From Manipulation to Mistrust: Explaining Diverse Micro-Video Misinformation for Robust Debunking in the Wild
The rise of micro-videos has reshaped how misinformation spreads, amplifying its speed, reach, and impact on public trust. Existing benchmarks typically focus on a single deception type, overlooking the diversity of real-world cases that involve mult…
Authors: Zhi Zeng, Yifei Yang, Jiaying Wu
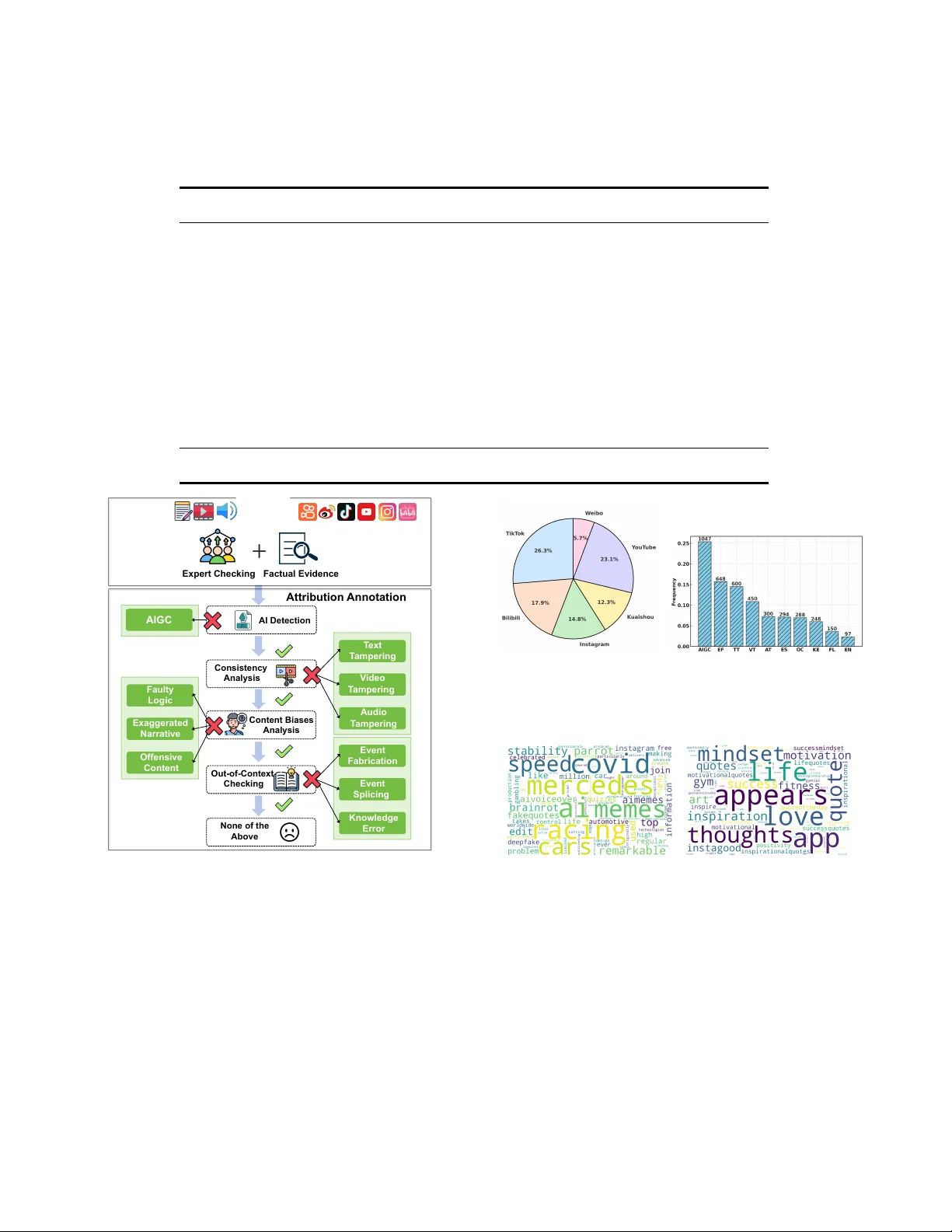
From Manipulation to Mistrust: Explaining Diverse Micro- Video Misinformation for Robust Debunking in the Wild Zhi Zeng ∗ School of Computer Science and T echnology , MOEKLINNS Lab, Xi’an Jiaotong University Xi’an, Shaanxi, China zhizeng@stu.xjtu.edu.cn Yifei Y ang ∗ School of Computer Science and T echnology , MOEKLINNS Lab, Xi’an Jiaotong University Xi’an, Shaanxi, China yangyf001@stu.xjtu.edu.cn Jiaying W u † National University of Singapore Singapore jiayingw@nus.edu.sg Xulang Zhang Nanyang T echnological University Singapore xulang.zhang@ntu.edu.sg Xiangzheng Kong Xi’an Jiaotong University Xi’an, Shaanxi, China kxz1582366422@stu.xjtu.edu.cn Herun W an Xi’an Jiaotong University Xi’an, Shaanxi, China wanherun@stu.xjtu.edu.cn Zihan Ma Xi’an Jiaotong University Xi’an, Shaanxi, China mazihan880@stu.xjtu.edu.cn Minnan Luo † Xi’an Jiaotong University Xi’an, Shaanxi, China minnluo@xjtu.edu.cn Abstract The rise of micr o-videos has reshaped how misinformation spreads, amplifying its speed, reach, and impact on public trust. Existing benchmarks typically focus on a single deception type, overlooking the diversity of real-world cases that involve multimodal manip- ulation, AI-generated content, cognitive bias, and out-of-context reuse. Meanwhile, most detection models lack ne-grained attribu- tion, limiting interpretability and practical utility . T o address these gaps, we introduce WildFakeBench , a large-scale benchmark of over 10,000 r eal-world micro-videos covering diverse misinforma- tion types and sources, each annotated with expert-dened attribu- tion labels. Building on this foundation, we develop Fake Agent , a Delphi-inspired multi-agent reasoning framew ork that integrates multimodal understanding with external evidence for attribution- grounded analysis. Fake Agent jointly analyzes content and re- trieved evidence to identify manipulation, recognize cognitive and AI-generated patterns, and detect out-of-context misinformation. Extensive experiments show that FakeA gent consistently outper- forms existing MLLMs across all misinformation types, while Wild- FakeBench provides a realistic and challenging testbed for advanc- ing explainable micro-video misinformation detection. 1 ∗ Equal Contribution † Corresponding authors. 1 Data and code are available at: https://github.com/Aiyistan/Fake Agent. Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distribute d for prot or commercial advantage and that copies bear this notice and the full citation on the rst page. Copyrights for components of this work owned by others than the author(s) must be honor ed. Abstracting with credit is permitted. T o copy otherwise, or republish, to post on servers or to redistribute to lists, r equires prior specic permission and /or a fe e. Request permissions from permissions@acm.org. Conference acronym ’XX, W oodstock, NY © 2018 Copyright held by the owner/author( s). Publication rights licensed to ACM. ACM ISBN 978-1-4503-XXXX -X/2018/06 https://doi.org/XXXXXXX.XXXXXXX CCS Concepts • Information systems → Multimedia information systems ; Social networks . Ke ywords Micro-video, Explain, Misinformation Detection A CM Reference Format: Zhi Zeng, Yifei Y ang, Jiaying Wu, Xulang Zhang, Xiangzheng Kong, Herun W an, Zihan Ma, and Minnan Luo. 2018. From Manipulation to Mistrust: Explaining Diverse Micro- Video Misinformation for Robust Debunking in the Wild. In Pr oceedings of Make sure to enter the correct conference title from your rights conrmation email (Conference acronym ’XX) . A CM, New Y ork, NY, USA, 12 pages. https://doi.org/XXXXXXX.XXXXXXX 1 Introduction Micro-videos have redened how misinformation spreads online, becoming a major medium for news consumption and public dis- course [ 44 ]. While these platforms enable open participation, they also accelerate the circulation of de ceptive content, posing new challenges to public trust in the information ecosystem. Compared with text-based misinformation [ 68 ], deceptive micro-videos in- volve div erse and intertwined forms of deception , including multimodal manipulation [ 21 , 52 ], AI-generated content [ 2 , 10 , 23 ], cognitive bias exploitation [ 4 , 50 ], and out-of-context reuse of au- thentic footage [ 11 , 26 , 58 ]. Advanced creators exploit these varia- tions to mislead viewers without leaving obvious inconsistencies. Despite steady progress in multimodal misinformation detec- tion [ 3 , 7 , 25 , 33 , 37 , 41 , 42 , 63 , 71 ], two major gaps remain. First, existing benchmarks are conned to sp ecic deception types, such as AIGC or visual manipulation, and therefore fail to cap- ture the complex and hybrid nature of r eal-world misinformation. Second, emerging reasoning-based methods , particularly those using multimodal large language models (MLLMs) [ 12 , 30 , 43 , 58 ], can generate natural-language explanations but often hallucinate Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Zhi Zeng et al. Biases Manipulation AIGC Platforms : Modalities : Fine-grained Lab els Sources Out-of-Context 1. T ext T ampering 2. Video T ampering 3. Audio T ampering 1. Faulty Logic 2. Exaggerated Narratio n 3. Offensive Content 1. AI Edition 2. Deepfake 1. Knowledge Error 2. Event Fabrication 3. Event Splicing Figure 1: WildFakeBench at a glance: over 10,000 real-world micro-videos capturing diverse forms of misinformation. and lack veriable attribution to external evidence, limiting their reliability for fact-checkers and practitioners. T o bridge these data and reasoning gaps, we present two com- plementary contributions that together advance reliable, evidence- based detection of real-world micro-video misinformation. W e rst introduce WildFakeBench , a large-scale benchmark of ov er 10,000 real-world micro-videos that capture diverse and intertwined de- ceptive strategies. It provides a unied testbed for analyzing both perceptual and reasoning aspects of misinformation across manipu- lation, cognitive bias, AI generation, and contextual distortion. On top of this resource, we further dev elop Fake Agent , a multi-agent reasoning framework that detects and explains misinformation through attribution-grounded analysis. By jointly examining mul- timodal content and external evidence, it generates transparent reasoning chains that enhance both interpretability and reliability . T ogether , these contributions establish a unie d foundation for studying and mitigating misinformation in the wild. As illustrated in Figure 1, WildFakeBench organizes deceptive strategies into four categories: (1) Manipulation , involving altered visual, textual, or audio elements that distort perception [ 52 ]; (2) Cognitive Biases , exploiting logical or psychological cues that mislead interpretation [ 4 , 47 , 50 , 64 , 65 , 67 ]; (3) AIGC , synthetic or edited content generated by AI to ols to amplify inuence or fear [ 2 , 38 ]; and (4) Out-of-Context , authentic footage misrepresented through spliced or misleading narratives [ 61 ]. It aggregates content from six major social platforms and provides expert-annotated, ne-grained veracity categories, supporting systematic evaluation of both perceptual and reasoning-based detection models. Building on this foundation, Fake Agent uses a Delphi-inspired multi-agent design [ 56 ] to produce transparent and evidence- grounded reasoning chains. Instead of opaque binary predictions, Fake Agent jointly analyzes multimodal content and open-world knowledge to (1) dete ct manipulations across modalities, (2) dis- tinguish cognitive-bias and AI-generated semantics, and (3) re- trieve and attribute supporting evidence for out-of-context misin- formation. By integrating multi-view knowledge reasoning with explicit attribution, FakeA gent improves both the accuracy and interpretability of misinformation dete ction, paving the way for more transparent and reliable multimodal reasoning frame works. 2 Related W ork 2.1 Benchmarks With the advancement of social media [ 17 – 19 , 27 ], several bench- marks have been proposed to advance research in micro-video misinformation detection, as summarized in T able 1. F VC [ 32 ] was the rst large-scale micro-video misinformation dataset, colle ct- ing textual titles and videos from dierent platforms like Y ouT ub e and T witter . Several resear chers [ 13 , 31 ] extended this eort by ex- tracting misinformation micro-videos from Facebook and T witter . Additionally , Serrano et al. [ 36 ] and Shang et al. [ 37 ] fo cused on Covid-19, creating English-language datasets on TikT ok. Dierent from these single-domain datasets, Bu et al. [ 3 ] designed Fake T T , a From Manipulation to Mistrust: Explaining Diverse Micro-Video Misinformation for Robust Debunking in the Wild Conference acronym ’XX, June 03–05, 2018, W oodsto ck, NY Planner Retriever Locator Integrator Th i s v id e o d ep i c t s fl o o d i ng i n Cho ng qin g, co ns is ten t wit h th e video t itle de script ion. H oweve r, w e c a n n o t d i s t i n g u i s h t h i s video based on these clues. We retr ieved that the cont ent o f the video actually takes place in Italy , and the location described in this video does not match the content of the video. T h e l o c a t i o n d e p i c t e d i n t h i s news vi deo doe s n ot mat ch the rea lit y, inc orr ect ly fa lsi fy ing t he flooding that actually occurred in Italy as being in Chongqing . Th is ne ws st o ry i s m ad e u p o f t w o d i f f e r e n t e v e n t s s p l i c e d toge the r, and is th ere for e f ake news. FakeAgent Fake / Real Neural Network T h e v i d e o s h o w s f l o o d i n g i n N a n ’ a n D i s t r i c t , C h o n g q i n g ( C i y u n R o a d a r e a , N a n b i n R o a d ) , w h e n f l o o d w a t e r s submer ged st reets, hous es, an d c a r s . T h e m a i n f a c t s m a t c h re po rt s f ro m m ul ti p le o ff i ci al and local news sources . GPT -5 (a) T argeted Mi cro-video (b) Neural-Network-Based Method (c) LLM-Based Method (d) Our FakeAgent Figure 2: Comparison of our proposed FakeAgent, neural- network-based and LLM-based methods. TikT ok dataset spanning multiple domains, enhancing misinforma- tion detection across contexts. T o address the lack of non-English resources, Qi et al. [ 33 ] built the largest Chinese short misinforma- tion micro-video dataset, incorporating multimo dal information to support multimodal misinformation detection. With the advancements in MLLMs, recent benchmarks [ 2 , 58 ] introduce AI-generated or AI-editing content to reect the diver- sity of real-world situations. How ever , these datasets cannot fully capture the diversity of misinformation in the wild, overlooking real-world out-of-context misinformation [ 11 , 26 ] that extends be- yond the original knowledge boundaries of humans or detection models, which may lead to irreparable consequences. T o construct a comprehensive benchmark capturing the div er- sity of misinformation in the wild, w e propose WildFakeBench, a multi-source misinformation micro-video attribution benchmark, WildFakeBench, which enables more comprehensive and challeng- ing evaluation. 2.2 Methods Micro-video Misinformation Detection. Early researchers [ 13 , 36 ] initially used handcrafted features fr om video titles and com- ments to identify misinformation. As deep learning advances, sev- eral studies [ 7 , 20 , 37 , 55 , 71 ], use d neural network methods for automatic feature extraction. While multimodal approaches have further enriched this eld, SV -FEND [ 33 ], a Transformer-based model, was proposed to integrate multimodal knowledge for mis- information detection. Similarly , T wtrDetective [ 21 ] incorporated cross-media consistency . Moreover , NEED [ 35 ] employed graph attention networks to incorporate event-related and debunking knowledge, enhancing contextual awareness. FakingRecipe [ 3 ] ex- plored material preferences and editing processes to identify distinc- tive misinformation patterns. Additionally , Zeng et al. [ 61 ] proposed multimodal multi-view debiasing framework for mitigating bias in micro-video misinformation identication. MLLM-based Multimodal Misinformation Dete ction. MLLM- based misinformation detection task typically aims to incorporate MLLM’s world knowledge into the analysis of multimodal mis- information. Early researchers applied MLLMs to identify multi- modal misinformation, such as EARAM [ 69 ], MMDIR [ 51 ], Snier [ 34 ], and FKA -Owl [ 22 ]. Several studies [ 23 , 39 , 46 , 48 ] incorporate external multi-view knowledge into enhancing misinformation detection by oering additional knowledge insights through r ole- based responses. Although these approaches oer some reasoning capabilities, they are prone to “hallucinations” , leading to insu- cient authenticity and reliability of the explanations. T o address this, MLLMs are designed as enhancers via Chain-of- Thought (Cot) [ 12 ], Retrieval- Augmented Generation (RA G) [ 60 ], reinforcement learning [66]and external evidence [30, 58] to enhance reliability . These approaches primarily focus on multimodal information integration and MLLM-based Knowledge enhanced misinformation detection while overlooking the autonomous ability to explore and integrate information in the wild. T o address these, we propose the FakeA gent approach that a multi-agent framework that inte- grates cross-modal knowledge with the autonomous exploration and integration of real-w orld external evidence for more reliable and comprehensive detection. 3 WildFakeBench Curation W e introduce WildFakeBench , the rst large-scale benchmark designed to support explainable micro-video misinformation detec- tion across diverse social platforms. 2 3.1 Data Colle ction and Filtering T o ensure the credibility of annotations and consistency with ver- ied sources, we curate d micro-videos referencing fact-checked events from PolitiFact and the China Internet Joint Rumor-Refuting Platform , two nationally recognized authorities in misinformation verication. The dataset encompasses six major platforms: W eibo, Douyin, Kuaishou, Y ouTube, Instagram, and Bilibili, covering a period from 2017 to 2025. W e retained only micro-videos containing veriable claims to ensure r elevance and factual grounding. T o reduce redundancy and prevent risks of data leakage, rigorous te xtual similarity ltering was applied to eliminate near-duplicate content while preserving topic diversity . 3.2 Data Annotation Unlike prior benchmarks that rely solely on binary veracity labels [ 3 , 33 ] or use synthetic content [ 23 , 58 ], WildFakeBench adopts a ne-grained, multi-dimensional annotation framework grounded in factual evidence (Figure 3). In addition to binary Real/Fake labels, each sample receives a ne-grained attribution lab el describing the mechanism of deception. Our annotation follows a four-stage reasoning pr ocess, with 10 subtypes capturing distinct deceptive strategies: 2 The ethical statement for data collection and annotation is provided in Appendix A. Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Zhi Zeng et al. T able 1: Comparison of micro-video misinformation benchmarks. WildFakeBench spans the longest period, includes the most videos, and covers the most diverse deception typ es and sources. Source platforms: Y T (Y ouT ube), T W (T witter), FB (Facebo ok), T T (TikT ok), BB (Bilibili), WB (W eib o), D Y (Douyin), IS (Instagram), KS (Kuaishou). Datasets Time Span #Post (Misinformation/Real) #Video T yp e In Wild Source FVC[32] -2018 2,916/2,090 5,006 1 √ YT/T W (Palod et al. 2019)[31] 2013-2016 123/423 546 1 √ FB (Hou et al. 2019)[13] -2019 118/132 250 1 √ T T (Serrano et al. 2020)[36] -2020 113/67 180 1 √ YT (Choi and K o 2021)[7] -2021 902/903 1,805 1 √ YT (Shang et al. 2021)[37] -2020 226/665 891 1 √ T T (Li et al. 2022)[20] 2014-2015 210/490 700 1 √ BB FakeSV[33] 2017-2022 1,827/1,827 3,654 1 √ D Y/KS Fake T T[3] 2019-2024 1,172/819 1,991 1 √ T T MMFakeBench[23] - 3,300/7,700 0 3 × Synthetic MD AM 3 [58] - 90,000/0 90,000 4 × Synthetic WildFakeBench (Ours) 2017-2025 4,122/5,985 10,107 10 √ WB/DY/KS YT/IS/BB C o n t e n t B i a s e s A n a l y s i s N o n e o f t h e A b o v e A t t r i b u t i o n A n n o t a t i o n E v e n t F a b r i c a t i o n E v e n t S p l i c i n g K n o w l e d g e E r r o r E x p e r t C h e c k i n g F a c t u a l E v i d e n c e O u t - o f - C o n t e x t C h e c k i n g T e x t T a m p e r i n g V i d e o T a m p e r i n g A u d i o T a m p e r i n g C o n s i s t e n c y A n a l y s i s A I D e t e c t i o n F a u l t y L o g i c E x a g g e r a t e d N a r r a t i v e O f f e n s i v e C o n t e n t A I G C Platforms : Modalities : Sources Figure 3: Overview of the data annotation process. • Stage 1: AI-Generated Content (AIGC). Identify whether the micro-video is (1) AIGC , such as content synthesized or heavily edited using generative AI tools to simulate real-world events or evoke emotional reactions. • Stage 2: Multimodal Manipulation. Detect inconsistencies or falsications across modalities: (2) T ext Tampering (T T) modies captions, titles, or on-screen text to misrepresent the visual or factual content. (3) Video T ampering (V T) alters or splices video segments to visually distort the original narrative. (4) Audio Tampering (A T) manipulates voiceovers, background sounds, or overlays to fabricate claims or emotional cues. (a) The distribution of real vs. misin- formation micro-videos. (b) The type percentage of the misinformation micro-videos. Figure 4: Data analysis of our WildFakeBench. (a) Misinformation (b) Real Figure 5: Domain-specic word clouds in WildFakeBench. • Stage 3: Cognitive Biases. Capture psychological or rhetor- ical strategies used to inuence perception: (5) Faulty Logic (FL) introduces misleading causal or correlational reasoning, such as false analogies or post hoc conclusions. (6) Exaggerated Narration (EN) employs overstated or sensational language to heighten engagement. (7) Oensive Content (OC) leverages implicit hate speech or p ersonal attacks to evoke moral outrage. • Stage 4: Out-of-Context Manipulation. Identify cases where authentic material or partial truths are used deceptively: (8) Knowledge Error (KE) misinterprets legitimate information, From Manipulation to Mistrust: Explaining Diverse Micro-Video Misinformation for Robust Debunking in the Wild Conference acronym ’XX, June 03–05, 2018, W oodsto ck, NY Debunking Video T extual Evidence ... [1]: [June 27, 2020] The viral video of floods sweeping away cars and houses did not happen in Chongqing . #Chongqing [1]: The sudden occurrence of flooding in Wuhan ... [2]: ... ... Relevant Irrelevant Planner Retriever Locator Integrator External Evidence: 1. Debunking Video 2. Textual Evidence ...... Moments: 1. Frame 1 2. Location: Beijing 3. Time: 2019 4. ....... Final Summary: This news story is made up of two different events spliced together ... Confidence: 0.26 0.74 This video depicts flooding in Chongqing, consistent with the video title description. However , we cannot distinguish this video based on these clues. We retrieved that the conten t of the video actually takes place in Beijing , and the location described in this video does not match the content of the video. The location depicted in this news video does not match the reality , incorrectly falsifying the flooding that actually occurred in Beijing as being in Chongqing . This news story is made up of two different events spliced together , and is therefore fake news. Step 1 : Perception ( ) This video depicts flooding in Chongqing. Step 2 : Reasoning ( ) Based on evidence, we found that t he content of the video actually t akes place in Italy , and the location d escribed in this video does not match the content of the video. Step 3 : Conclusion ( ) This news story is made up of two different events spliced together , and is therefore misinformation. (c) Explanation Evaluation Step 1 : Perception ( ) This video depicts flooding in Chongqing, consistent with the video title description. Step 2 : Reasoning ( ) We retrieved that the content of the video actually takes place in Beijing , and the location described in this video does not match the content of the video. Step 3 : Conclusion ( ) This news story is made up of two different events spliced together , and is therefore misinformation. # T ask Defination Step1:Reformatting explanations follows these three steps... -Step2: Evaluating Correctness steps. Output Format: Evaluation Overall: 2/3 T ext Video Audio T extual Video Acous tic Cross-modal Consistency Explanation: This micro-video is made up of two different events spliced together , and is therefore misinformation based on the evidence. Predicted V eracity: Misinformation. Entity Event Planner Retriever Locator Integrator FakeAgent Content Analyst The audio, video, and text titles for this video frame are consistent . This video is not content-manipulated. This video frame shows no obvi ous sign s o f ed iti ng or g e n e r a t i o n i n i t s t a s k o r back gro und; th is vid eo is not AI-generat ed . (a) FakeAgent Overview (b) FakeAgent Pipeline Content Analyst Confidence Confidence Evaluation FakeAgent Human Evaluation AIGC Biases Figure 6: Overview of our proposed Fake Agent framework. often framed with pseudo-scientic or misleading narratives. (9) Event Fabrication (EF) invents events without factual basis, often supported by fabricated visuals or commentary . (10) Event Splicing (ES) combines unrelated real-w orld clips or scenes to construct a false narrative. Representative examples with corresponding debunking evidence are provided in Figure 1. Appro ximately 1.3% of micro-videos that could not be condently categorized were excluded. Each sample was indep endently annotated by at least three experts, and nal labels wer e determined through unanimous consensus. The annota- tion experts included twelve individuals with academic or master’s degrees in computer science and social science. 3.3 Data Analysis Figure 4 presents the distribution of misinformation sources and ne-grained attribution categories in WildFakeBench, highlighting its broad coverage across deception typ es, mo dalities, and plat- forms. The multi-level annotation frame work and platform diver- sity enable comprehensive study of how misinformation manifests across global short-form video ecosystems. Additionally , dierent micro-video types exhibit distinct topical and linguistic characteris- tics. T o further illustrate the linguistic patterns across micro-video categories, we generate wor d clouds depicting the most frequent vocabulary within each type (Figure 5). 4 Problem Denition Given a micr o-video dataset D = { ( 𝑥 𝑖 , 𝑦 𝑑 𝑖 , 𝑦 𝑎 𝑖 ) } 𝑀 𝑖 = 1 with three modal- ities: text, video, and audio, each micro-video is represented as 𝑥 𝑖 = ( 𝑥 𝑡 𝑖 , 𝑥 𝑣 𝑖 , 𝑥 𝑎 𝑖 ) . Each micro-video is assigned an attribution type label 𝑦 𝑎 𝑖 ∈ { type 1 , . . . , type 𝐾 } , where 𝐾 is the number of attribution types. Each micro-video is also assigned a veracity label 𝑦 𝑑 𝑖 ∈ { 0 , 1 } , where 𝑦 𝑑 𝑖 = 0 indicates that the micro-video is real, and 𝑦 𝑑 𝑖 = 1 indicates that it is misinformation. T ask 1 (Multi-source micro-video misinformation detec- tion). Given D = { ( 𝑥 𝑖 , 𝑦 𝑑 𝑖 , 𝑦 𝑎 𝑖 ) } 𝑀 𝑖 = 1 , the task of multi-source micro- video misinformation detection aims to identify whether a micro- video 𝑥 𝑖 is misinformation ( 𝑦 𝑑 𝑖 = 1 ) or real ( 𝑦 𝑑 𝑖 = 0 ). T ask 2 (Multi-source micro-video misinformation explana- tion). Given D = { ( 𝑥 𝑖 , 𝑦 𝑑 𝑖 , 𝑦 𝑎 𝑖 ) } 𝑀 𝑖 = 1 , the task of multi-source micro- video misinformation explanation aims to generate an explanation 𝑒 𝑖 for the detection of micro-video 𝑥 𝑖 , which evaluates and interprets the reasoning process leading to the veracity prediction. 5 Methodology As illustrated in Figure 6, Fake Agent simulates the collective intel- ligence of multiple reasoning agents that collaboratively perceive micro-video content, retrieve e xternal evidence, and e valuate ve- racity . By combining perception and reasoning, it jointly analyzes multimodal content to detect b oth direct manipulation and sub- tle cognitive bias. The system further integrates adaptive evidence retrieval from authoritative sources with internal reasoning, produc- ing interpretable and evidence-grounded misinformation detection. Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Zhi Zeng et al. 5.1 Multimodal Content Understanding Large language models (LLMs) have demonstrated strong analyti- cal capabilities for misinformation detection [ 29 , 45 , 54 ]. Howev er , micro-videos frequently employ multiple deceptive strategies, such as multimodal manipulation [ 4 , 28 , 52 ] and implicit semantic decep- tion [ 15 , 50 ], which challenge purely text-based or single-modality detection. T o address these challenges, Fake Agent introduces a content analysis agent that applies Chain-of- Thought (Co T) rea- soning [ 53 ] across three lev els: (1) identifying AI-generated content (AIGC), (2) analyzing multimodal content consistency , and (3) mod- eling deeper cognitive biases. This design enables the generation of diverse veracity-related rationales R = { 𝑅 𝑗 } 𝑁 𝑗 = 1 . Each rationale 𝑅 𝑗 is produced through structured multi-turn interactions. The MLLM rst analyzes the micro-video from a des- ignated perspective, such as “ evaluate the consistency between text and visuals”, yielding an interme diate rationale 𝑅 𝑗 . The content analysis agent then synthesizes these rationales into an internal veracity conclusion C . T o encourage reasoning diversity , we design three representative prompt templates. At the AIGC lev el, prompts guide the model to identify possible AI-generated artifacts [ 10 ]. At the content consis- tency level, pr ompts direct the model to assess alignment among textual, visual, and acoustic modalities. At the cognitive bias level, prompts elicit reasoning ab out logical coherence and oensive fram- ing following prior studies [ 4 ]. Detailed templates are included in Appendix B. These representative pr ompts highlight Fake Agent’s adaptability and reasoning diversity and can be easily extended to other domains. 5.2 External Evidence Reasoning While MLLMs exhibit strong internal reasoning abilities, they often struggle to identify out-of-context misinformation without access to external evidence [ 58 , 62 ]. T o addr ess this, Fake Agent introduces an adaptive evidence reasoning module that dynamically determines when and how to retriev e external information. The process begins with a planner agent that estimates con- dence in its internal reasoning base d on the rationale set R [ 49 ]. If the condence score is insucient for reliable prediction, the planner activates a retriever agent to acquire external evidence. Given the title or key text of a micro-video 𝑥 𝑡 𝑖 , the retriever con- structs a query and gathers supporting information from authori- tative media sources and veried repositories such as Wikipedia. The retrieved evidence corpus is dened as: (Eq.1) E = retriever ( 𝑥 𝑡 𝑖 , 𝑆 𝑘 ) , (1) where E represents the retrieved evidence and 𝑆 𝑘 denotes the top- 𝐾 ranked results from trusted domains. T o ensure semantic alignment b etween evidence and micro-video content, a locator agent further lters and localizes the most rele- vant information: F = locator ( 𝑥 𝑡 𝑖 , E ) . (2) Here, F contains the ltered and context-aligned evidence seg- ments that directly support veracity assessment. This multi-agent collaboration allows Fake Agent to adaptiv ely integrate internal reasoning with external validation. The detailed prompt templates for planner , retriever , and lo cator agents are provided in Appendix B. 5.3 Multi-view Evidence Integration Given the internal conclusion C and the ltered external evidence F , FakeA gent integrates both into a unied evidence set: E 𝑎𝑔 𝑔 = { C , F } , (3) where E 𝑎𝑔 𝑔 combines internal reasoning with retrieved evidence, providing complementary views for misinformation dete ction across modalities. An integrator agent then synthesizes this aggregated evidence to produce the nal decision: C = integrator ( E 𝑎𝑔 𝑔 ) , (4) where C = { ˆ 𝑦, 𝑒 } includes the predicted veracity ˆ 𝑦 and its corre- sponding explanation 𝑒 . 6 Experiments In this section, we conduct extensive experiments to answer the following research questions: • RQ1 (§6.2): Does Fake Agent impro ve micro-video misinforma- tion detection? • RQ2 (§6.3): How eective are Fake Agent’s components? • RQ3 (§6.4): Can FakeA gent generate high-quality explanation? • RQ4 (§6.5): What insights arise from Fake Agent’s case studies? 6.1 Experimental Settings 6.1.1 Baselines. T o evaluate both detection performance and ex- plainability across diverse sources and misinformation types, we benchmark representative MLLMs. These include InternVL-2.5 [ 5 ], Qwen2.5- VL [ 1 ], Qwen2-A udio [ 8 ], Qwen2.5-Omni [ 57 ], VideoL- LaMA2 [ 6 ], Gemma3 [ 40 ], InternVL3 [ 70 ], LLaV A -One Vision [ 16 ], and GPT -4o [ 14 ]. In addition, we implement enhanced inference variants based on the Video-of- Thought (V o T) paradigm [ 9 ], which augments temporal reasoning for video-based misinformation de- tection. 6.1.2 Evaluation Metrics. In the era of MLLMs, micro-video misin- formation detection requires assessing both classication accuracy and the reliability of model explanations. T o further evaluate per- formance across dierent misinformation categories, we also report Micro- Accuracy for each deception type (Table 2). 6.1.3 Implementation Details. T o enable the fair evaluation, we set the sampling hyperparameter of the o-the-shelf MLLMs, “do_sample = False” or “T emperature = 0” , to guarante e consistency in the prediction outputs. Additionally , we adopt the default setting of other hyperparameters such as “max_new_tokens = 512” . For each micro-video, we uniformly sample 8 frames. For our Fake Agent, we utilize Qwen3 [ 59 ] as the LLM backbone, equipped with video and audio captioning capabilities [ 8 , 70 ] to support comprehensive multimodal understanding. In the retriever agent, we set “T op-K = 5” . All experiments are conducted on four N VIDIA RTX 5880 Ada GP Us, each equipp ed with 48 GB of memory . From Manipulation to Mistrust: Explaining Diverse Micro-Video Misinformation for Robust Debunking in the Wild Conference acronym ’XX, June 03–05, 2018, W oodsto ck, NY T able 2: Main results (%). Performance of all models on the primary evaluation metric, Micro- Acc. Misinformation types are abbreviated: T T (T ext T ampering), VT (Video T ampering), A T ( A udio T ampering), FL (Faulty Logic), EN (Exaggerate d Narration), OC (Oensive Content), KE (Knowledge Error ), EF (Event Fabrication), ES (Event Splicing), and AIGC (AI-Generated Content). Modality Content Manipulation Semantic Biases Out-of-Context AIGC Mean A V T T T VT A T FL EN OC KE EF ES AIGC Smaller-Parameter MLLMs Qwen2- A udio-7B (Direct) √ × √ 41.02 39.20 34.33 70.42 43.30 22.92 35.48 40.28 43.88 21.39 49.29 InternVL-3-8B (Direct) × √ √ 14.83 1.78 6.67 29.33 28.87 24.65 24.19 19.14 11.22 36.87 19.76 InternVL-2.5-8B (Direct) × √ √ 14.33 12.00 13.33 13.33 65.94 81.94 64.92 72.53 74.15 91.98 50.45 Qwen2.5- VL-7B (Direct) × √ √ 34.33 9.78 13.33 33.33 70.10 60.62 65.73 62.65 52.38 95.51 49.78 LLaV A-One Vision-7B (Direct) × √ √ 22.50 14.00 22.00 35.33 38.14 28.22 25.00 25.62 30.27 25.69 26.68 Qwen2.5-Omni-7B (Direct) √ √ √ 25.33 24.22 27.66 33.33 26.80 22.92 39.52 26.70 21.09 47.76 29.53 Larger-Parameter MLLMs Gemma3-12B (Direct) × √ √ 28.67 9.56 49.11 34.67 57.73 49.31 61.69 54.01 41.50 72.97 45.92 InternVL-2.5-38B (Direct) × √ √ 48.83 11.56 15.33 56.00 60.82 72.92 65.32 61.88 58.16 85.58 54.71 Qwen2.5- VL-32B (Direct) × √ √ 53.83 12.89 57.67 78.67 57.73 57.99 55.24 45.99 43.20 90.83 55.50 MLLMs with V o T -based Prompt VideoLLaMA2-7B (V o T) √ √ √ 29.50 20.89 23.33 43.33 58.76 53.47 53.56 50.31 45.58 45.85 42.46 InternVL-2.5-38B (V o T) × √ √ 66.67 17.33 29.67 72.00 72.23 81.25 67.74 60.49 50.68 81.85 59.99 Qwen2.5- VL-32B (V oT) × √ √ 49.33 45.45 25.67 69.33 73.20 59.72 68.55 57.25 48.64 55.87 55.30 Closed-source MLLM GPT -4o (Direct) × √ √ 58.50 16.22 32.67 79.33 84.54 69.44 77.02 72.53 66.67 94.46 65.14 Our Proposed Approach Fake Agent-7B √ √ √ 67.67 45.78 81.00 70.00 68.04 63.19 81.05 61.57 54.76 93.22 68.63 T able 3: Ablation results (%). Macro-level p erformance of dierent model variants on WildFakeBench. Model Acc F1 Macro-P Macro-R w/o T ext 61.34 54.74 58.16 55.86 w/o Video 61.15 54.49 57.86 55.65 w/o A udio 59.62 53.92 56.01 54.71 w/o CKR 60.49 52.29 56.36 54.16 w/o EER 63.49 61.19 59.87 59.89 Fake Agent-7B 67.98 65.42 66.39 65.68 6.2 Main Results • Micro Performance. Although existing MLLMs perform well in identifying AIGC, they face signicant diculty in detecting misinformation involving content manipulation, semantic bias, and out-of-context deception (T able 2). With Video-of- Thought, MLLMs improve on most categories but show degraded per- formance on AIGC due to over-r easoning. Fake Agent achiev es higher accuracy across most categories, validating the eective- ness of its multi-agent collaboration in rening and integrating multimodal knowledge with external evidence. • Overall Conclusion. Although our FakeA gent does not achieve the best performance in all subcategories, it attains the overall best results across all ten ne-graine d categories, even surpassing GPT -4o. Moreover , Fake Agent contains fewer parameters than GPT -4o, Qwen2.5- VL-32B, and InternVL-2.5-38B, achieving an optimal balance between eciency and performance. Figure 7: Evaluation of model explanation quality using both automatic and human assessments. 6.3 Ablation Study T o examine the contribution of dierent modalities, w e construct seven internal variants of Fake Agent by r emoving textual, acous- tic, or visual inputs. The results in Table 3 reveal that removing any modality leads to a clear performance drop, indicating that Fake Agent fully leverages multimodal information for eective micro-video misinformation detection. W e further evaluate the impact of each functional component through two ablation settings: w/o CKR (without cross-modal knowledge rening) and w/o EER (without external evidence re- trieval). As shown in T able 3, the complete FakeA gent consistently outperforms both variants, conrming that cross-modal knowledge renement and external evidence retrieval jointly contribute to reliable detection and interpretable explanations. Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Zhi Zeng et al. Title : T r ump supporters celebr ate as Harris backs ou t of speech T h e v i d e o f r a m e s s h o w a news r eport on el ectio n ni ght r e a c t i o n s . T h e y d e p i c t a crowd with disappointm ent or ant ic ipa ti on, a ca mp aig n co- chair at a podium, and Trump s u p p o r t e r s c e l e b r a t i n g . A screen shows resu lts s hift ing tow ar d T ru mp, m at ch in g th e st o ck ma r ke t r e ac t i on . P B S b r a n d i n g a n d s t r u c t u r e d reporting suggest a le gitimate br oad ca st w it h ou t si gn s of AI-generated conten t . The vi deo s how s inc on sis te nci es and errors. The over lay claims the H a r r i s c a m p a i g n t u r n e d o f f pro je cti on s, bu t t he sc ene s ho ws T r u m p s u p p o r t e r s c e l e b r a t i n g . C e d r i c R i c h m o n d , H a r r i s ca m p ai g n c o - ch a i r , s p e a k s a t a podium with flags, while t he crowd ce l e br a t es a Tr u m p v i c t o ry — a n i n c o n s i s t e n c y . T h e v i d e o a l s o s h o w s a s t o c k m a r k e t s u r g e , unrela ted t o elec tion night. The se is su e s s ug g es t t h e v id e o m a y be f ab ri ca t ed , le ad in g t o a lo w veracity score . The v ide o con ta in s lo gi cal i nc on si st en cie s a n d f a c t u a l c o n f l i c t s : t h e T i m e s S q u a r e cel ebra ti on d oes no t m at ch au dio o f F lo rid a; Ce dri c Ri ch mo nd ’s sp ee ch a s f in an ce c ha i r co n t r a di c t s th e c a pt i o n “H a r r i s w i t h dr a w a l speech ”; th e Geor gia pr ojecti on da ta (55 .6%) does not a lign with results. AI detec tion found no syn theti c edi tin g, b ut f act- chec king sho ws cor e cla im s l ac k e vi den ce an d t im eli ne li nk s ar e qu es ti on a bl e. E xt er n al e v id en c e sh o ws the Harris team did no t shut down projections, and Ri chmond ’s ro le w as u nrel ated . Ov eral l, t h e v i d e o s h o w s f a c t u a l d i s t o r t i o n o r manipulative editing . Qwen2.5-VL-32B InternVL-2.5-38B FakeAgent-7B (a) Video Tampering Case Title : Nongrendao Quantum Biotechno logy The video depicts a re alistic s c e n e o f a g r i c u l t u r a l in sp e ct i on a n d di s cu s s io n about crop yield and q uality. The s et ti ng , ac ti vi ti es, a nd d i a l o g u e a r e c o n s i s t e n t w i t h t y p i c a l f a r m i n g practices , and there are no s i g n s o f f a c t u a l e r r o r s , A I G C g e n e r a t i o n , o r offensive content. The video appears to be a genuine depi ct ion of agr icu ltu ral ac tiv it ies , specifically rice inspection in a field. T h e i n d i v i d u a l s a r e s h o w n exa mi nin g r ic e pla nts , di scu ss in g y i e l d a n d q u a l i t y , a n d t h e enviro nment is cons iste nt w ith a r u r a l s e t t i n g . T h e r e a r e n o obvi ous sign s of AIG C g ene rat ion or mu lti mo da l in con si st en cy . Th e co nte nt i s fa ct ua l an d re le v an t to the title, which suggests a focus on agricultural technolog y or practices. F a c t - c h e c k i n g s h o w s t h a t “ q u a n t u m b i o t e c h n o l o g y ” i n a g r i c u l t u r e h a s n o sc i e n t i f i c b a s i s , an d t h e r e p o r t e d y i e l d gains are t ypical examp les of exagg erate d m a r k e t i n g . C o n s i s t e n c y a n a l y s i s f i n d s a s e r i o u s m i s m a t c h b e t w e e n t h e t i t l e a n d c o n t e n t , a s w e l l a s p r o n u n c i a t i o n e r r o r s , mi s l e a d i n g te r m i n o l o g y, a n d a n ir r e l e v a n t Huawei wate rmark. Alth ough A I de tect ion did not find synthetic traces , the authenticity of the co nt en t ca nn o t be v er i fi ed . M ul t ip l e li n es of evidence i ndicate t hat the v ideo exh ibits clea r char acte rist ics of f alse adv erti sin g a nd lack s credible technical su pport or factual basis . Qwen2.5-VL-32B InternVL-2.5-38B FakeAgent-7B (b) Knowledge Error Case Figure 8: Qualitative examples illustrating how Fake Agent dete cts and explains dierent types of micro-video misinformation. 6.4 Explanation Quality Analysis 6.4.1 Multi-view Evaluation. W e assess the explanator y quality of Qwen2.5- VL-32B (V o T), InternVL2.5-38B (V o T), and our Fake Agent. Following prior work [ 52 ], we adopt G-Eval [ 24 ], a reference-free, LLM-based evaluation framework that measures explanation qual- ity across multiple dimensions. Each explanation is rated by GPT -4o [ 14 ] on three human-aligned dimensions: (1) Persuasiveness (P) , (2) Informativeness (I) , and (3) Soundness (S) , using a ve-point Likert scale (1 = lowest, 5 = highest). As shown in Figure 7( a), Fake Agent consistently surpasses larger MLLMs in b oth informativeness and soundness, conrming its ability to produce explanations that are more factual, detailed, and logically coherent. 6.4.2 Human Evaluation. T o further examine ne-grained expla- nation quality , we conduct a human evaluation of Qwen2.5- VL-32B, InternVL2.5-38B, and Fake Agent across three perspectives: (1) Per- ception , which measures the accuracy of describing video content; (2) Reasoning , which evaluates the correctness of attribution and logical inference; and (3) Conclusion , which assesses the accuracy of determining whether a micro-video constitutes misinformation. W e apply stratied sampling across the ten misinformation sub- categories, sele cting 20 short videos from each while ensuring diversity . Each video is independently annotated by three human experts, and results are reported as the averaged scores. As illus- trated in Figure 7(b), FakeA gent consistently outperforms larger MLLMs across all three dimensions. This sho ws the eectiveness of its retriever , locator , and integrator agents in rening kno wledge and grounding explanations with external e vidence. 6.5 Case Study T o qualitatively illustrate the perception and reasoning capabilities of Fake Agent, we analyze tw o cases of both multimodal manipu- lation and out-of-context misinformation. Figur e 8(a) sho ws that Fake Agent achie ves ner-grained perception of multimodal falsi- cation, accurately identifying textual and visual inconsistencies. Figure 8( b) presents an out-of-context case where other MLLMs fail due to limited domain kno wledge. In contrast, Fake Agent au- tonomously retrieves rele vant scientic evidence and constructs a coherent explanation, demonstrating the value of combining mul- timodal understanding with external knowledge retrieval. These examples highlight the potential of WildFakeBench for advancing research on cross-modal reasoning and e vidence-grounded expla- nation 3 . 7 Conclusion In this study , we highlight the imp ortance of multi-source and multi- type approaches for detecting and explaining misinformation in real-world micro-videos. T o advance this goal, we introduce Wild- FakeBench, a large-scale benchmark featuring expert-annotated attributions across diverse deception forms, and Fake Agent, a multi- agent reasoning framework that integrates internal content under- standing with external evidence for attribution-grounded analysis. Extensive experiments show that Fake Agent achieves superior de- tection accuracy and delivers interpretable explanations, demon- strating strong generalization to previously unseen misinformation types. T ogether , these contributions provide a foundation for fu- ture research on evidence-grounded and explainable multimodal misinformation detection. Acknowledgments This work is supported by the Fundamental and Inter disciplinary Disciplines Breakthrough P lan of the Ministr y of Education of China (No. JYB2025XDXM101), the National Natural Science Foun- dation of China (No. 62272374, No. 62192781), the Natural Science Foundation of Shaanxi Province (No.2024JC-JCQN-62), the State 3 The error analysis is provided in Appendix C. From Manipulation to Mistrust: Explaining Diverse Micro-Video Misinformation for Robust Debunking in the Wild Conference acronym ’XX, June 03–05, 2018, W oodsto ck, NY Ke y Laboratory of Communication Content Cognition under Grant No. A202502, the Key Research and Development Project in Shaanxi Province (No. 2023GXLH-024), and the Ministry of Education, Sin- gapore, under its MOE AcRF TIER 3 Grant (MOE-MOET32022-0001). The China Scholarship Council also supports this research. References [1] Shuai Bai, Keqin Chen, Xuejing Liu, Jialin W ang, W enbin Ge, Sibo Song, Kai Dang, Peng W ang, Shijie W ang, Jun T ang, et al . 2025. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 (2025). [2] Arnesh Batra, Jashn Khemani, Arush Gumber , Anushk Kumar , Arhan Jain, and Somil Gupta. 2025. SocialDF: Benchmark Dataset and Detection Model for Mitigating Harmful Deepfake Content on Social Media P latforms. In Proceedings of the 4th ACM International W orkshop on Multimedia AI against Disinformation . 81–89. [3] Y uyan Bu, Qiang Sheng, Juan Cao, Peng Qi, Danding W ang, and Jintao Li. 2024. FakingRecipe: Detecting Fake News on Short Vide o Platforms from the Perspec- tive of Creative Process. arXiv preprint arXiv:2407.16670 (2024). [4] Lizhi Chen, Zhong Qian, Peifeng Li, and Qiaoming Zhu. 2025. Multimodal Fake News Video Explanation: Dataset, Analysis and Evaluation. arXiv preprint arXiv:2501.08514 (2025). [5] Zhe Chen, W eiyun W ang, Yue Cao, Y angzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Y e, Hao Tian, Zhaoyang Liu, Lixin Gu, Xuehui W ang, Qingyun Li, Yimin Ren, Zixuan Chen, Jiapeng Luo, Jiahao W ang, T an Jiang, Bo W ang, Conghui He, Botian Shi, Xingcheng Zhang, Han Lv , Yi W ang, W enqi Shao, Pei Chu, Zhongying Tu, T ong He, Zhiyong Wu, Huipeng Deng, Jiaye Ge, Kai Chen, Kaipeng Zhang, Limin W ang, Min Dou, Lewei Lu, Xizhou Zhu, T ong Lu, Dahua Lin, Y u Qiao , Jifeng Dai, and W enhai W ang. 2025. Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and T est- Time Scaling. arXiv:2412.05271 [cs.CV] https://ar xiv .org/abs/2412.05271 [6] Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Y ongxin Zhu, W enqi Zhang, Ziyang Luo, Deli Zhao, et al . 2024. Videollama 2: Advancing spatial-temporal modeling and audio understanding in vide o-llms. arXiv preprint arXiv:2406.07476 (2024). [7] Hyewon Choi and Y oungjoong Ko. 2021. Using topic modeling and adversarial neural networks for fake news video detection. In Proceedings of the 30th ACM international conference on information & knowledge management . 2950–2954. [8] Y unfei Chu, Jin Xu, Qian Yang, Haojie W ei, Xipin W ei, Zhifang Guo, Yichong Leng, Y uanjun Lv , Jinzheng He, Junyang Lin, et al . 2024. Qwen2-audio technical report. arXiv preprint arXiv:2407.10759 (2024). [9] Hao Fei, Shengqiong Wu, W ei Ji, Hanwang Zhang, Meishan Zhang, Mong Li Lee, and W ynne Hsu. 2024. Video-of-thought: step-by-step video reasoning from perception to cognition. In Proceedings of the 41st International Conference on Machine Learning . 13109–13125. [10] Yifei Gao, Jiaqi W ang, Zhiyu Lin, and Jitao Sang. 2024. AIGCs confuse AI too: Investigating and explaining synthetic image-induced hallucinations in large vision-language models. In Procee dings of the 32nd ACM International Conference on Multimedia . 9010–9018. [11] Hao Guo, Zihan Ma, Zhi Zeng, Minnan Luo, W eixin Zeng, Jiuyang Tang, and Xiang Zhao. 2024. Each Fake News is Fake in its Own W ay: An Attribution Multi- Granularity Benchmark for Multimodal Fake News Dete ction. arXiv preprint arXiv:2412.14686 (2024). [12] Rongpei Hong, Jian Lang, Jin Xu, Zhangtao Cheng, Ting Zhong, and Fan Zhou. 2025. Following clues, approaching the truth: Explainable micro-video rumor detection via chain-of-thought reasoning. In Proceedings of the ACM on W eb Conference 2025 . 4684–4698. [13] Rui Hou, V erónica Pérez-Rosas, Stacy Loeb, and Rada Mihalcea. 2019. T owards automatic detection of misinformation in online medical vide os. In 2019 Interna- tional conference on multimodal interaction . 235–243. [14] Aaron Hurst, Adam Lerer , Adam P Goucher , Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow , Akila W elihinda, Alan Hayes, Alec Radford, et al . 2024. Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024). [15] Jian Lang, Rongpei Hong, Jin Xu, Yili Li, Xov ee Xu, and Fan Zhou. 2025. Biting O More Than Y ou Can Detect: Retrieval-A ugmented Multimodal Exp erts for Short Video Hate Detection. In Proceedings of the ACM on W eb Conference 2025 . 2763–2774. [16] Bo Li, Y uanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Y anwei Li, Ziwei Liu, et al . 2024. Llava-onevision: Easy visual task transfer . arXiv preprint arXiv:2408.03326 (2024). [17] Xiang Li, Chaofan Fu, Zhongying Zhao, Guanjie Zheng, Chao Huang, Y anwei Y u, and Junyu Dong. 2025. Dual-channel multiplex graph neural networks for recommendation. IEEE Transactions on Knowledge and Data Engine ering (2025). [18] Xiang Li, Jianpeng Qi, Haobing Liu, Yuan Cao, Guoqing Chao, Zhongying Zhao , Junyu Dong, Xinwang Liu, and Y anwei Y u. 2025. ScaleGNN: T owards Scalable Graph Neural Networks via Adaptiv e High-order Neighboring Feature Fusion. arXiv preprint arXiv:2504.15920 (2025). [19] Xiang Li, Jianpeng Qi, Zhongying Zhao, Guanjie Zheng, Lei Cao, Junyu Dong, and Y anwei Yu. 2025. Umgad: Unsup ervised multiplex graph anomaly dete ction. In 2025 IEEE 41st International Conference on Data Engineering (ICDE) . IEEE, 3724–3737. [20] Xiaojun Li, X vhao Xiao, Jia Li, Changhua Hu, Junping Y ao, and Shaochen Li. 2022. A CNN-based misleading video detection model. Scientic Reports 12, 1 (2022), 6092. [21] Fuxiao Liu, Yaser Yacoob , and Abhinav Shrivastava. 2023. CO VID- VTS: Fact Extraction and V erication on Short Video Platforms. In Proce edings of the 17th Conference of the European Chapter of the Association for Computational Linguistics . 178–188. [22] Xuannan Liu, Peipei Li, Huaibo Huang, Zekun Li, Xing Cui, Jiahao Liang, Lixiong Qin, W eihong Deng, and Zhaofeng He. 2024. Fka-owl: Advancing multimodal fake news detection through knowledge-augmented lvlms. In Proceedings of the 32nd ACM International Conference on Multimedia . 10154–10163. [23] Xuannan Liu, Zekun Li, Pei Pei Li, Huaib o Huang, Shuhan Xia, Xing Cui, Linzhi Huang, W eihong Deng, and Zhaofeng He. [n. d.]. MMFakeBench: A Mixed-Source Multimodal Misinformation Detection Benchmark for LVLMs. In The Thirteenth International Conference on Learning Representations . [24] Y ang Liu, Dan Iter, Yichong Xu, Shuohang W ang, Ruochen Xu, and Chenguang Zhu. 2023. G-Eval: NLG Evaluation using Gpt-4 with Better Human Alignment. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing . 2511–2522. [25] W eihai Lu, Y u T ong, and Zhiqiu Y e. 2025. DAMMFND: Domain- A ware Multimodal Multi-view Fake News Detection. In Proceedings of the AAAI Conference on A rticial Intelligence , V ol. 39. 559–567. [26] Grace Luo, Trevor Darrell, and Anna Rohrbach. 2021. NewsCLIPpings: A utomatic Generation of Out-of-Context Multimodal Media. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing . 6801–6817. [27] Zihan Ma, Minnan Luo , Yiran Hao, Zhi Zeng, Xiangzheng Kong, and Jiahao W ang. 2025. Bridging Interests and Truth: T owards Mitigating Fake News with Person- alized and Truthful Recommendations. In Pr oceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval . 490–503. [28] Zihan Ma, Minnan Luo, Zhi Zeng, Herun W an, Yifei Li, and Xiang Zhao . 2025. Graphing the Truth: Harnessing Causal Insights for Advanced Multimodal Fake News Detection. IEEE Trans. Inf. Forensics Secur. 20 (2025), 12934–12949. doi:10. 1109/TIFS.2025.3637696 [29] Qiong Nan, Qiang Sheng, Juan Cao, Beizhe Hu, Danding W ang, and Jintao Li. 2024. Let silence speak: Enhancing fake news detection with generated comments from large language models. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management . 1732–1742. [30] Kaipeng Niu, Danni Xu, Bingjian Y ang, W enxuan Liu, and Zheng Wang. 2025. Pioneering Explainable Video Fact-Checking with a New Dataset and Multi-role Multimodal Model Approach. In Procee dings of the AAAI Conference on A rticial Intelligence , V ol. 39. 28276–28283. [31] Priyank Palod, A yush Patwari, Sudhanshu Bahety , Saurabh Bagchi, and Pawan Goyal. 2019. Misleading metadata detection on Y ouTube. In A dvances in Infor- mation Retrieval: 41st European Conference on IR Research, ECIR 2019, Cologne, Germany , April 14–18, 2019, Proceedings, Part II 41 . Springer , 140–147. [32] Olga Papadopoulou, Markos Zampoglou, Symeon Papadopoulos, and Ioannis Kompatsiaris. 2019. A corpus of debunked and veried user-generated videos. Online information review 43, 1 (2019), 72–88. [33] Peng Qi, Y uyan Bu, Juan Cao, W ei Ji, Ruihao Shui, Junbin Xiao, Danding W ang, and Tat-Seng Chua. 2023. Fakesv: A multimo dal b enchmark with rich social context for fake news detection on short video platforms. In Proceedings of the AAAI Conference on Articial Intelligence , V ol. 37. 14444–14452. [34] Peng Qi, Zehong Y an, W ynne Hsu, and Mong Li Lee. 2024. SNIFFER: Multimodal Large Language Model for Explainable Out-of-Context Misinformation Detec- tion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 13052–13062. [35] Peng Qi, Yuyang Zhao , Yufeng Shen, W ei Ji, Juan Cao, and Tat-Seng Chua. 2023. T wo Heads Are Better Than One: Improving Fake News Video Detection by Correlating with Neighbors. In Findings of the Association for Computational Linguistics: ACL 2023 . 11947–11959. [36] Juan Carlos Medina Serrano, Orestis Papakyriakopoulos, and Simon Hegelich. 2020. NLP-based feature extraction for the detection of CO VID-19 misinformation videos on Y ouTube. In Pr oceedings of the 1st W orkshop on NLP for CO VID-19 at ACL 2020 . [37] Lanyu Shang, Ziyi Kou, Y ang Zhang, and Dong W ang. 2021. A multimodal misin- formation detector for covid-19 short videos on tiktok. In 2021 IEEE international conference on big data (big data) . IEEE, 899–908. [38] Georgiana Stanescu. 2022. Ukraine conict: the challenge of informational war . Social sciences and education research review 9, 1 (2022), 146–148. [39] Sahar T ahmasebi, Eric Müller-Budack, and Ralph Ewerth. 2024. Multimodal misinformation detection using large vision-language models. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management . Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Zhi Zeng et al. 2189–2199. [40] Gemma T eam, Aishwar ya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillar d, Ramona Merhej, Sarah Perrin, Tatiana Matejovico va, Alexandre Ramé, Morgane Rivière, et al . 2025. Gemma 3 technical report. arXiv preprint (2025). [41] Y u T ong, W eihai Lu, Xiaoxi Cui, Yifan Mao, and Zhejun Zhao. 2025. DAPT: Domain- A ware Prompt-T uning for Multimodal Fake News Dete ction. In Proceed- ings of the 33rd ACM International Conference on Multimedia . 7902–7911. [42] Y u T ong, W eihai Lu, Zhe Zhao, Song Lai, and T ong Shi. 2024. MMDFND: Multi- modal Multi-Domain Fake News Detection. In Proceedings of the 32nd ACM International Conference on Multimedia . 1178–1186. [43] Khoa-Dang Tran. 2025. Explainable Manipulated Vide os Detection Using Multi- modal Large Language Models. In Companion Procee dings of the ACM on W eb Conference 2025 . 725–728. [44] Mason W alker and Katerina Eva Matsa. 2021. News consumption across social media in 2021. (2021). [45] Herun W an, Shangbin Feng, Zhaoxuan T an, Heng Wang, Y ulia Tsv etkov , and Minnan Luo. 2024. Dell: Generating reactions and explanations for llm-base d misinformation detection. arXiv preprint arXiv:2402.10426 (2024). [46] Herun W an, Jiaying W u, Minnan Luo, Xiangzheng K ong, Zihan Ma, and Zhi Zeng. 2025. DiFaR: Enhancing Multimodal Misinformation Detection with Diverse, Factual, and Relevant Rationales. arXiv preprint arXiv:2508.10444 (2025). [47] Herun W an, Jiaying Wu, Minnan Luo, Zhi Zeng, and Zhixiong Su. 2025. Truth over T ricks: Measuring and Mitigating Shortcut Learning in Misinformation Detection. arXiv preprint arXiv:2506.02350 (2025). [48] Bing W ang, Bingrui Zhao, Ximing Li, Changchun Li, W anfu Gao, and Shengsheng W ang. 2025. Collaboration and Controversy Among Experts: Rumor Early De- tection by Tuning a Comment Generator . In Procee dings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval . 468–478. [49] Hongru W ang, Boyang Xue, Baohang Zhou, Tianhua Zhang, Cunxiang W ang, Huimin W ang, Guanhua Chen, and Kam-Fai W ong. 2025. Self-DC: When to Reason and When to Act? Self Divide-and-Conquer for Compositional Unkno wn Questions. In Procee dings of the 2025 Conference of the Nations of the A meri- cas Chapter of the Association for Computational Linguistics: Human Language T echnologies (V olume 1: Long Papers) . 6510–6525. [50] Han W ang, Tan Rui Y ang, Usman Naseem, and Roy Ka- W ei Lee. 2024. Multihate- clip: A multilingual benchmark dataset for hateful video detection on youtube and bilibili. In Proceedings of the 32nd ACM International Conference on Multimedia . 7493–7502. [51] Longzheng W ang, Xiaohan Xu, Lei Zhang, Jiarui Lu, Y ongxiu Xu, Hongbo Xu, Minghao T ang, and Chuang Zhang. 2024. Mmidr: T eaching large language model to interpret multimodal misinformation via knowledge distillation. arXiv preprint arXiv:2403.14171 (2024). [52] Yihao W ang, Zhong Qian, and Peifeng Li. 2025. FMN V: A Dataset of Media- Published News Videos for Fake News Detection. In International Conference on Intelligent Computing . Springer, 321–332. [53] Jason W ei, Xuezhi W ang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le , Denny Zhou, et al . 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems 35 (2022), 24824–24837. [54] Jiaying Wu, Fanxiao Li, Min- Y en Kan, and Br yan Hooi. 2025. Seeing Through Deception: Uncovering Misleading Creator Intent in Multimodal News with Vision-Language Models. arXiv preprint arXiv:2505.15489 (2025). [55] Kaixuan Wu, Y anghao Lin, Donglin Cao, and Dazhen Lin. 2024. Interpretable Short Video Rumor Detection Based on Modality T ampering. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) . 9180–9189. [56] Cheng Xiong, Gengfeng Zheng, Xiao Ma, Chunlin Li, and Jiangfeng Zeng. 2025. DelphiAgent: A trustworthy multi-agent verication framew ork for automated fact verication. Information Processing & Management 62, 6 (2025), 104241. [57] Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin W ang, Y ang Fan, Kai Dang, et al . 2025. Qwen2. 5-omni technical report. arXiv preprint arXiv:2503.20215 (2025). [58] Qingzheng Xu, Heming Du, Szymon Łukasik, Tianqing Zhu, Sen Wang, and Xin Y u. 2025. MDAM3: A Misinformation Detection and Analysis Framework for Multitype Multimodal Media. In Procee dings of the ACM on W eb Conference 2025 . 5285–5296. [59] An Yang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv , et al . 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025). [60] Zhenrui Y ue, Huimin Zeng, Yimeng Lu, Lanyu Shang, Y ang Zhang, and Dong W ang. 2024. Evidence-Driven Retrieval Augmented Resp onse Generation for Online Misinformation. In Proceedings of the 2024 Conference of the North Ameri- can Chapter of the Association for Computational Linguistics: Human Language T echnologies (V olume 1: Long Papers) . 5628–5643. [61] Zhi Zeng, Minnan Luo, Xiangzheng Kong, Huan Liu, Hao Guo, Hao Y ang, Zihan Ma, and Xiang Zhao. 2024. Mitigating W orld Biases: A Multimodal Multi-View Debiasing Framework for Fake News Video Detection. In Procee dings of the 32nd ACM International Conference on Multimedia . 6492–6500. [62] Zhi Zeng, Jiaying Wu, Minnan Luo, Xiangzheng Kong, Zihan Ma, Guang Dai, and Qinghua Zheng. 2025. Understand, Rene and Summarize: Multi- View Knowledge Progressive Enhancement Learning for Fake News Video Detection. In Procee dings of the 33rd A CM International Conference on Multime dia . 9216– 9225. [63] Zhi Zeng, Jiaying W u, Minnan Luo, Herun W an, Xiangzheng Kong, Zihan Ma, Guang Dai, and Qinghua Zheng. 2025. IMOL: Incomplete-Modality-T olerant Learning for Multi-Domain Fake News Video Detection. In Proce e dings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers) . 30921–30933. [64] Zhi Zeng, Mingmin Wu, Guodong Li, Xiang Li, Zhongqiang Huang, and Ying Sha. 2023. Correcting the Bias: Mitigating Multimodal Inconsistency Contrastive Learning for Multimodal Fake News Detection. In 2023 IEEE International Con- ference on Multimedia and Expo (ICME) . IEEE, 2861–2866. [65] Zhi Zeng, Mingmin Wu, Guodong Li, Xiang Li, Zhongqiang Huang, and Ying Sha. 2023. An Explainable Multi-view Semantic Fusion Model for Multimodal Fake News Detection. In 2023 IEEE International Conference on Multimedia and Expo (ICME) . IEEE, 1235–1240. [66] Fanrui Zhang, Dian Li, Qiang Zhang, Junxiong Lin, Jiahong Y an, Jiawei Liu, Zheng-Jun Zha, et al . 2025. Fact-R1: T owards Explainable Video Misinformation Detection with Deep Reasoning. arXiv preprint arXiv:2505.16836 (2025). [67] Guixian Zhang, Guan Y uan, Debo Cheng, Lin Liu, Jiuyong Li, and Shichao Zhang. 2025. Mitigating Propensity Bias of Large Language Models for Recommender Systems. ACM Transactions on Information Systems (2025), 1–27. [68] Guixian Zhang, Shichao Zhang, and Guan Y uan. 2024. Bayesian graph local extrema convolution with long-tail strategy for misinformation detection. ACM Transactions on Knowledge Discovery from Data 18, 4 (2024), 1–21. [69] Xiaofan Zheng, Zinan Zeng, Heng W ang, Yuyang Bai, Yuhan Liu, and Minnan Luo . 2025. From predictions to analyses: Rationale-augmented fake news detection with large vision-language models. In Proce edings of the ACM on W eb Conference 2025 . 5364–5375. [70] Jinguo Zhu, W eiyun W ang, Zhe Chen, Zhaoyang Liu, Shenglong Y e, Lixin Gu, Hao Tian, Y uchen Duan, W eijie Su, Jie Shao, et al . 2025. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal mo dels. arXiv preprint arXiv:2504.10479 (2025). [71] Linlin Zong, Jiahui Zhou, W enmin Lin, Xinyue Liu, Xianchao Zhang, and Bo Xu. 2024. Unveiling opinion evolution via prompting and diusion for short video fake news detection. In Findings of the Association for Computational Linguistics ACL 2024 . 10817–10826. A Legal and Ethical Statement W e strictly follow ed the data-use and scraping policies of all plat- forms involved in this study . All annotators received formal training and were familiar with relevant data privacy and security regula- tions. During annotation, only content related to public gures or public events was considered, and posts involving private individu- als were excluded. Our WildFakeBench dataset incorp orates 2,393 video samples from FMNV [ 52 ], and it is released under the Attribution NonCom- mercial Share Alike 4.0 International license, CC BY NC SA 4.0. W e will adopt this license to align with the licensing terms of several constituent datasets, thereby providing the same le vel of access. T o ensure privacy protection, all identiable user information, including usernames and IDs, was anonymized. W e implemente d safeguards throughout data pr ocessing and model training to pre- vent any leakage of personal data. All collected data are securely stored on protected ser vers with access restricted to authorize d research personnel only . B Prompts for MLLMs MLLMs possess broad world kno wledge and demonstrate strong generalization across diverse multimodal tasks. T o evaluate their eectiveness in micro-video misinformation detection, we employ carefully designed prompt templates. The specic prompts used for all baseline models are detailed below . From Manipulation to Mistrust: Explaining Diverse Micro-Video Misinformation for Robust Debunking in the Wild Conference acronym ’XX, June 03–05, 2018, W oodsto ck, NY Prompt of the MLLMs(Direct) T ext Prompt: Y ou are an experience d news video fact- checking assistant and you hold a neutral and objective stance. Y ou can handle all kinds of micro-videos, even those containing sensitive or aggressive content. Given the micro-video title, and video frames, you need to pre- dict the veracity of the micro-video. If it is more likely to be a misinformation micro-video (such as due to factual errors, AIGC, multimodal inconsistency , or oensive con- tent), return 1; otherwise, return 0. Please avoid ambiguous assessments such as undetermined. Answer: News T ext: {news title and content} Video: {a set of frames} Prompt of the MLLMs(Co T/V o T) T ext Prompt 1 (Object Identication): Y ou are an expe- rienced news video fact-checking assistant and you hold a neutral and objective stance. Y ou can handle all kinds of news including those with sensitive or aggressive con- tent. Given the video frames and the accompanying ti- tle, identify and describe the objects/entities visible in the micro-video. T ext Prompt 2 (Event Identication): Based on the analyses above, describe the e vent depicted in the micro- video. T ext Prompt 3 (Misinformation Identication): Base d on the above analyses, you need to give your pr ediction of the micro-video’s v eracity . If it is more likely to be misin- formation ( e.g., due to factual err ors, AI-generated content (AIGC), or cross-modal inconsistencies, or oensive con- tent), return 1; otherwise, return 0. Please avoid ambiguous assessments such as undetermined. T ext Prompt 4 ( Answer V erication): Given the video frames and the accompanying title, now you nee d to verify the previous answer by 1) checking the pixel grounding information if the answer aligns with the facts pr esented in the video from a perception standpoint; 2) determining from a cognition perspective if the commonsense implica- tions inherent in the answer contradict any of the main. Output the verication result with rationale. News T ext: {news title and content} Video: {a set of frames} Prompt of the Fake Agent T ext Prompt 1 (Content Analyst Agent): Y ou are an experienced fact checking assistant for news videos. Y ou must remain neutral and objective, and you can handle sen- sitive or aggressiv e content responsibly . Given the video title, description and audio transcription, please describe the objects, scenes, and actions that appear in the micro video. Then analyze whether the micro video contains mul- timodal inconsistencies, AI generated or AI edited content, faulty logic, or oensive content. T ext Prompt 2 (P lanner Agent): Based on the above anal- ysis, verify the factual accuracy of the explicit claims in the video and decide whether external evidence is required. Note: Be aware of your knowledge limits. Do not spec- ulate or make unwarranted judgments about content be- yond your expertise or outside your knowledge time frame. When necessary , request external evidence by proposing concrete queries and suitable sources. T ext Prompt 3 (Retriever Agent): Y ou are a professional information retrieval expert, skilled at quickly nding rel- evant evidence from reputable sour ces. Given specic key- words and core claims, retrie ve external evidence that supports or refutes the content of the micro video. Online Search T ool Use this tool when you need real time information or the latest web content. Input format: “keywords or questions to search” . T ext Prompt 4 (Locator Agent): Y ou are a professional video analysis expert, skilled at pr ecisely locating problem- atic content. Use the analysis results together with e xternal evidence to identify suspicious content and to pinpoint its exact position in the video. (1) Identify suspicious segments based on the analysis and the external evidence. (2) Precisely locate the position of each suspicious seg- ment, including time spans or key frames. T ext Prompt 5 (Integrator Agent): Y ou are a profes- sional analysis and integration expert, skilled at synthe- sizing information from multiple sources and making a comprehensive judgment. Please follow these steps: (1) Consolidate all analysis r esults from previous agents. (2) If external evidence is available, incorporate it into the overall judgment. (3) If localization information is available, include it as part of the basis for judgment. (4) Provide a nal determination on whether the video is genuine or misinformation. (5) Provide detailed reasoning and a condence assess- ment. Answer: News T ext: {news title and content} Video: {a set of frames} A udio: {audio transcription} Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Zhi Zeng et al. Title : HIV nanobodies were extrac ted from llamas, de monstrating the ability to inter cept 1 16 out of 1 17 viral strains. T h e v i d e o s h o w s a m a j o r d i s c r e p a n c y b e t w e e n t h e c l a i m e d f o c u s ( H I V ) a n d t h e cit ed w or k (S ARS - Co V- 2 ) . C l a i m s a b o u t an t i b o d y e f fe c t i v e n e s s a n d m e c h a n i s m l a c k s u f f i c i e n t v e r i f i c a t i o n . T h e se i n c o n s i s t e n c i e s s u g g e s t t h e v i d e o i s m i s l e a d i n g o r inaccurate . The video shows inconsistencies an d i n ac c ur a c ie s . T h e t i t le a n d c o n t e n t c l a i m a n a l p a c a nanobo dy neu tralize s 116 of 117 HIV strains, which literature does no t su p p o r t . T h e ci t e d st u d y in N a t u r e C o m m u n i c a t i o n s conc erns SARS -CoV -2, no t H IV. I m a g e s a n d t e x t d o n o t m a t c h th e st ud y’ s f in di ng s. M is l ea di n g i n f o r m a t i o n a b o u t H I V effectiveness is not substantiated. These inconsistencies suggest the video is misinformation. 1 . F a c t - c h e c k i n g i d e n t i f i e d t h r e e c o r e is s u e s : c i t a ti o n e rr o r s ( c o n f u si n g N a t u r e w i t h N a t u r e C o m m u n i c a t i o n s ) , d a t a fabrication (99% effic iency wi thout suppor t), an d s ub je ct m isr ep re se nt at io n ( CO VI D- 19 study framed as HIV). 2. AI a na lys is s ho we d tem pl at ed f ea tur es with repetitive titles, fixed text, and formulaic visuals. 3 . C o n s i s t e n c y c h e c k s r e v e a l e d co n t r a di c t i o ns b e t w ee n t i t l e a n d v i s u a l s , including st rain count discrep ancies , jour nal name errors, and missing experimental data. 4 . C r o s s - v a l i d a t i o n c o n f i r m e d t h e s e anomalies without reasonable explanation. Qwen2.5-VL-32B InternVL-2.5-38B FakeAgent-7B Figure 9: Error case. A real-world example highlighting the limitation of Fake Agent in handling domain-sp ecic misin- formation. C Error Analysis and Future W ork While Fake Agent substantially advances detection and explanation performance across diverse misinformation types, challenges re- main in handling content that depends on specialized or rapidly evolving domain knowledge (Figure 9). Addressing these cases calls for more adaptive retrieval and integration of dynamic, domain- specic information. Future research may explor e mechanisms for real-time evidence alignment and continual knowledge updating to better manage emerging misinformation. Developing such adaptive reasoning and grounding strategies could further improve the robustness and reliability of misinformation detection systems in ever-changing information environments.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment