A Wireless World Model for AI-Native 6G Networks
Integrating AI into the physical layer is a cornerstone of 6G networks. However, current data-driven approaches struggle to generalize across dynamic environments because they lack an intrinsic understanding of electromagnetic wave propagation. We in…
Authors: Ziqi Chen, Yi Ren, Yixuan Huang
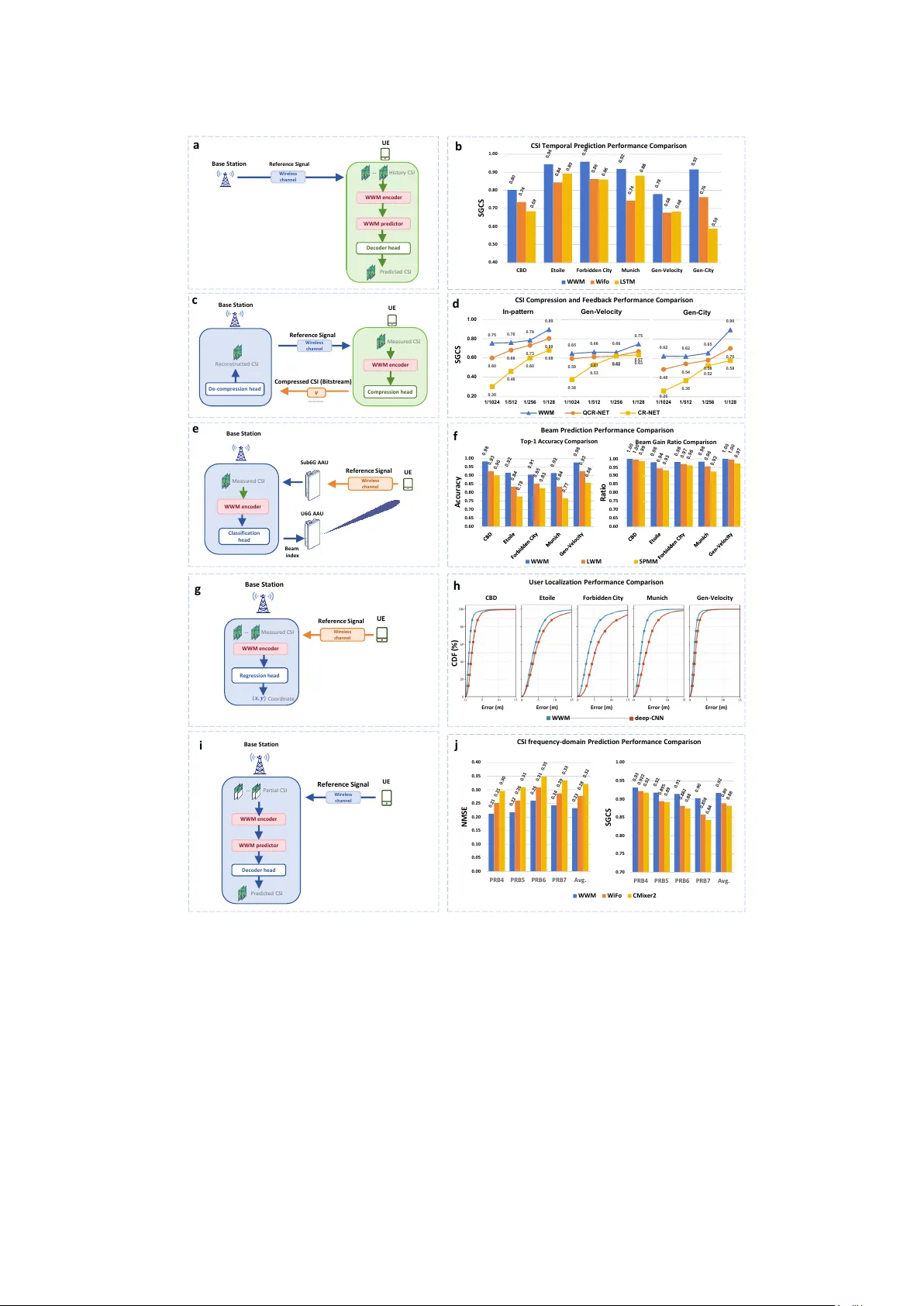
A Wireless W orld Mo del for AI-Nativ e 6G Net w orks Ziqi Chen 1* † , Yi Ren 1 † , Yixuan Huang 1 † , Qi Sun 1 † , Nan Li 1* , Y uhong Huang 1* , Chih-Lin I 1 , Yifan Li 1 , Liang Xia 1 1* China Mobile Researc h Institute, No. 32 Xuan W u Men W est Street, Beijing, 100053, China. *Corresp onding author(s). E-mail(s): chenziqiyjy@c hinamobile.com ; linan@c hinamobile.com ; h uangyuhong@chinamob ile.com ; Con tributing authors: renyiyjy@c hinamobile.com ; h uangyixuan@chinamobile.com ; sunqiyjy@chinamobile.com ; icl@c hinamobile.com ; liyifan 059052@qq.com ; xialiang@c hinamobile.com ; † These authors con tributed equally to this work. Abstract In tegrating AI into the physical lay er is a cornerstone of 6G netw orks. How ever, curren t data-driv en approac hes struggle to generalize across dynamic environ- men ts because they lac k an intrinsic understanding of electromagnetic wa ve propagation. W e in troduce the Wireless W orld Mo del (WWM), a multi-modal foundation framework predicting the spatiotemp oral evolution of wireless chan- nels by internalizing the causal relationship b et ween 3D geometry and signal dynamics. Pre-trained on a massive ray-traced m ulti-mo dal dataset, WWM o vercomes the data authen ticity gap, further v alidated under real-world measure- men t data. Using a joint-em b edding predictive architecture with a multi-modal mixture-of-exp erts T ransformer, WWM fuses c hannel state information, 3D p oin t clouds, and user tra jectories into a unified represen tation. Across the fiv e key downstream tasks supp orted by WWM, it achiev es remark able p er- formance in seen environmen ts, unseen generalization scenarios, and real-world measuremen ts, consistently outp erforming SOT A uni-mo dal foundation mo dels and task-specific models. This pav es the wa y for physics-a w are 6G intelligence that adapts to the physical world. Keyw ords: 6G, air in terface AI, wireless foundation model, joint embedding predictive architecture, m ulti-mo dal learning 1 1 In tro duction Sixth-generation (6G) wireless netw orks are envisioned as the core information infras- tructure for the AI era, necessitating a quan tum leap in p erformance and new capabilities lik e in tegrated AI and comm unication [ 1 , 2 ]. Cen tral to this evolution is the enhancement of sp ectral efficiency at the air interface—the most fundamental and historically c hallenging goal of ev ery mobile generation. The progression from 2G to 5G achiev ed this primarily b y increasing bandwidth and deploying large-scale Mutiple Input and Multiple Output (MIMO) antenna systems, guided b y Shannon’s informa- tion theory [ 3 ]. Ho wev er, this traditional scaling approac h has reac hed a b ottlenec k. F urther expanding to extremely large-massiv e MIMO systems introduces prohibitive o verhead for acquiring precise Channel State Information (CSI) and intractable com- putational complexity for preco ding [ 4 , 5 ]. F urthermore, a p ersisten t gap to the theoretical Shannon limit exists, widened b y hardw are non-idealities and complex net work interference that conv en tional signal pro cessing mo dels cannot adequately address [ 6 ]. AI presents a transformative solution, leveraging its adv anced capabilities in feature extraction and complex problem-solving to break these barriers [ 7 ]. This pro- p els the vision of an AI-native 6G air interface, where AI is fundamentally integrated in to core physical lay er functions [ 8 – 10 ]. Initial efforts to ward an AI-nativ e air inter- face relied on task-specific mo dels. How ev er, this approach is fundamen tally limited b y p o or generalization to dynamic environmen ts, and a disjointed design that creates significan t computational and management burdens at the base station (BS). In recen t y ears, foundation mo dels ha ve demonstrated superior p erformance and changed the landscap e of AI [ 11 – 14 ]. This has catalyzed a paradigm shift tow ard a more scalable wireless AI solution: the Wireless F oundation Mo del (WFM). A WFM is a large-scale mo del, pre-trained on diverse wireless data via self-sup ervision to improv e general- ization capabilit y , and designed to adapt to a wide range of do wnstream tasks with minimal fine-tuning. Early explorations into WFMs initially focused on adapting pre-trained Large Language Mo dels (LLMs) to wireless domain through fine-tuning or prompt engineering[ 15 – 21 ]. While this demonstrated the potential of large-scale AI mo del arc hitectures, the approach often yielded physically inconsistent predictions, as the mo dels lack ed an in trinsic understanding of electromagnetic wa ve propagation. This critical fla w spurred a necessary shift to ward the current generation of AI-native arc hitectures, such as WiF o [ 22 , 23 ] and WirelessGPT [ 24 ], which are pre-trained from the ground up on v ast, domain-sp ecific corp ora. Despite this progress, the field remains constrained by tw o limitations that form a ”generalization ceiling.” First is a data authen ticit y gap; most models are trained on statistical channel data that fails to capture real-world complexit y , a problem addressable by in tegrating high-fidelit y , ph ysics-based data like ray tracing [ 25 ]. Second is a mo dalit y gap, as existing solutions t ypically pro cess a single data type (e.g., CSI), neglecting complementary information from 3D environmen t, which are crucial for true environmen tal understanding. T o address these fundamental c hallenges, we prop ose the Wireless W orld Mo del (WWM), marking a shift from data-driven pattern matching to environmen t-a ware cognitiv e intelligence. Conceptually , a W orld Mo del generates internal predictive rep- resen tation of the environmen t that enables system to in ternalize physical la ws and 2 predict future states [ 26 – 28 ]. While a WFM excels at capturing statistical correlations within signal distributions, the WWM sp ecifically aims to learn the ”ph ysics of the wireless world”—the causal mapping b etw een 3D spatial geometry and electromag- netic propagation. By learning the causal mapping from environmen tal semantics to c hannel characteristics, the WWM develops a “world-cen tric” latent representation that captures how ph ysical ob jects and spatial dynamics dictate wa ve behavior. By p erceiving the environmen t as a structured physical entit y , the WWM exhibits three distinct features: environmen tal grounding, which links signal v ariations to physical ob jects; predictive consistency , ensuring channel estimations align with EM theory; and m ulti-task versatilit y , supp orting diverse downstream functions through a shared understanding of the underlying physical space and electromagnetic pattern. In this w ork, we present the first WWM implementation that leverages 3D point cloud physical information to bridge the “generalization ceiling”. The WWM intro- duces three fundamental inno v ations. First, w e construct a massive h ybrid multi-modal dataset of approximately 800 thousand samples by integrating high-fidelit y Sionna R T ray tracing simulations [ 29 ] with real-world 6G prototype BS field trials, ensuring that the mo del learns from b oth physically consistent and realistic electromagnetic en vironments. Second, the mo del adopts a Join t Em b edding Predictive Architecture (JEP A) [ 30 , 31 ], which shifts the learning ob jective from signal reconstruction to pre- diction in a seman tic feature space. This comp els the mo del to in ternalize the in trinsic causal la ws of w a ve propagation rather than merely fitting data correlations. Third, a Multi-Mo dal Mixture of Experts (MMoE) structure [ 32 ] is employ ed, enabling effi- cien t fusion of multi-modal data including c hannel signal, p oint cloud and tra jectory data within a unified T ransformer backbone. This holistic architecture enables a “one- mo del-for-all” paradigm, where a single pre-trained core can simultaneously p erform high-precision channel prediction, c hannel compression and feedbac k, beam manage- men t, and user localization through ligh tw eigh t, task-sp ecific heads. As the first model to systematically incorp orate 3D geometric priors into a wireless predictive frame- w ork, our WWM provides a crucial reference for future exploration in AI-native 6G and the developmen t of more sophisticated wireless autonomous agents. 2 Results 2.1 Wireless w orld mo del understands Electromagnetic propagation via pretraining W e introduce the WWM, a world model for wireless communications that not only reconstructs signals but also predicts the coherent spatiotemp oral ev olution of elec- tromagnetic environmen ts in a manner consistent with physical laws. By extensiv e pre-training on a massive dataset, WWM learns generalizable features that enable effectiv e adaptation to div erse do wnstream tasks, even with limited task-specific training data. Figure 1 depicts the o verall WWM framework. A hy brid large-sc ale m ulti-mo dal wireless dataset is constructed through ray tracing simulation by Sionna R T and field measurement with China Mobile 6G prototype system. By incorp orating MMoE mo del architecture within JEP A pre-training framework, WWM fuses hetero- geneous data—CSI, 3D p oin t clouds, and user tra jectories—into a unified semantic 3 O B S ER V ED M O D A LI T I ES U NI FI E D RE P RE SE N T A T I O N D O W N S T R E A M T A S K S a W i r e l e s s D a t a A b s t r a c t i on L a y e r b W i r e l e s s W or l d M od e l c D o w n st r e a m T a sk s D i s c ret i z ed S pa c e L a t e n t R epres ent a t i o n ∪ R ay - tr a c i ng S i m ul a ti o n F i el d M ea s u r emen t s Wir e le s s Wo r ld M o d e l w it h M o d a lit y - A wa re M i x t u re - of - Ex p e r t s T r a n s f or m e r ( M M oE) C S I E mb e d d i n g s P o i n t C l o u d s E mb e d d i n g s U E T r a j e c t o r y E mb e d d i n g s C h a n n e l P o in t C lo u d T r a j ec t o r y U ni f i ed W i rel es s W o rl d M o del E n a b l e d T a s k s Tr a je c t o r y C h a n n e l S ta te In f o r ma ti o n P o in t C lo u d Tr a je c t o r y S i o nna R T 6 G T e st b e d P r o t o t y p e P o in t C lo u d C h a n n e l S ta te In f o r ma ti o n L arg e - Sc ale M u lt imo d al D at as e t U ni f o r m phy s i ca l - l a y e r r e pr e s e nt a t i o n a cr o s s s i mul a t i o n a nd me a s ur e me nt H - FNN PC - FNN P - FNN M u lt i - S t r a t egi es M a sk i n g CS I Te m por a l P re d ic t io n B e am P re d ic t io n CS I Com pr e s s i on & Fe e dba c k U se r L o c al i z a t i o n . . . C o n v 3 D E m b e d d e r P o in t - B E RT E m b e d d e r M L P E m b e d d e r . . . + c o nc a t ena t e + c o nc a t ena t e . . . Sh a r e d Se lf - A tte n ti o n M . . . . . . M M M M M M S tr a te g y ① S tr a te g y ② S tr a te g y ③ . . . . . . . . . M M M M . . . . . . . . . . . . CS I Fr e que nc y - Dom a i n P re d ic t io n Fig. 1 The w orkflow of WWM. a, Multi-mo dal data source for pre-training and ev aluation. The ray tracing sim ulation is p erformed on Sionna R T, which consisted of channel State Information (CSI), 3D Poin t Clouds and User Equipment (UE) T rajectory . The Field Measurement is collected outdoor from China Mobile 6G protot yp e system. b, Pre-training model arc hitecture and pre-training tasks. The WWM is a pre-trained on JEP A, in volving an encoder-predictor architecture. Both encoder and predictor are Multi-mo dal Mixture of Exp ert T ransformer mo del, trained on 3 self-sup ervised mask tasks. c, Downstream tasks for v alidation based on WWM embedding. The representational capabilities of WWM is verified on 4 downstream tasks with simulated data, and its real-world generalization ability is ev aluated on CSI frequency-domain prediction based field measurement. represen tation. This unified approach enables a single pre-trained mo del to supp ort m ultiple netw ork optimization downstream tasks, including CSI prediction, channel compression and feedbac k, beam prediction, and user localization, without requiring separate, task-sp ecific Algorithms or AI mo dels. T o enable wireless w orld mo deling, we constructed a large-scale h ybrid multi- mo dal wireless dataset (Figure 2 ). The dataset integrates time–frequency–space CSI, scenario-lev el 3D p oin t clouds and sync hronized UE tra jectories collected across five represen tative urban environmen ts: Munich, Paris, Beijing CBD, the F orbidden City and W all Street. Using ph ysics-based ra y tracing [ 29 ], w e generated more than 700,000 c hannel samples under m ultiple user mobility regimes (5, 30 and 60 km/h), provi ding div erse spatio–temp oral wireless observ ations (Fig. 2 a). T o assess real-world applicabilit y , we further collected uplink CSI measurements from a 6G prototype system deploy ed at the China Mobile International Information P ort in Beijing (Fig. 2 b). This real-w orld dataset in tro duces hardw are impairments and en vironmental noise, enabling ev aluation of the model’s ability to transfer from sim ula- tion to practical wireless environmen ts. Detailed simulation parameters, measurement configurations and dataset comp osition are provided in Extended Data T ables 1–4. 4 Fig. 2 Large-scale multi-modal wireless dataset spanning diverse simulated and real- w orld environmen ts. Across these environmen ts, we collect multi-modal data including scenario 3D p oin t clouds, user tra jectories and time-synchronized CSI for each sample. a, Representativ e real- world photographs of the selected urban environmen ts used for ra y tracing sim ulation. F rom top to bottom: Place de l’ ´ Etoile (P aris), F orbidden Cit y (Beijing), Munich urban district (Germany), central business district (Beijing), and W all Street (New Y ork). b, Corresp onding 3D scenario mo d- els constructed from geographic data and ground signal cov erage maps generated in Sionna R T. c, Extracted 3D point clouds of corresp onding 3D scenario mo dels. d, Photograph of the real-world outdoor measurement en vironment used for c hannel data acquisition, with the base station (BS) location indicated. e, Satellite view of the measurement site, where the yello w cross marks the BS position and the green trap ezoid indicates the UE tra jectory . f, 3D p oin t clouds reconstructed from the measurement environmen t. g, BS hardware of the 6G prototype system used for real-world mea- surements. h, UE device used for outdo or channel data acquisition. As illustrated in Fig. 3 a, WWM adopts a JEP A pre-training framew ork, whic h fun- damen tally differs from traditional masked auto encoders [ 33 ]. Instead of reconstructing ra w data, WWM predicts wireless channel semantic representations in a latent space, forcing the model to understand and forecast electromagnetic ev olution abstractly lik e a world mo del. Before en tering the T ransformer backbone, eac h mo dalit y is pro cessed b y a dedicated embedder tailored to its physical characteristics. Central to this archi- tecture is a MMoE T ransformer (Fig. 3 b). This design enables the seamless fusion of heterogeneous mo dalities—CSI, 3D p oint clouds, and user tra jectories—into a unified laten t space, allowing a single pre-trained bac kb one to supp ort div erse downstream tasks. The intelligence of WWM emerges from its self-sup ervised pre-training strategy . W e used three complementary masking tasks (Fig. 3 c) during pre-training. First, fine- grained CSI masking encourages the reconstruction of lo cal multipath comp onen ts. Second, coarse CSI masking forces the model to infer global channel structures from en vironmental context. Third, tra jectory masking requires the model to deduce user motion solely from c hannel evolution. By alternating b etw een these tasks, WWM learns the mapping b et ween electromagnetic signal evolution and ph ysical user motion. 5 The effectiv eness of this pre-training is evident in the mo del’s abilit y to recon- struct missing information from context. W e pre-trained WWM based on sim ulation data across 4 cities (Munich, Paris, Beijing CBD, Beijing F orbidden City) as detailed in Extended Data T able 3, while the simulated data of fifth cit y (W all street) and of additional velocities in CBD is reserved for generalization testing, as detailed in Extended Data T able 4.) Fig. 4 a visualizes the reconstruction of a mask ed CSI sam- ple of 16 timesteps. Even when significant time-frequency blo c ks are mask ed, WWM accurately restores the channel structure by reasoning from the unmasked CSI blo c ks, 3D geometry and tra jectory cues. W e utilized t-distributed sto c hastic neigh b our em b edding (t-SNE) [ 34 ] to visualize the WWM enco der’s final-lay er CSI embeddings with different data lab el. The outcome, as illustrated in Fig. 4 b, rev ealed that the em b eddings pro duced by WWM organizes samples into meaningful clusters based on unique c haracteristics, demonstrating that it has successfully internalized a structured represen tation of the wireless ph ysical environmen t without explicit sup ervision. 2.2 WWM augmen ts RAN downstream tasks W e ev aluated the p erformance of the pre-trained WWM across four do wnstream tasks, b enc hmarking it against SOT A task-sp ecific models and representativ e WFMs, sp ecif- ically L WM [ 35 ] and WiF o [ 22 ]. T o ensure a rigorous comparison, WFMs were assessed using either official chec kp oin ts or c heckpoints pre-trained on the same m ulti-mo dal dataset (extended data table 3) if training co de is provided. W e kept backbone frozen for all foundation models, where task-sp ecific knowledge was captured by training ligh tw eight output heads. In contrast, task-sp ecific SOT A baselines were trained full- shot from scratc h using the full lab eled dataset for eac h respective task. As detailed in the follo wing sections, WWM consisten tly ac hieved SOT A performance across all four tasks. This demonstrates the sup erior adaptation and transferability of WWM’s laten t represen tations. F urthermore, ablation experiments rev eal that rev erting WWM to a single-mo dal configuration—by pre-training without 3D p oin t clouds and user tra jectory priors—observ es a obvious p erformance degradation. This underscores the necessit y of multi-modal environmen tal grounding for robust wireless representation. Implemen tation details and sp ecific task analyses are pro vided in the respective results sections as follow ed and further detailed in Metho ds. CSI temp oral prediction : T o assess whether WWM captures channel evolution b ey ond statistical correlation, w e ev aluated its p erformance on CSI temp oral predic- tion against SOT A baselines WiF o [ 22 ] and LSTM [ 36 ], As shown in Fig. 5 a. WWM enco der and predictor is configured to predict future CSI based on 14 history CSI timesteps in latent space, while a deco der is trained to recov er CSI from latent space represen tation. F or in-pattern urban environmen ts (CBD, Etoile, F orbidden City and Munic h), WWM ac hieves consistently high Squared Generalized Cosine Similarit y (SGCS) scores of 0.80–0.96, outp erforming b est baselines by an av erage of 0.12 (Fig. 5 b). Crucially , WWM breaks the generalization ceiling: in the completely unseen “W all Street” en vironment, labeled as Gen-Cit y , it sustains an SGCS of 0.92—a relative gain of 56% ov er LSTM (0.59) and 21% ov er WiF o (0.76). These results suggest that with the aid of m ulti-mo dal data, forecasting in the latent space, rather than directly in the ra w channel domain, leads to more robust c hannel predictions under seen and unseen 6 Sha re d Mu l t i - h ead S e lf - Att e n t io n UE P o s i t i o n x N Conv3D E m b ed d er H - FFN PC - FFN P - FFN P oint - net E m b ed d er MLP E m b ed d er Sw itch M o d al i t y E x p e r t s C h an n el Matri x P o i n t Clo u d Pr e d i c to r \ Remo v e maske d to ke n s C o n c a ten a te mask to ke n s . . . M a sk s P os i ti on s . . . En c o d e r . . . . . . . . . . . \ Remo v e mask to ke n s . . Lo s s Embedd e d T ok e n s EM A En c o d e r C h a n n e l M a tr i x Po i n t C l o u d s UE T r a j e c to r i e s EMA - b a sed on l i n e u p d a ti n g W i r e l e s s W o r l d M o d e l ① Fine - g r ained C SI m as k ing ② Coars e CSI m as k ing ③ Tr aj ec t ory m as k ing Ch ann e l M at rix P o i nt Cl o uds UE Traje ct o ries JEPA Style P re - training Pro c ess M u lti - M odal Mixt u re of Exp ert s ( M M oE) P re - training Maski n g Strategies a b c + + + + + + Fig. 3 The mo del and pre-training pro cess. a, WWM employs a Joint Embedding Predictive Architecture (JEP A) to infer masked m ulti-mo dal features in latent space. An online encoder pro cesses visible tokens while a predictor estimates masked embeddings, sup ervised by an Exp onen tial Mo ving Average (EMA) based momentum enco der to ensure represen tation stabilit y . b, Multi-mo dal Mixture of Exp erts (MMoE). Heterogeneous inputs—CSI, 3D p oin t clouds, and tra jectories—are tokenized via domain-specific embedders (Conv3D, Poin t-net, and MLP). Within each T ransformer blo c k, shared self-attention p erforms global cross-mo dal reasoning, follow ed by mo dalit y-sp ecific exp erts (H-FFN, PC-FFN, P-FFN) to preserve ph ysical inductive biases. c, Pre-training masking strategies. Three complementary strategies supervise the model: Fine-grained and coarse CSI masking to extract m ulti- scale spatio-temp oral propagation features. T ra jectory masking to capture kinematic dynamics and their interaction with the electromagnetic environmen t. propagation environmen ts. A detailed quantitativ e comparison across mo dels and test scenarios is provided in Extended Data T able 5. CSI compression and feedbac k : In massive MIMO systems, minimizing feed- bac k ov erhead while ensuring high CSI acquisition accuracy is critical for accurate preco ding and thus wireless transmission capacit y . Building on the output of WWM, a pair of highly efficient deep learning-based compressor and de-compressor net works can b e trained to significan tly reduce the feedback payload while maintaining CSI fidelity , as demonstrated in Fig. 5 c. Exp erimental results across v arious compression ratios (from 1/1024 to 1/128) demonstrate that the WWM-based compressor consistently ac hieves superior p erformance compared with baseline metho ds suc h as QCR-NET [ 37 ] and CR-NET [ 38 ], as shown in Fig. 5 d. F or in-pattern urban en vironments (CBD, 7 ( a ) O r i g i n a l ( b) M a s k e d ( c ) R e c o n s t r u c t e d a b E m be ddi ng D i s t r i but i o ns ( b) Cit ies ( c) L O S/NL O S ( a ) T o k en L ev el ( d) B a s e St a t io ns ( e) No is e L ev els M a s k s a n d R e con s t r u ct i on H e a t m a p s L O S N L O S CB D E t o ile F o rb i d d e n C i t y M u n i c h B S - 0 B S - 1 N o rma l 0d B E a c h C o l o r R e p re s e n t s a S a mp l e Fig. 4 Pre-training results. a, The visualizations of CSI reconstruction. 1st graph: Original 16 timestep CSI sample. 2nd graph: Masked CSI sample used as input to the WWM mo dels for fine- grained masking strategy . 3rd graph: Reconstructed CSI sample using masked input. b, The t-SNE [ 34 ] maps show the enco der’s final-la yer em b eddings across fiv e sampling sc hemes—randomly sampled token-lev el em b eddings, samples group ed b y cit y , samples grouped by LOS/NLOS conditions, samples grouped by BS and samples group ed by noise levels. Etoile, F orbidden City , and Munich), WWM maintains strong reconstruction fidelity with SGCS scores ranging from 0.65 to 0.95 across v arying compression ratios, out- p erforming the most comp etitiv e baseline (QCR-NET) by an av erage absolute SGCS gain of 0.13. Crucially , WWM exhibits robust generalization capabilities under shift- ing conditions: in the completely unseen cit y generalization scenario, it ac hieves an a verage relative gain of 21% o ver QCR-NET(0.58) and 62% ov er CR-NET(0.43) across all ev aluated compression ratios. Notably , even at the extreme compression ratio of 1/1024, it secures an SGCS of 0.62 in unseen cities compared to QCR-NET’s 0.48. Similarly , for velocity generalization, WWM consistently surpasses QCR-NET b y an a verage relative gain of 9%. These outcomes highlight the effectiveness of the WWM arc hitecture not only in preserving CSI with high accuracy but also in generalizing robustly to unseen propagation environmen ts and mobility conditions, underscoring its practical viability for real-world massive MIMO deploymen ts. A detailed quantita- tiv e comparison across compression rates and test scenarios is pro vided in Extended Data T able 6. Beam prediction : Sub-6 GHz signals propagate through the same physical envi- ronmen t as upp er-6G (U6G) signals and therefore their dominant propagation paths are shaped b y the same geometry . Lev eraging this prop ert y , the BS can use Sub-6 GHz CSI to predict the most suitable U6G b eam direction, thereb y av oiding an exhaustive 8 c d B ase S t at i on UE R e fer e nce S i g nal v C om pr e s s e d C S I (B i t s t r e am ) 1 0 1 1 0 0 1 0 1 1 0 1 … C o mp r e ss i o n he a d De - c o mp r e ss i o n he a d R ec o n s t r u c t ed CS I W i r e l e ss ch a n n e l UE W W M e nc o de r R e f e r e nc e S i g na l Hi s t o r y CS I B ase S t at i on … a b f g h UE Base S tati o n R e g r e ss i o n he a d ( 𝒙 , 𝒚 ) i j UE R e f e r e n c e S i g n al B ase S t at i on W W M pr e di c to r D e c o de r he a d W i r e l e ss ch a n n e l W W M e nc o de r Pr ed i c t ed CS I W W M e nc o de r M ea s u r ed CS I … Co o r d i n a t e W i r e l e ss ch a n n e l W W M e nc o de r Pa r t i a l CS I … W W M pr e di c to r D e c o de r he a d Pr ed i c t ed CS I e U6 G AA U S ub 6 G AA U C l a ss i f i c a ti o n he a d B e a m i nd e x W W M e nc o de r W i r e l e ss ch a n n e l R e fer e nce S i g nal UE B ase S t at i on W i r e l e ss ch a n n e l R e fer e nce S i g nal 0 . 0 0 0 . 0 5 0 . 1 0 0 . 1 5 0 . 2 0 0 . 2 5 0 . 3 0 0 . 3 5 0 . 4 0 P R B 4 P R B 5 P R B 6 P R B 7 A v g . N M S E W W M W i F o C M i x e r 2 0 . 7 0 0 . 7 5 0 . 8 0 0 . 8 5 0 . 9 0 0 . 9 5 1 . 0 0 P R B 4 P R B 5 P R B 6 P R B 7 A v g . S GCS 0 . 4 0 0 . 5 0 0 . 6 0 0 . 7 0 0 . 8 0 0 . 9 0 1 . 0 0 C B D E t o i l e F o r bi dd e n C i ty M un i c h Ge n-Ve l o c i ty Ge n-C i ty S GCS C S I Tempo r al Pr e d i c ti o n Pe r f o r man c e C o mp ar i so n W W M W i fo L S TM 0 . 6 0 0 . 6 5 0 . 7 0 0 . 7 5 0 . 8 0 0 . 8 5 0 . 9 0 0 . 9 5 1 . 0 0 A c c u r ac y To p - 1 A ccur acy C om pari s on W W M L W M S P M M 0 . 6 0 0 . 6 5 0 . 7 0 0 . 7 5 0 . 8 0 0 . 8 5 0 . 9 0 0 . 9 5 1 . 0 0 R atio B e am G ai n Rati o C om pari s on 0 . 7 5 0 . 7 6 0 . 7 8 0 . 8 9 0 . 6 0 0 . 6 8 0 . 7 3 0 . 8 0 0 . 3 0 0 . 4 6 0 . 6 0 0 . 6 8 0 .2 0 0 .4 0 0 .6 0 0 .8 0 1 .0 0 1 /1 0 2 4 1 /5 1 2 1 /2 5 6 1 /1 2 8 S GCS In - pat t e rn WWM QC R- NE T C R - N E T 0 . 6 2 0 . 6 2 0 . 6 5 0 . 9 0 0 . 4 8 0 . 5 4 0 . 5 8 0 . 7 0 0 . 2 6 0 . 3 6 0 . 5 2 0 . 5 8 1 /1 0 2 4 1 /5 1 2 1 /2 5 6 1 /1 2 8 Ge n - C i t y 0 . 6 5 0 . 6 6 0 . 6 6 0 . 7 5 0 . 5 9 0 . 6 1 0 . 6 2 0 . 6 7 0 . 3 8 0 . 5 3 0 . 6 2 0 . 6 3 1 /1 0 2 4 1 /5 1 2 1 /2 5 6 1 /1 2 8 Ge n - V e l ocity C B D E t oi l e For bi dde n C i t y M uni ch G e n - V e l oci t y E r r o r (m ) E r r o r ( m) E r r o r ( m) E r r o r ( m) E r r o r ( m) CDF (% ) C S I C o mp r e ssi o n an d F e e d b ac k Pe r f o r man c e C o mp ar i so n Beam P r e d i c ti o n Pe r f o r man c e C o mp ar i so n Use r L o c al i zati o n Pe r f o r man c e C o mp ar i so n C S I f r e q u e n c y - d o mai n Pr e d i c ti o n Pe r f o r man c e C o mp ar i so n WWM de e p - C NN M ea s u r ed CS I M ea s u r ed CS I Fig. 5 Downstream task and results comparison a, The CSI temp oral prediction task details. b, CSI temp oral prediction p erformance comparison with SOT A WFM Wifo and SOT A task-specific mo del LSTM. c, CSI compression and feedback task details. d, CSI compression and feedback p erformance comparison with SOT A task-sp ecific mo dels QCR-NET and CR-NET across v arious compression rate. e, Beam prediction task details. f, Beam prediction across frequency bands p erformance comparison with SOT A WFM L WM and SOT A task-sp ecific mo del SPMM. g, User lo calization task details. h, User lo calization p erformance comparison with SOT A task-sp ecific model deep-CNN. i, CSI frequency-domain prediction in real-world measurement task details. j, CSI frequency-domain prediction p erformance comparison with SOT A WFM Wifo and SOT A task- specific mo del C-Mixer. 9 pilot-based beam search and reducing b oth air-interface ov erhead and energy consump- tion (Fig. 5 e). W e ev aluate b eam prediction using top-1 classification accuracy and b eam gain ratio, where b eam gain ratio is the c hannel gain achiev ed b y predicted b eam divided by that of theoretical b est b eam. W e compare WWM against t wo baselines: (i) L WM [ 35 ], a SOT A uni-modal WFM and (ii) SPMM [ 39 ], a SOT A task-sp ecific. As sho wn in Fig. 5 f, WWM ac hieves an av erae T op-1 accuracy of 94.0%—a relative increase of 7.3% o ver L WM (87.6%) and 13.6% o ver SPMM (82.6%), demonstrating stronger feature extraction capability . It also demonstrates a very strong b eam gain ratio (99%), suggesting the predicted beam can alw ays achiev e near optimal c hannel gain. A detailed quantitativ e comparison across test scenarios is provided in Extended Data T able 7. User localization : Lev eraging its multi-modal understanding of the en vironment, WWM enables high-precision user lo calization b y treating wireless CSI as a distinctiv e “fingerprin t” (Fig. 5 g). W e quantify lo calization p erformance using the cum ulative distribution of 2D absolute error in meters, as sho wn in Fig. 5 h. WWM achiev ed an a verage lo calization error of 2.2 meters, compared with a conv en tional CNN-based regression baseline model whic h scored at 4.1 meters, WWM sho ws a reduction of 46% in terms of a verage localization error across all tested scenarios, highligh ting its ability to extract p osition-relev ant features directly from raw CSI and 3D p oin t clouds. A detailed quan titative comparison across test scenarios is pro vided in Extended Data T able 8. Ablation Study: T o quantify the contribution of m ulti-mo dal fusion to the WWM, we conducted ablation exp eriment in which the mo del was pre-trained using only CSI data, with 3D point cloud and user tra jectory modalities masked. This uni-mo dal v ariant preserves the same JEP A pre-training scheme and mo del architec- ture (despite removing 2 un-used mo dalit y-sp ecific exp ert FFNs), differing only in the absence of auxiliary modalities. When ev aluated on the CSI temporal prediction task, the uni-mo dal mo del exhibited consistently low er prediction SGCS (a decrease of 6.0% on av erage across all scenarios, from 0.886 to 0.833). These results indicate that geometric context and motion cues provide essential complementary information that cannot b e recov ered from CSI alone. Detailed quantitativ e comparisons b et w een the uni-mo dal and m ulti-mo dal v ariants are provided in the Extended Data T able 9. T o v alidate the deploymen t feasibility of WWM in RAN hardware, w e quan tified the end-to-end inference latency of WWM. F or the frozen WWM backbone (including enco der and predictor) paired with decoder heads, the av erage single-sample end-to- end inference latency is 8.5 ms on an NVIDIA R TX 4090 24GB GPU under mixed- precision bfloat16 inference. 2.3 WWM’s generalization capabilit y in Real-w orld measuremen t In time-division duplex (TDD) systems, uplink and do wnlink channels are recipro cal within the coherence time, allowing BS preco ding and multi-user co ordination to rely on uplink channel observ ations. Sounding reference signals (SRS) provide uplink CSI at the BS; inferring unmeasured frequency resources from partial SRS observ ations reduces measurement ov erhead while maintaining channel a wareness for preco ding, 10 sc heduling and link adaptation. Beyond its direct system-lev el relev ance, predicting CSI in frequency-domain serves as a critical test of mo del transferability from large- scale simulated CSI pre-training to real-world measurements. Sp ecifically , WWM is first pre-trained on simulated CSI data (Extended Data T able 3), and then fine-tuned using a comparativ ely small real-world measured CSI dataset collected from the 6G protot yp e system. Giv en CSI measured on four SRS Ph ysical Resource Blo c ks (PRBs) in frequency domain, the mo del predicts the CSI on adjacent four PRBs within the same time windo w (Fig. 5 i). As illustrated in Fig. 6 , the model’s CSI frequency-domain prediction outputs are visualized, showing strong agreement with the ground truth across real, imaginary , magnitude, and phase representations. Fig. 6 Visualization of CSI frequency-domain prediction based on SRS measuremen t. Comparison b et ween ground-truth and predicted channel tensors across real, imaginary , magnitude, and phase components for a representative sample. The horizontal axis corresp onds to the joint UE antenna and subband dimension, and the vertical axis corresp onds to base-station antennas. a, b, Ground-truth real and imaginary parts of the c hannel tensor. c, d, Corresponding predicted real and imaginary parts pro duced by the mo del. e, f, Squared error maps for the real and imaginary components, resp ectively , showing low reconstruction error across most spatial–frequency elements. g, h, Ground-truth channel magnitudes and phase. i, j, Corresponding predicted channel magnitudes and phase. k, l, Magnitude and Phase error map, indicating small deviations concentrated in limited regions, confirming accurate reconstruction of signal magnitudes and phase. Despite the substan tial gap b et ween simulated and measured c hannel—arising from hardw are impairments, measurement noise, and mismatched feature statistics—WWM rapidly adapts to real environmen ts and outperforms the baseline WFM metho d WiF o[ 22 ] and task-sp ecific mo del C-Mixer [ 40 ] (Extended Data T able 10). As shown 11 in Fig. 5 j, it achiev es improv ements of 15.9% and 27.6% in NMSE, and 3.1% and 4.0% in SGCS, resp ectiv ely . These results indicate that the mo del learns transferable represen tations of wireless dynamics that extend b ey ond the sp ecific characteristics of ray tracing simulations, and that limited real measuremen ts (13.2% of simulated pre-training data volume) are sufficient to sp ecialize the mo del to real-world systems. This observ ation suggests a practical path wa y for deploying foundation mo dels in future 6G net works, where large-scale s im ulation can b e lev eraged for pre-training, and ligh tw eight fine-tuning on sparse real data enables fast adaptation to new environmen ts and system configurations. 3 Discussion Our work establishes the WWM as a key step to ward transitioning wireless AI from fragmen ted, task-sp ecific “exp ert mo dels” to a unified and scalable foundation mo del. W e show that the limitations of existing sp ecialized models—including limited robust- ness, narro w cognitive scop e due to single-mo dalit y inputs—can b e ov ercome b y learning a univ ersal representation of the wireless en vironment. Our primary con tribu- tion is a multi-modal world mo del tailored to AI-Native 6G Netw ork integrated with a MMoE mo del arc hitecture. This arc hitecture enables fusion of heterogeneous data sources—CSI, 3D p oin t clouds, and user tra jectories—into a coheren t latent space. In addition, we introduce a large, high-fidelity hybrid dataset of more than 700,000 sam- ples that bridges ray tracing simulations and real-world 6G prototype measurements, setting a new b enc hmark for data diversit y and realism. WWM demonstrates strong p erformance across tasks, whic h we attribute to large- scale pre-training on div erse scenarios. This pre-training enables WWM to capture complex, non-linear dependencies in the channel that smaller, capacity-limited models fail to resolv e, consistent with empirical scaling laws for large mo dels. F urthermore, the multi-modal pre-training paradigm of the WWM transcends the limitations of con ven tional uni-mo dal mo dels by establishing a coherent physical mapping b et ween en vironmental geometry and electromagnetic propagation. By integrating 3D p oin t clouds and user tra jectories during self-sup ervised mask ed mo deling, the WWM in ter- nalizes a “physical prior” that characterizes ho w spatial dynamics dictate channel ev olution. Our ablation analysis highlights the criticality of this multi-modal integra- tion: for channel prediction tasks, the exclusion of geometric and mobility priors leads to a sharp degradation in prediction accuracy . The WWM arc hitecture represen ts a paradigm shift from the con ven tional “siloed” AI framework, where discrete, task-sp ecific mo dels are optimized for individual func- tions such as CSI prediction, beam management, and lo calization. By unifying these heterogeneous tasks within a single representational backbone, the WWM ac hieves remark able cross-site generalization. While the initial pre-training of such a founda- tion mo del in volv es computational ov erhead, our empirical results confirm this barrier is lo w: full pre-training can be completed on a single consumer-grade GPU in 87 hours, with the cost further amortized across the v ast net work of sites and diverse downstream tasks. This achiev es a long term computational equilibrium: the total lifecycle exp en- diture (pre-training plus fine-tuning) for a centralized WWM b ecomes significantly 12 more efficien t than the cumulativ e burden of training, deploying, and maintaining a large n um b er of fragmented task-sp ecific models across a massive RAN deplo yment. By consolidating the op erational management from thousands of site-sp ecific entities in to a single “world-a w are” engine, the WWM significantly mitigates the complex- it y of AI-native 6G netw orks, pro viding a scalable and maintainable tra jectory for automated netw ork evolution. Despite these adv ances, challenges remain. First, the current WWM relies on high-fidelit y 3D p oin t clouds, which may not b e av ailable in real-time for real deplo y- men ts. F uture w ork ma y explore inferring geometry directly from sparse channel measuremen ts. Second, while we v alidated the mo del on a 6G prototype system, scal- ing to massive multi-user interference scenarios requires further in v estigation. Third, the computational cost and inference latency can be further reduced through mo del ligh t-weigh ting technologies, including kno wledge distillation, mo del pruning, sparse atten tion mechanism, and mixed-precision computing. Lo oking forw ard, WWM estab- lishes the groundwork for autonomous wireless netw orks. By equipping netw orks with a predictive “world model”, w e mo ve closer to the ultimate vision of 6G: a self-evolving, ph ysics-aw are infrastructure that optimizes itself in harmony with the physical realit y it serves. 4 Metho ds 4.1 Large-scale m ulti-mo dal dataset construction T o establish a comprehensiv e and realistic data foundation for the wwm, we con- structed a large-scale multi-modal dataset integrating urban geometric information, wireless channel state information (CSI), and user tra jectories, alongside a comple- men tary real-world dataset to v alidate generalization under empirical conditions. Five represen tative urban en vironments w ere selected to capture diverse cit y structure: the F orbidden City (Beijing), the central business district (Beijing), Place de l’ ´ Etoile (P aris), an urban district of Munic h and W all Street (New Y ork). Ra w geographic data w ere obtained from Op enStreetMap, which pro vides building fo otprin ts, road lay outs and asso ciated metadata at city scale [ 41 ]. These map data were conv erted into three- dimensional urban scenes through a preprocessing pip eline in which building footprints w ere extruded using av ailable height information or standardized urban assumptions when height data were una v ailable. The resulting geometries were imp orted into Blender to refine scene structure and assign electromagnetic surface materials. Since Op enStreetMap-deriv ed meshes may contain non-manifold edges, self-in tersections and op en surfaces, all scenario elemen ts were further pro cessed using Mitsuba [ 42 ] to generate closed manifold triangular meshes. This pro cedure resolves non-manifold geometry , unifies surface normals and remov es degenerate triangles, ensuring geomet- ric consistency for ray-based electromagnetic sim ulation. The sanitized scenes were exp orted in a ra y-tracing-compatible format that serves as a unified geometric bac kend for b oth wireless c hannel simulation and environmen t p oin t-cloud generation. Wireless c hannels were generated using the ph ysics-based ray tracing framew ork pro vided by Sionna [ 29 ]. F or eac h scenario, m ultiple base-station placemen ts were sim- ulated, with CSI computed along con tinuous UE tra jectories spanning several city 13 blo c ks. The UE tra jectories follow straight-line paths at constant sp eeds typical of normal pedestrians and v ehicles. At regularly sampled time instan ts along eac h tra- jectory , frequency-selective MIMO channels were computed based on line-of-sight and sp ecular reflection propagation paths determined by the urban geometry and material prop erties. Eac h channel realization is represented as a complex-v alued tensor in the form C N UE × N r × N t × T × F , where N UE denotes the num b er of UE samples, N r and N t are the num b ers of receive and transmit an tenna ports, T is the num b er of timesteps p er sample and F is the n umber of sub carriers. The an tenna dimensions N t and N r are determined by the an tenna arra y size and p olarization configuration at the base station and UE. Simulation parameters and their corresp ondence to these v ariables are summarized in Extended Data T able 1. T o facilitate storage and mo del training, the complex CSI tensors were transformed in to a real-v alued representation b y separating real and imaginary comp onen ts and grouping sub carriers into non-ov erlapping subbands. The resulting representation has the form R N UE × 2 × T × N t × N ′ r , where the factor of tw o corresponds to real and imaginary comp onen ts and N ′ r = N r × N sb , with N sb denoting the num b er of subbands obtained b y aggregating consecutive 12 sub carriers. This represen tation preserves frequency selectivit y at the subband level while reducing the dimensionality of the channel tensor. In parallel with channel simulation, explicit geometric represen tations of the ph ysical en vironment were constructed as 3D p oint clouds. Using the same scene descriptions employ ed for ray tracing, p oin ts were sampled from the surfaces of all triangular meshes, pro ducing global-view p oin t clouds represented as R N PC × 3 that enco de the static geometry of each urban environmen t, where N PC denotes the n umber of p oin t clouds in the environmen t. All mo dalities—including CSI, 3D p oin t clouds and User tra jectories—are expressed in a unified global co ordinate system and temporally sync hronized. The final pre-training dataset contains 24 simulated subsets spanning four urban environmen ts (F orbidden City , Beijing CBD, Munich and Place de l’ ´ Etoile), m ultiple base-station deplo yments and UE sp eeds of 5, 30 and 60 km/h. T o ev aluate generalization, the W all Street datasets (5, 30 and 60 km/h) w ere excluded from pre-training and used exclusiv ely for scenario-level testing. In addition, Beijing CBD datasets collected at previously unseen sp eeds of 40 and 70 km/h were reserved for sp eed-level generaliza- tion ev aluation. Detailed dataset comp osition and splits are summarized in Extended Data T ables 3 and 4. T o ev aluate mo del p erformance under empirical wireless conditions, we collected a real-w orld wireless dataset con taining uplink CSI measuremen ts deriv ed from SRS cap- tured using a 6G protot yp e system dev elop ed b y the China Mobile Researc h Institute. The protot yp e platform in tegrates adv anced transmission tec hnologies and supp orts high-fidelit y wireless exp erimen tation and data acquisition. W e collected outdo or wire- less dataset at the China Mobile In ternational Information Port in Beijing using a carrier frequency of 6.6 GHz and a bandwidth of 400 MHz. The resulting dataset pro- vides realistic channel observ ations that include hardw are impairmen ts, en vironmental noise and non-ideal propagation effects. The 3D p oin t clouds and user tra jectories w ere constructed from on-site geospatial measurements. Detailed system parameters are summarized in Extended Data T able 2. 14 4.2 Mo del architecture The WWM is impleme n ted as a multi-modal JEP A. The mo del comprises three main comp onen ts: an online enco der f θ , a predictor g ϕ and a target enco der f ¯ θ whose param- eters are maintained as an exp onen tial moving av erage (EMA) of the online enco der. The online encoder operates on partially observed inputs and produces con text em b ed- dings, the predictor uses these em b eddings together with learnable mask tok ens to infer the representations of masked regions, and the target enco der provides slowly v arying target embeddings for the same inputs without masking. All sup ervision is applied in the latent space, and the mo del is nev er asked to reconstruct raw samples. JEP A-style multi-mo dal pr e diction F or eac h training sample, the raw input consists of three sync hronized mo dalities: a CSI tensor x CSI , a 3D p oin t cloud tensor x PC and a user tra jectory vector x POS in a BS-cen tered co ordinate frame. After modality-specific embedding (further explained in 4.2.1), the resulting token sets X CSI , X PC , X POS are concatenated into a unified sequence X 0 = Concat X CSI , X PC , X POS ∈ R N × D . A masking mo dule then selects t wo disjoint index sets ov er this sequence, I full = I enc ⊔ I pred , (1) whic h specify visible (con text) tok ens I enc and masked (prediction) tok ens I enc indices, resp ectiv ely . The online enco der f θ receiv es only the visible tokens and pro duces con text embeddings z ctx = f θ ( X ; I enc ) , (2) In parallel, the target encoder f ¯ θ pro cesses the complete, unmasked input and outputs target embeddings h = f ¯ θ ( X ; I full ) , (3) from whic h the targets at the masked p ositions h I pred are extracted. The predictor g ϕ then takes the con text embeddings together with a set of learnable mask tokens { m j ∈ R D } j ∈I pred , each asso ciated with a mask ed p osition in I pred , and pro duces predicted embeddings ˆ h I pred = g ϕ z ctx , { m j } j ∈I pred ; I pred , (4) A latent-space loss (here an ℓ 1 distance) is computed b etw een ˆ h I pred and h I pred , and gradien ts are applied to θ and ϕ only; the target parameters ¯ θ are up dated via EMA. This scheme encourages the mo del to learn stable, semantically meaningful embed- dings that capture the physical structure linking channel resp onses, geometry and motion. 4.2.1 Multi-mo dal input em b edding and unified token space T o enable joint pro cessing of heterogeneous mo dalities, all inputs are mapp ed to a shared embedding space with dimension D . Each mo dalit y is first con verted into a sequence of tokens using a mo dalit y-sp ecific enco der, and these tokens are then pro jected into the common latent dimension. 15 Channel (CSI) emb e dding The ra w CSI tensor x CSI ∈ R C in × T × H × W (where C in = 2 corresp onds to the real and imaginary comp onents) is treated as a 3D spatiotemp oral volume ov er time, frequency , and antenna (spatial) indices. A 3D conv olution with k ernel size and stride b oth equal to ( T p , H p , W p ) serves as the patchification operator: it partitions the volume in to non-ov erlapping tub es of size ( T p , H p , W p ) and simultaneously pro jects each tub e in to a D -dimensional embedding v ector, yielding N CSI = T T p × H H p × W W p CSI tok ens { X CSI i ∈ R D } N CSI i =1 . T o preserve the spatiotemp oral ordering, a fixed 3D sinusoidal p ositional enco ding is added to each tok en. Point-cloud emb e dding The raw 3D point cloud x PC ∈ R N PC × 3 is enco ded using a discrete-v ariational tok- enizer inspired b y p oin t-cloud auto-enco ding methods. F arthest-p oin t sampling selects a fixed n umber of centers, and lo cal neighborho o ds around these centers are con- structed b y nearest-neigh b or grouping. A light weigh t P ointNet-st yle enco der from P oint-BER T [ 43 ] extracts a feature v ector for eac h neigh b orhoo d, whic h is then passed through a learned co de b o ok via Gumbel–Softmax quantization and refined by a shal- lo w geometric netw ork. The result is a set of N PC patc h-level point cloud tok ens in the shared latent space, x PC → { X PC j ∈ R D } N PC j =1 . This pro cedure preserves lo cal geometry while compressing the raw p oint cloud into a compact, fixed-size sequence. T r aje ctory emb e dding The ra w user tra jectory vector x POS = { p t ∈ R 3 } T pos t =1 is represen ted as a sequence of p ositions o ver time. A small pro jection netw ork, implemented as a multi-la yer percep- tron with non-linear activ ations, maps each p osition to a D -dimensional embedding, and a temp oral p ositional enco ding is added: x POS → { X POS k ∈ R D } N POS k =1 . Unifie d token se quenc e After mo dalit y-sp ecific embedding, the three token sequences are concatenated along the sequence dimension in a fixed order, X 0 = Concat X CSI , X PC , X POS ∈ R N × D , (5) where N = N CSI + N PC + N POS and X CSI , X PC , X POS denote all the tokens for each mo dalit y . The mo del k eeps track of the segment lengths ( N CSI , N PC , N POS ) for use in the mo dalit y-a ware exp ert la yers. In our implementation, the num b ers of tokens for CSI, p oin t cloud, and tra jectory are N CSI = 512, N PC = 256, and N POS = 16, resp ectiv ely . 4.2.2 Shared cross-mo dal atten tion and mo dality-specific exp erts The unified token sequence X 0 is processed by a stack of L e T ransformer blo c ks. Within each blo ck, lay er-normalized tokens first pass through a shared multi-head self-atten tion (MHSA) lay er that op erates on all mo dalities jointly , enabling cross- mo dal information exchange. The output is then lay er-normalized, split b y modality 16 and routed to three parallel feed-forward sub-netw orks, each sp ecialized to CSI, p oin t cloud, or tra jectory tokens resp ectiv ely . The exp ert outputs are concatenated back and added as a residual. This t wo-stage process rep eats for L e la yers, yielding the final represen tation X L e . Shar e d self-attention Giv en the input X ℓ ∈ R N × D at lay er ℓ , a standard multi-head self-attention (MHSA) la yer with pre-normalization and residual connection is applied: X ′ ℓ = X ℓ + MHSA LN( X ℓ ) . (6) Because X ℓ con tains tokens from all three mo dalities, the atten tion mechanism learns to exc hange information across CSI, geometry and motion, for example by allo wing c hannel tokens to attend to nearby building structures or tra jectory tokens. Mo dality-sp e cific fe e d-forwar d exp erts Rather than a single shared feed-forward la yer, 3 feed-forw ard sub-netw ork, one for eac h mo dalit y , in each T ransformer blo c k is implemented as three parallel exp erts. After a second normalization, the sequence X ′ ℓ is partitioned into CSI, 3D p oin t cloud and user tra jectory segments according to the stored le ngths: X CSI ℓ , X PC ℓ , X POS ℓ = Split ( LN( X ′ ℓ ); N CSI , N PC , N POS ) . (7) Eac h segment is then passed through its own tw o-lay er feed-forward exp ert, ˜ X CSI ℓ = f CSI X CSI ℓ , ˜ X PC ℓ = f PC X PC ℓ , ˜ X POS ℓ = f POS X POS ℓ . (8) where each feed-forward exp ert f is a p osition-wise non-linear mapping with separate parameters. The up dated segmen ts are concatenated back to their original order and com bined with a residual connection: X ℓ +1 = X ′ ℓ + Concat ˜ X CSI ℓ , ˜ X PC ℓ , ˜ X POS ℓ . (9) This “shared-attention plus mo dalit y-exp ert” design can b e viewed as a multi-modal mixture-of-exp erts arc hitecture with deterministic routing based on mo dalit y iden tity . It allows global con text mo deling to b e shared across mo dalities, while maintaining sp ecialized pathw ays tuned to the statistics and physical constraints of CSI, 3D p oin t cloud, and use tra jectory . 4.2.3 Enco der and predictor configurations Both the online encoder f θ and the predictor g ϕ are built from the shared-attention plus mo dalit y-exp ert T ransformer blo c ks describ ed in the previous section, and share the same ViT-Small hyper-parameters ( D =384, L e = L p =12). Despite this architec- tural symmetry , the t wo netw orks serv e distinct roles: the encoder op erates directly on 17 the embedded input tokens at the visible p ositions I enc and must learn rich, general- purp ose representations of the observ ed context; the predictor, by con trast, receiv es the enco der’s output together with learnable mask tokens at p ositions I pred and is task ed with inferring the latent conten t of the masked regions. Both the enco der and predictor share an identical architecture, consisting of 12 MMoE T ransformer la yers with an em b edding dimension of 384, 6 attention heads, and a head dimension of 64. 4.3 Pre-training details The WWM was pre-trained in a self-sup ervised manner using JEP A describ ed ab ov e. In this setting, the mo del is presented with partially observed m ulti-mo dal inputs and is trained to predict the laten t representations of the mask ed regions in a shared embed- ding space, rather than reconstructing raw measurements. This approach encourages the enco der–predictor pair to capture the underlying ph ysical structure of the wireless en vironment. 4.3.1 Data prepro cessing Ra w CSI tensors acquired from either simulation or the 6G prototype system are prepro cessed in to a numerically stable representation to facilitate large-scale self-sup ervised training. Samples con taining zero-v alued elements are first discarded. The remaining CSI v alues span a wide dynamic range, whic h can hinder training stability . T o compress this range while preserving sign information, we apply a signed log transform: ˜ H = sign( H ) · log 1 + | H | /ϵ , (10) where H denotes the CSI tensor and ϵ = 10 − 7 is a small scaling constant that amplifies near-zero magnitudes b efore the logarithm, ensuring fine-grained distinctions among weak signal comp onen ts are retained. Finally , mean–v ariance standardization is applied to rescale the dataset to zero mean and unit standard deviation. This pip eline con verts heterogeneous raw inputs into clean, standardized tensors with controlled dynamic range, which is critical for stable JEP A pre-training across diverse cities and user sp eeds. 4.3.2 Masking strategies for CSI and tra jectories T o expose the model to complemen tary forms of partial observ ability , three masking configurations were interlea ved during pre-training. All configurations op erate on the unified token sequence obtained b y concatenating CSI, point-cloud and tra jectory tok ens, but place the emphasis on different asp ects of the wireless scenario. Fine-grained CSI masking : In the first configuration, the CSI volume is parti- tioned in to a 3D grid of spatiotemp oral patc hes along time, frequency and an tenna (or spatial) dimensions. F or eac h sample, several relatively small 3D blo c ks are sampled at random within this grid, and all CSI patches inside these blo c ks are designated as mask ed. Concretely , we sample 8 blocks per clip, each with a temporal extent co v ering 50% of the tub eletized time axis and a spatial extent corresp onding to approximately 18 15% of the CSI patch grid in b oth spatial dimensions. The remaining CSI patc hes, together with all point-cloud and tra jectory tok ens, form the visible context. This configuration yields a mo derate masking ratio ov er CSI and encourages the mo del to reconstruct fine-scale multipath structure when sufficient lo cal context is av ailable. Coarse CSI masking : In the second configuration, few er but substantially larger 3D blocks are masked in the CSI grid, pro ducing sizeable “holes” in time–frequency–space that m ust b e inferred from the remaining CSI context. Here we mask 2 blo c ks p er clip, each co vering 50% of the tub eletized time axis and roughly 70% of the patch grid in each spatial dimension. P oint-cloud and tra jectory tokens remain fully visible. Compared with the fine-grained configuration, this setting places more emphasis on long-range dep endencies and global consistency . T ra jectory masking : The third configuration targets user tra jectory inference. In this setting, all CSI patc hes and p oin t-cloud tokens remain fully visible. Instead, the en tire tra jectory token sequence is masked. The model thus receiv es a complete description of the c hannel ev olution and en vironment, but no explicit user coordinates, and is required to reconstruct the laten t em b eddings associated with the tra jectory . This configuration encourages the mo del to internalize the inv erse relationship from c hannel and geometry back to user motion patterns. Across a mini-batch, the three configurations are sampled with equal probabil- it y , and the total loss is obtained by av eraging the latent-space prediction losses from eac h configuration. This multi-task JEP A ob jectiv e ensures that the same pre- trained mo del is sim ultaneously optimized for b oth c hannel completion and tra jectory inference under different visibility patterns. 4.3.3 Pre-training configurations The WWM model, including encoder and predictor, w as pre-trained on a simulated large-scale multi-modal dataset (Extended Data T able 3), with each sample con taining CSI tokens of 16 time steps, 3D p oin t cloud tokens centered around user location and synchronized user tra jectory vector. The mo del was trained with a global batch size of 128 using the AdamW optimizer and the L1 loss function. F ollowing a cosine learning-rate sc hedule, the learning rate w as linearly w armed up from 1 . 0 × 10 − 5 to a p eak v alue of 2 . 0 × 10 − 5 o ver the first 2 ep o c hs, and then decay ed by a cosine sc heduler to a final learning rate of 1 . 0 × 10 − 5 b y the end of training. W eight decay w as fixed at 0 . 04 throughout. The target enco der w as up dated with a momen tum of 0 . 9925 (applied to b oth the enco der and predictor branches), providing a slowly ev olving target net work that stabilizes training in the JEP A setting. Pre-training was run for 16 ep ochs with a mixed-precision bfloat16 data type. Notably , the full pre- training workflo w on the complete multi-modal dataset was completed in 87 hours on a single NVIDIA R TX 4090 24GB consumer-grade GPU, demonstrating an extremely lo w training computational barrier compared to large-scale foundation mo dels in other domains. 19 5 Data and mo del a v ailability Once the pap er is accepted, all datasets and mo del chec kp oin ts used in this study will b e publicly av ailable via https://zenodo.org/communities/wwm/ . 6 Co de a v ailabilit y Once the pap er is accepted, the mo del pre-training, downstream task training and testing co de will b e publicly av ailable via GitHub at https://gith ub.com/Wireless- W orld-Mo del/WWM-V1 . 20 Extended data Extended Data T able 1 T able 1 Extended Data T able 1 — Simulation Dataset Configuration Symbol Description V alue f c Center frequency 2.6 GHz ∆ f Subcarrier spacing 15 kHz F Number of sub carriers 96 N sb Number of subbands 8 F sb Subcarriers p er subband 12 ∆ t T emporal sampling interv al 5 ms T T emporal samples p er sample 16 N t BS antenna p orts 32 = 4 hor iz ontal × 4 v ertical × 2 pol ariz ation N r UE antenna p orts 4 = 2 hor iz ontal × 1 v ertical × 2 pol ariz ation N ′ r Effective receive–frequency dimension 32 = N r × N sb d ant Antenna element spacing 0 . 5 wa velength N scen Urban scenarios 5 Extended Data T able 2 T able 2 Extended Data T able 2 — Real Measured Dataset Configuration Symbol Description V alue f c Center frequency 6.6 GHz ∆ f Subcarrier spacing 120 kHz N sb Number of sub carriers 3333 N RB Number of PRBs 264 N RB sample Number of PRBs per sample 8 ∆ t T emporal sampling interv al 10 ms T T emp oral samples p er sequence 16 N t BS antenna p orts 32 = 16 hor iz ontal × 1 v ertical × 2 pol ariz ation N r UE antenna p orts 4 = 4 hor iz ontal × 1 v ertical × 1 pol ariz ation N ′ r Effective receive–frequency dimension 32 = N r × N RB sample d ant Antenna element spacing 0 . 5 wa velength 21 Extended Data T able 3 T able 3 Extended Data T able 3 — Summary of simulation scenarios and dataset parameters. Scenario ID Cit y BS P osition UE Sp eed Data V olume 1 Munic h BS0 5 km/h 2048 (T ra jectories) × 16 (Time steps) × 7 (runs) p er scenario 2 30 km/h 3 60 km/h 4 BS1 5 km/h 5 30 km/h 6 60 km/h 7 BS2 5 km/h 8 30 km/h 9 60 km/h 10 Etoile BS0 5 km/h 11 30 km/h 12 60 km/h 13 BS1 5 km/h 14 30 km/h 15 60 km/h 16 Beijing F orbidden City BS0 5 km/h 17 BS1 5 km/h 18 BS2 5 km/h 19 Beijing CBD BS0 5 km/h 20 30 km/h 21 60 km/h 22 BS1 5 km/h 23 30 km/h 60 km/h 22 Extended Data T able 4 T able 4 Extended Data T able 4 — Summary of generalization scenarios and dataset parameters. This p ortion of the dataset is sp ecifically designed to ev aluate the mo del’s robustness to unseen velocities and urban environmen ts. Scenario ID Generalization Type BS P osition UE Sp eed Data V olume 1 V elo city Generalization (Beijing CBD) BS0 40 km/h 2048 (T ra jectories) × 16 (Time steps) p er scenario 2 70 km/h 3 BS1 40 km/h 4 70 km/h 5 Cit y Generalization (W all Street) BS0 5 km/h 6 30 km/h 7 60 km/h Extended Data T able 5 T able 5 Extended Data T able 5 — CSI temp oral prediction p erformance of WWM compared to other baselines across in-distribution and generalization scenarios. A Metric of SGCS of predicted CSI is listed Scenario WWM WiF o LSTM T=15 T=16 Avg. T=15 T=16 Avg. T=15 T=16 Avg. CBD 0.796 0.807 0.802 – – 0.736 0.697 0.674 0.685 Etoile 0.948 0.941 0.944 – – 0.844 0.896 0.890 0.893 F orbidden City 0.959 0.957 0.958 – – 0.863 0.861 0.859 0.860 Munic h 0.923 0.913 0.918 – – 0.743 0.879 0.882 0.881 V elo cit y Generalization 0.767 0.786 0.776 – – 0.677 0.694 0.671 0.682 Cit y Generalization 0.926 0.906 0.916 – – 0.763 0.590 0.585 0.588 23 Extended Data T able 6 T able 6 Extended Data T able 6 — Comprehensive comparison of CSI compression and feedback performance (SGCS) across varying compression ratios and scenarios. Performance is ev aluated for WWM and baselines (QCR-NET, CR-NET) under in-distribution and generalization regimes. Mo del Scenario 1/1024 1/512 1/256 1/128 WWM CBD 0.6516 0.6666 0.6610 0.7522 Etoile 0.8027 0.8027 0.8460 0.9556 F orbidden City 0.7901 0.8014 0.8244 0.9240 Munic h 0.7704 0.7652 0.7995 0.9467 V elo city Generalization 0.6468 0.6623 0.6598 0.7454 Cit y Generalization 0.6214 0.6187 0.6535 0.8961 QCR-NET CBD 0.5872 0.6109 0.6172 0.6652 Etoile 0.6084 0.7510 0.8118 0.8862 F orbidden City 0.3998 0.4847 0.5367 0.6220 Munic h 0.6651 0.7454 0.8150 0.8940 V elo city Generalization 0.5935 0.6122 0.6219 0.6693 Cit y Generalization 0.4828 0.5402 0.5781 0.7016 CR-NET CBD 0.3732 0.5217 0.6142 0.6273 Etoile 0.2941 0.4351 0.6054 0.7361 F orbidden City 0.1924 0.3158 0.4321 0.4744 Munic h 0.2893 0.4801 0.6432 0.7438 V elo city Generalization 0.3755 0.5297 0.6214 0.6342 Cit y Generalization 0.2565 0.3644 0.5208 0.5753 24 Extended Data T able 7 T able 7 Extended Data T able 7 — b eam prediction p erformance of WWM compared to other baselines across in-distribution and generalization scenarios. The Metrics of T op-1 accuracy of predicted DFT co dew ord and their resp ectiv e b eam gain ratio are used Scenario WWM L WM SPMM T op-1 Acc SE ratio T op-1 Acc SE ratio T op-1 Acc SE ratio CBD 0.983 1.000 0.927 0.995 0.902 0.987 Etoile 0.917 0.980 0.836 0.944 0.778 0.931 F orbidden City 0.906 0.981 0.854 0.970 0.828 0.963 Munich 0.915 0.984 0.836 0.956 0.767 0.926 V elocity Generalization 0.978 0.999 0.926 0.995 0.857 0.972 Extended Data T able 8 T able 8 Extended Data T able 8 — User lo calization performance of WWM compared to other baselines across in-distribution and generalization scenarios. A Metric of mean av erage error of 2D distance is used Scenario WWM deep-CNN CBD 1.212743 2.2889 Etoile 2.982986 5.2257 F orbidden City 2.868211 6.0771 Munich 2.718476 4.8768 V elocity Generalization 1.226949 1.9978 Extended Data T able 9 T able 9 Extended Data T able 9 — Ablation study comparing the full multimodal WWM with its unimo dal v ariant across scenarios, rep orting per-timestep SGCS results ( T =15, T =16) and their av erage. Scenario WWM WWM-Unimodal T=15 T=16 Avg. T=15 T=16 Avg. CBD 0.796 0.807 0.802 0.687 0.687 0.687 Etoile 0.948 0.941 0.944 0.935 0.922 0.928 F orbidden City 0.959 0.957 0.958 0.923 0.912 0.918 Munich 0.923 0.913 0.918 0.901 0.879 0.890 V elocity Generalization 0.767 0.786 0.776 0.653 0.662 0.657 City Generalization 0.926 0.906 0.916 0.927 0.904 0.915 25 Extended Data T able 10 T able 10 Extended Data T able 10 — CSI frequency-domain prediction p erformance of WWM compared to other baselines by metric of NMSE and SGCS. Scenario WWM WiF o C-Mixer NMSE SGCS NMSE SGCS NMSE SGCS PRB4 0.212 0.932 0.252 0.922 0.296 0.918 PRB5 0.218 0.918 0.261 0.895 0.308 0.892 PRB6 0.260 0.914 0.309 0.882 0.349 0.875 PRB7 0.243 0.902 0.287 0.858 0.334 0.843 Avg. 0.233 0.917 0.277 0.889 0.322 0.882 26 References [1] Liu, G., Huang, Y., Li, N., et al. : Vision, requirements and net work architecture of 6G mobile netw ork b ey ond 2030. China Communications 17 (9), 92–104 (2020) h ttps://doi.org/10.23919/JCC.2020.09.008 [2] W ang, C.-X., Y ou, X., Gao, X., et al. : On the Road to 6G: Visions, Requiremen ts, Key T echnologies, and T estb eds. IEEE Communications Surveys & T utorials 25 (2), 905–974 (2023) https://doi.org/10.1109/COMST.2023.3249835 [3] Shannon, C.E.: A mathematical theory of comm unication. The Bell System T ech- nical Journal 27 (3), 379–423 (1948) https://doi.org/10.1002/j.1538- 7305.1948. tb01338.x [4] W ang, Z., Zhang, J., Du, H., Niyato, D., Cui, S., Ai, B., Debbah, M., Letaief, K.B., P o or, H.V.: A tutorial on extremely large-scale mimo for 6g: F undamentals, signal processing, and applications. IEEE Communications Surveys & T utorials 26 (3), 1560–1605 (2024) https://doi.org/10.1109/COMST.2023.3349276 [5] Ziao, Q.: A review of co debo oks for csi feedback in 5g new radio and b ey ond. China Comm unications 22 (2), 112–127 (2025) h ttps://doi.org/10.23919/JCC.ja. 2023- 0117 [6] Y u, B., Qian, C., Lin, P ., Lee, J., Li, Q., Park, S., Kim, S., Y o on, C., Hu, S., Liu, L.: Light-w eight ai enabled non-linearity comp ensation leveraging high order mo dulations. IEEE T ransactions on Communications 72 (1), 539–552 (2024) h ttps://doi.org/10.1109/TCOMM.2023.3321735 [7] Shi, Y., Lian, L., Shi, Y., et al. : Machine learning for large-scale optimization in 6g wireless netw orks. IEEE Communications Surveys & T utorials 25 (4), 2088–2132 (2023) https://doi.org/10.1109/COMST.2023.3300664 [8] F arhadi, H., Banerjee, B., Berkvens, R., et al. : 6G AI-Driven Air Interface — Hexa-X-I I View. IEEE Communications Magazine 63 (10), 118–125 (2025) https: //doi.org/10.1109/MCOM.001.2400394 . Accessed 2026-01-22 [9] Hoydis, J., Aoudia, F.A., V alcarce, A., et al. : T ow ard a 6G AI-Native Air Inter- face. IEEE Communications Magazine 59 (5), 76–81 (2021) h ttps://doi.org/10. 1109/MCOM.001.2001187 . Accessed 2026-01-22 [10] Zheng, X., Xiao, H., Jin, S., et al.: Ai-native 6g ph ysical lay er with cross-mo dule optimization and co operative control agents. IEEE Journal on Selected Areas in Comm unications, 1–1 (2026) https://doi.org/10.1109/JSA C.2026.3652936 [11] Mo or, M., Banerjee, O., Abad, Z.S.H., Krumholz, H.M., Lesk o vec, J., T op ol, E.J., Ra jpurk ar, P .: F oundation mo dels for generalist medical artificial intelligence. Nature 616 (7956), 259–265 (2023) 27 [12] Abramson, J., Adler, J., Dunger, J., Ev ans, R., Green, T., Pritzel, A., Ron- neb erger, O., Willmore, L., Ballard, A.J., Bambric k, J., et al. : Accurate structure prediction of biomolecular interactions with alphafold 3. Nature 630 (8016), 493–500 (2024) [13] He, Y., F ang, P ., Shan, Y., P an, Y., W ei, Y., Chen, Y., Chen, Y., Liu, Y., Zeng, Z., Zhou, Z., et al.: Generalized biological foundation mo del with unified nucleic acid and protein language. Nature Machine Intelligence, 1–12 (2025) [14] Binz, M., Ak ata, E., Bethge, M., Br¨ andle, F., Callaw a y , F., Co da-F orno, J., Da yan, P ., Demircan, C., Eckstein, M.K., ´ Eltet˝ o, N., et al.: A foundation mo del to predict and capture human cognition. Nature, 1–8 (2025) [15] Shao, J., T ong, J., W u, Q., Guo, W., Li, Z., Lin, Z., Zhang, J.: Wirelessllm: Emp o w ering large language mo dels to wards wireless in telligence. Journal of Com- m unications and Information Netw orks 9 (2), 99–112 (2024) h ttps://doi.org/10. 23919/JCIN.2024.10582827 [16] Liu, B., Liu, X., Gao, S., et al. : Llm4cp: Adapting large language mo dels for c hannel prediction. Journal of Communications and Information Netw orks 9 (2), 113–125 (2024) https://doi.org/10.23919/JCIN.2024.10582829 [17] Cui, Y., Guo, J., W en, C.-K., et al.: Exploring the Poten tial of Large Language Mo dels for Massiv e MIMO CSI F eedbac k (2025) https://doi.org/10.48550/arXiv. 2501.10630 [18] Zheng, T., Dai, L.: Large Language Mo del Enabled Multi-T ask Ph ysical Lay er Net work (2025) https://doi.org/10.48550/arXiv.2412.20772 . [cs]. Accessed 2025-04-19 [19] W en, Y., Chen, X., Zhang, M., et al.: ICWLM: A Multi-T ask Wireless Large Mo del via In-Context Learning. arXiv (2025). h ttps://doi.org/10.48550/arXiv. 2507.18167 . [20] Noh, H., Shim, B., Y ang, H.J.: Adaptive resource allo cation optimization using large language mo dels in dynamic wireless en vironments. IEEE T ransactions on V ehicular T echnology 74 (10), 16630–16635 (2025) https://doi.org/10.1109/TVT. 2025.3572440 [21] Zhang, C., Zhang, H., Qiao, J., Li, Z., Alouini, M.-S.: TIDES: T raffic Intelli- gence with DeepSeek Enhanced Spatial T emp oral Prediction. IEEE Journal on Selected Areas in Comm unications, 1–1 (2025) https://doi.org/10.1109/JSA C. 2025.3643397 [22] Liu, B., Gao, S., Liu, X., et al.: Wifo: Wireless F oundation Mo del for Channel Prediction. SCIENCE CHINA Information Sciences 68 (6) (2025) h ttps://doi. org/10.1007/s11432- 025- 4349- 0 28 [23] Cheng, X., Liu, B., Liu, X., Liu, E., Huang, Z.: F oundation mo del emp o w- ered synesthesia of machines (som): Ai-nativ e in telligent multi-modal sensing- comm unication in tegration. IEEE T ransactions on Net work Science and Engi- neering 13 , 762–782 (2026) https://doi.org/10.1109/TNSE.2025.3587238 [24] Y ang, T., Zhang, P ., Zheng, M., et al. : WirelessGPT: A Generative Pre-T rained Multi-T ask Learning F ramework for Wireless Communication. IEEE Net work 39 (5), 58–65 (2025) h ttps://doi.org/10.1109/MNET.2025.3579496 . Accessed 2026-01-31 [25] He, D., Ai, B., Guan, K., et al. : The design and applications of high-p erformance ra y-tracing simulation platform for 5g and b ey ond wireless communications: A tutorial. IEEE Comm unications Surv eys & T utorials 21 (1), 10–27 (2019) h ttps: //doi.org/10.1109/COMST.2018.2865724 [26] Ha, D., Sc hmidhuber, J.: Recurren t w orld mo dels facilitate policy evolution. In: Bengio, S., W allach, H., Laro c helle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R. (eds.) Adv ances in Neural Information Pro cessing Systems, vol. 31, pp. 2451– 2463. Curran Asso ciates, Inc., Red Ho ok, NY, USA (2018) [27] LeCun, Y.: A path tow ards autonomous machine intelligence. Op enReview 1 (1), 1–64 (2022) [28] Ren, X., Lu, Y., Cao, T., Gao, R., Huang, S., Sab our, A., Shen, T., Pfaff, T., W u, J.Z., Chen, R., et al.: Cosmos-drive-dreams: Scalable syn thetic driving data generation with world foundation mo dels. arXiv preprint (2025) [29] Hoydis, J., et al.: Sionna: An op en-source library for next-generation physical la yer research. IEEE Journal on Selected Areas in Communications (2022) [30] Bardes, A., Garrido, Q., Ponce, J., Chen, X., Rabbat, M., LeCun, Y., Assran, M., Ballas, N.: Revisiting F eature Prediction for Learning Visual Representations from Video (2024). [31] Assran, M., Bardes, A., F an, D., Garrido, Q., How es, R., Muckley , M., Rizvi, A., Rob erts, C., Sinha, K., Zholus, A., et al.: V-jepa 2: Self-sup ervised video mo dels enable understanding, prediction and planning. arXiv preprint (2025) [32] W ang, W., Bao, H., Dong, L., Bjorck, J., P eng, Z., Liu, Q., Aggarwal, K., Mohammed, O.K., Singhal, S., Som, S., et al. : Image as a foreign language: Beit pretraining for vision and vision-language tasks. In: Pro ceedings of the IEEE/CVF Conference on Computer Vision and P attern Recognition, pp. 19175–19186 (2023) [33] He, K., Chen, X., Xie, S., Li, Y., Doll´ ar, P ., Girshick, R.: Mask ed autoenco ders 29 are scalable vision learners. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 16000–16009 (2022) [34] Maaten, L., Hinton, G.: Visualizing data using t-sne. Journal of machine learning researc h 9 (11) (2008) [35] Alikhani, S., Charan, G., Alkhateeb, A.: Large wireless mo del (lwm): A founda- tion mo del for wireless channels. arXiv preprint arXiv:2411.08872 (2024) [36] Grav es, A.: Long short-term memory . Sup ervised sequence labelling with recur- ren t neural netw orks, 37–45 (2012) [37] Zhang, X., Lu, Z., Zeng, R., W ang, J.: Quantization adaptor for bit-level deep learning-based massive mimo csi feedbac k. IEEE T ransactions on V ehicular T echnology 73 (4), 5443–5453 (2023) [38] Lu, Z., W ang, J., Song, J.: Multi-resolution csi feedbac k with deep learning in massive mimo system. In: ICC 2020-2020 IEEE International Conference on Comm unications (ICC), pp. 1–6 (2020). IEEE [39] Alrab eiah, M., Alkhateeb, A.: Deep learning for mm wa v e b eam and block age pre- diction using sub-6 ghz channels. IEEE T ransactions on Comm unications 68 (9), 5504–5518 (2020) [40] Chen, Z., Zhang, Z., Y ang, Z., Liu, L.: Channel mapping based on inter- lea ved learning with complex-domain mlp-mixer. IEEE Wireless Comm unications Letters 13 (5), 1369–1373 (2024) [41] Op enStreetMap Contributors: Op enStreetMap. https://www.openstreetmap.org . Accessed 2024 (2024) [42] Nimier-David, M., Vicini, D., Zeltner, T., Jakob, W.: Mitsuba 2: A retargetable forw ard and inv erse renderer. ACM T ransactions on Graphics (2019) [43] Y u, X., T ang, L., Rao, Y., Huang, T., Zhou, J., Lu, J.: P oint-bert: Pre-training 3d p oin t cloud transformers with masked p oin t mo deling. In: Pro ceedings of the IEEE/CVF Conference on Computer Vision and P attern Recognition, pp. 19313– 19322 (2022) [44] Gu, J., W ang, Z., Kuen, J., Ma, L., Shahroudy , A., Shuai, B., Liu, T., W ang, X., W ang, G., Cai, J., et al. : Recen t adv ances in con volutional neural net works. P attern recognition 77 , 354–377 (2018) 30 Supplemen tary Note Supplemen tary Note 1 Channel Prediction T ask Details W e ev aluate the WWM as a sequence mo del for short-horizon channel prediction. Here w e formulate channel prediction as a downstream task on top of the pre-trained WWM: given history CSI together with the corresp onding environmen t 3D p oin t cloud and user tra jectory , the mo del is asked to infer the CSI at a set of future time steps. In this setting, the WWM enco der and predictor op erate exactly as in the pre-training stage, but their parameters are kept frozen. A multi-time step CSI sample, along with the asso ciated p oin t cloud and user tra jectory , is fed into the enco der. Only the first 14 time steps in the sample are treated as visible con text, while the channel tok ens corresp onding to subsequent T pred = 2 time steps within the sample are designated as mask ed positions. The predictor receiv es the context embeddings and a set of learnable mask tokens at these future positions, and produces latent tok ens that represent the predicted CSI in the em b edding space. These predicted tokens, restricted to the CSI mo dalit y , are then passed to a dedicated channel deco der that maps them back to the complex CSI tensor on the original time–frequency–space format. The channel decoder is implemented as a compact transformer-based netw ork sp e- cialized for CSI reconstruction. It consists of a stack of T ransformer blo c ks op erating purely on CSI tok ens, follo wed by a pro jection head that reshap es the output into a tensor of shap e (2 , T pred , H , W ). Here, the first dimension corresp onds to real and imaginary parts; T pred denotes the n umber of future channel time steps b eing pre- dicted, H corresp onds to the num b er of base-station antennas (32 in our dataset), and W denotes the joint frequency–an tenna dimension defined by the product of user- side an tenna elements and subband groups (here 4 × 8). This structure allo ws the deco der to reconstruct the full complex CSI on time–frequency–space format from the predicted laten t tok ens. In our implementation, the deco der is a 6-la yer transformer trained with AdamW and a learning rate of 2 × 10 − 5 . The deco der is trained with a complex-v alued reconstruction loss that explicitly separates magnitude and phase comp onen ts of the channel, while also incorp orating a structural similarit y ob jective. Giv en predicted and ground-truth c hannels in the form ˆ Y , Y ∈ R 2 × T pred × H × W (real and imaginary parts separated in the first dimension), w e form complex tensors ˆ H , H ∈ C T pred × H × W and their magnitudes and phases of eac h element. The CSI loss combines a raw mean-squared error in the real–imaginary plane, a magnitude loss, a phase-consistency term, and an SGCS regularization term: L CSI = 1 N ˆ Y − Y 2 2 | {z } raw MSE + α 1 N | ˆ H | − | H | 2 2 | {z } magnitude loss + β 1 − 1 N X n cos( ˆ ϕ n − ϕ n ) | {z } phase-consistency loss + γ 1 T pred T pred X t =1 L SGCS ,t | {z } av erage SGCS loss . (11) Here N = 2 × T × H × W denotes the num b er of elements in ˆ Y , and ˆ ϕ n and ϕ n represen t the predicted and true phases at element n ≤ N . In implemen tation, L SGCS = 1 − SGCS is computed on the final predicted time step by reshaping the reconstructed c hannel in to subcarrier groups and measuring the similarit y betw een the 31 dominan t spatial singular vectors of the predicted and ground-truth CSI. Sp ecifically , for each sub carrier k , we reshap e the channel matrix as H k ∈ C N ue × N bs and p erform singular v alue decomp osition (SVD): H k = U k Σ k V H k , (12) where the first righ t singular vector v k (corresp onding to the largest singular v alue) captures the dominant spatial direction. Let ˆ v k and v k denote the dominant right singular vectors of the predicted and ground-truth CSI, resp ectively . The SGCS of a single CSI time step is computed as the av erage normalized inner product across all K sub carriers: SGCS = 1 K K X k =1 ˆ v H k v k ∥ ˆ v k ∥ 2 ∥ v k ∥ 2 . (13) In our training setup, the CSI-loss w eigh ts are progressiv ely adjusted across epo c hs to balance stable amplitude reconstruction, phase alignment, and SGCS optimization: ep ochs 1–10 use α = 1 . 0 and β = 0 . 2; ep ochs 11–15 use α = 1 . 0 and β = 0 . 5; ep ochs 16–20 use α = 1 . 0 and β = 1 . 0; and ep o c hs 21–25 use α = 1 . 0, β = 0 . 2, and γ = 1 . 0. During ev aluation, we rep ort SGCS to quantify the structural similarity b etw een the reconstructed and ground-truth CSI across the antenna arra y and frequency bands. T o assess performance and generalization, we compare the WWM against t wo baseline mo dels: Wifo[ 22 ]—a foundation mo del for wireless c hannel prediction, and Long short- term memory (LSTM)[ 36 ]. Supplemen tary Note 2 Channel Compression and F eedbac k T ask Details W e ev aluate the WWM as a learned c hannel compression and feedback mo dule. Here, c hannel compress ion is formulated as a downstream task op erating on the latent rep- resen tations extracted by the pre-trained WWM. Out of a 16-timestep CSI sample (pro cessed as 8 temporal tub elets), only the 4th tubelet (corresponding to time steps 7 and 8) is kept unmasked and fed in to WWM encoder (together with the corresponding 3D point cloud and User tra jectory), whic h produces N = 64 con tinuous CSI laten t tok ens Z csi ∈ R N × D in the em b edding space, eac h with a dimension of D = 384. A dedicated light weigh t compression head, implemented as CRNetT okens , is attached on top of these tok ens. The compression and quantization pro cess can b e formulated as: Z comp = Q µ,b ( f reduce ( Z csi ) ) (14) where f reduce ( · ) applies a dimensionalit y reduction lay er that shrinks the embedding dimension by a configurable reduction factor r (e.g., r = 96), follow ed b y a tok en- mixing stage. The function Q µ,b ( · ) represents a µ -law scalar quan tizer that maps the contin uous v ectors to 2 b discrete levels (e.g., b = 4 bits) and is optimized via a straigh t-through estimator during training. A decompressor f expand ( · ) subsequently expands the discrete feedback pa yload bac k to the original token dimension D . These reconstructed tokens are then passed to 32 a channel deco der D —a Vision T ransformer join tly fine-tuned with th e compressor—to reco ver the complex channel tensor the original time–frequency–space format: ˆ Y = D ( f expand ( Z comp ) ) (15) The compressor and deco der are trained end-to-end using the AdamW optimizer with a learning rate of 1 × 10 − 4 and a weigh t decay of 0 . 01. The training ob jectiv e is a complex-v alued CSI reconstruction loss that combines a ra w mean-squared error, a magnitude loss (weigh t α = 1 . 0), and a phase-consistency term (weigh t β = 0 . 5). W e ev aluate the WWM-based compressor against strong neural baselines (CR- NET [ 38 ] and QCR-NET[ 37 ]) under matched compression budgets. Generalization is assessed across three scenarios: in-distribution (seen cities and v elo cities), velo city gen- er alization (unseen sp eeds in seen environmen ts), and city gener alization (completely unseen urban la youts). By compressing in the semantically rich multimodal latent space rather than the raw channel domain, the WWM maintains high reconstruction fidelit y and exhibits strong robustness to unseen sp eeds and propagation conditions. Supplemen tary Note 3 Beam prediction task details The beam prediction task adopts the same urban scenarios and user v elo cit y ranges as those used for pre-training and oth er downstream tasks. F or each user tra jectory , CSI is collected at tw o distinct central frequency simultaneously: a Sub-6GHz band (2.6GHz) and an upper 6GHz (U6G) band (6.62505GHz). At every sampled UE position, the Sub-6GHz CSI tensor X sub-6 is used as input, together with the corresp onding 3D p oint cloud and user tra jectory . F rom the concurrent U6G channel, the optimal Preco ding matrix indicator (PIM) index b ∗ is determined as the b eam that maximizes the received p o w er ov er a predefined Type I Single-P anel Co debo ok of K b eams. Thus the task learns the mapping: f beam : X sub-6 − → b ∗ ∈ { 1 , 2 , . . . , K } , where f beam denotes the prediction model and X sub-6 ∈ R 2 × T × N t × N ′ r is the pro- cessed low-frequency CSI tensor. The mapping is learned using the pre-trained WWM as a frozen feature extractor, follow ed by a task-sp ecific 1-lay er attentiv e classifier. The attentiv e classifier tak es the enco ded feature tokens and outputs a probability distribution ov er the K b eams, trained with the cross-entrop y loss: L beam = − 1 N N X i =1 K X k =1 y i,k log( p i,k ) , where N is the batch size, y i,k is the one-hot encoding of the ground-truth beam index for the i -th sample, and p i,k is the predicted probabilit y for the k -th b eam. Throughout training, only the atten tive classifier parameters are up dated, while the WWM backbone remains fixed. T o assess p erformance and generalization, we compare the WWM-based predictor against t wo baseline mo dels: the L WM[ 35 ]—a general-purpose foundation mo del for wireless c hannels—and the Sub-6-Preds-mmW av e (SPMM)[ 39 ]—a deep neural net- w ork specifically designed for cross-band b eam prediction. W e measure the T op-1 33 classification accuracy , as w ell as the ac hieved b eam gain relative to the optimal beam. The b eam gain ratio for a set of M test samples is computed as: R BG = 1 M M X j =1 H U 6 G w ( j ) b H U 6 G w ( j ) b ∗ , where H U 6 G is the last timestep CSI of j -th sample in U6G band, w ( j ) b is the PMI corresp onding to predicted b eam index for the j -th sample, and w ( j ) b ∗ is the PMI corresp onding to the theoretical optimal b eam. This metric directly reflects ho w closely the mo del’s b eam selections approach the ideal link p erformance. Supplemen tary Note 4 User lo calization task details W e further ev aluate the WWM’s capability for high-precision user localization. In this do wnstream task, the mo del is required to infer the 2D geographical co ordinates ( x, y ) of a UE based on its CSI as well as the corresp onding 3D cloud p oin t. Similar to the c hannel prediction task, the pre-trained WWM backbone remains frozen to lev erage its in ternalized ph ysical represen tations. The explicit user tra jectory tok ens are in tention- ally omitted from WWM input, comp eling the mo del to derive p ositional information solely from the in teraction betw een CSI patterns and the geometric structure of the en vironment. The resulting latent tokens from the WWM enco der, which encapsulate join t EM-geometric features, are then fed into a dedicated attentiv e regression head. The attentiv e regression head is designed to regress the sequence of latent embed- dings in to a 2D co ordinate ˆ p = ( ˆ x, ˆ y ). The localization head is trained to minimize the Euclidean distance b et ween the predicted co ordinates and the ground-truth p osi- tion p = ( x, y ) corresp onding to the final p osition of the UE tra jectory . The ob jectiv e function is defined b y the mean squared error (MSE) loss. we quan tify p erformance using the CDF of the absolute lo calization error. W e compare the WWM-based lo calization framew ork against a CNN-based baseline[ 44 ]. Sp ecifically , the baseline consists of a one-lay er temp oral fusion mo dule, follo wed by a ResNet-18 backbone (comprising 17 conv olutional lay ers and 1 fully connected lay er), and a final linear regression lay er that directly outputs the 2D co or- dinates. The baseline model is trained from scratc h on the same lab eled dataset and tak es raw CSI tensors as input. Both mo dels are ev aluated across the same urban lay- outs used in the general b enc hmark to assess their robustness under environmen tal shifts. Our results indicate that, b y extracting high-lev el semantic features from the join t EM-geometric space, the WWM-based approach significan tly outp erforms the con ven tional regression baseline. Supplemen tary Note 5 CSI frequency-domain prediction based on SRS measuremen t task details W e introduce an CSI frequency-domain prediction task to ev aluate the mo del’s capa- bilit y to reduce uplink measuremen t o v erhead under realistic deploymen t conditions. The data are collected from a 6G prototype system in an outdo or slow-mobilit y sce- nario. In practical 6G systems, sounding reference signals (SRS) are transmitted ov er 34 m ultiple physical resource blo c ks (PRBs) in frequency domain for uplink channel esti- mation at the base station. Dense PRB-level measurements, ho wev er, incur substan tial signaling ov erhead. This task aims to infer CSI on on unmeasured SRS PRBs from partially observed PRBs within the same time windo w. The prototype system op erates at 6.6 GHz with 400 MHz bandwidth and 120 kHz sub carrier spacing. Each PRB contains 12 sub carriers (1.44 MHz bandwidth). The ra w measuremen ts comprise 264 PRBs, whic h are partitioned into 33 samples of 8 con- secutiv e PRBs. F or each sample, the first four PRBs serve as visible context, and the remaining four PRBs are designated as prediction targets. Each sample corresponds to a contin uous UE tra jectory containing 16 consecutiv e CSI time steps, which are join tly mo deled to capture temp oral channel evolution. The task is formulated as learning the m apping: f CSI : X vis → X mask , where X vis and X mask denote the CSI tensors of the observed and mask ed PRBs, resp ectiv ely . CSI frequency-domain prediction is implemented as a downstream task on top of the pre-trained WWM. The enco der and predictor retain the same architecture as in pre-training. In practice, training on the measured dataset is conducted in tw o stages. First, the enco der and predictor are jointly fine-tuned to adapt the pre-trained represen tations to real-w orld data. Then, the encoder is frozen, and the predictor is further optimized together with a light weigh t T ransformer-based channel deco der. A full 16-timestep tra jectory sample, together with its 3D p oin t cloud and user tra jec- tory tokens, is fed in to the enco der. Within eac h time step, only the first four PRBs are provided as input, while the remaining four PRBs are withheld as prediction targets. The predictor pro duces laten t represen tations corresp onding to the full CSI matrix, rather than only mask ed p ositions. These representations are passed to the c hannel deco der, which op erates solely on CSI tokens and outputs a complete CSI esti- mate. A final pro jection head reshap es the output in to a tensor of size (2 , T , H , W ), where the first dimension corresp onds to real and imaginary parts; T = 16 is the n umber of temp oral samples; H = 32 is the num b er of base-station antennas; and W denotes the joint frequency–antenna dimension (4 UE antennas × 8 PRBs). The mo del is trained using mean squared error b et ween the predicted and ground-truth CSI ov er the full frequency band, and p erformance is ev aluated with NMSE and SGCS. By reconstructing unobserv ed PRBs from partial observ ations, this task reflects the mo del’s ability to exploit frequency-domain channel correlations in real-world scenar- ios and provides a practical mechanism for reducing SRS o verhead in op erational 6G systems. T o assess p erformance, w e compare the WWM against baseline foundation mo del WiF o[ 22 ] and task-specific mo del C-Mixer [ 40 ]. T o ensure a rigorous and fair comparison, WiF o adopts the same training strategy as WWM—initial pre-training on simulated dataset follow ed b y sp ecialized fine-tuning on field-measured SRS data. In contrast, the task-specific C-Mixer is trained from scratch directly on the measured SRS dataset. 35
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment