Can LLMs Beat Classical Hyperparameter Optimization Algorithms? A Study on autoresearch
The autoresearch repository enables an LLM agent to search for optimal hyperparameter configurations on an unconstrained search space by editing the training code directly. Given a fixed compute budget and constraints, we use \emph{autoresearch} as a…
Authors: Fabio Ferreira, Lucca Wobbe, Arjun Krishnakumar
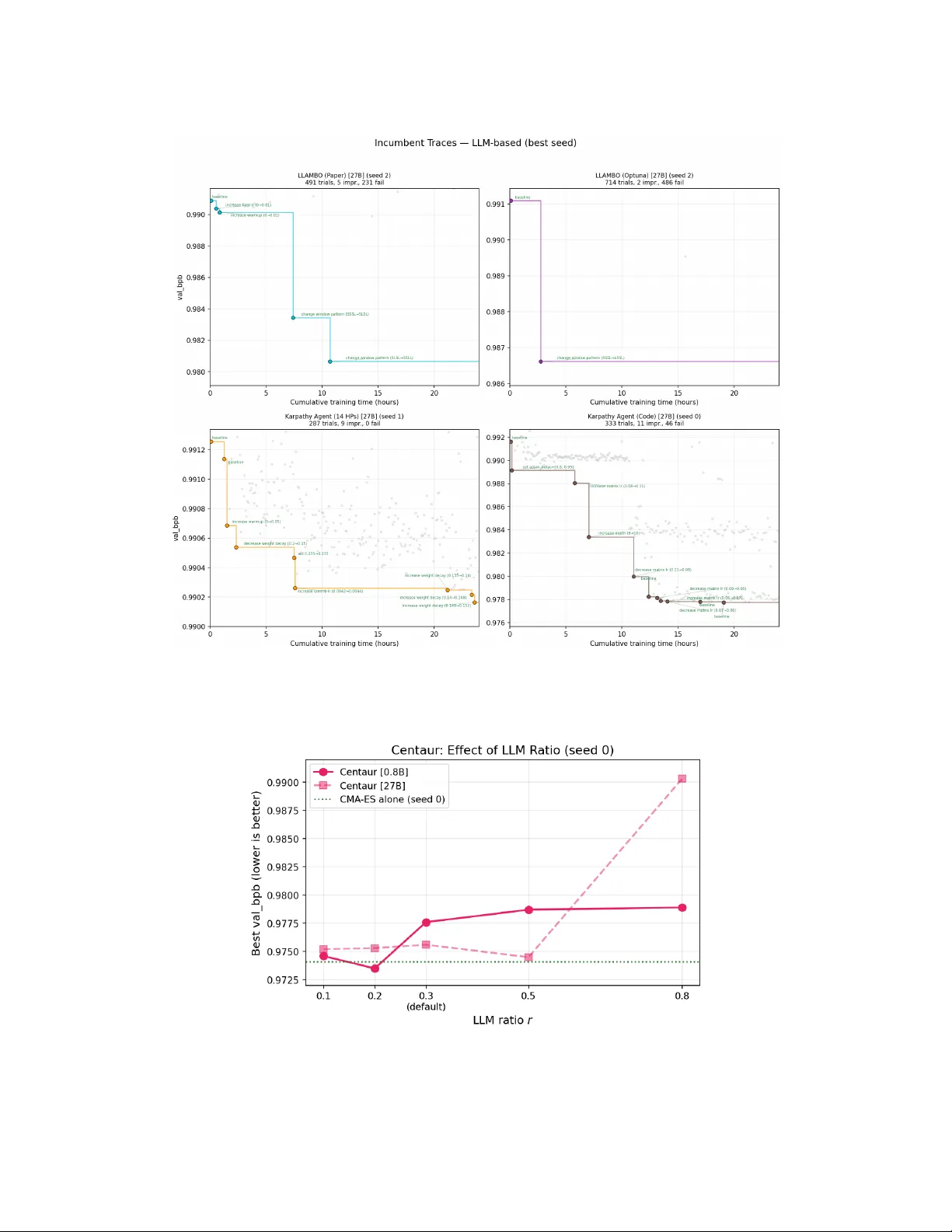
Can LLMs Beat Classical Hyperparameter Optimization Algorithms? A Study on autoresearch Fabio F erreira 1 , 2 , ∗ , Lucca W ob be 3 , Arjun Krishnakumar 2 , Frank Hutter 1 , 2 , 4 , ∗ , & Arber Zela 1 , ∗ 1 ELLIS Institute Tübingen 2 Univ ersity of Freibur g 3 Karlsruhe Institute of T echnology 4 Prior Labs Abstract The autor esearc h repository enables an LLM agent to search for optimal hyperpa- rameter configurations on an unconstrained search space by editing the training code directly . Giv en a fixed compute budget and constraints, we use autor esear ch as a testbed to compare classical hyperparameter optimization (HPO) algorithms against LLM-based methods on tuning the hyperparameters of a small language model. Within a fixed hyperparameter search space, classical HPO methods such as CMA-ES and TPE consistently outperform LLM-based agents. Howe ver , an LLM agent that directly edits training source code in an unconstrained search space narrows the g ap to classical methods substantially despite using only a self-hosted open-weight 27B model. Methods that av oid out-of-memory failures outperform those with higher search di versity , suggesting that reliability matters more than exploration breadth. While small and mid-sized LLMs struggle to track optimiza- tion state across trials, classical methods lack domain kno wledge. T o bridge this gap, we introduce Centaur , a hybrid that shares CMA-ES’ s internal state, including mean vector , step-size, and covariance matrix, with an LLM 2 . Centaur achie ves the best result in our experiments, with its 0.8B variant outperforming the 27B variant, suggesting that a cheap LLM suf fices when paired with a strong classical optimizer . The 0.8B model is insufficient for unconstrained code editing but suf fi- cient for hybrid optimization, while scaling to 27B pro vides no adv antage for fixed search space methods with the open-weight models tested. Code is available at https://github.com/ferreirafabio/autoresearch- automl . 1 Introduction autor esearc h [Karpathy, 2025a] demonstrated that an LLM agent can iterati vely edit training code to improv e a small language model ( ∼ 50M parameters), reaching a v al_bpb of ∼ 0.978 in less than 100 trials on a single H100. Building on that, Ziv [2025] showed that TPE, a classical AutoML method, with expert-designed hyperparameters can outperform Karpathy’ s agent within a similar budget. Hyperparameter optimization (HPO) is a central component of AutoML [Feurer and Hutter, 2019, Bischl et al., 2023]. These results raise two questions: (i) how do other classical HPO methods perform on this task? and (ii) can LLM-based HPO methods outperform classical ones? T o answer these questions, we benchmark 9 HPO methods, spanning 4 classical, 4 LLM-based, and 1 hybrid, on Karpathy’ s autoresearch task. All methods operate under the same 24-hour GPU training budget with 3 seeds. T o reduce human priors, we automatically extract 14 hyperparameters from the training script; while the ranges require some domain kno wledge, the HP selection itself is automated, ∗ Equal seniorship. Correspondence to fabioferreira@mailbox.org 2 Named after the mythological half-human, half-horse hybrid: our method merges LLM reasoning with classical optimization. Figure 1: Best V alidation Bits-Per-Byte (mean ± std across 3 seeds) of HPO algorithms against cumulati ve training time. All methods recei ve the same 24-hour GPU training budget; LLM inference ov erhead is excluded. All LLM-based methods use Qwen3.5-27B as the LLM optimizer . Classical methods such as CMA-ES and TPE con verge faster and to better final values than LLM-based methods. Centaur, our CMA-ES and LLM hybrid, achieves the best result in our e xperiments. removing manual search space curation. Figure 1 compares all 9 methods using 27B LLM v ariants against cumulati ve training wall-time, showing that classical methods find better configurations than LLM-based agents within the fix ed search space. The exception is Karpathy Agent (Code), which directly edits training source code and is competiti ve with classical methods, e ven though the latter find a similar performing h yperparameter configuration ∼ 4 × faster . Since all LLM methods use a self-hosted open-weight model (Qwen3.5-27B), stronger frontier models may narrow this gap further . Beyond this comparison, we propose Centaur, a hybrid method that combines CMA-ES with an LLM by sharing the optimizer’ s full internal state, including the mean v ector µ , step-size σ , and co variance matrix C . The hypothesis is that CMA-ES and LLMs have complementary strengths: CMA-ES learns the optimization landscape b ut lacks domain knowledge, while the LLM brings transformer training intuitions b ut, at the small and mid-sized scales we test (0.8B and 27B), struggles to track optimization state across trials reliably , e.g., LLM methods show OOM rates comparable to random search despite observing full trial history . This motiv ates pairing the LLM with a classical optimizer whose state can be shared explicitly . W e chose CMA-ES because its internal state is particularly interpretable for LLM communication (see Section 4). In summary , we make the following contrib utions: • W e benchmark 9 HPO methods on autoresearch [Karpathy, 2025a], supporting both fixed-HP and agentic code-editing optimization, under identical 24-hour budgets with 3 seeds. • W e show that classical HPO outperforms LLM agents within a fixed search space, while an LLM agent editing code directly narrows the gap substantially despite using only a self-hosted open-weight model. • W e introduce Centaur, a hybrid that shares CMA-ES’ s full internal state with the LLM and achiev es the best result in our experiments. • W e analyze search di versity , OOM rates, and model scaling across all methods, and release per -trial LLM con versation logs. 2 2 Related W ork Classical HPO spans a wide range of approaches [Bischl et al., 2023, Feurer and Hutter, 2019], from random search [Bergstra and Bengio, 2012] and Bayesian optimization with Gaussian process surrogates [Snoek et al., 2012] to sequential model-based approaches with random forests such as SMA C [Hutter et al., 2011], tree-structured Parzen estimators such as TPE [Bergstra et al., 2011], and e volution strategies such as CMA-ES [Hansen, 2016]. W e focus on single-task HPO methods without multi-fidelity or transfer to isolate each optimizer’ s ability to learn the landscape from scratch. Methods such as Hyperband [Li et al., 2017], BOHB [F alkner et al., 2018], transfer HPO [W istuba and Grabocka, 2021, Arango et al., 2024], and zero-shot approaches [Öztürk et al., 2022] could in principle be applied to this benchmark but are not in the scope of this study . In line with the increasing interest in open-ended agentic discov ery [Zhang et al., 2026, Novik ov et al., 2025, Lange et al., 2026, Liu et al., 2024, W ang et al., 2026], recent work e xplores LLMs as components in HPO pipelines. While in principle, methods such as AlphaEvolv e [Novik ov et al., 2025] or ShinkaEvolv e [Lange et al., 2026] can be tasked to optimize the objecti ve in autoresearch, we focus only on methods tailored specifically for HPO. LLAMBO [Y e et al., 2024] uses an LLM as a surrogate model inside Bayesian optimization, replacing the Gaussian process with LLM-based per- formance predictions. SLLMBO [Mahammadli and Ertekin, 2024] integrates an LLM with TPE into a joint sampler . Zhang et al. [2023] prompt LLMs directly for HP suggestions. LLaMA-ES [Kramer, 2024] uses LLMs to tune CMA-ES’ s own hyperparameters. Schwanke et al. [2026a] partition the search space into subregions via a bandit mechanism and use an LLM to propose candidates within each region. The authors further extend that to multi-objective optimization [Schwank e et al., 2026b]. Howe ver , none of these methods share the classical optimizer’ s full internal state with the LLM, which is the key idea behind Centaur . Our work dif fers from prior work in four ways. First, we use autoresearch [Karpathy, 2025a] as a real-world benchmark that naturally accommodates both classical HPO within a fix ed search space and agentic LLM optimization through direct code editing, enabling a head-to-head comparison under identical conditions. Second, we benchmark classical and LLM methods on this task following best practices for algorithm configuration [Eggensperger et al., 2019]. Third, we automatically extract HPs from the training script via Abstract Syntax T ree (AST) parsing to control for human priors in the search space. Fourth, we introduce Centaur, a hybrid that explicitly passes CMA-ES’ s mean, σ , and C to the LLM, enabling optimizer -informed suggestions rather than history-only LLM reasoning. In contrast, LLAMBO uses the LLM as a surrogate where the acquisition function decides, SLLMBO combines LLM and TPE proposals without e xposing optimizer internals, and HOLLM [Schwanke et al., 2026a] uses spatial partitioning to constrain the LLM rather than inform it with optimizer state. 3 Experimental Setup W e describe the benchmark task and hardware, then the ev aluation protocol and failure handling, followed by the LLM infrastructure, and finally the automated search space e xtraction. W e ev aluate all methods on nanochat [Karpathy, 2025b], a small decoder-only transformer [Radford et al., 2019] trained on FineW eb [Penedo et al., 2024], optimizing validation bits-per-byte (v al_bpb). Each trial ran for fiv e minutes on a single NVIDIA H200 GPU (141 GB HBM3e). W e ran each method for 24 hours with three seeds and report results both against 24-hour wall-clock time and on trial scale (up to 300 trials). Methods with high OOM rates accumulated more trials due to fast failures ( < 30 s per OOM) but sho w negligible improvement be yond trial 300. W e report failed trials (OOM) as v al_bpb = 100 . 0 , a finite penalty orders of magnitude worse than any v alid result while remaining compatible with all surrog ate models, so that optimizers learn to a void infeasible regions. All LLM-based methods use Qwen3.5 [T eam, 2026] as the LLM optimizer , self-hosted via vLLM [Kwon et al., 2023] on the same GPU that trains the optimizee (the ∼ 50M-parameter language model). T o ensure equal resource allocation, we capped training VRAM to 80 GB for all methods, comparable to the H100 used by Karpath y [Karpathy, 2025a], and reserved the remaining memory for the vLLM server . W e disabled Qwen3.5’ s thinking mode and sampled with temperature 0.7, limiting outputs to 2048 tokens for fixed-HP methods and 16384 tokens for code editing. All prompt templates are av ailable in our repository . 3 T able 1: Search space: 14 HPs auto-extracted via AST parsing. Ranges are set manually . Defaults are Karpathy’ s starting config. WINDOW_PATTERN controls the per-layer attention windo w: S = short (local) attention, L = long (full) attention. HP T ype Range Log Default DEPTH int 4–24 8 ASPECT_RATIO int 32–128 64 HEAD_DIM int 64–256 ✓ 128 DEVICE_BATCH_SIZE int 32–256 ✓ 128 TOTAL_BATCH_SIZE int 65 536–2 097 152 ✓ 524 288 EMBEDDING_LR float 0.01–2.0 ✓ 0.6 UNEMBEDDING_LR float 0.0005–0.05 ✓ 0.004 MATRIX_LR float 0.005–0.2 ✓ 0.04 SCALAR_LR float 0.05–2.0 ✓ 0.5 WEIGHT_DECAY float 0.0–0.5 0.2 WARMUP_RATIO float 0.0–0.3 0.0 WARMDOWN_RATIO float 0.1–0.8 0.5 FINAL_LR_FRAC float 0.0–0.2 0.0 WINDOW_PATTERN cat. {SSSL, SSLL, SLSL, LLLL, SSSS, LSSL} SSSL T o extract hyperparameters from train.py , we used Abstract Syntax T ree (AST) parsing: we walk through parse tree and collect all top-le vel assignments whose variable name is in ALL_CAPS format and have a right-hand as a literal v alue (integer , float, or string). This yielded 14 HPs (13 continuous/integer and one categorical), listed in T able 1 with their types, ranges, and defaults from Karpathy’ s starting configuration. While the ranges require some domain knowledge, the hyperparameter selection itself is fully automated in this way , remo ving manual search space curation. T able 2 summarizes the nine methods we ev aluated across four classical, four LLM-based, and one hybrid approach. 4 Centaur: CMA-ES Guided LLM Optimization Centaur shares CMA-ES’ s full internal state with the LLM on a fraction of trials. On e very trial, CMA-ES proposes a candidate configuration from its multiv ariate Gaussian, parameterized by mean vector µ , step-size σ , and cov ariance matrix C . On 30% of trials, the LLM receiv es CMA-ES’ s proposal along with µ , σ , C , the top-5 configurations, and the last 20 trials. The LLM may override the proposal, and in practice does so in nearly all cases: 100% of the time with the 27B model and 95% with the 0.8B model. Crucially , CMA-ES updates its internal state from all trial results, T able 2: Methods ev aluated. “Fixed” indicates the shared 14-HP search space; “Unconstrained” indicates direct source code editing. Method Search Space Description TPE Fixed T ree-structured Parzen Estimator via Op- tuna [Bergstra et al., 2011, Akiba et al., 2019] CMA-ES Fixed Cov ariance Matrix Adaptation via Optuna’ s CMA sampler [Hansen, 2016] SMA C Fixed Random forest surrogate [Hutter et al., 2011] Random Fixed Uniform random sampling LLAMBO (Optuna) Fixed OptunaHub port: binary surrogate labels, random categorical sampling LLAMBO (Paper) Fixed Reimplementation faithful to Y e et al. [2024]: con- tinuous labels, all HPs visible Karpathy Agent (14 HPs) Fixed LLM sees trial history , suggests configs within fixed space Karpathy Agent (Code) Unconstrained LLM directly edits train.py source code [Karpa- thy, 2025a] Centaur Fixed CMA-ES shares internal state with LLM (Section 4) 4 Algorithm 1: Centaur Input: Search space S , budget T , LLM ratio r =0 . 3 1 Initialize CMA-ES, H ← ∅ ; 2 for t = 1 , . . . , T do 3 if LLM turn (with pr obability r ) then 4 Extract µ , σ, C from CMA-ES; 5 x ← LLM( µ , σ, C , H , S ); 6 else 7 x ← CMA-ES.Propose(); 8 end 9 y ← Evaluate( x ); 10 CMA-ES.Update( x , y ); 11 H ← H ∪ { ( x , y ) } ; 12 end including those where the LLM overrode its proposal, so the optimizer continuously learns from the full trajectory . W e chose CMA-ES because its internal state is particularly interpretable for LLM communication: the mean is a concrete configuration, σ is a single scalar , and C is a labeled matrix. In contrast, TPE maintains density estimators that are dif ficult to summarize in natural language, and GP-BO maintains a high-dimensional posterior . W e provide the full procedure in Algorithm 1. 5 Results W e compare classical and LLM-based HPO methods across three axes: fixed search space perfor- mance, unconstrained code editing, and hybrid optimization. All methods started from the same baseline configuration (Karpathy’ s default, v al_bpb ≈ 0 . 991 ). W e exclude LLM inference o verhead from wall-time to isolate optimization quality from inference cost; see appendix for trial-number views. 5.1 Classical methods outperform LLMs in fixed sear ch spaces Figure 1 sho ws con vergence curves against cumulativ e training wall-time for all 27B methods. W ithin the fixed search space, classical HPO methods consistently outperformed pure LLM-based approaches. The top methods by mean best val_bpb are Centaur (0.9763), TPE (0.9768), SMA C (0.9778), CMA-ES (0.9785), and Karpathy Agent (Code) (0.9814). The gap to the best fix ed-space LLM method, LLAMBO (Paper) at 0.9862, is substantial, and sev eral pure LLM methods performed worse than random search, indicating that restricting LLMs to a fixed HP search space does not lev erage their strengths. OOM avoidance matters more than search div ersity . T able 3 shows that the top methods all have OOM rates at or belo w 16%, while the bottom four exceed 36%. Karpathy Agent (14 HPs) has the lowest div ersity by all metrics (T able 3), conv erging to a narrow region early . LLAMBO (Paper) is one of the most di verse methods yet underperforms classical methods due to its 48% OOM rate. These OOM rates also illustrate the state-tracking limitation of small and mid-sized LLMs: LLAMBO (Paper) and LLAMBO (Optuna) observe full trial history yet produce OOM rates (48% and 61%) comparable to random search (56%), suggesting they fail to learn which regions of the search space cause memory failures. In contrast, CMA-ES and TPE maintain explicit optimization state and keep OOM rates at 16% and 11%. CMA-ES explores broadly but efficiently: it cov ers 802 grid cells with only 16% OOM, showing that cov ariance adaptation learns which directions are safe. Howe ver , CMA-ES also has the highest v ariance among top methods (std 0.0036 vs 0.0019 for TPE), with its best seed achieving the single best result in the benchmark (0.9741) while its worst seed is mediocre (0.9829). W e report both LLAMBO variants because the OptunaHub implementation dif fers from the original paper in how it handles surrogate labels, categorical HPs, and failed trials, which substantially affects OOM rates and performance (see Section A.8 for details). 5 T able 3: Search diversity analysis (3 seeds, alphabetical). All LLM-based methods use the 27B variant; see T able 5 for 0.8B. T rials : mean ± std total per seed. Best : mean ± std best val_bpb (bold = best). Spread : mean per-HP std. Pairwise : mean L2 between config pairs. Step : mean L2 between consecutiv e trials. Cells : unique 5-bin cells (see Section A.5). Method T rials Best v al_bpb OOM% Spread Pairwise Step Cells Centaur 334 ± 5 0.9763 ± 0.0005 15% 0.115 0.550 0.341 330 CMA-ES 336 ± 13 0.9785 ± 0.0036 16% 0.158 0.794 0.580 802 Karpathy Agent (14 HPs) 289 ± 2 0.9904 ± 0.0002 1% 0.035 0.225 0.057 29 Karpathy Agent (Code) 324 ± 7 0.9814 ± 0.0046 12% – – – – LLAMBO (Optuna) 629 ± 64 0.9882 ± 0.0012 61% 0.251 1.247 1.130 458 LLAMBO (Paper) 496 ± 6 0.9862 ± 0.0041 48% 0.252 1.257 1.218 364 Random 568 ± 21 0.9873 ± 0.0021 56% 0.273 1.380 1.382 514 SMA C 431 ± 2 0.9778 ± 0.0020 36% 0.238 1.191 0.369 224 TPE 317 ± 12 0.9768 ± 0.0019 11% 0.196 0.996 0.413 518 Figure 2: 0.8B vs 27B LLM optimizer comparison (wall-time). Solid: 27B, dashed: 0.8B. TPE and Random shown as classical references. The 0.8B model appears insufficient for unconstrained code editing but suf ficient for hybrid optimization. 5.2 Unconstrained code editing is viable but r equires model scale Karpathy Agent (Code), which directly edits training source code rather than operating in the fixed search space, is the only pure LLM method competitive with classical approaches. Giv en the simplicity of the setup and the use of a self-hosted open-weight model (Qwen3.5-27B), the gap to classical methods is smaller than one might expect, and stronger frontier models may close it further . Scaling the LLM from 0.8B to 27B is essential for unconstrained code editing but provides no advantage for fix ed-HP optimization. Figure 2 shows that 0.8B is insufficient for unconstrained code editing (Karpathy Agent Code: 0.9910 vs 0.9814 with 27B), while fixed-HP methods saw no benefit from scaling (Karpathy Agent 14 HPs: 0.9904 vs 0.9908). All LLM methods used open-weight Qwen3.5, and the gap between unconstrained code editing and classical methods is already small; stronger frontier models may further impro ve LLM-based methods, particularly for unconstrained code editing where model capability directly determines the quality of code modifications. A preliminary comparison with Gemini 2.5 Flash [Comanici et al., 2025] (Section A.2) shows no improv ement over Qwen3.5-27B, though stronger or larger frontier models may yield different results. 6 5.3 Hybrid optimization: best of both worlds Centaur outperformed all methods including CMA-ES alone by using the LLM on only 30% of trials. As described in Section 4, the LLM receives CMA-ES’ s full internal state ( µ , σ , C ), the top-5 configurations, and the last 20 trials, and almost al ways o verrides CMA-ES’ s proposal (100% for 27B, 95% for 0.8B). Despite constituting only 30% of trials, LLM trials contributed 25% of incumbent improv ements (Section A.4), confirming that the LLM provides complementary v alue beyond what CMA-ES finds alone. Beyond improving the mean, Centaur substantially reduces CMA-ES’ s cross- seed variance: std drops from 0.0036 for CMA-ES alone to 0.0005 for Centaur, suggesting that the LLM stabilizes the optimizer by injecting domain knowledge that prevents unfav orable seeds from drifting. Notably , Centaur [0.8B] outperformed Centaur [27B] (0.9766 vs 0.9763), suggesting that a cheap LLM suffices when paired with a strong classical optimizer . This stands in contrast to unconstrained code editing, where the 0.8B model is insufficient: when the classical optimizer handles the search trajectory , the LLM’ s role reduces to refining promising candidates, a task that does not require the same lev el of model capability as generating code edits from scratch. W e ablate the LLM ratio r in Section A.6. For the 0.8B model, r =0 . 2 achiev es the best single-seed result (0.9735), slightly outperforming the default r =0 . 3 (0.9776), while r =0 . 8 degrades to 0.9789. For the 27B model, r =0 . 5 performs best (0.9745), but r =0 . 8 collapses to 0.9903, worse than CMA-ES alone. This confirms that CMA-ES should retain majority control of the optimization trajectory: the LLM is most effecti ve as an occasional informed perturbation, not as the primary search dri ver . 6 Conclusion W e benchmarked classical, LLM-based, and h ybrid HPO methods on small-scale language model training under the same budgets and constraints. Within the fixed, constrained search space, classical HPO methods such as CMA-ES and TPE consistently outperformed LLM-based agents, with OOM av oidance emerging as a stronger predictor of performance than search di versity . Restricting LLMs to a fixed hyperparameter search space does not leverage their strengths; the one setting where a pure LLM method competes with classical approaches is unconstrained code editing [Karpathy, 2025a], where the agent directly modifies training source code and narrows the gap to classical methods substantially despite using only a self-hosted open-weight model. Howe ver , this requires sufficient model scale: the 0.8B model is insuf ficient for unconstrained code editing, while it suf fices for hybrid optimization. Centaur achieved the best result in our experiments by using the LLM on only 30% of trials, preserving fast con ver gence from CMA-ES while benefiting from LLM-informed suggestions, with the 0.8B variant outperforming the 27B v ariant. Our study ev aluated a single task with open-weight models (Qwen3.5 0.8B and 27B). Given that unconstrained code editing already nearly matches classical methods with these models, stronger frontier models may shift the balance further in fav or of LLM-based approaches. While we automated hyperparameter selection, the search space ranges still require manual specification, introducing some human priors. Future work could benchmark unconstrained code editing with frontier models to determine whether increased model capability allows LLM agents to match or surpass hybrid and classical methods. Additionally , exploring other classical optimizers as the hybrid base and pairing CMA-ES with a code-editing LLM agent could allow the search space to co-e volve with the optimization trajectory . 7 References T . Akiba, S. Sano, T . Y anase, T . Ohta, and M. Ko yama. Optuna: A next-generation Hyperparameter Optimization framew ork. In Pr oc. of KDD’19 , pages 2623–2631, 2019. S. Pineda Arango, F . Ferreira, A. Kadra, F . Hutter , and J. Grabocka. Quick-tune: Quickly learning which pretrained model to finetune and how . In Pr oc. of ICLR’24 , 2024. J. Bergstra and Y . Bengio. Random search for hyper-parameter optimization. Journal of Machine Learning Resear ch , 13:281–305, 2012. J. Bergstra, R. Bardenet, Y . Bengio, and B. Kégl. Algorithms for hyper-parameter optimization. In Pr oc. of NeurIPS’11 , pages 2546–2554, 2011. B. Bischl, M. Binder , M. Lang, T . Pielok, J. Richter , S. Coors, J. Thomas, T . Ullmann, M. Becker , A.- L. Boulesteix, D. Deng, and M. Lindauer . Hyperparameter optimization: Foundations, algorithms, best practices, and open challenges. W iley Inter disciplinary Reviews: Data Mining and Knowledge Discovery , page e1484, 2023. Gheorghe Comanici, Eric Bieber , Mike Schaekermann, Ice Pasupat, Noveen Sachdev a, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Ev an Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality , long context, and next generation agentic capabilities. arXiv pr eprint arXiv:2507.06261 , 2025. K. Eggensperger , M. Lindauer, and F . Hutter . Pitfalls and best practices in algorithm configuration. Journal of Artificial Intellig ence Researc h , pages 861–893, 2019. S. Falkner , A. Klein, and F . Hutter . BOHB: Robust and efficient Hyperparameter Optimization at scale. In Pr oc. of ICML’18 , pages 1437–1446, 2018. M. Feurer and F . Hutter . Hyperparameter Optimization. In F . Hutter, L. K otthoff, and J. V anschoren, editors, Automated Machine Learning: Methods, Systems, Challenges , chapter 1, pages 3 – 38. Springer , 2019. A v ailable for free at http://automl.org/book . Nikolaus Hansen. The CMA ev olution strategy: A tutorial. arXiv pr eprint arXiv:1604.00772 , 2016. F . Hutter , H. Hoos, and K. Le yton-Brown. Sequential model-based optimization for general algorithm configuration. In Pr oc. of LION’11 , pages 507–523, 2011. Andrej Karpathy . autoresearch. https://github.com/karpathy/autoresearch , 2025a. Andrej Karpathy . nanochat. https://github.com/karpathy/nanochat , 2025b. Oliv er Kramer . LLaMA tunes CMA-ES. In European Symposium on Artificial Neural Networks (ESANN) , 2024. W oosuk Kwon, Zhuohan Li, Siyuan Zhuang, Y ing Sheng, Lianmin Zheng, Cody Hao Y u, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for lar ge language model serving with PagedAttention. In Pr oceedings of the ACM SIGOPS 29th Symposium on Oper ating Systems Principles , 2023. Robert Tjarko Lange, Y uki Imajuku, and Edoardo Cetin. Shinkaev olve: T owards open-ended and sample-efficient program ev olution. In The F ourteenth International Confer ence on Learning Repr esentations , 2026. L. Li, K. Jamieson, G. DeSalvo, A. Rostamizadeh, and A. T alwalkar . Hyperband: Bandit-based configuration ev aluation for Hyperparameter Optimization. In Pr oc. of ICLR’17 , 2017. Fei Liu, Rui Zhang, Zhuoliang Xie, Rui Sun, Kai Li, Xi Lin, Zhenkun W ang, Zhichao Lu, and Qingfu Zhang. Llm4ad: A platform for algorithm design with large language model. 2024. Kanan Mahammadli and Schahin Ertekin. Sequential large language model-based hyper-parameter optimization. arXiv preprint , 2024. 8 Alexander No vikov , Ngân V~u, Marvin Eisenberger , Emilien Dupont, Po-Sen Huang, Adam Zsolt W agner , Sergey Shirobokov , Borislav M. Kozlo vskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar , Abigail See, Swarat Chaudhuri, George Holland, Ale x Davies, Sebastian Now ozin, Pushmeet Kohli, Matej Balog, and Google DeepMind. Alphae volve: A coding agent for scientific and algorithmic discov ery . ArXiv , abs/2506.13131, 2025. E. Öztürk, F . Ferreira, H. S. Jomaa, L. Schmidth-Thieme, J. Grabocka, and F . Hutter . Zero-shot automl with pretrained models. In Pr oc. of ICML’22 , pages 1128–1135, 2022. G. Penedo, H. Kydlí ˇ cek, L. Ben allal, A. Lozhkov , M. Mitchell, C. Raffel, L. V on W erra, and T . W olf. The fine web datasets: Decanting the web for the finest text data at scale. In Pr oc. of NeurIPS’24 , 2024. A. Radford, J. W u, R. Child, D. Luan, D. Amodei, and I. Sutskev er . Language models are unsupervised multitask learners. OpenAI blog , 1(8):9, 2019. Andrej Schwanke, L yubomir Ivano v , David Salinas, F abio Ferreira, Aaron Klein, Frank Hutter, and Arber Zela. Improving LLM-based global optimization with search space partitioning. In The F ourteenth International Confer ence on Learning Representations , 2026a. Andrej Schwanke, L yubomir Ivano v , David Salinas, Frank Hutter , and Arber Zela. Multi-objectiv e hierarchical optimization with large language models. ArXiv , abs/2601.13892, 2026b. J. Snoek, H. Larochelle, and R. Adams. Practical Bayesian optimization of machine learning algorithms. In Pr oc. of NeurIPS’12 , pages 2960–2968, 2012. Qwen T eam. Qwen3.5: Accelerating producti vity with native multimodal agents, February 2026. URL https://qwen.ai/blog?id=qwen3.5 . W enyi W ang, Piotr Pi ˛ ekos, Li Nanbo, Firas Laakom, Y imeng Chen, Mateusz Ostaszewski, Mingchen Zhuge, and Jür gen Schmidhuber . Huxley-g\”odel machine: Human-lev el coding agent development by an approximation of the optimal self-improving machine. In The F ourteenth International Confer ence on Learning Representations , 2026. M. W istuba and J. Grabocka. Few-shot bayesian optimization with deep k ernel surrogates. In Proc. of ICLR’21 , 2021. Henry Y e, T ennison Liu, Nicolo Cadei, and Mihaela v an der Schaar . LLAMBO: Large language mod- els to enhance Bayesian optimization. In International Conference on Learning Repr esentations , 2024. Jenny Zhang, Shengran Hu, Cong Lu, Robert Tjarko Lange, and Jef f Clune. Darwin gödel machine: Open-ended e volution of self-improving agents. In The F ourteenth International Confer ence on Learning Repr esentations , 2026. Michael Zhang, Nishkrit Desai, Juhan Bae, Jonathan Lorraine, and Jimmy Ba. Using large language models for hyperparameter optimization. arXiv pr eprint arXiv:2312.04528 , 2023. Ravid Shwartz Zi v . Do LLM coding agents fool us? Karpathy’ s autoresearch experi- ment revisited. https://www.linkedin.com/posts/ravid- shwartz- ziv- 8bb18761_ do- llm- coding- agents- fool- us- karpathys- activity- 7437556522240536576- ygrQ , 2025. 9 A Additional Results A.1 Con vergence by T rial Number The main text reports con ver gence against cumulati ve training time, which is our primary comparison. Figures 3 and 4 sho w con vergence by trial number instead, measuring sample ef ficiency . These views can differ substantially because LLM-based methods spend additional time on inference between trials, compressing their wall-time curves e ven when the y are competitive per trial. Figure 3: Conv ergence by trial number (mean ± std across 3 seeds). Same methods as Figure 1. T rial-number view sho ws sample efficiency rather than w all-clock cost. A.2 Frontier Model Comparison: Gemini 2.5 Flash T o test whether a stronger LLM optimizer changes the balance between classical and LLM-based methods, we ran Centaur , Karpathy Agent (Code), and LLAMBO (P aper) with Gemini 2.5 Flash [Co- manici et al., 2025] as the LLM optimizer instead of Qwen3.5-27B. Figure 5 compares the two ov er cumulativ e training time. Classical methods (TPE, Random) are shown as references. W ithin this window , Gemini 2.5 Flash does not outperform Qwen3.5-27B on this task, suggesting that simply swapping to a frontier model does not automatically close the gap to classical methods. A.3 Incumbent T races Beyond aggre gate con vergence, we visualize per -method incumbent traces to re veal when and ho w each optimizer finds improvements. Figures 6 and 7 sho w incumbent traces against cumulative training time (hours) for all methods. Grey dots are all trials, colored dots are new incumbents, and the staircase line is the best-so-far trajectory . Each panel shows the best seed for that method. A.4 Qualitative Agent Beha vior The con vergence plots show that Centaur improves over CMA-ES alone; we now examine how the LLM uses the shared optimizer state in practice. In Centaur seed 0, trial 136 produced a new incumbent (val_bpb = 0 . 9837 ): • CMA-ES suggested: WINDOW_PATTERN=LLLL , DEVICE_BATCH_SIZE=61 , TOTAL_BATCH_SIZE=133143 , SCALAR_LR=0.208 10 Figure 4: 0.8B vs 27B by trial number (mean ± std across 3 seeds). Same methods as Figure 2. Solid lines: 27B, dashed: 0.8B. • LLM overr ode to: WINDOW_PATTERN=SSSS , DEVICE_BATCH_SIZE=64 , TOTAL_BATCH_SIZE=131072 , SCALAR_LR=0.3 Three overrides are notable: (1) Attention patter n (LLLL → SSSS): CMA-ES has no domain knowledge about attention patterns. The LLM chose all-short attention, which is memory-efficient at the gi ven depth (DEPTH = 10 ). This is transformer-specific kno wledge that CMA-ES cannot learn from scalar loss v alues. (2) Hardwar e-friendly rounding : the LLM chose power -of-2 batch sizes (64, 131072) instead of CMA-ES’ s arbitrary values (61, 133143), aligning with GPU memory and tensor core constraints. (3) Learning rate : the LLM boosted SCALAR_LR from 0.208 to 0.3, closer to the regime where good configs cluster . Overall in seed 0, 6 of 24 incumbent impro vements came from LLM trials (25%), while LLM trials constituted 88 out of 275 total trials (32%, close to the 30% target ratio). A.5 Diversity Metrics W e no w define the di versity metrics reported in T able 3. W e compute all metrics on the 13 continuous HPs, excluding the categorical WINDOW_PATTERN . W e normalize each HP to [0 , 1] within its bounds and use only successful (non-OOM) trials. • Spread : mean standard de viation per HP across all trials. Higher values indicate more di verse sampling across each dimension. • Pairwise : mean L2 distance between all pairs of configurations. Higher values indicate configs are more different from each other . • Step : mean L2 distance between consecutiv e trials. Higher v alues indicate larger jumps between suggestions. • Cells : we discretized each HP into 5 equal-width bins and counted the number of unique 13- dimensional bin vectors across all trials. The theoretical maximum is 5 13 ≈ 1 . 2 × 10 9 ; v alues in T able 3 range from 29 to 805, indicating that all methods cover a small fraction of the search space. A.6 Centaur LLM Ratio Ablation W e ablate the fraction of trials dele gated to the LLM in Centaur. T able 4 reports best v al_bpb for each ratio on seed 0. The default ratio of r =0 . 3 balances classical and LLM contrib utions; higher ratios 11 Figure 5: Gemini 2.5 Flash vs Qwen3.5-27B as LLM optimizer (cumulativ e training time). Solid: Gemini, dashed: Qwen3.5-27B. Same color per method. degrade performance, particul arly for the 27B model where r =0 . 8 performs worse than CMA-ES alone. This confirms that CMA-ES needs to retain majority control of the optimization trajectory , with the LLM contributing occasional informed suggestions rather than dominating the search. T able 4: Centaur LLM ratio ablation (seed 0). Best v al_bpb for each ratio. Bold = best per column. The default ratio is r =0 . 3 . LLM Ratio r Centaur [0.8B] Centaur [27B] 0.1 0.9746 0.9752 0.2 0.9735 0.9753 0.3 (default) 0.9776 0.9756 0.5 0.9787 0.9745 0.8 0.9789 0.9903 A.7 0.8B LLM V ariant Results The main text focuses on 27B v ariants; we now report the corresponding 0.8B results. T able 5 reports div ersity metrics for the 0.8B LLM variants of all LLM-based methods. T able 5: Diversity analysis for 0.8B LLM v ariants (3 seeds each). Method Trials Best val_bpb OOM% Spread Pairwise Step Cells Centaur 334 ± 4 0.9766 ± 0.0008 15% 0.133 0.651 0.390 359 Karpathy Agent (14 HPs) 338 ± 3 0.9908 ± 0.0002 16% 0.037 0.066 0.062 24 Karpathy Agent (Code) 369 ± 34 0.9910 ± 0.0001 20% – – – – LLAMBO (Optuna) 668 ± 29 0.9873 ± 0.0003 64% 0.297 1.498 1.311 691 LLAMBO (Paper) 605 ± 6 0.9894 ± 0.0007 59% 0.272 1.365 1.330 290 A.8 LLAMBO (Optuna) vs LLAMBO (Paper): Detailed Comparison W e include two LLAMBO v ariants because the OptunaHub port dif fers from the original paper in ways that substantially af fect performance. T able 6 summarizes the key implementation dif ferences. 12 Figure 6: Incumbent traces for classical and hybrid methods (wall-time, best seed). Grey dots: all trials. Colored dots: new incumbents. Staircase: best-so-far . T able 6: Key dif ferences between LLAMBO (Optuna) and LLAMBO (Paper). Aspect Original Paper OptunaHub Port Surrogate labels Continuous metric values Binary 0/1 (top 20% threshold) Categorical HPs All HPs in LLM prompts Delegated to random sampling Failed trials V isible to surrogate Hidden ( TrialState.FAIL ) 13 Figure 7: Incumbent traces for LLM-based methods (wall-time, best seed). Figure 8: Effect of LLM ratio on Centaur performance (seed 0). Higher ratios gi ve the LLM more trials. CMA-ES alone (dotted) shown as reference. T oo much LLM control degrades performance, especially for the 27B model at r =0 . 8 . 14
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment