Fast Iteration of Spaced k-mers
We present efficient approaches for extracting spaced k-mers from nucleotide sequences. They are based on bit manipulation instructions at CPU level, making them both simpler to implement and up to an order of magnitude faster than existing methods. …
Authors: Lucas Czech
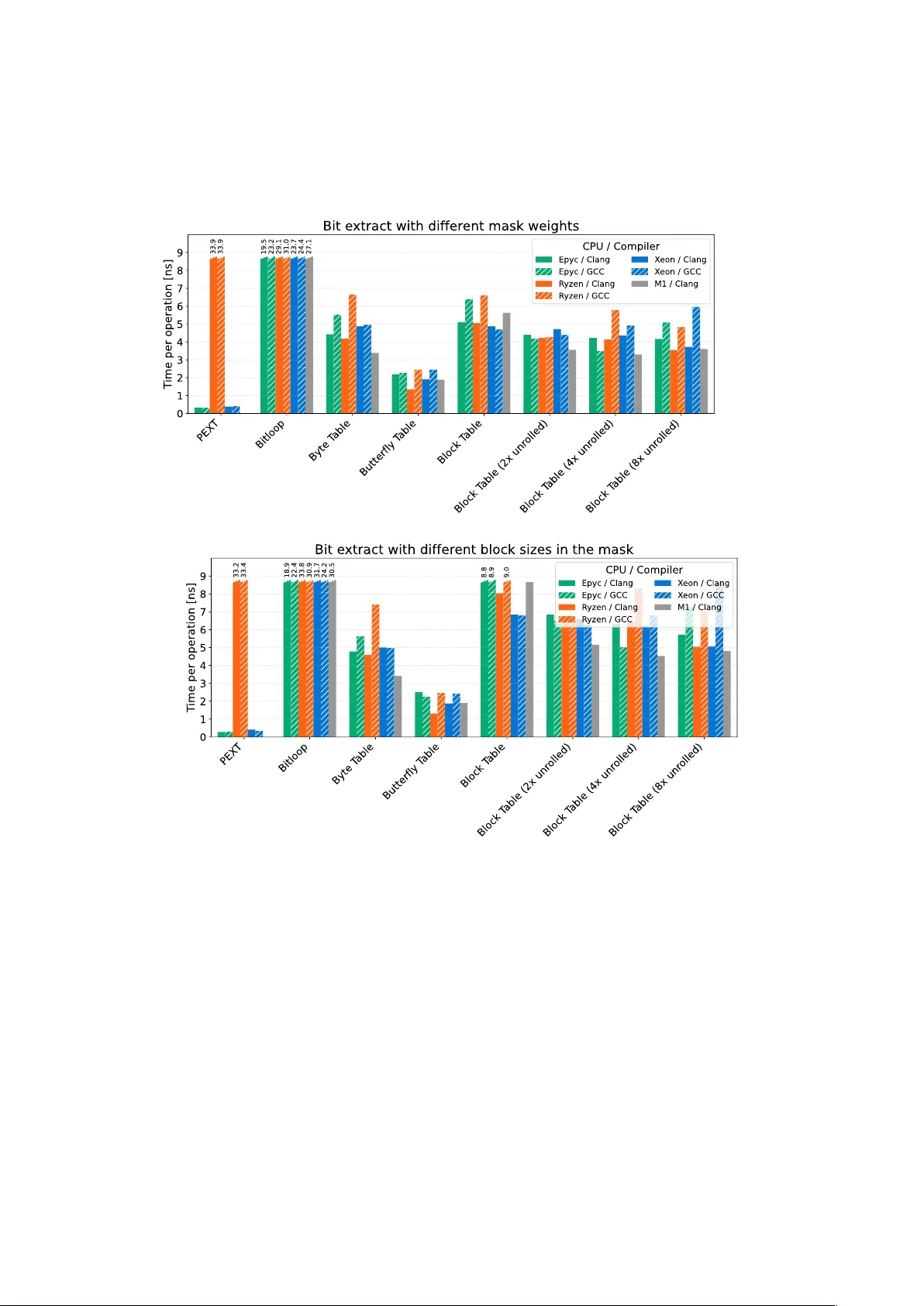
F ast Iteration of Spaced k -mers Lucas Czech Section for GeoGenetics , Globe Institute, Univ ersity of Copenhagen, Denmark; lucas.czech@sund.ku.dk W e present efficient approaches for e xtracting spaced k -mers from nucleotide sequences. They are based on bit manipulation instruc- tions at CPU level, making them both simpler to implement and up to an order of ma gnitude faster than existing methods. We further ev aluate common pitfalls in k -mer processing, which can cause ma- jor inefficiencies. Combined, our approaches allow the utilization of spaced k -mers in high-perf ormance bioinformatics applications without major performance degradation, offering a throughput of up to 750MB of sequence data per second per core. A vailability: The implementation in C++20 is published under the MIT license, and freely av ailable at github.com/lczech/fisk 1. Introduction A k -mer is a con tiguous substring of length k extracted from a biological sequence suc h as DNA nucleotides or amino acids. Due to their simplicity and efficiency , k -mers are a fundamen tal building block in computational genomics and bioinformatics ( 1 , 2 ), with applications ranging from genome assembly and read mapping to metagenomic clas- sification and alignment-free sequence comparison ( 3 ). F or the nucleotide alphab et { A , C , G , T } of DNA sequences, an example is shown in Fig. 1 (a-b). Although contiguous k -mers are computationally efficient, they are sensitive to mismatches. Man y methods exp ect exact matc hes of k -mers, for instance, to index and search genomic sequences. Thus, a single n ucleotide substitution dis- rupts all k -mers spanning the mismatching position. T o im- pro ve robustness to mutations and sequencing errors, spaced k -mers w ere introduced ( 4 , 5 ), where a fixed mask (or pat- tern) of length k is applied to select a subset of p ositions in a k -mer, as shown in Fig. 1 (c-d). The resulting subsequence captures a context of span k , while tolerating mismatches at mask ed p ositions. Carefully designed and optimized patterns can substan tially improv e sensitivity in homology search and sequence comparison compared to contiguous k -mers ( 5 – 8 ). Spaced k -mers hav e since b een adopted in a broad range of bioinformatics applications. They achiev e a fav orable balance betw een sensitivity and sp ecificit y , but also in tro duce computational challenges; previous w ork has hence been conducted on algorithms for efficien t spaced k -mer extraction ( 9 – 13 ). Here, we presen t methods to extract spaced k -mers for the case of k ≤ 32 ; extension to larger v alues of k is p ossible. Compared to existing metho ds, our approac hes are b oth simpler and faster. 2. Prob lem Statement DNA sequences consist of four nucleotides from the alphab et N = { A , C , G , T } . Here, a k -mer s is a sequence of length k of c haracters from this alphabet, i. e., s ∈ N k . This is often represented in a compact 2-bit enco ding, where A = 00 , C = 01 , G = 10 , T = 11 . This allo ws up to 32-mers to b e stored in a single 64-bit machine w ord, thus enabling efficien t storage and fast processing of k -mers via simple bit-wise operations on mo dern computer hardware. W e here fo cus on this nucleotide alphabet and enco ding; application to other alphab ets is straigh tforward. A spaced k -mer is defined by a binary mask m ∈ { 0 , 1 } k of length k to select certain p ositions of an underlying k -mer (1s), while skipping others (0s), see Fig. 1 (c-d). W e call k the span of the mask, and w its weigh t, with w = P i m i the n umber of p ositions in the mask that are 1 . The resulting spaced k -mer is here called a w -mer (as it has length w ), to distinguish it from the underlying k -mer it w as extracted from. The problem can then b e stated as follows. Given a nu- cleotide sequence r of length n o ver the alphab et N , slide a windo w of size k across r , yielding n − k + 1 windows; in eac h windo w, apply the mask, b y extracting the corresp onding bases where m is set to 1 to construct a w -mer. As evident from Fig. 1 (d), the resulting w -mers th us only share short sub-strings with eac h other, namely where runs of consec- utiv e 1s o verlap in m when shifted. This makes it difficult to “re-use” information across w -mers, which motiv ates the dev elopment of efficient tec hniques for this task. Remarks on terminology: In the existing literature, the mask m and the extracted w -mer are both called “seed” or “spaced seed” . This is how ever ov erloaded and ambiguous, as the term “seed” usually refers to some initial v alue. Thus, the ( a ) Input sequenc e 1 0 1 1 0 1 1 G T A C A G C A T A G T A C A G C A T A C A G C A A T A C A G C T A G C A C A 1 0 1 1 0 1 1 T A G A A 1 0 1 1 0 1 1 T A G C T G C A C A T A G A A T A G C T ( d) Spac ed k -mers (b ) E xtraction of k -mers ( c) Applic ation of the mask 0 0 0 Fig. 1. Spaced k -mer extraction. (a) An input sequence of nucleotide characters . (b) Three consecutive k -mers of length 8 are e xtracted from the sequence, each ov erlapping by k − 1 = 7 characters, forming a sliding window of length k ov er the sequence. (c) A fix ed mask m of span k = 8 and weight w = 5 is applied to each k -mer , to select characters where the mask is 1 , while lea ving out characters where the mask is 0 . (d) The final spaced k -mers, which we here call w -mers f or clarity . March 27, 2026 | 1 name “seed” makes sense when k -mers are used in a seed-and- extend approach, but not in the general case. F urther names for the mask m include “pattern”, “shap e”, and “template” . Existing methods also often use (spaced) k -mers as k eys in lo okup hash tables; hence, the term “ k -mer hash” has b een used, where the encoded k -mer is a p erfect hash v alue of itself. Ho w ev er, a “hash” is usually the result of a hash function, which takes arbitrary-length input instead of a fixed size k . W e thus refer to the 2-bit representation as the “enco ding” of the k -mer instead. 3. Results W e here presen t an ov erview of the algorithms and their b enc hmarks; for details, see the Supplementary T ext. All b enc hmarks are based on a sequence of randomly generated n ucleotide data, using the same set of masks as MISSH ( 12 ). The implementation is concise and well do cumen ted, in order to be easily adaptable; for a more complete suite of k -mer-related and other genomics functionality , see our C++ library genesis ( 14 ). 3.1. Encoding and k -mer Extraction The initial steps are to trav erse the input sequence, en- co de the ASCII-enco ded nucleotides into 2-bit encoding, and construct and iterate the k -mers. There are several pitfalls in these steps that lead to ma jor p erformance bottle- nec ks; unfortunately , they o ccasionally appear in published co de. Firstly , the enco ding can be implemented as a switch- statemen t or series of if-statemen ts, chec king for the four n ucleotides in N . The latter in particular, how ever, all but guaran tees several CPU branch predictor misses p er input c haracter. Secondly , eac h k -mer can b e fully re-extracted based on the underlying sequence, by applying the encoding k times p er k -mer, which is sub optimal. The more optimized approac h is to use a branc hless en- co ding function, and to apply bit shifts b et ween consecutive k -mers, thus re-using all ov erlapping bits from the previous k -mer in the sequence, and only encoding one new c haracter in each iteration. W e tested t w o v ariants of branchless character encoding. The first is based on bit op erations on the input character, and exploits a serendipit y in the ASCI I co de to obtain the 2-bit enco ding; the tec hnique was recently indep enden tly dis- co vered and utilized for bit-compressing genomic sequences ( 15 ). The second is a simple lo okup table containing the 2-bit codes for each single-byte c haracter; this w as more p erforman t in our benchmarks, and thus used henceforth. Unless the input has previously b een sanitized, there is one unav oidable branc h in the hot lo op, to c hec k if the curren t k -mer consists only of v alid characters. Ho w ever, in t ypical data with few inv alid characters not in N , the branc h prediction mostly eliminates the ov erhead for this. This yields a p erformance of ≈ 1ns p er extracted k -mer, or ≈ 1GB of sequence data p er second. W e also tested a SIMD- accelerated implementation based on enco ding 32 nucleotides at once with the ASCI I exploit, using the A VX2 instruction set, which yielded a p erformance of ≈ 0.8ns p er k -mer. Note that w e limited our implementation to k ≤ 32 , for b oth the initial and the extracted spaced k -mer. F or most applications, this is the typically sufficient limit anyw ay , and allows us to leverage rolling enco ding, as a k -mer fits in to a 64-bit word. Larger v alues of k are how ever possible with additional bit operations or adaptation to, e. g., 128-bit registers, but left as future work. 3.2. Spaced k -mer Extraction The main step then is the extraction of the spaced k -mers, i. e., the construction of the w -mers, at each p osition along the sequence. The “naiv e” extraction of a w -mer simply lo ops ov er the set of p ositions in the mask, and enco des each c haracter from the input anew. Obviously , this is equally as inefficien t as the corresp onding re-extraction approac h for k -mers, as it uses a lo op with w iterations p er w -mer. The more efficien t approach is to leverage the shift-based tra versal of k -mers, and extract the w -mers directly from there. That is, given a k -mer in 2-bit enco ding, and stored in a 64-bit word, w e need to extract the pairs of bits cor- resp onding to the p ositions set in the mask. Eac h bit pair then needs to b e shifted according to the num ber of “gaps” in the mask betw een its position in the k -mer and the end of the mask, as in Fig. 1 (c-d). This operation is called bit extract , whic h gathers all bits denoted in the mask tow ards one side of the word and zeros out the rest. This is also known as bit compression, bit gathering, or bit packing, and is a well-understoo d op era- tion with several implementations in soft w are and hardware, whic h we are exploiting here. On Intel CPUs (since Q2/2013), as well as recen t AMD CPUs (since Q4/2020), the PEXT in trinsic allows bit extrac- tion with high throughput, and is the most performant wa y to extract w -mers with only a few cycles of o v erhead com- pared to regular k -mer iteration. Older AMD CPUs (since Q2/2015) also offer the intrinsic, but implemen t it in slow micro code. On ARM architecture (Apple CPUs), it is not a v ailable. T o mitigate this, we tested several algorithms to perform bit extraction in softw are; see the Supplemen tary T ext for details. In our b enc hmarks, with no significant exceptions, the most efficient implementation is an existing algorithm that works in log 2 ( b ) stages for b bits, e. g., 6 stages for 64-bit words. In eac h stage, bits of the input are shifted in increasing p ow ers of tw o, such that any gap length in the mask can b e expressed as a combination of suc h shifts. F or instance, a bit with 42 gaps (unset bits) tow ards the end of the mask is shifted in stages 2, 4, and 6, corresponding to shifts of 2, 8, and 32 bits, resp ectiv ely . These shifts are solely dep enden t on the mask, and can b e pre-computed in a small table. Here, we call this the “Butterfly” algorithm, inspired by bit manipulation tec hniques that mov e bits across a machine word, where the pattern of mov ement resem bles the wings of a butterfly . As the stages of the Butterfly algorithm are fixed for a given mask, they can be applied to sev eral k -mers in parallel. W e th us implemen ted SIMD- accelerated v arian ts of this for the SSE2, A VX2, A VX512, and ARM Neon intrinsics, eac h computing one consecutive w -mer per 64-bit lane. Moreo ver, in many applications of spaced k -mers, multiple masks are applied, e. g., to increase the sensitivity of sequence searc hes ( 6 , 16 ). In that case, the encoding and k -mer iteration only need to be executed once, and the w -mers for each mask can be extracted from that k -mer. W e also implemen ted this with the ab o v e SIMD acceleration. The a v ailabilit y of an inefficien t PEXT on older AMD CPUs unfortunately prohibits us from simply testing for it at compile time. W e hence implemented dynamic selection mec hanisms at run time, where for a giv en mask, a short b enc hmark is run to select the fastest av ailable algorithm. Using C++ templates (or Rust generics, if ported), this mec hanism can b e used to switch b et ween algorithms without o verhead for function indirection. March 27, 2026 | 2 Fig. 2. Extracting spaced k -mers from a sequence. (a) Single mask. The time per w -mer is shown, i. e., total time divided by number of w -mers in the sequence, aver aged across r uns with distinct masks, for different hardware and compilers. The naive algorithm loops over the mask f or each w -mer ; the PEXT intrinsic is the fastest where av ailable as a dedicated hardware instruction; the Butterfly algorithm and its SIMD-accelerated variants off er a performant alter nativ e otherwise. (b) Multiple masks (here, 9 distinct masks). The resulting time per distinct w -mer is shown. Compared to a single mask, this amor tiz es the cost f or iterating o v er the underlying k -mers in the sequence, which only needs to be perf or med once, f ollowed by separ ate bit extr actions f or each mask. 3.3. Benchmarks Results for several CPU arc hitectures are shown in Fig. 2 ; extended results are presen ted in the Supplemen tary T ext. In short, b oth the In tel Xeon and the AMD Epyc offer fast PEXT , while the AMD R yzen and Apple M1 do not. F or ev ery hardware architecture tested, at least one of the im- plemen tations has a throughput of one spaced k -mer p er 1.3–1.8ns p er core, equiv alent to 520MB to 750MB per sec- ond for tra v ersing a sequence and constructing its w -mers. Compared to the baseline of ≈ 1 ns for regular (contiguous) k -mer extraction from a sequence, this is lik ely fast enough for most applications, whic h usually incur a more significant o verhead on top for their downstream computations. 3.4. Comparison to Existing Appr oaches CLARK-S ( 16 ) is an early tool that uses spaced k -mers for sensitivit y . It reported a ≈ 17-fold increase in run time compared to its previous v ariant CLARK with non-spaced k -mers ( 17 ), in contrast to an exp ected factor of 3 due to the to ol querying spaced k -mers with 3 distinct masks to increase sensitivit y . Insp ecting the CLARK-S co de, we found sev eral b ottlenec ks: It fully re-extracts k -mers rep eatedly for each of its three masks, and uses string comparisons and branching with guaranteed branch predictor misses in the hot path (i. e., p er c haracter of input). Eliminating these b ottlenec ks lead to an av erage 21-fold sp eedup in our tests. On the other hand, the extraction of spaced k -mers itself is implemented using an efficient hard-coded approach equiv alent to our Blo c k table algorithm (see Supplementary T ext). The apparen t slo wness of CLARK-S has motiv ated the dev elopment of several optimized metho ds, namely FSH ( 10 ), FISH ( 9 ), ISSH ( 11 ), MISSH ( 12 ), and DuoHash ( 13 ). FSH, ISSH, and MISSH are based on the observ ation that t ypical spaced masks still do share some p ositions that are present in ov erlapping k -mers. They exploit the auto-correlation b e- t ween these ov erlaps when sliding the mask along a sequence, to “rescue” bits that were already extracted. This ho w ev er requires to store previous w -mers, th us adding ov erhead. FISH and DuoHash instead use blocks of consecutiv e 1s in the mask to accelerate spaced k -mer extraction via large lo okup tables. Distinct from all other metho ds examined here, this allows them to compute actual k -mer hashes, which DuoHash show cases via the ntHash method ( 18 , 19 ). The o verhead for o v erlap bo okk eeping and lo okup tables in these metho ds is how ev er significant. A cross different hardware arc hitectures, our approaches are 3.4–4.2 times faster for single masks, and up to 9.5 faster per w -mer when comput- ing multiple masks; details in the Supplementary T ext. A t the same time, our ov erall approach is m uc h simpler (with added complexity for SIMD acceleration though), and does not need to keep previous k -mers in memory . Lastly , the more recent MaskJelly tool ( 20 ) uses a loop o ver mask p ositions to extract eac h w -mer, th us incurring w op erations p er w -mer. Implementing our approaches can at least double the p erformance. 4. Conclusion W e tackled the problem of spaced k -mer extraction from a sequence of n ucleotides, and presen ted highly efficien t hardw are-accelerated implemen tations for this task, yielding a throughput of 520MB to 750MB of sequence data p er sec- ond p er core, significan tly outpacing all existing techniques b y at least a factor of 3.2. With the presented optimizations, we remov e a b ottlenec k for metho ds utilizing spaced k -mers. W e thus conclude that the extraction of spaced k -mers does generally not pose a substantial barrier for high-p erformance computational genomics metho ds. Appendices Code A vailability The code for this pro ject is freely a v ailable under the MIT License at github.com/lczec h/fisk , which contains C++ im- plemen tations of all metho ds and benchmarks presented. Supplementary T ext W e pro vide details on the algorithms, their implemen tation, and their b enc hmarks in the Supplementary T ext. Ackno wledgments This work was supp orted b y the International Balzan F ounda- tion through the Balzan research pro ject of Esk e Willerslev. P ersonal thanks to Pierre Barb era for donating compute time on his Apple M1 Pro. Competing Interests The authors declare that they hav e no comp eting interests. March 27, 2026 | 3 References 1. Marchet C (2024) Advances in colored k-mer sets: essentials for the cur ious. arXiv [q-bio.GN] . 2. Marchet C (2024) Advances in practical k-mer sets: essentials for the curious. arXiv [q-bio.GN] . 3. Moeckel C, et al. (2024) A sur v ey of k-mer methods and applications in bioinformatics. Computational and structural biotechnology jour nal 23:2289–2303. 4. Burkhardt S, Kärkkäinen J (2001) Better filtering with gapped q-grams in Combinatorial Pattern Matching , Lecture Notes in Computer Science. (Spr inger Berlin Heidelberg, Berlin, Heidelberg), pp. 73–85. 5. Ma B, T romp J, Li M (2002) PatternHunter: faster and more sensitive homology search. Bioinformatics (Oxford, England) 18(3):440–445. 6. Hahn L, Leimeister CA, Ounit R, Lonardi S, Morgenstern B (2016) Rasbhar i: Optimiz- ing spaced seeds for database searching, read mapping and alignment-free sequence comparison. PLoS computational biology 12(10):e1005107. 7. Kucherov G, Noé L, Roytberg M (2006) A unifying framework for seed sensitivity and its application to subset seeds. Journal of Bioinformatics and Computational Biology 4(2):553–569. 8. Noé L (2017) Best hits of 11110110111: model-free selection and parameter-free sensitivity calculation of spaced seeds. Algorithms for Molecular Biology 12(1):1. 9. Girotto S, Comin M, Pizzi C (2018) Efficient computation of spaced seed hashing with block indexing. BMC bioinformatics 19(Suppl 15):441. 10. Girotto S, Comin M, Pizzi C (2018) FSH: fast spaced seed hashing exploiting adjacent hashes. Algorithms for molecular biology: AMB 13(1):8. 11. P etrucci E, Noé L, Pizzi C, Comin M (2020) Iterative Spaced Seed Hashing: Closing the gap between spaced seed hashing and k-mer hashing. Journal of computational biology: a journal of computational molecular cell biology 27(2):223–233. 12. Mian E, Petrucci E, Pizzi C , Comin M (2024) MISSH: F ast hashing of multiple spaced seeds. IEEE/ACM transactions on computational biology and bioinformatics 21(6):2330–2339. 13. Gemin L, Pizzi C, Comin M (2026) DuoHash: Fast hashing of spaced seeds with application to spaced K-mers counting in Lecture Notes in Computer Science , Lecture Notes in Computer Science. (Springer Nature Switzerland, Cham), pp. 28–39. 14. Czech L, Barbera P , Stamatakis A (2020) Genesis and Gappa: processing, analyzing and visualizing phylogenetic (placement) data. Bioinformatics p. 647958. 15. Corontzos C , Fr achtenberg E (2024) Direct-coding DNA with multile vel parallelism. IEEE computer architecture letters 23(1):21–24. 16. Ounit R, Lonardi S (2016) Higher classification sensitivity of shor t metagenomic reads with CLARK-S. Bioinformatics (Oxford, England) 32(24):3823–3825. 17. Ounit R, et al. (2015) CLARK: f ast and accur ate classification of metagenomic and genomic sequences using discriminative k-mers. BMC genomics 16(1):236. 18. Mohamadi H, Chu J, V andervalk BP , Birol I (2016) ntHash: recursive nucleotide hashing. Bioinformatics 32(22):3492–3494. 19. Kazemi P , et al. (2022) ntHash2: recursive spaced seed hashing for nucleotide sequences. Bioinformatics 38(20):4812–4813. 20. Häntze H, Horton P (2023) Effects of spaced k-mers on alignment-free genotyping. Bioin- formatics (Oxford, England) 39(39 Suppl 1):i213–i221. March 27, 2026 | 4 Supplementa ry T ext: F ast Iteration of Spaced k-mers Lucas Czec h Section for GeoGenetics, Globe Institute, Univ ersit y of Cop enhagen, Denmark. Contents 1 Overview 2 1.1 Notation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 1.2 Benc hmarks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 1.3 Hardw are . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 2 Enco ding and Iteration of k-mers 3 2.1 Nucleotide Enco ding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 2.2 Consecutiv e k -mer Iteration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 3 Bit Extract 5 3.1 Hardw are implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 3.2 Soft w are Implementations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8 4 Spaced k-mer Extraction 12 4.1 Single Mask . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12 4.2 Multiple Masks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12 4.3 SIMD Acceleration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 4.4 Dynamic Algorithm Selection . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 4.5 Differences b et w een compilers . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 4.6 Comparison with existing methods . . . . . . . . . . . . . . . . . . . . . . . . . 16 5 References 19 1 1 Overview This supplemen t elaborates on the bit extract algorithms and their application to spaced k -mer extraction, and presents detailed benchmarks of the implementations for different hardware arc hitectures. Our C++ implementation of all presen ted metho ds, as w ell as all b enc hmarks, are freely av ailable under the MIT license at github.com/lczec h/fisk 1.1 Notation F or ease of reading, we briefly rep eat the notation here. • N = { A , C , G , T } is the n ucleotide alphab et. • r ∈ N n is an input sequence of length n ov er th e alphab et N, enco ded as ASCI I characters. • A k -mer ∈ N k is a sub-sequence of r of length k , for whic h w e use 2-bit enco ding, where A = 00 , C = 01 , G = 10 , T = 11. • m ∈ { 0 , 1 } k is a binary mask of length k to select p ositions of an underlying k -mer (1s), while skipping others (0s). W e call k the span of the mask, and w its w eight, with w = P i m i the num b er of p ositions in the mask that are 1. • A w -mer ∈ N w is a spaced k -mer, i. e., a k -mer from whic h positions ha ve b een extracted according to m . Our goal then is to extract all consecutive w -mers while trav ersing the input sequence r . T ypically , applications will then use those w -mers to, e. g., p erform sequence searches or other relev an t tasks. Here, we focus only on the extraction itself. 1.2 Benchma rks Benc hmarks of the bit extraction functionalit y w ere run on randomly generated 64-bit v alues and masks. Benc hmarks of the (spaced) k -mer pro cessing w ere run on randomly generated sequences of one million n ucleotides, with a fraction of 0.001 of them randomly c hanged into in v alid c haracters not in N, whic h can o ccur in real-world data. Each benchmark was run in at least 4 repetitions, to reduce measurement noise. The masks are the same as those used in the MISSH approach [ 1 ]. F or single-mask b enc hmarks, w e used a set of 9 masks with k = 31 and w = 22, mark ed as “default” in MISSH. F or m ulti- mask b enc hmarks, each b enc hmark used a set of 9 masks, all applied at once to the same sequence, i. e., extracting 9 w -mers p er k -mer. W e used 5 such sets of masks, of increasing w eigh t, with ( k, w ) ∈ { (15 , 10) , (31 , 14) , (31 , 18) , (31 , 22) , (31 , 26) } . W e left out one set of masks with k = 45, as our approac h is curren tly limited to k ≤ 32. 2 1.3 Ha rdw a re W e b enchmark ed the code with the following CPUs and compilers: • AMD Epyc 7763, 64 cores, Zen 3 x86-64, released Q1/2021, tested via GitHub Actions with Clang 18.1.3 and GCC 13.3.0. • AMD Ep yz 9684X, 96 cores, Zen 4 x86-64, released Q2/2023, tested with Clang 17.0.0 and GCC 15.2.0. • AMD Ryzen 7 PR O 4750U, 8 cores, Zen 2 x86-64, released Q2/2020, tested with Clang 17.0.6 and GCC 14.2.0. • Apple M1, 8 cores, ARM, released Q4/2020, tested virtually via GitHub Actions with Apple Clang 17.0.0. • Apple M1 Pro, 8 cores, ARM, released Q4/2020, tested with Apple Clang 17.0.0. • Intel Xeon Platin um 8568Y+, 48 cores, x86-64, released Q4/2023, tested with Clang 17.0.0 and GCC 15.2.0. In this do cumen t, we only show the most relev ant and distinct of those b enc hmarks; see gith ub.com/lczec h/fisk for the full set of plots. In particular, w e are lea ving out the t w o CPUs tested via GitHub actions, and mostly fo cus on Clang, whic h has sho wn b etter p erformance in most of our b enc hmarks. 2 Enco ding and Iteration of k-mers W e enco de k -mers using 2-bit enco ding in a 64-bit w ord suc h that: (i) The least significan t (righ t-most) 2 k bits are used, while the remaining most significant (left-most) 64 − 2 k bits are zero; (ii) Bit order is the same as in the input sequence: The most significant used bits represen t the first c haracter of the k -mer, and the least significan t bits its last c haracter. This allo ws us to use regular integer comparison to get the lexicographical ordering of k -mers; this is not relev an t here, but can b e useful in other contexts. Note that not all existing implementations follo w this conv en tion. 2.1 Nucleotide Enco ding First, w e need a function enc ( c ) that pro duces the 2-bit enco ding for an input character c ∈ N from ASCI I enco ding, or signals an in v alid c haracter if c / ∈ N. Explicit checking. The most simplistic approac h for this enco ding is a switch statemen t or series of if statemen ts, taking a character and returning its 2-bit code, applied to eac h c haracter of input. F or a (more or less) random input sequence, this has on a verage 1.5 false 3 conditional c hec ks, inducing a high amoun t of CPU pip eline flushing due to failed branch predictions. This is highly inefficien t, but unfortunately often used in practice. The switch statemen t approac h takes 5.9–8.2ns p er character on Clang, and 0.42–0.58ns on GCC, which seems to implemen t this as a lo okup (jump) table. It how ever cannot b e relied on for the compiler to emit this. The if statemen t chain performs similar, with 5.1–8.1ns per c haracter across architectures. ASCI I exploit. A lesser-known lo w-level tec hnique is to exploit the b yte represen tation of the c haracters: The second and third least-significant bits of the ASCI I code of the characters in N (and their low er-case equiv alen ts) can b e mangled via bit op erations to obtain the desired 2-bit code. This is p ossible completely by chance, and was recently indep enden tly discov ered and utilized for bit-compressing genomic sequences [ 2 ]. This has the sligh t do wnside that an explicit chec k needs to b e p erformed to verify the c haracters to be in N, which how ever can also b e done via some bit op erations. W e refer to our implementation for details. All op erations are branc hless, and can b e v ery efficiently computed. W e also implemen ted a SIMD-accelerated approach for A VX2, with 32 c haracters enco ded at a time. Across the tested CPUs, applying this enco ding tak es 0.14–0.52ns p er c haracter (the lo wer v alue is ho w- ev er lik ely due to auto-v ectorization, which cannot alw a ys applied by the compiler in more complex circumstances outside of this simple test). The approach is particularly fast when input v alidation can be skipp ed; this is usually not the case for real-w orld data, but could b e applied if input is prepro cessed in some form already , suc h that inv alid characters cannot o ccur. Lo okup table. Lastly , a common tec hnique is a simple lo okup table with 256 en tries, one for eac h p ossible v alue of the input byte, giving either the 2-bit co de or an error v alue to indicate in v alid c haracters. This is branc hless and has the error c heck already built-in. As the table only consumes 256 b ytes, it is lik ely to live in an efficien t cac he lev el when used in the hot lo op o v er characters, and hence is very fast. The lookup table has the most predictable and fastest run time, with 0.21–0.37ns per c haracter, and is hence our recommended approac h for single-character encoding, only sligh tly outpaced b y the SIMD-accelerated ASCII exploit in some situations. The effects of the enco ding p erformance on k -mer extraction are shown in Figure S1 . 2.2 Consecutive k-mer Iteration Next, we tra v erse the input sequence to compute consecutive k -mers. Re-extraction. The naive approac h is to apply the abov e 2-bit enco ding for eac h k -mer anew. Ho w ev er, this is rather inefficien t, as every input character is enco ded k times, in a lo op with k iterations for eac h k -mer. The approach is also straigh tforw ard to apply to w -mers, b y only 4 extracting the p ositions as given in the mask. This at least a v oids extracting a full k -mer, only to then extract the w -mer from it, but still needs w iterations p er w -mer. Shifting. A more efficient approac h is to exploit that consecutive k -mers share k − 1 of their c haracters. Thus, almost all encodings can b e re-used b et ween iterations, by simply bit-shifting the previous v alue, and erasing the surplus 2 bits remaining from the previous iteration. This rolling tra v ersal has constan t sp eed independent of k , but cannot directly be used for spaced k -mers, as the spaces in the mask are affecting differen t positions of the input sequence in each iteration. Thus, the w -mer needs to b e extracted from the k -mer in a subsequen t step. The t w o approaches for k -mer extraction, com bined with the ab o v e v ariants of c haracter en- co dings, are sho wn in Figure S1 . F or obvious reasons, the second approac h is the predominan t one in high-p erformance k -mer methods. W e mention both, as the first approac h is still o cca- sionally used in practice, likely b ecause it is easiest to implement, as it do es not need to k eep trac k of k -mers across iterations. 3 Bit Extract W e no w ha v e an efficient lo op ov er all k -mers, extracting (unspaced) k -mers sliding along the input sequence. F or eac h k -mer, we then need to apply the mask m and extract the p ositions set in m to construct the desired w -mer. As mentioned ab o ve, one “naive” w a y to do this is to skip the construction of ther k -mer altogether, and instead re-extract the w -mer by directly enco ding the c haracters set in the mask from the input sequence, with a lo op with w iterations per w -mer. This is the baseline whic h the family of metho ds of FSH [ 3 ], FISH [ 4 ], ISSH [ 5 ], MISSH [ 1 ], and DuoHash [ 6 ] impro v es up on. W e also use this as the baseline here. In our impro ved approac hes, w e instead w e pro cess the k -mers, whic h allo ws fast iteration with bit shifting, and apply a generic bit extraction function to the k -mer to get the w -mer, see Figure S2(a) for an example. In other w ords, we k eep only the p ositions from a giv en k -mer that are set in the mask m , and pac k them densely in to the lo wer bits of the resulting w -mer, i. e., close the gaps left in the mask. The problem of bit extraction from machine words is more general and useful in other ap- plications. In terestingly , optimized code for the op eration has b een dev eloped in the c hess comm unit y . In chess soft w are, 64-bit w ords are used to succinctly represent the 64 squares on a c hess b oard; th us, bit extraction can b e used to test p ositions and p oten tial mo ves. Compared to chess and other applications, w e here usually hav e the adv an tage of ha ving a fixed mask (or small s et of masks) across the run time of our code. That is, masks are given once initially , but then do not c hange throughout the program, as this w ould induce a different spacing pattern. W e can exploit this to pre-compute a representation of the mask(s) that allo ws fast application to incoming v alues (the k -mers). In the follo wing, we describe different bit extraction implemen tations; their b enc hmarks are sho wn in Figure S3 – S5 . 5 Figure S1: Extracting k -mers from a sequence. F or different v alues of k ∈ [0 , 32], time per k -mer on tw o serv er CPUs is sho wn, with differen t compilers. Line colors corresp ond to the function used for conv erting input ASCII c haracters in to 2-bit enco ding; line st yles are dashed for the approac h of extracting the k -mer at eac h position anew (“re-extract”), and solid for the shifting up dates of consecutive k -mers b etw een iterations. This sho ws t w o imp ortan t observ ations: (i) The costs for re-extracting eac h k -mer quickly become dev astating even for smaller v alues of k . (ii) Compilers b ehav e differently in their optimizations of the enco ding function, ev en on the same architecture. The most efficient wa y of iterating k -mers is hence to use the branc h-less enco ding function via lookup table, and shifting k -mer trav ersal, as shown in the b ottom green line in all sub-figures, whic h is near the mark of 1ns p er k -mer. 3.1 Ha rdw a re implementation Mo dern x86 hardw are supports the PEXT (parallel bit extract) in trinsic 1 of BMI2 (Bit Manip- ulation Instruction Set 2). The name “parallel” indicates how it is implemen ted in hardw are; it is how ev er a single op eration on a 64-bit word. On Intel CPUs, it is av ailable since the Hasw ell architecture (Q2/2013) with a latency of 3 cycles, and a throughput of 1 instruction p er cycle. On AMD CPUs, the instruction is a v ailable since the Excav ator architecutre (Q2/2015), but implemen ted in slow micro co de, with a run time dep enden t on the weigh t of the mask, t ypically 18-20 cycles at least. Only since the Zen 3 arc hitecture (Q4/2020) ha v e AMD CPUs implemented PEXT in actual hardw are. On ARM hardw are (suc h as the Apple M series of CPUs), it is not a v ailable. Our benchmarks include CPU mo dels testing all these different arc hitectures. 1 intel.com/content/www/us/en/do cs/intrinsics- guide/index.html#text=pext&ig expand=5088 6 value mask result a b c d e f g h 1 0 1 1 0 1 0 0 1 ( a ) Bit extract operation 0 0 a c d g h mask 1 0 1 1 0 1 1 0 0 1 0 1 1 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 >> 2 >> 1 >> 4 ( d) Butter � y table 0 0 1 mask 1 0 1 1 0 1 1 0 0 1 0 1 1 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 >> 1 >> 0 >> 3 (b ) Block table 0 0 >> 2 >> 1 >> 4 h c 0 0 d g a 0 ( c) Butter � y network e b g h d a f c 0 h 0 0 g d c a h c 0 0 d g a 0 Figure S2: Bit extraction from words. (a) The bit extract op eration. Bits from a v alue are “extracted” according to a binary mask, and transferred to the lo w er bits of the resulting w ord. In other words, the “gaps” caused by 0s in the mask are closed. F or simplicit y , w e here only show 8 bits w orth of data; the actual instruction applies to 64-bit w ords. (b) The blo c k table is a decomposition of the mask in to blo c ks of consecutiv e 1s, accompanied by the resp ectiv e amoun t of shifting the block needs to receiv e to mov e to the target p ositions. It has as many ro ws as blo cks of 1s in the mask. (c) The butterfly net work connects each input bit to eac h output bit right of it (solid blac k arro ws), or to itself (dashed gray arrows), via a decomp osition into shifts of increasing p o wers of tw o. This allows any input v alue bit to b e shifted to any relev ant output bit. (d) The butterfly netw ork for a particular mask consists of a table, whic h indicates for each input bit whic h path it takes through the netw ork, i. e., whic h of the shifts are applied in eac h step. F or instance, the t w o bits in p ositions c and d need to be shifted by 1, and hence only o ccur in the first ro w of the table. The bits in positions g and h need to b e shifted b y 3 = 1 + 2 in total; the first row of the table marks them for a shift by 1, after whic h ro w t wo then marks them for a shift by 2. F or this 8-bit w ord, only the first three p o wers of tw o are needed; generally , for b -bit w ords, the table has log 2 ( b ) entries, i. e., 6 en tries for 64-bit words. Note: F or generalit y , we show the examples here with individual bits. In our use case how ever, a k -mer is typically represen ted with 2 bits per n ucleotide. Thus, in practice, for each sym b ol of the spaced mask, 2 consecutiv e bits need to b e set in the masks here to extract a n ucleotide. This has no effect on efficiency . 7 3.2 Soft w a re Implementations Bit lo op. A first naiv e approach is to lo op ov er the bits set in the mask, k eeping track of their p osition in the mask and the p ositions already extracted. This has run time dep enden t on the weigh t of the mask; for our spaced k -mer approach, it is even w orse than re-extracting w -mers from the input sequence, as w e need t wo bits p er n ucleotide here. Byte table. In this approac h, w e pre-compute a lo okup table for each byte of input and b yte of the mask, i. e., a 256 × 256 sized table, denoting the extracted bits for eac h com bination, as w ell as a smaller table with the corresp onding bit weigh t of the mask byte. Then, to extract a v alue, the extracted v alue of eac h corresp onding pair of b ytes of the v alue and mask is retriev ed from the table, and shifted according to the mask bit count. This approac h is a reasonably fast drop-in softw are equiv alent of PEXT , with constant sp eed indep enden t of the mask, alw a ys using exactly 8 iterations (one per b yte of the 64-bit word). Ho w ev er, for a fixed mask, further sp eed can be gained via pre-pro cessing of the mask. Blo ck table. The insigh t we exploit in this approac h is that typical masks for spaced k -mers ha v e longer runs (blocks) of consecutive 1s in the mask (all tested masks ha ve at most 8 suc h blo c ks). W e can th us pre-process the mask in to a table con taining a row for eac h block, k eeping trac k of a mask to extract that blo c k (an and operation) and a v alue to shift (a >> op eration) it to the desired p osition in the output. Applying this to an input w ord then is a simple lo op o v er the rows, p erforming b oth operations for eac h row, as sho wn in Figure S2(b) . A t most, this needs 32 activ e ro ws in the table, whic h happens with an alternating pattern of 1s and 0s in the mask. It can b e implemen ted with a fixed-sized table, stopping at the first mask that only con tains zeros (as a sentinel), in order to enable compiler optimizations. As eac h ro w is indep endent, it is w ell suited for CPU instruction pip elining, whic h can b e further increased through loop unrolling. F or instance, with a t ypical spaced k -mer mask with 8 blocks of 1s, extraction with 8-fold unrolling is a single lo op iteration. The approac h is used b y CLARK-S [ 7 ], alb eit for a set of three hard-co ded masks only . This allo ws them to op erate without an y loop, eliminating a conditional brac h on the hot path. Our implemen tation allows arbitrary masks. The idea is furthermore similar to the FISH metho d [ 4 ], in that it exploits the block structure of consecutive 1s in the mask. How ever, FISH constructs a data structure with distinct lo okup tables separated by the run lengths of blo c ks, whic h in tro duces ov erhead for p oin ter c hasing in those tables. Butterfly net w ork. The most efficien t approac h in our tests is to pre-pro cesses the mask as follo ws: F or ev ery bit set in the mask, w e get the n umber of unset bits right of it, whic h is the amoun t b y whic h the corresp onding input v alue bit at this position needs to b e shifted to its target p osition tow ards the low er end of the word. This amoun t is decomposed in to its sum of p o wers of t wo, suc h that the respective shifts can b e consecutively applied. This w a y , any input bit can b e right-shifted to any relev ant output bit, as sho wn in Figure S2(c) . W e call this the Butterfly netw ork, inspired b y similar bit-mixing techniques from the literature [ 8 ]; 8 admittedly , our righ t-shifting net w ork only resembles one wing of the butterfly . F or a given mask, the net w ork is applied to an input v alue in a series of steps, applying the p o wers-of-t wo shifts to eac h bit as needed. The steps are pre-pro cessed into ro ws of a table, indicating which bits need to b e shifted at this step; see Figure S2(d) for an example. F or b -bit w ords, the table has log 2 ( b ) en tries, eac h of size b bits itself, i. e., 6 entries for 64-bit w ords, corresp onding to shifts 1, 2, 4, 8, 16, 32. As the num b er of stages is fixed for a given bit width, there is no loop. How ever, as the stages dep end on eac h other in their execution order, parallelism through instruction pipelining is somewhat limited. Still, this is generally the most efficien t softw are implemen tation w e tested, see Figure S3 – S5 . Figure S3: Bit extraction p erformance for different w eigh ts (n umber of set bits) of the mask. The hardw are PEXT is by far the most p erforman t where av ailable as a dedicated in trinsic; note how ev er that on the older AMD Ryzen 7, where it is implemented in CPU micro code instead, p erformance is dependent on the mask weigh t (num b er of bits set in the mask), and p erforms worse ev en than our naive bitlo op implementation in softw are. The blo c k table implemen tation has as many steps as runs of consecutiv e 1s in the mask; for the randomly generated inputs used here, this thus has a b ell shap e. Generally , this implementation b enefits from lo op unrolling. The most consistently fast softw are implemen tation is ho w ev er the Butterfly netw ork, with p erformance indep enden t of the mask w eigh t. 9 Figure S4: Bit extraction performance for differen t num b er of runs of consecutiv e 1s (blo c ks) in the mask. Here, instead of increasing the weigh t of the mask, we tested differen t n um ber of runs of 1s, eac h with a random length (within the constrain ts of a 64-bit w ord). The maximum num b er of runs is 32, corresp onding to an alternating pattern of 1s and 0s. The bit extract implemen tations whose runtime dep ends on the weigh t of the mask (bitlo op and PEXT on the older AMD Ryzen 7) hence exhibit a similar runtime across masks, as the num ber of bits set is on a verage half the mask. The effect of lo op unrolling in the block table approac h is clearly visible here in form of “steps” at eac h lev el of unrolling; with 8-fold unrolling, the approac h is competitive with the butterfly netw ork for the runs of 1s that are most relev ant for spaced k -mers (up to 8 blo c ks). Again though, across all masks, the fast hardw are PEXT as w ell as the butterfly net w ork implementation dominate p erformance here, and are thus the tw o preferred approac hes. 10 Figure S5: Bit extraction performance for differen t weigh ts (top), and for different n um b er of blo c ks (bottom), across architectures and compilers. This sho ws the same underlying data as Figure S3 and Figure S4 , but as a summary of all tested architectures and compilers. It sho ws the a v erages across all cases, i. e., all w eigh ts of the mask and all n um b er of blocks, resp ectiv ely . Here, the adv an tage of the PEXT hardw are instruction is clearly visible, while the Butterfly net work table is the most p erforman t soft ware implementation. 11 4 Spaced k-mer Extraction W e can no w apply the generic bit extraction to the input k -mers to obtain w -mers. Note that the generic functions op erate on individual bits; our 2-bit encoding requires pairs of bits to be used instead. This has how ev er no effect on the performance of the relev an t algorithms (block table and butterfly net work). Input character validit y . One of the main goals of spaced k -mers is to b e able to skip inv alid c haracters in the input, if they fall in to one of the spaces of the mask, without ha ving to skip the whole k -mer. T o ac hiev e this, we need to adapt our ab o v e k -mer iteration to trac k v alid bases while trav ersing the input. This can b e implemented efficiently with a second 64-bit word, shifted in sync with the k -mer, and setting t w o bits to indicate character v alidity at the resp ectiv e p ositions in the k -mer. A simple bit comparison with the mask then reveals if all non-masked n ucleotides are v alid for an y giv en k -mer. The o v erhead for this c hec k did not significan tly influence performance in our tests: Assuming that most input c haracters are v alid (from N), the branc h predictor can easily a v oid slo wdo wn in most cases. Note that this is in principle similar to the desired prop ert y of spaced k -m ers to b e able to tolerate mismatches with a reference genome; here ho w ev er, we are solely op erating based on input character v alidit y . 4.1 Single Mask Benc hmarks are sho wn in Figure S6 ; these are detailed v ariants of Figure 2(a) from the main man uscript, for a represen tative selection of hardw are arc hitectures. In all cases, there is at least one implemen tation that ac hiev es pro cessing one w -mer p er 1.3–1.8ns. Note that the plots include SIMD accelerations as explained b elow. 4.2 Multiple Masks Man y applications of spaced k -mers use a set of distinct masks in order to increase sensitivit y . With multiple masks, the bit extraction is simply applied to each k -mer and for each mask individually , leading to a general increase in runtime p er additional mask. How ever, the n u- cleotide enco ding and k -mer iteration only has to b e p erformed once then, whic h amortizes the fraction of runtime for these tasks, and leading to an increase in p erformance when measuring throughput p er distinct mask and w -mer. F or ease of comparison with the single mask case, w e rep ort this time per w -mer here; note though that the runtime per k -mer th us needs to b e m ultiplied by the n um b er of masks used (here, 9 masks). Benc hmarks for 5 distinct sets of 9 masks each are shown in Figure S7 . In the b est case, on In tel Xeon, we achiev e 0.58ns per w -mer using the PEXT instruction. The plots again include SIMD accelerations as explained next. 12 Figure S6: Extraction sp eed of spaced k -mers for single masks. This sho ws the time needed per w -mer to trav erse an input sequence, including the k -mer pro cessing and bit extraction to obtain the w -mer. Bars are the a v erage across 9 distinct masks with w eigh t w = 22 and span k = 31, and whiskers sho w the minimum and maximum across these masks. 4.3 SIMD Acceleration The generic algorithms for the bit extract op eration as in tro duced ab o ve w ere so far applied indep enden tly on eac h k -mer to extract the w -mer. How ever, in our typical use case, we are tra v ersing a sequence, applying an extraction with the same mask to consecutiv e k -mers. T o accelerate this, we can exploit SIMD (single instruction, multiple data) intrinsics. The t w o most p erforman t implemen tations, blo c k table and butterfly netw ork, are particularly suitable for SIMD parallelization: They only need a small set of pre-computed v alues per mask, and can efficien tly apply them in parallel across multiple 64-bit lanes. W e ha ve implemen ted b oth approac hes for several SIMD instruction sets. These op erate on differen t underlying register sizes, and hence differ in the num b er of lanes they can pro cess at once. In particular, w e implemen ted b oth algorithms for SSE2 (128-bit; 2 lanes), A VX2 (256-bit; 4 lanes), A VX512 (512-bit, 8 lanes), and ARM Neon (128-bit, 2 lanes). The main lo op ov er the input sequence then extracts as many consecutiv e k -mers as av ailable lanes, and extracts w -mers in the lanes in parallel. Exemplary benchmarks are included in the previously described Figure S6 and Figure S7 ; a summary across all arc hitectures and compilers is provided in Figure S8 and in T able S1 . 13 Figure S7: Extraction speed of spaced k -mers for m ultiple masks. This shows the a v erage time needed p er w -mer to tra v erse an input sequence, including the k -mer pro- cessing and bit extraction to obtain all w -mers for the given set of masks. Bars are the a v erage across 5 distinct mask sets with 9 masks each, with span and w eigh t ( k , w ) ∈ { (15 , 10) , (31 , 14) , (31 , 18) , (31 , 22) , (31 , 26) } for the sets, and whiskers sho w the minimum and maxim um across the mask sets. Note that for comparability with the single mask case ab o v e, this shows the a v erage time p er w -mer; for the complete time to extract all 9 w -mers for a giv en mask set, v alues ha v e hence to be m ultiplied b y 9. 4.4 Dynamic Algorithm Selection Except for the basic implementations, our accelerations dep end on hardware av ailabilit y of CPU in trinsics: PEXT for the fastest bit extraction, as w ell as SSE2, A VX2, A VX512, and ARM Neon for our SIMD implemen tations of the blo c k table and butterfly net w ork algorithms. While these giv e significant sp eed impro v emen ts, not all instruction sets are av ailable on different hardw are architectures. Hence, t ypically , for full optimization, co de needs to b e compiled p er arc hitecture. Unfortunately , how ever, the PEXT instruction is a v ailable on older AMD CPUs, but v ery inefficien t, as sho wn ab o v e. Hence, simply testing for the underlying BMI2 instruction set at compile time could lead to significan t performance degradation. Th us, w e need to use a runtime dispatc h b et w een the differen t algorithms, and switch to the fastest av ailable implemen tation. T o facilitate this, and ease usage for dev elop ers, w e offer a mec hanism for dynamically selecting b et ween algorithms, b y running a short b enchmark with 14 Figure S8: Extraction sp eed of spaced k -mers for single (top) and m ultiple (b ot- tom) masks. This sho ws the same underlying data as Figure S6 and Figure S7 , but sum- marized across all architectures and compilers. It is an extension of Figure 2 in the main man uscript, containing benchmarks of all implementations presen ted here. randomly generated data. This is executed for a fixed mask, whic h is sufficien t for most t ypical use cases for spaced k -mers. The mechanism can be readily implemen ted in applications that wish to use our co de base. F or completeness, w e offer a similar dynamic selection for the generic bit extract functionalit y . These mec hanisms ha v e the additional adv antage of allowing cross compilation. As the al- gorithm is selected once dynamically at the b eginning of the program run time, an additional c hec k can b e performed to test if any giv en in trinsic is actually a v ailable on the curren t CPU, th us av oiding to crash the program with in v alid instructions. W e implemen ted this in our selection mec hanism. This is particularly useful to compile a program for platforms such as conda, where a single binary can then serv e an y hardw are architecture. T o minimize ov erhead due to the dispatch in hot lo ops o ver k -mers, and to allo w function inlining b y the compiler, w e recommend to use the result of the dynamic selection to dispatch once in an outer con text, using a switc h and C++ templates for the inner function. W e provide exemplary co de for this. 15 Single mask Multiple masks CPU / Compiler F astest algorithm Time Sp eed F astest algorithm Time T otal Sp eed Ep yc / Clang Butterfly A VX2 1.27 750 PEXT 0.64 5.72 167 Ep yc / GCC PEXT 1.47 648 Butterfly A VX512 1.41 12.68 75 Ryzen / Clang Butterfly A VX2 1.71 557 Butterfly A VX2 1.04 9.38 102 Ryzen / GCC Butterfly SSE2 1.84 517 Butterfly SSE2 2.18 19.59 49 Xeon / Clang PEXT 1.28 747 PEXT 0.58 5.21 183 Xeon / GCC PEXT 1.51 631 PEXT 1.08 9.71 98 M1 / Clang Butterfly Neon 1.39 687 Butterfly Neon 1.26 11.30 84 T able S1: Performance of the fastest algorithm across hardware arc hitectures. The table summarizes the ab o v e b enc hmarks, sho wing the time (ns per w -mer) and sp eed (MB/s) for the single mask case, as w ell as for the multiple mask case the total time p er input position (ns per k -mer) for all 9 masks com bined and the resulting speed. Note that t ypical applications usually use fewer masks; the sp eed here is th us exemplary only . 4.5 Differences b etw een compilers As can b e seen in the b enc hmarks ab o ve, the performance in some cases has significant dif- ferences b etw een compilers, ev en on the same hardware architecture. This is not surprising, as Clang and GCC tend to inline and optimize code differen tly . It is ho wev er out of scope of this man uscript to explore this in more detail. In an y practical application of the presented metho ds, the spaced k -mer extration is t ypically follo w ed by some do wnstream work anyw ay , whic h will cause compilers to optimize lo ops and functions in unpredictable wa ys. W e thus recommend to test performance of applications under different compilers. 4.6 Compa rison with existing metho ds W e compare our approac h to the existing metho ds FSH [ 3 ], FISH [ 4 ], ISSH [ 5 ], MISSH [ 1 ], and DuoHash [ 6 ]. W e here call these approaches the Comin & Pizzi family of metho ds. FSH, ISSH, and MISSH are build on the idea of re-using information across w -mers of previous p ositions along the input sequence. Using the auto-correlation of the bits in the mask with its shifted self, the metho ds find ov erlapping unmask ed blocks of n ucleotides of the underlying sequence. These are then re-used to fill the curren t w -mer based on previously observed ones, th us a voiding to re-extract information from the underlying sequence. The methods are based on the assumption that enco ding the c haracters in to their 2-bit represen tation is exp ensiv e. In their original implementation, this was indeed the case, as they used an exp ensiv e series of if -statemen ts, as explained in Section 2.1 . They ha v e since up dated this, with consequences as explained b elow. FISH and DuoHash on the other hand use blo cks of consecutiv e 1s in the mask to accelerate spaced k -mer extraction via lo okup tables. FISH has some conceptual similarity with our blo c k table algorithm, but instead of simply shifting blo c ks, it uses a set of lo okup tables for differen t block sizes. DuoHash similarly uses large lookup tables to re-use previously observed blo c ks of the input sequence. This makes DuoHash more general than simple enco ding of 16 Figure S9: Pro cessing sp eed of spaced k -mers with existing methods of the Comin & Pizzi family . W e impleme n ted a b enc hmark program using the suite of existing approaches, follo wing our b enc hmarks ab o ve. The figure sho ws av erage time for pro cessing a spaced k -mer on randomly generated data, as b efore. Across most architectures, the fastest metho d is ISSH, whic h is ho wev er still significantly slow er than our fastest algorithm on the same arc hitecture, resp ectiv ely , and only about twice as fast as the naiv e baseline implem en tation. the k -mers, as it can b e used for computing actual hash v alues of spaced k -mers, which they sho w case via the n tHash metho d [ 9 , 10 ]. W e how ever did not test the DuoHash metho d here, as the co de rep ository at github.com/CominLab/DuoHash do es not seem to con tain an actual implemen tation of the method (at the time of writing), and instead contains a concise in terface for all other methods of the family . These metho ds require a large amount of b ookkeeping to manage blo ck o verlaps and lo okup tables, which also introduces p ointer indirections to access their data structures. F urthermore, the o verlap-based metho ds require to k eep a list of previous w -mers during iteration, causing some slo wdown due to allo cations and memory accesses. In fact, DuoHash [ 6 ] states that “the sp eed-up generally tends to decrease sligh tly as the length of the reads increases”, whic h can b e explained by this. In their curren t implemen tation, they store the previous w -mers for the whole sequence, despite a short window sufficing; this could hence be optimized. T o compare our presented algorithms with the Comin & Pizzi family of metho ds, w e imple- men ted a b enc hmark for their methods in our fork of their DuoHash repository at github.com/ lczec h/DuoHash . There, w e added a simple program to the original co de that runs compara- ble b enc hmarks to the ones we sho w ed ab o ve, measuring the time p er k -mer for a randomly generated input string. Note that the DuoHash co de rep ository seems to hav e re-implemen ted their b enc hmarking harness compared to the original one used in MISSH at github.com/CominLab/MISSH . This up date has one particular c hange that significantly improv ed the performance of their methods: Previously , as men tioned, they used a series of if -statements to enco de the input characters in to 2-bit enco ding, while in their up date this is implemen ted as a fast lo okup table. This th us eliminates the b ottlenec k due to the encoding, diminishing the gains ac hieved with these metho ds compared to the naiv e baseline implemen tation, as shown in Figure S9 . Across almost all tested architectures, ISSH is the fastest of the Comin & Pizzi metho ds, ex- cept on the Apple M1, where MISSH ro w is relatively the fastest (but absolutely , slo wer than 17 on the x86 arc hitecture). In the b est case, the metho ds reached a throughput of 5.0ns p er extracted w -mer. Out of our algorithms presented here, PEXT is the fastest where a v ailable in hardware, and one of the SIMD Butterfly implementations otherwise. Across hardware ar- c hitectures, our algorithms for a single mask are 3.4–4.2 times faster, and for m ultiple masks 3.2–9.5 times faster, than the b est out of the Comin & Pizzi metho ds on the respective ar- c hitecture. Additionally , our basic algorithms are also significan tly e asier to implemen t (the SIMD acceleration adds some complexity though), and do not need to k eep the list of previous k -mers in memory during the iteration. 18 5 References [1] Mian E, P etrucci E, Pizzi C, Comin M (2024) MISSH: F ast hashing of multiple spaced seeds. IEEE/A CM tr ansactions on c omputational biolo gy and bioinformatics 21(6):2330– 2339. [2] Corontzos C, F rac h ten b erg E (2024) Direct-co ding DNA with multilev el parallelism. IEEE c omputer ar chite ctur e letters 23(1):21–24. [3] Girotto S, Comin M, Pizzi C (2018) FSH: fast spaced seed hashing exploiting adjacent hashes. Algorithms for mole cular biolo gy: AMB 13(1):8. [4] Girotto S, Comin M, Pizzi C (2018) Efficient computation of spaced seed hashing with blo c k indexing. BMC bioinformatics 19(Suppl 15):441. [5] Petrucci E, No´ e L, Pizzi C, Comin M (2020) Iterative Spaced Seed Hashing: Closing the gap betw een spaced seed hashing and k-mer hashing. Journal of c omputational biolo gy: a journal of c omputational mole cular c el l biolo gy 27(2):223–233. [6] Gemin L, Pizzi C, Comin M (2026) DuoHash: F ast hashing of spaced seeds with applica- tion to spaced K-mers counting in L e ctur e Notes in Computer Scienc e , Lecture Notes in Computer Science. (Springer Nature Switzerland, Cham), pp. 28–39. [7] Ounit R, Lonardi S (2016) Higher classification sensitivity of short metagenomic reads with CLARK-S. Bioinformatics (Oxfor d, England) 32(24):3823–3825. [8] W einstein CJ (1969) Quantization effects in digital filters, T echnical rep ort. [9] Mohamadi H, Ch u J, V anderv alk BP , Birol I (2016) n tHash: recursive n ucleotide hashing. Bioinformatics 32(22):3492–3494. [10] Kazemi P , et al. (2022) n tHash2: recursive spaced seed hashing for n ucleotide sequences. Bioinformatics 38(20):4812–4813. 19
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment