Spatiotemporal System Forecasting with Irregular Time Steps via Masked Autoencoder
Predicting high-dimensional dynamical systems with irregular time steps presents significant challenges for current data-driven algorithms. These irregularities arise from missing data, sparse observations, or adaptive computational techniques, reduc…
Authors: Kewei Zhu, Yanze Xin, Jinwei Hu
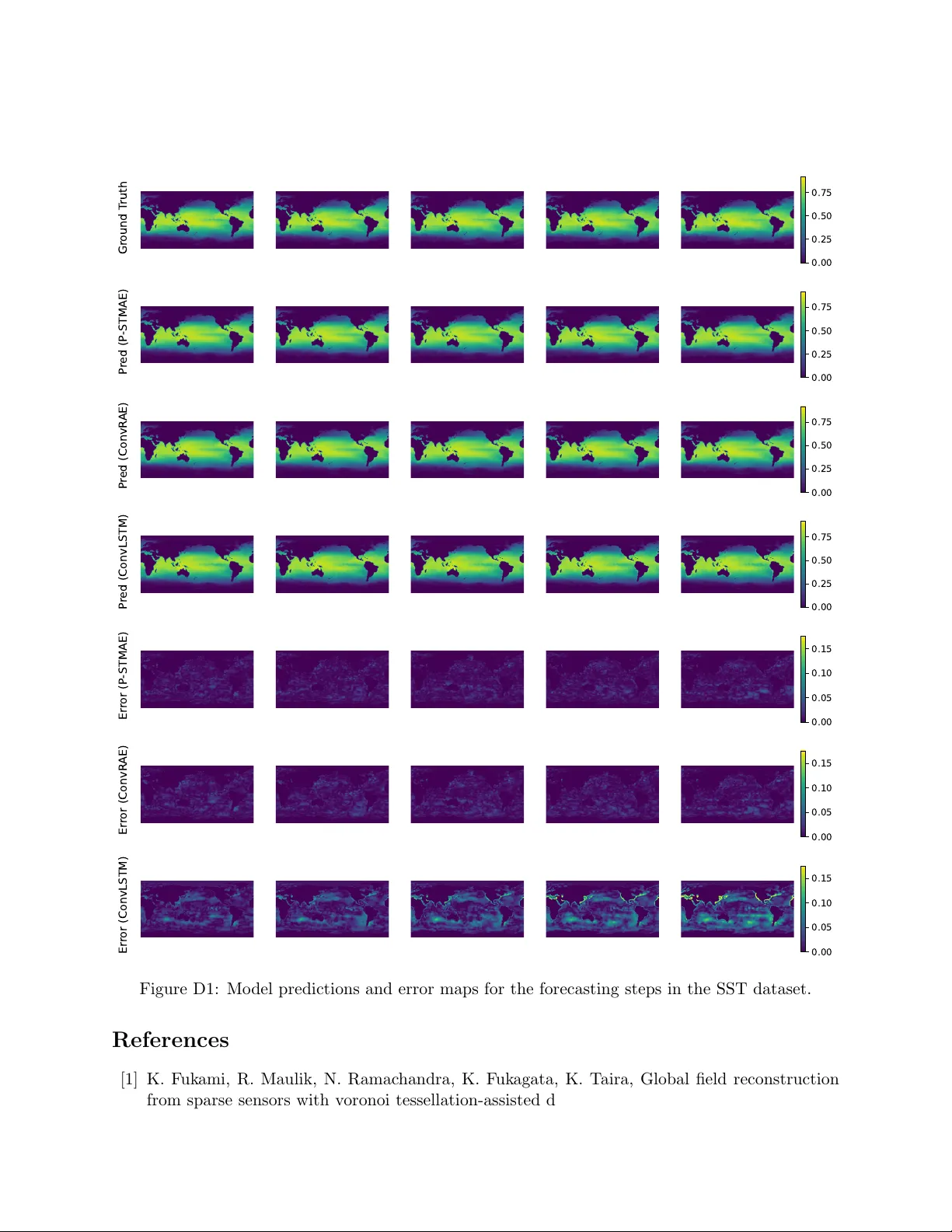
Spatiotemp oral system forecasting with irregular time steps via mask ed auto enco der Kew ei Zh u 1,* Y anze Xin 2,* Jin wei Hu 3 Xiao yuan Cheng 4 Yiming Y ang 5,6 Sib o Cheng 7, † 1 Departmen t of Chemical Engineering, Univ ersit y College London, UK 2 Departmen t of Computing, Imp erial College London, UK 3 Departmen t of Computer Science, Univ ersit y of Liv erp o ol, UK 4 Dynamic Systems Lab, Universit y College London, UK 5 Departmen t of Civil, Environmen tal & Geomatic Engineering, Univ ersity College London, UK 6 Departmen t of Statistical Science, Universit y College London, UK 7 CEREA, ENPC, EDF R&D, Institut Polytec hnique de Paris, F rance * These authors contributed equally to this work. † Corresp onding author: sibo.cheng@enpc.fr Abstract Predicting high-dimensional dynamical systems with irregular time steps presents signifi- can t challenges for curren t data-driv en algorithms. These irregularities arise from missing data, sparse observ ations, or adaptiv e computational techniques, reducing prediction accuracy . T o address these limitations, we prop ose a nov el metho d: a Physics-Spatiotemporal Masked Au- to encoder. This metho d integrates con volutional autoenco ders for spatial feature extraction with masked auto encoders optimised for irregular time series, lev eraging attention mec hanisms to reconstruct the entire physical sequence in a single prediction pass. The mo del a voids the need for data imputation while preserving the physical integrit y of the system. Here, ’ph ysics’ refers to high-dimensional fields generated from underlying dynamical systems, rather than en- forcing explicit physical constrain ts or PDE residuals. W e ev aluate this approac h on m ultiple sim ulated datasets and real-w orld o cean temp erature data. The results demonstrate that our metho d achiev es significant improv emen ts in prediction accuracy , robustness to nonlinearities, and computational efficiency o ver traditional con volutional and recurren t net work methods. The mo del sho ws potential for capturing complex spatiotemporal patterns without requiring domain- sp ecific knowledge, with applications in climate mo delling, fluid dynamics, o cean forecasting, en vironmental monitoring, and scientific computing. Keyw ords: Deep learning, Self-atten tion, Fluid dynamics, Spatiotemp oral forecasting, Climate prediction This is the accepted man uscript of an article accepted for publication in Physica D: Nonline ar Phenomena . 1 Acron yms P-STMAE Ph ysics Spatiotemp oral Masked Auto encoder PDE P artial Differential Equation ARIMA Auto-Regressiv e Integrated Mo ving Average MLP Multi-La yer Perceptron CNN Con volutional Neural Net work RNN Recurren t Neural Netw ork M-RNN Multi-directional Recurrent Neural Netw ork Seq2Seq Sequence-to-Sequence GR U Gated Recurrent Unit LSTM Long Short-T erm Memory Netw ork Con vRAE Deep Conv olutional Recurren t Auto encoder Con vLSTM Con volutional Long Short-T erm Memory Netw ork F C-LSTM F ully Connected LSTM NLP Natural Language Pro cessing BER T Bidirectional Enco der Represen tations from T ransformers R OM Reduced Order Mo delling POD Prop er Orthogonal Decomp osition DMD Dynamic Mo de Decomp osition PCA Principal Comp onent Analysis CAE Con volutional Auto encoder MAE Mask ed Auto encoder TiMAE Time Series Masked Auto encoder MSE Mean Squared Error SSIM Structural Similarity Index Measure PSNR P eak Signal-to-Noise Ratio SWE Shallo w W ater Equation SST NO AA Sea Surface T emperature V AE V ariational Auto encoder GAN Generativ e Adversarial Net work MSPCNN Multi-Scale Physics-Constrained Neural Netw ork PINN Ph ysics-Informed Neural Net work KAN Kolmogoro v-Arnold Netw ork 2 Main Notations x t Observ ation state in the full space at time step t ˆ x t Predicted state in the full space at time step t z t Observ ation state in the latent space at time step t ˆ z t Predicted state in the laten t space at time step t T in Set of input time steps T out Set of forecasting time steps T miss Set of missing time steps of the input T obs Set of observed time steps of the input t in Num b er of input time steps t out Num b er of forecasting time steps X T Ph ysical states for the set of time steps T ˆ X Reconstructed sequence in the full space Z T Laten t states for the set of time steps T ˆ Z Reconstructed sequence in the laten t space Φ x Placeholders in the full space ϕ x Ph ysical placeholder state Φ z Placeholders in the latent space ϕ z Laten t placeholding state d x Dimension of the physical state d z Dimension of the latent state d k Dimension of the attention v ector Q , K , V Atten tion m atrices of transformer blo c ks W Q , W K , W V T rainable w eight matrices of transformer blo c ks A A ttention weigh ts matrix O Output matrix from transformer blo c k O ′ Final output matrix from transformer blo ck f E Enco der function mapping physical to latent space f D Deco der function mapping latent to physical space θ E P arameters of the enco der θ D P arameters of the deco der δ t P ositional embedding at time step t L Overall loss function λ W eighting co efficien t for the latent loss 1 In tro duction Predicting high-dimensional dynamical systems is challenging when observ ations o ccur at irregu- lar time in terv als. Suc h irregularities frequen tly arise in scientific sim ulations and observ ational datasets due to sensor failures, sparse measurement netw orks [ 1 ], or adaptiv e time stepping in nu- merical solv ers based on P artial Differential Equati ons (PDEs) [ 2 – 4 ]. Conv en tional mac hine learning mo dels, such as Multi-Lay er Perceptrons (MLPs) and Recurren t Neural Netw orks (RNNs), t ypically assume regularly sampled data and struggle to generalise when faced with temp oral gaps or uneven sampling [ 5 ]. T o comp ensate, many w orkflows rely on prepro cessing techniques [ 6 ], such as resam- pling, in terp olation [ 7 ], or data assimilation [ 8 ] to pro duce uniformly spaced sequences. Ho wev er, these pro cedures can in tro duce bias, increase computational cost, and obscure the true temporal dynamics of the system [ 9 , 10 ]. There is a clear need for mo dels that can directly learn from irreg- 3 ular time series without prepro cessing while accurately capturing the underlying spatiotemporal structure of the physical system. T raditional approac hes to handling temp orally irregular observ ations include time series mo dels lik e Auto-Regressiv e Integrated Moving Av erage (ARIMA) [ 11 ] and data assimilation algorithms suc h as Kalman Filters [ 12 ]. While ARIMA models are effectiv e for univ ariate, stationary time series, they face limitations with high-dimensional, nonlinear systems [ 13 , 14 ]. Kalman Filters estimate the state of a linear system from incomplete measurements but rely on assumptions of linearit y and normalit y that often do not hold in complex, high-dimensional dynamics [ 15 ]. Ex- tended and Unscented Kalman Filters [ 16 – 19 ] attempt to address nonlinearities but still struggle with high dimensionality and irregular time steps common in real-world data. More recently , deep learning models lik e Conv olutional Neural Net works (CNNs) and RNNs ha ve sho wn adv an tages in surrogate mo delling of time series problems by lev eraging their ability to capture spatial and temporal patterns, resp ectiv ely . Deep Con v olutional Recurren t Auto encoder (Con vRAE) [ 20 ] combines CNNs with Long Short-T erm Memory Netw orks (LSTMs) to capture b oth spatial and temp oral patterns. Ho wev er, it inherits RNNs’ dra wbacks, such as v anishing and explo ding gradients [ 21 ], which b ecome detrimental for long sequences in high-dimensional dynam- ical systems [ 22 ]. Conv olutional Long Short-T erm Memory Net work (ConvLSTM) [ 23 ] combines con volutional operations with LSTM cells to directly model spatiotemp oral relations. Nev ertheless, these RNN-based approac hes rely on regularly sampled time series, limiting their applicability to irregular time steps. Alternativ e metho ds [ 24 ] require interpolation to estimate time points that do not align with the established time grid. These limitations prompt the need for m odels capa- ble of handling irregular time steps and incomplete data while preserving the in tegrity of physical pro cesses (see Fig. 1 ). Recen t adv ancemen ts in transformers [ 25 ] hav e in tro duced a p o w erful architecture for time series mo delling for handling irregular and incomplete data [ 26 , 27 ]. Originally developed for Natural Language Processing (NLP) [ 28 ], transformers are well-suited for sequences of v ariable lengths and missing elements due to their self-atten tion mechanism. Unlike RNNs that pro cess inputs sequen tially , this mechanism enables sim ultaneous atten tion to v arious parts of the input sequence and is highly parallelisable, thereby capturing long-range dep endencies ev en when parts of the data are missing or unevenly spaced. Methods lik e Bidirectional Encoder Represen tations from T ransformers (BER T) [ 29 ] in language understanding and Mask ed Autoenco der (MAE) [ 30 ] in image recognition demonstrate the efficacy of masking strategies for learning robust represen tations. Building on these successes, Time Series Mask ed Auto encoder (TiMAE) [ 31 ] has demonstrated the utilit y of self-sup ervised learning and masked mo delling for reconstructing missing data p oints in time series prediction. Ho wev er, this approac h has largely been applied in low-dimensional systems, suc h as financial [ 32 ] or healthcare [ 33 ] time series, and has not b een fully extended to more complex, high-dimensional dynamical systems gov erned by ph ysical pro cesses. Mo delling these systems presents c hallenges due to computational complexit y and memory usage asso ciated with high dimensionalit y , while maintaining spatial and temporal coherence under irregular observ ations remains difficult for traditional deep learning mo dels and common transformer v arian ts [ 34 ]. Existing approac hes for irregular time series mo delling in dynamical systems exhibit funda- men tal limitations. Neural ordinary differential equation (Neural ODE)-based metho ds require con tinuous-time solv ers and are often sensitiv e to stiffness and n umerical instability in high-dimensional PDE systems. In terp olation-based transformers and recurrent mo dels rely on resampling or impu- tation, which can distort the true temp oral dynamics. In contrast, mask ed reconstruction enables direct mo delling of irregularly sampled sequences without explicit interpolation or contin uous-time in tegration. T o address these challenges, we prop ose a nov el mo del called Physics Spatiotemp oral Masked 4 RNN Prediction P- STMAE Prediction Figure 1: Comparison of Sequence-to-Sequence(Seq2Seq) prediction metho ds in dynamical systems of irregular time steps. Left : T raditional RNN-based mo dels feature step-wise rolling out with necessary data imputation for handling missing steps, which ma y in tro duce biases and cum ulative errors. Righ t : Our mo del p erforms elemen t-wise predictions in the laten t space b y adaptive atten tion mechanism to reconstruct the complete sequence in a single pass. Auto encoder (P-STMAE). Unlike previous transformer mo dels primarily fo cused on lo w-dimensional data, P-STMAE is sp ecifically designed for mo delling high-dimensional dynamical systems, incor- p orating b oth spatial and temp oral dep endencies in a unified framew ork. The core inno v ation lies in combining a con v olutional auto enco der for spatial feature extraction with a masked auto encoder optimised for irregular time series prediction. The con volutional autoenco der compresses high- dimensional physical data into a low-dimensional laten t space, thereb y reducing computational complexit y while retaining essen tial spatiotemporal features. In the latent space, a mask ed au- to encoder uses the transformer’s self-attention mechanism to predict future states. The framework in tro duces placeholder and masking strategies to handle temporal dependencies among partially observ ed sequences, with p ositional enco dings preserving the temporal order under irregular se- quences. The training adopts a purely data-driven approac h [ 35 ], optimising a combination of ph ysical and laten t space losses without domain-sp ecific kno wledge. W e conduct n umerical exp erimen ts on three datasets: t wo simulated scenarios from PDEBench [ 36 ] (Shallo w W ater equations and Diffusion Reaction equations) and one real-w orld ocean fluid dataset, NO AA Sea Surface T emperature (SST) [ 37 ], obtained from satellite and ship-based observ ations. This combination ensures that P-STMAE adheres to scientific standards and generalises to div erse c hallenges in ph ysical systems. In summary , this pap er mak es the follo wing key con tributions: • A spatiotemp oral masked auto encoder for laten t dynamics mo delling. • Placeholder-based atten tion for handling irregular and missing time steps. • A unified framework for sequence reconstruction and forecasting. • The proposed mo del outp erforms Con vLSTM and ConvRAE with impro v ed efficiency and in terpretability . Our approac h provides computational adv antages ov er traditional ph ysics-based PDE solvers. T raditional time-stepping metho ds often require many small steps due to stabilit y constrain ts and 5 ma y in volv e iterative linear solves, whereas P-STMAE learns an approximation to the flow map and pro duces forecasts with a limited num b er of GPU-based forward passes [ 38 , 39 ], thereb y reducing inference time and energy consumption while preserving spatiotemp oral fidelity . T o av oid p oten tial am biguity , w e clarify that the notion of ”ph ysical consistency” in this w ork is relativ e rather than constraint-based. P-STMAE do es not explicitly enforce PDE residuals or conserv ation la ws. Instead, inspired b y masked auto encoder approac hes for time-series dynamics suc h as TS-MAE [ 40 ], it mo dels the temp oral evolution of ph ysical fields in a latent space and impro ves the stabilit y and coherence of the learned dynamics without in tro ducing hard physics constrain ts. Related latent-space forecasting approac hes ha ve also b een explored and v alidated in indep enden t studies [ 41 , 42 ]. T o the b est of our knowledge, our prop osed mo del is among the first to unify Conv olutional Auto encoder (CAE)-based spatial compression with mask ed temporal modelling using transformers in the laten t space, sp ecifically targeting high-dimensional, irregularly sampled dynamical systems. The remainder of this pap er is organised as follows: Section 2 pro vides related work on reduced order mo delling and deep learning-based approaches for high-dimensional dynamical systems. Sec- tion 3 introduces the prop osed P-STMAE mo del, detailing its architecture and metho dology . Sec- tion 4 presents the n umerical exp erimen ts conducted on b oth synthetic and real-w orld datasets to ev aluate the mo del’s performance. Finally , Section 5 discusses limitations and concludes the pap er. 2 Related w ork 2.1 T raditional approac hes to irregular time series T raditional approac hes to handling temporally irregular observ ations include time series mo dels lik e ARIMA [ 11 ] and data assimilation algorithms such as Kalman Filters [ 12 ]. While ARIMA mo dels are effectiv e for univ ariate, stationary time series, they face limitations with high-dimensional, nonlinear systems [ 13 , 14 ]. Kalman Filters estimate the state of a linear system from incomplete measuremen ts but rely on assumptions of linearity and normalit y that often do not hold in complex, high-dimensional dynamics [ 15 ]. Extended and Unscen ted Kalman Filters [ 16 , 17 ] attempt to address nonlinearities but still struggle with high dimensionality and irregular time steps common in real-w orld data. These limitations motiv ate the developmen t of deep learning approaches capable of handling high-dimensional, nonlinear dynamics with irregular temp oral sampling. 2.2 Reduced order mo delling and auto enco ders Reduced Order Mo delling (R OM) aims to reduce the computational cost of simulating high-fidelit y dynamical systems b y constructing efficien t surrogate mo dels that preserve essential system dy- namics [ 43 – 47 ]. These mo dels enable faster predictions by approximating the original system in a lo wer-dimensional space while retaining relev an t features for downstream tasks [ 48 , 49 ]. T raditional pro jection-based methods, such as Proper Orthogonal Decomp osition (POD) [ 50 ] or Dynamic Mo de Decomp osition (DMD), pro ject data onto optimal linear subspaces that explain most of the v ariance. Ho wev er, their effectiv eness is limited when the system exhibits strong nonlinearit y and time-v arying b ehaviour. Moreov er, they are often in trusiv e, requiring access to the gov erning equations or system op erators during the reduction pro cess [ 51 ]. Deep learning offers a non-intrusiv e and flexible alternativ e for R OM. In particular, autoen- co ders can learn nonlinear manifolds from data alone, making them effectiv e in compressing and reconstructing high-dimensional spatial features [ 52 , 53 ]. CAEs are widely used in spatiotemp oral 6 mo delling, where spatial patterns can b e compressed in to latent represen tations and later deco ded to reconstruct the original fields. F ormally , a CAE consists of an enco der and deco der: z t = f E ( x t ; θ E ) , (1) ˆ x t = f D ( z t ; θ D ) , (2) where t ∈ N represents each v alid time step, and f E : R d x → R d z represen ts the enco ding func- tion that maps the input physical state x t to the compressed latent space z t using the parameters θ E , commonly d z ≪ d x . Similarly , f D : R d z → R d x denotes the deco ding function that reconstructs the original physical state ˆ x t ∈ R d x using the parameters θ D . The training goal is to minimise the reconstruction loss, whic h measures the mean squared error b et w een the input and output physical states av eraged o ver total time steps T : θ ∗ E , θ ∗ D = arg min θ E ,θ D 1 T T X t =1 E h ∥ ˆ x t − x t ∥ 2 i . (3) A notable adv an tage of using deep autoenco ders in R OM is their ability to learn nonlinear manifolds, for high-dimensional and nonlinear dynamics, which are common in fluid mec hanics, climate systems, and biological sim ulations. 2.3 Sequence mo delling in laten t space RNNs [ 54 ] are a type of neural netw orks tailored for handling sequence data, making them effective for time series and sequential tasks. Unlik e traditional feed-forw ard neural netw orks, RNNs capture information from previous states through in ternal hidden memories, enabling them to main tain and pro cess temp oral dependencies [ 55 ]. Sp ecifically , LSTMs use three information gates, including input, forget, and output gates, to regulate what information should b e added, retained, or output from the cell state, thus main taining long-term dep endencies more effectively [ 56 ]. They are widely used in reduced-order spatiotemp oral system mo delling in computational ph ysics [ 57 , 58 ]. 2.3.1 Laten t sequence forecasting via Con vRAE and Con vLSTM One notable approach to employs RNNs for high-dimensional dynamical system mo delling is the Con vRAE [ 20 ]. The mo del first employs a deep con volutional auto enco der to compress a sequence of ph ysical fields { ( x t , t ) } T t =1 in to the laten t space { ( z t , t ) } T t =1 . The compressed represen tation is then sent in to an LSTM netw ork to mo del its temp oral ev olution, th us preserving future predictive capabilities by autoregressive rollouts. Mathematically , it predicts future states { ( ˆ z t , t ) } T in + T out t = T in +1 based on input states { ( z t , t ) } T in t =1 . F or eac h forecasting step, it predicts the next state ˆ z t +1 in an autoregressiv e manner based on the previous output ˆ z t and a hidden memory h t : ˆ z t +1 , h t +1 = LSTM-Cell( ˆ z t , h t ) . (4) Common loss suc h as Mean Squre Error (MSE) can be used to minimise the distance betw een predicted physical states and the ground truth, i.e. ˆ x t = f D ( ˆ z t ; θ D ) , (5) L ConvRAE = 1 T out T in + T out X t = T in +1 E h ∥ ˆ x t − x t ∥ 2 i . (6) 7 Con vRAE effectively integrates the strengths of CNNs in capturing lo calised spatial features and LSTMs in preserving temp oral dep endencies. How ev er, it inherits common drawbac ks asso ci- ated with RNNs, including susceptibility to v anishing and explo ding gradients [ 21 ], whic h b ecome problematic when dealing with long sequences t ypical in high-dimensional dynamical systems [ 22 ]. Another influential mo del is the ConvLSTM [ 23 ], which is sp ecifically designed for spatiotem- p oral sequence forecasting in a Seq2Seq framework. Con vLSTM extends the conv en tional F ully Connected LSTM (F C-LSTM) b y incorporating con volutional op erations directly in to the cell of the LSTM to mo del temp oral transitions at the full ph ysical space. Unlik e Con vRAE, which op er- ates as a tw o-stage method, ConvLSTM offers an end-to-end approac h that sim ultaneously captures b oth spatial and temporal dep endencies within a unified architecture. Ho w ever, both ConvRAE and Con vLSTM require regularly sampled time series, which limits their applicability to irregular time steps without prepro cessing. 2.3.2 Challenges with irregular time series While RNNs and their v arian ts excel in modelling regularly sampled time series, they face significan t c hallenges when dealing with irregular time steps [ 59 ] and high dimensionalit y [ 60 ]. Standard RNN- based Seq2Seq models inheren tly assume consisten t sampling in terv als, making it difficult to handle missing or unevenly spaced observ ations without additional prepro cessing steps. T o address this, man y RNN-based mo dels rely on explicit imputation or interpolation as a prepro cessing step [ 6 ], including statistical interpolation [ 7 , 61 ], nearest neigh b our searc h [ 62 ], and time-a ware data filling [ 63 ]. How ever, these prepro cessing pro cedures can in tro duce bias, increase computational cost, and obscure the true temp oral dynamics of the system [ 9 , 10 ], thereb y limiting their effectiveness in capturing complex spatiotemp oral dynamics under high sparsity . More recen t w ork has used generativ e mo dels suc h as V ariational Autoenco ders (V AEs) [ 64 ] and Generativ e Adversarial Netw orks (GANs) [ 65 , 66 ] to impute missing v alues. How ev er, these ap- proac hes may suffer from data inefficiency , instabilit y in long-term predictions, and non-uniqueness of outputs, limiting their use in physical system mo delling [ 64 , 67 , 68 ]. While probabilistic genera- tiv e mo dels are highly effective for noisy or underdetermined real-w orld systems and can explicitly represen t predictiv e uncertaint y [ 69 ], this work fo cuses on deterministic reconstruction to enable clarit y and controlled analysis of irregularly sampled laten t dynamics in deterministic PDE sim u- lation settings, where the go verning equations define a single-v alued flow map [ 70 ]. 2.4 Mask ed transformers and physics-informed latent mo delling Existing approaches for irregular time series mo delling in dynamical systems exhibit fundamen tal limitations. Neural ordinary differen tial equation (Neural ODE) based metho ds require con tin uous- time solvers and are often sensitive to stiffness and numerical instability in high-dimensional PDE systems. In terp olation-based transformers and recurren t mo dels rely on resampling or imputa- tion, whic h can distort the true temp oral dynamics. Mask ed reconstruction offe rs an alternativ e b y enabling direct mo delling of irregularly sampled sequences without explicit interpolation or con tinuous-time integration. Recen t transformer-based mo dels ha v e shown promise in mo delling long-range dependencies and handling irregular sequences directly through masked attention and learned time enco dings. W orks lik e Time-MAE and mask ed sequence mo dels [ 71 , 72 ] ha ve successfully addressed missing data without in terpolation. Building on these successes, TiMAE [ 31 ] has demonstrated the utilit y of self-sup ervised learning and mask ed mo delling for reconstructing missing data p oin ts in time series prediction. Ho wev er, these approac hes hav e primarily been applied to lo w-dimensional systems, 8 suc h as financial [ 32 ] or healthcare [ 33 ] time series, and hav e not b een fully extended to the more complex, high-dimensional dynamical systems gov erned by ph ysical pro cesses. Mo delling these systems presents c hallenges due to computational complexit y and memory usage asso ciated with high dimensionalit y , while maintaining spatial and temporal coherence under irregular observ ations remains difficult for traditional deep learning mo dels and common transformer v arian ts [ 34 ]. Sim ultaneously , there is a gro wing interest in combining physical priors with latent representa- tion learning [ 73 ]. Ph ysics-informed neural net works (PINNs) and h ybrid data-physics models hav e sho wn effectiv eness in preserving ph ysical consistency and impro ving generalisation under small data regimes. 3 Metho dology P-STMAE addresses irregular time series prediction using a masked mo delling strategy b y combin- ing a con volutional auto enco der for spatial representation and a masked transformer for temp oral mo delling. The framew ork directly handles irregular time steps through mask ed reconstruction, eliminating the need for prepro cessing or regular sampling that can in tro duce bias and computa- tional o v erhead. By lev eraging transformer self-attention instead of sequential RNNs processing, P-STMAE captures long-range dep endencies without suffering from v anishing gradients or requir- ing regular input sequences. In con trast to Neural ODE metho ds that require con tin uous-time solv ers, P-STMAE learns a discrete flo w map in a latent space, enabling efficien t inference without n umerical in tegration. T o address the computational challenges of applying transformers to high- dimensional systems, P-STMAE op erates in a compressed latent space and reduces memory usage while main taining spatiotemp oral coherence. This section outlines the o verall framework, the en- co der and deco der designs, the attention-based temp oral mo del, and the training loss form ulation. 3.1 Ov erall framew ork Mathematically , w e consider a ph ysical sequence consisting of input states X T in defined on input steps T in = { 1 , 2 , . . . , t in } , follow ed by forecasting states X T out on output steps T out = { t in + 1 , . . . , t in + t out } . W e denote: X T in = { ( x t , t ) | t ∈ T in } , X T out = { ( x t , t ) | t ∈ T out } , (7) where x t ∈ R d x is the physical state at time t . T o simulate irregularity , w e randomly split T in in to tw o disjoin t sets: T obs (observ ed steps) and T miss (missing steps), suc h that T obs ∪ T miss = T in . This design enables learning from partially observ ed sequences without data imputation or interpolation, thereb y addressing the limitations inheren t in prepro cessing-based approac hes. Missing and future steps are replaced with placeholder v ariables Φ x : Φ x = { ( ϕ x , t ) | t ∈ T miss ∪ T out } , ϕ x ∈ R d x . (8) The mo del then reconstructs the complete sequence ˆ X from X T obs and placeholders Φ x : ˆ X = P-STMAE( X T obs , Φ x ) = { ( ˆ x t , t ) | t ∈ T in ∪ T out } . (9) Fig. 2 illustrates the o verall pip eline of the prop osed P-STMAE framew ork. 9 (a) Enco der pip eline (b) Deco der pip eline (c) T ransformer blo c k Figure 2: Arc hitecture of the prop osed P-STMAE framew ork. (a) Con volutional enco der com- presses ph ysical states into latent representations. P ositional enco dings are added, and a masked transformer captures temporal dependencies in latent space. (b) Learnable masking tokens are padded at missing and future time steps. T ransformer blo c ks pro cess the sequence, and the con vo- lutional deco der reconstructs the complete physical fields. (c) Each transformer block consists of la yer normalization, multi-head self-attention, and a feedforw ard net work. Self-attention op erates only on observed latent states. 3.2 Spatial enco der: Con v olutional auto enco der T o reduce spatial redundancy and improv e computational efficiency , we adopt a CAE to pro ject high-dimensional inputs x t ∈ R d x in to compact latent represen tations z t ∈ R d z , where d z ≪ d x . This compression mitigates the computational complexit y and memory c hallenges of applying transformers directly to high-dimensional ph ysical fields, facilitating efficient temp oral modelling in the latent space. During enco ding, ph ysical placeholders Φ x are conv erted in to latent placeholders Φ z : Φ z = { ( ϕ z , t ) | t ∈ T miss ∪ T out } , ϕ z ∈ R d z . (10) These placeholders are excluded from bac kpropagation and later mask ed out in the transformer blo c ks. The placeholder states ϕ x and ϕ z are fixed tensors (set to zero after normalisation), excluded from gradien t backpropagation, and serve solely as positional anc hors for masking and atten tion mec hanisms. 3.3 T emporal modelling: Masked autoenco der The mask ed auto enco der learns laten t temp oral dynamics from partially observed sequences. By op erating directly on irregularly sampled latent states without preprocessing, this approach cir- 10 cum ven ts the bias and distortion that in terp olation metho ds typically introduce. It pro cesses the laten t inputs Z T obs = { ( z t , t ) | t ∈ T obs } using transformer blo c ks. 3.3.1 Mask ed transformer blo c ks T ransformer blo c ks (see Fig. 2 (c)) compute self-attention ov er observed latent states. In con trast to RNNs that pro cess sequences sequentially and are prone to v anishing gradients, self-attention enables parallel pro cessing and direct access to all observ ed time steps, capturing long-range de- p endencies without gradien t degradation. Giv en the hidden and attention dimension, the attention w eights are computed as: Q = Z T obs W Q , K = Z T obs W K , V = Z T obs W V , (11) A = softmax Q · K T √ d k , O = A · V , O ′ = Linear( O ) + Q . (12) 3.3.2 Deco der and masking tok ens The deco der uses a lighter transformer stack to reconstruct the full latent sequence ˆ Z = { ( ˆ z t , t ) | t ∈ T in ∪ T out } by attending to enco ded representations and learnable masks on missing steps. This enables parallel, non-autoregressive prediction, whic h eliminates the error accumulation inherent in autoregressive RNNs and facilitates efficient single-pass inference. 3.3.3 P ositional em b eddings W e inject sine-cosine p ositional embeddings δ t in to all laten t inputs: δ ( t, 2 i ) = sin t 10000 2 i d z , δ ( t, 2 i + 1) = cos t 10000 2 i d z , (13) z t ← z t + δ t , t ∈ T in ∪ T out (14) where δ t is non-trainable and ensure temp oral consistency across irregular steps. W e note that the sin usoidal positional encoding is used solely to enco de relativ e temp oral ordering among irregular time steps, rather than representing absolute physical time scales. Unlik e RNN-based models, our mask ed transformer supports single-step inference o ver the entire sequence, reducing latency and eliminating autoregressive error accumulation. This mask ed reconstruction paradigm is adv antageous for irregular time series. Rather than relying on explicit in terp olation or resampling that may distort temp oral dynamics, the mo del learns to infer missing or unevenly spaced observ ations directly from surrounding context. By training on partially observ ed sequences, P-STMAE naturally dev elops robustness to irregular sampling patterns. Operating in the laten t space further enhances this capability , as the mo del can exploit global spatiotemp oral dependencies while av oiding artifacts introduced by preprocessing, thereb y addressing the computational c hallenges of high-dimensional systems. This explains why mask ed auto enco ders demonstrate stronger adaptabilit y in irregular settings compared to RNN- based approaches that require regularised inputs. 11 3.4 Loss function and training ob jectiv e W e join tly minimise the prediction errors in b oth physical and laten t spaces: L = 1 T in + T out T in + T out X t =1 E h ∥ ˆ x t − x t ∥ 2 i + λ · E h ∥ ˆ z t − z t ∥ 2 i , (15) where λ balances ph ysical and latent consistency . Both terms in Eq. ( 15 ) emplo y the L2 norm (mean squared error), whic h is a standard choice for con tinuous physical fields and pro vides smo oth, stable gradien ts for training masked auto enco der architectures. 3.5 Ev aluation metrics T o comprehensiv ely ev aluate mo del performance, we emplo y three complemen tary metrics com- monly used in spatiotemp oral forecasting [ 20 , 36 ]: The MSE measures pixel-wise prediction accu- racy ov er all time steps [ 74 ]. The Structural Similarit y Index Measure (SSIM) quan tifies structural similarit y of spatial fields, capturing p erceptual qualit y and spatial coherence [ 75 ]. The Peak Signal-to-Noise Ratio (PSNR) assesses reconstruction fidelit y in decib els, pro viding a measure of signal-to-noise ratio [ 76 ]. These metrics collectiv ely capture p oin twise accuracy , structural preser- v ation, and reconstruction quality , whic h are essen tial for ev aluating spatiotemp oral predictions in ph ysical systems. 3.6 Ablation study design W e compare P-STMAE against tw o established RNN-based mo dels to ev aluate the effectiv eness of transformer-based latent mo delling versus recurrent approac hes: 1. Con vRAE [ 20 ] employs a tw o-stage approac h: a con volutional auto enco der for spatial com- pression follow ed b y LSTM for temp oral mo delling in the latent space. This enables a direct comparison of transformer-based versus LSTM-based temp oral mo delling within the same laten t representation framew ork. 2. Con vLSTM [ 23 ] integrates conv olutional operations with LSTM cells to model spatiotemporal relations directly in full ph ysical space. This pro vides a comparison with end-to-end full-space approac hes, contrasting with the latent-space metho ds used by Con vRAE and P-STMAE. T o ensure fair comparison, w e train these RNN-based baselines using ground truth inputs during training and autoregressive predictions during inference. Since RNN-based models require regularly sampled inputs, we adapt them to handle irregular time steps using linear in terp olation, following common practice in irregular time series mo delling [ 77 , 78 ]. This preprocessing step allo ws the baselines to pro cess the data while enabling comparison with P-STMAE, which handles irregular sampling directly without interpolation. 4 Exp erimen ts 4.1 Ov erview 4.1.1 Datasets and benchmarking F ollowing the metho dology outlined in Section 3 , w e ev aluate P-STMAE against the baseline models in tro duced in the Ablation Study Design on three representativ e datasets. These datasets span 12 syn thetic PDE simulations and real-w orld climate observ ations, enabling v alidation of b oth accuracy under controlled conditions and generalisation to noisy , large-scale data. Sp ecifically , we use tw o datasets from PDE simulations and one from real-world observ ations: • Shallo w W ater [ 79 ]: nonlinear fluid flow, testing robustness to chaotic dynamics. • Diffusion Reaction from PDEBenc h [ 36 ]: c hemical patterns, testing coupled-v ariable mo d- elling. • SST [ 37 ]: NO AA sea surface temp erature data, which are noisy data with long-range dep en- dencies. Eac h dataset is split into training, v alidation, and test sets with ratios of (0 . 8 , 0 . 1 , 0 . 1). Channel- wise normalisation is applied to transform data v alues into the range of [0 , 1] prior to b oth training and ev aluation. This ensures a consistent dynamic range across heterogeneous ph ysical v ariables. W e use a shifting window approach to sample input sequences from the original dataset, which con tains longer sequences generated from simulations. This approac h allo ws the mo del to fully lev erage all a v ailable input sequences, enhancing its adaptabilit y to v arious prediction scenarios. The input length is T in = 10, and the forecasting length is T out = 5 for all datasets. W e emphasise that this choice of forecasting length is made solely for fair comparison with ConvRAE and ConvL- STM baselines and do es not reflect a limitation of the prop osed mo del. In P-STMAE, future time steps are treated as mask ed p ositions in the laten t space and reconstructed in a non-autoregressive manner. As a result, the forecasting horizon can b e flexibly adjusted by sp ecifying a differen t set of masked future time indices, without any change to the mo del architecture or training pro cedure. T o mo del the irregular time series, missing steps are sampled with a random mask for each input sequence with a missing ratio of 0.5, except for Section 4.2.5 which uses mixed ratios, consisten t b et w een training and ev aluation. W e compare P-STMAE with t wo represen tative mo dels: Con vRAE, which also relies on latent represen tations with RNN temp oral mo delling, and Con vLSTM, whic h p erforms full-space sequence learning. This ensures a fair comparison b et ween laten t-space transformer, latent-space RNN, and full-space RNN-based approaches. Ev aluation metrics include: • MSE: pixel-wise accuracy , • SSIM: preserv ation of structural information, • PSNR: reconstruction fidelity and noise robustness. All metrics are computed on the normalised fields. In particular, SSIM and PSNR are ev aluated using their standard definitions after channel-wise normalisation, with the dynamic range parameter for PSNR set to MAX = 1. This a voids unit dep endence on the original ph ysical v ariables and enables consistent comparison across datasets [ 20 , 26 , 36 ]. 4.1.2 Implemen tation details Since b oth P-STMAE and ConvRAE use a CAE com bined with a laten t mo del structure, our goal is to compare their p erformance in latent space inference using the same spatial auto enco der. T o ac hieve this, we pre-trained an optimal CAE on the training dataset, then froze its parameters and used it with b oth mo dels in subsequent time series exp erimen ts. The latent dimension is set to 128 for all datasets. T o maintain consistency b et ween predictions and ground truth during 13 ev aluation, a Sigmoid activ ation function is applied at the output of the CAE deco der, ensuring that all reconstructed fields lie strictly within the normalised range of [0 , 1]. Both the enco der and deco der transformer blo c ks p ossess 2 heads, with the encoder having a depth of 4 and the deco der a depth of 1. The p ositional em b edding settings follo w those of the original T ransformer architecture [ 25 ]. An exception is made for SST data, where the mo del is expanded to include 8 heads and an encoder depth of 8. W e use the RAdam optimiser with a learning rate of 3 × 10 − 4 for training P-STMAE, and use the Adam optimiser with a learning rate of 1 × 10 − 3 for training RNN baselines. The batc h size is 32. The w eighting co efficien t of the com bined loss is set to λ = 0 . 5 as shown in Eq. ( 15 ). A common concern is that T ransformer-based mo dels require extremely large datasets, an ob- serv ation that primarily arises from applications in natural language pro cessing and natural-image mo delling, where data distributions are highly complex and high-entrop y [ 28 , 80 , 81 ]. In contrast, the scientific computing problems studied here are gov erned by smo oth, structured PDE dynamics that lie on lo w-dimensional manifolds. T ogether with latent-space compression via the con volutional auto enco der, this reduces temp oral mo delling complexity . As a result, dataset sizes of 10 5 –10 6 frames are sufficien t in our setting, and the T ransformer-based temp oral mo del do es not exhibit data inefficiency compared to ConvLSTM. The architecture is sho wn in Appendix T able A1 . All con v olutions use k ernel size 3 × 3 with same padding. T able 1 presents a comparison of test p erformance metrics across all three datasets. The results demonstrate that P-STMAE consistently ac hieves comp etitiv e or b etter p erformance compared to baseline mo dels. On the Shallo w W ater dataset, P-STMAE outperforms b oth Con vRAE and Con vLSTM across all metrics, ac hieving the low est MSE (6 . 16 × 10 − 5 ), highest SSIM (0.9538), and highest PSNR (43.90). F or the Diffusion-Reaction dataset, P-STMAE ac hieves the low est MSE (5 . 99 × 10 − 5 ) while ConvLSTM p erforms sligh tly b etter in SSIM and PSNR. On the real-w orld SST dataset, P-STMAE delivers the strongest ov erall performance, outp erforming b oth baselines with the low est MSE (8 . 02 × 10 − 5 ), highest SSIM (0.9817), and highest PSNR (41.03). These results indicate the robustness and generalisation capabilit y of P-STMAE across div erse spatiotemp oral systems, from synthetic PDE sim ulations to real-w orld climate observ ations. 4.2 Shallo w w ater test case 4.2.1 Dataset description Shallo w W ater Equations (SWEs) are a set of hyperb olic PDEs that model the flo w b eneath a pressure surface in a fluid. This dataset tests the mo dels’ ability to capture chaotic nonlinear fluid dynamics under v arying physical parameters, whic h are relev an t to geophysical flows such as atmospheric and o ceanic dynamics. The system is formulated as follows: ∂ h ∂ t + ∂ ( hu ) ∂ x + ∂ ( hv ) ∂ y = 0 , (16) ∂ u ∂ t + g ∂ h ∂ x + bu = 0 , (17) ∂ v ∂ t + g ∂ h ∂ y + bv = 0 , (18) where h is the surface height of w ater, u and v are the orthogonal velocity components a veraged in depth, g is the gravitational acceleration, and b is the friction co efficien t of the fluid. The initial condition is a cylinder bump in the w ater with a small height h abov e the surface a verage, with 14 T able 1: T est metrics in the full ph ysics space across all three datasets with a missing ratio of 0.5. Metrics for Shallo w W ater are av eraged o ver all h , u , and v v ariables; metrics for Diffusion-Reaction are a veraged ov er both u and v v ariables. Bold v alues indicate the b est p erformance among the three forecasting mo dels (excluding CAE). Dataset Mo del MSE SSIM PSNR Shallo w W ater CAE 5 . 32 × 10 − 5 0 . 9596 44 . 64 P-STMAE 6 . 16 × 10 − 5 0 . 9538 43 . 90 Con vRAE 9 . 86 × 10 − 5 0 . 9394 42 . 47 Con vLSTM 1 . 82 × 10 − 4 0 . 9231 40 . 72 Diffusion-Reaction CAE 3 . 66 × 10 − 5 0 . 9887 48 . 78 P-STMAE 5 . 99 × 10 − 5 0 . 9870 44 . 20 Con vRAE 8 . 48 × 10 − 5 0 . 9875 44 . 41 Con vLSTM 6 . 80 × 10 − 5 0 . 9928 47 . 36 SST CAE 7 . 11 × 10 − 5 0 . 9819 41 . 53 P-STMAE 8 . 02 × 10 − 5 0 . 9817 41 . 03 Con vRAE 1 . 03 × 10 − 4 0 . 9803 40 . 33 Con vLSTM 4 . 57 × 10 − 4 0 . 9384 36 . 84 a v ariable radius r , and zero velocities u and v . The b oundary conditions are p eriodic in b oth directions. Our numerical simulation is p erformed on a grid of size 128 × 128 with three v ariables [ h, u, v ]. W e sample snapshots from the sim ulation at fixed in terv als when generating eac h data sequence. The fixed time step is set to ∆ t = 10 − 4 , space step ∆ x = 10 − 2 , and gra vity g = 1 . 0. Other parameters, including the fluid friction b and the cen tre, radius, and height of the cylinder bump, and the snapshot gap, are randomised to pro duce differen t initial conditions of fluid dynamics. The detailed ranges of simulation parameters are shown in App endix T able B1 . W e generate 600 sequences, with each sequence ha ving 200 spatio-temp oral frames. 4.2.2 CAE reconstruction First, we train a conv olutional autoenco der on the shallow w ater dataset. The CAE can capture the spatial features of input ph ysical fields and reconstruct them with high fidelity . It achiev es an MSE of 5 . 32 × 10 − 5 , SSIM of 0.9596, and PSNR of 44.64 on the test set (see App endix Fig. ?? ). These strong reconstruction metrics indicate that the CAE provides reliable latent representations for subsequent sequence mo delling. 4.2.3 Mo del comparison The v alidation results for the shallo w w ater dataset demonstrate the efficacy of the P-STMAE mo del compared to the baseline mo dels. In terms of full-space MSE, the P-STMAE outp erforms b oth ConvRAE and ConvLSTM. The full-space MSE curve for P-STMAE lies m uch closer to that of the CAE’s p erformance, indicated b y the dotted line (see App endix Fig. ?? ). This pro ximity suggests that the time series mask ed auto enco der is effectiv e at exploiting the seman tic information hidden in laten t representations, making P-STMAE’s p erformance nearly matc h the reconstruction capabilit y of the CAE. Analysing the latent MSE curv es, we observe a consistent pattern whereby the P-STMAE surpasses the ConvRAE in terms of reducing prediction error within the latent 15 space. The p erformance indicates an abilit y to handle complex nonlinear spatiotemp oral patterns, whic h the baseline mo dels struggle with. This confirms that transformer-based laten t inference is more effective than RNN-based alternativ es in the presence of chaotic fluid dynamics. Despite its p erformance, the P-STMAE exhibits a relatively slow er con vergence sp eed compared to the RNN-based mo dels. This b eha viour can b e attributed to the complex self-attention mech- anisms within the transformer architecture, whic h require a slow er learning pro cess to adequately tune weigh ts to capture ov erall time series dep endencies. The test p erformance metrics for the shallow water dataset (see T able 1 ) further substan tiate the sup erior p erformance of the P-STMAE mo del o ver the baseline mo dels. Apart from the low est full-space MSE, the P-STMAE demonstrates the highest SSIM, reflecting its abilit y to main tain structural integrit y and p erceptual quality of the reconstructed ph ysical fields. In terms of PSNR, the P-STMAE also scores the highest, confirming its effectiv eness in minimising noise and enhancing the clarity of predictions compared to the other models. Fig. 3 provides a detailed visual comparison of prediction errors across all three mo dels. The error maps reveal that P-STMAE consistently pro duces the smallest prediction errors across successiv e forecasting steps, with error magnitudes lo wer than both Con vRAE and Con vLSTM. The spatial distribution of errors for P-STMAE is more uniform and concentrated in regions with higher ph ysical complexit y , while the baseline mo dels exhibit larger and more widespread error patterns in areas with strong nonlinear dynamics (see App endix Fig. ?? ). 4.2.4 Ablation study on loss weigh ting co efficien t W e conduct an ablation study on the shallow w ater dataset to in v estigate the sensitivit y of P- STMAE to the weigh ting co efficien t λ in the combined loss function (Eq. 15 ). The ablation study results demonstrate that mo del performance is not sensitive to λ within the range [0 . 2 , 1 . 0] (see App endix T able B2 and Fig. ?? ). Based on these findings, we fix λ = 0 . 5 for all exp erimen ts for simplicit y , as this v alue provides a balanced trade-off betw een physical and laten t space consistency while maintaining robust p erformance across different λ v alues. 4.2.5 Missing ratio analysis W e analyse mo del p erformance under v arying amoun ts of missing data to assess generalisation capabilit y as the n umber of missing steps increases. T o ev aluate their performance, w e train all mo dels with missing steps ranging from 1 to 6 with a fixed input sequence length of 10 and ev aluate them under corresp onding settings. During training, w e main tain a fixed missing ratio within eac h batc h and randomise this ratio b et ween differen t batches to leverage parallelism and accelerate training. Fig. 4 presents the results of these robustness exp erimen ts. Panel (a) sho ws p erformance com- parison under v arying n umbers of missing steps, while panel (b) sho ws test p erformance comparison regarding sampling dilations. F or missing ratio analysis (Fig. 4 (a)), P-STMAE consistently outper- forms the baseline mo dels in MSE across all missing step conditions. The error curves demonstrate that P-STMAE maintains consisten tly lo w prediction errors even as the n umber of missing steps increases from 1 to 6, with the MSE curve remaining relatively flat. In con trast, b oth ConvRAE and Con vLSTM show progressiv ely increasing errors as missing steps increase, with Con vLSTM exhibiting sharp degradation. This indicates that the transformer-based arc hitecture of P-STMAE, whic h lev erages atten tion mec hanisms and contextual enco ding, maintains low er prediction errors when reconstructing sequences with v arying levels of missing data. Con vLSTM p erforms well at lo w er missing steps (1 and 2) and ac hiev es higher PSNR v alues 16 Gr ound T ruth Er r or (P -STMAE) Er r or (ConvR AE) Er r or (ConvLSTM) 0.45 0.50 0.55 0.00 0.02 0.04 0.06 0.08 0.00 0.02 0.04 0.06 0.08 0.00 0.02 0.04 0.06 0.08 Figure 3: Ground truth (top) and error maps of P-STMAE, Con vRAE, and ConvLSTM for fore- casting the v ariable u in the shallow w ater dataset with a sampling dilation of 3. Columns represen t successiv e forecasting steps. Among the models, P-STMAE yields the smallest errors, indicating predictiv e accuracy . than P-STMAE in these conditions. As the n umber of missing steps increases, its p erformance deteriorates sharply , rev ealing sensitivity to temp oral disruptions and difficult y in handling irregular sequences due to its end-to-end prediction in full-space. ConvRAE exhibits a similar trend, with decen t p erformance at low er missing steps but a noticeable decline as missing data increases. The exp eriment demonstrates that P-STMAE main tains high p erformance across different miss- ing ratios. In con trast, the RNN-based mo dels are more effectiv e with limited missing data but struggle as gaps increase, highligh ting the adv antage of transformer-based attention mechanisms for handling irregular sampling. 4.2.6 Nonlinear robustness analysis W e explore nonlinear robustness b y in tro ducing dilations into the sampling window with a fixed missing ratio of 0.5. Dilation increases the time gaps b et ween consecutiv e data points by a fixed factor, testing whether mo dels can generalise when temp oral dynamics b ecome more irregular and c haotic. 17 Mathematically , giv en an original time series sequence: X = { x 1 , x 2 , x 3 , . . . , x T } , (19) where x t represen ts the v alue at time step t , and a dilated sequence with dilation factor d is defined as: X d = { x 1 , x 1+ d , x 1+2 d , . . . , x 1+ kd } , (20) where k is the largest in teger satisfying 1 + k d ≤ T . This means that ev ery d -th elemen t is sampled, increasing the time gap b etw een consecutive p oin ts. This op eration sim ulates irregular, nonlinear time steps b y introducing structured sparsity into the sequence. The dilation parameter d controls the degree of this gap expansion, allo wing us to in tro duce more v ariability in the time structure. As d increases, the sequence b ecomes less regular and more nonlinear, challenging the mo dels to generalise and capture complex, evolving temp oral dynamics. P anel (b) of Fig. 4 sho ws the test p erformance results o ver differen t dilations. The p erformance curv es rev eal distinct patterns: P-STMAE exhibits stable p erformance across different dilations, with MSE v alues remaining consistently low even as dilation increases, demonstrating robustness when faced with increasing nonlinearities. In con trast, Con vLSTM shows sensitivit y to dilation c hanges, performing well at minimal dilation but deteriorating rapidly as dilation increases, with error v alues rising. ConvRAE sho ws mo derate sensitivity , with p erformance declining gradually but remaining better than Con vLSTM at higher dilations. This suggests that Con vLSTM struggles to generalise in complex scenarios where temp oral dep endencies b ecome harder to capture due to high nonlinearities, likely because it op erates directly in full physics space where temp oral relations are chaotic on sparse features. Both P-STMAE and ConvRAE show resilience to dilation, suggesting that latent-space archi- tectures are b etter suited for handling c haotic data. By pro cessing spatial information into dense features via CAEs, they can manage complex, nonlinear patterns without b eing directly impacted b y irregularities in the full physics space. The p erformance gap b etw een P-STMAE and ConvRAE further reveals the transformer-based capability in capturing irregular temp oral dep endencies com- pared to RNNs. 4.3 Diffusion reaction test case 4.3.1 Dataset description The 2D diffusion-reaction equations are commonly employ ed to mo del phenomena where diffusion and reaction pro cesses in teract in a spatial domain, suc h as biological pattern formation. Compared to the shallow water case, this case emphasises coupled nonlinear in teractions and pattern forma- tion. The system consists of tw o nonlinearly coupled v ariables, the activ ator u and the inhibitor v . The equations gov erning their evolution are giv en by [ 36 ]: ∂ u ∂ t = α u ∂ 2 u ∂ x 2 + ∂ 2 u ∂ y 2 + F u ( u, v ) , (21) ∂ v ∂ t = α v ∂ 2 v ∂ x 2 + ∂ 2 v ∂ y 2 + F v ( u, v ) . (22) 18 1 2 3 4 5 6 Input Missing Steps 1 0 1 2 3 4 MSE × 1 0 4 P -STMAE ConvR AE ConvLSTM 1 2 3 4 5 6 Input Missing Steps 0.850 0.875 0.900 0.925 0.950 0.975 1.000 1.025 SSIM P -STMAE ConvR AE ConvLSTM 1 2 3 4 5 6 Input Missing Steps 35.0 37.5 40.0 42.5 45.0 47.5 50.0 52.5 PSNR P -STMAE ConvR AE ConvLSTM (a) Missing ratio analysis 1 2 3 4 Sampling Dilation 0 1 2 3 4 MSE × 1 0 4 P -STMAE ConvR AE ConvLSTM 1 2 3 4 Sampling Dilation 0.850 0.875 0.900 0.925 0.950 0.975 1.000 SSIM P -STMAE ConvR AE ConvLSTM 1 2 3 4 Sampling Dilation 35.0 37.5 40.0 42.5 45.0 47.5 50.0 52.5 55.0 PSNR P -STMAE ConvR AE ConvLSTM (b) Sampling dilation analysis Figure 4: Robustness analysis of P-STMAE on the shallo w w ater dataset. (a) P erformance com- parison under v arying n um b ers of missing steps in the input sequence with a length of 10. Each mo del is trained and ev aluated with missing steps ranging from 1 to 6. P-STMAE demonstrates consisten t p erformance and robustness, while the RNN-based mo dels, esp ecially ConvLSTM, show higher sensitivit y to increasing missing steps. (b) T est p erformance comparison regarding the sam- pling dilations of data sequences. All mo dels are separately trained on the shallo w water dataset of different dilations. Here, α u and α v denote the diffusion co efficients for the activ ator and inhibitor. The reaction functions F u and F v follo w the FitzHugh-Nagumo mo del: F u ( u, v ) = u − u 3 − c − v , (23) F v ( u, v ) = u − v , (24) where c is a constant parameter that affects the reaction kinetics. The domain for the sim ulation extends o ver x, y ∈ [ − 1 , 1] with time t ∈ (0 , 5]. The no-flo w Neumann b oundary conditions ensure that the flux of b oth u and v across the b oundaries remains zero. The training dataset, av ailable from the PDEBench [ 36 ] pro ject, is discretised into 128 × 128 spatial grid p oin ts and 100 temp oral steps, with 10,000 sample sequences. The 2D diffusion-reaction dataset p oses a challenge due to the nonlinear coupling betw een the activ ator and inhibitor, and its applicability to real-world problems such as biological pattern 19 Gr ound T ruth Er r or (P -STMAE) Er r or (ConvR AE) Er r or (ConvLSTM) 0.20 0.30 0.40 0.50 0.60 0.00 0.05 0.10 0.00 0.05 0.10 0.00 0.05 0.10 Figure 5: Ground truth (top) and error maps of P-STMAE, Con vRAE, and ConvLSTM for fore- casting the v ariable u in the diffusion-reaction dataset with a sampling dilation of 5. Columns represen t successive forecasting steps. The results show that P-STMAE consistently achiev es low er errors than the baselines, confirming its adv an tage. formation. 4.3.2 Mo del comparison F or the diffusion-reaction dataset (see T able 1 ), P-STMAE ac hieves the lo west MSE among the baselines, indicating numerical accuracy in minimising p oint wise error. How ever, P-STMAE sligh tly underp erforms in SSIM and PSNR compared to ConvLSTM, suggesting a trade-off b etw een pixel- wise accuracy and higher-order spatial consistency (see App endix Fig. C1 ). This ma y arise b ecause Con vLSTM op erates directly in the full ph ysics space, p oten tially b etter preserving structural patterns and p erceptual quality for complex coupled-v ariable systems, while P-STMAE’s laten t- space compression may introduce subtle spatial distortions despite p oin t wise accuracy . Fig. 5 provides a visual comparison of prediction errors across all three mo dels. The error maps demonstrate that P-STMAE consisten tly achiev es lo wer prediction errors than b oth baseline mo d- els across successive forecasting steps. The spatial error patterns reveal that P-STMAE maintains higher accuracy in regions with complex pattern formations, where the activ ator and inhibitor v ari- ables exhibit strong coupling. In con trast, ConvRAE and ConvLSTM show larger error magnitudes in areas where the reaction dynamics create intricate spatial structures (see App endix Fig. ?? ). 20 Gr ound T ruth Er r or (P -STMAE) Er r or (ConvR AE) Er r or (ConvLSTM) 0.00 0.25 0.50 0.75 0.00 0.05 0.10 0.15 0.00 0.05 0.10 0.15 0.00 0.05 0.10 0.15 Figure 6: Error maps of P-STMAE, ConvRAE, and Con vLSTM predictions for the forecasting steps in the SST dataset. 4.4 NO AA sea surface temp erature test case 4.4.1 Dataset description The SST [ 37 ] dataset pro vides a long-term climate record of weekly sea surface temperature ob- serv ations spanning the p erio d from 1981 to 2018. These data are collected from m ultiple sources, including satellites, ships, buo ys, and Argo floats, and are then interpolated to pro duce a con tin uous global grid of temp erature data. The spatial resolution of the dataset is 360 × 180, corresp onding to a global grid where each unit cov ers a 1-degree area of latitude and longitude. The dataset consists of 1914 snapshots, eac h represen ting the global distribution of sea surface temp eratures at weekly in terv als. These observ ations are stored as a single temp erature v ariable. The temporal and spatial con tinuit y of the dataset makes it v aluable for studying long-term climate trends, o ceanic pro cesses, and their influence on weather and marine ecosystems. The SST dataset is widely used for analysing climate v ariabilit y , detecting anomalies such as El Ni˜ no and La Ni ˜ na, and studying o ceanic heat conten t changes. This dataset presents a com- plex spatiotemp oral problem, as o cean temp eratures are influenced by long-term climatic patterns, o ceanic currents, and seasonal v ariations. 4.4.2 Mo del comparison The p erformance on the SST dataset (T able 1 , missing ratio 0.5) demonstrates P-STMAE’s strong generalisation to real-world climate data. P-STMAE deliv ers the strongest o verall performance, ac hieving the lo west MSE (8 . 02 × 10 − 5 ), highest SSIM (0.9817), and highest PSNR (41.03) compared with the baselines. The transformer arc hitecture enables P-STMAE to b etter handle irregularities 21 and capture long-term dependencies in the SST dataset, leading to more accurate temporal pre- dictions. The p erformance of Con vRAE closely follo ws P-STMAE, while ConvLSTM falls b ehind, suggesting that latent-space compression is crucial for mo delling real-world systems, and reduces the impact of noise and chaotic patterns that Con vLSTM struggles to capture at global scale. Fig. 6 presen ts error maps comparing all three mo dels across forecasting steps. The global error patterns rev eal that P-STMAE ac hieves the smallest prediction errors across most oceanic regions, with strong p erformance in areas with complex temp erature gradients suc h as ocean fron ts and up welling zones. The error distribution sho ws that P-STMAE maintains consistent accuracy across differen t latitudinal bands and o ceanic basins, demonstrating its ability to capture both large-scale climate patterns and regional temp erature v ariations. In contrast, Con vLSTM exhibits larger and more spatially widespread errors in regions with strong seasonal v ariations and complex curren t systems, highligh ting the challenges of full-space modelling for global-scale climate data (see App endix Fig. D1 ). 5 Conclusion and future w ork In this pap er, we in tro duced the P-STMAE, a nov el mo del designed to address irregular time series prediction in high-dimensional dynamical systems. By in tegrating CAEs with transformer-based mask ed auto encoders, P-STMAE employs placeholder-based attention to handle missing data and irregular time steps directly without prepro cessing T able B2 . Exp eriments across syn thetic PDE b enc hmarks and real-world SST data demonstrated its robustness, computational efficiency , and b etter accuracy compared to traditional RNN-based approac hes Fig. D1 . A key adv antage of P-STMAE is its laten t-space mask ed training, which enables efficien t pro- cessing of high-dimensional data. By op erating in a compressed representation, the mo del reduces computational cost while maintaining spatiotemp oral pattern learning. This efficiency is b eneficial for large-scale systems where computational resources are constrained. Despite its promising p erformance, several limitations highlight areas for future research. The quadratic complexit y of the transformer’s global self-atten tion p oses challenges for pro cessing very long sequences. Exploring alternatives like lo cal or sparse atten tion mec hanisms could enhance scalabilit y . T o efficiently handle relative time em b edding in irregular time series, future w ork could consider adv anced pos itional embedding techniques, suc h as A ttention with Linear Biases (AL- iBi) [ 82 ] and Rotary Position Em b edding (RoPE) [ 83 ], which can b etter capture relative temp oral relationships without explicit p ositional enco dings. Additionally , the reliance on the con volutional auto encoder may in tro duce a b ottlenec k, p oten tially limiting reconstruction fidelity . F uture w ork could in vestigate adv anced ph ysical field enco ding techniques, such as V AEs or Vision T ransform- ers, to o vercome this limitation. F urthermore, the observed trade-off b et ween minimizing p oin t- wise prediction errors and preserving structural fidelity in spatiotemporal data remains an op en c hallenge. F uture researc h could fo cus on m ulti-ob jective optimisation strategies that balance n u- merical accuracy with the preserv ation of global structures. Finally , while the encouraging results on SST pro vide an initial demonstration of real-world applicability , broader v alidation on div erse real-w orld datasets will b e essential to fully establish the mo del’s generalizability . In summary , this w ork adv ances irregular time series forecasting for high-dimensional dynamical systems. P-STMAE offers a purely data-driven, adaptable, and computationally efficient solution, positioning it as a promising to ol for scientific and industrial applications requiring accurate prediction of complex spatiotemp oral systems. 22 CRediT authorship con tribution statemen t Kew ei Zh u: W riting – original draft, Softw are, Inv estigation, F ormal analysis, Data curation. Y anze Xin: W riting – original draft, Metho dology , Inv estigation, F ormal analysis, Data curation. Jin w ei Hu: W riting – review & editing, V alidation, Metho dology . Xiao yuan Cheng: W riting – review & editing, V alidation, In vestigation. Yiming Y ang: W riting – review & editing, V alida- tion, In vestigation. Sibo Cheng: W riting – review & editing, V alidation, In vestigation, F unding acquisition, Conceptualization. Data a v ailabilit y The co de of this study is a v ailable at https://github.com/RyanXinOne/PSTMAE . Declaration of comp eting in terest The authors declare that they ha v e no kno wn competing financial interests or p ersonal relationships that could hav e app eared to influence the work rep orted in this pap er. A Detailed Visualization of Mo del Predictions A.1 Mo del arc hitecture T able A1: Net work structures of CAE enco der (left) and decoder (right) used in the P-STMAE. All of the conv olutions and transp ose conv olutions use the kernel size of 3 × 3 and the same padding. The input dimension and c hannel num b er can v ary dep ending on the dataset. La yer Type Output Shap e Activ ation Input (128, 128, 3) Con v 2D (128, 128, 8) GELU Con v 2D (64, 64, 16) GELU Con v 2D (32, 32, 32) GELU Con v 2D (16, 16, 64) GELU Con v 2D (8, 8, 128) GELU Linear (128) Input (128) Linear (8, 8, 128) GELU T ransConv 2D (16, 16, 64) GELU T ransConv 2D (32, 32, 32) GELU T ransConv 2D (64, 64, 16) GELU T ransConv 2D (128, 128, 8) GELU Con v 2D (128, 128, 3) Sigmoid 23 T able B1: Ranges of computational parameters used in the shallo w water equation sim ulations. All parameters are uniformly sampled. P arameter Sym b ol Min V alue Max V alue Initial bump centre (x) p x 54.00 74.00 Initial bump centre (y) p y 54.00 74.00 Bump height h 0.05 0.20 Bump radius r 8.94 12.65 F riction co efficien t b 0.02 2.00 Snapshot interv al (steps) – 60.00 100.00 T able B2: Quan titative ablation study on λ . λ MSE SSIM PSNR 0.01 5 . 85 × 10 − 5 0.9276 41.02 0.02 5 . 25 × 10 − 5 0.9317 41.52 0.05 4 . 72 × 10 − 5 0.9264 40.82 0.10 5 . 20 × 10 − 5 0.9315 41.60 0.20 6 . 10 × 10 − 5 0.9177 39.56 0.50 8 . 00 × 10 − 5 0.9356 42.07 0.60 2 . 17 × 10 − 4 0.9037 35.46 0.70 2 . 20 × 10 − 4 0.9017 35.38 1.00 2 . 18 × 10 − 4 0.9037 35.43 B Shallo w W ater T est Case C Diffusion Reaction T est Case 1 8 15 22 29 36 43 50 57 64 71 78 Epoch 1 0 4 1 0 3 F ull Space MSE (log) P -STMAE ConvR AE ConvLSTM CAE 1 8 15 22 29 36 43 50 57 64 71 78 Epoch 1 0 2 1 0 1 1 0 0 Latent MSE (log) P -STMAE ConvR AE Figure C1: V alidation MSEs on the diffusion reaction dataset with the sampling dilation of 5. 24 D NO AA Sea Surface T emp erature T est Case Gr ound T ruth P r ed (P -STMAE) P r ed (ConvR AE) P r ed (ConvLSTM) Er r or (P -STMAE) Er r or (ConvR AE) Er r or (ConvLSTM) 0.00 0.25 0.50 0.75 0.00 0.25 0.50 0.75 0.00 0.25 0.50 0.75 0.00 0.25 0.50 0.75 0.00 0.05 0.10 0.15 0.00 0.05 0.10 0.15 0.00 0.05 0.10 0.15 Figure D1: Mo del predictions and error maps for the forecasting steps in the SST dataset. References [1] K. F uk ami, R. Maulik, N. Ramac handra, K. F uk agata, K. T aira, Global field reconstruction from sparse sensors with v oronoi tessellation-assisted deep learning, Nat. Mac h. Intell. 3 (11) 25 (2021) 945–951. [2] L. A. Caffarelli, P . E. Souganidis, Rates of conv ergence for the homogenization of fully nonlinear uniformly elliptic p de in random media, In ven t. Math. 180 (2) (2010) 301–360. [3] M. Brin, G. Stuck, Introduction to Dynamical Systems, Cambridge univ ersity press, 2002. [4] S. L. Brun ton, B. W. Brunton, J. L. Proctor, E. Kaiser, J. N. Kutz, Chaos as an in termittently forced linear system, Nat. Comm un. 8 (1) (2017) 19. [5] S. Siami-Namini, N. T a v ak oli, A. S. Namin, The p erformance of LSTM and BiLSTM in fore- casting time series, in: 2019IEEE In ternational Conference on B ig Data (Big Data), IEEE, 2019, pp. 3285–3292. [6] P . B. W eerak o dy , K. W. W ong, G. W ang, W. Ela, A review of irregular time series data handling with gated recurrent neural netw orks, Neuro computing 441 (2021) 161–178. [7] B. Johnson, S. B. Munc h, An empirical dynamic mo deling framew ork for missing or irregular samples, Ecol. Mo dell. 468 (2022) 109948. [8] S. Cheng, C. Liu, Y. Guo, R. Arcucci, Efficien t deep data assimilation with sparse observ ations and time-v arying sensors, J. Comput. Phys. 496 (2024) 112581. [9] E. Afrifa-Y amoah, U. A. Mueller, S. M. T aylor, A. J. Fisher, Missing data imputation of high-resolution temp oral climate time series data, Meteorol. Appl. 27 (1) (2020) e1873. [10] H. Ahn, K. Sun, K. P . Kim, et al., Comparison of missing data imputation metho ds in time series forecasting, Comput. Mater. Con tinua 70 (1) (2022) 767–779. [11] B. K. Nelson, Time series analysis using autoregressive integrated moving a verage (ARIMA) mo dels, Acad. Emerg. Med. 5 (7) (1998) 739–744. [12] V. G´ omez, A. Mara v all, Estimation, prediction, and in terp olation for nonstationary series with the Kalman filter, J. Am. Stat. Asso c. 89 (426) (1994) 611–624. [13] V. I. Kontopoulou, A. D. P anagop oulos, I. Kakk os, G. K. Matsop oulos, A review of ARIMA vs. machine learning approac hes for time series forecasting in data driv en netw orks, F uture In ternet 15 (8) (2023) 255. [14] S. Siami-Namini, N. T av akoli, A. S. Namin, A comparison of ARIMA and LSTM in fore- casting time series, in: 2018 17th IEEE In ternational Conference on Machine Learning and Applications (ICMLA), Ieee, 2018, pp. 1394–1401. [15] A. Carrassi, M. Bo cquet, L. Bertino, G. Evensen, Data assimilation in the geosciences: an o verview of methods, issues, and p erspectives, Wiley Interdiscip. Rev. Clim. Change 9 (5) (2018) e535. [16] M. I. Rib eiro, Kalman and extended k alman filters: concept, deriv ation and prop erties, Inst. Syst. Rob. 43 (46) (2004) 3736–3741. [17] E. A. W an, R. V an Der Merw e, The unscented k alman filter for nonlinear estimation, in: Pro ceedings of the IEEE 2000 Adaptive Systems for Signal Pro cessing, Comm unications, and Con trol Symp osium (Cat. No. 00EX373), Ieee, 2000, pp. 153–158. 26 [18] S. Cheng, C. Quilo dr´ an-Casas, S. Ouala, A. F archi, C. Liu, P . T andeo, R. F ablet, D. Lucor, B. Io oss, J. Bra jard, et al., Mac hine learning with data assimilation and uncertaint y quantification for dynamical systems: a review, IEEE/CAA J. Autom. Sin. 10 (6) (2023) 1361–1387. [19] T. Gleiter, T. Janji ´ c, N. Chen, Ensem ble Kalman filter based data assimilation for tropical w av es in the MJO sk eleton mo del, Q. J. R. Meteorolog. So c. 148 (743) (2022) 1035–1056. [20] F. J. Gonzalez, M. Bala jewicz, Deep conv olutional recurren t auto enco ders for learning low- dimensional feature dynamics of fluid systems, (2018). [21] S. Hochreiter, The v anishing gradient problem during learning recurrent neural nets and prob- lem solutions, Int. J. Uncertain ty F uzziness Knowl. Based Syst. 6 (02) (1998) 107–116. [22] B. Chang, M. Chen, E. Hab er, E. H. Chi, AntisymmetricRNN: A dynamical system view on recurren t neural net works, (2019). [23] X. Shi, Z. Chen, H. W ang, D.-Y. Y eung, W.-K. W ong, W.-c. W o o, Con volutional LSTM net work: a machine learning approac h for precipitation no wcasting, Adv. Neural Inf. Pro cess. Syst. 28 (2015). [24] V. Iako vlev, H. L¨ ahdesm¨ aki, Mo deling Randomly Observed Spatiotemp oral Dynamical Sys- tems, (2024). [25] A. V aswani, N. Shazeer, N. Parmar, J. Uszk oreit, L. Jones, A. N. Gomez, L. Kaiser, I. P olo- sukhin, Atten tion is all you need, Adv. Neural Inf. Pro cess. Syst. 30 (2017), 6000–6010. [26] N. Genev a, N. Zabaras, T ransformers for mo deling physical systems, Neural Netw. 146 (2022) 272–289. [27] C. F eic htenhofer, Y. Li, K. He, et al., Mask ed auto enco ders as spatiotemp oral learners, Adv. Neural Inf. Pro cess. Syst. 35 (2022) 35946–35958. [28] A. Radford, J. W u, R. Child, D. Luan, D. Amo dei, I. Sutskev er, et al., Language mo dels are unsup ervised multitask learners, Op enAI blog 1 (8) (2019) 9. [29] J. Devlin, M.-W. Chang, K. Lee, K. T outano v a, Bert: Pre-training of deep bidirectional trans- formers for language understanding, (2018). [30] K. He, X. Chen, S. Xie, Y. Li, P . Doll´ ar, R. Girshic k, Masked auto encoders are scalable vision learners, in: Proceedings of the IEEE/CVF Conference on Computer Vision and P attern Recognition, 2022, pp. 16000–16009. [31] Z. Li, Z. Rao, L. Pan, P . W ang, Z. Xu, Ti-mae: Self-sup ervised masked time series autoen- co ders, (2023). [32] G. Karlsson, Detecting Anomalies in Im balanced Financial Data with a T ransformer Auto en- co der, 2024, [33] H. Patel, R. Qiu, A. Irwin, S. Sadiq, S. W ang, EMIT-Ev ent-Based Masked Auto Enco ding for Irregular Time Series, (2024). [34] Q. W en, T. Zhou, C. Zhang, W. Chen, Z. Ma, J. Y an, L. Sun, T ransformers in time series: A surv ey , (2022). 27 [35] C. Zhu, J. F u, D. Xiao, J. W ang, Nonlinear mo del order reduction of engineering turbulence using data-assisted neural netw orks, Comput. Phys. Comm un. 309 (2025) 109501. [36] M. T ak amoto, T. Praditia, R. Leiteritz, D. MacKinlay , F. Alesiani, D. Pfl ¨ uger, M. Niep ert, Pdeb enc h: an extensive b enc hmark for scientific mac hine learning, Adv. Neural Inf. Pro cess. Syst. 35 (2022) 1596–1611. [37] B. Huang, C. Liu, V. Banzon, E. F reeman, G. Graham, B. Hankins, T. Smith, H.-M. Zhang, Impro vemen ts of the daily optimum in terp olation sea surface temp erature (DOISST) version 2.1, J. Clim. 34 (8) (2021) 2923–2939. [38] R. J. LeV eque, Finite v olume metho ds for hyperb olic problems, 31, Cambridge universit y press, 2002. [39] S. Cheng, M. Bo cquet, W. Ding, T. S. Finn, R. F u, J. F u, Y. Guo, E. Johnson, S. Li, C. Liu, et al., Mac hine learning for mo delling unstructured grid data in computational physics: a review, Inf. F usion 114 (2025) 103255. [40] Q. Liu, J. Y e, H. Liang, L. Sun, B. Du, TS-MAE: a masked auto enco der for time series represen tation learning, Inf. Sci. 690 (2025) 121576. [41] Y.-Y. Xu, J. Luo, D. P an, W. Lu, T. Liu, G. Y uan, M. Zhong, Q. Li, H. Gong, A laten t- coupled neural net work for m ultiphysics long-term forecasting in reactor transien ts using sparse observ ations, Eng. Appl. Artif. Intell. 162 (2025) 112496. [42] S. Riv a, A. Missaglia, C. Introini, I. C. Bang, A. Cammi, A Comparison of P arametric Dynamic Mo de Decomp osition Algorithms for Thermal-Hydraulics Applications, (2025). [43] P . Benner, S. Gugercin, K. Willcox, A surv ey of pro jection-based model reduction metho ds for parametric dynamical systems, SIAM Rev. 57 (4) (2015) 483–531. [44] M. J. Asher, B. F. W. Crok e, A. J. Jakeman, L. J. M. Peeters, A review of surrogate mo dels and their application to groundw ater mo deling, W ater Resour. Res. 51 (8) (2015) 5957–5973. [45] R. F u, D. Xiao, A. G. Buc han, X. Lin, Y. F eng, G. Dong, A parametric nonlinear non-in trusiv e reduce-order mo del using deep transfer learning, Comput. Metho ds Appl. Mech. Eng. 438 (2025) 117807. [46] X. Pan, D. Xiao, Domain decomp osition for physics-data com bined neural net w ork based parametric reduced order mo delling, J. Comput. Ph ys. 519 (2024) 113452. [47] M. Abbaszadeh, A. Khodadadian, M. Parvizi, M. Dehghan, D. Xiao, A reduced-order least squares-supp ort v ector regression and isogeometric collo cation metho d to simulate Cahn- Hilliard-Na vier-Stokes equation, J. Comput. Phys. 523 (2025) 113650. [48] K. F uk ami, K. T aira, Grasping extreme aero dynamics on a low-dimensional manifold, Nat. Comm un. 14 (1) (2023) 6480. [49] J. Guo, D. Xiao, Nonlinear Mo del Reduction by Probabilistic Manifold Decomp osition, (2025). [50] A. Ma´ ckiewicz, W. Rata jczak, Principal comp onen ts analysis (PCA), Comput. Geosci. 19 (3) (1993) 303–342. 28 [51] B. Karas¨ ozen, S. Yıldız, M. Uzunca, Intrusiv e and data-driven reduced order mo delling of the rotating thermal shallow water equation, Appl. Math. Comput. 421 (2022) 126924. [52] P . Li, Y. Pei, J. Li, A comprehensiv e survey on design and application of auto enco der in deep learning, Appl. Soft. Comput. 138 (2023) 110176. [53] J. W u, D. Xiao, M. Luo, Deep-learning assisted reduced order mo del for high-dimensional flow prediction from sparse data, Ph ys. Fluids 35 (10) (2023) 103115. [54] L. R. Medsker, L. Jain, et al., Recurrent neural net works, Des. Appl. 5 (64–67) (2001) 2. [55] Z. C. Lipton, J. Berk owitz, C. Elk an, A critical review of recurren t neural netw orks for sequence learning, (2015). [56] M. Sundermeyer, R. Schl¨ uter, H. Ney , Lstm neural netw orks for language mo deling, in: In ter- sp eec h, 2012, 2012, pp. 194–197. [57] H. Gong, Q. Li, Accelerating long-term xenon dynamics prediction: a reduced-order h ybrid recurren t neural net work with in trinsic physics, Nucl. Sci. Eng. 200 (2025) 1–21. [58] S. Cheng, J. Chen, C. Anastasiou, P . Angeli, O. K. Matar, Y.-K. Guo, C. C. Pain, R. Ar- cucci, Generalised laten t assimilation in heterogeneous reduced spaces with machine learning surrogate mo dels, J. Sci. Comput. 94 (1) (2023) 11. [59] M. Lechner, R. Hasani, Learning long-term dependencies in irregularly-sampled time series, (2020). [60] Z. Y ang, Z. Dai, R. Salakh utdinov, W. W. Cohen, Breaking the softmax b ottlenec k: A high- rank RNN language mo del, (2017). [61] J. F an, Q. Li, J. Hou, X. F eng, H. Karimian, S. Lin, A spatiotemp oral prediction framework for air p ollution based on deep RNN, ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 4 (2017) 15–22. [62] P . M. T. Bro ersen, R. Bos, Estimating time-series mo dels from irregularly spaced data, IEEE T rans. Instrum. Meas. 55 (4) (2006) 1124–1131. [63] M. Lep ot, J.-B. Aubin, F. H. Clemens, In terp olation in time series: an in tro ductiv e o verview of existing metho ds, their p erformance criteria and uncertaint y assessment, W ater 9 (10) (2017) 796. [64] V. F ortuin, D. Baranch uk, G. R¨ atsch, S. Mandt, GP-V AE: deep probabilistic time series imputation, in: International Conference on Artificial In te lligence and Statistics, PMLR, 2020, pp. 1651–1661. [65] Z. Guo, Y. W an, H. Y e, A data imputation metho d for multiv ariate time series base d on generativ e adversarial net work, Neuro computing 360 (2019) 185–197. [66] Y. Luo, X. Cai, Y. Zhang, J. Xu, et al., Multiv ariate time series imputation with generative adv ersarial netw orks, Adv. Neural Inf. Pro cess. Syst. 31 (2018), 15944–15954. [67] C. F ang, C. W ang, Time series data imputation: A surv ey on deep learning approaches, (2020). 29 [68] J. Y oon, J. Jordon, M. Schaar, Gain: missing data imputation using generative adv ersarial nets, in: International Conference on Machine Learning, PMLR, 2018, pp. 5689–5698. [69] Y. Zhuang, S. Cheng, K. Duraisamy , Spatially-aw are diffusion mo dels with cross-attention for global field reconstruction with sparse observ ations, Comput. Metho ds Appl. Mech. Eng. 435 (2025) 117623. [70] S. Riv a, C. Introini, E. Zio, A. Cammi, Data-driv en reduced order mo delling with malfunc- tioning sensors reco very applied to the molten salt reactor case, EPJ Nuclear Sciences & T echnologies 11 (2025) 55. [71] P . Gao, T. Ma, H. Li, Z. Lin, J. Dai, Y. Qiao, Con vmae: Mask ed conv olution meets masked auto encoders, (2022). [72] G. Zerv eas, S. Jay araman, D. Patel, A. Bhamidipaty , C. Eic khoff, A transformer-based frame- w ork for multiv ariate time series representation learning, in: Pro ceedings of the 27th A CM SIGKDD Conference on Knowledge Disco very & Data Mining, 2021, pp. 2114–2124. [73] J. F u, D. Xiao, R. F u, C. Li, C. Zhu, R. Arcucci, I. M. Nav on, Physics-data combined mac hine learning for parametric reduced-order mo delling of nonlinear dynamical systems in small-data regimes, Comput. Metho ds Appl. Mech. Eng. 404 (2023) 115771. [74] G. Mahalakshmi, S. Sridevi, S. Ra jaram, A survey on forecasting of time series data, in: 2016 In ternational Conference on Computing T ec hnologies and Intelligen t Data Engineering (ICCTIDE’16), IEEE, 2016, pp. 1–8. [75] Z. W ang, A. C. Bo vik, H. R. Sheikh, E. P . Simoncelli, Image quality assessmen t: from error visibilit y to structural similarity , IEEE T rans. Image Pro cess. 13 (4) (2004) 600–612. [76] Q. Huynh-Thu, M. Ghanbari, The accuracy of PSNR in predicting video quality for different video scenes and frame rates, T elecomm un. Syst. 49 (2012) 35–48. [77] J. Y o on, W. R. Zame, M. v an der Sc haar, Estimating missing data in temp oral data streams using multi-directional recurren t neural net works, IEEE T rans. Biomed. Eng. 66 (5) (2018) 1477–1490. [78] Z. Che, S. Purushotham, K. Cho, D. Son tag, Y. Liu, Recurren t neural net works for multiv ariate time series with missing v alues, Sci. Rep. 8 (1) (2018) 6085. [79] S. Cheng, J.-P . Argaud, B. Io oss, D. Lucor, A. Pon¸ cot, Background error cov ariance iterative up dating with inv ariant observ ation measures for data assimilation, Sto c hastic Environ. Res. Risk Assess. 33 (11) (2019) 2033–2051. [80] J. Kaplan, S. McCandlish, T. Henighan, T. B. Bro wn, B. Chess, R. Child, S. Gray , A. Radford, J. W u, D. Amo dei, Scaling laws for neural language mo dels, (2020). [81] A. Dosovitskiy , An image is worth 16x16 w ords: T ransformers for image recognition at scale, (2020). [82] O. Press, N. A. Smith, M. Lewis, T rain short, test long: Atten tion with linear biases enables input length extrap olation, (2021). [83] J. Su, Y. Lu, S. Pan, B. W en, Y. Liu, RoF ormer: Enhanced transformer with rotary p osition em b edding, (2021). 30
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment