Forecasting with Guidance: Representation-Level Supervision for Time Series Forecasting
Nowadays, time series forecasting is predominantly approached through the end-to-end training of deep learning architectures using error-based objectives. While this is effective at minimizing average loss, it encourages the encoder to discard inform…
Authors: Jiacheng Wang, Liang Fan, Baihua Li
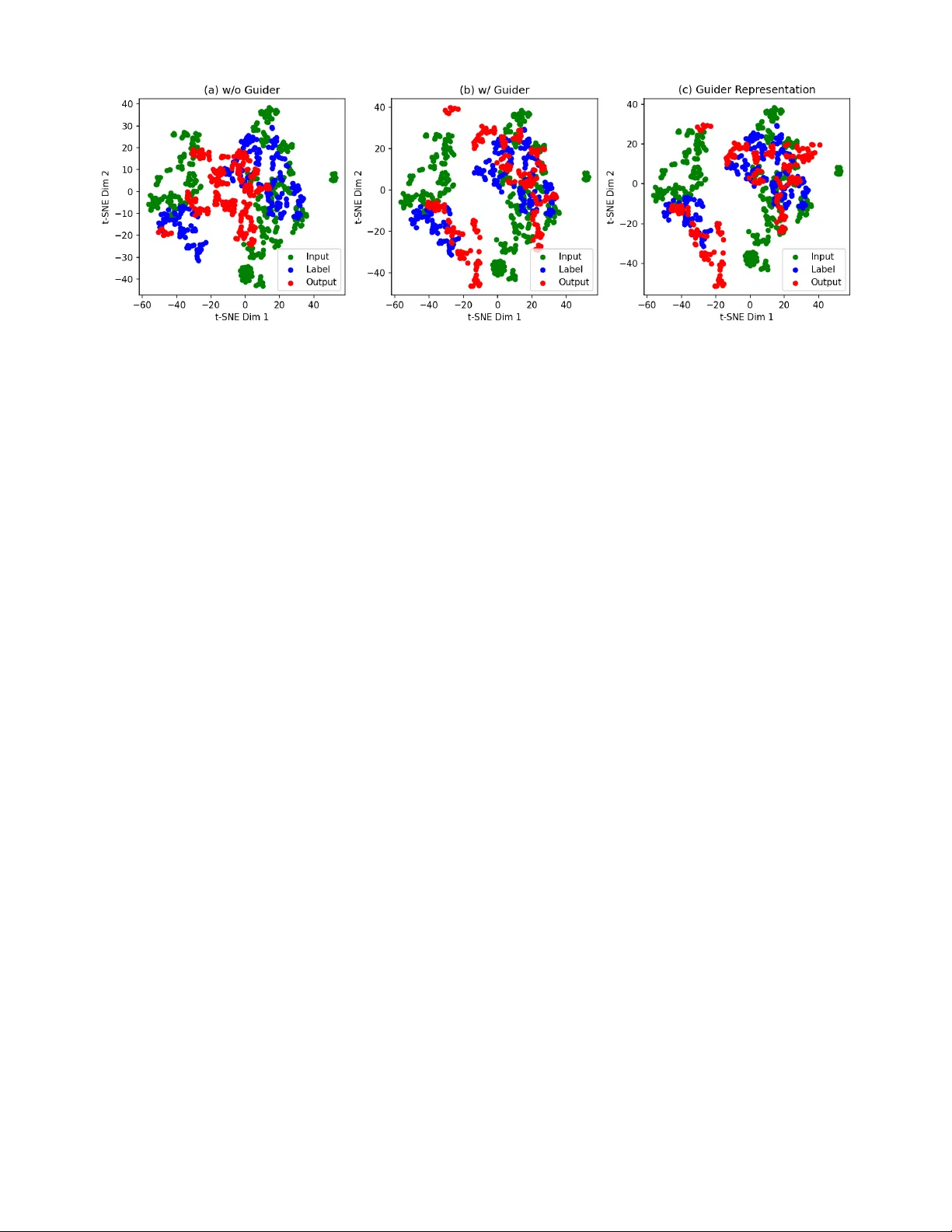
F orecasting with Guidance: Representation-Le v el Supervision for T ime Series F orecasting Jiacheng W ang Xijing University 2408540402040@stu.xijing.edu.cn ORCID: 0009-0003-2474-4223 Liang Fan and Baihua Li Loughbor ough University { L.Fan, B.Li } @lboro.ac.uk ORCID: 0000-0003-1464-8353, 0000-0002-0277-3651 Luyan Zhang * Northeastern University zhang.luya@northeastern.edu ORCID: 0009-0008-7385-373X Abstract —Nowadays, time series forecasting is predominantly approached through the end-to-end training of deep learning architectur es using err or -based objectiv es. While this is effective at minimizing average loss, it encourages the encoder to discard informati ve yet extreme patterns. This results in smooth predic- tions and temporal repr esentations that poorly capture salient dynamics. T o address this issue, we propose ReGuider, a plug-in method that can be seamlessly integrated into any for ecasting ar - chitecture. ReGuider leverages pretrained time series foundation models as semantic teachers. During training, the input sequence is processed together by the target forecasting model and the pre- trained model. Rather than using the pretrained model’s outputs directly , we extract its intermediate embeddings, which are rich in temporal and semantic information, and align them with the target model’s encoder embeddings through representation-le vel supervision. This alignment process enables the encoder to learn more expressive temporal representations, thereby improving the accuracy of downstream forecasting . Extensive experimentation across diverse datasets and architectur es demonstrates that our ReGuider consistently improv es for ecasting performance, confirming its effectiveness and versatility . Index T erms —Time Series forecasting, Foundation Model, Representation Learning I . I N T R O D U C T I O N T ime series forecasting (TSF) is central to many real- world applications, including finance [1], healthcare [2], and climate science [3]. The recent success of deep learning has brought substantial adv ances to the field, with architectures such as graph networks [4], [5], Linear-based models [6], [7], and transformers [8], [9] demonstrating strong predictiv e capabilities. By automatically e xtracting comple x temporal dependencies, deep learning models hav e surpassed classical statistical approaches and become the predominant choice for modern forecasting tasks. Ho wev er , achieving accurate and ro- bust predictions across di verse domains remains a fundamental challenge. Most deep learning approaches [10]–[12] to time series forecasting rely solely on error-based objectives such as mean squared error (MSE) and mean absolute error (MAE). While these objecti ves optimize predictive accuracy directly , they provide the encoder with limited guidance on ho w to cap- ture rich temporal dependencies. Consequently , models often reduce errors by av eraging predictions, which can result in the neglect of outlier events and the formation of ov erly smoothed representations [13]. This issue is particularly evident in the learned embeddings, which fail to encode sufficient temporal semantics. Such latent representations are often “semantically impov erished” as the y capture the trend but lose the underlying generativ e dynamics of the system. W e argue that the ke y to improving forecasting performance lies not in designing increasingly complex architectures, but in incorporating external semantic supervision. Moreov er , time series foundation models [14]–[16], trained on large-scale and div erse data, learn temporal representations that more faith- fully capture fine-grained and semantically rich patterns. T o address the limitations of error-only supervision, we propose explicitly guiding the encoder using representations extracted from time-series foundation models, enabling it to learn more meaningful temporal abstractions. The core idea is to enrich the embeddings of forecasting methods through external se- mantic supervision, thereby enhancing their representational capacity without increasing architectural complexity . T echnically , we propose ReGuider, a representation-le vel supervision plug-in designed to enhance time series fore- casting. The central concept inv olves lev eraging pretrained time series foundation models as semantic teachers. During training, both the target forecasting model and the pretrained model process the same input sequence. Instead of using the pretrained model’ s prediction head, we extract its interme- diate embeddings, which encode rich temporal dependencies and semantic structures. These embeddings are then aligned with the encoder representations of the target model, thereby encouraging the encoder to learn more expressi ve and tem- porally coherent representations. ReGuider is model-agnostic, enabling it to be seamlessly inte grated into a wide range of TSF methods without altering their original structure. In summary , this work makes the follo wing contributions: • W e identify the limitation of error-only supervision in deep learning-based forecasting and propose to enhance temporal embeddings through e xternal semantic guid- ance. • W e develop ReGuider, a plug-in method that aligns en- coder representations with pretrained time series founda- tion models, enriching the temporal semantics of learned embeddings. • W e conduct extensi ve experiments across diverse datasets and architectures, demonstrating that ReGuider consis- tently improves forecasting accuracy and generalizes ef- fectiv ely to dif ferent backbone models. I I . B AC K G RO U N D A N D R E L A T E D W O R K A. Deep Learning in T ime Series F or ecasting Deep learning has become the dominant paradigm in time series forecasting, with RNNs, CNNs, GNNs, and Trans- formers all demonstrating strong empirical results [11], [17]– [20]. Recently , the community has started training large scale time series foundation models using hierarchical transform- ers or masked autoencoders that hav e been pre-trained on millions of sequences [14]–[16], [21]. The immense capacity and extensiv e pre-training of these models enable them to capture universal temporal dynamics, ranging from short- term seasonality to long-term trends. Current practice in volv es either freezing or lightly fine-tuning these models for direct prediction or few-shot adaptation. Howe ver , we e xploit their internal representations as repositories of high-quality tempo- ral knowledge to enhance any downstream forecaster . B. Repr esentation Learning Representation learning is essential for enabling models to capture informative and transferable features. Across domains, it has been utilized to impose inductive biases that extend beyond simple task losses. For instance, in dif fusion models, it is applied to make noise patterns more structured and controllable, improving generation quality and stability [22]. In vision and language, aligning latent representations with pretrained models has proven effecti ve in enriching feature spaces and boosting downstream performance [23]. W ithin time series forecasting, traditionally , TSF models used supervised encoders to extract features for point-wise prediction [6], [11], [24]–[26]. Howe v er , these are prone to “representation collapse” when driven solely by MSE, filtering out critical regime shifts to minimize average loss. While self- supervised learning (SSL) and contrasti ve paradigms attempt to mitigate this, they often rely on heuristic augmentations and remain limited by the scale of individual datasets. The emergence of T ime Series Foundation Models (TSFMs) has redefined this landscape. Pretrained on billions of se- quences, TSFMs [14], [16], [27]–[29] dev elop a “univ ersal temporal v ocabulary” that captures nuanced seasonality and structural dependencies. ReGuider bridges the gap between these high-capacity models and ef ficient task-specific pre- dictors by using TSFM embeddings as a “semantic gold standard” for alignment. This representation-level supervision can highlight long-term seasonality , abrupt regime shifts, and inter-v ariable relations that are often overlook ed by error- driv en objectiv es, thereby leading to more accurate and robust predictions. I I I . M E T H O D A. Pr oblem Statement The goal of TSF is to predict a future sequence Y ∈ R C × T with horizon T from a past sequence X ∈ R C × L of length L , where C denotes the number of variables. Fig. 1: Overall architecture of ReGuider, which consists of the base predictor F θ ( · ) and the foundation model G ϕ ( · ) , serving as a representation guide. B. Ar chitectur e of ReGuider As sho wn in Fig. 1, ReGuider is designed to improv e time series forecasting by enriching encoder representa- tions through supervision with pre-trained foundation models. Specifically , giv en an input sequence X ∈ R C × L , it is pro- cessed through two parallel pathways: (1) the base predictor F θ ( · ) , representing the forecasting model to be trained, and (2) the foundation model G ϕ ( · ) , serving as a representation guide. The base predictor F θ ( · ) encodes X into a latent representation H f before passing it to the prediction head to generate an estimate of the target variable, denoted by Y . For the guider, rather than using the final prediction output of G ϕ ( · ) , we extract its intermediate embedding H g from the encoder . This captures the rich temporal patterns and high- lev el semantics learned during large-scale pretraining. W e then introduce a representation supervision objectiv e to minimise the distance between H f and H g . This guides the encoder of the base predictor to incorporate the temporal dependencies and semantic structures present in the pretrained G ϕ ( · ) . This supervision is seamlessly integrated into the training process alongside the standard forecasting loss, enabling the model to learn to minimize predicti ve error and produce embeddings that align with stronger temporal representation space simultaneously . This framework is also model-agnostic. ReGuider does not alter the backbone framework or inference process, making it applicable to various TSF models. C. Repr esentation Alignment with Supervised Repr esentations T o enable the base predictor to learn richer temporal de- pendencies, ReGuider introduces an auxiliary representation supervision objective that aligns the encoder embedding of the base predictor with that of a pretrained foundation model. Formally , gi ven an input sequence X ∈ R C × L , the base predictor F θ encodes it into a latent representation: H f = F enc θ ( X ) , (1) while the foundation model G ϕ encodes the same sequence into: H g = G enc ϕ ( X ) , (2) Models iTransfomer [10] + ReGuider PatchTST [12] + ReGuider DLinear [7] + ReGuider TimeMix er [24] + ReGuider Metric MSE MAE MSE MAE MSE MAE MSE MAE MSE MAE MSE MAE MSE MAE MSE MAE ETTh1 96 0.386 0.405 0.377 0.398 0.414 0.419 0.382 0.384 0.386 0.400 0.368 0.390 0.375 0.400 0.366 0.393 192 0.441 0.436 0.427 0.426 0.460 0.445 0.424 0.425 0.437 0.432 0.402 0.413 0.429 0.421 0.422 0.419 336 0.487 0.458 0.475 0.452 0.501 0.466 0.462 0.441 0.481 0.459 0.448 0.438 0.484 0.458 0.458 0.434 720 0.503 0.491 0.486 0.480 0.500 0.488 0.478 0.471 0.519 0.516 0.487 0.485 0.498 0.482 0.475 0.465 ETTh2 96 0.297 0.349 0.289 0.343 0.302 0.348 0.293 0.338 0.333 0.387 0.320 0.361 0.289 0.341 0.382 0.334 192 0.380 0.400 0.373 0.392 0.388 0.400 0.374 0.387 0.477 0.476 0.406 0.424 0.372 0.392 0.358 0.384 336 0.428 0.432 0.415 0.427 0.426 0.433 0.412 0.421 0.594 0.541 0.453 0.455 0.386 0.414 0.379 0.410 720 0.427 0.445 0.420 0.441 0.431 0.446 0.418 0.429 0.831 0.657 0.596 0.541 0.412 0.434 0.406 0.427 ETTm1 96 0.334 0.368 0.327 0.361 0.329 0.367 0.322 0.358 0.345 0.372 0.336 0.368 0.320 0.357 0.316 0.351 192 0.377 0.391 0.372 0.386 0.367 0.385 0.357 0.378 0.380 0.389 0.369 0.372 0.361 0.381 0.355 0.377 336 0.426 0.420 0.412 0.409 0.399 0.410 0.388 0.399 0.413 0.413 0.395 0.398 0.390 0.404 0.385 0.396 720 0.491 0.459 0.476 0.442 0.454 0.439 0.445 0.430 0.474 0.453 0.461 0.442 0.454 0.441 0.444 0.431 ETTm2 96 0.180 0.264 0.175 0.258 0.175 0.259 0.168 0.248 0.193 0.292 0.173 0.269 0.175 0.258 0.170 0.252 192 0.250 0.309 0.242 0.300 0.241 0.302 0.234 0.287 0.284 0.362 0.263 0.348 0.237 0.299 0.233 0.296 336 0.311 0.348 0.303 0.339 0.305 0.343 0.301 0.335 0.369 0.427 0.344 0.401 0.298 0.340 0.291 0.330 720 0.412 0.407 0.401 0.396 0.402 0.400 0.386 0.392 0.554 0.522 0.472 0.493 0.391 0.396 0.387 0.390 W eather 96 0.174 0.214 0.168 0.207 0.177 0.218 0.165 0.212 0.196 0.255 0.175 0.234 0.163 0.209 0.160 0.203 192 0.221 0.254 0.216 0.248 0.225 0.259 0.208 0.244 0.237 0.296 0.212 0.258 0.208 0.250 0.205 0.246 336 0.278 0.296 0.267 0.286 0.278 0.297 0.253 0.286 0.283 0.335 0.268 0.317 0.251 0.287 0.248 0.384 720 0.358 0.347 0.346 0.338 0.354 0.348 0.342 0.340 0.345 0.381 0.324 0.372 0.339 0.341 0.336 0.337 ECL 96 0.148 0.240 0.143 0.236 0.181 0.270 0.163 0.256 0.197 0.282 0.166 0.269 0.153 0.247 0.152 0.245 192 0.162 0.253 0.158 0.248 0.188 0.274 0.169 0.263 0.196 0.285 0.179 0.277 0.166 0.256 0.164 0.256 336 0.178 0.269 0.173 0.265 0.204 0.293 0.195 0.286 0.209 0.301 0.196 0.289 0.185 0.277 0.182 0.272 720 0.225 0.317 0.209 0.298 0.246 0.324 0.227 0.309 0.245 0.333 0.214 0.318 0.225 0.310 0.222 0.308 T raffic 96 0.395 0.268 0.379 0.262 0.462 0.295 0.405 0.272 0.650 0.396 0.521 0.293 0.462 0.285 0.397 0.270 192 0.417 0.276 0.402 0.268 0.466 0.296 0.420 0.278 0.598 0.370 0.546 0.308 0.473 0.296 0.422 0.281 336 0.433 0.283 0.431 0.276 0.482 0.304 0.434 0.292 0.605 0.373 0.552 0.329 0.498 0.296 0.441 0.290 720 0.467 0.302 0.454 0.295 0.514 0.322 0.474 0.310 0.645 0.394 0.568 0.343 0.506 0.313 0.483 0.297 T ABLE I: Long term forecasting results with varying predict lengths T ∈ { 96 , 192 , 336 , 720 } . The historical input length L is fixed at 96 for fair comparison. The best results are highlighted in bold . where H f , H g ∈ R d denote the embeddings before the pre- diction head, and θ , ϕ are the parameters of the base predictor and foundation model, respectiv ely . W e define the representation supervision loss as: L TSRA ( θ , ϕ ) = E X ∼D sim ( H f , H g ) , (3) where sim ( · , · ) is a similarity or distance function. Sev eral options are possible: Euclidean distance: sim ℓ 2 ( H f , H g ) = || H f − H g || 2 2 . (4) Cosine similarity: sim cos ( H f , H g ) = 1 − H ⊤ f H g || H f || 2 || H g || 2 . (5) KL divergence: sim KL ( H f , H g ) = D KL σ ( H f ) || σ ( H g ) , (6) where σ ( · ) denotes the softmax function. The overall training objectiv e combines the standard fore- casting loss with the representation supervision loss: L total = L Pred ( Y , ˆ Y ) + λ L TSRA ( θ , ϕ ) , (7) where λ is a trade-off hyperparameter . This joint objectiv e ensures that the predictor minimizes forecasting error while simultaneously learning embeddings guided by the pretrained foundation model. Models iTransformer [10] PatchTST [12] ED KLD Cos. Sim. ED KLD Cos. Sim. Metric MSE MAE MSE MAE MSE MAE MSE MAE MSE MAE MSE MAE ETTm1 96 0.327 0.361 0.334 0.369 0.325 0.362 0.322 0.358 0.329 0.364 0.324 0.360 192 0.372 0.386 0.379 0.392 0.373 0.388 0.357 0.378 0.363 0.385 0.359 0.378 336 0.412 0.409 0.421 0.418 0.415 0.411 0.388 0.399 0.395 0.404 0.390 0.403 720 0.476 0.442 0.482 0.451 0.479 0.445 0.445 0.430 0.452 0.435 0.447 0.431 W eather 96 0.168 0.207 0.173 0.213 0.169 0.207 0.165 0.212 0.171 0.214 0.166 0.210 192 0.216 0.248 0.224 0.252 0.218 0.247 0.208 0.244 0.214 0.246 0.209 0.245 336 0.267 0.286 0.276 0.292 0.270 0.287 0.253 0.286 0.259 0.288 0.254 0.285 720 0.346 0.338 0.354 0.345 0.347 0.339 0.342 0.340 0.349 0.342 0.341 0.339 ECL 96 0.143 0.236 0.151 0.241 0.145 0.238 0.163 0.256 0.167 0.259 0.165 0.258 192 0.158 0.248 0.166 0.253 0.160 0.247 0.169 0.263 0.175 0.266 0.170 0.262 336 0.173 0.265 0.182 0.271 0.177 0.266 0.195 0.286 0.201 0.291 0.198 0.288 720 0.209 0.298 0.217 0.305 0.210 0.297 0.227 0.309 0.234 0.314 0.228 0.310 Traf fic 96 0.379 0.262 0.382 0.265 0.381 0.265 0.405 0.272 0.406 0.273 0.410 0.275 192 0.402 0.268 0.404 0.269 0.406 0.271 0.420 0.278 0.421 0.277 0.424 0.280 336 0.431 0.276 0.433 0.278 0.433 0.280 0.434 0.292 0.435 0.290 0.437 0.294 720 0.454 0.295 0.456 0.296 0.460 0.299 0.474 0.310 0.475 0.309 0.478 0.312 T ABLE II: Results of Euclidean distance (ED), KL diver gence (KLD), and Cosine Similarity (Cos. Sim.) as optimization objectiv es for representation supervision. A critical design choice in ReGuider is the asymmetric gradient flow . The parameters ϕ of the foundation model are frozen to preserve the universal temporal vocab ulary: θ ∗ , ψ ∗ = arg min θ,ψ L P red ( Y , ˆ Y ) + λ L T S RA ( ˜ H f , sp ( H g )) , (8) where sp ( · ) denotes the stop gradient operation. This ensures that the foundation model acts as a stationary semantic an- chor , pre venting the representation drift that often occurs in traditional co-training paradigms. D. Discussions Although ReGuider inv olves an architecture like teacher- student, it differs from traditional kno wledge distillation (KD). Whereas con ventional KD focuses on output alignment by mimicking the teacher’ s final predictions or logits, ReGuider emphasizes representation alignment. F or time series, we argue that the ’teacher’ s’ value lies not in its specific forecast values, b ut in its universal temporal vocabulary . By aligning intermediate latent spaces, we avoid inheriting the teacher’ s potential predictiv e biases and instead focus on enriching the student’ s structural understanding. I V . E X P E R I M E N T S A. Setups Dataset . W e ev aluate the proposed ReGuider model on 7 commonly used time series benchmark datasets: ETTh1, ETTh2, ETTm1, ETTm2, W eather, Electricity , and T raf- fic [18]. Specifically , the ETT series (ETTh1, ETTh2, ETTm1, ETTm2) records power load and oil temperature from elec- tricity transformers at both hourly and 15-minute resolu- tions. The W eather dataset includes 21 meteorological indi- Models iTransformer [10] PatchTST [12] Base Large Ultra Base Large Ultra Metric MSE MAE MSE MAE MSE MAE MSE MAE MSE MAE MSE MAE ETTm1 96 0.325 0.361 0.327 0.361 0.334 0.368 0.324 0.357 0.322 0.358 0.336 0.370 192 0.370 0.387 0.372 0.386 0.379 0.392 0.355 0.376 0.357 0.378 0.383 0.395 336 0.414 0.412 0.412 0.409 0.420 0.416 0.386 0.400 0.388 0.399 0.423 0.419 720 0.475 0.443 0.476 0.442 0.486 0.450 0.447 0.432 0.445 0.430 0.490 0.452 W eather 96 0.169 0.208 0.168 0.207 0.170 0.209 0.166 0.211 0.165 0.212 0.171 0.210 192 0.217 0.247 0.216 0.248 0.219 0.249 0.208 0.243 0.208 0.244 0.210 0.246 336 0.265 0.285 0.267 0.286 0.270 0.287 0.254 0.287 0.253 0.286 0.255 0.288 720 0.345 0.340 0.346 0.338 0.348 0.339 0.343 0.341 0.342 0.340 0.344 0.342 ECL 96 0.148 0.240 0.143 0.236 0.152 0.243 0.167 0.259 0.163 0.256 0.160 0.255 192 0.161 0.250 0.158 0.248 0.165 0.253 0.172 0.266 0.169 0.263 0.168 0.263 336 0.178 0.270 0.173 0.265 0.181 0.272 0.196 0.287 0.195 0.286 0.192 0.284 720 0.211 0.301 0.209 0.298 0.208 0.300 0.229 0.312 0.227 0.309 0.228 0.311 Traf fic 96 0.391 0.270 0.379 0.262 0.376 0.263 0.412 0.276 0.405 0.272 0.405 0.270 192 0.414 0.274 0.402 0.268 0.403 0.268 0.422 0.280 0.420 0.278 0.420 0.278 336 0.439 0.280 0.431 0.276 0.433 0.275 0.436 0.291 0.434 0.292 0.432 0.289 720 0.468 0.299 0.454 0.295 0.454 0.295 0.476 0.311 0.474 0.310 0.475 0.309 T ABLE III: Results of T ime-MoE foundation model—base, large, and ultra—as representation guiders. cators collected ev ery 10 minutes, representing a typical low- dimensional physical sensing task. Electricity (ECL) tracks the hourly power consumption of 321 clients, serving as a mid- dimensional benchmark for demand forecasting. Finally , the T raffic dataset monitors hourly road occupancy rates from 862 sensors, providing a high-dimensional challenge for capturing complex spatial-temporal inter -dependencies. Consistent with classic work [11], [30], we use Mean Squared Error (MSE) and Mean Absolute Error (MAE) as performance e valuation metrics. Base Predictor and Base Representation Guider . For base predictor F ( · ) , it can be any mainstream deep learning- based time series forecasting model. W e select four widely recognized models in L TSF literature: iTransformer [10], PatchTST [12], DLinear [7], and T imeMix er [24]. W e compare their direct forecasting performance with their use as base predictors in our proposed ReGuider model. Furthermore, for foundation model G ( · ) for Self-Supervised representation, we choose T ime-MoE base [15]. B. Main Results As shown in T ab . I, ReGuider consistently improv es fore- casting performance when applied to various backbone predic- tors, including Transformer - and Linear-based architectures. Across four representati ve backbones, our method improv es forecasting accuracy by over 5% on av erage, demonstrating its effecti veness in enriching temporal representations through representation-lev el supervision and confirming its generality as a seamless plug-in. This performance boost is particu- larly pronounced in high-dimensional datasets such as T raffic, which contains 862 v ariables. In these complex scenarios, the alignment with a foundation model’ s “uni versal temporal Fig. 2: V isualisation of the iTransformer’ s and guider’ s representations. vocab ulary” allo ws the base predictor to better capture intricate inter-v ariable couplings that are typically lost when training with error-only objectives, which tend to fav or smoothed, uninformativ e av erages. Furthermore, ReGuider exhibits impressiv e stability as the forecasting horizon T increases from 96 to 720. In short- term forecasting ( T = 96 ), the representation-le vel guidance assists the predictor in identifying sharp seasonality and abrupt regime shifts that point-wise losses often overlook. As the horizon extends to T = 720 , where standard models typically suffer from a widening drifting latent states, ReGuider acts as a semantic anchor . By enforcing alignment with the foundation model’ s stable embeddings ( H g ), the student model sustains its predictiv e accuracy e ven at these challenging lengths, prevent- ing the prediction from decaying toward a simple conditional mean. C. Model Analysis T o further understand the behavior of ReGuider, we inv es- tigate the following research questions: RQ1 : How should the distance between the base predictor’ s embeddings and those of the foundation model be measured and optimized? RQ2 : How do different foundation models perform when serving as representation guiders? RQ3 : Does incorporating an additional guider significantly impact efficienc y? RQ4 : Can we observe clear richer representation under guidance? RQ1. Distance metrics for supervision. W e compare the use of Euclidean distance, KL di ver gence, and cosine simi- larity as optimization objecti ves for aligning the embeddings, and summarize the results in T ab . II. Of these three, Euclidean distance yields the best forecasting accuracy . This is because it directly measures point-wise closeness in the latent space, enforcing a tighter alignment between the two embedding distributions. In contrast, cosine similarity only constrains angular consistency without controlling magnitude, while KL div ergence relies on distributional assumptions that may not hold in high-dimensional embedding spaces. Consequently , Euclidean distance provides the most stable and effecti ve signal for representation supervision. RQ2. Effect of different foundation models. W e also ev aluate three versions of the T ime-MoE foundation model — base, large, and ultra — as representation guiders. As shown in T able 1, results indicate that dif ferent pretrained representations offer complementary strengths. For instance, on relativ ely small datasets such as ETT , the base version provides competitive guidance, demonstrating that lightweight models can effecti v ely transfer temporal semantics. Howe ver , on larger , more complex datasets such as T raffic, the ultra variant with the highest parameter count achiev es the best performance, highlighting the benefit of scaling foundation models to capture broader temporal patterns. These results suggest that the guider chosen should be adapted to the scale and complexity of the target dataset. RQ3. Efficiency considerations. In terms of computational cost, ReGuider only requires the foundation model to be in vok ed during training in order to extract intermediate em- beddings. While this introduces a marginal increase in training time, it does not affect inference since the foundation model is no longer needed once alignment is complete. Consequently , the method incurs negligible overhead at deployment, ensuring that the benefits of representation-lev el supervision are realised without any additional inference cost. RQ4. Representation Visualization. T o v erify the effect of supervision, we feed a randomly selected window from the ETTm1 test set into both the v anilla iT ransformer [10] encoder and the ReGuider-trained version of the same en- coder . W e then reduced the dimensions using t-SNE. As shown in Fig. 2, vanilla embeddings form a diffuse cloud with substantial overlap among trend classes, indicating weak temporal discrimination. After ReGuider supervision, the same encoder produces compact, well-separated clusters. This visual separation confirms that the guidance objective has transferred the foundation model’ s rich temporal structure to the encoder , providing a more informative latent space. V . C O N C L U S I O N In this study , we present ReGuider, a representation-lev el supervision method in the form of a plug-in for TSF . ReGuider enriches encoder embeddings by aligning them with repre- sentations extracted from pre-trained time series foundation models. This design allows forecasting architectures to capture richer temporal dependencies and semantic structures, de- liv ering consistent performance enhancements across various backbones and datasets. Extensiv e e xperimentation confirms that ReGuider is effecti ve and efficient, enhancing accuracy without incurring additional inference costs. Ultimately , W e believ e that this framework underscores the potential of foun- dation models as univ ersal representation guides, opening new av enues for semantically aware temporal modeling. V I . L L M U S A G E D E S C R I P T I O N Large Language Models (LLMs) were used solely as ad- ditional tools for refining the language. The authors had full autonomy ov er all aspects of the research, including its con- ceptualisation, experimental execution and data interpretation. No AI was in volv ed in the core scientific processes or the deriv ation of conclusions. R E F E R E N C E S [1] Y ifan Hu, Y uante Li, Peiyuan Liu, Y uxia Zhu, Naiqi Li, T ao Dai, Shu tao Xia, Dawei Cheng, and Changjun Jiang, “Fintsb: A comprehensive and practical benchmark for financial time series forecasting, ” arXiv pr eprint arXiv:2502.18834 , 2025. [2] Mustafa Gul and F Necati Catbas, “Statistical pattern recognition for structural health monitoring using time series modeling: Theory and experimental verifications, ” Mechanical Systems and Signal Processing , vol. 23, pp. 2192–2204, 2009. [3] Zahra Karevan and Johan AK Suykens, “Transducti ve lstm for time- series prediction: An application to weather forecasting, ” Neur al Networks , vol. 125, pp. 1–9, 2020. [4] Y ifan Hu, Guibin Zhang, Peiyuan Liu, Disen Lan, Naiqi Li, Dawei Cheng, T ao Dai, Shu-T ao Xia, and Shirui Pan, “Timefilter: P atch-specific spatial-temporal graph filtration for time series forecasting, ” in F orty- second International Conference on Machine Learning , 2025. [5] Zonghan W u, Shirui Pan, Guodong Long, Jing Jiang, Xiaojun Chang, and Chengqi Zhang, “Connecting the dots: Multi variate time series forecasting with graph neural networks, ” New Y ork, NY , USA, 2020, KDD ’20, Association for Computing Machinery . [6] Abhimanyu Das, W eihao K ong, Andrew Leach, Shaan Mathur , Rajat Sen, and Rose Y u, “Long-term forecasting with TiDE: T ime-series dense encoder , ” arXiv preprint , 2023. [7] Ailing Zeng, Muxi Chen, Lei Zhang, and Qiang Xu, “ Are transformers effecti ve for time series forecasting?, ” in Pr oceedings of the AAAI confer ence on artificial intelligence , 2023, vol. 37, pp. 11121–11128. [8] Peiyuan Liu, Beiliang Wu, Y ifan Hu, Naiqi Li, T ao Dai, Jigang Bao, and Shu-T ao Xia, “T imebridge: Non-stationarity matters for long-term time series forecasting, ” 2025. [9] T ian Zhou, Ziqing Ma, Qingsong W en, Xue W ang, Liang Sun, and Rong Jin, “FEDformer: Frequency enhanced decomposed transformer for long-term series forecasting, ” in International Confer ence on Machine Learning . PMLR, 2022, pp. 27268–27286. [10] Y ong Liu, T engge Hu, Haoran Zhang, Haixu Wu, Shiyu W ang, Lintao Ma, and Mingsheng Long, “iTransformer: Inv erted transformers are effecti ve for time series forecasting, ” International Conference on Learning Representations , 2024. [11] Haixu Wu, Jiehui Xu, Jianmin W ang, and Mingsheng Long, “ Auto- former: Decomposition transformers with auto-correlation for long-term series forecasting, ” Advances in Neural Information Processing Systems , vol. 34, pp. 22419–22430, 2021. [12] Y uqi Nie, Nam H Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam, “ A time series is worth 64 words: Long-term forecasting with transformers, ” in International Confer ence on Learning Repr esen- tations , 2023. [13] Y ifan Hu, Peiyuan Liu, Peng Zhu, Da wei Cheng, and T ao Dai, “ Adaptive multi-scale decomposition framework for time series forecasting, ” in Pr oceedings of the AAAI Confer ence on Artificial Intelligence , 2025, vol. 39, pp. 17359–17367. [14] Abdul Fatir Ansari, Lorenzo Stella, Ali Caner T urkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Ranga- puram, Sebastian Pineda Arango, Shubham Kapoor , Jasper Zschiegner , Danielle C. Maddix, Hao W ang, Michael W . Mahoney , Kari T orkkola, Andrew Gordon W ilson, Michael Bohlke-Schneider , and Bernie W ang, “Chronos: Learning the language of time series, ” T ransactions on Machine Learning Resear ch , 2024, Expert Certification. [15] Xiaoming Shi, Shiyu W ang, Y uqi Nie, Dianqi Li, Zhou Y e, Qingsong W en, and Ming Jin, “Time-moe: Billion-scale time series foundation models with mixture of experts, ” in The Thirteenth International Confer ence on Learning Representations , 2025. [16] Y ong Liu, Haoran Zhang, Chenyu Li, Xiangdong Huang, Jianmin W ang, and Mingsheng Long, “Timer: Generative pre-trained transformers are large time series models, ” in F orty-first International Confer ence on Machine Learning , 2024. [17] Y ifan Hu, Peiyuan Liu, Y uante Li, Dawei Cheng, Naiqi Li, T ao Dai, Jigang Bao, and Xia Shu-T ao, “Finmamba: Market-aware graph enhanced multi-lev el mamba for stock movement prediction, ” arXiv pr eprint arXiv:2502.06707 , 2025. [18] Haixu W u, T engge Hu, Y ong Liu, Hang Zhou, Jianmin W ang, and Mingsheng Long, “T imesNet: T emporal 2d-variation modeling for general time series analysis, ” in International Conference on Learning Repr esentations , 2023. [19] Huiqiang W ang, Jian Peng, Feihu Huang, Jince W ang, Junhui Chen, and Y ifei Xiao, “MICN: Multi-scale local and global context modeling for long-term series forecasting, ” in The eleventh international confer ence on learning repr esentations , 2023. [20] T aesung Kim, Jinhee Kim, Y unwon T ae, Cheonbok Park, Jang-Ho Choi, and Jaegul Choo, “Rev ersible instance normalization for accurate time- series forecasting against distribution shift, ” in International Conference on Learning Representations , 2021. [21] Peiyuan Liu, Hang Guo, T ao Dai, Naiqi Li, Jigang Bao, Xudong Ren, Y ong Jiang, and Shu-T ao Xia, “Calf: Aligning llms for time series fore- casting via cross-modal fine-tuning, ” arXiv pr eprint arXiv:2403.07300 , 2024. [22] Sihyun Y u, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie, “Representation alignment for generation: T raining diffusion transformers is easier than you think, ” in The Thirteenth International Conference on Learning Representations , 2025. [23] Jingfeng Y ao, Bin Y ang, and Xinggang W ang, “Reconstruction vs. generation: T aming optimization dilemma in latent diffusion models, ” in Proceedings of the Computer V ision and P attern Recognition Confer - ence , 2025, pp. 15703–15712. [24] Shiyu W ang, Haixu W u, Xiaoming Shi, T engge Hu, Huakun Luo, Lintao Ma, James Y Zhang, and Jun Zhou, “TimeMix er: Decomposable multiscale mixing for time series forecasting, ” International Conference on Learning Representations , 2024. [25] Y ifan Hu, Jie Y ang, Tian Zhou, Peiyuan Liu, Y ujin T ang, Rong Jin, and Liang Sun, “Bridging past and future: Distribution-aware alignment for time series forecasting, ” arXiv pr eprint arXiv:2509.14181 , 2025. [26] Gerald W oo, Chenghao Liu, Doyen Sahoo, Akshat Kumar , and Steven Hoi, “ETSformer: Exponential smoothing transformers for time-series forecasting, ” arXiv preprint , 2022. [27] Y ushan Jiang, W enchao Y u, Geon Lee, Dongjin Song, Kijung Shin, W ei Cheng, Y anchi Liu, and Haifeng Chen, “T imexl: Explainable multi- modal time series prediction with llm-in-the-loop, ” in The Thirty-ninth Annual Conference on Neural Information Pr ocessing Systems , 2025. [28] Abhimanyu Das, W eihao K ong, Rajat Sen, and Y ichen Zhou, “ A decoder-only foundation model for time-series forecasting, ” in F orty- first International Confer ence on Machine Learning , 2024. [29] Abdul Fatir Ansari, Oleksandr Shchur , Jaris K ¨ uken, Andreas Auer , Boran Han, Pedro Mercado, Syama Sundar Rangapuram, Huibin Shen, Lorenzo Stella, Xiyuan Zhang, et al., “Chronos-2: From univ ariate to univ ersal forecasting, ” arXiv pr eprint arXiv:2510.15821 , 2025. [30] Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and W ancai Zhang, “Informer: Beyond efficient transformer for long sequence time-series forecasting, ” in Pr oceedings of the AAAI confer ence on artificial intelligence , 2021, vol. 35, pp. 11106–11115.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment