When Is Collective Intelligence a Lottery? Multi-Agent Scaling Laws for Memetic Drift in LLMs
Multi-agent systems powered by large language models (LLMs) are increasingly deployed in settings that shape consequential decisions, both directly and indirectly. Yet it remains unclear whether their outcomes reflect collective reasoning, systematic…
Authors: Hidenori Tanaka
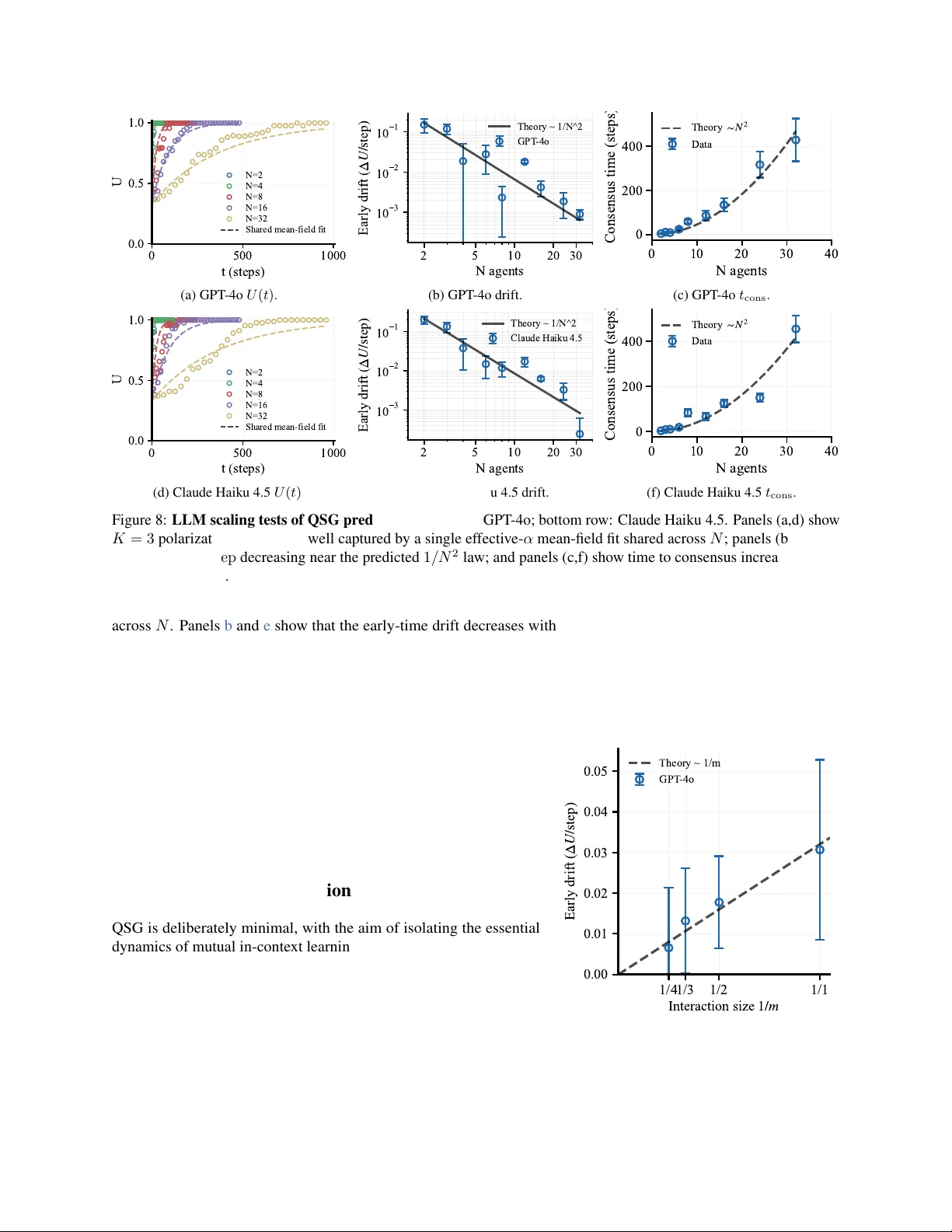
When Is Collectiv e Intelligence a Lottery? Multi-Agent Scaling Laws f or Memetic Drift in LLMs Hidenori T anaka CBS–NTT Program in Physics of Intelligence, Center for Brain Science, Harv ard Univ ersity Physics of Artificial Intelligence Group, NTT Research, Inc. tanaka@g.harvard.edu Multi-agent systems powered by lar ge language models (LLMs) are increasingly deployed in settings that shape consequential decisions, both directly and indirectly . Y et it remains unclear whether their outcomes reflect collective reasoning, systematic bias, or mere chance. Recent work has sharpened this question with naming games, sho wing that e ven when no indi vidual agent fav ors any label a priori , populations rapidly break symmetry and reach consensus. Here, we re veal the mechanism by introducing a minimal model, Quantized Simplex Gossip (QSG), and trace the microscopic origin of this agreement to mutual in-context learning . In QSG, agents maintain internal belief states but learn from one another’ s sampled outputs, so one agent’ s arbitrary choice becomes the next agent’ s e vidence and can compound tow ard agreement. By analogy with neutral e volution, we call this sampling-dri ven re gime memetic drift . QSG predicts a crossover from a drift-dominated re gime, where consensus is effecti vely a lottery , to a selection regime, where weak biases are amplified and shape the outcome. W e derive scaling la ws for drift-induced polarization as a function of population size, communication bandwidth, in-context adaptation rate, and agents’ internal uncertainty , and we v alidate them in both QSG simulations and naming-game e xperiments with LLM populations. T ogether , these results pro vide a frame work for studying the collecti ve mechanisms of social representation formation in multi-agent systems. 1 Introduction Collectiv e intelligence arises from interactions among indi vidual agents, but its outcomes often cannot be understood from any one agent alone and instead require principles at the le vel of the collecti ve [ 1 ]. Human language and shared con ventions are canonical examples, emerging from repeated exchanges in which ideas are transmitted, modified, and sometimes lost [ 2 – 4 ]. Recent advances in lar ge language models (LLMs) hav e made similar collectiv e dynamics rele vant be yond human populations. LLM systems are increasingly studied as interacting populations [ 5 – 9 ], and they are also being dev eloped and e valuated for consequential settings including la w , finance, healthcare, polic y , and scientific discov ery [ 10 – 14 ]. As these systems mo ve to ward consequential applications, a central question emerges: when an LLM population reaches consensus, does that outcome reflect collectiv e reasoning, systematic bias, or stochastic sampling? A gro wing empirical literature studies multi-agent LLM systems through debate, collaboration, and opinion dynamics [ 5 , 6 , 15 , 16 ]. These studies show that LLM populations can exhibit nontrivial collective behavior , but most work focuses on practically relev ant interaction settings, so systematic accounts of how microscopic interactions shape collectiv e dynamics remain limited. Answering the question abov e therefore requires a controlled setting in which coordination can be isolated from practical details. One such setting is the naming game, a canonical synthetic task for con v ention formation [ 2 , 3 ]. In a naming game, agents repeatedly propose labels for a shared referent and adapt through interaction, so population-le vel con v entions can emerge from local e xchanges. Recent work has shown that LLM populations in naming games can spontaneously break symmetry and reach consensus ev en when no individual agent fa vors an y label a priori [ 17 ], and that population size can strongly shape how deterministic and biased the resulting coordination becomes [ 18 ]. Here we isolate a neutral 0 5 10 15 20 25 30 Population rounds 0.0 0.2 0.4 0.6 0.8 1.0 Coordination (a) Mean coordination. 0.0 0.5 1.0 "fmhja" "hdsad" "vokhg" 0.0 0.5 1.0 Frequency 0 5 10 15 20 25 30 Population rounds 0.0 0.5 1.0 (b) Representativ e trajectories. vokhg vokhg vokhg vokhg vokhg vokhg vokhg vokhg vokhg fmhja fmhja fmhja fmhja fmhja fmhja fmhja fmhja fmhja hdsad hdsad hdsad hdsad hdsad hdsad hdsad hdsad hdsad (c) W inner-conditioned simple x paths. Figure 1: Symmetry breaking in an LLM naming game (GPT -4o, N = 24 , K = 3 ). (a) Mean coordination across trials (95% CI). (b) Representativ e label-frequency trajectories from three trials, one for each e ventual winner . (c) Mean simplex trajectories conditioned on the e ventual winning label. naming-game setting without explicit re w ards or ground truth, so any coordination must emer ge from interaction-driv en in-context learning alone. These results sharpen the problem: if the population begins neutral, what breaks symmetry , and what competing forces driv e the population tow ard consensus? Figure 1 shows this symmetry breaking in a representativ e LLM naming game. x i x j x L ? Mutual In-Context Learning In-Context Learning with Fixed Distribution Figure 2: Individual vs. mutual in-context learning . T op: standard in-context learning, where a single agent updates from i.i.d. tokens drawn from a stationary external distrib ution. Bottom: mutual in-context learning, where agents update from one another’ s sampled out- puts, so the population becomes its own e volv- ing data source. The key to understanding this symmetry breaking is that, unlike stan- dard in-context learning, the learning signal in multi-agent coordi- nation is generated by the population itself (Fig. 2 ). In the usual single-agent setting, an agent updates from tokens drawn from a fixed external distribution [ 19 – 23 ]. Here, by contrast, each agent updates from another agent’ s sampled output , which is itself a stochastic draw from a changing internal state. W e refer to this feedback loop as mu- tual in-context learning : agents learn from one another’ s sampled outputs as their internal states co-ev olve. This evidence-accumulation perspectiv e is also consistent with recent belief-dynamics accounts of in-context learning [ 24 ]. Under mutual in-conte xt learning, an arbitrary early sample can be reused as evidence and amplified into population- wide agreement; in the neutral setting we study , that sampling noise alone is enough to break symmetry and driv e consensus. This perspecti ve naturally connects the problem to e volutionary dy- namics, where collective outcomes arise from the balance between selection and stochastic drift [ 25 – 30 ]. In that language, neutral drift denotes fixation driv en by stochastic sampling, while selection denotes systematic asymmetry that fa v ors one outcome ov er another . Apply- ing this language to memes, understood here as culturally transmitted units, we call the neutral coordination regime memetic drift . As in population genetics, memetic drift provides a null baseline against which selection can be detected [ 26 , 31 , 32 ]; without such a baseline, apparent collective intelligence may be hard to distinguish from amplified sampling noise. T o study this regime quantitati vely , we introduce Quantized Simplex Gossip (QSG), a minimal, analytically tractable model of continuous beliefs, quantized communication, and in-context adaptation. At a high lev el, QSG captures a crossov er between a drift-dominated regime, where the winner is largely decided by luck, and a selection-dominated regime, where weak biases are collecti vely amplified. The location of that crossover depends on population size, communication bandwidth, and adaptation strength. Larger populations and higher-bandwidth communication suppress drift. Stronger adaptation speeds the dynamics overall, b ut for a fixed weak asymmetry it strengthens drift relati ve to bias and makes the same bias less decisive. Recent population-size effects in LLM naming games highlight the need to understand dif ferent coordination regimes [ 18 ]. Figure 3 previe ws the drift–selection crossover . Framed this way , the question of whether consensus is a lottery becomes a quantitativ e scaling question. 2 0 5 10 15 20 Population rounds 0.0 0.5 1.0 Frequency Cat Dog D C 5 5 (a) Drift at N = 8 . 0 5 10 15 20 Population rounds 0.0 0.5 1.0 Frequency Cat Dog D C 1 9 (b) Selection at N = 800 . 8 32 128 512 800 Population N 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 Fixation probability dog cat (c) Fixation vs. N . 10 1 10 2 10 3 Population N 0 . 50 0 . 75 1 . 00 1 . 25 1 . 50 1 . 75 2 . 00 T emperature T Γ = mN α 1 T − 1 (d) T emperature crossov er . Figure 3: Drift–selection crossover in multi-agent naming from GPT -4o experiments and QSG theory . Panels (a)–(c) show tw o-label (Dog, Cat) naming-game experiments with GPT -4o using random ordered speaker –listener pairs for a fixed referent r . (a) At N = 8 , runs show substantial run-to-run v ariability , and the inset shows winner counts across trials. (b) At N = 800 , a weak asymmetry consistently selects the same winner (Cat), again reflected in the inset counts. (c) Fixation probability versus N shows a finite-size crossover . (d) The corresponding tempered-sampling crossov er diagram deriv ed from QSG theory in ( T , mN /α ) ; the black curve marks Γ T = 1 , where Γ T = mN α 1 T − 1 . Specifically , we make the follo wing contributions: 1. Mutual in-context learning and memetic drift. W e identify the sampling-driven mechanism underlying symmetry breaking and consensus under neutrality in LLM populations, trace it to mutual in-context learning , and formalize the resulting regime as memetic drift . 2. Quantized Simplex Gossip (QSG). W e introduce QSG, a minimal and tractable model of continuous beliefs, quantized communication, and in-context adaptation for studying multi-agent coordination under neutrality (Sec. 2 ). 3. Drift–selection scaling laws. W e show ho w population size, communication bandwidth, adaptation rate, and internal uncertainty jointly determine whether consensus is dominated by amplified sampling noise or by systematic bias (Sec. 3 ). 4. Empirical validation. W e test these predictions in QSG simulations and naming-game experiments with LLM populations, finding agreement with the predicted scaling laws across multiple re gimes (Sec. 4 ). 2 Modeling: Quantized Simplex Gossip (QSG) Inspired by naming games, we consider N agents naming a fixed referent r using a K -way label set [ 2 , 3 ]. Unlike classical naming games, which use deterministic in ventory updates [ 2 – 4 ], QSG represents each agent’ s belief as a point on the probability simplex, which lets us analyze sampling noise directly . Each interaction selects an ordered speaker –listener pair , the speaker emits a message, and the listener records the e xchange. Because these episodes are the population’ s only experience, internal beliefs e volv e through them, and coordination arises through in-context learning rather than explicit re ward. The central modeling challenge is the mismatch between continuous internal beliefs and discrete communication. Even under neutrality , sampling a discrete message from a continuous distribution injects stochasticity that can destabilize symmetric states and dri ve consensus. W e capture this with Quantized Simplex Gossip (QSG) . Each agent holds a distribution x i ∈ ∆ K − 1 , the speaker sends a quantized message (Hard/T op- m /Soft), and the listener updates toward it with adaptation rate α [ 33 ]. Figure 4 schematizes the QSG interaction protocol, with random speaker–listener pairing, quantized communication, and listener adaptation. Agent state and neutrality . Fix K ≥ 2 con ventions and a population of N ≥ 2 agents. Agent i ∈ { 1 , . . . , N } maintains an internal probability distribution x i ∈ ∆ K − 1 , where ∆ K − 1 ≜ n x ∈ R K : x k ≥ 0 , K X k =1 x k = 1 o . 3 Figure 4: Quantized Simplex Gossip (QSG): interaction protocol. 1. A population of N agents, each with an internal state x i ∈ ∆ K − 1 . 2. An ordered speaker–listener pair is selected uniformly at random. 3. For a fixed referent, the speaker samples and sends a discrete message y from x S in the quantized regimes (Hard or T op- m ); Soft corresponds to transmitting the full distribution. 4. The listener updates tow ard the receiv ed message with adaptation rate α , x L ← (1 − α ) x L + α y . The population state is X = ( x 1 , . . . , x N ) ∈ (∆ K − 1 ) N . Throughout, token labels are neutral and exc hangeable : there is no intrinsic fitness difference, external reward signal, or prior bias associated with any con vention index k ∈ { 1 , . . . , K } . W e represent each agent by a continuous distribution x i because LLM token generation induces a distribution over discrete tokens, and uncertainty in that distribution is a central control variable. Communication, howe ver , is tokenized: agents exchange discrete outputs or short summaries, not real-v alued internal representations. This separation between continuous internal state and quantized message is the minimal mechanism that produces endogenous stochastic sampling under neutrality . Quantized communication. At each interaction, we sample an order ed pair ( S, L ) of distinct agents uniformly from all N ( N − 1) speaker –listener pairs. The speaker S samples a message y from its internal distrib ution x S and transmits it to the listener . This message is the only communicated object; it is a discrete sample or short list drawn from x S . W e parameterize the amount of information per interaction by an ef fectiv e bandwidth m ∈ { 1 , 2 , . . . } ∪ {∞} . Let { e k } K k =1 denote the standard basis in R K . • Hard ( m = 1 ): sample k ⋆ ∼ Cat( x S ) , i.e. Pr( k ⋆ = k ) = ( x S ) k , and transmit y = e k ⋆ . • T op- m ( m < ∞ ): sample k 1 , . . . , k m iid ∼ Cat( x S ) and transmit the empirical message y ( m ) = 1 m m X j =1 e k j . (1) • Soft ( m = ∞ ): transmit the full distribution y = x S deterministically . Under all three regimes, the conditional mean is identical, E [ y | x S ] = x S , while the conditional variance of the message decreases as m increases (scaling as 1 /m in the T op- m family). Soft is randomized gossip averaging [ 34 ]; Hard resembles a voter/Moran copying process [ 27 – 30 ]. T op- m is a multi-label / multi-bit variant: messages land on a higher-dimensional f ace of the simplex rather than a v ertex. The bandwidth parameter m controls how much e vidence the listener receives per interaction: a single discrete choice (one token) or a short transcript providing multiple draws. T op- m treats these v ariants uniformly by controlling message variance while keeping E [ y | x S ] fixed. Soft ( m = ∞ ) is an analytic baseline that remov es quantization noise; it does not assume literal transmission of hidden states, but serves as an infinite-bandwidth reference against which drift can be identified. 4 (a) Control parameters Symbol Meaning N population size α ∈ (0 , 1] adaptation rate m ∈ { 1 , . . . , ∞} communication bandwidth (b) Macroscopic obser vables Symbol Meaning ¯ x ∈ ∆ K − 1 population mean U = ∥ ¯ x ∥ 2 2 polarization V = P i ∥ x i − ¯ x ∥ 2 2 disagreement energy T able 1: QSG control parameters and macroscopic observ ables. Each agent holds an internal state x i ∈ ∆ K − 1 ov er K labels; the left panel lists the control parameters, and the right panel lists the macroscopic observ ables used in the drift analysis (Sec. 3 ). Listener update and in-context adaptation. After receiving a message y , the listener mov es a single step toward it. W ork on in-context learning interprets the forward pass as an implicit online update [ 19 – 22 ]. Recent work also suggests that in-context beha vior can reflect a mixture of distinct strategies rather than a single monolithic algorithm [ 35 ]. Motiv ated by that vie w , we model each interaction as a single in-context–style adaptation step with rate α ∈ (0 , 1] : x ′ L = (1 − α ) x L + α y , (2) while the speaker and all other agents remain unchanged. Equation ( 2 ) is a minimal abstraction of this viewpoint: the listener performs one adaptation step toward a tar get distribution encoded by the recei ved message. The con vex- combination form is the simplest contractiv e update on the simplex that isolates adaptation rate α while remaining analytically tractable. In the Soft case, this update reduces to DeGroot-style opinion averaging [ 36 , 37 ] with a simplex- valued opinion x i ∈ ∆ K − 1 ; in the quantized regimes, it is the corresponding update to ward a sampled message rather than a full belief state. Small α yields weak per-interaction adaptation (slo w accumulation of influence), whereas larger α amplifies the ef fect of each sampled message on the listener’ s belief state. QSG as a null model: explicit assumptions. QSG is defined by the follo wing assumptions, which we later treat as empirically testable approximations: A1. Simplex state Each agent i is represented by a probability distribution x i ∈ ∆ K − 1 ov er K competing con ventions, corresponding to a fixed naming-game prompt or referent r . A2. W ell-mixed pair selection At each step, an ordered speaker–listener pair ( S, L ) is sampled uniformly from the N ( N − 1) pairs with S = L . A3. Quantized message channel The speaker communicates a finite-bandwidth message obtained by sampling from x S (Hard or T op- m ), rather than transmitting the full distribution. A4. First-order adaptation (motiv ated by in-context learning) Each interaction induces a single adaptation step of the listener distribution to ward the receiv ed message, with magnitude controlled by a scalar adaptation rate α . Control parameters and macr oscopic observables. The core control parameters are ( N , α, m ) , with label count K fixed per experiment. For later use in the analysis, we also track the population mean ¯ x , the polarization U : = ∥ ¯ x ∥ 2 2 , and the disagreement energy V : = P i ∥ x i − ¯ x ∥ 2 2 . T able 1 summarizes this notation. 3 Analysis and Scaling Laws W e analyze QSG at the population lev el to ask when coordination is shaped mainly by selection versus stochastic drift, using macroscopic observ ables defined directly from the population state. The drift mechanism we isolate is not mutually exclusi ve with selection, but adds to an y systematic biases. 3.1 Macr oscopic observables W e analyze the QSG dynamics directly on the simplex using the update rules in Sec. 2 (Eqs. ( 1 ) and ( 2 ) ). This lets us track ho w sampling v ariance perturbs the mean dynamics near symmetry . The primary order parameter is the population 5 x x wug x dax x zep (a) Probabilistic naming. x wug x dax x zep x wug x dax x zep x 1 / 3 1 / 3 1 / 3 (b) Sampling noise from quantization. 0.0 0.2 0.4 0.6 1 − k x k 2 2 (c) Drift strength on the simplex. Figure 5: Probabilistic naming and sampling-noise geometry . (a) A referent is represented internally as a distribution ov er candidate labels. (b) Agent states lie on the simplex: near-uniform, high-entropy states generate larger sampling noise under quantization, whereas peaked, lo w-entropy states generate less. (c) Sampling-dri ven drift strength on the simplex, proportional to 1 − ∥ x ∥ 2 2 , is maximal near the center and vanishes at the v ertices. mean distribution, analogous to magnetization in statistical mechanics. ¯ x : = 1 N N X i =1 x i ∈ ∆ K − 1 . (3) From ¯ x we define the polarization (squared magnetization). U : = ∥ ¯ x ∥ 2 2 ∈ 1 K , 1 , (4) which equals 1 /K at perfect symmetry and 1 at consensus. It measures collective alignment re gardless of which label ultimately wins. W e also track a diagnostic for agent heterogeneity , the disagreement energy . V : = N X i =1 ∥ x i − ¯ x ∥ 2 2 ≥ 0 . (5) It measures how dispersed agents remain around the population mean. At the perfectly symmetric initialization, sampling noise is the only driver of motion; more generally , drift and selection can coexist, and these observables isolate the drift component. Figure 5 visualizes the simplex geometry and the sampling-noise–driv en drift strength that underlies the analysis. 3.2 Soft exchange pr eserves the mean in expectation and contracts disagr eement In Soft QSG, the speaker transmits y = x S and only the listener updates, x ′ L = (1 − α ) x L + αx S . Thus the population mean ¯ x : = 1 N P N i =1 x i ev olves as ¯ x ′ = ¯ x + α N ( x S − x L ) . (6) Conditioned on the current state X = ( x 1 , . . . , x N ) and the uniform random choice of ordered pair ( S, L ) with S = L , E [ ¯ x ′ | X ] = ¯ x, (7) so ¯ x is preserved in e xpectation (equiv alently , each coordinate ( ¯ x k ( t )) is a bounded martingale), but it is not generally in variant along individual trajectories. Moreov er , the disagreement energy V : = P N i =1 ∥ x i − ¯ x ∥ 2 2 contracts in expectation: E [∆ V | X ] = − 2 α N − 1 1 − α + α N V ≤ 0 . (8) Hence, if x i (0) = 1 /K for all i , then x i ( t ) = 1 /K for all t (no symmetry breaking). This provides the neutral baseline. Full-distribution exchange smooths disagreement but does not create spontaneous conv ention formation under neutrality . Against this baseline, an y symmetry breaking in the quantized re gimes must come from the extra sampling v ariance injected by communication itself. 6 3.3 Hard sampling injects an extra variance term Hard and Soft share the same conditional mean (since E [ e k ⋆ | x S ] = x S ), b ut Hard injects additional sampling v ariance. Theorem 1 (Hard sampling increases polarization via sampling v ariance) . Consider QSG with adaptation r ate α ∈ (0 , 1] . Let ¯ x be the population mean and define the polarization potential U : = ∥ ¯ x ∥ 2 2 . Conditioned on the curr ent state X , the expected one-step c hange in U satisfies E [∆ U | X ] hard = E [∆ U | X ] soft + α 2 N 2 E 1 − ∥ x S ∥ 2 2 | X , (9) wher e the expectation is over the random choice of ( S, L ) and (for Har d) the sample k ⋆ . The additional term in ( 9 ) is the sampling variance and is strictly positive whenever x S is not one-hot. In particular , at the perfectly symmetric initialization x i = 1 /K , we have E [∆ U | X ] soft = 0 b ut E [∆ U | X ] hard = α 2 N 2 1 − 1 K > 0 , (10) so symmetry is noise-unstable under Har d sampling. Pr oof. See Appendix A.1 . This variance injection driv es symmetry breaking in the neutral model under symmetric initialization and adds to any selection effects. T o see what Hard adds beyond Soft, note that under Soft exchange the symmetric state ¯ x = 1 /K is a fixed point and drift arises only from heterogeneity ( x S = x L ), so U gro ws only insofar as agents disagree. Hard/T op- m adds variance e ven when x S = x L , so the symmetric interior state becomes stochastically unstable and trajectories are pushed tow ard consensus. Equiv alently , E [∆ U | X ] soft = 2 α 2 N 2 ( N − 1) V , while Hard adds the positive term in Eq. ( 9 ). Mean-field approximation and consensus time. Under a mean-field ansatz where agents remain similar ( x i ≈ p for all i ), we hav e ∥ x S ∥ 2 2 ≈ U , yielding the mean-field ODE (approximating the expected trajectory) dU dt = α 2 mN 2 (1 − U ) . (11) Starting from the symmetric state U (0) = 1 /K , the solution is U ( t ) = 1 − 1 − 1 K exp − α 2 t mN 2 , (12) with characteristic time t char ∼ mN 2 /α 2 interaction steps, or equiv alently τ char ∼ mN /α 2 population rounds ( τ = t/ N ), with Hard corresponding to m = 1 . Mean-field predicts an approximate single-parameter collapse of U ( t ) across N when time is rescaled by mN 2 /α 2 . For a fix ed consensus threshold U ⋆ ∈ (1 /K , 1) , the mean-field hitting time satisfies t cons ( U ⋆ ) ≈ mN 2 α 2 log 1 − 1 /K 1 − U ⋆ . (13) The logarithmic factor depends only on ( K, U ⋆ ) , so t cons ∝ N 2 in steps (equiv alently τ cons = t cons / N ∝ N in population rounds). Physically , larger populations and higher -bandwidth messages weaken the stochastic push of any single interaction, whereas stronger in-context adaptation accelerates the approach to consensus. Figure 6a compares simulated Hard trajectories to the mean-field curve; trajectories track the mean-field prediction, consistent with the variance-injection mechanism in Theorem 1 . 3.4 T op- m reduces the symmetry-breaking drift as 1 /m T o quantify bandwidth, we model the candidate list as m i.i.d. samples from x S and transmit their empirical distribution. This preserves the mean b ut reduces sampling v ariance by 1 /m . 7 0 500 1000 1500 Population rounds 0 . 00 0 . 25 0 . 50 0 . 75 1 . 00 Polarization U = k ¯ x k 2 2 1 / K Hard (mean) Mean-field ODE (a) Mean-field trajectories. 0 . 0000 0 . 0002 0 . 0004 Predicted: α 2 mN 2 E [ 1 − k x S k 2 ] 0 . 0000 0 . 0001 0 . 0002 0 . 0003 0 . 0004 Measured: E [ ∆ U ] top- m − E [ ∆ U ] so ft y = x m = 1 m = 2 m = 3 m = 5 m = 10 (b) Measured vs. predicted drift. 0 . 0 0 . 5 1 . 0 1 / m 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 ( N 2 / α 2 ) · E [ ∆ U ] top- m m = 1* m = 2 m = 3 m = 5 m = 10 m = 20 * m = 1: ∆ U deterministic at symmetry R 2 = 1 . 0000 Theory: ( 1 − 1 / K ) / m Measured (c) 1 /m scaling at symmetry . Figure 6: QSG simulations validate the mean-field appr oximation and drift identities. (a) Hard-sampling trajectories and their ensemble mean track the mean-field solution in Eq. ( 12 ) ( N = 24 , K = 10 , α = 0 . 2 ). (b) One-step excess drift from shared snapshot states X , plotted against the predicted v ariance-injection term; dashed reference line y = x ( N = 24 , K = 10 , α = 0 . 5 ). (c) Symmetric 1 /m corollary . Under x i = 1 /K , the normalized excess drift follo ws the theoretical line (1 − 1 /K )(1 /m ) ( N = 24 , K = 10 , α = 0 . 5 ). The v ariance of the empirical message follo ws from the T op- m construction. Let k 1 , . . . , k m iid ∼ Cat( x S ) and define y ( m ) : = 1 m P m j =1 e k j . Then E [ y ( m ) | x S ] = x S and Co v y ( m ) | x S = 1 m diag( x S ) − x S x ⊤ S . (14) In particular , E ∥ y ( m ) − x S ∥ 2 2 | x S = 1 m 1 − ∥ x S ∥ 2 2 , i.e., variance scales as 1 /m . Theorem 2 (T op- m drift term scales as 1 /m ) . Consequently , under QSG with T op- m empirical communication y ( m ) , the polarization drift satisfies E [∆ U | X ] topm = E [∆ U | X ] soft + α 2 m N 2 E 1 − ∥ x S ∥ 2 2 | X . (15) At the perfectly symmetric initialization x i = 1 /K , this yields E [∆ U | X ] topm = α 2 mN 2 1 − 1 K . Thus, increasing bandwidth weakens symmetry-breaking drift linearly in 1 /m . Pr oof. See Appendix A.2 . 0.0 0.3 0.6 0.9 Internal uncertainty 1 − k x S k 2 2 1 2 4 6 8 10 Band w idth m 0.0 0.2 0.4 0.6 0.8 Drift strength Figure 7: Sampling-driven drift fr om uncer- tainty and bandwidth. For fixed α and N , the drift term in Eq. ( 15 ) scales as (1 − ∥ x S ∥ 2 2 ) /m , increasing with uncertainty and decreasing with bandwidth m . Figure 7 visualizes how the drift term depends on uncertainty and bandwidth, and Figure 6b tests Eq. ( 15 ) directly by estimating one- step conditional expectations from shared snapshot states and compar- ing the measured excess drift to the predicted variance-injection term (Appendix B.1.3 summarizes the estimator and parameters). Panel (c) of Fig. 6 sho ws the corresponding 1 /m scaling at the symmetric initialization. 3.5 Absorption at α = 1 and run-lev el symmetry breaking f or α < 1 For α = 1 (pure copying), after each agent has served as a listener at least once, all x i are one-hot and Hard QSG reduces to a finite- state copying Mark ov chain with absorbing consensus states { x i = e k , ∀ i } . For α < 1 the state space is continuous, and we do not claim finite-time consensus or almost-sure absorption. Our formal results in this regime are expectation-le vel drift identities and mean-field approximations. In simulations, the process tends to polarize and empirically select a winner in each run even though ensemble av erages preserve symmetry . This is the discrete analogue of the drift mechanism abov e. Randomness can 8 still select a winner even when the ensemble is neutral, but for α < 1 we treat this as an empirical run-le vel phenomenon rather than a proved absorption result. For α < 1 , Eq. ( 16 ) should be read as a diffusion-approximation description of run-lev el fixation behavior . In the hard-copying limit on a complete interaction graph, this reduction becomes a classical voter -model statement [ 28 , 29 ]. The process almost surely reaches a consensus vertex in finite time. If the initialization is exchangeable across token labels, for example x i (0) = 1 /K , the winning token is uniformly distrib uted ov er { 1 , . . . , K } . More generally , the probability that token k wins equals ¯ x k (0) , by the martingale property of the density process. Appendix A.3 gi ves the reduction and proof details. This neutral winner symmetry is the reference point that the weak asymmetries below perturb into the drift–selection crosso ver . 3.6 W eak asymmetry and the drift–selection crossover ( K = 2 ) T o model weak asymmetry , we tilt only the speaker channel by a small sampling bias (external field) h . For K = 2 , let p i := x i 1 and sample messages from ˜ p S = p S e h p S e h +(1 − p S ) (listener update unchanged). A dif fusion approximation (Appendix A.4 ) collapses fixation statistics onto the single parameter Γ h ≡ mN α h . This parameter measures the competition between systematic bias and endogenous drift. Larger N or m suppress the neutral sampling noise and make the same bias more decisiv e, whereas larger α strengthens drift relativ e to that same h . Defining the final magnetization M ∞ : = 2 ¯ x 1 ( ∞ ) − 1 , Pr( label 1 fixes ) ≈ 1 1 + exp( − Γ h ) , E [ M ∞ ] ≈ 2 Pr( label 1 fix es ) − 1 , N c ∼ α m | h | . (16) Thus fixation is approximately logistic in Γ h , with crossov er scale N c ∼ α/ ( m | h | ) (from | Γ h | ∼ 1 ). This crossover is pre viewed in Fig. 3 . W e use Γ h to distinguish this bias-based crossov er from the temperature-based Γ T in Appendix A.12 . Consequently , | Γ h | ≪ 1 yields near-neutral winners (near 1 / 2 ), while | Γ h | ≫ 1 yields bias-driv en amplification of the asymmetry . These results point to a single mechanism linking population size, bandwidth, adaptation strength, and internal uncertainty . Quantized communication injects sampling variance, and that v ariance controls both the speed of neutral consensus formation and the extent to which weak biases are amplified. That mechanism yields testable scalings, including 1 / N 2 and 1 /m early drift and a mean-field consensus time, which we e valuate next in LLM populations. 4 Experimental V alidation W e test the QSG scaling predictions in LLM populations using the Neutral Naming Drift (NND) protocol. In each run, N agents repeatedly name a fixed referent r using K neutral synthetic labels, with no external re ward or ground truth. Interactions are ordered speaker–listener updates. In the N -sweep, the speaker emits one label, whereas in the separate T op- m sweep the speaker emits exactly m labels. In both cases only the listener updates, so agents respond from their own memory rather than from a partner’ s current output. Empirical observables are estimated from probe outputs that are used only for measurement and are never incorporated into memory . At each probe time, we estimate the population-average label distrib ution p from sampled agent outputs, yielding the empirical counterpart of the theoretical population mean ¯ x defined in Sec. 3 . In the T op- m sweep, repeated probe draws support a direct estimate of U , whereas in the N -sweep the plotted squared-frequency statistic is a finite-sample proxy . W e therefore focus on ensemble scaling trends rather than exact pointwise agreement. W e estimate early drift as ∆ U / step , and for each trial define time to consensus as the first probe where U ≥ U ⋆ (here U ⋆ = 0 . 9 ). For scaling plots, we aggregate this quantity o ver trials that also finish abov e the same threshold at the run horizon. Because p is estimated from finite samples, U is itself noisy , so we report cross-trial variability rather than over -interpreting individual runs. Appendix B.2 details the probe cadence, sampling b udget, decoding controls, and prompt templates. Figure 8 summarizes the LLM scaling tests. Figure 8 shows strong scaling-le vel agreement between the QSG predictions and the LLM experiments in both GPT -4o and Claude Haiku 4.5. Panels a and d show that the raw (non-rescaled) U ( t ) trajectories for K = 3 are captured well by the mean-field form U ( t ) = 1 − (1 − 1 /K ) exp( − α 2 t/ ( mN 2 )) when fit with a single effecti ve α shared 9 0 500 1000 t (steps) 0.0 0.5 1.0 U N=2 N=4 N=8 N=16 N=32 Shared mean-field fit (a) GPT -4o U ( t ) . 2 5 10 20 30 N agents 1 0 3 1 0 2 1 0 1 E a r l y d r i f t ( U / s t e p ) Theory ~ 1/N^2 GPT -4o (b) GPT -4o drift. 0 10 20 30 40 N agents 0 200 400 Consensus time (steps) T h e o r y N 2 Data (c) GPT -4o t cons . 0 500 1000 t (steps) 0.0 0.5 1.0 U N=2 N=4 N=8 N=16 N=32 Shared mean-field fit (d) Claude Haiku 4.5 U ( t ) . 2 5 10 20 30 N agents 1 0 3 1 0 2 1 0 1 E a r l y d r i f t ( U / s t e p ) Theory ~ 1/N^2 Claude Haiku 4.5 (e) Claude Haiku 4.5 drift. 0 10 20 30 40 N agents 0 200 400 Consensus time (steps) T h e o r y N 2 Data (f) Claude Haiku 4.5 t cons . Figure 8: LLM scaling tests of QSG predictions. T op ro w: GPT -4o; bottom ro w: Claude Haiku 4.5. Panels (a,d) show K = 3 polarization trajectories well captured by a single effecti ve- α mean-field fit shared across N ; panels (b,e) show early drift ∆ U / step decreasing near the predicted 1 / N 2 law; and panels (c,f) sho w time to consensus increasing close to dashed cN 2 fits. across N . Panels b and e show that the early-time drift decreases with N close to the predicted 1 / N 2 law from the variance-injection term in Theorem 1 . Panels c and f sho w that time to consensus in total interactions (steps) grows close to quadratically in N , again matching the mean-field prediction t cons ∼ mN 2 /α 2 (Eq. ( 13 ) ). In population rounds τ = t/ N , the same scaling is linear in N . T aken together , the same variance-injection mechanism that or ganizes the QSG theory accounts for the main empirical patterns in both LLM families. For the T op- m setting, the LLM protocol mirrors Eq. ( 1 ). 1/1 1/2 1/3 1/4 I n t e r a c t i o n s i z e 1 / m 0.00 0.01 0.02 0.03 0.04 0.05 E a r l y d r i f t ( U / s t e p ) Theory ~ 1/m GPT -4o Figure 9: T op- m scaling in GPT -4o. Early- round drift follows the predicted 1 /m law . The speaker emits m labels, repeats are allo wed, and the transmitted list is treated as an unranked multiset; Appendix B.2 giv es the full protocol. Figure 9 shows that in GPT -4o the T op- m sweep follows the predicted 1 /m trend. Across the N -sweep and the T op- m sweep, and across two LLM families, QSG captures the main trends in the coordination dynamics. 5 Discussion and Conclusion QSG is deliberately minimal, with the aim of isolating the essential dynamics of mutual in-context learning at the population le vel rather than reproducing every practical detail of interacting LLM populations. Despite its simplicity , the model captures ho w quantized communica- tion injects sampling noise and ho w repeated interaction can amplify that noise into con vention formation. This picture leads to the insight that consensus can arise even when no individual agent prefers any output a priori , while weak asymmetries can be collectively amplified enough to overcome drift once the system crosses into the selection regime. Agreement in an LLM population is therefore not, on its own, e vidence of collectiv e reasoning or information aggregation; it can also be the consequence of memetic drift. 10 More broadly , the paper also suggests how multi-agent LLM systems can be mechanistically understood in ways that matter for alignment. There is by now a large empirical literature on multi-agent LLM systems, but most of it characterizes collectiv e behavior without theoretically isolating the mechanisms that produce it. By pairing a synthetic task such as the naming game with a minimal analytically tractable model, we can mov e beyond description and deriv e scaling laws from first principles, state them as quantitative predictions, and test them in controlled LLM experiments. The scaling laws for N , m , and α reported here, and the drift–selection crossover they predict, follo w from the variance-injection mechanism in QSG and are broadly consistent with both simulations and experiments with LLM populations. This result suggests that synthetic games combined with minimal models can open a productive route tow ard physics-style analysis in multi-agent LLM systems. W ithin that broader methodological view , the framew ork also suggests a population-le vel counterpart to mechanistic interpretability . Instead of asking only how a single model forms and uses internal representations through training or in- context learning, we can ask how collecti ve representations emerge, stabilize, and reorganize through social interaction, whether by con verging, fragmenting, polarizing, or otherwise becoming distorted. From a safety perspective, this also means that harmful collectiv e representations may form through interaction, echoing concerns about representation formation and bias that are already familiar from w ork on single models. One possible failure mode is the population- lev el amplification of sycophancy , in which strategically injected or socially reinforced signals steer a group to ward distorted con ventions. This in turn raises a broader question for future work about whether alignment at the lev el of individual agents composes under social interaction, or whether a society of individually aligned agents can still produce misaligned collective outcomes. Addressing that question will require extending the analysis to structured networks, heterogeneous agents, and training-data priors that act as selection forces, so that we can better understand what a population con verges on and why , not just whether it coordinates. QSG, the minimal theory de veloped here, should be understood in the spirit of the i deal gas law in thermodynamics, setting a bare-bones baseline for multi-agent coordination. More broadly , we see this work as a step to ward a physics of social representation formation in interacting model populations. Richer theories can then b uild on minimal models such as QSG tow ard a statistical mechanics of interacting agents. References [1] Claudio Castellano, Santo Fortunato, and V ittorio Loreto. Statistical physics of social dynamics. Reviews of Modern Physics , 81(2):591–646, 2009. doi: 10.1103/RevModPh ys.81.591. [2] Luc Steels. A self-organizing spatial v ocabulary . Artificial Life , 2(3):319–332, 1995. doi: 10.1162/artl.1995.2.3.319. [3] Andrea Baronchelli, Maddalena Felici, V ittorio Loreto, Emanuele Caglioti, and Luc Steels. Sharp transition tow ards shared vocab ularies in multi-agent systems. Journal of Statistical Mec hanics: Theory and Experiment , page P06014, 2006. doi: 10.1088/1742- 5468/2006/06/P06014. [4] Andrea Baronchelli, V ittorio Loreto, and Luc Steels. In-depth analysis of the Naming Game dynamics: the homogeneous mixing case. International Journal of Modern Physics C , 19(5):785–812, 2008. doi: 10.1142/S0129183108012522. [5] Y un-Shiuan Chuang, Agam Goyal, Nikunj Harlalka, Siddharth Suresh, Robert Hawkins, Sijia Y ang, Dhav an Shah, Junjie Hu, and T imothy Rogers. Simulating opinion dynamics with networks of LLM-based agents. In Ke vin Duh, Helena Gomez, and Stev en Bethard, editors, Findings of the Association for Computational Linguistics: N AACL 2024 , pages 3326–3346, Me xico City , Mexico, June 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.findings- naacl.211. [6] V incent C. Brockers, Da vid A. Ehrlich, and V iola Priesemann. Disentangling interaction and bias effects in opinion dynamics of large language models. arXiv preprint , 2025. doi: 10.48550/arXiv .2509.06858. [7] Xiutian Zhao, Ke W ang, and W ei Peng. An electoral approach to div ersify LLM-based multi-agent collectiv e decision-making. In Y aser Al-Onaizan, Mohit Bansal, and Y un-Nung Chen, editors, Pr oceedings of the 2024 Confer ence on Empirical Methods in Natural Language Pr ocessing , pages 2712–2727, Miami, Florida, USA, Nov ember 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.emnlp- main.158. 11 [8] Lars Benedikt Kaesberg, Jonas Beck er , Jan Philip W ahle, T erry Ruas, and Bela Gipp. V oting or consensus? decision-making in multi-agent debate. In W anxiang Che, Joyce Nabende, Ekaterina Shuto va, and Mohammad T aher Pilehvar , editors, F indings of the Association for Computational Linguistics: ACL 2025 , pages 11640–11671, V ienna, Austria, July 2025. Association for Computational Linguistics. ISBN 979-8-89176-256-5. doi: 10.18653/v1/2025.findings- acl.606. [9] Jonas Becker , Lars Benedikt Kaesberg, Niklas Bauer , Jan Philip W ahle, T erry Ruas, and Bela Gipp. MALLM: Multi-agent large language models frame work. In Ivan Habernal, Peter Schulam, and J ¨ org T iedemann, editors, Pr oceedings of the 2025 Conference on Empirical Methods in Natur al Language Pr ocessing: System Demonstrations , pages 418–439, Suzhou, China, No vember 2025. Association for Computational Linguistics. ISBN 979-8-89176-334-0. doi: 10.18653/v1/2025.emnlp- demos.29. [10] W illiam W atson, Nicole Cho, Nishan Srishankar , Zhen Zeng, Lucas Cecchi, Daniel Scott, Suchetha Siddagangappa, Rachneet Kaur , T ucker Balch, and Manuela V eloso. LA W: Legal agentic w orkflows for custody and fund services contracts. In Owen Rambow , Leo W anner , Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio, Stev en Schockaert, Kareem Darwish, and Apoorv Agarwal, editors, Pr oceedings of the 31st International Confer ence on Computational Linguistics: Industry T rack , pages 583–594, Ab u Dhabi, UAE, January 2025. Association for Computational Linguistics. [11] Y ijia Xiao, Edward Sun, Di Luo, and W ei W ang. TradingAgents: Multi-Agents LLM financial trading framework. arXiv pr eprint arXiv:2412.20138 , 2024. doi: 10.48550/arXiv .2412.20138. [12] Karthik Sreedhar , Alice Cai, Jenny Ma, Jeffre y V . Nickerson, and L ydia B. Chilton. Simulating cooperativ e prosocial behavior with multi-agent LLMs: Evidence and mechanisms for AI agents to inform policy decisions. In Pr oceedings of the 2025 International Conference on Intellig ent User Interfaces , pages 1272–1286, 2025. doi: 10.1145/3708359.3712149. [13] Y ubin Kim, Chanwoo Park, Hye won Jeong, Y ik Siu Chan, Xuhai Xu, Daniel McDuff, Hyeonhoon Lee, Marzyeh Ghassemi, Cynthia Breazeal, and Hae W on Park. MD Agents: An adaptive collaboration of LLMs for medical decision-making. In Advances in Neural Information Pr ocessing Systems 37 , 2024. do i: 10.52202/079017- 2522. [14] Juraj Gottweis, W ei-Hung W eng, Alexander Daryin, T ao Tu, Anil P alepu, Petar Sirkovic, Artiom Myasko vsky , Felix W eissenberger , Keran Rong, Ryutaro T anno, Khaled Saab, Dan Popovici, Jacob Blum, F an Zhang, Katherine Chou, A vinatan Hassidim, Burak Gokturk, Amin V ahdat, Pushmeet K ohli, Y ossi Matias, Andrew Carroll, Kavita K ulkarni, Nenad T omasev , Y uan Guan, V ikram Dhillon, Eeshit Dha val V aishnav , Byron Lee, T iago R D Costa, Jos ´ e R Penad ´ es, Gary Peltz, Y unhan Xu, Annalisa Pa wlosky , Alan Karthikesalingam, and V iv ek Natarajan. T o wards an AI co-scientist. arXiv preprint , 2025. doi: 10.48550/arXiv .2502.18864. [15] Y ilun Du, Shuang Li, Antonio T orralba, Joshua B. T enenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate. In Pr oceedings of the F orty-first International Confer ence on Machine Learning , volume 235 of Pr oceedings of Machine Learning Resear ch , pages 11733–11763. PMLR, 2024. [16] Jintian Zhang, Xin Xu, Ningyu Zhang, Ruibo Liu, Bryan Hooi, and Shumin Deng. Exploring collaboration mechanisms for LLM agents: A social psychology view . In Lun-W ei Ku, Andre Martins, and V iv ek Srikumar, editors, Pr oceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pages 14544–14607, Bangkok, Thailand, August 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.acl- long.782. [17] Ariel Flint Ashery , Luca Maria Aiello, and Andrea Baronchelli. Emergent social con ventions and collecti ve bias in LLM populations. Science Advances , 11(20):eadu9368, 2025. doi: 10.1126/sciadv .adu9368. [18] Ariel Flint, Luca Maria Aiello, Romualdo Pastor -Satorras, and Andrea Baronchelli. Group size effects and collectiv e misalignment in LLM multi-agent systems. arXiv pr eprint arXiv:2510.22422 , 2025. doi: 10.48550/arXiv .2510.22422. [19] Ekin Aky ¨ urek, Dale Schuurmans, Jacob Andreas, T engyu Ma, and Denny Zhou. What learning algorithm is in-context learning? in vestigations with linear models. In ICLR 2023 , 2023. [20] Johannes von Osw ald, Eyvind Niklasson, Ettore Randazzo, Joao Sacramento, Alexander Mordvintse v , Andrey Zhmoginov , and Max Vladymyrov . Transformers learn in-conte xt by gradient descent. In Pr oceedings of the 40th International Confer ence on Machine Learning , volume 202 of Pr oceedings of Machine Learning Resear ch , pages 35151–35174. PMLR, 2023. 12 [21] Damai Dai, Y utao Sun, Li Dong, Y aru Hao, Shuming Ma, Zhifang Sui, and Furu W ei. Why can GPT learn in-context? Language models secretly perform gradient descent as meta-optimizers. In F indings of the Association for Computational Linguistics: ACL 2023 , pages 4005–4019, T oronto, Canada, July 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings- acl.247. [22] Core Francisco Park, Andre w Lee, Ekdeep Singh Lubana, Y ongyi Y ang, Maya Okaw a, Kento Nishi, Martin W attenberg, and Hidenori T anaka. ICLR: In-Context Learning of Representations. In International Confer ence on Learning Repr esentations , 2025. [23] Core Francisco Park, Ekdeep Singh Lubana, and Hidenori T anaka. Competition dynamics shape algorithmic phases of in-context learning. In International Conference on Learning Repr esentations , 2025. Spotlight. [24] Eric Bigelow , Daniel W urgaft, Y ingQiao W ang, Noah Goodman, T omer Ullman, Hidenori T anaka, and Ekdeep Singh Lubana. Belief dynamics rev eal the dual nature of in-conte xt learning and acti vation steering. arXiv pr eprint arXiv:2511.00617 , 2025. doi: 10.48550/arXiv .2511.00617. [25] Motoo Kimura. Evolutionary rate at the molecular le vel. Natur e , 217(5129):624–626, 1968. doi: 10.1038/217624a0. [26] Motoo Kimura. The Neutral Theory of Molecular Evolution . Cambridge Univ ersity Press, Cambridge, 1983. ISBN 0521231094. [27] P . A. P . Moran. Random processes in genetics. Mathematical Pr oceedings of the Cambridge Philosophical Society , 54(1):60–71, 1958. doi: 10.1017/S0305004100033193. [28] Peter Clifford and Aidan Sudb ury . A model for spatial conflict. Biometrika , 60(3):581–588, 1973. doi: 10.1093/biomet/60.3.581. [29] Richard A. Holley and Thomas M. Liggett. Ergodic theorems for weakly interacting infinite systems and the voter model. The Annals of Pr obability , 3(4):643–663, 1975. doi: 10.1214/aop/1176996306. [30] Thomas M. Liggett. Stochastic Interacting Systems: Contact, V oter and Exclusion Pr ocesses . Number 324 in Grundlehren der mathematischen W issenschaften. Springer, Berlin, 1999. ISBN 9783540659952. doi: 10.1007/978- 3- 662- 03990- 8. [31] Thiparat Chotibut and Da vid R. Nelson. Population genetics with fluctuating population sizes. Journal of Statistical Physics , 167(3–4):777–791, 2017. doi: 10.1007/s10955- 017- 1741- y. [32] J. F . C. Kingman. The coalescent. Stochastic Pr ocesses and their Applications , 13(3):235–248, 1982. doi: 10.1016/0304- 4149(82)90011- 4. [33] Andr ´ e C. R. Martins. Continuous opinions and discrete actions in opinion dynamics problems. International Journal of Modern Physics C , 19(4):617–624, 2008. doi: 10.1142/S0129183108012339. [34] Stephen Boyd, Arpita Ghosh, Balaji Prabhakar , and Dev avrat Shah. Randomized gossip algorithms. IEEE T ransactions on Information Theory , 52(6):2508–2530, 2006. doi: 10.1109/TIT .2006.874516. [35] Daniel W urgaft, Ekdeep Singh Lubana, Core Francisco P ark, Hidenori T anaka, Gautam Reddy , and Noah D. Goodman. In-context learning strategies emer ge rationally . In Advances in Neural Information Pr ocessing Systems , 2025. doi: 10.48550/arXiv .2506.17859. [36] Morris H. DeGroot. Reaching a consensus. Journal of the American Statistical Association , 69(345):118–121, 1974. doi: 10.1080/01621459.1974.10480137. [37] Noah E. Friedkin and Eugene C. Johnsen. Social influence and opinions. Journal of Mathematical Sociolo gy , 15 (3-4):193–206, 1990. doi: 10.1080/0022250X.1990.9990069. 13 A Additional Theory f or Quantized Simplex Gossip (QSG) This appendix collects algebraic identities and full drift calculations used in Sec. 3 . A.1 Pr oof of Theorem 1 : hard-sampling drift decomposition Let only the listener update: x ′ L = (1 − α ) x L + αy , where y = x S (Soft) or y = e k ⋆ (Hard). Then ¯ x ′ = ¯ x + α N ( y − x L ) . Expanding U ′ = ∥ ¯ x ′ ∥ 2 2 giv es ∆ U = 2 α N ⟨ ¯ x, y − x L ⟩ + α 2 N 2 ∥ y − x L ∥ 2 2 . T aking conditional expectations yields E [∆ U | X ] = α 2 N 2 E ∥ y − x L ∥ 2 2 | X because unbiased messaging and uniform ordered-pair sampling giv e E [ y | X ] = ¯ x = E [ x L | X ] . For Hard, decompose y − x L = ( y − x S ) + ( x S − x L ) . Since E [ y − x S | x S ] = 0 , the cross term vanishes after conditioning on ( x S , x L ) , and E ⟨ y − x S , x S − x L ⟩ | x S , x L = 0 . Hence E ∥ y − x L ∥ 2 2 | X = E ∥ x S − x L ∥ 2 2 | X + E ∥ y − x S ∥ 2 2 | X . For one-hot y = e k ⋆ sampled from x S , E ∥ y − x S ∥ 2 2 = 1 − ∥ x S ∥ 2 2 . Substituting these two terms gives the Hard variance-injection formula in Theorem 1 . A.2 Pr oof of Theorem 2 : T op- m drift decomposition and scaling The same e xpansion applies with y replaced by the T op- m empirical message y ( m ) . W e ha ve x ′ L = (1 − α ) x L + αy ( m ) and hence ¯ x ′ = ¯ x + α N ( y ( m ) − x L ) , so expanding U ′ = ∥ ¯ x ′ ∥ 2 2 giv es ∆ U = 2 α N ⟨ ¯ x, y ( m ) − x L ⟩ + α 2 N 2 ∥ y ( m ) − x L ∥ 2 2 . T aking conditional expectations yields E [∆ U | X ] = α 2 N 2 E ∥ y ( m ) − x L ∥ 2 2 | X because unbiased messaging and uniform ordered-pair sampling gi ve E [ y ( m ) | X ] = ¯ x = E [ x L | X ] . Decompose y ( m ) − x L = ( y ( m ) − x S ) + ( x S − x L ) to obtain the Soft term plus an extra variance term α 2 N 2 E ∥ y ( m ) − x S ∥ 2 2 . More explicitly , conditioning on ( x S , x L ) gi ves E ⟨ y ( m ) − x S , x S − x L ⟩ | x S , x L = 0 , so E ∥ y ( m ) − x L ∥ 2 2 | X = E ∥ x S − x L ∥ 2 2 | X + E ∥ y ( m ) − x S ∥ 2 2 | X . By ( 28 ), E ∥ y ( m ) − x S ∥ 2 2 = 1 m (1 − ∥ x S ∥ 2 2 ) , yielding ( 15 ). A.3 V oter-model r eduction and winner symmetry W ith α = 1 , the listener is ov erwritten by the sampled one-hot message: x ′ L = e k ⋆ with k ⋆ ∼ Cat( x S ) . Under uniform random pair selection on the complete interaction graph, each agent is chosen as a listener infinitely often; hence after an almost-surely finite ”coupon collector” time, all x i lie on simplex vertices and remain there. From that time onward the dynamics is exactly the K -state voter/Moran copying process on a finite complete graph, which almost surely reaches a consensus (an absorbing verte x state) in finite time. For the winner distrib ution, fix a token k and define the population mean coordinate ¯ x k ( t ) : = 1 N P N i =1 x i,k ( t ) . In one update, ¯ x k ( t + 1) = ¯ x k ( t ) + 1 N y k − x L,k ( t ) where y = e k ⋆ . Conditioned on the current state F t , E [ y k | F t ] = E [ x S,k ( t ) | F t ] = ¯ x k ( t ) and also E [ x L,k ( t ) | F t ] = ¯ x k ( t ) , so E [ ¯ x k ( t + 1) | F t ] = ¯ x k ( t ) ; the expected v alue of ¯ x k is unchanged at each step (equiv alently , ( ¯ x k ( t )) is a bounded martingale). Let T cons be the (a.s. finite) consensus time; then ¯ x k ( T cons ) = 1 { winner = k } . By optional stopping for bounded martingales, Pr[ winner = k ] = E [ ¯ x k ( T cons )] = ¯ x k (0) . If the initialization is exchangeable across labels (e.g. x i (0) = 1 /K ), then ¯ x k (0) = 1 /K and the winner is uniform ov er { 1 , . . . , K } . A.4 Diffusion appr oximation for weak asymmetry For K = 2 , let ¯ p = 1 N P i p i with p i = x i 1 . Under a small bias h , expand ˜ p S = p S + h p S (1 − p S ) + O ( h 2 ) . Combining this with the QSG update and a mean-field approximation yields a one-dimensional diffusion for ¯ p in population rounds τ = t/ N , d ¯ p = µ ( ¯ p ) dτ + p D ( ¯ p ) dW, (17) with drift µ ( ¯ p ) ∝ α h ¯ p (1 − ¯ p ) and dif fusion D ( ¯ p ) ∝ ( α 2 / ( mN )) ¯ p (1 − ¯ p ) . Equiv alently , per interaction step the mean increment scales as E [∆ ¯ p ] ∝ ( α/ N ) h ¯ p (1 − ¯ p ) . The fixation probability π ( p 0 ) of this dif fusion surrogate solves the 14 backward equation µ ( ¯ p ) π ′ ( ¯ p ) + 1 2 D ( ¯ p ) π ′′ ( ¯ p ) = 0 with π (0) = 0 , π (1) = 1 , giving π ( p 0 ) = 1 − exp( − 2Γ h p 0 ) 1 − exp( − 2Γ h ) where Γ h = mN α h . From p 0 = 1 / 2 , this yields the approximate logistic/tanh form used in Eq. ( 16 ). A.5 Order parameters and second-moment identities Recall the population mean ¯ x : = 1 N P N i =1 x i and polarization potential U : = ∥ ¯ x ∥ 2 2 . Define the disagreement ener gy V : = N X i =1 ∥ x i − ¯ x ∥ 2 2 , (18) and the mean self-ov erlap q : = 1 N N X i =1 ∥ x i ∥ 2 2 . (19) Finally , we define the coordination rate S : = 1 N ( N − 1) X i = j x ⊤ i x j . (20) For an y population state X = ( x 1 , . . . , x N ) , the basic second-moment identities are V = N ( q − U ) , (21) S = U − V N ( N − 1) . (22) Expand V = P i ∥ x i − ¯ x ∥ 2 2 = P i ∥ x i ∥ 2 2 − N ∥ ¯ x ∥ 2 2 , gi ving V = N ( q − U ) . Also ∥ P i x i ∥ 2 2 = P i ∥ x i ∥ 2 2 + P i = j x ⊤ i x j . Since ∥ P i x i ∥ 2 2 = N 2 U and P i ∥ x i ∥ 2 2 = V + N U , we obtain P i = j x ⊤ i x j = N ( N − 1) U − V , hence ( 22 ). For a uniformly random ordered pair ( S, L ) with S = L , E ∥ x S − x L ∥ 2 2 | X = 2 N − 1 V . (23) Because the diagonal terms vanish, X i = j ∥ x i − x j ∥ 2 2 = X i,j ∥ x i − x j ∥ 2 2 . Expanding the right-hand side around the mean giv es P i,j ∥ x i − x j ∥ 2 2 = 2 N P i ∥ x i − ¯ x ∥ 2 2 = 2 N V . A veraging ov er the N ( N − 1) ordered pairs gi ves ( 23 ). A.6 Mean update and pr eservation in expectation For an y regime in which E [ y | x S ] = x S (Soft/Hard/T op- m ), ¯ x ′ = ¯ x + α N ( y − x L ) . (24) Conditioned on the current state X , E [ ¯ x ′ | X ] = ¯ x, (25) so each coordinate ( ¯ x k ( t )) t ≥ 0 is preserved in expectation from one step to the next (equiv alently , it is a bounded martingale). Only the listener changes: x ′ L − x L = α ( y − x L ) , so ¯ x ′ = ¯ x + 1 N ( x ′ L − x L ) , yielding ( 24 ) . Now condition on X . Since ( S, L ) is a uniformly random ordered pair with S = L , E [ x S | X ] = E [ x L | X ] = ¯ x . If E [ y | x S ] = x S , then E [ y | X ] = ¯ x . Thus E [ y − x L | X ] = 0 , implying E [ ¯ x ′ | X ] = ¯ x . A.7 Message variance f or T op- m Recall the empirical message y ( m ) = 1 m P m j =1 e k j with k j iid ∼ Cat( x S ) . 15 Conditioned on x S , E [ y ( m ) | x S ] = x S , (26) Co v( y ( m ) | x S ) = 1 m diag( x S ) − x S x ⊤ S , (27) E ∥ y ( m ) − x S ∥ 2 2 | x S = 1 m 1 − ∥ x S ∥ 2 2 . (28) Write y ( m ) = 1 m P m j =1 Y j with Y j = e k j i.i.d. Then E [ Y j | x S ] = x S and Co v( y ( m ) | x S ) = 1 m Co v( Y 1 | x S ) . Since E [ Y 1 Y ⊤ 1 | x S ] = diag( x S ) , Co v( Y 1 | x S ) = diag( x S ) − x S x ⊤ S . T aking trace gi ves ( 28 ). A.8 P olarization drift: full derivation of the variance-injection law Let U = ∥ ¯ x ∥ 2 2 . Assume unbiased messaging E [ y | x S ] = x S (true for Soft/Hard/T op- m ). For the listener update x ′ L = (1 − α ) x L + α y , E [∆ U | X ] = α 2 N 2 E ∥ y − x L ∥ 2 2 | X . (29) From ( 24 ) , ¯ x ′ = ¯ x + α N ( y − x L ) . Expand ∥ ¯ x ′ ∥ 2 2 − ∥ ¯ x ∥ 2 2 = 2 α N ⟨ ¯ x, y − x L ⟩ + α 2 N 2 ∥ y − x L ∥ 2 2 . Conditioned on X , unbiased messaging and uniform ordered-pair sampling gi ve E [ y | X ] = ¯ x = E [ x L | X ] , so E [ y − x L | X ] = 0 and the linear term vanishes. Soft exc hange . Under Soft exchange ( y = x S ), E [∆ U | X ] soft = α 2 N 2 E ∥ x S − x L ∥ 2 2 | X = 2 α 2 N 2 ( N − 1) V . (30) This is ( 29 ) with ( 23 ) substituted for E ∥ x S − x L ∥ 2 2 | X . Under T op- m empirical communication y = y ( m ) , E [∆ U | X ] top m = E [∆ U | X ] soft + α 2 mN 2 E 1 − ∥ x S ∥ 2 2 | X . (31) Start from ( 29 ) . Decompose y ( m ) − x L = ( x S − x L ) + ( y ( m ) − x S ) . Conditioned on ( x S , x L ) , E [ y ( m ) − x S | x S ] = 0 , so the cross term vanishes: E ∥ y ( m ) − x L ∥ 2 2 = E ∥ x S − x L ∥ 2 2 + E ∥ y ( m ) − x S ∥ 2 2 . The first term is the Soft contribution ( 30 ), and ( 28 ) gi ves the second term. Closed form in ( U, V ) . Using ( 21 ), so that q = U + V / N , E [∆ U | X ] top m = 2 α 2 N 2 ( N − 1) V + α 2 mN 2 1 − U − V N . (32) At perfect symmetry ( x i = 1 /K ), V = 0 and U = 1 /K , giving E [∆ U | X ] top m = α 2 mN 2 (1 − 1 /K ) . A.9 Disagr eement drift and coordination drift Let V = P i ∥ x i − ¯ x ∥ 2 2 . Under T op- m empirical communication, E [∆ V | X ] = − 2 α N − 1 1 − α + α N V + α 2 ( N − 1) mN 1 − U − V N . (33) Let ∆ x : = x ′ L − x L = α ( y − x L ) and ∆ ¯ x = ∆ x/ N . Write δ i = x i − ¯ x so P i δ i = 0 . A direct expansion gives V ′ = V + 2 ⟨ δ L , ∆ x ⟩ + N − 1 N ∥ ∆ x ∥ 2 2 . For the linear term, condition on ( x S , x L ) and use E [ y | x S ] = x S to replace ∆ x by α ( x S − x L ) in expectation. A veraging ov er uniformly sampled ordered pairs then gives the contraction contribution − 2 α N − 1 1 − α + α N V . For the quadratic term, decompose ∥ y − x L ∥ 2 2 = ∥ x S − x L ∥ 2 2 + ∥ y − x S ∥ 2 2 and apply ( 23 ) and ( 28 ) to obtain the injection term. Finally use 1 − E ∥ x S ∥ 2 2 = 1 − q = 1 − U − V / N . 16 Soft limit. Under Soft exchange ( m = ∞ ), the injection term vanishes and E [∆ V | X ] soft = − 2 α N − 1 1 − α + α N V ≤ 0 . (34) Coor dination drift. Using ( 22 ) and the drift formulas above, E [∆ S | X ] = 2 α N ( N − 1) 2 V ≥ 0 . (35) In particular , E [∆ S | X ] is nonne gative and depends on m only through the ev olution of V . A.10 Homogeneous mean-field closur e and consensus time scaling A common closure assumes agents remain approximately homogeneous: x i ≈ ¯ x , so V ≈ 0 and q ≈ U . Then ( 32 ) yields the per-step approximation E [∆ U | X ] ≈ α 2 mN 2 (1 − U ) . (36) Measuring time in population rounds τ = t/ N and treating the dynamics continuously giv es dU dτ ≈ α 2 mN (1 − U ) , U ( τ ) ≈ 1 − (1 − U 0 ) exp − α 2 mN τ . (37) Thus the characteristic timescale in population rounds scales as τ cons ∼ mN α 2 . A.11 Mean-field comparison at large α The mean-field approximation ( 37 ) is deriv ed as a continuous approximation to the discrete QSG dynamics. This approximation is most accurate when the adaptation rate α is small, so that each update produces an infinitesimal change. At α = 1 (the naming-game limit where the listener is completely o verwritten), the discrete dynamics dominate. Why does simulation exceed theory at large α ? At small α , the continuous ODE approximation is accurate, and a secondary ef fect becomes visible: agent heterogeneity . By Jensen’ s inequality , E [ ∥ x S ∥ 2 2 ] ≥ ∥ ¯ x ∥ 2 2 = U , so the actual drift term (1 − E [ ∥ x S ∥ 2 2 ]) is smaller than the mean-field approximation (1 − U ) . This causes simulation to sit below the theory curve (Fig. 6a ). At large α , howe ver , the discrete dynamics dominate. W ith α = 1 , listeners snap to one-hot vectors after a single interaction. These large jumps produce faster polarization than the smooth exponential predicted by the ODE, causing simulation to sit above the theory curve. Implication. At small α , agent heterogeneity makes the effectiv e drift smaller than the homogeneous mean-field approximation, so the mean-field curve typically over estimates polarization speed (and thus underestimates time to reach a fixed consensus threshold). At large α , discrete one-hot ov erwrites accelerate polarization relativ e to the smooth ODE, so the mean-field curve typically under estimates polarization speed (and thus over estimates time to threshold). A.12 T empered sampling and the crosso ver parameter Γ T For the tempered-sampling e xtension used in Fig. 3 , we define the temperature transform g T ( x ) k ∝ x 1 /T k , K X k =1 g T ( x ) k = 1 , (38) and generate messages from g T ( x S ) instead of x S (Hard/T op- m ). Then E [ y | x S ] = g T ( x S ) , and the mean-field dynamics of ¯ x becomes d ¯ x dτ ≈ α g T ( ¯ x ) − ¯ x . (39) 17 Linearizing around the symmetric point u = 1 /K with ¯ x = u + δ and P k δ k = 0 gi ves g T ( u + δ ) = u + 1 T δ + O ( ∥ δ ∥ 2 2 ) , ⇒ dδ dτ ≈ α 1 T − 1 δ. (40) Thus T < 1 deterministically amplifies small asymmetries while T > 1 damps them. Quantized communication injects sampling-driv en polarization at a characteristic population-round rate scale ∼ α 2 / ( mN ) (cf. ( 37 ) near symmetry). Comparing the deterministic linear rate α | 1 /T − 1 | to the quantization-driven scale α 2 / ( mN ) moti vates the dimensionless crossov er parameter Γ T : = mN α 1 T − 1 . (41) W e interpret Γ T ≈ 1 as a finite-size cr ossover between near -neutral (drift-dominated) and tempering-dominated regimes, not as a literal thermodynamic phase transition of the finite- N absorbing chain. A.13 Relating U to entropy and magnetization via a one-vs-r est ansatz T o connect second-moment theory to entropy/magnetization plots, a useful approximation is the one-vs-rest ansatz ¯ x ≈ p, 1 − p K − 1 , . . . , 1 − p K − 1 , p = max k ¯ x k ∈ [1 /K , 1] . Under this ansatz, U = p 2 + (1 − p ) 2 K − 1 , p ( U ) = 1 + p ( K − 1)( K U − 1) K . (42) The magnetization M = K p − 1 K − 1 becomes M ( U ) = r K U − 1 K − 1 . (43) The normalized entropy H ( ¯ x ) = − 1 log K P k ¯ x k log( ¯ x k + ε ) yields H ( U ) = − 1 log K p ( U ) log p ( U ) + (1 − p ( U )) log 1 − p ( U ) K − 1 , (44) where ε is used only for numerical stability in implementations. B Experiments B.1 Numerical simulations of QSG W e report QSG simulations comparing Soft, Hard, and T op- m dynamics across symmetry breaking, temperature sweeps, and entropy trajectories. The one-step drift identity test in Fig. 6b is reported in the main text; here we focus on additional dynamics and robustness sweeps. B.1.1 Setup Unless stated otherwise: • Population size N = 24 , vocab ulary size K = 10 (matching a common e xperimental setting in [ 17 ]). • Soft update: x L ← (1 − α ) x L + α x S . • Hard update: k ⋆ ∼ Cat( x S ) and x L ← (1 − α ) x L + α e k ⋆ . • T op- m update: sample m tokens i.i.d. with replacement and update to ward their empirical distribution. • W e track coordination rate S ( t ) (Eq. ( 20 )) and entropy H ( t ) . 18 System message You must output only valid JSON. No extra keys, no explanations, no markdown. Valid labels are exactly those in Allowed labels. Never output "". User message (speaker) Referent: ref 07 Allowed labels: ["hdsad", "vokhg", "fmhja"] The list order is randomized and has no meaning. Both players are choosing a label for the same referent in repeated interactions. The memory shows labels you observed from previous interactions with partners. Memory (last H observed messages, oldest -> newest, padded with ""): ["", "", "", "", "", "", "", "fmhja", "hdsad", "vokhg"] Each memory entry is a label string. Constraints: - Output JSON only. - Every label must be from Allowed labels. Output JSON exactly: {"label": "
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment