A capture-recapture hidden Markov model framework for register-based inference of population size and dynamics
Accurate inference on population dynamics, such as migration and changes in population size, is essential for policymaking, resource allocation and demographic research. Traditional censuses are expensive, infrequent and not timely, leading many coun…
Authors: Lucy Y Brown, Eleni Matechou, Bruno Santos
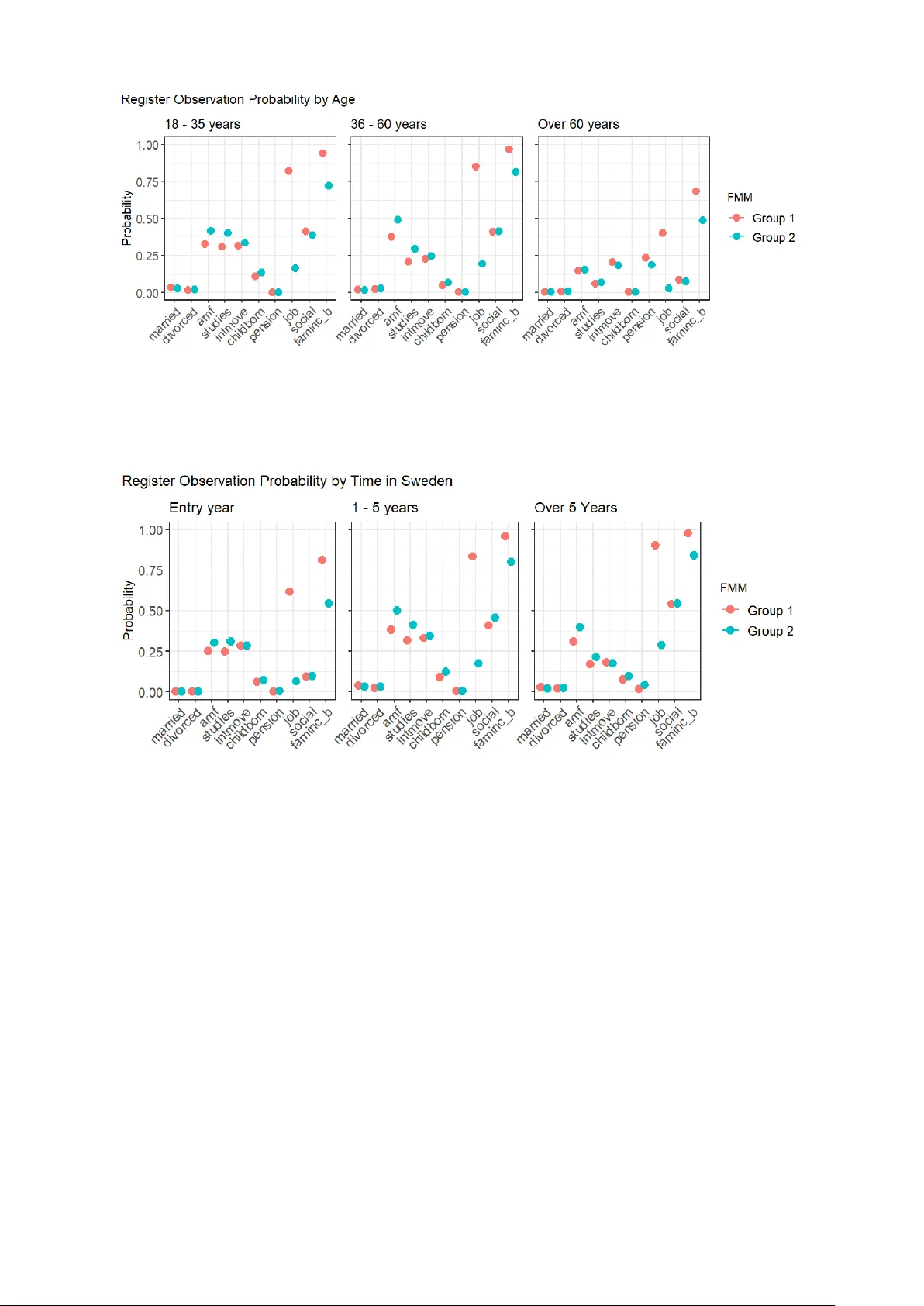
A capture-recapture hidden Mark o v mo del framew ork for register-based inference of p opulation size and dynamics Lucy Y. Bro wn ∗ 1 , Eleni Matec hou 2 , Bruno San tos 3 , and Eleonora Mussino 4,5 1 Sc ho ol of Engineering, Mathematics and Ph ysics, Universit y of Ken t, UK 2 Sc ho ol of Mathematical Sciences, Queen Mary Univ ersity of London, UK 3 CEA UL - Centro de Estat ´ ıstica e Aplica¸ c˜ oes, F aculdade de Ci ˆ encias, Univ ersidade de Lisb oa, Lisbon, Portugal 4 Departmen t of So ciology , Sto c kholm Univ ersity , Sw eden 5 Departmen t of So ciology , Ume ˚ a Univ ersity , Sw eden Abstract Accurate inference on p opulation dynamics, such as migration and changes in population size, is essen tial for p olicymaking, resource allo cation and demographic research. T raditional censuses are exp ensiv e, infrequent and not timely , leading man y coun tries to adopt administration register- based approaches to replace or complement them. A primary challenge in this shift is that such registers are incomplete: ev en when individuals are presen t in the population, their activities may not generate records in specific registers in a given perio d, resulting in false negative observ ation error at the register lev el. Con versely , some registers do not constitute a direct “sign of life” from the individual but arise from administrativ e or household-level pro cesses, so that individuals ma y app ear in registers despite b eing absent, leading to false p ositiv e observ ation error. Existing approac hes for register data often either rely on ad-ho c decisions that ignore one or b oth types of observ ation error, or only offer inference on population snapshots but not on dynamics, or are computationally to o slow to b e used in practice. W e prop ose a scalable framework for in- ferring population size and dynamics from register data, building on Cormack-Jolly-Seber type capture-recapture mo dels formulated as hidden Marko v mo dels. Inference is carried out using maxim um likelihoo d estimation, with uncertaint y quantified via the Bag of Little Bo otstraps. The mo del accounts for temp orary emigration, incorp orates an arbitrary n umber of p ossibly interact- ing observ ation registers sub ject to false p ositiv e and false negative observ ation error, and allo ws observ ation probabilities to v ary with individual characteristics and unobserv able heterogeneity . W e illustrate the approach using Sw edish population registers, where ov ercov erage - individuals registered as living in the country although they are no longer present - pro vides a motiv ating ex- ample. The application yields new insights into p opulation dynamics and individual tra jectories, demonstrating the p oten tial of the prop osed mo del for register-based demographic research. Keyw ords: register data, capture-recapture, hidden Marko v mo dels, observ ation errors, individual heterogeneit y 1 In tro duction 1.1 Bac kground Reliable inference on p opulation dynamics, encompassing b oth the monitoring of migration flo ws and the estimation of total population size, is a cornerstone of effectiv e p olicymaking, resource allo cation, ∗ Corresponding Author: lyb3@ken t.ac.uk 1 and demographic research [Office for National Statistics, 2024]. This task is particularly challenging for mobile p opulations, such as migrants, or for cryptic/hard-to-reach p opulations, such as drug users, for whom traditional censuses are often infeasible, exp ensiv e or not timely enough [B¨ ohning et al., 2018, Skinner, 2018]. Inaccurate p opulation size estimates, whether for the full p opulation or for sp ecific groups of individuals, lead to biases in k ey demographic rates, suc h as birth and death rates [W allace et al., 2025]. Reliable p opulation size estimation is therefore essen tial for providing p olicy- and decision-makers with realistic assessments of p opulation needs, allowing effective allo cation of resources and planning of in terven tions. As an alternativ e to a census, an increasing num b er of countries hav e adopted a register-based approac h for monitoring p opulations, to either replace or complement censuses [W allgren and W allgren, 2014]. Register data refers to administrativ e data that is regularly collected and updated via in teraction with official b o dies, suc h as the birth, marriage and emplo yment registers. Nordic coun tries ha ve a long history of a fully register-based system, and in the past 10 years the official statistics agencies of many other countries ha ve proposed plans to adopt register-based approaches for p opulation size estimation, suc h as the UK [Abbott et al., 2020], New Zealand [Bycroft, 2015] and Australia [Chipp erfield et al., 2024]. How ever, any single administrative source is inherently incomplete, as individual registers do not capture every member of the p opulation within a giv en p eriod (false negativ e observ ation error). While the use of multiple registers cov ering a diverse range of activities improv es ov erall co verage, the probabilit y of non-observ ation p ersists across all sources, and hence population size cannot b e inferred from the raw data as there exist individuals who do not appear in any register. On the other hand, registers may also con tain indirect observ ations (false p ositiv e observ ation error), defined as records that do not constitute a direct “sign of life” from the individual but are instead artefacts of administrative or household-level pro cesses. In suc h cases, an individual app ears on a register despite b eing absent from the p opulation. Additionally , emigration cannot be assumed p ermanen t, and therefore a p erio d of non-observ ation follo wed b y subsequent reappearance in registers do es not imply contin uous residence. The combination of false p ositiv e observ ation error and temp orary emigration in tro duce additional complexit y in determining an individual’s true lo cation. Importantly , observ ation probabilities are register- and individual-sp ecific, v arying as functions of individual cov ariates as well as unobserved individual heterogeneit y b eyond what is explained by observed cov ariates [W allgren and W allgren, 2014, B¨ ohning et al., 2018, Gimenez et al., 2018, F orsythe et al., 2021]. Finally , dep endence b et ween registers is often exhibited, such that activit y in one register can increase or decrease the probabilit y of app earing in another, as the underlying b eha viours are correlated, either p ositiv ely or negatively , or due to administrative pro cess links. These data challenges motiv ate the need for tailored statistical approac hes for reliable inference from register data. 1.2 Existing Approac hes A common, relativ ely simple but ad-hoc group of approac hes to estimate population size and dynamics is based on iden tifying a “sign of life” within administrative registers, alternativ ely referred to as “register-trace” approaches. Sign of life approaches trac k individuals o ver a series of administrative registers and only classify individuals that app ear on at least one of these registers as present in the coun try . They hav e b een used in official settings by countries suc h as Sweden [Statistics Sweden, 2015, 2018], Norw ay [Krokedal et al., 2024], Finland [Statistics Finland, 2024] and Italy [Solari et al., 2023], and prop osed as a p ossible approac h by others, suc h as the UK (sp ecifically England and W ales) [Abb ott et al., 2020]. Restrictions on the types of registers considered can b e made, for example the “zero personal income approach” in which individuals with no p ersonal income from a v ariety of sources in a giv en y ear are excluded and assumed to b e no longer residen t [W eitoft et al., 1999, Aradh ya et al., 2017]. How ever, these metho ds rely heavily on ad-ho c register rules to define p opulation size and cannot monitor p opulation dynamics such as migration, except where mov ements are officially do cumen ted. These ad-ho c metho ds must b e decided in adv ance and k ept consistent, resulting in difficult formalisation and application to other settings. A more formal class of metho ds is based on log-linear models for contingency tables, using the m ultiple systems estimation (MSE) framework. These mo dels treat the observ ed register com binations 2 as cells in a contingency table and infer the probability of b eing obse rv ed in each cell. This in turn allo ws estimation of the n umber of individuals in the unobserv ed “all-zero” cell, corresp onding to the n umber of individuals who do not app ear in any registers, allo wing population size estimation. In this setting, recently Mussino et al. [2023] allow ed for the inclusion of individual cov ariates and accoun ted for dep endence b et ween registers using interaction terms. In the sp ecial case of tw o administrativ e registers, dual system estimation (DSE) has b een prop osed as a wa y to estimate p opulation size. Recent applications in Australia [Chipp erfield et al., 2024] and Ireland [Dunne and Zhang, 2023] adapt the DSE framew ork to the realities of administrativ e data by addressing t wo key sources of observ ation error. First, records that do not corresp ond to genuine presence in the p opulation are mitigated through trimming which remov es implausible or lo w-quality observ ations (i.e. false p ositiv e observ ation error). Secondly , link age problems are handled b y incorp orating the probabilit y that records b elonging to the same individual were correctly link ed, giv en their individual characteristics. MSE approac hes are computationally efficient, allow individual- and register-sp ecific observ ation probabilities to dep end on individual cov ariates, and account for dep endence b et w een registers. Ho wev er, b ecause they op erate on an ann ual basis, they only pro vide a snapshot of the population size, and cannot b e used to infer p opulation dynamics or iden tify the underlying demographic pro cesses driving these dynamics. A related approach by Yildiz and Smith [2015] prop osed hierarchical log-linear mo dels with offsets to com bine an inaccurate administrativ e source with an auxiliary data source, but similarly operated on an ann ual basis and additionally required the existence of an auxiliary data source such as a cov erage surv ey . Finally , capture-recapture (CR) mo dels provide a natural framework for inferring p opulation dy- namics and p opulation size, while accounting for observ ation errors, and they form the foundation of the approac h w e develop in this pap er. Op en-population CR mo dels suc h as the Cormack-Jolly-Seber (CJS) framew ork [Cormack, 1964, Jolly, 1965, Seber, 1965] condition on an individual’s first capture in the study and mo del subsequent surviv al and recapture probabilities, allowing individuals to be follo wed ov er time. In classical CR models [Pollock, 2000, McCrea and Morgan, 2014], individuals are rep eatedly “captured” and “recaptured”, generating a capture history that records when each individ- ual is observed. A capture o ccasion refers to a single opp ortunit y to observe an individual at a given time p oin t. Although CR metho ds originated in ecology for estimating the size of wildlife p opulations, they are now widely used in h uman p opulation studies, including disease prev alence [Poorola jal et al., 2017, B¨ ohning et al., 2020, Thompson et al., 2023], homelessness estimation [Coumans et al., 2017], and other applications in the so cial and medical sciences. Ho wev er, within administrativ e register settings, the application of CR mo dels has b een limited [B¨ ohning et al., 2018], with the exception of Santos et al. [2024]. The Santos et al. [2024] work demon- strates the p oten tial of CR mo dels to recov er laten t demographic pro cesses from register data, but also highlights important practical limitations. In particular, their Ba yesian framew ork implemen ta- tion requires rep eatedly sampling individual- and time-sp ecific laten t states, and hence is unsuitable for realistic data sizes. It also doe s not accommodate false p ositiv e observ ation error; as a result, individuals who ha ve emigrated but contin ue to app ear in registers through administrative artefacts are misclassified as present, leading to o verestimation of p opulation size. Finally , it represents in- dividual heterogeneit y only through observed co v ariates rather than a flexible latent structure. In practice, how ev er, individuals may differ in their tendency to app ear in administrative registers due to behavioural or demographic factors that are not recorded, and such unobserv ed heterogeneit y is a w ell-known source of biased parameter estimate s in CR mo dels [Gimenez and Cho quet, 2010]. T ak en together, these limitations motiv ate the need for a new modelling approach tailored to administrativ e data. 1.3 Our Con tribution W e prop ose a unified framework that is the first to join tly address the key challenges of administrative register data - multiple in teracting registers sub ject to b oth t yp es of observ ation error, temp orary emi- gration, and unobserved individual heterogeneit y - while remaining scalable to full-p opulation datasets. W e employ a hidden Marko v mo del (HMM) formulation [Zucchini and MacDonald, 2016], whic h pro- 3 vides a link betw een an individual’s unobserv ed true states (e.g. present, dead, or emigrated) and their observ ations, allo wing us to efficiently mo del latent mo vemen t dynamics. A key metho dological inno- v ation is a multicategory logit mo del [Agresti, 2007] for the observ ation probabilities, which remov es the standard indep endence assumption across sampling o ccasions (registers) and allo ws observ ation probabilities to v ary with cov ariates and unobserved heterogeneity via a finite-mixture structure. T o ensure scalabilit y for large administrativ e datasets, w e integrate a Bag-of-Little-Bootstraps (BLB) pro- cedure [Kleiner et al., 2012, 2014] for uncertaint y quan tification. Standard b ootstrapping approac hes easily become computationally infeasible when w orking with large datasets, as is the case with national administrativ e data. T o our kno wledge, BLB has not previously b een applied in CR or HMM-based p opulation mo dels, despite its suitability for large-scale likelihoo d-based inference and abilit y to handle complex parameter structures that would b e nearly imp ossible in alternative uncertaint y quantification metho ds. T ogether these contributions provide a no vel, unified and flexible mo delling framework for register-based inference of population size and dynamics. 1.4 Motiv ating case study The motiv ation for this pap er comes from the Sw edish p opulation registers, sp ecifically for the migrant p opulation. In Sweden, as well as in many other Europ ean coun tries, all individuals whose actual or planned primary residence is within the coun try for at least one year are required to register with the Swedish T ax Agency , becoming part of the Register of T otal Population ( R e gistr et ¨ over totalb efolkningen - R TB). Up on registration, a p ersonal identification num b er is assigned, which is necessary for v arious life activities suc h as accessing banking and housing; these high incen tives to register result in minimal underco verage (incorrectly excluding individuals from the population) of the de jur e population, consisting only of individuals a waiting their immigration to b e pro cessed. Individuals are equally required to de-register when leaving Sw eden, but a combination of lac k of kno wledge and lo w incentiv es mean many individuals do not, resulting in ov ercov erage (incorrectly retaining individuals in the R TB after their departure from the coun try) [Andersson et al., 2023]. In this pap er we include a case study where we use Swedish administrative data for all foreign- b orn adults who first entered the coun try b et ween 2003 − 2016. This data is similar to that used b y previous pap ers [Mussino et al., 2023, Santos et al., 2024], allowing for meaningful comparison of p opulation size estimates across mo delling approaches. Our analysis also yields new insights into p opulation tra jectories, allo wing individual-lev el mo v ements to be follo w ed o ver time. While motiv ated b y the Sw edish con text, the metho ds prop osed are applicable to other settings in v olving administrativ e registers. This paper is structured as follo ws. In Section 2 w e in tro duce the prop osed mo delling approac h and inference pro cess. In Section 3 we present the motiv ating case study and results, including comparison with previous models. In Section 4 w e giv e concluding remarks and discuss some p ossible extensions for future work. Due to the sensitive and confiden tial nature of the data used in the case study , the dataset cannot b e made publicly av ailable; how ev er, the co de has b een pack aged and op enly accessible as the R pac k age over c over age (av ailable at: https://brsantos.github.io/overcoverage/ ). 2 Metho ds 2.1 Observ ed Data W e consider longitudinal administrative data on individuals i = 1 , ..., N who first enter the study area at some p oin t (year) during the observ ation p eriod t = 1 , ..., T . F ollo wing the standard CJS approach of conditioning on first en try , we mo del individuals from the year they first enter the p opulation of in terest. The n umber of new entran ts each year is denoted n t . As we condition on first entry , the mo delled p opulation at t = 1 consists only of those individuals whose entry o ccurs in that year, so for this cohort w e hav e a p opulation size N 1 = n 1 . Each year t individuals may app ear on a set of administrativ e registers k = 1 , ..., K . Therefore, for each individual and year we observe a vector of 4 register indicators Y it = ( Y it 1 , ..., Y itK ) where Y itk = 1 if individual i app ears in register k at time t and 0 otherwise. Eac h register k within year t constitutes a capture o ccasion, and the K registers within a giv en y ear collectiv ely form the observ ation record for that y ear. The observ ed register pattern Y it do es not rev eal whether an individual is present, temporarily abroad, permanently emigrated, or deceased. T o represent this unobserv ed and dynamic structure, w e introduce a laten t state v ariable and mo del the data using a hidden Marko v mo del, as in subsequent sections. In addition to the K observ ation registers, w e observ e administrative even t records corresponding to emigration, re-immigration, and death. These registers are treated differently from the K observ a- tion registers b ecause they corresp ond to transitions b et ween latent states, rather than observ ations conditional on a state, and they are assumed to occur only b et ween years. In particular, an emi- gration record is (p oten tially) generated only when an individual transitions from presen t to abroad, and a death record is (p oten tially) generated only when an individual transitions in to the dead state. T ogether, these data sources form the input to the HMM described below. 2.2 Laten t State Pro cess W e formulate CR mo dels as HMMs, whic h marginalise ov er latent states using the forw ard algorithm [Laak e, 2013, Zucchini and MacDonald, 2016, Jurafsky and Martin, 2026]. HMMs are well established in a wide range of fields, with applications in pattern recognition [Nefian and Hay es, 1998, Jurafsky and Martin, 2026] and time series mo delling, among others [Bouguila et al., 2022], including in ecological CR applications [Laake, 2013, Zucchini and MacDonald, 2016]. In an HMM, the latent state pro cess (e.g. aliv e, absent, dead), ev olves according to a Marko v chain, and the observed data is generated from an emission distribution that sp ecifies the probability of eac h observed outcome giv en the current laten t state. F or each individual i = 1 , ..., N and time p oin t t = 1 , ..., T , let Z it ∈ { 1 , ..., L } denote the corre- sp onding unobserved true state. Conceptually , the state space denotes whether an individual is (1) aliv e and present in the study area, (2) alive but abroad, or (3) dead, whic h is an absorbing state. These broad categories capture the demographic and geographic pro cesses relev ant for p opulation estimation. Individuals initially en ter the study alive and present, and subsequently independently ev olve ac- cording to a Marko v process, either remaining presen t, mo ving abroad through emigration, returning from abroad through re-immigration, or dying. 2.3 T ransition Mo del The transition model specifies ho w individuals mo ve b et ween laten t states from one y ear to the next. The evolution of each individual’s latent state b et ween times t and t + 1 is go verned by a set of demographic transition probabilities. These transitions are enco ded in an individual- and time-sp ecific L × L transition matrix Γ it , whose entries dep end on observ ed cov ariates. W e model the probability of three key life-even ts: surviv al s it , emigration e it , and re-immigration r it , whic h are defined suc h that for a generic life-even t, θ it is the probabilit y that it occurs for individual i transitioning betw een times t and t + 1. All three probabilities v ary across individuals and time, and are parameterised using logistic regression to incorp orate observed sources of heterogeneity [Agresti, 2007]. The non-zero en tries of Γ it are determined b y the surviv al, emigration, and re-immigration proba- bilities introduced ab o ve and the latent state follows a first-order Marko v chain Z i,t +1 | ( Z i,t = l ) ∼ Categorical(Γ it [ l, · ]) (1) suc h that the l th row of Γ it giv es the probabilities of transitioning from state l at time t to eac h p ossible state at time t + 1. This links the individual-level transition probabilities ( s it , e it and r it ) directly to the evolution of the latent state pro cess. 5 When considering the three conceptual states outlined previously , the transition matrix can b e sp ecified as follo ws: Γ it = s it (1 − e it ) s it e it 1 − s it s it r it s it (1 − r it ) 1 − s it 0 0 1 (1) Present (2) Abroad (3) Dead (2) This structure reflects the demographic pro cesses enco ded in the mo del. Individuals presen t in the study area may survive and remain present, die, or emigrate, and individuals who are abroad ma y surviv e and remain abroad, die abroad, or re-immigrate. The transition matrix is presented here in its most general form but can be tailored to sp ecific case studies dep ending on the registers that are collected and the administrativ e even ts that m ust b e accounted for. 2.4 Observ ation Mo del This section describ es how the observ ation mo del is constructed conditional on the individual latent state whilst accounting for false negative (Section 2.4.1) and false positive (Section 2.4.2) observ ation error and observ ations of migration and death even ts (Section 2.4.3). 2.4.1 Accoun ting for F alse Negative Observ ation Error When an individual is alive and present in the study area the observ ation Y it corresp onds to one of J p ossible register and cov ariate combinations, including unobserved in all registers. W e incorp orate categorical co v ariates by allo wing each register-cov ariate combination to define its own observ able category , effectiv ely extending the emission space in a wa y analogous to ho w MSE mo dels handle stratification. W e mo del Y it | ( Z it = 1) ∼ Multinomial(1; p i 1 t , ..., p iJ t ) (3) where the category probabilities are obtained from a multicategory logit mo del [Agresti, 2007]. In the baseline-category form ulation of multicategory logit mo dels, the log-o dds of eac h category relative to a chosen reference category are mo delled as linear functions of cov ariates. This framew ork allo ws the probability of each observ ation category to dep end on individual characteristics, time-v arying factors, and interactions b et w een predictors. By treating each register-co v ariate com bination as its own observ ation category , the model inherits a key strength of MSE approaches: the ability to stratify the observ ation process across finely defined register cells, allo wing dependence b et w een registers, co v ariate effects, and unobserved heterogeneity to b e represented jointly within a single emission mo del. T o our kno wledge, this bridging of CR and MSE observ ation structures has not previously b een prop osed within a CR or HMM framework. Let x ij t denote the design vector for observ ation category j containing indicators for the K registers, co v ariate categories, and their tw o- w ay interactions. The probability of observing category j is P r ( Y it = j | Z it = 1) = p ij t = exp( x T ij t γ ) P J h =1 exp( x T iht γ ) (4) T o accommodate unobserved individual heterogeneity in register activity , we in tro duce a finite mixture mo del with G laten t classes, eac h with parameter vector γ ( g ) and class-sp ecific probabilities p ( g ) ij t . Here ω ig denotes the class membership w eight for individual i and class g , computed as the probabilit y of b elonging to class g conditional on the individual’s observed data and curren t parameter estimations [McClintock, 2021]. The marginal emission probability is then p ij t = G X g =1 ω ig p ( g ) ij t (5) capturing differences in register activit y patterns that are not explained b y observed cov ariates. 6 2.4.2 Accoun ting for F alse Positiv e Observ ation Error In standard CR mo dels, any recorded observ ation is typically assumed to imply that the individual w as present in the study area at that time. While false negative errors (missed detections) are rou- tinely accommodated, false p ositiv e errors (an individual is recorded despite being absent) are rarely mo delled. Nev ertheless, related ideas app ear in the literature on misidentification in closed p opulations, where individuals may b e incorrectly recorded as presen t due to matching errors or am biguous iden tifiers [Y oshizaki et al., 2009, Link et al., 2010]. Motiv ated by this work, and by the fact that administrative registers can b e prone to false p ositive observ ation error, we extend the CR-HMM framework (open p opulation) to permit individuals who are abroad to app ear in some registers with non-zero probabilit y . Sp ecifically , for individuals who are abroad, we define P r ( Y it = j | Z it = 2) = q ij t (6) where q ij t = 0 for register combinations that cannot generate false p ositive observ ation errors and q ij t > 0 for combinations inv olving observ ation only on registers known to pro duce indirect administrativ e activit y . Incorp orating these probabilities enables the mo del to distinguish true presence, temp orary emi- gration, and erroneous administrativ e traces, whic h is essential for accurate p opulation size estimation in settings with incomplete de-registration. 2.4.3 Observ ations Asso ciated with Migration and Death A death record is generated only when an individual transitions in to the dead state. If an individual dies while present, the even t is observed with probability ϕ p it ; if the individual dies while abroad, the ev ent is observ ed with probability ϕ a it . Once the individual has entered the absorbing dead state, no further register activity can o ccur, and the only possible observ ation is “no observ ation”. Y it | ( Z it = 3) = no observ ation (7) An emigration even t o ccurs when an individual transitions from the present state to the abroad state, and this ev ent is observed with probability ψ e it . This parameter allows the general mo del to accommo date settings where emigration may b e fully observed, partially observed, or nev er observed, dep ending on administrative pro cesses. Once abroad, any app earance in an administrativ e register w ould constitute a false positive observ ation error. A re-immigration ev ent is recorded when an indi- vidual transitions from the abroad state to the presen t state, and this ev ent is observ ed with probability ψ r it . In the year of re-en try , the individual may also app ear on any of the usual J register-cov ariate com binations, giving rise to an additional set of J observ ation categories: observed on register-cov ariate com bination j and a re-immigration recorded. T aken together, the full observ ation space consists of 2 J +2 m utually exclusive categories: J register- co v ariate combinations when aliv e and presen t, one “emigrated” category , one “death registration” category , and J register-cov ariate com binations with a re-immigration recorded. In practice, the HMM includes additional single-y ear only intermediate states that ensure migration and death even ts are recorded in the correct y ear and that transitions b etw een the conceptual states (presen t, abroad and dead) are handled in line with the administrative registers. Therefore, the addi- tional “emigrated”, “death registration” and J register-cov ariate com binations with a re-immigration recorded categories are only observ able when an individual is in one of these intermediate states. 2.5 Inference 2.5.1 P arameter Estimation F or each individual i , the likelihoo d contribution is obtained by marginalising o ver the latent states using the forward algorithm. Let δ i denote the initial state distribution, P ( y it ) the diagonal matrix of 7 emission probabilities for observ ation y it , Γ it the transition matrix b etw een times t and t + 1 and 1 a v ector of ones. The individual contribution to the lik eliho o d function is L i = δ i P ( y i 1 )Γ i 1 P ( y i 2 ) ... Γ i,T − 1 P ( y iT ) 1 (8) The full likelihoo d is the pro duct o ver individuals, and the log-likelihoo d is maximised with resp ect to all mo del parameters, including the regression coefficients go verning the transition probabilities, the mixture-sp ecific observ ation parameters, and false-p ositiv e observ ation parameters. 2.5.2 Uncertain ty Quan tification Although maximum lik eliho od estimation provides point estimates for all mo del parameters and the hessian of the log-lik eliho o d yields standard errors for the directly estimated parameters, man y quanti- ties of interest are complex non-linear functions of these parameters. Propagating uncertaint y to such deriv ed quan tities is in tractable giv en the high-dimensional laten t state structure, mixture comp onen ts, and multicategory emission mo del, making resampling-based uncertaint y quan tification necessary . As administrative register dataset can contain hundreds of thousands of individuals ov er multi- ple years, traditional b ootstrap metho ds quickly b ecome computationally infeasible. Bag of Little Bo otstraps (BLB) [Kleiner et al., 2012, 2014] provides a scalable alternativ e that preserv es statistical accuracy while dramatically reducing computation. Given an original dataset of size n , BLB dra ws s subsets of size b = n γ (with γ ∈ [0 . 5 , 1]) without replacement. F or eac h subset, rep eated resamples of size n are generated with replacemen t, but only the b unique individuals in the subset con tribute to the lik eliho o d, w eighted b y their resample coun ts. Crucially , BLB exploits this fact, allowing the lik eliho od con tribution for each individual to b e computed once and then exp onen tiated according to the num b er of times that individual app ears in the resample. The CR-HMM is fitted to each weigh ted resample, pro ducing a distribution of parameter estimates for that subset. Aggregating across the s subsets yields point estimates, standard errors and confidence interv als. As each subset can b e pro cessed in- dep enden tly , BLB is naturally suited to parallel computation and scales efficiently to full-p opulation administrativ e data. 2.5.3 Laten t State Deco ding Once parameter estimates hav e b een obtained, we reconstruct the most probable latent state sequence for each individual using the Viterbi algorithm [Viterbi, 1967, F orney, 1973, Zucchini and MacDonald, 2016, Jurafsky and Martin, 2026]. This dynamic programming pro cedure computes, for eac h individual i , time t , and state j , v i 1 ( j ) = P r ( z 1 = j ) P j ( y i 1 ) v it ( j ) = S max s =1 v i,t − 1 ( s )Γ ij t P j ( y it ) (9) where v it ( j ) is the probability of the most likely path ending in state j at time t for individual i . F or mo dels incorporating finite mixtures in the observ ation process, the emission probabilities P j ( y it ) are replaced by mixture-w eighted probabilities using the individual-sp ecific weigh ts ω ig . Bac ktracking from the most probable final state yields the deco ded tra jectory ˆ Z i 1 , ..., ˆ Z iT for each individual. These tra jectories pro vide a bo otstrap realisation of the annual p opulation size, obtained b y counting the n umber of individuals whose deco ded state is presen t at eac h time t . Rep eating this pro cedure across all BLB resamples pro duces a distribution of N t for every year of the study , from whic h we obtain p oin t estimates, standard errors, and confidence in terv als for the p opulation size and an y subgroup-specific quan tities of interest. 3 Case Study 3.1 Data W e use administrative register data of the Sw edish population, including the Register of T otal P opu- lation (R TB), the Longitudinal Integrated Database for Health Insurance and Labour Market Studies 8 (LISA), the Intergenerational Register, and the In ternal and In ternational Mov es Register. This data has b een collected b y different agencies and provided b y the Statistics Sweden (SCB), Sweden’s official statistics agency . This information is compiled using personal identification num b ers and pro vides insigh t into v arious asp ects of an individual’s life, such as employmen t status and income, migration history and demographic details. Error relating to emigration, and therefore ov ercov erage, is known to b e particularly prev alent among mobile groups of individuals as they are more difficult to “capture”. While migratory ev ents ma y not b e accurately recorded, life even ts such as birth and death generally are, resulting in inflation of key demographic rates for sp ecific groups of individuals. In 2001 Sweden b ecame a mem b er of the Sc hengen Area and since then immigration has significantly increased, with international migrants making up one fifth of the resident p opulation in 2023 [Mussino et al., 2023]. F or these reasons we fo cus on data relating to all foreign-b orn residen ts who first en tered Sweden as adults b et ween 2003 and 2016. In total w e w ork with 721 , 854 individuals from 52 pre-sp ecified countries/coun try groups suc h as “UK and Ireland”, “India Nepal Bhutan” and “North Africa (except Egypt)”, with substantial n umbers coming from Eastern Europ e, the Middle East and other Nordic countries. F or this case study , coun try of birth is grouped as 1) Denmark and Norw ay , 2) Eastern Europ e, 3) Iceland/Finland, 4) Middle East and North Africa (MENA), 5) United States of America (USA), Canada and Oceania, 6) W estern Europ e and 7) rest of the W orld. W e also hav e information ab out sex, whic h is treated as binary , as w ell as age and time since first en tering Sw eden, which are b oth treated as categorical. Age is group ed as 1) 18 − 35, 2) 36 − 60 and 3) ov er 60 y ears old, while time since first entering Sw eden is group ed as 1) 0 (y ear of entry), 2) 1 − 5 y ears and 3) ov er 5 years. These age and country of birth groups hav e b een chosen in line with previous studies for consistency e.g. [Mussino et al., 2023, Santos et al., 2024] allo wing comparison, and we hav e chosen to use these time since first entering Sweden groups following their results regarding migration behaviour. Eac h year an individual is presen t in the country , we hav e a record of their observ ation in ten registers: registration of marriage or registered partnership; registration of div orce or separated part- nership; active unemploymen t, indicating individuals activ ely searc hing for w ork; enrolment in higher education during the autumn term; internal mov es within the country; birth of a c hild; income from p ensions, including old-age p ension, o ccupational pension and priv ate p ension insurance; employmen t related earnings, where the sum of earned income and work-related comp ensation (such as sic kness b enefit, pregnancy b enefit and parental b enefit) is greater than zero; so cial b enefits/allo wances, in- cluding a range of sources such as sickness allow ance, paren tal allow ance from the birth or adoption of a child, educational allow ance for doctoral students and work disability allow ance; and family income, where an individual is part of a household that has income. W e also ha ve information regarding an in- dividual’s migration history , i.e. immigration, emigration and re-immigration, as w ell as death records. Ho wev er, unlike the ten registers outlined abov e, which capture activity conditional on presence in the coun try , the migration and death records are sub ject to the recording limitations describ ed earlier in this section. 3.2 Mo del Sp ecification The general CR-HMM framework describ ed in Section 2 applies directly to the Swedish register data. In this setting, individuals may leav e the coun try either with or without formally de-registering their presence from the coun try , and the administrativ e system includes only recorded migration even ts. A recorded de-registration pro duces an observ ed emigration ev ent with certaint y , whereas failure to de-register results in o verco verage, where an individual is absent from the country but still app ears administrativ ely presen t. If an individual leav es the coun try and later re-en ters, their re-immigration will b e observ ed with certain ty only if they initially de-registered. In the general mo del, absence is represented b y a single “abroad” state. In the Swedish study , we distinguish four types of absence to reflect the administrative pro cesses go verning de-registration and re-registration, and refine the latent state space into the follo wing eigh t states: (1) presen t and alive, (2) present and death recorded, (3) abroad and emigration recorded, (4) abroad with known absence, (5) abroad with unkno wn absence (o verco verage), (6) abroad and death recorded, (7) returned and re- 9 registered, and (8) dead (absorbing). These states allow the model to separate (i) individuals who lea v e with a recorded emigration (i.e. de-registration), (ii) individuals who leav e without de-registering, and (iii) individuals who re-enter the country with a recorded re-registration. In this case study we ha ve t wo distinct emigration pro cesses that an individual can follo w (known vs unknown emigration), and as we are interested in inferring the num b er of individuals who are abroad without de-registering, we divide the general mo del’s “abroad” state to represen t these t wo pro cesses. As in the general model, the additional single-year intermediate states (2, 3, 6, 7) ensure administrative ev ents are recorded in the correct year. T ransitions b et ween these states are go verned b y the surviv al probability s it , the emigration proba- bilit y e it , and the re-immigration probability r it . In order to distinguish betw een emigrations that are formally recorded and those that are not, we introduce a de-registration probabilit y λ it that denotes the probability that an individual formally de-registers when emigrating. All four probabilities are sp ecified via logistic regression to incorporate individual- and time-v arying cov ariates. Consistent with the ann ual structure of the registers, w e allow at most one migration even t p er individual p er year. The resulting transition matrix is: Γ it = s it (1 − e it ) 1 − s it λ it s it e it 0 (1 − λ it ) s it e it 0 0 0 0 0 0 0 0 0 0 1 0 0 0 s it (1 − r it ) 0 1 − s it s it r it 0 0 0 0 s it (1 − r it ) 0 1 − s it s it r it 0 s it r it 0 0 0 s it (1 − r it ) 1 − s it 0 0 0 0 0 0 0 0 0 1 s it (1 − e it ) 1 − s it λ it s it e it 0 (1 − λ it ) s it e it 0 0 0 0 0 0 0 0 0 0 1 (10) The observ ation process also follo ws the general structure describ ed in Section 2. Individuals who are alive and present generate one of J register-co v ariate combination categories, with probabilities mo delled using a multicategory logit mo del and extended via a finite mixture to capture unobserved heterogeneit y . The FMM is incorp orated into the “job income” register with G = 2 latent mix- ture groups to accoun t for natural differences in individual’s prop ensit y to be emplo yed/ha ve income from emplo yment. Migration and death even ts correspond to additional observ ation categories (“emi- grated”, “death recorded”, and “re-immigration & register pattern”), each associated with the relev ant in termediate states. As in the general mo del, individuals who are abroad ma y generate false p ositiv e observ ations in registers where administrative activity can o ccur indirectly , despite the individual’s ph ysical absence from the country . In the Sw edish case, only the family income register can gener- ate indirect administrativ e activity: an individual may app ear in this register solely b ecause another household member has non-zero p ersonal income. W e therefore allo w false p ositiv e observ ations only for the category “unobserved in all registers except family income”, with probabilities q ij t en tering the emission matrix for states 5, 6, and 8. The general mo del includes even t recording probabilities for emigration, ψ e it , and for re-immigration, ψ r it , corresp onding to transitions into the abroad and present states resp ectiv ely . In the Swedish application, emigration is alwa ys recorded when an individual de-registers from the administrativ e registers (absence is known), and never recorded when an individual fails to de-register (absence is unknown); similarly , an individual’s re-immigration/re-registration will only b e recorded if they initially de-registered when emigrating. Therefore, w e set ψ e it = ψ r it = 1 when entering/lea ving the kno wn abroad state and ψ e it = ψ r it = 0 when entering/lea ving the unkno wn abroad state. Similarly , death registrations are fully observ ed when present and never observed when abroad (regardless of whic h abroad state the individual is in), corresponding to ϕ p it = 1 and ϕ a it = 0. Although, realistically , a small n umber of individuals die while abroad, the administrative pro cess for registering death outside Sw eden is complex and dep ends on the individual’s degree of ongoing attachmen t to the country . As these cases are rare and require unnecessary additional model complexit y , we assume deaths are never registered when absent. W e fit the model to 721 , 854 individuals observ ed ov er 14 y ears (2003 − 2016), with 10 administrativ e registers generating J = 2 10 m utually exclusiv e observ ation categories for each of 18 p ossible cov ariate 10 Figure 1: Estimated co efficien ts for life-even t probabilities with 95% confidence interv als for each co v ariate category . Numerical v alues are provided in the supplementary material. com binations. The laten t process uses the 8-state structure describ ed ab o ve, and the observ ation model includes G = 2 mixture classes to capture unobserved heterogeneit y in the “income from employmen t” register only . P arameter estimation pro ceeds via maximum lik eliho o d using the forward algorithm, with a total of 196 parameters estimated. Uncertain ty is quan tified using the Bag of Little Bo otstraps. W e draw s = 20 disjoint partitions of size b = 36 , 092 approximately , and for each subset generate 100 resamples of size 721 , 854, yielding a total of 2 , 000 mo del fits. The mo del is fit to eac h of the 20 partitions in parallel, with each partition taking appro ximately 5 − 6 days to complete. The resulting distribution of parameter estimates pro vides standard errors and confidence interv als for all transition and observ ation parameters. Finally , the mixture-w eighted Viterbi algorithm is used to deco de the most probable latent state sequence for each individual. These tra jectories allow us to classify each p erson as present, known absen t, unknown absent (o verco verage), or dead, and to estimate annual p opulation size and subgroup-sp ecific dynamics (e.g. by country of birth, sex, age group, and time since first entering Sweden). The annual p opulation size estimates are then compared against the n umber of individuals registered in the country each y ear in the R TB using the following form ula to obtain ov erco verage estimates. OC = 1 − p opulation size estimate R TB size × 100 (11) 3.3 Results Figure 1 presents the estimated regression co efficien ts for the four transition probabilities: emigration e it , re-immigration r it , de-registration λ it , and surviv al s it , together with 95% confidence in terv als. W e rep ort effects on the logit scale b ecause the mo del includes a large num b er of co v ariate combinations, and probability-scale plots would compress differences and obscure the relative contribution of each co v ariate. The logit scale therefore pro vides a clearer view of the direction and magnitude of cov ariate effects. Across co v ariates, w omen exhibit higher surviv al probabilities than men, consistent with known demographic patterns that women tend to hav e a longer life exp ectancy than men. Emigration probabilities v ary substantially by coun try of birth, with individuals from Denmark/Norwa y (base- line) showing the highest emigration probability , lik ely reflecting high mobility due to geographical 11 T able 1: Marginal register-lev el observ ation probabilities with 95% confidence interv als. Register Estimate (CI) Married 0.025 (0.023, 0.026) Div orced 0.020 (0.018, 0.021) Activ e Unemp. 0.385 (0.375, 0.398) Studies 0.303 (0.292, 0.314) In ternal Mo ve 0.287 (0.277, 0.295) Register Estimate (CI) Child b orn 0.092 (0.087, 0.097) P ension 0.009 (0.008, 0.009) Job Income 0.513 (0.505, 0.522) So cial 0.395 (0.382, 0.408) F amily Income 0.849 (0.842, 0.856) pro ximity . All other country of birth groups show substantially low er emigration co efficien ts, with MENA showing the largest negative effect. Individuals from Iceland/Finland show the highest de- registration probability , consistent with the 2004 Nordic p opulation registration agreement 1 , under whic h the receiving Nordic country automatically notifies the sending country up on registration, trig- gering automatic administrative de-registration. By contrast, migrants from Denmark/Norw ay sho w lo wer de-registration rates, whic h may reflect transnational mobilit y rather than administrative non- compliance. Individuals who ha ve been in Sweden for 5 or more y ears sho w notably lo wer emigration and re-immigration probabilities relative to recent arriv als, suggesting increasing settlement ov er time. In terpretation of all effects must account for p opulation comp osition, as some co v ariate groups (e.g. aged 60+, USA/Canada/Oceania and Iceland/Finland) are small, meaning individual even ts hav e a larger influence on estimated probabilities; see the supplementary material for figures relating to the p opulation comp osition. W e also estimate the co efficien ts of the baseline-category logit mo del gov erning observ ation prob- abilities. Due to the large num b er of register combinations (2 10 ) for each co v ariate combination, we rep ort the marginal observ ation probabilities for each register individually rather than for each com- bination. T able 1 presen ts these estimates. As exp ected, registers corresponding to even ts that occur only a limited num b er of times in an individual’s life, or only to sp ecific p opulation subgroups (mar- riage, divorce, p ension) hav e low observ ation probabilities. The family income register has the highest marginal probability (0 . 849), while p ension has the low est (0 . 009), with the latter explained by the age profile and recent migration history of the study p opulation. When stratified by age, p ension observ ation probabilities follow exp ected patterns (0 . 0009 for ages 18 − 35, 0 . 0051 for ages 36 − 60 and 0 . 213 for ages 60+). The FMM has b een incorp orated into the observ ation probabilities for the job income register, capturing unobserved heterogeneit y in emplo yment-related activit y not explained by observ ed co v ari- ates. W e specify G = 2 latent mixture classes, estimated as representing groups with high versus lo w probabilities of b eing observ ed on the job income register, with mixing prop ortion ˆ π = 0 . 523 (0 . 517 , 0 . 530). It is imp ortan t to note that the marginal probabilities in T able 1 are obtained b y w eighting the class-specific probabilities (plotted in Figure 2) by the estimated mixing prop ortion ˆ π . Figure 2 shows the observ ation probabilities across all registers broken down by FMM group. The t wo groups are clearly distinguished on the job income register by construction, but Figure 2 reveals that this separation extends meaningfully to other registers. These patterns confirm that the tw o la- ten t classes represen t distinct modes of economic participation rather than a statistical artefact, with Group 1 characterising individuals with sustained labour market attachmen t and Group 2 c haracteris- ing those with lo wer or no emplo yment activit y; how ever, both groups ha ve broadly similar observ ation probabilities on registers unrelated to employmen t such as marriage, div orce, internal mo ves, and birth of a child. FMM group assignments are highly stable across b o otstrap replicates: among individuals registered in 2016 and conditioning on registration in the country , only 504 ( < 0 . 1%) are inconsisten tly assigned (defined as < 90% agreement across b ootstraps). Figure 3 shows the distribution of assignments by sex, age, and time in Sweden (TIS). The pattern is consistent across b oth TIS groups sho wn. Men are substan tially more likely to belong to the high-employmen t-probability class (Group 1) than w omen across all age groups, and this gap is most pronounced for ages 18 − 35 and 36 − 60. Individuals aged 1 https://lo vdata.no/dokument/TRAKT A T/traktat/2004-11-01-41 12 Figure 2: Observ ation probabilit y estimates for each register, brok en down into FMM Group 1 (high job income observ ation probability) and Group 2 (low job income observ ation probabilit y), with 95% confidence interv als. 60+ are predominan tly assigned to Group 2 regardless of sex, reflecting expected withdraw al from the lab our mark et at older ages. Inconsisten t assignmen ts are negligible across all subgroups and are not visible in the figure, confirming the stability of the latent class structure. W e examine individuals who app ear only in the family income register in at least one y ear (the register for which false p ositiv e observ ation error is mo delled) and estimate the probabilit y that each suc h observ ation corresp onds to true presence v ersus absence from the coun try . Figure 4 presen ts these estimated probabilities as a function of the num b er of consecutive years of family-income-only observ ation, decomp osed b y sex (panel A) and coun try of birth (panel B). The count of individual-y ear observ ations underlying each estimate is provided in the supplemen tary material and cells with small coun ts of observ ations should be interpreted with caution. The most striking feature of b oth panels is the sharp decline in the probabilit y of true presence b et ween years 1 and 2, with probabilities remaining lo w and approximately stable from year 3 onw ards. A single year of family-income-only observ ation is therefore muc h more likely to reflect genuine presence than tw o or more consecutive y ears, which are increasingly indicative of physical absence combined with contin ued familial ties to Sweden. W omen sho w a higher probability of true presence than men at year 1 (0 . 697 vs 0 . 606), but both groups con verge to near zero by y ear 3. This is consistent with the disprop ortionate represen tation of w omen among family-income-only observ ations noted earlier, where financial dep endence on a household member’s income is more plausibly asso ciated with co-residence than with absence. Substantial v ariation by coun try of birth is also observ ed. Denmark/Norwa y stands out as the group with the lo west probability of true presence at year 1 (0 . 365), consistent with the transnational mobility patterns discussed in the transition probability results. At the other extreme, Iceland/Finland sho ws the highest probability of true presence at y ear 1 (0 . 794), consistent with the Nordic registration agreement but crucially these individuals do not benefit geographically in the same w ay individuals from Denmark/Norw ay do - since individuals from Iceland/Finland w ould very lik ely b e automatically de-registered up on emigrating, the mo del correctly infers that their con tinued appearance in an y register is more plausibly explained b y gen uine presence. T o assess the con tribution of the FMM and false p ositiv e mo delling components, we re-fitted the mo del to a 5% subsample (to reduce computational time) under three reduced sp ecifications: (i) without the FMM, (ii) without false-p ositiv e observ ation error mo delling, and (iii) without both. Figure 5 compares ov ercov erage estimates ov er time across these v ariants. All four mo dels show a broadly consistent temp oral pattern, with ov ercov erage rising to a p eak in 2009 − 2010, declining 13 Figure 3: Prop ortion of registered individuals in 2016 assigned to FMM groups 1 and 2 consisten tly ( ≥ 90% of bo otstraps) and inconsisten tly , decomp osed b y sex, age and time since first entering Sw eden (TIS). through 2015, and rising again in 2016. How ever, the level of ov ercov erage differs substantially across mo del v ariants. The t wo models that omit false positive observ ation error (No FP and No FMM & No FP) pro duce estimates approximately 3 − 4% lo wer than the full mo del throughout the study p eriod, demonstrating that allowing individuals to app ear in the family-income register while ph ysically absen t is a ma jor driver of increased ov ercov erage. The model without the FMM but retaining false p ositiv e mo delling (No FMM) pro duces estimates very close to the full mo del, with only a small upw ard shift, indicating that the FMM has a more modest but still consisten t effect on o verco v erage. The component comparison therefore confirms that b oth additions are con tributing genuine signal rather than noise. T aken together, the results demonstrate that the prop osed mo del recov ers a richer and more nu- anced picture of population dynamics than is p ossible with MSE or sign-of-life approaches. The transition probability estimates are broadly consistent with those of Santos et al. [2024], providing reassurance that the tw o mo dels are recov ering the same underlying demographic patterns despite differences in the observ ation pro cess, inference framework, and sample size. Ov ercov erage estimates follo w the same temp oral pattern, with both approac hes iden tifying a p eak around 2009 − 2010 follo wed b y a decline; how ever, our estimates are systematically higher throughout the study perio d, lik ely due to the explicit modelling of false p ositiv e observ ation errors as illustrated in Figure 5. Additional results provide further insight into the activit y of sp ecific (groups of ) individuals in the coun try and the prev alence of sp ecific ev ents. Direct comparison for the FMM groups and cov ariate groups for eac h register can b e found in the supplementary material, alongside plots relating to the 14 Figure 4: Estimated probability of true presence for individuals observed only in the family income register, as a function of consecutive years of suc h observ ations. P anel A shows results by sex and panel B by coun try of birth. Shaded bands show 95% confidence in terv als. Figure 5: Overco verage estimates ov er time for the full prop osed mo del and three reduced v ariants obtained by remo ving the FMM, false p ositiv e observ ation error mo delling, or b oth. Shaded bands sho w 95% confidence interv als. assignmen t of individuals to eac h FMM group and false p ositiv e observ ation state. The 95% confi- dence interv als for all mo del parameter estimates are v ery narro w due to the large sample size; the supplemen tary material con tains tables equiv alent to all figures presented in this section. 15 4 Discussion W e hav e developed an efficien t, scalable and highly flexible framework for p opulation size estimation and inferring p opulation dynamics using incomplete, ov erlapping administrative registers. By formulat- ing a CJS-t yp e CR mo del with a HMM structure, fitted using BLB, w e enable efficient marginalisation o ver laten t states and allow the model to b e fitted to full-p opulation administrative data. The frame- w ork accommo dates temp orary emigration, m ultiple interacting registers via a multicategory logit observ ation model, false p ositive and false negativ e observ ation errors, and individual heterogeneit y in the observ ation pro cess. Sev eral metho dological con tributions distinguish this work from existing approac hes. Unlike San tos et al. [2024], who relied on a Bay esian MCMC approach requiring sampling of all latent states and therefore analysed only a 5% sample, our HMM formulation combined with the BLB enables full- p opulation inference. The computational gains arise from marginalising o ver laten t states via the forw ard algorithm and exploiting parallel computation, making the approac h feasible for national- scale administrativ e data. Our m ulticategory observ ation model captures dep endence b etw een m ultiple registers within a year, extending standard CR assumptions and aligning with MSE-t yp e mo delling of list interactions. Crucially , by embedding this observ ation structure within an op en-p opulation CR framework, the mo del delivers what neither MSE nor sign-of-life approaches can: longitudinal individual tra jectories, the abilit y to trac k migration dynamics ov er time, and the abilit y to distinguish gen uine presence from administrative artefacts. Sign-of-life approaches rely on ad-ho c register rules and cannot identify individuals who remain administratively present after departure; MSE approaches op erate ann ually and cannot recov er the underlying demographic pro cesses driving p opulation c hange. The present framew ork addresses both limitations within a unified model. Our results highlight the ric hness of the individual-level inference produced by the model. W e find substan tial v ariation in migration dynamics across demographic groups, for example, the mo del yields predominan tly age-sp ecific surviv al estimates as a direct output of the framework, while country of birth is strongly asso ciated with different prop ensities for emigration, re-immigration, and de-registration, p oten tially reflecting differing migration motives. The observ ation mo del further reveals ho w individ- uals in teract with administrative systems, with finite-mixture comp onen ts capturing subgroups who differ in their probabilit y of app earing in sp ecific registers (in the case study this is the income from emplo yment register). This extends previous findings [Mussino et al., 2023, Santos et al., 2024] by pro- viding individual-sp ecific allo cations to laten t states and mixture comp onen ts, as w ell as identifying individuals likely to generate false p ositiv e observ ations. Our ov ercov erage estimates are higher than those rep orted in previous w ork [Mussino et al., 2023, San tos et al., 2024], and this warran ts discussion. W e believe this reflects, at least in part, the explicit mo delling of false positive observ ation errors – by allowing individuals who are abroad to generate administrativ e activit y through indirect register pro cesses such as family income, the mo del av oids misclassifying administrative artefacts as genuine presence. Mo dels that do not account for false p os- itiv e observ ation errors will tend to retain individuals in the presen t state for longer, underestimating o verco verage. Comparing mo del v ariants in Figure 5 supp orts this interpretation. In particular, the false positive observ ation mo del has a larger effect on ov ercov erage estimates than the finite mixture comp onen t, suggesting that practitioners in similar settings should prioritise modelling indirect regis- ter activity when register qualit y is imperfect. Nevertheless, our estimates remain notably low er than those pro duced by deterministic register-trace/sign-of-life approac hes, with and without the family income register, as shown in the supplementary material. Care m ust b e taken to ensure that the equiv alent version of the presen ted mo del is used for this comparison (i.e. without and with false p ositiv e observ ation error mo delling resp ectiv ely). Sev eral assumptions and mo delling c hoices merit further discussion. The mo del assumes at most one migration even t p er individual p er year; for highly mobile subgroups, suc h as individuals from neigh b ouring Nordic coun tries engaging in short-term cross-b order emplo yment, this assumption ma y b e violated. How ever, as most administrative registers are recorded annually , a finer temp oral resolu- tion is not a v ailable within the curren t data structure, and the ann ual timescale represents a practical constrain t rather than a mo delling choice. On identifiabilit y , the mo del inv olves a complex latent state 16 space, finite mixture comp onen ts, false p ositiv e observ ation parameters, and a large observ ation space. Iden tifiability is supp orted in our setting by the ric hness of the register data (ten registers observed ann ually ov er fourteen y ears, with substantial individual-level co v ariate information), but in settings with few er registers or shorter observ ation windows some parameters may b e weakly identified, and sensitivit y analysis would b e advisable. Heterogeneit y is currently included in one register (income from emplo yment); extending this to m ultiple registers or to life-even t transitions may improv e realism but could introduce identifiabilit y or computational challenges. Register interactions are limited to t wo-w ay terms, consisten t with standard MSE practice; higher-order interactions could in principle be included but would raise similar concerns. Our estimates of p opulation size and ov ercov erage depend on the set of registers included and on the treatmen t of false p ositiv e observ ation errors. The registers used here are “active” registers requiring individuals to engage in sp ecific activities to b e observ ed. Certain subp opulations suc h as home- mak ers or retirees with foreign p ensions, may therefore remain undetected. Extending the register set to include more passiv e lists, such as hospital or police records, could reduce this uncertain ty and improv e cov erage of otherwise unobserved individuals. Additionally , while w e follo w previous w ork in focusing on the migran t p opulation who en ter b et w een 2003 − 2016, the framew ork could b e extended with additional data, resulting in estimates more representativ e of the full migrant p opulation. Similarly , this w ork could b e extended to the full population of Sw eden by also considering Swedish b orn residents. Our use of a CJS-type mo del conditions on the first observ ed en try in to the p opulation. F or the Sw edish case study , undercov erage at entry (i.e. the individual enters the country unobserved) is b eliev ed to be negligible. In settings where individuals may enter unobserved, the framew ork could b e extended to a Jolly-Seb er formulation which infers entry times [Jolly, 1965, Seber, 1965]. W e restrict atten tion to the p erio d 2003 − 2016 b ecause earlier data is of low er quality and list definitions change o ver time. Starting in 2003 ensures consistent data and av oids inflating the sample with long-term residen ts who are more detectable and whose true entry times are unknown. The generalisability of this framew ork b eyond Sweden deserves consideration. The Swedish appli- cation b enefits from several features that make it particularly well-suited to this approac h: a compre- hensiv e system of linked administrative registers, universal p ersonal identification num b ers enabling reliable record link age, and strong institutional cov erage across the population. W e are curren tly ap- plying the mo del to equiv alent administrative data from Norwa y , which will provide a direct test of generalisabilit y across t wo countries with similar, well-established register-based systems and will allow comparison of migration dynamics under consistent mo delling assumptions. T ransferabilit y to coun- tries with weak er register infrastructure, less reliable link age, or few er a v ailable registers ma y require simplification of the observ ation mo del or additional sensitivit y analysis, and we would recommend b eginning with a reduced sp ecification in such settings b efore in tro ducing the full mo del complexity . Although individual-level inference is computationally in tensive, parallel computation is increas- ingly accessible, how ever, any mo del will even tually encounter computational limits as resources are finite and m uch larger p opulation data is common. A natural next step is to dev elop a p opulation-lev el MSE framew ork that incorp orates the k ey components of our CR-HMM model. W e are currently w ork- ing on this extension, with the aim of providing a more streamlined and scalable alternative for official statistics settings, while retaining the capacity to mo del complex longitudinal dep endence structures and observ ation errors. Ov erall, this work demonstrates that detailed, high-resolution mo delling of administrative registers is b oth feasible and informative at national scale. By combining HMM marginalisation, BLB, and an MSE-t yp e observ ation structure, we provide a p o werful and scalable approach for understanding p opulation dynamics in register-based systems, op ening new av en ues for methodological dev elopments and practical application. Ac kno wledgments The computations and data handling w ere enabled by resources provided b y the National Academic Infrastructure for Sup ercomputing in Sweden (NAISS), partially funded by the Swedish Research 17 Council through grant agreemen t no. 2022-06725. F unding This researc h was supp orted by the Swedish Research Council (VR), grant num b er 2021-00875. The first author was supp orted b y a do ctoral scholarship from the Migration and Mov ement Signature Researc h Theme, Univ ersity of Kent. The third author was partially financed b y national funds through F CT - F unda¸ c˜ ao para a Ciˆ encia e a T ecnologia under the pro jects UID/00006/2025 and UID/PRR/00006/2025. Supplemen tary Material Supplemen t to “A capture-recapture hidden Marko v mo del framew ork for register-based inference of p opulation size and dynamics” The supplementary material pro vides additional supp orting material for the main paper. It includes figures providing further detail on mo del sp ecification, n umerical tables corresp onding to all figures presen ted in the pap er, and additional mo del results. References Ow en Abb ott, Bec ky Tinsley , Stev e Milner, Andrew C T aylor, and Rosalind Archer. P opulation statistics without a census or register. Statistic al Journal of the IAOS , 36(1):97–105, 2020. Alan Agresti. An intr o duction to c ate goric al data analysis . John Wiley & Sons, 2nd edition, 2007. Gunnar Andersson, Andrea Monti, and Martin Kolk. V em bor h¨ ar?: en ESO-rapport om gamla o c h n ya folkr¨ akningar. R app. til l Exp ertgr. Stud. i Offent. Ekon , 2(2023), 2023. Siddartha Aradh ya, Kirk Scott, and Christopher D Smith. Rep eat immigration: A previously unob- serv ed source of heterogeneity? Sc andinavian Journal of Public He alth , 45(17 suppl):25–29, 2017. Dankmar B¨ ohning, John Bunge, and Peter GM Heijden. Captur e-r e c aptur e metho ds for the so cial and me dic al scienc es . CR C Press Bo ca Raton, 2018. Dankmar B¨ ohning, Irene Ro cc hetti, An tonello Maruotti, and Heinz Holling. Estimating the undetected infections in the covid-19 outbreak by harnessing capture–recapture metho ds. International Journal of Infe ctious Dise ases , 97:197–201, 2020. Nizar Bouguila, W entao F an, and Manar Amayri. Hidden Markov mo dels and applic ations . Springer, 2022. Christine Bycroft. Census transformation in New Zealand: Using administrativ e data without a p opulation register. Statistic al Journal of the IA OS , 31(3):401–411, 2015. James O Chipperfield, Randall Chu, Li-Chun Zhang, and Bernard Baffour. Robust statistical estima- tion for capture-recapture using administrative data. Journal of Official Statistics , 40(2):215–237, 2024. Ric hard M Cormack. Estimates of surviv al from the sigh ting of marked animals. Biometrika , 51(3/4): 429–438, 1964. AM Coumans, Maarten JLF Cruyff, Peter GM V an der Heijden, JRLM W olf, and HJSIR Schmeets. Estimating homelessness in the Netherlands using a capture-recapture approach. So cial Indic ators R ese ar ch , 130:189–212, 2017. 18 John Dunne and Li-Ch un Zhang. A system of p opulation estimates compiled from administrativ e data only . Journal of the R oyal Statistic al So ciety Series A: Statistics in So ciety , 187(1):3–21, 04 2023. ISSN 0964-1998. doi: 10.1093/jrsssa/qnad065. URL https://doi.org/10.1093/jrsssa/qnad065 . G David F orney . The viterbi algorithm. Pr o c e e dings of the IEEE , 61(3):268–278, 1973. Am y B F orsythe, T roy Day , and William A Nelson. Demystifying individual heterogeneit y . Ec olo gy L etters , 24(10):2282–2297, 2021. Olivier Gimenez and R´ emi Cho quet. Individual heterogeneity in studies on marked animals using n umerical in tegration: capture–recapture mixed mo dels. Ec olo gy , 91(4):951–957, 2010. Olivier Gimenez, Emmanuelle Cam, and Jean-Mic hel Gaillard. Individual heterogeneit y and capture– recapture mo dels: what, wh y and how? Oikos , 127(5):664–686, 2018. George M Jolly . Explicit estimates from capture-recapture data with b oth death and immigration- sto c hastic mo del. Biometrika , 52(1/2):225–247, 1965. Daniel Jurafsky and James H. Martin. Sp e e ch and L anguage Pr o c essing: An Intr o duction to Natur al L anguage Pr o c essing, Computational Linguistics, and Sp e e ch R e c o gnition, with L anguage Mo dels . 3rd edition, 2026. URL https://web.stanford.edu/ ~ jurafsky/slp3/ . Online manuscript released Jan uary 6, 2026. Ariel Kleiner, Ameet T alwalk ar, Purnamrita Sark ar, and Michael Jordan. The big data b ootstrap. arXiv pr eprint arXiv:1206.6415 , 2012. Ariel Kleiner, Ameet T alwalk ar, Purnamrita Sark ar, and Michael I Jordan. A scalable b o otstrap for massive data. Journal of the R oyal Statistic al So ciety Series B: Statistic al Metho dolo gy , 76(4): 795–816, 2014. Linn Krokedal, Stian Nerg ˚ ard, and Erling Kv alø. Uregistrert utv andring fra Norge: Kartlegging av omfanget. Notater 2024/3, Statistisk sentralb yr ˚ a (Statistics Norwa y), 2024. URL https://hdl. handle.net/11250/3129379 . W orking pap er / Notat. J. L. Laake. Capture-recapture analysis with hidden Marko v mo dels. T echnical Rep ort AFSC Processed Rep ort 2013-04, Alask a Fisheries Science Cen ter, NO AA National Marine Fisheries Service, Seattle, W A, 2013. William A Link, Jun Y oshizaki, Larissa L Bailey , and Kenneth H P ollo c k. Uncov ering a latent m ulti- nomial: analysis of mark–recapture data with misiden tification. Biometrics , 66(1):178–185, 2010. Brett T McClintock. W orth the effort? a practical examination of random effects in hidden Mark ov mo dels for animal telemetry data. Metho ds in Ec olo gy and Evolution , 12(8):1475–1497, 2021. Rac hel S McCrea and Byron JT Morgan. Analysis of c aptur e-r e c aptur e data . CRC Press, 2014. Eleonora Mussino, Bruno Santos, Andrea Monti, Eleni Matec hou, and Sven Drefahl. Multiple sys- tems estimation for studying ov er-cov erage and its heterogeneity in population registers. Quality & Quantity , pages 1–24, 2023. A V Nefian and MH Hay es. Hidden Marko v mo dels for face recognition. In Pr o c e e dings of the 1998 IEEE International Confer enc e on A c oustics, Sp e e ch and Signal Pr o c essing, ICASSP ’98 (Cat. No.98CH36181) , volume 5, pages 2721–2724 vol.5, 1998. doi: 10.1109/ICASSP .1998.678085. Office for National Statistics. The future of p opulation and migra- tion: a statistical design, 2024. URL https://www.ons.gov.uk/ peoplepopulationandcommunity/populationandmigration/populationestimates/ methodologies/thefutureofpopulationandmigrationastatisticaldesign . Metho dology article, released 15 July 2024. 19 Kenneth H Pollock. Capture-recapture mo dels. Journal of the Americ an Statistic al Asso ciation , 95 (449):293–296, 2000. ISSN 01621459, 1537274X. URL http://www.jstor.org/stable/2669550 . Jalal Poorola jal, Y ounes Mohammadi, and F arzad F arzinara. Using the capture-recapture metho d to estimate the h uman imm uno deficiency virus-positive p opulation. Epidemiolo gy and He alth , 39, 2017. Bruno San tos, Eleonora Mussino, Sven Drefahl, and Eleni Matec hou. Using p opulation register data and capture-recapture models to estimate ov er-cov erage in Sweden. Scientific R ep orts , 14(1):30551, 2024. George AF Seb er. A note on the multiple-recapture census. Biometrika , 52(1/2):249–259, 1965. Chris Skinner. Issues and challenges in census taking. Annual R eview of Statistics and Its Applic ation , 5(1):49–63, 2018. F abrizio Solari, Antonella Bernardini, and Nicoletta Cib ella. Statistical framework for fully register based p opulation coun ts. Metr on , 81(1):109–129, 2023. Statistics Finland. Preliminary population statistics: do cumen tation of statistics. https://stat.fi/ en/statistics/documentation/vamuu , 2024. Retrieved from stat.fi. Statistics Sweden. ¨ Ov ert¨ ackning i registret ¨ over totalb efolkningen—en registerstudie [ov ercov erage in the total p opulation register—a register study]. Befolkning o ch V¨ alf¨ ar d , 1, 2015. Statistics Sw eden. The registration bias—a metho dological report on the estimation of ov er-cov erage, under-co verage and registration at the wrong address. Swe dish:” F olkb okf¨ oringsfelet. En meto dr ap- p ort om skattning av ¨ overt¨ ackning, undert¨ ackning o ch folkb okf¨ or da p ˚ a fel adr ess.”) ¨ Or ebr o: SVB BV/REG and PMU/MI ¨ O , 2018. Katherine Thompson, Josh ua A Baro cas, Chris Delcher, Jungjun Bae, Lindsey Hammerslag, Jianing W ang, Redonna Chandler, Jennifer Villani, Sharon W alsh, and Jeffery T alb ert. The prev alence of opioid use disorder in Ken tucky’s counties: A t wo-y ear multi-sample capture-recapture analy- sis. Drug and A lc ohol Dep endenc e , 242:109710, 2023. ISSN 0376-8716. doi: https://doi.org/10. 1016/j.drugalcdep.2022.109710. URL https://www.sciencedirect.com/science/article/pii/ S0376871622004471 . Andrew Viterbi. Error b ounds for conv olutional co des and an asymptotically optimum deco ding algorithm. IEEE tr ansactions on Information The ory , 13(2):260–269, 1967. Matthew W allace, Courtney F ranklin, and Joseph Harrison. Long lives, p oor health? a comprehensive review of the evidence among international migrants. British Me dic al Bul letin , 156(1):ldaf014, 2025. Anders W allgren and Britt W allgren. R e gister-b ase d statistics: Statistic al metho ds for administr ative data . John Wiley & Sons, 2014. G Ringb¨ ac k W eitoft, Anders Gullbe rg, Anders Hjern, and M ˚ ans Ros´ en. Mortality statistics in im- migran t research: metho d for adjusting underestimation of mortalit y . International journal of epi- demiolo gy , 28(4):756–763, 1999. Dilek Yildiz and Peter WF Smith. Mo dels for combining aggregate-level administrative data in the absence of a traditional census. Journal of Official Statistics , 31(3):431–451, 2015. Jun Y oshizaki, Kenneth H Pollock, Cav ell Bro wnie, and Ra ymond A W ebster. Mo deling misiden- tification errors in capture–recapture studies using photographic identification of evolving marks. Ec olo gy , 90(1):3–9, 2009. W alter Zucc hini and Iain L MacDonald. Hidden Markov mo dels for time series: an intr o duction using R . Chapman and Hall/CRC, 2016. 20 Supplemen tary Material A capture-recapture hidden Mark ov mo del framew ork for register-based inference of p opulation size and dynamics Lucy Y Bro wn 1 , Eleni Matec hou 2 , Bruno San tos 3 , and Eleonora Mussino 4,5 1 Sc ho ol of Engineering, Mathematics and Physics, Universit y of Ken t, UK 2 Sc ho ol of Mathematical Sciences, Queen Mary Universit y of London, UK 3 CEA UL – Cen tro de Estatística e Aplicaçõ es, F aculdade de Ciências, Universidade de Lisb oa, Lisb on, P ortugal 4 Departmen t of So ciology , Stockholm Univ ersity , Sweden 5 Departmen t of So ciology , Umeå Univ ersity , Sweden Corresp ondence: lyb3@k en t.ac.uk Hidden Mark o v Mo del z 1 z 2 z 3 z T y 1 y 2 y 3 y T State Observ ation t = 1 t = 2 t = 3 . . . t = T Figure S1. Dep endence graph for the observ ation and latent state time series for HMMs. States dep end only on the previous state, while each observ ation is fully dep enden t on the curren t state. State and Observ ation Pro cess Figure S2. This diagram illustrates the p ossible observ ations when considering the Swedish register data. These 2 ( R +1) + 2 observ ations sp ecify the columns of the observ ation matrix Ω (where R is the num b er of registers considered), indicating whic h of the 8 states can pro duce each a v ailable observ ation. 1 Figure S3. This diagram illustrates how individuals can transition b et ween eac h of the 8 states we consider in our case study , along with the corresponding parameters. The parameters used are defined as follows: e is the emigration probabilit y , r is the re-immigration probabilit y , λ is the probability of de- registering when leaving the coun try , and s is the surviv al probability . The state “long dead” is absorbing, highligh ted b y the solid b o x b oundary , and the state “outside the country and did not de-register”, filled in grey , corresponds to o ver-co vered individuals. 2 F orward Algorithm F or each individual i and time p oin t t , the HMM is defined by an initial state distribution δ i = ( δ i 1 , ..., δ iS ) , a transition matrix Γ it of dimension S × S where Γ it ( a, b ) = P r ( Z i,t +1 = b | Z i,t = a ) , and an emission distribution P ( y it ) whic h is a diagonal matrix such that [ P ( y it )] j j = P r ( Y it = y it | Z it = j ) . The lik eliho o d con tribution for individual i is obtained b y marginalising ov er all p ossible latent state sequences. Using the forward algorithm, we define α i 1 = δ i P ( y i 1 ) α it = α i,t − 1 Γ i,t − 1 P ( y it ) (S1) and the marginal likelihoo d is L i = α iT 1 (S2) This formulation allo ws efficient computation ev en with large state spaces and individual- sp ecific transition matrices, and forms the basis for the transition and observ ation mo dels. Bag of Little Bo otstraps resample resample resample resample resample resample subsample subsample dataset b ootstrap approximation b ootstrap approximation BLB appro ximation Figure S4. A simplified flow chart sho wing the steps required for the Bag of Little Bo otstraps (BLB) appro ximation. Generalisation to a larger num b er of subsamples, for example 10 , and a reasonable n umber of resamples, for example 100 , is necessary for implemen tation. 3 Demographics Figure S5. The n umber of newly arriv ed individuals in each y ear of the study 2003 − 2015 (individuals are observed in 2016 but there are no new arriv ed that y ear). In the first year of the study ( 2003 ), only individuals who en ter that year are part of our p opulation of interest, and th us the true p opulation size in 2003 is known. Figure S6. The distribution of sex for newly arrived individuals in eac h year of the study 2003 − 2015 (individuals are observed in 2016 but there are no new arriv ed that year). 4 Figure S7. The distribution of coun try of birth for newly arrived individuals in each y ear of the study 2003 − 2015 (individuals are observ ed in 2016 but there are no new arrived that year). Figure S8. The distribution of age for newly arrived individuals in eac h year of the study 2003 − 2015 (individuals are observed in 2016 but there are no new arriv ed that year). The follo wing tables sho w the n umber of individuals observ ed on eac h register b eing considered, for each y ear of the study 2003 − 2016 . The final line of the table show the counts of individuals observ ed on only the family income register each year - these individuals motiv ate the incorp oration of uncertain sigh tings. 5 T able S1. Counts of individuals observed in eac h register, 2003–2016. Register 2003 2004 2005 2006 2007 2008 2009 Married 0 1,084 1,792 2,800 4,696 6,211 7,404 Div orced 0 404 1,013 2,079 3,425 4,487 5,703 A ctive Unemp. 5,853 15,028 23,905 40,309 55,528 67,895 86,978 Studies 5,319 13,103 21,333 33,412 38,270 45,891 57,405 In ternal Mo ve 8,263 17,448 26,151 44,562 58,013 69,237 80,106 Child b orn 2,176 5,757 8,721 12,570 16,864 20,328 24,440 P ension 4 27 58 132 284 487 799 Job Income 8,366 20,662 35,647 57,982 86,138 112,877 130,730 So cial 8,366 20,662 35,647 57,982 86,138 112,877 130,730 F amily Income 21,333 44,306 68,622 109,579 151,852 190,631 225,511 Only F amInc 5,129 7,261 9,731 14,013 19,809 24,291 27,668 Register 2010 2011 2012 2013 2014 2015 2016 Married 8,030 8,520 9,827 10,626 11,293 11,562 11,765 Div orced 7,137 7,588 8,362 9,298 9,612 9,566 9,535 A ctive Unemp. 111,248 127,193 146,330 170,500 194,234 218,563 209,938 Studies 67,494 70,608 130,128 150,115 168,826 182,401 162,430 In ternal Mo ve 88,512 94,881 102,660 113,899 132,424 148,615 133,284 Child b orn 28,406 30,052 32,979 36,126 40,151 42,790 41,802 P ension 1,211 1,870 2,611 3,482 4,639 6,204 9,757 Job Income 157,488 192,282 220,979 249,754 284,603 327,152 354,098 So cial 157,488 192,282 220,979 249,754 284,603 327,152 354,098 F amily Income 263,320 302,518 340,768 382,755 434,683 491,390 496,451 Only F amInc 27,860 29,728 24,161 26,121 28,708 31,122 28,702 6 A dditional Results Life Ev en t Probabilities Estimated co efficients for life even t probabilities with their 95% confidence interv als for eac h co v ariate category . These estimates are plotted on the logit scale and the baseline category has estimates e : 0 . 481 (0 . 475 , 0 . 487) , r : 0 . 084 (0 . 082 , 0 . 086) , λ : 0 . 529 (0 . 522 , 0 . 536) and s : 0 . 996 (0 . 995 , 0 . 996) . T able S2. Estimated cov ariate effects for the emigration e , re-immigration r , de-registration λ and surviv al s probabilities, with 95% confidence in terv als. Co v ariate Emigration Re-immigration F emale − 0 . 211 ( − 0 . 240 , − 0 . 185 ) 0 . 109 ( 0 . 084 , 0 . 136 ) Eastern Europ e − 1 . 932 ( − 1 . 960 , − 1 . 904 ) 0 . 442 ( 0 . 416 , 0 . 473 ) Iceland/Finland − 1 . 018 ( − 1 . 044 , − 0 . 990 ) − 0 . 947 ( − 0 . 974 , − 0 . 918 ) MENA − 2 . 385 ( − 2 . 413 , − 2 . 356 ) 1 . 026 ( 1 . 003 , 1 . 052 ) USA/Canada/Oceania − 1 . 027 ( − 1 . 052 , − 0 . 999 ) − 0 . 349 ( − 0 . 376 , − 0 . 319 ) W estern Europ e − 1 . 195 ( − 1 . 220 , − 1 . 167 ) − 0 . 122 ( − 0 . 149 , − 0 . 094 ) W orld − 1 . 687 ( − 1 . 715 , − 1 . 659 ) 0 . 407 ( 0 . 381 , 0 . 436 ) Aged 36–60 0 . 102 ( 0 . 075 , 0 . 129 ) 0 . 233 ( 0 . 203 , 0 . 259 ) Aged 60+ 1 . 671 ( 1 . 642 , 1 . 696 ) 0 . 497 ( 0 . 469 , 0 . 524 ) In Sw eden 1–5 yrs − 0 . 446 ( − 0 . 470 , − 0 . 419 ) 0 . 101 ( 0 . 072 , 0 . 131 ) In Sw eden 5+ yrs − 1 . 174 ( − 1 . 201 , − 1 . 146 ) − 0 . 890 ( − 0 . 920 , − 0 . 861 ) Co v ariate De-registration Surviv al F emale − 0 . 093 ( − 0 . 117 , − 0 . 064 ) 0 . 394 ( 0 . 367 , 0 . 420 ) Eastern Europ e − 0 . 764 ( − 0 . 794 , − 0 . 738 ) 0 . 984 ( 0 . 957 , 1 . 011 ) Iceland/Finland 2 . 188 ( 2 . 163 , 2 . 216 ) 0 . 163 ( 0 . 137 , 0 . 191 ) MENA − 1 . 270 ( − 1 . 297 , − 1 . 240 ) 1 . 508 ( 1 . 483 , 1 . 535 ) USA/Canada/Oceania 0 . 183 ( 0 . 156 , 0 . 213 ) 0 . 683 ( 0 . 655 , 0 . 711 ) W estern Europ e − 0 . 349 ( − 0 . 376 , − 0 . 322 ) 1 . 111 ( 1 . 085 , 1 . 140 ) W orld − 0 . 493 ( − 0 . 523 , − 0 . 464 ) 1 . 949 ( 1 . 922 , 1 . 976 ) Aged 36–60 − 0 . 661 ( − 0 . 687 , − 0 . 633 ) 0 . 101 ( 0 . 072 , 0 . 130 ) Aged 60+ − 2 . 126 ( − 2 . 155 , − 2 . 101 ) − 3 . 460 ( − 3 . 489 , − 3 . 431 ) In Sw eden 1–5 yrs 1 . 178 ( 1 . 151 , 1 . 205 ) 0 . 301 ( 0 . 274 , 0 . 329 ) In Sw eden 5+ yrs 1 . 386 ( 1 . 357 , 1 . 416 ) 1 . 087 ( 1 . 062 , 1 . 113 ) Marginal Observ ation Probabilities The m ulticategory logit emission model is defined o ver all possible register–cov ariate com binations. Let X denote the design matrix en umerating these com binations, and let p j denote the estimated emission probabilit y for category j (obtained from the fitted multicategory logit model). F or register k , the marginal probabilit y of observing an individu al in that register is obtained b y summing ov er all joint categories in whic h register k is observ ed: P r ( Y = k | Z = Presen t ) = X j : X j,k =1 p j 7 T able S3. Marginal register-level observ ation probabilities for the tw o finite mixture groups, alongside their 95% confidence in terv als. Register Group 1: Mean (95% CI) Group 2: Mean (95% CI) Married 0.028 (0.027, 0.030) 0.021 (0.020, 0.022) Div orced 0.019 (0.018, 0.020) 0.020 (0.019, 0.021) AMF 0.344 (0.334, 0.357) 0.430 (0.419, 0.443) Studies 0.264 (0.253, 0.274) 0.346 (0.335, 0.358) In ternal mov e 0.279 (0.269, 0.288) 0.295 (0.286, 0.304) Child b orn 0.082 (0.077, 0.086) 0.103 (0.097, 0.108) P ension 0.007 (0.006, 0.007) 0.011 (0.011, 0.012) Job income 0.827 (0.819, 0.834) 0.168 (0.161, 0.176) So cial 0.408 (0.395, 0.421) 0.380 (0.367, 0.394) F amily income 0.946 (0.943, 0.950) 0.743 (0.732, 0.753) W e also obtain estimates for the probability of being unobserv ed: for Group 1: 0 . 023 (0 . 022 , 0 . 025) , for Group 2: 0 . 111 (0 . 105 , 0 . 116) , and o verall: 0 . 065 (0 . 062 , 0 . 068) . F or co v ariate sp ecific categories (sex, age group, time in Sw eden), w e compute conditional probabilities b y normalising within the relev ant subset of categories. F or example, for sex: P r ( Y = k | Z = Presen t , Male ) = P j : X j,k =1 ,X j, sex =0 p j P j : X j, sex =0 p j Analogous expressions are used for age and time-in-Sweden groups. Figure S9. Observ ation probabilities for eac h register for eac h sex cov ariate group (male and female), brok en down in to FMM groups in which FMM Group 1 is more likely to b e observ ed in the register relating to income from a job, while FMM Group 2 is less lik ely . 8 Figure S10. Observ ation probabilities for each register for each age cov ariate group ( 18 − 35 , 36 − 60 and ov er 60 ), brok en do wn in to FMM groups in whic h FMM Group 1 is more likely to b e observed in the register relating to income from a job, while FMM Group 2 is less likely . Figure S11. Observ ation probabilities for eac h register for eac h time in Sweden cov ariate group (en try y ear, 1 − 5 years and ov er 5 y ears), brok en do wn in to FMM groups in whic h FMM Group 1 is more lik ely to b e observ ed in the register relating to income from a job, while FMM Group 2 is less likely . 9 T able S4. Overall and finite mixture group sp ecific conditional register-level observ ation probabilities for the sex cov ariate, alongside their 95% confidence interv als. Male Register Ov erall Group 1 Group 2 Married 0.026 (0.025, 0.027) 0.030 (0.029, 0.032) 0.021 (0.020, 0.022) Div orced 0.018 (0.017, 0.019) 0.018 (0.017, 0.019) 0.018 (0.017, 0.019) AMF 0.385 (0.375, 0.397) 0.355 (0.345, 0.368) 0.418 (0.407, 0.430) Studies 0.268 (0.258, 0.277) 0.237 (0.227, 0.247) 0.301 (0.292, 0.311) In ternal mov e 0.317 (0.308, 0.326) 0.310 (0.299, 0.319) 0.326 (0.317, 0.334) Child b orn 0.085 (0.081, 0.090) 0.078 (0.074, 0.083) 0.093 (0.089, 0.098) P ension 0.007 (0.007, 0.008) 0.006 (0.005, 0.006) 0.009 (0.008, 0.009) Job income 0.558 (0.550, 0.567) 0.869 (0.862, 0.874) 0.218 (0.209, 0.228) So cial 0.326 (0.315, 0.338) 0.354 (0.341, 0.366) 0.295 (0.284, 0.307) F amily income 0.819 (0.812, 0.826) 0.946 (0.943, 0.949) 0.679 (0.669, 0.691) F emale Register Ov erall Group 1 Group 2 Married 0.023 (0.022, 0.024) 0.026 (0.024, 0.027) 0.020 (0.019, 0.021) Div orced 0.021 (0.019, 0.022) 0.020 (0.019, 0.021) 0.021 (0.020, 0.023) AMF 0.383 (0.371, 0.397) 0.332 (0.320, 0.346) 0.440 (0.427, 0.455) Studies 0.336 (0.323, 0.349) 0.295 (0.282, 0.308) 0.381 (0.367, 0.394) In ternal mov e 0.257 (0.246, 0.266) 0.243 (0.232, 0.252) 0.272 (0.261, 0.282) Child b orn 0.097 (0.092, 0.103) 0.086 (0.080, 0.091) 0.110 (0.104, 0.117) P ension 0.010 (0.010, 0.011) 0.008 (0.007, 0.008) 0.013 (0.012, 0.014) Job income 0.469 (0.460, 0.478) 0.778 (0.768, 0.789) 0.129 (0.123, 0.136) So cial 0.459 (0.445, 0.474) 0.471 (0.457, 0.487) 0.446 (0.431, 0.462) F amily income 0.873 (0.866, 0.880) 0.947 (0.943, 0.951) 0.792 (0.781, 0.802) 10 T able S5. Overall and finite mixture group sp ecific conditional register-level observ ation probabilities for the age cov ariate, alongside their 95% confidence interv als. Aged 18–35 Register Ov erall Group 1 Group 2 Married 0.030 (0.029, 0.032) 0.034 (0.033, 0.036) 0.025 (0.024, 0.026) Div orced 0.017 (0.016, 0.018) 0.017 (0.016, 0.018) 0.018 (0.017, 0.019) AMF 0.370 (0.359, 0.382) 0.327 (0.316, 0.340) 0.417 (0.405, 0.429) Studies 0.352 (0.340, 0.363) 0.307 (0.295, 0.318) 0.400 (0.388, 0.412) In ternal mov e 0.326 (0.316, 0.335) 0.317 (0.307, 0.327) 0.335 (0.325, 0.344) Child b orn 0.119 (0.113, 0.125) 0.107 (0.101, 0.113) 0.133 (0.126, 0.140) P ension 0.001 (0.001, 0.001) 0.001 (0.001, 0.001) 0.001 (0.001, 0.001) Job income 0.508 (0.500, 0.517) 0.822 (0.815, 0.830) 0.164 (0.157, 0.171) So cial 0.400 (0.388, 0.414) 0.414 (0.401, 0.427) 0.385 (0.372, 0.399) F amily income 0.836 (0.829, 0.843) 0.941 (0.937, 0.944) 0.721 (0.710, 0.732) Aged 36–60 Register Ov erall Group 1 Group 2 Married 0.018 (0.017, 0.019) 0.020 (0.019, 0.021) 0.015 (0.014, 0.016) Div orced 0.024 (0.022, 0.025) 0.023 (0.021, 0.024) 0.025 (0.024, 0.027) AMF 0.431 (0.419, 0.445) 0.377 (0.365, 0.391) 0.490 (0.477, 0.504) Studies 0.251 (0.240, 0.262) 0.210 (0.200, 0.220) 0.296 (0.284, 0.308) In ternal mov e 0.236 (0.226, 0.245) 0.227 (0.217, 0.236) 0.245 (0.235, 0.254) Child b orn 0.057 (0.054, 0.061) 0.048 (0.045, 0.051) 0.067 (0.063, 0.071) P ension 0.005 (0.005, 0.005) 0.005 (0.005, 0.006) 0.005 (0.005, 0.005) Job income 0.538 (0.529, 0.547) 0.851 (0.843, 0.858) 0.194 (0.185, 0.204) So cial 0.412 (0.399, 0.427) 0.411 (0.397, 0.426) 0.414 (0.400, 0.429) F amily income 0.893 (0.887, 0.899) 0.965 (0.963, 0.968) 0.813 (0.804, 0.823) Aged o ver 60 Register Ov erall Group 1 Group 2 Married 0.004 (0.004, 0.004) 0.005 (0.005, 0.005) 0.003 (0.003, 0.003) Div orced 0.007 (0.006, 0.007) 0.007 (0.007, 0.008) 0.006 (0.006, 0.007) AMF 0.150 (0.143, 0.157) 0.146 (0.140, 0.153) 0.154 (0.147, 0.162) Studies 0.063 (0.060, 0.067) 0.060 (0.057, 0.064) 0.067 (0.063, 0.070) In ternal mov e 0.194 (0.187, 0.202) 0.206 (0.197, 0.214) 0.182 (0.175, 0.190) Child b orn 0.003 (0.003, 0.003) 0.003 (0.003, 0.003) 0.003 (0.003, 0.003) P ension 0.213 (0.202, 0.223) 0.235 (0.224, 0.247) 0.188 (0.178, 0.198) Job income 0.222 (0.213, 0.231) 0.400 (0.384, 0.414) 0.027 (0.026, 0.029) So cial 0.081 (0.077, 0.086) 0.087 (0.083, 0.092) 0.075 (0.070, 0.080) F amily income 0.589 (0.576, 0.604) 0.683 (0.669, 0.697) 0.486 (0.473, 0.502) 11 T able S6. Overall and finite mixture group sp ecific conditional register-level observ ation probabilities for the time since first en tering Sw eden cov ariate, alongside their 95% confidence interv als. En try year in Sw eden Register Ov erall Group 1 Group 2 Married 0.001 (0.001, 0.001) 0.001 (0.001, 0.002) 0.036 (0.034, 0.038) Div orced 0.001 (0.001, 0.001) 0.001 (0.001, 0.001) 0.023 (0.021, 0.024) AMF 0.276 (0.268, 0.284) 0.251 (0.244, 0.260) 0.384 (0.372, 0.399) Studies 0.276 (0.268, 0.285) 0.246 (0.238, 0.255) 0.318 (0.304, 0.330) In ternal mov e 0.284 (0.276, 0.291) 0.283 (0.275, 0.291) 0.331 (0.319, 0.341) Child b orn 0.065 (0.062, 0.068) 0.060 (0.057, 0.063) 0.090 (0.084, 0.096) P ension 0.002 (0.002, 0.003) 0.002 (0.002, 0.002) 0.002 (0.002, 0.003) Job income 0.353 (0.345, 0.361) 0.616 (0.605, 0.628) 0.834 (0.826, 0.841) So cial 0.093 (0.088, 0.097) 0.091 (0.087, 0.095) 0.410 (0.396, 0.425) F amily income 0.684 (0.675, 0.693) 0.813 (0.805, 0.820) 0.960 (0.957, 0.963) 1–5 y ears in Sw eden Register Ov erall Group 1 Group 2 Married 0.033 (0.031, 0.035) 0.001 (0.001, 0.001) 0.030 (0.028, 0.031) Div orced 0.025 (0.024, 0.027) 0.001 (0.001, 0.001) 0.028 (0.026, 0.030) AMF 0.440 (0.428, 0.455) 0.303 (0.294, 0.311) 0.501 (0.489, 0.516) Studies 0.362 (0.348, 0.374) 0.309 (0.301, 0.318) 0.410 (0.396, 0.423) In ternal mov e 0.337 (0.325, 0.347) 0.285 (0.277, 0.292) 0.343 (0.332, 0.353) Child b orn 0.104 (0.098, 0.111) 0.070 (0.067, 0.073) 0.120 (0.113, 0.128) P ension 0.004 (0.004, 0.004) 0.003 (0.003, 0.003) 0.006 (0.005, 0.006) Job income 0.519 (0.511, 0.528) 0.063 (0.061, 0.066) 0.175 (0.167, 0.183) So cial 0.431 (0.418, 0.445) 0.095 (0.090, 0.100) 0.454 (0.440, 0.469) F amily income 0.884 (0.878, 0.890) 0.543 (0.532, 0.553) 0.800 (0.791, 0.810) Ov er 5 y ears in Sw eden Register Ov erall Group 1 Group 2 Married 0.023 (0.022, 0.024) 0.025 (0.024, 0.027) 0.020 (0.019, 0.021) Div orced 0.021 (0.020, 0.023) 0.020 (0.019, 0.021) 0.023 (0.021, 0.024) AMF 0.350 (0.337, 0.363) 0.309 (0.297, 0.321) 0.395 (0.381, 0.409) Studies 0.190 (0.181, 0.200) 0.170 (0.161, 0.178) 0.213 (0.203, 0.223) In ternal mov e 0.176 (0.169, 0.184) 0.179 (0.171, 0.187) 0.174 (0.166, 0.181) Child b orn 0.085 (0.080, 0.090) 0.075 (0.071, 0.079) 0.096 (0.091, 0.101) P ension 0.027 (0.025, 0.029) 0.016 (0.015, 0.017) 0.039 (0.037, 0.041) Job income 0.610 (0.601, 0.619) 0.905 (0.900, 0.910) 0.286 (0.276, 0.298) So cial 0.542 (0.528, 0.556) 0.539 (0.524, 0.553) 0.545 (0.530, 0.561) F amily income 0.913 (0.908, 0.919) 0.979 (0.977, 0.980) 0.842 (0.832, 0.851) F or mo dels with t wo mixture comp onen ts, the marginal register probabilit y is P r ( Y = k ) = π P r ( Y = k | g = 1) + (1 − π ) P r ( Y = k | g = 2) where π is the estimated mixing prop ortion. F or eac h BLB resample, the ab o ve quantities are computed, yielding bo otstrap realisations of the marginal probabilities. The reported estimates and confidence interv als in Section 3.3 are obtained b y av eraging across BLB resamples. 12 P opulation Size and Ov ercov erage (a) P opulation size estimates. (b) Ov ercov erage estimates. Figure S12. Population size (plotted in red) and ov ercov erage estimates for the full population plotted alongside their 95% confidence interv als. The grey line in Figure 6(a) shows the size of the R TB, i.e. the n umber of registered individuals in the coun try each year. T able S7. Population size and ov ercov erage estimates for the full p opulation, alongside their 95% confidence interv als. Y ear P opulation Size (95% CI) Overco v erage (95% CI) 2004 58,466.61 (58,341.79, 58,588.07) 6.620 (6.425, 6.819) 2005 86,626.94 (86,493.97, 86,763.82) 8.257 (8.112, 8.397) 2006 133,375.28 (133,247.73, 133,534.16) 8.003 (7.894, 8.091) 2007 178,416.92 (178,232.08, 178,645.35) 9.497 (9.381, 9.591) 2008 218,317.14 (218,101.11, 218,607.73) 11.306 (11.188, 11.394) 2009 258,998.54 (258,713.61, 259,372.40) 12.468 (12.341, 12.564) 2010 300,178.39 (299,843.06, 300,607.61) 12.452 (12.327, 12.550) 2011 336,916.58 (336,609.81, 337,376.23) 11.716 (11.596, 11.797) 2012 375,098.63 (374,869.97, 375,360.08) 10.955 (10.893, 11.010) 2013 419,979.87 (419,698.63, 420,254.09) 10.192 (10.134, 10.252) 2014 476,111.61 (475,901.83, 476,331.60) 8.929 (8.886, 8.969) 2015 526,545.20 (526,344.76, 526,711.57) 8.789 (8.760, 8.824) 2016 497,418.41 (497,264.56, 497,466.29) 11.328 (11.319, 11.355) 13 Figure S13. Ov ercov erage estimates with 95% confidence in tervlas for each y ear, decomp osed by sex and country of birth cov ariates. T able S8. Population size estimates and ov ercov erage estimates with 95% confidence interv als for eac h y ear, b y the sex co v ariate. Y ear Sex Population Size (95% CI) Ov ercov erage (95% CI) 2004 F emale 30,597.70 (30,539.55, 30,698.41) 6.058 (5.749, 6.237) 2005 F emale 44,728.03 (44,655.46, 44,849.48) 7.621 (7.370, 7.771) 2006 F emale 66,828.44 (66,743.71, 66,965.48) 7.619 (7.430, 7.736) 2007 F emale 87,457.57 (87,364.03, 87,653.54) 9.349 (9.146, 9.446) 2008 F emale 108,185.45 (108,075.46, 108,424.12) 10.787 (10.590, 10.877) 2009 F emale 129,458.89 (129,320.50, 129,774.10) 11.692 (11.477, 11.786) 2010 F emale 149,337.09 (149,176.38, 149,695.35) 11.789 (11.577, 11.884) 2011 F emale 168,112.22 (167,982.32, 168,520.19) 11.113 (10.898, 11.182) 2012 F emale 189,587.86 (189,491.80, 189,801.26) 9.879 (9.777, 9.925) 2013 F emale 212,501.81 (212,419.02, 212,716.36) 9.052 (8.960, 9.087) 2014 F emale 237,565.94 (237,502.08, 237,737.28) 8.141 (8.075, 8.166) 2015 F emale 260,145.05 (260,096.39, 260,263.94) 8.142 (8.101, 8.160) 2016 F emale 247,183.20 (247,031.78, 247,226.42) 10.457 (10.441, 10.512) 2004 Male 27,868.91 (27,792.38, 27,898.78) 7.227 (7.128, 7.482) 2005 Male 41,898.92 (41,827.51, 41,923.32) 8.925 (8.872, 9.081) 2006 Male 66,546.84 (66,491.70, 66,576.05) 8.386 (8.345, 8.462) 2007 Male 90,959.35 (90,853.21, 90,999.23) 9.640 (9.600, 9.745) 2008 Male 110,131.69 (110,010.20, 110,188.96) 11.811 (11.765, 11.908) 2009 Male 129,539.66 (129,375.48, 129,606.48) 13.230 (13.185, 13.339) 2010 Male 150,841.30 (150,644.75, 150,926.24) 13.098 (13.049, 13.212) 2011 Male 168,804.36 (168,614.55, 168,874.78) 12.309 (12.272, 12.407) 2012 Male 185,510.76 (185,367.12, 185,568.70) 12.029 (12.002, 12.097) 2013 Male 207,478.06 (207,264.52, 207,553.50) 11.331 (11.299, 11.422) 2014 Male 238,545.67 (238,386.85, 238,607.01) 9.700 (9.676, 9.760) 2015 Male 266,400.16 (266,241.86, 266,462.58) 9.412 (9.391, 9.466) 2016 Male 250,235.20 (250,225.59, 250,248.17) 12.171 (12.167, 12.175) 14 T able S9. Population size estimates and ov ercov erage estimates with 95% confidence interv als for eac h y ear, b y the coun try of birth co v ariate. Y ear Country of Birth P opulation (95% CI) Ov ercov erage (95% CI) 2004 Denmark/Norwa y 5,662.00 (5,662.00, 5,662.00) 18.084 (18.084, 18.084) 2005 Denmark/Norwa y 7,088.49 (7,087.27, 7,094.49) 24.631 (24.567, 24.644) 2006 Denmark/Norwa y 8,862.63 (8,862.00, 8,870.70) 27.911 (27.845, 27.916) 2007 Denmark/Norwa y 9,986.94 (9,986.00, 9,998.58) 32.333 (32.254, 32.340) 2008 Denmark/Norwa y 9,971.40 (9,968.35, 9,989.42) 37.970 (37.857, 37.989) 2009 Denmark/Norwa y 10,246.05 (10,240.84, 10,263.47) 39.297 (39.194, 39.328) 2010 Denmark/Norwa y 10,680.54 (10,671.75, 10,693.72) 38.688 (38.612, 38.739) 2011 Denmark/Norwa y 11,091.33 (11,080.27, 11,103.85) 38.337 (38.267, 38.398) 2012 Denmark/Norwa y 11,446.66 (11,436.52, 11,464.35) 37.871 (37.775, 37.926) 2013 Denmark/Norwa y 11,593.43 (11,579.19, 11,607.77) 37.367 (37.289, 37.444) 2014 Denmark/Norwa y 11,781.06 (11,769.09, 11,797.85) 36.946 (36.856, 37.010) 2015 Denmark/Norwa y 12,239.26 (12,229.98, 12,251.09) 35.617 (35.554, 35.666) 2016 Denmark/Norwa y 9,961.35 (9,959.87, 9,969.13) 42.622 (42.577, 42.631) 2004 Eastern Europ e 12,774.69 (12,751.11, 12,802.26) 3.536 (3.328, 3.714) 2005 Eastern Europ e 20,623.63 (20,599.16, 20,649.77) 4.312 (4.191, 4.426) 2006 Eastern Europ e 33,617.46 (33,583.15, 33,654.21) 4.428 (4.324, 4.526) 2007 Eastern Europ e 46,809.34 (46,771.31, 46,892.17) 5.943 (5.777, 6.019) 2008 Eastern Europ e 58,026.98 (57,981.00, 58,100.21) 8.326 (8.210, 8.399) 2009 Eastern Europ e 66,992.51 (66,937.45, 67,100.66) 10.892 (10.748, 10.965) 2010 Eastern Europ e 76,073.59 (76,017.91, 76,181.58) 11.640 (11.515, 11.705) 2011 Eastern Europ e 86,005.93 (85,973.12, 86,105.15) 10.514 (10.411, 10.548) 2012 Eastern Europ e 95,897.94 (95,870.64, 95,955.02) 9.763 (9.709, 9.788) 2013 Eastern Europ e 105,467.25 (105,441.43, 105,518.52) 9.466 (9.421, 9.488) 2014 Eastern Europ e 116,778.35 (116,748.92, 116,835.04) 8.914 (8.870, 8.937) 2015 Eastern Europ e 127,696.63 (127,679.98, 127,729.85) 8.826 (8.802, 8.838) 2016 Eastern Europ e 121,113.92 (121,107.69, 121,124.23) 11.294 (11.286, 11.299) 2004 Iceland/Finland 2,522.04 (2,522.00, 2,522.60) 2.285 (2.263, 2.286) 2005 Iceland/Finland 3,103.20 (3,103.00, 3,105.38) 3.687 (3.619, 3.693) 2006 Iceland/Finland 3,675.73 (3,674.00, 3,677.91) 4.377 (4.321, 4.422) 2007 Iceland/Finland 4,212.11 (4,212.00, 4,213.61) 5.282 (5.248, 5.284) 2008 Iceland/Finland 4,552.18 (4,552.00, 4,553.66) 5.985 (5.955, 5.989) 2009 Iceland/Finland 5,096.79 (5,096.00, 5,097.48) 5.824 (5.812, 5.839) 2010 Iceland/Finland 5,662.53 (5,660.14, 5,663.78) 5.766 (5.745, 5.806) 2011 Iceland/Finland 6,252.03 (6,250.96, 6,253.36) 5.401 (5.381, 5.417) 2012 Iceland/Finland 6,889.06 (6,888.52, 6,890.05) 5.214 (5.200, 5.221) 2013 Iceland/Finland 7,411.08 (7,410.65, 7,412.26) 5.156 (5.141, 5.162) 2014 Iceland/Finland 8,070.14 (8,069.00, 8,072.86) 5.146 (5.115, 5.160) 2015 Iceland/Finland 9,051.11 (9,050.00, 9,053.33) 5.284 (5.260, 5.295) 2016 Iceland/Finland 7,980.82 (7,979.00, 7,982.77) 7.490 (7.468, 7.511) 2004 MENA 13,925.82 (13,884.11, 13,935.69) 5.189 (5.122, 5.473) 2005 MENA 20,280.87 (20,238.96, 20,305.49) 6.397 (6.284, 6.591) 2006 MENA 37,207.27 (37,173.70, 37,257.07) 4.877 (4.750, 4.963) 2007 MENA 53,061.57 (52,974.22, 53,147.60) 6.195 (6.043, 6.350) 2008 MENA 65,484.90 (65,378.27, 65,639.90) 7.759 (7.540, 7.909) 2009 MENA 80,114.52 (79,993.33, 80,281.98) 8.376 (8.184, 8.514) 2010 MENA 94,236.32 (94,089.85, 94,452.48) 8.645 (8.435, 8.787) 2011 MENA 105,936.58 (105,791.49, 106,219.22) 8.501 (8.257, 8.626) 2012 MENA 121,201.02 (121,106.93, 121,302.80) 6.967 (6.889, 7.039) 2013 MENA 140,569.27 (140,424.70, 140,689.82) 6.255 (6.174, 6.351) 2014 MENA 165,778.71 (165,669.95, 165,869.28) 5.429 (5.378, 5.491) 2015 MENA 190,590.77 (190,469.85, 190,679.25) 5.318 (5.274, 5.378) 2016 MENA 185,410.84 (185,261.58, 185,440.16) 6.911 (6.896, 6.986) 15 T able S10. (Contin ued) Population size estimates and ov erco verage estimates with 95% confidence in terv als for eac h year, b y the coun try of birth cov ariate. Y ear Country of Birth P opulation (95% CI) Overco verage (95% CI) 2004 USA/Canada/Oceania 1,974.31 (1,942.45, 1,992.43) 7.179 (6.327, 8.677) 2005 USA/Canada/Oceania 2,611.74 (2,605.44, 2,617.27) 9.940 (9.749, 10.157) 2006 USA/Canada/Oceania 3,139.98 (3,130.97, 3,148.85) 11.225 (10.974, 11.479) 2007 USA/Canada/Oceania 3,741.01 (3,734.42, 3,748.55) 13.463 (13.288, 13.615) 2008 USA/Canada/Oceania 4,456.87 (4,452.29, 4,464.90) 15.333 (15.180, 15.420) 2009 USA/Canada/Oceania 5,214.40 (5,201.61, 5,225.50) 16.703 (16.526, 16.907) 2010 USA/Canada/Oceania 6,203.77 (6,183.02, 6,218.42) 16.109 (15.910, 16.389) 2011 USA/Canada/Oceania 7,008.66 (6,991.72, 7,025.45) 15.252 (15.049, 15.457) 2012 USA/Canada/Oceania 7,518.77 (7,505.72, 7,530.28) 15.973 (15.844, 16.118) 2013 USA/Canada/Oceania 8,394.19 (8,376.25, 8,408.38) 14.970 (14.826, 15.151) 2014 USA/Canada/Oceania 9,227.33 (9,217.69, 9,234.56) 12.371 (12.302, 12.463) 2015 USA/Canada/Oceania 9,165.45 (9,157.84, 9,172.49) 14.109 (14.043, 14.180) 2016 USA/Canada/Oceania 7,690.86 (7,690.00, 7,693.01) 21.482 (21.460, 21.491) 2004 W estern Europ e 6,671.29 (6,656.03, 6,682.05) 8.875 (8.728, 9.083) 2005 W estern Europ e 9,585.40 (9,559.81, 9,599.45) 11.402 (11.272, 11.639) 2006 W estern Europ e 13,879.70 (13,856.64, 13,893.80) 11.397 (11.307, 11.544) 2007 W estern Europ e 18,080.81 (18,052.04, 18,101.56) 13.938 (13.839, 14.075) 2008 W estern Europ e 22,374.35 (22,342.32, 22,395.44) 15.845 (15.765, 15.965) 2009 W estern Europ e 25,043.03 (25,006.20, 25,079.97) 18.506 (18.386, 18.626) 2010 W estern Europ e 27,438.28 (27,395.45, 27,479.36) 19.642 (19.522, 19.767) 2011 W estern Europ e 30,920.84 (30,880.33, 30,949.73) 18.369 (18.293, 18.476) 2012 W estern Europ e 34,456.62 (34,417.36, 34,482.25) 17.536 (17.475, 17.630) 2013 W estern Europ e 38,254.42 (38,211.30, 38,284.65) 17.432 (17.367, 17.525) 2014 W estern Europ e 42,382.68 (42,344.70, 42,416.66) 17.090 (17.024, 17.164) 2015 W estern Europ e 46,121.58 (46,084.82, 46,142.43) 17.104 (17.067, 17.170) 2016 W estern Europ e 41,093.71 (41,092.29, 41,097.00) 21.810 (21.803, 21.812) 2004 Rest of the W orld 14,936.47 (14,902.57, 15,015.18) 5.099 (4.599, 5.314) 2005 Rest of the W orld 23,333.61 (23,275.29, 23,419.67) 6.129 (5.782, 6.363) 2006 Rest of the W orld 32,992.51 (32,938.94, 33,071.81) 6.664 (6.439, 6.815) 2007 Rest of the W orld 42,525.14 (42,466.37, 42,600.34) 8.092 (7.929, 8.219) 2008 Rest of the W orld 53,450.45 (53,387.94, 53,521.94) 9.542 (9.421, 9.648) 2009 Rest of the W orld 66,291.25 (66,195.26, 66,409.39) 10.404 (10.244, 10.534) 2010 Rest of the W orld 79,883.37 (79,772.59, 80,003.59) 9.893 (9.757, 10.018) 2011 Rest of the W orld 89,701.21 (89,598.04, 89,788.15) 9.387 (9.299, 9.491) 2012 Rest of the W orld 97,688.55 (97,604.08, 97,794.02) 9.777 (9.679, 9.855) 2013 Rest of the W orld 108,290.23 (108,206.49, 108,383.83) 8.750 (8.671, 8.820) 2014 Rest of the W orld 122,093.35 (122,050.92, 122,145.12) 6.402 (6.363, 6.435) 2015 Rest of the W orld 131,680.39 (131,648.50, 131,712.97) 6.645 (6.622, 6.668) 2016 Rest of the W orld 124,166.91 (124,163.16, 124,168.87) 9.310 (9.308, 9.312) 16 T able S11. Overco verage estimates with 95% confidence interv als for the prop osed model and three restricted versions: without the finite-mixture model, without false-p ositiv es, and without both. Y ear New Mo del No FMM No FP No FMM or FP 2004 6.619 (6.425, 6.819) 7.117 (7.117, 7.117) 4.419 (4.396, 4.458) 4.709 (4.651, 4.768) 2005 8.257 (8.112, 8.397) 8.674 (8.628, 8.748) 5.629 (5.593, 5.667) 5.868 (5.820, 5.912) 2006 8.003 (7.894, 8.091) 8.258 (8.221, 8.304) 5.543 (5.513, 5.579) 5.673 (5.640, 5.699) 2007 9.497 (9.381, 9.591) 9.823 (9.788, 9.863) 6.365 (6.336, 6.397) 6.485 (6.451, 6.522) 2008 11.306 (11.188, 11.394) 11.677 (11.630, 11.743) 7.667 (7.631, 7.715) 7.820 (7.786, 7.849) 2009 12.468 (12.341, 12.564) 12.878 (12.833, 12.968) 8.618 (8.574, 8.674) 8.797 (8.749, 8.831) 2010 12.452 (12.327, 12.550) 12.894 (12.843, 12.974) 8.606 (8.559, 8.665) 8.781 (8.731, 8.819) 2011 11.716 (11.596, 11.797) 12.096 (12.053, 12.171) 7.994 (7.955, 8.037) 8.075 (8.048, 8.108) 2012 10.955 (10.893, 11.010) 11.205 (11.170, 11.267) 7.868 (7.840, 7.898) 7.943 (7.922, 7.966) 2013 10.192 (10.134, 10.252) 10.443 (10.411, 10.508) 7.222 (7.197, 7.248) 7.268 (7.251, 7.293) 2014 8.929 (8.886, 8.969) 9.111 (9.079, 9.149) 6.030 (6.014, 6.047) 6.046 (6.036, 6.056) 2015 8.789 (8.760, 8.824) 8.927 (8.904, 8.954) 5.903 (5.886, 5.916) 5.915 (5.907, 5.922) 2016 11.328 (11.319, 11.355) 11.489 (11.414, 11.514) 7.745 (7.724, 7.775) 7.804 (7.802, 7.804) Figure S14. Overco verage estimates for reduced model v ariants compared with the full mo del. The estimates denoted by “New Mo del" are from the mo del prop osed in this pap er. The other three models are obtained by remo ving different asp ects: the finite mixture model, accoun ting for false positives, and b oth at the same time. All estimates are plotted alongside their corresp onding 95% confidence interv als. Also plotted are the ov ercov erage estimates obtained by the existing register-trace apprao c h, plotted with and without the family income register. 17 T able S12. Overco verage estimates with 95% confidence interv als for the prop osed mo del and the register trace approach (with and without the family income register). Y ear New Model R T (with) R T (without) 2004 6.619 (6.425, 6.819) 5.793 8.644 2005 8.257 (8.112, 8.397) 8.412 11.770 2006 8.003 (7.894, 8.091) 7.836 10.979 2007 9.497 (9.381, 9.591) 8.198 12.149 2008 11.306 (11.188, 11.394) 9.392 13.855 2009 12.468 (12.341, 12.564) 10.734 15.399 2010 12.452 (12.327, 12.550) 11.506 16.084 2011 11.716 (11.596, 11.797) 11.183 15.727 2012 10.955 (10.893, 11.010) 10.159 13.682 2013 10.192 (10.134, 10.252) 9.706 13.169 2014 8.929 (8.886, 8.969) 8.741 12.162 2015 8.789 (8.760, 8.824) 7.217 10.564 2016 11.328 (11.319, 11.355) 7.870 11.620 18 Uncertain Sigh tings Figure S15. Prop ortion of individuals in each sex, country of birth group, age group and time since first en tering Sw eden group for differen t groups in the p opulation. W e compare the proportion of individuals in each group in the full p opulation vs those observ ed only in the family income register at least one y ear, i.e. uncertain sigh tings. 19 Figure S16. Proportion of presen t vs absen t assignments for individuals who are uncertain sightings brok en down b y cov ariate category for sex, coun try of birth, age group and time since first entering Sw eden group. 20 Figure S17. Proportion of present vs absen t assignments for individuals who are uncertain sigh tings, conditional on coun try of birth group 1 - Denmark/Norwa y , broken do wn by cov ariate group com bination. Figure S18. Proportion of present vs absen t assignments for individuals who are uncertain sigh tings, conditional on country of birth group 2 - Eastern Europe, brok en down b y co v ariate group combination. 21 Figure S19. Proportion of present vs absen t assignments for individuals who are uncertain sigh tings, conditional on country of birth group 3 - Iceland/Finland, brok en do wn by cov ariate group combination. Figure S20. Proportion of present vs absen t assignments for individuals who are uncertain sigh tings, conditional on country of birth group 4 - MENA, broken do wn b y cov ariate group combination. 22 Figure S21. Proportion of present vs absen t assignments for individuals who are uncertain sigh tings, conditional on coun try of birth group 5 - USA/Canada/Oceania, brok en do wn b y co v ariate group com bination. Figure S22. Proportion of present vs absen t assignments for individuals who are uncertain sigh tings, conditional on country of birth group 6 - W estern Europ e, broken do wn b y cov ariate group com bination. 23 Figure S23. Proportion of present vs absen t assignments for individuals who are uncertain sigh tings, conditional on coun try of birth group 7 - rest of the W orld, broken down b y co v ariate group com bination. Figure S24. This figure highligh ts the prop ortion of individuals who are uncertain sightings that are assigned as presen t or absent in the coun ty , conditional on the n umber of consecutive years they hav e b een an uncertain sighting. 24 T able S13. Estimated probabilit y of true presence for individuals observ ed only in the family income register, as a function of consecutiv e y ears of such observ ations. These estimated probabilities are presented alongside their 95% confidence interv als. The coun ts of individuals in each co v ariate group for each n umber of consecutive y ears should be tak en into accoun t - these counts are presen ted in T able S14 Consecutiv e years in family income register only Group 1 2 3 4 Sex Male 0.606 (0.6596, 0.611) 0.111 (0.097, 0.115) 0.044 (0.043, 0.045) 0.035 (0.034, 0.035) F emale 0.697 (0.693, 0.714) 0.143 (0.134, 0.159) 0.040 (0.040, 0.041) 0.033 (0.033, 0.033) Country of birth Denmark/Norw ay 0.365 (0.361, 0.385) 0.087 (0.084, 0.092) 0.052 (0.052, 0.052) 0.042 (0.042, 0.042) Eastern Europ e 0.715 (0.710, 0.726) 0.144 (0.128, 0.184) 0.037 (0.037, 0.037) 0.029 (0.029, 0.029) Iceland/Finland 0.794 (0.792, 0.798) 0.333 (0.326, 0.348) 0.109 (0.104, 0.124) 0.061 (0.059, 0.078) MENA 0.630 (0.622, 0.651) 0.097 (0.089, 0.098) 0.023 (0.023, 0.023) 0.025 (0.025, 0.025) USA/Canada/Oceania 0.687 (0.685, 0.694) 0.251 (0.248, 0.261) 0.114 (0.113, 0.123) 0.055 (0.055, 0.055) W estern Europ e 0.600 (0.581, 0.605) 0.178 (0.139, 0.186) 0.077 (0.074, 0.078) 0.043 (0.043, 0.043) Rest of world 0.763 (0.761, 0.767) 0.172 (0.162, 0.190) 0.058 (0.058, 0.058) 0.051 (0.051, 0.051) Group 5 6 7 8 Sex Male 0.033 (0.032, 0.033) 0.033 (0.033, 0.033) 0.037 (0.037, 0.037) 0.026 (0.026, 0.026) F emale 0.035 (0.035, 0.035) 0.029 (0.029, 0.029) 0.026 (0.026, 0.026) 0.028 (0.028, 0.028) Country of birth Denmark/Norw ay 0.043 (0.043, 0.043) 0.037 (0.037, 0.037) 0.040 (0.040, 0.040) 0.027 (0.027, 0.027) Eastern Europ e 0.043 (0.043, 0.043) 0.025 (0.025, 0.025) 0.032 (0.032, 0.032) 0.016 (0.016, 0.016) Iceland/Finland 0.091 (0.091, 0.099) 0.071 (0.071, 0.071) 0.000 (0.000, 0.000) 0.048 (0.048, 0.048) MENA 0.024 (0.024, 0.024) 0.024 (0.024, 0.024) 0.021 (0.021, 0.021) 0.027 (0.027, 0.027) USA/Canada/Oceania 0.021 (0.021, 0.021) 0.048 (0.048, 0.048) 0.016 (0.016, 0.016) 0.023 (0.023, 0.023) W estern Europ e 0.043 (0.043, 0.043) 0.036 (0.036, 0.036) 0.025 (0.025, 0.025) 0.042 (0.042, 0.042) Rest of world 0.037 (0.037, 0.037) 0.052 (0.052, 0.052) 0.063 (0.063, 0.063) 0.038 (0.038, 0.038) Group 9 10 11 12 Sex Male 0.035 (0.035, 0.035) 0.031 (0.031, 0.031) 0.022 (0.022, 0.022) 0.016 (0.016, 0.016) F emale 0.025 (0.025 0.025) 0.021 (0.021, 0.021) 0.015 (0.015, 0.015) 0.000 (0.000, 0.000) Country of birth Denmark/Norw ay 0.025 (0.025, 0.025) 0.000 (0.000, 0.000) 0.025 (0.025, 0.025) 0.045 (0.045, 0.045) Eastern Europ e 0.031 (0.031, 0.031) 0.064 (0.064, 0.064) 0.036 (0.036, 0.036) 0.000 (0.000, 0.000) Iceland/Finland 0.000 (0.000, 0.000) 0.000 (0.000, 0.000) 0.000 (0.000, 0.000) 0.000 (0.000, 0.000) MENA 0.025 (0.025, 0.025) 0.007 (0.007, 0.007) 0.008 (0.008, 0.008) 0.000 (0.000, 0.000) USA/Canada/Oceania 0.000 (0.000, 0.000) 0.000 (0.000, 0.000) 0.000 (0.000, 0.000) 0.000 (0.000, 0.000) W estern Europ e 0.039 (0.039, 0.039) 0.040 (0.040, 0.040) 0.000 (0.000, 0.000) 0.000 (0.000, 0.000) Rest of world 0.044 (0.044, 0.044) 0.024 (0.024, 0.024) 0.25 (0.025, 0.025) 0.000 (0.000, 0.000) Group 13 14 Sex Male 0.136 (0.136, 0.136) 0.000 (0.000, 0.000) F emale 0.000 (0.000, 0.000) 0.000 (0.000, 0.000) Country of birth Denmark/Norw ay 0.125 (0.125, 0.125) 0.000 (0.000, 0.000) Eastern Europ e 0.143 (0.143, 0.143) 0.000 (0.000, 0.000) Iceland/Finland 0.000 (0.000, 0.000) 0.000 (0.000, 0.000) MENA 0.000 (0.000, 0.000) 0.000 (0.000, 0.000) USA/Canada/Oceania 0.000 (0.000, 0.000) 0.000 (0.000, 0.000) W estern Europ e 0.333 (0.333, 0.333) 0.000 (0.000, 0.000) Rest of world 0.000 (0.000, 0.000) 0.000 (0.000, 0.000) 25 T able S14. Number of observ ations b y co v ariate group and consecutive years observ ed in the family income register only . Consecutiv e years in family income register only Group 1 2 3 4 5 6 7 Sex Male 51,123 15,343 7,424 4,320 2,677 1,741 1,145 F emale 92,828 26,970 12,422 6,956 4,350 2,866 1,892 Country of birth Denmark/Norw ay 6,986 3,270 1,773 1,080 673 409 277 Eastern Europ e 29,244 8,451 4,015 2,321 1,489 1,009 659 Iceland/Finland 1,341 412 212 118 77 42 27 MENA 62,667 18,086 8,572 4,902 3,062 2,077 1,381 USA/Canada/Oceania 2,768 908 416 236 144 84 63 W estern Europ e 9,012 3,371 1,738 1,036 652 411 279 Rest of w orld 31,933 7,815 3,120 1,583 930 575 351 Group 8 9 10 11 12 13 14 Sex Male 726 462 262 134 64 22 5 F emale 1,187 747 429 202 93 33 12 Country of birth Denmark/Norw ay 186 120 76 40 22 8 2 Eastern Europ e 428 294 171 83 36 7 3 Iceland/Finland 21 8 4 3 1 1 1 MENA 853 518 284 132 50 22 5 USA/Canada/Oceania 44 30 21 14 7 3 1 W estern Europ e 168 102 50 24 14 3 1 Rest of w orld 213 137 85 40 27 11 4 26
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment