C-STEP: Continuous Space-Time Empowerment for Physics-informed Safe Reinforcement Learning of Mobile Agents
Safe navigation in complex environments remains a central challenge for reinforcement learning (RL) in robotics. This paper introduces Continuous Space-Time Empowerment for Physics-informed (C-STEP) safe RL, a novel measure of agent-centric safety ta…
Authors: Guihlerme Daubt, Adrian Redder
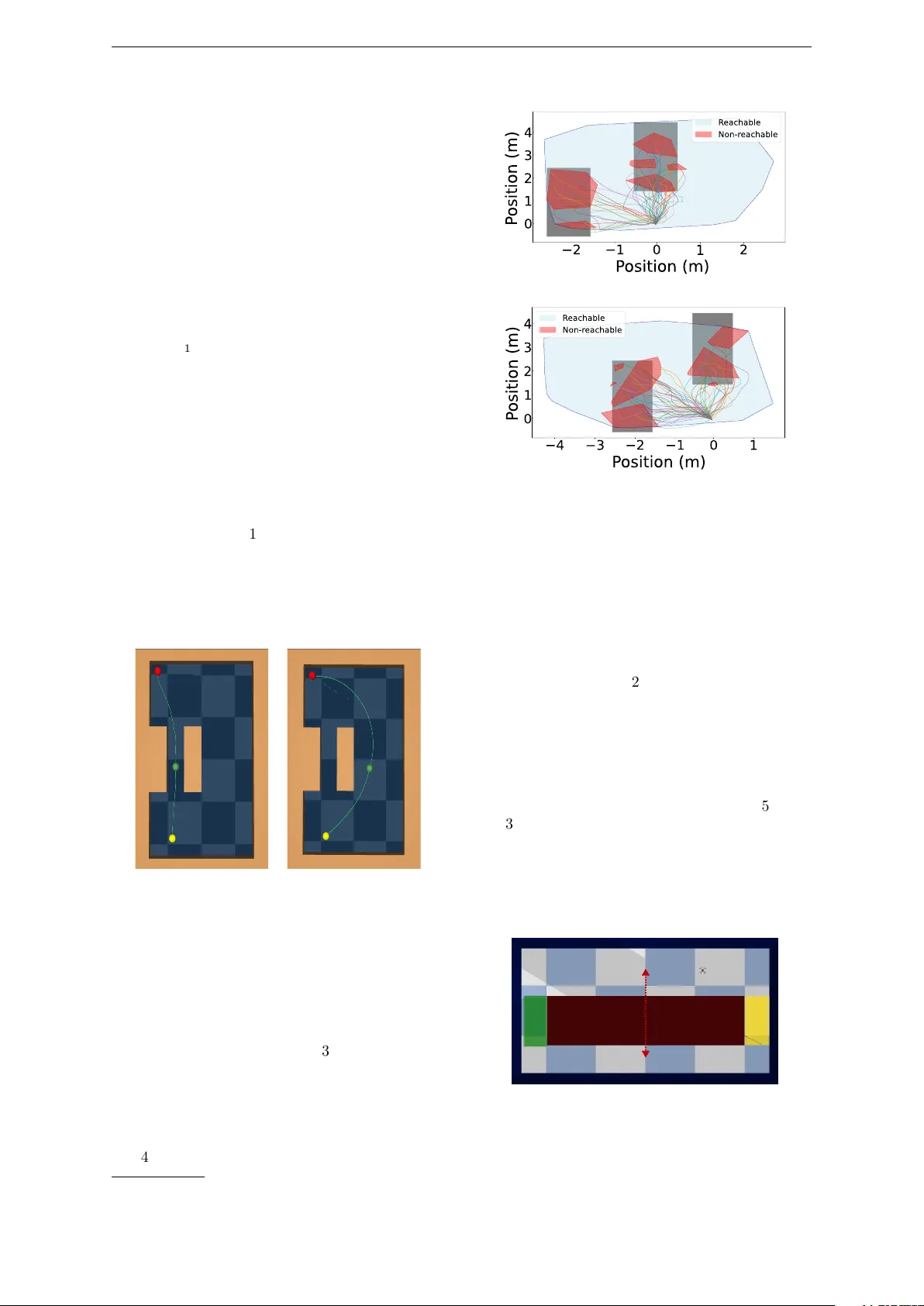
A ccepted at ICAAR T 2026 C-STEP: Con tin uous Space-Time Empow erment for Ph ysics-informed Safe Reinforcemen t Learning of Mobile Agen ts Guihlerme Daubt 1 a and A drian Redder 2 b 1 F aculty of T ec hnology , Bielefeld Universit y , German y 2 Departmen t of Electrical Engineering and Information T echnology , Paderborn Univ ersity , Germany gnmdaudt@gmail.com , aredder@mail.upb.de Keyw ords: Reinforcemen t Learning, Ph ysics-Informed Learning, Emp o wermen t, Reward Shaping, Safe Na vigation, Mobile Rob otic Systems, Mobile Agents Abstract: Safe na vigation in complex en vironments remains a cen tral challenge for reinforcement learn- ing (RL) in rob otics. This pap er introduces Con tin uous Space-Time Emp ow erment for Physics- informed (C-STEP) safe RL, a nov el measure of agent-cen tric safety tailored to deterministic, con tin uous domains. This measure can be used to design ph ysics-informed in trinsic rew ards b y augmen ting positive navigation reward functions. The rew ard incorporates the agen t’s in ternal states (e.g., initial velocity) and forw ard dynamics to dieren tiate safe from risky b ehavior. By in tegrating C-STEP with na vigation rewards, w e obtain an intrinsic rew ard function that join tly optimizes task completion and collision av oidance. Numerical results demonstrate few er collisions, reduced proximit y to obstacles, and only marginal increases in trav el time. Ov erall, C-STEP oers an interpretable, physics-informed approach to reward shaping in RL, contributing to safety for agen tic mobile rob otic systems. 1 INTR ODUCTION Agen tic mobile robotic systems require safe and robust con trol in dynamic en vironments to ensure reliable na vigation. A dv ances in reinforcement learning (RL) ha v e sho wn promise for develop- ing suc h highly adaptive p olicies. Previous works ha v e explored safe RL metho ds by using con- trol barrier functions (Emam et al., 2021; Dang et al., 2025), robustness prioritization ( Queeney et al., 2024), and risk-a voidance (Cho w et al., 2015). Nev ertheless, safet y remains a challenge when dealing with contin uous space-time dynam- ics and unkno wn en vironmental conditions. Re- cen t surv eys ha v e highligh ted the p oten tial of con- cepts from information theory for safe RL (Gu et al., 2024a; Brunke et al., 2022). Considering this, we introduce a no v el formu- lation of emp ow erment (Klyubin et al., 2005) for dynamical systems op erating in contin uous space and time. Emp ow erment is a measure of in trinsic agen t control capacity in an environmen t and has traditionally b een used in discrete-time sto chas- tic computer net works. Herein, w e prop ose a new denition of emp ow erment tailored for dynam- ical systems. By approximating emp ow erment through trajectory sampling and forw ard system a h ttps://orcid.org/0009-0002-3208-5734 b h ttps://orcid.org/0000-0001-7391-4688 dynamics, our approach captures the complex in- teraction b etw een control strategies and safety , yielding an in terpretable safety metric. With the emp o w ermen t appro ximation, we then formulate an in trinsic safe RL reward design. Our core con tribution is a ph ysics-informed in- trinsic reward design that incorp orates internal system states (such as velocity) to assess safet y in navigation via the lo cal emp ow erment appro xi- mation of a system. This emp ow erment approach can b e integrated with positive navigation rew ard functions, serving as a complementary enhance- men t to promote physics-informed safet y rather than replacing conv entional reward designs. The rest of this pap er is structured as follows. Sec- tion 2 provides bac kground material. Section 3 discusses prior researc h. Section 4 introduces our metho dology , starting with a new denition of emp o w ermen t for deterministic systems and cul- minating in our prop osed C-STEP framework. Section 5 presen ts numerical exp eriments high- ligh ting the safety benets of our approac h. Fi- nally , we discuss C-STEP in comparison to other safe RL paradigms in Section 6 and conclude with remarks on future work in Section 7 . 1 A ccepted at ICAAR T 2026 4 C-STEP: CONTINUOUS SP ACE-TIME EMPO WERMENT 2 Bac kground W e now recall bac kground on information the- ory and RL. F or in-depth background, see (Co ver, 2006) and (Sutton and Barto, 2018), resp ectiv ely . 2.1 Information Theory The dierential en tropy of a contin uous random v ariable Y with probabilit y density function f ( y ) and supp ort set Y ⊂ R n is dened as: h ( Y ) : = − ∫ Y f ( y ) log ( f ( y )) d y . (1) An important prop erty is that dieren tial entrop y is maximized by a uniform distribution (Co v er, 2006, Chap. 12), i.e., for an y Y with compact supp ort Y : max p ( y ) h ( Y ) = log ( λ ( Y )) , (2) where λ ( · ) is the n -dimensional v olume (Lebesgue measure). The conditional dierential entrop y h ( Y | X ) of random v ariables X , Y with probabilit y density function g ( x ) and conditional probabilit y density h ( y | x ) is dened as: h ( Y | X ) : = − ∫ X g ( x ) ∫ Y h ( y | x ) log ( h ( y | x )) d y d x . (3) The m utual information is then dened as I ( Y ; X ) : = h ( Y ) − h ( Y | X ) . Finally , the c hannel ca- pacit y from an “input” random v ariable X to an “output” v ariable Y is the maximal p ossible m u- tual information: C ( X → Y ) : = max p ( x ) I ( Y ; X ) . (4) In the follo wing sections, w e adapt these core con- cepts of channel capacit y and entrop y to formu- late a no vel, agent-cen tric safety measure for de- terministic rob otic systems. Our cen tral observ a- tion is that the c hannel capacity C ( X → Y ) can quan tify safet y . A system state is considered safe if the channel capacit y from system con trol inputs to successive system states is sucien tly large. F or deterministic systems, this capacit y will be re- lated to the logarithmic volume of reachable sets o v er a nite horizon. 2.2 Reinforcemen t Learning In RL, an agent learns to act in an en vironment dened by a Mark o v Decision Pro cess (MDP) with state space S , action space A , transition ker- nel p , and reward function r : S × A → R . At each state s ∈ S , the agent pic ks an action a ∈ A , re- ceiv es a rew ard r ( s , a ) , and transitions to a suc- cessor state s ′ with distribution p ( · | s , a ) . The ob jectiv e is to nd a p olicy π : S → A that maxi- mizes the discounted return R 0 : = ∑ ∞ k = 0 γ k r ( s k , a k ) . In mo del-free Deep RL, a p olicy π θ is parame- terized by a deep neural netw ork and improv ed iterativ ely using interaction data ( s , a , r , s ′ ) to ap- pro ximate a p olicy gradient. 3 Related W ork Sev eral studies hav e incorp orated information- theoretic measures to promote exploration and skill acquisition in RL. In (Mohamed and Jimenez Rezende, 2015), a v ariational low er b ound of empow erment is used as an intrinsic re- w ard for self-motiv ated learning. Building on this, (Levy et al., 2023) introduced a hierarchical em- p o w ermen t framework for skill learning. Other w orks ha ve applied empow erment to enhance self- optimizing netw orks (Kalm bac h et al., 2018) and to incen tivize exploration in sparse-reward sce- narios (Massari et al., 2021; Salge et al., 2014a). These metho ds typically approximate emp o w er- men t for discrete-time agents, often at high com- putational cost. Crucially , our work app ears to b e the rst to leverage readily av ailable forward dy- namics of contin uous-time mobile systems to ap- pro ximate emp o w ermen t. Another research direction integrates ph ysics- based insights in to reward design. F or instance, (Jiang et al., 2022) used principles lik e energy con- serv ation as intrinsic rew ards. Other methods use rew ard functions incorp orating mo del dynamics to facilitate diverse motion learning in complex agen ts (de Sousa et al., 2022) or ev aluate p erfor- mance based on v elo cit y relative to system dy- namics and a target (Ugurlu et al., 2025). In con- trast, our metho d ev aluates safety b y leveraging the agent’s internal states and sampled forward dynamics to appro ximate reac hable sets. W e then in tro duce a multiplicativ e emp ow erment term ap- plicable to any p ositive reward function. This metho d can b e applied on top of reward designs and in conjunction with v arious safe RL methods (Gu et al., 2024b). This has not b een explored in prior work, which used additive p enalties to pro- mote safet y . 4 C-STEP: Contin uous Space-Time Emp ow erment This section presen ts our core con tribution, the Contin uous Space-Time Emp ow erment for Ph ysics-informed (C-STEP) safe RL framework. W e b egin by illustrating why the classical deni- tion of emp ow erment is ill-suited for deterministic systems and propose a re-formulation. W e then dev elop an intrinsic, physics-informed reward for safe na vigation and provide a practical sampling- based metho d for its approximation. 2 A ccepted at ICAAR T 2026 4.1 Rethinking Emp o w erment for Deterministic Systems 4.1 Rethinking Empow erment for Deterministic Systems Emp o w ermen t, rst in tro duced in (Klyubin et al., 2005), measures the control an agent has ov er its future sensor states. F or a discrete-time p erception-action loop (P AL), where at every time k an agen t pic ks an action U k based on sensor state X k , leading to a subsequen t state X k + 1 , em- p o w ermen t is dened as the conditional channel capacit y from actions to subsequent states. Denition 1 (State-Dep endent Empow erment (Salge et al., 2014b)). F or a discrete-time P AL, state-dep enden t emp ow ermen t is: E ( x ) : = C ( U k → X k + 1 | X k = X ) . (5) A problem with Denition 1 arises when state transitions are deterministic in con tinuous spaces. In this setting, the relationship b etw een an action and the next state is p erfectly predictable, caus- ing the conditional entrop y h ( X k + 1 | U k ) to b ecome − ∞ . Consequen tly , emp ow erment b ecomes in- nite for any state, as a noiseless c hannel can en- co de unbounded information (Cov er, 2006, Sec- tion 9.3). Therefore, emp ow erment as stated in Denition 1 cannot measure the control or inu- ence a deterministic agen t has locally ov er its en- vironmen t. T o resolv e this, w e observ ed that adding small, state-indep enden t noise to a deterministic system mak es maximizing channel capacit y equiv alent to maximizing the dieren tial entrop y of the sub- sequen t state distribution. This observ ation, for whic h w e giv e further details in the app endix, mo- tiv ates a revised denition of emp ow erment for deterministic agen ts. Denition 2 (Deterministic Agent Emp ow er- men t). F or a deterministic P AL, emp o w erment is dened as: E ( s ) : = max p ( u ) h ( X k + 1 | X k = X ) . (6) F rom Eq.( 2 ) it follows that the maxim um em- p o w ermen t for deterministic agen ts in Denition ( 2 ) is ac hieved when actions induce a uniform dis- tribution ov er the set of reachable states. Emp ow- ermen t thus becomes the logarithm of the v olume of this reachable set. 4.2 F rom Emp ow erment to Safe RL Rew ards W e formalize our framew ork for a non- autonomous con tin uous-time dynamical system: ˙ x ( t ) = f ( x ( t ) , u ( t )) , (7) with states x ∈ R n , con trols u ∈ U ⊂ R m , and a collision-free conguration space X free ⊂ R n , such that an y x ∈ X free is a feasible state. Then, for T able 1: Key Denitions and Notation Sym b ol Denition X free The collision-free conguration space. R T ( x ) Set of reac hable states in R n from state x within time T with- out state constrain ts. R T , free ( x ) Set of reac hable states where the state tra jectory remains in X free . T T ( x ) The terminal set, R T ( x ) \ R T , free ( x ) . c A p ositive safet y co ecient scal- ing the emp ow ermen t rew ard. an y initial condition of the ODE in X free , we dene CST-Emp o w erment as the deterministic agen t emp ow erment where the action space is the space of all admissible contin uous nite-horizon input tra jectories. Key denitions and notation for this section are summarized in T able 1 . Denition 3 (CST-Empow erment). F or any T > 0 , the T -Horizon CST-Emp ow erment of ( 7 ) is de- ned as E T ( x ) : = max p ( u ( · )) h ( X ( T )) | x ( 0 ) = x 0 ) , ∀ x 0 ∈ X free , where X ( T ) is the random v ariable that describes the nal state of a T -horizon solution trajectory x ( t ) that starts from some x 0 ∈ X free and remains in X free giv en input trajectories from some distri- bution p ( u ( · )) . Giv en that dierential entrop y is maximized for uniform distributions, we can now conclude that the CST-Emp ow erment of an y state of a rst-order non-autonomous ODE equals the log- v olume of the T -reachable set of trajectories start- ing from that state and remaining in X free . Prop osition 1. Supp ose that f is Lipsc hitz contin- uous, then the CST-Empow erment of ( 7 ) is giv en b y E T ( x ) = log λ ( R T , free ( x )) , (8) = log ( λ ( R T ( x )) − λ ( T T ( x ))) , for all x ∈ R n with λ ( · ) the n -dim. volume on R n Pro of. See App endix. Based on Prop osition 1 , we prop ose Algo- rithm 1 to obtain practical, ecient appro xima- tions of CST-Emp ow erment using sampled tra jec- tories. F urther details on the sampling-based ap- pro ximation are discussed in Section 4.3. W e now leverage the av ailability of CST- Emp o w ermen t appro ximations based on Algo- rithm 1 to create an intrinsic reward for safe con- trol of contin uous time ODEs (7). By multiply- ing a task-sp ecic reward with our safety measure, i.e., CST-Emp ow erment, we encourage join t opti- mization of task completion and safety . T o giv e 3 A ccepted at ICAAR T 2026 5 NUMERICAL EXPERIMENTS Input: Curren t state x , time horizon T , n um b er of samples N ; Sample N admissible con trol tra jectories u ( · ) : [ 0 , T ] → U ; Calculate solution tra jectories x ( · ) for eac h u ( · ) with x ( 0 ) = x .; Initialize empt y sets R ← / 0 , T ← / 0 ; for eac h solution tra jectory x ( · ) do if trajectory is collision-free then A dd nal p osition x pos ( T ) to R ; else A dd nal p osition x pos ( T ) to T ; end end Compute estimate ˆ R T ( x ) of R T ( x ) from R ; Compute estimate ˆ T T ( x ) of T T ( x ) from T ; Return C-STEP Approximation ˆ E T ( x ) = log λ ( ˆ R T ( x )) − λ ( ˆ T T ( x )) ; Algorithm 1: C-STEP: Sampling-based CST- Emp o wermen t appro ximation algorithm a user a to ol to tune the degree of safety , w e in- tro duce a safety co ecient c > 0 that scales the emp o w ermen t. Denition 4 (Emp ow ered Navigation Rew ard F unction). Given a task rew ard r d : R n → [ 0 , 1 ] , the emp ow ered rew ard is dened as: r ( x ) : = r d ( x ) log c λ ( R T , free ( x )) . (9) with safet y co ecient c > 0 . Our emp ow ered reward design, Denition 4, has several key prop erties that we summarize next. T ec hnical prop erties: CST-Emp o w ermen t w eigh ts the navigation reward b y the log of the reac hable volume. Th us, emp ow ered rewards c haracterize a state’s safety b y the reachable v ol- ume from that state. Decreasing the co ecient c > 0 increases the safety of a learned p olicy; see b elo w for a more sp ecic connection b etw een c and safet y . Ph ysics-informed Intrinsic Design: CST- Emp o w ermen t incorp orates the forward dynam- ics of a system into a measure of how muc h space the system can reach from a starting state. It is in trinsic as it is specic to the given system dy- namics. Dep endence on Internal States: Most re- w ard designs for navigation incorporate external quan tities—suc h as p osition or velocity—to p e- nalize unsafe conditions. How ever, these quan- tities alone ma y b e misleading as internal states ma y b e close to b ecoming unstable. By contrast, our emp o w ered rew ard design captures the inu- ence of all internal states by lev eraging the full initial state and forward dynamics in the reac ha- bilit y calculation. En vironmen t Indep endence: T o approximate CST-Emp o w ermen t, it is only necessary to hav e a sensor function or an estimation to deter- mine/appro ximate whether a forward trajectory of a system leads to termination. No global map or prior information ab out obstacles is required. In terpretabilit y: If an RL agent is trained solely to maximize CST-Emp ow erment r ( x ) = E T ( x ) , its optimal b ehavior is to navigate to states from whic h it can reach the largest p ossible v ol- ume, promoting inherently safe and exible p o- sitioning. More generally , supp ose an agent is trained to maximize ( 9 ) and empirically a p osi- tiv e reward is observ ed in the mean after train- ing. Then one can conclude that on av erage λ ( R T , free ( x )) > c , whic h can b e translated to safet y margins for the dynamical system. 4.3 Sampling-based Appro ximation and Hyp erparameters Calculating the exact volume of R T , free ( x ) is of- ten intractable. W e therefore prop ose a practi- cal sampling-based approximation: First, w e com- pute the con vex h ull of reac hable endp oints to ap- pro ximate ˆ R T ( x ) , second, we compute the union of conv ex h ulls of clustered terminal points to ap- pro ximate ˆ T T ( x ) . Figure 2 illustrates how this ap- pro ximation eectiv ely captures the impact of ini- tial v elo cit y on safety . Our sampling-based approximation is agnos- tic to the method used to sample con trol trajec- tories. While it is p ossible to characterize how the approximation error decreases as the num- b er of sampled trajectories increases, this analysis lies outside the scop e of the present work. Al- though sampling many tra jectories can be appeal- ing in principle, it may become computationally prohibitiv e for complex non-linear systems. Con- sequen tly , the choice of how many tra jectories to sample m ust b e tuned according to the problem and a v ailable resources. A more critical h yp erparameter than the n um- b er of trajectories is the time horizon T for eac h tra jectory . A large T risks all tra jectories collid- ing (zero emp ow erment), while a short T oers little information. W e propose a heuristic that has work ed well for our numerical exp eriments: set T to the system’s worst-case stopping time from maxim um v elo city . This provides a reasoned baseline that can b e tuned for more conserv ative or aggressiv e b ehavior. 5 Numerical Exp erimen ts W e present 2D and 3D navigation tasks where agen ts must reac h targets while a voiding colli- sions. W e compare agents trained with a stan- dard navigation rew ard (”unemp ow ered”) against one trained with our emp ow ered reward function (”emp o w ered”). F or every exp eriment at every 4 A ccepted at ICAAR T 2026 5.1 Poin t Maze Environmen t time step, we use the standard navigation reward exp ( −∥ agent position − target p osition ∥ 2 ) . Note that the unemp o w ered agen ts still receiv e safet y feedback b ecause episodes terminate upon collision; thus, v alue function estimates will not b e b o otstrapp ed. It is imp ortant to note that our goal in this preliminary study is not to com- pare with other safe RL metho ds, but to under- stand the general behaviour of emp ow ered agen ts in basic na vigation tasks. F or all exp eriments, we use the Pro ximal P olicy Optimization (PPO) al- gorithm (Sc h ulman et al., 2017) from Stable Base- lines3 (Ran et al., 2021). The co de is av ailable on GitHub 1 . 5.1 P oint Maze Environmen t Our rst exp eriment considers a P oin t Maze en- vironmen t where a 2-DoF ball m ust b e na vigated to a target by applying a 2D force. The map has t w o paths: one narro w and one wide. The goal is placed so that the narro w path is the shortest route. The b ehaviour of the agents after training is shown in Figure 1 . The unemp ow ered agent learns to take the faster, riskier path, resulting in more collisions. In contrast, the empow ered agent learns to take the longer but safer route, thereby demonstrating a b ehavioral change tow ard prior- itizing safet y . (a) Behavior of the unemp o wered agen t. (b) Behavior of the emp o w ered agent. Figure 1: Poin t maze navigation. Green spheres are agen ts, red is the goal, and yello w is the start. The emp o wered agen t prefers the safer, wider path. 5.2 Drone PyBullet Environmen t Our second simulation considers a 3D drone in a dynamic environmen t (Figure 3 ). Both the em- p o w ered and the unempow ered agen t use rela- tiv e distance to the goal, drone v elo city , and 2D LiD AR data as state inputs. The map’s path widths are randomized eac h episo de, forcing re- liance on sensor data. The training progress (Fig- ure 4 ) shows the emp ow ered agen t successfully 1 https://github.com/gdaudt/empowerment- rl. (a) Initial v elo cit y (m/s) ( v x v y v z ) = ( 0 2 0 ) . (b) Initial v elo city (m/s) ( v x v y v z ) = ( 1 . 5 2 0 ) . Figure 2: Visualization of the sampling-based reach- able set approximation in 2D for dieren t initial ve- lo cities. The blue areas indicate total reac hable areas; red areas represen t the approximated terminal set vol- ume. learns, indicating our reward pro vides a meaning- ful learning signal. W e ev aluated a unemp ow ered agent and emp o w ered agents with safety co ecients c = { 0 . 5 , 1 , 10 } on 100 dierent map congurations. As sho wn in T able 2 , all emp ow ered agents ac hiev ed higher success rates than the unemp ow- ered baseline. The safest agen t ( c = 0 . 5 ) ac hieved a 99% success rate, compared to 82% for the base- line, with only a marginal increase in the time tak en to clear the obstacle. T o further quantify safety , we measured the time agents sp ent near obstacles (Figure 5 ). T a- ble 3 shows that emp ow ered agents consistently sp en t less time in close proximit y to w alls. F or instance, the agen t with c = 1 spent ov er 72% less time within 0.1m of an obstacle while only b eing 18.4% slo wer, a signican t safet y improv emen t for a small trade-o in task completion time. Figure 3: T op-down view of the PyBullet simulation en vironment. The agent starts in the yello w region and na vigates to the green goal region. The maro on- colored obstacle’s width and position are randomized in eac h episo de, indicated b y the red arro ws, requiring adaptiv e navigation. 5 A ccepted at ICAAR T 2026 7 CONCLUSION AND FUTURE WORK Figure 4: A v erage reward p er episo de for the em- p o wered agent ( c = 1 ). (Ev aluated ev ery 10 3 training steps.) Agent Success rate A vg. clear time (s) unempowered 82% 6.56 Empowered c = 10 89% 6.91 Empowered c = 1 92% 7.77 Empowered c = 0 . 5 99% 7.63 T able 2: Success rate and time to clear the obstacle. Figure 5: A v erage time sp ent under dierent distance thresholds for emp ow ered (blue lines) and unemp ow- ered (orange line) agents. 6 Discussion Established Safe RL metho ds (Gu et al., 2024b), suc h as Control Barrier F unctions (CBF s), typi- cally ensure safety b y dening a safe set in the state space and using a con troller that guarantees the agent’s state remains within this set, result- ing in hard, explicit safet y constraints. Again, we emphasize that our metho d can be used on top of established safe RL metho ds. In the future, we w an t to ev aluate how this com bination enhances v arious safe RL metho ds. Compared with standard safe RL metho ds that use additiv e rew ard p enalties for unsafe b e- ha vior, C-STEP oers a philosophically distinct approac h. Rather than imp osing hard constraints to quantify safe states, it shapes the reward land- scap e to create an intrinsic motiv ation for safety . The agent is not explicitly forbidden from entering certain states; instead, it is rewarded for main- taining a high degree of future maneuverabilit y (i.e., a large collision-free reac hable set). This en- courages the agen t to learn p olicies that emer- Distance Threshold (m) 0.1 0.2 0.3 0.4 0.5 Empowered c = 10 31.05% 10.70% 18.99% 14.14% 9.25% Empowered c = 1 72.61% 49.93% 43.34% 27.59% 3.01% Empowered c = 0 . 5 85.76% 64.66% 53.10% 33.98% 19.07% T able 3: P ercentage decrease in time sp ent near ob- stacles for empow ered agen ts relative to unempow ered baseline. gen tly exhibit safe b ehavior, such as main taining distance from obstacles not because of a penalty function, but b ecause doing so maximizes its fu- ture options. C-STEP can be view ed as a com- plemen tary to ol that promotes a broader form of robustness, whereas CBF s provide formal safet y guaran tees with respect to a predened safe set. A direct quantitativ e comparison against CBF s and other in trinsic rew ards remains an av enue for future w ork to understand the trade-os betw een these paradigms. 6.1 On Model F ree Learning Our metho d requires a simulator for ev aluating nite-horizon trajectories. Notably , w e do not re- quire dierentiable transition functions, as used b y v arious safe RL metho ds and mo del-predictive con trollers (Gu et al., 2024b). In addition, our metho d does not require an explicit c haracteriza- tion of safe states; the sim ulator only needs to dis- tinguish terminated and non-terminated trajecto- ries, ands our metho d infers state safety from the v olume sampled reachable set. In this wa y , our metho d may b e considered to lie b etw een pure mo del-free and mo del-based RL. 6.2 Bey ond Deterministic Dynamics W e formulated our metho d for a deterministic dynamical system. How ever, the implementa- tion naturally extends to sto chastic systems, since w e only require a simulator to ev aluate nite- horizon tra jectories. F urthermore, most real- w orld rob otic systems can b e mo deled as deter- ministic dynamical systems subject to environ- men tal uncertain ty and noise, and our theory should hold in approximation. 7 Conclusion and F uture W ork This w ork introduced CST-Emp ow erment as an in trinsic reward for adapting navigation reward functions to w ards enhanced safet y . W e demon- strated that our physics-informed, emp ow ered re- w ard function ecien tly enhances the safety of p olicies trained with RL for mobile rob otic navi- gation. W e also ackno wledge several limitations in our v alidation, whic h present directions for future re- searc h. First, a comprehensiv e ev aluation would include direct quantitativ e comparisons against 6 A ccepted at ICAAR T 2026 REFERENCES state-of-the-art baselines, statistical signicance tests, and ablation studies. F urthermore, v alidat- ing our approach on physical hardware would b e essen tial to assess its robustness in dynamic, real- w orld en vironmen ts. Theoretical guaran tees are also a natural next step. Other attractive future w ork includes train- ing p olicies solely to maximize emp ow erment for use in critical situations and testing C-STEP in com bination with other adv anced rew ard designs. W e b elieve emp ow erment is a p ow erful comple- men tary tool that can augmen t an y navigation re- w ard to promote ph ysics-informed in trinsic safet y . A CKNOWLEDGEMENTS This work has received funding from the EU Horizon pro ject SHEREC (HORIZON-CL4-2023- HUMAN-01-02). REFERENCES Brunk e, L., Gree, M., Hall, A. W., Y uan, Z., Zhou, S., Panerati, J., and Sc ho ellig, A. P . (2022). Safe learning in robotics: F rom learning-based control to safe reinforcement learning. Annual Review of Control, Rob otics, and Autonomous Systems, 5(V olume 5, 2022):411–444. Cho w, Y., Ghav amzadeh, M., Janson, L., and P av one, M. (2015). Risk-constrained rein- forcemen t learning with p ercentile risk criteria. ArXiv, abs/1512.01629. Co ver, T. M. (2006). Elements of information theory . John Wiley & Sons, second edition. Dang, V. H., Redder, A., Pham, H. X., Sarabakha, A., Ka yacan, E., et al. (2025). V ds-nav: V olumet- ric depth-based safe navigation for aerial robots– bridging the sim-to-real gap. IEEE Rob otics and A utomation Letters. de Sousa, A. S., Nunes, R. F., Vidal, C. A., Ca v alcante-Neto, J. B., and da Silv a, D. B. (2022). Ph ysics-based motion control through drl’s reward functions. Emam, Y., Notomista, G., Glotfelter, P ., Kira, Z., and Egerstedt, M. (2021). Safe reinforce- men t learning using robust con trol barrier func- tions. IEEE Robotics and A utomation Letters, 10:2886–2893. Gu, S., Y ang, L., Du, Y., Chen, G., W alter, F., W ang, J., and Knoll, A. (2024a). A review of safe rein- forcemen t learning: Metho ds, theories, and ap- plications. IEEE T ransactions on P attern Anal- ysis and Mac hine Intelligence, 46:11216–11235. Gu, S., Y ang, L., Du, Y., Chen, G., W alter, F., W ang, J., and Knoll, A. (2024b). A review of safe rein- forcemen t learning: Metho ds, theories and appli- cations. IEEE T ransactions on Pattern Analysis and Machine Intelligence. Jiang, J., F u, M., and Chen, Z. (2022). Physics in- formed intrinsic rewards in reinforcement learn- ing. In 2022 Australian & New Zealand Con trol Conference (ANZCC), pages 69–74. Kalm bach, P ., Zerwas, J., Babarczi, P ., Blenk, A., Kellerer, W., and Schmid, S. (2018). Emp ow er- ing self-driving net w orks. Klyubin, A. S., Polani, D., and Nehaniv, C. L. (2005). All else b eing equal b e emp ow ered. In Euro- p ean Conference on Articial Life, pages 744– 753. Springer. Levy , A., Rammohan, S., Allievi, A., Niekum, S., and Konidaris, G. (2023). Hierarchical emp ow- ermen t: T ow ards tractable emp ow erment-based skill learning. Massari, F., Biehl, M., Meeden, L., and Kanai, R. (2021). Exp erimental evidence that emp o wer- men t ma y drive exploration in sparse-reward en- vironmen ts. In 2021 IEEE International Con- ference on Developmen t and Learning (ICDL), pages 1–6. IEEE. Mohamed, S. and Jimenez Rezende, D. (2015). V aria- tional information maximisation for in trinsically motiv ated reinforcement learning. Adv ances in neural information pro cessing systems, 28. Queeney , J., Ozcan, E. C., P aschalidis, I., and Cassan- dras, C. (2024). Optimal transport perturbations for safe reinforcemen t learning with robustness guaran tees. T ransactions on Machine Learning Researc h. Ran, A., Hill, A., Gleav e, A., Kanervisto, A., Ernestus, M., and Dormann, N. (2021). Stable- baselines3: Reliable reinforcemen t learning im- plemen tations. Journal of Machine Learning Re- searc h, 22(268):1–8. Salge, C., Glac kin, C., and P olani, D. (2014a). Chang- ing the environmen t based on empow erment as in trinsic motiv ation. Entrop y , 16(5):2789–2819. Salge, C., Glac kin, C., and Polani, D. (2014b). Emp o w erment–an introduction. Guided Self- Organization: Inception, pages 67–114. Sc hulman, J., W olski, F., Dhariw al, P ., Radford, A., and Klimo v, O. (2017). Pro ximal policy opti- mization algorithms. Sutton, R. S. and Barto, A. G. (2018). Reinforcement Learning: An Introduction. The MIT Press, sec- ond edition. Ugurlu, H. I., Redder, A., and Kay acan, E. (2025). Ly apuno v-inspired deep reinforcemen t learning for robot navigation in obstacle en vironments. In 2025 IEEE Symp osium on Computational In tel- ligence on Engineering/Cyb er Physical Systems (CIES), pages 1–8. IEEE. APPENDIX 7.1 Understanding Empow erment of Deterministic Agen ts T o supp ort our new denition of emp ow er- men t, consider a real-v alued random v ariable S ′ = g ( S , A ) , which is a (measurable) function g of real- v alued random v ariables S and A . F urther, let W ε b e a zero mean normal random v ariable with v ariance ε 2 > 0 indep endent of ( S , A ) . Then, de- ne the p erturbation ˜ S ′ : = g ( S , A ) + W ε . The con- ditional density of ˜ S ′ giv en ( S , A ) is then giv en 7 A ccepted at ICAAR T 2026 REFERENCES b y N ( ˜ s ′ ; g ( s , a ) , ε 2 ) . It follows that h ( ˜ S ′ | S , A ) = ln ε √ 2 π e , the dierential entrop y of a normal random v ariable with arbitrary mean and v ari- ance ε 2 . Therefore, the c hannel capacit y is C ( A → ˜ S ′ | S ) = max p ( a ) h ( g ( S , A ) | S ) − ln ε √ 2 π e . (10) Supp ose that w e use (10) to determine realiza- tions of S that maximize capacit y . As ln ε √ 2 π e is state independent follows that the maximizer of (10) is indep endent of the p erturbation, and the states that maximize emp ow erment are those that maximize the rst term in (10). Consequen tly , dening the empow erment of deterministic agen ts as the maximum state-dep endent dierential en- trop y is p ertinent. 7.2 Pro of of Prop osition 1 By construction, the space of X ( T ) given x ( 0 ) = x 0 is R T ( x ) . As f is Lipschitz contin uous, the Picard–Lindelöf Theorem implies that every so- lution of Lipschitz contin uous ODEs is unique. Hence, there exists a (non-trivial) distribution on C ([ 0 , T ] ; U ) , suc h that X ( T ) is uniformly dis- tributed on the reachable set. As the dieren tial en trop y is maximized for uniform distributions, the statemen t follo ws. 7.3 Sim ulation Details The inner area of the maps used in our ev aluation set had dimensions of 5 m × 2 . 5 m × 2 m . The LiDAR sensor on the drone had 180 ev enly spaced b eams co v ering 360 ◦ . The drone’s start and goal z-axis p ositions were xed at 1 m . CTS-Emp o w ermen t Approximation T o model the drone’s dynamics, w e used its URDF le to incorp orate relev ant ph ysical prop erties into our tra jectory estimation. Hyp erparameters V alues T 1 second T ra jectories 150 P oin ts in tra jectory 100 T able 4: CST Empow erment hyperparameters used in exp eriments. PPO Hyp erparameters The netw ork architec- ture consisted of tw o fully connected hidden lay ers of 2048 and 512 neurons, resp ectively . Hyp erparameters V alues Horizon 2048 Batc h size 64 Discoun t ( γ ) 0.99 GAE P arameter ( λ ) 0.95 Clip range 0.2 Learning rate 3 × 10 − 5 SDE T rue Num. ep o chs 10 T able 5: PPO parameters for the PyBullet environ- men t. 8
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment