MP-MoE: Matrix Profile-Guided Mixture of Experts for Precipitation Forecasting
Precipitation forecasting remains a persistent challenge in tropical regions like Vietnam, where complex topography and convective instability often limit the accuracy of Numerical Weather Prediction (NWP) models. While data-driven post-processing is…
Authors: Huyen Ngoc Tran, Dung Trung Tran, Hong Nguyen
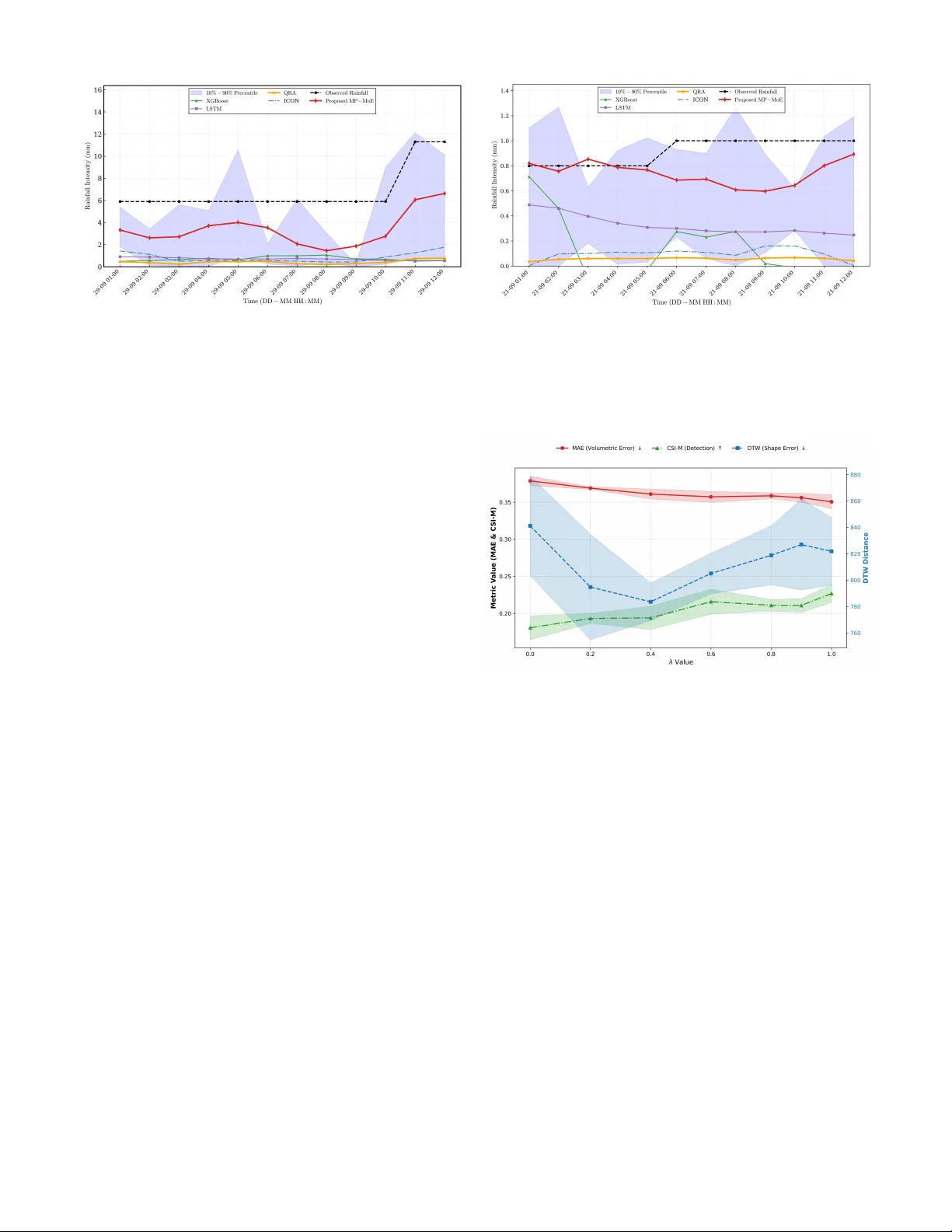
MP-MoE: Matrix Profile-Guided Mixture of Experts for Precipitation F orecasting Huyen Ngoc T ran † , Dung T rung T ran † , Hong Nguyen ‡ , Xuan V u Phan † , Nam-Phong Nguyen † † School of Electronics and Electrical Engineering, Hanoi Univ ersity of Science and T echnology ‡ Department of Electrical and Computer Engineering, Univ ersity of Southern California, United States Abstract —Precipitation for ecasting remains a persistent chal- lenge in tropical regions lik e Vietnam, wher e complex topography and con vectiv e instability often limit the accuracy of Numerical W eather Prediction (NWP) models. While data-driven post- processing is widely used to mitigate these biases, most existing frameworks rely on point-wise objective functions, which suffer from the “double penalty” effect under minor temporal mis- alignments. In this work, we propose the Matrix Profile-guided Mixture of Experts (MP-MoE), a framework that integrates con ventional intensity loss with a structural-awar e Matrix Profile objective. By le veraging subsequence-level similarity rather than point-wise errors, the proposed loss facilitates more reliable expert selection and mitigates excessive penalization caused by phase shifts. W e evaluate MP-MoE on rainfall datasets from two major river basins in V ietnam across multiple horizons, including 1-hour intensity and accumulated rainfall o ver 12, 24, and 48 hours. Experimental results demonstrate that MP-MoE outperforms raw NWP and baseline learning methods in terms of Mean Critical Success Index (CSI-M) f or heavy rainfall events, while significantly reducing Dynamic T ime W arping (DTW) values. These findings highlight the framew ork’s efficacy in cap- turing peak rainfall intensities and preser ving the morphological integrity of storm events. Index T erms —Double penalty , Matrix Pr ofile, Mixture of Experts, NWP post-processing, Precipitation F orecasting. I . I N T R O D U C T I O N Precipitation forecasting plays a vital role in mitigating natural hazards, optimizing reservoir operations, and ensur- ing sustainable agricultural planning. Traditionally , Numerical W eather Prediction (NWP) models [1]–[3] have been globally adopted as the standard for short-term rainfall forecasting due to their ability to simulate atmospheric dynamics. V arious operational frameworks, such as the W eather Research and Forecasting (WRF) system [4], hav e served as the primary physical foundation for these efforts by solving complex fluid dynamics and thermodynamic equations under specific initial and boundary conditions. Howe ver , despite their widespread applications, they are inherently constrained by the chaotic nature of the atmosphere and their sensitivity to initial pertur- bations. Such limitations often manifest as systematic biases and spatial displacement errors, particularly within tropical re- gions characterized by comple x topography , such as V ietnam. Recently , statistical post-processing has emerged as a well- established framework to calibrate ra w model outputs, encom- passing a wide range of methodologies. These approaches span from classic probabilistic techniques such as Bayesian Model A veraging (BMA) [5] and Quantile Regression A v eraging (QRA) [6] to more recent adv anced data-driv en models includ- ing XGBoost [7] and Long Short-T erm Memory (LSTM) [8]. While these methods have successfully improved calibration for general weather conditions and captured complex nonlinear dependencies, they often struggle to accurately resolve rapidly ev olving con vecti ve systems or extreme rainfall onsets. One of the fundamental limitations is that they rely on pointwise loss functions like Mean Squared Error (MSE) or Mean Absolute Error (MAE). This dependenc y triggers the well-kno wn “dou- ble penalty” problem, where a forecast that correctly captures a storm’ s structural evolution b ut is slightly displaced in time is penalized twice: once for the displacement and once for the perceiv ed false alarm [9], [10]. Mathematically , such an optimization landscape incentivizes models to produce overly smoothed, blurred predictions to minimize variance, resulting in the systematic suppression of peak rainfall intensities, a phenomenon commonly referred to as “peak-shaving” [11]. T o bridge these critical gaps, we propose the Magnitude- A ware Matrix Profile Mixture of Experts (MP-MoE). This neural post-processing framew ork shifts the optimization paradigm from strict point-wise accuracy to structural fidelity by integrating a shape-aw are objective into a dynamic expert selection mechanism. Unlike traditional methods, MP-MoE lev erages temporal subsequence similarity to mitigate the double penalty ef fect while preserving the physical magnitude of extreme ev ents. The key contrib utions of this work are summarized as follows: • A hybrid loss function is introduced that integrates MSE with a structural similarity penalty derived from an un- normalized MP distance [12]. This mechanism acts as a “soft” time-lag correction, re warding models that capture the true physical evolution of rainfall. • A gating network is proposed that uses large-scale GFS variables to dynamically assign weights to specific WRF experts based on meteorological regimes. This architec- ture allows the system to adaptiv ely switch strategies between stable stratiform and con vecti ve rainfall regimes. • Comprehensiv e e xperiments are conducted in two real- world hydrological basins in V ietnam, demonstrating that MP-MoE significantly reduces Dynamic T ime W arping (DTW) values [13] and reconstructs peak intensities. I I . R E L AT E D W O R K Rainfall forecasting has traditionally relied on NWP models, which provide a rigorous physical foundation but frequently exhibit systematic biases due to simplified atmospheric param- eterizations and coarse spatial resolutions [1], [14]. T o mitigate these discrepancies, statistical post-processing methods, such as BMA and QRA, hav e been widely implemented to refine raw NWP outputs. While effecti ve in improving probabilistic calibration, these frameworks often struggle to capture the complex, non-linear dependencies inherent in extreme meteo- rological events, particularly during rapid storm onsets where atmospheric conditions shift abruptly [14], [15]. Recent adv ances in deep learning ha ve accelerated the shift tow ard data-dri ven rainfall forecasting models. Early architec- tures advanced data-driven forecasting by transitioning from temporal modeling with LSTM to capturing joint spatiotem- poral dependencies via Con vLSTM and PredRNN [16], [17]. These foundations paved the way for high-capacity frame- works such as GraphCast [18], Earthformer [19], and Pangu- W eather [20], which e xcel at extracting multi-scale patterns from atmospheric data. Despite their success, a persistent challenge is that many such models rely predominantly on point-wise objective functions like MSE. For highly non- stationary rainfall processes, these losses tend to penalize temporal misalignment e xcessiv ely , leading to the well-known “peak-shaving” effect where intense precipitation e vents are smoothed or underestimated [9]. T o address the limitations of point-wise accuracy , structural distance measures such as DTW and Soft-DTW have been proposed to alleviate this issue by allowing elastic temporal matching between predicted and observed rainfall sequences [21], [22]. Nev ertheless, these methods suffer from quadratic computational complexity and may introduce non-physical temporal warpings, limiting their practicality for operational hydrological forecasting. While the MP paradigm has recently emerged as an efficient frame work for subsequence similarity search in data mining [12], [23], its potential as a structural penalty mechanism to guide expert selection remains largely unexploited. Unlike DTW’ s unre- stricted temporal w arping, MP identifies structurally similar patterns within a constrained temporal search range, thereby preserving the morphological characteristics of rainfall events while maintaining a much lo wer constant-factor overhead in practical ex ecution. In parallel with loss function optimization, the MoE archi- tecture has receiv ed increasing attention for managing het- erogeneous data regimes. Unlike static ensembles that apply fixed weights to model outputs, MoE utilizes a dynamic gating mechanism to route inputs to specialized experts based on the current context [24], [25]. While MoE has shown promise in general time-series tasks, its application in NWP post- processing remains under-explored, particularly regarding the use of structural similarity to guide the gating process. Our approach bridges this gap by inte grating MP-derived guidance into an MP-MoE architecture. By optimizing the selection process through a redefined structural loss, our framework ensures adaptive expert selection while preserving the in- tegrity of rainfall hydrographs, effecti vely connecting large- scale physical modeling with localized structural accuracy . I I I . M E T H O D O L O G Y A. Data Prepr ocessing and F eatur e Engineering T o ensure numerical stability , all physical features are Z- score normalized. T o facilitate the MP-guided objecti ve, we structure the data into two distinct temporal sequences: (i) an expert query sequence, comprising a 3-hour forecast trajectory from t − 2 to t ; and (ii) a ground truth search scope, spanning a symmetric 6-hour window centered at the target time, from t − 3 to t + 3 . By using the expert sequence to query this extended symmetric window , the loss function can identify the optimal structural match regardless of whether the forecast arriv es earlier or later than observed. Consequently , samples at the boundaries of the timeline, which lack suf ficient data to form the complete symmetric search window [ t − ∆ , t + ∆] , were excluded from the training set. B. Pr oposed F rame work: Matrix Pr ofile-Guided MoE The core of the MP-MoE framework is a gating network G , which dynamically determines the reliability of each e xpert based on the local meteorological state. At each time step t , the network processes a vector of lar ge-scale physical features X t (e.g., humidity , wind components from GFS) to modu- late the contribution of individual NWP experts. The gating mechanism, projects these features into a latent representation, followed by a Softmax activ ation to generate a probability distribution over the K experts: p k,t = exp( G k ( X t )) P K j =1 exp( G j ( X t )) , (1) where G k ( X t ) represents the logit assigned to the k-th expert, and p k,t denotes the adaptiv e weight assigned to the k − th expert, satisfying P K k =1 p k,t = 1 and p k,t ≥ 0 . The final rainfall estimate ˆ Y t is then computed as a weighted linear combination: ˆ Y t = K X k =1 p k,t · E k,t , (2) where E k,t is the forecast from the k − th NWP expert. C. Hybrid Objective Function Unlike canonical MP , which relies on Z-normalization to find shape motifs reg ardless of amplitude, we introduce an unnormalized Euclidean distance to ensure mass conservation and penalize volumetric errors. Although MSE loss functions are crucial for calibrating the overall rainfall magnitude, sole reliance on them yields smoothed predictions due to the “double penalty” effect discussed in section II. Therefore, we propose a hybrid objectiv e function that balances two complementary goals: (i) minimizing the rainfall intensity error via MSE, and (ii) preserving the temporal shape of storm ev ents via an MP-based guidance. L total = (1 − λ ) · L MSE + λ · L MP . (3) Rainfall intensity calibration. The first component of (3) focuses on minimizing the error in rainfall magnitude. W e Learnable Gating Network Physical Context Features X Σ A. MP-MoE Architecture B. Matrix Profile guided Hybrid Loss Fixed NWP Experts Ground truth Y Forecast E k P 1 P K-1 P 2 P K ... Expert E 1 Expert E 2 Expert E K-1 Expert E K ... Final Rainfall Prediction 𝑌 𝑡 𝑳 𝒕𝒐𝒕𝒂𝒍 = 𝟏 − 𝝀 ⋅ 𝑳 𝑴𝑺𝑬 + 𝝀 ⋅ 𝑳 𝑴𝑷 Ground truth Y Fig. 1: Schematic overvie w of the proposed MP-MoE framew ork. Panel A (left) illustrates the inference workflo w where the learnable gating netw ork processes large-scale physical features to assign importance weights to fixed NWP experts dynamically . Panel B (right) details the training strate gy using a hybrid loss function. Unlike standard MSE, which imposes se vere penalties for temporal shifts, the proposed matrix profile-guided objective scans a symmetric search windo w to minimize structural distance, thereby prioritizing shape fidelity ov er rigid alignment. employ the standard MSE between the aggregated forecast ˆ Y and the ground truth Y . L MSE = 1 N N X i =1 ( Y i − ˆ Y i ) 2 . (4) T emporal shape pr eservation. The second component of (3) penalizes structural dissimilarity rather than point-wise displacement. W e use the MP distance to align the temporal peaks of the forecast with the observations: L MP = 1 N N X t =1 K X k =1 P k,t · D min ( E ( t ) k , Y ( t ) ) , (5) where P k,t denotes the probability weight assigned to the k - th NWP expert for the t -th sample, while N and K are the number of training samples and experts, respecti vely . The term D min ( E ( t ) k , Y ( t ) ) is the MP distance (visualized in Fig. 1), calculated as the minimum Euclidean distance between the sliding window of the expert forecast and its best matching subsequence in the ground truth: D min ( E k , Y ) = min τ ∈ [ t − ∆ ,t +∆] ∥ w E k,t − w Y τ ∥ 2 , (6) where the sliding windows of length m are defined as w E k,t = [ e k,t − m +1 , . . . , e k,t ] for the k -th expert ending at time t , and w Y τ = [ y τ − m +1 , . . . , y τ ] for the candidate ground truth win- dow ending at τ . The parameter ∆ represents the maximum permissible temporal shift, creating a symmetric search scope [ t − ∆ , t + ∆] . The operation min τ searches within this scope to effecti v ely handle both early and delayed arriv al of rainfall ev ents. Crucially , since the NWP expert forecasts E and ground truth Y are fixed inputs, the term D min functions as a static penalty coefficient. This approach effecti vely simplifies the optimization process, as the Gating Network can update its parameters based on pre-computed modified MP distances without the need to differentiate through discrete time indices. I V . E X P E R I M E N T S A N D R E S U L T S A. Experimental Settings Datasets. The proposed framework is ev aluated using real- world rainfall data from the Ban Nhung and Song Chay basins, two mountainous hydrological catchments located in northern V ietnam. These regions are characterized by steep terrain with elev ations ranging from lo w v alleys to ov er 2,400 m, resulting in strong elev ation gradients and pronounced oro- graphic influences on rainfall. The Song Chay basin contains a dense ri ver network and receiv es high annual precipitation, typically exceeding 2,000 mm. In contrast, the Ban Nhung basin frequently experiences intense localized con v ectiv e rain- fall ev ents associated with complex mountainous meteorology . Such en vironmental conditions often lead to rapid runoff and flash flooding during heavy rainfall episodes, making these basins suitable testbeds for ev aluating a model’ s ability to capture both spatial displacement and peak rainfall intensity . W e employ a 7:3 chronological split to test the model across div erse meteorological regimes and terrain-induced variability . Baselines. T o e v aluate the ef ficacy of the MP-MoE framew ork, we consider two distinct categories of benchmarks: (i) a wide range of learning-based models, including regression- based ensembles and recurrent neural networks, and (ii) op- erational NWP experts. This setup is designed to isolate the specific contribution of our structural-aware gating mechanism in impro ving forecast fidelity ov er both standard point-wise ensemble techniques and purely physical models. By balancing subsequence matching with intensity calibration, we assess the framew ork’ s ability to bridge the gap between statistical post- processing and localized structural accuracy . Evaluation Metrics. Model performance is assessed using three complementary metrics: (i) MAE for 1-hour and accu- mulated rainfall (12h, 24h, 48h) to ev aluate volumetric error; (ii) DTW to quantify temporal shape alignment; and (iii) Mean Critical Success Index (CSI-M). Specifically , CSI- M averages CSI scores across thresholds r ∈ { 1 , 3 , 5 mm } , where continuous values are binarized ( ˆ y ≥ r ) to calculate Hits, Misses, and False Alarms. This multi-threshold approach T ABLE I: Quantitati ve performance comparison on the Ban Nhung and Song Chay basins. Evaluation metrics include MAE for 1-hour intensity and accumulated rainfall (12h, 24h, 48h), DTW distance for structural similarity , and CSI-M for e vent detection. Note: For learning-based models, results are reported as Mean ± STD ov er fi ve independent runs; physics-based experts are deterministic and report a single values. MP-MoE ( λ = 0 . 6 ) denotes our proposed method, showing consistent improv ements over both raw WRF experts and learning-based methods. Bold values indicate the best performance for each metric, while underlined values denote the second best. Basin / Method MAE [mm] (Accumulated Rainfall) ↓ DTW ↓ CSI-M ↑ 1h 12h 24h 48h Panel A: Ban Nhung Basin Physics-Based Experts COMS 0.669 7.243 14.246 27.739 2074.0 0.068 GFS 0.689 7.536 14.948 29.338 1985.9 0.041 MIT D02 1.000 10.930 21.536 41.996 2936.9 0.112 LING3 D02 0.850 9.042 17.817 34.733 2684.3 0.096 LINKF D02 1.014 10.953 21.511 41.750 3007.4 0.109 LINBMJ D02 0.692 6.534 12.656 24.086 2339.0 0.113 ET AKF D02 0.859 9.104 17.813 34.730 2609.6 0.116 ET AG3 D02 0.778 8.264 16.252 31.744 2257.2 0.106 ET ABMJ D02 0.592 5.527 10.641 20.078 1928.4 0.121 Learning-based Models Ensemble 0.546 ± 0 . 007 6.363 ± 0 . 074 12.530 ± 0 . 139 24.601 ± 0 . 266 1626.4 ± 47 . 0 0.004 ± 0 . 004 XGBoost 0.622 ± 0 . 006 7.092 ± 0 . 082 13.926 ± 0 . 164 27.110 ± 0 . 312 1325.8 ± 38 . 4 0.080 ± 0 . 002 LSTM 0.584 ± 0 . 024 6.026 ± 0 . 235 11.836 ± 0 . 483 23.271 ± 0 . 982 997.0 ± 51 . 5 0.024 ± 0 . 003 QRA 0.440 ± 0 . 005 5.065 ± 0 . 062 10.009 ± 0 . 114 19.734 ± 0 . 228 1117.9 ± 28 . 6 0.012 ± 0 . 001 BMA 0.741 ± 0 . 009 7.934 ± 0 . 084 15.642 ± 0 . 172 30.258 ± 0 . 344 1998.1 ± 42 . 6 0.062 ± 0 . 002 Linear Reg 0.503 ± 0 . 004 5.741 ± 0 . 068 11.236 ± 0 . 128 21.945 ± 0 . 256 1296.9 ± 31 . 2 0.031 ± 0 . 001 HGB 0.501 ± 0 . 004 5.824 ± 0 . 062 11.446 ± 0 . 118 22.458 ± 0 . 234 1531.9 ± 34 . 2 0.004 ± 0 . 001 RFR 0.595 ± 0 . 002 6.919 ± 0 . 018 13.620 ± 0 . 036 26.657 ± 0 . 075 1369.1 ± 37 . 9 0.070 ± 0 . 003 MP-MoE (Ours) 0.357 ± 0 . 007 3.639 ± 0 . 126 7.091 ± 0 . 250 13.764 ± 0 . 492 805.0 ± 15 . 4 0.216 ± 0 . 017 Panel B: Song Chay Basin Physics-Based Experts WRF84H 0.585 6.209 12.037 22.463 3879.2 0.083 COMS 0.500 5.442 10.440 19.534 2992.9 0.068 GFS 0.459 5.077 9.884 18.824 2780.2 0.044 ICON 0.405 4.662 9.159 17.707 2692.5 0.025 MIT D01 0.666 7.500 14.537 27.848 3729.4 0.056 MIT 0.703 7.825 15.192 28.630 4037.7 0.071 Learning-based Models Ensemble 1.105 ± 0 . 021 12.800 ± 0 . 270 25.016 ± 0 . 543 47.882 ± 1 . 093 5474.3 ± 137 . 9 0.073 ± 0 . 003 XGBoost 1.866 ± 0 . 018 20.359 ± 0 . 245 40.000 ± 0 . 480 77.932 ± 0 . 924 10052.2 ± 201 . 0 0.074 ± 0 . 002 LSTM 1.839 ± 0 . 126 20.019 ± 1 . 563 39.182 ± 3 . 128 76.215 ± 6 . 273 9840.5 ± 577 . 3 0.079 ± 0 . 008 QRA 0.528 ± 0 . 006 6.116 ± 0 . 078 11.920 ± 0 . 144 22.723 ± 0 . 264 2852.5 ± 56 . 4 0.025 ± 0 . 001 BMA 0.522 ± 0 . 006 5.843 ± 0 . 072 11.416 ± 0 . 142 21.914 ± 0 . 268 3274.2 ± 64 . 8 0.017 ± 0 . 001 Linear Reg 1.034 ± 0 . 012 12.023 ± 0 . 144 23.436 ± 0 . 282 44.651 ± 0 . 536 4417.1 ± 88 . 4 0.034 ± 0 . 001 HGB 0.927 ± 0 . 057 10.719 ± 0 . 665 20.891 ± 1 . 316 39.796 ± 2 . 650 5570.7 ± 180 . 0 0.062 ± 0 . 008 RFR 1.750 ± 0 . 022 20.272 ± 0 . 262 39.935 ± 0 . 525 78.289 ± 1 . 069 7711.3 ± 161 . 1 0.074 ± 0 . 001 MP-MoE (Ours) 0.282 ± 0 . 005 3.106 ± 0 . 064 6.100 ± 0 . 125 11.792 ± 0 . 245 1346.3 ± 41 . 4 0.174 ± 0 . 010 captures the model’ s capability in detecting ev ents ranging from light to high intensities. Implementation Details. Our framew ork is implemented in PyT orch and optimized using the Adam optimizer with a learning rate of 0.003 and a batch size of 64. The Gating Network employs a lightweight four -layer MLP to dynami- cally compute expert weights. T o balance structural fidelity with computational overhead, we set the subsequence length m and maximum permissible temporal shift ∆ are both set to 3 hours. A trade-off parameter λ is further introduced to regulate the hybrid loss function. Robustness is verified through five independent runs across seeds { 0 , 1 , 42 , 2024 , 2025 } , with results reported as mean ± standard deviation (STD) for stochastic models. B. Comparative P erformance Quantitative P erformance. T able I shows that while certain baselines excel in specific regions, MP-MoE maintains con- sistent accuracy across diverse hydrological settings. In the Ban Nhung basin, the QRA model is a competitiv e statistical baseline with a 1-hour MAE of 0.440 mm, whereas the physical ICON expert provides a more reliable benchmark in the Song Chay basin with an MAE of 0.405 mm. MP-MoE outperforms both, achie ving 1-hour MAEs of 0.357 mm and 0.282 mm for Ban Nhung and Song Chay , respectively . This consistency extends to structural metrics, where MP- MoE yields the minimum DTW distances in both basins, reaching 805.0 in Ban Nhung compared to 997.0 from the LSTM model. The framew ork also improves rainfall ev ent detection, with a CSI-M of 0.174 in Song Chay , nearly double (a) Ban Nhung Basin (b) Song Chay Basin Fig. 2: Comparativ e visualization of forecast trajectories. The proposed MP-MoE ( λ = 0 . 6 , solid red line) effecti vely captures high-intensity peaks and rapid onsets compared to the ground truth (black dashed line), whereas traditional baselines exhibit significant peak-shaving effects in the Ban Nhung and Song Chay basins. the scores of the WRF84H and LSTM baselines. For 48-hour accumulated rainfall, MP-MoE reduces systematic biases by lowering the Ban Nhung MAE to 13.764 mm, a substantial gain ov er the 24.086 mm from the top deterministic expert. These results suggest that MP guidance helps the gating network effecti vely adapt to varying meteorological regimes. Structural preser vation in extreme transition regimes. Fig. 2a illustrates a sharp rainfall surge in the Ban Nhung basin from 6 mm/h to nearly 12 mm/h. While all baselines fail to react and remain near the zero-axis, MP-MoE reflects the storm morphology by exhibiting a clear upward trajectory . Specifically , the proposed model reaches an intensity of approximately 6.7 mm/h, notably outperforming the flattened predictions of LSTM and ICON. Although the absolute peak remains underestimated, this ability to capture the rising trend demonstrates that the MP objective provides a superior gradient signal for structural alignment during extreme transitions. Consistency in sustained rainfall. The Song Chay basin (Fig. 2b) illustrates a sustained rainfall scenario, where ob- served intensity remains near 1.0 mm/h. In this setting, base- lines such as LSTM and XGBoost exhibit a dissipation bias, with predicted values rapidly decaying toward zero despite ongoing precipitation. By comparison, MP-MoE preserves temporal persistence by maintaining lev els around 0.8 mm/h. This demonstrates that our model effecti vely retains continu- ous patterns and mitig ates the premature attenuation typical of these data-driv en benchmarks. Parameter sensitivity analysis. The hyperparameter λ in (3) controls the balance between point-wise intensity calibration and structural alignment. As illustrated in Fig. 3, the choice of λ dictates the model priority across dif ferent forecast requirements. Specifically , if the primary goal is to minimize hourly intensity errors, a lower λ value focusing on MSE- based calibration is more suitable, though this often leads to the peak-shaving effect and poor ev ent detection. Con versely , Fig. 3: Sensitivity analysis (at Ban Nhung) of the hyperpa- rameter λ which regulates the trade-off between the intensity- based MSE loss and the Modified MP loss. The dual-axis chart shows MAE and CSI-M on the left axis, and DTW distance on the right axis. if the objectiv e is to maximize categorical detection and shape similarity , a higher λ value approaching 1.0 becomes preferable as it prioritizes subsequence matching over rigid point-wise alignment. W e identify λ = 0 . 6 as the most harmonious configuration for operational reliability . In this setting, the model achiev es a high CSI-M of 0.216 while significantly reducing the DTW distance, thereby maintain- ing necessary anchor -to-physical-magnitude constraints while prev enting the non-physical temporal warping associated with exclusi ve subsequence optimization. Consequently , this inter- mediate balance ensures that the gating network selects e xperts with both morphological fidelity and magnitude consistency across varying rainfall regimes. C. Ablation Study T able II ev aluates the contributions of MSE and MP com- ponents to structural fidelity . Omitting either term degrades T ABLE II: Ablation study results focusing on structural fi- delity DTW ↓ across two ri ver basins. Results are reported as Mean ± STD ov er fiv e independent runs. Basin / Configuration MP-MoE (Full) w/o MP Loss w/o MSE Loss Ban Nhung (DTW ↓ ) 805 . 0 ± 15 . 4 841 . 2 ± 37 . 7 821 . 8 ± 25 . 6 Song Chay (DTW ↓ ) 1346 . 3 ± 41 . 4 1350 . 4 ± 34 . 7 1782 . 2 ± 48 . 0 performance, confirming the necessity of a hybrid objec- tiv e. At Ban Nhung, excluding MP loss increases DTW to 841.2, showing that point-wise metrics alone struggle with temporal shifts. Similarly , Song Chay exhibits a substantial DTW increase to 1782.2 without MSE loss, as subsequence matching without intensity calibration leads to v olumetric distortions. By integrating both objectiv es, MP-MoE achiev es optimal stability , minimizing DTW to 805.0 and 1346.3. These findings validate that structural guidance prevents temporal warping while maintaining magnitude consistency . V . L I M I T A T I O N S A N D F U T U R E W O R K While the MP-MoE framework significantly advances struc- tural forecast accurac y , it lays a foundation with several directions for future dev elopment. The current implementation focuses on 1D time-series modeling at the basin scale, a choice that prioritizes local structural fidelity over broader spatiotemporal field correlations. Consequently , while the gat- ing network effecti vely routes trust among NWP experts, its performance is bounded by the diversity of the available expert pool. Furthermore, the use of fix ed hyperparameters, such as maximum permissible temporal shift ∆ and the loss- balancing coef ficient λ , represents an initial baseline that could be further refined through adaptiv e tuning to better capture the volatility of tropical monsoon regimes. Future research will focus on extending the framework to the spatiotemporal domain by incorporating graph-based dependencies, ensuring regional consistency across neighboring catchments. Addition- ally , exploring online learning mechanisms will allow the Gating Network to autonomously adapt to seasonal climate shifts and e volving atmospheric patterns, further enhancing the system’ s operational resilience. V I . C O N C L U S I O N This paper presented MP-MoE, a framew ork designed to address temporal misalignment in precipitation forecasting. By shifting the optimization paradigm to structural similarity via the hybrid loss objective, the model ef fectiv ely mitigates the double penalty and peak-shaving biases. Evaluations in V ietnam demonstrate that MP-MoE consistently outperforms operational NWP models and learning-based baselines, achie v- ing substantial reductions in DTW and improvements in CSI- M. These results v alidate the framework’ s reliability for oper - ational flood early warning and disaster management. A C K N O W L E D G M E N T The authors gratefully acknowledge WEA THERPLUS So- lution Joint Stock Company for providing the meteorological datasets used in this study , and AITHINGS Co. Ltd. for their support in conducting this research. R E F E R E N C E S [1] P . Bauer, A. Thorpe, and G. Brunet, “The quiet rev olution of numerical weather prediction, ” Natur e , pp. 47–55, 09 2015. [2] J. Fritsch et al. , “Quantitative precipitation forecasting: Report of the eighth prospectus development team, us weather research program, ” Bull. Amer . Meteor ol. Soc. , no. 2, pp. 285–299, 1998. [3] S. Mitsuishi, T . Ozeki, and T . Sumi, “ Applicability of a new flood control method utilizing rainfall prediction by wrf. ” 2011. [4] W . C. Skamarock et al. , “ A description of the advanced research wrf version 3, ” National Center for Atmospheric Research, T ech. Rep. NCAR/TN-475+STR, 2008. [5] A. E. Raftery et al. , “Using bayesian model averaging to calibrate forecast ensembles, ” Mon. W eather Rev . , no. 5, pp. 1155–1174, 2005. [6] J. B. Bremnes, “Probabilistic forecasts of precipitation in terms of quantiles using nwp model output, ” Mon. W eather Rev . , no. 1, pp. 338– 347, 2004. [7] T . Chen, “Xgboost: A scalable tree boosting system, ” Cornell University , 2016. [8] S. Hochreiter and J. Schmidhuber , “Long short-term memory , ” Neural Computation , pp. 1735–1780, 1997. [9] E. E. Ebert, “Fuzzy verification of high-resolution gridded forecasts: A revie w and proposed framework, ” Meteor ological Applications , no. 1, pp. 51–64, 2008. [10] Z. W ang and A. C. Bovik, “Mean squared error: Love it or leav e it? a new look at signal fidelity measures, ” IEEE Signal Pr ocess. Mag. , no. 1, pp. 98–117, 2009. [11] S. Ravuri et al. , “Skilful precipitation nowcasting using deep generative models of radar, ” Nature , pp. 672–677, 2021. [12] C.-C. M. Y eh et al. , “Matrix profile i: All pairs similarity joins for time series: A unifying view that includes motifs, discords, and shapelets, ” in Pr oceedings of the IEEE 16th International Conference on Data Mining (ICDM) . IEEE, 2016, pp. 1317–1322. [13] E. J. K eogh and M. J. P azzani, “Derivati ve dynamic time warping, ” in Pr oc. SDM . Society for Industrial and Applied Mathematics, 2001, pp. 1–11. [14] S. V annitsem et al. , “Statistical postprocessing for weather forecasts: Revie w , challenges, and avenues in a big data world, ” Bull. Amer . Meteor ol. Soc. , pp. E681–E699, 04 2021. [15] A. Graefe et al. , “Limitations of ensemble bayesian model averaging for forecasting social science problems, ” International Journal of F ore- casting , p. 943–951, 06 2015. [16] X. Shi et al. , “Con volutional lstm netw ork: A machine learning approach for precipitation nowcasting, ” 06 2015. [17] Y . W ang et al. , “Predrnn: A recurrent neural network for spatiotemporal predictiv e learning, ” 2022. [18] R. Lam et al. , “Graphcast: Learning skillful medium-range global weather forecasting, ” 2023. [19] Z. Gao et al. , “Earthformer: Exploring space-time transformers for earth system forecasting, ” 2023. [20] K. Bi et al. , “P angu-weather: A 3d high-resolution model for fast and accurate global weather forecast, ” 2022. [21] S. Salvador and P . Chan, “T o ward accurate dynamic time warping in linear time and space, ” Intell. Data Anal. , vol. 11, pp. 561–580, 10 2007. [22] M. Cuturi and M. Blondel, “Soft-dtw: a differentiable loss function for time-series, ” in Proceedings of the 34th International Conference on Machine Learning - volume 70 , ser . ICML ’17. JMLR.org, 2017, p. 894–903. [23] D. T . Tran et al. , “ Adapti ve rainfall forecasting from multiple geograph- ical models using matrix profile and ensemble learning, ” 2025. [24] R. A. Jacobs et al. , “ Adapti ve mixtures of local experts, ” Neural Computation , no. 1, pp. 79–87, 1991. [25] G. Hinton et al. , “Outrageously large neural networks: The sparsely- gated mixture-of-experts layer , ” 01 2017.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment