Cooperative Deep Reinforcement Learning for Fair RIS Allocation
The deployment of reconfigurable intelligent surfaces (RISs) introduces new challenges for resource allocation in multi-cell wireless networks, particularly when user loads are uneven across base stations. In this work, we consider RISs as shared inf…
Authors: Martin Mark Zan, Stefan Schwarz
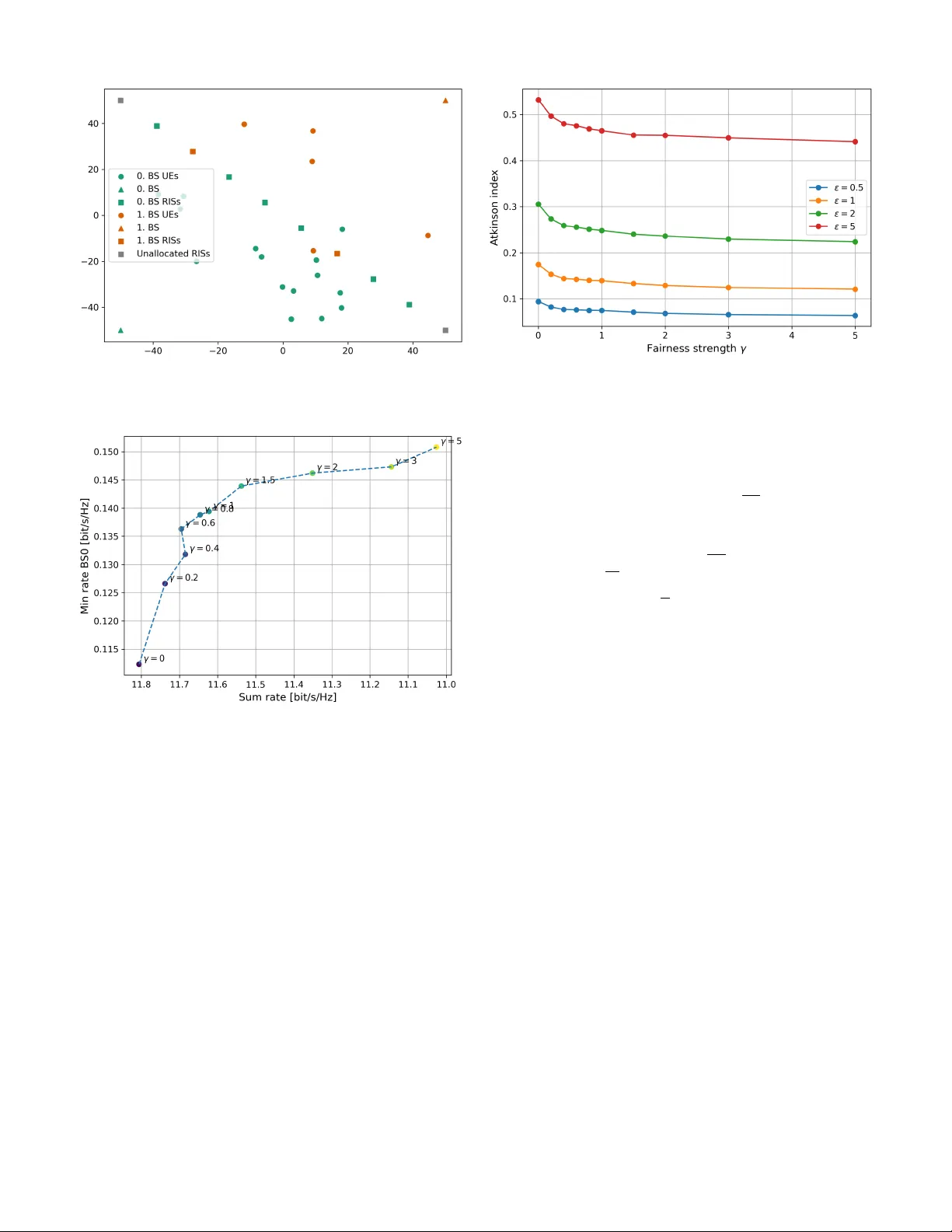
Cooperati v e Deep Reinforcement Learning for F air RIS Allocation 1 st Martin Mark Zan Institute of T elecommunications TU W ien V ienna, Austria martin.zan@tuwien.ac.at 2 nd Stefan Schwarz Institute of T elecommunications TU W ien V ienna, Austria stefan.schwarz@tuwien.ac.at © 2026 IEEE. Personal use of this material is permitted. This is the author’ s version of the work accepted for publication in International Symposium on Modeling and Optimization in Mobile, Ad hoc, and W ireless Networks (W iOpt 2026). Abstract —The deployment of reconfigurable intelligent sur - faces (RISs) introduces new challenges f or resource allocation in multi-cell wireless networks, particularly when user loads are uneven across base stations. In this work, we consider RISs as shared infrastructure that must be dynamically assigned among competing base stations, and we address this problem using a simultaneous ascending auction mechanism. T o mitigate performance imbalances between cells, we propose a fairness-aware collaborativ e multi-agent reinfor cement learning approach in which base stations adapt their bidding strategies based on both expected utility gains and relativ e service quality . A centrally computed performance-dependent fairness indicator is incorporated into the agents’ observations, enabling implicit coordination without direct inter-base-station communication. Simulation results show that the pr oposed framework ef- fectively redistributes RIS resources toward weaker -performing cells, substantially improving the rates of the worst-served users while preserving overall throughput. The results demonstrate that fairness-oriented RIS allocation can be achieved through cooperative learning, providing a flexible tool for balancing efficiency and equity in future wireless networks. Index T erms —Reconfigurable Intelligent Surfaces, Resource Allocation, A uctions, Reinforcement Learning, F airness, Multi- Agent Systems. I . I N T RO D U C T I O N I N the e volution to ward 6G wireless networks, intelligent resource management has become a central challenge in interference-limited environments. While advances in spectral efficienc y and massiv e antenna systems hav e significantly improv ed peak data rates, ensuring fair and reliable service across users and cells remains a key objective, particularly at the cell edge where propagation conditions are poor and competition for shared resources is most pronounced. While cell-edge performance limitations are addressed by techniques such as coordinated multipoint transmission (CoMP) [1], [2] and cell-free massi ve MIMO [3], [4], the prac- tical deployment of these approaches is constrained by limited coordination cluster sizes [5], [6]. As a result, full network- wide coordination remains infeasible, and performance degra- dation persists at the edges of coordination clusters rather than This research was funded in whole or in part by the Austrian Science Fund (FWF) 10.55776/P A T4490824. For open access purposes, the author has applied a CC BY public copyright license to any author accepted manuscript version arising from this submission. at conv entional cell boundaries. The framework considered in this work is therefore complementary to CoMP and cell-free MIMO. Reconfigurable intelligent surfaces (RISs) have recently emerged as a promising technology to address these challenges by enabling programmable control of the wireless propagation en vironment [7]. By adjusting the phase responses of nearly passiv e reflecting elements, RISs provide a cost- and energy- efficient means to enhance desired signal paths and mitigate interference, thereby complementing con ventional base station and user equipment capabilities [8], [9]. Despite their potential, practical RIS deployment raises system-lev el questions regarding placement and ef ficient allo- cation among multiple transmitters and users. These challenges are particularly pronounced in multi-cell scenarios, where RISs deployed near cell boundaries can benefit multiple base stations, leading to competition for shared infrastructure. T o address this competition, RISs are modeled as shared resources managed by an independent infrastructure provider and dynamically leased to base stations (BSs) via a market- inspired allocation mechanism. In particular, auction-based allocation provides a scalable and low-comple xity alternati ve to combinatorial optimization approaches [10], while e xplicitly capturing the strategic interactions among competing base stations. Similar auction formats hav e been successfully ap- plied in spectrum allocation, where simultaneous ascending auctions enable ef ficient distribution of scarce resources [11], [12]. An auction-based RIS allocation mechanism was recently studied in [13] for a multi-operator scenario, demonstrating the viability of this approach in RIS-assisted networks. Building on this framew ork, reinforcement learning (RL) enables optimized bidding strategies in dynamic and partially observable environments. By learning from repeated auction interactions, RL agents adapt their behavior to target high- value RISs while av oiding inefficient bidding, and hav e been shown to outperform heuristic approaches in performance–cost trade-offs [14]. Deep RL has been successfully used to co- ordinate a central resource provider and multiple competing operators in multi-RIS networks in [15]. Auction-based energy markets hav e been formulated as stochastic games, where rein- forcement learning is used to learn effecti ve bidding strategies under uncertainty and competition in [16]. In contrast to existing work, this paper studies fairness- aware RIS allocation in asymmetric multi-cell scenarios with uneven user distributions. W e introduce a performance- dependent fairness indicator into the RL agents’ observations, enabling implicit coordination that fav ors weaker-performing cells when beneficial. A tunable parameter controls the trade- off between total throughput and equitable resource distribu- tion. Simulation results sho w that the proposed cooperati ve multi- agent RL framew ork yields a more balanced RIS allocation, significantly improving minimum user rates in o verloaded cells and reducing the Atkinson inequality index, while maintaining competitiv e sum-rate performance. W e further demonstrate how fairness settings shape agent behavior and system-lev el outcomes. Notation: The multi-variate complex Gaussian distribu- tion with mean µ and cov ariance matrix C is denoted by C N ( µ , C ) , while the uniform distribution over the interval [ a, b ] is written as U ( a, b ) . For a vector x , the transpose and Hermitian transpose are x T and x H , respectively , and the i -th element is denoted by x [ i ] . The Euclidean norm of x is ∥ x ∥ . The cardinality of a set X is |X | , and the empty set is denoted by ∅ . The expectation operator is written as E [ · ] , and the phase of a complex number z is gi ven by arg ( z ) . I I . S Y S T E M M O D E L W e consider a multi-cell downlink scenario with N BS base stations, serving a total of N UE single-antenna users with the assistance of N RIS reconfigurable intelligent surfaces. Each BS is equipped with M BS antennas, while each RIS consists of M RIS reflecting elements. W e consider single-user MIMO, i.e., users are served on orthogonal resources. A. Channel Model W e consider both direct and RIS-assisted channels between each BS and each user . W e assume that the direct BS-user (UE) link is dominated by non-line-of-sight (NLOS) propagation and is strongly shadowed, which motiv ates the use of RIS- assisted transmission. The direct channel between user u and BS b is denoted by h direct u,b ∈ C M BS × 1 and modeled as h direct u,b = γ u,b g u,b , (1) where γ u,b is the path gain, and g u,b ∼ C N ( 0 , I ) is the fading component. The normalization is chosen such that E [ ∥ g u,b ∥ 2 ] = M BS , yielding E [ ∥ h direct u,b ∥ 2 ] = γ 2 u,b M BS . W e consider Rayleigh fading for this link to model strong multipath propagation under NLOS conditions. For the channel between BS b and RIS r , a strong line- of-sight (LOS) component is assumed, as RISs are typically deployed in locations with good visibility to nearby BSs. This directional LOS channel is represented by the matrix H r,b ∈ C M RIS × M BS and modeled as H r,b = γ r,b a ( ψ r,b ) a ( θ r,b ) T , (2) where γ r,b is the corresponding path gain, a ( ψ r,b ) denotes the RIS array response vector , and a ( θ r,b ) is the BS array response vector [17]. The angles ψ r,b and θ r,b describe the angle- of-arriv al at the RIS and the angle-of-departure at the BS, respectiv ely . W e assume that additional multipath components are negligible for this link. For the channel between RIS r and user u we consider both, a LOS component and additional multipath components modeled as Rayleigh fading. The ov erall RIS-user channel, denoted by h u,r ∈ C M RIS × 1 , therefore follows a Rician fading model h u,r = γ u,r s K u,r 1 + K u,r a ( θ u,r ) + s 1 1 + K u,r g u,r ! , (3) where γ u,r is the path gain, K u,r denotes the Rician K -factor , a ( θ u,r ) is the RIS array response vector , and g u,r ∼ C N ( 0 , I ) models the NLOS component. The angle-of-departure at the RIS is θ u,r . The pre viously defined path gains γ u,b , γ r,b , γ u,r depend on both distance and line-of-sight conditions. Each RIS applies a diagonal phase-shift matrix Φ r = diag e j ϕ r, 1 , . . . , e j ϕ r,M RIS , (4) where the phase shifts are configured to coherently align the LOS components of the RIS-assisted channel. W e assume that the random scattering components g u,r vary rapidly over time, which pre vents their reliable estimation. Consequently , these components cannot be coherently phase-aligned at the RIS and therefore contribute only incoherently to the recei ved signal. If a RIS is not assigned to the serving BS, its phase shifts are assumed to be random, i.e., ϕ r,i ∼ U (0 , 2 π ) . The aggregate RIS-assisted channel between BS b and user u , h indirect u,b ∈ C M BS × 1 is giv en by h indirect u,b = N RIS X r =1 h T u,r Φ r H r,b T . (5) The total channel h u,b ∈ C M BS × 1 is then h u,b = h direct u,b + h indirect u,b . (6) B. Beamforming Model W e assume strong shadowing of the direct link, such that users are ef fectiv ely served only via RISs. Consequently , base station beamforming is directed tow ard RISs and is based solely on the directional channel components represented by the array response vectors of the dominant paths. Rapidly varying NLOS components are not exploited, as they cannot be reliably estimated. W e point beams towards the RISs and we assign po wer across these beams in a user-specific way . Let f u,d ∈ C M BS × 1 denote the beamforming vector used by the serving base station d for user u , including the power allocation, such that E [ ∥ f u,d ∥ 2 ] = P d . When a set R ( d ) of RISs is assigned to base station d , the beamforming vector is constructed as f u,d = r 1 M BS X r ∈R ( d ) p P u,r,d a ∗ ( θ r,d ) , (7) where a ( θ r,d ) is the array response vector at the base station corresponding to the direction of RIS r , P u,r,d denotes the power allocated to user u via RIS r , and P r ∈R ( d ) P u,r,d = P d . The power allocation will be defined in Section III. If no RIS is assigned to base station d , directional infor- mation is unavailable. In this case, the base station applies random Gaussian beamforming for the users it serves. C. Signal Model W e consider a do wnlink transmission model in which each BS serves multiple users using orthogonal time-frequency resources. As a result, intra-cell interference is not present. Howe ver , inter-cell interference remains present due to simul- taneous transmissions from neighboring BSs. The recei ved signal at user u served by BS d is obtained as y u = h T u,d f u,d x u + X b = d h T j b ,b f j b ,b x j + n u , (8) where j b denotes the user which is served by BS b at the same time as user u is served by BS d , and n u ∼ C N (0 , σ 2 n ) is additiv e white Gaussian noise. The transmit symbol intended for user u is denoted by x u and satisfies E [ | x u | 2 ] = 1 . D. SINR Model The signal-to-interference-plus-noise ratio (SINR) for user u served by BS d is expressed as SINR ( d ) u = h T u,d f u,d 2 σ 2 n + P b = d 1 |U ( b ) | P j ∈U ( b ) h T u,b f j,b 2 . (9) The users assigned to base station b are denoted by U ( b ) . For tractability , we replace the instantaneous inter-cell interference by its av erage over users in neighboring cells, yielding a scheduling-agnostic interference model. This approximation reflects the fact that channel coding spans many resource elements with potentially varying interferers, and the resulting SINR is interpreted as an effecti ve long-term metric. The achie v able do wnlink rate of user u served by BS d is then giv en by r ( d ) u = log 2 1 + SINR ( d ) u . (10) I I I . S I N R A N D U T I L I T Y E S T I M A T I O N In order to ev aluate RIS allocations and guide the auction- based resource assignment, each base station requires an estimate of the achiev able performance under a giv en RIS configuration. Since instantaneous channel state information is not available prior to RIS allocation and configuration, we rely on macroscopic channel parameters and asymptotic properties of large antenna arrays to estimate the SINR and the resulting utility . A. Macr oscopic SINR Estimation W e approximate the instantaneous recei ved power terms by their respecti ve expected values. For suf ficiently large antenna arrays and RISs, this is justified by the law of large numbers. The estimated SINR of user u served by base station d is expressed as ˆ SINR ( d ) u = p d,u + p c,u + p i,u σ 2 n + i d,u + i i,u , (11) where p d,u denotes the direct signal power , p c,u and p i,u represent the coherent and incoherent RIS-assisted signal com- ponents, respectiv ely , and i d,u and i i,u denote direct and RIS- assisted interference. The noise is denoted by σ 2 n . B. Signal P ower Estimation It is justified to split the signal po wer from (9) into tw o parts, direct and indirect po wers, since we assume a Rayleigh fading link for the direct path. As the Rayleigh fading components are assumed to be unknown for beamforming and RIS con- figuration, this implies that the indirect RIS-assisted channels are not coherently combined with the direct NLOS channel. W e will first estimate the direct part. The beamforming vector is statistically independent from the direct channel, because it is matched to the RIS channel. W e have: E ( h direct u,d ) T f u,d 2 = E h γ u,d g T u,d f u,d 2 i = γ 2 u,d f H u,d E g ∗ u,d g T u,d f u,d = γ 2 u,d f u,d 2 = γ 2 u,d P d = p d,u , where E g ∗ u,d g T u,d = I . The RIS-assisted signal (the indirect part of the signal from (9)) is the following: E ( h indirect u,d ) T f u,d 2 = E h T u,r Φ r H r,d f u,d 2 . W e additionally assume asymptotic orthogonality: a ( θ r,d ) T a ( θ s,d ) ∗ ≈ 0 , ∀ s = r , a ( θ r,d ) T a ( θ r,d ) ∗ = M BS . The RIS-assisted signal contains both coherent and incoherent components. The coherent component arises from the line-of- sight parts of the RIS-UE channels that can be phase-aligned by the RISs, while the incoherent component is caused by the non-line-of-sight Rayleigh fading contributions, which cannot be coherently combined as they are assumed to be unkno wn. After substituting the channel and beamforming expressions, the coherent signal ov er RIS r ∈ R ( d ) is: s u,r,d = γ u,r γ r,d k u,r M RIS p M BS | {z } c u,r,d p P u,r,d | {z } m u,r,d , where k u,r = p K u,r / (1 + K u,r ) and m u,r,d is obtained from the po wer allocation. The total received signal over all allocated RISs is giv en by: p c,u = X r ∈R ( d ) c u,r,d m u,r,d 2 = m T u,d ( c u,d c T u,d ) m u,d , (12) where for r i ∈ R ( d ) : c u,d = [ c u,r 1 ,d , . . . , c u,r R ( d ) ,d ] and m u,d = [ m u,r 1 ,d , . . . , m u,r R ( d ) ,d ] . W e maximize (12) with respect to the power allocation with the constraint || m u,d || 2 = P d . The optimal power allocation is calculated as: m u,d = c u,d || c u,d || p P d , (13) Due to the asymptotic orthogonality assumption, only the allocated RISs contribute to the effecti ve channel. Furthermore, the coherent RIS-assisted signal power is given by p c,u = X r ∈R ( d ) s u,r,d 2 . (14) Regarding the non-coherent power we use similar steps, which results in the incoherent RIS-assisted signal power , giv en by: p i,u = X r ∈R ( d ) γ 2 u,r γ 2 r,d ¯ k 2 u,r M BS M RIS P u,r,d , (15) where ¯ k u,r = p 1 / (1 + K u,r ) . C. Interference P ower Estimation The interference po wer (analogously to the signal power) consists of two components: direct interference from other base stations and RIS-assisted interference caused by RISs not assigned to the serving base station. From the point-of-vie w of base station d , we consider the beamformers applied at the other interfering base stations as isotropically distributed. This makes sense, as the beamformers applied by the interfering base stations (which point to their assigned RISs) are not correlated with the interference channels. The direct interference power is giv en by i d,u = E h T u,b f j b ,b 2 = X b = d γ 2 u,b P b . (16) Under these assumptions, the RIS-assisted interference power is expressed as i i,u = X b = d X r / ∈R ( d ) γ 2 u,r γ 2 b,r P b M RIS . (17) Because of the isotropic beamforming assumption we do not apply av eraging over the users as in (9). The estimated achiev able rate of user u served by base station d then follows as ˆ r ( d ) u = log 2 1 + ˆ SINR ( d ) u . (18) D. Utility Function The utility function used for RIS allocation is based on the mean achiev able rate of the users served by each base station. For base station b , the utility associated with a given RIS allocation R ( b ) is defined as Util ( b ) ( R ( b ) ) = 1 |U ( b ) | X u ∈U ( b ) ˆ r ( b ) u . (19) This utility captures the av erage service quality e xperienced by the users associated with base station b . E. Auction F ormat RIS allocation among base stations is performed using a simultaneously ascending auction, which provides a low- complexity alternativ e to combinatorial mechanisms such as V ickrey–Clarke–Gro ves [10] while capturing competitive in- teractions. A similar RIS auction framework was considered in [13]. The auction proceeds in discrete rounds t . In each round, the auctioneer announces a uniform price p t , increased by a fixed increment ∆ p from the previous round. Each base station b submits a binary bid vector b ( b ) t ∈ { 0 , 1 } N RIS , where b ( b ) t [ r ] = 1 indicates willingness to bid for RIS r at price p t . RISs receiving a single bid are allocated at the current price; RISs with multiple bids remain contested and adv ance to the next round, while RISs receiving no bids remain unassigned and apply random phase shifts. An acti vity rule prev ents strategic re-entry , i.e., a base station cannot bid for a RIS in round t if it did not bid for it in round t − 1 [18]. The activity rule supports the identification of preferences among agents. The auction terminates once no RIS receiv es multiple bids. I V . B I D D I N G S T R A T E G I E S Let R ( b ) t − 1 denote the set of RISs already allocated to base station b in previous rounds. The set of RISs that remain av ailable at round t is given by R t = { 1 , . . . , N RIS } \ [ b R ( b ) t − 1 . (20) Ideally , a base station would ev aluate the utility of all pos- sible subsets of remaining RISs; howe ver , this combinatorial ev aluation becomes infeasible as the number of RISs grows. W e therefore adopt a simplified marginal approach, in which each base station estimates the utility gain of acquiring a single additional RIS, assuming no other RIS is acquired in the same round. A. Marginal Utility V alue Estimation The estimated marginal utility v alue of RIS r ∈ R t for base station b at auction round t is defined as V ( b ) t ( r ) = Util ( b ) R ( b ) t − 1 ∪ { r } − Util ( b ) R ( b ) t − 1 . (21) This v alue represents the expected improvement in the mean achiev able rate of the users served by base station b if RIS r were to be allocated to it. B. Normalization and Standardization While marginal utility v alues capture the relati ve desirability of RISs, their absolute scale depends on the channel realiza- tion, user distribution, and current allocation. Consequently , the magnitude of V ( b ) t ( r ) can vary significantly across RISs, auction rounds, and training episodes. T o obtain a bounded and numerically stable representation suitable for learning-based bidding, we apply a two-step standardization procedure. First, negativ e marginal values are clipped using a rectified linear unit (ReLU): ˜ V ( b ) t ( r ) = max V ( b ) t ( r ) , 0 , (22) such that only RISs expected to yield a performance improv e- ment are considered. A v alue of zero therefore indicates that no utility gain is anticipated from acquiring RIS r in the current round. Second, the remaining v alues are normalized by the maxi- mum positiv e marginal gain among all av ailable RISs, V ( b ) t ( r ) ← ˜ V ( b ) t ( r ) max r ′ ∈R t ˜ V ( b ) t ( r ′ ) , if max r ′ ∈R t ˜ V ( b ) t ( r ′ ) = 0 , 0 , otherwise . (23) This normalization maps marginal utility values to the inter- val [0 , 1] , where one corresponds to the RIS with the highest expected utility gain in the current auction round. The relative ranking of RISs is preserved, while numerical consistency across en vironments and training episodes is ensured. C. RL-Based Bidding T o enable adaptiv e and fairness-aw are bidding, we model the auction as a multi-agent reinforcement learning problem in which each base station acts as an autonomous agent. Through repeated interaction with the auction environment, agents learn bidding strategies that account for both their o wn utility gains and the relativ e performance of other base stations. Unlike purely local strategies, this formulation enables implicit coordination via shared information provided by the auctioneer . In particular , agents are informed of their relativ e service quality through a fairness-aw are weighting mechanism that biases bidding tow ard weaker-performing cells. 1) States: The complete en vironment state at auction round t is defined as S t = p t , V ( b ) t ( r ) , B ( b ) t , w ( b ) t ∀ b, r , (24) where p t denotes the current auction price, B ( b ) t is the re- maining budget of base station b , V ( b ) t ( r ) are the normalized marginal utility v alues, and w ( b ) t is a fairness weight associated with base station b . The fairness weights are computed centrally based on the current utility values of all base stations and are defined as w ( b ) t = Util ( b ) ( R ( b ) t − 1 ) γ P b ′ Util ( b ′ ) ( R ( b ′ ) t − 1 ) γ · N BS , (25) where γ ≥ 0 controls the strength of the fairness mechanism. For γ = 0 , all base stations are assigned identical weights, whereas larger v alues of γ increasingly emphasize perfor- mance dif ferences between base stations. The normalization ensures a unit av erage fairness weight across base stations, aiming to stabilize the total price expenditure without strictly enforcing constancy . 2) Observations: Each agent operates on an indi vidual observation derived from the global state. The observation av ailable to base station b at round t is given by O ( b ) t = p t , B ( b ) t , w ( b ) t , V ( b ) t ( r ) ∀ r . (26) The observ ation includes the fairness weights, enabling agents to condition their bidding behavior on the relative per- formance of other cells. This information e xchange is mediated by the auctioneer and does not require direct communication between base stations. T o ensure a fixed-length observation vector , the marginal values V ( b ) t ( r ) are set to − 1 for RISs that are no longer av ailable or for which base station b is inactiv e due to the enforced activity rule. 3) Actions: At each auction round, each agent selects a binary bid vector b ( b ) t ∈ { 0 , 1 } N RIS , (27) where b ( b ) t [ r ] = 1 indicates that base station b places a bid for RIS r at the current price p t , and b ( b ) t [ r ] = 0 otherwise. 4) Rewar d Function: The rew ard function is designed to encourage agents to bid for RISs that provide high expected utility gains, while discouraging excessi ve or budget-violating bidding behavior . F or base station b at auction round t , the rew ard is defined as r ( b ) t = R ( b ) 1 ,t − β w ( b ) t R ( b ) 2 ,t + R ( b ) 3 ,t , (28) where β is a constant that controls the overall aggressiveness of bidding [14]. Re wards are ev aluated before the auction outcome, i.e., after each bidding decision instead of only upon winning a RIS, enabling dense and immediate feedback during training. The three re ward components are specified as follo ws. The first component captures the total expected value of the bids placed by the agent in the current round: R ( b ) 1 ,t = N RIS X r =1 V ( b ) t ( r ) b ( b ) t [ r ] . (29) This term rew ards the agent for selecting RISs that are expected to improve its utility . The second component penalizes the monetary cost of the bids placed in the current round: R ( b ) 2 ,t = p t N RIS X r =1 b ( b ) t [ r ] . (30) This term discourages agents from placing unnecessary bids and promotes selectiv e bidding behavior . The third component introduces an additional penalty if the total bid cost exceeds the remaining budget of the base station: R ( b ) 3 ,t = 2 · max p t N RIS X r =1 b ( b ) t [ r ] − B ( b ) t , 0 ! . (31) This term explicitly discourages budget violations by penaliz- ing bids that exceed the available budget. The scaling factor emphasizes budget violations relative to regular bidding costs. Scaling the cost-related terms R ( b ) 2 ,t and R ( b ) 3 ,t by the fair- ness weight w ( b ) t biases bidding toward weaker-performing base stations, penalizing aggressiv e bids from stronger agents while allowing weaker agents to bid more aggressiv ely . This promotes a more balanced RIS allocation while preserving competition. The proposed fairness mechanism assumes truthful re- porting of performance-related information to the auctioneer . Strategic misreporting could introduce vulnerabilities, as a base station claiming lower performance would reduce its own fairness weight and make competing agents more conserv ative, potentially gaining an advantage. Addressing such behavior would require additional mechanism-design measures, such as verification or incentiv e-compatible reporting, which are beyond the scope of this work. D. Implementation The en vironment is implemented using the Gymnasium interface [19] with multi-agent support provided by PettingZoo [20] and SuperSuit [21]. Each training episode corresponds to a complete auction process, starting from the initial price and ending when RISs receiv e no further bids. Agents are trained using a policy-gradient-based method, specifically the Proximal Policy Optimization (PPO) algorithm [22] as implemented in Stable-Baselines3 [23]. An undis- counted return is employed, reflecting the finite-horizon nature of the auction process, where all decisions within an episode contribute equally to the final allocation outcome. Aside from the undiscounted return, all other hyperparameters were kept at the default values of the PPO implementation. Due to the nature of the PPO implementation CPU-based training was utilized to ensure optimal ex ecution speed. T raining is performed episodically across a large number of independent network realizations, where user locations, RIS positions, and channel parameters are randomized between episodes. The implementation supports a variable number of base stations, users, and RISs. The implementation will be made av ailable upon acceptance of the work at: https://github.com/MartinMarkZan. V . S I M U L AT I O N S In this section, we ev aluate the performance of the proposed fairness-aw are RIS allocation framework through numerical simulations. The focus is on quantifying the trade-off between system efficiency and user fairness, as well as on illustrat- ing how the proposed mechanism redistributes RIS resources across base stations. A. Simulation Setup W e consider a tw o-base-station scenario with a fix ed number of users and RIS elements. The base stations are located at the opposite edges of the region of interest, while the RISs are deployed along the cell edge on a straight line. The placement of the RISs increases the competition between the two base stations. User locations are generated uniformly within the cell area. One of the base stations is overloaded with users (denoted as BS0 in the figures); on av erage, it serves approximately three times as many users as the other base station (BS1). While this initial study focuses on a two- base-station scenario with RISs positioned at the cell edge to Fig. 1. Conv ergence of the episodic rew ard (left axis) and total auction cost (right axis) during training. Solid lines represent moving-average smoothed curves (window size=5), while semi-transparent lines show the raw data. T ABLE I S I MU L A T I ON P AR A M ET E R S Carrier frequency f c = 26 GHz Number of base stations N BS = 2 Number of base station antennas M BS = 50 Number of users N UE = 20 Number of RISs N RIS = 10 Number of RIS elements M RIS = 250 T ransmit power per subcarrier P = 100 mW Subcarrier bandwidth 15 kHz A WGN noise power spectral density − 174 dBm/Hz Noise figure 6 dB Path-loss exponent under LOS (NLOS) 2 (4 . 5) K -factor under LOS (NLOS) 100 (3) Distance-dependent LOS-probability p LOS ( d ) = e − d/ 25 Shadow fading variance 10 dB Auction initial price p 0 = 0 . 05 Auction price increment ∆ p = 0 . 05 Budget B ( b ) 0 = 1 clearly illustrate fundamental fairness-performance trade-offs, future work will inv olve more complex network topologies with a larger number of base stations, users, and di verse RIS placements. As illustrated in Fig. 1, the reinforcement learning agents con verged to stable re ward values during training, indicating reproducible learning behavior . The curves sho w that agents reliably discov er effecti ve bidding policies that maximize gains while maintaining stable b udget utilization, confirming robustness. During ev aluation, we used 200 macroscopic re- alizations (user positions and lar ge-scale path gains) and 20 independent microscopic fading realizations per macroscopic setup to aggregate the results. T able I summarizes the main simulation parameters. The geometry is shown in Fig. 2 for a random snapshot of user positions. Fig. 2. Representativ e network realization for γ = 0 . 2 , showing the locations of the two base stations, users, allocated RISs, and unassigned RISs. Fig. 3. T rade-off between sum rate and the minimum user rate of the overloaded base station (BS0). Each point corresponds to a model with a different value of the fairness strength γ . B. Efficiency-F airness T rade-off Fig. 3 visualizes the trade-off between system efficienc y and fairness using the sum rate versus the minimum user rate of the ov erloaded base station. As γ increases, the operating point moves along a Pareto- like frontier: the minimum rate of BS0 improv es by approx- imately 34% , while the sum rate of the two base stations decreases only moderately (less than 7% over the considered range). This confirms that the proposed mechanism is able to substantially improve the performance of the worst-served users without causing a se vere loss in overall system through- put. C. F airness Evaluation via Atkinson Index T o quantify fairness more systematically , Fig. 4 reports the Atkinson inequality index as a function of the fairness strength Fig. 4. Atkinson inequality index as a function of the fairness strength γ for different values of the sensitivity parameter ϵ , which controls the emphasis on low-rate users. γ . The index is defined as A ε ( y 1 , . . . , y N ) = 1 − E ε µ , (32) where E ε = 1 N P N i =1 y 1 − ε i 1 1 − ε , 0 ≤ ε = 1 , Q N i =1 y i 1 N , ε = 1 , min( y 1 , . . . , y N ) , ε = + ∞ , and µ is the mean of the input v alues. The Atkinson index takes values in [0 , 1] , where smaller values indicate more equal rate distributions. For all considered ϵ , increasing γ consistently reduces the inequality index, confirming that the proposed framework im- prov es fairness across users. Larger values of ϵ result in higher Atkinson indices, since the metric places greater emphasis on the worst-served users and penalizes residual disparities more strongly . The monotonic decrease of all curves with γ demonstrates that the fairness impro vement is robust with respect to the chosen fairness sensitivity . D. RIS Allocation Behavior Fig. 5 sho ws the a verage RIS allocation as a function of the fairness parameter γ . The figure reports the number of RISs assigned to BS0, BS1, and those remaining unallocated. As γ increases, RIS resources are progressi vely shifted from BS1 to the overloaded BS0, which directly explains the observed improvement in the minimum rate of BS0. At the same time, the number of unallocated RISs decreases, indicating more aggressi ve bidding behavior by the weaker - performing base station and a less competitiv e auction. For the considered operating point, the total price spent by the two base stations remains approximately constant across γ . Howe ver , this behavior is not guaranteed in general. Additional Fig. 5. Increasing γ shifts RIS resources from BS1 to the overloaded BS0, while also decreasing the number of unallocated RISs due to more aggressive bidding behavior . experiments with different cost-scaling parameters ( β ) sho w that stronger fairness pressure can also lead to increased ov erall expenditure. This highlights an inherent interaction between fairness objectiv es and economic efficienc y , which can be controlled through appropriate rew ard design. V I . C O N C L U S I O N In this work, we inv estigated auction-based allocation of reconfigurable intelligent surfaces in asymmetric multi-cell networks with a focus on fairness-aw are resource distribution. RISs were modeled as shared infrastructure and dynamically allocated through a simultaneous ascending auction, enabling scalable allocation in competiti ve cell-edge scenarios. T o ad- dress performance imbalances caused by unev en user distri- butions, we proposed a cooperative multi-agent reinforcement learning framew ork that integrates a performance-dependent fairness mechanism into the bidding process. Simulation results show that the proposed approach signif- icantly improves the performance of the worst-served users, while maintaining competitiv e sum-rate performance. By ad- justing the fairness parameter , the trade-off between data rate and equitable resource allocation can be explicitly controlled. These findings demonstrate the effecti veness of combining auction-based mechanisms with cooperative reinforcement learning for fair and ef ficient RIS utilization in future wireless networks. While the proposed framew ork demonstrates strong perfor- mance in moderate-sized scenarios, extending the approach to lar ge-scale networks with a higher number of base stations, users, and RISs remains an important research direction. Addi- tionally , other auction formats, such as sealed-bid mechanisms or dynamic pricing schemes, could be inv estigated to further improv e efficiency or fairness under dif ferent deployment assumptions. Future work can also consider non-stationary en vironments with time-varying users. R E F E R E N C E S [1] F . Irram, M. Ali, Z. Maqbool, F . Qamar and J. J. Rodrigues, ”Co- ordinated Multi-Point Transmission in 5G and Beyond Heteroge- neous Networks, ” 2020 IEEE 23rd International Multitopic Confer- ence (INMIC), Bahawalpur , Pakistan, 2020, pp. 1-6, doi: 10.1109/IN- MIC50486.2020.9318091 [2] S. Schwarz and M. Rupp, ”Exploring Coordinated Multipoint Beam- forming Strategies for 5G Cellular , ” in IEEE Access, vol. 2, pp. 930-946, 2014, doi: 10.1109/A CCESS.2014.2353137 [3] E. Nayebi, A. Ashikhmin, T . L. Marzetta and H. Y ang, ”Cell-Free Massiv e MIMO systems, ” 2015 49th Asilomar Conference on Signals, Systems and Computers, Pacific Grov e, CA, USA, 2015, pp. 695-699, doi: 10.1109/A CSSC.2015.7421222 [4] C. F . Mendoza, M. Kaneko, M. Rupp and S. Schwarz, ”Enhancing the Uplink of Cell-Free Massive MIMO through Prioritized Sampling and Personalized Federated Deep Reinforcement Learning, ” in IEEE T ransactions on Cognitive Communications and Networking, vol. 12, pp. 395-411, 2026, doi: 10.1109/TCCN.2025.3561289 [5] H. A. Ammar, R. Adve, S. Shahbazpanahi, G. Boudreau and K. V . Sriniv as, ”User-Centric Cell-Free Massi ve MIMO Networks: A Surve y of Opportunities, Challenges and Solutions, ” in IEEE Communications Surveys & Tutorials, vol. 24, no. 1, pp. 611-652, Firstquarter 2022, doi: 10.1109/COMST .2021.3135119 [6] C. F . Mendoza, S. Schwarz and M. Rupp, ”User-Centric Clustering in Cell-Free MIMO Networks using Deep Reinforcement Learning, ” ICC 2023 - IEEE International Conference on Communications, Rome, Italy , 2023, pp. 1036-1041, doi: 10.1109/ICC45041.2023.10279626 [7] S. Zeng, H. Zhang, B. Di, Z. Han, and L. Song, “Reconfigurable intelli- gent surface (RIS) assisted wireless coverage extension: RIS orientation and location optimization, ” IEEE Commun. Lett., vol. 25, no. 1, pp. 269–273, Jan. 2021. [8] M. A. Msleh, F . Heliot, and R. T afazolli, “Ergodic capacity analysis of reconfigurable intelligent surface assisted MIMO systems over Rayleigh- Rician channels, ” IEEE Commun. Lett., vol. 27, no. 1, pp. 75–79, Jan. 2023. [9] Q. N. Le, V .-D. Nguyen, O. A. Dobre, and R. Zhao, “Energy efficiency maximization in RIS-aided cell-free network with limited backhaul, ” IEEE Commun. Lett., vol. 25, no. 6, pp. 1974–1978, Jun. 2021. [10] N. Nisan and A. Ronen, “ Algorithmic mechanism design, ” Games Econ. Behav ., vol. 35, no. 1, pp. 166–196, 2001. [11] P . Cramton and A. Ockenfels, ”The German 4G Spectrum Auction, ” The Economic Journal, 127 (October), F305–F324, 2017. [12] P . Milgrom, ”Putting Auction Theory to W ork”, Stanford University , California, Cambridge Univ ersity Press, 2004. [13] S. Schwarz, “Gambling on Reconfigurable Intelligent Surfaces, ” IEEE Communications Letters, vol. 28, no. 4, pp. 957–961, April 2024. [14] M. M. Zan and S. Schwarz, “ Auction-Based RIS Allocation W ith DRL: Controlling the Cost-Performance T rade-Off,“ to be published in IEEE Open Journal of the Communications Society 2026. [15] H. Zhang, W . W ang, H. Zhou, Z. Lu and M. Li, “ A Hierarchical DRL Approach for Resource Optimization in Multi-RIS Multi-Operator Networks,“ 2025, [16] V . Nanduri and T . K. Das, ”A Reinforcement Learning Model to Assess Market Po wer Under Auction-Based Energy Pricing, ” in IEEE T ransactions on Power Systems, vol. 22, no. 1, pp. 85-95, Feb. 2007 [17] C. A. Balanis, “ Antenna Theory”, Hoboken, New Jersey , U.S.: John W iley & Sons, Inc., 2005. [18] T . Roughgarden, T wenty Lectures Algorithmic Game Theory . Cam- bridge, U.K.: Cambridge Univ . Press, 2016. [19] M. T owers et al. (Mar . 2025). Gymnasium. [Online]. A vailable: https://zenodo.org/records/14983111 [20] J. K. T erry et al., “PettingZoo: Gym for multi-agent reinforcement learning, ” 2021, [21] J. K. T erry , B. Black, and A. Hari, “SuperSuit: Simple microwrappers for reinforcement learning en vironments, ” 2020, [22] J. Schulman, F . W olski, P . Dhariwal, A. Radford, and O. Klimov , “Proximal policy optimization algorithms, ” 2017, [23] A. Raffin, A. Hill, A. Gleav e, A. Kanervisto, M. Ernestus, and N. Dormann, “Stable-Baselines3: Reliable reinforcement learning imple- mentations, ” J. Mach. Learn. Res., vol. 22, no. 268, pp. 1–8, 2021. [Online]. A vailable: http://jmlr .org/papers/v22/20-1364.html
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment