Knowledge-Guided Failure Prediction: Detecting When Object Detectors Miss Safety-Critical Objects
Object detectors deployed in safety-critical environments can fail silently, e.g. missing pedestrians, workers, or other safety-critical objects without emitting any warning. Traditional Out Of Distribution (OOD) detection methods focus on identifyin…
Authors: Jakob Paul Zimmermann, Gerrit Holzbach, David Lerch
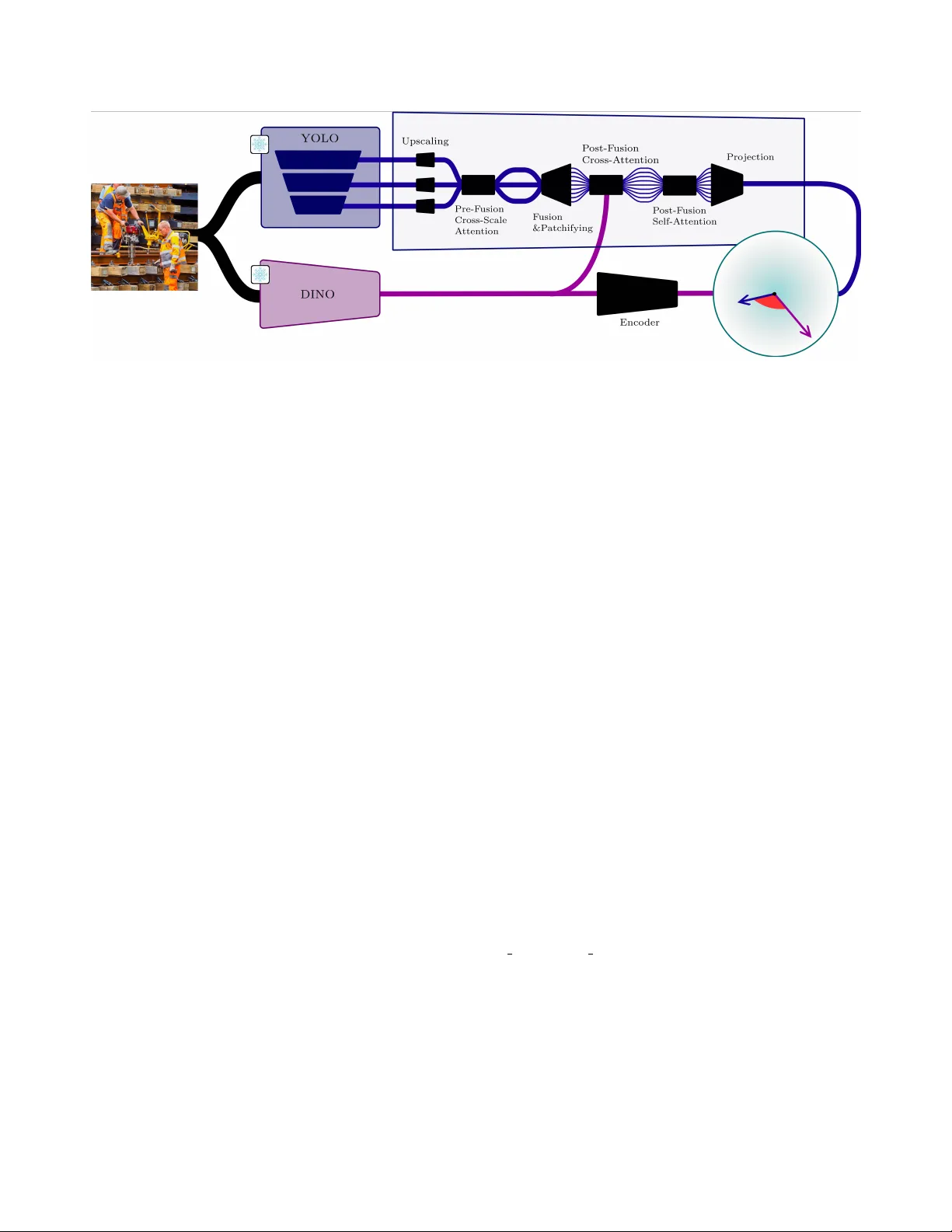
Knowledge-Guided F ailur e Prediction: Detecting When Object Detectors Miss Safety-Critical Objects * Jakob P aul Zimmermann Fraunhofer HHI Berlin, Germany jakob.zimmermann@campus.tu-berlin.de Gerrit Holzbach Fraunhofer IOSB Karlsruhe, Germany gerrit.holzbach@iosb.fraunhofer.de David Lerch Fraunhofer IOSB Karlsruhe, Germany david.lerch@iosb.fraunhofer.de Abstract Object detectors deployed in safety-critical en vir onments can fail silently , e.g . missing pedestrians, workers, or other safety-critical objects without emitting any warn- ing. T raditional Out-of-Distrib ution (OOD) detection meth- ods focus on identifying unfamiliar inputs, but do not di- r ectly pr edict functional failures of the detector itself. W e intr oduce Knowledge-Guided F ailur e Pr ediction (KGFP), a repr esentation-based monitoring framework that tr eats missed safety-critical detections as anomalies to be detected at runtime . KGFP measur es semantic misalignment between internal object detector featur es and visual foundation model embeddings using a dual-encoder arc hitecture with an an- gular distance metric. A ke y pr operty is that when either the detector is operating outside its competence or the vi- sual foundation model itself encounters novel inputs, the two embeddings diver ge, pr oducing a high-angle signal that r eliably flags unsafe images. W e compar e our novel KGFP method to baseline OOD detection methods. On COCO person detection, applying KGFP as a selective-pr ediction gate raises person r ecall among accepted images fr om 64.3% to 84.5% at 5% F alse P ositive Rate (FPR), and maintains str ong performance across six COCO-O visual domains, out- performing OOD baselines by lar ge margins. Our code, mod- els, and featur es ar e published at https://gitlab.cc- asp.fraunhofer.de/iosb_public/KGFP 1. Introduction Object detectors po wer safety-critical applications from au- tonomous driving to video surveillance, yet they fail un- * Accepted at the SAIAD W orkshop, CVPR 2026. predictably when encountering nov el or challenging visual conditions [ 10 , 11 ]. As automation increases, such percep- tion components are deplo yed more widely in operational decision loops and therefore increasingly f all under safety certification expectations in the sense of systematic AI sys- tems engineering [ 27 ]. A pedestrian detection system trained on clear weather may miss occluded pedestrians in fog; a construction site monitor [ 7 ] may fail to detect work ers in unusual poses. Figure 1. Ov erview of our proposed kno wledge-guided failure pre- diction for object detectors. T raditional failure prediction methods including OOD utilize only internal features of the object detector . W e le verage visual foundation model features to classify if an im- age is safe for person detection. 1 These silent failures —where detectors confidently return empty results despite objects present—can hav e catastrophic consequences. T raditional approaches to detector robustness focus on im- pr oving detection accuracy through domain adaptation [ 49 ], data augmentation, or architecture refinement [ 19 ]. How- ev er , e ven state-of-the-art detectors exhibit failure modes including missing objects in complex conte xts [ 37 ] and un- der no vel visual conditions [ 46 ]. For high-assurance settings, achieving the e vidence and risk reduction e xpected at Safety Integrity Le vel 4 [ 12 ] cannot rely on test set accurac y alone; it also requires mechanisms that detect and control unsafe behavior at runtime when assumptions are violated. Rather than attempting to eliminate failures entirely , runtime moni- toring [ 15 , 33 ] aims to detect anomalous situations in which the perception system is likely to miss safety-critical objects and to issue timely alerts. Such alerts are essential for the system to adapt and operate safely under uncertainty , en- abling downstream controllers to trigger f allback policies (e.g., initiating a minimal risk maneuver or querying a human operator) when functional failures are predicted. W e formulate failure pr ediction for safety-critical ob- jects as a supervised binary classification task: given an image and a detector’ s predictions, determine whether the detector has missed any safety-critical objects. Crucially , we focus on a safety-critical subset of object classes —for pedestrian detection systems, persons are the primary safety concern; objects like small birds or distant vehicles mat- ter less for immediate safety . This dif fers fundamentally from the typically unsupervised binary decision problem of Out-of-Distribution (OOD) detection [ 45 ]. Knowledge-Guided F ailure Prediction (KGFP) is trained to predict the safety of In-Distribution (ID) data, and demon- strates generalization capabilities to OOD data. A key challenge in anomaly-based monitoring is alarm fatigue. Unlike methods that flag any novel input, KGFP focuses on functional failures, significantly reducing f alse alarms by ignoring benign no velty that does not impact the detection of safety-critical objects. Moreover , unlik e con ven- tional OOD detection, it flags ID images where the detector is struggling. Recent foundation models trained on billions of im- ages [ 28 ] capture rich semantic knowledge beyond task- specific detectors. Self-supervised vision transformers like DINO [ 3 ] learn particularly po werful semantic represen- tations. Our key insight: semantic similarity between learned encodings of detector internal featur es and foun- dation model embeddings indicates detection r eliability . When encoded representations of YOLOv8’ s internal acti va- tions align with encoded DINO semantic embeddings, the detector operates within its competence zone. Misalignment signals potential failure. Our main contributions are as follo ws: 1. Safety-focused failure prediction : T o the best of our knowledge, we introduce the first framework that ex- plicitly predicts detector failures with respect to safety- critical object classes (persons) rather than generic dis- tribution membership, enabling tar geted monitoring of safety-critical detections. W e propose a nov el ev aluation metric that quantifies the percentage of ground-truth per- sons detected in accepted images (Person Recall) at a 5% false-alarm rate (False Positi ve Rate (FPR)) of the KGFP module. 2. Foundation model integration : W e demonstrate that self-supervised world-kno wledge (DINO) improves f ail- ure prediction over detector features alone through multi- scale fusion with cross-attention. W e propose a dual- encoder architecture that uses cosine similarity between encoded representations of Y OLOv8 internal features and DINO embeddings, where angular di vergence directly signals unsafe images in which safety-critical objects will be missed. 3. Comprehensi ve ev aluation : W e perform systematic ablations across architecture, training, and foundation model choices with strong baselines on both ID data and nov el visual domains. 2. Related W ork 2.1. Out-of-Distribution Detection OOD detection aims to identify inputs from unknown dis- tributions [ 44 , 45 ]. Classification-based methods le verage model outputs: Maximum Softmax Probability (MSP) [ 9 ], ODIN [ 18 ] with temperature scaling, Energy scores [ 21 ], and acti vation-based methods like ReAct [ 5 , 38 ]. Distance- based approaches measure feature space deviations: Ma- halanobis distance [ 17 ], K-Nearest Neighbors (KNN) [ 39 ], and recent improvements via feature normalization [ 23 , 26 ]. GRAM [ 32 ] computes Gram matrices (channel cov ariance) from Y OLOv8 feature maps at each scale using orders 1–5, fits min/max statistics per scale on training data, and flags test images as unsafe when Gram matrix elements fall out- side these bounds. W e use no spatial pooling to preserve full feature map statistics. KNN [ 39 ] stores spatially-pooled Y OLOv8 features from training images. At test time, it computes the Euclidean distance to the 5th nearest training neighbor per scale; high distances indicate anomalous inputs and potential failure. W e use L2 normalization for stable distance computation. V irtual-logit Matching (V iM) [ 43 ] fits Principal Component Analysis (PCA) with 100 components per Y OLOv8 scale on training features and projects test fea- tures onto the residual subspace (orthogonal to the principal components). Large residual norms indicate OOD samples, i.e. features that de viate from the low-dimensional ID man- ifold. W e also trained a DINO-V iM variant, where we use DINO embeddings instead of internal Y OLOv8 activ ations. 2 Although all of these methods excel at image classifi- cation OOD detection, object detection presents unique challenges : (1) spatial localization requirements, (2) multi- ple objects per image, (3) partial detection scenarios. Recent work adapts object detectors for OOD tasks [ 51 ], b ut focuses on flagging no vel concepts in the scene rather than predicting safety-critical failures (e.g., missed pedestrians). Angular margins ha ve proven ef fectiv e for learning dis- criminativ e embeddings in face recognition [ 1 , 4 , 22 ]. Re- cent work e xtends angular margins to OOD detection [ 29 ], showing that cosine-based similarity naturally separates ID from OOD samples when features are normalized. Our approach builds on these insights, using cosine similarity between dual-encoder projections as a safety metric, where angular distance directly measures semantic alignment be- tween detector and foundation model representations. 2.2. Runtime Monitoring f or Safety Runtime monitoring provides safety assurance for deployed ML systems [ 33 ]. Comprehensive frame works hav e been dev eloped for perception systems: Ferreira et al. [ 6 ] sur- ve y threats (ID errors, no vel visual conditions, adversarial attacks) and detection mechanisms, while T ran et al. [ 41 ] demonstrate simulation-based verification using Linear T em- poral Logic for autonomous dri ving. Model assertions [ 15 ] check intermediate acti vations agai n st e xpected distributions. Recent work by T orpmann-Hagen et al. [ 40 ] proposes a paradigm shift from binary OOD classification to regression- based loss prediction, training Generalized Additiv e Models to directly predict task loss (cross-entropy , Jaccard index) from OOD-ness features (MSP, Energy , KNN distance) for continuous risk assessment. While loss prediction provides continuous risk quantification, it relies on proxy re gression rather than directly predicting safety-critical e vents (missed persons). Our binary formulation enables end-to-end train- ing with explicit safety labels, learning semantic features that directly indicate when safety-critical objects are missed. For object detection specifically , Y ang et al. [ 46 ] predict false negati ves using detector uncertainty , while Y atbaz et al. [ 47 ] monitor early layer patterns in 3D detectors. He et al. [ 8 ] address YOLOv8 hallucinations on OOD inputs through proximal OOD fine-tuning. Most closely related, DECIDER [ 36 ] trains a separate classifier to predict whether a detector will fail on a given input, b ut does not incorporate foundation model knowledge or angular distance metrics. Howe ver , these approaches rely solely on detector -internal signals. Our work differs by incorporating external semantic knowledge from foundation models, enabling detection of failures where internal features appear normal b ut semantic misalignment indicates unreliable predictions. Unlike DECIDER [ 35 ], which requires computing sim- ilarity against class-specific textual attribute embeddings during inference to generate an auxiliary model’ s predic- tions, our frame work relies solely on the angular alignment with general-purpose visual foundation model features, elim- inating the dependency on predefined te xt definitions. 2.3. F oundation Models for Rob ustness Self-supervised image and video models like DINO [ 3 ] and DINOv2 [ 24 ] or vision-language models like CLIP [ 28 ] learn transferable representations from massi ve unlabeled data. Recent w ork applies these to zero-shot anomaly de- tection: W inCLIP [ 13 ], AnomalyCLIP [ 50 ], and DINO pro- totypes [ 34 ]. P et al. [ 25 ] fuse DINO with Y OLOv8 for data-efficient detection. Broader surveys [ 2 ] examine foun- dation models for visual anomaly detection across industrial and medical domains. Our work dif fers critically: while W ang et al. enhance detection accuracy , we leverage foun- dation models for failur e prediction . Modern detectors employ multi-scale feature pyra- mids [ 19 ]: Y OLO [ 30 ] predicts at multiple resolutions, Faster R-CNN [ 31 ] uses Region Proposal Networks, and DETR v ariants [ 3 ] apply transformers. Hoiem et al. [ 11 ] analyze detector failures systematically , finding size and occlusion as dominant factors. 3. Method W e present KGFP, a supervised monitoring framew ork that predicts when an object detector will miss safety-critical objects. Unlike standard OOD detection, which flags distri- butional novelty in an unsupervised manner , KGFP is trained with explicit safe/unsafe labels derived from detector per- formance, enabling it to distinguish harmful failures from benign distribution shifts. 3.1. Problem F ormulation Giv en an image x and object detector D , let Y safe = { y 1 , . . . , y n } denote ground-truth bounding boxes for safety- critical object classes . For example, in pedestrian detection systems, Y safe contains only persons, ignoring all other ob- ject classes. The detector produces predictions ˆ Y = D ( x ) across all classes. Define the failure label : z ( x ) = 1 (unsafe) if any y i ∈ Y safe undetected (IoU < 0 . 5 ) 0 (safe) if all safety-critical objects matched (1) The failure prediction task: predict z ( x ) from ( D ( x ) , x ) to identify unsafe images where D will miss safety-critical objects. This formulation differs from OOD detection by di- rectly measuring functional failur e on safety-critical objects rather than distributional no velty . The objecti ve of this study is to develop a model capa- ble of predicting the failure of the object detector on a test sample. The technical approach entails the identification of 3 this issue as OOD detection. In this conte xt, the ID samples are correctly classified, while the detector exhibits failure on OOD data. Our training and ev aluation is exclusiv ely focused on the person class, as pedestrian detection serves as the primary motiv ation for safety-critical applications. Conceptually , the default output of a safety monitor for random input should be a safety warning. As two high dimensional random vectors are close to orthogonal with high probability [ 42 ], this expected beha vior is built into the concept of KGFP. 3.2. Ar chitecture: Dual-Encoder with Angular Metric In order to ev aluate a specialized model like an object detec- tor we le verage the visual foundation model DINO [ 3 ]. W e introduce a dual-encoder architecture that processes multi- scale YOLOv8 [ 14 ] Feature Pyramid Network (FPN) acti- vations through cross-scale fusion and transformer blocks with self-attention and cross-attention to foundation model embeddings (see Figure 2 ). The resulting detector and world- knowledge representations are projected onto a shared em- bedding space, where their angular similarity provides a di- rect measure of detection reliability . In our ablation studies we show that our designed angular similarity metric per- forms on par on OOD and outperforms the MLP baseline on ID setting. This underscores the effecti veness of our angular failure metric. Multi-Scale Featur e Extraction For each image x , we extract two complementary representations: • Predictor features : Y OLOv8l [ 14 ] (large model) pro- duces multi-scale internal features from its FPN at le vels { P 3 , P 4 , P 5 } with channel dimensions { 256 , 512 , 512 } and spatial resolutions 80 × 80 , 40 × 40 , 20 × 20 respecti vely (at 640 × 640 input). These scales correspond to detec- tion of small (P3), medium (P4), and large (P5) objects. All scales are projected to a common channel dimension and upsampled to the largest spatial resolution ( 80 × 80 , matching P3). • W orld-knowledge features f wk ∈ R 768 : DINO [ 3 ] V i- sion T ransformer (V iT) global [CLS] embeddings ex- tracted from the input image resized to 518 × 518 [ 24 ]. The ov erall architecture is shown in Figure 2 . Pre-Fusion Cross-Scale Attention Before fusing YOLO’ s multi-scale features, we apply cross-scale attention to allow information exchange between pyramid le vels. Each scale attends to features from other scales, where each scale is treated as a single token. This allows the model to create scale-aware representations where, for example, P3 features (small objects) can lev erage context from P5 features (scene- lev el patterns). The three scales are fused by element-wise addition, patchified, and finally processed through trans- former blocks with self-attention. Post-Fusion T ransf ormer W e apply transformer blocks with both self-attention and cross-attention mechanisms. The fused Y OLOv8 features are patchified (4×4 patches) and pro- cessed through 2 self-attention blocks follo wed by 2 cross- attention blocks. h ′ pr = SelfAttn (2) ( f pr ) (2) h ′′ pr = CrossAttn (2) ( Q = h ′ pr , K = f wk , V = f wk ) (3) In the latter the queries are projections of the predictor em- beddings, whereas the keys and v alues are projections of the DINO embedding. This procedure allows the detector repre- sentations to query foundation model semantic knowledge. Self-attention refines YOLOv8 features by capturing long-range spatial dependencies across patches, while cross- attention allows the detector’ s representations to query DINO’ s semantic kno wledge. This two-stage refinement creates semantically-grounded, spatially-coherent represen- tations. W e use 8 attention heads, 2 self-attention blocks, and 2 cross-attention blocks. Dual Encoders Separate encoder heads map the refined features of the predictor and world-kno wledge model to a shared 64-dimensional embedding space R 64 , which we denote as e pr and e wk respectiv ely: e pr = E P R ( h ′′ pr ; θ pr ) ∈ R 64 (4) e wk = E W K ( f wk ; θ wk ) ∈ R 64 (5) The YOLOv8 encoder processes the post-fusion transformer output through global pooling and projection. The DINO encoder is a deep 5-layer Multi-Layer Perceptron (MLP): 768 → 1024 → 768 → 640 → 512 → 64 , with LayerNorm and Gaussian Error Linear Unit (GELU) activ ations. Angular F ailure Metric W e measure this angle between the two embedings e pr and e wk of the two encoders via cosine similarity s safety ( x ) = e pr · e wk ∥ e pr ∥ 2 ∥ e wk ∥ 2 . (6) High similarity (small angle) indicates semantic similarity and predicted safety , while low similarity (lar ge angle) sig- nals misalignment and likely detector failure. 3.3. T raining Objective W e train the model end-to-end using Binary Cross-Entropy (BCE) loss. The cosine similarity score s safety ( x ) ∈ [ − 1 , 1] is mapped to safety probability p safe ( x ) ∈ [0 , 1] via (1 − s ) / 2 , 4 Figure 2. The dual-encoder architecture of our KGFP. W e use pretrained DINO and Y OLO models as backbones. For our KGFP we freeze the pretrained backbones and fine-tune a fusion framew ork. During ev aluation the distance between DINO features and the fused features serves as the measure for our failure prediction. where -1 ( ± 180 ◦ angle) maps to 1 (unsafe) and +1 ( 0 ◦ angle) maps to 0 (safe). BCE loss is then applied with safety labels y ∈ { 0 , 1 } (0 = safe, all persons detected; 1 = unsafe, persons missed). With this encoding high cosine similarity (close embeddings) indicates safety , while low similarity (distant embeddings) indicates failure. For model training and threshold tuning respectiv ely we split COCO train 2017 (64,115 images) into training (90%) and validation (10%) sets [ 20 ]. COCO val2017 (2,693 im- ages) serves as our held-out test set for final e valuation. At test time, we compute the safety score s safety ( x ) . The final prediction is based on a threshold, that is tuned on a disjoint validation set to 5% FPR. In our experiments of the full KGFP, this threshold is set to 0 . 843 . That is, the probability for two random v ectors in 64 dimensions to hav e a cosine similarity abov e the threshold is negligible [ 42 ]. 4. Experimental Setup W e ev aluate KGFP and established baselines on their ability to predict the correctness of Y OLOv8’ s bounding boxes (IoU > 0 . 5 ). Both the object detector and visual foundation model backbones are frozen during all experiments. 4.1. Datasets COCO 2017 W e use only the person class from MS COCO [ 20 ]: 64,115 training images and 2,693 validation images with 262,465 and 10,777 person annotations respec- tiv ely . All other object classes are ignored, as we focus exclusi vely on detecting failures for safety-critical objects (persons). YOLOv8l is trained on COCO train split. Each image is labeled safe/unsafe based on whether YOLOv8l correctly detects all persons (IoU threshold 0.5, certainty threshold 0.5). COCO-O V isual Domains Follo wing [ 10 ], we ev alu- ate on 6 OOD domains: cartoon (artistic renderings), sketch (line drawings), painting (classical art), handmake (crafts/toys), tattoo (body art), and weather (rain/snow/fog corruptions). These represent diverse visual anomalies rang- ing from stylistic variations (cartoon, sketch) to en vironmen- tal corruptions (weather). 4.2. Implementation Details Model Configuration KGFP uses frozen Y OLOv8l [ 14 ] and DINO (V iT-B) [ 3 ] as feature extractors. YOLOv8l internal features are extracted from FPN levels { P 3 / 8 , P 4 / 16 , P 5 / 32 } at 640×640 resolution. DINO [CLS] tokens (768D) are extracted from 518×518 crops. The fusion architecture uses 8 attention heads with 2 self-attention blocks followed by 2 cross-attention blocks in the post-fusion transformer . Dual encoders project refined Y OLOv8 and DINO features to a shared 64-dimensional embedding space (ablations test 128D, 256D, 512D). For efficiency , DINO embeddings are pre-computed to Hierarchical Data Format 5 (HDF5) cache, while Y OLOv8 features are computed on-the-fly during training. KGFP is trained end-to-end using Layer-wise Adapti ve Rate Scaling (LARS) optimizer [ 48 ] with learning rate 0.00095, momentum 0.9, weight decay 0.0009, and LARS eta 0.001. T raining runs for 60 epochs with cosine annealing (T max=60, eta min=5e-7) and gradient clipping (max norm 1.0) for stability . W e use batch size 6. 4.3. Evaluation Metrics Person Recall @ 5% FPR : Primary safety metric - per- centage of ground-truth persons detected when accepting images where the safety score exceeds a threshold calibrated to yield 5% FPR on the ID validation split. Crucially , this single threshold is then applied unchanged to all COCO-O 5 T able 1. Person Recall [%] among accepted images at 5% FPR (selective prediction). Each method acts as a gate that rejects a fraction of images deemed unsafe; Person Recall is measured only on the images the gate accepts. YOLOv8 (base) accepts all images (no gating). Best results per column in bold . Method COCO COCO-O (Distribution Shift) COCO-O V al Cartoon Sketch Painting Handmake T attoo W eather A vg KGFP (Ours) 84.5 19.3 29.5 36.2 37.0 11.9 71.4 34.2 GRAM 65.4 13.2 26.0 31.0 31.5 9.5 67.8 29.8 KNN 65.1 14.3 32.7 32.8 38.5 10.1 68.3 32.8 V iM 65.5 14.9 34.1 32.3 34.5 11.2 67.3 32.4 DINO-MLP 69.1 13.6 26.3 33.4 33.1 8.2 65.2 30.0 DINO-V iM 65.2 15.4 34.0 32.1 34.8 7.5 66.6 31.7 YOLOv8 (base) 64.3 13.2 24.9 29.7 31.5 9.5 66.1 29.1 domains, simulating realistic deployment where no target- domain labels are a vailable for recalibration. This metric directly quantifies safety: higher person recall means fewer missed persons in accepted images. Remark that if we de- ploy a random selectiv e-prediction gate we expect the Person Recall @ 5% FPR to match the person recall of the original object detector, which serves as a random baseline for the metric. T rue P ositive Rate (TPR) @ 5% FPR : T rue positive rate (correct safety predictions on image le vel) at 5% FPR. Unlike Person Recall, this counts images correctly classified as safe/unsafe, not individual persons detected. Area Under ROC Curv e (A UROC) : Area under Re- ceiv er Operating Characteristic (ROC) curve for binary safety classification (safe vs. unsafe images). Rec Area Under Curve (A UC) and Pr ec A UC : Area under curve be- tween the KGFP module’ s FPR and YOLO’ s Person Recall and Person Precision respectiv ely on images predicted to be safe. 4.4. Baselines In order to demonstrate the effecti veness of visual founda- tion models in object detector failure prediction, we compare our KGFP against representativ e OOD detection methods adapted for object detection in safety monitoring. Since these methods were originally designed for image classi- fication, we adapt them to work with Y OLOv8l internal features extracted at multiple scales (P3, P4, P5). W e train the OOD baseline methods GRAM, KNN and V iM using only safe images from the ID training set, treating unsafe im- ages (where persons are missed) as anomalies in the classical OOD detection framing. In order to support our proposed angular failure metric, we also compare our KGFP to an MLPs baseline. Therefore, we train an ensemble of MLPs on the DINO embeddings. In our ablations we also train an MLPs head on DINO and Y OLO embeddings as a baseline to our KGFP (see T able 3 ). T able 2. Comparison with OOD detection baselines. Safety A U- R OC measures binary classification (safe vs unsafe). Person Rec. A UC measures Y OLOv8 Recall av eraged over the FPR of KGFP . Person Prec. A UC measures YOLOv8 precision av eraged over the FPR of KGFP. COCO V al COCO-O A vg Method Safety Rec. Prec. Safety Rec. Prec. A UR OC A UC A UC A UR OC A UC A UC KGFP 92.9 90.4 98.2 80.3 55.8 94.7 GRAM 52.5 65.6 94.1 52.4 31.1 93.4 VIM 53.3 67.5 89.4 66.2 44.4 90.5 KNN 54.3 66.6 90.0 68.9 47.5 92.7 0 10 20 30 40 50 60 70 80 90 100 60 70 80 90 100 5% FPR K GFP FPR (%) YOLO P erformance (%) Recall Precision Figure 3. KGFP performance on COCO V al. W e plot person recall (blue) and precision (red) on the y-axis [in %] versus KGFP FPR on the x-axis [in %]. 5. Results 5.1. Main Results T able 1 presents our main results. KGFP acts as a selecti ve- prediction gate: it rejects images deemed likely to contain missed persons and does not modify Y OLOv8’ s detections themselves. Among the accepted images, 84.5% of ground- 6 truth persons are correctly detected, compared to 64.3% when accepting all images without gating. On the COCO-O weather domain, gating raises person recall among accepted images from 66 . 1% to 71 . 4% at 5% FPR. This corresponds to a relati ve reduction of person ov ersights (YOLOv8 f alse negati ves) of 56 . 6% on COCO V al and 15 . 6% on the COCO- O weather split at 5% FPR compared to 0% FPR. W e adapt OOD detection methods for failure prediction by training them on safe images only , treating unsafe im- ages as OOD. On ID data, GRAM, KNN, and V iM achie ve 65.1–65.5% recall, only slightly above the Y OLOv8 baseline (64.3%). DINO-based variants (DINO-MLP: 69.1%, DINO- V iM: 65.2%) achie ve higher recall but remain belo w KGFP. KGFP outperforms the best baseline by +15.4 percentage points, indicating that the dual-encoder architecture with explicit failure supervision is more ef fective than treating failures as OOD samples. On COCO-O, KGFP achie ves the highest a verage per - son recall (34.2%) across all six COCO-O domains. Note that OOD baselines were trained to treat unsafe images as OOD samples (see Section 4.4), so they face a more chal- lenging task on COCO-O: distinguishing unsafe from safe images under genuinely nov el visual conditions. KGFP performs notably better on weather corruptions (71.4%), maintaining near-ID performance. On painting (36.2%) and handmake (37.0%), KGFP leads or matches the best baselines. These results indicate that the learned alignment between Y OLOv8 and DINO representations generalizes to nov el visual domains. T able 2 provides complementary area-under-curve met- rics. KGFP achieves 92.9% Safety A UR OC for binary safe/unsafe classification and 90.4% Person Rec. A UC on COCO V al, compared to 54.3% Safety A UR OC for the best baseline (KNN). On COCO-O, KGFP maintains 80.3% Safety A UR OC and 55.8% Person Rec. A UC on av erage across all nov el visual domains. 5.2. Ablation Studies T able 3 (left) analyzes architectural components. Remo ving all attention modules reduces ID recall by 2.3% (84.5% → 82.3%). Pre-fusion attention and post-fusion cross-attention each contribute ∼ 1% to ID performance, while post-fusion self-attention has negligible impact. Replacing cosine simi- larity with an MLP similarity head degrades Rec@5%FPR by 0.8%. Mean cosine similarity remains below 0.9 through- out training, indicating no embedding collapse; deeper DINO embedding MLPs (7+ layers) collapsed in preliminary ex- periments. T able 3 (right) reports results across embedding sizes d ∈ { 64 , 128 , 256 , 512 } and optimizers. The 64D embed- ding performs best on both COCO V al (84.5%) and COCO- O (34.2%) with only 2.6M parameters. Larger embeddings sho w diminishing returns, with clear ov erparameterization at 512D. LARS slightly outperforms Adam [ 16 ] at 64D, while Adam performs poorly at 256D. T able 3 (center) compares world-kno wledge encoders. DINO V iT-B/16 (86M parame- ters) achie ves the highest ID recall (85.1%) with the fewest parameters, outperforming CLIP V iT-L/14 (84.5%, 427M parameters), DINOv2 V iT-L/14 and SigLIP V iT-B/16. W e attribute this to DINO’ s self-distillation objecti ve producing spatially coherent attention maps that capture fine-grained visual cues as partial occlusions, atypical poses, unusual lighting [ 3 ], whereas CLIP’ s language-aligned features are shaped by caption-le vel semantics [ 28 ] and thus less sensi- tiv e to these sub-textual failure patterns. 5.3. Discussion Supervised vs. unsuper vised. KGFP substantially outper- forms all baselines on ID data. Howe ver , KGFP is supervised (trained with safe/unsafe labels) while the OOD baselines are unsupervised (fitted on safe images only). A fairer com- parison is with the supervised DINO-MLP and the MLP- head ablation (T able 3 ), which use the same labels. KGFP outperforms both, indicating that the dual-encoder cosine- similarity formulation provides a stronger inducti ve bias for failure prediction than direct classification, despite having fewer trainable parameters. Role of DINO features. Methods based solely on DINO features (DINO-MLP, DINO-V iM) perform worse than KGFP, confirming that DINO embeddings alone cannot re- liably predict Y OLOv8 failures—the fusion of both feature sources is essential. DINO provides complementary seman- tic context (scene-le vel patterns, occlusion cues) that is cor - related with detector failure but not directly accessible from Y OLOv8’ s task-specific features. OOD generalization. The unsupervised baselines show near-baseline performance on ID data, which is expected: failures on ID images do not necessarily correspond to dis- tributional novelty . On COCO-O, unsupervised baselines achiev e competitive or superior performance on specific domains—KNN on handmake (38.5% vs. 37.0%) and V iM on sketch (34.1% vs. 29.5%)—because genuine distribution shift correlates with detector failure in these stylistically extreme domains. Howe ver , KGFP achieves the highest av erage recall across all six domains, demonstrating more consistent generalization. Embedding dimensionality . The degradation at 256D and 512D (T able 3 , right) is attributable to overparamete ri- zation: larger embedding spaces require more data to learn meaningful angular structure, and cosine similarity becomes less discriminati ve at high dimensionality because random vectors concentrate around orthogonality [ 42 ]. The 64D space provides suf ficient capacity while maintaining a well- structured angular decision boundary . 7 T able 3. Ablation studies: (left) architecture components, (center) foundation model comparison, (right) embedding dimensions and optimizer . All v alues are Person Recall @ 5% FPR. ID: COCO V al; OOD: av erage over six COCO-O domains. Architecture abbreviations: pre-fn = pre-fusion, post-fn = post-fusion, attn = attention. Attention Ablation Head Ablation ID OOD Full KGFP 84.5 34.2 No pre-fn attn 83.4 31.0 No post-fn cross-attn 83.4 32.5 No post-fn self-attn 84.2 34.1 No attn 82.3 31.1 MLP head 83.7 34.2 W orld-Kno wledge Model (Parameter) ID OOD DINO (86M) 85.1 34.2 SigLIP (87M) 84.8 35.2 DINOv2 (304M) 84.4 33.9 CLIP (427M) 84.5 32.6 Embedding Dimension, Optimizer ID OOD 64D, Lars 84.5 34.2 64D, Adam 84.3 32.8 128D, LARS 83.1 33.1 256D, LARS 83.5 31.1 256D, Adam 65.1 29.3 512D, LARS 67.1 29.1 6. Limitations and Future W ork KGFP requires frozen foundation model embeddings. Changes to the foundation model or encounters with visual domains far beyond its training data could de grade perfor - mance. Future work should inv estigate continual adaptation of world-kno wledge encoders. The all-or-nothing safety la- bel (all persons detected vs. an y missed) may be too coarse for some applications. Extensions could predict expected miss counts or provide spatial failure localization. W e focus on person detection for clear safety implications. General- ization to multi-class scenarios requires rethinking the safety formulation—which objects are safety-critical? KGFP re- quires computing both Y OLOv8 and DINO forward passes, which introduces significant overhead. Latency is critical in real-time systems. Future work should in vestigate the la- tency of our architecture, how it could be reduced, and what the trade-offs would be. The Latenc y is mainly caused by the backbones and the classification head introduces negligible latency . Frame-skipping strategies (running safety checks ev ery N frames) can amortize costs for video streams, or deployment may benefit from model compression, distilla- tion, or ef ficient foundation model variants. W e e valuate on naturally occurring visual anomalies. Adversarial perturba- tions designed to fool both YOLOv8 and DINO could ev ade safety monitoring. Adversarial training or certified defenses warrant in vestigation. 7. Conclusion W e introduced KGFP, a runtime monitoring framework that detects unsafe images where a specific object detector misses safety-critical objects by measuring semantic alignment be- tween learned encodings of object detector’ s internal ac- tiv ations and DINO embeddings. The architecture fuses multi-scale Y OLOv8 features via pre-fusion cross-scale at- tention, then applies post-fusion cross-attention with DINO for semantic alignment measurement. KGFP provides action- able failure signals for safety-critical deployment. Focusing on safety-critical object classes (persons for pedestrian de- tection), KGFP achie ves 85% person recall at 5% FPR on both ID data and novel visual domains, substantially outper - forming traditional OOD detection methods and our angular failure metric outperforms an MLP baseline with fe wer pa- rameters. Comprehensiv e ablations re veal that foundation model world-kno wledge, cross-attention fusion, and angular metric learning are critical for rob ust failure prediction. As object detectors proliferate in autonomous vehicles, surveil- lance, and healthcare, explicit failure monitoring becomes es- sential. KGFP demonstrates that foundation models trained on billions of images can serve as semantic ”sanity checks” for task-specific detectors, identifying unsafe images before they cause harm. Broader Impact and Disclosur es Ethics Statement. KGFP is designed to enhance safety by detecting object detector failures. It functions as an ad- ditional safety layer, not a replacement for robust model dev elopment. Limitations include potential false neg atives or positi ves; users must carefully consider recall-precision trade-offs and e valuate performance across relev ant demo- graphic groups to mitigate potential dataset biases. LLM Usage. W e ackno wledge the use of Claude 3.5 Son- net and GitHub Copilot for writing refinement, coding assis- tance, and literature summarization. All novel algorithmic components, experimental designs, and scientific conclu- sions are the sole work of the human authors. The authors take full responsibility for all content, including any errors or inaccuracies that may have been introduced during LLM- assisted editing. References [1] Fadi Boutros, Naser Damer , Florian Kirchbuchner , and Arjan Kuijper . Elasticface: Elastic margin loss for deep face recog- nition. In Pr oceedings of the IEEE/CVF Conference on Com- 8 puter V ision and P attern Recognition W orkshops (CVPRW) , pages 1578–1587, 2022. 3 [2] Y unkang Cao, Xiaohao Xu, Jiangning Zhang, Y uqi Cheng, Xiaonan Huang, Guansong Pang, and W eiming Shen. A surve y on visual anomaly detection: Challenge, approach, and prospect, 2024. 3 [3] Mathilde Caron, Hugo T ouvron, Ishan Misra, Herv’e J’e gou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emer g- ing properties in self-supervised vision transformers. 2021 IEEE/CVF International Confer ence on Computer V ision (ICCV) , pages 9630–9640, 2021. 2 , 3 , 4 , 5 , 7 [4] Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular mar gin loss for deep face recogni- tion. In Pr oceedings of the IEEE/CVF Confer ence on Com- puter V ision and P attern Recognition (CVPR) , pages 4690– 4699, 2019. 3 [5] Andrija Djurisic, Nebojsa Bozanic, Arjun Ashok, and Rosanne Liu. Extremely simple activ ation shaping for out- of-distribution detection. In International Confer ence on Learning Repr esentations (ICLR) , 2023. 2 [6] Raul Sena Ferreira, Fr ´ ed ´ eric Gu ´ erin, Karine Delmas, J ´ er ´ emie Guiochet, and H ´ el ` ene W aeselynck. Safety monitoring of ma- chine learning perception functions: A surve y . arXiv pr eprint arXiv:2412.06869 , 2024. 3 [7] Raphael Hagmanns, Peter Mortimer, Miguel Granero, Thorsten Luettel, and Janko Petereit. Excav ating in the wild: The goose-ex dataset for semantic segmentation. In 2025 IEEE International Confer ence on Robotics and Automation (ICRA) , 2025. 1 [8] W eicheng He, Changshun W u, Chih-Hong Cheng, Xiao wei Huang, and Saddek Bensalem. Mitigating hallucinations in yolo-based object detection models: A revisit to out-of- distribution detection. arXiv pr eprint arXiv:2503.07330 , 2025. 3 [9] Dan Hendrycks and K evin Gimpel. A baseline for detecting misclassified and out-of-distribution examples in neural net- works. Pr oceedings of International Confer ence on Learning Repr esentations , 2017. 2 [10] Dan Hendrycks, K evin Zhao, Stev en Basart, Jacob Steinhardt, and Dawn Song. Natural adversarial examples. In Pr oceed- ings of the IEEE/CVF Conference on Computer V ision and P attern Recognition (CVPR) , pages 15262–15271, 2021. 1 , 5 [11] Derek Hoiem, Y odsawalai Chodpathumwan, and Qieyun Dai. Diagnosing error in object detectors. In Pr oceedings of the 12th Eur opean Confer ence on Computer V ision - V olume P art III , page 340–353, Berlin, Heidelberg, 2012. Springer-V erlag. 1 , 3 [12] International Electrotechnical Commission. IEC 61508: Func- tional safety of electrical/electronic/programmable electronic safety-related systems. Standard IEC 61508, International Electrotechnical Commission, Genev a, Switzerland, 2010. Parts 1-7. 2 [13] Jongheon Jeong, Y ang Zou, T ae wan Kim, Dongqing Zhang, A vinash Ravichandran, and Onkar Dabeer . Winclip: Zero- /few-shot anomaly classification and segmentation. 2023 IEEE/CVF Conference on Computer V ision and P attern Recognition (CVPR) , pages 19606–19616, 2023. 3 [14] Glenn Jocher , A yush Chaurasia, and Jing Qiu. Ultralytics Y OLOv8, 2023. V ersion 8.0.0. 4 , 5 [15] Daniel Kang, Deepti Raghavan, Peter Bailis, and Matei Za- haria. Model assertions for monitoring and improving ml models. In Pr oceedings of Machine Learning and Systems , pages 481–496, 2020. 2 , 3 [16] Diederik P . Kingma and Jimmy Ba. Adam: A method for stochastic optimization. International Conference on Learn- ing Repr esentations (ICLR) , 2015. 7 [17] Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. A simple unified framew ork for detecting out-of-distribution samples and adversarial attacks. In Pr oceedings of the 32nd International Confer ence on Neural Information Pr ocessing Systems , page 7167–7177, Red Hook, NY , USA, 2018. Curran Associates Inc. 2 [18] Shiyu Liang, Y ixuan Li, and R. Srikant. Enhancing the re- liability of out-of-distribution image detection in neural net- works, 2020. 2 [19] Tsung Y i Lin, Piotr Doll ´ ar , Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. In Proceedings - 30th IEEE Confer ence on Computer V ision and P attern Recognition, CVPR 2017 , pages 936–944, 2017. 2 , 3 [20] Tsung-Y i Lin, Michael Maire, Ser ge Belongie, James Hays, Pietro Perona, Dev a Ramanan, Piotr Doll ´ ar , and C Lawrence Zitnick. Microsoft coco: Common objects in context. In Eur opean Conference on Computer V ision (ECCV) , pages 740–755, 2014. 5 [21] W eitang Liu, Xiaoyun W ang, John D. Owens, and Y ixuan Li. Energy-based out-of-distrib ution detection. In Pr oceedings of the 34th International Confer ence on Neural Information Pr ocessing Systems , Red Hook, NY , USA, 2020. Curran As- sociates Inc. 2 [22] Qiang Meng, Shichao Zhao, Zhida Huang, and Feng Zhou. Magface: A universal representation for f ace recognition and quality assessment. In Pr oceedings of the IEEE/CVF Confer- ence on Computer V ision and P attern Recognition (CVPR) , pages 14225–14234, 2021. 3 [23] Maximilian M ¨ uller and Matthias Hein. Mahalanobis++: Im- proving OOD detection via feature normalization. In Pr o- ceedings of the 42nd International Conference on Machine Learning , pages 45151–45184. PMLR, 2025. 2 [24] Maxime Oquab, T imoth ´ ee Darcet, Th ´ eo Moutakanni, Huy V o, Marc Szafraniec, V asil Khalidov , Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby , et al. Dinov2: Learning robust visual features without supervision. T rans- actions on Machine Learning Research (TMLR) , 2024. 3 , 4 [25] Malaisree P , Y ouwai S, Kitkobsin T , Janrungautai S, Amorn- dechaphon D, and Rojanav asu P . Dino-yolo: Self-supervised pre-training for data-ef ficient object detection in civil engi- neering applications, 2025. 3 [26] Jaew oo Park, Jacky Chen Long Chai, Jaeho Y oon, and An- drew Beng Jin T eoh. Understanding the feature norm for out- of-distribution detection. In Pr oceedings - 2023 IEEE/CVF International Confer ence on Computer V ision, ICCV 2023 , pages 1557–1567, United States, 2023. Institute of Electrical and Electronics Engineers Inc. 2 9 [27] Julius Pfrommer , Thomas Usl ¨ ander , and J ¨ urgen Be yerer . Ki- engineering–ai systems engineering: Systematic de velop- ment of ai as part of systems that master complex tasks. at- Automatisierungstec hnik , 70(9):756–766, 2022. 1 [28] Alec Radford, Jong W ook Kim, Chris Hallacy , Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry , Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger , and Ilya Sutske ver . Learning transferable visual models from natural language supervision. In International Confer ence on Machine Learning , 2021. 2 , 3 , 7 [29] Deepak Ravikumar , Efstathia Soufleri, and Kaushik Roy . Im- prov ed out-of-distrib ution detection with additi ve angular margin loss. In Proceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition (CVPR) W orkshops , pages 3464–3471, 2025. 3 [30] Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. Y ou only look once: Unified, real-time object detec- tion. In Proceedings of the IEEE Conference on Computer V ision and P attern Recognition (CVPR) , 2016. 3 [31] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r -cnn: T o wards real-time object detection with region proposal networks. In Advances in Neural Information Pr o- cessing Systems . Curran Associates, Inc., 2015. 3 [32] Chandramouli S. Sastry and Sagee v Oore. Detecting out-of- distribution examples with gram matrices. In Proceedings of the 37th International Conference on Machine Learning . JMLR.org, 2020. 2 [33] Albert Schotschneider , Svetlana Pa vlitska, and J. Marius Z ¨ ollner . Runtime safety monitoring of deep neural netw orks for perception: A survey , 2025. 2 , 3 [34] Poulami Sinhamahapatra, Franziska Schwaiger , Shirsha Bose, Huiyu W ang, Karsten Roscher, and Stephan Gunnemann. Finding dino: A plug-and-play framework for zero-shot de- tection of out-of-distrib ution objects using prototypes. In Pr oceedings - 2025 IEEE W inter Confer ence on Applications of Computer V ision, W A CV 2025 , pages 8474–8483. Institute of Electrical and Electronics Engineers Inc., 2025. 3 [35] Rakshith Subramanyam, K owshik Thopalli, V iv ek Narayanaswamy , and Jayaraman J. Thiagarajan. Decider: Lev eraging foundation model priors for improved model failure detection and e xplanation. In Computer V ision – ECCV 2024: 18th Eur opean Conference, Milan, Italy , September 29–October 4, 2024, Pr oceedings, P art LXXIX , page 465–482, Berlin, Heidelberg, 2024. Springer -V erlag. 3 [36] Rakshith Subramanyam, K owshik Thopalli, V i vek Siv araman Narayanaswamy , and Jayaraman J. Thiagarajan. DECIDER: lev eraging foundation model priors for improved model fail- ure detection and explanation. In Computer V ision - ECCV 2024 - 18th Eur opean Conference , Milan, Italy , September 29- October 4, 2024, Pr oceedings, P art LXXIX , pages 465–482. Springer , 2024. 3 [37] Jin Sun and David W . Jacobs. Seeing what is not there: Learning context to determine where objects are missing. In Pr oceedings of the IEEE Confer ence on Computer V ision and P attern Reco gnition (CVPR) , 2017. 2 [38] Y iyou Sun, Chuan Guo, and Y ixuan Li. React: out-of- distribution detection with rectified activ ations. In Pr oceed- ings of the 35th International Conference on Neur al Informa- tion Pr ocessing Systems , Red Hook, NY , USA, 2021. Curran Associates Inc. 2 [39] Y iyou Sun, Y ifei Ming, Xiaojin Zhu, and Y ixuan Li. Out- of-distribution detection with deep nearest neighbors. In Pr oceedings of the 39th International Confer ence on Machine Learning , pages 20827–20840. PMLR, 2022. 2 [40] Birk T orpmann-Hagen, Michael A. Riegler , P ˚ al Halvorsen, and Dag Johansen. Runtime verification for visual deep learn- ing systems with loss prediction. IEEE Access , 13:48502– 48519, 2025. 3 [41] Duong Dinh T ran, T akashi T omita, and T oshiaki Aoki. Safety analysis of autonomous driving systems: A simulation-based runtime verification approach. IEEE T ransactions on Relia- bility , 74(4):4574–4588, 2025. 3 [42] Roman V ershynin. High-Dimensional Pr obability: An In- tr oduction with Applications in Data Science . Cambridge Univ ersity Press, 2018. 4 , 5 , 7 [43] Haoqi W ang, Zhizhong Li, Litong Feng, and W ayne Zhang. V im: Out-of-distribution with virtual-logit matching. In Pro- ceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Reco gnition , 2022. 2 [44] Jingkang Y ang, Kaiyang Zhou, Y ixuan Li, and Ziwei Liu. Generalized out-of-distribution detection: A survey . arXiv pr eprint arXiv:2110.11334 , 2021. 2 [45] Jingkang Y ang, Kaiyang Zhou, Y ixuan Li, and Ziwei Liu. Generalized out-of-distribution detection: A survey . Interna- tional J ournal of Computer V ision , 132(12):5635–5662, 2024. 2 [46] Qinghua Y ang, Hui Chen, Zhe Chen, and Junzhe Su. Intro- spectiv e false negati ve prediction for black-box object detec- tors in autonomous driving. Sensors , 21(8):2819, 2021. 2 , 3 [47] Hakan Y ekta Y atbaz, Ennio Poli, Sergio Capobianco, and Giorgio Di Natale. Run-time monitoring of 3d object detec- tion in automated driving systems using early layer neural activ ation patterns. In IEEE International Confer ence on Robotics and Automation (ICRA) , 2024. 3 [48] Y ang Y ou, Igor Gitman, and Boris Ginsburg. Large batch training of conv olutional networks. arXiv preprint arXiv:1708.03888 , 2017. 5 [49] Shanshan Zhang, Rodrigo Benenson, and Bernt Schiele. Oc- cluded pedestrian detection through guided attention in cnns. In Pr oceedings of the IEEE Conference on Computer V ision and P attern Reco gnition (CVPR) , pages 6995–7003, 2018. 2 [50] Qihang Zhou, Guansong P ang, Y u T ian, Shibo He, and Jiming Chen. Anomalyclip: Object-agnostic prompt learning for zero-shot anomaly detection. In The T welfth International Confer ence on Learning Representations , 2023. 3 [51] Alon Zolfi and Shai A vidan. Y olood: Utilizing object de- tection concepts for multi-label out-of-distribution detection. In Pr oceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition (CVPR) , pages 3603–3612, 2024. 3 10
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment