Trust as Monitoring: Evolutionary Dynamics of User Trust and AI Developer Behaviour
AI safety is an increasingly urgent concern as the capabilities and adoption of AI systems grow. Existing evolutionary models of AI governance have primarily examined incentives for safe development and effective regulation, typically representing us…
Authors: Adeela Bashir, Zhao Song, Ndidi Bianca Ogbo
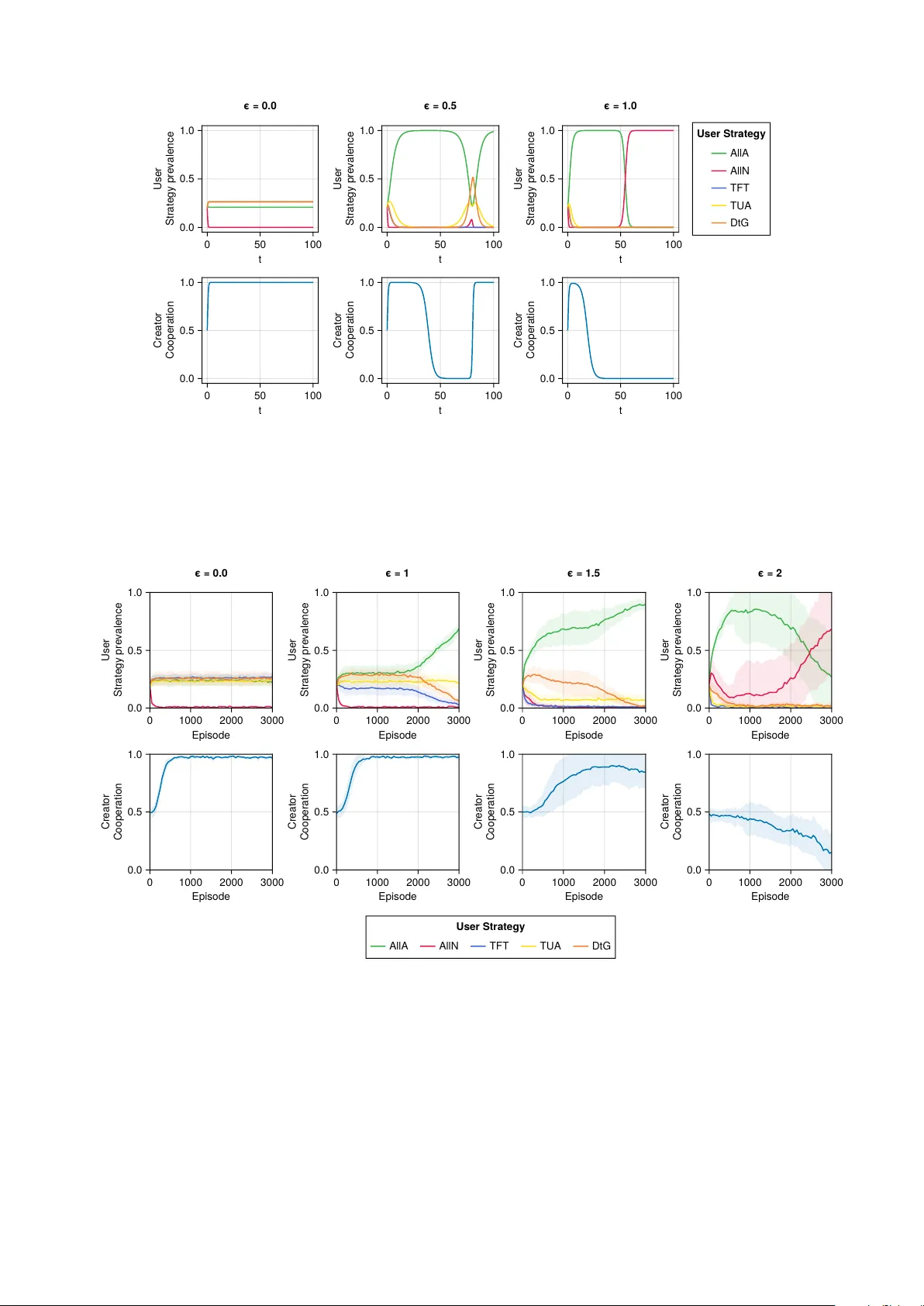
T rust as Monitoring: Ev olutionary Dynamics of User T rust and AI Dev elop er Beha viour Adeela Bashir 1 , † , Zhao Song 1 , † , Ndidi Bianca Ogb o 1 , † , Nataliy a Balabanov a 2 , † , Martin Smit 3 , † , Chin-wing Leung 4 , † , Paolo Bo v a 1 , Manuel Chica Serrano 5 , Dhanushk a Dissanay ak e 1 , Manh Hong Duong 2 , Elias F ern´ andez Domingos 6 , 7 , Nikita Hub er Kralj 1 , Marcus Krellner 8 , Andrew Po w ell 1 , Stefan Sark adi 9 , F ernando P . Santos 3 , Zia Ush Shamszaman 1 , Chaimaa T arzi 1 , P aolo T urrini 4 , Grace Ibukunolu w a Ufeoshi 1 , V ´ ıctor A. V argas-P´ erez 5 , Alessandro Di Stefano 1 , ‡ , Simon T. Po wers 10 , ‡ , and The Anh Han 1 , ‡ , ∗ 1 School Computing, Engineering and Digital T echnologies, T eesside Universit y 2 School of Mathematics, Universit y of Birmingham 3 Informatics Institute, Universit y of Amsterdam 4 Department of Computer Science, University of W arwic k 5 Department of Computer Science and Artificial In telligence (DECSAI) and Andalusian Researc h Institute DaSCI “Data Science and Computational Intelligence”, University of Granada, Spain 6 Machine Learning Group, Universit´ e libre de Bruxelles 7 AI Lab, V rije Universiteit Brussel 8 Universit y of T ec hnology Dresden 9 School of Engineering and Physical Sciences, University of Lincoln 10 Division of Computing Science and Mathematics, Universit y of Stirling † : equal first author ‡ : equal last author ⋆ Corresponding author: The Anh Han (T.Han@tees.ac.uk) ABSTRA CT AI safety is an increasingly urgent concern as the capabilities and adoption of AI systems grow. Existing ev olutionary mo dels of AI gov ernance hav e primarily examined incen tiv es for safe dev elopment and effective regulation, t ypically represen ting users’ trust as a one-shot adoption c hoice rather than as a dynamic, ev olving pro cess shap ed b y rep eated interactions. W e instead mo del trust as reduced monitoring in a rep eated, asym- metric interaction b et w een users and AI developers, where chec king AI b ehaviour is costly . Using evolutionary game theory , w e study ho w user trust strategies and developer c hoices b et ween safe (compliant) and unsafe (non-complian t) AI co-evolv e under different levels of monitoring cost and institutional regimes. W e comple- men t the infinite-p opulation replicator analysis with sto c hastic finite-p opulation dynamics and reinforcemen t learning (Q-learning) simulations. Across these approaches, w e find three robust long-run regimes: no adop- tion with unsafe developmen t, unsafe but widely adopted systems, and safe systems that are widely adopted. Only the last is desirable, and it arises when p enalties for unsafe behaviour exceed the extra cost of safet y and users can still afford to monitor at least occasionally . Our results formally support gov ernance prop osals that emphasise transparency , low-cost monitoring, and meaningful sanctions, and they show that neither regulation alone nor blind user trust is sufficient to preven t ev olutionary drift tow ards unsafe or lo w-adoption outcomes. Keyw ords: AI gov ernance, trust, game theory , replicator dynamics, reinforcemen t learning, trustw orth y AI 2 I. INTR ODUCTION Recen t w ork has examined how evolutionary game theory (EGT) mo dels can formalise some of the dilemmas of AI gov ernance and regulation [ 1 – 4 ]. This w ork has examined the incentiv es on AI creators tow ards safe and trust worth y developmen t, and on regulators for effectively enforcing regulations. How ever, these mo dels hav e not explicitly captured the dynamics of user trust – how do es the trust users place in an AI system change with differen t regulatory regimes? This is a pressing p olicy question, since AI regulations typically aim to help users place an appropriate amount of trust in AI systems (see, for example, the EU AI Act) [ 5 ], such that they are not exploited by ov er trusting the pro ducts of big tec h, but also do not miss out on p oten tial benefits through misplaced distrust. Existing EGT models of AI gov ernance hav e not addressed this because they ha ve fo cused on single shot in teractions betw een users and dev elop ers. That is, a single game is play ed in whic h a user c ho oses whether or not to adopt the AI system from a particular dev elop er, given the information they hav e ab out the state of the regulatory environmen t. This limits the ability to mo del trust, since trust is a dynamic and evolving pro cess that unfolds through rep eated interactions, shaped b y exp erience, exp ectations, and observed b eha viour [ 6 ]. Empirical and theoretical evidence suggests that ev en minimal exposure to prior in teractions, such as previously observing co op erativ e or non-co op erativ e b eha vior, can significantly influence subsequent trust and co op eration decisions, including in h uman-AI con texts [ 7 ]. Within game-theoretic frameworks, trust has long b een studied as a k ey mechanism to facilitate co op eration and co ordination in environmen ts where agen ts face the risk of exploitation. Ho w ever, traditional models often conflate trust with the co op erativ e act itself [ 8 – 10 ]. This includes the canonical T rust Game [ 11 ], whic h is effectiv ely a one-sided Prisoner’s Dilemma [ 12 ]. Similarly , in previous EGT mo dels of AI Gov ernance, trust has b een conflated with a user c ho osing to adopt an AI system [ 1 , 3 ]. In reality , trust is a factor that influenc es co operation or user adoption of AI. This raises the question of ho w trust can b e defined and measured in a game-theoretic framew ork. Here, w e build on recen t w ork that equates trust with a reduced frequency of monitoring a partner’s actions [ 13 ]. This captures the idea that trust is a heuristic that individuals use when monitoring – getting information ab out a partner’s actions – is costly . This accords with theories from so cial science that view the function of trust as reducing the complexity of so cial interactions, b y acting as a decision-making shortcut [ 14 ]. T rust as reduced monitoring has recen tly b een argued to b e a useful, pragmatic, definition of trust b et ween users and AI [ 15 – 20 ]. F urthermore, this definition of trust is measurable in b oth h uman and artificial agents, since it relies only on observing whether one agent monitors another, e.g. do es a user verify the output from a Large Language Mo del (LLM), or do they chec k on how a particular system has b een audited by regulators? How ever, trust-as-reduced monitoring has so far only been used to formulate symmetric games, suc h as repeated so cial dilemmas with monitoring costs [ 13 , 16 ]. With this definition of trust, we build an EGT mo del to analyse an asymmetric rep eated game b et w een users of AI systems and their creators. As AI creators co-evolv e their own strategies to maximise the v alue they extract from their users, we use this mo del to explain what the consequences are of different trust strategies by users on the ov erall risks AI systems p ose to them. W e show that the cost of monitoring is a key parameter driving safe and trustw orth y developmen t by creators and appropriate adoption of these systems by users. This provides formal supp ort for the v erbal arguments commonly found in the AI gov ernance literature that transparency of AI systems and their dev elopmen t, i.e. reduced monitoring costs, is imp ortan t to incentivise trustw orth y dev elopment by creators and to allow users to calibrate their trust in AI appropriately . In particular, we show that it is essen tial that users do not fully trust AI systems or their creators to av oid risk externalities. Otherwise, ev olutionary pressure driven by incentiv es on users and creators entails that AI companies can shift increasing risks onto their users. T o preven t this, p olicymakers should ensure that the cost of monitoring new AI systems for their safety and robustness characteristics remains low. Reinforcemen t learning (RL) has b ecome an imp ortan t paradigm for studying the emergence of co operation among autonomous learning agen ts [ 21 – 26 ]. Breakthroughs ha ve been achiev ed in scenarios in v olving the exploitation of common resources, particularly through the dev elopment of trust mechanisms among agen ts [ 24 , 27 , 28 ]. Contrary to replicator dynamics, in whic h agen ts’ strategic up dates dep end on the strategies of others (commonly referred to as so cial learning), RL agen ts up date their p olicies (the RL analogue of strategies) through trial-and-error based on their own experience. RL thus offers a complementary framew ork where agents learn optimal strategies through in teraction with the environmen t, up dating their behavior based on accum ulated rew ards and exp ectations [ 29 , 30 ]. This allows for a more realistic mo deling of trust as an endogenous and exp erience-driv en phenomenon [ 30 ]. By adapting our mo del to reinforcemen t learning agen ts, w e are able to show that our conclusions are robust to the learning dynamics used. Indeed, in the absence of monitoring costs, the Q-learning dynamics and replicator dynamics are consistent with each other. When monitoring costs increase, the co operation and trust b ehaviour tend to b e more robust among Q-learning agents. As the monitoring costs are high enough, b oth replicator and Q-learning dynamics result in a defective and un trustw orth y so ciety . 3 I I. MODELS AND METHODS W e first describe our mo del of a repeated t w o-play er game betw een users and developers, allowing for adaptiv e trust-based user strategies and strategic choices by developers. W e then s pecify the evolutionary dynamics we analyse in b oth infinite and finite p opulations. Finally , we pro vide details on Reinforcement Learning approac h. A. Rep eated user-creator game with trust-based strategies W e start by constructing a mo del of r ep e ate d interactions b etw een AI users and dev elop ers. In real-world AI deplo yment, users interact with the same AI creator or system across many episo des: they rep eatedly query a mo del, integrate it in to w orkflows, and up date their beliefs ab out its reliability based on past p erformance. T o formalise these ideas, w e consider tw o p opulations representing users and creators (developers). Within eac h p opulation, individuals may adopt differen t strategies (see T able I ). Users choose among fiv e strategies that differ in when they adopt the technology and ho w often they monitor the AI system’s outputs, including strategies that condition future adoption and monitoring decisions on observ ed coop eration or defection b y creators (e.g., tit-for-tat-like or threshold-based trust heuristics). Creators, in turn, can either coop erate by dev eloping safe (complian t) AI systems (C), incurring an additional cost, or defect b y creating unsafe (non- complian t) systems (D), av oiding this cost but p otentially exp osing users to harm. W e do not explicitly model regulators as an ev olving actor in this model. Ho w ever, the presence of regulations is reflected in the pa yoff structure, suc h that we treat regulations as an institution – part of the rules of the game [ 31 ]. Specifically , creators suffer an institutional punishment for releasing unsafe systems that do not comply with regulations. These regulatory choices shap e the effective incentiv es faced b y creators in the rep eated game with users: stronger punishmen t for unsafe behaviour makes co op eration (safe dev elopmen t) more attractive in the long run, while weak er enforcement allows unsafe strategies to p ersist or even dominate. In this wa y , the rep eated user–creator game b ecomes a basic building blo c k for analysing how user trust and dev elop er b ehaviour co-evolv e under different regulatory regimes. T ABLE I: Roles, actions, and b eha vioural in terpretation in the AI regulatory ecosystem. Role Strategy Description Users AllA Alw ays adopt the technology . AllN Nev er adopt the technology . TFT Initially adopt the tec hnology and subsequen tly condition the action on the outcome of the previous interaction. TUA Pla y TFT until observing θ T consecutiv e rounds of coop eration, then switc h to unconditional coop eration and only monitor with probability p . If defection is observed while monitoring in this phase, revert to the original θ T -thresholded TFT strategy . DtG Pla y TFT un til observing θ D consecutiv e rounds of defection, then switc h to unconditional defection and only monitor with probability p . If co op eration is observ ed while monitoring in this phase, revert to the original θ D -thresholded TFT strategy . Creators C Pro duces a safe (compliant) technology , incurring a cost but ensuring reliabilit y . D Pro duces an unsafe (non-compliant) tec hnology , a v oiding costs but risk- ing negative outcomes. The individual pay off earned in an y one round of the rep eated game dep ends on the strategies of the partici- pating individuals. In our setting, a game is play ed b etw een a single user and a single creator (dev elop er), and their pay offs are giv en by the matrix in T able I . Rows corresp ond to the user adoption strategy , while columns corresp ond to whether the creator co operates b y pro ducing a safe (complian t) tec hnology ( C ) or defects b y pro ducing an unsafe (non-complian t) technology ( D ). When the creator co op erates ( C ), a user who adopts the AI system obtains a b enefit b U from using a safe tec hnology . Depending on the user’s strategy , this b enefit may b e reduced by the cumulativ e cost of monitoring the system’s outputs. Monitoring is costly: each chec k incurs a cost ϵ > 0, and different user strategies in v olve differen t monitoring frequencies across the r rounds of in teraction. F or example, a user who alwa ys adopts (AllA) never monitors and therefore receives the full b enefit b U whenev er the creator co op erates. By con trast, a tit-for-tat (TFT) user starts b y adopting and monitoring, incurring a monitoring cost ϵ in every round, and then conditions future actions on observed past b eha viour, leading to the effective pay off b U − ϵ when paired with a co op erativ e creator. Threshold-based trust strategies such as TUA and DtG further mo dulate the exp ected monitoring cost o ver r rounds b y switching b etw een constant monitoring and low-probabilit y chec king after 4 T ABLE I I: Explanation of the k ey parameters of the models. P arameter Explanation b u Benefit a user receiv es when adopting a safe tec hnology b c Benefit a creator receiv es when their technology is adopted c Cost of the creator for co op erating v Institutional punishment for defecting creators µ Risk of adopting an unsafe AI, µ ∈ ( −∞ , 1] ϵ Cost of monitoring p T Probabilit y of chec king for TUA strategists p D Probabilit y of chec king for DtG strategists θ T Threshold for TUA θ D Threshold for DtG r Number of rounds FIG. 1: Interaction Sequences b et w een Strategies. Each blo c k represen ts an action of the user (left stac k) and the developer (righ t stac k), whic h can b e co operate (white) or defect (dark red). Users may also monitor the creator’s b eha viour, paying a cost (sym b ols to the righ t of the stacks of TFT, TUA and DtG). The figure illustrates the differences b etw een the conditional strategies: While TFT alw ays observ es, TUA ma y en ter a state of trust after observing that the creator co operated for θ T subsequen t rounds (in this example θ T = 3), whereas DtG ma y en ter a state of distrust after observing θ D defections. In those states, observ ation only happens with probabilit y p T and p D resp ectiv ely . observing sufficien tly long sequences of coop eration or defection; this results in the a veraged monitoring terms prop ortional to θ T , θ D , p T , and p D in T able I . When the creator defects ( D ), an adopting user faces an unsafe AI system. In this case, the user’s b enefit is scaled b y a risk factor µ ∈ ( −∞ , 1], so that adoption yields µb U instead of b U . Negativ e v alues of µ capture scenarios where unsafe AI leads to net harm. As b efore, users who monitor creator’s past b eha viours also incur the relev ant chec king costs, whic h are a v eraged o ver the r rounds according to their strategy . Users who never adopt (AllN) receive a pa yoff of 0 regardless of the creator’s b ehaviour, since they neither b enefit from safe AI nor suffer from unsafe AI. Creators receive a b enefit b c whenev er their technology is adopted b y the user, for instance through sales or usage-based reven ue. Pro ducing safe AI (co op erating) carries an additional developmen t cost c , so that a co operative creator’s pay off is b c − c whenev er the user adopts. Pro ducing unsafe AI (defecting) av oids this cost but may lead to institutional punishmen t of size v (e.g., through regulatory fines or liability) when unsafe b eha viour is detected. In the pay off matrix, this is reflected by the pay offs b c − v for defecting creators in 5 T ABLE I II: Pa yoff matrix . Eac h row sp ecifies an action profile of the users, and the columns contain the user and creator pay offs for the tw o creator strategies C and D . See T able I for detailed explanation of the actions. User Strategy Creator strategy C D User Pa yoff Creator Pa yoff User Pa yoff Creator Pa yoff AllA b u b c − c µ b u b c − v AllN 0 − c 0 0 TFT b u − ϵ b c − c µ b u r − ϵ b c − v r TUA b u − θ T ϵ + ( r − θ T ) p T ϵ r b c − c µ b u r − ϵ b c − v r DtG b u − ϵ b c − c µ b u r − θ D ϵ + ( r − θ D ) p D ϵ r b c − v r adoption states. The user’s strategy affects the creator only indirectly , through its impact on whether the tec hnology is adopted and on ho w often unsafe b eha viour is detected (via monitoring and punishment), but in this reduced mo del there are no explicit regulator or commentator play ers; their effects are subsumed into the parameters b c , c , and v . In summary , T able I summarise ho w com binations of user trust strategies and creator safety c hoices determine (i) the user’s exp ected b enefit from adoption, adjusted for monitoring costs and risk from unsafe AI, and (ii) the creator’s net gain from safe versus unsafe developmen t under the p ossibilit y of punishment. B. Ev olutionary dynamics: finite and infinite p opulation p erspectives 1. Sto chastic dynamics for finite p opulations a. Payoff c alculation. W e consider tw o differen t w ell-mixed p opulations of Users and Creators of sizes, resp ectiv ely N u and N c . Let x , y , z , w , and 1 − x − y − z − w b e resp ectively the fraction of users that adopting strategy All A , All N , T F T , T U A , and D tG , and let α and 1 − α b e resp ectiv ely the fraction of creators adopting strategy C and D . Therefore, the fitness that a user and creator obtain in each game is resp ectively given by: f U X ∈{ AllA,Al lN ,T F T ,T U A,D tG } = αP U X,C + (1 − α ) P U X,D , (1) f U Y ∈{ C,D } = xP C AllA,Y + y P C AllN ,Y + z P C T F T ,Y + w P C T U A,Y + (1 − x − y − z − w ) P C DtG,Y . (2) In each of the ab o ve form ulas, each term on the right-hand side is the (a verage) pay off that the fo cal play er obtains when interacting with the sp ecific opp onen t enco ded in the subscripts. The fitness (i.e. a verage pay off ) is then computed using the pay off matrix constructed in the mo dels (see T ables I I A ). The calculation of the fitness is a key step in applying evolutionary game theory , which translates a game-theoretical concept (the pa yoff ) to a biological or cultural one (the fitness). Here, we assume the cultural pro cess of pay off-biased so cial learning, in which individuals cop y successful strategies used b y other individuals in their p opulation. 6 No w w e calculate explicitly the difference of fitness b et w een t wo strategies in users: ∆ f U AllA,AllN = f U AllA − f U AllN = αb u + (1 − α ) µb u , (3) ∆ f U AllA,TFT = f U AllA − f U TFT = αϵ + (1 − α ) µb u − µb u r + ϵ , (4) ∆ f U AllA,TUA = f U AllA − f U TUA = α θ T ϵ + ( r − θ T ) p T ϵ r + (1 − α ) µb u − µb u r + ϵ , (5) ∆ f U AllA,DtG = f U AllA − f U DtG = αϵ + (1 − α ) µb u − µb u r + θ D ϵ + ( r − θ D ) p D ϵ r , (6) ∆ f U AllN,TFT = f U AllN − f U TFT = − α ( b u − ϵ ) − (1 − α ) µb u r − ϵ , (7) ∆ f U AllN,TUA = f U AllN − f U TUA = − α b u − θ T ϵ + ( r − θ T ) p T ϵ r − (1 − α )( µb u r − ϵ ) , (8) ∆ f U AllN,DtG = f U AllN − f U DtG − α ( b u − ϵ ) − (1 − α ) µb u r − θ D ϵ + ( r − θ D ) p D ϵ r , (9) ∆ f U TFT,TUA = f U TFT − f U TUA α θ T ϵ + ( r − θ T ) p T ϵ r , (10) ∆ f U TFT,DtG = f U TFT − f U DtG = (1 − α ) − ϵ + θ D ϵ + ( r − θ D ) p D ϵ r , (11) ∆ f U TUA,DtG = f U TUA − f U DtG = α ϵ − θ T ϵ + ( r − θ T ) p T ϵ r + (1 − α ) θ D ϵ + ( r − θ D ) p D ϵ r − ϵ (12) Similarly , the difference of the fitness betw een t w o strategies in creators is: ∆ f C C,D = f C C − f C D = b c (1 − y ) − c − x ( b c − v ) + (1 − x − y ) b c − v r . (13) b. Evolutionary dynamics. F or a finite p opulation setting, at eac h time step, a randomly selected individual A, with fitness f A , ma y adopt a different strategy b y imitating a randomly chosen individual B from the same p opulation (with fitness f B ) with probability given by the F ermi distribution [ 32 ]. p = [1 + e − β ( f B − f A ) ] − 1 , where β ≥ 0 is the strength of selection. β = 0 corresp onds to neutral drift where imitation decisions are random, while for large β → ∞ , the imitation decision b ecomes increasingly deterministic. In the absence of mutations or exploration, the end states of ev olution are inevitably monomorphic: once suc h a state is reac hed, it cannot b e escap ed through imitation. W e thus further assume that with a certain m utation probability , an agen t switches randomly to a different strategy without imitating another agen t. In the limit of small m utation rates, the dynamics will proceed with, at most, t w o strategies in the p opulation, suc h that the b ehavioural dynamics can b e conv eniently describ ed b y a Mark ov chain, where each state represents a monomorphic p opulation, while the transition probabilities are given by the fixation probability of a single m utant [ 33 – 35 ]. The resulting Marko v chain has a stationary distribution, which c haracterises the av erage time the p opulation sp ends in each of these monomorphic end states. No w, the probabilit y to c hange the num b er k of agents using strategy A b y ± one in each time step can b e written as ( Z is the population size) [ 32 ]: T ± ( k ) = Z − k Z k Z h 1 + e ∓ β [ f A ( k ) − f B ( k )] i − 1 . (14) The fixation probabilit y of a single mutan t with a strategy A in a p opulation of ( Z − 1) agents using B is given b y [ 32 , 34 ]: ρ B ,A = 1 + Z − 1 X i =1 i Y j =1 T − ( j ) T + ( j ) − 1 . (15) 7 The transition matrix Λ corresp onding to the set of { 1 , . . . , s } strategies is given by: Λ ij,j = i = ρ j i 2( n − 1) and Λ ii = 1 − s X j =1 ,j = i Λ ij . (16) Fixation probabilit y ρ ij denotes the likelihoo d that a p opulation transitions from a state i to a different state j when a mutan t of one of the p opulations adopts an alternate strategy n ( n = 5 for the user p opulation, while n = 2 for the creator p opulation). The fixation probability is divided by the num b er of p opulations (which is 2) representing the interaction of t w o pla yers at a time [ 36 , 37 ]. Additionally , we define the frequency of co op eration as P j = C,i ∈{ AllA,AllN ,T F T ,T U A,D tG } Λ ij , and the level of adoption as the frequency when users adopt (i.e. pla ying T with the creator). T ABLE IV: Risk-dominan t conditions for creator and user strategies. # Risk-dominan t transition Condition Creator strategy dominance 1 (AllA , C ) → (AllA , D ) c > v 2 (AllN , C ) → (AllN , D ) c > 0 3 (TFT , C ) → (TFT , D ) b (1 − r ) + r c > v 4 (TUA , C ) → (TUA , D ) b (1 − r ) + rc > v 5 (DtG , C ) → (DtG , D ) b (1 − r ) + rc > v User strategy dominance 6 (AllT , C ) → (AllN , C ) b u > 0 7 (AllT , C ) → (TFT , C ) ϵ > 0 8 (TFT , C ) → (TUA , C ) ϵ r − ( r − θ T ) p T < θ T c 9 (AllT , D ) → (AllN , D ) µb u > 0 10 (AllT , D ) → (TFT , D ) rϵ > µb u (1 − r ) 11 (TFT , D ) → (DtG , D ) ϵ r − ( r − θ D ) p D < θ D c The risk-dominant conditions provide clear insights into how incentiv es shap e b eha viour in the AI regulatory ecosystem. On the creator side, defection b ecomes dominan t when the cost of co operation c exceeds institutional punishmen t v , highlighting the critical role of enforcement mechanisms in sustaining safe AI dev elopment. F or rep eated interactions, the term b (1 − r ) + r c sho ws that longer engagement horizons ( r large) amplify the imp ortance of coop eration costs, making sustained coop eration harder without sufficient penalties. On the user side, se v eral conditions (e.g., b u > 0, ϵ > 0) are trivially satisfied, indicating that users naturally prefer adoption and basic monitoring. How ev er, non-trivial conditions inv olving ϵ , θ T , θ D , and chec king probabilities ( p T , p D ) go vern the transition to more sophisticated strategies suc h as TUA and DtG. These conditions rev eal a k ey trade-off: higher chec king costs discourage monitoring, while stronger thresholds and enforcement increase accoun tability . Overall, the results show that while users tend to adopt safe technologies, effective regulation m ust balance monitoring costs and penalties to ensure that creators hav e sufficient incentiv es to co op erate, thereb y reducing systemic risk from unsafe AI. 2. Population dynamics for infinite p opulations: The multi-p opulation r eplic ator dynamics In this section, we recall the framework of the replicator dynamics for multi-populations [ 38 – 40 ]. T o describ e the dynamics, w e consider a set of m differen t populations ( m is some positive in teger), which are infinitely large and well-mixed. Eac h p opulation i , i = 1 , . . . m , consists of n i ( n i is some p ositive integer) differen t strategies (t yp es). Let x ij , 1 ≤ i ≤ m, 1 ≤ j ≤ n i , b e the frequency of the strategy j in the p opulation i . W e denote by x i = ( x ij ) n i j =1 , which is the collection of all strategies in the p opulation i , and x = ( x 1 , . . . , x m ), which is the collection of all strategies in all p opulations. F or eac h i ∈ { 1 , . . . , m } and j ∈ { 1 , . . . , n i } , let f ij ( x ) be the fitness (repro ductiv e rate) of the strategy j in the p opulation i . This fitness is obtained when the strategy j interacts with all other strategies in all p opulations; th us, it dep ends on all the strategies in the p opulations. The av erage fitness of the p opulation i is defined b y ¯ f i ( x ) = n i X j =1 x ij f ij ( x ) . 8 The multi-population replicator dynamics is then given b y ˙ x ij = x ij ( f ij ( x ) − ¯ f i ( x )) , 1 ≤ i ≤ m, 1 ≤ j ≤ n i . (17) This is in general an ODE system of P m i =1 n i equations. Noting, ho w ev er that since P n i j =1 x ij = 1 for all i = 1 , . . . , m , we can reduce the ab ov e system to a system of P m i =1 n i − m equations. In the subsequent sections, w e emplo y ( 17 ) to our mo dels. a. Calculation of p ayoffs. Let x, y , z , w be the frequencies of the strategies Al lA , Al lN , T F T , T U A of the users and α b e the frequency of co operative creators. F rom the pay off matrix given in T able I I I , we compute the pay offs of the users depending on their respective strategies. F or the users, they will hav e the form f U AllA = f U x = αb u + (1 − α ) µb u = b u ( α ( − µ ) + α + µ ) f U AllN = f U y = α ∗ 0 + (1 − α ) ∗ 0 = 0 f U T F T = f U z = α ( b u − ϵ ) + (1 − α ) µb u r − ϵ = b u ( − αµ + µ + α r ) r − ϵ f U T U A = f U w = α b u − θ T ϵ + ( r − θ T ) p T ϵ r + (1 − α ) µb u r − ϵ = b u ( − αµ + µ + α r ) + αθ T ( p T − 1) ϵ + r ϵ ( α + α ( − p T ) − 1) r f U DtG = f U 1 − x − y − z − w = α ( b u − ϵ ) + (1 − α ) µb u r − ϵθ D + ( r − θ D ) ϵp D r = α ( b u − ϵ ) + ( α − 1)( − b u µ + p D ϵ ( r − θ D ) + θ D ϵ ) r . (18) No w, let us write the pay off of creators: f C r C = f C r α = x ( b c − c ) + y ( − c ) + z ( b c − c ) + w ( b c − c ) + (1 − x − y − z − w )( b c − c ) = ( b c − c ) − y b c f C r D = f C r 1 − α = x ( b c − v ) + y ∗ 0 + z b c − v r + w b c − v r + (1 − x − y − z − w ) b c − v r = x ( b c − v ) + (1 − x − y ) b c − v r . (19) Using the ab o ve expressions, one can write a verage fitnesses for the users: f U = ( α − 1) b u µ ( − r x + x + y − 1) r − αb u ( y − 1) + 1 r ϵ ( − r ( α + α ( p T − 2) w + w − α ( x + y + z ) + z ) + αθ T ( p T − 1) w − ( α − 1) p D ( r − θ D )( w + x + y + z − 1) − ( α − 1) θ D ( w + x + y + z − 1)) ! (20) and for the creators: f C r = ( α − 1) α ( b c ( r − 1)( x + y − 1) + cr + v ( − r x + x + y − 1)) r . (21) I II. FINITE POPULA TION ANAL YSIS W e now examine ev olutionary game dynamics in finite p opulations (see Methods, Section I I B 1 ). In con- trast to classical notions of ev olutionary stability and the dynamics of infinite p opulations, finite p opulations are strongly influenced by sto chastic effects, including errors in so cial learning, whic h can substan tially alter ev olutionary outcomes [ 41 – 43 ]. As a result, strategies with low er pay offs may o ccasionally spread by chance despite being at a selective disadv antage, whereas strategies with higher pa yoffs may go extinct. This sto c has- 9 Monitoring cost ( ε ) 0 . 0 0.5 1.0 S t r at e g y p r e v a l e n c e 0.0 0.5 1.0 Monitoring cost ( ε ) 0 . 0 0.5 1.0 S t r at e g y p r e v a l e n c e 0.0 0.5 1.0 Monitoring cost ( ε ) 0 . 0 0.5 1.0 S t r at e g y p r e v a l e n c e 0.0 0.5 1.0 Monitoring c ost ( ε ) 0.0 0.5 1.0 S t ra t e g y p r e v al e n c e 0.0 0.5 1.0 Monitoring c ost ( ε ) 0.0 0.5 1.0 S t ra t e g y p r e v al e n c e 0.0 0.5 1.0 Monitoring c ost ( ε ) 0.0 0.5 1.0 S t ra t e g y p r e v a l e n c e 0.0 0.5 1.0 Monitoring cost ( ε ) 0.0 0.5 1.0 U s e r a d o p t io n 0.0 0.5 1.0 Surplus adoption due to trust Monitoring cost ( ε ) 0.0 0.5 1.0 U s e r a d o p t i o n 0.0 0.5 1.0 Monitoring cost ( ε ) 0.0 0.5 1.0 U s e r a d o p t io n 0.0 0.5 1.0 Without Trust-Based Strategies With Trust-Bas ed Strategies v = 0.1 v = 0.5 v = 1 U ser Strategy AllA AllN TFT TUA DtG Developer Strategy Cooperate Defect Availability of Trust-Based Strategies Without With FIG. 2: T rust-based strategies enhance user adoption, while it declines as monitoring cost b ecomes exp ensiv e. The first and second columns show the stationary distributions of eac h state as a function of monitoring cost for scenarios without and with trust-based strategies, resp ectively . The third column displays the difference in user adoption levels b et ween these tw o cases across v arying monitoring costs. Ro ws from top to b ottom corresp ond to increasing levels of institutional punishment ( v = 0 . 1, 0 . 5, and 1). P arameters are set to b u = b c = 4, β = 0 . 1, Z u = Z c = 100, c = 0 . 5, µ = − 0 . 2, r = 10, θ t = θ D = 3, and p T = p D = 0 . 25. tic framew ork has prov en to b e v aluable in explaining the empirical patterns observed in h uman b ehavior exp erimen ts [ 42 , 43 ] and therefore provides an imp ortan t mo de of analysis for our mo dels. W e first inv estigate the impact of monitoring cost, and we find that the adoption improv es with the introduc- tion of trust-based b eha viours, but declines as monitoring b ecomes more costly . As shown in the first column of Figure 2 , without trust-based strategies, Tit-for-T at (TFT) serv es as the primary user strategy against a co operative creator, though its adoption falls as monitoring costs rise. In this scenario, unconditional adop- tion (AllA) only dominates under strong institutional punishment (e.g., v = 1). Conv ersely , when trust-based strategies are active (Figure 2 , second column), TUA and DtG co exist alongside TFT and AllA, becoming the dominan t strategies when monitoring is inexp ensive (around ϵ < 0 . 2). As institutional punishment increases, AllA once again emerges as the dominant strategy . F urthermore, a direct comparison of the t wo cases (Figure 2 , third column) reveals that the av ailabilit y of trust-based strategies consisten tly enhances user adoption levels regardless of the monitoring cost. Then we study the influence of institutional punishment, and the results show that trust-based strategies enhance user adoption, whic h further increases with stronger institutional punishment. In the scenario without trust-based strategies (Figure 3 , first column), low institutional punishmen t ( v ) results in the dominance of non-adoption (AllN) and dev eloper defection. How ever, as institutional punishmen t increases, unconditional adoption (AllA) and developer co op eration gradually tak e ov er the system. It is worth noting that when the monitoring cost is lo w ( ϵ = 0 . 1), TFT maintains a consistent presence regardless of institutional punishment. In the scenario with trust-based strategies (Figure 3 , second column), when the monitoring cost b ecomes high ( ϵ = 0 . 5 , 1), trust-based strategies lose their adv antage, and users primarily adopt AllN or AllA relying on institutional punishment. On the other hand, when the monitoring cost is low ( ϵ = 0 . 1), TUA and DtG 10 Institutional punishment (v) 0 . 0 0.5 1.0 S t r at e g y p r e v a l e n c e 0.0 0.5 1.0 Institutional punishment (v) 0 . 0 0.5 1.0 S t r at e g y p r e v a l e n c e 0.0 0.5 1.0 Institutional punishment (v) 0 . 0 0.5 1.0 S t r at e g y p r e v a l e n c e 0.0 0.5 1.0 Institutional pu n i shment (v) 0.0 0.5 1.0 S t ra t e g y p r e v al e n c e 0.0 0.5 1.0 Institutional pu n i shment (v) 0.0 0.5 1.0 S t ra t e g y p r e v al e n c e 0.0 0.5 1.0 Institutional pu n i shment (v) 0.0 0.5 1.0 S t ra t e g y p r e v a l e n c e 0.0 0.5 1.0 Institutional punishment (v) 0.0 0.5 1.0 U s e r a d o p t io n 0.0 0.5 1.0 Surplus adoption due to trust Institutional punishment (v) 0.0 0.5 1.0 U s e r a d o p t i o n 0.0 0.5 1.0 Institutional punishment (v) 0.0 0.5 1.0 U s e r a d o p t io n 0.0 0.5 1.0 Without Trust-Based Strategies With Trust-Bas ed Strategies ϵ = 0.1 ϵ = 0.5 ϵ = 1.0 U ser Strategy AllA AllN TFT TUA DtG Developer Strategy Cooperate Defect Availability of Trust-Based Strategies Without With FIG. 3: T rust-based strategies enhance user adoption, which further increases with stronger institutional punishment. The first and second columns sho w the stationary distributions of eac h state as a function of monitoring cost for scenarios without and with trust-based strategies, resp ectiv ely . The third column displays the difference in user adoption levels b et ween these tw o cases across v arying monitoring costs. Ro ws from top to b ottom corresp ond to increasing levels of institutional punishment ( ϵ = 0 . 1, 0 . 5, and 1). P arameters are set to b u = b c = 4, β = 0 . 1, Z u = Z c = 100, c = 0 . 5, µ = − 0 . 2, r = 10, θ t = θ D = 3, and p T = p D = 0 . 25. co exist with TFT and are largely unaffected by institutional punishment, while AllA and AllN show a similar tendency to the first scenario. In the comparison of user adoption b et ween the t w o cases (Figure 3 , last column), reliable high adoption is built due to the trust-based strategies and contin ues to rise as institutional punishment increases. Ultimately , while sufficien tly strong institutional punishment can indep enden tly enforce unconditional adop- tion (AllA), trust-based strategies play the critical role in fostering genuine trust and maximizing ov erall user adoption. IV. INFINITE POPULA TION ANAL YSIS A. Equations and equilibria Using the general framework ( 17 ), the replicator dynamics that describ es the ev olution of the frequencies x, y , z , w of the strategies Al lA , Al lN , T F T , T U A of the users and the frequency α of co op erative creators is 11 giv en b y ˙ x = x h f U AllA − f U i , (22a) ˙ y = y h f U AllN − f U i , (22b) ˙ z = z h f U T F T − f U i , (22c) ˙ w = w h f U T U A − f U i , (22d) ˙ α = α (1 − α )( f C r C − f C r D ) , (22e) ( x (0) , y (0) , z (0) , w (0) , α (0)) = ( x 0 , y 0 , z 0 , w 0 , z 0 ) , (22f ) where ( x 0 , y 0 , z 0 , w 0 ) ∈ [0 , 1] 4 is the initial data. W e recall that the frequency of D tG is given by 1 − x − y − z − w , so w e do not need to write an equation for it. Note again that the av erage fitness f U = f U ( x, y , z , w , α ) as well as f C r C = f C r C ( x, y , z , w , α ) and f C r D = f C r D ( x, y , z , w , α ) dep end on all the frequencies. Th us the system ( 22 ) is a non-trivial coupled system of ordinary differential equations. Equilibria of this system are those p oin ts ( x, y , z , w , α ) ∈ [0 , 1] 5 that make the righ t-hand side v anish. Explicit formulae for the equations can b e found in the App endix A in the equation ( A1 ). By solving all the pairwise equations f U ∗ = f U , for ∗ ∈ { Al lA, Al lN , T F T , T U A } and f C r C = f C r D , all the 17 c andidates for equilibria of ( 22 ) can b e found explicitly as shown in T ables V and A1 . Note that the ma jorit y of entries are p oin ts, but some (namely , p T and p D ) are sets. By definition, the dynamics happ en in the five-dimensional hypercub e [0 , 1] 5 . It is evident that the equilibria p T , . . . , p 11 are alw ays in [0 , 1] 5 for all v alues of parameters for which they exist. How ev er, for the rest of the p oin ts, some conditions need to b e imposed. The following holds: a b ∈ (0 , 1) ⇔ 0 < a < b or b < a < 0 . Using this condition, w e can determine when the points p 12 , . . . , p 17 are in [0 , 1] 5 (1) p 12 ∈ [0 , 1] 5 iff 0 ≤ c ≤ v , µ < 0. (2) p 13 ∈ [0 , 1] 5 iff 0 ≤ cr ≤ b c r − b c + v , µ r ≤ ϵ b u ≤ 1. (3) p 14 ∈ [0 , 1] 5 iff 0 ≤ cr ≤ b c r − b c + v , b u µ ≤ ϵ [ p D r + (1 − p D ) θ D ]. (4) p 15 / ∈ [0 , 1] 5 since − cr b c r − b c + v < 0 (5) p 16 / ∈ [0 , 1] 5 since − b u µ + b u µr + r ϵ b u µ ( r − 1) > 1. (6) p 17 / ∈ [0 , 1] 5 since − b u µ + b u µr + p D rϵ − θ D p D ϵ + θ D ϵ − b u µ + b u µr + p D rϵ − θ D p D ϵ − rϵ + θ D ϵ / ∈ [0 , 1]. Th us, w e ha ve the follo wing Lemma IV.1. The p oints and sets in the T able V c an b e e quilibria of the system ( 22 ). Among them, p T thr ough to p 11 ar e e quilibria for al l values of the p ar ameters. The p oints p 12 , p 13 , p 14 c an b e e quilibria, if the c onditions (1)-(3) fr om the list ab ove ar e satisfie d. The p oints p 15 , p 16 , p 17 do not lie in the five-dimensional hyp er cub e [0 , 1] 5 . Their c o or dinates c an b e found in the T able A1 . Ha ving determined the existence and location of the equilibria, w e need to address the question of their stabilit y . This can be done b y calculating the Jacobian of the system ( 22 ) at the equilibrium sets and points [ 44 ]. W e subsequently calculate the eigenv alues of the matrix, whic h allows us to determine (linear) stability of equilibria. Some of the explicit formulae for the eigenv alues can b e found in T able VI . Note that some of them are zero – and for sets of equilibria such as p T and p D that is to b e exp ected. Lemma IV.2. F or any values of p ar ameters, the fol lowing pr op erties hold true: 1. the set p T c onsists of de gener ate e quilibria that c annot b e stable, sinc e the last eigenvalue is b u µ ( r − 1) r > 0 . 2. the set p D c onsists of de gener ate e quilibria that c annot b e stable, sinc e the se c ond eigenvalue is e qual to ϵ > 0 . 3. the p oint p 4 is stable if and only if µ < 0 . This e quilibrium c orr esp onds to a situation wher e cr e ator plays unsafe and user do es not adopt. 12 T ABLE V: Co ordinates of the equilibrium p oin ts Eq. sets x y z w α p 1 0 0 1 − w ∈ [0 , 1] 0 p 2 0 0 ∈ [0 , 1] 0 1 p 3 0 0 1 0 0 p 4 0 1 0 0 0 p 5 1 0 0 0 0 p 6 0 0 0 1 0 p 7 0 0 0 0 0 p 8 0 1 0 0 1 p 9 1 0 0 0 1 p 10 0 0 0 1 1 p 11 0 0 0 0 1 p 12 c v v − c v 0 0 µ µ − 1 p 13 0 b c r − b c − cr + v b c r − b c + v cr b c r − b c + v 0 rϵ − b u µ b u ( r − µ ) p 14 0 b c r − b c − cr + v b c r − b c + v 0 0 − b u µ + p D rϵ − θ D p D ϵ + θ D ϵ − b u µ + b u r + p D rϵ − θ D p D ϵ − rϵ + θ D ϵ p 15 b c r − b c − cr + v ( r − 1)( b c − v ) 0 0 − cr b c r − b c + v b u µ − b u µr − r ϵ b u µ − b u µr + p T rϵ − θ T p T ϵ − rϵ + θ T ϵ p 16 b c r − b c − cr + v ( r − 1)( b c − v ) 0 − r ( c − v ) ( r − 1)( v − b c ) 0 − b u µ + b u µr + r ϵ b u µ ( r − 1) p 17 b c r − b c − cr + v ( r − 1)( b c − v ) 0 0 0 − b u µ + b u µr + p D rϵ − θ D p D ϵ + θ D ϵ − b u µ + b u µr + p D rϵ − θ D p D ϵ − rϵ + θ D ϵ 4. the p oint p 5 is stable if and only if µ > 0 and v − c < 0 . This e quilibrium c orr esp onds to a situation wher e the user adopts even when the cr e ator plays unsafe. 5. the p oint p 9 is stable if and only if c − v < 0 . This e quilibrium c orr esp onds to a situation wher e the user always adopts when the cr e ator plays safe. B. Numerical analysis Figure 4 depicts the n umerical plots for the ratios of AllA, AllN, TFT, TUA and DtG strategists among users, as well as the percentage of co operators among creators for v arying v alues of the monitoring cost ϵ . In the first column, the DtG is the prev alent strategy among the users, and creators con v erge fast to uniform co op eration. As the v alue of ϵ increases to 1 / 2, the dynamics b ecome p erio dic, with AllT b ecoming the prev alent strategy for the ma jorit y of time. Co operation rate among creators is p eriodic as well, starting out at complete co operation 13 T ABLE VI: Eigen v alues of equilibrium p oints Eq. sets λ 1 λ 2 λ 3 λ 4 λ 5 p 1 0 b c ( r − 1) − cr + v r − ( p D − 1) ϵ ( r − θ D ) r ϵ − b u µ r b u µ ( r − 1) r + ϵ p 2 0 b c ( − r )+ b c + cr − v r ϵ ϵ − b u − ( p T − 1) ϵ ( r − θ T ) r p 3 0 b c ( r − 1) − cr + v r − ( p D − 1) ϵ ( r − θ D ) r ϵ − b u µ r b u µ ( r − 1) r + ϵ p 4 − c b u µ b u µ r − ϵ b u µ r − ϵ b u µ + p D ϵ ( θ D − r )+ θ D ( − ϵ ) r p 5 v − c − b u µ b u µ 1 r − 1 − ϵ b u µ 1 r − 1 − ϵ − b u µ ( r − 1)+ p D ϵ ( θ D − r )+ θ D ( − ϵ ) r p 6 0 b c ( r − 1) − cr + v r − ( p D − 1) ϵ ( r − θ D ) r ϵ − b u µ r b u µ ( r − 1) r + ϵ p 7 b c ( r − 1) − cr + v r ( p D − 1) ϵ ( r − θ D ) r ( p D − 1) ϵ ( r − θ D ) r − b u µ + p D ϵ ( r − θ D )+ θ D ϵ r b u µ ( r − 1)+ p D ϵ ( r − θ D )+ θ D ϵ r p 8 b u c b u − ϵ b u − ϵ b u + θ T ( p T − 1) ϵ r − p T ϵ p 9 − b u c − v − ϵ − ϵ θ T ( p T − 1) ϵ r − p T ϵ p 10 b c ( − r )+ b c + cr − v r ϵ ( θ T + p T ( r − θ T )) r ( p T − 1) ϵ ( r − θ T ) r ( p T − 1) ϵ ( r − θ T ) r ϵ ( θ T + p T ( r − θ T )) r − b u p 11 0 b c ( − r )+ b c + cr − v r ϵ ϵ − b u − ( p T − 1) ϵ ( r − θ T ) r p 12 − i √ b u √ c √ c − v q µ − 1 µ √ v i √ b u √ c √ c − v q µ − 1 µ √ v r ( b u µ − µϵ + ϵ ) − b u µ ( µ − 1) r b u µ ( r − 1)+ p D ϵ ( r − θ D )+ ϵ ( θ D − µr ) ( µ − 1) r b u µ ( r − 1) − µϵ ( θ T + p T ( r − θ T ))+ rϵ ( µ − 1) r and subsequently dropping to complete defection. When ϵ = 1, the initial winning strategy is AllA, which is then replaced by AllN; the co op eration rate among creators experiences a sharp drop. Summary: Our analysis iden tifies three main candidate stable equilibria: p4 (AllN, D), where users nev er adopt and creators defect; p5 (AllA, D), where users alw ays adopt and creators defect; and p9 (AllA, C), where users alw ays adopt and creators co operate (safe systems). T rust-based strategies (TFT, TUA, DtG) primarily s hape the basins of attraction and transien t dynamics; in the strict equilibrium analysis, the long-run outcomes are still dominated by these simple pure strategy profiles. F rom a go vernance standp oint, the only clearly desirable stable equilibrium is p9 (AllA, C), ac hiev ed when institutional punishmen t is sufficien tly strong ( v > c ). By contrast, the system risks conv erging to p4 (no adoption, unsafe dev elopment) or p5 (unsafe but widely adopted AI) when punishment is w eak relative to safet y costs and/or unsafe AI remains b eneficial to users. These findings are consisten t with the finite-p opulation Marko v c hain analysis, where sto chasticit y smo oths sharp thresholds but the same qualitativ e picture emerges: weak enforcemen t and/or relativ ely lo w p er- ceiv ed harm from unsafe AI fa v our p4, whereas sufficiently strong punishment supp orts high-adoption, safe- dev elopment regimes. 14 t 0 50 100 U s e r S t r a t e g y p r e v al e n c e 0.0 0.5 1.0 t 0 50 100 C r e a to r C o op er a t i o n 0.0 0.5 1.0 t 0 50 100 U s e r S t r a t e g y p r e v a l e n c e 0.0 0.5 1.0 t 0 50 100 C r e a to r C o o p e r a t i o n 0.0 0.5 1.0 t 0 50 100 U s e r Str a t e g y p r ev a l e n c e 0.0 0.5 1.0 t 0 50 100 C r e a to r C o op e r a t i o n 0.0 0.5 1.0 ϵ = 0.0 ϵ = 0.5 ϵ = 1.0 User Strategy AllA AllN TFT TUA DtG FIG. 4: Numerical mo delling of user (top row) and creator (bottom row) co op eration rates for p T = 1 / 4 , p D = 1 / 4, θ T = 3, θ D = 3, b u = 4, b d = 4, r = 10 , µ = − 2 / 10, v = 1 / 10 , c = 1 / 2. The initial conditions were equal distribution of all strategies among the users and the creators. Episode 0 1000 2000 300 0 U s er S t r a t e g y p r e v al e n c e 0 .0 0 .5 1 .0 Episode 0 1000 2000 300 0 Crea t o r C oo p e r a t i o n 0 .0 0 .5 1 .0 Episode 0 1000 2000 300 0 U s er S t r at eg y p r e v a l e nc e 0.0 0.5 1.0 Episode 0 1000 2000 300 0 C rea t o r C o o p e r a t io n 0.0 0.5 1.0 Episode 0 1000 2000 3000 U s er St rat e g y p r e v a l e nc e 0.0 0.5 1.0 Episode 0 1000 2000 3000 Crea t o r C o o p e r a t i o n 0.0 0.5 1.0 Episode 0 1000 2000 300 0 U s er St rat e g y p r e v a l e nc e 0.0 0.5 1.0 Episode 0 1000 2000 300 0 Crea t o r C o o p e r a t i o n 0.0 0.5 1.0 ϵ = 0.0 ϵ = 1 ϵ = 1.5 ϵ = 2 Us e r Strategy AllA AllN TFT TUA DtG FIG. 5: P ercentage of users (top row) adopting different strategies and creator (b ottom row) co op eration rates across episo des under Q-learning. The game setting are p T = 1 / 4 , p D = 1 / 4, θ T = 3, θ D = 3, b u = 4, b d = 4, r = 10 , µ = − 2 / 10, v = 1 / 10 , c = 1 / 2. F or Q-learning, α = 0 . 05 and ϵ L = 0 . 05. V. REINF ORCEMENT LEARNING ANAL YSIS Next, we describ e the results obtained using RL. Sp ecifically , w e presen t the results using the Q-learning algorithm. First, we discuss how w e implemented the Q-learning algorithm in our analysis and then we show the exp erimental results obtained. 15 A. Q-learning W e conduct our analysis on p opulations of Q-learning agents. Q-learning [ 45 ] is a well-established reinforce- men t learning algorithm that op erates within the framew ork of a Marko v Decision Pro cess (MDP). Each agent i learns its p olicy indep enden tly . At each time step, the agent observes the current state of the environmen t, denoted as s t ∈ S , where S is the set of all possible states. The agen t then c ho oses an av ailable action a t ∈ A ( s t ), where A ( s t ) returns the set of av ailable actions in s t . W e denote the corresp onding Q-v alue as Q i ( s t , a t ), es- timating the exp ected accum ulated discounted rew ard of c ho osing action a t at state s t . After p erforming the action, the agent receives an immediate reward r t ∈ ℜ and enters the next state s t +1 ∈ S . The Q-v alue of the c hosen action of the agen t is up dated as follows: Q i ( s t , a t ) ← Q i ( s t , a t ) + α [ G t − Q i ( s t , a t )] , where G t the estimated accumulated reward, α ∈ [0 , 1] is the learning rate. F or the analysis on the rep eated user-creator game, since there is no state transition, the Q-learning is then simplified to Q i ( a t ) ← Q i ( a t ) + α [ r t − Q i ( a t )] (23) An exploration mechanism aims to strike a goo d balance b et ween exploitation and exploration, maximizing the agent’s p erformance during learning while ensuring desirable conv ergence guarantees. Epsilon-greedy ex- ploration is a commonly used mechanism, where the sto c hastic p olicy π i ( s ) = ( π ( s, a 1 ) , ..., π ( s, a | A | )) ∈ ∆ is ev aluated as: π ( s, a k ) = ϵ L | A | + 1 { a k ∈ argmax a Q i ( s, a ) } |{ argmax a Q i ( s, a ) }| (1 − ϵ L ) (24) where 1 {·} denotes the indicator function, ϵ L ∈ [0 , 1] is the exploration rate. B. Exp erimen tal Results W e conduct simulations with tw o p opulations of 100 Q-learning agents for the users and the creators. F or eac h episo de, users and creators are randomly paired to play the game and up date their Q-v alues. The learning rate and exploration rate are set as α = 0 . 05 and ϵ L = 0 . 05. The parameters of the rep eated user-creator game are the same as ab o v e, where w e v ary the monitoring cost ϵ from 0 to 2. Figure 5 shows the p ercen tage of users (top row) and creators (b ottom row) adopting different strategies across episo des, av eraged ov er 10 simulations. In the absence of monitoring costs, co operation emerged among the creators, and the users are adopting AllA, TFT, TUA, and DtG evenly . This is exp ected as the user’s pay offs are equiv alent for these strategies with co operating creators. As the monitoring costs increase to 1, the adv antage of AllA increases since those users are not pa ying extra costs, and we observe that the adoption of AllA rises o ver time. As the pa yoff of TUA is only sligh tly affected, w e observe its adoption rate remains, and this also preven ts creators from switc hing to defect. As the monitoring costs further increase ϵ = 1 . 5, the adoption of TUA reduces, and more creators are switc hing to adopt defection. Finally , when the monitoring costs grow to ϵ = 2, the adoption of TFT and TUA dies out quickly , and thus the creators become defective ov er time. This finally con tributes to the emergence of a defective and AllN society . VI. CONCLUSIONS Our analysis offers a rigorous accoun t of how user trust and AI dev elop er b eha viour co-ev olve in a repeated, asymmetric interaction, where trust is operationalised as reduced monitoring under costly observ ation [ 13 ]. Users choose be t w een unconditional adoption or non-adoption, persistent monitoring (TFT), and t w o trust- based heuristics (TUA and DtG) that adapt monitoring after observed co operation or defection. Creators c ho ose b et w een developing safe and unsafe AI , and migh t face institutional punishment when unsafe behaviour is detected. Our analysis adopts complementary stochastic finite-p opulation mo dels and infinite-population replicator dynamics, as w ell as reinforcement learning simulations, to characterise the parameter regimes under whic h safe developmen t and appropriate trust can emerge and p ersist. In doing so, the work pro vides the first integrated treatment of trust-as-monitoring in an asymmetric user–developer game, linking evolutionary dynamics and learning-based adaptation to concrete AI go vernance design questions. Across these approac hes, a consisten t picture emerges. When monitoring is relativ ely c heap and punishmen t for unsafe b eha viour is meaningful, dev elop ers tend to pro vide safe systems and users adopt them widely . When monitoring b ecomes to o costly or punishment is w eak, creators are increasingly pushed tow ards unsafe strategies, while users either stop adopting altogether or, more w orryingly , keep adopting unsafe systems. In the infinite-p opulation analysis, three simple long-run regimes dominate: one with non-adoption and unsafe 16 dev elopment, one with unsafe but widely adopted systems, and one with safe systems that are widely adopted. Only the last of these is so cially desirable, and it is sustained when it is clearly more attractive for dev elop ers to comply with safety requirements than to risk sanctions. T rust-based user strategies do not c hange whic h long-run regimes are p ossible, but they do strongly influence which of these regimes the system conv erges to, and ho w quickly . In finite p opulations and in reinforcement learning, they improv e adoption and help maintain co operation by creators when monitoring is affordable, but lose their adv antage once monitoring costs become high. These findings ha v e direct implications for AI go v ernance. First, they underline that trust worth y AI cannot b e delivered by rules alone or by exhorting users to trust. It dep ends on an ecosystem in which users can afford to remain at least partially vigilant [ 46 ]. P olicies that lo wer the real cost of c hecking AI systems, for instance through enhanced transparency , standardised do cumentation, accessible audits and ev aluation rep orts, directly supp ort this kind of calibrated trust and make it harder for unsafe strategies to spread. Second, they highligh t the imp ortance of sufficient enforcement for deterring unsafe b ehaviour: if the exp ected burden of complying with safety requirements is greater than the exp ected consequences of b eing caught, unsafe developmen t becomes ev olutionarily attractive even when users initially monitor. Finally , our results p oin t tow ards an understanding of trust in AI as an adaptiv e, ongoing process ab out when to monitor AI system safet y (e.g. via media in vestigation [ 2 , 3 ]). There are several limitations with our current mo del. First, w e treat users and dev elop ers as homogeneous p opulations. Second, w e leav e regulators implicit in the punishment structure. Three, we fo cus on a small set of representativ e strategies. F uture work should relax these assumptions by allowing for structured interactions (for example, m ultiple competing dev elop ers or jurisdictions), explicitly mo delling regulators and other o versigh t actors, and incorp orating richer, empirically grounded mo dels of human trust heuristics. Even so, the analysis here pro vides a useful conceptual and quan titativ e starting p oint for thinking ab out ho w to design AI go vernance arrangemen ts that support appropriate, w ell-calibrated trust while k e eping incen tives aligned with safe and resp onsible developmen t. A CKNOWLEDGEMENTS This w ork w as pro duced during the w orkshop “AI Go vernance Modelling” at T eesside Univ ersity , funded through the generous supp ort from the universit y P olicy F und. T.A.H. and Z.S. are supp orted b y EPSR C (gran t EP/Y00857X/1). M.H.D and N.B. are supp orted by EPSRC (grant EP/Y008561/1) and a Roy al International Exc hange Grant IES-R3-223047. E.F.D. is supp orted b y an F.W.O. Senior Postdoctoral Grant (12A7825N), A.M.F. and H.C.F. w ere supported b y INESC-ID and the pro ject CRAI C645008882-00000055/510852254 (IAP- MEI/PRR). D.P is supp orted by the Europ ean Union through the ERC INSPIRE grant (pro ject n um b er 101076926); views and opinions expressed are how ever those of the authors only and do not necessarily reflect those of the Europ ean Union, the European Research Council Executiv e Agency or the European Council. 17 T ABLE A1: Co ordinates of the equilibrium p oints Eq. points x y z w α p 15 b c r − b c − cr + v ( r − 1)( b c − v ) 0 0 − cr b c r − b c + v b u µ − b u µr − r ϵ b u µ − b u µr + p T rϵ − θ T p T ϵ − rϵ + θ T ϵ p 16 b c r − b c − cr + v ( r − 1)( b c − v ) 0 − r ( c − v ) ( r − 1)( v − b c ) 0 − b u µ + b u µr + r ϵ b u µ ( r − 1) p 17 b c r − b c − cr + v ( r − 1)( b c − v ) 0 0 0 − b u µ + b u µr + p D rϵ − θ D p D ϵ + θ D ϵ − b u µ + b u µr + p D rϵ − θ D p D ϵ − rϵ + θ D ϵ App endix A: Additional details for replicator dynamics analysis Belo w, w e presen t the explicit form of the equations for replicator dynamics. ˙ x = x b u ( α ( − µ ) + α + µ ) − ( α − 1) b u µ ( − rx + x + y − 1) r + αb u ( y − 1) − ϵ ( − r ( α + α ( p T − 2) w + w − α ( x + y + z )+ z )+ αθ T ( p T − 1) w − ( α − 1) p D ( r − θ D )( w + x + y + z − 1) − ( α − 1) θ D ( w + x + y + z − 1)) r ! , ˙ y = y − ( α − 1) b u µ ( − rx + x + y − 1) r + αb u ( y − 1) − ϵ ( − r ( α + α ( p T − 2) w + w − α ( x + y + z )+ z )+ αθ T ( p T − 1) w − ( α − 1) p D ( r − θ D )( w + x + y + z − 1) − ( α − 1) θ D ( w + x + y + z − 1)) r ! , ˙ z = 1 r z ( − ( α − 1) b u µ ( − r x + x + y ) + αb u r y + ϵ ( r ( α + α ( p T − 2) w + ( α − 1) p D ( w + x + y + z − 1) + w − α ( x + y + z ) + z − 1) − αθ T ( p T − 1) w − ( α − 1) θ D ( p D − 1)( w + x + y + z − 1))) ! , ˙ w = 1 r w ( − ( α − 1) b u µ ( − r x + x + y ) + αb u r y + ϵ ( r ( α ( p T − 2) w − α ( p T + x + y + z − 2) +( α − 1) p D ( w + x + y + z − 1) + w + z − 1) − αθ T ( p T − 1)( w − 1) − ( α − 1) θ D ( p D − 1)( w + x + y + z − 1))) ! , ˙ α = ( α − 1) α ( b c ( r − 1)( x + y − 1)+ cr + v ( − r x + x + y − 1)) r (A1) As w e mentioned ab o ve, not all p oints that turn the right hand side of the equations zero b elong to the [0 , 1] 5 h yp ercub e. The table A1 contains the zeros that are outside of the area of our consideration. 1. Ev olutionary dynamics in the absence of trust-based strategies In this section, we analyse the mo del without the trust-based strategies TUA and DtG. W e thus assume that users can adopt one of the following strategies: AllA, AllN or TFT. Adopting the latter still requires them to pa y a cost ϵ for chec king the action of creators in the previous round. W e now write the replicator dynamics for this mo del. The equations are a simplified version of ( 22 )– for brevity we do not giv e the explicit forms of the pay offs– and hav e the form ˙ x = x ( α − 1) b u µ (( r − 1)( x − 1) − y ) r + αb u y − ϵ ( x + y − 1) , ˙ y = y − ( α − 1) b u µ ( − rx + x + y − 1) r + αb u ( y − 1) − ϵ ( x + y − 1) , ˙ α = ( α − 1) α ( b c ( r − 1)( x + y − 1)+ cr + v ( − r x + x + y − 1)) r (A2) The p ossible equilibria are listed in T able A2 . W e can establish their stability b y calculating the Jacobian again. The eigenv alues are presented in T able ?? . W e can mak e the following claim: 18 Equilibrium p oints x y α q 1 0 1 − cr b c ( r − 1)+ v rϵ − b u µ b u r − b u µ q 2 0 1 0 q 3 1 0 0 q 4 0 0 0 q 5 0 1 1 q 6 1 0 1 q 7 0 0 1 q 8 c v 1 − c v µ µ − 1 T ABLE A2: Equilibria for replicator dynamics for three strategies. t 0 50 100 U s e r S t r a t e g y p r e v al e n c e 0.0 0.5 1.0 t 0 50 100 C r e a to r C o op er a t i o n 0.0 0.5 1.0 t 0 50 100 U s e r S t r a t e g y p r e v a l e n c e 0.0 0.5 1.0 t 0 50 100 C r e a to r C o o p e r a t i o n 0.0 0.5 1.0 t 0 50 100 U s e r Str a t e g y p r ev a l e n c e 0.0 0.5 1.0 t 0 50 100 C r e a to r C o op e r a t i o n 0.0 0.5 1.0 ϵ = 0.0 ϵ = 0.5 ϵ = 1.0 User Strategy AllA AllN TFT FIG. A1: Numerical mo delling of user(top ro w) and creator(b ottom ro w) co operation rates for p T = 1 / 4 , p D = 1 / 4, θ T = 3, θ D = 3, b u = 4, b d = 4, r = 10 , µ = − 2 / 10, v = 1 / 10 , c = 1 / 2. The initial conditions were equal distribution of all strategies among the users and the creators. Lemma A.1. The fol lowing pr op erties of e quilibria for thr e e str ate gies hold true: 1. q 2 is stable if and only if µ < 0 ; 2. q 3 is stable if and only if µ > 0 and v − c < 0 ; 3. q 6 is stable if and only if c < v . One can easily see that these results are rep eating the ones for fiv e strategies almost v erbatim; hence w e presen t them in the app endix. a. Numeric al mo del ling for thr e e-str ate gies r eplic ator dynamics. Figure A1 depicts the n umerics for plotting of the graphs of three strategies and the p ercen tage of co op erators among creators that ev olv e according to the la ws of replicator dynamics. The initial distribution is ev en. One can immediately see the similarities in the behaviour to that with five cases; though the former, of course, has a richer div ersity of b eha viour. When it costs nothing to c heck the creators’ b eha viour, the creators con verge to total co op eration; TFT is the predominan t strategy for users. With the increase of ϵ , b oth graphs b ecome oscillating; when ϵ = 1, the total distrust b ecomes the dominating strategy for the users, while co operation in creators drops to 0. T ABLE A3: Eigenv alues for replicator dynamics where user has three strategies. 19 App endix B: Additional details for finite p opulation analysis Monitoring cost ( ε ) 0 . 0 0.5 1.0 S t r at e g y p r e v a l e n c e 0.0 0.5 1.0 Monitoring cost ( ε ) 0 . 0 0.5 1.0 S t r at e g y p r e v a l e n c e 0.0 0.5 1.0 Monitoring cost ( ε ) 0 . 0 0.5 1.0 S t r at e g y p r e v a l e n c e 0.0 0.5 1.0 Monitoring c ost ( ε ) 0.0 0.5 1.0 S t ra t e g y p r e v al e n c e 0.0 0.5 1.0 Monitoring c ost ( ε ) 0.0 0.5 1.0 S t ra t e g y p r e v al e n c e 0.0 0.5 1.0 Monitoring c ost ( ε ) 0.0 0.5 1.0 S t ra t e g y p r e v a l e n c e 0.0 0.5 1.0 Monitoring cost ( ε ) 0.0 0.5 1.0 U s e r a d o p t io n 0.0 0.5 1.0 Monitoring cost ( ε ) 0.0 0.5 1.0 U s e r a d o p t i o n 0.0 0.5 1.0 Monitoring cost ( ε ) 0.0 0.5 1.0 U s e r a d o p t io n 0.0 0.5 1.0 Without Trust-Based Strategies With Trust-Bas ed Strategies v = 0.1 v = 0.5 v = 1 U ser Strategy AllA AllN TFT TUA DtG Developer Strategy Cooperate Defect Availability of Trust-Based Strategies Without With FIG. A2: Strong Punishmen t enforces co operation of creator when users b enefits from adopting defectiv e creators. The first and second columns sho w the stationary distributions of each state as a function of monitoring cost for scenarios without and with trust-based strategies, resp ectively . The third column displays the difference in user adoption levels b et ween these tw o cases across v arying monitoring costs. Ro ws from top to b ottom corresp ond to increasing levels of institutional punishment ( v = 0 . 1, 0 . 5, and 1). P arameters are set to b u = b c = 4, β = 0 . 1, Z u = Z c = 100, c = 0 . 5, µ = 0 . 2, r = 10, θ t = θ D = 3, and p T = p D = 0 . 25. 20 Institutional punishment (v) 0 . 0 0.5 1.0 S t r at e g y p r e v a l e n c e 0.0 0.5 1.0 Institutional punishment (v) 0 . 0 0.5 1.0 S t r at e g y p r e v a l e n c e 0.0 0.5 1.0 Institutional punishment (v) 0 . 0 0.5 1.0 S t r at e g y p r e v a l e n c e 0.0 0.5 1.0 Institutional pu n i shment (v) 0.0 0.5 1.0 S t ra t e g y p r e v al e n c e 0.0 0.5 1.0 Institutional pu n i shment (v) 0.0 0.5 1.0 S t ra t e g y p r e v al e n c e 0.0 0.5 1.0 Institutional pu n i shment (v) 0.0 0.5 1.0 S t ra t e g y p r e v a l e n c e 0.0 0.5 1.0 Institutional punishment (v) 0.0 0.5 1.0 U s e r a d o p t io n 0.0 0.5 1.0 Institutional punishment (v) 0.0 0.5 1.0 U s e r a d o p t i o n 0.0 0.5 1.0 Institutional punishment (v) 0.0 0.5 1.0 U s e r a d o p t io n 0.0 0.5 1.0 Without Trust-Based Strategies With Trust-Bas ed Strategies ϵ = 0.1 ϵ = 0.5 ϵ = 1.0 U ser Strategy AllA AllN TFT TUA DtG Developer Strategy Cooperate Defect Availability of Trust-Based Strategies Without With FIG. A3: User adoption dominates even without trust-based strategies, while creator co op eration relies on strong punishmen t. The first and second columns show the stationary distributions of eac h state as a function of institutional punishmen t for scenarios without and with trust-based strategies, resp ectively . The third column displays the difference in user adoption levels b etw een these t wo cases across v arying institutional punishment. Rows from top to b ottom corresp ond to increasing levels of monitoring cost ( ϵ = 0 . 1, 0 . 5, and 1). Parameters are set to b u = b c = 4, β = 0 . 1, Z u = Z c = 100, c = 0 . 5, µ = 0 . 2, r = 10, θ t = θ D = 3, and p T = p D = 0 . 25. 21 [1] Z. Alalawi, P . Bov a, T. Cimp eanu, A. Di Stefano, M. Hong Duong, E. F. Domingos, T. A. Han, M. Krellner, N. B. Ogb o, S. T. Po wers, and F. Zimmaro, “T rust AI Regulation? Discerning Users are Vital to Build Trust and Effective AI Regulation,” Applied Mathematics and Computation , vol. 508, p. 129627, 2026. [2] H. C. da F onseca, A. F ernandes, Z. Song, T. Cimp ean u, N. Balabanov a, A. Bashir et al. , “Can Media Act as a Soft Regulator of Safe AI Developmen t? a Game Theoretical Analysis,” ALIFE 2025: Ciphers of Life. Pr oc e e dings of the Artificial Life Confer enc e 2025 , p. 90, 10 2025. [3] N. Balabanov a, A. Bashir, P . Bov a, A. Buscemi, T. Cimp ean u, H. C. d. F onseca, A. D. Stefano, M. H. Duong, E. F. Domingos, A. F ernandes, T. A. Han, M. Krellner, N. B. Ogb o, S. T. Po wers, D. Prov erbio, F. P . Santos, Z. U. Shamszaman, and Z. Song, “Media and resp onsible AI gov ernance: a game-theoretic and LLM analysis,” Mar. 2025, arXiv:2503.09858 [cs]. [Online]. Av ailable: [4] A. Buscemi, D. Prov erbio, P . Bov a, N. Balabanov a, A. Bashir, T. Cimp eanu, H. C. da F onseca, M. H. Duong, E. F. Domingos, A. M. F ernandes et al. , “Do LLMs Trust AI Regulation? Emerging Behaviour of Game-theoretic LLM Agen ts,” arXiv pr eprint arXiv:2504.08640 , 2025. [5] J. Laux, S. W ach ter, and B. Mittelstadt, “T rustw orth y artificial intelligence and the europ ean union ai act: On the conflation of trustw orthiness and acceptability of risk,” R e gulation & Governance , vol. 18, no. 1, pp. 3–32, 2024. [6] E. F ouragnan et al. , “The neural computation of trust and reputation,” 2013. [7] I. Neto, A. S. Pires, F. Correia, and F. P . Santos, “Co op eration through indirect recipro cit y in child-robot interac- tions,” arXiv pr eprint arXiv:2512.20621 , 2025. [8] H. S. James Jr., “The trust paradox: a survey of economic inquiries into the nature of trust and trustw orthiness,” Journal of Ec onomic Behavior & Organization , vol. 47, no. 3, pp. 291–307, Mar. 2002. [Online]. Av ailable: h ttps://www.sciencedirect.com/science/article/pii/S0167268101002141 [9] T. Y amagishi, S. Kanazaw a, R. Mashima, and S. T erai, “Separating T rust from Co operation in a Dynamic Relationship: Prisoner’s Dilemma with V ariable Dep endence,” R ationality and So ciety , vol. 17, no. 3, pp. 275–308, Aug. 2005, publisher: SA GE Publications Ltd. [Online]. Av ailable: https://doi.org/10.1177/1043463105055463 [10] M. Banu, “How do we ev en trust? A critique of economic approaches on trust formation,” International Journal of Ec onomic Behavior (IJEB) , vol. 14, no. 1, pp. 23–38, Ma y 2024. [Online]. Av ailable: h ttps://journals.uniurb.it/index.php/ijmeb/article/view/4541 [11] J. Berg, J. Dickhaut, and K. McCabe, “T rust, recipro cit y , and social history,” Games and Ec onomic Behavior , v ol. 10, pp. 122–142, 1995. [12] V. Buskens, “The so cial structure of trust,” So cial Networks , v ol. 20, no. 3, pp. 265–289, Jul. 1998. [Online]. Av ailable: h ttps://www.sciencedirect.com/science/article/pii/S0378873398000057 [13] C. Perret, T. A. Han, E. F. Domingos, T. Cimp eanu, and S. T. P ow ers, “Disen tangling trust from co op eration: Ev olution of trust as reduced monitoring in so cial dilemmas,” Chaos, Solitons & F r actals , vol. 208, p. 118130, 2026. [14] N. Luhmann, T rust and Power . Chichester: John Wiley & Sons, 1979. [15] A. F errario, M. Loi, and E. Vigan` o, “In AI we trust incrementally: a multi-la y er mo del of trust to analyze human- artificial intelligence interactions,” Philosophy & T e chnology , vol. 33, no. 3, pp. 523–539, Sep. 2020. [16] T. A. Han, C. P erret, and S. T. Po wers, “When to (or not to) trust in telligen t mac hines: Insights from an ev olutionary game theory analysis of trust in rep eated games,” Co gnitive Systems R esear ch , v ol. 68, pp. 111–124, 2021. [17] A. F errario, M. Loi, and E. Vigan` o, “T rust do es not need to b e human: it is p ossible to trust medical AI,” Journal of Me dic al Ethics , vol. 47, no. 6, pp. 437–438, Jun. 2021. [18] A. F errario, “Being pragmatic ab out reliance and trust in artificial intelligence,” Minds and Machines , v ol. 36, no. 1, p. 5, Dec. 2025. [19] Z. Zahedi, S. Sengupta, and S. Kambhampati, “A game-theoretic mo del of trust in human–robot teaming: Guiding h uman observ ation strategy for monitoring rob ot b eha vior,” IEEE T r ansactions on Human-Machine Systems , v ol. 55, no. 1, pp. 37–47, F eb. 2025. [20] M. Loi, A. F errario, and E. Vigan` o, “How muc h do you trust me? A logico-mathematical analysis of the concept of the in tensity of trust,” Synthese , vol. 201, no. 6, p. 186, May 2023. [21] T. W. Sandholm and R. H. Crites, “Multiagen t reinforcement learning in the iterated prisoner’s dilemma,” Biosys- tems , v ol. 37, no. 1-2, pp. 147–166, 1996. [22] A. Dafoe, E. Hughes, Y. Bac hrac h, T. Collins, K. R. McKee, J. Z. Leibo, K. Larson, and T. Graep el, “Open problems in coop erative ai,” arXiv pr eprint arXiv:2012.08630 , 2020. [23] N. Dasgupta and M. Musolesi, “Inv estigating the impact of direct punishmen t on the emergence of co op eration in m ulti-agent reinforcemen t learning systems,” Autonomous A gents and Multi-A gent Systems , vol. 39, no. 1, pp. 1–37, 2025. [24] J. Z. Leib o, V. Zambaldi, M. Lanctot, J. Marec ki, and T. Graepel, “Multi-agen t reinforcemen t learning in se- quen tial so cial dilemmas,” in Pro c e e dings of the 16th Confer enc e on Autonomous A gents and MultiA gent Systems (AAMAS’17) , 2017. [25] M. Smit and F. P . Santos, “Learning fair coop eration in mixed-motive games with indirect recipro cit y ,” in Pr o c e e dings of the 33r d International Joint Conferenc e on Artificial Intel ligenc e (IJCAI’24) , 2024. [26] W. Barfuss, J. Flack, C. S. Gokhale, L. Hammond, C. Hilb e, E. Hughes, J. Z. Leib o, T. Lenaerts, N. Leonard, S. Levin et al. , “Collectiv e co operative intelligence,” Pro c e e dings of the National A c ademy of Scienc es , v ol. 122, no. 25, p. e2319948121, 2025. [27] J. P´ erolat, J. Z. Leibo, V. F. Zam baldi, C. Beattie, K. T uyls, and T. Graepel, “A m ulti- agen t reinforcemen t learning model of common-po ol resource appropriation,” in A dvanc es in Neur al Information Pr o c essing Systems , I. Guy on, U. von Luxburg, S. Bengio, H. M. W allach, R. F ergus, S. V. N. Vish w anathan, and R. Garnett, Eds., 2017, pp. 3643–3652. [Online]. Av ailable: h ttps: 22 //pro ceedings.neurips.cc/paper/2017/hash/2b0f658cbffd284984fb11d90254081f- Abstract.html [28] E. T ennant, S. Hailes, and M. Musolesi, “Dynamics of Moral Behavior in Heterogeneous Populations of Learning Agen ts,” in Pr o ce e dings of the 7th AAAI/ACM Confer enc e on AI, Ethics, and So ciety (AIES 2024) , 2024. [29] K. Xie and A. Szolnoki, “Reinforcement learning in evolutionary game theory: A brief review of recent develop- men ts,” Applie d Mathematics and Computation , vol. 510, p. 129685, 2026. [30] G. Zheng, J. Zhang, J. Zhang, W. Cai, and L. Chen, “Deco ding trust: A reinforcement learning p erspective,” New Journal of Physics , vol. 26, no. 5, p. 053041, 2024. [31] D. C. North, Institutions, institutional change and e c onomic p erformanc e . Cam bridge universit y press, 1990. [32] A. T raulsen, M. A. No wak, and J. M. Pac heco, “Sto chastic Dynamics of In v asion and Fixation,” Physical R e view E , v ol. 74, p. 11909, 2006. [33] L. A. Imhof, D. F uden b erg, and M. A. Now ak, “Evolutionary Cycles of Co operation and Defection,” Pr o c. Natl. A c ad. Sci. U.S.A. , vol. 102, pp. 10 797–10 800, 2005. [34] M. A. No wak, A. Sasaki, C. T aylor, and D. F uden b erg, “Emergence of Coop eration and Evolutionary Stability in Finite Populations,” Nature , vol. 428, pp. 646–650, 2004. [35] E. F. Domingos, F. C. Santos, and T. Lenaerts, “EGTto ols: Ev olutionary Game Dynamics in Python,” Iscience , v ol. 26, no. 4, 2023. [36] S. Encarna¸ c˜ ao, F. P . Santos, F. C. Santos, V. Blass, J. M. Pac heco, and J. P ortugali, “P aradigm Shifts and the In terplay Betw een State, Business and Civil Sectors,” R oyal Society open science , vol. 3, no. 12, p. 160753, 2016. [37] Z. Alalawi, T. A. Han, Y. Zeng, and A. Elragig, “P athw a ys to Go od Healthcare Services and Patient Satisfaction: An Ev olutionary Game Theoretical Approach,” in Artificial Life Confer enc e Pr o c e e dings . MIT Press, 2019, pp. 135–142. [38] P . D. T aylor, “Ev olutionarily Stable Strategies with Tw o Typ es of Play er,” Journal of applie d pr ob ability , vol. 16, no. 1, pp. 76–83, 1979. [39] J. Bauer, M. Bro om, and E. Alonso, “The Stabilization of Equilibria in Evolutionary Game Dynamics Through Mutation: Mutation Limits in Evolutionary Games,” Pr o c e e dings of the R oyal So ciety A , vol. 475, no. 2231, p. 20190355, 2019. [40] A. Bashir, Z. U. Shamszaman, Z. Song, and T. A. Han, “Co-ev olutionary dynamics of attack and defence in cyb ersecurit y ,” Know le dge-Base d Systems , p. 115750, 2026. [41] M. A. No wak, A. Sasaki, C. T aylor, and D. F uden b erg, “Emergence of Coop eration and Evolutionary Stability in Finite Populations,” Nature , vol. 428, no. 6983, pp. 646–650, 2004. [42] D. G. Rand, C. E. T arnita, H. Ohtsuki, and M. A. Now ak, “Evolution of Fairness in the One-shot Anonymous Ultimatum Game,” Pro c e e dings of the National A c ademy of Scienc es , vol. 110, no. 7, pp. 2581–2586, 2013. [43] I. Zisis, S. Di Guida, T. A. Han, G. Kirc hsteiger, and T. Lenaerts, “Generosit y Motiv ated b y Acceptance- Ev olutionary Analysis of an Anticipation Game,” Scientific rep orts , v ol. 5, no. 1, p. 18076, 2015. [44] J. Hofbauer and K. Sigmund, Evolutionary Games and Population Dynamics . Cambridge universit y press, 1998. [45] C. J. W atkins and P . Day an, “Q-learning,” Machine L e arning , vol. 8, pp. 279–292, 1992. [46] T. A. Han, J. Z. Leib o, T. Lenaerts, I. Rahw an, F. San tos, M. Perc, and V. Capraro, “Social physics in the age of artificial intelligence,” 2026. [Online]. Av ailable:
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment