Bayesian Propensity Score-Augmented Latent Factor Models for Causal Inference with Time-Series Cross-Sectional Data
We propose a Bayesian propensity score-augmented latent factor model for causal inference with time-series cross-sectional data. The framework explicitly models the treatment assignment mechanism by incorporating latent factor loadings, while the out…
Authors: Licheng Liu
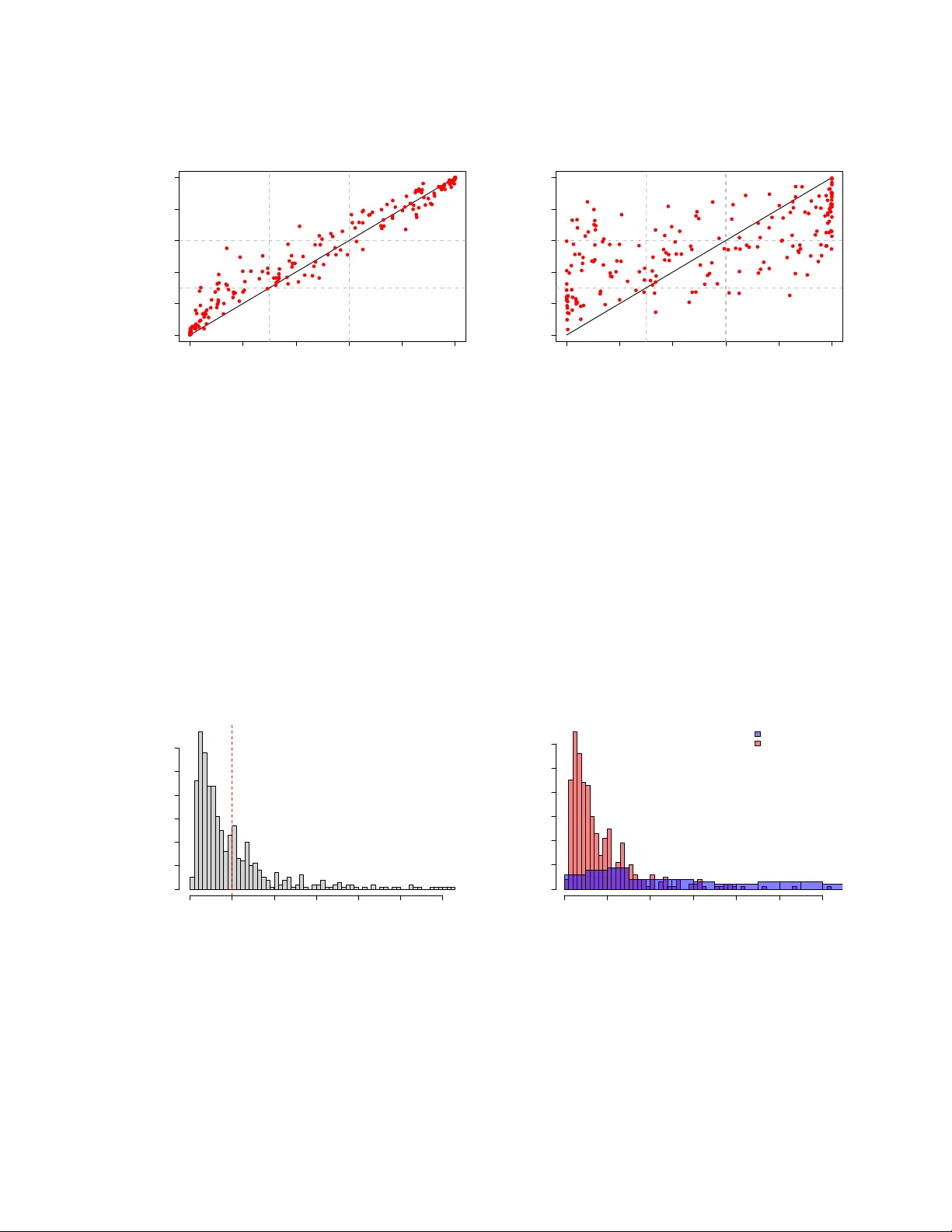
Ba y esian Prop ensit y Score-Augmen ted Laten t F actor Mo dels for Causal Inference with Time-Series Cross-Sectional Data Lic heng Liu ∗ Marc h 27, 2026 Abstract W e propose a Ba yesian propensity score–augmen ted laten t factor model for causal inference with time-series cross-sectional data. The framew ork explicitly mo dels the treatmen t assignmen t mec hanism b y incorp orating laten t factor loadings, while the outcome mo del flexibly incorp orates the prop ensity score, for example through strat- ification. Relativ e to existing approac hes, the prop osed metho d pro vides greater flex- ibilit y and captures additional heterogeneit y across prop ensity-score strata, enabling more credible comparisons b etw een treated and con trol units within eac h stratum. F or estimation and inference, we adopt an appro ximate Ba yesian pro cedure to ad- dress the model feedbac k problem common in Ba yesian prop ensit y score analysis. W e demonstrate the p erformance of the prop osed metho d through Monte Carlo sim ula- tions and an empirical application examining the effect of p olitical connections on firm v alue. Keywor ds: Ba yesian Prop ensit y Score, Laten t-F actor Mo del, Causal P anel Data Models ∗ Assistan t Professor, Department of P olitical Science, Universit y of Mic higan. Email: lichengl@umic h.edu . 1 1 In tro duction The prop ensit y score–based approach ( Rosen baum and Rubin , 1983 ) has b een widely adopted for estimating treatmen t effects from observ ational studies. Unlik e exp erimental settings, where the treatmen t assignmen t mechanism is kno wn to the researcher, observ a- tional studies t ypically rely on unconfoundedness assumptions to draw causal inferences b ecause researchers do not directly control treatment assignmen t. One example is the c onditional ignor ability assumption, which p osits that treatmen t assignment is as-if ran- domized conditional on a set of observed pre-treatment confounders. The prop ensit y score is therefore defined as the probability of receiving treatment given these pre-treatmen t confounders. The prop ensit y score p ossesses an imp ortan t balancing prop ert y: conditional on the prop ensit y score, treatmen t assignment is indep enden t of the observ ed confounders. In other words, the propensity score summarizes the information in the confounders relev ant to treatmen t assignment. This prop erty enables causal estimation using methods such as matc hing, inv erse probability w eigh ting, and sub classification, whic h aim to balance the distribution of pre-treatmen t confounders b et ween treated and con trol groups. Despite these app ealing prop erties, the use of prop ensit y score metho ds in time-series cross-sectional (TSCS) settings has developed more slowly . Most existing approac hes con tin ue to rely on v ariants of the conditional ignorability assumption when mo deling the probabilit y that a unit b elongs to the treated group, b oth in canonical difference-in- differences settings (e.g., Abadie , 2005 ) and in staggered adoption designs (e.g., Calla wa y and San t’Anna , 2021 ). In many cases, the prop ensity score is com bined with an outcome regression mo del to ac hieve double r obustness , whereby consisten t estimation of treatmen t effects is obtained if either the treatmen t assignment model or the outcome mo del is cor- rectly sp ecified. A defining feature of causal inference with TSCS data, ho wev er, is the likely presence of unobserv ed confounders. Mo del-based approaches typically appro ximate such confounders using additiv e tw o-wa y fixed effects or interactiv e fixed-effects structures (e.g., Abadie et al. , 2010 ; Xu , 2017 ). The associated iden tification assumption is often referred to as latent ig- nor ability ( F rangakis and Rubin , 1999 ), whic h relaxes standard conditional ignorability 2 b y allo wing for unobserv ed confounding. Nev ertheless, many existing mo del-based panel metho ds (e.g., Athey et al. , 2021 ) do not explicitly specify the treatmen t assignment mec h- anism or deriv e a corresp onding prop ensit y score under latent ignorabilit y . This is largely b ecause laten t confounders themselv es m ust b e estimated b efore a propensity score can b e constructed. Only recently hav e methods b een prop osed that explicitly model treatmen t assignmen t as dep ending on laten t confounders in panel data settings (e.g., F orino et al. , 2025 ; Schmidt et al. , 2025 ). T o address these c hallenges, we prop ose a no vel Ba yesian framew ork that join tly mod- els treatment assignmen t and p otential outcomes under control as functions of b oth ob- serv ed pre-treatmen t co v ariates and laten t confounders, enabling treatment effect estima- tion in time-series cross-sectional data. Sp ecifically , w e introduce a Ba yesian prop ensit y score–augmen ted latent factor model (PS-LFM), in which treatment assignmen t dep ends explicitly on laten t confounders while accounting for uncertaint y in the estimation of b oth laten t confounders and prop ensit y scores. Compared with conv entional frequen tist prop ensit y score approac hes, the prop osed Ba y esian framew ork formally incorporates uncertain t y in prop ensity score estimation in to treatmen t effect inference ( McCandless et al. , 2009 ; Alv arez and Levin , 2021 ). W e further establish iden tification of treatment effects under laten t ignorability and demonstrate the necessit y of explicitly mo deling the treatmen t assignment mechanism in the presence of unobserv ed confounding. Because latent confounders en ter b oth the treatmen t assignmen t and outcome mo dels, and b ecause the prop ensit y score also app ears in the outcome mo del 1 , a fully Bay esian analysis ma y induce substantial model feedbac k problem ( Zigler et al. , 2013 ). Such feedbac k can lead to inaccurate counterfactual predictions and biased treatment effect estimates. T o address this issue, w e adopt an appr oximate Bayesian analysis ( Zigler et al. , 2013 ; Zigler and Dominici , 2014 ) for coun terfactual prediction and treatment effect estimation, an approach sho wn to effectiv ely mitigate mo del feedback problems in Bay esian propensity score analysis. The proposed PS-LFM is implemented and publicly a v ailable in the op en- source R pac k age bpCausal . 1 This corresp onds to the outcome stage of prop ensit y score analysis in Rosenbaum and Rubin ( 1983 ). 3 This pap er contributes to the existing literature in three main w a ys. First, it con tributes to the design-based causal inference literature for TSCS data (e.g., Abadie , 2005 ; Callaw ay and San t’Anna , 2021 ; Arkhangelsky and Im b ens , 2022 ) b y explicitly mo deling the treatmen t assignmen t mec hanism under laten t ignorabilit y . Second, it con tributes to the Ba y esian causal inference literature ( Li et al. , 2023 ) b y extending Ba yesian propensity score analysis, previously dev elop ed primarily for cross-sectional settings (e.g., McCandless et al. , 2009 ; Zigler et al. , 2013 ; Zigler and Dominici , 2014 ; Alv arez and Levin , 2021 ), to TSCS data with p oten tially ric h unobserved confounding structures. Finally , it contributes to the panel data mo deling literature with group ed structures and interactiv e fixed effects (e.g., Mehrabani and P arsaeian , 2025 ) b y allo wing the latent grouping structure, through sub classification, to dep end on the prop ensit y score. The remainder of the pap er is organized as follo ws. Section 2 in tro duces the general framew ork, establishes identification results under the stated assumptions, and presen ts the prop osed metho dology . Section 3 describ es the Ba yesian estimation and inference for the prop osed PS-LFM. Section 4 presents Monte Carlo studies, and Section 5 illustrates the applicability of the metho d through a reanalysis of the effect of political connections on firm v alue. The final section concludes with a discussion of the metho d’s limitations. 2 Metho dology 2.1 Setup and notation W e consider a panel dataset consisting of N units observed o ver T time p erio ds, indexed b y i = 1 , 2 , . . . , N and t = 1 , 2 , . . . , T , resp ectively . F or eac h unit–time pair, w e observe an outcome v ariable Y it ∈ R , for which the effect of a binary treatment D it ∈ { 0 , 1 } is the primary quantit y of interest. F or eac h unit i , w e also observ e a ( p × 1) v ector of pre-treatmen t cov ariates Z i = ( Z i, 1 , . . . , Z i,p ) 2 . W e fo cus on a setting with staggered adoption of the treatment. Let 1 < T 0 < T denote 2 It is straigh tforward to include exogenous time-v arying cov ariates X it in the proposed metho dology . Ho wev er, w e omit the time-v arying cov ariates and just consider time-inv ariant Z i to illustrate treatmen t assignmen t mechanism. 4 the first p erio d in which an y unit receiv es treatment. Define A i as the adoption time for unit i , and set A i = T + 1 if unit i nev er adopts the treatmen t during the observ ation window. The treatment path is therefore fully determined by the adoption date, as D it = 1 { t ≥ A i } for t = 1 , . . . , T . Let D i = ( D i 1 , . . . , D iT ) denote the treatment sequence for unit i . W e imp ose the following assumption on the assignmen t of adoption dates. Assumption 1 (Randomization of adoption time for treated units) . Conditional on A i = T + 1 , the adoption time A i is r andomly dr awn fr om { T 0 , T 0 + 1 , . . . , T } for e ach i ∈ { 1 , . . . , N } . Assumption 1 states that, among units that even tually receive treatmen t, the timing of adoption is randomly assigned and do es not dep end on unit-lev el cov ariates. Accord- ingly , we define i ∈ T (treated units) if A i ∈ { T 0 , . . . , T } and i ∈ C (con trol units) if A i = ∞ . With a sligh t abuse of notation, let W i = 1 { i ∈ T } denote an indicator for whether unit i ev er receives treatmen t. Under this assumption, unit-lev el co v ariates ma y influence whether a unit is ev er treated (i.e., W i ), but conditional on W i = 1, the adoption timing A i is random. This assumption is satisfied, for example, when treatment timing is externally randomized, but it may b e violated if unit-level c haracteristics systematically affect adoption timing, as in the setting of Calla wa y and San t’Anna ( 2021 ). W e adopt the potential outcomes framew ork ( Rubin , 1974 ) to define treatmen t effects. The p oten tial outcome for unit i at time t is denoted Y it ( d i ), where d i = ( d 1 , . . . , d T ) ∈ { 0 , 1 } T represen ts a realization of the full treatment sequence. F ollowing Arkhangelsky and Imbens ( 2022 ) and A they and Im b ens ( 2022 ), W e imp ose the follo wing assumption of exclusion restriction, whic h rules out effects of b oth past and future treatmen ts. Assumption 2 (Exclusion restriction) . Ther e is no anticip ation of futur e tr e atment, and no c arryover effe cts fr om p ast tr e atment. Conse quently, Y it ( d i ) = Y it ( d it ) , for al l i , t , and d it ∈ { 0 , 1 } . Under Assumption 2 , there are only tw o p otential outcomes for eac h unit-time pair: Y it (1) and Y it (0). The individual treatmen t effect is therefore defined as: δ it = Y it (1) − Y it (0) . 5 Our primary estimand is the av erage treatmen t effect on the treated (A TT) r p eriods after treatmen t adoption, defined as: AT T r = P i,t 1 { A i = t } δ i,t + r P i,t 1 { A i = t } . (1) This quan tity is a conv ex com bination of individual treatment effects and represents the dynamic effect relativ e to treatment adoption. W e also consider the o verall a verage treat- men t effect on the treated, defined as AT T = P i,t D it δ it P i,t D it , whic h captures the av erage effect for treated units o v er the en tire sample perio d. T o identify the treatmen t effects abov e, w e assume the presence of b oth observ ed pre- treatmen t confounders Z i and unobserv ed, time-inv arian t unit-sp ecific confounders γ i . W e formalize this using a latent ignorabilit y assumption ( F rangakis and Rubin , 1999 ): Assumption 3 (Laten t ignorabilit y) . { Y it (0) , Y it (1) } ⊥ ⊥ W i | Z i , γ i , for al l i and t . This assumption states that the potential outcomes are independent of whether a unit is treated, conditional on Z i and γ i . In addition, let Pr( W i = 1 | Z i , γ i ) denote the prop ensit y score for treatment. W e in addition imp ose the p ositivity assumption, i.e., 0 < Pr( W i = 1 | Z i , γ i ) < 1, whic h ensures o v erlap in treatmen t assignmen t conditional on b oth observed and latent confounders. Relativ e to standard condition al ignorabilit y assumptions that rule out unobserved con- founding, Assumption 3 explicitly allo ws for time-in v ariant laten t confounders, making it particularly suitable for time-series cross-sectional settings. 2.2 Ba yes ian causal inference W e establish identification of the treatmen t effects within the Bay esian causal inference framew ork ( Rubin , 1978 ). The primary ob jective of Ba yesian causal inference is to deriv e the posterior predictiv e distributions of missing p oten tial outcomes. In our setting, because laten t confounders are unobserved, w e must jointly mo del the p osterior distribution of 6 the missing p oten tial outcomes and the latent confounders, and then integrate ov er the p osterior distribution of the latter. Since our estimands are the a v erage treatmen t effects on the treated (A TTs), w e focus on imputing the missing counterfactual outcomes under con trol for treated observ ations. Let Y i (0) = ( Y i 1 (0) , . . . , Y iT (0)) denote the tra jectory of p oten tial outcomes under con- trol for unit i , and stac k these to form Y (0) = ( Y 1 (0) ′ , . . . , Y N (0) ′ ) for all units. Lik ewise, let W = ( W 1 , . . . , W N ) denote the treatment group indicators, Z = ( Z 1 , . . . , Z N ) the ob- serv ed cov ariates, and Γ = ( γ 1 , . . . , γ N ) the laten t confounders. W e follo w Rubin ( 2005 ) and call f ( Y (0) , Z , Γ) a mo del on the “science” 3 . Assuming the observ ations of eac h unit are exchangable conditional on Z i and γ i , by de Finetti’s theorem, w e can write f ( Y (0) , Z , Γ) = Z N Y i =1 f ( Z i , γ i , Y i (0) | θ ) f ( θ ) dθ , (2) where θ represen ts a v ector of parameters in the p otential outcome mo del f ( ·| θ ), with f ( θ ) its prior distribution. W e partition the p oten tial outcomes under con trol as Y (0) = Y (0) obs , Y (0) mis , where Y (0) mis represen ts the missing counterfactual outcomes for treated observ ations. Because Γ is unobserved, w e deriv e the p osterior distribution of Y (0) mis conditional on Y (0) obs , W , Z as follo ws: f ( Y (0) mis | Y (0) obs , W , Z ) ∝ f ( W , Z , Y (0)) = Z f ( W , Z , Γ , Y (0)) d Γ = Z f ( W | Z , Γ , Y (0)) f ( Z , Γ , Y (0)) d Γ = Z f ( W | Z , Γ) f ( Y (0) mis | Z , Γ , Y (0) obs ) f ( Z , Γ , Y (0) obs ) d Γ ∝ Z f ( W | Z , Γ) f ( Y (0) mis | Z , Γ , Y (0) obs ) f (Γ | Z , Y (0) obs ) d Γ , (3) where the fifth line of Equation ( 3 ) follo ws from Assumption 3 , which implies indep endence b et ween treatment assignmen t W and potential outcomes Y (0) conditional on Z and Γ. 3 As in Rubin ( 2005 ), the science means the complete data ( Y (0) , Y (1) , Z , Γ). Here we omit Y (1) to fo cus on the imputation of missing Y (0). 7 It is w orth noting that the posterior predictiv e distribution ( 3 ) of Y (0) mis can b e ex- pressed as f ( Y (0) mis | Z , Γ , Y (0) obs ), the second component in the final in tegral, marginal- ized o v er the p osterior distribution of the latent confounders Γ. This posterior is propor- tional to the pro duct of the prop ensit y of treatment f ( W | Z , Γ) and the conditional distribution f (Γ | Z , Y (0) obs ). The first term characterizes the treatment assignment mec hanism, while the second reflects the extent to which Γ can b e learned from the ob- serv ed data. In the factor analysis literature, inference on laten t factors such as Γ t ypically relies on additional structural assumptions that enable their reco very from observ ed outcomes, sometimes referred to as “flexible data extraction” (e.g., Xu , 2017 ; Pang et al. , 2022 ). The robustness of treatmen t effect estimates to violations of these assumptions has b een examined in panel data settings; see, for example, Liu and Y amamoto ( 2025 ). According to Equation ( 2 ), the p osterior predictive distribution ab o ve can b e further expressed as: f ( Y (0) mis | Y (0) obs , W , Z ) ∝ Z f ( W | Z , Γ) f ( Y (0) mis | Z , Γ , Y (0) obs ) f (Γ | Z , Y (0) obs ) d Γ = Z Z f ( W | Z , Γ) f ( Y (0) mis | Z , Γ , θ ) f ( θ | Z , Γ , Y (0) obs ) f (Γ | Z , Y (0) obs ) d Γ dθ = Z Z f ( W | Z , Γ) f ( Y (0) mis | Z , Γ , θ ) f ( θ , Γ | Z , Y (0) obs ) d Γ dθ , (4) where f ( θ | Z , Γ , Y (0) obs ) in the third line of Equation ( 4 ) denotes the posterior distribution of the model parameters θ conditional on Z , Γ, and Y (0) obs . Ov erall, the re-expressed posterior predictiv e distribution ( 4 ) indicates that iden tifica- tion and estimation of the coun terfactuals rely on three comp onen ts: modeling the treat- men t assignmen t mec hanism, mo deling the p oten tial outcomes under con trol, and learning b oth the mo del parameters and latent confounders from the observ ed data. 2.3 Prop ensit y score-augmen ted outcome mo del The laten t ignorabilit y Assumption 3 implies that iden tification of treatmen t effect of D it on Y it requires controlling for both observ ed confounders Z i and unobserved time-inv arian t 8 confounders γ i . In mo del-based approaches to causal inference, the effect of γ i is often captured either through additiv e tw o-wa y fixed effects in difference-in-differences designs or through laten t factor structures in in teractive fixed-effects mo dels (e.g., Bai , 2009 ). A general functional form for the potential outcome mo del can be written as Y it (0) = g ( Z i , γ i , ε it ) , Y it (1) = δ it D it + Y it (0) , (5) where δ it denotes heterogeneous treatmen t effects and ε it is a mean-zero error term. Note that the p oten tial outcome mo del in Equation ( 5 ) corresp onds exactly to the second comp onen t in the final integral of the posterior ( 4 ). Giv en an outcome mo del, re- searc hers can impute the coun terfactual outcomes under con trol for treated observ ations and then estimate the av erage treatment effect on the treated b y av eraging the differences b et ween observed outcomes and predicted counterfactua ls. Such coun terfactual predic- tion–based approac hes are referred to as “causal panel data mo dels” in A they et al. ( 2021 ). F or example, a linear sp ecification incorp orating γ i through a laten t factor structure can b e written as Y it = δ it D it + Z ′ i α t + γ ′ i f t + ε it , (6) where α t denotes time-v arying co efficients for the observed pre-treatment cov ariates Z i . Here, γ i can b e interpreted as an ( r × 1) vector of factor loadings and f t as an ( r × 1) v ector of common factors, with the num b er of factors r t ypically unknown a priori . This sp ecification implies a latent factor mo del, Y it (0) = Z ′ i α t + γ ′ i f t + ε it , for potential outcomes under control. Despite its p opularit y as an empirical estimation strategy , the causal latent factor mo del ( 6 ) typically do es not explicitly mo del the treatment assignment mec hanism, re- lying instead on the latent ignorabilit y assumption. One reason is that mo deling treatment assignmen t requires accounting for laten t confounders, whic h m ust themselv es b e inferred from observed data, as discussed abov e. Moreo ver, b ecause the propensity score, defined as P r ( W i = 1 | Z i , Γ i ), summarizes information con tained in b oth Z i and the latent con- founders γ i , omitting this term from the outcome mo del may lead to mo del mis-sp ecification and, consequen tly , biased estimates of treatmen t effects. Only recen tly hav e methods b een 9 dev elop ed that explicitly mo del treatmen t assignment under latent ignorabilit y (e.g., F orino et al. , 2025 ; Sc hmidt et al. , 2025 ). T o address this limitation, we extend the ab o ve framew ork b y explicitly incorp orating the treatmen t assignment mec hanism as an additional stage. Sp ecifically , w e propose the follo wing joint mo del for treatmen t assignmen t and p oten tial outcomes: W i = 1 { Z ′ i λ z + γ ′ i λ γ + ν i ≥ 0 } , Y it (0) = g ( Z i , ps ( Z i , γ i ; λ )) ′ β t + γ ′ i f t + ε it , Y it (1) = δ it D it + Y it (0) , (7) where the first equation sp ecifies treatment assignmen t as a function of b oth observ ed co v ariates Z i and laten t factor loadings γ i , allowing unobserved confounders to influence b oth treatment assignmen t and outcomes. This component corresp onds to the prop ensity score stage in the Ba yesian prop ensit y score literature (e.g., McCandless et al. , 2009 ; Zigler et al. , 2013 ). The prop ensit y score implied b y the first equation in ( 7 ), defined as ps ( Z i , γ i ; λ ) = Pr( W i = 1 | Z i , γ i ), enters the outcome model directly through a flexible but presp ecified function g ( · ), together with Z i and γ i . This comp onen t constitutes the outcome stage. W e allo w these effects to v ary ov er time through the co efficient vector β t . The laten t factor term γ ′ i f t serv es as a residual adjustment, capturing v ariation not explained by the prop ensit y score–based comp onent. W e refer to the prop osed join t mo del ( 7 ) as the prop ensit y score–augmen ted laten t factor mo del (PS-LFM). F or the prop ensity score stage, without loss of generalit y , w e assume ν i ∼ N (0 , 1), whic h implies ps ( Z i , γ i ; λ ) = Φ( Z ′ i λ z + γ ′ i λ γ ) , (8) where Φ( · ) denotes the standard normal cum ulativ e distribution function. F or the outcome mo del, the function g ( Z i , ps ( Z i , γ i ; λ )) sp ecifies how the prop ensit y score enters the outcome model. One example is a prop ensity-score sub classification speci- fication with k strata ( Rosenbaum and Rubin , 1983 ; McCandless et al. , 2009 ). F or instance, 10 when k = 3 and 0 < q 1 < q 2 < 1 are t wo threshold v alues, g ( Z i , ps ( Z i , γ i ; λ )) = [1 , 0 , 0] ′ ⊗ Z i , 0 < ps ( Z i , γ i ; λ ) < q 1 , [0 , 1 , 0] ′ ⊗ Z i , q 1 ≤ ps ( Z i , γ i ; λ ) < q 2 , [0 , 0 , 1] ′ ⊗ Z i , q 2 ≤ ps ( Z i , γ i ; λ ) < 1 . (9) F ollowing the existing literature (e.g., McCandless et al. , 2009 ; Zigler et al. , 2013 ; Zigler and Dominici , 2014 ), w e assume that the thresholds q 1 and q 2 are predetermined b y the researc her prior to estimating the propensity score. Alternativ ely , the prop ensit y score ma y en ter the outcome mo del as a con tinuous co- v ariate, g ( Z i , ps ( Z i , γ i ; λ )) = [ Z ′ i , ps ( Z i , γ i ; λ )] ′ , (10) whic h can b e viewed as a contin uous analogue of prop ensit y-score stratification ( Rosen- baum and Rubin , 1983 ) . In the remainder of the pap er, w e focus on the subclassification sp ecification ( 9 ) to illustrate estimation and inference. 3 Ba y esian Estimation and Inference W e adopt a Bay esian approach for the estimation and inference of treatmen t effects based on the prop osed PS-LFM ( 7 ). Compared with frequentist approac hes, the Bay esian framew ork naturally incorporates uncertain t y in b oth prop ensit y score estimation (e.g., McCandless et al. , 2009 ; Alv arez and Levin , 2021 ) and factor selection (e.g., Samartsidis et al. , 2020 ; P ang et al. , 2022 ). 3.1 Re-parameterization, shrink age, and mo del selection F ollowing the literature on Ba y esian factor analysis (e.g., Gew eke and Zhou , 1996 ), w e assume that the factor loadings are dra wn from an i.i.d. m ultiv ariate normal distribution N (0 , Σ γ ), where Σ γ = Diag { ω 2 1 , . . . , ω 2 r } is an ( r × r ) diagonal matrix. The common factors are assumed to follo w an i.i.d. m ultiv ariate normal distribution N (0 , I r ), where I r denotes the iden tity matrix. The idiosyncratic error term ε it is assumed to be i.i.d. normal with 11 mean zero and v ariance σ 2 4 . F or mo del selection and estimation, w e adopt a re-parameterization of the original Mo del ( 7 ) following F r ¨ uh wirth-Sc hnatter and W agner ( 2010 ) and P ang et al. ( 2022 ). F or notational con venience, define ˜ Z i = g ( Z i , ps ( Z i , γ i ; λ )), so that ˜ Z i represen ts an expanded v ector of individual co v ariates augmen ted with the prop ensit y score. W e further decomp ose β t = β + ξ t , where β captures time-inv arian t effects and ξ t represen ts time-v arying ran- dom deviations with mean zero. In the terminology of mixed-effects mo dels, β corresp onds to fixed effects and ξ t to random effects. Although more flexible temp oral dep endence structures could b e incorp orated, as with the laten t factors, w e adopt the simpler hierar- c hical sp ecification ξ t iid ∼ N (0 , Σ ξ ), where Σ ξ is diagonal, in order to highligh t the role of prop ensit y-score augmen tation. Because prop ensit y-score sub classification ma y pro duce a high-dimensional expanded co v ariate v ector ˜ Z i , and b ecause the n umber of laten t factors is unkno wn, w e re-parameterize b oth the random effects ξ t and the factor loadings γ i to facilitate shrink age-based mo del selection. The resulting model can b e written as: W i = 1 { Z ′ i λ z + ( ω γ · ˜ γ i ) ′ λ γ + ν i ≥ 0 } , Y it (0) = g ( Z i , ps ( Z i , ω γ · ˜ γ i ; λ )) ′ β + g ( Z i , ps ( Z i , ω γ · ˜ γ i ; λ )) ′ ( ω ξ · ˜ ξ t ) + ( ω γ · ˜ γ i ) ′ f t + ε it , Y it = δ it D it + Y it (0) , ˜ ξ t ∼ N (0 , I p ) , ˜ γ i ∼ N (0 , I r ) , f t ∼ N (0 , I r ) , ν i ∼ N (0 , 1) , ε it ∼ N (0 , σ 2 ) . (11) T o illustrate model selection, consider the factor component. F or the j -th factor f t,j , if the associated scaling parameter ω γ ,j = 0, the corresp onding factor is excluded from b oth the outcome and treatment assignmen t mo dels, as ω γ ,j · ˜ γ i,j ≡ 0 ∀ i . Because the prior distribution for ω γ includes zero in the in terior of its supp ort, this contin uous shrink age re-parameterization enables factor selection through posterior shrink age. 4 It is natural to extend the static factor specification to more flexible dynamic structures, such as random-w alk factors or AR(1) pro cesses ( Pang et al. , 2022 ). More complex sp ecifications for the error term, such as stochastic v olatility (e.g., Belmon te et al. , 2014 ), can also b e incorp orated. F or notational simplicit y , we consider a static factor structure with i.i.d. normal errors. 12 It is p ossible that some laten t factor loadings affect treatmen t assignment but not p oten tial outcomes. In this case, such loadings do not constitute confounders and therefore do not need to b e con trolled for in the outcome mo del. Ho wev er, if priors were placed directly on factor loadings γ i in the original join t mo del ( 7 ), exact shrink age to zero would generally not b e ac hiev able. The same reasoning applies to the random-effect comp onen t ξ t . In addition to shrink age-based mo del selection, iden tification of the laten t factor struc- ture p oses another challenge. This issue has b een well do cumented in the in teractive fixed-effects literature (e.g., Bai , 2009 ). Let Γ = ( γ 1 , . . . , γ N ) ′ denote the N × r matrix of factor loadings and F = ( f 1 , . . . , f T ) ′ the T × r matrix of common factors. F or any in v ertible r × r matrix A , we hav e F Γ ′ = ( F A − 1 )( A Γ ′ ), implying that only a rotationally equiv alen t representation of the factor structure is iden tified. F requentist approac hes t ypically imp ose normalization conditions suc h as F ′ F /T = I r and Γ ′ Γ b eing diagonal with distinct en tries 5 . These normalization conditions are lik ewise assumed in F orino et al. ( 2025 ), where treatment assignmen t is sp ecified as a Logit model with factor loadings included as co v ariates. Ho w ever, recen t Bay esian w ork on shrink age-based factor selection (e.g., Bhattac harya and Dunson , 2011 ; Samartsidis et al. , 2020 ) has primarily fo cused on imputing coun ter- factual outcomes and estimating treatment effects, treating latent factors largely as n ui- sance parameters without imposing explicit iden tification constraints. Moreo v er, updates of h yp er-parameters in the shrink age priors typically rely on dra ws of factor loadings from their conditional posterior distributions. In our framew ork, how ever, the latent factors also en ter the treatmen t assignment mo del, making their identification necessary for coheren t estimation. In the next sub- section, we prop ose an approximate Bay esian algorithm that addresses the trade-off b e- t w een shrink age for model selection and normalization of factor loadings for mo deling the treatmen t assignment mec hanism. 5 In the Bay esian framework, b ecause the prior distribution for the factors already assumes an iden tity co v ariance matrix I r , an additional normalization prop osed b y Gewek e and Zhou ( 1996 ) imp oses an iden- tification restriction on the factor loadings. Sp ecifically , the loading matrix is partitioned as Γ = (Γ 1 , Γ 2 ), where Γ 1 is constrained to b e lo wer triangular with positive diagnoal v alues. 13 3.2 Mo del feedback and appro ximate Ba y esian inference The re-expressed PS-LFM ( 11 ) implies that the join t lik eliho o d of the treatment assignmen t and outcome model can b e expressed as follo ws: f ( Y (0) obs , W | Z , ˜ Γ , F , ˜ Ξ , ω , λ , β ) = N Y i =1 Φ( Z ′ i λ z + γ ′ i ( ω γ · ˜ γ i )) W i [1 − Φ( Z ′ i λ z + γ ′ i ( ω γ · ˜ γ i ))] 1 − W i × σ − ( N T − P i,t D it ) Y D it =0 exp ( − 1 2 σ 2 X D it =0 y it − ˜ Z ′ i β − ˜ Z ′ i ( ω ξ · ˜ ξ t ) − ( ω γ · ˜ γ i ) ′ f t 2 ) , (12) where ˜ Γ = ( ˜ γ 1 , . . . , ˜ γ N ) and ˜ Ξ = ( ˜ ξ 1 , . . . , ˜ ξ T ) denote the matrices of factor loadings and time-v arying co efficien ts, resp ectiv ely , and ω = ( ω γ , ω ξ ) denotes their asso ciated scale parameters that impose shrink age. Assigning prior distributions to the parameters Θ = ( ˜ Γ , F , ˜ Ξ , ω , λ , β ) allo ws straight- forw ard implementation of a fully Bay esian analysis b y sampling from the join t p osterior distribution f (Θ | Y (0) obs , W , Z ) ∝ f ( Y (0) obs , W | Z , Θ) f (Θ) . (13) While conceptually appealing, this approac h ma y adv ersely affect p osterior inference due to what is commonly referred to as mo del fe e db ack . Sp ecifically , when up dating the normalized factor loadings ˜ γ i , whic h app ear in b oth the treatmen t assignment and outcome mo dels, the posterior up dates w ould condition join tly on observ ed con trol outcomes and treatment assignmen ts. This issue has b een discussed in Zigler et al. ( 2013 ). T o illustrate this issue within the prop osed mo del, we consider the p osterior analysis of the factor loadings as an example. The problem of mo del feedbac k arises because the influence of factor loadings on treatmen t adoption, captured b y the parameters λ γ , is not separately iden tified from the scale of the factor loadings ( ω γ ) themselv es. F or example, dividing λ γ b y a scalar ℓ while m ultiplying the factor loadings by ℓ lea ves the treatmen t assignmen t mechanism unc hanged. How ever, such scaling am biguit y affects iden tification of the (normalized) factor loadings in the outcome mo del, p oten tially propagating non- iden tifiabilit y to other parameters and leading to unstable estimation of coun terfactual outcomes and, consequen tly , treatmen t effects. A similar issue arises for the prop ensit y 14 score, which is determined by the treatment assignment mechanism yet also enters the outcome mo del, creating analogous identification and inference challenges. T o mitigate this issue, rather than conducting a fully Ba yesian analysis, w e adopt an alternativ e pro cedure that cuts the feedback lo op b et ween the treatmen t assignment and outcome stages, yielding what is often referred to as an approximate Bay esian analysis. The k ey idea is that when parameters appear in b oth the treatmen t assignment and out- come mo dels, one component of the likelihoo d is omitted when up dating those parameters, pro ducing approximate posterior dra ws. F or instance, the factor loadings ˜ Γ are up dated using only the outcome mo del, whereas the propensity score parameters are updated using only the treatment assignmen t mo del, ev en though the factor loadings en ter the treatmen t assignment mo del and the prop ensity scores appear in the outcome model. This appro ximate Ba yesian approach, together with the residual adjustment terms in the outcome mo del, has b een sho wn to effectiv ely address mo del feedback issues in Ba yesian prop ensity score analysis ( Zigler et al. , 2013 ; Zigler and Dominici , 2014 ), and is therefore particularly suitable for settings with unobserved confounding, such as the causal panel data models. It is w orth noting that, by omitting the treatmen t-assignment likelihoo d comp onen t when up dating the factor loadings, the appro ximate Bay esian algorithm facilitates identifi- cation of ω γ and, consequently , coherent mo deling of the treatmen t assignment mec hanism. Because b oth ω γ and the laten t factors ˜ F are updated solely from the outcome mo del, we follo w Ando et al. ( 2022 ) and apply a “p ost-pro cessing” rotation to the dra ws of F and ˜ Γ 6 . Let ˆ Γ = ˜ Γ diag ( ω γ ), where diag ( ω γ ) is the ( r × r ) diagonal matrix whose diagonal entries are giv en b y ω γ . Define M = ( 1 T ˜ F ′ ˜ F ) 1 / 2 ( 1 N ˆ Γ ′ ˆ Γ)( 1 T ˜ F ′ ˜ F ) 1 / 2 . Compute the eigen decomp o- sition M = QD Q ′ , where Q is orthogonal and D is diagonal. Then define the rotated loadings and factors as Γ = ˆ Γ( 1 T ˜ F ′ ˜ F ) 1 / 2 Q, and F = ˜ F ( 1 T ˜ F ′ ˜ F ) − 1 / 2 Q . By construction, the rotated (Γ , F ) satisfy the normalization restrictions in Bai ( 2009 ). W e then insert the rotated Γ in to the treatmen t assignment mo del to update the parameters λ γ and λ z . 6 Ando et al. ( 2022 ) prop ose an EM algorithm for estimating a panel Probit mo del with in teractive fixed effects. Their pro cedure up dates factors and loadings sequen tially without imposing normalization restrictions during the EM iterations and applies a rotation after conv ergence to enforce standard identifying restrictions. 15 The implemen tation pro cedure for the appro ximate Bay esian analysis is summarized in Algorithm 1 . F or prior sp ecification, we assign hierarc hical shrink age priors ( P ark and Casella , 2008 ) to β , ω γ , and ω ξ to facilitate mo del selection, and conjugate normal priors to λ z and λ γ . Details of the prior sp ecifications and the Mark ov chain Monte Carlo (MCMC) algorithm are pro vided in A . Algorithm 1 An Approximately Ba y esian MCMC Sampler With the most up dated parameters, at iteration ( h + 1): 1. Rotate ˜ F and ˆ Γ, as defined ab o ve, to obtain factor loadings Γ that satisfy the nor- malization restrictions, 2. Up date co efficients λ z and λ γ in the treatment assignment mo del and up date the prop ensit y score for each unit, 3. Up date ˜ Z i giv en the updated propensity scores, 4. Jointly Up date parameters β , ω ξ and ω γ , 5. Up date factor loadings ˜ γ i for i ∈ { 1 , . . . , N } using only the outcome model, 6. Jointly Up date time-v arying random effects ˜ ξ t and laten t factors f t for t ∈ { 1 , . . . , T } , 7. Up date error v ariance σ 2 in the outcome mo del, 8. Up date the h yp erparameters in the corresp onding shrink age priors, 9. Up date counterfacutal outcome Y it (0) and individual treatmen t effect δ it = Y it − Y it (0) for observ ations under treatmen t ( D it = 1), 10. Average o v er δ it for observ ations under treatmen t as an estimate of the A TTs. Rep eat Steps ab ov e at the next iteration un til the Mark ov c hains conv erge. 4 Mon te Carlo Studies W e conduct a series of Mon te Carlo sim ulations to in vestigate the prop erties of the pro- p osed prop ensit y score–augmen ted Bay esian factor mo del (PS-LFM) and to compare its p erformance with that of the canonical Ba yesian factor model (DM-LFM), and some other mo del specifications, for treatmen t effect estimation. Our primary estimand is the av erage treatmen t effect on the treated, and we ev aluate estimator p erformance in terms of bias, ro ot mean squared error (RMSE), the sampling standard deviation (Sampling SD) of the 16 p osterior mean as a p oin t estimator, and the co verage rate of the 95% p osterior credible in terv als. In particular, w e examine how the prop osed metho d p erforms relative to alternativ e mo dels under tw o scenarios: (i) when units are stratified in to prop ensit y score strata and the co efficients v ary across strata, and (ii) when no such stratification is presen t, so that the DM-LFM is correctly sp ecified and propensity score adjustment is unnecessary . W e consider a setting with N = 200 units observed ov er T = 50 p erio ds with stag- gered treatmen t adoption. F or the case inv olving prop ensit y score stratification, simulated datasets are generated according to the following data-generating pro cess (DGP). F or each unit i , we generate tw o observed unit-lev el co v ariates, Z i 1 and Z i 2 , which are dra wn in- dep enden tly from standard normal distributions, and t w o latent factor loadings, γ i 1 and γ i 2 , that satisfy the restrictions in for identification. T reatmen t assignment follows the probabilistic rule: W i = 1 { Z i 1 + Z i 2 + γ i 1 + γ i 2 + ν i ≥ 0 } , where ν i i.i.d. ∼ N (0 , 1). Then corresp onding propensity score is Pr( W i = 1) = Φ( Z i 1 + Z i 2 + γ i 1 + γ i 2 ). Among treated units, half are randomly designated as “early adopters”, which receiv e treatmen t from p erio d t = 45, while the remaining half are “late adopters”, receiving treat- men t from t = 48. Units are stratified into three prop ensity score strata using thresholds of 0 . 3 and 0 . 6. Sp ecifically , a unit is assigned to group 1 if its prop ensit y score is less than 0 . 3, to group 3 if its prop ensity score exceeds 0 . 6, and to group 2 otherwise. P oten tial outcomes under con trol follo w the laten t factor specification: Y it (0) = X ′ it β ( g ) + Z ′ i ( g ) ξ ( g ) t + γ ′ i f t + ε it , where g ∈ { 1 , 2 } indexes the prop ensit y score stratum. Without loss of generalit y , we set the group-sp ecific time-v arying coefficients to follo w heterogeneous sin usoidal time trends. The laten t factors f t and idiosyncratic errors ε it are dra wn indep enden tly from standard normal distributions. T reatmen t effects are set to zero for all treated units in p ost-treatment p eriods. F or mo del estimation, w e allo w up to fiv e laten t factors with shrink age priors for mo del selection for b oth the DM-LFM and the prop osed PS-LFM. F or comparison, w e consider 17 three alternativ e sp ecifications. The first is an oracle mo del in which the true prop ensit y scores, corresp onding prop ensit y score strata, and the true num b er of latent factors are assumed known, thereby eliminating uncertain t y in prop ensit y score estimation and mo del selection. W e refer to this sp ecification as “Oracle”. The second one is the doubly robust difference-in-differences estimator for staggered adoption settings prop osed b y Calla w ay and San t’Anna ( 2021 ), which w e denote as “CS-DID”. F or the CS-DID estimator, we include only the time-in v ariant cov ariates in b oth the treatmen t assignmen t and outcome mo dels. The last estimator is the fixed effects counterfactual (“FEct”) estimator prop osed b y Liu et al. ( 2024 ), which imputes coun terfactual outcomes using an in teractiv e fixed effects mo del. F or the FEct estimator, w e set the num b er of factors equal to the true v alue. W e conduct 500 Mon te Carlo replications, and the results are rep orted in T able 1 . In addition, a sim ulated example comparing the estimated prop ensity scores and dynamic treatmen t effects across the v arious mo del sp ecifications described ab o ve is presen ted in B . The Oracle estimator exhibits the lo west bias, close to zero, and its 95% credible in terv al ac hiev es cov erage rates near the nominal lev el. This is exp ected, as the true prop ensity score, and hence the prop ensit y score strata, is known b y construction. The proposed PS- LFM estimator has a larger bias than the Oracle estimator, which is reasonable b ecause the prop ensit y score must be estimated from a treatmen t assignmen t mo del in which the laten t factor loadings, serving as unobserved confounders, are inferred from the outcome mo del. Nevertheless, the co verage rate of the 95% credible in terv al remains close to the nominal level. In contrast, b oth the DM-LFM and FEct estimators exhibit larger bias and RMSE relativ e to the PS-LFM, as they ignore the prop ensit y score strata. Their co verage rates are also b elo w the nominal level compared to the PS-LFM. Finally , the CS-DID estimator p erforms w orse than both the DM-LFM and FEct estimators. This is b ecause the DGP incorp orates a laten t factor structure that fav ors laten t factor–based estimators, whereas CS-DID is a doubly robust estimator that relies on observ ed cov ariates to mo del b oth the treatmen t assignment and the (difference in) outcome. 18 T able 1: Monte Carlo Study Results for DGP with Prop ensit y Score Strata Mo del Bias RMSE Sampling SD Co verage Rate Oracle 0 . 006 0 . 147 0 . 147 0 . 960 PS-LFM − 0 . 036 0 . 138 0 . 134 0 . 945 DM-LFM − 0 . 100 0 . 183 0 . 153 0 . 880 CS-DID − 0 . 907 1 . 636 1 . 365 0 . 330 FEct − 0 . 097 0 . 298 0 . 283 0 . 915 5 Empirical Application T o illustrate the applicability of the prop osed PS-LFM in so cial sciences study , w e re- examine the effect of prior connections with Timoth y Geithner on abnormal sto ck returns of financial firms during the first ten trading da ys follo wing the announcemen t of his nom- ination as U.S. T reasury Secretary in No vem b er 2008. It is originally studied b y Acemoglu et al. ( 2016 ), as the v alue of political connections remains an important topic in the p olitical econom y literature. In their analysis, the authors adopt tw o approaches to ev aluate the effect of p olitical connection on firm v alue. The key step is estimating abnormal returns, defined as the difference b etw een observ ed daily returns and counterfactual returns that w ould hav e b een realized had firms not p ossessed prior connections. First, they estimate counterfactual returns using a linear regression of firm returns on mark et returns, proxied b y the S&P 500 index. As a robustness chec k, they implement the synthetic con trol metho d (SCM; Abadie et al. , 2010 ), constructing counterfactual returns as conv ex com binations of returns from firms without p olitical connections. The authors con trol for three firm-lev el co v ariates commonly used in asset pricing studies: firm size measured b y total assets (on a log scale), profitabilit y captured by return on equit y (ROE), and lev erage measured as the ratio of total debt to total capital in 2008 7 . They also apply prop ensit y score matching based on these cov ariates to impro ve co v ariate balance b et ween treated and con trol firms. Both approac hes are grounded in factor-mo del p erspectives on asset pricing ( Gew eke and Zhou , 1996 ), suggesting that the proposed metho d, which incorp orates latent factor 7 These firm-level cov ariate data are taken from the W orldscop e database. 19 structures, pro vides a flexible framework for constructing coun terfactual returns. Moreov er, concerns ab out unobserv ed firm-lev el confounders motiv ate our re-analysis. Financial firms with similar prop ensities for Geithner connection may share exp osure to unobserved eco- nomic or political factors affecting sto c k returns, p oten tially differing systematically from firms with lo wer connection prop ensities. The proposed PS-LFM is therefore w ell suited to improv e robustness in abnormal return estimation. F or the re-analysis, w e consider a sample of 536 financial firms, among whic h 53 firms ha v e prior connections with Timothy Geithner 8 . The treatment indicator equals one for firms with suc h prior connections. The outcome v ariable is the daily stock return for eac h firm. Consisten t with the original study , w e regard Nov ember 21, 2008, as the treatment date, with all treated firms receiving treatment sim ultaneously . The pre-treatmen t p eriod includes all trading days in 2008 ending 30 da ys b efore the announcemen t, yielding 226 pre- treatmen t observ ations for mo del fitting. W e then examine ten trading days follo wing the announcemen t as the post-treatment p erio d, resulting in elev en p ost-treatmen t observ ations in total. F or mo del sp ecification, w e con trol for the three firm-level cov ariates describ ed ab o ve and allo w their effects to v ary o ver time and across prop ensity score strata. Because appro ximately 10% of firms are treated, we use a threshold of 0.1 to form tw o prop ensit y score strata. T o account for unobserv ed factors in the return-generating pro cess ( Gewek e and Zhou , 1996 ), w e include 5 laten t factors with shrink age priors for mo del selection. The treatmen t assignmen t pro cess is modeled such that the prop ensity for connection dep ends on both observ ed firm-lev el co v ariates and latent factor loadings. In addition, w e con trol for the daily return of the S&P 500 index as an observ ed common factor in the outcome model, allowing for firm-sp ecific effects through a m ulti-level sp ecification. The p osterior distributions of the co efficien ts for the three firm-level co v ariates in the treatment assignmen t mo del, sho wn in Figure 1 , indicate that these co v ariates influence the prop ensit y for connection with Timoth y Geithner, consisten t with the findings of the original study . 8 F ollowing Acemoglu et al. ( 2016 ), a firm is considered connected if it satisfies at least one of three criteria: sc heduled interactions with executives during 2007–2009, p ersonal connections, or headquarters lo cated in New Y ork. 20 T o highlight the role of incorp orating prop ensit y scores together with latent factor loadings, w e also estimate the DM-LFM as a b enchmark for comparison. The estimated abnormal returns based on either model sp ecification are displa yed in Figure 2 . Due to lim- ited space, we only sho w four pre-treatment perio ds b efore the announcement. In general, the tra jectories of abnormal returns based on either mo del sp ecifications match closely to eac h other. Ho wev er, for the announcement da y , the 95% CI of abnormal return based on the PS-LFM co vers zero, while based on the DM-LFM do es not cov er zero. This also ap- plies to the nin th trading da y after the announcement, indicating slight y et non-negligible difference in abnormal return estimation when incorporating propensity score stratification. As additional results, w e examine the estimated time-v arying effects of the three firm- lev el cov ariates. While firm size do es not displa y significant heterogeneit y across the t wo prop ensit y score strata, profitabilit y and leverage exhibit substantial heterogeneity in their time-v arying effects. T o further assess the v alidity of the estimates, w e also conduct a placeb o test b y treating the t wo trading days prior to the announcemen t as placeb o p erio ds. The estimated placeb o effects for both the proposed PS-LFM and the original DM-LFM are close to zero, and the corresp onding 95% CIs co ver zero, whic h further supp orts the v alidit y of the estimates. These additional results are rep orted in C . Firm Size Frequency 0.3 0.4 0.5 0.6 0.7 0.8 0.9 0 200 400 Profitablity Frequency −0.4 −0.3 −0.2 −0.1 0.0 0.1 0.2 0 100 300 500 Lev erage Frequency −0.7 −0.5 −0.3 −0.1 0 100 300 500 Figure 1: Firm lev el Co v ariates and Prop ensit y of Geithner Connection Note : Histogram represents p osterior distribution and red dashed line is the p osterior mean. 21 0 5 10 −0.10 −0.05 0.00 0.05 0.10 T rading Date Relativ e to the Announcement Dynamic Abnor mal Return DM−LFM PS−LFM Figure 2: Dynamic Effect of Geithner Connection on Abnormal Return Note : The dots are the p osterior means and the error bars represent corresp onding 95% credible interv als. 6 Conclusion In this paper, we pro p ose a no vel Ba yesian prop ensity score–augmen ted laten t factor model for estimating treatmen t effects from time-series cross-sectional data. Compared with canonical causal panel data mo dels that primarily emphasize outcome mo deling, the pro- p osed framework explicitly mo dels the treatmen t assignmen t mec hanism b y incorporating laten t factor loadings into the treatmen t assignmen t model. In addition, in the outcome stage, the p otential outcome mo del incorp orates the prop ensit y score through stratifica- tion or other sp ecifications lik e including it as an additional cov ariate. Relativ e to existing approac hes, this framework provides greater flexibilit y and can capture additional hetero- geneit y across prop ensity score strata, whic h enables more credible comparisons b etw een treated and con trol units within each stratum. Although the Ba yesian propensity score framew ork naturally incorp orates uncertain ty in prop ensit y score estimation, it also introduces a mo del feedbac k problem b ecause the prop ensit y score appears in both the treatmen t assignmen t and outcome stages. T o address this issue, we prop ose an approximate Ba yesian algorithm in which factor loadings are estimated solely from the outcome model, after whic h appropriately rotated loadings are 22 included as additional controls in the treatment assignmen t mo del. The propensity score is then estimated indep endently of the outcome mo del. This procedure mitigates the mo del feedbac k problem while balancing mo del selection considerations and iden tification of the laten t factor structure. Despite these adv antages, the prop osed metho d has sev eral limitations. First, al- though the propensity score–augmented sp ecification allows for heterogeneous effects across prop ensit y score strata, it still relies on parametric assumptions for both the treatmen t as- signmen t and outcome mo dels. In particular, b ecause the effect of the prop ensit y score in the outcome model is assumed to follo w a presp ecified functional form, mis-sp ecification, suc h as incorrect thresholds used for prop ensit y score stratification, may lead to biased treatmen t effect estimates. Second, because latent factor loadings are estimated from the outcome mo del and subsequen tly incorporated in to the treatmen t assignment mo del, the prop osed approac h do es not fully satisfy the classical double-robustness prop ert y: correct sp ecification of either the treatment or outcome mo del alone is insufficien t for consistent estimation. Nev ertheless, this dep endence reflects the latent ignorability assumption re- quired for identification in the presence of unobserv ed confounding. F uture researc h aimed at addressing these limitations is w orth pursuing. 23 References Abadie, A. (2005). Semiparametric difference-in-differences estimators. The r eview of e c onomic studies 72 (1), 1–19. 2 , 4 Abadie, A., A. Diamond, and J. Hainm ueller (2010). Syn thetic con trol metho ds for compar- ativ e case studies: Estimating the effect of california’s tobacco con trol program. Journal of the A meric an statistic al Asso ciation 105 (490), 493–505. 2 , 19 Acemoglu, D., S. Johnson, A. Kermani, J. Kwak, and T. Mitton (2016). The v alue of connections in turbulen t times: Evidence from the united states. Journal of Financial Ec onomics 121 (2), 368–391. 19 , 20 Alb ert, J. H. and S. Chib (1993). Ba yesian analysis of binary and p olyc hotomous resp onse data. Journal of the A meric an statistic al Asso ciation 88 (422), 669–679. 29 Alv arez, R. M. and I. Levin (2021). Uncertain neigh b ors: Ba y esian prop ensit y score matc h- ing for causal inference. arXiv pr eprint arXiv:2105.02362 . 3 , 4 , 11 Ando, T., J. Bai, and K. Li (2022). Ba yesian and maximum lik eliho o d analysis of large-scale panel choice mo dels with unobserv ed heterogeneit y . Journal of Ec onometrics 230 (1), 20– 38. 15 Arkhangelsky , D. and G. W. Imbens (2022). Doubly robust iden tification for causal panel data mo dels. The Ec onometrics Journal 25 (3), 649–674. 4 , 5 A they , S., M. Ba yati, N. Doudc henk o, G. Imbens, and K. Khosravi (2021). Matrix com- pletion metho ds for causal panel data models. Journal of the Americ an Statistic al As- so ciation 116 (536), 1716–1730. 3 , 9 A they , S. and G. W. Im b ens (2022). Design-based analysis in difference-in-differences settings with staggered adoption. Journal of Ec onometrics 226 (1), 62–79. 5 Bai, J. (2009). P anel data mo dels with in teractive fixed effects. Ec onometric a 77 (4), 1229–1279. 9 , 13 , 15 , 29 24 Belmon te, M. A., G. Koop, and D. Korobilis (2014). Hierarchical shrink age in time-v arying parameter mo dels. Journal of F or e c asting 33 (1), 80–94. 12 Bhattac hary a, A. and D. B. Dunson (2011). Sparse ba yesian infinite factor mo dels. Biometrika , 291–306. 13 Bro dersen, K. H., F. Gallusser, J. Ko ehler, N. Remy , and S. L. Scott (2015). Inferring causal impact using ba y esian structural time-series mo dels. The A nnals of Applie d Statistics , 247–274. 31 Calla w ay , B. and P . H. Sant’Anna (2021). Difference-in-differences with multiple time p eriods. Journal of e c onometrics 225 (2), 200–230. 2 , 4 , 5 , 18 F orino, A., A. Mercatan ti, and G. Morelli (2025). Prop ensit y score with factor loadings: the effect of the paris agreemen t. arXiv pr eprint arXiv:2507.08764 . 3 , 10 , 13 F rangakis, C. E. and D. B. Rubin (1999). Addressing complications of inten tion-to-treat analysis in the combined presence of all-or-none treatmen t-noncompliance and subse- quen t missing outcomes. Biometrika 86 (2), 365–379. 2 , 6 F r ¨ uhwirth-Sc hnatter, S. and H. W agner (2010). Sto c hastic model specification searc h for gaussian and partial non-gaussian state space mo dels. Journal of Ec onometrics 154 (1), 85–100. 12 Gew ek e, J. and G. Zhou (1996). Measuring the pricing error of the arbitrage pricing theory . The r eview of financial studies 9 (2), 557–587. 11 , 13 , 19 , 20 Li, F., P . Ding, and F. Mealli (2023). Bay esian causal inference: a critical review. Philo- sophic al T r ansactions of the R oyal So ciety A: Mathematic al, Physic al and Engine ering Scienc es 381 (2247). 4 Liu, L., Y. W ang, and Y. Xu (2024). A practical guide to counterfactual estimators for causal inference with time-series cross-sectional data. A meric an Journal of Politic al Scienc e 68 (1), 160–176. 18 25 Liu, L. and T. Y amamoto (2025). Ba yesian sensitivity analysis for unmeasured confounding in causal panel data mo dels. Politic al Analysis , 1–20. 8 McCandless, L. C., P . Gustafson, and P . C. Austin (2009). Ba y esian prop ensit y score analysis for observ ational data. Statistics in me dicine 28 (1), 94–112. 3 , 4 , 10 , 11 Mehrabani, A. and S. Parsaeian (2025). Shrink age estimation and identification of laten t group structures in panel data with interactiv e fixed effects. Journal of Business & Ec onomic Statistics (just-accepted), 1–26. 4 P ang, X., L. Liu, and Y. Xu (2022). A ba yesian alternativ e to synthetic con trol for com- parativ e case studies. Politic al Analysis 30 (2), 269–288. 8 , 11 , 12 P ark, T. and G. Casella (2008). The ba yesian lasso. Journal of the Americ an Statistic al Asso ciation 103 (482), 681–686. 16 Rosen baum, P . R. and D. B. Rubin (1983). The cen tral role of the prop ensity score in observ ational studies for causal effects. Biometrika 70 (1), 41–55. 2 , 3 , 10 , 11 Rubin, D. B. (1974). Estimating causal effects of treatmen ts in randomized and nonran- domized studies. Journal of e duc ational Psycholo gy 66 (5), 688. 5 Rubin, D. B. (1978). Bay esian inference for causal effects: The role of randomization. The A nnals of statistics , 34–58. 6 Rubin, D. B. (2005). Causal inference using p oten tial outcomes: Design, mo deling, deci- sions. Journal of the A meric an statistic al Asso ciation 100 (469), 322–331. 7 Samartsidis, P ., S. R. Seaman, S. Montagna, A. Charlett, M. Hic kman, and D. D. Angelis (2020). A bay esian m ultiv ariate factor analysis mo del for ev aluating an in terven tion b y using observ ational time series data on m ultiple outcomes. Journal of the R oyal Statistic al So ciety Series A: Statistics in So ciety 183 (4), 1437–1459. 11 , 13 Sc hmidt, C., S. R. Seaman, B. Emmanouil, L. Reid, S. Smith, D. De Angelis, and P . Samart- sidis (2025). A bay esian factor analysis mo del for non-randomised staggered designs. arXiv pr eprint arXiv:2508.09554 . 3 , 10 26 Xu, Y. (2017). Generalized syn thetic con trol metho d: Causal inference with in teractive fixed effects models. Politic al Analysis 25 (1), 57–76. 2 , 8 Zigler, C. M. and F. Dominici (2014). Uncertaint y in propensity score estimation: Bay esian metho ds for v ariable selection and model-av eraged causal effects. Journal of the Americ an Statistic al Asso ciation 109 (505), 95–107. 3 , 4 , 11 , 15 Zigler, C. M., K. W atts, R. W. Y eh, Y. W ang, B. A. Coull, and F. Dominici (2013). Model feedbac k in ba yesian propensity score estimation. Biometrics 69 (1), 263–273. 3 , 4 , 10 , 11 , 14 , 15 27 SUPPLEMENT AR Y INF ORMA TION A MCMC Algorithm W e provide the details of the proposed MCMC algorithm for sampling from the conditional p osteriors of relev ant parameters to estimate and mak e inference on the treatment effects. The priors for parameters to be estimated are as follows. W e assign shrink age priors for parameters β , ω ξ and ω γ in the outcome model, and weakly informativ e conjugate priors for λ z and λ γ in the treatmen t assignmen t model. • λ z and λ γ : λ z ∼ N ( ¯ λ z , B z ) , λ γ ∼ N ( ¯ λ γ , B γ ) . (14) • β : β j | τ 2 β j ∼ N (0 , τ 2 β j ) , ∀ 1 ≤ j ≤ p τ 2 β j | κ β ∼ E xp ( κ 2 β 2 ) κ 2 β ∼ Gamma ( a 1 , a 2 ) (15) • ω ξ : ω ξ j | τ 2 ξ j ∼ N (0 , τ 2 ξ j ) , ∀ 1 ≤ j ≤ p τ 2 ξ j | κ ξ ∼ E xp ( κ 2 ξ 2 ) κ 2 ξ ∼ Gamma ( c 1 , c 2 ) (16) • ω γ : ω γ j | τ 2 γ j ∼ N (0 , ω 2 γ j ) , ∀ 1 ≤ j ≤ r ω 2 γ j | κ γ ∼ E xp ( κ 2 γ 2 ) κ 2 γ ∼ Gamma ( k 1 , k 2 ) (17) • σ 2 : σ − 2 ∼ Gamma ( e 1 , e 2 ) (18) The steps of the Gibbs sampler are summarized as follo ws: 28 1. Using the up dated v alues of ˜ γ i , f t , and ω γ , p erform the rotation describ ed in sub- section 3.2 to obtain rotated (Γ , F ) that satisfy the normalization restrictions in Bai ( 2009 ). Then up date λ = ( λ z , λ γ ) in the treatmen t assignmen t model using the laten t outcome augmentation approach of Alb ert and Chib ( 1993 ), and then the propensity score ps ( Z i , ω γ · ˜ γ i ; λ ) for eac h unit. 2. Jointly up date β , ω ξ and ω γ : Denote ˜ Z it = g ( Z i , ps ( Z i , ω γ · ˜ γ i ; λ )) , g ( Z i , ps ( Z i , ω γ · ˜ γ i ; λ )) · ˜ ξ t , ˜ γ i · f t , ( β ′ , ω ′ ξ , ω ′ γ ) ′ ∼ N ( ¯ β , B 1 ) , B 1 = σ − 2 X D it =0 ˜ Z it ˜ Z ′ it + B − 1 0 ! − 1 , ¯ β = B 1 σ − 2 X D it =0 ˜ Z it Y it ! , B − 1 0 = Diag( τ − 2 β 1 , . . . , τ − 2 β p , τ − 2 ω ξ 1 , . . . , τ − 2 ω ξ p τ − 2 ω γ 1 , . . . , τ − 2 ω γ r ) . (19) 3. Up date ˜ γ i for i ∈ { 1 , . . . , N } using only the outcome model 9 : Denote ˜ f t = ˜ ω γ · f t , ˜ γ i ∼ N ( ¯ γ , Γ 1 ) , Γ 1 = σ − 2 X t : D it =0 ˜ f t ˜ f ′ t + I r ! − 1 , ¯ γ = Γ 1 σ − 2 X t : D it =0 ˜ f t R it ! , R it = y it − g ( Z i , ps ( Z i , ω γ · ˜ γ i ; λ )) ′ β − g ( Z i , ps ( Z i , ω γ · ˜ γ i ; λ )) ′ ( ω ξ · ˜ ξ t ) . (20) 4. Jointly up date ( ˜ ξ ′ t , f ′ t ) ′ for t ∈ { 1 , . . . , T } : 9 I r stands for ( r × r ) iden tity matrix. 29 Denote Ψ t = ( ˜ ξ ′ t , f ′ t ) ′ , ˜ A it = g ( Z i , ps ( Z i , ω γ · ˜ γ i ; λ )) ′ · ω ′ ξ , ω ′ γ · ˜ γ ′ i ′ , Ψ t ∼ N (Ω − 1 t µ t , Ω − 1 t ) µ t = σ − 2 X t,D it =0 ˜ A it U it , Ω t = I ( p + r ) + σ − 2 X t,D it =0 ˜ A it ˜ A ′ it , U it = y it − X ′ it β . (21) 5. Up date τ 2 β j 10 : τ − 2 β j ∼ I G ( s κ 2 β β 2 j , κ 2 β ) , ∀ 1 ≤ j ≤ p (22) 6. Up date τ 2 ξ j : τ − 2 ξ j ∼ I G ( s κ 2 ξ ω 2 ξ j , κ 2 ξ ) , ∀ 1 ≤ j ≤ p (23) 7. Up date τ 2 γ j : τ − 2 γ j ∼ I G ( s κ 2 γ ω 2 γ j , κ 2 γ ) , ∀ 1 ≤ j ≤ r (24) 8. Up date κ 2 β : κ 2 β ∼ Gamma ( p + a 1 , 1 2 p X j =1 τ 2 β j + a 2 ) (25) 9. Up date κ 2 ξ : κ 2 ξ ∼ Gamma ( p + c 1 , 1 2 p X j =1 τ 2 ξ j + c 2 ) (26) 10. Up date κ 2 γ : κ 2 γ ∼ Gamma ( r + k 1 , 1 2 r X j =1 τ 2 γ j + k 2 ) (27) 11. Up date σ 2 : 10 Here “IG” stands for inv erse Gaussian distribution. 30 σ − 2 ∼ Gamma ( N obs + e 1 , 1 2 X D it =0 ( y it − U it ) 2 + e 2 ) N obs = N × T − N X i =1 T X t =1 D it , U it = g ( Z i , ps ( Z i , ω γ · ˜ γ i ; λ )) ′ β + g ( Z i , ps ( Z i , ω γ · ˜ γ i ; λ )) ′ ( ω ξ · ˜ ξ t ) + ( ω γ · ˜ γ i ) ′ f t . (28) 12. Up date the coun terfacutal outcome Y it (0) if D it = 1: Y it (0) ∼ N ( R it , σ 2 ) , R it = g ( Z i , ps ( Z i , ω γ · ˜ γ i ; λ )) ′ β + g ( Z i , ps ( Z i , ω γ · ˜ γ i ; λ )) ′ ( ω ξ · ˜ ξ t ) + ( ω γ · ˜ γ i ) ′ f t . (29) 13. Up date δ it if D it = 1: δ it = Y it − Y it (0) . (30) The proposed MCMC algorithm iterates through Steps 1–13 until con v ergence. Each of these steps corresp onds to sampling from the conditional p osterior distribution of the resp ectiv e (cluster of ) parameters given the remaining parameters and the observed data. Under standard regularity conditions, the resulting dra ws approximate samples from the join t p osterior distribution after conv ergence. In the final step, w e impute the individual-level causal effects δ it for treated observ ations. These dra ws are then summarized to obtain the av erage treatment effect on the treated ( Bro dersen et al. , 2015 ). B Additional Mon te Carlo Studies B.1 A Sim ulated Example In this subsection, w e apply the prop osed metho d, along with alternative mo del sp ecifica- tions, to a simulated dataset generated from the same DGP with prop ensity score strata describ ed in Section 4 , with δ it = 0 for all i and t . That is, AT T t ≡ 0 for each p ost- treatmen t p erio d. The estimated dynamic treatmen t effects for fiv e pre-treatmen t perio ds and ten post-treatment p eriods are presen ted in Figure 3 . 31 The upper panel displays the estimation results from the factor mo dels. F or the Oracle mo del, the posterior mean treatmen t effect is close to zero for b oth pre-treatmen t and p ost- treatmen t p eriods, and the 95% credible interv als consisten tly cov er zero. Similar patterns are observed for the prop osed PS-LFM: p osterior mean estimates remain close to zero across all p erio ds, and the 95% credible interv als co ver zero throughout. Ho wev er, these CIs are generally wider than those of the Oracle mo del, as additional uncertain t y arises from prop ensity score estimation, prop ensity score stratification, and mo del selection. By con trast, the DM-LFM exhibits evidence of bias. In particular, during the fourth p ost-treatmen t perio d, the 95% credible interv al do es not include zero, suggesting bias in- duced b y mo del mis-sp ecification when propensity score stratification is ignored. Moreov er, p osterior mean estimates from the DM-LFM tend to deviate further from zero compared with b oth the Oracle mo del and the PS-LFM. The lo wer panel rep orts results based on the CS-DID estimator. Several pre-treatmen t estimates are significantly differen t from zero, indicating p oten tial violations of parallel trends due to unaccounted laten t confounding. In addition, the confidence interv als are generally wider as w e ignore the time-v arying cov ariates in outcome mo del. W e next assess the go o dness of fit of the treatmen t assignment mo del under the PS- LFM, where factor loadings are estimated solely from the outcome model to mitigate the mo del feedbac k problem. Figure 4 compares the estimated prop ensit y scores with the true prop ensit y scores. The left panel plots the estimated prop ensit y scores from the PS-LFM against their true v alues. The estimates align closely with the 45-degree line ( Y = X ), indicating go o d fit of the treatment assignmen t mo del. F or comparison, the right panel sho ws prop ensity score estimates obtained from a Probit mo del that includes only observ ed unit-lev el co v ariates ( Z i 1 and Z i 2 ) while ignoring laten t factor loadings. In this case, the estimated prop ensit y scores deviate substantially from the true v alues, suggesting that omitting latent confounders leads to p o or mo del fit. C Additional Results for the Empirical Application F or additional results from the empirical application, w e first examine the distribution of the estimated prop ensit y scores, using the p osterior mean as the p oint estimate. Figure 5 32 presen ts these distributions. The left panel shows that the estimated prop ensity scores are righ t-skew ed, indicating that most financial firms hav e a relatively lo w prop ensit y for connection with Timothy Geithner, while only a small fraction exhibit high connection prop ensit y . The righ t panel compares the distributions separately for connected and un- connected firms. As sho wn, the prop ensit y scores for connected firms are more disp ersed than those for firms without connections. Figure 9 displays the p osterior distributions of the co efficien ts asso ciated with eac h factor loading, along with the intercept, in the treatment assignmen t model. The p osterior means of the factor-loading co efficients are close to zero, suggesting limited additional latent confounding after con trolling for firm size, profitabilit y , and lev erage. W e next examine whether the time-v arying effects of firm-level cov ariates differ across prop ensit y score strata and compare these estimates with those obtained from the DM- LFM. The results, sho wn in Figures 8 , indicate that the time-v arying cov ariate effects can indeed v ary across prop ensit y score strata and, in some p erio ds, differ substan tially from the DM-LFM estimates. As an additional robustness c heck, we conduct a placeb o test by treating the t wo trading da ys prior to the announcemen t as placeb o perio ds. The results, rep orted in Figures 6 in App endix C , show that the 95% credible in terv als cov er zero during the placebo p erio ds for b oth model sp ecifications, providing reassurance against spurious estimated abnormal returns. 33 −4 −2 0 2 4 −1.0 −0.5 0.0 0.5 1.0 Time Relativ e to the T reatment Estimated Dynamic Eff ect DM−LFM PS−LFM Oracle −4 −2 0 2 4 −4 −2 0 2 4 Time Relativ e to the T reatment Estimated Dynamic Eff ect CS−DID −4 −2 0 2 4 −3 −2 −1 0 1 2 3 Time Relativ e to the T reatment Estimated Dynamic Eff ect FEct Figure 3: Estimated Dynamic T reatment Effects Note : The dots are the p osterior means and the error bars represent corresp onding 95% credible interv als. 34 0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0 T rue PS Estimated PS 0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0 T rue PS Estimated PS PS-LFM Probit Mo del w/o Loadings Figure 4: Estimated Propensity Scores with F actor Augmentation Note : Posterior me an is used as the p oin t estimate of prop ensit y score. The blac k solid line represents the 45-degree line ( Y = X ). Grey dashed lines indicate the thresholds (0.3 and 0.6) that determine the prop ensit y score strata. Estimated Propensity Score Frequency 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0 10 20 30 40 50 60 Estimated Propensity Score Frequency 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0 10 20 30 40 50 60 Firms w/ Connection Firms w/o Connection Figure 5: Distribution of Estimated Prop ensity Scores Note : Posterior mean is used as the p oin t estimate of prop ensity score. 35 0 5 10 −0.10 −0.05 0.00 0.05 0.10 T rading Date Relativ e to the Announcement Dynamic Abnor mal Return DM−LFM PS−LFM Figure 6: Placeb o T est on the Estimated Dynamic Effect Note : The dots are the p osterior means and the error bars represent corresp onding 95% credible interv als. −5 0 5 10 −0.04 −0.02 0.00 0.02 0.04 T rading Date Relative to the Announcement T rading Da y Random Effects DM−LFM PS−LFM: Group 1 PS−LFM: Group 2 Figure 7: Estimated Time Random Effects Note : The dots are the p osterior means and the error bars represent corresp onding 95% credible interv als. 36 −5 0 5 10 −0.004 0.000 0.004 T rading Date Relative to the Announcement Time−V ar ying Effects of Firm Size DM−LFM PS−LFM: Group 1 PS−LFM: Group 2 −5 0 5 10 −0.04 −0.02 0.00 0.02 0.04 T rading Date Relative to the Announcement Time−V ar ying Effects of Profitab lity DM−LFM PS−LFM: Group 1 PS−LFM: Group 2 −5 0 5 10 −0.010 0.000 0.005 0.010 T rading Date Relative to the Announcement Time−V ar ying Effects of Le ver age DM−LFM PS−LFM: Group 1 PS−LFM: Group 2 Figure 8: Time-v arying Effects of Firm-level Co v araites Note : The dots are the p osterior means and the error bars represent corresp onding 95% credible interv als. 37 F actor Loading 1 Frequency −15 −10 −5 0 5 10 0 100 300 F actor Loading 2 Frequency −10 −5 0 5 10 0 200 400 600 F actor Loading 3 Frequency −10 −5 0 5 10 0 200 400 600 F actor Loading 4 Frequency −10 −5 0 5 10 0 200 400 600 F actor Loading 5 Frequency −10 −5 0 5 10 0 200 400 600 Intercept Frequency −10 −8 −6 −4 0 200 600 Figure 9: F actor Loadings and Prop ensit y of Geithner Connection Note : Histogram represents p osterior distribution and red dashed line is the p osterior mean. 38
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment