Lightweight GenAI for Network Traffic Synthesis: Fidelity, Augmentation, and Classification
Accurate Network Traffic Classification (NTC) is increasingly constrained by limited labeled data and strict privacy requirements. While Network Traffic Generation (NTG) provides an effective means to mitigate data scarcity, conventional generative m…
Authors: Giampaolo Bovenzi, Domenico Ciuonzo, Jonatan Krolikowski
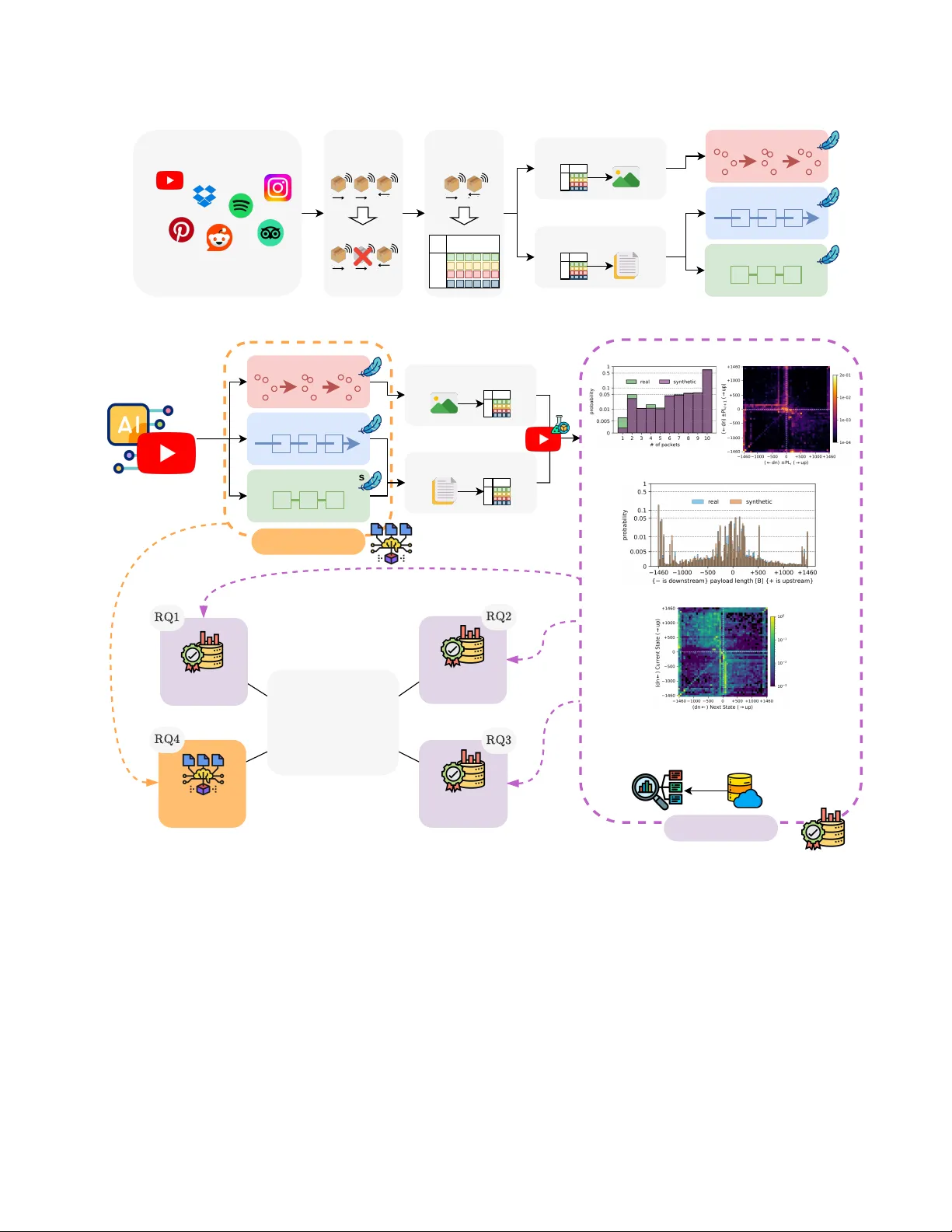
1 Lightweight GenAI for Network T raf fic Synthesis: Fidelity , Augmentation, and Classification Giampaolo Bov enzi, Domenico Ciuonzo, Jonatan Kroliko wski, Antonio Montieri, Alfredo Nascita, Antonio Pescap ` e, Dario Rossi Abstract —Accurate Network T raffic Classification (NTC) is in- creasingly constrained by limited labeled data and strict privacy requir ements. While Network T raffic Generation (NTG) pr ovides an effective means to mitigate data scarcity , con ventional genera- tive methods struggle to model the complex temporal dynamics of modern traffic or/and often incur significant computational cost. In this article, we address the NTG task using lightweight Gen- erative Artificial Intelligence (GenAI) architectures, including transformer -based, state-space, and diffusion models designed for practical deployment. W e conduct a systematic evaluation along four axes: ( 𝑖 ) (synthetic) traffic fidelity , ( 𝑖𝑖 ) synthetic-only training, ( 𝑖𝑖𝑖 ) data augmentation under low-data regimes, and ( 𝑖 𝑣 ) com- putational efficiency . Experiments on two heterogeneous datasets show that lightweight GenAI models preser ve both static and temporal traffic characteristics, with transf ormer and state-space models closely matching real distributions across a complete set of fidelity metrics. Classifiers trained solely on synthetic traffic achieve up to 87% F1-score on real data. In low-data settings, GenAI-driven augmentation impr oves NTC performance by up to + 40% , substantially reducing the gap with full-data training. Overall, transformer -based models provide the best trade-off between fidelity and efficiency , enabling high-quality , priv acy- aware traffic synthesis with modest computational overhead. I N T R O D U C T I O N The rapid ev olution of Generative Artificial Intelligence (GenAI) is reshaping communications, accelerating the vision of autonomous and self-e volving networks [1]. Large gener- ativ e models have demonstrated remarkable potential across telecom domains, exploiting massi ve datasets to learn com- plex patterns and generate new content. Applications already span physical-layer optimization and channel modeling [2], semantic communications, and network planning [1]. While their adoption for data-centric network monitoring and man- agement [3] is also blooming, it remains an open frontier . W ithin this landscape, Network Traf fic Classification (NTC) remains pi votal for network management and security across mobile, wired, and capillary Internet of Things (IoT) environ- ments. While accurate NTC enables various critical functions, such as anomaly detection, quality of service provisioning, and security policy enforcement, traditional data-dri ven solu- tions often struggle to meet practical desiderata. Despite the advancements fueled by Machine Learning (ML), practical constraints like limited labeled data, imbalanced classes, and strict priv acy regulations act as severe roadblocks. These constraints hinder scalability and reduce rob ustness in real- world settings [4]. G. Bov enzi, D. Ciuonzo, A. Montieri, A. Nascita, and A. Pescap ` e are with the DIETI, University of Naples Federico II, Italy . J. Krolikowski and D. Rossi are with Huawei T echnologies France SASU. T o address these limitations, Network Traf fic Generation (NTG) has been widely e xplored to synthesize realistic traf- fic data, enrich training sets, and strengthen classification robustness. Ne vertheless, con ventional approaches fall short. Classical data augmentation and traditional ML-based NTC rely on handcrafted statistical features, limiting adaptability to ev olving traffic patterns and f ailing to capture rich tem- poral dependencies. Meanwhile, con ventional NTG solutions struggle with a core trade-of f: producing high-fidelity synthetic traffic while maintaining the computational efficienc y required by modern networks [3]. In this article, we advocate for a shift to ward lightweight GenAI architectur es for practical NTG. As depicted in Fig. 1, we propose a modular NTG pipeline specifically tailored for GenAI. Rather than synthesizing fine-grained payload bytes using massive foundation models, our approach generates a compact traf fic repr esentation derived fr om header fields of the first packets in each network flow . This choice enables training and operating advanced GenAI models, namely T ransformers , State Space Models (SSMs) , and Diffusion Models (DMs) , under a budget of 1 – 2 million parameters , ensuring computa- tional efficienc y without sacrificing generation fidelity . T o validate this lightweight paradigm, we formulate f our Research Questions (RQs) aligned with real-world network- ing challenges (Fig. 1, bottom left). W e assess both generated data quality from dif ferent viewpoints ( T raffic Evaluation – RQ1 to RQ3) and GenAI model efficienc y ( Model Evaluation – RQ4): RQ1: Can lightweight GenAI faithfully reproduce real traf fic patterns? RQ2: Can GenAI synthetic traf fic enable priv acy-preserving NTC without degrading performance? RQ3: Can GenAI synthetic data mitigate training scarcity in low-data regimes? RQ4: Are lightweight GenAI models computationally efficient for deployment? T o answer these RQs, our work provides an e xtensive eval- uation of synthetic traf fic generated via lightweight GenAI models by ( 𝑖 ) defining a comprehensi ve fidelity assessment pr ocedure , and tackling two piv otal do wnstream NTC tasks, namely ( 𝑖𝑖 ) synthetic-only training and ( 𝑖𝑖𝑖 ) data augmentation for low-data r e gimes . Complementarily , we deliv er an ( 𝑖 𝑣 ) usability assessment in terms of space and time complexity . Experiments on two public datasets— Mirage - 2019 ( 40 mobile apps) and CESNET - TLS22 - 80 ( 80 network services)—demonstrate that lightweight GenAI models achiev e strong fidelity , preserving both static and temporal 2 Data Augmentation TrafficMatrix2Image Diffusion Models Transformers Traffic Segmentation Feature Extraction Packets Fields BF Real Network Traffic Mobile apps or network services Diffusion Models Transformers State-Space Model s Image2TrafficMatrix Token2TrafficMatrix Generation conditioned on app or service (e.g., Y ouTube) State-Space Models Downstream Task Model (e.g., network traffic classifier) Fidelity Evalutation (Few) Real T raffic Data # packets histogram 2-gram histogram 1-gram histogram Synthetic T raffic Data Markov transition matrix T raining Phase Workflow Generation Phase Work flow Fidelity Synthetic Training Efficiency Real World Challenges • Generation reliability • Privacy concerns • Data scarcity • Computational overhead Model Evaluation T raffic Evaluation TrafficMatrix2Token Fig. 1. Overvie w of the proposed lightweight GenAI-based network traffic generation pipeline and real-world challenges linked with our Research Questions . T raining phase workflow: real network traces are segmented into biflows and mapped into canonical image- or token-based representations; these serve as inputs to train diffusion, transformer, or state-space generative models. Generation phase workflow: trained GenAI models are conditioned to generate image- or token-based representations for a given traffic class; these are then converted into traffic matrices to feed downstream network traffic classifiers; generation efficacy is assessed in terms of both model and traffic ev aluation. traffic patterns. Compared to traditional NTG baselines (e.g., CVAE , SMOTE, and domain-expert transformations) and DMs, T ransformers and SSMs (i.e. LLaMA and Mamba , respectiv ely) exhibit higher performance. Classifiers trained exclusi vely on synthetic data reach up to 87% F1-score on real traffic, while GenAI-driven augmentation improves F1-scores by up to + 40% in low-data regimes. Last b ut not least, resource analysis rev eals a clear trade-off between architectural complexity and computational cost, with T ransformer-based models of fering the most fav orable balance for practical deployment, combining a moderate memory footprint with the lowest generation latency . The remainder of the article explores the background and related work shaping the current NTG landscape and presents the proposed lightweight GenAI-based pipeline. It then details the experimental setup and discusses the results addressing the four RQs, before concluding with directions for future work. 3 T H E G E N A I P A R A D I G M S H I F T I N N E T W O R K T R A FFI C G E N E R A T I O N This section frames NTG ev olution, categorizing existing work into three phases: early statistical methods and con- ventional ML models, current large-scale GenAI models, and the emerging need for lightweight solutions addressing our research gap. T raditional Generative Methods. Early NTG relied on sta- tistical generative models (e.g., Mark ov models) to capture sequential dependencies through state transitions. Though in- tuitiv e and lightweight, they do not scale well to mid- or long- range dependencies. Con ventional ML models improved ex- pressiv e power [5]. V ariational Autoencoders learn probabilis- tic latent representations that enhance reconstruction accuracy , while Normalizing Flows provide exact likelihood estimation at the cost of a higher computational overhead. Generati ve Ad- versarial Networks, in contrast, focus on high-fidelity sampling but often suffer from training instability and mode collapse. Although traditional methods support downstream tasks like intrusion detection and traf fic classification [3, 5], the y struggle to balance training stability , computational efficienc y , and fidelity in modeling complex, evolving traffic patterns. Recent GenAI Advancements. Since 2021, NTG has been impacted by the growing popularity of T ransformers , DMs , and SSMs , each employing distinct strate gies for traf fic rep- resentation. Originating from Natural Language Processing (NLP), T ransformer-based models (e.g., GPTs and T5 ) [6– 10] and SSMs (i.e. Mamba ) [11] treat network traffic as token sequences, learning networking “grammar” to model flow dynamics. Input sequences range from ra w packet bytes [8, 11] and header fields (e.g., packet sizes, inter-arri val times, and di- rections [6]) to tcpdump / tshark packet summaries [7, 10]. T o further bridge the modality gap between natural language and network data, the authors of [9] combine specialized traffic-domain tokenization and multimodal learning to un- derstand expert instructions and learn task-specific traffic representations simultaneously . Crucially , generation strategies operate either iteratively , constructing flows “token-by-token” akin to sentences in NLP [8], or natively synthesize complete sequences [6, 11]. A notable exception is the work in [7], which generates Python code interacting with the Scapy li- brary , acting more as traf fic replay than GenAI synthesis. Con versely , DMs, originating from computer vision, hav e recently gained traction across the entire networking stack, from physical-layer channel generation and resource manage- ment [2] to NTG [12, 13]. DMs synthesize traf fic by iterati vely denoising random data until structured patterns emerge. This requires encoding traf fic into image-like representations [12] or directly modeling raw byte streams [13] to capture high- fidelity details. Although these “large” models achie ve high fidelity , their byte-lev el processing and iterative generation often make them impractical for network deployment. Positioning . Our work di ver ges from the emer ging trend of massiv e network foundation models [10] to in vestigate the feasibility of lightweight GenAI . Indeed, while foundation models offer generalization and fine-tuning capabilities, they impose prohibitive computational costs. Instead, we explore NTG solutions based on T ransformers, SSMs, and DMs under strict resource constraints (i.e. 1 – 2 M parameters), prioritiz- ing deployability and training/inference speed. Unlike related works focused on generating raw packet bytes [11, 13] (which increases complexity and risks payload data leakage), we synthesize lightweight traf fic features constituting the network fingerprint of applications. Specifically , we model the time series of payload lengths and packet directions ( PL × DIR ), akin to [6, 8, 12], but explicitly discard inter-arri val times, as these depend on network conditions rather than application logic [14]. Furthermore, we address the lack of rigorous validation in prior studies by introducing adv anced fidelity metrics, including PL × DIR 𝑛 -grams and Markov transition matrices, to assess temporal integrity . Finally , targeting practi- cal downstream tasks for NTG, our comprehensiv e ev aluation demonstrates that lightweight GenAI enables effecti ve classi- fier training ev en in ( 𝑎 ) synthetic-only or ( 𝑏 ) low-data re gimes, ensuring efficienc y for real-world deployment. L I G H T W E I G H T G E N A I - B A S E D N T G P I P E L I N E A T W O R K Figure 1 depicts the modular NTG pipeline po wered by lightweight GenAI models, structured around two distinct phases . The training phase pre-processes real network traces to train GenAI models, while the generation phase leverages them to synthesize high-fidelity , application-conditioned traffic data. T raining Phase W orkflow . The training phase ingests r eal network traffic traces (e.g., from mobile apps or network services). T o bypass the computational overhead and priv acy risks associated with raw payload utilization, data undergoes traf fic se gmentation to group packets into bidirectional flows (biflows) 1 , follo wed by featur e extraction . This produces a highly ef ficient traf fic matrix representation, where ro ws are packets and columns are packet fields. Specifically , we extract the Payload Length (PL) and Packet Direction (DIR) of the first 10 packets of each biflow . Depending on the GenAI model, this matrix under goes a specific modality-mapping before training: • TrafficMatrix2Image : Image-based models, such as DMs, interpret the (potentially preprocessed) traffic matrix as a structured 2D image. This enables DMs to learn complex 2D patterns that encode both the under- lying features and the temporal dynamics of the flo ws, generating the entire traffic representation in a single, non-autoregressi ve step. • TrafficMatrix2Token : Sequence-based models, such as T ransformers and SSMs, treat the matrix as a multiv ariate time series, serializing it into a sequence of discrete tokens, where each token encodes the v ectorial values of the sequence steps. This enables autoregressiv e generation that explicitly captures complex temporal de- pendencies across packets and fields. 1 A biflow is a network flow consisting of packets flowing bidirectionally between the same network and transport endpoints—IPs, ports, and L4 protocol. It represents both directions of communication as a single entity . 4 Giv en this mapped data, the goal of the selected GenAI models is to learn a distribution that faithfully captures the underlying structure of the real network traces. Generation Phase W orkflo w . Once the GenAI models are trained, they are deployed to synthesize new traffic samples. Generation is conditioned via a token prompt, which dictates the target network class (e.g., a certain mo- bile app like Y ouT ube, or a network service). The GenAI architectures generate synthetic samples in their nati ve for- mats: 2D images for DMs or token sequences for Trans- formers and SSMs. T o lev erage these outputs for downstream NTC, an in verse mapping step is needed. Specifically , the Image2TrafficMatrix and Token2TrafficMatrix steps reconstruct the generated samples back into the original traf fic matrix format, recovering the corresponding synthetic PLs and DIRs. Generation ef ficacy is ev aluated from two complementary viewpoints: • T raffic Evaluation: T o assess generation fidelity , we quantify the div ergence between real and synthetic traffic distributions using distance metrics, such as the Jensen- Shannon Div ergence (JSD). More precisely , we compute these distances across the traffic properties illustrated in Fig. 1: packet count histograms for session-lev el behavior , 1-gr am histogr ams for mar ginal probabilities of PL and DIR, 2-gram histograms for temporal de- pendencies across consecutive packet pairs, and Markov transition matrices for first-order transition dynamics. Beyond fidelity , we ev aluate the utility of generated traf fic in two practical downstream NTC scenarios: synthetic- only training , where classifiers are trained exclusi vely on synthetic data and tested on real samples, and data augmentation , assessing whether enriching a few real samples with synthetic ones boosts classification perfor- mance. • Model Evaluation: T o v alidate the deplo yment feasibility of our lightweight GenAI models, we also profile their computational efficiency during training and inference, ev aluating training time, generation latency , GPU mem- ory utilization, and on-disk model footprint. Addition- ally , we in vestigate post-training quantization to assess whether these architectures can be further optimized for resource-constrained en vironments. Lightweight GenAI Models. T o implement our NTG pipeline under strict computational constraints, we leverage lightweight GenAI models ( ≈ 1 – 2 M parameters) belonging to different families: • Diffusion Models (DMs): DMs iteratively reverse a noising process to reconstruct realistic samples. W e use NetDiffus - NR [12], a refined architecture operating on 2D Grammian Angular Summation Field (GASF) images. A post-generation refinement step accurately maps the 2D GASF images back to traffic sequences, minimizing reconstruction errors and improving the quality of the T ABLE I C O N FI G U R ATI O N O F T H E G E N A I M O D E L S , G RO U P E D B Y M A I N A T T R I B U T E S . T H E L A S T C O L U M N P R OV I D E S T H E R E P O S I T O RY L I N K . Model HS IS #L #AH Repo CVAE 500 / 250 20 6 – – LLaMA 160 320 4 8 Mamba 72 144 4 – NetDiffus - NR 32 – 4 4 § Legend: HS – Hidden Size; IS – Intermediate Size; #L – Number of Layers; #AH – Number of Attention Heads; Repo – Repository (clickable icon). synthesized traffic traces. 2 • T ransf ormer-based Models: T ransformers excel at se- quence modeling by capturing temporal dependencies through self-attention. W e adopt LLaMA [15], a causal decoder-only architecture designed to model long-range dependencies efficiently . It leverages optimized attention mechanisms to autoregressi vely synthesize high-fidelity sequences while maintaining computational scalability . • Structur ed State-Space Models (SSMs): T o comple- ment T ransformers, we explore SSMs designed for ef- ficient sequence processing. W e employ Mamba [11], which replaces standard attention with a selectiv e state- space formulation. Operating causally , it achiev es linear- time scalability , well-suited for modeling per-biflo w traf- fic sequences. E X P E R I M E N TA L E V A L UA T I O N This section e v aluates our lightweight GenAI-based NTG pipeline to answer the four RQs formulated in the Introduction. First, we outline the experimental setup, encompassing the employed datasets and generation configurations. Then, we provide the corresponding Research Answers (RAs), covering the traffic ev aluation for generation fidelity (RA1) and down- stream NTC utility (RA2 and RA3), follo wed by the model ev aluation profiling computational efficienc y and deployment feasibility (RA4). Experimental Setup. Our ev aluation relies on two public network traf fic datasets: Mirage - 2019 3 , containing 40 An- droid apps with ≈ 100 k biflo ws, and CESNET - TLS22 - 80 , a CESNET - TLS22 subset 4 downsampled to cover the top 80 ser- vices and obtain a sample size comparable to Mirage - 2019 . Raw traf fic data are pre-processed into sequences of the first 10 signed PLs ( ± PLs), where negati ve and positiv e values encode downstream and upstream DIRs, respectiv ely . For a fair cross-architecture comparison, all lightweight GenAI models are bounded to 1 – 2 M trainable parameters. Alongside these models, we employ a Conditional V aria- tional Autoencoder ( CVAE ) baseline for class-aware traf fic generation. T able I summarizes their key hyperparameters. 2 W e e xclude heavier byte-le vel alternati ves like NetDiffusion [13] from our ev aluation, as its massiv e scale (hundreds of millions of parameters) and simplified direction modeling contradict our lightweight, time-series focus. 3 https://traffic.comics.unina.it/mirage/mirage- 2019.html 4 https://www .liberouter .org/datasets/cesnet- tls22 5 C V A E N e t D i f f u s - N R L L a M A M a m b a J S D N u m P a c k e t s J S D 1 - g r a m J S D 2 - g r a m J S D M a r k o v L e a k a g e U n i q A l i g n 1 0.75 0.50 0.25 0 Mirage - 2019 J S D N u m P a c k e t s J S D 1 - g r a m J S D 2 - g r a m J S D M a r k o v L e a k a g e U n i q A l i g n 1 0.75 0.50 0.25 0 CESNET - TLS22 - 80 Fig. 2. Radar plots of 6 fidelity metrics comparing real and syn- thetic traffic data across generative models for Mirage - 2019 (left) and CESNET - TLS22 - 80 (right). For all considered metrics, lower values indicate better performance (with 0 being optimal). Note that the axes are scaled with 0 at the outer edge, meaning that models producing larger polygon areas exhibit higher generative fidelity . For sequence-based models, the vocab ulary assigns a unique token to each signed PL value, resulting in 2 × PL max possible tokens, augmented with an token and N tokens ( 𝑁 = 40 for Mirage - 2019 and 𝑁 = 80 for CESNET - TLS22 - 80 ). T o ensure fixed-length inputs during training, biflows with fe wer than 10 packets are right-padded via tokens. RA1 – Fidelity Ev aluation. T o answer RQ1, we quantitati vely assess the fidelity of generated traffic through the six metrics reported in the radar plots of Fig. 2. First, we translate the visual properties depicted in Fig. 1 into numerical metrics by computing the macro-av eraged JSD between real and synthetic distributions for packet count histograms (JSD NumPackets ), 1- gram histograms (JSD 1-gram ), 2-gram histograms (JSD 2-gram ), and Markov transition matrices (JSD Markov ). Furthermore, we assess the realism and priv acy of generated biflows via two additional metrics [5]: (i) UniqAlign e valuates data realism by computing the uniqueness score (i.e. the proportion of distinct sequences) independently for the real and synthetic datasets, and then measuring their absolute difference; a lower score indicates that synthetic traf fic accurately replicates the repetition patterns of real data. (ii) Leakage directly quantifies the exact sequence overlap between real and synthetic datasets via Jaccard similarity; a lo wer score indicates no vel biflow generation rather than mere memorization of training data, thereby mitigating pri vac y leakage risks. Figure 2 summarizes the performance of generati ve mod- els. Since all metrics follo w a “lower -is-better” logic, radar plot axes are in verted, meaning that larger areas correspond to higher generation fidelity . Results are consistent across Mirage - 2019 and CESNET - TLS22 - 80 . LLaMA and Mamba outperform all alternatives, achie ving near -zero JSD scores across all ev aluated traffic properties. They effecti vely capture both marginal PL × DIR distributions ( 1 -gram) and more com- plex temporal dependencies ( 2 -gram and Markov). Notably , LLaMA achie ves the best JSD Markov , confirming its ability to model advanced sequential transitions. Also, both sequence- based models exhibit near -optimal UniqAlign and Leakage scores. This demonstrates that their generated samples closely T ABLE II F 1 - S C O R E S O F A N RF C L A S S I FI E R T R A I N E D O N S Y N T H E T I C A N D T E S T E D O N R E A L Mirage - 2019 ( O R A N G E ) A N D CESNET - TLS22 - 80 ( A Z U R E ) T R A FFI C . B E S T G E N A I M O D E L S A R E I N B O L D . (GenAI) Appr oach Mirage - 2019 CESNET - TLS22 - 80 T rain on Real 85 . 84% 91 . 80% CVAE 66 . 73% 75 . 44% NetDiffus - NR 46 . 83% 65 . 84% LLaMA 78.78% 87.43% Mamba 76 . 07% 85 . 09% match the real traffic distribution, synthesizing highly div erse and realistic sequences without merely memorizing the train- ing set (with Mamba showing a slight edge over LLaMA in leakage mitigation). Interestingly , the CVAE baseline suit- ably performs only on coarse-grained properties, successfully matching the biflow length distrib ution (JSD NumPackets ≈ 0 ). Howe ver , its fidelity drops when capturing complex pat- terns, exposing its structural limitations in modeling fine- grained traf fic dynamics, though it still limits data leakage. NetDiffus - NR consistently yields the lo west fidelity . It struggles to capture structural traffic properties, exhibiting the highest JSD scores (i.e. the smallest polygon area) and failing to accurately model ev en the biflow lengths. Despite these limitations, it achie ves a moderate UniqAlign and successfully minimizes Leakage . RA2 – NTC: T rain on Synthetic T raffic. T o address RQ2, we ev aluate generated data utility via a train-on-synthetic, test- on-real approach. W e train a Random Forest ( RF ) downstream classifier exclusi vely on synthetic samples and ev aluate its generalization on unseen real traffic from Mirage - 2019 and CESNET - TLS22 - 80 . Performance under this setting reflects both the fidelity of the synthetic samples and their alignment with real-world class distributions. T able II shows that RF models trained on synthetic traf- fic exhibit an expected performance gap relati ve to real- data training, reflecting the inherent difficulty of fully repro- ducing realistic traf fic characteristics. Nevertheless, LLaMA and Mamba generated data lead to consistently higher clas- sification performance, outperforming the CVAE baseline and NetDiffus - NR . On Mirage - 2019 , the RF trained on LLaMA and Mamba samples achie ves 78 . 78% and 76 . 07% F1-scores, respectively , substantially reducing the gap with the real-data upper bound ( 85 . 84% ). Similarly , on CESNET - TLS22 - 80 , the synthetic-trained RF reaches 87 . 43% ( LLaMA ) and 85 . 09% ( Mamba ) F1-scores, closely trailing the 91 . 80% obtained with real traffic. In contrast, NetDiffus - NR severely underperforms across both datasets, confirming that this DM struggles to capture traffic character- istics relev ant for downstream classification. T o summarize, LLaMA and Mamba of fer the best balance of generation fidelity and utility for downstream tasks, enabling synthetic-to- real generalization and priv acy-preserving NTC with minimal performance degradation, whereas NetDiffus - NR appears less suitable for realistic traffic synthesis. RA3 – NTC: Data A ugmentation. W e in vestigate GenAI- 6 real LLaMa Mamba CVAE NetDiffus-NR SMOTE Fast Retr. 5 10 20 50 P er centage of R eal Samples [%] 40 50 60 70 80 F1-Scor e [%] Model R e a l O n l y L L a M a M a m b a C V A E * N e t D i f f u s * S M O T E F a s t R e t r . Mirage - 2019 5 10 20 50 P er centage of R eal Samples [%] 72.5 75.0 77.5 80.0 82.5 85.0 87.5 90.0 F1-Scor e [%] R e a l O n l y L L a M a M a m b a C V A E * N e t D i f f u s * S M O T E F a s t R e t r . CESNET - TLS22 - 80 Fig. 3. F1-score in data augmentation scenarios under low-data regimes for Mirage - 2019 (left) and CESNET - TLS22 - 80 (right) using an RF classifier . Colors indicate the approach family: orange for sequence-based GenAI, green for other generative models, red for statistical techniques, violet for expert transformations, black for real-only training. driv en data augmentation under data-scarcity conditions, where only a limited fraction of real training samples is av ailable to the do wnstream classifier . The GenAI model is trained on the full labeled dataset and used to generate synthetic samples. The downstream classifier is trained with few real samples plus synthetic data. This reflects a practical use case of a network operator with limited data lev eraging a pre-trained GenAI model to augment the training dataset. T o establish a more extensi ve benchmark, we compare GenAI models against two non-AI baselines: ( 𝑖 ) F ast Retransmit [14], a domain-expert traf fic transformation , and ( 𝑖𝑖 ) SMO TE , a sta- tistical synthesis technique. Fast Retransmit probabilistically delays a single packet to mimic a TCP retransmission, while SMO TE generates new samples by replicating or interpolating existing ones. Unlike GenAI models, which are trained offline on the entire dataset, Fast Retransmit and SMOTE operate directly on the limited data av ailable at augmentation time. In detail, we ev aluate augmentation utility by training an RF classifier on mixed real and synthetic traffic. T o this end, we upsample all classes with synthetic samples to match the size of the majority class from the original training set, yielding a perfectly balanced set. In the low-data regime (i.e. 5 – 20% of the original train- ing set), Fig. 3 shows that GenAI-based augmentation pro- duces substantial F1-score improv ements. On Mirage - 2019 , LLaMA and Mamba samples significantly boost the classi- fication performance compared to real-only training, rapidly approaching the F1-scores achiev ed with abundant real data. On CESNET - TLS22 - 80 , the gains remain consistent, albeit more moderate ( 10 – 15% F1-score improv ement ov er train- ing without augmentation). Conv ersely , traditional statisti- cal augmentation methods exhibit limited impact: SMO TE typically matches, or even slightly underperforms, real-only training. Fast Retransmit exhibits more fav orable behav- ior , yielding moderate gains in the lo w-data regime on CESNET - TLS22 - 80 . Nonetheless, its impact diminishes on Mirage - 2019 and remains strictly below that of LLaMA and Mamba . The other generati ve methods exhibit markedly dif- ferent behaviors across datasets. CVAE consistently improv es upon real-only training, confirming its ability to model rele vant traffic characteristics. NetDiffus - NR , instead, shows lim- T ABLE III T R A I N I N G A N D G E N E R A T I O N R E S O U R C E U S AG E ( T I M E , G P U U T I L I Z A T I O N , M E M O RY , A N D O N - D I S K S I Z E ) F O R E AC H M O D E L O N A H I G H - E N D D A TAC E N T E R G P U ( 4 8 G B ) , M E A S U R E D O V E R 1 0 RU N S A N D R E P O RT E D A S M E D I A N S . T R A I N I N G : 10 E P O C H S , 5 C L A S S E S , 500 S A M P L E S / C L A S S , B A T C H S I Z E 1 . G E N E R A T I O N : 100 S A M P L E S / C L A S S , BAT C H S I Z E 1 . Model T raining Generation Model Size Time [ s/epoch ] GPU [ % ] Mem [ MB ] Time [ ms/sample ] GPU [ % ] Mem [ MB ] on Disk [ MB ] CVAE 22 . 568 18 379 0 . 50 1 291 3 . 9 NetDiffus - NR 117 . 029 21 387 860 . 67 19 355 4 . 2 LLaMA 36 . 810 20 393 31 . 21 17 353 7 . 9 Mamba 108 . 477 15 377 148 . 52 14 359 15 . 5 LLaMA - PTQ int8 - WO — — — 45 . 33 16 357 3 . 5 LLaMA - PTQ int8 - DA — — — 990 . 04 14 347 3 . 4 ited effecti veness, yielding marginal gains on Mirage - 2019 and systematically underperforming on CESNET - TLS22 - 80 . Overall, sequence-based GenAI augmentation consistently achiev es the best performance across both datasets, highlight- ing its clear superiority ov er traditional statistical, expert- driv en, and other generative alternatives. RA4 – Computational Efficiency . Addressing RQ4, we analyze computational efficienc y by measuring training time, generation latenc y , GPU utilization, memory consumption, and on-disk footprint. All generati ve models were trained for 10 epochs with 500 samples per class ( 5 classes, batch size of 1 ) using a high-end datacenter GPU ( 48 GB), and subsequently used to generate 100 synthetic samples per class. The results rev eal a clear trade-off between computational cost and architectural complexity . During training, times range from 22 . 6 s/epoch for CVAE to ≈ 108 – 117 s/epoch for mod- els with more structured generati ve mechanisms. Notably , LLaMA stands out as an exception, achie ving a highly com- petitiv e 36 . 8 s/epoch despite its autoregressi ve architecture. NetDiffus - NR exhibits the highest GPU utilization dur- ing training ( 21% ), followed by LLaMA ( 20% ) and CVAE ( 18% ), whereas Mamba is the most efficient ( 15% ). Mem- ory usage remains uniform across all models, ranging from 377 MB ( Mamba ) to 393 MB ( LLaMA ), suggesting that the dominant memory cost is the framework o verhead rather than the model itself. Generation latency varies substantially . CVAE is the fastest ( 0 . 50 ms/sample), followed by LLaMA ( 31 . 21 ms/sample), whereas Mamba and NetDiffus - NR incur considerably higher latencies ( 148 . 52 ms/sample and 860 . 67 ms/sample, respectively). Regarding on-disk footprint, Mamba is by far the lar gest model at 15 . 5 MB, while the others range from 3 . 9 MB ( CVAE ) to 7 . 9 MB ( LLaMA ). Lastly , we explore P ost-T raining Quantization (PTQ) to assess whether these models can be further optimized for resource-constrained environments. W e apply PTQ exclu- siv ely to LLaMA , as its optimal trade-off between archi- tectural footprint (substantially smaller than Mamba ) and generation fidelity makes it the ideal candidate for a tiny- footprint gener ative ar chitectur e . Specifically , we in vestigate two int8 PTQ variants: weight-only ( LLaMA - PTQ int8 - WO ) and dynamic activation ( LLaMA - PTQ int8 - DA ). The weight- only variant preserves GPU memory consumption while more than halving the model size (from 7 . 9 MB to 3 . 5 MB) and 7 reducing GPU utilization from 19% to 16% . This enhance- ment comes at the cost of a moderate increase in generation latency ( 45 . 33 ms/sample). Con versely , the dynamic activ ation variant further reduces the model size ( 3 . 4 MB) and GPU utilization ( 14% ), b ut incurs a substantial latency penalty ( ≈ + 960 ms/sample) due to the o verhead of on-the-fly acti vation quantization. Notably , both quantized LLaMA variants achieve fidelity metrics and real-traffic classification performance con- sistent with the non-quantized model up to tw o significant figures, confirming that quantization introduces no meaningful degradation. T aken together , these findings demonstrate that lightweight GenAI architectures, particularly LLaMA coupled with quantization, can achiev e the computational efficiency required for practical deployment. C O N C L U S I O N This work presented a comprehensiv e study on generativ e approaches for network traffic synthesis, focusing on fidelity , downstream classification, and deployment feasibility . Overall, our results highlight LLaMA and Mamba as the most promis- ing models for realistic traffic synthesis, pri vac y-preserving classification, and effecti ve data augmentation. In fidelity assessment (RQ1), both models achiev e near-zero JSD scores across all properties; LLaMA excels on Markov transition matrices, while Mamba shows a slight edge in leakage miti- gation. In synthetic-only training (RQ2), LLaMA and Mamba reach 78 . 78% and 76 . 07% F1-score on Mirage - 2019 , and 87 . 43% and 85 . 09% on CESNET - TLS22 - 80 , narro wing the gap with real-data training to ≈ 9% and ≈ 13% , respec- tiv ely . In data augmentation (RQ3), sequence-based GenAI improv es classification by up to + 40% F1-score in the low- data regime ( 5 – 20% of real training set) on Mirage - 2019 , with consistent + 10 – 15% gains on CESNET - TLS22 - 80 . Re- garding computational efficienc y (RQ4), LLaMA offers the best trade-of f with 36 . 8 s/epoch training time, 31 . 21 ms/sample generation latency , and a 7 . 9 MB on-disk footprint, further reducible to 3 . 5 MB via int8 weight-only post-training quan- tization, without meaningful degradation in generation fidelity or classification performance. Con versely , diffusion models ( NetDiffus - NR ) and baselines ( CVAE ) prov ed less ef fectiv e, either incurring prohibiti ve generation latencies or failing to capture fine-grained temporal dynamics. Future work will explore adapti ve generation strategies and hybrid pipelines combining generativ e models with domain- specific transformations. Furthermore, we aim to ev aluate these lightweight architectures in real-world deployment sce- narios, such as integrating quantized models into edge-based intrusion detection systems for on-the-fly , priv acy-preserving traffic analysis. Lastly , e xtending this paradigm to ward Agentic AI powered by lightweight models represents a promising frontier to enable autonomous, closed-loop network simulation and proactiv e defense mechanisms. R E F E R E N C E S [1] L. Bariah et al. , “Large generativ e AI models for telecom: The next big thing?” IEEE Commun. Mag . , vol. 62, no. 11, pp. 84–90, 2024. [2] X. Xu et al. , “Generative artificial intelligence for mobile communica- tions: A diffusion model perspecti ve, ” IEEE Commun. Mag. , 2024. [3] G. Bov enzi et al. , “Mapping the landscape of generative AI in network monitoring and management, ” IEEE T rans. Netw . Service Manag. , 2025. [4] G. Aceto et al. , “AI-powered internet traffic classification: Past, present, and future, ” IEEE Commun. Mag. , vol. 62, no. 9, pp. 168–175, 2023. [5] ——, “Synthetic and priv acy-preserving traffic trace generation using generativ e ai models for training network intrusion detection systems, ” Journal of Network and Computer Applications , p. 103926, 2024. [6] R. F . Bikmukhamedov and A. F . Nadeev , “Multi-class network traffic generators and classifiers based on neural networks, ” in Systems of Signals Generating and Proc. in the F ield of on Boar d Comm. , 2021. [7] D. K. Kholgh and P . K ostakos, “P A C-GPT: A novel approach to generating synthetic network traffic with GPT -3, ” IEEE Access , vol. 11, pp. 114 936–114 951, 2023. [8] J. Qu et al. , “Traf ficGPT: Breaking the token barrier for efficient long traffic analysis and generation, ” arXiv preprint , 2024. [9] T . Cui et al. , “Traf ficLLM: Enhancing large language models for net- work traffic analysis with generic traffic representation, ” arXiv pr eprint arXiv:2504.04222 , 2025. [10] S. Mayhoub et al. , “T alk like a packet: Rethinking network traffic analysis with transformer foundation models, ” IEEE Commun. Mag. , 2026, in press. [11] A. Chu et al. , “Feasibility of state space models for network traffic generation, ” in Pr oc. of the SIGCOMM W orkshop on Networks for AI Computing , 2024, pp. 9–17. [12] N. Siv aroopan et al. , “NetDiffus: Network traf fic generation by diffusion models through time-series imaging, ” Computer Networks , vol. 251, p. 110616, 2024. [13] X. Jiang et al. , “Netdiffusion: Network data augmentation through protocol-constrained traffic generation, ” Proc. of the ACM on Measur e- ment and Analysis of Computing Systems , vol. 8, no. 1, pp. 1–32, 2024. [14] C. W ang et al. , “Data augmentation for traffic classification, ” in Int. Conf. on P assive and Active Network Measurement , 2024, pp. 159–186. [15] H. T ouvron et al. , “Llama: Open and ef ficient foundation language models, ” arXiv preprint , 2023. Giampaolo Bovenzi (giampaolo.bovenzi@unina.it) is an Assistant Professor at the University of Napoli Federico II. His research concerns (anonymized and encrypted) traffic classification and network security . Domenico Ciuonzo [SM] (domenico.ciuonzo@unina.it) is an Associate Pro- fessor at the Uni versity of Napoli Federico II. His research concerns data fusion, network analytics, IoT , signal processing, and AI. Jonatan Kroliko wski (jonatan.krolikowski@hua wei.com) is a senior research engineer at the DataCom Lab of Huawei’ s Paris Research Center . His research interests include ML- and operations research-driven optimization of real- world networks and the modeling and analysis of network-related problems, with a recent focus on time series modeling. Antonio Montieri (antonio.montieri@unina.it) is an Assistant Professor at the Univ ersity of Napoli Federico II. His research concerns network measure- ments, traffic classification, modeling and prediction, and AI for networks. Alfredo Nascita (alfredo.nascita@unina.it) is an Assistant Professor at the Univ ersity of Napoli Federico II. His research interests include Internet network traffic analysis, machine and deep learning, and explainable artificial intelligence. Antonio Pescap ´ e [SM] (pescape@unina.it) is a Full Professor at the Univer- sity of Napoli Federico II. His work focuses on measurement, monitoring, and analysis of the Internet. Dario Rossi [SM] (dario.rossi@huawei.com) is network AI CTO and director of the DataCom Lab at Huawei T echnologies, France. He has coauthored 15+ patents and over 200+ papers in leading conferences and journals, and has receiv ed 9 best paper awards, a Google Faculty Research A ward (2015), and an IR TF Applied Network Research Prize (2016).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment