Multi-GPU Hybrid Particle-in-Cell Monte Carlo Simulations for Exascale Computing Systems
Particle-in-Cell (PIC) Monte Carlo (MC) simulations are central to plasma physics but face increasing challenges on heterogeneous HPC systems due to excessive data movement, synchronization overheads, and inefficient utilization of multiple accelerat…
Authors: Jeremy J. Williams, Jordy Trilaksono, Stefan Costea
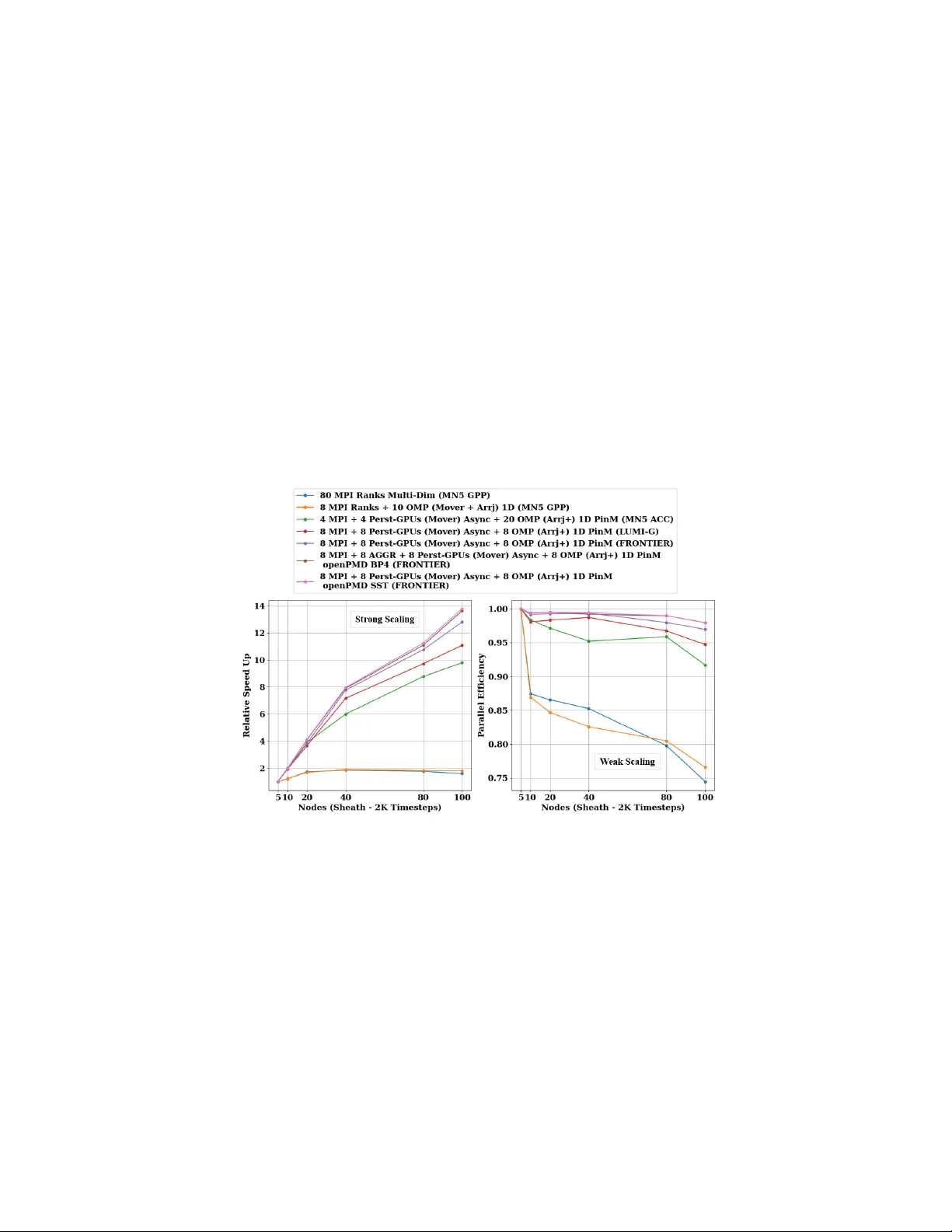
Multi-GPU Hybrid P article-in-Cell Mon te Carlo Sim ulations for Exascale Computing Systems Jerem y J. Williams 1 , Jordy T rilaksono 2 , Stefan Costea 3 , Yi Ju 6 , Luca P ennati 1 , Jonah Ek elund 1 , David T skhak a ya 4 , Leon K os 3 , Ales P o dolnik 4 , Jakub Hromadk a 4 , Allen D. Malony 5 , Sameer Shende 5 , Tilman Dannert 6 , F rank Jenko 2 , Erwin Laure 6 , and Stefano Markidis 1 1 KTH Ro yal Institute of T ec hnology , Sto c kholm, Sw eden 2 Max Planck Institute for Plasma Ph ysics, Garching, Germany 3 F aculty of Mec hanical Engineering, Univ ersity of Ljubljana, Ljubljana, Slov enia 4 Institute of Plasma Physics of the CAS, Prague, Czech Republic 5 Univ ersity of Oregon, Eugene, Oregon, USA 6 Max Planck Computing and Data F acility , Garching, Germany Abstract. P article-in-Cell (PIC) Monte Carlo (MC) simulations are cen tral to plasma ph ysics but face increasing challenges on heterogeneous HPC systems due to excessive data mo v ement, synchronization o ver- heads, and inefficien t utilization of multiple accelerators. In this w ork, w e present a p ortable, multi-GPU hybrid MPI+Op enMP implementa- tion of BIT1 that enables scalable execution on both Nvidia and AMD accelerators through OpenMP target tasks with explicit dep endencies to o verlap computation and communication across devices. Portabilit y is ac hieved through persistent device-residen t memory , an optimized con- tiguous one-dimensional data lay out, and a transition from unified to pinned host memory to improv e large data-transfer efficiency , together with GPU Direct Memory A ccess (DMA) and run time in terop erabil- it y for direct device-pointer access. Standardized and scalable I/O is pro vided using op enPMD and ADIOS2, supporting high-p erformance file I/O, in-memory data streaming, and in-situ analysis and visualiza- tion. P erformance results on pre-exascale and exascale systems, includ- ing F rontier (OLCF-5) for up to 16,000 GPUs, demonstrate significan t impro vemen ts in run time, scalability , and resource utilization for large- scale PIC MC simulations. Keyw ords: Heterogeneous Computing · Hybrid MPI+Op enMP · BIT1 · Nvidia · AMD · Persisten t GPU Memory · Asynchronous Multi-GPU Execution · Plasma Edge Mo deling · Large-Scale PIC MC Simulations 1 In tro duction High-p erformance computing (HPC) is rapidly mo ving to ward heterogeneous arc hitectures [8], where efficien t orchestration of computation, memory manage- men t, and ov erlap of communication and computation are essen tial for large-scale particle-based plasma sim ulations on pre-exascale and exascale systems [18]. 2 Jerem y J. Williams et al. BIT1 is a massiv ely parallel Particle-in-Cell (PIC) Mon te Carlo (MC) co de for simulating plasma systems and plasma material interactions. While earlier MPI-only v ersions show ed strong scalability on CPU clusters [17], the transi- tion to GPU accelerated sup ercomputers exp osed limitations in on-no de com- m unication, memory usage, and efficient multi-GPU utilization. T o address these c hallenges, BIT1 w as extended with hybrid MPI+Op enMP and MPI+OpenACC parallelization for shared-memory execution and initial GPU acceleration, which also identified key b ottlenec ks such as the particle mov er and arranger [20,22,24], and w as complemen ted b y scalable data management and I/O based on the op enPMD standard with parallel [21], streaming [25], and in-situ workflo ws [23] to reduce storage ov erhead and p ost-processing costs. In this work, we present a portable multi-GPU h ybrid MPI+Op enMP BIT1 implemen tation with p ersisten t device-resident memory , optimized data trans- fers, GPU runtime interoperability for seamless in tegration b et w een CUDA, HIP , and OpenMP run times, and asynchronous m ulti-GPU execution. By keeping data resident on the GPU, minimizing redundant transfers, and coordinating k ernels async hronously across devices, BIT1 efficiently exploits modern GPU accelerated systems while maintaining large-scale MPI scalability and p ortabil- it y across Nvidia and AMD GPU architectures. The main con tributions of this w ork are: – W e design hybrid MPI+Op enMP versions of BIT1 to improv e performance on a single no de and in both strong and weak scaling tests, employing a task- based approac h to mitigate load im balance and optimize resource utilization. – W e extend Op enMP GPU offloading on Nvidia and AMD GPUs enabling p ortabilit y using Op enMP target tasks with nowait and depend clauses, o verlapping computation and comm unication, flattening three dimensional (3D) arrays into contiguous one dimensional (1D) lay outs, maintaining per- sisten t device-residen t memory across time steps using Op enMP target enter /exit data regions, and switching from unified to pinned host memory for large arrays to reduce data mov ement o verheads. – W e implement vendor-specific GPU optimizations to improv e data-transfer efficiency , using compile-time pinned memory on Nvidia and Op enMP pinned allo cators on AMD, enabling higher throughput and low er-latency host-to- device (HtoD) transfers for large arrays. – W e integrate standardized I/O with op enPMD and ADIOS2 using the BP4 and SST back ends to reduce I/O b ottlenec ks and enable high-throughput file I/O and in-memory streaming, with in-situ analysis and visualization pro viding real-time insights and reducing p ost-processing times without in- terrupting runtime on Nvidia and AMD GPUs architectures at scale. 2 Bac kground The PIC metho d is one of the most widely used computational approaches for plasma simulations and is applied across a broad range of plasma environmen ts, Multi-GPU Hybrid PIC MC Sim ulations for Exascale Computing Systems 3 including space and astrophysical plasmas, lab oratory exp erimen ts, industrial pro cesses, and fusion devices [16,20]. Fig. 1: A diagram representing the PIC Metho d on HPC architectures. After initialization, the PIC metho d rep eats at each time step. In gray , we highlight the particle mo ver step that w e parallelize in the p ortable m ulti-GPU hybrid BIT1. As seen in Fig. 1, the classi- cal PIC metho d b egins with an initialization stage, in which the sim ulation setup and initial con- ditions are defin ed. The main sim- ulation lo op then executes four phases: (i) the particle mo ver, whic h up dates particle p ositions and velocities; (ii) dep osition to the grid, whic h maps particle c harges and currents to the mesh; (iii) the field solver, which com- putes electromagnetic or electro- static fields by solving Maxwell’s or P oisson’s equations; and fi- nally (iv) particle force ev alua- tion, whic h in terpolates the grid fields back to the particle p osi- tions. This cycle is rep eated for eac h time step, with each step representing a small fraction of the character- istic plasma timescale in order to accurately capture plasma dynamics [20,24]. In this work, w e use the Berkeley Innsbruck Tbilisi 1D3V (BIT1) co de, an application tool designed for large-scale plasma sim ulations on HPC systems and tailored to modeling plasma edge and tok amak div ertor ph ysics [15,17]. BIT1 is a sp ecialized one-dimensional, three-velocity (1D3V) electrostatic PIC MC co de, derived from the XPDP1 code dev eloped b y Birdsall’s group at the Univ ersity of California, Berkeley , in the 1990s [19]. W ritten en tirely in C and comprising appro ximately 31,600 lines of co de, BIT1 relies on native implemen- tations of the Poisson solver, particle mo ver, and smo othing op erators, without dep endencies on external n umerical libraries. BIT1 employs the "natural sort- ing" metho d [15], which accelerates collision operators by up to a factor of five, but increases memory requirements and in tro duces challenges for GPU offloading and load balance in regions of high particle density [20,24]. T o address these limi- tations and ensure p ortabilit y across modern sup ercomputing platforms, BIT1 is ev olving tow ard a h ybrid parallel programming mo del that combines MPI-based domain decomp osition with Op enMP shared-memory parallelism, reducing com- m unication o verhead and improving scalability on multi-core and heterogeneous arc hitectures [22,24]. 2.1 Op enMP Memory Allo cators, Unified & Pinned Host Memory Op enMP (Op en Multi-Pro cessing) provides a standardized mechanism for con- trolling memory allo cation through memory al lo c ators (T able 1), whic h return logically con tiguous memory from a sp ecified memory space and guaran tee that 4 Jerem y J. Williams et al. allo cations do not o verlap. The b eha vior of an allo cator is configured using al lo- c ator tr aits (T able 2) that define sync hronization exp ectations, alignmen t, acces- sibilit y , fallback b eha vior, pinning and memory placemen t, providing a p ortable abstraction for heterogeneous memory hierarc hies without relying on vendor- sp ecific API capabilities. Op enMP Allo cator Name Asso ciated Memory Space Primary Use omp_default_mem_alloc omp_default_mem_space Default system storage omp_large_cap_mem_alloc omp_large_cap_mem_space Storage with large capacity omp_const_mem_alloc omp_const_mem_space Storage optimized for reading omp_high_bw_mem_alloc omp_high_bw_mem_space Storage with high bandwidth omp_low_lat_mem_alloc omp_low_lat_mem_space Storage with low latency T able 1: Predefined OpenMP allo cators and memory spaces. [10,12] OpenMP Allocator T rait Allow ed V alues Default Setting sync_hint contended , uncontended , serialized , private contended alignment Positiv e integer value that is a p ow er of two 1 byte access all , cgroup , pteam , thread all pool_size Positiv e integer value Implementation defined fallback default_mem_fb , null_fb , abort_fb , allocator_fb default_mem_fb fb_data Allocator handle (none) pinned true , false false partition environment , nearest , blocked , interleaved environment T able 2: Op enMP allo cator traits, accepted v alues, and default settings. [10,12] Efficien t data mo v ement is critical for particle-based PIC co des on heterogeneous systems. Unified (managed) memory (UM) offers a single virtual address space with on-demand page mi- gration betw een CPU and GPU, simplifying programming but p o- ten tially incurring ov erheads due to page faults and runtime mi- grations for irregular or latency- sensitiv e access patterns [9]. In con trast, pinned (page-lock ed) host memory (PinM) enables higher-bandwidth and lo wer-latency transfers, supp orts asynchronous copies and GPU DMA, but must b e managed explicitly and can increase pressure on host memory resources. F or p erformance critical PIC MC kernels, such as particle mo vers and collision op erators, PinM is therefore commonly preferred when ex- plicit data mov ement and o verlap of communication and computation are re- quired [2,11]. 2.2 op enPMD Standard, op enPMD-api Integration & ADIOS2 The op enPMD (op en P article-Mesh Data) standard defines a portable, extensi- ble data mo del for particle and mesh data, supp orting multiple storage bac kends suc h as HDF5, ADIOS1, ADIOS2, and JSON in serial and MPI w orkflows [3]. The op enPMD-api library provides a unified interface, storing physical quan- tities as m ulti-dimensional records for mesh fields or particle data, with time- dep enden t data organized as iterations [4]. ADIOS2 (Adaptable Input/Output System version 2) is an op en-source par- allel I/O framework for scalable HPC data mov ement, offering a unified API for multi-dimensional v ariables, attributes, and time steps, with mo dular en- gines including BP4 (high-throughput file I/O) and SST (low-latency stream- Multi-GPU Hybrid PIC MC Sim ulations for Exascale Computing Systems 5 ing for in-situ MPI-parallel workflo ws) [25]. In h ybrid BIT1, we use BP4 for high-throughput file I/O [21,23] and SST for in-memory data streaming [25] indep enden tly , enabling in-situ analysis and visualization without interrupting async hronous m ulti-GPU execution on pre-exascale and exascale systems. 3 Related W ork The rapid transition of scientific simulations tow ard exascale has driven a shift from traditional CPU implementations to heterogeneous, accelerator fo cused, and hybrid programming mo dels capable of efficien tly lev eraging multiple GPU devices. Early w ork in hybrid parallelization for particle-based simulations ex- plored Op enMP and MPI for scalable p erformance on HPC clusters [1]. GPU programming mo dels hav e ev olved significantly , with Op enMP offloading emerg- ing as a promising framew ork for p ortabilit y across Nvidia, AMD, and In tel GPUs [7]. Studies ha ve ev aluated Op enMP offloading for computational kernels and data-transfer strategies, demonstrating p erformance comparable to vendor optimized numerical libraries on H100 and MI250X GPUs [6]. Other inv estiga- tions ha ve fo cused on p ortable GPU run times, with Tian et al. [13] showing that Op enMP 5.1, with minor compiler extensions, can replace v endor-sp ecific run- times such as CUDA or HIP without p erformance loss, enabling efficient compi- lation across LL VM/Clang toolchains for multiple GPU architectures. Similarly , p ortable implementations of MC particle transport co des, such as Op enMC, ha ve b een successfully p orted to heterogeneous GPUs using Op enMP target offload- ing, with large-scale b enc hmarks confirming efficiency across AMD, Nvidia, and In tel accelerators [14]. 4 Metho dology & Exp erimental Setup In this w ork, we fo cus on a p ortable, m ulti-GPU h ybrid MPI+Op enMP im- plemen tation of BIT1 for PIC MC sim ulations on exascale systems, leveraging p ersisten t GPU memory , contiguous 1D data lay outs, runtime in terop erabilit y , async hronous multi-GPU execution, and Op enMP target offloading with vendor- sp ecific optimizations, while integrating high-p erformance file and streaming I/O, and in-situ workflo ws using op enPMD and ADIOS2. 4.1 P ortable Multi-GPU Hybrid BIT1 Op enMP is a widely adopted programming mo del for shared-memory parallelism in HPC, supp orted by ma jor compilers including GCC, LL VM, and Intel, pro- viding p ortabilit y across platforms and simplifying the developmen t of parallel applications through directiv es and runtime routines. Op enMP T arget P arallelization, Data Structure & Memory Lay out. Previously , Williams et al. [5,22,24] dev elop ed an Op enMP target tasks im- plemen tation for the particle mo ver in h ybrid BIT1. In this function, parti- cle p ositions and v elocities are stored in x[species][cell][particle] and 6 Jerem y J. Williams et al. vx[species][cell][particle] , where nsp , nc and np[species][cell] denote the num b er of sp ecies, cells and particles p er cell, resp ectiv ely [15]. 1 / / E n t e r u n s t r u c t u r e d O p e n M P t a r g e t d a t a r e g i o n 2 # p r a g m a o m p t a r g e t e n t e r d a t a m a p ( t o : c h s p [ : l e n A ] , 3 s n 2 d [ : l e n A ] , d i n j [ : l e n A ] , p o f f [ : l e n A ] , n s t e p [ : l e n A ] , 4 m a x L [ : l e n A ] , n p _ G P U [ : l e n A ] , x _ G P U [ : l e n A ] , 5 y _ G P U [ : l e n A ] , v x _ G P U [ : l e n A ] , v y _ G P U [ : l e n A ] ) 6 / / P e r s i s t e n t d e v i c e - r e s i d e n t ( G P U ) m e m o r y a l l o c a t i o n 7 { 8 w h i l e ( t s t e p < l a s t _ s t e p ) { 9 .. . 10 .. . 11 ( * m o v e _ p ) ( ) ; / / P a r t i c l e m o v e r - > m o v e 0 , m o v e b 12 . . . 13 . . . 14 x a r r j ( ) ; / / P a r t i c l e a r r a n g e r - > a r rj , n a r r j 15 . . . 16 . . . 17 / / I / O - > o p e n P M D , A D I O S 2 , d u m p s t e p , d a t f i l e s 18 . . . 19 . . . 20 } / / E n d o f w h i l e ( t s t e p < l a s t _ s t e p ) 21 . . . 22 } 23 / / E x i t u n s t r u c t u r e d O p e n M P t a r g e t d a t a r e g i o n 24 # p r a g m a o m p t a r g e t e x i t d a t a m a p ( d e l e t e : x _ G P U [ : l e n A ] , 25 y _ G P U [ : l e n A ] ) 26 / / R e l e a s e p e r s i s t e n t d e v i c e - r e s i d e n t ( G P U ) m e m o r y Listing 1.1: Simplified C code snipp et illustrating the Persisten t Async hronous GPU Op enMP Offloading Suc h 3D data la youts cause non- con tiguous GPU accesses [26], reducing memory efficiency and bandwidth. T o improv e GPU run- time p erformance, hybrid BIT1 adopts a revised data lay out after iden tifying limitations in large 3D arra ys, suc h as x[species][cell] [particle] . These large arrays w ere restructured into con tiguous 1D arrays ( x_GPU[species*cell *particle] or x_GPU[:LenA] ) to enable sequen tial memory access, simpler indexing and higher sus- tained throughput in GPU k ernels. HtoD data mov ement is optimized using PinM to ensure fixed physical data residency , supporting efficien t asyn- c hronous transfers and GPU DMA. On Nvidia GPUs, PinM is selected at compile-time, while on AMD GPUs, where compile-time UM/PinM is unav ail- able, Op enMP memory allo cators explicitly manage memory placement and se- lectiv e pinning of p erformance critical arra ys, minimizing o verhead while main- taining p ortabilit y across heterogeneous GPU architectures. P ersistent Device-Residen t Memory Allo cation. Building on the asyn- c hronous GPU acceleration of the particle mo ver [24], hybrid BIT1 reduces 1 / * I n i t i a l i z e O M P P i n n e d A l l o c a t o r * / 2 o m p _ a l l o c a t o r _ h a n d l e _ t p i n n e d _ a l l o c = o m p _ n u l l _ a l l o c a t o r ; 3 . . . 4 / / C r e a t e P i n n e d O p e n M P M e m o r y A l l o c a t o r 5 i f ( p i n n e d _ a l l o c = = o m p _ n u l l _ a l l o c a t o r ) { 6 o m p _ a l l o c t r a i t _ t t r a i t s [ 1 ] ; 7 . . . 8 p i n n e d _ a l l o c = 9 o m p _ i n i t _ a l l o c a t o r ( o m p _ d e f a u l t _ m e m _ s p a c e , 10 1 , t r a i t s ) ; 11 . . . 12 } 13 / / P i n n e d A l l o c a t i o n 14 x _ G P U = ( f l o a t * ) o m p _ a l l o c ( l e n A * s i z e o f ( f l o a t ) , p i n n e d _ a l l o c ) ; 15 . . . 16 / / P e r s i s t e n t D e v i c e - R e s i d e n t ( G P U ) M e m o r y A l l o c a t i o n 17 . . . 18 / / G P U O p e n M P O f f l o a d i n g , S o r t i n g , C o m p u t a t i o n , I / O 19 . . . 20 / / R e l e a s e P e r s i s t e n t D e v i c e - R e s i d e n t ( G P U ) M e m o r y 21 . . . 22 / / F i n a l I / O - > o p e n P M D , A D I O S 2 , d u m p s t ep , d a t f i l e s 23 . . . 24 / / D e s t r o y a n d C l e a n u p O p e n M P P i n n e d M e m o r y 25 i f ( p i n n e d _ a l l o c ! = o m p _ n u l l _ a l l o c a t o r ) { 26 o m p _ f r e e ( x _ G P U , p i n n e d _ a l l o c ) ; 27 . . . 28 o m p _ d e s t r o y _ a l l o c a t o r ( p i n n e d _ a l l o c ) ; 29 p i n n e d _ a l l o c = o m p _ n u l l _ a l l o c a t o r ; 30 } 31 . . . Listing 1.2: Simplified C code snipp et illustrating Op enMP memory allo cators with the PinM trait enabled. GPU data mov ement o verhead by using p ersisten t device-residen t memory allo cation. In Listing 1.1, rather than repeatedly transfer- ring and allocating large arrays ( x_GPU[:LenA] , vx_GPU[:LenA] , y_GPU[:LenA] , vy_GPU[:LenA] ) eac h time step, a single #pragma omp target enter data region p ersisten tly allo cates all relev ant arra ys and con trol data ( chsp , sn2d , dinj , poff , nstep , maxL , np_GPU ) on the GPU. The main sim ulation lo op then iterates ov er time steps, executing the particle mo ver ( move0, moveb ), particle arranger ( arrj, narrj ), and per- forming in-situ I/O without re- p eated data transfers. After the Multi-GPU Hybrid PIC MC Sim ulations for Exascale Computing Systems 7 sim ulation, #pragma omp target exit data map(delete: ...) releases the device-residen t memory . Predefined Op enMP Memory Allo cators. Efficient data mo vemen t is crit- ical in GPU accelerated hybrid BIT1, esp ecially for large particle arrays. List- ing 1.2 shows how hybrid BIT1 reduces rep eated allo cations and transfers (par- ticularly on AMD GPUs) by using Op enMP PinM memory allo cators, which pro- vide fixed residency , high-throughput asynchronous transfers, and GPU DMA while preserving p ortabilit y . The allo cator is initialized once at startup, allo cat- ing large arrays ( x_GPU , y_GPU , vx_GPU , vy_GPU ) p ersistently on the GPU for all time steps, enabling asynchronous offloading with ov erlapping computation and I/O. A t simulation end, arrays are released, PinM is freed via omp_free , and the allo cator destroy ed with omp_destroy_allocator , ensuring clean memory managemen t. Enable GPU Runtime Intero p erabilit y . F ollowing the transition from UM to PinM to optimize data transfers, h ybrid BIT1 further enables GPU runtime in terop erabilit y via direct device-p oin ter access using Op enMP use_device_ptr 1 / / H o s t p o i n t e r a l r e a d y m a p p e d i n t o i t s d e v i c e p o i n t e r 2 # p r a g m a o m p t a r g e t d a t a u s e _ d e v i c e _ p t r ( n p _ G P U , x _ G P U , 3 y _ G P U , v x _ G P U , v y _ G P U ) 4 { 5 f o r ( i s p = 0 ; i s p < n s p ; i s p + + ) { 6 . . . 7 # p r a g m a o m p t a r g e t t e a m s d i s t r i b u t e p a r a l l e l f o r 8 / / D o n o t m a p ; p o i n t e r a l r e a d y d e v i c e - r e s i d e n t 9 i s _ d e v i c e _ p t r ( p o f f , n s t e p , m a xL , n p _ G P U , 10 x _ GP U , v x _ G P U ) 11 d e p e n d ( i n o u t : x _ G P U [ : l e n A ] ) 12 d e p e n d ( i n : p o f f [ : l e n A ] , n s t e p [ : l e n A ] , 13 m a x L [ : l e n A ] , v x _ G P U [ : l e n A ] , n p _ G P U [ : l e n A ] ) 14 f i r s t p r i v a t e ( c i 0 ) p r i v a t e ( i , j , i d x , i d x0 , c i j ) 15 t h r e a d _ l i m i t ( 5 1 2 ) n u m _ t e a m s ( 3 9 1 ) n o w a i t 16 f o r ( j = 0 ; j < n c ; j + + ) { 17 i d x 0 = p o f f [ i s p ] + j * m a x L [ i s p ] ; 18 c i j = c i 0 + j ; 19 # p r a g m a o m p s i m d 20 f o r ( i = 0 ; i < n p _ G P U [ c i j ] ; i + + ) { 21 i d x = i d x 0 + i ; 22 x _ G P U [ i d x ] + = n s t e p [ i s p ] * v x _ G P U [ i d x ] ; 23 } 24 } 25 . . . 26 } e l s e { 27 . . . 28 . . . 29 } / / e n d o f # p r a g m a o m p t a r g e t d a t a r e g i o n 30 31 / / W a i t f o r a l l a s y n c h r o n o u s O p e n M P t a s k s ( G P U k e r n e l s ) 32 # p r a g m a o m p t a s k w a i t Listing 1.3: Simplified C code snipp et illustrating Op enMP T arget T asks with "no wait" and "dep end" clauses, and enabling GPU runtime interoperability using "use_device_ptr" and "is_device_ptr" clauses for direct device-p oin ter access. and is_device_ptr clauses. In Listing 1.3, the #pragma omp target data use_device_ptr (x_GPU, y_GPU, vx_GPU, vy_GPU) region informs the runtime that the host p oin ters are already mapp ed to device memory , allow- ing GPU kernels to access device- residen t data directly without ad- ditional mapping or allo cation. Within this data region, GPU ker- nels are launched with #pragma omp target teams distribute parallel for is_device_ptr (...) so that arrays such as poff , nstep , maxL , np_GPU , x_GPU , y_GPU , vx_GPU , and vy_GPU are used as device p ointers. The GPU k ernels are issued asyn- c hronously using nowait and are ordered through explicit depend (in/out/inout) clauses, with a final #pragma omp taskwait ensuring that all Op enMP tasks (GPU k ernels) are completed. 4.2 Use Case & Exp erimen tal Environmen t W e fo cus on ev aluating the p erformance of h ybrid BIT1 on t wo test cases that differ in problem size and BIT1 functionality . W e consider tw o cases: i) a rela- tiv ely straightforw ard run sim ulating neutral particle ionization due to interac- tions with electrons, and ii) the formation of a high-densit y sheath in front of 8 Jerem y J. Williams et al. so-called divertor plates in future magnetic confinemen t fusion devices, such as the ITER and DEMO fusion devices. More precisely , the tw o cases are as follows: – Neutral P article Ionization Sim ulation. An unbounded, unmagnetized plasma of electrons, D + ions, and D neutrals is considered. Neutral concen- tration decreases via ∂ n/∂ t = nn e R , with n , n e , and R the neutral density , plasma density , and ionization rate co efficien t. W e use a 1D geometry with 100K cells, three sp ecies, and initial 100 particles p er cell p er species (total 30M). Simulations run for 200K time steps unless stated otherwise. An im- p ortan t p oin t of this test is that it do es not use the Field solver and smo other phases. Baseline sim ulation: one no de (Dardel), 128 MPI pro cesses [20,24]. – High-Densit y Sheath Simulation. A double-bounded, magnetized plasma la yer b et ween tw o walls is considered, initially filled with electrons and D + ions. Plasma is absorbed at the walls, recycling D + ions into D neutrals and forming a sheath. The 1D geometry has 3M cells, three sp ecies, and initial 200 particles p er cell p er c harged sp ecies ( ≈ 1.2B total). Simulations run for 100K time steps unless stated otherwise. Baseline sim ulation: five no des (Dardel), 640 MPI pro cesses, exceeding single-no de memory [20,24]. In this work, w e simulate h ybrid BIT1 on four HPC systems (T able 3) using key parameters in T able 4. Characteristic Dardel CPU/GPU MareNostrum5 (MN5) GPP/ACC LUMI-C / LUMI-G F rontier (OLCF-5) HPC System HPE Cray EX Supercomputer Pre-Exascale EuroHPC Sup ercomputer Pre-Exascale EuroHPC Supercomputer HPE Cra y EX Exascale supercomputer Processor 2 × AMD EPYC Zen2 (64 cores) 2 × Intel Sapphire Rapids 8480+ (56 cores) 2 × AMD EPYC 7763 (64 cores) 1 × AMD EPYC (64 cores) CPU No des 1,278 6,480 2,048 – CPU + GPU Nodes 62 1,120 2,978 9,856 GPUs p er Node 4 x AMD MI250X (w/ 2 x GCDs) 4 × Nvidia H100 4 x AMD MI250X (w/ 2 x GCDs) 4 x AMD MI250X (w/ 2 x GCDs) Memory p er Node 256 GB – 2 TB 128 GB HBM – 1 TB 256 GB – 1 TB 512 GB DDR4 Network Slingshot 200 GB/s NDR200 InfiniBand Slingshot-11 Slingshot up to 800 Gb/s Storage 679 PB 248 PB Online / 402 PB Archive 117 PB 679 PB Location KTH Royal Institute of T echnology Barcelona Sup ercomputing Center CSC – IT Center for Science Oak Ridge Leadership Computing F acility T able 3: Key characteristics of the HPC systems used in p erformance tests. Parameter Description Minimal I/O & Diagnostics Heavy I/O & Diagnostics slow Sets the plasma profiles and distribution function diagnostics (default=0). 0 0 datfile Enables time-averaged diagnostics of plasma and particle distributions. 0 1000 dmpstep Defines when the simulation state is written for restart or checkpointing. 0 5000 mvflag Specifies a diagnostic snapshot av eraged over mvflag time steps. 0 1000 mvStep Sets the interv al b et ween successive diagnostic outputs. 0 (< Last_step) 5000 Last_step Sp ecifies the final time step at which the simulation terminates. 2000 10000 origdmp Sets the format; 1=File (Serial) I/O & 2=openPMD (Parallel) BP4/SST. 1/2 1/2 T able 4: Main input parameters for simulation output and control, with key flags for Minimal and Heavy I/O & Diagnostics. [21,23] 5 P erformance Results In this work, we ev aluate a p ortable, m ulti-GPU hybrid MPI+Op enMP BIT1 using p ersistent GPU memory , con tiguous 1D la y outs, run time interoperabil- it y , asynchronous execution, OpenMP offloading, and in tegrated op enPMD and ADIOS2 on Nvidia and AMD GPU arc hitectures. Multi-GPU Hybrid PIC MC Sim ulations for Exascale Computing Systems 9 5.1 Profiling & Understanding the Impact of op enPMD on BIT1 W e b egin by utilizing gprof , an op en-source profiling tool, to analyze execu- tion time and iden tify the most frequently used functions across MPI pro cesses. The consolidated gprof rep ort provides a detailed p erformance analysis of the Original BIT1 with and without op enPMD and the ADIOS2 bac kends. Fig. 2: Ionization case function p ercen tage breakdown (using gprof ) on Dardel, sho wing where most of the execution time is sp en t for Original BIT1, op enPMD BP4, and op enPMD SST simulations [20,23,25]. The arrj sorting function (yello w) dominates but drops from 75.5% (Original BIT1) to 65.5% (BP4) and 35.5% (SST). As previously rep orted by Williams et al. [20,23,25], Fig. 2 shows the most time-consuming functions in the "BIT1 op enPMD SST" simulation compared with the "BIT1 op enPMD BP4" and "Original BIT1" simulations. In the “Orig- inal BIT1”, arrj (a sorting function) dominates at 75.5%, decreasing to 65.5% in BP4 and 35.5% in SST, highlighting impro ved data handling. The particle mo ver move0 drops from 18% to 9.2%, and the particle remo v al routine rempar2 from 14% to 2%. The neutral particle mov er nmove increases in BP4 but falls to 3.9% in SST. The profiling functions avq_mpi (profile computation) and accum_mpi (smo othed profile computation) increase in BP4 and SST, reflecting enhanced MPI communication, while the others functions grows in SST, indicating redis- tributed computation. Overall, the "BIT1 op enPMD SST" simulation sp ends the least amount of time in the most time-consuming functions, reducing the cost of arrj and move0 compared with the "BIT1 op enPMD BP4" and "Original BIT1" simulations, and improving parallel efficiency and o verall p erformance. 5.2 P orting & A ccelerating Hybrid BIT1 with Op enMP on 4 GPUs Next, we extend BIT1 by combining MPI with Op enMP in a task-based h ybrid v ersion to mitigate load imbalance and optimize resource utilization, and then p ort it to MN5 ACC (GPU partition) using one no de with four MPI ranks and four GPUs (one GPU p er rank) to analyze the impact of a contiguous 1D data la yout, Op enMP target parallelism, and multi-GPU asynchronous execution. As seen in Fig. 3, the original BIT1 version, using 4 MPI + 4 GPUs (Mov er) with a 3D data lay out and UM, executed with a total sim ulation time of ≈ 1919 s, 10 Jerem y J. Williams et al. with the arrj function dominating at ≈ 1242 s and the mover function taking ≈ 568 s. T ransitioning to a 1D UM lay out improv es memory access, reducing the total time to ≈ 830 s and lo w ering the mover and arrj times to ≈ 292 s and ≈ 430 s, resp ectiv ely . In tro ducing Op enMP thread parallelism to the arrj function further decreases its execution time to ≈ 94 s, bringing the total simula- tion time to ≈ 397 s. Using PinM for the mover reduces data transfer o verhead, decreasing the total time to ≈ 269 s, and combining PinM with Op enMP arrj parallelism further reduces it to ≈ 215 s. Finally , the fully optimized v ersion with p ersisten t GPU memory , asynchronous mover execution, and Op enMP arrj parallelism reduces the mover time to near zero ( ≈ 0.06 s) and arrj to ≈ 11.5 s, resulting in a total simulation time of around ≈ 113 s, corresp onding to a 17.04 × sp eed up ov er the original BIT1 (3D data lay out + UM) simulation. Fig. 3: Hybrid BIT1 (Ionization Case) T otal Simulation (Dev elopment Progression) strong scaling on 1 Node (4 MPI ranks & 4 GPUs) on MN5 ACC for 2K times steps. 5.3 Hybrid BIT1 (Minimal I/O & Diagnostics) up to 800 GPUs Mo ving to the high-density sheath (production-like case), we ev aluate the p ortable, m ulti-GPU hybrid MPI+OpenMP asynchronous version of BIT1 in b oth strong and weak scaling tests under minimal I/O and diagnostics. This is p erformed using a 2K time step sheath simulation up to 100 no des (up to 800 GPUs), with the parameters listed in T able 4, representing a near compute-only w orkload with a final chec kp oin t at the end of the simulation. As seen in Fig. 4, the original BIT1 version on MN5 GPP saturates under strong scaling b ey ond 20 no des, with total execution times betw een ≈ 211 s and ≈ 247 s at 40–100 no des, while the optimized CPU version shows only mo dest impro vemen ts and follo ws a similar trend. In contrast, the hybrid BIT1 v er- sions exhibit substan tially b etter scaling. On MN5 A CC, the total time de- Multi-GPU Hybrid PIC MC Sim ulations for Exascale Computing Systems 11 creases from ≈ 283.99 s at 5 no des to ≈ 29.02 s at 100 no des, corresp onding to a speed up of 9.73 × . On LUMI-G, execution time decreases from ≈ 175.21 s to ≈ 15.81 s (11.08 × sp eed up). On F rontier, the fully optimized GPU version reac hes ≈ 12.96 s (12.80 × sp eed up). Enabling op enPMD with ADIOS2 intro- duces only marginal ov erhead, with the BP4 and SST back ends completing in ≈ 11.85 s (13.64 × sp eed up) and SST in ≈ 11.71 s (13.81 × sp eed up) respectively . F or weak scaling, where the problem size increases prop ortionally with the n umber of no des, the h ybrid GPU v ersions maintain nearly constant execution times from 5 to 100 no des, whereas b oth CPU versions show a steady increase. On F ron tier, execution time remains almost flat, increasing from ≈ 165.84 s at 5 no des to ≈ 171.06 s at 100 no des, resulting in a parallel efficiency (PE) of 97.0%. With op enPMD BP4, execution increases from ≈ 161.45 s to ≈ 164.84 s (97.9% PE), and with SST, from ≈ 161.36 s to ≈ 164.75 s (98.0% PE), demonstrating that the GPU versions achiev e substantial acceleration while maintaining high w eak scaling efficiency under minimal I/O and diagnostics. Fig. 4: Hybrid BIT1 (Sheath) T otal Simulation (Relative) Sp eed Up (left) and PE (Righ t) - Strong and W eak Scaling up to 100 Nodes (up to 800 GPUs) on MN5 ACC, LUMI-G and F rontier for 2K times steps. 5.4 Hybrid BIT1 (Heavy I/O & Diagnostics) up to 16,000 GPUs W e ev aluate the exascale readiness of the p ortable, m ulti-GPU hybrid MPI +Op enMP version of BIT1 in b oth strong and w eak scaling tests under heavy I/O and diagnostics b y p erforming a 10K time-step sheath sim ulation on F ron- tier up to 2000 no des (up to 16,000 GPUs) with the parameters listed in T able 4. 12 Jerem y J. Williams et al. This represents a hea vier diagnostic workload with frequent time dep endent out- put and chec kp oin ting, which heavily stresses computation, communication, I/O, in-situ analysis and visualization, and most imp ortan tly , the file system. As seen in Fig. 5 and strong scaling tests, the original hybrid BIT1 GPU (serial I/O) version achiev es a sp eed up of 2.99 × when scaling from 50 to 2,000 no des. In con trast, the openPMD GPU (parallel I/O) implementation with the ADIOS2 BP4 back end reac hes a speed up of 4.90 × , while the SST bac kend further improv es this to 5.25 × sp eed up. This demonstrates that both op enPMD bac kends improv es scalability under heavy I/O, with SST providing the highest scaling efficiency for large GPU runs. Fig. 5: Hybrid BIT1 (Sheath) T otal Simulation (Relative) Sp eed Up (left) and PE (Righ t) - Strong and W eak Scaling up to 2000 No des (up to 16,000 GPUs) on F rontier for 10K times steps. F or weak scaling, the corresp onding PE at 2,000 no des is 67.9% for the orig- inal h ybrid BIT1 GPU v ersion, while the openPMD GPU v ersion with BP4 sustains 72.0% PE, and the op enPMD GPU v ersion with SST further improv es this to 73.6% PE. Despite the extremely heavy diagnostic and I/O w orkload, the op enPMD GPU implemen tations with ADIOS2 back ends (BP4 and SST) consisten tly maintain higher PE than the original h ybrid BIT1 GPU implemen- tation, indicating more robust weak scaling b eha vior and improv ed resilience to I/O and diagnostics pressure at scale. 6 Discussion & Conclusion This work presen ts a p ortable, m ulti-GPU h ybrid MPI+Op enMP implemen ta- tion of BIT1 for large-scale PIC MC sim ulations on pre-exascale and exascale Multi-GPU Hybrid PIC MC Sim ulations for Exascale Computing Systems 13 sup ercomputing architectures. By combining p ersisten t device-resident memory , a con tiguous 1D data lay out, PinM, run time interoperability and async hronous m ulti-GPU execution using Op enMP target tasks with explicit dep endencies, BIT1 effectiv ely reduces data mov ement and synchronization ov erheads while impro ving utilization of m ultiple accelerators. On F rontier, hybrid BIT1 demonstrates go od scalability under b oth mini- mal and heavy I/O and diagnostics. With minimal I/O and diagnostics up to 100 no des (up to 800 GPUs), the fully optimized GPU version reaches ≈ 12.96 s (12.80 × speed up), while op enPMD BP4 and SST achiev e 13.64 × and 13.81 × sp eed up, resp ectiv ely , with weak scaling remaining nearly flat ( ≈ 165.84– ≈ 171.06 s, 97%–98% PE). Under heavy I/O and diagnostics from 50 to 2000 no des (up to 16,000 GPUs), strong scaling sp eed up reaches 5.07 × (BP4) and 5.25 × (SST), while w eak scaling achiev es 72.0%–73.6% PE, sustaining intensiv e I/O and fre- quen t diagnostics, demonstrating the effectiveness of com bining asynchronous m ulti-GPU execution with standardized data managemen t at scale. Fig. 6: A single time step Hybrid BIT1 AMD MI250X GPU activit y trace sho wing HSA and HIP activity , ROCTX regions, async hronous data copies, and mov er k ernel execution, obtained using rocprof and visualized with Perfetto on Dardel GPU, with corresp onding confirmation traces on b oth LUMI-G and F rontier. F uture research will extend hybrid BIT1 to Intel GPU platforms at exas- cale, targeting Aurora , and Europ e’s first exascale system, JUPITER Booster , to assess p ortabilit y across Nvidia, AMD and Intel GPUs, and to identify any remaining architecture sp ecific limitations. Deep er p erformance analysis will b e carried out using sp ecialized profiling and tracing to ols, including Nvidia Nsight Systems (Nvidia GPUs), the op en-source p ortable profiling and trac- ing to olkit Tuning and Analysis Utilities (T AU), and AMD GPU profiling and tracing to ols, such as AMD R OC-Profiler ( rocprof ). F or instanc e, w e can use rocprof to collect correlated traces of Heterogeneous System Architecture 14 Jerem y J. Williams et al. (HSA) and Heterogeneous-computing In terface for P ortabilit y (HIP) activity , including ROCm T o ols Extension (ROCTX) regions ( roctxRangePush() and roctxRangePop() ), asynchronous data transfers, and GPU kernel execution, all captured in JSON format for use with Perfetto, enabling immediate visualiza- tion of key hybrid BIT1 trace activity (see Fig. 6). Finally , the in tegration of HPC workflo ws with AI-based metho ds will b e in vestigated to further enhance real-time analysis, adaptive control, and p erformance optimization beyond pre- exascale and exascale sup ercomputing capabilities. A ckno wledgmen ts. F unded by the European Union. This w ork has received funding from the Europ ean High Performance Computing Joint Undertaking (JU) and Swe- den, Finland, Germany , Greece, F rance, Slov enia, Spain, and Czech Republic under gran t agreemen t No 101093261 (Plasma-PEPSC). The computations/data handling w ere/was enabled by resources provided by the National A cademic Infrastructure for Sup ercomputing in Sw eden (NAISS), partially funded by the Swedish Research Coun- cil through grant agreement no. 2022-06725. This research used resources of the Oak Ridge Leadership Computing F acility at the Oak Ridge National Lab oratory , whic h is supp orted by the A dv anced Scientific Computing Research programs in the Office of Science of the U.S. Departmen t of Energy under Contract No. DE-AC05-00OR22725 References 1. Chaudh ury , B., et al.: Hybrid Parallelization of Particle in Cell Monte Carlo Colli- sion (PIC-MCC) Algorithm for Sim ulation of Lo w T emp erature Plasmas. In: W ork- shop on Softw are Challenges to Exascale Computing. pp. 32–53. Springer (2018) 2. Choi, J., et al.: Comparing Unified, Pinned, and Host/Device Memory Allo cations for Memory-Intensiv e W orkloads on T egra SoC. Concurrency and Computation: Practice and Exp erience 33 (4), e6018 (2021) 3. Huebl, A., et al.: op enPMD: A meta data standard for particle and mesh based data (2015). https://doi.org/10.5281/zenodo.591699, av ailable at: https://www. openPMD.org , https://github.com/openPMD 4. Huebl, A., et al.: openPMD-api: C++ & Python API for Scientific I/O with op enPMD (06 2018). https://doi.org/10.14278/rodare.27, a v ailable at: https: //github.com/openPMD/openPMD- api 5. IPP-CAS: Bit1 OpenMP T asks P article Mo ver Parallelization. (2025), a v ailable at: https://repo.tok.ipp.cas.cz/tskhakaya/bit1/- /blob/feature/ CPU- OpenMP/BIT1_c8/mover.c (updated: 2025-12-12) 6. Krishnaam y , E., et al.: Op enMP Offloading on AMD and NVIDIA GPUs: Pro- grammabilit y and P erformance Analysis. In: Pro ceedings of the 2025 9th In terna- tional Conference on High Performance Compilation, Computing and Communi- cations. pp. 44–56 (2025) 7. Meh ta, N., et al.: Ev aluating P erformance P ortability of Op enMP for Snap on Nvidia, Intel, and AMD GPUs using the Ro ofline Metho dology. In: International W orkshop on A ccelerator Programming Using Directives. pp. 3–24. Springer (2020) 8. Milo jicic, D., F arab oschi, P ., Dub e, N., Ro weth, D.: F uture of HPC: Div ersify- ing Heterogeneity . In: 2021 Design, Automation & T est in Europ e Conference & Exhibition (DA TE). pp. 276–281. IEEE (2021) 9. Mishra, A., et al.: Benchmarking and Ev aluating Unified Memory for OpenMP GPU offloading. In: Pro ceedings of the F ourth W orkshop on the LL VM Compiler Infrastructure in HPC. pp. 1–10 (2017) Multi-GPU Hybrid PIC MC Sim ulations for Exascale Computing Systems 15 10. Neth, B., et al.: Beyond Explicit T ransfers: Shared and Managed Memory in Op enMP. In: In ternational W orkshop on OpenMP . pp. 183–194. Springer (2021) 11. Noa je, G., et al.: MultiGPU computing using MPI or Op enMP. In: Pro ceedings of the 2010 IEEE 6th International Conference on In telligent Computer Commu- nication and Pro cessing. pp. 347–354. IEEE (2010) 12. Sew all, J., et al.: A mo dern memory management system for Op enMP. In: 2016 Third W orkshop on Accelerator Programming Using Directives (W ACCPD). pp. 25–35. IEEE (2016) 13. Tian, S., et al.: Exp erience Rep ort: W riting a Portable GPU Run time with Op enMP 5.1. In: International W orkshop on Op enMP . pp. 159–169. Springer (2021) 14. T ramm, J., et al.: T ow ard Portable GPU A cceleration of the OpenMC Monte Carlo Particle T ransp ort Co de. In: In ternational Conference on Ph ysics of Reactors (PHYSOR 2022). Pittsburgh, USA (2022) 15. T skhak a ya, D., et al.: Optimization of PIC Co des by Improv ed Memory Manage- men t. Journal of Computational Physics 225 (1), 829–839 (2007) 16. T skhak a ya, D., et al.: The P article-in-Cell Method. Contributions to Plasma Ph ysics 47 (8-9), 563–594 (2007) 17. T skhak a ya, D., et al.: PIC/MC Co de BIT1 for Plasma Simulations on HPC. In: 2010 18th Euromicro Conference on P arallel, Distributed and Netw ork-based Pro- cessing. pp. 476–481. IEEE (2010) 18. V asilesk a, I., et al.: Mo dernization of the PIC co des for exascale plasma sim ula- tion. In: 2020 43rd International Con ven tion on Information, Communication and Electronic T ec hnology (MIPRO). pp. 209–213. IEEE (2020) 19. V erb oncoeur, J., et al.: Simultaneous P otential and Circuit Solution for 1D Bounded Plasma P article Sim ulation Codes. Journal of Computational Physics 104 (2), 321–328 (1993) 20. Williams, J., et al.: Leveraging HPC Profiling and T racing T o ols to Understand the P erformance of Particle-in-Cell Monte Carlo Simulations. In: European Conference on Parallel Pro cessing. pp. 123–134. Springer (2023) 21. Williams, J., et al.: Enabling High-Throughput P arallel I/O in Particle-in-Cell Mon te Carlo Simulations with Op enPMD and Darshan I/O Monitoring. In: 2024 IEEE In ternational Conference on Cluster Computing W orkshops (CLUSTER W orkshops). pp. 86–95. IEEE (2024) 22. Williams, J., et al.: Optimizing BIT1, a Particle-in-Cell Mon te Carlo Co de, with Op enMP/OpenACC and GPU A cceleration. In: International Conference on Com- putational Science. pp. 316–330. Springer (2024) 23. Williams, J., et al.: Understanding the Impact of Op enPMD on BIT1, a Particle-in- Cell Monte Carlo Co de, Through Instrumen tation, Monitoring, and In-Situ Anal- ysis. In: Europ ean Conference on P arallel Pro cessing. pp. 214–226. Springer (2024) 24. Williams, J., et al.: A ccelerating P article-in-Cell Monte Carlo Sim ulations with MPI, Op enMP/OpenACC and Asynchronous Multi-GPU Programming. Journal of Computational Science p. 102590 (2025) 25. Williams, J., et al.: In tegrating High Performance In-Memory Data Streaming and In-Situ Visualization in Hybrid MPI+ OpenMP PIC MC Sim ulations T ow ards Exascale. The International Journal of High Performance Computing Applications (2026) 26. W u, B., et al.: Complexity Analysis and Algorithm Design for Reorganizing Data to Minimize Non-Coalesced Memory A ccesses on GPU. ACM SIGPLAN Notices 48 (8), 57–68 (2013)
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment