A Distribution-to-Distribution Neural Probabilistic Forecasting Framework for Dynamical Systems
Probabilistic forecasting provides a principled framework for uncertainty quantification in dynamical systems by representing predictions as probability distributions rather than deterministic trajectories. However, existing forecasting approaches, w…
Authors: Tianlin Yang, Hailiang Du, Louis Aslett
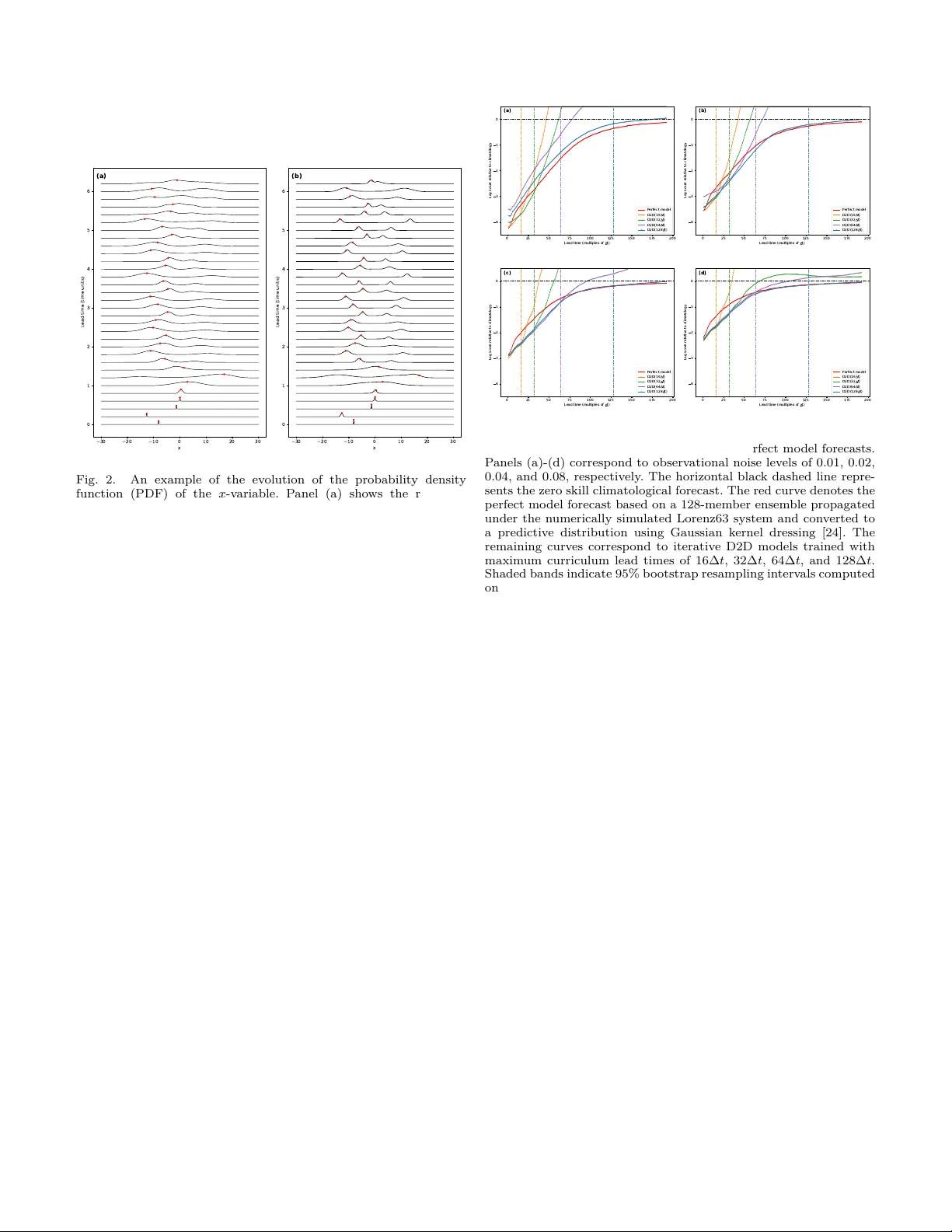
1 A Distribution-to-Distribution Neural Probabilistic F orecasting F ramew ork for Dynamical Systems Tianlin Y ang 1 , Hailiang Du 1,2,3,* , and Louis Aslett 1 1 Departmen t of Mathematical Sciences, Durham Universit y , Durham DH1 3LE, United Kingdom 2 Sc ho ol of Mathematics, East China Universit y of Science and T echnology , Shanghai 200237, China 3 Data Science Institute, The London School of Economics and Political Science, London W C2A 2AE, United Kingdom * Corresp onding author: Hailiang Du. Email: hailiang.du@durham.ac.uk. Abstract—Probabilistic forecasting provides a principled framew ork for uncertain t y quantication in dynamical sys- tems b y representing predictions as probability distributions rather than deterministic trajectories. How ever, existing fore- casting approaches, whether ph ysics-based or neural-net work- based, remain fundamen tally tra jectory-orien ted: predictive distributions are usually accessed through ensembles or sam- pling, rather than evolv ed directly as dynamical ob jects. A distribution-to-distribution (D2D) neural probabilistic fore- casting framew ork is dev eloped to operate directly on pre- dictiv e distributions. The framework introduces a distribu- tional encoding and deco ding structure around a replaceable neural forecasting module, using kernel mean em b eddings to represen t input distributions and mixture density netw orks to parameterise output predictiv e distributions. This design enables recursiv e propagation of predictiv e uncertaint y within a unied end-to-end neural arc hitecture, with mo del training and ev aluation carried out directly in terms of probabilistic forecast skill. The framew ork is demonstrated on the Lorenz63 c haotic dynamical system. Results show that the D2D mo del captures non trivial distributional evolution under nonlinear dy- namics, produces skillful probabilistic forecasts without explicit ensem ble simulation, and remains comp etitive with, and in some cases outp erforms, a simplied p erfect mo del b enchmark. These ndings p oin t to a new paradigm for probabilistic forecasting, in which predictiv e distributions are learned and ev olv ed directly rather than reconstructed indirectly through ensem ble-based uncertaint y propagation. Index T erms—Probabilistic forecasting, Dynamical systems, Uncertain t y Quan tication, Neural netw orks, Distribution-to- distribution learning. I. Introduction Prediction of complex systems across science and en- gineering is often formulated in terms of dynamical sys- tems gov erned by ordinary or partial dierential equa- tions, grounded in physical knowledge of the underlying pro cesses. Such physics-based models underpin a wide range of applications, including geophysical ows, climate and w eather prediction, engineering control systems, and biological dynamics. Alongside these approac hes, data- driv en metho ds hav e long b een explored as alternativ e or complementary to ols for forecasting dynamical sys- tems. Recent adv ances in mac hine learning hav e led to signican t progress in data-driv en forecasting, particularly neural netw ork based forecasters, which ac hiev e predictive skill comparable to, and in some cases exceeding, that of physics-based mo dels, while oering substan tial gains in computational eciency [1]–[4]. Despite their dier- en t form ulations, both physics-based and existing neural net w ork based forecasters share a fundamen tal structural limitation: they ev olv e single system states forw ard in time, pro ducing deterministic tra jectories rather than explicitly ev olving predictiv e distributions. As is w ell known, for deterministic mo dels go verned b y ordinary or partial dierential equations, propagating full distributions would require solving the Liouville or F okk er–Planc k equation, a task that is computationally in tractable for high-dimensional nonlinear systems [5], [6]. This structural limitation poses a fundamental challenge for uncertaint y quantication. In complex, nonlinear and often c haotic systems, uncertaint y arises from multiple sources, including for example observ ational noise, unre- solv ed processes, and mo del discrepancy . Quan tifying and propagating this uncertaint y is essen tial for b oth scientic understanding and decision-making, particularly when forecasts are used to assess risk, threshold exceedance, or lo w-probabilit y high-impact ev en ts. A wide range of uncertain ty quan tication approaches ha v e b een dev elop ed, with ensemble-based metho ds form- ing the bac kb one of practical uncertaint y representation in many forecasting systems. Initial condition ensembles are commonly used to represen t uncertaint y arising from imp erfect observ ations and data assimilation. Parameter ensem bles, often referred to as perturb ed-physics ensem- bles, aim to capture uncertain ty asso ciated with model pa- rameterisation. Multi-mo del ensem bles further attempt to address structural model discrepancy by combining fore- casts from models with dieren t formulations. In practice, these ensemble strategies are designed to address dierent sources of uncertaint y in a rather indep enden t manner. When combined, their joint use can incur substantial computational cost and may lead to ov erly disp ersed predictiv e distributions, thereby reducing the practical v alue of the forecast. Bey ond ensemble-based approaches [7], [8], a v ariety of other uncertaint y quantication metho ds ha ve b een dev elop ed, including Bay esian inference and ltering tech- niques [9], [10], stochastic parameterisations [11], and p ost hoc statistical calibration methods [12]. While these approac hes pro vide v aluable to ols for characterising uncer- tain t y in sp ecic settings, uncertaint y is typically treated as an auxiliary quantit y added to an underlying determin- 2 istic forecast. Similar uncertain ty quantication strategies hav e also b een widely adopted in mac hine learning based forecast- ing, particularly for neural netw ork models. Ensemble- based approac hes are commonly used to represen t pre- dictiv e uncertain ty by training multiple netw orks with dieren t initialisations, data subsets, or perturbations, mirroring ensem ble tec hniques in physics-based modelling. In addition, a range of metho ds hav e b een developed sp ecically for neural netw orks, including appro ximate Ba y esian tec hniques such as dropout-based inference [13], as w ell as more recen t generative approac hes based on diusion and probabilistic latent v ariable mo dels [14]– [16]. While these models can pro duce rich probabilistic forecasts for a single forward step, multi-step forecasting t ypically relies on propagating sampled trajectories rather than explicitly ev olving the predictiv e distribution itself. T ak en together, traditional uncertain t y quantication approac hes for b oth ph ysics-based mo dels and mac hine learning mo dels typically treat uncertaint y as an auxiliary quan tit y added to an underlying deterministic forecast, rather than as an intrinsic part of the mo del evolution. Probabilistic forecasting provides a principled and natu- ral framew ork for uncertaint y quan tication by represent- ing predictions as full probabilit y distributions, which oer the most complete description of predictiv e uncertaint y . Crucially , the quality of uncertaint y quantication can then b e ev aluated using proper probabilistic scoring rules, suc h as the logarithmic score [17]. In this setting, the skill of a probabilistic forecast directly reects the quality of the asso ciated uncertaint y quantication. F rom this p ersp ective, uncertaint y quantication is no longer an auxiliary diagnostic, but should b e treated as a primary modelling ob jective that is explicitly optimised during training. Ac hieving this objective in dynamical forecasting requires predictive uncertain ty to b e propa- gated coheren tly through time, so that the evolution of the system is describ ed in terms of predictiv e distribu- tions rather than individual trajectories. Ho wev er, existing dynamical forecasting mo dels, whether physics-based or neural-net w ork-based, remain fundamentally tra jectory- based. In this work, a neural netw ork arc hitecture is prop osed that enables distribution-to-distribution (D2D) learning, allo wing predictive distributions themselves to b e treated as rst-class ob jects that are propagated through the forecasting mo del. The framework op erates directly on predictiv e distributions rather than individual system states. Input distributions are enco ded using kernel mean em b eddings and pro cessed by a neural forecasting mod- ule, while the outputs are decoded in to parameterised predictiv e distributions via mixture densit y netw orks. By enabling predictiv e distributions to be propagated dynam- ically through successiv e forecast steps, the framew ork mak es uncertain t y an in trinsic comp onen t of the mo del ev olution and allows mo del training and optimisation to b e driven explicitly b y probabilistic p erformance metrics. The remainder of the paper is organised as follows. Section I I describ es the prop osed D2D framework, includ- ing the output distribution parameterisation, the kernel- based enco ding of input distributions, the logarithmic- score training objective, and the asso ciated training strate- gies. Section II I presents a proof-of-concept exp erimental demonstration based on the Lorenz63 system. Section IV concludes the pap er with a summary of the main results and a discussion of limitations and future extensions. I I. D2D F ramework The core idea of the prop osed distribution-to- distribution (D2D) framew ork is to treat predictiv e dis- tributions, rather than p oint states, as the fundamental ob jects of dynamical forecasting. In the presen t work, this idea is realised at the level of marginal predictive distributions for individual state v ariables, rather than the full join t distribution ov er the complete state vector. Instead of learning a mapping from x t to x t +1 in state space, the D2D architecture learns a transformation F Θ : Q → Q , where Q denotes a suitable space of parameterised marginal predictive distributions. In this formulation, both inputs and outputs of the forecasting mo del are predictiv e distributions, enabling uncertaint y to b e propagated ex- plicitly and coherently through successive forecast steps. Fig. 1 illustrates the o verall D2D neural netw ork arc hitec- ture. The framew ork consists of three main comp onents: 1) A distribution enco der, which maps input distribu- tions into a nite-dimensional represen tation suit- able for neural pro cessing; 2) A replaceable neural forecasting mo dule, which transforms the enco ded representation through stan- dard neural architectures (e.g., LSTM [18], T rans- former [19], or other backbone mo dels); 3) A distribution deco der, whic h maps the neural out- puts back to parameterised predictive distributions. Fig. 1. Schematic illustration of the proposed D2D neural netw ork architecture. This modular design allows existing neural forecasting arc hitectures to be incorp orated in to the D2D pipeline with minimal structural mo dication. The k ey inno v ation lies not in replacing neural backbone mo dels, but in 3 redening their input and output in terfaces so that predic- tiv e distributions b ecome rst-class computational ob jects. In the presen t implemen tation, these objects correspond to marginal predictiv e distributions for eac h state dimension, rather than a fully coupled joint predictive distribution. Extending the framework to full joint distribution-to- distribution forecasting would require scalable parameter- isations of high-dimensional dependence structures and co v ariance representations, whic h remains a substantial c hallenge and is b eyond the scop e of the present w ork. F ormally , let p t = { p ( j ) t } d j =1 denote the collection of predictiv e marginal distributions at time t , where d is the state dimension. The D2D mo del pro duces p t +1 = F Θ ( p t ) , where F Θ denotes the neural net w ork mo del parameterised b y the full set of trainable parameters Θ . F or m ulti-step forecasting, this mapping can b e iterated: p t + k = F ( k ) Θ ( p t ) , where F ( k ) Θ represen ts k successiv e applications of the same net work. This iterative structure allows predictiv e marginal distributions to evolv e dynamically through time, as illustrated by the feedback lo op in Fig. 1. By op erating directly on predictive distributions, the D2D framework eliminates the need for external en- sem ble sampling or p ost ho c uncertaint y reconstruction. Instead, uncertain ty , represented as predictive marginal distributions, is enco ded, dynamically propagated through time, and deco ded within a unied end-to-end neural net w ork architecture. Therefore, the arc hitecture aims to learn a distributional forecasting op erator that pro duces skillful predictive marginal distributions consisten t with the underlying system dynamics. The following subsections detail the four central techni- cal comp onen ts of the framew ork: (i) the parameterisation of neural netw ork outputs as predictiv e distributions, (ii) the encoding of input distributions for neural pro cessing, (iii) the c hoice of loss function used to train the netw ork, and (iv) the training strategy used for distributional forecasting. A. F rom Neural Net work Outputs to Predictive Distribu- tions One of the key features of the proposed distribution- to-distribution (D2D) framew ork is its ability to pro duce predictiv e distributions directly . Existing probabilistic forecasting approac hes often rely on ensembles (nite samples) to represent predictive uncertain t y , with con- tin uous predictive densities obtained only through post- pro cessing when needed. While widely used, ensem ble- based approaches exhibit sev eral limitations as a general framew ork for uncertaint y quan tication in dynamical forecasting: predictive uncertaint y is represented only through a nite ensemble, rather than as an explicit predictiv e distribution; m ultiple forw ard ev aluations of the forecasting model are required, increasing computational cost; and uncertain ty representation remains an auxiliary la y er added on top of the forecasting mo del rather than an intrinsic part of it, so that its quality is not directly optimised during training. More recent neural probabilistic forecasting metho ds include diusion-based generative mo dels [16], [20] and discretisation-based approaches [21], [22]. Diusion models can capture complex and m ultimo dal uncertaint y , but t ypically rely on iterativ e sampling pro cedures and re- main computationally demanding for dynamical forecast- ing. Discretisation-based metho ds are straightforw ard to implemen t and train, but they yield piecewise-constan t predictiv e distributions whose resolution is constrained b y the bin design. Ac hieving ner granularit y requires a larger num b er of bins, which increases mo del complexit y and computational cost, and can also lead to data sparsit y in individual bins. These considerations motiv ate the use of mixture den- sit y net works (MDNs) [23] as an in tegral comp onen t of the prop osed architecture, enabling predictiv e distributions to b e pro duced directly by the mo del outputs. Rather than generating a single p oint prediction, the netw ork outputs the parameters of a mixture distribution in a single forw ard pass, providing a exible and computationally ecien t framew ork for probabilistic forecasting. F ormally , giv en a multiv ariate input x , the MDN outputs a set of parameters { π i ( x ) , µ i ( x ) , σ i ( x ) } M i =1 , corresp onding to the mixture weigh ts, means, and stan- dard deviations of an M -comp onen t Gaussian mixture. In the presen t formulation, this parameterisation is used for the predictiv e marginal distribution of a single target state v ariable. The predictive marginal density is then giv en b y p ( y | x ) = M i =1 π i ( x ) N y | µ i ( x ) , σ 2 i ( x ) , (1) where the mixture weigh ts π i ( x ) are constrained to b e p ositiv e and sum to one via a softmax activ ation, and the standard deviations σ i ( x ) are enforced to b e p ositive using an exp onential activ ation. Conceptually , MDNs are closely related to kernel dress- ing [24], as b oth represent predictive distributions as nite mixtures of k ernel functions, typically Gaussians. The crucial distinction lies in parameterisation: k ernel dressing uses xed kernel parameters applied uniformly across samples, whereas MDNs learn the mixture weigh ts, means, and v ariances as nonlinear functions of the input through the neural netw ork itself. In the presen t setting, this exibilit y enables MDNs to capture non-Gaussian and multimodal predictive marginal distributions with minimal additional computational ov erhead relativ e to mo dern neural netw ork architectures. T ak en together, MDNs provide a natural and ecient mec hanism for conv erting neural net work outputs in to predictiv e distributions, making them a key building blo ck of the prop osed D2D framework. 4 B. Enco ding Input Distribu tions for Neural Pro cessing A key technical challenge in distribution-to-distribution learning is ho w to represen t input distributions in a form suitable for neural netw ork processing. While mixture den- sit y net works enable exible parameterisation of output distributions, the mo del must also accept distributions as inputs. More imp ortantly , the distributions pro duced by the MDN deco der must themselves b e re-enco ded and fed bac k into the netw ork, so that predictive distributions can b e iteratively propagated across forecast steps. This requires a principled and computationally tractable repre- sen tation of predictive distributions in a nite-dimensional space. In this work, k ernel mean embedding (KME) [25], [26] is adopted to enco de input distributions. Given a p ositiv e denite kernel k : X × X → R dened on the state space X , the kernel mean embedding of a probability distribution P o ver X is dened as µ k ( P ) := E X ∼ P [ k ( X , · ) ] , where X is a random v ariable with distribution P . The resulting ob ject µ k ( P ) lies in the repro ducing kernel Hilb ert space (RKHS) asso ciated with the k ernel k [27]. Under characteristic k ernels (e.g., the Gaussian RBF k er- nel used in this work), this embedding uniquely represents the distribution [26], [28]. In practice, the embedding is ev aluated at a nite set of centres { c j } n c j =1 , yielding a nite-dimensional represen tation z P = µ k ( P )( c 1 ) , . . . , µ k ( P )( c n c ) ⊤ , whic h serves as the input to the neural forecasting module. In the present w ork, a one-dimensional Gaussian radial basis function (RBF) k ernel is employ ed for the predictiv e marginal distribution of each state dimension: k ( x, c ) = exp − ( x − c ) 2 2 ℓ 2 , where ℓ > 0 is the kernel bandwidth parameter. When the input distribution is Gaussian, P = N ( µ, σ 2 ) , the em b edding admits a closed-form expression, obtained by ev aluating a standard Gaussian in tegral (equiv alently , the con v olution of t w o Gaussians) [25], [28]: µ k ( P )( c ) = ℓ 2 ℓ 2 + σ 2 exp − ( µ − c ) 2 2( ℓ 2 + σ 2 ) . This closed-form expression enables ecient and exact ev aluation of the embedding at the selected kernel centres for Gaussian predictiv e distributions, without resorting to n umerical in tegration or Mon te Carlo appro ximation. The kernel bandwidth ℓ plays a critical role in con- trolling the smo othness and sensitivit y of the embedding. In classical kernel-based metho ds, kernel hyperparameters suc h as the Gaussian bandwidth are often c hosen using heuristic rules, for example in maximum mean discrepancy (MMD)–based applications [29]. While such c hoices are often eective in generic distribution-comparison settings, they are not tailored to the predictiv e forecasting task considered here. In the presen t framew ork, the bandwidth is treated as a learnable parameter. F or each state di- mension, ℓ is optimised jointly with the neural netw ork parameters, sub ject to p ositivit y constrain ts enforced via an absolute-v alue transformation. This adaptiv e treatment allo ws the em b edding represen tation to align with the scale and v ariability of predictive uncertaint y learned from data. A further crucial property of k ernel mean embeddings is their linearity with respect to the underlying distribution: µ k i w i P i = i w i µ k ( P i ) . This linearit y pla ys a central role in the proposed frame- w ork. Since the MDN deco der pro duces predictive distri- butions in the form of Gaussian mixtures, the embedding of a mixture distribution can b e computed analytically as the weigh ted sum of the embeddings of its individual Gaussian comp onents. Consequently , the encoding is nat- urally matched to the MDN-based output representation, ensuring that input and output distributions are expressed within the same functional form. This alignment enables seamless iteration of the D2D mapping, allowing predic- tiv e marginal distributions to b e propagated consistently through successiv e forecasting steps. It is worth noting that neither the mixture distribution pro duced b y the MDN nor the kernel choice is restricted to the Gaussian form. While Gaussian mixtures combined with Gaussian RBF kernels provide analytical conv enience and com- putational eciency , the D2D framework only requires structural compatibility b etw een the chosen mixture dis- tribution family and the kernel function. Ov erall, kernel mean embedding provides a principled and computationally tractable mechanism for mapping predictiv e marginal distributions into nite-dimensional neural represen tations, while preserving compatibility with Gaussian mixture outputs. More general m ultiv ariate extensions and theoretical prop erties of k ernel em b eddings are discussed in [28], [30]. C. The Imp ortance of Using Logarithmic Score Recen t adv ances in machine learning hav e led to re- markable and highly visible success in classication tasks, including spam detection, image recognition, and medical diagnosis. Man y of the most inuen tial mo dern AI systems are built up on classication-based form ulations at their core. F or example, large language mo dels perform next- tok en prediction as a multi-class classication problem, and game-playing systems such as AlphaGo rely on classication-based arc hitectures in k ey decision-making comp onen ts [31]–[33]. In contrast, the impact of machine learning on regression and con tinuous-v alued prediction problems has b een comparatively less prominent. This con trast betw een classication and regression per- formance is likely ro oted in dierences in the ev aluation paradigm asso ciated with these tasks. In classication 5 tasks, mo dels are trained to output categorical proba- bilit y distributions, and cross-entrop y (equiv alently , the negativ e log-lik eliho o d) is almost univ ersally c hosen as the loss function. In con trast, regression tasks are most often approac hed through deterministic point prediction, with mean squared error (MSE) adopted as the default training ob jective. Note that minimising MSE is equiv alen t to minimising the negativ e log-likelihoo d of Gaussian predictive distributions with constant v ariance. In practice, nonlinear dynamics are the norm rather than the exception in real-world systems, and uncertain t y propagated through such non- linear mechanisms rarely preserv es a Gaussian structure. As a result, the true conditional predictiv e distribution is seldom w ell appro ximated b y a Gaussian form. It is imp ortant to note that there exist many other p ossible wa ys to ev aluate probabilistic predictions. F or example, accuracy , the Brier score [34], and A UC are commonly used in classication [35], [36], while the con tin uous ranked probability score (CRPS) is widely adopted in contin uous-v alued forecasting [37], [38]. In practice, how ever, cross-en tropy has b ecome the de facto standard as a training loss function in classication, not primarily b ecause of its probabilistic interpretation as log-lik eliho o d, but rather because of its computational con v enience: its dierentiabilit y and seamless integration with gradien t-based optimisation hav e made it the natural c hoice for training mo dern classication architectures. A t the ev aluation stage, alternative performance metrics such as accuracy , Brier score, and AUC remain widely used. F ormally , cross-en tropy , equiv alently the negative log- lik eliho o d, is identical to the logarithmic score [17] (also kno wn as Ignorance) [39] in the forecasting literature. F rom a theoretical standp oint, the logarithmic score o c- cupies a uniquely distinguished p osition: it is the only prop er lo cal scoring rule [40], meaning that it uniquely rew ards “truthful” probabilit y assignmen ts based solely on the realised outcome. As discussed in [41], the log- arithmic score p ossesses sev eral distinctive adv antages o v er alternative prop er scoring rules: Unlike the log- arithmic score, nonlo cal scoring rules such as CRPS, can admit “unfortunate” ev aluations that ma y fav our forecasts placing negligible or even zero probabilit y mass on the realised outcome; the logarithmic score admits a direct interpretation in terms of probabilities and bits of information, quan tifying forecast skill as information gain; and it is the only prop er scoring rule inv ariant under smo oth transformations of the forecast v ariable, ensuring coheren t ev aluation across equiv alen t represen- tations of predictiv e uncertain t y . F urthermore, Smith and Du (2026) demonstrate that the logarithmic score is the only metric of forecast skill consistent with the basic axioms of probability [42]. Despite this strong theoretical foundation, the logarithmic score is not uniformly adopted as the primary ev aluation metric in practical forecasting applications, where alternativ e p erformance measures are often preferred. Somewhat paradoxically , the widespread success of modern AI in classication may ow e m uch to the fact that its training ob jective coincides with the uniquely principled logarithmic score. A unied probabilistic p ersp ective implies that the logarithmic score should serve as the standard crite- rion for b oth classication and regression tasks, and for both mo del training and forecast ev aluation. While classication already aligns with this principle through the widespread use of cross-entrop y as the training loss, regression or con tinuous-v alued forecasting do not consis- ten tly adopt the same standard. A unied probabilistic framew ork demands that predictiv e mo dels b e trained and assessed directly through the logarithmic score, so that uncertaint y quantication and predictive skill are ev aluated under a coherent and theoretically principled criterion. Within the prop osed D2D framew ork, this persp ective has direct practical implications. Since b oth inputs and outputs of the mo del are probability distributions, the natural training ob jectiv e is the negative log-lik eliho o d of the realised outcome under the predicted distribu- tion. F or a collection of N forecasts with predictive densities { p i ( x ) } N i =1 and corresponding observed outcomes { x obs i } N i =1 , the empirical loss function is dened as L = − 1 N N i =1 log p i x obs i , whic h corresp onds exactly to minimising the empirical log- arithmic score. More broadly , this c hoice sets the standard for ev aluating the quality of uncertain ty quantication in forecasting. D. T raining the D2D Mo del Within the D2D framework, tw o training strategies can be adopted for probabilistic forecasting of dynamical systems. a) Direct strategy: A D2D model can b e trained directly for a sp ecic lead time τ , learning a mapping from the initial state distribution to the predictiv e distribution at lead time τ . The initial state distribution represents uncertain t y in the initial conditions. The training ob jective is dened as the empirical logarithmic score o v er N indep enden tly initialised forecasts. Sp ecically , let p ( i ) τ ( x ) denote the predictive marginal density for the i -th forecast at lead time τ , and let x ( i ) , obs τ denote the corresp onding observ ed outcome. The loss function is L direct = − 1 N N i =1 log p ( i ) τ x ( i ) , obs τ , whic h corresp onds to minimising the empirical logarithmic score at the target lead time. b) Iterative strategy: A D2D mo del can also b e trained for a smaller time incremen t ∆ t and then recur- siv ely applied to propagate the predictive distribution to longer lead times. In this iterative setting, the training ob jectiv e accoun ts for multiple forecast steps. Suppose the mo del is applied recursiv ely for K steps, corresp onding to lead times k ∆ t , k = 1 , . . . , K . Let p ( i ) k ∆ t ( x ) denote 6 the predictiv e marginal density for the i -th forecast at lead time k ∆ t , and let x ( i ) , obs k ∆ t denote the corresp onding observ ed outcome. The loss is then dened as L iter = − 1 N N i =1 K k =1 log p ( i ) k ∆ t x ( i ) , obs k ∆ t , whic h join tly optimises the empirical logarithmic score o v er m ultiple lead times. In practice, training the iterative mo del can b e stabilised using a curriculum learning strategy ov er lead times [43]. The mo del is rst trained for one-step forecasting, and the maxim um training lead time is then progressiv ely extended from ∆ t to 2∆ t, 3∆ t, . . . by increasing K in stages. At each stage, the same multi-lead time logarithmic score ob jective is used, allowing the mo del to gradually learn stable recursiv e distributional propagation while mitigating optimisation instability caused by early error accum ulation. More generally , the contributions from dieren t forecast steps could b e weigh ted dierently in the iterativ e objective. F or simplicit y , ho wev er, the presen t study adopts uniform weigh ting across all lead times. c) Comparison of the tw o strategies: While the it- erativ e approac h generally requires greater computational resources during training than the direct strategy , it oers sev eral conceptual and practical adv antages. Firstly , a single iteratively trained D2D mo del can generate forecasts for arbitrary lead times k ∆ t without retraining, whereas the direct strategy requires a separately trained mo del for eac h lead time of interest. Secondly , the iterativ e ob jective incorp orates information from m ultiple forecast lead times sim ultaneously , thereby exp osing the mo del to a richer set of dynamical constraints during training. This encourages the learned transformation to approximate the underlying dynamics rather than ov ertting to a sp ecic forecast lead time. In con trast, a direct mo del optimised solely for a xed lead time τ learns a lead-time-sp ecic mapping. If suc h a mo del is subsequently iterated to pro duce multi- step forecasts, its p erformance is exp ected to degrade substan tially , since it was not trained to maintain dy- namical consistency across successive applications. F rom a dynamical systems persp ectiv e, the iterativ e approac h is therefore b etter aligned with the ob jective of learning a distributional evolution op erator, rather than a collection of lead-time-sp ecic predictors. I I I. Experimental Demonstration T o demonstrate the capability of the prop osed D2D framew ork, and in particular its ability to propagate predictiv e uncertaint y iteratively through distribution-to- distribution mappings, exp eriments are conducted on the classical Lorenz63 chaotic dynamical system [44]. The Lorenz63 system provides a w ell-established b enchmark for nonlinear and c haotic dynamics, where uncertain t y propagation plays a cen tral role due to strong sensitiv- it y to initial conditions. This sensitivit y leads to rapid error growth and makes informative long-range forecast- ing intrinsically c hallenging, a diculty that is further exacerbated in real-world applications by unav oidable mo del discrepancy . Although low-dimensional, the system captures fundamen tal mec hanisms of nonlinear instability and uncertaint y growth that are characteristic of man y real-w orld dynamical systems. Consequently , demonstrat- ing distribution-to-distribution learning in this setting pro vides meaningful evidence of the framework’s p otential applicabilit y to broader classes of nonlinear dynamical forecasting problems. F ollo wing [44], the Lorenz63 equations are simulated n umerically using a fourth-order R unge–Kutta sc heme with a simulation time step of 0.01 time units, and the resulting discrete-time numerical system is treated as the underlying true dynamical system (i.e. p erfect mo del) in the exp eriments. Observ ations are obtained b y sampling the simulated tra jectories every 0.05 time units and adding independent and iden tically distributed Gaussian observ ational noise to eac h of the three state v ariables. The resulting noisy observ ations are then used to construct a probabilistic time series forecasting problem, for which predictions are pro duced using the prop osed D2D neural net w ork. The internal forecasting module of the D2D framework adopts a standard LSTM arc hitecture [18], with eac h forecast based on an input sequence consisting of ve dela y ed states. While more adv anced architectures suc h as bidirectional LSTMs [45], Gated Recurrent Unit (GRU) [46], or T ransformers [19] could b e employ ed, the purpose of this study is to v alidate the D2D framew ork itself rather than to optimise the sp ecic temp oral neural architecture. A conv entional LSTM is therefore sucient to demon- strate the feasibility and eectiveness of distribution-to- distribution learning. A t each forecast step, the MDN deco der outputs a predictiv e distribution in the form of a Gaussian mixture consisting of M = 5 comp onen ts for each of the three state v ariables. F or the kernel mean embedding of eac h state dimension, the cen tres { c j } n c j =1 are selected as n c = 50 uniformly spaced p oints b etw een the minim um and max- im um v alues of that v ariable in the dataset. The num b er of mixture comp onents M and the n um ber of cen tres n c are tunable hyperparameters: increasing M enhances the expressive capacity of the predictive distribution and allows more complex m ultimo dal structures to b e represen ted, whereas increasing n c yields a ner nite- dimensional representation of the input distribution, at the cost of increased computational exp ense and mo del complexit y . In the present exp eriments, M = 5 and n c = 50 were found to pro vide a suitable balance betw een exibilit y and stabilit y . A t the initial forecast time, the input to the D2D mo del is specied as a Gaussian distribution for eac h state v ariable. The mean is tak en as the observed v alue, and the v ariance is set according to the observ ational noise level. Here, the noise level is dened as the ratio b etw een the observ ational noise standard deviation and the empirical standard deviation of the corresponding state v ariable. F or compatibilit y with the MDN output representation, this 7 initial Gaussian distribution is represen ted internally as a mixture of M identical Gaussian comp onents. −30 −20 −10 0 10 20 30 x 0 1 2 3 4 5 6 L ead time (time units) (a) −30 −20 −10 0 10 20 30 x 0 1 2 3 4 5 6 L ead time (time units) (b) Fig. 2. An example of the evolution of the probability density function (PDF) of the x -v ariable. Panel (a) sho ws the reference distributional ev olution under the underlying true dynamical sys- tem, approximated empirically by propagating a large ensemble of initial conditions under the n umerically simulated Lorenz63 system. Panel (b) shows the corresp onding PDF evolution generated by the proposed D2D mo del trained with the iterativ e strategy . Red dots indicate the corresp onding observ ed v alues at eac h lead time. As a rst qualitative demonstration of the prop osed framew ork, Fig. 2 visualises an example of the ev olution of the initial distribution for the x -v ariable under the underlying true dynamical system in panel (a), and compares it with the corresp onding ev olution generated b y the D2D mo del in panel (b). The initial distribution at time 0 is tak en to b e Gaussian, with mean equal to the observed v alue and v ariance determined by the observ ational noise level, which is set to 0 . 01 in this example. The PDF of this initial distribution is propagated forw ard in time, as shown in Fig. 2(a), b y ensemble sim ulation using an ensemble of 10,000 initial conditions ev olv ed under the n umerically sim ulated Lorenz63 system. The resulting PDF ev olution exhibits progressiv e deforma- tion, stretching, and non-Gaussian structure induced by nonlinear dynamics. Fig. 2(b) presents the corresp onding PDF ev olution generated b y the prop osed D2D mo del. The mo del is trained using the iterative strategy with time increment ∆ t = 0 . 05 , curriculum expansion up to a maxim um lead time of 128∆ t = 6 . 4 time units, and 30,000 training samples. The D2D mo del successfully captures the nonlinear deformation of the predictiv e distribution o v er time through recursive distributional prop agation. This result demonstrates that the D2D framework is capable of learning a distribution-to-distribution evolu- tion op erator, enabling coherent propagation of predictiv e uncertain t y without explicit ensem ble sim ulation. T o pro vide a quantitativ e assessment of predictive skill, iterativ e D2D forecasts trained with dierent maximum curriculum lead times are compared against perfect mo del 0 25 50 75 100 125 150 175 200 L ead time (multiples of t) 4 3 2 1 0 L og scor e r elative to climatology (a) P erfect model D2D(16 t) D2D(32 t) D2D(64 t) D2D(128 t) 0 25 50 75 100 125 150 175 200 L ead time (multiples of t) 4 3 2 1 0 L og scor e r elative to climatology (b) P erfect model D2D(16 t) D2D(32 t) D2D(64 t) D2D(128 t) 0 25 50 75 100 125 150 175 200 L ead time (multiples of t) 4 3 2 1 0 L og scor e r elative to climatology (c) P erfect model D2D(16 t) D2D(32 t) D2D(64 t) D2D(128 t) 0 25 50 75 100 125 150 175 200 L ead time (multiples of t) 4 3 2 1 0 L og scor e r elative to climatology (d) P erfect model D2D(16 t) D2D(32 t) D2D(64 t) D2D(128 t) Fig. 3. Logarithmic score skill relativ e to climatology as a function of lead time for iterative D2D forecasts and p erfect model forecasts. Panels (a)-(d) corresp ond to observ ational noise levels of 0.01, 0.02, 0.04, and 0.08, resp ectively . The horizontal black dashed line repre- sents the zero skill climatological forecast. The red curve denotes the perfect model forecast based on a 128-member ensem ble propagated under the n umerically sim ulated Lorenz63 system and con verted to a predictiv e distribution using Gaussian kernel dressing [24]. The remaining curves correspond to iterative D2D mo dels trained with maximum curriculum lead times of 16∆ t , 32∆ t , 64∆ t , and 128∆ t . Shaded bands indicate 95% b o otstrap resampling in terv als computed on the test set. forecasts constructed from the underlying true dynam- ical system, as illustrated in Fig. 3, where eac h panel corresp onds to a dierent observ ational noise lev el. All forecast p erformance is ev aluated using the logarithmic score relative to the climatological forecast, whic h serves as the zero-skill reference sho wn by the horizontal blac k line in Fig. 3. The climatological forecast distribution is obtained by applying k ernel dressing to the full set of historical observ ations, using Gaussian k ernels centred at eac h historical observ ation and a k ernel standard deviation tuned using a large v alidation set. F or the p erfect mo del forecasts (red curves), an en- sem ble of 128 initial conditions is propagated forward under the numerically simulated Lorenz63 system, and the resulting ensemble forecast is con verted into a predictiv e distribution at each lead time using kernel dressing. Eac h k ernel is tak en to b e Gaussian, centred at an ensem ble member, with kernel standard deviation tuned separately for each lead time using a large v alidation set. The remaining curv es corresp ond to iterative D2D mo dels trained with dierent maximum curriculum lead times, corresponding to 16∆ t , 32∆ t , 64∆ t , and 128∆ t . The vertical dashed lines indicate these corresp onding maxim um curriculum lead times. All mo dels are trained on 30,000 observ ations, with hyperparameters tuned on a separate v alidation set of 30,000 observ ations, and nal ev aluation carried out on an independent test set of 30,000 observ ations. T o quan tify sampling uncertain t y in the rep orted test p erformance, bo otstrap resampling is applied 8 to the test set, and 95% in terv als are shown for eac h forecast curve. These interv als are barely visible at the plotting scale, suggesting that sampling v ariability in the rep orted test p erformance is very small. Mo dels trained with short maximum curriculum lead times, suc h as 16∆ t and 32∆ t , sho w relativ ely strong p erformance at short lead times but deteriorate rapidly once forecasts extend beyond the lead-time range co vered during training. This is consisten t with the fact that these mo dels are explicitly optimised for short term forecast p erformance and, b ecause they are trained with to o few recursiv e steps, do not access enough dynamical infor- mation to learn the underlying evolution. F urthermore, these mo dels do not alw a ys achiev e the b est p erformance ev en at their nominal target training lead times. This is particularly eviden t at low observ ational noise lev els: for example, the 16∆ t mo del is not consisten tly optimal at lead time 16∆ t , and the 128∆ t mo del even outperforms the 64∆ t mo del across all lead times. A t larger noise levels, the p erformance of the 128∆ t and 64∆ t models is also comparable to that of the 16∆ t and 32∆ t mo dels at short lead times. This suggests that capturing the underlying dynamical evolution can b ecome more imp ortant than optimising for a shorter target lead time, so longer curriculum training can impro v e forecast skill ev en at shorter lead times. A cross the dieren t noise levels sho wn in Fig. 3, the p erfect model forecast do es not uniformly outperform the D2D mo dels. A t low observ ational noise, it remains a strong b enchmark, but as the observ ational noise level increases, the 64∆ t and 128∆ t mo dels match or surpass the perfect mo del forecast o v er almost the en tire lead-time range. This is b ecause the perfect model forecast in these exp erimen ts is initialised from a simplied probability distribution rather than through a more adv anced data assimilation procedure 1 . As a result, the inuence of observ ational noise on the perfect mo del forecast becomes progressiv ely stronger as the noise lev el increases. F rom this p ersp ective, the fact that the D2D mo dels can outp erform the p erfect mo del benchmark indicates that the learned D2D dynamics appro ximate the underlying system ev olution while also capturing part of the eective correction that would otherwise b e introduced through data assimilation. Moreov er, the fact that the performance of the 128∆ t mo del conv erges to wards the climatolog- ical forecast at longer lead times also indicates that the mo del represents long-range predictive uncertaint y in a physically sensible wa y , naturally approaching the 1 In the ideal case, the relev ant ob ject would be the p erfect initial predictive distribution, although this is generally not av ailable analytically in practice. A corresp onding p erfect ensemble can in principle b e constructed by sampling states that are consistent b oth with the observ ational uncertainty and with the long-term dynamics of the system; with a nite observ ation windo w, this is more precisely a dynamically consisten t ensem ble [47]. How ever, constructing such ensembles is computationally prohibitiv e and lies beyond the scope of the present study . It should b e noted, how ever, that the D2D model is intended to approximate not only the underlying system evolution but also the predictive eect of such a dynamically consistent initial distribution. climatological limit as predictive information is lost. More broadly , these results provide indirect supp ort for the cen tral idea of the D2D framew ork: for the purp ose of skillful probabilistic forecasting, it is not necessary to quantify dieren t sources of uncertaint y separately , including initial-condition uncertain ty , parameter uncer- tain t y , and model discrepancy . Instead, the D2D mo del can accoun t for their com bined eect within a unied end- to-end probabilistic forecasting framework. −30 −20 −10 0 10 20 30 x 0 1 2 3 4 5 6 L ead time (time units) (a) −30 −20 −10 0 10 20 30 x 0 1 2 3 4 5 6 L ead time (time units) (b) Fig. 4. Evolution of the predictive PDF for the x -v ariable generated by the 32∆ t iterativ e D2D model, using the same initial condition as in Fig. 2. Panel (a) corresp onds to observ ational noise level 0 . 01 , and panel (b) corresponds to observ ational noise lev el 0 . 08 . An interesting and somewhat coun terintuitiv e obser- v ation from Fig. 3 is that, for mo dels trained with short maxim um curriculum lead times, long-range forecast p erformance improv es as the observ ational noise lev el increases; for example, this is clearly visible for the 32∆ t mo del when comparing panels (a) and (d). This can b e explained by the fact that, at low noise lev els, the short lead time target distributions tend to b e relatively narro w and often close to Gaussian, so short range iterativ e mo dels can achiev e go o d lo cal skill without b eing sucien tly exp osed to non-Gaussian or otherwise complex input-output distribution mappings. As a result, they ha v e limited opportunity during training to learn ho w to handle the ric her distributional structures that become common at longer lead times. By contrast, when the observ ational noise lev el is larger, ev en short lead time target distributions may already exhibit substantial non- Gaussianit y , including bimo dality . In that setting, short range iterative models are forced to learn more complex probabilistic transformations during training, or at least to pro duce wider output distributions, which explains their improv ed robustness at longer lead times. This in terpretation is supported by Fig. 4, which sho ws the PDF ev olution generated by the 32∆ t model for the same initial condition under noise levels 0 . 01 and 0 . 08 . Under the higher noise setting, the 32∆ t mo del generates broader 9 and more non-Gaussian predictive distributions ov er the en tire lead-time range. 0 25 50 75 100 125 150 175 200 L ead time (multiples of t) 4 3 2 1 0 1 2 3 4 L og scor e r elative to climatology (a) Dir ect D2D D2D(128 t) 0 25 50 75 100 125 150 175 200 L ead time (multiples of t) 4 3 2 1 0 1 2 3 4 L og scor e r elative to climatology (b) Dir ect D2D D2D(128 t) 0 25 50 75 100 125 150 175 200 L ead time (multiples of t) 4 3 2 1 0 1 2 3 4 L og scor e r elative to climatology (c) Dir ect D2D D2D(128 t) 0 25 50 75 100 125 150 175 200 L ead time (multiples of t) 4 3 2 1 0 1 2 3 4 L og scor e r elative to climatology (d) Dir ect D2D D2D(128 t) Fig. 5. Logarithmic score skill relative to climatology for the direct and iterativ e D2D strategies under dieren t observ ational noise levels. Panels (a)–(d) corresp ond to the same observ ational noise levels as in Fig. 3. The blue curve denotes the iterativ e D2D model trained with maximum curriculum lead time 128∆ t . The red curv e denotes the direct-forecast strategy , constructed from multiple direct D2D models trained at xed lead times 1∆ t , 2∆ t , 4∆ t , . . . , 128∆ t and composed through a hierarc hical temp oral aggregation strategy to pro duce forecasts at arbitrary lead times. T o further compare the iterative and direct strategies, Fig. 5 sho ws forecast skill under dieren t observ ational noise levels, with panels (a)–(d) corresponding to the same four noise settings as in Fig. 3. The blue curve denotes the iterativ e D2D mo del trained with maximum curriculum lead time 128∆ t , while the red curve denotes the direct-forecast strategy . F or the direct strategy , a collection of direct D2D mo dels is trained separately for xed lead times 1∆ t , 2∆ t , 4∆ t , . . . , 128∆ t . T o mimic the common op erational practice in mo dern neural weather forecasters [1], multiple xed lead time direct mo dels are com bined through a hierarchical temp oral aggregation strategy to pro duce forecasts at arbitrary lead times. When the target lead time coincides with one of these trained lead times, the corresp onding direct mo del is applied directly . Otherwise, the forecast is produced by sequen tially comp osing the a v ailable direct mo dels in a greedy manner, alwa ys using the largest admissible lead time rst; for example, a forecast at 7∆ t is obtained by applying the 4∆ t , 2∆ t , and 1∆ t mo dels in succession. Compared with the iterativ e D2D mo del, the direct D2D forecasts constructed through the hierarc hical temp oral aggregation strategy perform p o orly across all four noise lev els in Fig. 5, exhibiting large uctuations and repeated spik es in logarithmic score across lead times. This is b ecause the hierarc hical temp oral aggregation strategy is not fully consistent with the w a y the direct mo dels are trained. Each direct model is trained using a Gaussian initial input distribution, whereas the output of a direct forecast, esp ecially at longer lead times, is generally non- Gaussian. When one direct forecast is used as the input to another, the downstream model is therefore applied to distributions that lie outside the regime on which it w as trained, naturally leading to unstable and degraded forecast p erformance. F or the individually trained direct mo dels at xed lead times 1∆ t , 2∆ t , 4∆ t , . . . , 128∆ t , an adv antage ov er the iterativ e 128∆ t mo del is observed only at very short lead times. Ev en this short-range adv antage diminishes as the observ ational noise level increases, suggesting that the iterativ e mo del b enets more from information that w ould otherwise need to b e incorp orated through data assimilation, b ecause its longer recursive training allows it to exploit a richer range of dynamical information. IV. Summary and Discussion This w ork prop oses a distribution-to-distribution (D2D) probabilistic forecasting framework for dynamical systems, in whic h predictive distributions are treated as the pri- mary objects of forecasting. A key innov ation of the pro- p osed D2D framework is its distributional enco ding and deco ding structure, which allo ws existing neural forecast- ing mo dules to op erate directly on predictive distributions, thereb y enabling recursiv e uncertain ty propagation and direct optimisation under the logarithmic score. More sp ecically , the prop osed framework provides a practical route for learning the dynamical ev olution of predictiv e distributions using neural netw orks, thereby bypassing a fundamen tal limitation of traditional physics-based dy- namical models, in which probability distributions cannot in general b e evolv ed directly; it mak es probabilistic forecasting an intrinsic part of the mo del rather than something constructed externally through ensembles or p ost ho c calibration; and it oers a unied approach to uncertain t y quantication, in which dierent sources of uncertain t y need not alwa ys b e represented separately; instead, the framework can learn their com bined eective impact within a single end-to-end probabilistic mo del, with probabilistic forecast skill pro viding the dening criterion for the quality of uncertaint y quantication. Exp erimen ts on the Lorenz63 system provide a pro of-of- concept demonstration that the proposed framew ork can learn non trivial distributional ev olution under nonlinear c haotic dynamics. The iterative D2D mo del captures the deformation of predictiv e distributions ov er time and yields skillful probabilistic forecasts without explicit ensem ble sim ulation. Quantitativ e ev aluation using log- arithmic score shows that mo dels trained with longer recursiv e curriculum lead times generally achiev e more robust p erformance across a broad range of forecast lead times, whereas mo dels trained only o ver short lead times deteriorate rapidly once applied b ey ond the regime encoun tered during training. The iterative strategy also substan tially outp erforms the direct strategy when fore- casts are extended or comp osed across multiple lead times, underscoring the imp ortance of learning a dynamically consisten t distributional ev olution operator rather than a 10 collection of lead-time-specic predictors. F urthermore, it- erativ e D2D mo dels are sho wn to b e capable of competing with, and in some cases even outp erforming, a simplied p erfect mo del b enchmark, suggesting that the framew ork captures not only the underlying system evolution but also part of the predictive eect of dynamically consisten t initialisation normally asso ciated with data assimilation. Although the current implemen tation models marginal predictiv e distributions rather than the full joint state distribution, the input to the forecasting mo dule consists of a time window of embedded marginal distributions rather than an isolated marginal at a single time. As a result, the model exploits temp oral information ab out the underlying dynamical state and its dep endence structure. This is consisten t with the intuition of T ak ens-type dela y em b edding [48], in whic h a sequence of partial observ ations con tains sucien t information to reconstruct the eective system dynamics. F rom a broader p ersp ective, this is also related to part of the role of data assimilation, whose aim is to use dynamical information together with observ ations to recov er and exploit information ab out the underlying joint state distribution. Although the D2D framew ork do es not explicitly mo del or op erate on the full join t distribution, each up date still uses temp orally em b edded distributional information that reects asp ects of the underlying joint evolution. More broadly , one of the deeper reasons for the ef- fectiv eness of the D2D framework is that it represents uncertain t y directly in the form of probabilistic forecasts, thereb y enabling b oth training and ev aluation to b e carried out using the logarithmic score, whic h provides the unique principled standard for assessing probabilistic forecast skill. This may also help explain, at least in part, why neural netw orks ha v e ac hiev ed greater success in classication problems, where cross-en tropy provides a natural probabilistic ob jective, than in con tinuous-v alued forecasting and regression, where no equally univ ersal standard is as consisten tly adopted. F rom this persp ective, the D2D framework p oints tow ard a broader direction for AI-based forecasting, in whic h the direct probabilistic represen tation and quantication of uncertaint y , together with its ev aluation through logarithmic score, b ecome cen tral design principles. A c kno wledgments Hailiang Du ackno wledges supp ort from the National Natural Science F oundation of China (NSFC, Grant No. 42450196) and additional supp ort from the EPSRC- funded pro ject Virtual Po wer Plant with Articial In- telligence for Resilience and Decarb onisation (Gran t No. EP/Y005376/1) for the completion of this work. Louis Aslett was supp orted by the EPSRC research grant ”P o oling INference and COm bining Distributions Exactly: A Ba yesian approac h (PINCODE)” (EP/X028100/1), and b y the UKRI grant, ”On intelligenCE And Netw orks (OCEAN)” (EP/Y014650/1). References [1] K. Bi, L. Xie, H. Zhang, X. Chen, X. Gu, and Q. Tian, “Accurate medium-range global weather forecasting with 3d neural netw orks,” Nature, vol. 619, no. 7970, pp. 533–538, 2023. [2] R. Lam, A. Sanc hez-Gonzalez, M. Willson, P . Wirnsberger, M. F ortunato, F. Alet, S. Ra vuri, T. Ew alds, Z. Eaton-Rosen, W. Hu et al., “Learning skillful medium-range global weather forecasting,” Science, vol. 382, no. 6677, pp. 1416–1421, 2023. [3] D. K o chk o v, J. Y uv al, I. Langmore, P . Norgaard, J. Smith, G. Mo o ers, M. Klöw er, J. Lottes, S. Rasp, P . Düb en et al., “Neural general circulation mo dels for weather and climate,” Nature, vol. 632, no. 8027, pp. 1060–1066, 2024. [4] D. L. Marino, K. Amarasinghe, and M. Manic, “Building energy load forecasting using deep neural networks,” in IECON 2016-42nd ann ual conference of the IEEE industrial electronics society . IEEE, 2016, pp. 7046–7051. [5] D. Ruelle, Chaotic Evolution and Strange Attractors: The Statistical Analysis of Time Series for Deterministic Nonlinear Systems. Cam bridge, UK: Cambridge Universit y Press, 1989. [6] A. J. Ma jda and J. Harlim, Filtering Complex T urbulen t Systems. Cam bridge, UK: Cambridge Universit y Press, 2012. [7] C. E. Leith, “Theoretical skill of monte carlo forecasts,” Mon thly W eather Review, v ol. 102, no. 6, pp. 409–418, 1974. [8] Z. T oth and E. Kalnay , “Ensem ble forecasting at ncep and the breeding method,” Mon thly W eather Review, vol. 125, no. 12, pp. 3297–3319, 1997. [9] G. Evensen, “The ensemble kalman lter: Theoretical formula- tion and practical implemen tation,” Ocean Dynamics, v ol. 53, no. 4, pp. 343–367, 2003. [10] M. C. Kennedy and A. O’Hagan, “Bay esian calibration of computer models,” Journal of the Roy al Statistical Society: Series B (Statistical Methodology), vol. 63, no. 3, pp. 425–464, 2001. [11] R. Buizza, M. Milleer, and T. N. P almer, “Sto chastic represen- tation of mo del uncertainties in the ecmwf ensemble prediction system,” Quarterly Journal of the Roy al Meteorological So ciety , vol. 125, no. 560, pp. 2887–2908, 1999. [12] T. Gneiting, F. Balabdaoui, and A. E. Raftery , “Probabilistic forecasts, calibration and sharpness,” Journal of the Roy al Statistical Society Series B: Statistical Methodology , v ol. 69, no. 2, pp. 243–268, 2007. [13] Y. Gal and Z. Ghahramani, “Dropout as a bayesian approxi- mation: Represen ting mo del uncertain ty in deep learning,” in international conference on machine learning. PMLR, 2016, pp. 1050–1059. [14] B. Lakshminaray anan, A. Pritzel, and C. Blundell, “Simple and scalable predictive uncertaint y estimation using deep en- sembles,” Adv ances in Neural Information Pro cessing Systems, vol. 30, 2017. [15] D. P . Kingma and M. W elling, “Auto-encoding v ariational bay es,” arXiv preprin t arXiv:1312.6114, 2013. [16] I. Price, A. Sanchez-Gonzalez, F. Alet, T. R. Andersson, A. El- Kadi, D. Masters, T. Ewalds, J. Stott, S. Mohamed, P . Battaglia et al., “Probabilistic weather forecasting with mac hine learn- ing,” Nature, vol. 637, no. 8044, pp. 84–90, 2025. [17] I. J. Goo d, “Rational decisions,” Journal of the Ro yal Statistical Society: Series B (Methodological), vol. 14, no. 1, pp. 107–114, 1952. [18] S. Ho chreiter and J. Schmidh ub er, “Long short-term memory ,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997. [19] A. V aswani, N. Shazeer, N. P armar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. P olosukhin, “Attention is all you need,” Adv ances in Neural Information Pro cessing Systems, vol. 30, 2017. [20] L. Li, R. Carver, I. Lop ez-Gomez, F. Sha, and J. Anderson, “Seeds: Emulation of weather forecast ensembles with diusion models,” arXiv preprin t arXiv:2306.14066, 2023. [21] L. Espeholt, S. Agraw al, C. Sønderby , M. Kumar, J. Heek, C. Bromberg, C. Gazen, R. Carver, M. Andryc howicz, J. Hic key et al., “Deep learning for tw elve hour precipitation forecasts,” Nature Communications, v ol. 13, no. 1, p. 5145, 2022. [22] M. Andrycho wicz, L. Espeholt, D. Li, S. Merchant, A. Merose, F. Zyda, S. Agra w al, and N. Kalc hbrenner, “Deep learning for da y forecasts from sparse observ ations,” arXiv preprint arXiv:2306.06079, 2023. 11 [23] C. M. Bishop, “Mixture density netw orks,” Neural Computing Research Group Report:NCRG/94/004, 1994. [24] M. S. Roulston and L. A. Smith, “Combining dynamical and statistical ensembles,” T ellus A: Dynamic Meteorology and Oceanography , v ol. 55, no. 1, pp. 16–30, 2003. [25] A. Smola, A. Gretton, L. Song, and B. Schölk opf, “A hilbert space em b edding for distributions,” in International conference on algorithmic learning theory . Springer, 2007, pp. 13–31. [26] B. K. Sriperumbudur, A. Gretton, K. F ukumizu, B. Sc hölk opf, and G. R. Lanckriet, “Hilb ert space embeddings and metrics on probability measures,” The Journal of Machine Learning Research, vol. 11, pp. 1517–1561, 2010. [27] N. Aronsza jn, “Theory of repro ducing kernels,” T ransactions of the American Mathematical So ciety , vol. 68, no. 3, pp. 337–404, 1950. [28] K. Muandet, K. F ukumizu, B. Sriperumbudur, B. Schölkopf et al., “Kernel mean em bedding of distributions: A review and b eyond,” F oundations and T rends® in Machine Learning, vol. 10, no. 1-2, pp. 1–141, 2017. [29] A. Gretton, K. M. Borgw ardt, M. J. Rasc h, B. Sc hölkopf, and A. Smola, “A kernel tw o-sample test,” The Journal of Machine Learning Research, vol. 13, no. 1, pp. 723–773, 2012. [30] F.-X. Briol, A. Gessner, T. Karvonen, and M. Mahsereci, “A dictionary of closed-form k ernel mean embeddings,” arXiv preprint arXiv:2504.18830, 2025. [31] A. Radford, J. W u, R. Child, D. Luan, D. Amo dei, I. Sutskev er et al., “Language mo dels are unsupervised m ultitask learners,” OpenAI blog, v ol. 1, no. 8, p. 9, 2019. [32] T. Brown, B. Mann, N. R yder, M. Subbiah, J. D. Kaplan, P . Dhariwal, A. Neelakantan, P . Sh y am, G. Sastry , A. Askell et al., “Language models are few-shot learners,” Adv ances in Neural Information Pro cessing Systems, vol. 33, pp. 1877–1901, 2020. [33] D. Silver, J. Schritt wieser, K. Simony an, I. Antonoglou, A. Huang, A. Guez, T. Hub ert, L. Baker, M. Lai, A. Bolton et al., “Mastering the game of go without h uman knowledge,” Nature, vol. 550, no. 7676, pp. 354–359, 2017. [34] G. W. Brier et al., “V erication of forecasts expressed in terms of probability ,” Monthly W eather Review, vol. 78, no. 1, pp. 1–3, 1950. [35] J. A. Hanley and B. J. McNeil, “The meaning and use of the area under a receiv er operating c haracteristic (roc) curve. ” Radiology , vol. 143, no. 1, pp. 29–36, 1982. [36] A. P . Bradley , “The use of the area under the ro c curve in the ev aluation of mac hine learning algorithms,” P attern Recognition, vol. 30, no. 7, pp. 1145–1159, 1997. [37] J. E. Matheson and R. L. Winkler, “Scoring rules for contin uous probability distributions,” Management science, vol. 22, no. 10, pp. 1087–1096, 1976. [38] T. Gneiting and A. E. Raftery , “Strictly prop er scoring rules, prediction, and estimation,” Journal of the American Statistical Association, v ol. 102, no. 477, pp. 359–378, 2007. [39] M. S. Roulston and L. A. Smith, “Ev aluating probabilistic forecasts using information theory ,” Monthly W eather Review, vol. 130, no. 6, pp. 1653–1660, 2002. [40] J. Bröck er and L. A. Smith, “Scoring probabilistic forecasts: The importance of b eing prop er,” W eather and F orecasting, vol. 22, no. 2, pp. 382–388, 2007. [41] H. Du, “Beyond strictly proper scoring rules: The imp ortance of being lo cal,” W eather and F orecasting, v ol. 36, no. 2, pp. 457–468, 2021. [42] L. A. Smith and H. Du, “Cauch y’s functional equation and the evolution of probabilit y forecasts,” 2026. [Online]. A v ailable: https://durham- repository.worktribe.com/output/4991987 [43] Y. Bengio, J. Louradour, R. Collobert, and J. W eston, “Curricu- lum learning,” in Pro ceedings of the 26th ann ual international conference on machine learning, 2009, pp. 41–48. [44] E. N. Lorenz, “Deterministic nonperio dic ow,” Journal of Atmospheric Sciences, v ol. 20, no. 2, pp. 130–141, 1963. [45] M. Sch uster and K. K. P aliwal, “Bidirectional recurren t neural netw orks,” IEEE transactions on Signal Processing, v ol. 45, no. 11, pp. 2673–2681, 1997. [46] K. Cho, B. V an Merriënbo er, Ç. Gulçehre, D. Bahdanau, F. Bougares, H. Sch wenk, and Y. Bengio, “Learning phrase rep- resentations using rnn encoder–deco der for statistical machine translation,” in Pro ceedings of the 2014 conference on empirical methods in natural language pro cessing (EMNLP), 2014, pp. 1724–1734. [47] L. A. Smith, “Accoun tability and error in ensem ble forecasting,” in Pro c. Seminar on Predictabilit y , vol. 1, 1996, pp. 351–368. [48] F. T akens, “Detecting strange attractors in turbulence,” in Dynamical Systems and T urbulence, W arwick 1980: proceedings of a symposium held at the University of W arwick 1979/80. Springer, 2006, pp. 366–381.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment