐺 , trained to match measured diffraction statistics without ground-truth images. Data model and notation. Eac h training sample comprises 𝐶 𝑔 diffraction amplitude images { 𝑥 𝑘 } 𝐶 𝑔 𝑘 = 1 acquired at probe coordinates { ® 𝑟 𝑘 } 𝐶 𝑔 𝑘 = 1 . The netw ork 𝐺 ( 𝑥 , 𝑟 ) outputs 𝐶 𝑔 comple x object patches { 𝑂 𝑘 } 𝐶 𝑔 𝑘 = 1 on an 𝑁 × 𝑁 g r id. W e use: • T Δ ® 𝑟 [ ·] : real-space translation by Δ ® 𝑟 , • Pad [ ·] : zero-padding to a canv as lar g e enough to contain all translated patches, • Pad 𝑁 / 4 [ ·] : zero-padding that embeds a central 𝑁 / 2 × 𝑁 / 2 tile into an 𝑁 × 𝑁 gr id, (a) Idealized — CDI (b) Idealized — Ptyc ho (c) Semi-synthetic — CDI (d) Semi-synthetic — Ptyc ho Fig. 1. Reconstruction comparison across probe types and acquisition modes. Ro ws: idealized probe (Gaussian-smoothed disk, uniform phase) vs semi-synthetic (experi- mental probe, synthetic object). Columns: single-shot CDI v s o v erlapped ptychograph y . • Crop 𝑁 [ ·] : center -cropping to 𝑁 × 𝑁 , • 1 : an all-ones ar ray of appropriate size, • ⊙ : elementwise (Hadamard) product. Constraint map ( 𝐹 𝑐 ): translation-aw are merging. T o enf orce o ver lap consistency , per -patch reconstructions are merg ed in a translation-aligned frame: 𝑂 region ( ® 𝑟 ) = Í 𝐶 𝑔 𝑘 = 1 T − ® 𝑟 𝑘 [ Pad ( 𝑂 𝑘 ) ] Í 𝐶 𝑔 𝑘 = 1 T − ® 𝑟 𝑘 [ Pad ( 1 ) ] + 𝜖 , 𝜖 = 10 − 3 . (1) This "translational pooling” applies to arbitrary scan geometries. Coordinate-a war e grouping. T raining groups are f ormed locally by neares t-neighbor sampling. For each anchor ® 𝑟 𝑖 , let N 𝐾 ( ® 𝑟 𝑖 ) be its 𝐾 nearest distinct neighbors. A group G 𝑖 , 𝑗 dra ws 𝐶 𝑔 − 1 neighbors uniformly without replacement: G 𝑖 , 𝑗 = { ® 𝑟 𝑖 } ∪ 𝑆 𝑖 , 𝑗 , 𝑆 𝑖 , 𝑗 ⊂ N 𝐾 ( ® 𝑟 𝑖 ) , | 𝑆 𝑖 , 𝑗 | = 𝐶 𝑔 − 1 , repeated 𝑛 samples times per anc hor . If duplicate neighbor sets are disallo w ed, the effective number of distinct groups per anchor is 𝑛 eff = min 𝑛 samples , 𝐾 𝐶 𝑔 − 1 , so the total number of training examples is 𝑁 scan × 𝑛 eff , with the combinator ial upper bound 𝑁 scan 𝐾 𝐶 𝑔 − 1 . Choosing 𝑛 samples > 1 augments the dataset through combinator ial re-g rouping while preser ving local spatial consistency . Coordinates within each group are expressed in a stable local frame by re-centering to the group centroid ® 𝑟 global = 1 𝐶 𝑔 𝐶 𝑔 𝑘 = 1 ® 𝑟 𝑘 , ® 𝑟 rel 𝑘 = ® 𝑟 𝑘 − ® 𝑟 global . Diffraction map ( 𝐹 𝑑 ): coherent scattering. Giv en 𝑂 region , the 𝑘 th translated object patch and e xit wa v e are 𝑂 ′ 𝑘 ( ® 𝑟 ) = Crop 𝑁 h T ® 𝑟 rel 𝑘 𝑂 region i , (2) Ψ 𝑘 = F 𝑂 ′ 𝑘 ( ® 𝑟 ) · 𝑃 ( ® 𝑟 ) , (3) where 𝑃 ( ® 𝑟 ) is the (estimated) probe and F is the 2D Fourier transf or m. Predicted detector -plane amplitudes include a global intensity scale 𝑒 𝛼 log that links normalized network outputs to ph y sical photon counts: ˆ 𝐴 𝑘 = | Ψ 𝑘 | 𝑒 𝛼 log . (4) 2.2. Data Preprocessing A dataset consists of diffraction images from one or more objects measured with a fix ed probe illumination 𝑃 . After grouping imag es into samples of 𝐶 𝑔 diffraction patterns eac h (Section 2.1), w e normalize the raw diffraction amplitudes to ensure f a v orable neural net activ ation magnitudes during training: 𝑥 𝑘 = 𝑥 ′ 𝑘 · ( 𝑁 / 2 ) 2 Í 𝑖 , 𝑗 | 𝑥 ′ 𝑖 𝑗 | 2 , (5) where 𝑥 ′ denotes raw measurements and the av erage is ov er all imag es in the dataset. This c hoice ensures order -unity activations in the neural network: b y Parse val’ s theorem, unit-amplitude real-space objects produce diffraction pow er of appro ximately 𝑁 2 / 4 , so this normalization maps e xperimental amplitude images to internal activations of order unity . A dditionally , w e introduce a trainable scalar 𝛼 log that conv erts between the dimensionless internal model activations and absolute per -pixel integrated amplitudes. The final, scaled, netw ork input is 𝑥 in = 𝑥 · 𝑒 − 𝛼 log . 2.3. Neural Network Architecture The inv erse map 𝐺 f ollo ws an encoder–decoder design (as in [22]; see also [23] f or a PyT orch implementation and nov el training procedures), conditioned on { 𝑥 𝑘 } 𝐶 𝑔 𝑘 = 1 and { ® 𝑟 rel 𝑘 } 𝐶 𝑔 𝑘 = 1 , and outputs comple x patches { 𝑂 𝑘 } 𝐶 𝑔 𝑘 = 1 . T o respect ov ersampling while a v oiding probe tr uncation artifacts, the decoder allocates most capacity to the central, w ell-posed region and a lightw eight continuation to the periphery . Handling extended probes. Con volutional neural network (CNN) arc hitectures are limited to modest dimensions ( 𝑁 ≤ 128 ) because con v olutional receptiv e fields capture long-range interactions only inefficiently in this F ourier in v ersion setting, and we must further more res trict high-resolution reconstruction to the central 𝑁 / 2 × 𝑁 / 2 region to satisfy ov ersampling conditions [24]. Probes with e xtended tails f orce inefficient use of this limited number of pixels because the real-space area br ightly illuminated b y the probe is small compared to the total probe area that mus t be represented to av oid truncation ar tifacts from non-zero amplitude at the edge of the real-space g r id. Consequentl y , given the modes t magnitude of 𝑁 , fully inscribing the probe—tails in- cluded—within the central 𝑁 / 2 × 𝑁 / 2 pix els may require too much binning. This causes a dilemma: one must choose between truncation ar tifacts (and possible lack of conv erg ence due to the associated phy sical inconsistency) and violation of the diffraction-space ov ersampling condition for coherent imaging. W e resolv e this b y reconstructing the object in high resolution in the central 𝑁 / 2 × 𝑁 / 2 region of the real-space gr id and low resolution in the per iphery . Presuming the absence of high spatial frequency components in the probe tail, extending the probe times object reconstruction into the peripher y does not compromise well-posedness of the inv erse problem. Concretely , w e split the penultimate decoder la y er’ s c hannels into a ma jority set f or the central region and the remaining 4 channels to coarsely reconstr uct the per iphery: 𝑂 amp = Pad 𝑁 / 4 𝜎 𝐴 ( Conv ( 𝐻 central 𝐴 ) ) + 𝜎 𝐴 ( ConvU p ( 𝐻 border 𝐴 ) ) ⊙ 𝑀 border , (6) 𝑂 phase = Pad 𝑁 / 4 𝜋 tanh ( Con v ( 𝐻 central 𝜙 ) ) + 𝜋 tanh ( Con vUp ( 𝐻 border 𝜙 ) ) ⊙ 𝑀 border , (7) 𝑂 𝑘 = 𝑂 amp · e xp 𝑖 𝑂 phase , (8) where 𝐻 central { · } targ ets the central region, 𝐻 border { · } (the last 4 channels) produces a low -resolution continuation, and 𝑀 border is a binary mask that isolates the boundar y contr ibutions to the outer region. This modification av oids ar tifacts from truncation of the exit wa v e and enables stable reconstruction with experimentall y-realis tic probes. 2.4. T r aining Objective and Optimization P oisson negativ e log-lik elihood (NLL). The training procedure optimizes the in v erse map 𝐺 using a negativ e log-likelihood loss under Poisson statistics: L Poiss = − 𝑘 , 𝑖 , 𝑗 log 𝑓 Poiss ( 𝑁 𝑘 𝑖 𝑗 ; 𝜆 𝑘 𝑖 𝑗 ) = 𝑘 , 𝑖 , 𝑗 𝜆 𝑘 𝑖 𝑗 − 𝑁 𝑘 𝑖 𝑗 log 𝜆 𝑘 𝑖 𝑗 , (9) where 𝑁 𝑘 𝑖 𝑗 = | 𝑥 ′ 𝑘 𝑖 𝑗 | 2 is the measured photon count and 𝜆 𝑘 𝑖 𝑗 = | ˆ 𝐴 𝑘 𝑖 𝑗 | 2 is the predicted count. Since the network operates on normalized inputs (Eq. 5) f or numer ical stability , a scale parameter 𝑒 𝛼 log bridges nor malized and phy sical units. When the mean photon flux 𝑁 photons is kno wn, we initialize: 𝑒 𝛼 log ← 2 𝑁 photons 𝑁 . (10) This ensures predicted intensities match measurement statis tics. The parameter 𝑒 𝛼 log ma y be fix ed or lear ned (see T able 3); learning it can absorb modes t calibration er rors. Amplitude loss f or unkno wn counts. For datasets lacking absolute photon counts, w e resor t to mean absolute error (MAE) on normalized amplitudes: L MAE = 𝑘 , 𝑖 , 𝑗 𝑥 𝑘 𝑖 𝑗 − ˆ 𝐴 𝑘 𝑖 𝑗 𝑒 − 𝛼 log . In the results reported here we do not use an y real-space loss; training is dr iven solely b y the diffraction-domain losses (Poisson NLL or MAE). Implementation notes. All operators in 𝐹 𝑐 and 𝐹 𝑑 are differentiable and implemented with padding-a ware translations and f ast Fourier transf or m (FFT)-based diffraction. Batching is performed ov er groups G 𝑖 , 𝑗 ; nearest-neighbor sampling with 𝑛 samples > 1 pro vides dataset augmentation while preser ving local spatial consistency . Default architectural and training h yper parameters are summarized in T able 3. 2.5. Super vised Baseline The supervised baseline uses the same encoder -decoder backbone and input representation as Pty choPINN (cf. Pty choNN [7]). It is trained with direct real-space super vision on paired diffraction/ref erence-reconstruction data, without enf orcing the differentiable f or ward model in the training loss. Data splits, nor malization, and scan-coordinate conditioning are matched to the Pty choPINN r uns so the comparison isolates training paradigm rather than architecture. 2.6. Datasets and Evaluation Protocol W e ev aluate on an APS V elociprobe Siemens-s tar dataset, an LCLS X -ra y Pump-Probe (XPP) test patter n dataset (hereafter , LCLS XPP dataset), a synthetic Siemens-s tar dataset simulated from APS Siemens-star reconstructions (ground tr uth f or T able 1), and a synthetic line-patter n dataset of randomly oriented high-aspect-ratio f eatures from [22] (used for the o ver lap ablation in T able 2). APS and LCLS e xper iments are r un in single-shot mode (one diffraction frame per group), e xcept where o v er lap ablations are e xplicitl y labeled. For the Siemens-star e xper iments, w e use a spatial holdout: the top half of the scan is used f or training and the bottom half for testing. For out-of-distribution transf er , models trained on APS data are ev aluated on LCLS data without retraining, with beamline-specific f or ward parameters (probe/geometry) substituted at inf erence. 3. Results W e report results on the APS V elociprobe Siemens-star data, the LCLS XPP dataset, the synthetic Siemens-star dataset, and the synthetic line-patter n dataset; see Methods for dataset definitions and evaluation protocol. 3.1. Reconstruction Quality Figure 2 compares reconstructions on the APS Siemens-star data across two sampling budg ets (512 and 8192 diffraction patterns), using a spatial holdout where the top half of the scan is used f or training and the bottom half f or testing. At 8192 patter ns (Fig. 2b), the supervised baseline reconstructs training-region data w ell but degrades on held-out positions, whereas Ptyc hoPINN maintains consistent quality across both. At 512 patterns, this train–test g ap widens further f or the supervised baseline. On the synthetic Siemens-star dataset (simulated from APS Siemens-star reconstructions), Pty choPINN also attains higher phase fidelity than the super vised baseline; see T able 1. T able 1. Recons truction q uality metr ics at maximum training set size (16,384 images): peak signal-to-noise ratio (PSNR) and structural similar ity index measure (SSIM). V alues shown are mean ± standard de viation across 5 trials. Best v alues per dataset are highlighted in green . PSNR (dB) SSIM Dataset Method Amplitude Phase Amplitude Phase synthetic Siemens-star Supervised baseline 84 . 83 ± 0 . 23 68 . 62 ± 0 . 02 0 . 930 ± 0 . 002 0 . 912 ± 0 . 003 Pty choPINN 85 . 53 ± 0 . 02 70 . 54 ± 0 . 06 0 . 955 ± 0 . 001 0 . 962 ± 0 . 001 3.2. Overlap-F ree Reconstr uction In o ver lap-free operation, w e set the group size to a single diffraction frame ( 𝐶 𝑔 = 1 ), remo ving o v erlap-based real-space consistency . Reconstruction then relies entirely on the diffraction likelihood and the kno wn probe structure (def ocused probe/Fresnel g eometr y). Figure 1 illustrates this single-frame mode compared with multi-position ptyc hography . Quantitativ e comparisons across o ver lap and probe-structur ing v ariants on a synthetic line-pattern dataset are summarized in T able 2 (o ver lap-free 𝐶 𝑔 = 1 vs ov erlap 𝐶 𝑔 = 4 ). With an e xper imental probe, remo ving ov erlap reduces amplitude SSIM by 0.064 (0.968 to 0.904) and PSNR by 4.14 dB (73.03 to 68.89). T able 2. Synthetic line-patter n amplitude reconstruction metrics on the test split. Ground tr uth is the simulated object (amplitude only; the object has constant zero phase). Case PSNR (dB) SSIM o v er lap-free ( 𝐶 𝑔 = 1 ) + idealized probe 60.67 0.620 o v er lap-free ( 𝐶 𝑔 = 1 ) + experimental probe 68.89 0.904 o v er lap ( 𝐶 𝑔 = 4 ) + idealized probe 71.34 0.952 o v er lap ( 𝐶 𝑔 = 4 ) + experimental probe 73.03 0.968 3.3. Photon-Limited P erformance Figure 3 compares resolution using the 50% Fourier r ing cor relation cr iter ion (FR C50) as a function of photon dose f or Poisson NLL v ersus MAE training objectives. A t lo w dose ( ∼ 10 4 photons/frame), the Poisson NLL achie v es comparable resolution to MAE at roughly 10 × higher dose, cor responding to an order-of-magnitude improv ement in dose efficiency . This advantag e ar ises because the P oisson likelihood cor rectly models photon-counting noise, preserving sensitivity to the low -count, high- 𝑞 components that car ry fine spatial detail but are o v erwhelmed b y br ight-pixel residuals under an amplitude MAE. (a) 512 diffraction patterns of the Siemens star test pattern. (b) 8192 diffraction patterns of the Siemens star test pattern. Fig. 2. Compar ison of reconstruction quality with different numbers of diffraction patterns. 3.4. Data Efficiency Figure 4 illustrates the reconstruction quality (phase SSIM) as a function of dataset size. Pty choPINN maintains high fidelity (SSIM > 0 . 85 ) from as f e w as 1024 diffraction patterns. In contrast, the super vised baseline deg rades rapidly below 2048 samples. At small training set sizes, Pty choPINN achie v es comparable quality using roughly an order of magnitude less training data. This sugg ests that the ph ysical constraints enf orced by the training procedure act as an effective pr ior f or this inv erse-imaging task. 3.5. Out-of-distribution Generalization Figure 5 compares an in-distribution LCLS control (train LCLS XPP , test LCLS XPP) with an out-of-distribution transf er setting (train APS, test LCLS XPP). Under APS → LCLS shift, the supervised baseline lar gel y collapses, whereas Ptyc hoPINN preser ves edge structure, albeit with visible phase artifacts. The reference column is an e xtended pty chographic iterative engine (ePIE) reconstruction of the LCLS data. 3.6. Computational P erformance Pty choPINN processes appro ximately 6.1k diffraction patter ns per second at 64 × 64 image resolution and 2.6k patterns per second at 128 × 128 in single-GPU inf erence measurements, MAE objective P oisson NLL objectiv e 10 9 photons 10 4 photons (a) Reconstruction compar ison at 10 9 and 10 4 photons for MAE versus Poisson NLL objectives (left: representative diffraction patter ns). (b) Resolution (FRC50) as a function of on-sample photon dose. Fig. 3. Photon-limited per f ormance for two self-super vised PtychoPINN variants trained with mean absolute er ror (MAE) and P oisson negativ e log likelihood (NLL) reconstruction penalties. Fig. 4. Structural similarity of Ptyc hoPINN and the supervised baseline as a function of training set size. e x cluding stitching/reassembl y time. As a high-per f ormance con v entional baseline, w e bench- marked LSQ-ML with pty-chi [25] at 128 × 128 (batch size 96) and measured 1.444 s per epoch o v er 10,304 frames. Assuming 100 iterations f or con v erg ence, this cor responds to 71.36 frames/s 10 , 304 / ( 100 × 1 . 444 ) . At matched 128 × 128 resolution, Pty choPINN therefore pro vides an appro ximatel y 40 × throughput adv antag e o ver LSQ-ML. 4. Discussion Overlap-free reconstruction T able 2 rev eals a clear interaction between probe structure and o v erlap. With the idealized (flat-phase) probe, removing o v erlap ( 𝐶 𝑔 = 1 ) drops amplitude SSIM from 0.952 to 0.620; with the e xper imental (curved) probe, the same chang e yields 0.968 to 0.904. Probe curvature larg ely compensates for the loss of o v erlap-based redundancy , consistent with the e xpected role of structured phase diversity in Fresnel CDI. These trends indicate that o ver lap and probe diversity are par tially substitutable sources of cons traint, but their interaction warrants further s tudy across a broader range of probe geometries. Making o v er lap a tunable parameter rather than a hard requirement has concrete implications f or e xperimental design. Scans can use fe w er positions, less o v erlap, or —in the Fresnel regime—no scanning at all, reducing acquisition time and total dose. The frame w ork is also more tolerant of position jitter than o v erlap-dependent methods, since the reconstr uction does not rely on precise inter -frame registration to enf orce real-space consistency . T ogether , these proper ties are par ticularly rele vant f or dynamic or radiation-sensitive samples at high-rate sources, where o v er lap requirements, scan precision, and photon budget are simultaneous constraints. Diffraction-space supervision The f or ward model pro vides dense ph y sical cons traint per measurement: each diffraction patter n encodes the full e xit-wa ve amplitude, and the Poisson NLL cor rectly weights ev ery detector pix el—including the low -count, high- 𝑞 pix els where fine spatial detail resides (Fig. 3). By contrast, real-space supervision constrains the netw ork ag ainst a single reference reconstruction that already car r ies the ambiguities intrinsic to the inv erse problem, suc h as global phase offsets. Out-of-Distribution (T rain A → T est B) In-Distribution (T rain B → T est B) Refer ence (ePIE) Ptyc hoPINN Supervised A APS-2-ID; B LCLS XPP; A APS-2-ID; B LCLS XPP; Fig. 5. Comparison of methods f or an in-distribution LCLS control (train LCLS XPP , test LCLS XPP) and out-of-distr ibution transfer (train APS, test LCLS XPP). The ref erence column sho ws an ePIE reconstruction of the LCLS data. Because these nuisance parameters are not uniquely deter mined by the data, a super vised netw ork can o v er fit to them, which lik ely explains both the supervised baseline’ s train–test gap on held-out scan positions (Fig. 2) and its collapse under cross-facility transfer (Fig. 5). Data efficiency f ollo ws from the same mechanism: the f orward-model constraint is f ar more informativ e per sample than a pixel-wise real-space loss, so the netw ork con v erg es with roughly an order of magnitude fe w er training patterns (Fig. 4). Open problems The main methodological limitation is the fix ed-probe assumption: the cur rent f ormulation uses a pre-estimated probe and fixed scan coordinates during training, so it does not correct probe dr ift or position er rors. A direct extension is to jointly refine probe and position parameters within the same self-super vised loop. The frame w ork is modular: inv erse backbone, differentiable f orward model, and loss are separable components. This design should allow further speedups from mixed precision and architecture-le v el optimization without changing the architecture or training procedure. At higher resolution, the dominant scaling bottlenec k is the CNN inv erse bac kbone. Replacing it with a Fourier neural operator (FN O) backbone is a likel y next step, because global spectral mixing is expected to scale better with imag e size 𝑁 and impro ve high-resolution reconstruction quality . The same modular structure should also simplify adaptation to other coherent imaging geometries, including Bragg CDI. 5. Conclusions W e presented an extended Ptyc hoPINN framew ork that unifies o v erlap-free single-shot Fresnel coherent diffraction imaging and ov erlapped ptyc hography within a single self-supervised f ormulation. The method combines a differentiable coherent-scatter ing f or w ard model with diffraction-domain training losses and supports arbitrary scan geometries through coordinate- a ware grouping. A cross APS and LCLS e xperiments, we measured appro ximatel y 6 . 1 × 10 3 diffraction patterns/s at 64 × 64 and 2 . 6 × 10 3 at 128 × 128 in single-GPU inference. In o v er lap ablations on synthetic line-pattern data with an e xper imental probe, ov erlap-free reconstr uction reached amplitude SSIM 0.904 v ersus 0.968 for o v er lap-constrained reconstruction. In photon- limited regimes, Poisson NLL training impro v ed dose efficiency by roughly an order of magnitude relativ e to MAE at comparable FR C50. Relativ e to a supervised baseline with the same backbone, the method maintained high quality with substantiall y fe wer training samples. Future work will f ocus on joint probe/position refinement and higher -capacity inv erse-mapping neural network backbones f or large-imag e reconstructions. Appendix A: Ke y Configuration P arameters These parameters control critical aspects of the reconstruction process and should be tuned based on experimental conditions and computational constraints. T able 3. Model parameters, default code values, and settings used for the APS/LCLS e xperiments in this paper Parame ter Default Description N 64 Patc h dimension (pix els) C_g 1 Patterns per group (code default: 4) K 4 Neares t neighbors f or scan-position grouping pad_object T r ue Res trict object to 𝑁 / 2 × 𝑁 / 2 f or o versampling probe.mask F alse Apply circular mask to probe gaussian_smoothing_sigma 0.0 Gaussian smoothing 𝜎 applied to probe illumination intensity_scale.trainable T r ue Whether 𝛼 log is optimized during training n_filters_scale 2 Netw ork width multiplier amp_activation sigmoid Amplitude decoder activation offset 4 Scan step size (pixels) 𝑑 3-5 Encoder depth (resolution-dependent) T able 4. Symbol definitions Symbol T ype / Structure Description 𝑥 ′ Set of 𝐶 𝑔 real images Ra w diffraction patter ns for one sample 𝑥 Set of 𝐶 𝑔 real images Normalized diffraction patterns f or one sample ® 𝑟 𝑘 2D Position V ector Absolute scan position f or the 𝑘 -th imag e within a sample ® 𝑟 global 2D Position V ector Centroid of a solution region (group of scans) ® 𝑟 rel 𝑘 2D Offset V ector Relativ e scan offset within a solution region 𝑒 𝛼 log Scalar (trainable or fix ed) Log-intensity scale parameter 𝑁 photons Scalar T arg et a v erag e total photons per diffraction pattern 𝑃 ( ® 𝑟 ) 𝑁 × 𝑁 comple x array Effectiv e probe function 𝑂 𝑘 𝑁 × 𝑁 comple x array 𝑘 -th object patc h decoded b y the netw ork 𝐺 𝑂 region 𝑀 × 𝑀 comple x array Merg ed object representation for a solution region 𝑂 ′ k 𝑁 × 𝑁 comple x array Object patch e xtracted from 𝑂 region f or forw ard model Ψ 𝑘 𝑁 × 𝑁 comple x array Predicted complex wa v efield at the detector ˆ 𝐴 𝑘 𝑁 × 𝑁 real array Predicted final diffraction amplitude f or one patch 𝜆 𝑖 𝑗 𝑘 Scalar Poisson rate parameter f or a single pix el 𝑁 : patch dimension, 𝐶 𝑔 : patches per group, 𝑀 : merged region size Funding. This w ork was supported by the U .S. Department of Energy , Laborator y Directed Research and Dev elopment program at SLA C N ational Accelerator Laborator y , under Contract N o. DE-A C02-76SF00515. Disclosures. The authors declare no conflicts of interest. Data av ailability . Data and code supporting this study are a vailable from the cor responding author upon reasonable request. The Pty choPINN source code is a vailable at https://github.com/ hoidn/Ptyc hoPINN . References 1. SLA C National Accelerator Laboratory, “LCLS-II-HE: Design and Perf ormance, ” https:// lcls.slac.stanf ord.edu/ lcls- ii- he/ design- and- per formance (2023). Accessed: 2025-08-14. 2. M. Guizar-Sicairos and P . Thibault, “Pty chograph y: A solution to the phase problem,” Ph ys. T oda y 74 , 42–48 (2021). 3. O. Bunk, M. Dierolf, S. K ynde, et al. , “Influence of the ov erlap parameter on the conv ergence of the pty chographical iterativ e engine, ” Ultramicroscopy 108 , 481–487 (2008). 4. A. M. Maiden and J. M. R odenburg, “ An improv ed ptychographical phase retrieval algorithm for diffractiv e imaging, ” Ultramicroscopy 109 , 1256–1262 (2009). 5. S. Marchesini, H. Krishnan, B. J. Daurer, et al. , “Sharp: a distr ibuted gpu-based pty chographic solv er, ” J. Appl. Crystallogr. 49 , 1245–1252 (2016). 6. A. V . Babu, T . Zhou, S. Kandel, e t al. , “Deep lear ning at the edge enables real-time streaming ptychographic imaging, ” Nat. Commun. 14 , 7059 (2023). 7. M. J. Cherukara, T . Zhou, Y . S. G. N ashed, et al. , “ Ai-enabled high-resolution scanning coherent diffraction imaging, ” Appl. Phy s. Lett. 117 , 044103 (2020). 8. C. A. Metzler, P . Schniter , A. V eeraragha van, and R. G. Baraniuk, “prdeep: Robus t phase retr iev al with a fle xible deep network, ” in Proceedings of the 35th International Confer ence on Machine Learning, vol. 80 of Proceedings of Machine Learning Researc h (2018), pp. 3501–3510. 9. A. R. C. McCray , S. M. Ribet, G. V arnavides, and C. Ophus, “ A ccelerating iterative ptyc hography with an integrated neural network, ” J. Microsc. 300 , 180–190 (2025). 10. V . Sitzmann, J. N . P . Mar tel, A. W . Bergman, e t al. , “Implicit neural representations with per iodic activ ation functions, ” in Advances in Neural Inf ormation Pr ocessing Systems, v ol. 33 (2020), pp. 7462–7473. 11. M. Du, T . Zhou, J. Deng, et al. , “Predicting ptyc hography probe positions using single-shot phase retrieval neural netw ork, ” Opt. Express 32 , 36757–36780 (2024). 12. W . Gan, Q. Zhai, M. T . McCann, et al. , “Pty chodv: Vision transformer -based deep unrolling network f or ptychographic image reconstruction, ” IEEE Open J. Signal Process. 5 , 539–547 (2024). 13. Y . Y ao, H. Chan, S. K. R. S. Sankaranaray anan, et al. , “ Autophasenn: unsuper vised phy sics-aw are deep lear ning of 3d nanoscale bragg coherent diffraction imaging, ” npj Comput. Mater. 8 , 124 (2022). 14. P . Thibault and M. Guizar-Sicairos, “Maximum-likelihood refinement f or coherent diffractiv e imaging, ” New J. Ph y s. 14 , 063004 (2012). 15. J. P . Seifert, Z. Chen, M.-J. Y oon, et al. , “Maximum-likelihood ptyc hography in the presence of poisson–gaussian noise, ” Opt. Lett. 48 , 4897–4900 (2023). 16. G. J. Williams, H. M. Quine y , B. B. Dhal, et al. , “Fresnel coherent diffractive imaging, ” Phy s. Rev. Lett. 97 , 025506 (2006). 17. M. Stockmar , P . Cloetens, I. Zanette, et al. , “Near -field ptyc hography : phase retriev al for inline holography using a structured illumination, ” Sci. R epor ts 3 , 1927 (2013). 18. P . Sidorenk o and O. Cohen, “Single-shot pty chograph y , ” Optica 3 , 9–14 (2016). 19. K. Khar itonov , M. Mehr joo, M. Ruiz-Lopez, et al. , “Single-shot pty chography at a soft x-ray free-electron laser, ” Sci. Reports 12 , 14430 (2022). 20. F . Zhang, I. P eterson, J. Vila-Comamala, et al. , “Phase retriev al by coherent modulation imaging, ” Nat. Commun. 7 , 13367 (2016). 21. X. Dong, X. Pan, C. Liu, and J. Zhu, “Single shot multi-w a velength phase retrieval with coherent modulation imaging, ” Opt. Lett. 43 , 1762–1765 (2018). 22. O. Hoidn, A. A. Mishra, and A. Mehta, “Ph ysics constrained unsupervised deep learning for rapid, high resolution scanning coherent diffraction reconstruction, ” Sci. Reports 13 , 22789 (2023). 23. A. V ong, S. Henk e, O. Hoidn, et al. , “T ow ards generalizable deep pty chograph y neural netw orks, ” arXiv abs/2509.25104 , 1–1 (2025). 24. J. Miao, P . Charalambous, J. Kirz, and D. Sayre, “Extending the methodology of x-ray crystallograph y to allo w imaging of micrometre-sized non-crystalline specimens, ” Nature 400 , 342–344 (1999). 25. M. Du, H. R uth, S. Henke, et al. , “Pty -chi: A pytorch-based modern ptyc hographic data analy sis packag e, ” arXiv abs/2510.20929 , 1–1 (2025).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment