Semantic-Aware Interruption Detection in Spoken Dialogue Systems: Benchmark, Metric, and Model
Achieving natural full-duplex interaction in spoken dialogue systems (SDS) remains a challenge due to the difficulty of accurately detecting user interruptions. Current solutions are polarized between "trigger-happy" VAD-based methods that misinterpr…
Authors: Kangxiang Xia, Bingshen Mu, Xian Shi
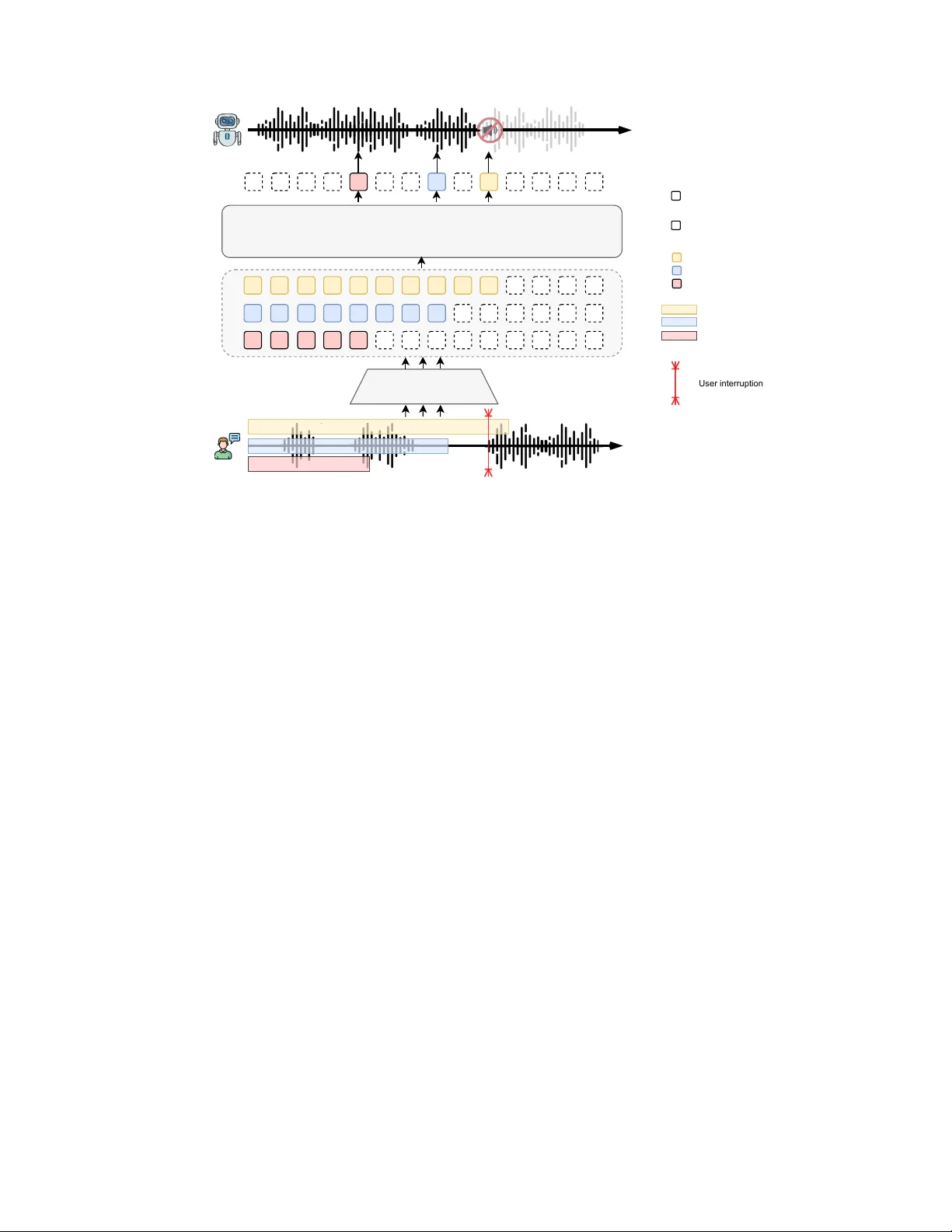
Semantic-A ware Interruption Detection in Spoken Dialogue Systems: Benchmark, Metric, and Model Kangxiang Xia 1 , Bingshen Mu 1 , Xian Shi 1 , Jin Xu 1* , Lei Xie 2 1 Qwen T eam, Alibaba 2 Independent Researcher Abstract —Achieving natural full-duplex interaction in spoken dialogue systems (SDS) remains a challenge due to the difficulty of accurately detecting user interruptions. Current solutions are polarized between ”trigger -happy” V AD-based methods that misinterpret backchannels and rob ust end-to-end models that exhibit unacceptable response delays. Moreov er , the absence of real-world benchmarks and holistic metrics hinders progress in the field. This paper presents a comprehensive frame- work to over come these limitations. W e first intr oduce SID-Bench, the first benchmark for semantic-aware interruption detection built entirely from real-world human dialogues. T o provide a rigorous assessment of the responsiv eness-rob ustness trade-off, we propose the A verage Penalty Time (APT) metric, which assigns a temporal cost to both false alarms and late responses. Building on this framework, we design an LLM- based detection model optimized through a novel training paradigm to capture subtle semantic cues of intent. Experimental results show that our model significantly outperforms mainstream baselines, achieving a nearly thr eefold reduction in APT . By successfully resolving the long- standing tension between speed and stability , our work establishes a new state-of-the-art f or intelligent interruption handling in SDS. T o facilitate future research, SID-Bench and the associated code are av ailable at: https://github .com/xkx-hub/SID-bench. Index T erms —SID-Bench, APT , interruption detection I . I N T RO D U C T I O N The pursuit of human-like, fluent spoken interaction is a long- standing goal in the field of Spoken Dialogue Systems (SDS) [1]– [7]. A critical milestone toward this goal is full-duplex technology , which allows systems to “listen” and “speak” simultaneously [8]– [11]. Ho wev er , achieving bidirectional transmission at a technical lev el is not the final destination. The faithful measure of interactional naturalness lies in a system’ s capacity to handle dynamic, non- sequential conv ersational behaviors [12]–[14]. Among these, intel- ligent handling of user interruptions is of paramount importance, as it elev ates an interaction from a rigid, turn-taking model to a collaborativ e, efficient real-world con versation. Despite the clear importance of interruption detection, current solutions often fall short. Mainstream full-duplex systems rely on V oice Activity Detection (V AD) to identify interruptions [15], [16]. While fast, these systems are often “trigger-happy”, they frequently mistake simple user backchannels (like “uh-huh” or “right”) or brief hesitations as signals to stop, causing the system to cut itself off inappropriately . On the other end of the spectrum, some end-to-end models [8] prioritize robustness but suffer from high latency , failing to stop promptly e ven when the user clearly intends to take the floor . At their core, existing systems lack a deep understanding of the user’ s underlying intent, making interactions feel mechanical and clumsy . A more severe challenge than the technical implementation itself is the absence of adequate ev aluation methods. Methodologies for assessing interruption capabilities have lagged behind technological advancements. Human evaluation, while nuanced, is too costly , sub- jectiv e, and difficult to replicate for rapid system dev elopment [17]. * Corresponding Author . This work was done when Kangxiang Xia was an intern in Qwen T eam, Alibaba, Beijin, China. T o address this, fully automated benchmarks such as full-duplex- bench series [17]–[19] and FD-Bench [20] have recently emerged, making significant strides in the systematic ev aluation of ov erlapping speech. Howev er , these advanced works still exhibit several key limitations. Fundamentally , both rely on synthetic data, text generated by LLMs and spoken by TTS. While scalable, this approach fails to capture the intricate blend of timing, prosody , and emotion found in spontaneous human speech, leaving a gap in “real-world” realism [21], [22]. Furthermore, existing automated metric systems are either too complex to be easily interpretable or lack a unified composite score to balance different performance dimensions, such as responsiveness versus robustness. Moreov er , these works primarily focus on “diagnosing the problem” rather than providing a validated, constructiv e solution to enhance the model’ s interruption capabilities. Therefore, a framework based on real-world data, featuring a concise and compelling evaluation system, and capable of guiding model optimization, remains a significant gap in the field. T o bridge these dual gaps in evaluation and model capabilities, this paper presents the following contributions. First, we introduce the Semantic Interruption Detection Benchmark (SID-Bench), a no vel benchmark constructed from real-world, recorded human con versa- tions, designed explicitly for evaluating interruption handling. Unlike methods reliant on synthetic data, SID-Bench captures the div erse and spontaneous interruption patterns found in authentic interactions. Second, to enable a precise measurement of interruption intelligence, we define a new set of ev aluation metrics focusing on accuracy and latency . T o address their intrinsic trade-off, we propose a composite score that provides a unified performance indicator by encapsulating the penalties associated with both false alarms and delayed responses. Third, to establish a strong baseline on this benchmark, we propose a novel LLM-based model for interruption detection. By employing a ’large-scale pre-training then few-shot fine-tuning’ paradigm, this approach leverages pre-existing knowledge to acquire specialized interruption detection skills without requiring extensi ve task-specific annotated data. Finally , we conduct a comprehensiv e e valuation on SID-Bench, benchmarking our proposed model against several mainstream full-duplex systems. Experimental results demonstrate that our model significantly outperforms existing systems, proving not only the effecti veness of our approach but also validating the efficac y and necessity of SID-Bench in differentiating the interruption capabilities of various models. I I . S I D - B E N C H T o address the critical gap in ecologically v alid ev aluation, we introduce the SID-Bench, a novel benchmark meticulously designed to assess the interruption-handling capabilities of SDS. In contrast to prior works that rely on synthetic data, SID-Bench is built upon authentic, recorded human-human conv ersations, ensuring that the ev aluation scenarios accurately reflect the complex and spontaneous nature of real-world interactions. Its core contribution lies in pro- LLM-n Kaldi LLM-1 ... ... Y eah, but I have a better idea. Y eah, but I have a better idea. check and filter WA V TEXT Annotation Information Fusion Break_point: 1.0625s yeah: 0.10 ~ 0.65s but: 1.06 ~ 1.30 s I: 1.31 ~ 1.49 s have: 1.50 ~ 1.83 s a: 1.84 ~ 1.87 s better:1.88 ~ 2.30 s idea: 2.31 ~ 2.60 s Fig. 1. The semi-automated annotation pipeline for SID-Bench. The process begins with raw audio and its transcription. In the Annotation stage, the audio is processed by the Kaldi toolkit for forced alignment to obtain word-le vel timestamps, while the text is analyzed by a series of LLMs to semantically identify the interruption point, marked with a < break > tag. In the final Information Fusion stage, the semantic < break > tag is aligned with the precise start time of the corresponding word from Kaldi, establishing a semantically meaningful and temporally accurate ground-truth Break point. viding an e v aluation frame work that not only measures a system’ s responsiv eness but also, crucially , its ability to differentiate between genuine interruptions and non-interruptiv e backchannels. This section outlines the data collection, annotation methodology , and statistical properties of the resulting benchmark. A. Data Collection and Sour ces The foundation of SID-Bench is the use of real-world con v er- sational data, as we believ e that the subtle acoustic and semantic cues inherent in human interruptions can only be captured through authentic recordings. The benchmark is bilingual, comprising both Chinese and English conv ersations. The Chinese data was profes- sionally recorded by a data vendor , featuring natural dialogues. The English portion combines similarly recorded vendor data with a curated subset from the widely-recognized Switchboard [23] corpus, a standard resource known for its spontaneous con versational style. The final benchmark comprises a total of 3,700 ev aluation in- stances, extracted from approximately 10 hours of curated audio. The included conv ersational turns are not pre-selected based on whether they contain an interruption; instead, they represent a natural distribu- tion of overlapping speech ev ents found in human-human dialogue. SID-Bench considers genuine interruption, simple backchannels, and ambiguous cases, creating a realistic and challenging testbed for a model’ s judgment. B. Definition and Annotation of Interruption Events A primary limitation of existing systems is their inability to dis- tinguish between ov erlapping speech and true interruption intent. T o facilitate a more nuanced ev aluation, we establish a clear , functional definition for interruption ev ents. W e define a true Interruption as an ev ent where a speaker begins their turn with a new communicative intent that semantically warrants the other speaker to yield their turn. In contrast, a Backchannel is an utterance used to ackno wledge, agree, T ABLE I T H E CO M P O S I TI O N A N D STA T I S TI C S O F SI D - B E N C H DAT A S ET . Language Category Count Chinese Interruption at the beginning 500 Interruption in the middle 600 Uninterrupted 500 English Interruption at the beginning 500 Interruption in the middle 600 Uninterrupted 500 Noise/Silence En vironmental noise 200 Silence with subtle sounds 300 or sho w continued attention while not altering the con versational goal, ex emplified by expressions such as “uh-huh, ” “right, ” and “I see. ” T o accurately and consistently label the precise moment of in- terruption, we dev eloped a semi-automated annotation pipeline, as illustrated in Figure 1. This pipeline uniquely combines the semantic analysis of LLMs with high-precision temporal information from forced alignment. First, we prompt powerful LLMs, Qwen-max, Qwen-plus [24], to analyze the raw text of a speaker’ s turn and insert a < break > tag at the exact word where the utterance transitions from non-substanti ve backchanneling to e xpressing a ne w , substantiv e intent. T o ground this semantic breakpoint in the time domain, we utilize the Kaldi toolkit to perform forced alignment on the raw audio, thereby generating precise timestamps for each word and phoneme. By integrating these two stages, we define the ground-truth interruption time as the start time of the first phoneme of the first substantiv e w ord identified by the LLM. This hybrid approach ensures our labels are not only temporally precise but also semantically meaningful, directly reflecting the speaker’ s underlying intent. C. Statistics of SID-Bench T able I outlines the composition of SID-Bench, a benchmark designed for the comprehensive ev aluation of interruption handling, including three main data categories. The collection of 3,200 conv ersational instances is evenly split between Chinese and English. These instances are further classified based on the user’ s overlapping speech patterns. Among them, 500 instances are designated as Uninterrupted , containing only non- substantiv e backchannels or filler words without any intent to take the conv ersational turn. The other 1,100 instances represent genuine interruptions, which are further partitioned into 500 Interruption at the Beginning cases, where intent is immediately apparent, and 600 Interruption in the Middle cases, where an initial backchannel ev olves into a substanti ve interjection. The detailed categorization enables a rigorous assessment of a model’ s intent differentiation performance. Furthermore, the Noise and Silence set of 500 instances is included to test the system’ s robustness against non-semantic acoustic phenomena. This set is composed of 300 Silence clips and 200 Noise clips. The Silence clips are synthesized by concatenating near-silent segments from original recordings to a duration of 10 seconds; these segments might include low-le v el audio artifacts like breathing or microphone hiss. The Noise clips contain prev alent en vironmental sounds, such as rain and keyboard typing. This set is vital for verifying that the model responds specifically to semantic speech cues rather than reacting to any arbitrary acoustic energy . I I I . E V A L UA T I O N M E T R I C S A quantitativ e assessment of what we term “interruption intelli- gence” necessitates an ev aluation framework that transcends tradi- tional metrics. The core challenge in designing such a system is resolving the inherent trade-of f between tw o competing demands. The first is accuracy , the system’ s ability to prevent spurious interruptions. The second is timeliness, its capacity to respond promptly to v alid interruptions. T o formally capture this balance, we introduce a suite of metrics. These include two primary indicators adopted from [20], the False Interruption Rate (FIR) and the Interruption Response Latency (IRL). T o provide a holistic measure, we also formulate a single composite score, the A verage Penalty Time (APT), which synthesizes the penalties associated with both false alarms and delayed responses. Our entire metric set is systematically deri ved from the four distinct outcomes of user-system interaction, detailed in Figure 2. True Positive User Model True Negative False Negative IRL False Positive User Model User Model User Model Uh-huh... yeah...But I think ... ... Uh-huh... yeah...But I think ... ... Wait a minute, let me explain. Uh-huh........ yeah......That's right! Fig. 2. Illustration of the four ev aluation scenarios and their associated time penalties. The user’s utterance contains a ground-truth interruption intent marked by < break > . (a) T rue Positive: The system correctly stops after the < break > point. The penalty is IRL, shown in blue. (b) False Positive: The system incorrectly stops in response to a backchannel before the < break > . This is a catastrophic failure, and the penalty , shown in red, applies to the entire turn’ s duration. (c) False Negative: The system fails to stop, forcing the user to listen to superfluous speech. The penalty , shown in red, is the duration of this unwanted audio. (d) T rue Negative: The system correctly ignores a backchannel and continues speaking when no < break > is present, thus incurring zero penalty . A. Primary Metrics: FIR and IRL FIR measures a system’ s robustness. It is the proportion of test cases in which a system incorrectly stops its utterance in response to a non-interruptive vocalization, such as a backchannel. A lower FIR indicates a less “trigger-happy” and more natural-sounding system. FIR can be calculated as: FIR = Number of False Interruptions T otal Number of T est Cases . (1) IRL measures a system’ s responsiveness. For correctly handled interruptions (True Positiv es), it is the time elapsed from the ground- truth interruption intent T break to the system’ s stop time T model stop . A lower IRL signifies a more agile system. IRL can be calculated as: IRL = T model stop − T break . (2) B. Composite Score: APT T o provide a single, holistic measure, we introduce APT . This score combines accuracy and timeliness by assigning a “time cost” equiv alent to ev ery system action for the user, as visualized in Figure 2. The penalty for each outcome is defined as follows: • T rue Positive: The penalty is the unavoidable latency , IRL . • F alse Positive: A catastrophic failure that derails the conv er- sation. The penalty is therefore the total planned duration of the turn , representing a complete loss of that interactional opportunity . • F alse Negative: Force the user to listen to unwanted speech. The penalty is the duration of this superfluous audio after the user has expressed their intent. • T rue Negative: An ideal behavior incurs zero penalty . The final APT score is the av erage penalty across all N test cases, providing a powerful and intuitiv e measure of overall performance: APT = 1 N N X i =1 PenaltyT ime i , (3) a lower APT signifies a superior system that better balances respon- siv eness and robustness. I V . M E T H O D O L O G Y T o facilitate precise, real-time identification of user interruption intent, we propose a framework built upon a large-scale multimodal architecture. The core of our approach lies in reframing interruption detection as a sequential classification problem. Through a specialized two-stage training paradigm and a rob ust inference strategy , the model learns to generate timely decisions grounded in a semantic understanding of the user’ s utterance. A. Model Arc hitectur e Our primary objective is to move beyond V AD tow ard a deep semantic comprehension of con versational intent. As illustrated in Figure 3, our model comprises two primary components: an audio encoder and a LLM decoder . The architecture is inspired by state- of-the-art multimodal designs such as Qwen3-Omni [25], aiming for a seamless fusion of acoustic features and linguistic semantics. W e employ an Audio Transformer (AuT) as the audio encoder to e xtract high-dimensional acoustic embeddings from raw signals. These embeddings are then fed into Qwen-0.6b [26], a lightweight yet po werful LLM that serv es as the central reasoning engine. By lev eraging its adv anced contextual modeling capabilities, the LLM processes the sequence of feature frames and generates a binary classification output, determining whether the accumulated audio context constitutes a genuine interruption intent. B. T raining P aradigm T o ef ficiently teach the model “when to interrupt”, we designed a two-stage “pre-training for alignment, fine-tuning for detection” paradigm, augmented with several training strategies tailored to the interruption task. The initial phase aims to bridge the representation gap between acoustic and linguistic modalities. W e pre-train the entire pipeline on large-scale ASR datasets. By optimizing for the ASR task, the model is forced to map acoustic signals onto their corresponding textual units, ensuring that the audio encoder’ s output can be effecti vely interpreted by the LLM’ s language space. This stage establishes a robust multimodal foundation for subsequent intent detection phase. In the second phase, the model is fine-tuned specifically for the interruption detection task. W e utilize a bilingual dialogue corpus processed similarly to SID-Bench, providing a training set with pre- cise interruption timestamps T break . As depicted in Figure 3, training samples are generated using a randomized temporal cropping method. For any given utterance containing a ground-truth interruption T break , we extract segments of varying lengths. Each segment is assigned a binary label based on its endpoint relative to T break : a segment Language Model Audio Encoder N N N N N N N N Y Y Y Y ......Uh-huh............yeah, you are right............. But I think it should be ... ... batch N N Y User interruption Random audio clip Training audio frame sequence N Y No interrupt signal Interrupt signal ① ② ③ ④ Fig. 3. The overall architecture of the proposed SID-model for real-time interruption detection. (1) During training, we use audio with a pre-labeled user interruption point. This audio is randomly cropped into clips of varying lengths, represented by different colors. Each clip is assigned a ground-truth label: ‘Y’, interrupt, if its endpoint is after the user interruption point, and ‘N’ otherwise. (2) The audio clips are processed by an Audio Encoder (AuT) to extract features. (3) The resulting audio frame sequences are fed into a LLM (Qwen3-0.6b). (4) The model sequentially predicts whether to issue an interrupt signal or not, enabling the system to stop its speech in a timely manner . The user interruption points are annotated following the procedure of the SID-bench. is labeled as a positive instance if its endpoint exceeds T break , and a negati v e instance otherwise. This label serves as the supervision signal for the LLM’ s final hidden state, training the model to ev aluate whether the gro wing audio context provides suf ficient evidence of an interruption intent. T o address the inherent ambiguity and temporal sensitivity of interruption behaviors, we incorporate two specialized boundary- aware training strategies: intent confirmation delay and boundary- aware sampling. First, in authentic interactions, confirming an intent often requires a brief context following the initial trigger word. T o simulate this, we apply a one-word temporal shift to the ground-truth T break during label generation. This forces the model to integrate more evidence before issuing a positiv e prediction, thereby enhancing robustness against premature and erroneous interruptions. Second, the interv al immediately surrounding T break represents the most critical decision-making window . T o ensure the model effecti vely learns these subtle distinctions, we increase the sampling density of clips whose endpoints fall near this boundary . Specifically , for each source utterance, we guarantee that at least two sampled clips span opposite sides of T break , forcing the model to discriminate between non-substantiv e backchannels and the onset of substantive intent. C. Inference Process T o emulate a real-world streaming dialogue scenario, our inference process operates on a continuous stream of user audio. The incoming audio is segmented into fixed-length chunks. At each step, these chunks are cumulativ ely concatenated and fed into the model (e.g., chunk 1 , chunk 1+2 , chunk 1+2+3 , ...), allowing the model to make predictions based on all available historical context. Howe ver , the acoustic and semantic signals around an interruption boundary are often ambiguous, which can cause the model’ s predictions to be unstable and oscillate between Continue and Interrupt. T o mitigate the risk of false positives triggered by this momentary prediction jitter, we implement a decision smoothing policy . A definitiv e interruption ev ent is registered, and a stop command is issued to the dialogue system, only after the model outputs Interrupt for K consecutiv e steps. This hyperparameter K allows for a direct trade-off between responsiv eness and decision stability . In our experiments, we set K = 3 . V . E X P E R I M E N T S W e applied our proprietary SID-Bench benchmark to ev aluate the open-source FDSDS models, which serve as strong performance baselines. This process is designed to validate the efficac y of our proposed model and the diagnostic power of SID-Bench itself. A. Baselines W e compare our approach against four representativ e open-source systems, each reflecting a mainstream technical paradigm for inter - ruption handling: (1) FSMN-V AD [27] is an efficient V AD model that represents the most fundamental interruption strategy , which treats any detected user speech as an interruption trigger . (2) Freeze-Omni (Silero-V AD) [15] is an open-source cascaded full-duplex system that combines a frozen LLM with chunked streaming audio input and turn-taking management. User input detection is handled by the widely used Silero-V AD, representing a typical deployment of T ABLE II C O M P A R IS O N O F D I FF E R EN T M O D E LS O N A V E RA G E I R L , F A LS E I N T E RR U PT I O N R AT E , A N D A V ER A GE P E NA LT Y T I M E AC RO S S E N , Z H , A N D N O I S E C O N DI T I O N S . L OW E R V A L U E S A R E B E T TE R ( I N D IC AT ED B Y ↓ ) . EN ZH Noise Silence A verage Model IRL ↓ FIR ↓ APT ↓ IRL ↓ FIR ↓ APT ↓ FIR ↓ APT ↓ IRL ↓ FIR ↓ APT ↓ FSMN-V AD [27] 0 0.906 3.328 0 0.915 3.563 0.392 4.791 0 0.840 3.627 Free-Omni(Silero V AD) [15] 0.141 0.669 2.429 0.186 0.513 1.977 0.154 1.658 0.173 0.532 2.129 FireRedChat (pV AD) [28] 0.474 0.734 2.997 1.170 0.338 2.311 0.098 2.458 1.045 0.476 2.627 Moshi [8] 2.517 0.010 1.749 - - - 0.464 7.810 2.517 0.118 3.192 SID-model (proposed) 0.444 0.140 0.921 0.338 0.138 0.656 0.026 0.215 0.389 0.124 0.711 V AD in SDS. (3) FireRedChat (pV AD) [28] is another adv anced, open-source, full-duplex system. Its key component is a proprietary V AD, specifically engineered for robustness against non-interrupti ve sounds, which enables a more optimized V AD-based approach. (4) Moshi [8] is an end-to-end, real-time speech-to-speech model. It employs an “Inner Monologue” mechanism and a multi-stream design to improve fluency and handle overlapping speech, ex emplifying the capabilities of fully integrated end-to-end architectures. B. Evaluation T o validate our proposed model and establish the utility of our new benchmark, we conduct a rigorous comparativ e analysis. All systems are ev aluated on SID-Bench using three key metrics from Section 3: 1) FIR to quantify robustness against spurious triggers; 2) IRL to measure timeliness; and 3) APT , our proposed composite metric that provides a single, holistic score of a system’ s ability to balance the trade-off between accuracy and timeliness. Giv en the significant architectural and input-output differences across these systems, we establish a unified e valuation protocol on SID-Bench focused solely on measuring the response time aligned with the user’ s interruption intent. For the V AD-based baselines, we take the onset time detected by the corresponding V AD as the model’ s user barg e-in time point , and compute all metrics with respect to this timestamp. For the end-to-end model Moshi, which does not expose an explicit barge-in signal, we design a dedicated procedure. While Moshi is generating a response to a preset prompt, we start playing a SID-Bench test audio file at a fixed time. W e fix the random seed to ensure a deterministic initial response from Moshi. W e then record the timestamp at which Moshi stops its ongoing output, and treat the onset of our test audio playback as the user barg e-in time point for ev aluation. This protocol allows us to consistently assess Moshi’s end-to-end responsi veness. C. Main Results and Analysis The comparativ e performance of our model against the baselines across all test conditions is presented in T able II. The results demonstrate that our proposed model achieves a dominant advantage in the composite APT metric, and is the only model to strike an ideal balance between low IRL and low FIR. Pure V AD Model (FSMN-V AD): Fast b ut Fundamentally Flawed. The FSMN-V AD baseline exemplifies a “trigger-happy” strategy , reacting instantaneously to any detected vocal energy . This results in a nominal IRL of 0 but at the cost of an extremely high FIR, which a verages 0.840 and exceeds 0.90 in con versational contexts. Such an approach, while maximally responsi ve, lacks the discernment to distinguish genuine interruptions from simple backchannels. The resulting cascade of false positiv es severely disrupts con v ersational flow , culminating in the highest APT of 3.627s. This outcome confirms that relying solely on acoustic energy is an inadequate foundation for intelligent interruption handling. End-to-End Model (Moshi): Robust but Prohibitively Slow . At the opposite end of the spectrum, the Moshi model embodies an “overly cautious” strategy . It demonstrates remarkable robustness against backchannels, achieving the lo west av erage FIR 0.118 and a near-perfect 0.010 on the English set. Howev er , this accurac y is achiev ed at the expense of cripplingly slow responsiv eness. With an av erage IRL of 2.517s, it is the slowest model, making its latency unacceptable for fluid con versation. This sluggishness translates to a high APT of 3.192s, rendering the model effecti ve in theory but impractical in application. Optimized V AD Models: Incremental but Insufficient Improve- ments. The models featuring enhanced V ADs offer incremental gains but ultimately fail to resolve the core challenge. While Freeze-Omni strikes a good trade-off than to achieve the lowest APT among the baselines (2.129s), its FIR remains prohibitively high at 0.532. Sim- ilarly , FireRedChat’ s pV AD shows promise in controlled conditions, exhibiting strong robustness to non-speech sounds (FIR of 0.098 on the Noise/Silence set). Ho we ver , it falters in realistic dialogue, where its FIR is still high and its IRL climbs to 1.045s. These results indicate that such optimizations, while beneficial for noise suppression, do not imb ue the models with the semantic understanding required to differentiate interruption intent from simple backchannels in complex con versations. Our Model: Achieving the Optimal Balance. In stark con- trast, our proposed model decisively outperforms all baselines by successfully resolving the core responsiveness-rob ustness trade-off. It achieves the lowest av erage APT of 0.711s—a nearly threefold reduction compared to the best-performing baseline. This superior performance is not limited to con versational data; it extends to challenging acoustic conditions. In the Noise/Silence tests, our model demonstrates exceptional resilience, posting a near-zero FIR of 0.026. This result highlights not only the model’ s accuracy but also its robustness and generalizability against non-semantic acoustic inter - ference, a critical capability where other systems falter . D. Qualitative Analysis While the quantitativ e results in T able II clearly establish our model’ s superiority , they also re veal two seemingly counter-intuiti ve outcomes that warrant deeper inv estigation. This analysis aims to dissect these puzzles, providing a more nuanced understanding of the behaviors of dif ferent interruption handling strategies. A key observation is that Moshi, which achie ved outstanding robustness on the English conv ersational dataset, with FIR of 0.010, paradoxically yielded a high o verall APT , 3.192s. The root of this discrepancy lies in its performance on the Noise/Silence set. While highly robust to human backchannels, Moshi proved surprisingly T ABLE III C O M P A R IS O N O F FA L S E A L A RM N U M B E R A N D A V ER A GE P E NA LT Y T I M E F O R D I FF E RE N T M O D E L S U N D E R S I L E NC E A N D N O I S E C O N DI T I O N S . Silence Noise Model F AN APT F AN APT FSMN-V AD 159 5.420 37 3.846 Freeze-Omni 67 2.286 10 0.716 FireRedChat 0 0 49 6.145 Moshi 168 5.720 64 7.810 SID-model (proposed) 10 0.340 3 0.028 sensitiv e to subtle, non-semantic noises, leading to a high FIR of 0.464 and a catastrophic APT of 7.810s in this condition. This suggests that Moshi’ s robustness is not rooted in a true semantic understanding of interruption intent. Rather , its mechanism appears to be based on a pattern-matching model that distinguishes human speech from other acoustic patterns. It fails when presented with non- speech sounds that it misinterprets as turn-taking cues, rev ealing a critical flaw in its approach. Another puzzling result is that on the Noise/Silence set, FireRed- Chat incurred a significantly higher APT , 2.458s, than Freeze-Omni, 1.658s, despite achie ving a lo wer overall FIR, 0.098 vs. 0.154. The data in T able III reveals that FireRedChat’ s pV AD is highly effecti ve at filtering out the short, low-energy sounds in the Silence clips, triggering FIR fewer alarms than Freeze-Omni. Howe ver , it is frequently and incorrectly triggered by the sustained sounds in the long Noise clips. Since the penalty for a False Positi ve is defined by the total remaining duration of the current turn, a single error in a long-duration noise clip incurs a much heavier penalty than multiple errors in short silence segments. Therefore, although FireRedChat commits fewer total false alarms, its failure to handle sustained noise disproportionately inflates its APT . This observation highlights the APT metric’ s ability to penalize “catastrophic” errors—those that would lead to prolonged system malfunction—more heavily than transient glitches, providing a more ecologically valid measure of system reliability . V I . C O N C L U S I O N In this paper, we address the critical challenge of intelligent interruption handling in spoken dialogue systems by introducing SID- Bench, a nov el real-world benchmark, and a corresponding e v aluation framew ork centered on the APT metric. W e also propose a novel LLM-based interruption detection model designed to understand user intent at a semantic level. Our extensi ve e xperiments demonstrate that this model resolves the long-standing trade-off between responsiv e- ness and robustness, achie ving a nearly three-fold improvement in APT o ver the best-performing baseline. This work not only v alidates our semantic-driv en approach but also provides the community with a robust tool for future research. Future work will focus on integrating this module into a comprehensiv e, fully generativ e SDS, expanding SID-Bench to support additional languages, and correlating our automated metrics with human perceptual judgments. R E F E R E N C E S [1] Y aniv Leviathan and Y ossi Matias, “Google Duplex: An AI system for accomplishing real-world tasks over the phone, ” Google AI blog . [2] Jin Xu, Zhifang Guo, and et al., “Qwen2.5-Omni T echnical Report, ” arXiv pr eprint arXiv:2503.20215 , 2025. [3] Rongjie Huang, Mingze Li, and et al., “AudioGPT : Understanding and Generating Speech, Music, Sound, and T alking Head, ” in Pr oc. AAAI , 2024, pp. 23802–23804. [4] Dong Zhang, Shimin Li, and et al., “SpeechGPT : Empowering Large Language Models with Intrinsic Cross-Modal Conversational Abilities, ” in Pr oc. EMNLP , 2023, pp. 15757–15773. [5] Xuelong Geng, Qijie Shao, and et al., “OSUM-EChat: Enhancing End- to-End Empathetic Spoken Chatbot via Understanding-Driven Spoken Dialogue, ” arXiv preprint , 2025. [6] W enyi Y u, Siyin W ang, and et al., “SALMONN-omni: A Standalone Speech LLM without Codec Injection for Full-duplex Conv ersation, ” arXiv pr eprint arXiv:2505.17060 , 2025. [7] Qichao W ang, Ziqiao Meng, and et al., “NTPP: Generative Speech Language Modeling for Dual-Channel Spoken Dialogue via Ne xt-T oken- Pair Prediction, ” in F orty-second International Confer ence on Machine Learning, ICML 2025, V ancouver , BC, Canada, July 13-19, 2025 , 2025. [8] Alexandre D ´ efossez, Laurent Mazar ´ e, and et al., “Moshi: a speech- text foundation model for real-time dialogue, ” arXiv pr eprint arXiv:2410.00037 , 2024. [9] Qian Chen, Y afeng Chen, and et al., “MinMo: A Multimodal Lar ge Language Model for Seamless V oice Interaction, ” arXiv preprint arXiv:2501.06282 , 2025. [10] Ziyang Ma, Y akun Song, and et al., “Language Model Can Listen While Speaking, ” in Proc. AAAI , 2025, pp. 24831–24839. [11] Bandhav V eluri, Benjamin N. Peloquin, and et al., “Beyond Turn-Based Interfaces: Synchronous LLMs as Full-Duple x Dialogue Agents, ” in Pr oceedings of the 2024 Conference on Empirical Methods in Natural Language Pr ocessing, EMNLP 2024, Miami, FL, USA, November 12-16, 2024 , 2024, pp. 21390–21402. [12] Agust ´ ın Gravano and Julia Hirschberg, “T urn-taking cues in task- oriented dialogue, ” Computer Speech & Language , vol. 25, no. 3, pp. 601–634, 2011. [13] Starkey Duncan, “Some signals and rules for taking speaking turns in con versations, ” Journal of personality and social psychology , vol. 23, no. 2, pp. 283, 1972. [14] Antoine Raux and Maxine Esk ´ enazi, “Optimizing the turn-taking behavior of task-oriented spoken dialog systems, ” ACM Tr ansactions on Speech and Language Processing , vol. 9, no. 1, pp. 1–23, 2012. [15] Xiong W ang, Y angze Li, and et al., “Freeze-Omni: A Smart and Low Latency Speech-to-speech Dialogue Model with Frozen LLM, ” in Proc. ICML , 2025. [16] Chaoyou Fu, Haojia Lin, Zuwei Long, and et al., “VIT A: T owards Open-Source Interactive Omni Multimodal LLM, ” arXiv preprint arXiv:2408.05211 , 2024. [17] Guan-Ting Lin, Shih-Y un Shan Kuan, and et al., “Full-duplex-bench-v2: A multi-turn ev aluation framework for duplex dialogue systems with an automated examiner , ” arXiv pr eprint arXiv:2510.07838 , 2025. [18] Guan-Ting Lin, Jiachen Lian, and et al., “Full-Duplex-Bench: A Benchmark to Evaluate Full-duplex Spoken Dialogue Models on Turn- taking Capabilities, ” arXiv preprint , 2025. [19] Guan-Ting Lin, Shih-Y un Shan Kuan, and et al., “Full-duplex-bench v1. 5: Evaluating overlap handling for full-duplex speech models, ” arXiv pr eprint arXiv:2507.23159 , 2025. [20] Yizhou Peng, Y i-W en Chao, and et al., “FD-Bench: A Full-Duplex Benchmarking Pipeline Designed for Full Duplex Spoken Dialogue Systems, ” in Proc. Interspeech , 2025, pp. 176–180. [21] Gabriel Skantze, “T urn-taking in Conversational Systems and Human- Robot Interaction: A Review , ” Comput. Speech Lang. , vol. 67, pp. 101178, 2021. [22] Mattias Heldner and Jens Edlund, “P auses, gaps and overlaps in con versations, ” J. Phonetics , vol. 38, no. 4, pp. 555–568, 2010. [23] John J. Godfrey , Edward Holliman, and Jane McDaniel, “SWITCH- BO ARD: telephone speech corpus for research and development, ” in Pr oc. ICASSP , 1992, pp. 517–520. [24] An Y ang, Baosong Y ang, and et al., “Qwen2.5 technical report, ” arXiv pr eprint arXiv:2412.15115 , 2024. [25] Jin Xu, Zhifang Guo, and et al., “Qwen3-omni technical report, ” arXiv pr eprint arXiv:2509.1776 , 2025. [26] An Y ang, Anfeng Li, and et al., “Qwen3 T echnical Report, ” arXiv pr eprint arXiv:2505.09388 , 2025. [27] Shiliang Zhang, Ming Lei, and et al., “Deep-FSMN for large vocabulary continuous speech recognition, ” in Proc. ICASSP , 2018, pp. 5869–5873. [28] Junjie Chen, Y ao Hu, and et al., “Fireredchat: A pluggable, full-duplex voice interaction system with cascaded and semi-cascaded implementa- tions, ” arXiv preprint , 2025.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment