Improving online FDR procedures via online analogs of e-closure and compound e-values
In many scientific applications, hypotheses are generated and tested continuously in a stream. We develop a framework for improving online multiple testing procedures with false discovery rate (FDR) control under arbitrary dependence. Our approach is…
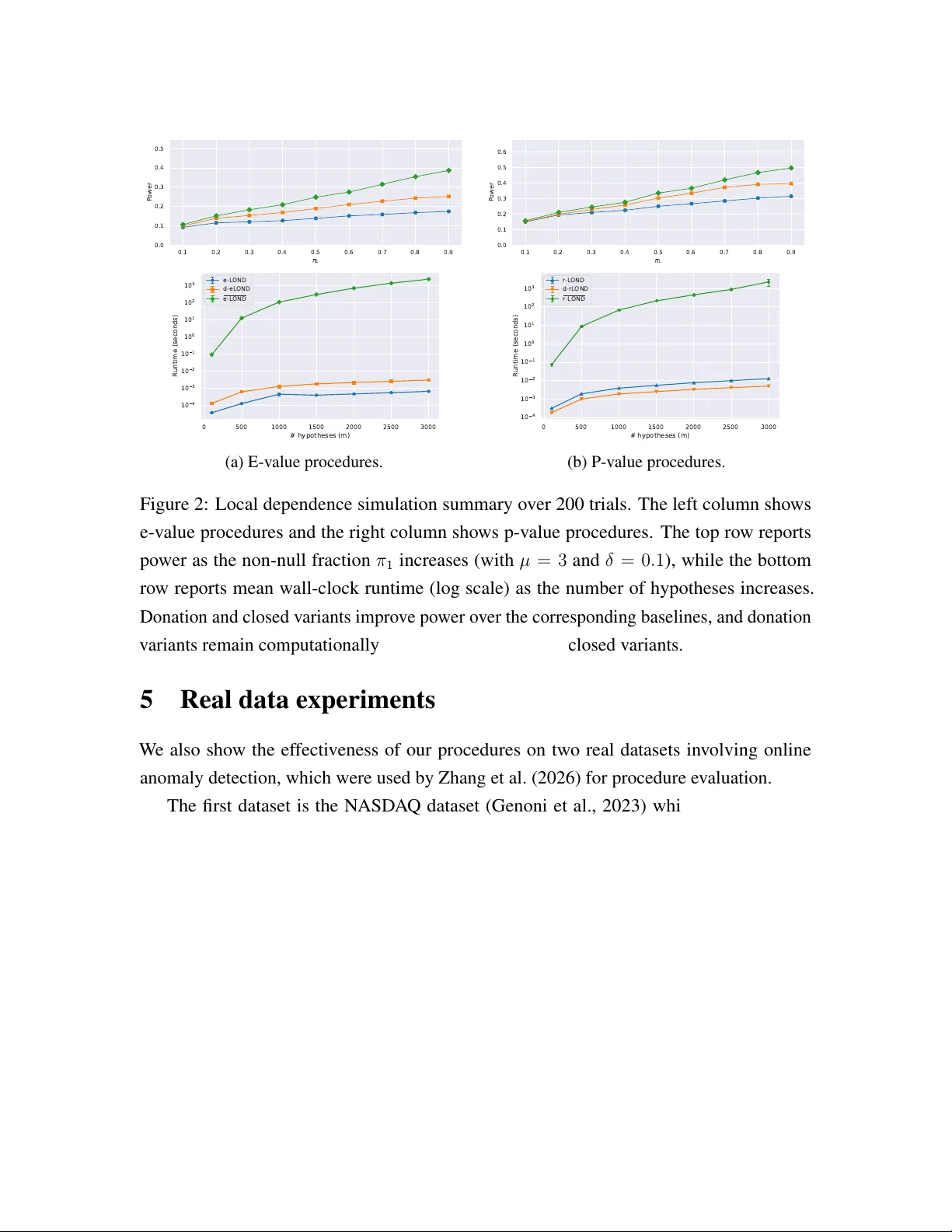
Authors: Ziyu Xu, Lasse Fischer, Aaditya Ramdas
Impro ving online FDR procedures via online analogs of e-closure and compound e-v alues Ziyu Xu * Lasse Fischer † Aaditya Ramdas ‡ Abstract In many scientific applications, hypotheses are generated and tested continuously in a stream. W e dev elop a frame work for improving online multiple testing procedures with false disco very rate (FDR) control under arbitrary dependence. Our approach is two-fold: we construct methods via the online e-closure principle, as well as a no vel formulation of online compound e-v alues that is defined through donations. This yields strict po wer improv ements ov er state-of-the-art e-v alue and p-v alue procedures while retaining FDR control. W e further deri ve algorithms that compute the decision at time t in O (log t ) time, and we demonstrate impro ved empirical performance on synthetic and real data. Contents 1 Introduction 3 2 Impro ving e-value based pr ocedur es 7 2.1 The online SupFDR e-closure principle . . . . . . . . . . . . . . . . . . . 8 2.2 Compound e-v alues via donation . . . . . . . . . . . . . . . . . . . . . . . 10 * Department of Statistics and Data Science, Carnegie Mellon Uni versity . xzy@cmu.edu † Competence Center for Clinical T rails Bremen, Uni versity of Bremen. fischer1@uni-bremen.de ‡ Departments of Statistics and Data Science, and Machine Learning, Carnegie Mellon Uni versity . aramdas@cmu.edu 1 3 Impro ving p-value based pr ocedur es 12 4 Simulations 14 5 Real data experiments 15 6 Extensions 16 7 Related work 17 8 Conclusion 19 A Methodological details of online closed procedur es 23 A.1 General weighted e-collections and closure enlargement . . . . . . . . . . . 23 A.2 Alternativ e e-collection for e-LOND . . . . . . . . . . . . . . . . . . . . . 24 A.3 Computation details of r-LOND . . . . . . . . . . . . . . . . . . . . . . . 25 B Deferred pr oofs 26 B.1 Proof of Theorem 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27 B.2 Proof of Theorem 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28 B.3 Proof of Proposition 5 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29 B.4 Proof of Proposition 6 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29 B.5 Proof of Proposition 7 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30 B.6 Proof of Theorem 8 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30 B.7 Proof of Theorem 9 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31 B.8 Proof of Theorem 10 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32 C Simulation extensions 34 C.1 Additional simulations . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34 C.2 Simulation details . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34 D Impro vements via donation bey ond online multiple testing 35 D.1 Online donation e-BH for acceptance-to-rejection (ARC) . . . . . . . . . . 35 D.1.1 Simulation results . . . . . . . . . . . . . . . . . . . . . . . . . . 36 D.2 Donation e-TO AD for decision deadlines . . . . . . . . . . . . . . . . . . 36 D.3 Donation e-BH for of fline multiple testing . . . . . . . . . . . . . . . . . . 39 2 E Randomization for donation algorithms 41 E.1 Simulation results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42 1 Intr oduction Large-scale hypothesis testing has become pre v alent in multiple industries, such as A/B testing, genomics, clinical trials, neuroscience, etc., where the scientist wishes to filter for hypotheses where a true disco very is made and further in vestigation or action is merited. Au- tomated methods for doing so hav e become particularly prev alent as of late, with the rapidly improving capabilities of large language models (LLMs) to either act as an autonomous agent for generating h ypotheses that it can then in vestigate, or as part of a human-in-the-loop system where the human scientist generates hypotheses and the model helps to triage them. In either case, hypotheses are often formulated in a sequential manner where the scientist (or LLM agent) generates some candidate hypotheses, g athers data or analyzes the data in the context of h ypotheses, and then continues to generate more hypotheses to further elucidate their model of the world. Thus, one must pro vide statistical guardrails to such a system to ensure that the agent or system does not mak e too many f alse discov eries, and o verfit their conclusions to the data at hand. This motiv ates the problem of online multiple hypothesis testing (Foster and Stine, 2008), where we assume that there is an infinite stream of hypotheses H 1 , H 2 , . . . , and a ne w hypothesis arri ves at each time step. As each hypothesis arri ves, we assume we must make the decision whether to reject or accept the null hypothesis. Let N ⊂ N : = { 1 , 2 , . . . } denote the set of null hypotheses, i.e., the subset of indices where the null hypothesis is true. Consequently , we output a monotonically growing sequence of discov ery sets R 1 ⊆ R 2 , . . . for each time step t ∈ N , where R t contains t if and only if we reject the t th null hypothesis. Error metrics to control. The false positiv e criterion we wish to control is an online version of the false discovery rate (FDR) (Benjamini and Hochber g, 1995), an error criterion that has been central to statistical methodology in the offline multiple testing setting, where the number of hypotheses is kno wn beforehand, for the past two decades. W e define the FDR, along with the false disco very proportion (FDP), as follo ws: FDP S ( R ) : = | S ∩ R | | R | ∨ 1 , FDR ( R ) : = E [ FDP N ( R )] . 3 Existing offline result Our online extension Our online shortcut FDR e-Closure Principle (Xu et al., 2025) Online SupFDR e-Closure Principle (Theorem 1) Dynamic programming (Theorem 2) FDR control with compound e-values (Ignatiadis et al., 2025) SupFDR control with γ -online compound e-values (Proposition 5) γ -weighted donations (Theorem 8) (this paper) Figure 1: Summary of the paper’ s main technical contributions. In the abov e notation for FDP , S is a candidate set of null hypotheses and R is the discov ery set the error metric is being ev aluated on. The FDR is defined as the expectation of the FDP on the true null hypotheses N . In the online setting, we output a novel disco very set at each time step t , which motiv ates the following online error metric that was recently proposed by Fischer et al. (2025): SupFDR ( R ) : = E sup t ∈ N FDP ( R t ) . Online multiple testing with false disco very rate (FDR) control has been studied exten- si vely in recent w ork (Xu and Ramdas, 2024). In this problem, we recei ve h ypotheses in a stream, along with some data associated with those hypotheses. W e then wish to produce a discov ery set with control of the FDR at a fix ed le vel δ ∈ (0 , 1] , and maximize the number of discoveries that we make. An interesting challenge that the online setting presents, in contrast to the classical offline multiple testing setting where one possesses a fix ed, kno wn number of hypotheses beforehand, is ho w to define the notion of FDR, now that one will output multiple discov ery sets (usually one per time step). Xu and Ramdas (2024) initiated a line of study in the use of e-values for onlineFDR control, a weaker form of FDR control for the online multiple testing setting (although Fischer et al. (2025) later showed that their methods controlled SupFDR as well), and assumed that the dependence between the data collected for different hypotheses was unkno wn. E-values are nonne gati ve random v ariables with expectation at most 1 under the null hypothesis, and ha ve been sho wn to be useful for multiple testing in both offline and online settings — see Ramdas and W ang (2025) for an overvie w . Practically , many settings where online multiple testing is utilized (e.g., platform clinical trials (Robertson et al., 2023; Zehetmayer et al., 2022)) in volve adaptive and sequential data collection, where e-v alues 4 are more natural to construct than p-v alues (Ramdas et al., 2022). Further , offline e-closure ideas (Xu et al., 2025) suggest a unified way to characterize and improve e-v alue procedures, which we no w adapt to the online SupFDR setting. Contributions In this paper we introduce a framew ork that improves the po wer of existing online multiple testing procedures with FDR control. W e first introduce an online e-closure principle for SupFDR control and apply it to impro ve a wide v ariety of online e-v alue and calibrated p-v alue procedures. This methodology yields strict improvements o v er the status quo, b ut the resulting closed procedures are computationally expensi ve and may require O ( t 2 ) time to compute the rejection decision at time t . This quickly becomes costly in long streams. Thus, another of the key contrib utions of this paper is deriving a practical algorithm that can improv e po wer while being computationally tractable in the online setting. W e provide a nov el frame work for generally impro ving e-v alue based online multiple testing procedures with FDR control, and show that it has practical po wer improv ements ov er existing methods while requiring only O (log t ) time to compute the rejection decision at time t . Our method is based on a novel notion of online compound e-values , which generalizes the notion of compound e-v alues for offline multiple testing (Ignatiadis et al., 2025) to the online setting. W e show that online compound e-v alues can be used to generally improve online multiple testing procedures with FDR control, and demonstrate its empirical performance on both synthetic and real data. W e also provide a user -friendly implementation of our methods in the accompanying code, and demonstrate that online compound e-value based methods are also computationally more ef ficient in practice. Our primary contributions are as follo ws, and are also visually summarized in Figure 1. 1. Closur e-based strict power impr ovements for standar d online testing. W e introduce an online e-closure principle for SupFDR control and use it to formulate strict improv e- ments ov er e-LOND (Xu and Ramdas, 2024) and r-LOND (Zrnic et al., 2021). W e deri ve no vel e xplicit formulations for the next test lev el, which in volv es an optimiza- tion problem o ver subsets of the first t − 1 hypotheses. Since nai ve optimization w ould require computation that is e xponential in t , we also pro vide dynamic programming decomposition that only requires O ( t 2 ) time to compute the ne xt test le vel. 2. A computationally ef ficient donation frame work for strict impr ovement. Since O ( t 2 ) computation remains inefficient for moderately large v alues of t (i.e., in the thousands), 5 Setting Base Improvements (Ours) Method Compute/Step Standard e-LOND (Xu and Ramdas, 2024) Closed e-LOND (Section 2.1) O ( t 2 ) Donation donation e-LOND (Section 2.2) O (log t ) r-LOND (Zrnic et al., 2021) Closed r-LOND (Section 3) O ( t 2 ) Donation donation r-LOND (Section 3) O (log t ) ARC online e-BH (Fischer et al., 2025) Donation donation online e-BH (Section D) O ( t log t ) Decision deadlines e-T O AD (Fisher, 2022) Donation donation e-TO AD (Section D) O ( t log t ) Offline e-BH (W ang and Ramdas, 2022) Closed eBH (Xu et al., 2025) O ( m 2 log m ) Donation donation e-BH (Section D.3) O ( m log m ) T able 1: Method summary of improv ed procedures we introduce in this paper grouped by setting and base procedure. For online methods, the “Compute/Step” column contains the asymptotic complexity of computing the t th rejection decision in online settings, while m is the total number of hypotheses in the of fline setting. we introduce a no vel frame work based on donations and online compound e-v alues, and show that it can also strictly improv e e-LOND and r-LOND while remaining computationally tractable, requiring only O (log t ) computation per time step. A central technical ingredient is our notion of online compound e-values , which powers the donation frame work. 3. Extensions be yond the standar d online multiple testing setting . Our donation frame- work is not restricted to only improving standard online multiple testing algorithms. W e e xtend our frame work to v ariants of the online multiple testing problem such as the acceptance-to-rejection setting of Fischer et al. (2025) and the decision deadlines setting of Fisher (2022), where we also deri ve strict improv ements of e xisting algo- rithms. Lastly , we show that we can construct an efficient v ersion of eBH (W ang and Ramdas, 2022) that is strictly more po werful for of fline multiple testing, and is computationally more efficient than the eBH procedures of Xu et al. (2025); for m hypotheses, we require O ( m log m ) computation as opposed to the O ( m 2 log m ) required by eBH. W e then demonstrate the empirical performance of our method on both synthetic and real data, where we see that both the power and computational improv ements of the methods in this paper are nontri vial. By default, theorem proofs are deferred to Section B. 6 2 Impr oving e-v alue based pr ocedur es Each arri ving hypothesis H t is paired with either an e-v alue E t or a p-v alue P t , depending on the procedure under consideration. F ormally , the t th e-value and p-value satisfy the follo wing properties, respecti vely: E [ E t ] ≤ 1 if t ∈ N . (1) P ( P t ≤ s ) ≤ s for all s ∈ [0 , 1] if t ∈ N . Online multiple testing algorithms can be viewed as producing a sequence of test le vels α , where α t is the le v el used at time t . For e-value procedures, we reject H t when E t ≥ α − 1 t ; for p-v alue procedures, we reject H t when P t ≤ α t . Thus, the induced discovery sets are: R t : = { i ∈ [ t ] : E i ≥ α − 1 i } for e-v alues { i ∈ [ t ] : P i ≤ α i } for p-v alues , where [ t ] : = { 1 , . . . , t } . W e say that a procedure with discovery sets R strictly impr oves another procedure with disco very sets R ′ if R t ⊇ R ′ t for all t ∈ N almost surely , and there exists a data-generating distrib ution such that P ( ∃ t ∈ N : R t ⊃ R ′ t ) > 0 . Under unknown dependence between e-v alues, e-LOND controls SupFDR (Xu and Ramdas, 2024; Fischer et al., 2025). The e-LOND procedure uses a sequence of test lev els α defined by α t : = δ γ t ( | R t − 1 | ∨ 1) , (2) where γ is a fixed nonne gati ve sequence of user -chosen constants such that P t ∈ N γ t ≤ 1 . Similarly , Zrnic et al. (2021); Jav anmard and Montanari (2018) showed that the follo wing sequence of test le vels α ensures FDR control for p-values with arbitrary dependence: α t : = δ γ t β t ( | R t − 1 | ∨ 1) , (3) where ( β t ) is a sequence of reshaping functions (Blanchard and Roquain, 2008). A function β : [0 , ∞ ) → [0 , ∞ ) is a reshaping function if β can be written as β ( r ) = R r 0 x dν ( x ) where ν is any probability measure on [0 , ∞ ) . A typical choice, which is the online analog of the Benjamini and Y ekutieli (2001) correction for offline multiple testing under arbitrary dependence, is β t ( r ) = ( ⌊ r ⌋ ∧ t ) /ℓ t , where ℓ t : = P i ∈ [ t ] i − 1 is the t th harmonic number . W e will demonstrate ho w to improv e on both of these methods in the online setting in this paper , among others. 7 2.1 The online SupFDR e-closur e principle W e de velop an online e-closure principle that improves on existing methods in the online setting. Recently , Xu et al. (2025) proposed an e-Closure Principle and used this to improve the e-BH and the BY procedure for offline FDR control. Fischer et al. (2024) generalized the classical Closure Principle for FWER control (Marcus et al., 1976) to the online setting by using increasing families of local tests. In the following, we e xtend these ideas to introduce a SupFDR e-Closure Principle for the online setting. Let ( F t ) t ∈ N be a filtration where F t denotes information a v ailable by time t . Let σ ( X ) denote the sigma-algebra formed by a set X . Thus, we define each element of the filtration as the sigma-algebra F t = σ ( { E i } i ∈ [ t ] ) if one is working with e-v alues, and F t = σ ( { P i } i ∈ [ t ] ) if one is working with p-values. For the purposes of this framew ork, we consider a more general type of online procedure that outputs a collection C t ∈ 2 [ t ] of candidate rejection sets at each time t , with C t being measurable w .r .t. F t . An e-collection is a family ( E S ) S ∈ 2 N such that each E S is an e-value for the intersection null H S = ∩ i ∈ S H i . In our online setting, we require incr easing e-collections: E S ≤ E S ∪ S ′ for all S, S ′ ⊂ N s.t. min S ′ > sup S . Gi ven an increasing e-collection, define: C t : = R ⊆ [ t ] : E S ≥ FDP S ( R ) δ for all S ∈ 2 [ t ] . (4) When ( E S ) is increasing, the collections are nested ( C 1 ⊆ C 2 ⊆ . . . ), which is needed to obtain SupFDR control. Theorem 1 (Online SupFDR e-closure) . Let ( E S ) S ∈ 2 N be an incr easing e-collection. Assume E S is measurable with respect to F sup( S ) for all finite nonempty S . Then the associated e-closur e collections ( C t ) t ∈ N in (4) form an online pr ocedur e that satisfies E sup t ∈ N sup R ∈C t FDP N ( R ) ≤ δ. Consequently , any discovery sequence R with R t ∈ C t for all t ∈ N contr ols SupFDR at level δ . Proof details are deferred to Section B.1. When working with a stream of e-v alues, one explicit increasing e-collection is E S = X i ∈ S γ | S ∩ [ i ] | E i for all S ∈ 2 N . (5) 8 For e xample, E { 2 , 3 } = γ 1 E 2 + γ 2 E 3 . This e-collection is increasing: if we append indices larger than max S , the existing summands stay unchanged and we only add nonnegati ve terms. As a result, we get the follo wing constraint on E t for making a disco very at time t , i.e., for R t − 1 ∪ { t } to be in C t : FDP S ( R t − 1 ∪ { t } ) ≤ δ E S for all S ∈ 2 [ t ] . W ith this closure framework in place, we now begin our first construction: applying the abov e increasing e-collection to deriv e a procedure that strictly improv es ov er e-LOND. Rearranging the abov e constraints yields the follo wing test le vels; we call the resulting procedure e-LOND (closed e-LOND) : α t = min S ⊆ [ t − 1] δ γ | S | +1 ( | R t − 1 | + 1) 1 + | S ∩ R t − 1 | − δ E S ( | R t − 1 | + 1) . (6) Theorem 2. The e-LOND pr ocedur e defined by the test le vels in (6) ensur es SupFDR contr ol at level δ under arbitrary dependence between e-values, and strictly impr oves over e-LOND when γ is nonincreasing . The proof is deferred to Section B.2. Computation via dynamic pr ogramming. Although we hav e shown that e-LOND strictly improv es o ver e-LOND, it is expensi ve to compute. While Xu et al. (2025) dev eloped computational shortcuts for the offline e-closure principle, it is not obvious how to adapt such shortcuts to the online setting due to the weighted mer ging of e-values inv olved in solving the maximization problem in (6) . A naiv e computation would require exponential time in t , while dynamic programming reduces this to a w orst-case O ( t 2 ) computation per time step. T o carry out this computation, we define: v t ( i, k ) : = max S ⊆ [ i ]: | S | = k | S ∩ R t − 1 | − δ E S ( | R t − 1 | + 1) . The e-LOND choice of α t in (6) can be computed as α t = min k ∈{ 0 }∪ [ t − 1] δ γ k +1 ( | R t − 1 | + 1) 1 + v t ( t − 1 , k ) . W e can compute v t ( i, k ) for i ∈ [ t − 1] and k ∈ { 0 } ∪ [ t − 1] using the follo wing dynamic programming formula (for k ≥ 1 , and with v t ( i, 0) = 0 ): v t ( i, k ) = max { v t ( i − 1 , k ) , v t ( i − 1 , k − 1) + 1 { i ∈ R t − 1 } − δ γ k E i ( | R t − 1 | + 1) } . 9 Thus, computing the dynamic program requires O ( t 2 ) time. Howe ver , this quickly becomes computationally costly in practice, moti v ating the need for more ef ficient methods. Remark 3 . One minor drawback of the e-collection in (5) is that sho wing strict impro vement in Theorem 2 requires γ to be nonincreasing. T o av oid this restriction, we can define E S = X i ∈ S γ i,S E i , where γ i,S : = P j ∈ N S ( i ) γ j and N S ( i ) : = { max( S ∩ [ i − 1]) + 1 , . . . , i } , with the con vention max( ∅ ) = 0 . Intuitively , this is still a weighted sum of the e-values in S , but each weight aggregates γ -mass between consecuti ve selected indices in time order . This requires different computational shortcuts for test-le vel computation; see Section A.2. 2.2 Compound e-values via donation So far , online multiple testing methods ha ve primarily treated e-v alues either as direct inputs or as intermediaries for improving p-value procedures. Ho we ver , we will instead le verage the notion of compound e-values to substantially impro ve po wer . In of fline multiple testing with a fixed m ∈ N , one calls nonnegati ve random variables ( ˜ E 1 , . . . , ˜ E m ) compound e-values if P i ∈N E [ ˜ E i ] ≤ m (Ignatiadis et al., 2025). This relaxes the usual e-v alue condition in (1) . W e now introduce the online, γ -weighted analog together with donation sequences used to construct it. Fix a nonnegati ve sequence γ = ( γ t ) t ∈ N with P t ∈ N γ t ≤ 1 . Definition 4 ( γ -online compound e-values and γ -weighted donations) . For this fixed γ : (i) ˜ E = ( ˜ E t ) t ∈ N is a stream of γ -online compound e-values if P i ∈N γ i E [ ˜ E i ] ≤ 1 . (ii) B = ( B t ) t ∈ N is a γ -weighted donation if P i ∈ [ t ] γ i B i ≤ 0 for all t ∈ N , and B t ≥ − ( E t ∧ 1) for all t ∈ N . W e first note that weighted self-consistenc y applied to online compound e-values has v alid SupFDR control. Define the following collection of weighted self-consistent discov ery sets: C : = R ⊂ N : ˜ E t ≥ 1 δ γ t | R | for all t ∈ R (7) Proposition 5. Let ˜ E 1 , ˜ E 2 , . . . be a str eam of γ -online compound e-values. Then, E sup R ∈ C FDP ( R ) ≤ δ. 10 A full proof is provided in Section B.3. Now that we ha ve sho wn that online compound e-v alues can be used to control SupFDR, we introduce a construction that, when combined with the test le vels of e-LOND, strictly dominates e-LOND applied only to the original e-v alues. This construction is computationally ef ficient, requiring only O (log t ) time to compute the compound e-v alue and hence the rejection decision at each time step. Further , it is robust to unkno wn dependence between e-values. Now , we will define how to construct online compound e-v alues via donation . Let B be any γ -weighted donation sequence as in Theorem 4. Note that B can be arbitrarily dependent with E . W e first note the following property . Proposition 6. Let ˜ E t = E t + B t . Then, for all t ∈ N , ˜ E is a valid sequence of γ -online compound e-values. Proof details are deferred to Section B.4. As a result, we can choose any γ -weighted donation B to construct online compound e-v alues ˜ E for e-LOND while retaining SupFDR control. Furthermore, we can take a supremum over choices of B and still retain FDP control. Let C ( B ) be the collection of discov ery sets defined by the online weighted self-consistenc y condition in (7) with online compound e-values ˜ E t = E t + B t for a specific choice of B . For a stream of arbitrarily dependent e-v alues E , let B be the set of all valid γ -weighted donations. Then we ha ve: Proposition 7. F or any str eam of e-values E 1 , E 2 , . . . , we have that E " sup B ∈B sup R ∈C ( B ) FDP ( R ) # ≤ δ. See Section B.5 for the proof. As a result, we can define an algorithm that is equiv alent to choosing the following test le vels. Define the follo wing “wealth” quantity for each t ∈ N : ¯ W t : = X i ∈ R t − 1 γ i E i − 1 δ γ i ( | R t − 1 | + 1) ∧ 1 + X i ∈ R t − 1 γ i ( E i ∧ 1) , where R t − 1 = { i ∈ [ t − 1] : E i ≥ α − 1 i } is defined by the follo wing test lev els: α t : = δ γ t ( | R t − 1 | + 1) 1 − ( δ ( | R t − 1 | + 1) ¯ W t ∧ 1) . (8) 11 W e refer to this procedure as donation e-LOND . Note that (1 − ( δ ( | R t − 1 | + 1) ¯ W t ∧ 1)) − 1 ≥ 1 , so donation e-LOND al ways has test le vels at least as lar ge as e-LOND. W e no w ha ve the follo wing result. Theorem 8. Donation e-LOND contr ols the SupFDR at level δ , and strictly impr oves over e-LOND. The proof appears in Section B.6. Efficient donation computation. T o efficiently compute the test lev els in (8) , we need to update ¯ W t ef ficiently at each time step. The only nontri vial component to compute is the summation ov er terms in R t − 1 , i.e., our term of interest is ¯ W R t : = X i ∈ R t − 1 γ i E i − 1 δ γ i ( | R t − 1 | + 1) ∧ 1 = X i ∈ R t − 1 γ i ∧ γ i E i − 1 δ ( | R t − 1 | + 1) . Define ¯ w ( i ) t : = γ i ∧ γ i E i − 1 δ ( | R t − 1 | + 1) = γ i E i − 1 δ ( | R t − 1 | +1) if γ i ( E i − 1) ≤ 1 δ ( | R t − 1 | +1) γ i otherwise. As a result, we need to threshold on the v alue of γ i ( E i − 1) for each i ∈ [ t ] to determine what v alue ¯ w ( i ) t takes on. T o compute the sum of ¯ w ( i ) t ef ficiently , we maintain an augmented binary search tree where the key is γ i ( E i − 1) for each i ∈ R t − 1 . W e augment each node with sums of γ i E i , γ i and a count of nodes for all nodes i that are in the tree. Therefore, when split on γ i ( E i − 1) , we ha ve already computed our desired quantities. Consequently , the computation is simply O (log( | R t − 1 | )) ≤ O (log t ) whene ver we mak e a disco very , i.e., the insertion cost into the augmented binary search tree. 3 Impr oving p-v alue based pr ocedur es Using the abov e results for improving e-v alue based procedures, we can also improv e the r-LOND procedure for p-v alue based procedures. Xu and Ramdas (2024) observed that the 12 r-LOND procedure was equi valent to applying e-LOND where the e-values were defined by E t = f t ( P t ) , where we let f t be the following calibrator similar to the calibrator for r -LOND Xu and Ramdas (2024) for each t ∈ N : f t ( p ) = 1 { p ≤ δ γ t t/ℓ t } δ γ t ⌈ ( pℓ t / ( δ γ t )) ∨ 1 ⌉ . (9) As a result, we can apply online e-closure principle to p-value based procedures and achie ve SupFDR control. Notably , unlike the formulation of r-LOND as the application of e-LOND to calibrated p-v alues f t ( P t ) for t ∈ N , we instead construct a ne w e-collection. Let E S = X i ∈ S γ | S ∩ [ i ] | f | S ∩ [ i ] | ( P i ) = 1 δ X i ∈ S 1 { P i ≤ δ γ | S ∩ [ i ] | | S ∩ [ i ] | /ℓ | S ∩ [ i ] | } ⌈ ( P i ℓ | S ∩ [ i ] | / ( δ γ | S ∩ [ i ] | )) ∨ 1 ⌉ . (10) Consequently , we define r-LOND (closed r -LOND) as α t = min S ⊆ [ t − 1]: ∆ E S ( t ) > 0 δ γ | S | +1 ℓ | S | +1 ( δ ∆ E S ( t )) − 1 ∧ ( | S | + 1) (11) where ∆ E S ( t ) : = 1 + | S ∩ R t − 1 | δ ( | R t − 1 | + 1) − E S . Note that the constraint set is ne ver empty since we can al ways select S = ∅ . Theorem 9. r-LOND contr ols the SupFDR at level δ for arbitr arily dependent p-values. Further , when iγ i /ℓ i is nonincr easing in i for i ∈ N , r-LOND strictly impr oves over r -LOND. The proof is deferred to Section B.7. W e also elaborate on computational details for r-LOND in Section A.3, b ut they are similar to that of e-LOND , and it consequently requires only O ( t 2 ) computation at each time step. Define the donation excess-wealth term ¯ W t as we do in (8) , but using the calibrated e-v alues deriv ed via E t = f t ( P t ) . W e then obtain the follo wing test lev els for arbitrarily dependent p-v alues: α t = δ γ t ℓ t | R t − 1 | + 1 1 − ( δ ( | R t − 1 | + 1) ¯ W t ∧ 1) ∧ t . (12) Theorem 10. Donation r -LOND contr ols the SupFDR at level δ for arbitrarily dependent p-values, and can strictly impr ove over r -LOND. A proof of the abov e is deferred to Section B.8. 13 4 Simulations W e compare our procedures in a local dependence setup inspired by Zrnic et al. (2021). Each hypothesis t ∈ [ m ] produces a single Gaussian observation with µ 0 = 0 under the null and µ 1 = 3 under the alternativ e; we set m = 200 . For a fixed lag L = 100 , samples within distance L of one another share Gaussian copula dependence: the co v ariance matrix satisfies Σ i,j = 0 . 5 | i − j | for | i − j | ≤ L and zero otherwise. The resulting e-v alues and p-v alues are based on Gaussian likelihood ratios and the Gaussian c.d.f. — see Section C.2 for details. Each design is a veraged ov er n = 200 trials. For all methods, we use the sequence where γ t = ( t ( t + 1)) − 1 for each t ∈ N unless otherwise stated. W e also consider additional simulation settings in Section C.1. W e see in Figure 2 the results of applying the base procedure of e-LOND and r-LOND, as well as the po wer gain our procedures offer over both e-LOND and r-LOND. Both donation e-LOND and e-LOND outperform e-LOND, with e-LOND ’ s power dif ferential increasing ov er donation e-LOND as the proportion of non-nulls increases. Similarly , both donation r -LOND and r-LOND also outperform r -LOND, with r-LOND ’ s power differential increasing ov er donation r-LOND as the proportion of non-nulls increases. Thus, we see that our frame works for impro ving the po wer of both procedures hav e practical results. Runtime comparison T o quantify the tradeof f between computation and po wer for closed vs. donation v ariants of each procedure, we run simulations using the same local dependence Gaussian data model as above, with a fixed setting of π = 0 . 3 . W e choose hypothesis counts up to m = 3000 with n = 80 trials. W e av erage the wall-clock runtime of each procedure ov er all trials. W all-clock times were measured on a serv er with an AMD Ryzen 9 9950X CPU (16 cores, 32 threads, up to 5.756 GHz) running in a single-threaded fashion. W e visualize the results of these measurements in Figure 2 — note that the y-axis for runtime in the figure is on a log scale. W e can see that as the number of hypotheses increases, the runtime of e-LOND goes from milliseconds to on the order of an hour . On the other hand, standard e-LOND as well as donation e-LOND remain in the millisecond range. W e see a similar pattern with the v ariants of r-LOND as well. 14 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.0 0.1 0.2 0.3 0.4 0.5 P ower 1 = 3 , m = 2 0 0 , = 0 . 1 0 Method e-L OND d-eL OND e - L O N D 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.0 0.1 0.2 0.3 0.4 0.5 0.6 P ower 1 = 3 , m = 2 0 0 , = 0 . 1 0 Method r -L OND d-rL OND r - L O N D 0 500 1000 1500 2000 2500 3000 # hypotheses (m) 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 1 0 1 1 0 2 1 0 3 R untime (seconds) e-family R untime e-L OND d-eL OND e - L O N D 0 500 1000 1500 2000 2500 3000 # hypotheses (m) 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 1 0 1 1 0 2 1 0 3 R untime (seconds) r -family R untime r -L OND d-rL OND r - L O N D (a) E-v alue procedures. 0 500 1000 1500 2000 2500 3000 # hypotheses (m) 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 1 0 1 1 0 2 1 0 3 R untime (seconds) e-family R untime e-L OND d-eL OND e - L O N D 0 500 1000 1500 2000 2500 3000 # hypotheses (m) 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 1 0 1 1 0 2 1 0 3 R untime (seconds) r -family R untime r -L OND d-rL OND r - L O N D (b) P-v alue procedures. Figure 2: Local dependence simulation summary over 200 trials. The left column shows e-v alue procedures and the right column sho ws p-v alue procedures. The top row reports po wer as the non-null fraction π 1 increases (with µ = 3 and δ = 0 . 1 ), while the bottom ro w reports mean wall-clock runtime (log scale) as the number of hypotheses increases. Donation and closed v ariants improv e po wer over the corresponding baselines, and donation v ariants remain computationally practical compared with closed v ariants. 5 Real data experiments W e also sho w the effecti veness of our procedures on two real datasets in volving online anomaly detection, which were used by Zhang et al. (2026) for procedure e v aluation. The first dataset is the N ASD A Q dataset (Genoni et al., 2023) which contains daily returns of the N ASD A Q inde x. In this experiment we use lik elihood-ratio e-values from a unit-root style construction (Dicke y and Fuller (1979)) to detect b ubble regimes, with δ = 0 . 005 . The NYC taxi dataset (La vin and Ahmad, 2015) also uses a likelihood-ratio construction to detect anomalous demand surges, where we first fit a null likelihood on a calibration set of data points, and then construct a likelihood ratio with an alte rnativ e likelihood estimated using a kernel density estimator . W e use δ = 0 . 4 when applying methods on this dataset. For each of these datasets, there are annotated anomaly sections where it is kno wn a priori that an anomaly occurred, which we can use to verify the detection capability of our procedures. T able 2 summarizes the method vs. the number of detected 15 Experiment Detected anomalies e-LOND d-eLOND e-LOND N ASD A Q 10 21 178 NYC T axi 8 16 10 T able 2: T rue discov eries made by each e-value procedure on real datasets. Donation e-LOND and e-LOND both outperform e-LOND on both datasets. anomalies (rejections inside annotated anomaly windows) for variants of our procedures. The lar gest detected-anomaly count within each experiment is bolded. W e see that both e-LOND and donation e-LOND outperform e-LOND in terms of detected anomalies, with e-LOND having the lar gest gain in the NASD A Q dataset and donation e-LOND having the largest gain in the NYC taxi dataset. Thus, we can see that the theoretical power improv ements of both procedures translate into practical gains in real-data settings as well. W e also visualize the disco veries made by the best performing procedure on each dataset against the performance of e-LOND in Figure 3. 6 Extensions In addition to improving the aforementioned online multiple testing algorithms, the donation frame work can also be used to impro ve the po wer of three other classes of algorithms. 1. Online acceptance-to-r ejection (ARC) and decision deadlines. Fischer et al. (2025) introduced the online ARC problem — here, one still receiv es a stream of hypotheses and corresponding statistics, b ut no longer is forced to immediately make a decision before recei ving the next hypothesis and associated statistic. W e can use the donation to improv e their online e-BH procedure in a computationally efficient manner . Fisher (2022) considers an intermediate setting where each hypothesis t has a (rejection) decision deadline d t ≥ t , and we show that we can improve the power of their procedure using donations as well. W e elaborate on this in Section D. 2. Offline multiple testing. While Xu et al. (2025) used the e-closure principle to improv e the eBH procedure for of fline multiple testing, it can require quadratic time to compute the rejection set for m hypotheses. Using donations, we can construct compound e-v alues that can be used with eBH to improve its po wer while computing 16 0 5000 10000 15000 20000 25000 01−1978 01−1988 01−1998 01−2008 01−2018 01−2028 Date Stock Price Bubbles marked b y e−LOND procedure 0 5000 10000 15000 20000 25000 01−1978 01−1988 01−1998 01−2008 01−2018 01−2028 Date Stock Price Bubbles marked b y e−LOND procedure (a) Plot of N ASD A Q price over time, with the blue and red highlighted periods indicating bub- bles. The blue dots are discov eries made by the respectiv e procedure, and one can see that e-LOND makes more discov eries than e-LOND in the bubble periods. 0 10000 20000 30000 Nov−01−2014 Dec−01−2014 Jan−01−2015 Feb−01−2015 Timestamp Remainder Anomalies marked by e−LOND procedure 0 10000 20000 30000 40000 Nov−01−2014 Dec−01−2014 Jan−01−2015 Feb−01−2015 Timestamp Remainder Anomalies marked by d−eLOND procedure (b) Plot of NYC taxi usage over time, with red highlighted periods indicating anomalous peri- ods. W e can see donation e-LOND making more discov eries in these periods than e-LOND (cir- cled in black). Figure 3: Plots of discoveries made by e-value procedures along with the accompanying real dataset. a strictly more powerful discov ery set in O ( m log m ) time. W e elaborate on this in Section D.3. 3. Randomization : Xu and Ramdas (2023) introduced the notion of randomization for improving the po wer of multiple testing procedures, and Xu and Ramdas (2024) ap- plied it to improv e both e-LOND and r -LOND. Similarly , we can apply randomization to improv e the po wer of donation procedures. W e elaborate on this in Section E. 7 Related work In addition to the aforementioned works, online multiple testing with FDR control has been studied extensi vely in recent years. Jav anmard and Montanari (2018) introduced an online notion of FDR control and formulated the LORD procedure for control under independence. 17 As a result, there has been a line of literature that has de veloped increasingly po werful online multiple testing algorithms under either independence or conditional v alidity assumption Ramdas et al. (2017); Zrnic et al. (2020). Ramdas et al. (2018) and T ian and Ramdas (2019) formulate adapti ve and discarding versions of LORD in the style of Storey (2002) and Zhao et al. (2019), respectiv ely , that allow the procedure to adapt to the frequency of the true null hypotheses. These works hav e restricted their focus to p-value based methods. More recently Zhang et al. (2026) proposed a new method under the conditional validity assumption that applies to both p-v alues and e-v alues. A line of work has also considered designing methods under other kinds of dependency structures. In addition to defining the r-LOND procedure and considering general arbitrary dependence, Zrnic et al. (2021) considers p-value based methods for global positi v e depen- dence among test statistics and local forms of dependence. Fisher (2024) sho w that under a dif ferent definition of positi ve dependence, LORD and SAFFR ON also ha ve v alid FDR control. Jankovic et al. (2025) considers online FWER control for weakly dependent data, although their control is asymptotic. Outside of Xu and Ramdas (2024), e-v alues ha ve also been utilized in online multiple testing with family-wise error rate (FWER) control. Fischer and Ramdas (2025) showed that e-v alues are necessary for constructing admissible online methods with control of FDP tail probabilities. Different online multiple testing analogs of FDR. SupFDR is a relativ ely ne w error criterion, b ut it is v aluable in the sense that it is stronger than both of the more classical notions of FDR control that hav e de veloped for online multiple testing. The first of these is onlineFDR, which was introduced in Jav anmard and Montanari (2018) and is defined as the follo wing: onlineFDR ( R ) : = sup t ∈ N FDR ( R t ) . Fischer et al. (2025) also considered a stopping time version of onlineFDR, which the y called StopFDR and defined as: StopFDR ( R ) : = sup τ ∈T FDR ( R τ ) , where T is the set of all stopping times with respect to the filtration generated by the data. Both onlineFDR and StopFDR control are implied by SupFDR control, as observed by 18 Fischer et al. (2025). One can see that since sup t E [ FDP ( R t )] ≤ E [sup t FDP ( R t )] , and FDP ( R τ ) ≤ sup t FDP ( R t ) for an y stopping time τ . Thus, our de velopment of procedures for SupFDR control implies v alidity under previous error metrics considered in prior literature. 8 Conclusion W e introduced a general frame work for improving sev eral online multiple testing procedures under unkno wn dependence, with a focus on SupFDR control. W e presented two approaches that trade of f po wer and computational cost while both strictly improving over e xisting methods. Our first approach uses the online e-closure principle to produce closed procedures that dominate their baselines, including e-LOND for e-v alues and r-LOND for p-v alues. These closed procedures can yield the lar gest po wer gains b ut are computationally expensi ve in long streams. Our second approach is the donation frame work, which constructs online compound e-v alues via γ -weighted donations and yields computationally efficient, strictly improv ed procedures such as donation e-LOND and donation r-LOND. T ogether , these results pro vide a principled menu of improvements: methods using the online e-closure principle are a uniformly more po werful but more expensiv e benchmark, while donation methods retain po wer impro vements with ef ficient test-le vel computation. An interesting direction for future work is to further narrow the computational gap between closed and donation procedures, or sho w that there is an irreducible dif ference between them. Refer ences Y oa v Benjamini and Y osef Hochberg. Controlling the False Disco very Rate: A Practical and Po werful Approach to Multiple T esting. Journal of the Royal Statistical Society . Series B (Methodological) , 57(1):289–300, 1995. Y oa v Benjamini and Daniel Y ekutieli. The control of the false discovery rate in multiple testing under dependency . The Annals of Statistics , 29(4):1165–1188, 2001. Gilles Blanchard and Etienne Roquain. T wo simple suf ficient conditions for FDR control. Electr onic Journal of Statistics , 2:963–992, 2008. David A. Dickey and W ayne A. Fuller . Distribution of the estimators for autore gressiv e time 19 series with a unit root. Journal of the American Statistical Association , 74(366):427–431, 1979. Lasse Fischer and Aaditya Ramdas. Admissible online closed testing must employ e-values. arXi v:2407.15733, 2025. Lasse Fischer , Marta Bofill Roig, and W erner Brannath. The online closure principle. The Annals of Statistics , 52(2):817–841, 2024. Lasse Fischer , Ziyu Xu, and Aaditya Ramdas. An online generalization of the (e-)Benjamini- Hochberg procedure. arXiv:2407.20683, 2025. Aaron Fisher . Online false discovery rate control for LORD++ and SAFFR ON under positi ve, local dependence. Biometrical Journal , 66(1):2300177, 2024. Aaron J. Fisher . Online Control of the F alse Discov ery Rate under ”Decision Deadlines”. In International Confer ence on Artificial Intelligence and Statistics , 2022. Dean P . Foster and Robert A. Stine. α -in vesting: A procedure for sequential control of expected f alse discov eries. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , 70(2):429–444, 2008. Giulia Genoni, Piero Quatto, and Gianmarco V acca. Dating financial b ubbles via online multiple testing procedures. F inance Researc h Letters , 58:104238, 2023. Nikolaos Ignatiadis, Ruodu W ang, and Aaditya Ramdas. Asymptotic and compound e- v alues: Multiple testing and empirical Bayes. arXi v:2409.19812, 2025. V incent Jankovic, Lasse Fischer , and W erner Brannath. Asymptotic Online FWER Control for Dependent T est Statistics. arXiv:2401.09559, 2025. Adel Jav anmard and Andrea Montanari. Online rules for control of false discov ery rate and false disco very e xceedance. The Annals of Statistics , 46(2):526–554, 2018. Alexander La vin and Sub utai Ahmad. Evaluating Real-T ime Anomaly Detection Algorithms – The Numenta Anomaly Benchmark. In IEEE International Confer ence on Machine Learning and Applications , 2015. Ruth Marcus, Peritz Eric, and K Ruben Gabriel. On closed testing procedures with special reference to ordered analysis of v ariance. Biometrika , 63(3):655–660, 1976. 20 Aaditya Ramdas and Ruodu W ang. Hypothesis testing with e-v alues. 2025. Aaditya Ramdas, Fann y Y ang, Martin J W ainwright, and Michael I Jordan. Online control of the false discovery rate with decaying memory . In Advances in Neural Information Pr ocessing Systems , volume 30, 2017. Aaditya Ramdas, T ijana Zrnic, Martin W ainwright, and Michael Jordan. SAFFRON: An Adapti ve Algorithm for Online Control of the False Disco very Rate. In International Confer ence on Machine Learning , 2018. Aaditya Ramdas, Johannes Ruf, Martin Larsson, and W outer K oolen. Admissible anytime- v alid sequential inference must rely on nonnegati ve martingales. arXi v:2009.03167, 2022. David S Robertson, James MS W ason, Franz K ¨ onig, Martin Posch, and Thomas Jaki. Online error rate control for platform trials. Statistics in Medicine , 42(14):2475–2495, 2023. John D. Storey . A direct approach to false discov ery rates. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , 64(3):479–498, 2002. W eijie J. Su. The FDR-Linking theorem. arXiv:1812.08965, 2018. Jinjin T ian and Aaditya Ramdas. ADDIS: An adaptiv e discarding algorithm for online FDR control with conserv ati ve nulls. In Neural Information Pr ocessing Systems 32 , 2019. Vladimir V ovk and Ruodu W ang. E-values: Calibration, combination and applications. The Annals of Statistics , 49(3):1736–1754, 2021. Ruodu W ang and Aaditya Ramdas. False discov ery rate control with e-v alues. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , 84(3):822–852, 2022. Ian W audby-Smith and Aaditya Ramdas. Estimating means of bounded random v ariables by betting. J ournal of the Royal Statistical Society: Series B (Statistical Methodolo gy) , 2023. Ziyu Xu and Aaditya Ramdas. More powerful multiple testing under dependence via randomization. arXiv:2305.11126, 2023. 21 Ziyu Xu and Aaditya Ramdas. Online multiple testing with e-v alues. In International Confer ence on Artificial Intelligence and Statistics , 2024. Ziyu Xu, Aldo Solari, Lasse Fischer , Rianne de Heide, Aaditya Ramdas, and Jelle Goeman. Bringing Closure to False Discovery Rate Control: A General Principle for Multiple T esting. arXiv:2509.02517, 2025. Sonja Zehetmayer , Martin Posch, and Franz K oenig. Online control of the false discov ery rate in group-sequential platform trials. Statistical Methods in Medical Researc h , 31(12): 2470–2485, 2022. Y ifan Zhang, Zijian W ei, Haojie Ren, and Changliang Zou. e-GAI: e-value-based General- ized α -In vesting for Online F alse Disco very Rate Control. In International Confer ence on Machine Learning , 2026. Qingyuan Zhao, Dylan S. Small, and W eijie Su. Multiple T esting When Many p-V alues are Uniformly Conservati ve, with Application to T esting Qualitative Interaction in Educa- tional Interv entions. J ournal of the American Statistical Association , 114(527):1291–1304, 2019. T ijana Zrnic, Daniel Jiang, Aaditya Ramdas, and Michael Jordan. The Po wer of Batching in Multiple Hypothesis T esting. In International Confer ence on Artificial Intelligence and Statistics , 2020. T ijana Zrnic, Aaditya Ramdas, and Michael I. Jordan. Asynchronous Online T esting of Multiple Hypotheses. Journal of Mac hine Learning Resear ch , 22(33):1–39, 2021. 22 A Methodological details of online closed pr ocedur es This section collects methodological details that are deferred from the main text. W e first record a general weighted e-collection construction and its relation to weighted self- consistency . W e then present an alternati ve e-collection for e-LOND (referenced in Sec- tion A.2) and computation details for r-LOND. A.1 General weighted e-collections and closur e enlargement Fix a nonnegati ve sequence γ = ( γ t ) t ∈ N with P t ∈ N γ t ≤ 1 . For each finite S ⊂ N , let ( γ S i ) i ∈ S satisfy: (i) P i ∈ S γ S i ≤ 1 and γ S i ≥ γ i for all i ∈ S ; (ii) if i ∈ S ∩ T and S ∩ [ i ] = T ∩ [ i ] , then γ S i = γ T i . Define E S : = X i ∈ S γ S i E i . Under H S , this gi ves E [ E S ] ≤ P i ∈ S γ S i ≤ 1 , so ( E S ) S ∈ 2 N is an e-collection. Condition (ii) ensures this e-collection is increasing. Proposition 11. Let ( E S ) be defined above and let R ⊂ [ t ] be nonempty . If R is weighted self-consistent for ( γ i , E i ) , i.e., γ i E i ≥ 1 δ | R | for all i ∈ R, then R ∈ C t . Pr oof. For an y S ⊆ [ t ] , E S = X i ∈ S γ S i E i ≥ X i ∈ S ∩ R γ i E i ≥ | S ∩ R | δ | R | = FDP S ( R ) δ . Hence R satisfies all constraints in (4), so R ∈ C t . The closure set can be strictly larger than the weighted self-consistent family . For example, let γ 1 = γ 2 = 1 / 2 , γ { 1 } 1 = 1 2 , γ { 1 , 2 } 1 = γ { 1 , 2 } 2 = 1 2 , γ { 2 } 2 = 1 , and choose E 1 = 1 / (2 δ ) , E 2 = 3 / (2 δ ) . Then no nonempty weighted self-consistent rejection set exists, b ut { 2 } ∈ C 2 . 23 A.2 Alternati ve e-collection f or e-LOND In Theorem 2, we used E S = P i ∈ S γ | S ∩ [ i ] | E i as the e-collection to construct e-LOND . That choice requires a nonincreasing γ sequence in the strict-improv ement argument. Here we record an alternati ve e-collection that a voids that monotonicity requirement. For a finite set S = { s 1 < · · · < s m } , define s 0 : = 0 and γ s j ,S : = s j X ℓ = s j − 1 +1 γ ℓ , E S : = m X j =1 γ s j ,S E s j . For each t and S ⊆ [ t − 1] , define Γ t ( S ) : = t X ℓ =max( S ∪{ 0 } )+1 γ ℓ . Then E S ∪{ t } = E S + Γ t ( S ) E t . Theorem 12. The pr ocedur e with test levels α t = min S ⊆ [ t − 1]: 1+ | S ∩ R t − 1 |− δ E S ( | R t − 1 | +1) > 0 δ Γ t ( S )( | R t − 1 | + 1) 1 + | S ∩ R t − 1 | − δ E S ( | R t − 1 | + 1) contr ols SupFDR at level δ under arbitrary dependence , and dominates e-LOND for any nonne gative γ with P i ∈ N γ i ≤ 1 . A sufficient condition for strict impr ovement at time t is that S = ∅ attains the minimum and P t i =1 γ i > γ t . Pr oof. For each finite S = { s 1 < · · · < s m } , E [ E S ] ≤ m X j =1 γ s j ,S = s m X ℓ =1 γ ℓ ≤ 1 under H S , so ( E S ) S ∈ 2 N is a v alid e-collection. For S ⊆ [ t − 1] , requiring R t − 1 ∪ { t } ∈ C t is equi v alent to FDP S ∪{ t } ( R t − 1 ∪ { t } ) ≤ δ ( E S + Γ t ( S ) E t ) , i.e., E t ≥ FDP S ∪{ t } ( R t − 1 ∪ { t } ) − δ E S δ Γ t ( S ) . 24 T aking the maximum over S ⊆ [ t − 1] yields exactly the displayed test lev el, so R t ∈ C t for all t . SupFDR control then follows from Theorem 1. T o compare with e-LOND, use R t − 1 ∈ C t − 1 to get | S ∩ R t − 1 | ≤ δ E S | R t − 1 | , hence 1 + | S ∩ R t − 1 | − δ E S ( | R t − 1 | + 1) ≤ 1 . Also Γ t ( S ) ≥ γ t for e very S ⊆ [ t − 1] . Therefore each candidate term in the minimum is at least δ γ t ( | R t − 1 | + 1) , which is the e-LOND lev el, so dominance holds. If S = ∅ is a minimizer and P t i =1 γ i > γ t , then α t = δ t X i =1 γ i ( | R t − 1 | + 1) > δ γ t ( | R t − 1 | + 1) , gi ving strict improv ement at time t . Simulation r esults. W e compare e-LOND, e-LOND , and the alternati ve- γ closed e-LOND using the same local dependence simulation setup as in the main simulations section in Figure 4 and plot the empirical FDP in Figure 5. W e see that the alternativ e- γ e-LOND has worse power than the original γ , while still being much more powerful than the original e-LOND procedure. All methods control the empirical FDP at the appropriate δ = 0 . 1 le vel. A.3 Computation details of r -LOND The minimization in (11) can be carried out in O ( t 2 ) time via a dynamic program mirroring the e-LOND case in Section 2.2. Define for i ∈ [ t − 1] and k ∈ { 0 } ∪ [ t − 1] , g t ( i, k ) : = max S ⊆ [ i ]: | S | = k | S ∩ R t − 1 | − δ ( | R t − 1 | + 1) E S . Initialize g t (0 , 0) = 0 and g t (0 , k ) = −∞ for k > 0 . For i ≥ 1 , set g t ( i, 0) = 0 , and for k ∈ { 1 , . . . , i } update g t ( i, k ) = max n g t ( i − 1 , k ) , g t ( i − 1 , k − 1) + 1 { i ∈ R t − 1 } − ( | R t − 1 | + 1) P i ℓ k δ γ k ∨ 1 − 1 o . 25 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.0 0.1 0.2 0.3 0.4 0.5 P ower 1 = 3 , m = 2 0 0 , = 0 . 1 0 Method e-L OND e - L O N D e - L O N D a l t - 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.0 0.2 0.4 0.6 0.8 1.0 P ower 1 = 4 , m = 2 0 0 , = 0 . 1 0 Method e-L OND e - L O N D e - L O N D a l t - Figure 4: Power comparison for alternati ve choice of γ for e-LOND. Then α r-LOND t = min ( 1 , min k ∈{ 0 ,...,t − 1 } 1+ g t ( t − 1 ,k ) > 0 δ γ k +1 ℓ k +1 | R t − 1 | + 1 1 + g t ( t − 1 , k ) ∧ ( k + 1) ) . The state space only tracks k = | S | , so the algorithm requires O ( t 2 ) time and O ( t ) memory per step; in practice we restrict i to indices in R t − 1 to reduce the constant factors. B Deferr ed pr oofs This section contains deferred proofs for the main theoretical results in the paper , including the closure-based improv ements, the donation frame work lemmas, and the p-v alue analogs. 26 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.0 0.1 0.2 0.3 0.4 0.5 FDR 1 = 3 , m = 2 0 0 , = 0 . 1 0 Method e-L OND e - L O N D e - L O N D a l t - 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.00 0.02 0.04 0.06 0.08 0.10 0.12 0.14 0.16 FDR 1 = 4 , m = 2 0 0 , = 0 . 1 0 Method e-L OND e - L O N D e - L O N D a l t - Figure 5: FDR for the alternativ e- γ closure comparison. All methods stay controlled at the target le vel δ = 0 . 1 . B.1 Pr oof of Theorem 1 Pr oof. Since each E S is measurable with respect to F sup( S ) , the collection ( C t ) t ∈ N is an online procedure. Define C ∞ : = R ⊂ N , R finite : FDP S ( R ) δ ≤ E S for all S ⊆ N . For any t and R ∈ C t , let S t : = S ∩ [ t ] for S ⊆ N . Then FDP S ( R ) = FDP S t ( R ) and, by monotonicity of ( E S ) , E S t ≤ E S . Thus FDP S ( R ) /δ ≤ E S for all S ⊆ N , i.e., R ∈ C ∞ . Hence sup t ∈ N sup R ∈C t FDP N ( R ) ≤ sup R ∈C ∞ FDP N ( R ) . By construction of C ∞ , E sup R ∈C ∞ FDP N ( R ) ≤ δ E [ E N ] ≤ δ . This yields E sup t ∈ N sup R ∈C t FDP N ( R ) ≤ δ. 27 This prov es the first claim; the stated consequence for any discov ery sequence with R t ∈ C t is immediate. B.2 Pr oof of Theorem 2 Pr oof. W e will show that e-LOND controls SupFDR by showing it produces a set inside C t for all t ∈ N almost surely . By Theorem 1, this will imply that e-LOND controls the SupFDR at le vel δ . W e note that t ∈ R t if f E t ≥ α − 1 t = max S ⊆ [ t − 1] FDP S ∪{ t } ( R t − 1 ∪ { t } ) − δ E S δ γ | S | +1 . No w , we note that the abo ve is equiv alent to the following condition holding for all S ⊆ [ t − 1] : FDP S ∪{ t } ( R t − 1 ∪ { t } ) ≤ δ γ | S | +1 E t + δ E S = δ E S ∪{ t } . W ith this, we can see that t ∈ R t if f R t − 1 ∪ { t } ∈ C t , which sho ws our desired result. T o see that e-LOND strictly improv es o ver e-LOND, we note that FDP S ( R t − 1 ) ≤ δ E S for all S ⊆ [ t − 1] since R t − 1 ∈ C t − 1 almost surely . Thus, we can see that | S ∩ R t − 1 | − δ E S | R t − 1 | ≤ 0 and naturally 1 − δ E S ≤ 1 , which makes the choice of α t in (6) always at least as large as that of e-LOND in (2). A concise suf ficient condition for strict inequality at time t is that S = ∅ is a minimizer in (6) and δ γ 1 ( | R t − 1 | + 1) > α e-LOND t . In that case, α e-LOND t = δ γ 1 ( | R t − 1 | + 1) > α e-LOND t . T o show that e-LOND strictly improv es over e-LOND, we can take t = 2 and consider a distribution where E 1 = ( δ γ 1 ) − 1 with positi ve probability . On this e vent, both procedures reject H 1 , so R 1 = { 1 } and, for S = { 1 } , 1 + | S ∩ R 1 | − δ E S ( | R 1 | + 1) = 2 − 2 δ γ 1 E 1 = 0 . Hence α e-LOND 2 = 2 δ γ 1 > δ γ 2 = α e-LOND 2 . Therefore, if additionally P E 1 = ( δ γ 1 ) − 1 , ( α e-LOND 2 ) − 1 ≤ E 2 < ( α e-LOND 2 ) − 1 > 0 , then e-LOND rejects H 2 while e-LOND does not. Thus, strict improvement holds. 28 B.3 Pr oof of Proposition 5 Pr oof. W e prove this by restricting C to the first t hypotheses for each t ∈ N first, and then proving the result by taking limits. Let max( t ) ∈ ar gmax i ∈ [ t ] FDP N ( R i ) be an inde x of at most t that maximizes the FDP in the sequence R . For each t ∈ N , we ha ve that E " sup R ∈ C ∩ [ t ] FDP ( R ) # = E FDP ( R max( t ) ) = X i ∈N ∩ [ t ] E " 1 { ˜ E i ≥ ( δ γ i R max( t ) ) − 1 } | R max( t ) | # ≤ δ X i ∈N ∩ [ t ] γ i E [ ˜ E i ] ≤ δ X i ∈ N γ i = δ, where the first inequality is by 1 { x ≥ 1 } ≤ x for all x ≥ 0 , and the second inequality is by the definition of online compound e-values. Now , we can apply the dominated con ver gence theorem to conclude that E sup R ∈ C FDP ( R ) = E " lim t →∞ sup R ∈ C ∩ [ t ] FDP ( R ) # = lim t →∞ E " sup R ∈ C ∩ [ t ] FDP ( R ) # ≤ δ. This conclusion implies our desired result. B.4 Pr oof of Proposition 6 Pr oof. For all t ∈ N , we note that X i ∈N ∩ [ t ] γ i E [ ˜ E i ] = X i ∈N ∩ [ t ] γ i E [ E i + B i ] = X i ∈N ∩ [ t ] γ i E [ E i ] − X i ∈ [ t ] \N γ i E [ B i ] ≤ X i ∈N ∩ [ t ] γ i E [ E i ] + X i ∈ [ t ] \N γ i ≤ 1 . The last equality and first inequality is due to the definition of B as a γ -weighted donation. The last inequality is due to the fact that E i is an e-value for all i ∈ N and γ sum to at most 1. 29 B.5 Pr oof of Proposition 7 Pr oof. Since there exists some R ε ∈ ∪ B ∈B C ( B ) such that FDP ( R ε ) > sup B ∈B sup R ∈C ( B ) FDP ( R ) − ε for all ε > 0 , there also exists a choice of ( B t ) such that R ε ∈ C ( B ) . Thus, we get that E " sup B ∈B sup R ∈C ( B ) FDP ( R ) # − ε ≤ E [ FDP ( R ε )] ≤ δ . W e get our desired result as we take ε → 0 . B.6 Pr oof of Theorem 8 Pr oof. For each t ∈ N , we can define a γ -weighted donation sequence B ( t ) as follo ws B ( t ) i = ¯ W t /γ t if i = t, (( δ γ i ( | R t − 1 | + 1)) − 1 − E i ) ∨ − 1 if i ∈ R t − 1 , − ( E i ∧ 1) otherwise. By induction, we can sho w that such a choice of B ( t ) immediately implies that R t ∈ C ( B ( t ) ) if f E t ≥ α − 1 t . Since ˜ E ( t ) i : = E i + B ( t ) i ≥ ( δ γ i ( | R t − 1 | + 1)) − 1 for each i ∈ [ t − 1] by construction of B ( t ) , we only need to consider the constraint on E t . Now , we can deri ve that R t − 1 ∪ { t } ∈ C ( B ( t ) ) if f ˜ E ( t ) t : = E t + B ( t ) t ≥ 1 δ γ t ( | R t − 1 | + 1) . W e note that this is equiv alent to sho wing that E t ≥ 1 δ γ t ( | R t − 1 | + 1) − ¯ W t /γ t = 1 − δ ( | R t − 1 | + 1) ¯ W t δ γ t ( | R t − 1 | + 1) . Hence, we can see that this condition is equi v alent to satisfying E t ≥ α − 1 t , as E t is nonnegati ve. This completes the induction. W e also can see that γ t B ( t ) t = ¯ W t = − P i ∈ [ t − 1] γ i B ( t ) i , which sho ws that B ( t ) is a v alid γ -weighted donation. As a result, by Theorem 7, we ha ve that donation e-LOND controls the SupFDR at le vel δ . 30 Lastly , we sho w that donation e-LOND strictly impro ves ov er e-LOND. Let R d-eLOND t and R e-LOND t and α d-eLOND t and α e-LOND t be the discovery sets and test lev els of donation e-LOND and e-LOND respecti vely . Then, if we assume R d-eLOND t − 1 ⊇ R e-LOND t − 1 by induction, we hav e that α d-eLOND t = δ γ t ( | R d-eLOND t − 1 | + 1) 1 − ( δ ( | R d-eLOND t − 1 | + 1) ¯ W t ∧ 1) ≥ δ γ t ( | R e-LOND t − 1 | + 1) = α e-LOND t , since (1 − ( δ ( | R d-eLOND t − 1 | + 1) ¯ W t ∧ 1)) − 1 ≥ 1 . For a concrete instance where donation e-LOND make strictly more discoveries than e-LOND with positi ve probability , take t = 2 and let γ 1 > γ 2 . If E 1 ≥ ( δ γ 1 ) − 1 , then both methods reject H 1 and R 1 = { 1 } , so α d-eLOND 2 > α e-LOND 2 . Therefore, whenev er P E 1 ≥ ( δ γ 1 ) − 1 and ( α d-eLOND 2 ) − 1 ≤ E 2 < ( α e-LOND 2 ) − 1 > 0 , donation e-LOND rejects H 2 while e-LOND does not, which proves our desired result. B.7 Pr oof of Theorem 9 Pr oof. The abov e choice of E S in (10) is a v alid e-v alue for H S since f t is a v alid calibrator for all t ∈ N and we are taking a weighted mean of ( f | S ∩ [ i ] | ( P i )) i ∈ S with weights ( γ | S ∩ [ i ] | ) i ∈ S . Thus, since we want to ha ve R t ∈ C t , we need to satisfy for all S ⊆ [ t − 1] that δ E S ∪{ t } = 1 { P t ≤ δ γ | S | +1 ( | S | + 1) /ℓ | S | +1 } ( P t ℓ | S | +1 / ( δ γ | S | +1 )) ∨ 1 + δ E S ≥ FDP S ∪{ t } ( R t − 1 ∪ { t } ) . If we rearrange this, we get the follo wing condition for all S ⊆ [ t − 1] : 1 { P t ≤ δ γ | S | +1 ( | S | + 1) /ℓ | S | +1 } ( P t ℓ | S | +1 / ( δ γ | S | +1 )) ∨ 1 ≥ ∆ E S ( t ) . If ∆ E S ( t ) ≤ 0 , this constraint is trivially satisfied by an y P t ∈ [0 , 1] . Otherwise, we can deri ve the follo wing condition on P t : P t ≤ δ γ | S | +1 ℓ | S | +1 ( δ ∆ E S ( t )) − 1 ∧ ( | S | + 1) . 31 Thus, we get that the abo ve is equi v alent to P t ≤ α t where α t is gi ven in (11) . As a result, we get that SupFDR control is ensured by r-LOND as a result of Theorem 1. T o show that r-LOND strictly improv es ov er r -LOND, we first prov e that the test lev els of r-LOND are always at least as lar ge as those of r-LOND. Because R t − 1 ∈ C t − 1 , we hav e FDP S ( R t − 1 ) ≤ δ E S for all S ⊆ [ t − 1] . Thus, we also get that | S ∩ R t − 1 | ≤ δ E S | R t − 1 | . As a result 1 + | S ∩ R t − 1 | − δ E S ( | R t − 1 | + 1) ≤ 1 − δ E S ≤ 1 . Plugging this bound into (11) sho ws that α t is always as lar ge as the α t of r-LOND as gi ven in (3), since γ | S | +1 ≥ γ t and ℓ | S | +1 ≤ ℓ t for all S ⊆ [ t − 1] . A concise suf ficient condition to attain a strict impro vement at time t is that the terms being minimized ov er are all v acuous, i.e., that ∆ E S ( t ) ≤ 0 for all nonempty S ⊆ [ t − 1] . As a result, we get that the minimization in (11) is achie ved by S = ∅ which in turn implies that α t = δ γ 1 > δ γ t ( | R t − 1 | + 1) for any t ∈ N since we hav e defined tγ t /ℓ t to be nonincreasing in t . A concrete instance of this for t = 2 is on the e vent P 1 ≤ δ γ 1 . Then both r-LOND and r-LOND reject H 1 making R 1 = { 1 } . Then, we have that ∆ E { 1 } (2) = 1 + |{ 1 } ∩ R 1 | δ ( | R 1 | + 1) − E { 1 } = 1 δ − 1 δ = 0 , because f 1 ( P 1 ) = 1 / ( δ γ 1 ) and hence E { 1 } = γ 1 f 1 ( P 1 ) = 1 /δ . No w , we use α r-LOND t and α r-LOND t to dif ferentiate the test le vels of the dif ferent procedures. W e hav e that α r-LOND 2 = δ γ 1 , while α r-LOND 2 = δ γ 2 /ℓ 2 . If iγ i /ℓ i is nonincreasing, then γ 1 ≥ 2 γ 2 /ℓ 2 , so α r-LOND 2 > α r-LOND 2 . Consequently , any distrib ution that satisfies P P 1 ≤ δ γ 1 , α r-LOND 2 < P 2 ≤ α r-LOND 2 > 0 , will have r-LOND reject H 2 while r-LOND does not with positi ve probability , which establishes strict improv ement. B.8 Pr oof of Theorem 10 Pr oof. Let E t = f t ( P t ) for each t ∈ N . The calibrator f t of V ovk and W ang (2021) guarantees that E are v alid e-v alues e ven under arbitrary dependence. Let α d-eLOND t denote the test lev el of donation e-LOND from (8) , and let α d-rLOND t denote the test le vel of donation r-LOND from (12). Donation r -LOND therefore enjoys SupFDR control by Theorem 8. 32 T o sho w that rejecting when P t ≤ α d-rLOND t is equi v alent to rejecting when f t ( P t ) ≥ ( α d-eLOND t ) − 1 , we directly compare rejection decisions. By the definition of f t , the donation e-LOND condition f t ( P t ) ≥ ( α d-eLOND t ) − 1 is equi v alent to P t ≤ δ γ t t ℓ t and ⌈ ( P t ℓ t / ( δ γ t )) ∨ 1 ⌉ ≤ α d-eLOND t δ γ t . Since the left-hand side is integer v alued, the second inequality is equiv alent to ⌈ ( P t ℓ t / ( δ γ t )) ∨ 1 ⌉ ≤ α d-eLOND t δ γ t . Combining with the indicator constraint P t ≤ δ γ t t/ℓ t , we get the equi v alent condition P t ≤ δ γ t ℓ t α d-eLOND t δ γ t ∧ t . Substituting (8) for α d-eLOND t yields e xactly the threshold in (12) . Thus the rejection sets of donation r-LOND coincide with those of donation e-LOND, so the SupFDR control conclusion transfers. Lastly , we show that donation r-LOND can strictly impro ve o ver r -LOND. Let α d-rLOND t and α r-LOND t denote the test lev els of donation r-LOND and r -LOND respecti vely . A concise suf ficient condition for strict inequality at time t is that both procedures agree up to time t − 1 , with | R t − 1 | ≥ 1 and δ ( | R t − 1 | + 1) ¯ W t ≥ 0 . Using | R t − 1 | + 1 ≤ t together with 0 ≤ δ ( | R t − 1 | + 1) ¯ W t ∧ 1 ≤ 1 , we have α d-rLOND t . 6 = δ γ t ℓ t | R t − 1 | + 1 1 − ( δ ( | R t − 1 | + 1) ¯ W t ∧ 1) ∧ t ≥ δ γ t ℓ t ( | R t − 1 | + 1) > δ γ t ℓ t | R t − 1 | = α r-LOND t . For a concrete witness e vent, take t = 2 . If P 1 ≤ δ γ 1 and ( | R 1 | + 1) ¯ W 2 ≥ 0 , then both procedures reject H 1 , so R 1 = { 1 } and α d-rLOND 2 ≥ 2 δ γ 2 /ℓ 2 > δ γ 2 /ℓ 2 = α r-LOND 2 . Hence, whene ver P P 1 ≤ δ γ 1 , ( | R 1 | + 1) ¯ W 2 ≥ 0 , α r-LOND 2 < P 2 ≤ α d-rLOND 2 > 0 , donation r-LOND rejects H 2 while r-LOND does not, which gi ves strict improv ement. 33 C Simulation extensions W e provide additional simulation results and construction details referenced in the main text. C.1 Additional simulations W e also include simulation in the same setup as Section 4, although with µ = 4 in Figure 6. W e similar results of the closed and donation variants of each procedure improving o ver the corresponding baselines as the non-null fraction π 1 increases. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.0 0.2 0.4 0.6 0.8 1.0 P ower 1 = 4 , m = 2 0 0 , = 0 . 1 0 Method e-L OND d-eL OND e - L O N D (a) E-v alue procedures. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.0 0.2 0.4 0.6 0.8 1.0 P ower 1 = 4 , m = 2 0 0 , = 0 . 1 0 Method r -L OND d-rL OND r - L O N D (b) P-v alue procedures. Figure 6: Po wer-only local dependence simulation results ov er 200 trials for alternativ e signals of µ = 4 and δ = 0 . 1 . In both e-value and p-v alue families, donation and closed v ariants improv e ov er the corresponding baselines as the non-null fraction π 1 increases. C.2 Simulation details Each X i t is a sample from the Beta ( a, b ) distribution, where we let a + b = 10 − 2 , which is shifted and rescaled to be supported on [ − 4 , 4] . The following Hoef fding-based martingale ( M i t ) i was sho wn by W audby-Smith and Ramdas (2023) to yield valid e-v alues for random v ariables bounded in [ ℓ, u ] if E [ X i t ] = 0 for i ∈ [ N ] . M i t = exp i X j =1 λ j t X j t − ( λ j t ( u − ℓ )) 2 8 ! , for any sequence of ( λ j t ) j ∈ [ N ] that is predictable, i.e., λ j t can be determined by X 1 t , . . . , X j − 1 t . W e let λ j t = p 8 log(1 / ( δ γ t )) / (( u − ℓ ) 2 N ) as per W audby-Smith and Ramdas (2023, eq. 3.6). 34 Our e-v alues and p-v alues e v aluate the terminal v alue after all N samples: E t = M N t and P t = min 1 , 1 max i ∈ [ N ] M i t . W e do not employ stopping times or sequential updates within this construction. D Impr ov ements via donation bey ond online multiple test- ing W e will discuss sev eral improv ements we can make to e-v alue procedures using the donation frame work that is beyond the online multiple testing setting. In particular , we will consider ho w we can use the donation framew ork to improve methods for the acceptance-to-rejection (ARC) model of Fischer et al. (2025), the decision deadlines setup of Fisher (2022), as well as the traditional of fline multiple testing setting with a finite number of hypotheses. D .1 Online donation e-BH f or acceptance-to-r ejection (ARC) The acceptance-to-rejection (ARC) setup of Fischer et al. (2025) assumes that once one makes a rejection on a hypothesis, they cannot rev oke it at a future time step, but allo ws one to make rejections on all pre vious unrejected hypotheses. This is equiv alent to restricting the rejection set at each time step to be nested, i.e., R 1 ⊆ R 2 , . . . . The online e-BH procedur e In the ARC setting, Fischer et al. (2025) showed that one can apply a weighted version of the e-BH procedure to an infinite stream of hypotheses using the weighted self-consistency frame work and maintain FDR control. The concept of weighted self-consistency is a generalization of the online e-BH and e-LOND procedure, since the discov ery sets of both are included in the simultaneous weighted self-consistenc y collection of discov ery sets in (7) , which guarantees control ov er the supremum of FDP of all discov ery sets in the collection. For a giv en fixed sequence γ , the online e-BH pr ocedur e makes the follo wing number of discov eries at time t : r o-eBH t : = max r ∈ [ t ] : X i ∈ [ t ] 1 E i ≥ 1 δ γ i r ≥ r , (13) 35 with r o-eBH t = 0 if the set is empty . The rejection set is then defined as: R t = i ∈ [ t ] : E i ≥ 1 δ γ i r o-eBH t . Using the donation framew ork, we can improve online e-BH. First, we define the notion of weighted order e-values, i.e., let γ ( i ): t and E ( i ): t be the values of γ j and E j corresponding to the i th largest γ j E j among j ∈ [ t ] . Thus, we get the online donation e-BH pr ocedur e as follo ws. W e can define the number of discov eries made as r o-DeBH t : = max ( r ∈ [ t ] : X i ∈ [ r ] ( γ ( i ): t E ( i ): t − ( δ r ) − 1 ) ∧ γ ( i ): t + X i ∈{ r +1 ,...,t } γ ( i ): t ( E ( i ): t ∧ 1) ≥ 0 ) , (14) As a result, the discov ery set R t simply rejects the r o-DeBH t largest indices of γ i E i among i ∈ [ t ] . Theorem 13 (Online donation e-BH controls SupFDR) . Online donation e-BH with the afor ementioned rejection sets R satisfies SupFDR ( R ) ≤ δ for arbitrarily dependent e- values, and strictly impr oves over online e-BH. D.1.1 Simulation results W e compare online e-BH and donation online e-BH in the ARC setting using the same local dependence simulation setup as in the main simulations section. D .2 Donation e-TO AD f or decision deadlines On the other hand, Fisher (2022) studies an intermediate regime where each h ypothesis t has a deterministic deadline d t ≥ t , i.e., one must make a rejection decision at time d t for the t th hypothesis, or else the null hypothesis will be accepted and remain unrejected permanently . Let A t : = { i ∈ [ t ] : d i ≤ t } denote the set of hypotheses whose deadlines hav e not yet passed by time t . The ARC model corresponds to setting d t = ∞ for each t ∈ N , while the classical online multiple testing setting corresponds to making d t = t for each t ∈ N . 36 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.0 0.1 0.2 0.3 0.4 0.5 P ower 1 = 3 , m = 2 0 0 , = 0 . 1 0 Method o -eBH o -DeBH 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.0 0.2 0.4 0.6 0.8 P ower 1 = 4 , m = 2 0 0 , = 0 . 1 0 Method o -eBH o -DeBH Figure 7: Po wer for online e-BH and donation online e-BH in ARC under the same setup as the main simulations section. The e-TO AD procedur e Fisher’ s TO AD rule (Fisher, 2022) now restricts rejection sets at certain deadlines. Let m t : = |A t | be the number of hypotheses whose deadlines ha ve arri ved by time t . Now , we let γ ( i ): A t and E ( i ): A t denote the values of γ i and E i corresponding to the i th largest γ i E i among i ∈ A t . Define r eTO AD t : = max ( r ∈ {| R t − 1 \ A t | , . . . , m t } : X i ∈A t 1 E i ≥ 1 δ γ i r ≥ r − | R t − 1 \ A t | ) , where r eTO AD t = 0 if no such r exists. Then, we define the corresponding discov ery set as R t = R t − 1 ∪ i ∈ A t : E i ≥ 1 δ γ i r eTO AD t . 37 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.0 0.1 0.2 0.3 0.4 0.5 FDR 1 = 3 , m = 2 0 0 , = 0 . 1 0 Method o -eBH o -DeBH 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.000 0.025 0.050 0.075 0.100 0.125 0.150 0.175 0.200 FDR 1 = 4 , m = 2 0 0 , = 0 . 1 0 Method o -eBH o -DeBH Figure 8: FDR for online e-BH and donation online e-BH in ARC. Both methods stay controlled at the target le vel δ = 0 . 1 . When d t = t for all t ∈ N , this is equiv alent to e-LOND, and if d t = ∞ , then this is the same as online e-BH. W e can then define online donation e-TO AD using the following quantities: ¯ W DeTO AD t ( r ) : = X i ∈ R t − 1 \A t ( γ i E i − ( δ r ) − 1 ) ∧ γ i + X i ∈ [ t ] \ ( A t ∪ R t − 1 ) γ i ( E i ∧ 1) , r DeTO AD t : = max ( r ∈ {| R t − 1 \ A t | , . . . , m t } : X i ∈ [ r −| R t − 1 \A t | ] ( γ ( i ): A t E ( i ): A t − ( δ r ) − 1 ) ∧ γ ( i ): A t + X i ∈{ r −| R t − 1 \A t | +1 ,...,m t } γ ( i ): A t ( E ( i ): A t ∧ 1) + ¯ W DeTO AD t ( r ) ≥ 0 ) , 38 with r DeTO AD t = 0 if no such r exists. Here, ¯ W DeTO AD t ( r ) is the excessi ve “wealth” that can be donated to (or accounted for from) e-values in A t if a total of r discov eries are made at time t . The rejection set R t is then defined as making r DeTO AD t − | R t − 1 | ne w discov eries corresponding to the indices in A t with the largest γ i E i v alues. Theorem 14 (Donation e-TO AD controls SupFDR) . Donation e-TO AD with afor ementioned discovery sets satisfies SupFDR ( R ) ≤ δ for arbitrarily dependent e-values, and strictly impr oves over e-T O AD. Pr oof of Theor ems 13 and 14. The proofs of both of these theorems are similar to that of donation e-LOND: at each time t , there exists a γ -weighted donation sequence B ( t ) with B ( t ) i ≥ − ( E i ∧ 1) and P i ∈ [ t ] γ i B i ≤ 0 such that the compound e-v alues ˜ E ( t ) i = E i + B i satisfy γ i ˜ E ( t ) i ≥ ( δ | R t | ) − 1 for all i ∈ R t . By Theorem 6, ( ˜ E ( t ) i ) i ∈ [ t ] are valid γ -weighted compound e-v alues. The weighted self-consistency collection C ( B ( t ) ) from (7) applied to these compound e-v alues contains the rejection set R t for both procedures. Hence, we get SupFDR control via Theorem 7. The choice of B ( t ) i for both procedures can be chosen as follo ws: B ( t ) i : = (( δ γ i r o-DeBH t ) − 1 − E i ) ∨ − 1 , i ∈ R t , − ( E i ∧ 1) , i ∈ R t . By definition of each procedure this B ( t ) is a γ -weighted donation sequence in both cases. Thus, we hav e shown our desired results. Similar to donation e-LOND, both donation online e-BH and donation e-TO AD strictly improv e their non-donation counterparts since the y consider a superset of rejection sets at each time t . D .3 Donation e-BH f or offline multiple testing W e treat the offline batch as the t = m snapshot of the ARC model with all deadlines at ∞ and with γ 1 = · · · = γ m = 1 /m and γ t = 0 for all t > m . Thus, we can order hypotheses directly by e-v alues E i , writing E (1) ≥ · · · ≥ E ( m ) . In this case, we can view eBH and donation eBH as taking R m of online eBH and online donation eBH, respecti vely . 39 Baseline e-BH. The classical e-BH rule has the same weighted self-consistenc y form as (13): r eBH : = max r ∈ [ m ] : X i ∈ [ m ] 1 n E i ≥ m δ r o ≥ r , R eBH = n i ∈ [ m ] : E i ≥ m δ r eBH o . Donation-derived compound e-values. Here, we only need to consider vectors B = ( B i ) i ∈ [ m ] . A vector is a v alid donation sequence if B i ≥ − ( E i ∧ 1) and P m i =1 B i ≤ 0 . Let ˆ E i : = E i + B i . Proposition 15. If ( E i ) i ∈ [ m ] ar e e-values and B is a valid donation sequence, then ( ˆ E i ) i ∈ [ m ] ar e compound e-values, i.e., P i ∈N E [ ˆ E i ] ≤ m . This follo ws from Theorem 6. Donation e-BH. The of fline donation method can be seen as using (14) with t = m : r DeBH : = max n r ∈ [ m ] : X i ∈ [ r ] ( γ ( i ) E ( i ) − ( δ r ) − 1 ) ∧ γ ( i ) + m X i = r +1 γ ( i ) ( E ( i ) ∧ 1) ≥ 0 o . Then, we let the discov ery set R DeBH reject the r DeBH largest e-v alues. Theorem 16. Donation e-BH satisfies E [ FDP N ( R DeBH )] ≤ δ for arbitrarily dependent e-values and strictly impr oves over e-BH . The proof follo ws from Theorem 13 since the of fline method can be seen as a special case of the online ARC model. Remark 17 . While we hav e primarily discussed e-v alue based methods in this section, our results directly imply improv ements of p-value methods. This includes the online BH method of Fischer et al. (2025) and the offline Su method (Su, 2018) using the calibrator de veloped in Xu et al. (2025), as well as the and Benjamini-Y ekutieli (Benjamini and Y ekutieli, 2001) methods via the calibrator specified in (9) . W e will not go into details here, the improvements follow directly from calibration of the p-value to an e-value, and then applying one of the online or of fline donation e-BH procedures, or the e-T O AD procedure if one is to use p-v alues in the decision deadlines setting. 40 E Randomization f or donation algorithms Xu and Ramdas (2023) introduced the notion of using randomization in the form of stochastic rounding to improv e the po wer of a v ariety of multiple testing procedures, and Xu and Ramdas (2024) was able to show that randomized versions of e-LOND and r-LOND can be deri ved using this technique. W e extend the use of randomization to donat ion procedures, and show that one can utilize randomization to further improv e the power of donation e-LOND and donation r-LOND. The key idea we recognize here is that while donation procedures utilize part of the excess wealth of e-v alues ov er the rejection threshold, it does not use it completely . Thus, when there is excess wealth remaining ev en after donation (e.g., an e-v alue is just slightly belo w the threshold of rejection e ven after donating), we can use it to improv e the po wer of a procedure. A stochastically rounded e-value (or compound e-value) is one where we hav e an e-value (or any nonne gati ve random v ariable) X and a test le vel ˆ α ∈ [0 , 1] that might be arbitrarily dependent on X , and we produce the following random v ariable S ˆ α ( X ) : = 1 { U ≤ ˆ α X } ˆ α − 1 . Here, U is a uniform random v ariable on [0 , 1] that is independent of both X and ˆ α , i.e., produced through e xternal randomness. It is easy to see that E [ S ˆ α ( X )] ≤ E [ X ] . Thus, we can replace a compound e-v alue or an e-v alue with its stochastically rounded version and still maintain the v alidity properties of interest. As a result of the flexibility of stochastic rounding, there can be many ways to incorporate it into the donation frame work. W e will focus on impro ving donation e-LOND as an e xample, and sho w there is a simple way that will allow it to strictly impro ve o ver donation e-LOND. W e first define a restricted version of stochastic rounding, where we only round the part of an unrejected e-value that cannot be utilized by the donation frame work, i.e., ( E t − 1) if E t ≥ 1 and 0 otherwise. Thus, we define the r estricted stochastic r ounding of X at le vel ˆ α as ¯ S ˆ α ( X ) : = X X ≤ 1 or X ≥ ˆ α − 1 , 1 + 1 n U ≤ ˆ α ( X − 1) 1 − ˆ α o ( ˆ α − 1 − 1) , X ∈ (1 , ˆ α − 1 ) . Thus, we can apply the donation e-LOND sequence of test le vels α in (8) to e-v alues ¯ S α 1 ( E 1 ) , ¯ S α 2 ( E 2 ) , . . . and refer to this as r andomized donation e-LOND . W e first define the 41 follo wing quantities. ˆ α t : = δ γ t ( | R t − 1 | + 1) 1 − ( δ ( | R t − 1 | + 1) ¯ R t ∧ 1) . ¯ R t : = X i ∈ R t − 1 ( γ i ¯ S ˆ α i ( E i ) − δ ( | R t − 1 | + 1) − 1 ) ∧ γ i + X i ∈ [ t − 1] \ R t − 1 γ i ( S ˆ α i ( E i ) ∧ 1) . = X i ∈ R t − 1 ( γ i ¯ S ˆ α i ( E i ) − δ ( | R t − 1 | + 1) − 1 ) ∧ γ i + X i ∈ [ t − 1] \ R t − 1 γ i ( E i ∧ 1) . ˆ α t is the threshold for the t th hypothesis such that it will be deterministically rejected (i.e., doesn’t rely on randomization). ¯ R t is the analog of ¯ W t for donation e-LOND, but utilizes the stochastically rounded e-v alues instead. W e then observ e that we reject the t th hypothesis when α t = ˆ α t U t (1 − ˆ α t ) + ˆ α t . where U 1 , U 2 , . . . are uniform random variables on [0 , 1] independent of E . Theorem 18. The randomized donation e-LOND algorithm ensur es contr ol of SupFDR, and strictly impr oves over donation e-LOND. Pr oof. W e note SupFDR control arises from the fact that ¯ S ˆ α t ( E 1 ) , . . . are valid e-values due to the definition of restricted stochastic rounding. Thus, Theorem 8 immediately implies SupFDR control. W e can see the strict improvement via the fact that U t has nonzero chance of increasing α t ov er ˆ α t , which also is at least as large as α t of donation e-LOND defined in (8) via construction. Thus, we hav e sho wn our desired result. E.1 Simulation r esults W e compare donation e-LOND and randomized donation e-LOND under the same local dependence simulation setup as in the main simulations section. 42 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.0 0.1 0.2 0.3 0.4 P ower 1 = 3 , m = 2 0 0 , = 0 . 1 0 Method d-eL OND r d-eL OND 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.0 0.2 0.4 0.6 0.8 P ower 1 = 4 , m = 2 0 0 , = 0 . 1 0 Method d-eL OND r d-eL OND Figure 9: Power for donation e-LOND and randomized donation e-LOND under the same setup as the main simulations section. 43 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.0 0.2 0.4 0.6 0.8 1.0 FDR 1 = 3 , m = 2 0 0 , = 0 . 1 0 Method d-eL OND r d-eL OND 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.000 0.025 0.050 0.075 0.100 0.125 0.150 0.175 0.200 FDR 1 = 4 , m = 2 0 0 , = 0 . 1 0 Method d-eL OND r d-eL OND Figure 10: FDR for donation e-LOND and randomized donation e-LOND. Both methods stay controlled at the target le vel δ = 0 . 1 . 44
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment