Missing-Aware Multimodal Fusion for Unified Microservice Incident Management
Automated incident management is critical for microservice reliability. While recent unified frameworks leverage multimodal data for joint optimization, they unrealistically assume perfect data completeness. In practice, network fluctuations and agen…
Authors: Wenzhuo Qian, Hailiang Zhao, Ziqi Wang
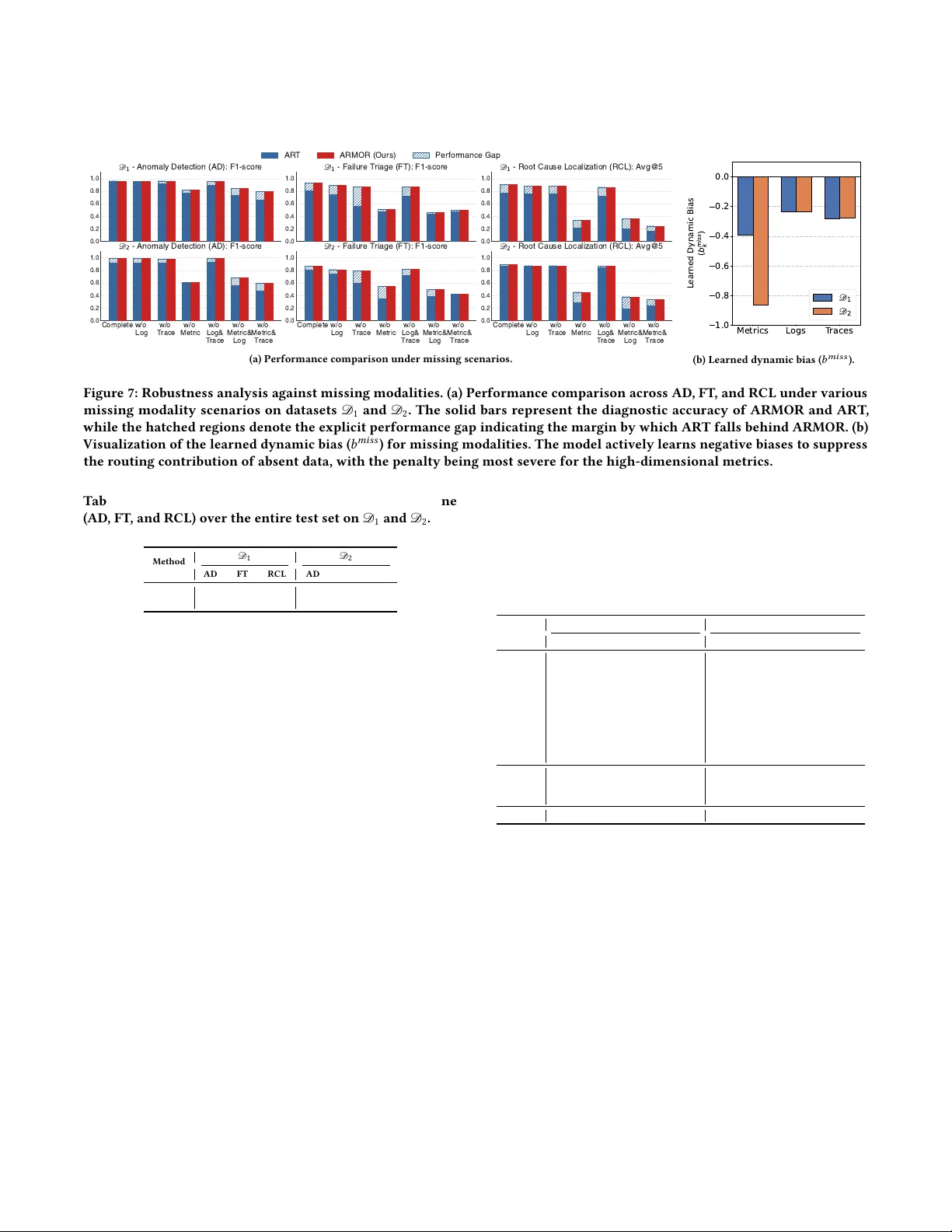
Missing- A ware Multimodal Fusion for Unified Microservice Incident Management W enzhuo Qian Zhejiang University Hangzhou, China qwz@zju.edu.cn Hailiang Zhao ∗ Zhejiang University Hangzhou, China hliangzhao@zju.edu.cn Ziqi W ang Zhejiang University Hangzhou, China wangziqi0312@zju.edu.cn Zhipeng Gao Zhejiang University Hangzhou, China 22551125@zju.edu.cn Jiayi Chen Zhejiang University Hangzhou, China jyichen@zju.edu.cn Zhiwei Ling Zhejiang University Hangzhou, China zwling@zju.edu.cn Shuiguang Deng ∗ Zhejiang University Hangzhou, China dengsg@zju.edu.cn Abstract A utomated incident management is critical for microservice re- liability . While recent unied frameworks leverage multimo dal data for joint optimization, they unr ealistically assume perfect data completeness. In practice, network uctuations and agent failur es frequently cause missing modalities. Existing approaches relying on static placeholders introduce imputation noise that masks anom- alies and degrades performance. T o addr ess this, we propose AR- MOR, a robust self-sup ervised framework designed for missing modality scenarios. ARMOR features: (i) a modality-specic asym- metric encoder that isolates distribution disparities among metrics, logs, and traces; and (ii) a missing-aware gated fusion mechanism utilizing learnable placeholders and dynamic bias compensation to prev ent cross-modal interference from incomplete inputs. By employing self-supervise d auto-regression with mask-guided r e- construction, ARMOR jointly optimizes anomaly detection (AD ), failure triage (FT), and root cause localization (RCL). AD and RCL require no fault labels, while FT relies solely on failure-type an- notations for the downstream classier . Extensive experiments demonstrate that ARMOR achieves state-of-the-art p erformance under complete data conditions and maintains robust diagnostic accuracy even with sev ere modality loss. CCS Concepts • Softwar e and its engineering → Software maintenance tools . ∗ Corresponding author . Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for prot or commercial advantage and that copies bear this notice and the full citation on the rst page. Copyrights for components of this work owned by others than the author(s) must be honor ed. Abstracting with credit is permitted. T o copy otherwise, or republish, to post on servers or to redistribute to lists, r equires prior spe cic permission and /or a fe e. Request permissions from permissions@acm.org. Conference acronym ’XX, W oodstock, N Y © 2018 Copyright held by the owner/author(s). Publication rights licensed to A CM. ACM ISBN 978-1-4503-XXXX -X/2018/06 https://doi.org/XXXXXXX.XXXXXXX Ke ywords Microservice Systems, Anomaly Detection, Failure Triage, Root Cause Localization, Missing Modality A CM Reference Format: W enzhuo Qian, Hailiang Zhao, Ziqi W ang, Zhipeng Gao, Jiayi Chen, Zhi- wei Ling, and Shuiguang Deng. 2018. Missing-A ware Multimodal Fusion for Unied Microservice Incident Management. In Procee dings of Make sure to enter the correct conference title from your rights conrmation email (Conference acronym ’XX) . ACM, New Y ork, N Y , USA, 12 pages. https: //doi.org/XXXXXXX.XXXXXXX 1 Introduction Microservice architectures have become the foundational infras- tructure for modern cloud-nativ e applications due to their inherent scalability and agility [ 12 , 35 ]. Howev er , the massive scale and dy- namic complexity of these distributed systems make performance anomalies and system failures inevitable, frequently leading to severe service disruptions and substantial nancial losses [ 29 ]. Con- sequently , ensuring system reliability through automated incident management has become a priority for site reliability engineers (SREs) [42]. T o manage incidents eectively , SREs rely heavily on multimodal monitoring data, including continuous metrics, semi-structured logs, and distribute d traces, which collectively capture the over- all system state [ 16 , 28 , 39 , 41 ]. As Figure 1 illustrates, these di- verse data streams sequentially drive a standard incident manage- ment pipeline comprising three diagnostic tasks: anomaly detection (AD ) [ 3 – 5 , 7 , 10 , 14 , 15 , 17 , 51 ], failure triage (FT) [ 22 , 23 , 36 , 37 , 43 ], and root cause localization (RCL) [ 13 , 21 , 31 , 34 , 38 ]. Initially , AD continuously monitors system states to trigger alerts upon detect- ing abnormal behaviors. Subse quently , FT categorizes the dete cted anomalies into spe cic failure types for appropriate engine ering teams. Finally , RCL identies the exact culprit instance responsible for the failure. Current intelligent incident management approaches generally fall into two categories. Early methods rely on isolated, single-task Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Qian et al. M u l t i mo d a l M o n i t o r i n g Da t a I n c i d e n t M a n a g e me n t P i p e l i n e C ont i nuous M e t ri c s Se m i - st r uct ur ed Logs D ist r ibut ed T r aces [ 2025 - 12 - 21 10: 00: 01] [ I NF O ] R eques t pr oc es s i ng s t ar t ed, [ 2025 - 12 - 21 10: 00: 05] [ E RRO R ] C onnec t i on t i m eout t o dat abas e ‘ m ai n_db ’ MS1 MS2 MS4 MS3 75m s M e t r ics ( C P U , M e m or y , ...) Logs ( S y s tem ev ents ) T r aces ( S er v i c e topol ogi es ) A nom aly D et ect ion ( AD) M oni tor s s y s tem s tates & i s s ues al er ts Fa i l ure T r iage ( FT) C ategor i z es fai l ur e ty pes R oot C ause Localiz at ion ( RCL ) Identi fi es the r oot c aus e i ns tanc e Tr i gger Al e rt A s s i gn to D B Team R oot C ause: Ins tanc e_D B _1 SRE Figure 1: O verview of the multimo dal incident management pipeline. Diverse observability data (metrics, logs, and traces) drives three sequential tasks: AD , FT , and RCL. techniques for dierent diagnostic stages [ 17 , 19 , 43 ]. However , decoupling these related tasks ignores the shared diagnostic con- text emb edded in system deviations, often leading to redundant maintenance overhead, inecient resource utilization, and delayed mitigation responses [ 28 ]. T o address these limitations, recent re- search shifts toward unied multi-task frameworks [ 16 , 28 , 39 , 41 ]. Instead of maintaining separate pipelines, these metho ds extract shared knowledge from multimodal monitoring data to jointly opti- mize AD , FT , and RCL. By modeling inherent dependencies across these stages, such end-to-end solutions achieve signicant perfor- mance improvements and streamline troubleshooting under ideal conditions. Despite their success, existing unie d frameworks [ 16 , 28 , 39 , 41 ] assume that the collected multimodal monitoring data is p erfectly aligned and complete. Howev er , in real-world production environ- ments, observability infrastructure vulnerabilities, such as network uctuations, telemetry agent crashes, and conguration errors, fre- quently cause missing modalities regardless of the actual microser- vice status [ 9 , 52 ]. When processing incomplete data, current mod- els typically fuse the available inputs with static placeholders [ 2 , 49 ], causing signicant performance degradation. Although sup ervised approaches attempt to handle incomplete modalities, the extr eme scarcity of industrial fault labels renders them prone to overtting and dicult to deploy . Adopting a self-super vised approach pro- vides a practical alternative to eliminate reliance on manual anno- tations. Nevertheless, developing a robust, self-supervised incident management framework capable of handling missing modalities requires addressing three primary challenges: (1) Tightly couple d encoding makes any modality absence corrupt sur viving signals. When obser vability infrastructure fails, multiple modalities may b ecome unavailable at the same time, and SREs cannot predict which combination will drop ne xt. Exist- ing methods tightly couple metrics, logs, and traces during early representation learning, so missing modalities corrupt the repre- sentations built from the survivors [ 16 , 39 , 41 , 51 ]. The structural asymmetry b etween dense continuous metrics and sparse discrete logs and traces makes this worse: encoding heterogeneous signals with a shared architecture forces the surviving modalities into a rep- resentation space shaped by the absent ones, losing the diagnostic clues they actually carry . (2) Static imputation masks real failures by mimicking a healthy idle state. When a Prometheus agent goes oine, lling its missing channels with zero tells the model that every monitored resource sits at exactly zero consumption. That is precisely the signature of a healthy idle service, not a failing one. Conventional fusion mechanisms [ 28 , 41 , 51 ] adopt rigid early concatenation and rely on static imputation [ 2 , 49 ] for structural consistency . The resulting pseudo-normal signal o verwhelms the anomaly indicators captured by surviving logs and traces, suppressing the deviations that SREs would otherwise use to diagnose the incident. (3) Distorte d representations break unied diagnosis across all three tasks. Without a repr esentation that holds up under miss- ing data, SRE teams lose the ability to run a single unied AD , FT , and RCL pipeline. Each missing modality scenario produces a dif- ferent distortion in the fused representation, forcing teams back to maintaining separate per-modality diagnostic congurations and reintroducing the fragmentation ov erhead that unied frameworks were designed to eliminate. Self-supervised mo dels derive diagnos- tic signals from predictive errors [ 38 , 41 , 51 ], but static imputation biases those errors toward normal states. Deriving a stable failure signature under these distorted inputs, one that simultaneously supports all three tasks without manual annotations, r emains an unresolved problem. T o address these limitations, we pr opose ARMOR, an A utomated and R obust framework handling M issing m O dality for R oot cause analysis in microservices. Specically , ARMOR comprises three core mo dules designed to systematically resolv e the aforementioned challenges: (1) Modality-sp ecic status learning. W e design an asym- metric encoder tailored to the distinct distribution properties of continuous metrics and sparse events. This decoupled architecture hierarchically disentangles temporal, channel, and spatial depen- dencies, preventing the absence of a single modality from corrupt- ing the repr esentations of the others. (2) Missing-aware global fusion. W e introduce an attention-guided gating mechanism incorporating learnable placeholders and targeted biases. Instead of employing static imputation, this module explicitly recognizes absent inputs and adaptively compensates for their routing contributions, pre- venting static placeholders from inducing cr oss-modal interference. (3) Online diagnosis via unied representations. ARMOR constructs a robust unied representation by concatenating explicit reconstruc- tion errors with latent system emb eddings. This comprehensive signature establishes a shared foundation to concurrently support AD , FT , and RCL, even under se vere modality dropouts and strict label scarcity . The main contributions of this work are as follows. • W e present ARMOR, which, to the best of our knowledge, is the rst self-super vised incident management framework explicitly designed to handle missing modalities in microser- vices, enabling label-free AD and RCL, with FT requiring only failure-type annotations for the frozen-encoder classi- er . • W e devise a modality-specic asymmetric encoder and a missing-aware gated fusion mechanism. By leveraging learn- able placeholders and dynamic bias compensation, ARMOR Missing- A ware Multimodal Fusion for Unifie d Microservice Incident Management Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y eectively mitigates imputation noise and pr events spurious correlations caused by incomplete inputs. • Extensive experiments on benchmark microservice systems demonstrate that ARMOR achieves state-of-the-art p erfor- mance under complete data settings and maintains superior diagnostic stability even under severe modality loss, signi- cantly outperforming existing baselines. 2 Motivation This section motivates the proposed framework by exploring the gap between ideal academic assumptions and complex industrial realities. Specically , we examine the inevitability of missing modal- ities in production environments and demonstrate how current multimodal fusion strategies remain fundamentally vulnerable to such incomplete data. 2.1 Why Are Missing Modalities Inevitable in Production Environments? Existing r esearch on unied modeling relies heavily on the assump- tion of perfectly complete and aligne d multimo dal datasets (e .g., metrics, logs, and distributed traces) [ 16 , 28 , 41 ]. Howe ver , such ideal conditions rarely exist in industrial cloud-native environments. Due to the scale and dynamic complexity of microservice architec- tures, the absence of modalities is a common occurrence rather than an infrequent edge case. This data absence is primarily driven by vulnerabilities within the obser vability infrastructure [ 2 , 40 , 49 , 52 ] (e.g., data collection and transmission pipelines) rather than by failures within the business microservices themselves. Figure 2 illustrates how practical factors, such as agent failures and network policies, cause abrupt data gaps even when the un- derlying ser vices remain healthy . For example, telemetry agents (e .g., Prometheus node_exporter ) operate in resour ce-constrained environments and are highly susceptible to out-of-memory errors due to high monitoring overhead. At timestamp T1, an agent crash causes a sudden and prolonged absence of metrics; however , the continuous output of normal information logs conrms that the business ser vice continues to process requests without interruption. Similarly , network uctuations and aggressive sampling strategies create substantial data gaps. During extreme trac surges, oper- ations teams routinely downgrade the obser vability pipeline to preserve bandwidth for core transactions. At timestamp T2, this conguration results in traces being actively dropped by the gate- way , yet the persistent stream of logs again veries the operational stability of the service. Beyond such runtime interruptions, cong- uration errors and system heterogeneity hinder data generation. Modern systems frequently incorporate legacy ser vices or third- party components that lack proper instrumentation, leading to an inherent absence of specic modalities without triggering explicit business errors [2, 40, 49, 52]. As Figure 2 shows, missing modalities occur as complete channel- level outages that arrive irregularly across dierent services and time steps, primarily due to collection and transmission issues. Be- cause extreme trac and resource contention often precede actual system failures, the absence of observational data frequently coin- cides with the exact incidents that site reliability engine ers must diagnose. 0 20 40 Metrics (CPU %) Metrics Missing Interval [T1] Prometheus Agent OOM (Metrics Collection Fails) [T2] Traffic Surge & Sampling=0 (Traces Dropped by Gateway) CPU Usage (%) Logs (Events) Normal Info Logs 0 20 40 60 80 100 Timeline (Minutes) 0 100 200 Traces (Latency ms) Traces Missing Interval Trace Latency Figure 2: The generation of missing mo dalities in production environments. This timeline illustrates how vulnerabilities in the obser vability infrastructure (e.g., agent crashes or ag- gressive sampling) cause abrupt data loss, even while the un- derlying microservice op erates normally and outputs logs. Finding 1: In industrial microservices, observability infras- tructure vulnerabilities produce complete modality-level blackouts: a process crash or network failure can eliminate an entire data stream instantaneously . Since such outages frequently coincide with actual system failures, methods requiring perfectly complete data are highly impractical. 2.2 How Do Existing Frameworks Perform with Missing Modalities? Given the inevitability of missing modalities in distribute d systems, evaluating how state-of-the-art unied frame works [ 16 , 28 , 41 ] han- dle incomplete inputs is critical for practical deplo yment. W e probe ART [ 41 ], the best-performing self-super vised unied baseline un- der complete data, as the repr esentative: as Figure 3 illustrates, it experiences severe and asymmetric p erformance degradation under missing modalities. Although the framework maintains moderate resilience when discrete logs ar e missing, the absence of continuous metrics causes a signicant decline, particularly in the accuracy of RCL. This result conrms that conventional static imputation fails to bridge the semantic gap left by missing modalities, leaving the automated monitoring pipeline highly vulnerable. The degradation is most severe when metrics are absent: unlike logs and traces, which record discrete events at coarse granularity , metrics provide dense, continuous resour ce measurements across ev ery time step, so their loss leaves the surviving modalities with far less signal to compensate. This systemic vulnerability stems from the rigid nature of early- concatenation fusion mechanisms. When a sp ecic modality b e- comes unavailable, existing methods routinely employ static im- putation (e.g., lling missing dimensions with default constants) Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Qian et al. Complete w/o Log w/o Trace w/o Metric w/o Log& Trace w/o Metric& Log w/o Metric& Trace 0.0 0.5 1.0 Anomaly Detection: F1-score Failure Triage: F1-score Root Cause Localization: Avg@5 Performance Drop Figure 3: Performance degradation of ART [ 41 ], the strongest self-supervise d unie d baseline, under missing modalities. Metric loss causes a steep drop in RCL accuracy , conrming that static imputation cannot compensate for absent contin- uous streams. Normal State Anomalous State (Complete Modalities) Anomalous State (Static Imputation) Figure 4: The impact of static imputation on latent feature distributions. A t-SNE visualization demonstrates how non- adaptive default values force the features of anomalous in- stances into the normal cluster , creating spurious correla- tions that suppress actual diagnostic signals. to maintain structural consistency . Although computationally con- venient, this naive alignment entirely ignores semantic validity . Consequently , high-dimensional neural networks mistakenly inter- pret these deterministic placeholders as high-condence features indicating a stable operational state. This pervasive “pseudo-normal” signal introduces severe cross- modal interference. As the t-SNE projection in Figure 4 demon- strates, static imputation forcefully shifts the latent features of anomalous instances, which other wise form distinct and separa- ble clusters, directly into the dense cluster of normal states. This mathematical distortion heavily suppresses the subtle anomalous deviations successfully captured by the remaining available modal- ities, thereby systematically reducing o verall diagnostic accuracy . Therefore, eliminating this imputation-induced distortion is a pre- requisite for robust incident management. Finding 2: The naive imputation of missing mo dalities biases joint representations toward normal states, sev erely degrading diagnostic performance and necessitating the development of robust, missing-aware fusion mechanisms. 3 Preliminaries 3.1 Self-supervise d Learning Self-supervise d learning derives supervisory signals directly from unlabeled data via pretext tasks, such as reconstruction [ 30 , 32 ], to learn generalizable representations. In microservice incident management, acquiring manual fault annotations across large-scale environments is prohibitiv ely expensive and labor-intensive [ 41 ]. Self-supervise d learning mitigates this challenge by eliminating re- liance on extensiv e labeled data. Unlike traditional sup ervised joint learning requiring complex loss balancing [ 9 , 16 ], self-supervised learning naturally facilitates unied multi-task mo deling. By learn- ing generalized failure semantics, a single self-super vised pipeline seamlessly supp orts AD, FT , and RCL at the representation lev el [ 41 ]. Therefore, w e adopt it as our foundational methodology . 3.2 Missing Modalities in Multimodal Fusion Although multimodal learning constructs comprehensive system representations, it frequently encounters missing mo dalities in real-world deployments. Existing solutions primarily involve data imputation and robust representation learning [ 46 ]. Generative imputation [ 18 , 20 ] synthesizes missing channels but introduces substantial computational overhead and risks fabricating false diag- nostic signals. In contrast, r epresentation-level methods [ 27 , 47 ] ad- just available modality contributions via dynamic routing. However , these approaches often rely on a primary modality for alignment, rendering them ineective when key signals drop . A critical yet overlooked issue in microservice incident man- agement is the structural asymmetry of obser vability data. Unlike standard multimodal tasks with symmetric latent spaces [ 46 ], mi- croservice data comprises dense, continuous metrics (infrastructure states) and sparse, discrete logs/traces (software events). Conven- tional frameworks handle missing data via static imputation (e.g., zero-lling). In this asymmetric context, static placeholders for miss- ing dense metrics are erroneously interpreted by neural networks as strong pseudo-normal signals . This introduces severe distribu- tion shifts, causing cross-modal interference that suppresses subtle anomaly indicators in surviving sparse modalities [ 47 ]. Therefore, a reliable framework must explicitly account for this asymmetry by isolating modality-specic semantics prior to fusion, thereby pre- venting imputation noise from corrupting the diagnostic manifold. 3.3 Problem Formulation Let I = { 1 , . . . , 𝑁 } denote the set of 𝑁 interconnected microser- vice instances. For a spe cic time window , the complete multi- modal observation for instance 𝑖 is dened as 𝑋 𝑖 = ( 𝑋 M 𝑖 , 𝑋 L 𝑖 , 𝑋 T 𝑖 ) , where 𝑋 M 𝑖 ∈ R 𝑇 × 𝑑 𝑚 represents continuous metric time series, 𝑋 L 𝑖 denotes semi-structured log sequences, and 𝑋 T 𝑖 captures dis- tributed trace graphs. The system-wide input is aggregated as Missing- A ware Multimodal Fusion for Unifie d Microservice Incident Management Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Metric Trace Info Err Tcp accept *service resuse Log Anomaly Detection Failure Tri a g e Root Cause Localization ③ Diagnostic T asks 1 2 3 Modality -Specific Asymmetric Encoder Metric Embedding Missing Embedding Trace Embedding Missing- Awa re Gated Fusion Adaptive Penalty GA T MLP Next Step Observed Data Next Step Predicted Data Calculate Reconstruction Loss ① Modality - Specific Status Learning ② Missing - Awa re Gl oba l F usi on High Dim Block (Metric) Temporal Fusion Channel Fusion Instance Fusion Low Dim Block (Log & Trace) Penalized Cross- Modal Routing 𝑋 ! ∈ ℝ " × $ ! ×% 𝑋 &' ∈ ℝ " × $ "# ×% 𝑋 ( ∈ ℝ " × $ $ ×% 𝑋 ∈ ℝ " × $ %&''() Figure 5: Overview of the propose d missing-aware incident management framework. It comprises three core modules: (1) Modality-Specic Status Learning, extracting intra-modality features via an asymmetric encoder; (2) Missing-A ware Global Fusion, integrating isolate d embeddings through an attention-guided gating me chanism and a top ology-aware graph network; and (3) Diagnostic T asks, optimizing the network via o line self-supervised reconstruction and executing online AD, FT , and RCL using the unied representations. 𝑋 = { 𝑋 𝑖 } 𝑁 𝑖 = 1 . T o formalize missing modalities caused by infras- tructure vulnerabilities, we dene an obser vation mask vector 𝑂 = [ 𝑜 M , 𝑜 L , 𝑜 T ] ∈ { 0 , 1 } 3 , where 𝑜 𝑘 = 1 indicates successful col- lection of modality 𝑘 ∈ {M , L , T } , and 𝑜 𝑘 = 0 denotes its absence. The actual incomplete input is ˜ 𝑋 = { ˜ 𝑋 𝑖 } 𝑁 𝑖 = 1 , with each mo dality dened as ˜ 𝑋 𝑘 𝑖 = 𝑋 𝑘 𝑖 if 𝑜 𝑘 = 1 , and ˜ 𝑋 𝑘 𝑖 = 0 (a structure-compatible static placeholder) otherwise. Unlike existing methods [ 28 , 39 , 41 ] assuming 𝑂 = [ 1 , 1 , 1 ] , we aim to learn a robust mapping 𝐹 𝜃 : ( ˜ 𝑋 , 𝑂 ) → ( 𝑦, 𝑠 , 𝑃 ) that ex- plicitly leverages 𝑂 to mitigate imputation noise. This function jointly optimizes three tasks: (1) AD , predicting a binary indicator 𝑦 ∈ { 0 , 1 } ; (2) FT , classifying the failure typ e 𝑠 ∈ S from a prede- ned taxonomy; and (3) RCL, estimating a probability distribution 𝑃 = [ 𝑝 1 , . . . , 𝑝 𝑁 ] ∈ [ 0 , 1 ] 𝑁 over instances. The core challenge is en- suring 𝐹 𝜃 remains invariant to distributional shifts induce d by static placeholders ( 0 ) when 𝑜 𝑘 = 0 , preserving the diagnostic delity of available modalities. 4 Methodology 4.1 Overview As shown in Figure 5, ARMOR operates in two phases. During the oine phase, Mo dule 1 rst partitions the multimodal input and extracts modality-specic features independently for each modal- ity from anomaly-free operational data, preserving the distinct semantics of continuous metrics and sparse events. Module 2 then integrates these isolated embeddings via a masked gating mecha- nism and a topology-aware graph network, establishing a normal operating baseline through self-supervised reconstruction so that subsequent anomalous deviations become identiable. During the online phase, the trained model enco des incoming data to obtain latent embeddings alongside next-step predictions; the continuous deviations between predictions and obser vations are concatenated with the latent embeddings to form unie d failure representations. These representations serve as the shared foundation for Module 3, which sequentially monitors for anomalies, determines the failure type upon detection, and lo calizes the root cause instance. 4.2 Modality-Specic Status Learning Multimodal Data Serialization. Following established practices [ 16 , 41 ], we transform metrics, logs, and traces into aligned time series. While metrics only require standard normalization, logs are parse d into event frequency series, and traces are aggregated into minute- level statistics ( e.g., average latency , request counts). W e concate- nate these into a fused multivariate time series 𝑀 = [ 𝑀 𝑚𝑒 𝑡 𝑟 𝑖𝑐 ∥ 𝑀 𝑙 𝑜𝑔 ∥ 𝑀 𝑡 𝑟 𝑎𝑐 𝑒 ] and apply nearest-neighbor interpolation to stan- dardize the resolution to one minute . Finally , z-score standardiza- tion [ 1 ] over a sliding window produces the normalized input se- quence 𝑋 = { 𝑋 ( 1 ) , . . . , 𝑋 ( 𝑇 ) } , where 𝑇 denotes the window length, and each snapshot 𝑋 ( 𝑡 ) ∈ R 𝑁 × 𝐾 encompasses 𝑁 instances and 𝐾 channels. This preliminary fusion ee ctively aligns heterogeneous data [ 14 , 16 , 38 , 41 , 53 ], leaving complex dependency modeling to the subsequent network. Modality-Specic Feature Extraction. Directly pr ocessing the con- catenated 𝐾 channels o verlooks the fundamental structural asym- metry of cloud-native telemetry: metrics reect macroscopic, con- tinuous resource states, whereas logs and traces record microscopic, discrete execution events. T o address this, we partition the se- quence into modality-specic sub-matrices 𝑋 M , 𝑋 L , and 𝑋 T . Let 𝑋 𝑚 ∈ R 𝑁 × 𝐾 𝑚 × 𝑇 denote the input for modality 𝑚 . W e employ a domain-guided asymmetric encoder based on ModernTCN [ 11 ] to hierarchically disentangle dependencies. Large-kernel depthwise convolutions rst capture long-term temporal trends ( e.g., memory leaks): 𝐻 𝑚,𝑡 𝑒𝑚𝑝 = DepthwiseConv ( 𝑋 𝑚 ) . (1) Pointwise convolutions then integrate intra-instance channel cor- relations (e .g., simultaneous latency and I/O spikes): 𝐻 𝑚,𝑐ℎ𝑎𝑛 = PointwiseConv 𝑐ℎ𝑎𝑛 ( 𝐻 𝑚,𝑡 𝑒𝑚𝑝 ) . (2) Finally , to facilitate early spatial interactions, we p ermute dimen- sions and apply instance-level convolution: 𝐻 𝑚 = PointwiseConv 𝑖𝑛𝑠 𝑡 Permute ( 𝐻 𝑚,𝑐ℎ𝑎𝑛 ) . (3) Crucially , applying symmetric extractors to such heterogeneous in- puts risks overtting on sparse events or undertting on volatile re- sources. Therefore , our asymmetric design congures high-capacity Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Qian et al. M e t r i c s L o g s T r a c e s 𝐸 𝑚 𝑖𝑠 𝑠 L e a r n a b l e P l a c e h o l d e r A t t e n t i o n I n t e r a ct i o n A d a p t i v e P e n a l t y − 𝑏 𝑚 𝑖𝑠 𝑠 L e a r n a b l e m i s s i n g b i a s M a sk R o b u s t R e p r e s e n t a t i o n Figure 6: Missing-aware gated fusion. When a telemetry out- age occurs (e.g., absent logs), the mo dule rst isolates the missing modality by injecting an explicit placeholder ( 𝐸 𝑚𝑖𝑠 𝑠 ). After cross-modal attention interaction, it applies an adap- tive penalty ( − 𝑏 𝑚𝑖𝑠 𝑠 ) to downgrade the imputation noise, ulti- mately producing a robust instance representation ModernTCN blocks for continuous metrics to capture intricate uc- tuations, while employing lightw eight blocks for sparse logs and traces. This physical alignment prevents infrastructure-level noise from overwhelming discrete event semantics. Consequently , the resulting emb eddings retain distinct hidden dimensions: 𝐻 M ∈ R 𝑁 × 𝑑 M , 𝐻 L ∈ R 𝑁 × 𝑑 L , and 𝐻 T ∈ R 𝑁 × 𝑑 T , with 𝑑 M > 𝑑 L , 𝑑 T . 4.3 Missing- A ware Global Fusion Constructing a comprehensiv e system repr esentation from isolated unimodal embeddings requires addressing the frequent telemetry outages (e.g., agent crashes or network throttling) prevalent in production environments. Inspired by robust multimodal routing paradigms [ 27 ], we design a missing-awar e global fusion module that employs an attention-guided gating mechanism for incomplete inputs and a graph neural network for spatial ser vice dependencies. W e rst project unimodal embeddings 𝐻 M , 𝐻 L , 𝐻 T to a unied dimension 𝑑 , forming a token sequence 𝑉 = [ 𝑣 M , 𝑣 L , 𝑣 T ] per in- stance. A critical challenge arises when a mo dality collapses: replac- ing the missing high-dimensional tensor with static zero-padding induces a severe distribution shift , causing the network to misinter- pret the absence of data as a "healthy idle " state (i.e., pseudo-normal noise). T o explicitly isolate this infrastructure-induced artifact, we replace absent tokens ( 𝑜 𝑘 = 0 ) with a learnable placeholder em- bedding 𝐸 𝑚𝑖𝑠 𝑠 ∈ R 𝑑 . Unlike static zeros, 𝐸 𝑚𝑖𝑠 𝑠 acts as a structural negative signal , informing the fusion layer of telemetr y loss rather than fabricating false stability . W e further add a modality-specic embedding 𝐸 𝑚𝑜𝑑 ,𝑘 to preserve semantics. The mask-adjuste d token 𝑣 ′ 𝑘 is formulated as: 𝑣 ′ 𝑘 = 𝑜 𝑘 𝑣 𝑘 + ( 1 − 𝑜 𝑘 ) 𝐸 𝑚𝑖𝑠 𝑠 + 𝐸 𝑚𝑜𝑑 ,𝑘 . (4) As shown in Figure 6, the adjusted sequence 𝑉 ′ passes through a multi-head attention (MHA) layer to captur e cross-modal interac- tions: 𝑈 = LayerNorm 𝑉 ′ + Dropout MHA ( 𝑉 ′ , 𝑉 ′ , 𝑉 ′ ) . (5) W e then dynamically calculate a gating w eight for each enriche d modality token 𝑈 𝑘 . In a highly dynamic microservice architecture, relying equally on a generalized placeholder and actual telemetry data can derail root cause localization. Since the placeholder lacks the precise execution context of the missing modality , the network must adaptively downgrade its routing contribution and redirect diagnostic attention toward the sur viving, reliable signals from other modalities. T o enforce this adaptiv e penalization during cross- modal routing, we compute the gating logit 𝑠 𝑘 by applying a shared linear projection 𝑊 𝑠 ∈ R 1 × 𝑑 and adding a learnable missing bias 𝑏 𝑚𝑖𝑠 𝑠 𝑘 ∈ R exclusively when 𝑜 𝑘 = 0 : 𝑠 𝑘 = 𝑊 𝑠 𝑈 𝑘 + ( 1 − 𝑜 𝑘 ) 𝑏 𝑚𝑖𝑠 𝑠 𝑘 . (6) The fusion weights 𝛼 𝑘 are obtained via a softmax function o ver the logits. Subsequently , the robust instance representation 𝐸 ∈ R 𝑁 × 𝑑 is computed as the weighted sum of the enriched tokens across all modalities, where 𝑁 represents the total numb er of microservice instances: 𝐸 = 𝑘 ∈ { M , L , T } 𝛼 𝑘 𝑈 𝑘 . (7) Microservice systems operate on complex spatial topologies de- ned by inv ocation dependencies. T o capture these structural inter- actions, we model the system as a directed graph G = ( V , E ) , where V represents the microservice instances and E denotes the interac- tion links. W e apply a multi-layer graph attention network [ 28 , 44 ] to propagate the fused features 𝐸 along this behavioral graph. Let N ( 𝑖 ) denote the set of topological neighb ors for instance 𝑖 , includ- ing the instance itself. The graph convolution aggregates spatial features by computing attention coecients 𝛼 𝑐 𝑖 𝑗 that quantify the inuence of neighbor 𝑗 on instance 𝑖 . T o process information from multiple representation subspaces, we congure the network with a multi-head attention mechanism. The feature update for instance 𝑖 at the ( 𝑙 + 1 ) -th layer is formulated as: 𝑍 𝑙 + 1 𝑖 = ELU © « 1 𝐶 𝐶 𝑐 = 1 𝑗 ∈ N ( 𝑖 ) 𝛼 𝑐 𝑖 𝑗 𝑊 𝑐 𝑍 𝑙 𝑗 ª ® ¬ , (8) where 𝑍 𝑙 𝑖 represents the latent feature of instance 𝑖 at the 𝑙 -th layer , and the initial node feature is set to the fused representation 𝑍 0 = 𝐸 . The parameter 𝐶 species the number of independent attention heads, while 𝑊 𝑐 denotes the linear pr ojection matrix for head 𝑐 . T o prevent o vertting during spatial propagation, dropout operations are applied to b oth the feature matrices and the attention co e- cients. Finally , the exponential linear unit [ 8 ] activation function is applied after averaging the aggregated outputs fr om all attention heads. 4.4 O line Model Optimization Although Figure 5 primarily illustrates the online diagnostic pipeline, the eectiveness of the unied repr esentations depends entirely on the oine training phase. During this stage, we optimize the entire framework via a self-supervised auto-regression task. T o simulate infrastructure-level outages, w e apply stochastic modality dropout augmentation: during each training iteration, the binary observa- tion mask 𝑂 is generated by indep endently dropping entire modal- ity channels, forcing the framework to infer missing op erational states from the sur viving signals of topologically correlated mi- croservices. A multi-layer perceptron projects the topology-aware representation 𝑍 ( 𝑇 ) to predict the full-channel data of the next time step: ˆ 𝑋 ( 𝑇 + 1 ) = MLP ( 𝑍 ( 𝑇 ) ) . By reconstructing both observed and masked modalities, the model learns cross-modal invariants (e .g., inferring CP U trends from trace volumes). The training objective Missing- A ware Multimodal Fusion for Unifie d Microservice Incident Management Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y comprises two masked mean squared error terms: L 𝑜𝑏 𝑠 = 1 Í 𝑂 ( ˆ 𝑋 ( 𝑇 + 1 ) − 𝑋 ( 𝑇 + 1 ) ) ⊙ 𝑂 2 𝐹 , (9) L 𝑚𝑖𝑠 𝑠 = 1 Í ( 1 − 𝑂 ) ( ˆ 𝑋 ( 𝑇 + 1 ) − 𝑋 ( 𝑇 + 1 ) ) ⊙ ( 1 − 𝑂 ) 2 𝐹 . (10) Note that L 𝑚𝑖𝑠 𝑠 is computable during training because the oine phase uses complete historical archives; missing channels are pro- duced by stochastic dropout augmentation, not structural absence. The total objective is L = L 𝑜𝑏 𝑠 + 𝜆 L 𝑚𝑖𝑠 𝑠 , with 𝜆 serving as a bal- ancing weight. For downstream diagnostic tasks, we construct a unied failure signature by concatenating reconstruction errors and latent embeddings as 𝑅 ( 𝑡 ) = [ ( ˆ 𝑋 ( 𝑡 ) − 𝑋 ( 𝑡 ) ) ∥ 𝑍 ( 𝑡 ) ] , where ∥ denotes concatenation. 4.5 Online Diagnostic T asks During online execution, unied repr esentations drive three sequen- tial diagnostic tasks. AD and RCL require no manual annotations; FT relies solely on failure-type labels for its downstream classier . Anomaly Detection. Explicit reconstruction errors often miss subtle deviations in latent topological states. Therefore, we project the unied representation 𝑅 ( 𝑡 ) at each time step 𝑡 into a scalar sys- tem deviation score 𝑆 ( 𝑡 ) to improve sensitivity . Instead of relying on predened distribution assumptions, we dynamically calculate the detection threshold using the streaming peaks-over-thr eshold method base d on extreme value theory [ 33 ], tted to normal op- erating scores [ 24 , 25 , 53 ]. An anomaly is agged whenev er 𝑆 ( 𝑡 ) exceeds this threshold. T o distinguish actual system failures fr om benign uctuations (e.g., workload spikes), the system generates a formal alert ( 𝑦 = 1 ) and routes it to the triage mo dule only if the anomalous state persists across a delay window 𝑊 𝑑 . Failure Triage. By ke eping the upstream encoder frozen, SREs can retrain the failure classier for new fault categories without retraining the entire model, supporting incremental adaptation as system b ehavior evolves. Prior studies typically emplo y naive mean pooling, which smooths out critical transient spikes and oscillating faults. T o accurately assess the failure category 𝑠 ∈ { 1 , . . . , 𝐾 } , we construct an enriched system-level representation o ver the failure window by applying comprehensive statistical pooling to 𝑅 across time steps, dened as 𝑅 𝑠 𝑦𝑠 = Concat ( Mean ( 𝑅 ) , Max ( 𝑅 ) , Std ( 𝑅 ) ) . Specically , mean p ooling captures baseline deviations, max pool- ing identies peak severities, and standard deviation measures volatility . W e feed the global representation 𝑅 𝑠 𝑦𝑠 into a lightweight extreme gradient boosting [ 6 ] classier using sample weighting to dynamically handle class imbalance. Root Cause Localization. T raditional te chniques relying strictly on raw error vectors ignore encoded contextual semantics. By us- ing unie d representations, our approach compares explicit and implicit signatures. W e calculate the cosine similarity b etween each local instance vector 𝑅 ( 𝑡 ) 𝑖 and the aggregated global vector 𝑅 ( 𝑡 ) 𝑠 𝑦𝑠 across the failure window of length 𝑊 𝑓 : 𝑝 𝑖 = 1 𝑊 𝑓 𝑊 𝑓 𝑡 = 1 𝑅 ( 𝑡 ) 𝑖 · 𝑅 ( 𝑡 ) 𝑠 𝑦𝑠 ∥ 𝑅 ( 𝑡 ) 𝑖 ∥ ∥ 𝑅 ( 𝑡 ) 𝑠 𝑦𝑠 ∥ . (11) This computation yields a ranke d probability distribution 𝑃 = [ 𝑝 1 , . . . , 𝑝 𝑁 ] across all instances, where higher similarity indicates a greater probability of being the root cause. 5 Evaluation In this section, we address the following resear ch questions: (1) RQ1: How well does ARMOR perform in AD, FT , and RCL? (2) RQ2: How robust is ARMOR under missing modalities? (3) RQ3: Does each core component contribute to ARMOR? (4) RQ4: How do the major hyperparameters inuence the perfor- mance of ARMOR? 5.1 Experimental Setup 5.1.1 Datasets. T o maintain fairness with existing metho ds and ensure comprehensive benchmarking, we evaluate ARMOR on two industry-standard datasets ( 𝒟 1 and 𝒟 2 ) representing distinct microservice architectures. Both datasets encompass continuous metrics, discrete logs, and distributed traces, with each incident containing ground-truth annotations for the timestamp, failure type, and root cause instance. 𝒟 1 originates from a cloud-deployed e-commerce simulation replaying authentic historical incidents. It features a 46-no de archi- tecture (40 microser vices and 6 virtual machines) with 5 distinct system-level failure categories (e .g., CP U, memory , and network faults). The dataset comprises 3,714 normal p eriods and 210 failure cases. Its extensive multimodal r ecords include 44,858,388 traces, 66,648,685 logs, and 20,917,746 metrics [41]. 𝒟 2 originates from the International AIOps Challenge 2021 1 , representing the core management system of a top-tier commer- cial bank. It is composed of 18 heterogeneous instances spanning six months of operation. The dataset includes 12,297 normal peri- ods and 133 failure cases across 6 distinct failur e types (e .g., JVM and node-level anomalies). Its massive telemetry records comprise 214,337,882 traces, 21,356,870 logs, and 12,871,809 metrics. Following established chronological evaluation practices [ 14 , 26 , 41 ], we split each dataset using the rst timestamp in the last 40% of failure cases as the cuto point. This ensures temporal continuity between the training (rst 60%) and testing (remaining 40%) phases. 5.1.2 Baseline A pproaches. W e compare ARMOR against nine state- of-the-art baselines, which include multi-task framew orks and single-task metho ds. The multi-task frameworks consist of ART [ 41 ], TrioXpert [ 39 ], Eadro [ 16 ], DiagFusion [ 50 ], and Dejevu [ 19 ]. For single-task methods, we select Hades [ 17 ] and ChronoSage [ 51 ] for AD, MicroCBR [ 22 ] for FT , and DeepHunt [ 38 ] for RCL. The baselines are congured according to the original papers, with dataset-specic adjustments (e.g., window length). T o ensure an independent evaluation, we assume known incident timestamps when assessing FT and RCL for the methods that lack AD mod- ules [41]. 5.1.3 Simulation of Mo dality Collapse. As discussed in Section 2.1, microservice systems experience infrastructure-level modality col- lapse (e.g., agent crashes), losing entire observability streams. W e 1 https://aiops-challenge.com Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Qian et al. T able 1: Overall performance comparison of AD , FT , and RCL on datasets 𝒟 1 and 𝒟 2 under complete data conditions. The best results are highlighted in bold. T ype Method 𝒟 1 𝒟 2 AD FT RCL AD FT RCL Precision Recall F1 Precision Recall F1 T op1 T op3 A V G@5 Precision Recall F1 Precision Recall F1 T op1 T op3 A V G@5 Multiple ARMOR 0.925 1.0 0.961 0.946 0.941 0.938 0.821 0.941 0.910 0.993 1.0 0.997 0.882 0.870 0.869 0.815 0.907 0.893 ART [41] 0.899 0.990 0.942 0.836 0.809 0.812 0.667 0.810 0.776 0.877 0.960 0.917 0.851 0.796 0.802 0.722 0.889 0.870 TrioXpert [39] 0.880 0.972 0.924 0.852 0.768 0.807 0.651 0.778 0.773 0.854 0.972 0.909 0.814 0.725 0.767 0.550 0.775 0.750 Eadro [16] 0.425 0.946 0.586 - - - 0.137 0.315 0.302 0.767 0.935 0.842 - - - 0.157 0.315 0.310 DiagFusion [50] - - - 0.675 0.500 0.568 0.310 0.452 0.467 - - - 0.797 0.527 0.593 0.582 0.709 0.695 Dejevu [19] - - - 0.369 0.621 0.415 0.411 0.679 0.625 - - - 0.718 0.340 0.417 0.402 0.667 0.619 Single Hades [17] 0.866 0.863 0.865 - - - - - - 0.867 0.868 0.868 - - - - - - ChronoSage [51] 0.904 0.842 0.872 - - - - - - 0.945 1.0 0.972 - - - - - - MicroCBR [22] - - - 0.667 0.796 0.717 - - - - - - 0.629 0.678 0.636 - - - DeepHunt [38] - - - - - - 0.796 0.905 0.897 - - - - - - 0.731 0.893 0.873 therefore simulate complete modality missingness rather than ne- grained noise. During training, sto chastic modality dropout aug- mentation randomly drops entire modalities. During evaluation, a binary vector 𝑂 ∈ { 0 , 1 } 3 systematically masks specic mo dali- ties; e.g., 𝑂 = [ 0 , 1 , 1 ] zeroes out all metric channels, mirroring the Prometheus blackout in Figure 2. 5.1.4 Evaluation Metrics. W e formulate AD and FT as classica- tion tasks. AD is a binar y classication problem that identies whether a failure occurred, whereas FT is a multi-class classica- tion problem that determines the specic failure type. W e calculate the precision, recall, and F1-score based on true p ositive, false pos- itive, and false negative samples. Specically , these metrics are formulated as Precision = 𝑇 𝑃 / ( 𝑇 𝑃 + 𝐹 𝑃 ) , Recall = 𝑇 𝑃 / ( 𝑇 𝑃 + 𝐹 𝑁 ) , and F1 = 2 · Precision · Recall / ( Precision + Recall ) . T o handle the imbalanced distribution of the failure types in FT , we report the weighted average F1-score . For RCL, we evaluate the ranking ac- curacy of the culprit instances by using the T op@ 𝐾 metric, which is dened as T op@ 𝐾 = 1 𝑁 Í 𝑁 𝑖 = 1 ( 𝑔𝑡 𝑖 ∈ 𝑃 𝑖 [ 1: 𝐾 ] ) . Here, 𝑁 denotes the total number of evaluated failures, 𝑔𝑡 𝑖 represents the ground-truth root cause for the 𝑖 -th failure case, and 𝑃 𝑖 [ 1: 𝐾 ] denotes the top- 𝐾 predicted candidates. W e also compute the average score across the top ve results, which is formulated as A vg@5 = 1 5 Í 5 𝐾 = 1 T op@ 𝐾 . 5.1.5 Implementation. W e implement ARMOR and all the baseline methods by using Python 3.9.13, Py T orch 1.12.1 (CUD A 11.6), and DGL 0.9.0 (CUDA 11.6). All the experiments are conducte d on a dedicated server equipped with a 20-vCP U Intel Xeon P latinum 8470Q processor and a single NVIDIA RTX 4090 GP U (24GB). 5.2 RQ1: Overall Performance As T able 1 shows, ARMOR consistently achieves the highest perfor- mance across all tasks on both datasets. Single-task methods (e.g., Hades, ChronoSage, Micr oCBR, De epHunt) are competitive on indi- vidual tasks but ignore shared contextual semantics, exacerbating cascading errors. Supervised multi-task frameworks ( e.g., Eadro, DiagFusion, DejaVu) rely heavily on historical fault labels, limiting generalization. Self-supervise d frameworks ( e.g., ART , TrioXpert) reduce label dependency but employ rigid fusion paradigms that fail to accommodate the structural asymmetr y between dense con- tinuous metrics and sparse discrete ev ents. In contrast, ARMOR’s domain-guided asymmetric encoder and self-supervise d reconstruc- tion are aligned with the physical reality of microservice teleme- try , ee ctively mitigating negative transfer across tasks. Across all methods and b oth datasets, ARMOR achieves the b est results on every metric. Particularly in the Failure T riage (FT) task, ARMOR improves over the overall best-performing baseline by 15.5% in F1-score on 𝒟 1 and 8.4% on 𝒟 2 . Furthermore, in Root Cause Local- ization (RCL), it surpasses the strongest multi-task baseline by up to 17.3% in A vg@5 on 𝒟 1 . Beyond diagnostic accuracy , Table 2 shows that ARMOR con- sistently achieves low er latency than ART across all tasks on both datasets, conrming that the shared encoder and parallelized fusion introduce minimal overhead for online deployment. 5.3 RQ2: Robustness under Missing Modalities T o evaluate framework robustness against incomplete data, we sim- ulate vulnerabilities in the observability infrastructure by system- atically masking specic modality combinations during the online inference phase. W e design six distinct missing scenarios that en- compass single-modality and dual-mo dality absences. W e focus on ART as the robustness reference: it shares ARMOR’s self-sup ervised orientation and unied task scope, making it the most meaningful counterpart. Super vised baselines require fault labels incompat- ible with our protocol; single-task methods cover only pipeline subsets. Figure 7a compares ARMOR against ART . T o ensure a fair comparison, we retrain ART under the same modality dropout augmentation protocol applied to ARMOR, additionally equipping it with three standard imputation strategies (zero-padding, mean imputation, and KNN imputation), and report its b est result p er scenario. Hatched regions denote the performance gap. ARMOR outperforms ART across all scenarios on both datasets. The performance degradation exhibits a distinct asymmetry de- pending on the missing modalities. While the absence of sparse events (such as logs or traces) causes relatively constrained declines, the absence of continuous metrics, which encode critical system states, triggers a sever e systemic collapse in the baseline model. Across all var ying degrees of data corruption, ARMOR consistently maintains a highly stable functional baseline. The performance gap between the two models widens substantially as more modalities are remov ed: when the metric modality is absent, ARMOR retains over 60% higher RCL accuracy than ART across both datasets. This empirical superiority dir ectly validates the proposed missing-aware Missing- A ware Multimodal Fusion for Unifie d Microservice Incident Management Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y 1 1 1 2 2 2 (a) Performance comparison under missing scenarios. Metrics L ogs T races 1.0 0.8 0.6 0.4 0.2 0.0 L ear ned Dynamic Bias ( b m i s s k ) 1 2 (b) Learned dynamic bias ( 𝑏 𝑚𝑖𝑠 𝑠 ). Figure 7: Robustness analysis against missing modalities. (a) Performance comparison across AD , FT , and RCL under various missing modality scenarios on datasets 𝒟 1 and 𝒟 2 . The solid bars represent the diagnostic accuracy of ARMOR and ART , while the hatched regions denote the explicit performance gap indicating the margin by which ART falls behind ARMOR. (b) Visualization of the learned dynamic bias ( 𝑏 𝑚𝑖𝑠 𝑠 ) for missing modalities. The model actively learns negative biases to suppress the routing contribution of absent data, with the penalty being most severe for the high-dimensional metrics. T able 2: T otal execution time (s) of the diagnostic pipeline (AD , FT , and RCL) over the entire test set on 𝒟 1 and 𝒟 2 . Method 𝒟 1 𝒟 2 AD FT RCL AD FT RCL ART [41] 6.81 5.05 22.46 28.81 4.01 12.91 ARMOR 5.23 1.56 21.52 6.71 1.45 8.08 global fusion mechanism. Because ART is rigidly designed under the assumption of complete data, encountering missing mo dalities forces the use of naive static padding to maintain input dimensions. This passive imputation introduces pseudo-normal noise that dis- torts the surviving healthy signals. In contrast, ARMOR inherently accommodates missing data by using learnable placeholders and dynamic gating biases to adaptively redistribute routing attention and isolate the semantic impact of missing data. Figure 7b visualizes the learned dynamic bias 𝑏 𝑚𝑖𝑠 𝑠 𝑘 for each missing modality . T wo obser vations validate our design: (1) all learned biases are strictly negative , conrming that the network actively penalizes placeholder tokens to suppress their routing contributions; (2) the penalty magnitude aligns with structural asymmetry: the model learns a signicantly larger negative bias (approaching − 1 . 0 ) for missing metrics than for sparser logs and traces, as metric placeholders introduce the most severe pseudo- normal noise. This conrms that ARMOR automatically quanties and mitigates the var ying degrees of semantic threat posed by dierent modality failures. 5.4 RQ3: Ablation Study T o evaluate the key technical contributions of ARMOR, we design twelve variants groupe d into two categories. The rst categor y assesses the modality-specic status learning and missing-aware global fusion. Specically , variants A1, A2, and A3 remove the temporal, channel, and variable fusions, respectively . V ariant A4 replaces the missing-aware gated fusion with a naive mean fusion. T able 3: Ablation study on datasets 𝒟 1 and 𝒟 2 . V ariants A1- A9 evaluate the encoder and global fusion components. V ariants B1-B3 evaluate task-specic unied representation strate- gies. Hyphens indicate that the variant evaluates a specic downstream task and remains identical to the base model for the other tasks. The best results are highlighted in bold. V ariant 𝒟 1 𝒟 2 AD (F1) FT (F1) RCL (A vg@5) AD (F1) FT (F1) RCL (A vg@5) A1 0.956 0.897 0.902 0.983 0.843 0.874 A2 0.937 0.915 0.883 0.980 0.787 0.885 A3 0.937 0.914 0.891 0.987 0.861 0.870 A4 0.942 0.926 0.900 0.990 0.794 0.878 A5 0.939 0.887 0.875 0.964 0.771 0.856 A6 0.946 0.883 0.860 0.941 0.822 0.885 A7 0.960 0.895 0.857 0.973 0.831 0.867 A8 0.946 0.895 0.829 0.959 0.859 0.882 A9 0.933 0.927 0.860 0.987 0.865 0.889 B1 0.956 - - 0.964 - - B2 - 0.908 - - 0.830 - B3 - - 0.767 - - 0.889 ARMOR 0.961 0.938 0.910 0.997 0.869 0.893 V ariant A5 replaces the learnable missing placeholder with static zero-padding. V ariant A6 trains the mo del exclusively on complete modalities, removing missing modality augmentation. V ariants A7, A8, and A9 mo dify the graph network by removing it entirely , replacing it with GCN, or replacing it with GraphSAGE, respectively . The second categor y evaluates the unied repr esentation strategies for do wnstream tasks. In this category , B1 and B3 r emove the latent embeddings for AD and RCL, respectively , whereas B2 removes the standard deviation feature for FT . T able 3 shows that ARMOR outperforms all variants on b oth datasets. Performance drops when remo ving the temporal, channel, or variable fusions (A1– A3), conrming that hierarchical e xtraction is essential for capturing complex telemetry dynamics. The decline in A4 prov es that naive mean fusion fails to suppress imputation Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Qian et al. 0.8 1.0 1 1 2 3 4 Layers of High Dim Blocks 0.8 1.0 1 2 3 4 Layers of Low Dim Blocks 1 2 3 4 5 Layers of GAT 1 2 3 4 5 6 7 Window Sizes 2 Anomaly Detection: F1-score Failure Triage: F1-score Root Cause Localization: Avg@5 Figure 8: Sensitivity analysis of four core hyperparameters (Layers of High Dim Blo cks, Layers of Low Dim Blocks, Layers of GA T , and Window Sizes) across AD , FT , and RCL on datasets 𝒟 1 and 𝒟 2 . noise, validating the gating mechanism. The drops in A5 and A6 conrm our two-pronged missing modality strategy: static zero- padding misleads the network with pseudo-normal signals ( A5), and training without modality dropout prevents r obust representation learning (A6). Replacing or removing the graph network ( A7– A9) degrades localization, indicating that attention-guided spatial prop- agation b etter models heterogeneous inv ocation dependencies than convolutional aggregators. Modifying the task-specic representa- tions (B1–B3) consistently reduces performance , conrming that reconstruction errors, deviation v olatility , and topology-encode d embeddings each provide indispensable diagnostic signals for their respective tasks. 5.5 RQ4: Hyperparameter Sensitivity As Figure 8 illustrates, for High Dim Blocks and GA T , performance peaks at moderate depth and degrades b eyond it due to overtting and over-smoothing; Low Dim Blocks are optimal at depth 1, reect- ing the simpler structure of sparse mo dalities. This asymmetry is consistent with the structural dierence between dense continuous metrics and sparse discr ete logs and traces, where deeper extraction benets the former but hurts the latter . Window size 𝑇 follows the same trend: too small misses failure dynamics, too large intr oduces noise, with 𝑇 = 6 providing the best balance. These results con- rm that ARMOR is robust to reasonable hyperparameter choices without dataset-specic tuning. 6 Discussion 6.1 Limitations and Possible Solutions ARMOR’s oine training assumes that historical records are struc- turally complete enough to serve as reconstruction targets for L 𝑚𝑖𝑠 𝑠 . In the rare case where a modality has be en persistently absent from the archiv e to an extent beyond the sto chastic dropout sim- ulated during training, the missing-aware fusion module loses its explicit training signal. Replacing strict numerical reconstruction with cross-instance contrastive learning, aligning incomplete in- stances against fully observed peers, oers a viable path forward without requiring perfect historical targets. A second limitation is topology evolution: the dependency graph is built from histori- cal records, so frequent instance cr eation or destruction requires periodic updates; incremental graph learning is a natural extension. 6.2 Threats to V alidity One threat concerns construct validity . Our robustness experiments mask entire modality channels, directly mirroring the complete- stream blackouts in Section 2.1: process crashes and network blocks eliminate an entire channel at once. Sub-channel partial loss is a strictly less severe case for ARMOR’s gating mechanism; ner- grained evaluation is left to future work. Furthermore, both b ench- mark datasets provide complete multimodal ar chives for the normal training period, so evaluating training-time structural missingness is similarly deferred to futur e work. A second threat concerns in- ternal validity: to rule out imputation bias, we r etrain ART under the same modality dropout augmentation protocol as ARMOR, ad- ditionally equipping it with zero-padding, mean imputation, and KNN imputation, and report its best result per scenario; the ob- served gap therefore reects architectural dierences rather than training asymmetry . A third threat concerns external validity: both datasets originate from controlled testbed environments with fewer instances than large-scale industrial deployments and may not cap- ture cascading or timing-sensitiv e failures. Extending e valuation to live industrial traces remains important future work. 7 Related W ork Single- T ask Incident Diagnosis. Early approaches address individual incident management stages, such as AD [ 3 – 5 , 7 , 10 , 14 , 15 , 17 , 51 ], FT [ 23 , 36 , 37 , 43 ], and RCL [ 13 , 21 , 31 , 34 , 38 ], in isolation. Although eective locally , isolating these related tasks ignores shared diagnostic contexts, increases maintenance overhead, and renders independent pipelines vulnerable to severe error cascading [41]. Unied Multi- T ask Frameworks. Re cent multi-task approaches extract shared knowledge from multimodal data (metrics, logs, and traces) to construct unied frame works that ov ercome these limitations. Supervised multi-task mo dels [ 9 , 16 ] integrate hetero- geneous events but require extensiv e fault-labeled data throughout training, limiting practical deployment in environments where labeled fault data is prohibitively expensive. T o eliminate label de- pendency , self-super vised unied approaches [ 28 , 39 , 41 ] employ cascaded representation learning to jointly optimize AD , FT , and RCL. Howev er , both sup ervised and self-sup ervised te chniques as- sume perfectly complete obser vability data, leaving them without Missing- A ware Multimodal Fusion for Unifie d Microservice Incident Management Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y a principled missing-aware strategy for production deployment. ARMOR addresses this gap by combining the lab el-free orientation of self-supervised frameworks with explicit architectural support for modality absence. Missing Modality Learning. Handling incomplete multimodal inputs has been studied in general settings through generative im- putation [ 45 , 48 ] and representation-lev el routing [ 18 , 20 , 27 , 46 , 47 ]. Howev er , these metho ds either introduce substantial computational overhead from data synthesis or rely on a primar y modality for alignment, which fails when the most information-dense stream drops. More critically , microservice observability data exhibits struc- tural asymmetr y between dense continuous metrics and sparse discrete logs and traces, a property that general missing modality methods do not account for . T o our knowledge, ARMOR is the rst self-supervise d framework to address missing modalities in the unied incident management setting, treating observability gaps as a rst-class design concern rather than a post-hoc fallback that requires fault-labeled training data. 8 Conclusion This paper presents ARMOR, a r obust self-supervise d framework for automated incident management under missing modalities. ARMOR employs a modality-specic asymmetric encoder and a missing-aware gated fusion mechanism with learnable placeholders and dynamic bias compensation to isolate imputation noise. The unied failure representations concurrently support label-free AD and RCL, with FT requiring only failure-type annotations for a lightweight downstr eam classier . Extensive evaluations demon- strate state-of-the-art performance under complete data and strong robustness under severe modality loss. Future work will investigate cross-instance contrastive learning to reduce reliance on complete historical archives. References [1] Luai Al Shalabi, Zyad Shaaban, and Basel Kasasbeh. 2006. Data mining: A preprocessing engine. Journal of Computer Science 2, 9 (2006), 735–739. [2] Sachin Ashok, Vipul Harsh, Brighten Godfrey , Radhika Mittal, Srinivasan Parthasarathy , and Larisa Shwartz. 2024. T raceweaver: Distributed request trac- ing for microservices without application modication. In Proceedings of the ACM SIGCOMM 2024 Conference . 828–842. [3] Julien Audibert, Pietro Michiardi, Frédéric Guyard, Sébastien Marti, and Maria A Zuluaga. 2020. Usad: Unsupervised anomaly detection on multivariate time series. In Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining . 3395–3404. [4] Feiyi Chen, Zhen Qin, Mengchu Zhou, Yingying Zhang, Shuiguang Deng, Lunting Fan, Guansong Pang, and Qingsong W en. 2024. Lara: A light and anti-o vertting retraining approach for unsupervised time series anomaly detection. In Proce ed- ings of the ACM W eb Conference 2024 . 4138–4149. [5] Feiyi Chen, Yingying Zhang, Lunting Fan, Yuxuan Liang, Guansong Pang, Qing- song W en, and Shuiguang Deng. 2024. Cluster-wide task slowdown detection in cloud system. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining . 266–277. [6] Tianqi Chen and Carlos Guestrin. 2016. Xgboost: A scalable tree boosting system. In Procee dings of the 22nd acm sigkdd international conference on knowledge discovery and data mining . 785–794. [7] Dongchan Cho, Jiho Han, K eumyeong Kang, Minsang Kim, Honggyu Ryu, and Namsoon Jung. 2025. Structur ed T emporal Causality for Interpretable Multi- variate Time Series Anomaly Detection. In The Thirty-ninth A nnual Conference on Neural Information Processing Systems . https://openreview .net/forum?id= V5kzCSeaXF [8] Djork- Arné Clevert, Thomas Unterthiner , and Sepp Hochreiter . 2015. Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs). arXiv preprint arXiv:1511.07289 (2015). [9] Kaiqi Ding, Y uanmu Ma, and Kaigui Bian. 2025. Adaptive Modality Compensation via Bi-Mamba Dual-Stream Learning for Microservice Failure Diagnosis Under Incomplete Multimodal Data. In International Conference on Ser vice-Oriented Computing . Springer , 171–188. [10] Kaiqi Ding, Y uanmu Ma, Zijian Song, and Kaigui Bian. 2025. Enhancing Microser- vices Anomaly Detection via Multimodal Data Fusion in the W avelet Domain and Spatiotemporal Graph-based Diusion Probabilistic Model. In Proce edings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2 . 510–520. [11] Luo donghao and wang xue. 2024. ModernTCN: A Modern Pure Convolution Structure for General Time Series Analysis. In The T welfth International Confer- ence on Learning Representations . https://op enreview .net/forum?id=vpJMJerXHU [12] Nicola Dragoni, Saverio Giallorenzo , Alberto Lluch Lafuente, Manuel Mazzara, Fabrizio Montesi, Ruslan Mustan, and Larisa Sana. 2017. Microservices: yes- terday , today, and tomorrow . Present and ulterior software engineering (2017), 195–216. [13] Xiao Han, Saima Absar , Lu Zhang, and Shuhan Yuan. 2025. Root Cause Analysis of Anomalies in Multivariate Time Series through Granger Causal Discovery . In The Thirteenth International Conference on Learning Representations . https: //openreview .net/forum?id=k38Th3x4d9 [14] Jun Huang, Y ang Y ang, Hang Yu, Jianguo Li, and Xiao Zheng. 2023. T win graph- based anomaly detection via attentive multi-mo dal learning for microservice system. In 2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE) . 66–78. [15] Hyungi Kim, Jisoo Mok, Dongjun Lee, Jaihyun Lew , Sungjae Kim, and Sungroh Y oon. 2025. Causality-A ware Contrastive Learning for Robust Multivariate Time- Series Anomaly Detection. In International Conference on Machine Learning . PMLR, 30591–30608. [16] Cheryl Lee, Tianyi Y ang, Zhuangbin Chen, Yuxin Su, and Michael R Lyu. 2023. Eadro: An end-to-end troubleshooting framework for microservices on multi- source data. In 2023 IEEE/A CM 45th International Conference on Software Engi- neering (ICSE) . IEEE, 1750–1762. [17] Cheryl Lee, Tianyi Y ang, Zhuangbin Chen, Yuxin Su, Y ongqiang Y ang, and Michael R Lyu. 2023. Heterogeneous anomaly detection for software systems via semi-supervised cross-modal attention. In 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) . 1724–1736. [18] Sijie Li, Chen Chen, and Jungong Han. 2025. Simmlm: A simple framework for multi-modal learning with missing modality . In Proceedings of the IEEE/CVF International Conference on Computer Vision . 24068–24077. [19] Zeyan Li, Nengwen Zhao, Mingjie Li, Xianglin Lu, Lixin W ang, Dongdong Chang, Xiaohui Nie, Li Cao, W enchi Zhang, Kaixin Sui, et al . 2022. Actionable and interpretable fault localization for recurring failures in online service systems. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering . 996–1008. [20] Ziyi Li, W ei-Long Zheng, and Bao-Liang Lu. 2025. Multimodal emotion recogni- tion with missing modality via a unied multi-task pre-training framew ork. In Proceedings of the 33rd ACM International Conference on Multimedia . 5717–5725. [21] Cheng-Ming Lin, Ching Chang, W ei- Yao W ang, Kuang-Da W ang, and W en-Chih Peng. 2024. Ro ot cause analysis in microservice using neural granger causal discovery . In Procee dings of the AAAI Conference on Articial Intelligence . 206– 213. [22] Fengrui Liu, Y ang Wang, Zhenyu Li, Rui Ren, Hongtao Guan, Xian Y u, Xiaofan Chen, and Gaogang Xie. 2022. Microcbr: Case-base d reasoning on spatio-temporal fault knowledge graph for microservices troubleshooting. In International confer- ence on case-based reasoning . Springer , 224–239. [23] Minghua Ma, Zheng Yin, Shenglin Zhang, Sheng W ang, Christopher Zheng, Xin- hao Jiang, Hanwen Hu, Cheng Luo, Yilin Li, Nengjun Qiu, et al . 2020. Diagnosing root causes of intermittent slow queries in cloud databases. Proceedings of the VLDB Endowment 13, 8 (2020), 1176–1189. [24] Minghua Ma, Shenglin Zhang, Junjie Chen, Jim Xu, Haozhe Li, Y ongliang Lin, Xiaohui Nie, Bo Zhou, Y ong W ang, and Dan Pei. 2021. Jump-Starting multivariate time series anomaly detection for online service systems. In 2021 USENIX Annual T echnical Conference (USENIX A TC 21) . 413–426. [25] Minghua Ma, Shenglin Zhang, Dan Pei, Xin Huang, and Hongwei Dai. 2018. Robust and rapid adaption for concept drift in software system anomaly detection. In 2018 IEEE 29th International Symposium on Software Reliability Engineering (ISSRE) . IEEE, 13–24. [26] W eibin Meng, Ying Liu, Yichen Zhu, Shenglin Zhang, Dan Pei, Y uqing Liu, Yihao Chen, Ruizhi Zhang, Shimin T ao, Pei Sun, et al . 2019. Loganomaly: Unsupervised detection of sequential and quantitative anomalies in unstructur ed logs.. In IJCAI , V ol. 19. 4739–4745. [27] Payal Mohapatra, Y ueyuan Sui, Akash Pandey , Stephen Xia, and Qi Zhu. 2025. MAESTRO : Adaptive Sparse Attention and Robust Learning for Multimodal D y- namic Time Series. In The Thirty-ninth Annual Conference on Neural Information Processing Systems . https://openreview .net/forum?id=1K28gV5MeF [28] Xiaohui Nie, Hang Cui, Changhua Pei, Haotian Si, Ke Xiang, Jingjing Li, Y anbiao Li, Gaogang Xie, and Dan Pei. 2025. DeST: An Unsuper vised Decoupled Spatio- T emporal Framework for Microservice Incident Management. In 2025 IEEE 36th International Symposium on Software Reliability Engineering (ISSRE) . IEEE, 335– 346. Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Qian et al. [29] Parametric. 2023. Cloud Outage and the Fortune 500 . Retrieved Februar y 28, 2026 from https://www .parametrixinsurance.com/reports- white- papers/cloud- outage- and- the- fortune- 500 [30] Deepak Pathak, Philipp Krahenbuhl, Je Donahue, Tre vor Darrell, and Alexei A Efros. 2016. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE conference on computer vision and pattern recognition . 2536–2544. [31] Luan P ham, Huong Ha, and Hongyu Zhang. 2024. Root cause analysis for microservice system based on causal inference: How far are we? . In Proce e dings of the 39th IEEE/A CM International Conference on Automated Software Engineering . 706–715. [32] David E Rumelhart, Georey E Hinton, and Ronald J Williams. 1986. Learning representations by back-propagating errors. nature 323, 6088 (1986), 533–536. [33] Alban Sier , Pierre- Alain Fouque, Alexandre T ermier , and Christine Largouet. 2017. Anomaly detection in streams with extreme value theory . In Proceedings of the 23rd A CM SIGKDD international conference on knowledge discovery and data mining . 1067–1075. [34] Gagan Somashekar , Anurag Dutt, Mainak Adak, Tania Lorido Botran, and Anshul Gandhi. 2024. GAMMA: Graph Neural Network-Based Multi-Bottleneck Local- ization for Microservices Applications. In Pr oceedings of the ACM W eb Conference 2024 . 3085–3095. [35] Akshitha Sriraman, Abhishek Dhanotia, and Thomas F W enisch. 2019. Softsku: Optimizing server architectures for microservice diversity@ scale. In Procee dings of the 46th International Symposium on Computer A rchitecture . 513–526. [36] Yicheng Sui, Yuzhe Zhang, Jianjun Sun, Ting Xu, Shenglin Zhang, Zhengdan Li, Y ongqian Sun, Fangrui Guo, Junyu Shen, Yuzhi Zhang, et al . 2023. Logkg: Log failure diagnosis through knowledge graph. IEEE Transactions on Services Computing 16, 5 (2023), 3493–3507. [37] Wu Sun, Panfeng Chen, Mei Chen, Hui Li, Y anhao Wang, Gang Huang, and Hongyuan Li. 2025. Failure Classication for Microservice Systems Based on V ariational Graph Auto-Encoders. In International Conference on Service-Oriented Computing . Springer , 189–204. [38] Y ongqian Sun, Zihan Lin, Binpeng Shi, Shenglin Zhang, Shiyu Ma, Pengxiang Jin, Zhenyu Zhong, Lemeng Pan, Yicheng Guo, and Dan Pei. 2025. Interpretable failure localization for microservice systems based on graph auto encoder . ACM Transactions on Software Engine ering and Methodology 34, 2 (2025), 1–28. [39] Y ongqian Sun, Yu Luo , Xidao W en, Yuan Yuan, Xiaohui Nie, Shenglin Zhang, T ong Liu, and Xi Luo. 2025. TrioXpert: An A utomated Incident Management Frame- work for Microservice System. In 2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE) . IEEE, 3239–3250. [40] Y ongqian Sun, Xijie Pan, Xiao Xiong, Lei T ao, Jiaju W ang, Shenglin Zhang, Yuan Y uan, Yuqi Li, and Kunlin Jian. 2025. ClusterRCA: An End-to-End Approach for Network Fault Localization and Classication for HPC System. In 2025 IEEE 36th International Symposium on Software Reliability Engineering (ISSRE) . IEEE, 347–358. [41] Y ongqian Sun, Binpeng Shi, Mingyu Mao, Minghua Ma, Sibo Xia, Shenglin Zhang, and Dan Pei. 2024. Art: A unied unsupervise d framework for incident manage- ment in microservice systems. In Procee dings of the 39th IEEE/ACM International Conference on A utomated Software Engineering . 1183–1194. [42] Lei T ao, Xianglin Lu, Shenglin Zhang, Jiaqi Luan, Yingke Li, Mingjie Li, Zeyan Li, Qingyang Y u, Hucheng Xie, Ruijie Xu, et al . 2024. Diagnosing performance issues for large-scale microservice systems with heterogeneous graph. IEEE Transactions on Services Computing 17, 5 (2024), 2223–2235. [43] Lei Tao, Shenglin Zhang, Zedong Jia, Jinrui Sun, Minghua Ma, Zhengdan Li, Y ongqian Sun, Canqun Yang, Yuzhi Zhang, and Dan Pei. 2024. Giving every modality a voice in microservice failure diagnosis via multimodal adaptive opti- mization. In Proceedings of the 39th IEEE/ACM International Conference on A uto- mated Software Engineering . 1107–1119. [44] Petar V eličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Y oshua Bengio. 2018. Graph Attention Networks. In International Confer- ence on Learning Representations . https://openreview .net/forum?id=rJXMpikCZ [45] Hu W ang, Yuanhong Chen, Congbo Ma, Jodie A very, Louise Hull, and Gustav o Carneiro. 2023. Multi-modal learning with missing modality via shared-specic feature modelling. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition . 15878–15887. [46] Renjie Wu, Hu W ang, Hsiang- Ting Chen, and Gustavo Carneiro. 2026. Deep Multimodal Learning with Missing Mo dality: A Survey . Transactions on Machine Learning Research (2026). https://openreview .net/forum?id=tc7RFcx4hT Survey Certication. [47] W enxin Xu, Hexin Jiang, and Xuefeng Liang. 2024. Leveraging knowledge of modality experts for incomplete multimodal learning. In Procee dings of the 32nd ACM International Conference on Multimedia . 438–446. [48] W enfang Y ao, Kejing Yin, William K Cheung, Jia Liu, and Jing Qin. 2024. Drfuse: Learning disentangled repr esentation for clinical multi-modal fusion with missing modality and modal inconsistency. In Procee dings of the AAAI conference on articial intelligence , V ol. 38. 16416–16424. [49] Lei Zhang, Zhiqiang Xie, V aastav Anand, Y mir Vigfusson, and Jonathan Mace. 2023. The b enet of hindsight: Tracing { Edge-Cases } in distributed systems. In 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23) . 321–339. [50] Shenglin Zhang, Pengxiang Jin, Zihan Lin, Y ongqian Sun, Bicheng Zhang, Sibo Xia, Zhengdan Li, Zhenyu Zhong, Minghua Ma, W a Jin, et al . 2023. Robust failure diagnosis of microservice system through multimodal data. IEEE Transactions on Services Computing 16, 6 (2023), 3851–3864. [51] Shenglin Zhang, Yingke Li, Jianjin T ang, Chenyu Zhao, W enwei Gu, Y ongqian Sun, and Dan Pei. 2025. Integrating GraphSAGE and Mamba for Self-Supervised Spatio- T emporal Fault Dete ction in Microservice Systems. In 2025 IEEE 36th International Symposium on Software Reliability Engineering (ISSRE) . IEEE, 323– 334. [52] Zekun Zhang, Jian Wang, Bing Li, and Liuxiaoxiao Zhang. 2025. ReconRCA: Root Cause Analysis in Microser vices with Incomplete Metrics. In 2025 IEEE International Conference on W eb Services (ICWS) . IEEE, 116–126. [53] Chenyu Zhao, Minghua Ma, Zhenyu Zhong, Shenglin Zhang, Zhiyuan T an, Xiao Xiong, LuLu Yu, Jiayi Feng, Y ongqian Sun, Yuzhi Zhang, et al . 2023. Robust multimodal failure detection for microservice systems. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining . 5639–5649.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment