Unveiling the Resilience of LLM-Enhanced Search Engines against Black-Hat SEO Manipulation
The emergence of Large Language Model-enhanced Search Engines (LLMSEs) has revolutionized information retrieval by integrating web-scale search capabilities with AI-powered summarization. While these systems demonstrate improved efficiency over tradi…
Authors: Pei Chen, Geng Hong, Xinyi Wu
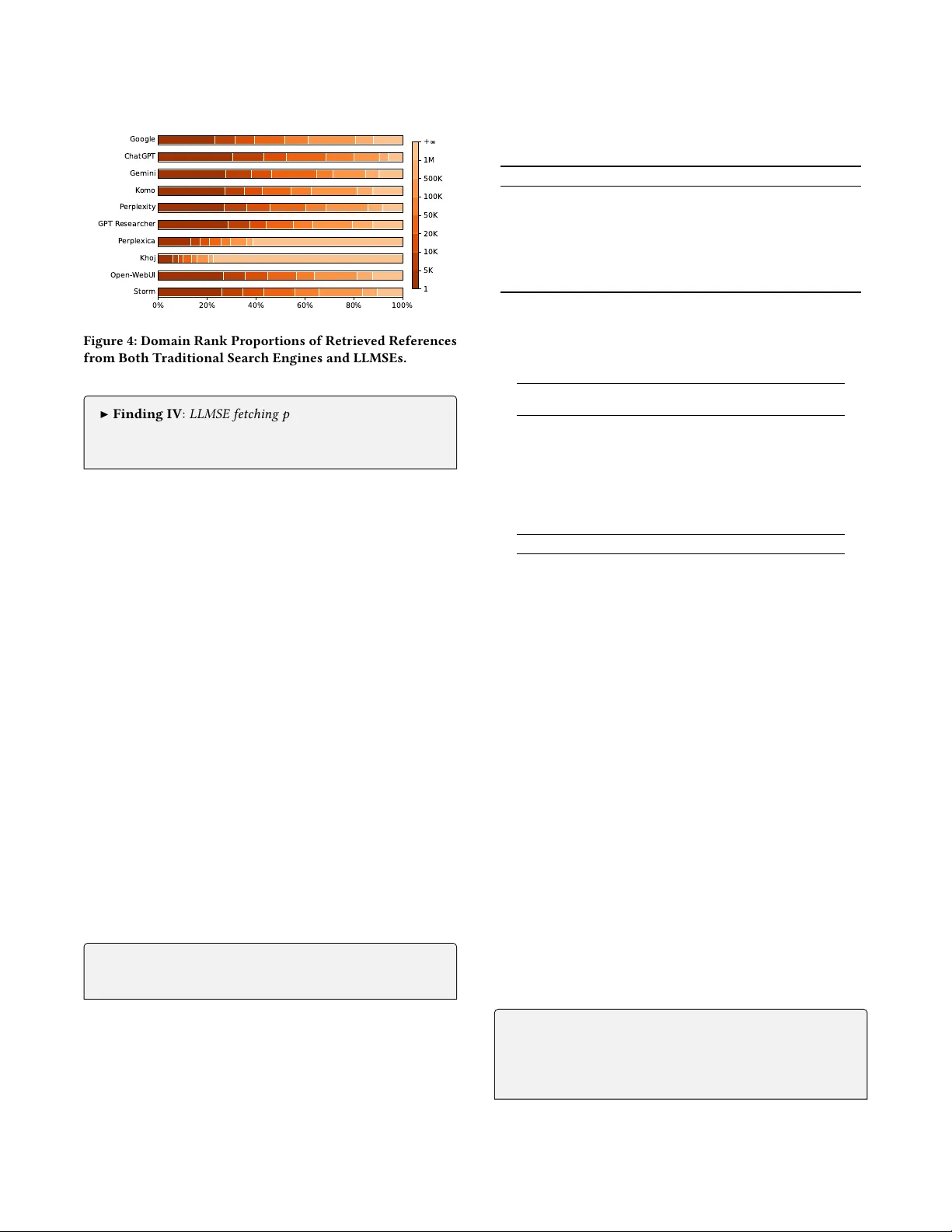
Unveiling the Resilience of LLM-Enhance d Search Engines against Black-Hat SEO Manipulation Pei Chen peichen19@fudan.edu.cn Fudan University Shanghai, China Geng Hong B ghong@fudan.edu.cn Fudan University Shanghai, China Xinyi W u xinyiwu20@fudan.edu.cn Fudan University Shanghai, China Mengying W u wumy21@m.fudan.edu.cn Fudan University Shanghai, China Zixuan Zhu zhuzx24@m.fudan.edu.cn Fudan University Shanghai, China Mingxuan Liu liumx@mail.zgclab.edu.cn Zhongguancun Laboratory Beijing, China Baojun Liu lbj@tsinghua.edu.cn T singhua Univ ersity Beijing, China Mi Zhang mi_zhang@fudan.edu.cn Fudan University Shanghai, China Min Y ang B m_yang@fudan.edu.cn Fudan University Shanghai, China Abstract The emergence of Large Language Model-enhanced Search En- gines (LLMSEs) has revolutionized information retrieval by inte- grating web-scale search capabilities with AI-powered summariza- tion. While these systems demonstrate improved eciency over traditional search engines, their security implications against well- established black-hat Search Engine Optimization (SEO) attacks remain unexplored. In this paper , we present the rst systematic study of SEO at- tacks targeting LLMSEs. Specically , we e xamine ten representative LLMSE products (e.g., ChatGPT , Gemini) and construct SEO-Bench, a benchmark comprising 1,000 real-world black-hat SEO websites, to evaluate both open- and close d-source LLMSEs. Our measure- ments show that LLMSEs mitigate o ver 99.78% of traditional SEO attacks, with the phase of retrieval serving as the primary lter , intercepting the vast majority of malicious queries. W e further pro- pose and evaluate seven LLMSEO attack strategies, demonstrating that o-the-shelf LLMSEs are vulnerable to LLMSEO attacks, i.e., rewritten-query stung and segmented texts double the manip- ulation rate compared to the baseline. This work oers the rst in-depth security analysis of the LLMSE ecosystem, providing prac- tical insights for building more resilient AI-driven sear ch systems. W e have responsibly reported the identie d issues to major ven- dors. CCS Concepts • Security and privacy → W eb application security . Ke ywords LLM-Enhanced Search Engine, Search Engine Optimization, Black- Hat SEO B Corresponding authors. T o appear in Proceedings of the A CM W eb Conference 2026 (W WW 2026). The impact of LLMSE Gemini Meet Gemini , your personal AI assistant ... Gemini can make mistakes, so double - check How LLM Impacts Jobs Aug 23, 2024 A new study weighs the positive and negative impacts of LLMs … Tra d i ti o n al S ea r c h E n gi n e LLM - enhanced Search Engine (LLMSE) The impact of LLMSE LLMSE LLMSE Impact LLM Impact Analyze the search keys… Referen ces (3) ① dl.acm.or g LLM - enhanced Search Engine. … improving the ability of content summarization, … ② wikipedia.org LL M Application. … with real - time web indexing and source verificat ion …. ③ … The Impact of LLMSE - Fisrt , Integration of Search and LLM Capabilities . ① - Second , Improved User Experience. ② - Third , Shift in SEO and Content Strategies . ③ The answer will help you a lot. Find 10 referenc es… Summarize the answers… Figure 1: Examples of Traditional Search Engines vs. LLM- Enhanced Search Engines (LLMSE). 1 Introduction Among the emerging applications of large language models (LLMs), the large language model-enhanced search engine (LLMSE) com- bines the vast search capabilities of the W eb with ecient and pre- cise responses to user queries. Due to their objectivity and ability to synthesize information, LLMSEs are increasingly being regarded as alternatives to traditional search engines. For instance, Perplexity , raise funds at an $18 billion valuation in early 2025 [7]. Figure 1 illustrates a comparison between LLMSE and traditional search engines. The user begins by inputting a query to a practical problem, such as “Impact of LLMSE?” . The traditional search en- gines r eturn se veral separate W eb sour ces of information, e .g. news, forums. while LLMSE directly generates a well-structured response providing clearer information in a w ell-dened overview . Despite these advantages, are LLMSEs truly mor e reliable than traditional search engines? Search engine optimization (SEO) [ 10 ], including black-hat SEO [ 32 , 35 , 43 , 47 , 64 , 67 ], has damaged search result quality on the traditional sear ch engines for decades. With many attackers now turning to LLMSEs, likely reusing established SEO methods and e ven inventing ne w manipulations, the emerging LLMSE systems are facing a qualitatively new threat, underscoring the urgency of understanding and mitigating such risks. Pei Chen et al. Research Gap. Despite the growing deployment of LLMSEs, their security under SEO manipulation remains insuciently understood. On one hand, as a rapidly emerging eld, most work on LLMSEs focuses on improving search eciency , accuracy , and veriabil- ity [ 39 , 42 , 57 , 65 ]. On the other hand, the security-related w orks pay attention to the model-level attack techniques[ 1 , 45 , 54 , 70 ]. For example, PoisonedRA G [ 70 ] manipulates RA G results by poisoning knowledge databases, and GEO [ 1 ] tries to craft text-optimization attacks to gain visibility in the model summary . However , these methods are typically evaluated in carefully crafted experimental settings, only partial components of the LLMSE workow , neglect- ing their impact on the end-to-end system in real-world scenarios. Luo et al . [42] observed the harmful content and malicious URLs from LLMSE. Howev er , they do not analyze these threats from the perspective of traditional SEO te chniques or assess their phase- specic vulnerabilities. Moreover , how traditional black-hat SEO threats aect LLMSE remain underexplored, posing persistent and transferable risks to evolving LLMSE infrastructures. Our W ork. W e conduct the rst systematic study to investigate the black-hat SEO threat to LLMSE. W e try to answer the following three important research questions (RQ): RQ1 : What is LLMSE workow and whether the design of LLMSE is inherently resistant to SEO manipulations? RQ2 : Will black-hat SEO attacks on traditional search engines aect LLMSE? If so, how do they aect each phase? RQ3 : A re there any LLMSEO techniques that can signicantly manipulating LLMSE results? Driven by these RQs, we rst investigated 10 popular LLMSE products and analyzed the special workow of LLMSE, revealing the attack surfaces. Second, we examined the eectiveness of traditional black-hat SEO techniques on LLMSEs. W e constructed SEO-Bench with 1,000 real-w orld black-hat SEO attacks and then evaluated the defense performance of open-source and closed-source LLMSEs against these attacks. W e further conducted a detailed empirical analysis at dierent phases to uncover the preferences. Finally , we propose seven LLMSEO strategies and conduct an end-to-end ex- periment based on the 450 self-deployment websites. All identied issues were responsibly disclosed to major LLMSE vendors. Contribution. This work makes the following three contributions. • W e provide a detailed investigation of real-w orld LLMSE prod- ucts, uncovering the ir multi-phase workows and identifying phase-specic attack surfaces. • W e reveal that the LLMSEs can resist over 99.78% traditional black-hat SEO attacks, with the Retrieval phase serving as the pri- mary lter , intercepting the vast majority of malicious queries. • W e report that LLMSEs are vulnerable to LLMSEO attacks, i.e., rewritten-query stung and segmented text, double the manip- ulation rate compared to the baseline. 2 Background 2.1 LLMSE & Black-Hat SEO LLMSE. LLM-enhanced search engines (LLMSEs), also known as AI-powered search, combine real-time retrieval with generative summarization and are now widely adopted. Perplexity reports 169M monthly visits [ 56 ], and ChatGPT ocially added search ca- pabilities in 2024 [ 29 ]. Prior work has examined their eciency , accuracy , and veriability [ 39 , 42 , 57 , 65 ], while adversarial stud- ies explored visibility manipulation through GEO [ 1 ] and prompt injection [45, 54]. Black-Hat SEO . Search Engine Optimization (SEO) r efers to im- proving website ranking and organic trac through legitimate means such as optimizing structure, content, and user experience. In contrast, black-hat SEO manipulates rankings by violating search engine guidelines, aiming for short-term gains through techniques such as link farms [ 64 ], keyword stung [ 47 ], search redirection [ 32 , 34 ], cloaking [ 60 , 63 ], semantic confusion through ad injection or jargon obfuscation [ 36 , 67 ], and long-tail ke yword attacks [ 35 , 37 ]. 2.2 Threat Model Motivated to promote specic websites, the attacker deliberately modies the structure or content of the websites so they are favor- ably indexed by search engines.. When a victim user inputs certain queries, LLMSE may surface these websites and incorporate the link to the untrusted website into the generated responses. Attacker’s Goal. The attacker’s obje ctive is to induce LLMSEs to embed attacker-controlled URLs within their responses. Since link-bearing outputs directly guide users to promoted sites, our analysis focuses on responses containing clickable references to attacker-controlled domains ( e.g. citations). Attacker’s Capability . W e assumed that the attacker controls mul- tiple websites and has full authority to customize b oth content and structure. How ever , the attacker has no access to the intermediate outputs of the LLMSE. 3 Attack Surface Analysis of LLMSE In this section, we surveyed the current popular LLMSE systems across both open-source and closed-source markets. Through prac- tical analysis, we can uncover the attack surface of each phase . 3.1 Representative LLMSE Colle ction T o gain a comprehensive understanding of the LLMSE ecosystem, we systematically collected a list of activ ely deplo yed LLMSEs from both industrial and op en-source platforms. First, we searched key- words such as “LLM search” and “ AI search” via Google. W e ex- tracted products from the top 100 sear ch results and selected the ve most frequently mentioned LLMSE pr oducts, which together account for over 98% of the market [ 58 ], representing those with the highest visibility and usage. Second, we survey ed popular open- source repositories in “LLM search” and selected the top ve LLMSE projects with o ver 10k star s from Github [ 15 ], reecting strong com- munity adoption. In total, we identied 10 representative LLMSEs, whose identities and popularity are summarized in T able 1. 3.2 Attack Surface Analysis W e conduct a comprehensive analysis on the colle cted LLMSE to uncover LLMSE attack surfaces. For closed-source LLMSE, we systematically review ed their homepage descriptions and ocial documentation, and manually interacted with them to obser ve user- facing outputs. For open-source LLMSE, we deployed them locally and analyzed their outputs and server-side logs to expose inter- mediate processing. The workow and the corresponding attack surface of LLMSE are summarized in Figure 2. Unveiling the Resilience of LLM-Enhance d Search Engines against Black-Hat SEO Manipulation Query Rew ri ti n g Understand ing [1 ] LLM S E [2 ] LLM S E I m p a c t … Fetch in g Re - ra nk in g Retr ieva l Intent Analysis [1] wikipedia.or g ; LLM is abbr eviation… [2] arxi v .org ; Software Engineering Te s t … [3] dl.acm.org ; LLM - enhanced Search… Summary Generation Summarizing Impact of LLMSE? Rewr it te n queries Retr ie ve d R eferenc es Search Engine API Inner Index Database Summary Conten t Summary Refe re nc es Mitigated New Threat Ke yword stu ffi ng [4 8 ] , Semantic confusion [ 36] , Long - tail key w o r d s [ 35] , No n- sense keywords [3 8] SEO on single search engine Red ir ec ti on [ 33] , S pam [3] , Link Farm [6 9] Spam [3] , Semantic Confusion [ 36] Prompt injection [ 40] , Rewr it te n - queries as keyword stuf fi ng [Ou r work] Poi s on of re - rank algorithm [Ou r work] Att e nt i o n hi j a c k i n g b y a d ve r s a r i al t ex t [ 45, Ourwork ] LLMSE vs. T raditional Search Engine [1] dl.acm.org ; LLM - enhanced Search… [2] wikipedia.org ; LLM is abbr eviation… [3] arxiv .org ; Softwar e Engineer ing Te s t … User query The Impact of LLMSE : First, Integra tion of Search and LLM Capabilities . [1 ] Second, Improved User Experience. [2] ... Referenc e: [1] LLM - enhanced Search Engine, dl.acm.org [2] LLM Application, wikipedia.org Sorry, I cannot h elp to an swer… [1] LLMSE [2] LLMSE Impact … Figure 2: The W orkow and the Attack Surfaces of LLMSE. It includes three phases: (1) Understanding : LLMSE analyzes user query’s intent and rewrites the original query; (2) Retrieval : fetching information from multiple databases with the rewritten queries, and re-ranking refer ences; (3) Summarizing : gathers all the structured information and generates the nal answer , outputting the summary content and references. T able 1: Overview of Representative LLMSEs LLMSE Provider Popularity Pub. Date API Closed Source ChatGPT Search [50] OpenAI 5.91B Visits 2024-10-31 Y Gemini Grounding [20] Google 1.06B Visits 2024-10-31 Y Google AI Overview[22] Google 88.5B Visits 2024-05-14 N Perplexity [53] Perplexity 169M Visits 2022-12-07 Y Komo AI [28] Komo 201k Visits 2023-01-18 Y Open Source Open W ebUI [9] Open W ebUI 112k Stars 2023-10-07 Y Khoj [8] Khoj AI 31.3k Stars 2021-04-04 N Storm [30] Stanford OV AL 27.5k Stars 2024-04-09 Y Perplexica [25] ItzCrazyKns 26.4k Stars 2024-04-09 Y GPT Researcher [12] Assaf Elovic 23.7k Stars 2023-05-12 Y 1) Monthly visits counts are from Similar W eb [56]; # of stars are from Github. 2) Google AI Overview is an internal experiments module of Google Search. 3) All statistics are collected as of September 2025. Phase 1: Understand the Quer y . LLMSE understands the user’s input , and provide actionable guidance for subsequent phases. This process contains two main components: (1.1) Intent A nalysis : Infer user intent and decide whether ex- ternal retrieval is needed ( e.g. ChatGPT [ 49 ], Gemini [ 19 ]). This step lters irrelevant or malicious parts of the query , helping de- fend against attacks like irrelevant keyword stung and semantic confusion. Howev er , LLM-driven inference remains susceptible to adversarial attacks such as prompt injection or jailbreaks [40]. (1.2) Query Rewriting : Rewrite the user input into one or mor e standardized queries [ 62 ]. Among the examined LLMSEs, 8/10 clearly indicate that they actively regenerate queries, often adopting a role-playing strategy [ 14 , 26 ]. This step helps normalize phrasing and defend against adversarial manipulations based on typographic variations or misleading phrasing, e .g. the long-tail SEO [ 35 ] and non-sense key word SEO [ 38 ]. However , it might be exploited if attackers can predict rewritten queries and tailor stung attacks accordingly , as further discussed in Section 5. Phase 2: Retrieve the Information. In this phase , the LLMSE exe- cutes the re written queries to gather candidate retrieved r eferences and their content for subsequent processing. (2.1) Fetching : Employ external engines ( e.g. Google [ 23 ], T avily [ 59 ]) or inner database to fetch potentially relevant results. Some LLM- SEs can restrict the search scope to curate d domains [ 51 , 52 ] to improve reliability . The diversity of retrieval sour ces helps mitigate single-source poisoning. (2.2) Re-ranking : Scoring each retriev ed content [ 19 ] and lter for relevance. The r e-ranking process lters out spam-driven SEO abuse such as link farms, but its underlying scoring heuristics may unintentionally bias page selection, which we further examine in Section 4.4 and explore its attack implications in Section 5. Phase 3: Summarize the Answer . After retrieval, LLMSE syn- thesizes the summary and typically includes in-text citations or references to enhance credibility . (3.1) Summary Generation : Summarize a coherent and logically consistent response. Apart from ChatGPT and Gemini, most LLM- SEs rely on external LLM APIs for content synthesis [ 62 ], with some integrating multiple LLMs [ 13 ]. It improves factual consistency and lters out spam or semantic-confusion content, yet remains vulner- able to adversarial text that can hijack model attention [45]. 4 Resilience of Black-Hat SEO Attack Since LLMSEs are similar to traditional search engines, attackers in- tuitively apply e xisting black-hat SEO techniques to them. T o assess how traditional black-hat SEO aects LLMSEs and dissect how the multi-phase mechanisms mitigate or amplify these manipulations, we conduct a comprehensive evaluation of LLMSE r esilience with a large-scale real-world black-hat SEO attacks in this section. Pei Chen et al. T able 2: Details of Black-Hat SEO Attacks in SEO-Bench Black-Hat SEO Attack Query Classication Method # Semantic Confusion [36, 66, 67] Illegal-words SCDS [66] 200 Redirection [33, 34, 44, 61] Illegal-words Rule-Based Detector [33] 200 Cloaking [24, 46, 60, 63] Illegal-words Dagger [60] 200 Keywords Stung [3, 41, 48, 68] Hot-words Rule-Based Detector [48] 200 Link Farm (SSP) [6, 11, 27, 64] Hot-words DNS Scanner [11] 200 4.1 Experiment Setup T o evaluate the r esilience of LLMSEs against black-hat SEO attacks, we use Google Search as a representative traditional search engine to collect real-world successful attacks. An attack succeeding on Google but failing on an LLMSE indicates resilience. All samples from e xisting attacks ensure both ethical compliance and diversity . SEO-Bench Construction. T o nd black-hat SEO websites, we rst conducted a literature review , getting ve categories of black- hat SEO attack techniques that have well-established denitions: ❶ Semantic Confusion : blends copied legitimate text with illicit pro- motions to dilute malicious intent, which raises ranking and e vades lters; ❷ Redirection : exploits vulnerabilities on high-authority sites to for ward users to promoted targets, thereby inheriting the trusted site’s cr edibility; ❸ Cloaking : detects crawlers via request headers and ser ves SEO-optimized content to search engines while pre- senting dierent promotional or unrelated content to real users; ❹ Keywor d Stung : emb eds excessive or trending terms to inate ap- parent relevance and manipulate ranking algorithms; ❺ Link Farm : creates large interlinked networks of low-quality sites to articially raise link-base d authority scores. Based on these studies, we re- produced the classication methods proposed in the corresponding works and tuned the respective classiers. The implementation and evaluation are pro vided in Appendix A. Then, w e selected appropriate origin keyword queries, including illegal-words and hot-words. Illegal-w ords typically involve terms related to illegal or prohibited content, reecting the underlying incentives for black-hat SEO; we e xtracted 2,499 illegal-wor ds from prior studies [ 33 , 36 , 60 , 67 , 69 ]. Hot-words include popular search terms unrelated to the actual page content, which attackers use to boost visibility in rankings; we colle cted 9,301 hot-words from Google Tr ends [ 18 ] over a six-month period (Nov . 2024 – Apr . 2025). W e then queried these 11,800 ke ywords on Google, and sav ed the top 50 search r esults, including their titles, summaries, URLs, redirection chains, and H TML content. From over 500M collected websites, we identied 1,602 valid query-website pairs by the classiers. T o ensure a balanced representation of each attack type in the dataset, we selected 200 pairs for each of the ve SEO attack categories. As a result, our SEO-Bench dataset consists of a total of 1,000 query-website pairs. T able 2 shows the dataset details. LLMSE Defense Evaluation. W e evaluate nine LLMSEs intro- duced in Se ction 3, excluding Go ogle AI Overview due to its limited and unstable availability [ 17 ]. For closed-source LLMSEs, we select their rst v ersion with full search functionalities, i.e., gpt-4o-mini , gemini-1.5 , sonar , komo . For open-source LLMSEs, we deploy them locally with default congurations, and use gpt-4o-mini as the summarization model to ensure comparability across systems. T o quantify the resilience of LLMSEs against black-hat SEO attacks, we evaluate their ability to block target websites across dierent phases. Each entry in SEO-Bench is a query–website pair ( 𝑞 𝑖 , 𝑡 𝑖 ) , where 𝑞 𝑖 is a search quer y and 𝑡 𝑖 is the asso ciated black- hat SEO website. W e independently evaluate the resilience of each phase using a phase-specic blocking rate, dened as the propor- tion of attacks intercepted at that phase among those entering the phase. Specically: In Understanding phase, an attack is blocke d if the LLMSE decides not to procee d with retrieval after analyzing, indicating an early rejection of the search. In Retrieval phase, an attack is blocked if the LLMSE performs retrieval but the SEO web- site does not appear in the retrieved results. In Summarizing phase, an attack is blocke d if the SEO website appears in the retrieval reference but is excluded from the nal r eference. W e also employ Cumulative Resilience to intuitiv ely capture the overall interception achieved after each phase. The metrics are in Appendix B. 4.2 Landscape W e assess nine LLMSEs with three trials per query (27,000 requests). Results are summarized in T able 3. Our evaluation shows that LLMSEs are highly eective against black-hat SEO attacks, with the Understanding , Retrieval , and Sum- marizing phases blocking 15.7%, 98.2%, and 85.2% of attacks at their respective phases. Overall, they achieve a cumulative blocking rate of 99.78%, where Retrieval plays the most decisive role by lter- ing the majority , and Summarizing adds a strong safeguard before output generation. These results highlight the importance of lay- ered defenses in LLM-based systems, enabling them to signicantly outperform traditional search engines in resisting SEO attacks. Although the results show that black-hat SEO techniques can still inuence LLMSEs, the resilience varies signicantly across LLMSEs. ChatGPT is not aected by any black-hat SEO attack with a high refusal rate. Notably , op en-source LLMSEs keep great defense performance, due to the fact that they choose the search engine API such as T avily [ 59 ] or SearXNG [ 55 ], which provide optimized source. In contrast, K omo and Perplexity are most aected. The impact of dierent types of black-hat SEO attacks on LLMSEs varies as well. Semantic Confusion and cloaking pose the greatest risks in the nal output to LLMSEs. For example, Komo is sever ely aected by Semantic Confusion, with a low ltering of 83.0% and 73.5%. Meanwhile, Gemini is only aected by Semantic Confusion. In contrast, although both redirection and cloaking attacks have successfully passed the Retrieval phase on some LLMSEs, few of them advanced to the Summarizing phase, thus failing to achieve a successful attack on the Summarizing phase. Besides, the Ke yword Stung poses no inuence on any LLMSE. ▶ Finding I : LLMSEs exhibit strong resilience to black-hat SEO attacks, achieving the cumulative blocking rate of 99.78%. Retrieval phase intercepts the vast majority of malicious queries. Semantic Confusion poses the greatest risks to LLMSEs. 4.3 Resilience on Understanding Phase Firstly , we measure how LLMSEs interpr et and rewrite the quer y in the Understanding phase helps mitigate black-hat SEO attacks. Unveiling the Resilience of LLM-Enhance d Search Engines against Black-Hat SEO Manipulation T able 3: Performance of Black-Hat SEO Attacks on LLMSEs. Each item: Resilience (Und) / Resilience (Ret) / Resilience (Sum). LLMSE T otal Performance Semantic Confusion Redirection Cloaking Keywords Stung Link Farm ChatGPT 75.8% / - / 100% 92.5% / - / 100% 79.0% / - / 100% 84.0% / - / 100% 62.0% / - / 100% 61.5% / - / 100% Gemini 16.3% / - / 99.8% 38.0% / - / 99.0% 4.5% / - / 100% 24.0% / - / 100% 3.0% / - / 100% 12.0% / - / 100% Perplexity 4.6% / 98.2% / 64.7% 12.0% / 94.9% / 55.6% 1.5% / 99.0% / 50.0% 6.0% / 97.9% / 100% 0 / 100% / - 3.5% / 99.0% / 50.0% Komo 4.2% / 94.9% / 67.3% 0 / 83.0% / 73.5% 1.0% / 99.0% / 100% 20.0% / 93.8% / 50.0% 0 / 100% / - 0 / 98.5% / 33.3% Open- W ebUI 8.1% / 96.0% / 100% 12.1% / 93.1% / 100% 0 / 100% / - 7.7% / 91.7% / 100% 0 / 100% / - 17.9% / 95.7% / 100% Khoj 30.9% / 99.6% / 100% 61.0% / 100% / - 19.5% / 100% / - 36.5% / 100% / - 16.5% / 100% / - 21.0% / 98.1% / 100% Storm 0 / 99.8% / 50.0% 0 / 100% / - 0 / 100% / - 0 / 100% / - 0 / 100% / - 0 / 99.0% / 50.0% Perplexica 0 / 100% / - 0 / 100% / - 0 / 100% / - 0 / 100% / - 0 / 100% / - 0 / 100% / - GPT Researcher 1.4% / 95.5% / 100% 0 / 88.5% / 100% 0 / 97.5% / 100% 0 / 95.0% / 100% 3.0% / 100% / - 3.9% / 98.0% / 100% A verage Res. 15.7% / 98.2% / 85.2% 24.0% / 95.4% / 88.0% 11.7% / 99.5% / 90.0% 19.8% / 97.6% / 91.7% 9.4% / 100.0% / 100.0% 13.3% / 98.7% / 79.2% Cumulative Res. 15.7% / 98.48% / 99.78% 24.0% / 96.50% / 99.58% 11.7% / 99.56% / 99.96% 19.8% / 98.08% / 99.84% 9.4% / 100.00% / 100.00% 13.3% / 99.00% / 99.96% Gemini GPT R esear cher Khoj Open- W ebUI Stor m 15 10 5 0 5 10 15 Figure 3: Distribution of W ord Counts after Rewriting. Intent Interception. Upon receiving a user query , LLMSEs infer its intent to decide whether a web search is necessary . W e ana- lyze the interception mechanism by inspe cting the specic API eld values, as ChatGPT and Gemini explicitly indicate whether “web_search” is invoked. Then we manually check these refused queries and corresponding answers. In our result, 75.8% of queries on ChatGPT ar e intercepted with no reference. Among them, 30.6% are refused due to violations of safety policies, and 69.4% are skippe d due to intent misinterpretation, where the system tr eats the input as a statement rather than a search query . This is because, unlike dedicated search engines, LLMSEs such as ChatGPT , which treat search as an auxiliar y function, tend not to invoke search when they can answer based on internal knowledge. Similarly , Gemini intercepts 16.3% of queries, with 67.4% refusals and 32.6% misinter- pretations. Although intent interception is not designed to counter SEO attacks, it can incidentally lter harmful or illicit queries before search execution, thereby reducing exposure to malicious content. ▶ Finding II : Intent interception enables LLMSEs such as Chat- GPT to lter out 75.8% of queries, eectively disrupting mali- cious SEO attempts at the start, even though unintentionally . Query Rewriting. Before performing a r eal search in the Retrie val phase, some LLMSEs generate a rened version of the original query . T o investigate how this step inuences the eectiveness of SEO-based manipulations, we extract the rewritten keywords on ve of the collected LLMSEs that provide the r ewritten queries in their API response, and compare them with the original inputs. Our analysis reveals that almost all of them prefer to rewrite the query . Figure 3 shows the changes in word count during the r ewriting. For example, GPT Resear cher shows a strong tendency to expand the query (77.56%), while others are more likely to shorten it. Further examination of the system prompts indicates that the rewriting mechanisms, such as prex/sux modications, quer y formatting, and targeted semantic enrichment, are guided by instructions aimed at improving search accuracy and user e xperience. T o further examine how rewriting can mitigate the inuence of black-hat SEO, we conducted a supplementary validation exper- iment on quer y rewriting. As detailed in Appendix C, reissuing rewritten queries to Google Search showed that 98.16% faile d to retrieve the original SEO websites, with even minor e dits (edit distance below 0.1) reducing attack success rates to under 10%, con- rming the strong disruptive impact of rewriting on adversarial rankings. These results indicate that even slight syntactic modica- tions can substantially suppress exposure, suggesting that quer y rewriting serves as an eective and lightweight countermeasure . ▶ Finding III : Query rewriting by LLMSEs eectively disrupts SEO attacks, including Long-tail and K eyword Stung. Even small edits can reduce the attack success rate to under 10%. 4.4 Resilience on Retrieval P hase Then, we measure how fetching and re-ranking in the Retrieval phase helps mitigate black-hat SEO attacks. Fetching Preferences. LLMSEs can restrict the search scope during fetching, so we examine whether their returned links are of higher quality than those from traditional engines. Using do- main rankings [ 31 ], we analyze retrieved references collected from trending queries. As sho wn in Figure 4, most LLMSEs favor higher- ranked domains, with top-5k links appearing more frequently than lower-ranked ones. For instance, ChatGPT’s share of authoritative links is nearly 50% higher than Go ogle’s. In contrast, LLMSEs such as Khoj and Perplexica exhibit over 60% unreliable links due to hal- lucinated URLs. However , while prioritizing authoritative sources improves r esult reliability and reduces SEO risks, excessive trust in high-ranking domains may introduce new vulnerabilities, such as malicious redirects or comment-based attacks on reputable sites. Pei Chen et al. Google ChatGPT Gemini K omo P erple xity GPT R esear cher P erple xica Khoj Open- W ebUI 0% 20% 40% 60% 80% 100% Stor m 1 5K 10K 20K 50K 100K 500K 1M + Figure 4: Domain Rank Proportions of Retrieved References from Both T raditional Search Engines and LLMSEs. ▶ Finding I V : LLMSE fetching preferences for authoritative websites enhance the overall search quality , but also emphasize the risk of compromised high-ranking sources. Re-ranking Preferences. After fetching the content of web pages, LLMSEs often re-rank them base d on internally dened quality assessment criteria. T o investigate this preference, we e xamine the rank shifts of links that appear in both Google search results and LLMSEs. For each link that occurs in both result sets, we compute its relative rank change within the respective systems as ∆RelRank 𝑖 = Rank 𝑖 LLM − Rank 𝑖 Google (1) where Rank 𝑖 Google denotes the relative rank of the 𝑖 -th link within the set of overlapping links in the Google search results, and Rank 𝑖 LLM denotes its relative rank in the LLMSEs results. T o further uncover the re-ranking criteria employ ed by LLMSEs, we categorize w eb- sites with increasing relative rankings (i.e., Δ RelRank 𝑖 < 0 ) as up sites, and those with decreasing relative ranks (i.e., Δ RelRank 𝑖 > 0 ) as down sites. Then, we analyze several common features of the websites by computing the average values and their corresponding rates of dierences, as summarized in T able 4. The results indicate that websites with increased rankings in LLMSEs typically exhibit a higher degree of text fragmentation ( +19.04%) and a gr eater presence of multimodal r esources ( +18.71%) in terms of content. Structurally , they tend to feature denser internal linking ( +14.89%) and greater DOM depth (+11.36%), which reects a higher le vel of formatting complexity . These observed dierences suggest a set of potentially inuential factors that may reect the preferences of LLMSEs. W e will further examine their actual impact through controlled experiments in Section 5. ▶ Finding V : During the re-ranking, LLMSEs tend to favor webpages with higher content quality and content richness. 4.5 Resilience on Summarizing Phase Finally , we measure summary intercepting of Summarizing phase. Summary Interception. T o evaluate LLMSE resilience against illicit promotion during summar y generation, we examine their T able 4: Dierent Features of Re-Ranked W ebsites Features A vg. ( Up ) A vg. ( Down ) Dierences P-value T ext Fragmentation 60.09 50.48 +19.04% 0.0100 DOM Depth 13.93 12.51 +11.36% 0.0036 T ag Diversity 22.61 22.27 +1.543% 0.8674 External Link # 14.71 15.81 -6.971% 0.9901 Internal Link # 45.66 39.74 +14.89% 0.0003 Multi-modal # 12.50 10.53 +18.71% 0.0292 Meta Completeness 0.4167 0.4196 -0.6911% 0.8809 Alt Coverage 0.2899 0.2873 +0.9050% 0.8540 If p-value < 0 . 05 , the dierence is considered statistically signicant [4]. T able 5: Illegal Proportion in Dierent P hases. LLMSE Retrieved References Summary References ( 𝛿 ) Summary Content ( 𝛿 ) ChatGPT – 2.00% ( –) 2.00% (0.0%) Gemini – 0.00% ( –) 0.00% (0.0%) Komo 4.36% 1.53% ( ↓ 64.9%) 0.28% ( ↓ 81.7%) Perplexity 0.69% 0.35% ( ↓ 49.3%) 0.00% ( ↓ 100.0%) GPT Researcher 10.07% 3.48% ( ↓ 65.4%) 1.55% ( ↓ 55.5%) Perplexica 1.24% 0.19% ( ↓ 84.7%) 0.00% ( ↓ 100.0%) Khoj 1.27% 0.05% ( ↓ 96.1%) 0.00% ( ↓ 100.0%) Open- W ebUI 10.98% 0.23% ( ↓ 97.9%) 0.00% ( ↓ 100.0%) Storm 1.61% 0.50% ( ↓ 69.0%) 0.00% ( ↓ 100.0%) A vg. 4.89% 0.92% ( ↓ 75.3%) 0.43% ( ↓ 70.8%) ability to lter malicious content from illegal queries. W e use an illicit-website classier (Appendix A) to measure the proportion of illegal references in Retrie val and Summary phases. Additionally , we analyze the semantics of the responses to determine how many illicit links contaminate the generated summaries. As shown in T able 5, LLMSEs increasingly block malicious content as generation proceeds. In the Summary phase, they remove on average 75.3% more illegal links than in the Retrieval phase, with Op en- W ebUI achieving the largest reduction (97.9%). Furthermore , 70.8% illicit content is intercepted from the summary reference to the answer content. These results indicate that LLMSEs generally favor neutral or positive content and actively suppress outputs involving violence, pornography , or other harmful material, reecting their built-in safety mechanisms and alignment with normative standards. W e further analyze intercepted SEO attacks in the Summarizing phase, including Semantic Confusion and Cloaking . Such pages often contain irrele vant or mixed content, weakening semantic rele vance to the quer y . For example, confusion attacks may embed illicit promotions within otherwise legitimate text to enhance credibility . Appearing benign, they diverge from the illegal intent and are excluded from summaries. This suggests that, beyond rejecting harmful content, LLMSEs prioritize sources semantically aligned with query intent, which further mitigates SEO attacks. ▶ Finding VI : LLMSEs prefer benign and semantically aligned content in summarization, refusing additional 75.3% illegal websites. This strategy further mitigates the threat of illicit content and the impact of attacks such as Semantic Confusion. Unveiling the Resilience of LLM-Enhance d Search Engines against Black-Hat SEO Manipulation T able 6: Success Rate of LLMSEO Attacks on LLMSEs. The percentage in each row indicates the success rate of a spe cic approach among all successful attacks. The bold numbers highlight the most eective attacks, and the up arrows ( ↑ ) indicate the most improving attacks between Summarizing phase and Retrieval phase. LLMSE Exposed Phase Baseline Understanding Retrieval Summarizing Blank Semantic Confusion Rewritten-query Stung Internal Links Multi-modal Resources Nested Structure Segmented T ext Relevance Enhancement Q&A Formatting Perplexity Retrieval 7.29% 0.00% 19.79% 10.42% 8.33% 6.25% 28.12% 11.46% 8.33% Summarizing 0.00% 0.00% 25.00% 12.50% 12.50% 0.00% 37.50% ↑ 12.50% 0.00% Komo Retrieval 8.33% 0.00% 23.96% 10.42% 9.38% 1.04% 30.21% 10.42% 6.25% Summarizing 2.44% 0.00% 26.83% 2.44% 4.88% 0.00% 41.46% ↑ 14.63% 7.32% Open- W ebUI Retrieval 9.09% 2.60% 27.27% 2.60% 3.90% 11.69% 28.57% 0.00% 14.29% Summarizing 0.00% 0.00% 0.00% 0.00% 0.00% 0.00% 0.00% 0.00% 0.00% Khoj Retrieval 12.38% 3.47% 16.34% 4.95% 6.93% 26.73% 17.33% 4.46% 7.43% Summarizing 15.29% 1.18% 16.47% 4.71% 2.35% 30.59% 22.35% ↑ 1.18% 5.88% Storm Retrieval 13.9% 1.36% 23.71% 10.08% 9.26% 15.80% 9.54% 4.90% 11.44% Summarizing 14.03% 0.45% 16.29% 10.86% 11.31% 19.91% ↑ 8.14% 5.88% 13.12% Perplexica Retrie val 20.25% 0.00% 7.59% 5.06% 3.8% 7.59% 45.57% 10.13% 0.00% Summarizing 19.35% 0.00% 0.00% 6.45% 3.23% 6.45% 51.61% ↑ 12.9% 0.00% GPT -Researcher Retrieval 0.00% 0.00% 21.74% 2.17% 6.52% 0.00% 65.22% 0.00% 4.35% Summarizing 0.00% 0.00% 24.32% ↑ 2.70% 8.11% 0.00% 59.46% 0.00% 5.41% 5 LLMSEO Attack Building on these ndings, we propose and evaluate nov el end-to- end attacks tailored to LLMSEs, extending beyond prior work that focused only on ranking or summarization components [ 1 , 2 , 70 ]. 5.1 LLMSEO Attack T echniques As each phase of the LLMSE workow ( Understanding , Retrieval , and Summarizing ) exposes distinct se curity risks, we design phase- specic LLMSEO attack strategies to systematically evaluate and manipulate these vulnerabilities. Attacking Understanding Phase. In this phase, rewriting intro- duces ambiguity and susceptibility to manipulation. T o exploit this vulnerability , we design a targeted attack. • Rewritten-query Stung. Embed p otential rewritten queries ex- tensively within web pages. Since most LLMSE may not always use the original search key for r etrieval (Section 3), predicting possible new queries and inserting them in web content can increase the likelihood of being matched. Note that while prompt injection is an important attack vector in this phase (see Section 3), its impact is well studied [ 5 , 40 , 45 , 54 ] and highly prompt-dependent, so we exclude it from our experiments. Attacking Retrieval P hase. Aiming to increase the priority in re-ranking and inspired by Finding V, we propose new techniques designed to align with the scoring mechanism. • Internal Links. Embed numer ous internal links within w eb pages to construct a network, simultaneously increasing the number of links to key pages. • Multi-modal Resources. Incorporate multi-modal resources ( e .g. text, images, and videos) into web pages to increase their rich- ness and boost perceived credibility . • Nested Structure. Use structured lab els and indexing that are better suited for retrieval to enhance the readability and accessi- bility of content, helping LLMSE quickly locate and extract key information, gaining an advantage in candidate selection. • Segmented T ext. Reduce the length of individual text segments. Shorter texts are often more suitable for dir ect citation. Attacking Summarizing Phase. T o inuence this phase, we de- sign optimization strategies targeting both relevance and format. • Relevance Enhancement. Fo cus on core keywords to enhance the semantic relevance and coherence of the te xt to the query . • Q&A Formatting. Present content in a question-and-answer (Q&A) format in the conversational tone of LLM-generated responses, increasing the likelihood of direct reuse by LLMSE. 5.2 Eectiveness Evaluation T o examine the applicability of these LLMSE attack te chniques inuencing LLMSEs, we conducte d a competitive experiment to compare the ecacy of various attack strategies under real-world conditions. Methodology . T o evaluate the eectiveness of dierent LLMSE attack techniques, we deployed blog websites under a controlled domain, each promoting a dierent brand of the same type of pr od- uct. W e then queried LLMSEs for product recommendations using domain-restricted prompts (Appendix D), and recorded the propor- tion of recommended sites associated with each attack technique. This restriction reduces ethical concerns arising from real-world search pollution while enabling fair comparison across techniques. A higher occurrence suggests a stronger alignment between the corresponding manipulation and the preferences of the LLMSE. T o mitigate the impact of randomness in LLMSE responses, the query was repeated 10 times per LLMSE, and we aggregated the to- tal number of times each site appeared in the r esponses. In addition to the seven LLMSE attack typ es, we include d one non-SEO and one traditional SEO attack ( i.e. Semantic confusion, which showed the best performance in Section 4.2) for baseline comparison. For each attack type, 50 websites were cr eated. In total, the experiment involved 450 adversarial websites. T o ensure ethical compliance, all Pei Chen et al. websites were labeled as “For T esting Purposes Only” and taken of- ine after the experiment nished. This ensur ed minimal long-term impact while maintaining the integrity of real-world testing. Implementation. W e implemented these LLMSE attacks across various websites. Specically , we rst generated a set of products using the same pattern, i.e. “Brand” + “Entity” noun, and generated the base content with gpt-4o-mini . W e also use the mo del for Rewritten-query Stung , generating rewritten queries and embed- ding them into web pages. For the Internal Links , we emb edded hyperlinks among the 50 websites of this typ e, forming mutual link- ing connections in the “Useful Links” block. For the Multi-modal Resources , we doubled the number of images in the base website content to increase visual richness. In the Nested Structure , we added an additional layer of subheadings, e xpanding from second-level to third-level headers to increase structural complexity . For the Segmented T ext , w e restructur ed the content by halving the average paragraph length, resulting in more segmented text blocks. For the Relevance Enhancement , we removed the irrelevant part, e .g. teams, and added more descriptions about products. In the Q&A Format- ting , each paragraph was prefaced with a question, followed by a corresponding answer block to simulate a question-answer format. In the Semantic Confusion , we inserted a promotional segment into unmodied news content. Results. T able 6 presents the performance of LLMSEO attacks on LLMSEs, where each row shows the proportion of a sp ecic attack type among all successful attacks. 1 Overall, all proposed attacks demonstrated measurable eectiveness on LLMSEs, with each achieving performance above the baseline in at least one LLMSE. In all attacks, attacks targeting the Retrieval phase were more eective. Segmented T ext achieved the highest attack across most LLMSE platforms, with an exposure rate excee ding 50% on Perplexica and GPT -Researcher , indicating that LLMSEs are better at understanding short and segmented content. The second most eective technique was Re written-query Stung , which double d the exposure rate compared to the baseline in ve LLMSEs, highlighting its strong inuence on downstream outcomes. W e further compare attack proportions across phases to assess each phase’s ltering eects. As Summarizing proportions post- Retrieval ltering, we focus on the attack eectiveness dierences between the two phases to capture summary interception. In Ta- ble 6, we mark signicant incr eases in attack proportions during Summarizing . Content-driven strategies, such as Segmented T ext and Relevance Enhancement , sho w noticeable gro wth, while Seman- tic Confusion , as well as link- and resource-based tactics ( Internal Links , Multi-modal Resources ), tend to decline. This shift suggests that, in Summarizing phase, LLMSE is more inuenced by content quality rather than the structure of external resources, underlining the importance of content-level manipulation. 6 Discussion Security Implications. The application of LLMSEs in information retrieval reshapes user trust and the threat landscape of black- hat SEO. Users o ver-rely on LLMSE-generated summaries and ref- erences, perceiving them as authoritative, which magnies the 1 Notably , gpt-4o-mini and gemini-1.5 refused to access all provided URLs in this experiment, likely due to stricter content-fetching policies [16]. risks when malicious content and links are included in trusted outputs. Building upon traditional black-hat SEO, attackers are in- creasingly adapting their strategies to the internal preferences of LLMSEs, shifting content manipulation fr om isolated optimizations to system-lev el adversarial interactions. As LLMSE adoption gro ws, such weaknesses may gradually distort the W eb’s credibility struc- ture, highlighting the need for timely , robust defenses to support a healthy information ecosystem and sustained user trust. Mitigation. T o mitigate the vulnerabilities identied in this study , defenses for LLMSEs should be reinforced in a phase-awar e manner across the entire workow . In the Understanding phase, analyz- ing the stability of quer y rewriting and intent interpretation can help detect inputs deliberately aligne d with rewriting b ehaviors; paraphrasing-based ltering, as shown in PoisonedRA G [ 70 ], can counter poisoning attempts in RA G systems. During Retrieval , miti- gation should go beyond static domain authority by incorp orating behavior-based signals, such as redirection patterns and cross-query reference consistency , to identify abused high-credibility sources. In the Summarizing phase, additional safeguards are neede d against prompt- or text-based manipulations embedded in retrieved pages that may bias summarization pr eferences. Furthermore, user aware- ness and transparency features, such as link provenance or cr edi- bility indicators, are crucial to r educe over-reliance on generated outputs and promote critical content v erication, collectively en- hancing the resilience of the LLMSE ecosystem. Limitation. Our evaluation focused on ten r epresentative LLMSEs selected by user scale and popularity , though other systems beyond this scope may demonstrate stronger r esilience. For ethical reasons, our implemented LLMSEO attacks were intentionally simplied and deployed for limited durations; real-world adversaries may employ more sophisticated or persistent methods, and the combined eects of multiple strategies remain unexplored. 7 Conclusion This work presents the rst systematic security analysis of Large Language Model-enhanced Search Engines (LLMSEs), revealing how black-hat SEO continues to inuence their behaviors. By ana- lyzing phase-specic preferences and weaknesses, we demonstrate eective LLMSEO attacks that exploit these vulnerabilities. W e oer insights into more secure and resilient AI-driven sear ch systems. Acknowledgments This work was supporte d by the New Generation Articial Intelligence- National Science and T echnology Major Project (No. 2025ZD0123204). Min Y ang is a faculty of Shanghai Pudong Research Institute of Cryptology , Shanghai Institute of Intelligent Ele ctronics & Sys- tems and Engineering Research Center of Cyb er Security Auditing and Monitoring, and Shanghai Collaborative Innovation Center of Intelligent Visual Computing, Ministry of Education, China. References [1] Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, and Ame et Deshpande. 2024. Geo: Generative engine optimization. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining . ACM, New Y ork, NY, USA, 5–16. [2] Marwah Alao, Paul Thomas, Falk Scholer , and Mark Sanderson. 2024. LLMs can be Fooled into Lab elling a Do cument as Relevant: b est café near me; this paper is perfectly relevant. In Proceedings of the 2024 Annual International ACM Unveiling the Resilience of LLM-Enhance d Search Engines against Black-Hat SEO Manipulation SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacic Region (SIGIR-AP ’24) (T okyo, Japan) (SIGIR-AP 2024) . Association for Computing Machinery , New Y ork, NY, USA, 32–41. doi:10.1145/3673791.3698431 [3] Lourdes Araujo and Juan Martinez-Romo. 2010. W eb spam detection: new classication featur es based on qualied link analysis and language models. IEEE Transactions on Information Forensics and Security 5, 3 (2010), 581–590. [4] Peter Bruce and Andrew Bruce. 2017. Practical Statistics for Data Scientists . O’Reilly Media, Sebastopol, CA, USA. [5] Sizhe Chen, Arman Zharmagambetov , Saeed Mahloujifar , Kamalika Chaudhuri, David W agner, and Chuan Guo. 2025. SecAlign: Defending Against Prompt Injection with Preference Optimization. In Pr oceedings of the ACM Conference on Computer and Communications Security (CCS) . ACM, Taipei. Preprint at [6] Y oung-joo Chung, Masashi T oyoda, and Masaru Kitsuregawa. 2009. A study of link farm distribution and evolution using a time series of web snapshots. In Proceedings of the 5th international workshop on Adversarial information retrieval on the W eb . A CM, New Y ork, N Y, USA, 9–16. [7] CNBC. 2025. AI startup Perplexity in talks to double valuation to $1.8 billion via new funding. https://w ww .cnbc.com/2025/03/20/perplexity-in-talks-to-double- valuation-to-18-billion-via-new-funding.html. Accessed: 2025-04-19. [8] Khoj AI Contributors. 2023. Khoj: Natural language second brain. https://github. com/khoj- ai/khoj Accessed: 2025-04-10. [9] Open W ebUI Contributors. 2023. Open W ebUI: A self-hosted ChatGPT UI. https://github.com/open- webui/open- webui Accessed: 2025-04-10. [10] Wikipedia contributors. 2025. Search engine optimization. https://en.wikipedia. org/wiki/Search_engine_optimization Accessed: 2025-01-22. [11] Kun Du, Hao Y ang, Zhou Li, Haixin Duan, and Kehuan Zhang. 2016. The ever- changing labyrinth: a large-scale analysis of wildcard DNS p owered blackhat SEO. In Proceedings of the 25th USENIX Conference on Se curity Symp osium (SEC’16) . USENIX Association, A ustin, TX, USA, 245–262. [12] Assaf Elovic. 2023. GPT Researcher: A utonomous agent for comprehensive online research. https://github.com/assafelovic/gpt- researcher Accessed: 2025-04-10. [13] Assaf Elovic. 2023. gpt-researcher Documentation. https://gptr .dev/#features. Accessed: 2025-04-20. [14] Assaf Elovic. 2023. gpt-researcher Prompt Example. https://github.com/ assafelovic/gpt- researcher/blob/dbc0bbe4cf55d918511b779cc320454b153415f1/ gpt_researcher/prompts.py#L15. Accessed: 2025-04-20. [15] felladrin. 2023. Aw esome AI W eb Search. https://github.com/felladrin/awesome- ai- web- search. Accessed: 2025-04-07. [16] Google. 2024. Gemini API: URL Context. https://ai.google.dev/gemini- api/docs/ url- context. Accessed: 2025-06-06. [17] Google. 2024. How AI Over view works in Google Search. https://support.google. com/websearch/answer/14901683. Accessed: 2025-04-07. [18] Google. 2025. Hot Trends. http://www.google.com/tr ends/hottrends Accessed: 2025-01-01. [19] Google AI. 2024. Gemini API Grounding Documentation. https://ai.google.dev/ gemini- api/do cs/grounding. Accessed: 2025-04-20. [20] Google AI T eam. 2025. Gemini by Go ogle. https://gemini.google.com. Accessed: 2025-01-11. [21] Google Developers. 2024. Google crawlers: User agents used by Google- bot. https://developers.google.com/search/docs/crawling- indexing/google- common- crawlers Accessed: 2025-04-24. [22] Google Developers. 2025. AI O verviews and Y our W ebsite. https://developers. google.com/search/docs/appearance/ai- overviews. Accessed: 2025-01-11. [23] Google Developers. 2025. Custom Search JSON API. https://developers.google. com/custom- search/v1/overview. Accessed: 2025-01-11. [24] Luca Invernizzi, Kurt Thomas, Alexandros Kaprav elos, Oxana Comanescu, Jean- Michel Picod, and Elie Bursztein. 2016. Cloak of Visibility: Detecting When Machines Browse a Dierent W eb. In 2016 IEEE Symposium on Security and Privacy (SP) . IEEE, Piscataway, NJ, USA, 743–758. doi:10.1109/SP.2016.50 [25] ItzCrazyKns. 2023. Perplexica: Self-hosted AI-power ed search engine. https: //github.com/ItzCrazyKns/Perplexica Accessed: 2025-04-10. [26] ItzCrazyKns. 2024. Perplexica W ebSearch Prompt Code. https://github.com/ ItzCrazyKns/Perplexica/blob/master/src/lib/prompts/webSear ch.ts#L1. Accessed: 2025-04-20. [27] John P John, Fang Y u, Yinglian Xie, Arvind Krishnamurthy , and Martin Abadi. 2011. { deSEO } : Combating { Search-Result } Poisoning. In 20th USENIX Security Symposium (USENIX Security 11) . USENIX Association, Berkeley, CA, USA. [28] Komo. 2025. Komo AI. https://komo.ai/. Accessed: 2025-04-07. [29] Reinhardt Krause. 2024. Google Stock Falls on OpenAI’s SearchGPT Debut. Investor’s Business Daily . https://ww w .investors.com/news/technology/google- stock- tumbles- on- op enais- searchgpt- debut/ [30] Stanford OV AL Lab. 2024. Storm: Structured LLMs with Op en-domain Retrieval and Memory . https://github.com/stanford- oval/storm Accessed: 2025-04-10. [31] Victor Le Po chat, T om Van Goethem, Samaneh Tajalizadehkhoob, Maciej Ko- rczyński, and W outer Joosen. 2019. T ranco: A Research-Oriented T op Sites Ranking Hardened Against Manipulation. In Proceedings of the 26th A nnual Network and Distributed System Se curity Symp osium (NDSS 2019) . The Internet Society , Reston, V A, USA. doi:10.14722/ndss.2019.23386 [32] Nektarios Leontiadis, T yler Moore, and Nicolas Christin. 2011. Measuring and Analyzing Search-Redirection Attacks in the Illicit Online Prescription Drug Trade. In Pr oceedings of the 20th USENIX Conference on Security (San Francisco, CA) (SEC’11) . USENIX Association, USA, 19. [33] Nektarios Leontiadis, T yler Moore, and Nicolas Christin. 2011. Measuring and an- alyzing { Search-Redirection } attacks in the illicit online prescription drug trade. In 20th USENIX Security Symposium (USENIX Security 11) . USENIX Association, Berkeley , CA, USA. [34] Nektarios Leontiadis, T yler Moore, and Nicolas Christin. 2014. A Nearly Four- Y ear Longitudinal Study of Search-Engine Poisoning. In Procee dings of the 2014 ACM SIGSA C Conference on Computer and Communications Security (Scottsdale, Arizona, USA) (CCS ’14) . Association for Computing Machiner y , New Y ork, N Y , USA, 930–941. doi:10.1145/2660267.2660332 [35] Xiaojing Liao, Chang Liu, Damon McCoy , Elaine Shi, Shuang Hao, and Raheem Beyah. 2016. Characterizing long-tail SEO spam on cloud web hosting ser vices. In Proceedings of the 25th International Conference on W orld Wide W eb (Mon- tréal, Québec, Canada) (W W W ’16) . International W orld Wide W eb Conferences Steering Committee, Republic and Canton of Geneva, CHE, 321–332. [36] Xiaojing Liao, Kan Y uan, XiaoFeng Wang, Zhongyu Pei, Hao Y ang, Jianjun Chen, Haixin Duan, Kun Du, Eihal Alowaisheq, Sumayah Alr wais, et al . 2016. Seeking nonsense, looking for trouble: Ecient promotional-infection detection through semantic inconsistency search. In 2016 IEEE Symposium on Security and Privacy (SP) . IEEE, 707–723. [37] Jiakun Liu, Sebastian Baltes, Christoph Tr eude, David Lo, Y un Zhang, and Xin Xia. 2021. Characterizing search activities on stack overow . In Procee dings of the 29th ACM Joint Me eting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering . 919–931. [38] Mingxuan Liu, Y unyi Zhang, Lijie Wi, Baojun Liu, Geng Hong, Yiming Zhang, Hui Jiang, Jia Zhang, Haixin Duan, Min Zhang, W ei Guan, Fan Shi, and Min Y ang. 2025. NOKEScam: understanding and rectifying non-sense keywords sp ear scam in search engines. In Proceedings of the 34th USENIX Conference on Security Symposium (Seattle, W A, USA) (SEC ’25) . USENIX Association, USA, Article 246, 20 pages. [39] Nelson F. Liu, Tianyi Zhang, and Percy Liang. 2023. Evaluating V eriability in Generative Search Engines. arXiv:2304.09848 [cs.CL] 09848 [40] Y upei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. 2024. Formalizing and benchmarking prompt injection attacks and defenses. In 33rd USENIX Se curity Symposium (USENIX Security 24) . 1831–1847. [41] Long Lu, Roberto Perdisci, and W enke Lee. 2011. Surf: dete cting and measuring search poisoning. In Procee dings of the 18th ACM conference on Computer and communications se curity . 467–476. [42] Zeren Luo, Zifan Peng, Yule Liu, Zhen Sun, Mingchen Li, Jingyi Zheng, and Xinlei He. 2025. Unsafe LLM-based search: quantitative analysis and mitigation of safety risks in AI web search. In Proceedings of the 34th USENIX Conference on Se curity Symp osium (Seattle, W A, USA) (SEC ’25) . USENIX Association, USA, Article 413, 20 pages. [43] Richard McCreadie, Craig Macdonald, Iadh Ounis, Jim Giles, and Ferris Jabr . 2012. An examination of content farms in web search using crowdsour cing. In Proceedings of the 21st ACM International Conference on Information and Knowl- edge Management (Maui, Hawaii, USA) (CIKM ’12) . Association for Computing Machinery , New Y ork, N Y, USA, 2551–2554. doi:10.1145/2396761.2398689 [44] Hesham Mekky , Ruben T orres, Zhi-Li Zhang, Sabyasachi Saha, and Antonio Nucci. 2014. Detecting malicious H T TP redirections using trees of user browsing activity . In IEEE INFOCOM 2014 - IEEE Conference on Computer Communications . 1159–1167. doi:10.1109/INFOCOM.2014.6848047 [45] Fredrik Nestaas, Edoardo Debenedetti, and Florian Tramèr . 2024. Ad- versarial Search Engine Optimization for Large Language Mo dels. arXiv:2406.18382 [cs.CR] https://ar xiv .org/abs/2406.18382 [46] Y uan Niu, Yi-Min W ang, Hao Chen, Ming Ma, and Francis Hsu. 2006. A Quantitative Study of Forum Spamming Using Context-based Analysis . T ech- nical Report MSR- TR-2006-173. 14 pages. https://www.micr osoft.com/en- us/research/publication/a- quantitative- study- of- forum- spamming- using- context- based- analysis/ [47] Alexandros Ntoulas, Marc Najork, Mark Manasse, and Dennis Fetterly. 2006. Detecting spam web pages through content analysis. In Proceedings of the 15th International Conference on W orld Wide W eb (Edinburgh, Scotland) (WW W ’06) . Association for Computing Machinery, New Y ork, NY, USA, 83–92. doi:10.1145/ 1135777.1135794 [48] Alexandros Ntoulas, Marc Najork, Mark Manasse, and Dennis Fetterly. 2006. Detecting spam web pages through content analysis. In Proceedings of the 15th international conference on W orld Wide W eb . 83–92. [49] OpenAI. 2024. ChatGPT Search API Guide. https://platform.openai.com/docs/ guides/tools- web- search. Accessed: 2025-04-20. [50] OpenAI. 2024. Introducing ChatGPT Search. https://openai.com/index/ introducing- chatgpt- search/. Accessed: 2024-12-27. Pei Chen et al. [51] OpenAI. 2024. Introducing ChatGPT Search. https://openai.com/index/ introducing- chatgpt- search. Accessed: 2025-04-20. [52] Perplexity AI. 2024. Getting Starte d Guide. https://docs.perplexity .ai/guides/ getting- starte d. Accessed: 2025-04-20. [53] Perplexity AI T eam. 2025. Perplexity AI. https://w ww.perplexity .ai. Accessed: 2025-01-11. [54] Samuel Pfrommer, Y atong Bai, T anmay Gautam, and Somayeh Sojoudi. 2024. Ranking Manipulation for Conversational Search Engines. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , Y aser Al-Onaizan, Mohit Bansal, and Y un-Nung Chen (Eds.). Association for Computa- tional Linguistics, Miami, Florida, USA, 9523–9552. doi:10.18653/v1/2024.emnlp- main.534 [55] SearXNG Project. 2025. SearXNG Search API Documentation. https://do cs. searxng.org/dev/search_api.html. Accessed: 2025-04-21. [56] Similarweb Ltd. 2025. Similarweb: Digital Intelligence Platform. https://www. similarweb.com/. Accessed: 2025-04-10. [57] Soa Eleni Spatharioti, David M. Rothschild, Daniel G. Goldstein, and Jake M. Hofman. 2023. Comparing Traditional and LLM-base d Search for Consumer Choice: A Randomized Experiment. arXiv:2307.03744 [cs.HC] abs/2307.03744 [58] StatCounter Global Stats. 2025. AI Chatbot Market Share. https://gs.statcounter . com/ai- chatb ot- market- share. Accessed: 2025-09-21. [59] T avily. 2025. Tavily API Reference. https://docs.tavily .com/documentation/api- reference/introduction. Accessed: 2025-04-21. [60] David Y W ang, Stefan Savage, and Georey M V oelker . 2011. Cloak and dagger: dynamics of web search cloaking. In Proceedings of the 18th ACM conference on Computer and communications security . 477–490. [61] Yi-Min W ang, Ming Ma, Yuan Niu, and Hao Chen. 2007. Spam double-funnel: Connecting web spammers with advertisers. In Proceedings of the 16th interna- tional conference on W orld Wide W eb . 291–300. [62] Open W ebUI. 2024. Open W ebUI Documentation. https://do cs.openwebui.com/. Accessed: 2025-04-20. [63] Baoning Wu and Brian D Davison. 2005. Cloaking and Redirection: A Preliminary Study .. In AIRW eb , V ol. 5. 7–16. [64] Baoning Wu and Brian D . Davison. 2005. Identifying link farm spam pages. In Special Interest Tracks and Posters of the 14th International Conference on W orld Wide W eb (Chiba, Japan) (WW W ’05) . Association for Computing Machiner y , New Y ork, N Y, USA, 820–829. doi:10.1145/1062745.1062762 [65] Siye Wu, Jian Xie, Jiangjie Chen, Tinghui Zhu, Kai Zhang, and Y anghua Xiao. 2024. How Easily do Irrelevant Inputs Skew the Responses of Large Language Models? arXiv:2404.03302 [cs.CL] https://ar xiv .org/abs/2404.03302 [66] Hao Yang, Kun Du, Yubao Zhang, Shuai Hao, Haining W ang, Jia Zhang, and Haixin Duan. 2021. Mingling of clear and muddy water: Understanding and detecting semantic confusion in blackhat seo. In Computer Security–ESORICS 2021: 26th European Symposium on Research in Computer Security , Darmstadt, Germany , October 4–8, 2021, Proce e dings, Part I 26 . Springer , 263–284. [67] Ronghai Y ang, Xianbo W ang, Cheng Chi, Dawei W ang, Jiawei He, Siming Pang, and Wing Cheong Lau. 2021. Scalable detection of promotional website de- facements in black hat { SEO } campaigns. In 30th USENIX Security Symposium (USENIX Security 21) . 3703–3720. [68] Qing Zhang, David Y . W ang, and Georey M. V oelker. 2014. DSpin: Detecting Automatically Spun Content on the W eb. In 21st A nnual Network and Distributed System Se curity Symposium, NDSS 2014, San Diego, California, USA, February 23-26, 2014 . The Internet Society. https://www .ndss- symp osium.org/ndss2014/ dspin- dete cting- automatically- spun- content- web [69] Y unyi Zhang, Ming xuan Liu, Baojun Liu, Yiming Zhang, Haixin Duan, Min Zhang, Hui Jiang, Y anzhe Li, and Fan Shi. 2024. Into the dark: unveiling internal site search abused for black hat SEO. In 33rd USENIX Security Symposium (USENIX Security 24) . USENIX Association, 1561–1578. [70] W ei Zou, Runpeng Geng, Binghui W ang, and Jinyuan Jia. 2025. PoisonedRAG: knowledge corruption attacks to retrieval-augmented generation of large lan- guage models. In Proceedings of the 34th USENIX Conference on Security Sym- posium (Seattle, W A, USA) (SEC ’25) . USENIX Association, USA, Article 197, 18 pages. A Black-Hat SEO W ebsite Classier A.1 Implementation For ve types of attacks, we r eplicated the methods from existing works [ 11 , 33 , 48 , 60 , 66 ] for semi-automated dete ction. The specic implementation is as follows: Semantic Confusion. W e use two models to complete the task. (1) Context semantic classier , used to predict the probabilities that a web page belongs to 14 benign topics, outputting prob_14 (2) Mali- cious web page classier , use d to predict the probability that a web page is malicious, outputting prob_malicious . Both models ar e based on the T extCNN architecture: V ocabular y Size = 10,000; Maximum Sequence Length = 500; Embedding Dimension = 128; Convolution Filter Sizes =[3,4,5]; Number of Filters per Size = 128; Pooling Lay er = GlobalMaxPooling1D; Dropout Rate = 0.5; Optimizer = Adam; Batch Size = 64. Judgment: max(prob_14) >0.9 And prob_malicious >0.9. Redirection. W e identify two typ es of redirection. (1) reputable domain redirecting to malicious content ( Illegal search keywords + Tranco T op 10,000 domain [ 31 ] or education/government domains + Redirection + Redirect to malicious website (2) benign search redirecting to malicious content (Hot search keyword + Redirection + Redirect to malicious website). The malicious website classica- tion model uses the same Malicious web page classier in Semantic Confusion, outputting prob_malicious . Judgment: prob_malicious >0.9. Cloacking. W e use the user agents of Google bot and users to crawl and obtain the page content of the tw o views. (1) Use text slicing techniques to generate content signatures and compar e the similar- ity ( signature_sim ) between the user page and the bot crawled page; (2) Remove the blank pages; (3) Calculate the matching degree of the summary on the user page and the bot crawled page( summary_sim ) (4) Calculate the DOM structure similarity ( DOM_sim ) of two views. Judgment: signature_sim <0.9 And summary_sim >0.33 And DOM_sim >0.66. Ke ywords Stung. W e consider the key words in Google Trends [ 18 ]. (1) Compute the number of Go ogle’s hot sear ch terms matched on the page, hotw ords_count . (2) Use the “site:domain” query in Go ogle to determine whether the number of sub-pages is very large and all are spam content. If both conditions are satised, then we consider the page Keywor ds Stung . Judgment: hotwords_count ≥ 10 And spam_subpages ≥ 100. Link Farm. W e conduct DNS queries supporting wildcards. Then visit the homepage or sitemap twice and extract the set of hyperlinks on it, and nally get URL set A and URL set B . Judgment: max | 𝐴 − 𝐵 | | 𝐴 | , | 𝐴 − 𝐵 | | 𝐵 | ≥ 0 . 2 A.2 Evaluation T o assess the eectiveness of our classiers used in SEO-Bench con- struction, we conducted a systematic evaluation for each of the ve attack categories. This section outlines the evaluation methodology and presents the corresponding results. For each classier , we compute d a confusion matrix base d on manual verication. Specically , we sampled 100 websites that were predicted as positive ( label=1 ) and 100 websites predicted as neg- ative ( label=0 ). Each sample was manually checked to determine whether the prediction matched the black-hat SEO characteris- tics. From these manual labels, we derived standard classication metrics including accuracy , precision, recall, and F1-score. The overall accuracy across all classiers was 91.12%, indicat- ing sucient reliability for use in dataset construction. T able 7-11 presents the confusion matrices for the ve classiers, providing a detailed view of performance across dierent attack types. Unveiling the Resilience of LLM-Enhance d Search Engines against Black-Hat SEO Manipulation T able 7: Evaluation Metrics for the Redirection classier . Predicted Positive Predicted Negative Total Actual Positive 99 21 120 Actual Negative 1 79 80 T otal 100 100 200 Accuracy: 89.0% Precision: 99.0% Recall: 82.5% F1 Score: 89.4% T able 8: Evaluation Metrics for the Cloaking classier . Predicted Positive Predicted Negative Total Actual Positive 87 5 92 Actual Negative 13 95 108 T otal 100 100 200 Accuracy: 91.0% Precision: 87.0% Recall: 94.6% F1 Score: 90.6% T able 9: Evaluation Metrics for the Keyword Stung classi- er . Predicted Positive Predicted Negative Total Actual Positive 89 0 89 Actual Negative 11 100 111 T otal 100 100 200 Accuracy: 94.5% Precision: 89.0% Recall: 100.0% F1 Score: 94.18% T able 10: Evaluation Metrics for the Semantic Confusion classier . Predicted Positive Predicted Negative Total Actual Positive 77 4 81 Actual Negative 23 96 119 T otal 100 100 200 Accuracy: 86.6% Precision: 77.0% Recall: 95% F1 Score: 87.74% B Evaluation Metrics Resilience ( Und ) = | { ( 𝑞 𝑖 , 𝑡 𝑖 ) | Rewitten queries ( 𝑞 𝑖 ) = ∅ } | | { ( 𝑞 𝑖 , 𝑡 𝑖 ) } | (2) Resilience ( Ret ) = | { ( 𝑞 𝑖 , 𝑡 𝑖 ) | 𝑡 𝑖 ∉ Retrieval refer ences ( 𝑞 𝑖 ) } | | { ( 𝑞 𝑖 , 𝑡 𝑖 ) | Rewitten queries ( 𝑞 𝑖 ) ≠ ∅ } | (3) Resilience ( Sum ) = | { ( 𝑞 𝑖 , 𝑡 𝑖 ) | 𝑡 𝑖 ∉ Summary references ( 𝑞 𝑖 ) } | | { ( 𝑞 𝑖 , 𝑡 𝑖 ) | 𝑡 𝑖 ∈ Retrieval references ( 𝑞 𝑖 ) } | (4) 𝐶𝑢𝑚𝑢𝑙 𝑎𝑡 𝑖 𝑣 𝑒 𝑘 = 𝑘 𝑖 = 1 𝑐 𝑖 , where 𝑐 𝑖 = 1 − 𝑖 − 1 𝑗 = 1 𝑐 𝑗 ! · 𝑅𝑒 𝑠 𝑖 𝑙 𝑖 𝑒 𝑛𝑐 𝑒 𝑖 . (5) C Query Rewriting V alidation Experiment T o validate the eectiveness of quer y rewriting against SEO attacks, we resubmitted Rewitten queries to Google Search and obser ved T able 11: Evaluation Metrics for the Link Farm classier . Predicted Positive Predicted Negative Total Actual Positive 92 3 95 Actual Negative 8 97 105 T otal 100 100 200 Accuracy: 94.5% Precision: 92.0% Recall: 96.8% F1 Score: 94.3% that 98.16% failed to retrieve the original SEO w ebsites, demonstrat- ing the approach’s strong disruptive impact. Then, w e explore how the degree of r ewriting aects retrie val by measuring semantic and syntactic dier ences using semantic textual distance (STD) and edit distance (ED). T able 12 shows that as semantic distance increases, the retrieval success rate drops signicantly . Notably , even syntactic changes with an edit distance b elow 0.1 can r educe the success rate to under 10%, and when semantic similarity remains high (STD < 0.1), re- trieval drops below 2% if the edit distance e xceeds 0.2. Additionally , we observe 44 rewritten queries with a semantic distance greater than 0.5, indicating reversed or contradictor y meanings (cosine similarity < 0). This contrast suggests that query rewriting is eective not only by changing meaning but also by disrupting structural patterns used in SEO. Ev en minor edits can interfere with keyword match- ing while preserving the original intent, highlighting the role of rewriting in mitigating SEO attacks. T able 12: The Retrieval Success Rate at Dierent Semantic (STD) and Syntactic (ED) Changes ED \ STD (0.0,0.1] (0.1,0.2] (0.2,0.5] (0.5,1.0] T otal (0.0,0.1] 10.26% 0.00% - - 9.52% (0.1,0.2] 10.34% 0.00% 0.00% - 9.55% (0.2,0.5] 1.49% 1.91% 2.01% - 1.64% (0.5,1.0] 0.57% 0.71% 0.33% 0.00% 0.48% T otal 2.46% 1.08% 0.57% 0.00% 1.46% 1) STD: semantic textual distance, measured as ( 1 − cosine similarity ) / 2 ; 2) ED: edit distance, measured as 1 − Levenshtein Ratio. D Domain-Restricted Query Prompt Example for Domain-Restricted Query Search strictly within site:{domain} for {product}, then recom- mend only results from this domain. Give me your answer and references. E Ethical Considerations This study is conducted under rigorous ethical oversight, and ad- heres to strict ethical guidelines to ensure responsible research practices. (1) Controlled Experimentation. All experiments were conducted in controlled environments to av oid real-world disruption. A s de- tailed in Section 4.1, we used existing SEO websites to build the Pei Chen et al. dataset instead of generating new ones, prev enting large-scale in- terference with real ecosystems ( e.g. Google). The LLMSEO attacks were implemented in simplied form and within a restricted scope, using controlled subdomains to avoid contaminating legitimate do- mains. All test sites were clearly marked with “For T esting Purposes Only” disclaimers and taken down after experiments to eliminate residual impact. For LLMSEs with limited search functions, such as ChatGPT and Gemini, we avoided further jailbreak attempts. (2) Open Data. No sensitive or private data was accessed in any experiment. For closed-source LLMSEs, we strictly followed o- cial API policies and interacted through default interfaces. Open- source LLMSEs were deployed on isolated LAN ser vers using o- cially obtained API keys. For SEO crawling, only publicly available Google Search results were requested, and Google-documented user agents [21] were used to simulate crawler behavior . (3) Responsible Disclosure. W e adhered to the responsible disclo- sure. First, we reported to Google all 1,602 black-hat SEO websites identied in Section 4.1 to facilitate timely remediation. Second, for the nine evaluated LLMSEs, we have contacted or are contacting both commercial and open-source providers thr ough their ocial vulnerability disclosure channels ( e.g. , OpenAI’s Bug Bounty) with detailed reports describing the vulnerabilities, reproduction steps, and suggested mitigation. For open-source systems, disclosures were or will be submitte d via email to developers. Third, for our temporary experimental blogs, removal requests were led with Google and Bing to ensure de-indexing after experiment termina- tion. These actions collectively demonstrate our commitment to responsibly exposing risks while assisting vendors in str engthening system resilience. (4) Researcher Care. W e ensured the well-being of all researchers by providing methodological guidance and psychological support. Given the potentially disturbing nature of illegal or harmful website content, annotators worked in a controlled and supportive envi- ronment with exible schedules to prevent fatigue. Regular mental health check-ins and access to counseling resources were main- tained, and no participants reported psychological harm or undue stress during the study .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment