LanteRn: Latent Visual Structured Reasoning
While language reasoning models excel in many tasks, visual reasoning remains challenging for current large multimodal models (LMMs). As a result, most LMMs default to verbalizing perceptual content into text, a strong limitation for tasks requiring …
Authors: André G. Viveiros, Nuno Gonçalves, Matthias Lindemann
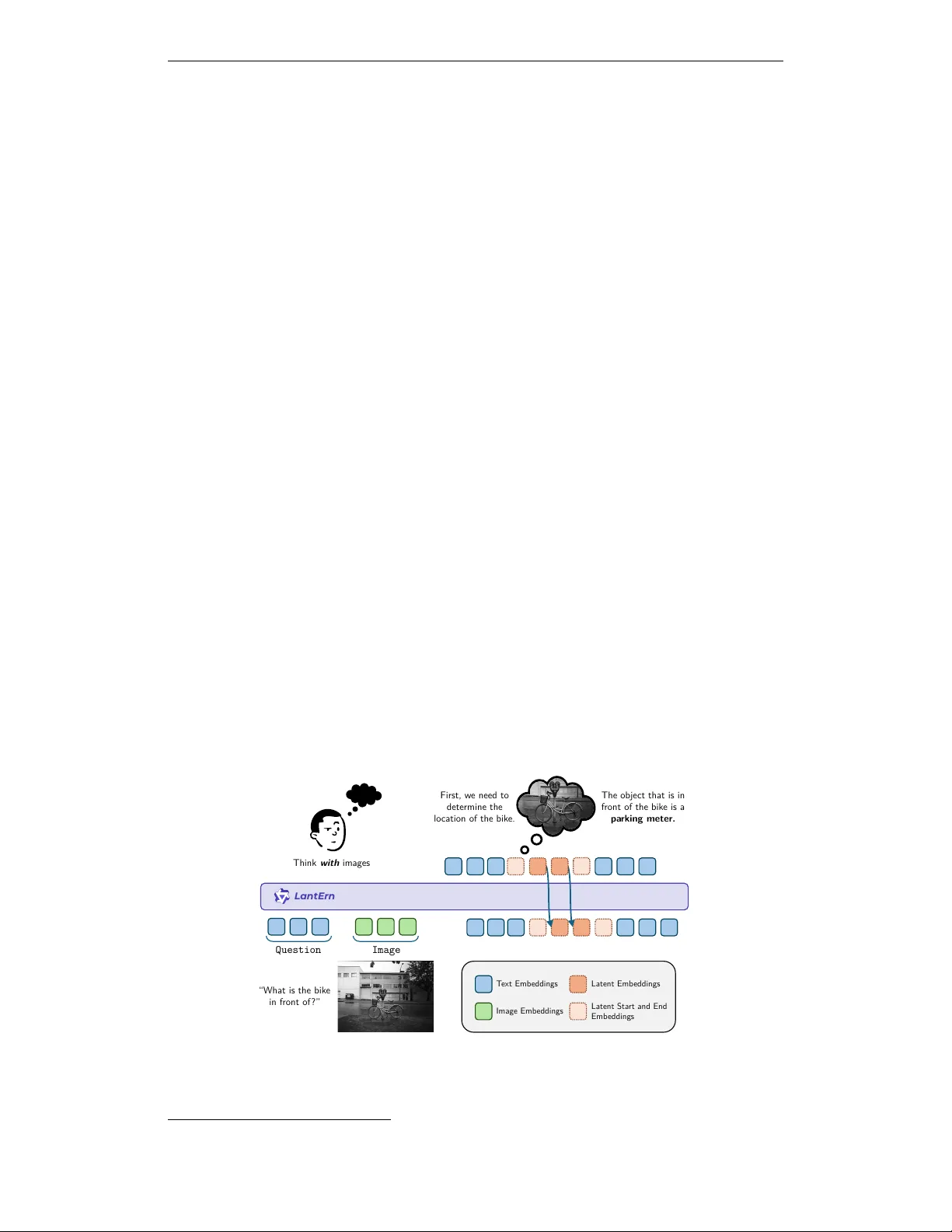
Published at ICLR 2026 W orkshop on Multimo dal In telligence LanteRn: La tent Visual Str uctured Reasoning André G. Viv eiros ∗ 1 , 2 Nuno Gonçalv es 1 , 2 , 3 Matthias Lindemann 1 André F. T. Martins 1 , 2 1 Instituto de T elecom unicaçõ es 2 Instituto Sup erior T écnico, Univ ersidade de Lisb oa 3 Carnegie Mellon Univ ersit y Abstra ct While language reasoning mo dels excel in man y tasks, visual reasoning remains c hallenging for curren t large m ultimo dal mo dels (LMMs). As a result, most LMMs default to verbalizing p erceptual conten t into text, a strong limitation for tasks requiring fine-grained spatial and visual under- standing. While recen t approaches tak e steps tow ard thinking with images b y inv oking to ols or generating in termediate images, they either rely on external mo dules, or incur unnecessary computation b y reasoning directly in pixel space. In this pap er, we introduce LanteRn , a framework that enables LMMs to in terlea v e language with compact laten t visual represen tations, allo w- ing visual reasoning to occur directly in laten t space. LanteRn augmen ts a vision-language transformer with the ability to generate and attend to con tin uous visual “though t” embeddings during inference. W e train the mo del in t w o stages: sup ervised fine-tuning to ground visual features in laten t states, follow ed by reinforcemen t learning to align latent reasoning with task-lev el utilit y . W e ev aluate LanteRn on three perception-centric b enc hmarks (VisCoT, V ⋆ , and Blink), observing consistent impro vemen ts in visual grounding and fine-grained reasoning. These results suggest that in ternal laten t represen tations pro vide a promising direction for more effi- cien t m ultimo dal reasoning. Q u e s t i o n I m a g e “What is the bik e in front of ?” L antEr n First, w e need to determine the lo cation of the bik e. The object that is in front of the bik e is a pa rking meter. T ext Emb eddings Image Emb eddings Latent Emb eddings Latent Sta rt and End Emb eddings Think with images Figure 1: The LanteRn framework enables interlea ved reasoning b etw een text and laten t represen tations that enco de visual “though ts” . During inference, LanteRn can automati- cally decide when to start laten t reasoning b y outputting a sp ecial token. ∗ Corresp onding author: andre.viveiros@tecnico.ulisboa.pt . 1 Published at ICLR 2026 W orkshop on Multimo dal In telligence 1 Intr oduction Large Multimo dal Mo dels (LMMs) hav e achiev ed strong p erformance in a wide range of vision-language tasks Alayrac et al. (2022); Liu et al. (2023); Bai et al. (2025), yet their reasoning pro cesses remain predominan tly linguistic. In most current systems, visual inputs are enco ded once and all subsequen t reasoning is carried out in text, a regime referred to as ‘thinking ab out images’ . This forces high-dimensional perceptual information into a lo w- bandwidth symbolic medium, a limitation that b ecomes particularly eviden t on p erception- hea vy b enchmarks, where purely textual c hains of thought fail to capture fine-grained spatial and visual structure (F u et al., 2024; Xiao et al., 2024). T o ov ercome these limitations, recen t work has shifted to w ard ‘thinking with images’, in whic h visual information actively participates in the reasoning pro cess rather than b eing consumed only at the input stage. Existing approaches in this category can b e broadly divided in to tw o streams. The first consists of to ol-b ase d visual r e asoning metho ds, which allo w mo dels to inv oke external vision modules during inference, such as cropping, ob ject detection, or image generation to ols (Y ang et al., 2023; Surís et al., 2023; Chameleon T eam, 2025). These approaches are limited to a set of predefined to ols and often incur significan t computational ov erhead. The second stream p erforms reasoning b y explicitly generating images during the reasoning c hain, forcing intermediate visual thoughts to b e e xpressed in pixel space and sp ending significant computation on photorealistic details that ma y b e irrelev an t for the task, whic h is w asteful (Chameleon T eam, 2025; Deng et al., 2025). More recently , latent visual r e asoning has emerged as an in ternalized form of thinking with images, in whic h mo dels maintain and manipulate con tinuous visual represen tations in latent space throughout the reasoning pro cess (Li et al., 2025; Y ang et al., 2025b). By interlea ving laten t visual states with text, these metho ds a void explicit image generation while preserving visual structure, enabling reasoning to op erate ov er abstract visual representations rather than pixel space. In this w ork, w e in tro duce LanteRn (Latent Visual Structured Reasoning), a framew ork that enables LMMs to reason using compact latent visual tokens in terlea v ed with language. LanteRn augmen ts a vision-language transformer with the ability to emit and attend to laten t visual states, allo wing reasoning to occur directly in the visual feature space of the mo del. W e train LanteRn in t wo stages. First, w e perform supervised fine-tuning on a custom dataset with annotated visual reasoning traces, grounding latent states in the outputs of the mo del’s vision enco der. Second, w e apply reinforcement learning to optimize b oth textual and latent reasoning as a sequen tial decision-making pro cess, using final answer correctness as the rew ard signal. W e ev aluate LanteRn on challenging visual reasoning b enchmarks, including Visual- CoT (Shao et al., 2024a), V ⋆ (Cheng et al., 2025), and Blink (F u et al., 2024). A cross all settings, laten t visual reasoning ac hieves comparable or sup erior performance, suggest- ing that internal visual representations offer a promising direction for multimodal reasoning. 2 Rela ted Work T ext-based and to ol-based visual reasoning. Early m ultimo dal reasoning approaches extended textual chain-of-though t metho ds to vision-language tasks, reasoning entirely in text after a single visual enco ding pass (Zhang et al., 2024; Shao et al., 2024a). T o ad- dress their p erceptual limitations, subsequent w ork introduced to ol-augmented reasoning, enabling models to iteratively in teract with images through external operations suc h as cropping, detection, and image generation (Y ang et al., 2023; Surís et al., 2023; Chameleon T eam, 2025). While effective, these approac hes dep end on hand-designed to ols and do not learn in ternal visual abstractions. Laten t visual reasoning. Laten t visual reasoning aims to in ternalize perceptual pro- cesses by allo wing mo dels to generate contin uous visual represen tations during inference. Li et al. (2025) introduces Latent Visual Reasoning (L VR), a metho d that conditions the final answ er on latent visual tokens. Similarly , Y ang et al. (2025b) introduce machine mental 2 Published at ICLR 2026 W orkshop on Multimo dal In telligence imagery through latent image representations. These works show that preserving visual information in laten t space can improv e fine-grained reasoning. Ho wev er, unlik e prior ap- proac hes that primarily app end laten t visual representations to supp ort downstream decod- ing, LanteRn formulates this paradigm as an interle ave d reasoning pro cess that alternates b et w een text and latent visual tokens, allowing iterative refinement of internal visual repre- sen tations and tigh ter coupling b et w een p erception and language. 3 Our Method: LanteRn LanteRn provide s a structured mechanism for incorporating visually grounded latent states alongside textual reasoning in LMMs. Standard LMMs are constrained to verbalize ev- ery step of visual pro cessing, often forcing high-dimensional visual information in to low- bandwidth natural language. W e propose a mo deling approac h where the mo del learns to generate compressed, non-v erbal “though t” v ectors deriv ed directly from visual features, in terlea ving these laten t states with discrete text generation. 3.1 Modeling La tent Visual Reasoning W e model reasoning as a hybrid trajectory τ = [ s 1 , s 2 , . . . , s T ] , where each state s t lies in either the discrete vocabulary space V or the con tinuous laten t space R d , with d denoting the mo del’s hidden dimension. A t each step t , the mo del outputs either a token w t ∈ V (text mo de) or a laten t v ector z t ∈ R d (visual laten t mo de). T o implemen t this, we build on the Qwen2.5-VL architecture (Bai et al., 2025) and extend its vocabulary with three control tok ens: <|lvr_start|> , <|lvr_sep|> , and <|lvr_end|> . These tok ens act as gating signals that regulate transitions b et w een op erating mo des: 1. T ext Mo de: The mo del functions as a standard autoregressiv e language mo del. The hidden state at time t , h t , is passed through the language mo deling head to predict a probabilit y distribution o v er the v o cabulary V . 2. Visual Latent Mo de: Up on generating <|lvr_start|> , for the subsequent K time steps (where K is a fixed latent size hyperparameter), the mo del b ypasses the language mo deling head and outputs the unpro jected hidden states of the final transformer lay er. These K v ectors, denoted z 1 , z 2 , . . . , z K constitute a blo ck of latent “though t” em b ed- dings. After K steps, a terminating token <|lvr_end|> is introduced and the mo del returns to text mo de. The laten t v ectors serv e as internal reasoning con text, allow- ing the mo del to attend to its o wn high-dimensional visual thoughts without having to v erbalize that information in to text. 3.2 Super vised Fine-Tuning: Grounding La tent St a tes in Vision A fundamen tal c hallenge in laten t reasoning is defining a ground truth for the model’s in ternal visual though ts. Since h uman annotators cannot pro vide high-dimensional vector sup ervision, w e devise a strategy to gr ound the latent states using the mo del’s o wn visual enco der as a teac her signal. 3.2.1 Visual Fea ture Extraction as Super vision W e leverage the pre-trained vision enco der of the base mo del as a teac her for the LMM laten t states. Consider a training sample ( I , Q, A, T ) consisting of an image I , a question Q , the correct answer A , and a human-written reasoning trace T that references certain visual regions. Let B b e the set of b ounding boxes in T corresp onding to relev ant regions of I that the reasoning trace attends to. F or eac h reasoning step asso ciated with a region b ∈ B , we construct a target latent representation Z target as follo ws: F b = VisionEncoder ( I , b ) , (1) Z target = P o ol ( F b ) ∈ R K × d , (2) 3 Published at ICLR 2026 W orkshop on Multimo dal In telligence where F b is the feature map extracted from the vision enco der (e.g. patc h em b eddings) corresp onding to region b . T o pro duce the laten t tok ens, we follow the approach of Y ang et al. (2025b) and apply an av erage p o oling op eration to F b to produce a fixed-size sequence of K p o oled feature vectors. This sequence Z target = [ z (1) target , . . . , z ( K ) target ] serv es as the target for the mo del’s latent block, effectively capturing an aggregated representation of the visual region b as p erceiv ed b y the vision enco der. 3.2.2 Hybrid Objective Function W e train LanteRn with a multi-task ob jective that jointly optimizes for language genera- tion and laten t visual alignmen t. The total loss is a sum of tw o comp onents: L LanteRn = L text + γ L latent , (3) where γ is a weigh ting hyperparameter. T ext Generation Loss ( L text ). F or standard (non-latent) tokens, w e use a cross-en tropy loss on the next-token prediction, as in conv entional language mo del fine-tuning. This term L text preserv es the mo del’s verbal fluency and ensures it can articulate answers correctly in natural language. Laten t Alignment Loss ( L latent ). F or each blo c k of K laten t tok ens generated b etw een a <|lvr_start|> and <|lvr_end|> marker, w e apply a regression loss that encourages these laten t v ectors to matc h the visual encoder’s features for the corresp onding region of interest. Let H gen = [ h (1) gen , . . . , h ( K ) gen ] b e the sequence of K hidden states pro duced by the LLM in laten t mo de, and Z target = [ z (1) target , . . . , z ( K ) target ] b e the p o oled target embeddings as defined ab o v e. W e minimize the mean-squared error (MSE) b etw een these tw o sequences: L latent = 1 K K X i =1 h ( i ) gen − z ( i ) target 2 2 . (4) This encourages the LLM to autoregressively predict the laten t representations computed in Eq. equation 2. By learning to minimize the discrepancy || h gen − z target || 2 , the mo del is effectiv ely learning to “imagine” the visual con ten t in its latent space, reconstructing the k ey visual features needed to answer the question. The goal of this phase is to distill latent visual reasoning capabilities in to the LLM through explicit sup ervision of a predefined set of laten t visual though ts. This trains the model to p erform interlea ved reasoning o v er text and laten t visual representations, grounding its explanations in in ternal visual states without requiring it to v erbalize every aspect of its visual “though ts. ” Ho wev er, this sup ervised ob jectiv e primarily encourages represen tational fidelity , motiv ating the subsequen t stage to further align free-form laten t reasoning with task-lev el utilit y . 3.3 Reinfor cement Learning While SFT grounds latent representations in visual features, it primarily enforces a r e c on- struction ob jective. This can lead to latent representations that match p erceptual repre- sen tations, y et suboptimal for downstream reasoning. W e therefore explore Reinforcemen t Learning (RL) as a free-form mec hanism to align laten t visual reasoning with task util- ity , rather than visual fidelit y alone. W e form ulate latent visual reasoning as a sequen tial decision-making problem and inv estigate whether p olicy optimization can encourage the mo del to generate latent states that improv e final answer correctness, similar in spirit to outcome-driv en RL for language mo dels (Ouy ang et al., 2022; Sc hulman et al., 2017). P olicy Optimization with Hybrid Action Spaces. W e adopt Group Relative Policy Optimization (GRPO) (Shao et al., 2024b) as our primary optimization algorithm. GRPO is a PPO-style method that stabilizes training by normalizing rew ards within sampled groups, and has recently b een shown to b e effective for reasoning-hea vy language mo del fine-tuning (Guo et al., 2025; Olmo et al., 2025). Unlik e standard RL for LLMs, whic h 4 Published at ICLR 2026 W orkshop on Multimo dal In telligence op erates ov er a discrete token space, in terleav ed latent reasoning is naturally formulated as a hybrid action sp ac e : actions corresp ond either to discrete text tokens or to contin uous laten t vectors z ∈ R d . This raises a conceptual challenge, as policy gradien t objectives are traditionally defined ov er categorical distributions. Rather than defining an explicit proba- bilit y densit y ov er latent vectors, we treat latent generation as an intermediate computation that conditions subsequen t text generation, following prior work on differen tiable laten t reasoning in language mo dels (Li et al., 2025; Y ang et al., 2025b). Under this formulation, optimization is applied only to the likelihoo d of discrete text to- k ens, while gradients propagate through the laten t states via standard bac kpropagation. This design implicitly encourages the mo del to generate latent representations that improv e do wnstream tok en predictions and, ultimately , task rew ard. 3.3.1 La tent-A w are GRPO Objective Giv en an input query q and image I , w e sample a group of G rollouts { o 1 , . . . , o G } from the old p olicy π θ old . Each rollout consists of in terlea v ed text and laten t blo c ks. W e define the GRPO ob jective ov er the discrete text tokens while treating laten t states as contextual conditioning v ariables: ˜ L i,t ( θ ) = min r i,t ( θ ) ˆ A i , clip( r i,t ( θ ) , 1 − ϵ, 1 + ϵ ) ˆ A i J ( θ ) = E { o i }∼ π θ old 1 G G X i =1 1 | o i | | o i | X t =1 ˜ L i,t ( θ ) − β D KL π θ ( · ) ∥ π ref ( · ) q , I , (5) where π θ ( y i,t ) ≡ π θ ( y i,t | q , I , ˜ h latent i , y i, , for the reasoning c hain, laten t reasoning delimiters <|lvr_start|> and <|lvr_end|> and <|answer|> , for the final answer. This discourages collapse to purely textual reasoning and enforces the presence of a latent blo c k. Ov erall, this RL stage is in tended to test the h yp othesis that outcome-dri ven optimization can shift laten t represen tations from merely encoding visual app earance tow ard selectiv ely represen ting task-critical visual information. Rather than assuming that visually faithful laten t states are optimal, w e explore whether RL can induce more abstract and utility-driv en in ternal visual reasoning. 5 Published at ICLR 2026 W orkshop on Multimo dal In telligence 4 Experiments W e ev aluate LanteRn through a tw o-stage training pipeline. First, we p erform super- vised fine-tuning (SFT) to initialize latent visual reasoning b y grounding latent states in p erceptual features. Second, we apply reinforcemen t learning (RL) to ev aluate whether outcome-driv en optimization can further refine the mo del’s laten t reasoning capabilities. 4.1 Super vised Fine-Tuning Setup Dataset Construction. T o train the mo del to asso ciate latent states with visually rele- v an t regions, we construct a synthetic dataset derived from Visual-CoT (Shao et al., 2024a). Visual-CoT provides image–question pairs accompanied by detailed reasoning traces and a b ounding b ox highlighting the region of the image the mo del should fo cus on in order to answ er the question effectiv ely , making it a suitable foundation for structured latent sup ervision. W e emplo y a large-scale reasoning-oriented multimodal mo del, Qw en3-VL-235B- Thinking (Y ang et al., 2025a), as the reference mo del. F or each image–question pair and its auxiliary images, w e prompt the mo del to generate a structured reasoning trace consisting of three comp onen ts: 1. Pre-visual though t: A textual plan describing the visual information required (e.g., “I ne e d to identify the game title shown on the scr e en” ). 2. Visual grounding: A set of b ounding b oxes highlighting regions of interest (ROIs) that are relev an t for answ ering the question (matc hing the ground-truth b oxes). 3. P ost-visual though t: A textual deduction derived sp ecifically from the visual con tent within those R OIs. This pro cedure yields training samples in which b ounding b oxes are explicitly aligned with individual reasoning steps in the sup ervision signal. During SFT, these b ounding b oxes are used exclusively to extract the corresp onding target feature representations from the vision enco der, whic h are then used as regression targets for the mo del’s latent blo cks. Imp ortantly , the b ounding b o xes themselv es are nev er exp osed to the mo del during training. T raining Configuration. W e initialize all models from Qw en2.5-VL-3B-Instruct (Bai et al., 2025). T o study the effect of laten t capacity , we train v ariants with differen t laten t blo c k sizes, each dubb ed Lan tErn-SFT- { K } , where K ∈ { 4 , 8 , 16 , 32 } . W e use a w eighting factor γ = 0 . 1 for the laten t alignmen t loss. These ablations allo w us to examine how the dimensionalit y of laten t tok ens affect do wnstream reasoning b eha vior. Baselines. T o isolate the con tribution of con tinuous laten t reasoning, w e also train a v ersion with only next-token prediction, namely LantErn-NTP . This baseline uses the same backbone architecture, same data, and sp ecial control tok ens (e.g., <|lvr_start|> , <|lvr_end|> ), but treats the in termediate reasoning sequence as standard discrete text to- k ens. In particular, these intermediate reasoning tokens are autoregressiv ely predicted using the standard language mo deling head, just like regular text tokens. The language mo deling head is never bypassed and no latent regression loss is applied. This comparison controls for additional computation steps and token structure, ensuring that any observed differences can b e attributed sp ecifically to the presence of contin uous latent represen tations. W e also include Qwen2.5-VL-3B as the base pretrained mo del without task-sp ecific fine-tuning. W e do not include direct comparisons with previously prop osed latent visual reasoning metho ds (e.g., L VR and Mirage) b ecause they are trained and ev aluated with significan tly larger bac kb one mo dels (typically ∼ 7B parameters), whereas our exp eriments are conducted with a 3B-scale mo del. Giv en the substan tial impact of mo del scale on multimodal reasoning p erformance, such comparisons would not provide a con trolled ev aluation of the proposed training approac h. Hyp erparameters. All mo dels are trained using Adam W with a learning rate of 1 × 10 − 5 and a cosine learning rate sc hedule, together with a warm up ratio of 0 . 05 . A dditionally , the 6 Published at ICLR 2026 W orkshop on Multimo dal In telligence Model VisCoT V ⋆ V ⋆ DA V ⋆ RP Blink Blink OL Blink RP Qwen2.5-VL-3B 0.66 0.70 0.75 0.63 0.65 0.48 0.81 LantErn-NTP-4 0.80 0.72 0.71 0.72 0.60 0.45 0.72 LantErn-SFT-4 0.80 0.62 0.68 0.57 0.61 0.51 0.72 LantErn-SFT-8 0.81 0.65 0.71 0.60 0.60 0.52 0.68 LantErn-SFT-16 0.80 0.60 0.65 0.55 0.54 0.53 0.55 LantErn-SFT-32 0.79 0.72 0.72 0.71 0.58 0.49 0.66 T able 1: SFT ev aluation results on V ⋆ , Blink and a subset of VisCoT datasets. DA = Direct A ttribution, RP = Relativ e P osition, OL = Ob ject Lo calization. vision enco der is frozen to b oth simplify training and improv e training stability , allowing the mo del to fo cus on learning effectiv e laten t visual reasoning on top of fixed visual features. 4.2 Ev alua tion Benchmarks T o ev aluate LanteRn ’s p erformance, we used a subset of Visual-CoT and tw o vision-centric b enc hmarks V ⋆ W u & Xie (2023) and a subset of Blink F u et al. (2024). V ⋆ assesses a mo del’s ability to p erform visual search in real-world scenarios, a fundamen tal capability of human cognitiv e reasoning process in v olving visual information. Blink ev aluates core visual p erception skills in scenarios where solving the task using text alone (textual priors) is extremely c hallenging. W e used a subset of Blink that fo cuses on ob ject localization and direct attribution, as it closely aligns with the skills learned in the previous stage 4.1. T ogether, these b enc hmarks pro vide a basis for ev aluating the use of laten t visual represen tations. 4.3 SFT Resul ts As sho wn in T able 1, all LanteRn v ariants improv e o v er the Qwen2.5-VL-3B baseline on Visual-CoT, indicating generalization b eyond the sup ervision data. Ho wev er, these gains are comparable to the text-only Lan tErn-NTP baseline (0.80), suggesting that sup ervised laten t grounding alone already yields task-level b enefits. SFT mainly improv es p erception- cen tric skills: for example, LantErn-SFT-8 increases Blink OL p erformance from 0.45 to 0.52, indicating stronger ob ject localization and perceptual grounding. In contrast, p erformance on relational subsets ( V ⋆ RP and Blink RP ) remains similar or w orse than Lan tErn-NTP , sug- gesting that laten t represen tations are not y et reliably used for complex reasoning. Another observ ation is that p erformance do es not increase monotonically with the latent size K . F or example, larger latent blo cks can lead to degradation on some b enchmarks (e.g., Blink RP drops from 0.72 at K =4 to 0.66 at K =32 ), indicating a trade-off b etw een latent capacit y and effective reasoning. This highligh ts a limitation of fixed-size latent reasoning and suggests that future work could b enefit from mechanisms that adapt latent capacity to matc h the task complexit y . Ov erall, the SFT results suggest that sup ervised latent grounding provides p erceptual struc- ture but is insufficient on its own to pro duce consistent task-level improv ements, motiv ating the subsequen t reinforcemen t learning stage. 4.4 Reinfor cement Learning Setup F ollo wing SFT, w e apply RL on the Lan tErn-SFT-8 mo del to further refine the laten t reasoning p olicy . At the same time we k eep the same baselines as b efore. Dataset. F or the RL stage, w e use the VIRL-39k dataset (W ang et al., 2025), whic h con tains a diverse collection of visual reasoning problems without explicit region-level su- p ervision. This setting allows us to ev aluate whether RL can guide LanteRn in the absence of b ounding b o x annotations, relying only on task-lev el feedbac k. 7 Published at ICLR 2026 W orkshop on Multimo dal In telligence Model VisCoT V ⋆ V ⋆ DA V ⋆ RP Blink Blink OL Blink RP Qwen2.5-VL-3B 0.66 0.70 0.75 0.63 0.65 0.48 0.81 NTP-RL 0.82 0.66 0.75 0.57 0.64 0.47 0.80 LantErn-RL-8 0.83 0.71 0.76 0.67 0.68 0.54 0.81 T able 2: RL ev aluation results on VStar, Blink and a subset of Viscot datasets. DA = Direct A ttribution, RP = Relativ e P osition, OL = Ob ject Lo calization. Implemen tation Details. W e implement the RL training lo op using the TRL li- brary (v on W erra et al., 2023), extending the standard GRPOTrainer to support latent state r eplay . As described in Section 3, latent replay records the con tinuous hidden states generated during the rollout phase and reinjects them during the policy up date step. This mo dification stabilizes training by ensuring that importance sampling ratios are computed under a fixed latent tra jectory , while still allowing gradients to propagate to the parameters resp onsible for laten t generation. Hyp erparameters. W e train with a learning rate of 5 × 10 − 6 and a warm up ratio of 0 . 03 and latent size k = 8 , as using 8 latent tokens seems to yield the best ov erall p erformance, as indicated in Section 4.3). W e set the KL regularization co efficien t to β = 0 . 1 to limit p olicy drift from the SFT initialization. During the rollout phase, we sample G = 4 completions p er prompt using temperature T = 0 . 6 and top- p = 0 . 85 to encourage exploration of diverse latent reasoning trajectories. The reward function combines a sparse accuracy reward (weigh t 1.0) with a format reward (w eigh t 1.0), which encourages the explicit use of laten t reasoning blo cks and prev ents collapse to purely textual solutions. 4.5 RL Resul ts Applying RL on top of LantErn-SFT-8 leads to consistent p erformance improv emen ts, out- p erforming b oth the base mo del and the NTP-RL v ariant, across all ev aluated b enchmarks. The largest gains app ear on out-of-distribution, p erception-heavy b enc hmarks. No- tably , p erformance on Blink RP impro v es from 0.68 (SFT) to 0.81, representing a substan tial gain. This trend is consisten t across additional tasks: compared to the NTP baseline, p er- formance increases on V ⋆ RP (0.57 → 0.67) and Blink OL (0.47 → 0.54), further indicating impro v ed spatial and relational reasoning. These results supp ort our hypothesis that RL is the stage at which latent states transi- tion from p erceptually faithful reconstruction to task-driven internal visual representations. Although additional ablations are needed to fully c haracterize this effect, the consisten t gains across benchmarks indicate that RL enables more effective in ternal use of visual in- formation. Finally , achieving parity with a 7B mo del on several b enchmarks highlights the p oten tial of latent visual reasoning as a compute-efficient alternativ e to mo del scaling for p erception-cen tric tasks. 5 Conclusions In this paper, w e presen t LanteRn as a nov el m ultimo dal hybrid reasoning framew ork that interlea ves latent visual reasoning with standard text generation. Our framework is trained in t w o stages. First, we p erform SFT to distill this capability into the mo del by explicitly join t supervision in the laten t represen tations and text tok ens, enabling it to align these latent representations with visual concepts and to form abstract visual thoughts. In the second stage, w e apply RL to further train the mo del to generate its own latent represen tations without b eing constrained to maintain strict fidelit y enforced by the previous stage. This grants the mo del greater freedom to explore task-sp ecific solutions and to rev amp abstract visual though ts, resulting in improv ed p erformance on visual reasoning b enchmarks. 8 Published at ICLR 2026 W orkshop on Multimo dal In telligence Limitations and F uture W ork : Despite its effectiveness, the framework has some limita- tions. First, interlea ved latent reasoning dep ends on the quality and diversit y of multimodal tra jectories, which are currently concentrated in a narrow visual domain. Second, the mo del uses a fixed num b er of latent tokens; enabling dynamically sized latent blo cks that adapt to task complexit y is a promising direction. Finally , a deep er analysis of latent dep endencies is needed, including metho ds to visualize latent representations and b etter understand their utilit y and alignmen t with generated text. A cknowledgments This work was supp orted by the P ortuguese Recov ery and Resilience Plan through pro ject C645008882-00000055 (Center for ResponsibleAI), by the project DECOLLAGE (ER C- 2022-CoG 101088763), and by FCT/MECI through national funds and when applicable co-funded EU funds under UID/50008: Instituto de T elecomunicações. 6 Ethics St a tement LanteRn is a multimodal reasoning framework designed to impro v e visual reasoning capa- bilities in large vision–language models. While suc h systems can enable beneficial applica- tions in accessibility , education, and scientific analysis, they also raise ethical considerations related to misuse, bias, and transparency . Multimo dal mo dels may inherit biases presen t in their training data, including cultural, demographic, or representational imbalances. These biases can affect mo del outputs and may disproportionately impact underrepresented groups. Although Lan tern fo cuses on reasoning mechanisms rather than dataset expansion, it re- lies on existing multimodal corp ora whose limitations may propagate into the mo del. Care should b e tak en when deplo ying suc h systems in high-stak es settings. 7 Repr oducibility St a tement W e prioritize repro ducibilit y b y pro viding detailed descriptions of the Lantern architecture, training pip eline, and ev aluation proto cols. The pap er sp ecifies the mo del backbone, latent reasoning mechanism, and the tw o-stage training pro cedure (sup ervised fine-tuning and re- inforcemen t learning). Hyp erparameters, optimization settings, and dataset comp ositions are rep orted in the main text and app endix. W e use publicly a v ailable benchmarks for ev aluation and clearly describ e prepro cessing and ev aluation pro cedures. All exp eriments are conducted using deterministic training configurations where possible, including fixed random seeds and do cumented hardware setups. T o facilitate replication, we plan to release implemen tation details, training scripts, and configuration files up on publication. These materials will include instructions for repro ducing the main exp erimen ts, along with pre- trained chec kp oints where licensing p ermits. W e ackno wledge that training large multimodal mo dels requires significan t computational resources. T o mitigate this barrier, we provide ablation studies and smaller-scale configurations that repro duce key findings using reduced compute budgets. References Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Y ana Has- son, Karel Lenc, Arthur Mensc h, Katherine Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, T engda Han, Zhitao Gong, Sina Samango o ei, Marianne Mon teiro, Jacob L Menick, Sebastian Borgeaud, Andy Bro c k, Aida Nematzadeh, Sahand Sharifzadeh, Mikoł a j Bińko wski, Ricardo Barreira, Oriol Viny als, Andrew Zisserman, and Karén Simony an. Flamingo: a visual language mo del for few-shot learning. In S. Ko yejo, S. Mohamed, A. Agarw al, D. Belgrav e, K. Cho, and A. Oh (eds.), A dvanc es in Neur al Information Pr o c essing Systems , volume 35, pp. 23716–23736. Curran Asso ciates, Inc., 2022. 9 Published at ICLR 2026 W orkshop on Multimo dal In telligence Sh uai Bai, Keqin Chen, Xuejing Liu, Jialin W ang, W enbin Ge, Sib o Song, Kai Dang, Peng W ang, Shijie W ang, Jun T ang, Humen Zhong, Y uanzhi Zhu, Mingkun Y ang, Zhaohai Li, Jianqiang W an, Pengfei W ang, W ei Ding, Zheren F u, Yiheng Xu, Jiab o Y e, Xi Zhang, Tian bao Xie, Zesen Cheng, Hang Zhang, Zhibo Y ang, Haiy ang Xu, and Juny ang Lin. Qw en2.5-vl tec hnical rep ort, 2025. URL . Chameleon T eam. Chameleon: Mixed-mo dal early-fusion foundation mo dels, 2025. URL https://arxiv.org/abs/2405.09818 . Zixu Cheng, Jian Hu, Ziquan Liu, Cheny ang Si, W ei Li, and Shaogang Gong. V- star: Benchmarking video-llms on video spatio-temp oral reasoning, 2025. URL https: //arxiv.org/abs/2503.11495 . Chaorui Deng, Dey ao Zh u, Kunc hang Li, Chenhui Gou, F eng Li, Zeyu W ang, Shu Zhong, W eihao Y u, Xiaonan Nie, Ziang Song, Guang Shi, and Hao qi F an. Emerging properties in unified m ultimo dal pretraining, 2025. URL . Xingyu F u, Y ushi Hu, Bangzheng Li, Y u F eng, Haoyu W ang, Xudong Lin, Dan Roth, Noah A Smith, W ei-Chiu Ma, and Ranjay Krishna. Blink: Multimo dal large language mo dels can see but not p erceiv e. arXiv pr eprint arXiv:2404.12390 , 2024. Da y a Guo, Dejian Y ang, Hao wei Zhang, Junxiao Song, P eiyi W ang, Qihao Zh u, Runxin Xu, Ruo yu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcemen t learning. Natur e , 645(8081):633–638, 2025. Bangzheng Li, Ximeng Sun, Jiang Liu, Ze W ang, Jialian W u, Xiaodong Y u, Hao Chen, Emad Barsoum, Muhao Chen, and Zicheng Liu. Latent visual reasoning, 2025. URL https://arxiv.org/abs/2509.24251 . Haotian Liu, Chun yuan Li, Qingyang W u, and Y ong Jae Lee. Visual instruction tuning. In A dvanc es in Neur al Information Pr o c essing Systems , 2023. URL abs/2304.08485 . T eam Olmo, :, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, Da vid Graham, Da vid Heineman, Dirk Gro eneveld, F aeze Brahman, Fin barr Tim b ers, Hamish Ivison, Jacob Morrison, Jake P oznanski, Kyle Lo, Luca Soldaini, Matt Jordan, May ee Chen, Michael Noukho vitc h, Nathan Lambert, Pete W alsh, Pradeep Dasigi, Rob ert Berry , Saumy a Malik, Saurabh Shah, Scott Geng, Shane Arora, Shashank Gupta, T aira Anderson, T eng Xiao, Tyler Murray , T yler Romero, Victoria Graf, Akari Asai, Akshita Bha- gia, Alexander W ettig, Alisa Liu, Aman Rangapur, Chlo e Anastasiades, Costa Huang, Dustin Sc h w enk, Harsh T riv edi, Ian Magnu sson, Jaron Lochner, Jiac heng Liu, Lester James V. Miranda, Maarten Sap, Malia Morgan, Mic hael Sc hmitz, Michal Guerquin, Mic hael Wilson, Regan Huff, Ronan Le Bras, Rui Xin, Rulin Shao, Sam Skjonsberg, Shannon Zejiang Shen, Shuyue Stella Li, T uck er Wilde, V alentina Pyatkin, Will Merrill, Y ap ei Chang, Y uling Gu, Zhiyuan Zeng, Ashish Sabharwal, Luke Zettlemoy er, Pang W ei K oh, Ali F arhadi, Noah A. Smith, and Hannaneh Ha jishirzi. Olmo 3, 2025. URL https://arxiv.org/abs/2512.13961 . Long Ouy ang, Jeffrey W u, Xu Jiang, Diogo Almeida, Carroll W ain wright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray , John Sch ul- man, Jacob Hilton, F raser Kelton, Luk e Miller, Maddie Simens, Amanda Askell, P eter W elinder, Paul F Christiano, Jan Leike, and R yan Lo we. T raining lan- guage mo dels to follow instructions with human feedback. In S. Ko yejo, S. Mo- hamed, A. Agarw al, D. Belgrav e, K. Cho, and A. Oh (eds.), A dvanc es in Neu- r al Information Pr o c essing Systems , volume 35, pp. 27730–27744. Curran Asso ciates, Inc., 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/file/ b1efde53be364a73914f58805a001731- Paper- Conference.pdf . John Sch ulman, Filip W olski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Pro ximal p olicy optimization algorithms, 2017. URL . 10 Published at ICLR 2026 W orkshop on Multimo dal In telligence Hao Shao, Sheng ju Qian, Han Xiao, Guanglu Song, Zhuofan Zong, Letian W ang, Y u Liu, and Hongsheng Li. Visual cot: Adv ancing multi-modal language mo dels with a comprehensive dataset and b enchmark for c hain-of-thought reasoning. In The Thirty-eight Confer enc e on Neur al Information Pr o c essing Systems Datasets and Benchmarks T r ack , 2024a. URL https://openreview.net/forum?id=aXeiCbMFFJ . Zhihong Shao, Peiyi W ang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haow ei Zhang, Mingc h uan Zhang, Y. K. Li, Y. W u, and Day a Guo. Deepseekmath: Pushing the limits of mathematical reasoning in op en language mo dels, 2024b. URL abs/2402.03300 . Dídac Surís, Sachit Menon, and Carl V ondrick. Vip ergpt: Visual inference via p ython exe- cution for reasoning. In 2023 IEEE/CVF International Confer enc e on Computer V ision (ICCV) , pp. 11854–11864, 2023. doi: 10.1109/ICCV51070.2023.01092. Leandro von W erra, Y ounes Belkada, Victor Sanh, et al. T rl: T ransformer reinforcement learning. https://github.com/huggingface/trl , 2023. Haozhe W ang, Chao Qu, Zuming Huang, W ei Chu, F angzhen Lin, and W enhu Chen. Vl- rethink er: Incen tivizing self-reflection of vision-language mo dels with reinforcement learn- ing. arXiv pr eprint arXiv:2504.08837 , 2025. P enghao W u and Saining Xie. V*: Guided visual search as a core mechanism in multimodal llms, 2023. URL . Yijia Xiao, Edward Sun, Tianyu Liu, and W ei W ang. Logicvista: Multimo dal llm logical rea- soning b enchmark in visual contexts, 2024. URL . An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Bin yuan Hui, Bo Zheng, Bow en Y u, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, F an Zhou, F ei Huang, F eng Hu, Hao Ge, Haoran W ei, Huan Lin, Jialong T ang, Jian Y ang, Jianhong T u, Jian w ei Zhang, Jianxin Y ang, Jiaxi Y ang, Jing Zhou, Jingren Zhou, Juny ang Lin, Kai Dang, Keqin Bao, Kexin Y ang, Le Y u, Lianghao Deng, Mei Li, Mingfeng Xue, Mingze Li, P ei Zhang, P eng W ang, Qin Zhu, Rui Men, Ruize Gao, Shixuan Liu, Shuang Luo, Tianhao Li, Tian yi T ang, W en biao Yin, Xingzhang Ren, Xinyu W ang, Xinyu Zhang, Xuancheng Ren, Y ang F an, Y ang Su, Yichang Zhang, Yinger Zhang, Y u W an, Y uqiong Liu, Zekun W ang, Zeyu Cui, Zhenru Zhang, Zhip eng Zhou, and Zihan Qiu. Qwen3 technical rep ort, 2025a. URL . Zeyuan Y ang, Xueyang Y u, Delin Chen, Maohao Shen, and Chuang Gan. Mac hine mental imagery: Emp ow er multimodal reasoning with latent visual tokens, 2025b. URL https: //arxiv.org/abs/2506.17218 . Zhengyuan Y ang, Linjie Li, Jianfeng W ang, Kevin Lin, Ehsan Azarnasab, F aisal Ahmed, Zic heng Liu, Ce Liu, Michael Zeng, and Lijuan W ang. Mm-react: Prompting chatgpt for m ultimo dal reasoning and action, 2023. URL . Zh uosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. Multi- mo dal chain-of-though t reasoning in language mo dels, 2024. URL abs/2302.00923 . 11
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment