HASS: Hierarchical Simulation of Logopenic Aphasic Speech for Scalable PPA Detection
Building a diagnosis model for primary progressive aphasia (PPA) has been challenging due to the data scarcity. Collecting clinical data at scale is limited by the high vulnerability of clinical population and the high cost of expert labeling. To cir…
Authors: Harrison Li, Kevin Wang, Cheol Jun Cho
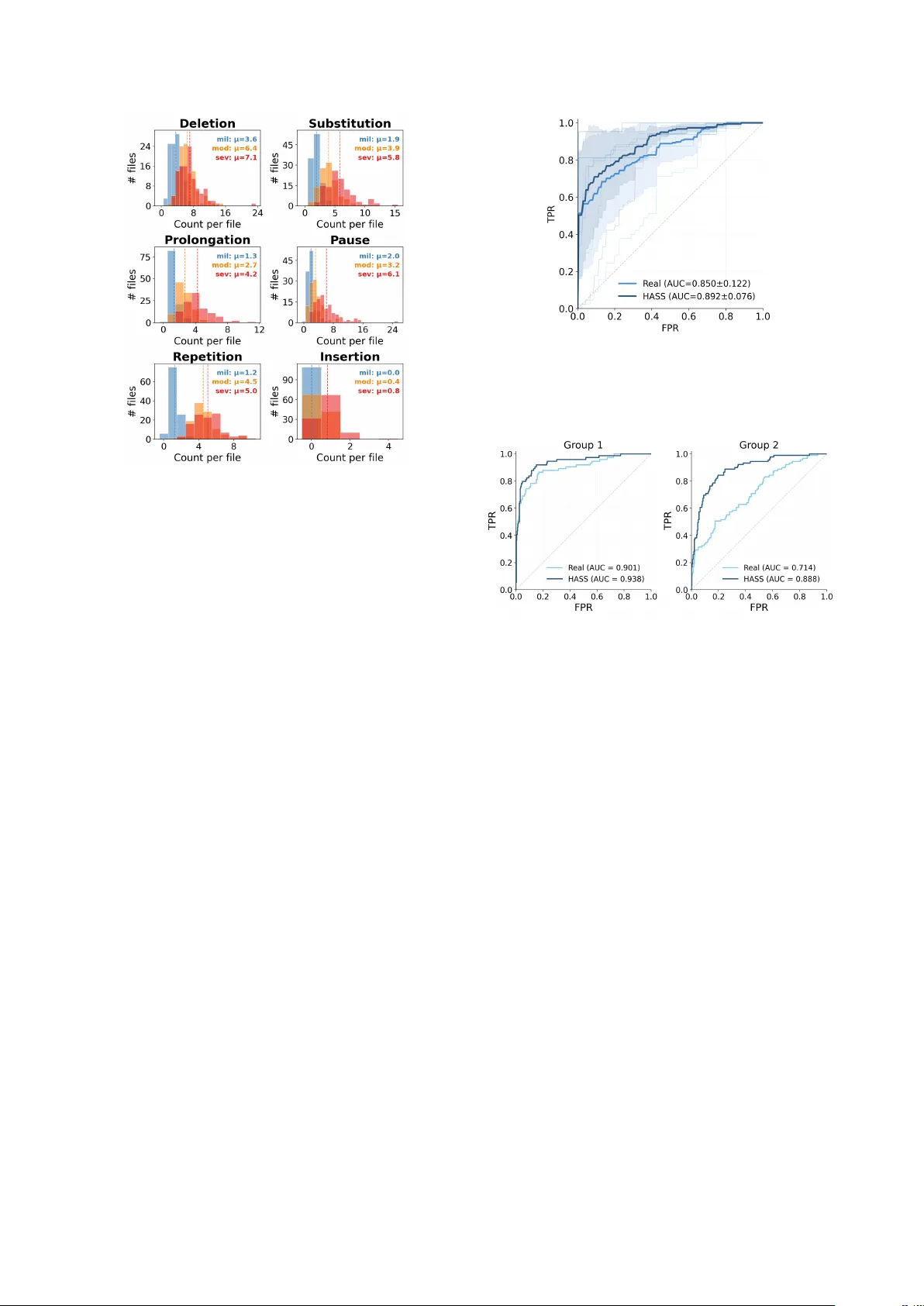
HASS: Hierar chical Simulation of Logopenic A phasic Speech f or Scalable PP A Detection Harrison Li 1 , K evin W ang 1 , Cheol J un Cho 1 , Jiac hen Lian 1 , Rabab Rangwala 2 , Chenxu Guo 3 , Emma Y ang 4 , L ynn K urteff 2 , Zoe Ezzes 2 , W illa K ee gan-Rodewald 2 , J et V onk 2 , Siddarth Ramkrishnan 2 , Giada Antonicelli 5 , Zachary Miller 2 , Marilu Gorno T empini 2 , Gopala Anumanchipalli 1 1 UC Berkele y , USA 2 UCSF , USA 3 Zhejiang Uni versity , China 4 Columbia Uni versity , USA 5 Basque Center on Cognition, Brain and Language, Spain liharrison@berkeley.edu, kwang3170@berkeley.edu, gopala@berkeley.edu Abstract Building a diagnosis model for primary progressiv e aphasia (PP A) has been challenging due to the data scarcity . Collect- ing clinical data at scale is limited by the high vulnerability of clinical population and the high cost of expert labeling. T o cir- cumvent this, previous studies simulate dysfluent speech to gen- erate training data. Ho wev er , those approaches are not compre- hensiv e enough to simulate PP A as holistic, multi-level pheno- types, instead relying on isolated dysfluencies. T o address this, we propose a nov el, clinically grounded simulation framew ork, Hierarchical Aphasic Speech Simulation (HASS). HASS aims to simulate beha viors of logopenic v ariant of PP A (lvPP A) with varying degrees of se verity . T o this end, semantic, phonolog- ical, and temporal deficits of lvPP A are systematically identi- fied by clinical experts, and simulated. W e demonstrate that our framew ork enables more accurate and generalizable detection models. Code: h t tp s: // g i th ub .c o m /h ar i b ar y/ HA SS Index T erms : Primary progressiv e aphasia, pathological speech simulation, dysfluency modeling 1. Introduction Primary progressive aphasia (PP A) is a neurodegenerativ e dis- order characterized by progressi ve language impairment. Be- cause the hallmark of PP A is progressive deterioration of lan- guage function, connected (spontaneous) speech provides rich diagnostic information for PP A variant characterization and is widely used in clinical and research assessment [1, 2, 3]. As speech-based machine learning methods advance, there is growing interest in automated screening frame works for PP A [4, 5, 6]. Howe ver , such approaches are constrained by the lim- ited av ailability of high-quality naturalistic speech datasets from clinically characterized PP A patients. Data collection typically requires expert diagnosis, structured elicitation protocols, and careful annotation under strict ethical and pri v acy constraints [7, 8, 9]. Public resources such as DementiaBank and Aphasi- aBank provide in valuable connected-speech samples, b ut re- main limited in size and institutional representation, constrain- ing model dev elopment and cross-corpus rob ustness [7, 8, 9]. Synthetic data generation of fers a potential solution, but prior dysfluency simulation efforts have largely focused on in- jecting isolated dysfluency e vents (e.g., repetitions, insertions, or pauses) into otherwise fluent speech [10, 11, 12, 13, 14, 15]. Howe ver , behavioral deficits in some PP A variants arise from disruptions on multiple le vels (phonological, word and content) of speech [3]. Phonological deficits simulated in isolation fail to capture these interactions. As a result, such simulations of- ten lack clinical plausibility and fail to model simultaneous dis- ruptions across phoneme, lexical, and content levels. Further- more, most simulations using LLM-based or agentic generation pipelines are not grounded in the production mechanisms of a specific clinical phenotypes, limiting their utility because mod- els trained on such data may learn generic surface-le vel dys- fluency patterns rather than disorder-specific impairment signa- tures [12, 15, 16, 17]. T o date, no end-to-end simulation frame- work has explicitly modeled a neurodegenerativ e language dis- order using clinically grounded production mechanisms. Among PP A variants, lvPP A is characterized by impaired word retriev al that cascades into phonological errors and halting speech [3, 18], making it an ideal test case for a multi-lev el sim- ulation framework. Thus, we introduce the Hierarchical Apha- sic Speech Simulation (HASS), a clinically grounded hierarchi- cal simulation frame work for logopenic variant PP A (lvPP A) that models clinically defined impairment mechanisms in a tw o- layer production model: (1) a lexical retrie v al impairment layer that generates sev erity-conditioned content-le vel disruptions and (2) a phonological encoding disruption layer that introduces sev erity-conditioned phoneme-le vel errors on a word-aligned representation. HASS produces severity-controlled synthetic lvPP A speech with co-occurring content-le vel and phonological dysfluencies, alongside matched controls generated using the same pipeline but without impairment injection. This enables scalable augmentation of low-resource clinical datasets while ensuring classifier dif ferences are attributable to the simulated disorder rather than synthesis artifacts. Our experiments show that HASS improv es the performance of the diagnosis model during ev aluation. W e will release all data, models, and code to support reproducibility . W e summarize our contributions as follows: • W e propose HASS, an exclusiv e clinician-guided simulation pipeline and the first frame work to model a neurodegener - ativ e aphasia (lvPP A) as a holistic, structural disease rather than a collection of isolated, disconnected dysfluencies. • W e introduce a scalable recipe for clinical data augmenta- tion, releasing a comprehensi ve, severit y-controlled synthetic dataset that accurately reflects the multi-level impairments of PP A. • W e demonstrate that HASS-generated data improves auto- mated PP A classification, with classifiers trained on HASS speech outperforming those trained on clinical recordings. W e ev aluate both in-domain capability and cross-site gener- alization. 2. Simulation 2.1. Dysfluent T ext Generation W e introduce a two-layer dysfluent text generation pipeline de- signed to model language production deficits characteristic of Logopenic V ariant primary progressive aphasia (lvPP A). In par- ticular , we recruit an LLM (Gemini 3 [19]) to simulate patho- logical beha viors with detailed, clinically guided instructions. The simulator encodes clinically defined lvPP A symptoms, and was developed with SLP oversight. LvPP A ’ s primary impair - ment is in lexical retriev al and its downstream phonological consequences, which inspired the factorization of dysfluency modeling into content-lev el and phoneme-le vel processes. During generation, the LLM is constrained by sev eral clin- ically grounded rules: • Lexical Bias: In lvPP A, content and phonological dysfluen- cies are correlated. Dysfluencies are applied non-uniformly , heavily biasing tow ard high lexical-demand loci such as lo w- frequency content words and multisyllabic tar gets. • Syntactic Adherence: Disruptions are constrained to plau- sible syntactic and discourse boundaries (e.g., clause bound- aries or pre-content-word positions). • Phenotype Exclusion: Features characteristic of non- fluent/agrammatic and semantic PP A v ariants (e.g., persistent agrammatism, apraxia-of-speech-like distortions, or semanti- cally empty fluent speech) are e xplicitly penalized to pre vent phenotype drift. 2.1.1. W or d Level Non-pathological spontaneous text is first generated using a di- verse set of prompts modelled in the style of connected speech questions sourced from the Quick Aphasia Battery[1]. The out- put is directed into two pipelines: the synthetic control pipeline data are injected with naturalistic dysfluencies on the word lev el and the synthetic dysfluency pipeline where this te xt no w serves as the ground truth. In the dysfluency pipeline, ground-truth text is first passed to the word-lev el (content) dysfluenc y layer . Conditioned on the chosen sev erity variable, we instruct an LLM to introduce lvPP A-like lexical retriev al phenomena, including circumlocu- tions, false starts, and filled pauses, while preserving the in- tended message. The resulting word-le vel dysfluent te xt is then con verted to a word-aligned IP A representation using [20]. Stress markers and word boundaries are retained to enable consistent alignment for downstream phonological editing and speech synthesis. 2.1.2. Phoneme Level The phoneme-le vel layer edits the word-aligned IP A sequence, conditioned on both the word-le vel dysfluent text and its IP A target form. W e instruct LLMs to insert inline markers for six error types organized in a clinically motiv ated hierarchy . The three primary markers are [PAU] (pause insertion), [SUB] (phoneme substitution), and [DEL] (phoneme deletion), re- flecting the dominant temporal and phonological disruptions in lvPP A, where slow speaking rate, word-finding halts, and phonological paraphasias predominate [21, 18, 3, 22, 23]. Next, tw o secondary markers are also modelled: [REP] (sound/syllable repetition), modeled as a byproduct of self- repair during failed retrie v al [3], [PRO] (phoneme prolonga- tion), reflecting mild hesitation-related lengthening [3]. Fi- nally , [INS] (phoneme insertion), is treated as a rare dysflu- ency since it is reported at lower rates than other phonologi- cal paraphasias [24]. Furthermore, marker rates are sev erity- conditioned and biased toward content words ( ≥ 80%), with disruption probability increasing with word length and sylla- ble complexity . Repetition is restricted to repair contexts, and within-word marker co-occurrence is capped at higher se veri- ties to maintain a realistic density of dysfluencies. The output is a marked IP A string used for subsequent speech synthesis. 2.2. Synthesis of Dysfluent Speech W e synthesize speech with TTS (VITS)[25] while explicitly preserving dysfluency . Phoneme-level markers ([DEL], [SUB], [INS], [REP]) are applied upstream during IP A generation, while [P A U] is realized by inserting a silence segment during and [PRO] by prolonging the target phoneme during inference. W e provide both sentence-level audio outputs and concatenated utterances; sentence audio is concatenated downstream using a 50 ms crossf ade. 3. Data 3.1. Marker Distrib ution Analysis Figure 2 confirms that the generated data respect the clinical marker hierarchy . Across all se verity levels, pause, deletion, and substitution account for the majority of dysfluency e vents, while prolongation and repetition occur less frequently and in- sertion remains rare. Distributions shift tow ard higher counts with increasing sev erity: summing mean counts across mark- ers yields T mild = 10 . 0 , T mod = 21 . 1 , and T sev = 29 . 0 markers per file ( 2 . 1 × and 2 . 9 × increases relative to mild). The three primary markers account for 75 . 0% of mild events ( 7 . 5 / 10 . 0 ), 64 . 0% of moderate ( 13 . 5 / 21 . 1 ), and 65 . 5% of se- vere ( 19 . 0 / 29 . 0 ). At the e xtremes, insertion av erages fe wer than one ev ent per file e ven at se vere ( µ INS = 0 . 0 , 0 . 4 , 0 . 8 ), whereas the dominant markers reach substantially higher rates ( µ DEL = 7 . 1 , µ SUB = 5 . 8 , µ P AU = 6 . 1 at sev ere). 3.2. Dataset Composition The HASS corpus comprises 4,773 sentence-level clips to- talling 12.81 hours of synthesized audio. Of these, 2,007 are control utterances and 2,766 are dysfluent (871 mild, 1,101 moderate, 794 severe). Speech is synthesized using 95 speak ers from the VCTK corpus (out of 109 av ailable voices) across 40 unique ground-truth prompts. Controls are generated through the same synthesis pipeline, speakers, and prompts but without lvPP A-specific dysfluency injection, ensuring that any classifier differences are attributable to the simulated impairment rather than speaker or synthesis artifacts. 4. Experiments and Results T o validate the clinical utility of our synthetic corpus, we e val- uate a classification model trained on HASS-generated data and assess its zero-shot generalization on real-world clinical record- ings. W e ev aluate on real lvPP A patient audio from the Baycrest Figure 1: Overview of the HASS hierar chical simulation pipeline. T able 1: Example output acr oss severity levels for a single gr ound-truth sentence. T ext : word-level dysfluent output. IP A : phoneme- level output with inline marker s. Gr ound truth: “The house would go completely dark, sa ve for the single amber glo w of a hearth fire. ” Severity Output C O N T RO L T ext: The house would go completely dark, sa ve for the single amber glo w of a hearth fire. IP A: D@ h"aUs wUd g"oU k@mpl"i ` utli d"A` uˆ ok, s"eIv f3ˆ oD@ s"INg@l "æmb3ˆ o gl"oU @v@ h"A ` uˆ oh f"aI@ ˆ o M I L D T ext: The house would go comple [DEL] ly dark, except for the single, you know , the ori [SUB] mge light of the, the place where you burn the w ood , the hearth fire. IP A: D@ h"aUs wUd g ` oU k@mpl"i ` u [DEL] li d"A` u ˆ ok, Eks"Ept f3ˆ oD@ s"INg@l, ju` u n"oU, DI "Oˆ oim [SUB] dZ l"aIt VvD@, D@ pl"eIs w` Eˆ o ju` u b"3` un D@ w"Ud, D@ h"A ` uˆ oh f"aI@ ˆ o M O D E R A T E T ext: The house would go, it would go comple [DEL] ly dark, except for the, the oran [SUB] z light, the am [DEL] ber glow from the, the place where you b urn the wood, [PAU] the hea [DEL] th. IP A: D@ h"aUs wUd g"oU, It wUd g` oU k@mpl"i` u [DEL] li d"A ` u ˆ ok, Eks"Ept f3ˆ oD@, DI "O ˆ oIndz [SUB] l"aIt, DI "æm [DEL] b3ˆ o gl"oU fˆ o VmD@, D@ pl"eIs w` E ˆ o ju ` u b"3 ` un D@ w"Ud, [PAU] D@ h"A ` u [DEL] T S E V E R E T ext: It was, it went, uh, [PAU] no ligh [DEL] , just the, the one, the fi [PRO] re thin [SUB] , in. . . inside [REP] IP A: It w"Vz, It w"Ent, "V, [PAU] n"oU l"aI [DEL] , dZ"Vst D@, D@ w"Vn, D@ f"aI [PRO] @ ˆ o T"In [SUB] , I. . . Ins"aId [REP] T able 2: Cr oss-site performance comparison (mean ± std). Model A UC F1 Recall (Dys) Baseline 0.850 ± 0.122 0.778 ± 0.165 0.659 ± 0.238 HASS 0.892 ± 0.076 0.800 ± 0.072 0.899 ± 0.066 PP A Protocol corpus [26] and the Hopkins PP A corpus [27] in DementiaBank, and on two control datasets: the Delaware cor- pus [9] from DementiaBank and the Capilouto corpus [28] from AphasiaBank. Both control datasets are selected using explicit exclusion criteria (e.g., no neurological or cognitively deterio- rating conditions, fluent English, and no clinically significant depression). Baycrest, Delaware, and Capilouto share the stan- dard T alkBank discourse protocol [7, 8, 9], whereas Hopkins uses a clinical assessment battery [27] comprising naming, pas- sage reading, counting, and story retelling. Classifiers are ev al- uated in a strictly cross-site design: trained on Baycrest lvPP A and Delaware controls and tested on Hopkins dysfluent and Capilouto controls, then vice versa. This protocol and recording mismatch across four independent sites provides a stringent test of cross-corpus generalization. 4.1. Modeling details W e fine-tune W av2V ec 2.0 [29] with the base model size using Low-Rank Adaptation (LoRA) [30]. W e apply LoRA adapters exclusi vely to the query and value projection layers ( Q pro j , V pro j ). W e compare two distinct training regimes: • Baseline : Due to the limited size of the real clinical datasets, we employ 5-fold cross-validation to ensure reliable per- formance estimates. Data is grouped by speaker to pre- vent train/test contamination. T o mitigate confounding back- ground variability , all baseline train data is enhanced with MossFormer2 SE 48K [31] prior to feature extraction. • HASS : This model is trained using all samples from our gen- erated HASS corpus. W e sample fixed-length 15 s windows (240,000 samples at 16 kHz) from concatenated synthetic au- dio, which is grouped by ground-truth prompt, sev erity , and speaker . W e apply on-the-fly augmentation with speed perturbation (0.9– 1.1), additiv e Gaussian noise (10–20 dB SNR), volume jit- ter ( ± 6 dB), and re verberation via synthetic room impulse re- sponses (R T60 0.2–0.8 s), with per-sample probabilities of 0.5, 0.5, 0.5, and 0.3, respectiv ely . Each test fold is balanced to the minority class and e valuated on pr e-enhanced audio. W e report A UC-ROC, macro F1, and recall metrics all fi ve folds. 4.2. Cross-Site Model Ev aluation T o further evaluate the adv antage of our simulated data, we compare models trained on synthetic speech against baseline models in a strict cross-site scenario. In particular , we ev alu- ate generalization by training a model on data from one clinical site and testing it on another . W e partition our real datasets into Figure 2: Distribution of phonological dysfluency marker s acr oss severity levels. Dashed lines indicate per-severity means. two ev aluation domains: Domain A comprises Baycrest (dys- fluent) and Dela ware (control), while Domain B comprises JHU (dysfluent) and Capilouto (control). W e separate Baycrest and JHU into different domains due to their contrasting protocols for cross-domain e v aluation. All models are trained with the same setting as §4.1 using W av2V ec 2.0 base. • Baseline : Trained on real patient recordings and controls. W e train a separate baseline model for each cross-site scenario (i.e., trained on Domain A and tested on Domain B, and vice versa). • HASS : A single model is trained e xclusiv ely on HASS- generated streams. This model is then ev aluated on the real cross-site test domains. 4.3. Results HASS pr ovides synthetic samples that enable more accu- rate automatic lvPP A diagnosis T able 2 summarizes perfor- mance of the comparison of HASS-trained model and the base- line models The HASS model outperforms the baseline mod- els which only use limited real-w orld data across all primary metrics. Figure 3 illustrates this adv antage, as a HASS-trained model not only achieves higher mean A UC-R OC, but displays tighter variance across folds, indicating a more stable learning signal. HASS-trained models demonstrate rob ust cr oss-site generalization. W e ev aluated cross-site classification capabil- ity of HASS-trained model. As illustrated in Figure 4, the model trained exclusi vely on HASS-generated data outperforms base- line models trained on real clinical recordings when ev aluated on recordings from different clinical sites. Notably , the HASS- trained model achie ves a higher A UC-ROC in a strict cross-site setting (trained on one institutional dataset and tested on an- other , and vice versa). Cross-site robustness is essential for real- world clinical utility . Overfitting to local variations in record- ing environments and elicitation protocols remains the primary Figure 3: Comparison of ROC curves for LoRA models trained on real vs HASS speech, evaluated using 5-fold cross- validation. Mean ROC curve and ±1 standard deviation shad- ing. Figure 4: Cross-site ROC curves for LoRA SFT on w2v2-base. T est data as follows - Gr oup 1: JHU + Capilouto. Gr oup 2: Baycr est + Delawar e. barrier to deplo ying uni versal, scalable diagnostic models. This highlights two key advantages of our synthetic approach: gener- alization and scalability . HASS provides a mechanism to gener - ate virtually limitless, highly div erse training samples that cap- ture the core clinical phenotype of lvPP A without ov erfitting to the acoustic artifacts or demographic biases of a single clinical site. 5. Conclusion In this work, we introduced HASS, a novel, clinician-guided hi- erarchical simulation frame work designed to address the critical data scarcity bottleneck in automated primary progressive apha- sia (PP A) screening. By explicitly modeling the complex, multi- lev el language deficits characteristic of the logopenic variant (lvPP A) at both the le xical and phonological le vels, HASS gen- erates highly realistic, sev erity-controlled synthetic speech. Our empirical ev aluations demonstrate that the diagnostic model trained on HASS-generated data not only outperform base- lines trained strictly on real clinical recordings, but also exhibit superior robustness and generalization in stringent, cross-site ev aluations. Ultimately , this frame work provides a scalable, priv acy-preserving pathway for augmenting lo w-resource clini- cal datasets, paving the way for more reliable and robust speech- based diagnostic tools for neurodegenerati ve diseases. Limitations. Standard phoneme-to-speech architectures like VITS are inherently optimized for fluent speech and may not perform when forced to generate sev ere phonological errors. Furthermore, the neurological v ariability of dysfluent speech remains highly complex and under activ e study; because indi- vidual symptoms progress heterogeneously , true PP A se verity manifests in more nuanced ways. 6. References [1] S. M. Wilson, D. K. Eriksson, S. M. Schneck, and J. M. Lucanie, “A quick aphasia battery for efficient, reliable, and multidimen- sional assessment of language function, ” PLoS One , vol. 13, no. 2, p. e0192773, Feb . 2018. [2] J. A. Matias-Guiu, P . Su ´ arez-Coalla, M. Y us, V . Pytel, L. Hern ´ andez-Lorenzo, C. Delgado-Alonso, A. Delgado- ´ Alvarez, N. G ´ omez-Ruiz, C. Polidura, M. N. Cabrera-Mart ´ ın, J. Mat ´ ıas- Guiu, and F . Cuetos, “Identification of the main components of spontaneous speech in primary progressiv e aphasia and their neu- ral underpinnings using multimodal MRI and FDG-PET imag- ing, ” Cortex , v ol. 146, pp. 141–160, Jan. 2022. [3] M. L. Gorno-T empini, A. E. Hillis, S. W eintraub, A. Kertesz, M. Mendez, S. F . Cappa, J. M. Ogar, J. D. Rohrer , S. Black, B. F . Boev e, F . Manes, N. F . Dronkers, R. V andenberghe, K. Rascov- sky , K. Patterson, B. L. Miller , D. S. Knopman, J. R. Hodges, M. M. Mesulam, and M. Grossman, “Classification of primary progressiv e aphasia and its variants, ” Neur ology , vol. 76, no. 11, pp. 1006–1014, Mar . 2011. [4] N. Rezaii, D. Hochberg, M. Quimby , B. W ong, M. Brickhouse, A. T ouroutoglou, B. C. Dickerson, and P . W olff, “ Artificial intelligence classifies primary progressi ve aphasia from connected speech, ” Br ain , vol. 147, no. 9, pp. 3070–3082, 06 2024. [Online]. A vailable: https://doi.org/10.1093/brain/awae196 [5] F . Peters, W . R. Bev an-Jones, G. Threlf all, J. M. Harris, J. S. Snowden, M. Jones, J. C. Thompson, D. J. Blackburn, and H. Christensen, “ Automatic Detection and Sub-typing of Primary Progressiv e Aphasia from Speech: Integrating T ask-Specific Fea- tures and Spatio-Semantic Graphs, ” in Interspeech 2025 , 2025, pp. 5288–5292. [6] J. M. J. V onk, J. Lian, Z. Ezzes, C. J. Cho, B. T . Morin, R. Bogley , Z. Miller, M. L. Mandelli, G. Anumanchipalli, and M. L. Gorno- T empini, “ Automated lexical dysfluency analysis to dif ferentiate primary progressiv e aphasia v ariants, ” in Alzheimer’ s Association International Confer ence , 2025. [7] M. M. Forbes, D. Fromm, and B. MacWhinney , “ Aphasiabank: A resource for clinicians, ” Seminars in Speech and Langua ge , 2012, pMCID: PMC4073291. [Online]. A vailable: h t tp s : //pmc.ncbi.nlm.nih.gov/articles/PMC4073291/ [8] B. MacWhinney , D. Fromm, M. Forbes, and A. Holland, “ Aphasiabank: Methods for studying discourse, ” Aphasiology , vol. 25, no. 11, pp. 1286–1307, 2011, pMID: 22923879. [Online]. A vailable: https://doi.org/10.1080/02687038.2011.589893 [9] A. M. Lanzi, A. K. Saylor, D. Fromm, H. Liu, B. MacWhinney , and M. L. Cohen, “Dementiabank: Theoretical rationale, protocol, and illustrative analyses, ” American Journal of Speech- Language P athology , vol. 32, no. 2, pp. 426–438, 2023. [Online]. A vailable: https ://pubs.as ha.org/do i/abs/10.1 044/2022 A JSLP- 2 2- 00281 [10] J. Lian, C. Feng, N. F arooqi, S. Li, A. Kashyap, C. J. Cho, P . Wu, R. Netzorg, T . Li, and G. K. Anumanchipalli, “Unconstrained dysfluency modeling for dysfluent speech transcription and de- tection, ” in 2023 IEEE Automatic Speech Recognition and Under - standing W orkshop (ASRU) . IEEE, 2023, pp. 1–8. [11] J. Lian, X. Zhou, Z. Ezzes, J. V onk, B. Morin, D. P . Baquirin, Z. Miller, M. L. Gorno T empini, and G. Anumanchipalli, “Ssdm: Scalable speech dysfluency modeling, ” in Advances in Neural In- formation Pr ocessing Systems , vol. 37, 2024. [12] J. Zhang, X. Zhou, J. Lian, S. Li, W . Li, Z. Ezzes, R. Bogley , L. W auters, Z. Miller , J. V onk, B. Morin, M. Gorno-T empini, and G. Anumanchipalli, “ Analysis and Evaluation of Synthetic Data Generation in Speech Dysfluency Detection, ” pp. 1853– 1857, 2025. [13] J. Lian, X. Zhou, C. Guo, Z. Y e, Z. Ezzes, J. V onk, B. Morin, D. Baquirin, Z. Mille, M. L. G. T empini, and G. K. Anu- manchipalli, “ Automatic detection of articulatory-based disfluen- cies in primary progressiv e aphasia, ” 2025. [14] X. Zhou, A. Kashyap, S. Li, A. Sharma, B. Morin, D. Baquirin, J. V onk, Z. Ezzes, Z. Miller, M. T empini, J. Lian, and G. Anu- manchipalli, “YOLO-Stutter: End-to-end Re gion-W ise Speech Dysfluency Detection, ” in Interspeech 2024 , 2024, pp. 937–941. [15] T . Kourkounakis, A. Hajavi, and A. Etemad, “Fluentnet: End-to- end detection of stuttered speech disfluencies with deep learning, ” IEEE/ACM T ransactions on Audio, Speech, and Language Pro- cessing , vol. 29, pp. 2986–2999, 2021. [16] G. C. Imaezue and H. Marampelly , “ Abcd: A simulation method for accelerating con versational agents with applications in aphasia therapy , ” Journal of Speec h, Languag e, and Hearing Resear ch , vol. 68, no. 7, pp. 3322–3336, 2025. [Online]. A vailable: https://pubs.asha.org/doi/abs/10.1044/2025 JSLHR- 25- 00003 [17] J. M. Pittman, A. P . Jr ., Y . Medina-Santos, and B. C. Stark, “T owards a method for synthetic generation of persons with aphasia transcripts, ” 2025. [Online]. A vailable: ht t ps : //arxiv .org/abs/2510.24817 [18] M. L. Gorno-T empini, S. M. Brambati, V . Ginex, J. Ogar, N. F . Dronkers, A. Marcone, D. Perani, V . Garibotto, S. F . Cappa, and B. L. Miller, “The logopenic/phonological variant of primary pro- gressiv e aphasia, ” Neur ology , vol. 71, no. 16, pp. 1227–1234, Oct. 2008. [19] Gemini T eam Google, “Gemini: A family of highly capable mul- timodal models, ” arXiv preprint , 2023. [20] M. Bernard and H. Titeux, “Phonemizer: T ext to phones transcription for multiple languages in python, ” Journal of Open Sour ce Softwar e , vol. 6, no. 68, p. 3958, 2021. [Online]. A vailable: https://doi.org/10.21105/joss.03958 [21] The Association for Frontotemporal Degeneration (AFTD), “Know the signs. . . know the symptoms: Logopenic variant ppa, ” https://www . theaftd.org/wp- content/uploads/201 8/03/FTD- Signs - and- Symptoms- lvPP A.pdf, 2018. [22] M. L. Henry and S. M. Grasso, “ Assessment of individuals with primary progressiv e aphasia, ” Seminars in Speech and Language , vol. 39, no. 3, pp. 231–241, 2018, pMCID: PMC6464628. [Online]. A vailable: ht tps://pmc.ncbi. nlm.nih.gov/articl es/PMC6 464628/ [23] D. Petroi, J. R. Duf fy , A. Borgert, E. A. Strand, M. M. Machulda, M. L. Senjem, C. R. Jack, K. A. Josephs, and J. L. Whitwell, “Neuroanatomical correlates of phonologic errors in logopenic progressiv e aphasia, ” Brain and Language , vol. 204, p. 104773, 2020. [Online]. A vailable: ht tps://www .sc iencedirect.com/ scienc e/article/pii/S0093934X20300328 [24] S. G. H. Dalton, C. Shultz, M. L. Henry , A. E. Hillis, and J. D. Richardson, “Describing phonological paraphasias in three variants of primary progressive aphasia, ” Am. J. Speec h. Lang . P athol. , vol. 27, no. 1S, pp. 336–349, Mar . 2018. [25] J. Kim, J. K ong, and J. Son, “Conditional v ariational autoencoder with adversarial learning for end-to-end text-to- speech, ” in Pr oceedings of the 38th International Conference on Machine Learning , ser . Proceedings of Machine Learning Research, M. Meila and T . Zhang, Eds., vol. 139. PMLR, 18–24 Jul 2021, pp. 5530–5540. [Online]. A vailable: h tt ps : //proceedings.mlr .press/v139/kim21f.html [26] A. Kielar , T . Deschamps, R. Jokel, and J. A. Meltzer , “ Abnor- mal language-related oscillatory responses in primary progressi ve aphasia, ” Neur oImage Clin. , v ol. 18, pp. 560–574, Mar . 2018. [27] D. C. Tippett, C. B. Thompson, C. Demsky , R. Sebastian, A. Wright, and A. E. Hillis, “Differentiating between subtypes of primary progressiv e aphasia and mild cognitive impairment on a modified v ersion of the frontal behavioral in ventory , ” PloS One , vol. 12, no. 8, p. e0183212, 2017. [28] G. Capilouto, “AphasiaBank english protocol capilouto corpus, ” doi:10.21415/HTMN-5P65, 2026, accessed 2026-03-04. [29] A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framew ork for self-supervised learning of speech repre- sentations, ” Advances in neural information processing systems , vol. 33, pp. 12 449–12 460, 2020. [30] E. J. Hu, Y . Shen, P . W allis, Z. Allen-Zhu, Y . Li, S. W ang, L. W ang, W . Chen et al. , “Lora: Low-rank adaptation of large language models. ” Iclr , vol. 1, no. 2, p. 3, 2022. [31] S. Zhao, Y . Ma, C. Ni, C. Zhang, H. W ang, T . H. Nguyen, K. Zhou, J. Y ip, D. Ng, and B. Ma, “Mossformer2: Combining transformer and rnn-free recurrent network for enhanced time- domain monaural speech separation, ” 2024. [Online]. A vailable: https://arxiv .org/abs/2312.11825
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment