How unconstrained machine-learning models learn physical symmetries
The requirement of generating predictions that exactly fulfill the fundamental symmetry of the corresponding physical quantities has profoundly shaped the development of machine-learning models for physical simulations. In many cases, models are buil…
Authors: Michelangelo Domina, Joseph William Abbott, Paolo Pegolo
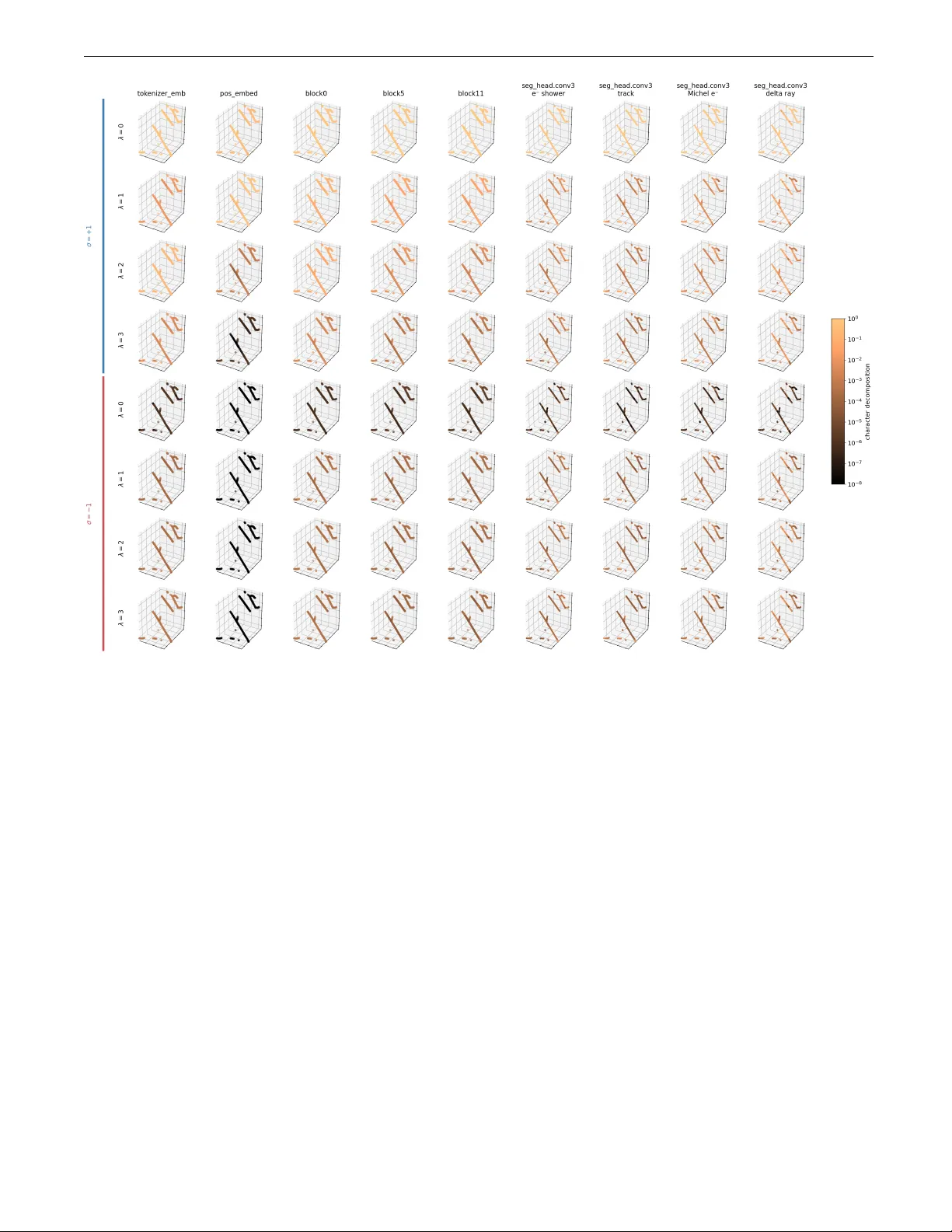
Ho w unconstrained mac hine-learning mo dels learn ph ysical symmetries M. Domina, 1 , ∗ J. W. Abb ott, 1 , ∗ P . Pegolo, 1 , ∗ F. Bigi, 1 and M. Ceriotti 1 1 L ab or atory of Computational Scienc e and Mo deling, Institut des Mat´ eriaux, ´ Ec ole Polyte chnique F´ ed´ er ale de L ausanne, 1015 L ausanne, Switzerland (Dated: March 27, 2026) The requiremen t of generating predictions that exactly fulfill the fundamental symmetry of the corresp onding ph ysical quantities has profoundly shaped the developmen t of machine-learning mod- els for ph ysical sim ulations. In many cases, models are built using constrained mathematical forms that ensure that symmetries are enforced exactly . Ho wev er, unconstrained mo dels that do not ob ey rotational symmetries are often found to hav e comp etitive performance, and to b e able to le arn to a high level of accuracy an approximate equiv arian t b eha vior with a simple data augmentation strat- egy . In this pap er, w e introduce rigorous metrics to measure the symmetry conten t of the learned represen tations in suc h mo dels, and assess the accuracy by whic h the outputs fulfill the equiv ari- an t condition. W e apply these metrics to t wo unconstrained, transformer-based mo dels op erating on decorated p oint clouds (a graph neural netw ork for atomistic sim ulations and a Poin tNet-style arc hitecture for particle physics) to inv estigate how symmetry information is pro cessed across ar- c hitectural lay ers and is learned during training. Based on these insights, we establish a rigorous framew ork for diagnosing spectral failure modes in ML models. Enabled by this analysis, w e demon- strate that one can achiev e sup erior stability and accuracy by strategically injecting the minimum required inductive biases, preserving the high expressivity and scalability of unconstrained architec- tures while guaranteeing physical fidelity . I. INTR ODUCTION Symmetries are a cornerstone of mo dern ph ysics. Their profound connection with conserv ation laws is enshrined in No ether’s theorem, a principle that has long guided the formalization of empirical phenomena into theoreti- cal framew orks and served as a foundation for the devel- opmen t of new theories [1, 2]. Differen t fields of physical science are characterized b y distinct symmetry groups, suc h as the orthogonal group O(3) in molecular me- c hanics [3], the Lorentz group SO(1 , 3) in high-energy ph ysics [4, 5], and the sp ecial unitary groups SU(2 N ) and SU(3) in quan tum mechanics and chromodynam- ics, respectively [6 – 8]. Consequently , in the dev elopmen t of data-driven mo dels for ph ysics, incorp orating ph ysical symmetries has b een often regarded as the most natural c hoice. This approach has led to the rapid and fruitful dev elopment of machine-learning (ML) approaches across the physical sciences, with atomistic simulations stand- ing out as a v ery succ essful application domain [3, 9 – 13]. Ho wev er, ensuring that a model strictly preserves group equiv ariance, guaran teeing that outputs transform pre- dictably under group actions on the input, imposes rigid arc hitectural constrain ts that can be computationally ex- p ensiv e, and limits the expressivity of mo dels [14, 15]. Con versely , mainstream computer science and mac hine learning methods hav e ev olved to maximize architectural expressivit y and efficiency , letting domain-sp ecific induc- tiv e biases b e learned directly from the data. Recently , there has b een growing interest in applying these “un- constrained” models to physics and chemistry , with no- ∗ M. Domina, J. W. Abb ott and P . P egolo contributed equally to this work. table examples b eing the release of AlphaF old 3, which relaxed the strict equiv ariant constrain ts of previous ver- sions [16], the classification of plasma crystals [17], galaxy morphology [18], and particle traces [19] using Poin tNet- lik e arc hitectures [20]. By relaxing strict equiv ariance constrain ts, these mo dels aim for increased fitting p ow er and computational efficiency at the expense of ha ving to learn fundamen tal symmetries from data, typically through data augmentation o ver symmetry groups [21], with recen t works [22, 23] showing that errors due to appro ximate symmetry are negligible compared to the baseline mo del accuracy . In the field of atomistic simulations, unconstrained mo dels are gaining traction as successful alternatives to explicitly equiv ariant models, providing fast, accurate, and transferrable surrogate models for quan tum mec han- ics. Mac hine-learning interatomic potentials (MLIPs), that predict the p otential energy surface (PES) (i.e. en- ergies, atomic forces, and cell stresses) from atomic p o- sitions and chemical t yp es, curren tly are, in particu- lar, one of the most active areas in this regard. Re- cen t w orks [13, 24 – 26] demonstrate that unconstrained mo dels can match or outp erform inv ariant and equiv ari- an t architectures on b enc hmarks, while offering sup erior scalabilit y through op erations that can b e implemented efficien tly in current accelerated architectures. The ca- pabilit y of unconstrained MLIPs extends beyond b enc h- marks, excelling in realistic scenarios such as complex materials science sim ulations [24] and high-throughput screening [27, 28]. More recently , unconstrained architectures ha ve been applied to tasks b eyond inv ariant prediction (e.g., en- ergy), extending to vectorial (e.g., forces [29, 30]) and higher-rank tensorial targets [31 – 33]. These tasks are significan tly more demanding, requiring the mo del to 2 Inputs Ta r g e t H e a d s Outputs 𝑦 " ! 𝑦 " " 𝑦 " # Backbone Model, 𝑓 … Representation Backbone features ℎ 𝑥 𝑦 $ ! 𝑓 𝑥′ 𝑦 $ ! " 𝑓 ℎ scalar vector tensor Outputs match for any input iff is equivariant 𝑓 𝑦 $ ! 𝑓 ! 𝑑ℎ ! 𝑥 back- transform 𝐴 ! (𝑓 , 𝑥 ) ℎ #$ … … hidden layer output feature vector, 𝒕 component- wise character decomposition onto irreps 𝛼 of group 𝐺 + 𝑡 " 𝑡 " ! + 𝑡 " !! + ( … 𝑡 𝐵 ! (𝑡, 𝑥) “A - metric” à equivariance erro r “B - metric” à character projection a) b) c) 𝑥 𝑦 $ ! variance over group e.g., decorated point cloud FIG. 1. Ov erview of the structure of a symmetry-a ware ML mo del, the conditions of group equiv ariance, and the symme- try diagnostic metrics introduced in this work. a) the ML mo del is represented by a generic smo oth function, f , that predicts the ph ysical properties (tensors of differen t rank), ˆ y , of an input, e.g. a decorated p oint cloud, x . f can b e a symmetry-preserving (i.e. equiv ariant) or unconstrained mo del. b) Group equiv ariance is preserved if and only if the mo del predictions transform like the inputs under the action of the appropriate group symmetry op erations. c) The met- rics A α and B α in tro duced in this w ork quantify the equiv- ariance error of mo del predictions and the group symmetry con tent of internal features. F or a set of inputs given by Haar in tegration of x ov er the group, the e quivarianc e err or , A α , is giv en by the v ariance of bac k-transformed mo del predictions, while the char acter proje ctions , B α , gives the group symme- try decomp osition of mo del features from arbitrary la yers. learn complex transformation la ws via data augmen ta- tion. Unconstrained arc hitectures app ear capable of ris- ing to these challenges, though p oten tially at the cost of longer trainings required to sample the group orbits that equiv arian t mo dels enco de by design [28]. Giv en the empirical evidence that these models c an learn symmetry , natural questions arise: when and how are these symmetries learned, b oth across the mo del ar- c hitecture and throughout the training pro cess? And can this knowledge driv e the design of better perform- ing architectures? W e introduce metrics to quan tify ho w m uch the outputs of a model violate the equiv ariant con- ditions, as well as to partition the information enco ded in the mo del in terms of the irreducible representations of the relev an t groups, and use them to analyze quan- titativ ely the flo w of symmetry information across the arc hitecture, and its evolution during training. W e will then sho w that, indeed, lo oking inside the mo del “black b o x” and understanding the interpla y of symmetry and data at every lev el of the arc hitecture allows one to mak e informed decisions regarding which inductiv e biases are essen tial and which are sup erfluous, ultimately improv- ing mo del p erformance. I I. QUANTIFYING SYMMETR Y IN ML MODELS W e fo cus on a class of ML mo dels that op erate on dec- orated p oint clouds to predict physically relev an t quan- tities (see Figure 1a), even though similar apply to more general settings, such as 3D shape recognition. Com- mon examples range from inv ariant quantities, suc h as p oten tial energy in atomistic simulations, lo cal pressure in fluid dynamics [34], or seman tic class lab els in vision mo dels [35], to geometric tensors such as fluid velocity fields [34] and surface normals [36]. T reating the mo del as a generic smo oth function f mapping an input x to an output y , physical consistency dictates that this output m ust transform predictably under the symmetry group G relev an t to the system. When equiv ariance is hard-co ded in to the architecture, these transformation la ws are ex- act (see Figure 1b): the energy of a molecule is in v arian t under global rotation, while velocities rotate co v arian tly with the reference frame. F ormally , a function f is equiv- arian t with respect to a group G if f ( g x ) = ρ ( g ) f ( x ) for all g ∈ G , where ρ is the represen tation of the group act- ing on the output space. F or scalar targets (e.g., energy), ρ ( g ) is the identit y , reco v ering the definition of inv ari- ance: f ( g x ) = f ( x ). Generally , if the output b elongs to an irreducible represen tation (irrep) α of dimension d α , the group action is mediated b y the matrix ρ α ( g ). When equiv ariance is learned from data rather than enforced, it is inherently approximate. T o quantify the fidelit y of a mo del f to the transformation rules of a represen tation α , we use the e quivarianc e err or A α : A α ( f , x ) = r D ∥ f ( hx ) − ⟨ ρ α ( g − 1 ) f ( g hx ) ⟩ g ∈ G ∥ 2 2 E h ∈ G , (1) Here, angled brac k ets ⟨·⟩ denote the Haar a v erage ov er the group with resp ect to the transformations of the in- put for an y contin uous group, or a group av erage for dis- crete groups. Note that the term ρ α ( g − 1 ) f ( g x ) repre- sen ts the output transformed back to the reference frame of x ; for a p erfectly equiv ariant function, this quan tity is constan t (equal to f ( x )). Therefore, A α effectiv ely mea- sures the standard deviation of the re-pro jected outputs o ver the group orbit (Figure 1c). This metric has b een already introduced in Ref. 37 ov er a carefully designed subset of group elements, later used in Ref. 22 to give an estimate of the equiv ariance error ov er forces predicted 3 b y the Poin t-Edge T ransformer (PET) MLIP mo del and, recen tly , in Ref. 38 to quantify appro ximate equiv ariance in unconstrained mo dels trained with a p enalt y term en- forcing equiv ariance. In the SI we provide pro ofs that this is a prop er metric of equiv ariance as it v anishes if and only if f is exactly equiv arian t with respect to α . Practically , as sho wn in the SI, this metric can b e writ- ten as A α ( f , x ) = q ⟨∥ f ∥ 2 2 ⟩ G − ∥⟨ ρ α ( g − 1 ) f ( g x ) ⟩ g ∈ G ∥ 2 2 , (2) whic h can b e computed more efficien tly , as it only re- quires a single group a verage and a voids the ev aluation of the mo del f o v er comp ositions of group elements. While the final output is optimized to b e equiv arian t, the in ternal features of an unconstrained mo del are not b ound to an y sp ecific symmetry constraints. Hidden lay- ers may mix comp onen ts of different equiv ariant c harac- ters while still effectiv ely propagating information. T o prob e the symmetry conten t within the latent space, w e in tro duce a sp ectral decomp osition of the feature norm. Analogously to the pow er sp ectrum of a signal, we de- comp ose the group-av eraged norm of an y in ternal feature t (for example, the output of any hidden lay er deep in- side the model—see Figure 1c) into contributions from differen t irreps: ⟨∥ t ∥ 2 2 ⟩ G = X α B α ( t, x ) . (3) Essen tially , we lo ok for a quantit y that tell us the frac- tion of t that transforms as the irrep α (more formally , the squared norm of the character-filtered comp onen ts asso ciated with the irrep α , consistent with the P eter- W eyl decomp osition[39]). The quantit y of interest here is the char acter pr oje ction B α : B α ( t, x ) = d 2 α χ α ( h − 1 ) t ( hg x ) h ∈ G 2 2 g ∈ G , (4) where χ α ( g ) = T r ρ α ( g ) are the group c haracters [40]. B α ( t, x ), effectively defined in terms of group con volu- tions [41 – 43]. F or con venience, w e will use normalized c haracter pro jections, B α ( t, x ) / ⟨∥ t ∥ 2 2 ⟩ G , to simplify com- parisons b et ween differen t features and differen t lay ers of the architecture. Details ab out this quantit y can b e found in the SI, including an efficien t ev aluation s c heme to minimize the required n umber of calls to the mo del function. W e remark that other approaches [44] can give complemen tary information to the metrics introduced here [45]. Both A α and B α are independent of the choice of refer- ence frame for the input x (see the SI), which makes the t wo metrics in trinsic prop erties of the m odel and the in- put, rather than artifacts of a particular c hoice of orien ta- tion. T ogether, they provide complemen tary information on the symmetry of a mo del, with A α b eing appropriate to measure how accurately the outputs of the model obey the desired symmetry , and B α b eing able to assess the represen tation characters that contaminate the outputs, and more broadly to iden tify the sp e ctr al c ontent of the mo del’s in ternal features. Although in this work we fo cus on O(3), the construc- tion of A α and B α extends naturally to an y compact group, including finite groups, by replacing the group a verage, irreducible representations, and characters with those of the symmetry group of in terest. F or compact groups such as SU(3), this generalization is therefore for- mal and direct. By con trast, for non-compact groups suc h as the Lorentz group SO(1 , 3), a normalized Haar a verage ov er the full group is not av ailable, so practical coun terparts of the present diagnostics would require re- stricted or task-dep enden t sampling measures ov er the group orbit. I II. UNCONSTRAINED MODELS F OR A TOMISTIC SIMULA TIONS Surrogate mo dels that target the outputs of quantum mec hanical calculations of atomic-scale structures are an ideal starting p oint to demonstrate the conceptual and heuristic v alue of a symmetry analysis based on the in tro- duced metrics. These mo dels’ inputs are usually atomic p ositions and c hemical sp ecies, formally describ ed as de c- or ate d p oint clouds . The p oin t cloud edges are equiv ari- an t under any combination of global rotations, in versions, and translations, making the relev ant group here the Eu- clidean group, E(3). T ranslational in v ariance is easily enforced by using interatomic distances rather than ab- solute p ositions, as is typical for graph-based mo dels, so w e can just fo cus on the orthogonal group O(3). Ph ysical prop erties targeted by these models naturally transform under (selected) irreps of O(3), and therefore unconstrained mo dels must learn the appropriate trans- formation laws via data augmentation. W e indicate the irreducible represen tations of the O(3) group by ( λ, σ ), where λ = 0 , 1 , 2 , . . . is the angular or der , and σ = ± 1 the p arity under in version, which discriminates b et ween the prop er subspace ( σ = +1) and its pseudo complement ( σ = − 1). F or example, scalars are proper in v arian ts (0 , +1), v ectors b elong to (1 , +1), and pseudo vectors to (1 , − 1). In the SI, we pro vide a detailed discussion of the explicit form of the equiv ariance error and the c harac- ter pro jections for this group. In practice, the required group a v erages are computed using a pro duct in tegration grid (Leb edev [46] on the sphere, plus trap ezoidal o ver the remaining Euler angle [40, 47]), whic h affords a com- putationally efficien t and exact ev aluation of the metrics in tro duced earlier (details and pro ofs in the SI). W e fo cus our analysis on the PET architecture, a transformer-based graph neural netw ork (GNN) that tak es b oth edge distances and vectors of an atomic-point cloud as inputs [13]. It has demonstrated excellen t p er- formance as an MLIP in b oth standard b enc hmarks [13, 28] and materials science applications [24, 48, 49], and it serv es as a represen tativ e example of a growing family of 4 transformer-based architectures in this domain [26, 50]. Data augmentation during training helps the mo del learn the O(3) in v ariance of the PES, leading to negligible equiv ariance errors compared to baseline accuracy , and to stable dynamics in the condensed phase [22]. W e study the PET architecture in steps of increasing complexit y to highlight differen t asp ects of diagnostics and design. W e start in section I I I A by diagnosing a univ ersal MLIP trained on the MAD-1.5 dataset [51], tar- geting the potential energy (scalar, (0 , +1) irrep), atomic forces (vectors, (1 , +1) irrep), and cell stress (symmet- ric, rank-2 Cartesian tensor, (0 , +1) and (2 , +1) irreps). Then, in section I I I B, w e track the sp ectral decomp osi- tion of angular information across v arious lay ers of the arc hitecture, from random initialization through to the fully trained mo del. With the insights gained here, in sec- tion II I C, we propose a simple p ost-hoc pro cessing of the readout w eights that further purifies the symmetry con- ten t of the outputs, leading to low er equiv ariance errors. Finally , in sections I I I D and I II E, we in vestigate ho w the inductiv e biases built into PET affect learning dynamics for ph ysical targets b eyond the PES, and demonstrate ho w a symmetry analysis can inform simple but effective arc hitectural modifications to impro v e learning dynamics and mo del accuracy . A. Learning the p oten tial energy surface W e trained a PET MLIP on the 1.5 version [51] of the Massive Atomic Div ersity (MAD) dataset [52]. W e train the model from scratch for 2000 epo chs to prop erly examine its symmetry conten t at random initialization and track its ev olution during training. W e first ev aluate the trained mo del on energy , forces, and stress of a sub- set of the MAD-1.5 test split. The top panel of Figure 2 sho ws a comparison of the resulting distribution of equiv- ariance errors with that of the absolute mo del errors. In all cases, the distribution of equiv ariance errors is shifted to wards smaller v alues than that of the absolute errors, with the median of their ratios b eing 10%, 31%, and 26% for energy , non-conserv ative forces, and non-conserv ativ e stress, resp ectively . W e fo cus on forces and stresses pre- dicted directly as outputs of the netw ork to inv estigate the symmetry b eha vior of PET for higher order irreps, as when computing them as deriv ativ es of the energy the tensorial nature arises due to the differential op erators and it is therefore directly tied to the inv ariant behavior of the energy . Giv en that the outputs are not exactly equiv arian t, we can use the normalized character pro jections to inv esti- gate the nature of the errors (Figure 2, bottom panel, sho wing B α ( y , x ) for 150 randomly sampled test struc- tures). As exp ected, the scalar channel hea vily domi- nates the energy predictions, with negligible contribu- tions from higher angular-momentum or pseudo subspace c hannels [53]. F orces manifest as vectors with active λ = 1 channels, while the stress tensor (a symmetric 10 ° 3 10 0 10 3 Error 0 1 2 Normalized count E (meV/atom) AE A Æ 10 0 10 3 Error f (meV/ ˚ A) 10 0 10 3 Error S (meV/ ˚ A 3 ) 0 2 4 6 8 ∏ 10 ° 10 10 ° 6 10 ° 2 Normalized B Æ æ =+ 1 æ = ° 1 0 2 4 6 8 ∏ 0 2 4 6 8 ∏ 𝐒 !" "( meV /Å # ) 𝐸 "( meV /atom) 𝐟 !" "( meV /Å) FIG. 2. Equiv ariance diagnostics for a PET MLIP . T op: dis- tributions of the absolute error (AE) and equiv ariance er- ror, A α , for energy E , non-conserv ativ e forces f NC , and non- conserv ativ e stress S NC . The arrows on the x-axis indicate the distribution medians. Bottom: normalized c haracter pro jec- tions, B α , for the corresponding quan tities as a function of the prob ed angular momentum c hannel λ . Solid lines and mark- ers are av eraged ov er 150 randomly sampled test structures, while faint lines show the individual structure pro jections. Cartesian tensor of rank 2) activ ates b oth b oth λ = 0 and λ = 2 prop er c hannels [54, 55]. The second imp or- tan t p oint to note is that pseudo c hannels are alwa ys less activ e than proper ones. This is dramatically evident in the case of energy , while the difference is less marked for forces and stress. In particular, the pseudoscalar (0 , − 1) c hannel carries very low signal in tensity in all cases, and do es not follow the exp onen tially decaying trend seen for the higher-angular order terms of the pseudo-subspace ( λ > 0 , σ = − 1). One can get more insights by monitoring how the c har- acters evolv e during a training run. T o this end, we in tro- duce c haracter pro jection heatmaps (Figure 3a) to visual- ize the evolution of B α for different angular momen tum and parity channels, starting from the un trained, ran- domly initialized mo del all the wa y to the fully trained mo del. Dark colors indicate smaller components, and brigh t colors indicate larger components for each given c hannel. At an y giv en vertical slice (i.e., ep och), the heatmaps visualize the spectral decomp osition analogous to those seen in the bottom panels of Figure 2. F or each of the outputs of the PET mo del along train- ing, we monitor the test-set model error, equiv ariance er- ror and c haracter pro jection heatmaps (Figure 3b). One can see that randomly initialized mo del has a strong bias to wards scalar (0 , +1) character and hav e near-zero spec- tral conten t for λ > 2 and/or σ = − 1. This also man- ifests in the predictions during the first ∼ 20 ep o c hs of training regardless of the specific target. Then w e ob- serv e a sudden transition, that is most eviden t for the non-conserv ativ e force prediction: the scalar c haracter drops, and the (1 , +1) v ectorial character becomes dom- 5 10 ! 10 " 10 # 10 $ 𝐒 !" #$% "( meV /Å & ) 10 %" 10 ! 10 " 10 # Epoch 10 # 10 ! 10 " 10 $ U 10 $ 10 ! 10 " 10 # 10 & 𝐸 "( meV / atom ) 𝜎 = +1 𝜎 = −1 𝜆 0 2 4 Epoch U 10 % 10 ' 10 ( 10 & 𝜎 = +1 𝜎 = −1 𝜆 0 2 4 0 2 4 untrained model dynami cal evolu tion of character projectio ns during trainin g angular order of character projecti on onto O(3) group projecti ons for even and odd inversion parity Epoch 10 # 10 ! 10 " 10 $ U 10 & 10 $ 10 ! 10 " 𝐟 !" "( meV /Å) 10 ' 0 2 4 𝜆 0 2 4 0 2 4 𝜎 = +1 𝜎 = − 1 10 %( 10 # 10 %& Intensity of the character projecti on, 𝐵 ! a) Characte r projection heatmaps b) Dynamical evolution of test - set metr ics for PET M LIP 10 %" 𝐒 !" #$' "( meV /Å & ) FIG. 3. (a) Character pro jection heatmaps rep ort on the mag- nitude of the c haracter pro jection B α for a quan tity as a func- tion of the c haracter α of the relev ant group and along succes- siv e ep o c hs of a training run. In this case the characters are the ( λ, σ ) irreps of the O(3) group. (b) T raining curves and c haracter heatmaps for energy , E , non-conserv ative forces, f NC , and the t w o irreducible spherical components of the non- conserv ativ e stress, S NC . inan t, accompanied by a sudden jump in high- λ , and σ = − 1 components. At the same point in the train- ing run, the non-scalar errors in the energy output drop to almost zero. During later ep o c hs, as both the tar- get RMSE and equiv ariance errors decrease, the charac- ter decomp osition b ecomes more sharply p eaked around the desired irreps, without other sudden transitions apart from the app earance of the λ = 2 stress comp onent at ep och ∼ 200. The scalar stress comp onent is the only target whose equiv ariance error increases during training from its initial v alue: the reason is that at the begin- ning of the training the scalar stress predictions are close to zero, which is trivially in v arian t. A similar increase is seen, for a similar reason, for the λ = 2 comp onen t of the stress. The late onset of learning for the non-conserv ative stress implies that the model is not fully con verged at the end of the run, with consequences that will b e apparent in Section I I I C. B. Lo oking in to the black b o x The character decomp osition analysis of PET demon- strates that there is a lot of structure in the symmetry- breaking errors, and that the mo del p erforms esp ecially w ell on inv ariant targets. T o understand why , and to ho w to mak e PET better at learning targets that are not in v arian t, w e hav e to look deeper at how it learns symme- try . T o do so, w e explore the information con ten t of PET features on the t w o aforementioned axes: across lay ers of the architecture and throughout the training pro cess. Figure 4 introduces a high-level ov erview of the PET MLIP architecture. F or the outputs of several imp or- tan t hidden lay ers of the mo del trained in the previ- ous section, we p erform character decomp osition anal- ysis, with the resulting heatmaps annotating the archi- tecture. The atom-centered environmen ts of a molecule or material form the input to the architecture as dec- orated p oin t clouds (Figure 4a). Internal representa- tions of these environmen ts are generated by the back- b one PET architecture. This is comprised of a series of message-passing GNN la yers, eac h of which contains sev eral modules (Figure 4b). The resulting bac kb one fea- tures (BBF) con tain rich geometric information common to all mo del outputs. These are transformed into last- la yer features (LLF) by target-sp ecific nonlinear heads, whic h are mapp ed to mo del outputs b y linear readout la yers. A t the coarsest level, the internal represen ta- tions constructed by the backbone architecture ev olv e with ric h dynamics during training, developing high- λ as well as pseudotensorial ( σ = − 1) c haracters, whic h are esp ecially strong for the edge features. In analyzing the finer details of the backbone architec- ture, w e can see ho w the character trends w e observed for the mo del outputs dev elop. F or a giv en lo cal atomic en vironment in the batch, the chemical nature of the cen tral atom and its neighbors are embedded as learn- able scalar tokens (center em b eddings (CE) and neigh- b or embeddings (NE)), with geometry embeddings (GE) represen ting the local 3D structure—sp ecifically , the dis- tances r ij and interatomic vectors r ij to each neighbor (Figure 4b). These GE ha v e pure scalar and vectorial na- ture, which do es not change during training (heatmaps A). A multi-la y er p erceptron con verts the GE into fixed- size edge em b eddings (EE). The nonlinearit y generates higher- λ characters, but still lacks pseudo-tensorial char- acter (heatmaps B). The transformer blo c ks, at the heart of the PET ar- c hitecture, are capable of generating ric h geometric fea- 6 TH RL TH RL TH RL 𝑖 = 1 , ∀ & 𝑗 L Inside the PET MLIP architecture 𝐸 𝐟 !" c Σ ! Σ ! 𝐒 !" 10 !" 10 # 10 $ Intensity of the character projection 𝑖 = 1 … Batch 𝑖 = 0 𝑖 → atom center 𝑗 ! ( → neighbor of 𝑖 𝑎 " → species of atom 𝑖 𝑎 " # □ → species of atom 𝑗 𝒓 " # □ → 𝑖 → 𝑗 ! edge vector Model Inputs 𝑖 Local env. of atom 𝑖 with cutoff 𝑟 $%& 𝒓 !" ! 𝑎 ! 𝑎 !" ! 𝑎 !" " 𝑎 !" # 𝒓 !" " 𝒓 !" # 𝑟 #$% B – Edge Embedding D – Transforme r 0 (edge) F – GNN 0 (ed ge) G – Edge Embedding I – GNN 1 (ed ge) A – Geometry Embed ding 𝜎 = +1 𝜎 = −1 𝜆 0 2 4 0 2 4 untrained model Epoch 10 ' 10 ( 10 ) 10 * U 𝐓𝐋 # $ 𝐄𝐄 $ 𝐓𝐋 $ $ CE GNN Layer 𝒌 = 𝟎 𝐓𝐋 # # 𝐄𝐄 # 𝐓𝐋 $ # GNN Layer 𝒌 = 𝟏 𝐌𝐏 # TH RL TH RL TH RL 𝑖 = 0, ∀&𝑗 B C D E F G H I J K PET backbo ne 𝐌𝐏 $ 𝐍𝐄 $ 𝐆𝐄 % A &'()*+ , - . !"# Geometry Embed der (GE) 𝑟 "# (𝒓 "# geometry embedding /01 2 - . $%&' Center Embedder (CE) 𝑎 " 3 ( ) *$*+ , Neighbor Embedder (NE) /01 2 - . !"# 𝑎 "# 4 (- ) *$*+ , Backbone Modul es 𝐍𝐄 5 𝐆𝐄 6 78(9*: ;&< =. !"# - . !"# 𝑒 "# +,- Edge Embedder of GNN 𝒌 > 𝟎 ( 𝐄𝐄 . ) 𝑚 "# +,/)- Transform er Layer (TL ) 𝑣 7 " +,- 𝑒8 "# +,- 𝑒 "# +,- 𝑣 " +,- Multi ( Head Attention … … 𝐆𝐄 % 78(9*: ;&< >. !"# - . !"# 𝑒 "# +,0'- Edge Embedder of GNN 𝒌 = 𝟎 ( 𝐄𝐄 1 ) 4 (- ) *$*+ , • 𝑘( → GN N layer index • 𝑣 " +,- →( node embedd ing • 𝑒 "# +,- → edge embedding • 𝑚 "# +,- → edge message • 𝑑 234 → edge feature s ize • 𝑑 5678 → node feature size • 𝑑 98:7 → last layer feature size Node features Edge features ?@ . Message passing AB / . Transfor mer Layer C Center Embedder CE DE 0 Geometry Embedder TH Target - specific Head (ML P) RL Target - specific Readout Layer(s) Epoch 10 ' 10 ( 10 ) 10 * U K – LLF (node & edge) 𝐸 𝐟 !" 𝐒 !" b a 10 ' 10 ( 10 ) 10 * U 10 ' 10 ( 10 ) 10 * U 10 ' 10 ( 10 ) 10 * U 10 ' 10 ( 10 ) 10 * U 10 ' 10 ( 10 ) 10 * U C – Transformer 0 (node) E – GNN 0 (no de) H – GNN 1 (n ode) J – BBF (node & edge) Epoch 10 ' 10 ( 10 ) 10 * U 10 ' 10 ( 10 ) 10 * U 10 ' 10 ( 10 ) 10 * U 10 ' 10 ( 10 ) 10 * U 𝜆 0 2 4 0 2 4 𝜆 0 2 4 0 2 4 𝜆 0 2 4 0 2 4 𝜆 0 2 4 0 2 4 FIG. 4. Overview of a PET MLIP arc hitecture and dynamical evolution of the in ternal features. (a) Local atomic environmen ts of atoms in a molecule/material are represented as decorated p oin t clouds. The atomic sp ecies of the central atom ( a i ) and its neigh b ors ( a ij ), together with the edge vectors ( r ij ) and their magnitudes ( r ij ), form the inputs to PET. (b) Backbone mo dules: embedding mo dules map the inputs to the latent space via Center, Neighbor, and Geometry Embedders. These feed into one Edge Embedder per GNN lay er, which then enters the T ransformer Lay ers. (c) F ull arc hitecture: the complete mo del pipeline leading to predictions for energy E , non-conserv ative forces f NC , and non-conserv ativ e stress S NC . The following arc hitecture hyperparameters w ere chosen: num b er of GNN la yers n GNN = 2, num b er of transformer la yers n TL = 2, cutoff r cut = 4 . 5 ˚ A, edge feature size d PET = 128, no de feature size d node = 256, LLF size d head = 128. The surrounding heatmaps, lab eled with red letters (A–L), corresp ond to specific p oints in the arc hitecture. They display the in tensity of the normalized c haracter pro jections, B α / ⟨∥ t ∥ 2 2 ⟩ G , as a function of the training ep o c h ( x -axis, log-scale) and the prob ed λ channel ( y -axis). Within each heatmap group, the top and b ottom panels represent the σ channels, resp ectively (as detailed in heatmap A). The thin, isolated column on the far left of each heatmap represen ts the untrained mo del, denoted by “U” on the x -axis. tures thanks to the atten tion mec hanism, whic h mixes information from multiple edges and enables activ ation of pseudo-tensorial c hannels (heatmaps C–F). This is es- p ecially true for edge features, though the signal still remains weak. After t w o transformer lay ers, the first GNN la yer is complete, and at this p oin t the mo del has b een able to combine geometric information within a sin- gle neigh b orhoo d. Ev en at initialization, with random w eights, the outputs of the GNN blo ck are dominated b y the scalar character, but con tain significant higher- λ comp onen ts (heatmaps E, F). The message passing step com bines geometric information with edge messages from the previous step. As suc h, the pseudotensorial activ a- tion gained in the first GNN lay er propagates to the next and is therefore visible in the new EE (heatmaps G), while no other notable changes in the outputs of the sec- ond GNN la yer (heatmaps H, I) compared to the first exist. The BBF are obtained after aggregation of the outputs of all GNN lay ers. Interestingly , this aggrega- tion suppresses λ > 2 and all σ = − 1 channels, with a strong surviving scalar expression. The BFF are then split b etw een several target-sp ecific nonlinear heads and mapp ed to the LLF (heatmaps K). These are the last nonlinear op erations in the netw ork. In the randomly initialized mo del the LLF ha v e only low- order c haracter, but at later stages they dev elop a richer geometric structure, that p ersists until the end of the training. This can b e seen particularly for the forces. Fi- nally , the LLF are mapp ed to predictions via the linear readout lay ers. These can only mo dulate the magnitude of the existing comp onen ts, and act as a filter that deter- mines the final characters and equiv ariance errors of the 7 predictions, as seen previously in Figure 3. This detailed analysis provides a compelling picture of ho w PET learns to be (approximately) equiv arian t. It also gives indications that could b e useful for the design of equiv arian t mo dels, b ecause the c haracter decomp osi- tion learned by the unconstrained arc hitecture suggests what t yp es of symmetry c hannels are needed to learn ef- ficien tly energy , forces and stresses. It sho ws that, with the GE we use, PET is strongly biased tow ards lo w- λ comp onen ts, and that even if the net work has the expres- siv e p ow er to generate higher-order c haracter features, it uses this p ow er sparingly , conv erging to intermediate represen tations dominated by low- λ , σ = +1 c haracter. This is consistent with the observ ation that equiv arian t net works can often yield reasonably accurate predictions with internal representations capp ed at λ max = 2 [56]. The presence of high-order comp onen ts in the edge rep- resen tations suggests how ever that a higher resolution is imp ortan t to process geometric message-passing informa- tion, so it might be useful to exp eriment with equiv ariant mo dels that inv est some computational budget into in- cluding higher- λ terms, at least for some of the GNN la yers. C. Symmetry purification of the readout In the previous section w e observ ed that the final read- out lay ers must filter out undesired symmetry conten t from the LLF. This is achiev ed through symmetry aug- men tation with random rotations during training, result- ing in a mo del with equiv ariance error that is a small fraction of the mo del error. Still, the LLF tokens are con- taminated by a significant fraction of irreps not needed to describ e the target subspace. W e prop ose here a sim- ple proto col to purify the linear readout, whic h can b e form ulated as a regularized regression problem. If ϕ ( x ) are the LLF for the input x , the linear readout can b e expressed as y ( x ) = θ T ϕ ( x ). By computing the LLF o v er a group orbit (or a grid, in the case of contin uous groups suc h as O (3)) we can define tw o loss terms, L µ = D ρ ( g − 1 ) θ T ϕ ( g x ) − y 2 2 E g ∈ G , L σ = ∥ θ T ϕ ( g x ) ∥ 2 2 g ∈ G − ∥ ρ ( g − 1 ) θ T ϕ ( g x ) g ∈ G ∥ 2 2 . (5) The first describ es the model mean-square error av er- aged ov er the group, while the second corresp onds to the squared equiv ariance error A . The combined loss L = L µ + γ L σ , where γ con trols the relative w eighting of the equiv ariance p enalty . can b e cast into an explicit least-squares prob lem, and solv ed for the readout w eigh ts θ . All the terms needed to determine θ can b e computed with a single sweep ov er the training set. The deriv ation of a closed form for the optimal weigh ts that minimize this loss is rep orted in the SI. F or the PET mo del w e find that this pro cedure yields a mo dest impro vemen t of the equiv ariance error for most 1.000 1.005 1.010 1.015 1.020 1.025 1.030 RMSE / RMSE( ∞ =0 ) 0.4 0.5 0.6 0.7 0.8 0.9 1.0 A / A ( ∞ =0 ) E (meV/at.): RMSE=75, A =1.0 f (meV/ ˚ A): RMSE=230, A =101 S 0 (meV/ ˚ A 3 ): RMSE=159, A =2.5 S 2 (meV/ ˚ A 3 ): RMSE=16, A =1.5 10 ° 1 10 0 10 1 10 2 10 3 ∞ 𝐟 !" 𝐸 𝐒 !" #$% 𝐒 !" #$& FIG. 5. Model error and equiv ariance error for the energy E , non-conserv ative forces f NC and λ = 0 , 2 comp onents of the non-conserv ativ e stress S NC for a universal PET model (trained and tested on MAD-1.5) whose energy and non- conserv ativ e force readout lay ers hav e b een retrained with a loss L = L µ + γ L σ com bining model error and an equiv ariance error p enalty . The mark er colors corresp ond to the weigh ting of the equiv ariance p enalty , γ . of the outputs, confirming that on-the-fly augmen tation p erformed during conv en tional mo del training succeeds in minimizing A . The exception is the conserv ativ e stress, for which we noted that the prop er symmetry channels b ecame activ e only tow ards the end of the training. In this case, by tuning the weigh t of L σ , the equiv ariance error can b e reduced b y a factor of 2 sac rificing less than 1% in the RMSE relative to the target. The inclusion of an explicit equiv ariance p enalt y during primary train- ing, as in Ref. 38 would also influence the optimization of the bac kb one weigh ts, but requires m ultiple mo del ev al- uations p er structure, increasing the computational cost of training. Instead, the equiv arian t readout optimiza- tion we propose here has a cost equiv alen t to running symmetrized inference only once on each structure in the dataset, and can b e applied routinely as a wa y to v ali- date, and p ossibly improv e, the symmetry prop erties of unconstrained mo dels. D. Stress-testing the geometric expressivity of the mo del The fact that the in ternal representations are dom- inated by low-order characters raises the question of whether PET can learn targets with a symmetry that is not naturally expressed by the initial random w eigh ts, whic h we are going to inv estigate next. The clearest sig- nal from the symmetry analysis of the mo del features is that σ = − 1 irreps, and pseudoscalars in particular, 8 0 3 +1 EE 0 3 − 1 0 3 +1 BBF 0 3 − 1 0 3 +1 LLF 0 3 − 1 0 3 +1 Q 0 3 − 1 10 0 10 1 10 2 10 3 10 4 Epoch 10 − 3 10 − 1 10 1 T est set metric RMSE A α 10 − 8 10 − 4 10 0 Intensity of the character projection λ FIG. 6. Equiv ariance diagnostic for the geometric pseu- doscalar training. T op: Character pro jection heatmaps for a PET mo del across arc hitectural la yers o ver the course of train- ing. Bottom: T est set RMSE and a verage equiv ariance error. The region b et ween the red and the green dashed lines marks the onset of rapid learning. This phase is driven by a strong activ ation of the pseudoscalar c hannel across all capable lay- ers, accompanied b y a broader, weak er activ ation of higher- order tensorial ( σ = +1) and pseudo-tensorial ( σ = − 1) chan- nels (indicated on the right). ha ve negligible character throughout the PET architec- ture. T o determine whether this impacts the represen- tation p ow er of the mo del, w e define a purely geometric pseudoscalar target Q as the the triple pro ducts of all triplets of b onds in a molecular system: Q = X i 𝟎 ( 𝐄𝐄 * ) 𝑚 "# '(+,) 𝐆𝐄 9 23#4%5 6!7 :) !"# ( ) !"# 𝑒 "# '(-.) Edge Embedder of GNN 𝒌 = 𝟎 ( 𝐄𝐄 / ) / (- ) *$*+ , • 𝑘 $ → G NN layer index • 𝑣 " '() →$ node features • 𝑒 "# '() → edge features • 𝑚 "# '() → edge me ssage • 𝑑 012 → edge f eature size • 𝑑 3456 → node feature size • 𝑑 7685 → last lay er feature size !%;$& <3&+ Transform er Layer (TL) 𝑣 2 " '() 𝑒3 "# '() !"#$%& ) $%&' ( ) !"# 23#4%5 6= > . + split !"#$%& ) !"# ( ) $%&' ?@+ A$$BA3&C%&B ) $%&' ( ) $%&' !%;$&<3&+ ?@+ !%;$& <3&+ ?@+ nodes edges ?@+ A$$BA3&C%&B ) !"# ( ) !"# 𝑣 " '() 𝑒 "# '() ? ) $%&' D ) !"# ) $%&' E ) !"# ? ) $%&' D ) !"# ) $%&' E ) !"# Cartesian Tr ansformer 3 GNN modu les 4 𝐓𝐋 F 0 … EE k 𝐓𝐋 G 0 GNN Layer 𝒌 > 𝟎 𝑣 " '(+,) 𝑚 "# '(+,) 𝑣 " '() 𝑒 "# '() Message Passing (MP) 𝑣 " '() 𝑣 " '() 𝑒 "# '() &$H$&?$ -
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment