NERO-Net: A Neuroevolutionary Approach for the Design of Adversarially Robust CNNs
Neuroevolution automates the complex task of neural network design but often ignores the inherent adversarial fragility of evolved models which is a barrier to adoption in safety-critical scenarios. While robust training methods have received signifi…
Authors: Inês Valentim, Nuno Antunes, Nuno Lourenço
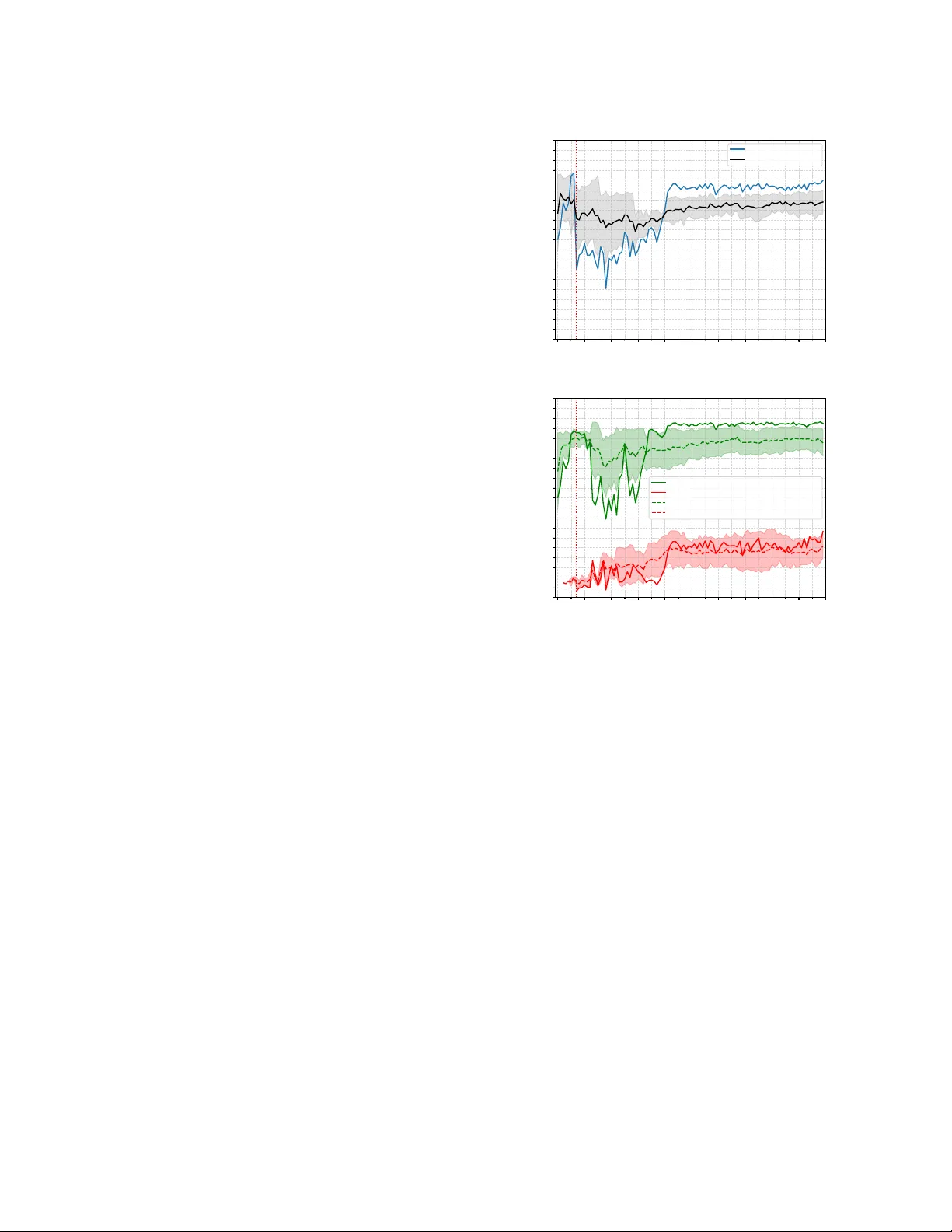
NERO-Net: A Neuroev olutionar y Approach for the Design of Adv ersarially Robust CNNs Inês V alentim University of Coimbra, CISUC/LASI, DEI Coimbra, Portugal valentim@dei.uc.pt Nuno Antunes University of Coimbra, CISUC/LASI, DEI Coimbra, Portugal nmsa@dei.uc.pt Nuno Lourenço University of Coimbra, CISUC/LASI, DEI Coimbra, Portugal naml@dei.uc.pt Abstract Neuroevolution automates the complex task of neural network de- sign but often ignores the inherent adversarial fragility of evolv ed models which is a barrier to adoption in safety-critical scenarios. While robust training methods have received signicant attention, the design of architectures exhibiting intrinsic robustness remains largely unexplored. In this paper , we propose NERO-Net, a neu- roevolutionary approach to design convolutional neural netw orks better equipped to resist adversarial attacks. Our search strategy iso- lates architectural inuence on robustness by avoiding adversarial training during the evolutionary loop. As such, our tness function promotes candidates that, even trained with standard (non-robust) methods, achieve high p ost-attack accuracy without sacricing the accuracy on clean samples. W e assess NERO-Net on CIF AR-10 with a sp ecic focus on 𝐿 ∞ -robustness. In particular , the ttest individual emerged from evolutionary search with 33% accuracy against FGSM, used as an ecient estimator for robustness during the search phase, while maintaining 87% clean accuracy . Further standard training of this individual boosted these metrics to 47% adversarial and 93% clean accuracy , suggesting inherent architec- tural robustness. A dversarial training brings the o verall accuracy of the model up to 40% against Auto Attack. CCS Concepts • Computing methodologies → Neural networks ; Bio-inspired approaches ; • Security and privacy → Software and applica- tion security . Ke ywords Adversarial Examples, Neur oevolution, Robustness 1 Introduction The ubiquity of Articial Neural Networks (ANNs) means that the vulnerabilities of these models have also become the center of attention of malicious actors. In the image domain, a critical vul- nerability lies in adversarial e xamples [ 19 , 37 ]: inputs containing small perturbations designed to de ceive ANNs and induce misclas- sications. Humans are often immune to these attacks, since the perturbed samples tend to be visually indistinguishable from their clean counterparts. This vulnerability has triggered an arms race , with adversarial training [ 30 ] (i.e., augmenting training data with adversarial ex- amples) emerging as the standard defense. While alternatives like adversarial detection [ 31 ] exist, resear ch remains skewed to ward robust learning and regularization [ 32 ], largely overlooking the potential of intrinsically robust architectures. While NeuroEvolution (NE) automates complex architecture design, it has historically prioritized predictive performance over robustness. The limited literature addressing this gap often makes compromising decisions to manage computational costs. Speci- cally , the prevalent use of cell-based search spaces with xed back- bones [ 13 , 17 , 32 ] restricts the emergence of novel topologies, while the integration of adversarial training [ 20 ] during the search con- ceals the architecture ’s contribution to robustness. T o address these limitations, we propose a N euro E v olutionary approach for the design of adversarially RO bust articial neural Net works (NERO-Net). W e introduce novel mechanisms at the evaluation level, employing a tness function that co-optimizes adversarial and clean performance. Candidate solutions undergo standard training, ensuring that the resulting robustness is intrinsic to the architecture rather than a by-product of adversarial training. Focusing on image classication tasks and the design of robust Convolutional Neural Networks (CNNs), we show NERO-Net’s ecacy on CIF AR-10 [ 28 ]. Under restricted evolutionary training budgets, the ttest individual achieved 33% adversarial accuracy (FGSM adversary in 𝐿 ∞ ) and 87% clean accuracy . Extended standard training improved these metrics to 47% and 93%, respectively . When further rened via adversarial training, the model reached ∼ 40% robust accuracy against A uto Attack. Remarkably , the discovered architecture exhibits multi-threat robustness, resisting 𝐿 2 -bounded perturbations despite being optimized solely for an 𝐿 ∞ threat mo del. In summary , our contributions are: • W e propose NERO-Net , a neur oevolutionary framework that employs specialized tness evaluation mechanisms to co-optimize accuracy and adversarial robustness; • W e introduce a exible genotypic representation that ex- pands the search space by enco ding tunable computa- tional blocks and supp orting a wider spe ctrum of top o- logical connectivity patterns ; • W e demonstrate that evolution can successfully navigate this complex landscape to disco ver architectures exhibiting intrinsic robustness , independent of specialized defenses. The remainder of this paper is organized as follows. Section 2 introduces key concepts related to adversarial robustness and Sec- tion 3 reviews related work. Section 4 details the proposed approach. The experimental setup and the main ndings of our experiments are presented and discussed in Sections 5 and 6, focusing on the evolutionary search and on further training after evolution, respec- tively . Section 7 concludes the paper and addresses future work. Inês Valentim, Nuno Antunes, and Nuno Lourenço 2 Adversarial Robustness In the image domain, an adv ersarial example 𝑥 𝑎𝑑 𝑣 [ 19 , 37 ] is typi- cally generated by adding small 𝐿 𝑝 -norm perturbations to a benign sample 𝑥 , such that ∥ 𝑥 − 𝑥 𝑎𝑑 𝑣 ∥ 𝑝 ≤ 𝜖 , where 𝜖 is the p erturbation budget and usually 𝑝 ∈ { 0 , 1 , 2 , ∞ } [ 5 , 15 ]. Although 𝑥 𝑎𝑑 𝑣 is simi- lar to the clean sample, the model gives it a highly dier ent (and incorrect) prediction [18, 37]. Considering an untargeted setting (a sample is misclassied as any incorrect class [ 6 ]) where the attacker has full access to the model, the Fast Gradient Sign Metho d (FGSM) [ 19 ] is a one-step gradient-based attack dened as follows for the 𝐿 ∞ -norm: 𝑥 𝑎𝑑 𝑣 = 𝑥 + 𝜖 · sign ( ∇ 𝑥 𝐿 ( 𝑥 , 𝑦 ) ) where 𝑦 is the true label, ∇ 𝑥 𝐿 ( 𝑥 , 𝑦 ) is the gradient of the cross- entropy (CE) loss with respect to the clean image and 𝑥 𝑎𝑑 𝑣 is clipped to the valid data range. The Projected Gradient Descent (PGD) method [ 30 ] is an iterative, and stronger , variant of FGSM with smaller update steps. The starting point of the attack is usually a randomly perturb ed sample (bounded by 𝜖 ) around the original input 𝑥 [ 30 ]. The APGD method [ 9 ] further extends the PGD attack to progressiv ely reduce the step size in an automated way , based on how the optimization is proceeding. A momentum term is also added, allowing the previous update to inuence the current one. These attacks can be adapted to the 𝐿 2 -norm [ 31 ]: the clipping operation is changed to the projection onto the 𝐿 2 -ball, and each update step follows the direction of the normalized gradient, i.e., ∇ 𝑥 𝐿 ( 𝑥 ,𝑦 ) ∥ ∇ 𝑥 𝐿 ( 𝑥 ,𝑦 ) ∥ 2 . A targeted version of the attacks can also be obtained by minimizing the loss for a specic target class, instead of maximizing it for the true class. Heuristic approaches that appr oximate the robustness of a model by performing adversarial attacks are the standard evaluation prac- tice [ 7 ], since exact computations are usually intractable [ 5 , 7 ]. A uto Attack ( AA) [ 9 ] stands out among these approaches and tests adversarial robustness through an ensemble of diverse attacks: an untargeted APGD attack on the CE loss, an APGD attack on the targeted version of the Dierence of Logits Ratio (DLR) loss, a tar- geted Fast Adaptive Boundary (F AB) attack [ 8 ], as well as a Square attack [ 1 ]. It is adopted by the RobustBench [ 7 ] benchmark, which uses standardized evaluation methodologies to keep track of the progress made in adversarial r obustness. 3 Related W ork There is a body of work in the literature that specically explor es the relationship between architecture and adversarial robustness [ 24 , 25 , 34 ]. That is the case of the work by Huang et al . [ 24 ], which focuses on evaluating the impact of netw ork width and depth on the robustness of a wide residual network. Their results suggest that reduced width and depth at the last stage of the model can be benecial. Another work [ 25 ] designs a family of adversarially robust r esidual netw orks (RobustResNets) after studying the contri- bution of several architectural components, both at the block level (e.g., layer parameterization and order) and the network scaling level (e.g., depth and width of each block in the network), to the robustness of the models. Howev er , a aw of these studies is their focus on adversarially trained networks [ 30 ], making it dicult to assess the true role of architectural patterns and choices in the intrinsic robustness of models. Furthermore, they tend to analyze a single family of ANNs, with residual networks being the prevalent choice . Considering an adversarial training setting, the role played by the choice of activation function [ 10 , 34 , 41 ], specically smooth and parameterized activation functions, and the inclusion of batch normalization layers [ 40 ] has also been studied. Huang et al . [ 25 ] further argue that the benets associated with a particular activa- tion function depend on other design choices regar ding the training setup (e.g., w eight decay). There is also a research line that applies NAS to automate the search for adversarially robust architectur es [ 13 , 17 , 20 , 27 , 32 , 35 ]. Howev er , a signicant portion relies on cell-based search spaces [ 13 , 20 , 32 ]. While ecient, these constrained spaces hinder the emergence of no vel architectural patterns. Furthermore, these stud- ies often rely on adversarial training [ 20 , 35 ], once again making it dicult to isolate the architecture ’s contribution to robustness. Among NE-based approaches, R-NAS [ 27 ] and RoCo-NAS [ 17 ] explicitly optimize robustness alongside clean accuracy ( and com- putational complexity in RoCo-NAS). Both estimate adversarial ro- bustness using pre-generated adversarial examples (transfer-based attacks) to minimize computational o verhead. W e argue that this surrogate metric is insucient compar ed to dir ect evaluation strate- gies. Additionally , the nal validation protocol in R-NAS r emains ambiguous. Devaguptapu et al. [11] and V alentim et al. [38] share the same goal of evaluating and comparing the adversarial robustness of models designed both by human experts and via NAS approaches, with an emphasis on NE in the case of V alentim et al . [ 38 ]. In both works, the models under evaluation are not explicitly designed to resist adversarial attacks. While De vaguptapu et al . [ 11 ] only con- sider 𝐿 ∞ -robustness, V alentim et al . [ 38 ] also include 𝐿 2 -robustness in their experimental campaign. Jung et al . [ 26 ] come closer to providing a standardized way to assess the robustness of candidate solutions in a NAS-base d set- ting by extending the NAS-Bench-201 benchmark [ 14 ] with several metrics, including some related to 𝐿 ∞ -robustness. The authors use the pre-trained models from the baseline benchmark, which were optimized with standard (non-robust) training methods. Although there are dierent use cases for this extended version of the bench- mark, the y ar e limited to appr oaches that adopt the same cell-based search space and pre-dened operation set. 4 NERO-Net In this work, we propose NERO-Net ( N euro E v olution of adver- sarially RO bust articial neural Net works), a framework for de- signing intrinsically robust CNNs. Our method builds upon Fast- DENSER [ 3 ], an extension of the original DENSER algorithm [ 2 ]. The following sections detail the modications made to tailor Fast- DENSER for this task, focusing primarily on the redesign of the tness function and the evaluation strategy for candidate solutions. 4.1 Overview of DENSER DENSER relies on a hierarchical two-lev el representation for each individual. The outer level denes the ANN’s macro-structure as an ordered sequence of evolutionary units (e.g., layers). The inner level NERO-Net: A Neuroevolutionary Approach for the Design of Adversarially Robust CNNs governs the parameterization of these units using a schema based on Dynamic Structured Grammatical Evolution (DSGE), encoding parameters as a se quence of grammatical derivation steps. Un- like traditional DSGE implementations, the inner level of DENSER encodes real-valued parameters directly , allowing continuous opti- mization within the grammatical framework. At the outer level, units represent ANN layers or auxiliary com- ponents, like learning policies. Each unit is categorized by a type, where contiguous units of the same typ e form a module. These typ es correspond to non-terminal symbols in the inner level context-fr ee grammar , ensuring a consistent structural denition across the two-level r epresentation. Overall, the search space of a DENSER-based approach and the valid genotype structure is dictated by the conguration of the outer level and the grammatical rules of the inner level. The outer level structure is specied through a sequence of 3-element tuples, each representing a distinct module. These tuples enforce structural constraints by dening the type of the module’s units (linked to a grammar non-terminal) and its size bounds (minimum and maxi- mum number of units). Finally , the inner level resolves the specic parameters via the grammar’s production rules. Fast-DENSER instantiates the DENSER framework using a ( 1 + 𝜆 ) Evolutionary Strategy (ES) [ 3 ]. It further renes the architecture by incorporating a distinct genotypic level for layer connectivity , where units explicitly refer ence their inputs. The associated varia- tion operators encompass structural changes (adding, r eplicating, or removing units, and adding or removing connections), parameter tuning (grammatical and real-value mutations), and training time adjustments. 4.2 Fitness Function W e aim at designing CNNs that balance high clean accuracy with intrinsic adversarial robustness. Similarly to DENSER, individuals are optimized via standard training procedures. However , contrary to the original DENSER formulation, which relies solely on stan- dard performance metrics, our quality assessment uses 𝐹 𝛽 , a tness function that explicitly combines clean accuracy ( 𝐶 ) with adversar- ial accuracy ( 𝐴 ). Formally , this resembles the weighted Harmonic Robustness Score (HRS) [ 11 ], where the parameter 𝛽 controls the weight given to pr eserving performance on benign data over per- turbed data. As such, it is dened as: 𝐹 𝛽 = ( 1 + 𝛽 2 ) · 𝐶 × 𝐴 𝐶 + 𝛽 2 · 𝐴 𝐶 = Í 𝑁 𝑖 = 1 𝐼 ( 𝑦 𝑖 , 𝑦 𝑐𝑙 𝑒𝑎𝑛 𝑖 ) 𝑁 = 𝑁 𝑐 𝑁 𝐴 = Í 𝑁 𝑐 𝑖 = 1 𝐼 ( 𝑦 𝑖 , 𝑦 𝑎𝑑 𝑣 𝑖 ) 𝑁 𝑐 where 𝑁 is the number of clean samples, 𝑁 𝑐 is the number of clean samples that are correctly classied, 𝑦 𝑐𝑙 𝑒𝑎𝑛 and 𝑦 𝑎𝑑 𝑣 are the predicted labels for a clean or an adversarial sample, respectively , and 𝐼 ( 𝑦, ˆ 𝑦 ) is an indicator function that is 1 when 𝑦 = ˆ 𝑦 . The tness evaluation is inher ently computationally intensive due to the requirement of training individuals via backpr opagation. Consequently , we employ the FGSM attack to estimate adversarial accuracy eciently . W e acknowledge that FGSM is a single-step attack and may yield an optimistic estimation of robustness. How- ever , since candidate solutions do not undergo explicit adversarial training, stronger attacks would likely drive adversarial accuracy to near-zero values across the entire population. Such a performance degradation would eliminate selective pressure, rendering the ev o- lutionary algorithm unable to distinguish between individuals with varying degrees of intrinsic robustness. Bearing in mind that only the correctly classie d clean samples are taken into consideration when generating the adversarial e x- amples for an individual, the numb er of attacked samples typically varies among the individuals in the population. W arm-up Perio d. T o facilitate the emergence of viable ar chitec- tures, our approach incorporates a warm-up phase . During this initial period, adversarial examples are not considered, and the t- ness function is reduced solely to clean accuracy ( 𝐶 ). This strategy allows the ev olutionary search to establish a baseline of predic- tive performance before introducing the constraint of adversarial robustness. The duration of this phase is adaptive, governed by a hyper-parameter 𝜏 . Specically , at the end of each generation, we evaluate the population’s mean tness, and once it meets or exceeds the threshold 𝜏 , the optimization objective permanently transitions to the composite function 𝐹 𝛽 . Detection of Ill-Fitted Individuals. Preliminary experiments re- vealed that the evolutionary search occasionally converged toward degenerate solutions, which we term ill-tted individuals . These manifested in two primary forms: (1) numerical instability , char- acterized by exploding loss values during training; and (2) trivial classication, where models predicted a single class for the vast majority of samples. The latter created a “robustness trap”: since adversarial accuracy is conditional on correct initial classication, a model that blindly guesses one class may achieve articially high robustness on that specic subset. T o mitigate this, we implemented a validity constraint. An indi- vidual is agged as ill-tted if: (1) Its training history contains non-nite loss values (NaN or innity); or (2) The prediction fr equency for any single class exceeds a threshold of 100 × 1 − 1 𝑁 𝑐𝑙 𝑎𝑠𝑠𝑒 𝑠 %. If either condition is met, the e xpensive adversarial evaluation is bypassed, and the quality of the individual penalized. 4.3 Representation and V ariation Operators Blocks of Layers. In DENSER, a one-to-one mapping b etween non-terminal symbols and ANN layers originates a highly exi- ble, but excessively large search space. T o address this, we lever- age the observation that state-of-the-art CNNs recurrently rely on composite blocks of op erations — such as Batch Normalization (BN), rectied linear unit (ReLU) activation, and convolution ( conv) — rather than isolated layers [ 23 ]. The operation ordering varies across well-established architectures [21, 22]. Consequently , we introduce new non-terminal symb ols (and new layer types — convblock and poolblock ) that encode these layer groupings directly into the grammar (see Figure 1). The conv-block symbol encapsulates a convolutional layer , an activation function, and an optional BN layer , preserving all the standard convolution parameters (e.g., kernel size , lter count) and letting the grammati- cal rules determine the internal ordering of the operations. Inês Valentim, Nuno Antunes, and Nuno Lourenço ⟨ conv-block ⟩ :: = layer:convblock ⟨ act-position ⟩ ⟨ activation ⟩ ⟨ bn-position ⟩ [num-lters,int,1,32,256] [lter-shap e,int,1,1,5] [stride,int,1,1,3] ⟨ padding ⟩ ⟨ bias ⟩ ⟨ act-position ⟩ :: = act-pos:preconv | act-pos:postconv ⟨ bn-position ⟩ :: = bn:pre | bn:mid | bn:p ost | bn:none Figure 1: Snippet of a grammar with new rules for the convblock layer type. input 1 2 3 4 FC output Figure 2: An illustration of the connections between layers, assuming the numb er of lev els back is 2. The original imple- mentation does not allow layer 3 to have layer 1 as its only input (red connection). Layer 2 would always have to b e an input of layer 3 (dashed red connection). No changes to the genotype-to-phenotype mapping are required; only the model compilation is updated. Internally , the block’s layers are connected sequentially . Then, the rst and last layers serve as the interface to the global network topology , receiving and aggregat- ing the block’s inputs, and acting as the block’s output, respe ctively . Connections between Layers. In Fast-DENSER, each layer can aggregate inputs from multiple preceding layers. This connectivity is gov erned by a parameter called “levels back” , which establishes a maximum range for valid connections. Indirectly , it also controls the maximum number of inputs that each layer can have . Furthermore, by being module-spe cic, this parameter allows dierent architec- tural blocks to enforce distinct local connectivity constraints. Howev er , in the original implementation, each layer must always be connecte d to the previous one. Consequently , it would not be possible to design a CNN like the one shown in Figure 2, since layer 3 would also have to be connected to layer 2 (dashed red connection). W e no longer impose this constraint, this way allowing for skip connections to occur (red connection between layer 1 and layer 3). T o support these new connectivity patterns, we updated the initialization pr ocedure and the mutation operators. Every new unit must have at least one input connection from its valid prede- cessors, without being restricted to the immediate pre vious layer . Consequently , mutations for adding or removing connections treat the link to the immediate predecessor under the same probabilistic constraints as any other viable candidate . T o prevent “ dead ends” in the architecture, w e implemented a validity check: if any inter- mediate layer lacks outbound connections, we force a connection to a randomly selected valid successor (respecting the look-back limit). This repair mechanism is triggered during initialization and post-mutation. Finally , the outer level denition of modules is ex- tended to 4-element tuples, where the additional parameter spec- ies whether the module permits the new skip connections or is restricted to the legacy connectivity scheme. New T ypes for Real- V alued Parameters. At the inner level repre- sentation, real-valued parameters appear as 5-element tuples in the grammar , containing the parameter’s name and type (originally , either integer or oat), the number of values to generate, the mini- mum and the maximum possible value that can be generated. W e added int_power2 and int_power10 as new types: for both cases, we randomly generate as many integers as dened in the tuple, within the valid range of values. The parameter is then mappe d to either 2 or 10 to the power of the generated integer(s). For decimal numbers, the search space can be gr eatly reduced by using these new parameter types. Training Time Mutation. In the latest DENSER iteration, the train- ing duration is dynamic and can be extended through two distinct mechanisms. First, a mutation op erator can incrementally increase an individual’s training budget by a xed default interval. Second, the selection operator can autonomously extend the training time to ensure a fair comparison between high-performing candidates that have been trained for dierent durations. While benecial for accuracy , this unb ounded growth can lead to excessive computational costs. T o mitigate this, we introduce an upper bound on training time. If the mutation to extend training is triggered but the individual has already reached this cap, the operation is eectively “short-circuited”: the mutation is ignored, and, in a strict r esetting protocol, the training time is reverted to its default value and other genetic modications can take place. Initial Population. The initial population of Fast-DENSER is ran- domly generated: 𝜆 individuals are created with up to a maximum pre-dened number of layers that are randomly connected, accord- ing to the congured set of hyp er-parameters. Additionally , any other outer lev el units (e.g., unit encoding the learning strategy) are randomly initialized. Following this approach, the rst generation of individuals most likely exhibits poor tness. W e add the possibility of using a known architecture as a seed for the evolutionary process, but the corresponding genotype must b e dened manually . The goal is to speed up evolution by introducing genetic material associated with a promising candidate solution early on in the search process. When choosing this option, the initial population consists of an individual with the given architecture, plus 𝜆 − 1 individuals created from it through mutation. W e maintain the random initialization of other outer level units. 5 Evolutionary Search W e evaluate NERO-Net on the design of CNNs for CIF AR-10 [ 28 ]. W e fo cus on 𝐿 ∞ -robustness for several reasons: a brief perusal of the RobustBench leaderboards 1 reveals that this threat model receives the most attention, with almost 100 entries; and this also seems to be the preferred threat model for works that combine NAS and adversarial robustness [ 13 , 20 , 32 ]. In sum, this choice makes it easier for our work to be compared with the existing literature. The specication of the outer-level structure and the design of the grammar are partly motivated by the results of prior works that evaluate the adversarial robustness of models designed via NE approaches [ 11 , 38 ]. Accor ding to these studies, the NSGA -Net [ 29 ] model from a macro search space (the connections b etween blocks of layers are the sole target of evolution) seems to show some degree of resistance to simpler attacks like FGSM. Therefore, our choices aimed at designing a search space that would encompass the 1 https://robustbench.github.io NERO-Net: A Neuroevolutionary Approach for the Design of Adversarially Robust CNNs ⟨ stem ⟩ :: = layer:convblock act-pos:postconv act:linear bn:none [num-lters,int,1,16,256] lter-shape:3 stride:1 ⟨ padding ⟩ bias:False ⟨ features ⟩ :: = ⟨ macr o-node ⟩ | ⟨ macro-node ⟩ | ⟨ transition-block ⟩ ⟨ macro-node ⟩ :: = layer:macro-node ⟨ no de-activation ⟩ [num-lters,int,1,16,256] lters-mult:4 ⟨ node-activation ⟩ :: = act:relu | act:swish ⟨ transition-block ⟩ :: = layer:transition act-pos:postconv ⟨ node-activation ⟩ conv-bn:mid [num-lters,int,1,16,256] conv-lter-shape:1 conv-stride:1 conv-padding:valid conv-bias:False ⟨ pooling-type ⟩ pool-kernel-size:2 pool-stride:2 pool-padding:valid pool-bn:none ⟨ last-transition ⟩ :: = layer:transition act-pos:postconv ⟨ node-activation ⟩ conv-bn:mid [num-lters,int,1,16,256] conv-lter-shape:1 conv-stride:1 conv-padding:valid conv-bias:False ⟨ pooling-type ⟩ [pool-kernel-size,int,1,2,7] pool-stride:1 pool-padding:valid pool-bn:none ⟨ classication ⟩ :: = layer:fc ⟨ act-function ⟩ [num-units,int,1,128,2048] ⟨ bias ⟩ ⟨ pooling-type ⟩ :: = pooling:avg | pooling:max ⟨ padding ⟩ :: = padding:same | padding:valid ⟨ bias ⟩ :: = bias:True | bias:False ⟨ act-function ⟩ :: = act:relu | act:relu | act:swish | act:swish | act:sigmoid ⟨ softmax ⟩ :: = layer:fc act:softmax num-units:10 bias:True ⟨ learning ⟩ :: = ⟨ optimizer-algo ⟩ [early_stop,int,1,5,20] [batch_size,int_power2,1,5,9] ep ochs:10000 ⟨ optimizer-algo ⟩ :: = ⟨ gradient-descent ⟩ | ⟨ rmsprop ⟩ | ⟨ adam ⟩ ⟨ gradient-descent ⟩ :: = learning:gradient-descent ⟨ learning-rate ⟩ [momentum,oat,1,0.68,0.99] ⟨ nestero v ⟩ ⟨ nesterov ⟩ :: = nesterov:True | nesterov:False ⟨ adam ⟩ :: = learning:adam ⟨ learning-rate ⟩ [beta1,oat,1,0.5,1] [beta2,oat,1,0.5,1] ⟨ rmsprop ⟩ :: = learning:rmsprop ⟨ learning-rate ⟩ [rho,oat,1,0.5,1] ⟨ learning-rate ⟩ :: = [ lr ,int_power10,1,-6,-1] [decay ,int_power10,1,-6,-3] Figure 3: Grammar used in NERO-Net. architecture of the NSGA-Net model. W e can view our search space as a less restricted version of the NSGA -Net’s macro search space, since we do not dene a xed macro-structure of the architecture and some layer parameters still undergo evolution, instead of also being dened apriori ( e.g., number of convolution lters). However , we have to deal with a larger search space and a higher number of candidate solutions. W e use the grammar presented in Figure 3 in conjunction with the following outer level structur e: [( stem , 0, 1, false), ( features , 1, 30, true), ( last-transition , 0, 1, false), ( classification , 0, 5, false), ( softmax , 1, 1, false), ( learning , 1, 1)] Our grammar encodes CNNs with a DenseNet-like backbone [ 23 ], with an optional 3 × 3 convolutional stem that increases the num- ber of initial channels. The core featur e extraction portion of the network relies on two unit types, where macro-nodes are selected with higher probability than transition-blocks to mimic the structural phases of NSGA -Net. The primary computational units, macro-nodes , consist of a bottleneck block ( 1 × 1 convolution with 4 × expansion) followed by a 3 × 3 convolutional block. Both blocks adopt a xed BN-activation-conv order , with ev olvable parameters T able 1: NERO-Net experimental parameters. Parameter V alue Number of runs 5 Number of generations 100 Number of ospring ( 𝜆 ) 4 Add layer mutation rate 25% Replicate layer mutation rate 35% Remove layer mutation rate 25% Add connection mutation rate 15% Remove connection mutation rate 15% Grammatical mutation rate (layer unit) 15% Grammatical mutation rate (learning unit) 30% Gaussian mutation (oat) 𝜇 = 0 . 00 , 𝜎 = 0 . 15 Increase training time mutation rate 10% Evolutionary training set 43000 instances Evolutionary control set 3500 instances Fitness evaluation set 3500 instances Default training time 10 minutes Maximum training time 30 minutes W arm-up period threshold ( 𝜏 ) 0.80 Fitness function weight factor ( 𝛽 ) 4 for lter count and activation function (ReLU or Swish/SiLU). These are complemented by transition-blocks , which reduce spatial resolution via a 1 × 1 convolutional block (conv-BN-activation) followed by stride-2 pooling; here, the pooling type (av erage/max), lter count, and activation are free parameters. The features units are the only to support the new skip connections with a look-back depth of 5 layers. Following feature extraction, an op- tional last-transition unit performs global po oling ( stride 1) with an evolvable kernel size . Unlike standard single-lay er heads, the classication head can hav e up to 5 fully-connected units (fully- connected layer + activation) b efore the nal softmax layer , a choice motivated by previous DENSER results [ 2 ]. Finally , the learning unit optimizes training hyper-parameters, including batch size, early stopping, and the optimizer (SGD , A dam, or RMSProp) with an evolvable inverse time decay learning rate schedule. 5.1 Experimental Setup In what follows, we detail the experimental setup used for running NERO-Net, with the main parameters summarized in T able 1. The new threshold 𝜏 and weight factor 𝛽 were set after analyzing the results of preliminary experiments, while the remaining parameters were set accor ding to general congurations from DENSER [ 2 ] and Fast-DENSER [ 4 ]. Nevertheless, we use a higher mutation rate for replicating a lay er as an attempt to stir the search towar ds modular architectures, particularly regar ding macro-node blocks. W e also lower the probability of applying the training time mutation as an eort to enfor ce a b etter exploration of the search space , since there is a higher chance of producing ospring that are not exact copies of the parent’s architecture . Additionally , we use the architecture of the NSGA-Net model from their macro search space as a seed for the initial population, as described in Se ction 4.3. During each evolutionary run, we evaluate 400 individuals. These do not necessarily encode 400 dierent architectures, since a child can have the same architecture of the parent, for instance, if the training time mutation is applied. Inês Valentim, Nuno Antunes, and Nuno Lourenço Dataset. W e use CIF AR-10 ( 32 × 32 RGB images, 10 classes), nor- malizing pixel values to [ 0 , 1 ] . Following the partitioning scheme of V alentim et al . [ 39 ], the standard test set (10,000 images) is strictly isolated from the search process. In each evolutionary run, the 50,000 training images ar e randomly divided into three subsets, using distinct seeds to ensure experimental independence. Training Strategy . Candidates are traine d on the evolutionary training set using standard data augmentation (4-pixel padding, random horizontal ips, and cropping) [ 2 , 36 ], while the control set regulates early stopping. A xed L2 regularization ( 5 × 10 − 4 ) is applied exclusively to convolutional and fully-connected kernels. Fitness Evaluation. During evolution, candidates ar e evaluated on the tness subset. Prior to reaching the warm-up threshold 𝜏 , tness is dened solely by clean accuracy . Once 𝜏 has been sur- passed, we transition to the 𝐹 𝛽 metric (with 𝛽 = 4 , see T able 1). Adversarial accuracy is computed using an FGSM adv ersary with perturbations bounde d by 𝜖 = 8 / 255 ( 𝐿 ∞ -norm) and a batch size of 128. This standar d perturbation budget [ 7 ] balances attack strength against the intrinsic vulnerability of undefended models, ensuring meaningful dierentiation between candidates. 5.2 Results and Analysis In this section, we present the r esults of the independent runs of NERO-Net. Figure 4a shows the pr ogress of the tness of the best individual per generation, b oth averaged across all runs (gray area represents standard deviation) and for the run with the ov erall best individual. The red dotted line represents the rst generation where the tness function is 𝐹 𝛽 (i.e., the threshold 𝜏 was met in the previous generation) during the best run. The warm-up periods tend to be relatively short, which w e at- tribute to the evolution not starting from randomly generated indi- viduals, but rather from an architecture known to perform well on the CIF AR-10 classication task. However , we also observe a high variance up to, approximately , the 30th generation. In fact, for the run with the longest warm-up period, 𝜏 is met at generation 29. The tness of the best individual usually drops signicantly right after the transition to the 𝐹 𝛽 function. Keeping in mind that the duration of the warm-up period varies between runs, we can easily conclude that the high variance at the start of the evolutionary process is related to this phenomenon. Figure 4a also shows that the average tness starts impr oving from around the 30th generation onward, but it does not seem to follow a monotonically increasing trend. Figure 4b sho ws how the clean and adversarial accuracy of the best individuals from each generation evolve thr oughout the search process. W e can see that the drop in tness after 𝜏 is reached is mainly due to the low adversarial accuracy of the best individuals of the rst post-transition generations. After a certain point in the ev olu- tionary pr ocess, the clean accuracy of the best individuals stabilizes, with tness uctuations being mainly due to changes in adversar- ial accuracy . In our experiments, we noticed that small genotypic changes lead to more unpredictable outcomes in terms of adversar- ial accuracy than in terms of clean accuracy . Thus, we hypothesize that incorporating adversarial accuracy in the objective function leads to more intricate tness landscapes. 0 10 20 30 40 50 60 70 80 90 100 Generation 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 F itness best run average across runs (a) Fitness 0 10 20 30 40 50 60 70 80 90 100 Generation 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 Accuracy clean accuracy - best run adversarial accuracy - best run clean accuracy - average across runs adversarial accuracy - average across runs (b) Clean Accuracy vs. Adversarial Accuracy Figure 4: Evolution of the best individual per generation. The red dotted lines mark the transition based on the 𝜏 threshold. The clean accuracy of the best individuals of the last genera- tions is, on average, around 80%, which equals the value of 𝜏 . This means that, at the end of the evolutionary process, the clean ac- curacy of these individuals is close to the mean population tness before adversarial robustness is incorporated as an optimization goal. Moreover , comparing the last generations with the early ones, the results suggest gains of more than 18 percentage points in ad- versarial accuracy . Thus, it is safe to say that NERO-Net succeeds in nding CNNs that are inherently more robust, while remaining competitive in terms of predictive accuracy on clean data samples. The best individual across all generations and evolutionary runs attains a tness of 0.7983, a result of a clean accuracy of 87.49% and an adversarial accuracy of 33.25%. W e reiterate that these measure- ments are obtained on data from the tness evaluation set, without the inclusion of any adversarial defense. This individual contains a convolutional stem, but not a nal global pooling unit. The feature extraction portion of the network has 13 macro-nodes and 7 transition-blocks (5 average vs. 2 max p ooling). The ratio between ReLU and SiLU in these blocks is almost 1:1. These evolutionary units take advantage of real skip connections, and unlike what happens with traditional mod- els, some macro-nodes connect to others that precede the closest transition-block . The classication head b efore the nal soft- max layer has 4 fully-conne cted units (3 SiLU vs. 1 ReLU activation). NERO-Net: A Neuroevolutionary Approach for the Design of Adversarially Robust CNNs 6 Further Training and Evaluation While Fast-DENSER typically yields fully converged models, NERO- Net enforces a strict 30-minute training cap to ensure computational tractability (Section 4.3). An analysis of the ttest individuals rev eals that a majority (322/500) saturate this budget, averaging only ≈ 50 epochs. W e hyp othesize that the b est evolved architecture requires extended training to reach its potential. Ther efore, we evaluate the ttest individual using both prolonged standard training and complementary adversarial training. 6.1 Experimental Setup As far as NERO-Net is concerned, we select the ttest individual ( as given by the tness on the tness evaluation data subset) across all generations and evolutionary runs. Additionally , we also train and evaluate the NSGA -Net [ 29 ] model from the macro search space, whose architecture (i.e., the pre-dened macro-structure 2 and the genotype of each phase 3 ) is publicly available on the source code repository of NSGA -Net. Due to the stochastic nature of the process, we train each model 10 times, using dierent see ds for the random generators. W e then run each adv ersarial attack 10 times, such that each trained model is used once p er adversarial attack. Dataset. Following V alentim et al . [ 39 ], we merge the original training set back together for these additional training runs, and evaluate the trained models on the original test set. As before, the only pre-processing applied to the data is to normalize the pixel values to the interval [0, 1]. Standard Training Setting. For the standard (non-robust) training method, we use a stochastic gradient descent (SGD) optimizer with momentum (set to 0.90) for 350 epochs, with a batch size of 128. The initial learning rate is 0.025 and it is annealed to zero through a cosine decay schedule. W e use a weight decay of 3 × 10 − 4 and gradient norm clipping (threshold of 5.0). W e apply the same data augmentation scheme use d during the evolutionary search runs (padding, horizontal ipping, and random cr opping). This setting closely resembles how the NSGA -Net mo del is trained in the orig- inal work, hence its adoption her e. One of the main dierences resides in the fact that we do not include cutout [ 12 ] in our data augmentation scheme. Adversarial Training Setting. For adversarial training, we con- sider a 7-step PGD adversary , with 𝜖 = 8 / 255 and step size 𝜖 / 4 . W e use an SGD optimizer with momentum (set to 0.90) for 200 epochs, with a batch size of 64. The initial learning rate is 0.10, and it is decayed by a factor of 0.1 at epochs 100 and 150. W e use a weight decay of 1 × 10 − 4 and gradient norm clipping (threshold of 5.0). As in the standard training setting, we apply the same data augmentation scheme used during the evolutionary runs. This set- ting is commonly adopted by approaches that combine NAS and adversarial robustness [ 16 , 20 , 32 ], which in turn tend to follow the adversarial training method proposed by Madry et al. [30]. Threat Models and Attacks. W e consider the threat model used during evolutionary search ( 𝐿 ∞ -norm with 𝜖 = 8 / 255 ). Addition- ally , we evaluate the models under a thr eat model with 𝐿 2 -bounded 2 https://github.com/iwhalen/nsga- net/blob/master/models/macro_models.py 3 https://github.com/iwhalen/nsga- net/blob/master/models/macro_genotypes.py T able 2: Clean and adversarial accuracy on CIF AR-10, with 𝜖 = 8 / 255 in 𝐿 ∞ and 𝜖 = 0 . 5 in 𝐿 2 . Best results for standard and adversarial training are underlined and in b old, respectively . Norm Attack Standard Training Adversarial Training NSGA -Net NERO-Net NSGA -Net NERO-Net - None 95.55 ± 0.11 93.47 ± 0.15 84.89 ± 0.22 84.08 ± 0.40 𝐿 ∞ FGSM 39.73 ± 1.20 47.88 ± 1.11 64.93 ± 0.59 60.09 ± 0.62 PGD20 00.00 ± 0.00 00.13 ± 0.07 50.75 ± 0.74 44.69 ± 0.64 AA - - 47.13 ± 0.86 40.40 ± 0.66 𝐿 2 FGM 54.99 ± 0.83 58.35 ± 0.72 76.25 ± 0.52 77.88 ± 0.39 PGD20 00.28 ± 0.04 08.69 ± 0.58 64.45 ± 1.19 72.83 ± 0.49 AA a - - 60.79 ± 1.31 70.98 ± 0.61 a Custom version with only APGD-CE and APGD- T . perturbations ( 𝜖 = 0 . 5 ), to examine how they b ehave when pre- sented with data perturbations not seen during ev olution. W e run all the attacks with a batch size of 32. W e use the T ensorFlow im- plementations by the Adversarial Robustness T oolbox library [ 33 ] for all attacks except AA, for which we use the original Py T orch implementation 4 . 6.2 Results and Analysis W e rst evaluate the models trained with a standard (non-robust) method. T able 2 shows the results for FGSM, PGD with 20 iterations (step size 𝜖 / 4 ), and the standard v ersion of AA. W e conrm our hypothesis that our ttest individual benets from further training, even without an explicit form of adversar- ial defense. Considering the same threat model that was use d to guide the evolutionary sear ch, the clean and the adv ersarial ac- curacy against an FGSM adversary are boosted to around 93.47% and 47.88%, on average , after undergoing the extended training. Furthermore, the individual also shows some robustness against 𝐿 2 - bounded p erturbations, even if such samples were not seen during evolution: the accuracy on adversarial examples generated by FGM (the 𝐿 2 equivalent of FGSM) is around 58.35%. Although the clean accuracy of the NERO-Net model is slightly lower when compared to the NSGA -Net model, the overall post-attack accuracy (i.e., the number of correctly classied samples taking the full test set into account instead of only 𝑁 𝑐 ) of NERO-Net remains higher under both threat models (44.76% vs. 37.97% and 54.54% vs. 52.55% in 𝐿 ∞ and 𝐿 2 , respectively). Nevertheless, it would be misleading to say that our ttest indi- vidual is robust under these threat models, since the more powerful PGD adversary still brings its overall accuracy to near-zero values, with 𝐿 ∞ perturbations, and below 10% ( worse than a random classi- er), in the case of 𝐿 2 . The same happens with the NSGA-Net model, which reaches near-zero accuracies under both threat models. Thus, we complement the models’ inherent capability of resisting attacks by performing adversarial training. W e consider stronger adversaries in this scenario, namely the standar d AA ensemble of attacks, to avoid ov erestimating robustness. Results ar e presented in T able 2. As e xpected, adversarial training impr oves the robustness of our ttest individual in the 𝐿 ∞ scenario, although at the cost of clean accuracy , which drops to 84.08% (pre viously 93.47%), on average. If 4 https://github.com/fra31/auto- attack Inês Valentim, Nuno Antunes, and Nuno Lourenço we focus on the attack that guide d our evolutionary search, we see that adopting this defense allo ws for gains around 12 percentage points in comparison with the corresponding undefended model (60.09% vs. 47.88%). Moreover , the adversarial accuracy after the complete AA ensemble now reaches, on average , 40.40%. W e note that the last two attacks in AA (targeted F AB attack and Square at- tack) have a negligible contribution to the success of this adversary ( < 0 . 1 percentage points). Therefore, an ensemble with only the APGD attack on the CE loss ( APGD-CE) followed by the targeted APGD attack on the DLR loss ( APGD- T) would already give a good robustness estimate while saving computational resources. Finally , if we also take the misclassications of clean samples into account, the overall accuracy of the NERO-Net mo del is, on average, 33.96%. W e acknowledge that this result falls short of the one attaine d with the NSGA -Net model, whose overall accuracy after AA is, on average, around 40%. Howev er , we hypothesize that there are two aspects that nega- tively impact the robustness of NERO-Net. On the one hand, the NERO-Net model (26.72 million parameters) is a considerably larger model than the NSGA-Net model (3.37 million parameters), and so, it makes sense that it requires more resources (both in terms of data and time) for its training to converge. On the other hand, we adopted the same adv ersarial training setting for the two models to promote a fair comparison, but it may be more suitable for smaller sized models. Thus, we argue that a p ersonalized adversarial train- ing setup could potentially allow the NERO-Net model to achieve better results. W e conducte d some preliminar y experiments and, for the same model architecture and a standard training setting, we were able to evolve learning strategies that had a measurable impact on the adversarial accuracy of the models. Further valida- tion is needed, but we nd it safe to assume that the same would happen in an adversarial training setting, esp ecially if we take into consideration the ndings of other works in the literature ( e.g., Peng et al. [34]). W e also extend our analysis to 𝐿 2 -robustness for the adversar- ially trained mo dels. Initial assessments revealed similar trends regarding the contribution of each individual attack to the success of the AA adversary , and so, instead of running the standard ensem- ble, we ran a custom version with only two attacks (APGD-CE and APGD- T). Contrary to what happens in 𝐿 ∞ , the NERO-Net model is more robust than the NSGA -Net one when it comes to perturbations bounded by the 𝐿 2 -norm, with dierences around 10 percentage points under AA. As such, guiding the evolutionary search towards 𝐿 ∞ -robust mo dels seems to provide the additional b enet of the evolved models being able to resist 𝐿 2 -bounded attacks. W e argue that this multi-threat robustness, and the superior results when a standard training method is adopted, compensates for the less impressive results of the adversarially trained NERO-Net model under 𝐿 ∞ . 7 Conclusion In this work, we propose NERO-Net, a neur oevolutionary approach based on Fast-DENSER that incorporates the adversarial robustness of the searched CNNs into the tness function and evaluation of candidate solutions. Besides the modications directly linked with assessing the quality of the individuals in a robustness-aware sce- nario, we also intr oduce changes at the inner level repr esentation (enabling an e volutionary unit to encode blocks of layers instead of a single one) and the genotypic le vel responsible for encoding layer connectivity , this way allowing NERO-Net to explore a larger set of CNN architectures. Our search space is more complex than those typically adopted in NAS-based approaches. However , we show that NERO-Net still succeeds in nding architectures that better resist adversarial at- tacks, especially in the absence of a specialized adversarial defense. Incorporating adversarial training into the nal models further boosts their robustness, but the results do not quite match those of other models designed via NAS for all the threat models that were consider ed. W e hypothesize that this shortcoming could be overcome by optimizing the adversarial training setting for our evolved models, which we leave for futur e work. Another aspect that requires further analysis is the relation- ship between the robustness of a model trained with a standard method vs. adversarial training. It remains unclear whether the ttest model in a standard setting corresponds to the ttest model under a dierent optimization framework. Y et another challenge that we identied is the much mor e volatile response of a model, in terms of adversarial accuracy , to small changes at the genotypic level. Therefor e, we nd a more in-depth analysis of this relation- ship worth pursuing in future endeavors. Directly related to this issue is the study of the choices made during the ev olutionary pro- cess and the analysis of emergent architectural patterns associate d with enhanced robustness in the ttest individuals. Moreover , the computational cost of NE continues to be a draw- back, even more so when the optimization objectives go beyond the standard accuracy of the evolv ed models. The use of zero-cost proxies in tness evaluation, specically designed with adversarial robustness in mind [ 16 ], is one alternative we intend to pursue in the future. Acknowledgments This work is funded by national funds through FCT – Foundation for Science and T echnology , I.P. within the scope of the research unit UID/00326 - Centre for Informatics and Systems of the University of Coimbra. It is also supported by the Portuguese Recovery and Resilience P lan (PRR) through project C645008882-00000055, Center for Responsible AI. The rst author is also funded by the FCT under the individual grant UI/BD/151047/2021 (https://doi.org/10.54499/ UI/BD/151047/2021). References [1] Maksym Andriushchenko, Francesco Croce, Nicolas Flammarion, and Matthias Hein. 2020. Square Attack: A Query-Ecient Black-Box Adversarial Attack via Random Search. In Computer Vision – ECCV 2020 , Andrea V edaldi, Horst Bischof, Thomas Brox, and Jan-Michael Frahm (Eds.). Springer International Publishing, 484–501. doi:10.1007/978- 3- 030- 58592- 1_29 [2] Filipe Assunção, Nuno Lourenço, Penousal Machado, and Bernardete Rib eiro. 2019. DENSER: Deep Evolutionary Network Structured Representation. Genetic Programming and Evolvable Machines 20, 1 (2019), 5–35. doi:10.1007/s10710- 018- 9339- y [3] Filipe Assunção, Nuno Lourenço, Bernardete Rib eiro, and Penousal Machado. 2021. Fast-DENSER: Fast Deep Evolutionary Network Structured Representation. SoftwareX 14 (2021), 100694. doi:10.1016/j.softx.2021.100694 [4] Filipe Assunção, Nuno Lourenço, Penousal Machado, and Bernardete Rib eiro. 2019. Fast DENSER: Ecient Deep NeuroEvolution. In European Conference NERO-Net: A Neuroevolutionary Approach for the Design of Adversarially Robust CNNs on Genetic Programming (EuroGP) . Springer International Publishing, 197–212. doi:10.1007/978- 3- 030- 16670- 0_13 [5] Nicholas Carlini, Anish Athalye, Nicolas Papernot, Wieland Brendel, Jonas Rauber , Dimitris Tsipras, Ian Go odfellow , Aleksander Madr y , and Alexey Ku- rakin. 2019. On Evaluating Adversarial Robustness . arXiv:1902.06705 [cs.LG] doi:10.48550/arXiv .1902.06705 [6] Nicholas Carlini and David W agner. 2017. T owards Evaluating the Robustness of Neural Networks. In 2017 IEEE Symp osium on Se curity and Privacy (SP) . IEEE Computer Society , 39–57. doi:10.1109/SP.2017.49 [7] Francesco Croce, Maksym Andriushchenko, Vikash Sehwag, Edoardo Debenedetti, Nicolas Flammarion, Mung Chiang, Prateek Mittal, and Matthias Hein. 2021. RobustBench: A Standar dized Adversarial Robustness Benchmark. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks , V ol. 1. [8] Francesco Croce and Matthias Hein. 2020. Minimally Distorted Adversarial Examples with a Fast Adaptive Boundary Attack. In Proceedings of the 37th International Conference on Machine Learning , V ol. 119. PMLR, 2196–2205. https: //proceedings.mlr .press/v119/croce20a.html [9] Francesco Croce and Matthias Hein. 2020. Reliable Evaluation of Adversarial Robustness with an Ensemble of Diverse Parameter-Free Attacks. In Proceedings of the 37th International Conference on Machine Learning , V ol. 119. PMLR, 2206– 2216. https://proceedings.mlr .press/v119/croce20b.html [10] Sihui Dai, Saeed Mahloujifar , and Prateek Mittal. 2022. Parameterizing Activa- tion Functions for Adversarial Robustness. In 2022 IEEE Security and Privacy W orkshops (SP W) . 80–87. doi:10.1109/SP W54247.2022.9833884 [11] Chaitanya Devaguptapu, Devansh Agarwal, Gaurav Mittal, Pulkit Gopalani, and Vineeth N Balasubramanian. 2021. On Adv ersarial Robustness: A Neural Architecture Search Perspective. In 2021 IEEE/CVF International Conference on Computer Vision W orkshops (ICCV W) . 152–161. doi:10.1109/ICCVW54120.2021. 00022 [12] T errance DeV ries and Graham W . T aylor. 2017. Improved Regularization of Convolutional Neural Networks with Cutout . arXiv:1708.04552 [cs.CV] doi:10. 48550/arXiv .1708.04552 [13] Minjing Dong, Y anxi Li, Y unhe W ang, and Chang Xu. 2025. Adversarially Robust Neural Architectures. 47, 5 (2025), 4183–4197. doi:10.1109/TP AMI.2025.3542350 [14] Xuanyi Dong and Yi Yang. 2019. NAS-Bench-201: Extending the Scope of Re- producible Neural Architecture Search. In International Conference on Learning Representations . https://openreview .net/forum?id=HJxyZkBKDr [15] Yinpeng Dong, Fangzhou Liao, Tianyu Pang, Hang Su, Jun Zhu, Xiaolin Hu, and Jianguo Li. 2018. Boosting Adversarial Attacks with Momentum. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition . 9185–9193. doi:10.1109/CVPR.2018.00957 [16] Y uqi Feng, Y uwei Ou, Jiahao Fan, and Yanan Sun. 2025. Zero-Cost Proxy for Adversarial Robustness Evaluation. In The Thirteenth International Conference on Learning Representations . https://openreview .net/forum?id=zHf7hOfeer [17] V ahid Geraeinejad, Sima Sinaei, Mehdi Modarressi, and Masoud Daneshtalab. 2021. RoCo-NAS: Robust and Compact Neural Architecture Search. In 2021 International Joint Conference on Neural Networks (IJCNN) . 1–8. doi:10.1109/ IJCNN52387.2021.9534460 [18] Ian Goodfellow , Y oshua Bengio, and Aaron Courville. 2016. Deep Learning . MI T Press. [19] Ian J. Goodfellow , Jonathon Shlens, and Christian Szegedy . 2015. Explaining and Harnessing Adversarial Examples. In International Conference on Learning Representations . arXiv:1412.6572 [stat.ML] doi:10.48550/arXiv .1412.6572 [20] Minghao Guo, Yuzhe Y ang, Rui Xu, Ziwei Liu, and Dahua Lin. 2020. When NAS Meets Robustness: In Search of Robust Architectures Against A dversarial Attacks. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) . 628–637. doi:10.1109/CVPR42600.2020.00071 [21] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep Residual Learning for Image Recognition. In 2016 IEEE Conference on Computer Vision and Pattern Re cognition (CVPR) . 770–778. doi:10.1109/CVPR.2016.90 [22] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Identity Map- pings in Deep Residual Networks. In Computer Vision – ECCV 2016 , Bastian Leib e, Jiri Matas, Nicu Sebe, and Max W elling (Eds.). Springer International Publishing, 630–645. doi:10.1007/978- 3- 319- 46493- 0_38 [23] Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q. W einberger. 2017. Densely Connected Convolutional Networks. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) . 2261–2269. doi:10.1109/CVPR. 2017.243 [24] Hanxun Huang, Yisen W ang, Sarah Erfani, Quanquan Gu, James Bailey , and Xingjun Ma. 2021. Exploring Architectural Ingredients of Adv ersarially Robust Deep Neural Networks. In Advances in Neural Information Processing Systems , V ol. 34. Curran Associates, Inc., 5545–5559. https://proceedings.neurips.cc/ paper/2021/hash/2bd7f907b7f5b6bbd91822c0c7b835f6- Abstract.html [25] Shihua Huang, Zhichao Lu, Kalyanmoy Deb , and Vishnu Naresh Boddeti. 2023. Revisiting Residual Networks for Adversarial Robustness. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) . 8202–8211. doi:10. 1109/CVPR52729.2023.00793 [26] Steen Jung, Jovita Lukasik, and Margret Keuper . 2023. Neural Architecture Design and Robustness: A Dataset. In The Eleventh International Conference on Learning Representations . https://openreview .net/forum?id=p8coElqiSDw [27] Shashank Kotyan and Danilo V asconcellos V argas. 2020. T owards Evolving Robust Neural Architectures to Defend from Adversarial Attacks. In Proceedings of the 2020 Genetic and Evolutionary Computation Conference Companion (New Y ork, N Y, USA) (GECCO ’20) . Association for Computing Machinery , 135–136. doi:10.1145/3377929.3389962 [28] Alex Krizhevsky . 2009. Learning Multiple Layers of Features from Tiny Images . Technical Report. University of T oronto. [29] Zhichao Lu, Ian Whalen, Vishnu Boddeti, Y ashesh Dhebar , Kalyanmoy Deb, Erik Goodman, and W olfgang Banzhaf. 2019. NSGA -Net: Neural Architecture Search Using Multi-Objective Genetic Algorithm. In Pr oceedings of the Genetic and Evolutionary Computation Conference (New Y ork, N Y , USA) (GECCO ’19) . Association for Computing Machinery , 419–427. doi:10.1145/3321707.3321729 [30] Aleksander Madry , Aleksandar Makelov , Ludwig Schmidt, Dimitris T sipras, and Adrian Vladu. 2018. T owards Deep Learning Models Resistant to A dversar- ial Attacks. In International Conference on Learning Representations . https: //openreview .net/forum?id=rJzIBfZAb [31] Jan Hendrik Metzen, Tim Genewein, V olker Fischer , and Bastian Bischo. 2017. On Detecting Adversarial Perturbations. In International Conference on Learning Representations . https://openreview .net/forum?id=SJzCSf9xg [32] Jisoo Mok, Byunggook Na, Hyeokjun Choe, and Sungroh Y oon. 2021. AdvRush: Searching for Adversarially Robust Neural Ar chitectures. In Proceedings of the IEEE/CVF International Conference on Computer Vision . 12322–12332. https: //openaccess.thecvf.com/content/ICCV2021/html/Mok_AdvRush_Searching_ for_Adversarially_Robust_Neural_Architectures_ICCV_2021_paper .html [33] Maria-Irina Nicolae, Mathieu Sinn, Minh Ngo c Tran, Beat Buesser , Ambrish Rawat, Martin Wistuba, V alentina Zantedeschi, Nathalie Baracaldo, Bryant Chen, Heiko Ludwig, Ian M. Molloy , and Ben Edwards. 2019. Adv ersarial Robustness T oolbox v1.0.0 . arXiv:1807.01069 [cs.LG] doi:10.48550/arXiv .1807.01069 [34] ShengY un Peng, W eilin Xu, Cory Cornelius, Matthew Hull, Kevin Li, Rahul Duggal, Mansi Phute, Jason Martin, and Duen Horng Chau. 2023. Ro- bust Principles: Ar chitectural Design Principles for Adversarially Robust CNNs . arXiv:2308.16258 [cs.CV] doi:10.48550/arXiv .2308.16258 [35] Mathieu Sinn, Martin Wistuba, Beat Buesser , Maria-Irina Nicolae, and Minh Tran. 2019. Evolutionar y Search for Adversarially Robust Neural Netw orks. In Safe Machine Learning W orkshop at ICLR . [36] Masanori Suganuma, Shinichi Shirakawa, and T omoharu Nagao. 2017. A Genetic Programming Approach to Designing Convolutional Neural Network Architec- tures. In Proceedings of the Genetic and Evolutionary Computation Conference (New Y ork, N Y, USA ) (GECCO ’17) . Association for Computing Machinery , 497– 504. doi:10.1145/3071178.3071229 [37] Christian Szegedy , W ojciech Zaremba, Ilya Sutskev er , Joan Bruna, Dumitru Erhan, Ian Goodfellow , and Rob Fergus. 2014. Intriguing Properties of Neu- ral Networks. In International Conference on Learning Representations . arXiv . arXiv:1312.6199 [cs.CV] doi:10.48550/arXiv .1312.6199 [38] Inês V alentim, Nuno Lourenço , and Nuno Antunes. 2022. Adversarial Robustness Assessment of NeuroEvolution Approaches. In 2022 IEEE Congress on Evolution- ary Computation (CEC) . 1–8. doi:10.1109/CEC55065.2022.9870202 [39] Inês V alentim, Nuno Lour enço, and Nuno Antunes. 2024. Evolutionary Model V alidation—An Adversarial Robustness Perspective. In Handbook of Evolutionar y Machine Learning , W olfgang Banzhaf, Penousal Machado, and Mengjie Zhang (Eds.). Springer Nature, 457–485. doi:10.1007/978- 981- 99- 3814- 8_15 [40] Haotao W ang, Aston Zhang, Shuai Zheng, Xingjian Shi, Mu Li, and Zhangyang W ang. 2022. Removing Batch Normalization Boosts Adversarial Training. In Proceedings of the 39th International Conference on Machine Learning , V ol. 162. PMLR, 23433–23445. https://proceedings.mlr .press/v162/wang22ap.html [41] Cihang Xie, Mingxing T an, Boqing Gong, Alan Yuille, and Quo c V . Le. 2021. Smooth Adversarial Training . arXiv:2006.14536 [ cs.LG] doi:10.48550/arXiv .2006. 14536
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment