Social Hippocampus Memory Learning
Social learning highlights that learning agents improve not in isolation, but through interaction and structured knowledge exchange with others. When introduced into machine learning, this principle gives rise to social machine learning (SML), where …
Authors: Liping Yi, Zhiming Zhao, Qinghua Hu
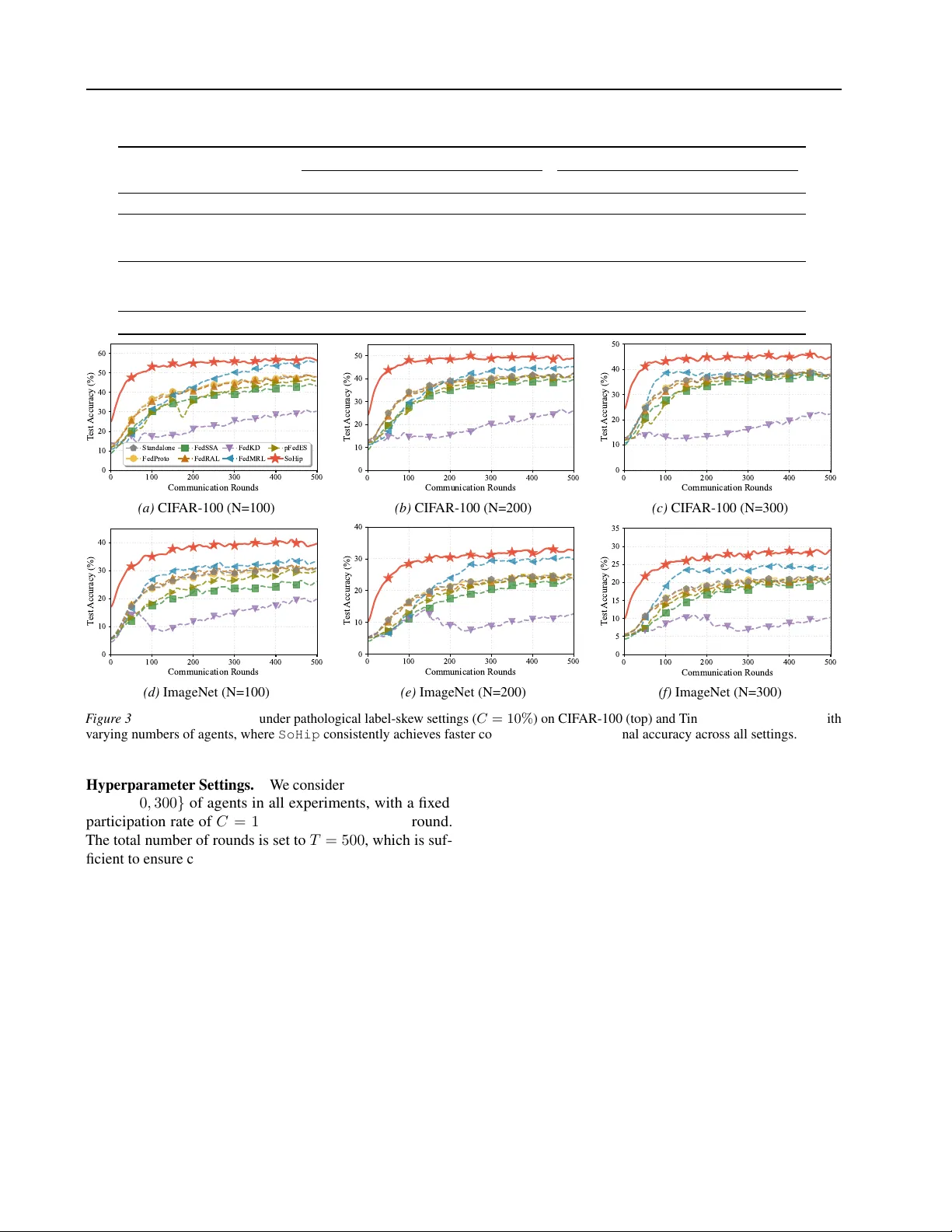
Social Hippocampus Memory Learning Liping Y i 1 Zhiming Zhao 1 Qinghua Hu 1 Abstract Social learning highlights that learning agents improv e not in isolation, but through interaction and structured kno wledge exchange with others. When introduced into machine learning, this prin- ciple gi ves rise to social mac hine learning (SML), where multiple agents collaboratively learn by sharing abstracted kno wledge. Federated learning (FL) provides a natural collaboration substrate for this paradigm, yet existing heterogeneous FL approaches often rely on sharing model parame- ters or intermediate representations, which may expose sensiti ve information and incur additional ov erhead. In this w ork, we propose SoHip ( So cial Hip pocampus Memory Learning), a memory- centric social machine learning frame work that en- ables collaboration among heterogeneous agents via memory sharing rather than model sharing. SoHip abstracts each agent’ s indi vidual short- term memory from local representations, con- solidates it into indi vidual long-term memory through a hippocampus-inspired mechanism, and fuses it with collectiv ely aggregated long-term memory to enhance local prediction. Through- out the process, ra w data and local models re- main on-de vice, while only lightweight memory are exchanged. W e provide theoretical analysis on con ver gence and pri vac y preservation proper - ties. Experiments on two benchmark datasets with sev en baselines demonstrate that SoHip consis- tently outperforms existing methods, achie ving up to 8.78% accurac y improv ements. The code of SoHip is av ailable at https://anonymous. 4open.science/r/SoHip- A77C . 1. Introduction Social learning emphasizes that indi viduals do not learn in isolation by pure trial-and-error , but instead improve effi- 1 College of Artificial Intelligence, T ianjin University . Corre- spondence to: Liping Y i < lipingyi@tju.edu.cn > . Pr eprint. J an. 28, 2026. Collective Memory Aggregation Agent 1 Agent 2 Agent 3 Agent 4 Agent N No Raw Data Sharing No Model Parameter Sharing Only Memory Sharing Individual Memory Server F igur e 1. Memory-centric social machine learning framew ork. ciently through interaction, observation, and information sharing with others. This idea can be traced back to Ban- dura’ s seminal work ( Locke , 1997 ), as stated belo w: “Learning would be exceedingly laborious, not to mention haz- ar dous, if people had to r ely solely on the effects of their own actions to inform them what to do. F ortunately , most human behavior is learned observationally thr ough modeling: fr om observing others one forms an idea of how new behaviors ar e performed, and on later occasions this coded information serves as a guide for action. ” — Bandura (1977) These observ ations suggest that abstracting experience, stor - ing knowledge, and sharing memory are central mechanisms underlying effecti ve social learning. When introduced into machine learning, this principle nat- urally leads to the paradigm of social machine learning (SML) ( Y ao et al. , 2024 ), where multiple learning enti- ties (commonly modeled as autonomous agents) collabo- rate and improve collecti vely through structured kno wledge exchange. A v ariety of classical collective learning ap- proaches, including ant colony optimization ( Dorigo et al. , 2007 ), bee colony algorithms ( Karaboga & Akay , 2009 ), ensemble learning ( Sagi & Rokach , 2018 ), and federated learning ( McMahan et al. , 2017 ), can be viewed as concrete instantiations of social machine learning. Among them, federated learning (FL) ( Kairouz et al. , 2021 ; Y ang et al. , 2019 ) has recei ved particular attention due to its ability to enable collaborative training without sharing 1 Social Hippocampus Memory Learning raw data, making it especially suitable for priv acy-sensitiv e applications such as financial risk control ( Cheng et al. , 2020 ) and medical diagnosis ( Rauniyar et al. , 2023 ). In this work, we adopt FL as the underlying collaboration substrate and further explore ho w social learning properties can be systematically incorporated into priv acy-constrained collaborativ e learning. FL coordinates multiple distributed agents through a central server to achie ve collectiv e optimization without e xposing local data. Despite its success, FL faces se veral funda- mental challenges in real-world deployments. Local data across agents are often highly non-independent and non- identically distrib uted (non-IID) ( Zhu et al. , 2021 ; T an et al. , 2022a ); system capabilities such as communication, com- putation, and storage are heterogeneous ( Horv ´ ath , 2021 ; Diao , 2021 ); and in many scenarios, agents maintain inher - ently heterogeneous model architectures ( Y e et al. , 2024 ; Y i et al. , 2023 ). T o address these issues, existing hetero- geneous FL approaches typically rely on sharing aligned subsets of model parameters ( Collins et al. , 2021 ; Liang et al. , 2020 ), exchanging intermediate representations ( T an et al. , 2022b ) or model outputs ( Jeong et al. , 2018 ), or intro- ducing additional homogeneous auxiliary models as knowl- edge carriers ( Shen et al. , 2020 ; W u et al. , 2022 ). Although effecti ve to some extent, these strategies may still expose sensitiv e model- or data-related information and often incur non-negligible computational and communication ov erhead. T o enable efficient and pri vac y-friendly collaboration among agents with heterogeneous models, we revisit knowledge sharing in FL from a social learning perspectiv e. In so- cial learning, individuals do not directly replicate others’ behaviors or decisions; instead, they abstract, store, and integrate others’ e xperiences into reusable internal kno wl- edge representations. Moti v ated by this observation, we propose SoHip ( So cial Hip pocampus Memory Learning), a memory-centric social machine learning frame work built upon federated collaboration. SoHip introduces memory as the primary carrier of social knowledge exchange, sho wn as Fig. 1 . (1) Specifically , each agent first extracts representations using its local hetero- geneous model and forms individual short-term memory through a short-term memory abstraction module. (2) In- spired by the role of the hippocampus in consolidating short-term experiences into long-term memory , SoHip in- tegrates indi vidual short-term memory with historical in- dividual long-term memory via a hippocampus-inspired short-to-long memory con version module, thereby updating individual long-term memory . (3) The updated indi vidual long-term memory is then fused with the collective long- term memory receiv ed from the server through an individual– collecti ve memory fusion module, yielding a complete mem- ory representation that enhances local prediction. (4) After local training, each agent uploads its updated individual long-term memory to the server , where collectiv e aggrega- tion produces a new collective long-term memory that is broadcast in the next communication round. Throughout the entire SoHip workflo w , raw data and local model pa- rameters remain strictly on-de vice; only highly abstracted memory are exchanged, enabling effecti ve collaboration while preserving both data and model priv acy . The main contributions are summarized as follo ws: • W e propose SoHip , a novel social machine learn- ing frame work that introduces memory as a so- cial knowledge-sharing carrier , enabling collaborativ e learning across data, system, and model heterogeneity without sharing raw data or model parameters. • W e provide theoretical analysis on the con ver gence behavior and priv acy preservation properties of the proposed frame work, offering principled guarantees for its effecti veness. • Extensiv e e xperiments on tw o benchmark datasets against se ven representati ve baselines demonstrate that SoHip consistently achieves superior performance, yielding up to 8.78% accuracy impro vements. 2. Related W ork 2.1. Social Learning and Social Machine Lear ning Social learning ( Locke , 1997 ) originates from behavioral and cognitiv e science and emphasizes that individuals im- prov e their behavior not only through isolated trial-and- error , but also by observing others, interacting with peers, and sharing accumulated experience. Rooted in social learn- ing theory , this perspectiv e highlights the central roles of experience abstraction, memory formation, and kno wledge reuse in efficient learning processes. When these principles are introduced into machine learn- ing systems, they gi ve rise to social machine learning ( Y ao et al. , 2024 ), where multiple learning agents collaborativ ely improv e through structured information exchange. Repre- sentativ e paradigms under this umbrella include sw arm in- telligence methods such as ant colony ( Dorigo et al. , 2007 ) and bee colony optimization ( Karaboga & Akay , 2009 ), ensemble learning ( Sagi & Rokach , 2018 ), and federated learning ( McMahan et al. , 2017 ). In these approaches, learn- ing agents benefit from shared or aggreg ated knowledge to achiev e improv ed group-lev el performance. Despite their success, most existing social machine learn- ing methods either assume homogeneous models or rely on tightly coupled interaction mechanisms, which limits their applicability in heterogeneous and pri vac y-constrained en vi- ronments. In contrast, SoHip instantiates social machine 2 Social Hippocampus Memory Learning learning from a memory-centric perspecti ve, enabling het- erogeneous agents to interact via abstracted memory without exposing ra w data or local model parameters. 2.2. Heterogeneous F ederated Learning Federated learning enables collaborativ e model training across distributed clients without sharing raw data, and has become a prominent paradigm for priv acy-preserving collaborativ e learning ( Y ang et al. , 2019 ; Qiang et al. , 2020 ; Kairouz et al. , 2021 ; Randy et al. , 2023 ). In prac- tical deployments, ho wev er , clients often exhibit significant heterogeneity in data distributions ( Zhu et al. , 2021 ; T an et al. , 2022a ; Chen et al. , 2022 ; Matsuda et al. , 2024 ), sys- tem resources ( Horv ´ ath , 2021 ; Diao , 2021 ; Y i et al. , 2022 ; 2024b ; a ), and model architectures ( Y e et al. , 2024 ). T o address these challenges, e xisting heterogeneous feder- ated learning approaches typically rely on three represen- tativ e strategies: (i) sharing aligned homogeneous subsets of model parameters by decoupling local models into het- erogeneous and homogeneous components, so that only ho- mogeneous parameters are aggregated across clients ( Liang et al. , 2020 ; Chen et al. , 2021 ; Collins et al. , 2021 ; Oh et al. , 2022 ; Pillutla et al. , 2022 ; Jang et al. , 2022 ; Liu et al. , 2022 ; Y i et al. , 2023 ); (ii) exchanging intermedi- ate representations or prediction outputs to transfer task- relev ant information while av oiding direct parameter shar - ing ( i.e . , FedProto ( T an et al. , 2022b ), FedSSA ( Y i et al. , 2024c ), FedRAL ( Y i et al. , 2025a ) and others ( Jeong et al. , 2018 ; Ahn et al. , 2019 ; 2020 ; He et al. , 2020 ; Revie w , 2026 )); and (iii) introducing auxiliary homogeneous models shared across clients to serve as intermediaries for knowl- edge transfer between heterogeneous local models, suhc as FedKD ( W u et al. , 2022 ), FedMRL ( Y i et al. , 2024d ), pFedES ( Y i et al. , 2025b ) and others ( Shen et al. , 2020 ; Kalra et al. , 2023 ; Qin et al. , 2023 ). While effecti ve in certain scenarios, these strategies may still expose partial model behavior or incur additional computation and commu- nication ov erhead, which can limit scalability and priv acy guarantees. In contrast to prior work, SoHip re visits collaborati ve learn- ing from a social learning perspecti ve and introduces mem- ory as the primary carrier of social kno wledge exchange. Rather than sharing model parameters, intermediate fea- tures, or predictions, each agent abstracts local e xperience into short-term memory , consolidates it into long-term mem- ory via a hippocampus-inspired mechanism, and exchanges only compact long-term memory with the server for collec- tiv e aggregation. By decoupling knowledge sharing from model structure and data semantics, SoHip enables ef fec- tiv e collaboration across heterogeneous agents while pre- serving both data pri vac y and model autonomy , providing a memory-centric view of social machine learning under heterogeneity and priv acy constraints. 3. Problem Definition W e consider a social mac hine learning problem in volving N distributed learning agents, each associated with a priv ate local dataset and a potentially heterogeneous model. Agent i holds a local dataset D i and maintains a feature extractor F i together with a local classifier H i . The local data distri- butions {D i } N i =1 are generally non-IID, and the local model architectures {F i , H i } may dif fer across agents. The agents aim to collaborati vely impro ve their predicti ve performance by lev eraging experience from others, while satisfying the following fundamental constraints: (1) raw local data must remain strictly on-device; (2) local model parameters are not directly shared across agents; and (3) collaboration must be robust to data, system, and model heterogeneity . Such constraints naturally arise in priv acy- sensitiv e and resource-heterogeneous en vironments, and preclude direct parameter or representation sharing. From a social learning perspecti ve, we vie w collaboration as a process of memory-based knowledge exc hange . Rather than sharing model parameters, intermediate features, or prediction outputs, we assume that each agent maintains an internal memory state that abstracts and stores its accumu- lated experience. Specifically , at communication round t , agent i maintains an individual memory M t i ∈ R m , where m denotes a shared memory dimension. A central server maintains a collective memory M t ∈ R m , which aggregates individual memories and serves as a shared repository of group-lev el kno wledge. The objectiv e of social machine learning in this setting is to improv e the local prediction performance of each heteroge- neous agent i through memory exchange: min {F i , H i } N X i =1 E ( x ,y ) ∼D i ℓ H i ( F i ( x )) , y , (1) subject to the constraint that cross-agent interaction is con- ducted exclusively through memory { M t i } N i =1 and M t . The central challenge addressed in this work is therefore: How can ag ents with heter ogeneous models effectively ab- stract, consolidate , and exchang e memory to enable social machine learning, while pr eserving data and model privacy and r emaining r obust to hetero geneity? In the follo wing section, we introduce SoHip , a memory-centric frame work that provides a principled solution to this challenge. 1 1 The key notations are summarized in Appendix A . 3 Social Hippocampus Memory Learning G S individual short memory G in G f G o Classifier y Feature Extractor x Attention Gate Attention Gate Input Gate Forget Gate Output Gate En coder historical long memory Features G o G G Step (2) Hippocampus - Inspired Memory Consolidation Client i complete memory De coder G G collective long memory new individual long memory Memory- Enhanced Features Step (1) Individual Short Memory Abs traction Step (3) Individual – Collective Memory Fusion G S G in G f Memory Collection Server A ggregation N × new individual long memory collective long memory Step (4) Collective Memory Aggregation F igur e 2. Overvie w of SoHip . SoHip operates sequentially by (1) abstracting individual short-term memory from local representations, (2) consolidating it into individual long-term memory via a hippocampus-inspired mechanism, (3) fusing it with collective long-term memory for enhanced prediction, and (4) aggregating updated indi vidual long-term memories to form an updated collecti ve memory . 4. The Proposed SoHip Algorithm W e present SoHip , a memory-centric social machine learn- ing framework designed to enable collaboration among heterogeneous agents without sharing ra w data or local model parameters. Instead of exchanging parameters or intermediate representations, SoHip introduces memory as the primary carrier of social knowledge. As illustrated in Figure 2 , the frame work consists of four functional mod- ules that progressi vely abstract, consolidate, and exchange memory across agents. The complete SoHip algorithm is described in Alg. 1 . 4.1. Individual Short-T erm Memory Abstraction In social learning, indi viduals do not retain all ra w experi- ences; instead, recent observations are selecti vely abstracted into compact short-term memory , where salient information is emphasized and redundant or noisy signals are suppressed. Follo wing this principle, each agent first extracts latent rep- resentations from its pri vate data using a heterogeneous feature extractor . Giv en a mini-batch B t i , agent i computes Z t i = F i ( B t i ) , Z t i ∈ R B t i × d i , (2) where B t i denotes the batch size and d i is the feature di- mension of agent i . T o abstract recent experience, the repre- sentations are projected into a shared memory space via a lightweight encoder (one linear layer): Z t i, enc = E i ( Z t i ) , Z t i, enc ∈ R B t i × m , (3) where m ≤ d i is the shared memory dimension. Batch- lev el information is summarized by av eraging along the batch dimension: ¯ z t i = 1 B t i B t i X b =1 Z t i, enc ,b ∈ R m . (4) Rather than directly storing this summary , SoHip intro- duces a lightweight gating unit to assess the importance of the current observ ations. The gate acts as an adapti ve filter , highlighting informativ e dimensions while attenuating less relev ant or noisy signals: α S ,t i = σ G S ( ¯ z t i ) , (5) where G S ( · ) is a lightweight gating unit implemented as a single linear layer , and σ ( · ) denotes the sigmoid acti vation that produces dimension-wise importance scores in (0 , 1) . The resulting individual short-term memory is defined as M S ,t i = α S ,t i · ¯ z t i , (6) which encodes a compact and selectively weighted repre- sentation of the agent’ s recent experience. 4.2. Hippocampus-Inspired Memory Consolidation In human cognition, the hippocampus plays a critical role in consolidating short-term experiences into long-term mem- ory by selectiv ely integrating new information while pre- serving pre viously acquired knowledge. Inspired by this biological mechanism, SoHip updates individual long-term memory through a gated short-to-long memory consolida- tion process. Specifically , the newly formed short-term memory M S ,t i and the historical long-term memory M L ,t − 1 i are first con- catenated as u t i = M S ,t i ; M L ,t − 1 i . (7) 4 Social Hippocampus Memory Learning Based on this combined representation, three gating units are employed to regulate memory consolidation: α in ,t i = σ G in ( u t i ) , α f ,t i = σ G f ( u t i ) , α o ,t i = σ G o ( u t i ) , (8) where G in ( · ) , G f ( · ) , and G o ( · ) are lightweight gating units implemented as single linear layers, and σ ( · ) denotes the sigmoid activ ation. The input gate α in ,t i controls how much newly abstracted short-term memory should be incorporated, the for get gate α f ,t i regulates the retention of historical long- term memory , and the output gate α o ,t i modulates the o verall strength of the consolidated memory . The updated indi vidual long-term memory is then computed as M L ,t i = α o ,t i α in ,t i · M S ,t i + α f ,t i · M L ,t − 1 i . (9) Through this gated consolidation mechanism, each agent selectiv ely integrates informati ve ne w experience while pre- serving stable historical kno wledge, thereby enabling robust and continual memory accumulation under non-IID data and model heterogeneity . 4.3. Individual–Collectiv e Memory Fusion Beyond consolidating indi vidual e xperience, ef fective social learning further requires each agent to selectively absorb useful collecti ve kno wledge that complements its local un- derstanding. After updating individual long-term memory , SoHip integrates it with the collectiv e long-term memory aggregated in the pre vious round and broadcast to agents. Specifically , the updated individual long-term memory M L ,t i and the recei ved collectiv e long-term memory M L ,t − 1 are concatenated to form the fusion input: v t i = M L ,t i ; M L ,t − 1 . (10) A fusion gating unit is then applied to determine which components of the collecti ve memory are beneficial to the local agent: α G ,t i = σ G G ( v t i ) , (11) where G G ( · ) is implemented as a single linear layer, and σ ( · ) denotes the sigmoid acti vation. The resulting gate α G ,t i assigns dimension-wise importance scores, enabling each agent to selectiv ely absorb the shared collectiv e knowledge relev ant to its local context. The complete memory is then constructed as M t i = α G ,t i · M L ,t − 1 + M L ,t i . (12) T o enhance local prediction, the complete memory is pro- jected back to the original feature space via a lightweight decoder (one linear layer): ˜ m t i = R i ( M t i ) , ˜ m t i ∈ R d i . (13) The decoded memory is expanded along the batch dimen- sion and combined with the original representations through a residual connection: ˆ Z t i = Z t i + Expand( ˜ m t i ) . (14) Finally , predictions are obtained as ˆ Y t i = H i ( ˆ Z t i ) . (15) 4.4. Collective Memory Aggr egation At the group lev el, SoHip accumulates social knowledge through collectiv e memory aggregation. After local consoli- dation, each participating agent uploads its updated individ- ual long-term memory M L ,t i to the server . The server aggregates the received memories to form the collectiv e long-term memory for the next round: M L ,t +1 = X i ∈S t p i M L ,t i , (16) where S t denotes the set of participating agents and p i is the aggregation weight ( e .g. , proportional to local data size). Unlike con ventional parameter aggregation, this operation aggregates highly abstracted long-term memory , which en- capsulates distilled experience from heterogeneous agents. The resulting collecti ve memory serves as a shared repos- itory of social kno wledge and is broadcast to agents in the next round, where it is selecti vely absorbed via the individual–collecti ve memory fusion module. Through iter- ativ e aggregation and selecti ve absorption, SoHip enables continual refinement of collectiv e experience across hetero- geneous agents while preserving data and model priv acy . 5. Theoretical Analysis W e analyze the conv ergence behavior and priv acy properties of SoHip . Our analysis shows that memory-based social machine learning preserves the con ver gence guarantees of federated optimization, while pre venting direct leakage of local data or model parameters. Theorem 5.1 (Con vergence of SoHip ) . Assume that each local objective f i is L -smooth and stochastic gradients have bounded variance. Under a suitable stepsize, the sequence generated by SoHip satisfies 1 T T − 1 X t =0 E ∥∇ f ( θ t ) ∥ 2 = O 1 √ T + O (∆ het ) , wher e f ( θ ) = P N i =1 p i f i ( θ ) and ∆ het char acterizes the effect of data and model heter ogeneity acr oss agents. Discussion. The above result indicates that introducing gated memory abstraction, hippocampus-inspired consoli- dation, and individual–collecti ve memory fusion does not 5 Social Hippocampus Memory Learning Algorithm 1 SoHip 1: Input: Agents { ( D i , F i , H i , E i , R i ) } N i =1 ; memory dimen- sion m ; participation rate C ; aggregation weights { p i } ; initial collectiv e memory M L , 0 ∈ R m ; initial individual long-term memories { M L , 0 i ∈ R m } . 2: for round t = 1 , 2 , . . . , T do 3: Server samples participating set S t with |S t | = ⌊ C N ⌋ and broadcasts M L ,t − 1 . 4: f or all agent i ∈ S t in parallel do 5: Sample mini-batch B t i from D i . 6: (I) Individual short-term memory abstraction. 7: Z t i ← F i ( B t i ) // Z t i ∈ R B t i × d i 8: Z t i, enc ← E i ( Z t i ) // Z t i, enc ∈ R B t i × m 9: ¯ z t i ← 1 B t i P B t i b =1 Z t i, enc ,b // ¯ z t i ∈ R m 10: α S ,t i ← σ ( G S ( ¯ z t i )) // α S ,t i ∈ (0 , 1) m 11: M S ,t i ← α S ,t i ⊙ ¯ z t i // M S ,t i ∈ R m 12: (II) Hippocampus-inspired memory consolidation. 13: u t i ← [ M S ,t i ; M L ,t − 1 i ] 14: α in ,t i ← σ ( G in ( u t i )) , α f ,t i ← σ ( G f ( u t i )) , 15: α o ,t i ← σ ( G o ( u t i )) 16: M L ,t i ← α o ,t i ⊙ α in ,t i ⊙ M S ,t i + α f ,t i ⊙ M L ,t − 1 i 17: (III) Individual–collectiv e memory fusion. 18: v t i ← [ M L ,t i ; M L ,t − 1 ] 19: α G ,t i ← σ ( G G ( v t i )) 20: M t i ← α G ,t i ⊙ M L ,t − 1 + M L ,t i 21: ˜ m t i ← R i ( M t i ) // ˜ m t i ∈ R d i 22: ˆ Z t i ← Z t i + Expand( ˜ m t i ) // ˆ Z t i ∈ R B t i × d i 23: ˆ Y t i ← H i ( ˆ Z t i ) 24: Update local parameters of F i , H i , E i , R i and gating units by minimizing the local loss on B t i . 25: Upload M L ,t i to the server . 26: end f or 27: (IV) Collective memory aggr egation. 28: M L ,t ← P i ∈S t p i M L ,t i . 29: end for 30: Output: Final local heterogeneous models { ( F i , H i ) } N i =1 . hinder conv ergence. The additional heterogeneity term ∆ het is unav oidable in heterogeneous settings and is empirically mitigated by memory-based kno wledge sharing. Theorem 5.2 (Pri vac y Preservation) . During training, SoHip never tr ansmits raw data, local model par ameters, intermediate featur es, or pr ediction outputs. Only compact long-term memory repr esentations ar e exc hanged, which are dimension-r educed and temporally ag gr e gated abstractions of local experience. Therefor e, SoHip pr ovides intrinsic pr otection against dir ect data and model leakage. Discussion. Unlike parameter- or representation-sharing methods, SoHip decouples collaboration from model struc- ture and data semantics. This design ensures that social knowledge exchange is achie ved without exposing sensi- tiv e information, making SoHip particularly suitable for priv acy-sensitiv e and heterogeneous en vironments. Formal assumptions and proofs are provided in Appendix B . 6. Experiments All experiments are implemented in PyT orch and conducted on a workstation equipped with NVIDIA R TX 3090 GPUs. 6.1. Experimental Setup Datasets and Data Partition. W e conduct experiments on two image classification benchmarks, CIF AR-100 with 100 classes 2 ( Krizhevsk y et al. , 2009 ) and T iny-ImageNet 3 ( Chrabaszcz et al. , 2017 ) with 200 classes. T o simulate pathological non-IID data distributions, we adopt a label- ske w partition strategy . F or CIF AR-100, each agent is as- signed data from 10 classes, while for Tin y-ImageNet, each agent is assigned data from 20 classes. Classes are randomly selected for each agent, resulting in highly heterogeneous local data distributions across agents. Models. W e e valuate SoHip under a heterogeneous model setting, where different agents emplo y con volutional neural networks with heterogeneous structures. This setup follo ws the common practice in heterogeneous collaborativ e learning ( e.g . , FedMRL ) and allows us to assess the rob ust- ness of memory-based social collaboration among agents, without requiring architectural alignment across agents. Baselines. W e compare SoHip with representative base- lines cov ering different collaboration paradigms among het- erogeneous agents. Standalone trains each agent inde- pendently without any collaboration. Intermediate repr esen- tation sharing methods, including FedProto ( T an et al. , 2022b ), FedSSA ( Y i et al. , 2024c ), and FedRAL ( Y i et al. , 2025a ), enable collaboration by exchanging or aligning in- termediate representations across agents. Auxiliary homog e- neous model sharing methods, such as FedKD ( W u et al. , 2022 ), FedMRL ( Y i et al. , 2024d ), and pFedES ( Y i et al. , 2025b ), introduce an additional homogeneous model as a knowledge transfer medium between heterogeneous agents. These baselines represent state-of-the-art approaches for collaborativ e learning under heterogeneity and provide a comprehensiv e comparison for e valuating SoHip . Evaluation Metric. W e report average test accuracy across all agents. After training, each agent e valuates its local model on the corresponding test set, and the overall performance is computed as Acc = 1 N P N i =1 Acc i , where Acc i denotes the classification accuracy of agent i . This metric reflects the ov erall collaborati ve performance under model heterogeneity and non-IID data. All reported results are a veraged ov er multiple runs with different random seeds. 2 https://www.cs.toronto.edu/%7Ekriz/cifar.html 3 https://tiny- imagenet.herokuapp.com/ 6 Social Hippocampus Memory Learning T able 1. A verage test accurac y (%) under the pathological label-ske w partition with client participation rate C = 10% and v arying number of clients N . Results are reported as mean ± standard deviation ov er three runs. Best results in each column are in bold. Method CIF AR-100 ImageNet N =100 N =200 N =300 N =100 N =200 N =300 Standalone 53.59 ± 0.48 47.35 ± 0.52 42.92 ± 0.61 35.36 ± 0.57 28.29 ± 0.63 25.94 ± 0.69 FedProto ( T an et al. , 2022b ) 53.54 ± 0.44 45.25 ± 0.58 43.90 ± 0.55 34.43 ± 0.60 28.05 ± 0.66 24.66 ± 0.72 FedSSA ( Y i et al. , 2024c ) 47.39 ± 0.63 42.98 ± 0.69 41.04 ± 0.74 29.99 ± 0.71 25.90 ± 0.77 22.51 ± 0.81 FedRAL ( Y i et al. , 2025a ) 53.32 ± 0.46 45.56 ± 0.51 44.62 ± 0.59 35.31 ± 0.55 27.82 ± 0.61 25.82 ± 0.67 FedKD ( W u et al. , 2022 ) 35.39 ± 0.82 29.86 ± 0.91 26.56 ± 0.96 24.54 ± 0.88 17.08 ± 0.94 13.37 ± 1.02 FedMRL ( Y i et al. , 2024d ) 60.26 ± 0.41 48.77 ± 0.56 42.39 ± 0.64 37.42 ± 0.49 33.96 ± 0.57 29.81 ± 0.62 pFedES ( Y i et al. , 2025b ) 50.02 ± 0.59 46.71 ± 0.62 42.44 ± 0.68 36.83 ± 0.54 28.96 ± 0.66 23.71 ± 0.73 SoHip (Ours) 63.33 ± 0.36 54.33 ± 0.42 50.10 ± 0.48 46.20 ± 0.41 36.12 ± 0.46 34.30 ± 0.51 (a) CIF AR-100 (N=100) (b) CIF AR-100 (N=200) (c) CIF AR-100 (N=300) (d) ImageNet (N=100) (e) ImageNet (N=200) (f) ImageNet (N=300) F igur e 3. T est accuracy curves under pathological label-ske w settings ( C = 10% ) on CIF AR-100 (top) and Tin y-ImageNet (bottom) with varying numbers of agents, where SoHip consistently achieves f aster con vergence and higher final accurac y across all settings. Hyperparameter Settings. W e consider the number N = { 100 , 200 , 300 } of agents in all experiments, with a fixed participation rate of C = 10% per communication round. The total number of rounds is set to T = 500 , which is suf- ficient to ensure con ver gence for all compared methods. All agents are optimized using SGD with a learning rate of 0 . 01 . The local batch size is set to 512 , and each agent performs 10 local epochs per round. Unless otherwise specified, all hyperparameters use these default settings. 6.2. Experimental Results 6 . 2 . 1 . O V E R A L L P E R F O R M A N C E C O M PA R I S O N Perf ormance comparison. As shown in T able 1 , SoHip achiev es the highest test accuracy in all ev aluated set- tings on both CIF AR-100 and T iny-ImageNet. On CIF AR- 100, SoHip improv es the best competing method by up to +5.56% (54.33% → 48.77% at N=200) and maintains clear adv antages as the number of agents increases. On T iny-ImageNet, the improv ement is ev en more pronounced, reaching up to +8.78% (46.20% → 37.42% at N=100), demonstrating the ef fecti veness of memory-based collabora- tion under more challenging fine-grained classification tasks. These consistent g ains indicate that SoHip enables more ef- fectiv e kno wledge sharing than parameter-, representation-, or auxiliary-model-based methods. Con vergence behavior . Figure 3 further illustrates the training dynamics under different agent numbers. SoHip con ver ges significantly faster and reaches a higher accuracy plateau than all baselines across all settings. The accurac y gap emerges early in training and remains stable through- out communication rounds, suggesting that the proposed short-term memory abstraction and long-term memory con- solidation allow agents to e xploit shared knowledge more efficiently . In contrast, baseline methods exhibit slower 7 Social Hippocampus Memory Learning 0 20 40 60 80 100 The Number of Classes 0 20 40 60 T est A ccuracy (%) SoHip F edMRL Default (a) CIF AR-100 (Pathological) 0 20 40 60 80 100 The Number of Classes 0 20 40 T est A ccuracy (%) (b) ImageNet (Pathological) 0.1 0.2 0.3 0.4 0.5 D i r i c h l e t ( ) 20 40 60 T est A ccuracy (%) SoHip F edMRL Default (c) CIF AR-100 (Practical) 0.1 0.2 0.3 0.4 0.5 D i r i c h l e t ( ) 35 40 45 50 T est A ccuracy (%) (d) ImageNet (Practical) F igur e 4. Impact of non-IID degree under pathological label-ske w by varying classes per agent and practical label-ske w by Dirichlet partition with concentration α ( ⋆ is default in T able 1 ). con ver gence and lower final performance, especially as the number of agents increases. Summary . The abo ve results demonstrate that SoHip not only achieves the highest final accuracy but also provides faster and more stable con ver gence, v alidating the adv antage of memory-centric social machine learning under heteroge- neous model and non-IID data conditions. 6 . 2 . 2 . I M PAC T O F N O N - I I D D E G R E E . Figure 4 reports the impact of data heterogeneity under two partition strategies. Across all settings, SoHip consistently outperforms FedMRL , indicating more effecti ve kno wledge transfer under heterogeneous data. As the number of classes per agent or the Dirichlet parameter α increases, the non- IID de gree is reduced and the ov erall accuracy gradually decreases. This trend suggests that reduced data hetero- geneity weakens inter -agent complementarity , limiting the benefit of collaborativ e memory sharing. In contrast, under stronger non-IID conditions, SoHip better exploits di verse and complementary local experience through memory ex- change, resulting in superior performance than FedMRL . 6 . 2 . 3 . I M PAC T O F H Y P E R PA R A M E T E R . W e in vestig ate the impact of the memory dimension m , the only core hyperparameter in SoHip . Figure 5 shows that increasing the memory dimension d m initially improv es performance, while overly large memory leads to slight degradation due to redundant or noisy information. No- tably , SoHip consistently outperforms the strongest base- line FedMRL under all memory dimension settings. This verifies that SoHip is robust to memory dimension choices 100 200 300 400 500 M e m o r y D i m e n s i o n ( m ) 60 61 62 63 64 T est A ccuracy (%) 63.33% (a) CIF AR-100 100 200 300 400 500 M e m o r y D i m e n s i o n ( m ) 40 42 44 46 48 T est A ccuracy (%) 46.2% (b) ImageNet F igur e 5. Impact of memory dimension m on SoHip . SoHip A B C D 60 61 62 63 64 T est A ccuracy (%) 63.33 62.95 61.16 62.94 61.08 (a) CIF AR-100 SoHip A B C D 42 43 44 45 46 47 T est A ccuracy (%) 46.20 44.93 44.76 44.68 43.52 (b) ImageNet F igur e 6. Ablation results of SoHip . and does not require careful hyperparameter tuning. 4 6 . 2 . 4 . A B L AT I O N S T U DY W e ev aluate the contribution of each memory component in SoHip by progressi vely removing them. V ariant A re- mov es the importance gating in short-term memory abstrac- tion, B discards the hippocampus-inspired consolidation and directly replaces new long-term memory with short-term memory , C removes collectiv e long-term memory fusion, and D removes all memory modules. Figure 6 shows that the full SoHip consistently achiev es the best performance on both datasets, while all ablated v ariants suffer perfor- mance degradation, with the largest drop observed in D . These results demonstrate that importance-aware short-term abstraction, hippocampus-inspired consolidation, and indi- vidual–collectiv e memory fusion are necessary and jointly contribute to the ef fecti veness of SoHip . 7. Conclusion This work proposes SoHip , a memory-centric social ma- chine learning framework that enables effecti ve collabo- ration among heterogeneous agents without sharing raw data or local model parameters. By abstracting, consolidat- ing, and exchanging memory , SoHip provides a principled mechanism for social knowledge sharing under heterogene- ity and priv acy constraints. Theoretical analysis establishes con ver gence and pri vac y properties, and empirical results demonstrate consistent performance gains ov er existing het- erogeneous federated learning methods. 4 The impacts of agent participation rate and learning rate on SoHip are giv en in Appendix C . 8 Social Hippocampus Memory Learning Impact Statement This paper presents work whose goal is to advance the field of Machine Learning. There are many potential societal consequences of our work, none which we feel must be specifically highlighted here. References Ahn, J. et al. W ireless federated distillation for distrib uted edge learning with heterogeneous data. In Pr oc. PIMRC , pp. 1–6, Istanbul, T urkey , 2019. IEEE. Ahn, J. et al. Cooperativ e learning VIA federated distillation O VER fading channels. In Pr oc. ICASSP , pp. 8856–8860, Barcelona, Spain, 2020. IEEE. Chen, D. et al. pfl-bench: A comprehensi ve benchmark for personalized federated learning. In Pr oc. NeurIPS , pp. 1, New Orleans, LA, USA, 2022. 1. Chen, J. et al. Fedmatch: Federated learning over hetero- geneous question answering data. In Pr oc. CIKM , pp. 181–190, virtual, 2021. A CM. Cheng, Y ., Liu, Y ., Chen, T ., and Y ang, Q. Federated learn- ing for priv acy-preserving ai. Communications of the A CM , 63(12):33–36, 2020. Chrabaszcz, P ., Loshchilov , I., and Hutter , F . A do wnsam- pled variant of imagenet as an alternativ e to the CIF AR datasets. CoRR , abs/1707.08819, 2017. Collins, L. et al. Exploiting shared representations for per - sonalized federated learning. In Pr oc. ICML , v olume 139, pp. 2089–2099, virtual, 2021. PMLR. Diao, E. Heterofl: Computation and communication ef- ficient federated learning for heterogeneous clients. In Pr oc. ICLR , pp. 1, V irtual Event, Austria, 2021. Open- Revie w .net. Dorigo, M., Birattari, M., and Stutzle, T . Ant colon y opti- mization. IEEE computational intelligence magazine , 1 (4):28–39, 2007. He, C. et al. Group knowledge transfer: Federated learning of large cnns at the edge. In Proc. NeurIPS , virtual, 2020. . Horv ´ ath, S. FjORD: F air and accurate federated learning un- der heterogeneous targets with ordered dropout. In Pr oc. NIPS , pp. 12876–12889, V irtual, 2021. OpenRevie w .net. Jang, J. et al. Fedclassa vg: Local representation learning for personalized federated learning on heterogeneous neural networks. In Pr oc. ICPP , pp. 76:1–76:10, virtual, 2022. A CM. Jeong, E. et al. Communication-efficient on-de vice machine learning: Federated distillation and augmentation under non-iid pri vate data. In Pr oc. NeurIPS W orkshop on Machine Learning on the Phone and other Consumer Devices , virtual, 2018. . Kairouz, P . et al. Advances and open problems in federated learning. F oundations and T rends in Machine Learning , 14(1–2):1–210, 2021. Kalra, S. et al. Decentralized federated learning through proxy model sharing. Natur e communications , 14(1): 2899, 2023. Karaboga, D. and Akay , B. A comparati ve study of arti- ficial bee colony algorithm. Applied mathematics and computation , 214(1):108–132, 2009. Krizhevsk y , A. et al. Learning multiple layers of features fr om tiny imag es . T oronto, ON, Canada, , 2009. Liang, P . P . et al. Think locally , act globally: Federated learning with local and global representations. arXiv pr eprint arXiv:2001.01523 , 1(1), 2020. Liu, C. et al. Completely heterogeneous federated learning. CoRR , abs/2210.15865, 2022. Locke, E. A. Self-efficac y: The exercise of control. P erson- nel psychology , 50(3):801, 1997. Matsuda, K. et al. Benchmark for personalized federated learning. IEEE Open J. Comput. Soc. , 5:2–13, 2024. McMahan, B. et al. Communication-efficient learning of deep networks from decentralized data. In Proc. AIST ATS , volume 54, pp. 1273–1282, Fort Lauderdale, FL, USA, 2017. PMLR. Oh, J. et al. Fedbabu: T oward enhanced representation for federated image classification. In Pr oc. ICLR , virtual, 2022. OpenRevie w .net. Pillutla, K. et al. Federated learning with partial model personalization. In Pr oc. ICML , volume 162, pp. 17716– 17758, virtual, 2022. PMLR. Qiang, Y ., Lixin, F ., and Han, Y . F ederated Learning: Pri- vacy and Incentive . Springer , Cham, 2020. Qin, Z. et al. Fedapen: Personalized cross-silo federated learning with adaptability to statistical heterogeneity . In Pr oc. KDD , pp. 1954–1964, Long Beach, CA, USA, 2023. A CM. Randy , G., Han, Y ., Boi, F ., Lixin, F ., and Zehui, X. T rust- worthy F ederated Learning . Springer, Cham, 2023. 9 Social Hippocampus Memory Learning Rauniyar , A., Hagos, D. H., Jha, D., H ˚ akeg ˚ ard, J. E., Bagci, U., Raw at, D. B., and Vlassov , V . Federated learning for medical applications: A taxonomy , current trends, challenges, and future research directions. IEEE Internet of Things Journal , 11(5):7374–7398, 2023. Revie w , U. Federated jitter learning for gradient smoothing. In Pr oc. ICML . , 2026. Sagi, O. and Rokach, L. Ensemble learning: A surve y . W iley inter disciplinary r eviews: data mining and knowledge discovery , 8(4):e1249, 2018. Shen, T . et al. Federated mutual learning. CoRR , abs/2006.16765, 2020. T an, A. Z. et al. T ow ards personalized federated learning. IEEE T rans. Neural Networks Learn. Syst. , 1(1):1–17, 2022a. doi: 10.1109/TNNLS.2022.3160699. T an, Y . et al. Fedproto: Federated prototype learning across heterogeneous clients. In Pr oc. AAAI , pp. 8432–8440, virtual, 2022b. AAAI Press. W u, C. et al. Communication-efficient federated learning via kno wledge distillation. Natur e Communications , 13 (1):2032, 2022. Y ang, Q., Liu, Y ., Cheng, Y ., Kang, Y ., Chen, T ., and Y u, H. F ederated Learning . Morg an & Claypool Publishers, , 2019. Y ao, X., W ang, Y ., Zhu, P ., Lin, W ., Li, J., Li, W ., and Hu, Q. Socialized learning: Making each other better through multi-agent collaboration. In F orty-first International Confer ence on Machine Learning , 2024. Y e, M. et al. Heterogeneous federated learning: State-of- the-art and research challenges. A CM Comput. Surv . , 56 (3):79:1–79:44, 2024. Y i, L., W ang, G., and Liu, X. QSFL: A two-le vel uplink communication optimization framework for federated learning. In Pr oc. ICML , volume 162, pp. 25501–25513. PMLR, 2022. Y i, L., W ang, G., Liu, X., Shi, Z., and Y u, H. Fedgh: Het- erogeneous federated learning with generalized global header . In Pr oceedings of the 31st ACM International Confer ence on Multimedia (A CM MM’23) , pp. 11, Canada, 2023. A CM. Y i, L., Shi, X., W ang, N., Zhang, J., W ang, G., and Liu, X. Fedpe: Adapti ve model pruning-expanding for federated learning on mobile de vices. IEEE T ransactions on Mobile Computing , pp. 1–18, 2024a. Y i, L., W ang, G., W ang, X., and Liu, X. Qsfl: T wo-le vel communication-efficient federated learning on mobile edge devices. IEEE T ransactions on Services Computing , pp. 1–16, 2024b. Y i, L., Y u, H., Shi, Z., W ang, G., Liu, X., Cui, L., and Li, X. FedSSA: Semantic Similarity-based Aggreg ation for Efficient Model-Heterogeneous Personalized Federated Learning. In IJCAI , 2024c. Y i, L. et al. Federated model heterogeneous matryoshka representation learning. In Pr oc. NeurIPS , V ancouver , Canada, 2024d. . Y i, L. et al. Federated representation angle learning. In Pr oc. ICCV , pp. 1314–1324, Honolulu, Hawai’i, USA, 2025a. Y i, L. et al. pfedes: Generalized proxy feature extractor sharing for model heterogeneous personalized federated learning. In Pr oc. AAAI , pp. 22146–22154, Philadelphia, P A, USA, 2025b. AAAI Press. Zhu, H. et al. Federated learning on non-iid data: A survey . Neur ocomputing , 465:371–390, 2021. 10 Social Hippocampus Memory Learning A. K ey Notations. T able 2 summarizes the ke y notations used throughout the paper . T able 2. Summary of notations used in SoHip . Notation Description N T otal number of agents (clients). i Index of an agent, i ∈ { 1 , . . . , N } . t Communication round inde x. D i Local priv ate dataset of agent i . F i Heterogeneous feature extractor of agent i . H i Local classifier (prediction head) of agent i . E i Local memory encoder (linear projection to memory space). R i Local memory decoder (linear projection to feature space). B t i Mini-batch sampled from D i at round t . Z t i ∈ R B t i × d i Latent representations extracted from B t i by F i . d i Feature dimension of agent i ’ s local model. m Shared memory dimension across all agents. ¯ z t i ∈ R m Batch-av eraged encoded representation at round t . α S ,t i ∈ (0 , 1) m Short-term memory gating vector controlling importance of recent observ ations. M S ,t i ∈ R m Individual short-term memory of agent i at round t . M L ,t i ∈ R m Individual long-term memory of agent i after consolidation at round t . M L ,t ∈ R m Collectiv e long-term memory aggregated by the serv er at round t . α in ,t i ∈ (0 , 1) m Input gate controlling incorporation of short-term memory . α f ,t i ∈ (0 , 1) m For get gate controlling retention of historical long-term memory . α o ,t i ∈ (0 , 1) m Output gate modulating consolidated long-term memory strength. α G ,t i ∈ (0 , 1) m Fusion gate controlling absorption of collecti ve memory . M t i ∈ R m Complete memory of agent i after individual–collecti ve fusion. ˜ m t i ∈ R d i Decoded memory projected back to the feature space. ˆ Z t i Memory-enhanced representations for prediction. ˆ Y t i Prediction outputs of agent i at round t . ℓ ( · , · ) Local prediction loss function (e.g., cross-entropy). L Global objectiv e function aggregating all local losses. S t Set of participating agents at round t . p i Aggregation weight of agent i (e.g., proportional to |D i | ). C Client participation rate per communication round. σ ( · ) Sigmoid activ ation function. 11 Social Hippocampus Memory Learning B. Theoretical Analysis This appendix provides detailed analysis supporting the con vergence and pri v acy claims presented in Section 5 . W e follow standard assumptions in federated and distrib uted optimization and adapt them to the memory-based social machine learning setting of SoHip . B.1. Preliminaries and Assumptions W e consider the global objecti ve f ( θ ) = N X i =1 p i f i ( θ ) , (17) where f i ( θ ) := E ( x ,y ) ∼D i ℓ ( H i ( F i ( x )) , y ) denotes the local objectiv e of agent i , and p i ≥ 0 , P i p i = 1 . Assumption 1 (Smoothness). Each local objectiv e f i is L -smooth, i.e., ∥∇ f i ( θ ) − ∇ f i ( θ ′ ) ∥ ≤ L ∥ θ − θ ′ ∥ , ∀ θ , θ ′ . Assumption 2 (Unbiased Stochastic Gradients). Each agent computes stochastic gradients ∇ f i ( θ ; ξ ) such that E ξ [ ∇ f i ( θ ; ξ )] = ∇ f i ( θ ) , with bounded variance E ξ ∥∇ f i ( θ ; ξ ) − ∇ f i ( θ ) ∥ 2 ≤ σ 2 . Assumption 3 (Bounded Heterogeneity). There exists ∆ het ≥ 0 such that N X i =1 p i ∥∇ f i ( θ ) − ∇ f ( θ ) ∥ 2 ≤ ∆ het , ∀ θ . These assumptions are standard in noncon ve x federated optimization and hold independently of the memory abstraction mechanism. B.2. Con vergence Analysis W e analyze the ef fect of memory-based collaboration on the optimization dynamics of SoHip . In SoHip , local model updates are performed using memory-enhanced representations, where the memory modules (short- term abstraction, consolidation, and fusion) act as deterministic, differentiable transformations parameterized by lightweight neural networks. Importantly , memory exchange does not introduce additional stochasticity into gradient estimation. Let θ t denote the collection of local model parameters at communication round t . Follo wing standard analysis for stochastic gradient methods, we hav e E [ f ( θ t +1 )] ≤ E [ f ( θ t )] − η E ∥∇ f ( θ t ) ∥ 2 + Lη 2 2 E ∥ g t ∥ 2 , (18) where g t denotes the aggregated stochastic gradient and η is the learning rate. Using Assumptions 1–3 and standard variance decomposition, the gradient norm can be bounded as E ∥ g t ∥ 2 ≤ 2 E ∥∇ f ( θ t ) ∥ 2 + 2( σ 2 + ∆ het ) . (19) Substituting the bound and telescoping ov er t = 0 , . . . , T − 1 yields 1 T T − 1 X t =0 E ∥∇ f ( θ t ) ∥ 2 ≤ O 1 η T + O ( ησ 2 ) + O ( η ∆ het ) . (20) Choosing η = O (1 / √ T ) leads to the con vergence rate stated in Theorem 5.1 : 1 T T − 1 X t =0 E ∥∇ f ( θ t ) ∥ 2 = O 1 √ T + O (∆ het ) . 12 Social Hippocampus Memory Learning Remarks. The key observ ation is that memory abstraction, consolidation, and fusion do not alter the fundamental optimization structure. They act as bounded, differentiable transformations applied consistently across iterations. Therefore, SoHip preserves the con vergence guarantees of federated optimization while impro ving empirical performance through structured knowledge sharing. B.3. Privacy Pr eservation Analysis W e analyze the pri vac y properties of SoHip from an architectural perspectiv e. Observation 1 (No Raw Data Sharing). At no stage does SoHip transmit raw samples x or labels y . All operations in volving ra w data (feature extraction, memory abstraction, and prediction) are performed locally on-de vice. Observation 2 (No Model Parameter Sharing). Local model parameters F i , H i , as well as memory encoders and decoders, are nev er transmitted. Only memory v ectors M L ,t i ∈ R m are uploaded to the server . Observation 3 (Abstracted and Non-In vertible Memory). The transmitted memory is: (i) dimension-reduced ( m ≪ d i ); (ii) gated and nonlinear; (iii) temporally aggregated across batches and rounds. These properties make direct reconstruction of local data or model parameters ill-posed. Proposition. Given only the transmitted long-term memory M L ,t i , recov ering the original local data or model parameters is underdetermined without access to priv ate encoders, gating functions, and historical context. Discussion. Unlike dif ferential privac y mechanisms, SoHip provides structural privacy by design. Memory acts as a high-lev el abstraction of experience, not a carrier of raw information. This makes SoHip compatible with existing priv acy-enhancing techniques (e.g., DP or secure aggregation), while already of fering strong intrinsic protection against direct information leakage. 13 Social Hippocampus Memory Learning C. More Experimental Results 0.2 0.4 0.6 0.8 1.0 A g e n t P a r t i c i p a t i o n R a t e ( C ) 0 20 40 60 T est A ccuracy (%) CIF AR -100 ImageNet Default (a) Impact of agent participation rate. 0.001 0.01 0.1 1.0 L e a r i n g R a t e ( ) 20 40 60 T est A ccuracy (%) (b) Impact of learning rate. F igur e 7. Sensitivity analysis of SoHip with respect to agent participation rate and learning rate. Impact of Agent Participation Rate. Figure 7a reports the impact of the agent participation rate on SoHip under CIF AR-100 and ImageNet. As the participation fraction increases, the test accuracy of SoHip shows a mild decreasing trend on both datasets. This behavior can be attributed to the f act that higher participation introduces more heterogeneous and potentially conflicting local updates within each round, which increases the difficulty of consolidating consistent long-term memory . Ne vertheless, SoHip remains stable across a wide range of participation rates, and the def ault setting achie ves a fa vorable balance between performance and communication ef ficiency , demonstrating the rob ustness of memory-based collaboration under varying participation le vels. Impact of Learning Rate. Figure 7b illustrates the impact of the learning rate on SoHip across CIF AR-100 and ImageNet. The performance exhibits a clear unimodal trend: very small learning rates lead to slo w and suboptimal conv ergence, while excessi vely lar ge learning rates cause unstable updates and significant performance degradation. An intermediate learning rate (default setting) consistently yields the best accuracy on both datasets, indicating a good balance between con ver gence speed and training stability . These results suggest that SoHip is relati vely robust to learning rate choices within a reasonable range, while extreme settings may hinder ef fecti ve memory consolidation and fusion. 14
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment