Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
On-policy distillation (OPD) is appealing for large language model (LLM) post-training because it evaluates teacher feedback on student-generated rollouts rather than fixed teacher traces. In long-horizon settings, however, the common sampled-token v…
Authors: Yuqian Fu, Haohuan Huang, Kaiwen Jiang
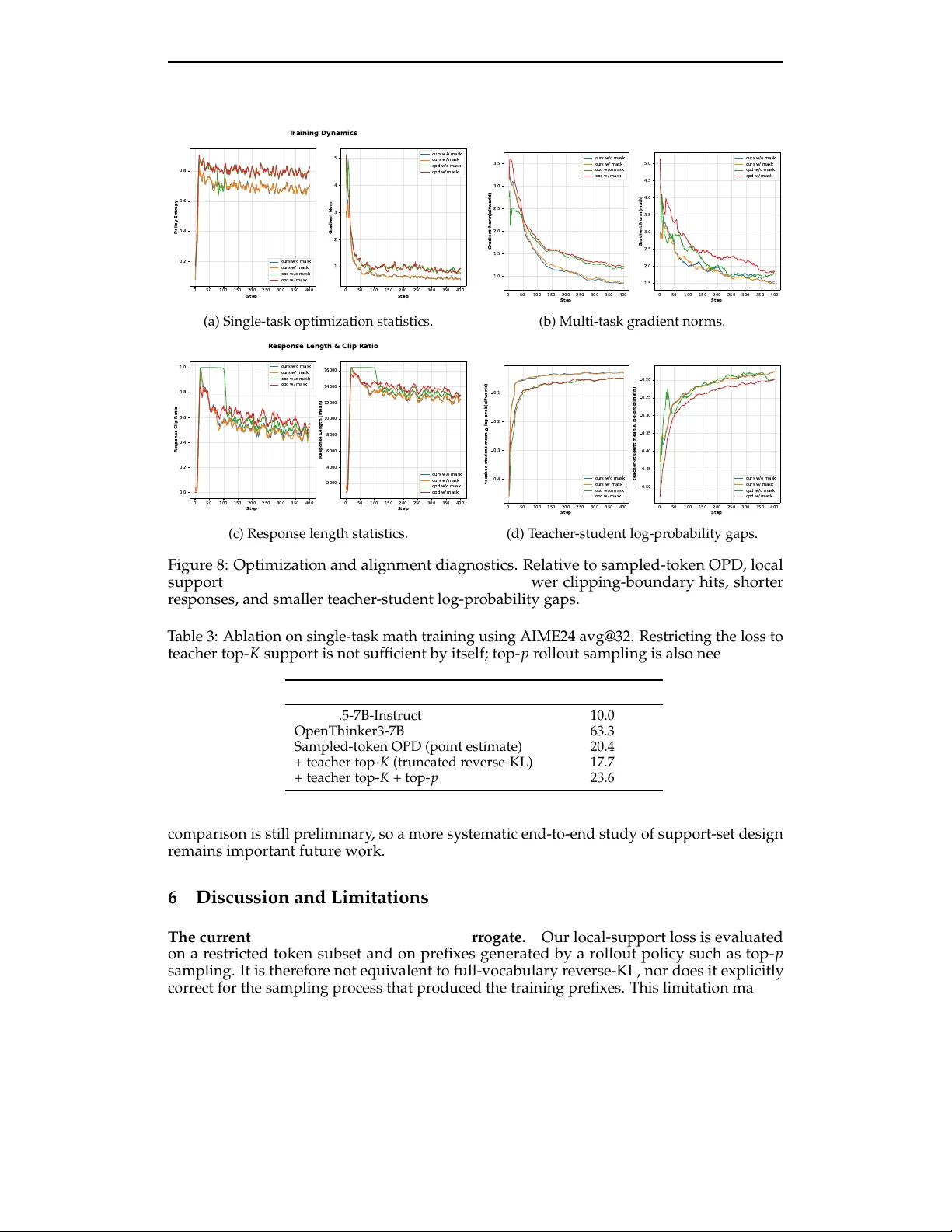
Preprint. Under review . Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes Y uqian Fu ∗ Haohuan Huang ∗ Kaiwen Jiang Y uanheng Zhu † Dongbin Zhao State Key Laboratory of Multimodal Artificial Intelligence Systems, CASIA School of Artificial Intelligence, UCAS {fuyuqian2022, yuanheng.zhu}@ia.ac.cn Abstract On-policy distillation (OPD) is appealing for large language model (LLM) post-training because it evaluates teacher feedback on student-generated rollouts rather than fixed teacher traces. In long-horizon settings, however , the common sampled-token variant is fragile: it r educes distribution match- ing to a one-token signal and becomes increasingly unreliable as rollouts drift away from prefixes the teacher commonly visits. W e revisit OPD from the estimator and implementation sides. Theoretically , token-level OPD is biased relative to sequence-level reverse-KL, but it has a much tighter worst-case variance bound; our toy study shows the same trade- off empirically , with stronger future-rewar d coupling producing higher gradient variance and less stable learning. Empirically , we identify three failure modes of sampled-token OPD: an imbalanced one-token signal, unreliable teacher guidance on student-generated pr efixes, and distortions caused by tokenizer or special-token mismatch. W e addr ess these issues with teacher top- K local support matching, implemented as truncated reverse-KL with top- p rollout sampling and special-token masking. Across single-task math reasoning and multi-task agentic-plus-math training, this objective yields more stable optimization and better downstream perfor- mance than sampled-token OPD. Code Blog 1 Introduction On-policy distillation (OPD) trains a student on its own rollouts while evaluating local feedback with a str onger teacher . This makes OPD attractive for long-horizon reasoning and agentic post-training, where the student quickly reaches pr efixes that ar e rare or absent in fixed teacher traces ( Agarwal et al. , 2024 ; Gu et al. , 2024 ). The practical question is ther efore not whether on-policy teacher supervision is useful in principle, but which objective r emains reliable once training is driven by student-generated trajectories. In current language-model pipelines, OPD is usually implemented as a sampled-token comparison: at each decoding step, the student is updated only through the log-ratio on its sampled token. This approximation is cheap, but brittle for at least three reasons. It turns a distribution-level discrepancy into a highly imbalanced one-token signal; it can over -trust the teacher on prefixes that ar e common for the student but atypical for the teacher; and it is easily distorted by tokenizer or special-token mismatch. There is a corresponding estimator tradeoff. A more sequence-coupled objective can recover information that token-level OPD discards, but str onger rewar d coupling can also make optimization much noisier . W e study this tradeoff first at the estimator level. Sequence-level reverse-KL couples each token update to futur e rewar ds, whereas token-level OPD drops those terms. T oken-level OPD is therefor e biased r elative to the sequence-level objective, but it has a much tighter ∗ Equal contribution. † Corresponding authors. ‡ W ork in progr ess. 1 Preprint. Under review . worst-case variance bound. Our toy experiment shows the same pattern empirically: as future-r eward coupling incr eases, gradient variance rises and optimization becomes less stable. This suggests a simple design tar get for long-horizon post-training: keep supervision local enough to control variance, while making the local comparison less brittle than a one-token point estimate. Motivated by this view , we replace sampled-token supervision with teacher top- K local support matching. At each pr efix, we compare teacher and student distributions on the teacher ’s locally plausible support instead of rewarding only the sampled token. W e implement this objective as truncated r everse-KL with top- p rollout sampling and special- token masking. The resulting update is still local and inexpensive, but less sensitive to idiosyncratic sampled continuations and tokenization artifacts than sampled-token OPD. Contributions. Our main contributions are thr eefold. • W e analyze the estimator tradeoff in OPD: token-level OPD is biased relative to sequence-level OPD, but its worst-case variance grows much more slowly with sequence length, which matters in long-horizon LLM post-training. • W e identify three practical failure modes of sampled-token OPD: an imbalanced one-token signal, unr eliable teacher guidance on student-generated pr efixes, and distortions caused by tokenizer or special-token mismatch. • W e propose teacher top- K local support matching, implemented as truncated reverse-KL with top- p rollouts and special-token masking, and show stronger optimization behavior and downstream performance than sampled-token OPD in both single-task math reasoning and multi-task agentic-plus-math training. 2 Related W ork Our work is most closely related to on-policy distillation for language models. Offline distillation matches teacher outputs or logits on fixed traces, wher eas OPD-style methods evaluate teacher signals on student-generated pr efixes ( Agarwal et al. , 2024 ; Gu et al. , 2024 ). W e focus on a narrower question within this family: once supervision is computed on the student’s own rollouts, what local comparison rule remains stable in long-horizon training? Recent model reports from Qwen3 ( Y ang et al. , 2025 ), MiMo-V2-Flash ( Xiao et al. , 2026 ), GLM-5 ( Zeng et al. , 2026 ), and Thinking Machines Lab ( Lu & Lab , 2025 ) suggest that this regime is becoming r elevant in practice. Another relevant line of work studies how to preserve useful supervision under rollout drift. Representative directions include EMA-anchor stabilization with top- K KL ( Zhang & Ba , 2026 ), off-policy correction ( Liu et al. , 2025 ), perturbation-based stabilization ( Y e et al. , 2026 ), and hybrid rollout mixing between teacher and student policies ( Zhang et al. , 2026 ). These methods stabilize training by changing the broader optimization procedur e or rollout source. Our method is more local: we revisit the per-pr efix OPD comparison itself and ask how to preserve informative teacher guidance once teacher and student begin to diver ge on student-generated trajectories. 3 Understanding Sampled-token OPD: T radeof fs and Failure Modes 3.1 From reverse-KL to token-level OPD W e begin with the sequence-level objective behind OPD. For a pr ompt x , the reverse-KL objective is J OPD ( θ ) = E x ∼ D [ D KL ( π θ ( · | x ) ∥ q ( · | x ) )] . where π θ and q are the student and teacher models, respectively . Using the scor e-function identity , its gradient can be written as ∇ θ J OPD ( θ ) = E x , y ∼ π θ ( · | x ) log π θ ( y | x ) − log q ( y | x ) ∇ θ log π θ ( y | x ) . 2 Preprint. Under review . For each decoding step t , let c t = ( x , y < t ) denote the prefix context, and let g t = ∇ θ log π θ ( y t | c t ) , r t = log π θ ( y t | c t ) q ( y t | c t ) . Using the autoregr essive factorization log π θ ( y | x ) − log q ( y | x ) = T ∑ t ′ = 1 r t ′ , ∇ θ log π θ ( y | x ) = T ∑ t = 1 g t , we obtain the sequence-level estimator ˆ g seq = T ∑ t = 1 T ∑ t ′ = 1 r t ′ ! g t . (1) For t ′ < t , we have E [ r t ′ g t ] = 0 because r t ′ depends only on the prefix befor e step t , while E [ g t | x , y < t ] = ∑ y t π θ ( y t | c t ) ∇ θ log π θ ( y t | c t ) = 0. The same gradient can therefor e be written in causal return-to-go form: E [ ˆ g seq ] = E " T ∑ t = 1 T ∑ t ′ = t r t ′ ! g t # . A common approximation in LLM training keeps only the immediate term at each position: ˆ g tok = T ∑ t = 1 r t g t . (2) W e refer to ( 2 ) as token-level OPD. This approximation removes futur e-rewar d coupling, so the update for token y t depends only on its immediate rewar d. Consequently , it is biased relative to the sequence-level reverse-KL estimator , but exhibits lower variance in long-horizon settings. This difference is r eflected in their variance scaling. Under bounded rewar ds and bounded score-function gradients, the worst-case variance upper bound of token-level OPD scales as O ( T 2 ) , whereas the sequence-level estimator scales as O ( T 4 ) . W e provide a detailed derivation in Appendix B . T o interpolate between these extremes, we consider the discounted return-to-go estimator ˆ g γ = T ∑ t = 1 T ∑ t ′ = t γ t ′ − t r t ′ ! g t , γ ∈ [ 0, 1 ] . (3) The case γ = 0 recovers token-level OPD, while γ = 1 recovers the causal sequence-level estimator . W e conduct a two-task toy experiment, where increasing γ is observed to induce substantially higher gradient variance and less stable optimization; see Figure 1 for an illustration and Appendix C for additional experimental details. 3 Preprint. Under review . 0 250 500 750 1000 1250 1500 1750 2000 Iteration 1 0 1 1 0 2 1 0 3 1 0 4 1 0 5 1 0 6 1 0 7 Gradient V ariance Left T ask (odd iterations) =0 (tok en-level) =0.25 =0.5 =0.75 =1.0 0 250 500 750 1000 1250 1500 1750 2000 Iteration 1 0 1 1 0 2 1 0 3 1 0 4 1 0 5 1 0 6 1 0 7 1 0 8 Gradient V ariance Right T ask (even iterations) =0 (tok en-level) =0.25 =0.5 =0.75 =1.0 (a) Gradient variance in the toy experiment. Larger γ generally yields higher variance in both tasks. 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 time step 8 6 4 2 0 2 4 6 8 position s tok-level Left T ask (init=2) 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 time step seq-level(gamma0.5) Left T ask (init=2) 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 time step seq-level(gamma1.0) Left T ask (init=2) 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 time step 8 6 4 2 0 2 4 6 8 position s tok-level Right T ask (init=-2) 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 time step seq-level(gamma0.5) Right T ask (init=-2) 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 time step seq-level(gamma1.0) Right T ask (init=-2) 0.0 0.2 0.4 0.6 0.8 1.0 nor malized visitation (sqrt scale) (b) State visitation under γ ∈ { 0.0, 0.5, 1.0 } in the toy environment. For γ = 1.0, the policy model fails to consistently move toward the tar get, and instead exhibits drifting behavior . Figure 1: Effect of increasing γ in the toy experiment. Larger γ yields a higher and more persistent variance regime and, in the sequence-level limit, drifting policies in state space. 3.2 Why sampled-token OPD is brittle in practice Although token-level OPD is attractive from a bias–variance perspective, the sampled-token comparison can be brittle in practice. W e isolate three distinct issues: (1) the distillation signal is highly imbalanced, (2) the teacher signal becomes less reliable on student-generated prefixes, and (3) tokenizer and special-token mismatch can further distort a one-token comparison. A highly imbalanced sampled-token signal. In sampled-token OPD, the update at step t is driven by the log-ratio on a single sampled token: log q ( y t | c t ) − log π θ ( y t | c t ) . Negative rewar ds arise whenever the student assigns higher probability to a sampled token than the teacher . As shown in Figure 2 , most sampled tokens receive negative rewar ds, and the positive learning signal is concentrated on a r elatively small subset of tokens with positive advantage. The result is an imbalanced training signal in which optimization is disproportionately driven by a few locally favorable tokens. T raining can then become sensitive to short continuations that the teacher locally prefers, such as fillers or hesitation markers, even when those tokens contribute little to overall trajectory quality . The teacher signal can become unreliable on student-generated prefixes. Sampled-token OPD implicitly assumes that the probability the teacher assigns to a student-generated token is a useful proxy for trajectory quality . This assumption weakens when rollouts enter prefixes that are common under the student but uncommon for the teacher . On such prefixes, the teacher may assign high probability to tokens that appear plausible, while the trajectory has already deviated from a desirable dir ection. In our logs, this behavior is associated with patterns such as repetition loops, self-resetting reasoning, and malformed continuations 4 Preprint. Under review . 0.0 0.2 0.4 0.6 0.8 1.0 Student probability 0.0 0.2 0.4 0.6 0.8 1.0 T eacher probability y=x Figure 2: Scatter of token probabilities (student vs teacher). Sampled-token OPD at the first training iteration on Qwen2.5-7B-It ( Qwen et al. , 2025 ), using OpenThinker3-7B ( Guha et al. , 2025 ) as the teacher model. The sampled-token signal is heavily skewed toward penalizing the current student token rather than pr oviding a balanced rewar d. R E S E A R C H V I S U A L I Z A T I O N · T O K E N P R O B A B I L I T Y T R A C E T e a c h e r v s S t u d e n t D i s t r i b u t i o n T h i s l a y o u t f o c u s e s o n t h e r e a d a b l e q u e s t i o n / r e s p o n s e v i e w f r o m t h e p o l i s h e d r e f e r e n c e e x a m p l e w h i l e k e e p i n g t h e o r i g i n a l s t a t i s t i c s a n d d e b u g m e t a d a t a i n a c o l l a p s i b l e p a n e l . S t e p 1 0 3 S a m p l e 0 T a s k m a t h G e n e r a t e d 2 0 2 6 - 0 2 - 2 4 1 0 : 5 1 : 0 1 M E A N S I G N E D D I F F ( P - R ) + 0 . 0 3 2 9 T h e p o l i c y i s m o r e c o n f i d e n t t h a n t h e r e f e r e n c e o n a v e r a g e . T h e l a r g e s t t o k e n - l e v e l a b s o l u t e g a p r e a c h e s 0 . 9 9 9 9 . S u m m a r y S t a t i s t i c s a n d D e b u g M e t a d a t a Q U E S T I O N Find the product of all real val ues of $r$ fo r which $\fr ac{1}{2x}=\f rac{r-x}{7 }$ has exa ctly one real solution. Teac her stro nger Stud ent stro nger R E S P O N S E ### Final Answer : \ boxed {- 1 4 } ``` latex \ boxed {- 1 4 } ``` ### Final Answer : \ boxed {- 1 4 } ### Final Answer : \ boxed {- 1 4 } \ boxed {- 1 4 } The process confirms that the values of \( r \) are \( \ pm \ sqrt { 1 4 } \ ), their product is \ (- 1 4 \ ). ### Final Answer : \ boxed {- 1 4 } \ boxed {- 1 4 } Final Answer : \ boxed {- 1 4 } ``` latex \ boxed {- 1 4 } ``` ### Final Answer : \ boxed {- 1 4 } The product of the real values of \( r \) is \ boxed {- 1 4 }. ``` latex \ boxed {- 1 4 } ``` ### Final Answer : \ boxed {- 1 4 } The final answer is \ boxed {- 1 4 }. \ boxed {- 1 4 } ** Final Answer :** \ boxed {- Figure 3: The student falls into a repetition loop, but the teacher model maintains highly aligned with the student model on the repeating tokens, indicating a lack of proper penalty for such behavior . (Figure 3 ; Appendix D ). These observations suggest an objective-level mismatch: OPD encourages token-level agreement with the teacher , but such proxy does not necessarily correspond to trajectory-level quality , especially on pr efixes that are out-of-distribution for the teacher . W e hypothesize that two factors amplify this issue. First, teacher distributions are often sharp, so even modest student-teacher disagreement can produce large log-ratio values. Second, differ ences between the teacher ’s generation pattern and the student’s make student prefixes more likely to fall outside the teacher ’s typical context. The same failure also appears in how the teacher signal changes with position. Figure 4 shows the distribution of teacher-student log-pr obability gaps acr oss token positions; it is relatively concentrated at early positions and becomes progr essively wider later in the sequence, with more extr eme values on long rollouts. T okenizer and special-token mismatch. Sampled-token OPD compares the exact token generated by the student using the teacher distribution. When the two models use different tokenizations, the same raw text can be segmented differently , so a student generated token may not correspond to a natural token under the teacher . For example, the student may generate as <, think, > , while the teacher expects . Then token < receives low probability from the teacher , even though both models produce the same semantic content. Similar mismatches arise for special tokens such as end-of-sequence markers. In this setting, a one-token comparison confuses semantic disagreement with 5 Preprint. Under review . 0 1k 2k 3k 4k 5k 6k 7k 8k 9k 10k 11k 12k 13k 14k 15k 16k T oken P osition 1.2 1.0 0.8 0.6 0.4 0.2 0.0 0.2 teacher log prob - student log prob Figure 4: Distribution of teacher-student log-pr obability gaps across token positions. Later positions show wider distributions and mor e extr eme values, indicating a noisier teacher signal on long student-generated rollouts. < , t h i n k , > … <| i m _e n d |> < th , i n k , > … <| e n d of t e xt |> Ra w T e x t S t u d e n t t o k e n i za t i o n T e a c h e r t o k e n i za t i o n Ok a y , let’ s … F in a l a n s we r is \ b o x e d {7 } \ n S p urio us p enal t y f ro m t o k en m is m a t c h Figure 5: T oken-level comparison can penalize semantically correct outputs due to tokenizer mismatch. tokenizer mismatch. Since supervision is applied on a single token, such artifacts can distort the rewar d signal. These observations motivate moving beyond one-token supervision: instead of comparing only the sampled token, we compare teacher and student over a set of plausible next-token continuations at each prefix, while r etaining token-level updates for stability . 4 Method Our method r etains token-level OPD but r eplaces one-token supervision with a distribution- level comparison over a teacher-selected support set at each pr efix. This yields a truncated reverse-KL objective that maintains computing efficiency while improving the balance of the training signal. Section 4.1 introduces the objective, and Section 4.2 describes the practical choices that ensure stable training. 4.1 T eacher top-K local support matching Instead of comparing teacher and student on a single sampled token, we compare them over a teacher-defined local support. A natural starting point is the full-vocabulary reverse-KL at a prefix c t : L full ( c t ) = ∑ v ∈ V π θ ( v | c t ) log π θ ( v | c t ) q ( v | c t ) . (4) Sampled-token OPD can be viewed as a one-sample Monte Carlo approximation to this quantity: L sample ( c t , y t ) = log π θ ( y t | c t ) q ( y t | c t ) , y t ∼ π θ ( · | c t ) . (5) This approximation is computationally attractive, while concentrating entir e update on a sampled-token. W e instead compar e teacher and student over a teacher-supported token set at each prefix. 6 Preprint. Under review . For each prompt x , we sample a group of outputs { o i } G i = 1 using the student inference policy . Let c i , t = ( x , y i , < t ) be the prefix at position t of output o i , and define the teacher support set S ( c i , t ) = T opK q ( c i , t ) , (6) which contains the K highest-probability tokens under the teacher at that pr efix. W e then renormalize both teacher and student distributions inside this local support: ˆ π θ ( v | c i , t ) = π θ ( v | c i , t ) ∑ u ∈ S ( c i , t ) π θ ( u | c i , t ) , ˆ q ( v | c i , t ) = q ( v | c i , t ) ∑ u ∈ S ( c i , t ) q ( u | c i , t ) . (7) Our training objective averages the truncated r everse-KL over all rollout positions: L LSM = E x , { o i }∼ π θ ,infer 1 ∑ G i = 1 | o i | G ∑ i = 1 | o i | ∑ t = 1 ∑ v ∈ S ( c i , t ) ˆ π θ ( v | c i , t ) log ˆ π θ ( v | c i , t ) ˆ q ( v | c i , t ) . (8) Relative to sampled-token OPD, this objective performs a distribution-level comparison inside the teacher-supported local region rather than rewarding or penalizing only one sampled token. The resulting update redistributes positive and negative adjustments across all teacher-supported candidates at a prefix, yielding a mor e balanced training signal while remaining far cheaper than full-vocabulary KL. 4.2 Practical stabilization choices Support-set renormalization. Renormalization is necessary because the objective is evalu- ated on a truncated support rather than the full vocabulary . W ithout it, optimization can become unstable because the teacher and student mass inside the support is not directly comparable. T op- p rollout sampling. W e generate rollouts with top- p sampling. Unconstrained sam- pling occasionally produces extr emely low-pr obability tokens, which in turn cr eates pr efixes where the teacher distribution is less informative and the student distribution is already deteriorating. T op- p sampling keeps trajectories closer to typical continuations and makes the teacher signal more r eliable. Special-token masking. W e mask problematic special tokens to reduce false negatives caused by incompatible tokenization conventions. This is an orthogonal engineering fix: in our experiments it materially helps the sampled-token OPD baseline, while our local support objective is much less sensitive to it. In principle, one could also merge multi-token marker variants or average over equivalent tokenizations, but we do not pursue those tokenizer-specific r emedies here because masking is the simplest model-agnostic correction. 5 Experiments 5.1 Setup W e implement local support matching on top of an existing OPD training pipeline, using Qwen2.5-7B-Instruct ( Qwen et al. , 2025 ) as the student. W e consider two settings: (1) a single-task math reasoning setting , where OpenThinker3-7B ( Guha et al. , 2025 ) serves as the teacher and training uses the English portion of DAPO-Math-17K ( Y u et al. , 2025 ) with a maximum context length of 16K; and (2) a multi-task setting that alternates between math reasoning and a multi-turn agentic task based on ALFW orld ( Shridhar et al. , 2021 ), where math uses OpenThinker3-7B ( Guha et al. , 2025 ) and the agentic task uses the r eleased GiGPO-Qwen2.5-7B-Instruct-ALFW orld checkpoint ( Feng et al. , 2025 ) as the teacher . All runs use batch size 128, mini-batch size 64, learning rate 2 × 10 − 6 , and temperature 1 by default. Rollouts are sampled with top- p = 0.9. W e report pass@1 on the math benchmarks and success rate on ALFW orld, unless other- wise specified. In a small number of cases, we additionally report average@32 for math evaluation. 7 Preprint. Under review . T able 1: Single-task math reasoning r esults. Local support matching improves over sampled- token OPD, and the gain remains after adding special-token masking to the baseline. Method Math500 AIME24 AIME25 Minerva OlympiadBench A vg. Qwen2.5-7B-It 68.2 13.3 0.0 26.5 32.9 28.2 OpenThinker3-7B 92.2 53.3 40.0 39.0 55.6 56.0 Sampled-token OPD 80.0 10.0 16.7 32.4 43.1 36.4 Sampled-token OPD w/ mask 81.4 26.7 16.7 34.2 44.7 40.7 Ours w/o mask 80.4 23.3 26.7 34.2 43.9 41.0 Ours w/ mask 82.0 23.3 23.3 34.9 43.9 41.5 T able 2: Results for multi-task training that alternates between ALFW orld and math reason- ing. Local support matching preserves strong ALFW orld performance while improving the math side of the mixture. Method ALFW orld Math500 AIME24 AIME25 Minerva OlympiadBench A vg. Qwen2.5-7B-It 21.9 68.2 13.3 0.0 26.5 32.9 28.2 GiGPO-Qwen2.5-7B-It-Alfworld 95.3 – – – – – – OpenThinker3-7B – 92.2 53.3 40.0 39.0 55.6 56.0 Sampled-token OPD 90.6 74.8 13.3 13.3 32.1 40.5 34.8 Sampled-token OPD w/ mask 93.8 76.0 20.0 13.3 33.5 40.4 36.6 Ours w/o mask 95.3 82.0 33.3 16.7 32.7 44.0 41.7 Ours w/ mask 97.7 79.0 20.0 16.7 34.6 42.5 38.6 5.2 Single-task math reasoning T able 1 shows that local support matching impr oves over sampled-token OPD in single-task math reasoning. Sampled-token OPD already raises the average score from 28.2 to 36.4, but still trails the teacher by a large mar gin. Special-token masking alone further improves the sampled-token baseline to 40.7, which indicates that tokenization artifacts are a material part of the problem. Our full method achieves an average of 41.5. The improvement persists after applying the same masking fix to the baseline, indicating that it is not solely due to mismatch handling but also reflects a str onger local distillation signal. By contrast, masking has only a modest effect on our method (41.0 vs. 41.5), consistent with distribution-level support matching being less sensitive to tokenizer mismatch than one-token supervision. 5.3 Multi-task agentic-plus-math training T able 2 shows a more asymmetric pattern in alternating multi-task training. The sampled- token OPD baseline is already strong on ALFW orld, so the main room for improvement lies on the math side. The unmasked version of our method improves Math500 from 76.0 to 82.0 and raises the av- erage math score fr om 36.6 to 41.7 while remaining competitive on ALFW orld. The masked version achieves the best ALFW orld result at 97.7 but gives up some of the math gains. T aken together , these results suggest that local support matching helps most where long-horizon token-level supervision is most brittle, while preserving str ong agentic performance. 5.4 T raining dynamics and alignment Figures 6 , 7 , and 8 pr ovide a more detailed view of the optimization dynamics. Better learning curves. On math r easoning, our method improves both training rewar d and evaluation performance thr oughout learning rather than only at the final checkpoint. This pattern holds in both the single-task setting and the alternating multi-task setting. More stable optimization. Our method yields smaller gradient norms and lower clipping- boundary fractions while maintaining sufficient policy entropy , and this indicates more 8 Preprint. Under review . 0 100 200 300 400 Step 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 T rain Score(DAPO -Math-17k) ours w/o mask ours w/ mask opd w/o mask opd w/ mask 100 150 200 250 300 350 400 Step 0.16 0.18 0.20 0.22 0.24 T est Score(AIME24_avg@32) ours w/o mask ours w/ mask opd w/o mask opd w/ mask Performance on Math Reasoning T asks Figure 6: Single-task training curves for math reasoning. Local support matching improves training rewar d and final evaluation over the course of training. Figure 7: Multi-task learning curves for ALFW orld and math reasoning. The main gains appear on the math side while agentic performance remains str ong. stable optimization. W e also observe that special-token masking substantially reduces the clipping-boundary fraction of sampled-token OPD during early and middle training, while having only minor effects on our method. Improved teacher-student alignment. The teacher-student log-probability gap on sampled tokens also becomes smaller , suggesting that the truncated local support objective improves alignment even under the sampled-token diagnostic used by the baseline. 5.5 Ablations T able 3 and Figure 9 suggest that the gains arise from several design choices rather than any single modification. T eacher top- K comparison alone is not sufficient: the rollout policy must also r emain in a stable r egion, and adding top- p sampling turns an initially weaker top- K variant into a stronger configuration. Renormalization inside the truncated support is essential, as r emoving it leads to rapid collapse. Performance is not especially sensitive to the exact support size once K is large enough, but training becomes unstable when the support is too small or rollouts ar e fully unconstrained. T op- K support variants. Our main experiments define the truncated expectation on the teacher ’s top- K support. A natural question is whether this choice itself is critical, or whether nearby support definitions perform similarly . W e therefor e compare thr ee variants: teacher top- K (used in the main results), student top- K , and teacher top- K augmented with the student sampled token. T able 4 suggests that the benefit is fairly robust across nearby support definitions. No single choice dominates across all benchmarks: teacher top- K remains competitive, student top- K is strong on several individual datasets, and teacher top- K augmented with the sampled token achieves the best average score in this preliminary comparison. This points to the main benefit coming from replacing single-token comparison with local distribution-level matching rather than from one uniquely optimal support-set choice. At the same time, the 9 Preprint. Under review . 0 50 100 150 200 250 300 350 400 Step 0.2 0.4 0.6 0.8 Policy Entropy ours w/o mask ours w/ mask opd w/o mask opd w/ mask 0 50 100 150 200 250 300 350 400 Step 1 2 3 4 5 Gradient Norm ours w/o mask ours w/ mask opd w/o mask opd w/ mask T raining Dynamics (a) Single-task optimization statistics. 0 50 100 150 200 250 300 350 400 Step 1.0 1.5 2.0 2.5 3.0 3.5 Gradient Norm(alfworld) ours w/o mask ours w/ mask opd w/o mask opd w/ mask 0 50 100 150 200 250 300 350 400 Step 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 Gradient Norm(math) ours w/o mask ours w/ mask opd w/o mask opd w/ mask (b) Multi-task gradient norms. 0 50 100 150 200 250 300 350 400 Step 0.0 0.2 0.4 0.6 0.8 1.0 Response Clip Ratio ours w/o mask ours w/ mask opd w/o mask opd w/ mask 0 50 100 150 200 250 300 350 400 Step 2000 4000 6000 8000 10000 12000 14000 16000 Response Length (mean) ours w/o mask ours w/ mask opd w/o mask opd w/ mask Response Length & Clip Ratio (c) Response length statistics. 0 50 100 150 200 250 300 350 400 Step 0.4 0.3 0.2 0.1 teacher-student mean log-prob(alfworld) ours w/o mask ours w/ mask opd w/o mask opd w/ mask 0 50 100 150 200 250 300 350 400 Step 0.50 0.45 0.40 0.35 0.30 0.25 0.20 teacher-student mean log-prob(math) ours w/o mask ours w/ mask opd w/o mask opd w/ mask (d) T eacher-student log-pr obability gaps. Figure 8: Optimization and alignment diagnostics. Relative to sampled-token OPD, local support matching yields smaller gradient norms, fewer clipping-boundary hits, shorter responses, and smaller teacher -student log-probability gaps. T able 3: Ablation on single-task math training using AIME24 avg@32. Restricting the loss to teacher top- K support is not sufficient by itself; top- p rollout sampling is also needed. Method AIME24 avg@32 Qwen2.5-7B-Instruct 10.0 OpenThinker3-7B 63.3 Sampled-token OPD (point estimate) 20.4 + teacher top- K (truncated reverse-KL) 17.7 + teacher top- K + top- p 23.6 comparison is still pr eliminary , so a mor e systematic end-to-end study of support-set design remains important futur e work. 6 Discussion and Limitations The current objective is still a truncated surrogate. Our local-support loss is evaluated on a restricted token subset and on prefixes generated by a rollout policy such as top- p sampling. It is therefore not equivalent to full-vocabulary reverse-KL, nor does it explicitly correct for the sampling process that produced the training pr efixes. This limitation matters most in two places that r emain under explored in our study: how to incorporate the sampled token when augmenting teacher top- K support, and whether importance-weighting-style corrections are needed when rollout and training policies differ . W e therefore view the current formulation as a practical design point rather than a final answer to support-set construction. The reward-hacking explanation is still a mechanism hypothesis. Our qualitative cases make the failur e mode concrete, but they do not isolate a complete causal mechanism. In 10 Preprint. Under review . 0 100 200 300 400 Step 0 2 4 6 8 10 Policy Entropy w/o nor malization w/ nor malization 0 100 200 300 400 Step 0.0 0.1 0.2 0.3 0.4 0.5 T rain Score(DAPO -Math-17k) w/o nor malization w/ nor malization (a) Support renormalization. 0 100 200 300 400 Step 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 Policy Entropy k=16 k=32 k=48 100 150 200 250 300 350 400 Step 0.14 0.16 0.18 0.20 0.22 0.24 T est Score(AIME24_avg@32) k=16 k=32 k=48 (b) Support size K . 0 100 200 300 400 Step 0 1 2 3 4 5 6 Policy Entropy top_p=1.0 top_p=0.9 top_p=0.8 100 150 200 250 300 350 400 Step 0.14 0.16 0.18 0.20 0.22 0.24 T est Score(AIME24_avg@32) top_p=1.0 top_p=0.9 top_p=0.8 (c) Rollout top- p . Figure 9: Ablations of the main design choices. Renormalization is requir ed for stability , very small support sets hurt learning, and unconstrained rollout sampling degrades optimization. T able 4: Ablation on alternative support-set definitions. W e report AIME24 avg@32 for the early-ablation metric and pass@1 for the remaining benchmarks; the final column averages only the pass@1 metrics. Method AIME24 avg@32 Math500 AIME24 AIME25 Minerva OlympiadBench A vg. T eacher top- K 23.6 80.4 23.3 26.7 34.2 43.9 41.0 Student top- K 22.3 82.4 30.0 16.7 35.7 44.9 41.9 T eacher top- K + sampled token 22.4 81.6 26.7 23.3 36.4 46.7 42.9 particular , the hypothesis that sharp teacher distributions and off-distribution pr efixes jointly create misleading local r ewards should be tr eated as a plausible explanation supported by evidence rather than as a fully identified causal account. T eacher matching remains an imperfect proxy for task success. Even when OPD is well defined as a teacher-matching objective, the resulting reward can still diverge from the underlying notion of successful behavior . Our reward-hacking cases make this gap concrete: locally teacher-pr eferred continuations can remain rewar dable even when the overall trajectory is already unhelpful or harmful. A noticeable gap to the teacher also remains in our experiments, which suggests that better local supervision is only one part of the distillation problem, especially when teacher and student differ substantially . Closing that gap may requir e stronger r ollout control, better handling of distribution shift, better use of teacher uncertainty , and combinations with outcome-verifiable rewards. 7 Conclusion This paper revisits OPD in long-horizon post-training. The central tradeoff is straight- forward: sequence-level coupling is closer to the underlying objective but can be much higher-variance, whereas sampled-token OPD is easy to optimize but often too brittle to provide reliable supervision. T eacher top- K local support matching occupies the middle ground by keeping the objective local while r eplacing one-token supervision with a tr un- cated distribution-level comparison. Across single-task math reasoning and alternating agentic-plus-math training, it improves optimization behavior and downstream perfor- mance over sampled-token OPD. The r emaining gap between teacher matching and task success suggests that better local objectives should be pair ed with stronger control of rollout drift and teacher uncertainty . 11 Preprint. Under review . References Rishabh Agarwal, Nino V ieillar d, Y ongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. In The T welfth International Confer ence on Learning Represen- tations , 2024. URL https://openreview.net/forum?id=3zKtaqxLhW . 1 , 2 Lang Feng, Zhenghai Xue, T ingcong Liu, and Bo An. Group-in-group policy optimization for LLM agent training. In The Thirty-ninth Annual Conference on Neural Information Processing Systems , 2025. URL https://openreview.net/forum?id=QXEhBMNrCW . 7 Y uxian Gu, Li Dong, Furu W ei, and Minlie Huang. MiniLLM: Knowledge distillation of large language models. In The T welfth International Conference on Learning Representations , 2024. URL https://openreview.net/forum?id=5h0qf7IBZZ . 1 , 2 Etash Guha, R yan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, T rung V u, Zayne Sprague, et al. Openthoughts: Data recipes for r easoning models. arXiv preprint , 2025. 5 , 7 Jiacai Liu, Y ingru Li, Y uqian Fu, Jiawei W ang, Qian Liu, and Zhuo Jiang. When speed kills stability: Demystifying RL collapse from the training-inference mismatch, September 2025. URL https://richardli.xyz/rl- collapse . 2 Kevin Lu and Thinking Machines Lab. On-policy distillation. Thinking Machines Lab: Connectionism , 2025. doi: 10.64434/tml.20251026. https://thinkingmachines.ai/blog/on- policy-distillation. 2 Qwen, An Y ang, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran W ei, Huan Lin, Jian Y ang, Jianhong T u, Jianwei Zhang, Jianxin Y ang, Jiaxi Y ang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Y ang, Le Y u, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, T ianhao Li, T ianyi T ang, T ingyu Xia, Xingzhang Ren, Xuancheng Ren, Y ang Fan, Y ang Su, Y ichang Zhang, Y u W an, Y uqiong Liu, Zeyu Cui, Zhenru Zhang, and Zihan Qiu. Qwen2.5 technical report, 2025. URL . 5 , 7 Mohit Shridhar , Xingdi Y uan, Marc-Alexandr e Cote, Y onatan Bisk, Adam T rischler , and Matthew Hausknecht. ALFW orld: Aligning text and embodied environments for in- teractive learning. In International Conference on Learning Representations , 2021. URL https://openreview.net/forum?id=0IOX0YcCdTn . 7 Bangjun Xiao, Bingquan Xia, Bo Y ang, Bofei Gao, Bowen Shen, Chen Zhang, Chenhong He, Chiheng Lou, Fuli Luo, Gang W ang, et al. Mimo-v2-flash technical report. arXiv preprint arXiv:2601.02780 , 2026. 2 An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chang Gao, Chengen Huang, Chenxu Lv , et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388 , 2025. 2 Chenlu Y e, Xuanchang Zhang, Y ifan Hao, Zhou Y u, Ziji Zhang, Abhinav Gullapalli, Hao Chen, and T ong Zhang. Adaptive layerwise perturbation: Unifying off-policy corrections for LLM RL, February 2026. 2 , 14 Qiying Y u, Zheng Zhang, Ruofei Zhu, Y ufeng Y uan, Xiaochen Zuo, Y uY ue, W einan Dai, T iantian Fan, Gaohong Liu, Juncai Liu, LingJun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Y uxuan T ong, Chi Zhang, Mofan Zhang, Ru Zhang, W ang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi W ang, Hongli Y u, Y uxuan Song, Xiangpeng W ei, Hao Zhou, Jingjing Liu, W ei-Y ing Ma, Y a-Qin Zhang, Lin Y an, Y onghui W u, and Mingxuan W ang. DAPO: An open-source LLM r einforcement learning system at scale. In The Thirty-ninth Annual Conference on Neural Information Processing Systems , 2025. URL https://openreview.net/forum?id=2a36EMSSTp . 7 Aohan Zeng, Xin Lv , Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Y in, Chendi Ge, Chengxing Xie, Cunxiang W ang, et al. GLM-5: from vibe coding to agentic engineer- ing. arXiv preprint , 2026. 2 12 Preprint. Under review . Juzheng Zhang, Abhimanyu Hans, John Kirchenbauer , Micah Goldblum, Ashwinee Panda, and T om Goldstein. Learning from mixed rollouts: Logit fusion as a bridge between imitation and exploration. Notion Blog , 2026. URL https://juzhengz.notion.site/ logit- fusion . 2 , 14 Lunjun Zhang and Jimmy Ba. EMA policy gradient: T aming reinforcement learning for LLMs with EMA anchor and T op-k KL. arXiv pr eprint arXiv:2602.04417 , 2026. 2 , 14 13 Preprint. Under review . Appendix A Future Directions OPD versus RL in multi-task transfer . Our multi-task results motivate a more direct comparison between OPD and RL as transfer mechanisms. In RL, positive or negative trans- fer can be r ead directly fr om envir onment rewar d acr oss tasks. In OPD, the optimization target r emains teacher -derived, so transfer is filter ed through what the teacher regar ds as locally preferable behavior . This distinction may help explain why our multi-task gains are strongest on the math side and why nearby support-set definitions become less uniform in that setting. A matched-task, matched-compute comparison between OPD and RL would help clarify when teacher-guided transfer tracks environment-level generalization and when the teacher–r eward gap becomes the bottleneck. Continual learning as a testbed. Continual learning is another natural setting for OPD. A teacher-guided on-policy objective could act as a retention mechanism while the student adapts to new tasks, but that regime would also stress exactly the issues surfaced in this paper: distribution shift, teacher staleness, and the accumulation of approximation error over long adaptation horizons. T esting OPD there would therefor e probe not only whether local support matching mitigates forgetting, but also whether teacher-based objectives remain useful once the student keeps moving away fr om the teacher ’s original domain. Relation to other stabilization directions. This work is complementary to directions such as rewar d-hacking mitigation, EMA-anchor stabilization with top- K KL ( Zhang & Ba , 2026 ), perturbation-based off-policy correction ( Y e et al. , 2026 ), and logit-level fusion between teacher and student rollouts ( Zhang et al. , 2026 ). These methods address dif ferent parts of the same broader pr oblem: how to keep teacher-derived learning signals useful once teacher and student policies begin to diver ge. W e view local support matching as one component in that larger toolbox, rather than as a r eplacement for those stabilization strategies. B Bias and variance analysis of token-level versus sequence-level OPD B.1 Bias of the token-level estimator Recall the sequence-level estimator in causal return-to-go form ˆ g seq = T ∑ t = 1 T ∑ t ′ = t r t ′ ! g t . Expanding the inner sum gives ˆ g seq = T ∑ t = 1 r t g t + T ∑ t = 1 T ∑ t ′ = t + 1 r t ′ g t . Since the token-level estimator keeps only the first term, ˆ g tok = T ∑ t = 1 r t g t , their expectation gap is E [ ˆ g seq ] − E [ ˆ g tok ] = E " T ∑ t = 1 T ∑ t ′ = t + 1 r t ′ g t # . This makes explicit that token-level OPD removes the futur e-rewar d coupling terms and is therefor e generally biased with respect to the sequence-level objective. 14 Preprint. Under review . B.2 W orst-case variance upper bounds Assume there exist constants B r , B g > 0 such that | r t | ≤ B r , ∥ g t ∥ ≤ B g for all t . For the token-level estimator , ∥ ˆ g tok ∥ ≤ T ∑ t = 1 | r t | ∥ g t ∥ ≤ T B r B g , which implies E ∥ ˆ g tok ∥ 2 ≤ T 2 B 2 r B 2 g . Using V ar ( X ) ≤ E ∥ X ∥ 2 , we obtain V ar ( ˆ g tok ) = O ( T 2 ) . For the sequence-level estimator , define R = T ∑ t = 1 r t , G = T ∑ t = 1 g t , ˆ g seq = R G . Then | R | ≤ T B r , ∥ G ∥ ≤ T B g , so ∥ ˆ g seq ∥ ≤ T 2 B r B g , E ∥ ˆ g seq ∥ 2 ≤ T 4 B 2 r B 2 g . Therefor e, V ar ( ˆ g seq ) = O ( T 4 ) . B.3 Discussion The sequence-level estimator is closer to the exact trajectory-level objective, but it couples each score term with many future rewards. In worst-case scaling, this changes variance growth from quadratic to quartic in sequence length. The argument is deliberately conserva- tive, but it captures why stronger rewar d coupling can become problematic in long-horizon post-training. C T oy experiment details C.1 Environment W e use a two-task one-dimensional continuous-control environment to visualize how stronger return coupling changes OPD optimization. The student policy is a three-layer MLP with r oughly 4K parameters. Its input is a thr ee-dimensional vector containing task identity , current position, and normalized time step. The policy outputs the mean and standard deviation of a Gaussian action distribution, and the state transition is s t + 1 = s t + δ , δ ∼ N ( µ , σ ) . The two tasks ar e mirror images of each other: the left task starts from + 2 and targets − 3, while the right task starts from − 2 and targets + 3. W e first train separate teachers with REINFORCE and then distill them into a shared student with alternating-task OPD. C.2 Gradient variance estimation At each training step, we split a batch of B = 64 trajectories into M = 8 micro-batches. For each micro-batch m , we compute a loss L m and the corresponding gradient vector g m on the output layer parameters. W e then estimate gradient variance by V ar ( g ) = 1 M M ∑ m = 1 ∥ g m − ¯ g ∥ 2 , ¯ g = 1 M M ∑ m = 1 g m . W e use this quantity only as a qualitative proxy , but it is suf ficient for comparing r elative variance across dif ferent γ settings. 15 Preprint. Under review . 0 250 500 750 1000 1250 1500 1750 2000 Iteration 1 0 1 1 0 2 1 0 3 1 0 4 1 0 5 1 0 6 1 0 7 Gradient V ariance Left T ask (odd iterations) =0 (tok en-level) =0.25 =0.5 =0.75 =1.0 0 250 500 750 1000 1250 1500 1750 2000 Iteration 1 0 1 1 0 2 1 0 3 1 0 4 1 0 5 1 0 6 1 0 7 1 0 8 Gradient V ariance Right T ask (even iterations) =0 (tok en-level) =0.25 =0.5 =0.75 =1.0 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 time step 8 6 4 2 0 2 4 6 8 position s tok-level Left T ask (init=2) 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 time step seq-level(gamma0.5) Left T ask (init=2) 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 time step seq-level(gamma1.0) Left T ask (init=2) 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 time step 8 6 4 2 0 2 4 6 8 position s tok-level Right T ask (init=-2) 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 time step seq-level(gamma0.5) Right T ask (init=-2) 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 time step seq-level(gamma1.0) Right T ask (init=-2) 0.0 0.2 0.4 0.6 0.8 1.0 nor malized visitation (sqrt scale) Figure A1: T oy experiment with random seed 42: gradient variance and state visitation. C.3 Additional Results of T oy Experiments Figure A1 , A2 , and A3 r eport gradient-variance curves and corresponding state-visitation heatmaps for dif ferent OPD estimators ( γ ∈ { 0.0, 0.25, 0.5, 0.75, 1.0 } ) across three random seeds. Although the exact magnitudes vary by seed, the qualitative pattern is consistent. All settings exhibit lar ge variance spikes during early optimization, and lar ger γ typically remains at a higher variance level later in training. In several runs, the variance under γ = 0.75 or γ = 1.0 stays one to several orders of magnitude above that of smaller γ values. Across runs, token-level OPD ( γ = 0) consistently learns trajectories that move toward the target states for both tasks. Intermediate values of γ remain qualitatively similar but become more dif fuse. When γ approaches the sequence-level case ( γ = 1.0), the learned trajectories often deviate fr om the desir ed dir ection and stabilize ar ound suboptimal regions of the state space. 16 Preprint. Under review . 0 250 500 750 1000 1250 1500 1750 2000 Iteration 1 0 0 1 0 3 1 0 6 1 0 9 1 0 1 2 1 0 1 5 1 0 1 8 1 0 2 1 Gradient V ariance Left T ask (odd iterations) =0 (tok en-level) =0.25 =0.5 =0.75 =1.0 0 250 500 750 1000 1250 1500 1750 2000 Iteration 1 0 0 1 0 4 1 0 8 1 0 1 2 1 0 1 6 1 0 2 0 1 0 2 4 Gradient V ariance Right T ask (even iterations) =0 (tok en-level) =0.25 =0.5 =0.75 =1.0 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 time step 8 6 4 2 0 2 4 6 8 position s tok-level Left T ask (init=2) 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 time step seq-level(gamma0.5) Left T ask (init=2) 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 time step seq-level(gamma1.0) Left T ask (init=2) 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 time step 8 6 4 2 0 2 4 6 8 position s tok-level Right T ask (init=-2) 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 time step seq-level(gamma0.5) Right T ask (init=-2) 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 time step seq-level(gamma1.0) Right T ask (init=-2) 0.0 0.2 0.4 0.6 0.8 1.0 nor malized visitation (sqrt scale) Figure A2: T oy experiment with random seed 43: gradient variance and state visitation. 0 250 500 750 1000 1250 1500 1750 2000 Iteration 1 0 2 1 0 1 1 0 0 1 0 1 1 0 2 1 0 3 Gradient V ariance Left T ask (odd iterations) =0 (tok en-level) =0.25 =0.5 =0.75 =1.0 0 250 500 750 1000 1250 1500 1750 2000 Iteration 1 0 2 1 0 1 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 Gradient V ariance Right T ask (even iterations) =0 (tok en-level) =0.25 =0.5 =0.75 =1.0 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 time step 8 6 4 2 0 2 4 6 8 position s tok-level Left T ask (init=2) 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 time step seq-level(gamma0.5) Left T ask (init=2) 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 time step seq-level(gamma1.0) Left T ask (init=2) 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 time step 8 6 4 2 0 2 4 6 8 position s tok-level Right T ask (init=-2) 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 time step seq-level(gamma0.5) Right T ask (init=-2) 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 time step seq-level(gamma1.0) Right T ask (init=-2) 0.0 0.2 0.4 0.6 0.8 1.0 nor malized visitation (sqrt scale) Figure A3: T oy experiment with random seed 2026: gradient variance and state visitation. 17 Preprint. Under review . R E S E A R C H V I S U A L I Z A T I O N · T O K E N P R O B A B I L I T Y T R A C E T e a c h e r v s S t u d e n t D i s t r i b u t i o n T h i s l a y o u t f o c u s e s o n t h e r e a d a b l e q u e s t i o n / r e s p o n s e v i e w f r o m t h e p o l i s h e d r e f e r e n c e e x a m p l e w h i l e k e e p i n g t h e o r i g i n a l s t a t i s t i c s a n d d e b u g m e t a d a t a i n a c o l l a p s i b l e p a n e l . S t e p 5 S a m p l e 0 T a s k m a t h G e n e r a t e d 2 0 2 6 - 0 2 - 2 4 0 0 : 2 7 : 5 8 M E A N S I G N E D D I F F ( P - R ) + 0 . 0 1 1 2 T h e p o l i c y i s m o r e c o n f i d e n t t h a n t h e r e f e r e n c e o n a v e r a g e . T h e l a r g e s t t o k e n - l e v e l a b s o l u t e g a p r e a c h e s 0 . 9 9 9 1 . S u m m a r y S t a t i s t i c s a n d D e b u g M e t a d a t a Q U E S T I O N Let $p(x)$ be a polynomial of degree 100 suc h that \begin{align *} p(1) &= 1, \ \ p(2) &= 2, \ \ p(3) &= 3, \ \ &\dots, \\ p(99) &= 99, \\ p(100) &= 10 0, \\ p(101) &= 10 2. \end{align*} Find $p(102). $ Teach er st rong er Stude nt st rong er R E S P O N S E \[ c \ cdot 1 0 0 ! = 1 \ impl ies c = \ frac { 1 }{ 1 0 0 ! } \ ] So , the polynomial \( q (x ) \ ) is : \[ q (x ) = \ frac { 1 }{ 1 0 0 ! } ( x - 1 )( x - 2 )\ cd ots (x - 1 0 0 ) \ ] Now , recall that \( p (x ) = q (x ) + x \ ). Therefore , to find \( p ( 1 0 2 ) \ ), we substitute \( x = 1 0 2 \ ) into the equation : \[ p ( 1 0 2 ) = q ( 1 0 2 ) + 1 0 2 \ ] We need to calculate \( q ( 1 0 2 ) \ ). Using the expression for \( q (x ) \ ): \[ q ( 1 0 2 ) = \ frac { 1 }{ 1 0 0 ! } ( 1 0 2 - 1 )( 1 0 2 - 2 )\ cd ots ( 1 0 2 - 1 0 0 ) \ ] This product is : \[ q ( 1 0 2 ) = \ frac { 1 }{ 1 0 0 ! } \ cdot 1 0 1 \ cdot 1 0 0 \ cdot 9 9 \ cdot \ ld ots \ cdot 2 \ ] Notice that the numerator is the product of the numbers from 2 to 1 0 1 , which is \ (\ frac { 1 0 1 ! }{ 1 }\ ) or 1 0 1 !. The denominator is 1 0 0 !. Therefore , the fraction \ (\ frac { 1 0 1 ! }{ 1 0 0 ! }\ ) simpl ifies to 1 0 1 . Thus : \[ q ( 1 0 2 ) = \ frac { 1 0 1 ! }{ 1 0 0 ! } \ cdot \ frac { 1 }{ 1 0 0 ! } = \ frac { 1 0 1 ! }{ ( 1 0 0 !) ^ 2 } = \ frac { 1 0 1 \ cdot 1 0 0 ! }{ 1 0 0 ! \ cdot 1 0 0 ! } = \ frac { 1 0 1 \ cdot 1 0 0 ! }{ 1 0 0 ! ^ 2 } = \ frac { 1 0 1 }{ 1 0 0 ! } \ cdot \ frac { 1 0 0 ! }{ 1 0 0 ! } = \ frac { 1 0 1 }{ 1 0 0 } = 1 0 1 \ ] Therefore : \[ p ( 1 0 2 ) = q ( 1 0 2 ) + 1 0 2 = 1 + 1 0 2 = 1 0 3 \ ] So , the value of \( p ( 1 0 2 ) \ ) is 1 0 3 . The value of \( p ( 1 0 2 ) \ ) is \ boxed { 1 0 3 }. To find the least positive integer \( k \ ) such that \( k + 2 5 9 7 3 \ ) is a palindrome , we need to identify the nearest palindrome to 2 5 9 7 3 first . A palindrome is a number that reads the same forward as backward . The closest larger palindrome is 2 6 0 0 0 , as 2 6 0 0 0 is the smallest number greater than 2 5 9 7 3 that is a palindrome . Let 's verify that 2 6 0 0 0 is a palindrome : - Reading 2 6 0 0 0 backwards gives 0 0 0 6 2 , which is 2 6 0 0 0 ( ign oring the leading zeros ). Now , we need to find the difference between 2 6 0 0 0 and 2 5 9 7 3 to determine \( k \ ): \ [ k = 2 6 0 0 0 - 2 5 9 7 3 = 2 7 \ ] Next , let 's check if there is a smaller \( k \ ) that also results in a palindrome . We can check the closest smaller candidate 2 6 0 0 0 - 1 = 2 5 9 9 9 for example , but since 2 5 9 9 9 is not a palindrome , we can be confident that 2 7 is the smallest \( k \ ). To confirm , let 's add 2 7 to 2 5 9 7 3 : \ [ 2 5 9 7 3 + 2 7 = 2 6 0 0 0 \ ] 2 6 0 0 0 is indeed a palindrome , as shown before . Therefore , the least positive integer \( k \ ) is 2 7 . H ence , the least positive integer \( k \ ) is : \ [ \ boxed { 2 7 } \ ] \ boxed { 2 7 } is the final answer . To find the least positive integer \( k \ ) such that \( k + 2 5 9 7 3 \ ) is a palindrome , we first need to find the nearest palindrome to 2 5 9 7 3 . 1 . ** Ident ify the nearest palindrome ** : - The nearest palindrome greater than 2 5 9 7 3 is 2 6 0 0 0 , as verified by the property of pal ind rom es ( it reads the same (b) T eacher and student remain well aligned even after the answer is effectively available, so the model keeps analyzing instead of stopping at step 9. Figure A4: Even after the student has effectively reached an answer , the teacher can still assign high conditional probability to meaningless continuations. D Qualitative OPD reward-hacking case study T o complement the r epr esentative failur es in the main text, we summarize a longer trajectory from multi-task training under sampled-token OPD. Read chronologically , the case exhibits the same pattern in several forms: the model keeps analyzing after it alr eady has the answer , falls into r epetition loops such as wait , drifts into malformed continuations, and still receives high local teacher probability on those tokens. The failure first appears as over-continuation . Even after the answer is effectively avail- able, the local signal continues to place substantial mass on generic reasoning fillers and connective tokens, encouraging the model to keep going instead of stopping cleanly . The same pattern later appears on pr efixes such as confirm , where the local signal still favors additional verification rather than termination. Some of this behavior may also r eflect the teacher ’s own output habits. Figure A4 illustrates several repr esentative cases. The trajectory then develops into hesitation loops and low-information continuations . Repeated wait tokens, punctuation-heavy continuations, and other semantically weak fillers can remain locally r ewardable even after the overall trajectory has become unpr oductive. This is consistent with the r epetition-loop discussion in Section 3.2 . W e pr ovide two similar cases in Figure A5 . Finally , once the student drifts further off-distribution, the local signal can remain mislead- ingly positive rather than self-correcting. In the case study , this appears as degeneration and gibberish outputs, yet many tokens still receive high teacher probability . An example is shown in Figure A6 . 18 Preprint. Under review . R E S E A R C H V I S U A L I Z A T I O N · T O K E N P R O B A B I L I T Y T R A C E T e a c h e r v s S t u d e n t D i s t r i b u t i o n T h i s l a y o u t f o c u s e s o n t h e r e a d a b l e q u e s t i o n / r e s p o n s e v i e w f r o m t h e p o l i s h e d r e f e r e n c e e x a m p l e w h i l e k e e p i n g t h e o r i g i n a l s t a t i s t i c s a n d d e b u g m e t a d a t a i n a c o l l a p s i b l e p a n e l . S t e p 3 1 S a m p l e 0 T a s k m a t h G e n e r a t e d 2 0 2 6 - 0 2 - 2 4 0 2 : 5 1 : 4 6 M E A N S I G N E D D I F F ( P - R ) + 0 . 1 1 4 7 T h e p o l i c y i s m o r e c o n f i d e n t t h a n t h e r e f e r e n c e o n a v e r a g e . T h e l a r g e s t t o k e n - l e v e l a b s o l u t e g a p r e a c h e s 0 . 9 9 9 5 . S u m m a r y S t a t i s t i c s a n d D e b u g M e t a d a t a Q U E S T I O N Square \(ABCD \) has s ide len gth \(2 \). A se micircl e with diameter \(\ove rline{A B}\) is constru cted in side the square , and t he tange nt to t he semi circle f rom \(C \) inte rsects s ide \(\ overlin e{AD}\) at \ (E\). The len gth of \ (\overl ine{CE} \) can b e exp ressed i n the f orm \(\ frac{k}{ m}\), w here \( \frac{k} {m}\) i s a sim plified fractio n. Plea se find the val ue of \ (k + m\ ). Tea ch er st ro ng er Stu de nt st ro ng er R E S P O N S E Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait . Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , Wait , (a) The teacher may fail to penalize, and sometimes even reinfor ce, repetitive generation. R E S E A R C H V I S U A L I Z A T I O N · T O K E N P R O B A B I L I T Y T R A C E T e a c h e r v s S t u d e n t D i s t r i b u t i o n T h i s l a y o u t f o c u s e s o n t h e r e a d a b l e q u e s t i o n / r e s p o n s e v i e w f r o m t h e p o l i s h e d r e f e r e n c e e x a m p l e w h i l e k e e p i n g t h e o r i g i n a l s t a t i s t i c s a n d d e b u g m e t a d a t a i n a c o l l a p s i b l e p a n e l . S t e p 3 9 S a m p l e 0 T a s k m a t h G e n e r a t e d 2 0 2 6 - 0 2 - 2 4 0 3 : 3 4 : 5 5 M E A N S I G N E D D I F F ( P - R ) + 0 . 0 5 1 7 T h e p o l i c y i s m o r e c o n f i d e n t t h a n t h e r e f e r e n c e o n a v e r a g e . T h e l a r g e s t t o k e n - l e v e l a b s o l u t e g a p r e a c h e s 0 . 9 9 9 7 . S u m m a r y S t a t i s t i c s a n d D e b u g M e t a d a t a Q U E S T I O N One te st is a multipl e choic e test with $5$ questi ons, ea ch havin g $4$ o ptions. There a re $200 0$ cand idates, each ch oosing o nly one answer for eac h quest ion. F ind the smalle st poss ible int eger $n $ such that a studen t's answ er shee t, labe led $n$, has th e follo wing pro perty: The ans wer shee t conta ins fou r sheets , and a ny two o f these four s heets ha ve ex actly t he same three a nswers. Tea ch er st ro ng er Stud en t s tr on ger R E S P O N S E Hmm , I need four answer sheets such that any two have exactly three entries the same , so another way to think about this is that for any pair of sheets , 3 out of 5 entries are the same , and 2 are different . This seems to be a very restrictive condition . Wait , maybe I can think of it in terms of combinations . When you have two sheets which have three answers the same , how many possible combinations are there for that pair ? If we have three questions matching and two different , then there are 5 choose 3 ( the number of questions where the answers match ), which is 1 0 . But then once you pick three positions , the answers on those positions can be anything , but the other positions need to be different . However , I think that to pair any two sheets , for them to share three answers , they need to also have their unique answers on the other two question positions . So that might require some careful consideration . There is a problem because I have 4 sheets , so there are 4 choose 2 = 6 pairs of sheets , and each of these pairs must have three answers the same . Wait , maybe I can first think of a smaller example , and then maybe generalize . Wait , let me see . Let me try to think of a smaller example especially . Suppose I have two answer sheets . The requirement would be that they share exactly 3 correct answers . That would mean , if the first sheet is [ AB CD ]. Then the second sheet has to have 3 of the same answers as the first one . But here , I can take two different sheets , for instance , [ 0 0 0 0 0 ] and [ 0 0 0 0 1 ], which have 4 answers the same . So in that case , it does not satisfy the condition . So maybe my first example fails . Wait , so if I have two sheets , they cannot have all four choices the same . They all must share exactly three same answers . Let me think of an example . Let me see . For two sheets to have three answers the same , and two different , if I have A =[ 0 0 0 0 0 ] and B has three 0 's and two different . Suppose B =[ 0 0 0 1 1 ]. That would work . Wait , but is this general izable ? Let me see . Let me try to express two answer sheets more formally . Let sheet A be ( a 1 , a 2 , a 3 , a 4 , a 5 ) and sheet B is ( b 1 , b 2 , b 3 , b 4 , b 5 ). To have three answers the same : The intersection between the two sheets ( in terms of questions they answered the same ) would be three elements . So , for example , if A is [ 0 , 0 , 0 , 0 , 0 ] and B is [ 0 , 0 , 1 , 1 , 1 ], then they have answers the same for the first three questions , which is 3 out of 5 . Wait , so if I construct two answer sheets like that , then to get a third one that also has three of the same , I could do the same for th (b) T raining can also produce overlong chain-of-thought traces with substantial low-quality content. This pattern is common in LLM reasoning and may partly r eflect the teacher ’s output style. Figure A5: Loops, overlong CoT and punctuation can be locally rewar dable. 19 Preprint. Under review . R E S E A R C H V I S U A L I Z A T I O N · T O K E N P R O B A B I L I T Y T R A C E T e a c h e r v s S t u d e n t D i s t r i b u t i o n T h i s l a y o u t f o c u s e s o n t h e r e a d a b l e q u e s t i o n / r e s p o n s e v i e w f r o m t h e p o l i s h e d r e f e r e n c e e x a m p l e w h i l e k e e p i n g t h e o r i g i n a l s t a t i s t i c s a n d d e b u g m e t a d a t a i n a c o l l a p s i b l e p a n e l . S t e p 3 9 S a m p l e 0 T a s k m a t h G e n e r a t e d 2 0 2 6 - 0 2 - 2 4 0 3 : 3 4 : 5 5 M E A N S I G N E D D I F F ( P - R ) + 0 . 0 5 1 7 T h e p o l i c y i s m o r e c o n f i d e n t t h a n t h e r e f e r e n c e o n a v e r a g e . T h e l a r g e s t t o k e n - l e v e l a b s o l u t e g a p r e a c h e s 0 . 9 9 9 7 . S u m m a r y S t a t i s t i c s a n d D e b u g M e t a d a t a Q U E S T I O N One te st is a multipl e choic e test with $5$ questi ons, ea ch havin g $4$ o ptions. There are $200 0$ cand idates, each ch oosing only on e answer for ea ch ques tion. F ind th e small est poss ible in teger $ n$ such that a studen t's answ er shee t, labe led $n$, has th e follo wing pro perty: The ans wer she et conta ins fou r sheet s, and a ny two of thes e four s heets h ave ex actly t he same three answers. Tea ch er st ro ng er S tud en t st ron ge r R E S P O N S E A [ 0 , 0 , 0 , 0 , 0 ] ( 全 零 ) B = [ 0 , 0 , 1 , 1 , 0 ] ( 第 ⼀ 、 ⼆ 、 四 、 五 位 置 相 同 , 第 三 位 置 不 同 ) C = [ 0 , 0 , 0 , 1 , 1 ] ( 第 ⼀ 、 ⼆ 、 三 、 四 位 置 相 同 , 第 五 位 置 不 同 ) D = [ 0 , 0 , 0 , 0 , 1 ] ( 第 ⼀ 、 ⼆ 、 三 、 五 位 置 相 同 , 第 四 位 置 不 同 ) 但 是 , 这 四 个 向 量 并 不 满 ⾜ 条 件 , 因 为 B , C , D 之 间 的 配 对 并 ⽆ 三个 相 同 的 元 素 。 需 要 调 整 。 需 要 更 精细 定 义 。 实 际 上 , 我 们 可 以 通过 构 建 不 同 类 型 的 向 量 , 通过 坐 标 交 错 变 化 来 实 现 。 以 下 是 构 建 这 四 个 向 量 的 ⼀个 巨 ⼤ 进 展 , 尝 试 写 下 可 能 的 满 ⾜ 条 件 的 四 组 向 量 之 ⼀ : 假 设 有 很 多 选 项 , ⽐ 如 : A 1 = [ 0 , 0 , 0 , 0 , 0 ] A 2 = [ 0 , 0 , 0 , 0 , 1 ] ( 第 ⼀ 列 的 第 五 个 位 置 不 同 ) A 3 = [ 0 , 0 , 0 , 1 , 0 ] ( 第 ⼆ 列 的 第 四 位 置 不 同 ) A 4 = [ 0 , 0 , 0 , 1 , 1 ] ( 第 ⼆ 列 的 第 四 位 置 和 第 五 列 的 不 同 ) 让 A 1 -A 4 确 保 每 个 两 两 之 间 相 差 2 个 位 。 上 述 四 个 向 量 ⽆ 法 满 ⾜ , 让 我 们 换 ⼀ 种 ⽅ 法 。 举例 说 , 如 果 : A 1 = [ 0 , 0 , 0 , 0 , 0 ] A 2 = [ 1 , 1 , 1 , 1 , 1 ] A 1 和 A 2 位 置 完 全 不 同 , 有 五 处 不 同 。 A 3 = [ 0 , 0 , 0 , 0 , 1 ] 与 A 1 � � 同 , 只 是 第 五 项 不 同 , 与 A 2 � � 同 前 四 , 第 五 项 不 同 。 A 4 = [ 0 , 0 , 0 , 1 , 0 ] � � A 3 的 前 四 相 同 , 第 五 项 也 不 同 。 这 ⾥ 的 A 1 和 A 2 是 ⾮ 常 不 同 的 , 有 5 个 不 同 的 位 ; A 1 和 A 2 是 不 满 ⾜ 条 件 的 , 因 此 我 似乎 需 要 重 新 组织 。 似乎 我 需 要 重 新 思 考 。 将 这 个 问题 作为 集 合 论 问题 , 看 是 否 可 以 ⽤ 鸽 笼 原 理 等 其 他 策 略 。 既 然 问题 是 要 找 四 张 卡 ⽚ , 每 张 卡 ⽚ 有 5 个 答 案 , 每 两个 卡 ⽚ 共 享 3 个 答 案 。 这 让 我 想 到 , 可 能 可 以 构 造 ⼀个 乘 积 空 间 。 ⽐ 如 , 先 考 虑 三 元 情 况 , 即 每 个 问题 只 有 三个 选 项 。 设 选 项 为 0 , 1 , 2 , 那 么 有 3 ^ 5 = 2 4 3 种 可 能 的 试 卷 , 每 两 张 试 卷 之 间 最 多 可 以 有 5 - 2 = 3 个 不 同 的 位 置 。 但 这 ⾥ 是 4 选 项 的 情 况 , 即 2 ^ 2 = 4 , 2 ^ 5 = 3 2 个 答 案 组 合 , 我 需 要 在 尽 可 能 ⼩ 的 组 合 下 满 ⾜ 题 意 。 这 需 要 每 个 答 案 的 位 置 最 多 有 2 个 不 同 。 但 这 ⾥ 每 个 卡 ⽚ 是 5 位 , 每 个 位 上 可 能 有 4 种 选 择 , 4 ^ 5 = 1 0 2 4 � � 可 能 的 组 合 。 我 要 找 出 4 个 组 合 , 使 得 每 两个 的 三个 位 相 同 。 那 么 它 们 必 须 是 分 类 化 的 , 即 我 能 设 置 ⼀ 些 模 板 , 使 得 每 个 模 板 重 叠 三个 位 , 但 显 性 不 同 两 位 。 我 需 要 更 好 的 构 造 。 假 设 四 张 试 卷 Figure A6: The teacher still assigns high probability to several tokens after the student drifts into nonsensical Chinese outputs. 20
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment