Large Language Model Guided Incentive Aware Reward Design for Cooperative Multi-Agent Reinforcement Learning
Designing effective auxiliary rewards for cooperative multi-agent systems remains a precarious task; misaligned incentives risk inducing suboptimal coordination, especially where sparse task feedback fails to provide sufficient grounding. This study …
Authors: Dogan Urgun, Gokhan Gungor
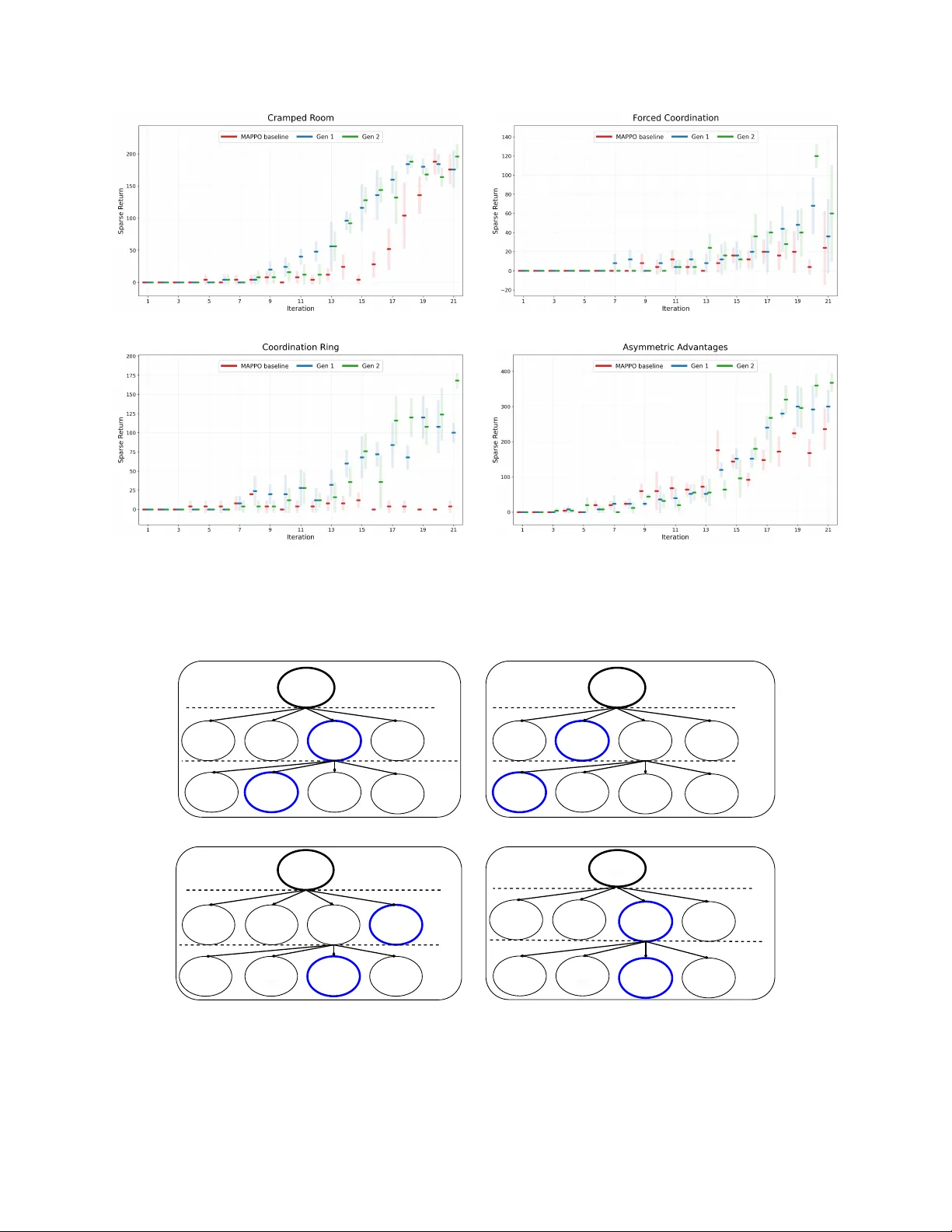
L A R G E L A N G UA G E M O D E L G U I D E D I N C E N T I V E A W A R E R E W A R D D E S I G N F O R C O O P E R A T I V E M U L T I - A G E N T R E I N F O R C E M E N T L E A R N I N G ∗ Dogan Urgun Department of Electrical and Electronics Engineering Karabuk Uni versity 78050 Karabuk, Türkiye durgun@karabuk.edu.tr Gokhan Gungor Department of Mechatronics Engineering Karabuk Uni versity 78050 Karabuk, Türkiye gokhangungor@karabuk.edu.tr A B S T R AC T Designing effecti ve auxiliary re wards for cooperativ e multi-agent systems remains a precarious task; misaligned incenti ves risk inducing suboptimal coordination, especially where sparse task feedback fails to pro vide suf ficient grounding. This study introduces an automated re ward design framework that le verages large language models to synthesize e xecutable rew ard programs from en vironment instrumentation. The procedure constrains candidate programs within a formal validity env elope and ev aluates their efficac y by training policies from scratch under a fixed computational budget; selection depends exclusi vely on the sparse task return. The frame work is ev aluated across four distinct Overcooked-AI layouts characterized by varied corridor congestion, handof f dependencies, and structural asymmetries. Iterati ve search generations consistently yield superior task returns and deliv ery counts, with the most pronounced gains occurring in en vironments dominated by interaction bottlenecks. Diagnostic analysis of the synthesized shaping components indicates increased interde- pendence in action selection and impro ved signal alignment in coordination-intensi ve tasks. These results demonstrate that the search for objectiv e-grounded rew ard programs can mitigate the burden of manual engineering while producing shaping signals compatible with cooperativ e learning under finite budgets. K eyw ords Deep learning · large language models · multi-agent learning · reinforcement learning · reward shaping 1 Introduction Rew ard specification remains a primary bottleneck in reinforcement learning (RL). In many domains, the intended objectiv e is inherently sparse or delayed; consequently , empirical performance often depends more on the design of auxiliary feedback than on improvements to the optimization algorithm itself. In cooperativ e multi-agent reinforcement learning (MARL), this challenge is further amplified: as agents interact within a Marko v game [1], auxiliary re wards influence not only credit assignment and e xploration, but also the incenti ves necessary for coordination. As a result, rew ard shaping that accelerates learning in one setting can induce brittle strategies in another , including behaviors that maximize a proxy signal while failing to improv e the true task return. A formal framework for rew ard shaping is provided by potential-based reward transformations, which augment the rew ard with a shaped term defined as the discounted difference of a potential function across transitions. Such transformations are known to preserve the set of optimal policies under standard assumptions, such as the use of a consistent discount factor and a state-dependent potential function [2]. This policy-in variance property clarifies the conditions under which an auxiliary learning signal can be introduced without altering the true objectiv e. Although subsequent research expanded the frame work to incorporate richer features, such as state-action formulations [3], and extended it to multi-agent settings [4], such formal advances do not alleviate the practical burden of specifying an ∗ This work is currently under peer re view . effecti ve potential function. Furthermore, they fail to cover the broad class of heuristic event bonuses and penalties commonly used in applied systems. Beyond theoretical limitations, the reliance of deep RL on function approximation and finite training b udgets renders optimization dynamics highly sensiti ve to auxiliary re wards; accordingly , theoretically policy-in variant shaping may still yield mixed empirical outcomes in complex multi-agent settings [5]. Consequently , re ward shaping typically requires extensi ve manual tuning, and the potential for rew ard misspecification remains a recurring concern. At the core of this challenge lies a fundamental mismatch between the implemented rew ard and the intended objectiv e, which is formally addressed by in verse rew ard design. By treating the specified reward as evidence of intent that requires contextual interpretation, this approach re veals that optimizing an underspecified proxy can lead to unintended side effects [6], thereby necessitating that automated re ward design methods be used against the true objecti ve, rather than the auxiliary signals they generate. T o mitigate the reliance on manual engineering, data-dri ven paradigms attempt to automate rew ard design by learning functional representations directly from demonstrations or feedback. In verse Reinforcement Learning (IRL) opera- tionalizes this by inferring underlying reward functions from e xpert trajectories [7-8], while preference-based learning recov ers rew ard signals through pairwise comparisons of trajectory segments [9]. Although these approaches are powerful when high-quality demonstrations or labels are accessible, they entail substantial data collection and interface ov erhead, which often prov es prohibitiv e in complex, simulation-heavy MARL en vironments. Furthermore, ev en when a shaping re ward is pro vided, its efficac y often varies across the state space. This inconsistency requires methods that determine when and how much to rely on shaping [10]. Large Language Models (LLMs) emerge as a scalable alternativ e to data-intensive methods, offering a path toward automated reward generation without the overhead of human-in-the-loop labeling. Transformers facilitate robust conditional generation [11], and lar ge-scale pretrained models demonstrate broad competence in program synthesis from structured context [12]. Recent advances in code generation further support the feasibility of producing nontrivial ex ecutable artifacts from natural language specifications [13]. Based on these capabilities, recent frame works utilize LLMs to propose re ward programs that improve through empirical feedback in RL settings [14]. LLMs also facilitate the production of shaped re ward programs from language-conditioned task descriptions [15]. Nev ertheless, autonomous rew ard generation presents two primary technical challenges: generated functions require basic correctness and boundedness, while candidate re wards require objecti ve-aligned ev aluation to mitigate the risk of optimizing spurious proxies. T o address these requirements, this work introduces an LLM-guided rew ard shaping search framework for cooperati ve MARL. The proposed approach represents reward function candidates as e xecutable programs, e valuates them through end-to-end training against a fixed baseline, and selects the optimal candidates based solely on the sparse task objectiv e. By doing so, the framework ensures that the shaping signals remain grounded in the true mission goal while leveraging the generati ve prior of LLMs. W e e valuate this method on a standard cooperative coordination benchmark across multiple tasks and analyze the resulting rew ard candidates to characterize their impact on multi-agent coordination. The contributions of this work are threefold. First, we introduce an automated reward search frame work for cooperative MARL that le verages objecti ve-grounded selection to ensure alignment with global goals. Second, we provide empirical validation across four coordination tasks, incorporating incentiv e diagnostics to characterize the signals induced by candidate re wards. Finally , we present a systematic diagnostic analysis that illustrates ho w synthesized re ward functions shape specific coordination behaviors and influence the underlying multi-agent learning dynamics. 2 Related W ork Reduction of re ward engineering has been studied from several perspectiv es, including rew ard shaping and credit assignment in cooperati ve MARL, rew ard construction or optimization from data and interaction, and programmatic rew ard generation using LLMs. Reward shaping remains a common practical tool for accelerating learning with sparse objectiv es, but it introduces design choices that can change learning dynamics and, in multi-agent settings, can change incentiv es. Polic y-inv ariant shaping provides a principled baseline for adding auxiliary signal without altering the underlying objectiv e [2], and later work broadens the class of potential-based constructions [3]. In cooperativ e MARL, the re ward signal also serv es as a mechanism for credit assignment, moti vating designs that better reflect each agent’ s contribution to team performance; potential-based dif ference rewards are an e xample of this direction [4]. These lines of work clarify that auxiliary rew ards can be useful, but the y do not remove the need to specify ef fective shaping terms for a giv en domain, nor do they ensure that heuristically chosen e vent-based shaping will a void proxy optimization. A second set of methods aims to reduce manual tuning by modifying or learning how re wards are used during training. Some approaches e xplicitly optimize the re ward function so that, under a fixed learning procedure, the induced behavior 2 Figure 1: The proposed objectiv e-grounded reward search frame work. better matches a target notion of alignment [16]. Other work studies how an agent can learn to rely on shaping rew ards selectiv ely when shaping quality varies across the state space [10]. These approaches motiv ate two design choices adopted in the present work: reward candidates are ev aluated through end-to-end training under a fixed baseline, and selection is performed using the true task objective rather than the shaped signal. Rew ard specification can also be addressed by inferring objecti ves from demonstrations or feedback. In verse RL infers a re ward function from expert behavior [7-8], and preference-based learning infers re wards from human comparisons [9]. Such methods reduce the need to handcraft shaping terms, but require demonstrations, preferences, or interacti ve supervision. The present work targets a complementary regime in which repeated simulation and en vironment instrumentation are a vailable and in which rew ard candidates can be tested by training and ev aluation without collecting additional human labels. Recent work has le veraged LLMs to generate e xecutable artif acts, enabled by T ransformer-based conditional generation [11-12], and demonstrated in general-purpose code synthesis [13]. Building on these capabilities, LLMs hav e been used to propose reward programs that are improved through empirical feedback in RL [14], and to generate shaped rew ard programs from task descriptions [15]. Our approach diver ges from these frameworks in two aspects critical to cooperativ e MARL: candidate rewards are ex ecutable programs over instrumentation signals, and candidates are accepted only when the y improv e the sparse task objectiv e under a fixed multi-agent learning baseline, which is intended to limit proxy optimization effects [6]. 3 Method The general framew ork of the proposed method is illustrated in fig. 1. The system implements an iterativ e, closed-loop rew ard engineering process that leverages the generati ve capabilities of LLMs and the e valuati ve precision of MARL. An objectiv e-grounded reward search procedure is described for cooperativ e MARL. At a high level, an LLM proposes ex ecutable rew ard candidates conditioned on a structured task description and an archiv e of prior outcomes. Each candidate is constrained by a v alidity en velope that enforces implementability and discourages e xploitable proxies.V alid candidates are used to train policies from scratch with a fixed MARL learner under a fixed b udget, and their performance is ev aluated solely with the sparse task objectiv e. In addition, descripti ve incentiv e diagnostics are computed from rollouts and used as structured feedback for subsequent candidate generation. 3 3.1 Problem Setting and Reward Interfaces W e consider a cooperati ve Marko v game [1] defined by the tuple G = ⟨S , {A i } n i = 1 , P , r sparse , γ ⟩ , with n agents interacting in the state space S . At each time step t , the en vironment is in state s t ∈ S . Each agent i ∈ { 1 , . . . , n } selects an action a t , i from its indi vidual action space A i , forming a joint action a t = ( a t , 1 , . . . , a t , n ) ∈ A , where A is the joint action space. The system dynamics follow the transition probability kernel P : S × A × S → [ 0 , 1 ] , which defines the probability P ( s t + 1 | s t , a t ) of transitioning to state s t + 1 gi ven the current state s t and joint action a t . Furthermore, r sparse : S × A → R defines the rew ard function for shared sparse tasks, and γ ∈ [ 0 , 1 ] is the discount factor . In this cooperati ve setting, the task re ward is sparse and shared; specifically , a scalar rew ard r sparse , t = r sparse ( s t , a t ) is produced by the en vironment and assigned equally to all agents. The performance objecti ve is to maximize the e xpected discounted sparse return: J ( π ) = E τ ∼ π " T − 1 ∑ t = 0 γ t r sparse , t # , (1) where π denotes the joint policy , τ represents a trajectory induced by π , and T is the episode horizon. In addition to the sparse reward, the simulator e xposes structured instrumentation through an information record info t . A deterministic feature map φ is used to conv ert the transition and instrumentation into a feature vector , x t = φ ( s t , a t , s t + 1 , info t ) . (2) A re ward candidate is represented as an e xecutable program p that produces agent-specific shaping signals from the instrumentation. Giv en the state features x t and the global sparse task reward r sparse , t , the program generates a vector of auxiliary shaping r ( p ) t = p ( x t , r sparse , t ) ∈ R n , (3) where the i -th component r ( p ) t , i denotes the shaping signal assigned to agent i at step t . During training, each agent receiv es an augmented reward ˜ r t , i = r sparse , t + λ r ( p ) t , i , (4) where λ ≥ 0 is the fixed scaling factor . The sparse rew ard term preserves the intended task objectiv e, while the shaping term is used only to impro ve learning under finite budgets. In all results reported, the candidates are compared using the sparse objectiv e in eq. (1), not the shaped return. 3.2 Objective-Gr ounded Search and Selection Let Train ( · ; θ θ θ , ξ ) denote training with a fixed MARL learner (MAPPO) using fixed hyperparameters θ θ θ and randomness ξ . The candidate e valuation process adheres to the Centralized T raining, Decentralized Execution (CTDE) paradigm, as illustrated in fig. 2. During the centralized training phase (fig. 2a), a centralized critic V leverages a shared buffer of global states and joint observations to e valuate the collectiv e policy and deriv e training feedback. This centralized value estimate is utilized to provide adv antage signals that guide the policy updates for all agents. Conv ersely , during the decentralized ex ecution phase (fig. 2b), the decentralized actors π i select actions based strictly on local observ ations. Upon completion of training with the augmented re wards defined in eq. (4), the candidate is ev aluated exclusi vely via the sparse task objectiv e G to obtain the empirical estimate b J ( p ) . The search process e volves over a total of G generations. At each generation inde x g ∈ { 1 , . . . , G } , a structured context c g is constructed from the task description, the instrumentation schema, the reward interface, and summaries of previously e valuated candidates. The LLM proposes K rew ard candidates by sampling from a conditional distribution q ψ ( p | c g ) . Each candidate p is filtered by a validity env elope before training. The en velope enforces correct input and output signatures, determinism, bounded outputs via clipping, and robustness to missing instrumentation keys. Candidates failing v alidation are rejected, and when failures are syntactic or runtime in nature, a bounded number of repair attempts are performed by conditioning on the error trace. W ithin each generation, candidates are trained and ev aluated, and the best candidate is selected based on the sparse return: p ⋆ g ∈ arg max k ∈ V g b J ( p g , k ) , (5) where p g , k is the k -th candidate in generation g for k ∈ V g ⊆ { 1 , . . . , K } , and V g denotes the set of indices for candidates that pass validation. Selection is objective-grounded because only the sparse return is used for promotion. The complete procedure, which encompasses LLM-based iterativ e rew ard generation and the inner MARL ev aluation loop, is summarized in Algorithm 1. 4 Mult-Agent Envronment Centralzed T ranng Phase V Agent 1 Agent 2 Agent n V Polcy Crtc Tranng Feedback Observaton Acton (a) Centralized T raining Phase Mult-Agent Envronment Observaton Acton Polcy Decentralzed Executon Phase (b) Decentralized Execution Phase Figure 2: Overvie w of the CTDE paradigm for multi-agent reinforcement learning. (a) Centralized Training: A shared critic ( V ) utilizes global state information and joint observ ation buf fers to guide policy updates via training feedback. (b) Decentralized Execution: Indi vidual actors ( π i ) rely exclusi vely on local observations for action selection, ensuring scalability in partially observable en vironments. Algorithm 1: Objectiv e-grounded incentiv e-aware re ward search. Require : T ask specification and instrumentation schema; validity en velope; learner settings θ θ θ ; generations G ; candidates per generation K 1 Initialize archive A ← / 0, and best score b J best ← − ∞ 2 for g = 1 to G do 3 Construct context c g from task description and archiv e summaries 4 Sample candidates { p g , k } K k = 1 ∼ q ψ ( p | c g ) 5 for k = 1 to K do 6 V alidate and, if needed, repair p g , k 7 if p g , k is valid then 8 T rain policy π π π g , k ← Train ( · ; θ θ θ , ξ ) using augmented rew ards ˜ r t , i 9 Evaluate estimate b J ( p g , k ) using sparse reward only 10 Compute diagnostics d ( p g , k ) from rollouts 11 A ← A ∪ { ( p g , k , b J ( p g , k ) , d ( p g , k )) } 12 end if 13 end for 14 Update context summaries in A 15 end for Return : Best candidate p ⋆ = arg max ( p , · , · ) ∈ A b J ( p ) 3.3 Incentive Diagnostics Used for Feedback The candidate program can assign different shaping signals to dif ferent agents, ev en when the task objective is shared. For interpretability , the shaping component is analyzed separately from the sparse rew ard. Using the agent-specific shaping signal r ( p ) t , i , the discounted shaping return for agent i on a rollout is defined as: S i ( p ) = T − 1 ∑ t = 0 γ t r ( p ) t , i . (6) 5 These returns are computed on the shaping component only and therefore can be asymmetric e ven when the en vironment rew ard is a shared team reward. 3.3.1 Pay off imbalance. Payof f imbalance measures the disparity in shaping returns across n agents. T o ensure the metric remains bounded and interpretable, we define it as the normalized sum of all-pairs differences: ∆ ( p ) = ∑ n i = 1 ∑ n j = i + 1 | S i ( p ) − S j ( p ) | ( n − 1 ) ∑ n k = 1 | S k ( p ) | + ε , (7) where ε > 0 is a small constant for numerical stability . This formulation is bounded within [ 0 , 1 ] , where ∆ ( p ) → 0 indicates a symmetric distribution of re wards and lar ger values signal a disproportionate concentration on a subset of agents. 3.3.2 Incentive alignment Incentiv e alignment measures the degree to which per -step shaping signals concurrently reinforce the agents. For an ensemble of n agents, we define this as the av erage pairwise Pearson correlation across all time steps in an episode: ρ ( p ) = 2 n ( n − 1 ) n ∑ i = 1 n ∑ j = i + 1 corr r ( p ) t , i , r ( p ) t , j . (8) Strongly positiv e values ( ρ → 1 ) indicate that the shaping signals are synchronized, suggesting that the rew ard program p induces mutually reinforcing beha viors. Conv ersely , values near zero or ne gati ve suggest decoupled or conflicting incentiv es, potentially signaling a breakdown in cooperati ve dynamics or the optimization of competitiv e proxy goals. 3.3.3 Action Coupling Action coupling quantifies the statistical dependence between the agents’ decision-making processes under the policy optimized via program p . For an ensemble of n agents, we report the average pairwise Normalized Mutual Information (NMI) across all time steps: NMI ( p ) = 2 n ( n − 1 ) n ∑ i = 1 n ∑ j = i + 1 I ( A i ; A j ) p H ( A i ) H ( A j ) , (9) where I ( A i ; A j ) denotes the mutual information between the action distributions of agents i and j , and H ( A i ) represents the mar ginal entropy of the discrete action random variable A i estimated from rollout data. Unlike raw mutual information, this geometric mean normalization ensures the metric is bounded within [ 0 , 1 ] , where higher NMI indicates more interdependent action selection. This serves as a proxy for identifying whether the synthesized re ward signals induce emergent coordination or lead to independent, decoupled strate gies. 3.3.4 Diagnostic Feedback and Logging Upon the completion of each ev aluation rollout, the frame work logs a comprehensiv e diagnostic tuple for e very candidate: d ( p ) = b J ( p ) , ∆ ( p ) , ρ ( p ) , NMI ( p ) , (10) which characterizes the candidate’ s performance, payoff distribution, signal alignment, and behavioral coupling, respectiv ely . While these diagnostics serve as high-dimensional descriptiv e feedback to guide the LLM proposer in subsequent generations, the final selection and promotion mechanism remains strictly exclusi ve to the sparse task return b J ( p ) . This decoupling ensures that while the search process is informed by comple x coordination metrics, the optimization objectiv e remains grounded in the true en vironment goal, preventing the emer gence of reward-hacking or the optimization of unintended proxy behaviors. 4 Results In this section, we ev aluate the effecti veness of our diagnostic-grounded reward search in discovering rew ards that strengthen multi-agent coordination. W e begin by introducing the benchmark layouts and the specific coordination challenges inherent in each. W e then analyze the objective performance gains across successi ve generations, highlighting learning dynamics in en vironments characterized by significant interaction bottlenecks. Finally , we provide a detailed diagnostic analysis to clarify how the discov ered shaping signals influence agent interdependence, incentiv e alignment, and payoff distrib ution. 6 Figure 3: Layouts used in the reported experiments: Cramped Room, Forced Coordination, Coordination Ring, and Asymmetric Advantages. 4.1 Layout Characteristics and Coordination Challenges Evaluation is performed on the Ov ercooked-AI cooperati ve cooking en vironment [17], where two agents ( n = 2 ) must coordinate navigation, resource handling, and timed handoffs to deli ver completed soups. The task reward is sparse and is provided only for v alid deliv eries. W e select four layouts representing a div erse spectrum of dyadic coordination challenges (see Fig. 3): Cramped Room, Forced Coordination, Coordination Ring, and Asymmetric Advantages. Cramped Room is a compact shared workspace in which both agents repeatedly tra verse narrow corridors and compete for space. Forced Coordination separates ke y resources, so progress depends on repeated handoffs and turn-taking at constrained interaction points. Coordination Ring requires synchronized navig ation around a ring-like topology with limited passing, which makes deadlocks and mistimed detours costly under sparse feedback. Asymmetric Advantages introduces asymmetric access paths and staging locations, which induces complementary roles while still requiring compatible joint ex ecution. 4.2 Objective Perf ormance and Learning Dynamics The empirical success of the diagnostic-grounded search is demonstrated by the progression of the sparse task return J across two successi ve generations. As reported in T able 1, each search generation is conducted on top of a MAPPO baseline, where candidates are trained from scratch under a fixed computational budget and selected e xclusively based on the sparse task objectiv e. Across all ev aluated layouts, we observe a consistent monotonic increase in both sparse returns and successful deliv ery counts in later generations. The most substantial gains are realized in Coordination Ring and Forced Coordination, where baseline performance is se verely constrained by the difficulty of credit assignment under tight interaction bottlenecks. In these scenarios, the baseline agent frequently suffers from coordination failures such as deadlocks, mistimed passing, and handoff synchronization issues. The synthesized reward programs from later generations effecti vely bridge this exploration gap by providing dense auxiliary signals for intermediate progress. This acceleration in coordination discovery is clearly reflected in the results: for instance, in the Coordination Ring layout, the Gen 2 candidate achiev es a nearly twelve-fold increase in successful deli veries compared to the baseline ( 7 . 65 vs. 0 . 15 ), while simultaneously reducing in valid deliveries from 11 . 30 to 0 . 85 . In more straightforward layouts like Cramped Room and Asymmetric Adv antages, where the baseline performance is naturally stronger , the framework still yields incremental yet statistically significant improvements within the same compute budget. T able 1: Final ev aluation on four Overcooked layouts. J denotes sparse return (mean ± std across ev aluation episodes). Deliv eries and in valid deli veries are episode means. Layout J Deliveries In valid Deliveries Baseline Gen 1 Gen 2 Baseline Gen 1 Gen 2 Baseline Gen 1 Gen 2 Cramped Room 148 ± 39 180 ± 25 188 ± 10 7 . 40 9 . 00 9 . 40 1 . 15 0 . 25 0 . 75 Forced Coordination 32 ± 14 55 ± 26 103 ± 29 1 . 60 2 . 75 5 . 15 0 . 80 1 . 25 0 . 30 Coordination Ring 13 ± 5 102 ± 28 153 ± 24 0 . 15 5 . 10 7 . 65 11 . 30 3 . 50 0 . 85 Asymmetric Advantages 231 ± 38 322 ± 36 381 ± 25 11 . 55 16 . 10 19 . 05 6 . 15 3 . 45 1 . 55 7 (a) Cramped Room (b) Forced Coordination (c) Coordination Ring (d) Asymmetric Advantages Figure 4: Learning curves of e valuation sparse return J for the MAPPO baseline and the selected candidates from the first and second generations. Shaded regions indicate v ariability across ev aluation episodes. Baselne Sparse return 148 ± 39 C 0 Sparse return 148 ± 39 C 1 Sparse return 171 ±25 C 2 Sparse return 180 ±25 C 3 Sparse return 152 ±25 C 0 Sparse return 184 ±10 C 1 Sparse return 188 ±10 C 2 Sparse return 170 ±10 C 3 Sparse return 178 ±10 Cramped Room Generaton 1 (T op 4) Generaton 0 (MAPPO Baselne) Generaton 2 (T op 4) Baselne Sparse return 32 ±14 C 0 Sparse return 39 ±26 C 1 Sparse return 55 ±26 C 2 Sparse return 28 ±26 C 3 Sparse return 47 ±26 C 0 Sparse return 103 ±29 C 1 Sparse return 92 ±29 C 2 Sparse return 64 ±29 C 3 Sparse return 78 ±29 Forced Coordnaton Generaton 1 (T op 4) Generaton 0 (MAPPO Baselne) Generaton 2 (T op 4) Baselne Sparse return 231 ±38 C 0 Sparse return 304 ±36 C 1 Sparse return 287 ±36 C 2 Sparse return 322 ±36 C 3 Sparse return 255 ±36 C 0 Sparse return 332 ±25 C 1 Sparse return 365 ±25 C 2 Sparse return 381 ±25 C 3 Sparse return 348 ±25 Asymmetrc Advantages Generaton 1 (T op 4) Generaton 0 (MAPPO Baselne) Generaton 2 (T op 4) Baselne Sparse return 13 ±5 C 0 Sparse return 88 ±28 C 1 Sparse return 71 ±28 C 2 Sparse return 43 ±28 C 3 Sparse return 102 ±28 C 0 Sparse return 1 10 ±24 C 1 Sparse return 142 ±24 C 2 Sparse return 153 ±24 C 3 Sparse return 126 ±24 Coordnaton Rng Generaton 1 (T op 4) Generaton 0 (MAPPO Baselne) Generaton 2 (T op 4) Figure 5: Candidate promotion diagram. Nodes summarize ev aluated candidates and objecti ve scores, and edges indicate the promotion path used to condition subsequent generations. The temporal e volution of agent performance, illustrated through the learning curv es in fig. 4, reveals the critical role of synthesized re wards in accelerating coordination. In nearly all layouts, the MAPPO baseline (red) exhibits either 8 (a) Cramped Room: Increasing trends in Action Coupling (NMI) and Incenti ve Alignment ( ρ ) signify reduced collision rates in high-density areas. (b) Forced Coordination: A sharp decline in Payof f Imbalance ( ∆ ) alongside rising NMI indicates a shift from single-agent dominance to equitable workload distrib ution. (c) Coordination Ring: Steady growth in ρ and NMI demon- strates the emergence of synchronized circular motion and tem- poral waiting beha viors. (d) Asymmetric Advantages: The upward trajectory in NMI confirms the LLM’ s ability to synthesize specialized rew ard structures for agents with distinct roles. Figure 6: Empirical Coordination Diagnostics across Overcooked-AI Layouts. The plots illustrate the iterativ e improv ement from Baseline to Generation 2. Blue solid lines represent Action Coupling (NMI), while green dashed lines show Incenti ve Alignment ( ρ ) and the orange dotted line indicates Payoff Imbalance ( ∆ ). high v ariance or premature con vergence to suboptimal policies. In contrast, candidates from Generation 1 (blue) and Generation 2 (green) consistently demonstrate higher sample efficienc y and asymptotic performance. This trend is most prominent in the Coordination Ring (fig. 4c), where the baseline fails to achiev e meaningful progress, while successiv e search generations progressiv ely unlock higher-order cooperati ve behaviors, leading to a substantial vertical shift in the rew ard curves. T o further elucidate the search process, fig. 5 provides a structural lineage of candidate promotion across generations. Each node represents an independent training run of a synthesized rew ard program, with edges indicating the genealogi- cal path used to condition subsequent LLM prompts. This hierarchical selection mechanism ensures that the search space is effecti vely pruned to ward objectiv e-aligned regions. The lineage diagrams highlight a robust compounding ef fect: for instance, in Forced Coordination, the jump from Baseline ( 32 ± 14 ) to Gen 2 ( 103 ± 29 ) is not merely a result of luck, b ut the outcome of a structured refinement process where successful shaping strategies from the first generation serve as a foundation for more comple x incentiv es in the second. This iterativ e improv ement confirms that the LLM-proposer can successfully interpret the diagnostic feedback d ( p ) from previous iterations to mitigate coordination bottlenecks, such as deadlocks and synchronization failures, which otherwise impede the baseline learner . 9 4.3 Coordination Diagnostics and Shaping Signals The incenti ve diagnostics in Sect. 3.3 clarify the e volution of interaction patterns and shaping signals across generations. These quantities represent descripti ve summaries from rollouts rather than claims of equilibrium properties. Notably , payoff imbalance and incentiv e alignment calculations focus on the candidate shaping component r ( p ) t , i instead of the shared sparse task rew ard. Consequently , these metrics capture the distribution of the auxiliary learning signal among agents. Figure 6 reports the mean diagnostic v alues for candidate pools that satisfy a minimum sparse-return criterion. T wo primary trends emer ge from these results. First, the action coupling, measured through NMI, increases across successiv e search generations in all layouts (Fig. 6a- d). This trend indicates that high-performance reward candidates f acilitate more interdependent action selection. In the Overcook ed en vironment, effecti ve performance relies on precise coordinated timing and mutual adaptation. This requirement includes corridor yield maneuv ers, the sequencing of interactions at shared stations, and the synchronization of trav el paths. The observed increase in NMI remains consistent with the emergence of these strate gic dependencies. Second, incenti ve alignment ( ρ ) increases in Cramped Room, Coordination Ring, and Asymmetric Adv antages (Fig. 6a, c, d). This result indicates that the proposed shaping signals for both agents exhibit a higher positiv e correlation in later generations. In practice, this pattern aligns with shaping programs that reinforce intermediate progress to ward shared subgoals. This alignment prev ents the introduction of competing gradients that might destabilize coordination. A layout-specific pattern is evident in Forced Coordination (Fig. 6b). Because this layout depends on repeated handoffs, shaping that concentrates auxiliary return on a single agent can create asymmetric learning dynamics. In such cases, one agent receiv es strong gradients, while the other receives weak or noisy guidance. The payoff imbalance diagnostic ( ∆ ) decreases between generations in Forced Coordination, which indicates a more uniform distribution of shaping signals for the selected later -generation candidates. This behavior remains consistent with rew ard programs that provide guidance for both roles necessary for successful handoffs. 5 Conclusion An objectiv e-grounded approach to autonomous reward program synthesis for cooperati ve MARL has been presented. In this frame work, a large language model generates candidate shaping programs from en vironment instrumentation. These candidates remain constrained by a formal v alidity en velope and undergo ev aluation under a fixed MAPPO learner . Selection across successi ve generations depends solely on the sparse task return; consequently , performance improv ements are directly related to the intended objective, rather than to the auxiliary shaping signal itself. Across four Overcooked-AI layouts, later search generations exhibit higher sparse returns and increased deli very counts. The most pronounced gains appear in layouts dominated by interaction bottlenecks under sparse feedback. Diagnostic trends for the shaping component indicate increased action coupling and higher alignment of shaping signals in coordination-heavy tasks. Furthermore, a reduction in the shaping concentration on a single agent is evident in handoff-dri ven layouts. These results suggest that objective-grounded re ward program search can mitigate the b urden of manual rew ard engineering while it yields shaping signals compatible with stable cooperative learning under finite training budgets. References [1] Michael L. Littman. Marko v games as a framework for multi-agent reinforcement learning. In Pr oceedings of the Eleventh International Confer ence on Machine Learning (ICML) , pages 157–163. Mor gan Kaufmann, 1994. [2] Andrew Y . Ng, Daishi Harada, and Stuart J. Russell. Polic y in variance under re ward transformations: Theory and application to re ward shaping. In Pr oceedings of the Sixteenth International Confer ence on Machine Learning (ICML) , pages 278–287. Morgan Kaufmann, 1999. [3] Anna Harutyunyan, Sam Devlin, Peter Vrancx, and Ann Nowé. Expressing arbitrary rew ard functions as potential- based advice. In Pr oceedings of the T wenty-Ninth AAAI Confer ence on Artificial Intelligence (AAAI) , pages 2652–2658, 2015. [4] Sam De vlin, Logan Yliniemi, Daniel Kudenk o, and Kagan T umer . Potential-based dif ference rewards for multiagent reinforcement learning. In Proceedings of the 13th International Confer ence on Autonomous Agents and Multiagent Systems (AAMAS) , pages 165–172, 2014. [5] Sam De vlin, Marek Grze ´ s, and Daniel K udenko. An empirical study of potential-based re ward shaping and advice in complex, multi-agent systems. Advances in Complex Systems , 14(2):251–278, 2011. 10 [6] Dylan Hadfield-Menell, Smitha Milli, Pieter Abbeel, Stuart Russell, and Anca Dragan. In verse rew ard design. In Advances in Neural Information Pr ocessing Systems (NeurIPS) , 2017. [7] Andrew Y . Ng and Stuart J. Russell. Algorithms for inv erse reinforcement learning. In Pr oceedings of the Seventeenth International Confer ence on Machine Learning (ICML) , pages 663–670. Mor gan Kaufmann, 2000. [8] Brian D. Ziebart, Andrew Maas, J. Andre w Bagnell, and Anind K. Dey . Maximum entropy in verse reinforcement learning. In Pr oceedings of the T wenty-Thir d AAAI Confer ence on Artificial Intelligence (AAAI) , pages 1433–1438, 2008. [9] Paul F . Christiano, Jan Leike, T om B. Brown, Miljan Martic, Shane Le gg, and Dario Amodei. Deep reinforcement learning from human preferences. In Advances in Neural Information Pr ocessing Systems (NeurIPS) , 2017. [10] Y ujing Hu, W enxuan W ang, Jiahang Tian, Y ixiang W u, Y ingfeng Chen, Jianye Hao, Feng W u, and Changjie Fan. Learning to utilize shaping rew ards: A new approach of reward shaping. In Advances in Neural Information Pr ocessing Systems (NeurIPS) , 2020. [11] Ashish V aswani, Noam Shazeer , Niki Parmar , Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neur al Information Processing Systems (NeurIPS) , 2017. [12] T om B. Brown, Benjamin Mann, Nick Ryder , Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Prana v Shyam, Girish Sastry , Amanda Ask ell, Ariel Herbert-V oss, Gretchen Krueger , T om Henighan, Rew on Child, Aditya Ramesh, Daniel Ziegler , Jeffre y W u, Clemens W inter, Christopher Hesse, Mark Chen, Eric Sigler , Mateusz Litwin, Scott Gray , Benjamin Chess, Jack Clark, Christopher Berner , Sam McCandlish, Alec Radford, Ilya Sutske ver , and Dario Amodei. Language models are few-shot learners. In Advances in Neural Information Pr ocessing Systems (NeurIPS) , 2020. [13] Y ujia Li, David Choi, Junyoung Chung, et al. Competition-lev el code generation with AlphaCode. Science , 378(6624):1092–1097, 2022. [14] Y echeng Jason Ma, William Liang, Guanzhi W ang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Y uke Zhu, Linxi Fan, and Anima Anandkumar . EUREKA: Human-lev el reward design via coding large language models. In International Confer ence on Learning Representations (ICLR) , 2024. [15] T ianbao Xie, Siheng Zhao, Chen Henry W u, Y itao Liu, Qian Luo, V ictor Zhong, Y anchao Y ang, and T ao Y u. T ext2re ward: Reward shaping with language models for reinforcement learning. In International Confer ence on Learning Repr esentations (ICLR) , 2024. [16] Dhaw al Gupta, Y ash Chandak, Scott M. Jordan, Philip S. Thomas, and Bruno Castro da Silva. Behavior alignment via rew ard function optimization. In Advances in Neural Information Pr ocessing Systems (NeurIPS) , 2023. [17] Micah Carroll, Rohin Shah, Mark K. Ho, T om Griffiths, Sanjit A. Seshia, Pieter Abbeel, and Anca D. Dragan. On the utility of learning about humans for human-ai coordination. In Advances in Neural Information Pr ocessing Systems (NeurIPS) , pages 5175–5186, 2019. 11
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment