Calorimeter Shower Superresolution with Conditional Normalizing Flows: Implementation and Statistical Evaluation
In High Energy Physics, detailed calorimeter simulations and reconstructions are essential for accurate energy measurements and particle identification, but their high granularity makes them computationally expensive. Developing data-driven technique…
Authors: Andrea Cosso
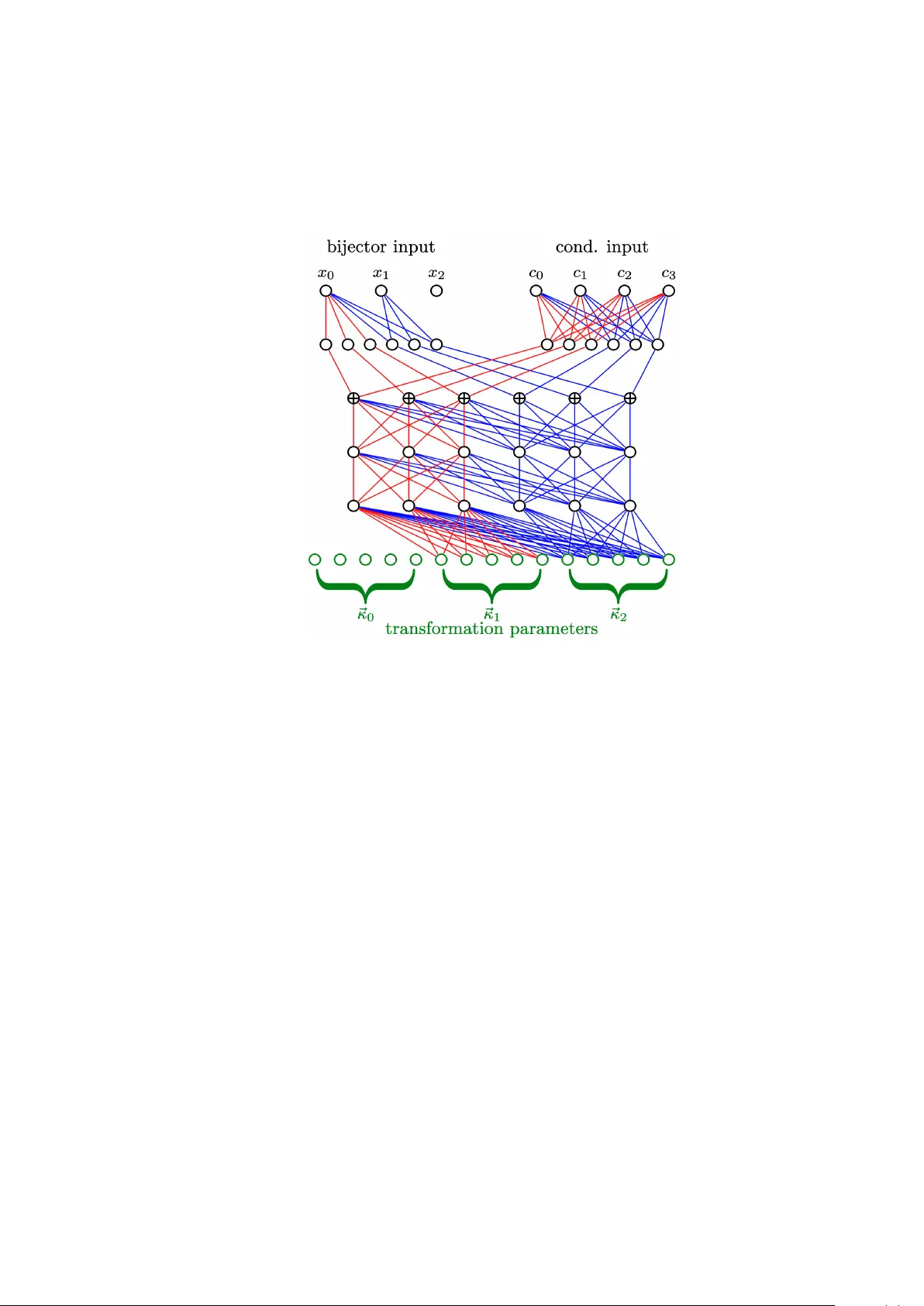
Universit à degli Studi di Geno v a Scuola di Scienze Ma tema tiche, Fisiche e Na turali La urea Magistrale in Fisica Calo rimeter Sho w er Sup erresolution with Conditional no rmalizing Flo ws: Implementation and Statistical Evaluation Candidato Andrea Cosso Relatori Dott. Riccardo T orre Dott. Marco Letizia Correlatore Dott. Andrea Co ccaro Anno a ccademico 2024/2025 Contents Abstract . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . vi In tro duction 1 1 Mac hine Learning Essen tials 6 1.1 Mac hine Learning in Ph ysics . . . . . . . . . . . . . . . . . . . . . 6 1.1.1 The three paradigms of mac hine learning . . . . . . . . . . 6 1.1.2 Data discussion . . . . . . . . . . . . . . . . . . . . . . . . 8 1.1.3 Statistical learning . . . . . . . . . . . . . . . . . . . . . . 9 1.1.3.1 The Loss function . . . . . . . . . . . . . . . . . 9 1.1.3.2 An introduction to the statistical mo del . . . . . 11 1.2 In tro duction to neural net works . . . . . . . . . . . . . . . . . . . 22 1.2.1 P erceptron . . . . . . . . . . . . . . . . . . . . . . . . . . . 22 1.2.2 Multi-la yer p erceptron . . . . . . . . . . . . . . . . . . . . 24 2 F rom Generation to V alidation: Principles and Ev aluation Met- rics 26 2.1 Generativ e mo dels in ph ysics . . . . . . . . . . . . . . . . . . . . . 26 2.2 Normalizing Flows: F ormalism and Overview . . . . . . . . . . . . 33 2.2.1 The core idea . . . . . . . . . . . . . . . . . . . . . . . . . 33 2.2.2 The formalism of normalizing Flo ws . . . . . . . . . . . . . 33 2.2.3 Coupling and A utoregressive flo ws . . . . . . . . . . . . . . 36 2.3 Mask ed A utoregressive Flo w (MAF) . . . . . . . . . . . . . . . . . 39 2.3.1 MADE: Masked A uto enco der for Distribution Estimation . 41 2.3.2 Rational Quadratic Spline (RQS) . . . . . . . . . . . . . . 45 2.4 Ev aluating Generativ e Mo dels . . . . . . . . . . . . . . . . . . . . 47 2.4.1 T w o-sample h yp othesis testing . . . . . . . . . . . . . . . . 49 2.4.2 T est statistics . . . . . . . . . . . . . . . . . . . . . . . . . 51 ii 2.4.2.1 Sliced W asserstein distance . . . . . . . . . . . . 51 2.4.2.2 K olmogorov-Smirno v (KS) inspired test statistics 52 2.4.2.3 Maxim um Mean Discrepancy (MMD) . . . . . . 54 2.4.2.4 F réc het Gaussian Distance (F GD) . . . . . . . . . 55 2.4.2.5 Lik eliho o d-ratio . . . . . . . . . . . . . . . . . . . 55 3 Calorimeter Ph ysics and Detector Principles 57 3.1 Electromagnetic calorimetry . . . . . . . . . . . . . . . . . . . . . 60 3.1.1 In teraction with matter . . . . . . . . . . . . . . . . . . . . 60 3.1.2 Electron-Photon cascades . . . . . . . . . . . . . . . . . . 60 3.1.3 Homogeneous calorimeters . . . . . . . . . . . . . . . . . . 63 3.1.4 Sampling calorimeters . . . . . . . . . . . . . . . . . . . . 63 3.2 Hadron calorimetry . . . . . . . . . . . . . . . . . . . . . . . . . . 63 3.2.1 Hadronic show ers . . . . . . . . . . . . . . . . . . . . . . . 64 3.3 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64 3.4 Calorimeter sup erresolution . . . . . . . . . . . . . . . . . . . . . 66 4 Implemen tation and Exp erimen tal Setup 68 4.1 Dataset Description . . . . . . . . . . . . . . . . . . . . . . . . . . 68 4.1.1 The dataset . . . . . . . . . . . . . . . . . . . . . . . . . . 68 4.2 Building the datasets . . . . . . . . . . . . . . . . . . . . . . . . . 70 4.2.1 The vo xelization . . . . . . . . . . . . . . . . . . . . . . . 70 4.2.2 Conditional inputs . . . . . . . . . . . . . . . . . . . . . . 72 4.2.3 Prepro cessing steps . . . . . . . . . . . . . . . . . . . . . . 73 4.3 Arc hitecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74 4.4 T raining Strategy . . . . . . . . . . . . . . . . . . . . . . . . . . . 78 4.4.1 Hardw are and Softw are Environmen t . . . . . . . . . . . . 78 4.4.2 Loss F unction . . . . . . . . . . . . . . . . . . . . . . . . . 80 4.4.3 Optimizer and Learning Rate Sc hedule . . . . . . . . . . . 80 4.5 Ev aluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81 4.6 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88 4.6.1 T raining results . . . . . . . . . . . . . . . . . . . . . . . . 88 4.6.2 Qualitativ e comparison of generated and reference show ers 90 4.6.3 Statistical ev aluation . . . . . . . . . . . . . . . . . . . . . 91 4.6.3.1 Results at full dimensionality . . . . . . . . . . . 92 4.6.3.2 Ph ysically inspired observ ables . . . . . . . . . . 97 iii 5 Lessons Learned and What Comes Next 100 5.1 Summary of Findings . . . . . . . . . . . . . . . . . . . . . . . . . 100 5.2 Ph ysics Implications . . . . . . . . . . . . . . . . . . . . . . . . . 102 5.3 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103 5.4 Outlo ok and F uture W ork . . . . . . . . . . . . . . . . . . . . . . 104 A ckno wledgemen ts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107 A More on Loss F unctions 109 B Second order optimizer: The Newton-Raphson metho d 112 C Use of AI-assisted to ols 114 iv Abstract In High Energy Ph ysics, detailed calorimeter sim ulations and reconstructions are essen tial for accurate energy measuremen ts and particle identification, but their high gran ularity mak es them computationally exp ensive. Dev eloping data-driven tec hniques capable of recov ering fine-grained information from coarser readouts, a task kno wn as calorimeter sup erresolution, offers a promising w a y to reduce b oth computational and hardware costs while preserving detector p erformance. This thesis in vestigates whether a generativ e mo del originally designed for fast sim ulation can b e effectiv ely applied to calorimeter sup erresolution. Sp ecifically , the model prop osed in Ref. [1] is re-implemen ted independently and trained on the CaloChallenge 2022 dataset based on the Gean t4 Par04 calorimeter geometry . Finally , the mo del’s performance is assessed through a rigorous statistical ev aluation framew ork, following the metho dology introduced in Ref. [2], to quan- titativ ely test its abilit y to repro duce the reference distributions. vi Intro duction In High Energy Physics (HEP), the Large Hadron Collider (LHC) plays a cen tral role in testing the predictions of the Standard Mo del and exploring p ossible signs of new physics. Bridging theoretical predictions and exp erimental observ ations requires highly detailed simulations grounded in first-principles physics. In this con text, HEP relies extensiv ely on sim ulations, follo wing a complex pip eline that encompasses even t generation, detector sim ulation, and reconstruction. Detector in teractions are typically mo deled with high-precision Mon te Carlo tec hniques, most notably implemen ted in Geant4 [3]. Because the accuracy of man y LHC measuremen ts dep ends on suc h sim ulations, the increased data volume an tici- pated in future runs will significantly raise the demand for syn thetic even ts and, consequen tly , for computational resources. This gro wing need is exp ected to b e- come a ma jor computational bottleneck in the near future [4–6]. Indeed, the High Luminosity LHC (HL-LHC), whic h will commence op eration in 2030, will increase the luminosit y by a factor of 10, from an in tegrated luminosity of appro ximately ≃ 300 fb − 1 (in Run 3) to L ≃ 3000 fb − 1 [7], dramatically increasing the need for computational resources (see Figure 1). A ma jor part of the computational p ow er go es in to the detector response simulation, particularly that of the calorimeter. In fact, calorimeters are esp ecially computationally demanding due to the high n umber of secondary particles that must b e trac ked and simulated. Therefore, in recent years, with the dev elopmen t of adv anced machine learning techniques, there has b een a gro wing in terest in developing faster calorimeter sim ulations. A t presen t, most fast calorimeter simulations are based on parametrized calorimeter resp onses, th us b ypassing the computationally heavy Geant4 simulations. The problem with these algorithms is that they lac k the fidelity needed to meet the precision requirements of HEP measurements [8–10]. F or this reason, there is a strong global effort to develop new generativ e models capable of addressing the curren t and future c hallenges of detector sim ulation [11]. 1 Intro duction 2 Efficien t sup er-resolution metho ds can offer an alternativ e path: instead of p erforming full fine-granularit y simulations, one can simulate at a coarser dis- cretization and then “upsample” to fine resolution using learned mo dels. This reduces simulation cost, memory usage, and data v olume while reco vering (or appro ximating) the physics fidelit y of fine segmen tation. Preserving fine-grained detector information is essen tial for the accurate re- construction and iden tification of particles from detector signatures, which form the basis of all ph ysics analyses. T o illustrate the imp ortance of calorimeter gran ularity , we can consider an example in tro duced in Ref. [12], inv olving single high-energy photons at the LHC, of great interest for precision measurements in Quantum Chromodynamics (QCD) and Electro weak theory [13]. At hadron colliders, the main background source for photons is the electromagnetic decay of high-energy mesons, most frequently π 0 → γ γ , since neutral pions are com- monly pro duced in hadronic in teractions. The signature of such decays at high- energy is often measured as a “fak e single photon” due to the large Loren tz b o ost, whic h results in a small separation b et ween the tw o photons. Resolving the tw o distinct signals from the decay of a single meson requires high spatial resolu- tion, ac hieved b y increasing the calorimeter segmen tation. This is not alwa ys p ossible, since increasing granularit y en tails significan t tec hnical and financial c hallenges. Indeed, high-gran ularity (HG) directly translates into more readout c hannels, more electronics, higher data rates, increased co oling and p o wer re- quiremen ts, more material, and greater calibration effort, thus making the costs of HG calorimeters prohibitive [14]. Beyond this example, man y physics anal- yses rely on subtle features of calorimeter show ers, such as energy fractions in la yers, cluster substructure, the identification of o v erlapping sho w ers, and similar observ ables [12]. Therefore, sup er-resolution can offer a solution b y virtual ly in- creasing the calorimeter resolution without physically adding c hannels, leading to b etter p erformance in ph ysics tasks such as impro ved particle iden tification (ID), more accurate reconstruction of ob jects (photons, π 0 , jets), enhanced energy and p osition resolution, and reduced systematic uncertainties. Another important application of sup er-resolution arises in the con text of aging calorimeters. In real exp eriments, detectors inevitably age, front-end elec- tronics degrade, calibrations drift, and gran ularit y may effectiv ely degrade. With time and radiation, cells may fail (dead channels) or b e disabled due to high lev els of noise or false hits that contaminate the measuremen ts [15–17]. In this context, Intro duction 3 a sup er-resolution mo del trained to reconstruct fine-grained sho w er structures from coarse or incomplete data could, in principle, b e used to fill in or recov er the missing energy pattern in dead or disabled regions. Suc h an approac h would offer significant benefits, including the reco v ery of otherwise lost information, mitigation of p erformance degradation in aging detectors, and the con tinued use of partially degraded calorimeter sections without ma jor recalibration or replace- men t. Finally , lo oking ahead to the High-Luminosit y LHC (HL-LHC), pile-up may b ecome a critical issue [18]. In a proton–proton collider like the LHC, protons are group ed in bunc hes containing roughly 10 11 protons each. These bunc hes cross each other ev ery 25 ns at the interaction p oin ts (A TLAS, CMS, etc.). Each time t wo bunches cross, more than one proton–proton in teraction can o ccur. All these interactions o ccur within the same detector readout windo w, causing their signals to o verlap. This phenomenon, known as pile-up, refers to the o v erlap of signals from multiple interactions o ccurring in the same or neighboring bunc h crossings. During R un 2 at the LHC, the av erage pile-up w as appro ximately 32 [19, 20], while for Run 3 the v alue was appro ximately 60 [21]. A t the HL- LHC, the av erage num b er of interactions p er bunc h crossing is exp ected to reach 140 to 200 [18], greatly increasing reconstruction complexit y . Sup er-resolution, b y virtual ly increasing the calorimeter resolution, can b ecome a p ow erful to ol to impro ve reconstruction p erformance. In this thesis, w e indep endently replicate the generative mo del in tro duced in Ref. [1] in resp onse to the F ast Calorimeter Simulation Chal lenge (CaloChal- lenge) initiated in 2022 [11], a comm unity challenge for fast calorimetry simula- tion. P articipants were task ed with training their preferred generativ e mo dels on the pro vided calorimeter show er datasets, with the goal of accelerating and ex- panding the dev elopmen t of fast calorimeter sim ulations, while providing common b enc hmarks and a shared ev aluation pip eline for fair comparison. The idea explored in Ref. [1] was to use auxiliary mo dels to generate a coarse represen tation of a calorimeter sho w er and implement a super-resolution algo- rithm to upsample the sho w ers to their fine-grained represen tation. In this con- text, our goal is to replicate only the final upsampling mo del, implemen ted as a Normalizing Flow [22, 23] using R ational Quadr atic Spline transformations [24]. The mo del has b een trained on the dataset pro vided by the CaloChal lenge , sp ecif- ically on Dataset 2 , whic h w as generated with the Par04 example of Geant4 . Intro duction 4 The model is then ev aluated follo wing the metho dology in tro duced in Ref. [2]. In the scientific domain, where high levels of precision and accuracy are required, v alidation presents critical c hallenges. Many existing v alidation metho ds lac k a rigorous statistical foundation, making it difficult to provide robust and reli- able ev aluations. The high precision required in HEP , where accurate mo deling of features, correlations, and higher-order momen ts is essen tial, demands robust p erformance assessment of generative mo dels. T wo-sample h yp othesis testing pro vides a natural statistical framework for p erformance ev aluation. Reference [2] prop oses a robust metho dology for ev aluating tw o-sample tests, fo cusing on non-parametric tests based on univ ariate in tegral probabilit y measures (IPMs). The approach extends 1D-based tests, suc h as the Kolmogoro v–Smirno v [25, 26] or W asserstein distance [27, 28], to higher dimensions by a v eraging or slicing (i.e. pro jecting data onto random directions on the unit sphere). The recen tly pro- p osed unbiased F réchet Gaussian Distance (F GD) [29, 30] and Maximum Mean Discrepancy (MMD) [31, 32] are also included. Reference [2] addressed the c hal- lenges p osed b y state-of-the-art ev aluation models, suc h as their low scalability to higher dimensions and the difficulty of assessing the p erformance of classifier- based ev aluations. The structure of this thesis follows a progressiv e path from the general con- cepts of Machine Learning to their concrete application in calorimeter sho wer mo deling and statistical ev aluation. In Chapter 1, the fundamen tal ideas of Mac hine Learning are introduced, with a particular fo cus on their relev ance in Ph ysics. The main paradigms of learning are presen ted together with an ov erview of neural net w orks, establishing the basis for the more adv anced arc hitectures dis- cussed in the follo wing c hapters. Building on these notions, Chapter 2 explores the principles of generative mo deling in HEP , describing the main families of generativ e mo dels and fo cusing on Normalizing Flows as the cen tral framew ork adopted in this work. The mathematical form ulation of flow-based mo dels is dis- cussed in detail, with emphasis on the Maske d A utor e gr essive Flow (MAF) and the R ational Quadr atic Spline (R QS) transformations used throughout the thesis. The same c hapter also in tro duces the statistical ev aluation framework emplo yed to assess mo del p erformance. The focus then shifts, in Chapter 3, to the ph ysical and exp erimental con text of calorimetry at the Large Hadron Collider (LHC). The w orking principles of electromagnetic calorimeters are describ ed together with their role in HEP ex- Intro duction 5 Figure 1: Projected CPU requirements. Left: Atlas [33] Right: CMS [34] p erimen ts, leading to the definition of the c alorimeter shower sup er-r esolution problem that motiv ates this researc h. Subsequently , Chapter 4 presents the prac- tical realization of the prop osed approac h, detailing the dataset used (Dataset 2 from the CaloChallenge 2022), the prepro cessing and conditional input form u- lation, and the arc hitecture of the implemen ted conditional MAF mo del. The training pro cedure, h yp erparameter configuration, and n umerical considerations are also discussed to pro vide a complete picture of the experimental setup. Fi- nally , Chapter 5 summarizes the main findings and lessons learned, highlighting the implications of the results for future developmen ts in fast calorimeter sim- ulation and possible directions for extending this work tow ard more adv anced generativ e mo deling frameworks in HEP . Chapter 1 Machine Lea rning Essentials 1.1 Machine Lea rning in Physics Mac hine learning, a branc h of artificial in telligence, fo cuses on dev eloping algo- rithms that enable systems to learn patterns directly from data. The central idea is to design mo dels capable of generalizing knowledge gained from previous examples to unseen situations. While the sp ecific ob jectives dep end on the appli- cation domain, the task, and the data represen tation, the main goal is to p erform meaningful operations without b eing explicitly programmed for eac h case. In recen t y ears, with the increase in computational p ow er, adv ances in algorithms, and an explosion of av ailable data, machine learning has b ecome an imp ortant part of the scien tific landscap e and beyond. In High Energy Ph ysics, for exam- ple, it is emplo yed in a wide range of tasks, including particle identification, ev en t classification, and fast detector sim ulation. This section is based on Ref. [35]. 1.1.1 The three pa radigms of machine lea rning Learning can b e classified in three main categories, or paradigms. In this section w e presen t an in tro duction to these categories pro viding some of their applications in physics. Sup ervised lea rning Sup ervised learning relies on data that is lab ele d , which means that each p oin t in the dataset x is asso ciated with a known target y . The mo del then tries to learn a function y = f ( x ) . Classical examples of sup ervised learning tasks in physics 6 Chapter 1. Machine Lea rning Essentials 7 include: • Regression : Predicting contin uous v alues, suc h as estimating the energy dep osition in a calorimeter based on the particle’s v elo city and type. • Classification : Assigning data p oin ts to discrete categories, suc h as classi- fying particles into t yp es (e.g., electron vs. photon) based on their detector resp onse. • Time series forecasting : Predicting the future b eha vior of ph ysical sys- tems, suc h as forecasting the p ositions of a particle in a magnetic field using historical data. • Generation and sampling : Generating new ph ysical ev en t data that resem bles real-world data, suc h as sim ulating particle in teractions in a de- tector based on learned distributions. Unsup ervised lea rning Unsup ervised learning uses only the data x without an y target, so an unsup er- vised algorithm attempts to learn properties from the distribution of x . Common tasks for unsup ervised learning in physics include: • Densit y estimation : Estimating the underlying probabilit y distribution of particle energies or momen ta, for example, learning the distribution of cosmic ray in tensities in different regions of space. • Anomaly detection : Identifying unusual even ts in detector data, suc h as detecting anomalous particle in teractions that do not conform to exp ected ph ysics mo dels. • Generation and sampling : Generating new samples of ph ysical ev ents, suc h as pro ducing syn thetic ev ents for Mon te Carlo sim ulations or generat- ing data sim ulating the b ehavior of new particles. • Imputation of missing v alues : Filling in missing data caused by sensor failures or incomplete measurements, suc h as predicting the missing hit data within a detector grid based on neigh b oring readings. • Denoising : Removing noise from experimental data, suc h as cleaning up noisy signals in a particle’s tra jectory reconstructed from detector hits. Chapter 1. Machine Lea rning Essentials 8 • Clustering : Grouping similar even ts or particles based on their c haracter- istics, such as clustering ev ents in a detector based on energy dep osits and spatial arrangement (e.g., hadron vs. electron sho wers). Reinfo rcement lea rning Reinforcemen t learning mimics the trial-and-error pro cess humans use to learn tasks, b y training soft w are agen ts to mak e decisions that optimize an ob jective. Ev ery action that w orks to w ard the goal is reinforced, while actions opp osing the goal are ignored. While the first tw o paradigms are well explored in physics, reinforcement learning is less common and still under exploration. 1.1.2 Data discussion One of the cornerstones of the success of machine learning algorithms is the a v ailabilit y and quality of data. In this section, w e briefly discuss these asp ects within the scien tific domain. A fundamental distinction can b e made b et ween observational and exp erimental sciences. Observ ational sciences In these fields, the amount of av ailable data is often limited b y external constraints. F or example, in medicine, statistical limitations and priv acy regulations restrict data accessibilit y , while in astronom y or clima- tology , the quantit y and qualit y of data dep end on the duration, frequency , and precision of observ ations, as well as on the nature of the systems b eing studied. Exp erimen tal sciences In contrast, exp erimen tal sciences are primarily lim- ited b y our abilit y to pro duce and collect data. Examples include the luminosit y ac hiev able at a particle collider or the p erformance of the detector technology used for data acquisition. Since the exp erimen tal apparatus is designed and con- trolled b y the exp erimenter, it can, to some exten t, b e optimized to maximize the amount and quality of collected data. Chapter 1. Machine Lea rning Essentials 9 1.1.3 Statistical learning The term statistic al le arning does not ha ve a single, univ ersally accepted defi- nition. In this thesis, it refers to the branch of machine learning grounded in statistical theory and inference. Historically , mac hine learning has b een primar- ily concerned with prediction, whereas statistics has emphasized inference and uncertain ty quan tification. Statistical learning thus represen ts the intersection of these t wo p ersp ectives, combining principles from statistics, computer science, and data science. In this section, we in tro duce the main concepts, metho ds, and c hallenges of statistical learning, together with the fundamental comp onen ts of learning algorithms. 1.1.3.1 The Loss function One of the basic assumptions of statistical learning is that every learning pro cess can b e form ulated as an optimization problem, usually in terms of the mini- mization of one or more obje ctive functions , called L oss or Cost functions. The ob jectiv e functions usually dep end on the data { ( x i , y i ) } , mo del f ( · ; θ ) and pa- rameters θ . The follo wing discussion fo cuses on the sup ervised learning case for simplicit y , although the same principles can b e extended to unsup ervised settings. The loss function (or simply loss ) should give a measure of the distance be- t ween the true output and the observ ed one in case of sup ervised learning, a measure of ho w w ell the mo del is describing the underlying data distribution in unsup ervised learning, or it can b e something more complex suc h as a cum ulative score function in case of reinforcemen t learning. The loss function should satisfy t wo k ey requiremen ts: • Should b e as simple as p ossible to ev aluate and minimize, since computa- tional efficiency is imp ortant. • Should b e as close as possible to the figur e of merit that one aims to optimize for the giv en problem. The choice of the loss function is a crucial asp ect in the result of the learning task, since differen t n umerical optimization algorithms and differen t functions can lead to different results. The figure of merit is the function used for the ev aluation of the model. In practice, it is not alw ays p ossible to use the exact figure of merit as the loss Chapter 1. Machine Lea rning Essentials 10 function, since it ma y b e difficult to ev aluate or to optimize directly . The loss function should therefore appro ximate or b e closely related to a figure of merit that is meaningful for the problem under study , ensuring—at least in princi- ple—that minimizing the loss corresponds to minimizing the true figure of merit, at least at a theoretical level, the minim um of the loss function must coincide with the minimum of the figure of merit. A brief ov erview of tw o widely used loss functions for sup ervised and unsupervised tasks is presented b elo w, while additional examples are provided in App endix A. It is imp ortan t to note that the mo del output depends on the parameters θ , while ˆ θ denotes the optimal parameters that minimize the loss function through the optimization pro cess. Mean Squared Error (MSE) is the av erage of the squared differences b e- t ween the predicted and the true output. It is one of the simplest yet effectiv e losses used for the sup ervised tasks. Usually employ ed in regression tasks due to its relation with Maxim um Lik eliho o d Estimation (MLE) , it is sensitiv e to the tails and penalizes outliers. Its functional form can b e written in a sim- ple w ay , for an output vector y (i.e. the target v ector) in n dimensions and N samples: L MSE = 1 N N X i =1 ∥ y i − f ( x i ; θ ) ∥ 2 2 where ∥·∥ 2 is the Euclidean 2-norm, defined by ∥ x ∥ 2 : = v u u t n X i =1 x 2 i Negativ e Log-Likelihoo d (NLL) In probabilistic mo deling, the output of a mo del is treated as a random v ariable whose distribution is parametrized b y the mo del parameters. In other words, instead of predicting a single deterministic v alue, the mo del sp ecifies a Probabilit y Density F unction (PDF) p ( X ; θ ) in the unsup ervised case, or a conditional PDF p ( Y | X ; θ ) in the sup ervised case. The learning objective is then defined as the ne gative lo g-likeliho o d of the observ ed data giv en the model parameters, that is, the negativ e logarithm of the probabilit y assigned b y the model to the observed samples. F or a supervised task, the loss can b e written as: L (sup) NLL = − N X i =1 log p ( y i | x i ; θ ) , Chapter 1. Machine Lea rning Essentials 11 while for the unsup ervised case it b ecomes: L (unsup) NLL = − N X i =1 log p ( x i ; θ ) . (1.1) Under the assumption of Gaussian outputs, it can b e shown that the NLL loss reduces to the Mean Squared Error (MSE) loss plus a constant term. This explains why the MSE loss is widely used in practice: when the data distribution is appro ximately Gaussian, one can b ypass the explicit probabilistic form ulation and obtain the maxim um-likelihoo d estimate of the parameters simply b y minimizing the MSE. 1.1.3.2 An introduction to the statistical mo del A statistical mo del, defined b y a set of mathematical op erations acting on the input data, can b e seen as a sophisticated if-then rule that, b y using a set of parameters, can b e trained to solv e the task it w as built for. The parameters are simply called mo del p ar ameters or mo del weights (those that multiply features) and bias (the additive term). T o clarify the difference b etw een w eights and biases, tak e as an example a simple p olynomial mo del, defined b y y = d X i =1 ω i x i + b, where y is the output of the mo del, { ω i } the set of w eights and b the bias. W e refer to a hyp othesis as a sp ecific instance of the mo del obtained by fixing the parameter v alues θ = ( ω 1 , . . . , ω d , b ) . The collection of all suc h h yp otheses, obtained b y v arying these parameters, defines the hyp othesis sp ac e of the mo del. The parameters that are not optimized during training, but instead fixed b efore the training pro cess b egins, are called hyp erp ar ameters . They in tro duce the need of mo del sele ction and the validation set that will b e discussed later in the text. An example of hyperparameter can b e found in the simple p olynomial mo del as the maximum degree of the p olynomial d : it is fixed in the training pro cedure but will need to b e c hosen in the mo del selection instance, since a priori one migh t not know what its optimal v alue is. Other examples of h yp erparameters will b e discussed later in the text. It is imp ortan t to note that hyperparameters are not b ound to the h yp othesis space but can b e parameters of the optimization algorithm, such as the num b er of tr aining steps and the le arning r ate whic h will b e further discussed in a dedicated section. Chapter 1. Machine Lea rning Essentials 12 T raining, V alidation and T esting The training procedure of a mac hine learning mo del b egins with the definition of distinct datasets, each serving a sp ecific purp ose in the learning pro cess. Although this is a simplified description, the structure can c hange when techniques such as cr oss-validation 1 are employ ed. T ypically , the a v ailable data are divided into three indep endent and non-ov erlapping sets: • T raining set: used to fit the mo del parameters by minimizing the loss function. • V alidation set: used to monitor the mo del’s p erformance during training and guide mo del selection. • T est set: used to ev aluate the final p erformance of the mo del after training is complete. T o understand the need for this partitioning, it is useful to briefly outline the training pro cess. During training, the mo del receiv es one or more input samples (organized in b atches or mini-b atches , as discussed later in the optimization sec- tion) from the training set. The mo del’s predictions are compared to the true targets through the loss function, and the resulting error is used to up date the w eights via the b ackpr op agation algorithm 2 . This iterativ e process con tinues un til con vergence. After eac h up date, the mo del’s p erformance is assessed on the v alidation set b y computing the v alidation loss. Unlik e the training loss, this quantit y is not used to up date the parameters; instead, it provides a measure of ho w well the mo del generalizes to unseen data and serves as a criterion for mo del sele ction , i.e., for choosing the mo del that b est balances fit and generalization. The concept of mo del selection will b e further discussed in a dedicated section. Finally , the test set is employ ed only once the training and mo del selection are completed. It pro vides an un biased estimate of the mo del’s p erformance on new, unseen data, typically ev aluated through metrics that depend on the sp ecific task. 1 Cross v alidation go es beyond the scop e of this thesis; a detailed in tro duction can be found in Ref. [35] 2 Geoffrey Hin ton won the Nob el Prize in 2024 for the introduction of bac kpropagation [36] Chapter 1. Machine Lea rning Essentials 13 Capacit y Capacit y is defined as the ability of the mo del, or a particular hypothesis, to ac- curately describ e a dataset. W e can distinguish b etw een r epr esentational c ap acity and effe ctive c ap acity : Represen tational capacity is defined as the capacity of the mo del to accu- rately describ e a large v ariety of true data mo dels. It does not depend on the data and is related to the n umber of parameters, num b er of features, complexity of the mo del’s functional form, and so on. In the example of the polynomial mo del, a high-degree polynomial can accurately describe m ultiple true data mo dels with differen t degrees. F or this reason, we say that a high degree p olynomial has a higher representational capacit y than a lo w degree one. Effectiv e capacity n the other hand, tak es into account the data, regulariza- tion tec hniques, optimization metho ds, and other secondary factors. It is a more empirical definition of capacit y and can b e defined as the practical abilit y of the mo del to capture the imp ortant features in the training data, given additional effects, such as the finite training dataset size, noise, regularization tec hniques and optimization algorithms. Optimal capacit y although its definition heavily dep ends on the specific prob- lem and on the figure of merit, the optimal capacity can b e determined by opti- mizing the trade-off b etw een learning in detail the training ( overfitting ) data and the capabilities of generalizing to new, unseen data. Generalization, overfitting and underfitting In machine learning, gener alization can b e defined as the abilit y of a mo del to describ e previously unseen data. Giv en a function that measures the error, such as the losses describ ed earlier, its v alue computed on the training set is called tr aining err or , while the v alues computed on the v alidation and test set are called validation err or and test err or resp ectively . The gener alization err or is the error the mo del mak es on unseen data, which quan tifies how w ell it generalizes b eyond the training samples. Since the true generalization error cannot b e measured directly , it is commonly appro ximated b y the test err or . The v alidation error cannot b e a robust measure of the generalization error, in fact, the v alidation set Chapter 1. Machine Lea rning Essentials 14 is used for mo del selection and thus is seen by the mo del during optimization. Ev en with a p erfect fit of the mo del to the data, the generalization error alwa ys has a non-zero lo wer b ound. This irr e ducible generalization error is commonly referred to as Bayes err or and is related to the fact that the noise in the training data preven ts the mo del from learning the true underlying mo del. T o train an ML algorithm, there are tw o crucial ob jectiv es: • The model should b e able to describ e w ell the training data it used to estimate its parameters. This translates into the smallest p ossible training error. • The mo del should b e able to generalize well to new, unseen data. So the generalization error m ust also b e as small as possible and, p ossibly , mini- mizing the gener alization gap , defined as the difference b et ween the training and generalization errors. When the first objective cannot b e satisfied, we sa y that the mo del is underfitting , while the c hallenge asso ciated with the second ob jectiv e is called overfitting , whic h means that the model has learned "to o w ell" the training dataset and has a big generalization gap. Underfitting: Occurs when a mo del do es not hav e enough capacity to ev en describ e the training data, or the optimization task hasn’t con verged. Note that, ev en though the theoretical optimal v alue for the loss is kno wn a priori, a prop er “scale” for the actual problem as w ell as the asso ciated Bay es error is not kno wn. F or this reason, generally , it is not a trivial task to understand whether we are underfitting or not. Underfitting is t ypically recognized a p osteriori : when the mo del capacity or training configuration is adjusted, the training error decreases, indicating that the previous mo del w as to o simple to capture the underlying structure of the data. Underfitting is related to the effectiv e capacit y , not to the represen tational capacity; indeed, ev en if a theoretical hypothesis is general enough to b e, in principle, capable of mo deling the data, the actual optimization task ma y b ecome too difficult, and the model could not conv erge to the right parameters, leading to underfitting. Ov erfitting: Capacit y can increase b y changing the n umber of parameters or b y c hanging the hyperparameters. When the num b er of parameters of the mo del Chapter 1. Machine Learning Essentials 15 Figure 1.1: Overfitting example. By fitting noisy data with sufficiently high degree p olynomials, the curve is able to pa rametrize noise. approac hes the n umber of data p oints in the training set, the mo del can start describing the data p erfectly , almost indep enden tly of the sp ecific mo del. At this stage, the train error could b ecome arbitrarily small due to the fact that the mo del can learn ev en the noise in the data. The result is a v ery goo d fit for the training data, with a v ery p o or generalization, whic h translates to a large generalization gap. This is what w e call ov erfitting . In contrast to underfitting, the o verfitting can be identified during training. T o do this, w e look at the learning curve , i.e., a plot of the training and v alidation losses v ersus the training steps. A t ypical indicator of ov erfitting is that the training error contin ues to decrease while the v alidation error remains constant or increases. In this instance, the mo del can b e to o sensitive to the noise or the capacity to o large. A simple example of o verfitting can b e found in Figure 1.1, where it is clear that a sufficien tly high degree p olynomial can fit noise in the data. The essence of training a mac hine learning model is to find the p erfect balance b et ween o v erfitting and underfitting, either by training strategies or by choosing the righ t mo del (this is what w e defined as effective capacit y). This concept is commonly referred as the Bias-V arianc e tr ade-off . Regula rization W e should briefly discuss some of the most commonly used tec hniques to find the balance b etw een o verfitting and underfitting. A cquiring the balance by merely engineering the mo del is usually to o difficult, if not imp ossible, in most cases. One Chapter 1. Machine Learning Essentials 16 w ay to find such balance is to start with a really simple model with“av erage” re- sults and then slo wly increase the capacity un til the generalization gap starts to increase, while the training error is still decreasing. At this p oint, the mo del is starting to o verfit. W e can push a bit further in the o verfit direction b y adding a r e gularizer . Regularization is any technique that aims at lo w ering the gen- eralization gap without affecting (at all or in a marginal part) the train error. In practice, this is almost never p ossible, so the train error is affected, and it increases. F or this reason, the mo del capacit y is usually increased along with reg- ularization to decrease the generalization gap, while main taining the train error constan t. Regularization can b e seen as prior kno wledge for the mo del or as a penalty to the loss and can be applied in different wa ys. A general w ay to apply regular- ization is to add a p enalt y term to the ob jective function for training. Note that this is not alw a ys true; indeed, some form of regulations cannot b e written this w ay , for example e arly stopping and dr op out that will b e discussed later in the text. In mathematical form w e can write a p enalty term as: ˜ L ( θ ) = L ( θ ) + λ Ω( θ ) with λ ∈ [ 0 , + ∞ ) , where t ypically , Ω is chosen to affect the parameters but not the biases, and λ may dep end on the stage of the algorithm to address different problems dep ending on the stage of the calculation. In order to clarify the concept of regularization, some illustrativ e examples are presen ted. This discussion is in tended as an in tro duc- tion to the most widely used regularization methods, rather than an exhaustiv e o verview. L1 and L2 regularizers L2 and L1 regularizers are the most known p enalty terms in deep learning. The solution to linear mo dels using L2 regularizer is called Ridge r e gr ession , while the solution using L1 is called L asso r e gr ession . L2 p enalizes large weigh ts b y the L2 norm of the weigh t tensor (for this reason, L2 is also kno wn as weight de c ay ). L2 is expressed in formulae as L L2 = λ ∥ ω ∥ 2 = λ d X i =0 ω 2 i with λ ∈ [0 , + ∞ ) . L1 regularization, on the other hand, promotes sparsit y (i.e. encourages many w eights to b e exactly zero) b y p enalizing the L1 norm: L L1 = λ ∥ ω ∥ 1 = λ d X i =0 | ω i | with λ ∈ [0 , + ∞ ) Chapter 1. Machine Learning Essentials 17 W e no w consider regularization methods that are not form ulated as explicit p enalt y terms in the loss function. Data Augmen tation Data augmentation refers to a set of techniques that aim at increasing the div ersity and amount of data a v ailable for the training pro cess without collecting new data. It is based on the creation of mo dified samples of data, so that the mo del can impro ve robustness and expressivity , without en tering the o verfitting regime. Being particularly useful when the dataset dimension is small or collecting data is exp ensiv e, data augmentation is hea vily dep enden t on the problem at hand. A t ypical example can b e giv en b y geometric transformation for images, such as rotation, flip, zoom, and color space transformation suc h as con trast enhancement, brigh tness scale adjustmen t, or noise injection. Another p ossible wa y is to generate new synthetic data using Generative AI mo dels or non-parametric algorithms to increase the div ersit y and amount of training data. It may b e stressed that data augmentation ma y not b e considerate adequate for some p ossible mac hine learning applications. Early stopping Early stopping is one of the most simple, yet effectiv e regu- larization techniques; it do es not require any additional computational cost com- pared to the previously discussed techniques. The k ey idea is to stop the training pro cess when the model’s performances on the v alidation set start to statistically deteriorate. This is done by monitoring the v alidation loss during training and stopping the pro cess when it starts to increase, or it remains constan t. It can b e sho wn how early stopping can b e effectiv ely considered as a regularization tec hnique b y making explicit its connection with L2 regularization but is beyond the scop e of this thesis. Drop out The last regularization metho d describ ed is differen t from the others, since, during training, it temp orarily mo difies the structure (architecture) of the mo del b y randomly deactiv ating some parts of it. T ypical v alues of drop out rate (the p ercentage of the parameter to disconnect) range b etw een 0 . 2 and 0 . 5 and, b eing it a hyperparameter, the actual b est v alue is found empirically with mo del selection. Drop out preven ts ov erfitting b y a v oiding certain“areas” of the mo del to sp ecialize excessiv ely on certain features of the data, forcing the mo del to develop a more resilien t represen tation of the acquired knowledge. Chapter 1. Machine Learning Essentials 18 Drop out can also b e seen as a wa y of training an ensem ble of mo dels alto- gether, with ev ery training step fo cusing on a differen t incarnation of the ensem- ble. It is imp ortant to note that Drop out is only implemen ted during the training pro cess, during inference, the en tire mo del is activ e, and the output must b e scaled by the drop out rate to comp ensate for the larger effectiv e mo del size. Numerical optimization Numerical optimization is quintessen tial in mac hine learning, since all the train- ing pro cess is based on the optimization of the ob jective function. In the training pro cess, the optimization consists in a recursiv e op eration where, after each iter- ation, the parameters are adjusted to minimize the loss function. F or this reason, optimization is at the heart of mac hine learning, and bridges the gap b etw een theoretical mo dels and practical, effectiv e learning algorithms. A numerical ap- proac h is usually the only w a y to optimize complex loss functions; in fact, it allo ws finding the optimal parameters in high-dimensional spaces where analyt- ical solutions are in tractable. T ak e for example the GPT-4, with an estimated n umber of parameters that ranges b etw een 1 . 7 and 1 . 8 tril lion parameters. An analytical solution to a minimization of a function of this man y v ariables is prac- tically imp ossible, hence the numerical optimization is the only w a y to proceed. Optimization problems can b e divided into t wo categories: Con v ex optimization problems are those where the ob jectiv e function forms a conv ex set, meaning that any segmen t b etw een t w o p oin ts in the graph of the functions do es not cut the graph. An imp ortant prop ert y of con v ex functions is that any lo cal minim um is also a global minim um, simplifying the optimization pro cess. Non-Con v ex optimization problems on the other hand do not exhibit this prop erty , leading to lo cal minima or saddle p oints. This is the most frequent problem one has to address when training machine learning mo del, especially with neural net works that are highly non-conv ex. in this case, the c hoice of optimization algorithm b ecomes crucial as the problem shifts from finding the global minim um to finding a minimum which is "go o d enough" for exp ected p er- formances. Chapter 1. Machine Learning Essentials 19 W e no w in tro duce the most widely used optimization algorithms, focusing on A dam but with a brief o v erview on the intermediate algorithms such as momentum- based metho ds, sto c hastic or adaptive gradien t tec hniques. A dam optimizer Building up on the principles of gr adient desc ent (GD), A dam is one of the most widely used optimization algorithms in deep learning. T o understand its role, it is useful to first in tro duce the basic concept of gradien t descen t. GD is the protot yp e of a first-order algorithm (it only uses the first-order deriv ative at eac h step) and due to its simplicity and effectiv eness, is particularly w ell suited for large-scale optimization tasks. Being able to navigate through conv ex and non-con vex landscapes, GD iterativ ely up dates the parameters b y moving in the direction opp osed to the steep est ascen t without information on the curv ature. The step size is controlled by a hyperparameter called L e arning R ate and the n+1-th step is given b y: ˆ ω n +1 = ˆ ω n − α ∇ f ( ˆ ω n ) where α , the learning rate, is crucial in determining the con vergence and stability of the algorithm. A prop er v alue of α is crucial: if it is to o small, the algorithm tak es to o man y iterations to conv erge, while if it is to o large, the algorithm migh t o vershoot the minim um, leading to div ergence. The c hoice of α is a trade- off b et ween training sp eed and stabilit y , and it is often tuned using the v alidation data. Other hyperparameters are the initial guess ˆ ω 0 and the total n umber of iterations. A natural extension of gradient descen t is Sto chastic Gr adient Desc ent (SGD) , that mo difies the wa y gradient is computed from the data and the w ay mo del parameters are up dated. Instead of computing the gradient and up dating the w eights for all training samples as in standard GD, SGD computes the gradi- en t for each training sample individually or a small subset of samples, called mini-b atch . The reason to introduce this generalization is t wofold: first, it can significan tly increase the computational efficiency , esp ecially for large datasets, since the gradient is computed on a smaller subset of data. Second, it in tro duces a certain lev el of noise in the gradient, which can help the algorithm escap e lo cal minima and saddle p oin ts, potentially leading to better generalization. The full Chapter 1. Machine Learning Essentials 20 batc h v ersion of GD is often called Batch Gr adient Desc ent . F rom a practical p oint of view, the model w eights are usually updated once p er ep o ch , where an ep o ch refers to a complete pass through the entire training dataset. So in the up date the resulting gradient is av eraged ov er all the single samples or o ver all the mini-batc hes. Notice that this generalization of the gra- dien t descent algorithm (i.e., extending the up date to a batch of samples) can b e done also for the more adv anced algorithms introduced later in the text, so usually they are used b oth. The sto chastic and mini-batch modification of GD hav e some cons, suc h as the fact that the conv ergence can b e less stable due to the noise introduced and the fact that the choice of the mini-batc h size and learning rate can significan tly affect the p erformance of the algorithm. F rom the GD update rule, w e can in terpret the second term as a v elo city v ector, in that case prop ortional to the gradient of the loss function. In the presence of high curv ature or noisy gradien ts, this can lead to oscillation and slo w conv ergence. Momentum-b ase d metho ds aim at addressing this issue b y in tro ducing a velocity term that accumulates the gradien t o v er time, allowing the algorithm to build up sp eed in directions of consisten t descen t and damp en oscillations in directions of high curv ature. The added term acts as a lo w-pass filter on the gradients, smo othing out rapid changes and allo wing the algorithm to main tain a consisten t direction of descent. The additional term is parametrized b y a h yp erparameter usually called β , where a higher v alue of β gives more w eight to past gradients, leading to smo other up dates, while a lo wer v alue makes the algorithm more resp onsiv e to recent gradien ts. T o increase resp onsiv eness to the loss curv ature has been introduced Nester ov A c c eler ate d Gr adient (NA G) , that instead of calculating the gradient at the cur- ren t p osition, computes it at a future p osition of the parameters as an ticipated b y the current momen tum. In the presence of sharp b ends in the loss landscap e, this subtle shift allows for a b etter choice of the parameter up date, leading to faster conv ergence and reduced oscillations. The next step tow ards the Adam algorithm is the in tro duction of algorithms kno wn as adaptive le arning r ate algorithms that instead of mo difying the gradi- en t function, adapts the learning rate. The first example of these algorithms is A dagr ad , that adapts the learning rate for eac h parameter individually by scaling it in versely prop ortional to the square ro ot of the sum of all past gradien ts. P a- Chapter 1. Machine Learning Essentials 21 rameters that hav e b een up dated frequen tly receiv e smaller learning rates, while those that ha ve b een up dated infrequently receive larger learning rates. This is particularly useful in the case of sparse dataset since it allows for an automatic feature scaling. It is also useful in the case of a large num b er of features, since the learning rate can be scaled according to the v arying importance of differen t features. T o o vercome the limitations of A dagrad, which is not discussed here as it lies b ey ond the scop e of this thesis, RMSpr op (R o ot Me an Squar e Pr op agation) has b een in tro duced. RMSprop mo difies the accumulation mec hanism b y replacing it with a moving a verage. Com bined with mini-batch up date, Adam is probably the most widely used optimizer algorithm in deep learning, since it merges the b enefits of RMSprop with the ones of momen tum-based GD. It accumulates b oth the first and the second order gradien t moments to up date the parameters using b oth the adaptiv e learning rate and a gradien t function with momentum as in momentum-based GD. By using the comp onent notation, the up date rules for Adam are given b y: ( ˆ ω i ) n +1 = ( ˆ ω i ) n − α q ( ˜ v ii ) n + ϵ ( ˜ m i ) n , ( ˜ m i ) n = ( ˜ m i ) n 1 − β n 1 , ( ˜ v ii ) n = ( ˜ m ii ) n 1 − β n 2 (1.2) with ( m i ) n = β 1 ( m i ) n − 1 + (1 − β 1 ) ∂ i L ( ˆ ω n ) , ( v ii ) n = β 2 ( v ii ) n − 1 + (1 − β 2 )( ∂ i L ( ˆ ω n )) 2 (1.3) and ( m i ) 0 = 0 , ( v ii ) 0 = 0 (1.4) where ( ˜ m i ) n and ( ˜ v ii ) n are bias-corrected estimates of the first and second mo- men ts ( ( m i ) n and ( v ii ) n ) resp ectiv ely , β 1 and β 2 are the exp onen tial decay rate for these momen t estimates which are usually set close to one, like 0.9 and 0.999 resp ectiv ely and ϵ is the usual constan t added for n umerical stabilit y , usually set around 10 − 8 . The bias correction ensures accurate initial estimates when ( m i ) n and ( v ii ) n migh t b e biased tow ards zero, esp ecially when β 1 and β 2 are set close to one. The effectiveness of Adam comes from the fact that it is capable not only of adjusting the trajectory direction with the memory of past gradien ts, but also to adjust the step size according to the geometry of the data. An example of second order optimizer is rep orted in app endix. Chapter 1. Machine Learning Essentials 22 1.2 Intro duction to neural net w o rks Neural Net works are a class of machine learning mo dels originally inspired by ho w the biological systems pro cess information. The first concept of neural net- w ork arose in mid-20 th cen tury but only in recent decades the field saw concrete adv ancemen ts in p erformance and architectures. As will b e further shown later in the text, neural net works are made up of in terconnected no des or neurons that, via the learning pro cess, are capable of p erforming complex tasks. Only in the last few y ears ha v e we witnessed breakthrough in computer vision, natural language pro cessing and sp eec h recognition that hav e revolutionized the w ay w e interact with tec hnology and the in tegration into so ciet y contin ues, with the rise of ethical considerations. The scop e of this section is to in tro duce the basic concepts of neural net work b efore moving on to more adv anced mo dels. 1.2.1 P erceptron A Perceptron [37] is the t ypical building blo c k of a neural net w ork (NN) ar- c hitecture. In tro duced in 1958 b y F. Rosenblatt to model a human neuron, the p erceptron is single artificial neuron, capable of manipulating m ultiple inputs (i.e. real n umbers) to pro duce an output. The manipulation consists in a weigh ted sum of the inputs plus a bias term, where the weigh ts are to b e considered pa- rameters, and the result is passed through an activation function that produces the output. In the original form ulation, the activ ation function is the Hea viside step function and, interestingly enough, the p erceptron was originally in tended to not b e a program, but an actual, physical machine and w as subsequently im- plemen ted in a custom-built hardw are designed for image recognition, and known as the Mark I p erceptron [38]. The p erceptron can b e form ulated in mathematical form by writing: y = h n X i =1 ω i x i + b ! where h ( x ) is the activation function and b the bias term. A schematic, accom- panied by the forward pass illustration is rep orted in Figure 1.2. Chapter 1. Machine Learning Essentials 23 F orw ard pass • T ak e inputs x 1 , . . . , x n • Compute z = P i ω i x i + b , where b is the bias term. • Output y = h ( z ) x 1 x 2 . . . x n P h y ω 1 ω 2 ω n + b Figure 1.2: Description of the forw a rd pass (left) and the p erceptron schematic (right). A ctivation functions A ctiv ation functions are responsible for one of the k ey strengths of Neural Net- w orks: non-line arity . In fact, without any activ ation function the output w ould b e a linear combination of the input, limiting the expressiv eness of the net work. Eac h activ ation function has its own use, and it should b e c hosen based on the problem at hand. • Sigmoid or logistic activ ation function: defined as f ( x ) = 1 1 + e − x , b y construction we ha v e f ( x ) ∈ (0 , 1) ∀ x , whic h is imp ortant for tasks in whic h the output m ust b e in terpreted as a probabilit y , suc h as classification tasks in which, usually , the output no des represent the probabilit y of the input to b e in the asso ciated class. • Hyp erb olic tangen t activ ation function: similar to the sigmoid activ a- tion function but with output in ( − 1 , 1) . It has the adv an tage of mitigating the problem of v anishing gradients (i.e., the gradien ts used to up date the parameters b ecome exponentially small due to small deriv ativ es of the ac- tiv ation functions multiplied man y times for the weigh ts up date) and it is defined by: f ( x ) = e x − e − x e x + e − x • Rectified Linear Unit (ReLU) activ ation function [39]: it is defined b y: f ( x ) = max (0 , x ) Chapter 1. Machine Learning Essentials 24 so it outputs the input if p ositive or zero otherwise. Given its simplicit y and its computational efficiency it is a very p opular choice. Multi-output perceptron As the name suggests, it is a trivial generalization of the p erceptron capable of generating multiple outputs, allowing to address problems with m ultiple target v ariables or output labels. This is also useful for tasks in which the output v ariables are correlated, as the perceptron can learn the relationship b etw een them. A mathematical form ulation of a multi-output p erceptron can b e written lik e this: y i = h ( X j ω ij X j ) where i = 1 , . . . , m with m the num b er of output nodes and h ( · ) is the activ ation function. Notice ho w in this form ulation there is no explicit presence of the bias term. That is b ecause the bias term is incorp orated in the vector X and will b e m ultiplied b y a w eight (non-trainable) fixed to one: ω b = 1 . T o b e more explicit the input vector will b e represented as X = ( x 1 , . . . , x n , b 1 , . . . , b m ) and the weigh t matrix will hav e ω i,n +1 = 1 fixed ∀ i suc h that in the pro duct the bias term will alw ays b e multiplied b y one. A schematic represen tation is shown in Figure 1.3 where we made explicit the bias summation. x 1 x 2 x 3 P h y 1 P h y 2 + b 1 + b 2 Figure 1.3: Multi-output p erceptron: three inputs feed t wo output units; each output p erfo rms a weighted sum, adds a bias, then applies activation h ( · ) . 1.2.2 Multi-la y er p erceptron The natural extension of a m ulti-output perceptron is to add multiple la y ers of no des, or neurons in b etw een the input and the output. A collection of no des op erating at the same depth is called a layer and the la yers in betw een the input and the output are called hidden layers . The hidden lay ers are mean t to extract features from the input layer and send them to the output layer . So naturally Chapter 1. Machine Learning Essentials 25 increasing the num b er of hidden la yers or the num b er of no des in each of them will increase the complexit y . This arc hitecture is called MLP (Multi-Lay er Per- ceptron) but differen t names could b e found in literature, such as DNN (Deep Neural Net w ork) or feed-forw ard neural net works. One can then experiment with differen t connection patterns b et ween the no des of consecutiv e lay ers; how ev er, the simplest and most common configuration is the ful ly c onne cte d neural net- w ork, in which ev ery no de in a la y er is connected to ev ery no de in the next la yer. As we will see in the section dedicated to the normalizing Flows , this is not the only choice for an MLP architecture. The hidden la y ers transform the m ulti-output p erceptron in to a universal function appro ximator, since it approximate any function f tak es an input v ari- able x into the output v ariable y . The MLP approximates the function f b y defining a mapping y = g ( x ; θ ) and finding the optimal parameters θ that result in the b est approximation of the function f by g . A sc hematic represen tation of a fully connected MLP is shown in Figure 1.4, where the opacity of the connections (sometimes called e dges ) represen ts their magnitude, the colors represen t the sign of the w eight asso ciated with the edge. Figure 1.4: The scheme of an MLP , the input la yer has 20 no des, 2 hidden la yers of 15 no des each and 10 no des in the output la yer. Edge colo r sho ws sign (blue = p ositive, o range = negative) and opacity scales with the weight magnitude. Image inspired by Ref. [40] In the next chapter, more adv anced arc hitectures will b e in tro duced, man y of whic h are based on the foundations of the MLP . Chapter 2 F rom Generation to V alidation: Principles and Evaluation Metrics 2.1 Generative mo dels in physics Generativ e mo dels hav e b ecome an imp ortan t to ol in many areas of ph ysics b e- cause they can learn complex, high-dimensional probabilit y distributions directly from data. In exp erimental and theoretical ph ysics, many problems in volv e sam- pling from or approximating such distributions, which are often too exp ensive to compute with traditional metho ds. F or example, Mon te Carlo simulations are widely used to generate ev ents, propagate particles through detectors, or simu- late radiation show ers. While these sim ulations are accurate, they are extremely time-consuming and computationally exp ensive. Generative mo dels can act as fast simulators , repro ducing realistic samples with a fraction of the computational cost [41]. Bey ond fast sim ulation, generativ e mo dels can also b e used for a v ariet y of other ph ysics tasks. In data analysis, they can help to p erform likeliho o d-fr e e in- fer enc e by learning the mapping b et ween theory parameters and observ able data, allo wing one to estimate or constrain ph ysical parameters ev en when the exact lik eliho o d function is not av ailable. In anomaly detection, they can iden tify un- usual or rare ev en ts that deviate from the learned data distribution, potentially p oin ting to new ph ysics signals that differ from the Standard Mo del. In theoret- ical mo deling, they can learn complicated probabilit y densities that describ e, for example, parton distribution functions or energy flo w in jets. In detector ph ysics, and esp ecially in calorimetry , the use of generativ e models 26 Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 27 is motiv ated b y the large amount of data and the fine spatial resolution of modern detectors. Accurate sim ulation of electromagnetic or hadronic show ers requires mo deling complex correlations b et ween thousands of detector cells. T raditional sim ulation tools suc h as Geant4 provide high accuracy but are computationally hea vy . Generativ e mo dels, in contrast, can repro duce similar distributions m uch faster once trained, enabling large-scale simulation and fast even t generation for studies at the High-Luminosity LHC and future exp eriments. F or all these reasons, the developmen t of reliable and in terpretable generative mo dels has b ecome a growing area of researc h in high-energy ph ysics. They pro vide an opp ortunity to reduce sim ulation costs, accelerate data analysis, and impro ve the understanding of complex systems by learning directly from data, while main taining the physical consistency required in scien tific applications [41]. The classical foundations are gener ative adversarial networks (GANs) [42], variational auto enc o ders (V AEs) [43, 44], and normalizing flows (NF s) [22]. In recen t y ears, diffusion and sc or e-b ase d mo dels [45, 46] together with c onditional flow-matching mo dels (CFMs), based on neural ODE dynamics [47, 48], ha ve be- come leading approac hes for high-fidelit y and fast calorimeter show er generation. This trend is do cumented by the CaloChallenge review [11], in which the b est p erformances w ere obtained with con tin uous flow matching and diffusion based mo dels. An overview of the main a rchitectures In this subsection, w e giv e a short in tro duction to the most common generative mo del architectures used in mo dern machine learning. The goal is to present their main ideas and training principles, without going into full technical detail. Less emphasis will b e placed on normalizing flows , as a complete theoretical and practical discussion is provided in the next dedicated section, due to their central role in this thesis. V a riational A uto enco ders (V AEs). V ariational A uto enco ders [43, 44] are probabilistic mo dels that describe data generation as a tw o-step pro cess: first, a latent v ariable z is sampled from a simple prior distribution p ( z ) , usually a standard normal; s econd, the observed data x is generated from this laten t v ariable through a decoder distribution p θ ( x | z ) , where Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 28 θ are the mo del parameters. The c hallenge is that the true posterior distribution p θ ( z | x ) is generally in tractable. V AEs introduce an encoder q ϕ ( z | x ) , parametrized b y ϕ , that approximates the posterior. The mo del is trained by maximizing the so-called Evidenc e L ower Bound (ELBO): L V AE = E q ϕ ( z | x ) [log p θ ( x | z )] − KL[ q ϕ ( z | x ) ∥ p ( z )] . The first term encourages the deco der to reconstruct the input data correctly from the latent representation, while the second term (Kullbac k-Leibler diver- gence [49]) regularizes the laten t space, pushing the appro ximate p osterior q ϕ ( z | x ) close to the prior p ( z ) . This prev en ts the enco der from ov erfitting and ensures that meaningful samples can be generated by dra wing z directly from p ( z ) . In prac- tice, the mo del is trained end-to-end b y using the r ep ar ameterization trick [43], whic h allo ws gradients to pass through the stochastic laten t v ariable during op- timization. Figure 2.1: Overview of a va riational auto enco der (V AE) [44]. The enco der q ϕ ( z | x ) maps data x to latent va riables z , while the deco der p θ ( x | z ) reconstructs the data from samples dra wn from the latent space. V AEs are widely used when b oth data generation and uncertain ty quan tifi- cation are needed. How ev er, the Gaussian assumptions and the v ariational ap- Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 29 pro ximation may lead to blurry samples or ov ersimplified distributions. Despite these limitations, they remain a cornerstone in generativ e mo deling due to their stabilit y and probabilistic form ulation. Generative A dversa rial Net w orks (GANs). Generativ e A dversarial Net works [42] represent a different philosophy . Instead of explicitly mo deling a probability distribution, they define an implicit generativ e pro cess through a neural netw ork G θ ( z ) , which maps latent v ariables z ∼ p ( z ) to synthetic samples x ′ = G θ ( z ) . The qualit y of the generated samples is judged b y a second net work, called the discriminator D ψ ( x ) , whic h tries to distinguish b et ween real data and generated samples. The tw o netw orks are trained in an adv ersarial game with the ob jective: min G max D L GAN = E x ∼ p data ( x ) [log D ψ ( x )] + E z ∼ p ( z ) [log(1 − D ψ ( G θ ( z )))] . The discriminator learns to assign high scores to real samples and lo w scores to fak e ones, while the generator learns to produce samples that the discriminator cannot distinguish from real data. A t equilibrium, the generator repro duces the data distribution p data ( x ) as closely as possible. A diagram explaining the w orking principles of GANs is rep orted in Figure 2.2. GANs are p ow erful b ecause they can pro duce v ery sharp and realistic sam- ples, but their training can b e unstable. The minimax optimization often suffers from non-con vergence and mo de collapse, where the generator only repro duces a subset of the data. Many extensions hav e b een prop osed, suc h as the W asser- stein GAN (WGAN), whic h replaces the standard cross-entrop y ob jective with the W asserstein distance b etw een real and generated distributions to stabilize training. In physics applications, GANs hav e b een used for fast detector simulation, jet generation, and calorimeter show er mo deling. Their ability to learn complex, high-dimensional correlations makes them suitable for these tasks, but the lac k of a tractable lik eliho o d and the sensitivit y to h yp erparameters mak e quan titative v alidation more c hallenging compared to likelihoo d-based mo dels suc h as V AEs and normalizing flo ws. Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 30 Generato r Discriminato r Real Data Generated Data Noise F ake Real Figure 2.2: Schematic of a Generative Adversa rial Net w ork (GAN): the generato r maps noise to data samples, which a re evaluated b y the discriminator alongside real data to p redict fak e or real . The diagram is strongly inspired b y Ref. [50]. No rmalizing Flo ws (NF s). Normalizing flows learn invertible tr ansformations that map a simple base distri- bution to the data distribution. Because the mappings are bijective, they admit an explicit probabilit y densit y via the change-of-v ariables formula, enabling exact log-lik eliho o ds and exact sampling. These prop erties make flo ws attractiv e for ph ysics, where tractable densities aid statistical v alidation and anomaly detection, and fast sampling accelerates sim ulation. A detailed treatmen t of arc hitectures and training is provided in Section 2.2. Diffusion Models Diffusion mo dels represent a more recent and p ow erful approach to generativ e mo deling. Their main idea is to mo del the data distribution as the result of a gradual denoising process. T raining is based on learning ho w to reverse a diffusion that progressiv ely adds Gaussian noise to the data. Let x 0 denote a data sample and x t the same sample after t diffusion steps. The forw ard pro cess adds noise according to q ( x t | x t − 1 ) = N x t ; q 1 − β t x t − 1 , β t I , Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 31 where β t con trols the noise lev el. After man y steps, the data become nearly Gaussian. The mo del then learns the reverse pro cess p θ ( x t − 1 | x t ) , whic h gradually remo ves noise to reconstruct a clean sample. In the contin uous-time limit, this pro cess can b e describ ed b y a sto c hastic differential equation (SDE) whose drift is parametrized by a neural net work trained to predict the added noise [45, 46, 51]. In Figure 2.3 a diagram illustrates the diffusion pro cess. Figure 2.3: Diagram of the diffusion process. Image from Ref. [46] Diffusion mo dels hav e recen tly sho wn outstanding p erformance in generat- ing realistic and div erse samples across man y domains, including high-energy ph ysics. Their training is stable, they pro vide go o d mo de co verage, and they can capture highly non-linear correlations in calorimeter sho wers. How ev er, the sam- pling pro cess is relatively slow b ecause it requires solving man y denoising steps. This limitation has motiv ated the developmen t of faster alternativ es such as Con- ditional flow-matching mo dels , whic h combine the stabilit y of diffusion training with the efficiency of deterministic flows. Conditional Flo w Matching (CFM) Mo dels Conditional Flow Matc hing (CFM) mo dels are a recent class of generativ e mo dels that unify ideas from normalizing flo ws and diffusion mo dels. Instead of learn- ing a sequence of discrete transformations (as in standard NF s) or a sto chastic denoising pro cess (as in diffusion mo dels), CFMs learn a contin uous-time deter- ministic transformation that transp orts samples from a simple base distribution to the data distribution. This transformation is defined by an ordinary differen tial equation (ODE) in time: dx t dt = v θ ( x t , t ) , where v θ ( x t , t ) is a neural netw ork that predicts the instan taneous velocity of each p oin t along the flow. The mo del is trained so that this velocity field correctly transforms the base distribution in to the data distribution. A simple example is sho wn in Figure 2.4. Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 32 The k ey idea of flow matching [52] is to train the netw ork to matc h the true optimal transp ort field b etw een tw o distributions, av oiding the need to estimate log-determinan ts or to solv e a sto chastic pro cess during training. The c onditional v ersion (CFM) extends this framework b y conditioning the flo w on auxiliary information, suc h as the particle t yp e or inciden t energy in calorimeter sim ulations [53]. This conditioning allo ws the model to generate show ers consisten t with sp ecific physical parameters, which is crucial for detector mo deling. Figure 2.4: Illustration of densit y flow in a conditional flo w-matching framew ork, adapted from [48]. The figure shows the continuous evolution of the probabilit y den- sit y p ( z ( t )) governed b y an ODE solver p erfo rming optimal transp o rt b et ween a simple Gaussian base distribution p ( z ( t 0 )) and the complex ta rget distribution p ( z ( t 1 )) . The central panel depicts the vecto r field that drives the transfo rmation, while the top and b ottom panels sho w the marginal densities at the start and end of the flo w. CFM mo dels com bine the main adv antages of diffusion mo dels (stable training and go o d mode co v erage) with those of normalizing flo ws (fast sampling and deterministic inference). F or this reason, they curren tly represen t one of the most promising approaches for high-fidelit y and efficien t generation in HEP , as sho wn b y the latest CaloChallenge results [11]. Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 33 2.2 No rmalizing Flo ws: F o rmalism and Overview Normalizing Flows are a class of neural density estimators. They emerged as a p o werful branch of generativ e mo dels as they can approximate complex dis- tributions from whic h to sample. They also provide, b y construction, densit y estimation. 2.2.1 The core idea As in tro duced in the previous section, the basic principle is to learn a tar get distribution b y applying a c hain of in vertible transformations to a (kno wn) b ase distribution. The purp ose of an NF is to estimate the unkno wn underlying distri- bution of some data. Since the parameters of b oth the base distribution and the transformation are fully known, one can sample from the target distribution b y generating some samples from the base distribution and then applying the trans- formation. This is known as the gener ative dir e ction of the flo w. F urthermore, since the transformations are in vertible, one can obtain the probabilit y of a true sample b y in verting the transformations. This is called the normalizing dir e ction . 2.2.2 The formalism of normalizing Flo ws T o b etter understand the formalism b ehind Normalizing Flo ws, w e can define a normalizing flo w as a parametric diffe omorphism f θ (also called a bije ctor ) b et ween a laten t space with kno wn distribution π ϕ ( z ) and a data space of inter- est with unknown distribution p ( x ) . The foundation of a NF is the c hange-of- v ariables formula for a PDF: let us define Z , X ∈ R D and π ϕ , p : R D → R suc h that Z ∼ π ϕ ( z ) and X ∼ p ( x ) . W e assume the distribution π to b e c haracterized b y some parameters ϕ (typically π is chosen to b e a multiv ariate Gaussian, so ϕ typically contains the means and the correlation matrix). Let f θ b e the para- metric diffeomorphism (bijectiv e map) suc h that f θ : Z → X with in verse g θ and θ = { θ i } with i = 0 , . . . , N , where N is the num b er of parameters. Then the t wo PDF s are related by: p ( x ) = π ϕ ( f − 1 θ ( x )) | det J f θ ( x ) | − 1 = π ϕ ( g θ ( x )) | det J g θ ( x ) | (2.1) where J f θ ( z ) = ∂ f θ ∂ z and J g θ ( x ) = ∂ g θ ∂ x are the Jacobians of f θ ( z ) and g θ ( x ) resp ec- tiv ely . T o k eep the flo w computationally efficien t, the determinan t of the Jacobian Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 34 m ust b e simple and easy to compute. Therefore, transformations with triangular Jacobian matrices are preferable so that the determinan t can be written as the pro duct of the elemen ts on the main diagonal. This keeps the computation of the Jacobian determinan t efficien t. W e can leverage the relation in Eq. 2.1 to extract samples from the unkno wn, complex distribution p by drawing samples from the simple distribution π ϕ and applying the function g θ , pro vided that the function f θ is expressiv e enough. Constructing arbitrarily complicated non-linear inv ertible bijectors can b e difficult, but one approach is to note that the comp osition of in vertible functions is itself in vertible, and the determinan t of the Jacobian of the comp osition is the pro duct of the determinan ts of the Jacobians of the individual functions. Then, for the generativ e direction, we can choose f = f 1 ◦ · · · ◦ f N and the determinan t of the Jacobian matrix: det J f = Y i det J f i ( x ) . Also note that the in verse function can b e easily written as g = g N ◦ · · · ◦ g 1 . One can then p erform a maximum likelihoo d estimation of the parameters Φ = { ϕ, θ } : the log-likelihoo d of the observ ed data D = { x I } N I =1 is given b y log p ( D | Φ) = N X I =1 log p ( x I | Φ) = N X I =1 log π ϕ ( g θ ( x I )) + log | det J g θ ( x I ) | , (2.2) and the b est estimate is given b y: ˆ Φ = arg max Φ log p ( D | Φ) (2.3) The diffeomorphism f θ should also satisfy some other prop erties: • It should b e computationally efficient, b oth in the normalizing direction and in the generative one. • The Jacobians should b e easy to compute. • It should b e sufficiently expressiv e to mo del the target distribution. Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 35 T ypically , a NF is implemented using NNs to determine the parameters of the bijectors. An illustrative example of the bidirectional mapping p erformed by Normal- izing Flows is sho wn in Figure 2.5. In the gener ative dir e ction , a simple latent v ariable drawn from a base distribution, a standard Gaussian in the sp ecific ex- ample, is transformed through a sequence of inv ertible mappings in to a complex target distribution represen ting the data space. Con versely , the normalizing dir e c- tion corresp onds to the inv erse transformation, where observed data are mapp ed bac k to the latent space, enabling exact likelihoo d ev aluation via the change-of- v ariables form ula. The deformation of the background grid highlights how these transformations smoothly warp the space while preserving inv ertibilit y , pro viding an intuitiv e geometric in terpretation of the flo w mec hanism. Figure 2.5: Illustration of the bidirectional mapping in Normalizing Flows In the generative direction (top), a simple latent variable sampled from a base distribution (t ypically a standa rd Gaussian) is transfo rmed through a sequence of invertible map- pings into a complex ta rget distribution in data space. Conversely , in the no rmalizing direction (b ottom), data samples a re mapped back to the latent space, allowing fo r exact lik eliho o d evaluation via the change-of-variables formula. The defo rmation of the background grid visually represents the smooth and invertible transfo rmations that characterize flo w-based mo dels. Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 36 2.2.3 Coupling and A uto regressive flo ws normalizing flows can b e divided in to t w o main arc hitectural structures: Coupling- layer flows and A utor e gr essive flows . In the former, the input vector is separated in to tw o or more pieces and then transforms some of them with a function of the others; in the latter, the input dimensions are ordered and each of them is transformed according to the previous ones. This distinction will b ecome more clear after the discussion of differen t examples. It is imp ortan t to note that, in normalizing flows, the parameters of the transformation are typically deter- mined by neural net works, whic h are generally not in v ertible. In the tw o distinct structures this problem is addressed in differen t w ays and will b e thoroughly dis- cussed below. Although coupling and autoregressiv e flo ws ma y appear differen t in structure, they are closely related. In fact, autoregressive flows can be seen as a limiting case of coupling flows in whic h the partition of the input is p erformed at every single dimension. In coupling la yers, a subset of v ariables remains fixed while the other subset is transformed conditionally . In autoregressive flows, this conditioning is extended to all previous v ariables, providing maximal flexibilit y at the cost of slow er computation. Conv ersely , coupling flo ws trade a small loss in expressiveness for significantly faster parallel computation. This connection w as first discussed in [23, 54]. Coupling-la y er examples RealNVP The name comes from the fact that it uses Real-v alued Non-V olume Preserving transformations [55]. A general principle that will b e thoroughly dis- cussed in the more technical chapters is that the determinan t of a triangular matrix is given b y the pro duct of the elemen ts on its main diagonal. This will b e v ery imp ortant from a n umerical p oint of view since we will ha v e to calculate the determinant of the Jacobian matrix of the transformations. The RealNVP implemen ts an inv ertible transformation (c hosen in the original pap er to b e an affine transformation) based on a simple but pow erful idea. The input vector is split in to t wo parts: x = ( x 1 , . . . , x d , x d +1 , . . . , x D ) ≡ ( x A , x B ) , with A = { 1 , . . . , d } , B = { d + 1 , . . . , D } . Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 37 The first split is used to compute the transformation parameters, while the second split is transformed according to these parameters. The forw ard (genera- tiv e) transformation can b e written as: y A = x A , y B = x B ⊙ exp s ( x A ) + t ( x A ) , where s : R d → R D − d , t : R d → R D − d . In comp onents, for each i ∈ B : y i = x i e s i − d ( x 1: d ) + t i − d ( x 1: d ) . The inv erse transformation is equally simple and can b e written as: x A = y A , x B = y B − t ( y A ) ⊙ exp − s ( y A ) . Ev en though the functions s and t are implemented by neural netw orks that are not themselv es in v ertible, the o v erall transformation remains in vertible. This is guaranteed b ecause the parameters of the transformation depend only on the un transformed subset x A . The Jacobian of the transformation is triangular, and its log-determinant can b e computed efficiently as: log | det J | = X i s i ( x A ) . This prop erty mak es RealNVP n umerically stable and computationally efficient, forming the foundation for many later flow-based mo dels suc h as GLO W, briefly discussed b elow, and NICE [56]. GLO W The GLO W arc hitecture [57] builds upon the RealNVP mo del and extends it with improv ed expressiveness and training stabilit y . It is comp osed of a sequence of flo w steps, eac h consisting of three transformations applied in order: an activation normalization (actnorm), an invertible 1 × 1 c onvolution , and an affine c oupling layer . The o verall transformation remains in vertible, and the log- determinan t of the Jacobian can b e computed efficien tly , allo wing exact lik eliho o d estimation. Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 38 A ctnorm. In place of traditional batch normalization, GLOW introduces an actnorm lay er that p erforms a c hannel-wise affine transformation of the acti- v ations: y = s ⊙ x + b , where s and b are learnable scale and bias parameters. They are initialized using a single minibatc h so that each output channel has zero mean and unit v ariance, ensuring numerically stable initialization. Afterward, these parameters b ecome trainable and data-indep enden t. Because the transformation is affine, the inv erse and the log-determinan t of the Jacobian are easy to compute: log | det J | = X i log | s i | . In v ertible 1 × 1 con volution. The inv ertible 1 × 1 conv olution replaces the fixed channel p ermutations used in RealNVP , allowing the mo del to learn more flexible dependencies across channels. It can b e seen as a learnable generalization of a p erm utation, where the weigh t matrix W ∈ R c × c is initialized as a random rotation matrix to ensure in v ertibility . The log-determinan t of this transformation for a tensor of shap e ( h, w , c ) is given b y: log det d conv2D( h ; W ) d h ! = h · w · log | det( W ) | . (2.4) This op eration efficiently mixes information across feature channels while pre- serving inv ertibilit y . Coupling lay er. The final comp onent in eac h GLO W blo ck is the affine c oupling layer , whic h follo ws the same principle as in RealNVP . The input is split in to t wo parts: one remains unc hanged, while the other is transformed using scale and translation parameters predicted b y a neural netw ork conditioned on the unc hanged part. This ensures that the transformation remains inv ertible and that the Jacobian determinan t is easy to compute. The coupling la yers, combined with learned c hannel mixing through 1 × 1 con v olutions, allow GLO W to capture complex dep endencies b et ween input dimensions. Ov erall, GLOW provides a stable and efficient framework for flow-based gen- erativ e mo deling, improving o v er RealNVP in terms of expressiveness and con- v ergence. It remains one of the key references for inv ertible neural netw orks and densit y-based generativ e mo deling. Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 39 A uto regressive net wo rks This section provides an in tro duction to A utor e gr essive networks [23, 58]. F urther details are left to the next section. W e can introduce autoregressiv e mo dels as a generalization of coupling flo ws in whic h the transformation is implemented b y a DNN. Eac h output i is mo deled by the DNN according to the previously transformed dimensions. Let h ( · ; θ ) : R → R b e a bijector parametrized by θ . Then we can define the autoregressive model function g : R D → R D suc h that y = g ( x ) , where eac h en try of y is conditioned on the previous output: y i = h ( x i ; Θ( y 1: i − 1 )) (2.5) where y 1: i − 1 is a short notation for ( y 1 , ..., y i − 1 ) and i = 2 , ..., D , with D the n umber of dimensions. The Θ function is called a c onditioner . The inv erse transformation is then given b y: x i = h − 1 ( y i ; Θ i ( y 1: i − 1 )) (2.6) W e could hav e c hosen a conditioner that depends only on the un transformed dimensions of the input: y i = h ( x i , Θ( x 1: i − 1 )) (2.7) The Jacobian matrix of an autoregressive transformation is triangular, giving a big adv an tage in the calculation of the determinan t, whic h now b ecomes the pro duct of the elements in the principal diagonal: det( J g ) = D Y i =1 ∂ y i ∂ x i (2.8) 2.3 Mask ed A uto regressive Flo w (MAF) In this section, w e in tro duce a sp ecific approach to autoregressiv e netw orks, built on the realization (pointed out by Kingma et al. (2016) [23]) that autoregressive mo dels, when used to generate data, correspond to a deterministic transformation of an external source of randomness (t ypically obtained b y random num b er gen- eration). This transformation, due to the autoregressiv e property , has a tractable Jacobian b y design and, for certain autoregressive transformations, is also inv ert- ible, precisely corresp onding to a normalizing flow in tro duced earlier in the text (Section 2.2). Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 40 The sp ecific implementation in tro duced in this section is the Maske d A utor e- gr essive Flow (MAF) [54] using the Maske d A uto enc o der for Distribution Estima- tion (MADE) [59] as the building blo ck. It corresp onds to a generalization of the R e alNVP , and it is closely related to the Inverse A utor e gr essive Flow (IAF) [58, 60]. The key idea of a MAF is to impro ve mo del fit by stac king m ultiple instances of the mo del into a deep er flow. Given autoregressiv e mo dels M 1 , M 2 , . . . , M n , an estimate of the ob jective PDF is found b y transforming the output of the first blo c k M 1 with the subsequen t block M 2 ; the output of M 2 is then transformed by M 3 and so on un til the last blo c k. The autoregressive blo cks are t ypically chosen to b e MADE blo cks that will be further discussed later in the section. In other w ords, w e call MAF an implemen tation of stacking MADE blo cks in to a flow. In the original implementation, eac h MADE blo ck w as resp onsible for out- putting the parameters of an affine transformation α and µ . In the gener ative dir e ction , the transformations are written as: x i = u i · e α i + µ i where µ i = f µ i ( x 1: i − 1 ) , α i = f α i ( x 1: i − 1 ) and u i ∼ N (0 , 1) 1 . This is not the only p ossible c hoice and, in the next paragraphs, one of the most p ow erful alternativ es, the R ational Quadr atic Spline (RQS) , will b e further discussed since it will b e one of the fundamental asp ects of the implemen tation. The follo wing is an extract of Ref. [54]. An imp ortant p oin t to note is that MADE remo ves the need to compute activ ations sequentially within a la yer: thanks to its masking scheme (detailed in the next section), all units can b e ev aluated in parallel while still resp ecting the autoregressiv e dep endencies. How ev er, a MAF remains autoregressive at the lev el of the transformation: each output comp onent z i dep ends only on the prefix x m ( k ) = 1 if d > m ( k ) 0 otherwise with d ∈ { 1 , . . . , D } and k ∈ { 1 , . . . , K } . The difference in the tw o expressions comes from the fact that we need to encode the constrain t that the d th output unit is only connected to x m ( k ) 1 m ( k ) ≥ d Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 44 If d ′ ≤ d there are no v alues for m ( k ) such that it is b oth strictly less than d ′ and greater or equal to d , th us M V,W d ′ ,d is 0. This demonstrates the autoregressive prop ert y of the masked autoenco der if masks are built with the illustrated rules. The question now b ecomes how to generalize this logic to a deep auto enco der. This can b e s imply generalized b y assigning a maximum num b er of connected inputs to each of the hidden units and constructing similar masks to satisfy the autoregressiv e prop erty . F or netw orks with L > 1 hidden la yers, sup erscripts are in tro duced to index lay ers. The first hidden la yer matrix is no w W 1 , the second la yer matrix is W 2 , and so on. This notation will b e extended also to the integers assigned to the hidden units; the maximum n um b er of connected inputs to the k th unit in the l th la yer is denoted with m l ( k ) , with k ∈ { 1 , . . . , K l } and K l b eing the num b er of units in the l th hidden lay er. Referring to the first lay er mask already discussed, the generalization to an L = 2 auto enco der can b e done b y making sure that each unit k ′ (in the second hidden la y er) is only connected to first la y er units connected to at most m 2 ( k ′ ) inputs, i.e. the first lay er units such that m 1 ( k ) ≤ m 2 ( k ′ ) . By following this argumen t, the rules are generalized to a deep auto enco der: M W l k ′ ,k = 1 m l ( k ′ ) ≥ m l − 1 ( k ) = 1 if m l ( k ′ ) ≥ m l − 1 ( k ) 0 otherwise and M V d,k = 1 d>m L ( k ) = 1 if d > m L ( k ) 0 otherwise In the discussion the ordering in the first and last lay er w as left to the natural ordering introduced by the input vector x . This is not mandatory and will b e v ery imp ortan t for the or der-agnostic tr aining . Indeed, ha ve shown that training an autoregressiv e model on al l orderings can b e b eneficial. It can b e achiev ed by assigning in teger v alues to the input lay er and using them to build the masks. Note that the in teger v alues must b e the same (in the same order) for the input and output v ector. Figure 2.6 illustrates the conceptual transition from a conv en tional auto en- co der to the Masked A uto enco der for Distribution Estimation (MADE). In a standard autoenco der (left), the net work is fully connected, and eac h output unit dep ends on all input v ariables, making the mo del suitable for represen tation learning but not for autoregressiv e densit y estimation. In contrast, the MADE Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 45 Figure 2.6: On the left there is the conventional autoenco der with three hidden la yers. The netw o rks are o riented from top to b ottom and the input passes through three fully connected la yers. Note that since the output attempts at reconstructing the inputs, and it dep ends entirely on the inputs, the standard A uto enco der is not suitable fo r data generation. On the Right the net w orks has the same structure as the standard A uto enco der, but some connections have b een removed, such that each input unit is only predicted based on the previous ones, using multiplicative bina ry masks. In the example, the ordering of the inputs has b een changed to 3,1,2. Masks a re constructed following the discussion illustrated in Section 2.3.1. arc hitecture (righ t) introduces binary masks that selectively remov e connections b et ween lay ers, enforcing an autoregressive prop erty such that each output di- mension is conditioned only on a subset of the inputs according to a predefined ordering. This masking mec hanism allows the netw ork to model the join t prob- abilit y as a pro duct of conditional distributions, thereby transforming a con ven- tional feed-forward auto enco der into an efficient autoregressiv e mo del. 2.3.2 Rational Quadratic Spline (RQS) A spline is, in general, a piecewise-p olynomial or a piecewise-rational function whic h is sp ecified by K+1 p oin ts n ( x ( k ) i , y ( k ) i ) o K k =0 (K bins) called knots , through whic h the spline passes. This notation is used to define the knots co ordinates, defined for eac h dimension of the v ectors x i and y i . The requirement for the spline to b e in vertible is translated in to the requiremen t for the spline to b e monotone, meaning that x i < x i +1 and y i < y i +1 . Usually , the spline is defined on compact Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 46 in terv als [62]. An example of a spline, in tro duced by Ref. [24] is the Rational Quadratic Spline that in tro duces a more exp ensive transformation that remains in vertible and computationally efficien t. As the name suggests, the spline defines a dif- feren t rational quadratic function for eac h bin defined b y the knots. The knots are defined to b e monotonically increasing b et ween { ( x (0) i , y (0) i ) = ( − B , − B ) } to { ( x ( K ) i , y ( K ) i ) = ( B , B ) } . W e call the domain of the spline B = [ − B , B ] . The spline is defined b y follo wing the metho d introduced in Ref. [24]. The metho d starts from defining: h ( k ) i = x ( k +1) i − x ( k ) i , ∆ ( k ) i = ( y ( k +1) i − y ( k ) i ) /h ( k ) i where ∆ ( k ) i represen ts the v ariation of y i with resp ect to the v ariation of x i within the k -th bin. F or this reason, b eing the spline monotonically increasing b y construction, it is alwa ys non-negativ e. The goal will b e to build a bijector g ( x i ) , mapping the B in terv al to itself, such that g ( x ( k ) i ) = y ( k ) i and deriv ativ es d ( k ) i = dy ( k ) i /dx ( k ) i satisfying the conditions: d ( k ) i = d ( k +1) i = 0 , if ∆ ( k ) i = 0 , d ( k ) i > 0 , d ( k +1) i > 0 , if ∆ ( k ) i > 0 , necessary and sufficient, in the case of a rational quadratic function, to ensure monotonicit y [24, 63]. Notice that, in this specific instance, the deriv ativ es at the b oundaries are left unconstrained, assuming linear tails implemen tation outside the spline domain. Sometimes an identit y map is used outside the spline domain and additional constrain ts must be introduced on the deriv atives: d (0) i = d ( K ) i = 1 . F or x i ∈ [ x ( k ) i , x ( k +1) i ] , with k = 0 , . . . , K − 1 , w e define θ i = ( x i − x ( k ) i ) h ( k ) i suc h that θ i ∈ [0 , 1] . W e also define y i = P ( k ) i ( θ i ) Q ( k ) i ( θ i ) , (2.9) where the functions P and Q are defined by P ( k ) i ( θ i ) = ∆ ( k ) i y ( k +1) i θ 2 i + ∆ ( k ) i y ( k ) i (1 − θ i ) 2 + y ( k ) i d ( k +1) i + y ( k +1) i d ( k ) i θ i (1 − θ i ) , Q ( k ) i ( θ i ) = ∆ ( k ) i + d ( k +1) i + d ( k ) i − 2 ∆ ( k ) i θ i (1 − θ i ) . Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 47 Figure 2.7: Example of a RQS transformation defined on the interval B = [ − 7 , 7] , with 6 bins and 7 knots. Equation 2.9 can then b e written in the simplified form y i = y ( k ) i + ( y ( k +1) i − y ( k ) i )(∆ ( k ) i θ 2 i + d ( k ) i θ i (1 − θ i )) ∆ ( k ) i + ( d ( k +1) i + d ( k ) i − 2 ∆ ( k ) i ) θ i (1 − θ i ) . The Jacobian J g is then diagonal ( y i only dep ends on x i ) and can b e written as ∂ y i ∂ x i = ∆ ( k ) i 2 d ( k +1) i θ 2 i + 2 ∆ ( k ) i θ i (1 − θ i ) + d ( k ) i (1 − θ i ) 2 ∆ ( k ) i + d ( k +1) i + d ( k ) i − 2 ∆ ( k ) i θ i (1 − θ i ) 2 with i = 1 , . . . , D . The in verse transformation can b e obtained from 2.9 b y solving the quadratic equation with resp ect to x i . B and K are fixed v ariables (hyperparameters) to b e c hosen in the design phase. On the contrary , { ( x ( k ) i , y ( k ) i ) } K k =0 and { d ( k ) i } K − 1 k =0 are 2( K + 1) plus K − 1 parameters mo deled b y a NN, which determine the shap e of the spline function. Figure 2.7 sho ws an example of a RQS transformation defined on the interv al B = [ − 7 , 7] , with 6 bins and 7 knots. 2.4 Evaluating Generative Mo dels Before statistically grounded proto cols, ev aluation in ph ysics used simple chec ks on a small set of hand-crafted observ ables. Typical studies compared one- or t wo-dimensional histograms and rep orted global scores built from physics fea- tures, suc h as the F réchet and Kernel Ph ysics Distances (FPD/KPD) [64]. The Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 48 CaloChallenge help ed standardize this practice and made cross-mo del compar- isons easier, sometimes adding classifier-based c hec ks as a complemen t [11, 64]. These to ols were practical and interpretable, but they mixed heterogeneous met- rics and had w eak con trol of statistical uncertaint y . Rep orted differences often de- p ended on binning, sample size, or h yp erparameters, and it was not clear whether they were significan t or due to fluctuations. Reference [2] addressed these issues by casting v alidation as a tw o-sample hy- p othesis test. The paper studies families of tests in a single framew ork: pro jection- based distances (e.g., sliced W asserstein, mean-KS, sliced-KS) and multiv ariate baselines (e.g., un biased MMD, F réc het Gaussian Distance). It prescribes the construction of empirical null and alternative distributions for eac h test statis- tic and rep orts calibrated p -v alues and p ow er at fixed sample cost. This gives a common language, clear uncertain ty quantification, and repro ducible comparisons across datasets and mo dels. A key result is that w ell-designed one-dimensional pro jection tests can match the sensitivit y of heavier m ultiv ariate metrics while b eing muc h cheaper and easier to parallelize. Why new metho ds w ere necessa ry High-energy ph ysics data are high-dimensional (from 10 2 up to 10 4 + features p er even t). Naive m ultiv ariate distances are often too costly or unstable in this regime. Ev aluation must therefore: • Scale in dimension and sample size: tests should remain efficient for large datasets and many features. • Pro vide calibrated error control: rep ort p -v alues at a c hosen signifi- cance and p o wer curv es at fixed cost. • Be robust to finite samples: av oid conclusions driv en by binning choices or small fluctuations. • Capture correlations and tails: assess structure b ey ond a few marginals and remain sensitiv e in rare regions. • Supp ort repro ducibility and comparability: use a shared procedure, so results can b e fairly compared. Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 49 The framework in [2] meets these needs. It treats data and generated samples symmetrically , uses empirical nulls for calibration, and exposes the trade-off b e- t ween sensitivit y and compute. Ph ysics-a ware summaries suc h as FPD/KPD remain useful as diagnostics and headline indicators, but they are most reliable when embedded in a calibrated testing pip eline rather than used alone [11, 64]. In this thesis, that calibrated framework is adopted. Null and alternativ e en- sem bles are built from truth and generated sho w ers. Rep orted results include p -v alues, test p ow er, and computational cost, with pro jection-based tests as the main high-dimensional to ols and ph ysics-aw are summaries and classifier c hecks as complementary diagnostics. 2.4.1 T w o-sample hyp othesis testing Giv en tw o random v ariables x and y , defined on a space X ⊆ R d , let us consider t wo samples X = { x i } where i = 1 , . . . , n and Y = { y j } where j = 1 , . . . , m , with the assumption of them b eing indep endent and iden tically distributed according to the distributions p and q , respectively . W e can denote with x i,I ( y j,J ) the scalar v alue of the i -th ( j -th) element of sample X ( Y ) along the I -th ( J -th) dimension, with I ( J ) = 1 , . . . , d . T w o-sample testing aims at determining whether the n ull h yp othesis H 0 : p = q (2.10) can b e rejected based on finite data. The alternative h yp othesis is the negation of the n ull: H 1 : p = q (2.11) Giv en the h yp otheses, we need to define the test statistic , t : ( X ) n × ( X ) m − → R , and calculate its v alue on the observed data: t obs = t ( X , Y ) . (2.12) Then, a binary test is defined b y comparing the observ ed t obs to a threshold t α defined by: α = P ( t ≥ t α | H 0 ) = Z ∞ t α f ( t | H 0 ) dt, (2.13) where α is defined as the signific anc e of the test and f ( t | H 0 ) the distribution of the test statistic under the n ull h yp othesis H 0 . The significance represen ts a pr esele cte d probabilit y of type-I error, i.e., the r ate of false p ositives (rejecting Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 50 Figure 2.8: Illustration of T yp e I and T yp e I I erro rs for a test statistic t . The blue curve is the sampling distribution f ( t | H 0 ) under the null hyp othesis, and the o range curve is f ( t | H 1 ) under the alternative. A decision threshold t ⋆ defines the shaded H 0 rejection region (to the right). The T yp e I erro r rate α is the blue tail area b ey ond t ⋆ (rejecting H 0 when H 0 is true). The T yp e I I erro r rate β is the o range a rea to the left of t ⋆ (failing to reject H 0 when H 1 is true). the null h yp othesis if true). The null h yp othesis H 0 is rejected if t obs > t α . In Fig 2.8 is rep orted a diagram sho wing the Type I and T yp e I I errors. Another quan tity can then b e calculated, the p-value , defined as the proba- bilit y of observing a test statistic as extreme as t obs under H 0 : p obs = P ( t ≥ t obs | H 0 ) . (2.14) Giv en α , the Neyman-P earson construction provides a metho d to compare the p erformance of differen t tests. This consists in in tro ducing t yp e-I I error, or the r ate of false ne gatives , defined as the probabilit y of accepting the null hypothesis H 0 if the alternativ e h yp othesis H 1 is true: β = P ( t < t obs | H 1 ) = Z t α −∞ f ( t | H 1 ) dt, (2.15) where f ( t | H 1 ) is the distribution of the test statistic under the alternativ e hy- p othesis. The p ower of the test can then b e defined as p o wer = P ( t ≥ t α | H 1 ) = 1 − β (2.16) The b est statistic is usually the one with the higher p o wer giv en a significance lev el α , i.e. the one with the smallest rate of false negatives giv en a fixed rate of false p ositiv es. T o compute the quantities in Eqs. 2.13 and 2.16, the distribution of the test statistic under b oth the n ull and alternative h yp othesis, f ( t | H 0 ) and f ( t | H 1 ) , must b e known or estimated. In some cases, analytical appro ximation for finite sample size or asymptotic b ehavior can b e used, for the KS test and Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 51 for lik eliho o d ratio-based tests. In general, how ev er, non-parametric testing often relies on empirical estimates. In this con text a go o dness-of-fit test can b e in tro duced, by designating one of the samples as the r efer enc e one. W e will b e in terested in testing the compatibility of a generated dataset with the true v alues obtained by Mon te Carlo sim ulation, so w e will fix as reference the Monte Carlo data and the generated samples as the alternativ e. A ccept H 0 Reject H 0 H 0 true H 0 false Correct decision (T rue negativ e) T yp e I error ( α ) (F alse positive) T yp e I I error ( β ) (F alse negativ e) Correct decision (T rue positive) Figure 2.9: Possible outcomes of a statistical test. Colo red cells highlight T yp e I and T yp e I I erro rs. 2.4.2 T est statistics With the exception of the F réc het Gaussian Distance (F GD), all the test statistics are derived from or based on in tegral probability metrics (IPMs). IPMs are a broad class of probability distribution distances, defined as d F ( p, q ) = sup f ∈F ( E x ∼ p [ f ( x )] − E y ∼ q [ f ( y )]) . (2.17) where F is a class of real-v alued, scalar functions defined ov er the set X : ∀ f ∈ F , f : X → R . W e will now illustrate the relev an t examples of test statistics in tro duced in [2]. 2.4.2.1 Sliced W asserstein distance The sliced W asserstein (SW) distance [65] inv olv es a veraging the 1D pro jections of the W asserstein distance ov er “all” directions on the unit d -dimensional sphere. Being a computationally efficient v arian t of the W distance, it is a natural c hoice for tw o-sample testing. Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 52 W e fo cus on the 1-W asserstein distance, commonly referred to as e arth mover’s distanc e . In one dimension, it is defined as W n,m = Z R | F n ( u ) − G m ( u ) | du (2.18) where F n and G m are eCDF s 2 (Empirical Cum ulative Distribution F unctions). This distance measures the minimal cost of transforming one distribution in to another and dep ends linearly on the Euclidean distance b etw een data p oin ts. It can b e interpreted as an IPM b y taking as F the space of 1-Lipschitz functions. In case of tw o 1D samples with an equal n umber of data points m = n , the W distance can b e easily computed as W n = 1 n n X i =1 | x i − x ′ i | , where the underlined v ariables represen t elemen ts in the set obtained b y p ermut- ing the original sample with a p erm utation P that sorts the p oin ts: { x } = P ( { x }| x 1 ≤ · · · ≤ x n ) (2.19) The Sliced v arian t takes the form: t SW = 1 K X θ ∈ Ω K W θ n = 1 K X θ ∈ Ω K 1 n n X i =1 | x θ i − x ′ θ i | ! (2.20) where Ω K is a set of K directions selected uniformly at random on the unit sphere Ω = { θ ∈ R d | ∥ θ ∥ = 1 } and { x θ i } n i =1 = { θ T x i } n i =1 are the sorted data p oin ts pro jected on the direction θ . It is imp ortant to note that the asymptotic b eha vior of the test statistic is not distribution-free, in fact in the limit m, n → ∞ with m/n → c = 0 , ∞ , the distribution of the test statistic in Eq. 2.20 under the n ull h yp othesis will dep end on the underlying data distribution. 2.4.2.2 K olmogo rov-Smirnov (KS) inspired test statistics The KS test [25, 26] is a widely used non-parametric metho d for b oth go o dness- of-fit and t wo-sample testing. It measures the largest absolute difference betw een 2 A CDF of a random v ariable X , ev aluated at x , is the probability of measuring X less than or equal to x . In form ulae: F ( x ) = P ( X ≤ x ) It is a non-decreasing function and, if the random v ariable is contin uous, it is defined as F X ( x ) = R x −∞ f X ( t ) dt , otherwise defined as F X ( x ) = P x i ≤ x P ( X = x i ) = P x i ≤ x f X ( x i ) , where f X is the PDF of the distribution of X . An empirical cum ulative distribution function, is an approximation of the CDF built from an empirical measure of a sample. Giv en a sample ( X 1 , . . . , X n ) , it is defined b y F n ( x ) = 1 n P n i =1 1 X i ≤ x , with 1 X i ≤ x = 1 if X i ≤ x or 1 X i ≤ x = 0 if X i > x . Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 53 the tw o eCDF s of the samples. Defined as t KS = s nm n + m sup u | F n ( u ) − G m ( u ) | , (2.21) it can b e viewed as an IPM with F chosen to b e the class of indicator functions 1 ( −∞ ,t ] for all t ∈ R . In Eq. 2.21, F n ( u ) and G m ( u ) are the eCDF of the t wo samples. The prefactor ensures that, under the n ull h yp othesis (i.e. the tw o samples are dra wn from the same distribution), and as m, n → ∞ with m/n → c = 0 , ∞ , the test statistic follows the Kolmogoro v distribution, with the following CDF F K ( x ) = 1 − 2 ∞ X k =1 ( − 1) k − 1 e − 2 k 2 x 2 , (2.22) and PDF f K ( x ) = d dx F K ( x ) = 8 x ∞ X k =1 ( − 1) k − 1 k 2 e − 2 k 2 x 2 . (2.23) Widely used for 1D data, the KS test has limited application in higher dimen- sions due to its computational cost. F or this reason, tw o efficien t m ultiv ariate extensions are in tro duced. Mean KS The mean KS test extends the KS test to higher dimensions by a veraging the KS statistic computed along each dimension of the data. The test statistic is defined by t KS = 1 d d X I =1 s nm n + m sup u | F I n ( u ) − G I m ( u ) | , (2.24) where F I n ( u ) and G I m ( u ) are the eCDF s of the pro jected samples along the I -th dimension. This approac h mak es the KS distance computationally feasible in higher dimensions, with the downside that, since it is uniquely defined by the 1D marginals, it is not exp ected to b e directly sensitiv e to correlations b etw een dimensions. T o impro ve the sensitivity to such correlation, another v arian t has b een introduced in [2]. Sliced KS Similarly to the W asserstein distance case, the KS metho d is ex- tended b y projecting the original d -dimensional data onto 1D subspaces. The subspaces are c hosen to b e K uniformly random directions sampled from the unit sphere. F or eac h direction θ , the KS test statistic is computed as t θ KS = s nm n + m sup u | F θ n ( u ) − G θ m ( u ) | , (2.25) Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 54 where F θ n ( u ) and G θ m ( u ) are the eCDF s of the projected samples along the direc- tion θ . The Sliced KS statistic (SKS), is then computed as the a verage of the KS statistics across the K random directions: t SKS = 1 K X θ ∈ Ω K t θ KS = 1 K X θ ∈ Ω K s nm n + m sup u | F θ n ( u ) − G θ m ( u ) | . (2.26) This approach, due to the random directions of pro jections, might be sensitive to correlations b etw een dimensions, but remains computationally feasible due to the 1D KS tests. 2.4.2.3 Maximum Mean Discrepancy (MMD) In tro duced in [31, 32], MMD is a statistical measure of the distance b etw een t w o probabilit y distributions. Its IPM form ulation can be found b y taking as F the unit ball in a repro ducing kernel Hilb ert space (RKHS) [66]. F ollowing Ref. [32], an unbiased empirical estimate of MMD is given b y t MMD = 1 n ( n − 1) n X i =1 X j = i k ( x i , x j ) + 1 m ( m − 1) m X i =1 X j = i k ( y i , y j ) − 2 nm n X i =1 m X j =1 k ( x i , y j ) , (2.27) where k ( x, x ′ ) is the kernel function defining the RKHS. In Ref. [64] a fourth- order p olynomial k ernel w as used: k ( x, x ′ ) = 1 d x T x ′ + 1 4 . This k ernel is not char acteristic , meaning that k ( x, x ′ ) is not a true metric on the space of probability measures. Sp ecifically , for this k ernel, the condition p = q is sufficient for t MMD ( p, q ) = 0 but not necessary . In fact this kernel cannot dis- tinguish b etw een distributions that differ b eyond their fourth momen t. Since the p olynomial k ernel is not characteristic, we say that this instance of MMD is a pseudo-metric . In con trast, characteristic k ernels, such as Gaussian and Lapla- cian k ernels, are capable of fully distinguishing b etw een different distributions. Ho wev er, they require tuning h yp erparameters (lik e the k ernel bandwidth) based on the data, not necessary for the polynomial k ernel. F rom a computational p oin t of view, the MMD test statistic b etw een t wo datasets of size n scales as O ( n 2 ) due to the need to store the full kernel matrix K , where each elemen t is giv en b y K i,j = k ( x i , x ′ j ) . This mak es MMD computationally exp ensiv e, esp ecially in large-scale scenarios or when the test needs to b e ev aluated multiple times. Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 55 2.4.2.4 F réchet Gaussian Distance (FGD) The FGD 3 (in tro duced in Ref. [64]) is a pseudo-metric; specifically , it in v olves fit- ting a m ultiv ariate Gaussian distribution to the features of in terest, and then cal- culating the F réc het distance (or 2-W asserstein distance). The fitted distributions are c haracterized b y means µ 1 , µ 2 ∈ R d and co v ariance matrices Σ 1 , Σ 2 ∈ R d × d . The FGD b et ween t wo samples of sizes n and m is giv en b y: F GD n,m = d X I =1 ( µ I 1 ,n − µ I 2 ,m ) 2 + tr Σ 1 ,n + Σ 2 ,m − 2 q Σ 1 ,n Σ 2 ,m , (2.28) where µ I 1 ,n and µ I 2 ,m represen t the I -th comp onen ts of the sample means µ 1 ,n and µ 2 ,m , resp ectively . As p oin ted out in Ref. [68], this distance happens to b e biased when computed on finite samples. T o mitigate this bias, an un biased asymptotic extrap olation can b e in tro duced, as prop osed in Ref. [69]. This asymptotic v alue, denoted as t FGD : = F GD ∞ = lim n,m →∞ F GD m,n (2.29) is estimated b y fitting a linear mo del to FGD v alues computed at different finite sample sizes. In the following, w e refer to F GD ∞ simply as F GD. 2.4.2.5 Lik eliho o d-ratio Detecting deviations from a reference mo del can b e framed as a go o dness-of- fit test b etw een tw o comp eting statistical mo dels. F or simple hypotheses, the Neyman-P earson lemma shows that the most p ow erful test in this scenario is the lik eliho o d-ratio test [70]. The test statistic for the lik eliho o d ratio will b e found b y follo wing the approach of Ref. [2]. The lik eliho o d function for the datasets X and Y under the n ull h yp othesis (where b oth samples follow the reference distribution p ) is written as L H 0 = Y x ∈ X p ( x ) Y y ∈ Y p ( y ) . (2.30) Under the alternativ e hypothesis (where the sample Y follows a differen t distri- bution q ), the lik eliho o d is: L H 1 = Y x ∈ X p ( x ) Y y ∈ Y q ( y ) . (2.31) 3 In [64] w e tak e inspiration from the F réchet Inception Distance (FID) (Ref. [67]), whic h at the time (2023) w as the standard metric for ev aluation in computer vision (image generators, suc h as GANs or diffusion-based metho ds). Chapter 2. F rom Generation to V alidation: Principles and Evaluation Metrics 56 The ratio of the lik eliho o d under the n ull and alternativ e h yp otheses is then given b y Λ = L H 0 L H 1 = Y y ∈ Y p ( y ) q ( y ) , (2.32) The test statistic for the LLR test is then defined as: t LLR = − 2 log Λ . (2.33) Notice ho w the test statistic for the likelihoo d ratio dep ends explicitly on b oth the distribution p and q . Consequently , it can b e used only if an analytic expression for the PDF s is a v ailable. Chapter 3 Calo rimeter Physics and Detecto r Principles In this c hapter, w e presen t an in tro duction to HEP experiments, specifically at LHC, emphasizing the cen tral role pla yed b y calorimetry . A ma jor part of the discussion has b een inspired b y Ref. [71, 72]. Calorimeters are one of the fundamen tal comp onents of high-energy particle exp erimen ts. Originally , a c alorimeter is an instrumen t used to measure the heat pro duced in c hemical reactions or ph ysical transformations. F or instance, the calories in fo o d are measured by burning a sample inside what is called a b omb c alorimeter . In this context, calorimetry (the science of calorimeters) is explored in its application to High Energy Physics (HEP), whic h is quite differen t from its applications in other sciences. In HEP , the purpose is to measure the energy of the particles resulting from a collision through the total absorption of the particle energy in a bulk of material, follo w ed by the measurement of the dep osited energy . The structure and w orking principles of calorimeters in HEP heavily dep end on the sp ecific particle for whic h they are designed. As will b e discussed later in the text, the pro cesses used to measure the energy of leptons and hadrons are quite differen t; th us, the calorimeter structure needs to address these differences. Before discussing the mec hanism b y whic h a calorimeter can measure the energy of incoming particles, w e will discuss ho w an exp eriment at the LHC w orks. At the LHC (Large Hadron Collider), v ery energetic protons are made to collide, and the resulting pro ducts are analyzed. The biggest detectors at the LHC hav e similar fundamen tal structures, and a significan t part of the detector is o ccupied b y calorimeters. T ake, for example, the A TLAS detector [73, 74], which is the 57 Chapter 3. Calo rimeter Physics and Detecto r Principles 58 largest detector ev er built at a collider; it is 46 meters long, 25 meters in diameter, and weighs 7000 tons (similar to the w eigh t of the Eiffel T o w er). It is designed in concen tric la y ers cen tered around the in teraction p oint, with each la yer sp ecialized in differen t measuremen ts. It can be divided in to four major systems, eac h made up of differen t la yers: • Inner detector: begins a few centimeters from the proton b eam to a radius of 1 . 2 meters. Its basic function is to track charged particles b y detect- ing their interactions with matter in discrete p oints. It has 3 sub-la yers, eac h sp ecialized in a sp ecific task. The inner detector is surrounded b y a solenoidal magnet, whic h is fundamen tal for measuring the momen tum of c harged particles by assessing their curv ature in the magnetic field. • Calorimeters, situated directly outside the solenoidal magnet, are resp onsi- ble for measuring the energy of the incident particles. They are arranged in t wo sub-systems: the inner electromagnetic calorimeter and the outer hadron calorimeter. Calorimeters are usually built with a structure of vol- umetric pixels , also called voxels , allowing us to infer the incident particle direction and th us ac hieve b etter even t reconstruction. • Muon sp ectrometer: the cross-section for the interaction of muons is to o small for them to b e absorb ed. So muons need a dedicated system that, in this sp ecific case, is extremely large; it starts at 4 . 25 meters from the in teraction p oint and extends to the full length of the radii (appro ximately 11 meters). The large dimension of the muon section is necessary to pre- cisely measure the momentum of m uons b y assessing the curv ature in high magnetic fields. • Magnetic system: as already mentioned, there is a solenoid surrounding the inner detector that pro duces a 2 T esla magnetic field, allo wing it to curve ev en v ery energetic particles. There is another sup erconducting toroidal magnet in the m uon section that v aries b etw een 2 and 8 T esla. A toroidal magnet is c hosen because a solenoidal magnet of the requested size w ould ha ve prohibitiv e costs. Chapter 3. Calo rimeter Physics and Detecto r Principles 59 Figure 3.1: Schematic cross-section of the A TLAS detector (not to scale). F rom the b eam pip e out wa rd: silicon pixel and strip track ers and the T ransition Radiation T rack er inside a solenoid; the liquid-argon electromagnetic calorimeter; the TileCal hadronic calo rimeter; and the outer muon sp ectrometer. Example pa rticle signatures a re shown: an electron and a photon producing electromagnetic show ers, hadrons sho wering in the hadronic calorimeter, a muon traversing to the muon system, and a neutrino leaving no visible trace (seen as missing transverse momentum). A dapted from A TLAS public outreach material. Chapter 3. Calo rimeter Physics and Detecto r Principles 60 3.1 Electromagnetic calo rimetry The discussion ab out electromagnetic calorimetry must start with how electrons and photons can lose energy in matter. It is imp ortant to recall that the discussion is based on HEP applications, so the interactions describ ed are prev alent at high energies. 3.1.1 Interaction with matter Electrons lose energy in matter almost exclusiv ely through br emsstr ahlung (from German br emsen “to brake” and Str ahlung “radiation”), i.e., radiation emitted from an accelerated c harged particle. In a medium, an electron is deflected by other c harged particles, typically b y the electric fields of atomic n uclei. The radiativ e energy-loss rate can b e written as: − d E d x ! rad = 4 αN A Z 2 A r 2 e E log 183 Z 1 3 con venien tly rewritten as: − d E d x ! rad = E X 0 with X 0 = A 4 αN A Z 2 r 2 e log 183 Z 1 3 where X 0 is the Radiation Length , defined as the length o v er whic h an electron reduces its energy by 1 /e through radiation emission. Photons On the other hand, at high energies, photons lose energy predominan tly through pair pro duction , i.e., a photon in the field of an atomic n ucleus con verts into an electron-positron pair. The mean free path of a photon b efore it con verts is appro ximately: λ pair ≈ 9 7 X 0 where X 0 is again the radiation length. 3.1.2 Electron-Photon cascades Based on the in teractions with matter discussed ab o ve, an electron (or a photon) en tering a medium can giv e rise to an electromagnetic sho wer [72]: a high-energy Chapter 3. Calo rimeter Physics and Detecto r Principles 61 Figure 3.2: Energy loss in lead (right) and copp er (left). electron en tering a bulk of material emits a photon via bremsstrahlung. After roughly one radiation length, the photon con verts in to a pair; the electron and p ositron subsequently each emit a photon after about one radiation length, and the process con tin ues. This is a simple explanation of how a single particle, either an electron or a photon, could create a sho w er of secondary particles. T o analyze the sho wer dev elopmen t, w e in tro duce a v ariable t = x X 0 that is the distance normalized to radiation length. Let us assume that the energy is symmetrically shared among the particles at each step. The num b er of sho wer particles (electrons, p ositrons, or photons) at depth t is N ( t ) = 2 t and the energy of eac h individual particle is given b y E ( t ) = E 0 · 2 − t The m ultiplication con tinues as long as E 0 / N > E c , after whic h the particles are absorb ed through ionization for electrons and through Compton and photo electric effects for photons. The p osition of the maximum of the sho wer is reached for E c = E 0 · e − t max and by solving for t max t max = log( E 0 /E c ) log(2) After the show er maximum, electrons and p ositrons are absorb ed in a lay er of ab out one radiation length, while photons of the same energy can penetrate m uch longer distances. T o absorb 95% of the pro duced photons in a show er, one needs Chapter 3. Calo rimeter Physics and Detecto r Principles 62 an additional 7 − 9 X 0 , whic h implies that the thickness of a calorimeter with high sho wer containmen t should b e at least 14 − 16 X 0 . Being a simple mo del to describ e electromagnetic show ers, it nev ertheless captures the most imp ortan t c haracteristics: • T o absorb most of the inciden t energy , the calorimeter should b e at least 14 − 16 X 0 • The thickness of the calorimeter should increase logarithmically with the energy • Leakage from the sides ( later al le akage ) and from the bac k ( r e ar le akage ) is resp onsible for most of the missing energy . A t presen t, an accurate description of electromagnetic sho w ers is obtained through Mon te Carlo simulations. Notice that the angles of emission for bremsstrahlung and pair pro duction are v ery narro w. This implies that most of the lateral width of the sho w er is deter- mined primarily b y multiple scattering. It can b e characterized by the Molièr e r adius R M = 21 Me V E c X 0 {g/cm 2 } E 0 0 1 2 3 4 5 6 7 8 t [ X 0 ] Figure 3.3: A simplified diagram explaining the process of show er generation. W avy lines represent photons while straight lines rep resent electrons. Diagram inspired b y Ref. [72] Chapter 3. Calo rimeter Physics and Detecto r Principles 63 3.1.3 Homogeneous calorimeters Homogeneous calorimeters are built from a material that combines absorb er and detector prop erties. It means that the en tire volume of the calorimeter is sensitiv e to the dep osition of energy . These calorimeters are based on the measuremen t of scin tillation light (scintillation crystals, liquid noble gases), ionization (liquid noble gases), and Cherenko v light (lead glass or hea vy transparen t crystals). • Crystal calorimeters are based on heavy scin tillation crystals, i.e. materi- als that can con vert absorbed energy into visible ligh t and transfer this ligh t to an optical receiv er for measurements. Scintillation materials can b e inorganic crystals, organic comp ounds, liquids, and gases. The general principle for a material to emit light is the excitation of atoms or bands b y energetic particles, which emit photons to return to the ground state. The disadv an tage of this type of calorimeter is the high cost of scin tillation crystals and limitations in their pro duction. • Ionization calorimeters are built as an arra y of ionization c hambers im- mersed in liquid xenon or krypton. 3.1.4 Sampling calorimeters Sampling calorimeters, on the other hand, are far simpler and more economical. The k ey idea is to alternate thin lay ers of coun ters with la yers of absorbers. The sho wer in teracts with the absorb er, and the pro ducts are measured b y the coun- ters. In this t yp e of calorimeter, only a sample of energy is measured; hence the name sampling c alorimeters . The principal disadv antage of sampling calorimeters is that, in addition to the general leakage, the energy resolution is also affected b y sampling fluctuations. The principal adv an tage is the significan tly lo wer cost and simplicity . 3.2 Hadron calo rimetry In principle, a hadron calorimeter works along the same lines as the electromag- netic ones; the principal difference is that, in most detector materials, the show er length is m uch larger. The longitudinal dev elopment is determined b y the av erage Chapter 3. Calo rimeter Physics and Detecto r Principles 64 in teraction length defined b y: λ I ≈ 35 A 1 / 3 g / cm 2 F or this reason, hadron calorimeters hav e to b e muc h larger than the electromag- netic ones. 3.2.1 Hadronic show ers Due to the str ong inter action in hadrons, in addition to the electromagnetic (EM) in teraction, hadronic sho wers are m uc h more complex than their EM coun- terparts. In fact, the interaction of hadrons with atomic nuclei produces many particles through v arious pro cesses. There are t wo main comp onents: • Hadronic comp onent: p opulated b y c harged pions, kaons, protons, neu- trons, etc. • EM comp onent: primarily due to neutr al pions , which, on av erage, account for about one third of the total pions and deca y in to t wo photons, generating EM show ers. Electrons, p ositrons, and photons can also app ear in final states and will generate EM show ers. A large p ortion of the energy loss is invisible to the calorimeter, including the energy used to release protons and neutrons from n uclei, as w ell as nuclear recoil. A significan t fraction is also lost to ev ap oration neutrons. Giv en the complexity of the show er pro cess, it do es not p ossess a profile that can b e parametrized. In fact, the first interaction of the incident particle will determine the EM fraction, whic h is not kno wn a priori. Notice that in the hadronic pro cess there is a large transfer of transv erse momen tum, making the hadronic show er muc h wider. 3.3 Limitations In real calorimeters, the resp onse drifts with time b ecause the activ e scintillator tiles and wa v elength-shifting (WLS) fibers accum ulate total ionizing dose (TID). As an example, w e rep ort the measured aging in the A TLAS Tile Calorimeter Chapter 3. Calo rimeter Physics and Detecto r Principles 65 (TileCal). While the aging measured during R un 2 did not hav e a large impact on the measuremen ts [15], here w e consider the near-future HL-LHC scenario. In collider calorimeters, the resp onse drifts with time b ecause the activ e medium and the optical chain (plastic scin tillator tiles, wa v elength-shifting fibers, photo detectors) accumulate total ionizing dose, and parts of the front-end age; the practical signatures are a progressive loss of ligh t yield, gro wing inter-cell non- uniformities, and o ccasionally , channels that b ecome noisy or fail and must b e mask ed. In the A TLAS Tile Calorimeter (TileCal) this b ehavior is conv enien tly monitored in terms of the relativ e light yield I /I 0 , and the detector granularit y is organized in three radial lay ers: A (inner), B/BC (middle), D (outer), with cell names suc h as A13 denoting the lay er and the η bin. The p er-cell HL-LHC pro jec- tion in Figure 3.4 mak es this structure explicit while showing the spatial pattern of the expected atten uation [15]. During R un 2, the reconstructed energy scale w as k ept stable at the percent level b y the laser, 137 Cs, and minim um-bias cali- bration systems, while the most irradiated A-lay er cells exhibited an end-of-run ligh t-yield loss of about 3 – 10% and the other barrel lay ers show ed no measurable loss within the ∼ 1% sensitivit y; the detector con tributed 99 . 65% efficient high- qualit y data and few er than 1 . 1% of cells w ere non-op erational at the end of each data-taking y ear [16]. Aging dep ends on b oth total dose and dose rate, there- fore for a fixed integrated luminosit y higher instantaneous luminosit y increases the effectiv e degradation, a b eha vior also observ ed in plastic scintillators of the CMS hadron endcap calorimeter [15, 17]. Extrap olating the Run 2 mo del to the HL-LHC scenario ( L ≃ 4000 fb − 1 , instantaneous luminosity ab out sev en times R un 2), the typical A-la y er is pro jected to lose roughly 48 – 60% of ligh t resp onse b y the end of the program, with the most exp osed A12/A13 cells reac hing ab out 66 – 69% loss, while typical B/BC and D lay ers are exp ected within ∼ 17 – 25% and ∼ 7 – 16% loss, resp ectively , and cells with more than 50% exp ected loss carry a relative uncertaint y of order 50% [15]. In terms of p erformance, resp onse non-uniformities induced b y aging con tribute to the constan t term in the usual calorimeter energy-resolution parametrization σ E /E = a/ √ E ⊕ b ⊕ c/E [75], and if not fully corrected they increase b and bias in ter-calibration across cells, although in TileCal Run 2 measurements k ept non-uniformity within sp ecifica- tions and sim ulations indicate a weak dependence of the muon response ev en for large ligh t-yield reductions [15, 16], the HL-LHC pro jections in Figures 3.4 and 3.5 p oin t to substantial attenuation in the inner lay ers together with a higher Chapter 3. Calo rimeter Physics and Detecto r Principles 66 Figure 3.4: Exp ected residual light yield I /I 0 at the end of HL-LHC (assumed 4000 fb − 1 and a dose rate 7 × R un 2) for each TileCal ba rrel cell. La yer letters enco de the radial depth ( A inner, B/BC middle, D outer); indices enco de the η - bin. Shaded ranges in [15] T able 2 summarize typical cells p er lay er (A: 48 – 60% loss; B/BC: 17 – 25% ; D: 7 – 16% ), while sp ecific wo rst-case cells (e.g. A12/A13 with 66 – 69% loss) a re called out explicitly . Figure adapted from [15, Figure 18]. probabilit y of disabled or noisy c hannels, which can degrade hadronic energy and p osition resolution, distort longitudinal and transverse sho wer shap es, and impair cluster splitting and jet or photon identification if not comp ensated, these consid- erations motiv ate generative sup er-resolution approaches that aim to reconstruct fine-grained energy patterns in regions with reduced or missing resp onse and to regularize spatial non-uniformit y , thereby stabilizing the effectiv e constant term under HL-LHC irradiation. 3.4 Calo rimeter sup erresolution W e presen t our task form ulation by starting with the notation: w e denote by E coarse the energy dep osits measured on a coarse segmentation (larger cells or ag- gregated readout) and b y E fine the corresp onding dep osits on a finer segmentation (smaller cells resolving more structure). Then, the sup erresolution problem is the task of inferring the fine-grained sho wer given the coarse observ ation, whic h w e form ulate as learning the conditional distribution p E fine | E coarse . (3.1) Chapter 3. Calo rimeter Physics and Detecto r Principles 67 Figure 3.5: A verage relative light yield I /I 0 fo r TileCal A13 cells versus simulated dose d (b ottom axis) and integrated luminosity L (top axis). P oints sho w in-situ measurements: 137 Cs (dots) and minimum-bias currents (triangles). V ertical lines ma rk end of Run 3 ( ∼ 530 fb − 1 ) and end of HL-LHC ( 4000 fb − 1 ). The solid curve rep resents the extrap olation including dose-rate effects exp ected at HL-LHC, while the dashed line, rep resents the extrap olation neglecting dose-rate. Image tak en from [15]. This formulation is in tentionally probabilistic: m ultiple fine-grained patterns can b e compatible with the same coarse measurement, so a calibrated mo del should represen t a distribution o v er plausible E fine rather than a single deterministic map. W e note that (3.1) is one of the v alid formulations but not the only one. In particular, when parts of the calorimeter are unav ailable (dead or disabled c hannels) and only a subset of fine cells is recorded, w e could p ose the problem as fil ling in missing values . Let m ∈ { 0 , 1 } N fine b e a binary mask o ver the fine segmen tation, with m j = 1 for observed cells and m j = 0 for missing ones; write E fine = ( E obs , E miss ) accordingly , and learn the distribution p E miss E obs , E coarse , m . (3.2) This wa y , the missing fine-cell energies are reconstructed consisten tly with the a v ailable fine measuremen ts. Chapter 4 Implementation and Exp erimental Setup 4.1 Dataset Description 4.1.1 The dataset The dataset is taken from the F ast Calorimeter Simulation Chal lenge ( CaloChal- lenge ). More sp ecifically , this w ork is based on Dataset 2 of the CaloChal lenge , whic h is illustrated in detail below. The goal of the CaloChal lenge is to encourage the developmen t of fast and high-fidelit y calorimeter show er surrogate mo dels. The detector geometry is made up of concen tric cylinders with particles prop- agating along the z direction. It is segmented into lay ers along the z axis. Eac h la yer is sub-segmen ted into radial bins and angular bins. T o clarify the detector geometry , Figure 4.1 shows the front view (right) illustrating the lay er segmenta- tion and a 3D view of the detector (left) showing the ov erall geometry . W e refer to each individual segment of the detector as a vo xel (volumetric pixel). Getting more in depth ab out the sp ecific structure of Dataset 2 , it was sim u- lated using the P ar04 example of Geant4 [76]. The Par04 example implemen ts an idealized calorimeter consisting of concentric cylinders of alternating absorb er and active material (sampling calorimeter). The calorimeter has 90 lay ers, eac h comp osed of 1 . 4 mm of tungsten (W) as absorb er and 0 . 3 mm of silicon (Si) as activ e material. A schematic of its lay out is presented in Figure 4.2. Particle sho wers are generated b y electrons en tering the detector perp endicular to the cylinder’s axis, as shown by the top electron in Figure 4.2. Show ers with axes at 68 Chapter 4. Implementation and Exp erimental Setup 69 Figure 4.1: Schematic view of the vo xelization of the detecto r. In the sp ecific example the detector has 3 la yers, 3 radial bins, and 6 angular bins. differen t inciden t angles are b ey ond the scop e of the c hallenge. As the P ar04 example only writes out the energy dep osited in the active ma- terial, it m ust b e corrected for the deposit in the absorb er. F rom the sim ulation, a simple scaling factor has b een derived: f = 1 / 0 . 033 , constan t for all energies and cells of the detector. This means that, on av erage, only 3 . 3% of the inciden t energy is registered in the detector. F or Dataset 2 a threshold was fixed at a lo w v alue of 15 . 15 ke V, below which cell energy is not registered. The same cutoff will b e applied to the generated samples. The calorimeter geometry for Dataset 2 has 45 la yers, 16 angular bins, and 9 radial bins, for a total of 6480 vo xels. Therefore, the size of the readout cells is ∆ r × ∆ ϕ × ∆ z , with ∆ z = 3 . 4 mm, ∆ ϕ = 2 π / 16 ≈ 0 . 393 rad, and, considering only the absorb er’s Molière radius, ∆ r = 4 . 65 mm / 9 . 327 mm = 0 . 5 R M . T aking in to account only the radiation length for the absorb er ( X 0 ( W ) = 3 . 504 mm), the size along the z -axis is approximately ∆ z = 2 · 1 . 4 mm / 3 . 504 mm = 0 . 8 X 0 . Dataset 2 consists of t w o .hdf5 files (built using Python’s h5py pac kage), eac h con taining 100k sho wers (or ev en ts), with energies sampled from a log-uniform dis- tribution ranging from 1 Ge V to 1 T e V; one is used for training, the other for ev alu- ation. Within each file there are t w o separate hdf5-datasets: incident_energies has shap e (num_events, 1) and contains the energy of the inciden t particles in Me V; showers has shap e (num_events, num_voxels) and stores the energy de- p osited in each v oxel, flattened. The mapping of array index to vo xel lo cation follo ws the order (radial bins, angular bins, la yer), so the first entries corresp ond Chapter 4. Implementation and Exp erimental Setup 70 Figure 4.2: A schematic fo r the detector of the P a r04 example. It consists of la y ers of abso rb er (red) and active material (blue). The energy deposit is recorded in a cylindrical readout (black). to the radial bins of the first angular slice in the first lay er. Then, the radial bins of the next angular slice of the first la yer follo w, and so on. 4.2 Building the datasets In the previous section, the dataset w as describ ed in detail. In this section, w e describ e the prepro cessing steps and the form ulation of the problem to solv e. 4.2.1 The voxelization T o replicate the results obtained in Sup erCalo [1], we need to create the coarse v oxels from the full-resolution show ers. This is done by grouping neigh b oring v oxels; ho wev er, there are man y p ossible c hoices for grouping. Reference [1] considers tw o choices of coarse vo xelization: • Choice A: 1 coarse vo xel = 1 r × 2 α × 5 z . The resulting coarse v o xel geometry has nine lay ers along the z -axis, nine radial bins, and eight angular bins, for a total of 648 coarse vo xels. This c hoice has the adv an tage of allo wing the mo del to learn the in ter-correlations Chapter 4. Implementation and Exp erimental Setup 71 among the fine vo xels within each coarse v oxel. The do wnside is that the correlation betw een fine v o xels in neigh b oring coarse v oxels along the radial and angular directions is lost. • Choice B: 1 coarse vo xel = 3 r × 4 α × 1 z . With this choice of coarse v oxelization, the detector geometry has 45 lay- ers, three radial bins, and four angular bins, for a total of 540 coarse v oxels. This c hoice ensures that the total de p osited energy in eac h fine lay er is learned correctly . Ho wev er, it does not guarantee the correct inter-la y er correlations b etw een fine v oxels. Figure 4.3 sho ws a 3D diagram of the calorimeter geometry with highlighted the v oxellization c hoices. In red c hoice A , in green c hoice B . The goal is no w to reco ver the fine vo xel energies ˆ e fine ,i giv en the coarse v oxel energy E coarse ,i . W e refer to SuperCaloA for choice A and SuperCaloB for choice B . Three-dimensional coarse graining has b een explored in Ref. [1], but it has led to p o orer-qualit y results. In this thesis we fo cus on c hoice A and do not consider choice B . Figure 4.3: 3D diagram from Ref. [1] illustrating the calorimeter voxel geometry fo r Dataset 2 (fine representation) in Grey and the t w o choices of vo xellization intro duced in Section 4.2.1. In Red is sho wn the choice A and in Green the choice B . Chapter 4. Implementation and Exp erimental Setup 72 4.2.2 Conditional inputs Since the energy distributions inside each coarse v oxel are highly structured, de- p ending on the incoming particle and the p osition in the calorimeter, additional conditional inputs are introduced. Here is a brief discussion of the input param- eters: • Dep osited energy in the coarse vo xel i , E coarse ,i . • Inciden t energy of the incoming particle, E inc . • Fine lay er energies of la yers spanned by coarse vo xel i (5 la yers for SuperCalo A and 1 lay er for SuperCalo B ) 1 . • Dep osited energy in neigh b oring coarse v oxels in the radial, angular, and z directions. • One-hot enco ded coarse lay er num b er. • One-hot enco ded coarse radial bin. Scop e note. F ollowing the prescription of Ref. [1], this thesis adopts an oracle- conditioned v arian t of sup er-resolution: the conditional v ector includes the true fine per-lay er energy totals for eac h coarse vo xel (5 lay ers in SuperCaloA ). These quan tities are not av ailable from the coarse representation and would b e disal- lo wed in a strict sup er-resolution setting. They are used here as a controlled first step to stabilize training and v alidate the ev aluation pip eline. Results ob- tained under this c hoice should b e in terpreted as an upp er-b ound b aseline on what is ac hiev able when accurate longitudinal aggregates are a v ailable (for example, when such sums are separately measured or provided by simulation). This con- figuration do es not represen t missing-v alue or dead-channel scenarios in whic h the lay er totals w ould b e incomplete; therefore, it should not b e interpreted as imputation of lost charge. F uture work will rep eat the analysis without these inputs (or with corrupted/noisy v ersions) to study the pure sup er-resolution case and quantify the gain pro vided b y la yer totals. It is also important to note that every coarse v o xel has a maxim um of 6 neigh b oring v oxels, and for coarse v o xels with fewer than 6 neigh b ors, the missing 1 This choice will b e further discussed later in the text, due to the fact that this information is not obtainable from the coarse represen tation of the detector Chapter 4. Implementation and Exp erimental Setup 73 energy v alues are set to zero. The n umber of v alues for each c hoice of coarse v oxelization is rep orted in T able 4.1. Finally , one-hot encoding is a metho d for con verting categorical v ariables in to binary format. It consists in asso ciating a new column with eac h category v alue, where 1 means the category is presen t and 0 means it is not. As an example, take a calorimeter with 6 lay ers and take a v oxel in the 2nd lay er. T o sp ecify its p osition in the calorimeter w e can use one-hot enco ding and write 010000 . Choice Dep osited energy Inciden t energy Fine la yer energies Neigh b ors energy Coarse la yer n umber Coarse radial bin T otal A 1 1 5 6 9 9 31 B 1 45 3 57 T able 4.1: Numb er of each comp onent of the conditional input fo r each choice of coa rse vo xelization. 4.2.3 Prep ro cessing steps The incident energy of the incoming particle, E inc , is prepro cessed as E inc − → log 10 E inc 10 4 . 5 Me V ∈ [ − 1 . 5 , 1 . 5] The coarse v o xel energies are prepro cessed according to a logit transform. The first step is defined as E coarse ,i − → x i : = log 10 (( E coarse ,i + rand [ 0 , 1 ke V ]) /E coarse , max ) and then the logit transform is applied y i = log u i 1 − u i , u i : = α + (1 − 2 α ) x i where E coarse , max is the maximum coarse vo xel energy in the whole dataset. The energies of neighboring coarse v o xels are preprocessed in the same wa y but with- out an y added noise. The fine la yer energies are obtained by summing the fine v oxel energies and prepro cessed as E lay er ,i − → E lay er ,i 65 Ge V One-hot enco ded inputs are not prepro cessed. Chapter 4. Implementation and Exp erimental Setup 74 Figure 4.4: Effect of prep ro cessing on the raw distribution. In Blue the log-uniform distribution of the ra w data and in Red , the distribution of the p reprocessed data. Notice ho w the values of the p reprocessed data are bound in the range [ − 13 . 82 , 13 . 82] given by log( α ) and log (1 /α ) , with α = 1 · 10 − 6 . Lastly , the fine v o xel energies e fine ,ij asso ciated with the i th coarse v o xel are prepro cessed as e fine ,ij − → ˆ x i : = ( e fine ,ij + rand [ 0 , 0 . 1 ke V ]) /E coarse ,i and again a logit transform is applied ˜ y i = log ˜ u i 1 − ˜ u i , ˜ u i : = α + (1 − 2 α ) x i Note that the parameter α act as n umerical regularizer and is fixed at 1 · 10 − 6 . After the generation phase, the preprocessing is in verted for the outputs of the flo w to reco ver the correct physical v alues. A low er cutoff at 15 k e V is applied to the output v alues to adhere to the minim um fine v oxel energy in the original data. This means that every sampled fine vo xel energy v alue below 15 ke V is set to zero. 4.3 Architecture As in tro duced in the previous chapters, the task of sup er-resolution is achiev ed b y learning the conditional PDF p ( E fine | E coarse ) (4.1) Chapter 4. Implementation and Exp erimental Setup 75 where it should now b e clear that E fine represen ts all the fine v oxel energies and E coarse is the coarse-grained representation of them. How ev er, given the high dimensionalit y of the problem (6480 fine vo xels to b e generated), generating a full calorimeter show er in a single pass would hav e prohibitive computational costs. F or this reason, the paradigm ( SuperCalo ) explored in this work attempts to ov ercome the high computational costs by exploring physically motiv ated ap- pro ximations to the full density . The motiv ated ansatz leveraged in Ref. [1] is to assume that eac h coarse v oxel is upsampled to its fine vo xels with a universal sup er-resolution function that, as discussed in the previous section, may b e conditioned on additional information: p ( E fine | E coarse ) = N coarse Y i =1 p ( e fine ,i | E coarse ,i , . . . ) Notice that this ansatz assumes that, after upsampling, e fine ,i are all indep enden t of eac h other. The model is th us built to upsample a single coarse v o xel to its fine v oxel representation; how ev er, thanks to parallel calculations on the GPU, it is p ossible to upsample multiple coarse v o xels in one forw ard pass. The conditional inputs for eac h coarse vo xel are built and later passed to the mo del in batc hes. The mo del to approximate the PDF in Eq. 4.1 is chosen to b e a Maske d A utor e gr essive Flow (MAF) implemen ting a comp osition of R ational Quadr atic Splines (R QS) parametrized b y MADE ( Maske d A uto enc o der for Distribution Estimation ) blo cks. Splines. F ollowing the prepro cessing results, splines are chosen to b e defined in [ − 14 , 14] , while outside this domain linear tails are introduced with slop es matc hing the deriv ativ e of the RQS to main tain differen tiability at the domain b oundaries. F or the sp ecific application, 8 bins are used, for a total of 23 param- eters: • Co ordinates for the knots account for 16 parameters ( 9 · 2 − 2 = 16 ), since the first knot is fixed at ( x 0 , y 0 ) = ( − 14 , 0) . • Deriv ativ es at each inner knot accoun t for 7 parameters. The deriv ativ es at the b oundaries are not fixed, since linear tails are used. Bijectors. F ollowing Ref. [1], we emplo y a chain of eight autoregressiv e bijectors in terleav ed with permutations of the feature indices. The p ermutations alternate Chapter 4. Implementation and Exp erimental Setup 76 deterministically b et ween a fixed rev erse ordering and an indep endently seeded random p ermutation, yielding the sequence B 1 → P rev → B 2 → P rand → . . . → B 7 → P rev → B 8 , with no p erm utation after B 8 . Each B i is a conditional MADE + RQS bijector; the interv ening P rev /P rand la yers merely reshuffle co ordinates (zero log-determinan t) to promote mixing across dimensions while preserving training and likelihoo d ev aluation mec hanics. An illustrativ e diagram is rep orted in Figure 4.5. Sample base z B 1 : MADE + RQS P rev B 2 : MADE + RQS P rand B 3 : MADE + RQS . . . P rev B 8 : MADE + RQS Output sample x Conditioning c Figure 4.5: Conditional MAF architecture with eight bijectors interleaved b y alternat- ing p ermutations. Chapter 4. Implementation and Exp erimental Setup 77 Base distribution. In a normalizing flow the data x are obtained by pushing forw ard laten t v ariables z dra wn from a simple b ase distribution through an in- v ertible map f θ (here, the conditional MADE + RQS c hain): x = f θ ( z ; c ) . W e tak e the base to b e an isotropic Gaussian on R D b , z ∼ N ( 0 , I D b ) , D b = 10 for choice A , 12 for choice B , (4.2) implemen ted as a diagonal m ultiv ariate normal with zero mean and unit v ariance p er comp onent. The base is kept indep endent of the conditioning v ariables c ; all dep endence on c is in tro duced b y the bijector f θ ( · ; c ) . This choice offers closed- form log-densities, full supp ort on R D b (matc hing the R QS domain with linear tails), and efficien t, numerically stable training. With this setup the conditional log-lik eliho o d follo ws from the c hange of v ariables formula, log p ( x | c ) = log p Z f − 1 θ ( x ; c ) + log det ∂ f − 1 θ ∂ x , (4.3) where p Z is the standard normal densit y in (4.2). Because each B i is autoregres- siv e, the Jacobian of f − 1 θ is triangular, so the determinan t in (4.3) reduces to a sum ov er diagonal terms, preserving the usual O ( D b ) ev aluation cost. In practice, w e use double precision ( float64 ) for the base and log-determinant computations to reduce numerical error during training. A detailed discussion about training instabilit y is left to the follo wing sections. In the previous section, w e introduced the coarse vo xelization choices and, as sp ecified, choice A groups together 10 fine vo xels, while choice B includes 12 fine vo xels. This explains the n umber of output v alues rep orted in T able 4.2, since the RQS outputs 23 parameters for each dimension. In case of c hoice A , the parameters are 10 · 23 = 230 , while in case of B the output parameters are 12 · 23 = 276 . In Figure 4.6 is rep orted a diagram that is useful for explaining ho w conditional inputs are inserted in the mo del. It is shown as an example a MADE blo c k that, as in tro duced in Chapter 2, is the fundamental building block of the MAF arc hitecture. In the example, the MADE blo ck has 3 v ariables ( x i ) to b e transformed and 4 additional v ariables ( c i ) on whic h the transformation is conditioned. There is an input la yer of 6 nodes and tw o hidden la yers of 6 no des eac h. The conditional inputs and the v ariables are fully connected to separate input lay ers, with the same dimensionality as the first hidden la y er (6 in this case) and the logits (outputs of the lay er) are summed term by term (the summing row Chapter 4. Implementation and Exp erimental Setup 78 Mo del Base distribution dimensions Num b er of MADE blocks MADE la yer sizes R QS bins Input Hidden Output A 10 8 41 2 × 128 230 8 B 12 8 69 2 × 128 276 8 T able 4.2: Configuration of the different flo w mo dels. The input la y er dimension is defined to b e the sum of the number of dimensions in the base distribution and the numb er of conditional inputs, discussed in Section 4.2.2. Note that 2 × 128 is a sho rthand notation for 2 hidden la yers of 128 no des each. in the diagram). This w ay the conditional inputs enter the MADE block without affecting the autoregressiv e prop ert y . The diagram in Figure 4.6, also gives the opportunity to b etter understand ho w the R QS transformation is implemented. In fact, the output la yer presents three v ectors, one for eac h dimension to transform ( x i ) and eac h vector has 5 dimensions itself, necessary to implemen t a R QS with t wo bins: 1 deriv ativ e and 2 knots described b y the co ordinates ( x 1 , y 1 ) and ( x 2 , y 2 ) . F urthermore, the red connections show that k 1 only dep end on x 0 and c , while the blue connections sho w that k 2 dep ends on x 0 , x 1 and c . As in tro duced in Section 4.2.1, w e explore only SuperCaloA , in fact, Ref. [1] prioritized the in ter-lay er correlations b et ween fine vo xels. 4.4 T raining Strategy In this section, w e introduce the h yp erparameters used for the training pro cess and describ e the working en vironment. 4.4.1 Ha rdw a re and Soft wa re Environment All exp eriments w ere executed on the INFN TEOGPU cluster, using a single NVIDIA L40S GPU equipp ed with 45 GiB of memory . The implementation is based on TensorFlow 2.12 and TensorFlow Probability 0.20 , with n umerical op- erations and data management handled primarily through NumPy , h5py , and Matplotlib . Additional utilities for statistical ev aluation and visualization rely on SciPy , pandas , and seaborn . All the source co de used in this w ork, including data handling scripts, mo del training routines, and ev aluation utilities, is publicly Chapter 4. Implementation and Exp erimental Setup 79 Figure 4.6: Schematic of a conditional MADE blo ck used inside a MAF. Three va ri- ables x = ( x 0 , x 1 , x 2 ) a re transfo rmed while four context variables c = ( c 0 , . . . , c 3 ) p rovide conditioning. Inputs are split into tw o pa rallel streams (one for x , one fo r c ), each fully connected to a width-6 hidden la yer; their pre-activations are then added element-wise (the “ + ” ro w), so conditioning enters without breaking the autoregres- sive masking. T wo width-6 hidden lay ers are sho wn. The output lay er produces three vecto rs k i (one p er transfo rmed dimension x i ); each has 5 comp onents implementing a t wo-bin Rational Quadratic Spline (one derivative and tw o knot co ordinate pairs ( x 1 , y 1 ) , ( x 2 , y 2 ) ). Colored edges illustrate auto regressive dep endencies: in red, k 1 dep ends only on x 0 and c ; in blue, k 2 dep ends on x 0 , x 1 and c . Choice B is only rep o rted fo r completeness, in this thesis w e only explore choice A . Chapter 4. Implementation and Exp erimental Setup 80 a v ailable at github.com/andreacosso/Thesis [77]. The training and ev aluation pip elines were dev elop ed within a mo dular Python co debase designed for repro ducible workflo ws and c heckpointed mo del weigh ts. This framework extends the public implementation introduced in Ref. [58], origi- nally built to compare normalizing-flo w arc hitectures for calorimeter sho wer mod- eling. In the present work, the codebase was modified to incorp orate conditional inputs and other details necessary for the architecture c hoice, such as the linear tails of the rational quadratic spline transformation. 4.4.2 Loss Function The mo del is trained b y minimizing the ne gative lo g-likeliho o d (introduced in Section 1.1.3.1) on the flo w output. This corresponds to maximizing the lik eliho o d of the data under the learned transformation and provides an exact, tractable densit y ob jective for normalizing flows. F ollowing the prescription of Ref. [1], no regularization has b een introduced. 4.4.3 Optimizer and Lea rning Rate Schedule T raining is p erformed using the A dam optimizer (describ ed in Section 1.1.3.2), with default exp onen tial decay rates ( β 1 , β 2 ) = (0 . 9 , 0 . 999) and ϵ = 10 − 8 . Still follo wing Ref. [1], w e emplo yed the OneCycle learning rate (LR) p olicy , originally prop osed in Ref. [78] to ac hieve sup er-c onver genc e in deep net w orks. The metho d is based on the in tuition that training benefits from briefly exp osing the mo del to high learning rates, encouraging rapid exploration of the loss landscape, follow ed b y a smo oth annealing phase that refines the parameters around wide, flat min- ima. T o increase training stability at a high learning rate, an inv erse cycle on β 1 momen tum is implemented. In our configuration, the LR increases linearly from a base v alue α base = 1 × 10 − 5 to a maximum v alue α max = 8 × 10 − 4 in 30 ep o c hs, then decreases follo wing a cosine profile back to α base o ver 46 ep o c hs, and finally undergo es a short linear annihilation phase of 4 ep o chs do wn to α annihil. = 1 × 10 − 6 . Momen tum starts from β 1 = 0 . 95 decreases in 30 ep o chs to β 1 = 0 . 85 and returns to β 1 = 0 . 95 in 50 epo chs. This three-phase sc hedule (warm-up, co oldown, and annihilation) promotes faster conv ergence in the early stage and smo other stabilization at the end of training. In Figure 4.7, a plot of the LR cycle is rep orted. In Ref. [1], the Chapter 4. Implementation and Exp erimental Setup 81 authors were able to reac h faster con vergence b y training for 40 ep o c hs with 18 ep o c hs of w arm-up and 18 of co oldo wn, with 4 annihilation epo chs, but our results follo wing this pro cedure w ere w orse than what we obtained with the parameters in tro duced. No gradient clipping is applied during the training pro cess. Although man y framew orks provide built-in One-Cycle sc hedulers, most no- tably PyTorch ’s OneCycleLR , there is currently no standardized implementation in TensorFlow . F or this reason, a custom schedule was implemented for this w ork, faithfully repro ducing the same learning rate and momentum dynamics. Figure 4.7: Three-phase One-Cycle learning rate schedule used for mo del training. W e chose 30 ep o chs of w arm-up, 46 of co oldo wn, and 4 ep o chs of annihilation. T raining is carried out with mini-batc hes of 10k ev en ts without early stopping. A summary of the training strategy is rep orted in T able 4.3. 4.5 Evaluation The ev aluation pro cedure pla ys a central role in this work. In Ref. [1], the as- sessmen t of mo del p erformance was inspired b y the procedure adopted within the CaloChal lenge [11], although it do es not fully repro duce the official ev alu- ation pip eline. The prop osed ev aluation com bines a classifier-based score with the Jensen–Shannon divergence, pro viding a practical but not y et statistically rigorous assessment of the generativ e qualit y . Using a classifier to assess the p erformance of a generativ e mo del in HEP is not recommended. First, deep neural netw orks (DNNs) are often seen as “black- b o x” mo dels [79], whic h mak es it difficult to understand whic h features of the generated data they consider differen t or similar. Second, their p erformance dep ends strongly on b oth the netw ork arc hitecture and the training dataset, and Chapter 4. Implementation and Exp erimental Setup 82 T able 4.3: Summa ry of training hyp erparameters. P arameter V alue Optimizer A dam LR scheduler OneCycle Initial learning rate 1 × 10 − 5 Max learning rate 8 × 10 − 4 ( β 1 , β 2 , ϵ ) (0.9, 0.999, 10 − 8 ) Batc h size 10k T otal ep o chs 80 (w arm-up, co oldo wn, annihilation) (30, 46, 4) Regularization None Gradien t clipping None Early stopping patience None F ramew ork T ensorFlo w 2.12 + TFP 0.20 Hardw are NVIDIA L40S (45 GiB) T able 4.4: T raining pa rameters summa ry there is no clear w a y to define a single architecture that w orks well for all datasets and t yp es of discrepancies. In addition, DNN training is sto chastic, in v olving the optimization of a complex loss function with many lo cal minima, and is usually slo w. Because of this, it is sensitive to the initial conditions and h yp erparameters that are not directly related to the problem, making the results hard to repro duce and the pro cess less efficien t. The Jensen-Shannon div ergence, b elonging to the broader class of f -div ergences, quan tifies differences p oint-b y-p oint in probabilit y density and is inv ariant under reparameterization, but it do esn’t accoun t for the geometry of the underlying sample space. As discussed in Ref. [80], this limitation can lead to misleading conclusions when ev aluating generativ e mo dels. F or instance, tw o generated dis- tributions that differ only b y a small shift in a physically meaningful v ariable (suc h as jet mass or show er centroid) can b e assigned the same f -divergence, despite one clearly providing a more realistic physical description. In contrast, metrics based on Integral Probabilit y Metrics (IPMs), introduced in Section 2.4, explicitly incorp orate the metric structure of the space, allo wing them to recog- Chapter 4. Implementation and Exp erimental Setup 83 nize when generated and real samples are close in a geometric or ph ysical sense. As outlined in Section 2.4, the ev aluation pip eline adopted in this work is implemen ted follo wing the statistical pro cedure introduced in Ref. [2], for which the authors pro vide a Python mo dule [81]. T o summarize, the key idea is to take numerical samples, build the n ull and alternative hypotheses, and compare them using statistically robust, high- dimensional scalable t wo-sample tests. The model has b een ev aluated on a dataset of 100,000 full sho w ers not pre- sen ted to the mo del during the training pro cess. The ev aluation (sampling) pro- cess consisted of taking the dataset and building, for eac h fine show er, its coarse represen tation as presen ted in the previous chapter. Then one conditional input v ector for each coarse vo xel is constructed as describ ed in the previous sections. The conditional inputs are then passed to the mo del to obtain the generated sam- ples. The generativ e process is rep orted in the flo wc hart in Fig 4.8. The model passes the samples from the base distribution through the chain of conditioned bijectors to obtain the sampled v alue x . Sample base z Bijector f 1 (MADE + RQS) . . . Bijector f N Output sample x Conditioning c Figure 4.8: Conditional MAF (vertical la yout): generative flow from a base dra w z through a sequence of bijecto rs f 1 , . . . , f N to obtain a sample x . Each bijector is pa rametrized b y a MADE blo ck (RQS transfo rm) and receives the conditioning c . Chapter 4. Implementation and Exp erimental Setup 84 Metrics and testing strategy In what follo ws, w e apply , for eac h feature in tro duced below, the family of test statistics review ed in Section 2.4 (see the T est statistics subsection). In practice, w e com bine complementary metrics so that sensitivit y is not driv en b y a single notion of discrepancy: • Sliced W asserstein (SW) captures geometry-a ware shifts along random 1D pro jections, scalable to high dimensions via a veraging o ver K directions. • K olmogorov–Smirno v v ariants (mean-KS on marginals and sliced-KS on random pro jections) to detect lo calized CDF mismatc hes in 1D and along pro jected axes with lo w computational ov erhead. • Maxim um Mean Discrepancy (MMD) with a fixed p olynomial k ernel pro vides a k ernel-based, moment-sensitiv e IPM that complements SW/SKS; used with the same k ernel c hoice throughout for consistency . • F réc het Gaussian Distance (FGD) as a simple, low-v ariance Gaussian summary of mean/co v ariance mismatches in mo derate dimensions. The resulting ev aluation is feature-wise and metric-wise: for eac h feature space w e compute the observ ed test statistic on (truth, generated) samples, and we es- timate the empirical distributions of the statistic under both H 0 and H 1 . F rom these, we rep ort the p -v alue taking as the observed statistic the me dian of the alternativ e distribution. W e also visualize the separation of null vs. alternativ e distributions. This multi-metric approach ensures robustness to differen t fail- ure mo des (global shifts, tail distortions, correlation c hanges), while remaining scalable through slicing/pro jection strategies and batched computation. Due to their p o or scalability , we only ev aluate the p erformance on F GD and MMD in lo w dimensionalit y scenarios. Implementation notes. The same random-seeded set of pro jection directions is used across runs for SW/SKS to reduce v ariance; k ernel choices and pro jection coun ts K are kept fixed across features to enable fair, cross-feature comparisons; batc h size and the n umber of exp erimen tal replicates are c hosen to balance sta- tistical precision with runtime and are rep orted alongside the results. Chapter 4. Implementation and Exp erimental Setup 85 F ull dimensionalit y features Lev eraging the high scalability of the ev aluation pro cedure in tro duced in Ref. [2] with the dimension, we ev aluate the p erformance of the mo del also on the full dimensionalit y of the show er and its coarse representation. Sp ecifically , as in- tro duced in the previous sections, the fine representation of the sho wer has 6480 dimensions, while the coarse represen tation, for choice A , has a dimensionality of 648 . Due to the p o or scalability of the metrics F GD and MMD, w e c hose to exclude them from the ev aluation, and we only implemented the KS based statistics together with the SWD. This approach represents one of the metho dological nov elties in tro duced in this w ork. As highlighted in earlier sections, Previous studies in calorimeter sho wer generation t ypically relied on the ev aluation of lo w-dimensional ph ysics- inspired features (such as la yer energies, centroids, or sho wer widths) to assess the p erformance of generative mo dels. While suc h observ ables are physically in- terpretable, they inevitably compress the information contained in the original data and may conceal discrepancies detectable only in the full feature space. In con trast, the framework applied in this thesis enables a robust statistical com- parison directly in the native, high-dimensional vo xel space of the calorimeter, without resorting to handcrafted observ ables. This allo ws for a more faithful and un biased assessment of the mo del’s ability to reproduce the underlying data distribution. Physically inspired features W e c hose to ev aluate the p erformance of the mo del also on lo w-dimensional, ph ysically inspired features: • T otal inciden t energy : Being 1D, it is fast and simple. W e sum all the energy dep osits in the fine v oxels for b oth the true and sampled data and compare their distributions. E inc = n X i =1 e fine ,i , (4.4) where n = 6480 is the n umber of fine v oxels in the calorimeter. • Fine lay er energies : These are the distributions of the energies con tained in eac h of the fine v o xel la y ers. Giv en the structure of the calorimeter Chapter 4. Implementation and Exp erimental Setup 86 presen ted in Section 4.1, this feature is 45D, one dimension for each lay er. T o build the distributions, we sum the energies in the radial and angular directions. E lay er ,j = ˜ n X i =1 e ( j ) fine ,i , (4.5) where ˜ n = 144 is the n um b er of fine vo xels in each lay er (16 angular bins and 9 radial bins). W e denoted with e ( j ) fine ,i the i -th fine vo xel contained in the j -th la yer. • Energy cen troid p osition : we compare the distributions of the p ositions of the cen troid in the radial, angular and longitudinal directions, defined by ¯ ϕ = P i E i ϕ i P i E i , ¯ r = P i E i r i P i E i , ¯ z = P i E i z i P i E i , (4.6) where ϕ i , r i and z i are the p ositions of the fine v oxel with energy E i . • Ro ot Mean Square (RMS) along the longitudinal, lateral and an- gular axis : energy-weigh ted RMS pro vides a compact and physically in ter- pretable description of the show er’s spatial exten t. It is therefore a natural c hoice for statistical comparison b etw een real and generated show ers. Note that RMS only captures the second momen t of the distribution, leav ing out asymmetries, tails, and multi-modal structures. RMS can b e calculated as σ x = s P i E i ( x i − ¯ x ) 2 P i E i , ¯ x = P i E i x i P i E i , (4.7) with x ∈ { z , r, ϕ } . In the next section we introduce the hypothesis for the test and how the test statistics are computed according to the distributions. Null hypothesis construction The ev aluation pro cedure is based on the definition of a statistical n ull h yp oth- esis, which states that the real and generated samples are drawn from the same underlying probability distribution, H 0 : P real = P gen , (4.8) while the alternativ e h yp othesis assumes that the tw o distributions differ, H 1 : P real = P gen . (4.9) Chapter 4. Implementation and Exp erimental Setup 87 Under H 0 , an y discrepancy b etw een the samples is attributed solely to random fluctuations due to finite statistics. T o estimate the sampling distribution of eac h test statistic under this assumption, the com bined dataset is repeatedly resh uffled, randomly exchanging elemen ts b et ween the real and generated sets. F or each reshuffling, the test statistic is recomputed, resulting in an empirical distribution that appro ximates the true n ull distribution. W e adopt the following terminology . An exp eriment denotes a single Mon te– Carlo replicate in whic h w e compute one realization of the test statistic from batch_size samples per distribution. W e rep eat exp erimen ts n_iter times. If the av ailable dataset con tains fewer than n_iter × batch_size samples, we form eac h batc h by non-parametric b o otstrap resampling (sampling with replacemen t) from the finite sample [82]. F or sliced metho ds, Sliced Kolmogoro v-Smirno v (SKS) and Sliced W asserstein Distance (SWD), we set the num b er of random pro jections ( slic es ) to nslices . Pro jection directions are fixed for all exp eri- men ts. An imp ortant thing to note is that larger batch_size makes the tests more sensitiv e due to the fact that sampling noise decreases as we use more p oin ts. Indeed, b oth the null and the alternativ e sampling distributions include random sampling noise. If T n is the test statistic computed from batches of size n p er sample, you can think of it as signal + noise . Under H 0 the signal is zero, so T n fluctuates around 0 ; under H 1 there is a genuine difference b etw een the t w o distributions (the signal is p ositiv e), so T n fluctuates around a nonzero v alue. In b oth cases, the sampling noise shrinks at the canonical 1 / √ n rate as w e increase batch_size , which tightens the null and the alternative histograms. Because the critical threshold is calibrated on the n ull, a tigh ter null lo w ers that threshold, while the alternative remains centered at a p ositiv e v alue due to the true differ- ence; the ov erlap b et ween the t wo distributions decreases and rejections b ecome more lik ely . F or slice-based metho ds (SKS, SWD) the same logic holds within eac h 1D pro jection: each slice uses n p oin ts p er sample, so its p er-slice v ariabilit y also falls like 1 / √ n . A dding more nslices mainly av erages out the randomness from the choice of directions, whereas increasing batch_size directly sharp ens eac h slice’s estimate and th us impro ves detectabilit y . As a toy example, imagine t wo coins: the real pro cess has head probabilit y p = 0 . 50 , while the mo del has p ′ = 0 . 52 , so the true gap is δ = p ′ − p = 0 . 02 . If w e estimate eac h probabilit y from n flips, the sampling error of the observed head rate is ab out q p (1 − p ) /n Chapter 4. Implementation and Exp erimental Setup 88 (the binomial standard error). With n = 100 p er coin this is ≈ 0 . 05 (5%), which is larger than the signal δ , so the t wo samples often look indistinguishable. With n = 10 , 000 the error drops to ≈ 0 . 005 (0.5%), and the same fixed gap δ = 0 . 02 b ecomes large relativ e to the noise (ab out four standard errors), making it easy for any tw o-sample test to detect. This is precisely how a larger batch_size raises p o wer: the discrepancy b et ween the underlying distributions is fixed, while sampling v ariabilit y shrinks like 1 / √ n , improving the signal-to-noise ratio. This data-driven construction allo ws one to ev aluate ho w m uch the observ ed v alue of the statistic deviates from what w ould b e expected if both samples origi- nated from the same pro cess. The resulting null distribution serv es as a reference for all subsequent comparisons, including the computation of confidence lev els, p -v alues, and the ev aluation of statistical p o wer. This approac h ensures a statistically rigorous and reproducible estimation of the n ull and alternativ e distributions, providing a solid foundation for the subsequen t comparison of real and generated calorimeter sho wers. The Co de in tro duce in Reference [2] is a v ailable at Reference [81]. 4.6 Results In this section w e presen t the results from the training and ev aluation pro cedure thoroughly described in the sections ab ov e. First are illustrated the qualita- tiv e results of the training pro cedure by in tro ducing qualitativ e plots. Secondly the results from the statistically robust ev aluation pro cedure are presen ted. T o presen t the results, we selected the mo del that achiev ed the lo w er v alidation loss across all the runs made to explore the h yp erparameter space. The corresponding h yp erparameters are presented in Section 4.4. 4.6.1 T raining results The mo del presented as detailed in Section 4.3 was trained for 80 ep o chs with details on the parameters illustrated in Section 4.4. The training and v alidation loss curv e is rep orted in Figure 4.9. The lo west v alue of the v alidation loss was obtained in the last ep o ch (80). This suggests that the optimization task hasn’t fully con verge to ward an optimal loss v alue and this leav es ro om for improv emen t. Another indication supp orting this h yp othesis is the v ery small generalization Chapter 4. Implementation and Exp erimental Setup 89 gap; in fact, the training loss reached its minimum at ep o c h 80 with L ( train ) min = − 0 . 497 , while the v alidation loss minimum (still at epo ch 80), registered L ( v al. ) min = − 0 . 496 . W e tried increasing the co oldo wn phase and changing the base and max LR, without achieving b etter results. This indicates the need for a fine tuning of the h yp erparameters. The steep descen t around ep o ch 55 in Figure 4.9 can b e explained b y the sup er-c onver genc e effect of the OneCycle [78] sc heduler discussed in Section 4.4. Figure 4.9: Plot of the validation and training loss es over the course of training. Lo wer validation loss value was obtained at ep o ch 80. W e also notice that reducing the batc h size yielded modest impro v ements probably due to increased noise in the gradient fa v oring exploration. W e c hose to k eep a batc h size of 10 , 000 to balance exploration with training time. In fact, the mo del has sp en t appro ximately 27 . 5 ho urs to complete the training pro cess, while using a batc h size of 30 k would ha ve tak en around 21 . 5 hours. A comparison is illustrated in Figure 4.10. W e hav e not b een able to obtain similar results follo wing the prescription of Ref. [1], that inv olv es a OneCycle sc heduler with 18 ep o chs of warm-up, 18 of co oldo wn and 4 epo chs of annihilation, with a batch size of 60 , 000 samples. They c hose a base LR of 2 · 10 − 5 and a max LR of 1 · 10 − 3 . A summary of the main differences in the training configuration is rep orted in T able 4.5. During training w e encoun tered numerical instabilities that caused the mo del w eights to div erge to NaN . This issue was resolved by increasing the numerical precision from float32 to float64 , at the cost of increased memory usage and Chapter 4. Implementation and Exp erimental Setup 90 Figure 4.10: A compa rison b et ween runs with different batch size. There is a clear difference of training time if w e compare a batch size of 10 k or 30 k. The absolute difference in total training time is ab out six hours. longer training time. Minor adjustmen ts to the learning rate sc hedule or batc h size could further refine performance, but the obtained mo del already pro vides a solid basis for the subsequen t ev aluation and comparison with reference results. 4.6.2 Qualitative compa rison of generated and reference sho w- ers T o pro vide a qualitative visual assessment of the model p erformance b efore apply- ing quan titativ e statistical tests, w e compare a selection of distributions computed on the generated (sampled) and reference (true) show ers. Figure 4.11 shows the normalized histograms of the sho wer cen troids; Figure 4.12 sho ws the RMS nor- malized distribution in the longitudinal, lateral, and angular directions. In Figure 4.13, the total energy dep osition in lay ers 1, 10, 20, and 45 is rep orted. In lay ers 20 and 45, some artifacts are visible near the small v alues of energy deposition. W e ha ve not been able to explain these artifacts, and they will require an in-depth analysis. Besides the artifacts in the la y er distributions, w e find a goo d o verlap b etw een the reference and generated data indicating that the model was able at capturing the main ph ysical c haracteristics of the sho wers. Chapter 4. Implementation and Exp erimental Setup 91 T able 4.5: Comparison of training configurations betw een the present w ork and the reference implementation. P arameter This work Reference run (Ref. [1]) W arm-up epo chs 30 18 Co oldo wn ep o chs 46 18 Annihilation epo chs 4 4 Batc h size 10 000 60 000 Base learning rate ( α base ) 1 × 10 − 5 2 × 10 − 5 Maxim um learning rate ( α max ) 8 × 10 − 4 1 × 10 − 3 Optimizer A dam Adam Learning rate p olicy One-Cycle One-Cycle Regularization None None Figure 4.11: Centroids distributions along the longitudinal, angular and radial direc- tion. T ruth samples ( Geant4 ) a re filled in blue and generated samples are rep orted as orange line. 4.6.3 Statistical evaluation In this section, the results of the statistical tests introduced in Section 2.4 and further discussed in Section 4.5 are presented. W e b egin the discussion b y high- ligh ting the fact that the tw o-sample tests ev aluated ha ve some h yp erparameters that hav e only b een briefly explored. The presented results are therefore only in tro ductory , and an in-depth exploration is left to future w ork. The h yp erpa- rameters hav e b een in tro duced in Section 4.5 and consist mainly in batch_size and nslices . Chapter 4. Implementation and Exp erimental Setup 92 Figure 4.12: RMS distributions along the longitudinal, lateral and (radial), and angula r direction. Reference distribution is filled in blue, while results from generated show ers is rep orted in orange. Figure 4.13: Distributions of the total energy dep osited in la yers 1, 10, 20 and 45. Can be obtained b y summing the energy deposition in each fine vo xel in radial and angula r direction. The distribution of the Geant4 is filled in blue wh ile the o range line represent the generated samples. 4.6.3.1 Results at full dimensionalit y Regarding high-dimensional features, whic h, as introduced previously , pla y a cen- tral role in this thesis, we tested the p erformance of the mo del with differen t h yp erparameter v alues. A summary of the results is presen ted in T able 4.6. Fine representation: Figure 4.14, compares the n ull (truth–truth) and al- ternativ e (truth–mo del) sampling distributions of the KS, SKS, and SWD test statistics for d = 6480 and batch size 1 · 10 3 . The separation is most pronounced for the av erage KS, with most of the bulk falling in the 99%, while it is almost n ull for the SKS and SWD metrics. This indicates that H 0 is rejected with significance 2 . 41 σ for the av erage KS, while the other t wo metrics accept H 0 . Figure 4.15, shows another comparison b etw een the null and alternativ e dis- tributions of the same tests as in the previous comparison, for the same dimen- Chapter 4. Implementation and Exp erimental Setup 93 F eature Metric batch_size n_slices p -v alue Significance ( σ ) Coarse show er KS 1000 - 0.495 1 . 3 · 10 − 2 SKS 500 0.487 3 . 3 · 10 − 2 SWD 500 0.470 7 . 6 · 10 − 2 Coarse show er KS 5000 - 0.503 8 · 10 − 3 SKS 500 0.505 1 . 3 · 10 − 2 SWD 500 0.489 2 . 8 · 10 − 2 Fine show er KS 1000 - 7 . 99 · 10 − 3 2.41 SKS 1000 0.483 4 . 3 · 10 − 2 SWD 1000 0.473 6 . 8 · 10 − 2 Fine show er KS 1000 - 7 . 99 · 10 − 3 2.41 SKS 7000 0.480 5 . 0 · 10 − 2 SWD 7000 0.469 7 . 8 · 10 − 2 Fine show er KS 5000 - 9 . 99 · 10 − 4 3.09 SKS 1000 0.419 2 . 04 · 10 − 1 SWD 1000 0.464 0 . 90 · 10 − 2 T able 4.6: Summa ry of p -values obtained fo r different configurations and metrics. sionalit y ( 6480 D) but with batch_size = 5 · 10 3 . As exp ected, the p o wer of all the tests increases slightly (a small shift tow ards the righ t for the alternative dis- tribution), ev en if the sliced test are still not able to detect differences. The p ow er of the av erage KS test increases, rejecting the n ull h yp othesis with significance 3 . 09 σ (see T able 4.6). Coarse representation. The same comparison implemen ted for the fine vo xel represen tation is now discussed for the coarse representation. The coarse rep- resen tation is obtained from the fine one b y summing the fine v o xel energies according to the pro cess described in Section 4.2.1, resulting in 1 · 10 5 samples, eac h with 648 dimensions (recall Section 4.2.1 where choice A was in tro duced), in which w e group 10 fine v oxels to build a single coarse v oxel. W e compare t wo differen t c hoices of batch_size and different c hoices of nslices . Figure 4.16, sho ws the comparison betw een the test statistics distribution for the n ull and alternativ e hypotheses with batch_size = 1 · 10 3 and nslices = 5 · 10 2 . The plot shows (from left to righ t: av erage KS, SKS, and SWD), that Chapter 4. Implementation and Exp erimental Setup 94 Figure 4.14: Null vs. alternative hyp othesis distributions of three test statistics at full dimensionality ( d = 6480 ; batch_size = 1 · 10 3 ; nslices = 1 · 10 3 ). Each panel shows density-no rmalized histograms on a log y -axis: the null (truth–truth, red fill) and the alternative (truth–mo del, blue outline). From left to right: average K ol- mogo rov–Smirnov (KS), Sliced KS (SKS), and Sliced Wasserstein distance (SWD). V ertical dashed lines mark the 68%, 95%, and 99% confidence levels estimated from the null; the shaded bands indicate the co rresp onding right-tailed rejection regions. A rightw a rd shift of the blue curve relative to the red one signals increased p ow er (greater separation from the null). Figure 4.15: Same conventions as Figure 4.14. Here d = 6480 , batch_size = 5 · 10 3 and nslices = 1 · 10 3 . Increased the batch size to probe the hyperparameter space. none of the test statistics ev aluated w ere able to distinguish b et ween the truth Geant4 samples and the generated samples. Figure 4.17 sho ws the same metrics ev aluated on batch_size = 5 · 10 3 . This plot sho ws, according to the previous results, that the metrics are not able to reject H 0 . Learning the conserv ation of energy . The difficulties of the tw o-sample tests described ab ov e in distinguishing the true data from the generated samples suggest that the mo del has learned the conserv ation of energy in eac h coarse vo xel. Chapter 4. Implementation and Exp erimental Setup 95 Figure 4.16: Same conventions as Figure 4.14. Here d = 648 , batch_size = 1 · 10 3 and nslices = 5 · 10 2 . The metrics are not able to reject H 0 . Figure 4.17: Same conventions as Figure 4.14. Here d = 648 , batch_size = 5 · 10 3 and nslices = 5 · 10 2 . The metrics are not able to reject H 0 . Although no hard constrain t forces the sums to match, maxim um-likelihoo d train- ing on data satisfying P v ∈ b E v = C b encourages the conditional mo del p θ ( fine | C, . . . ) to assign probability mass to fine patterns whose totals equal the pro vided C . Empirically , this yields E θ [ P v ∈ b ˆ E v | C b ] ≈ C b and small even t-wise residuals, so the marginal distribution of re-aggregated coarse energies coincides with that of the conditioning inputs. A ccordingly , coarse-level tests hav e little p ow er here, and v alidation should fo cus on the fine-scale allo cation and correlations within eac h blo c k. Under-p erforming of slice-based tests in this setting. Increasing the n umber of slices from 10 3 to 7 × 10 3 at fixed batc h size do es not c hange the conclusion (Figure 4.18 versus Figure 4.14). This b eha vior is exp ected when the discrepancies b etw een truth and mo del are sp arse across co ordinates, i.e., con- fined to a comparativ ely small subset of the D = 6480 marginals—rather than b eing global. Co ordinate-wise tests such as the a verage KS examine eac h marginal Chapter 4. Implementation and Exp erimental Setup 96 directly and therefore “see” ev ery affected vo xel with the full sample size, which yields strong separation under H 1 . In contrast, slice-based tests (SKS, SWD) first pro ject the D -dimensional v ectors on to random directions u ∈ S D − 1 and then ap- ply a 1D test. Let δ ∈ R D denote the (signed) discrepancy across co ordinates, supp orted on k ≪ D entries. F or a random slice, one has E u h ( u ⊤ δ ) 2 i = ∥ δ ∥ 2 2 D = ⇒ | u ⊤ δ | ∼ ∥ δ ∥ 2 D − 1 / 2 ∝ q k D , so the 1D signal in a t ypical slice is attenuated b y a factor q k /D due to dilution o v er mostly w ell-mo deled co ordinates (a concentration-of-measure effect in high dimension). A v eraging ov er more slices primarily reduces the Monte Carlo v ariance of this estimate ( ∝ 1 / √ nslices) but does not increase its median (or mean); hence moving from 10 3 to 7 × 10 3 slices leav es the null–alt separa- tion essen tially unchanged. By contrast, increasing the batc h size n b o osts the p o wer of all tests roughly as √ n , which explains the mo dest right w ard shift of the alternativ e curves when going from n = 10 3 to n = 5 × 10 3 (Figure 4.15). Summarizing, the strong p erformance of KS, together with the w eak SKS/SWD separation at d = 6480 , is consisten t with vo xel-lo cal (sparse) biases rather than broad geometry-level mismo deling. Figure 4.18: Same conventions as Figure 4.14. Here d = 6480 , batch_size = 1 · 10 3 and nslices = 7 · 10 3 to investigate the role of the slicing in the discrimination p erfo rmance of the tests. Summary . Regarding the ev aluation of the full, fine-sho w er feature, the av erage KS was able to reject the Null hypothesis H 0 with a significance of 2 . 41 σ for batch_size = 1 · 10 3 and 3 . 09 σ for batch_size = 5 · 10 3 ; slice-based metho ds w ere not able to reject the hypothesis H 0 , and w e pro vided a p ossible explanation Chapter 4. Implementation and Exp erimental Setup 97 for the lo w p o wer of these metho ds in such high-dimensional settings. In the ev aluation of the coarse represen tation of the sho wer, w e found that none of the tests, with the batch_size c hoices analyzed, w ere able to reject the n ull h yp othesis, suggesting that a form of energy conserv ation w as efficien tly learned. 4.6.3.2 Physically inspired observables In this section w e presen t the results obtained from the ev aluation of the ph ysically- inspired features presen ted in Section 4.5 with the metrics introduce in Section 2.4. Although the dimensionalit y of most of the features presen ted in this section is very low (with the exception of the lay er wise energy dep osits whic h is 45D), w e c hose to ev aluate the p erformances mainly on the IPM-based statistics, i.e., the a verage KS, sliced KS and sliced WD. This choice is motiv ated by the large difference in execution time and by the fact that in Ref. [2], comparable results ha ve b een found. T able 4.7 summarizes the h yp othesis tests on the low-dimensional, physics- motiv ated features introduced in Section 4.5. Overall, the p -v alues cluster around 0 . 3 – 0 . 55 across features (lay er centroids, la yer energies, sho wer RMS, and inci- den t energy) and metrics (a verage KS, SKS, SWD, with o ccasional MMD/F GD). Hence, for all tested configurations w e do not reject H 0 at con ven tional signifi- cance levels. In other w ords, none of the ev aluated metrics, in these settings, was able to distinguish the sampled data from the truth. Regarding the role of sample size, w e observ e the exp ected trend that in- creasing batch_size generally impro v es p o wer (smaller p -v alues). This is most eviden t for KS on the la yer-wise energy deposits ( 45 D), where p decreases from 0 . 521 at batch_size = 10 3 to 0 . 406 at 5 · 10 3 and 0 . 330 at 10 4 , and is also visible for KS on the sho wer RMS ( 3 D), from 0 . 460 to 0 . 408 to 0 . 308 . SWD often follo ws a similar pattern (e.g., la y er energy: 0 . 482 → 0 . 474 → 0 . 418 ). By con trast, SKS can b ehav e non-monotonically at fixed nslices (e.g., lay er cen- troid: 0 . 494 → 0 . 534 → 0 . 468 ), which is consistent with the additional Monte Carlo v ariabilit y introduced by random pro jections and with the dilution effects already discussed for high-dimensional slices in Section 2.4. Finally , we note a tension betw een qualitativ e visual chec ks of some one- dimensional marginals (where small artifacts are visible) and the formal tests, whic h still return relativ ely large p -v alues. A t presen t, w e do not ha ve a defini- tiv e explanation. P ossible contributors include the small effect size of lo calized Chapter 4. Implementation and Exp erimental Setup 98 discrepancies (e.g., restricted to tails or to a subset of coordinates), av eraging across coordinates (for KS) or across random directions (for SKS/SWD), and limited sensitivit y of the c hosen h yp erparameters ( batch_size , nslices ) to suc h lo calized differences. A more systematic study , v arying batch_size and nslices more widely , using targeted tests on the sp ecific regions where artifacts appear, and exploring complementary metrics (e.g., tuned kernels for MMD/F GD), is left to future w ork. Wh y many p -v alues exceed 0 . 5 . The frequen t o ccurrence of p > 0 . 5 in T able 4.7 and T able 4.6 can be explained b y t wo effects of our setup and of the learned mo del. First, w e summarize the alternativ e b y aggregating many replicates (e.g. taking the median across replicate v alues of the test statistic), while the empirical n ull is shown as single-replicate dra ws. This creates a v ariance asymmetry: the aggregation on the alternative side acts as a shrink er and remov es o ccasional large excursions of sup- or distance-based statistics. A t w o-sample statistic can b e sketc hed as T ≈ S ( F , G ) + N , where S ( F , G ) is a small structural shift betw een truth F and mo del G , and N is sampling noise. Aggregating man y alternativ e replicates reduces the contribution of N , so the observ ed (aggregated) alternativ e can lie to the left of typical single n ull replicates even when S ( F , G ) = 0 . Second, the trained mo del shows signs of varianc e shrinkage (milder tails and smo other fluctuations) compared to truth. In a truth–truth comparison, b oth samples explore the full tail v ariabilit y , pro ducing a wider env elop e of empirical fluctuations. In a truth–mo del comparison, one side is tigh ter, so supremum-t yp e distances (a v erage KS) or sliced distances (SKS, SWD) can de cr e ase b ecause ran- dom fluctuations are smaller, partly masking a small deterministic shift. Under our right-tailed con ven tion (“larger statistic ⇒ evidence against H 0 ”), this leads naturally to large p -v alues. In summary , a large right-tailed p -v alue means we lac k evidence for an in- flation -t yp e discrepancy (increased distance). If the difference tak es the form of c ontr action (reduced spread or tail occupancy), a left-tailed or t w o-sided calibra- tion may b e more sensitive. A systematic study of these options is left to future w ork. Chapter 4. Implementation and Exp erimental Setup 99 F eature Dimensions Metric batch_size n_slices p -v alue Significance ( σ ) Lay er centroid 3 KS 1000 - 0.505 0.0125 SKS 100.0 0.494 0.0150 SWD 100.0 0.440 0.151 MMD - 0.498 0.00501 FGD - 0.476 0.0601 Lay er centroid 3 KS 5000 - 0.462 0.0954 SKS 100.0 0.534 0.0853 SWD 100.0 0.486 0.0351 MMD - - FGD - - Lay er centroid 3 KS 10000 - 0.385 0.292 SKS 100.0 0.468 0.0803 SWD 100.0 0.494 0.0150 MMD - - - FGD - - - Lay er energy 45 KS 1000 - 0.521 0.0527 SKS 100.0 0.507 0.0175 SWD 100.0 0.482 0.0451 MMD - - - FGD - - - Lay er energy 45 KS 5000 - 0.406 0.238 SKS 100.0 0.476 0.0602 SWD 100.0 0.474 0.0652 MMD - - - FGD - - - Lay er energy 45 KS 10000 - 0.330 0.440 SKS 100.0 0.496 0.0100 SWD 100.0 0.418 0.207 MMD - - - FGD - - - RMS 3 KS 1000 - 0.460 0.100 SKS 100.0 0.488 0.0300 SWD 100.0 0.505 0.0125 MMD - 0.496 0.0100 FGD - 0.490 0.0250 RMS 3 KS 5000 - 0.408 0.233 SKS 100.0 0.529 0.0200 SWD 100.0 0.454 0.116 MMD - - - FGD - - - RMS 3 KS 10000 - 0.308 0.502 SKS 100.0 0.434 0.166 SWD 100.0 0.446 0.136 MMD - - - FGD - - - T otal energy 1 KS 5000 - 0.474 0.0652 SKS - - - SWD - - - MMD - 0.464 0.0904 FGD - 0.454 0.116 T able 4.7: Summary of p -values from all the evaluation of physically inspired features. Chapter 5 Lessons Lea rned and What Comes Next 5.1 Summa ry of Findings This thesis addresses calorimeter sho w er super-resolution b y indep endently repli- cating the results of Ref. [1]. Building upon the co de framework from Ref. [58], w e implemen ted a Conditional normalizing Flow , sp ecifically a Maske d A utor e- gr essive Flow (MAF) [54]. The architecture lev erages the Maske d A uto enc o der for Distribution Estimation (MADE) [59] to parametrize R ational Quadr atic Spline (R QS) transformations. T raining w as performed on Dataset 2 from the F ast Calorimeter Simulation Chal lenge (CaloChal lenge) , a comm unity driv en b enc h- mark for adv ancing high fidelit y fast calorimeter simulation. This dataset com- prises tw o files, each con taining 100 k full calorimeter show er ev en ts with 6480 fine v oxel energies p er sho wer, one file for training and one for ev aluation. The task was formulated b y aggregating neighboring fine v oxels to construct a c o arse r epr esentation , from whic h the model generates the underlying fine v oxel energies. Conditioning features include the inciden t particle energy , neigh b oring coarse vo xel energies, one-hot encoded position in the calorimeter, the exam- ined coarse vo xel energy , and the sum of fine vo xel energies within each coarse v oxel. While this last feature deviates from a pure sup er-resolution setting, it w as included to stabilize training and v alidate the pipeline as a pro of-of-concept. T raining proceeded for 80 ep o chs using the OneCycle [78] learning rate sched- uler, requiring approximately 27 . 5 hours on a single Nvidia L40S GPU. Initial training instability w as resolved b y increasing numerical precision from float32 100 Chapter 5. Lessons Learned and What Comes Next 101 to float64 . After h yp erparameter tuning, we achiev ed stable, monotonic im- pro vemen ts throughout training. P erformance ev aluation emplo y ed a statistically robust t wo sample testing metho dology from Ref. [2]. Unlik e man y existing approac hes for generativ e mod- els, whic h lac k rigorous statistical foundations, this framew ork pro vides reliable assessmen t. W e applied this formalism to b oth v ery high dimensional features, the full show er (6480D) and its coarse represen tation (648D), as well as phys- ically motiv ated low er dimensional features: energy centroid co ordinates (3D), RMS along longitudinal, lateral, and angular directions (3D), total inciden t en- ergy (1D), and lay er wise energy dep osits (45D). The preliminary statistical ev aluation (Section 2.4, Section 4.5) indicates a clear pattern across dimensionalities and hyperparameters. A t full dimensionalit y ( d = 6480 ), the av erage K olmogorov–Smirno v (KS) test distinguishes the model from truth with increasing significance as the sample size gro ws: for batch_size = 1 · 10 3 w e observ e p = 7 . 99 × 10 − 3 ( 2 . 41 σ ; Figure 4.14), whic h strengthens to p = 9 . 99 × 10 − 4 ( 3 . 09 σ ) for batch_size = 5 · 10 3 (Figure 4.15); see T able 4.6. In con trast, slice-based tests (Sliced KS (SKS) and Sliced W asserstein Distance (SWD)) do not sho w separation in this setting, remaining consistent with the Null hypothesis ( p ≃ 0 . 42 – 0 . 48 across configurations), that means that the true and generated samples can not b e distinguished. Increasing the num b er of slices from 10 3 to 7 · 10 3 at fixed batch_size lea v es this conclusion unc hanged (Figure 4.18), which is consisten t with a discrepancy that is sp arse across coordinates at d = 6480 : coordinate-wise tests lik e the av eraged KS retain sensitivit y to vo xel- lo cal biases, while random pro jections dilute suc h lo calized effects and primarily b enefit from larger sample size rather than more slices. A t the coarse representa- tion lev el ( d = 648 ), none of the tests reject H 0 across the explored h yp erparam- eters ( batch_size = 1 · 10 3 and 5 · 10 3 , nslices = 5 · 10 2 ; Figures 4.16–4.17), whic h is compatible with the mo del having effectiv ely learned coarse-block energy conserv ation from the conditioning: re-aggregated fine samples match the con- ditioning totals, lea ving coarse-lev el marginals virtually indistinguishable from truth (Section 4.2.1). Ov erall, these results suggest (i) detectable but lo calized mismo deling at full dimensionality captured b y the a veraged KS, (ii) limited p o wer of sliced tests under sparse discrepancies at fixed statistics, and (iii) strong agreemen t at the coarse level consistent with learned energy conserv ation. W e Chapter 5. Lessons Learned and What Comes Next 102 emphasize that these findings are preliminary: only a mo dest region of the hy- p erparameter space ( batch_size , nslices ) has b een explored so far. F or physically inspired lo w-dimensional features (3D centroids, 3D RMS, 45D lay er energies, 1D inciden t energy), p -v alues t ypically lie in the 0 . 3 – 0 . 55 range and do not indicate mismo deling; we still see the expected trend that larger batch_size impro ves p o wer, e.g. KS on la yer energies decreases from 0 . 521 ( 10 3 ) to 0 . 406 ( 5 × 10 3 ) to 0 . 330 ( 10 4 ), with a similar pattern for SWD ( 0 . 482 → 0 . 474 → 0 . 418 ), while SKS can b e non-monotonic due to pro jection v ariabilit y . T aken together, these findings p oin t to lo calized discrepancies at the fine-v oxel level (pic ked up b y a veraged KS at d = 6480 ), strong agreement after coarse re-aggregation (consistent with learned energy conserv ation), and gener- ally large right-tailed p -v alues in low dimensions, which w e argued can arise from aggregation asymmetry and v ariance shrinkage in the mo del. A broader sw eep o ver batch_size and nslices , and targeted tests for sp ecific marginal artifacts, are left to future w ork. 5.2 Physics Implications As outlined in the Introduction, this approach has several implications for re- construction qualit y , analysis sensitivity , and computing strategy . Learning a mapping from coarse to fine segmentation enables reco very of information that w ould otherwise require exp ensive high gran ularity sim ulation or hardw are up- grades, while remaining compatible with existing reconstruction workflo ws. Restoring fine-grained energy patterns reduces bias and v ariance in recon- structed energy while impro ving p osition estimates. F eature lev el metrics on cen troids and longitudinal, lateral, and angular RMS (see Section 4.6) indicate that salien t sho wer shap es are retained, supp orting impro ved calibration and more stable resp onse across lay ers. This preserv ation of sho wer shap e v ariables is particularly relev an t for particle identification, as the metho d virtually increases segmen tation, sharpening features that feed particle identification taggers and clustering algorithms. Bey ond reconstruction impro vemen ts, higher effectiv e gran ularity helps mit- igate pile up confusion at the HL-LHC by impro ving topological clustering, iso- lation definitions, and separation of nearby dep osits. Learned upsampling based on coarse observ ables can assist reconstruction under high o ccupancy without de- Chapter 5. Lessons Learned and What Comes Next 103 tector mo difications. The approac h also offers a route to comp ensate for effectiv e gran ularity loss from aging, mask ed cells, or noisy readouts. By inferring lo cal energy patterns from av ailable coarse measuremen ts, it can p otentially recov er p erformance in degraded regions without hardware replacemen t, particularly at- tractiv e for long term op erations where granular replacemen ts are impractical. F rom a computational persp ective, using this metho d as a p ost processor for coarse, fast sim ulation can deliver fine-grained show ers at a fraction of the Gean t4 cost, reducing CPU, memory , and storage requirements. The generative nature also enables controlled v ariations for systematic studies (e.g., la y er wise re- sp onse or lateral spread), facilitating stress tests of analysis selections. In tegration in to reconstruction chains is straigh tforward: the metho d can b e inserted after coarse clustering and calibration, before high level particle identification and ob- ject building, with minimal in terface c hanges since it relies on observ ables already presen t in reconstruction. F or online use, inference sp eed is the main constrain t; autoregressiv e flo ws ma y require arc hitectural modifications (e.g., IAF v arian ts, distillation, batc hing, or hardware acceleration) before inclusion in trigger paths, whereas offline w orkflows can adopt the metho d so oner. Conditional normalizing flo ws can th us enhance the fidelity of calorimeter information a v ailable to physics analyses, ease computing pressure b y replacing p ortions of fine-grained sim ulation, and provide a practical to ol to counteract pile up and aging effects. The approach represen ts a viable candidate for in tegration in to end to end HEP w orkflows. 5.3 Limitations This thesis’s conclusions are b ounded by assumptions in the data domain, mo d- eling c hoices, and ev aluation metho dology . T raining and testing w ere restricted to a single simulated geometry and dataset (Par04, CaloChallenge Dataset 2; see Section 4.1), without explicitly mo deling detector effects such as time dependent aging, coherent noise, out of time pile up, and mask ed c hannels. Generalization to other geometries, operating conditions, or real data therefore remains unv erified. F or stabilization and pip eline v alidation, one conditioning feature included information una v ailable in a strict sup er-resolution setting (the sum of fine vo xel energies within each coarse v o xel). This simplifies part of the task and should b e view ed as a pro of-of-concept choice to b e remo ved in future w ork. Chapter 5. Lessons Learned and What Comes Next 104 The adopted autoregressive architecture (MAF with MADE conditioner and R QS transforms) offers flexibilit y but incurs sequential sampling and higher in- ference latency . Numerical stability required float64 precision (Section 4.4), increasing memory and compute costs. P erformance ma y b e sensitiv e to conditioning design, p erm utation strategy , spline hyperparameters, and prepro cessing near zero energies. These factors w ere not exhaustively explored. Approximate energy conserv ation is encouraged through conditioning and ev aluation rather than enforced by design, so small residual biases, particularly in rare tails, cannot b e excluded. The ev aluation framew ork emplo ys a statistically robust tw o sample approach with T ruth–T ruth baselines (Section 2.4), con trolling false discov eries but with finite statistical p ow er. Dep ending on metric choice and h yp erparameters (e.g., n umber of slices or batch size), v ery lo cal mismatches ma y go undetected. Per ev ent calibrated uncertain t y estimates are not pro vided, and the resp onse has not b een anchored to con trol samples, limiting immediate use in precision analyses requiring uncertaint y propagation. Finally , computational budget constrain ts limited the hyperparameter search and training schedule. The reported behavior should b e considered represen- tativ e of the c hosen configuration rather than globally optimal. F ull bit wise repro ducibilit y across platforms and drivers is not guaran teed. 5.4 Outlo ok and F uture W o rk High fidelity calorimeter sho wer sup er-resolution can provide v aluable lev erage to address c hallenges posed b y the HL-LHC and future colliders suc h as the F utur e Cir cular Col lider (F CC) or the Muon Col lider . This thesis left man y op en questions and several promising directions for future researc h: 1. T ransition to a genuine sup er-resolution task b y remo ving the conditioning on fine v oxel energy sums, and addressing practical scenarios suc h as missing v alues from dead cells or noisy readouts. 2. Replace MAF with an Inverse A utor e gr essive Flow (IAF) , increasing sam- pling sp eed while maintaining fidelit y . 3. Explore the h yp erparameter space systematically to achiev e sup er-c onver genc e and reduce training time. Chapter 5. Lessons Learned and What Comes Next 105 4. Enhance computational efficiency through further optimization of the cur- ren t TensorFlow2 implementation. 5. Conduct systematic performance assessmen t through structured exploration of the h yp erparameter space. 6. Up date the architecture to state-of-the-art mo dels suc h as Conditional Flow Matching and Diffusion mo dels , whic h ha v e demonstrated promising results in fast, high fidelity sho wer generation. The indep enden t implementation, conditioning strategy , and statistically robust ev aluation demonstrate that conditional normalizing flows can provide analysis grade sup er-resolution. With optimized inference and speed improv emen ts, the approac h represents a credible candidate for in tegration into mo dern HEP recon- struction chains. A ckno wledgements I w ould like to thank my supervisors, Dr. Riccardo T orre , Dr. Marco Letizia , and m y reviewer Dr. Andrea Co ccaro , for their guidance, patience, and many constructiv e discussions throughout this work. Their feedbac k and supp ort w ere essen tial at every stage of the thesis. I also thank the INFN Sezione di Geno v a and the Universit y of Genoa for the opp ortunit y to carry out this researc h. Computations were p erformed on the T e o GPU cluster. 107 App endix A Mo re on Loss F unctions This app endix pro vides a concise theoretical ov erview of additional loss functions widely used in mac hine learning and information theory . In particular, it fo cuses on the Kullbac k–Leibler (KL) div ergence and the cross-entrop y loss, both of whic h establish a formal connection b etw een probabilistic mo deling and optimization in statistical learning. These quantities pla y a fundamental role in understanding lik eliho o d-based ob jectives suc h as the Negative Log-Lik eliho o d (NLL). Kullback–Leibler Divergence (KL) Giv en tw o probability densit y functions (PDF s) defined ov er the same v ariable X , denoted by p and q , the KL div ergence (or KL distance) measures ho w one distribution diverges from the other. In the con text of unsup ervised learning, it is defined as: D KL ( p ∥ q ) = E X ∼ p " log p ( X ) q ( X ) !# = Z p ( x ) log p ( x ) q ( x ) ! d x = Z p ( x ) log p ( x ) − log q ( x ) d x . An empirical estimation of this integral can b e obtained by sampling N p oin ts from the distribution p ( x ) and computing the a verage of the logarithmic ratio b et ween the PDF s: D KL ( p ∥ q ) ≈ 1 N N X i =1 log p ( x i ) q ( x i ) ! . In the case of sup ervised tasks, each PDF becomes a conditional one, as discussed in the ov erview of the NLL loss. If the distribution of the output is assumed to b e Gaussian, and w e define p ( Y | X ) as the true output PDF and 109 App endix A. More on Loss F unctions 110 q ( Y | X ; θ ) as the mo del-predicted PDF, one can sho w that minimizing the KL div ergence b etw een the predicted and true PDF s again reduces to minimizing the MSE loss up to constan t terms. In information theory , the KL div ergence b elongs to a broader class of diver- gences used to measure the distance b et ween probability distributions, known as f -div ergences. Cross-Entrop y The term cr oss-entr opy originates from the concept of differ ential entr opy , which generalizes the notion of Shannon entrop y to con tinuous v ariables. Differential Entropy Differen tial entrop y is the contin uous analogue of the Shannon en trop y , whic h measures the a v erage amount of information pro duced b y a discrete random v ari- able. It is defined as the exp ected v alue of the information con tent (also called self-information or surprisal ) of the v ariable. F or a v ariable x distributed ac- cording to the Probabilit y Mass F unction (PMF) P ( x ) , the information conten t is defined as: I ( x ) = log 1 P ( x ) = − log P ( x ) , and it quan tifies the uncertaint y asso ciated with the o ccurrence of the even t x . The Shannon en tropy is then giv en b y: H ( X ) = E X ∼ P [ I ( X )] = E X ∼ P [ − log P ( X )] ≈ − X x ∈ χ P ( x ) log P ( x ) , where χ is the sample space , i.e. the set of all possible outcomes of the random v ariable X . A higher entrop y corresp onds to a more unpredictable v ariable. This concept can b e extended to contin uous v ariables. Given a contin uous random v ariable X with PDF p ( X ) , the differen tial en trop y is defined as: H ( X ) = E X ∼ p [ I ( X )] = − Z p ( X ) log p ( X ) d X . In contrast to Shannon en tropy , differential en tropy can take negativ e v alues and is not in v arian t under a c hange of v ariables. Because it dep ends on the scale of the PDF, it is not directly comparable across different v ariables and cannot App endix A. More on Loss F unctions 111 b e interpreted as a direct measure of uncertain ty . It quan tifies the spread of a con tinuous distribution but not necessarily the amount of information it con tains. F or a finite sample { x i } of N p oints drawn from p ( X ) , the differen tial entrop y can b e appro ximated as: H ( X ) ≈ − 1 N N X i =1 log p ( x i ) . F rom this expression, w e can see that, up to normalization factors, for a finite sample the differential en tropy is approximated b y the negativ e log-lik eliho o d of the data under the true underlying distribution. F rom KL Divergence to Cross-Entrop y The cross-entrop y loss can b e obtained by rewriting the KL divergence as: D KL ( p ∥ q ) = E X ∼ p [log p ( X ) − log q ( X )] = − H ( p ) − E X ∼ p [log q ( X )] . W e can iden tify the cross-entrop y as the term H ( p, q ) : = − E X ∼ p [log q ( X )] . F ollo wing the same reasoning as with differen tial en trop y , if w e ha ve a finite dataset, the cross-en tropy can b e appro ximated as: H ( p, q ) = − E X ∼ p data [log q ( X ; θ )] ≈ − 1 N N X i =1 log q ( x i ; θ ) . Th us, the cross-en tropy loss corresp onds to the NLL (up to a constant factor) of the data giv en the mo del parameters. F or sup ervised learning tasks, the only difference is that every PDF is replaced by its conditional counterpart. Although the m ultiplicativ e and additiv e constan ts appearing across these differen t loss definitions are theoretically irrelev an t to the optimization objective, they can significan tly affect the n umerical b ehavior of the algorithms used for training. App endix B Second o rder optimizer: The Newton-Raphson metho d The Newton-Raphson metho d is one of the most app ealing in its theoretical for- m ulation; ho wev er, its application has some disadv antages. The Newton-Raphson metho d (NR), under particular conditions, it is known to hav e quadratic con- v ergence , making it a fast metho d (we will get to what this means later). It is said to be a metho d of the second order since it leverages both first and second order deriv ativ es, namely , the gradient and the Hessian , to iteratively find the extrema of the function. Giv en a m ultiv ariate function f ( ω ) , with ω ∈ R n . The (n+1)-th step is expressed b y the NR metho d as: ˆ ω n +1 = ˆ ω n − [ H ( f ( ˆ ω n ))] − 1 ∇ f ( ˆ ω n ) (B.1) where ˆ ω n is the n-th step approximate solution, ∇ f ( ω ) is the gradien t vector and H ( f ( ω )) the Hessian matrix, defined by: ( ∇ f ( ˆ ω n )) i = ∂ f ( ω ) ∂ ω i ω = ˆ ω n and ( H ( f ( ˆ ω n ))) ij = ∂ 2 f ( ω ) ∂ ω i ∂ ω j ω = ˆ ω n Equation B.1 lev erages the T ailor expansion of the function around the n-th step, assuming the functio n is sufficien tly differen tiable, and the Hessian matrix is non-singular. The gradient v ector ∇ f ( ˆ ω n ) indicates the direction of the steep est ascen t of the function at ˆ ω n . So the algorithm will c hange the parameter b y mo ving in the direction of the steep est descent b y a quantit y prop ortional to the in v erse of the curv ature (The Hessian matrix). The algorithm mo ves in the direction of the steep est descent with a large step if the curv ature is small and a 112 App endix B. Second o rder optimizer: The Newton-Raphson metho d 113 small step if the curv ature is large. It can b e sho wn that for functions that are smo oth enough and for a sufficiently large n , the NR metho d allows y ou to: ∥ ϵ n +1 ∥ ≤ C ∥ ϵ n ∥ 2 , whic h is the definition of quadratic con v ergence. It is important to note that quadratic con vergence is con tingen t up on the function b eing sufficiently smo oth and the initial estimate b eing reasonably close to the true solution. Additionally , the requiremen ts that the Hessian matrix b e non-singular and p ositiv e (semi- )definite at every iteration to ensure con v ergence migh t not alwa ys be satisfied, particularly in high-dimensional optimization problems or when the function ex- hibits m ultiple local minima. F urthermore, for non-con vex functions, NR metho d can quickly con verge to saddle p oin ts or lo cal minima, making it less effective. The practical challenges asso ciated with the NR metho d that limit its use for mac hine learning mo dels can b e summarized in three p oints: • Non-Convex functions : as already stressed, the NR metho d with non- con vex functions quickly con verges to a saddle p oin t or lo cal minima. • Computational c ost : the computational cost of calculating the Hessian ma- trix and its inv erse at eac h step can b e prohibitively exp ensiv e. • Implementation chal lenges : Ensuring the Hessian matrix remains p ositive definite and managing numerical stabilit y can b e difficult, the efficiency quic kly diminishes in high-dimensional spaces. In practice, for conv ex optimization problems, some Newton-inspired algorithms can mitigate the c hallenges associated with the standard Newton-Raphson metho d b y approximating the Hessian matrix instead of calculating it at each step (Quasi- Newton metho ds) or by lev eraging the curv ature information to impro ve robust- ness and con vergence. App endix C Use of AI-assisted to ols Throughout this w ork, AI-based tools such as ChatGPT, Copilot, DeepSeek, and Gemini were used to supp ort the research pro cess. Their use was limited to technical and exploratory purp oses, including clarifying asp ects of co de im- plemen tation, assisting in debugging and optimization, and verifying details of mac hine-learning arc hitectures suc h as normalizing flo ws. All conceptual and technical dev elopments, analyses, and interpretations were en tirely carried out b y the author. An y AI-assisted material w as critically re- view ed, adapted, and integrated solely to enhance clarit y or efficiency . The final text, results, tables, figures, and conclusions presented in this thesis reflect the author’s indep endent understanding and original work. 114 Bibliography [1] Ian Pang, Da vid Shih, and John Andrew Raine. “Calorimeter show er su- p erresolution”. In: Physic al R eview D 109.9 (Ma y 2024). issn : 2470-0029. doi : 10 . 1103 / physrevd . 109 . 092009 . url : http : / / dx . doi . org / 10 . 1103/PhysRevD.109.092009 . [2] Samuele Grossi, Marco Letizia, and Riccardo T orre. R efer e eing the R efer- e es: Evaluating Two-Sample T ests for V alidating Gener ators in Pr e cision Scienc es . 2024. arXiv: 2409.16336 [stat.ML] . url : abs/2409.16336 . [3] T ullio Basaglia et al. Ge ant4: a Game Changer in High Ener gy Physics and R elate d A pplic ative Fields . 2024. arXiv: 2405 . 12159 [physics.comp-ph] . url : . [4] G Ap ollinari et al. High Luminosity L ar ge Hadr on Col lider HL-LHC . en. 2015. doi : 10 . 5170 / CERN - 2015 - 005 . 1 . url : https : / / cds . cern . ch / record/2120673 . [5] CMS Offline Softw are and Computing. CMS Phase-2 Computing Mo del: Up date Do cument . T ech. rep. Genev a: CERN, 2022. url : https : / / cds . cern.ch/record/2815292 . [6] A TLAS HL-LHC Computing Conc eptual Design R ep ort . T ech. rep. Genev a: CERN, 2020. url : https://cds.cern.ch/record/2729668 . [7] Istituto Nazionale di Fisica Nucleare (INFN). Seminario: CMS . Presen ta- tion (PDF) on the INFN agenda site. A v ailable at: https://agenda.infn. it / event / 26541 / attachments / 81157 / 106222 / Seminario _ INFN _ CMS . pdf (accessed 2025-11-10). 2022. [8] Coll A TLAS et al. The simulation principle and p erformanc e of the A TLAS fast c alorimeter simulation F astCaloSim . T ech. rep. Genev a: CERN, 2010. url : https://cds.cern.ch/record/1300517 . 115 BIBLIOGRAPHY 116 [9] Performanc e of the F ast A TLAS T r acking Simulation (F A TRAS) and the A TLAS F ast Calorimeter Simulation (F astCaloSim) with single p articles . T ec h. rep. Genev a: CERN, 2014. url : https : / / cds . cern . ch / record / 1669341 . [10] G. Aad et al. “AtlF ast3: The Next Generation of F ast Simulation in A T- LAS”. In: Computing and Softwar e for Big Scienc e 6.1 (Mar. 2022). issn : 2510-2044. doi : 10 . 1007 / s41781 - 021 - 00079 - 7 . url : http : / / dx . doi . org/10.1007/s41781- 021- 00079- 7 . [11] Claudius Krause et al. CaloChal lenge 2022: A Community Chal lenge for F ast Calorimeter Simulation . 2024. arXiv: 2410.21611 [physics.ins-det] . url : . [12] Johannes Erdmann et al. “SR-GAN for SR-gamma: sup er resolution of pho- ton calorimeter images at collider experiments”. In: The Eur op e an Physic al Journal C 83.11 (No v. 2023). issn : 1434-6052. doi : 10.1140/epjc/s10052- 023 - 12178 - 3 . url : http : / / dx . doi . org / 10 . 1140 / epjc / s10052 - 023 - 12178- 3 . [13] X. Chen et al. “Single photon production at hadron colliders at NNLO QCD with realistic photon isolation”. In: Journal of High Ener gy Physics 2022.8 (Aug. 2022). issn : 1029-8479. doi : 10 . 1007 / jhep08(2022 ) 094 . url : http://dx.doi.org/10.1007/JHEP08(2022)094 . [14] Ulrich Heintz et al. Instrumentation for the Ener gy F r ontier . 2013. arXiv: 1309 . 0162 [physics.ins-det] . url : https : / / arxiv . org / abs / 1309 . 0162 . [15] J. Abdallah et al. “Study of the radiation hardness of the A TLAS Tile Calorimeter optical instrumen tation with R un 2 data”. In: Journal of In- strumentation 20.06 (June 2025), P06006. issn : 1748-0221. doi : 10.1088/ 1748 - 0221 / 20 / 06 / p06006 . url : http : / / dx . doi . org / 10 . 1088 / 1748 - 0221/20/06/P06006 . [16] G. Aad et al. “Op eration and p erformance of the A TLAS tile calorimeter in LHC R un 2”. In: The Eur op e an Physic al Journal C 84.12 (Dec. 2024). issn : 1434-6052. doi : 10 . 1140 / epjc / s10052 - 024 - 13151 - 4 . url : http : //dx.doi.org/10.1140/epjc/s10052- 024- 13151- 4 . BIBLIOGRAPHY 117 [17] V. Khac hatryan et al. “Dose rate effects in the radiation damage of the plastic scin tillators of the CMS hadron endcap calorimeter”. In: Journal of Instrumentation 11.10 (Oct. 2016), T10004–T10004. issn : 1748-0221. doi : 10.1088/1748- 0221/ 11 /10/t10004 . url : http: //dx.doi.org /10.1088/ 1748- 0221/11/10/T10004 . [18] Xavier Buffat et al. HL-LHC Exp eriment Data Quality W orking Gr oup Summary R ep ort . T ec h. rep. Genev a: CERN, 2022. url : https : / / cds . cern.ch/record/2802720 . [19] CMS Collab oration. How CMS we e ds out p articles fr om pileup . https : / / cms . cern / news / how - cms - weeds - out - particles - pile . A ccessed No vem b er 2025. 2018. [20] Pile-up mitigation te chniques in the A TLAS exp eriment . T ec h. rep. A TLAS- CONF-2017-065. A TLAS public note, accessed No vem b er 2025. A TLAS Collab oration, 2017. url : https://cds.cern.ch/record/2281055 . [21] G. Aad et al. “Softw are Performance of the A TLAS T rack Reconstruction for LHC Run 3”. In: Computing and Softwar e for Big Scienc e 8.1 (Apr. 2024). issn : 2510-2044. doi : 10. 1007 / s41781 - 023 - 00111 - y . url : http: //dx.doi.org/10.1007/s41781- 023- 00111- y . [22] Danilo Jimenez Rezende and Shakir Mohamed. V ariational Infer enc e with Normalizing Flows . 2016. arXiv: 1505 . 05770 [stat.ML] . url : https : / / arxiv.org/abs/1505.05770 . [23] Diederik P . Kingma et al. Impr oving V ariational Infer enc e with Inverse A utor e gr essive Flow . 2017. arXiv: 1606 . 04934 [cs.LG] . url : https : / / arxiv.org/abs/1606.04934 . [24] Conor Durkan et al. “Neural Spline Flows”. In: A dvanc es in Neur al Infor- mation Pr o c essing Systems 32 (2019). arXiv: 1906.04032 [stat.ML] . url : https://arxiv.org/abs/1906.04032 . [25] Andrei Nikolaevic h Kolmogoro v. “Sulla determinazione empirica di una legge di distribuzione”. In: Giornale del l’Istituto Italiano de gli A ttuari 4 (1933), pp. 83–91. [26] N. V. Smirno v. “T able for Estimating the Go o dness of Fit of Empirical Distributions”. In: A nnals of Mathematic al Statistics 19 (1948), pp. 279– 281. url : https://api.semanticscholar.org/CorpusID:120842954 . BIBLIOGRAPHY 118 [27] Gabriel P eyré and Marco Cuturi. “Computational Optimal T ransp ort”. In: F ound. T r ends Mach. L e arn. 11 (2018), pp. 355–607. url : https : / / api . semanticscholar.org/CorpusID:73725148 . [28] Cédric Villani. “T opics in Optimal T ransp ortation”. In: 2003. url : https: //api.semanticscholar.org/CorpusID:118448577 . [29] Min Jin Chong and David Alexander F orsyth. “Effectiv ely Un biased FID and Inception Score and Where to Find Them”. In: 2020 IEEE/CVF Con- fer enc e on Computer V ision and Pattern R e c o gnition (CVPR) (2019). url : https://api.semanticscholar.org/CorpusID:208138613 . [30] Mikolaj Bink owski et al. “Dem ystifying MMD GANs”. In: A rXiv 1801.01401 (2018). url : https://api.semanticscholar.org/CorpusID:3531856 . [31] Arthur Gretton et al. “A Kernel Metho d for the T w o-Sample-Problem”. In: Neur al Information Pr o c essing Systems . 2006. url : https : / / api . semanticscholar.org/CorpusID:1993257 . [32] Arthur Gretton et al. “A Kernel T w o-Sample T est”. In: J. Mach. L e arn. R es. 13 (2012), pp. 723–773. url : https : / / api . semanticscholar . org / CorpusID:10742222 . [33] A TLAS Softwar e and Computing HL-LHC R o admap . T ec h. rep. Genev a: CERN, 2022. url : https://cds.cern.ch/record/2802918 . [34] CMS Offline and Computing Public R esults . T ech. rep. CERN. url : https: / / twiki . cern . ch / twiki / bin / view / CMSPublic / CMSOfflineComputing Results . [35] Di Bello T orre Co ccaro. Machine L e arning for Physicists . Master’s course, Univ ersity of Genoa. Lecture notes and materials from the academic year 2023/2024. 2024. [36] David E R umelhart, Geoffrey E Hinton, and Ronald J Williams. “Learning represen tations b y bac k-propagating errors”. In: natur e 323.6088 (1986), pp. 533–536. [37] F. Rosen blatt. “The p erceptron: A probabilistic mo del for information stor- age and organization in the brain.” In: Psycholo gic al R eview 65.6 (1958), pp. 386–408. issn : 0033-295X. doi : 10 .1037 /h0042519 . url : http :/ /dx . doi.org/10.1037/h0042519 . BIBLIOGRAPHY 119 [38] Lav een N. Kanal. “P erceptron”. In: Encyclop e dia of Computer Scienc e . GBR: John Wiley and Sons Ltd., 2003, pp. 1383–1385. isbn : 0470864125. [39] Vino d Nair and Geoffrey E. Hin ton. “Rectified Linear Units Improv e Re- stricted Boltzmann Mac hines”. In: Pr o c e e dings of the 27th International Confer enc e on Machine L e arning (ICML) . 2010, pp. 807–814. url : https: //icml.cc/Conferences/2010/papers/432.pdf . [40] Grant Sanderson. What is a Neur al Network? Y ouT ub e video. Accessed No vem b er 2025. 2017. url : https :/ /www . youtube . com/ watch? v =aircAr uvnKk . [41] Anja Butter et al. “Machine learning and LHC even t generation”. In: Sci- Post Physics 14.4 (Apr. 2023). issn : 2542-4653. doi : 10 . 21468 / scipostp hys.14.4 .079 . url : http: //dx. doi .org/10 . 21468/SciPostPhys. 14 .4. 079 . [42] Ian J. Go o dfellow et al. Gener ative A dversarial Networks . 2014. arXiv: 1406.2661 [stat.ML] . url : https://arxiv.org/abs/1406.2661 . [43] Diederik P Kingma and Max W elling. A uto-Enc o ding V ariational Bayes . 2022. arXiv: 1312.6114 [stat.ML] . url : 6114 . [44] Diederik P . Kingma and Max W elling. “An In tro duction to V ariational A uto enco ders”. In: F oundations and T r ends ® in Machine L e arning 12.4 (2019), pp. 307–392. issn : 1935-8245. doi : 10 . 1561 / 2200000056 . url : http://dx.doi.org/10.1561/2200000056 . [45] Jascha Sohl-Dic kstein et al. De ep Unsup ervise d L e arning using None quilib- rium Thermo dynamics . 2015. arXiv: 1503 . 03585 [cs.LG] . url : https : //arxiv.org/abs/1503.03585 . [46] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising Diffusion Pr ob a- bilistic Mo dels . 2020. arXiv: 2006 . 11239 [cs.LG] . url : https : / / arxiv . org/abs/2006.11239 . [47] Ricky T. Q. Chen et al. Neur al Or dinary Differ ential Equations . 2019. arXiv: 1806.07366 [cs.LG] . url : . [48] Will Grathw ohl et al. FFJORD: F r e e-form Continuous Dynamics for Sc al- able R eversible Gener ative Mo dels . 2018. arXiv: 1810.01367 [cs.LG] . url : https://arxiv.org/abs/1810.01367 . BIBLIOGRAPHY 120 [49] Jonathon Shlens. Notes on K ul lb ack-L eibler Diver genc e and Likeliho o d . 2014. arXiv: 1404.2000 [cs.IT] . url : . [50] He Xiangnan. A Be ginner-F riend ly Guide to Gener ative A dversarial Net- works (GAN) . A ccessed: 2025-11-06. 2020. url : https: / / medium. com / @h exiangnan / beginner - friendly - guide - to - generative - adversarial - networks- gan- 34a63fc2bbcb . [51] Y ang Song et al. Sc or e-Base d Gener ative Mo deling thr ough Sto chastic Dif- fer ential Equations . 2021. arXiv: 2011 . 13456 [cs.LG] . url : https : / / arxiv.org/abs/2011.13456 . [52] Y aron Lipman et al. Flow Matching for Gener ative Mo deling . 2023. arXiv: 2210.02747 [cs.LG] . url : https://arxiv.org/abs/2210.02747 . [53] Alexander T ong et al. Impr oving and gener alizing flow-b ase d gener ative mo dels with minib atch optimal tr ansp ort . 2024. arXiv: 2302.00482 [cs.LG] . url : . [54] George Papamakarios, Theo Pa vlak ou, and Iain Murray . Maske d A utor e- gr essive Flow for Density Estimation . 2018. arXiv: 1705.07057 [stat.ML] . url : . [55] Laurent Dinh, Jasc ha Sohl-Dickstein, and Samy Bengio. Density estimation using R e al NVP . 2017. arXiv: 1605.08803 [cs.LG] . url : https://arxiv. org/abs/1605.08803 . [56] Laurent Dinh, Da vid Krueger, and Y oshua Bengio. NICE: Non-line ar In- dep endent Comp onents Estimation . 2015. arXiv: 1410.8516 [cs.LG] . url : https://arxiv.org/abs/1410.8516 . [57] Diederik P . Kingma and Prafulla Dhariw al. “Glo w: Generativ e Flow with In vertible 1x1 Conv olutions”. In: (2018). arXiv: 1807 . 03039 [stat.ML] . url : . [58] Andrea Co ccaro et al. “Comparison of Affine and Rational Quadratic Spline Coupling and Autoregressiv e Flows through Robust Statistical T ests”. In: Symmetry 16.8 (July 2024), p. 942. issn : 2073-8994. doi : 10 . 3390 / sym 16080942 . url : http://dx.doi.org/10.3390/sym16080942 . BIBLIOGRAPHY 121 [59] Mathieu Germain et al. “MADE: Mask ed Autoenco der for Distribution Es- timation”. In: Pr o c e e dings of the 32nd International Confer enc e on Machine L e arning (ICML) . PMLR, 2015, pp. 881–889. arXiv: 1502.03509 [cs.LG] . url : . [60] Diederik P . Kingma et al. “Improving V ariational A uto enco ders with In- v erse A utoregressive Flo w”. In: A dvanc es in Neur al Information Pr o c ess- ing Systems (NeurIPS) . V ol. 29. 2016. arXiv: 1606 . 04934 [cs.LG] . url : https://arxiv.org/abs/1606.04934 . [61] Geoffrey E. Hinton and Ruslan R. Salakh utdinov. “Reducing the Dimen- sionalit y of Data with Neural Net works”. In: Scienc e 313.5786 (2006), pp. 504– 507. doi : 10 . 1126 / science . 1127647 . url : https : / / www . science . org / doi/10.1126/science.1127647 . [62] Carl De Bo or. A pr actic al guide to splines . Applied mathematical sciences. Berlin: Springer, 2001. url : https://cds.cern.ch/record/1428148 . [63] John A. Gregory and Rob ert Delb ourgo. “Piecewise Rational Quadratic In terp olation to Monotonic Data”. In: IMA Journal of Numeric al A nalysis 2.2 (1982), pp. 123–130. doi : 10.1093/imanum/2.2.123 . [64] Raghav Kansal et al. “Ev aluating generativ e mo dels in high energy ph ysics”. In: Physic al R eview D 107.7 (Apr. 2023). issn : 2470-0029. doi : 10 . 1103 / physrevd . 107 . 076017 . url : http : / / dx . doi . org / 10 . 1103 / PhysRevD . 107.076017 . [65] Charlie F rogner et al. L e arning with a W asserstein L oss . 2015. arXiv: 1506. 05439 [cs.LG] . url : https://arxiv.org/abs/1506.05439 . [66] Jonathan H. Man ton and Pierre-Olivier Am blard. A Primer on R epr o ducing K ernel Hilb ert Sp ac es . 2015. arXiv: 1408 . 0952 [math.HO] . url : https : //arxiv.org/abs/1408.0952 . [67] Martin Heusel et al. GANs T r aine d by a Two Time-Sc ale Up date R ule Con- ver ge to a L o c al Nash Equilibrium . 2018. arXiv: 1706.08500 [cs.LG] . url : https://arxiv.org/abs/1706.08500 . [68] Mikolaj Bink o wski et al. “Demystifying MMD GANs”. In: A rXiv abs/1801.01401 (2018). url : https://api.semanticscholar.org/CorpusID:3531856 . BIBLIOGRAPHY 122 [69] Min Jin Chong and Da vid F orsyth. “Effectiv ely Un biased FID and Incep- tion Score and Where to Find Them”. In: 2020 IEEE/CVF Confer enc e on Computer Vision and Pattern R e c o gnition (CVPR) . 2020, pp. 6069–6078. doi : 10.1109/CVPR42600.2020.00611 . [70] Christina Winkler et al. “Learning Lik eliho o ds with Conditional Normaliz- ing Flo ws”. In: A rXiv abs/1912.00042 (2019). url : https://api.semanti cscholar.org/CorpusID:208527755 . [71] J.-B. Sauv an. Calorimetry (extende d version) . Lecture slides, INFN School of Statistics and Data Analysis, CERN. A ccessed No vem b er 2025. 2021. url : https : / / indico . cern . ch / event / 1064512 / contributions / 4474572/attachments/2355773/4055061/calorimetry_extended.pdf . [72] Particle Data Group. “Calorimetry , in Review of Particle Ph ysics”. In: Pr o gr ess of The or etic al and Exp erimental Physics 2024.8 (2024). Review of Particle Ph ysics, Section on Calorimeters, p. 083C01. doi : 10 . 1093 / ptep / ptae052 . url : https : / / pdg . lbl . gov / 2024 / reviews / rpp2024 - rev- calorimeters.pdf . [73] The A TLAS Collab oration. “Ov erview of the A TLAS Detector”. In: Journal of Instrumentation 3 (2008). “The dimensions of the detector are 25 m in heigh t and 44–46 m in length. The ov erall weigh t . . . appro x. 7,000 tonnes”, S08003. url : https://jinst.sissa.it/LHC/ATLAS/ch01.pdf . [74] A TLAS Collab oration. Dete ctor & T e chnolo gy – A TLAS Exp eriment at CERN . W eb page. Accessed Nov ember 2025; “A TLAS has . . . 46 m long, 25 m in diameter . . . w eighs 7,000 tonnes”. 2025. url : https : / / atlas . cern/Discover/Detector . [75] Particle Data Group, R. L. W orkman, et al. “Review of P article Ph ysics: De- tectors and P article Iden tification”. In: Pr o gr ess of The or etic al and Exp eri- mental Physics 2024.8 (2024). See section on “Detectors at accelerators”, en- ergy resolution parametrisation., p. 083C01. doi : 10.1093/ptep/ptae072 . [76] Geant4 Collab oration. Par04: Extende d/Par ameterisations Example in Ge ant4 . https : / / gitlab . cern . ch / geant4 / geant4/ - /tree / master / examples / extended/parameterisations/Par04 . Gean t4 example, accessed 2025-09- 02. 2025. [77] Andrea Cosso. Sour c e Co de . § https://github.com/username/project . BIBLIOGRAPHY 123 [78] Leslie N. Smith and Nic hola y T opin. Sup er-Conver genc e: V ery F ast T r aining of Neur al Networks U sing L ar ge L e arning R ates . 2018. arXiv: 1708.07120 [cs.LG] . url : https://arxiv.org/abs/1708.07120 . [79] Riccardo Guidotti et al. A Survey Of Metho ds F or Explaining Black Box Mo dels . 2018. arXiv: 1802 . 01933 [cs.CY] . url : https : / / arxiv . org / abs/1802.01933 . [80] Raghav Kansal et al. “Ev aluating generativ e mo dels in high energy ph ysics”. In: Physic al R eview D 107.7 (Apr. 2023). issn : 2470-0029. doi : 10 . 1103 / physrevd . 107 . 076017 . url : http : / / dx . doi . org / 10 . 1103 / PhysRevD . 107.076017 . [81] Samuele Grossi, Marco Letizia, and Riccardo T orre. GMetrics: Statistic al T ests for Evaluating Gener ative Mo dels . https://github . com/TwoSample Tests/GMetrics . GitHub rep ository. 2024. [82] Ajinkya More. Survey of r esampling te chniques for impr oving classific ation p erformanc e in unb alanc e d datasets . 2016. arXiv: 1608 . 06048 [stat.AP] . url : .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment