Post-selection inference in generalized linear models via parametric programming
We propose a unified framework to draw inferences for regression coefficients in a generalized linear model (GLM) following Lasso-based variable selection. We adapt to non-Gaussian GLMs a recently developed parametric programming strategy for post-se…
Authors: Qinyan Shen, Karl Gregory, Xianzheng Huang
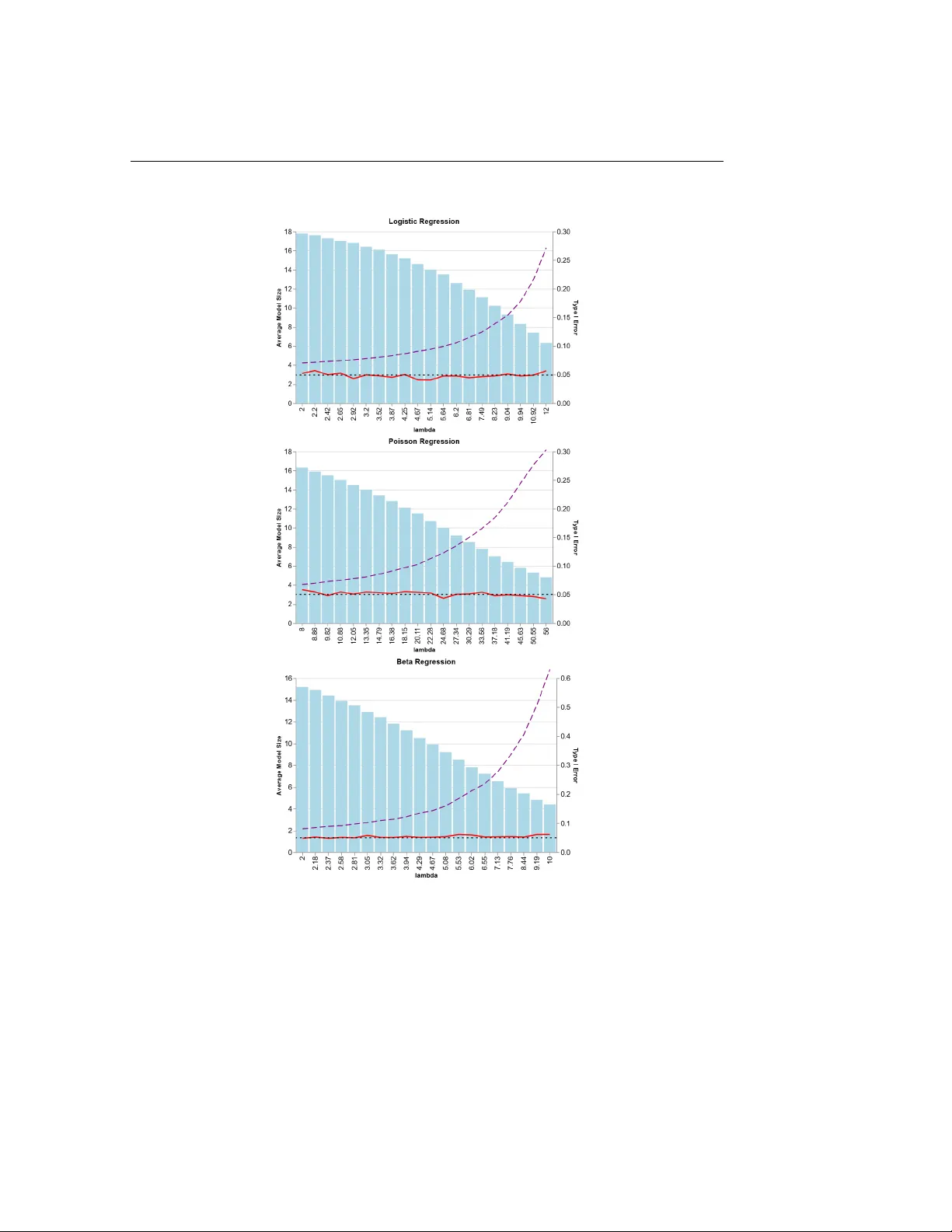
Statistica Sinica P ost-selection infer ence in generalized linear models via parametric pr ogramming Qinyan Shen, Karl Gre gory , Xianzheng Huang University of South Car olina Abstract: W e propose a unified framew ork to draw inferences for re gression coefficients in a generalized linear model (GLM) following Lasso-based variable selection. W e adapt to non-Gaussian GLMs a recently developed parametric programming strategy for post- selection inference in the linear model with a Gaussian response by drawing parallels between maximum likelihood estimation in GLMs and least squares estimation in linear models. W e then conduct post-selection inference based on a linearized model for pseudo response and co variate data strate gically created based on the raw data. Using synthetic data generated from regression models for three different types of non-Gaussian responses in simulation experiments, we demonstrate that the proposed method effecti vely corrects the nai ve inference that ignores v ariable selection while achie ving greater ef ficiency than a polyhedral-based post-selection adjustment. K e y wor ds and phrases: beta regression, Lasso, logistic regression, Poisson regression, selection ev ent 1 1. Introduction T raditional statistical inference assumes all hypotheses of interest are for- mulated prior to the observation of data. In regression conte xts, practitioners often explore their data in order to select from a set of av ailable variables a sub- set to use as cov ariates and, after fitting a model with these cov ariates, wish to make inferences on their ef fects. Such a strategy permits the data to dic- tate which h ypotheses are ultimately tested, wherein lies the danger of incurring higher T ype I error rates than intended. This danger has motiv ated the dev elop- ment of many post-selection inference methods to account for model selection. W e may categorize these as data splitting methods (W asserman and Roeder, 2009; Meinshausen et al., 2009; Rinaldo et al., 2019; Rasines and Y oung, 2023), simultaneous inference methods (Berk et al., 2013; Zhang and Cheng, 2017; Ba- choc et al., 2019, 2020), and conditioning methods (Lee et al., 2016; Tibshirani et al., 2016; T aylor and T ibshirani, 2018; Kuchibhotla et al., 2020; Pirenne and Claeskens, 2024; Neufeld et al., 2022). W e here pursue a conditioning method, whereby we make inferences on a parameter in the selected model based on the conditional sampling distribution of a rele v ant statistic gi ven the selection e vent. The seminal work Lee et al. (2016) studied the sampling distribution of a linear contrast of Gaussian responses in 2 a linear model giv en selection via L 1 -penalization of the least-squares criterion, sho wing that the selection e vent can be characterized as the union of many poly- hedra in the support of the response data. T o obtain a more tractable sampling distribution of the statistic, these authors further condition on the signs of the selected regression coefficients. This additional conditioning costs efficienc y in statistical inference, leading to wider-than-necessary confidence intervals that, although guaranteeing a nominal cov erage probability , could have infinite ex- pected width (Kiv aranovic and Leeb, 2021). Some recent dev elopments in this vein e xtend beyond linear models and Lasso regularization, where one seeks a useful conditional sampling distribution of the target statistic after intersecting the selection ev ent with additional characteristics of the selected model so that the conditional e vent is (approximately) polyhedral in the support of the response data (Panigrahi and T aylor, 2023; Zhao et al., 2022; Shen et al., 2024; T aylor and T ibshirani, 2018). W e refer to these methods as polyhedral methods. Le Duy and T ak euchi (2021) made improv ements to the work of Lee et al. (2016) by introducing a parametric programming (PP) approach to find the sam- pling distribution of a linear contrast of the response data conditional only on the selection e vent, a voiding the efficienc y loss incurred by the sign-conditioning of the polyhedral method. Pirenne and Claesk ens (2024) extended the PP approach to inference following model selection via adapti ve Lasso, adaptiv e elastic net, 3 and group Lasso. In our work we adapt the PP approach to generalized linear models (GLMs) for non-Gaussian responses. Our proposed strategy consists of two steps. Section 2 provides the dev elop- ment of the first step, in which we “linearize” the regression problem specified by a GLM for non-Gaussian data. Section 3 elaborates on the second step, where we apply the PP method to the linearized regression model. Section 4 describes in detail the implementation of the proposed method in three non-Gaussian re- gression settings. Section 5 presents simulation studies comparing the proposed method with the naive method (the method which ignores model selection), the polyhedral method. Section 6 presents three case studies in which we make in- ferences on co v ariate effects following variable selection using dif ferent types of non-Gaussian data arising from real-life applications. Section 7 outlines ke y takea ways and suggestions for future research. 2. Pre-selection inference in GLMs Suppose we observe ( x 1 , Y 1 ) , . . . , ( x n , Y n ) , where x 1 , . . . , x n ∈ R p are fixed cov ariate vectors and Y 1 , . . . , Y n are independent responses such that Y i ∼ f ( y ; η i , ϕ ) = exp y η i − b ( η i ) a ( ϕ ) − c ( y , ϕ ) , (2.1) where η i ≡ β 0 + x ⊤ i β , for i = 1 , . . . , n , where a ( · ) , b ( · ) and c ( · , · ) are known functions, ϕ is a dispersion parameter , and β 0 and β ≡ ( β 1 , . . . , β p ) ⊤ are pa- 4 2.1 Maximum likelihood estimation in a submodel rameters with unknown v alues. This is the canonical generalized linear model (GLM); see McCullagh and Nelder (1989). Note that the mean and variance of Y i are b ′ ( η i ) and a ( ϕ ) b ′′ ( η i ) , respecti vely , where b ′ ( · ) and b ′′ ( · ) are the first two deri v ati ves of b ( · ) . Throughout, let M 0 = { j ∈ { 1 , . . . , p } : β j = 0 } be the set of indices corresponding to nonzero regression coef ficients. W e will consider making inferences follo wing the selection of a model M ⊂ { 1 , . . . , p } . 2.1 Maximum likelihood estimation in a submodel T o focus on making inferences on the regression coef ficients in the GLM specified by (2.1), we will for most of the paper assume ϕ is known. The max- imum likelihood estimator (MLE), which we denote by ( ˆ β 0 , ˆ β ) , of the tuple ( β 0 , β ) can be obtained by maximizing the log-lik elihood ℓ ϕ ( t 0 , t ) ≡ 1 a ( ϕ ) n X i =1 ( Y i η i ( t 0 , t ) − b ( η i ( t 0 , t ))) − n X i =1 c ( Y i , ϕ ) ov er ( t 0 , t ) ∈ R × R p , where η i ( t 0 , t ) ≡ t 0 + x ⊤ i t . Instead of including all cov ariates, one may consider selecting a model M ⊂ { 1 , . . . , p } indexing which cov ariates to include in the construction of the linear predictors η 1 , . . . , η n . The MLE in model M , denoted by ( ˆ β mle 0 ,M , ˆ β mle M ) , maximizes the function ℓ ϕ,M ( t 0 , t ) ≡ 1 a ( ϕ ) n X i =1 ( Y i η i,M ( t 0 , t ) − b ( η i,M ( t 0 , t ))) − n X i =1 c ( Y i , ϕ ) ov er ( t 0 , t ) ∈ R × R | M | , where η i,M ( t 0 , t ) ≡ t 0 + ( x i ) ⊤ M t , | M | is the cardinality of 5 2.1 Maximum likelihood estimation in a submodel M , and ( x i ) M is the vector constructed from the entries of x i with indices in M . Under regularity conditions (White, 1982), as n → ∞ , ( ˆ β mle 0 ,M , ˆ β mle M ) con ver ges in probability to the limiting v alue of ( β ∗ 0 ,M , β ∗ M ) ≡ arg max ( t 0 , t ) ∈ R × R | M | E 1 n { ℓ ϕ ( β 0 , β ) − ℓ ϕ,M ( t 0 , t ) } , where the maximand is proportional to the Kullback-Leibler div ergence of the true model from model M . One may therefore regard ( β ∗ 0 ,M , β ∗ M ) as the target of estimation when model M is considered. Denoting by β M the v ector containing the entries of β with indices in M , we will ha ve ( β ∗ 0 ,M , β ∗ M ) = ( β 0 , β M ) if M contains all the indices in which β is nonzero, that is if M ⊃ M 0 . If model M results from v ariable selection based on the observed data, v alid inferences for β ∗ M using the same data should account for the selection e vent. In this study , we focus on Lasso-based variable selection. For example, one may select a model by finding the L 1 -penalized MLE, defined as ( ˆ β mle 0 ,λ , ˆ β mle λ ) ≡ arg min ( t 0 , t ) ∈ R × R p n − 1 n ℓ ϕ ( t 0 , t ) + λ ∥ t ∥ 1 o , (2.2) where ∥ t ∥ 1 is the L 1 -norm of t and λ > 0 is a tuning parameter governing the sparsity of ˆ β mle λ . A selected model is then ˆ M mle λ ≡ { j : ( ˆ β mle λ ) j = 0 } . T o make inferences on ( β ∗ M ) j based ( ˆ β mle M ) j , where for a generic v ector v we denote by ( v ) i entry i of v , it is necessary to obtain the conditional sampling distrib ution of ( ˆ β mle M ) j gi ven the selection ev ent { ˆ M mle λ = M } . Ho we ver , this conditional 6 2.2 Model linearization distribution does not appear to be analytically tractable in the GLM setting. For this reason we pursue a two-step strategy whereby we first “linearize” the GLM and then apply a post-selection inference method dev eloped for the linear model. 2.2 Model linearization In linear regression with a Gaussian response, the exact conditional distri- bution of ( ˆ β mle M ) j |{ ˆ M mle λ = M } has been found (Lee et al., 2016; Le Duy and T akeuchi, 2021). This motiv ates our strategy of linearizing the GLM and then performing model selection and post-selection inference in the linearized model. Our linearization step is inspired by the Newton-Raphson (NR) update leading to the MLEs of ( β 0 , β ) , which we describe next. For each ( t 0 , t ) ∈ R × R p define z ( t 0 , t ) as the v ector with entries z i ( t 0 , t ) ≡ p b ′′ ( η i ( t 0 , t )) η i ( t 0 , t ) + Y i − b ′ ( η i ( t 0 , t )) p b ′′ ( η i ( t 0 , t )) , the vector u 0 ( t 0 , t ) with entries p b ′′ ( η i ( t 0 , t )) , and the matrix U ( t 0 , t ) with ro ws p b ′′ ( η i ( t 0 , t )) x ⊤ i for i = 1 , . . . , n . Then, with initial v alue ( t (0) 0 , t (0) ) , the iterati vely re weighted least squares formulation of the NR update is ( t ( k ) 0 , t ( k ) ) ← arg min ( t 0 , t ) ∈ R × R p ∥ z ( k − 1) − ( u ( k − 1) 0 t 0 + U ( k − 1) t ) ∥ 2 , (2.3) where z ( k − 1) ≡ z ( t ( k − 1) 0 , t ( k − 1) ) , u ( k − 1) 0 ≡ u 0 ( t ( k − 1) 0 , t ( k − 1) ) , and U ( k − 1) ≡ U ( t ( k − 1) 0 , t ( k − 1) ) ; see Davison (2003). 7 2.2 Model linearization Upon con ver gence of ( t ( k ) 0 , t ( k ) ) to ( ˆ β 0 , ˆ β ) , define ˆ z ≡ z ( ˆ β 0 , ˆ β ) , ˆ u 0 ≡ u ( ˆ β 0 , ˆ β ) , and ˆ U ≡ U ( ˆ β 0 , ˆ β ) . T o focus on the parameters in β , we now de- fine “centered” versions of the response vector ˆ z and the design matrix ˆ U . First define P 0 ( t 0 , t ) ≡ ∥ u 0 ( t 0 , t ) ∥ − 2 u 0 ( t 0 , t ) u 0 ( t 0 , t ) ⊤ as well as z 0 ( t 0 , t ) = ( I − P 0 ( t 0 , t )) z ( t 0 , t ) and U 0 ( t 0 , t ) ≡ ( I − P 0 ( t 0 , t )) U ( t 0 , t ) . Then set ˆ P 0 ≡ P 0 ( ˆ β 0 , ˆ β ) as well as ˆ z 0 ≡ ( I − ˆ P 0 ) ˆ z and ˆ U 0 ≡ ( I − ˆ P 0 ) ˆ U , noting that ˆ P 0 is the orthogonal projection onto the space spanned by the “intercept” vector ˆ u 0 . Then we hav e ˆ β = arg min t ∈ R p ∥ ˆ z 0 − ˆ U 0 t ∥ 2 , so that we may regard ˆ β as the least squares estimator in linear regression with response vector ˆ z 0 and design matrix ˆ U 0 . From here our strategy will be to treat the response vector ˆ z 0 as though it arose from a Gaussian linear model with design matrix ˆ U 0 and to apply a post-selection inference method de veloped for Gaussian linear re gression. Since our strategy is to treat ˆ z 0 and ˆ U 0 as Gaussian linear model data, we propose to select a model via L 1 -penalization of the Gaussian log-likelihood with ˆ z 0 and ˆ U 0 plugged in. That is, we propose computing the sparse estimator ˆ β λ ≡ arg min t ∈ R p 1 2 n ∥ ˆ z 0 − ˆ U 0 t ∥ 2 + λ ∥ t ∥ 1 , (2.4) for some λ > 0 and selecting the model ˆ M λ ≡ { j : ( ˆ β λ ) j = 0 } . Note that the model selected in this way may be distinct from the model ˆ M mle λ selected via L 1 -penalization of the original GLM log-likelihood; ho wever , in Section 2.3 we argue that these models should be reliably similar as n → ∞ . Then, on the ev ent 8 2.3 The idealized linear model that the model ˆ M λ = M is chosen, we consider the conditional distribution of the vector ˆ β M ≡ arg min t ∈ R p ∥ ˆ z 0 − ˆ U 0 ,M t ∥ 2 , the entries of which may be e xpressed as contrasts in the vector ˆ z 0 of the form ( ˆ β M ) j = e T j ( ˆ U ⊤ 0 ,M ˆ U 0 ,M ) − 1 ˆ U ⊤ 0 ,M ˆ z 0 , (2.5) for j = 1 , . . . , | M | , where e j is the | M | × 1 vector with entry j equal to one and remaining entries equal to zero. In order to study the conditional distributions of contrasts of the form in (2.5), we next introduce idealized counterparts to ˆ z 0 and ˆ U 0 , which we denote by z 0 and U 0 , which one would observe if one knew the true values of the parameters β 0 and β . 2.3 The idealized linear model The response vector ˆ z , the vector ˆ u 0 , and design matrix ˆ U can be viewed as approximations to unobserv able, idealized counterparts z , u 0 , and U , respec- ti vely , which we define as z ≡ z ( β 0 , β ) , u 0 ≡ u 0 ( β 0 , β ) , and U ≡ U ( β 0 , β ) . Moreov er , letting z 0 ≡ z 0 ( β 0 , β ) and U 0 ≡ U 0 ( β 0 , β ) , we obtain idealized counterparts to the “centered” response vector ˆ z 0 and design matrix ˆ U 0 . If one could observe z 0 and U 0 , one could base inferences on the idealized linear estimator of β gi ven by ˜ β ≡ arg min t ∈ R p ∥ z 0 − U 0 t ∥ 2 . Like wise, one 9 2.3 The idealized linear model could compute the idealized sparse estimator ˜ β λ ≡ arg min t ∈ R p 1 2 n ∥ z 0 − U 0 t ∥ 2 + λ ∥ t ∥ 1 , (2.6) and the corresponding idealized selected model ˜ M λ ≡ { j : ( ˜ β λ ) j = 0 } . Fur - thermore, on the e vent ˜ M λ = M , one could make conditional inferences by considering the conditional distributions of the entries of the idealized estima- tor ˜ β M ≡ arg min t ∈ R p ∥ z 0 − U 0 ,M t ∥ 2 , which could be expressed as contrasts in the vector z 0 with form ( ˜ β M ) j ≡ e ⊤ j ( U ⊤ 0 ,M U 0 ,M ) − 1 U ⊤ 0 ,M z 0 . (2.7) Note that the contrast in (2.7) is an idealized v ersion of the contrast in (2.5). Defining for each M ⊂ { 1 , . . . , p } and j = 1 , . . . , | M | the v ector c M ,j ( t 0 , t ) ⊤ = e ⊤ j ( U 0 ,M ( t 0 , t ) ⊤ U 0 ,M ( t 0 , t )) − 1 U 0 ,M ( t 0 , t ) ⊤ , where U 0 ,M ( t 0 , t ) is the matrix formed with the columns of U 0 ( t 0 , t ) having indices in M , we set ˆ c M ,j ≡ c M ,j ( ˆ β 0 , ˆ β ) , which has idealized counterpart c M ,j ≡ c M ,j ( β 0 , β ) . This allo ws us to write (2.5) and (2.7) as ( ˆ β M ) j = ˆ c ⊤ M ,j ˆ z 0 and ( ˜ β M ) j = c ⊤ M ,j z 0 , respecti vely . Our first result gi ves conditions under which, prior to model selection, one can make inferences based on the observ able ˆ z 0 and ˆ U 0 which are asymptotically equi v alent to those based on their idealized counterparts z 0 and U 0 . T o state our 10 2.3 The idealized linear model result, define for any ( t 0 , t ) ∈ R × R p the function g M ,j,n ( t 0 , t ; β ) ≡ c M ,j ( t 0 , t ) ⊤ ( z ( t 0 , t ) − U ( t 0 , t ) β ) p c M ,j ( t 0 , t ) ⊤ c M ,j ( t 0 , t ) . Then the function g M ,j,n ( t 0 , t ; β ) may be used to construct some useful piv otal quantities. Specifically we define ˆ g M ,j,n ( β ) ≡ g M ,j,n ( ˆ β 0 , ˆ β ; β ) = ˆ c ⊤ M ,j ( ˆ z 0 − ˆ U 0 β ) q ˆ c ⊤ M ,j ˆ c M ,j as a feasible pi v otal quantity and g M ,j,n ( β ) ≡ g M ,j,n ( β 0 , β ; β ) = c ⊤ M ,j ( z 0 − U 0 β ) q c ⊤ M ,j c M ,j as its idealized counterpart. After stating an assumption, we can present our first main result. Assumption 1. Given M ⊂ { 1 , . . . , p } and an inde x j = 1 , . . . , | M | , suppose (i) ∥ c M ,j ∥ ∞ / ∥ c M ,j ∥ → 0 as n → ∞ and (ii) for some n 0 ≥ 1 and δ , C ∈ [0 , ∞ ) , E | g M ,j,n ( t 0 , t ; β ) − g M ,j,n ( β 0 , β ; β ) | ≤ C ∥ ( t 0 , t ⊤ ) ⊤ − ( β 0 , β ⊤ ) ⊤ ∥ for all n > n 0 for all ( t 0 , t ) suc h that ∥ ( t 0 , t ⊤ ) ⊤ − ( β 0 , β ⊤ ) ⊤ ∥ ≤ δ . Assumption 1(i) is mild and holds if the maximum le verage in the linear model with design matrix U M con ver ges to zero; see Huber (2011). Assumption 1(ii) is a smoothness condition on the function g n ( t 0 , t ; β ) in the neighborhood 11 2.3 The idealized linear model of the tuple ( β 0 , β ) . Namely , it requires that the expected change in the (random) function g M ,j,n ( t 0 , t ; β ) as ( t 0 , t ) moves aw ay from ( β 0 , β ) is bounded above by some constant times the distance between ( t 0 , t ) and ( β 0 , β ) . Both assumptions describe conditions on the sequence of design vectors { x n } n ≥ 1 . Theorem 1. Under Assumption 1 we have (i) g M ,j,n ( β ) d → N (0 , a ( ϕ )) and (ii) | ˆ g M ,j,n ( β ) − g M ,j,n ( β ) | p → 0 as n → ∞ . The following corollary shows how Theorem 1 would enable inference on an entry of β M based on the observ able ˆ z 0 and ˆ U 0 . Corollary 1. Under Assumption 1, if M ⊃ M 0 then, as n → ∞ , we have ( ˆ β M ) j − ( β M ) j q e T j ( ˆ U ⊤ 0 ,M ˆ U 0 ,M ) − 1 e j d → N (0 , a ( ϕ )) . Note that if M ⊃ M 0 , then the estimation targets in the linearized model become the entries of the vector ˜ β ∗ M ≡ ( U ⊤ 0 ,M U 0 ,M ) − 1 U ⊤ 0 ,M U 0 β . (2.8) Note that Theorem 1 and Corollary 1 gi ve asymptotic distributions which are not yet conditioned on the selection of a model. In order to establish asymp- totic equiv alence of conditional inferences after model selection based on the observ able linear model data ˆ z 0 and ˆ U 0 and those based on the idealized linear model data z 0 and U 0 , we must in vestigate whether the selected model ˆ M λ based 12 2.3 The idealized linear model on the sparse estimator ˆ β λ in (2.4) and the selected model ˜ M λ based on ˜ β λ in (2.6) will agree with high probability . If so, one may assume in e very step of the analysis that one has observed the idealized response z 0 and design matrix U 0 instead of their observable counterparts ˆ z 0 and ˆ U 0 . Proofs of Theorem 1 and Corollary 1 are gi ven in the Supplementary Material. Defining the vector of correlations ˜ r λ ≡ ˜ U ⊤ 0 ( ˜ z 0 − ˜ U 0 ˜ β λ ) , the KKT con- ditions giv e that | ( ˜ r λ ) j | = λ for all j ∈ ˜ M λ and | ( ˜ r λ ) j | ≤ λ for all j / ∈ ˜ M λ . Like wise defining ˆ r λ ≡ ˆ U ⊤ 0 ( ˆ z 0 − ˆ U 0 ˆ β λ ) , we hav e | ( ˆ r λ ) j | = λ for all j ∈ ˆ M λ and | ( ˆ r λ ) j | ≤ λ for all j / ∈ ˆ M λ . If one assumes for the idealized pseudo-data that (i) | ( ˜ r λ ) j | ≤ λ (1 − ρ ) for all j / ∈ ˜ M λ for some ρ ∈ (0 , 1) , a condition called strict dual feasibility (W ainwright, 2009), and (ii) min j ∈ ˜ M λ | ( ˜ β λ ) j | ≥ c > 0 , a so-called beta-min condition (Zhao and Y u, 2006), hold with probability tending to one as n → ∞ , then P ( ˆ M λ = ˜ M λ ) → 1 pro vided ∥ ˆ r λ − ˜ r λ ∥ p → 0 and ∥ ˆ β λ − ˜ β λ ∥ p → 0 (2.9) as n → ∞ . This is due to the fact that under (i), the first con ver gence in (2.9) implies that for all indices j for which | ( ˜ r λ ) j | < λ (and therefore ( ˜ β λ ) j = 0 ), we will also hav e | ( ˆ r λ ) j | < λ (and therefore ( ˆ β λ ) j = 0 ). So we will have ( ˆ β λ ) j = 0 for all j such that ( ˜ β λ ) j = 0 . Under the beta-min condition (ii), the second con vergence in (2.9) implies that for all j such that ( ˜ β λ ) j = 0 , we will hav e ( ˆ β λ ) j = 0 . The con vergences in (2.9) can be established under 13 2.4 V ariable selection after linearization mild smoothness and con ve xity conditions on the objectiv e function defined by q n ( s ; t 0 , t ) ≡ (2 n ) − 1 ∥ z 0 ( t 0 , t ) − U 0 ( t 0 , t ) s ∥ 2 + λ ∥ s ∥ 1 , for which we can write ˜ β λ = arg min s q n ( s ; β 0 , β ) and ˆ β λ = arg min s q n ( s ; ˆ β 0 , ˆ β ) . Under such condi- tions, ∥ ( ˆ β 0 , ˆ β ⊤ ) ⊤ − ( β 0 , β ⊤ ) ⊤ ∥ p → 0 will imply the con vergences in (2.9). W e next describe post-selection inference based on treating ˆ z 0 and ˆ U 0 as though they were equal to z 0 and U 0 and treating ˆ M λ as though it matched ˜ M λ . 2.4 V ariable selection after linearization Here we consider whether v ariable selection in the linear model with pseudo- data ˆ z 0 and ˆ U 0 will be perform similarly to variable selection based on L 1 - penalization of the original GLM likelihood; that is, we consider ho w likely it is that selected models ˆ M λ and ˆ M mle λ will match. W e find that if the conditions are met for model selection consistency by L 1 -penalization of the GLM likelihood, then the conditions are also met for model selection consistency by L 1 -penalization in the linear model with the idealized pseudo-data z 0 and U 0 . In particular, Lee et al. (2015) present two main assumptions allowing for model selection consistency of a class of regu- larized M-estimators. These are a restricted strong con vexity (RSC) condition and the so-called irrepresentable condition, the first version of which appeared in Zhao and Y u (2006). T o express these conditions in our GLM setting with L 1 - 14 2.4 V ariable selection after linearization penalization, denote the Hessian of the scaled ne gativ e log-likelihood appearing in (2.2) by Q ( t 0 , t ) ≡ ( na ( ϕ )) − 1 P n i =1 b ′′ ( η i ( t 0 , t )) ˜ x i ˜ x ⊤ i , where ˜ x i ≡ [1 x ⊤ i ] ⊤ , i = 1 , . . . , n , and set Q ϕ ≡ Q ( β 0 , β ) . Now let C 0 × C ⊂ R × R p be a kno wn con ve x set containing ( β 0 , β ) and set M 0 ≡ span { e j , j ∈ M 0 } , where { e j , j = 1 , . . . , p } are elementary basis vectors in R p . Furthermore let ˜ δ represent a vec- tor ˜ δ ≡ ( δ 0 , δ ⊤ ) ⊤ for ( δ, δ ) ∈ R × R p . Then the RSC condition in our GLM setting becomes ˜ δ T Q ϕ ( t 0 , t ) ˜ δ ≥ κ ∥ ˜ δ ∥ for all ( δ 0 , δ ) , ( t 0 , t ) ∈ C 0 × ( C ∩ M 0 ) for some κ > 0 (cf. Assumption 3.1 of Lee et al. (2015)). In addition, the irrepre- sentable condition becomes ∥Q ϕ,M c 0 ,M 0 Q − 1 ϕ,M 0 ,M 0 sign( β M 0 ) ∥ ∞ ≤ 1 − ξ for some ξ ∈ (0 , 1) , where Q ,ϕ, A , B denotes the matrix constructed from Q ϕ by keeping ro ws with indices in A and columns with indices in B . No w , in the idealized linear model the Hessian of the loss function ∥ z 0 − ( u 0 t 0 + Ut ) ∥ 2 is exactly Q ϕ . Therefore if the RSC condition holds, then the same condition holds when Q ϕ ( t 0 , t ) is replaced by Q ϕ = Q ϕ ( β 0 , β ) , since ( β 0 , β ) belongs to the set C 0 × ( C ∩ M 0 ) . Therefore, if the RSC is satisfied for the GLM, it will also be satisfied in the idealized linear model. Moreo ver , the irrepresentable condition for the GLM is identical to its counterpart in the linear model with the idealized pseudo-data, as it is formulated in terms of Hessian e v aluated at the true parameter v alues. Therefore, if these conditions are met for consistent v ariable selection via 15 L 1 -penalization of the GLM log-likelihood, they will also be met for consistent v ariable selection via L 1 -penalization of the least-squares criterion in the ideal- ized pseudo-data. By the discussion at the end of Section 2.3, model selections based on ˆ z 0 and ˆ U 0 will reliably match those based on the idealized z 0 and U 0 , so that, by extension, model selection via L 1 -penalization of the least-squares criterion in ˆ z 0 and ˆ U 0 , gi ving ˆ M λ , will be reliable whene ver model selection via L 1 -penalization of the GLM log-likelihood, giving ˆ M mle λ , is reliable. In support of these findings, we present an empirical comparison of selected models ˆ M λ and ˆ M mle λ on simulated data sets in the Supplementary Material. 3. Post-selection inference based on the linearized model The (centered) idealized response vector z 0 may be written as z 0 = U 0 β + ξ 0 , (3.1) where the term ξ 0 is defined as the centered v ersion ξ 0 ≡ ( I − P 0 ) ξ of the vector ξ ≡ ( ξ 1 , . . . , ξ n ) ⊤ , where ξ i ≡ ( Y i − b ′ ( η i )) / p b ′′ ( η i ) , i = 1 , . . . , n are independent random variables with mean zero and v ariance a ( ϕ ) , so that the cov ariance matrix of ξ 0 is ( I − P 0 ) a ( ϕ ) . Here we apply the parametric programming (PP) approach in Le Duy and T akeuchi (2021) for making post-selection inferences based on observing the idealized data z 0 and U 0 in (3.1), treating this as a Gaussian linear model. 16 3.1 Post-selection sampling distribution of idealized LSE 3.1 Post-selection sampling distribution of idealized LSE Gi ven a model M ⊂ { 1 , . . . , p } the estimator ˜ β M has entry j gi ven by ( ˜ β M ) j = c ⊤ M ,j z 0 , and its estimation target is ( ˜ β ∗ M ) j with ˜ β ∗ M defined in (2.8). Recall that ˜ M λ is the model selected via L 1 -penalization in (2.6) of the least- squares criterion in the idealized pseudo-data z 0 and U 0 . Giv en the ev ent ˜ M λ = M , we consider making conditional inferences on ( ˜ β ∗ M ) j based on the condi- tional distribution of ( ˜ β M ) j |{ ˜ M λ = M } . This is reminiscent of the problem raised in Section 2.1 of finding the dis- tribution of ( ˆ β mle M ) j |{ ˆ M mle λ = M } in order to make inferences on ( β ∗ M ) j in the GLM setting. In essence, we transform the original intractable problem in GLMs to an easier (and solved) problem in linear models. The analogy of these two problems is justified by the asymptotic equiv alence of the pi votal quantities con- sidered in Theorem 1 and, moreov er , as we discuss in Section 2.4, the fact that selected models ˆ M mle λ and ˆ M λ will be reliably similar under standard conditions. T reating ξ 0 as multiv ariate Gaussian, the estimator ( ˜ β M ) j , prior to condi- tioning on the selection of model M , has the N (( ˜ β ∗ M ) j , a ( ϕ ) ∥ c M ,j ∥ 2 ) distribu- tion, where this approximately holds when ξ 0 is non-Gaussian, by Theorem 1(i). T o account for v ariable selection, inference should be based on the conditional distribution of ( ˜ β M ) j gi ven the selection e vent { ˜ M λ = M } = { z 0 ∈ R n : 17 3.1 Post-selection sampling distribution of idealized LSE ˜ M λ ( z 0 ) = M } , where we use ˜ M λ ( z 0 ) to indicate the dependence of ˜ M λ on z 0 Gi ven any contrast c ⊤ z 0 of interest, the main idea of the PP approach of Le Duy and T akeuchi (2021) is to “parameterize” all the rele vant response vec- tors z 0 in R n by linking them to a “parameter” τ in R so that the selection e vent can be identified with a subset of parameter v alues in R rather than with a subset of response vectors in R n . T o achiev e this parameterization, we define another ev ent { z 0 ∈ R n : ˆ q ( z 0 ) = q } , where ˆ q ( z 0 ) ≡ ( I − P c ) z 0 , where P c ≡ ∥ c ∥ − 2 cc ⊤ , and q is in the column space of ( I − P c ) as a realization of ˆ q ( z 0 ) in a gi ven application where M is the realization of ˜ M λ ( z 0 ) . By construc- tion, ˆ q ( z 0 ) and c ⊤ z 0 are uncorrelated, and since we are treating ξ 0 as multi v ari- ate Gaussian, they are independent. Thus, using “ d = ” to refer to “equiv alent in distribution, ” we hav e c ⊤ z 0 |{ z 0 ∈ R n : ˜ M λ ( z 0 ) = M } d = c ⊤ z 0 |{ z 0 ∈ R n : ˜ M λ ( z 0 ) = M , ˆ q ( z 0 ) = q } d = c ⊤ z 0 |{ z 0 ∈ R n : ˜ M λ ( z 0 ) = M , ( I − P c ) z 0 = q } d = c ⊤ z 0 |{ z 0 ∈ R n : ˜ M λ ( z 0 ) = M , z 0 = q + P c z 0 } d = c ⊤ z 0 |{ z 0 ∈ R n : ˜ M λ ( q + P c z 0 ) = M } d = c ⊤ z 0 |{ z 0 ∈ R n : ˜ M λ ( q + ∥ c ∥ − 2 cc ⊤ z 0 ) = M } d = c ⊤ z 0 |{ τ ∈ R : ˜ M λ ( z 0 ( τ )) = M } , (3.2) 18 3.1 Post-selection sampling distribution of idealized LSE with z 0 ( τ ) ≡ q + τ ∥ c ∥ − 2 c , index ed by τ , so that it moves across the support of z 0 as τ mo ves across R . Similarly , we “parameterize” the models selected via the minimization in (2.6) be writing ˜ β λ ( τ ) ≡ arg min t ∈ R p 1 2 n ∥ z 0 ( τ ) − U 0 t ∥ 2 + λ ∥ t ∥ 1 , (3.3) so that ˜ M λ ( z 0 ( τ )) ≡ { j : ( ˜ β λ ( τ )) j = 0 } as τ varies in R . This translates the search of z 0 in R n for the selection ev ent { ˜ M λ ( z 0 ) = M } to the search of τ in R that satisfies ˜ M λ ( z 0 ( τ )) = M for a giv en model M . Le Duy and T akeuchi (2021) provided an efficient algorithm to identify the values of τ in T M ≡ { τ ∈ R : ˜ M λ ( z 0 ( τ )) = M } as a union of disjoint interv als in R . W ith c = c M ,j and T M ,j as the support of the conditional distribution of ( ˜ β M ) j = c ⊤ M ,j z 0 , by (3.2) we hav e ( ˜ β M ) j |{ ˜ M λ ( z 0 ) = M } ∼ N T M ,j (( ˜ β ∗ M ) j , a ( ϕ ) ∥ c M ,j ∥ 2 ) , where N T M ,j ( a, b ) represents the normal distribution with mean a and variance b truncated to hav e support on T M ,j . Denoting by F T M ,j ( · ; a, b ) the cumulativ e distribution function (CDF) of this distribution, we can pass ( ˜ β M ) j through its o wn CDF to construct a piv otal quantity with which a post-selection (1 − α )100% confidence interv al for ( β ∗ M ) j may be constructed as CI M ,j ≡ n µ ∈ R : α/ 2 ≤ F T M ,j (( ˜ β M ) j ; µ, a ( ϕ ) ∥ c M ,j ∥ 2 ) ≤ 1 − α/ 2 o (3.4) 19 3.2 Accounting for penalty parameter selection for α ∈ [0 , 1 / 2] . Similarly , a post-selection p -value for testing ( ˜ β ∗ M ) j = 0 versus ( ˜ β ∗ M ) j = 0 for j ∈ M based on ( ˜ β M ) j can be defined as 2 × min n F T M (( ˜ β M ) j ; 0 , a ( ϕ ) ∥ c M ,j ∥ 2 ) , 1 − F T M (( ˜ β M ) j ; 0 , a ( ϕ ) ∥ c M ,j ∥ 2 ) o . (3.5) W e propose carrying out these steps, substituting for z 0 and U 0 the observ- able counterparts ˆ z 0 and ˆ U 0 after selecting the model ˆ M λ based on the estimator ˆ β λ in (2.4). 3.2 Accounting for penalty parameter selection Instead of being pre-specified as assumed in Section 3.1, we may allow the penalty parameter λ to be selected based on the data z 0 and U 0 , as is usually done in practice. This change demands a revision of the selection ev ent in (3.2) to ackno wledge the additional selection of λ . This extra selection can again be “parameterized” via τ when λ is chosen based on one partition of ( z 0 , U 0 ) into a training set, ( z train 0 , U train 0 ) , and a v alidation set, ( z val 0 , U val 0 ) . More specifically , the selection of λ can be formulated as an optimization index ed by τ , ˜ λ ( z 0 ( τ )) ≡ arg min λ ∈ Λ ∥ z val 0 ( τ ) − U val 0 ˜ β train λ ( z ( τ )) ∥ 2 , where Λ is the set of candidate values for λ , and, for each λ ∈ Λ , mimicking (3.3), ˜ β train λ ( z 0 ( τ )) ≡ arg min t ∈ R p (2 n ) − 1 ∥ z train 0 ( τ ) − U train 0 t ∥ 2 + λ ∥ t ∥ 1 . Define T λ ≡ { τ ∈ R : ˜ λ ( z 0 ( τ )) = λ } , vie wing λ as a realization of ˜ λ ( z 0 ( τ )) correspond- 20 ing to M as the realization of ˜ M λ ( z 0 ( τ )) . Then the complete selection ev ent is T λ ∩ T M ,j ≡ { τ ∈ R : ˜ λ ( z 0 ( τ )) = λ, ˜ M λ ( z 0 ( τ )) = M } , and thus ( ˜ β M ) j |{ ˜ M λ = M } ∼ N T λ ∩T M ,j (( ˜ β ∗ M ) j , a ( ϕ ) ∥ c M ,j ∥ 2 ) . Le Duy and T akeuchi (2021) de veloped an algorithm for identifying T λ . It is no w straightforward to obtain a (1 − α )100% confidence interval for ( ˜ β ∗ M ) j and to compute the p -v alue for testing the signif- icance of this co v ariate effect based on ( ˜ β M ) j : one simply changes the support of the post-selection sampling distribution of ( ˜ β M ) j from T M ,j to T λ ∩ T M ,j in the distribution function in (3.4) and (3.5). 4. Implementation of the proposed method Here we describe the construction of ˆ z 0 and ˆ U 0 in three non-Gaussian mod- els. The first two are GLMs, while the third, though not a GLM, admits a con- struction of ˆ z 0 and ˆ U 0 analogous to that in GLMs. W e note that if the MLE is undefined due to, for example, a complete or quasi-complete separation in binary response data (Albert and Anderson, 1984), or if p > n , we prescribe re- placing the MLE with a slightly regularized estimator , such as an L 1 -penalized estimator with weak penalization. Theorem 1(ii) will hold as long as ˆ z 0 and ˆ U 0 are constructed with a consistent estimator of ( β 0 , β ) . 21 4.1 Logistic and Poisson models 4.1 Logistic and P oisson models For a binary response, the logistic regression model is most widely used. Here a ( ϕ ) = 1 and b ( η ) = log(1 + e η ) for all η ∈ R in (2.1), yielding b ′ ( η ) = e η / (1 + e η ) and b ′′ ( η ) = b ′ ( η )(1 − b ′ ( η )) as the key quantities needed to e v aluate the ˆ z 0 and ˆ U 0 . For responses which are counts, the Poisson regression model is often used. Here a ( ϕ ) = 1 and b ( η ) = b ′ ( η ) = b ′′ ( η ) = e η for all η ∈ R . If a GLM in volves an unknown ϕ , we prescribe substituting for ϕ the MLE ˆ ϕ . This is also our strategy for dealing with a nuisance parameter irrele vant to the linear predictor η in the third regression model described next. 4.2 Beta regression For continuous responses Y 1 , . . . , Y n ∈ [0 , 1] , such as rates or proportions, observed with x 1 , . . . , x n ∈ R p , Ferrari and Cribari-Neto (2004) considered beta regression under which Y i ∼ Beta ( µ i ϕ, ν i ϕ ) with µ i ≡ 1 / (1 + e − η i ) and ν i ≡ 1 − µ i and η i as before, for i = 1 , . . . , n , where ϕ > 0 is a precision parameter . In this model Y i has mean µ i and variance µ i (1 − µ i ) / (1 + ϕ ) for i = 1 , . . . , n . The NR update is not the same in this setting as in Section 2.2 due to the fact that the Hessian of the log-likelihood depends on the responses (see Appendix A in Ferrari and Cribari-Neto, 2004). As an alternati ve to NR, we adopt Fisher scoring (Davison, 2003, Section 4.4.1), whereby the Hessian is replaced by its 22 4.2 Beta regression expected value. If ϕ is known, we can describe the Fisher scoring update by setting µ i ( t 0 , t ) ≡ 1 / (1 + e − η i ( t 0 , t ) ) and ν i ( t 0 , t ) ≡ 1 − µ i ( t 0 , t ) with η i ( t 0 , t ) ≡ t 0 + x ⊤ i t as well as ˜ Y i ≡ log( Y i / (1 − Y i )) and ˜ µ i ( t 0 , t ) ≡ ψ ( µ i ( t 0 , t ) ϕ ) − ψ ( ν i ( t 0 , t ) ϕ ) for i = 1 , . . . , n , where ψ ( · ) is the digamma function. From here we define weights w i ( t 0 , t ) ≡ p ϕµ i ( t 0 , t ) ν i ( t 0 , t ) p ψ ′ ( µ i ( t 0 , t ) ϕ ) + ψ ′ ( ν i ( t 0 , t ) ϕ ) for i = 1 , . . . , n and the v ector z ( t 0 , t ) ha ving entries z i ( t 0 , t ) = w i ( t 0 , t ) η i ( t 0 , t ) + µ i ( t 0 , t ) ν i ( t 0 , t )( ˜ Y i − ˜ µ ( t 0 , t )) /w i ( t 0 , t ) , the vector u 0 ( t 0 , t ) ha ving entries w i ( t 0 , t ) and the matrix U ( t 0 , t ) ha ving rows w i ( t 0 , t ) x ⊤ i for i = 1 , . . . , n . Then, for a fixed value of ϕ , an initial value ( t (0) 0 , t (0) ) can be updated as in (2.3). T o estimate unkno wn ϕ , one maximizes the log-likelihood ev aluated at the current ( t ( k ) 0 , t ( k ) ) with respect to ϕ (the maximizer can be obtained in closed form); then one updates ( t ( k ) 0 , t ( k ) ) via (2.3) with ϕ fixed at its current estimate. Iterating until con ver gence yields the MLE ( ˆ β 0 , ˆ β , ˆ ϕ ) of ( β 0 , β , ϕ ) . As before, we set ˆ z ≡ z ( ˆ β 0 , ˆ β ) , ˆ u 0 ≡ u 0 ( ˆ β 0 , ˆ β ) , and ˆ U ≡ U ( ˆ β 0 , ˆ β ) as the pseudo-data, and to disregard the intercept we construct ˆ z 0 and ˆ U 0 as in Section 2.2. The idealized counterparts to ˆ z , ˆ u 0 , and ˆ U are defined, as before, as z ≡ z ( β 0 , β ) , u 0 ≡ u 0 ( β 0 , β ) , and U ≡ U ( β 0 , β ) , and the “centered versions” 23 are also obtained as before. Thus we may write z 0 = U 0 β + ξ 0 as in (3.1), where ξ 0 = ( I − P 0 ) ξ , except that in beta regression the vector ξ has entries ξ i ≡ w − 1 i µ i ν i ( ˜ Y i − ˜ µ i ) with w i ≡ w i ( β 0 , β ) and ˜ µ i ≡ ˜ µ i ( β 0 , β ) for i = 1 , . . . , n . Since ˜ Y i has mean ˜ µ i and v ariance ψ ′ ( µ i ϕ ) + ψ ′ ( ν i ϕ ) , ξ i has mean zero and v ariance ϕ − 1 for i = 1 , . . . , n . The cov ariance matrix of ξ 0 is thus ( I − P 0 ) ϕ − 1 in beta regression. Therefore, in Section 3.1 a ( ϕ ) is replaced with a ( ϕ ) ≡ ϕ − 1 , where for the v alue of ϕ we plug in the MLE. 5. Simulation study Here compare on simulated data sets the performance of the proposed method of applying parametric programming after linearization, which we abbre viate as PPL, with i) standard W ald-type inference in the selected model without any conditioning on the selection e vent and with ii) polyhedral-based post-selection inference as in Lee et al. (2016) following out linearization step. Comparisons of PPL and data-splitting are provided in the Supplementary Material. 5.1 Parametric programming versus the naiv e method Under the logistic, Poisson, and beta regression models in Section 4, we generate response data after drawing cov ariate v ectors x 1 , . . . , x n ∈ R p having independent N (0 , 1) entries under n = 500 and p = 20 . On each of 1000 24 5.1 Parametric programming v ersus the naiv e method simulated data sets we implement our PPL method as well as the nai ve method to construct confidence intervals for the coefficients in the selected model ˆ M λ . On each data set we perform model selection at each value in a grid of twenty v alues for λ , equally spaced on logarithmic scale. In each model we set β 0 = − 2 and M 0 = { 1 , 2 , 3 } . For logistic regression we set β M 0 = (2 , 2 , 1) ⊤ , for Poisson, β M 0 = (1 , 1 , − 1) ⊤ , and for beta, β M 0 = (1 , − 1 / 2 , 1 / 2) ⊤ and consider a set of λ v alues in the interv als [2 , 12] , [8 , 56] , and [2 , 10] , respecti vely , where these interv als were chosen to yield wide spreads of model sizes. For each simulated data set, at each λ , we perform post-selection inference by constructing the confidence interval CI M ,j in (3.4) at α = 0 . 05 for each index j in the selected model M . W e then record a realization of the T ype I error rate as the proportion of unimportant cov ariates in M for which a nonzero regression coef ficient is inferred, that is, we record the ratio T ype I error ≡ |{ j ∈ M : 0 / ∈ CI M ,j and ( β M ) j = 0 }| |{ j ∈ M : ( β M ) j = 0 }| , where CI M ,j is defined in (3.4). If |{ j ∈ M : β j = 0 }| = 0 , we record a zero for the T ype I error . For the naiv e method, we use W ald-type confidence intervals based on ˆ β mle M that ignore selection e vents. Figure 1 shows the av erage T ype I error achiev ed by the PPL method across 1000 Monte Carlo replicates for all regression settings at each λ with the average T ype I error from the nai ve method overlaid. The average sizes of the selected 25 5.1 Parametric programming v ersus the naiv e method models at each λ are also depicted (by the heights of the bars). As expected, the naiv e method leads to increasingly inflated T ype I error rates as λ increases. In contrast, our PPL method provides reliable inference after model selection, maintaining a T ype I error close to the nominal le vel of 0 . 05 across all λ v alues. W e also compare the average T ype I error achiev ed by the PPL and nai ve methods under data-based selection of the tuning parameter λ . Here we se- lect a v alue of λ from among the grid of twenty values as described in Section 3.2 using a single 70% / 30% split of the data. F or logistic regression, the aver - age T ype I error rates achie ved by the PPL and nai ve methods under α = 0 . 05 were 0 . 049 and 0 . 198 , respecti vely; for Poisson re gression these were 0 . 044 and 0 . 269 , respecti vely; and for beta regression these were 0 . 048 and 0 . 349 respec- ti vely . Here also we see that the proposed method maintains an av erage T ype I error close to 0 . 05 across all three regression settings, whereas the nai ve method leads to drastically inflated T ype I errors. This also showcases the v ersatility of the PPL method when compared with the polyhedral method, which cannot ac- commodate data-driv en penalty parameter selection. Even without in volving the additional selection of λ , our method still outperforms the polyhedral method, as we sho w next. 26 5.1 Parametric programming v ersus the naiv e method Figure 1: A verage T ype I error across 1000 Monte Carlo replicates ov er the grid of λ values for logistic, Poisson, and beta regression achiev ed by the PPL method (solid lines) and by the naiv e method (dashed lines). Heights of bars indicate av erage sizes of the selected models across the λ v alues. 27 5.2 Parametric programming v ersus polyhedral method 5.2 Parametric programming versus polyhedral method Our method of parametric programming after lineariza tion (PPL) prescribes applying the PP approach to a linear model following a linearization step. Alter- nati vely , follo wing the linearization step, one could apply the polyhedral method described in Lee et al. (2016). The advantages of the PP method over the polyhe- dral method are twofold. First, the PP method av oids the “overconditioning” (on the signs of selected coefficients) that the polyhedral method in volves. The min- imal conditioning of the PP method enhances the statistical efficienc y compared to that of the polyhedral method. Second, the PP method can easily account for data-dri ven selection of λ . Focusing on logistic regression, we compare in T able 1 the performances of 95% confidence intervals based on these two strategies. As two v alid post- selection inference methods, they both preserve coverage probabilities close to the nominal lev el of 95%. F or the truly non-zero coefficient β 2 , the a verage widths of the CIs obtained from the PP method tend to be wider than those ob- tained from the polyhedral method for most λ values. But, for β 4 and β 6 , which are truly equal to zero, the CIs from the PP method are substantially tighter than those from the polyhedral method. This indicates that the over -conditioning (on signs) required by the polyhedral method is particularly detrimental to statistical 28 5.2 Parametric programming v ersus polyhedral method po wer when inferring a null cov ariate effect, as the signs of these regression co- ef ficients in the estimated model can be positiv e or negati ve with non-vanishing probability ev en as the sample size grows. In contrast, coef ficients that are far aw ay from zero will, with high probability , ha ve the correct signs in the selected model, so conditioning on their signs has less impact on statistical po wer . T able 1: A verage lo wer and upper bounds, av erage width, and empirical cov- erage probability of 95% confidence interv als from the PPL method and the polyhedral method at certain λ values. Coef ficient PPL Polyhedral 95% CI W idth Cov erage 95% CI W idth Cov erage λ = 2 β 2 [ 0 . 50 , 1 . 52 ] 1 . 02 93 . 0 [ 0 . 54 , 1 . 61 ] 1 . 07 93 . 5 β 4 [ − 0 . 49 , 0 . 54 ] 1 . 03 95 . 8 [ − 0 . 74 , 1 . 33 ] 2 . 07 94 . 8 β 6 [ − 0 . 50 , 0 . 52 ] 1 . 02 94 . 9 [ − 0 . 74 , 1 . 35 ] 2 . 07 95 . 1 λ = 3 . 5 β 2 [ 1 . 36 , 2 . 71 ] 1 . 35 95 . 8 [ 1 . 57 , 2 . 70 ] 1 . 13 90 . 5 β 4 [ − 0 . 42 , 0 . 44 ] 0 . 86 94 . 8 [ − 0 . 62 , 0 . 61 ] 1 . 23 93 . 8 β 6 [ − 0 . 44 , 0 . 43 ] 0 . 87 96 . 6 [ − 0 . 61 , 0 . 57 ] 1 . 18 94 . 9 λ = 8 . 2 β 2 [ 1 . 13 , 2 . 57 ] 1 . 44 96 . 6 [ 1 . 56 , 2 . 53 ] 0 . 97 93 . 6 β 4 [ − 0 . 41 , 0 . 46 ] 0 . 87 94 . 9 [ − 0 . 66 , 0 . 59 ] 1 . 25 94 . 7 β 6 [ − 0 . 49 , 0 . 42 ] 0 . 91 95 . 5 [ − 0 . 61 , 0 . 59 ] 1 . 20 97 . 6 λ = 12 β 2 [ 1 . 20 , 2 . 47 ] 1 . 27 96 . 5 [ 1 . 53 , 2 . 42 ] 0 . 89 93 . 5 β 4 [ − 0 . 42 , 0 . 47 ] 0 . 89 94 . 6 [ − 0 . 56 , 0 . 57 ] 1 . 13 93 . 8 β 6 [ − 0 . 44 , 0 . 43 ] 0 . 87 93 . 5 [ − 0 . 58 , 0 . 62 ] 1 . 20 96 . 9 29 6. Illustrations on real data sets 6.1 Logistic regression for binary data The Spambase data set from the UCI Machine Learning Repository con- tains descriptiv e information for n = 4601 emails, each classified as spam or not spam (Hopkins et al., 1999). There are p = 57 numeric features giving, for ex- ample, the frequencies of certain words or symbols, or the lengths of sequences of capital letters. W e fit a logistic regression model to predict whether to clas- sify an email as spam. After selecting λ using 70% of the data as training data and 30% as v alidation data, 25 variables were selected. Our PPL method for post-selection inference found 13 of the variables to be significant in classifying emails as spam or not spam, while nai ve inference found 19 of the v ariables to be significant at the 0.05 significance le vel. T able 2 summarizes the results, showing confidence intervals from the PPL method and the naiv e method, along with p -v alues associated with the 19 vari- ables deemed significant according to the latter . The proposed method produces CIs generally wider than those from the naiv e method, and with larger p -values than their naiv e counterparts. All selected features fall in the three types of fea- tures frequently reported as strong predictors in existing studies (Prerika et al., 2025): word frequency features, capital letter features, and special character 30 6.1 Logistic regression for binary data frequency features. Among the six selected features identified as statistically significant by the nai ve method but deemed insignificant by the PPL method, three ( wor d_fr eq_all , word_fr eq_will , wor d_fr eq_email ) are not among the top features selected by most existing studies. T able 2: Inferences on selected cov ariate effects for the Spambase data set for the 19 co v ariates found to be significant according to the naiv e method. Names of cov ariates found insignificant by PPL are italicized. PPL Naive Covariate p -value CI Width p -v alue CI W idth wor d_freq_all 0 . 32 [ − 0 . 11 , 0 . 20 ] 0 . 31 0 . 02 [ 0 . 02 , 0 . 20 ] 0 . 18 word_freq_our 0 . 00 [ 0 . 22 , 0 . 49 ] 0 . 26 0 . 00 [ 0 . 23 , 0 . 40 ] 0 . 17 word_freq_ov er 0 . 02 [ 0 . 04 , 0 . 32 ] 0 . 28 0 . 00 [ 0 . 11 , 0 . 31 ] 0 . 19 word_freq_remov e 0 . 00 [ 0 . 54 , 0 . 96 ] 0 . 42 0 . 00 [ 0 . 84 , 1 . 25 ] 0 . 41 word_freq_internet 0 . 00 [ 0 . 11 , 0 . 38 ] 0 . 27 0 . 00 [ 0 . 21 , 0 . 43 ] 0 . 23 wor d_freq_will 0 . 18 [ − 0 . 34 , 0 . 09 ] 0 . 43 0 . 00 [ − 0 . 39 , − 0 . 15 ] 0 . 24 word_freq_free 0 . 00 [ 0 . 53 , 0 . 95 ] 0 . 42 0 . 00 [ 0 . 40 , 0 . 69 ] 0 . 30 word_freq_b usiness 0 . 01 [ 0 . 08 , 0 . 43 ] 0 . 34 0 . 00 [ 0 . 18 , 0 . 41 ] 0 . 24 wor d_freq_email 0 . 21 [ − 0 . 06 , 0 . 26 ] 0 . 33 0 . 01 [ 0 . 03 , 0 . 23 ] 0 . 20 word_freq_you 0 . 00 [ 0 . 05 , 0 . 32 ] 0 . 27 0 . 00 [ 0 . 31 , 0 . 52 ] 0 . 21 wor d_freq_your 0 . 14 [ − 0 . 12 , 0 . 42 ] 0 . 54 0 . 00 [ 0 . 27 , 0 . 47 ] 0 . 20 word_freq_000 0 . 00 [ 0 . 36 , 0 . 82 ] 0 . 47 0 . 00 [ 0 . 60 , 1 . 07 ] 0 . 47 word_freq_money 0 . 00 [ 0 . 10 , 0 . 38 ] 0 . 28 0 . 00 [ 0 . 24 , 0 . 63 ] 0 . 39 word_freq_re 0 . 05 [ − 1 . 13 , − 0 . 00 ] 1 . 02 0 . 00 [ − 1 . 18 , − 0 . 62 ] 0 . 55 wor d_freq_edu 0 . 80 [ − 1 . 59 , 3 . 68 ] 5 . 27 0 . 00 [ − 1 . 66 , − 0 . 72 ] 0 . 95 char_freq_! 0 . 00 [ 0 . 24 , 0 . 53 ] 0 . 29 0 . 00 [ 0 . 54 , 0 . 90 ] 0 . 36 char_freq_$ 0 . 00 [ 0 . 56 , 0 . 98 ] 0 . 42 0 . 00 [ 0 . 70 , 1 . 03 ] 0 . 33 capital_run_length_longest 0 . 05 [ 0 . 00 , 0 . 30 ] 0 . 29 0 . 00 [ 0 . 35 , 0 . 66 ] 0 . 31 capital_run_length_total 0 . 32 [ − 0 . 20 , 0 . 36 ] 0 . 56 0 . 00 [ 0 . 08 , 0 . 29 ] 0 . 21 31 6.2 Poisson regression for count data 6.2 Poisson regression f or count data Here, we analyze the Medicaid1986 data from the R package AER (Kleiber and Zeileis, 2008) using Poisson regression. These are Medicaid utilization data from the 1986 Medicaid Consumer Survey . Considering only those records un- der the Aid to Families with Dependent Children program and encoding cate- gorical v ariables with indicators, the data set contains n = 485 observations and p = 12 co v ariates. The response is the number of doctor visits. After selecting the penalty parameter λ with 70% of the data used for train- ing data and 30% used as v alidation data, we select 4 co v ariates. Naiv e post- selection inference finds all four significantly associated with the number of doctor visits; ho wever , our post-selection inference procedure finds only three to be significant. T able 3 summarizes the results, sho wing that the nai ve method claims stronger cov ariate ef fects after model selection than our PPL method. For example, the p -value associated with the cov ariate school from the PPL method is above 0.05, while the naiv e method produces a nearly zero p -value. Pre vious analyses on the data (Gurmu, 1997) confirmed that health status measures, such as health1 , are among the most important predictors for the number of doctor visits; cov ariates such as school become less important once these measures are included in the model. 32 6.3 Beta regression for proportion data T able 3: Inferences on selected cov ariate effects for the Medicaid data set. Names of cov ariates found insignificant by PPL are italicized. PPL Naive Covariate p -v alue CI W idth p -v alue CI W idth children 0 . 01 [ − 0 . 27 , − 0 . 06 ] 0 . 21 0 . 00 [ − 0 . 27 , − 0 . 11 ] 0 . 16 health1 0 . 00 [ 0 . 36 , 0 . 50 ] 0 . 14 0 . 00 [ 0 . 36 , 0 . 47 ] 0 . 11 access 0 . 01 [ 0 . 06 , 1 . 35 ] 1 . 29 0 . 00 [ 0 . 08 , 0 . 22 ] 0 . 14 school 0 . 07 [ − 0 . 02 , 0 . 26 ] 0 . 28 0 . 00 [ 0 . 10 , 0 . 26 ] 0 . 16 6.3 Beta regression for proportion data Lastly , we perform beta regression on the Student Performance data set from the UCI Machine Learning Repository (Hussain, 2018), which examines stu- dent achiev ement at two Portuguese secondary schools. Cov ariate information includes students’ grades and demographic, social, and school-related attrib utes. After encoding categorical variables and remo ving outliers, the data set contains n = 649 observ ations and p = 39 cov ariates. The response variable is a student’ s final grade (ranging from 0 to 20) di vided by 20. Using beta regression, after selecting λ with 70% of the data used as train- ing data and 30% as validation data, 27 cov ariates were included in the selected model. Our post-selection method identifies 10 v ariables as significant, while the naiv e method identifies 13 variables. T able 4 displays the inference results from the two methods. After adjusting for model selection, the PPL method is less aggressiv e in claiming the strength of cov ariate effects, with wider interval 33 6.3 Beta regression for proportion data estimates and larger p -values than those from the nai ve method. In particular , the PPL method concludes that the co variates, goout and health , are statistically insignificant, although they are significant at the 0.05 significance lev el accord- ing to the naiv e method. The findings of the PPL method are more in line with the consensus in the literature (Bhatia et al., 2025; K esgin et al., 2025): among the non-grade features, the cov ariate absences and failur es are top-ranked fea- tures, study time and academic support matter (e.g., studytime , schoolsup_yes , higher_yes ) also tend to be highly influential on a student’ s final grade, parental education ( Medu ) is moderately influential, whereas some social and lifestyle v ariables, such as goout and health , ha ve much weak er predicti ve po wer . 34 T able 4: Inferences on selected cov ariate ef fects for the student performance data set for the 13 co variates found to be significant according to the naive method. Names of cov ariates found insignificant by PPL are italicized. PPL Naive Covariate p -value CI W idth p -value CI W idth age 0 . 00 [ 0 . 04 , 0 . 13 ] 0 . 09 0 . 00 [ 0 . 04 , 0 . 13 ] 0 . 08 Medu 0 . 02 [ 0 . 02 , 0 . 23 ] 0 . 21 0 . 01 [ 0 . 02 , 0 . 11 ] 0 . 10 studytime 0 . 02 [ 0 . 01 , 0 . 10 ] 0 . 09 0 . 01 [ 0 . 02 , 0 . 10 ] 0 . 08 failures 0 . 00 [ − 0 . 19 , − 0 . 10 ] 0 . 09 0 . 00 [ − 0 . 19 , − 0 . 10 ] 0 . 08 goout 0 . 17 [ − 0 . 11 , 0 . 02 ] 0 . 14 0 . 04 [ − 0 . 09 , − 0 . 00 ] 0 . 09 health 0 . 14 [ − 0 . 08 , 0 . 02 ] 0 . 10 0 . 03 [ − 0 . 08 , − 0 . 00 ] 0 . 08 absences 0 . 00 [ − 0 . 14 , − 0 . 03 ] 0 . 10 0 . 00 [ − 0 . 12 , − 0 . 04 ] 0 . 08 school_MS 0 . 03 [ − 0 . 12 , − 0 . 00 ] 0 . 11 0 . 00 [ − 0 . 11 , − 0 . 02 ] 0 . 08 sex_M 0 . 02 [ − 0 . 11 , − 0 . 01 ] 0 . 10 0 . 00 [ − 0 . 11 , − 0 . 02 ] 0 . 09 Fjob_teacher 0 . 03 [ 0 . 01 , 0 . 10 ] 0 . 09 0 . 01 [ 0 . 02 , 0 . 10 ] 0 . 08 r eason_reputation 0 . 13 [ − 0 . 02 , 0 . 10 ] 0 . 12 0 . 02 [ 0 . 01 , 0 . 09 ] 0 . 08 schoolsup_yes 0 . 00 [ − 0 . 12 , − 0 . 04 ] 0 . 08 0 . 00 [ − 0 . 12 , − 0 . 04 ] 0 . 08 higher_yes 0 . 00 [ 0 . 07 , 0 . 14 ] 0 . 08 0 . 00 [ 0 . 07 , 0 . 15 ] 0 . 08 7. Discussion W e propose parametric programming following a linearization step for per- forming post-selection inference in generalized linear models, which can be adapted to models outside of GLMs, such as the beta re gression model. The proposed method addresses key limitations of the polyhedral method, which in volv es ov er-conditioning, leading to wider confidence intervals and compro- mised statistical power . The proposed method can also adjust for data-based penalty parameter selection, in contrast to the polyhedral method, which as- 35 REFERENCES sumes a fixed penalty parameter chosen prior to the observ ation of the data. Compared to the work by T aylor and T ibshirani (2018), where e xtension of the polyhedral method in generalized re gression models was considered, our work provides more insight into inferences and v ariable selection based on the pseudo-data in a linear model and those based on the original data in a GLM. The gained insight can potentially lead to further extension of the proposed method- ology in se veral interesting directions. These include post-selection inference in nonparametric regression models, or when response data are partially observed and prone to error as in group testing settings, or when cov ariates are prone to measurement error . Our current approach is grounded in maximum likelihood estimation. Generalizing it to the broader M-estimation framew ork is another reachable goal that can broaden its applicability . Computer code for implementing our proposed method and competing meth- ods considered in the simulation study are a v ailable at https://github. com/kateshen28/InfGLM . References Albert, A. and J. A. Anderson (1984). On the existence of maximum likelihood estimates in logistic regression models. Biometrika 71 (1), 1–10. Bachoc, F ., H. Leeb, and B. M. Pötscher (2019). V alid confidence intervals for post-model-selection pre- 36 REFERENCES dictors. The Annals of Statistics 47 (3), 1475–1504. Bachoc, F ., D. Preinerstorfer , and L. Steinberger (2020). Uniformly valid confidence interv als post-model- selection. The Annals of Statistics 48 (1), 440–463. Berk, R., L. Brown, A. Buja, K. Zhang, L. Zhao, et al. (2013). V alid post-selection inference. The Annals of Statistics 41 (2), 802–837. Bhatia, R., S. Y adav , R. Sharma, Shubneet, A. R. Y adav , and N. S. T alwandi (2025). A comparative study of feature selection techniques for predicting student academic performance using educational data. In International Confer ence on Data Analytics & Management , pp. 352–362. Springer . Davison, A. C. (2003). Statistical models , V olume 11. Cambridge university press. Ferrari, S. and F . Cribari-Neto (2004). Beta re gression for modelling rates and proportions. Journal of applied statistics 31 (7), 799–815. Gurmu, S. (1997). Semi-parametric estimation of hurdle regression models with an application to Medicaid utilization. Journal of Applied Econometrics 12 (3), 225–242. Hopkins, M., E. Reeber , G. Forman, and J. Suermondt (1999). Spambase. UCI Machine Learning Reposi- tory . DOI: https://doi.org/10.24432/C53G6X. Huber , P . J. (2011). Robust statistics. In International encyclopedia of statistical science , pp. 1248–1251. Springer . Hussain, S. (2018). Student Academics Performance. UCI Machine Learning Repository . DOI: https://doi.org/10.24432/C50W30. 37 REFERENCES Kesgin, K., S. Kiraz, S. Kosunalp, and B. Stoyche va (2025). Beyond performance: Explaining and ensuring fairness in student academic performance prediction with machine learning. Applied Sciences 15 (15), 8409. Kiv aranovic, D. and H. Leeb (2021). On the length of post-model-selection confidence interv als conditional on polyhedral constraints. Journal of the American Statistical Association 116 (534), 845–857. Kleiber , C. and A. Zeileis (2008). Applied Econometrics with R . New Y ork: Springer-V erlag. Kuchibhotla, A. K., L. D. Brown, A. Buja, J. Cai, E. I. Geor ge, and L. H. Zhao (2020). V alid post-selection inference in model-free linear regression. The Annals of Statistics 48 (5), 2953 – 2981. Le Duy , V . N. and I. T akeuchi (2021). Parametric programming approach for more powerful and general lasso selectiv e inference. International conference on artificial intelligence and statistics , 901–909. Lee, J. D., D. L. Sun, Y . Sun, J. E. T aylor , et al. (2016). Exact post-selection inference, with application to the lasso. Annals of Statistics 44 (3), 907–927. Lee, J. D., Y . Sun, and J. E. T aylor (2015). On model selection consistency of regularized M-estimators. Electr onic Journal of Statistics 9 (1), 608 – 642. McCullagh, P . and J. A. Nelder (1989). Generalized Linear Models , V olume 37. CRC Press. Meinshausen, N., L. Meier , and P . Bühlmann (2009). P-values for high-dimensional regression. Journal of the American Statistical Association 104 (488), 1671–1681. Neufeld, A. C., L. L. Gao, and D. M. Witten (2022). Tree-v alues: selectiv e inference for regression trees. The Journal of Mac hine Learning Researc h 23 (1), 13759–13801. 38 REFERENCES Panigrahi, S. and J. T aylor (2023). Approximate selectiv e inference via maximum likelihood. Journal of the American Statistical Association 118 (544), 2810–2820. Pirenne, S. and G. Claeskens (2024). Parametric programming-based approximate selectiv e inference for adaptiv e lasso, adaptive elastic net and group lasso. J ournal of Statistical Computation and Simula- tion 94 (11), 2412–2435. Prerika, Nitika, and K. Kumar (2025). Email spam detection using artificial neural network with hybrid feature selection. In L. Garg, N. K esswani, and I. Brigui (Eds.), AI T echnologies for Information Systems and Management Science , Cham, pp. 108–117. Springer Nature Switzerland. Rasines, D. G. and G. A. Y oung (2023). Splitting strategies for post-selection inference. Biometrika 110 (3), 597–614. Rinaldo, A., L. W asserman, M. G’Sell, et al. (2019). Bootstrapping and sample splitting for high- dimensional, assumption-lean inference. Annals of Statistics 47 (6), 3438–3469. Shen, Q., K. Gre gory , and X. Huang (2024). Post-selection inference in re gression models for group testing data. Biometrics 80 (3), ujae101. T aylor, J. and R. Tibshirani (2018). Post-selection inference for-penalized likelihood models. Canadian Journal of Statistics 46 (1), 41–61. T ibshirani, R. J., J. T aylor , R. Lockhart, and R. T ibshirani (2016). Exact post-selection inference for sequential regression procedures. Journal of the American Statistical Association 111 (514), 600– 620. 39 REFERENCES W ainwright, M. J. (2009). Sharp thresholds for high-dimensional and noisy sparsity recov ery using l1- constrained quadratic programming (lasso). IEEE transactions on information theory 55 (5), 2183– 2202. W asserman, L. and K. Roeder (2009). High dimensional variable selection. Annals of statistics 37 (5A), 2178–2201. White, H. (1982). Maximum likelihood estimation of misspecified models. Econometrica: J ournal of the Econometric Society 50 , 1–25. Zhang, X. and G. Cheng (2017). Simultaneous inference for high-dimensional linear models. Journal of the American Statistical Association 112 (518), 757–768. Zhao, P . and B. Y u (2006). On model selection consistency of lasso. The Journal of Machine Learning Resear ch 7 , 2541–2563. Zhao, Q., D. S. Small, and A. Ertefaie (2022). Selective inference for ef fect modification via the lasso. Journal of the Royal Statistical Society Series B: Statistical Methodolo gy 84 (2), 382–413. Univ ersity of South Carolina E-mail: qshen@email.sc.edu Univ ersity of South Carolina E-mail: gregorkb@stat.sc.edu Univ ersity of South Carolina E-mail: huang@stat.sc.edu 40
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment