TAAC: A gate into Trustable Audio Affective Computing
With the emergence of AI techniques for depression diagnosis, the conflict between high demand and limited supply for depression screening has been significantly alleviated. Among various modal data, audio-based depression diagnosis has received incr…
Authors: Xintao Hu, Feng-Qi Cui
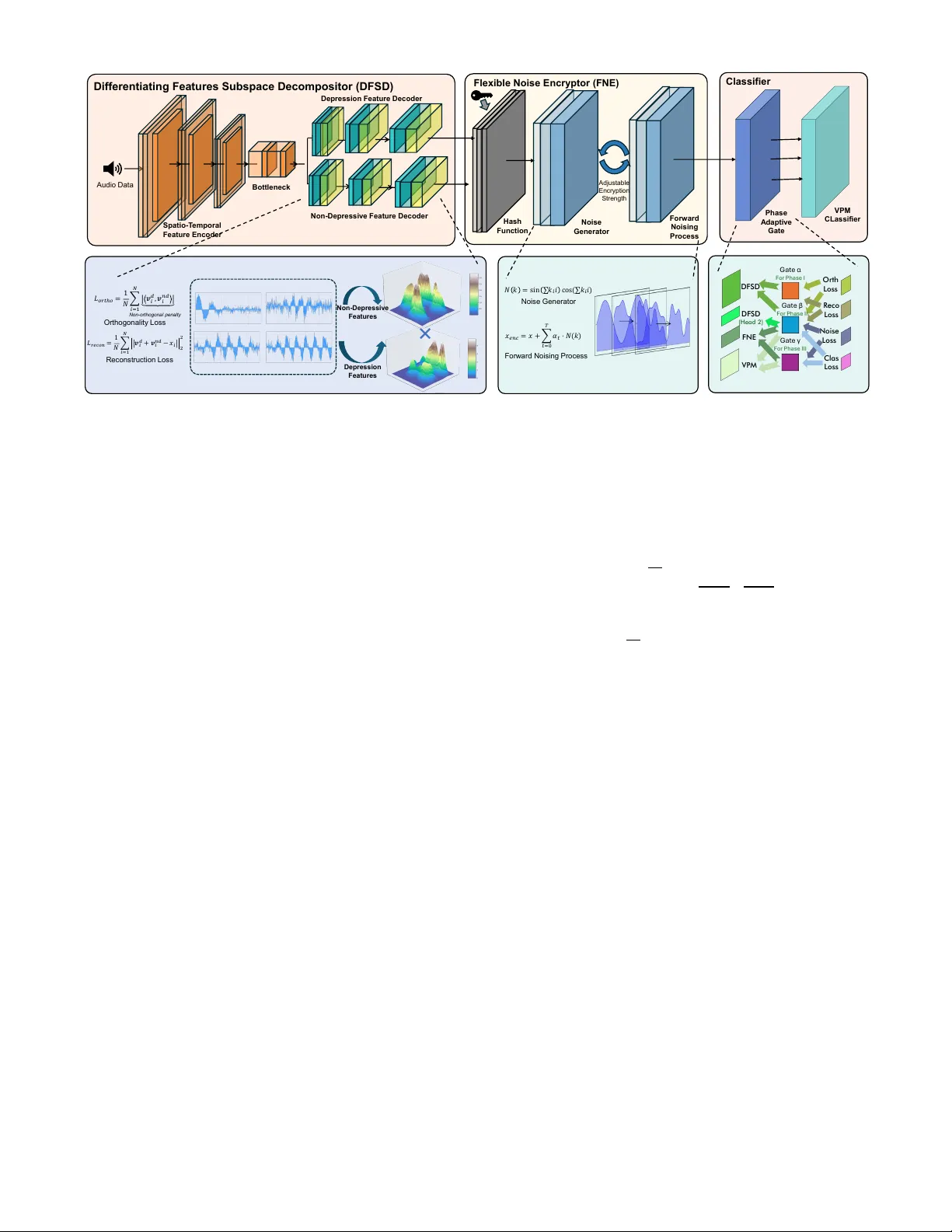
T AA C : A gate into T rustable A udio Affective Computing Xintao Hu Hefei University of T echnology Hefei, China Feng-Qi Cui Hefei University of T echnology Hefei, China Abstract —With the emergence of AI techniques f or depression diagnosis, the conflict between high demand and limited supply for depression screening has been significantly alleviated. Among various modal data, audio-based depression diagnosis has r eceived increasing attention from both academia and industry since audio is the most common carrier of emotion transmission. Unfortu- nately , audio data also contains User -sensiti ve Identity Inf ormation (ID), which is extremely vulnerable and may be maliciously used during the smart diagnosis process. Among previous methods, the clarification between depression features and sensitiv e featur es has always serve as a barrier . It is also critical to the problem for intr oducing a safe encryption methodology that only encrypts the sensitive features and a powerful classifier that can correctly diagnose the depression. T o track these challenges, by leveraging adversarial loss-based Subspace Decomposition, we propose a first practical framework T AA C presented for T rustable A udio Affective Computing, to perf orm automated depression detection through audio within a trustable envir onment. The key enablers of T AA C are Differentiating Featur es Subspace Decompositor (DFSD), Flexible Noise Encryptor (FNE) and Staged T raining Paradigm, used f or decomposition, ID encryption and perf ormance enhancement, respectively . Specifically , to separate different types of features for pr otecting user privacy , by employing subspace- based distenglement loss to dual-end A uto Encoder , we propose DFSD to maximally decompose the features between id-r elated and depression-related. Then, by employing progressi ve noise ad- dition, we propose a Deterministic Diffusion (Encryption) process and introduce FNE, for encrypting the id-related data with ad- justable encryption strength. Then, by goal-oriented mulfunctional segment-based collaborativ e training, a noval staged training paradigm that enables different modules to specialize in their respecti ve predefined functions is designed. Extensive experiments with existing encryption methods demonstrate our framework’ s preeminent performance in depression detection, ID reser vation and audio reconstruction. Meanwhile, the experiments across various setting demonstrates our model’s stability under different encryption strengths. Thus proving our framework’s excellence in Confidentiality , Accuracy , T raceability , and Adjustability . Index T erms —Depression Diagnosis, Personal Information Protec- tion, Security , T rustable Affective Computing 1. Introduction 1.1. Backgrounds and Motivations Depression is a widespread mental health condition affect- ing an estimated 5% of adults globally [1], [2]. Left untreated, depression can escalate to more sev ere symptoms. Recently , Ra w Audi o Da t a Thir d P a r t y D e p r e s s ion R e s u lt P e r s o n a l I n f o r m a t ion P r evio us D e p r e s s ion O u r s Mi x e d Fea t u r e s N e u r a l N e t w o r k ID De p r e s s i o n Fea tu r e Dep r es s i on F ea tu r e ID F ea tu r e ID F ea tu r e Non - Rel at ed F ea tu r e … … … … I n d ic a t o r s Tra n s f e r S A FE UNSA FE Figure 1 The kernel insight of our implementation rapid and efficient audio-based AI solutions, such as automated PHQ-9 screenings [3], ha ve been integrated into clinical work- flows, which has greatly helped mitigate the shortage of mental health professionals. Compared to visual-based depression detection meth- ods, audio-driv en approaches offer enhanced con venience and stronger priv acy preserv ation for users. Howe ver , T rustability remains underexplored in depression detection systems across both visual and acoustic modalities. Academic studies hav e long emphasized that audio contains voiceprints embedding User - sensitiv e Identity Information (hereafter refer as ID) [4]. Re- cent adv ances in speaker verification, such as the SpeechBrain framew ork achie ving a 0.69% Equal Error Rate [5], demon- strate the near-biometric precision of current ID extraction technologies. More critically , during PHQ-9 assessments, users are required to verbally respond to sensitiv e questions about personal experiences and emotions, the leakage of such voice recordings could enable large-scale ID breaches. In real-world deployments, while patients provide raw au- dio recordings containing embedded ID, they lack technical mechanisms to audit or constrain downstream data usage [6], [7]. Malicious actors could exploit these vulnerabilities through multiple attack vectors, such as bulk-reselling speech samples on black or reconstructing identity vectors from audio snippets to facilitate voice phishing campaigns. A particularly concern- ing scenario in volv es critical institutional processes, such as mandatory depression screenings during corporate hiring. If audio data collected during corporate mental health assessments is compromised, employee voiceprints - directly linked to their identities, professional roles, and organizational occupations, could be illicitly acquired by third-party headhunters. Early research efforts, in audio-based depression detection hav e primarily focused on improving diagnostic accuracy , often assuming raw audio data is explicitly accessible and trust- worthy . Many studies leverage semantic content ( e .g. , spoken words) extracted directly from audio signals to infer depression se verity [8], [9], [10], which, under trustworthy AI frameworks, represent sensiti ve attributes requiring protection. 1.2. Challenges and Contributions Three major chanllenges need to be formally addressed before establishing a trustable audio depression detection en- vironment (Hereafter, the data owner is referred to as Party A, and the deleg ated processor conducting depression detection is termed Party B): • Confidentiality : In a trustable en vironment, mecha- nisms must be established to prevent Party B from directly accessing ID embedded in the audio data. This necessitates supplementing additional obfuscation meth- ods to mask identity-related features. Crucially , Party B must be technically restricted from correlating audio samples with their speakers. • Accuracy : While obfuscating ID in audio data, we must ensure that depression-related information can still be extracted reliably and that the system accurately detects whether a speaker has depression—without ev er learning the speaker’ s identity . • T raceability : While ensuring Party B cannot access identity information in the audio data, Party A must retain the capability to reconstruct the original audio and map depression detection results back to individual speakers upon recei ving processed data from Party B. An additional requirement may be introduced that Party A should be able to dynamically adjust the encryption strength based on operational priorities, lowering priv acy-preserving intensity in scenarios prioritizing detection accuracy while in- creasing it in contexts demanding heightened security . This flexibility inherently allows data owners to make context-aware tradeoffs between analytical fidelity and confidentiality , en- suring compliance with both clinical and organizational con- straints. T o address these challenges, this paper proposes a novel pri vac y-preserving depression detection frame work. As illus- trated by 1, in the lagacy frame work, Party B is capable of il- legally misusing identity information. Whereas in the proposed frame work, Party B is UN ABLE to extract the identity infor- mation while Party A ’ s ability to reconstruct identity attributes is preserved. Howe v er , within this novel framew ork, the co-design of encryption modules and feature extraction networks remains a critical challenge, requiring these components to be carefully architected to achiev e two objectiv es: (1) preserving sufficient information for accurate depression detection, and (2) guar- anteeing the computational irrev ersibility of ID. T o achieve these objecti ves, we design three major components that inte- grates Subspace Decomposition for feature disentanglement and Noise-dif fusion Encryption for identity obfuscation, which em- ploys hierarchical progressi v e training with multiple losses to isolate depression biomarkers from speaker -specific attributes. Implementation details will be introduced in Sec. 4. In brief, our contrib utions can be broadly summarized as follo ws: • T o the best of our knowledge, this is the first work to formalize and address the trustability challenge in depression detection, with a particular focus on data protection in practical deployment. • W e propose a Dif ferentiating Features Subspace De- composition (DFSD) netw ork that employs subspace- based disentanglement loss on a dual-end autoencoder , effecti v ely separating depression-related features from ID. • T o support di v erse application scenarios with varying security lev els, we de velop a Deterministic T ensor Dif- fusion (DTD) encryption strategy based on conditional probability and progressi ve noise injection via a Markov chain, achie ving a flexible balance between detection accuracy and information confidentiality while resisting advanced decryption models. • W e design a goal-oriented, multifunctional, segment- based collaborative training paradigm that enables each module to specialize in its predefined role, improving both depression recognition accuracy and feature disen- tanglement. • Extensi ve experiments confirm that the proposed frame- work achieves complete ID obfuscation while maintain- ing near -state-of-the-art accuracy in depression detec- tion. The rest of the paper is organized as follows. Sec. 2 and 3 discusses numerous related studies and preliminaries. Then, we describe the T AAC system design in Sec. 4. Implementation, ev aluation, and the impacts of various factors on T AAC perfor- mance are presented in Sec. 5. Finally , we conclude our work in Sec. 6 2. Related W ork 2.1. Depression Detection Depression Detection aims to automatically identify depres- siv e symptoms and assess their sev erity levels by analyzing an individual’ s beha vioral patterns, speech, physiological signals, or neural acti vity . Its applications include telemedicine, mental health screening, and personalized treatment [11], [12]. In recent years, the integration of multimodal data (such as speech, text, video, and physiological signals) with deep learning tech- niques has emerged as a major focus of research in this field [13], [14]. The Audio/V isual Emotion Challenge (commonly known as A VEC) [15], [16] is an internationally renowned multimodal emotion recognition competition 1 . Since 2013, it has repeat- edly hosted the Depression Sub-Challenge, a dedicated task for depression detection, significantly advancing algorithmic dev elopment in this field. Its primary datasets include DAIC- WOZ [17], D-Vlog [18], and MODMA [19], among others. In depression detection tasks, many current models hav e adopted Language Models (LMs) or transformer -based architec- tures, integrating transformers into hybrid frameworks to lev er- age their contextual comprehension capabilities for enhanced depression screening [13], [20], [21], [22]. Moreover , a gro w- ing number of models are adopting multimodal fusion tech- niques, integrating data across diverse modalities (Audio, T ext, V ideo, Biological Signals) for depression detection, le veraging comprehensi ve multi-aspect information to improve diagnostic accuracy [14], [23]. 1. A VEC benchmarks ran annually from 2013 to 2019; the first three years (2013-2015) and the final year (2019) are specifically cited here. In the domain of audio-based depression detection, prior research has explored v arious methodologies, Including Graph Neural Networks (GNNs) [24] to model latent connections within/between audio signals and hybrid frameworks or uti- lizing MFCC-deriv ed spectrogram features processed through Con v olutional Neural Networks (CNNs) [25]. Additionally , some studies have proposed using the pretrained W av2V ec model for feature extraction, combined with lightweight fine- tuning networks, achieving highly effecti ve detectionn results [26]. The table 1 lists some of representati ve methods with their reported classification metrics (Precision, Recall, F-1 score and Accuracy). 2.2. A udio Encryption Chaos Maps-Based Encryption (CMBE) is a data protec- tion technique rooted in the properties of nonlinear dynamical systems, which has garnered significant attention in the field of audio encryption in recent years. Primarily applied to au- dio transmission and storage, this method le verages dynamic response capabilities and resistance to statistical analysis. A defining feature is that ev en slight variations in the encryption key trigger drastic changes in output, while the generated chaotic sequences mimic random noise, ef fecti vely obscuring the statistical characteristics of the original audio signals [31]. In addition to chaotic encryption, several other encryp- tion algorithms have been proposed. For example, the Cosine Number Transform (CNT) lev erages recursive finite-field trans- formations and overlapping block selection rules to achieve global diffusion [32]. Alternativ ely , Permutation-Substitution Architecture-based methods employ bit-lev el scrambling op- erations follo wed by dynamic substitution driv en by pseudo- random sequences [33]. Furthermore, homomorphic encryption (HE) is a crypto- graphic technique frequently employed in cloud computing and machine learning scenarios. It enables direct arithmetic opera- tions ( e.g. , addition, multiplication) on encrypted data, ensuring that decrypted results match those obtained from equiv alent computations performed on plaintext. Its defining property lies in preserving the operational utility of data while remaining encrypted [34]. 3. Preliminaries And Observations 3.1. Subspace Decomposition At first glance, deploying conv entional encryption methods to securely transmit audio data to Party B for depression detec- tion via specialized models seems theoretically feasible. How- e ver , our analysis rev eals a critical limitation: conv entional en- cryption methods prioritize data confidentiality by transforming raw signals into randomized noise patterns. While this ensures security , the inherent unpredictability and non-decryptability of such encrypted data se v erely impede the model’ s ability to iden- tify depression-specific features from chaotic representations, thereby undermining detection accuracy . Homomorphic Encryption (HE) has also been explored for this task. While HE enables encrypted audio processing within depression detection models [34], empirical evidence demonstrates that despite voice content being obfuscated, ID extraction models can still reliably determine whether two en- crypted audio clips originate from the same speaker , indicating that the indi vidual’ s ID remains exposed. Thus, it necessitates a novel encryption paradigm capable of maximally disentangling ID from depression-related features, selectiv ely obfuscating identity-sensiti ve attrib utes while pre- serving the integrity of depression-related features. T o this end, we implement Subspace Decomposition [35], [36]: S = U nd α + U d β , (1) Here, U nd ∈ R d × k and U d ∈ R d × m are orthogonal matrices ( U T nd U d = 0 ), they correspond to the orthonormal basis vectors of the NON-depressi ve feature subspace and the depression- specific feature subspace, respectively . α ∈ R k and β ∈ R m are coefficient vectors. Note that U nd is defined as the NON-depressive feature subspace rather than a dedicated ID subspace, due to poten- tial ov erlaps between depression-related and identity-sensiti v e attributes. Our method ensures that depression-specific features are retained in U d , while enforcing orthogonality constraints between U d and the non-depressiv e feature subspace U nd , which maximizes ID-related feature retention. Subspace decomposition exhibits two critical properties: (1) Disentanglement, where two sub-features are maximally decoupled across orthogonal subspaces, U T nd U d = 0 , and (2) Reconstructability , enabling approximate signal recovery via S ≈ U nd α + U d β . These properties jointly establish the theoretical foundation for deploying subspace decomposition in our framew ork. 3.2. Differential Priv acy Differential Priv acy ( i.e. , DP) [37], [38] is a rigorous math- ematical framework designed to protect individual data priv acy in statistical analyses and machine learning. It ensures that the presence or absence of any single individual’ s data in a dataset has a negligible impact on the algorithm’ s output, preventing adversaries from inferring sensitiv e information about specific participants. Under Differential Priv ac y (DP), for two neighboring datasets D and D (which differ by exactly one record, e.g . , D = D ∪ x ), the ( ϵ, δ ) -Differential Pri v acy requirement states that for all possible output subsets S ⊆ Rang e ( A ) : Pr[ A ( D ) ∈ S ] ≤ e ϵ · Pr[ A ( D ′ ) ∈ S ] + δ, (2) Here, ϵ is the priv ac y budget which controls the strength of priv ac y guarantees. δ is the failure probability , which allows a small probability of violating the priv acy bound. And A is the randomized algorithm. W e proposed a model variant that implements Differential Priv ac y and conducted corresponding ablation studies. The implementation and results are reported in 4.2 and 5.7 3.3. Progressi ve T raining Progressiv e Training refers to a strategy where multiple submodules of a model are trained in a specific sequence or priority , typically divided into multiple stages. Each stage focuses on optimizing parameters of a specific component, ultimately achieving overall performance improvement through combination or joint fine-tuning. Its strength lies in progressiv e enhancement — gradually introducing complex functionalities across stages — and dynamic adaptability , which allo ws flexible adjustments to subsequent training strategies based on interme- diate results. T ABLE 1 A brief summary of representati ve methods. Method PRE REC F1 A CC Unsupervised Autoencoder [27] 85% 80% 83% - MFCC-based RNN [28] 75%(70%) 95%(26%) 84%(38%) 74% Feature Fusion based on spectral analysis [29] 83% 100% 91% 85% Attenti ve LSTM Network [30] - - 94.01% 90.2% Graph Neural Network [24] 92.36±2.53% 92.18±1.55% 92.23±2.01% 92.21±1.86% MFCC & CNN generated spectrogram features [25] 86.4%(93.4%) 93.6%(85.9%) 89.85%(89.5%) 90.26% V oice-based Pre-training Model [26] 93.96%(97.65%) 94.87%(97.21%) 94.41%(97.43%) 96.48% * This table only lists existing methods and their reported results on D AIC-WOZ dataset. Due to differences in experimental setups, these results cannot be directly compared. The strength of our model lies in its ability to process encrypted data, and therefore the accuracy on raw data is not the focus of our in vestig ation. Progressiv e Learning is commonly employed in adversarial training, such as in Generativ e Adversarial Networks ( i.e. , GANs), where the generator and discriminator are alternately trained to compete and learn from each other [39]. Additionally , it is applied to Cascaded Models, where submodels are trained sequentially following a processing pipeline, and to Mixture of Experts ( i.e . , MoE), where multiple submodels (”experts”) specialize in different input subspaces and dynamically combine their outputs through a gating mechanism [40]. In our implementation, the model in volv es multiple loss functions and components serving distinct purposes. T o opti- mize training, we adopt Progressiv e Learning, leveraging its capability for progressiv e enhancement, and dynamically adjust training configurations based on task-specific requirements to maximize performance. 4. System Design This section presents the proposed scheme design, which utilizes the Subspace Decomposition of two heterogeneous fea- tures. The frame work remains secure and trustable ev en when Party B attempts to illegally access or misuse the data. 4.1. System Overview The general design of our model is shown by 2, which is composed of Three main parts: Subspace Decomposition Auto Encoder , Noise-Based Encrpytor and VPM Classifier . Subspace Decomposition A uto Encoder The SDAE is designed to disentangle raw audio inputs into two mutually orthogonal latent subspaces, isolating Depression-related fea- tures and the non-depressiv e features by enforcing orthogonality constraints during training. It retains the ability to reconstruct the original input through feature recombination and further supports priv acy-preserving data encryption by selecti vely per- turbing non-depressi ve components via encryption. Adjustable Noise Encryptor Drawing inspiration from De- noising Dif fusion Probabilistic Models (DDPMs), our encryptor employs a controlled hierarchical noise infusion mechanism designed to fulfill three critical requirements: (1) ensuring secure data transformation, (2) maintaining model-processable signal integrity , and (3) enabling adjustable encryption intensity . Mirroring the progressiv e noise scheduling inherent to DDPMs, this mechanism strategically introduces structured perturbations across sequential dif fusion steps. VPM Classifier For the final classification layer , we ad- here to the architectural configuration proposed in the V oice- based Pretrained Model (VPM) framework: a simple fine-tuning network is directly attached to the pretrained feature extractor to serve as the ultimate classification head. This design de- liberately av oids complex architectural modifications, retaining only essential projection layers for task-specific adaptation. Empirical results demonstrate that within our T AA C framework, such a straightforward implementation suf fices to achieve the desired performance. During the preprocessing stage, we implement a three-phase audio preprocessing pipeline. At the foundational phase, we perform uniform amplitude scaling based on peak values: x norm = x max( | x | ) This operation linearly maps each audio sample to the [-1, 1] range while preserving dynamic relationships. W e adopt this scaling to address inherent volume variations across datasets and between individual recordings. This scaling process can be conceptually regarded as a specialized form of normalization. In phase II, we selectiv ely extract participant-specific vocal segments from raw audio and perform duration-adjusted intra- subject reassembly — exclusi vely recombining speech clips from the same individual based on their temporal lengths, such that each recombined clip has an approximate duration of 2 second. This step filters out noises and interviewer speech artifacts, adapted from [26], with a slight modification whereby the recombination yields clips with an approximate duration of 2 seconds. The details will be introduced in Section 5.3. In Phase III, we implement temporal resampling on all recombined audio segments to achiev e uniform time-series lengths across samples. This temporal standardization ensures extracted digital representations maintain identical temporal dimensions—a prerequisite for consistent batch processing in deep neural networks. Bo tt le ne c k S pa tio - T e mpora l Fe a tu re E nc oder Depre s s ion Fe a tu re Dec oder No n - Depre s s iv e Fe a tu re Dec oder Differ entiatin g Fea tures Sub spa ce Dec ompo sitor (DFSD) N on - D ep ressiv e Fe atures D ep ression Fe atures Or th og on ality Lo ss N o n - o r t h o g o n a l p e n a lt y Reco n stru ctio n L o ss A dj ust abl e Encr y pt i on S t r ength Flexib le No ise E ncr y p t or (F NE) A u d io Dat a P ha s e A da pt iv e Ga te Has h Function No is e Ge ne ra to r Noise Ge n e rato r Forw ard N oising Process Fo rw ar d No is ing P roc e s s VPM CL a s s ifie r Classifier Ga t e α F or Ph as e I Ga te β F or Phas e I I Ga te γ F or Ph as e I I I DF SD F NE DF SD (He a d 2) VPM O rth Los s R e c o Los s Noise Los s Clas Los s Figure 2 General design of our proposed model. 4.2. Subsapce Decomposition A uto Encoder Subsapce Decomposition Auto Encoder [41], [42] (Here- after refer as SD AE) is a specialized v ariant of autoencoders that integrates subspace decomposition techniques. Serving as the ”gate way component” of our network architecture, it oper- ates at the highest hierarchical le vel to decompose input data into orthogonal subspaces, thereby enabling efficient feature disentanglement. The theoretical foundation of the Subspace Decomposition Autoencoder (SD AE) is illustrated in Equation 3. Here, we define the notation and their meanings: U nd ∈ R d × k is the Non-depressiv e feature. U d ∈ R d × m is the Depression-specific feature (note that U nd is not the PII feature, a distinction clarified in Section 3). α ∈ R k and β ∈ R m are coefficient vectors, ϵ is the noise term. Based on our model’ s architectural design, we set k = m . Consequently , we define α = β = 1 . S = U nd α + U d β + ϵ, (3) Prior to inputting audio into the model, specialized prepro- cessing is required, including target speech extraction, duration- based segmentation, and reintegration to meet the model’ s input specifications, as introduced in 4.1. W ithin the Spatio-T emporal Feature Encoder, the audio input is segmented and processed synchronously . This strat- egy reduces computational complexity , lowers memory require- ments during training, and accelerates con vergence. The archi- tecture employs three consecuti ve fully-connected (FC) layers interleav ed with nonlinear acti vation modules, coupled with Residual Blocks (ResBlocks), to ensure precise extraction of spatio-temporal feature representations. The encoded features are subsequently propagated and refined as latent variables within the bottleneck layer . T wo feature decoders are subsequently introduced to sep- arately extract depression-specific features ( U d ) and non- depressi ve features ( U nd ). These features reside in distinct subspaces that are designed to be orthogonal and uncorrelated – a critical property aligned with the subspace decomposition frame work, U T nd U d = 0 . Still, an additional requirement — reconstructability — necessitates that the feature vectors from both subspaces can be effecti vely recombined to reconstruct the original audio. T o jointly enforce these dual constraints, two loss functions are introduced within the optimization frame- work: L ortho = 1 N N X i =1 ⟨ v ( d ) i , v ( nd ) i ⟩ | {z } N on − or thogonal penalty , (4) L recon = 1 N N X i =1 ∥ v ( d ) i + v ( nd ) i − x i ∥ 2 2 , (5) In Equation 4, v ( d ) i and v ( nd ) i represent the depression and non-depressiv e features of each sample in subspaces U d and U nd ( U d = span { v ( d ) 1 , v ( d ) 2 , · · · , v ( d ) N } , Similarly for U nd ). This Orthogonality Loss is designed to enforce U d and U nd to form mutually orthogonal subspaces. Lemma 1 (Geometric Orthogonality) . [43] Given two orthog- onal matrices Q a , Q b ∈ R n × k , the following statements are equivalent: 1) Q ⊤ a Q b = 0 2) Q a ⊥ Q b 3) ∀ u ∈ R ( Q a ) , v ∈ R ( Q b ) : ⟨ u , v ⟩ = 0 4) R ( Q a ) ∩ R ( Q b ) = { 0 } W e aim to enforce sample-level orthogonality: ⟨ v ( d ) i , v ( nd ) j ⟩ = 0 , ∀ i, j ∈ 1 , ..., N , (6) The current Orthogonality Loss implicitly implements a weakly-constrained formulation via the summation relaxation: N X i,j =1 |⟨ v ( d ) i , v ( nd ) j ⟩| → 0 , (7) Thereby promoting the subspace orthogonality U T nd U d = 0 based on Lemma 1. In Equation 5, v ( d ) i and v ( nd ) i represent the depression and non-depressiv e features of each sample in subspaces U d and U nd , while x i represents the original signal of the audio sample. By minimizing the Mean Squared Error (MSE) reconstruction loss, we aim to ensure that the two sub-features decomposed by the SD AE can optimally recombine to reconstruct the original audio signal. Both decoders adopt a three-layer FC architecture identical to the encoder , complete with nonlinear activ ation modules, ensuring consistent output feature dimensions across both path- ways. These features will under go phase-specific transforma- tions — including encryption, fusion, or direct processing — depending upon the current training phase’ s operational require- ments. Differential Privacy is a rigorous priv acy frame work that ensures the output of a data analysis algorithm does not re veal whether an y single indi vidual’ s data is included in the input dataset. The formal definition and background are introduced in Sec. 3.2. In this work, we explore the integration of Dif ferential Pri- vac y into our model by constructing a variant trained with DP- SGD (Dif ferentially Priv ate Stochastic Gradient Descent) [44]. Specifically , we apply DP-SGD to train the SD AE module, with the goal of protecting latent variables from leaking user-specific information. This is achiev ed by injecting calibrated Gaussian noise during training to limit the influence of individual data points. The theoretical correctness of DP-SGD has been for - mally prov en in prior work [38], [44]. DP-SGD modifies the standard SGD optimization procedure in three main steps: 1) Per-e xample gradient computation: Gradients are com- puted for each example individually , rather than for the entire batch. 2) Gradient clipping: The ℓ 2 -norm of each per-example gradient is clipped to a predefined threshold C to bound the influence of any single example. 3) Noise addition: Gaussian noise, scaled by C , is added to the averaged gradient across the batch, ensuring that the update satisfies ( ε, δ ) -dif ferential priv acy . W e ev aluate the impact of this DP-preserving variant through an ablation study in the experimental section 5.7, analyzing how incorporating DP-SGD affects the performance of our model. 4.3. Adjustable Noise Encryptor The proposed encryption paradigm establishes a bijecti ve mapping between the original feature space U and the obfus- cated space ˜ U through a Deterministic T ensor Diffusion mech- anism. As depicted in 1, the core lies in the ke y-conditioned noise generation and parameterized dif fusion scheduling. Let x ∈ X denote the raw feature vector and k ∈ K the secret key . The encryption process implements an iterativ e nonlinear transformation: ˜ x ( t +1) = ˜ x ( t ) + α ( t ) · Φ(Γ( k )) , (8) where, Γ( k ) = P m j =1 k i · j generates a key-specific hash code. Φ( · ) denotes the nonlinear projector: sin ( · ) cos ( · ) . α ( t ) = 1 − t/T defines the annealed noise scheduler . The noise pattern Φ(Γ( k )) is key-dependent yey input- agnostic, ensuring that E k [ ˜ x | x ] = x + ϵ, ϵ ∼ N (0 , σ 2 I ) . The perfect reversibility is also achieved when k is known. The decay factor α ( t ) follows a curriculum annealing strategy , Algorithm 1 Deterministic noise-based encryption. 1: Input: Feature x , Ke y k , Steps T 2: Output: Obfuscated feature e x 3: Initialize e x (0) ← x 4: Compute key hash: Γ ← P m j =1 k j · j 5: Generate base noise: Φ ← sin(Γ) ⊙ cos(Γ) 6: for t = 1 to T do 7: α ← 1 − t/T 8: e x ( t ) ← e x ( t − 1) + α · Φ 9: end for 10: retur n e x ( T ) which theoretically guarantees con vergence. During the encryption process, we modulate the encryption strength by adjusting the value of parameter T , thereby achiev- ing an optimal trade-off between confidentiality and accuracy , demonstrated by subsequent experiments in section 5. 4.4. VPM Classifier In terms of the output architecture, our model adopts the strategic framework from the V oice-based Pre-training Model (VPM) [26], where a compact fine-tuning netw ork serves as the final classification layers to generate depression prediction scores. Prior to the VPM Classifier , we implement a Phase- Adaptiv e Gating Mechanism that dynamically regulates data throughput according to three predefined training phases, ca- pable of operating in three distinct modes: full transmission, partial transmission, and complete blockage of data flow , gov- erned by phase-dependent policies. In the initial two tiers of the VPM architecture, we ar- chitect a con volutional neural network (CNN) [45] backbone incorporating batch normalization, nonlinear activ ation layers, and dropout regularization. The terminal layer employs a fully- connected projection head to map the refined representations into depression classification logits. For the classification loss, we employ the Cross Entrop y loss with label smoothing, a mathematically principled choice for optimizing probabilistic predictions in depression detection: L C = P N i =1 ( z i,y i − l og ( P K k =1 e z ik )) N , (9) where z ik represents the unnormalized logit value of the i-th sample for class k , and y i denotes the ground-truth class label. This loss function ensures stable optimization. 4.5. V arious T raining Phases The framew ork is executed through three sequential training phases. In Phase I, we focus on training the Differentiating Features Subspace Decompositor (DFSD) to decompose raw audio samples into two orthogonal subspaces—depressive and non-depressi ve features—while strictly enforcing orthogonality and reconstruction constraints. The encryptor remains untrained as a deterministic module, where its output is fully determined by predefined encryption keys and strength parameters. During Phase II, the VPM Classifier is trained on unencrypted data, which is reconstructed directly from the two subspaces, estab- lishing baseline diagnostic performance for raw audio process- ing. Finally , Phase III adapts the classifier to encrypted inputs: non-depressi ve features are first encrypted and then recombined with depressi ve features to synthesize priv acy-preserving audio samples. The VPM Classifier undergoes fine-tuning via back- propagation on these encrypted samples. Phase I In this training phase, we utilize three loss func- tions: Orthogonality Loss, Reconstruction Loss, and Classifi- cation Loss. The Orthogonality Loss and Reconstruction Loss ensure the DFSD fulfills its core functionality , while the Classi- fication Loss enforces strong relev ance between depressiv e fea- tures and depression detection. The combined effect of Orthog- onality Loss and Classification Loss minimizes the diagnostic influence of features from the other decoder . During this phase, the DFSD and VPM Classifier are em- ployed. The depression-related features are fed directly into the VPM Classifier to compute the Classification Loss. While the Classification Loss is backpropagated through the entire network, the Orthogonality Loss and Reconstruction Loss gra- dients only update the DFSD. T o prioritize DFSD training, we introduce a hyperparameter to amplify the emphasis on Orthog- onality/Reconstruction Losses and attenuate the Classification Loss influence. Phase II Subsequently , we proceed to Phase II. During this and subsequent phases, DFSD’ s parameters are frozen to preserve its orthogonality and reconstruction constraints. The depression and non-depressiv e features extracted by DFSD are reintegrated and fed into the VPM Classifier (without encryp- tion). This training phase is dedicated to training a model capable of processing unencrypted data. Phase III In the final Phase III, the DFSD’ s parameters remain frozen. The encrypted non-depressive features are fused with depression features and fed into the VPM Classifier for training, establishing a model optimized for processing en- crypted clinical audio data. 5. Experimental Evaluation 5.1. Dataset W e employ the dataset following established research con- ventions — DAIC-W OZ (Distress Analysis Intervie w Corpus- W izard of Oz). The Distress Analysis Intervie w Corpus (D AIC) contains clinical intervie ws designed to support the diagnosis of psy- chological distress conditions such as anxiety , depression, and post traumatic stress disorder . The intervie ws are conducted by humans, human controlled agents and autonomous agents, and the participants include both distressed and non-distressed indi viduals [17]. 5.2. Implementation & Hyperparameters Across different experimental configurations, certain implementation-specific hyperparameters may v ary . Here we present the standardized experimental protocols and hyperparameters consistently adopted across all trials. All experiments were conducted on a single NVIDIA GeForce R TX 4090 D GPU with 24GB VRAM, running under Python 3.9.13. The SD AE’ s three-layer encoder-decoder architecture ex- hibits feature dimensionalities of 32,000, 8,000, and 2,000 across successi ve layers. The weighting factors for orthogo- nality loss and reconstruction loss are both set to 10, with configurations: dropout rate = 0.2, learning rate = 1e-4, and weight decay = 0.01. The final depression classification task is formulated as a binary classification problem, where the output 0/1 indicates whether the individual doesn’t have depression (0 indicates depression, 1 indicates no depression). W e set the batch size to 32, with the total number of epochs set to 10. After conducting grid experiments, we determined that the optimal threshold for ev aluating the model output is 0.4 — that is, if the predicted score is greater than 0.4, it is classified as depressed; otherwise, as non-depressed. Interestingly , this threshold coincides with the proportion corresponding to the depression cut-off in the PHQ- 8 score (the PHQ-8 ranges from 0 to 24, and scores abov e 9 are considered indicati ve of depression, so 10 25 = 0 . 4 ). In contrast, the PII identification task for each data point is formulated as a pairwise comparison task, where the model is presented with two data samples and outputs whether the two audio recordings come from the same individual. This setup simulates the real-world scenario in which malicious actors exploit audio data by comparing it against a known database to determine the source of the audio. 5.3. Data Prepr ocessing T o meet our specific experimental requirements and enhance the data, we performed preprocessing on the dataset, consisting of three stages: amplification, extraction/recombination, and resampling. In the second stage, we decomposed the audio data in DAIC-W OZ into 32,400 segments and recombined them into 9,753 audio clips. After the third stage, every clip can be loaded into digital form of length 32000. Additionally , in the Depression Detection task, we randomly partitioned the dataset into ten different train-test splits, ev alu- ated the model on each split, and av eraged the results to ensure the rob ustness of the model. In the PII Identification task, we randomly paired the data, resulting in 189 positive pairs and 611 negati ve pairs, for a total of 800 pairs of samples. 5.4. Metrics In this paper , we leverage the following metrics to ev aluate the performance of the proposed architecture on depression detection: 1) Recall. Giv en a series of input data and the correspond- ing outcomes, the r ecall can be defined as: Recal l = T P T P + F N , (10) where T P , F N represent True Positive and False Neg- ati ve, respecti vely . Recall measures the proportion of actual positi ve cases that are correctly identified. 2) Pr ecision. Giv en a series of input data and the corre- sponding outcomes, the pr ecision can be expressed as: P r ecision = T P T P + F P , (11) where F P represents the False Positive. Precision mea- sures the proportion of predicted positive cases that are truly positi ve. 3) F1-scor e. The F1-scor e can be represented as: F1-scor e = 2 × P r ecision × Recal l P r ecision + R ecall . (12) The F1-score provides a harmonic mean of precision and recall, balancing the two metrics. 4) Accuracy . Giv en a series of input data and the corre- sponding outcomes, the accuracy can be defined as: Accur acy = T P + T N T P + T N + F P + F N , (13) where T N represents T rue Negati ve. Accuracy mea- sures the overall proportion of correctly classified cases. In the PII Identification task, we will focus more on the other three metrics. 5) F alse Acceptance Rate (F AR). The F alse Acceptance Rate is a metric used to ev aluate the rate at which ne g- ati ve samples (i.e., non-matching cases) are incorrectly accepted as positiv e in a classification or authentication system. It can be defined as: F AR = F P F P + T N , (14) where F P represents the False Positive, and T N repre- sents the T rue Negati ve. F AR indicates how frequently the system incorrectly identifies a negati ve sample as positi ve, which is a critical metric for security-sensitiv e applications like biometric authentication. 6) F alse Rejection Rate (FRR). The F alse Rejection Rate measures the rate at which positiv e samples (i.e., match- ing cases) are incorrectly rejected by the system. It can be expressed as: F RR = F N F N + T P , (15) where F N represents the False Negativ e, and T P represents the T rue Positive. FRR indicates how often the system fails to correctly identify positiv e samples, which is crucial for user experience in systems such as facial recognition or fingerprint scanning. 7) Equal Err or Rate (EER). The Equal Err or Rate is a metric commonly used in biometric systems, such as speaker recognition or face recognition. EER is the point at which the False Acceptance Rate (F AR) equals the False Rejection Rate (FRR). It represents a threshold where both types of errors occur at the same rate. Mathematically , it can be described as: E E R = F AR = FRR , (16) where F AR is the rate of incorrectly accepting a negati ve sample as positive, and FRR is the rate of rejecting a true positiv e. The EER provides a single value to e valuate the trade-of f between false positives and false negati ves at the operating point where they are balanced. These three metrics are used because, in the speaker recog- nition task, we focus on balancing the trade-off between false acceptances (F AR) and false rejections (FRR), which directly impact both security and user experience. F AR and FRR are more rele vant than Precision and Recall, as they better reflect the system’ s ability to correctly handle authorized and unautho- rized users. At the same time, we will also report the Accuracy result. 5.5. Evaluation of Depr ession Detection The e valuations in this part primarily assess the performance of T AAC on depression detection task, which contain depression T ABLE 2 Ev aluation results on depression detection task. Our Arthitecture - T AAC A CC REC PRE F1 Unencrypted 84.75% 0.88 0.86 0.87 Encrypted (Strength 5) 80.17% 0.88 0.85 0.86 Encrypted (Strength 10) 83.62% 0.92 0.84 0.88 Encrypted (Strength 25) 78.28% 0.91 0.8 0.85 Other Methods A CC REC PRE F1 Chaos Maps-Based Encryption 64.00% 0.72 0.83 0.77 Homomorphic Encryption 84.23% 0.88 0.86 0.87 detection on unencrypted data and on encrypted data. Since the ef fect of encryption predominantly depends on encryption strength and keys, we ev aluate our modal on 3 different encryp- tion strengthes from each of the 4 large-size keys across the 12 experimental scenarios. T o ensure the full representation of experimental ef fects in unfamiliar en vironments, the data used for each testing session are not included in the training set. T o assess the usability of T AAC , we first ev aluate the model on unencrypted audios. As stated in 5.2, for each ev aluation, we set the batch size to 32, the total epochs to 10, and the threshold to 0.4. The average results of cross validation are reported in T ab. 2. The experimental findings demonstrate that the proposed arthitecture effecti vely detects depression with unencrypted audios. The subsequent part of the ev aluation focuses on the per- formance of the model on encrypted audios. W e e valuate our model under three encryption strengths: 5, 10, and 25, and report the average results obtained over experiments conducted with four dif ferent keys for each strength. The a verage precision is 86 . 5% , and the av erage recall is 86 . 2% . The experiments confirm the system’ s capability to accurately identify large- size ke ys from a series of acoustic inputs. The recognition of the Space and Enter keys exhibits slightly higher accuracy compared to other ke ys, attributed to their distincti ve timbre. Al- though occasional identification errors may occur , these samples can be easily deleted due to their significant offset in location estimation. Next, we assess the performance of our model against other methods as part of an ablation study to v alidate the effecti veness of our approach. Specifically , we conduct experiments using two representati ve techniques: Chaos Maps-Based Encryption [31], [46] and Homomorphic Encryption [34]. Following the same experimental setup as before, we report their Accuracy , Recall, Precision, and F1 scores for comparison in T ab. 2. Finally , we also report the confusion matrices under four different thresholds at encryption strengths of 10 and 25, as sho wn in Fig. 3 and Fig. 4, to further analyze the model’ s classification behavior and demonstrate ho w its performance varies with different threshold settings. As sho wn in T able 2, our model achie ves an accuracy of 84.75% and an F1 score of 0.87 on the original (unencrypted) data, which represents a strong performance. After applying our Encryptor structure, the model maintains comparable per- formance under a weak Encryption Strength of 5, achieving an accuracy of 80.17%, with an F1 score nearly equiv alent to that on the unencrypted data. Even under a strong Encryption Figure 3 Confusion matrix on depression detection with enc- Strength 25. Figure 4 Confusion matrix on depression detection with enc- Strength 10. Strength of 25, the model still achieves 78.28% accuracy and an F1 score of 0.85. These results demonstrate that our model meets the Accuracy requirement outlined in the Three Major Challenges. Moreover , users can dynamically adjust the en- cryption strength to balance between model accuracy and data confidentiality . It is worth noting that as the encryption strength increases, the remaining depression-related information in the PII sub- space becomes increasingly obfuscated. As a consequence, we observe that the model tends to predict samples as non- depressed. Combined with the issue of class imbalance in the dataset—where non-depressiv e samples greatly outnumber depressi ve ones—this bias leads to an increase in recall but a drop in precision, with recall consistently remaining high. As shown in T able 2, when applying Chaos Maps-Based Encryption, the accuracy drops to only 64%. This demonstrates that merely using e xisting encryption methods leads to complete obfuscation of feature information, making it impossible for the model to learn meaningful patterns from the data. While Homomorphic Encryption achiev es strong performance on the Depression Detection task, the comparison in Fig. 5 reveals that it fails to pre vent malicious actors from stealing PII. 5.6. Perf ormance of PII Extraction W e first report the statistical differences between the en- crypted audio, the reconstructed audio, and the original audio in T ab. 3. The reported metrics include MSE, MAE, and PSNR. A lo wer MSE/MAE indicates higher similarity . PSNR (Peak Signal-to-Noise Ratio) represents the ratio of signal po wer to T ABLE 3 Statistical differences between the encrpyted audio, the reconstructed audio and the original audio. Data - Method MSE MAE PSNR Encrypted ( T AAC ) 7.56 2.75 -30.02dB Reconstructed ( T AAC ) 2.7e-4 1.0e-2 14.46dB Encrypted (Chaos Maps-Based) 1.4e+7 2.7e+3 -1.91dB Reconstructed (Chaos Maps-Based) 82.90 0.55 50.3dB Encrypted (Homomorphic) 0.91 0.95 -20.82dB Reconstructed (Homomorphic) 0.00 0.00 98.77dB T ABLE 4 Ev aluation results on PII extraction task. Our Arthitecture - T AAC A CC F AR FRR EER Encrypted (Strength 5) 75.40% 0.48 0.01 0.26 Encrypted (Strength 10) 58.47% 0.83 0.01 0.3 Encrypted (Strength 25) 50.53% 0.97 0.02 0.49 Other Methods A CC F AR FRR EER Unencrypted 100.00% 0 0 0 Chaos Maps-Based Encryption 51.06% 0.75 0.23 0.35 Homomorphic Encryption 99.74% 0.01 0 0.01 noise power . A higher PSNR indicates less distortion and better quality . From T ab . 3, it can be observed that audio encrypted using the Chaos Maps-based method dif fers the most from the original audio, offering the highest lev el of confidentiality . In contrast, audio encrypted using the Homomorphic method shows less de- viation from the source data b ut achieves the best reconstruction fidelity . Our method lies between these two extremes. Next, we ev aluate the model’ s performance on the PII Extraction task following the experimental setup described in Section 5.2. with a slight modification: multiple audio samples from the same individual are concatenated into a longer audio segment (ranging from 30 seconds to 1 minute), as the model used for this task requires longer inputs to achiev e reliable comparison accuracy . The model used is the comparison model provided by SpeechBrain [5]. The dataset is divided into 378 pairs, among which 189 pairs contain two audio samples from the same individual, while the remaining 189 pairs are com- posed of samples from different indi viduals. W e report the model’ s performance in terms of Accuracy , F AR, FRR, and EER in T ab. 4, with the threshold set to 0.85. W e first use the trained SD AE and the Encryptor under different encryption strengths (5, 10, and 25) to encrypt the data. The encrypted data is then passed to the v erification model for prediction. The results are sho wn in T able III. It is worth noting that under full encryption, the verification model tends to classify all audio samples as belonging to the same individual, as the signals become completely randomized and chaotic — which causes the accuracy to fluctuate around 50% at worst. Next, we feed the original, unencrypted audio into the model. This step is intended to demonstrate that the verification TEA (encStrength =10) Cha os Maps-B ased Encrypt i on Homom orp h ic Encrypt i on 54 sec 83.62% Depres s ion Detection Ac cu rac y ↑ Inv erse A v erage Proc es s i ng T i me Inv erse Rec ons tructi on Los s Inv erse PII Extr ac ti on Ac c ur acy ↑ 72.5 se c 64.00 % 84.23 % 152 sec 99.60% 0.00 57.27 % 2.7e - 4 82. 90 51.06% Figure 5 Radar chart comparison of the three encryption methods. Since lo wer v alues of PII Extraction Accuracy , Reconstruction Loss, and A verage Processing T ime indicate better performance, we present their inv erse values in the figure to make the comparison more intuitive. model possesses strong discriminati ve power and can accurately determine whether two audio samples belong to the same indi vidual when the data is not obfuscated. Finally , we also present the performance of the two afore- mentioned encryption methods on the PII Extraction task within T ab. 4, to compare it with their performance on the Depression Detection task. In addition, we pro vide a visual comparison in Fig. 5 to offer a more intuiti ve understanding of the Pros and Cons. One of the primary contributions of our work is the ability to ensure the obfuscation and invisibility of PII within the data, and the results in T ab . 4 demonstrate that our model achie ves this goal. When the data is unencrypted, the model achie ves 100% accuracy and an EER of 0, indicating that the SpeechBrain model can perfectly identify whether two audio samples come from the same individual in a clean setting. Ho wev er , after encryption, we observe a decrease in accuracy and a significant increase in EER as the encryption strength increases. At encryption strength of 25, the accuracy reaches 50.53%, and the EER increases to 0.49. A detailed analysis re veals that after encryption, the model classifies nearly all audio pairs as coming from the same individual, due to the encrypted noises being highly similar to each other . As a result, the FRR remains low , while the F AR becomes extremely high, and the accuracy fluctuates around 50% at worst. As shown in the T ab . 4 and Fig. 5, the results obtained from data encrypted using Chaos Map-Based Encryption are compa- rable to those achiev ed by our model under high encryption strength. This demonstrates that our model provides a level of PII protection similar to traditional encryption methods. Ho w- e ver , unlike those methods, our model still retains the ability to extract depression-related features from the encrypted audio. In contrast, the accuracy and EER after Homomorphic Encryption remain close to those of the unencrypted case, indicating that although Homomorphic Encryption achieves good performance on the Depression Detection task, it fails to adequately protect PII information. T ABLE 5 Ev aluation results on DP vs. non-DP . A CC REC PRE F1 T ime † non-DP 81.40% 0.96 0.84 0.90 24min DP 76.00% 0.87 0.83 0.85 112min † Here we report the average time required to train for 10 epochs across different splits. 5.7. Deep Dive into T AA C The main purpose of this section is to demonstrate the impacts of various factors, e.g., environmental factors, dataset- related factors, and data processing factors, on the T AA C sys- tem. T o isolate the impact of individual factors on the experi- mental results and effecti vely control variables, the experiments in this section are conducted with the encryption strength fixed at 10 and the threshold fixed at 0.4. Since the follo wing experiments are not strongly related to the main achiev ements of our model, they are conducted using only a single key on three splits. 5.7.1. Impact of DP-SGD. In this experimental setup, we con- ducted experiments on both the DP and non-DP versions using the configurations described above. During the experiments, we observed that the DP version had significantly longer processing times; therefore, we additionally report the a verage training time of the models in the table. The experimental results are reported in T ab. 5. From the table, it can be seen that after applying DP , the av erage processing time increased by 4 to 5 times, while the accuracy decreased but remained within an acceptable range. Since DP enhances security under the differentially priv ate setting, it can be of fered as an optional feature for users. 5.7.2. Impact of Noises. In the DAIC-W OZ dataset, each orig- inal audio contains the participant’ s speech, the intervie wer’ s speech, and background noise. Through data preprocessing, we remov ed the interviewer’ s voice and background noise from the audio, ensuring a strong correlation between the data and the participant in our experiments. T o e valuate the system’ s robustness against noise, we con- duct experiments under three dif ferent scenarios with varying noise lev els. The scenarios and corresponding noise types are detailed in T ab . 6. Specifically , the noise intensity ranges from 43 . 31 dB to 46 . 36 dB . The results are reported in T ab . 7 As shown in the table, the accuracy slightly decreases after introducing en vironmental When more third-party noise is introduced, the accuracy drops substantially . Through analysis, we find that the model tends to classify the interviewer’ s voice as non-depressiv e, leading to almost all samples being predicted as non-depressi ve. 5.7.3. Impact of V arious A udio Lengths. In the original experimental setup, each audio was recombined to approxi- mately 2 seconds. In this experiment, we e valuate the impact on accuracy when the audio is recombined to different lengths. The results are reported in T ab. 8 As shown in the T ab . 8, the experimental results are barely affected by different audio lengths, indicating that under rel- ativ ely short durations, varying audio lengths do not have a significant impact on our model. Howe ver , it is worth noting T ABLE 6 Scenarios and types of noises. Scenarios T ype of noises Clean None En vironmental Noise Ambient environmental noise (46.36dB, 10%) Speech Noise Ambient environmental noise (46.36dB, 10%), Interviewer’ s speech noise (43.31dB, 10%) T ABLE 7 Ev aluation results on noises A CC REC PRE F1 Clean 81.4% 0.96 0.84 0.90 En vironmental Noise 79.88% 0.96 0.8 0.87 Speech Noise 75.2% 0.99 0.68 0.81 T ABLE 8 Ev aluation results on v arious audio lengths A CC REC PRE F1 2 sec 81.4% 0.96 0.84 0.90 3 sec 80.6% 0.96 0.83 0.89 5 sec 81.2% 0.96 0.84 0.90 that as the audio length increases, the training cost grows expo- nentially , and our training hardw are can only support processing up to a maximum audio length of 5 seconds. W e present in Fig. 6 the changes in GPU memory requirements under dif ferent audio lengths. 6. Conclusion This paper presents a practical and trustworthy data pro- cessing framework, T AAC , for performing depression detection on audio data within a trustable setting. T o address the trade- of f between encryption and accuracy , we le verage Subspace Decomposition and propose a novel architecture, SDAE. Ex- tensiv e experimental results demonstrate that, compared with existing purely encryption-based methods such as Chaos Maps- Based Encryption and Homomorphic Encryption, the proposed system effecti vely balances accuracy and security—whereas prior methods tend to ensure only one. Furthermore, by dra wing inspiration from diffusion models, we introduce a Adjustable Noise Encryptor , enabling T AAC to preserve the original data structure post-encryption. This allows the encrypted audio to remain processable by the model. Additionally , the frame- work incorporates an adjustable Encryption Strength parameter , granting users the flexibility to balance accuracy and priv acy , thereby enhancing the system’ s practicality . By varying ke y experimental parameters, we further validate ho w different Encryption Strength and Threshold settings impact both the Depression Detection and PII Extraction tasks. With the in- tegration of a VPM Classifier and the Progressiv e Training method, the classification performance is further improv ed. Even when handling noisy audio data or samples of varying Figure 6 Changes of GPU memory requirements under dif- ferent audio lengths (unit: MB). lengths and sources, our model demonstrates robust and reliable performance. Our work discusses the risk that user audio data in depression-detection systems may be misused by service providers. This concern is not a novel disclosure; rather , it reflects a widely recognized issue that has attracted substan- tial attention from stakeholders, with existing national policies already restricting abusi ve data practices. The primary contribution of our paper is to introduce a tech- nical approach that fundamentally eliminates the possibility of such misuse. Following publication, we welcome engagement with developers and vendors and encourage the adoption of our approach in real-world systems. Through this work, we intend to further emphasize to the public the importance of safeguarding audio data and to encourage vendors to critically re-examine their own security practices. Our study makes use of the DAIC-W OZ dataset, a publicly av ailable corpus of clinical interviews designed to support the diagnosis of psychological distress. The dataset was originally collected by the Uni versity of Southern California (USC) In- stitute for Creativ e T echnologies. According to the original publications and our inv estigation, the data collection procedure receiv ed approval from the corresponding Institutional Revie w Board (IRB), and all participants provided informed consent. Although the dataset is publicly accessible, we adhered strictly to ethical guidelines for handling sensitive data. W e clearly communicated our research intentions to the dataset provider and obtained access only after approv al of our ap- plication. In our analysis, we used solely anonymized audio data and relied on anonymized participant identifiers. No data linking participants to their real-world identities was exposed or processed at any stage of the study . Acknowledgments Anonymous for now . References [1] W orld Health Organization, “Depressive disorder (depression), ” https:// www .who.int/news- room/fact- sheets/detail/depression, March 2023, [Ac- cessed: Apr, 29, 2025]. [2] W orld Health Organization, “Depression rates by country 2025, ” https://worldpopulationre view .com/country- rankings/ depression- rates- by- country, 2025, [Accessed: Apr, 29, 2025]. [3] Y in W u, Brooke Levis, Kira E. Riehm, Nazanin Saadat, Alexander W . Levis, Marleine Azar , Danielle B. Rice, Jill Boruf f, Pim Cuijpers, Simon Gilbody , and et al., “Equiv alency of the diagnostic accuracy of the phq- 8 and phq-9: a systematic revie w and individual participant data meta- analysis, ” Psychological Medicine , vol. 50, no. 8, pp. 1368–1380, 2020. [4] Kurt Kroenke, “Phq-9: Global uptake of a depression scale, ” W orld Psychiatry , vol. 20, no. 1, pp. 135–136, 2021. [5] Mirco Rav anelli, T itouan Parcollet, Peter Plantinga, Aku Rouhe, Samuele Cornell, Loren Lugosch, Cem Subakan, Nauman Dawalatabad, Abdelwa- hab Heba, Jianyuan Zhong, Ju-Chieh Chou, Sung-Lin Y eh, Szu-W ei Fu, Chien-Feng Liao, Elena Rastorgue va, Franc ¸ ois Grondin, W illiam Aris, Hwidong Na, Y an Gao, et al., “Speechbrain: A general-purpose speech toolkit, ” 2021. [6] Zhiyuan Y u, Y uanhaur Chang, Ning Zhang, and Chao wei Xiao, “SMACK: Semantically meaningful adversarial audio attack, ” in 32nd USENIX Security Symposium (USENIX Security 23) , Anaheim, CA, Aug. 2023, pp. 3799–3816, USENIX Association. [7] Jiahe Lan, Jie W ang, Baochen Y an, Zheng Y an, and Elisa Bertino, “ FlowMur: A Stealthy and Practical Audio Backdoor Attack with Limited Knowledge , ” in 2024 IEEE Symposium on Security and Privacy (SP) , Los Alamitos, CA, USA, May 2024, pp. 1646–1664, IEEE Computer Society . [8] Jiayu Y e, Y anhong Y u, Qingxiang W ang, W entao Li, Hu Liang, Y unshao Zheng, and Gang Fu, “Multi-modal depression detection based on emotional audio and evaluation text, ” Journal of Affective Disor ders , vol. 295, pp. 904–913, 2021. [9] Y ing Shen, Huiyu Y ang, and Lin Lin, “ Automatic depression detection: An emotional audio-textual corpus and a gru/bilstm-based model, ” in Pr oceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . 2022, pp. 6247–6251, IEEE. [10] Penghao W ang, Shuo Huai, Y etong Cao, Chao Liu, and Jun Luo, “Threat from windshield: V ehicle windows as involuntary attack sources on au- tomotiv e voice assistants, ” in Proceedings of the ACM Conference on Computer and Communications Security (CCS) . 10 2025, ACM. [11] Guangke Chen, Y edi Zhang, Fu Song, T ing W ang, Xiaoning Du, and Y ang Liu, “Songbsab: A dual prev ention approach against singing voice con version based illegal song covers, ” in Pr oceedings of the Network and Distributed System Security Symposium (NDSS) . NDSS, 2025. [12] Jiangyi Deng, Fei T eng, Y anjiao Chen, Xiaofu Chen, Zhaohui W ang, and W enyuan Xu, “V -Cloak: Intelligibility-, naturalness- & Timbre- Preserving Real-Time voice anonymization, ” in 32nd USENIX Security Symposium (USENIX Security 23) , Anaheim, CA, Aug. 2023, pp. 5181– 5198, USENIX Association. [13] Haodi W ang, Kai Dong, Zhilei Zhu, Haotong Qin, Aishan Liu, Xiaolin Fang, Jiakai W ang, and Xianglong Liu, “Transferable multimodal attack on vision-language pre-training models, ” in 2024 IEEE Symposium on Security and Privacy (SP) , 2024, pp. 1722–1740. [14] Luming Y ang, Lin Liu, Jun-Jie Huang, Zhuotao Liu, Shiyu Liang, Shao- jing Fu, and Y ongjun W ang, “Mm4flow: A pre-trained multi-modal model for versatile network traffic analysis, ” in Proceedings of the 32nd ACM Confer ence on Computer and Communications Security (CCS) . ACM, 2025. [15] F . Ringeval, B. Schuller, M. V alstar , N. Cummins, R. Cowie, L. T avabi, M. Schmitt, S. Alisamir, S. Amiriparian, E.-M. Messner , S. Song, S. Liu, Z. Zhao, A. Mallol-Ragolta, Z. Ren, M. Soleymani, and M. Pantic, “ A vec 2019 workshop and challenge: State-of-mind, detecting depression with ai, and cross-cultural affect recognition, ” in Proceedings of the 9th In- ternational W orkshop on A udio/V isual Emotion Challenge and W orkshop, Nice, F rance , 2019, pp. 3–12. [16] Kaiming Cheng, Jeffery F . Tian, T adayoshi Kohno, and Franziska Roes- ner , “Exploring user reactions and mental models towards perceptual manipulation attacks in mixed reality , ” in 32nd USENIX Security Sym- posium (USENIX Security 23) , Anaheim, CA, Aug. 2023, pp. 911–928, USENIX Association. [17] J. Gratch, R. Artstein, G. M. Lucas, G. Stratou, S. Scherer, A. Nazarian, R. W ood, J. Boberg, D. DeV ault, S. Marsella, and D. R. T raum, “The distress analysis interview corpus of human and computer interviews, ” in Pr oceedings of the 9th Language Resources and Evaluation Conference (LREC 2014) , 2014, pp. 3123–3128. [18] J. Y oon, C. Kang, S. Kim, and J. Han, “D-vlog: Multimodal vlog dataset for depression detection, ” Pr oceedings of the AAAI Conference on Artificial Intelligence , vol. 36, no. 11, pp. 12226–12234, 2022, [Data set]. [19] H. Cai, Y . Gao, S. Sun, N. Li, F . Tian, H. Xiao, J. Li, Z. Y ang, X. Li, Q. Zhao, Z. Liu, Z. Y ao, M. Y ang, H. Peng, J. Zhu, X. Zhang, X. Hu, and B. Hu, “Modma dataset: A multi-modal open dataset for mental-disorder analysis, ” arXiv preprint arXiv:2002.09283, 2020, [Data set]. [20] H. Fan, X. Zhang, Y . Xu, J. F ang, S. Zhang, X. Zhao, and J. Y u, “T ransformer-based multimodal feature enhancement networks for mul- timodal depression detection integrating video, audio and remote pho- toplethysmograph signals, ” Information Fusion , vol. 104, pp. 102161, 2024. [21] R. Qin, K. Y ang, A. Abbasi, D. Dobolyi, S. Seyedi, E. Griner , H. Kwon, R. Cotes, Z. Jiang, G. Clifford, and R. A. Cook, “Language models for online depression detection: A revie w and benchmark analysis on remote interviews, ” A CM T ransactions on Management Information Systems , vol. 16, no. 2, pp. Article 12, 2025. [22] Y ongfeng T ao, Minqiang Y ang, Huiru Li, Y ushan W u, and Bin Hu, “Depmstat: Multimodal spatio-temporal attentional transformer for de- pression detection, ” IEEE T ransactions on Knowledge and Data Engi- neering , vol. 36, no. 7, pp. 2956–2966, 2024. [23] Shu W ang, Kun Sun, and Qi Li, “Compensating removed frequency components: Thwarting v oice spectrum reduction attacks, ” in Pr oceedings of the Network and Distributed System Security Symposium (NDSS) . NDSS, 2024. [24] C Sun, M Jiang, L Gao, Y Xin, and Y Dong, “ A nov el study for depression detecting using audio signals based on graph neural network, ” Biomedical Signal Processing and Control , vol. 88, pp. 105675, 2024. [25] A. K. Das and R. Naskar , “ A deep learning model for depression detection based on mfcc and cnn generated spectrogram features, ” Biomedical Signal Processing and Control , vol. 90, pp. 105898, 2024. [26] X. Huang, F . W ang, and Y . Gao, “Depression recognition using voice- based pre-training model, ” Scientific Reports , vol. 14, pp. 12734, 2024. [27] S. Sardari, B. Nakisa, M. N. Rastgoo, and P . Eklund, “ Audio based depression detection using con volutional autoencoder , ” Expert Systems with Applications , vol. 189, pp. 116076, 2022. [28] Emna Rejaibi, Ali Komaty , Fabrice Meriaudeau, Said Agrebi, and Alice Othmani, “Mfcc-based recurrent neural network for automatic clinical depression recognition and assessment from speech, ” Biomedical Signal Pr ocessing and Control , vol. 71, pp. 103107, 2022. [29] Xiaolin Miao, Y ao Li, Min W en, Y ongyan Liu, Ibegbu Nnamdi Julian, and Hao Guo, “Fusing features of speech for depression classification based on higher-order spectral analysis, ” Speech Communication , vol. 143, pp. 46–56, 2022. [30] Y an ZHA O, Y ue XIE, Ruiyu LIANG, Li ZHANG, Li ZHAO, and Chengyu LIU, “Detecting depression from speech through an attentive lstm network, ” IEICE TRANSACTIONS on Information , vol. E104-D, no. 11, pp. 2019–2023, November 2021. [31] E. A. Albahrani, T . K. Alshekly , and S. H. Lafta, “ A revie w on audio encryption algorithms using chaos maps-based techniques, ” Journal of Computer Science and Network Security , vol. 11, no. 1, pp. 53–82, 11 2021. [32] B. Ustubioglu, B. K ¨ uc ¸ ¨ uku ˘ gurlu, and G. Ulutas, “Robust copy-move detection in digital audio forensics based on pitch and modified discrete cosine transform, ” Multimedia T ools and Applications , vol. 81, pp. 27149– 27185, 2022. [33] A. S. Alanazi, N. Munir, M. Khan, et al., “ A novel design of audio signals encryption with substitution permutation network based on the genesio-tesi chaotic system, ” Multimedia T ools and Applications , vol. 82, pp. 26577–26593, 2023. [34] L. Nguyen, B. Phan, L. Zhang, and et al., “ An efficient approach for securing audio data in ai training with fully homomorphic encryption, ” T echRxiv , 2024, Preprint. [35] Ruixiang Deng, Y ingwei Zhang, Chaomin Luo, and Zhuming Bi, “Mul- timode process monitoring based on common and unique subspace de- composition, ” IEEE T ransactions on Industrial Informatics , vol. 20, no. 9, pp. 10933–10945, 2024. [36] Xiangtian Meng, Bingxia Cao, Lingda Ren, Fenggang Y an, Maria Greco, and Fulvio Gini, “V irtual array modeling and performance analysis of half-dimensional real-valued subspace decomposition method, ” Signal Pr ocessing , vol. 240, pp. 110371, 2026. [37] Jinshuo Dong, Aaron Roth, and W eijie J. Su, “Gaussian differential priv acy , ” Journal of the Royal Statistical Society Series B: Statistical Methodology , vol. 84, no. 1, pp. 3–37, 02 2022. [38] Jalpesh V asa and Amit Thakkar, “Deep learning: Differential privac y preservation in the era of big data, ” Journal of Computer Information Systems , vol. 63, no. 3, pp. 608–631, 2023. [39] Ian Goodfellow , Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David W arde-Farley , Sherjil Ozair, Aaron Courville, and Y oshua Bengio, “Gen- erativ e adversarial networks, ” Commun. A CM , vol. 63, no. 11, pp. 139–144, Oct. 2020. [40] W illiam Fedus, Barret Zoph, and Noam Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and ef ficient sparsity , ” Journal of Machine Learning Resear ch , vol. 23, no. 120, pp. 1–39, 2022. [41] Gehang Zhang, Jiawei Sheng, Shicheng W ang, and Tingwen Liu, “Noise- disentangled graph contrastiv e learning via low-rank and sparse subspace decomposition, ” in ICASSP 2024 - 2024 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2024, pp. 5880– 5884. [42] Y aganteeswarudu Akkem, Saroj K umar Biswas, and Aruna V aranasi, “ A comprehensive revie w of synthetic data generation in smart farming by using v ariational autoencoder and generativ e adversarial network, ” Engineering Applications of Artificial Intelligence , vol. 131, pp. 107881, 2024. [43] W .L. Burke, Spacetime, Geometry , Cosmology , Dover Publications, 2020. [44] T akao Murakami, Y uichi Sei, and Reo Eriguchi, “ Augmented Shuffle Protocols for Accurate and Rob ust Frequency Estimation Under Differ- ential Pri vacy , ” in 2025 IEEE Symposium on Security and Privacy (SP) , Los Alamitos, CA, USA, May 2025, pp. 3892–3911, IEEE Computer Society . [45] Jiadong Lou, Xu Y uan, Rui Zhang, Xingliang Y uan, Neil Zhenqiang Gong, and Nian-Feng Tzeng, “ GRID: Protecting Training Graph from Link Stealing Attacks on GNN Models , ” in 2025 IEEE Symposium on Security and Privacy (SP) , Los Alamitos, CA, USA, May 2025, pp. 2095–2113, IEEE Computer Society . [46] Liron David, Omer Berkman, A vinatan Hassidim, David Lazarov , Y ossi Matias, and Moti Y ung, “Extended diffie-hellman encryption for secure and efficient real-time beacon notifications, ” in 2025 IEEE Symposium on Security and Privacy (SP) , 2025, pp. 4406–4418.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment