Are LLMs Overkill for Databases?: A Study on the Finiteness of SQL
Translating natural language to SQL for data retrieval has become more accessible thanks to code generation LLMs. But how hard is it to generate SQL code? While databases can become unbounded in complexity, the complexity of queries is bounded by rea…
Authors: Yue Li, David Mimno, Unso Eun Seo Jo
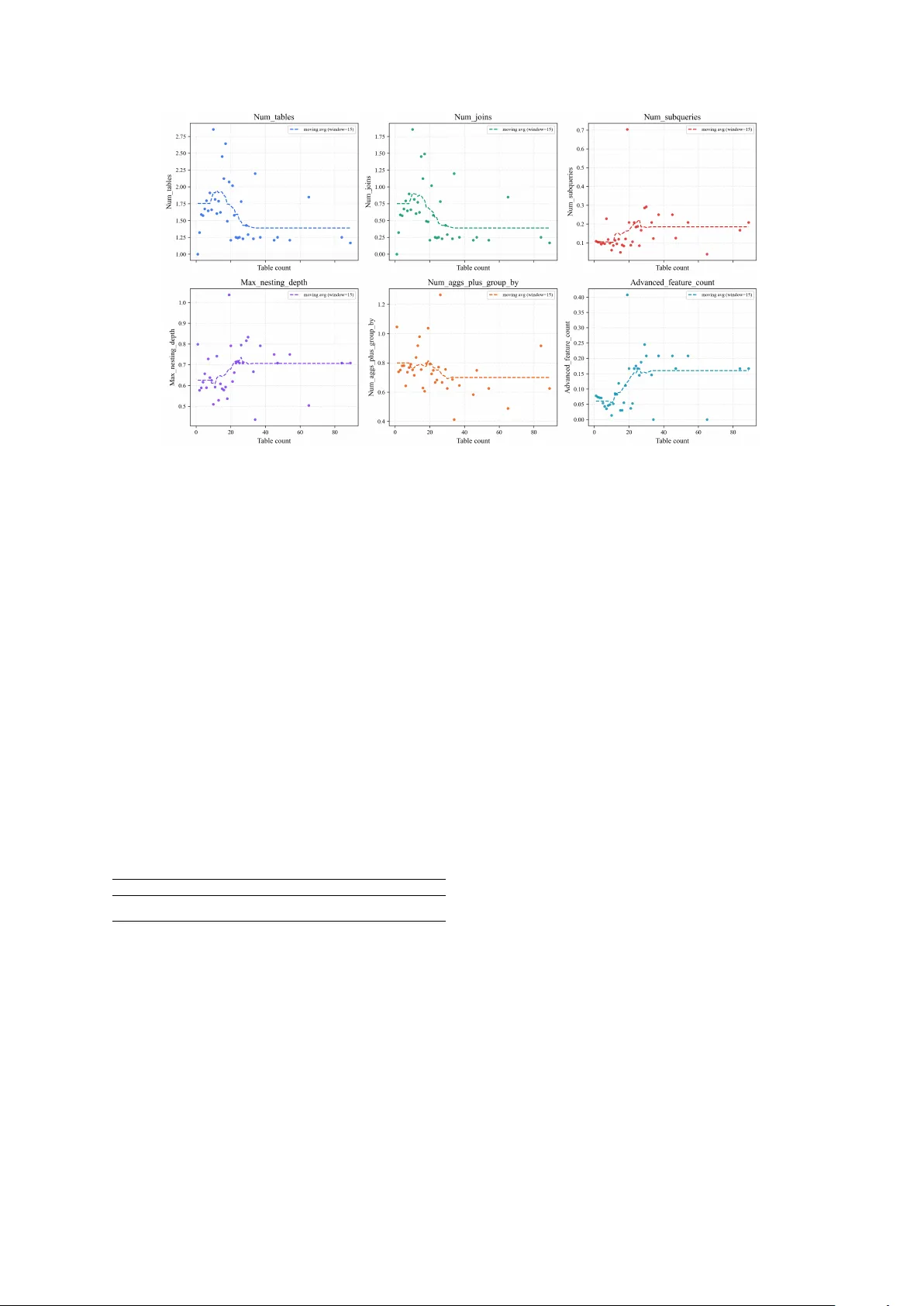
Ar e LLMs Overkill f or Databases?: A Study on the Finiteness of SQL Y ue Li * , Da vid Mimno, Unso Eun Seo Jo Cornell Uni versity {yl3865, mimno, unsojo}@cornell.edu Abstract T ranslating natural language to SQL for data retriev al has become more accessible thanks to code generation LLMs. But how hard is it to generate SQL code? While databases can be- come unbounded in comple xity , the complexity of queries is bounded by real life utility and human needs. W ith a sample of 376 databases, we show that SQL queries, as translations of natural language questions are finite in pr acti- cal complexity . There is no clear monotonic relationship between increases in database ta- ble count and increases in comple xity of SQL queries. In their template forms, SQL queries follow a Power Law-like distribution of fre- quency where 70% of our tested queries can be cov ered with just 13% of all template types, in- dicating that the high majority of SQL queries are predictable. This suggests that while LLMs for code generation can be useful, in the do- main of database access, the y may be operating in a narrow , highly formulaic space where tem- plates could be safer , cheaper , and auditable. 1 Introduction The text-to-SQL task predates the rise of language models ( W oods , 1973 ; Harris , 1977 ), but is cur- rently dominated by LLM-based approaches ( Li et al. , 2025 ). For instance, on the premier BIRD text-to-SQL benchmark, almost all of the top rank- ing methods on the public site are either agent- based ( Pourreza and Rafiei , 2024 ) or LLM-based ( LongShine AI Research , 2025 ). While these ap- proaches are ef fecti ve, they can get e xpensi ve, cost- ing several dollars in token-count per query , and potentially unreliable, whereas enterprise database queries are highly sensiti v e to ef ficiency and secu- rity . T o what extent is this code boilerplate, pre- dictable, or templatizable? In this work, we probe whether full code generation is really necessary for SQL applications. * Corresponding author . Figure 1: Frequency curv e of soft templates. W e e xplore the pr actical boundaries of SQL through empirical experiments. W e curate 376 database schemas from benchmarks and open source database repository , dr awSQL 1 and generate ov er 20,000 natural language questions (NLQ) and matching SQL queries based on schema designs. Using counts of proxies for complexity such as JOIN clause count, subclause count, and length of query , we show that there is no monotonic relation- ship between increase in table count of databases and increase in proxy count. W e observe there is a “ceiling” of proxy-based comple xity in SQL queries re gardless of the complexity and size of the database schema design. When templated and analyzed by frequency , SQL queries exhibit a po wer -law-lik e distrib ution (Figure 1 ). W e find that the top 13% of tem- plates account for 90% of all queries: only 7 templates cov er 10%, and about 40 cover 30%. High-frequency templates tend to be less complex (e.g., fe wer JOINs), suggesting that relati vely sim- ple structures suf fice to cov er most user questions. Overall, a fe w hundred templates are suf ficient to capture the v ast majority of database queries. 1 drawsql.app/templates 1 Source #DB #T/DB #Q Bird23-train-filtered ( Li et al. , 2023 ) 69 7.57 6,601 Spider 1.0 ( Y u et al. , 2018 ) 196 5.15 11,245 Spider 2.0-lite ( Lei et al. , 2024 ) 15 14.87 287 KaggleDBQA ( Lee et al. , 2021 ) 8 2.12 244 drawSQL 88 14.34 2,112 Overall 376 8.07 20,489 T able 1: Statistics of database schemas collected from text-to-SQL benchmarks and dra wSQL. #DB indicates the number of databases from each data source, #T/DB indicates the average number of tables per database, and #Q indicates the number of SQL queries per source. For drawSQL, we manually generate three dif ficulty le v els of NLQs: easy , medium, and difficult. Appendix A provides concrete e xamples. 2 Related W ork T ext-to-SQL has long been studied as a semantic parsing task using deep learning models ( Zhong et al. , 2017 ; Xu et al. , 2017 ). Recent advances in LLMs hav e shifted this paradigm, with state- of-the-art systems adopting LLM-dri ven pipelines with iterati ve reasoning, self-correction, and agent- based workflo ws ( Pourreza and Rafiei , 2023 ). While LLM-based SQL generation has signif- icantly improved accuracy , limited work has ex- amined the empirical science of database queries. T o our knowledge, this is the first work to e xplore the boundaries of SQL queries, enabled by the re- cent av ailability of lar ge-scale, high-quality AI- generated SQL data that allo ws systematic analysis of query patterns and user intents. 3 Methodology 3.1 Database and Query Collection W e collect NLQ–SQL pairs and database schemas from online benchmarks and an open source reposi- tory , drawSQL . W e use database schemas and gold label queries from classic text-to-SQL benchmarks such as Spider 1.0 ( Y u et al. , 2018 ). W e take schema designs from drawSQL and construct NLQ– SQL pairs using Claude-Sonnet-4.6 ( Anthropic , 2026 ) with varying le vels of dif ficulty . T able 1 sho ws the statistics of database schemas collected from these sources. W e manually verify all gener - ated NLQ–SQL pairs to ensure semantic correct- ness and e xecutable v alidity . T o ensure consistency in template extraction and metric computation, we restrict all SQL queries to SQLite dialect. 3.2 SQL T emplates Extraction T o analyze the frequency of repeat SQL queries by “type”, we templatize or generalize the queries with uniform methods. W e hav e two different categories of SQL templates: (1) hard templates keep more distincti ve traits, and (2) soft templates uniformize more strictly to allo w for looser categorization. T ype 1: Hard T emplates. W e construct hard SQL templates by abstracting dataset-specific iden- tifiers and literals from SQL queries while preserv- ing their structural and logical forms. This process normalizes queries into canonical templates that represent the underlying SQL pattern. Hard tem- plates hav e stricter and more detailed extraction rules to transform SQL queries into SQL templates. W e keep entity types such as table, column, and alias names as placeholders. Appendix C shows detailed hard templates extraction rules. T ype 2: Soft T emplates. In addition to the mask- ing presented by hard templates, we further gen- eralize the v ariables and focus on preserving the underlying SQL structure and keyw ords. Function- specific keyw ords such as alias and table are all uniformly treated as v ariables. W ith this transfor- mation, some distinct “hard” templates could be mapped to the same soft template. Appendix D sho ws detailed soft template extraction rules. Example: T emplate Generation Procedur e. The original SQL query is translated into templates in stages: SQL → Har d T emplate → Soft T emplate . SQL Query SELECT c.name FROM customers AS c JOIN orders AS o ON c.id = o.customer_id WHERE o.amount > 100 ORDER BY o.amount DESC LIMIT 10 Hard T emplate SELECT table_alias0.col_name FROM table_name AS table_alias0 JOIN table_name AS table_alias1 ON table_alias0.col_name = t able_alias1.col_name WHERE table_alias1.col_name > num ORDER BY table_alias1.col_name DESC LIMIT num Soft T emplate 2 SELECT variable FROM variable AS variable JOIN variable AS variable ON variable = variable WHERE variable > num ORDER BY variable DESC LIMIT num This example illustrates ho w hard templates pre- serve precise alias and schema structure, while soft templates collapse identifier roles into a single v ari- able tok en. Appendix B presents more hard and soft template extraction e xamples. 3.3 Proxies f or Complexity One way to quantify “complexity” of SQL queries is to count the appearance of certain proxy traits. W e identify 6 proxies used to characterize SQL query complexity . These include structural proper- ties of queries (number of tables, joins, subqueries, and maximum nesting depth) as well as analytical operations such as aggre gations with GROUP BY and adv anced SQL features (e.g., windo w functions, percentile functions, FILTER , set operations, and CTEs). T able 2 provides the full list of all proxies. 4 Results Non-monotonic SQL Query Complexity T rend There is no observ able monotonic relationship be- tween increase in database schema complexity and increase in SQL query comple xity . SQL queries do not grow more and more complex as database schemas do. Figure 2 presents the moving a ver - age v alues of six proxies (windo w size = 15). All curves exhibit a similar pattern: they increase to some peak value at a br eaking point , and then grad- ually stall or decline, suggesting that the SQL query complexity measured by these proxies does not continuously gro w with the number of tables in the database. Instead, the complexity of SQL queries appears to follow a bounded trend rather than mono- tonically increasing as database size gro ws. T able 5 in Appendix F reports the Spearman Correlation results, showing the absence of a monotonic rela- tionship between the proxies and the table count. T able 3 summarizes the statistics of the six prox- ies across all SQL queries. Most of the proxies appear on average less than once per query . The count of table variables is higher: there are queries that include as many as 27 table v ariables. But the av erage table count seems bounded at around 2. Figure 2: Moving average v alues of six proxies (window size = 15). Po wer Law-like Distrib ution of T emplate Fre- quency . When templatized and grouped by fre- quency , the 20,489 queries follow a near Power Law distrib ution. The hard and soft templates both exhibit long-tail distributions: a small number of templates appear v ery frequently while most tem- plates occur only a fe w times or once. Figure 4 in Appendix E shows the long-tail pattern. This indicates a limited set of templates dominate while the majority of templates hav e more specialized SQL structures. The Power Law hypothesis is re- jected by bootstrap goodness-of-fit test ( Clauset et al. , 2009 ) ( p ≈ 0 ), but the curves are Po wer Law-lik e in the tail. W e plot hard and soft template frequencies on log-log scale in figure 3 showing an approxi- mately linear trend. W e draw fitted lines follow- ing the linear representation of the Power Law distribution: log P ( x ) = − α log x + C ,where C is a constant. The fitted lines for hard and soft template frequency log–log scale distributions are log y = − 0 . 7258 log x + 6 . 1106 (hard) and log y = − 0 . 8858 log x + 7 . 1968 (soft), respec- ti vely . Not surprisingly , soft templates follow a steeper distribution, where the “top” frequency tem- plates hav e higher counts. T able 7 in Appendix 7 sho ws soft templates hav e 28 templates with more than 100 counts whereas hard templates ha v e just 19. Both distributions have long tails of single appearance queries making up 60% of the hard template distribution. 70% SQL queries can be cov er ed using only 13.19% soft templates. T able 4 shows that a small number of templates can cover a dispro- portionate v olume of queries with the appropriate 3 Proxy Definition Num_tables # of distinct tables referenced (i.e., number of data sources in v olved) Num_joins # of JOIN operations (capturing cross-table relational reasoning) Num_subqueries # of nested subqueries (capturing hierarchical reasoning) Max_nesting_depth Maximum depth of nested queries (i.e., lev els of embedding) Num_aggs_plus_group_by # of aggregation operations (e.g., COUNT , SUM) and GR OUP BY clauses Advanced_feature_count # of adv anced constructs (e.g., windo w functions, FIL TER, set operations, CTEs) T able 2: Structural proxies for SQL query complexity , capturing aspects such as multi-table interactions, hierarchical structure, and advanced analytical operations. T able 3: Summary statistics and peak characteristics of six SQL complexity proxies. Proxy Median A verage Min Max Peak V alue Num_tables 2.00 1.73 1 27 1.94 Num_joins 1.00 0.73 0 26 0.90 Num_subqueries 0.00 0.11 0 7 0.22 Max_nesting_depth 1.00 0.62 0 5 0.74 Num_aggs_plus_group_by 0.00 0.74 0 9 0.81 Advanced_feature_count 0.00 0.06 0 6 0.17 T able 4: Number of templates required to cover different proportions of SQL queries. Numbers in parentheses denote the cumulativ e percentage of templates. T emplate T ype Query Coverage (%) 10 30 50 70 90 100 Hard 9 (0.13%) 58 (0.87%) 306 (4.57%) 1616 (24.12%) 4677 (69.82%) 6699 (100%) Soft 7 (0.15%) 42 (0.92%) 140 (3.05%) 605 (13.19%) 2565 (55.92%) 4587 (100%) schema linking of table and column names. The Po wer Law ef fect is more dramatic with soft tem- plates, where up to 70% of all queries are deri v ed from about 13% of templates. It takes only about 600 soft templates to cov er 70% of 20,489 queries. The most frequent 140 templates cov er about 50% of all queries. The two most frequent soft templates are SELECT variable FROM variable WHERE variable = string and SELECT COUNT(*) FROM variable . For example, the former corresponds to NLQ such as “List all users whose status is ‘ac- ti ve‘, ” while the latter corresponds to NLQ such as “Ho w many users are there in total?” T able 6 in Appendix H also shows the average proxy count of complexity negati vely correlates with frequency as we expected. The simpler tem- plates are more likely to be used in more conte xts. 5 Conclusion Relational and other databases are the middle ground of data storage and organization between human understanding and computational ef ficiency . SQL was proposed in the 1970s as a way to bridge the gap between human natural language and com- puter ex ecution. LLMs have emerged as the addi- tional layer over this with its seemingly magical code generation capabilities. But our e xperiments (a) Log–log plot of Hard T emplates (b) Log–log plot of Soft T emplates Figure 3: Log–log plots for hard and soft templates. sho w LLMs code generation in the SQL domain may not be as impressiv e as they operate under a ceiling of complexity where just a few hundred templates cov er the v ast majority of query cases. Limitations One limitation of template-based analysis is that SQL queries do not hav e canonical forms and many dif ferent queries can be isomorphic. In other words, it is possible to generate code that looks completely dif ferent, and therefore hav e different templates, but retrie ve the same “answer” or table result. W e experimented with w ays of homogenizing the over - all style of generated queries to test different le vels 4 of maximizing template frequenc y , but ultimately decided that we wanted to test the queries (and resulting templates) in the most unadulterated, as- found forms. Acknowledgments W e thank the anonymous revie wers and area chairs for their v aluable feedback. References Anthropic. 2026. Introducing claude sonnet 4.6. https://www.anthropic.com/news/ claude- sonnet- 4- 6 . Aaron Clauset, Cosma Rohilla Shalizi, and M. E. J. Newm an. 2009. Power -law distributions in empirical data. SIAM Review , 51(4):661–703. Larry R. Harris. 1977. Robot: A high performance nat- ural language data base query system. Proceedings of the National Computer Confer ence (NCC) , pages 229–237. Dongjoon Lee, Seokhwan Park, Jinhyuk Kim, and Sungjin Lee. 2021. Kaggledbqa: Realistic e valuation of text-to-sql parsers. In A CL F indings . Fangyu Lei, Jixuan Chen, Y uxiao Y e, Ruisheng Cao, Dongchan Shin, Hongjin Su, Zhaoqing Suo, Hongcheng Gao, W enjing Hu, Pengcheng Y in, and 1 others. 2024. Spider 2.0: Evaluating language mod- els on real-world enterprise text-to-sql workflows. arXiv pr eprint arXiv:2411.07763 . Jinyang Li, Bin yuan Hui, Ge Qu, Jiaxi Y ang, Binhua Li, Bowen Li, Bailin W ang, Bowen Qin, Ruiying Geng, Nan Huo, Xuanhe Zhou, Chenhao Ma, Guoliang Li, Ke vin C.C. Chang, Fei Huang, Reynold Cheng, and Y ongbin Li. 2023. Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls. In Pr oceedings of the 37th International Confer ence on Neural Information Pr ocessing Systems , NIPS ’23, Red Hook, NY , USA. Curran Associates Inc. Y ue Li, Ran T ao, Derek Hommel, Y usuf Denizay Dön- der , Sungyong Chang, David Mimno, and Unso Eun Seo Jo. 2025. Agent bain vs. agent mckinsey: A new text-to-sql benchmark for the b usiness domain. arXiv pr eprint arXiv:2510.07309 . LongShine AI Research. 2025. Longdata-sql: Scaling text-to-sql with long context modeling. T echnical report. Mohammadreza Pourreza and Davood Rafiei. 2023. Din-sql: Decomposed in-context learning of text- to-sql with self-correction. In NeurIPS . Mohammadreza Pourreza and Davood Rafiei. 2024. Chase-sql: Multi-path reasoning and schema link- ing for text-to-sql. arXiv pr eprint arXiv:2410.01943 . W illiam A. W oods. 1973. Progress in natural lan- guage understanding: An application to lunar ge- ology . AFIPS Conference Pr oceedings , 42:441–450. Xiaojun Xu, Chang Liu, and Dawn Song. 2017. Sqlnet: Generating structured queries from natural language without reinforcement learning. In ICLR . T ao Y u, Rui Zhang, Kai Y ang, Michihiro Y asunaga, Dongxu W ang, Zifan Li, James Ma, Irene Li, Qingn- ing Y ao, Shanelle Roman, Zilin Zhang, and Dragomir Radev . 2018. Spider: A large-scale human-labeled dataset for complex and cross-domain semantic pars- ing and te xt-to-SQL task . In Pr oceedings of the 2018 Confer ence on Empirical Methods in Natural Lan- guage Processing , pages 3911–3921, Brussels, Bel- gium. Association for Computational Linguistics. V ictor Zhong, Caiming Xiong, and Richard Socher . 2017. Seq2sql: Generating structured queries from natural language using reinforcement learning. In EMNLP . A Examples of Generated NLQs by Difficulty Lev el W e use the cachet database from the drawSQL dataset as an illustrative example, and present NLQ–SQL pairs across three dif ficulty le vels: easy , medium, and dif ficult. A.1 Example 1 (Easy , cachet). NLQ: Ho w many subscribers are there in total? SQL Query: SELECT COUNT(*) FROM subscribers; A.2 Example 2 (Medium, cachet). NLQ: Ho w many acti vity log entries do not ha ve a match- ing component? SQL Query: SELECT COUNT(*) FROM actions a LEFT JOIN components b ON a.taggable_id = b.id WHERE b.id IS NULL; A.3 Example 3 (Hard, cachet). NLQ: For each class, count the number of activity log entries, and return only those classes whose count is abov e the av erage count across all classes. Sort the results in descending order of the count. SQL Query: 5 WITH grouped AS ( SELECT class_name, COUNT(*) AS cnt FROM actions GROUP BY class_name ) SELECT * FROM grouped WHERE cnt > ( SELECT AVG(cnt) FROM grouped ) ORDER BY cnt DESC; B T emplates Extraction Examples T o illustrate the template abstraction process, we present se veral examples sho wing the transforma- tion pipeline from SQL queries to hard templates and soft templates. Example 1: Simple Selection SQL SELECT name FROM employees WHERE salary > 50000 Hard T emplate SELECT col_name FROM table_name WHERE col_name > num Soft T emplate SELECT variable FROM variable WHERE variable > num Example 2: J oin with Aliases SQL SELECT T1.name FROM employees AS T1 JOIN departments AS T2 ON T1.dept_id = T2.id WHERE T2.location = ' NY ' Hard T emplate SELECT table_alias0.col_name FROM table_name AS table_alias0 JOIN table_name AS table_alias1 ON table_alias0.col_name = table_alias1.col_name WHERE table_alias1.col_name = string Soft T emplate SELECT variable FROM variable AS variable JOIN variable AS variable ON variable = variable WHERE variable = string Example 3: Aggr egation SQL SELECT department, COUNT(*) FROM employees GROUP BY department ORDER BY COUNT(*) DESC LIMIT 5 Hard T emplate SELECT col_name, COUNT(*) FROM table_name GROUP BY col_name ORDER BY COUNT(*) DESC LIMIT num Soft T emplate SELECT variable, COUNT(*) FROM variable GROUP BY variable ORDER BY COUNT(*) DESC LIMIT num Example 4: Subquery SQL SELECT name FROM employees WHERE salary > (SELECT AVG(salary) FROM employees) Hard T emplate SELECT col_name FROM table_name WHERE col_name > (SELECT AVG(col_name) FROM table_name) Soft T emplate SELECT variable FROM variable WHERE variable > (SELECT AVG(variable) FROM variable) 6 Example 5: CTE with J oin and Aggregation SQL WITH dept_avg AS ( SELECT dept_id, AVG(salary) AS avg_salary FROM employees GROUP BY dept_id ) SELECT d.name FROM departments d JOIN dept_avg a ON d.id = a.dept_id WHERE a.avg_salary > 70000 Hard T emplate WITH CTE0 AS ( SELECT col_name, AVG(col_name) AS column_alias0 FROM table_name GROUP BY col_name ) SELECT table_alias0.col_name FROM table_name AS table_alias0 JOIN CTE0 AS table_alias1 ON table_alias0.col_name = table_alias1.col_name WHERE table_alias1.column_alias0 > num Soft T emplate WITH CTE0 AS ( SELECT variable, AVG(variable) AS variable FROM variable GROUP BY variable ) SELECT variable FROM variable AS table_alias0 JOIN CTE0 AS table_alias1 ON variable = variable WHERE variable > num C Complete Hard T emplates Extraction Rules The generation procedure consists of the following steps: 1. Prepr ocessing. W e remove comments (e.g., – , /* */ ) and blank lines from the SQL query and perform case-insensitive matching to stan- dardize the input representation. 2. Literal Abstraction. All literal values are replaced with typed placeholders. Numeric constants are mapped to num , string literals to string , date literals to date , boolean v alues to boolean , and NULL v alues to others . This step remov es value-le vel v ariability while pre- serving type signals. 3. Schema-aware Identifier Replacement. Us- ing the database schema, table names are re- placed with table_name and column refer- ences with col_name . Identifiers that do not appear in the schema are mapped to special placeholders such as new_table , new_view , or new_column depending on their SQL con- text. 4. Alias Normalization. T able aliases intro- duced in FROM or JOIN clauses are normalized as table_alias0 , table_alias1 , etc., ac- cording to their order of appearance. Column aliases defined via AS are similarly replaced with column_alias0 , column_alias1 , etc. 5. Qualified Reference Resolution. F or qualified expressions (e.g., alias.column ), the qualifier is replaced by its normalized form (e.g., table_name or table_aliasN ), while the column component is mapped to col_name or new_column . The resulting SQL statement forms a hard tem- plate that preserves the structural semantics of the original query while abstracting a way dataset- specific details. D Complete Soft T emplates Extraction Rules The generation procedure consists of the following steps: 1. Identifier Generalization. All identi- fier placeholders produced during hard template extraction (e.g., table_name , col_name , new_table , new_column , cte , and alias tokens such as table_aliasN and column_aliasN ) are replaced with a single token variable . This token represents any table or column identifier , collapsing different schema roles into a unified symbol. 2. Literal T ype Preser vation. Unlike identi- fiers, typed literal placeholders introduced in the hard template (e.g., num , string , date , 7 (a) Hard templates (b) Soft templates Figure 4: Frequency curves for hard and soft templates. boolean , jsonb , others ) are preserved. This maintains the semantic role of constants in predicates and clauses such as LIMIT num or variable = string . 3. K eyword and Structur e Retention. All SQL ke ywords, operators, and syntactic structure (e.g., SELECT , JOIN , GROUP BY , ORDER BY ) remain unchanged so that the generalized tem- plate still reflects the underlying query logic. The resulting SQL statement forms a soft tem- plate that preserves the structural semantics of the original query . E Frequency Cur ves for Hard and Soft T emplates Figure 4 shows the frequenc y distributions of hard and soft templates, both of which exhibit a Po wer Law–lik e pattern. The fitted distributions follo w P ( x ) ∝ x − 0 . 726 and P ( x ) ∝ x − 0 . 886 , respec- ti vely . F Spearman Correlation T est Results T able 5 shows the Spearman Correlation test results. T able 5: Spearman correlation test for the monotonic relationship between each proxy and the table count. Proxy ρ p-value Num_tables -0.3673 2 . 33 × 10 − 2 Num_joins -0.3839 1 . 73 × 10 − 2 Num_subqueries 0.4481 4 . 79 × 10 − 3 Max_nesting_depth 0.3124 5 . 62 × 10 − 2 Num_aggs_plus_group_by -0.4263 7 . 61 × 10 − 3 Advanced_feature_count 0.4921 1 . 70 × 10 − 3 T able 6: A verage proxy values across template fre- quency groups. The maximum v alue in each row is highlighted in bold. Metric T ype High Middle Long T ail Once Num_tables Soft 1.41 1.74 1.83 2.12 Hard 1.12 1.55 1.91 2.21 Num_joins Soft 0.41 0.74 0.82 1.10 Hard 0.12 0.55 0.91 1.20 Num_subqueries Soft 0.03 0.11 0.14 0.23 Hard 0.04 0.13 0.11 0.15 Max_nesting_depth Soft 0.41 0.54 0.72 1.06 Hard 0.43 0.54 0.64 0.86 Num_aggs_plus_group_by Soft 0.49 0.64 0.94 1.09 Hard 0.51 0.62 0.87 0.90 Advanced_feature_count Soft 0.00 0.10 0.07 0.04 Hard 0.00 0.10 0.07 0.02 G Individual Plots f or Six Proxies In figure 5 , each point represents the average v alue of a proxy metric for a specific table count. The dashed line denotes the moving av erage of the proxy v alues with a window size of 15. H A verage Pr oxy V alues Across template frequency gr oups. T able 6 presents the average proxy v alues across hard and soft templates. I T emplate Frequency Distrib ution. T able 7 shows the template frequency distribution. 8 Figure 5: Individual Plots for Six Proxies. Each point represents the average v alue of a proxy metric for a specific table count. The dashed line denotes the moving a verage of the proxy values with a windo w size of 15. T able 7: T emplate frequency distrib ution. Percentages indicate the proportion of templates in each frequenc y category . T emplate Type High ( ≥ 100) Middle (10–99) Long T ail (2–9) Once (1) Hard 19 (0.3%) 223 (3.3%) 2358 (35.2%) 4099 (61.2%) Soft 28 (0.6%) 260 (5.7%) 1958 (42.7%) 2341 (51.0%) 9
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment